---
license: apache-2.0
---
Unlocking Aha Moments via Reinforcement Learning: Advancing Collaborative Visual Comprehension and Generation




Kaihang Pan1*, Yang Wu2*, Wendong Bu1*, Kai Shen1‡, Juncheng Li1†, Yingting Wang2,
Yunfei Li2, Siliang Tang1, Jun Xiao1, Fei Wu1, Hang Zhao2, Yueting Zhuang1
1Zhejiang University, 2Ant Group
*Equal Contribution, ‡Project Leader, †Corresponding Author
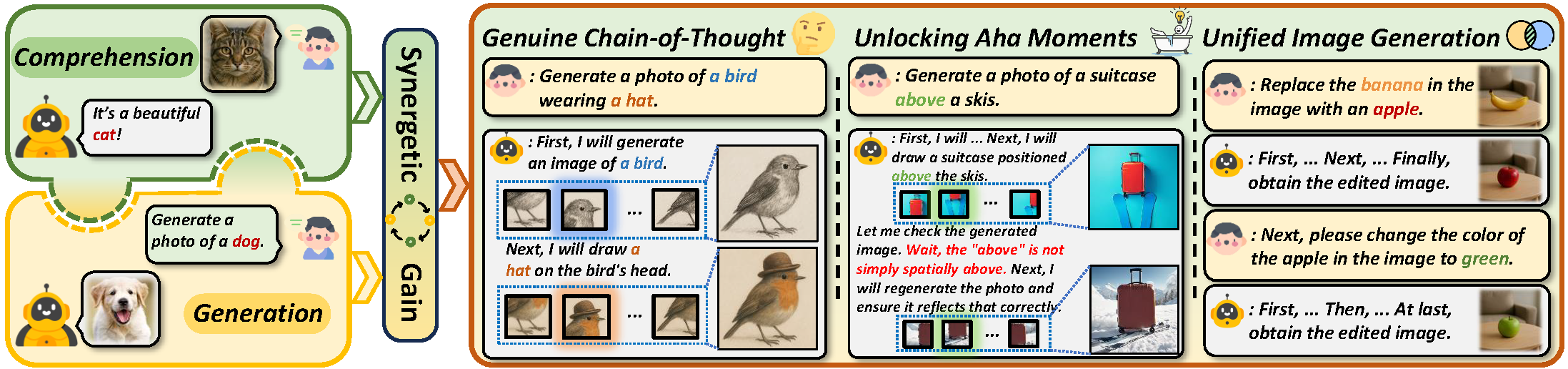
## 🚀 Overview
We propose a **two-stage training paradigm** to enable introspective text-to-image generation via genuine reasoning chains (CoT), unlocking what we call **Aha Moments** in visual generation:
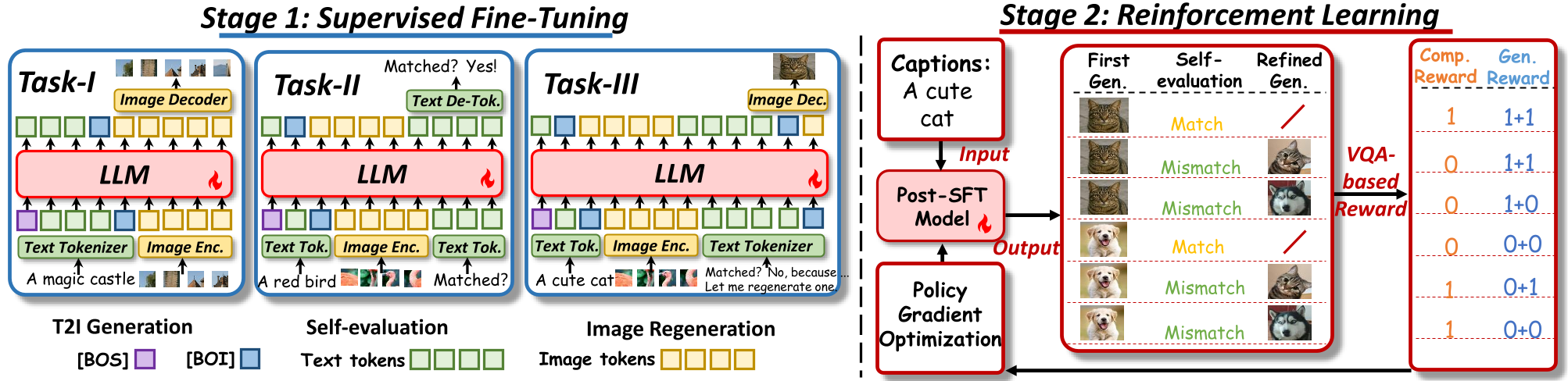
- **Stage 1 – Supervised Fine-Tuning (SFT):**
The model learns structured visual reasoning through three subtasks:
- Text-to-image generation
- Image-text consistency self-evaluation
- Image regeneration through reflection
- **Stage 2 – Reinforcement Learning (RL):**
The model is trained using a token-level Markov decision process with bi-level QA-based rewards to encourage spontaneous reasoning and correction, optimizing via GRPO.
