
MiniMax M2 DWQ
Collection
4 items
•
Updated
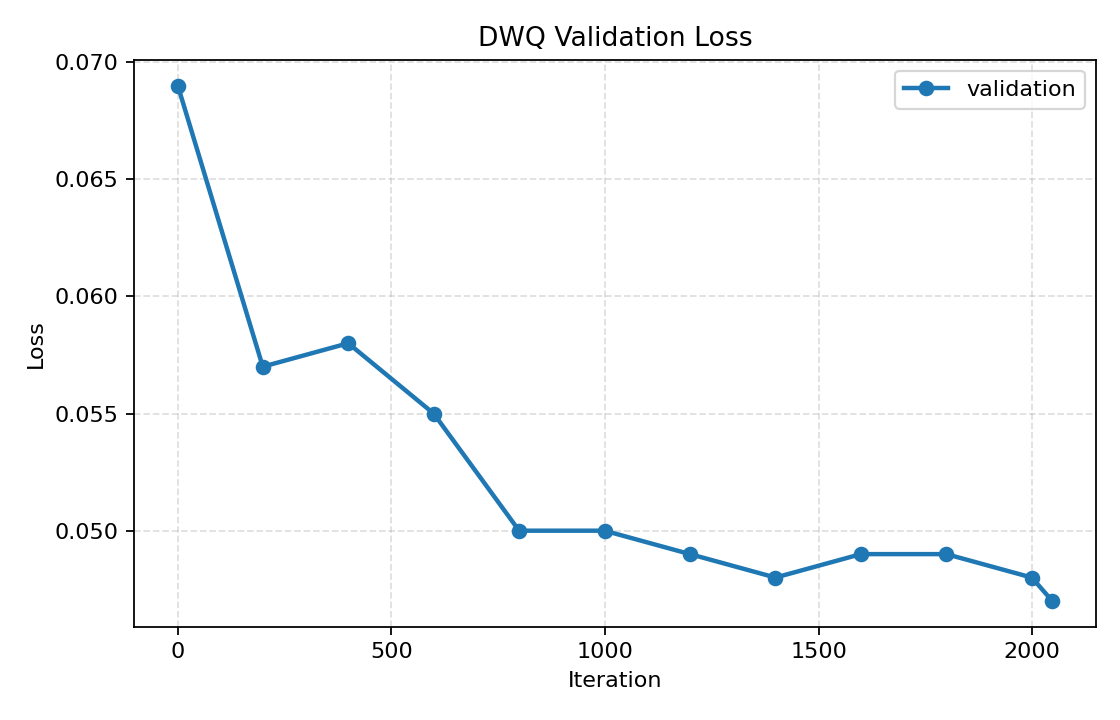
This model was quantized to 4-bit using DWQ with mlx-lm version 0.28.4.
| Parameter | Value |
|---|---|
| DWQ learning rate | 3e-7 |
| Batch size | 1 |
| Dataset | allenai/tulu-3-sft-mixture |
| Initial validation loss | 0.069 |
| Final validation loss | 0.047 |
| Relative KL reduction | ≈32 % |
| Tokens processed | ≈1.09 M |
pip install mlx-lm
from mlx_lm import load, generate
model, tokenizer = load("catalystsec/MiniMax-M2-4bit-DWQ")
prompt = "hello"
if tokenizer.chat_template is not None:
prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
print(response)
4-bit
Base model
MiniMaxAI/MiniMax-M2