
text
stringlengths 454
608k
| url
stringlengths 17
896
| dump
stringclasses 91
values | source
stringclasses 1
value | word_count
int64 101
114k
| flesch_reading_ease
float64 50
104
|
|---|---|---|---|---|---|
#include "petscsf.h" PetscErrorCode PetscSFSetGraphWithPattern(PetscSF sf,PetscLayout map,PetscSFPattern pattern)Collective
With PETSCSF_PATTERN_ALLGATHER, the routine creates a graph that if one does Bcast on it, it will copy x to sequential vectors y on all ranks.
With PETSCSF_PATTERN_GATHER, the routine creates a graph that if one does Bcast on it, it will copy x to a sequential vector y on rank 0.
In above cases, entries of x are roots and entries of y are leaves.
With PETSCSF_PATTERN_ALLTOALL, map is insignificant. Suppose NP is size of sf's communicator. The routine creates a graph that every rank has NP leaves and NP roots. On rank i, its leaf j is connected to root i of rank j. Here 0 <=i,j<NP. It is a kind of MPI_Alltoall with sendcount/recvcount being 1. Note that it does not mean one can not send multiple items. One just needs to create a new MPI datatype for the mulptiple data items with MPI_Type_contiguous() and use that as the <unit> argument in SF routines.
In this case, roots and leaves are symmetric.
|
https://www.mcs.anl.gov/petsc/petsc-dev/docs/manualpages/PetscSF/PetscSFSetGraphWithPattern.html
|
CC-MAIN-2020-05
|
refinedweb
| 180
| 65.42
|
Tips and tricks from my Telegram-channel @pythonetc, June 2019
It is a new selection of tips and tricks about Python and programming from my Telegram-channel @pythonetc.
← Previous publications
The
\symbol in regular string have special meaning.
\tis tab character,
\ris carriage return and so on.
You can use raw-strings to disable this behaviour.
r'\t'is just backslash and
t.
You obviously can’t use
'inside
r'...'. However, it still can be escaped by
\, but
\is preserved in the string:
>>> print(r'It\'s insane!') It\'s insane!
List comprehensions may contain more than one
forand
ifclauses:
In : [(x, y) for x in range(3) for y in range(3)] Out: [ (0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2) ] In : [ (x, y) for x in range(3) for y in range(3) if x != 0 if y != 0 ] Out: [(1, 1), (1, 2), (2, 1), (2, 2)]
Also, any expression within
forand
ifmay use all the variables that are defined before:
In : [ (x, y) for x in range(3) for y in range(x + 2) if x != y ] Out: [ (0, 1), (1, 0), (1, 2), (2, 0), (2, 1), (2, 3) ]
You can mix
ifs and
fors however you want:
In : [ (x, y) for x in range(5) if x % 2 for y in range(x + 2) if x != y ] Out: [ (1, 0), (1, 2), (3, 0), (3, 1), (3, 2), (3, 4) ]
The
sortedfunction allows you to provide custom method for sorting. It’s done with the
keyargument, which describes how to convert original values to values that are actually compared:
>>> x = [dict(name='Vadim', age=29), dict(name='Alex', age=4)] >>> sorted(x, key=lambda v: v['age']) [{'age': 4, 'name': 'Alex'}, {'age': 29, 'name': 'Vadim'}]
Alas, not all libraries that work with comparison support something like this
keyargument. Notable examples are
heapq(partial support) and
bisect(no support).
There are two ways to deal with the situation. The first is to use custom objects that do support proper comparsion:
>>> class User: ... def __init__(self, name, age): ... self.name = name ... self.age = age ... def __lt__(self, other): ... return self.age < other.age ... >>> x = [User('Vadim', 29), User('Alex', 4)] >>> [x.name for x in sorted(x)] ['Alex', 'Vadim']
However, you may have to create several versions of such classes since there are more than one way to compare objects. It can be tiresome, but can be easily solved by the second way.
Instead of creating custom objects you may use tuples
(a, b)where
ais the value to compare (a.k.a. prioirty) and
bis the original value:
>>> users = [dict(name='Vadim', age=29), dict(name='Alex', age=4)] >>> to_sort = [(u['age'], u) for u in users] >>> [x[1]['name'] for x in sorted(to_sort)] ['Alex', 'Vadim']
The difference between function definition and generator definition is the presence of the
yieldkeyword in the function body:
In : def f(): ...: pass ...: In : def g(): ...: yield ...: In : type(f()) Out: NoneType In : type(g()) Out: generator
That means that in order to create an empty generator you have to do something like this:
In : def g(): ...: if False: ...: yield ...: In : list(g()) Out: []
However, since
yield fromsupports simple iterators that better looking version would be this:
def g(): yield from []
In Python, you can chain comparison operators:
>>> 0 < 1 < 2 True >>> 0 < 1 < 0 False
Such chains don’t have to be mathematically valid, you can mix
>and
<:
>>> 0 < 1 > 2 False >>> 0 < 1 < 2 > 1 > 0 True
Other operators such as
==,
isand
inare also supported:
>>> [] is not 3 in [1, 2, 3] True
Every operator is applied to the two nearest operands.
a OP1 b OP2 cis strictly equal to
(a OP1 b) AND (b OP2 c). No comparison between
aand
cis implied:
class Spy: def __init__(self, x): self.x = x def __eq__(self, other): print(f'{self.x} == {other.x}') return self.x == other.x def __ne__(self, other): print(f'{self.x} != {other.x}') return self.x != other.x def __lt__(self, other): print(f'{self.x} < {other.x}') return self.x < other.x def __le__(self, other): print(f'{self.x} <= {other.x}') return self.x <= other.x def __gt__(self, other): print(f'{self.x} > {other.x}') return self.x > other.x def __ge__(self, other): print(f'{self.x} >= {other.x}') return self.x >= other.x s1 = Spy(1) s2 = Spy(2) s3 = Spy(3) print(s1 is s1 < s2 <= s3 == s3)
Output:
1 < 2 2 <= 3 3 == 3 True
Only users with full accounts can post comments. Log in, please.
|
https://habr.com/en/company/mailru/blog/458688/
|
CC-MAIN-2019-30
|
refinedweb
| 770
| 72.36
|
Overview
Atlassian SourceTree is a free Git and Mercurial client for Windows.
Atlassian SourceTree is a free Git and Mercurial client for Mac.
minibsdiff: a miniature, portable version of bsdiff
Colin Percival's bsdiff is a popular tool for creating and applying patches
to binary software. This is a stripped down copy of
bsdiff that's designed to
be portable and reusable as a library in your own software (if you wanted to
say, create your own update system.) Many people end up reusing bsdiff (it's
stable, well-known, works great, and has a good license,) but I haven't found a
standalone copy of the library somewhere that I could easily reuse, so I wrote
one.
This code is based on bsdiff v4.3.
The main differences:
Control and data blocks in the patch output are not
bzip2compressed. You'll have to apply your own compression method. This is a very important part of bsdiff's design, and if you don't apply a compression method at some level when using this library, it won't buy you anything. Please see the 'Usage' section below.
Patches produced by this library are incompatible with those produced by the classic bsdiff tool. (The header format has changed appropriately so they are both incompatible with each other.) You're encouraged to change this when using the library yourself - see 'Usage' below.
The code has been refactored into a reusable API (documented below) consisting of a few simple functions in
bsdiff.hand
bspatch.h. It should be easily usable from any programming language. It has zero external dependencies.
It works everywhere (even under MSVC.)
There's a simple example included that should show you how to get started.
Because there are no external dependencies and it's so small, minibsdiff is great place to start if you need to customize bsdiff yourself! You'll inevitably want to do this as time goes on, and most of the work is done for you.
Usage
Building
Copy
bsdiff.{c,h},
bspatch.{c,h},
minibsdiff-config.h and
{stdbool,stdint}-msvc.h in your source tree and you're ready to go. You
shouldn't need any special build settings for it to Just Work(TM).
API
#include "bsdiff.h" #include "bspatch.h" /*- * Determine the maximum size of a patch between two files. This function * should be used to allocate a buffer big enough for `bsdiff` to store * its output in. */ off_t bsdiff_patchsize_max(off_t oldsize, off_t newsize); /*- * Create a binary patch from the buffers pointed to by oldp and newp (with * respective sizes,) and store the result in the buffer pointed to by 'patch'. * * The input pointer 'patch' must not be NULL, and the size of the buffer must * be at least 'bsdiff_patchsize_max(new,old)' in length. * * Returns -1 if `patch` is NULL, the 'patch' buffer is not large enough, or if * memory cannot be allocated. * Otherwise, the return value is the size of the patch that was put in the * 'patch' buffer. * * This function is memory-intensive, and requires max(17*n,9*n+m)+O(1) bytes * of memory, where n is the size of the new file and m is the size of the old * file. It runs in O((n+m) log n) time. */ int bsdiff(u_char* oldp, off_t oldsize, u_char* newp, off_t newsize, u_char* patch, off_t patchsize); /*- * Determine if the buffer pointed to by `patch` of a given `size` is * a valid patch. */ bool bspatch_valid_header(u_char* patch, ssize_t patchsz); /*- * Determine the size of the new file that will result from applying * a patch. Returns -1 if the patch header is invalid, otherwise returns * the size of the new file. */ ssize_t bspatch_newsize(u_char* patch, ssize_t patchsize); /*- * Apply a patch stored in 'patch' to 'oldp', result in 'newp', and store the * result in 'newp'. * * The input pointers must not be NULL. * * The size of 'newp', represented by 'newsz', must be at least * 'bspatch_newsize(oldsz,patchsz)' bytes in length. * * Returns -1 if memory can't be allocated, or the input pointers are NULL. * Returns -2 if the patch header is invalid. Returns -3 if the patch itself is * corrupt. * Otherwise, returns 0. * * This function requires n+m+O(1) bytes of memory, where n is the size of the * old file and m is the size of the new file. It does no allocations. * It runs in O(n+m) time. */ int bspatch(u_char* oldp, ssize_t oldsz, u_char* patch, ssize_t patchsz, u_char* newp, ssize_t newsz);
Building the example program.
For an full example of using the API, see
minibsdiff.c, which roughly
reimplements the standard
bsdiff/bspatch in a single tool (without
compression.) To build it:
Running
makeon Linux or OS X. If you have MinGW installed and on your
PATHthen you can do
make MinGW=YESwhich will build an
.exeon Windows.
There is a
CMakeLists.txtfile you can use to generate Ninja, MSVC or MinGW makefile projects for Windows as well. You can of course use
cmakeon Linux/OS X as well.
Customization notes.
You can change the patch file's magic number by modifying
BSDIFF_CONFIG_MAGIC
in
minibsdiff-config.h. It must be 8 bytes long (anything beyond that will be
ignored.) This library by default has the magic number
MBSDIF43.
You should really, really, really compress the output in some way. Whether or not you do that directly in the diff/patch routines or on the result you get from calling them is irrelevant. If you don't do this, bsdiff will buy you nothing.
Briefly, bsdiff is based on the concept of finding approximate matches between two executable files, and calculating and storing their bytewise differences in the patch file. The patch format is roughly composed of a control block specifying how to add and insert changes from the new executable into the old one, and a difference block actually composed of the differences.
Binary updates to software packages tend to have disproportionate amounts of binary-level differences from just a few source code changes. The key observation however is that most code is still the same, but relocated in such a way that things like internal pointers are always offset in a predictable manner. For example, if you have a single translation unit with 5 functions, and you fix a small bug in this code and ship it to users, the symbolic representation has not changed all that much, but the change will result in executable differences affecting all 5 functions, such that e.g. relative pointers must all be adjusted properly, across all of them.
But even then, many of these 'relocations' will be small (a byte or two,) and more than that, they will often be very regular, meaning the differences are highly redundant, and thus compressible.
As a result, an uncompressed patch from bsdiff is roughly on par with the new file in size, but compression can reduce it's size dramatically due to repeated data in the differences (by a factor of 10x or 20x.) In fact, without some sort of compression, it practically defeats the purpose of using it in the first place!
Not having compression by default is still a feature, though - it keeps the library simple and portable, and you can layer it in however you want because the source is small and easy to hack. But realistically, you'll always want to compress it at one point or another in the Real World.
Here are some good compression libraries you might be interested in:
In my non-scientific experiments, bzip at compression level 9 gives the best output size out of all the ones listed above. It's obviously worth sacrificing compression time/speed for smaller updates that decompress quickly.
Join in
File bugs in the GitHub issue tracker.
Master git repository:
git clone
There's also a BitBucket mirror:
git clone
If you're going to submit a pull request or send a patch, sign off on your
changes by using
git commit -s. I manage the
Signed-off-by field like
git: by signing off, you acknowledge that the code you are submitting for
inclusion abides by the license of the project. An
Acked-by field states that
someone has reviewed this code, and at the very least it is not completely
insane.
Authors
See AUTHORS.txt.
License
2-clause BSD. See
LICENSE.txt for terms of copyright and redistribution.
|
https://bitbucket.org/thoughtpolice/minibsdiff
|
CC-MAIN-2015-18
|
refinedweb
| 1,391
| 63.49
|
31 July 2008 09:26 [Source: ICIS news]
MUMBAI (ICIS news)--Indian Oil Corp (IOC) will soon start a detailed feasibility study on a rupees (Rs) 8-9bn ($188.2-211.8m) joint venture styrene butadiene rubber (SBR) unit downstream of its cracker project in Panipat, Haryana, said a company source on Thursday.?xml:namespace>
“We plan to execute a heads of agreement with two joint-venture partners by end- August and simultaneously start the study for a 120,000 tonnes/year SBR plant. The project is planned for completion at end-2011 or early 2012,” the source added.
The source declined to name the joint-venture partners but said that one of the companies would supply technology for the project, while the second, an international trading company, would offtake product for exports.
“About 20-25% of the production is likely to be exported,” he said.
Final investment clearance from the company’s board is expected after the completion of the study, said the source.
The economics of the project looked good and IOC was likely to go ahead with it despite the recent financial crunch, said the source.
“If the SBR project is implemented on a 1:1 debt equity ratio, IOC’s stake would only be Rs2bn,” the source said.
Feedstock butadiene would come from a 138,000 tonne/year plant downstream of the 857,000 tonne/year Panipat cracker, said the source.
About 75,000 tonnes/year of butadiene would be needed for the SBR plant and IOC would initially produce this volume and offer it to the joint venture on a transfer pricing basis, he said.
To utilise the surplus butadiene IOC was also looking at polybutadiene rubber (PBR) production at Panipat, he said.
“?xml:namespace>
ICIS news had earlier reported that IOC was mulling various C4 and C5 derivatives to improve the viability of the Panipat naphtha cracker project.
IOC’s Panipat cracker was planned for completion by end-2009, said the source.
IOC’s finances are currently under pressure with its key refining business losing money as prices of refined products, which are state controlled, have not increased in line with crude oil prices. This has affected some of the company’s planned projects.
Earlier this month, IOC had said that it would postpone paraxylene and other petrochemical projects that were part of a planned refinery and petrochemical complex in Paradip on the east coast of
|
http://www.icis.com/Articles/2008/07/31/9144361/ioc-plans-feasibility-study-on-200m-sbr-project.html
|
CC-MAIN-2014-42
|
refinedweb
| 402
| 57.61
|
Are you sure?
This
. 20 20 20 20 23 28 28 31 36 41 41 44 53 55 62 63 66 66 67 68 82 82 83 83 83 84 87 88 88 89 90 93 96 96 98 98 98 99 99 Preprocessors . . . . . . . . . . . . . . . . . . . . . 2. .2. . . . .6 alert syslog . . . . . . . . Config . . . . . . . .13 ARP Spoof Preprocessor . . . . . . . .3. . . . . . .2 2. . . . . . Reverting to original behavior . . . . . . . . . . . . . .1 2. . . . . . . . . . . . . . . . . . . . . . . . .3. . . . . . . . . . . . . . . . . . . . . . . . .2. . . . . . . . . . . . . . . . . . . .2 2. . . . . . . . . . . . .5 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2. . . . . . . .2. . . . . . .11 DNS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1. . . . . . . . . . . . .2.1 2. . . . . . . . . . . . . . . . . . . database . . . . . .1. . . . . . . . . . . . . . . . . . . .2 2. . . . . . . . .1 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2. . . . . . . . . . . .3 2. . . . . . . . . . . . . . . . . . . . . . .2 Format .6 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2. . .1 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8 2. . . . . . . . . 2. alert fast . . . . . . . . . . . . . . . . . . . . .2 2. .1 2. . . . . . . . . . . . . . . . . . . . . . . . . SSH . . . 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6. . . . . .2 2. . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .14 DCE/RPC 2 Preprocessor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2 Configuring Snort 2. . . . . . . . . . . . . . . . . . . .7 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2. . . . . . FTP/Telnet Preprocessor . Variables . . . . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10 DCE/RPC . . . . . . . . . . . . . . . sfPortscan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . . alert unixsock .4 Rate Filtering . . . . . . . . . . . . . . .6. . . .2. . . . . . .2. . . . . . . . . . . . . . . . . . . . . . . . . . . . log tcpdump . . . . .2. . . . . . . . . . . . . . . . . . . .3 2. . . . . . .5. . . . . . . . . . . . . . . . . . . . . . . .6 Output Modules . . . 2. . . . . .1. . . . . . . . . . . . . . . . .1 Includes . . . . . . . . . . 2. .12 SSL/TLS . . . . . . . . . . . . . . 2. .5 Performance Profiling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2. . . . . . . . . . . . . .3 2. . . . 2. . . . . . . . . . . SMTP Preprocessor . . . . . . . . 2. . . . . . . . . . . . . . . . . . . . . . . . . . . .9 Frag3 . . . . . . . . . . alert full . . . . . . . . . . . . . . . . 3 . . .2. . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . 2. . . . . . . .6.4 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . .6. . . . . . . . . . HTTP Inspect . . . Event Filtering . . . .4. . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . RPC Decode . . . . . . .3 Rule Profiling . . . . . . . . . . . . . . . . . . Performance Monitor . . . . . . . . . . . . . . . . . . . . . . . . . . . . Packet Performance Monitoring (PPM) . . Preprocessor Profiling . . . . . . . . . . . . . . . .1 2. . . .2. . . . . . . . . . . 2. . . . . . . . . . Stream5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4 Configuring . . . . . . . . . . .2. . . . . . . . . . . . . . . . . . . Event Processing . . . . . . . . . . . . . . . . . . . . . . .5 2. . . . . . . . . . . . . . . . . . . . .2. . . . . . . . . . . .3 Decoder and Preprocessor Rules . . . . . . . . .4 2. . . . . . . . . . . . . . . .3 2. . .2. . . . . . . . . . .6. . . . .6. . . . . . . . . . . . . . . . . . . . . . . . . .2 2. . Event Logging . . . . . . Event Suppression . . . . . . . . . . . . . . . . . . . . .
. . 116 General Rule Options . . . . . . . . . . . . . . . .2 2. . . . . . . . . . . . . . . . . . 113 Rules Headers . . . . . . . . .8. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119 priority . . . . . . . . . . . . . . . . . . . . . . . . . .4. . 117 gid . . . . . . . . . . . . . 104 2. . . . . . . . . . . . . . . . . . . .4. . . . . . . . .2. .6. . . . . . 117 3. . . . . . . . . 118 rev .9. . . . . . . . . .10. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4 3. . . . . . . . . . . . . . . . . . . . . . . . . . . .9 Reloading a Snort Configuration . . .2 Configuration Specific Elements . . 113 3. . .6 3. .6. . . . . . . . . . . . . . . . . . . .4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100 unified . . . . . . 103 2. . . .8 Configuration Format . . . . . . . . . . . 118 sid . . . . . . . . . . . . . .2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1 3. . . . 113 Protocols . . . . . 103 2. . .8.12 alert aruba action . . . . . . .9 csv . . . . . . . . . . . .2. . . . . 108 2. . . . .6. . . . . . . . . . . . . . 107 Non-reloadable configuration options . . . . . . . . . . .4 Rule Options . . . . . .10. . . . . . . . . . . . . . . . .3 3. . . . 110 2. . . . . . . . . . 115 The Direction Operator . . . . . . . . . . . . . . . . . . . . . . .3 3. . . . . . . . . . . . .1 2. .2 3. . . 109 2. . . . . . . . . . . . . . . . . 115 Activate/Dynamic Rules . . . .7 Host Attribute Table . . . . . . . . . . . . .9. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119 classtype . . . . . . . . . . . . . . . . . . . . . . . . . . . .10. . . . . . . . . .2 2. . . . . . . .2 113 The Basics . . . . . .9. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . . . . . . . . . . .3 How Configuration is applied? . . . . . . . . . . . . . . . . . .7 2. . . . . .4 3. .6 Rule Actions . . . .2. . . . . . . . . 102 2. . . . . . . . . . . . 109 2. . . 101 unified 2 . . . . . . . . . . . . 112 3 Writing Snort Rules 3. . . . . . . . . . . . . . . . . . . . . .4. . 114 Port Numbers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1 Creating Multiple Configurations . . . . . . . . . . . . 114 IP Addresses . . . . . . . . . . . 104 Attribute Table File Format . . . . . . . . . . .1 3. . . . . . 106 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2. . . . . . . . . . . . . .1 2. . . 120 4 . . . . . . . . . . . . . . .7. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2. . . . . . . . .8 2. . . . . . . . 107 Reloading a configuration . . . . . 116 3. . . . . . . . . . . . . . . . . . . . . . . . . . .6. . . . . . . . . .2. . . . . . . . . . . . . . .2 Format . . . . . . . . . . . . . . . 106 Directives .3 Enabling support . . . .1 2. . . . . . . . . . . . . . . . . . . . . . .5 3. . . . . . . .2 3. . . . . . . . . .11 log null . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117 reference . . . . . . . . . . . . . .4. . . . .10 Multiple Configurations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107 2. . . . . . . . . . . . . . . . . .7. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1 3. 102 2. . . . . . . . . . . . . . . . . . . . . 104 Dynamic Modules . . . . . . . . . . . . . . . . . . . . .3 3. .6. . . . . . 107 2. . . . . . . . . . . . . . .5 3. . . . . . . .4. . . . . . . . . . . . . . . . . . .7 msg . . . . . . . . . . . . . . .10 alert prelude . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . .5. . . . . .2 3. . . . . . . . . . . . . . . . 139 flow . .5. . . . . . . . . . . . . . . . . . .6. . . . . . . . .1 3. . . . . . . . . .10 http header . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .21 asn1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5. 135 3. . . . . . . . . . . 124 within . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . .6. . . . . . . . . . . . . . . . . . . . . . . . .6 3. . . . . . . . . . 138 flags . . . . . 128 3. . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . .6. . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124 offset . . . . . . . . . .16 isdataat . . . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124 distance . . . . . . . . . . . .5. . . .5. . . . . . . . . . . . . . . . . . . . .14 uricontent . . . . . . . . . . . . . . . . . .3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8 3. . . .6 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137 ipopts . . . . . . 122 3. . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . . .6. . . . . . . .6 Non-Payload Detection Rule Options . . . . . . . . . . . . . . . .23 dce iface . . . . .5. 127 3. . .5. . . . . . . . . . .15 urilen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130 3. . . .5 3. . . . . . . . . . . . . . .11 http method . . . . 126 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129 3. . . . . . . . . . . . . . .8 3.19 byte jump . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . 133 3. . . . . . . . . . .5. . . .4 3. . . . . . . . . . . . . . . . . . . . . .4. . . . . . . . . 135 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4. 125 http cookie . . . .5. . . . . . . . . . . . . . . . . . .5 metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129 3. . . . . . . . . . . .5. . . . . .9 content . . . . . . 133 3. . . . . . . . . . . . . . . . . . 125 3. . . . 135 3. . . . . . . . .26 Payload Detection Quick Reference . . . . . . . . . . . . . . . .9 3. 136 id . . . . . . . . . . . . . . . . . . . . . . . . . . .24 dce opnum . . . . . .4 3. . . . . . . .20 ftpbounce . 136 tos . . . . . . . . . . 132 3. . .7 3. . .5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3 3. . . . . . .25 dce stub data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125 http client body . . . . . . . . . . . . . . . . . . . . . . .1 3. . . . . . . 139 5 . .5. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121 General Rule Quick Reference . . . . . . . . . .12 http uri . . .5 3. . . . . . . . . . . . . . . . . . . 134 3. . . . . . . . . . . . 137 fragbits . . . . . . . . . . .22 cvs .17 pcre . . . . .7 3. . . . . . . . .9 fragoffset . . . 136 3. . . .3 3. . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . .6. 123 depth . . . . . . . . 127 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . .6.6. .5. . . . . . . . . . .6. . . . . . . . . . . 138 dsize . . .2 3. . . . . . . . 121 Payload Detection Rule Options . . . . . . . . . . . . . . . . . . . .8 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18 byte test . . 136 ttl . . . . . . .13 fast pattern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6. . 123 rawbytes . . . . . . . . . 135 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5. . . . . . . . . . . . . . .5. . . . . . . . . . . . . . . . .5. . . . . 122 nocase . . . . . 128
they are logged to a directory Note that if with a name based on the higher of the two port numbers or./log Of course. in the case of a tie.0/24 This rule tells Snort that you want to print out the data link and TCP/IP headers as well as application data into the directory . The last command could also be typed out as: . you may notice that Snort sometimes uses the address of the remote computer as the directory in which it places packets and sometimes it uses the local host address. When Snort runs in this mode. you don’t need to run in verbose mode or specify the -d or -e switches because in binary mode the entire packet is logged.0 class C network. If you don’t./log -b Note the command line changes here.This instructs Snort to display the packet data as well as the headers. which eliminates the need to tell it how to format the output directory structure. All incoming packets will be recorded into subdirectories of the log directory./snort -l .3 Packet Logger Mode OK. do this: . and you want to log the packets relative to the 192./log -h 192.1./log./snort -d -v -e and it would do the same thing./snort -dev -l . you need to specify a logging directory and Snort will automatically know to go into packet logger mode: . but if you want to record the packets to the disk. We don’t need to specify a home network any longer because binary mode logs everything into a single file. Snort will exit with an error message. this assumes you have a directory named log in the current directory. these switches may be divided up or smashed together in any combination. In order to log relative to the home network. you can read the packets back out of the file with any sniffer that supports the tcpdump binary format (such as tcpdump or Ethereal).168. Additionally. Once the packets have been logged to the binary file./snort -vde (As an aside. with the directory names being based on the address of the remote (non-192. you need to tell Snort which network is the home network: . not just sections of it.168.168. showing the data link layer headers.. Snort can also read the packets back by using the 9 . you should consider logging in binary mode. Binary mode logs the packets in tcpdump format to a single binary file in the logging directory: . it collects every packet it sees and places it in a directory hierarchy based upon the IP address of one of the hosts in the datagram. If you’re on a high speed network or you want to log the packets into a more compact form for later analysis. ! △NOTE both the source and destination hosts are on the home network. If you just specify a plain -l switch. all of these commands are pretty cool. If you want an even more descriptive display.) 1. the source address./snort -dev -l .1.1) host.
-r switch. fast. console.168. socket.log You can manipulate the data in the file in a number of ways through Snort’s packet logging and intrusion detection modes. For example. The full alert mechanism prints out the alert message in addition to the full packet headers. Turns off alerting./snort -dev -l . it will default to /var/log/snort. 1. simply specify a BPF filter at the command line and Snort will only see the ICMP packets in the file: ./log -h 192.log icmp For more info on how to use the BPF interface.0/24 -c snort. logging packets that trigger rules specified in the snort. It’s also not necessary to record the data link headers for most applications. These options are: Option -A fast -A full -A -A -A -A unsock none console cmg Description Fast alert mode.1. Full alert mode. There are several other alert output modes available at the command line.1 NIDS Mode Output Options There are a number of ways to configure the output of Snort in NIDS mode. alert message.4. . This will apply the rules configured in the snort. and none. Six of these modes are accessed with the -A command line switch. 1. Alert modes are somewhat more complex. try this: . Writes the alert in a simple format with a timestamp. source and destination IPs/ports.168. Packets from any tcpdump formatted file can be processed through Snort in any of its run modes.conf is the name of your rules file. the -v switch should be left off the command line for the sake of speed.conf This will configure Snort to run in its most basic NIDS form. too. Generates “cmg style” alerts. and packets can be dropped while writing to the display.. syslog.0/24 -l . if you only wanted to see the ICMP packets from the log file./log -c snort. Sends alerts to a UNIX socket that another program can listen on. cmg. The default logging and alerting mechanisms are to log in decoded ASCII format and use full alerts.conf in plain ASCII to disk using a hierarchical directory structure (just like packet logger mode). if you wanted to run a binary log file through Snort in sniffer mode to dump the packets to the screen. which puts it into playback mode. Sends “fast-style” alerts to the console (screen). If you don’t specify an output directory for the program. There are seven alert modes available at the command line: full./snort -d -h 192.conf where snort./snort -dvr packet./snort -dv -r packet. This is the default alert mode and will be used automatically if you do not specify a mode. 10 . For example. you can try something like this: .1. so you can usually omit the -e switch.conf file to each packet to decide if an action based upon the rule type in the file should be taken. The screen is a slow place to write data to. One thing to note about the last command line is that if Snort is going to be used in a long term way as an IDS. as well as two logging facilities.
In this case. For output modes available through the configuration file. this tells the user what component of Snort generated this alert. This allows Snort to log alerts in a binary form as fast as possible while another program performs the slow actions. such as writing to a database. For a list of preprocessor SIDs. we know that this event came from the “decode” (116) component of Snort. To disable packet logging altogether. The second number is the Snort ID (sometimes referred to as Signature ID).conf 11 .168. use the output plugin directives in the rules files./snort -c snort. use the following command line to log to the default facility in /var/log/snort and send alerts to a fast alert file: . See Section 2. as each rendition of the rule should increment this number with the rev option.0/24 1.6. 56 represents a T/TCP event. use the following command line to log to default (decoded ASCII) facility and send alerts to syslog: .168./snort -b -A fast -c snort. The default facilities for the syslog alerting mechanism are LOG AUTHPRIV and LOG ALERT. This number is primarily used when writing signatures. see Section 2.3 High Performance Configuration If you want Snort to go fast (like keep up with a 1000 Mbps connection). please read etc/generators in the Snort source. This allows debugging of configuration issues quickly via the command line. use the -N command line switch. you need to use unified logging and a unified log reader such as barnyard.2 Understanding Standard Alert Output When Snort generates an alert message.4. The third number is the revision ID.4. For a list of GIDs./snort -c snort. it will usually look like the following: [**] [116:56:1] (snort_decoder): T/TCP Detected [**] The first number is the Generator ID. but still somewhat fast. For example: .conf -A fast -h 192. try using binary logging with the “fast” output mechanism./log -h 192.Packets can be logged to their default decoded ASCII format or to a binary log file via the -b command line switch. To send alerts to syslog. If you want to configure other facilities for syslog output. Rule-based SIDs are written directly into the rules with the sid option.map. In this case.conf -l .1. For example. This will log packets in tcpdump format and produce minimal alerts.1 for more details on configuring syslog output.1. 1.0/24 -s As another example. ! △NOTE Command line logging options override any output options specified in the configuration file. use the -s switch. If you want a text file that’s easily parsable.6. please see etc/gen-msg.
you could use the following command to read the packets from a log file and dump them to the screen.6. This is useful if you don’t care who sees the address of the attacking host.168.1. the --create-pidfile switch can be used to force creation of a PID file even when not running in daemon mode. you might want to use the -O switch.2 Running in Rule Stub Creation Mode If you need to dump the shared object rules stub to a directory. you can the add -D switch to any combination described in the previous sections. you must specify the full path to the Snort binary when you start it. obfuscating only the addresses from the 192.6 Miscellaneous 1.conf: config dump-dynamic-rules-path: /tmp/sorules In the above mentioned scenario the dump path is set to /tmp/sorules.6. the daemon creates a PID file in the log directory.conf \ --dump-dynamic-rules=/tmp This path can also be configured in the snort.conf \ --dump-dynamic-rules snort.1 Running Snort as a Daemon If you want to run Snort as a daemon. Use the --nolock-pidfile switch to not lock the PID file.1. Additionally. These rule stub files are used in conjunction with the shared object rules. /usr/local/bin/snort -c /usr/local/etc/snort. This is handy if you don’t want people on the mailing list to know the IP addresses involved.168.6.6. the --pid-path command line switch causes Snort to write the PID file in the directory specified. For example. The PID file will be locked so that other snort processes cannot start. Snort PID File When Snort is run as a daemon . The path can be relative or absolute. This switch obfuscates your IP addresses in packet printouts.1. You can also combine the -O switch with the -h switch to only obfuscate the IP addresses of hosts on the home network.0/24 \ -l /var/log/snortlogs -c /usr/local/etc/snort.conf -s -D Relative paths are not supported due to security concerns.0/24 15 ./snort -d -v -r snort.log -O -h 192.168. for example: /usr/local/bin/snort -d -h 192. Please notice that if you want to be able to restart Snort by sending a SIGHUP signal to the daemon. /usr/local/bin/snort -c /usr/local/etc/snort.0/24 class C network: . 1. In Snort 2. you might need to use the –dump-dynamic-rules option.3 Obfuscating IP Address Printouts If you need to post packet logs to public mailing lists.
Sorted in ascii order. Snort will read and analyze the packets as if they came off the wire. This option can be used when running multiple instances of snort. This filter will apply to any --pcap-file or --pcap-dir arguments following. --pcap-no-filter --pcap-reset --pcap-show 1. Note that Snort will not try to determine whether the files under that directory are really pcap files or not.pcap $ snort --pcap-single=foo.7.txt foo1. foo2. without this option.4 Specifying Multiple-Instance Identifiers In Snort v2. Reset to use no filter when getting pcaps from file or directory. however. you can give it a packet capture to read. or on the same CPU but a different interface.1. Same as -r. 1. reset snort to post-configuration state before reading next pcap. Users can specify either a decimal value (-G 1) or hex value preceded by 0x (-G 0x11). Shell style filter to apply when getting pcaps from file or directory.4. 1. If reading multiple pcaps.pcap and all files under /home/foo/pcaps.pcap /home/foo/pcaps $ snort --pcap-file=foo. This is also supported via a long option --log. either on different CPUs. This can be useful for testing and debugging Snort. the -G command line option was added that specifies an instance identifier for the event logs. A directory to recurse to look for pcaps. Print a line saying what pcap is currently being read. Note.7 Reading Pcaps Instead of having Snort listen on an interface.2 Examples Read a single pcap $ snort -r foo.6. i. A space separated list of pcaps to read. Option -r <file> --pcap-single=<file> --pcap-file=<file> --pcap-list="<list>" --pcap-dir=<dir> --pcap-filter=<filter> Description Read a single pcap. Can specifiy path to pcap or directory to recurse to get pcaps. that specifying --pcap-reset and --pcap-show multiple times has the same effect as specifying them once. 16 .pcap foo2.txt This will read foo1.pcap.7.pcap Read pcaps from a file $ cat foo.e. File that contains a list of pcaps to read.1 Command line arguments Any of the below can be specified multiple times on the command line (-r included) and in addition to other Snort command line options. Each Snort instance will use the value specified to generate unique event IDs. Added for completeness. is not to reset state. The default.
pcap” will only be applied to the pcaps in the file ”foo. the first filter will be applied to foo.pcap /home/foo/pcaps $ snort --pcap-filter="*.pcap foo2. Using filters $ cat foo. etc.txt \ > --pcap-no-filter --pcap-dir=/home/foo/pcaps In this example.cap" --pcap-dir=/home/foo/pcaps In the above.pcap and foo3.pcap foo2.txt \ > --pcap-filter="*. $ snort --pcap-filter="*.Read pcaps from a command line list $ snort --pcap-list="foo1.pcap. so all files found under /home/foo/pcaps will be included. The addition of the second filter ”*. $ snort --pcap-filter="*. the first filter ”*. the first filter will be applied to foo.txt.cap” will be included from that directory.pcap”.txt.txt \ > --pcap-no-filter --pcap-dir=/home/foo/pcaps \ > --pcap-filter="*.txt $ snort --pcap-filter="*.cap" --pcap-dir=/home/foo/pcaps2 In this example.cap” will be applied to files found under /home/foo/pcaps2. so all files found under /home/foo/pcaps will be included. Resetting state $ snort --pcap-dir=/home/foo/pcaps --pcap-reset The above example will read all of the files under /home/foo/pcaps. in other words. For each pcap. so only files ending in ”. 17 . then the filter ”*. but after each pcap is read. meaning all buffers will be flushed.pcap.pcap" --pcap-dir=/home/foo/pcaps The above will only include files that match the shell pattern ”*. Snort will be reset to a post-configuration state.pcap foo3.cap” will cause the first filter to be forgotten and then applied to the directory /home/foo/pcaps. statistics reset. it will be like Snort is seeing traffic for the first time.pcap --pcap-file=foo.pcap" --pcap-file=foo.txt foo1. $ snort --pcap-filter="*. any file ending in ”.pcap”. foo2. then no filter will be applied to the files found under /home/foo/pcaps. then no filter will be applied to the files found under /home/foo/pcaps. Read pcaps under a directory $ snort --pcap-dir="/home/foo/pcaps" This will include all of the files under /home/foo/pcaps.pcap --pcap-file=foo.pcap" This will read foo1.pcap --pcap-file=foo.txt” (and any directories that are recursed in that file).
2. Previously.0/24.2.2.2.2.!1. IP lists now OR non-negated elements and AND the result with the OR’ed negated elements. Variables.1. See below for some valid examples if IP variables and IP lists. but it will be deprecated in a future release.2. or any combination of the three. IP variables should be specified using ’ipvar’ instead of ’var’. Lists of ports must be enclosed in brackets and port ranges may be specified with a ’:’.3]] alert tcp $EXAMPLE any -> any any (msg:"Example". as a CIDR block.2.2.1.!1.1.2.) Different use of !any: ipvar EXAMPLE !any alert tcp $EXAMPLE any -> any any (msg:"Example".2.7.0 to 2.2 and 2.0.2.2.0/16] Port Variables and Port Lists Portlists supports the declaration and lookup of ports and the representation of lists and ranges of ports. IP lists.0. Use of !any: ipvar EXAMPLE any alert tcp !$EXAMPLE any -> any any (msg:"Example". IPs. ranges.0/8. with the exception of IPs 2. Using ’var’ for an IP variable is still allowed for backward compatibility.2.2.2. in a list.1. The element ’any’ can be used to match all IPs. Also.0/24. each element in a list was logically OR’ed together.888:900] 21 . Also. Valid port ranges are from 0 to 65535.1.1.1] Nonsensical negations: ipvar EXAMPLE [1.1.1.1.) Logical contradictions: ipvar EXAMPLE [1.1.2. although ’!any’ is not allowed. negated IP ranges that are more general than non-negated IP ranges are not allowed.2. ipvar EXAMPLE [1.2.) alert tcp [1.1.1.1.1 and IP from 2.!1.![2.2.0/24.sid:3. If IPv6 support is enabled. [1. Negation is handled differently compared with Snort versions 2.255.0/24] any -> any any (msg:"Example". such as in: [10:50.2. or lists may all be negated with ’!’.0.1. and CIDR blocks may be negated with ’!’. The following example list will match the IP 1. sid:1.2. but ’!any’ is not allowed.sid:3.![2.IP Variables and IP Lists IPs may be specified individually.1. ’any’ will specify any ports.1.3.2.3]] The order of the elements in the list does not matter.2.sid:2.1.2.) The following examples demonstrate some invalid uses of IP variables and IP lists.x and earlier.2.2.1.
sid:2.100:200] alert tcp any $EXAMPLE1 -> any $EXAMPLE2_PORT (msg:"Example". sid:5.) Several invalid examples of port variables and port lists are demonstrated below: Use of !any: portvar EXAMPLE5 !any var EXAMPLE5 !any Logical contradictions: portvar EXAMPLE6 [80. sid:3. a ’var’ can still be used to declare a port variable.91:95.) Port variable used as an IP: alert tcp $EXAMPLE1 any -> any any (msg:"Example". The following examples demonstrate several valid usages of both port variables and port lists. provided the variable name either ends with ’ PORT’ or begins with ’PORT ’.!80] Ports out of range: portvar EXAMPLE7 [65536] Incorrect declaration and use of a port variable: var EXAMPLE8 80 alert tcp any $EXAMPLE8 -> any any (msg:"Example". For backwards compatibility. as described in the following table: 22 . The use of ’var’ to declare a port variable will be deprecated in a future release. portvar EXAMPLE1 80 var EXAMPLE2_PORT [80:90] var PORT_EXAMPLE2 [1] portvar EXAMPLE3 any portvar EXAMPLE4 [!70:90] portvar EXAMPLE5 [80.9999:20000] (msg:"Example".Port variables should be specified using ’portvar’.) Variable Modifiers Rule variable names can be modified in several ways.) alert tcp any 90 -> any [100:1000. You can define meta-variables using the $ operator. These can be used with the variable modifier operators ? and -. sid:4.) alert tcp any $PORT_EXAMPLE2 -> any any (msg:"Example". sid:1.
They should be renamed instead: Invalid redefinition: var pvar 80 portvar pvar 90 2.0/24 log tcp any any -> $(MY_NET:?MY_NET is undefined!) 23 Limitations When embedding variables. Here is an example of advanced variable usage in action: ipvar MY_NET 192. Valid embedded variable: portvar pvar1 80 portvar pvar2 [$pvar1.Variable Syntax var $(var) or $var $(var:-default) $(var:?message) Description Defines a meta-variable.90] Invalid embedded variable: var pvar1 80 portvar pvar2 [$pvar1. but old-style variables (with the ’var’ keyword) can not be embedded inside a ’portvar’.3 Config Many configuration and command line options of Snort can be specified in the configuration file. Replaces the contents of the variable var with “default” if var is undefined.168. port variables can be defined in terms of other port variables.1. types can not be mixed. For instance. variables can not be redefined if they were previously defined as a different type.90] Likewise. Replaces with the contents of variable var or prints out the error message and exits. Format config <directive> [: <value>] 23 .1. Replaces with the contents of variable var.
Only useful if Snort was configured with –enable-inline-init-failopen. high performance) – ac-bnfa Aho-Corasick NFA (low memory. noicmp. icmp or all. high performance) – acs Aho-Corasick Sparse (small memory. udp. 24 . Sets the alerts output file. Values: none. Chroots to specified dir (snort -t). notcp. Forks as a daemon (snort -D). (snort --disable-inline-init-failopen) Disables IP option length validation alerts. Types of packets to calculate checksums. Specify disabled to disable loading rules. The following options can be used: • search-method <ac | ac-std | ac-bnfa | acs | ac-banded | ac-sparsebands | lowmem > – ac Aho-Corasick Full (high memory. Global configuration directive to enable or disable the loading of rules into the detection engine. tcp. best performance) – ac-std Aho-Corasick Standard (moderate memory. Disables failopen thread that allows inline traffic to pass while Snort is starting up. Decodes Layer2 headers (snort -e). icmp or all (only applicable in inline mode and for packets checked per checksum mode config option). moderate performance) – ac-banded Aho-Corasick Banded (small memory. this option will cause Snort to revert back to it’s original behavior of alerting if the decoder or preprocessor generates an event.2 for a list of classifications. Values: none. See Section 3. high performance) – lowmem Low Memory Keyword Trie (small memory. noip. Makes changes to the detection engine. moderate performance) – ac-sparsebands Aho-Corasick Sparse-Banded (small memory. If Snort was configured to enable decoder and preprocessor rules. udp. tcp. noudp. ip. Specifies the maximum number of nodes to track when doing ASN1 decoding. noicmp. noip. low performance) • no stream inserts • max queue events<integer> config disable decode alerts config disable inline init failopen config disable ipopt alerts Turns off the alerts generated by the decode phase of Snort.5. See Table 3. ip drop if invalid checksums. Specifies BPF filters (snort -F). Default (with or without directive) is enabled. noudp.21 for more information and examples. notcp.
config enable ipopt drops Enables the dropping of bad packets with bad/truncated IP options (only applicable in inline mode). By default.. Default is <bytes> 1048576 bytes (1 megabyte). By default. config Enables the dropping of bad packets with experimental TCP openable tcpopt experimental drops tion. Turns off alerts generated by T/TCP options.4 for more information and examples. When this option is off and MPLS multicast traffic is detected. You can use the <num>] [log <num>] [order events following options: <order>] • max queue <integer> (max events supported) • log <integer> (number of events to log) • order events [priority|content length] (how to order events within the queue) See Section 2. config event queue: [max queue Specifies conditions about Snort’s event queue. config enable mpls overlapping ip Enables support for overlapping IP addresses in an MPLS network. Turns off alerts generated by experimental TCP options. config enable tcpopt drops Enables the dropping of bad packets with bad/truncated TCP option (only applicable in inline mode). there could be situations where two private networks share the same IP space and different MPLS labels are used to differentiate traffic from the two VPNs. enable decode oversized alerts must also be enabled for this to be effective (only applicable in inline mode). Snort will generate an alert. This option is needed when the network allows MPLS multicast traffic. config enable decode oversized alerts Enable alerting on packets that have headers containing length fields for which the value is greater than the length of the packet. Dumps raw packet starting at link layer (snort -X). enable tcpopt ttcp drops Enables the dropping of bad packets with T/TCP option. config event filter: memcap Set global memcap in bytes for thresholding. enable ttcp drops Enables the dropping of bad packets with T/TCP option. it is off.Turns off alerts generated by obsolete TCP options. Turns on character dumps (snort -C). this configuration option should be turned on. In a normal situation. (only applicable in inline mode). config enable mpls multicast Enables support for MPLS multicast. In such a situation. config enable decode oversized drops Enable dropping packets that have headers containing length fields for which the value is greater than the length of the packet. Turns off alerts generated by T/TCP options.4. Dumps application layer (snort -d). (only applicable in inline mode). config enable tcpopt obsolete drops Enables the dropping of bad packets with obsolete TCP option. (only applicable in inline mode). (only applicable in inline mode). Enables the dropping of bad packets identified by decoder (only applicable in inline mode). However. 25 . it is off. where there are no overlapping IP addresses. this configuration option should not be turned. Sets a limit on the maximum number of hosts to read from the attribute table. Specifies ports to ignore (useful for ignoring noisy NFS traffic).7). 26 . Port ranges are supported. Default is on) • bad ipv6 frag alert on|off (Specify whether or not to alert. The default value without this option is 4. Its default value is -1. UDP. In addition to ipv4. Sets a Snort-wide limit on the number of MPLS headers a packet can have. (Snort must be compiled with –enableflexresp2) Specify the memcap for the hash table used to track the time of responses. Default is 1048576 bytes. (Snort must be compiled with –enable-flexresp2) Specify the number of rows for the hash table used to track the time of responses. Sets a Snort-wide MPLS payload type. Note: Alerts will still occur. Minimum value is 32 and the maximum is 524288 (512k). The times (hashed on a socket pair plus protocol) are used to limit sending a response to the same half of a socket pair every couple of seconds. Sets a Snort-wide minimum ttl to ignore all traffic. Default is 1024 rows.5. If the number of hosts in the attribute table exceeds this value. (snort -N). Specify the protocol (TCP. Disables pcre pattern matching. an error is logged and the remainder of the hosts are ignored. See Section 1. or ICMP)] [. This option is only supported with a Host Attribute Table (see section 2. (Snort must be compiled with –enable-flexresp2) Specifies the maximum number of flowbit tags that can be used within a rule set. followed by a list of ports. max frag sessions <max-track>] Specify the number of TCP reset packets to send to the source of the attack. (Snort must be compiled with –enable-flexresp2) Specify the response interface to use. Disables logging. The default is 10000. Obfuscates IP Addresses (snort -O). frag timeout <secs>] [. Valid values are 0 to 20. The default MPLS payload type is ipv4 Disables promiscuous mode (snort -p). bad ipv6 frag alert on|off] [. IP. In Windows this can also be the interface number. Sets the network interface (snort -i). Sets the logdir (snort -l). which means that there is no limit on label chain length. The following options can be used: • bsd icmp frag alert on|off (Specify whether or not to alert. however values less than 4 will default to 4. ipv6 and ethernet are also valid options.
Sets assurance mode for stream (stream is established). eg: pass alert log activation. Restricts the amount of stack used by a given PCRE option.before Snort has had a chance to load a previous configuration. Set the snaplength of packet. Adds a new reference system to Snort. A value of 0 results in no PCRE evaluation.5. 27 . A value of -1 allows for unlimited PCRE. The default value when this option is not configured is 256 packets. same effect as -P <snaplen> or --snaplen <snaplen> options. When a metric other than packets is used in a tag option in a rule. Sets UID to <id> (snort -u). Default is 1048576 bytes (1 megabyte).7. Setting this option to a value of 0 will disable the packet limit. See Section 2. it will limit the number of nested repeats within a pattern. See Section 2. Set global memcap in bytes for thresholding.5. Sets umask when running (snort -m). Default is 3600 (1 hour). A value of 0 results in no PCRE evaluation.an attempt is made to name the log directories after the IP address that is not in the reference net. Specifies a pcap file to use (instead of reading from network). same effect as -r <tf> option.com/?id= For IP obfuscation. In addition. Supply versioning information to configuration files. Base version should be a string in all configuration files including included ones. Note this option is only available if Snort was built to use time stats with --enable-timestats. Use config event filter instead.) Set the amount of time in seconds between logging time stats. up to the PCRE library compiled limit (around 10 million).2 for more details. A value of -1 allows for unlimited PCRE. Restricts the amount of backtracking a given PCRE option. The snort default value is 1500. the obfuscated net will be used if the packet contains an IP address in the reference net. up to the PCRE library compiled limit (around 10 million). For example. Print statistics on preprocessor performance. See Section 3.5 on using the tag option when writing rules for more details. this option sets the maximum number of packets to be tagged regardless of the amount defined by the other metric. (This is deprecated. Print statistics on rule performance.1 for more details. Changes GID to specified GID (snort -g). Shows year in timestamps (snort -y). Also used to determine how to set up the logging directory structure for the session post detection rule option and ascii output plugin . This option is only useful if the value is less than the pcre match limit Exits after N packets (snort -n). eg: myref. The snort default value is 1500. binding version must be in any file configured with config binding. This option is used to avoid race conditions when modifying and loading a configuration within a short time span . Disables banner and status reports (snort -q).
there are ambiguities in the way that the RFCs define some of the edge conditions that may occurr and when this happens different people implement certain aspects of their IP stacks differently. When IP stacks are written for different operating systems. We can also present the IDS with topology information to avoid TTL-based evasions and a variety of other issues. check out the famous Ptacek & Newsham paper at. This is where the idea for “target-based IDS” came. but after the packet has been decoded. As I like to say.2.org/vern/papers/activemap-oak. The packet can be modified or analyzed in an out-of-band manner using this mechanism. Target-based analysis is a relatively new concept in network-based intrusion detection.1 Frag3 The frag3 preprocessor is a target-based IP defragmentation module for Snort.config utc config verbose Uses UTC instead of local time for timestamps (snort -U). For more detail on this issue and how it affects IDS.5 of Snort. Target-based host modeling anti-evasion techniques. 2.pdf. they are usually implemented by people who read the RFCs and then write their interpretation of what the RFC outlines into code. Frag3 uses the sfxhash data structure and linked lists for data handling internally which allows it to have much more predictable and deterministic performance in any environment which should aid us in managing heavily fragmented environments. 28 . heavily fragmented environments the nature of the splay trees worked against the system and actually hindered performance. Unfortunately.snort.org/docs/ idspaper/. Frag3 is intended as a replacement for the frag2 defragmentation module and was designed with the following goals: 1.2 Preprocessors Preprocessors were introduced in version 1. The format of the preprocessor directive in the Snort rules file is: preprocessor <name>: <options> 2. They allow the functionality of Snort to be extended by allowing users and programmers to drop modular plugins into Snort fairly easily. it is possible to evade the IDS. but that’s a topic for another day..icir. Uses verbose logging to STDOUT (snort -v). Preprocessor code is run before the detection engine is called. The basic idea behind target-based IDS is that we tell the IDS information about hosts on the network so that it can avoid Ptacek & Newsham style evasion attacks based on information about how an individual target IP stack operates. Preprocessors are loaded and configured using the preprocessor keyword. Check it out at. 2. In an environment where the attacker can determine what style of IP defragmentation is being used on a particular target. if the attacker has more information about the targets on a network than the IDS does. Once we have this information we can start to really change the game for these complex modeling problems. For an IDS this is a big problem. Frag3 was implemented to showcase and prototype a target-based module within Snort to test this idea. Splay trees are excellent data structures to use when you have some assurance of locality of reference for the data that you are handling but in high speed.
and the maximum is ”255”.Timeout for fragments. Fragments smaller than or equal to this limit are considered malicious and an event is raised.Defines smallest fragment size (payload size) that should be considered valid. detect anomalies option must be configured for this option to take effect. – policy <type> .Select a target-based defragmentation mode. Available types are first. Default value is all. This engine will only run for packets with destination addresses contained within the IP List. if detect anomalies is also configured. Anyone who develops more mappings and would like to add to this list please feel free to send us an email! 29 . Default is 8192. – min fragment length <number> . – memcap <bytes> . There are at least two preprocessor directives required to activate frag3. Use preallocated fragment nodes (faster in some situations).Limits the number of overlapping fragments per packet. This is an optional parameter. linux. and the maximum is ”255”. Default is 4MB. – detect anomalies . bsdright. – timeout <seconds> . Fragments in the engine for longer than this period will be automatically dropped. Default is 1. the minimum is ”0”. The known mappings are as follows. – max frags <number> .Frag 3 Configuration Frag3 configuration is somewhat more complex than frag2.Maximum simultaneous fragments to track. The default is ”0” (unlimited). last. – min ttl <value> . The Paxson Active Mapping paper introduced the terminology frag3 is using to describe policy types. Default type is bsd. the minimum is ”0”. a global configuration directive and an engine instantiation. There can be an arbitrary number of engines defined at startup with their own configuration.IP List to bind this engine to. bsd. – overlap limit <number> .Minimum acceptable TTL value for a fragment packet.Detect fragment anomalies. but only one global configuration. Global Configuration • Preprocessor name: frag3 global • Available options: NOTE: Global configuration options are comma separated. Default is 60 seconds. detect anomalies option must be configured for this option to take effect. This is an optional parameter. – prealloc frags <number> .Alternate memory management mode. Engine Configuration • Preprocessor name: frag3 engine • Available options: NOTE: Engine configuration options are space separated.Memory cap for self preservation. – bind to <ip list> . The default is ”0” (unlimited).
1.2 OSF1 V4.5.1.0/24] policy last.5.10.1 SunOS 4.16.0 Linux 2.Platform AIX 2 AIX 4.5. first and last policies assigned.4.168.0 OSF1 V3.0.14-5.47. detect_anomalies 30 .5.3) MacOS (version unknown) NCD Thin Clients OpenBSD (version unknown) OpenBSD (version unknown) OpenVMS.7.2.5.5.9.4.2 IRIX 6.0.4 SunOS 5.7-10 Linux 2.20 HP-UX 11.10 Linux 2. Packets that don’t fall within the address requirements of the first two engines automatically fall through to the third one.1 OS/2 (version unknown) OSF1 V3.1-7.0/24.9-31SGI 1.0.10smp Linux 2.0.172.00 IRIX 4.0/24 policy first.3 IRIX64 6.2smp Linux 2.19-6.2.8 Tru64 Unix V5.1. bind_to [10. The first two engines are bound to specific IP address ranges and the last one applies to all other traffic. bind_to 192.3 8.0A.16-3 Linux 2.5F IRIX 6.2.1.6.2.8.4 (RedHat 7.4 Linux 2.3 Cisco IOS FreeBSD HP JetDirect (printer) HP-UX B.
identify sessions that may be ignored (large data transfers. etc) that can later be used by rules. For example. and the policies supported by Stream5 are the results of extensive research with many target operating systems.2. like Frag3. The methods for handling overlapping data. data received outside the TCP window.Frag 3 Alert Output Frag3 is capable of detecting eight different types of anomalies. Its event output is packet-based so it will work with all output modes of Snort. [max_tcp <number>]. a few operating systems allow data in TCP SYN packets. etc are configured via the detect anomalies option to the TCP configuration. \ [track_icmp <yes|no>]. [max_icmp <number>]. the rule ’flow’ and ’flowbits’ keywords are usable with TCP as well as UDP traffic. UDP sessions are established as the result of a series of UDP packets from two end points via the same set of ports. preprocessor stream5_global: \ [track_tcp <yes|no>]. [max_udp <number>]. It is capable of tracking sessions for both TCP and UDP.2 Stream5 The Stream5 preprocessor is a target-based TCP reassembly module for Snort. \ [track_udp <yes|no>]. Data on SYN. \ [prune_log_max <bytes>] 31 . Some of these anomalies are detected on a per-target basis. TCP Timestamps. while others do not. Read the documentation in the doc/signatures directory with filenames that begin with “123-” for information on the different event types. Stream5 Global Configuration Global settings for the Stream5 preprocessor. FIN and Reset sequence numbers. Target-Based Stream5. which effectively terminate a TCP or UDP session. With Stream5. Stream API Stream5 fully supports the Stream API. \ [memcap <number bytes>]. ICMP messages are tracked for the purposes of checking for unreachable and service unavailable messages. \ [flush_on_alert]. 2. etc. Transport Protocols TCP sessions are identified via the classic TCP ”connection”. and update the identifying information about the session (application protocol. other protocol normalizers/preprocessors to dynamically configure reassembly behavior as required by the application layer protocol. such as data on SYN packets. direction. [show_rebuilt_packets]. introduces target-based actions for handling of overlapping data and other TCP anomalies. Anomaly Detection TCP protocol anomalies. etc).
The default is ”8388608” (8MB). preprocessor stream5_tcp: \ [bind_to <ip_addr>]. Print/display packet after rebuilt (for debugging). [min_ttl <number>]. The default is ”yes”. \ [policy <policy_id>]. \ [overlap_limit <number>]. \ [ports <client|server|both> <all|number [number]*>]. maximum is ”1052672”. maximum is ”1073741824” (1GB). minimum is ”0” (unlimited). the minimum is ”1”. [detect_anomalies]. and the maximum is ”86400” (approximately 1 day). \ [dont_store_large_packets]. per policy that is bound to an IP address or network. [dont_reassemble_async]. The default is set to any. The default is ”1048576” (1MB). This can have multiple occurances. Print a message when a session terminates that was consuming more than the specified number of bytes. Track sessions for UDP. [max_window <number>]. minimum is ”1”. Maximum simultaneous ICMP sessions tracked. [timeout <number secs>]. The default is ”yes”. other than by the memcap. [use_static_footprint_sizes]. Maximum simultaneous UDP sessions tracked. Memcap for TCP packet storage. maximum is ”1052672”. minimum is ”32768” (32KB). maximum is not bounded. The default is ”yes”. The default is ”256000”. minimum is ”1”. The default is set to off. Flush a TCP stream when an alert is generated on that stream. 32 . The default is ”64000”. maximum is ”1052672”. \ [check_session_hijacking]. [max_queued_segs <number segs>]. The default is ”30”. Backwards compatibilty. Session timeout. \ [require_3whs [<number secs>]]. The default is ”128000”. The default is set to off. One default policy must be specified. Stream5 TCP Configuration Provides a means on a per IP address target to configure TCP policy. Maximum simultaneous TCP sessions tracked. Track sessions for ICMP. minimum is ”1”. \ [max_queued_bytes <bytes>]. \ [ignore_any_rules] Option bind to <ip addr> timeout <num seconds> Description IP address or network for this policy. and that policy is not bound to an IP address or network.
