---
base_model:
- VanishD/Agentic-R1
language:
- en
license: mit
pipeline_tag: text-generation
library_name: transformers
tags:
- qwen2
- reasoning
- tool-use
- llm
---
# Agentic-R1: Distilled Dual-Strategy Reasoning
The model was presented in the paper [Agentic-R1: Distilled Dual-Strategy Reasoning](https://huggingface.co/papers/2507.05707).
Code: https://github.com/StigLidu/DualDistill
## Abstract
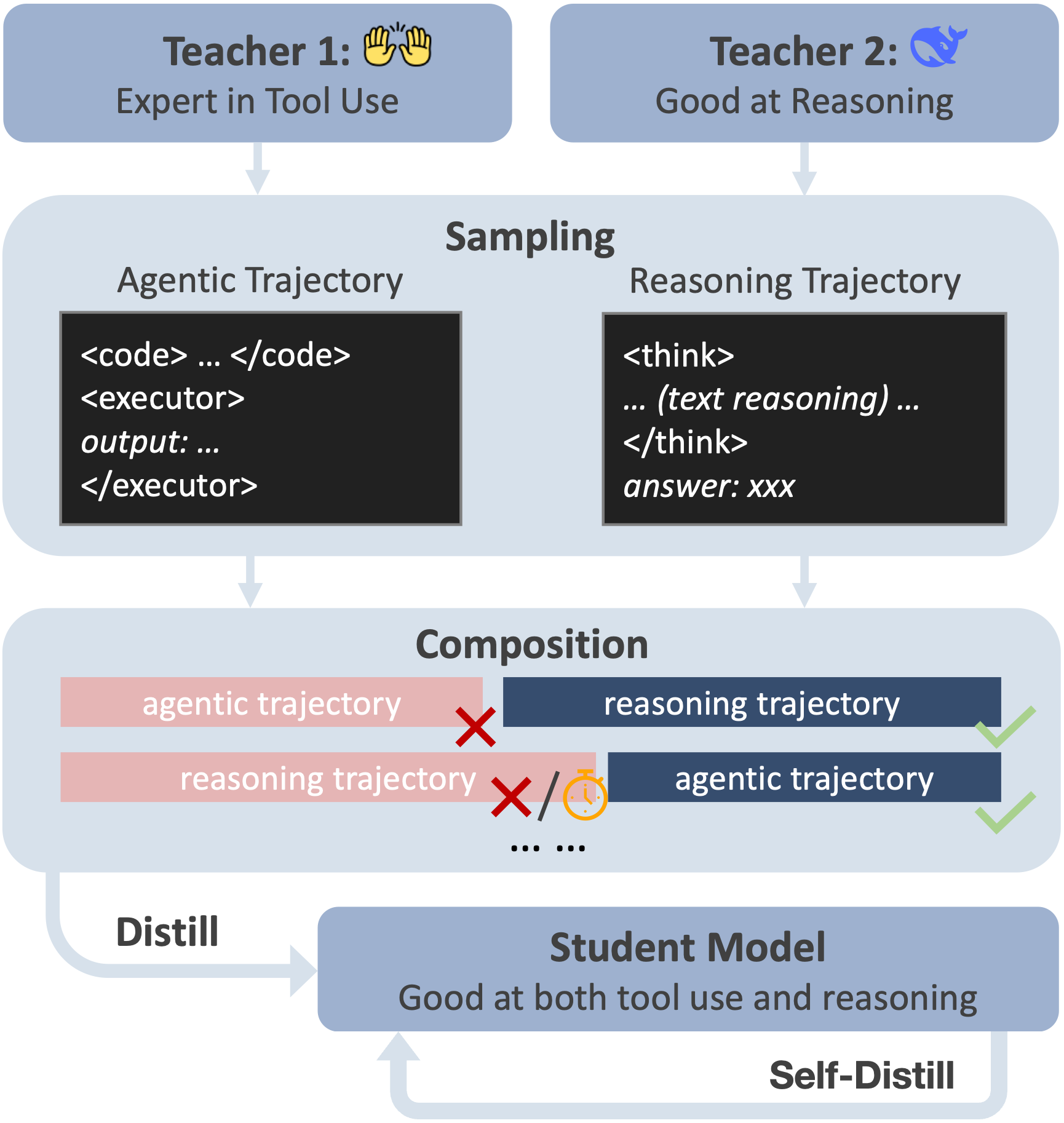
Current long chain-of-thought (long-CoT) models excel at mathematical reasoning but rely on slow and error-prone natural language traces. Tool-augmented agents address arithmetic via code execution, but often falter on complex logical tasks. We introduce a fine-tuning framework, DualDistill, that distills complementary reasoning strategies from multiple teachers into a unified student model. Using this approach, we train Agentic-R1, which dynamically selects the optimal strategy for each query, invoking tools for arithmetic and algorithmic problems, and using text-based reasoning for abstract ones. Our method improves accuracy across a range of tasks, including both computation-intensive and standard benchmarks, demonstrating the effectiveness of multi-strategy distillation in achieving robust and efficient reasoning.
