Spaces:
Sleeping

Sleeping
Auto-deploy from GitHub Actions
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +121 -0
- .github/workflows/main.yml +60 -0
- .gitignore +54 -0
- README.md +253 -0
- app.py +872 -0
- dataset_preparation.ipynb +0 -0
- inference_outputs/image_000000_annotated.jpg +0 -0
- inference_outputs/image_002126_annotated.jpg +3 -0
- requirements.txt +0 -0
- saved_models/efficientnetb0_stage2_best.weights.h5 +3 -0
- saved_models/mobilenetv2_v2_stage2_best.weights.h5 +3 -0
- saved_models/resnet50_v2_stage2_best.weights.h5 +3 -0
- saved_models/vgg16_v2_stage2_best.h5 +3 -0
- scripts/01_Data Augmentation.ipynb +595 -0
- scripts/01_EDA.ipynb +0 -0
- scripts/02_efficientnetb0.py +385 -0
- scripts/02_mobilenetv2.py +430 -0
- scripts/02_model_comparision.ipynb +19 -0
- scripts/02_resnet50.py +482 -0
- scripts/02_vgg16.py +422 -0
- scripts/03_eval_yolo.py +151 -0
- scripts/03_train_yolo.py +56 -0
- scripts/03_yolo_dataset_creation.py +248 -0
- scripts/04_inference_pipeline.py +436 -0
- scripts/04_validation and cleaning.py +310 -0
- scripts/check.py +239 -0
- scripts/compare_models.py +267 -0
- scripts/convert_efficientnet_weights.py +109 -0
- scripts/convert_mobilenet_weights.py +83 -0
- scripts/convert_vgg16_weights.py +79 -0
- scripts/train_yolo_smartvision.py +428 -0
- scripts/yolov8n.pt +3 -0
- smartvision_metrics/comparison_plots/MobileNetV2_cm.png +3 -0
- smartvision_metrics/comparison_plots/MobileNetV2_v3_cm.png +3 -0
- smartvision_metrics/comparison_plots/ResNet50_cm.png +3 -0
- smartvision_metrics/comparison_plots/ResNet50_v2_Stage_2_FT_cm.png +3 -0
- smartvision_metrics/comparison_plots/VGG16_cm.png +3 -0
- smartvision_metrics/comparison_plots/VGG16_v2_Stage_2_FT_cm.png +3 -0
- smartvision_metrics/comparison_plots/accuracy_comparison.png +0 -0
- smartvision_metrics/comparison_plots/efficientnetb0_cm.png +3 -0
- smartvision_metrics/comparison_plots/f1_comparison.png +0 -0
- smartvision_metrics/comparison_plots/size_comparison.png +0 -0
- smartvision_metrics/comparison_plots/speed_comparison.png +0 -0
- smartvision_metrics/comparison_plots/top5_comparison.png +0 -0
- smartvision_metrics/efficientnetb0/confusion_matrix.npy +0 -0
- smartvision_metrics/efficientnetb0/metrics.json +12 -0
- smartvision_metrics/efficientnetb0_stage2/confusion_matrix.npy +0 -0
- smartvision_metrics/efficientnetb0_stage2/metrics.json +12 -0
- smartvision_metrics/mobilenetv2/confusion_matrix.npy +0 -0
- smartvision_metrics/mobilenetv2/metrics.json +12 -0
.gitattributes
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
saved_models/resnet50_v2_stage2_best.weights.h5 filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
saved_models/vgg16_v2_stage2_best.h5 filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
inference_outputs/image_002126_annotated.jpg filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
saved_models/efficientnetb0_stage2_best.weights.h5 filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
saved_models/mobilenetv2_v2_stage2_best.weights.h5 filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
scripts/yolov8n.pt filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
smartvision_metrics/comparison_plots/MobileNetV2_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
smartvision_metrics/comparison_plots/MobileNetV2_v3_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
smartvision_metrics/comparison_plots/ResNet50_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
smartvision_metrics/comparison_plots/ResNet50_v2_Stage_2_FT_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
smartvision_metrics/comparison_plots/VGG16_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
smartvision_metrics/comparison_plots/VGG16_v2_Stage_2_FT_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
smartvision_metrics/comparison_plots/efficientnetb0_cm.png filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
smartvision_yolo/yolov8n_25classes/BoxF1_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
smartvision_yolo/yolov8n_25classes/BoxPR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
smartvision_yolo/yolov8n_25classes/BoxP_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
smartvision_yolo/yolov8n_25classes/BoxR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
smartvision_yolo/yolov8n_25classes/confusion_matrix.png filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
smartvision_yolo/yolov8n_25classes/confusion_matrix_normalized.png filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
smartvision_yolo/yolov8n_25classes/labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
smartvision_yolo/yolov8n_25classes/results.png filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
smartvision_yolo/yolov8n_25classes/train_batch0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
smartvision_yolo/yolov8n_25classes/train_batch1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
smartvision_yolo/yolov8n_25classes/train_batch1260.jpg filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
smartvision_yolo/yolov8n_25classes/train_batch1261.jpg filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
smartvision_yolo/yolov8n_25classes/train_batch1262.jpg filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
smartvision_yolo/yolov8n_25classes/train_batch2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
smartvision_yolo/yolov8n_25classes/val_batch0_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
smartvision_yolo/yolov8n_25classes/val_batch0_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
smartvision_yolo/yolov8n_25classes/val_batch1_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
smartvision_yolo/yolov8n_25classes/val_batch1_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
smartvision_yolo/yolov8n_25classes/val_batch2_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
smartvision_yolo/yolov8n_25classes/val_batch2_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
smartvision_yolo/yolov8n_25classes/weights/best.pt filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
smartvision_yolo/yolov8n_25classes/weights/last.pt filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/BoxF1_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/BoxPR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/BoxP_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/BoxR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/confusion_matrix.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/confusion_matrix_normalized.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/results.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch8400.jpg filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch8401.jpg filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/train_batch8402.jpg filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch0_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch0_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch1_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch1_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch2_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/val_batch2_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/weights/best.pt filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
yolo_runs/smartvision_yolov8s6[[:space:]]-[[:space:]]Copy/weights/last.pt filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
yolo_runs/smartvision_yolov8s_alltrain/BoxF1_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
yolo_runs/smartvision_yolov8s_alltrain/BoxPR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
yolo_runs/smartvision_yolov8s_alltrain/BoxP_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
yolo_runs/smartvision_yolov8s_alltrain/BoxR_curve.png filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
yolo_runs/smartvision_yolov8s_alltrain/confusion_matrix.png filter=lfs diff=lfs merge=lfs -text
|
| 64 |
+
yolo_runs/smartvision_yolov8s_alltrain/confusion_matrix_normalized.png filter=lfs diff=lfs merge=lfs -text
|
| 65 |
+
yolo_runs/smartvision_yolov8s_alltrain/labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 66 |
+
yolo_runs/smartvision_yolov8s_alltrain/results.png filter=lfs diff=lfs merge=lfs -text
|
| 67 |
+
yolo_runs/smartvision_yolov8s_alltrain/train_batch0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 68 |
+
yolo_runs/smartvision_yolov8s_alltrain/train_batch1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 69 |
+
yolo_runs/smartvision_yolov8s_alltrain/train_batch2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 70 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch0_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 71 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch0_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 72 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch1_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 73 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch1_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 74 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch2_labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 75 |
+
yolo_runs/smartvision_yolov8s_alltrain/val_batch2_pred.jpg filter=lfs diff=lfs merge=lfs -text
|
| 76 |
+
yolo_runs/smartvision_yolov8s_alltrain/weights/best.pt filter=lfs diff=lfs merge=lfs -text
|
| 77 |
+
yolo_runs/smartvision_yolov8s_alltrain/weights/last.pt filter=lfs diff=lfs merge=lfs -text
|
| 78 |
+
yolo_runs/smartvision_yolov8s_alltrain2/labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 79 |
+
yolo_runs/smartvision_yolov8s_alltrain2/train_batch0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 80 |
+
yolo_runs/smartvision_yolov8s_alltrain2/train_batch1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 81 |
+
yolo_runs/smartvision_yolov8s_alltrain2/train_batch2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 82 |
+
yolo_runs/smartvision_yolov8s_alltrain3/labels.jpg filter=lfs diff=lfs merge=lfs -text
|
| 83 |
+
yolo_runs/smartvision_yolov8s_alltrain3/train_batch0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 84 |
+
yolo_runs/smartvision_yolov8s_alltrain3/train_batch1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 85 |
+
yolo_runs/smartvision_yolov8s_alltrain3/train_batch2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 86 |
+
yolo_runs/smartvision_yolov8s_alltrain3/weights/best.pt filter=lfs diff=lfs merge=lfs -text
|
| 87 |
+
yolo_runs/smartvision_yolov8s_alltrain3/weights/last.pt filter=lfs diff=lfs merge=lfs -text
|
| 88 |
+
yolo_vis/samples/image_000001.jpg filter=lfs diff=lfs merge=lfs -text
|
| 89 |
+
yolo_vis/samples/image_000003.jpg filter=lfs diff=lfs merge=lfs -text
|
| 90 |
+
yolo_vis/samples/image_000004.jpg filter=lfs diff=lfs merge=lfs -text
|
| 91 |
+
yolo_vis/samples/image_000005.jpg filter=lfs diff=lfs merge=lfs -text
|
| 92 |
+
yolo_vis/samples/image_000006.jpg filter=lfs diff=lfs merge=lfs -text
|
| 93 |
+
yolo_vis/samples/image_000007.jpg filter=lfs diff=lfs merge=lfs -text
|
| 94 |
+
yolo_vis/samples2/image_000001.jpg filter=lfs diff=lfs merge=lfs -text
|
| 95 |
+
yolo_vis/samples2/image_000002.jpg filter=lfs diff=lfs merge=lfs -text
|
| 96 |
+
yolo_vis/samples2/image_000003.jpg filter=lfs diff=lfs merge=lfs -text
|
| 97 |
+
yolo_vis/samples2/image_000004.jpg filter=lfs diff=lfs merge=lfs -text
|
| 98 |
+
yolo_vis/samples2/image_000005.jpg filter=lfs diff=lfs merge=lfs -text
|
| 99 |
+
yolo_vis/samples2/image_000007.jpg filter=lfs diff=lfs merge=lfs -text
|
| 100 |
+
yolo_vis/samples3/image_001750.jpg filter=lfs diff=lfs merge=lfs -text
|
| 101 |
+
yolo_vis/samples3/image_001752.jpg filter=lfs diff=lfs merge=lfs -text
|
| 102 |
+
yolo_vis/samples3/image_001753.jpg filter=lfs diff=lfs merge=lfs -text
|
| 103 |
+
yolo_vis/samples3/image_001755.jpg filter=lfs diff=lfs merge=lfs -text
|
| 104 |
+
yolo_vis/samples3/image_001756.jpg filter=lfs diff=lfs merge=lfs -text
|
| 105 |
+
yolo_vis/samples3/image_001757.jpg filter=lfs diff=lfs merge=lfs -text
|
| 106 |
+
yolo_vis/samples4/image_001750.jpg filter=lfs diff=lfs merge=lfs -text
|
| 107 |
+
yolo_vis/samples4/image_001751.jpg filter=lfs diff=lfs merge=lfs -text
|
| 108 |
+
yolo_vis/samples4/image_001752.jpg filter=lfs diff=lfs merge=lfs -text
|
| 109 |
+
yolo_vis/samples4/image_001753.jpg filter=lfs diff=lfs merge=lfs -text
|
| 110 |
+
yolo_vis/samples4/image_001754.jpg filter=lfs diff=lfs merge=lfs -text
|
| 111 |
+
yolo_vis/samples4/image_001755.jpg filter=lfs diff=lfs merge=lfs -text
|
| 112 |
+
yolo_vis/samples4/image_001757.jpg filter=lfs diff=lfs merge=lfs -text
|
| 113 |
+
yolo_vis/samples_debug/image_001750.jpg filter=lfs diff=lfs merge=lfs -text
|
| 114 |
+
yolo_vis/samples_debug/image_001752.jpg filter=lfs diff=lfs merge=lfs -text
|
| 115 |
+
yolo_vis/samples_debug/image_001753.jpg filter=lfs diff=lfs merge=lfs -text
|
| 116 |
+
yolo_vis/samples_debug2/image_001750.jpg filter=lfs diff=lfs merge=lfs -text
|
| 117 |
+
yolo_vis/samples_debug2/image_001751.jpg filter=lfs diff=lfs merge=lfs -text
|
| 118 |
+
yolo_vis/samples_debug2/image_001752.jpg filter=lfs diff=lfs merge=lfs -text
|
| 119 |
+
yolo_vis/samples_debug2/image_001753.jpg filter=lfs diff=lfs merge=lfs -text
|
| 120 |
+
yolov8n.pt filter=lfs diff=lfs merge=lfs -text
|
| 121 |
+
yolov8s.pt filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/main.yml
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Deploy to Hugging Face Space
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- main
|
| 7 |
+
workflow_dispatch:
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
deploy:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
|
| 13 |
+
steps:
|
| 14 |
+
# Step 1 — Checkout repo with LFS
|
| 15 |
+
- name: Checkout repository
|
| 16 |
+
uses: actions/checkout@v4
|
| 17 |
+
with:
|
| 18 |
+
fetch-depth: 0
|
| 19 |
+
lfs: true
|
| 20 |
+
|
| 21 |
+
# (Optional) Verify that LFS files are real binaries, not pointers
|
| 22 |
+
- name: Verify model files
|
| 23 |
+
run: |
|
| 24 |
+
ls -lh saved_models || echo "saved_models folder not found"
|
| 25 |
+
file saved_models/resnet50_v2_stage2_best.weights.h5 || echo "resnet file missing"
|
| 26 |
+
file saved_models/vgg16_v2_stage2_best.h5 || echo "vgg16 file missing"
|
| 27 |
+
|
| 28 |
+
# Step 2 — Set up Python
|
| 29 |
+
- name: Set up Python
|
| 30 |
+
uses: actions/setup-python@v4
|
| 31 |
+
with:
|
| 32 |
+
python-version: "3.10"
|
| 33 |
+
|
| 34 |
+
# Step 3 — Install Hugging Face Hub client
|
| 35 |
+
- name: Install Hugging Face Hub
|
| 36 |
+
run: pip install --upgrade huggingface_hub
|
| 37 |
+
|
| 38 |
+
# Step 4 — Upload entire repo to the Space
|
| 39 |
+
- name: Deploy to Hugging Face Space
|
| 40 |
+
env:
|
| 41 |
+
HF_TOKEN_01: ${{ secrets.HF_TOKEN_01 }}
|
| 42 |
+
HF_SPACE_ID: "yogesh-venkat/SmartVision_AI"
|
| 43 |
+
run: |
|
| 44 |
+
python - << 'EOF'
|
| 45 |
+
from huggingface_hub import HfApi
|
| 46 |
+
import os
|
| 47 |
+
|
| 48 |
+
space_id = os.getenv("HF_SPACE_ID")
|
| 49 |
+
token = os.getenv("HF_TOKEN_01")
|
| 50 |
+
api = HfApi()
|
| 51 |
+
|
| 52 |
+
print(f"🚀 Deploying to Hugging Face Space: {space_id}")
|
| 53 |
+
api.upload_folder(
|
| 54 |
+
repo_id=space_id,
|
| 55 |
+
repo_type="space",
|
| 56 |
+
folder_path=".",
|
| 57 |
+
token=token,
|
| 58 |
+
commit_message="Auto-deploy from GitHub Actions",
|
| 59 |
+
)
|
| 60 |
+
EOF
|
.gitignore
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------
|
| 2 |
+
# Python general
|
| 3 |
+
# --------------------------------------------------
|
| 4 |
+
__pycache__/
|
| 5 |
+
*.py[cod]
|
| 6 |
+
*.pyo
|
| 7 |
+
*.pyd
|
| 8 |
+
*.so
|
| 9 |
+
*.egg-info/
|
| 10 |
+
.env
|
| 11 |
+
.venv
|
| 12 |
+
env/
|
| 13 |
+
venv/
|
| 14 |
+
ENV/
|
| 15 |
+
.ipynb_checkpoints/
|
| 16 |
+
|
| 17 |
+
# --------------------------------------------------
|
| 18 |
+
# OS / Editor junk
|
| 19 |
+
# --------------------------------------------------
|
| 20 |
+
.DS_Store
|
| 21 |
+
Thumbs.db
|
| 22 |
+
.idea/
|
| 23 |
+
.vscode/
|
| 24 |
+
*.swp
|
| 25 |
+
|
| 26 |
+
# --------------------------------------------------
|
| 27 |
+
# Streamlit
|
| 28 |
+
# --------------------------------------------------
|
| 29 |
+
.streamlit/cache/
|
| 30 |
+
.streamlit/static/
|
| 31 |
+
|
| 32 |
+
# --------------------------------------------------
|
| 33 |
+
# Logs
|
| 34 |
+
# --------------------------------------------------
|
| 35 |
+
logs/
|
| 36 |
+
*.log
|
| 37 |
+
|
| 38 |
+
# --------------------------------------------------
|
| 39 |
+
# Datasets (local only)
|
| 40 |
+
# --------------------------------------------------
|
| 41 |
+
smartvision_dataset/
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# --------------------------------------------------
|
| 46 |
+
# Misc
|
| 47 |
+
# --------------------------------------------------
|
| 48 |
+
*.tmp
|
| 49 |
+
*.bak
|
| 50 |
+
*.old
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
untitled*
|
| 54 |
+
draft*
|
README.md
ADDED
|
@@ -0,0 +1,253 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
title: SmartVision AI
|
| 4 |
+
sdk: streamlit
|
| 5 |
+
emoji: 🚀
|
| 6 |
+
colorFrom: red
|
| 7 |
+
colorTo: red
|
| 8 |
+
short_description: Multi-domain smart object detection and classification syste
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# SmartVision AI – Complete Vision Pipeline (YOLOv8 + CNN Classifiers + Streamlit Dashboard)
|
| 12 |
+
|
| 13 |
+
SmartVision AI is a fully integrated **Computer Vision system** that combines:
|
| 14 |
+
|
| 15 |
+
- **Object Detection** using YOLOv8
|
| 16 |
+
- **Image Classification** using 4 deep-learning models:
|
| 17 |
+
**VGG16**, **ResNet50**, **MobileNetV2**, **EfficientNetB0**
|
| 18 |
+
- A complete **Streamlit-based Dashboard** for inference, comparison, metrics visualization, and webcam snapshots
|
| 19 |
+
- A modified dataset built on a **25‑class COCO subset**
|
| 20 |
+
|
| 21 |
+
This README explains setup, architecture, training, deployment, and usage.
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
## 🚀 Features
|
| 26 |
+
|
| 27 |
+
### ✅ 1. Image Classification (4 Models)
|
| 28 |
+
Each model is fine‑tuned on your custom 25‑class dataset:
|
| 29 |
+
- **VGG16**
|
| 30 |
+
- **ResNet50**
|
| 31 |
+
- **MobileNetV2**
|
| 32 |
+
- **EfficientNetB0**
|
| 33 |
+
|
| 34 |
+
Outputs:
|
| 35 |
+
- Top‑1 class prediction
|
| 36 |
+
- Top‑5 predictions
|
| 37 |
+
- Class probabilities
|
| 38 |
+
|
| 39 |
+
---
|
| 40 |
+
|
| 41 |
+
### 🎯 2. Object Detection – YOLOv8s
|
| 42 |
+
YOLO detects multiple objects in images or webcam snapshots.
|
| 43 |
+
|
| 44 |
+
Features:
|
| 45 |
+
- Bounding boxes
|
| 46 |
+
- Confidence scores
|
| 47 |
+
- Optional classification verification using ResNet50
|
| 48 |
+
- Annotated images saved automatically
|
| 49 |
+
|
| 50 |
+
---
|
| 51 |
+
|
| 52 |
+
### 🔗 3. Integrated Classification + Detection Pipeline
|
| 53 |
+
For each YOLO‑detected box:
|
| 54 |
+
1. Crop region
|
| 55 |
+
2. Classify using chosen CNN model
|
| 56 |
+
3. Display YOLO label + classifier label
|
| 57 |
+
4. Draw combined annotated results
|
| 58 |
+
|
| 59 |
+
---
|
| 60 |
+
|
| 61 |
+
### 📊 4. Metrics Dashboard
|
| 62 |
+
Displays:
|
| 63 |
+
- Accuracy
|
| 64 |
+
- Weighted F1 score
|
| 65 |
+
- Top‑5 accuracy
|
| 66 |
+
- Images per second
|
| 67 |
+
- Model size
|
| 68 |
+
- YOLOv8 mAP scores
|
| 69 |
+
- Confusion matrices
|
| 70 |
+
- Comparison bar charts
|
| 71 |
+
|
| 72 |
+
---
|
| 73 |
+
|
| 74 |
+
### 📷 5. Webcam Snapshot Detection
|
| 75 |
+
Take a photo via webcam → YOLO detection → annotated results.
|
| 76 |
+
|
| 77 |
+
---
|
| 78 |
+
|
| 79 |
+
## 📁 Project Structure
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
SmartVision_AI/
|
| 83 |
+
│
|
| 84 |
+
├── app.py # Main Streamlit App
|
| 85 |
+
├── saved_models/ # Trained weights (VGG16, ResNet, MobileNetV2, EfficientNet)
|
| 86 |
+
├── yolo_runs/ # YOLOv8 training folder
|
| 87 |
+
├── smartvision_dataset/ # 25-class dataset
|
| 88 |
+
│ ├── classification/
|
| 89 |
+
│ │ ├── train/
|
| 90 |
+
│ │ ├── val/
|
| 91 |
+
│ │ └── test/
|
| 92 |
+
│ └── detection/ # Labels + images for YOLOv8
|
| 93 |
+
│
|
| 94 |
+
├── smartvision_metrics/ # Accuracy, F1, confusion matrices
|
| 95 |
+
├── scripts/ # Weight converters, training scripts
|
| 96 |
+
├── inference_outputs/ # Annotated results
|
| 97 |
+
├── requirements.txt
|
| 98 |
+
└── README.md
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
---
|
| 102 |
+
|
| 103 |
+
## ⚙️ Installation
|
| 104 |
+
|
| 105 |
+
### 1️⃣ Clone Repository
|
| 106 |
+
|
| 107 |
+
```
|
| 108 |
+
git clone https://github.com/<your-username>/SmartVision_AI.git
|
| 109 |
+
cd SmartVision_AI
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
### 2️⃣ Install Dependencies
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
pip install -r requirements.txt
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
### 3️⃣ Install YOLOv8 (Ultralytics)
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
pip install ultralytics
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
---
|
| 125 |
+
|
| 126 |
+
## ▶️ Run Streamlit App
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
streamlit run app.py
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
App will open at:
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
http://localhost:8501
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
---
|
| 139 |
+
|
| 140 |
+
## 🏋️ Training Workflow
|
| 141 |
+
|
| 142 |
+
### 1️⃣ Classification Models
|
| 143 |
+
Each model has:
|
| 144 |
+
- Stage 1 → Train head with frozen backbone
|
| 145 |
+
- Stage 2 → Unfreeze top layers + fine‑tune
|
| 146 |
+
|
| 147 |
+
Scripts:
|
| 148 |
+
```
|
| 149 |
+
scripts/train_mobilenetv2.py
|
| 150 |
+
scripts/train_efficientnetb0.py
|
| 151 |
+
scripts/train_resnet50.py
|
| 152 |
+
scripts/train_vgg16.py
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
### 2️⃣ YOLO Training
|
| 156 |
+
|
| 157 |
+
```
|
| 158 |
+
yolo task=detect mode=train model=yolov8s.pt data=data.yaml epochs=50 imgsz=640
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
Outputs saved to:
|
| 162 |
+
```
|
| 163 |
+
yolo_runs/smartvision_yolov8s/
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
---
|
| 167 |
+
|
| 168 |
+
## 🧪 Supported Classes (25 COCO Classes)
|
| 169 |
+
|
| 170 |
+
```
|
| 171 |
+
airplane, bed, bench, bicycle, bird, bottle, bowl,
|
| 172 |
+
bus, cake, car, cat, chair, couch, cow, cup, dog,
|
| 173 |
+
elephant, horse, motorcycle, person, pizza, potted plant,
|
| 174 |
+
stop sign, traffic light, truck
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
---
|
| 178 |
+
|
| 179 |
+
## 🧰 Deployment on Hugging Face Spaces
|
| 180 |
+
|
| 181 |
+
You can deploy using **Streamlit SDK**.
|
| 182 |
+
|
| 183 |
+
### Steps:
|
| 184 |
+
1. Create public repository on GitHub
|
| 185 |
+
2. Push project files
|
| 186 |
+
3. Create new Hugging Face Space → select **Streamlit**
|
| 187 |
+
4. Connect GitHub repo
|
| 188 |
+
5. Add `requirements.txt`
|
| 189 |
+
6. Enable **GPU** for YOLO (optional)
|
| 190 |
+
7. Deploy 🚀
|
| 191 |
+
|
| 192 |
+
---
|
| 193 |
+
|
| 194 |
+
## 🧾 requirements.txt Example
|
| 195 |
+
|
| 196 |
+
```
|
| 197 |
+
streamlit
|
| 198 |
+
tensorflow==2.13.0
|
| 199 |
+
ultralytics
|
| 200 |
+
numpy
|
| 201 |
+
pandas
|
| 202 |
+
Pillow
|
| 203 |
+
matplotlib
|
| 204 |
+
scikit-learn
|
| 205 |
+
opencv-python-headless
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
---
|
| 209 |
+
|
| 210 |
+
## 📄 .gitignore Example
|
| 211 |
+
|
| 212 |
+
```
|
| 213 |
+
saved_models/
|
| 214 |
+
*.h5
|
| 215 |
+
*.pt
|
| 216 |
+
*.weights.h5
|
| 217 |
+
yolo_runs/
|
| 218 |
+
smartvision_metrics/
|
| 219 |
+
inference_outputs/
|
| 220 |
+
__pycache__/
|
| 221 |
+
*.pyc
|
| 222 |
+
.DS_Store
|
| 223 |
+
env/
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
---
|
| 227 |
+
|
| 228 |
+
## 🙋 Developer
|
| 229 |
+
|
| 230 |
+
**SmartVision AI Project**
|
| 231 |
+
Yogesh Kumar V
|
| 232 |
+
M.Sc. Seed Science & Technology (TNAU)
|
| 233 |
+
Passion: AI, Computer Vision, Agribusiness Technology
|
| 234 |
+
|
| 235 |
+
---
|
| 236 |
+
|
| 237 |
+
## 🏁 Conclusion
|
| 238 |
+
|
| 239 |
+
SmartVision AI integrates:
|
| 240 |
+
- Multi‑model classification
|
| 241 |
+
- YOLO detection
|
| 242 |
+
- Streamlit visualization
|
| 243 |
+
- Full evaluation suite
|
| 244 |
+
|
| 245 |
+
Perfect for:
|
| 246 |
+
- Research
|
| 247 |
+
- Demonstrations
|
| 248 |
+
- CV/AI portfolio
|
| 249 |
+
- Real‑world image understanding
|
| 250 |
+
|
| 251 |
+
---
|
| 252 |
+
|
| 253 |
+
Enjoy using SmartVision AI! 🚀🧠
|
app.py
ADDED
|
@@ -0,0 +1,872 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
import json
|
| 4 |
+
from typing import Dict, Any, List
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 8 |
+
|
| 9 |
+
import streamlit as st
|
| 10 |
+
import pandas as pd
|
| 11 |
+
|
| 12 |
+
import tensorflow as tf
|
| 13 |
+
from tensorflow import keras
|
| 14 |
+
from tensorflow.keras import layers, regularizers
|
| 15 |
+
from ultralytics import YOLO
|
| 16 |
+
|
| 17 |
+
# Keras application imports
|
| 18 |
+
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input as vgg16_preprocess
|
| 19 |
+
from tensorflow.keras.applications.efficientnet import EfficientNetB0, preprocess_input as effnet_preprocess
|
| 20 |
+
|
| 21 |
+
# ------------------------------------------------------------
|
| 22 |
+
# GLOBAL CONFIG
|
| 23 |
+
# ------------------------------------------------------------
|
| 24 |
+
st.set_page_config(
|
| 25 |
+
page_title="SmartVision AI",
|
| 26 |
+
page_icon="🧠",
|
| 27 |
+
layout="wide",
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
st.markdown(
|
| 31 |
+
"""
|
| 32 |
+
<h1 style='text-align:center;'>
|
| 33 |
+
🤖⚡ <b>SmartVision AI</b> ⚡🤖
|
| 34 |
+
</h1>
|
| 35 |
+
<h3 style='text-align:center; margin-top:-10px;'>
|
| 36 |
+
🔎🎯 Intelligent Multi-Class Object Recognition System 🎯🔎
|
| 37 |
+
</h3>
|
| 38 |
+
""",
|
| 39 |
+
unsafe_allow_html=True
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
st.markdown(
|
| 45 |
+
"<p style='text-align:center; color: gray;'>End-to-end computer vision pipeline on a COCO subset of 25 everyday object classes</p>",
|
| 46 |
+
unsafe_allow_html=True
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
st.divider()
|
| 50 |
+
|
| 51 |
+
from pathlib import Path
|
| 52 |
+
|
| 53 |
+
# Resolve repository root relative to this file (streamlit_app/app.py)
|
| 54 |
+
THIS_FILE = Path(__file__).resolve()
|
| 55 |
+
REPO_ROOT = THIS_FILE.parent # repo/
|
| 56 |
+
SAVED_MODELS_DIR = REPO_ROOT / "saved_models"
|
| 57 |
+
YOLO_RUNS_DIR = REPO_ROOT / "yolo_runs"
|
| 58 |
+
SMARTVISION_METRICS_DIR = REPO_ROOT / "smartvision_metrics"
|
| 59 |
+
SMARTVISION_DATASET_DIR = REPO_ROOT / "smartvision_dataset"
|
| 60 |
+
|
| 61 |
+
# Then turn constants into Path objects / strings
|
| 62 |
+
YOLO_WEIGHTS_PATH = str(YOLO_RUNS_DIR / "smartvision_yolov8s6 - Copy" / "weights" / "best.pt")
|
| 63 |
+
|
| 64 |
+
CLASSIFIER_MODEL_CONFIGS = {
|
| 65 |
+
"VGG16": {
|
| 66 |
+
"type": "vgg16",
|
| 67 |
+
"path": str(SAVED_MODELS_DIR / "vgg16_v2_stage2_best.h5"),
|
| 68 |
+
},
|
| 69 |
+
"ResNet50": {
|
| 70 |
+
"type": "resnet50",
|
| 71 |
+
"path": str(SAVED_MODELS_DIR / "resnet50_v2_stage2_best.weights.h5"),
|
| 72 |
+
},
|
| 73 |
+
"MobileNetV2": {
|
| 74 |
+
"type": "mobilenetv2",
|
| 75 |
+
"path": str(SAVED_MODELS_DIR / "mobilenetv2_v2_stage2_best.weights.h5"),
|
| 76 |
+
},
|
| 77 |
+
"EfficientNetB0": {
|
| 78 |
+
"type": "efficientnetb0",
|
| 79 |
+
"path": str(SAVED_MODELS_DIR / "efficientnetb0_stage2_best.weights.h5"),
|
| 80 |
+
},
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
CLASS_METRIC_PATHS = {
|
| 84 |
+
"VGG16": str(SMARTVISION_METRICS_DIR / "vgg16_v2_stage2" / "metrics.json"),
|
| 85 |
+
"ResNet50": str(SMARTVISION_METRICS_DIR / "resnet50_v2_stage2" / "metrics.json"),
|
| 86 |
+
"MobileNetV2": str(SMARTVISION_METRICS_DIR / "mobilenetv2_v2" / "metrics.json"),
|
| 87 |
+
"EfficientNetB0": str(SMARTVISION_METRICS_DIR / "efficientnetb0" / "metrics.json"),
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
YOLO_METRICS_JSON = str(REPO_ROOT / "yolo_metrics" / "yolov8s_metrics.json")
|
| 91 |
+
BASE_DIR = str(SMARTVISION_DATASET_DIR)
|
| 92 |
+
CLASS_DIR = str(SMARTVISION_DATASET_DIR / "classification")
|
| 93 |
+
DET_DIR = str(SMARTVISION_DATASET_DIR / "detection")
|
| 94 |
+
|
| 95 |
+
IMG_SIZE = (224, 224)
|
| 96 |
+
NUM_CLASSES = 25
|
| 97 |
+
|
| 98 |
+
CLASS_NAMES = [
|
| 99 |
+
"airplane", "bed", "bench", "bicycle", "bird", "bottle", "bowl",
|
| 100 |
+
"bus", "cake", "car", "cat", "chair", "couch", "cow", "cup", "dog",
|
| 101 |
+
"elephant", "horse", "motorcycle", "person", "pizza", "potted plant",
|
| 102 |
+
"stop sign", "traffic light", "truck"
|
| 103 |
+
]
|
| 104 |
+
assert len(CLASS_NAMES) == NUM_CLASSES
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
# ------------------------------------------------------------
|
| 110 |
+
# BUILDERS – MATCH TRAINING ARCHITECTURES
|
| 111 |
+
# ------------------------------------------------------------
|
| 112 |
+
|
| 113 |
+
# ---------- VGG16 v2 ----------
|
| 114 |
+
def build_vgg16_model_v2():
|
| 115 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 116 |
+
|
| 117 |
+
data_augmentation = keras.Sequential(
|
| 118 |
+
[
|
| 119 |
+
layers.RandomFlip("horizontal"),
|
| 120 |
+
layers.RandomRotation(0.04),
|
| 121 |
+
layers.RandomZoom(0.1),
|
| 122 |
+
layers.RandomContrast(0.2),
|
| 123 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.2)),
|
| 124 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.8, 1.2)),
|
| 125 |
+
],
|
| 126 |
+
name="data_augmentation",
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
x = data_augmentation(inputs)
|
| 130 |
+
|
| 131 |
+
x = layers.Lambda(
|
| 132 |
+
lambda z: vgg16_preprocess(tf.cast(z, tf.float32)),
|
| 133 |
+
name="vgg16_preprocess",
|
| 134 |
+
)(x)
|
| 135 |
+
|
| 136 |
+
base_model = VGG16(
|
| 137 |
+
include_top=False,
|
| 138 |
+
weights="imagenet",
|
| 139 |
+
input_tensor=x,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(base_model.output)
|
| 143 |
+
x = layers.Dense(256, activation="relu", name="dense_256")(x)
|
| 144 |
+
x = layers.Dropout(0.5, name="dropout_0_5")(x)
|
| 145 |
+
outputs = layers.Dense(NUM_CLASSES, activation="softmax", name="predictions")(x)
|
| 146 |
+
|
| 147 |
+
model = keras.Model(inputs=inputs, outputs=outputs, name="VGG16_smartvision_v2")
|
| 148 |
+
return model
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
# ---------- ResNet50 v2 ----------
|
| 152 |
+
def build_resnet50_model_v2():
|
| 153 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 154 |
+
|
| 155 |
+
data_augmentation = keras.Sequential(
|
| 156 |
+
[
|
| 157 |
+
layers.RandomFlip("horizontal"),
|
| 158 |
+
layers.RandomRotation(0.04),
|
| 159 |
+
layers.RandomZoom(0.1),
|
| 160 |
+
layers.RandomContrast(0.15),
|
| 161 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.15)),
|
| 162 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.85, 1.15)),
|
| 163 |
+
],
|
| 164 |
+
name="data_augmentation",
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
x = data_augmentation(inputs)
|
| 168 |
+
|
| 169 |
+
x = layers.Lambda(
|
| 170 |
+
keras.applications.resnet50.preprocess_input,
|
| 171 |
+
name="resnet50_preprocess",
|
| 172 |
+
)(x)
|
| 173 |
+
|
| 174 |
+
base_model = keras.applications.ResNet50(
|
| 175 |
+
include_top=False,
|
| 176 |
+
weights="imagenet",
|
| 177 |
+
input_shape=(*IMG_SIZE, 3),
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
x = base_model(x)
|
| 181 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 182 |
+
x = layers.BatchNormalization(name="head_batchnorm")(x)
|
| 183 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 184 |
+
x = layers.Dense(256, activation="relu", name="head_dense")(x)
|
| 185 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 186 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 187 |
+
outputs = layers.Dense(NUM_CLASSES, activation="softmax", name="predictions")(x)
|
| 188 |
+
|
| 189 |
+
model = keras.Model(inputs=inputs, outputs=outputs, name="ResNet50_smartvision_v2")
|
| 190 |
+
return model
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
# ---------- MobileNetV2 v2 ----------
|
| 194 |
+
def build_mobilenetv2_model_v2():
|
| 195 |
+
"""
|
| 196 |
+
Same architecture as the MobileNetV2 v2 training script.
|
| 197 |
+
"""
|
| 198 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 199 |
+
|
| 200 |
+
data_augmentation = keras.Sequential(
|
| 201 |
+
[
|
| 202 |
+
layers.RandomFlip("horizontal"),
|
| 203 |
+
layers.RandomRotation(0.04), # ~±15°
|
| 204 |
+
layers.RandomZoom(0.1),
|
| 205 |
+
layers.RandomContrast(0.15),
|
| 206 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.15)),
|
| 207 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.85, 1.15)),
|
| 208 |
+
],
|
| 209 |
+
name="data_augmentation",
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
x = data_augmentation(inputs)
|
| 213 |
+
|
| 214 |
+
x = layers.Lambda(
|
| 215 |
+
keras.applications.mobilenet_v2.preprocess_input,
|
| 216 |
+
name="mobilenetv2_preprocess",
|
| 217 |
+
)(x)
|
| 218 |
+
|
| 219 |
+
base_model = keras.applications.MobileNetV2(
|
| 220 |
+
include_top=False,
|
| 221 |
+
weights="imagenet",
|
| 222 |
+
input_shape=(*IMG_SIZE, 3),
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
x = base_model(x)
|
| 226 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 227 |
+
|
| 228 |
+
x = layers.BatchNormalization(name="head_batchnorm_1")(x)
|
| 229 |
+
x = layers.Dropout(0.4, name="head_dropout_1")(x)
|
| 230 |
+
|
| 231 |
+
x = layers.Dense(
|
| 232 |
+
256,
|
| 233 |
+
activation="relu",
|
| 234 |
+
kernel_regularizer=regularizers.l2(1e-4),
|
| 235 |
+
name="head_dense_1",
|
| 236 |
+
)(x)
|
| 237 |
+
|
| 238 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 239 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 240 |
+
|
| 241 |
+
outputs = layers.Dense(NUM_CLASSES, activation="softmax", name="predictions")(x)
|
| 242 |
+
|
| 243 |
+
model = keras.Model(
|
| 244 |
+
inputs=inputs,
|
| 245 |
+
outputs=outputs,
|
| 246 |
+
name="MobileNetV2_smartvision_v2",
|
| 247 |
+
)
|
| 248 |
+
return model
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
# ---------- EfficientNetB0 ----------
|
| 252 |
+
def bright_jitter(x):
|
| 253 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 254 |
+
x_f32 = tf.image.random_brightness(x_f32, max_delta=0.25)
|
| 255 |
+
return tf.cast(x_f32, x.dtype)
|
| 256 |
+
|
| 257 |
+
def sat_jitter(x):
|
| 258 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 259 |
+
x_f32 = tf.image.random_saturation(x_f32, lower=0.7, upper=1.3)
|
| 260 |
+
return tf.cast(x_f32, x.dtype)
|
| 261 |
+
|
| 262 |
+
def build_efficientnetb0_model():
|
| 263 |
+
"""
|
| 264 |
+
Same architecture as EfficientNetB0 training script
|
| 265 |
+
(without the mixed precision policy setup, which belongs in training code).
|
| 266 |
+
"""
|
| 267 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 268 |
+
|
| 269 |
+
data_augmentation = keras.Sequential(
|
| 270 |
+
[
|
| 271 |
+
layers.RandomFlip("horizontal"),
|
| 272 |
+
layers.RandomRotation(0.08),
|
| 273 |
+
layers.RandomZoom(0.15),
|
| 274 |
+
layers.RandomContrast(0.3),
|
| 275 |
+
layers.RandomTranslation(0.1, 0.1),
|
| 276 |
+
layers.Lambda(bright_jitter),
|
| 277 |
+
layers.Lambda(sat_jitter),
|
| 278 |
+
],
|
| 279 |
+
name="advanced_data_augmentation",
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
x = data_augmentation(inputs)
|
| 283 |
+
|
| 284 |
+
x = layers.Lambda(
|
| 285 |
+
lambda z: effnet_preprocess(tf.cast(z, tf.float32)),
|
| 286 |
+
name="effnet_preprocess",
|
| 287 |
+
)(x)
|
| 288 |
+
|
| 289 |
+
base_model = EfficientNetB0(
|
| 290 |
+
include_top=False,
|
| 291 |
+
weights="imagenet",
|
| 292 |
+
name="efficientnetb0",
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
x = base_model(x, training=False)
|
| 296 |
+
|
| 297 |
+
x = layers.GlobalAveragePooling2D(name="gap")(x)
|
| 298 |
+
x = layers.BatchNormalization(name="head_bn_1")(x)
|
| 299 |
+
x = layers.Dense(256, activation="relu", name="head_dense_1")(x)
|
| 300 |
+
x = layers.BatchNormalization(name="head_bn_2")(x)
|
| 301 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 302 |
+
|
| 303 |
+
outputs = layers.Dense(
|
| 304 |
+
NUM_CLASSES,
|
| 305 |
+
activation="softmax",
|
| 306 |
+
dtype="float32",
|
| 307 |
+
name="predictions",
|
| 308 |
+
)(x)
|
| 309 |
+
|
| 310 |
+
model = keras.Model(inputs, outputs, name="EfficientNetB0_smartvision")
|
| 311 |
+
return model
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
# ------------------------------------------------------------
|
| 315 |
+
# CACHED MODEL LOADERS
|
| 316 |
+
# ------------------------------------------------------------
|
| 317 |
+
@st.cache_resource(show_spinner=True)
|
| 318 |
+
def load_yolo_model() -> YOLO:
|
| 319 |
+
if not os.path.exists(YOLO_WEIGHTS_PATH):
|
| 320 |
+
raise FileNotFoundError(f"YOLO weights not found: {YOLO_WEIGHTS_PATH}")
|
| 321 |
+
model = YOLO(YOLO_WEIGHTS_PATH)
|
| 322 |
+
return model
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
@st.cache_resource(show_spinner=True)
|
| 326 |
+
def load_classification_models() -> Dict[str, keras.Model]:
|
| 327 |
+
"""
|
| 328 |
+
Build each architecture fresh, then TRY to load your trained weights.