With self-reflective capabilities, this approach bridges the gap between text-to-image generation and image editing, enabling a unified and coherent visual reasoning process.
## ✨️ Quickstart
**1. Prepare Environment**
First, the python environment for inference is the same as that for SFT. Specifically, please clone our repo and prepare the python environment. We recommend using Python>=3.10.
```bash
git clone https://github.com/wendell0218/Janus-Pro-R1.git
cd Janus-Pro-R1
conda create -n janus-pro-r1-sft python=3.11
conda activate janus-pro-r1-sft
pip install -r requirements-sft.txt
```
**2. Prepare Pretrained Model**
Janus-Pro-R1-7B utilizes `Janus-Pro-7B` as the pretrained model for subsequent training. You can download the corresponding model using the following command:
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/Janus-Pro-7B
cd Janus-Pro-7B
git lfs pull
```
**3. Start Generating!**
We illustrate the inference process of introspective text-to-image generation under the simplest scenario, where the model performs a one-time image self-evaluation and image regeneration after the initial text-to-image generation.
```python
import os
import json
import torch
import PIL.Image
import numpy as np
from typing import List
from torchvision import transforms
from transformers import AutoModelForCausalLM
from models import MultiModalityCausalLM, VLChatProcessor
from tqdm import tqdm
import math
def center_crop_arr(pil_image, image_size):
while min(*pil_image.size) >= 2 * image_size:
pil_image = pil_image.resize(
tuple(x // 2 for x in pil_image.size), resample=PIL.Image.BOX
)
scale = image_size / min(*pil_image.size)
pil_image = pil_image.resize(
tuple(round(x * scale) for x in pil_image.size), resample=PIL.Image.BICUBIC
)
arr = np.array(pil_image)
crop_y = (arr.shape[0] - image_size) // 2
crop_x = (arr.shape[1] - image_size) // 2
return PIL.Image.fromarray(arr[crop_y: crop_y + image_size, crop_x: crop_x + image_size])
@torch.no_grad()
def generate_with_refine(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
input_ids,
attention_mask,
temperature: float = 1,
parallel_size: int = 4,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
img_top_k: int = None,
img_top_p: float = None,
txt_top_k: int = None,
txt_top_p: float = None,
max_reflect_len: int = 80,
task_list: List[int] = [1,2,3],
):
prompt = [
'\nLet me think Does this image match the prompt...',
'<|end▁of▁sentence|>\nNext, I will draw a new image'
]
all_imgs_1,embeds_1,attention_mask_1 = [],[],[]
output_text_ids,selfcheck,attention_mask_txt = [],[],[]
all_imgs_2 = []
parallel_size = input_ids.shape[0]
if 1 <= task_list[-1]:
tokens = torch.repeat_interleave(input_ids,2,dim=0)
for i in range(tokens.size(0)):
if i % 2 != 0:
pad_list = torch.where(tokens[i]==vl_chat_processor.pad_id)[0]
if pad_list.shape[0]==0:
st = 1
else:
st = pad_list[-1].item()+2
tokens[i, st:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
embeds_1 = inputs_embeds
attention_mask_1 = torch.repeat_interleave(attention_mask, 2, dim=0)
cur_atten_mask = attention_mask_1
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in tqdm(range(image_token_num_per_image)):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, attention_mask=cur_atten_mask, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
if img_top_k:
v, _ = torch.topk(logits, min(img_top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf")
probs = torch.softmax(logits / temperature, dim=-1)
if img_top_p:
probs_sort, probs_idx = torch.sort(probs,
dim=-1,
descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > img_top_p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
else:
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
cur_atten_mask = torch.cat([cur_atten_mask, torch.ones(cur_atten_mask.size(0), 1).to(attention_mask)], dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
for i in range(parallel_size):
all_imgs_1.append(PIL.Image.fromarray(visual_img[i]))
if 2 <= task_list[-1]:
inputs_embeds = embeds_1[::2,:,:]
under_embeds = torch.zeros((parallel_size, image_token_num_per_image, 4096), dtype=torch.bfloat16).cuda()
for i in range(parallel_size):
img_prompt = ""
prepare_inputs = vl_chat_processor(
prompt=img_prompt, images=[all_imgs_1[i]], force_batchify=True
).to(input_ids.device)
img_embeds = mmgpt.prepare_inputs_embeds(**prepare_inputs)
img_embeds = img_embeds[:,2:-1,:]
under_embeds[i,:,:] = img_embeds
inputs_embeds = torch.cat((inputs_embeds, under_embeds), dim=1)
selfcheck_ids = vl_chat_processor.tokenizer.encode(prompt[0])[1:]
selfcheck_ids = torch.LongTensor(selfcheck_ids)
selfcheck_tokens = torch.zeros((parallel_size, len(selfcheck_ids)), dtype=torch.int).cuda()
for i in range(parallel_size):
selfcheck_tokens[i, :] = selfcheck_ids
selfcheck_embeds = mmgpt.language_model.get_input_embeddings()(selfcheck_tokens)
inputs_embeds = torch.cat((inputs_embeds, selfcheck_embeds), dim=1)
reflect_tokens = torch.zeros((parallel_size, max_reflect_len), dtype=torch.int).cuda()
reflect_len = 0
eos_list = torch.zeros((parallel_size, 1), dtype=torch.int).cuda()
add_padding = torch.zeros((parallel_size, 1), dtype=torch.int).cuda()
eos_token = vl_chat_processor.tokenizer.encode("<|end▁of▁sentence|>")[-1]
padding_token = vl_chat_processor.tokenizer.encode("<|▁pad▁|>")[-1]
yes_token = vl_chat_processor.tokenizer.encode("Yes")[-1]
no_token = vl_chat_processor.tokenizer.encode("No")[-1]
attn_mask = torch.ones((parallel_size, inputs_embeds.shape[1]), dtype=torch.int).cuda()
yes_list = torch.zeros((parallel_size), dtype=torch.int).cuda()
for i in range(max_reflect_len):
outputs = mmgpt.language_model(inputs_embeds=inputs_embeds, attention_mask=attn_mask, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
logits = outputs.logits
logits = logits[:,-1,:]
if i == 0:
allowed_tokens = [yes_token, no_token]
allowed_tokens_logits = logits[:,allowed_tokens]
logits[:,:] = -math.inf
logits[:,allowed_tokens] = allowed_tokens_logits
if txt_top_k:
v, _ = torch.topk(logits, min(txt_top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf")
probs = torch.softmax(logits / temperature, dim=-1)
if txt_top_p:
probs_sort, probs_idx = torch.sort(probs,
dim=-1,
descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > txt_top_p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
else:
next_token = torch.multinomial(probs, num_samples=1)
if i >= 1:
add_padding = ((reflect_tokens[:, i-1] == eos_token) | (reflect_tokens[:, i-1] == padding_token)).unsqueeze(1).to(torch.int)
next_token = add_padding*padding_token + (1-add_padding)*next_token
if i == 0:
yes_list = (next_token == yes_token)
reflect_tokens[:, i] = next_token.squeeze(dim=-1)
is_eos = (next_token == eos_token)
eos_list = eos_list | is_eos.to(torch.int)
new_attn = 1-add_padding
new_attn = new_attn & (~is_eos)
attn_mask = torch.cat((attn_mask, new_attn), dim=1)
inputs_embeds = mmgpt.language_model.get_input_embeddings()(next_token)
reflect_len = i
if eos_list.all():
break
reflect_tokens = reflect_tokens[:,:reflect_len+1]
max_relect_len = reflect_len+1
output_text_ids = reflect_tokens
attention_mask_txt = torch.ones_like(output_text_ids).cuda()
attention_mask_txt[output_text_ids == padding_token] = 0
attention_mask_txt[output_text_ids == eos_token] = 0
selfcheck = yes_list.bool()
if 3 <= task_list[-1]:
tokens = torch.repeat_interleave(input_ids,2,dim=0)
for i in range(tokens.size(0)):
if i % 2 != 0:
pad_list = torch.where(tokens[i]==vl_chat_processor.pad_id)[0]
if pad_list.shape[0]==0:
st = 1
else:
st = pad_list[-1].item()+2
tokens[i, st:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
gen_transform = transforms.Compose([
transforms.Lambda(lambda pil_image: center_crop_arr(pil_image, 384)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True)
])
gen_embeds_list = []
for i in range(len(all_imgs_1)):
img = gen_transform(all_imgs_1[i])
img = img.unsqueeze(0).to(torch.bfloat16).cuda()
_, _, all_image_ids = mmgpt.gen_vision_model.encode(img)
image_ids = all_image_ids[2]
embed = mmgpt.gen_aligner(mmgpt.gen_embed(image_ids))
gen_embeds_list.append(embed)
gen_embeds_list.append(embed)
gen_embeds = torch.cat(gen_embeds_list, dim=0)
inputs_embeds = torch.cat((inputs_embeds, gen_embeds), dim=1)
selfcheck_ids = vl_chat_processor.tokenizer.encode(prompt[0])[1:]
selfcheck_ids = torch.LongTensor(selfcheck_ids)
selfcheck_tokens = torch.zeros((2*parallel_size, len(selfcheck_ids)), dtype=torch.int).cuda()
for i in range(2*parallel_size):
selfcheck_tokens[i, :] = selfcheck_ids
selfcheck_embeds = mmgpt.language_model.get_input_embeddings()(selfcheck_tokens)
inputs_embeds = torch.cat((inputs_embeds, selfcheck_embeds), dim=1)
attn_mask = torch.ones((2*parallel_size, inputs_embeds.shape[1]), dtype=torch.int).cuda()
reflect_embeds = torch.ones((2*parallel_size, max_relect_len), dtype=torch.int).cuda()
for i in range(2*parallel_size):
reflect_embeds[i] = output_text_ids[i//2]
new_attn = torch.ones((2*parallel_size, max_relect_len), dtype=torch.int).cuda()
for i in range(2*parallel_size):
new_attn[i] = attention_mask_txt[i//2]
reflect_embeds = mmgpt.language_model.get_input_embeddings()(reflect_embeds)
inputs_embeds = torch.cat((inputs_embeds, reflect_embeds), dim=1)
attn_mask = torch.cat((attn_mask, new_attn), dim=1)
regen_ids = vl_chat_processor.tokenizer.encode(prompt[1])[1:]
regen_ids = torch.LongTensor(regen_ids)
regen_tokens = torch.zeros((2*parallel_size, len(regen_ids)), dtype=torch.int).cuda()
for i in range(2*parallel_size):
regen_tokens[i, :] = regen_ids
regen_embeds = mmgpt.language_model.get_input_embeddings()(regen_tokens)
inputs_embeds = torch.cat((inputs_embeds, regen_embeds), dim=1)
new_attn = torch.ones((2*parallel_size, regen_ids.shape[0]), dtype=torch.int).cuda()
attn_mask = torch.cat((attn_mask, new_attn), dim=1)
new_generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in tqdm(range(image_token_num_per_image)):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, attention_mask=attn_mask, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
new_attn = torch.ones((2*parallel_size, 1), dtype=torch.int).cuda()
attn_mask = torch.cat((attn_mask, new_attn), dim=1)
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
if img_top_k:
v, _ = torch.topk(logits, min(img_top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf")
probs = torch.softmax(logits / temperature, dim=-1)
if img_top_p:
probs_sort, probs_idx = torch.sort(probs,
dim=-1,
descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > img_top_p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
else:
next_token = torch.multinomial(probs, num_samples=1)
new_generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
new_dec = mmgpt.gen_vision_model.decode_code(new_generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
new_dec = new_dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
new_dec = np.clip((new_dec + 1) / 2 * 255, 0, 255)
new_visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
new_visual_img[:, :, :] = new_dec