This option is intended to prevent a DoS against Stream5 by an attacker using an abnormally large window. so using a value near the maximum is discouraged.x and newer linux Linux 2. That is the highest possible TCP window per RFCs. The default is set to off. The default is ”0” (unlimited). and the maximum is ”86400” (approximately 1 day). there are no checks performed. Alerts are generated (per ’detect anomalies’ option) for either the client or server when the MAC address for one side or the other does not match. Use static values for determining when to build a reassembled packet to allow for repeatable tests.4 and newer old-linux Linux 2. bsd FresBSD 4. The default is ”1”. This option should not be used production environments. Detect and alert on TCP protocol anomalies. The default is set to off. The optional number of seconds specifies a startup timeout. The default is ”0” (don’t consider existing sessions established). This allows a grace period for existing sessions to be considered established during that interval immediately after Snort is started. the minimum is ”0”.3 and newer Minimum TTL. OpenBSD 3.x and newer. Limits the number of overlapping packets per session. Check for TCP session hijacking.x and newer hpux HPUX 11 and newer hpux10 HPUX 10 irix IRIX 6 and newer macos MacOS 10.x and newer. The default is set to off. The default is set to off. The policy id can be one of the following: Policy Name Operating Systems. and the maximum is ”1073725440” (65535 left shift 14). The default is set to queue packets. and the maximum is ”255”. Don’t queue packets for reassembly if traffic has not been seen in both directions. The default is ”0” (unlimited). Windows XP. Establish sessions only on completion of a SYN/SYN-ACK/ACK handshake. Windows 95/98/ME win2003 Windows 2003 Server vista Windows Vista solaris Solaris 9. Using this option may result in missed attacks. Performance improvement to not queue large packets in reassembly buffer. the minimum is ”1” and the maximum is ”255”. Default is ”1048576” (1MB). the minimum is ”0”. A message is written to console/syslog when this limit is enforced. with a non-zero minimum of ”1024”. and a maximum of ”1073741824” (1GB). If an ethernet layer is not part of the protocol stack received by Snort. last Favor first overlapped segment. This check validates the hardware (MAC) address from both sides of the connect – as established on the 3-way handshake against subsequent packets received on the session. first Favor first overlapped segment. A value of ”0” means unlimited. NetBSD 2. Limit the number of bytes queued for reassembly on a given TCP session to bytes. Maximum TCP window allowed. 33 .2 and earlier windows Windows 2000. The default is set to off. the minimum is ”0”.
there should be only one occurance of the UDP configuration. Stream5 UDP Configuration Configuration for UDP session tracking. the ignore any rules option will be disabled in this case. if a UDP rule that uses any -> any ports includes either flow or flowbits.max queued segs <num> ports <client|server|both> <all|number(s)> ignore any rules Limit the number of segments queued for reassembly on a given TCP session. This is a performance improvement and may result in missed attacks. the minimum is ”1”. if a UDP rule specifies destination port 53. Don’t process any -> any (ports) rules for UDP that attempt to match payload if there are no port specific rules for the src or destination port. The default is ”off”. or byte test options. This is a performance improvement and may result in missed attacks. and a maximum of ”1073741824” (1GB). preprocessor stream5_udp: [timeout <number secs>]. This option can be used only in default policy. but NOT to any other source or destination port. The default is ”2621”. ! △NOTE With the ignore any rules option. only those with content. the ’ignored’ any -> any rule will be applied to traffic to/from port 53. For example. The default settings are ports client 21 23 25 42 53 80 110 111 135 136 137 139 143 445 513 514 1433 1521 2401 3306. Rules that have flow or flowbits will never be ignored. 34 . a UDP rule will be ignored except when there is another port specific rule that may be applied to the traffic. The minimum port allowed is ”1” and the maximum allowed is ”65535”. If only a bind to option is used with no other options that TCP policy uses all of the default values. A list of rule SIDs affected by this option are printed at Snort’s startup. or byte test options. [ignore_any_rules] Option timeout <num seconds> ignore any rules Description Session timeout. server. Rules that have flow or flowbits will never be ignored. A value of ”0” means unlimited. ! △NOTE With the ignore any rules option. PCRE. and the maximum is ”86400” (approximately 1 day). Using this does not affect rules that look at protocol headers. Since there is no target based binding. A message is written to console/syslog when this limit is enforced. only those with content. Because of the potential impact of disabling a flowbits rule. Using this does not affect rules that look at protocol headers. ! △NOTE If no options are specified for a given TCP policy. This can appear more than once in a given config. the ignore any rules option is effectively pointless. Specify the client. with a non-zero minimum of ”2”. The default is ”off”. PCRE. The default is ”30”. that is the default TCP policy. derived based on an average size of 400 bytes. or both and list of ports in which to perform reassembly. Don’t process any -> any (ports) rules for TCP that attempt to match payload if there are no port specific rules for the src or destination port.
Stream5 ICMP Configuration Configuration for ICMP session tracking. Limit on number of overlapping TCP packets reached 8. Window size (after scaling) larger than policy allows 7. Data after Reset packet 35 stream5_global: track_tcp yes stream5_tcp: bind_to 192. It is not ICMP is currently turned on by default. ! △NOTE untested. all of which relate to TCP anomalies. This example configuration is the default configuration in snort. preprocessor stream5_icmp: [timeout <number secs>] Option timeout <num seconds> Description Session timeout.0/24. It is capable of alerting on 8 (eight) anomalies. the minimum is ”1”. use_static_footprint_sizes preprocessor stream5_udp: \ ignore_any_rules 2. SYN on established session 2. TCP Timestamp is outside of PAWS window 5. there should be only one occurance of the ICMP configuration. preprocessor stream5_global: \ max_tcp 8192. track_tcp yes.0/24. The default is ”30”. with all other traffic going to the default policy of Solaris. This configuration maps two network segments to different OS policies. track_icmp no preprocessor stream5_tcp: \ policy first. The list of SIDs is as follows: 1. Since there is no target based binding.1.conf and can be used for repeatable tests of stream reassembly in readback mode.1. one for Windows and one for Linux. policy linux stream5_tcp: policy solaris .1. Example Configurations 1. preprocessor preprocessor preprocessor preprocessor Alerts Stream5 uses generator ID 129. overlap adjusted size less than/equal 0 6. and the maximum is ”86400” (approximately 1 day). in minimal code form and is NOT ready for use in production networks. track_udp yes. Data sent on stream not accepting data 4.168. policy windows stream5_tcp: bind_to 10. There are no anomalies detected relating to UDP or ICMP. Data on SYN packet 3. Bad segment.
In the nature of legitimate network communications. so we track this type of scan through the scanned host. this phase would not be necessary. one host scans multiple ports on another host. This is the traditional place where a portscan takes place. This is used to evade an IDS and obfuscate command and control hosts. This tactic helps hide the true identity of the attacker. One of the most common portscanning tools in use today is Nmap.2. Most of the port queries will be negative. sfPortscan alerts for the following types of portsweeps: • TCP Portsweep • UDP Portsweep • IP Portsweep 36 .3 sfPortscan The sfPortscan module. of the current portscanning techniques. ! △NOTE Negative queries will be distributed among scanning hosts. an attacker determines what types of network protocols or services a host supports.2. is designed to detect the first phase in a network attack: Reconnaissance. sfPortscan will currently alert for the following types of Nmap scans: • TCP Portscan • UDP Portscan • IP Portscan These alerts are for one→one portscans. and rarer still are multiple negative responses within a given amount of time. otherwise. This phase assumes the attacking host has no prior knowledge of what protocols or services are supported by the target. if not all. In the Reconnaissance phase.. Distributed portscans occur when multiple hosts query one host for open services. negative responses from hosts are rare. most queries sent by the attacker will be negative (meaning that the service ports are closed). As the attacker has no beforehand knowledge of its intended target. developed by Sourcefire. only the attacker has a spoofed source address inter-mixed with the real scanning address. sfPortscan alerts for the following types of distributed portscans: • TCP Distributed Portscan • UDP Distributed Portscan • IP Distributed Portscan These are many→one portscans. which are the traditional types of scans. sfPortscan was designed to be able to detect the different types of scans Nmap can produce. since most hosts have relatively few services available. Nmap encompasses many.
such as NATs. This usually occurs when a new exploit comes out and the attacker is looking for a specific service. but tags based on the orginal scan alert. Stream gives portscan direction in the case of connectionless protocols like ICMP and UDP. Active hosts. It’s also a good indicator of whether the alert is just a very active legitimate host. Open port events are not individual alerts. ! △NOTE The characteristics of a portsweep scan may not result in. as described in Section 2. The parameters you can use to configure the portscan module are: 1. On TCP scan alerts. can trigger these alerts because they can send out many connection attempts within a very small amount of time. we will most likely not see many negative responses. sfPortscan will only track open ports after the alert has been triggered.2. You should enable the Stream preprocessor in your snort. if an attacker portsweeps a web farm for port 80.conf. One host scans a single port on multiple hosts. On TCP sweep alerts however.• ICMP Portsweep These alerts are for one→many portsweeps. For example. sfPortscan only generates one alert for each host pair in question during the time window (more on windows below). sfPortscan will also display any open ports that were scanned. sfPortscan Configuration Use of the Stream5 preprocessor is required for sfPortscan.2. A filtered alert may go off before responses from the remote hosts are received. proto <protocol> Available options: • TCP 37 .
etc). ignore scanned <ip1|ip2/cidr[ [port|port2-port3]]> Ignores the destination of scan alerts. proxies. 7.“High” alerts continuously track hosts on a network using a time window to evaluate portscan statistics for that host. 38 .“Low” alerts are only generated on error packets sent from the target host. The parameter is the same format as that of watch ip. watch ip <ip1|ip2/cidr[ [port|port2-port3]]> Defines which IPs. ignore scanners <ip1|ip2/cidr[ [port|port2-port3]]> Ignores the source of scan alerts. and so will generate filtered scan alerts. If file does not contain a leading slash.“Medium” alerts track connection counts. 5. The list is a comma separated list of IP addresses. 9. This can lead to false alerts. IP address using CIDR notation. This setting is based on a static time window of 60 seconds. sense level <level> Available options: • low . and specific ports on those hosts to watch. The parameter is the same format as that of watch ip. afterwhich this window is reset.• UDP • IGMP • ip proto • all 2. • high . This setting may false positive on active hosts (NATs. A ”High” setting will catch some slow scans because of the continuous monitoring. networks. this can lead to false alerts. and because of the nature of error responses. ports are specified after the IP address/CIDR using a space and can be either a single port or a range denoted by a dash. this file will be placed in the Snort config dir. However. scan type <scan type> Available options: • portscan • portsweep • decoy portscan • distributed portscan • all 3. detect ack scans This option will include sessions picked up in midstream by the stream module. 8. IPs or networks not falling into this range are ignored if this option is used. especially under heavy load with dropped packets. • medium . this setting should see very few false postives. this setting will never trigger a Filtered Scan alert because of a lack of error responses. 6. Optionally. which is why the option is off by default. especially under heavy load with dropped packets. logfile <file> This option will output portscan events to the file specified. 4. which is necessary to detect ACK scans. but is very sensitive to active hosts. DNS caches. However. This most definitely will require the user to tune sfPortscan. include midstream This option will include sessions picked up in midstream by Stream5. which is why the option is off by default. so the user may need to deploy the use of Ignore directives to properly tune this directive.
168.3. connection count. The characteristics of the packet are: Src/Dst MAC Addr == MACDAD IP Protocol == 255 IP TTL == 0 Other than that. The open port information is stored in the IP payload and contains the port that is open. Log File Output Log file output is displayed in the following format. the packet looks like the IP portion of the packet that caused the portscan alert to be generated.200 bytes. and port range. then the user won’t see open port alerts. IP count. This includes any IP options.169. IP range. The sfPortscan alert output was designed to work with unified packet logging. snort generates a pseudo-packet and uses the payload portion to store the additional portscan information of priority count. etc. port count.168. This means that if an output system that doesn’t print tagged packets is used.4 Port/Proto Count: 200 Port/Proto Range: 20:47557 If there are open ports on the target.603880 event_id: 2 192.168.169.168. The payload and payload size of the packet are equal to the length of the additional portscan information that is logged. Open port alerts differ from the other portscan alerts. one or more additional tagged packet(s) will be appended: Time: 09/08-15:07:31. so it is possible to extend favorite Snort GUIs to display portscan alerts and the additional information in the IP payload using the above packet characteristics. because open port alerts utilize the tagged packet output system.603881 event_ref: 2 39 .3 -> 192.5 (portscan) TCP Filtered Portscan Priority Count: 0 Connection Count: 200 IP Count: 2 Scanner IP Range: 192. and explained further below: Time: 09/08-15:07:31.169. The size tends to be around 100 .169.
Event id/Event ref These fields are used to link an alert with the corresponding Open Port tagged packet 2. 6. Depending on the type of alert that the host generates. Tuning sfPortscan The most important aspect in detecting portscans is tuning the detection engine for your network(s). syslog servers. DNS cache servers.192. If the host is generating portscan alerts (and is the host that is being scanned). but be aware when first tuning sfPortscan for these IPs. sfPortscan will watch all network traffic. 3. 40 . For active hosts this number will be high regardless. Scanned/Scanner IP Range This field changes depending on the type of alert. and nfs servers. If the host continually generates these types of alerts. IP Range. 3. 4. Port Count. and Port Range to determine false positives. Portsweep (one-to-many) scans display the scanned IP range.168. Use the watch ip. and is more of an estimate for others. Portscans (one-to-one) display the scanner IP. Some of the most common examples are NAT IPs.5 (portscan) Open Port Open Port: 38458 1. Make use of the Priority Count. 2. Many times this just indicates that a host was very active during the time period in question. 5. We use this count (along with IP Count) to determine the difference between one-to-one portscans and one-to-one decoys. When determining false positives.169.3 -> 192. add it to the ignore scanners list or use a lower sensitivity level. the alert type is very important. So be much more suspicious of filtered portscans. add it to the ignore scanned option. Priority Count Priority Count keeps track of bad responses (resets. unreachables). and ignore scanned options. Whether or not a portscan was filtered is determined here. IP Count. this is a low number. Connection Count. Most of the false positives that sfPortscan may generate are of the filtered scan alert type. and one-to-one scans may appear as a distributed scan. Connection Count Connection Count lists how many connections are active on the hosts (src or dst). the analyst will know which to ignore it as. then add it to the ignore scanners option. Port Count Port Count keeps track of the last port contacted and increments this number when that changes. This is accurate for connection-based protocols. High connection count and low priority count would indicate filtered (no response received from target).168. the more bad responses have been received. ignore scanners. For one-to-one scans. If the host is generating portsweep events. The analyst should set this option to the list of Cidr blocks and IPs that they want to watch. sfPortscan may not generate false positives for these types of hosts. IP Count IP Count keeps track of the last IP to contact a host. The ignore scanners and ignore scanned options come into play in weeding out legitimate hosts that are very active on your network. Filtered scan alerts are much more prone to false positives. It’s important to correctly set these options. and increments the count if the next IP is different. The watch ip option is easy to understand. Here are some tuning tips: 1.169. If no watch ip is defined. The higher the priority count.
The easiest way to determine false positives is through simple ratio estimations. For portscans. but for now the user must manually do this. In the future.). indicating that the scanning host connected to few ports but on many hosts. You get the best protection the higher the sensitivity level. By default. This includes: 41 . but it’s also important that the portscan detection engine generate alerts that the analyst will find informative. this ratio should be low. this ratio should be high. lower the sensitivity level.5 Performance Monitor This preprocessor measures Snort’s real-time and theoretical maximum performance. it will only process client-side traffic. If stream5 is enabled. If all else fails. The reason that Priority Count is not included. where statistics get printed to the specified file name.2. These responses indicate a portscan and the alerts generated by the low sensitivity level are highly accurate and require the least tuning. it should have an output mode enabled. If none of these other tuning techniques work or the analyst doesn’t have the time for tuning. The low sensitivity level does not catch filtered scans. For portscans.4 RPC Decode The rpc decode preprocessor normalizes RPC multiple fragmented records into a single un-fragmented record. this ratio should be high. For portsweeps. it runs against traffic on ports 111 and 32771. For portsweeps. Don’t alert when a single fragment record exceeds the size of one packet.The portscan alert details are vital in determining the scope of a portscan and also the confidence of the portscan. this ratio should be low. 2. 4. It does this by normalizing the packet into the packet buffer.2. we hope to automate much of this analysis in assigning a scope level and confidence level. Snort’s real-time statistics are processed. The low sensitivity level only generates alerts based on error responses. The following is a list of ratios to estimate and the associated values that indicate a legimite scan and not a false positive. either “console” which prints statistics to the console window or “file” with a file name. Whenever this preprocessor is turned on. For portsweeps. Format preprocessor rpc_decode: \ <ports> [ alert_fragments ] \ [no_alert_multiple_requests] \ [no_alert_large_fragments] \ [no_alert_incomplete] Option alert fragments no alert multiple requests no alert large fragments no alert incomplete Description Alert on any fragmented RPC record. the higher the better. For portscans. since these are more prone to false positives. This indicates that each connection was to a different port. this ratio should be high and indicates that the scanned host’s ports were connected to by fewer IPs. Don’t alert when there are multiple records in one packet. This indicates that there were many connections to the same port. this ratio should be low. 2. Connection Count / Port Count: This ratio indicates an estimated average of connections per port. Don’t alert when the sum of fragmented records exceeds one packet. is because the priority count is included in the connection count and the above comparisons take that into consideration. lower the sensitivity level. Connection Count / IP Count: This ratio indicates an estimated average of connections per IP. By default. . Both of these directives can be overridden on the command line with the -Z or --perfmon-file options. • max file size . HTTP Inspect works on both client requests and server responses. HTTP Inspect will decode the buffer. This boosts performance.Turns on the theoretical maximum performance that Snort calculates given the processor speed and current performance. • events . The minimum is 4096 bytes and the maximum is 2147483648 bytes (2GB). and will be fooled if packets are not reassembled. and normalize the fields. • time . Given a data buffer.6 HTTP Inspect HTTP Inspect is a generic HTTP decoder for user applications. since checking the time sample reduces Snort’s performance. reset is used. Before the file exceeds this size.Defines the maximum size of the comma-delimited file. You may also use snortfile which will output into your defined Snort log directory. it will be rolled into a new date stamped file of the format YYYY-MM-DD.Represents the number of seconds between intervals.profile max console pktcnt 10000 preprocessor perfmonitor: \ time 300 file /var/tmp/snortstat pktcnt 10000 2. This means that HTTP Inspect looks for HTTP fields on a packet-by-packet basis. • atexitonly . Not all statistics are output to this file. since many operating systems don’t keep accurate kernel statistics for multiple CPUs.Defines which type of drop statistics are kept by the operating system.Prints statistics in a comma-delimited format to the file that is specified.Prints statistics at the console.Turns on event reporting. • file .Dump stats for entire life of Snort.Prints out statistics about the type of traffic and protocol distributions that Snort is seeing. • max . where x will be incremented each time the comma delimiated file is rolled over. this is 10000. • accumulate or reset .Adjusts the number of packets to process before checking for the time sample. The current version of HTTP Inspect only handles stateless processing. This works fine when there is 44 . This is only valid for uniprocessor machines. • pktcnt .x. By default. This shows the user if there is a problem with the rule set that they are running. By default. followed by YYYY-MM-DD. The default is the same as the maximum. Examples preprocessor perfmonitor: \ time 30 events flow file stats. find HTTP fields. This option can produce large amounts of output. • console ).
which should allow the user to emulate any type of web server. you’ll get an error if you try otherwise. For US servers. HTTP Inspect has a very “rich” user configuration.c. Global Configuration The global configuration deals with configuration options that determine the global functioning of HTTP Inspect. Blind firewall proxies don’t count.map and should be used if no other codepoint map is available. Don’t turn this on if you don’t have a default server configuration that encompasses all of the HTTP server ports that your users might access. The iis unicode map is a required configuration parameter. Configuration 1. iis unicode map <map filename> [codemap <integer>] This is the global iis unicode map file. but for right now. A Microsoft US Unicode codepoint map is provided in the Snort source etc directory by default. and alerts if HTTP traffic is seen. So. please only use this feature with traditional proxy environments. The map file can reside in the same directory as snort. the codemap is usually 1252.. It is called unicode. Users can configure individual HTTP servers with a variety of options. 2. The iis unicode map file is a Unicode codepoint map which tells HTTP Inspect which codepage to use when decoding Unicode characters. then you may get a lot of proxy alerts.another module handling the reassembly. there are two areas of configuration: global and server. which is available at. Future versions will have a stateful processing mode which will hook into various reassembly modules. 3. In the future. but there are limitations in analyzing the protocol. we want to limit this to specific networks so it’s more useful. ! △NOTE Remember that this configuration is for the global IIS Unicode map. proxy alert This enables global alerting on HTTP server proxy usage. A tool is supplied with Snort to generate custom Unicode maps--ms unicode generator. this inspects all network traffic.conf or be specified via a fully-qualified path to the map file. By configuring HTTP Inspect servers and enabling allow proxy use.org/ dl/contrib/.snort. Within HTTP Inspect. detect anomalous servers This global configuration option enables generic HTTP server traffic inspection on non-HTTP configured ports. Please note that if users aren’t required to configure web proxy use. you will only receive proxy use alerts for web users that aren’t using the configured proxies or are using a rogue proxy server. individual servers can reference their own IIS Unicode map. 45 .
the only difference being that specific IPs can be configured.3. We alert on the more serious forms of evasions.1. the only difference being that multiple IPs can be specified via a space separated list. all The all profile is meant to normalize the URI using most of the common tricks available. apache.1 10. This is a great profile for detecting all types of attacks. whether set to ‘yes’ or ’no’.1. profile all sets the configuration options described in Table 2. The ‘yes/no’ argument does not specify whether the configuration option itself is on or off.1 profile all ports { 80 } Configuration by Multiple IP Addresses This format is very similar to “Configuration by IP Address”. regardless of the HTTP server. Example IP Configuration preprocessor http_inspect_server: \ server 10.Example Global Configuration preprocessor http_inspect: \ global iis_unicode_map unicode. This argument specifies whether the user wants the configuration option to generate an HTTP Inspect alert or not. HTTP normalization will still occur. and rules based on HTTP traffic will still trigger. profile <all|apache|iis|iis5 0|iis4 0> Users can configure HTTP Inspect by using pre-defined HTTP server profiles. Most of your web servers will most likely end up using the default configuration.2.1.map 1252 Server Configuration There are two types of server configurations: default and by IP address.1. 1.0/24 } profile all ports { 80 } Server Configuration Options Important: Some configuration options have an argument of ‘yes’ or ‘no’.2. iis5 0. Example Default Configuration preprocessor http_inspect_server: \ server default profile all ports { 80 } Configuration by IP Address This format is very similar to “default”. There are five profiles available: all. 46 . Default This configuration supplies the default server configuration for any server that is not individually configured. but are not required for proper operation. only the alerting functionality. Profiles allow the user to easily configure the preprocessor for a certain type of server. and iis4 0. Example Multiple IP Configuration preprocessor http_inspect_server: \ server { 10. There is a limit of 40 IP addresses or CIDR notations per http inspect server line. In other words. 1-A. iis.
bare-byte encoding. like IIS does. Apache also accepts tabs as whitespace. iis4 0.4: Options for the apache Profile Option Setting server flow depth 300 client flow depth 300 post depth 0 chunk encoding alert on chunks larger than 500000 bytes ascii decoding on.4.0 and IIS 5.5. alert on utf 8 encoding. Table 2. number of headers not checked 1-C. etc. %u encoding. alert off multiple slash on. backslashes. profile iis sets the configuration options described in Table 2. header length not checked max headers 0. alert on %u decoding on. alert off non strict url parsing on tab uri delimiter is set max header length 0. alert off webroot on. alert on iis backslash on. apache The apache profile is used for Apache web servers.Table 2. 1-D. there was a double decoding vulnerability.0. alert on bare byte decoding on. double decoding. alert off apache whitespace on. profile apache sets the configuration options described in Table 2. So that means we use IIS Unicode codemaps for each server. alert off webroot on. alert off iis delimiter on. iis5 0 In IIS 4. alert on non strict URL parsing on tab uri delimiter is set max header length 0. iis The iis profile mimics IIS servers. alert off double decoding on. alert off directory normalization on. alert on iis unicode codepoints on. 47 . alert off directory normalization on. This differs from the iis profile by only accepting UTF-8 standard Unicode encoding and not accepting backslashes as legitimate slashes. alert off multiple slash on. These two profiles are identical to iis. alert on apache whitespace on. number of headers not checked 1-B. header length not checked max headers 0.
alert off directory normalization on.Table 2. alert off apache whitespace non strict URL parsing on max header length 0. alert off directory normalization on. Double decode is not supported in IIS 5. alert on %u decoding on.6: Default HTTP Inspect Options Option Setting port 80 server flow depth 300 client flow depth 300 post depth 0 chunk encoding alert on chunks larger than 500000 bytes ascii decoding on. number of headers not checked except they will alert by default if a URL has a double encoding. alert on non strict URL parsing on max header length 0. default. alert on bare byte decoding on. alert on iis backslash on. alert off multiple slash on. alert off utf 8 encoding on. 1-E. alert on apache whitespace on. header length not checked max headers 0. alert on iis unicode codepoints on. alert off webroot on. alert off iis delimiter on. alert off multiple slash on. so it’s disabled by default. alert off iis delimiter on.6. alert off webroot on. header length not checked max headers 0. no profile The default options used by HTTP Inspect do not use a profile and are described in Table 2. Table 2. alert on double decoding .1 and beyond. alert on iis backslash on.
So. A small percentage of Snort rules are targeted at this traffic and a small flow depth value may cause false negatives in some of these rules. or the content that is likely to be in the first hundred or so bytes of non-header data.c. use the SSL preprocessor. To ignore HTTPS traffic. 49 . 5. >]} This is how the user configures which ports to decode on the HTTP server. ports {<port> [<port>< .• • • • • • • • • client flow depth post depth no alerts inspect uri only oversize dir length normalize headers normalize cookies max header length max headers These options must be specified after the profile option. But the ms unicode generator program tells you which codemap to use for you server. 3. Most of these rules target either the HTTP header. This value can be set from -1 to 1460. Example preprocessor http_inspect_server: \ server 1. to get the specific Unicode mappings for an IIS web server.snort. HTTPS traffic is encrypted and cannot be decoded with HTTP Inspect. a value of 0 causes Snort to inspect all HTTP server payloads defined in ports (note that this will likely slow down IDS performance). However. post depth <integer> This specifies the amount of data to inspect in a client post message. You can select the correct code page by looking at the available code pages that the ms unicode generator outputs. it’s the ANSI code page. The value can be set from 0 to 65495. the user needs to specify the file that contains the IIS Unicode map and also specify the Unicode map to use. Executing this program generates a Unicode map for the system that it was run on. you run this program on that server and use that Unicode map in this configuration. Values above 0 tell Snort the number of bytes to inspect in the first packet of the server response. and has a default value of 300..1.1 profile all ports { 80 3128 } 2. A value of -1 causes Snort to ignore all server side traffic for ports defined in ports. 4. 6. but your mileage may vary. server flow depth <integer> This specifies the amount of server response payload to inspect.. client flow depth <integer> This specifies the amount of raw client request payload to inspect. which will be deprecated in a future release. This option significantly increases IDS performance because we are ignoring a large part of the network traffic (HTTP server response payloads).1. It is similar to server flow depth (above). This increases the perfomance by inspecting only specified bytes in the post message.org/dl/contrib/ directory. This program is located on the Snort. iis unicode map <map filename> codemap <integer> The IIS Unicode map is generated by the program ms unicode generator. this is usually 1252. For US servers.org web site at. The default value is 0. Inversely. ! △NOTE server flow depth is the same as the old flow depth option. When using this option. Headers are usually under 300 bytes long. It primarily eliminates Snort fro inspecting larger HTTP Cookies that appear at the end of many client request Headers.
it seems that all types of iis encoding is done: utf-8 unicode.>]} This option lets users receive an alert if certain non-RFC chars are used in a request URI. ASCII encoding is also enabled to enforce correct behavior. this option will not work. ascii <yes|no> The ascii decode option tells us whether to decode encoded ASCII chars. because you could configure it to say. When utf 8 is enabled. 9. because base36 won’t work. This option is based on info from:. etc. so for any Apache servers.k. 10.or. 12. and %u. alert on all ‘/’ or something like that. a user may not want to see null bytes in the request URI and we can alert on that. Apache uses this standard. If %u encoding is enabled. non rfc char {<byte> [<byte . 8. doing decodes in each one. iis unicode uses the default codemap. Don’t use the %u option. You have to use the base36 option with the utf 8 option. An ASCII character is encoded like %u002f = /. utf 8 <yes|no> The utf-8 decode option tells HTTP Inspect to decode standard UTF-8 Unicode sequences that are in the URI. ASCII decoding is also enabled to enforce correct functioning. base36 <yes|no> This is an option to decode base36 encoded chars. When base36 is enabled. 50 . The iis unicode option handles the mapping of non-ASCII codepoints that the IIS server accepts and decodes normal UTF-8 requests.patch. because there are no legitimate clients that encode UTF-8 this way since it is non-standard. because we are not aware of any legitimate clients that use this encoding.rim. and then UTF-8 is decoded in the second stage. To alert on UTF-8 decoding. It is normal to see ASCII encoding usage in URLs. If no iis unicode map is specified before or after this option. because it is seen mainly in attacks and evasion attempts. you must enable also enable utf 8 yes.jp/˜ shikap/patch/spp\_http\_decode. the default codemap is used.a %2f = /. When iis unicode is enabled. double decode <yes|no> The double decode option is once again IIS-specific and emulates IIS functionality. like %uxxxx... the following encodings are done: ascii. When double decode is enabled. This abides by the Unicode standard and only uses % encoding. ASCII and UTF-8 decoding are also enabled to enforce correct decoding. 11. %2e = . This value can most definitely be ASCII. How the %u encoding scheme works is as follows: the encoding scheme is started by a %u followed by 4 characters. as all non-ASCII values have to be encoded with a %. We leave out utf-8 because I think how this works is that the % encoded utf-8 is decoded to the Unicode byte in the first pass. ascii. It’s flexible. The xxxx is a hex-encoded value that correlates to an IIS Unicode codepoint. %u002e = . In the first pass. How this works is that IIS does two passes through the request URI. make sure you have this option turned on. The alert on this decoding should be enabled. If there is no iis unicode map option specified with the server config. so be careful. So it is most likely someone trying to be covert. You should alert on %u encodings. this is really complex and adds tons of different encodings for one character.7. Bare byte encoding allows the user to emulate an IIS server and interpret non-standard encodings correctly. u encode <yes|no> This option emulates the IIS %u encoding scheme. Please use this option with care. etc. bare byte <yes|no> Bare byte encoding is an IIS trick that uses non-ASCII characters as valid values when decoding UTF-8 values. Anyway. As for alerting.yk. and %u. so ASCII is also enabled to enforce correct decoding.. bare byte. In the second pass.. you may be interested in knowing when you have a UTF-8 encoded URI. a. so it is recommended that you disable HTTP Inspect alerting for this option. 14. For instance. iis unicode <yes|no> The iis unicode option turns on the Unicode codepoint mapping. bare byte. 13. You should alert on the iis unicode option. This is not in the HTTP standard. but this will be prone to false positives as legitimate web clients use this type of encoding.
18. apache whitespace <yes|no> This option deals with the non-RFC standard of using tab for a space delimiter. specify no.” 17. then configure with a yes. non strict This option turns on non-strict URI parsing for the broken way in which Apache servers will decode a URI. pipeline requests are inspected for attacks. This picks up the Apache chunk encoding exploits. we always take this as standard since the most popular web servers accept it. otherwise. so something like: “foo/////////bar” get normalized to “foo/bar. Since this is common. and is a performance enhancement if needed. directory <yes|no> This option normalizes directory traversals and self-referential directories. pipeline requests are not decoded and analyzed per HTTP protocol field. but may also be false positive prone.15. The non strict option assumes the URI is between the first and second space even if there is no valid HTTP identifier after the second space. but when this option is enabled.” If you want an alert when multiple slashes are seen. 20. and may also alert on HTTP tunneling that uses chunk encoding. 16. otherwise. iis backslash <yes|no> Normalizes backslashes to slashes. The directory: /foo/fake\_dir/. enable this option. This is again an IIS emulation. no pipeline req This option turns HTTP pipeline decoding off. 19..html alsjdfk alsj lj aj la jsj s\n”. 21. Apache uses this. since some web sites refer to files using directory traversals. multi slash <yes|no> This option normalizes multiple slashes in a row. 51 . Alerts on this option may be interesting. 22./bar gets normalized to: /foo/bar If you want to configure an alert. So a request URI of “/foo\bar” gets normalized to “/foo/bar. chunk length <non-zero positive integer> This option is an anomaly detector for abnormally large chunk sizes. iis delimiter <yes|no> This started out being IIS-specific. so if the emulated web server is Apache. but Apache takes this non-standard delimiter was well. It is only inspected with the generic pattern matching. use no. But you can still get an alert on this option. This alert may give false positives. Only use this option on servers that will accept URIs like this: ”get /index. specify yes./bar gets normalized to: /foo/bar The directory: /foo/. By default.
This generates much fewer false positives than the directory option. If the proxy alert keyword is not enabled. multi-slash.0\r\n\r\n No alert will be generated when inspect uri only is enabled. content: "foo". directory. 25. specify an integer argument to max header length of 1 to 65535. It’s important to note that if this option is used without any uricontent rules. Whether this option is on or not. This alert is off by default. no alerts This option turns off all alerts that are generated by the HTTP Inspect preprocessor module. inspect uri only This is a performance optimization. webroot <yes|no> This option generates an alert when a directory traversal traverses past the web server root directory. The allow proxy use keyword is just a way to suppress unauthorized proxy use for an authorized server. normalize headers This option turns on normalization for HTTP Header Fields. an alert is generated. 27. 24. IIS does not. If a url directory is larger than this argument size. 52 . Apache accepts tab as a delimiter. which is associated with certain web attacks.). only the URI portion of HTTP requests will be inspected for attacks. and if there are none available. It only alerts when the directory traversals go past the web server root directory. 31. Specifying a value of 0 is treated as disabling the alert. It is useful for normalizing data in HTTP Cookies that may be encoded. not including Cookies (using the same configuration parameters as the URI normalization (ie. then this option does nothing. So if you need extra performance. a tab in the URI should be treated as any other character. A good argument value is 300 characters. This has no effect on HTTP rules in the rule set. max header length <positive integer up to 65535> This option takes an integer as an argument. then no inspection will take place. The integer is the maximum length allowed for an HTTP client request header field. because it doesn’t alert on directory traversals that stay within the web server directory structure. ) and the we inspect the following URI: get /foo.23. 30. This is obvious since the URI is only inspected with uricontent rules. etc. enable this optimization. For example. the user is allowing proxy use on this server. It is useful for normalizing Referrer URIs that may appear in the HTTP Header. if we have the following rule set: alert tcp any any -> any 80 ( msg:"content". then there is nothing to inspect. allow proxy use By specifying this keyword.htm http/1. The argument specifies the max char directory length for URL directory.). 26. For IIS. This should limit the alerts to IDS evasion type attacks. etc. multi-slash. 29. No argument is specified. normalize cookies This option turns on normalization for HTTP Cookie Fields (using the same configuration parameters as the URI normalization (ie. This means that no alert will be generated if the proxy alert global keyword has been used. tab uri delimiter This option turns on the use of the tab character (0x09) as a delimiter for a URI. oversize dir length <non-zero positive integer> This option takes a non-zero positive integer as an argument. No argument is specified. directory. 28. Requests that exceed this length will cause a ”Long Header” alert. To enable. a tab is treated as whitespace if a space character (0x20) precedes it. like whisker -i 4. As this field usually contains 90-95% of the web attacks. you’ll catch most of the attacks. The inspect uri only configuration turns off all forms of detection except uricontent inspection. When enabled.
2.7 SMTP Preprocessor The SMTP preprocessor is an SMTP decoder for user applications. The alert is off by default. SMTP handles stateless and stateful processing. and TLS data. To enable.1. specify an integer argumnet to max headers of 1 to 1024. 53 . a loss of coherent stream data results in a loss of state). Requests that contain more HTTP Headers than this value will cause a ”Max Header” alert. Examples preprocessor http_inspect_server: \ server 10. It will also mark the command.1.32. data header data body sections. However maintaining correct state is dependent on the reassembly of the client side of the stream (ie. The integer is the maximum number of HTTP client request header fields. Specifying a value of 0 is treated as disabling the alert. It saves state between individual packets. max headers <positive integer up to 1024> This option takes an integer as an argument. SMTP will decode the buffer and find SMTP commands and responses. Given a data buffer.
normalize <all | none | cmds> This turns on normalization. regular mail data can be ignored for an additional performance boost. 5. max command line len <int> Alert if an SMTP command line is longer than this value. Typically. 8. which improves performance. this is relatively safe to do and can improve the performance of data inspection. SMTP command lines can be normalized to remove extraneous spaces.. Default is an empty list. this will include 25 and possibly 465. ports { <port> [<port>] . 10. 7. TLS-encrypted traffic can be ignored. ignore tls data Ignore TLS-encrypted data when processing rules. We do not alert on commands in this list. Since so few (none in the current snort rule set) exploits are against mail data.Configuration SMTP has the usual configuration items. no alerts Turn off all alerts for this preprocessor. for encrypted SMTP. Space characters are defined as space (ASCII 0x20) or tab (ASCII 0x09). } This specifies on what ports to check for SMTP data. such as port and inspection type. all checks all commands none turns off normalization for all commands. 2. valid cmds { <Space-delimited list of commands> } List of valid commands. Absence of this option or a ”0” means never alert on command line length. Absence of this option or a ”0” means never alert on response line length. . The configuration options are described below: 1. Also. In addition.. 3. RFC 2821 recommends 512 as a maximum response line length. 12. RFC 2821 recommends 1024 as a maximum data header line length. 9. Absence of this option or a ”0” means never alert on data header line length. invalid cmds { <Space-delimited list of commands> } Alert if this command is sent from client side. 4. 11. inspection type <stateful | stateless> Indicate whether to operate in stateful or stateless mode. max response line len <int> Alert if an SMTP response line is longer than this value. max header line len <int> Alert if an SMTP DATA header line is longer than this value. cmds just checks commands listed with the normalize cmds parameter. Normalization checks for more than one space character after a command. Default is an empty list. alt max command line len <int> { <cmd> [<cmd>] } Overrides max command line len for specific commands. ignore data Ignore data section of mail (except for mail headers) when processing rules. RFC 2821 recommends 512 as a maximum command line length.
FTP/Telnet will decode the stream. For the preprocessor configuration. the preprocessor actually maps RCPT and MAIL to the correct command name. 55 . print cmds List all commands understood by the preprocessor. FTP/Telnet works on both client requests and server responses. } \ } \ HELO ETRN } \ VRFY } 2. respectively. Default is enable.. 15. they are referred to as RCPT and MAIL.13. This not normally printed out with the configuration because it can print so much data. alert unknown cmds Alert if we don’t recognize command. 14. 16. Default is off.2. Within the code. normalize cmds { <Space-delimited list of commands> } Normalize this list of commands Default is { RCPT VRFY EXPN }. Drop if alerted. xlink2state { enable | disable [drop] } Enable/disable xlink2state alert.
there are four areas of configuration: Global. The default is to run FTP/Telent in stateful inspection mode. Example Global Configuration preprocessor ftp_telnet: \ global inspection_type stateful encrypted_traffic no 56 . ! △NOTE When inspection type is in stateless mode. meaning it looks for information and handles reassembled data correctly. checks for encrypted traffic will occur on every packet.FTP/Telnet has the capability to handle stateless processing. similar to that of HTTP Inspect (See 2. FTP/Telnet has a very “rich” user configuration. 2. and FTP Server. check encrypted Instructs the the preprocessor to continue to check an encrypted session for a subsequent command to cease encryption. ! △NOTE options have an argument of yes or no. The FTP/Telnet global configuration must appear before the other three areas of configuration.2. Users can configure individual FTP servers and clients with a variety of options. which should allow the user to emulate any type of FTP server or FTP Client. The presence of the option indicates the option itself is on. while the yes/no argument applies to the alerting functionality associated with that option. you’ll get an error if you try otherwise. whereas in stateful mode. This argument specifies whether the user wants Some configuration the configuration option to generate a ftptelnet alert or not.6). Global Configuration The global configuration deals with configuration options that determine the global functioning of FTP/Telnet. Within FTP/Telnet. a particular session will be noted as encrypted and not inspected any further. Configuration 1. meaning it only looks for information on a packet-bypacket basis. encrypted traffic <yes|no> This option enables detection and alerting on encrypted Telnet and FTP command channels. 3. inspection type This indicates whether to operate in stateful or stateless mode. Telnet. The following example gives the generic global configuration format: Format preprocessor ftp_telnet: \ global \ inspection_type stateful \ encrypted_traffic yes \ check_encrypted You can only have a single global configuration. FTP Client.
. 57 ... The detect anomalies option enables alerting on Telnet SB without the corresponding. Rules written with ’raw’ content options will ignore the normailzed buffer that is created when this option is in use. >]} This is how the user configures which ports to decode as telnet traffic. detect anomalies In order to support certain options. Default This configuration supplies the default server configuration for any FTP server that is not individually configured.Telnet Configuration The telnet configuration deals with configuration options that determine the functioning of the Telnet portion of the preprocessor. the telnet decode preprocessor. 2. 3. Per the Telnet RFC. 4. certain implementations of Telnet servers will ignore the SB without a cooresponding SE. SSH tunnels cannot be decoded. It is only applicable when the mode is stateful. normalize This option tells the preprocessor to normalize the telnet traffic by eliminating the telnet escape sequences. ayt attack thresh < number > This option causes the preprocessor to alert when the number of consecutive telnet Are You There (AYT) commands reaches the number specified. Most of your FTP servers will most likely end up using the default configuration. Configuration 1. subnegotiation begins with SB (subnegotiation begin) and must end with an SE (subnegotiation end). However. ports {<port> [<port>< . Telnet supports subnegotiation. This is anomalous behavior which could be an evasion case. Being that FTP uses the Telnet protocol on the control connection. It functions similarly to its predecessor. so adding port 22 will only yield false positives. and subsequent instances will override previously set values. Typically port 23 will be included. it is also susceptible to this behavior.
as well as any additional commands as needed.. outside of the default FTP command set as specified in RFC 959.1. cmd validity cmd < fmt > This option specifies the valid format for parameters of a given command. alt max param len <number> {cmd[cmd]} This specifies the maximum allowed parameter length for the specified FTP command(s). ports {<port> [<port>< .Example Default FTP Server Configuration preprocessor ftp_telnet_protocol: \ ftp server default ports { 21 } Refer to 60 for the list of options set in default ftp server configuration. Configuration by IP Address This format is very similar to “default”. Typically port 21 will be included. For example the USER command – usernames may be no longer than 16 bytes. fmt must be enclosed in <>’s and may contain the following: 58 . 5.1.. 7. print cmds During initialization. so the appropriate configuration would be: alt_max_param_len 16 { USER } 6. This may be used to allow the use of the ’X’ commands identified in RFC 775. Example IP specific FTP Server Configuration preprocessor _telnet_protocol: \ ftp server 10. For example: ftp_cmds { XPWD XCWD XCUP XMKD XRMD } 4. >]} This is how the user configures which ports to decode as FTP command channel traffic. 2. def max param len <number> This specifies the default maximum allowed parameter length for an FTP command. It can be used as a more specific buffer overflow detection. This option specifies a list of additional commands allowed by this server. 3. this option causes the preprocessor to print the configuration for each of the FTP commands for this server. the only difference being that specific IPs can be configured.1 ports { 21 } ftp_cmds { XPWD XCWD } FTP Server Configuration Options 1. It can be used as a basic buffer overflow detection..
org/internetdrafts/draft-ietf-ftpext-mlst-16.n[n[n]]] ] string > MDTM is an off case that is worth discussing. telnet cmds <yes|no> This option turns on detection and alerting when telnet escape sequences are seen on the FTP command channel. | {}. Some FTP servers do not process those telnet escape sequences. accept a format using YYYYMMDDHHmmss[. These examples are the default checks. [] Description Parameter must be an integer Parameter must be an integer between 1 and 255 Parameter must be a single character. cmd_validity MODE < char ASBCZ > # Allow for a date in the MDTM command. cmd_validity MDTM < [ date nnnnnnnnnnnnnn[.uuu]. Injection of telnet escape sequences could be used as an evasion attempt on an FTP command channel.Value int number char <chars> date <datefmt> string host port long host port extended host port {}. # This allows additional modes. including mode Z which allows for # zip-style compression. separated by | One of the choices enclosed within {}. The most common among servers that do..ietf. use the following: cmd_validity MDTM < [ date nnnnnnnnnnnnnn[{+|-}n[n]] ] string > 8. certain FTP servers accept MDTM commands that set the modification time on a file. per RFC 959 and others performed by the preprocessor. per RFC 2428 One of choices enclosed within.txt) To check validity for a server that uses the TZ format. per RFC 959 Parameter must be a long host port specified. Some others accept a format using YYYYMMDDHHmmss[+—]TZ format. + . where: n Number C Character [] optional format enclosed | OR {} choice of options . 9. one of <chars> Parameter follows format specified. While not part of an established standard. per RFC 1639 Parameter must be an extended host port specified. The example above is for the first case (time format as specified in. 59 . optional value enclosed within [] Examples of the cmd validity option are shown below. ignore telnet erase cmds <yes|no> This option allows Snort to ignore telnet escape sequences for erase character (TNC EAC) and erase line (TNC EAL) when normalizing FTP command channel.literal Parameter is a string (effectively unrestricted) Parameter must be a host/port specified.
If your rule set includes virus-type rules.10. especially with large file transfers from a trusted source. Setting this option to ”yes” means that NO INSPECTION other than TCP state will be performed on FTP data transfers. especially with large file transfers from a trusted source. FTP Server Base Configuration Options The base FTP server configuration is as follows. it is recommended that this option not be used. It can be used to improve performance. ignore data chan <yes|no> This option causes the rest of Snort (rules. It can be used to improve performance. 11. If your rule set includes virus-type rules. and by IP address. ”data chan” will be removed in a future release. Most of your FTP clients will most likely end up using the default configuration. The other options will override those in the base configuration. Using this option means that NO INSPECTION other than TCP state will be performed on FTP data transfers. the FTP client configurations has two types: default. Use of the ”data chan” option is deprecated in favor of the ”ignore data chan” option. other preprocessors) to ignore FTP data channel connections. data chan This option causes the rest of snort (rules.. Default This configuration supplies the default client configuration for any FTP client that is not individually configured. Options specified in the configuration file will modify this set of options. other preprocessors) to ignore FTP data channel connections. Example Default FTP Client Configuration preprocessor ftp_telnet_protocol: \ ftp client default bounce no max_resp_len 200 60 . FTP commands are added to the set of allowed commands.
168.1.1. It can be used as a basic buffer overflow detection.168.conf preprocessor ftp_telnet: \ global \ encrypted_traffic yes \ inspection_type stateful preprocessor ftp_telnet_protocol:\ telnet \ normalize \ ayt_attack_thresh 200 61 .1.[port|portlow. bounce_to { 192.1.2.Configuration by IP Address This format is very similar to “default”.162.20020.1.78. bounce_to { 192. bounce to < CIDR.52.20020 192.20020 } • Allow bounces to 192.1.1 ports 20020 through 20040 – ie. the use of PORT 192.20040 } • Allow bounces to 192. Examples/Default Configuration from snort.porthi] > When the bounce option is turned on.1.162.1.1. telnet cmds <yes|no> This option turns on detection and alerting when telnet escape sequences are seen on the FTP command channel. A few examples: • Allow bounces to 192.162.2 port 20030.168. 3.168. ignore telnet erase cmds <yes|no> This option allows Snort to ignore telnet escape sequences for erase character (TNC EAC) and erase line (TNC EAL) when normalizing FTP command channel.1. 2. An FTP bounce attack occurs when the FTP PORT command is issued and the specified host does not match the host of the client.1 bounce yes max_resp_len 500 FTP Client Configuration Options 1.1.168. Injection of telnet escape sequences could be used as an evasion attempt on an FTP command channel. 5.1 port 20020 and 192.1.1. bounce <yes|no> This option turns on detection and alerting of FTP bounce attacks. the only difference being that specific IPs can be configured.1.xx.1.1.1 port 20020 – ie. Some FTP clients do not process those telnet escape sequences. It can be used to deal with proxied FTP connections where the FTP data channel is different from the client.168. max resp len <number> This specifies the maximum allowed response length to an FTP command accepted by the client.78. where xx is 52 through 72 inclusive.168.20030 } 4. bounce_to { 192.1. the use of PORT 192. this allows the PORT command to use the IP address (in CIDR format) and port (or inclusive port range) without generating an alert. Example IP specific FTP Client Configuration preprocessor ftp_telnet_protocol: \ ftp client 10.
>]} This option specifies which ports the SSH preprocessor should inspect traffic to. Both attacks involve sending a large payload (20kb+) to the server immediately after the authentication challenge. server ports {<port> [<port>< . max client bytes < number > The number of unanswered bytes allowed to be transferred before alerting on Challenge-Response Overflow or CRC 32. an alert is generated. 4. all alerts are disabled and the preprocessor checks traffic on port 22. Both Challenge-Response Overflow and CRC 32 attacks occur after the key exchange. Once max encrypted packets packets have been seen. Set CWD to allow parameter length of 200 MODE has an additional mode of Z (compressed) Check for string formats in USER & PASS commands Check MDTM commands that set modification time on the file.. The Secure CRT and protocol mismatch exploits are observable before the key exchange. max encrypted packets < number > The number of encrypted packets that Snort will inspect before ignoring a given SSH session. 1.. the SSH preprocessor counts the number of bytes transmitted to the server.# # # # # This is consistent with the FTP rules as of 18 Sept 2004. max server version len < number > 62 . Snort ignores the session to increase performance. or else Snort will ignore the traffic. Configuration By default. CRC 32. and are therefore encrypted. This number must be hit before max encrypted packets packets are sent. Since the Challenge-Response Overflow only effects SSHv2 and CRC 32 only effects SSHv1. The SSH vulnerabilities that Snort can detect all happen at the very beginning of an SSH session. the SSH version string exchange is used to distinguish the attacks.9 SSH The SSH preprocessor detects the following exploits: Challenge-Response Buffer Overflow. To detect the attacks. Secure CRT. preprocessor ftp_telnet_protocol: \ ftp server default \ def_max_param_len 100 \ alt_max_param_len 200 { CWD } \ cmd_validity MODE < char ASBCZ > \ cmd_validity MDTM < [ date nnnnnnnnnnnnnn[.2. 3. 2. The available configuration options are described below. and the Protocol Mismatch exploit. If those bytes exceed a predefined limit within a predefined number of packets.
enable ssh1crc32 Enables checking for the CRC 32 exploit. Example Configuration from snort. or if a client generates server traffic. try increasing the number of required client bytes with max client bytes. With the preprocessor enabled. For instance. enable srvoverflow Enables checking for the Secure CRT exploit. the preprocessor only handles desegmentation (at SMB and TCP layers) and defragmentation of DCE/RPC. Snort rules can be evaded by using both types of fragmentation. enable badmsgdir Enable alerts for traffic flowing the wrong direction. 5. and only decodes SMB to get to the potential DCE/RPC requests carried by SMB. Currently. if the presumed server generates client traffic. 7. 12. enable paysize Enables alerts for invalid payload sizes.The maximum number of bytes allowed in the SSH server version string before alerting on the Secure CRT server version string overflow. 6.conf Looks for attacks on SSH server port 22. If Challenge-Respone Overflow or CRC 32 false positive. autodetect Attempt to automatically detect SSH. 10. 8. At the SMB layer. Other methods will be handled in future versions of the preprocessor. 63 . After max encrypted packets is reached.10 DCE/RPC The dcerpc preprocessor detects and decodes SMB and DCE/RPC traffic. enable recognition Enable alerts for non-SSH traffic on SSH ports. The SSH preprocessor should work by default. 9. the preprocessor will stop processing traffic for a given session. the rules are given reassembled DCE/RPC data to examine. enable respoverflow Enables checking for the Challenge-Response Overflow exploit. It is primarily interested in DCE/RPC requests. preprocessor ssh: \ server_ports { 22 } \ max_client_bytes 19600 \ max_encrypted_packets 20 \ enable_respoverflow \ enable_ssh1crc32 2.2. 11. enable protomismatch Enables checking for the Protocol Mismatch exploit. only segmentation using WriteAndX is currently reassembled. Alerts at 19600 unacknowledged bytes within 20 encrypted packets for the Challenge-Response Overflow/CRC32 exploits.
If subsequent checks are nonsensical. try to autodetect DCE/RPC sessions. They are described below: • autodetect In addition to configured ports.. Configuration The proprocessor has several optional configuration options. it ends processing. • memcap <number> Maximum amount of memory available to the DCE/RPC preprocessor for desegmentation and defragmentation. Default is 100000 kilobytes. Unless you are experiencing severe performance issues.. Autodetection of DCE/RPC is not as reliable. this option should not be configured as DCE/RPC fragmentation provides for an easy evasion opportunity.. • ports dcerpc { <port> [<port> <. • alert memcap Alert if memcap is exceeded. • disable smb frag Do not do SMB desegmentation. • ports smb { <port> [<port> <. This option is not configured by default. Assuming that the data is a DCE/RPC header. one byte is checked for DCE/RPC version 5 and another for a DCE/RPC PDU type of Request. This option is not configured by default.. this option should not be configured as SMB segmentation provides for an easy evasion opportunity. as well as checking the NetBIOS header (which is always present for SMB) for the type ”Session Message”. This will potentially catch an attack earlier and is useful if in inline mode..Autodetection of SMB is done by looking for ”\xFFSMB” at the start of the SMB data. Default are ports 139 and 445. Default is 3000 bytes. in bytes. Since the preprocessor looks at TCP reassembled packets (to avoid 64 .>] } Ports that the preprocessor monitors for DCE/RPC over TCP traffic. • disable dcerpc frag Do not do DCE/RPC defragmentation. Default is port 135. This option is not configured by default. Currently. the preprocessor proceeds with the assumption that it is looking at DCE/RPC data. Unless you are experiencing severe performance issues. Note that DCE/RPC can run on practically any port in addition to the more common ports. • max frag size <number> Maximum DCE/RPC fragment size to put in defragmentation buffer. in kilobytes. two bytes are checked in the packet. If both match.>] } Ports that the preprocessor monitors for SMB traffic. before the final desegmentation or defragmentation of the DCE/RPC request takes place.
Not recommended if Snort is running in passive mode as it’s not really needed.000 kilobytes. Set memory cap for desegmentation/defragmentation to 50.000 kilobytes. detect on DCE/RPC (or TCP) ports 135 and 2103 (overrides default). which is triggered when the preprocessor has reached the memcap limit for memory allocation.TCP overlaps and segmentation evasions). however. Snort will potentially take a performance hit. Truncate DCE/RPC fragment if greater than 4000 bytes. 65 . this option is disabled. A value of 0 will in effect disable this option as well. so looking at the data early will likely catch the attack before all of the exploit data has gone through. the default configuration will look like: preprocessor dcerpc: \ ports smb { 139 445 } \ ports dcerpc { 135 } \ max_frag_size 3000 \ memcap 100000 \ reassemble_increment 0 Preprocessor Events There is currently only one alert. Note At the current time. preprocessor dcerpc: \ ports dcerpc { 135 2103 } \ memcap 200000 \ reassemble_increment 1 Default Configuration If no options are given to the preprocessor. Configuration Examples In addition to defaults. sid 1. preprocessor dcerpc: \ autodetect \ disable_smb_frag \ max_frag_size 4000 In addition to defaults. The argument to the option specifies how often the preprocessor should create a reassembled packet if there is data in the segmentation/fragmentation buffers. Note. Create a reassembly packet every time through the preprocessor if there is data in the desegmentation/defragmentation buffers. (Since no DCE/RPC defragmentation will be done the memory cap will only apply to desegmentation. If not specified. there is not much to do with the dcerpc preprocessor other than turn it on and let it reassemble fragmented DCE/RPC packets. The alert is gid 130. don’t do DCE/RPC defragmentation.) preprocessor dcerpc: \ disable_dcerpc_frag \ memcap 50000 In addition to the defaults. Set memory cap for desegmentation/defragmentation to 200. Don’t do desegmentation on SMB writes. the last packet of an attack using DCE/RPC segmented/fragmented evasion techniques may have already gone through before the preprocessor looks at it. autodetect SMB and DCE/RPC sessions on non-configured ports. that in using this option.
the session is not marked as encrypted. enable experimental types Alert on Experimental (per RFC 1035) Record Types 4. By default. If one side responds with an indication that something has failed. documented below. Therefore. enable obsolete types Alert on Obsolete (per RFC 1035) Record Types 3. no further inspection of the data on the connection is made.2. DNS looks at DNS Response traffic over UDP and TCP and it requires Stream preprocessor to be enabled for TCP decoding. >]} This option specifies the source ports that the DNS preprocessor should inspect traffic. the user should use the ’trustservers’ option.2. and Experimental Record Types. Do not alert on obsolete or experimental RData record types.conf Looks for traffic on DNS server port 53. Once the traffic is determined to be encrypted. The SSL Dynamic Preprocessor (SSLPP) decodes SSL and TLS traffic and optionally determines if and when Snort should stop inspection of it. enable rdata overflow Check for DNS Client RData TXT Overflow The DNS preprocessor does nothing if none of the 3 vulnerabilities it checks for are enabled.11 DNS The DNS preprocessor decodes DNS Responses and can detect the following exploits: DNS Client RData Overflow. SSLPP looks for a handshake followed by encrypted traffic traveling to both sides. By enabling the SSLPP to inspect port 443 and enabling the noinspect encrypted option. In some cases. such as the handshake. Examples/Default Configuration from snort. Configuration By default.12 SSL/TLS Encrypted traffic should be ignored by Snort for both performance reasons and to reduce false positives. 1. 2. It will not operate on TCP sessions picked up midstream. Verifying that faultless encrypted traffic is sent from both endpoints ensures two things: the last client-side handshake packet was not crafted to evade Snort. and that the traffic is legitimately encrypted. SSL is used over port 443 as HTTPS. the only observed response from one endpoint will be TCP ACKs. especially when packets may be missed. Obsolete Record Types. Check for the DNS Client RData overflow vulnerability. The available configuration options are described below. if a user knows that server-side encrypted data can be trusted to mark the session as encrypted.. only the SSL handshake of each connection will be inspected.. 66 . ports {<port> [<port>< .2. all alerts are disabled and the preprocessor checks traffic on port 53. preprocessor dns: \ ports { 53 } \ enable_rdata_overflow 2. and it will cease operation on a session if it loses state because of missing data (dropped packets). Typically.
This requires the noinspect encrypted option to be useful.2. the preprocessor checks for unicast ARP requests. preprocessor ssl: noinspect_encrypted 2. Examples/Default Configuration from snort.Configuration 1. noinspect encrypted Disable inspection on traffic that is encrypted. An alert with GID 112 and SID 1 will be generated if a unicast ARP request is detected. trustservers Disables the requirement that application (encrypted) data must be observed on both sides of the session before a session is marked encrypted. an alert with GID 112 and SID 2 or 3 is generated.. >]} This option specifies which ports SSLPP will inspect traffic on. Specify a pair of IP and hardware address as the argument to arpspoof detect host. the preprocessor inspects Ethernet addresses and the addresses in the ARP packets. and inconsistent Ethernet to IP mapping. When inconsistency occurs. When ”-unicast” is specified as the argument of arpspoof. Use this option for slightly better performance if you trust that your servers are not compromised. Format preprocessor arpspoof[: -unicast] preprocessor arpspoof_detect_host: ip mac 67 . ports {<port> [<port>< . Specify one host IP MAC combo per line. The host with the IP address should be on the same layer 2 segment as Snort is. The preprocessor will use this list when detecting ARP cache overwrite attacks. Alert SID 4 is used in this case. Default is off. unicast ARP requests... When no arguments are specified to arpspoof.13 ARP Spoof Preprocessor The ARP spoof preprocessor decodes ARP packets and detects ARP attacks. 3. Default is off.conf Enables the SSL preprocessor and tells it to disable inspection on encrypted traffic. By default.
40. preprocessor arpspoof preprocessor arpspoof_detect_host: 192. Read Block Raw and Read AndX.1 and 192. the dcerpc2 preprocessor will enable stream reassembly for that session if necessary.1 f0:0f:00:f0:0f:00 preprocessor arpspoof_detect_host: 192. Example Configuration The first example configuration does neither unicast detection nor ARP mapping monitoring. Transaction.40. UDP and RPC over HTTP v. • Stream reassembly must be performed for TCP sessions.168.40. • IP defragmentation should be enabled.168. The preprocessor requires a session tracker to keep its data.168. Write AndX.40. i. • Stream session tracking must be enabled. either through configured ports.e. 68 .1 proxy and server. TCP. The Ethernet address corresponding to the preceding IP. the frag3 preprocessor should be enabled and configured. preprocessor arpspoof: -unicast preprocessor arpspoof_detect_host: 192.168.2 f0:0f:00:f0:0f:01 2. Transaction Secondary. i. If it is decided that a session is SMB or DCE/RPC.1 f0:0f:00:f0:0f:00 preprocessor arpspoof_detect_host: 192. The preprosessor merely looks for Ethernet address inconsistencies.2. preprocessor arpspoof The next example configuration does not do unicast detection but monitors ARP mapping for hosts 192. Write Block Raw. SMB desegmentation is performed for the following commands that can be used to transport DCE/RPC requests and responses: Write. servers or autodetecting. Read.168. Write and Close.40. stream5. Dependency Requirements For proper functioning of the preprocessor: • The dcerpc preprocessor (the initial iteration) must be disabled.14 DCE/RPC 2 Preprocessor The main purpose of the preprocessor is to perform SMB desegmentation and DCE/RPC defragmentation to avoid rule evasion using these techniques.e. The following transports are supported for DCE/RPC: SMB.2.2 f0:0f:00:f0:0f:01 The third example configuration has unicast detection enabled.168.Option ip mac Description IP address.40. reduce false positives and reduce the count and complexity of DCE/RPC based rules. New rule options have been implemented to improve performance.
however.22 in that deleting the UID or TID used to create the named pipe instance also invalidates it. Windows 2000 Windows 2000 is interesting in that the first request to a named pipe must use the same binding as that of the other Windows versions. It also follows Samba greater than 3. since it is necessary in making a request to the named pipe. Samba 3. Accepted SMB commands Samba in particular does not recognize certain commands under an IPC$ tree. if the TID used in creating the FID is deleted (via a tree disconnect). share handle or TID and file/named pipe handle or FID must be used to write data to a named pipe. the FID that was created using this TID becomes invalid.0.0. no binding. However.0. deleting either the UID or TID invalidates the FID. If the TID used to create the FID is deleted (via a tree disconnect). i. AndX command chaining 69 . no more requests can be written to that named pipe instance. does not accept: Open Write And Close Read Read Block Raw Write Block Raw Windows (all versions) Accepts all of the above commands under an IPC$ tree. no more requests can be written to that named pipe instance. Windows 2003 Windows XP Windows Vista These Windows versions require strict binding between the UID. i. requests after that follow the same binding as Samba 3. If the UID used to create the named pipe instance is deleted (via a Logoff AndX). i. The binding between these is dependent on OS/software version. along with a valid FID can be used to make a request.e. the FID becomes invalid.22 and earlier Any valid UID and TID. along with a valid FID can be used to make a request. Therefore.e. Some important differences: Named pipe instance tracking A combination of valid login handle or UID. TID and FID used to make a request to a named pipe instance.e. the FID that was created using this TID becomes invalid. Samba greater than 3.22 Any valid TID. Both the UID and TID used to open the named pipe instance must be used when writing data to the same named pipe instance.0.22 and earlier.Target Based There are enough important differences between Windows and Samba versions that a target based approach has been implemented. However. only the UID used in opening the named pipe can be used to make a request using the FID handle to the named pipe instance. Samba (all versions) Under an IPC$ tree.