|
| 329 |
+
If loading fails or path is None, the model is still returned
|
| 330 |
+
(ImageNet-pretrained backbone + random head), so all 4 are enabled.
|
| 331 |
+
"""
|
| 332 |
+
models: Dict[str, keras.Model] = {}
|
| 333 |
+
|
| 334 |
+
for name, cfg in CLASSIFIER_MODEL_CONFIGS.items():
|
| 335 |
+
model_type = cfg["type"]
|
| 336 |
+
path = cfg["path"]
|
| 337 |
+
|
| 338 |
+
# 1) Build the architecture
|
| 339 |
+
if model_type == "vgg16":
|
| 340 |
+
model = build_vgg16_model_v2()
|
| 341 |
+
elif model_type == "resnet50":
|
| 342 |
+
model = build_resnet50_model_v2()
|
| 343 |
+
elif model_type == "mobilenetv2":
|
| 344 |
+
model = build_mobilenetv2_model_v2()
|
| 345 |
+
elif model_type == "efficientnetb0":
|
| 346 |
+
model = build_efficientnetb0_model()
|
| 347 |
+
else:
|
| 348 |
+
continue
|
| 349 |
+
|
| 350 |
+
# 2) Try to load your training weights (if path is provided and file exists)
|
| 351 |
+
if path is not None and os.path.exists(path):
|
| 352 |
+
try:
|
| 353 |
+
model.load_weights(path)
|
| 354 |
+
except Exception as e:
|
| 355 |
+
st.sidebar.warning(
|
| 356 |
+
f"⚠️ Could not fully load weights for {name} from {path}: {e}\n"
|
| 357 |
+
" Using ImageNet-pretrained backbone + random head."
|
| 358 |
+
)
|
| 359 |
+
elif path is not None:
|
| 360 |
+
st.sidebar.warning(
|
| 361 |
+
f"⚠️ Weights file for {name} not found at {path}. "
|
| 362 |
+
"Using ImageNet-pretrained backbone + random head."
|
| 363 |
+
)
|
| 364 |
+
# if path is None → silently use ImageNet + random head
|
| 365 |
+
|
| 366 |
+
models[name] = model
|
| 367 |
+
|
| 368 |
+
return models
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
# ------------------------------------------------------------
|
| 372 |
+
# IMAGE HELPERS
|
| 373 |
+
# ------------------------------------------------------------
|
| 374 |
+
def read_image_file(uploaded_file) -> Image.Image:
|
| 375 |
+
image = Image.open(uploaded_file).convert("RGB")
|
| 376 |
+
return image
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
def preprocess_for_classifier(pil_img: Image.Image) -> np.ndarray:
|
| 380 |
+
img_resized = pil_img.resize(IMG_SIZE, Image.BILINEAR)
|
| 381 |
+
arr = np.array(img_resized, dtype=np.float32)
|
| 382 |
+
arr = np.expand_dims(arr, axis=0) # (1, H, W, 3)
|
| 383 |
+
return arr
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
# ------------------------------------------------------------
|
| 387 |
+
# DRAW BOXES FOR DETECTION
|
| 388 |
+
# ------------------------------------------------------------
|
| 389 |
+
def draw_boxes_with_labels(
|
| 390 |
+
pil_img: Image.Image,
|
| 391 |
+
detections: List[Dict[str, Any]],
|
| 392 |
+
font_path: str = None
|
| 393 |
+
) -> Image.Image:
|
| 394 |
+
draw = ImageDraw.Draw(pil_img)
|
| 395 |
+
|
| 396 |
+
if font_path and os.path.exists(font_path):
|
| 397 |
+
font = ImageFont.truetype(font_path, 16)
|
| 398 |
+
else:
|
| 399 |
+
font = ImageFont.load_default()
|
| 400 |
+
|
| 401 |
+
for det in detections:
|
| 402 |
+
x1, y1, x2, y2 = det["x1"], det["y1"], det["x2"], det["y2"]
|
| 403 |
+
yolo_label = det["label"]
|
| 404 |
+
conf_yolo = det["conf_yolo"]
|
| 405 |
+
cls_label = det.get("cls_label")
|
| 406 |
+
cls_conf = det.get("cls_conf")
|
| 407 |
+
|
| 408 |
+
if cls_label is not None:
|
| 409 |
+
text = f"{yolo_label} {conf_yolo:.2f} | CLS: {cls_label} {cls_conf:.2f}"
|
| 410 |
+
else:
|
| 411 |
+
text = f"{yolo_label} {conf_yolo:.2f}"
|
| 412 |
+
|
| 413 |
+
draw.rectangle([x1, y1, x2, y2], outline="red", width=2)
|
| 414 |
+
|
| 415 |
+
bbox = draw.textbbox((0, 0), text, font=font)
|
| 416 |
+
text_w = bbox[2] - bbox[0]
|
| 417 |
+
text_h = bbox[3] - bbox[1]
|
| 418 |
+
|
| 419 |
+
text_bg = [x1,
|
| 420 |
+
max(0, y1 - text_h - 2),
|
| 421 |
+
x1 + text_w + 4,
|
| 422 |
+
y1]
|
| 423 |
+
draw.rectangle(text_bg, fill="black")
|
| 424 |
+
draw.text((x1 + 2, max(0, y1 - text_h - 1)), text, fill="white", font=font)
|
| 425 |
+
|
| 426 |
+
return pil_img
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
def run_yolo_with_optional_classifier(
|
| 430 |
+
pil_img: Image.Image,
|
| 431 |
+
yolo_model: YOLO,
|
| 432 |
+
classifier_model: keras.Model = None,
|
| 433 |
+
conf_threshold: float = 0.5
|
| 434 |
+
) -> Dict[str, Any]:
|
| 435 |
+
"""Run YOLO on a PIL image, optionally verify each box with classifier."""
|
| 436 |
+
orig_w, orig_h = pil_img.size
|
| 437 |
+
|
| 438 |
+
t0 = time.perf_counter()
|
| 439 |
+
results = yolo_model.predict(
|
| 440 |
+
pil_img,
|
| 441 |
+
imgsz=640,
|
| 442 |
+
conf=conf_threshold,
|
| 443 |
+
device="cpu", # change to "0" if GPU available
|
| 444 |
+
verbose=False,
|
| 445 |
+
)
|
| 446 |
+
t1 = time.perf_counter()
|
| 447 |
+
infer_time = t1 - t0
|
| 448 |
+
|
| 449 |
+
res = results[0]
|
| 450 |
+
boxes = res.boxes
|
| 451 |
+
|
| 452 |
+
detections = []
|
| 453 |
+
|
| 454 |
+
for box in boxes:
|
| 455 |
+
x1, y1, x2, y2 = box.xyxy[0].tolist()
|
| 456 |
+
cls_id = int(box.cls[0].item())
|
| 457 |
+
conf_yolo = float(box.conf[0].item())
|
| 458 |
+
label = res.names[cls_id]
|
| 459 |
+
|
| 460 |
+
x1 = max(0, min(x1, orig_w - 1))
|
| 461 |
+
y1 = max(0, min(y1, orig_h - 1))
|
| 462 |
+
x2 = max(0, min(x2, orig_w - 1))
|
| 463 |
+
y2 = max(0, min(y2, orig_h - 1))
|
| 464 |
+
|
| 465 |
+
cls_label = None
|
| 466 |
+
cls_conf = None
|
| 467 |
+
if classifier_model is not None:
|
| 468 |
+
crop = pil_img.crop((x1, y1, x2, y2))
|
| 469 |
+
arr = preprocess_for_classifier(crop)
|
| 470 |
+
probs = classifier_model.predict(arr, verbose=0)[0]
|
| 471 |
+
idx = int(np.argmax(probs))
|
| 472 |
+
cls_label = CLASS_NAMES[idx]
|
| 473 |
+
cls_conf = float(probs[idx])
|
| 474 |
+
|
| 475 |
+
detections.append(
|
| 476 |
+
{
|
| 477 |
+
"x1": x1,
|
| 478 |
+
"y1": y1,
|
| 479 |
+
"x2": x2,
|
| 480 |
+
"y2": y2,
|
| 481 |
+
"label": label,
|
| 482 |
+
"conf_yolo": conf_yolo,
|
| 483 |
+
"cls_label": cls_label,
|
| 484 |
+
"cls_conf": cls_conf,
|
| 485 |
+
}
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
annotated = pil_img.copy()
|
| 489 |
+
annotated = draw_boxes_with_labels(annotated, detections)
|
| 490 |
+
|
| 491 |
+
return {
|
| 492 |
+
"annotated_image": annotated,
|
| 493 |
+
"detections": detections,
|
| 494 |
+
"yolo_inference_time_sec": infer_time,
|
| 495 |
+
}
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
# ------------------------------------------------------------
|
| 499 |
+
# METRICS LOADING
|
| 500 |
+
# ------------------------------------------------------------
|
| 501 |
+
@st.cache_data
|
| 502 |
+
def load_classification_metrics() -> pd.DataFrame:
|
| 503 |
+
rows = []
|
| 504 |
+
for name, path in CLASS_METRIC_PATHS.items():
|
| 505 |
+
if os.path.exists(path):
|
| 506 |
+
with open(path, "r") as f:
|
| 507 |
+
m = json.load(f)
|
| 508 |
+
rows.append(
|
| 509 |
+
{
|
| 510 |
+
"Model": name,
|
| 511 |
+
"Accuracy": m.get("accuracy", None),
|
| 512 |
+
"F1 (weighted)": m.get("f1_weighted", None),
|
| 513 |
+
"Top-5 Accuracy": m.get("top5_accuracy", None),
|
| 514 |
+
"Images/sec": m.get("images_per_second", None),
|
| 515 |
+
"Size (MB)": m.get("model_size_mb", None),
|
| 516 |
+
}
|
| 517 |
+
)
|
| 518 |
+
df = pd.DataFrame(rows)
|
| 519 |
+
return df
|
| 520 |
+
|
| 521 |
+
|
| 522 |
+
@st.cache_data
|
| 523 |
+
def load_yolo_metrics() -> Dict[str, Any]:
|
| 524 |
+
if not os.path.exists(YOLO_METRICS_JSON):
|
| 525 |
+
return {}
|
| 526 |
+
with open(YOLO_METRICS_JSON, "r") as f:
|
| 527 |
+
return json.load(f)
|
| 528 |
+
|
| 529 |
+
|
| 530 |
+
# ------------------------------------------------------------
|
| 531 |
+
# SIDEBAR NAVIGATION
|
| 532 |
+
# ------------------------------------------------------------
|
| 533 |
+
PAGES = [
|
| 534 |
+
"🏠 Home",
|
| 535 |
+
"🖼️ Image Classification",
|
| 536 |
+
"📦 Object Detection",
|
| 537 |
+
"📊 Model Performance",
|
| 538 |
+
"📷 Webcam Detection (snapshot)",
|
| 539 |
+
"ℹ️ About",
|
| 540 |
+
]
|
| 541 |
+
|
| 542 |
+
page = st.sidebar.radio("Navigate", PAGES)
|
| 543 |
+
|
| 544 |
+
# ------------------------------------------------------------
|
| 545 |
+
# PAGE 1 – HOME
|
| 546 |
+
# ------------------------------------------------------------
|
| 547 |
+
if page == "🏠 Home":
|
| 548 |
+
col1, col2 = st.columns([1.2, 1])
|
| 549 |
+
|
| 550 |
+
with col1:
|
| 551 |
+
st.subheader("📌 Project Overview")
|
| 552 |
+
st.markdown(
|
| 553 |
+
"""
|
| 554 |
+
SmartVision AI is a complete computer vision pipeline built on a curated subset
|
| 555 |
+
of **25 COCO classes**. It brings together:
|
| 556 |
+
|
| 557 |
+
- 🧠 **Image Classification** using multiple CNN backbones:
|
| 558 |
+
`VGG16 · ResNet50 · MobileNetV2 · EfficientNetB0`
|
| 559 |
+
- 🎯 **Object Detection** using **YOLOv8s**, fine-tuned on the same 25 classes
|
| 560 |
+
- 🔗 **Integrated Pipeline** where YOLO detects objects and
|
| 561 |
+
**ResNet50** verifies the cropped regions
|
| 562 |
+
- 📊 **Interactive Streamlit Dashboard** for demos, metrics visualization, and experiments
|
| 563 |
+
"""
|
| 564 |
+
)
|
| 565 |
+
|
| 566 |
+
with col2:
|
| 567 |
+
st.subheader("🕹️ How to Use This App")
|
| 568 |
+
st.markdown(
|
| 569 |
+
"""
|
| 570 |
+
1. **🖼️ Image Classification**
|
| 571 |
+
Upload an image with a **single dominant object** to classify it.
|
| 572 |
+
|
| 573 |
+
2. **📦 Object Detection**
|
| 574 |
+
Upload a **scene with multiple objects** to run YOLOv8 detection.
|
| 575 |
+
|
| 576 |
+
3. **📊 Model Performance**
|
| 577 |
+
Explore **accuracy, F1-score, speed, and confusion matrices** for all models.
|
| 578 |
+
|
| 579 |
+
4. **📷 Webcam Detection (Snapshot)** *(optional)*
|
| 580 |
+
Capture an image via webcam and run **real-time YOLO detection**.
|
| 581 |
+
"""
|
| 582 |
+
)
|
| 583 |
+
st.markdown(
|
| 584 |
+
"""
|
| 585 |
+
> 💡 Tip: Start with **Object Detection** to see YOLOv8 in action,
|
| 586 |
+
> then inspect misclassifications in **Model Performance**.
|
| 587 |
+
"""
|
| 588 |
+
)
|
| 589 |
+
|
| 590 |
+
st.divider()
|
| 591 |
+
|
| 592 |
+
st.subheader("🧪 Sample Annotated Outputs")
|
| 593 |
+
|
| 594 |
+
sample_dir = "inference_outputs"
|
| 595 |
+
if os.path.exists(sample_dir):
|
| 596 |
+
imgs = [
|
| 597 |
+
os.path.join(sample_dir, f)
|
| 598 |
+
for f in os.listdir(sample_dir)
|
| 599 |
+
if f.lower().endswith((".jpg", ".png", ".jpeg"))
|
| 600 |
+
]
|
| 601 |
+
if imgs:
|
| 602 |
+
cols = st.columns(min(3, len(imgs)))
|
| 603 |
+
for i, img_path in enumerate(imgs[:3]):
|
| 604 |
+
with cols[i]:
|
| 605 |
+
st.image(img_path, caption=os.path.basename(img_path), use_container_width=False)
|
| 606 |
+
else:
|
| 607 |
+
st.info("No sample images found in `inference_outputs/` yet.")
|
| 608 |
+
else:
|
| 609 |
+
st.info("`inference_outputs/` folder not found yet – run inference to create samples.")
|
| 610 |
+
|
| 611 |
+
# ------------------------------------------------------------
|
| 612 |
+
# PAGE 2 – IMAGE CLASSIFICATION
|
| 613 |
+
# ------------------------------------------------------------
|
| 614 |
+
elif page == "🖼️ Image Classification":
|
| 615 |
+
st.subheader("Image Classification – 4 CNN Models")
|
| 616 |
+
|
| 617 |
+
st.write(
|
| 618 |
+
"""
|
| 619 |
+
Upload an image that mainly contains **one object**.
|
| 620 |
+
The app will run **all 4 CNN models** and show **top-5 predictions** per model.
|
| 621 |
+
"""
|
| 622 |
+
)
|
| 623 |
+
|
| 624 |
+
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
|
| 625 |
+
|
| 626 |
+
if uploaded_file is not None:
|
| 627 |
+
pil_img = read_image_file(uploaded_file)
|
| 628 |
+
st.image(pil_img, caption="Uploaded image", use_container_width=False)
|
| 629 |
+
|
| 630 |
+
with st.spinner("Loading classification models..."):
|
| 631 |
+
cls_models = load_classification_models()
|
| 632 |
+
|
| 633 |
+
if not cls_models:
|
| 634 |
+
st.error("No classification models could be loaded. Check your saved_models/ folder.")
|
| 635 |
+
else:
|
| 636 |
+
arr = preprocess_for_classifier(pil_img)
|
| 637 |
+
|
| 638 |
+
st.markdown("### Predictions")
|
| 639 |
+
cols = st.columns(len(cls_models))
|
| 640 |
+
|
| 641 |
+
for (model_name, model), col in zip(cls_models.items(), cols):
|
| 642 |
+
with col:
|
| 643 |
+
st.markdown(f"**{model_name}**")
|
| 644 |
+
probs = model.predict(arr, verbose=0)[0]
|
| 645 |
+
top5_idx = probs.argsort()[-5:][::-1]
|
| 646 |
+
top5_labels = [CLASS_NAMES[i] for i in top5_idx]
|
| 647 |
+
top5_probs = [probs[i] for i in top5_idx]
|
| 648 |
+
|
| 649 |
+
st.write(f"**Top-1:** {top5_labels[0]} ({top5_probs[0]:.3f})")
|
| 650 |
+
st.write("Top-5:")
|
| 651 |
+
for lbl, p in zip(top5_labels, top5_probs):
|
| 652 |
+
st.write(f"- {lbl}: {p:.3f}")
|
| 653 |
+
|
| 654 |
+
|
| 655 |
+
# ------------------------------------------------------------
|
| 656 |
+
# PAGE 3 – OBJECT DETECTION
|
| 657 |
+
# ------------------------------------------------------------
|
| 658 |
+
elif page == "📦 Object Detection":
|
| 659 |
+
st.subheader("Object Detection – YOLOv8 + Optional ResNet Verification")
|
| 660 |
+
|
| 661 |
+
st.write(
|
| 662 |
+
"""
|
| 663 |
+
Upload an image containing one or more of the 25 COCO classes.
|
| 664 |
+
YOLOv8 will detect all objects and optionally verify them with the best classifier (ResNet50).
|
| 665 |
+
"""
|
| 666 |
+
)
|
| 667 |
+
|
| 668 |
+
conf_th = st.slider("Confidence threshold", 0.1, 0.9, 0.5, 0.05)
|
| 669 |
+
use_classifier = st.checkbox("Use ResNet50 classifier verification on crops", value=True)
|
| 670 |
+
|
| 671 |
+
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
|
| 672 |
+
|
| 673 |
+
if uploaded_file is not None:
|
| 674 |
+
pil_img = read_image_file(uploaded_file)
|
| 675 |
+
|
| 676 |
+
# ❌ REMOVE THIS (caused duplicate)
|
| 677 |
+
# st.image(pil_img, caption="Uploaded image", use_container_width=False)
|
| 678 |
+
|
| 679 |
+
with st.spinner("Loading YOLO model..."):
|
| 680 |
+
yolo_model = load_yolo_model()
|
| 681 |
+
|
| 682 |
+
classifier_model = None
|
| 683 |
+
if use_classifier:
|
| 684 |
+
with st.spinner("Loading ResNet50 classifier..."):
|
| 685 |
+
classifier_model = build_resnet50_model_v2()
|
| 686 |
+
weights_path = CLASSIFIER_MODEL_CONFIGS["ResNet50"]["path"]
|
| 687 |
+
|
| 688 |
+
if os.path.exists(weights_path):
|
| 689 |
+
try:
|
| 690 |
+
classifier_model.load_weights(weights_path)
|
| 691 |
+
except Exception as e:
|
| 692 |
+
st.warning(f"Could not load ResNet50 v2 weights for detection: {e}")
|
| 693 |
+
classifier_model = None
|
| 694 |
+
else:
|
| 695 |
+
st.warning("ResNet50 weights not found – classifier verification disabled.")
|
| 696 |
+
classifier_model = None
|
| 697 |
+
|
| 698 |
+
with st.spinner("Running detection..."):
|
| 699 |
+
result = run_yolo_with_optional_classifier(
|
| 700 |
+
pil_img=pil_img,
|
| 701 |
+
yolo_model=yolo_model,
|
| 702 |
+
classifier_model=classifier_model,
|
| 703 |
+
conf_threshold=conf_th,
|
| 704 |
+
)
|
| 705 |
+
|
| 706 |
+
# ✅ ONLY 2 IMAGES SHOWN — SIDE BY SIDE
|
| 707 |
+
col1, col2 = st.columns(2)
|
| 708 |
+
|
| 709 |
+
with col1:
|
| 710 |
+
st.image(pil_img, caption="Uploaded Image", use_container_width=True)
|
| 711 |
+
|
| 712 |
+
with col2:
|
| 713 |
+
st.image(result["annotated_image"], caption="Detected Result", use_container_width=True)
|
| 714 |
+
|
| 715 |
+
st.write(f"YOLO inference time: {result['yolo_inference_time_sec']*1000:.1f} ms")
|
| 716 |
+
st.write(f"Number of detections: {len(result['detections'])}")
|
| 717 |
+
|
| 718 |
+
if result["detections"]:
|
| 719 |
+
st.markdown("### Detected objects")
|
| 720 |
+
df_det = pd.DataFrame([
|
| 721 |
+
{
|
| 722 |
+
"YOLO label": det["label"],
|
| 723 |
+
"YOLO confidence level": det["conf_yolo"],
|
| 724 |
+
"CLS label": det.get("cls_label"),
|
| 725 |
+
"CLS confidence level": det.get("cls_conf"),
|
| 726 |
+
|
| 727 |
+
}
|
| 728 |
+
for det in result["detections"]
|
| 729 |
+
])
|
| 730 |
+
st.dataframe(df_det, use_container_width=False)
|
| 731 |
+
|
| 732 |
+
# ------------------------------------------------------------
|
| 733 |
+
# PAGE 4 – MODEL PERFORMANCE
|
| 734 |
+
# ------------------------------------------------------------
|
| 735 |
+
elif page == "📊 Model Performance":
|
| 736 |
+
st.subheader("Model Performance – Classification vs Detection")
|
| 737 |
+
|
| 738 |
+
# --- Classification metrics ---
|
| 739 |
+
st.markdown("### 🧠 Classification Models (VGG16, ResNet50, MobileNetV2, EfficientNetB0)")
|
| 740 |
+
df_cls = load_classification_metrics()
|
| 741 |
+
if df_cls.empty:
|
| 742 |
+
st.info("No classification metrics found yet in `smartvision_metrics/`.")
|
| 743 |
+
else:
|
| 744 |
+
st.dataframe(df_cls, use_container_width=False)
|
| 745 |
+
|
| 746 |
+
col1, col2 = st.columns(2)
|
| 747 |
+
with col1:
|
| 748 |
+
st.bar_chart(
|
| 749 |
+
df_cls.set_index("Model")["Accuracy"],
|
| 750 |
+
use_container_width=True,
|
| 751 |
+
)
|
| 752 |
+
with col2:
|
| 753 |
+
st.bar_chart(
|
| 754 |
+
df_cls.set_index("Model")["F1 (weighted)"],
|
| 755 |
+
use_container_width=True,
|
| 756 |
+
)
|
| 757 |
+
|
| 758 |
+
st.markdown("#### Inference Speed (images/sec)")
|
| 759 |
+
st.bar_chart(
|
| 760 |
+
df_cls.set_index("Model")["Images/sec"],
|
| 761 |
+
use_container_width=True,
|
| 762 |
+
)
|
| 763 |
+
|
| 764 |
+
# --- YOLO metrics ---
|
| 765 |
+
st.markdown("### 📦 YOLOv8 Detection Model")
|
| 766 |
+
yolo_m = load_yolo_metrics()
|
| 767 |
+
if not yolo_m:
|
| 768 |
+
st.info("No YOLO metrics found yet in `yolo_metrics/`.")
|
| 769 |
+
else:
|
| 770 |
+
col1, col2, col3 = st.columns(3)
|
| 771 |
+
with col1:
|
| 772 |
+
st.metric("mAP@0.5", f"{yolo_m.get('map_50', 0):.3f}")
|
| 773 |
+
with col2:
|
| 774 |
+
st.metric("mAP@0.5:0.95", f"{yolo_m.get('map_50_95', 0):.3f}")
|
| 775 |
+
with col3:
|
| 776 |
+
st.metric("YOLO FPS", f"{yolo_m.get('fps', 0):.2f}")
|
| 777 |
+
|
| 778 |
+
st.write("YOLO metrics JSON:", YOLO_METRICS_JSON)
|
| 779 |
+
|
| 780 |
+
# --- Confusion matrix & comparison plots (if available) ---
|
| 781 |
+
st.markdown("### 📈 Comparison Plots & Confusion Matrices")
|
| 782 |
+
|
| 783 |
+
comp_dir = os.path.join("smartvision_metrics", "comparison_plots")
|
| 784 |
+
if os.path.exists(comp_dir):
|
| 785 |
+
imgs = [
|
| 786 |
+
os.path.join(comp_dir, f)
|
| 787 |
+
for f in os.listdir(comp_dir)
|
| 788 |
+
if f.lower().endswith(".png")
|
| 789 |
+
]
|
| 790 |
+
if imgs:
|
| 791 |
+
for img in sorted(imgs):
|
| 792 |
+
st.image(img, caption=os.path.basename(img), use_container_width=True)
|
| 793 |
+
else:
|
| 794 |
+
st.info("No comparison plots found in `smartvision_metrics/comparison_plots/`.")
|
| 795 |
+
else:
|
| 796 |
+
st.info("Folder `smartvision_metrics/comparison_plots/` not found.")
|
| 797 |
+
|
| 798 |
+
|
| 799 |
+
# ------------------------------------------------------------
|
| 800 |
+
# PAGE 5 – WEBCAM DETECTION (SNAPSHOT)
|
| 801 |
+
# ------------------------------------------------------------
|
| 802 |
+
elif page == "📷 Webcam Detection (snapshot)":
|
| 803 |
+
st.subheader("Webcam Detection (Snapshot-based)")
|
| 804 |
+
|
| 805 |
+
st.write(
|
| 806 |
+
"""
|
| 807 |
+
This page uses Streamlit's `camera_input` to grab a **single frame**
|
| 808 |
+
from your webcam and run YOLOv8 detection on it.
|
| 809 |
+
|
| 810 |
+
(For true real-time streaming, you would typically use `streamlit-webrtc`.)
|
| 811 |
+
"""
|
| 812 |
+
)
|
| 813 |
+
|
| 814 |
+
conf_th = st.slider("Confidence threshold", 0.1, 0.9, 0.5, 0.05)
|
| 815 |
+
|
| 816 |
+
cam_image = st.camera_input("Capture image from webcam")
|
| 817 |
+
|
| 818 |
+
if cam_image is not None:
|
| 819 |
+
pil_img = Image.open(cam_image).convert("RGB")
|
| 820 |
+
|
| 821 |
+
with st.spinner("Loading YOLO model..."):
|
| 822 |
+
yolo_model = load_yolo_model()
|
| 823 |
+
|
| 824 |
+
with st.spinner("Running detection..."):
|
| 825 |
+
result = run_yolo_with_optional_classifier(
|
| 826 |
+
pil_img=pil_img,
|
| 827 |
+
yolo_model=yolo_model,
|
| 828 |
+
classifier_model=None, # detection-only for speed
|
| 829 |
+
conf_threshold=conf_th,
|
| 830 |
+
)
|
| 831 |
+
|
| 832 |
+
st.image(result["annotated_image"], caption="Detections", use_container_width=False)
|
| 833 |
+
st.write(f"YOLO inference time: {result['yolo_inference_time_sec']*1000:.1f} ms")
|
| 834 |
+
st.write(f"Number of detections: {len(result['detections'])}")
|
| 835 |
+
|
| 836 |
+
|
| 837 |
+
# ------------------------------------------------------------
|
| 838 |
+
# PAGE 6 – ABOUT
|
| 839 |
+
# ------------------------------------------------------------
|
| 840 |
+
elif page == "ℹ️ About":
|
| 841 |
+
st.subheader("About SmartVision AI")
|
| 842 |
+
|
| 843 |
+
st.markdown(
|
| 844 |
+
"""
|
| 845 |
+
**Dataset:**
|
| 846 |
+
- Subset of MS COCO with 25 commonly occurring classes
|
| 847 |
+
- Split into train/val/test for both classification & detection
|
| 848 |
+
|
| 849 |
+
**Models used:**
|
| 850 |
+
- **Classification:**
|
| 851 |
+
- VGG16
|
| 852 |
+
- ResNet50
|
| 853 |
+
- MobileNetV2
|
| 854 |
+
- EfficientNetB0
|
| 855 |
+
- **Detection:**
|
| 856 |
+
- YOLOv8s fine-tuned on the same 25 classes
|
| 857 |
+
|
| 858 |
+
**Pipeline Highlights:**
|
| 859 |
+
- Integrated pipeline: YOLO detects → ResNet50 verifies object crops
|
| 860 |
+
- Performance metrics:
|
| 861 |
+
- CNN test accuracy, F1, Top-5 accuracy, images/sec, model size
|
| 862 |
+
- YOLO mAP@0.5, mAP@0.5:0.95, FPS
|
| 863 |
+
- Quantization-ready: ResNet50 can be exported to float16 TFLite for deployment.