for i in range(parallel_size):
all_imgs_2.append(PIL.Image.fromarray(new_visual_img[i]))
return all_imgs_1, all_imgs_2, (output_text_ids.cpu(), selfcheck.squeeze().cpu())
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", type=str, default="deepseek-ai/Janus-Pro-7B")
parser.add_argument("--ckpt_path", type=str, default=None)
parser.add_argument("--caption", type=str, default="a brown giraffe and a white stop sign")
parser.add_argument("--gen_path", type=str, default="results/samples")
parser.add_argument("--reason_path", type=str, default='results/reason.jsonl')
parser.add_argument("--regen_path", type=str, default='results/regen_samples')
parser.add_argument("--cfg", type=float, default=5.0)
parser.add_argument("--parallel_size", type=int, default=4)
args = parser.parse_args()
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(args.model_path)
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(args.model_path, trust_remote_code=True)
if args.ckpt_path is not None:
state_dict = torch.load(f"{args.ckpt_path}", map_location="cpu")
vl_gpt.load_state_dict(state_dict)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
# You can flexibly modify the code here to perform batched inference.
allprompts = []
# prompt = f'<|User|>: {args.caption}\n\n<|Assistant|>:'
conversation = [
{
"role": "<|User|>",
"content": args.caption,
},
{"role": "<|Assistant|>", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
allprompts.append(prompt)
tokenized_input = vl_chat_processor.tokenizer(
allprompts,
return_tensors="pt",
padding='longest',
max_length=200, truncation=True
).to('cuda')
prompt_ids = tokenized_input['input_ids']
prompt_mask = tokenized_input['attention_mask']
images, regen_images, (output_text_ids, selfcheck) = generate_with_refine(
vl_gpt,
vl_chat_processor,
input_ids=prompt_ids, attention_mask=prompt_mask,
parallel_size = args.parallel_size,
cfg_weight = args.cfg,
)
os.makedirs(args.gen_path, exist_ok=True)
os.makedirs(args.reason_path, exist_ok=True)
os.makedirs(args.regen_path, exist_ok=True)
for i in range(args.parallel_size):
img_name = str(i).zfill(4)+".png"
save_path = os.path.join(args.gen_path, img_name)
images[i].save(save_path)
with open(args.reason_path, 'w') as f:
for i in range(args.parallel_size):
reason_data = {"prompt": args.caption}
img_name = str(i).zfill(4)
reason_data["filename"] = os.path.join(args.gen_path, f"{img_name}.png")
reason_data["correct"] = bool(selfcheck[i])
reason_data["reason"] = vl_chat_processor.tokenizer.decode(output_text_ids[i].cpu().tolist(), skip_special_tokens=True)
reason_data = json.dumps(reason_data, ensure_ascii=False)
f.write(reason_data+'\n')
for i in range(args.parallel_size):
img_name = str(i).zfill(4)+".png"
save_path = os.path.join(args.regen_path, img_name)
if selfcheck[i]:
images[i].save(save_path)
else:
regen_images[i].save(save_path)
```
## 🤝 Acknowledgment
Our project is developed based on the following repositories:
- [Janus-Series](https://github.com/deepseek-ai/Janus): Unified Multimodal Understanding and Generation Models
- [Open-R1](https://github.com/huggingface/open-r1): Fully open reproduction of DeepSeek-R1
## 📜 Citation
If you find this work useful for your research, please cite our paper and star our git repo:
```bibtex
@article{pan2025unlocking,
title={Unlocking Aha Moments via Reinforcement Learning: Advancing Collaborative Visual Comprehension and Generation},
author={Pan, Kaihang and Wu, Yang and Bu, Wendong and Shen, Kai and Li, Juncheng and Wang, Yingting and Li, Yunfei and Tang, Siliang and Xiao, Jun and Wu, Fei and others},
journal={arXiv preprint arXiv:2506.01480},
year={2025}
}
```