It is necessary to track this so as not to munge these requests together (which would be a potential evasion opportunity). Any binding after that must use the Alter Context request. Windows (all versions) For all of the Windows versions. login/logoff and tree connect/tree disconnect. The PID represents the process this request is a part of.20 and earlier Any amount of Bind requests can be made. having the same FID) are fields in the SMB header representing a process id (PID) and multiplex id (MID). If another Bind is made. If a Bind after a successful Bind is made. is very lax and allows some nonsensical combinations. whereas in using the Write* commands. Multiple Transaction requests can be made simultaneously to the same named pipe. Samba. data is written to the named pipe as it is received by the server. DCE/RPC Fragmented requests . Windows (all versions) The context id that is ultimately used for the request is contained in the first fragment. What distinguishes them (when the same named pipe is being written to. Samba later than 3. i. Segments for each ”thread” are stored separately and written to the named pipe when all segments are received. Samba (all versions) The context id that is ultimately used for the request is contained in the last fragment. all previous interface bindings are invalidated. all previous interface bindings are invalidated. Multliple. Samba (all versions) Uses just the MID to define a ”thread”. Ultimately. Samba 3. we don’t want to keep track of data that the server won’t accept.Operation number 70 . the client has to explicitly send one of the Read* requests to tell the server to send the response and (2) a Transaction request is not written to the named pipe until all of the data is received (via potential Transaction Secondary requests) whereas with the Write* commands. only one Bind can ever be made on a session whether or not it succeeds or fails. An evasion possibility would be accepting a fragment in a request that the server won’t accept that gets sandwiched between an exploit.Context ID Each fragment in a fragmented request carries the context id of the bound interface it wants to make the request to. multiple logins and tree connects (only one place to return handles for these).Windows is very strict in what command combinations it allows to be chained. on the other hand.0.20 Another Bind request can be made if the first failed and no interfaces were successfully bound to. e. Transaction tracking The differences between a Transaction request and using one of the Write* commands to write data to a named pipe are that (1) a Transaction performs the operations of a write and a read from the named pipe. These requests can also be segmented with Transaction Secondary commands. DCE/RPC Fragmented requests .0. Windows (all versions) Uses a combination of PID and MID to define a ”thread”.g. An MID represents different sub-processes within a process (or under a PID).e. The context id field in any other fragment can contain any value.
cl] OFF 1024-4194303 (kilobytes) 1514-65535 pseudo-event | event | ’[’ event-list ’]’ "none" | "all" event | event ’. The opnum field in any other fragment can contain any value. Samba (all versions) The byte order of the stub data is that which is used in the request carrying the stub data.. Windows Vista The opnum that is ultimately used for the request is contained in the first fragment. Samba (all versions) Windows 2000 Windows 2003 Windows XP The opnum that is ultimately used for the request is contained in the last fragment..’ event-list "memcap" | "smb" | "co" | "cl" 0-65535 Option explanations memcap 71 . co. DCE/RPC Stub data byte order The byte order of the stub data is determined differently for Windows and Samba..
Run-time memory includes any memory allocated after configuration. Default is not set. (See Events section for an enumeration and explanation of events. If the memcap is reached or exceeded. in effect. events [smb. Defaults are smb. events smb memcap 50000. smb] reassemble_threshold 500 Default global configuration preprocessor dcerpc2: memcap 102400. Default is disabled. max_frag_len 14440 disable_defrag. A value of 0 supplied as an argument to this option will. co. events Specifies the classes of events to enable. events [memcap. Alert on events related to connectionless DCE/RPC processing. disable this option. Option examples memcap 30000 max_frag_len 16840 events none events all events smb events co events [co] events [smb. co. cl Stands for connectionless DCE/RPC. it is truncated before being added to the defragmentation module. max frag len Specifies the maximum fragment size that will be added to the defragmention module. co] events [memcap. reassemble threshold Specifies a minimum number of bytes in the DCE/RPC desegmentation and defragmentation buffers before creating a reassembly packet to send to the detection engine. alert. events [memcap. smb Alert on events related to SMB processing. Alert on events related to connection-oriented DCE/RPC processing. Default is 100 MB. co and cl. cl] Server Configuration 72 . co Stands for connection-oriented DCE/RPC.) memcap Only one event. co. This option is useful in inline mode so as to potentially catch an exploit early before full defragmentation is done. If a fragment is greater than this size. Default is to do defragmentation. smb. memcap 300000. disable defrag Tells the preprocessor not to do DCE/RPC defragmentation.Specifies the maximum amount of run-time memory that can be allocated. cl]. smb..
preprocessor dcerpc2_server The dcerpc2 server configuration is optional. A net configuration matches if the packet’s server IP address matches an IP address or net specified in the net configuration. tcp 135. the default configuration is used if no net configurations match. Option explanations default Specifies that this configuration is for the default server configuration. Option syntax Option default net policy detect Argument NONE <net> <policy> <detect> Required YES YES NO NO Default NONE NONE policy WinXP detect [smb [139. At most one default configuration can be specified. For any dcerpc2 server configuration.’ ’"’ ’]’ ’[’ 0-255 Because the Snort main parser treats ’$’ as the start of a variable and tries to expand it.’ ’"’ ’]’ ’[’ ’$’ graphical ascii characters except ’.conf CANNOT be used.’ detect-list transport | transport port-item | transport ’[’ port-list ’]’ "smb" | "tcp" | "udp" | "rpc-over-http-proxy" | "rpc-over-http-server" port-item | port-item ’. 73 .0. If a net configuration matches.445]. ’.’ share-list word | ’"’ word ’"’ | ’"’ var-word ’"’ graphical ascii characters except ’. udp 1025:. shares with ’$’ must be enclosed quotes. udp 135. Note that port and ip variables defined in snort. Zero or more net configurations can be specified. it will override the default configuration. rpc-over-http-server 593] autodetect [tcp 1025:. the defaults will be used. if non-required options are not specified. default values will be used for the default configuration. A dcerpc2 server configuration must start with default or net options.’ port-list port | port-range ’:’ port | port ’:’ | port ’:’ port 0-65535 share | ’[’ share-list ’]’ share | share ’. If no default configuration is specified.20" "none" | detect-opt | ’[’ detect-list ’]’ detect-opt | detect-opt ’.22" | "Samba-3. The net option supports IPv6 addresses. The default and net options are mutually exclusive. When processing DCE/RPC traffic.
168. UDP and RPC over HTTP server.168. policy Specifies the target-based policy to use when processing. The configuration will only apply to the IP addresses and nets supplied as an argument. detect Specifies the DCE/RPC transport and server ports that should be detected on for the transport. feab:45b3::/32] net [192. tcp 135.net Specifies that this configuration is an IP or net specific configuration. tcp [135.TCP/UDP.445] detect [smb [139.168.10.168. Option examples net 192. smb max chain Specifies the maximum amount of AndX command chaining that is allowed before an alert is generated. Defaults are ports 139 and 445 for SMB. Note that most dynamic DCE/RPC ports are above 1024 and ride directly over TCP or UDP.22 detect none detect smb detect [smb] detect smb 445 detect [smb 445] detect smb [139.2103]] detect [smb [139.168. Default maximum is 3 chained commands. 135 for TCP and UDP.0.0/24] net 192. smb invalid shares Specifies SMB shares that the preprocessor should alert on if an attempt is made to connect to them via a Tree Connect or Tree Connect AndX. RPC over HTTP server. This option is useful if the RPC over HTTP proxy configured with the detect option is only used to proxy DCE/RPC traffic.445]] detect [smb. Default is ”WinXP”.10 net 192.0.0/24 net [192. the preprocessor will always attempt to autodetect for ports specified in the detect configuration for rpc-over-http-proxy. Defaults are 1025-65535 for TCP. The order in which the preprocessor will attempt to autodetect will be . A value of 0 disables this option. autodetect Specifies the DCE/RPC transport and server ports that the preprocessor should attempt to autodetect on for the transport.255.0. udp 135.0. no autodetect http proxy ports By default.0.445]. RPC over HTTP proxy and lastly SMB.255.0/255. Default is empty.0.0/24. feab:45b3:ab92:8ac4:d322:007f:e5aa:7845] policy Win2000 policy Samba-3. 593 for RPC over HTTP server and 80 for RPC over HTTP proxy. This is because the proxy is likely a web server and the preprocessor should not look at all web traffic.168.6002:6004]] 74 . Default is to autodetect on RPC over HTTP proxy detect ports. The autodetect ports are only queried if no detect transport/ports match the packet.0. tcp] detect [smb 139. It would be very uncommon to see SMB on anything other than ports 139 and 445. rpc-over-http-server [593.
"C$"] smb_max_chain 1 Configuration examples preprocessor dcerpc2_server: \ default preprocessor dcerpc2_server: \ default. policy Win2000 preprocessor dcerpc2_server: \ default.0/24. tcp].11.10. detect smb.3003:] autodetect [tcp [2025:3001. rpc-over-http-proxy 8081]. autodetect [tcp. udp 135. smb_max_chain 1 preprocessor dcerpc2_server: \ net [10.56. udp 2025:] autodetect [tcp 2025:.4. autodetect tcp 1025:. smb_max_chain 3 Events The preprocessor uses GID 133 to register events. \ detect [smb [139. policy Samba. rpc-over-http-server [1025:6001. udp 1025:. policy Win2000.4.10.445]. autodetect none Default server configuration preprocessor dcerpc2_server: default.0/24. "ADMIN$"] preprocessor dcerpc2_server: net 10.6005:]]. tcp 135. smb_max_chain 3 Complete dcerpc2 default configuration preprocessor dcerpc2: \ memcap 102400. events [smb. \ detect [smb [139. udp 135. tcp.feab:45b3::/126].6005:]] smb_invalid_shares private smb_invalid_shares "private" smb_invalid_shares "C$" smb_invalid_shares [private. policy Win2000 preprocessor dcerpc2_server: \ net [10.10.0/24.11. rpc-over-http-server 593].feab:45b3::/126]. detect [smb.4. cl] preprocessor dcerpc2_server: \ default. \ smb_invalid_shares ["C$". \ detect [smb.4.autodetect none autodetect tcp autodetect [tcp] autodetect tcp 2025: autodetect [tcp 2025:] autodetect tcp [2025:3001. policy WinXP.445]. policy WinVista. udp.4. policy WinXP. tcp 135. rpc-over-http-server 1025:]. co.57]. \ autodetect [tcp 1025:. Memcap events 75 . \ autodetect [tcp 1025:.3003:]] autodetect [tcp. \ smb_invalid_shares ["C$". udp 1025:. "C$"] smb_invalid_shares ["private". "ADMIN$"]. rpc-over-http-proxy [1025:6001. rpc-over-http-server 593]. rpc-over-http-server 1025:]. no_autodetect_http_proxy_ports preprocessor dcerpc2_server: \ net [10. "D$".10. udp] autodetect [tcp 2025:. policy WinVista.
The word count of the command header is invalid. Note that since the preprocessor does not yet support SMB2. Request (only from client). Negative Response (only from server). the preprocessor will alert. the preprocessor will alert.) The preprocessor will alert if the total amount of data sent in a transaction is greater than the total data count specified in the SMB command header. the preprocessor will alert. especially the commands from the SMB Core implementation require a data format field that specifies the kind of data that will be coming next. Some SMB commands. . If this field is zero.. Valid types are: Message. The preprocessor will alert if the remaining NetBIOS packet length is less than the size of the SMB command data size specified in the command header. An SMB message type was specified in the header. Some commands require a minimum number of bytes after the command header. 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 76 . The preprocessor will alert if the remaining NetBIOS packet length is less than the size of the SMB command byte count specified in the command header. Many SMB commands have a field containing an offset from the beginning of the SMB header to where the data the command is carrying starts. If a command requires this and the byte count is less than the minimum required byte count for that command. The preprocessor will alert if the byte count minus a predetermined amount based on the SMB command is not equal to the data size. The preprocessor will alert if the format is not that which is expected for that command. The preprocessor will alert if the NetBIOS Session Service length field contains a value less than the size of an SMB header. have a field containing the total amount of data to be transmitted. The SMB id does not equal \xffSMB. If this offset puts us before data that has already been processed or after the end of payload. such as Transaction. (The byte count must always be greater than or equal to the data size. Some commands require a specific format for the data. SMB commands have pretty specific word counts and if the preprocessor sees a command with a word count that doesn’t jive with that command. The preprocessor will alert if the remaining NetBIOS packet length is less than the size of the SMB command header to be decoded. Positive Response (only from server). Some commands. id of \xfeSMB is turned away before an eventable point is reached.SID 1 Description If the memory cap is reached and the preprocessor is configured to alert. Either a request was made by the server or a response was given by the client. Retarget Response (only from server) and Keep Alive. SMB events SID 2 Description An invalid NetBIOS Session Service type was specified in the header. the preprocessor will alert.
Connection-oriented DCE/RPC events SID 27 28 Description The preprocessor will alert if the connection-oriented DCE/RPC major version contained in the header is not equal to 5. they are responded to in the order they were sent. A Logoff AndX request is sent by the client to indicate it wants to end the session and invalidate the login handle. essentially connects to a share and disconnects from the same share in the same request and is anomalous behavior. A Tree Connect AndX command is used to connect to a share. essentially logins in and logs off in the same request and is anomalous behavior. If multiple Read* requests are sent to the server. there is no indication in the Tree Connect response as to whether the share is IPC or not. 77 . There should be under normal circumstances no more than a few pending tree connects at a time and the preprocessor will alert if this number is excessive. only one place in the SMB header to return a login handle (or Uid). (The preprocessor is only interested in named pipes as this is where DCE/RPC requests are written to. however. When a Session Setup AndX request is sent to the server. does not contain this file id.) The Close command is used to close that file or named pipe. however. Windows does not allow this behavior. however Samba does. The preprocessor will alert if it sees this. With AndX command chaining it is possible to chain multiple Tree Connect AndX commands within the same request. The preprocessor will alert if it sees this. essentially opens and closes the named pipe in the same request and is anomalous behavior. The preprocessor will alert if the number of chained commands in a single request is greater than or equal to the configured amount (default is 3). With commands that are chained after a Session Setup AndX request. so it need to be queued with the request and dequeued with the response. The Tree Disconnect command is used to disconnect from that share. however Samba does. only one place in the SMB header to return a tree handle (or Tid). the server responds (if the client successfully authenticates) which a user id or login handle. The combination of a Open AndX or Nt Create AndX command with a chained Close command. The Read* request contains the file id associated with a named pipe instance that the preprocessor will ultimately send the data to. The preprocessor will alert if it sees any of the invalid SMB shares configured. It looks for a Tree Connect or Tree Connect AndX to the share. Unlike the Tree Connect AndX response. The combination of a Session Setup AndX command with a chained Logoff AndX command. This is anomalous behavior and the preprocessor will alert if it happens. An Open AndX or Nt Create AndX command is used to open/create a file or named pipe. There is. This is anomalous behavior and the preprocessor will alert if it happens. With AndX command chaining it is possible to chain multiple Session Setup AndX commands within the same request. There is. it issues a Read* command to the server to tell it to send a response to the data it has written. The server response. however. The preprocessor will alert if it sees this. The combination of a Tree Connect AndX command with a chained Tree Disconnect command. the preprocessor has to queue the requests up and wait for a server response to determine whether or not an IPC share was successfully connected to (which is what the preprocessor is interested in). The preprocessor will alert if the connection-oriented DCE/RPC minor version contained in the header is not equal to 0. There should be under normal circumstances no more than a few pending Read* requests at a time and the preprocessor will alert if this number is excessive. In this case the preprocessor is concerned with the server response.18 19 20 21 22 23 24 25 26 For the Tree Connect command (and not the Tree Connect AndX command). This is used by the client in subsequent requests to indicate that it has authenticated. the login handle returned by the server is used for the subsequent chained commands. After a client is done writing data using the Write* commands. Windows does not allow this behavior.
The preprocessor will alert if a non-last fragment is less than the size of the negotiated maximum fragment length. The call id for a set of fragments in a fragmented request should stay the same (it is incremented for each complete request). this number should stay the same for all fragments. The preprocessor will alert if the sequence number uses in a request is the same or less than a previously used sequence number on the session. The preprocessor will alert if in a Bind or Alter Context request.29 30 31 32 33 34 35 36 37 38 39 The preprocessor will alert if the connection-oriented DCE/RPC PDU type contained in the header is not a valid PDU type. The preprocessor will alert if the connectionless DCE/RPC pdu type is not a valid pdu type. this number should stay the same for all fragments. The preprocessor will alert if it changes in a fragment mid-request. The preprocessor will alert if the remaining fragment length is less than the remaining packet size. The preprocessor will alert if the packet data length is less than the size of the connectionless header. The preprocessor will alert if a fragment is larger than the maximum negotiated fragment length. wrapping the sequence number space produces strange behavior from the server. The byte order of the request data is determined by the Bind in connection-oriented DCE/RPC for Windows. The preprocessor will alert if the fragment length defined in the header is less than the size of the header. The context id is a handle to a interface that was bound to. there are no context items specified. . The preprocessor will alert if in a Bind or Alter Context request. In testing. If a request if fragmented. The preprocessor will alert if the opnum changes in a fragment mid-request. If a request is fragmented. there are no transfer syntaxes to go with the requested interface. It is anomalous behavior to attempt to change the byte order mid-session. The operation number specifies which function the request is calling on the bound interface. so this should be considered anomalous behavior. Most evasion techniques try to fragment the data as much as possible and usually each fragment comes well below the negotiated transmit size. The preprocessor will alert if the context id changes in a fragment mid-request.
This tracking is required so that when a request is processed. specify one or more service interfaces to bind to. The server will respond with the interface UUIDs it accepts as valid and will allow the client to make requests to those services. since the beginning of subsequent fragments are already offset some length from the beginning of the request. hexlong and hexshort will be specified and interpreted to be in big endian order (this is usually the default way an interface UUID will be seen and represented). Instead of using flow-bits. Syntax <uuid> [ ’. A DCE/RPC request can specify whether numbers are represented as big endian or little endian. This option requires tracking client Bind and Alter Context requests as well as server Bind Ack and Alter Context responses for connection-oriented DCE/RPC in the preprocessor. if the any frag option is used to specify evaluating on all fragments. The any frag argument says to evaluate for middle and last fragments as well. This option is used to specify an interface UUID. a DCE/RPC request can be broken up into 1 or more fragments. The server response indicates which interfaces it will allow the client to make requests to . 4b324fc8-1670-01d3-1278-5a47bf6ee188. 4b324fc8-1670-01d3-1278-5a47bf6ee188. A rule which is looking for data. An interface contains a version. the client specifies a list of interface UUIDs along with a handle (or context id) for each interface UUID that will be used during the DCE/RPC session to reference the interface. however. will be looking at the wrong data on a fragment other than the first. not a fragment) since most rules are written to start at the beginning of a request. it will specify the context id so the server knows what service the client is making a request to.<2. greater than (’>’). Optional arguments are an interface version and operator to specify that the version be less than (’<’). say 5 bytes into the request (maybe it’s a length field).=1. a middle or the last fragment. by default the rule will only be evaluated for a first fragment (or full request. The representation of the interface UUID is different depending on the endianness specified in the DCE/RPC previously requiring two rules . using this rule option. However. This can eliminate false positives where more than one service is bound to successfully since the preprocessor can correlate the bind UUID to the context id used in the request. it can. Also.’ .any_frag. When a client sends a bind request to the server. As an example. This can be a source of false positives in fragmented DCE/RPC traffic. equal to (’=’) or not equal to (’!’) the version specified. since subsequent fragments will contain data deeper into the DCE/RPC request. It is necessary for a client to bind to a service before being able to make a call to it. Some versions of an interface may not be vulnerable to a certain exploit.’ <operator> <version> ] [ ’.it either accepts or rejects the client’s wish to bind to a certain interface. i. Flags (and a field in the connectionless header) are set in the DCE/RPC header to indicate whether the fragment is the first. Also. whether or not the client has bound to a specific interface UUID and whether or not this client request is making a request to it. the following Messenger interface UUID as taken off the wire from a little endian Bind request: 79 . When a client makes a request. 4b324fc8-1670-01d3-1278-5a47bf6ee188. The preprocessor eliminates the need for two rules by normalizing the UUID. the context id used in the request can be correlated with the interface UUID it is a handle for. By default it is reasonable to only evaluate if the request is a first fragment (or full request). Each interface is represented by a UUID. Many checks for data in the DCE/RPC request are only relevant if the DCE/RPC request is a first fragment (or full request). a rule can simply ask the preprocessor.e. Each interface UUID is paired with a unique index (or context id) that future requests can use to reference the service that the client is making a call to.dce iface For DCE/RPC based rules it has been necessary to set flow-bits based on a client bind to a service to avoid false positives.one for big endian and one for little endian. For each Bind and Alter Context request.any_frag.
dce iface) usually we want to know what function call it is making to that service. This option matches if any one of the opnums specified match the opnum of the DCE/RPC request. After is has been determined that a client has bound to a specific interface and is making a request to it (see above .18-20. 80 .. 15. This reduces the number of rule option checks and the complexity of the rule. 15. dce stub data Since most netbios rules were doing protocol decoding only to get to the DCE/RPC stub data. The opnum of a DCE/RPC request will be matched against the opnums specified with this option. This option will not match if the fragment is not a first fragment (or full request) unless the any frag option is supplied in which case only the interface UUID and version need match. dce opnum The opnum represents a specific function call to an interface. It is likely that an exploit lies in the particular DCE/RPC function call. the remote procedure call or function call data.e. Note that a defragmented DCE/RPC request will be considered a full request. This option is used to specify an opnum (or operation number). This option takes no arguments.20-22. this option will alleviate this need and place the cursor at the beginning of the DCE/RPC stub data.’ opnum-list opnum | opnum-range opnum ’-’ opnum 0-65535 Examples dce_opnum: dce_opnum: dce_opnum: dce_opnum: 15. 15-18. Syntax <opnum-list> opnum-list opnum-item opnum-range opnum = = = = opnum-item | opnum-item ’. Example dce_stub_data. i. opnum range or list containing either or both opnum and/or opnum-range. the version operation is true.17.
the following normal byte jump arguments will not be allowed: big.’ "relative" ] [ ’.35000.align. the following normal byte test arguments will not be allowed: big. \ byte_test:4.to_server.>. byte test Syntax <convert> ’.relative.relative.-4. \ classtype:attempted-admin.) 81 . string.relative.relative.’ <value> [ ’.445.4.to_server. There are no arguments to this option. dec.’ <offset> [ ’.post_offset -4.dce.’ <offset> [ ’.align. string. oct and from beginning. regardless of preceding rule options. reference:bugtraq.’ "post_offet" <adjustment-value> ] ’. dec and oct.139.23470.256. it will be able to do the correct conversion.dce.) alert udp $EXTERNAL_NET any -> $HOME_NET [135.{12})/sR". \ classtype:attempted-admin.{12}(\x00\x00\x00\x00|.align.dce. but since the DCE/RPC preprocessor will know the endianness of the request.relative. \ pcre:"/ˆ.multiplier 2. little.-4.4.593.{12}(\x00\x00\x00\x00|. little. \ byte_test:4.23470.dce.relative.{12})/sR". byte_jump:4. hex. hex. byte test and byte jump A DCE/RPC request can specify whether numbers are represented in big or little endian.2007-1748. reference:cve. byte_test: 2. reference:bugtraq.-10.’ "multiplier" <mult-value> ] \ [ ’.’ "dce" convert offset mult-value adjustment-value = = = = 1 | 2 | 4 -65535 to 65535 0-65535 -65535 to 65535 Example byte_jump:4. dce_opnum:0-11.>. \ dce_iface:50abc2a4-574d-40b3-9d66-ee4fd5fba076.’ [ ’!’ ] <operator> ’. \ dce_iface:50abc2a4-574d-40b3-9d66-ee4fd5fba076. dce_stub_data.dce. byte jump Syntax <convert> ’.>. sid:1000069. dce_opnum:0-11.1024:] \ (msg:"dns R_Dnssrv funcs2 overflow attempt".’ "align" ] [ ’. flow:established.’ "dce" convert operator value offset = = = = 1 | 2 | 4 ’<’ | ’=’ | ’>’ | ’&’ | ’ˆ’ 0-4294967295 -65535 to 65535 Examples byte_test: 4.relative. byte_jump:4. \ pcre:"/ˆ.2007-1748. sid:1000068. This option matches if there is DCE/RPC stub data. reference:cve. These rule options will take as a new argument dce and will work basically the same as the normal byte test/byte jump.2280.dce.-4. dce_stub_data.’ "relative" ]] \ ’. When using the dce argument to a byte test.0. Example of rule complexity reduction The following two rules using the new rule options replace 64 (set and isset flowbit) rules that are necessary if the new rule options are not used: alert tcp $EXTERNAL_NET any -> $HOME_NET [135. flow:established.This option is used to place the cursor (used to walk the packet payload in rules processing) at the beginning of the DCE/RPC stub data.dce.256.1024:] \ (msg:"dns R_Dnssrv funcs2 overflow attempt". When using the dce argument to a byte jump.!=.
2.) to drop ( msg: "DECODE_NOT_IPV4_DGRAM".3.g.2. Of course. define the path to where the rules are located and uncomment the include lines in snort./configure --enable-decoder-preprocessor-rules The decoder and preprocessor rules are located in the preproc rules/ directory in the top level source tree. These files are updated as new decoder and preprocessor events are added to Snort. include $PREPROC_RULE_PATH/preprocessor. gid: 116. 82 . classtype:protocol-command-decode.rules and preprocessor. var PREPROC_RULE_PATH /path/to/preproc_rules . \ metadata: rule-type decode . these options will take precedence over the event type of the rule. rev: 1.conf. just comment it with a # or remove the rule completely from the file (commenting is recommended). just replace alert with the desired rule type.rules. For example.rules and preprocessor.rules include $PREPROC_RULE_PATH/decoder.. config enable decode drops. gid: 116. decoder events will not be generated regardless of whether or not there are corresponding rules for the event. if config disable decode alerts is in snort. the drop cases only apply if Snort is running inline.. sid: 1. To enable these rules in snort. Also note that if the decoder is configured to enable drops.decode for config options that control decoder events. To change the rule type or action of a decoder/preprocessor rule. README.conf or the decoder or preprocessor rule type is drop. sid: 1. e.conf that reference the rules files. Any one of the following rule types can be used: alert log pass drop sdrop reject For example one can change: alert ( msg: "DECODE_NOT_IPV4_DGRAM". See README. See doc/README.conf.decode.) to drop (as well as alert on) packets where the Ethernet protocol is IPv4 but version field in IPv4 header has a value other than 4. and have the names decoder.rules To disable any rule.gre and the various preprocessor READMEs for descriptions of the rules in decoder. rev: 1.1 Configuring The following options to configure will enable decoder and preprocessor rules: $ . classtype:protocol-command-decode.rules respectively. They also allow one to specify the rule type or action of a decoder or preprocessor event on a rule by rule basis. Decoder config options will still determine whether or not to generate decoder events. \ metadata: rule-type decode .
7. • Event Filters You can use event filters to reduce the number of logged events for noisy rules. This is covered in section 3. 2. you also have to remove the decoder and preprocessor rules and any reference to them from snort.2. the following config option in snort. apply_to <ip-list>] The options are described in the table below .10. \ count <c>.1 Rate Filtering rate filter provides rate based attack prevention by allowing users to configure a new action to take for a specified time when a given rate is exceeded. \ track <by_src|by_dst|by_rule>.all are required except apply to. This option applies to rules not specified and the default behavior is to alert. which is optional. This can be tuned to significantly reduce false alarms.2 Reverting to original behavior If you have configured snort to use decoder and preprocessor rules. and the first applicable action is taken. seconds <s>. \ new_action alert|drop|pass|log|sdrop|reject. 2. 83 . Format Rate filters are used as standalone configurations (outside of a rule) and have the following format: rate_filter \ gen_id <gid>.4. sig_id <sid>. Multiple rate filters can be defined on the same rule.conf..3.conf will make Snort revert to the old behavior: config autogenerate_preprocessor_decoder_rules Note that if you want to revert to the old behavior. • Event Suppression You can completely suppress the logging of unintersting events. \ timeout <seconds> \ [.4 Event Processing Snort provides a variety of mechanisms to tune event processing to suit your needs: • Detection Filters You can use detection filters to specifiy a threshold that must be exceeded before a rule generates an event.
sig_id 1. and block further connections from that IP address for 10 seconds: rate_filter \ gen_id 135. \ count 100. seconds 0. timeout 10 2. For example. \ count 100.4. then rule action is never reverted back. \ new_action drop. source and destination means client and server respectively. \ new_action drop. then ignores events for the rest of the time interval. revert to the original rule action after t seconds. 0 seconds only applies to internal rules (gen id 135) and other use will produce a fatal error by Snort. or they are aggregated at rule level. There are 3 types of event filters: • limit Alerts on the 1st m events during the time interval. and sdrop can be used only when snort is used in inline mode. even if the rate falls below the configured limit. for each unique destination IP address. rate filter may be used to detect if the number of connections to a specific server exceed a specific count. new action replaces rule action for t seconds. and block further connection attempts from that IP address for 10 seconds: rate_filter \ gen_id 135.2 Event Filtering Event filtering can be used to reduce the number of logged alerts for noisy rules by limiting the number of times a particular event is logged during a specified time interval. \ track by_src. or by rule. \ track by_src.Option track by src | by dst | by rule count c seconds s new action alert | drop | pass | log | sdrop | reject timeout t apply to <ip-list> Description rate is tracked either by source IP address.allow a maximum of 100 connection attempts per second from any one IP address. This can be tuned to significantly reduce false alarms. sig_id 2. An event filter may be used to manage number of alerts after the rule action is enabled by rate filter. This means the match statistics are maintained for each unique source IP address. c must be nonzero value. sdrop and reject are conditionally compiled with GIDS. seconds 1. Examples Example 1 . Note that events are generated during the timeout period. 84 . 0 seconds means count is a total count instead of a specific rate. track by rule and apply to may not be used together. If t is 0. the maximum number of rule matches in s seconds before the rate filter limit to is exceeded.allow a maximum of 100 successful simultaneous connections from any one IP address. the time period over which count is accrued. drop. reject. destination IP address. track by rule and apply to may not be used together. restrict the configuration to only to source or destination IP address (indicated by track parameter) determined by <ip-list>. For rules related to Stream5 sessions. timeout 10 Example 2 .
\ count <c>. sig_id <sid>. threshold is deprecated and will not be supported in future releases. Type both alerts once per time interval after seeing m occurrences of the event. if they do not block an event from being logged. event filters with sig id 0 are considered ”global” because they apply to all rules with the given gen id. or for each unique destination IP addresses. then ignores any additional events during the time interval. gen id 0. then the filter applies to all rules. This means count is maintained for each unique source IP addresses. Standard filtering tests are applied first. Format event_filter \ gen_id <gid>. number of rule matching in s seconds that will cause event filter limit to be exceeded. then ignores any additional events during the time interval. sig id 0 specifies a ”global” filter because it applies to all sig ids for the given gen id. Thresholds in a rule (deprecated) will override a global event filter. sig id. sig id pair. Ports or anything else are not tracked. track by src|by dst count c seconds s ! △NOTE Only one event filter may be defined for a given gen id. c must be nonzero value. then ignores events for the rest of the time interval. If more than one event filter is applied to a specific gen id. Both formats are equivalent and support the options described below . Snort will terminate with an error while reading the configuration information. s must be nonzero value. Specify the signature ID of an associated rule. Global event filters do not override what’s in a signature or a more specific stand-alone event filter. rate is tracked either by source IP address. • both Alerts once per time interval after seeing m occurrences of the event.all are required. 85 . sig_id <sid>. \ track <by_src|by_dst>. or destination IP address. seconds <s> threshold \ gen_id <gid>. (gen id 0. If gen id is also 0. \ track <by_src|by_dst>. \ count <c>.• threshold Alerts every m times we see this event during the time interval. seconds <s> threshold is an alias for event filter. \ type <limit|threshold|both>. type limit alerts on the 1st m events during the time interval. sig id != 0 is not allowed). the global filtering test is applied. Option gen id <gid> sig id <sid> type limit|threshold|both Description Specify the generator ID of an associated rule. sig id 0 can be used to specify a ”global” threshold that applies to all rules. time period over which count is accrued. Type threshold alerts every m times we see this event during the time interval. \ type <limit|threshold|both>.
count 1. \ count 1. sig_id 1851. track by_src. \ type limit. \ count 1. track by_src. seconds 60 Events in Snort are generated in the usual way. sig_id 0. sig_id 1852. \ type threshold. Such events indicate a change of state that are significant to the user monitoring the network. \ type both. \ type limit. Users can also configure a memcap for threshold with a “config:” option: config event_filter: memcap <bytes> # this is deprecated: config threshold: memcap <bytes> \ 86 . event filters are handled as part of the output system. but only if we exceed 30 events in 60 seconds: event_filter \ gen_id 1.map for details on gen ids. seconds 60 Limit logging to every 3rd event: event_filter \ gen_id 1. track by_src. track by_src. seconds 60 Limit to logging 1 event per 60 seconds per IP. \ count 3. Examples Limit logging to 1 event per 60 seconds: event_filter \ gen_id 1. \ type limit. the first new action event of the timeout period is never suppressed. seconds 60 Limit to logging 1 event per 60 seconds per IP triggering each rule (rule gen id is 1): event_filter \ gen_id 1. however. Read genmsg. \ count 30. seconds 60 Limit logging to just 1 event per 60 seconds. sig_id 1853. triggering each rule for each event generator: event_filter \ gen_id 0.! △NOTE event filters can be used to suppress excessive rate filter alerts. track by_src. sig_id 0.
sig id 0 specifies a ”global” filter because it applies to all sig ids for the given gen id. Format The suppress configuration has two forms: suppress \ gen_id <gid>. This allows a rule to be completely suppressed. ip <ip-list> Option gen id <gid> sig id <sid> track by src|by dst ip <list> Description Specify the generator ID of an associated rule. track by_src. Examples Suppress this event completely: suppress gen_id 1. ip 10. Specify the signature ID of an associated rule.0/24 87 . Suppression tests are performed prior to either standard or global thresholding tests. \ suppress \ gen_id <gid>. sig_id <sid>. ip must be provided as well. Suppression uses an IP list to select specific networks and users for suppression. You may also combine one event filter and several suppressions to the same non-zero SID. SIDs. track by_dst. \ track <by_src|by_dst>. You may apply multiple suppressions to a non-zero SID.1.1.1. but if present.3 Event Suppression Event suppression stops specified events from firing without removing the rule from the rule base. sig_id 1852. sig_id <sid>. ip must be provided as well. sig_id 1852. or suppressed when the causative traffic is going to or coming from a specific IP or group of IP addresses.1. gen id 0. ip 10. This is optional.54 Suppress this event to this CIDR block: suppress gen_id 1.2. sig_id 1852: Suppress this event from this IP: suppress gen_id 1. Restrict the suppression to only source or destination IP addresses (indicated by track parameter) determined by ¡list¿. If track is provided. and IP addresses via an IP list . sig id 0 can be used to specify a ”global” threshold that applies to all rules. Suppress by source IP address or destination IP address.4. Suppression are standalone configurations that reference generators.
1. max queue This determines the maximum size of the event queue. If the append option is not present. only 8 events will be stored for a single packet or stream. The default value is content length. The method in which events are ordered does not affect rule types such as pass. For example. Each require only a simple config option to snort.’.5 Performance Profiling Snort can provide statistics on rule and preprocessor performance. We currently have two different methods: •. order events This argument determines the way that the incoming events are ordered. The default value is 8. 3. 2.2. log. 88 .Rules are ordered before decode or preprocessor alerts. alert. • content length . and rules that have a longer content are ordered before rules with shorter contents. but change event order: config event_queue: order_events priority Use the default event queue values but change the number of logged events: config event_queue: log 2 2. When a file name is provided in profile rules or profile preprocs. the statistics will be saved in these files.conf and Snort will print statistics on the worst (or all) performers on exit. You can’t log more than the max event number that was specified. The default value is 3. such as max content length or event ordering using the event queue. if the event queue has a max size of 8. etc.The highest priority (1 being the highest) events are ordered first. previous data in these files will be overwritten.4 Event Logging Snort supports logging multiple events per packet/stream that are prioritized with different insertion methods.4. log This determines the number of events to log for a given packet or stream.. sorted by number of checks config profile rules: print all. sort avg ticks • Print all rules. \ sort <sort_option> \ [.txt append • Print the top 10 rules.txt config profile rules filename rules stats. based on total time config profile rules: print 100. save results to perf.2. based on highest average time config profile rules: print 10. and append to file rules stats. sort by avg ticks.txt with timestamp in filename config profile rules: print 20. sort total ticks • Print with default options. sort checks • Print top 100 rules.5.txt append • Print top 20 rules.1 Rule Profiling Format config profile_rules: \ print [all | <num>]. sort by avg ticks (default configuration if option is turned on) config profile rules • Print all rules. save results to performance. filename perf.txt each time config profile rules: filename performance.txt 89 .
the few options may or may not match. it makes sense to leave it alone.0 0.0 Avg/Match Avg/Nonmatch ========= ============ 385698.0 53911. Quick to check.0 46229.0 90054 45027. By default. \ sort <sort_option> \ [. If ”append” is not specified. sort total ticks 2.0 0. that most likely contains PCRE.0 92458 46229. The filenames will have timestamps appended to them. will be high for rules that have no options) • Alerts (number of alerts generated from this rule) • CPU Ticks • Avg Ticks per Check • Avg Ticks per Match • Avg Ticks per Nonmatch Interpreting this info is the key. this information will be printed to the console when Snort exits..1: Rule Profiling Example Output Output Snort will print a table much like the following at exit.conf to specify a file where this will be written. These files will be found in the logging directory.0 0. You can use the ”filename” option in snort.2 Preprocessor Profiling Format config profile_preprocs: \ print [all | <num>]. especially those with low SIDs. A high Avg/Check is a poor performing rule. if that rule is causing alerts.0 45027.0 107822 53911. filename <filename> [append]] • <num> is the number of preprocessors to print 90 . High Checks and low Avg/Check is usually an any->any rule with few rule options and no content. The Microsecs (or Ticks) column is important because that is the total time spent evaluating a given rule. print 4. But. We are looking at moving some of these into code.0 Figure 2. a new file will be created each time Snort is run.0 0.5.
sorted by number of checks config profile preprocs: Output Snort will print a table much like the following at exit. should ALWAYS match Checks. These files will be found in the logging directory. etc) • Exits (number of corresponding exits – just to verify code is instrumented correctly. a new file will be created each time Snort is run. Because of task swapping. subroutines within preprocessors. Layer 1 preprocessors are listed under their respective caller (and sorted similarly). unless an exception was trapped) • CPU Ticks • Avg Ticks per Check • Percent of caller . • Checks (number of times preprocessor decided to look at a packet. this identifies the percent of the caller’s ticks that is spent for this subtask. filename preprocs stats. sort avg ticks • Print all preprocessors. ports matched. the Pct of Caller field will not add up to 100% of the caller’s time.conf to specify a file where this will be written.• <sort option> is one of: checks avg ticks total ticks • <filename> is the output filename • [append] dictates that the output will go to the same file each time (optional) Examples • Print all preprocessors.e. By default. and append to file preprocs stats. sort by avg ticks (default configuration if option is turned on) config profile preprocs • Print all preprocessors. 91 print all. You can use the ”filename” option in snort.txt append • Print the top 10 preprocessors. The filenames will have timestamps appended to them. based on highest average time config profile preprocs: print 10. i. If ”append” is not specified. • Preprocessor Name • Layer .The number is indented for each layer. sort total_ticks The columns represent: • Number (rank) . app layer header was correct. sort checks . Configuration line used to print the above table: config profile_rules: \ print 3. It does give a reasonable indication of how much relative time is spent within each subtask.txt config profile preprocs.When printing a specific number of preprocessors all subtasks info for a particular preprocessor is printed for each layer 0 preprocessor stat. and other factors. non-instrumented code. this information will be printed to the console when Snort exits. sort by avg ticks.For non layer 0 preprocessors.
00 0.07 0.00 0.62 3.20 0.70 0.04 0.10 0.06 3.85 84.77 0.00 0.10 1.94 3.58 0.00 0.06 0.16 0.12 0.00 0.02 0.88 44.24 0.40 28.43 39.78 1.01 0.06 0.12 12.94 99.00 0.32 0.89 2.72 1.17 18.53 21.22 15657.01 19.77 0.00 0.01 0.70 0.73 1.37 0.00 0.25 77.81 6.91 15.02 0.14 307.51 2.79 0.01 0.06 0.00 0.27 0.00 0.56 0.46 99.01 0.56 39.81 93.92 3.20 34.21 1.77 39.08 0.65 1.20 19.2: Preprocessor Profiling Example Output 92 .01 0.80 0.11 0.30 0.15 0.57 1.39 13.34 0.51 6.78 2.03 0.04 0.00 0.00 0.00 0.02 11.73 1.06 0.14 25.81 39.01 0.17 21.07 17.17 21.86 4.34 Figure 2.32 0.84 0.66 0.83 0.03 8.00 0.04 0.33 8.87 0.68 38.84 0.16 0.59 0.87 71.14 0.16 1.89 0.41 0.02 0.53 21.23 21.09 0.00 4.00 0.20 47.06 0.00 0.16 0.07 6.00 0.00 0.00 0.37 0.29 2.62 17.59 19.00 65.01 0.08 9.34 1.00 0.02 47.00 0.70 0.12 0.
you must build with the –enable-ppm or the –enable-sourcefire option to configure. \ rule-log [log] [alert] Packets and rules can be configured separately. PPM is configured as follows: # Packet configuration: config ppm: max-pkt-time <micro-secs>. Packet and rule monitoring is independent. \ debug-pkts # Rule configuration: config ppm: max-rule-time <micro-secs>. as above. The following sections describe configuration. To use PPM. so one or both or neither may be enabled. \ fastpath-expensive-packets. . and some implementation details worth noting. It does not provide a hard and fast latency guarantee but should in effect provide a good average latency control. or together in just one config ppm statement. \ threshold count.5. \ pkt-log. sample output.3 Packet Performance Monitoring (PPM) PPM provides thresholding mechanisms that can be used to provide a basic level of latency control for snort.2. Both rules and packets can be checked for latency. \ suspend-timeout <seconds>. \ suspend-expensive-rules. The action taken upon detection of excessive latency is configurable.
then no action is taken other than to increment the count of the number of packets that should be fastpath’d or the rules that should be suspended. threshold 5 If fastpath-expensive-packets or suspend-expensive-rules is not used.Rule Configuration Options max-rule-time <micro-secs> • enables rule latency thresholding using ’micros-secs’ as the limit. A summary of this information is printed out when snort exits. Example 2: The following suspends rules and aborts packet inspection. 94 . These rules were used to generate the sample output that follows..
15385 usecs PPM: Process-EndPkt[61] PPM: Process-BeginPkt[62] caplen=342 PPM: Pkt[62] Used= 65. suspend-expensive-rules. Sample Snort Exit Output Packet Performance Summary: max packet time : 50 usecs packet events : 1 avg pkt time : 0. Process-BeginPkt[63] caplen=60 Pkt[63] Used= 8.394 usecs Process-EndPkt[63] PPM: Process-BeginPkt[64] caplen=60 PPM: Pkt[64] Used= 8. 0 rules. debug-pkt config ppm: \ max-rule-time 50. threshold 5..3659 usecs PPM: Process-EndPkt[62] PPM: PPM: PPM: PPM: Pkt-Event Pkt[63] used=56... \ pkt-log.config ppm: \ max-pkt-time 50. 1 nc-rules tested. fastpath-expensive-packets. PPM: Process-BeginPkt[61] caplen=60 PPM: Pkt[61] Used= 8..0438 usecs.633125 usecs Rule Performance Summary: 95 . packet fastpathed. \ suspend-timeout 300.21764 usecs PPM: Process-EndPkt[64] . .
latency thresholding is presently only available on Intel and PPC platforms. Output modules are loaded at runtime by specifying the output keyword in the rules file: output <name>: <options> output alert_syslog: log_auth log_alert 2.1 alert syslog This module sends alerts to the syslog facility (much like the -s command line switch). Available Keywords Facilities • log auth • log authpriv • log daemon 96 . This was a conscious design decision because when a system is loaded.6. Multiple output plugins may be specified in the Snort configuration file.6. Therefore this implementation cannot implement a precise latency guarantee with strict timing guarantees. • Since this implementation depends on hardware based high performance frequency counters. giving users greater flexibility in logging alerts. they are stacked and called in sequence when an event occurs. • This implementation is software based and does not use an interrupt driven timing mechanism and is therefore subject to the granularity of the software based timing tests. 2. As with the standard logging and alerting systems. The output modules are run when the alert or logging subsystems of Snort are called. the latency for a packet is based on the total system time. They allow Snort to be much more flexible in the formatting and presentation of output to its users. not processor usage by Snort. Due to the granularity of the timing measurements any individual packet may exceed the user specified packet or rule processing time limit. Latency control is not enforced after each preprocessor. after the preprocessors and detection engine. alert) are specified. This module also allows the user to specify the logging facility and priority within the Snort rules file. Therefore. not just the processor time the Snort application receives. When multiple plugins of the same type (log.2675 usecs • Enforcement of packet and rule processing times is done after processing each rule. it is recommended that you tune your thresholding to operate optimally when your system is under load. Hence the reason this is considered a best effort approach. output plugins send their data to /var/log/snort by default or to a user directed directory (using the -l command line switch). • Time checks are made based on the total system time.max rule time rule events avg nc-rule time Implementation Details : 50 usecs : 0 : 0.6 Output Modules Output modules are new as of version 1. The format of the directives in the rules file is very similar to that of the preprocessors.
The default host is 127. output alert_syslog: \ [host=<hostname[:<port>].0.1. The default port is 514.0.] \ <facility> <priority> <options> 97 . a hostname and port can be passed as options.
These files will be decoded packet dumps of the packets that triggered the alerts. The creation of these files slows Snort down considerably.1:514. <facility> <priority> <options> 2. Format alert_unixsock Example output alert_unixsock 98 . Format alert_full: <output filename> Example output alert_full: alert.6.3 alert full This will print Snort alert messages with full packet headers. This output method is discouraged for all but the lightest traffic situations.6.full 2. The alerts will be written in the default logging directory (/var/log/snort) or in the logging directory specified at the command line. Inside the logging directory.4 alert unixsock Sets up a UNIX domain socket and sends alert reports to it.2 alert fast This will print Snort alerts in a quick one-line format to a specified output file. External programs/processes can listen in on this socket and receive Snort alert and packet data in real time. This is currently an experimental interface.Example output alert_syslog: 10. It is a faster alerting method than full alerts because it doesn’t need to print all of the packet headers to the output file Format alert_fast: <output filename> Example output alert_fast: alert.1.6.1. a directory will be created per IP.fast 2.
Blobs are not used because they are not portable across databases.3x the size of the binary Searchability . If a non-zero-length string is specified. Format log_tcpdump: <output filename> Example output log_tcpdump: snort. Storage requirements .not readable requires post processing 99 .Specify your own name for this Snort sensor. So i leave the encoding option to you. Without a host name.Represent binary data as a base64 string.Database name user .Represent binary data as a hex string. Format database: <log | alert>.6 database This module from Jed Pickel sends Snort data to a variety of SQL databases. port . <database type>.org web page.Because the packet payload and option data is binary. Note that the file name will have the UNIX timestamp in seconds appended the file name.Password used if the database demands password authentication sensor name . You can choose from the following options. This is useful for performing post-process analysis on collected traffic with the vast number of tools that are available for examining tcpdump-formatted files. The arguments to this plugin are the name of the database to be logged to and a parameter list.impossible without post processing Human readability . Each has its own advantages and disadvantages: hex (default) . there is no one simple and portable way to store it in a database. Parameters are specified with the format parameter = argument.6. This module only takes a single argument: the name of the output file. This is so that data from separate Snort runs can be kept distinct.Port number to connect to at the server host. requires post processing base64 . More information on installing and configuring this module can be found on the [91]incident.very good Human readability .log 2. <parameter list> The following parameters are available: host .not readable unless you are a true geek.∼1. If you do not specify a name. it will connect using a local UNIX domain socket.2. TCP/IP communication is used.6.2x the size of the binary Searchability . one will be generated automatically encoding . or socket filename extension for UNIX-domain connections.Database username for authentication password .Host to connect to. dbname . Storage requirements .3 for example usage. see Figure 2.5 log tcpdump The log tcpdump module logs packets to a tcpdump-formatted file.
’. the plugin will be called on the log output chain.Log only a minimum amount of data. mysql. and odbc. If you set the type to log.Represent binary data as an ASCII string.How much detailed data do you want to store? The options are: full (default) . Setting the type to alert attaches the plugin to the alert output chain within the program. source port. Set the type to match the database you are using.Log all details of a packet that caused an alert (including IP/TCP options and the payload) fast . The following fields are logged: timestamp. source ip. destination ip. but this is still the best choice for some applications. These are mssql. signature. the output is in the order the formatting option is listed.output database: \ log.7. postgresql. See section 3. log and alert.very good for searching for a text string impossible if you want to search for binary human readability . The list of formatting options is below.<. Storage requirements .slightly larger than the binary because some characters are escaped (&. If the formatting option is default. If you choose this option.7 csv The csv output plugin allows alert data to be written in a format easily importable to a database. there is a logging method and database type that must be defined. Non-ASCII Data is represented as a ‘. mysql.very good detail . oracle. There are two logging types available. then data for IP and TCP options will still be represented as hex because it does not make any sense for that data to be ASCII. The plugin requires 2 arguments: a full pathname to a file and the output formatting option.6.>) Searchability .5 for more details. Setting the type to log attaches the database logging functionality to the log facility within the program. • timestamp • sig generator • sig id • sig rev • msg • proto • src • srcport 100 . tcp flags. There are five database types available in the current version of the plugin.3: Database Output Plugin Configuration ascii . destination port. dbname=snort user=snort host=localhost password=xyz Figure 2. 2. This is the only option where you will actually lose data. ! △NOTE The database output plugin does not have the ability to handle alerts that are generated by using the tag keyword. You severely limit the potential of some analysis applications if you choose this option. and protocol) Furthermore.
port. and a log file.csv default output alert_csv: /var/log/alert. message id). an alert file. The log file contains the detailed packet information (a packet dump with the associated event ID). allowing another programs to handle complex logging mechanisms that would otherwise diminish the performance of Snort.h. as the unified output plugin creates two different files.6.csv timestamp. ! △NOTE file creation time (in Unix Epoch format) appended to each file when it is created. Files have the 101 . Both file types are written in a bimary format described in spo unified. The unified output plugin logs events in binary format.8 unified The unified output plugin is designed to be the fastest possible method of logging Snort events. The alert file contains the high-level details of an event (eg: IPs. msg 2. The name unified is a misnomer. protocol.
Likewise. simply specify unified2.alert. <limit <size in MB>] [. limit 128. alert logging.9 unified 2 The unified2 output plugin is a replacement for the unified output plugin. <limit <file size limit in MB>] Example output alert_unified: snort.10 alert prelude ! △NOTE support to use alert prelude is not built in by default.log. limit 128.log. limit 128. <limit <file size limit in MB>] output log_unified: <base file name> [.8 on unified logging for more information. unified file. or true unified logging. Unified2 can work in one of three modes. snort must be built with the –enable-prelude argument passed to . <limit <size in MB>] [. It has the same performance characteristics. MPLS labels can be included in unified2 events./configure. mpls_event_types 2.Format output alert_unified: <base file name> [. alert logging will only log events and is specified with alert unified2. limit 128 output log_unified: snort.6. nostamp] output unified2: \ filename <base file name> [.alert. nostamp] [. See section 2. <limit <size in MB>] [. nostamp] [. packet logging. mpls_event_types] output log_unified2: \ filename <base filename> [. Format output alert_unified2: \ filename <base filename> [. 102 . nostamp unified2: filename merged. then MPLS labels will be not be included in unified2 events. unified 2 files have the file creation time (in Unix Epoch format) appended to each file when it is created. mpls_event_types] Example output output output output alert_unified2: filename snort.6. Use option mpls event types to enable this. To use alert prelude. If option mpls event types is not used. ! △NOTE By default. nostamp unified2: filename merged.6. nostamp log_unified2: filename snort. To include both logging styles in a single. limit 128. When MPLS support is turned on.log. but a slightly different logging format. Packet logging includes a capture of the entire packet and is specified with log unified2.log. nostamp. limit 128 2.
6. see. In Snort 1. Communicates with an Aruba Networks wireless mobility controller to change the status of authenticated users. Format output log_null Example output log_null # like using snort -n ruletype info { type alert output alert_fast: info.alert output log_null } 2. Format output alert_prelude: \ profile=<name of prelude profile> \ [ info=<priority number for info priority alerts>] \ [ low=<priority number for low priority alerts>] \ [ medium=<priority number for medium priority alerts>] Example output alert_prelude: profile=snort info=4 low=3 medium=2 2. This allows Snort to take action against users on the Aruba controller to control their network privilege levels.arubanetworks. the log null plugin was introduced.11 log null Sometimes it is useful to be able to create rules that will alert to certain types of traffic but will not cause packet log entries./configure. For more information on Aruba Networks access control.The alert prelude output plugin is used to log to a Prelude database. This is equivalent to using the -n command line option but it is able to work within a ruletype. Format output alert_aruba_action: \ <controller address> <secrettype> <secret> <action> 103 .6.12 alert aruba action ! △NOTE Support to use alert aruba action is not built in by default. For more information on Prelude. see http: //. To use alert aruba action.com/.org/. snort must be built with the –enable-aruba argument passed to .8.
used to reduce the size of the file for common data elements.Blacklist the station by disabling all radio communication. and IP-Frag policy (see section 2. An example of the file format is shown below. The mapping section is optional.2.7.9. secret . action . This information is stored in an attribute table.1.8. a mapping section. which is loaded at startup. For rule evaluation. blacklist .Aruba mobility controller address. if applicable.6 cleartext foobar setrole:quarantine_role 2.1 Configuration Format attribute_table filename <path to file> 2. <SNORT_ATTRIBUTES> <ATTRIBUTE_MAP> <ENTRY> <ID>1</ID> <VALUE>Linux</VALUE> </ENTRY> <ENTRY> <ID>2</ID> 104 . Snort must be configured with the –enable-targetbased flag. or the traffic doesn’t have any matching service information.Authentication secret configured on the Aruba mobility controller with the ”aaa xml-api client” configuration command.Action to apply to the source IP address of the traffic generating an alert. secrettype . ”md5” or ”cleartext”.Change the user´ role to the specified rolename.2 Attribute Table File Format The attribute table uses an XML format and consists of two sections. the rule relies on the port information. s Example output alert_aruba_action: \ 10. service information is used instead of the ports when the protocol metadata in the rule matches the service corresponding to the traffic. Snort associates a given packet with its attribute data from the table. If the rule doesn’t have protocol metadata.The following parameters are required: controller address . setrole:rolename . one of ”sha1”. 2. or a cleartext password.2).7.2. The table is re-read during run time upon receipt of signal number 30.3. Snort has the capability to use information from an outside source to determine both the protocol for use with Snort rules.1) and TCP Stream reassembly policies (see section 2. ! △NOTE To use a host attribute table. represented as a sha1 or md5 hash. and the host attribute section.7 Host Attribute Table Starting with version 2.Secret type..9p1</ATTRIBUTE_VALUE> <CONFIDENCE>93</CONFIDENCE> </VERSION> </APPLICATION> </SERVICE> <SERVICE> <PORT> <ATTRIBUTE_VALUE>23</ATTRIBUTE_VALUE> <CONFIDENCE>100</CONFIDENCE> </PORT> <IPPROTO> <ATTRIBUTE_VALUE>tcp</ATTRIBUTE_VALUE> <CONFIDENCE>100</CONFIDENCE> </IPPROTO> <PROTOCOL> <ATTRIBUTE_VALUE>telnet</ATTRIBUTE_VALUE> <CONFIDENCE>100</CONFIDENCE> 105 .<VALUE>ssh</VALUE> </ENTRY> </ATTRIBUTE_MAP> <ATTRIBUTE_TABLE> <HOST> <IP>192.
only the IP protocol (tcp.conf or via command-line options. 2. 2. and protocol (http.1.0</ATTRIBUTE_VALUE> <CONFIDENCE>89</CONFIDENCE> </VERSION> </APPLICATION> </CLIENT> </CLIENTS> </HOST> </ATTRIBUTE_TABLE> </SNORT_ATTRIBUTES> ! △NOTE With Snort 2. etc).8. Snort must be configured with the --disable-dynamicplugin flag. etc) are used. The application and version for a given service attribute. port.8. and any client attributes are ignored.1 Format <directive> <parameters> 106 .8 Dynamic Modules Dynamically loadable modules were introduced with Snort 2. ! △NOTE To disable use of dynamic modules. A DTD for verification of the Host Attribute Table XML file is provided with the snort packages. Of the service attributes. They can be loaded via directives in snort.<. ssh. They will be used in a future release. udp. the stream and IP frag information are both used.6. for a given host entry.
To disable this behavior and have Snort exit instead of restart.1 Enabling support To enable support for reloading a configuration. Or. followed by the full or relative path to the shared library. Or. See chapter 5 for more information on dynamic preprocessor libraries. All newly created sessions will. the main Snort packet processing thread will swap in the new configuration to use and will continue processing under the new configuration. Tells snort to load the dynamic detection rules shared library (if file is used) or all dynamic detection rules shared libraries (if directory is used).9.3 below). (Same effect as --dynamic-detection-lib or --dynamic-detection-lib-dir options). to initiate a reload.2 Directives Syntax dynamicpreprocessor [ file <shared library path> | directory <directory of shared libraries> ] Description Tells snort to load the dynamic preprocessor shared library (if file is used) or all dynamic preprocessor shared libraries (if directory is used). See chapter 5 for more information on dynamic engine libraries. There is also an ancillary option that determines how Snort should behave if any non-reloadable options are changed (see section 2. ! △NOTE is not currently supported in Windows. Then. specify directory. (Same effect as --dynamic-engine-lib or --dynamic-preprocessor-lib-dir options).conf (the file passed to the -c option on the command line). When a swappable configuration object is ready for use. Specify file. followed by the full or relative path to the shared library. followed by the full or relative path to a directory of preprocessor shared libraries.8. followed by the full or relative path to a directory of detection rules shared libraries. Tells snort to load the dynamic engine shared library (if file is used) or all dynamic engine shared libraries (if directory is used). e. send Snort a SIGHUP signal. however. Specify file. add --enable-reload to configure when compiling. specify directory.9. Note that for some preprocessors.g. This option is enabled by default and the behavior is for Snort to restart if any nonreloadable options are added/modified/removed. use the new configuration.2 Reloading a configuration First modify your snort. dynamicengine [ file <shared library path> | directory <directory of shared libraries> ] dynamicdetection [ file <shared library path> | directory <directory of shared libraries> ] 2. add --disable-reload-error-restart in addition to --enable-reload to configure when compiling. existing session data will continue to use the configuration under which they were created in order to continue with proper state for that session. A separate thread will parse and create a swappable configuration object while the main Snort packet processing thread continues inspecting traffic under the current configuration. specify directory. Specify file. This functionality 2. followed by the full or relative path to the shared library. Or. followed by the full or relative path to a directory of preprocessor shared libraries. See chapter 5 for more information on dynamic detection rules libraries. (Same effect as --dynamic-preprocessor-lib or --dynamic-preprocessor-lib-dir options).2. 107 . 2.