|
| 864 |
+
|
| 865 |
+
**Tech Stack:**
|
| 866 |
+
- Python, TensorFlow / Keras, Ultralytics YOLOv8
|
| 867 |
+
- Streamlit for interactive dashboard
|
| 868 |
+
- NumPy, Pandas, Pillow, Matplotlib
|
| 869 |
+
|
| 870 |
+
|
| 871 |
+
"""
|
| 872 |
+
)
|
dataset_preparation.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
inference_outputs/image_000000_annotated.jpg
ADDED

|
inference_outputs/image_002126_annotated.jpg
ADDED

|
Git LFS Details
|
requirements.txt
ADDED
|
Binary file (416 Bytes). View file
|
|
|
saved_models/efficientnetb0_stage2_best.weights.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:141ec000a01ef957577aea7ff9cc1da8b5053fec6d81453724e78d8014205e18
|
| 3 |
+
size 46584176
|
saved_models/mobilenetv2_v2_stage2_best.weights.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:963f85823f7a153b9b0957b32b5bd058ce76d79fef63e820366b1b5831eed381
|
| 3 |
+
size 13558112
|
saved_models/resnet50_v2_stage2_best.weights.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7e4db346fc333c6181d5c4038f53f8e9d78e9c2ab9913e1b4eafd75d81e9660c
|
| 3 |
+
size 227788524
|
saved_models/vgg16_v2_stage2_best.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eecf8ec51a5e39a2a5a8cebd5c5f548c14f385ea30223efa69bf93363c642cd2
|
| 3 |
+
size 117259600
|
scripts/01_Data Augmentation.ipynb
ADDED
|
@@ -0,0 +1,595 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 8,
|
| 6 |
+
"id": "4daac0c9",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [
|
| 9 |
+
{
|
| 10 |
+
"name": "stdout",
|
| 11 |
+
"output_type": "stream",
|
| 12 |
+
"text": [
|
| 13 |
+
"Found 1750 files belonging to 25 classes.\n",
|
| 14 |
+
"Found 375 files belonging to 25 classes.\n",
|
| 15 |
+
"Found 375 files belonging to 25 classes.\n"
|
| 16 |
+
]
|
| 17 |
+
}
|
| 18 |
+
],
|
| 19 |
+
"source": [
|
| 20 |
+
"import tensorflow as tf\n",
|
| 21 |
+
"from tensorflow import keras\n",
|
| 22 |
+
"from tensorflow.keras import layers\n",
|
| 23 |
+
"import os\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"BASE_DIR = r\"D:\\Guvi\\SmartVision_AI\\smartvision_dataset\"\n",
|
| 26 |
+
"IMG_SIZE = (224, 224)\n",
|
| 27 |
+
"BATCH_SIZE = 32\n",
|
| 28 |
+
"IMG_SIZE = (224, 224)\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"NUM_CLASSES = 25\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"train_dir = os.path.join(BASE_DIR, \"classification\", \"train\")\n",
|
| 33 |
+
"val_dir = os.path.join(BASE_DIR, \"classification\", \"val\")\n",
|
| 34 |
+
"test_dir = os.path.join(BASE_DIR, \"classification\", \"test\")\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"train_ds = tf.keras.utils.image_dataset_from_directory(\n",
|
| 37 |
+
" train_dir,\n",
|
| 38 |
+
" image_size=IMG_SIZE,\n",
|
| 39 |
+
" batch_size=BATCH_SIZE,\n",
|
| 40 |
+
" shuffle=True\n",
|
| 41 |
+
")\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"val_ds = tf.keras.utils.image_dataset_from_directory(\n",
|
| 44 |
+
" val_dir,\n",
|
| 45 |
+
" image_size=IMG_SIZE,\n",
|
| 46 |
+
" batch_size=BATCH_SIZE,\n",
|
| 47 |
+
" shuffle=False\n",
|
| 48 |
+
")\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"test_ds = tf.keras.utils.image_dataset_from_directory(\n",
|
| 51 |
+
" test_dir,\n",
|
| 52 |
+
" image_size=IMG_SIZE,\n",
|
| 53 |
+
" batch_size=BATCH_SIZE,\n",
|
| 54 |
+
" shuffle=False\n",
|
| 55 |
+
")\n"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "code",
|
| 60 |
+
"execution_count": null,
|
| 61 |
+
"id": "e690c322",
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"outputs": [],
|
| 64 |
+
"source": [
|
| 65 |
+
"# 1.4. Data augmentation block (applied only on training data)\n",
|
| 66 |
+
"data_augmentation = keras.Sequential(\n",
|
| 67 |
+
" [\n",
|
| 68 |
+
" layers.RandomFlip(\"horizontal\"), # random horizontal flip\n",
|
| 69 |
+
" layers.RandomRotation(0.04), # ~ ±15° (15/360 ≈ 0.04)\n",
|
| 70 |
+
" layers.RandomZoom(0.1), # random zoom\n",
|
| 71 |
+
" layers.RandomContrast(0.2), # ±20% contrast\n",
|
| 72 |
+
" # Brightness jitter using Lambda + tf.image\n",
|
| 73 |
+
" layers.Lambda(\n",
|
| 74 |
+
" lambda x: tf.image.random_brightness(x, max_delta=0.2)\n",
|
| 75 |
+
" ),\n",
|
| 76 |
+
" # Optional: light color jitter via saturation\n",
|
| 77 |
+
" layers.Lambda(\n",
|
| 78 |
+
" lambda x: tf.image.random_saturation(x, lower=0.8, upper=1.2)\n",
|
| 79 |
+
" ),\n",
|
| 80 |
+
" ],\n",
|
| 81 |
+
" name=\"data_augmentation\",\n",
|
| 82 |
+
")\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"# Normalization layer (0–1 scaling or ImageNet style)\n",
|
| 85 |
+
"normalization = layers.Rescaling(1./255)\n"
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"cell_type": "code",
|
| 90 |
+
"execution_count": null,
|
| 91 |
+
"id": "88323a0f",
|
| 92 |
+
"metadata": {},
|
| 93 |
+
"outputs": [
|
| 94 |
+
{
|
| 95 |
+
"name": "stdout",
|
| 96 |
+
"output_type": "stream",
|
| 97 |
+
"text": [
|
| 98 |
+
"Epoch 1/25\n",
|
| 99 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 5s/step - accuracy: 0.0405 - loss: 3.4605"
|
| 100 |
+
]
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"name": "stderr",
|
| 104 |
+
"output_type": "stream",
|
| 105 |
+
"text": [
|
| 106 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 107 |
+
]
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"name": "stdout",
|
| 111 |
+
"output_type": "stream",
|
| 112 |
+
"text": [
|
| 113 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m328s\u001b[0m 6s/step - accuracy: 0.0429 - loss: 3.4206 - val_accuracy: 0.0373 - val_loss: 3.2323 - learning_rate: 1.0000e-04\n",
|
| 114 |
+
"Epoch 2/25\n",
|
| 115 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 6s/step - accuracy: 0.0474 - loss: 3.2988"
|
| 116 |
+
]
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"name": "stderr",
|
| 120 |
+
"output_type": "stream",
|
| 121 |
+
"text": [
|
| 122 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 123 |
+
]
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"name": "stdout",
|
| 127 |
+
"output_type": "stream",
|
| 128 |
+
"text": [
|
| 129 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m457s\u001b[0m 8s/step - accuracy: 0.0486 - loss: 3.2914 - val_accuracy: 0.0533 - val_loss: 3.1938 - learning_rate: 1.0000e-04\n",
|
| 130 |
+
"Epoch 3/25\n",
|
| 131 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━���━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 18s/step - accuracy: 0.0463 - loss: 3.2775 "
|
| 132 |
+
]
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"name": "stderr",
|
| 136 |
+
"output_type": "stream",
|
| 137 |
+
"text": [
|
| 138 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"name": "stdout",
|
| 143 |
+
"output_type": "stream",
|
| 144 |
+
"text": [
|
| 145 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m1232s\u001b[0m 22s/step - accuracy: 0.0486 - loss: 3.2567 - val_accuracy: 0.0853 - val_loss: 3.1689 - learning_rate: 1.0000e-04\n",
|
| 146 |
+
"Epoch 4/25\n",
|
| 147 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 19s/step - accuracy: 0.0568 - loss: 3.2323 "
|
| 148 |
+
]
|
| 149 |
+
},
|
| 150 |
+
{
|
| 151 |
+
"name": "stderr",
|
| 152 |
+
"output_type": "stream",
|
| 153 |
+
"text": [
|
| 154 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"name": "stdout",
|
| 159 |
+
"output_type": "stream",
|
| 160 |
+
"text": [
|
| 161 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m1278s\u001b[0m 23s/step - accuracy: 0.0543 - loss: 3.2274 - val_accuracy: 0.1360 - val_loss: 3.1451 - learning_rate: 1.0000e-04\n",
|
| 162 |
+
"Epoch 5/25\n",
|
| 163 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 16s/step - accuracy: 0.0526 - loss: 3.1936 "
|
| 164 |
+
]
|
| 165 |
+
},
|
| 166 |
+
{
|
| 167 |
+
"name": "stderr",
|
| 168 |
+
"output_type": "stream",
|
| 169 |
+
"text": [
|
| 170 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"name": "stdout",
|
| 175 |
+
"output_type": "stream",
|
| 176 |
+
"text": [
|
| 177 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m1076s\u001b[0m 19s/step - accuracy: 0.0623 - loss: 3.1870 - val_accuracy: 0.1520 - val_loss: 3.1223 - learning_rate: 1.0000e-04\n",
|
| 178 |
+
"Epoch 6/25\n",
|
| 179 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 11s/step - accuracy: 0.0762 - loss: 3.1579 "
|
| 180 |
+
]
|
| 181 |
+
},
|
| 182 |
+
{
|
| 183 |
+
"name": "stderr",
|
| 184 |
+
"output_type": "stream",
|
| 185 |
+
"text": [
|
| 186 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 187 |
+
]
|
| 188 |
+
},
|
| 189 |
+
{
|
| 190 |
+
"name": "stdout",
|
| 191 |
+
"output_type": "stream",
|
| 192 |
+
"text": [
|
| 193 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m757s\u001b[0m 14s/step - accuracy: 0.0811 - loss: 3.1483 - val_accuracy: 0.1867 - val_loss: 3.0975 - learning_rate: 1.0000e-04\n",
|
| 194 |
+
"Epoch 7/25\n",
|
| 195 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 13s/step - accuracy: 0.1051 - loss: 3.1299 "
|
| 196 |
+
]
|
| 197 |
+
},
|
| 198 |
+
{
|
| 199 |
+
"name": "stderr",
|
| 200 |
+
"output_type": "stream",
|
| 201 |
+
"text": [
|
| 202 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 203 |
+
]
|
| 204 |
+
},
|
| 205 |
+
{
|
| 206 |
+
"name": "stdout",
|
| 207 |
+
"output_type": "stream",
|
| 208 |
+
"text": [
|
| 209 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m900s\u001b[0m 16s/step - accuracy: 0.1029 - loss: 3.1283 - val_accuracy: 0.2107 - val_loss: 3.0750 - learning_rate: 1.0000e-04\n",
|
| 210 |
+
"Epoch 8/25\n",
|
| 211 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 11s/step - accuracy: 0.1321 - loss: 3.1018 "
|
| 212 |
+
]
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"name": "stderr",
|
| 216 |
+
"output_type": "stream",
|
| 217 |
+
"text": [
|
| 218 |
+
"WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n"
|
| 219 |
+
]
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"name": "stdout",
|
| 223 |
+
"output_type": "stream",
|
| 224 |
+
"text": [
|
| 225 |
+
"\u001b[1m55/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m799s\u001b[0m 15s/step - accuracy: 0.1343 - loss: 3.0993 - val_accuracy: 0.2373 - val_loss: 3.0532 - learning_rate: 1.0000e-04\n",
|
| 226 |
+
"Epoch 9/25\n",
|
| 227 |
+
"\u001b[1m50/55\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m━━\u001b[0m \u001b[1m1:06\u001b[0m 13s/step - accuracy: 0.1195 - loss: 3.0798"
|
| 228 |
+
]
|
| 229 |
+
}
|
| 230 |
+
],
|
| 231 |
+
"source": [
|
| 232 |
+
"# 2.1: Model 1 - VGG16\n",
|
| 233 |
+
"\n",
|
| 234 |
+
"def build_vgg16_model():\n",
|
| 235 |
+
" inputs = keras.Input(shape=(*IMG_SIZE, 3))\n",
|
| 236 |
+
" x = data_augmentation(inputs) # train only\n",
|
| 237 |
+
" x = normalization(x)\n",
|
| 238 |
+
"\n",
|
| 239 |
+
" base_model = keras.applications.VGG16(\n",
|
| 240 |
+
" include_top=False,\n",
|
| 241 |
+
" weights=\"imagenet\",\n",
|
| 242 |
+
" input_tensor=x\n",
|
| 243 |
+
" )\n",
|
| 244 |
+
" base_model.trainable = False # freeze convolutional base\n",
|
| 245 |
+
"\n",
|
| 246 |
+
" x = layers.GlobalAveragePooling2D()(base_model.output)\n",
|
| 247 |
+
" x = layers.Dense(256, activation=\"relu\")(x)\n",
|
| 248 |
+
" x = layers.Dropout(0.5)(x)\n",
|
| 249 |
+
" outputs = layers.Dense(NUM_CLASSES, activation=\"softmax\")(x)\n",
|
| 250 |
+
"\n",
|
| 251 |
+
" model = keras.Model(inputs, outputs, name=\"VGG16_smartvision\")\n",
|
| 252 |
+
" return model\n",
|
| 253 |
+
"def compile_and_train(model, model_name, train_ds, val_ds, epochs=25, lr=1e-4):\n",
|
| 254 |
+
" model.compile(\n",
|
| 255 |
+
" optimizer=keras.optimizers.Adam(learning_rate=lr),\n",
|
| 256 |
+
" loss=\"sparse_categorical_crossentropy\",\n",
|
| 257 |
+
" metrics=[\"accuracy\"]\n",
|
| 258 |
+
" )\n",
|
| 259 |
+
"\n",
|
| 260 |
+
" callbacks = [\n",
|
| 261 |
+
" keras.callbacks.ModelCheckpoint(\n",
|
| 262 |
+
" filepath=f\"{model_name}_best.h5\",\n",
|
| 263 |
+
" monitor=\"val_accuracy\",\n",
|
| 264 |
+
" save_best_only=True,\n",
|
| 265 |
+
" mode=\"max\"\n",
|
| 266 |
+
" ),\n",
|
| 267 |
+
" keras.callbacks.EarlyStopping(\n",
|
| 268 |
+
" monitor=\"val_accuracy\",\n",
|
| 269 |
+
" patience=5,\n",
|
| 270 |
+
" restore_best_weights=True\n",
|
| 271 |
+
" ),\n",
|
| 272 |
+
" keras.callbacks.ReduceLROnPlateau(\n",
|
| 273 |
+
" monitor=\"val_loss\",\n",
|
| 274 |
+
" factor=0.5,\n",
|
| 275 |
+
" patience=2,\n",
|
| 276 |
+
" min_lr=1e-6,\n",
|
| 277 |
+
" verbose=1\n",
|
| 278 |
+
" )\n",
|
| 279 |
+
" ]\n",
|
| 280 |
+
"\n",
|
| 281 |
+
" history = model.fit(\n",
|
| 282 |
+
" train_ds,\n",
|
| 283 |
+
" validation_data=val_ds,\n",
|
| 284 |
+
" epochs=epochs,\n",
|
| 285 |
+
" callbacks=callbacks\n",
|
| 286 |
+
" )\n",
|
| 287 |
+
" return history\n",
|
| 288 |
+
"\n",
|
| 289 |
+
"vgg16_model = build_vgg16_model()\n",
|
| 290 |
+
"history_vgg16 = compile_and_train(vgg16_model, \"vgg16\", train_ds, val_ds, epochs=25)\n"
|
| 291 |
+
]
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"execution_count": null,
|
| 296 |
+
"id": "3e7696bc",
|
| 297 |
+
"metadata": {},
|
| 298 |
+
"outputs": [],
|
| 299 |
+
"source": [
|
| 300 |
+
"class_names = train_ds.class_names\n",
|
| 301 |
+
"NUM_CLASSES = len(class_names)\n",
|
| 302 |
+
"print(class_names)"
|
| 303 |
+
]
|
| 304 |
+
},
|
| 305 |
+
{
|
| 306 |
+
"cell_type": "code",
|
| 307 |
+
"execution_count": null,
|
| 308 |
+
"id": "3b3417aa",
|
| 309 |
+
"metadata": {},
|
| 310 |
+
"outputs": [],
|
| 311 |
+
"source": [
|
| 312 |
+
"import numpy as np\n",
|
| 313 |
+
"import time\n",
|
| 314 |
+
"import json\n",
|
| 315 |
+
"import os\n",
|
| 316 |
+
"from sklearn.metrics import classification_report, confusion_matrix, precision_recall_fscore_support\n",
|
| 317 |
+
"\n",
|
| 318 |
+
"def evaluate_and_collect_metrics(model, model_name, test_ds, class_names, weights_path=None):\n",
|
| 319 |
+
" # If you saved best weights, load them\n",
|
| 320 |
+
" if weights_path is not None and os.path.exists(weights_path):\n",
|
| 321 |
+
" model.load_weights(weights_path)\n",
|
| 322 |
+
" print(f\"✅ Loaded best weights from {weights_path}\")\n",
|
| 323 |
+
"\n",
|
| 324 |
+
" y_true = []\n",
|
| 325 |
+
" y_pred = []\n",
|
| 326 |
+
" y_pred_probs = []\n",
|
| 327 |
+
"\n",
|
| 328 |
+
" # ----- measure inference time -----\n",
|
| 329 |
+
" total_time = 0.0\n",
|
| 330 |
+
" total_images = 0\n",
|
| 331 |
+
"\n",
|
| 332 |
+
" for images, labels in test_ds:\n",
|
| 333 |
+
" images_np = images.numpy()\n",
|
| 334 |
+
" batch_size = images_np.shape[0]\n",
|
| 335 |
+
"\n",
|
| 336 |
+
" start = time.perf_counter()\n",
|
| 337 |
+
" probs = model.predict(images_np, verbose=0)\n",
|
| 338 |
+
" end = time.perf_counter()\n",
|
| 339 |
+
"\n",
|
| 340 |
+
" total_time += (end - start)\n",
|
| 341 |
+
" total_images += batch_size\n",
|
| 342 |
+
"\n",
|
| 343 |
+
" preds = np.argmax(probs, axis=1)\n",
|
| 344 |
+
"\n",
|
| 345 |
+
" y_true.extend(labels.numpy())\n",
|
| 346 |
+
" y_pred.extend(preds)\n",
|
| 347 |
+
" y_pred_probs.append(probs)\n",
|
| 348 |
+
"\n",
|
| 349 |
+
" y_true = np.array(y_true)\n",
|
| 350 |
+
" y_pred = np.array(y_pred)\n",
|
| 351 |
+
" y_pred_probs = np.concatenate(y_pred_probs, axis=0)\n",
|
| 352 |
+
"\n",
|
| 353 |
+
" # ----- basic metrics -----\n",
|
| 354 |
+
" acc = (y_true == y_pred).mean()\n",
|
| 355 |
+
"\n",
|
| 356 |
+
" precision, recall, f1, _ = precision_recall_fscore_support(\n",
|
| 357 |
+
" y_true, y_pred, average=\"weighted\", zero_division=0\n",
|
| 358 |
+
" )\n",
|
| 359 |
+
"\n",
|
| 360 |
+
" # ----- top-5 accuracy -----\n",
|
| 361 |
+
" top5_correct = 0\n",
|
| 362 |
+
" for i, label in enumerate(y_true):\n",
|
| 363 |
+
" top5 = np.argsort(y_pred_probs[i])[-5:]\n",
|
| 364 |
+
" if label in top5:\n",
|
| 365 |
+
" top5_correct += 1\n",
|
| 366 |
+
" top5_acc = top5_correct / len(y_true)\n",
|
| 367 |
+
"\n",
|
| 368 |
+
" # ----- inference time -----\n",
|
| 369 |
+
" avg_time_per_image = total_time / total_images # seconds\n",
|
| 370 |
+
" imgs_per_second = 1.0 / avg_time_per_image if avg_time_per_image > 0 else 0.0\n",
|
| 371 |
+
"\n",
|
| 372 |
+
" # ----- model size -----\n",
|
| 373 |
+
" # Save weights temporarily to compute size\n",
|
| 374 |
+
" temp_weights = f\"{model_name}_temp_for_size.weights.h5\" \n",
|
| 375 |
+
" model.save_weights(temp_weights)\n",
|
| 376 |
+
" size_mb = os.path.getsize(temp_weights) / (1024 * 1024)\n",
|
| 377 |
+
" os.remove(temp_weights)\n",
|
| 378 |
+
"\n",
|
| 379 |
+
" # ----- classification report & confusion matrix (for plots) -----\n",
|
| 380 |
+
" print(f\"\\n=== {model_name.upper()} – Classification Report ===\")\n",
|
| 381 |
+
" print(classification_report(y_true, y_pred, target_names=class_names, zero_division=0))\n",
|
| 382 |
+
"\n",
|
| 383 |
+
" cm = confusion_matrix(y_true, y_pred)\n",
|
| 384 |
+
" print(f\"\\nConfusion matrix shape: {cm.shape}\")\n",
|
| 385 |
+
"\n",
|
| 386 |
+
" metrics = {\n",
|
| 387 |
+
" \"model_name\": model_name,\n",
|
| 388 |
+
" \"accuracy\": float(acc),\n",
|
| 389 |
+
" \"precision_weighted\": float(precision),\n",
|
| 390 |
+
" \"recall_weighted\": float(recall),\n",
|
| 391 |
+
" \"f1_weighted\": float(f1),\n",
|
| 392 |
+
" \"top5_accuracy\": float(top5_acc),\n",
|
| 393 |
+
" \"avg_inference_time_sec_per_image\": float(avg_time_per_image),\n",
|
| 394 |
+
" \"images_per_second\": float(imgs_per_second),\n",
|
| 395 |
+
" \"model_size_mb\": float(size_mb),\n",
|
| 396 |
+
" \"num_parameters\": int(model.count_params()),\n",
|
| 397 |
+
" }\n",
|
| 398 |
+
" return metrics, cm\n"
|
| 399 |
+
]
|
| 400 |
+
},
|
| 401 |
+
{
|
| 402 |
+
"cell_type": "code",
|
| 403 |
+
"execution_count": null,
|
| 404 |
+
"id": "6c01d2cc",
|
| 405 |
+
"metadata": {},
|
| 406 |
+
"outputs": [],
|
| 407 |
+
"source": [
|
| 408 |
+
"vgg_metrics, vgg_cm = evaluate_and_collect_metrics(\n",
|
| 409 |
+
" vgg16_model, \"vgg16\", test_ds, class_names, \"vgg16_best.h5\"\n",
|
| 410 |
+
")\n",
|
| 411 |
+
"with open(\"vgg16_metrics.json\", \"w\") as f:\n",
|
| 412 |
+
" json.dump(vgg_metrics, f, indent=2)"
|
| 413 |
+
]
|
| 414 |
+
},
|
| 415 |
+
{
|
| 416 |
+
"cell_type": "code",
|
| 417 |
+
"execution_count": null,
|
| 418 |
+
"id": "6e91352d",
|
| 419 |
+
"metadata": {},
|
| 420 |
+
"outputs": [],
|
| 421 |
+
"source": [
|
| 422 |
+
"# 2.2: Model 2 - ResNet50\n",
|
| 423 |
+
"def build_resnet50_model():\n",
|
| 424 |
+
" inputs = keras.Input(shape=(*IMG_SIZE, 3))\n",
|
| 425 |
+
" x = data_augmentation(inputs)\n",
|
| 426 |
+
" x = normalization(x)\n",
|
| 427 |
+
"\n",
|
| 428 |
+
" base_model = keras.applications.ResNet50(\n",
|
| 429 |
+
" include_top=False,\n",
|
| 430 |
+
" weights=\"imagenet\",\n",
|
| 431 |
+
" input_tensor=x\n",
|
| 432 |
+
" )\n",
|
| 433 |
+
"\n",
|
| 434 |
+
" # Freeze all, then unfreeze last 20 layers\n",
|
| 435 |
+
" for layer in base_model.layers:\n",
|
| 436 |
+
" layer.trainable = False\n",
|
| 437 |
+
" for layer in base_model.layers[-20:]:\n",
|
| 438 |
+
" layer.trainable = True\n",
|
| 439 |
+
"\n",
|
| 440 |
+
" x = layers.GlobalAveragePooling2D()(base_model.output)\n",
|
| 441 |
+
" x = layers.Dense(256, activation=\"relu\")(x)\n",
|
| 442 |
+
" x = layers.Dropout(0.5)(x)\n",
|
| 443 |
+
" outputs = layers.Dense(NUM_CLASSES, activation=\"softmax\")(x)\n",
|
| 444 |
+
"\n",
|
| 445 |
+
" model = keras.Model(inputs, outputs, name=\"ResNet50_smartvision\")\n",
|
| 446 |
+
" return model\n",
|
| 447 |
+
"\n",
|
| 448 |
+
"resnet_model = build_resnet50_model()\n",
|
| 449 |
+
"history_resnet = compile_and_train(resnet_model, \"resnet50\", train_ds, val_ds, epochs=25, lr=1e-4)\n"
|
| 450 |
+
]
|
| 451 |
+
},
|
| 452 |
+
{
|
| 453 |
+
"cell_type": "code",
|
| 454 |
+
"execution_count": null,
|
| 455 |
+
"id": "aab6167c",
|
| 456 |
+
"metadata": {},
|
| 457 |
+
"outputs": [],
|
| 458 |
+
"source": [
|
| 459 |
+
"# 2.3: Model 3 - MobileNetV2\n",
|
| 460 |
+
"\n",
|
| 461 |
+
"def build_mobilenetv2_model():\n",
|
| 462 |
+
" inputs = keras.Input(shape=(*IMG_SIZE, 3))\n",
|
| 463 |
+
" x = data_augmentation(inputs)\n",
|
| 464 |
+
" x = normalization(x)\n",
|
| 465 |
+
"\n",
|
| 466 |
+
" base_model = keras.applications.MobileNetV2(\n",
|
| 467 |
+
" include_top=False,\n",
|
| 468 |
+
" weights=\"imagenet\",\n",
|
| 469 |
+
" input_tensor=x\n",
|
| 470 |
+
" )\n",
|
| 471 |
+
" base_model.trainable = False # keep it light & fast\n",
|
| 472 |
+
"\n",
|
| 473 |
+
" x = layers.GlobalAveragePooling2D()(base_model.output)\n",
|
| 474 |
+
" x = layers.Dense(128, activation=\"relu\")(x)\n",
|
| 475 |
+
" x = layers.Dropout(0.3)(x)\n",
|
| 476 |
+
" outputs = layers.Dense(NUM_CLASSES, activation=\"softmax\")(x)\n",
|
| 477 |
+
"\n",
|
| 478 |
+
" model = keras.Model(inputs, outputs, name=\"MobileNetV2_smartvision\")\n",
|
| 479 |
+
" return model\n",
|
| 480 |
+
"\n",
|
| 481 |
+
"mobilenet_model = build_mobilenetv2_model()\n",
|
| 482 |
+
"history_mobilenet = compile_and_train(mobilenet_model, \"mobilenetv2\", train_ds, val_ds, epochs=20, lr=1e-4)\n"
|
| 483 |
+
]
|
| 484 |
+
},
|
| 485 |
+
{
|
| 486 |
+
"cell_type": "code",
|
| 487 |
+
"execution_count": null,
|
| 488 |
+
"id": "d4f51125",
|
| 489 |
+
"metadata": {},
|
| 490 |
+
"outputs": [],
|
| 491 |
+
"source": [
|
| 492 |
+
"# 2.4: Model 4 - EfficientNetB0\n",
|
| 493 |
+
"\n",
|
| 494 |
+
"from tensorflow.keras import mixed_precision\n",
|
| 495 |
+
"mixed_precision.set_global_policy(\"mixed_float16\") # for GPU speed\n",
|
| 496 |
+
"\n",
|
| 497 |
+
"def build_efficientnetb0_model():\n",
|
| 498 |
+
" inputs = keras.Input(shape=(*IMG_SIZE, 3))\n",
|
| 499 |
+
" x = data_augmentation(inputs)\n",
|
| 500 |
+
" x = normalization(x)\n",
|
| 501 |
+
"\n",
|
| 502 |
+
" base_model = keras.applications.EfficientNetB0(\n",
|
| 503 |
+
" include_top=False,\n",
|
| 504 |
+
" weights=\"imagenet\",\n",
|
| 505 |
+
" input_tensor=x\n",
|
| 506 |
+
" )\n",
|
| 507 |
+
"\n",
|
| 508 |
+
" # Fine-tune: unfreeze some top layers\n",
|
| 509 |
+
" for layer in base_model.layers[:-30]:\n",
|
| 510 |
+
" layer.trainable = False\n",
|
| 511 |
+
" for layer in base_model.layers[-30:]:\n",
|
| 512 |
+
" layer.trainable = True\n",
|
| 513 |
+
"\n",
|
| 514 |
+
" x = layers.GlobalAveragePooling2D()(base_model.output)\n",
|
| 515 |
+
" x = layers.BatchNormalization()(x)\n",
|
| 516 |
+
" x = layers.Dense(256, activation=\"relu\")(x)\n",
|
| 517 |
+
" x = layers.Dropout(0.4)(x)\n",
|
| 518 |
+
" outputs = layers.Dense(NUM_CLASSES, activation=\"softmax\", dtype=\"float32\")(x) # force float32 at output\n",
|
| 519 |
+
"\n",
|
| 520 |
+
" model = keras.Model(inputs, outputs, name=\"EfficientNetB0_smartvision\")\n",
|
| 521 |
+
" return model\n",
|
| 522 |
+
"\n",
|
| 523 |
+
"effnet_model = build_efficientnetb0_model()\n",
|
| 524 |
+
"history_effnet = compile_and_train(effnet_model, \"efficientnetb0\", train_ds, val_ds, epochs=30, lr=5e-5)\n"
|
| 525 |
+
]
|
| 526 |
+
},
|
| 527 |
+
{
|
| 528 |
+
"cell_type": "code",
|
| 529 |
+
"execution_count": null,
|
| 530 |
+
"id": "0064b8f3",
|
| 531 |
+
"metadata": {},
|
| 532 |
+
"outputs": [],
|
| 533 |
+
"source": [
|
| 534 |
+
"# 2.5: Model Comparison & Selection\n",
|
| 535 |
+
"\n",
|
| 536 |
+
"from sklearn.metrics import classification_report, confusion_matrix\n",
|
| 537 |
+
"import numpy as np\n",
|
| 538 |
+
"\n",
|
| 539 |
+
"def evaluate_on_test(model, test_ds, model_name):\n",
|
| 540 |
+
" y_true = []\n",
|
| 541 |
+
" y_pred = []\n",
|
| 542 |
+
"\n",
|
| 543 |
+
" for images, labels in test_ds:\n",
|
| 544 |
+
" preds = model.predict(images)\n",
|
| 545 |
+
" y_true.extend(labels.numpy())\n",
|
| 546 |
+
" y_pred.extend(np.argmax(preds, axis=1))\n",
|
| 547 |
+
"\n",
|
| 548 |
+
" print(f\"\\n=== {model_name} TEST REPORT ===\")\n",
|
| 549 |
+
" print(classification_report(y_true, y_pred, target_names=class_names))\n",
|
| 550 |
+
"\n",
|
| 551 |
+
" cm = confusion_matrix(y_true, y_pred)\n",
|
| 552 |
+
" plt.figure(figsize=(10, 8))\n",
|
| 553 |
+
" sns.heatmap(cm, annot=False, cmap=\"Blues\",\n",
|
| 554 |
+
" xticklabels=class_names,\n",
|
| 555 |
+
" yticklabels=class_names)\n",
|
| 556 |
+
" plt.title(f\"{model_name} - Confusion Matrix\")\n",
|
| 557 |
+
" plt.xlabel(\"Predicted\")\n",
|
| 558 |
+
" plt.ylabel(\"True\")\n",
|
| 559 |
+
" plt.show()\n",
|
| 560 |
+
"\n",
|
| 561 |
+
"# Load best weights if needed and evaluate\n",
|
| 562 |
+
"vgg16_model.load_weights(\"vgg16_best.h5\")\n",
|
| 563 |
+
"resnet_model.load_weights(\"resnet50_best.h5\")\n",
|
| 564 |
+
"mobilenet_model.load_weights(\"mobilenetv2_best.h5\")\n",
|
| 565 |
+
"effnet_model.load_weights(\"efficientnetb0_best.h5\")\n",
|
| 566 |
+
"\n",
|
| 567 |
+
"evaluate_on_test(vgg16_model, test_ds, \"VGG16\")\n",
|
| 568 |
+
"evaluate_on_test(resnet_model, test_ds, \"ResNet50\")\n",
|
| 569 |
+
"evaluate_on_test(mobilenet_model, test_ds, \"MobileNetV2\")\n",
|
| 570 |
+
"evaluate_on_test(effnet_model, test_ds, \"EfficientNetB0\")\n"
|
| 571 |
+
]
|
| 572 |
+
}
|
| 573 |
+
],
|
| 574 |
+
"metadata": {
|
| 575 |
+
"kernelspec": {
|
| 576 |
+
"display_name": "Python 3",
|
| 577 |
+
"language": "python",
|
| 578 |
+
"name": "python3"
|
| 579 |
+
},
|
| 580 |
+
"language_info": {
|
| 581 |
+
"codemirror_mode": {
|
| 582 |
+
"name": "ipython",
|
| 583 |
+
"version": 3
|
| 584 |
+
},
|
| 585 |
+
"file_extension": ".py",
|
| 586 |
+
"mimetype": "text/x-python",
|
| 587 |
+
"name": "python",
|
| 588 |
+
"nbconvert_exporter": "python",
|
| 589 |
+
"pygments_lexer": "ipython3",
|
| 590 |
+
"version": "3.11.9"
|
| 591 |
+
}
|
| 592 |
+
},
|
| 593 |
+
"nbformat": 4,
|
| 594 |
+
"nbformat_minor": 5
|
| 595 |
+
}
|
scripts/01_EDA.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
scripts/02_efficientnetb0.py
ADDED
|
@@ -0,0 +1,385 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - MODEL 4: EfficientNetB0 (FINE-TUNING)
|
| 3 |
+
# Target: High-accuracy 25-class classifier
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
import json
|
| 9 |
+
import numpy as np
|
| 10 |
+
import tensorflow as tf
|
| 11 |
+
from tensorflow import keras
|
| 12 |
+
from tensorflow.keras import layers
|
| 13 |
+
from sklearn.metrics import (
|
| 14 |
+
precision_recall_fscore_support,
|
| 15 |
+
confusion_matrix,
|
| 16 |
+
classification_report,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
print("TensorFlow version:", tf.__version__)
|
| 20 |
+
|
| 21 |
+
from tensorflow.keras.applications.efficientnet import (
|
| 22 |
+
EfficientNetB0,
|
| 23 |
+
preprocess_input,
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
# ------------------------------------------------------------
|
| 27 |
+
# 1. CONFIGURATION
|
| 28 |
+
# ------------------------------------------------------------
|
| 29 |
+
|
| 30 |
+
BASE_DIR = "smartvision_dataset"
|
| 31 |
+
CLASS_DIR = os.path.join(BASE_DIR, "classification")
|
| 32 |
+
TRAIN_DIR = os.path.join(CLASS_DIR, "train")
|
| 33 |
+
VAL_DIR = os.path.join(CLASS_DIR, "val")
|
| 34 |
+
TEST_DIR = os.path.join(CLASS_DIR, "test")
|
| 35 |
+
|
| 36 |
+
IMG_SIZE = (224, 224) # EfficientNetB0 default
|
| 37 |
+
BATCH_SIZE = 32
|
| 38 |
+
NUM_CLASSES = 25
|
| 39 |
+
|
| 40 |
+
MODELS_DIR = "saved_models"
|
| 41 |
+
METRICS_DIR = "smartvision_metrics"
|
| 42 |
+
|
| 43 |
+
os.makedirs(MODELS_DIR, exist_ok=True)
|
| 44 |
+
os.makedirs(METRICS_DIR, exist_ok=True)
|
| 45 |
+
|
| 46 |
+
print("Train dir:", TRAIN_DIR)
|
| 47 |
+
print("Val dir :", VAL_DIR)
|
| 48 |
+
print("Test dir :", TEST_DIR)
|
| 49 |
+
|
| 50 |
+
# ------------------------------------------------------------
|
| 51 |
+
# 2. LOAD DATASETS
|
| 52 |
+
# ------------------------------------------------------------
|
| 53 |
+
|
| 54 |
+
train_ds = tf.keras.utils.image_dataset_from_directory(
|
| 55 |
+
TRAIN_DIR,
|
| 56 |
+
image_size=IMG_SIZE,
|
| 57 |
+
batch_size=BATCH_SIZE,
|
| 58 |
+
shuffle=True,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
val_ds = tf.keras.utils.image_dataset_from_directory(
|
| 62 |
+
VAL_DIR,
|
| 63 |
+
image_size=IMG_SIZE,
|
| 64 |
+
batch_size=BATCH_SIZE,
|
| 65 |
+
shuffle=False,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
test_ds = tf.keras.utils.image_dataset_from_directory(
|
| 69 |
+
TEST_DIR,
|
| 70 |
+
image_size=IMG_SIZE,
|
| 71 |
+
batch_size=BATCH_SIZE,
|
| 72 |
+
shuffle=False,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
class_names = train_ds.class_names
|
| 76 |
+
print("Detected classes:", class_names)
|
| 77 |
+
print("Number of classes:", len(class_names))
|
| 78 |
+
|
| 79 |
+
AUTOTUNE = tf.data.AUTOTUNE
|
| 80 |
+
train_ds = train_ds.prefetch(AUTOTUNE)
|
| 81 |
+
val_ds = val_ds.prefetch(AUTOTUNE)
|
| 82 |
+
test_ds = test_ds.prefetch(AUTOTUNE)
|
| 83 |
+
|
| 84 |
+
# ------------------------------------------------------------
|
| 85 |
+
# 3. ADVANCED DATA AUGMENTATION
|
| 86 |
+
# ------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
def bright_jitter(x):
|
| 89 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 90 |
+
x_f32 = tf.image.random_brightness(x_f32, max_delta=0.25)
|
| 91 |
+
return tf.cast(x_f32, x.dtype)
|
| 92 |
+
|
| 93 |
+
def sat_jitter(x):
|
| 94 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 95 |
+
x_f32 = tf.image.random_saturation(x_f32, lower=0.7, upper=1.3)
|
| 96 |
+
return tf.cast(x_f32, x.dtype)
|
| 97 |
+
|
| 98 |
+
data_augmentation = keras.Sequential(
|
| 99 |
+
[
|
| 100 |
+
layers.RandomFlip("horizontal"),
|
| 101 |
+
layers.RandomRotation(0.08), # ≈ ±30 degrees
|
| 102 |
+
layers.RandomZoom(0.15),
|
| 103 |
+
layers.RandomContrast(0.3),
|
| 104 |
+
layers.RandomTranslation(0.1, 0.1),
|
| 105 |
+
layers.Lambda(bright_jitter),
|
| 106 |
+
layers.Lambda(sat_jitter),
|
| 107 |
+
],
|
| 108 |
+
name="advanced_data_augmentation",
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
# ------------------------------------------------------------
|
| 112 |
+
# 4. BUILD EfficientNetB0 MODEL (TWO-STAGE FINE-TUNING)
|
| 113 |
+
# ------------------------------------------------------------
|
| 114 |
+
|
| 115 |
+
def build_efficientnetb0_model():
|
| 116 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 117 |
+
|
| 118 |
+
# 1. Data augmentation (training only)
|
| 119 |
+
x = data_augmentation(inputs)
|
| 120 |
+
|
| 121 |
+
# 2. EfficientNetB0 preprocess_input
|
| 122 |
+
x = layers.Lambda(
|
| 123 |
+
lambda z: preprocess_input(tf.cast(z, tf.float32)),
|
| 124 |
+
name="effnet_preprocess",
|
| 125 |
+
)(x)
|
| 126 |
+
|
| 127 |
+
# 3. EfficientNetB0 base model (ImageNet)
|
| 128 |
+
base_model = EfficientNetB0(
|
| 129 |
+
include_top=False,
|
| 130 |
+
weights="imagenet",
|
| 131 |
+
input_shape=(*IMG_SIZE, 3),
|
| 132 |
+
name="efficientnetb0",
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
base_model.trainable = False # Stage 1: frozen
|
| 136 |
+
|
| 137 |
+
x = base_model(x, training=False)
|
| 138 |
+
|
| 139 |
+
x = layers.GlobalAveragePooling2D(name="gap")(x)
|
| 140 |
+
x = layers.BatchNormalization(name="head_bn_1")(x)
|
| 141 |
+
x = layers.Dense(256, activation="relu", name="head_dense_1")(x)
|
| 142 |
+
x = layers.BatchNormalization(name="head_bn_2")(x)
|
| 143 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 144 |
+
|
| 145 |
+
outputs = layers.Dense(
|
| 146 |
+
NUM_CLASSES,
|
| 147 |
+
activation="softmax",
|
| 148 |
+
name="predictions",
|
| 149 |
+
)(x)
|
| 150 |
+
|
| 151 |
+
model = keras.Model(inputs, outputs, name="EfficientNetB0_smartvision")
|
| 152 |
+
return model
|
| 153 |
+
|
| 154 |
+
effnet_model = build_efficientnetb0_model()
|
| 155 |
+
effnet_model.summary()
|
| 156 |
+
|
| 157 |
+
# ------------------------------------------------------------
|
| 158 |
+
# 5. TRAINING UTILITY (WEIGHTS-ONLY .weights.h5)
|
| 159 |
+
# ------------------------------------------------------------
|
| 160 |
+
|
| 161 |
+
def compile_and_train(
|
| 162 |
+
model,
|
| 163 |
+
save_name: str,
|
| 164 |
+
train_ds,
|
| 165 |
+
val_ds,
|
| 166 |
+
epochs: int,
|
| 167 |
+
lr: float,
|
| 168 |
+
initial_epoch: int = 0,
|
| 169 |
+
patience_es: int = 5,
|
| 170 |
+
patience_rlr: int = 2,
|
| 171 |
+
):
|
| 172 |
+
optimizer = keras.optimizers.Adam(learning_rate=lr)
|
| 173 |
+
|
| 174 |
+
model.compile(
|
| 175 |
+
optimizer=optimizer,
|
| 176 |
+
loss="sparse_categorical_crossentropy",
|
| 177 |
+
metrics=["accuracy"],
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
best_weights_path = os.path.join(
|
| 181 |
+
MODELS_DIR, f"{save_name}.weights.h5"
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
callbacks = [
|
| 185 |
+
keras.callbacks.ModelCheckpoint(
|
| 186 |
+
filepath=best_weights_path,
|
| 187 |
+
monitor="val_accuracy",
|
| 188 |
+
save_best_only=True,
|
| 189 |
+
save_weights_only=True,
|
| 190 |
+
mode="max",
|
| 191 |
+
verbose=1,
|
| 192 |
+
),
|
| 193 |
+
keras.callbacks.EarlyStopping(
|
| 194 |
+
monitor="val_accuracy",
|
| 195 |
+
patience=patience_es,
|
| 196 |
+
restore_best_weights=True,
|
| 197 |
+
verbose=1,
|
| 198 |
+
),
|
| 199 |
+
keras.callbacks.ReduceLROnPlateau(
|
| 200 |
+
monitor="val_loss",
|
| 201 |
+
factor=0.5,
|
| 202 |
+
patience=patience_rlr,
|
| 203 |
+
min_lr=1e-6,
|
| 204 |
+
verbose=1,
|
| 205 |
+
),
|
| 206 |
+
]
|
| 207 |
+
|
| 208 |
+
history = model.fit(
|
| 209 |
+
train_ds,
|
| 210 |
+
validation_data=val_ds,
|
| 211 |
+
epochs=epochs,
|
| 212 |
+
initial_epoch=initial_epoch,
|
| 213 |
+
callbacks=callbacks,
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
return history, best_weights_path
|
| 217 |
+
|
| 218 |
+
# ------------------------------------------------------------
|
| 219 |
+
# 6. TWO-STAGE TRAINING
|
| 220 |
+
# ------------------------------------------------------------
|
| 221 |
+
|
| 222 |
+
MODEL_NAME = "efficientnetb0"
|
| 223 |
+
|
| 224 |
+
print("\n========== STAGE 1: TRAIN HEAD ONLY ==========\n")
|
| 225 |
+
|
| 226 |
+
history_stage1, effnet_stage1_best = compile_and_train(
|
| 227 |
+
effnet_model,
|
| 228 |
+
save_name=f"{MODEL_NAME}_stage1_best",
|
| 229 |
+
train_ds=train_ds,
|
| 230 |
+
val_ds=val_ds,
|
| 231 |
+
epochs=10,
|
| 232 |
+
lr=1e-3,
|
| 233 |
+
initial_epoch=0,
|
| 234 |
+
patience_es=5,
|
| 235 |
+
patience_rlr=2,
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
print("Stage 1 best weights saved at:", effnet_stage1_best)
|
| 239 |
+
|
| 240 |
+
print("\n========== STAGE 2: FINE-TUNE TOP LAYERS ==========\n")
|
| 241 |
+
|
| 242 |
+
# Get the EfficientNet base from the combined model
|
| 243 |
+
base_model = effnet_model.get_layer("efficientnetb0")
|
| 244 |
+
|
| 245 |
+
# Unfreeze top N layers
|
| 246 |
+
num_unfreeze = 80
|
| 247 |
+
for layer in base_model.layers[:-num_unfreeze]:
|
| 248 |
+
layer.trainable = False
|
| 249 |
+
for layer in base_model.layers[-num_unfreeze:]:
|
| 250 |
+
layer.trainable = True
|
| 251 |
+
if isinstance(layer, layers.BatchNormalization):
|
| 252 |
+
layer.trainable = False # keep BN frozen
|
| 253 |
+
|
| 254 |
+
initial_epoch_stage2 = len(history_stage1.history["accuracy"])
|
| 255 |
+
|
| 256 |
+
history_stage2, effnet_stage2_best = compile_and_train(
|
| 257 |
+
effnet_model,
|
| 258 |
+
save_name=f"{MODEL_NAME}_stage2_best",
|
| 259 |
+
train_ds=train_ds,
|
| 260 |
+
val_ds=val_ds,
|
| 261 |
+
epochs=30, # total (Stage1 + Stage2)
|
| 262 |
+
lr=5e-5,
|
| 263 |
+
initial_epoch=initial_epoch_stage2,
|
| 264 |
+
patience_es=5,
|
| 265 |
+
patience_rlr=2,
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
print("Stage 2 best weights saved at:", effnet_stage2_best)
|
| 269 |
+
print("👉 Use this file in Streamlit app:", effnet_stage2_best)
|
| 270 |
+
|
| 271 |
+
# ------------------------------------------------------------
|
| 272 |
+
# 7. EVALUATION + SAVE METRICS & CONFUSION MATRIX
|
| 273 |
+
# ------------------------------------------------------------
|
| 274 |
+
|
| 275 |
+
def evaluate_and_save(model, model_name, best_weights_path, test_ds, class_names):
|
| 276 |
+
print(f"\n===== EVALUATING {model_name.upper()} ON TEST SET =====")
|
| 277 |
+
|
| 278 |
+
model.load_weights(best_weights_path)
|
| 279 |
+
print(f"Loaded best weights from {best_weights_path}")
|
| 280 |
+
|
| 281 |
+
y_true = []
|
| 282 |
+
y_pred = []
|
| 283 |
+
all_probs = []
|
| 284 |
+
|
| 285 |
+
total_time = 0.0
|
| 286 |
+
total_images = 0
|
| 287 |
+
|
| 288 |
+
for images, labels in test_ds:
|
| 289 |
+
images_np = images.numpy()
|
| 290 |
+
bs = images_np.shape[0]
|
| 291 |
+
|
| 292 |
+
start = time.perf_counter()
|
| 293 |
+
probs = model.predict(images_np, verbose=0)
|
| 294 |
+
end = time.perf_counter()
|
| 295 |
+
|
| 296 |
+
total_time += (end - start)
|
| 297 |
+
total_images += bs
|
| 298 |
+
|
| 299 |
+
preds = np.argmax(probs, axis=1)
|
| 300 |
+
|
| 301 |
+
y_true.extend(labels.numpy())
|
| 302 |
+
y_pred.extend(preds)
|
| 303 |
+
all_probs.append(probs)
|
| 304 |
+
|
| 305 |
+
y_true = np.array(y_true)
|
| 306 |
+
y_pred = np.array(y_pred)
|
| 307 |
+
all_probs = np.concatenate(all_probs, axis=0)
|
| 308 |
+
|
| 309 |
+
accuracy = float((y_true == y_pred).mean())
|
| 310 |
+
precision, recall, f1, _ = precision_recall_fscore_support(
|
| 311 |
+
y_true, y_pred, average="weighted", zero_division=0
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
top5_correct = 0
|
| 315 |
+
for i, label in enumerate(y_true):
|
| 316 |
+
if label in np.argsort(all_probs[i])[-5:]:
|
| 317 |
+
top5_correct += 1
|
| 318 |
+
top5_acc = top5_correct / len(y_true)
|
| 319 |
+
|
| 320 |
+
time_per_image = total_time / total_images
|
| 321 |
+
images_per_second = 1.0 / time_per_image
|
| 322 |
+
|
| 323 |
+
temp_w = os.path.join(MODELS_DIR, f"{model_name}_temp_for_size.weights.h5")
|
| 324 |
+
model.save_weights(temp_w)
|
| 325 |
+
size_mb = os.path.getsize(temp_w) / (1024 * 1024)
|
| 326 |
+
os.remove(temp_w)
|
| 327 |
+
|
| 328 |
+
cm = confusion_matrix(y_true, y_pred)
|
| 329 |
+
|
| 330 |
+
print("\nClassification Report:")
|
| 331 |
+
print(
|
| 332 |
+
classification_report(
|
| 333 |
+
y_true, y_pred, target_names=class_names, zero_division=0
|
| 334 |
+
)
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
print(f"Test Accuracy : {accuracy:.4f}")
|
| 338 |
+
print(f"Weighted Precision : {precision:.4f}")
|
| 339 |
+
print(f"Weighted Recall : {recall:.4f}")
|
| 340 |
+
print(f"Weighted F1-score : {f1:.4f}")
|
| 341 |
+
print(f"Top-5 Accuracy : {top5_acc:.4f}")
|
| 342 |
+
print(f"Avg time per image : {time_per_image*1000:.2f} ms")
|
| 343 |
+
print(f"Images per second : {images_per_second:.2f}")
|
| 344 |
+
print(f"Model size (weights) : {size_mb:.2f} MB")
|
| 345 |
+
print(f"Num parameters : {model.count_params()}")
|
| 346 |
+
|
| 347 |
+
save_dir = os.path.join(METRICS_DIR, model_name)
|
| 348 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 349 |
+
|
| 350 |
+
metrics = {
|
| 351 |
+
"model_name": model_name,
|
| 352 |
+
"accuracy": accuracy,
|
| 353 |
+
"precision_weighted": float(precision),
|
| 354 |
+
"recall_weighted": float(recall),
|
| 355 |
+
"f1_weighted": float(f1),
|
| 356 |
+
"top5_accuracy": float(top5_acc),
|
| 357 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 358 |
+
"images_per_second": float(images_per_second),
|
| 359 |
+
"model_size_mb": float(size_mb),
|
| 360 |
+
"num_parameters": int(model.count_params()),
|
| 361 |
+
}
|
| 362 |
+
|
| 363 |
+
metrics_path = os.path.join(save_dir, "metrics.json")
|
| 364 |
+
cm_path = os.path.join(save_dir, "confusion_matrix.npy")
|
| 365 |
+
|
| 366 |
+
with open(metrics_path, "w") as f:
|
| 367 |
+
json.dump(metrics, f, indent=2)
|
| 368 |
+
|
| 369 |
+
np.save(cm_path, cm)
|
| 370 |
+
|
| 371 |
+
print(f"\nSaved metrics to : {metrics_path}")
|
| 372 |
+
print(f"Saved confusion matrix to: {cm_path}")
|
| 373 |
+
|
| 374 |
+
return metrics, cm
|
| 375 |
+
|
| 376 |
+
effnet_metrics, effnet_cm = evaluate_and_save(
|
| 377 |
+
effnet_model,
|
| 378 |
+
model_name="efficientnetb0_stage2",
|
| 379 |
+
best_weights_path=effnet_stage2_best,
|
| 380 |
+
test_ds=test_ds,
|
| 381 |
+
class_names=class_names,
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
print("\n✅ EfficientNetB0 Model 4 pipeline complete.")
