

Update README for pretrained weights and save metrics in evaluate
Browse files- README.md +17 -12
- configs/evaluate.json +14 -1
- configs/metadata.json +2 -1
- docs/README.md +17 -12
README.md
CHANGED
|
@@ -8,12 +8,17 @@ license: apache-2.0
|
|
| 8 |
# Model Overview
|
| 9 |
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
|
| 10 |
|
| 11 |
-
The model is trained to simultaneously segment and classify nuclei
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 15 |
|
| 16 |
-
|
| 17 |
|
| 18 |
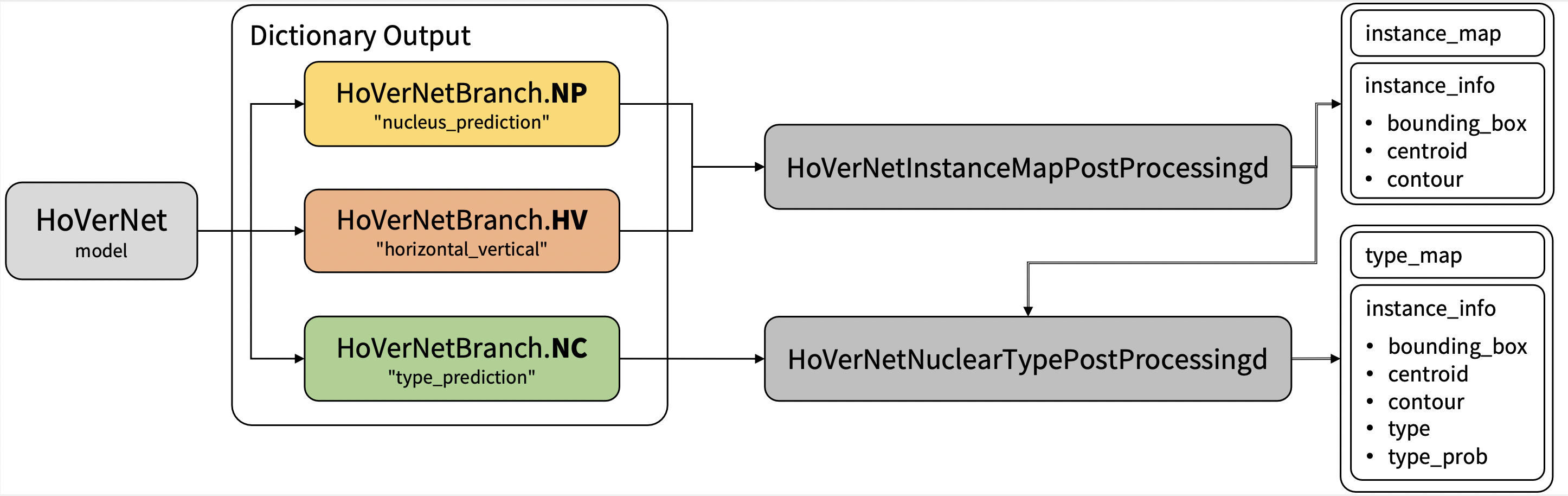
|
| 19 |
|
|
@@ -29,10 +34,10 @@ The provided labelled data was partitioned, based on the original split, into tr
|
|
| 29 |
|
| 30 |
### Preprocessing
|
| 31 |
|
| 32 |
-
After download the datasets, please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in
|
| 33 |
|
| 34 |
```
|
| 35 |
-
python scripts/prepare_patches.py
|
| 36 |
```
|
| 37 |
|
| 38 |
## Training configuration
|
|
@@ -63,9 +68,9 @@ Fast mode:
|
|
| 63 |
- PQ: 0.4973
|
| 64 |
- F1d: 0.7417
|
| 65 |
|
| 66 |
-
Note:
|
| 67 |
-
|
| 68 |
-
|
| 69 |
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 70 |
|
| 71 |
#### Training Loss and Dice
|
|
@@ -93,24 +98,24 @@ For more details usage instructions, visit the [MONAI Bundle Configuration Page]
|
|
| 93 |
|
| 94 |
- Run first stage
|
| 95 |
```
|
| 96 |
-
python -m monai.bundle run --config_file configs/train.json --
|
| 97 |
```
|
| 98 |
|
| 99 |
- Run second stage
|
| 100 |
```
|
| 101 |
-
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --
|
| 102 |
```
|
| 103 |
|
| 104 |
#### Override the `train` config to execute multi-GPU training:
|
| 105 |
|
| 106 |
- Run first stage
|
| 107 |
```
|
| 108 |
-
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --
|
| 109 |
```
|
| 110 |
|
| 111 |
- Run second stage
|
| 112 |
```
|
| 113 |
-
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --
|
| 114 |
```
|
| 115 |
|
| 116 |
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
|
|
|
| 8 |
# Model Overview
|
| 9 |
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
|
| 10 |
|
| 11 |
+
The model is trained to simultaneously segment and classify nuclei, and a two-stage training approach is utilized:
|
| 12 |
|
| 13 |
+
- Initialize the model with pre-trained weights, and train the decoder only for 50 epochs.