9. etc. dynamicengine and dynamicpreprocessor are not reloadable. Non-reloadable configuration options of note: • Adding/modifying/removing shared objects via dynamicdetection.$ kill -SIGHUP <snort pid> ! △NOTE is not enabled. Reloadable configuration options of note: • Adding/modifying/removing text rules and variables are reloadable. • Any changes to output will require a restart. i.g. • Adding/modifying/removing preprocessor configurations are reloadable (except as noted below). $ snort -c snort. Snort will restart (as it always has) upon receipt of a SIGHUP. e.e.conf -T 2. Modifying any of these options will cause Snort to restart (as a SIGHUP previously did) or exit (if --disable-reload-error-restart was used to configure Snort). any new/modified/removed shared objects will require a restart. so you should test your new configuration An invalid before issuing a reload . startup memory allocations. If reload support ! △NOTEconfiguration will still result in Snort fatal erroring.
using the following configuration line: config binding: <path_to_snort. Each configuration can have different preprocessor settings and detection rules. Those parameters are listed below the relevant config option or preprocessor.1 Creating Multiple Configurations Default configuration for snort is specified using the existing -c option.conf> vlan <vlanIdList> config binding: <path_to_snort..10. 2.10 Multiple Configurations Snort now supports multiple configurations based on VLAN Id or IP subnet within a single instance of Snort.dynamicdetection dynamicengine dynamicpreprocessor output In certain cases.conf> net <ipList> 109 . only some of the parameters to a config option or preprocessor configuration are not reloadable...
their value applies to all other configurations. vlanIdList . Spaces are allowed within ranges.e. The following config options are specific to each configuration.conf . Valid vlanId is any number in 0-4095 range. The format for ranges is two vlanId separated by a ”-”. the default values of the option (not the default configuration values) take effect. non-payload detection options. ! △NOTE Vlan and Subnets can not be used in the same line. Configurations can be applied based on either Vlans or Subnets not both. If a rule is not specified in a configuration then the rule will never raise an event for the configuration. . config config config config config config config config config config config config config config Rules Rules are specific to configurations but only some parts of a rule can be customized for performance reasons. Subnets can be CIDR blocks for IPV6 or IPv4. policy_id policy_mode policy_version The following config options are specific to each configuration. and post-detection options.Refers to ip subnets. 2.path to snort. Parts of the rule header can be specified differently across configurations. ipList . they are included as valid in terms of configuring Snort.2 Configuration Specific Elements Config Options Generally config options defined within the default configuration are global by default i.Refers to the absolute or relative path to the snort.Refers to the comma seperated list of vlandIds and vlanId ranges. Negative vland Ids and alphanumeric are not supported.conf for specific configuration. including the general options. ! △NOTE Even though Vlan Ids 0 and 4095 are reserved.10. A rule shares all parts of the rule options. payload detection options. If not defined in a configuration.
the address/CIDR combination 192. 8. then act as a log rule 6. alert . and dynamic.168.log the packet 3.alert and then turn on another dynamic rule 5.2. say. and then log the packet 2.2 Protocols The next field in a rule is the protocol. In addition.1. dynamic . and sdrop. reject. ICMP. OSPF. The keyword any may be used to define any address. etc.make iptables drop the packet but do not log it. log . IPX. if you are running Snort in inline mode. The rule action tells Snort what to do when it finds a packet that matches the rule criteria. In the future there may be more. This example will create a type that will log to just tcpdump: ruletype suspicious { type log output log_tcpdump: suspicious. pass . 1. You can then use the rule types as actions in Snort rules. UDP. A CIDR block mask of /24 indicates a Class C network.make iptables drop the packet.make iptables drop the packet and log the packet 7. user=snort dbname=snort host=localhost } 3. log. For example. /16 a Class B network. 114 .168.1. RIP. the destination address would match on any address in that range. There are 5 available default actions in Snort. activate .ignore the packet 4. There are four protocols that Snort currently analyzes for suspicious behavior – TCP. and then send a TCP reset if the protocol is TCP or an ICMP port unreachable message if the protocol is UDP. You can also define your own rule types and associate one or more output plugins with them.0/24 would signify the block of addresses from 192. GRE.1.168.3 IP Addresses The next portion of the rule header deals with the IP address and port information for a given rule. reject . and /32 indicates a specific machine address.2. activate.generate an alert using the selected alert method.action. IGRP. and IP. 3. The CIDR designations give us a nice short-hand way to designate large address spaces with just a few characters.remain idle until activated by an activate rule . mysql.1 to 192. The addresses are formed by a straight numeric IP address and a CIDR[3] block. drop . log it. pass. alert. Snort does not have a mechanism to provide host name lookup for the IP address fields in the rules file. such as ARP. Any rule that used this designation for.255. you have additional options which include drop. sdrop .
0/24 any -> 192.).168. static port definitions. which would translate to none. Port ranges are indicated with the range operator :. the IP list may not include spaces between the addresses. Static ports are indicated by a single port number. etc.1.4: Port Range Examples 115 .2.168. if for some twisted reason you wanted to log everything except the X Windows ports.2. ranges.0 Class C network.0/24.168. This rule’s IP addresses indicate any tcp packet with a source IP address not originating from the internal network and a destination address on the internal network. An IP list is specified by enclosing a comma separated list of IP addresses and CIDR blocks within square brackets.5. \ msg: "external mountd access".3 for an example of an IP list in action.4.4 Port Numbers Port numbers may be specified in a number of ways.1. such as in Figure 3.10. 3.1.10.. For the time being.) Figure 3. how Zen. and by negation. The IP address and port numbers on the left side of the direction operator is considered to be the traffic coming from the source log udp any any -> 192.alert tcp !192. Any ports are a wildcard value.168. the source IP address was set to match for any computer talking. The negation operator is indicated with a !.1.0/24 1:1024 log udp traffic coming from any port and destination ports ranging from 1 to 1024 log tcp any any -> 192.) Figure 3. See Figure 3.168. You may also specify lists of IP addresses.168. 3.2. you could do something like the rule in Figure 3.1.0/24 :6000 log tcp traffic from any port going to ports less than or equal to 6000 log tcp any :1024 -> 192. 23 for telnet. including any ports.0/24 111 \ (content: "|00 01 86 a5|". such as 111 for portmapper. and the destination address was set to match on the 192.1. This operator tells Snort to match any IP address except the one indicated by the listed IP address. There is an operator that can be applied to IP addresses. For example.1..1.3: IP Address Lists In Figure 3. or direction.1.0/24 500: log tcp traffic from privileged ports less than or equal to 1024 going to ports greater than or equal to 500 Figure 3.5 The Direction Operator The direction operator -> indicates the orientation. meaning literally any port.1.0/24.168.1. or 80 for http. the negation operator.2: Example IP Address Negation Rule alert tcp ![192.168.0/24] any -> \ [192. msg: "external mountd access". of the traffic that the rule applies to. The negation operator may be applied against any of the other rule types (except any.0/24] 111 (content: "|00 01 86 a5|". an easy modification to the initial example is to make it alert on any traffic that originates outside of the local net with the negation operator as shown in Figure 3.1.1. Port negation is indicated by using the negation operator !. For example. The range operator may be applied in a number of ways to take on different meanings.
Dynamic rules act just like log rules.6. the direction operator did not have proper error checking and many people used an invalid token.) dynamic tcp !$HOME_NET any -> $HOME_NET 143 (activated_by: 1. Activate/dynamic rule pairs give Snort a powerful capability. Also.5: Example of Port Negation log tcp !192.10).5) and flowbits (3.2.8. You can now have one rule activate another when it’s action is performed for a set number of packets. Rule option keywords are separated from their arguments with a colon (:) character.1.168. such as telnet or POP3 sessions. Activate rules are just like alerts but also tell Snort to add a rule when a specific network event occurs. Dynamic rules are just like log rules except are dynamically enabled when the activate rule id goes off.1. 3. The reason the <. Activate rules act just like alert rules.3 Rule Options Rule options form the heart of Snort’s intrusion detection engine. This is very useful if you want to set Snort up to perform follow on recording when a specific rule goes off.168.) Figure 3. activates: 1. count.7. except they have a *required* option field: activates.1. which is indicated with a <> symbol. 3. there’s a very good possibility that useful data will be contained within the next 50 (or whatever) packets going to that same service port on the network. \ msg: "IMAP buffer overflow!".6.168.) character. This is handy for recording/analyzing both sides of a conversation. These rules tell Snort to alert when it detects an IMAP buffer overflow and collect the next 50 packets headed for port 143 coming from outside $HOME NET headed to $HOME NET. In Snort versions before 1.does not exist is so that rules always read consistently.0/24 any <> 192.7. combining ease of use with power and flexibility. note that there is no <.7. If the buffer overflow happened and was successful. and the address and port information on the right side of the operator is the destination host.operator. \ content: "|E8C0FFFFFF|/bin". so there’s value in collecting those packets for later analysis.log tcp any any -> 192. All Snort rule options are separated from each other using the semicolon (.6: Snort rules using the Bidirectional Operator host.7: Activate/Dynamic Rule Example 116 . This tells Snort to consider the address/port pairs in either the source or destination orientation. Put ’em together and they look like Figure 3. Dynamic rules have a second required field as well.0/24 !6000:6010 Figure 3. but they have a different option field: activated by. There is also a bidirectional operator.0/24 23 Figure 3.6 Activate/Dynamic Rules ! △NOTE Activate and Dynamic rules are being phased out in favor of a combination of tagging (3. An example of the bidirectional operator being used to record both sides of a telnet session is shown in Figure 3. count: 50. activate tcp !$HOME_NET any -> $HOME_NET 143 (flags: PA.
] Examples alert tcp any any -> any 7070 (msg:"IDS411/dos-realaudio". It is a simple text string that utilizes the \ as an escape character to indicate a discrete character that might otherwise confuse Snort’s rules parser (such as the semi-colon . content:"|31c031db 31c9b046 cd80 31c031db|".4).com/bid/. This plugin is to be used by output plugins to provide a link to additional information about the alert produced.) alert tcp any any -> any 21 (msg:"IDS287/ftp-wuftp260-venglin-linux". The plugin currently supports several specific systems as well as unique URLs.1 msg The msg rule option tells the logging and alerting engine the message to print along with a packet dump or to an alert. content:"|fff4 fffd 06|".com/vil/dispVirus.securityfocus. Table 3.cgi?name= are four major categories of rule options. Format msg: "<message text>".1: Supported Systems URL Prefix. reference:arachn.org/pub-bin/sigs-search. character).4.whitehats.nessus. \ flags:AP.” 3. Make sure to also take a look at General Rule Options 3.php3?id= (currently down). \ 117 .cgi/ for a system that is indexing descriptions of alerts based on of the sid (See Section 3.2 reference The reference keyword allows rules to include references to external attack identification systems.<id>. 3. \ flags:AP.org/plugins/dump. [reference: <id system>.mitre.com/info/IDS.<id>.asp?virus k= http:// System bugtraq cve nessus arachnids mcafee url Format reference: <id system>.IDS411.nai.
Note that the gid keyword is optional and if it is not specified in a rule.4. it is recommended that a value greater than 1.000 Rules included with the Snort distribution • >1.1387.map contains contains more information on preprocessor and decoder gids. sid:1000983.3 gid The gid keyword (generator id) is used to identify what part of Snort generates the event when a particular rule fires. This option should be used with the rev keyword. it is not recommended that the gid keyword be used.5) • <100 Reserved for future use • 100-1. gid:1000001.) 3. This information allows output plugins to identify rules easily. \ reference:cve. Example This example is a rule with the Snort Rule ID of 1000983. rev:1. reference:bugtraq. rev:1. This information is useful when postprocessing alert to map an ID to an alert message. This option should be used with the sid keyword.4.reference:arachnids. alert tcp any any -> any 80 (content:"BOB". Format sid: <snort rules id>.4 sid The sid keyword is used to uniquely identify Snort rules. it will default to 1 and the rule will be part of the general rule subsystem.4. To avoid potential conflict with gids defined in Snort (that for some reason aren’t noted it etc/generators). See etc/generators in the source tree for the current generator ids in use.000 be used. (See section 3. sid:1. (See section 3.) 3.000. alert tcp any any -> any 80 (content:"BOB". Example This example is a rule with a generator id of 1000001.000.4) The file etc/gen-msg.4.CAN-2000-1574.) 118 .000 Used for local rules The file sid-msg. For general rule writing. For example gid 1 is associated with the rules subsystem and various gids over 100 are designated for specific preprocessors and the decoder.000.map contains a mapping of alert messages to Snort rule IDs. Format gid: <generator id>.IDS287.
2.4. \ content:"expn root". classtype:attempted-recon. Example This example is a rule with the Snort Rule Revision of 1. alert tcp any any -> any 80 (content:"BOB". Revisions. Table 3. sid:1000983.<default priority> These attack classifications are listed in Table 3. nocase. rev:1.4. allow signatures and descriptions to be refined and replaced with updated information.4) Format rev: <revision integer>. A priority of 1 (high) is the most severe and 3 (low) is the least severe.<class description>.) 3. Format classtype: <class name>. along with Snort rule id’s. The file uses the following syntax: config classification: <class name>.5 rev The rev keyword is used to uniquely identify revisions of Snort rules. (See section 3.3. Snort provides a default set of attack classes that are used by the default set of rules it provides. Defining classifications for rules provides a way to better organize the event data Snort produces.4 .6 classtype The classtype keyword is used to categorize a rule as detecting an attack that is part of a more general type of attack class. Example alert tcp any any -> any 25 (msg:"SMTP expn root".config file. flags:A+.) Attack classifications defined by Snort reside in the classification. They are currently ordered with 3 default priorities. This option should be used with the sid keyword.
priority:10 ). \ dsize: >128. Examples alert TCP any any -> any 80 (msg: "WEB-MISC phf attempt".conf by using the config classification option priority The priority tag assigns a severity level to rules. \ content: "/cgi-bin/phf". flags:A+. Format priority: <priority integer>.4.) alert tcp any any -> any 80 (msg:"EXPLOIT ntpdx overflow". Examples of each case are given below. classtype:attempted-admin.config that are used by the rules it provides. Snort provides a default set of classifications in classification. A classtype rule assigns a default priority (defined by the config classification option) that may be overridden with a priority rule. 120 . priority:10.
3. Examples alert tcp any any -> any 80 (msg: "Shared Library Rule Example". with keys separated by commas.) 3. typically in a key-value format. Multiple keys are separated by a comma. metadata: key1 value1. metadata: key1 value1. Certain metadata keys and values have meaning to Snort and are listed in Table 3. key2 value2. The first uses multiple metadata keywords.4: General rule option keywords Keyword msg reference gid Description The msg keyword tells the logging and alerting engine the message to print with the packet dump or alert. . Keys other than those listed in the table are effectively ignored by Snort and can be free-form.3.) alert tcp any any -> any 80 (msg: "Shared Library Rule Example". The reference keyword allows rules to include references to external attack identification systems.4. Format The examples below show an stub rule from a shared library rule. the rule is not applied (even if the ports specified in the rule match). \ metadata:service http. The gid keyword (generator id) is used to identify what part of Snort generates the event when a particular rule fires. \ metadata:engine shared. Table 3. See Section 2. When the value exactly matches the service ID as specified in the table. with a key and a value. the rule is applied to that packet.4. soid 3|12345.9 General Rule Quick Reference Table 3. 121 . otherwise. \ metadata:engine shared.) alert tcp any any -> any 80 (msg: "HTTP Service Rule Example".7 for details on the Host Attribute Table. the second a single metadata keyword. while keys and values are separated by a space.8 metadata The metadata tag allows a rule writer to embed additional information about the rule. metadata:soid 3|12345.
Examples alert tcp any any -> any 139 (content:"|5c 00|P|00|I|00|P|00|E|00 5c|". the result will return a match. Note that multiple content rules can be specified in one rule. The classtype keyword is used to categorize a rule as detecting an attack that is part of a more general type of attack class. The metadata keyword allows a rule writer to embed additional information about the rule. typically in a key-value format.5 Payload Detection Rule Options 3. use isdataat as a pre-cursor to the content. Bytecode represents binary data as hexadecimal numbers and is a good shorthand method for describing complex binary data. Whenever a content option pattern match is performed. The binary data is generally enclosed within the pipe (|) character and represented as bytecode.) alert tcp any any -> any 80 (content:!"GET". the test is successful and the remainder of the rule option tests are performed. within:50. modifiers included. The example below shows use of mixed text and binary data in a Snort rule. \ " Format content: [!] "<content string>". For example.) ! △NOTE A ! modifier negates the results of the entire content search. If the rule is preceded by a !. If there must be 50 bytes for a valid match. if using content:!"A". and there are only 5 bytes of payload and there is no ”A” in those 5 bytes. This is useful when writing rules that want to alert on packets that do not match a certain pattern ! △NOTE Also note that the following characters must be escaped inside a content rule: : . This allows rules to be tailored for less false positives.sid rev classtype priority metadata The sid keyword is used to uniquely identify Snort rules.1 content The content keyword is one of the more important features of Snort. 122 . The option data for the content keyword is somewhat complex. the alert will be triggered on packets that do not contain this content. the Boyer-Moore pattern match function is called and the (rather computationally expensive) test is performed against the packet contents. The priority keyword assigns a severity level to rules.5. The rev keyword is used to uniquely identify revisions of Snort rules. it can contain mixed text and binary data. It allows the user to set rules that search for specific content in the packet payload and trigger response based on that data. If data exactly matching the argument data string is contained anywhere within the packet’s payload. Be aware that this test is case sensitive. 3.
nocase modifies the previous ’content’ keyword in the rule.7 http client body 3. These modifier keywords are: Table 3.5: Content Modifiers Modifier Section nocase 3. alert tcp any any -> any 21 (msg: "Telnet NOP". nocase.5.5.5.5. ignoring any decoding that was done by preprocessors.) 3. content:"USER root". Format nocase.5.5. Example This example tells the content pattern matcher to look at the raw traffic.5.4 offset 3.11 http uri 3. content: "|FF F1|". instead of the decoded traffic provided by the Telnet decoder. rawbytes.5 distance 3.9 http header 3.5.13 3. ignoring case.5. The modifier keywords change how the previously specified content works.5.1 option. This acts as a modifier to the previous content 3.) 123 .5.6 within 3.5.5.Changing content behavior The content keyword has a number of modifier keywords.12 fast pattern 3.10 http method 3. Example alert tcp any any -> any 21 (msg:"FTP ROOT".3 depth 3.3 rawbytes The rawbytes keyword allows rules to look at the raw packet data.2 rawbytes 3.8 http cookie 3. format rawbytes.5.5.2 nocase The nocase keyword allows the rule writer to specify that the Snort should look for the specific pattern.. content: "DEF". and depth search rule. there must be a content in the rule before ’offset’ is specified. offset modifies the previous ’content’ keyword in the rule. offset:4.3. An offset of 5 would tell Snort to start looking for the specified pattern after the first 5 bytes of the payload. As this keyword is a modifier to the previous ’content’ keyword. depth:20. Example The rule below maps to a regular expression of /ABC.) 3.) 124 .5). Example The following example shows use of a combined content. This can be thought of as exactly the same thing as offset (See Section 3. Format offset: <number>.5. As the depth keyword is a modifier to the previous ‘content’ keyword. alert tcp any any -> any any (content:"ABC".5.5. alert tcp any any -> any 80 (content: "cgi-bin/phf". offset.{1}DEF/. Format distance: <byte count>.5 offset The offset keyword allows the rule writer to specify where to start searching for a pattern within a packet. distance:1. Format depth: <number>. 3.5. depth modifies the previous ‘content’ keyword in the rule. except it is relative to the end of the last pattern match instead of the beginning of the packet.
2.5.6) rule option.5.8 http client body The http client body keyword is a content modifier that restricts the search to the NORMALIZED body of an HTTP client request. 125 .3. Format http_client_body. 3. As this keyword is a modifier to the previous ’content’ keyword. Examples This rule constrains the search for the pattern ”EFG” to the NORMALIZED body of an HTTP client request.1 ). within:10. content: "EFG".5. Format http_cookie. Format within: <byte count>. there must be a content in the rule before ’http cookie’ is specified.6). Examples This rule constrains the search of EFG to not go past 10 bytes past the ABC match.5.7 within The within keyword is a content modifier that makes sure that at most N bytes are between pattern matches using the content keyword ( See Section 3. As this keyword is a modifier to the previous ’content’ keyword.9 http cookie The http cookie keyword is a content modifier that restricts the search to the extracted Cookie Header field of an HTTP client request. content: "EFG". http_client_body. alert tcp any any -> any any (content:"ABC".) ! △NOTE The http client body modifier is not allowed to be used with the rawbytes modifier for the same content. alert tcp any any -> any 80 (content:"ABC". there must be a content in the rule before ’http client body’ is specified.5. The extracted Cookie Header field may be NORMALIZED. per the configuration of HttpInspect (see 2.) 3. It’s designed to be used in conjunction with the distance (Section 3.
per the configuration of HttpInspect (see 2.2. Format http_method. Format http_header. http_cookie. http_header. 3. As this keyword is a modifier to the previous ’content’ keyword.5. there must be a content in the rule before ’http method’ is specified. Examples This rule constrains the search for the pattern ”EFG” to the extracted Header fields of an HTTP client request.5..) ! △NOTE The http cookie modifier is not allowed to be used with the rawbytes or fast pattern modifiers for the same content. alert tcp any any -> any 80 (content:"ABC". 3. content: "EFG". 126 .11 http method The http method keyword is a content modifier that restricts the search to the extracted Method from an HTTP client request. The extracted Header fields may be NORMALIZED.6). content: "EFG"..Examples This rule constrains the search for the pattern ”EFG” to the extracted Cookie Header field of an HTTP client request. alert tcp any any -> any 80 (content:"ABC".
5.) ! △NOTE modifier is not allowed to be used with the rawbytes modifier for the same content. Examples This rule causes the pattern ”EFG” to be used with the Fast Pattern Matcher. alert tcp any any -> any 80 (content:"ABC". http_uri. content: "EFG". even though it is shorter than the earlier pattern ”ABCD”. Using a content rule option followed by a http uri modifier is the same as using a uricontent by itself (see: 3. It overrides the default of using the longest content within the rule.14).13 fast pattern The fast pattern keyword is a content modifier that sets the content within a rule to be used with the Fast Pattern Matcher. Examples This rule constrains the search for the pattern ”EFG” to the NORMALIZED URI.) ! △NOTE modifier is not allowed to be used with the rawbytes modifier for the same content.12 http uri The http uri keyword is a content modifier that restricts the search to the NORMALIZED request URI field . As this keyword is a modifier to the previous ’content’ keyword.5. there must be a content in the rule before ’http uri’ is specified. fast_pattern. fast pattern may be specified at most once for each of the buffer modifiers (excluding the http cookie modifier). The http method 3. there must be a content in the rule before ’fast pattern’ is specified.) 127 . Format fast_pattern. content: "EFG".5. content: "GET". alert tcp any any -> any 80 (content:"ABCD". alert tcp any any -> any 80 (content:"ABC". The http uri 3. As this keyword is a modifier to the previous ’content’ keyword. http_method. Format http_uri.Examples This rule constrains the search for the pattern ”GET” to the extracted Method from an HTTP client request.
exe?/c+ver will get normalized into: /winnt/system32/cmd.14 uricontent The uricontent keyword in the Snort rule language searches the NORMALIZED request URI field. or range of URI lengths to match. Format uricontent:[!]<content string>. You can write rules that look for the non-normalized content by using the content option.6... (See Section 3. the URI: /cgi-bin/aaaaaaaaaaaaaaaaaaaaaaaaaa/. do not include directory traversals.5. see the content rule options in Section 3. This means that if you are writing rules that include things that are normalized. The reason is that the things you are looking for are normalized out of the URI buffer. the URI: /scripts/.5.1) For a description of the parameters to this function. ! △NOTE uricontent cannot be modified by a rawbytes modifier.%252fp%68f? will get normalized into: /cgi-bin/phf? When writing a uricontent rule./winnt/system32/cmd.1.5.. This option works in conjunction with the HTTP Inspect preprocessor specified in Section 2. nor with a content that is negated with a !. if Snort normalizes directory traversals.15 urilen The urilen keyword in the Snort rule language specifies the exact length.5. the maximum length. 128 . the minimum length.%c0%af. such as %2f or directory traversals. write the content that you want to find in the context that the URI will be normalized. For example.! △NOTE The fast pattern modifier is not allowed to be used with the http cookie modifier for the same content. 3.exe?/c+ver Another example.2. 3. For example. these rules will not alert.
then verifies that there is not a newline character within 50 bytes of the end of the PASS string. 3. and 3. within:50. 3. \ content:!"|0a|". Example alert tcp any any -> any 111 (content:"PASS".5.17 pcre The pcre keyword allows rules to be written using perl compatible regular expressions. See tables 3. Format isdataat:<int>[. The post-re modifiers set compile time flags for the regular expression. The modifiers 129 .6. optionally looking for data relative to the end of the previous content match.org Format pcre:[!]"(/<regex>/|m<delim><regex><delim>)[ismxAEGRUBPHMCO]".16 isdataat Verify that the payload has data at a specified location.2. ! △NOTE R and B should not be used together. urilen: [<.Format urilen: int<>int. isdataat:50.relative]. For more detail on what can be done via a pcre regular expression.7. 3. check out the PCRE web site.>] <int>.8 for descriptions of each modifier.5.6..relative.pcre. then verifies there is at least 50 bytes after the end of the string PASS.) This rule looks for the string PASS exists in the packet.
6: Perl compatible modifiers for pcre case insensitive include newlines in the dot metacharacter By default. <value>. PCRE when used without a uricontent only evaluates the first URI. ˆ and $ match at the beginning and ending of the string.<endian>] [.relative] [. ˆ and $ match immediately following or immediately before any newline in the buffer.i s m x Table 3. alert ip any any -> any any (pcre:"/BLAH/i". Format byte_test: <bytes to convert>. <offset> [.5. Inverts the ”greediness” of the quantifiers so that they are not greedy by default.9.<number type>. please read Section 3. $ also matches immediately before the final character if it is a newline (but not before any other newlines). the string is treated as one big line of characters. Without E.7: PCRE compatible modifiers for pcre the pattern must match only at the start of the buffer (same as ˆ ) Set $ to match only at the end of the subject string.5. whitespace data characters in the pattern are ignored except when escaped or inside a character class A E G Table 3. When m is set. Capable of testing binary values or converting representative byte strings to their binary equivalent and testing them. [!]<operator>. string]. For a more detailed explanation. In order to use pcre to inspect all URIs. you must use either a content or a uricontent.18 byte test Test a byte field against a specific value (with operator). \ 130 .) ! △NOTE Snort’s handling of multiple URIs with PCRE does not work as expected. as well as the very start and very end of the buffer. Example This example performs a case-insensitive search for the string BLAH in the payload. but become greedy if followed by ”?”. 3.
} 131 .bitwise OR value offset relative endian Value to test the converted value against Number of bytes into the payload to start processing Use an offset relative to last pattern match Endian type of the number being read: • big .3) Option bytes to convert operator Description Number of bytes to pick up from the packet Operation to perform to test the value: • < .14 for quick reference).2.greater than • = .R U P H M C B O Table 3.Process data as big endian (default) • little .Converted string data is represented in decimal • oct . Any of the operators can also include ! to check if the operator is not true. If the & operator is used.8: Snort specific modifiers for pcre Match relative to the end of the last pattern match. then it would be the same as using if (data & value) { do something(). (Similar to distance:0.less than • > . ! △NOTE Snort uses the C operators for each of these operators.bitwise AND • ˆ .Process data as little endian string number type Data is stored in string format in packet Type of number being read: • hex . See section 2.Converted string data is represented in octal dce Let the DCE/RPC 2 preprocessor determine the byte order of the value to be converted.Converted string data is represented in hexadecimal • dec .14 for a description and examples (2.2. If ! is specified without an operator.not • & .equal • ! . then the operator is set to =.
hex. 1234.big] [.) alert udp any any -> any 1235 \ (byte_test: 3. \ byte_test: 4. =. within: 4. 132 . \ msg: "got 123!".) alert udp any any -> any 1236 \ (byte_test: 2.hex] [. 1234567890.>. =. distance: 4. relative. The byte jump option does this by reading some number of bytes. By having an option that reads the length of a portion of data. rules can be written that skip over specific portions of length-encoded protocols and perform detection in very specific locations. =. For a more detailed explanation.relative] [. convert them to their numeric representation. 0xdeadbeef.) alert udp any any -> any 1234 \ (byte_test: 4. 0.post_offset <adjustment value>]. \ byte_test: 4.) alert tcp $EXTERNAL_NET any -> $HOME_NET any \ (msg:"AMD procedure 7 plog overflow ".Examples alert udp $EXTERNAL_NET any -> $HOME_NET any \ (msg:"AMD procedure 7 plog overflow ".5. 0.1000.) 3. 123. dec.) alert udp any any -> any 1237 \ (byte_test: 10. within: 4. =. distance: 4.string]\ [. \ msg: "got DEADBEEF!".5. relative. please read Section 3. Format byte_jump: <bytes_to_convert>. string. This pointer is known as the detect offset end pointer.dec] [. 0.19 byte jump The byte jump keyword allows rules to be written for length encoded protocols trivially. string. \ content: "|00 00 00 07|". 0. dec. \ msg: "got 1234567890!".9. move that many bytes forward and set a pointer for later detection. \ content: "|00 00 00 07|". or doe ptr. string. \ content: "|00 04 93 F3|". \ content: "|00 04 93 F3|". >. 20. dec. 12. =. 20.multiplier <multiplier value>] [.little][. \ msg: "got 1234!". then skips that far forward in the packet. \ msg: "got 12!". 1000. dec. <offset> \ [. string.) alert udp any any -> any 1238 \ (byte_test: 8. string. 0.align] [.oct] [.from_beginning] [.
The preferred usage is to use a space between option and argument. pcre:"/ˆPORT/smi".) 3.14 for a description and examples (2. relative. 20. content:"PORT". nocase.1 options provide programmatic detection capabilities as well as some more dynamic type detection. See section 2. within: 4.1 detection plugin decodes a packet or a portion of a packet. 133 . sid:3441.5. align. \ byte_jump: 4. \ flow:to_server.21 asn1 The ASN. \ msg: "statd format string buffer overflow". Example alert tcp $EXTERNAL_NET any -> $HOME_NET 21 (msg:"FTP PORT bounce attempt". 12. >. ftpbounce. and looks for various malicious encodings. Example alert udp any any -> any 32770:34000 (content: "|00 01 86 B8|".\ classtype:misc-attack. \ content: "|00 00 00 01|".2. Skip forward or backwards (positive of negative value) by <value> number of bytes after the other jump options have been applied. distance: 4. relative.5.2. 900. the option and the argument are separated by a space or a comma. rev:1. Format ftpbounce. The ASN. If an option has an argument. the whole option evaluates as true.14 for quick reference). \ byte_test: 4.established.). Let the DCE/RPC 2 preprocessor determine the byte order of the value to be converted. Multiple options can be used in an ’asn1’ option and the implied logic is boolean OR.20 ftpbounce The ftpbounce keyword detects FTP bounce attacks. So if any of the arguments evaluate as true.
then this keyword is evaluated as true. content:"foo".g.22 cvs The CVS detection plugin aids in the detection of: Bugtraq-10384. So if you wanted to start decoding and ASN. relative_offset 0. Offset values may be positive or negative. which is a way of causing a heap overflow (see CVE-2004-0396) and bad pointer derefenece in versions of CVS 1.1 type lengths with the supplied argument. Detects a double ASCII encoding that is larger than a standard buffer. ! △NOTEcannot do detection over encrypted sessions. Compares ASN.11. This is known to be an exploitable function in Microsoft. “oversize length 500”. relative offset has one argument.) 3. but it is unknown at this time which services may be exploitable. This is the relative offset from the last content match or byte test/jump. e. absolute_offset 0. asn1: bitstring_overflow. relative_offset 0’. CVE-2004-0396: ”Malformed Entry Modified and Unchanged flag insertion”. \ asn1: oversize_length 10000. Default CVS server ports are 2401 and 514 and are included in the default ports for stream reassembly. Examples alert tcp any any -> any 2401 (msg:"CVS Invalid-entry". \ asn1: bitstring_overflow. This plugin Format cvs:<option>. . . if you wanted to decode snmp packets.) alert tcp any any -> any 80 (msg:"ASN1 Relative Foo". SSH (usually port 22).5. For example. you would specify ’content:"foo".15 and before. Option bitstring overflow double overflow Description Detects invalid bitstring encodings that are known to be remotely exploitable. you would say “absolute offset 0”. Offset may be positive or negative. The syntax looks like.established.1 type is greater than 500. oversize length <value> absolute offset <value> relative offset <value> Examples alert udp any any -> any 161 (msg:"Oversize SNMP Length". This is the absolute offset from the beginning of the packet. This keyword must have one argument which specifies the length to compare against. absolute offset has one argument.Format asn1: option[ argument][. option[ argument]] .) 134 . cvs:invalid-entry. the offset value.1 sequence right after the content “foo”. \ flow:to_server. the offset number. This means that if an ASN. Option invalid-entry Description Looks for an invalid Entry string.
See the DCE/RPC 2 Preprocessor section 2.5. The pcre keyword allows rules to be written using perl compatible regular expressions.2.9: Payload detection rule option keywords Keyword content rawbytes depth offset distance Description The content keyword allows the user to set rules that search for specific content in the packet payload and trigger response based on that data.2. See the DCE/RPC 2 Preprocessor section 2.2. The depth keyword allows the rule writer to specify how far into a packet Snort should search for the specified pattern.2. The asn1 detection plugin decodes a packet or a portion of a packet.14 for a description and examples of using this rule option. and looks for various malicious encodings. The isdataat keyword verifies that the payload has data at a specified location. The distance keyword allows the rule writer to specify how far into a packet Snort should ignore before starting to search for the specified pattern relative to the end of the previous pattern match.2.14.3. See the DCE/RPC 2 Preprocessor section 2.23 dce iface See the DCE/RPC 2 Preprocessor section 2. The offset keyword allows the rule writer to specify where to start searching for a pattern within a packet.14 for a description and examples of using this rule option. The rawbytes keyword allows rules to look at the raw packet data. The cvs keyword detects invalid entry strings.24 dce opnum See the DCE/RPC 2 Preprocessor section 2. The byte jump keyword allows rules to read the length of a portion of data. The uricontent keyword in the Snort rule language searches the normalized request URI field. The ftpbounce keyword detects FTP bounce attacks.5. then skip that far forward in the packet.5.25 dce stub data See the DCE/RPC 2 Preprocessor section 2. 3.26 Payload Detection Quick Reference Table 3. The within keyword is a content modifier that makes sure that at most N bytes are between pattern matches using the content keyword.14 for a description and examples of using this rule option. within uricontent isdataat pcre byte test byte jump ftpbounce asn1 cvs dce iface dce opnum dce stub data 135 . 3. 3. The byte test keyword tests a byte field against a specific value (with operator).2.5.14.14. ignoring any decoding that was done by preprocessors.
6 Non-Payload Detection Rule Options 3. 136 . 3.) 3. Example This example looks for a tos value that is not 4 tos:!4. Format tos:[!]<number>. Format fragoffset:[<|>]<number>.2 ttl The ttl keyword is used to check the IP time-to-live value. To catch all the first fragments of an IP session.6.1 fragoffset The fragoffset keyword allows one to compare the IP fragment offset field against a decimal value. you could use the fragbits keyword and look for the More fragments option in conjunction with a fragoffset of 0. ttl:3-5. fragoffset: 0. Example alert ip any any -> any any \ (msg: "First Fragment". ttl:<3.6. Example This example checks for a time-to-live value that is less than 3. fragbits: M.6. This example checks for a time-to-live value that between 3 and 5.3. This option keyword was intended for use in the detection of traceroute attempts.3 tos The tos keyword is used to check the IP TOS field for a specific value. Format ttl:[[<number>-]><=]<number>.
3. ipopts:lsrr.Strict Source Routing satid . Format id:<number>.Time Stamp sec . The following options may be checked: rr . Format ipopts:<rr|eol|nop|ts|sec|esec|lsrr|ssrr|satid|any>.5 ipopts The ipopts keyword is used to check if a specific IP option is present.Loose Source Routing ssrr .Stream identifier any . the value 31337 is very popular with some hackers.6.IP Security esec .4 id The id keyword is used to check the IP ID field for a specific value.End of list nop . Example This example looks for the IP Option of Loose Source Routing. 137 .No Op ts . for example. id:31337.IP Extended Security lsrr .6.any IP options are set The most frequently watched for IP options are strict and loose source routing which aren’t used in any widespread internet applications.Record Route eol .3. Example This example looks for the IP ID of 31337. Some tools (exploits. scanners and other odd programs) set this field specifically for various purposes.
Example This example looks for a dsize that is between 300 and 400 bytes.Warning Only a single ipopts keyword may be specified per rule. 3. fragbits:MD+. This may be used to check for abnormally sized packets.Don’t Fragment R . Example This example checks if the More Fragments bit and the Do not Fragment bit are set.6. Format dsize: [<>]<number>[<><number>]. In many cases. 138 .6. plus any others * match if any of the specified bits are set ! match if the specified bits are not set Format fragbits:[+*!]<[MDR]>. The following bits may be checked: M .Reserved Bit The following modifiers can be set to change the match criteria: + match on the specified bits. regardless of the size of the payload. it is useful for detecting buffer overflows.More Fragments D . dsize:300<>400. 3. Warning dsize will fail on stream rebuilt packets.6 fragbits The fragbits keyword is used to check if fragmentation and reserved bits are set in the IP header.7 dsize The dsize keyword is used to test the packet payload size.
Reserved bit 1 (MSB in TCP Flags byte) 2 .3. 139 . ignoring reserved bit 1 and reserved bit 2.2). plus any others * .12 if one wishes to find packets with just the syn bit. Format flags:[!|*|+]<FSRPAU120>[.ACK U .<FSRPAU120>].PSH A .FIN (LSB in TCP Flags byte) S . regardless of the values of the reserved bits. A rule could check for a flags value of S.12.SYN R .match on the specified bits.9 flow The flow keyword is used in conjunction with TCP stream reassembly (see Section 2.match if the specified bits are not set To handle writing rules for session initiation packets such as ECN where a SYN packet is sent with the previously reserved bits 1 and 2 set.Reserved bit 2 0 .RST P .No TCP Flags Set The following modifiers can be set to change the match criteria: + . The following bits may be checked: F . This allows rules to only apply to clients or servers.) 3.match if any of the specified bits are set ! .8 flags The flags keyword is used to check if specific TCP flag bits are present. Example This example checks if just the SYN and the FIN bits are set. an option mask may be specified.6. The established keyword will replace the flags: A+ used in many places to show established TCP connections. alert tcp any any -> any any (flags:SF.URG 1 .6.2. This allows packets related to $HOME NET clients viewing web pages to be distinguished from servers running in the $HOME NET. It allows rules to only apply to certain directions of the traffic flow.
Sets the specified state if the state is unset. This string should be limited to any alphanumeric string including periods. as it allows rules to generically track the state of an application protocol. \ flow:stateless. Checks if the specified state is not set. and underscores.). Cause the rule to not generate an alert. dashes.2). otherwise unsets the state if the state is set.(no_stream|only_stream)]. Unsets the specified state for the current flow. Examples alert tcp any 143 -> any any (msg:"IMAP login". Checks if the specified state is set. The flowbits option is most useful for TCP sessions. regardless of the rest of the detection options.(to_client|to_server|from_client|from_server)] [. Examples alert tcp !$HOME_NET any -> $HOME_NET 21 (msg:"cd incoming detected". \ flow:from_client. nocase. There are seven keywords associated with flowbits.6. 140 . Format flowbits: [set|unset|toggle|isset|reset|noalert][. It allows rules to track states across transport protocol sessions.Options Option to client to server from client from server established stateless no stream only stream Format flow: [(established|stateless)] [.2. content:"CWD incoming".10 flowbits The flowbits keyword is used in conjunction with conversation tracking from the Stream preprocessor (see Section2.<STATE_NAME>]. Most of the options need a user-defined name for the specific state that is being checked.) alert tcp !$HOME_NET 0 -> $HOME_NET 0 (msg: "Port 0 TCP traffic". Option set unset toggle isset isnotset noalert Description Sets the specified state for the current flow.
12 ack The ack keyword is used to check for a specific TCP acknowledge number. window:55808. Format seq:<number>. flowbits:set. Format ack: <number>.11 seq The seq keyword is used to check for a specific TCP sequence number.logged_in. content:"LIST". Example This example looks for a TCP acknowledge number of 0.13 window The window keyword is used to check for a specific TCP window size.6. 3. ack:0. flowbits:isset.) 3. 3. Format window:[!]<number>.6.content:"OK LOGIN". 141 .6.) alert tcp any any -> any 143 (msg:"IMAP LIST". Example This example looks for a TCP window size of 55808. seq:0.logged_in. Example This example looks for a TCP sequence number of 0. flowbits:noalert.
Format itype:[<|>]<number>[<><number>].16 icmp id The icmp id keyword is used to check for a specific ICMP ID value. Example This example looks for an ICMP ID of 0.6. This particular plugin was developed to detect the stacheldraht DDoS agent.3. This is useful because some covert channel programs use static ICMP fields when they communicate. Format icmp_id:<number>.6. icmp_id:0. code:>30. Example This example looks for an ICMP code greater than 30.17 icmp seq The icmp seq keyword is used to check for a specific ICMP sequence value. 3.15 icode The icode keyword is used to check for a specific ICMP code value. This particular plugin was developed to detect the stacheldraht DDoS agent. Example This example looks for an ICMP type greater than 30.6. itype:>30. This is useful because some covert channel programs use static ICMP fields when they communicate. Format icode: [<|>]<number>[<><number>]. 3. 142 . 3.6.14 itype The itype keyword is used to check for a specific ICMP type value.
For a list of protocols that may be specified by name.3. Example The following example looks for an RPC portmap GETPORT request.) 3.19 ip proto The ip proto keyword allows checks against the IP protocol header.18 rpc The rpc keyword is used to check for a RPC application. 143 . Warning Because of the fast pattern matching engine. [<procedure number>|*]>. [<version number>|*]. Example This example looks for IGMP traffic. Wildcards are valid for both version and procedure numbers by using ’*’. version.*. the RPC keyword is slower than looking for the RPC values by using normal content matching. 3.6.Format icmp_seq:<number>. alert tcp any any -> any 111 (rpc: 100000. Format rpc: <application number>. icmp_seq:0.20 sameip The sameip keyword allows rules to check if the source ip is the same as the destination IP.).6. Format ip_proto:[!|>|<] <name or number>. and procedure numbers in SUNRPC CALL requests. 3. alert ip any any -> any any (ip_proto:igmp.6. see /etc/protocols. Example This example looks for an ICMP Sequence of 0.
6. The tos keyword is used to check the IP TOS field for a specific value.greater than or equal Example For example. The ttl keyword is used to check the IP time-to-live value. alert ip any any -> any any (sameip. Format stream_size:<server|client|both|either>. Example This example looks for any traffic where the Source IP and the Destination IP is the same.less than or equal • >= .Format sameip.) 3.not • <= .22 Non-Payload Detection Quick Reference Table 3. use: alert tcp any any -> any any (stream_size:client. as determined by the TCP sequence numbers.less than • > .<operator>.<number> Where the operator is one of the following: • < . The id keyword is used to check the IP ID field for a specific value.21 stream size The stream size keyword allows a rule to match traffic according to the number of bytes observed.6.6.greater than • = .10: Non-payload detection rule option keywords Keyword fragoffset ttl tos id Description The fragoffset keyword allows one to compare the IP fragment offset field against a decimal value.) 3. to look for a session that is less that 6 bytes from the client side.<.equal • != . ! △NOTE The stream size option is only available when the Stream5 preprocessor is enabled. 144 .
The icode keyword is used to check for a specific ICMP code value. The ip proto keyword allows checks against the IP protocol header. version. 3. The icmp id keyword is used to check for a specific ICMP ID value. HTTP CGI scans. The flow keyword allows rules to only apply to certain directions of the traffic flow.7 Post-Detection Rule Options 3. 145 .7. The rpc keyword is used to check for a RPC application. It should be noted that this option does not work when Snort is in binary logging mode. The flowbits keyword allows rules to track states across transport protocol sessions. This is especially handy for combining data from things like NMAP activity. ftp. The dsize keyword is used to test the packet payload size. etc.7.1 logto The logto keyword tells Snort to log all packets that trigger this rule to a special output log file. There are many cases where seeing what users are typing in telnet. printable or all. The itype keyword is used to check for a specific ICMP type value. The all keyword substitutes non-printable characters with their hexadecimal equivalents. The fragbits keyword is used to check if fragmentation and reserved bits are set in the IP header. or even web sessions is very useful. There are two available argument keywords for the session rule option. The printable keyword only prints out data that the user would normally see or be able to type. 3. Format logto:"filename". Format session: [printable|all]. The sameip keyword allows rules to check if the source ip is the same as the destination IP. The window keyword is used to check for a specific TCP window size.2 session The session keyword is built to extract user data from TCP Sessions. The seq keyword is used to check for a specific TCP sequence number. The flags keyword is used to check if specific TCP flag bits are present. and procedure numbers in SUNRPC CALL requests. rlogin. The icmp seq keyword is used to check for a specific ICMP sequence value. The ack keyword is used to check for a specific TCP acknowledge number.
) It is easy to be fooled into interfering with normal network traffic as well. resp:rst_all.3 resp The resp keyword is used to attempt to close sessions when an alert is triggered. 3.) Warnings Using the session keyword can slow Snort down considerably. In Snort. Example The following example attempts to reset any TCP connection to port 1524. alert tcp any any -> any 1524 (flags:S.<resp_mechanism>]]. log tcp any any <> any 23 (session:printable. Use the – –enable-flexresp flag to configure when building Snort to enable this functionality. this is called flexible response. Be very careful when using Flexible Response. Warnings This functionality is not built in by default.) 146 .Example The following example logs all printable strings in a telnet packet.7.. It is quite easy to get Snort into an infinite loop by defining a rule such as: alert tcp any any -> any any (resp:rst_all. The session keyword is best suited for post-processing binary (pcap) log files. so it should not be used in heavy load situations. Format resp: <resp_mechanism>[.<resp_mechanism>[.
napster and porn sites. Format tag: <type>. Format react: block[. The basic reaction is blocking interesting sites users want to access: New York Times.Log packets in the session that set off the rule • host . the database output plugin.close connection and send the visible notice The basic argument may be combined with the following arguments (additional modifiers): • msg .) Be very careful when using react.) Warnings React functionality is not built in by default. Once a rule is triggered. <metric>. The react keyword should be placed as the last one in the option list. react: block. additional traffic involving the source and/or destination host is tagged.7.Log packets from the host that caused the tag to activate (uses [direction] modifier) count 147 . or something really important . 3. type • session .4 react This keyword implements an ability for users to react to traffic that matches a Snort rule. The notice may include your own comment. slashdot.7. msg. The following arguments (basic modifiers) are valid for this option: • block . does not properly handle tagged alerts.3. Currently. proxy 8000. <react_additional_modifier>].1. you must configure with –enable-react to build it.0/24 80 (content: "bad.168. Tagged traffic is logged to allow analysis of response codes and post-attack traffic.htm". tagged alerts will be sent to the same output plugins as the original alert. Causing a network traffic generation loop is very easy to do with this functionality.include the msg option text into the blocking visible notice • proxy <port nr> .6. The React code allows Snort to actively close offending connections and send a visible notice to the browser. [direction]. \ msg: "Not for children!".use the proxy port to send the visible notice Multiple additional arguments are separated by a comma. but it is the responsibility of the output plugin to properly handle these special alerts. Example alert tcp any any <> 192.5 tag The tag keyword allow rules to log more than just the single packet that triggered the rule. described in Section 2. (Note that react may now be enabled independently of flexresp and flexresp2.6. <count>.
1. For example.only relevant if host type is used.seconds.1. any packets that generate an alert will not be tagged. You can disable this packet limit for a particular rule by adding a packets metric to your tag option and setting its count to 0 (This can be done on a global scale by setting the tagged packet limit option in snort. Units are specified in the <metric> field.1.Tag the host/session for <count> seconds • bytes . a tagged packet limit will be used to limit the number of tagged packets regardless of whether the seconds or bytes count has been reached. • dst .conf to 0). alert tcp any any <> 10. See Section 3.600. Note.src.7.6 for more information. tag:host.Tag packets containing the source IP address of the packet that generated the initial event. Format activates: 1. tag:session.1.3 on how to use the tagged packet limit config option).1.tagged.600.12.1.1.1.tagged.conf file (see Section 2.6 activates The activates keyword allows the rule writer to specify a rule to add when a specific network event occurs.src. The flowbits option would be useful here.Tag packets containing the destination IP address of the packet that generated the initial event.Tag the host/session for <count> bytes direction .) Example This example logs the first 10 seconds or the tagged packet limit (whichever comes first) of any telnet session.• <integer> . alert tcp any any -> any 23 (flags:s. Doing this will ensure that packets are tagged for the full amount of seconds or bytes and will not be cut off by the tagged packet limit.600. 148 . no packets will get tagged.1 any (tag:host.packets.seconds.1.10. (Note that the tagged packet limit was introduced to avoid DoS situations on high bandwidth sensors for tag rules with a high seconds or bytes counts.src.1 any \ (content:"TAGMYPACKETS".1.1.1.1. The default tagged packet limit value is 256 and can be modified by using a config option in your snort.seconds.seconds.0. alert tcp any any <> 10. • src .) alert tcp 10.1 any (flowbits:isnotset. it may seem that the following rule will tag the first 600 seconds of any packet involving 10.1.) 3.) Also note that if you have a tag option in a rule that uses a metric other than packets.) However.4 any -> 10.1.2. since the rule will fire on every packet involving 10.Count is specified as a number of units. tag:host. metric • packets .Tag the host/session for <count> packets • seconds . flowbits:set.
Format activated_by: 1.8 count The count keyword must be used in combination with the activated by keyword. 3.10 detection filter detection filter defines a rate which must be exceeded by a source or destination host before a rule can generate an event.1.6 for more information. At most one detection filter is permitted per rule. Snort evaluates a detection filter as the last step of the detection phase. count: 50.7.100 during one sampling period of 60 seconds. one per content. See Section 3. This means count is maintained for each unique source IP address or each unique destination IP address. after the first 30 failed login attempts: 149 . seconds <s>. detection filter has the following format: detection_filter: \ track <by_src|by_dst>. The value must be nonzero.2.3.6 for more information. The maximum number of rule matches in s seconds allowed before the detection filter limit to be exceeded.7. C must be nonzero. \ count <c>.2.2.7. See Section 3.5 for more on operating in inline mode. See section 1. 3. Format activated_by: 1.this rule will fire on every failed login attempt from 10. Example . after evaluating all other rule options (regardless of the position of the filter within the rule source). 3. You can have multiple replacements within a rule. Time period over which count is accrued. replace: <string>.9 replace The replace keyword is a feature available in inline mode which will cause Snort to replace the prior matching content with the given string. Both the new string and the content it is to replace must have the same length.7 activated by The activated by keyword allows the rule writer to dynamically enable a rule when a specific activate rule is triggered.7. Option track by src|by dst count c seconds s Description Rate is tracked either by source IP address or destination IP address. It allows the rule writer to specify how many packets to leave the rule enabled for after it is activated.
3.8 Rule Thresholds ! △NOTE are deprecated and will not be supported in a future release. flow:established.11 Post-Detection Quick Reference Table 3.to_server. This can be done using the ‘limit’ type of threshold.2. threshold can be included as part of a rule. activated by This keyword allows the rule writer to dynamically enable a rule when a specific activate rule is triggered. There is a logical difference. count This keyword must be used in combination with the activated by keyword.1. It allows the rule writer to specify how many packets to leave the rule enabled for after it is activated. rev:1. or event filters (2. offset:0. It makes sense that the threshold feature is an integral part of this rule. Some rules may only make sense with a threshold. \ content:"SSH". nocase. For instance.10) within rules.2) as standalone configurations instead. tag The tag keyword allow rules to log more than just the single packet that triggered the rule. These should incorporate the threshold into the rule. react This keyword implements an ability for users to react to traffic that matches a Snort rule by closing connection and sending a notice. activates This keyword allows the rule writer to specify a rule to add when a specific network event occurs. session The session keyword is built to extract user data from TCP Sessions.1.drop tcp 10. 3. a rule for detecting a too many login password attempts may require more than 5 attempts. or using a standalone threshold applied to the same rule. or you can use standalone thresholds that reference the generator and SID they are applied to. resp The resp keyword is used attempt to close sessions when an alert is triggered. Rule thresholds Use detection filters (3. \ sid:1000001. replace Replace the prior matching content with the given string of the same length. Format 150 . count 30.1.4. a detection filter would normally be used in conjunction with an event filter to reduce the number of logged events.100 22 ( \ msg:"SSH Brute Force Attempt". There is no functional difference between adding a threshold to a rule. detection filter Track by source or destination IP address and if the rule otherwise matches more than the configured rate it will fire.7.100 any > 10. \ detection_filter: track by_src.11: Post-detection rule option keywords Keyword logto Description The logto keyword tells Snort to log all packets that trigger this rule to a special output log file. seconds 60.) Since potentially many events will be generated.7. depth:4. Available in inline mode only.
\ classtype:web-application-activity. alert tcp $external_net any -> $http_servers $http_ports \ (msg:"web-misc robots. nothing gets logged. So if less than 10 events occur in 60 seconds. \ track <by_src|by_dst>.txt access".10302. then ignores any additional events during the time interval. count 10 . reference:nessus.txt". reference:nessus. sid:1000852. threshold: type threshold. or destination IP address. \ uricontent:"/robots. established. flow:to_server. \ uricontent:"/robots. established. threshold: type both . rev:1. or for each unique destination IP addresses. Option type limit|threshold|both Description type limit alerts on the 1st m events during the time interval. reference:nessus. track \ by_dst. then ignores events for the rest of the time interval.txt access". sid:1000852.9 Writing Good Rules There are some general concepts to keep in mind when developing Snort rules to maximize efficiency and speed. seconds <s>. count 10 . seconds 60 . Ports or anything else are not tracked. seconds 60 .) 3. \ track by_dst. a new time period starts for type=threshold. \ classtype:web-application-activity. time period over which count is accrued.txt".10302. nocase. Type threshold alerts every m times we see this event during the time interval. \ count <c>. 151 . \ classtype:web-application-activity. established.txt access".threshold: \ type <limit|threshold|both>. count 1 . alert tcp $external_net any -> $http_servers $http_ports \ (msg:"web-misc robots. track by src|by dst count c seconds s Examples This rule logs the first event of this SID every 60 seconds. Once an event is logged. threshold: type limit. s must be nonzero value. \ uricontent:"/robots. Type both alerts once per time interval after seeing m occurrences of the event. flow:to_server. This means count is maintained for each unique source IP addresses. rev:1. rate is tracked either by source IP address. track \ by_src. seconds 60 . rev:1.) This rule logs at most one event every 60 seconds if at least 10 events on this SID are fired. number of rule matching in s seconds that will cause event filter limit to be exceeded. c must be nonzero value.10302. flow:to_server. sid:1000852.) This rule logs every 10th event on this SID during a 60 second interval.txt". nocase. nocase. alert tcp $external_net any -> $http_servers $http_ports \ (msg:"web-misc robots.
look for a the vulnerable command with an argument that is too large. pcre:"/user\s+root/i". In FTP. followed by root. Not the Exploit Try to write rules that target the vulnerability. looking for root.established. • The rule has a content option. the rule needs more smarts than a simple string match.) There are a few important things to note in this rule: • The rule has a flow option. If at all possible. the more exact the match. ignoring case. Rules without content (or uricontent) slow the entire system down. While some detection options. 3.9. This option is added to allow Snort’s setwise pattern match detection engine to give Snort a boost in speed. For example. followed at least one space character (which includes tab). the rule is less vulnerable to evasion when an attacker changes the exploit slightly. a good rule will handle all of the odd things that the protocol might handle when accepting the user command. instead of a specific exploit.0 detection engine changes the way Snort works slightly by having the first phase be a setwise pattern match. • The rule has a pcre option. perform detection in the payload section of the packet.9. the client sends: user username_here A simple rule to look for FTP root login attempts could be: alert tcp any any -> any any 21 (content:"user root". which is the longest. A good rule that looks for root login on ftp would be: alert tcp any any -> any 21 (flow:to_server. 152 . \ content:"root".3 Catch the Oddities of the Protocol in the Rule Many services typically send the commands in upper case letters.9. try and have at least one content option if at all possible.1 Content Matching The 2. FTP is a good example. The longer a content option is. to send the username. verifying this is traffic going to the server on an enstablished session. By writing rules for the vulnerability. each of the following are accepted by most FTP servers: user root user root user root user root user<tab>root To handle all of the cases that the FTP server might handle.) While it may seem trivial to write a rule that looks for the username root. most unique string in the attack. For example. 3. such as pcre and byte test. they do not use the setwise pattern matching engine. instead of shellcode that binds a shell.3.2 Catch the Vulnerability. looking for user.
4 Optimizing Rules The content matching portion of the detection engine has recursion to handle a few evasion cases. because of recursion. the following rule options are not optimized: content:"|13|". The way the recursion works now is if a pattern matches. but it is needed. take the following rule: alert ip any any -> any any (content:"a". . dsize:1. the content 0x13 would be found again starting after where the previous 0x13 was found. On first read. However. By looking at this rule snippit. and because of recursion. that may not sound like a smart idea. Rules that are not properly written can cause Snort to waste time duplicating checks. then the dsize option would fail. it is obvious the rule looks for a packet with a single byte of 0x13. within:1. once it is found. and if any of the detection options after that pattern fail. even though it is obvious that the payload “aab” has “a” immediately followed by “b”. then look for the pattern again after where it was found the previous time. Reordering the rule options so that discrete checks (such as dsize) are moved to the begining of the rule speed up Snort.3. Without recursion. For example. because the first ”a” is not immediately followed by “b”. as the dsize check is the first option checked and dsize is a discrete check without recursion. For example.9. content:"b". the recursion implementation is not very smart. While recursion is important for detection. Why? The content 0x13 would be found in the first byte. then check the dsize again. A packet of 1024 bytes of 0x13 would fail immediately. the payload “aab” would fail.) This rule would look for “a”. content:"|13|". repeating until 0x13 is not found in the payload again. a packet with 1024 bytes of 0x13 could cause 1023 too many pattern match attempts and 1023 too many dsize checks. Repeat until the pattern is not found again or the opt functions all succeed. immediately followed by “b”. The optimized rule snipping would be: dsize:1.
89 00 00 00 09 00 00 01 9c 00 00 87 e2 00 02 88 the rpc rpc rpc request id..... and then null bytes to pad the length of the string to end on a 4 byte boundary...... Let’s break this up... and figure out how to write a rule to catch this exploit....system.................. ......./ ...metasplo it.............../..e... The number 26 would show up as 0x0000001a........... as RPC uses simple length based encoding for passing data..metasplo it.. ....... ..... @(:........... ..... • Strings are written as a uint32 specifying the length of the string....... There are a few things to note with RPC: • Numbers are written as uint32s. ............ let’s go through an exploit attempt against the sadmind service. unique to each request type (call = 0. the string... . ................... .. a random uint32. taking four bytes.... RPC was the protocol that spawned the requirement for these two rule options......./bin/sh.. ........ ........... ........... describe each of the fields.... In order to understand why byte test and byte jump are useful. ............ response = 1) version (2) program (0x00018788 = 100232 = sadmind) 154 ............./..........• seq • session • tos • ttl • ack • window • resp • sameip 3. The string “bob” would show up as 0x00000003626f6200.......5 Testing Numerical Values The rule options byte test and byte jump were written to support writing rules for protocols that have length encoded data... ..@(:.../.... ..9..
However. In english.verifier flavor (0 = auth\_null.unix timestamp (0x40283a10 = 1076378128 = feb 10 01:55:28 2004 gmt) . but we want to skip over it and check a number value after the hostname. depth:4. depth:4. offset:4. offset:16. To do that in a Snort rule. we need to make sure that our packet is a call to sadmind. aka none) .length of verifier (0. depth:4. content:"|00 01 87 88|". aligning on the 4 byte boundary. First. we are now at: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 which happens to be the exact location of the uid.uid of requesting user (0) 00 00 00 00 .extra group ids (0) 00 00 00 00 00 00 00 00 . we need to make sure that our packet has auth unix credentials. content:"|00 00 00 01|".gid of requesting user (0) 00 00 00 00 . the value we want to check. offset:20. aka none) The rest of the packet is the request that gets passed to procedure 1 of sadmind. Starting at the length of the hostname. depth:4. and turn those 4 bytes into an integer and jump that many bytes forward. we need to make sure that our packet is a call to the procedure 1. We don’t care about the hostname.metasploit 00 00 00 00 . content:"|00 00 00 01|".. Then. content:"|00 00 00 00|". sadmind runs any request where the client’s uid is 0 as root . Then. turn it into a number. and jump that many bytes forward. we have decoded enough of the request to write our rule.length of the client machine name (0x0a = 10) 53 50 4c 4f 49 54 00 00 . making sure to account for the padding that RPC requires on strings. If we do that. we need to make sure that our packet is an RPC call. we know the vulnerability is that sadmind trusts the uid coming from the client. we want to read 4 bytes. offset:12. As such. Then. This is where byte test is useful. 36 bytes from the beginning of the packet. the vulnerable procedure. we use: 155 .
depth:4. depth:4. so we should combine those patterns. content:"|00 00 00 00|". instead of reading the length of the hostname and jumping that many bytes forward.align. Now that we have all the detection capabilities for our rule.>.byte_jump:4. byte_jump:4. offset:12. To do that. offset:16.36. within:4.36. content:"|00 00 00 00|". 00 00 01|". depth:8. 156 . within:4. depth:4. offset:20. offset:4.36. depth:4. byte_test:4.200. We end up with: content:"|00 00 00 00|". depth:4. content:"|00 01 87 88|". depth:4. offset:12. content:"|00 00 00 00|". we would read 4 bytes. turn it into a number.>.36. starting 36 bytes into the packet. content:"|00 00 00 00|". Our full rule would be: content:"|00 00 00 00|". content:"|00 01 87 88|". depth:8. we do: byte_test:4. content:"|00 01 87 88|". content:"|00 00 00 01|". content:"|00 00 00 01 00 00 00 01|". content:"|00 00 00 01 00 byte_jump:4. depth:4. If the sadmind service was vulnerable to a buffer overflow when reading the client’s hostname.align. depth:4. then we want to look for the uid of 0. offset:4. within:4. offset:12. offset:16. The 3rd and fourth string match are right next to each other. let’s put them all together.200. offset:16. offset:4. content:"|00 00 00 01|". In Snort.align.36. we would check the length of the hostname to make sure it is not too large. and then make sure it is not too large (let’s say bigger than 200 bytes).
enabling the ring buffer is done via setting the enviornment variable PCAP FRAMES.lanl. Phil Woods (cpw@lanl. PCAP FRAMES is the size of the ring buffer. 157 . This change speeds up Snort by limiting the number of times the packet is copied before Snort gets to perform its detection upon it.Chapter 4 Making Snort Faster 4. as this appears to be the maximum number of iovecs the kernel can handle. the maximum size is 32768. Instead of the normal mechanism of copying the packets from kernel memory into userland memory. libpcap will automatically use the most frames possible.gov/cpw/. According to Phil. By using PCAP FRAMES=max.1 MMAPed pcap On Linux.gov) is the current maintainer of the libpcap implementation of the shared memory ring buffer. The shared memory ring buffer libpcap can be downloaded from his website at. libpcap is able to queue packets into a shared buffer that Snort is able to read directly. a modified version of libpcap is available that implements a shared memory ring buffer. for a total of around 52 Mbytes of memory for the ring buffer alone. this ends up being 1530 bytes per frame. by using a shared memory ring buffer. Once Snort linked against the shared memory libpcap. On Ethernet.