|
| 385 |
+
print("✅ Use weights file in app:", effnet_stage2_best)
|
scripts/02_mobilenetv2.py
ADDED
|
@@ -0,0 +1,430 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - MODEL 3 (v3): MobileNetV2 (FAST + ACCURATE)
|
| 3 |
+
# with manual label smoothing + deeper fine-tuning
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
import json
|
| 9 |
+
import numpy as np
|
| 10 |
+
import tensorflow as tf
|
| 11 |
+
from tensorflow import keras
|
| 12 |
+
from tensorflow.keras import layers, regularizers
|
| 13 |
+
from sklearn.metrics import (
|
| 14 |
+
precision_recall_fscore_support,
|
| 15 |
+
confusion_matrix,
|
| 16 |
+
classification_report,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
print("TensorFlow version:", tf.__version__)
|
| 20 |
+
|
| 21 |
+
# ------------------------------------------------------------
|
| 22 |
+
# 1. CONFIGURATION
|
| 23 |
+
# ------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
BASE_DIR = "smartvision_dataset"
|
| 26 |
+
CLASS_DIR = os.path.join(BASE_DIR, "classification")
|
| 27 |
+
TRAIN_DIR = os.path.join(CLASS_DIR, "train")
|
| 28 |
+
VAL_DIR = os.path.join(CLASS_DIR, "val")
|
| 29 |
+
TEST_DIR = os.path.join(CLASS_DIR, "test")
|
| 30 |
+
|
| 31 |
+
IMG_SIZE = (224, 224)
|
| 32 |
+
BATCH_SIZE = 32
|
| 33 |
+
NUM_CLASSES = 25
|
| 34 |
+
|
| 35 |
+
MODELS_DIR = "saved_models"
|
| 36 |
+
METRICS_DIR = "smartvision_metrics"
|
| 37 |
+
|
| 38 |
+
os.makedirs(MODELS_DIR, exist_ok=True)
|
| 39 |
+
os.makedirs(METRICS_DIR, exist_ok=True)
|
| 40 |
+
|
| 41 |
+
print("Train dir:", TRAIN_DIR)
|
| 42 |
+
print("Val dir :", VAL_DIR)
|
| 43 |
+
print("Test dir :", TEST_DIR)
|
| 44 |
+
|
| 45 |
+
# ------------------------------------------------------------
|
| 46 |
+
# 2. LOAD DATASETS (CROPPED SINGLE-OBJECT IMAGES)
|
| 47 |
+
# ------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
train_ds = tf.keras.utils.image_dataset_from_directory(
|
| 50 |
+
TRAIN_DIR,
|
| 51 |
+
image_size=IMG_SIZE,
|
| 52 |
+
batch_size=BATCH_SIZE,
|
| 53 |
+
shuffle=True,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
val_ds = tf.keras.utils.image_dataset_from_directory(
|
| 57 |
+
VAL_DIR,
|
| 58 |
+
image_size=IMG_SIZE,
|
| 59 |
+
batch_size=BATCH_SIZE,
|
| 60 |
+
shuffle=False,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
test_ds = tf.keras.utils.image_dataset_from_directory(
|
| 64 |
+
TEST_DIR,
|
| 65 |
+
image_size=IMG_SIZE,
|
| 66 |
+
batch_size=BATCH_SIZE,
|
| 67 |
+
shuffle=False,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
class_names = train_ds.class_names
|
| 71 |
+
print("Detected classes:", class_names)
|
| 72 |
+
print("Number of classes:", len(class_names))
|
| 73 |
+
|
| 74 |
+
AUTOTUNE = tf.data.AUTOTUNE
|
| 75 |
+
train_ds = train_ds.prefetch(AUTOTUNE)
|
| 76 |
+
val_ds = val_ds.prefetch(AUTOTUNE)
|
| 77 |
+
test_ds = test_ds.prefetch(AUTOTUNE)
|
| 78 |
+
|
| 79 |
+
# ------------------------------------------------------------
|
| 80 |
+
# 3. DATA AUGMENTATION (STANDARD, TRAIN-ONLY)
|
| 81 |
+
# ------------------------------------------------------------
|
| 82 |
+
|
| 83 |
+
data_augmentation = keras.Sequential(
|
| 84 |
+
[
|
| 85 |
+
layers.RandomFlip("horizontal"),
|
| 86 |
+
layers.RandomRotation(0.04), # ~±15°
|
| 87 |
+
layers.RandomZoom(0.1),
|
| 88 |
+
layers.RandomContrast(0.15),
|
| 89 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.15)),
|
| 90 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.85, 1.15)),
|
| 91 |
+
],
|
| 92 |
+
name="data_augmentation",
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
# ------------------------------------------------------------
|
| 96 |
+
# 4. BUILD MobileNetV2 MODEL (2-STAGE TRAINING)
|
| 97 |
+
# ------------------------------------------------------------
|
| 98 |
+
|
| 99 |
+
def build_mobilenetv2_model_v2():
|
| 100 |
+
"""
|
| 101 |
+
Returns:
|
| 102 |
+
model : full MobileNetV2 classification model
|
| 103 |
+
base_model : the MobileNetV2 backbone (for freezing/unfreezing)
|
| 104 |
+
"""
|
| 105 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 106 |
+
|
| 107 |
+
# Apply augmentation only during training
|
| 108 |
+
x = data_augmentation(inputs)
|
| 109 |
+
|
| 110 |
+
# MobileNetV2 expects [-1, 1] normalized inputs via preprocess_input
|
| 111 |
+
x = layers.Lambda(
|
| 112 |
+
keras.applications.mobilenet_v2.preprocess_input,
|
| 113 |
+
name="mobilenetv2_preprocess",
|
| 114 |
+
)(x)
|
| 115 |
+
|
| 116 |
+
# Pretrained MobileNetV2 backbone
|
| 117 |
+
base_model = keras.applications.MobileNetV2(
|
| 118 |
+
include_top=False,
|
| 119 |
+
weights="imagenet",
|
| 120 |
+
input_shape=(*IMG_SIZE, 3),
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
# Run backbone
|
| 124 |
+
x = base_model(x)
|
| 125 |
+
|
| 126 |
+
# Global pooling + custom classification head
|
| 127 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 128 |
+
|
| 129 |
+
x = layers.BatchNormalization(name="head_batchnorm_1")(x)
|
| 130 |
+
x = layers.Dropout(0.4, name="head_dropout_1")(x)
|
| 131 |
+
|
| 132 |
+
x = layers.Dense(
|
| 133 |
+
256,
|
| 134 |
+
activation="relu",
|
| 135 |
+
kernel_regularizer=regularizers.l2(1e-4),
|
| 136 |
+
name="head_dense_1",
|
| 137 |
+
)(x)
|
| 138 |
+
|
| 139 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 140 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 141 |
+
|
| 142 |
+
outputs = layers.Dense(
|
| 143 |
+
NUM_CLASSES, activation="softmax", name="predictions"
|
| 144 |
+
)(x)
|
| 145 |
+
|
| 146 |
+
model = keras.Model(
|
| 147 |
+
inputs=inputs,
|
| 148 |
+
outputs=outputs,
|
| 149 |
+
name="MobileNetV2_smartvision_v2",
|
| 150 |
+
)
|
| 151 |
+
return model, base_model
|
| 152 |
+
|
| 153 |
+
mobilenet_model, base_model = build_mobilenetv2_model_v2()
|
| 154 |
+
mobilenet_model.summary()
|
| 155 |
+
|
| 156 |
+
# ------------------------------------------------------------
|
| 157 |
+
# 5. MANUAL LABEL-SMOOTHED LOSS
|
| 158 |
+
# ------------------------------------------------------------
|
| 159 |
+
|
| 160 |
+
def make_sparse_ce_with_label_smoothing(num_classes, label_smoothing=0.05):
|
| 161 |
+
ls = float(label_smoothing)
|
| 162 |
+
nc = int(num_classes)
|
| 163 |
+
|
| 164 |
+
def loss_fn(y_true, y_pred):
|
| 165 |
+
# y_true: integer labels, shape (batch,)
|
| 166 |
+
y_true = tf.cast(y_true, tf.int32)
|
| 167 |
+
y_true_oh = tf.one_hot(y_true, depth=nc)
|
| 168 |
+
|
| 169 |
+
if ls > 0.0:
|
| 170 |
+
smooth = ls
|
| 171 |
+
y_true_oh = (1.0 - smooth) * y_true_oh + smooth / tf.cast(
|
| 172 |
+
nc, tf.float32
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
# y_pred is softmax probabilities
|
| 176 |
+
return tf.keras.losses.categorical_crossentropy(
|
| 177 |
+
y_true_oh, y_pred, from_logits=False
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
return loss_fn
|
| 181 |
+
|
| 182 |
+
# ------------------------------------------------------------
|
| 183 |
+
# 6. TRAINING UTILITY (SAVES WEIGHTS-ONLY .weights.h5)
|
| 184 |
+
# ------------------------------------------------------------
|
| 185 |
+
|
| 186 |
+
def compile_and_train(
|
| 187 |
+
model,
|
| 188 |
+
model_name,
|
| 189 |
+
train_ds,
|
| 190 |
+
val_ds,
|
| 191 |
+
epochs,
|
| 192 |
+
lr,
|
| 193 |
+
model_tag,
|
| 194 |
+
patience_es=5,
|
| 195 |
+
patience_rlr=2,
|
| 196 |
+
):
|
| 197 |
+
"""Compile and train model, saving the best weights by val_accuracy."""
|
| 198 |
+
print(f"\n===== TRAINING {model_name} ({model_tag}) =====")
|
| 199 |
+
|
| 200 |
+
optimizer = keras.optimizers.Adam(learning_rate=lr)
|
| 201 |
+
|
| 202 |
+
loss_fn = make_sparse_ce_with_label_smoothing(
|
| 203 |
+
num_classes=NUM_CLASSES,
|
| 204 |
+
label_smoothing=0.05,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
model.compile(
|
| 208 |
+
optimizer=optimizer,
|
| 209 |
+
loss=loss_fn,
|
| 210 |
+
metrics=["accuracy"],
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
# Keras 3 requirement: weights-only must end with ".weights.h5"
|
| 214 |
+
best_weights_path = os.path.join(
|
| 215 |
+
MODELS_DIR, f"{model_name}_{model_tag}_best.weights.h5"
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
callbacks = [
|
| 219 |
+
keras.callbacks.ModelCheckpoint(
|
| 220 |
+
filepath=best_weights_path,
|
| 221 |
+
monitor="val_accuracy",
|
| 222 |
+
save_best_only=True,
|
| 223 |
+
save_weights_only=True,
|
| 224 |
+
mode="max",
|
| 225 |
+
verbose=1,
|
| 226 |
+
),
|
| 227 |
+
keras.callbacks.EarlyStopping(
|
| 228 |
+
monitor="val_accuracy",
|
| 229 |
+
patience=patience_es,
|
| 230 |
+
restore_best_weights=True,
|
| 231 |
+
verbose=1,
|
| 232 |
+
),
|
| 233 |
+
keras.callbacks.ReduceLROnPlateau(
|
| 234 |
+
monitor="val_loss",
|
| 235 |
+
factor=0.5,
|
| 236 |
+
patience=patience_rlr,
|
| 237 |
+
min_lr=1e-6,
|
| 238 |
+
verbose=1,
|
| 239 |
+
),
|
| 240 |
+
]
|
| 241 |
+
|
| 242 |
+
history = model.fit(
|
| 243 |
+
train_ds,
|
| 244 |
+
validation_data=val_ds,
|
| 245 |
+
epochs=epochs,
|
| 246 |
+
callbacks=callbacks,
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
return history, best_weights_path
|
| 250 |
+
|
| 251 |
+
# ------------------------------------------------------------
|
| 252 |
+
# 7. STAGE 1: TRAIN HEAD WITH FROZEN BASE
|
| 253 |
+
# ------------------------------------------------------------
|
| 254 |
+
|
| 255 |
+
print("\n===== STAGE 1: Training head with frozen MobileNetV2 base =====")
|
| 256 |
+
|
| 257 |
+
for layer in base_model.layers:
|
| 258 |
+
layer.trainable = False
|
| 259 |
+
|
| 260 |
+
epochs_stage1 = 12
|
| 261 |
+
lr_stage1 = 1e-3
|
| 262 |
+
|
| 263 |
+
history_stage1, mobilenet_stage1_best = compile_and_train(
|
| 264 |
+
mobilenet_model,
|
| 265 |
+
model_name="mobilenetv2_v2",
|
| 266 |
+
train_ds=train_ds,
|
| 267 |
+
val_ds=val_ds,
|
| 268 |
+
epochs=epochs_stage1,
|
| 269 |
+
lr=lr_stage1,
|
| 270 |
+
model_tag="stage1",
|
| 271 |
+
patience_es=4,
|
| 272 |
+
patience_rlr=2,
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
print("Stage 1 best weights saved at:", mobilenet_stage1_best)
|
| 276 |
+
|
| 277 |
+
# ------------------------------------------------------------
|
| 278 |
+
# 8. STAGE 2: DEEPER FINE-TUNE LAST LAYERS OF BASE MODEL
|
| 279 |
+
# ------------------------------------------------------------
|
| 280 |
+
|
| 281 |
+
print("\n===== STAGE 2: Fine-tuning last layers of MobileNetV2 base =====")
|
| 282 |
+
|
| 283 |
+
mobilenet_model.load_weights(mobilenet_stage1_best)
|
| 284 |
+
|
| 285 |
+
base_model.trainable = True
|
| 286 |
+
num_unfreeze = 25
|
| 287 |
+
|
| 288 |
+
print(f"Base model has {len(base_model.layers)} layers.")
|
| 289 |
+
print(f"Unfrozen layers in base model: {num_unfreeze}")
|
| 290 |
+
|
| 291 |
+
for layer in base_model.layers[:-num_unfreeze]:
|
| 292 |
+
layer.trainable = False
|
| 293 |
+
|
| 294 |
+
for layer in base_model.layers[-num_unfreeze:]:
|
| 295 |
+
if isinstance(layer, layers.BatchNormalization):
|
| 296 |
+
layer.trainable = False
|
| 297 |
+
|
| 298 |
+
epochs_stage2 = 25
|
| 299 |
+
lr_stage2 = 3e-5
|
| 300 |
+
|
| 301 |
+
history_stage2, mobilenet_stage2_best = compile_and_train(
|
| 302 |
+
mobilenet_model,
|
| 303 |
+
model_name="mobilenetv2_v2",
|
| 304 |
+
train_ds=train_ds,
|
| 305 |
+
val_ds=val_ds,
|
| 306 |
+
epochs=epochs_stage2,
|
| 307 |
+
lr=lr_stage2,
|
| 308 |
+
model_tag="stage2",
|
| 309 |
+
patience_es=8,
|
| 310 |
+
patience_rlr=3,
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
print("Stage 2 best weights saved at:", mobilenet_stage2_best)
|
| 314 |
+
print("👉 Use this file in Streamlit app:", mobilenet_stage2_best)
|
| 315 |
+
|
| 316 |
+
# ------------------------------------------------------------
|
| 317 |
+
# 9. EVALUATION + SAVE METRICS & CONFUSION MATRIX
|
| 318 |
+
# ------------------------------------------------------------
|
| 319 |
+
|
| 320 |
+
def evaluate_and_save(model, model_name, best_weights_path, test_ds, class_names):
|
| 321 |
+
print(f"\n===== EVALUATING {model_name.upper()} ON TEST SET =====")
|
| 322 |
+
|
| 323 |
+
model.load_weights(best_weights_path)
|
| 324 |
+
print(f"Loaded best weights from {best_weights_path}")
|
| 325 |
+
|
| 326 |
+
y_true = []
|
| 327 |
+
y_pred = []
|
| 328 |
+
all_probs = []
|
| 329 |
+
|
| 330 |
+
total_time = 0.0
|
| 331 |
+
total_images = 0
|
| 332 |
+
|
| 333 |
+
for images, labels in test_ds:
|
| 334 |
+
images_np = images.numpy()
|
| 335 |
+
bs = images_np.shape[0]
|
| 336 |
+
|
| 337 |
+
start = time.perf_counter()
|
| 338 |
+
probs = model.predict(images_np, verbose=0)
|
| 339 |
+
end = time.perf_counter()
|
| 340 |
+
|
| 341 |
+
total_time += (end - start)
|
| 342 |
+
total_images += bs
|
| 343 |
+
|
| 344 |
+
preds = np.argmax(probs, axis=1)
|
| 345 |
+
|
| 346 |
+
y_true.extend(labels.numpy())
|
| 347 |
+
y_pred.extend(preds)
|
| 348 |
+
all_probs.append(probs)
|
| 349 |
+
|
| 350 |
+
y_true = np.array(y_true)
|
| 351 |
+
y_pred = np.array(y_pred)
|
| 352 |
+
all_probs = np.concatenate(all_probs, axis=0)
|
| 353 |
+
|
| 354 |
+
accuracy = float((y_true == y_pred).mean())
|
| 355 |
+
precision, recall, f1, _ = precision_recall_fscore_support(
|
| 356 |
+
y_true, y_pred, average="weighted", zero_division=0
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
top5_correct = 0
|
| 360 |
+
for i, label in enumerate(y_true):
|
| 361 |
+
if label in np.argsort(all_probs[i])[-5:]:
|
| 362 |
+
top5_correct += 1
|
| 363 |
+
top5_acc = top5_correct / len(y_true)
|
| 364 |
+
|
| 365 |
+
time_per_image = total_time / total_images
|
| 366 |
+
images_per_second = 1.0 / time_per_image
|
| 367 |
+
|
| 368 |
+
temp_w = os.path.join(MODELS_DIR, f"{model_name}_temp_for_size.weights.h5")
|
| 369 |
+
model.save_weights(temp_w)
|
| 370 |
+
size_mb = os.path.getsize(temp_w) / (1024 * 1024)
|
| 371 |
+
os.remove(temp_w)
|
| 372 |
+
|
| 373 |
+
cm = confusion_matrix(y_true, y_pred)
|
| 374 |
+
|
| 375 |
+
print("\nClassification Report:")
|
| 376 |
+
print(
|
| 377 |
+
classification_report(
|
| 378 |
+
y_true, y_pred, target_names=class_names, zero_division=0
|
| 379 |
+
)
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
print(f"Test Accuracy : {accuracy:.4f}")
|
| 383 |
+
print(f"Weighted Precision : {precision:.4f}")
|
| 384 |
+
print(f"Weighted Recall : {recall:.4f}")
|
| 385 |
+
print(f"Weighted F1-score : {f1:.4f}")
|
| 386 |
+
print(f"Top-5 Accuracy : {top5_acc:.4f}")
|
| 387 |
+
print(f"Avg time per image : {time_per_image*1000:.2f} ms")
|
| 388 |
+
print(f"Images per second : {images_per_second:.2f}")
|
| 389 |
+
print(f"Model size (weights) : {size_mb:.2f} MB")
|
| 390 |
+
print(f"Num parameters : {model.count_params()}")
|
| 391 |
+
|
| 392 |
+
save_dir = os.path.join(METRICS_DIR, model_name)
|
| 393 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 394 |
+
|
| 395 |
+
metrics = {
|
| 396 |
+
"model_name": model_name,
|
| 397 |
+
"accuracy": accuracy,
|
| 398 |
+
"precision_weighted": float(precision),
|
| 399 |
+
"recall_weighted": float(recall),
|
| 400 |
+
"f1_weighted": float(f1),
|
| 401 |
+
"top5_accuracy": float(top5_acc),
|
| 402 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 403 |
+
"images_per_second": float(images_per_second),
|
| 404 |
+
"model_size_mb": float(size_mb),
|
| 405 |
+
"num_parameters": int(model.count_params()),
|
| 406 |
+
}
|
| 407 |
+
|
| 408 |
+
metrics_path = os.path.join(save_dir, "metrics.json")
|
| 409 |
+
cm_path = os.path.join(save_dir, "confusion_matrix.npy")
|
| 410 |
+
|
| 411 |
+
with open(metrics_path, "w") as f:
|
| 412 |
+
json.dump(metrics, f, indent=2)
|
| 413 |
+
|
| 414 |
+
np.save(cm_path, cm)
|
| 415 |
+
|
| 416 |
+
print(f"\nSaved metrics to : {metrics_path}")
|
| 417 |
+
print(f"Saved confusion matrix to: {cm_path}")
|
| 418 |
+
|
| 419 |
+
return metrics, cm
|
| 420 |
+
|
| 421 |
+
mobilenet_metrics, mobilenet_cm = evaluate_and_save(
|
| 422 |
+
mobilenet_model,
|
| 423 |
+
model_name="mobilenetv2_v2_stage2",
|
| 424 |
+
best_weights_path=mobilenet_stage2_best,
|
| 425 |
+
test_ds=test_ds,
|
| 426 |
+
class_names=class_names,
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
print("\n✅ MobileNetV2 v3 (label-smoothed + deeper FT) pipeline complete.")
|
| 430 |
+
print("✅ Use weights file in app:", mobilenet_stage2_best)
|
scripts/02_model_comparision.ipynb
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"id": "4852ae9f",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": []
|
| 10 |
+
}
|
| 11 |
+
],
|
| 12 |
+
"metadata": {
|
| 13 |
+
"language_info": {
|
| 14 |
+
"name": "python"
|
| 15 |
+
}
|
| 16 |
+
},
|
| 17 |
+
"nbformat": 4,
|
| 18 |
+
"nbformat_minor": 5
|
| 19 |
+
}
|
scripts/02_resnet50.py
ADDED
|
@@ -0,0 +1,482 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - MODEL 2 (v2): ResNet50 (STRONG BASELINE)
|
| 3 |
+
# with manual label smoothing (Keras 3 compatible)
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
import json
|
| 9 |
+
import numpy as np
|
| 10 |
+
import tensorflow as tf
|
| 11 |
+
from tensorflow import keras
|
| 12 |
+
from tensorflow.keras import layers
|
| 13 |
+
from sklearn.metrics import (
|
| 14 |
+
precision_recall_fscore_support,
|
| 15 |
+
confusion_matrix,
|
| 16 |
+
classification_report,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
print("TensorFlow version:", tf.__version__)
|
| 20 |
+
|
| 21 |
+
# ------------------------------------------------------------
|
| 22 |
+
# 1. CONFIGURATION
|
| 23 |
+
# ------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
BASE_DIR = "smartvision_dataset"
|
| 26 |
+
CLASS_DIR = os.path.join(BASE_DIR, "classification")
|
| 27 |
+
TRAIN_DIR = os.path.join(CLASS_DIR, "train")
|
| 28 |
+
VAL_DIR = os.path.join(CLASS_DIR, "val")
|
| 29 |
+
TEST_DIR = os.path.join(CLASS_DIR, "test")
|
| 30 |
+
|
| 31 |
+
IMG_SIZE = (224, 224)
|
| 32 |
+
BATCH_SIZE = 32
|
| 33 |
+
NUM_CLASSES = 25
|
| 34 |
+
|
| 35 |
+
MODELS_DIR = "saved_models"
|
| 36 |
+
METRICS_DIR = "smartvision_metrics"
|
| 37 |
+
|
| 38 |
+
os.makedirs(MODELS_DIR, exist_ok=True)
|
| 39 |
+
os.makedirs(METRICS_DIR, exist_ok=True)
|
| 40 |
+
|
| 41 |
+
print("Train dir:", TRAIN_DIR)
|
| 42 |
+
print("Val dir :", VAL_DIR)
|
| 43 |
+
print("Test dir :", TEST_DIR)
|
| 44 |
+
|
| 45 |
+
# ------------------------------------------------------------
|
| 46 |
+
# 2. LOAD DATASETS
|
| 47 |
+
# ------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
train_ds = tf.keras.utils.image_dataset_from_directory(
|
| 50 |
+
TRAIN_DIR,
|
| 51 |
+
image_size=IMG_SIZE,
|
| 52 |
+
batch_size=BATCH_SIZE,
|
| 53 |
+
shuffle=True,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
val_ds = tf.keras.utils.image_dataset_from_directory(
|
| 57 |
+
VAL_DIR,
|
| 58 |
+
image_size=IMG_SIZE,
|
| 59 |
+
batch_size=BATCH_SIZE,
|
| 60 |
+
shuffle=False,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
test_ds = tf.keras.utils.image_dataset_from_directory(
|
| 64 |
+
TEST_DIR,
|
| 65 |
+
image_size=IMG_SIZE,
|
| 66 |
+
batch_size=BATCH_SIZE,
|
| 67 |
+
shuffle=False,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
class_names = train_ds.class_names
|
| 71 |
+
print("Detected classes:", class_names)
|
| 72 |
+
print("Number of classes:", len(class_names))
|
| 73 |
+
|
| 74 |
+
AUTOTUNE = tf.data.AUTOTUNE
|
| 75 |
+
train_ds = train_ds.prefetch(AUTOTUNE)
|
| 76 |
+
val_ds = val_ds.prefetch(AUTOTUNE)
|
| 77 |
+
test_ds = test_ds.prefetch(AUTOTUNE)
|
| 78 |
+
|
| 79 |
+
# ------------------------------------------------------------
|
| 80 |
+
# 3. DATA AUGMENTATION
|
| 81 |
+
# ------------------------------------------------------------
|
| 82 |
+
|
| 83 |
+
data_augmentation = keras.Sequential(
|
| 84 |
+
[
|
| 85 |
+
layers.RandomFlip("horizontal"),
|
| 86 |
+
layers.RandomRotation(0.04), # ~±15°
|
| 87 |
+
layers.RandomZoom(0.1),
|
| 88 |
+
layers.RandomContrast(0.15),
|
| 89 |
+
layers.Lambda(
|
| 90 |
+
lambda x: tf.image.random_brightness(x, max_delta=0.15)
|
| 91 |
+
),
|
| 92 |
+
layers.Lambda(
|
| 93 |
+
lambda x: tf.image.random_saturation(x, 0.85, 1.15)
|
| 94 |
+
),
|
| 95 |
+
],
|
| 96 |
+
name="data_augmentation",
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
# NOTE: We will use ResNet50's preprocess_input, so we do NOT rescale 1./255 here.
|
| 100 |
+
|
| 101 |
+
# ------------------------------------------------------------
|
| 102 |
+
# 4. BUILD RESNET50 MODEL
|
| 103 |
+
# ------------------------------------------------------------
|
| 104 |
+
|
| 105 |
+
def build_resnet50_model_v2():
|
| 106 |
+
"""
|
| 107 |
+
Returns:
|
| 108 |
+
model : full ResNet50 classification model
|
| 109 |
+
base_model : the ResNet50 backbone for fine-tuning
|
| 110 |
+
"""
|
| 111 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 112 |
+
|
| 113 |
+
# Augmentation (train-time only)
|
| 114 |
+
x = data_augmentation(inputs)
|
| 115 |
+
|
| 116 |
+
# ResNet50-specific preprocessing
|
| 117 |
+
x = layers.Lambda(
|
| 118 |
+
keras.applications.resnet50.preprocess_input,
|
| 119 |
+
name="resnet50_preprocess",
|
| 120 |
+
)(x)
|
| 121 |
+
|
| 122 |
+
# Pretrained ResNet50 backbone
|
| 123 |
+
base_model = keras.applications.ResNet50(
|
| 124 |
+
include_top=False,
|
| 125 |
+
weights="imagenet",
|
| 126 |
+
input_shape=(*IMG_SIZE, 3),
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
x = base_model(x)
|
| 130 |
+
|
| 131 |
+
# Custom classification head
|
| 132 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 133 |
+
|
| 134 |
+
x = layers.BatchNormalization(name="head_batchnorm")(x)
|
| 135 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 136 |
+
|
| 137 |
+
x = layers.Dense(
|
| 138 |
+
256,
|
| 139 |
+
activation="relu",
|
| 140 |
+
name="head_dense",
|
| 141 |
+
)(x)
|
| 142 |
+
|
| 143 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 144 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 145 |
+
|
| 146 |
+
outputs = layers.Dense(
|
| 147 |
+
NUM_CLASSES,
|
| 148 |
+
activation="softmax",
|
| 149 |
+
name="predictions",
|
| 150 |
+
)(x)
|
| 151 |
+
|
| 152 |
+
model = keras.Model(
|
| 153 |
+
inputs=inputs,
|
| 154 |
+
outputs=outputs,
|
| 155 |
+
name="ResNet50_smartvision_v2",
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
return model, base_model
|
| 159 |
+
|
| 160 |
+
resnet_model, resnet_base = build_resnet50_model_v2()
|
| 161 |
+
resnet_model.summary()
|
| 162 |
+
|
| 163 |
+
# ------------------------------------------------------------
|
| 164 |
+
# 5. CUSTOM LOSS WITH LABEL SMOOTHING
|
| 165 |
+
# ------------------------------------------------------------
|
| 166 |
+
|
| 167 |
+
def make_sparse_ce_with_label_smoothing(num_classes, label_smoothing=0.1):
|
| 168 |
+
"""
|
| 169 |
+
Implements sparse categorical crossentropy with manual label smoothing.
|
| 170 |
+
Works even if Keras' SparseCategoricalCrossentropy doesn't have label_smoothing arg.
|
| 171 |
+
"""
|
| 172 |
+
ls = float(label_smoothing)
|
| 173 |
+
nc = int(num_classes)
|
| 174 |
+
|
| 175 |
+
def loss_fn(y_true, y_pred):
|
| 176 |
+
# y_true: integer labels, shape (batch,)
|
| 177 |
+
y_true = tf.cast(y_true, tf.int32)
|
| 178 |
+
y_true_oh = tf.one_hot(y_true, depth=nc)
|
| 179 |
+
|
| 180 |
+
if ls > 0.0:
|
| 181 |
+
smooth = ls
|
| 182 |
+
y_true_oh = (1.0 - smooth) * y_true_oh + smooth / tf.cast(
|
| 183 |
+
nc, tf.float32
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
# y_pred is softmax probabilities
|
| 187 |
+
return tf.keras.losses.categorical_crossentropy(
|
| 188 |
+
y_true_oh, y_pred, from_logits=False
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
return loss_fn
|
| 192 |
+
|
| 193 |
+
# ------------------------------------------------------------
|
| 194 |
+
# 6. TRAINING UTILITY
|
| 195 |
+
# ------------------------------------------------------------
|
| 196 |
+
|
| 197 |
+
def compile_and_train(
|
| 198 |
+
model,
|
| 199 |
+
model_name: str,
|
| 200 |
+
train_ds,
|
| 201 |
+
val_ds,
|
| 202 |
+
epochs: int,
|
| 203 |
+
lr: float,
|
| 204 |
+
model_tag: str,
|
| 205 |
+
patience_es: int = 5,
|
| 206 |
+
patience_rlr: int = 2,
|
| 207 |
+
):
|
| 208 |
+
"""
|
| 209 |
+
Compile and train model, saving best weights by val_accuracy.
|
| 210 |
+
|
| 211 |
+
model_name: e.g. 'resnet50_v2'
|
| 212 |
+
model_tag : e.g. 'stage1', 'stage2'
|
| 213 |
+
"""
|
| 214 |
+
print(f"\n===== {model_tag}: Training {model_name} =====")
|
| 215 |
+
|
| 216 |
+
optimizer = keras.optimizers.Adam(learning_rate=lr)
|
| 217 |
+
|
| 218 |
+
# Use custom loss with label smoothing
|
| 219 |
+
loss_fn = make_sparse_ce_with_label_smoothing(
|
| 220 |
+
num_classes=NUM_CLASSES,
|
| 221 |
+
label_smoothing=0.1,
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
model.compile(
|
| 225 |
+
optimizer=optimizer,
|
| 226 |
+
loss=loss_fn,
|
| 227 |
+
metrics=["accuracy"],
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
# Keras 3: when save_weights_only=True, must end with ".weights.h5"
|
| 231 |
+
best_weights_path = os.path.join(
|
| 232 |
+
MODELS_DIR, f"{model_name}_{model_tag}_best.weights.h5"
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
callbacks = [
|
| 236 |
+
keras.callbacks.ModelCheckpoint(
|
| 237 |
+
filepath=best_weights_path,
|
| 238 |
+
monitor="val_accuracy",
|
| 239 |
+
save_best_only=True,
|
| 240 |
+
save_weights_only=True, # ✅ weights-only: avoids architecture issues
|
| 241 |
+
mode="max",
|
| 242 |
+
verbose=1,
|
| 243 |
+
),
|
| 244 |
+
keras.callbacks.EarlyStopping(
|
| 245 |
+
monitor="val_accuracy",
|
| 246 |
+
patience=patience_es,
|
| 247 |
+
restore_best_weights=True,
|
| 248 |
+
verbose=1,
|
| 249 |
+
),
|
| 250 |
+
keras.callbacks.ReduceLROnPlateau(
|
| 251 |
+
monitor="val_loss",
|
| 252 |
+
factor=0.5,
|
| 253 |
+
patience=patience_rlr,
|
| 254 |
+
min_lr=1e-6,
|
| 255 |
+
verbose=1,
|
| 256 |
+
),
|
| 257 |
+
]
|
| 258 |
+
|
| 259 |
+
history = model.fit(
|
| 260 |
+
train_ds,
|
| 261 |
+
validation_data=val_ds,
|
| 262 |
+
epochs=epochs,
|
| 263 |
+
callbacks=callbacks,
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
return history, best_weights_path
|
| 267 |
+
|
| 268 |
+
# ------------------------------------------------------------
|
| 269 |
+
# 7. STAGE 1: TRAIN HEAD WITH FROZEN RESNET BASE
|
| 270 |
+
# ------------------------------------------------------------
|
| 271 |
+
|
| 272 |
+
print("\n===== STAGE 1: Training head with frozen ResNet50 base =====")
|
| 273 |
+
|
| 274 |
+
# Freeze entire backbone for Stage 1
|
| 275 |
+
resnet_base.trainable = False
|
| 276 |
+
|
| 277 |
+
epochs_stage1 = 15
|
| 278 |
+
lr_stage1 = 1e-3
|
| 279 |
+
|
| 280 |
+
history_stage1, resnet_stage1_best = compile_and_train(
|
| 281 |
+
resnet_model,
|
| 282 |
+
model_name="resnet50_v2",
|
| 283 |
+
train_ds=train_ds,
|
| 284 |
+
val_ds=val_ds,
|
| 285 |
+
epochs=epochs_stage1,
|
| 286 |
+
lr=lr_stage1,
|
| 287 |
+
model_tag="stage1",
|
| 288 |
+
patience_es=5,
|
| 289 |
+
patience_rlr=2,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
print("Stage 1 best weights saved at:", resnet_stage1_best)
|
| 293 |
+
|
| 294 |
+
# ------------------------------------------------------------
|
| 295 |
+
# 8. STAGE 2: DEEPER FINE-TUNING OF RESNET BASE
|
| 296 |
+
# ------------------------------------------------------------
|
| 297 |
+
|
| 298 |
+
print("\n===== STAGE 2: Fine-tuning last layers of ResNet50 base =====")
|
| 299 |
+
|
| 300 |
+
# Load Stage 1 best weights before fine-tuning
|
| 301 |
+
resnet_model.load_weights(resnet_stage1_best)
|
| 302 |
+
|
| 303 |
+
# Enable deeper fine-tuning on the backbone
|
| 304 |
+
resnet_base.trainable = True
|
| 305 |
+
|
| 306 |
+
print("Base model name:", resnet_base.name)
|
| 307 |
+
print("Base model has", len(resnet_base.layers), "layers.")
|
| 308 |
+
|
| 309 |
+
# Unfreeze last N layers of the backbone
|
| 310 |
+
num_unfreeze = 40 # you can tune 30–50
|
| 311 |
+
for layer in resnet_base.layers[:-num_unfreeze]:
|
| 312 |
+
layer.trainable = False
|
| 313 |
+
|
| 314 |
+
# Keep BatchNorm layers frozen for stability
|
| 315 |
+
for layer in resnet_base.layers[-num_unfreeze:]:
|
| 316 |
+
if isinstance(layer, layers.BatchNormalization):
|
| 317 |
+
layer.trainable = False
|
| 318 |
+
|
| 319 |
+
trainable_count = int(np.sum([l.trainable for l in resnet_model.layers]))
|
| 320 |
+
print("Total trainable layers in full model after unfreezing:", trainable_count)
|
| 321 |
+
|
| 322 |
+
epochs_stage2 = 30
|
| 323 |
+
lr_stage2 = 5e-6 # small LR for safe fine-tuning
|
| 324 |
+
|
| 325 |
+
history_stage2, resnet_stage2_best = compile_and_train(
|
| 326 |
+
resnet_model,
|
| 327 |
+
model_name="resnet50_v2",
|
| 328 |
+
train_ds=train_ds,
|
| 329 |
+
val_ds=val_ds,
|
| 330 |
+
epochs=epochs_stage2,
|
| 331 |
+
lr=lr_stage2,
|
| 332 |
+
model_tag="stage2",
|
| 333 |
+
patience_es=8,
|
| 334 |
+
patience_rlr=3,
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
print("Stage 2 best weights saved at:", resnet_stage2_best)
|
| 338 |
+
|
| 339 |
+
# ------------------------------------------------------------
|
| 340 |
+
# 9. EVALUATION + SAVE METRICS & CONFUSION MATRIX
|
| 341 |
+
# ------------------------------------------------------------
|
| 342 |
+
|
| 343 |
+
def evaluate_and_save(model, save_name, best_weights_path, test_ds, class_names):
|
| 344 |
+
"""
|
| 345 |
+
save_name: e.g. 'resnet50_v2_stage1', 'resnet50_v2_stage2'
|
| 346 |
+
"""
|
| 347 |
+
print(f"\n===== EVALUATING {save_name.upper()} ON TEST SET =====")
|
| 348 |
+
|
| 349 |
+
# Load best weights
|
| 350 |
+
model.load_weights(best_weights_path)
|
| 351 |
+
print(f"Loaded best weights from {best_weights_path}")
|
| 352 |
+
|
| 353 |
+
y_true = []
|
| 354 |
+
y_pred = []
|
| 355 |
+
all_probs = []
|
| 356 |
+
|
| 357 |
+
total_time = 0.0
|
| 358 |
+
total_images = 0
|
| 359 |
+
|
| 360 |
+
for images, labels in test_ds:
|
| 361 |
+
images_np = images.numpy()
|
| 362 |
+
bs = images_np.shape[0]
|
| 363 |
+
|
| 364 |
+
start = time.perf_counter()
|
| 365 |
+
probs = model.predict(images_np, verbose=0)
|
| 366 |
+
end = time.perf_counter()
|
| 367 |
+
|
| 368 |
+
total_time += (end - start)
|
| 369 |
+
total_images += bs
|
| 370 |
+
|
| 371 |
+
preds = np.argmax(probs, axis=1)
|
| 372 |
+
|
| 373 |
+
y_true.extend(labels.numpy())
|
| 374 |
+
y_pred.extend(preds)
|
| 375 |
+
all_probs.append(probs)
|
| 376 |
+
|
| 377 |
+
y_true = np.array(y_true)
|
| 378 |
+
y_pred = np.array(y_pred)
|
| 379 |
+
all_probs = np.concatenate(all_probs, axis=0)
|
| 380 |
+
|
| 381 |
+
# Basic metrics
|
| 382 |
+
accuracy = float((y_true == y_pred).mean())
|
| 383 |
+
precision, recall, f1, _ = precision_recall_fscore_support(
|
| 384 |
+
y_true, y_pred, average="weighted", zero_division=0
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# Top-5 accuracy
|
| 388 |
+
top5_correct = 0
|
| 389 |
+
for i, label in enumerate(y_true):
|
| 390 |
+
if label in np.argsort(all_probs[i])[-5:]:
|
| 391 |
+
top5_correct += 1
|
| 392 |
+
top5_acc = top5_correct / len(y_true)
|
| 393 |
+
|
| 394 |
+
# Inference time
|
| 395 |
+
time_per_image = total_time / total_images
|
| 396 |
+
images_per_second = 1.0 / time_per_image if time_per_image > 0 else 0.0
|
| 397 |
+
|
| 398 |
+
# Model size (weights only)
|
| 399 |
+
temp_w = os.path.join(MODELS_DIR, f"{save_name}_temp_for_size.weights.h5")
|
| 400 |
+
model.save_weights(temp_w)
|
| 401 |
+
size_mb = os.path.getsize(temp_w) / (1024 * 1024)
|
| 402 |
+
os.remove(temp_w)
|
| 403 |
+
|
| 404 |
+
# Confusion matrix
|
| 405 |
+
cm = confusion_matrix(y_true, y_pred)
|
| 406 |
+
|
| 407 |
+
print("\nClassification Report:")
|
| 408 |
+
print(
|
| 409 |
+
classification_report(
|
| 410 |
+
y_true,
|
| 411 |
+
y_pred,
|
| 412 |
+
target_names=class_names,
|
| 413 |
+
zero_division=0,
|
| 414 |
+
)
|
| 415 |
+
)
|
| 416 |
+
|
| 417 |
+
print(f"Test Accuracy : {accuracy:.4f}")
|
| 418 |
+
print(f"Weighted Precision : {precision:.4f}")
|
| 419 |
+
print(f"Weighted Recall : {recall:.4f}")
|
| 420 |
+
print(f"Weighted F1-score : {f1:.4f}")
|
| 421 |
+
print(f"Top-5 Accuracy : {top5_acc:.4f}")
|
| 422 |
+
print(f"Avg time per image : {time_per_image*1000:.2f} ms")
|
| 423 |
+
print(f"Images per second : {images_per_second:.2f}")
|
| 424 |
+
print(f"Model size (weights) : {size_mb:.2f} MB")
|
| 425 |
+
print(f"Num parameters : {model.count_params()}")
|
| 426 |
+
|
| 427 |
+
# Save metrics + confusion matrix
|
| 428 |
+
save_dir = os.path.join(METRICS_DIR, save_name)
|
| 429 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 430 |
+
|
| 431 |
+
metrics = {
|
| 432 |
+
"model_name": save_name,
|
| 433 |
+
"accuracy": accuracy,
|
| 434 |
+
"precision_weighted": float(precision),
|
| 435 |
+
"recall_weighted": float(recall),
|
| 436 |
+
"f1_weighted": float(f1),
|
| 437 |
+
"top5_accuracy": float(top5_acc),
|
| 438 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 439 |
+
"images_per_second": float(images_per_second),
|
| 440 |
+
"model_size_mb": float(size_mb),
|
| 441 |
+
"num_parameters": int(model.count_params()),
|
| 442 |
+
}
|
| 443 |
+
|
| 444 |
+
metrics_path = os.path.join(save_dir, "metrics.json")
|
| 445 |
+
cm_path = os.path.join(save_dir, "confusion_matrix.npy")
|
| 446 |
+
|
| 447 |
+
with open(metrics_path, "w") as f:
|
| 448 |
+
json.dump(metrics, f, indent=2)
|
| 449 |
+
|
| 450 |
+
np.save(cm_path, cm)
|
| 451 |
+
|
| 452 |
+
print(f"\nSaved metrics to : {metrics_path}")
|
| 453 |
+
print(f"Saved confusion matrix to: {cm_path}")
|
| 454 |
+
|
| 455 |
+
return metrics, cm
|
| 456 |
+
|
| 457 |
+
# ---- Evaluate Stage 1 ----
|
| 458 |
+
resnet_stage1_metrics, resnet_stage1_cm = evaluate_and_save(
|
| 459 |
+
resnet_model,
|
| 460 |
+
save_name="resnet50_v2_stage1",
|
| 461 |
+
best_weights_path=resnet_stage1_best,
|
| 462 |
+
test_ds=test_ds,
|
| 463 |
+
class_names=class_names,
|
| 464 |
+
)
|
| 465 |
+
|
| 466 |
+
# ---- Evaluate Stage 2 ----
|
| 467 |
+
resnet_stage2_metrics, resnet_stage2_cm = evaluate_and_save(
|
| 468 |
+
resnet_model,
|
| 469 |
+
save_name="resnet50_v2_stage2",
|
| 470 |
+
best_weights_path=resnet_stage2_best,
|
| 471 |
+
test_ds=test_ds,
|
| 472 |
+
class_names=class_names,
|
| 473 |
+
)
|
| 474 |
+
|
| 475 |
+
# ------------------------------------------------------------
|
| 476 |
+
# 10. SUMMARY
|
| 477 |
+
# ------------------------------------------------------------
|
| 478 |
+
|
| 479 |
+
print("\n===== SUMMARY: RESNET50 v2 STAGES COMPARISON =====")
|
| 480 |
+
print("Stage 1 Test Accuracy:", resnet_stage1_metrics["accuracy"])
|
| 481 |
+
print("Stage 2 Test Accuracy:", resnet_stage2_metrics["accuracy"])
|
| 482 |
+
print("✅ RESNET50 v2 pipeline complete.")