## Key Features
- **Efficient Training**: Integrates tool use into long-chain-of-thought (CoT) reasoning using only 4 × A6000 GPUs
- **Unified Reasoning**: Fuses heterogeneous reasoning traces from multiple teacher models into a single student model
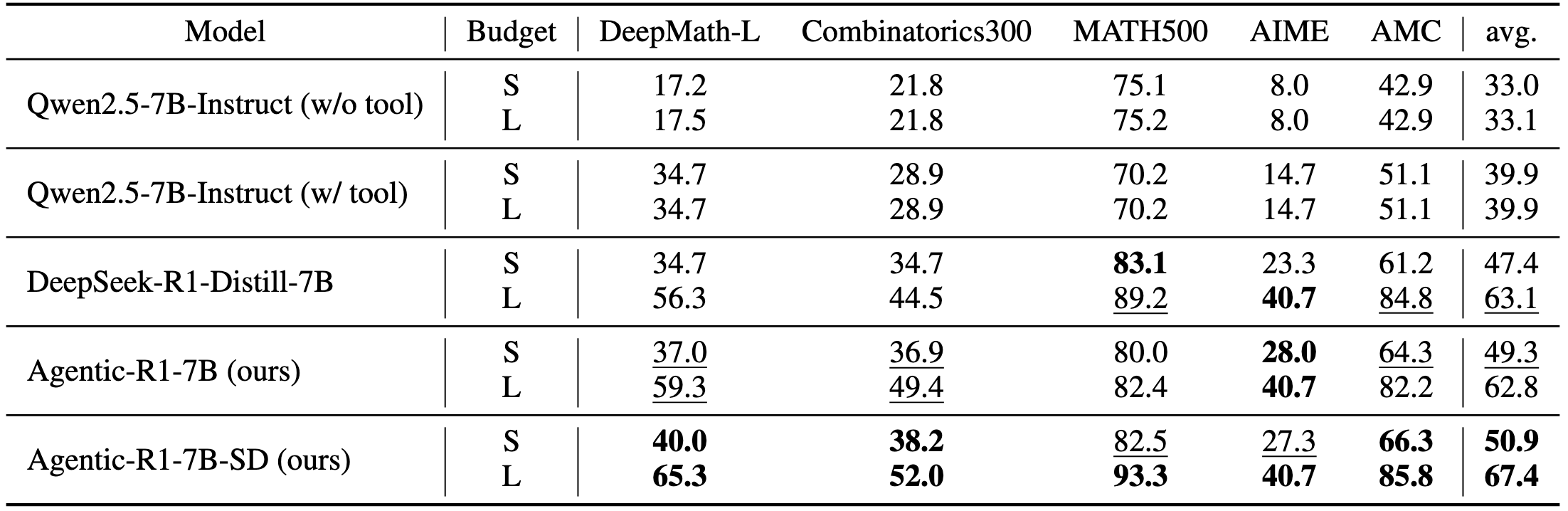
- **Agentic-R1** demonstrates significant performance gains on **DeepMath-L** and **Combinatorics300**, where both complex reasoning and tool use are crucial for success.
- **Agentic-R1-SD** (Self-Distilled) further enhances performance through our self-distillation approach, consistently outperforming baseline models across nearly all evaluation tasks.
## Quick Start
### Installation
1. **Clone the repository**:
```bash
git clone https://github.com/StigLidu/DualDistill.git
cd DualDistill
```
2. **Create environment** (optional but recommended):
```bash
conda create -n dualdistill python=3.11
conda activate dualdistill
```
3. **Install dependencies**:
```bash
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
```
### Inference Server and Evaluation
To run inference and evaluation using the provided scripts:
1. **Start inference server**:
```bash
bash script/eval_script/start_inference_server.sh [model_path] [display_name] [port]
```
2. **Run Evaluation**:
```bash
bash script/eval_script/eval_remote_server.sh \
[url] [display_name] [data_path] [code_mode] [max_token]
```
**Example**:
```bash
bash script/eval_script/eval_remote_server.sh \
"http://localhost:8080/v1" "agentic-r1" "dataset/test/math.json" "true" "4096"
```
## Trained Models
| Model | Description | HuggingFace Link |
|-------|-------------|------------------|
| **Agentic-R1-7B** | Base model with teacher distillation | [🤗 Download](https://huggingface.co/VanishD/Agentic-R1) |
| **Agentic-R1-7B-SD** | Enhanced model with self-distillation | [🤗 Download](https://huggingface.co/VanishD/Agentic-R1-SD) |
## ⚠️ Important Notes
- **Code Execution Safety**: The evaluation scripts execute model-generated code locally. Only use trusted models before execution.
- **Inference Config**: If you are using vLLM (a recent version) and encounter an error regarding the maximum context length. You may need to modify the `model_max_length` in `tokenizer_config.json`.
- **Self-Distillation Warning**: The self-distillation step requires sampling many trajectories and can be time-consuming.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Acknowledgments
We thank the following open-source projects for their foundational contributions:
- [OpenHands](https://github.com/All-Hands-AI/OpenHands) - Agent framework
- [DeepMath-103K](https://huggingface.co/datasets/zwhe99/DeepMath-103K) - Mathematical reasoning dataset
- [vLLM](https://github.com/vllm-project/vllm) - High-performance inference engine
## Contact
For questions or support, please contact:
- **Weihua Du**: [weihuad@cs.cmu.edu](mailto:weihuad@cs.cmu.edu)
## Citation
If you find our work useful, please consider citing:
```bibtex
@article{du2025agentic,
title={Agentic-R1: Distilled Dual-Strategy Reasoning},
author={Du, Weihua and Aggarwal, Pranjal and Welleck, Sean and Yang, Yiming},
journal={arXiv preprint arXiv:2507.05707},
year={2025}
}
```
---