|
| 14 |
+
- Finetune all layers for another 50 epochs.
|
| 15 |
+
|
| 16 |
+
There are two training modes in total. If "original" mode is specified, [270, 270] and [80, 80] are used for `patch_size` and `out_size` respectively. If "fast" mode is specified, [256, 256] and [164, 164] are used for `patch_size` and `out_size` respectively. The results shown below are based on the "fast" mode.
|
| 17 |
+
|
| 18 |
+
In this bundle, the first stage is trained with pre-trained weights from some internal data. The [original author's repo](https://github.com/vqdang/hover_net) and [torchvison](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet18_Weights) also provide pre-trained weights but for non-commercial use.
|
| 19 |
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 20 |
|
| 21 |
+
If you want to train the first stage with pre-trained weights, just specify `--network_def#pretrained_url <your pretrain weights URL>` in the training command below, such as [ImageNet](https://download.pytorch.org/models/resnet18-f37072fd.pth).
|
| 22 |
|
| 23 |

|
| 24 |
|
|
|
|
| 34 |
|
| 35 |
### Preprocessing
|
| 36 |
|
| 37 |
+
After download the datasets, please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in `<your concep dataset path>`/Prepared. The implementation is referring to <https://github.com/vqdang/hover_net>. The command is like:
|
| 38 |
|
| 39 |
```
|
| 40 |
+
python scripts/prepare_patches.py --root <your concep dataset path>
|
| 41 |
```
|
| 42 |
|
| 43 |
## Training configuration
|
|
|
|
| 68 |
- PQ: 0.4973
|
| 69 |
- F1d: 0.7417
|
| 70 |
|
| 71 |
+
Note:
|
| 72 |
+
- Binary Dice is calculated based on the whole input. PQ and F1d were calculated from https://github.com/vqdang/hover_net#inference.
|
| 73 |
+
- This bundle is non-deterministic because of the bilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
|
| 74 |
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 75 |
|
| 76 |
#### Training Loss and Dice
|
|
|
|
| 98 |
|
| 99 |
- Run first stage
|
| 100 |
```
|
| 101 |
+
python -m monai.bundle run --config_file configs/train.json --stage 0
|
| 102 |
```
|
| 103 |
|
| 104 |
- Run second stage
|
| 105 |
```
|
| 106 |
+
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --stage 1
|
| 107 |
```
|
| 108 |
|
| 109 |
#### Override the `train` config to execute multi-GPU training:
|
| 110 |
|
| 111 |
- Run first stage
|
| 112 |
```
|
| 113 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --stage 0
|
| 114 |
```
|
| 115 |
|
| 116 |
- Run second stage
|
| 117 |
```
|
| 118 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --stage 1
|
| 119 |
```
|
| 120 |
|
| 121 |
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
configs/evaluate.json
CHANGED
|
@@ -90,7 +90,20 @@
|
|
| 90 |
},
|
| 91 |
{
|
| 92 |
"_target_": "StatsHandler",
|
| 93 |
-
"output_transform": "$lambda x: None"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 94 |
}
|
| 95 |
],
|
| 96 |
"validate#inferer": {
|
|
|
|
| 90 |
},
|
| 91 |
{
|
| 92 |
"_target_": "StatsHandler",
|
| 93 |
+
"output_transform": "$lambda x: None",
|
| 94 |
+
"iteration_log": false
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"_target_": "MetricsSaver",
|
| 98 |
+
"save_dir": "@output_dir",
|
| 99 |
+
"metrics": [
|
| 100 |
+
"val_mean_dice"
|
| 101 |
+
],
|
| 102 |
+
"metric_details": [
|
| 103 |
+
"val_mean_dice"
|
| 104 |
+
],
|
| 105 |
+
"batch_transform": "$monai.handlers.from_engine(['image_meta_dict'])",
|
| 106 |
+
"summary_ops": "*"
|
| 107 |
}
|
| 108 |
],
|
| 109 |
"validate#inferer": {
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_hovernet_20221124.json",
|
| 3 |
-
"version": "0.1.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.1.7": "Update README Formatting",
|
| 6 |
"0.1.6": "add non-deterministic note",
|
| 7 |
"0.1.5": "update benchmark on A100",
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_hovernet_20221124.json",
|
| 3 |
+
"version": "0.1.8",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.1.8": "Update README for pretrained weights and save metrics in evaluate",
|
| 6 |
"0.1.7": "Update README Formatting",
|
| 7 |
"0.1.6": "add non-deterministic note",
|
| 8 |
"0.1.5": "update benchmark on A100",
|
docs/README.md
CHANGED
|
@@ -1,12 +1,17 @@
|
|
| 1 |
# Model Overview
|
| 2 |
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
|
| 3 |
|
| 4 |
-
The model is trained to simultaneously segment and classify nuclei
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 8 |
|
| 9 |
-
|
| 10 |
|
| 11 |

|
| 12 |
|
|
@@ -22,10 +27,10 @@ The provided labelled data was partitioned, based on the original split, into tr
|
|
| 22 |
|
| 23 |
### Preprocessing
|
| 24 |
|
| 25 |
-