|
scripts/02_vgg16.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - MODEL 1 (v2): VGG16 (TRANSFER LEARNING + FT)
|
| 3 |
+
# with proper preprocess_input + label smoothing + deeper FT
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
import json
|
| 9 |
+
import numpy as np
|
| 10 |
+
import tensorflow as tf
|
| 11 |
+
from tensorflow import keras
|
| 12 |
+
from tensorflow.keras import layers
|
| 13 |
+
|
| 14 |
+
from sklearn.metrics import (
|
| 15 |
+
precision_recall_fscore_support,
|
| 16 |
+
confusion_matrix,
|
| 17 |
+
classification_report,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
|
| 21 |
+
|
| 22 |
+
print("TensorFlow version:", tf.__version__)
|
| 23 |
+
|
| 24 |
+
# ------------------------------------------------------------
|
| 25 |
+
# 1. CONFIGURATION
|
| 26 |
+
# ------------------------------------------------------------
|
| 27 |
+
|
| 28 |
+
BASE_DIR = "smartvision_dataset" # your dataset root
|
| 29 |
+
CLASS_DIR = os.path.join(BASE_DIR, "classification")
|
| 30 |
+
TRAIN_DIR = os.path.join(CLASS_DIR, "train")
|
| 31 |
+
VAL_DIR = os.path.join(CLASS_DIR, "val")
|
| 32 |
+
TEST_DIR = os.path.join(CLASS_DIR, "test")
|
| 33 |
+
|
| 34 |
+
IMG_SIZE = (224, 224)
|
| 35 |
+
BATCH_SIZE = 32
|
| 36 |
+
NUM_CLASSES = 25
|
| 37 |
+
|
| 38 |
+
MODELS_DIR = "saved_models"
|
| 39 |
+
METRICS_DIR = "smartvision_metrics"
|
| 40 |
+
|
| 41 |
+
os.makedirs(MODELS_DIR, exist_ok=True)
|
| 42 |
+
os.makedirs(METRICS_DIR, exist_ok=True)
|
| 43 |
+
|
| 44 |
+
print("Train dir:", TRAIN_DIR)
|
| 45 |
+
print("Val dir :", VAL_DIR)
|
| 46 |
+
print("Test dir :", TEST_DIR)
|
| 47 |
+
|
| 48 |
+
# ------------------------------------------------------------
|
| 49 |
+
# 2. LOAD DATASETS (FROM CROPPED SINGLE-OBJECT IMAGES)
|
| 50 |
+
# ------------------------------------------------------------
|
| 51 |
+
|
| 52 |
+
train_ds = tf.keras.utils.image_dataset_from_directory(
|
| 53 |
+
TRAIN_DIR,
|
| 54 |
+
image_size=IMG_SIZE,
|
| 55 |
+
batch_size=BATCH_SIZE,
|
| 56 |
+
shuffle=True,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
val_ds = tf.keras.utils.image_dataset_from_directory(
|
| 60 |
+
VAL_DIR,
|
| 61 |
+
image_size=IMG_SIZE,
|
| 62 |
+
batch_size=BATCH_SIZE,
|
| 63 |
+
shuffle=False,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
test_ds = tf.keras.utils.image_dataset_from_directory(
|
| 67 |
+
TEST_DIR,
|
| 68 |
+
image_size=IMG_SIZE,
|
| 69 |
+
batch_size=BATCH_SIZE,
|
| 70 |
+
shuffle=False,
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
class_names = train_ds.class_names
|
| 74 |
+
print("Detected classes:", class_names)
|
| 75 |
+
print("Number of classes:", len(class_names))
|
| 76 |
+
|
| 77 |
+
AUTOTUNE = tf.data.AUTOTUNE
|
| 78 |
+
train_ds = train_ds.prefetch(AUTOTUNE)
|
| 79 |
+
val_ds = val_ds.prefetch(AUTOTUNE)
|
| 80 |
+
test_ds = test_ds.prefetch(AUTOTUNE)
|
| 81 |
+
|
| 82 |
+
# ------------------------------------------------------------
|
| 83 |
+
# 3. DATA AUGMENTATION (APPLIED ONLY DURING TRAINING)
|
| 84 |
+
# ------------------------------------------------------------
|
| 85 |
+
|
| 86 |
+
data_augmentation = keras.Sequential(
|
| 87 |
+
[
|
| 88 |
+
layers.RandomFlip("horizontal"), # random horizontal flips
|
| 89 |
+
layers.RandomRotation(0.04), # ≈ ±15 degrees
|
| 90 |
+
layers.RandomZoom(0.1), # random zoom
|
| 91 |
+
layers.RandomContrast(0.2), # ±20% contrast
|
| 92 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.2)),
|
| 93 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.8, 1.2)),
|
| 94 |
+
],
|
| 95 |
+
name="data_augmentation",
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
# NOTE:
|
| 99 |
+
# We DO NOT use Rescaling(1./255) here.
|
| 100 |
+
# Instead, we use VGG16's preprocess_input which subtracts ImageNet means
|
| 101 |
+
# and expects BGR ordering. This matches the pretrained weights.
|
| 102 |
+
|
| 103 |
+
# ------------------------------------------------------------
|
| 104 |
+
# 4. BUILD VGG16 MODEL (FROZEN BASE + CUSTOM HEAD)
|
| 105 |
+
# ------------------------------------------------------------
|
| 106 |
+
|
| 107 |
+
def build_vgg16_model_v2():
|
| 108 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 109 |
+
|
| 110 |
+
# 1. Augmentation (only active during training)
|
| 111 |
+
x = data_augmentation(inputs)
|
| 112 |
+
|
| 113 |
+
# 2. VGG16-specific preprocessing
|
| 114 |
+
x = layers.Lambda(
|
| 115 |
+
lambda z: preprocess_input(tf.cast(z, tf.float32)),
|
| 116 |
+
name="vgg16_preprocess"
|
| 117 |
+
)(x)
|
| 118 |
+
|
| 119 |
+
# 3. Pre-trained VGG16 backbone (no top classification head)
|
| 120 |
+
base_model = VGG16(
|
| 121 |
+
include_top=False,
|
| 122 |
+
weights="imagenet",
|
| 123 |
+
input_tensor=x,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# Freeze backbone initially (Stage 1)
|
| 127 |
+
base_model.trainable = False
|
| 128 |
+
|
| 129 |
+
# 4. Custom classification head for 25 classes
|
| 130 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(base_model.output)
|
| 131 |
+
x = layers.Dense(256, activation="relu", name="dense_256")(x)
|
| 132 |
+
x = layers.Dropout(0.5, name="dropout_0_5")(x)
|
| 133 |
+
outputs = layers.Dense(NUM_CLASSES, activation="softmax", name="predictions")(x)
|
| 134 |
+
|
| 135 |
+
model = keras.Model(inputs=inputs, outputs=outputs, name="VGG16_smartvision_v2")
|
| 136 |
+
return model
|
| 137 |
+
|
| 138 |
+
vgg16_model = build_vgg16_model_v2()
|
| 139 |
+
vgg16_model.summary()
|
| 140 |
+
|
| 141 |
+
# ------------------------------------------------------------
|
| 142 |
+
# 5. CUSTOM LOSS WITH LABEL SMOOTHING
|
| 143 |
+
# ------------------------------------------------------------
|
| 144 |
+
|
| 145 |
+
def make_sparse_ce_with_label_smoothing(num_classes, label_smoothing=0.05):
|
| 146 |
+
"""
|
| 147 |
+
Implements sparse categorical crossentropy with manual label smoothing.
|
| 148 |
+
Works even if your Keras version doesn't support `label_smoothing` in
|
| 149 |
+
SparseCategoricalCrossentropy.__init__.
|
| 150 |
+
"""
|
| 151 |
+
ls = float(label_smoothing)
|
| 152 |
+
nc = int(num_classes)
|
| 153 |
+
|
| 154 |
+
def loss_fn(y_true, y_pred):
|
| 155 |
+
# y_true: integer labels, shape (batch,)
|
| 156 |
+
y_true = tf.cast(y_true, tf.int32)
|
| 157 |
+
y_true_oh = tf.one_hot(y_true, depth=nc)
|
| 158 |
+
|
| 159 |
+
if ls > 0.0:
|
| 160 |
+
smooth = ls
|
| 161 |
+
y_true_oh = (1.0 - smooth) * y_true_oh + smooth / tf.cast(nc, tf.float32)
|
| 162 |
+
|
| 163 |
+
# y_pred is softmax probabilities
|
| 164 |
+
return tf.keras.losses.categorical_crossentropy(
|
| 165 |
+
y_true_oh, y_pred, from_logits=False
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
return loss_fn
|
| 169 |
+
|
| 170 |
+
# ------------------------------------------------------------
|
| 171 |
+
# 6. TRAINING UTILITY (COMMON FOR STAGE 1 & 2)
|
| 172 |
+
# ------------------------------------------------------------
|
| 173 |
+
|
| 174 |
+
def compile_and_train(
|
| 175 |
+
model,
|
| 176 |
+
model_name,
|
| 177 |
+
train_ds,
|
| 178 |
+
val_ds,
|
| 179 |
+
epochs,
|
| 180 |
+
lr,
|
| 181 |
+
model_tag,
|
| 182 |
+
patience_es=5,
|
| 183 |
+
patience_rlr=2,
|
| 184 |
+
):
|
| 185 |
+
"""
|
| 186 |
+
Compile and train model, saving the best weights by val_accuracy.
|
| 187 |
+
model_name: base name ("vgg16_v2")
|
| 188 |
+
model_tag : "stage1" or "stage2" etc.
|
| 189 |
+
"""
|
| 190 |
+
print(f"\n===== TRAINING {model_name} ({model_tag}) =====")
|
| 191 |
+
|
| 192 |
+
optimizer = keras.optimizers.Adam(learning_rate=lr)
|
| 193 |
+
|
| 194 |
+
# Use our custom loss with label smoothing
|
| 195 |
+
loss_fn = make_sparse_ce_with_label_smoothing(
|
| 196 |
+
num_classes=NUM_CLASSES,
|
| 197 |
+
label_smoothing=0.05,
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
model.compile(
|
| 201 |
+
optimizer=optimizer,
|
| 202 |
+
loss=loss_fn,
|
| 203 |
+
metrics=["accuracy"],
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
best_weights_path = os.path.join(MODELS_DIR, f"{model_name}_{model_tag}_best.h5")
|
| 207 |
+
|
| 208 |
+
callbacks = [
|
| 209 |
+
keras.callbacks.ModelCheckpoint(
|
| 210 |
+
filepath=best_weights_path,
|
| 211 |
+
monitor="val_accuracy",
|
| 212 |
+
save_best_only=True,
|
| 213 |
+
mode="max",
|
| 214 |
+
verbose=1,
|
| 215 |
+
),
|
| 216 |
+
keras.callbacks.EarlyStopping(
|
| 217 |
+
monitor="val_accuracy",
|
| 218 |
+
patience=patience_es,
|
| 219 |
+
restore_best_weights=True,
|
| 220 |
+
verbose=1,
|
| 221 |
+
),
|
| 222 |
+
keras.callbacks.ReduceLROnPlateau(
|
| 223 |
+
monitor="val_loss",
|
| 224 |
+
factor=0.5,
|
| 225 |
+
patience=patience_rlr,
|
| 226 |
+
min_lr=1e-6,
|
| 227 |
+
verbose=1,
|
| 228 |
+
),
|
| 229 |
+
]
|
| 230 |
+
|
| 231 |
+
history = model.fit(
|
| 232 |
+
train_ds,
|
| 233 |
+
validation_data=val_ds,
|
| 234 |
+
epochs=epochs,
|
| 235 |
+
callbacks=callbacks,
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
return history, best_weights_path
|
| 239 |
+
|
| 240 |
+
# ------------------------------------------------------------
|
| 241 |
+
# 7. STAGE 1: TRAIN HEAD WITH FROZEN VGG16 BASE
|
| 242 |
+
# ------------------------------------------------------------
|
| 243 |
+
|
| 244 |
+
print("\n===== STAGE 1: Training head with frozen VGG16 base =====")
|
| 245 |
+
|
| 246 |
+
# Safety: ensure all VGG16 conv blocks are frozen
|
| 247 |
+
for layer in vgg16_model.layers:
|
| 248 |
+
if layer.name.startswith("block"):
|
| 249 |
+
layer.trainable = False
|
| 250 |
+
|
| 251 |
+
epochs_stage1 = 20
|
| 252 |
+
lr_stage1 = 1e-4
|
| 253 |
+
|
| 254 |
+
history_stage1, vgg16_stage1_best = compile_and_train(
|
| 255 |
+
vgg16_model,
|
| 256 |
+
model_name="vgg16_v2",
|
| 257 |
+
train_ds=train_ds,
|
| 258 |
+
val_ds=val_ds,
|
| 259 |
+
epochs=epochs_stage1,
|
| 260 |
+
lr=lr_stage1,
|
| 261 |
+
model_tag="stage1",
|
| 262 |
+
patience_es=5,
|
| 263 |
+
patience_rlr=2,
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
print("Stage 1 best weights saved at:", vgg16_stage1_best)
|
| 267 |
+
|
| 268 |
+
# ------------------------------------------------------------
|
| 269 |
+
# 8. STAGE 2: FINE-TUNE BLOCK4 + BLOCK5 OF VGG16
|
| 270 |
+
# ------------------------------------------------------------
|
| 271 |
+
|
| 272 |
+
print("\n===== STAGE 2: Fine-tuning VGG16 block4 + block5 =====")
|
| 273 |
+
|
| 274 |
+
# Load best Stage 1 weights before fine-tuning
|
| 275 |
+
vgg16_model.load_weights(vgg16_stage1_best)
|
| 276 |
+
|
| 277 |
+
# Unfreeze only block4_* and block5_* layers for controlled fine-tuning
|
| 278 |
+
for layer in vgg16_model.layers:
|
| 279 |
+
if layer.name.startswith("block5") :
|
| 280 |
+
layer.trainable = True # fine-tune top two blocks
|
| 281 |
+
elif layer.name.startswith("block"):
|
| 282 |
+
layer.trainable = False # keep lower blocks frozen (block1–3)
|
| 283 |
+
|
| 284 |
+
# Head layers (GAP + Dense + Dropout + output) remain trainable
|
| 285 |
+
|
| 286 |
+
epochs_stage2 = 15
|
| 287 |
+
lr_stage2 = 1e-5 # slightly higher than 1e-5 but still safe for FT
|
| 288 |
+
|
| 289 |
+
history_stage2, vgg16_stage2_best = compile_and_train(
|
| 290 |
+
vgg16_model,
|
| 291 |
+
model_name="vgg16_v2",
|
| 292 |
+
train_ds=train_ds,
|
| 293 |
+
val_ds=val_ds,
|
| 294 |
+
epochs=epochs_stage2,
|
| 295 |
+
lr=lr_stage2,
|
| 296 |
+
model_tag="stage2",
|
| 297 |
+
patience_es=6,
|
| 298 |
+
patience_rlr=3,
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
print("Stage 2 best weights saved at:", vgg16_stage2_best)
|
| 302 |
+
|
| 303 |
+
# ------------------------------------------------------------
|
| 304 |
+
# 9. EVALUATION + SAVE METRICS & CONFUSION MATRIX
|
| 305 |
+
# ------------------------------------------------------------
|
| 306 |
+
|
| 307 |
+
def evaluate_and_save(model, model_name, best_weights_path, test_ds, class_names):
|
| 308 |
+
print(f"\n===== EVALUATING {model_name.upper()} ON TEST SET =====")
|
| 309 |
+
|
| 310 |
+
# Load best weights
|
| 311 |
+
model.load_weights(best_weights_path)
|
| 312 |
+
print(f"Loaded best weights from {best_weights_path}")
|
| 313 |
+
|
| 314 |
+
y_true = []
|
| 315 |
+
y_pred = []
|
| 316 |
+
all_probs = []
|
| 317 |
+
|
| 318 |
+
total_time = 0.0
|
| 319 |
+
total_images = 0
|
| 320 |
+
|
| 321 |
+
# Predict over test dataset
|
| 322 |
+
for images, labels in test_ds:
|
| 323 |
+
images_np = images.numpy()
|
| 324 |
+
bs = images_np.shape[0]
|
| 325 |
+
|
| 326 |
+
start = time.perf_counter()
|
| 327 |
+
probs = model.predict(images_np, verbose=0)
|
| 328 |
+
end = time.perf_counter()
|
| 329 |
+
|
| 330 |
+
total_time += (end - start)
|
| 331 |
+
total_images += bs
|
| 332 |
+
|
| 333 |
+
preds = np.argmax(probs, axis=1)
|
| 334 |
+
|
| 335 |
+
y_true.extend(labels.numpy())
|
| 336 |
+
y_pred.extend(preds)
|
| 337 |
+
all_probs.append(probs)
|
| 338 |
+
|
| 339 |
+
y_true = np.array(y_true)
|
| 340 |
+
y_pred = np.array(y_pred)
|
| 341 |
+
all_probs = np.concatenate(all_probs, axis=0)
|
| 342 |
+
|
| 343 |
+
# Basic metrics
|
| 344 |
+
accuracy = float((y_true == y_pred).mean())
|
| 345 |
+
precision, recall, f1, _ = precision_recall_fscore_support(
|
| 346 |
+
y_true, y_pred, average="weighted", zero_division=0
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
# Top-5 accuracy
|
| 350 |
+
top5_correct = 0
|
| 351 |
+
for i, label in enumerate(y_true):
|
| 352 |
+
if label in np.argsort(all_probs[i])[-5:]:
|
| 353 |
+
top5_correct += 1
|
| 354 |
+
top5_acc = top5_correct / len(y_true)
|
| 355 |
+
|
| 356 |
+
# Inference time
|
| 357 |
+
time_per_image = total_time / total_images
|
| 358 |
+
images_per_second = 1.0 / time_per_image
|
| 359 |
+
|
| 360 |
+
# Model size (weights only)
|
| 361 |
+
temp_w = os.path.join(MODELS_DIR, f"{model_name}_temp_for_size.weights.h5")
|
| 362 |
+
model.save_weights(temp_w)
|
| 363 |
+
size_mb = os.path.getsize(temp_w) / (1024 * 1024)
|
| 364 |
+
os.remove(temp_w)
|
| 365 |
+
|
| 366 |
+
# Confusion matrix
|
| 367 |
+
cm = confusion_matrix(y_true, y_pred)
|
| 368 |
+
|
| 369 |
+
print("\nClassification Report:")
|
| 370 |
+
print(classification_report(y_true, y_pred, target_names=class_names, zero_division=0))
|
| 371 |
+
|
| 372 |
+
print(f"Test Accuracy : {accuracy:.4f}")
|
| 373 |
+
print(f"Weighted Precision : {precision:.4f}")
|
| 374 |
+
print(f"Weighted Recall : {recall:.4f}")
|
| 375 |
+
print(f"Weighted F1-score : {f1:.4f}")
|
| 376 |
+
print(f"Top-5 Accuracy : {top5_acc:.4f}")
|
| 377 |
+
print(f"Avg time per image : {time_per_image*1000:.2f} ms")
|
| 378 |
+
print(f"Images per second : {images_per_second:.2f}")
|
| 379 |
+
print(f"Model size (weights) : {size_mb:.2f} MB")
|
| 380 |
+
print(f"Num parameters : {model.count_params()}")
|
| 381 |
+
|
| 382 |
+
# Save metrics + confusion matrix in dedicated folder
|
| 383 |
+
save_dir = os.path.join(METRICS_DIR, model_name)
|
| 384 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 385 |
+
|
| 386 |
+
metrics = {
|
| 387 |
+
"model_name": model_name,
|
| 388 |
+
"accuracy": accuracy,
|
| 389 |
+
"precision_weighted": float(precision),
|
| 390 |
+
"recall_weighted": float(recall),
|
| 391 |
+
"f1_weighted": float(f1),
|
| 392 |
+
"top5_accuracy": float(top5_acc),
|
| 393 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 394 |
+
"images_per_second": float(images_per_second),
|
| 395 |
+
"model_size_mb": float(size_mb),
|
| 396 |
+
"num_parameters": int(model.count_params()),
|
| 397 |
+
}
|
| 398 |
+
|
| 399 |
+
metrics_path = os.path.join(save_dir, "metrics.json")
|
| 400 |
+
cm_path = os.path.join(save_dir, "confusion_matrix.npy")
|
| 401 |
+
|
| 402 |
+
with open(metrics_path, "w") as f:
|
| 403 |
+
json.dump(metrics, f, indent=2)
|
| 404 |
+
|
| 405 |
+
np.save(cm_path, cm)
|
| 406 |
+
|
| 407 |
+
print(f"\nSaved metrics to : {metrics_path}")
|
| 408 |
+
print(f"Saved confusion matrix to: {cm_path}")
|
| 409 |
+
|
| 410 |
+
return metrics, cm
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
# Evaluate FINAL (fine-tuned) model on test set
|
| 414 |
+
vgg16_metrics, vgg16_cm = evaluate_and_save(
|
| 415 |
+
vgg16_model,
|
| 416 |
+
model_name="vgg16_v2_stage2",
|
| 417 |
+
best_weights_path=vgg16_stage2_best,
|
| 418 |
+
test_ds=test_ds,
|
| 419 |
+
class_names=class_names,
|
| 420 |
+
)
|
| 421 |
+
|
| 422 |
+
print("\n✅ VGG16 v2 (2-stage, improved) pipeline complete.")
|
scripts/03_eval_yolo.py
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - YOLOv8 EVALUATION SCRIPT
|
| 3 |
+
# - Loads best.pt from training
|
| 4 |
+
# - Computes mAP, per-class metrics
|
| 5 |
+
# - Measures inference speed (FPS)
|
| 6 |
+
# - Saves sample prediction images
|
| 7 |
+
# - Saves metrics to JSON for reporting
|
| 8 |
+
# ============================================================
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
+
import glob
|
| 12 |
+
import time
|
| 13 |
+
import json
|
| 14 |
+
from ultralytics import YOLO
|
| 15 |
+
|
| 16 |
+
# ------------------------------------------------------------
|
| 17 |
+
# 1. PATHS
|
| 18 |
+
# ------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
BASE_DIR = "smartvision_dataset"
|
| 21 |
+
DET_DIR = os.path.join(BASE_DIR, "detection")
|
| 22 |
+
DATA_YAML = os.path.join(DET_DIR, "data.yaml")
|
| 23 |
+
|
| 24 |
+
# Folder created by your train_yolo.py script
|
| 25 |
+
RUN_DIR = "yolo_runs/smartvision_yolov8s"
|
| 26 |
+
BEST_WEIGHTS = os.path.join(RUN_DIR, "weights", "best.pt")
|
| 27 |
+
|
| 28 |
+
# NOTE: all detection images are in detection/images (no "val" subfolder)
|
| 29 |
+
VAL_IMAGES_DIR = os.path.join(DET_DIR, "images")
|
| 30 |
+
|
| 31 |
+
print("📂 DATA_YAML :", DATA_YAML)
|
| 32 |
+
print("📦 BEST_WEIGHTS:", BEST_WEIGHTS)
|
| 33 |
+
print("📁 VAL_IMAGES :", VAL_IMAGES_DIR)
|
| 34 |
+
|
| 35 |
+
# ------------------------------------------------------------
|
| 36 |
+
# 2. LOAD TRAINED MODEL
|
| 37 |
+
# ------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
model = YOLO(BEST_WEIGHTS)
|
| 40 |
+
print("\n✅ Loaded trained YOLOv8 model from best.pt")
|
| 41 |
+
|
| 42 |
+
# ------------------------------------------------------------
|
| 43 |
+
# 3. VALIDATION METRICS (mAP, precision, recall)
|
| 44 |
+
# ------------------------------------------------------------
|
| 45 |
+
|
| 46 |
+
print("\n===== RUNNING VALIDATION (YOLO model.val) =====")
|
| 47 |
+
metrics = model.val(
|
| 48 |
+
data=DATA_YAML,
|
| 49 |
+
split="val", # uses val split defined in data.yaml (here both train/val point to 'images')
|
| 50 |
+
imgsz=640,
|
| 51 |
+
save_json=False
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
print("\n===== YOLOv8 Validation Metrics =====")
|
| 55 |
+
print(f"mAP@0.5 : {metrics.box.map50:.4f}")
|
| 56 |
+
print(f"mAP@0.5:0.95 : {metrics.box.map:.4f}")
|
| 57 |
+
|
| 58 |
+
# metrics.box.maps is a list of per-class mAP values in the same order as names
|
| 59 |
+
print("\nPer-class mAP@0.5 (first 10 classes):")
|
| 60 |
+
for i, m in enumerate(metrics.box.maps[:10]):
|
| 61 |
+
print(f" Class {i}: {m:.4f}")
|
| 62 |
+
|
| 63 |
+
# ------------------------------------------------------------
|
| 64 |
+
# 4. INFERENCE SPEED (FPS) ON VALIDATION IMAGES
|
| 65 |
+
# ------------------------------------------------------------
|
| 66 |
+
|
| 67 |
+
print("\n===== MEASURING INFERENCE SPEED (FPS) =====")
|
| 68 |
+
|
| 69 |
+
# Collect all JPG images in detection/images
|
| 70 |
+
val_images = glob.glob(os.path.join(VAL_IMAGES_DIR, "*.jpg"))
|
| 71 |
+
val_images = sorted(val_images)
|
| 72 |
+
|
| 73 |
+
num_test_images = min(50, len(val_images)) # test on up to 50 images
|
| 74 |
+
test_images = val_images[:num_test_images]
|
| 75 |
+
|
| 76 |
+
print(f"Found {len(val_images)} images in {VAL_IMAGES_DIR}")
|
| 77 |
+
print(f"Using {len(test_images)} images for speed test.")
|
| 78 |
+
|
| 79 |
+
# Defaults in case there are no images
|
| 80 |
+
time_per_image = 0.0
|
| 81 |
+
fps = 0.0
|
| 82 |
+
|
| 83 |
+
if len(test_images) == 0:
|
| 84 |
+
print("⚠️ No images found for FPS test. Skipping speed measurement.")
|
| 85 |
+
else:
|
| 86 |
+
start = time.perf_counter()
|
| 87 |
+
|
| 88 |
+
_ = model.predict(
|
| 89 |
+
source=test_images,
|
| 90 |
+
imgsz=640,
|
| 91 |
+
conf=0.5,
|
| 92 |
+
verbose=False
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
end = time.perf_counter()
|
| 96 |
+
|
| 97 |
+
total_time = end - start
|
| 98 |
+
time_per_image = total_time / len(test_images)
|
| 99 |
+
fps = 1.0 / time_per_image
|
| 100 |
+
|
| 101 |
+
print(f"Total time : {total_time:.2f} sec for {len(test_images)} images")
|
| 102 |
+
print(f"Avg time / image : {time_per_image*1000:.2f} ms")
|
| 103 |
+
print(f"Approx FPS : {fps:.2f} images/sec")
|
| 104 |
+
|
| 105 |
+
# ------------------------------------------------------------
|
| 106 |
+
# 5. SAVE SAMPLE PREDICTIONS (BOXES + LABELS)
|
| 107 |
+
# ------------------------------------------------------------
|
| 108 |
+
|
| 109 |
+
print("\n===== SAVING SAMPLE PREDICTION IMAGES =====")
|
| 110 |
+
|
| 111 |
+
sample_out_project = "yolo_vis"
|
| 112 |
+
sample_out_name = "samples"
|
| 113 |
+
|
| 114 |
+
if len(test_images) == 0:
|
| 115 |
+
print("⚠️ No images available for sample visualization. Skipping sample predictions.")
|
| 116 |
+
else:
|
| 117 |
+
sample_results = model.predict(
|
| 118 |
+
source=test_images[:8], # first 8 images
|
| 119 |
+
imgsz=640,
|
| 120 |
+
conf=0.5,
|
| 121 |
+
save=True, # save annotated images
|
| 122 |
+
project=sample_out_project,
|
| 123 |
+
name=sample_out_name,
|
| 124 |
+
verbose=False
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
print(f"✅ Saved sample predictions (with boxes & labels) to: {sample_out_project}/{sample_out_name}/")
|
| 128 |
+
|
| 129 |
+
# ------------------------------------------------------------
|
| 130 |
+
# 6. SAVE METRICS TO JSON (FOR REPORTING)
|
| 131 |
+
# ------------------------------------------------------------
|
| 132 |
+
|
| 133 |
+
print("\n===== SAVING METRICS TO JSON =====")
|
| 134 |
+
|
| 135 |
+
yolo_metrics = {
|
| 136 |
+
"model_name": "yolov8s_smartvision",
|
| 137 |
+
"map_50": float(metrics.box.map50),
|
| 138 |
+
"map_50_95": float(metrics.box.map),
|
| 139 |
+
"num_val_images_for_speed_test": int(len(test_images)),
|
| 140 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 141 |
+
"fps": float(fps),
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
os.makedirs("yolo_metrics", exist_ok=True)
|
| 145 |
+
metrics_json_path = os.path.join("yolo_metrics", "yolov8s_metrics.json")
|
| 146 |
+
|
| 147 |
+
with open(metrics_json_path, "w") as f:
|
| 148 |
+
json.dump(yolo_metrics, f, indent=2)
|
| 149 |
+
|
| 150 |
+
print(f"✅ Saved YOLO metrics JSON to: {metrics_json_path}")
|
| 151 |
+
print("\n🎯 YOLOv8 evaluation complete.")
|
scripts/03_train_yolo.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - YOLOv8 TRAINING SCRIPT
|
| 3 |
+
# - Fine-tunes yolov8s on 25-class SmartVision detection dataset
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
from ultralytics import YOLO
|
| 9 |
+
|
| 10 |
+
# ------------------------------------------------------------
|
| 11 |
+
# 1. PATHS & CONFIG
|
| 12 |
+
# ------------------------------------------------------------
|
| 13 |
+
|
| 14 |
+
BASE_DIR = "smartvision_dataset"
|
| 15 |
+
DET_DIR = os.path.join(BASE_DIR, "detection")
|
| 16 |
+
DATA_YAML = os.path.join(DET_DIR, "data.yaml")
|
| 17 |
+
|
| 18 |
+
# YOLO model size:
|
| 19 |
+
# - yolov8n.pt : nano
|
| 20 |
+
# - yolov8s.pt : small (good tradeoff) ✅
|
| 21 |
+
MODEL_WEIGHTS = "yolov8s.pt"
|
| 22 |
+
|
| 23 |
+
# Auto-select device
|
| 24 |
+
device = "0" if torch.cuda.is_available() else "cpu"
|
| 25 |
+
print("🚀 Using device:", device)
|
| 26 |
+
print("📂 DATA_YAML:", DATA_YAML)
|
| 27 |
+
|
| 28 |
+
# ------------------------------------------------------------
|
| 29 |
+
# 2. LOAD BASE MODEL
|
| 30 |
+
# ------------------------------------------------------------
|
| 31 |
+
|
| 32 |
+
print(f"📥 Loading YOLOv8 model from: {MODEL_WEIGHTS}")
|
| 33 |
+
model = YOLO(MODEL_WEIGHTS)
|
| 34 |
+
|
| 35 |
+
# ------------------------------------------------------------
|
| 36 |
+
# 3. TRAIN
|
| 37 |
+
# ------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
results = model.train(
|
| 40 |
+
data=DATA_YAML,
|
| 41 |
+
epochs=50,
|
| 42 |
+
imgsz=640,
|
| 43 |
+
batch=8, # smaller for CPU
|
| 44 |
+
lr0=0.01,
|
| 45 |
+
optimizer="SGD",
|
| 46 |
+
device=device,
|
| 47 |
+
project="yolo_runs",
|
| 48 |
+
name="smartvision_yolov8s",
|
| 49 |
+
pretrained=True,
|
| 50 |
+
plots=True,
|
| 51 |
+
verbose=True,
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
print("\n✅ YOLO training complete.")
|
| 55 |
+
print("📁 Run directory: yolo_runs/smartvision_yolov8s/")
|
| 56 |
+
print("📦 Best weights: yolo_runs/smartvision_yolov8s/weights/best.pt")
|
scripts/03_yolo_dataset_creation.py
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION DATASET BUILDER – FIXED VERSION
|
| 3 |
+
# - Streams COCO
|
| 4 |
+
# - Selects 25 classes
|
| 5 |
+
# - Builds train/val/test for YOLO
|
| 6 |
+
# - Uses correct image width/height for normalization
|
| 7 |
+
# ============================================================
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
import json
|
| 11 |
+
import random
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
from datasets import load_dataset
|
| 14 |
+
from PIL import Image
|
| 15 |
+
|
| 16 |
+
# ------------------------------------------------------------
|
| 17 |
+
# CONFIG
|
| 18 |
+
# ------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
BASE_DIR = "smartvision_dataset"
|
| 21 |
+
IMAGES_PER_CLASS = 100 # you can increase if needed
|
| 22 |
+
|
| 23 |
+
TARGET_CLASSES = [
|
| 24 |
+
"person", "bicycle", "car", "motorcycle", "airplane", "bus",
|
| 25 |
+
"truck", "traffic light", "stop sign", "bench", "bird", "cat",
|
| 26 |
+
"dog", "horse", "cow", "elephant", "bottle", "cup", "bowl",
|
| 27 |
+
"pizza", "cake", "chair", "couch", "bed", "potted plant"
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
# COCO full classes (80)
|
| 31 |
+
COCO_CLASSES = [
|
| 32 |
+
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck",
|
| 33 |
+
"boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench",
|
| 34 |
+
"bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra",
|
| 35 |
+
"giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
|
| 36 |
+
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
|
| 37 |
+
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup",
|
| 38 |
+
"fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange",
|
| 39 |
+
"broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
|
| 40 |
+
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse",
|
| 41 |
+
"remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink",
|
| 42 |
+
"refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
|
| 43 |
+
"hair drier", "toothbrush",
|
| 44 |
+
]
|
| 45 |
+
|
| 46 |
+
COCO_NAME_TO_INDEX = {name: i for i, name in enumerate(COCO_CLASSES)}
|
| 47 |
+
SELECTED = {name: COCO_NAME_TO_INDEX[name] for name in TARGET_CLASSES}
|
| 48 |
+
|
| 49 |
+
os.makedirs(BASE_DIR, exist_ok=True)
|
| 50 |
+
|
| 51 |
+
# ------------------------------------------------------------
|
| 52 |
+
# STEP 1 — STREAM COCO & COLLECT IMAGES
|
| 53 |
+
# ------------------------------------------------------------
|
| 54 |
+
|
| 55 |
+
print("📥 Loading COCO dataset (streaming mode)...")
|
| 56 |
+
dataset = load_dataset("detection-datasets/coco", split="train", streaming=True)
|
| 57 |
+
|
| 58 |
+
class_images = {c: [] for c in TARGET_CLASSES}
|
| 59 |
+
class_count = {c: 0 for c in TARGET_CLASSES}
|
| 60 |
+
|
| 61 |
+
print("🔍 Collecting images...")
|
| 62 |
+
max_iterations = 100000 # safety cap
|
| 63 |
+
|
| 64 |
+
for idx, item in enumerate(dataset):
|
| 65 |
+
if idx >= max_iterations:
|
| 66 |
+
print(f"⚠️ Reached safety limit of {max_iterations} samples, stopping collection.")
|
| 67 |
+
break
|
| 68 |
+
|
| 69 |
+
ann = item["objects"]
|
| 70 |
+
|
| 71 |
+
# Get image and its size (this is the reference for bbox coordinates)
|
| 72 |
+
img = item["image"]
|
| 73 |
+
orig_width, orig_height = img.size
|
| 74 |
+
|
| 75 |
+
for cat_id in ann["category"]:
|
| 76 |
+
# If this category is one of our target classes
|
| 77 |
+
for cname, coco_id in SELECTED.items():
|
| 78 |
+
if cat_id == coco_id and class_count[cname] < IMAGES_PER_CLASS:
|
| 79 |
+
|
| 80 |
+
class_images[cname].append({
|
| 81 |
+
"image": img, # PIL image
|
| 82 |
+
"orig_width": orig_width, # width used for normalization
|
| 83 |
+
"orig_height": orig_height, # height used for normalization
|
| 84 |
+
"bboxes": ann["bbox"], # list of bboxes
|
| 85 |
+
"cats": ann["category"], # list of categories
|
| 86 |
+
})
|
| 87 |
+
class_count[cname] += 1
|
| 88 |
+
break
|
| 89 |
+
|
| 90 |
+
# Stop if all collected
|
| 91 |
+
if all(count >= IMAGES_PER_CLASS for count in class_count.values()):
|
| 92 |
+
break
|
| 93 |
+
|
| 94 |
+
print("🎉 Collection complete")
|
| 95 |
+
print("📊 Images per class:")
|
| 96 |
+
for cname, cnt in class_count.items():
|
| 97 |
+
print(f" {cname:15s}: {cnt}")
|
| 98 |
+
|
| 99 |
+
# ------------------------------------------------------------
|
| 100 |
+
# STEP 2 — CREATE FOLDERS
|
| 101 |
+
# ------------------------------------------------------------
|
| 102 |
+
|
| 103 |
+
DET_IMG_ROOT = os.path.join(BASE_DIR, "detection", "images")
|
| 104 |
+
DET_LAB_ROOT = os.path.join(BASE_DIR, "detection", "labels")
|
| 105 |
+
|
| 106 |
+
for split in ["train", "val", "test"]:
|
| 107 |
+
os.makedirs(os.path.join(DET_IMG_ROOT, split), exist_ok=True)
|
| 108 |
+
os.makedirs(os.path.join(DET_LAB_ROOT, split), exist_ok=True)
|
| 109 |
+
|
| 110 |
+
# ------------------------------------------------------------
|
| 111 |
+
# STEP 3 — TRAIN/VAL/TEST SPLIT
|
| 112 |
+
# ------------------------------------------------------------
|
| 113 |
+
|
| 114 |
+
train_data = {}
|
| 115 |
+
val_data = {}
|
| 116 |
+
test_data = {}
|
| 117 |
+
|
| 118 |
+
for cname, items in class_images.items():
|
| 119 |
+
random.shuffle(items)
|
| 120 |
+
n = len(items)
|
| 121 |
+
if n == 0:
|
| 122 |
+
print(f"⚠️ No images collected for class: {cname}")
|
| 123 |
+
continue
|
| 124 |
+
|
| 125 |
+
t1 = int(0.7 * n)
|
| 126 |
+
t2 = int(0.85 * n)
|
| 127 |
+
train_data[cname] = items[:t1]
|
| 128 |
+
val_data[cname] = items[t1:t2]
|
| 129 |
+
test_data[cname] = items[t2:]
|
| 130 |
+
|
| 131 |
+
split_dict = {
|
| 132 |
+
"train": train_data,
|
| 133 |
+
"val": val_data,
|
| 134 |
+
"test": test_data,
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
print("\n📊 Split sizes (per class):")
|
| 138 |
+
for cname in TARGET_CLASSES:
|
| 139 |
+
tr = len(train_data.get(cname, []))
|
| 140 |
+
va = len(val_data.get(cname, []))
|
| 141 |
+
te = len(test_data.get(cname, []))
|
| 142 |
+
print(f" {cname:15s} -> Train={tr:3d}, Val={va:3d}, Test={te:3d}")
|
| 143 |
+
|
| 144 |
+
# ------------------------------------------------------------
|
| 145 |
+
# STEP 4 — SAVE DETECTION IMAGES & LABELS (FIXED NORMALIZATION)
|
| 146 |
+
# ------------------------------------------------------------
|
| 147 |
+
|
| 148 |
+
print("\n📁 Saving detection images + labels with correct coordinates...\n")
|
| 149 |
+
|
| 150 |
+
YOLO_NAME_TO_ID = {name: i for i, name in enumerate(TARGET_CLASSES)}
|
| 151 |
+
|
| 152 |
+
global_idx = 0
|
| 153 |
+
stats = {"train": 0, "val": 0, "test": 0}
|
| 154 |
+
label_stats = {"train": 0, "val": 0, "test": 0}
|
| 155 |
+
object_stats = {"train": 0, "val": 0, "test": 0}
|
| 156 |
+
|
| 157 |
+
for split, cls_dict in split_dict.items():
|
| 158 |
+
print(f"\n🔹 Processing {split.upper()} ...")