Chapter 5 Dynamic Modules Preprocessors. It is defined in sf dynamic meta. or detection engine).h as: #define MAX_NAME_LEN 1024 #define TYPE_ENGINE 0x01 #define TYPE_DETECTION 0x02 #define TYPE_PREPROCESSOR 0x04 typedef struct _DynamicPluginMeta { int type. rules. and rules can now be developed as dynamically loadable module to snort. check the appropriate header files for the current definitions. The definition of each is defined in the following sections. char *libraryPath. detection capabilities. the version information.1. detection engines. int build. This inclues functions to register the preprocessor’s configuration parsing. int major. char uniqueName[MAX_NAME_LEN]. } DynamicPluginMeta. 5. and rules as a dynamic plugin to snort. and path to the shared library. and processing functions. 5. 5. A shared library can implement all three types.1.2 DynamicPreprocessorData The DynamicPreprocessorData structure defines the interface the preprocessor uses to interact with snort itself. but typically is limited to a single functionality such as a preprocessor. When enabled via the –enable-dynamicplugin configure option. Beware: the definitions herein may be out of date. int minor.1 Data Structures A number of data structures are central to the API. exit.1 DynamicPluginMeta The DynamicPluginMeta structure defines the type of dynamic module (preprocessor. restart. It includes 158 . the dynamic API presents a means for loading dynamic libraries and allowing the module to utilize certain functions within the main snort code. The remainder of this chapter will highlight the data structures and API functions used in developing preprocessors.
UriInfo *uriBuffers[MAX_URIINFOS]. } DynamicEngineData. It and the data structures it incorporates are defined in sf snort packet. and debugging info as well as a means to register and check flowbits. It also includes information for setting alerts. #ifdef HAVE_WCHAR_H DebugWideMsgFunc debugWideMsg. It also includes a location to store rule-stubs for dynamic rules that are loaded. Check the header file for the current definitions. RegisterBit flowbitRegister. RegisterRule ruleRegister. 5.h. PCREExecFunc pcreExec. LogMsgFunc errMsg. 159 . fatal errors. GetRuleData getRuleData. It is defined in sf dynamic preprocessor. LogMsgFunc logMsg. SetRuleData setRuleData.h as: typedef struct _DynamicEngineData { int version.function to log messages.1.4 SFSnortPacket The SFSnortPacket structure mirrors the snort Packet structure and provides access to all of the data contained in a given packet. DetectAsn1 asn1Detect. 5.3 DynamicEngineData The DynamicEngineData structure defines the interface a detection engine uses to interact with snort itself. It is defined in sf dynamic engine. #endif char **debugMsgFile. access to the StreamAPI. errors. CheckFlowbit flowbitCheck.h. fatal errors. handling Inline drops. DebugMsgFunc debugMsg. errors. u_int8_t *altBuffer. LogMsgFunc fatalMsg. and it provides access to the normalized http and alternate data buffers. and it provides access to the normalized http and alternate data buffers. and debugging info. This includes functions for logging messages. Additional data structures may be defined to reference other protocol fields. GetPreprocRuleOptFuncs getPreprocOptFuncs. char *dataDumpDirectory. PCRECompileFunc pcreCompile.1. Check the header file for the current definition. PCREStudyFunc pcreStudy. int *debugMsgLine. This data structure should be initialized when the preprocessor shared library is loaded.
used internally */ /* Flag with no alert.5 Dynamic Rules A dynamic rule should use any of the following data structures. priority. revision. 160 .h. That includes protocol. used internally */ /* Rule option count. signature ID. where the parameter is a pointer to the SFSnortPacket structure. generator and signature IDs. The following structures are defined in sf snort plugin api.1. u_int32_t revision. classification. revision. /* NULL terminated array of references */ } RuleInformation. u_int32_t numOptions. /* NULL terminated array of RuleOption union */ ruleEvalFunc evalFunc. /* String format of classification name */ u_int32_t priority. char noAlert. u_int32_t sigID. classification. priority. Rule The Rule structure defines the basic outline of a rule and contains the same set of information that is seen in a text rule. RuleReference **references. typedef struct _RuleInformation { u_int32_t genID. It also includes a list of rule options and an optional evaluation function. message text. /* Rule Initialized. char *classification. /* } Rule. address and port information and rule information (classification. char initialized. char *message.5. and a list of references). /* NULL terminated array of references */ RuleMetaData **meta. RuleInformation The RuleInformation structure defines the meta data for a rule and includes generator ID. and a list of references. void *ruleData. RuleInformation info. #define RULE_MATCH 1 #define RULE_NOMATCH 0 typedef struct _Rule { IPInfo ip. RuleOption **options. used internally */ Hash table for dynamic data pointers */ The rule evaluation function is defined as typedef int (*ruleEvalFunc)(void *).
OPTION_TYPE_ASN1. destination address and port. /* non-zero is bi-directional */ char * dst_addr. Some of the standard strings and variables are predefined .any. IPInfo The IPInfo structure defines the initial matching criteria for a rule and includes the protocol. OPTION_TYPE_SET_CURSOR. typedef struct _IPInfo { u_int8_t protocol. OPTION_TYPE_BYTE_EXTRACT. . OPTION_TYPE_FLOWFLAGS. typedef struct _RuleReference { char *systemName. /* 0 for non TCP/UDP */ } IPInfo. OPTION_TYPE_CURSOR. etc. and direction. Each option has a flags field that contains specific flags for that option as well as a ”Not” flag. OPTION_TYPE_PCRE. OPTION_TYPE_BYTE_JUMP. } RuleReference.RuleReference The RuleReference structure defines a single rule reference. HOME NET. /* 0 for non TCP/UDP */ char direction. OPTION_TYPE_FLOWBIT. OPTION_TYPE_MAX 161 . char * src_addr. HTTP PORTS. including the system name and rereference identifier. char * dst_port. OPTION_TYPE_CONTENT. HTTP SERVERS. OPTION_TYPE_BYTE_TEST. char *refIdentifier. char * src_port. OPTION_TYPE_LOOP. src address and port. The ”Not” flag is used to negate the results of evaluating that option. OPTION_TYPE_HDR_CHECK.
u_int32_t depth. if no ContentInfo structure in a given rules uses that flag. unicode. such as the compiled PCRE information. that which distinguishes this rule as a possible match to a packet. • OptionType: Content & Structure: ContentInfo The ContentInfo structure defines an option for a content search. relative. u_int8_t *patternByteForm. FlowFlags *flowFlags. depth and offset. LoopInfo *loop. u_int32_t patternByteFormLength. PCREInfo *pcre. u_int32_t flags. should be marked for fast pattern evaluation. and a designation that this content is to be used for snorts fast pattern evaluation. URI or normalized – to search). typedef struct _ContentInfo { u_int8_t *pattern. It includes the pattern. union { void *ptr. the integer ID for a flowbit. PreprocessorOption *preprocOpt. and flags (one of which must specify the buffer – raw. Asn1Context *asn1. } ContentInfo. BoyerMoore content information. typedef struct _RuleOption { int optionType. u_int32_t incrementLength. FlowBitsInfo *flowBit. } RuleOption. the one with the longest content length will be used. ByteData *byte. /* must include a CONTENT_BUF_X */ void *boyer_ptr. The most unique content.}. The option types and related structures are listed below. Additional flags include nocase. #define NOT_FLAG 0x10000000 Some options also contain information that is initialized at run time. ContentInfo *content. HdrOptCheck *hdrData. ByteExtract *byteExtract. . } option_u. In the dynamic detection engine provided with Snort. etc. CursorInfo *cursor. int32_t offset.
h provides flags: PCRE_CASELESS PCRE_MULTILINE PCRE_DOTALL PCRE_EXTENDED PCRE_ANCHORED PCRE_DOLLAR_ENDONLY PCRE_UNGREEDY */ typedef struct _PCREInfo { char *expr. u_int32_t flags. u_int32_t id. /* must include a CONTENT_BUF_X */ } PCREInfo. void *compiled_extra. pcre flags such as caseless. • OptionType: Flow Flags & Structure: FlowFlags The FlowFlags structure defines a flow option. • OptionType: Flowbit & Structure: FlowBitsInfo The FlowBitsInfo structure defines a flowbits option. which specify the direction (from server. void *compiled_expr. isset. /* pcre. etc. #define FLOW_ESTABLISHED 0x10 #define FLOW_IGNORE_REASSEMBLED 0x1000 #define FLOW_ONLY_REASSMBLED 0x2000 163 . to server). It includes the PCRE expression. toggle. u_int8_t operation. established session. unset. It includes the name of the flowbit and the operation (set. } FlowBitsInfo. isnotset). u_int32_t flags. u_int32_t compile_flags.#define CONTENT_BUF_RAW #define CONTENT_BUF_URI 0x200 0x400 • OptionType: PCRE & Structure: PCREInfo The PCREInfo structure defines an option for a PCRE search. and flags to specify the buffer. It includes the flags.h. as defined in PCRE. flags. /* specify one of CONTENT_BUF_X */ • OptionType: Protocol Header & Structure: HdrOptCheck The HdrOptCheck structure defines an option to check a protocol header for a specific value. unsigned int max_length. • OptionType: Cursor Check & Structure: CursorInfo The CursorInfo structure defines an option for a cursor evaluation.1 & Structure: Asn1Context The Asn1Context structure defines the information for an ASN1 option. This can be used to verify there is sufficient data to continue evaluation. int offset. It mirrors the ASN1 rule option and also includes a flags field. a mask to ignore that part of the header field. a value. int print. } Asn1Context.etc). • OptionType: ASN.is option xx included */ IP Time to live */ IP Type of Service */ #define TCP_HDR_ACK /* TCP Ack Value */ 164 . the operation (¡. u_int32_t flags.=. #define ASN1_ABS_OFFSET 1 #define ASN1_REL_OFFSET 2 typedef struct _Asn1Context { int bs_overflow. as related to content and PCRE searches.¿.#define #define #define #define FLOW_FR_SERVER FLOW_TO_CLIENT FLOW_TO_SERVER FLOW_FR_CLIENT 0x40 0x40 /* Just for redundancy */ 0x80 0x80 /* Just for redundancy */ typedef struct _FlowFlags { u_int32_t flags. } FlowFlags. It includes an offset and flags that specify the buffer. int length. int offset_type. } CursorInfo. It incldues the header field. int double_overflow. The cursor is the current position within the evaluation buffer. -. typedef struct _CursorInfo { int32_t offset. similar to the isdataat rule option. and flags. as well as byte tests and byte jumps.
It includes the number -. multiplier. } ByteData. The flags must specify the buffer. • OptionType: Set Cursor & Structure: CursorInfo See Cursor Check above. ¡. a value.DynamicElement The LoopInfo structure defines the information for a set of options that are to be evaluated repeatedly. u_int32_t multiplier. an operation (for ByteTest. end.=. The loop option acts like a FOR loop and includes start. • OptionType: Loop & Structures: LoopInfo. u_int32_t flags. for checkValue. and flags.¿. /* u_int32_t value. /* u_int32_t op.32bits is MORE than enough */ must include a CONTENT_BUF_X */ • OptionType: Byte Jump & Structure: ByteData See Byte Test above. /* /* /* /* /* /* Number of bytes to extract */ Type of byte comparison. } HdrOptCheck. and increment values as well as the comparison operation for 165 .ByteExtract. or extracted value */ Offset from cursor */ Used for byte jump -. for checkValue */ Value to compare value against. u_int32_t op. . /* u_int32_t flags. an offset. int32_t offset. u_int32_t a dynamic element. DynamicElement *increment. flags specifying the buffer. /* type of this field .. 166 . /* u_int32_t multiplier. /* void *memoryLocation. It includes a cursor adjust that happens through each iteration of the loop. u_int8_t initialized. /* Holder */ int32_t staticInt. the value is filled by a related ByteExtract option that is part of the loop. /* } ByteExtract. } DynamicElement. typedef struct _LoopInfo { DynamicElement *start. multiplier. /* u_int32_t flags. One of those options may be a ByteExtract. typedef struct _ByteExtract { u_int32_t bytes. 5.termination. a reference to a RuleInfo structure that defines the RuleOptions are to be evaluated through each iteration. and a reference to the DynamicElement. u_int32_t op. struct _Rule *subRule. } LoopInfo.2 Required Functions Each dynamic module must define a set of functions and data objects to work within this framework. u_int32_t flags. specifies The ByteExtract structure defines the information to use when extracting bytes for a DynamicElement used a in Loop evaltion. an offset. #define DYNAMIC_TYPE_INT_STATIC 1 #define DYNAMIC_TYPE_INT_REF 2 typedef struct _DynamicElement { char dynamicType. /* reference ID (NULL if static) */ union { void *voidPtr.static or reference */ char *refId. It includes the number of bytes. /* Value of static */ int32_t *dynamicInt. DynamicElement *end. CursorInfo *cursorAdjust. /* Pointer to value of dynamic */ } data. /* char *refId. /* int32_t offset.
PCRE evalution data. • int InitializeEngineLib(DynamicEngineData *) This function initializes the data structure for use by the engine. – int processFlowbits(void *p.Rule **) This is the function to iterate through each rule in the list and write a rule-stop to be used by snort to control the action of the rule (alert. u int8 t *cursor) This function extracts the bytes from a given packet. This uses the individual functions outlined below for each of the rule options and handles repetitive content issues.5. u int8 t **cursor) This function evaluates a single content for a given packet. These are defined in the file sf dynamic preproc lib. It will interact with flowbits used by text-based rules. checking for the existence of that content as delimited by ContentInfo and cursor.h. dpd and invokes the setup function.c. • int LibVersion(DynamicPluginMeta *) This function returns the metadata for the shared library. – int contentMatch(void *p.1 Preprocessors Each dynamic preprocessor library must define the following functions.2. etc). log. the with option corresponds to depth. ContentInfo* content. ByteExtract *byteExtract. • int InitializePreprocessor(DynamicPreprocessorData *) This function initializes the data structure for use by the preprocessor into a library global variable. • int DumpRules(char *. and register flowbits. • int LibVersion(DynamicPluginMeta *) This function returns the metadata for the shared library. drop. and the distance option corresponds to offset. 5.2 Detection Engine Each dynamic detection engine library must define the following functions. Rule *rule) This is the function to evaluate a rule if the rule does not have its own Rule Evaluation Function. as specified by FlowBitsInfo. etc). The metadata and setup function for the preprocessor should be defined sf preproc info. • int ruleMatch(void *p. – int checkFlow(void *p. FlowFlags *flowflags) This function evaluates the flow for a given packet. With a text rule. Cursor position is updated and returned in *cursor. – int extractValue(void *p. 167 . Each of the functions below returns RULE MATCH if the option matches based on the current criteria (cursor position.2.. as specified by ByteExtract and delimited by cursor. initialize it to setup content searches. Value extracted is stored in ByteExtract memoryLocation paraneter. FlowBitsInfo *flowbits) This function evaluates the flowbits for a given packet.
Cursor position is updated and returned in *cursor. PCREInfo *pcre. Asn1Context *asn1. – int checkCursor(void *p. u int8 t *cursor) This is a wrapper for extractValue() followed by checkValue(). 5. – int loopEval(void *p. CursorInfo *cursorInfo. u int8 t **cursor) This is a wrapper for extractValue() followed by setCursor(). New cursor position is returned in *cursor.3 Rules Each dynamic rules library must define the following functions. – int byteJump(void *p. u int8 t **cursor) This function evaluates the preprocessor defined option.h. PreprocessorOption *preprocOpt.2. and pcreMatch to adjust the cursor position after a successful match. u int8 t **cursor) This function evaluates a single pcre for a given packet. u int8 t *cursor) This function validates that the cursor is within bounds of the specified buffer. ByteData *byteData. • int LibVersion(DynamicPluginMeta *) This function returns the metadata for the shared library. It is also used by contentMatch.1 check for a given packet. – void revertTempCursor(u int8 t **temp cursor. Cursor position is updated and returned in *cursor. Cursor position is updated and returned in *cursor. – void setTempCursor(u int8 t **temp cursor. – int checkHdrOpt(void *p. u int8 t **cursor) This function iterates through the SubRule of LoopInfo. – int byteTest(void *p. u int8 t **cursor) This function is used to handled repetitive contents to save off a cursor position temporarily to be reset at later point. u int8 t *cursor) This function compares the value to the value stored in ByteData. – int detectAsn1(void *p. – int checkValue(void *p. ByteData *byteData. patterns that occur more than once may result in false negatives.– int setCursor(void *p. as delimited by LoopInfo and cursor. as spepcifed by PreprocessorOption. HdrOptCheck *optData) This function evaluates the given packet’s protocol headers. u int8 t *cursor) This function evaluates an ASN. ! △NOTE If you decide to write you own rule evaluation function. checking for the existence of the expression as delimited by PCREInfo and cursor. byteJump. This should be done for both content and PCRE options. Take extra care to handle this situation and search for the matched pattern again if subsequent rule options fail to match.c The metadata and setup function for the preprocessor should be defined in sfsnort dynamic detection lib. 168 . u int8 t **cursor) This function adjusts the cursor as delimited by CursorInfo. It handles bounds checking for the specified buffer and returns RULE NOMATCH if the cursor is moved out of bounds. Examples are defined in the file sfnort dynamic detection lib. • int EngineVersion(DynamicPluginMeta *) This function defines the version requirements for the corresponding detection engine library. u int8 t **cursor) This function is used to revert to a previously saved temporary cursor position. – int preprocOptionEval(void *p. as delimited by Asn1Context and cursor. u int32 t value. ByteData *byteData. as specified by HdrOptCheck. LoopInfo *loop. – int pcreMatch(void *p. CursorInfo *cursorInfo.
• int InitializeDetection() This function registers each rule in the rules library.conf.• int DumpSkeletonRules() This functions writes out the rule-stubs for rules that are loaded. The sample code provided with Snort predefines those functions and uses the following data within the dynamic rules library. DEBUG_WRAP(_dpd. register flowbits. #define GENERATOR_EXAMPLE 256 extern DynamicPreprocessorData _dpd.registerPreproc("dynamic_example".c into lib sfdynamic preprocessor example. This assumes the the files sf dynamic preproc lib. 5.h. • Rule *rules[] A NULL terminated list of Rule structures that this library defines. "Preprocessor: Example is setup\n").c and sf dynamic preproc lib. defined in sf preproc info. 169 . void ExampleInit(unsigned char *). etc. ExampleInit). This preprocessor always alerts on a Packet if the TCP port matches the one configured.1 Preprocessor Example The following is an example of a simple preprocessor.h are used.. } The initialization function to parse the keywords from snort.3 Examples This section provides a simple example of a dynamic preprocessor and a dynamic rule.). It should set up fast pattern-matcher content. This is the metadata for this preprocessor. void ExampleProcess(void *. The remainder of the code is defined in spp example.debugMsg(DEBUG_PLUGIN. void *). 5.c and is compiled together with sf dynamic preproc lib.so. void ExampleSetup() { _dpd.
arg).logMsg(" } else { _dpd. . 10). if (!arg) { _dpd.fatalMsg("ExamplePreproc: Missing port\n"). } port = strtoul(arg. PRIORITY_TRANSPORT. } portToCheck = port. arg)) { arg = strtok(NULL.debugMsg(DEBUG_PLUGIN. return */ return. ID 10000 */ _dpd. port). " \t\n\r"). #define SRC_PORT_MATCH 1 #define SRC_PORT_MATCH_STR "example_preprocessor: src port match" #define DST_PORT_MATCH 2 #define DST_PORT_MATCH_STR "example_preprocessor: dest port match" void ExampleProcess(void *pkt. if(!strcasecmp("port".fatalMsg("ExamplePreproc: Invalid option %s\n".u_int16_t portToCheck. "\t\n\r"). } /* Register the preprocessor function. arg = strtok(args. char *argEnd. if (!p->ip4_header || p->ip4_header->proto != IPPROTO_TCP || !p->tcp_header) { /* Not for me. _dpd. if (port < 0 || port > 65535) { _dpd. unsigned long port.fatalMsg("ExamplePreproc: Invalid port %d\n".addPreproc(ExampleProcess. portToCheck). void ExampleInit(unsigned char *args) { char *arg. 10000). Transport layer. DEBUG_WRAP(_dpd. _dpd. } The function to process the packet and log an alert if the either port matches.). &argEnd. void *context) { SFSnortPacket *p = (SFSnortPacket *)pkt. } if (p->src_port == portToCheck) { 170 Port: %d\n". "Preprocessor: Example is initialized\n").logMsg("Example dynamic preprocessor configuration\n").
0). SRC_PORT_MATCH_STR. \ content:"NetBus".3.established. SID 109. } if (p->dst_port == portToCheck) { /* Destination port matched. } } 5. log alert */ _dpd.401. 3. 1. 1. 3. return. Per the text version. return. The snort rule in normal format: alert tcp $HOME_NET 12345:12346 -> $EXTERNAL_NET any \ (msg:"BACKDOOR netbus active". defined in detection lib meta. SRC_PORT_MATCH. 0). classtype:misc-activity. • Flow option Define the FlowFlags structure and its corresponding RuleOption. \ sid:109. reference:arachnids. static FlowFlags sid109flow = { FLOW_ESTABLISHED|FLOW_TO_CLIENT }. 0. DST_PORT_MATCH_STR.established. take from the current rule set. DST_PORT_MATCH. static RuleOption sid109option1 = { 171 . 0. log alert */ _dpd. Declaration of the data structures. /*.2 Rules The following is an example of a simple rule. It is implemented to work with the detection engine provided with snort.alertAdd(GENERATOR_EXAMPLE.h. flow is from server. rev:5.) This is the metadata for this rule library.c. flow:from_server.alertAdd(GENERATOR_EXAMPLE./* Source port matched.
static RuleOption sid109option2 = { OPTION_TYPE_CONTENT. /* holder for 0. and non-relative. static RuleReference sid109ref_arachnids = { "arachnids". NULL }. /* pattern to 0. /* offset */ CONTENT_BUF_NORMALIZED. Rule options are evaluated in the order specified. content is ”NetBus”. static ContentInfo sid109content = { "NetBus". Per the text version. NOTE: This content will be used for the fast pattern matcher since it is the longest content option for this rule and no contents have a flag of CONTENT FAST PATTERN.OPTION_TYPE_FLOWFLAGS. no depth or offset. Search on the normalized buffer by default. /* Type */ "401" /* value */ }. • Content Option Define the ContentInfo structure and its corresponding RuleOption. /* flags */ NULL. /* depth */ 0. The list of rule options. RuleOption *sid109options[] = { &sid109option1. case sensitive. search for */ boyer/moore info */ byte representation of "NetBus" */ length of byte representation */ increment length */ 172 . { &sid109content } }. /* holder for NULL. { &sid109flow } }. NULL }. • Rule and Meta Data Define the references. /* holder for 0 /* holder for }. static RuleReference *sid109refs[] = { &sid109ref_arachnids. &sid109option2.
173 . etc). flowbits. /* source port(s) */ 0. Rule *rules[] = { &sid109. etc. option count. /* metadata */ { 3. /* proto */ HOME_NET. used internally */ • The List of rules defined by this rules library The NULL terminated list of rules.use 3 to distinguish a C rule */ 109. /* Holder. /* revision */ "misc-activity". /* destination port */ }. Rule sid109 = { /* protocol header. no alert. akin to => tcp any any -> any any */ { IPPROTO_TCP. pcre. /* sigid */ 5. message. /* classification */ 0. /* Holder. /* ptr to rule options */ NULL. /* genid -. sid109options. /* Direction */ EXTERNAL_NET. extern Rule sid109. /* message */ sid109refs /* ptr to references */ }. /* destination IP */ ANY_PORT. meta data (sid. /* source IP */ "12345:12346". /* Holder. used internally */ 0. used internally for flowbits */ NULL /* Holder.The rule itself. NULL }. &sid637. used internally */ 0. /* Use internal eval func */ 0. not yet initialized. extern Rule sid637. rule data. classification. /* priority */ "BACKDOOR netbus active". The InitializeDetection iterates through each Rule in the list and initializes the content. with the protocl header.
Packets are then sent through the detection engine. Each of the keyword options is a plugin. Features go into HEAD. a TCP analysis preprocessor could simply return if the packet does not have a TCP header. If you are going to be helping out with Snort development. Packets are then sent through the registered set of preprocessors.net mailing list. End users don’t really need to be reading this section.2.1 Preprocessors For example.2 Snort Data Flow First. This is intended to help developers get a basic understanding of whats going on quickly. Bugfixes are what goes into STABLE. Similarly. traffic is acquired from the network link via libpcap. It will someday contain references on how to create new detection plugins and preprocessors.sourceforge. Packets are passed through a series of decoder routines that first fill out the packet structure for link level protocols then are further decoded for things like TCP and UDP ports. this chapter is here as a place holder. 6. 6.h for the list of pkt * constants. We’ve had problems in the past of people submitting patches only to the stable branch (since they are likely writing this stuff for their own IDS purposes). 6.Chapter 6 Snort Development Currently. Check out src/decode. It can do this by checking: if (p->tcph==null) return. Patches should done with the command diff -nu snort-orig snort-new. The detection engine checks each packet against the various options listed in the Snort rules files. Each preprocessor checks to see if this packet is something it should look at. 174 . there are a lot of packet flags available that can be used to mark a packet as “reassembled” or logged. please use the HEAD branch of cvs. This allows this to be easily extensible.1 Submitting Patches Patches to Snort should be sent to the snort-devel@lists.
we’ll document what these few things are.2 Detection Plugins Basically. 175 .2.6. Later. We are currently cleaning house on the available output options.3 Output Plugins Generally. 6.2. new output plugins should go into the barnyard project rather than the Snort project. look at an existing output plugin and copy it to a new item and change a few things. .6.
whitehats.pcre.org 177 .com/mag/phrack/phrack49/p49-06 [2] [4] [5] [3] [6] [1].
|
https://www.scribd.com/document/35714167/Snort-Manual-2-8-5-1
|
CC-MAIN-2018-09
|
refinedweb
| 49,099
| 60.82
|
Multiple image tiles
Hello. I'm new to Pythonista. I'm working on a simple app that request data from a music api. What I want to do on my main view is show the image of the top 10 albums. I don't know how to implement this onto a view. My json data for the image uses a url. Is there a method that I can use to pass in the url the show the image? Can someone please give me a simple example of how to do this.
Can:
- Webmaster4o
The answer that you site does mention the preferred way which is what I advocated. Try cycling thru a long list of large images and see if problems emerge.
Pythonista is an implementation of cPython so it does indeed have a garbage collector. However Apple only allows iOS apps to have a single thread of execution (still true in iOS9?) so Python instances tend run longer in Pythonista than they would on your Mac or PC. On those other platforms garbage collection is less disruptive because it can be done in a separate thread of execution. This means that GC is run less often in Pythonista makes it more sensitive to unclosed resources than other platforms. Images can take up a lot of memory compounds the issue.
pythonista uses ref counting, so no close is needed. here is a way to check, using weakref handlers:
# coding: utf-8 import io, weakref def handler(ref): print 'buffer closed' def f(): buffer = io.BytesIO() ref = weakref.ref(buffer, handler) buffer.write('something') return buffer.getvalue() for i in xrange(5): print 'before' f() print 'after'
as an aside, i think ios does allow threads, just not multiple processes.
- MartinPacker
@Webmaster4o Note: Garbage Collection (GC) is not a universal panacea. If, for example, you hang on to objects or handles you might (inadvertently) defeat GC.
And I like @ccc's response on GC pragmatics.
Pedagogical point: GC schemes are a big factor in (languages like) java's performance. They've evolved over the years.
And I'm requesting the "im:image" url
@Webmaster4o sounds great. I'll try this ASAP. Also what if I didn't want a cover flow, I was thinking more of a table of images.
@ccc i would this the ui module would be more appropriate. Isn't scene and canvas more for a game interface?
Part I: Get the image URLs for the Top 10 iTunes songs:
import feedparser url = '' def get_image_urls(itunes_url): for entry in feedparser.parse(itunes_url).entries: yield entry['summary'].partition('src="')[2].partition('"')[0] print('\n'.join(get_image_urls(url)))
Part II: Adds a ui.View...
- Webmaster4o
It has to do with the spacing between the pictures. Try adjusting the value and seeing what happens.
This post is deleted!last edited by
|
https://forum.omz-software.com/topic/2258/multiple-image-tiles
|
CC-MAIN-2020-45
|
refinedweb
| 470
| 68.67
|
Details
Description
I know - silly of me to have a page with no <body></body> element. I spent an entire day trying to figure out why the javascript wasn't getting included.
It was my error, but I can see other people making the same mistake...a little error-reporting would be nice.
Activity
The thing is that we don't just publish to html, we also publish to html fragments (<div>), fbml (facebook, <fbml>), and even json (packaging kind of like partial render). So i want to make sure that if you do decide this is an error, not make it a fatal error, and make it so we can turn off the logging on it, since that might fail often.
Also, we had a hard time trying to properly override the RenderSupport and MarkupRenderFilter structure to properly handle the other options of rendering. If we had a good way to change contributions it would be much easier (we could replace standard RenderSupport with ours). Or if the RenderSupport was somehow a service we could decorate it would be much easier, etc etc..
The case described here concerns just full page renders, so HTML fragments (as part of an Ajax request) are handled quite differently.
I'm looking at but can't quite figure out the structure of the document.
That being said, I believe what I'll be doing is making it easier to override the DocumentLinker, which will be its own Environmental object, seperate from the RenderSupport. This will make it easier to keep Tapestry's logic as is, but change the rules for how the CSS links, JavaScript links and initialization JavaScript are linked (or "integrated") with the overall page. Eventually, some of these interfaces will migrate out to the public API space.
In terms of overrides; my intention was that you could place a "competing" filter into the pipeline just after the filter being replaced. It would, in effect, intercept all the calls to the built-in filter ... in other words, Tapestry's RenderSupport instance would be present, but would never be invoked, because your custom, Facebook-compatible RenderSupport instance would be the one visible to the rest of the application during the render.
the fbml document is really like an xhtml fragment that allows elements from the facebook namespace. So the only thing is that the RederSupport needs to know about <fbml> rather than <html><head><body>.
Yes I kind of figured out that the DocumentLinker was the thing that needed to be overridden, but the way it was coded, it was privately owned and used by RenderSupport.. so I had to override RenderSupport, to be able to override DocumentLinker.
Right ... I want to offer the ability to override DocumentLinker seperately from RenderSupport (so that you don't need to change RenderSupport).
I know that your intention was to allow people to place a filter after the real RenderSupport and allow easy overriding that way, but it did not pan out that way for various reasons:
1) There was no way for me to turn off RenderSupport, in that i always did work, even if I took over much of the work for it.. ( it still called 'commit' and 'render' on the way out of the markupfilter..
2) The other markupfilters that depend on RenderSupport know about that ( before:RenderSupport, after:RenderSupport ), but do not know about my secondary overriding filter.. so it's unreliable to me to override it.. basically i would need a third option ( directly-after:RenderSupport, override:RenderSupport ), to make sure that my Filter went right after RenderSupport, but before anyone that was depending on it..
Because of these things, it still boils down to the configuration system is trying to hide too many things from people using it.. And I hold that not exposing a clean way to override or change configurations made by underlying libraries is a deficiency.. We can come up with work arounds and various other ideas, but I think we'll always come back to this.
If you're going to be enhancing the DocumentLinker, please make it mutable as well
This allows us to be much more fancy stuff. Like having a service that reviews the desired javascript and replaces the url with a compressed version. Or it can collapse various javascript assets into one ( like YUI does ), or.. or.. or.. All without having to make your own DocumentLinker, simply looking into it's list of assets and modifying it as required.
I've split DocumentLinker from RenderSupport.
In RenderSupportImpl:
public void commit()
{
if (focusFieldId != null)
if (init.length() > 0){ addScript("Tapestry.init(%s);", init); }
}
This means that if you provide an alternate version of RenderSupport, and the default one receives no method invocations, then the commit() will do nothing. So it is replaceable.
In terms of making DL "mutable" ... we're sharing some ideas for 5.1 (or 5.2, depending). Anyway, the point is, you can replace the DocumentLinker implementation in the Environment before the RenderSupport filter grabs it, and your implementation can do whatever. In terms of Facebook support, you'll want an implementation that expects the root element to be <fbml> and put the necessary <link> and <script> tags there.
Tapestry will no require a root <html> element (and report it, if missing). It will create <head> and <body> elements within the root element, as needed.
Yes; I think this should be an error, not just skipped logic. It would be clearer as an error.
|
https://issues.apache.org/jira/browse/TAP5-184
|
CC-MAIN-2014-10
|
refinedweb
| 915
| 61.67
|
Is it possible to check to see if a user has used a floating point number as of an integer?
This is a discussion on Floating point within the C++ Programming forums, part of the General Programming Boards category; Is it possible to check to see if a user has used a floating point number as of an integer?...
Is it possible to check to see if a user has used a floating point number as of an integer?
Take input as a string. Attempt to convert the string to an int. If it fails, try to convert it to a floating point value. If it is a value that could be either, such as "42", make your own rule for handling it.
ok thank you i've done this soo far....
which is all dandy.... but how do i check if the string contains letters? because i need to convert it back to an integerwhich is all dandy.... but how do i check if the string contains letters? because i need to convert it back to an integerCode:int check_string(string x1){ unsigned int pos = x1.find(".",0); int y = 0; if(pos != string::npos){ cout << "Invalid input! Conversion Failed"<<endl; y = 1; } return (y); }
Code:#include <iostream> using namespace std; int main() { double input; cout << "Enter a number: "; cin >> input; if ( (input / static_cast<int>(input)) == 1) { //Is int...do whatever } else {} return 0; }
Last edited by Enahs; 12-04-2005 at 02:06 PM.
Or !isdigit(). (<cctype>):#include <iostream> #include <fstream> #include <sstream> #include <string> using namespace std; // for homework and toy programs int main() { ifstream file("file.txt"); string info; while ( getline(file, info) ) { istringstream iss(info); char c; float afloat; if ( (iss >> afloat) && !iss.get(c) ) { cout << " afloat = " << afloat << endl; } } return 0; } /* file.txt abc 123 123.456 0x14 9a */ /* my output afloat = 123 afloat = 123.456 */
Or use strtod() and see if there is a '.' between the start and end pointer (and check errno as well).
A simple way to check the input straight from cin is to read into an int. If it succeeds, then the first characters of the input were numbers. Then check the next character in the stream to see if it is a newline (from the user hitting enter to send the input). If it isn't, then the input isn't valid because they entered a decimal point or a non-numeric character.The clear and ignore clean out the fail state and any and all bad characters.The clear and ignore clean out the fail state and any and all bad characters.Code:int val = 0; while (!(cin >> val) || cin.get() != '\n') { cin.clear(); cin.ignore(numeric_limits<streamsize>::max(), '\n'); // Invalid input! }
|
http://cboard.cprogramming.com/cplusplus-programming/73120-floating-point.html
|
CC-MAIN-2014-35
|
refinedweb
| 454
| 75.61
|
Created on 2014-04-17 01:01 by bgailer, last changed 2015-08-06 05:09 by zach.ware. This issue is now closed.
Documentation for str.translate only mentions a dictionary for the translation table. Actually any iterable can be used, as long as its elements are integer, None or str.
Recommend wording:
str.translate(translation_table)
Return a copy of the s where all characters have been "mapped" through the translation_table - which must be either a dictionary mapping Unicode ordinals (integers) to Unicode ordinals, strings or None,
or an iterable. In this case the ord() of each character in s is used as an index into the iterable; the corresponding element of the iterable replaces the character. If ord() of the character exceeds the index range of the iterator, no substitution is made.
Example: to shift any of the first 255 ASCII characters to the next:
>>> 'Now is the time for all good men'.translate(range(1, 256))
'Opx!jt!uif!ujnf!gps!bmm!hppe!nfo'
COMMENT: I placed mapped in quotes as technically this only applies to dictionaries. Not sure what the best word is.
I suspect “iterable” is the wrong term.
>>> isinstance(set(), Iterable)
True
>>> "abc".translate(set())
TypeError: 'set' object does not support indexing
>>> "abc".translate(object())
TypeError: 'object' object is not subscriptable
Maybe “indexable” or “subscriptable” would be more correct? If this behaviour is part of the API, it would be nice to document, because it would have saved me a few times from implementing the __len__() and __iter__() methods of the mapping interface in my custom lookup tables.
Here is my suggestion:
str.translate(table):
Return a copy of the string where all characters have been mapped through “table”, a lookup table. The lookup table must be a subscriptable object, for instance a dictionary or list, mapping Unicode ordinals (integers) to Unicode ordinals, strings or None. If a character is not in the table, the subscript operation should raise LookupError, and the character is left untouched. Characters mapped to None are deleted.
For the record, I have intentionally used bytes.maketrans to make translation table for str.translate for precisely this reason; it's much faster to look up a ordinal in a bytes object than in a dictionary. Before the recent (partial) patch for str.translate performance (#21118), this was a huge improvement if you only needed to worry about latin-1 characters (though encoding to latin-1, using bytes.translate, then decoding again was still faster). It's still faster than using a dictionary even with the patch from #21118, but it's not nearly as significant.
I have created a patch based on Martin Panter's suggestions. Please let me know if it is off or there should be additional changes included.
The docstring is more accurate.
">>> str.translate.__doc__
'S.translate(table) -> str\n\nReturn a copy of the string S, where all characters have been mapped\nthrough the given translation table, which must be a mapping of\nUnicode ordinals to Unicode ordinals, strings, or None.\nUnmapped characters are left untouched. Characters mapped to None\nare deleted.'""
To me, even this is a bit unclear on exceptions and 'unmapped'. Based on experiments and then reading the C source, I determined that LookupErrors mean 'unmapped' while other exceptions are passed on and terminate the translation.
"Return a copy of the string S, where all characters have been mapped through the given translation table. When subscripted by a Unicode ordinal (integer in range(1048576)), the table must return a Unicode ordinal, string, or None, or else raise a LookupError. A LookupError, which includes instances of subclasses IndexError and KeyError, indicates that the character is unmapped and should be left untouched. Characters mapped to None are deleted."
class Table:
def __getitem__(self, key):
if key == 99: raise LookupError() #'c'
elif key == 100: return None # 'd'
elif key == 101: return 'xyz' # 'e'
else: return key+1
print('abcdef'.translate(Table()))
# bccxyzg
The current doc ends with "Note
An even more flexible approach is to create a custom character mapping codec using the codecs module (see encodings.cp1251 for an example)."
I don't see how this is supposed to help. Encodings.cp1251 uses a string of 256 chars as a lookup table.
I see that we mostly added the same info.
Update patch with typo fixed, removed note about the “codecs” module (which I never found useful either), and updated the doc string with similar wording.
Terry, do you think the wording in the patch is good enough, or do you think some of your proposed wording should be included?
Many people may not know that IndexError and KeyError are subclasses of LookupError. I have not decided what to add yet, but I think we are close.
Kindly ignore message #2 on the Rietveld page (sorry for the channel noise). Here's my suggested revision:
Return a copy of the string *str* in which each character has been mapped through the given translation *table*. The table must be a subscriptable object, for instance a list or dictionary; when subscripted (indexed) by a Unicode ordinal (an integer in range(1048576)), the table object can:
* return a Unicode ordinal or a string, to map the character to one or more other characters.
* return None, to delete the character from the return string.
* raise a LookupError (possibly an instance of subclass IndexError or KeyError), to map the character to itself.
I’m largely happy with any of these revisions. If I end up doing another patch I would omit the *str* (it is a class name, not a parameter). Also I would omit the range(2^20) claim. Unless people think it is important; why is it different to sys.maxunicode + 1 = 0x110000?
Here is a new patch based on John’s suggestion
Regarding Martin's patch of 12-18:
stdtypes.rst -- looks good to me
unicodeobject.c -- I suggest changing this sentence:
If a character is not in the table, the subscript operation should raise LookupError, and the character is left untouched.
... to:
If the subscript operation raises a LookupError, the character is left untouched.
Patch v4 with John’s doc string wording
Patch of 12-21 looks good, Martin.
Proposed wording looks superfluously verbose to me.
Look also at description in Include/unicodeobject.h:
/* Translate a string by applying a character mapping table to it and
return the resulting Unicode object.
The mapping table must map Unicode ordinal integers to Unicode
ordinal integers or None (causing deletion of the character).
Mapping tables may be dictionaries or sequences. Unmapped character
ordinals (ones which cause a LookupError) are left untouched and
are copied as-is.
*/
It is repeated (more detailed) in Doc/c-api/unicode.rst. Isn't it pretty clear?
Serhiy can you point out which bits are too verbose? Perhaps you prefer it without the bullet list like in the earlier 2014-12-13 version of the patch.
Looking at the C API, I see a couple problems there:
* Omits mentioning that an ordinal can map to a replacement string
* It looks like the documented None behaviour applies when errors="ignore", otherwise it invokes a codec error handler
> Serhiy can you point out which bits are too verbose? Perhaps you prefer it
> without the bullet list like in the earlier 2014-12-13 version of the
> patch.
I prefer it without the bullet list and without LookupError expansion (there
is a link to LookupError definition where IndexError and KeyError should be
mentioned). Instead of new term "subscriptable objects" use "mappings or
sequences" with links to glossary.
> Looking at the C API, I see a couple problems there:
Yes, it is slightly outdated and needs updates.
I agree with Serhiy: no bullet points, links to glossary (at least in doc), without repeating.
The problem with mappings and sequences is that they both require len() and iter() implementations, but str.translate() only requires __getitem__(). Perhaps a qualifier could work, like:
The table must implement the __getitem__() method of mappings and sequences.
issue21279.v5.patch tries to apply the comments in msg233013, msg233014, and msg233025 to the Doc/library/stdtypes.rst writeup. Then it applies some of the same language to the docstring in Objects/unicodeobject.c.
I’m happy with the new wording in v5. Maybe the docstring in the C module could be reflowed though.
Per Martin's suggestion, deltas from issue21279.v5.patch:
* no change to patch for doc/library/stdtypes.rst
* doc string reflowed in patch for objects/unicodeobject.c
Patch v6 looks okay, so I think it is ready to commit.
New changeset ae53bd5decae by Zachary Ware in branch '3.4':
Issue #21279: Flesh out str.translate docs
New changeset 064b569e38fe by Zachary Ware in branch '3.5':
Issue #21279: Merge with 3.4
New changeset 967c9a9fe724 by Zachary Ware in branch 'default':
Closes #21279: Merge with 3.5
Very minor grammatical fixes, reflowed the .rst docs, and re-added the codecs module mention in a less obtrusive manner, but the patch is committed. Thank you Kinga, Martin, and John!
|
https://bugs.python.org/issue21279
|
CC-MAIN-2021-25
|
refinedweb
| 1,507
| 66.03
|
I'm trying to write a for loop but one of the values won't update. R
I'm just trying to write a simple for loops so I can see how much the person would owe after each consecutive year. It ends up printing the statement with only the n value ever changed. The A stays the same as the first time.
for (n in 1:15){ A <- 5000 * (1+ .115/100) ^n sprintf("%.2f owed after %.f years", A, n) }
I have no clue what to do to fix it. Thanks
1 answer
See also questions close to this topic
-?
- Using a bayesian network with sparklyr
My Question: What is the best (easiest) way to implement a bayesian network in Apache Spark with R?
Usually I am using Sparklyr (R interface for Apache Spark). I am able to impelment machine learning algorithms in a Spark cluster via the machine learning functions within sparklyr. However I would like to build a bayesian network which is not supported by sparklyr. What is the best way to implement a bayesian network in Apache Spark with R?
- Speed up python list search (Nested for loops)
I'm currently working on moving some excel worksheets over to python automation, and have come across a speed issue.
I have a list of lists containing around 10.000 lists each with 20 or so columns. I also have a list of account numbers (100.000 numbers)
I wish to iterate over my list of lists and then pick out values from the list, if the account number in the lists matches one in the account list.
By running this code, i am able to get my desired result, however it is painfully slow.
calc = 0 for row in listOfLists: if row[1] in Accounts: calc += row[8]
Any ideas on how to optimize for speed?
- Calculate checksum in Java
I'm trying to calculate the crc based on below condition:
Calculate checksum using 1021(hex) polynomial and initial value FFFF(hex).
The resulting is in 2 byte hexadecimal value.
Here's my code:
public class CRCCalculator { int crc = 0xFFFF; int polynomial = 0x1021; public static void main(String[] args) throws UnsupportedEncodingException { int crc = 0xFFFF; // initial value int polynomial = 0x1021; // 0001 0000 0010 0001 (0, 5, 12) String str = "000201010212153125000344000203441000000000000065204597253033445403" + "1005802HK5913Test Merchant6002HK6260012020171027154249002240052020" + "171027154249002241070800000003"; byte[] bytes = str.getBytes(); for (byte b : bytes) { for (int i = 0; i < 8; i++) { boolean bit = ((b >> (7 - i) & 1) == 1); boolean c15 = ((crc >> 15 & 1) == 1); crc <<= 1; if (c15 ^ bit) { crc ^= polynomial; } } } crc &= 0xffff; System.out.println("CRC16-CCITT = " + Integer.toHexString(crc).toUpperCase()); } }
The actual output should be
0D5F, but I get
AD9D.
- Get item value in a loop with failed tasks in Ansible
There is a one interesting thing I try to perform with Ansible but something goes wrong.
Example:
- A text file contains IP addresses of some hosts.
- I need to read each line in the file and check whether SSH port is open for every IP address.
- If I get a timeout while checking host port then I should know what IP address seems to have a problem and pass this item into the variable to perform additional checks.
File content:
1.1.1.1 1.1.1.2 1.1.1.2
Ansible playbook:
- hosts: localhost connection: local gather_facts: no tasks: - name: Get list of IP adresses shell: cat /home/file register: ip_addrs - name: Check SSH port wait_for: host: "{{ item }}" port: 22 timeout: 5 with_items: "{{ ip_addrs.stdout_lines }}" ignore_errors: true
My playbook ends with results:
ok - 1.1.1.1 ok - 1.1.1.2 timeout - 1.1.1.3
The result of the loop includes results of every task in one reply. My question: How can I extract the value of the item in a loop which caused my task to fail?
Something like
register: resultfor task in a loop and some command for the item
when: result|failed.
- unable to get the list of weblogic deployments printed using WLST
I'm trying to get the list of services deployed on my Weblogic. Below is the simple for loop i'm using, but i'm facing syntax issue.
connect(sys.argv[2],sys.argv[3],sys.argv[5]) deploymentList=cmo.getAppDeployments()
for deployment in deploymentList: try: deploymentname = deployment.getName() print deploymentname except java.lang.Exception, ex:print 'Exception on Changing the...'
this deployment name will again be used to stop that Application.
- how to get from previous for loop value(hard to title)
Hey guys I am newbie in Python , hope for some help here :)
My question is how to make for loop like this :
for x in range(5): print x + value which i got in previous loop
Maybe I am not super clear here so I will try to explain
for loop is going to print for me numbers 0,1,2,3,4 , right? So what i want is every time it will print a value for example "3" it will plus previous one which in this case "2". Anybody can help me to explain how to do that ?
I am newbie in coding , so please be easy on me :D
Thank you!
- iterating over an array with for loop JS
I have an array of objects (contacts) and I need to write one function that should check if firstName (first parameter of the function) is an actual contact's firstName and the given property (prop is the second parameter of the function) is a property of that contact. If both are true, then return the "value" of that property.
If firstName does not correspond to any contacts then return "No such contact"
If prop does not correspond to any valid properties then return "No such property"
I know what I need to do, the sudo I wrote it but to write it in actual JavaScript I am having a blockage.
Below what I wrote so far:(firstName, prop) { var value; for (i = 0; i < 2; i++) { if (contacts[i].firstName === true && contacts[i].prop === true) { value = contacts[i].prop; return value; } } }
|
http://codegur.com/48215574/im-trying-to-write-a-for-loop-but-one-of-the-values-wont-update-r
|
CC-MAIN-2018-05
|
refinedweb
| 1,008
| 71.24
|
Using Reflection Emit to Cache .NET Assemblies
Simon Guest
Microsoft Corporation
February 2002
Applies to:
Microsoft® .NET Framework
Microsoft® Visual Studio® .NET 2002
Summary: Details a non-intrusive caching solution that uses Reflection Emit in the Microsoft .NET Framework. (26 printed pages)
Download Installer.msi.
Contents
Introduction
The Challenge
Solving the Caching Problem using the ACGEN Tool
Customizing the ACGEN Tool
How the ACGEN Tool Works
Conclusion
Introduction
There are few automated ways of caching methods within a Microsoft .NET Assembly or Web Service without writing a significant amount of the logic into the application. And sometimes, if the Web Service or .NET Assembly is from a third party, it isn't possible.
This article outlines a non-intrusive caching solution that uses Reflection Emit in the Microsoft .NET Framework. Reflection Emit is the ability to generate assemblies, types, methods, and MSIL (Microsoft Intermediate Language) on the fly in .NET. This generated code can then either by run dynamically or saved to disk as an assembly.
This article is divided into two parts: The first outlines a sample scenario and explains the problem, requirements and introduces a tool that was developed to meet these requirements. The second part covers how this tool works in detail, with some ideas on how the approach could be used in other applications.
This article has been written for developers and architects who are familiar with the System.Reflection namespace in .NET, and have an appreciation of MSIL (Microsoft Intermediate Language). It is recommended that the audience read and understand the System.Reflection and the System.Reflection.Emit samples that are provided as part of the Microsoft .NET Framework SDK.
The Challenge
To help understand the concepts, we will use the following example in our explanations and sample code.
Our Sample Scenario
Imagine we have written a 'StockTicker' Class (as either a .NET assembly or a Web Service).
This class exposes a public method called GetQuote. The GetQuote method takes a parameter of type String, which is the symbol of the stock to obtain a price for. The GetQuote method returns a value of type Double, which happens to be the current stock quote for the symbol passed.
This method could look as follows:
public double GetQuote(String Symbol).
By referencing the StockTicker Class from our client application, we can call the GetQuote method and pass the value MSFT. As expected, a value of the stock price for this symbol is returned.
Simple stuff so far. However, the next time we call this method—even if the symbol we pass is the same ("MSFT"), the GetQuote method will still have to perform the lookup for the stock quote—even though it may have seen the last request only a short time ago. Now let's imagine that the GetQuote method takes some time to retrieve the quote (e.g. it has to extract the quote price from a streaming quote server elsewhere on the network), and that the quotes are typically only updated every 15 minutes or so.
The performance of the overall application would be increased, and the network hops reduced, by returning a cached result rather than going away and recalculating the result—as long as the method is called with the same parameter within a certain period of time. Traditionally, if we wanted to add this functionality we would have to write extra code for the StockTicker service itself. To create our own caching methods, we could store the incoming values in memory, check to see whether they had already been called within a certain period of time, and if so, return the cached result instead of re-doing the calculation. The problem with this approach is that we require some direct modification of the service method itself. What if we don't have access to the source code? What if the exposed method is via a Web Service that is maintained by another company we work with? And what if caching is required for a number of users/instances, but is not required nor is desirable for others?
Looking at our Requirements
We want some standard way of universally caching methods from any .NET assembly or exposed Web Service. From our previous scenario, we can derive the following requirements:
- The caching must be performed on the client to minimize the number of network hops required for cached results.
- The caching of these methods must require no additional coding to the exposed method/assembly.
- The caching must not include any major changes to the client calling the application.
- It must be tailored such that certain methods in an assembly/Web Service can be included/excluded as desired.
- It must include the ability to provide a TTL (Time to Live) value for each application.
- It must include the ability to use a custom caching algorithm/methodology if so desired.
Solving the Caching Problem using the ACGEN Tool
ACGEN (Assembly Cache GENerator)
ACGEN, a command line utility, is a tool that we will use in this article to present a solution to the caching requirements. The primary usage of this tool is to provide a complete example of the power of using Reflection Emit in .NET.
ACGEN works by creating a 'cached proxy' of any .NET assembly. The cached proxy that is generated 'looks' very similar to the original assembly, and can be referenced by the calling application in exactly the same way as the original.
When a method of the cached assembly is called, a check is made, based on the parameters passed to the method, to see whether the result of the method call is stored in a cache. (The actual cache values live in a separate assembly called the CacheAPI).
If there is a matching call, the cached result is returned—if not, the method in the original assembly is called, and the resulting value is stored to the cache for the next time before being passed back to the calling application. All of this functionality is transparent to the developer.
To install the source code example
To install the source code example supplied with this article, follow these instructions:
- Download and run the installer.msi file.
- During installation, select a destination directory for the source code. Underneath this directory, four sub-directories will be created, ACGEN, CacheAPI, MyStockTicker and MyStockTickerClient.
- ACGEN contains the source for the tool itself. CacheAPI contains the source for the Caching API example. MyStockTicker contains a dummy stock ticker assembly as described in this article. MyStockTickerClient contains a simple Windows Form application used to call the MyStockTicker class.
- Open Microsoft Visual Studio .NET and create a blank solution.
- In Solution Explorer, select Add Existing Project and add the .csproj file located in each of the four subdirectories to assemble the entire project.
- Click Build.
To test the installation without caching
- In Solution Explorer, right-click MyStockTickerClient and select Set as Startup Project. Run the application. The client Windows Form should be displayed.
- Enter the value MSFT in the text box and click the Get Quote button. A dialog box should be displayed showing a dummy stock price, and (more importantly!) a second dialog box will display how long the operation took. This should be around 500ms.
- Repeat the operation a couple of times. Note how every operation takes 500ms, even though the symbol we are asking for remains the same. (Other stock symbols you can also try are MYCO and MYCO2).
Note To simulate the service having to 'do some work' in order to return the quote, a 500ms time delay has been added to our dummy service. This is purely to prove that the caching implementation is working during our test, but this could be realistic in a production environment where the value was being obtained from a Web Service via the Internet.
We will now use the ACGEN tool to generate a cached proxy of the MyStockTicker assembly. To do this:
- Close the client application and return to Visual Studio. NET.
- Open an MS-DOS command prompt.
- At the command prompt, change directory to the output directory of the ACGEN project (For example, CD C:\CodeExample\ACGEN\bin\Debug).
- From this directory, type the following command:
This should produce the following:
- In Visual Studio.NET Solution Explorer, in the MyStockTickerClient, add a reference (right-click the MyStockTickerClient project and click Add Reference).
- In the Add Reference Dialog box, click Browse and navigate to the MyStockTicker\bin\Debug directory. Open the Cached_MyStockTicker.dll assembly and click OK.
- View the code for the Form1.cs file in the MyStockTickerClient. Scroll down to line 25 and replace the following line:
with
- Click Build and re-run the MyStockTickerClient application using the same stock ticker symbol as before.
If the tool has worked correctly, you should observe the following:
On the first attempt to retrieve the stock value, the operation should take the same time as before (around 500ms). This is the first time that we've called the StockTicker, so the cache will be empty.
On the second and future attempts however, the response from the StockTicker assembly should be much quicker (around the 10ms range). The cached proxy that we have built intercepts the call to the assembly, returning a result from cache if the stock symbol was the same. Returning the value from cache is obviously much quicker than retrieving the value from the original assembly again.
After 10 seconds (10000ms) has elapsed, the value in the cache will expire. (The default TTL for the cache is 10000ms). Once this value becomes invalidated, the client will have to make another call to the assembly to retrieve the value and repopulate the cache.
Customizing the ACGEN Tool
In the above example, we called ACGEN from the command line with few parameters.
Calling ACGEN from the command line with no parameters, however, lists all of the available options. These are shown as follows:
C:\acgen>acgen Microsoft (R) .NET Assembly Cache Generator. [Version acgen, Version=1.1.650.26975, Culture=neutral, PublicKeyToken=null] Copyright (C) Microsoft Corp 2000-2001. All Rights Reserved. Usage : acgen <assembly to cache> [OPTIONS], where OPTIONS are : [/CACHEAPI:<filename>] Filename of the Cache API to use. (Default CacheAPI.DLL in the same dir) [/OUTPUTASSEMBLY:<filename>] Filename of the output assembly to generate. (Default = 'Cached_'+orig. in the same dir.) [/PREFIX:<prefixString>] Specifies the prefix for the new namespace. (Default = 'Cached_') [/DERIVED] Cache derived / inherited methods and properties [/VERBOSE] Produces Verbose Output. [/NOLOGO] Supresses the logo
To select what methods to cache, use either:
or
The following options are available:
The first parameter is required. This specifies which assembly to cache. For example, if we have an Assembly called MyStockTicker.DLL, the following could be used:
A path to the DLL can also be specified. (The cached proxy will be saved in the same directory as the original assembly).
The ACGEN tool ships with a simple cache that uses a hash table and queue to store values.
If a custom caching algorithm is required, a custom assembly can be referenced using the /CACHEAPI parameter. (Note: To work correctly, the custom assembly must implement a strictly defined interface—this is detailed in the next section).
By default, if no value is passed with the CACHEAPI parameter, the ACGEN tool will look for a Caching API in a DLL called CacheAPI.DLL in the same directory as the tool.
Alternative locations for the Caching .dll can be specified by path:
This Caching API should also be accessible to the calling client application (you will notice in the source code example we have a reference to CacheAPI defined in the project file). A future extension of the tool could be to place this CacheAPI assembly in the GAC (Global Assembly Cache), making it a shared assembly.
This parameter specifies the name of the assembly to generate. If an output assembly name is not specified, the tool appends a Cached_ prefix before the name.
For example:
will produce a cached assembly called Cached_MyStockTicker.dll
will produce a cached assembly called MyNewStockTicker.dll
The /PREFIX parameter specifies the prefix for the namespace of the generated assembly. The default is 'Cached_'. For example, if the namespace of the original assembly is 'MyStockTickerFunctions', then the new namespace name will be 'Cached_MyStockTickerFunctions', unless specified with this parameter.
Using a different namespace prefix allows both the cached and non-cached methods to be used in the same calling application.
If the original assembly type derives from a class and the /DERIVED parameter is specified, then the derived methods will also be cached.
The /VERBOSE parameter produces verbose output used for troubleshooting.
The /NOLOGO parameter suppresses the logo/banner.
Specifying Which Methods in the Original Assembly to Cache
One of the design goals of the solution is to give the developer the ability to specify which methods in the assembly should and should not be cached, and how long to retain the results in cache.
Additional parameters can be used from the command line to specify these methods. If none of the following options are specified, then all methods that return a value in the original assembly will be cached, with a default TTL of 10000ms.
Specifies the TTL (Time To Live) value in milliseconds for the cached assembly.
or
Allows methods in the original assembly to be included/excluded as deemed necessary. For example, if only certain methods in our example should be cached, the following could be used:
If however, all of the methods should be cached with the exception of only a few, the exclude method can be used:
Multiple methods must be divided by a comma with no spaces, and should include the class name (if multiple classes are present in the assembly). If methods specified after include or exclude parameter cannot be found in the original assembly, they will be ignored.
Specifying the CachedAttribute Attribute in the Original Assembly
The /ATTRIBUTED parameter can be used to signify that only methods in the original assembly that have been marked with the [CacheAPI.CachedAttribute] attribute will be cached.
For scenarios where the source code of the original assembly is available, the CacheAPI class provides an Attribute class called [CachedAttribute]. To use this on methods within the original assembly, simple add a reference to the CacheAPI class, and prefix each method that needs to be cached with this attribute.
For example:
specifies that the GetQuote Method will be cached when the /ATTRIBUTED parameter is supplied.
The CachedAttribute also allows the TTL (in ms) to be specified on a method by method basis :
To specify the TTL for each method, simply place the value as the first parameter of the attribute. As with the command line option, tf the [CachedAttribute] attribute is applied without a TTL value, a value of 10000 is used by default.
Referencing the Cached Assembly from your Application
Referencing the cached assembly in Visual Studio .NET is simply a case of adding the reference in to the client project in Solution Explorer (by right-clicking the References folder within the project and clicking Add Reference).
Once we have added the reference, we simply need to change the namespace of the assembly to the cached equivalent. For example:
We simply replace the reference to the MyStockTicker namespace with the cached version:
We recompile, run the client application, and methods within the MyStockTicker class are now cached based on our settings.