After download the datasets, please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in
|
| 26 |
|
| 27 |
```
|
| 28 |
-
python scripts/prepare_patches.py
|
| 29 |
```
|
| 30 |
|
| 31 |
## Training configuration
|
|
@@ -56,9 +61,9 @@ Fast mode:
|
|
| 56 |
- PQ: 0.4973
|
| 57 |
- F1d: 0.7417
|
| 58 |
|
| 59 |
-
Note:
|
| 60 |
-
|
| 61 |
-
|
| 62 |
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 63 |
|
| 64 |
#### Training Loss and Dice
|
|
@@ -86,24 +91,24 @@ For more details usage instructions, visit the [MONAI Bundle Configuration Page]
|
|
| 86 |
|
| 87 |
- Run first stage
|
| 88 |
```
|
| 89 |
-
python -m monai.bundle run --config_file configs/train.json --
|
| 90 |
```
|
| 91 |
|
| 92 |
- Run second stage
|
| 93 |
```
|
| 94 |
-
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --
|
| 95 |
```
|
| 96 |
|
| 97 |
#### Override the `train` config to execute multi-GPU training:
|
| 98 |
|
| 99 |
- Run first stage
|
| 100 |
```
|
| 101 |
-
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --
|
| 102 |
```
|
| 103 |
|
| 104 |
- Run second stage
|
| 105 |
```
|
| 106 |
-
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --
|
| 107 |
```
|
| 108 |
|
| 109 |
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|
|
|
|
| 1 |
# Model Overview
|
| 2 |
A pre-trained model for simultaneous segmentation and classification of nuclei within multi-tissue histology images based on CoNSeP data. The details of the model can be found in [1].
|
| 3 |
|
| 4 |
+
The model is trained to simultaneously segment and classify nuclei, and a two-stage training approach is utilized:
|
| 5 |
|
| 6 |
+
- Initialize the model with pre-trained weights, and train the decoder only for 50 epochs.
|
| 7 |
+
- Finetune all layers for another 50 epochs.
|
| 8 |
+
|
| 9 |
+
There are two training modes in total. If "original" mode is specified, [270, 270] and [80, 80] are used for `patch_size` and `out_size` respectively. If "fast" mode is specified, [256, 256] and [164, 164] are used for `patch_size` and `out_size` respectively. The results shown below are based on the "fast" mode.
|
| 10 |
+
|
| 11 |
+
In this bundle, the first stage is trained with pre-trained weights from some internal data. The [original author's repo](https://github.com/vqdang/hover_net) and [torchvison](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet18_Weights) also provide pre-trained weights but for non-commercial use.
|
| 12 |
Each user is responsible for checking the content of models/datasets and the applicable licenses and determining if suitable for the intended use.
|
| 13 |
|
| 14 |
+
If you want to train the first stage with pre-trained weights, just specify `--network_def#pretrained_url <your pretrain weights URL>` in the training command below, such as [ImageNet](https://download.pytorch.org/models/resnet18-f37072fd.pth).
|
| 15 |
|
| 16 |

|
| 17 |
|
|
|
|
| 27 |
|
| 28 |
### Preprocessing
|
| 29 |
|
| 30 |
+
After download the datasets, please run `scripts/prepare_patches.py` to prepare patches from tiles. Prepared patches are saved in `<your concep dataset path>`/Prepared. The implementation is referring to <https://github.com/vqdang/hover_net>. The command is like:
|
| 31 |
|
| 32 |
```
|
| 33 |
+
python scripts/prepare_patches.py --root <your concep dataset path>
|
| 34 |
```
|
| 35 |
|
| 36 |
## Training configuration
|
|
|
|
| 61 |
- PQ: 0.4973
|
| 62 |
- F1d: 0.7417
|
| 63 |
|
| 64 |
+
Note:
|
| 65 |
+
- Binary Dice is calculated based on the whole input. PQ and F1d were calculated from https://github.com/vqdang/hover_net#inference.
|
| 66 |
+
- This bundle is non-deterministic because of the bilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
|
| 67 |
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
|
| 68 |
|
| 69 |
#### Training Loss and Dice
|
|
|
|
| 91 |
|
| 92 |
- Run first stage
|
| 93 |
```
|
| 94 |
+
python -m monai.bundle run --config_file configs/train.json --stage 0
|
| 95 |
```
|
| 96 |
|
| 97 |
- Run second stage
|
| 98 |
```
|
| 99 |
+
python -m monai.bundle run --config_file configs/train.json --network_def#freeze_encoder False --stage 1
|
| 100 |
```
|
| 101 |
|
| 102 |
#### Override the `train` config to execute multi-GPU training:
|
| 103 |
|
| 104 |
- Run first stage
|
| 105 |
```
|
| 106 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 8 --network_def#freeze_encoder True --stage 0
|
| 107 |
```
|
| 108 |
|
| 109 |
- Run second stage
|
| 110 |
```
|
| 111 |
+
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']" --batch_size 4 --network_def#freeze_encoder False --stage 1
|
| 112 |
```
|
| 113 |
|
| 114 |
#### Override the `train` config to execute evaluation with the trained model, here we evaluated dice from the whole input instead of the patches:
|