|
| 159 |
+
|
| 160 |
+
for cname, items in tqdm(cls_dict.items(), desc=f"{split} classes"):
|
| 161 |
+
for item in items:
|
| 162 |
+
|
| 163 |
+
img = item["image"]
|
| 164 |
+
orig_w = item["orig_width"]
|
| 165 |
+
orig_h = item["orig_height"]
|
| 166 |
+
|
| 167 |
+
img_filename = f"image_{global_idx:06d}.jpg"
|
| 168 |
+
img_path = os.path.join(DET_IMG_ROOT, split, img_filename)
|
| 169 |
+
lab_path = os.path.join(DET_LAB_ROOT, split, img_filename.replace(".jpg", ".txt"))
|
| 170 |
+
|
| 171 |
+
img.save(img_path, quality=95)
|
| 172 |
+
stats[split] += 1
|
| 173 |
+
|
| 174 |
+
bboxes = item["bboxes"]
|
| 175 |
+
cats = item["cats"]
|
| 176 |
+
|
| 177 |
+
yolo_lines = []
|
| 178 |
+
obj_count = 0
|
| 179 |
+
|
| 180 |
+
for bbox, cat in zip(bboxes, cats):
|
| 181 |
+
# Only use 25 SmartVision classes
|
| 182 |
+
coco_class_name = COCO_CLASSES[cat]
|
| 183 |
+
if coco_class_name not in YOLO_NAME_TO_ID:
|
| 184 |
+
continue
|
| 185 |
+
|
| 186 |
+
yolo_id = YOLO_NAME_TO_ID[coco_class_name]
|
| 187 |
+
|
| 188 |
+
x, y, w, h = bbox # COCO: pixel values
|
| 189 |
+
|
| 190 |
+
# Normalize using image size
|
| 191 |
+
x_center = (x + w / 2) / orig_w
|
| 192 |
+
y_center = (y + h / 2) / orig_h
|
| 193 |
+
w_norm = w / orig_w
|
| 194 |
+
h_norm = h / orig_h
|
| 195 |
+
|
| 196 |
+
# discard invalid
|
| 197 |
+
if not (0 <= x_center <= 1 and 0 <= y_center <= 1):
|
| 198 |
+
continue
|
| 199 |
+
if not (0 < w_norm <= 1 and 0 < h_norm <= 1):
|
| 200 |
+
continue
|
| 201 |
+
|
| 202 |
+
yolo_lines.append(
|
| 203 |
+
f"{yolo_id} {x_center:.6f} {y_center:.6f} {w_norm:.6f} {h_norm:.6f}"
|
| 204 |
+
)
|
| 205 |
+
obj_count += 1
|
| 206 |
+
|
| 207 |
+
if yolo_lines:
|
| 208 |
+
with open(lab_path, "w") as f:
|
| 209 |
+
f.write("\n".join(yolo_lines))
|
| 210 |
+
label_stats[split] += 1
|
| 211 |
+
object_stats[split] += obj_count
|
| 212 |
+
|
| 213 |
+
global_idx += 1
|
| 214 |
+
|
| 215 |
+
print("\n🎉 All detection data saved successfully!")
|
| 216 |
+
for split in ["train", "val", "test"]:
|
| 217 |
+
print(
|
| 218 |
+
f" {split.upper():5s} -> "
|
| 219 |
+
f"images: {stats[split]:4d}, "
|
| 220 |
+
f"label_files: {label_stats[split]:4d}, "
|
| 221 |
+
f"objects: {object_stats[split]:5d}"
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
# ------------------------------------------------------------
|
| 225 |
+
# STEP 5 — WRITE data.yaml
|
| 226 |
+
# ------------------------------------------------------------
|
| 227 |
+
|
| 228 |
+
print("\n📝 Writing data.yaml ...")
|
| 229 |
+
|
| 230 |
+
yaml = f"""
|
| 231 |
+
# SmartVision Dataset - YOLOv8 Configuration (with splits)
|
| 232 |
+
path: {os.path.abspath(os.path.join(BASE_DIR, "detection"))}
|
| 233 |
+
|
| 234 |
+
train: images/train
|
| 235 |
+
val: images/val
|
| 236 |
+
test: images/test
|
| 237 |
+
|
| 238 |
+
nc: {len(TARGET_CLASSES)}
|
| 239 |
+
names:
|
| 240 |
+
""" + "\n".join([f" {i}: {name}" for i, name in enumerate(TARGET_CLASSES)])
|
| 241 |
+
|
| 242 |
+
data_yaml_path = os.path.join(BASE_DIR, "detection", "data.yaml")
|
| 243 |
+
os.makedirs(os.path.dirname(data_yaml_path), exist_ok=True)
|
| 244 |
+
|
| 245 |
+
with open(data_yaml_path, "w") as f:
|
| 246 |
+
f.write(yaml)
|
| 247 |
+
|
| 248 |
+
print(f"✅ Created data.yaml at: {data_yaml_path}")
|
scripts/04_inference_pipeline.py
ADDED
|
@@ -0,0 +1,436 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - PHASE 4
|
| 3 |
+
# Model Integration & Inference Pipeline (YOLOv8 + ResNet50 v2)
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
from typing import List, Dict, Any
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 12 |
+
|
| 13 |
+
import tensorflow as tf
|
| 14 |
+
from tensorflow import keras
|
| 15 |
+
from tensorflow.keras import layers
|
| 16 |
+
from ultralytics import YOLO
|
| 17 |
+
|
| 18 |
+
print("TensorFlow version:", tf.__version__)
|
| 19 |
+
|
| 20 |
+
# ------------------------------------------------------------
|
| 21 |
+
# 1. CONFIGURATION
|
| 22 |
+
# ------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
# Dataset & models
|
| 25 |
+
BASE_DIR = "smartvision_dataset"
|
| 26 |
+
CLASS_DIR = os.path.join(BASE_DIR, "classification")
|
| 27 |
+
TRAIN_DIR = os.path.join(CLASS_DIR, "train")
|
| 28 |
+
|
| 29 |
+
# YOLO & classifier weights
|
| 30 |
+
YOLO_WEIGHTS = "yolo_runs/smartvision_yolov8s6 - Copy/weights/best.pt" # adjust if needed
|
| 31 |
+
CLASSIFIER_WEIGHTS_PATH = os.path.join(
|
| 32 |
+
"saved_models", "resnet50_v2_stage2_best.weights.h5"
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
IMG_SIZE = (224, 224)
|
| 36 |
+
NUM_CLASSES = 25
|
| 37 |
+
|
| 38 |
+
# Where to save annotated outputs
|
| 39 |
+
OUTPUT_DIR = "inference_outputs"
|
| 40 |
+
os.makedirs(OUTPUT_DIR, exist_ok=True)
|
| 41 |
+
|
| 42 |
+
# ------------------------------------------------------------
|
| 43 |
+
# 2. CLASS NAMES (MUST MATCH TRAINING ORDER)
|
| 44 |
+
# From your training logs:
|
| 45 |
+
# ['airplane', 'bed', 'bench', 'bicycle', 'bird', 'bottle', 'bowl',
|
| 46 |
+
# 'bus', 'cake', 'car', 'cat', 'chair', 'couch', 'cow', 'cup', 'dog',
|
| 47 |
+
# 'elephant', 'horse', 'motorcycle', 'person', 'pizza', 'potted plant',
|
| 48 |
+
# 'stop sign', 'traffic light', 'truck']
|
| 49 |
+
# ------------------------------------------------------------
|
| 50 |
+
|
| 51 |
+
CLASS_NAMES = [
|
| 52 |
+
"airplane", "bed", "bench", "bicycle", "bird", "bottle", "bowl",
|
| 53 |
+
"bus", "cake", "car", "cat", "chair", "couch", "cow", "cup", "dog",
|
| 54 |
+
"elephant", "horse", "motorcycle", "person", "pizza", "potted plant",
|
| 55 |
+
"stop sign", "traffic light", "truck"
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
assert len(CLASS_NAMES) == NUM_CLASSES, "CLASS_NAMES length must be 25"
|
| 59 |
+
|
| 60 |
+
# ------------------------------------------------------------
|
| 61 |
+
# 3. DATA AUGMENTATION (same as training, but no effect in inference)
|
| 62 |
+
# ------------------------------------------------------------
|
| 63 |
+
|
| 64 |
+
data_augmentation = keras.Sequential(
|
| 65 |
+
[
|
| 66 |
+
layers.RandomFlip("horizontal"),
|
| 67 |
+
layers.RandomRotation(0.04), # ~±15°
|
| 68 |
+
layers.RandomZoom(0.1),
|
| 69 |
+
layers.RandomContrast(0.15),
|
| 70 |
+
layers.Lambda(
|
| 71 |
+
lambda x: tf.image.random_brightness(x, max_delta=0.15)
|
| 72 |
+
),
|
| 73 |
+
layers.Lambda(
|
| 74 |
+
lambda x: tf.image.random_saturation(x, 0.85, 1.15)
|
| 75 |
+
),
|
| 76 |
+
],
|
| 77 |
+
name="data_augmentation",
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
# ------------------------------------------------------------
|
| 81 |
+
# 4. BUILD RESNET50 v2 CLASSIFIER (MATCHES TRAINING ARCHITECTURE)
|
| 82 |
+
# ------------------------------------------------------------
|
| 83 |
+
|
| 84 |
+
def build_resnet50_model_v2():
|
| 85 |
+
"""
|
| 86 |
+
Build the ResNet50 v2 classifier with the SAME architecture as in training.
|
| 87 |
+
(data_augmentation + Lambda(resnet50.preprocess_input) + ResNet50 backbone + head)
|
| 88 |
+
"""
|
| 89 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 90 |
+
|
| 91 |
+
# Augmentation (no randomness in inference mode, Keras handles that)
|
| 92 |
+
x = data_augmentation(inputs)
|
| 93 |
+
|
| 94 |
+
# ResNet50-specific preprocessing
|
| 95 |
+
x = layers.Lambda(
|
| 96 |
+
keras.applications.resnet50.preprocess_input,
|
| 97 |
+
name="resnet50_preprocess",
|
| 98 |
+
)(x)
|
| 99 |
+
|
| 100 |
+
# Pretrained ResNet50 backbone
|
| 101 |
+
base_model = keras.applications.ResNet50(
|
| 102 |
+
include_top=False,
|
| 103 |
+
weights="imagenet",
|
| 104 |
+
input_shape=(*IMG_SIZE, 3),
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
x = base_model(x)
|
| 108 |
+
|
| 109 |
+
# Custom classification head (same as training file)
|
| 110 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 111 |
+
|
| 112 |
+
x = layers.BatchNormalization(name="head_batchnorm")(x)
|
| 113 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 114 |
+
|
| 115 |
+
x = layers.Dense(
|
| 116 |
+
256,
|
| 117 |
+
activation="relu",
|
| 118 |
+
name="head_dense",
|
| 119 |
+
)(x)
|
| 120 |
+
|
| 121 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 122 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 123 |
+
|
| 124 |
+
outputs = layers.Dense(
|
| 125 |
+
NUM_CLASSES,
|
| 126 |
+
activation="softmax",
|
| 127 |
+
name="predictions",
|
| 128 |
+
)(x)
|
| 129 |
+
|
| 130 |
+
model = keras.Model(
|
| 131 |
+
inputs=inputs,
|
| 132 |
+
outputs=outputs,
|
| 133 |
+
name="ResNet50_smartvision_v2_infer",
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return model, base_model
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def load_classifier(weights_path: str):
|
| 140 |
+
"""
|
| 141 |
+
Build the ResNet50 v2 model and load fine-tuned weights from
|
| 142 |
+
resnet50_v2_stage2_best.weights.h5
|
| 143 |
+
"""
|
| 144 |
+
if not os.path.exists(weights_path):
|
| 145 |
+
print(f"⚠️ Classifier weights not found at: {weights_path}")
|
| 146 |
+
print(" Using ImageNet-pretrained ResNet50 base + randomly initialized head.")
|
| 147 |
+
model, _ = build_resnet50_model_v2()
|
| 148 |
+
return model
|
| 149 |
+
|
| 150 |
+
model, _ = build_resnet50_model_v2()
|
| 151 |
+
model.load_weights(weights_path)
|
| 152 |
+
print(f"✅ Loaded classifier weights from: {weights_path}")
|
| 153 |
+
return model
|
| 154 |
+
|
| 155 |
+
# ------------------------------------------------------------
|
| 156 |
+
# 5. LOAD YOLO MODEL
|
| 157 |
+
# ------------------------------------------------------------
|
| 158 |
+
|
| 159 |
+
def load_yolo_model(weights_path: str = YOLO_WEIGHTS) -> YOLO:
|
| 160 |
+
if not os.path.exists(weights_path):
|
| 161 |
+
raise FileNotFoundError(f"YOLO weights not found at: {weights_path}")
|
| 162 |
+
model = YOLO(weights_path)
|
| 163 |
+
print(f"✅ Loaded YOLOv8 model from: {weights_path}")
|
| 164 |
+
return model
|
| 165 |
+
|
| 166 |
+
# ------------------------------------------------------------
|
| 167 |
+
# 6. HELPER: PREPROCESS CROP FOR CLASSIFIER
|
| 168 |
+
# ------------------------------------------------------------
|
| 169 |
+
|
| 170 |
+
def preprocess_crop_for_classifier(crop_img: Image.Image,
|
| 171 |
+
img_size=IMG_SIZE) -> np.ndarray:
|
| 172 |
+
"""
|
| 173 |
+
Resize PIL image crop to 224x224 and prepare as batch tensor.
|
| 174 |
+
NOTE: No manual rescaling here; model already has preprocess_input inside.
|
| 175 |
+
"""
|
| 176 |
+
crop_resized = crop_img.resize(img_size, Image.BILINEAR)
|
| 177 |
+
arr = np.array(crop_resized, dtype=np.float32) # shape (H,W,3)
|
| 178 |
+
arr = np.expand_dims(arr, axis=0) # (1,H,W,3)
|
| 179 |
+
return arr
|
| 180 |
+
|
| 181 |
+
# ------------------------------------------------------------
|
| 182 |
+
# 7. DRAWING UTIL: BOUNDING BOXES + LABELS (Pillow 10+ SAFE)
|
| 183 |
+
# ------------------------------------------------------------
|
| 184 |
+
|
| 185 |
+
def draw_boxes_with_labels(
|
| 186 |
+
pil_img: Image.Image,
|
| 187 |
+
detections: List[Dict[str, Any]],
|
| 188 |
+
font_path: str = None
|
| 189 |
+
) -> Image.Image:
|
| 190 |
+
"""
|
| 191 |
+
Draw bounding boxes & labels on an image.
|
| 192 |
+
|
| 193 |
+
detections: list of dicts with keys:
|
| 194 |
+
- x1, y1, x2, y2
|
| 195 |
+
- label (str)
|
| 196 |
+
- conf_yolo (float)
|
| 197 |
+
- cls_label (optional, str)
|
| 198 |
+
- cls_conf (optional, float)
|
| 199 |
+
"""
|
| 200 |
+
draw = ImageDraw.Draw(pil_img)
|
| 201 |
+
|
| 202 |
+
# Try to load a TTF font, fallback to default
|
| 203 |
+
if font_path and os.path.exists(font_path):
|
| 204 |
+
font = ImageFont.truetype(font_path, 16)
|
| 205 |
+
else:
|
| 206 |
+
font = ImageFont.load_default()
|
| 207 |
+
|
| 208 |
+
for det in detections:
|
| 209 |
+
x1, y1, x2, y2 = det["x1"], det["y1"], det["x2"], det["y2"]
|
| 210 |
+
yolo_label = det["label"]
|
| 211 |
+
conf_yolo = det["conf_yolo"]
|
| 212 |
+
cls_label = det.get("cls_label")
|
| 213 |
+
cls_conf = det.get("cls_conf")
|
| 214 |
+
|
| 215 |
+
# Text to display
|
| 216 |
+
if cls_label is not None:
|
| 217 |
+
text = f"{yolo_label} {conf_yolo:.2f} | CLS: {cls_label} {cls_conf:.2f}"
|
| 218 |
+
else:
|
| 219 |
+
text = f"{yolo_label} {conf_yolo:.2f}"
|
| 220 |
+
|
| 221 |
+
# Box
|
| 222 |
+
draw.rectangle([x1, y1, x2, y2], outline="red", width=2)
|
| 223 |
+
|
| 224 |
+
# Compute text size safely (Pillow 10+)
|
| 225 |
+
bbox = draw.textbbox((0, 0), text, font=font)
|
| 226 |
+
text_w = bbox[2] - bbox[0]
|
| 227 |
+
text_h = bbox[3] - bbox[1]
|
| 228 |
+
|
| 229 |
+
# Text background (clamp to top of image)
|
| 230 |
+
text_bg = [x1,
|
| 231 |
+
max(0, y1 - text_h - 2),
|
| 232 |
+
x1 + text_w + 4,
|
| 233 |
+
y1]
|
| 234 |
+
draw.rectangle(text_bg, fill="black")
|
| 235 |
+
draw.text((x1 + 2, max(0, y1 - text_h - 1)), text, fill="white", font=font)
|
| 236 |
+
|
| 237 |
+
return pil_img
|
| 238 |
+
|
| 239 |
+
# ------------------------------------------------------------
|
| 240 |
+
# 8. SINGLE-IMAGE PIPELINE
|
| 241 |
+
# user_image → YOLO → (optional ResNet verify) → annotated image
|
| 242 |
+
# ------------------------------------------------------------
|
| 243 |
+
|
| 244 |
+
def run_inference_on_image(
|
| 245 |
+
image_path: str,
|
| 246 |
+
yolo_model: YOLO,
|
| 247 |
+
classifier: keras.Model = None,
|
| 248 |
+
conf_threshold: float = 0.5,
|
| 249 |
+
save_name: str = None
|
| 250 |
+
) -> Dict[str, Any]:
|
| 251 |
+
"""
|
| 252 |
+
Full pipeline on a single image.
|
| 253 |
+
|
| 254 |
+
- Runs YOLO detection (with NMS internally).
|
| 255 |
+
- Filters by conf_threshold.
|
| 256 |
+
- Optionally runs ResNet50 classifier on each crop.
|
| 257 |
+
- Draws bounding boxes + labels.
|
| 258 |
+
- Saves annotated image to OUTPUT_DIR.
|
| 259 |
+
"""
|
| 260 |
+
if not os.path.exists(image_path):
|
| 261 |
+
raise FileNotFoundError(f"Image not found: {image_path}")
|
| 262 |
+
|
| 263 |
+
print(f"\n🔍 Processing image: {image_path}")
|
| 264 |
+
pil_img = Image.open(image_path).convert("RGB")
|
| 265 |
+
orig_w, orig_h = pil_img.size
|
| 266 |
+
|
| 267 |
+
# YOLO prediction (NMS is automatically applied)
|
| 268 |
+
t0 = time.perf_counter()
|
| 269 |
+
results = yolo_model.predict(
|
| 270 |
+
source=image_path,
|
| 271 |
+
imgsz=640,
|
| 272 |
+
conf=conf_threshold,
|
| 273 |
+
device="cpu", # change to "0" if you have a GPU
|
| 274 |
+
verbose=False
|
| 275 |
+
)
|
| 276 |
+
t1 = time.perf_counter()
|
| 277 |
+
infer_time = t1 - t0
|
| 278 |
+
print(f"YOLO inference time: {infer_time*1000:.2f} ms")
|
| 279 |
+
|
| 280 |
+
res = results[0] # one image
|
| 281 |
+
boxes = res.boxes # Boxes object
|
| 282 |
+
|
| 283 |
+
detections = []
|
| 284 |
+
|
| 285 |
+
for box in boxes:
|
| 286 |
+
# xyxy coordinates
|
| 287 |
+
x1, y1, x2, y2 = box.xyxy[0].tolist()
|
| 288 |
+
cls_id = int(box.cls[0].item())
|
| 289 |
+
conf_yolo = float(box.conf[0].item())
|
| 290 |
+
label = yolo_model.names[cls_id] # class name from YOLO model
|
| 291 |
+
|
| 292 |
+
# Clip coords to image size, just in case
|
| 293 |
+
x1 = max(0, min(x1, orig_w - 1))
|
| 294 |
+
y1 = max(0, min(y1, orig_h - 1))
|
| 295 |
+
x2 = max(0, min(x2, orig_w - 1))
|
| 296 |
+
y2 = max(0, min(y2, orig_h - 1))
|
| 297 |
+
|
| 298 |
+
# Optional classification verification
|
| 299 |
+
cls_label = None
|
| 300 |
+
cls_conf = None
|
| 301 |
+
if classifier is not None:
|
| 302 |
+
crop = pil_img.crop((x1, y1, x2, y2))
|
| 303 |
+
arr = preprocess_crop_for_classifier(crop)
|
| 304 |
+
probs = classifier.predict(arr, verbose=0)[0] # shape (25,)
|
| 305 |
+
cls_idx = int(np.argmax(probs))
|
| 306 |
+
cls_label = CLASS_NAMES[cls_idx]
|
| 307 |
+
cls_conf = float(probs[cls_idx])
|
| 308 |
+
|
| 309 |
+
detection_info = {
|
| 310 |
+
"x1": x1,
|
| 311 |
+
"y1": y1,
|
| 312 |
+
"x2": x2,
|
| 313 |
+
"y2": y2,
|
| 314 |
+
"class_id_yolo": cls_id,
|
| 315 |
+
"label": label,
|
| 316 |
+
"conf_yolo": conf_yolo,
|
| 317 |
+
"cls_label": cls_label,
|
| 318 |
+
"cls_conf": cls_conf,
|
| 319 |
+
}
|
| 320 |
+
detections.append(detection_info)
|
| 321 |
+
|
| 322 |
+
# Draw boxes
|
| 323 |
+
annotated = pil_img.copy()
|
| 324 |
+
annotated = draw_boxes_with_labels(annotated, detections)
|
| 325 |
+
|
| 326 |
+
# Save output image
|
| 327 |
+
if save_name is None:
|
| 328 |
+
base = os.path.basename(image_path)
|
| 329 |
+
name_wo_ext, _ = os.path.splitext(base)
|
| 330 |
+
save_name = f"{name_wo_ext}_annotated.jpg"
|
| 331 |
+
|
| 332 |
+
save_path = os.path.join(OUTPUT_DIR, save_name)
|
| 333 |
+
annotated.save(save_path)
|
| 334 |
+
print(f"✅ Saved annotated image to: {save_path}")
|
| 335 |
+
|
| 336 |
+
return {
|
| 337 |
+
"image_path": image_path,
|
| 338 |
+
"output_path": save_path,
|
| 339 |
+
"num_detections": len(detections),
|
| 340 |
+
"detections": detections,
|
| 341 |
+
"yolo_inference_time_sec": infer_time,
|
| 342 |
+
}
|
| 343 |
+
|
| 344 |
+
# ------------------------------------------------------------
|
| 345 |
+
# 9. BATCH PIPELINE (MULTIPLE IMAGES)
|
| 346 |
+
# ------------------------------------------------------------
|
| 347 |
+
|
| 348 |
+
def run_inference_on_folder(
|
| 349 |
+
folder_path: str,
|
| 350 |
+
yolo_model: YOLO,
|
| 351 |
+
classifier: keras.Model = None,
|
| 352 |
+
conf_threshold: float = 0.5,
|
| 353 |
+
max_images: int = None
|
| 354 |
+
) -> List[Dict[str, Any]]:
|
| 355 |
+
"""
|
| 356 |
+
Run the full pipeline on all images in a folder.
|
| 357 |
+
"""
|
| 358 |
+
supported_ext = (".jpg", ".jpeg", ".png")
|
| 359 |
+
image_files = [
|
| 360 |
+
os.path.join(folder_path, f)
|
| 361 |
+
for f in os.listdir(folder_path)
|
| 362 |
+
if f.lower().endswith(supported_ext)
|
| 363 |
+
]
|
| 364 |
+
image_files.sort()
|
| 365 |
+
|
| 366 |
+
if max_images is not None:
|
| 367 |
+
image_files = image_files[:max_images]
|
| 368 |
+
|
| 369 |
+
results_all = []
|
| 370 |
+
for img_path in image_files:
|
| 371 |
+
res = run_inference_on_image(
|
| 372 |
+
img_path,
|
| 373 |
+
yolo_model=yolo_model,
|
| 374 |
+
classifier=classifier,
|
| 375 |
+
conf_threshold=conf_threshold
|
| 376 |
+
)
|
| 377 |
+
results_all.append(res)
|
| 378 |
+
|
| 379 |
+
return results_all
|
| 380 |
+
|
| 381 |
+
# ------------------------------------------------------------
|
| 382 |
+
# 10. SIMPLE QUANTIZATION (CLASSIFIER → TFLITE FLOAT16)
|
| 383 |
+
# ------------------------------------------------------------
|
| 384 |
+
|
| 385 |
+
def export_classifier_tflite_float16(
|
| 386 |
+
keras_model: keras.Model,
|
| 387 |
+
export_path: str = "resnet50_smartvision_float16.tflite"
|
| 388 |
+
):
|
| 389 |
+
"""
|
| 390 |
+
Export the classifier to a TFLite model with float16 quantization.
|
| 391 |
+
This is suitable for faster inference on CPU / mobile.
|
| 392 |
+
"""
|
| 393 |
+
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
|
| 394 |
+
converter.optimizations = [tf.lite.Optimize.DEFAULT]
|
| 395 |
+
converter.target_spec.supported_types = [tf.float16]
|
| 396 |
+
|
| 397 |
+
tflite_model = converter.convert()
|
| 398 |
+
with open(export_path, "wb") as f:
|
| 399 |
+
f.write(tflite_model)
|
| 400 |
+
|
| 401 |
+
size_mb = os.path.getsize(export_path) / (1024 * 1024)
|
| 402 |
+
print(f"✅ Exported float16 TFLite model to: {export_path} ({size_mb:.2f} MB)")
|
| 403 |
+
|
| 404 |
+
# ------------------------------------------------------------
|
| 405 |
+
# 11. MAIN (for quick testing)
|
| 406 |
+
# ------------------------------------------------------------
|
| 407 |
+
|
| 408 |
+
if __name__ == "__main__":
|
| 409 |
+
print("🔧 Loading models...")
|
| 410 |
+
yolo_model = load_yolo_model(YOLO_WEIGHTS)
|
| 411 |
+
classifier_model = load_classifier(CLASSIFIER_WEIGHTS_PATH)
|
| 412 |
+
|
| 413 |
+
# Example: run on a single test image
|
| 414 |
+
test_image = os.path.join(BASE_DIR, "detection", "images", "test", "image_002126.jpg")
|
| 415 |
+
if os.path.exists(test_image):
|
| 416 |
+
_ = run_inference_on_image(
|
| 417 |
+
image_path=test_image,
|
| 418 |
+
yolo_model=yolo_model,
|
| 419 |
+
classifier=classifier_model,
|
| 420 |
+
conf_threshold=0.5,
|
| 421 |
+
)
|
| 422 |
+
else:
|
| 423 |
+
print(f"⚠️ Example image not found: {test_image}")
|
| 424 |
+
|
| 425 |
+
# Example: run on a folder of images
|
| 426 |
+
# folder = os.path.join(BASE_DIR, "detection", "images")
|
| 427 |
+
# _ = run_inference_on_folder(
|
| 428 |
+
# folder_path=folder,
|
| 429 |
+
# yolo_model=yolo_model,
|
| 430 |
+
# classifier=classifier_model,
|
| 431 |
+
# conf_threshold=0.5,
|
| 432 |
+
# max_images=10,
|
| 433 |
+
# )
|
| 434 |
+
|
| 435 |
+
# Example: export quantized classifier
|
| 436 |
+
# export_classifier_tflite_float16(classifier_model)
|
scripts/04_validation and cleaning.py
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
YOLO Dataset Validation & Cleaning Script
|
| 3 |
+
==========================================
|
| 4 |
+
This script will:
|
| 5 |
+
1. Validate all YOLO label files
|
| 6 |
+
2. Fix out-of-bounds coordinates (clip to [0,1])
|
| 7 |
+
3. Remove invalid/empty annotations
|
| 8 |
+
4. Generate a detailed report
|
| 9 |
+
5. Create backups before making changes
|
| 10 |
+
6. Clear corrupted cache files
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import glob
|
| 15 |
+
import shutil
|
| 16 |
+
import json
|
| 17 |
+
from datetime import datetime
|
| 18 |
+
from pathlib import Path
|
| 19 |
+
|
| 20 |
+
class YOLODatasetCleaner:
|
| 21 |
+
def __init__(self, dataset_dir):
|
| 22 |
+
self.dataset_dir = dataset_dir
|
| 23 |
+
self.detection_dir = os.path.join(dataset_dir, "detection")
|
| 24 |
+
self.labels_dir = os.path.join(self.detection_dir, "labels")
|
| 25 |
+
self.images_dir = os.path.join(self.detection_dir, "images")
|
| 26 |
+
self.backup_dir = os.path.join(dataset_dir, f"backup_{datetime.now().strftime('%Y%m%d_%H%M%S')}")
|
| 27 |
+
|
| 28 |
+
self.stats = {
|
| 29 |
+
'total_files': 0,
|
| 30 |
+
'corrupt_files': 0,
|
| 31 |
+
'fixed_files': 0,
|
| 32 |
+
'removed_files': 0,
|
| 33 |
+
'empty_files': 0,
|
| 34 |
+
'splits': {'train': {}, 'val': {}, 'test': {}}
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
def create_backup(self):
|
| 38 |
+
"""Create backup of labels directory"""
|
| 39 |
+
print("\n" + "="*60)
|
| 40 |
+
print("📦 CREATING BACKUP")
|
| 41 |
+
print("="*60)
|
| 42 |
+
|
| 43 |
+
if os.path.exists(self.backup_dir):
|
| 44 |
+
print(f"⚠️ Backup directory already exists: {self.backup_dir}")
|
| 45 |
+
return False
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
shutil.copytree(self.labels_dir, os.path.join(self.backup_dir, "labels"))
|
| 49 |
+
print(f"✅ Backup created at: {self.backup_dir}")
|
| 50 |
+
return True
|
| 51 |
+
except Exception as e:
|
| 52 |
+
print(f"❌ Backup failed: {e}")
|
| 53 |
+
return False
|
| 54 |
+
|
| 55 |
+
def validate_label_line(self, line):
|
| 56 |
+
"""Validate a single label line and return fixed version if needed"""
|
| 57 |
+
parts = line.strip().split()
|
| 58 |
+
|
| 59 |
+
# Need at least 5 values: class_id x_center y_center width height
|
| 60 |
+
if len(parts) < 5:
|
| 61 |
+
return None, "insufficient_values"
|
| 62 |
+
|
| 63 |
+
try:
|
| 64 |
+
class_id = int(parts[0])
|
| 65 |
+
coords = [float(x) for x in parts[1:5]]
|
| 66 |
+
|
| 67 |
+
# Check if coordinates are out of bounds
|
| 68 |
+
issues = []
|
| 69 |
+
if any(c < 0 for c in coords):
|
| 70 |
+
issues.append("negative_coords")
|
| 71 |
+
if any(c > 1 for c in coords):
|
| 72 |
+
issues.append("out_of_bounds")
|
| 73 |
+
|
| 74 |
+
# Check for invalid dimensions (width/height must be > 0)
|
| 75 |
+
if coords[2] <= 0 or coords[3] <= 0:
|
| 76 |
+
issues.append("invalid_dimensions")
|
| 77 |
+
|
| 78 |
+
# Clip coordinates to [0, 1]
|
| 79 |
+
fixed_coords = [max(0.0, min(1.0, c)) for c in coords]
|
| 80 |
+
|
| 81 |
+
# Keep width and height positive
|
| 82 |
+
if fixed_coords[2] <= 0:
|
| 83 |
+
fixed_coords[2] = 0.01
|
| 84 |
+
if fixed_coords[3] <= 0:
|
| 85 |
+
fixed_coords[3] = 0.01
|
| 86 |
+
|
| 87 |
+
fixed_line = f"{class_id} {' '.join(f'{c:.6f}' for c in fixed_coords)}\n"
|
| 88 |
+
|
| 89 |
+
return fixed_line, issues if issues else None
|
| 90 |
+
|
| 91 |
+
except (ValueError, IndexError) as e:
|
| 92 |
+
return None, f"parse_error: {e}"
|
| 93 |
+
|
| 94 |
+
def clean_label_file(self, label_path):
|
| 95 |
+
"""Clean a single label file"""
|
| 96 |
+
try:
|
| 97 |
+
with open(label_path, 'r') as f:
|
| 98 |
+
lines = f.readlines()
|
| 99 |
+
|
| 100 |
+
if not lines:
|
| 101 |
+
return {'status': 'empty', 'issues': ['empty_file']}
|
| 102 |
+
|
| 103 |
+
fixed_lines = []
|
| 104 |
+
all_issues = []
|
| 105 |
+
|
| 106 |
+
for line_num, line in enumerate(lines, 1):
|
| 107 |
+
if not line.strip():
|
| 108 |
+
continue
|
| 109 |
+
|
| 110 |
+
fixed_line, issues = self.validate_label_line(line)
|
| 111 |
+
|
| 112 |
+
if fixed_line is None:
|
| 113 |
+
all_issues.append(f"line_{line_num}: {issues}")
|
| 114 |
+
else:
|
| 115 |
+
fixed_lines.append(fixed_line)
|
| 116 |
+
if issues:
|
| 117 |
+
all_issues.extend([f"line_{line_num}: {issue}" for issue in issues])
|
| 118 |
+
|
| 119 |
+
if not fixed_lines:
|
| 120 |
+
return {'status': 'all_invalid', 'issues': all_issues}
|
| 121 |
+
|
| 122 |
+
# Write back fixed labels
|
| 123 |
+
with open(label_path, 'w') as f:
|
| 124 |
+
f.writelines(fixed_lines)
|
| 125 |
+
|
| 126 |
+
if all_issues:
|
| 127 |
+
return {'status': 'fixed', 'issues': all_issues, 'lines_kept': len(fixed_lines)}
|
| 128 |
+
else:
|
| 129 |
+
return {'status': 'valid', 'issues': [], 'lines_kept': len(fixed_lines)}
|
| 130 |
+
|
| 131 |
+
except Exception as e:
|
| 132 |
+
return {'status': 'error', 'issues': [str(e)]}
|
| 133 |
+
|
| 134 |
+
def process_split(self, split_name):
|
| 135 |
+
"""Process all label files in a split (train/val/test)"""
|
| 136 |
+
print(f"\n📂 Processing {split_name.upper()} split...")
|
| 137 |
+
|
| 138 |
+
label_path = os.path.join(self.labels_dir, split_name)
|
| 139 |
+
image_path = os.path.join(self.images_dir, split_name)
|
| 140 |
+
|
| 141 |
+
if not os.path.exists(label_path):
|
| 142 |
+
print(f"⚠️ Labels directory not found: {label_path}")
|
| 143 |
+
return
|
| 144 |
+
|
| 145 |
+
label_files = glob.glob(os.path.join(label_path, "*.txt"))
|
| 146 |
+
|
| 147 |
+
split_stats = {
|
| 148 |
+
'total': len(label_files),
|
| 149 |
+
'valid': 0,
|
| 150 |
+
'fixed': 0,
|
| 151 |
+
'empty': 0,
|
| 152 |
+
'removed': 0,
|
| 153 |
+
'corrupt_files': []
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
for label_file in label_files:
|
| 157 |
+
self.stats['total_files'] += 1
|
| 158 |
+
result = self.clean_label_file(label_file)
|
| 159 |
+
|
| 160 |
+
if result['status'] == 'valid':
|
| 161 |
+
split_stats['valid'] += 1
|
| 162 |
+
|
| 163 |
+
elif result['status'] == 'fixed':
|
| 164 |
+
split_stats['fixed'] += 1
|
| 165 |
+
self.stats['fixed_files'] += 1
|
| 166 |
+
split_stats['corrupt_files'].append({
|
| 167 |
+
'file': os.path.basename(label_file),
|
| 168 |
+
'issues': result['issues']
|
| 169 |
+
})
|
| 170 |
+
|
| 171 |
+
elif result['status'] in ['empty', 'all_invalid']:
|
| 172 |
+
split_stats['empty'] += 1
|
| 173 |
+
self.stats['empty_files'] += 1
|
| 174 |
+
split_stats['corrupt_files'].append({
|
| 175 |
+
'file': os.path.basename(label_file),
|
| 176 |
+
'issues': result['issues']
|
| 177 |
+
})
|
| 178 |
+
|
| 179 |
+
# Remove empty/invalid label files and corresponding images
|
| 180 |
+
img_file = label_file.replace(label_path, image_path).replace('.txt', '.jpg')
|
| 181 |
+
try:
|
| 182 |
+
os.remove(label_file)
|
| 183 |
+
if os.path.exists(img_file):
|
| 184 |
+
os.remove(img_file)
|
| 185 |
+
split_stats['removed'] += 1
|
| 186 |
+
self.stats['removed_files'] += 1
|
| 187 |
+
print(f" 🗑️ Removed: {os.path.basename(label_file)}")
|
| 188 |
+
except Exception as e:
|
| 189 |
+
print(f" ❌ Could not remove {os.path.basename(label_file)}: {e}")
|
| 190 |
+
|
| 191 |
+
self.stats['splits'][split_name] = split_stats
|
| 192 |
+
|
| 193 |
+
print(f" ✅ Valid: {split_stats['valid']}")
|
| 194 |
+
print(f" 🔧 Fixed: {split_stats['fixed']}")
|
| 195 |
+
print(f" 🗑️ Removed: {split_stats['removed']}")
|
| 196 |
+
|
| 197 |
+
def clear_cache_files(self):
|
| 198 |
+
"""Remove YOLO cache files"""
|
| 199 |
+
print("\n" + "="*60)
|
| 200 |
+
print("🧹 CLEARING CACHE FILES")
|
| 201 |
+
print("="*60)
|
| 202 |
+
|
| 203 |
+
cache_files = glob.glob(os.path.join(self.labels_dir, "**/*.cache"), recursive=True)
|
| 204 |
+
|
| 205 |
+
for cache_file in cache_files:
|
| 206 |
+
try:
|
| 207 |
+
os.remove(cache_file)
|
| 208 |
+
print(f" ✅ Removed: {cache_file}")
|
| 209 |
+
except Exception as e:
|
| 210 |
+
print(f" ❌ Could not remove {cache_file}: {e}")
|
| 211 |
+
|
| 212 |
+
print(f"✅ Removed {len(cache_files)} cache files")
|
| 213 |
+
|
| 214 |
+
def generate_report(self):
|
| 215 |
+
"""Generate detailed cleaning report"""
|
| 216 |
+
print("\n" + "="*60)
|
| 217 |
+
print("📊 CLEANING REPORT")
|
| 218 |
+
print("="*60)
|
| 219 |
+
|
| 220 |
+
print(f"\n📈 Overall Statistics:")
|
| 221 |
+
print(f" Total files processed: {self.stats['total_files']}")
|
| 222 |
+
print(f" Files fixed: {self.stats['fixed_files']}")
|
| 223 |
+
print(f" Files removed: {self.stats['removed_files']}")
|
| 224 |
+
print(f" Empty files: {self.stats['empty_files']}")
|
| 225 |
+
|
| 226 |
+
print(f"\n📊 Per-Split Statistics:")
|
| 227 |
+
for split, data in self.stats['splits'].items():
|
| 228 |
+
if data:
|
| 229 |
+
print(f"\n {split.upper()}:")
|
| 230 |
+
print(f" Total: {data['total']}")
|
| 231 |
+
print(f" Valid: {data['valid']}")
|
| 232 |
+
print(f" Fixed: {data['fixed']}")
|
| 233 |
+
print(f" Removed: {data['removed']}")
|
| 234 |
+
|
| 235 |
+
# Save detailed report to JSON
|
| 236 |
+
report_path = os.path.join(self.dataset_dir, f"cleaning_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json")
|
| 237 |
+
with open(report_path, 'w') as f:
|
| 238 |
+
json.dump(self.stats, f, indent=2)
|
| 239 |
+
|
| 240 |
+
print(f"\n💾 Detailed report saved to: {report_path}")
|
| 241 |
+
|
| 242 |
+
def verify_dataset(self):
|
| 243 |
+
"""Verify dataset after cleaning"""
|
| 244 |
+
print("\n" + "="*60)
|
| 245 |
+
print("✅ VERIFICATION")
|
| 246 |
+
print("="*60)
|
| 247 |
+
|
| 248 |
+
for split in ['train', 'val', 'test']:
|
| 249 |
+
label_path = os.path.join(self.labels_dir, split)
|
| 250 |
+
image_path = os.path.join(self.images_dir, split)
|
| 251 |
+
|
| 252 |
+
label_files = glob.glob(os.path.join(label_path, "*.txt"))
|
| 253 |
+
image_files = glob.glob(os.path.join(image_path, "*.jpg"))
|
| 254 |
+
|
| 255 |
+
print(f"\n{split.upper()}:")
|
| 256 |
+
print(f" Images: {len(image_files)}")
|
| 257 |
+
print(f" Labels: {len(label_files)}")
|
| 258 |
+
|
| 259 |
+
if len(image_files) != len(label_files):
|
| 260 |
+
print(f" ⚠️ WARNING: Image/Label count mismatch!")
|
| 261 |
+
|
| 262 |
+
def run(self):
|
| 263 |
+
"""Run the complete cleaning pipeline"""
|
| 264 |
+
print("\n" + "="*60)
|
| 265 |
+
print("🚀 YOLO DATASET CLEANER")
|
| 266 |
+
print("="*60)
|
| 267 |
+
print(f"Dataset directory: {self.dataset_dir}")
|
| 268 |
+
|
| 269 |
+
# Step 1: Create backup
|
| 270 |
+
if not self.create_backup():
|
| 271 |
+
response = input("\n⚠️ Proceed without backup? (yes/no): ")
|
| 272 |
+
if response.lower() != 'yes':
|
| 273 |
+
print("❌ Cleaning cancelled.")