Caching a Web Service
The ACGEN tool can also be used to cache output from Web Services. Unlike the Microsoft ASP.NET OutputCache, this caching is performed on the client instead of the server. This offers the benefit of returning the result from the cache to the client application without having to make a call over the network.
To do this, we need to generate a Web Service proxy DLL before running the ACGEN utility.
From the command line, wsdl.exe (a tool that comes as part of the .NET Framework SDK) can be used to generate such an assembly. Wsdl.exe takes a parameter that must specify the URL of the Web Service.
For example:
Once we have the proxy representation of the Web Service, we can simply compile from the command line to generate the actual DLL:
If we now look in the same directory, we have a Service1.dll. This .dll can be run against the ACGEN tool to create a cached version:
To reference the cached Web Service from within the Visual Studio .NET IDE, it is now just a case of adding a reference to the cached DLL generated by the ACGEN tool. This new reference replaces the existing Web Reference to the Web Service.
How the ACGEN Tool Works
The previous section covered the tool itself and how to use it to cache one or more methods in an assembly. We are now going to look at the mechanics of the tool and how it is able to generate the cached proxy.
The tool uses a number of steps to examine the original assembly, produce a second assembly (the cached proxy), and insert MSIL (MS Intermediate Language) using Reflection Emit. We will cover these steps in some detail.
Examining the Original Assembly
Using reflection, the ACGEN tool starts by reading the namespace, types, constructors and methods within the original assembly. During the process of reading these details, a second assembly (the cached proxy) is created.
Figure 1. The cached proxy is created by the ACGEN tool
To keep the proxy unique, the second assembly's output DLL name and namespace are prefixed with 'Cached_' (as outlined in the previous section, the tool allows this to be changed).
This allows the end user to reference both the regular and cached versions of the assembly from within Visual Studio .NET, if so desired. It was anticipated that there may be situations where method calls would require caching to be 'turned on and off' in the same application. By renaming the namespace and DLL, we can call both assemblies from the same calling application to achieve this.
If we look at the code required to create the cached proxy, we can observe the following:
First, we create an assembly name for the cached proxy. With the current AppDomain referenced, we call the DefineDynamicAssembly method to create an assembly using Reflection Emit. Passed to this method are the name of the assembly, and a constant value to indicate we wish to save this output to disk (instead of running the code on the fly).
Once the framework of the assembly has been created, we then need to start iterating through the types in the original assembly. For each type that we find in the original assembly, we create a new type with the same name in the cached proxy.
Creating a New Type in the Cached Proxy
To create a new type in the cached proxy, we use TypeBuilder within Reflection Emit. Using the DefineType method we can create a new type by supplying the name and protection level.
When we create a new type we also create two additional field values within the type. These are used as references. One is a reference to the original assembly, the other is a reference to the Cache API. Within Reflection Emit we have access to a FieldBuilder that allows us to create fields on the fly.
If we use ILDASM (The MSIL Disassembler) to investigate the Cached_MyStockTicker.dll, we will see the following output:
As shown in the above output, the namespace (Cached_MyStockTicker) has been created with a public class called Service.
Within this class, the MyStockTicker.Service field will be used to reference the original assembly of type MyStockTicker. The CacheAPI.Engine field will be used to reference the Caching API.
Writing the Constructor for the New Cached Type
We are now starting to build up the 'skeletal' new assembly that contains the definition for the new cached type. We now need to start populating this assembly with code. The first part of code to write is the constructor for the new type.
The new constructor must initialize the two fields that we created (that reference the original assembly and the CacheAPI) and make a call to the super constructor (i.e. the constructor of the original assembly).
To do this, we first iterate through all of the constructors in the type (remember that a type can have more than one constructor based on the parameters passed!). For each constructor found in the original type, we use the ConstructorBuilder in Reflection Emit to create a replica constructor in our own cached proxy:
To generate the code to initialize the two fields and to call the super constructor of the original assembly, we need to firstly get an IL generator for the constructor and then Emit the IL we require. To obtain the IL generator, we can call the GetILGenerator method from the constructor itself.
We then have to initialize the first field in the constructor (this is the reference to the type in the original assembly).
You'll notice that we are calling the constructor in the original assembly with the same parameters that the cached constructor was called with (ctorParams was extracted when we examined the original assembly). This is important, for if the cached assembly is created with parameters in the constructor, we want to create a reference to the original that matches it.
The following code is used to create the reference to the CacheAPI (we refer to it as the Cache Engine in the code) and to call the super constructor of the original assembly.
constructorIL.Emit(OpCodes.Ldarg_0); constructorIL.Emit(OpCodes.Newobj, cacheEngineAssemblyType.GetConstructor(new Type[0])); constructorIL.Emit(OpCodes.Stfld,cacheEngine); constructorIL.Emit(OpCodes.Ldarg_0); ConstructorInfo superConstructor = typeof(Object).GetConstructor(new Type[0]); constructorIL.Emit(OpCodes.Call,superConstructor);
Using this code produces the following IL:
.method public specialname rtspecialname instance void .ctor() cil managed { // Code size 29 (0x1d) .maxstack 2 IL_0000: ldarg.0 IL_0001: newobj instance void [MyStockTicker]MyStockTicker.Service::.ctor() IL_0006: stfld class [MyStockTicker]MyStockTicker.Service Cached_MyStockTicker.Service::MyStockTicker IL_000b: ldarg.0 IL_000c: newobj instance void [CACHEAPI]CacheAPI.Engine::.ctor() IL_0011: stfld class [CACHEAPI]CacheAPI.Engine Cached_MyStockTicker.Service::cacheEngine IL_0016: ldarg.0 IL_0017: call instance void [mscorlib]System.Object::.ctor() IL_001c: ret } // end of method Service::.ctor
As can be shown, both fields are initialized in the constructor of the new type. If we were to compare this to similar commands in C#, this initialization would be similar to:
At this point, we now have an assembly declared with types and all of the constructors that these types require. We now need to investigate the methods themselves and create equivalents within the cached proxy using Reflection Emit.
Writing the Methods in the Cached Proxy
Before we look at the code, it is important to understand the logic of each method that we are going to be writing in the cached proxy.
What we will do is create a method in the cached proxy (keeping the same name) for each of the methods in the original assembly. As can be shown in our diagram below, a duplicate GetQuote method will be created using Reflection Emit.
After this is created, we will then populate this method with three steps (in IL) that do the following:
- Try the cache to see if it has a return result for the method, based on the parameters passed.
- If the cache does not have a return result (an exception will be thrown to determine this), a call will be made to the original method.
- The result from the original method will be stored in the cache and return to the calling application.
Figure 2. The schematic for the ''GetQuote' method in the cached proxy
Where (and What) is the Cache ?
The initial thinking behind the design of the tool was to include all of the caching code required. It was thought that this code could be emitted using Reflection.Emit in the same way that the other parts of the assembly were being generated.
After a number of prototypes it became clear that any caching code that was included would not be flexible enough to meet the needs of every problem. For example, some requirements may dictate that the cache is stored in memory to provide a fast, temporary store—others may require that the cache is stored in a more permanent, shared location on a central server. We could never predict every scenario.
To overcome this, we define an interface that could be implemented by anyone. This interface includes the GetFromCache and StoreToCache methods shown in the above diagram, along with the CacheException that is thrown if a value cannot be retrieved from cache. The actual interface is defined as follows:
The GetFromCache call accepts a key (of type String) and must return an object that relates to that key. If no object is available in the cache, a CacheEngineException must be thrown. This exception will instruct the wrapped assembly to make a method call to the original.
Once this call has been made, the result is passed to StoreToCache. StoreToCache accepts a key (to store the result under), the result itself (which is passed as an object) and a TTL (Time To Live) value for this object. Most caches are designed to dispose of old data after a certain period of time—the TTL value allows for this.
Now that we have this interface defined, we can see how the try/catch block fits in:
Figure 3. The schematic for the ''GetQuote' method in the cached proxy showing the call to the Cache
When the method in the cached proxy assembly is called, it first tries to get the result for that method by asking the cache. If no result is found, a call is made to the original method with the same parameters. The result of this call is stored in the cache, and then passed back to the calling application.
Specifying the Key for the Cache
We now have a cache to call, but we need a unique key with which to reference each method.
It was decided that the following items should make up the key for the cache:
- Strong name of the original assembly
- Return type of the method
- Method name
- Hash code for each passed parameter
The hash code is important if variable names are passed instead of values. For example, when a method is called we can differentiate between:
GetQuote("MSFT") and
GetQuote("MYCO")
but we cannot so easily differentiate between
GetQuote(x) and
GetQuote(x)
as the values of x may have changed between calls. To overcome this, a hash code is generated for the values of x and is used instead of the values.
Note The GetHashCode algorithm supplied in .NET doesn't necessarily guarantee uniqueness between values—this was understood, and it was decided that the system was unique enough for our tool. If we were concerned about the uniqueness of this value, we could look at an algorithm which produced a more unique signature for each value.
For our example, a key could look as follows:
The key is made up from the strong name, the return type of the method, the fully qualified method name, and the hash code of the parameters passed (for the example, we're assuming that the text "MSFT" generates a hash code of 2088827544!).
Generating the Cache Key in IL
Now that we have a format for the key, we need emit the IL to construct the key for this method, and the method itself.
We start by creating the method itself:
As with the constructor, we use the ILGenerator to start emitting IL to the cached proxy:
We then declare a number of local variables that are going to be used. The first local is used for building up the cache key itself, the second and third are used to store the object returned from the cache and the original assembly respectively. The fourth is used for storing the hash code for each of the parameters, and the fifth is used for a string representation of this value.
We can build up the first part of the Cache Key (known in the code as cachedMethodID) as follows:
For our example, this would give us the following in IL:
.method public instance float64 GetQuote(string A_1) cil managed { // Code size 157 (0x9d) .maxstack 8 .locals init (string V_0, object V_1, float64 V_2, int32 V_3, string V_4) IL_0000: ldstr "MyStockTicker, Version=1.0.766.37543, Culture=neut" + "ral, PublicKeyToken=null System.Double Service.GetQuote(" IL_0005: stloc.0
This gives us the first part of the key.
Obviously, the values of the parameters passed to this method are not going to be known until runtime—therefore we can't specify them when we are emitting the assembly. However we do know how many values are being passed to this method (in our GetQuote example, we only have one).
Therefore, we iterate through the parameters at runtime, get the values passed, generate the hash code for these values and append the values to the Cache Key.
For each parameter, we call a block of IL code to add the hash code to the key. This is emitted with the following block of code:
outputIL.Emit(OpCodes.Ldloc_0); outputIL.Emit(OpCodes.Ldarg_S,b); outputIL.Emit(OpCodes.Callvirt, typeof(System.Object).GetMethod("GetHashCode")); outputIL.Emit(OpCodes.Stloc_3); outputIL.Emit(OpCodes.Ldloca_S,3); outputIL.Emit(OpCodes.Callvirt, typeof(System.Int32).GetMethod("ToString",new Type[]{})); outputIL.Emit(OpCodes.Stloc_S,4); outputIL.Emit(OpCodes.Ldloc_S,4); outputIL.Emit(OpCodes.Call,typeof(System.String).GetMethod("Concat", new Type[]{typeof(String),typeof(String)})); outputIL.Emit(OpCodes.Stloc_0);
The above code loads the current Cache Key string (ldloc_0) and the n'th argument that has been passed (we are iterating through the parameters—this is part of a for loop) and generates a hash code for this parameter. This has code is stored into the third local, and a ToString method stores a string representation of it into the fourth. This string representation is then concatenated with the original value that was loaded at the start.
After each of the values a comma is added to break up the parameters in the cache key. If the final parameter is being dealt with, a closed bracket is added instead. If we were to look at the IL generated by these Reflection Emit statements, we would see the following:
IL_0006: ldloc.0 IL_0007: ldarg.s A_1 IL_000c: callvirt instance string [mscorlib]System.Object::ToString() IL_0011: call string [mscorlib]System.String::Concat(string, string) IL_0016: stloc.0 IL_0017: ldloc.0 IL_0018: ldarg.s A_1 IL_001d: callvirt instance int32 [mscorlib]System.Object::GetHashCode() IL_0022: stloc.3 IL_0023: ldloca.s V_3 IL_0028: callvirt instance string [mscorlib]System.Int32::ToString() IL_002d: stloc.s V_4 IL_0032: ldloc.s V_4 IL_0037: call string [mscorlib]System.String::Concat(string, string) IL_003c: stloc.0 IL_003d: ldloc.0 IL_003e: ldstr ")" IL_0043: callvirt instance string [mscorlib]System.Object::ToString() IL_0048: call string [mscorlib]System.String::Concat(string, string) IL_004d: stloc.0
To summarize, we wrote the IL to first load the strong name, return type and method name in to the key—then iterate through each of the parameters passed to the method, appending the hash code value of each to the key as required.
This gives us the unique key that is critical to making the cache work.
Calling the Caching API
We now have a unique key for the method being generated and the parameters that it has been called with. We now need to call the caching API with this key.
To do this in IL, we start by defining the required try block. This is done with the BeginExceptionBlock method:
We now need to call the GetFromCache method in the Cache API. We use the private field reference to the CacheAPI (defined in the type) to call this:
As shown above, we have used the OpCodes.Callvirt opcode in order to call the required method. Before we store the result in the local we need to do two operations.
The GetFromCache method returns a value of type System.Object—before we can store this in a local register of type System.Double we must first convert it. We use the UnBox OpCode to first convert the value type. We then make a call to a ConvertType function (which is listed at the bottom of the acgenengine.cs source code). This function makes sure it is in the correct format on the evaluation stack.
Once this is complete, we can use the OpCode.Stloc_2 command to store the value in the local register.
If we look at the IL generated for the above commands, we get the following:
.try { IL_004e: ldarg.0 IL_004f: ldfld class [CacheAPI]CacheAPI.Engine Cached_MyStockTicker.Service::cacheEngine IL_0054: ldloc.0 IL_0055: callvirt instance object [CacheAPI]CacheAPI.Engine::GetFromCache(string) IL_005a: unbox [mscorlib]System.Double IL_005f: ldind.r8 IL_0060: stloc.2 IL_0061: leave IL_0099 } // end .try
The end .try IL output is automatically generated when we start outputting the catch block using Reflection Emit.
The Catch Block
The code in the catch block is executed if no matching value was found in the cache (i.e. a cache miss occurred). This code needs to do two operations—call the method in the original assembly (with of course the same parameter values as were passed to this method) and store this value in the cache before returning.
The call to the method in the original assembly is constructed using a similar process to when we generated the key for the cache. We know how many parameters to pass, but we don't know the values of these parameters until runtime.
The BeginCatchBlock method is used to start the catch.
We then iterate through the parameters required to call the original method and load them from locals within IL.
Once these are loaded, we then make the call to the original assembly, and store the result returned in the defined local for later use.
These commands produce IL that looks similar to the following:
We now have the result after calling the method in the original assembly.
Before returning the value to the caller, we need to store this result in the cache for possible use later. We need to make a call to the StoreToCache method in the CacheAPI.
To start, we load the reference to the cache engine, and the two of the locals we require to pass to the StoreToCache method—the first local is the Cache Key, the second is the actual object itself (that was returned from the above call to the original assembly).
Before we pass the value to the StoreToCache method, we need to box it (makes a copy of the value type for use in the object). To achieve this in the code sample, we use another function that emits the correct box command based on the type of the value.
We then need to load the TTL value (this is calculated based on what was passed to the tool)—and convert it to an Int64 value (The StoreToCache interface defines that the TTL has to be an Int64 value type).
We are now ready to call the StoreToCache method. This is done with the following Callvirt IL command:
…and the catch block can be finalized.
If we were to look at the IL generated, we should see something similar to:
IL_0078: ldarg.0 IL_0079: ldfld class [CacheAPI]CacheAPI.Engine Cached_MyStockTicker.Service::cacheEngine IL_007e: ldloc.0 IL_007f: ldloc.2 IL_0080: box [mscorlib]System.Double IL_0085: ldc.i4 0x2710 IL_008a: nop IL_008b: nop IL_008c: nop IL_008d: nop IL_008e: conv.i8 IL_008f: callvirt instance void [CacheAPI]CacheAPI.Engine::StoreToCache(string, object, int64) IL_0094: leave IL_0099 } // end handler
Once the StoreToCache method has been called, we can exit the catch block. All we need to do now is to return the value to the caller. We use the following code to clean up and return the value to the calling application.
This produces the following IL to end the method we have created in the cached proxy:
Once all methods and types have been iterated, we 'bake' the assembly with the CreateType method:
We can then save the assembly to disk and exit the tool.
Conclusion
Small Extract
This article shows only a small portion of the code of the ACGEN tool, specifically the parts that use Reflection Emit. The source code for the ACGEN tool makes use of several parts of the .NET Framework, which can be examined offline.
Using Reflection Emit as a Solution for Similar Problems
The main purpose of this article is to introduce some of the functionality provided by the Reflection Emit namespace in .NET.
One of the key success factors of this tool is the ability to abstract the actual caching algorithms from the code that performs the Reflection Emit/IL output. A developer can write a completely alternative caching algorithm, and providing it exposes the same interface, it will work with no problems.
This leads to thoughts about other uses of the application, effectively using Reflection Emit to 'intercept' method calls in other assemblies. This could be a powerful tool. A few examples of this might include: making a call to an API that monitors time taken to run a particular piece of code (i.e. a profiling utility); an extension of this could be to log each method call to provide a detailed overview of methods called, and parameters that were passed. The number of methods called by our client application could be compared to the total number of methods in a particular assembly—giving a 'coverage analysis' for testing purposes.
This article and its caching example offer insight into the uses of Reflection and Reflection Emit to help you create your own powerful and flexible applications in .NET.
|
https://msdn.microsoft.com/en-us/library/ms973916.aspx
|
CC-MAIN-2018-51
|
refinedweb
| 6,304
| 63.29
|
Composite two images according to a mask image with Python, Pillow
In the
Image module of the image processing library Pillow (PIL) of Python,
composite() for compositing two images according to a mask image is provided.
Here, the following contents will be described.
- Parameters of
Image.composite()
- Sample code of
Image.composite()
- Composite the whole area at a uniform rate
- Create mask image by drawing
- Use existing image as mask image
Please refer to the following post for the installation and basic usage of Pillow (PIL).
Note that
composite() is a function to composite two images of the same size. Use the
paste() to composite images of different sizes.
paste() allows you to mask a small image and paste it anywhere on the large image.
Image composition is possible with OpenCV and NumPy instead of Pillow. See the article below.
Parameters of Image.composite()
There are three parameers for
composite(). All three must be
Image objects, all of the same size.
image1, image2
Two images to composite.
mask
Mask image.
mode must be one of the following three types.
1: 1 bit image (binary image)
L: 8-bit grayscale image
RGBA: Image with alpha channel
image1 and
image2 are alpha-blended according to the value of
mask.
# For 1bit result = mask * image1 + (1 - mask) * image2 # For 8bit result = mask / 255 * image1 + (1 - mask / 255 ) * image2
Ssmple code of Image.composite()
Import
Image from
PIL and load images.
ImageDraw and
ImageFilter are used when drawing a figure and creating a mask image. When reading an image file and using it as a mask image, they may be omitted.
from PIL import Image, ImageDraw, ImageFilter im1 = Image.open('data/src/lena.jpg') im2 = Image.open('data/src/rocket.jpg').resize(im1.size)
This time, the second image is reduced by
resize() to match the size. If you cut out part of the image and adjust the size, use
crop(). See the post below.
Composite the whole area at a uniform rate
When a solid image is used as a mask image, the entire image is composited at a uniform ratio.
As an example, create a solid image with a value of 128 with
Image.new() and use it as a mask image.
mask = Image.new("L", im1.size, 128) im = Image.composite(im1, im2, mask) # im = Image.blend(im1, im2, 0.5)
blend() method can also be used if you want to composite the entire surface at a uniform ratio. Specify a constant of
0.0 to
1.0 as the parameter
alpha instead of
mask.
Create mask image by drawing
If you want to mask and composite with simple shape such as circle and rectangle, drawing with
ImageDraw module is convenient. For details on drawing, see the following post. You can also draw polygons.
Draw a white circle on a black background to create a mask image.
mask = Image.new("L", im1.size, 0) draw = ImageDraw.Draw(mask) draw.ellipse((140, 50, 260, 170), fill=255) im = Image.composite(im1, im2, mask)
The boundaries can be composited smoothly by blurring the mask image with
ImageFilter.
mask_blur = mask.filter(ImageFilter.GaussianBlur(10)) im = Image.composite(im1, im2, mask_blur)
Use existing image as mask image
An existing image can be read and used as a mask image. It makes possible to composite in complex = Image.open('data/src/horse.png').convert('L').resize(im1.size) im = Image.composite(im1, im2, mask)
If you want to reverse the black and white of the mask image, please refer to the following post.
As another example, it is composited so as to gradually change spatially using the gradation image. The gradation image was generated using NumPy.
mask = Image.open('data/src/gradation_h.jpg').convert('L').resize(im1.size) im = Image.composite(im1, im2, mask)
|
https://note.nkmk.me/en/python-pillow-composite/
|
CC-MAIN-2020-40
|
refinedweb
| 628
| 60.61
|
0
First time using void functions. Apologies again for the noobish thread.
I have a few questions on this problem.
1) Since the variables miles, gallons and milesPerGallon are used in both main and void, do I need to initialize them in each place? Or if they're initialized in main do I need to initialize them in void as well?
2) I'm not passing any arguments to the void, but rather expecting void to return two values to main. How do I set up the void prototype and the actual function call?
The professor wants us to fill in the prototype and documentation, fill in the code to invoke to void function, and fill in the void function heading, documentation, and actual prompts and read-ins of miles and gallons.
#include <iostream> #include <iomanip> using namespace std; void GetMnG (float, float); // This function asks user to input two real numbers, miles and gallons. it then calculates milesPerGallon and displays it to the page int main () { float miles = 0; float gallons = 0; float milesPerGallon = 0; void GetMnG (); cout << fixed << showpoint; cout << setw(10) << miles << setw(10) << gallons << setw(10) << milesPerGallon << endl; return 0; } //***************************************************** void GetMnG () { // Precondition: This function requires two real number inputs, miles and gallons // Post Condition: This function feeds back the two numbers to main, which calculates and displays miles ped gallon float miles = 0; float gallons = 0; float milesPerGallon = 0; cout << "Input miles as a real number and enter" << endl; cin >> miles; cout << "Input gallons as a real number and enter" << endl; cin >> gallons; milesPerGallon = miles / gallons; }
Edited by PTRMAN1: n/a
|
https://www.daniweb.com/programming/software-development/threads/275602/void-functions
|
CC-MAIN-2018-43
|
refinedweb
| 266
| 62.11
|
Re: Solution for sorting an array alpha-numerically
- From: "Nick Malik [Microsoft]" <nickmalik@xxxxxxxxxxxxxxxxxx>
- Date: Fri, 15 Jul 2005 08:16:18 -0700
Thank you for the clarification, Lacey.
I admit that I had not seen the distinction that you are drawing, and I
appreciate the effort you put into describing it. I personally have not run
into this problem, but, by the effort you have gone to describe an answer,
it is clearly important for the applications that you create. I defer to
you on those requirements.
I suppose I would have solved the problems you describe by breaking the
strings up into groups and sorting the groups seperately, which is not
necessarily a better solution. For the kinds of data you are seeing, you
have a good answer.
I do not know if this kind of sorting is specifically "on the plate" for
anyone. If you'd like to see Microsoft implement any feature, I suggest
that you send that description to the MSWish@xxxxxxxxxxxxx e-mail address.
(perhaps package up your code and the solution below and send it in). You
could also submit an article to a developer magazine to describe your
problem and solution, or create a small project in GotDotNet.com to share
the code. These techniques make it easier for folks to find and reuse your
code than posting on a newsgroup.
Thanks again,
--
---:CE9856AA-F8E2-42DB-8387-03C6D7DD59C3@xxxxxxxxxxxxxxxx
> Hi Nick,
>
> You and I are on two different topics. You are talking about lexographic
> sorting (like a dictionary) and I am talking about alphanumeric sorting.
> .NET Framework does not support alphanumeric sorting. (I'll prove it.
> Keep
> breathing, Nick! Grab some coffee!)
>
> Let's start with a definition for "alphanumeric sort": a re-ordering of
> data
> so that numeric and alphabetic data sort as seperate groups. This is
> unlike
> a "lexicographic sort" which re-orders data like a dictionary.
>
> I looked through the articles you suggested. In all the examples, the
> author either:
> 1. Compared strings that are completely numeric (for example: (int)"11"
> compared to (int)"2")
> 2. Compared strings that are completely alphabetic (for example: "John"
> compared to "Adam")
> 3. Or, displayed the same problem I solved:
> (See how
> "dgExample2.aspx" is listed after "dgExample19.aspx"?)
>
> None of these articles address the problem of alphanumeric sorting with
> mixed strings like "22Beers" versus "3Beers".
>
> For example, try this with the CompareTo method you suggested:
> int intCompare = "22Beers".CompareTo("3Beers");
> PROBLEM: The result is -1, meaning that "22Beers" < "3Beers". If we are
> doing an alphabetic comparison, this is correct. But if we are doing an
> alphanumeric comparison, this is incorrect because the number 22 is not
> less
> than the number 3.
>
> Let's look at a simple example with an array:
> 1. Create a web page with three labels (lblOriginal, lblLexo, lblAlphaNum)
> 2. In the Page_Load:
> string[] arrOriginal = {"a3", "a111", "a2", "a1", "a11", "a22"};
> for (int i = 0; i < arrOriginal.Length; i++ ) lblOriginal.Text +=
> (arrOriginal[i].ToString() + "<BR>");
>
> string[] arrLexo = {"a3", "a111", "a2", "a1", "a11", "a22"};
> Array.Sort(arrLexo);
> for (int j = 0; j < arrLexo.Length; j++ ) lblLexo.Text +=
> (arrLexo[j].ToString() + "<BR>");
>
> string[] arrAlphaNum = {"a3", "a111", "a2", "a1", "a11", "a22"};
> Array.Sort(arrAlphaNum, new AlphaNumCompare());
> for (int k = 0; k < arrAlphaNum.Length; k++ ) lblAlphaNum.Text +=
> (arrAlphaNum[k].ToString() + "<BR>");
>
> 3. To the same project as the web page, add the class AlphaNumCompare()
> which implements IComparer (provided in my previous posting).
>
> Run the page, and you'll see the problem.
> My original strings:
> a3
> a111
> a2
> a1
> a11
> a22
>
> Microsoft .NET sort:
> a1
> a11
> a111
> a2
> a22
> a3
>
> Custom alphanumeric sort:
> a1
> a2
> a3
> a11
> a22
> a111
>
> See how a11 is before a2 in the Lexographic sort? This is a common
> problem
> - getting string arrays to sort alphanumerically. I found a lot of
> postings
> from programmers also looking for solutions. For example, if I have an
> array
> of chapter titles for a book, my array needs to sort as:
> 1.1 Introduction
> 2.0 Procurement
> ...
> 2.9 Department-Specific Accounting
> 2.10 Delivery Addresses
> 3.0 Forms
>
> You may want to check out this article from Microsoft which says "The .NET
> Framework supports word [culture-sensitive comparison of strings], string
> [similar to a word sort, except that there are no special cases], and
> ordinal
> sort [compares the numeric value of each character; for example, a = 65]
> rules." Note that it does not have any mention of comparing strings with
> both alphabetic and numeric character and treating these character types
> as
> seperate groups:
>)
>
> I hope Microsoft soon includes support for alphanumeric sorting of
> strings.
>
> Lacey
>
> "Nick Malik [Microsoft]" wrote:
>
>> Fascinating.
>>
>> You make the following statement:
>> > .NET does not support alphanumeric sort of arrays.
>>
>> This is simply not true. For your example, you simply have to implement
>> IComparable for your complex type, you don't need to implement a string
>> comparison. That is built in.
>>
>> In other words, you could replace the line:
>> > return CompareAlphaNum(a, b);
>>
>> with
>> return a.CompareTo(b);
>>
>> and delete the entire "CompareAlphaNum" routine.
>>
>>
>> Note that the CompareAlphaNum routine below doesn't use the same
>> collation
>> order that .Net uses. Perhaps you meant that .Net doesn't sort a capital
>> 'Z' in front of a lowercase 'a'. If that is what you meant, you are
>> right.
>> However, it is patently false to say that .Net doesn't support
>> alphanumeric
>> sorting.
>>
>> Some reference articles for you to read:
>>
>>
>>
>>
>>
>> --
>> ---:1190A7FA-8A5A-41F2-82EA-5E45D1C257AA@xxxxxxxxxxxxxxxx
>> > .NET does not support alphanumeric sort of arrays. (I hope that
>> > changes
>> > soon!) Meanwhile, here is a solution.
>> >
>> > You could use this in your listbox by sorting the items in an array and
>> > then
>> > adding the array items from 0 to length to your listbox.
>> >
>> > 1. Create a custom comparer class that implements IComparer:
>> > using System;
>> > using System.IO;
>> >
>> > namespace Test1CSharp
>> > {
>> > /// <summary>
>> > /// Lacey Orr
>> > /// 29 June 2005
>> > /// Alpha-numeric sorting solution.
>> > /// </summary>
>> >
>> > public class AlphaNumCompare : System.Collections.IComparer
>> > {
>> > public int Compare(Object a1, Object b1)
>> > {
>> > //In my case, I compared Directory objects. So I took
>> > out
>> > // the filenames / foldernames from the parameter
>> > objects and
>> > // passed those to the sort.
>> >
>> > //The string variables to compare
>> > string a = "";
>> > string b = "";
>> >
>> > //Is a1 a FileInfo?
>> > if (a1.GetType() == System.Type.GetType("FileInfo"))
>> > a = ((FileInfo)a1).Name;
>> > else
>> > a = a1.ToString();
>> >
>> > //Is b1 a FileInfo?
>> > if (b1.GetType() == System.Type.GetType("FileInfo"))
>> > b = ((FileInfo)b1).Name;
>> > else
>> > b = b1.ToString();
>> >
>> > return CompareAlphaNum(a, b);
>> > }
>> >
>> > // CompareAlphaNum: Does an alphabetic sort.
>> > private static int CompareAlphaNum (string a, string
>> > b)
>> > {
>> > //Do a quick check for empty strings. If one
>> > string
>> > is empty, then we
>> > // can get out without doing any work.
>> >
>> > if (a.Length == 0 && b.Length > 0)
>> > return -1;
>> > else if (a.Length > 0 && b.Length == 0)
>> > return 1;
>> > else if (a.Length == 0 && b.Length == 0)
>> > return 0;
>> >
>> > //The order of chars - make this however you
>> > want.
>> > string strNums = "0123456789";
>> > string strSortOrder = "
>> > .!#$%&'()*+,-/:;<=>?@[]^_{}~0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
>> >
>> > //Variables for comparing
>> > bool aSmaller = true;
>> > bool isFound = false;
>> > int intIndex = 0;
>> > // intLength determines the number of times to
>> > loop.
>> > We will loop
>> > // until we hit the end of the shorter
>> > string -
>> > a
>> > or b.
>> > int intLength = (a.Length < b.Length? a.Length:
>> > b.Length);
>> > string strNumA = "";
>> > string strNumB = "";
>> > int numA = 0;
>> > int numB = 0;
>> > int j = 0;
>> > int k = 0;
>> >
>> > //Do the compare while we are not at the end of
>> > either string and haven't found
>> > // the result.
>> > while (!isFound && intIndex < intLength)
>> > {
>> > // if we are dealing with numbers, then
>> > sort
>> > the numbers numerically
>> > if (strNums.IndexOf(a[intIndex]) > -1 &&
>> > strNums.IndexOf(b[intIndex]) > -1)
>> > {
>> > //Get all the numbers in string A
>> > until
>> > we hit a non-number
>> > j = intIndex;
>> > while (j < a.Length &&
>> > strNums.IndexOf(a[j]) > -1)
>> > {
>> > strNumA += a[j].ToString();
>> > j++;
>> > }
>> > //Get all the numbers in string B
>> > until
>> > we hit a non-number
>> > k = intIndex;
>> > while (k < b.Length &&
>> > strNums.IndexOf(b[k]) > -1)
>> > {
>> > strNumB += b[k].ToString();
>> > k++;
>> > }
>> >
>> > numA = Convert.ToInt32(strNumA);
>> > numB = Convert.ToInt32(strNumB);
>> >
>> > if (numA < numB) // a is before b in
>> > sort order; a < b
>> > return -1;
>> > else if (numA > numB) // b is before
>> > a
>> > in sort order; a > b
>> > return 1;
>> > else if (numA == numB)
>> > {
>> > //The numbers are the same.
>> > Remove the number part from the strings
>> > // and compare the
>> > remainder
>> > of
>> > the string.
>> > return
>> > CompareAlphaNum(a.Substring(strNumA.Length, a.Length-strNumA.Length),
>> > b.Substring(strNumB.Length, b.Length-strNumB.Length));
>> > }
>> > }
>> > else
>> > {
>> > if
>> > (strSortOrder.IndexOf(b[intIndex]) <
>> > strSortOrder.IndexOf(a[intIndex]))
>> > {
>> > // If string a < b in a sort,
>> > then
>> > we're done
>> > aSmaller = false;
>> > isFound = true;
>> > }
>> > else if
>> > (strSortOrder.IndexOf(b[intIndex]) > strSortOrder.IndexOf(a[intIndex]))
>> > {
>> > // If string a > b in a sort,
>> > then
>> > we're done
>> > aSmaller = true;
>> > isFound = true;
>> > }
>> > else if (( b.Length < a.Length) &&
>> > (intIndex == intLength - 1))
>> > {
>> > // If the strings are equal up
>> > to
>> > the length-th char but a is longer,
>> > // then we're done.
>> > aSmaller = false;
>> > isFound = true;
>> > }
>> > else
>> > {
>> > // Otherwise, keep sorting
>> > intIndex ++;
>> > }
>> > }
>> > }
>> >
>> > if ((a.Length == b.Length) && !isFound)
>> > return 0; //strings are the same.
>> > else if (aSmaller)
>> > return -1; // a is before b in sort order;
>> > a
>> > < b
>> > else
>> > return 1; // b is before a in sort order;
>> > ; a
>> >> b
>> > }
>> > }
>> > }
>> >
>> >
>> > 2. Use the custom class using Array.Sort(myArray, new
>> > MyCompareClass()).
>> >
>> > a. Add a new web page
>> >
>> > b. Add:
>> > using System.IO;
>> > using System.Text;
>> >
>> > c. Add a label to the form (lblDir) to display the sort
>> >
>> > d. In the page load:
>> >
>> > private void Page_Load(object sender, System.EventArgs e)
>> > {
>> > //Get files in dir
>> > String strDir = MapPath("~/./");
>> > DirectoryInfo curDir = new DirectoryInfo(strDir);
>> > FileInfo [] fiArray = curDir.GetFiles();
>> > string [] strFilenames = new string[fiArray.Length];
>> > for (int j = 0; j < fiArray.Length; j++)
>> > {
>> > strFilenames[j] = fiArray[j].Name;
>> > }
>> >
>> > // Sort files
>> > Array.Sort(strFilenames, new AlphaNumCompare());
>> >
>> > //Display files
>> > StringBuilder sbFiles = new StringBuilder();
>> > for (int k = 0; k < strFilenames.Length; k++)
>> > {
>> > sbFiles.Append(strFilenames[k] + "<BR>");
>> > }
>> > lblDir.Text = sbFiles.ToString();
>> > }
>> >
>> > Lacey
>> >
>> > "Federico G. Babelis" wrote:
>> >
>> >> Hi All:
>> >>
>> >> I have this line of code, but the syntax check in VB.NET 2003 and also
>> >> in
>> >> VB.NET 2005 Beta 2 shows as unknown:
>> >>
>> >> Dim local4 As Byte
>> >>
>> >> Fixed(local4 = AddressOf dest(offset))
>> >>
>> >> CType(local4, Short) = CType(src, Short)
>> >>
>> >> Return
>> >>
>> >> End Fixed
>> >>
>> >> What is the "FIXED and END FIXED" and how the syntax error can be
>> >> "fixed"
>> >> ???
>> >>
>> >> Thx,
>> >>
>> >> Federico
>> >>
>> >>
>> >>
>>
>>
>>
.
- References:
- New functions in .NET 2.0 ???
- From: Federico G. Babelis
- Solution for sorting an array alpha-numerically
- From: Lacey
- Re: Solution for sorting an array alpha-numerically
- From: Nick Malik [Microsoft]
- Re: Solution for sorting an array alpha-numerically
- From: Lacey
- Prev by Date: Strange Error
- Next by Date: Re: SQL Server Express
- Previous by thread: Re: Solution for sorting an array alpha-numerically
- Next by thread: Re: Solution for sorting an array alpha-numerically
- Index(es):
|
http://www.tech-archive.net/Archive/DotNet/microsoft.public.dotnet.general/2005-07/msg00784.html
|
crawl-002
|
refinedweb
| 1,769
| 59.9
|
Originally posted by Gary Farms: I can only seem to access a static variable when I put it in a static method with a static inner class. Can't they be put in non-static methods and classes? The following program generates a compile error unless I make the inner class static and the fn method static. Why? Here's the program: public class PixelOps { public static void main(String[] args) { PixelOps ec = new PixelOps(); PixelOps.Inner mc = ec.new Inner(); // PixelOps.Inner mc = new PixelOps.Inner(); mc.fn(); } public class Inner { static int result=94; public void fn() { // int result =95; System.out.println("result = " + result); } } }
Originally posted by Gregg Bolinger: I am having a problem with your problem. What I mean is, you said that you get a compile error unless you make the fn method static. Well, even that shouldn't compile. [b]Inner Classes cannot have static declarations. Now, the other rule is that non-static variables cannot be accessed from a static context. So, This would NOT be valid
public class Hello {
String hello;
public static void main(Strings[] args) {
hello = "Hello";
}
} Whereas this WOULD be valid.
public class Hello {
static String hello;
public static void main(Strings[] args) {
hello = "Hello";
}
} Why is this? Well, to be honest, I don't know the legistics as to why. But I am sure that someone smarter than me does and will tell you once they read all this. Hope that helps a little. [/B]
|
http://www.coderanch.com/t/390340/java/java/static-variables
|
CC-MAIN-2014-35
|
refinedweb
| 247
| 67.04
|
How to Install CakePHP?
Are you in love with the development of websites with PHP (an acronym for hypertext preprocessor), then a web development framework is waiting to make your life easy and now you can lay emphasis at your business logic rather than messing around with setting up all architectural logistics from scratch?
- CakePHP is that sound framework, likely to offer you more than enough, just you must do is to incorporate PHP version 7.3 favorably ( or at least PHP 5.6.0 ).
- Are you juggling up with performance issues of your existing site and looking for something which could fix the stuff right up there for you, then CakePHP carries all those characteristics and can make your web application development faster, not excessively coded i.e. no complicated XML or YAML files, just you need to set up your database and you are done.
- While developing applications the prime objective is to keep it secure along with functional requirements, CakePHP has built-in tools for input data validation, CSRF tokens are there to keep track of every request and response ( keeping them unique and less vulnerable to hacking attacks). This framework also has features like SQL injection prevention (thereby keeping your database safe) and XSS prevention (cross-site-scripting).
Pre-requisites Of CakePHP
Let’s describe certain pre-requisites which are to be satisfied to install CakePHP.
- HTTP Server ( Apache, Nginx or Microsoft IIS)
- PHP 7.3
- mbstring PHP extension
- intl PHP extension ( if using XAMPP, intl extension shall be included but make sure to uncomment extension = php_intl.dll in Php.ini and restart the XAMPP server through control panel, in case you are using WAMP, the intl extension is activated by default, just you have to do is to go to php folder and copy all files synonymous to icu*.dll and paste them to apache bin directory, then restart the services ).
- SimpleXML PHP extension
- PDO PHP extension
Any databases among given list shall be installed in your machine :
- MySQL ( v5.5.3 or greater )
- MariaDB (v 5.5 or greater)
- PostgreSQL
- SQLite3
- Microsoft SQL server ( >= version 2008)
Steps to Install CakePHP
Now the steps which are required to install CakePHP are described as follows:
Again you are reminded to likely carry PHP version greater than 5.6 ( preferably 7.3), you can check that by running command php -v
Composer Installation
This is a tool used for dependency management
Step 1: Go to for windows installation, the windows installer shall have a glance at the readme.md file present at this GIT repository
Step 2: The mac/ Linux users can run the scripts provided at and then execute the given command:
mv composer.phar /usr/local/bin/composer
Step 3: After the successful installation, you will get the response image as attached below :
So you are done with the installation part and now we can head with the project created using the CakePHP
Create a Project
Use composer’s command named as “composer create-project -prefer-dist CakePHP/app custom_application_name”
Once you do this, CakePHP will start the application structure download.
You need to make sure that the directories named as logs, tmp and their subdirectories are permitted to be written by CakePHP web server user.
Development Server
Open CakePHP’s console for running PHP’s built-in web server and you can access the application at. From the app directory, execute bin/cake server
In case there appear any conflicts with localhost or port then you can direct CakePHP to run a web server on a specific host or port, you can use following arguments to do that:
bin/cake server -H 192.168.13.37 -p 5673
Production
Production installation is also a way to setup/install CakePHP, it makes entire domain to act as single CakePHP application.
Developers using Apache should set the DocumentRoot directive for the domain to:
DocumentRoot /cake_install/webroot
Configurations to Install CakePHP
Few database configurations are required to be done here and few optional configurations too.
- Configurations are installed in the php/ini files and when the application is bootstrapped these files are loaded. One configuration file is by default incorporated in the CakePHP, you just need to add additional config files. Cake\Core\Configure is used for global configuration
- Load all of your configuration files (if they are multiple) in php ( you should have created those in config/ directory.
- Debug – It changes the CakePHP debugging output, if production mode = true then warnings and errors are shown else if it is set to false then hopefully, no errors and warning.
- Add.namespace – This is default namespace, in case you need to make the same change in the composer.json file to avoid errors.
- App.baseURL – Its presence enables Apache’s mod_rewrite with CakePHP, in case you don’t want to use this then uncomment this line and remove .htaccess files too.
- App.base – App resides in this base directory, if it is turned false then it is autodetected else one shall ensure that the string starts with / ( doesn’t end with / ).
- App.webroot – It is a web root directory
- App.wwwRoot – It is a file path to webroot.
- App.fullBaseUrl – Represents the absolute URL. By default, this is generated using $_SERVER environment
- App.imageBaseUrl – Web path to public images directory placed in the webroot.
- App.cssBaseUrl – Web path to CSS directory placed in the webroot.
- App.jsBaseUrl – Web path to js directory placed in webroot.
- App.paths – Includes the path configuration for non-class based resources, templates, plugins, locale subkeys are supported.
- Security.salt – Used for hashing, this value further which is used as HMAC salt for encryption purpose.
- Asset.timestamp – Asset URLs have a suffix containing the last modified timestamp for the particular file in the picture. It can take true, false and a string ‘force’ value, the false value stops the appending of timestamp, true appends the timestamp when debug is true and the ‘force’ argument makes compulsive to append the timestamp.
- Asset.cacheTime – This determines the HTTP header’s cache-control and expires time for assets. The default value is 1 day.
In case you need to use a CDN then App. imageBaseUrl, App.jsBaseUrl, App.cssBaseUrl shall be updated to point to CDN URI.
Recommended Articles
This has been a guide to Install CakePHP. Here we have discussed how to install CakePHP with pre-requisites and configurations respectively. You may also look at the following articles to learn more –
|
https://www.educba.com/install-cakephp/?source=leftnav
|
CC-MAIN-2020-50
|
refinedweb
| 1,075
| 52.09
|
by Redkillerbot
GitHub Readme.md
A Telegram Torrent (and youtube-dl) Leecher based on Pyrogram
✓ Telegram File mirrorring to cloud along with its unzipping, unrar and untar ✓ Drive/Teamdrive support/All other cloud services rclone.org supports ✓ Unzip ✓ Unrar ✓ Untar ✓ Custom file name ✓ Custom commands ✓ Get total size of your working cloud directory ✓ You can also upload files downloaded from /ytdl command to gdrive using `/ytdl gdrive` command. ✓ You can also deploy this on your VPS ✓ Option to select either video will be uploaded as document or streamable ✓ Added /renewme command to clear the downloads which are not deleted automatically. ✓ Added support for youtube playlist 😐 ✓
Simply clone the repository and run the main file:
git clone cd PublicLeech python3 -m venv venv . ./venv/bin/activate pip install -r requirements.txt # <Create config.py appropriately> python3 -m tobrot
from tobrot.sample_config import Config class Config(Config): TG_BOT_TOKEN = "" APP_ID = 6 API_HASH = "eb06d4abfb49dc3eeb1aeb98ae0f581e" AUTH_CHANNEL = [-1001234567890]
TG_BOT_TOKEN: Create a bot using @BotFather, and get the Telegram API token.
APP_ID
API_HASH: Get these two values from my.telegram.org/apps.
AUTH_CHANNEL: Create a Super Group in Telegram, add
@GoogleIMGBot to the group, and send /id in the chat, to get this value.
RCLONE_CONFIG: Create the rclone config using the rclone.org and read the rclone section for the next.
DESTINATION_FOLDER: Name of your folder in ur respective drive where you want to upload the files using the bot.
OWNER_ID: ID of the bot owner, He/she can be able to access bot in bot only mode too.
rclone.conffile. will look like this
[NAME] type = scope = token = client_id = client_secret =
rclone.conf
type = scope = token = client_id = client_secret = and everythin except `[NAME]`
Paste copied config in
RCLONE_CONFIG
Hit deploy button.
Examples:-
DOWNLOAD_LOCATION
MAX_FILE_SIZE
TG_MAX_FILE_SIZE
FREE_USER_MAX_FILE_SIZE
MAX_TG_SPLIT_FILE_SIZE
CHUNK_SIZE
MAX_MESSAGE_LENGTH
PROCESS_MAX_TIMEOUT
ARIA_TWO_STARTED_PORT
EDIT_SLEEP_TIME_OUT
MAX_TIME_TO_WAIT_FOR_TORRENTS_TO_START
FINISHED_PROGRESS_STR
UN_FINISHED_PROGRESS_STR
TG_OFFENSIVE_API
CUSTOM_FILE_NAME
LEECH_COMMAND
YTDL_COMMAND
TELEGRAM_LEECH_COMMAND_G
UPLOAD_AS_DOC: Takes two option True or False. If True file will be uploaded as document. This is for people who wants video files as document instead of streamable.
INDEX_LINK: (Without
/ at last of the link, otherwise u will get error) During creating index, plz fill
Default Root ID with the id of your
DESTINATION_FOLDER after creating. Otherwise index will not work properly.
/ytdl: This command should be used as reply to a supported link
/pytdl: This command will download videos from youtube playlist link and will upload to telegram.
/ytdl gdrive: This will download and upload to your cloud.
/pytdl gdrive: This download youtube playlist and upload to your cloud.
/leech: This command should be used as reply to a magnetic link, a torrent link, or a direct link. [this command will SPAM the chat and send the downloads a seperate files, if there is more than one file, in the specified torrent]
/leech archive: This command should be used as reply to a magnetic link, a torrent link, or a direct link. [This command will create a .tar.gz file of the output directory, and send the files in the chat, splited into PARTS of 1024MiB each, due to Telegram limitations]
/gleech: This command should be used as reply to a magnetic link, a torrent link, or a direct link. And this will download the files from the given link or torrent and will upload to the cloud using rclone.
/gleech archive This command will compress the folder/file and will upload to your cloud.
/leech unzip: This will unzip the .zip file and dupload to telegram.
/gleech unzip: This will unzip the .zip file and upload to cloud.
/leech unrar: This will unrar the .rar file and dupload to telegram.
/gleech unrar: This will unrar the .rar file and upload to cloud.
/leech untar: This will untar the .tar file and upload to telegram.
/gleech untar: This will untar the .tar file and upload to cloud..
/tleech: This will mirror the telegram files to ur respective cloud cloud.
/tleech unzip: This will unzip the .zip telegram file and upload to cloud.
/tleech unrar: This will unrar the .rar telegram file and upload to cloud.
/tleech untar: This will untar the .tar telegram file and upload to cloud.
/getsize: This will give you total size of your destination folder in cloud.
/renewme: This will clear the remains of downloads which are not getting deleted after upload of the file or after /cancel command.
[Only work with direct link for now]It is like u can add custom name as prefix of the original file name.
Like if your file name is
gk.txt uploaded will be what u add in
CUSTOM_FILE_NAME +
gk.txt
Only works with direct link.No magnet or torrent.
And also added custom name like...
You have to pass link as | new.txt
the file will be uploaded as
new.txt.
git clone cd TorrentLeech-Gdrive
sudo apt install python3
Install Docker by following the official docker docs
cp tobrot/g_config.py tobrot/config.py
Follow and fill all the required variables that were already filled in the sample config file, but with your details. And you can also fill all other variables according to your need and all those are explained above already.
sudo dockerd
sudo docker build . -t TorrentLeech-Gdrive
sudo docker run TorrentLeech-Gdrive
|
https://elements.heroku.com/buttons/redkillerbot/x24
|
CC-MAIN-2020-34
|
refinedweb
| 863
| 66.94
|
By Gary simon - Mar 26, 2018
There are a lot of ways to get up and running with RxJS, and frameworks like Angular already have it integrated.
For the purpose of this course, we're going to set up our own development environment where we're not going to rely on any frontend JS frameworks like Angular, React, etc., because I would prefer to keep this framework agnostic.
We will use TypeScript, but you can omit that part if you wish.
So, let's get up and running!
Be sure to Subscribe to the Official Coursetro Youtube Channel for more videos.
Open up your console and create a new project folder, then hop into it:
> mkdir rxjs && cd rxjs
We're going to use yarn for adding packages, but you can use npm as well. Run the following command to create a package.json file:
> yarn init -y
Next, we'll use yarn to add RxJS, Webpack and TypeScript:
> yarn add rxjs webpack webpack-dev-server typescript ts-loader
We need to install webpack-cli as a dev dependency:
> yarn add webpack-cli --dev
Great. Now we're ready to create some files.
Open up your preferred code editor (if you use Visual Studio Code, you can type code . in the console within the current folder and it will load up the project for you).
Open the package.json file and add the following:
{ "name": "rxjs", "version": "1.0.0", "main": "index.js", "license": "MIT", // Add this "scripts": { "start": "webpack-dev-server --mode development" },
We'll run yarn run start shortly, which will create a development server for us while we're learning RxJS.
Create a file called webpack.config.js and paste the following boilerplate code:
const path = require('path'); module.exports = { entry: './src/code.ts', devtool: 'inline-source-map', module: { rules: [ { test: /\.tsx?$/, use: 'ts-loader', exclude: /node_modules/ } ] }, resolve: { extensions: [ '.ts', '.js', '.tsx' ] }, output: { filename: 'bundle.js', path: path.resolve(__dirname, 'dist') } };
The only important part to note here is that we're defining our app's entry point to ./src/code.ts -- this is where we will be working in throughout this series. Notice the .ts extension, this is for TypeScript. If you didn't want to use TypeScript, you would just change this to a regular .js file.
Create another file called tsconfig.json and paste the following config settings:
{ "compilerOptions": { "outDir": "./dist/", "noImplicitAny": true, "module": "es6", "moduleResolution": "node", "sourceMap": true, "target": "es6", "typeRoots": [ "node_modules/@types" ], "lib": [ "es2017", "dom" ] } }
This config allows us to use es2017 JavaScript (es8) while compiling down to 2015 (es6).
Create an index.html file and paste the following contents:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http- <title>Learn RxJS with Coursetro</title> <style> body { font-family: 'Arial'; background: #ececec; } ul { list-style-type: none; padding: 20px; } li { padding: 20px; background: white; margin-bottom: 5px; } </style> </head> <body> <ul id="output"></ul> <script src="/bundle.js"></script> </body> </html>
Instead of console.logging everything while we learn RxJS, we're going to output most of the results within our unordered list #output.
I also have some basic styling as you can see.
Next, create a new folder called /src/ and inside of it, a file called code.ts with the following contents:
import * as Rx from "rxjs/Observable"; console.log(Rx);
Go to your console within the project folder and type:
> yarn run start
Visit in your browser and view the console (CTRL-SHIFT-i) and you should use > Object.
This means that RxJS is ready to go!
Now that our RxJS project is setup, we're going to start learning all about the basics going forward.
|
https://coursetro.com/posts/code/147/How-to-Install-RxJS---Setting-up-a-Development-Environment
|
CC-MAIN-2020-50
|
refinedweb
| 621
| 66.33
|
In Out key, When we passed variables as out arguments that time we initialized to the variables within the methods. It is also known as output parameter.
Ref keyword is a one-way communication while the out keyword is a two-ways communication.
Ref keyword is a one-way communication while the out keyword is a two-ways communication.
- Initialized must be inside the methods.
- Before calling the methods may be initialized or not initialized the values of the variables.
public class OutClass
{
static void Method(out int i)
{
i = 10;
}
static void Main()
{
int value;
Method(out value);
}
}
Some important notes as given below
- The ref and out keywords are treated differently at run-time but they are treated the same at compile time.
- Methods cannot be overloaded if one method takes a ref keyword and the other takes an out keyword.
You Might Also Like
|
https://www.code-sample.com/2015/04/ref-and-out-keyword-in-c.html
|
CC-MAIN-2018-34
|
refinedweb
| 147
| 64.1
|
bugprone-reserved-identifier¶
cert-dcl37-c and cert-dcl51-cpp redirect here as an alias for this check.
Checks for usages of identifiers reserved for use by the implementation.
The C and C++ standards both reserve the following names for such use:
- identifiers that begin with an underscore followed by an uppercase letter;
- identifiers in the global namespace that begin with an underscore.
The C standard additionally reserves names beginning with a double underscore, while the C++ standard strengthens this to reserve names with a double underscore occurring anywhere.
Violating the naming rules above results in undefined behavior.
namespace NS { void __f(); // name is not allowed in user code using _Int = int; // same with this #define cool__macro // also this } int _g(); // disallowed in global namespace only
The check can also be inverted, i.e. it can be configured to flag any identifier that is _not_ a reserved identifier. This mode is for use by e.g. standard library implementors, to ensure they don’t infringe on the user namespace.
This check does not (yet) check for other reserved names, e.g. macro names identical to language keywords, and names specifically reserved by language standards, e.g. C++ ‘zombie names’ and C future library directions.
This check corresponds to CERT C Coding Standard rule DCL37-C. Do not declare or define a reserved identifier as well as its C++ counterpart, DCL51-CPP. Do not declare or define a reserved identifier.
|
https://clang.llvm.org/extra/clang-tidy/checks/bugprone-reserved-identifier.html
|
CC-MAIN-2021-17
|
refinedweb
| 239
| 56.15
|
I want the commands that run a python file with console
are in an independent window
my code:
def update(self):
self.prombt("sh /usr/script/update.sh")
self.close(None)
def prombt(self, com):
self.session.open(Console,_("sTaRt ShElL cOm: %s") % (com), ["%s" % com])
You can realize this using the subprocess module.
import subprocess subprocess.call(["gnome-terminal", "-x", "sh", "/usr/script/update.sh"])
In this example I used "gnome-terminal" as my terminal emulator. On your system you may not have this emulator and you should replace it with the one you use (e.g. Konsole for KDE). You must then also find the appropriate parameter (in this case "-x") to execute the command, when opening the emulator.
|
https://codedump.io/share/wzl7puXuPai1/1/console-in-new-window
|
CC-MAIN-2017-30
|
refinedweb
| 122
| 51.75
|
Keep Your Hook Script in Source Control: Python
Keep Your Hook Script in Source Control: Python
Join the DZone community and get the full member experience.Join For Free
Commit your hook script (say pre-commit.sh) at the root of your project and include the installation instructions in your README/documentation to encourage all developers use it.
Installation is nothing more than:
ln -s ../../pre-commit.sh .git/hooks/pre-commit
Then everyone benefits from running the same set of tests before committing and updates are picked up automatically.
Stash unstaged changes before running tests
Ensure that code that isn't part of the prospective commit isn't tested within your pre-commit script. This is missed by many sample pre-commit scripts but is easily acheived with git stash:
# pre-commit.sh git stash -q --keep-index # Test prospective commit ... git stash pop -q
The -q flags specify quiet mode.
Run your test suite before each commit
Obviously.
It's best to have a script (say run_tests.sh) that encapsulates the standard arguments to your test runner so your pre-commit script doesn't fall out of date. Something like:
# pre-commit.sh git stash -q --keep-index ./run_tests.sh RESULT=$? git stash pop -q [ $RESULT -ne 0 ] && exit 1 exit 0
where a sample run_tests.sh implementation for a Django project may look like:
# run_tests.sh ./manage.py test --settings=settings_test -v 2
Skip the pre-commit hook sometimes
Be aware of the --no-verify option to git commit. This bypasses the pre-commit hook when committing, which is useful is you have just manually run your test suite and don't need to see it run again when committing.
I use a git aliases to make this easy:
# ~/.bash_aliases alias gc='git commit' alias gcv='git commit --no-verify'
Search your sourcecode for debugging code
At some point, someone will try and commit a file containing
import pdb; pdb.set_trace()
or some other debugging code. This can be easily avoided using the pre-commit.sh file to grep the staged codebase and abort the commit if forbiden strings are found.
Here's an example that looks for console.log:
FILES_PATTERN='\.(js|coffee)(\..+)?$' FORBIDDEN='console.log' git diff --cached --name-only | \ grep -E $FILES_PATTERN | \ GREP_COLOR='4;5;37;41' xargs grep --color --with-filename -n $FORBIDDEN && echo 'COMMIT REJECTED Found "$FORBIDDEN" references. Please remove them before commiting' && exit 1
It's straightforward to extend this code block to search for other terms.