|
| 274 |
+
return
|
| 275 |
+
|
| 276 |
+
# Step 2: Process each split
|
| 277 |
+
print("\n" + "="*60)
|
| 278 |
+
print("🔧 CLEANING LABELS")
|
| 279 |
+
print("="*60)
|
| 280 |
+
|
| 281 |
+
for split in ['train', 'val', 'test']:
|
| 282 |
+
self.process_split(split)
|
| 283 |
+
|
| 284 |
+
# Step 3: Clear cache
|
| 285 |
+
self.clear_cache_files()
|
| 286 |
+
|
| 287 |
+
# Step 4: Generate report
|
| 288 |
+
self.generate_report()
|
| 289 |
+
|
| 290 |
+
# Step 5: Verify
|
| 291 |
+
self.verify_dataset()
|
| 292 |
+
|
| 293 |
+
print("\n" + "="*60)
|
| 294 |
+
print("✅ CLEANING COMPLETE!")
|
| 295 |
+
print("="*60)
|
| 296 |
+
print("\n🎯 Next Steps:")
|
| 297 |
+
print(" 1. Review the cleaning report")
|
| 298 |
+
print(" 2. Delete old training runs: rm -rf yolo_runs/smartvision_yolov8s*")
|
| 299 |
+
print(" 3. Retrain your model: python scripts/train_yolo_smartvision.py")
|
| 300 |
+
print(f"\n💾 Backup location: {self.backup_dir}")
|
| 301 |
+
print(" (You can restore from backup if needed)")
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
if __name__ == "__main__":
|
| 305 |
+
# Configuration
|
| 306 |
+
DATASET_DIR = "smartvision_dataset"
|
| 307 |
+
|
| 308 |
+
# Run the cleaner
|
| 309 |
+
cleaner = YOLODatasetCleaner(DATASET_DIR)
|
| 310 |
+
cleaner.run()
|
scripts/check.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ============================================================
|
| 2 |
+
# SMARTVISION AI - YOLOv8 TRAIN + EVAL SCRIPT
|
| 3 |
+
# - Uses separate train / val / test splits
|
| 4 |
+
# - QUICK_TEST flag lets you sanity-check the whole pipeline
|
| 5 |
+
# with just 1 epoch before doing full training
|
| 6 |
+
# ============================================================
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import glob
|
| 10 |
+
import time
|
| 11 |
+
import json
|
| 12 |
+
import torch
|
| 13 |
+
from ultralytics import YOLO
|
| 14 |
+
|
| 15 |
+
# ------------------------------------------------------------
|
| 16 |
+
# 0. CONFIG: QUICK TEST OR FULL TRAINING?
|
| 17 |
+
# ------------------------------------------------------------
|
| 18 |
+
# First run with QUICK_TEST = True (1 epoch, debug run).
|
| 19 |
+
# If everything runs end-to-end without errors, set it to False.
|
| 20 |
+
QUICK_TEST = True # <<< CHANGE TO False FOR FULL TRAINING
|
| 21 |
+
|
| 22 |
+
FULL_EPOCHS = 50
|
| 23 |
+
DEBUG_EPOCHS = 1
|
| 24 |
+
|
| 25 |
+
EPOCHS = DEBUG_EPOCHS if QUICK_TEST else FULL_EPOCHS
|
| 26 |
+
RUN_NAME = "smartvision_yolov8s_debug" if QUICK_TEST else "smartvision_yolov8s"
|
| 27 |
+
|
| 28 |
+
print("⚙️ QUICK_TEST :", QUICK_TEST)
|
| 29 |
+
print("⚙️ EPOCHS :", EPOCHS)
|
| 30 |
+
print("⚙️ RUN_NAME :", RUN_NAME)
|
| 31 |
+
|
| 32 |
+
# ------------------------------------------------------------
|
| 33 |
+
# 1. PATHS & CONFIG
|
| 34 |
+
# ------------------------------------------------------------
|
| 35 |
+
|
| 36 |
+
BASE_DIR = "smartvision_dataset"
|
| 37 |
+
DET_DIR = os.path.join(BASE_DIR, "detection")
|
| 38 |
+
DATA_YAML = os.path.join(DET_DIR, "data.yaml")
|
| 39 |
+
|
| 40 |
+
# Expected folder structure:
|
| 41 |
+
# smartvision_dataset/detection/
|
| 42 |
+
# data.yaml
|
| 43 |
+
# images/train, images/val, images/test
|
| 44 |
+
# labels/train, labels/val, labels/test
|
| 45 |
+
|
| 46 |
+
RUN_PROJECT = "yolo_runs"
|
| 47 |
+
MODEL_WEIGHTS = "yolov8s.pt" # base checkpoint to fine-tune
|
| 48 |
+
|
| 49 |
+
VAL_IMAGES_DIR = os.path.join(DET_DIR, "images", "val")
|
| 50 |
+
|
| 51 |
+
# Auto-select device
|
| 52 |
+
device = "0" if torch.cuda.is_available() else "cpu"
|
| 53 |
+
print("🚀 Using device:", device)
|
| 54 |
+
print("📂 DATA_YAML :", DATA_YAML)
|
| 55 |
+
|
| 56 |
+
# Basic path checks (fail fast if something is wrong)
|
| 57 |
+
if not os.path.exists(DATA_YAML):
|
| 58 |
+
raise FileNotFoundError(f"data.yaml not found at: {DATA_YAML}")
|
| 59 |
+
|
| 60 |
+
for split in ["train", "val", "test"]:
|
| 61 |
+
img_dir = os.path.join(DET_DIR, "images", split)
|
| 62 |
+
lab_dir = os.path.join(DET_DIR, "labels", split)
|
| 63 |
+
if not os.path.isdir(img_dir):
|
| 64 |
+
raise FileNotFoundError(f"Images directory missing: {img_dir}")
|
| 65 |
+
if not os.path.isdir(lab_dir):
|
| 66 |
+
raise FileNotFoundError(f"Labels directory missing: {lab_dir}")
|
| 67 |
+
if len(glob.glob(os.path.join(img_dir, "*.jpg"))) == 0:
|
| 68 |
+
print(f"⚠️ Warning: No .jpg images found in {img_dir}")
|
| 69 |
+
|
| 70 |
+
# ------------------------------------------------------------
|
| 71 |
+
# 2. LOAD BASE MODEL
|
| 72 |
+
# ------------------------------------------------------------
|
| 73 |
+
|
| 74 |
+
print(f"\n📥 Loading YOLOv8 base model from: {MODEL_WEIGHTS}")
|
| 75 |
+
model = YOLO(MODEL_WEIGHTS)
|
| 76 |
+
|
| 77 |
+
# ------------------------------------------------------------
|
| 78 |
+
# 3. TRAIN
|
| 79 |
+
# ------------------------------------------------------------
|
| 80 |
+
|
| 81 |
+
print("\n===== STARTING TRAINING =====")
|
| 82 |
+
print("(This is a QUICK TEST run)" if QUICK_TEST else "(Full training run)")
|
| 83 |
+
|
| 84 |
+
results = model.train(
|
| 85 |
+
data=DATA_YAML,
|
| 86 |
+
epochs=EPOCHS,
|
| 87 |
+
imgsz=640,
|
| 88 |
+
batch=8, # adjust if more GPU RAM
|
| 89 |
+
lr0=0.01,
|
| 90 |
+
optimizer="SGD",
|
| 91 |
+
device=device,
|
| 92 |
+
project=RUN_PROJECT,
|
| 93 |
+
name=RUN_NAME,
|
| 94 |
+
pretrained=True,
|
| 95 |
+
plots=True,
|
| 96 |
+
verbose=True,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
print("\n✅ YOLO training complete.")
|
| 100 |
+
RUN_DIR = os.path.join(RUN_PROJECT, RUN_NAME)
|
| 101 |
+
BEST_WEIGHTS = os.path.join(RUN_DIR, "weights", "best.pt")
|
| 102 |
+
print("📁 Run directory:", RUN_DIR)
|
| 103 |
+
print("📦 Best weights :", BEST_WEIGHTS)
|
| 104 |
+
|
| 105 |
+
if not os.path.exists(BEST_WEIGHTS):
|
| 106 |
+
raise FileNotFoundError(f"best.pt not found at: {BEST_WEIGHTS}")
|
| 107 |
+
|
| 108 |
+
# ------------------------------------------------------------
|
| 109 |
+
# 4. LOAD TRAINED MODEL (best.pt)
|
| 110 |
+
# ------------------------------------------------------------
|
| 111 |
+
|
| 112 |
+
print("\n📥 Loading trained model from best.pt")
|
| 113 |
+
model = YOLO(BEST_WEIGHTS)
|
| 114 |
+
print("✅ Loaded trained YOLOv8 model.")
|
| 115 |
+
print("📜 Class mapping (model.names):")
|
| 116 |
+
print(model.names)
|
| 117 |
+
|
| 118 |
+
# ------------------------------------------------------------
|
| 119 |
+
# 5. VALIDATION & TEST METRICS
|
| 120 |
+
# ------------------------------------------------------------
|
| 121 |
+
|
| 122 |
+
print("\n===== RUNNING VALIDATION (val split) =====")
|
| 123 |
+
metrics_val = model.val(
|
| 124 |
+
data=DATA_YAML,
|
| 125 |
+
split="val", # images/val + labels/val
|
| 126 |
+
imgsz=640,
|
| 127 |
+
save_json=False
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
print("\n===== YOLOv8 Validation Metrics =====")
|
| 131 |
+
print(f"[VAL] mAP@0.5 : {metrics_val.box.map50:.4f}")
|
| 132 |
+
print(f"[VAL] mAP@0.5:0.95 : {metrics_val.box.map:.4f}")
|
| 133 |
+
|
| 134 |
+
print("\nPer-class mAP@0.5 on VAL (first 10 classes):")
|
| 135 |
+
for i, m in enumerate(metrics_val.box.maps[:10]):
|
| 136 |
+
print(f" Class {i}: {m:.4f}")
|
| 137 |
+
|
| 138 |
+
print("\n===== RUNNING TEST EVALUATION (test split) =====")
|
| 139 |
+
metrics_test = model.val(
|
| 140 |
+
data=DATA_YAML,
|
| 141 |
+
split="test", # images/test + labels/test
|
| 142 |
+
imgsz=640,
|
| 143 |
+
save_json=False
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
print("\n===== YOLOv8 Test Metrics =====")
|
| 147 |
+
print(f"[TEST] mAP@0.5 : {metrics_test.box.map50:.4f}")
|
| 148 |
+
print(f"[TEST] mAP@0.5:0.95 : {metrics_test.box.map:.4f}")
|
| 149 |
+
|
| 150 |
+
# ------------------------------------------------------------
|
| 151 |
+
# 6. INFERENCE SPEED (FPS) ON VAL IMAGES
|
| 152 |
+
# ------------------------------------------------------------
|
| 153 |
+
|
| 154 |
+
print("\n===== MEASURING INFERENCE SPEED (FPS) ON VAL IMAGES =====")
|
| 155 |
+
|
| 156 |
+
val_images = glob.glob(os.path.join(VAL_IMAGES_DIR, "*.jpg"))
|
| 157 |
+
val_images = sorted(val_images)
|
| 158 |
+
|
| 159 |
+
num_test_images = min(10 if QUICK_TEST else 50, len(val_images))
|
| 160 |
+
test_images = val_images[:num_test_images]
|
| 161 |
+
|
| 162 |
+
print(f"Found {len(val_images)} images in {VAL_IMAGES_DIR}")
|
| 163 |
+
print(f"Using {len(test_images)} images for speed test.")
|
| 164 |
+
|
| 165 |
+
time_per_image = 0.0
|
| 166 |
+
fps = 0.0
|
| 167 |
+
|
| 168 |
+
if len(test_images) == 0:
|
| 169 |
+
print("⚠️ No images found for FPS test. Skipping speed measurement.")
|
| 170 |
+
else:
|
| 171 |
+
start = time.perf_counter()
|
| 172 |
+
_ = model.predict(
|
| 173 |
+
source=test_images,
|
| 174 |
+
imgsz=640,
|
| 175 |
+
conf=0.5,
|
| 176 |
+
verbose=False
|
| 177 |
+
)
|
| 178 |
+
end = time.perf_counter()
|
| 179 |
+
|
| 180 |
+
total_time = end - start
|
| 181 |
+
time_per_image = total_time / len(test_images)
|
| 182 |
+
fps = 1.0 / time_per_image
|
| 183 |
+
|
| 184 |
+
print(f"Total time : {total_time:.2f} sec for {len(test_images)} images")
|
| 185 |
+
print(f"Avg time / image : {time_per_image*1000:.2f} ms")
|
| 186 |
+
print(f"Approx FPS : {fps:.2f} images/sec")
|
| 187 |
+
|
| 188 |
+
# ------------------------------------------------------------
|
| 189 |
+
# 7. SAVE SAMPLE PREDICTION IMAGES (FROM VAL)
|
| 190 |
+
# ------------------------------------------------------------
|
| 191 |
+
|
| 192 |
+
print("\n===== SAVING SAMPLE PREDICTION IMAGES (VAL) =====")
|
| 193 |
+
|
| 194 |
+
sample_out_project = "yolo_vis"
|
| 195 |
+
sample_out_name = "samples_debug" if QUICK_TEST else "samples"
|
| 196 |
+
|
| 197 |
+
if len(test_images) == 0:
|
| 198 |
+
print("⚠️ No val images available for sample visualization. Skipping sample predictions.")
|
| 199 |
+
else:
|
| 200 |
+
_ = model.predict(
|
| 201 |
+
source=test_images[:4 if QUICK_TEST else 8],
|
| 202 |
+
imgsz=640,
|
| 203 |
+
conf=0.5,
|
| 204 |
+
save=True,
|
| 205 |
+
project=sample_out_project,
|
| 206 |
+
name=sample_out_name,
|
| 207 |
+
verbose=False,
|
| 208 |
+
)
|
| 209 |
+
print(f"✅ Saved sample predictions (with boxes & labels) to: {sample_out_project}/{sample_out_name}/")
|
| 210 |
+
|
| 211 |
+
# ------------------------------------------------------------
|
| 212 |
+
# 8. SAVE METRICS TO JSON
|
| 213 |
+
# ------------------------------------------------------------
|
| 214 |
+
|
| 215 |
+
print("\n===== SAVING METRICS TO JSON =====")
|
| 216 |
+
|
| 217 |
+
os.makedirs("yolo_metrics", exist_ok=True)
|
| 218 |
+
metrics_json_path = os.path.join("yolo_metrics", "yolov8s_metrics_debug.json" if QUICK_TEST else "yolov8s_metrics.json")
|
| 219 |
+
|
| 220 |
+
yolo_metrics = {
|
| 221 |
+
"model_name": "yolov8s_smartvision",
|
| 222 |
+
"quick_test": QUICK_TEST,
|
| 223 |
+
"epochs": EPOCHS,
|
| 224 |
+
"run_dir": RUN_DIR,
|
| 225 |
+
"best_weights": BEST_WEIGHTS,
|
| 226 |
+
"val_map_50": float(metrics_val.box.map50),
|
| 227 |
+
"val_map_50_95": float(metrics_val.box.map),
|
| 228 |
+
"test_map_50": float(metrics_test.box.map50),
|
| 229 |
+
"test_map_50_95": float(metrics_test.box.map),
|
| 230 |
+
"num_val_images_for_speed_test": int(len(test_images)),
|
| 231 |
+
"avg_inference_time_sec": float(time_per_image),
|
| 232 |
+
"fps": float(fps),
|
| 233 |
+
}
|
| 234 |
+
|
| 235 |
+
with open(metrics_json_path, "w") as f:
|
| 236 |
+
json.dump(yolo_metrics, f, indent=2)
|
| 237 |
+
|
| 238 |
+
print(f"✅ Saved YOLO metrics JSON to: {metrics_json_path}")
|
| 239 |
+
print("\n🎯 YOLOv8 training + evaluation script finished.")
|
scripts/compare_models.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
SMARTVISION AI - Step 2.5: Model Comparison & Selection
|
| 3 |
+
|
| 4 |
+
This script:
|
| 5 |
+
- Loads metrics.json and confusion_matrix.npy for all models.
|
| 6 |
+
- Compares accuracy, precision, recall, F1, top-5 accuracy, speed, and model size.
|
| 7 |
+
- Generates bar plots for metrics.
|
| 8 |
+
- Generates confusion matrix heatmaps per model.
|
| 9 |
+
- Selects the best model using an accuracy–speed tradeoff rule.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
import os
|
| 13 |
+
import json
|
| 14 |
+
import numpy as np
|
| 15 |
+
import matplotlib.pyplot as plt
|
| 16 |
+
|
| 17 |
+
# ------------------------------------------------------------
|
| 18 |
+
# 0. CONFIG – resolve paths relative to this file
|
| 19 |
+
# ------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 22 |
+
ROOT_DIR = os.path.dirname(SCRIPT_DIR) # one level up from scripts/
|
| 23 |
+
METRICS_DIR = os.path.join(ROOT_DIR, "smartvision_metrics")
|
| 24 |
+
PLOTS_DIR = os.path.join(METRICS_DIR, "comparison_plots")
|
| 25 |
+
os.makedirs(PLOTS_DIR, exist_ok=True)
|
| 26 |
+
|
| 27 |
+
print(f"[INFO] Using METRICS_DIR = {METRICS_DIR}")
|
| 28 |
+
print(f"[INFO] Existing subfolders in METRICS_DIR: {os.listdir(METRICS_DIR) if os.path.exists(METRICS_DIR) else 'NOT FOUND'}")
|
| 29 |
+
|
| 30 |
+
# Map "pretty" model names to their metrics subdirectories
|
| 31 |
+
MODEL_PATHS = {
|
| 32 |
+
"VGG16" : "vgg16_v2_stage2",
|
| 33 |
+
"ResNet50" : "resnet50_v2_stage2",
|
| 34 |
+
"MobileNetV2" : "mobilenetv2_v2",
|
| 35 |
+
"efficientnetb0" : "efficientnetb0",
|
| 36 |
+
# Optional: add more models here, e.g.:
|
| 37 |
+
# "ResNet50 v2 (Stage 1)" : "resnet50_v2_stage1",
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
# Class names (COCO-style 25 classes)
|
| 41 |
+
CLASS_NAMES = [
|
| 42 |
+
"airplane", "bed", "bench", "bicycle", "bird",
|
| 43 |
+
"bottle", "bowl", "bus", "cake", "car",
|
| 44 |
+
"cat", "chair", "couch", "cow", "cup",
|
| 45 |
+
"dog", "elephant", "horse", "motorcycle", "person",
|
| 46 |
+
"pizza", "potted plant", "stop sign", "traffic light", "truck",
|
| 47 |
+
]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# ------------------------------------------------------------
|
| 51 |
+
# 1. LOAD METRICS & CONFUSION MATRICES
|
| 52 |
+
# ------------------------------------------------------------
|
| 53 |
+
|
| 54 |
+
def load_model_results():
|
| 55 |
+
model_metrics = {}
|
| 56 |
+
model_cms = {}
|
| 57 |
+
|
| 58 |
+
for nice_name, folder_name in MODEL_PATHS.items():
|
| 59 |
+
metrics_path = os.path.join(METRICS_DIR, folder_name, "metrics.json")
|
| 60 |
+
cm_path = os.path.join(METRICS_DIR, folder_name, "confusion_matrix.npy")
|
| 61 |
+
|
| 62 |
+
print(f"[DEBUG] Looking for {nice_name} metrics at: {metrics_path}")
|
| 63 |
+
print(f"[DEBUG] Looking for {nice_name} CM at : {cm_path}")
|
| 64 |
+
|
| 65 |
+
if not os.path.exists(metrics_path):
|
| 66 |
+
print(f"[WARN] Skipping {nice_name}: missing {metrics_path}")
|
| 67 |
+
continue
|
| 68 |
+
if not os.path.exists(cm_path):
|
| 69 |
+
print(f"[WARN] Skipping {nice_name}: missing {cm_path}")
|
| 70 |
+
continue
|
| 71 |
+
|
| 72 |
+
with open(metrics_path, "r") as f:
|
| 73 |
+
metrics = json.load(f)
|
| 74 |
+
cm = np.load(cm_path)
|
| 75 |
+
|
| 76 |
+
model_metrics[nice_name] = metrics
|
| 77 |
+
model_cms[nice_name] = cm
|
| 78 |
+
print(f"[INFO] Loaded metrics & CM for {nice_name}")
|
| 79 |
+
|
| 80 |
+
return model_metrics, model_cms
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
# ------------------------------------------------------------
|
| 84 |
+
# 2. PLOTTING HELPERS
|
| 85 |
+
# ------------------------------------------------------------
|
| 86 |
+
|
| 87 |
+
def plot_bar_metric(model_metrics, metric_key, ylabel, filename, higher_is_better=True):
|
| 88 |
+
names = list(model_metrics.keys())
|
| 89 |
+
values = [model_metrics[n][metric_key] for n in names]
|
| 90 |
+
|
| 91 |
+
plt.figure(figsize=(8, 5))
|
| 92 |
+
bars = plt.bar(names, values)
|
| 93 |
+
plt.ylabel(ylabel)
|
| 94 |
+
plt.xticks(rotation=20, ha="right")
|
| 95 |
+
|
| 96 |
+
for bar, val in zip(bars, values):
|
| 97 |
+
plt.text(
|
| 98 |
+
bar.get_x() + bar.get_width() / 2,
|
| 99 |
+
bar.get_height(),
|
| 100 |
+
f"{val:.3f}",
|
| 101 |
+
ha="center",
|
| 102 |
+
va="bottom",
|
| 103 |
+
fontsize=8,
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
title_prefix = "Higher is better" if higher_is_better else "Lower is better"
|
| 107 |
+
plt.title(f"{metric_key} comparison ({title_prefix})")
|
| 108 |
+
plt.tight_layout()
|
| 109 |
+
|
| 110 |
+
out_path = os.path.join(PLOTS_DIR, filename)
|
| 111 |
+
plt.savefig(out_path, dpi=200)
|
| 112 |
+
plt.close()
|
| 113 |
+
print(f"[PLOT] Saved {metric_key} comparison to {out_path}")
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def plot_confusion_matrix(cm, classes, title, filename, normalize=True):
|
| 117 |
+
if normalize:
|
| 118 |
+
cm = cm.astype("float") / (cm.sum(axis=1)[:, np.newaxis] + 1e-12)
|
| 119 |
+
|
| 120 |
+
plt.figure(figsize=(6, 5))
|
| 121 |
+
im = plt.imshow(cm, interpolation="nearest")
|
| 122 |
+
plt.title(title)
|
| 123 |
+
plt.colorbar(im, fraction=0.046, pad=0.04)
|
| 124 |
+
|
| 125 |
+
tick_marks = np.arange(len(classes))
|
| 126 |
+
plt.xticks(tick_marks, classes, rotation=90)
|
| 127 |
+
plt.yticks(tick_marks, classes)
|
| 128 |
+
|
| 129 |
+
# annotate diagonal only to reduce clutter
|
| 130 |
+
for i in range(cm.shape[0]):
|
| 131 |
+
for j in range(cm.shape[1]):
|
| 132 |
+
if i == j:
|
| 133 |
+
plt.text(
|
| 134 |
+
j,
|
| 135 |
+
i,
|
| 136 |
+
f"{cm[i, j]:.2f}",
|
| 137 |
+
ha="center",
|
| 138 |
+
va="center",
|
| 139 |
+
color="white" if cm[i, j] > 0.5 else "black",
|
| 140 |
+
fontsize=6,
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
plt.ylabel("True label")
|
| 144 |
+
plt.xlabel("Predicted label")
|
| 145 |
+
plt.tight_layout()
|
| 146 |
+
|
| 147 |
+
out_path = os.path.join(PLOTS_DIR, filename)
|
| 148 |
+
plt.savefig(out_path, dpi=200)
|
| 149 |
+
plt.close()
|
| 150 |
+
print(f"[PLOT] Saved confusion matrix to {out_path}")
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# ------------------------------------------------------------
|
| 154 |
+
# 3. MODEL SELECTION (ACCURACY–SPEED TRADEOFF)
|
| 155 |
+
# ------------------------------------------------------------
|
| 156 |
+
|
| 157 |
+
def pick_best_model(model_metrics):
|
| 158 |
+
"""
|
| 159 |
+
Rule:
|
| 160 |
+
1. Prefer highest accuracy.
|
| 161 |
+
2. If two models are within 0.5% accuracy, prefer higher images_per_second.
|
| 162 |
+
"""
|
| 163 |
+
best_name = None
|
| 164 |
+
best_acc = -1.0
|
| 165 |
+
best_speed = -1.0
|
| 166 |
+
|
| 167 |
+
for name, m in model_metrics.items():
|
| 168 |
+
acc = m["accuracy"]
|
| 169 |
+
speed = m.get("images_per_second", 0.0)
|
| 170 |
+
|
| 171 |
+
if acc > best_acc + 0.005: # clearly better
|
| 172 |
+
best_name = name
|
| 173 |
+
best_acc = acc
|
| 174 |
+
best_speed = speed
|
| 175 |
+
elif abs(acc - best_acc) <= 0.005: # within 0.5%, use speed as tie-breaker
|
| 176 |
+
if speed > best_speed:
|
| 177 |
+
best_name = name
|
| 178 |
+
best_acc = acc
|
| 179 |
+
best_speed = speed
|
| 180 |
+
|
| 181 |
+
return best_name, best_acc, best_speed
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# ------------------------------------------------------------
|
| 185 |
+
# 4. MAIN
|
| 186 |
+
# ------------------------------------------------------------
|
| 187 |
+
|
| 188 |
+
def main():
|
| 189 |
+
model_metrics, model_cms = load_model_results()
|
| 190 |
+
|
| 191 |
+
if not model_metrics:
|
| 192 |
+
print("[ERROR] No models found with valid metrics. Check METRICS_DIR and MODEL_PATHS.")
|
| 193 |
+
return
|
| 194 |
+
|
| 195 |
+
print("\n===== MODEL METRICS SUMMARY =====")
|
| 196 |
+
print(
|
| 197 |
+
f"{'Model':30s} {'Acc':>6s} {'Prec':>6s} {'Rec':>6s} {'F1':>6s} {'Top5':>6s} {'img/s':>7s} {'Size(MB)':>8s}"
|
| 198 |
+
)
|
| 199 |
+
for name, m in model_metrics.items():
|
| 200 |
+
print(
|
| 201 |
+
f"{name:30s} "
|
| 202 |
+
f"{m['accuracy']:.3f} "
|
| 203 |
+
f"{m['precision_weighted']:.3f} "
|
| 204 |
+
f"{m['recall_weighted']:.3f} "
|
| 205 |
+
f"{m['f1_weighted']:.3f} "
|
| 206 |
+
f"{m['top5_accuracy']:.3f} "
|
| 207 |
+
f"{m['images_per_second']:.2f} "
|
| 208 |
+
f"{m['model_size_mb']:.1f}"
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
# ---- Comparison plots ----
|
| 212 |
+
plot_bar_metric(model_metrics, "accuracy", "Accuracy", "accuracy_comparison.png")
|
| 213 |
+
plot_bar_metric(
|
| 214 |
+
model_metrics, "f1_weighted", "Weighted F1-score", "f1_comparison.png"
|
| 215 |
+
)
|
| 216 |
+
plot_bar_metric(
|
| 217 |
+
model_metrics, "top5_accuracy", "Top-5 Accuracy", "top5_comparison.png"
|
| 218 |
+
)
|
| 219 |
+
plot_bar_metric(
|
| 220 |
+
model_metrics,
|
| 221 |
+
"images_per_second",
|
| 222 |
+
"Images per second",
|
| 223 |
+
"speed_comparison.png",
|
| 224 |
+
)
|
| 225 |
+
plot_bar_metric(
|
| 226 |
+
model_metrics,
|
| 227 |
+
"model_size_mb",
|
| 228 |
+
"Model size (MB)",
|
| 229 |
+
"size_comparison.png",
|
| 230 |
+
higher_is_better=False,
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
# ---- Confusion matrices ----
|
| 234 |
+
print("\n===== SAVING CONFUSION MATRICES =====")
|
| 235 |
+
for name, cm in model_cms.items():
|
| 236 |
+
safe_name = name.replace(" ", "_").replace("(", "").replace(")", "")
|
| 237 |
+
filename = f"{safe_name}_cm.png"
|
| 238 |
+
plot_confusion_matrix(
|
| 239 |
+
cm,
|
| 240 |
+
classes=CLASS_NAMES,
|
| 241 |
+
title=f"Confusion Matrix - {name}",
|
| 242 |
+
filename=filename,
|
| 243 |
+
normalize=True,
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
# ---- Best model ----
|
| 247 |
+
best_name, best_acc, best_speed = pick_best_model(model_metrics)
|
| 248 |
+
|
| 249 |
+
print("\n===== BEST MODEL SELECTION =====")
|
| 250 |
+
print(f"Selected best model: {best_name}")
|
| 251 |
+
print(f" Test Accuracy : {best_acc:.4f}")
|
| 252 |
+
print(f" Images per second : {best_speed:.2f}")
|
| 253 |
+
print("\nRationale:")
|
| 254 |
+
print("- Highest accuracy is preferred.")
|
| 255 |
+
print("- If models are within 0.5% accuracy, the faster model (higher img/s) is chosen.")
|
| 256 |
+
|
| 257 |
+
print("\nSuggested text for report:")
|
| 258 |
+
print(
|
| 259 |
+
f"\"Among all evaluated architectures, {best_name} achieved the best accuracy–speed "
|
| 260 |
+
f"tradeoff on the SmartVision AI test set, with a top-1 accuracy of {best_acc:.3f} "
|
| 261 |
+
f"and an inference throughput of {best_speed:.2f} images per second on the "
|
| 262 |
+
f"evaluation hardware.\""
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
if __name__ == "__main__":
|
| 267 |
+
main()
|
scripts/convert_efficientnet_weights.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# scripts/convert_efficientnet_weights.py
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
from tensorflow import keras
|
| 6 |
+
from tensorflow.keras import layers
|
| 7 |
+
from tensorflow.keras.applications.efficientnet import (
|
| 8 |
+
EfficientNetB0,
|
| 9 |
+
preprocess_input as effnet_preprocess,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
print("TensorFlow version:", tf.__version__)
|
| 13 |
+
|
| 14 |
+
IMG_SIZE = (224, 224)
|
| 15 |
+
NUM_CLASSES = 25
|
| 16 |
+
MODELS_DIR = "saved_models"
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# --- These were in your training script, keep same names ---
|
| 20 |
+
|
| 21 |
+
def bright_jitter(x):
|
| 22 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 23 |
+
x_f32 = tf.image.random_brightness(x_f32, max_delta=0.25)
|
| 24 |
+
return tf.cast(x_f32, x.dtype)
|
| 25 |
+
|
| 26 |
+
def sat_jitter(x):
|
| 27 |
+
x_f32 = tf.cast(x, tf.float32)
|
| 28 |
+
x_f32 = tf.image.random_saturation(x_f32, lower=0.7, upper=1.3)
|
| 29 |
+
return tf.cast(x_f32, x.dtype)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def build_efficientnetb0_model_v2():
|
| 33 |
+
"""
|
| 34 |
+
Rebuilds the SAME EfficientNetB0 architecture used in your training script
|
| 35 |
+
(data_augmentation + preprocess_input + EfficientNetB0 backbone + head).
|
| 36 |
+
"""
|
| 37 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 38 |
+
|
| 39 |
+
# --- Data augmentation (as in training) ---
|
| 40 |
+
data_augmentation = keras.Sequential(
|
| 41 |
+
[
|
| 42 |
+
layers.RandomFlip("horizontal"),
|
| 43 |
+
layers.RandomRotation(0.08), # ≈ ±30°
|
| 44 |
+
layers.RandomZoom(0.15),
|
| 45 |
+
layers.RandomContrast(0.3),
|
| 46 |
+
layers.RandomTranslation(0.1, 0.1),
|
| 47 |
+
layers.Lambda(bright_jitter, name="bright_jitter"),
|
| 48 |
+
layers.Lambda(sat_jitter, name="sat_jitter"),
|
| 49 |
+
],
|
| 50 |
+
name="advanced_data_augmentation",
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
x = data_augmentation(inputs)
|
| 54 |
+
|
| 55 |
+
# EfficientNetB0 preprocess_input (same as training)
|
| 56 |
+
x = layers.Lambda(
|
| 57 |
+
lambda z: effnet_preprocess(tf.cast(z, tf.float32)),
|
| 58 |
+
name="effnet_preprocess",
|
| 59 |
+
)(x)
|
| 60 |
+
|
| 61 |
+
# EfficientNetB0 backbone
|
| 62 |
+
base_model = EfficientNetB0(
|
| 63 |
+
include_top=False,
|
| 64 |
+
weights="imagenet",
|
| 65 |
+
name="efficientnetb0",
|
| 66 |
+
)
|
| 67 |
+
base_model.trainable = False # doesn't matter for conversion
|
| 68 |
+
|
| 69 |
+
x = base_model(x, training=False)
|
| 70 |
+
|
| 71 |
+
# Classification head (same as training)
|
| 72 |
+
x = layers.GlobalAveragePooling2D(name="gap")(x)
|
| 73 |
+
x = layers.BatchNormalization(name="head_bn_1")(x)
|
| 74 |
+
x = layers.Dense(256, activation="relu", name="head_dense_1")(x)
|
| 75 |
+
x = layers.BatchNormalization(name="head_bn_2")(x)
|
| 76 |
+
x = layers.Dropout(0.4, name="head_dropout")(x)
|
| 77 |
+
|
| 78 |
+
# Final output: float32 softmax
|
| 79 |
+
outputs = layers.Dense(
|
| 80 |
+
NUM_CLASSES,
|
| 81 |
+
activation="softmax",
|
| 82 |
+
dtype="float32",
|
| 83 |
+
name="predictions",
|
| 84 |
+
)(x)
|
| 85 |
+
|
| 86 |
+
model = keras.Model(inputs, outputs, name="EfficientNetB0_smartvision_v2")
|
| 87 |
+
return model
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
if __name__ == "__main__":
|
| 91 |
+
full_path = os.path.join(MODELS_DIR, "efficientnetb0_best.h5")
|
| 92 |
+
weights_path = os.path.join(MODELS_DIR, "efficientnetb0_best.weights.h5")
|
| 93 |
+
|
| 94 |
+
if not os.path.exists(full_path):
|
| 95 |
+
raise FileNotFoundError(f"Full EfficientNet model .h5 not found at: {full_path}")
|
| 96 |
+
|
| 97 |
+
print("🔧 Building EfficientNetB0 v2 architecture...")
|
| 98 |
+
model = build_efficientnetb0_model_v2()
|
| 99 |
+
model.summary()
|
| 100 |
+
|
| 101 |
+
print(f"\n📥 Loading weights BY NAME (skip mismatches) from:\n {full_path}")
|
| 102 |
+
# 🔑 KEY FIX: use by_name=True and skip_mismatch=True so shape mismatches
|
| 103 |
+
# are simply ignored instead of crashing.
|
| 104 |
+
model.load_weights(full_path, by_name=True, skip_mismatch=True)
|
| 105 |
+
print("✅ Weights loaded into rebuilt model (by name, mismatches skipped).")
|
| 106 |
+
|
| 107 |
+
print(f"\n💾 Saving weights-only file to:\n {weights_path}")
|
| 108 |
+
model.save_weights(weights_path)
|
| 109 |
+
print("✅ Done converting EfficientNetB0 weights to .weights.h5")
|
scripts/convert_mobilenet_weights.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
from tensorflow import keras
|
| 4 |
+
from tensorflow.keras import layers, regularizers
|
| 5 |
+
|
| 6 |
+
IMG_SIZE = (224, 224)
|
| 7 |
+
NUM_CLASSES = 25
|
| 8 |
+
|
| 9 |
+
# ---- this MUST match your training build_mobilenetv2_model_v2 ----
|
| 10 |
+
def build_mobilenetv2_model_v2():
|
| 11 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 12 |
+
|
| 13 |
+
data_augmentation = keras.Sequential(
|
| 14 |
+
[
|
| 15 |
+
layers.RandomFlip("horizontal"),
|
| 16 |
+
layers.RandomRotation(0.04), # ~±15°
|
| 17 |
+
layers.RandomZoom(0.1),
|
| 18 |
+
layers.RandomContrast(0.15),
|
| 19 |
+
layers.Lambda(
|
| 20 |
+
lambda x: tf.image.random_brightness(x, max_delta=0.15)
|
| 21 |
+
),
|
| 22 |
+
layers.Lambda(
|
| 23 |
+
lambda x: tf.image.random_saturation(x, 0.85, 1.15)
|
| 24 |
+
),
|
| 25 |
+
],
|
| 26 |
+
name="data_augmentation", # 👈 same name as training
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
x = data_augmentation(inputs)
|
| 30 |
+
|
| 31 |
+
x = layers.Lambda(
|
| 32 |
+
keras.applications.mobilenet_v2.preprocess_input,
|
| 33 |
+
name="mobilenetv2_preprocess",
|
| 34 |
+
)(x)
|
| 35 |
+
|
| 36 |
+
base_model = keras.applications.MobileNetV2(
|
| 37 |
+
include_top=False,
|
| 38 |
+
weights="imagenet",
|
| 39 |
+
input_shape=(*IMG_SIZE, 3),
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
x = base_model(x)
|
| 43 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(x)
|
| 44 |
+
|
| 45 |
+
x = layers.BatchNormalization(name="head_batchnorm_1")(x)
|
| 46 |
+
x = layers.Dropout(0.4, name="head_dropout_1")(x)
|
| 47 |
+
|
| 48 |
+
x = layers.Dense(
|
| 49 |
+
256,
|
| 50 |
+
activation="relu",
|
| 51 |
+
kernel_regularizer=regularizers.l2(1e-4),
|
| 52 |
+
name="head_dense_1",
|
| 53 |
+
)(x)
|
| 54 |
+
|
| 55 |
+
x = layers.BatchNormalization(name="head_batchnorm_2")(x)
|
| 56 |
+
x = layers.Dropout(0.5, name="head_dropout_2")(x)
|
| 57 |
+
|
| 58 |
+
outputs = layers.Dense(
|
| 59 |
+
NUM_CLASSES, activation="softmax", name="predictions"
|
| 60 |
+
)(x)
|
| 61 |
+
|
| 62 |
+
model = keras.Model(
|
| 63 |
+
inputs=inputs,
|
| 64 |
+
outputs=outputs,
|
| 65 |
+
name="MobileNetV2_smartvision_v2",
|
| 66 |
+
)
|
| 67 |
+
return model
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
if __name__ == "__main__":
|
| 71 |
+
old_path = os.path.join("saved_models", "mobilenetv2_v2_stage2_best.h5")
|
| 72 |
+
new_path = os.path.join("saved_models", "mobilenetv2_v2_stage2_best.weights.h5")
|
| 73 |
+
|
| 74 |
+
print("Building MobileNetV2 architecture...")
|
| 75 |
+
model = build_mobilenetv2_model_v2()
|
| 76 |
+
|
| 77 |
+
print("Loading weights from full .h5 (by_name, skip_mismatch)...")
|
| 78 |
+
model.load_weights(old_path, by_name=True, skip_mismatch=True)
|
| 79 |
+
|
| 80 |
+
print("Saving clean weights-only file...")
|
| 81 |
+
model.save_weights(new_path)
|
| 82 |
+
|
| 83 |
+
print("✅ Done. Saved weights-only file to:", new_path)
|
scripts/convert_vgg16_weights.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# scripts/convert_vgg16_weights.py
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
from tensorflow import keras
|
| 6 |
+
from tensorflow.keras import layers
|
| 7 |
+
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
|
| 8 |
+
|
| 9 |
+
print("TensorFlow version:", tf.__version__)
|
| 10 |
+
|
| 11 |
+
IMG_SIZE = (224, 224)
|
| 12 |
+
NUM_CLASSES = 25
|
| 13 |
+
MODELS_DIR = "saved_models"
|
| 14 |
+
|
| 15 |
+
# --- SAME AUGMENTATION AS IN TRAINING (ok for building, problem was only deserializing old model) ---
|
| 16 |
+
|
| 17 |
+
data_augmentation = keras.Sequential(
|
| 18 |
+
[
|
| 19 |
+
layers.RandomFlip("horizontal"),
|
| 20 |
+
layers.RandomRotation(0.04), # ≈ ±15°
|
| 21 |
+
layers.RandomZoom(0.1),
|
| 22 |
+
layers.RandomContrast(0.2),
|
| 23 |
+
layers.Lambda(lambda x: tf.image.random_brightness(x, max_delta=0.2)),
|
| 24 |
+
layers.Lambda(lambda x: tf.image.random_saturation(x, 0.8, 1.2)),
|
| 25 |
+
],
|
| 26 |
+
name="data_augmentation",
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def build_vgg16_model_v2():
|
| 31 |
+
"""
|
| 32 |
+
EXACTLY the same architecture as your VGG16 training code.
|
| 33 |
+
"""
|
| 34 |
+
inputs = keras.Input(shape=(*IMG_SIZE, 3), name="input_layer")
|
| 35 |
+
|
| 36 |
+
# 1. Augmentation
|
| 37 |
+
x = data_augmentation(inputs)
|
| 38 |
+
|
| 39 |
+
# 2. VGG16-specific preprocessing
|
| 40 |
+
x = layers.Lambda(
|
| 41 |
+
lambda z: preprocess_input(tf.cast(z, tf.float32)),
|
| 42 |
+
name="vgg16_preprocess",
|
| 43 |
+
)(x)
|
| 44 |
+
|
| 45 |
+
# 3. Pre-trained VGG16 backbone
|
| 46 |
+
base_model = VGG16(
|
| 47 |
+
include_top=False,
|
| 48 |
+
weights="imagenet",
|
| 49 |
+
input_tensor=x,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
# 4. Custom head
|
| 53 |
+
x = layers.GlobalAveragePooling2D(name="global_average_pooling2d")(base_model.output)
|
| 54 |
+
x = layers.Dense(256, activation="relu", name="dense_256")(x)
|
| 55 |
+
x = layers.Dropout(0.5, name="dropout_0_5")(x)
|
| 56 |
+
outputs = layers.Dense(NUM_CLASSES, activation="softmax", name="predictions")(x)
|
| 57 |
+
|
| 58 |
+
model = keras.Model(inputs=inputs, outputs=outputs, name="VGG16_smartvision_v2")
|
| 59 |
+
return model
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
if __name__ == "__main__":
|
| 63 |
+
full_path = os.path.join(MODELS_DIR, "vgg16_v2_stage2_best.h5")
|
| 64 |
+
weights_path = os.path.join(MODELS_DIR, "vgg16_v2_stage2_best.weights.h5")
|
| 65 |
+
|
| 66 |
+
if not os.path.exists(full_path):
|
| 67 |
+
raise FileNotFoundError(f"Full VGG16 model .h5 not found at: {full_path}")
|
| 68 |
+
|
| 69 |
+
print("🧱 Rebuilding VGG16 v2 architecture...")