Published at DZone with permission of Paul Hammant , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}{{ parent.urlSource.name }}
|
https://dzone.com/articles/keep-your-hook-script-source
|
CC-MAIN-2019-18
|
refinedweb
| 450
| 57.77
|
>> I have a PostScript file which contains the following lines (the numbers >> are for reference only and are *not* in the file): >> >> 1 << >> 2 /Policies << >> 3 /PageSize 3 >> 4 >> >> 5 >> setpagedevice >> >> I want to open the the file and read it, find these five lines and then >> replace the lines with something different. >> >> Here's some code I'm using to replace just a *single* line in the >> PostScript file (Note - I'm changing the BoundingBox which is in the >> same file, but is *not* one of the five lines above). >> >> <code> >> import fileinput >> >> class ChangeBBox: >> pass >> >> def getBBox(self, filename): >> f = open(filename, "rb") >> buffer = 1000 >> tmp = f.readlines(buffer) >> f.close() >> for line in tmp: >> if line.startswith('%%BoundingBox:'): >> return line.strip() >> >> def modifyBBox(self, filename): >> old = self.getBBox(filename) >>> for line in fileinput.input(filename, inplace=1): >> print line.replace(old, new), >> </code> > > > A few comments on the above.. > - You don't need to put these functions in a class, the class isn't > adding any value. (OK, it puts the two functions in a single namespace > but a module would be more appropriate for that.) > - The 'pass' statement is not needed. Yeah, I have the above code in its own module. I've been trying to 'clean-up' my main module (which has way too much 'stuff' going on in it) and put logical parts & pieces together in separate modules. Not sure how that pass statement got in there.. must have been from testing at some point, oops :-) > - You are adding blank lines to the file - the lines returned by > fileinput.input() contain newlines, and print adds another. Avoid this > using sys.stdout.write() instead of print. Much nicer than print! I'll change it. > - A simpler way to iterate the lines in a file is > for line in f: > > In fact the whole pre-search is really not needed, you could write this > as (untested!): > import fileinput, sys > def modifyBBox(filename): > for line in fileinput.input(filename, inplace=1): > if line.startswith('%%BoundingBox:'): > sys.stdout.write(line) Much simpler, will take a look at this. > >> Can anyone offer suggestions on how to find all five lines? I don't >> think I'll have a problem replacing the lines, it's just getting them >> all into one variable that stumping me :-) > > > OK, none of my suggestions gets you closer to this...the simplest way is > if you can read the whole file into memory. Then you can just replace > the strings in place and write it out again. For example: > > > > > f = open(filename) > data = f.read() > f.close() > data.replace(oldPolicies, newPolicies) > f = open(filename, 'w') > f.write(data) > f.close() > > Replacing the bounding box is a little trickier because you have to > search for the end of line. You can do this with a regular expression or > a couple of find() calls on the string. I'm out of time now so maybe > someone else will fill that in. I'll test out this suggestion later, unfortunately, I've gotta get to work :-( Thanks for the reply, Kent!! I really appreciate it! Bill
|
https://mail.python.org/pipermail/tutor/2005-November/043080.html
|
CC-MAIN-2016-44
|
refinedweb
| 518
| 75.3
|
hot sale high quality cherry fruit
US $2-5 / Kilogram
100 Kilograms (Min. Order)
bagged china fresh cherries price lower and high quality
US $50-70 / Box
200 Boxes (Min. Order)
hot sale high quality new crop sweet fresh cherry
US $2.5-6.9 / Kilogram
20 Kilograms (Min. Order)
Fresh cherries
1 Twenty-Foot Container (Min. Order)
Dried Cherry
8 Metric Tons (Min. Order)
Accept custom order corrugated fruit carton box for apple, cherry fresh fruit
US $0.1-0.8 / Piece
1000 Pieces (Min. Order)
Hard duty lid and bottom paper packing for 2-15kg cherry fresh fruit and vegetable on sale
US $0.33-0.65 / Piece | Buy Now
500 Pieces (Min. Order)
Recycle corrugated paper box for fresh fruit / strawberry / cherry
US $0.4-0.6 / Pieces
3000 Pieces (Min. Order)
bagged china fresh cherries high quality
US $50-70 / Box
200 Boxes (Min. Order)
hot sale high quality fresh cherry export
US $80-100 / Metric Ton
25 Metric Tons (Min. Order)
Hard duty lid and bottom carton fresh banana paper packing box for fruit and vegetable in cheap price
US $0.8-1 /)
Disposable fruit use plastic cherry container
US $0.01-0.5 / Piece
50000 Pieces (Min. Order)
2016 custom made fresh apple fruit cardboard packaging box for fruit and vegetable
US $0.38-0.78 / Piece
1000 Pieces (Min. Order)
promotion supermarket use fresh fruit tray 5 lbs for cherry with custom logo
US $0.8-0.88 / Pieces
500 Pieces (Min. Order)
250g PET Tomato plastic fruit container
US $0.05-0.1 / Piece
1 Piece (Min. Order)
Water-proof Custom Fresh Cherry Berry Baskets
US $0.05-0.07 / Piece
30000 Pieces (Min. Order)
Disposable Plastic fresh fruit tray packaging box for cherry, tomato
US $0.01-0.11 / Piece
5000 Pieces (Min. Order)
Custom logo printed fresh cherry paper packing box for 1-15kg on sale
US $0.01-1.98 / Piece
1000 Pieces (Min. Order)
PET Disposable Clamshells Deli Container HC-16 high transparency Clamshell PET cherries fresh fruit packaging box tray
US $0.01-0.1 / Cubic Meter
30 Cubic Meters (Min. Order)
popular product cherry packaging ,fruit packaging
US $0.3-5 / Piece
1 Piece (Min. Order)
Brand new china custom new style wholesale paper cherry packing boxes fruit box with low price
US $0.3-1 / Piece
1000 Pieces (Min. Order)
top quality fresh mushroom packing box with best quality and low price
US $0.01-2.5 / Piece
200 Pieces (Min. Order)
Clear plastic food disposable container / fresh cherry tomato packing or packaging boxes Sancho
US $0.02-0.03 / Piece
2000 Pieces (Min. Order)
accept custom order and blister process plastic cherry packaging
US $0.02-0.15 / Piece
10000 Pieces (Min. Order)
Storage strong waxed corrugated carton shipped fresh cherry tomato packaging boxes
US $0.01-2.99 / Piece
1000 Pieces (Min. Order)
Heavy Hold Custom Print Corrugated Fresh Fruit Cherry Tomato Packaging For Export
US $0.5-2.89 / Piece
500 Pieces (Min. Order)
Customized recycled paper pulp mold colorful cherry packaging box
US $0.45-0.5 / Pieces
50000 Pieces (Min. Order)
Wholesale template corrugated cherry fruites box carton packaging
US $0.02-5 / Piece
500 Pieces (Min. Order)
Multifunctional transparent blurberry/cherry packaging
US $0.03-0.05 / Piece
1000 Pieces (Min. Order)
corrugated paper box for fresh cherry
US $0.652-1.5 / Piece
500 Pieces (Min. Order)
OEM Solid Custom Corrugated Fresh Cherry Fruit packaging Box Production With Window
US $0.39-0.68 / Pieces
500 Pieces (Min. Order)
high transparency Clamshell PET fruit cherries fresh packaging box
US $0.05-0.055 / Piece
50000 Pieces (Min. Order)
import china products fresh cherry high quality bagged
US $25-30 / Carton
200 Cartons (Min. Order)
hot sale high quality cherry
US $80-100 / Metric Ton
25 Metric Tons (Min. Order)
- About product and suppliers:
Alibaba.com offers 1,315 fresh cherry fruit products. such as free samples. There are 1,315 295 with Other, 284 with ISO9001, and 137 with HACCP certification.
Buying Request Hub
Haven't found the right supplier yet ? Let matching verified suppliers find you. Get Quotation NowFREE
Do you want to show fresh cherry fruit or other products of your own company? Display your Products FREE now!
Supplier Features
Supplier Types
Recommendation for you
related suppliers
|
http://www.alibaba.com/countrysearch/CN/fresh-cherry-fruit.html
|
CC-MAIN-2018-09
|
refinedweb
| 721
| 70.5
|
Online:
Note: This learning guide introduces Flash video and provides you with tools for developing
your skills. The Flash product documentation is the source of many of these materials; always
consult Flash Help (also available in Flash LiveDocs) first when learning to use new features.
Flash video lets you easily put video on a web page in a format that almost anyone can view.
This guide provides an introduction to Flash video, including information on how to create and
publish Flash video.
Requirements
To follow along with this learning guide, you will need to install the following software:
Flash CS3 Professional
Try
Buy
Note: This learning guide is for Flash CS3 Professional users. Please see the previous
version of the Flash video learning guide if you are still using Flash Professional 8.
Checklist for creating Flash video
The following steps describe how to create Flash video content and publish it online. The
procedures for creating and publishing on demand (pre-recorded) video are different from
those for creating and publishing live video.
For information on live video, see the Flash Media Server Developer Center.
To create on-demand Flash video:
1. Acquire some video. Either capture it yourself with a digital video camera or obtain it
from someone else.
2. Decide on a delivery mechanism. See Delivery options for Flash video.
3. Encode the video in the Flash video (FLV) format. See Capturing and encoding video.
4. Add the video to your web pages, and publish the pages to the web. See Adding
Flash video to your web page.:
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Bandwidth limitations.
Complexity of authoring video for the web
The tool sets for creating interactivity, navigation control, and fusion of video with other rich
media content have not been standardized. Furthermore, the majority of video playback
clients are not pre-installed on most visitors' systems, so many visitors must pause to
download a plug-in or third-party.
For more information about video, see Overview of video standards.
About Flash video
Flash video offers technological and creative benefits that allow designers to create
immersive, rich experiences that fuse video together with data, graphics, sound, and dynamic
interactive control. The advantages of using Flash to present video online include:
Ubiquity
Since the 2002 introduction of Flash video,.
Rich, interactive, contextual video
Flash video provides immersive and interactive experiences. Because Flash treats Flash
video as simply another media type, you can layer, script, and control video content
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
contain graphics, text, and client logic (for creating video controls, for example). It can refer to
an external FLV file, and it plays in Flash Player. An FLV file contains primarily audio and
video, and it plays inside a SWF file (see Figure 1).
Figure 1. Flash video file playing inside a SWF file
About Flash video features and production tools
The following is a list of tools, features, servers, and services that you can use to create and
deliver compelling Flash video experiences.
Adobe Flash CS3 Professional video features:
Flash CS3 Professional is the primary tool used for producing the Flash video user interface:
Flash Video Import wizard: Simply choose File > Import > Import Video to import
video into Flash. The Import Video dialog guides you through converting video files to
FLV format and configuring the FLVPlayback component.
Video encoding and cue point export to XML: You can export encoding options
and cue point settings to an XML file using the Flash Video Import Wizard or the
Flash CS3 Video Encoder utility. The XML settings can be imported through the same
mechanism for consistency and ease of use across video production.
FLVPlayback component: Use this component to play external FLV files and to
connect to Flash Media Server. Flash CS3 Professional includes an ActionScript 3.0
FLVPlayback component that has been updated to the ActionScript 3.0 component
structure. The FLVPlayback from Flash Professional 8 is still available when using an
ActionScript 2.0 file.
FLVPlayback Custom UI components: Use these components as an easy way to
create your own configuration of controls for the FLVPlayback component. See the
Skinning the FLVPlayback article for more information.
FLVPlaybackCaptioning component: New to Flash CS3 Professional, this
component allows you to display synchronized captioning for the FLVPlayback
component in an ActionScript 3.0 file. See Adding video synchronization and
captioning.
New layout and sizing features: The ActionScript 3.0 FLVPlayback component
features sizing and layout improvements including external video preview, sizing
control while viewing multiple videos, and full screen mode.
Video codecs: Flash Player 7 introduced the Sorenson Spark codec. Flash Player 8
introduced the On2 VP6 codec.
Encoding options: You can now encode Flash video in three ways: through the
Flash Video Import wizard, with the stand-alone Flash 8 Video Encoder and through
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
the Flash Video QuickTime Export plug-in, which lets you encode audio and video
into the FLV file format when exporting from third-party video editing applications that
support QuickTime exporter plug-ins.
Adobe Flash CS3 Video Encoder: This stand-alone utility allows you to encode
source video into FLV format. The Flash CS3 Video Encoder is installed along with
Flash CS3 Professional.
Adobe Flash Player 9: This high-performance, lightweight runtime plays Flash video
and other Flash content.
Additional applications, servers, and video service features
In addition to Flash CS Video Streaming Service: This service from third parties uses Flash Media
Server to provide hosted streaming video with high-performance requirements and
worldwide scalability. If you can't or don't want to set up your own Flash Media
Server, you can use a hosted service.
Flash Media Encoder: Adobe's latest media encoding technology is designed to
enable technical producers to capture audio and video while streaming it live to Flash
Media Server (FMS) or the Flash Video Streaming Service (FVSS).
Adobe Dreamweaver CS3: This web design tool includes a Flash video import
mechanism to put Flash video onto a web page easily, with a more limited number of
customization or "skinning" options for the video player. Note that you must have an
encoded FLV file available before you can use it in Dreamweaver.
Adobe After Effects CS3 Professional and Premiere Pro CS3: Adobe's industry-
standard motion graphics and video production tools can export to FLV format if Flash
CS3 Professional is installed.
About Flash video delivery options
Before you can use Flash video on your site, you need to decide how to deliver the video; the
two primary options are to deliver it as a progressive download or as a streaming video. (One
important distinction to note is that FLV files download progressively by default. Use of the
Flash Media Server is required to download streaming video.)
Note: A third option is to embed video in the Flash Timeline. However, this is recommended
only for very short video clips with no audio track.
For help deciding which delivery option to use, see Table 1. Find your situation in the left
column, and then see which delivery options are recommended. If two options are marked,
then either one is recommended.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Table 1. Flash video delivery options
Embedded Progressive Streaming
Clip is under 5 seconds long X X
Clip is 5 to 30 seconds long X X
Clip is over 30 seconds long X
Low viewership expected X
Medium to high viewership expected X
Instant start X
Intellectual property protection X
Live video streams X
Variable streaming rates based on visitor's bandwidth X
SMIL usage to control file selection X
For more information about delivery options, see Delivery options for Flash video. Flash video into an HTML-based page layout.
If you need to build a more interactive experience or need to heavily customize the look and
feel of the video, you must use the video features in Flash CS3. You also need Flash CS3
Professional to encode Flash video (FLV) files.
For more information about authoring options, see Adding Flash video to your web page.
Delivery options for Flash video
There are a variety of options for delivering Adobe Flash video on your site. You must choose
a delivery option before you can add Flash video to your site.
Summary of delivery options
Flash CS3 Professional lets you deliver on demand video in any of the following ways:
Using embedded video within SWF files: See Embedding video within SWF files.
Using progressive download FLV files: See About progressive download.
Streaming video from your own Flash Media Server (formerly Flash Communication
Server) or from a hosted server using Flash Video Streaming Services
For live video, you must use streaming. For more information about live video, see
Detailed comparison of delivery options.
For more details, see Chris Hock's article, Understanding the Difference Between Progressive
Download and Streaming.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -., you must publish the entire video file. This can add significant time to the
authoring process.
For web delivery, the entire video file must be downloaded from the web server
before video playback can begin.
At runtime, the entire video file must fit into the local memory of the playback system.
After approximately 120 seconds of continuous video playback, users may
experience audio
objects in ActionScript to set the FLV file to play back, and to control the Play, Pause, Seek
(to a timecode), and Close behaviors and the buffer playback control to your Flash
project. In Flash CS3 Professional, the FLVPlayback component provides support for both
progressive download and streaming FLV files. This component is easy to "skin" or
customize, so that you can make your video player match your site design. See Dan Carr's
article, Skinning the ActionScript 3.0 FLVPlayback component, for more details.
Flash CS3 Professional also includes a set of behaviors that can be used in conjunction with
media components to create automated interactions between video sequences and slides in a
project. Note that behaviors are available in Flash CS3 if your file is set to use ActionScript
2.0. (For details on using ActionScript 2.0 and video components, see the reference guide
using the Flash Help panel. For more information on using video behaviors in Flash
Professional 8 or with an ActionScript 2.0 file in Flash CS3 Professional, see Dan Carr's
article, Controlling Flash video with the FLVPlayback behaviors.)
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -..
While using an ActionScript 2.0 file, the video begins playing as soon as the first
segment has been downloaded and cached to the local disk.
While using an ActionScript 3.0 file, the video begins playing only when enough of it
has downloaded so that it can play the FLV file from start to finish. This behavior can
be altered using ActionScript..
Note: An FLV file will always download progressively when loaded directly from the server.
The Flash Media Server is required to have the option of streaming the file.
About streaming video
The most complete, consistent, and robust delivery option is to stream video and audio files
from a server running Flash Media Server (formerly Flash Communication, including allows you.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -. an Adobe-authorized Content
Delivery Network partner.
New to the Flash Media Server realm of products is Adobe Flash Media Encoder, which is
capable integrating with plug-and-play cameras and microphones to allow you to capture
audio and video while streaming it to Flash Media Server. For more information on the
streaming video and broadcasting live video, see the Flash Media Server Developer Center.
Detailed comparison of delivery options
Table 2 provides a comparison of the characteristics of Flash video delivery techniques.
Table 2. Flash video delivery techniques
Embedded Video Progressive FLV Streaming FLV
FLV files are encoded
during export from various
By default, the Flash Video professional editing and Same as Progressive FLV. In
Import wizard encodes encoding applications addition, bandwidth detection
video using the VP6 video through the FLV QuickTime capabilities in streaming
codec for use with Flash Export plug-in, through the enable you to detect client
Player 8, and the Sorenson Flash Video Import wizard connection and feed the
Spark codec for use with in Flash Professional 8, or appropriately encoded video.
Encoding
Flash Player 7. the video files can be You can capture live video
Alternatively, FLV files encoded with the stand- feeds from client-side
(encoded elsewhere) can alone Flash Video Encoder. webcams or digital video (DV)
be imported and placed on cameras and control live
the Flash Timeline (re- encoding variables
encoding is not necessary). Note: These options programmatically.
require Flash Professional
8 or later.
SWF files contain video and
audio streams and the
Flash interface, resulting in
SWF and FLV files are kept
a single, larger file size.
File size separate resulting in a Same as Progressive FLV.
SWF files can load each
smaller SWF file size.
other, enabling you to break
up individual video clips into
multiple files.
When embedded in the
Flash Timeline, video
appears on individual
Video is played back only
keyframes and can be
Timeline at runtime. Individual
treated like any other object Same as Progressive FLV.
access keyframes are not visible
on the Stage. Ideal for
on the Flash Stage.
creating interactions based
on individual keyframes of
video.
FLV files are only
referenced at runtime.
Each time the Flash content
Publishing does not require
is published or tested the Same as Progressive FLV.
referencing the video file
entire video file is You can dynamically pull FLV
directly, and is much faster
Publishing republished. Changes to from virtual locations, such as
than the embedded video
video files require manually your SAN or the Flash Video
approach. FLV files can be
reimporting the files into the Streaming Service CDN.
updated or modified without
Flash Timeline.
changing the SWF files for
a project.
Video frame rate and SWF The FLV video file can Same as Progressive FLV.
Frame rate frame rate must be the have a different frame rate Live video capture has
same. than the SWF file, allowing programmable control over
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Table 2. Flash video delivery techniques
Embedded Video Progressive FLV Streaming FLV
for separate timings frame rate.
between video and the
other Flash content.
Video playback and control
Same as Progressive FLV.
is achieved by controlling
You can also use server-side
the SWF content's playback You can use the netStream
ActionScript to provide
on the Flash Timeline. object in ActionScript to
ActionScript additional functionality such as
Flash CS3 Professional Load, Play, Pause, and
access synchronization of streams,
provides several behaviors Seek through multiple
server-side playlists, smart
for controlling video and external FLV files.
delivery adjusted to client
audio playback while using
connection speed, and more.
an ActionScript 2.0 file.
You can use media
You can use media components (Flash MX
components (Flash MX Professional 2004 or later) of
Professional 2004 or later) the FLVPlayback component
or the FLVPlayback (Flash Professional 8 or later)
No video-specific component (Flash with video streamed from
Components
components. Professional 8 or later) to Flash Media Server or Flash
set up and display external Video Streaming Service. Also,
FLV files together with you can use Flash Media
transport controls (Play, Server communication
Pause, and Search). components for streaming live
and multiway video.
The SWF file progressively
downloads, unless you
FLV files are progressively FLV files are streamed from
embed it in a movie clip. In
downloaded, cached, and Flash Media Server, played on
that case, the entire video
Web delivery then played from the local the client's machine, and then
must be downloaded to the
disk. The entire video clip discarded from memory in a
client and loaded into
need not fit in memory. play-as-you-go method.
memory before it plays
back.
Improved performance over
embedded SWF video, with Provides the best performance
Audio and video
bigger and longer video from a web delivery
synchronization is limited
and reliable audio perspective, with optimal bit
after approximately 120
synchronization. Provides rate delivery on an as-needed
Performance seconds of video. Total file
best image quality, which is basis to as many customers as
duration is limited to
limited only by the amount necessary. Image quality
available RAM on the
of available hard drive limited to bit rates that can be
playback system.
space on the playback delivered in real time.
system.
Shorter video clips (less
Large quantities of video, very
than 1 minute) that are Longer video clips that are
long video clips, and live and
smaller (less than 320 x larger (720 x 480 and
Usage multiway streaming (such as
240), and have a lower greater) and have a higher
webcam chats and live event
frame rate (12 frames per frame rate (up to 30 fps).
broadcasts).
second (fps)).
Flash Player 7 for
Flash Player 6 and later
Sorenson Squeeze codec,
Compatibility (On2 VP6 codec requires Flash Player 6 and later.
Flash Player 8 for On2 VP6
Flash Player 8 or later.)
codec.
Capturing and encoding video
Before you can add on demand (pre-recorded) video to your web page, you must acquire the
video and encode it, which involves converting it to the Adobe Flash video (FLV) format.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -..
For some tips on capturing video, see Capturing good video .
For information on how to convert (encode) your existing video to FLV format, see the
Encoding and creating Flash video (FLV) files section below.
To capture and publish live video, use Adobe Flash Player and Macromedia Flash Media
Server (formerly Flash Communication Server). For more information, see the Flash Media
Server Developer Center. CS3 Professional includes
the Flash CS3 Video Encoder and the QuickTime Exporter.
Flash CS3 Video Encoder
The Flash CS3 Video Encoder lets you batch process video clips, allowing you to encode
several clips at a time without having to interrupt your workflow. In addition to selecting
encoding options for video and audio content, the Flash CS3 Video Encoder also lets you
embed cue points into video clips you encode, and edit the video using crop-and-trim
controls.
For more information, see the online help included with the Flash CS3 Video Encoder
application.
Note: Both the Flash Video Import wizard and the Flash CS3 Video Encoder allow you to
export encoding and cue point settings to XML files for reuse across other video production
efforts.
FLV QuickTime Export plug-in
If you have Adobe Flash CS3 Professional and Apple)
Adobe Premiere Professional (Windows)
Apple Final Cut Pro (Macintosh)
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Apple QuickTime Pro (Windows and Macintosh)
Avid Xpress DV (Windows and Macintosh)
Using the FLV QuickTime Export plug-in to export FLV files from either Flash CS3, the Flash CS3 Video Encoder exports encoded video using the On2 VP6 video
codec for use with Flash Player 8 or later, Flash SWF versions 6 or 7, and viewing the content
using Flash Player 8 or later, you avoid having to recreate your SWF files for use with Flash
Player 9.
Caution: Only Flash Player 8 or later supports both publish and playback of VP6 video.
Content (SWF) version (publish Flash Player version (required for
Codec
version) playback)
Sorenson 6 6, 7, 8, 9
Spark 7 7, 8, 9
6 8, 9
7 8, 9
On2 VP6
8 8, 9
9 9).
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -..
The greater the motion within your video clip, the more information the encoder has to
compress. If your clip is relatively still (such as a talking head video), there isn't much pixel
change from frame to frame. The video compressor uses a method of dropping frames and
then encoding a series of fully uncompressed frames. These uncompressed frames, called
keyframes,. A few of
these settings are discussed in general terms in this section; for technical details on some of
the other settings, see Overview of video standards.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
For detailed information about specific values to use for various settings, see Kevin Towes'
article, Encoding Best Practices for Prerecorded Flash Video. This article provides a table of
recommended settings..
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Adding Flash video to your web page
There are two general approaches to adding Flash video to your web pages: using
Dreamweaver and using Flash.
Before you can add video to your pages, you must decide which delivery mechanism to use:
progressive download or streaming. For more information, see Delivery options for Flash
video.
You can use Dreamweaver to quickly add video to your web page without having to use
Flash. For more advanced capabilities—such as adding interactivity, selecting from a wider
range of custom interfaces, layering video with other Flash animation, and synchronizing the
video with text and graphics—use Flash.
When you add Flash video to a page, you should also add a behavior to the page to detect for
Flash Player. In particular, you should check that any visitor trying to view the page has a
version of Flash Player that lets them view the content you're providing. For details on
detecting plug-ins, see Robert Hoekman's article, Best Practices for Flash Player Detection.
Importing Flash video into Dreamweaver
The following procedure describes how to add Flash video to a web page within
Dreamweaver. You must have an encoded Flash video (FLV) file before you begin.
To add Flash video to a web page using Dreamweaver:
1. Capture and/or encode an FLV file. For details, see Capturing and encoding video.
2. Select Insert > Media > Flash Video.
3. In the Insert Flash Video dialog box, select Progressive Download or Streaming Video
from the Video Type pop-up menu.
4. Complete the rest of the dialog box options.
You can select an option that inserts code that detects the Flash Player version required to
view the Flash video and that prompts the user to download the latest version of Flash Player
if they don't have the correct version.
For a tutorial on creating a project in Dreamweaver that includes Flash video, see Jen
deHaan's article, Presenting Video with the Flash Video Component in Dreamweaver 8.
Authoring with Flash
You can use the Flash authoring environment to build a rich interface for playing your video in
the browser.
The following procedure describes how to use components to author Flash video. You can
import a video file that is already deployed to a web server, or you can select a video file that
is stored locally on your computer, and upload the video file to the server after importing it into
your FLA file. For information on hand-coding your video controls using ActionScript, go to the
Flash LiveDocs section, "Playing back external FLV files dynamically." (Select Using Flash >
Working with video > Using ActionScript to play external Flash video > Playing back external
FLV files dynamically.)
To import video for progressive download:
1. To import the video clip into the current Flash document, select File > Import > Import
video. The Import Video wizard is displayed.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
2. Select the video clip you want to import. You can select either a video clip stored on
your local computer, or you can enter the URL of a video already uploaded to a web
server.
3. Select Progressive Download from a standard web server.
4. (Optional) If the video you are deploying is not in FLV format, the Import Video wizard
displays the Encoding panel. For information on encoding your video using the Import
Video wizard, see the Flash LiveDocs section, "Selecting a video encoding profile."
on
the server. For more information, see Dan Carr's article, Skinning the
ActionScript 3.0 FLVPlayback component, or the Flash LiveDocs section
"Creating a new skin." (Select Using ActionScript 3.0 Components > Using
the FLVPlayback Component > Customizing the FLVPlayback component >
Creating a new skin.)
The Video Import wizard will encode your source video clip into the FLV
format (if it isn't already in FLV format) and create a video component on the
Stage that you can use to test video playback locally.
6. Upload the following assets to the web server hosting your video:
o The FLV encoded video clip (which is located in the same folder as the
source video clip you selected with a .flv extension).
Note: If the video clip is in FLV format, Flash uses a relative path to point to
the FLV file (relative to the SWF), letting you use the same directory structure
locally that you use on the server
o The video skin SWF file (if you chose to use a skin).
If you choose to use a predefined skin, Flash copies the skin SWF file into the
same folder as the FLA file
o The SWF file containing the video component.
You must edit the component's URL field to that of the web server to which you are uploading
the video using the Component Inspector panel. For more information, see the Flash
LiveDocs section, "Specifying the contentPath parameter." (Select Using Flash > Working
with video > Using ActionScript to play external Flash video > Specifying the contentPath
parameter.)
Note: The contentPath parameter as described in the section above is available when using
the ActionScript 2.0 version of the FLVPlayback component. For more information on the
source parameter in the ActionScript 3.0 version, see Flash LiveDocs section, "Specifying the
source parameter." (Select Using ActionScript 3.0 Components > Using the FLVPlayback
component > FLVPlayback component parameters > Specifying the source parameter.)
To import video for streaming of Flash Video Streaming Service:
You can import a video file that is already deployed to a Flash Media Server (formerly Flash
Communication Server) or FVSS, or you can select a video file that is stored locally on your
computer, and upload the video file to the server after importing it into your FLA file.
1. To import the video clip into the current Flash document, select File > Import > Import
Video. The Import Video wizard is displayed.
2. Select the video clip you want to import. You can select either a video clip stored on
you local computer, or you can enter the URL of a video already uploaded to your
own Flash Media Server or a Flash Video Streaming Service (FVSS).
3. Select Stream from Flash Video Streaming Service (FVSS) or Stream from Flash
Media Server (formerly Flash Communication Server).
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
4. (Optional) If the video you are deploying is not in FLV format, you can use the
Encoding panel to select an encoding profile, and crop, trim and split the video clip.
Note: This step only applies if you are uploading the video from your local computer.
Video clips that are already deployed to a server must have previously been encoded
in the FLV format.
When the video you are deploying is not in FLV format, the Import Video wizard
displays the Encoding panel. For information on encoding your video using the Import
Video wizard, see "Selecting a video encoding profile" in Flash LiveDocs. SWF
file on the server.
The Video Import wizard will encode your source video clip into the FLV format (if it
isn't already in FLV format) and create a video component on the Stage that you can
use to test video playback locally.
6. Upload the following assets to the Flash Media Server or FVSS hosting your video:
o The FLV encoded video clip (which is located in the same folder as the
source video clip you selected with a .flv extension).
Note: If the video you are working with has previously been deployed to your
Flash Media Server (or Flash Communication Server) or FVSS hosting your
video, you can skip this step.
o The video skin SWF file (if you chose to use a skin).
If you choose to use a predefined skin, Flash copies the skin into the same
folder as the FLA file.
o The SWF file containing the video component
You must change the FLVPlayback component URL field to specify the web
server to which you are uploading the video.
Adding video synchronization and captioning
So far you have learned about producing Flash video and displaying it in your web page. The
next logical next step is to utilize Flash's strengths and synchronize the video with content and
caption displays in your movie. Flash CS3 Professional.0 component features for video captioning.
For detailed articles and example files on video synchronization, see the Flash video
templates page.
About video cue points
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Cue points are markers that you place in the FLV file to specify the times at which you will
synchronize content or activity. Understanding the basics of cue points will allow you to start
coordinating endless possibilities for combining video with other types of Flash content.
Three types of video cue points
There are three types of cue points; navigation, event, and ActionScript. Navigation and event
cue points are embedded directly into the FLV file during encoding. Navigation cue points are
ideal for Flash user interfaces where navigation to exact locations in the video is necessary.
The encoder forces a whole keyframe in the location where the cue point is added allowing
for accurate navigation to that point. Event cue points are also embedded during encoding
and can be used to synchronize times in the video to timed text caption files and other events.
ActionScript cue points are not embedded in FLV file—they are added at runtime via
ActionScript.
Note: Using navigation cue points embedded directly into the video is the only way to create
accurate seeking to a time in a progressively delivered video. When creating interfaces where
buttons allow the viewer to jump to specific times in the video, it is recommended that you
embed the cue points directly in the video at the time of encoding.
Creating cue points
Navigation and event cue points can be added using the Flash Video Import wizard or the
Flash CS3 Video Encoder at the time of encoding. ActionScript cue points can be added
using the FLVPlayback component's cuePoint parameter in the Property inspector while
authoring the movie or by using ActionScript at runtime.
Note: Cue points can be exported to an XML file during encoding using the Flash Video
Import wizard or the Flash CS3 Video Encoder. The saved XML file can then be imported
while working on other videos to create consistency and save time during production.
Responding to cue points
Once you have created your cue points, you have to respond to them using a bit of Flash.0 version of the FLVPlayback
component or the ActionScript 3.0 version of the component.
For documentation on handling ActionScript 2.0 video events and cue point parameters, see
the Flash LiveDocs section, "Listening for cuePoint events". (See ActionScript 2.0
Components Language Reference > FLVPlayback Component > Using cue points > Listening
for cuePoint events.)
For documentation on handling ActionScript 3.0 video events and cue point parameters, see
the Flash LiveDocs section, "Listening for cuePoint events". (See Using ActionScript 3.0
Components > Using the FLVPlayback Component > Using the FLVPlayback component >
Using cue points > Listening for cuePoint events.)
Cue point parameters
When you catch a cue point event in ActionScript, the event handler function is passed an
event object which contains information about the cue point. This is significant as you use this
information to decide what to do in response to the event.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
The following properties are contained in a cue point event object's info property:
name: The name of the cue point.
time: The time associated with the cue point.
type: The type of cue point (navigation, event, or ActionScript).
parameters: An object containing variables associated with the cue point.
Common ways to synchronize Flash video to Flash content
Once you have written the code that responds to the cue point event notifications and have
access to the cue point parameters, you are authoring in the correct timing and need to do
something. The two most common ways to synchronize to Flash content are to navigate to
frames containing frame labels that match the name of the cue point (in a timeline-based file)
or to navigate to slides named the same as the cue point names (in a screens-based file).
The key is to use the cue point name as a way to navigate to a location in Flash that contains
the content that should appear with the corresponding time in the video.
Checklist for creating video synchronized to Flash content
The following list describes common steps involved in creating a Flash file containing video
synchronized to text or graphics along the Flash Timeline.
To create a synchronized video presentation:
1. Acquire a source video and determine the points at which you want to synchronize
content.
2. Encode the video to FLV format and embed the navigation cue points at the desired
locations.
3. Create a Flash file and add keyframes at any interval along the main Timeline. Add a
keyframe for each cue point in the video and add a frame label to each keyframe that
corresponds to the name of the related cue point.
4. Place content on the keyframes where the content corresponds to the correct cue
point name (frame label).
5. Import the FLV file using the Flash Video Import wizard or the FLVPlayback
component parameters.
6. Add a cuePoint event listener to the FLVPlayback component and add the event
listener code pattern to frame 1 of the main Timeline.
7. In the event handler code, add a gotoAndStop action that targets a frame label of the
same name as the cue point parameter name.
Using the ActionScript 3.0 video captioning features
The ActionScript 3.0 version of the FLVPlayback components includes the new
FLVPlaybackCaptioning component. The FLVPlaybackCaptioning component provides an
easy way to include captioning content for accessibility or standard text captioning uses.
The ActionScript 3.0 component provides two ways to include captioning text:
1. Using a W3C standard caption XML file, called a Timed Text file.
2. Using an XML file containing event cue points with captions associated with the
parameters field of the cue point..
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
The FLVPlaybackCaptioning component contains the following features:
Captioning timing can be specified (also duration if a Timed Text file is used)
Captioning text can be formatted via the XML file definition
Captioning can be toggled on and off using the Captioning button
Captioning supports multiple language tracks
Captioning can be assigned to multiple FLVPlayback instances
For documentation on working ActionScript 3.0 FLVPlayback captioning, see the Flash
LiveDocs section, "Using the FLVPlaybackCaptioning Component". (See Using ActionScript
3.0 Components > Using the FLVPlaybackCaptioning Component.).
Neither video standard is optimal for presentation on computer monitors; each poses different
challenges when you are trying to optimize video for web delivery (summarized in Table 3):
Frame size: NTSC and PAL have different image sizes, both of which differ from the
available image sizes of computer monitors.
Frame rate: NTSC and PAL have different frame rates for the display of images, both
of which differ from those used by computer monitors.
Pixel aspect ratio: NTSC and PAL share a pixel aspect ratio (referred to as D1
Aspect Ratio, which is essentially rectangular), but this ratio is different from that used
by computer monitors (which is square).
Display: NTSC and PAL consist of two separate "interlaced" fields, while computer
monitors display "progressive" images.
Table 3. Video standard differences
Image size Frame rate Aspect ratio Display
NTSC 720 x 480 29.97 D1 Interlaced
PAL 720 x 576 25 D1 Interlaced
Varies
Computer – Square Progressive
(much larger) x 480 frame. The
difference between the D1 spec and the DV spec is only 6 vertical pixels. Many compression
algorithms, including DV compression, work best with pixel dimensions that are multiples of
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
16. By removing 6 pixels from the D1 resolution, the DV format achieved a native resolution
with a multiple of 16.
For PAL video images, frames are always 720 x 576 pixels, regardless of video source.
Because PAL's vertical resolution, 576, is a multiple of 16, no change is necessary for DV
compression.
Frame rate. There are still 30
frames, but they run 0.1 percent slower than actual time, resulting in an actual frame rate of
29.97 fps.
When working with compressed video in a format like Flash).
Pixel aspect ratio
The D1/DV NTSC and PAL specifications specify non-square pixels (often called D1 aspect
ratio), while computer monitor pixels are square. D1 pixels are vertically shorter. For this
reason, when you look at a D1 video image on a computer monitor, the images appear to be
squashed vertically—making actors appear to be shorter. When this image is displayed on a
broadcast monitor, the pixels are wider than they are tall and appear normal (see Figure 2).
Figure 2. Image displayed on a video monitor (left) and computer monitor (right)
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -. final version of the video sequence is destined to be displayed on a
square pixel monitor, and therefore should be hard-rendered to compensate for the
discrepancy.
Interlaced and progressive video
Video use progressive display (images are drawn in
one pass from top to bottom). A single group of lines is known as a field. The two fields are
referred to as the upper field and the lower field, or Field 1 and Field 2, or odd and even, or
top and bottom; unfortunately there is no standard nomenclature—all of these terms refer to
the two interlaced video fields. As a television image is displayed, the fields are drawn in rapid
succession overlapping each other (see Figure 3).
Figure 3. Interlaced video consisting of two video fields
combined together in one frame.
Therefore, to display crisp video on a computer monitor, video frames must be de-interlaced
by eliminating one of the fields. Half the information of each frame is discarded and the
remaining information doubled or interpolated. For NTSC, this results in 30 frames of 30
distinct points in time, which provides a much clearer video image (see Figure 4).
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
Figure 4. Interlaced (left) and de-interlaced (right) frame of a video still
Modern video standards for digital television have eschewed interlacing in favor of
progressive scan display techniques..
About the author
This content was authored by Adobe Systems, Inc.
InterLake GmbH, P.O.Box, D-88012 Friedrichshafen, Germany -.
|
https://www.scribd.com/document/19118406/Adobe-Flash-Video-Guide-En
|
CC-MAIN-2019-04
|
refinedweb
| 6,486
| 62.58
|
C++ is a very flexible language when it comes to formatting and writing code. It is also a strongly typed language, meaning there are rules about declaring the types of variables, which you can use to your advantage by making the compiler help you write better code. In this section, we will cover how to format C++ code and rules on declaring and scoping variables.
Other than string literals, you have free usage of white space (spaces, tabs, newlines), and are able to use as much or as little as you like. C++ statements are delimited by semicolons, so in the following code there are three statements, which will compile and run:
int i = 4; i = i / 2; std::cout << "The result is" << i << std::endl;
The entire code could be written as follows:
int i=4;i=i/2; std::cout<<"The result is "<<i<<std::endl;
There are some cases where whitespace is needed (for example, when declaring a variable you must have white space between the type and the variable name), but the convention is to be as judicious as possible to make the code readable. And while it is perfectly correct, language-wise, to put all the statements on one line (like JavaScript), it makes the code almost completely unreadable.
Note
If you are interested in some of the more creative ways of making code unreadable, have a look at the entries for the annual International Obfuscated C Code Contest (). As the progenitor of C++, many of the lessons in C shown at IOCCC apply to C++ code too.
Bear in mind that, if the code you write is viable, it may be in use for decades, which means you may have to come back to the code years after you have written it, and it means that other people will support your code, too. Making your code readable is not only a courtesy to other developers, but unreadable code is always a likely target for replacement.
Inevitably, whoever you are writing code for will dictate how you format code. Sometimes it makes sense, for example, if you use some form of preprocessing to extract code and definitions to create documentation for the code. In many cases, the style that is imposed on you is the personal preference of someone else.
Note
Visual C++ allows you to place XML comments in your code. To do this you use a three--slash comment (
///) and then compile the source file with the
/doc switch. This creates an intermediate XML file called an
xdc file with a
<doc> root element and containing all the three--slash comments. The Visual C++ documentation defines standard XML tags (for example,
<param>,
<returns> to document the parameters and return value of a function). The intermediate file is compiled to the final document XML file with the
xdcmake utility.
There are two broad styles in C++: K&R and Allman.
Kernighan and Ritchie (K&R) wrote the first, and most influential book about C (Dennis Ritchie was the author of the C language). The K&R style is used to describe the formatting style used in that book. In general, K&R places the opening brace of a code block on the same line of the last statement. If your code has nested statements (and typically, it will) then this style can get a bit confusing:
if (/* some test */) { // the test is true if (/* some other test */) { // second test is true } else { // second test is false } } else { // the test is false }
This style is typically used in Unix (and Unix-like) code.
The Allman style (named after the developer Eric Allman) places the opening brace on a new line, so the nested example looks as follows:
if (/* some test */) { // the test is true if (/* some other test */) { // second test is true } else { // second test is false } } else { // the test is false }
The Allman style is typically used by Microsoft.
Remember that your code is unlikely to be presented on paper, so the fact that K&R is more compact will save no trees. If you have the choice, you should choose the style that is the most readable; the decision of this author, for this book, is that Allman is more readable.
If you have multiple nested blocks, the indents can give you an idea of which block the code resides in. However, comments can help. In particular, if a code block has a large amount of code, it is often helpful to comment the reason for the code block. For example, in an
if statement, it is helpful to put the result of the test in the code block so you know what the variable values are in that block. It is also useful to put a comment on the closing brace of the test:
if (x < 0) { // x < 0 /* lots of code */ } // if (x < 0) else { // x >= 0 /* lots of code */ } // if (x < 0)
If you put the test as a comment on a closing brace, it means that you have a search term that you can use to find the test that resulted in the code block. The preceding lines make this commenting redundant, but when you have code blocks with many tens of lines of code, and with many levels of nesting, comments like this can be very helpful.
A statement can be a declaration of a variable, an expression that evaluates to a value, or it can be a definition of a type. A statement may also be a control structure to affect the flow of the execution through your code.
A statement ends with a semicolon. Other than that, there are few rules about how to format statements. You can even use a semicolon on its own, and this is called a null statement. A null statement does nothing, so having too many semicolons is usually benign.
An expression is a sequence of operators and operands (variables or literals) that results in some value. Consider the following:
int i; i = 6 * 7;
On the right side
6 * 7 is an expression, and the assignment (from
i on the left-hand side to the semicolon on the right) is a statement.
Every expression is either an lvalue or an rvalue. You are most likely to see these keywords used in error descriptions. In effect, an lvalue is an expression that refers to some memory location. Items on the left-hand side of an assignment must be lvalues. However, an lvalue can appear on the left- or right-hand side of an assignment. All variables are lvalues. An rvalue is a temporary item that does not exist longer than the expression that uses it; it will have a value, but cannot have a value assigned to it, so it can only exist on the right-hand side of an assignment. Literals are rvalues. The following shows a simple example of lvalues and rvalues:
int i; i = 6 * 7;
In the second line,
i is an lvalue, and the expression
6 * 7 results in an rvalue (
42). The following will not compile because there is an rvalue on the left:
6 * 7 = i;
Broadly speaking, an expression becomes a statement by when you append a semicolon. For example, the following are both statements:
42; std::sqrt(2);
The first line is an rvalue of
42, but since it is temporary it has no effect. A C++ compiler will optimize it away. The second line calls the standard library function to calculate the square root of
2. Again, the result is an rvalue and the value is not used, so the compiler will optimize this away. However, it illustrates that a function can be called without using its return value. Although it is not the case with
std::sqrt, many functions have a lasting effect other than their return value. Indeed, the whole point of a function is usually to do something, and the return value is often used merely to indicate if the function was successful; often developers assume that a function will succeed and ignore the return value.
Operators will be covered later in this chapter; however, it is useful to introduce the comma operator here. You can have a sequence of expressions separated by a comma as a single statement. For example, the following code is legal in C++:
int a = 9; int b = 4; int c; c = a + 8, b + 1;
The writer intended to type
c = a + 8 / b + 1; and
: they pressed comma instead of a
/. The intention was for
c to be assigned to 9 + 2 + 1, or 12. This code will compile and run, and the variable
c will be assigned with a value of 17 (
a + 8). The reason is that the comma separates the right-hand side of the assignment into two expressions,
a + 8 and
b + 1, and it uses the value of the first expression to assign
c. Later in this chapter, we will look at operator precedence. However, it is worth saying here that the comma has the lowest precedence and
+ has a higher precedence than
=, so the statement is executed in the order of the addition: the assignment and then the comma operator (with the result of
b + 1 thrown away).
You can change the precedence using parentheses to group expressions. For example, the mistyped code could have been as follows:
c = (a + 8, b + 1);
The result of this statement is: variable
c is assigned to 5 (or
b + 1). The reason is that with the comma operator expressions are executed from left to right so the value of the group of expressions is the tight-most one. There are some cases, for example, in the initialization or loop expression of a
for loop, where you will find the comma operator useful, but as you can see here, even used intentionally, the comma operator produces hard-to-read code.
It is useful to give basic information here. C++ is a strongly typed language, which means that you have to declare the type of the variables that you use. The reason for this is that the compiler needs to know how much memory to allocate for the variable, and it can determine this by the type of the variable. In addition, the compiler needs to know how to initialize a variable, if it has not been explicitly initialized, and to perform this initialization the compiler needs to know the type of the variable.
Note
C++11 provides the
auto keyword, which relaxes this concept of strong typing. However, the type checking of the compiler is so important that you should use type checking as much as possible.
C++ variables can be declared anywhere in your code as long as they are declared before they are used. Where you declare a variable determines how you use it (this is called the scope of the variable). In general, it is best to declare the variable as close as possible to where you will use it, and within the most restrictive scope. This prevents name clashes, where you will have to add additional information to disambiguate two or more variables.
You may, and should, give your variables descriptive names. This makes your code much more readable and easier to understand. C++ names must start with an alphabetic character, or an underscore. They can contain alphanumeric characters except spaces, but can contain underscores. So, the following are valid names:
numberOfCustomers NumberOfCustomers number_of_customers
C++ names are case-sensitive, and the first
2,048 characters are significant. You can start a variable name with an underscore, but you cannot use two underscores, nor can you use an underscore followed by a capital letter (these are reserved by C++). C++ also reserves keywords (for example,
while and
if), and clearly you cannot use type names as variable names, neither built in type names (
int,
long, and so on) nor your own custom types.
You declare a variable in a statement, ending with a semicolon. The basic syntax of declaring a variable is that you specify the type, then the name, and, optionally, any initialization of the variable.
Built-in types must be initialized before you use them:
int i; i++; // C4700 uninitialized local variable 'i' used std::cout << i;
There are essentially three ways to initialize variables. You can assign a value, you can call the type constructor (constructors for classes will be defined in Chapter 4, Classes) or you can initialize a variable using function syntax:
int i = 1; int j = int(2); int k(3);
These three are all legal C++, but stylistically the first is the better because it is more obvious: the variable is an integer, it is called
i, and it is assigned a value of 1. The third looks confusing; it looks like the declaration of a function when it is actually declaring a variable.
Chapter 4, Classes will cover classes, your own custom types. A custom type may be defined to have a default value, which means that you may decide not to initialize a variable of a custom type before using it. However, this will result in poorer performance, because the compiler will initialize the variable with the default value and subsequently your code will assign a value, resulting in an assignment being performed twice.
Each type will have a literal representation. An integer will be a numeric represented without a decimal point and, if it is a signed integer, the literal can also use the plus or minus symbol to indicate the sign. Similarly, a real number can have a literal value that contains a decimal point, and you may even use the scientific (or engineering) format including an exponent. C++ has various rules to use when specifying literals in code. Some examples of literals are shown here:
int pos = +1; int neg = -1; double micro = 1e-6; double unit = 1.; std::string name = "Richard";
Note that for the
unit variable, the compiler knows that the literal is a real number because the value has a decimal point. For integers, you can provide a hexadecimal literal in your code by prefixing the number with
0x, so
0x100 is
256 in decimal. By default, the output stream will print numeric values in base 10; however, you can insert a manipulator into an output stream to tell it to use a different number base. The default behavior is
std::dec, which means the numbers should be displayed as base 10,
std::oct means display as octal (base 8), and
std::hex means display as hexadecimal (base
16). If you prefer to see the prefix printed, then you use the stream manipulator
std::showbase (more details will be given in Chapter 5, Using the Standard Library Containers).
C++ defines some literals. For
bool, the logic type, there are
true and
false constants, where
false is zero and
true is 1. There is also the
nullptr constant, again, zero, which is used as an invalid value for any pointer type.
In some cases, you will want to provide constant values that can be used throughout your code. For example, you may decide to declare a constant for
π. You should not allow this value to be changed because it will change the underlying logic in your code. This means that you should mark the variable as being constant. When you do this, the compiler will check the use of the variable and if it is used in code that changes the value of the variable the compiler will issue an error:
const double pi = 3.1415; double radius = 5.0; double circumference = 2 * pi * radius;
In this case the symbol
pi is declared as being constant, so it cannot change. If you subsequently decide to change the constant, the compiler will issue an error:
// add more precision, generates error C3892 pi += 0.00009265359;
Once you have declared a constant, you can be assured that the compiler will make sure it remains so. You can assign a constant with an expression as follows:
#include <cmath> const double sqrtOf2 = std::sqrt(2);
In this code, a global constant called
sqrtOf2 is declared and assigned with a value using the
std::sqrt function. Since this constant is declared outside a function, it is global to the file and can be used throughout the file.
The problem with this approach is that the preprocessor does a simple replacement. With constants declared with
const, the C++ compiler will perform type checking to ensure that the constant is being used appropriately.
You can also use
const to declare a constant that will be used as a constant expression. For example, you can declare an array using the square bracket syntax (more details will be given in Chapter 2, Working with Memory, Arrays, and Pointers):
int values[5];
This declares an array of five integers on the stack and these items are accessed through the
values array variable. The
5 here is a constant expression. When you declare an array on the stack, you have to provide the compiler with a constant expression so it knows how much memory to allocate and this means the size of the array must be known at compile time. (You can allocate an array with a size known only at runtime, but this requires dynamic memory allocation, explained in Chapter 2, Working with Memory, Arrays, and Pointers.) In C++, you can declare a constant to do the following:
const int size = 5; int values[size];
Elsewhere in your code, when you access the
values array, you can use the
size constant to make sure that you do not access items past the end of the array. Since the
size variable is declared in just one place, if you need to change the size of the array at a later stage, you have just one place to make this change. The
const keyword can also be used on pointers and references (see Chapter 2, Working with Memory, Arrays, and Pointers) and on objects (see Chapter 4, Classes); often, you'll see it used on parameters to functions (see Chapter 3, Using Functions). This is used to get the compiler to help ensure that pointers, references, and objects are used appropriately, as you intended.
C++11 introduces a keyword called
constexpr. This is applied to an expression, and indicates that the expression should be evaluated at compile type rather than at runtime:
constexpr double pi = 3.1415; constexpr double twopi = 2 * pi;
This is similar to initializing a constant declared with the
const keyword. However, the
constexpr keyword can also be applied to functions that return a value that can be evaluated at compile time, and so this allows the compiler to optimize the code:
constexpr int triang(int i) { return (i == 0) ? 0 : triang(i - 1) + i; }
In this example, the function
triang calculates triangular numbers recursively. The code uses the conditional operator. In the parentheses, the function parameter is tested to see if it is zero, and if so the function returns zero, in effect ending the recursion and returning the function to the original caller. If the parameter is not zero, then the return value is the sum of the parameter and the return value of
triang called with the parameter is decremented.
This function, when called with a literal in your code, can be evaluated at compile time. The
constexpr is an indication to the compiler to check the usage of the function to see if it can determine the parameter at compile time. If this is the case, the compiler can evaluate the return value and produce code more efficiently than by calling the function at runtime. If the compiler cannot determine the parameter at compile-time, the function will be called as normal. A function marked with the
constexpr keyword must only have one expression (hence the use of the conditional operator
?: in the
triang function).
A final way to provide constants is to use an
enum variable. In effect, an
enum is a group of named constants, which means that you can use an
enum as a parameter to a function. For example:
enum suits {clubs, diamonds, hearts, spades};
This defines an enumeration called
suits, with named values for the suits in a deck of cards. An enumeration is an integer type and by default the compiler will assume an
int, but you can change this by specifying the integer type in the declaration. Since there are just four possible values for card suits, it is a waste of memory to use
int (usually
4 bytes) and instead, we can use
char (a single byte):
enum suits : char {clubs, diamonds, hearts, spades};
When you use an enumerated value, you can use just the name; however, it is usual to scope it with the name of the enumeration, making the code more readable:
suits card1 = diamonds; suits card2 = suits::diamonds;
Both forms are allowed, but the latter makes it more explicit that the value is taken from an enumeration. To force developers to specify the scope, you can apply the keyword
class:
enum class suits : char {clubs, diamonds, hearts, spades};
With this definition and the preceding code, the line declaring
card2 will compile, but the line declaring
card1 will not. With a scoped
enum, the compiler treats the enumeration as a new type and has no inbuilt conversion from your new type to an integer variable. For example:
suits card = suits::diamonds; char c = card + 10; // errors C2784 and C2676
The
enum type is based on
char but when you define the
suits variable as being scoped (with
class) the second line will not compile. If the enumeration is defined as not being scoped (without
class) then there is an inbuilt conversion between the enumerated value and
char.
By default, the compiler will give the first enumerator a value of 0 and then increment the value for the subsequent enumerators. Thus
suits::diamonds will have a value of 1 because it is the second value in
suits. You can assign values yourself:
enum ports {ftp=21, ssh, telnet, smtp=25, http=80};
In this case,
ports::ftp has a value of 21,
ports::ssh has a value of 22 (21 incremented),
ports::telnet is 22,
ports::smtp is 25, and
ports::http is 80.
Note
Often the point of enumerations is to provide named symbols within your code and their values are unimportant. Does it matter what value is assigned to
suits::hearts? The intention is usually to ensure that it is different from the other values. In other cases, the values are important because they are a way to provide values to other functions.
Enumerations are useful in a
switch statement (see later) because the named value makes it clearer than using just an integer. You can also use an enumeration as a parameter to a function and hence restrict the values passed via that parameter:
void stack(suits card) { // we know that card is only one of four values }
Since we are covering the use of variables, it is worth explaining the syntax used to define pointers and arrays because there are some potential pitfalls. Chapter 2, Working with Memory, Arrays, and Pointers, covers this in more detail, so we will just introduce the syntax so that you are familiar with it.
In C++, you will access memory using a typed pointer. The type indicates the type of the data that is held in the memory that is pointed to. So, if the pointer is an (
4 byte) integer pointer, it will point to four bytes that can be used as an integer. If the integer pointer is incremented, then it will point to the next four bytes, which can be used as an integer.
Note
Don't worry if you find pointers confusing at this point. Chapter 2, Working with Memory, Arrays, and Pointers, will explain this in more detail. The purpose of introducing pointers at this time is to make you aware of the syntax.
In C++, pointers are declared using the
* symbol and you access a memory address with the
& operator:
int *p; int i = 42; p = &i;
The first line declares a variable,
p, which will be used to hold the memory address of an integer. The second line declares an integer and assigns it a value. The third line assigns a value to the pointer
p to be the address of the integer variable just declared. It is important to stress that the value of
p is not
42; it will be a memory address where the value of
42 is stored.
Note how the declaration has the
* on the variable name. This is common convention. The reason is that if you declare several variables in one statement, the
* applies only to the immediate variable. So, for example:
int* p1, p2;
Initially, this looks like you are declaring two integer pointers. However, this line does not do this; it declares just one pointer to integer called
p1. The second variable is an integer called
p2. The preceding line is equivalent to the following:
int *p1; int p2;
If you wish to declare two integers in one statement, then you should do it as follows:
int *p1, *p2;
Namespaces give you one mechanism to modularize code. A namespace allows you to label your types, functions, and variables with a unique name so that, using the scope resolution operator, you can give a fully qualified name. The advantage is that you know exactly which item will be called. The disadvantage is that using a fully qualified name you are in effect switching off C++'s argument-dependent lookup mechanism for overloaded functions where the compiler will choose the function that has the best fit according to the arguments passed to the function.
Defining a namespace is simple: you decorate the types, functions, and global variables with the
namespace keyword and the name you give to it. In the following example, two functions are defined in the
utilities namespace:
namespace utilities { bool poll_data() { // code that returns a bool } int get_data() { // code that returns an integer } }
Now when you use these symbols, you need to qualify the name with the namespace:
if (utilities::poll_data()) { int i = utilities::get_data(); // use i here... }
The namespace declaration may just declare the functions, in which case the actual functions would have to be defined elsewhere, and you will need to use a qualified name:
namespace utilities { // declare the functions bool poll_data(); int get_data(); } //define the functions bool utilities::poll_data() { // code that returns a bool } int utilities::get_data() { // code that returns an integer }
One use of namespaces is to version your code. The first version of your code may have a side-effect that is not in your functional specification and is technically a bug, but some callers will use it and depend on it. When you update your code to fix the bug, you may decide to allow your callers the option to use the old version so that their code does not break. You can do this with a namespace:
namespace utilities { bool poll_data(); int get_data(); namespace V2 { bool poll_data(); int get_data(); int new_feature(); } }
Now callers who want a specific version can call the fully qualified names, for example, callers could use
utilities::V2::poll_data to use the newer version and
utilities::poll_data to use the older version. When an item in a specific namespace calls an item in the same namespace, it does not have to use a qualified name. So, if the
new_feature function calls
get_data, it will be
utilities::V2::get_data that is called. It is important to note that, to declare a nested namespace, you have to do the nesting manually (as shown here); you cannot simply declare a namespace called
utilities::V2.
The preceding example has been written so that the first version of the code will call it using the namespace
utilities. C++11 provides a facility called an inline namespace that allows you to define a nested namespace, but allows the compiler to treat the items as being in the parent namespace when it performs an argument-dependent lookup:
namespace utilities { inline namespace V1 { bool poll_data(); int get_data(); } namespace V2 { bool poll_data(); int get_data(); int new_feature(); } }
Now to call the first version of
get_data, you can use
utilities::get_data or
utilities::V1::get_data.
Fully qualified names can make the code difficult to read, especially if your code will only use one namespace. To help here you have several options. You can place a
using statement to indicate that symbols declared in the specified namespace can be used without a fully qualified name:
using namespace utilities; int i = get_data(); int j = V2::get_data();
You can still use fully qualified names, but this statement allows you to ease the requirement. Note that a nested namespace is a member of a namespace, so the preceding
using statement means that you can call the second version of
get_data with either
utilities::V2::get_data or
V2::get_data. If you use the unqualified name, then it means that you will call
utilities::get_data.
A namespace can contain many items, and you may decide that you only want to relax the use of fully qualified names with just a few of them. To do this, use
using and give the name of the item:
using std::cout; using std::endl; cout << "Hello, World!" << endl;
This code says that, whenever
cout is used, it refers to
std::cout. You can use
using within a function, or you can put it as file scope and make the intention global to the file.
You do not have to declare a namespace in one place, you can declare it over several files. The following could be in a different file to the previous declaration of
utilities:
namespace utilities { namespace V2 { void print_data(); } }
The
print_data function is still part of the
utilities::V2 namespace.
You can also put an
#include in a namespace, in which case the items declared in the header file will now be part of the namespace. The standard library header files that have a prefix of
c (for example,
cmath,
cstdlib, and
ctime) give access to the C runtime functions by including the appropriate C header in the
std namespace.
The great advantage of a namespace is to be able to define your items with names that may be common, but are hidden from other code that does not know the namespace name of. The namespace means that the items are still available to your code via the fully qualified name. However, this only works if you use a unique namespace name, and the likelihood is that, the longer the namespace name, the more unique it is likely to be. Java developers often name their classes using a URI, and you could decide to do the same thing:
namespace com_packtpub_richard_grimes { int get_data(); }
The problem is that the fully qualified name becomes quite long:
int i = com_packtpub_richard_grimes::get_data();
You can get around this issue using an alias:
namespace packtRG = com_packtpub_richard_grimes; int i = packtRG::get_data();
C++ allows you to define a namespace without a name, an anonymous namespace. As mentioned previously, namespaces allow you to prevent name clashes between code defined in several files. If you intend to use such a name in only one file you could define a unique namespace name. However, this could get tedious if you had to do it for several files. A namespace without a name has the special meaning that it has internal linkage, that is, the items can only be used in the current translation unit, the current file, and not in any other file.
Code that is not declared in a namespace will be a member of the
global namespace. You can call the code without a namespace name, but you may want to explicitly indicate that the item is in the
global namespace using the scope resolution operator without a namespace name:
int version = 42; void print_version() { std::cout << "Version = " << ::version << std::endl; }
The compiler will compile your source files as individual items called translation units. The compiler will determine the objects and variables you declare and the types and functions you define, and once declared you can use any of these in the subsequent code within the scope of the declaration. At its very broadest, you can declare an item at the global scope by declaring it in a header file that will be used by all of the source files in your project. If you do not use a namespace it is often wise when you use such global variables to name them as being part of the global namespace:
// in version.h extern int version; // in version.cpp #include "version.h" version = 17; // print.cpp #include "version.h" void print_version() { std::cout << "Version = " << ::version << std::endl; }
This code has the C++ for two source files (
version.cpp and
print.cpp) and a header file (
version.h) included by both source files. The header file declares the global variable
version, which can be used by both source files; it declares the variable, but does not define it. The actual variable is defined and initialized in
version.cpp; it is here that the compiler will allocate memory for the variable. The
extern keyword used on the declaration in the header indicates to the compiler that
version has external linkage, that is, the name is visible in files other than where the variable is defined. The
version variable is used in the
print.cpp source file. In this file, the scope resolution operator (
::) is used without a namespace name and hence indicates that the variable
version is in the global namespace.
You can also declare items that will only be used within the current translation unit, by declaring them within the source file before they are used (usually at the top of the file). This produces a level of modularity and allows you to hide implementation details from code in other source files. For example:
// in print.h void usage(); // print.cpp #include "version.h" std::string app_name = "My Utility"; void print_version() { std::cout << "Version = " << ::version << std::endl; } void usage() { std::cout << app_name << " "; print_version(); }
The
print.h header contains the interface for the code in the file
print.cpp. Only those functions declared in the header will be callable by other source files. The caller does not need to know about the implementation of the
usage function, and as you can see here it is implemented using a call to a function called
print_version that is only available to code in
print.cpp. The variable
app_name is declared at file scope, so it will only be accessible to code in
print.cpp.
If another source file declares a variable at file scope, that is called
app_name, and is also a
std::string the file will compile, but the linker will complain when it tries to link the object files. The reason is that the linker will see the same variable defined in two places and it will not know which one to use.
A function also defines a scope; variables defined within the function can only be accessed through that name. The parameters of the function are also included as variables within the function, so when you declare other variables, you have to use different names. If a parameter is not marked as
const then you can alter the value of the parameter in your function.
You can declare variables anywhere within a function as long as you declare them before you use them. Curly braces (
{}) are used to define code blocks, and they also define local scope; if you declare a variable within a code block then you can only use it there. This means that you can declare variables with the same name outside the code block and the compiler will use the variable closest to the scope it is accessed.
Before finishing this section, it is important to mention one aspect of the C++ storage class. A variable declared in a function means that the compiler will allocate memory for the variable on the stack frame created for the function. When the function finishes, the stack frame is torn down and the memory recycled. This means that, after a function returns, the values in any local variables are lost; when the function is called again, the variable is created anew and initialized again.
C++ provides the
static keyword to change this behavior. The
static keyword means that the variable is allocated when the program starts just like variables declared at global scope. Applying
static to a variable declared in a function means that the variable has internal linkage, that is, the compiler restricts access to that variable to that function:
int inc(int i) { static int value; value += i; return value; } int main() { std::cout << inc(10) << std::endl; std::cout << inc(5) << std::endl; }
By default, the compiler will initialize a static variable to
0, but you can provide an initialization value, and this will be used when the variable is first allocated. When this program starts, the
value variable will be initialized to
0 before the
main function is called. The first time the
inc function is called, the
value variable is incremented to 10, which is returned by the function and printed to the console. When the
inc function returns the
value variable is retained, so that when the
inc function is called again, the
value variable is incremented by
5 to a value of
15.
Operators are used to compute a value from one or more operands. The following table groups all of the operators with equal precedence and lists their associativity. The higher in the table, the higher precedence of execution the operator has in an expression. If you have several operators in an expression, the compiler will perform the higher-precedence operators before the lower-precedence operators. If an expression contains operators of equal precedence, then the compiler will use the associativity to decide whether an operand is grouped with the operator to its left or right.