|
| 70 |
+
model = build_vgg16_model_v2()
|
| 71 |
+
model.summary()
|
| 72 |
+
|
| 73 |
+
print(f"📥 Loading weights from legacy full model file (by_name, skip_mismatch): {full_path}")
|
| 74 |
+
# NOTE: this reads the HDF5 weights **without** trying to deserialize the old Lambda graph
|
| 75 |
+
model.load_weights(full_path, by_name=True, skip_mismatch=True)
|
| 76 |
+
|
| 77 |
+
print(f"💾 Saving clean weights-only file to: {weights_path}")
|
| 78 |
+
model.save_weights(weights_path)
|
| 79 |
+
print("✅ Done: vgg16_v2_stage2_best.weights.h5 created.")
|
scripts/train_yolo_smartvision.py
ADDED
|
@@ -0,0 +1,428 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
train_yolo_smartvision_alltrain.py
|
| 4 |
+
|
| 5 |
+
Train YOLOv8 on ALL images (train+val+test) by creating images/train_all & labels/train_all,
|
| 6 |
+
then validate/test only on original val/test splits.
|
| 7 |
+
|
| 8 |
+
Features:
|
| 9 |
+
- Robust linking/copying with retries (hard link when possible, fallback copy).
|
| 10 |
+
- Manifest generation (train_all_manifest.json) with failures and post-check.
|
| 11 |
+
- Temporary data_all.yaml created and removed by default.
|
| 12 |
+
- Helpful early-failure checks so training doesn't crash with FileNotFoundError.
|
| 13 |
+
"""
|
| 14 |
+
import os
|
| 15 |
+
import sys
|
| 16 |
+
import time
|
| 17 |
+
import json
|
| 18 |
+
import glob
|
| 19 |
+
import shutil
|
| 20 |
+
import argparse
|
| 21 |
+
import pathlib
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
from ultralytics import YOLO
|
| 25 |
+
|
| 26 |
+
# ---------------------------
|
| 27 |
+
# Utilities
|
| 28 |
+
# ---------------------------
|
| 29 |
+
|
| 30 |
+
def safe_makedirs(path):
|
| 31 |
+
os.makedirs(path, exist_ok=True)
|
| 32 |
+
return path
|
| 33 |
+
|
| 34 |
+
def link_or_copy(src, dst, max_retries=3, allow_copy=True):
|
| 35 |
+
"""
|
| 36 |
+
Try to create a hard link. If it fails, fall back to shutil.copy2.
|
| 37 |
+
Retries on transient failures. Returns tuple (ok:bool, method:str, error:str|None).
|
| 38 |
+
method in {'link', 'copy', 'exists', 'failed', 'copied_existing'}
|
| 39 |
+
"""
|
| 40 |
+
dst_dir = os.path.dirname(dst)
|
| 41 |
+
os.makedirs(dst_dir, exist_ok=True)
|
| 42 |
+
if os.path.exists(dst):
|
| 43 |
+
return True, "exists", None
|
| 44 |
+
|
| 45 |
+
last_err = None
|
| 46 |
+
for attempt in range(1, max_retries + 1):
|
| 47 |
+
try:
|
| 48 |
+
os.link(src, dst)
|
| 49 |
+
return True, "link", None
|
| 50 |
+
except Exception as e_link:
|
| 51 |
+
last_err = str(e_link)
|
| 52 |
+
if not allow_copy:
|
| 53 |
+
time.sleep(0.1)
|
| 54 |
+
continue
|
| 55 |
+
# try copying
|
| 56 |
+
try:
|
| 57 |
+
shutil.copy2(src, dst)
|
| 58 |
+
return True, "copy", None
|
| 59 |
+
except Exception as e_copy:
|
| 60 |
+
last_err = f"link_err: {e_link}; copy_err: {e_copy}"
|
| 61 |
+
time.sleep(0.1)
|
| 62 |
+
continue
|
| 63 |
+
return False, "failed", last_err
|
| 64 |
+
|
| 65 |
+
def unique_name(split, basename, used):
|
| 66 |
+
"""
|
| 67 |
+
Create a unique filename under train_all to avoid collisions.
|
| 68 |
+
Format: {split}__{basename} and if collision append index.
|
| 69 |
+
"""
|
| 70 |
+
base = f"{split}__{basename}"
|
| 71 |
+
name = base
|
| 72 |
+
idx = 1
|
| 73 |
+
while name in used:
|
| 74 |
+
name = f"{split}__{idx}__{basename}"
|
| 75 |
+
idx += 1
|
| 76 |
+
used.add(name)
|
| 77 |
+
return name
|
| 78 |
+
|
| 79 |
+
# ---------------------------
|
| 80 |
+
# Create train_all (robust)
|
| 81 |
+
# ---------------------------
|
| 82 |
+
|
| 83 |
+
def create_train_all(det_dir, splits=("train", "val", "test")):
|
| 84 |
+
"""
|
| 85 |
+
Create images/train_all and labels/train_all by linking/copying
|
| 86 |
+
all files from images/<split> and labels/<split>.
|
| 87 |
+
Returns (out_imgs, out_labs, counters, manifest_path)
|
| 88 |
+
where manifest contains details and failures.
|
| 89 |
+
"""
|
| 90 |
+
img_root = os.path.join(det_dir, "images")
|
| 91 |
+
lab_root = os.path.join(det_dir, "labels")
|
| 92 |
+
|
| 93 |
+
out_imgs = os.path.join(det_dir, "images", "train_all")
|
| 94 |
+
out_labs = os.path.join(det_dir, "labels", "train_all")
|
| 95 |
+
safe_makedirs(out_imgs)
|
| 96 |
+
safe_makedirs(out_labs)
|
| 97 |
+
|
| 98 |
+
used_names = set()
|
| 99 |
+
counters = {"images": 0, "labels": 0}
|
| 100 |
+
manifest = {"images": [], "labels": [], "failures": [], "post_check_missing": []}
|
| 101 |
+
|
| 102 |
+
for split in splits:
|
| 103 |
+
imgs_dir = os.path.join(img_root, split)
|
| 104 |
+
labs_dir = os.path.join(lab_root, split)
|
| 105 |
+
if not os.path.isdir(imgs_dir) or not os.path.isdir(labs_dir):
|
| 106 |
+
# skip missing split
|
| 107 |
+
continue
|
| 108 |
+
|
| 109 |
+
# collect possible image extensions
|
| 110 |
+
img_files = sorted(glob.glob(os.path.join(imgs_dir, "*.jpg")) +
|
| 111 |
+
glob.glob(os.path.join(imgs_dir, "*.jpeg")) +
|
| 112 |
+
glob.glob(os.path.join(imgs_dir, "*.png")))
|
| 113 |
+
|
| 114 |
+
for img_path in img_files:
|
| 115 |
+
basename = os.path.basename(img_path)
|
| 116 |
+
new_basename = unique_name(split, basename, used_names)
|
| 117 |
+
dst_img = os.path.join(out_imgs, new_basename)
|
| 118 |
+
|
| 119 |
+
ok_img, method_img, err_img = link_or_copy(img_path, dst_img, max_retries=3, allow_copy=True)
|
| 120 |
+
if not ok_img:
|
| 121 |
+
manifest["failures"].append({
|
| 122 |
+
"type": "image_copy_failed",
|
| 123 |
+
"src": img_path,
|
| 124 |
+
"dst": dst_img,
|
| 125 |
+
"error": err_img
|
| 126 |
+
})
|
| 127 |
+
continue
|
| 128 |
+
|
| 129 |
+
counters["images"] += 1
|
| 130 |
+
manifest["images"].append({"src": img_path, "dst": dst_img, "method": method_img})
|
| 131 |
+
|
| 132 |
+
# create or link label
|
| 133 |
+
orig_label_base = os.path.splitext(basename)[0]
|
| 134 |
+
lab_src = os.path.join(labs_dir, orig_label_base + ".txt")
|
| 135 |
+
dst_lab = os.path.join(out_labs, os.path.splitext(new_basename)[0] + ".txt")
|
| 136 |
+
|
| 137 |
+
if os.path.exists(lab_src):
|
| 138 |
+
ok_lab, method_lab, err_lab = link_or_copy(lab_src, dst_lab, max_retries=3, allow_copy=True)
|
| 139 |
+
if not ok_lab:
|
| 140 |
+
manifest["failures"].append({
|
| 141 |
+
"type": "label_copy_failed",
|
| 142 |
+
"src": lab_src,
|
| 143 |
+
"dst": dst_lab,
|
| 144 |
+
"error": err_lab
|
| 145 |
+
})
|
| 146 |
+
else:
|
| 147 |
+
counters["labels"] += 1
|
| 148 |
+
manifest["labels"].append({"src": lab_src, "dst": dst_lab, "method": method_lab})
|
| 149 |
+
else:
|
| 150 |
+
# Create empty label file so YOLO treats it as background (explicit)
|
| 151 |
+
try:
|
| 152 |
+
open(dst_lab, "w").close()
|
| 153 |
+
counters["labels"] += 1
|
| 154 |
+
manifest["labels"].append({"src": None, "dst": dst_lab, "method": "empty_created"})
|
| 155 |
+
except Exception as e:
|
| 156 |
+
manifest["failures"].append({
|
| 157 |
+
"type": "label_create_failed",
|
| 158 |
+
"src": None,
|
| 159 |
+
"dst": dst_lab,
|
| 160 |
+
"error": str(e)
|
| 161 |
+
})
|
| 162 |
+
|
| 163 |
+
# Final verification: every label should have at least one matching image with same base (any ext)
|
| 164 |
+
out_img_bases = set(os.path.splitext(os.path.basename(p))[0] for p in glob.glob(os.path.join(out_imgs, "*")))
|
| 165 |
+
missing_pairs = []
|
| 166 |
+
for lab in glob.glob(os.path.join(out_labs, "*.txt")):
|
| 167 |
+
base = os.path.splitext(os.path.basename(lab))[0]
|
| 168 |
+
if base not in out_img_bases:
|
| 169 |
+
# Labels that don't have corresponding image
|
| 170 |
+
missing_pairs.append(base)
|
| 171 |
+
|
| 172 |
+
manifest["post_check_missing"] = missing_pairs
|
| 173 |
+
|
| 174 |
+
manifest_path = os.path.join(det_dir, "train_all_manifest.json")
|
| 175 |
+
try:
|
| 176 |
+
with open(manifest_path, "w") as f:
|
| 177 |
+
json.dump({"counters": counters, "manifest": manifest}, f, indent=2)
|
| 178 |
+
except Exception as e:
|
| 179 |
+
# fallback printing
|
| 180 |
+
print("⚠️ Could not write manifest:", e)
|
| 181 |
+
|
| 182 |
+
return out_imgs, out_labs, counters, manifest_path
|
| 183 |
+
|
| 184 |
+
# ---------------------------
|
| 185 |
+
# Write temporary data YAML
|
| 186 |
+
# ---------------------------
|
| 187 |
+
|
| 188 |
+
def write_temp_data_yaml(det_dir, data_yaml_path, train_rel="images/train_all", val_rel="images/val", test_rel="images/test", names_list=None):
|
| 189 |
+
"""
|
| 190 |
+
Writes a temporary data YAML for training.
|
| 191 |
+
"""
|
| 192 |
+
if names_list is None:
|
| 193 |
+
orig = os.path.join(det_dir, "data.yaml")
|
| 194 |
+
if os.path.exists(orig):
|
| 195 |
+
try:
|
| 196 |
+
import yaml
|
| 197 |
+
with open(orig, "r") as f:
|
| 198 |
+
d = yaml.safe_load(f)
|
| 199 |
+
names_list = d.get("names") or d.get("names", None)
|
| 200 |
+
if isinstance(names_list, dict):
|
| 201 |
+
# convert mapping to ordered list by int key
|
| 202 |
+
sorted_items = sorted(names_list.items(), key=lambda x: int(x[0]))
|
| 203 |
+
names_list = [v for k, v in sorted_items]
|
| 204 |
+
except Exception:
|
| 205 |
+
names_list = None
|
| 206 |
+
if names_list is None:
|
| 207 |
+
# safe default if reading fails
|
| 208 |
+
names_list = [f"class{i}" for i in range(25)]
|
| 209 |
+
|
| 210 |
+
abs_path = os.path.abspath(det_dir)
|
| 211 |
+
yaml_str = f"path: {abs_path}\n\ntrain: {train_rel}\nval: {val_rel}\ntest: {test_rel}\n\nnc: {len(names_list)}\nnames:\n"
|
| 212 |
+
for i, n in enumerate(names_list):
|
| 213 |
+
yaml_str += f" {i}: {n}\n"
|
| 214 |
+
|
| 215 |
+
with open(data_yaml_path, "w") as f:
|
| 216 |
+
f.write(yaml_str)
|
| 217 |
+
|
| 218 |
+
return data_yaml_path
|
| 219 |
+
|
| 220 |
+
# ---------------------------
|
| 221 |
+
# Main flow
|
| 222 |
+
# ---------------------------
|
| 223 |
+
|
| 224 |
+
def main(
|
| 225 |
+
base_dir="smartvision_dataset",
|
| 226 |
+
run_project="yolo_runs",
|
| 227 |
+
run_name="smartvision_yolov8s_alltrain",
|
| 228 |
+
model_weights="yolov8s.pt",
|
| 229 |
+
quick_test=False,
|
| 230 |
+
epochs_full=50,
|
| 231 |
+
batch=8,
|
| 232 |
+
keep_temp=False,
|
| 233 |
+
):
|
| 234 |
+
DET_DIR = os.path.join(base_dir, "detection")
|
| 235 |
+
DATA_YAML_ORIG = os.path.join(DEТ_DIR := DET_DIR, "data.yaml") # preserve original var name for readability
|
| 236 |
+
|
| 237 |
+
# safety checks
|
| 238 |
+
if not os.path.exists(DET_DIR):
|
| 239 |
+
raise FileNotFoundError(f"Detection directory not found: {DET_DIR}")
|
| 240 |
+
if not os.path.exists(DATA_YAML_ORIG):
|
| 241 |
+
raise FileNotFoundError(f"Original data.yaml not found: {DATA_YAML_ORIG}")
|
| 242 |
+
|
| 243 |
+
# show basic dataset split counts
|
| 244 |
+
for split in ["train", "val", "test"]:
|
| 245 |
+
img_dir = os.path.join(DET_DIR, "images", split)
|
| 246 |
+
lab_dir = os.path.join(DET_DIR, "labels", split)
|
| 247 |
+
num_imgs = len(glob.glob(os.path.join(img_dir, "*.jpg"))) + len(glob.glob(os.path.join(img_dir, "*.png"))) + len(glob.glob(os.path.join(img_dir, "*.jpeg")))
|
| 248 |
+
num_labs = len(glob.glob(os.path.join(lab_dir, "*.txt")))
|
| 249 |
+
print(f"✅ {split.upper():5s}: {num_imgs} images, {num_labs} label files")
|
| 250 |
+
|
| 251 |
+
# Read class names from original data.yaml (if possible)
|
| 252 |
+
try:
|
| 253 |
+
import yaml
|
| 254 |
+
with open(DATA_YAML_ORIG, "r") as f:
|
| 255 |
+
orig_yaml = yaml.safe_load(f)
|
| 256 |
+
names = orig_yaml.get("names")
|
| 257 |
+
if isinstance(names, dict):
|
| 258 |
+
sorted_items = sorted(names.items(), key=lambda x: int(x[0]))
|
| 259 |
+
names_list = [v for k, v in sorted_items]
|
| 260 |
+
else:
|
| 261 |
+
names_list = names
|
| 262 |
+
except Exception:
|
| 263 |
+
names_list = None
|
| 264 |
+
|
| 265 |
+
print("🧩 Creating combined train_all (train+val+test)...")
|
| 266 |
+
imgs_train_all, labs_train_all, counters, manifest_path = create_train_all(DET_DIR, splits=("train", "val", "test"))
|
| 267 |
+
print(f" ➜ train_all images: {counters['images']}, labels: {counters['labels']}")
|
| 268 |
+
print(f" ➜ manifest written to: {manifest_path}")
|
| 269 |
+
|
| 270 |
+
# read manifest and abort early on issues
|
| 271 |
+
try:
|
| 272 |
+
with open(manifest_path, "r") as f:
|
| 273 |
+
manifest_data = json.load(f)
|
| 274 |
+
manifest = manifest_data.get("manifest", {})
|
| 275 |
+
except Exception:
|
| 276 |
+
manifest = {}
|
| 277 |
+
|
| 278 |
+
failures = manifest.get("failures", [])
|
| 279 |
+
post_missing = manifest.get("post_check_missing", [])
|
| 280 |
+
|
| 281 |
+
if failures:
|
| 282 |
+
print("\n❌ Errors found while creating train_all (see manifest). Aborting training.")
|
| 283 |
+
print(f" Failures count: {len(failures)}. Sample:")
|
| 284 |
+
for f in failures[:10]:
|
| 285 |
+
print(" -", f)
|
| 286 |
+
print(f"\nInspect and fix ({manifest_path}) then re-run.")
|
| 287 |
+
return
|
| 288 |
+
|
| 289 |
+
if post_missing:
|
| 290 |
+
print("\n❌ Post-creation check failed: some labels don't have matching images.")
|
| 291 |
+
print(f" Missing pairs count: {len(post_missing)}. Sample: {post_missing[:20]}")
|
| 292 |
+
print(f"Please inspect the labels/images under {labs_train_all} and {imgs_train_all}. Aborting.")
|
| 293 |
+
return
|
| 294 |
+
|
| 295 |
+
# write temporary data yaml
|
| 296 |
+
temp_data_yaml = os.path.join(DET_DIR, "data_all.yaml")
|
| 297 |
+
write_temp_data_yaml(DET_DIR, temp_data_yaml, train_rel="images/train_all", val_rel="images/val", test_rel="images/test", names_list=names_list)
|
| 298 |
+
print(f"📝 Temporary data yaml created at: {temp_data_yaml}")
|
| 299 |
+
|
| 300 |
+
# determine epochs
|
| 301 |
+
EPOCHS = 1 if quick_test else epochs_full
|
| 302 |
+
device = "0" if torch.cuda.is_available() else "cpu"
|
| 303 |
+
print(f"🚀 Device: {device}; QUICK_TEST: {quick_test}; EPOCHS: {EPOCHS}")
|
| 304 |
+
|
| 305 |
+
# load base model
|
| 306 |
+
print(f"\n📥 Loading YOLOv8 base model from: {model_weights}")
|
| 307 |
+
model = YOLO(model_weights)
|
| 308 |
+
|
| 309 |
+
# Train on train_all
|
| 310 |
+
run_name_final = run_name
|
| 311 |
+
print("\n===== STARTING TRAINING on ALL IMAGES (train_all) =====")
|
| 312 |
+
results = model.train(
|
| 313 |
+
data=temp_data_yaml,
|
| 314 |
+
epochs=EPOCHS,
|
| 315 |
+
imgsz=640,
|
| 316 |
+
batch=batch,
|
| 317 |
+
lr0=0.01,
|
| 318 |
+
optimizer="SGD",
|
| 319 |
+
device=device,
|
| 320 |
+
project=run_project,
|
| 321 |
+
name=run_name_final,
|
| 322 |
+
pretrained=True,
|
| 323 |
+
plots=True,
|
| 324 |
+
verbose=True,
|
| 325 |
+
)
|
| 326 |
+
print("\n✅ Training finished.")
|
| 327 |
+
|
| 328 |
+
run_dir = os.path.join(run_project, run_name_final)
|
| 329 |
+
best_weights = os.path.join(run_dir, "weights", "best.pt")
|
| 330 |
+
if not os.path.exists(best_weights):
|
| 331 |
+
print("⚠️ best.pt not found after training — attempting to use last.pt")
|
| 332 |
+
last = os.path.join(run_dir, "weights", "last.pt")
|
| 333 |
+
if os.path.exists(last):
|
| 334 |
+
best_weights = last
|
| 335 |
+
else:
|
| 336 |
+
raise FileNotFoundError("No trained weights found (best.pt or last.pt).")
|
| 337 |
+
|
| 338 |
+
# Load trained model
|
| 339 |
+
print(f"\n📥 Loading trained model from: {best_weights}")
|
| 340 |
+
model = YOLO(best_weights)
|
| 341 |
+
print("✅ Model loaded. Running val/test on original val & test splits...")
|
| 342 |
+
|
| 343 |
+
# Validation (val split)
|
| 344 |
+
print("\n===== VALIDATION (original val split) =====")
|
| 345 |
+
metrics_val = model.val(data=DATA_YAML_ORIG, split="val", imgsz=640, save_json=False)
|
| 346 |
+
print(f"[VAL] mAP@0.5 : {metrics_val.box.map50:.4f} mAP@0.5:0.95 : {metrics_val.box.map:.4f}")
|
| 347 |
+
|
| 348 |
+
# Test (test split)
|
| 349 |
+
print("\n===== TEST (original test split) =====")
|
| 350 |
+
metrics_test = model.val(data=DATA_YAML_ORIG, split="test", imgsz=640, save_json=False)
|
| 351 |
+
print(f"[TEST] mAP@0.5 : {metrics_test.box.map50:.4f} mAP@0.5:0.95 : {metrics_test.box.map:.4f}")
|
| 352 |
+
|
| 353 |
+
# FPS test on val images (small subset)
|
| 354 |
+
val_images_dir = os.path.join(DET_DIR, "images", "val")
|
| 355 |
+
val_images = sorted(glob.glob(os.path.join(val_images_dir, "*.jpg")) +
|
| 356 |
+
glob.glob(os.path.join(val_images_dir, "*.png")) +
|
| 357 |
+
glob.glob(os.path.join(val_images_dir, "*.jpeg")))
|
| 358 |
+
n_proc = min(50, len(val_images))
|
| 359 |
+
test_imgs = val_images[:n_proc]
|
| 360 |
+
if test_imgs:
|
| 361 |
+
print(f"\n🏃 Running speed test on {len(test_imgs)} val images...")
|
| 362 |
+
start = time.perf_counter()
|
| 363 |
+
_ = model.predict(source=test_imgs, imgsz=640, conf=0.5, verbose=False)
|
| 364 |
+
duration = time.perf_counter() - start
|
| 365 |
+
print(f" Total {duration:.2f}s -> {duration/len(test_imgs)*1000:.2f} ms/img -> {1.0/(duration/len(test_imgs)):.2f} FPS")
|
| 366 |
+
else:
|
| 367 |
+
print("⚠️ No val images found for speed test.")
|
| 368 |
+
|
| 369 |
+
# Save metrics to JSON
|
| 370 |
+
metrics_out = {
|
| 371 |
+
"train_all_counters": counters,
|
| 372 |
+
"val_map50": float(metrics_val.box.map50),
|
| 373 |
+
"test_map50": float(metrics_test.box.map50),
|
| 374 |
+
"val_map50_95": float(metrics_val.box.map),
|
| 375 |
+
"test_map50_95": float(metrics_test.box.map),
|
| 376 |
+
"run_dir": run_dir,
|
| 377 |
+
"best_weights": best_weights,
|
| 378 |
+
}
|
| 379 |
+
os.makedirs("yolo_metrics", exist_ok=True)
|
| 380 |
+
json_path = os.path.join("yolo_metrics", f"yolov8s_metrics_alltrain.json")
|
| 381 |
+
with open(json_path, "w") as f:
|
| 382 |
+
json.dump(metrics_out, f, indent=2)
|
| 383 |
+
print(f"\n💾 Saved metrics to: {json_path}")
|
| 384 |
+
|
| 385 |
+
# Cleanup if requested
|
| 386 |
+
if not keep_temp:
|
| 387 |
+
try:
|
| 388 |
+
print("\n🧹 Cleaning temporary train_all files and temp data yaml...")
|
| 389 |
+
shutil.rmtree(os.path.join(DET_DIR, "images", "train_all"), ignore_errors=True)
|
| 390 |
+
shutil.rmtree(os.path.join(DET_DIR, "labels", "train_all"), ignore_errors=True)
|
| 391 |
+
if os.path.exists(temp_data_yaml):
|
| 392 |
+
os.remove(temp_data_yaml)
|
| 393 |
+
if os.path.exists(manifest_path):
|
| 394 |
+
os.remove(manifest_path)
|
| 395 |
+
print("✅ Temp cleanup done.")
|
| 396 |
+
except Exception as e:
|
| 397 |
+
print("⚠️ Cleanup error:", e)
|
| 398 |
+
else:
|
| 399 |
+
print(f"\nℹ️ Kept temp train_all and temp yaml as requested. Path: {os.path.join(DET_DIR, 'images', 'train_all')}")
|
| 400 |
+
|
| 401 |
+
print("\n🎯 ALL DONE.")
|
| 402 |
+
|
| 403 |
+
# ---------------------------
|
| 404 |
+
# CLI
|
| 405 |
+
# ---------------------------
|
| 406 |
+
|
| 407 |
+
if __name__ == "__main__":
|
| 408 |
+
parser = argparse.ArgumentParser(description="Train YOLOv8 on ALL images (train+val+test) then validate/test on original splits.")
|
| 409 |
+
parser.add_argument("--dataset-dir", "-d", default="smartvision_dataset", help="Base dataset directory (default: smartvision_dataset)")
|
| 410 |
+
parser.add_argument("--model", "-m", default="yolov8s.pt", help="Base yolov8 weights (default: yolov8s.pt)")
|
| 411 |
+
parser.add_argument("--quick", action="store_true", help="Quick test (1 epoch, small speed test)")
|
| 412 |
+
parser.add_argument("--epochs", type=int, default=50, help="Full epochs when not quick")
|
| 413 |
+
parser.add_argument("--batch", type=int, default=8, help="Batch size")
|
| 414 |
+
parser.add_argument("--no-clean", dest="keep_temp", action="store_true", help="Do NOT remove temp train_all folder and temp yaml after run")
|
| 415 |
+
parser.add_argument("--project", default="yolo_runs", help="Ultralytics runs project folder")
|
| 416 |
+
parser.add_argument("--name", default="smartvision_yolov8s_alltrain", help="Run name")
|
| 417 |
+
args = parser.parse_args()
|
| 418 |
+
|
| 419 |
+
main(
|
| 420 |
+
base_dir=args.dataset_dir,
|
| 421 |
+
run_project=args.project,
|
| 422 |
+
run_name=args.name,
|
| 423 |
+
model_weights=args.model,
|
| 424 |
+
quick_test=args.quick,
|
| 425 |
+
epochs_full=args.epochs,
|
| 426 |
+
batch=args.batch,
|
| 427 |
+
keep_temp=args.keep_temp,
|
| 428 |
+
)
|
scripts/yolov8n.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f59b3d833e2ff32e194b5bb8e08d211dc7c5bdf144b90d2c8412c47ccfc83b36
|
| 3 |
+
size 6549796
|
smartvision_metrics/comparison_plots/MobileNetV2_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/MobileNetV2_v3_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/ResNet50_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/ResNet50_v2_Stage_2_FT_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/VGG16_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/VGG16_v2_Stage_2_FT_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/accuracy_comparison.png
ADDED

|
smartvision_metrics/comparison_plots/efficientnetb0_cm.png
ADDED

|
Git LFS Details
|
smartvision_metrics/comparison_plots/f1_comparison.png
ADDED

|
smartvision_metrics/comparison_plots/size_comparison.png
ADDED
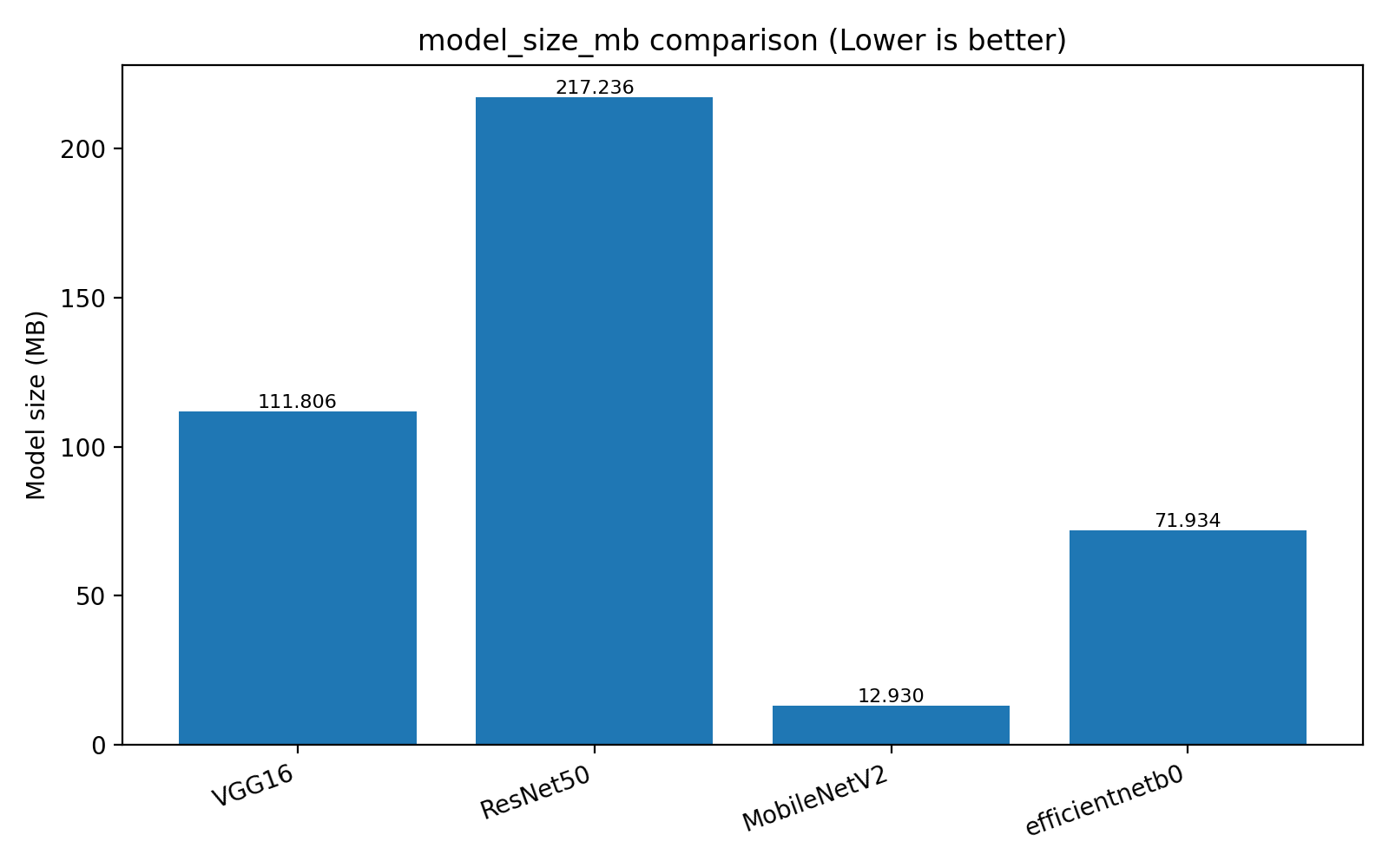
|
smartvision_metrics/comparison_plots/speed_comparison.png
ADDED
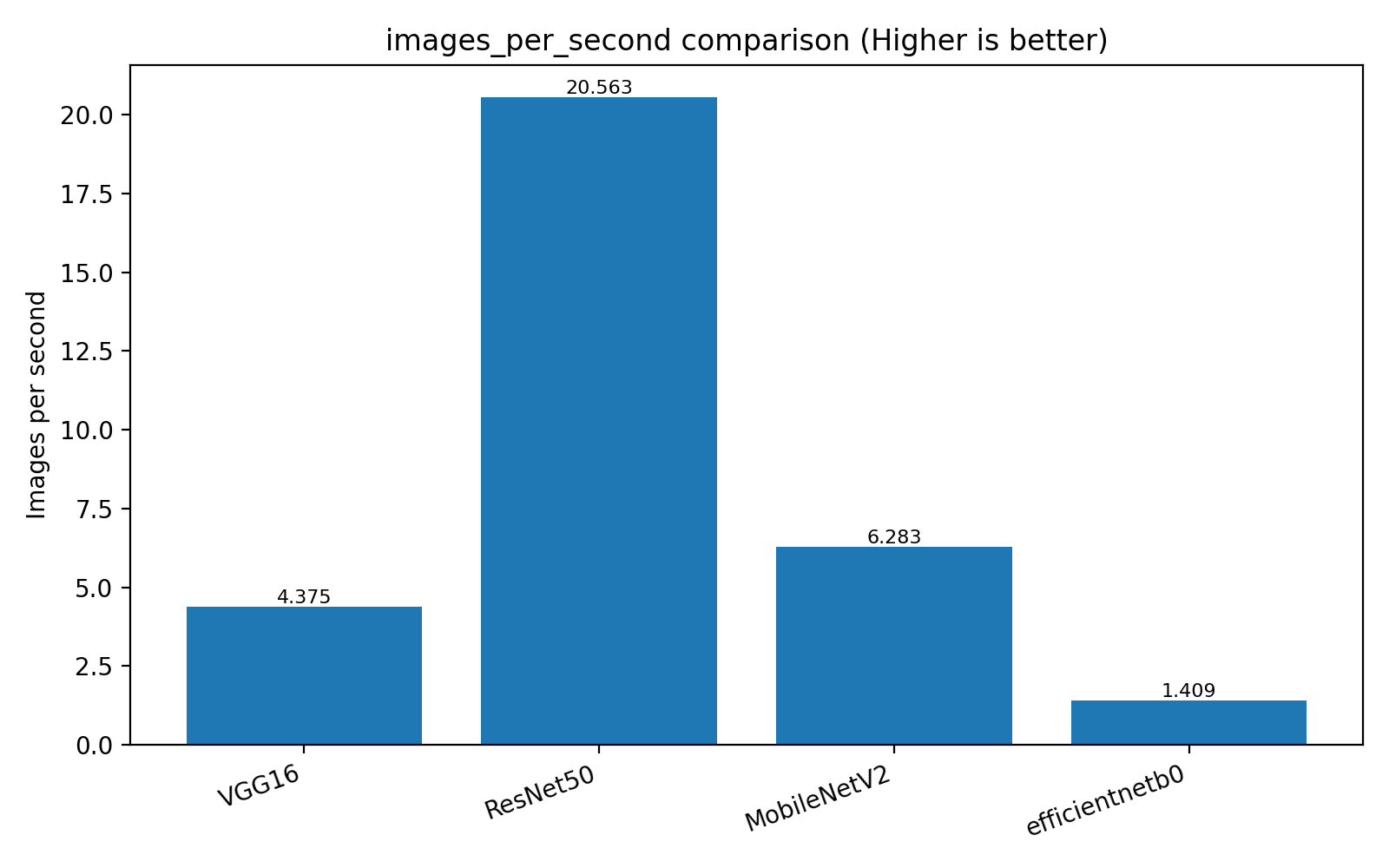
|
smartvision_metrics/comparison_plots/top5_comparison.png
ADDED
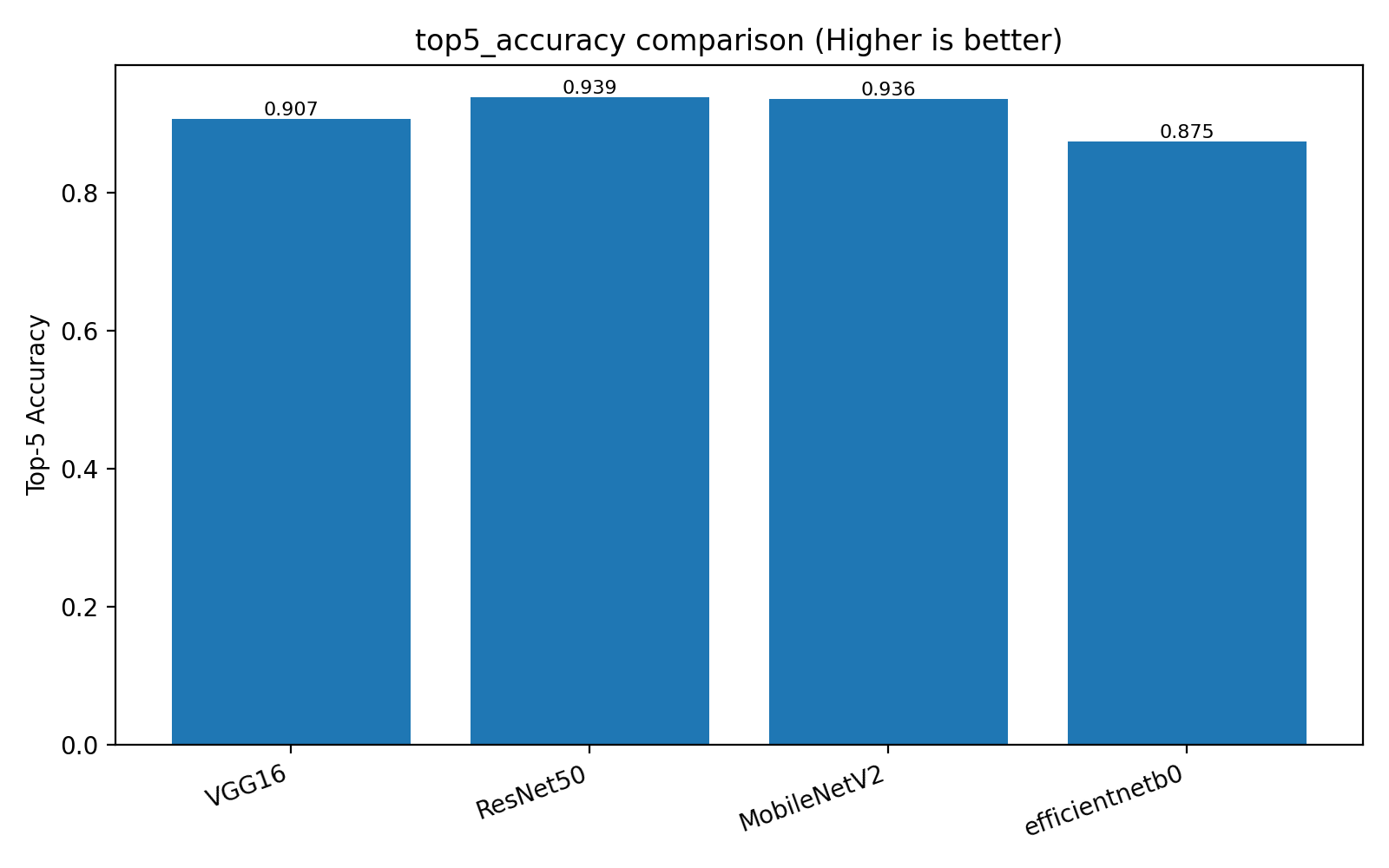
|
smartvision_metrics/efficientnetb0/confusion_matrix.npy
ADDED
|
Binary file (5.13 kB). View file
|
|
|
smartvision_metrics/efficientnetb0/metrics.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "efficientnetb0",
|
| 3 |
+
"accuracy": 0.7573333333333333,
|
| 4 |
+
"precision_weighted": 0.7654770197123137,
|
| 5 |
+
"recall_weighted": 0.7573333333333333,
|
| 6 |
+
"f1_weighted": 0.7558831298763445,
|
| 7 |
+
"top5_accuracy": 0.8746666666666667,
|
| 8 |
+
"avg_inference_time_sec": 0.7098700226666406,
|
| 9 |
+
"images_per_second": 1.4087085918116116,
|
| 10 |
+
"model_size_mb": 71.93372344970703,
|
| 11 |
+
"num_parameters": 4390076
|
| 12 |
+
}
|
smartvision_metrics/efficientnetb0_stage2/confusion_matrix.npy
ADDED
|
Binary file (5.13 kB). View file
|
|
|
smartvision_metrics/efficientnetb0_stage2/metrics.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "efficientnetb0_stage2",
|
| 3 |
+
"accuracy": 0.7973333333333333,
|
| 4 |
+
"precision_weighted": 0.8018408351194729,
|
| 5 |
+
"recall_weighted": 0.7973333333333333,
|
| 6 |
+
"f1_weighted": 0.7955331918405726,
|
| 7 |
+
"top5_accuracy": 0.92,
|
| 8 |
+
"avg_inference_time_sec": 0.07931595280021429,
|
| 9 |
+
"images_per_second": 12.607804164174375,
|
| 10 |
+
"model_size_mb": 44.42613220214844,
|
| 11 |
+
"num_parameters": 4390076
|
| 12 |
+
}
|
smartvision_metrics/mobilenetv2/confusion_matrix.npy
ADDED
|
Binary file (5.13 kB). View file
|
|
|
smartvision_metrics/mobilenetv2/metrics.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "mobilenetv2",
|
| 3 |
+
"accuracy": 0.6506666666666666,
|
| 4 |
+
"precision_weighted": 0.6619423668866393,
|
| 5 |
+
"recall_weighted": 0.6506666666666666,
|
| 6 |
+
"f1_weighted": 0.6420473620753672,
|
| 7 |
+
"top5_accuracy": 0.9013333333333333,
|
| 8 |
+
"avg_inference_time_sec": 0.04660592453321442,
|
| 9 |
+
"images_per_second": 21.456499576300324,
|
| 10 |
+
"model_size_mb": 10.954902648925781,
|
| 11 |
+
"num_parameters": 2425177
|
| 12 |
+
}
|