Note
There are some ambiguities in this table. A pair of parentheses can mean a function call or a cast and in the table these are listed as
function() and
cast(); in your code you will simply use
(). The
+ and
- symbols are either used to indicate sign (unary plus and unary minus, given in the table as
+x and
-x), or addition and subtraction (given in the table as
+ and
-). The
& symbol means either "take the address of" (listed in the table as
&x) or bitwise
AND (listed in the table as
&). Finally, the postfix increment and decrement operators (listed in the table as
x++ and
x--) have a higher precedence than the prefix equivalents (listed as
++x and
--x).
For example, take a look at the following code:
int a = b + c * d;
This is interpreted as the multiplication being performed first, and then the addition. A clearer way to write the same code is:
int a = b + (c * d);
The reason is that
* has a higher precedence than
+ so that the multiplication is carried out first, and then the addition is performed:
int a = b + c + d;
In this case, the
+ operators have the same precedence, which is higher than the precedence of assignment. Since
+ has left to right associativity the statement is interpreted as follows:
int a = ((b + c) + d);
That is, the first action is the addition of
b and
c, and the result is added to
d and it is this result that is used to assign
a. This may not seem important, but bear in mind that the addition could be between function calls (a function call has a higher precedence than
+):
int a = b() + c() + d();
This means that the three functions are called in the order
b,
c,
d, and then their return values are summed according to the left-to-right associativity. This may be important because
d may depend on global data altered by the other two functions.
It makes your code more readable and easier to understand if you explicitly specify the precedence by grouping expressions with parentheses. Writing
b + (c * d) makes it immediately clear which expression is executed first, whereas
b + c * d means you have to know the precedence of each operator.
The built-in operators are overloaded, that is, the same syntax is used regardless of which built-in type is used for the operands. The operands must be the same type; if different types are used, the compiler will perform some default conversions, but in other cases (in particular, when operating on types of different sizes), you will have to perform a cast to indicate explicitly what you mean.
C++ comes with a wide range of built-in operators; most are arithmetic or logic operators, which will be covered in this section. The memory operators will be covered in Chapter 2, Working with Memory, Arrays, and Pointers, and the object-related operators in Chapter 4, Classes.
The arithmetic operators
+,
-,
/,
*, and
% need little explanation other than perhaps the division and modulus operators. All of these operators act upon integer and real numeric types except for
%, which can only be used with integer types. If you mix the types (say, add an integer to a floating-point number) then the compiler will perform an automatic conversion. The division operator
/ behaves as you expect for floating point variables: it produces the result of the division of the two operands. When you perform the division between two integers
a / b, the result is the whole number of the divisor (
b) in the dividend (
a). The remainder of the division is obtained by the modulus
%. So, for any integer,
b (other than zero), one could say that, an integer
a can be expressed as follows:
(a / b) * b + (a % b)
Note that the modulus operator can only be used with integers. If you want to get the remainder of a floating-point division, use the standard function,
std:;remainder.
Be careful when using division with integers, since fractional parts are discarded. If you need the fractional parts, then you may need to explicitly convert the numbers into real numbers. For example:
int height = 480; int width = 640; float aspect_ratio = width / height;
This gives an aspect ratio of
1 when it should be
1.3333 (or
4 : 3). To ensure that floating-point division is performed, rather than integer division, you can cast either (or both) the dividend or divisor to a floating-point number.
There are two versions of these operators, prefix and postfix. As the name suggests, prefix means that the operator is placed on the left of the operand (for example,
++i), and a postfix operator is placed to the right (
i++). The
++ operator will increment the operand and the
-- operator will decrement it. The prefix operator means "return the value after the operation," and the postfix operator means "return the value before the operation." So the following code will increment one variable and use it to assign another:
a = ++b;
Here, the prefix operator is used so the variable
b is incremented and the variable
a is assigned to the value after
b has been incremented. Another way of expressing this is:
a = (b = b + 1);
The following code assigns a value using the postfix operator:
a = b++;
This means that the variable
b is incremented, but the variable
a is assigned to the value before
b has been incremented. Another way of expressing this is:
int t; a = (t = b, b = b + 1, t);
Note
Note that this statement uses the comma operator, so
a is assigned to the temporary variable
t in the right-most expression.
The increment and decrement operators can be applied to both integer and floating point numbers. The operators can also be applied to pointers, where they have a special meaning. When you increment a pointer variable it means increment the pointer by the size of the type pointed to by the operator.
Integers can be regarded as a series of bits,
0 or
1. Bitwise operators act upon these bits compared to the bit in the same position in the other operand. Signed integers use a bit to indicate the sign, but bitwise operators act on every bit in an integer, so it is usually only sensible to use them on unsigned integers. In the following, all the types are marked as
unsigned, so they are treated as not having a sign bit.
The
& operator is bitwise AND, which means that each bit in the left-hand operand is compared with the bit in the right-hand operand in the same position. If both are 1, the resultant bit in the same position will be 1; otherwise, the resultant bit is zero:
unsigned int a = 0x0a0a; // this is the binary 0000101000001010 unsigned int b = 0x00ff; // this is the binary 0000000000001111 unsigned int c = a & b; // this is the binary 0000000000001010 std::cout << std::hex << std::showbase << c << std::endl;
In this example, using bitwise
& with
0x00ff has the same effect as providing a mask that masks out all but the lowest byte.
The bitwise OR operator
| will return a value of 1 if either or both bits in the same position are 1, and a value of 0 only if both are 0:
unsigned int a = 0x0a0a; // this is the binary 0000101000001010 unsigned int b = 0x00ff; // this is the binary 0000000000001111 unsigned int c = a & b; // this is the binary 0000101000001111 std::cout << std::hex << std::showbase << c << std::endl;
One use of the
& operator is to find if a particular bit (or a specific collection of bits) is set:
unsigned int flags = 0x0a0a; // 0000101000001010 unsigned int test = 0x00ff; // 0000000000001111 // 0000101000001111 is (flags & test) if ((flags & test) == flags) { // code for when all the flags bits are set in test } if ((flags & test) != 0) { // code for when some or all the flag bits are set in test }
The
flags variable has the bits we require, and the
test variable is a value that we are examining. The value
(flags & test) will have only those bits in the
test variables that are also set in
flags. Thus, if the result is non-zero, it means that at least one bit in
test is also set in
flags; if the result is exactly the same as the
flags variable then all the bits in
flags are set in
test.
The exclusive OR operator
^ is used to test when the bits are different; the resultant bit is
1 if the bits in the operands are different, and
0 if they are the same. Exclusive OR can be used to flip specific bits:
int value = 0xf1; int flags = 0x02; int result = value ^ flags; // 0xf3 std::cout << std::hex << result << std::endl;
The final bitwise operator is the bitwise complement
~. This operator is applied to a single integer operand and returns a value where every bit is the complement of the corresponding bit in the operand; so if the operand bit is 1, the bit in the result is 0, and if the bit in the operand is 0, the bit in the result is 1. Note that all bits are examined, so you need to be aware of the size of the integer.
The
== operator tests whether two values are exactly the same. If you test two integers then the test is obvious; for example, if
x is 2 and
y is 3, then
x == y is obviously
false. However, two real numbers may not be the same even when you think so:
double x = 1.000001 * 1000000000000; double y = 1000001000000; if (x == y) std::cout << "numbers are the same";
The
double type is a floating-point type held in 8 bytes, but this is not enough for the precision being used here; the value stored in the
x variable is
1000000999999.9999 (to four decimal places).
The
!= operator tests if two values are not true. The operators
> and
<, test two values to see if the left-hand operand is greater than, or less than, the right-hand operand, the
>= operator tests if the left-hand operand is greater than or equal to the right-hand operand, and the
<= operator tests if the left-hand operand is less than or equal to the right-hand operand. These operators can be used in the
if statement similar to how
== is used in the preceding example. The expressions using the operators return a value of type
bool and so you can use them to assign values to Boolean variables:
int x = 10; int y = 11; bool b = (x > y); if (b) std::cout << "numbers same"; else std::cout << "numbers not same";
The assignment operator (
=) has a higher precedence than the greater than (
>=) operator, but we have used the parentheses to make it explicit that the value is tested before being used to assign the variable. You can use the
! operator to negate a logical value. So, using the value of
b obtained previously, you can write the following:
if (!b) std::cout << "numbers not same"; else std::cout << "numbers same";
You can combine two logical expressions using the
&& (AND) and
|| (OR) operators. An expression with the
&& operator is true only if both operands are
true, whereas an expression with the
|| operator is
true if either, or both, operands are
true:
int x = 10, y = 10, z = 9; if ((x == y) || (y < z)) std::cout << "one or both are true";
This code involves three tests; the first tests if the
x and
y variables have the same value, the second tests if the variable
y is less than
z, and then there is a test to see if either or both of the first two tests are
true.
In a
|| expression such as this, where the first operand (
x==y) is
true, the total logical expression will be
true regardless of the value of the right operand (here,
y < z). So there is no point in testing the second expression. Correspondingly, in an
&& expression, if the first operand is
false then the entire expression must be
false, and so the right-hand part of the expression need not be tested.
The compiler will provide code to perform this short-circuiting for you:
if ((x != 0) && (0.5 > 1/x)) { // reciprocal is less than 0.5 }
This code tests to see if the reciprocal of
x is less than 0.5 (or, conversely, that
x is greater than 2). If the
x variable has value 0 then the test
1/x is an error but, in this case, the expression will never be executed because the left operand to
&& is
false.
Bitwise shift operators shift the bits in the left-hand operand integer the specified number of bits given in the right-hand operand, in the specified direction. A shift by one bit left multiplies the number by two, a shift one bit to the right divides by 2. In the following a 2-byte integer is bit-shifted:
unsigned short s1 = 0x0010; unsigned short s2 = s1 << 8; std::cout << std::hex << std::showbase; std::cout << s2 << std::endl; // 0x1000 s2 = s2 << 3; std::cout << s2 << std::endl; // 0x8000
In this example, the
s1 variable has the fifth bit set (
0x0010 or 16). The
s2 variable has this value, shifted left by 8 bits, so the single bit is shifted to the 13th bit, and the bottom 8 bits are all set to 0 (
0x10000 or 4,096). This means that
0x0010 has been multiplied by 28, or 256, to give
0x1000. Next, the value is shifted left by another 3 bits, and the result is
0x8000; the top bit is set.
The operator discards any bits that overflow, so if you have the top bit set and shift the integer one bit left, that top bit will be discarded:
s2 = s2 << 1; std::cout << s2 << std::endl; // 0
A final shift left by one bit results in a value 0.
It is important to remember that, when used with a stream, the operator
<< means insert into the stream, and when used with integers, it means bitwise shift.
The assignment operator
= assigns an lvalue (a variable) on the left with the result of the rvalue (a variable or expression) on the right:
int x = 10; x = x + 10;
The first line declares an integer and initializes it to 10. The second line alters the variable by adding another 10 to it, so now the variable
x has a value of 20. This is the assignment. C++ allows you to change the value of a variable based on the variable's value using an abbreviated syntax. The previous lines can be written as follows:
int x = 10; x += 10;
An increment operator such as this (and the decrement operator) can be applied to integers and floating-point types. If the operator is applied to a pointer, then the operand indicates how many whole items addresses the pointer is changed by. For example, if an
int is 4 bytes and you add
10 to an
int pointer, the actual pointer value is incremented by 40 (10 times 4 bytes).
In addition to the increment (
+=) and decrement (
-=) assignments, you can have assignments for multiply (
*=), divide (
/=), and remainder (
%=). All of these except for the last one (
%=) can be used for both floating-point types and integers. The remainder assignment can only be used on integers.
You can also perform bitwise assignment operations on integers: left shift (
<<=), right shift (
>>=), bitwise AND (
&=), bitwise OR (
|=), and bitwise exclusive OR (
^=). It usually only makes sense to apply these to unsigned integers. So, multiplying by eight can be carried out by both of these two lines:
i *= 8; i <<= 3;
C++ provides many ways to test values and loop through code.
The most frequently used conditional statement is
if. In its simplest form, the
if statement takes a logical expression in a pair of parentheses and is immediately followed by the statement that is executed if the condition is
true:
int i; std::cin >> i; if (i > 10) std::cout << "much too high!" << std::endl;
You can also use the
else statement to catch occasions when the condition is
false:
int i; std::cin >> i; if (i > 10) std::cout << "much too high!" << std::endl; else std::cout << "within range" << std::endl;
If you want to execute several statements, you can use braces (
{}) to define a code block.
The condition is a logical expression and C++ will convert from numeric types to a
bool, where 0 is
false and anything not 0 is
true. If you are not careful, this can be a source of an error that is not only difficult to notice, but also can have an unexpected side-effect. Consider the following code, which asks for input from the console and then tests to see if the user enters -1:
int i; std::cin >> i; if (i == -1) std::cout << "typed -1" << endl; std::cout << "i = " << i << endl;
This is contrived, but you may be asking for values in a loop and then performing actions on those values, except when the user enters -1, at which point the loop finishes. If you mistype, you may end up with the following code:
int i; std::cin >> i; if (i = -1) std::cout << "typed -1" << endl; std::cout << "i = " << i << endl;
In this case, the assignment operator (
=) is used instead of the equality operator (
==). There is just one character difference, but this code is still correct C++ and the compiler is happy to compile it.
The result is that, regardless of what you type at the console, the variable
i is assigned to -1, and since -1 is not zero, the condition in the
if statement is
true, hence the true clause of the statement is executed. Since the variable has been assigned to -1, this may alter logic further on in your code. The way to avoid this bug is to take advantage of the requirement that in an assignment the left-hand side must be an lvalue. Perform your test as follows:
if (-1 == i) std::cout << "typed -1" << endl;
Here, the logical expression is
(-1 == i), and since the
== operator is commutative (the order of the operands does not matter; you get the same result), this is exactly the same as you intended in the preceding test. However, if you mistype the operator, you get the following:
if (-1 = i) std::cout << "typed -1" << endl;
In this case, the assignment has an rvalue on the left-hand side, and this will cause the compiler to issue an error (in Visual C++ this is
C2106 '=' : left operand must be l-value).
You are allowed to declare a variable in an
if statement, and the scope of the variable is in the statement blocks. For example, a function that returns an integer can be called as follows:
if (int i = getValue()) { // i != 0 // can use i here } else { // i == 0 // can use i here }
While this is perfectly legal C++, there are a few reasons why you would want to do this.
In some cases, the conditional operator
?: can be used instead of an
if statement. The operator executes the expression to the left of the
? operator and, if the conditional expression is
true, it executes the expression to the right of the
?. If the conditional expression is
false, it executes the expression to the right of the
:. The expression that the operator executes provides the return value of the conditional operator.
For example, the following code determines the maximum of two variables,
a and
b:
int max; if (a > b) max = a; else max = b;
This can be expressed with the following single statement:
int max = (a > b) ? a : b;
The main choice is whichever is most readable in the code. Clearly, if the assignment expressions are large it may well be best to split them over lines in an
if statement. However, it is useful to use the conditional statement in other statements. For example:
int number; std::cin >> number; std::cout << "there " << ((number == 1) ? "is " : "are ") << number << " item" << ((number == 1) ? "" : "s") << std::endl;
This code determines if the variable
number is 1 and if so it prints on the console
there is 1 item. This is because in both conditionals, if the value of the
number variable is 1, the test is
true and the first expression is used. Note that there is a pair of parentheses around the entire operator. The reason is that the stream
<< operator is overloaded, and you want the compiler to choose the version that takes a string, which is the type returned by the operator rather than
bool, which is the type of the expression
(number == 1).
If the value returned by the conditional operator is an lvalue then you can use it on the left-hand side of an assignment. This means that you can write the following, rather odd, code:
int i = 10, j = 0; ((i < j) ? i : j) = 7; // i is 10, j is 7 i = 0, j = 10; ((i < j) ? i : j) = 7; // i is 7, j is 10
The conditional operator checks to see if
i is less than
j and if so it assigns a value to
i; otherwise, it assigns
j with that value. This code is terse, but it lacks readability. It is far better in this case to use an
if statement.
If you want to test to see if a variable is one of several values, using multiple
if statements becomes cumbersome. The C++
switch statement fulfills this purpose much better. The basic syntax is shown here:
int i; std::cin >> i; switch(i) { case 1: std::cout << "one" << std::endl; break; case 2: std::cout << "two" << std::endl; break; default: std::cout << "other" << std::endl; }
Each
case is essentially a label as to the specific code to be run if the selected variable is the specified value. The
default clause is for values where there exists no
case. You do not have to have a
default clause, which means that you are testing only for specified cases. The
default clause could be for the most common case (in which case, the cases filter out the less likely values) or it could be for exceptional values (in which case, the cases handle the most likely values).
A
switch statement can only test integer types (which includes
enum), and you can only test for constants. The
char type is an integer, and this means that you can use characters in the
case items, but only individual characters; you cannot use strings:
char c; std::cin >> c; switch(c) { case 'a': std::cout << "character a" << std::endl; break; case 'z': std::cout << "character z" << std::endl; break; default: std::cout << "other character" << std::endl; }
The
break statement indicates the end of the statements executed for a
case. If you do not specify it, execution will fall through and the following
case statements will be executed even though they have been specified for a different case:
switch(i) { case 1: std::cout << "one" << std::endl; // fall thru case 2: std::cout << "less than three" << std::endl; break; case 3: std::cout << "three" << std::endl; break; case 4: break; default: std::cout << "other" << std::endl; }
This code shows the importance of the
break statement. A value of 1 will print both
one and
less than three to the console, because execution falls through to the preceding
case, even though that
case is for another value.
It is usual to have different code for different cases, so you will most often finish a
case with
break. It is easy to miss out a
break by mistake, and this will lead to unusual behavior. It is good practice to document your code when deliberately missing out the
break statement so that you know that if a
break is missing, it is likely to be a mistake.
You can provide zero or more statements for each
case. If there is more than one statement, they are all executed for that specific case. If you provide no statements (as for
case 4 in this example) then it means that no statements will be executed, not even those in the
default clause.
The
break statement means break out of this code block, and it behaves like this in the loop statements
while and
for as well. There are other ways that you can break out of a
switch. A
case could call
return to finish the function where the
switch is declared; it can call
goto to jump to a label, or it can call
throw to throw an exception that will be caught by an exception handler outside the
switch, or even outside the function.
So far, the cases are in numeric order. This is not a requirement, but it does make the code more readable, and clearly, if you want to fall through the
case statements (as in
case 1 here), you should pay attention to the order the
case items.
If you need to declare a temporary variable in a
case handler then you must define a code block using braces, and this will make the scope of the variable localized to just that code block. You can, of course, use any variable declared outside of the
switch statement in any of the
case handlers.
Since enumerated constants are integers, you can test an
enum in a
switch statement:
enum suits { clubs, diamonds, hearts, spades }; void print_name(suits card) { switch(card) { case suits::clubs: std::cout << "card is a club"; break; default: std::cout << "card is not a club"; } }
Although the
enum here is not scoped (it is neither
enum class nor
enum struct), it is not required to specify the scope of the value in the
case, but it makes the code more obvious what the constant refers to.
Most programs will need to loop through some code. C++ provides several ways to do this, either by iterating with an indexed value or testing a logical condition.
There are two versions of the
for statement, iteration and range-based. The latter was introduced in C++11. The iteration version has the following format:
for (init_expression; condition; loop_expression) loop_statement;
You can provide one or more loop statements, and for more than one statement, you should provide a code block using braces. The purpose of the loop may be served by the loop expression, in which case you may not want a loop statement to be executed; here, you use the null statement,
; which means do nothing.
Within the parentheses are three expressions separated by semicolons. The first expression allows you to declare and initialize a loop variable. This variable is scoped to the
for statement, so you can only use it in the
for expressions or in the loop statements that follow. If you want more than one loop variable, you can declare them in this expression using the comma operator.
The
for statement will loop while the condition expression is
true; so if you are using a loop variable, you can use this expression to check the value of the loop variable. The third expression is called at the end of the loop, after the loop statement has been called; following this, the condition expression is called to see if the loop should continue. This final expression is often used to update the value of the loop variable. For example:
for (int i = 0; i < 10; ++i) { std::cout << i; }
In this code, the loop variable is
i and it is initialized to zero. Next, the condition is checked, and since
i will be less than 10, the statement will be executed (printing the value to the console). The next action is the loop expression;
++i, is called, which increments the loop variable,
i, and then the condition is checked, and so on. Since the condition is
i < 10, this means that this loop will run ten times with a value of
i between 0 and 9 (so you will see
0123456789 on the console).
The loop expression can be any expression you like, but often it increments or decrements a value. You do not have to change the loop variable value by 1; for example, you can use
i -= 5 as the loop expression to decrease the variable by 5 on each loop. The loop variable can be any type you like; it does not have to be integer, it does not even have to be numeric (for example, it could be a pointer, or an iterator object described in Chapter 5, Using the Standard Library Containers), and the condition and loop expression do not have to use the loop variable. In fact, you do not have to declare a loop variable at all!
If you do not provide a loop condition then the loop will be infinite, unless you provide a check in the loop:
for (int i = 0; ; ++i) { std::cout << i << std::endl; if (i == 10) break; }
This uses the
break statement introduced earlier with the
switch statement. It indicates that execution exits the
for loop, and you can also use
return,
goto, or
throw. You will rarely see a statement that finishes using
goto; however, you may see the following:
for (;;) { // code }
In this case, there is no loop variable, no loop expression, and no conditional. This is an everlasting loop, and the code within the loop determines when the loop finishes.
The third expression in the
for statement, the loop expression, can be anything you like; the only property is that it is executed at the end of a loop. You may choose to change another variable in this expression, or you can even provide several expressions separated by the comma operator. For example, if you have two functions, one called
poll_data that returns
true if there is more data available and
false when there is no more data, and a function called
get_data that returns the next available data item, you could use
for as follows (bear in mind; this is a contrived example, to make a point):
for (int i = -1; poll_data(); i = get_data()) { if (i != -1) std::cout << i << std::endl; }
When
poll_data returns a
false value, the loop will end. The
if statement is needed because the first time the loop is called,
get_data has not yet been called. A better version is as follows:
for (; poll_data() ;) { int i = get_data(); std::cout << i << std::endl; }
Keep this example in mind for the following section.
There is one other keyword that you can use in a
for loop. In many cases, your
for loop will have many lines of code and at some point, you may decide that the current loop has completed and you want to start the next loop (or, more specifically, execute the loop expression and then test the condition). To do this, you can call
continue:
for (float divisor = 0.f; divisor < 10.f; ++divisor) { std::cout << divisor; if (divisor == 0) { std::cout << std::endl; continue; } std::cout << " " << (1 / divisor) << std::endl; }
In this code, we print the reciprocal of the numbers 0 to 9 (
0.f is a 4-byte floating-point literal). The first line in the
for loop prints the loop variable, and the next line checks to see if the variable is zero. If it is, it prints a new line and continues, that is, the last line in the
for loop is not executed. The reason is that the last line prints the reciprocal and it would be an error to divide any number by zero.
C++11 introduces another way to use the
for loop, which is intended to be used with containers. The C++ standard library contains templates for container classes. These classes contain collections of objects, and provide access to those items in a standard way. The standard way is to iterate through collections using an iterator object. More details about how to do this will be given in Chapter 5, Using the Standard Library Containers; the syntax requires an understanding of pointers and iterators, so we will not cover them here. The range-based
for loop gives a simple mechanism to access items in a container without explicitly using iterators.
The syntax is simple:
for (for_declaration : expression) loop_statement;
The first thing to point out is that there are only two expressions and they are separated by a colon (
:). The first expression is used to declare the loop variable, which is of the type of the items in the collection being iterated through. The second expression gives access to the collection.
Note
In C++ terms, the collections that can be used are those that define a
begin and
end function that gives access to iterators, and also to stack-based arrays (that the compiler knows the size of).
The Standard Library defines a container object called a
vector. The
vector template is a class that contains items of the type specified in the angle brackets (
<>); in the following code, the
vector is initialized in a special way that is new to C++11, called list initialization. This syntax allows you to specify the initial values of the vector in a list between curly braces. The following code creates and initializes a
vector, and then uses an iteration
for loop to print out all the values:
using namespace std; vector<string> beatles = { "John", "Paul", "George", "Ringo" }; for (int i = 0; i < beatles.size(); ++i) { cout << beatles.at(i) << endl; }
Note
Here a
using statement is used so that the classes
vector and
string do not have to be used with fully qualified names.
The
vector class has a member function called
size (called through the
. operator, which means "call this function on this object") that returns the number of items in the
vector. Each item is accessed using the
at function passing the item's index. The one big problem with this code is that it uses random access, that is, it accesses each item using its index. This is a property of
vector, but other Standard Library container types do not have random access. The following uses the range-based
for:
vector<string> beatles = { "John", "Paul", "George", "Ringo" }; for (string musician : beatles) { cout << musician << endl; }
This syntax works with any of the standard container types and for arrays allocated on the stack:
int birth_years[] = { 1940, 1942, 1943, 1940 }; for (int birth_year : birth_years) { cout << birth_year << endl; }
In this case, the compiler knows the size of the array (because the compiler has allocated the array) and so it can determine the range. The range-based
for loop will iterate through all the items in the container, but as with the previous version you can leave the
for loop using
break,
return,
throw, or
goto, and you can indicate that the next loop should be executed using the
continue statement.
In the previous section we gave a contrived example, where the condition in the
for loop polled for data:
for (; poll_data() ;) { int i = get_data(); std::cout << i << std::endl; }
In this example, there is no loop variable used in the condition. This is a candidate for the
while conditional loop:
while (poll_data()) { int i = get_data(); std::cout << i << std::endl; }
The statement will continue to loop until the expression (
poll_data in this case) has a value of
false. As with
for, you can exit the
while loop with
break,
return,
throw, or
goto, and you can indicate that the next loop should be executed using the
continue statement.
The first time the
while statement is called, the condition is tested before the loop is executed; in some cases you may want the loop executed at least once, and then test the condition (most likely dependent upon the action in the loop) to see if the loop should be repeated. The way to do this is to use the
do-while loop:
int i = 5; do { std::cout << i-- << std::endl; } while (i > 0);
Note the semicolon after the
while clause. This is required.
This loop will print 5 to 1 in reverse order. The reason is that the loop starts with
i initialized to 5. The statement in the loop decrements the variable through a postfix operator, which means the value before the decrement is passed to the stream. At the end of the loop, the
while clause tests to see if the variable is greater than zero. If this test is
true, the loop is repeated. When the loop is called with
i assigned to 1, the value of 1 is printed to the console and the variable decremented to zero, and the
while clause will test an expression that is
false and the looping will finish.
The difference between the two types of loop is that the condition is tested before the loop is executed in the
while loop, and so the loop may not be executed. In a
do-while loop, the condition is called after the loop, which means that, with a
do-while loop, the loop statements are always called at least once.
C++ supports jumps, and in most cases, there are better ways to branch code; however, for completeness, we will cover the mechanism here. There are two parts to a jump: a labeled statement to jump to and the
goto statement. A label has the same naming rules as a variable; it is declared suffixed with a colon, and it must be before a statement. The
goto statement is called using the label's name:
int main() { for (int i = 0; i < 10; ++i) { std::cout << i << std::endl; if (i == 5) goto end; } end: std::cout << "end"; }
The label must be in the same function as the calling
goto.
Jumps are rarely used, because they encourage you to write non-structured code. However, if you have a routine with highly nested loops or
if statements, it may make more sense and be more readable to use a
goto to jump to clean up code.
Let's now use the features you have learned in this chapter to write an application. This example is a simple command-line calculator; you type an expression such as
6 * 7, and the application parses the input and performs the calculation.
Start Visual C++ and click the
File menu, and then
New, and finally, click on the
File... option to get the
New File dialog. In the left-hand pane, click on
Visual C++, and in the middle pane, click on
C++ File (.cpp), and then click on the
Open button. Before you do anything else, save this file. Using a Visual C++ console (a command line, which has the Visual C++ environment), navigate to the
Beginning_C++ folder and create a new folder called
Chapter_02. Now, in Visual C++, on the
File menu, click
Save Source1.cpp As... and in the
Save File As dialog locate the
Chapter_02 folder you just created. In the
File name box, type
calc.cpp and click on the
Save button.
The application will use
std::cout and
std::string; so at the top of the file, add the headers that define these and, so that you do not have to use fully qualified names, add a
using statement:
#include <iostream> #include <string> using namespace std;
You will pass the expression via the command-line, so add a
main function that takes command line parameters at the bottom of the file:
int main(int argc, char *argv[]) { }
The application handles expressions in the form
arg1 op arg2 where
op is an operator and
arg1 and
arg2 are the arguments. This means that, when the application is called, it must have four parameters; the first is the command used to start the application and the last three are the expression. The first code in the
main function should ensure that the right number of parameters is provided, so at the top of this function add a condition, as follows:
if (argc != 4) { usage(); return 1; }
If the command is called with more or less than four parameters, a function
usage is called, and then the
main function returns, stopping the application.
Add the
usage function before the
main function, as follows:
void usage() { cout << endl; cout << "calc arg1 op arg2" << endl; cout << "arg1 and arg2 are the arguments" << endl; cout << "op is an operator, one of + - / or *" << endl; }
This simply explains how to use the command and explains the parameters. At this point, you can compile the application. Since you are using the C++ Standard Library, you will need to compile with support for C++ exceptions, so type the following at the command-line:
C:\Beginning_C++Chapter_02\cl /EHsc calc.cpp
If you typed in the code without any mistakes, the file should compile. If you get any errors from the compiler, check the source file to see if the code is exactly as given in the preceding code. You may get the following error:
'cl' is not recognized as an internal or external command, operable program or batch file.
This means that the console is not set up with the Visual C++ environment, so either close it down and start the console via the Windows Start menu, or run the
vcvarsall.bat batch file.
Once the code has compiled you may run it. Start by running it with the correct number of parameters (for example,
calc 6 * 7), and then try it with an incorrect number of parameters (for example,
calc 6 * 7 / 3). Note that the space between the parameters is important:
C:\Beginning_C++Chapter_02>calc 6 * 7 C:\Beginning_C++Chapter_02>calc 6 * 7 / 3 calc arg1 op arg2 arg1 and arg2 are the arguments op is an operator, one of + - / or *
In the first case, the application does nothing, so all you see is a blank line. In the second example, the code has determined that there are not enough parameters, and so it prints the usage information to the console.
Next, you need to do some simple parsing of the parameters to check that the user has passed valid values. At the bottom of the
main function, add the following:
string opArg = argv[2]; if (opArg.length() > 1) { cout << endl << "operator should be a single character" << endl; usage(); return 1; }
The first line initializes a C++
std::string object with the third command-line parameter, which should be the operator in the expression. This simple example only allows a single character for the operator, so the subsequent lines check to make sure that the operator is a single character. The C++
std::string class has a member function called
length that returns the number of characters in the string.
The
argv[2] parameter will have a length of at least one character (a parameter with no length will not be treated as a command-line parameter!), so we have to check if the user typed an operator longer than one character.
Next you need to test to ensure that the parameter is one of the restricted set allowed and, if the user types another operator, print an error and stop the processing. At the bottom of the
main function, add the following:
char op = opArg.at(0); if (op == 44 || op == 46 || op < 42 || op > 47) { cout << endl << "operator not recognized" << endl; usage(); return 1; }
The tests are going to be made on a character, so you need to extract this character from the
string object. This code uses the
at function, which is passed the index of the character you need. (Chapter 5, Using the Standard Library Containers, will give more details about the members of the
std::string class.) The next line checks to see if the character is not supported. The code relies on the following values for the characters that we support:
As you can see, if the character is less than
42 or greater than
47 it will be incorrect, but between
42 and
47 there are two characters that we also want to reject:
, (
44) and
. (
46). This is why we have the preceding conditional: "if the character is less than 42 or greater than
47, or it is
44 or
46, then reject it."
The
char data type is an integer, which is why the test uses integer literals. You could have used character literals, so the following change is just as valid:
if (op == ',' || op == '.' || op < '+' || op > '/') { cout << endl << "operator not recognized" << endl; usage(); return 1; }
You should use whichever you find the most readable. Since it makes less sense to check whether one character is greater than another, this book will use the former.
At this point, you can compile the code and test it. First try with an operator that is more than one character (for example,
**) and confirm that you get the message that the operator should be a single character. Secondly, test with a character that is not a recognized operator; try any character other than
+,
*,
-, or
/, but it is also worth trying
. and
,.
Bear in mind that the command prompt has special actions for some symbols, such as "
&" and "
|", and the command prompt may give you an error from it by parsing the command-line before even calling your code.
The next thing to do is to convert the arguments into a form that the code can use. The command-line parameters are passed to the program in an array of strings; however, we are interpreting some of those parameters as floating-point numbers (in fact, double-precision floating-point numbers). The C runtime provides a function called
atof, which is available through the C++ Standard Library (in this case,
<iostream> includes files that include
<cmath>, where
atof is declared).
Note
It is a bit counter-intuitive to get access to a math function such as
atof through including a file associated with stream input and output. If this makes you uneasy, you can add a line after the
include lines to include the
<cmath> file. The C++ Standard Library headers have been written to ensure that a header file is only included once, so including
<cmath> twice has no ill effect. This was not done in the preceding code, because it was argued that
atof is a string function and the code includes the
<string> header and, indeed,
<cmath> is included via the files the
<string> header includes.
Add the following lines to the bottom of the
main function. The first two lines convert the second and fourth parameters (remember, C++ arrays are zero-based indexed) to
double values. The final line declares a variable to hold the result:
double arg1 = atof(argv[1]); double arg2 = atof(argv[3]); double result = 0;
Now we need to determine which operator was passed and perform the requested action. We will do this with a
switch statement. We know that the
op variable will be valid, and so we do not have to provide a
default clause to catch the values we have not tested for. Add a
switch statement to the bottom of the function:
double arg1 = atof(argv[1]); double arg2 = atof(argv[3]); double result = 0; switch(op) { }
The first three cases,
+,
-, and
*, are straightforward:
switch (op) { case '+': result = arg1 + arg2; break; case '-': result = arg1 - arg2; break; case '*': result = arg1 * arg2; break; }
Again, since
char is an integer, you can use it in a
switch statement, but C++ allows you to check for the character values. In this case, using characters rather than numbers makes the code much more readable.
After the
switch, add the final code to print out the result:
cout << endl; cout << arg1 << " " << op << " " << arg2; cout << " = " << result << endl;
You can now compile the code and test it with calculations that involve
+,
-, and
*.
Division is a problem, because it is invalid to divide by zero. To test this out, add the following lines to the bottom of the
switch:
case '/': result = arg1 / arg2; break;
Compile and run the code, passing zero as the final parameter:
C:\Beginning_C++Chapter_02>calc 1 / 0 1 / 0 = inf
The code ran successfully, and printed out the expression, but it says that the result is an odd value of
inf. What is happening here?
The division by zero assigned
result to a value of
NAN, which is a constant defined in
<math.h> (included via
<cmath>), and means "not a number." The
double overload of the insertion operator for the
cout object tests to see if the number has a valid value, and if the number has a value of
NAN, it prints the string
inf. In our application, we can test for a zero divisor, and we treat the user action of passing a zero as being an error. Thus, change the code so that it reads as follows:
case '/': if (arg2 == 0) { cout << endl << "divide by zero!" << endl; return 1; } else { result = arg1 / arg2; } break;
Now when the user passes zero as a divisor, you will get a
divide by zero! message.
You can now compile the full example and test it out. The application supports floating-point arithmetic using the
+,
-,
*, and
/ operators, and will handle the case of dividing by zero.
In this chapter, you have learned how to format your code, and how to identify expressions and statements. You have learned how to identify the scope of variables, and how to group collections of functions and variables into namespaces so that you can prevent name clashes. You have also learned the basic plumbing in C++ of looping and branching code, and how the built-in operators work. Finally, you put all of this together in a simple application that allows you to perform simple calculations at the command line.
In the following chapter, you will learn about working with memory, arrays, and pointers.
|
https://www.packtpub.com/product/modern-c-efficient-and-scalable-application-development/9781789951738
|
CC-MAIN-2021-21
|
refinedweb
| 14,632
| 63.93
|
Version 2.104 can be downloaded from here:
Sorry for taking so long to get this out. I have had both my linux and
windows machines re-installed since the last release (a year ago!), and
lost some of my install scripts. I re-wrote them, except for the linux
rpm script. Also did not include the linux compiled package. This
would likely not be that useful, as I think, because of a shared libc
file, it would not run on older linux boxes anyway. If anyone really
wants the rpm and/or linux compiled packages, let me know and maybe we
can reserect those.
This release is from the 2.104 branch, so should be stable (lots of folk
running on that code). It does not include the recent Insteon changes
that Gregg has been working on in the main branch, as well as Howard's
recent organizer changes. Now that I have the install scripts
re-done and am better settled here in New York, I should be able to more
easily and more quickly do the next release as needed.
I doubt anyone will want to read this in detail, but for completeness,
SVN change log is attached. 231 changes in the last year, a bit over 4
per week.
Bruce
--------
**
*Detailed List of Changes from the SVN log:*
Gregg Liming :: Fri Oct 5 2007 - Revised parsing of state_monitor and
device_monitor so that they properly strip spaces and allow both colon
and equals signs as delimitters. Bug idenfified by Ron Klinkien.
Matthew Williams :: Tue Sep 25 2007 - Made some print_logs dependent on
Debug flags as per Chris Barrett's suggestion.
Matthew Williams :: Tue Sep 25 2007 - Dave Lounsberry's patch to
vv_tts.pl to fix a few problems: 1. vv_tts.pl errors out on missing
right bracket. # ./vv_tts.pl -help Missing right curly or square bracket
at ./vv_tts.pl line 296, at end of line syntax error at ./vv_tts.pl line
296, at EOF Execution of ./vv_tts.pl aborted due to compilation errors.
I noticed that sometime since 2.100 was released the end curly bracket
for the BEGIN statement was moved up to the end of last line with text
instead of on a line by itself. Moving the bracket back to a line by
itself fix the error on what I run, perl 5.8.8 on Linux/Ubuntu. There is
a comment on that line about making perl2exe happy. Maybe that change
was required for perl2exe? Not sure. 2. I use the swift TTS engine which
was not released back when I wrote vv_tts a long time ago. Added swift
as an -engine option along side theta. Also changed the debug line
noting the engine used. 3. Change some minor cosmetics and my email address.
Matthew Williams :: Tue Sep 18 2007 - Fixing iButton list routine so
that it doesn't repeat results twice if you don't have a second iButton
serial port. Bug report and fix supplied by Chris Barrett.
Gregg Liming :: Wed Sep 12 2007 - Force reinit of organizer_tasks on
reload in case reload action causes empty tasks.tab.
Gregg Liming :: Mon Sep 10 2007 - Constrained output of element color to
print_log to occur only if debug is set to weather_graph. Bug and
suggested fix provided by Chris Barrett.
Gregg Liming :: Wed Sep 5 2007 - Protect against bad date formats
(entered via web or perhaps from the flawed "stock" tab files).
Gregg Liming :: Wed Sep 5 2007 - Trap write errors when upgrading vsDBs
(if permissions or ownership is wrong).
Gregg Liming :: Wed Sep 5 2007 - Rewrite vsdb upgrade function to be
"safe" to include handling absent databases and databases w/ differing
existing schemas.
Gregg Liming :: Tue Sep 4 2007 - Ensure setby in set_receiver_RF_item is
set to 'rf'.
Gregg Liming :: Mon Sep 3 2007 - Wrap vsDB access code with eval to
prevent errors from leaving incompletely generated organizer_*.pl code.
Gregg Liming :: Fri Aug 31 2007 - Fix support for x10 security devices
(e.g., ms10a). Fix based on submission from James Armstrong.
Gregg Liming :: Fri Aug 31 2007 - Fix proper generation of speak
announcement for all day events.
Gregg Liming :: Fri Aug 31 2007 - Update version id to 2.104.
Matthew Williams :: Wed Aug 29 2007 - Copied from: trunk revision 1176
Creating branch for 2.104 stabilization.
Gregg Liming :: Sun Aug 26 2007 - Change add method to support adding an
array of devices
Gregg Liming :: Sun Aug 26 2007 - Add task category and exception driven
scheduling (initial) support.
Gregg Liming :: Sun Aug 26 2007 - Fix handling of startdate for tasks
and add task category support.
David Norwood :: Sun Aug 26 2007 - documentation updates
David Norwood :: Sun Aug 26 2007 - changed monitoring to include x10
commands transmitted by the Ocelot
David Norwood :: Sun Aug 26 2007 - downloaded latest area code list from
internet
David Norwood :: Sun Aug 26 2007 - documentation updates
David Norwood :: Sun Aug 26 2007 - Minor changes
David Norwood :: Sun Aug 26 2007 - I added support for ANALOG_SENSOR items.
David Norwood :: Sun Aug 26 2007 - I enabled the photo resize feature,
which was not functional before. There are new ini parameters to control
this. See mh/bin/mh.ini for details.
Howard Plato :: Sat Aug 25 2007 - Significant rewrite of the calendar
and organizer code, allowing importing of iCal calendars directly into
MH. To use edit the i2v.cfg and add the appropriate config_parms
specified in organizer.pl. Kudos to Gregg for the huge assistance and
contribution to making this work! The web scripts still need some work
as data can be entered without format checking and will be updated at a
later date.
Gregg Liming :: Sat Aug 25 2007 - Forward on all "display_room" parms in
route_display_rooms to allow extending to other device functions.
Gregg Liming :: Fri Aug 24 2007 - Initial submission of the win32
wrapper to ical2vsdb.
Gregg Liming :: Fri Aug 24 2007 - Protect against undefined Tk grid object.
Gregg Liming :: Fri Aug 24 2007 - Libs needed for iCal support (see
newest bin/ical2vsdb and code/common/organizer.pl)
Matthew Williams :: Thu Aug 23 2007 - Mike Pieper's patch to add EIB15
support to EIB_Items and to add more detailed state support for EIB7 to
http_server.pl. I also added descriptions for the recently added EIB3/4
stuff to the top of EIB_Items.pm
Gregg Liming :: Thu Aug 23 2007 - Added use reference to Weather_Common.
Thanks to "declang" for the bug catch.
Matthew Williams :: Wed Aug 22 2007 - Reverted r1158's patch to
Voice_Text that I accidently included in the EIB patch.
Matthew Williams :: Wed Aug 22 2007 - Added Ralf Kl�Á�be's enhancements
that add EIB3 and EIB4 functionality.
Matthew Williams :: Sun Aug 19 2007 - Added RK's patch to allow EIS5
values to be sent from MH to the bus.
Gregg Liming :: Tue Aug 14 2007 - Force print statements at startup to
be controlled by debug=zone_minder.
Gregg Liming :: Tue Aug 14 2007 - Add "writable" method so that class
works well with Base_Item.pm and other inherited classes.
David Norwood :: Mon Aug 13 2007 - I fixed a bug that Matthew Williams
found that caused X10_Appliance items to always display as Off on the
buttons web interface. I introduced the bug six months ago when I
modified the interpretation of the $level instance variable for dimmers,
but forgot to also test appliance items. I also modified X10_Appliance
so its on off status is restored after a reload.
Gregg Liming :: Wed Aug 8 2007 - Wrapped event eval with pair of package
statements so that evaluation occurred in main namespace and not
AnalogSensor_Item.
Gregg Liming :: Wed Aug 8 2007 - Add call to check_tied_event_conditions
in measurement method to ensure that event conditions are evaluated.
Other minor errata improvements. Changes prompted by Andy McCallum.
Gregg Liming :: Tue Aug 7 2007 - Added ability to optionally flip first
and last names (when no comma delim) based on ini param,
cid_reverse_names set. This is needed to compensate for certain US phone
systems that can't/won't do things correctly.
Gregg Liming :: Tue Aug 7 2007 - Allow non-US formatted phone numbers
(such as VoIP extensions, etc.) to be parsed from callerid logs.
Gregg Liming :: Sun Aug 5 2007 - Reverted to version prior to DOS attack
fix due to problems encountered with POST.
Howard Plato :: Sun Aug 5 2007 - added a file check to ensure that image
files are not overwritten by 'file not found' message
Howard Plato :: Sun Aug 5 2007 - Fixed minor spelling mistake on title
window
Howard Plato :: Sun Aug 5 2007 - Added config_parms to make 2.103 code
act like 2.102 (async speech, no voice response to voice_cmd's)
Howard Plato :: Sun Aug 5 2007 - Updated phone log system. caller id
information is now updated while system is running, rather than reading
in files at startup. Also includes wav and group functionality. Also
includes updated set_func.pl by David S. that properly escapes single quotes
Howard Plato :: Sat Aug 4 2007 - minor change to fix find_members that
will work with SysDiag_xAP items
Gregg Liming :: Sat Aug 4 2007 - Update reference to reliance of oxc to
now include owfs.
Howard Plato :: Sat Jul 28 2007 - Minor fix to allow fontsize if no
$fontname. status_line now works for Audrey (font=1)
Gregg Liming :: Sat Jul 28 2007 - Prevent remote DOS exploitation by
sending false http header size value; instead, read socket data as it
exists and failover accordingly.
Gregg Liming :: Fri Jul 27 2007 - Setup setby as "web [ipaddress]" for
voice command so that the respond will properly target the browser *if*
the voice command menus are used in the context of web (vice nonweb).
Gregg Liming :: Fri Jul 27 2007 - Rename pa_control_stub to
xap_pa_control_stub so that this common code can coexist w/ pa_control.pl
Gregg Liming :: Thu Jul 26 2007 - Alternatively, echo messages received
by the hub from mh back to mh if debug=xap or debug=xpl
Gregg Liming :: Thu Jul 26 2007 - Allow hub to echo mh generated xAP or
xPL messages back to mh listener port if xap_hub_echo=1 or xpl_hub_echo=1
Matthew Williams :: Wed Jul 25 2007 - Reverted part of David Norwood's
r1101 patch to http_server.pl that inadvertantly introduced a security
hole. All users that are using r1101 or above are stronly advised to
upgrade to this rev. Many thanks Chris Barrett for discovering the problem.
David Norwood :: Sat Jul 21 2007 - Committed a bunch of changes on
behalf of Chris Barrett
Gregg Liming :: Fri Jul 20 2007 - Allow use of simple "instance" names
(e.g., "house) or fully qualified xAP source address to initialize
attached xAP_Item as listener.
Gregg Liming :: Fri Jul 20 2007 - Allow use of simple "instance" name
(e.g., house) as xAP source address or fully qualified xAP source
address when initializing attached BSC_Items (as listeners).
Gregg Liming :: Fri Jul 13 2007 - Align xPL send methods to recent
changes to xAP_Items.pm
Gregg Liming :: Fri Jul 13 2007 - Added on_set_message to permit ease of
automating xpl-cmnd messages sent when setting an xPL_Item. [based on
requests by Andy McCallum]. Additional, misc. bug fixes.
Bruce Winter :: Tue Jul 10 2007 - - generalize security check for ../ in
url pats.
Gregg Liming :: Tue Jul 3 2007 - Prevent "state_value" tracking from
reverting to message summary if the tracked state_value key is missing
from the message. Change resulting from testing/suggestion from Andy
McCallum.
Gregg Liming :: Thu Jun 21 2007 - Initial implementation provided by
Howard Plato. Provides support to collect systems informtation reported
by psixc (also implemented by hplato). psixc is available at
Gregg Liming :: Thu Jun 21 2007 - Added support for ANALOG_SENSOR_R
items and update to include new separate AnalogSensor_Item lib
Gregg Liming :: Thu Jun 21 2007 - Refactored AnalogSensor_Item out for
use as a separate lib
Gregg Liming :: Thu Jun 21 2007 - AnalogSensor_Item was refactored from
OneWire_xAP to be more common and usable for other purposes.
Gregg Liming :: Thu Jun 7 2007 - Don't send volume property in tts.speak
if it is blank.
David Norwood :: Mon Jun 4 2007 - updated documentation so it displays
better on the common code activation web interface
David Norwood :: Mon Jun 4 2007 - changed trigger code
David Norwood :: Mon Jun 4 2007 - fixed minor bug
David Norwood :: Mon Jun 4 2007 - fixed minor bug
Gregg Liming :: Mon Jun 4 2007 - Fix flaw with composing UID in query method
Gregg Liming :: Mon Jun 4 2007 - Add support for xAP cid.incoming schema
Gregg Liming :: Mon Jun 4 2007 - Add support for the param:
callerid_raw_numbers such that the "raw" CID number string is spoken
rather than "speakable" text. This is useful when forwarding on to xAP
speak.
Gregg Liming :: Mon Jun 4 2007 - Add ability to support other xAP
sources than oxc--specifically, allowing flexibility with source addressing
Matthew Williams :: Fri May 11 2007 - Missing semicolon inserted.
Matthew Williams :: Fri May 11 2007 - Previous attempt to fix the
weather graph color problem caused a failure for default installations
as the default apparent temperature was set to '' and there was no check
for empty colors.
Matthew Williams :: Tue May 8 2007 - Fixed problem where graph color
customizations were ignored. Bug and fix provided by Rick Steeves.
Gregg Liming :: Wed Apr 25 2007 - Revised sending xAP weather messages
to be more compliant (to include appropriate units switching) to the
current schema
Jason Sharpee :: Sun Apr 15 2007 - Add support for anti-water hammer
zone overlap. ->|zone_hammer(5)|; #5 second zone overlap
Matthew Williams :: Sun Apr 8 2007 - Fixed rate rate calculation. Bug
and fix found by Greg Satz.
David Norwood :: Fri Apr 6 2007 - added trigger
Gregg Liming :: Thu Apr 5 2007 - Allow BSC_Items to represent "gateways"
not just "endpoints".
Gregg Liming :: Mon Apr 2 2007 - Extended manual method to allow
optional on-state timer and off-state timer so that manual mode will
revert to automatic mode after "x" seconds. Added restrict_off property
to control whether a Light_Restriction item will prevent a Light item
from turning off.
Jason Sharpee :: Sun Apr 1 2007 - - Generic Irrigation cycle logic
Jason Sharpee :: Sun Apr 1 2007 - - Generic Irrigation cycle logic
Jason Sharpee :: Tue Mar 27 2007 - - Add support for the WGL Designs
Rain8 UPB sprinkler controller:
Jason Sharpee :: Tue Mar 27 2007 - Add WGL Designs Rain8 UPB sprinkler
controller support.
David Norwood :: Mon Mar 26 2007 - added some sanity checks to the items
web interface
David Norwood :: Mon Mar 26 2007 - modified the mh4 interface to work
with internet explorer 7, including changes to http_server.pl which fix
"target" frame syntax for item lists. Also fixed some problems related
to X10 brightness levels displayed on the web interface
David Norwood :: Mon Mar 26 2007 - added a new resume instance variable
to X10_Item to hold the level the light will come back on at. This was
being stored in the level variable but that meant we couldn't tell if
the light was off in certain cases
Matthew Williams :: Sun Mar 25 2007 - Added CM11 macro clearing code
copied from heyu along with the appropriate copyright notice. This code
is currently not proven.
Matthew Williams :: Sun Mar 25 2007 - Added "--alt-y-grid" to parameters
for generating pressure graphs to have saner y-axis grid spacing.
Gregg Liming :: Tue Mar 20 2007 - Prevent errors thrown if no
ZM_ZoneItems are attached to the monitor (credit to Bruce W. for
identifying the fix)
Gregg Liming :: Tue Mar 6 2007 - Minor annoyance fix: reduce debug
verbosity for state_now section processing
Matthew Williams :: Thu Mar 1 2007 - Applied Chris Barrett's patch to
allow complete configuration of activity detection timers. The
configuration parameter MS13_Battery_timer now correctly controls
activity timeouts.
Matthew Williams :: Thu Mar 1 2007 - Disabled saving process states in
Windows as we don't have a method for successfuly regaining visibility
of Windows child processes.
Jason Sharpee :: Mon Feb 26 2007 - CruiseControl Status Monitor Plugin
for Misterhouse.
Matthew Williams :: Sat Feb 24 2007 - Made "die" message more verbose
when the rrd_dir can't be opened.
Matthew Williams :: Sat Feb 17 2007 - Updated "creators" regex as
"Archie" comic web page source changed. The new regex is more forgiving.
Matthew Williams :: Fri Feb 16 2007 - Patch to internet_im.pl to allow
sessionless Jabber authorization. This code allows {password_allow}
regexes to match on the Jabber id stripped of its session. Patched
supplied by Brian Rudy.
Gregg Liming :: Mon Feb 12 2007 - Add support for messenger.cmd/event
xAP schema--the default for xAP Four and axc.
Gregg Liming :: Mon Feb 12 2007 - Allow xAPSend to support a single
value rather than a hash--as is needed to support sending xAPBSC.query
messages.
Matthew Williams :: Wed Feb 7 2007 - Fixed typos that referred to legacy
{foobar_ws} weather elements instead of the new {foobar} weather
elements. Bug found by Mike Bahr.
Gregg Liming :: Thu Jan 25 2007 - Added "allow_local_set_state(flag)"
method to allow a change over the default behavior (which allows any
programatic set to cause a state change) and instead (if flag set to 0)
requires state change only on receipt of the device's BSC event or info
message. Change resulting from need established by Martin Hagelin.
Matthew Williams :: Sun Jan 21 2007 - Fixed some wonky html. Problems
found by Chris Barrett.
Matthew Williams :: Sun Jan 21 2007 - Modified purging of old data to
keep data from today through 7 days from now. Change suggested by Jim Duda.
Jim Duda :: Tue Jan 16 2007 - I qualified the print_log statement with
$::Debug{network} in order to remove some chatter from the log files.
Jim Duda :: Tue Jan 16 2007 - I turned all the print statements into
print statements with a $main::Debug{group} qualifier in order to remove
some chatter from the log files.
Matthew Williams :: Fri Jan 12 2007 - Updated rules for speed bump and
archie.
Gregg Liming :: Thu Jan 11 2007 - Remove check on setby == $self in
BSC's set method. Bug identified by Martin Hagelin
Matthew Williams :: Thu Jan 11 2007 - Added new creators class to handle
changes to the following comics: - B.C. - Andy Capp - Wizard of Id
Bruce Winter :: Thu Jan 11 2007 - Mark Monnin updated lib/TI103 to
Handle the limited transmit buffer and CRC messages and changed the
support of PRESET_DIM1 and PRESET_DIM.
David Norwood :: Wed Jan 10 2007 - added sanity checks for data input by
user, spaces in item name converted to underscores
David Norwood :: Sun Jan 7 2007 - Minor doc change
David Norwood :: Sun Jan 7 2007 - Added "set ramp rate" and "set on
level" states for SwitchLincs
David Norwood :: Sun Jan 7 2007 - Fixed to work with item files that
have spaces in name, will now create item file if none exists.
Matthew Williams :: Sun Jan 7 2007 - Moved all '<base target="...">'
into <head> sections, creating new <head> sections where needed. This is
to fix frame issues with IE7.
Matthew Williams :: Sun Jan 7 2007 - Moved mh/web/organzier/vsEmail.pm
to mh/lib and removed mh/web/organizer/vsLock.pm as a duplicate version
already exists in mh/lib.
Matthew Williams :: Sun Jan 7 2007 - Removed v1.3.0 of vsDB.pm from
mh/lib and moved v1.3.9 from mh/web/organizer to mh/lib.
Matthew Williams :: Sat Jan 6 2007 - Changed foxtrot to use gocomic's
DRM scheme.
Matthew Williams :: Sat Jan 6 2007 - Added ability to specify font face
in status lines.
Matthew Williams :: Sat Jan 6 2007 - Modified "clearing" logic. Instead
of erasing old data from a single day only, it clears all old data,
except the data from the past few days.
Matthew Williams :: Sat Jan 6 2007 - Added logic to limit humidity to
100% when calculated from dew point and temperature. If there are
measurement errors or the sources for outdoor temp and dew point are
different, then this is a possibility.
Matthew Williams :: Sat Jan 6 2007 - Added a mh specified block that
searches all @INC paths for libnet.cfg, allowing existing site specific
network configs to be used
Matthew Williams :: Sat Jan 6 2007 - Changed voice command "set the
house mp3 player ..." to "set house mp3 player ..." to make it
consistent with mp3.pl's "set house mp3 player to playlist...". Change
suggested by Rick Steeve's
Matthew Williams :: Sat Jan 6 2007 - Corrected recognition of
internet_internet_usgl.pl - Rick Steeven to internet_usgs.pl - Rick Steeve.
Matthew Williams :: Sat Jan 6 2007 - Added support for Jabber services
that require component_name to be set. One example is Google Talk. Code
submitted by Brian Rudy.
Matthew Williams :: Sat Jan 6 2007 - Fixed unintentional comment split typo.
Matthew Williams :: Sat Jan 6 2007 - Added support for water sensor from
ibuttonlink. Code from Rick Steeves.
Matthew Williams :: Mon Jan 1 2007 - Modified regexes for temperature,
dew point and pressure as they were occasionally being triggered on the
wrong data fields. For example, the temperature/dew point regex was
being triggered by "R32/6000FT/N"
tbs007 :: Wed Dec 20 2006 - added 3 message types for the RCS UPB Thermostat
Bruce Winter :: Sun Dec 17 2006 - John Wohlers added
code/common/internet_weather_noaa.pl to collect and parse the XML
weather data feeds from NOAA and populates the Weather_Common hash.
Jim Duda :: Wed Dec 13 2006 - I updated the code module to attempt a
restart of the ibws client every hour.
Jim Duda :: Wed Dec 13 2006 - I'm restoring the changes I made to take
advantage of the restore_string method. I found the problem I introduced
to this method. I now have a proper method for handling the @cmd array.
Matthew Williams :: Wed Dec 13 2006 - Two patches from Howard Plato. 1.
New parameter mp3_no_tkupdates that disables the tk interface from
checking the mp3 playlist every second. 2. New parameter
net_mail_scan_timeout_cycles that allows internet_mail.pl to check VERY
slow mail servers without prematurely timing out.
Matthew Williams :: Wed Dec 13 2006 - Fixed some minor doc issues found
by Rick Steeves.
Matthew Williams :: Wed Dec 13 2006 - Forgot to increase the regex index
in rev 1052. This completes the patchs.
Matthew Williams :: Wed Dec 13 2006 - Patch submitted by Gregg Liming.
Changed one of the regex patterns to allow PoPs to be reported as "near
x percent".
Gregg Liming :: Wed Dec 13 2006 - Allow less restricted eval on checking
tied conditions to permit references to undeclared refs. In addition,
include eval error in reported (printed) error.
Gregg Liming :: Mon Dec 11 2006 - Modify handling of info_callback to
ignore state=toggle (Submitted by Martin Hagelin)
Jim Duda :: Mon Dec 11 2006 - I'm backing out the recent changes that I
made to Process_Item.pl to use the restore_string method. There is
something wrong, causing duplicates in the process $cmd string. I need
to do better regression testing before pushing these changes.
Matthew Williams :: Sun Dec 10 2006 - Made windows library paths
absolute instead of relative. Commented out waitpid when sound_fork is
used. This is to prevent unnecessary pauses on Linux boxes.
Gregg Liming :: Sat Dec 9 2006 - Adjusted parsing to accomodate extra
LNs. Altered URLs to match current preference. Submission thanks to
Winston Gadsby.
Matthew Williams :: Thu Dec 7 2006 - Fixed small bug where a file handle
wasn't being closed.
Matthew Williams :: Thu Dec 7 2006 - Fixed bug found by Dan Stern with
patch suggested by Jim Serack. Added uppercase conversion to
&X10_Interface::processData as there are cases (such as with
x10_rf_relay) where incoming data may be in lower case and mh's X10 code
relies on the data being uppercase..
Gregg Liming :: Wed Dec 6 2006 - Force processing of respond targets if
the object's target property or the target parm is declared. Pass the
app param as well.
Matthew Williams :: Fri Nov 24 2006 - Modifed sensor validation regex to
allow whitespace before and after sensor value. This ability was
requested by Jim Duda to support his weather_iB_OWW_client.pl changes.
Jim Duda :: Fri Nov 24 2006 - I modified this code segment to use the
latest %Weather hash values. This module now calls
Weather_Common::weather_updated to annouce the updates. This module uses
the weather_uom variables to do unit conversions. I removed the updates
to windchill as those updates are done in Weather_Common now.
Matthew Williams :: Wed Nov 22 2006 - Changed default file format for MS
TTS generated files from 8 bit 8 kHz to 16 bit 16 kHz as the former
wasn't being correctly written to the file. Also added additional
conditional debug statements.
Jim Duda :: Mon Nov 20 2006 - I added the restore_active method to the
restore_string method. This is necessary to add the process to the
active_processes array upon restart. Failure to do so prevents a process
to be harvested when it completes after a resart is executed.
Gregg Liming :: Fri Nov 17 2006 - Added support for "peer-based" speech
proxies so that individual mh instances can proxy speech for each other.
In addition, added per-function parms to enable/disable operation.
Defaults to everything enabled.
Gregg Liming :: Mon Nov 13 2006 - Fix faulty calculation of measurement
change on submission of measurement
Matthew Williams :: Thu Nov 9 2006 - Howard Plato's modified "newclock"
that fits Audrey better and pulls the temperature directly from
$Weather{TempOutdoor}.
Matthew Williams :: Wed Nov 8 2006 - Howard Plato's improvements to the
built-in calendar that allow days to be marked as holidays and/or
vacations. organizer_vmode.pl will use this data to automatically set
$mode_occupied to 'vacation' if today is a vacation day.
Gregg Liming :: Mon Nov 6 2006 - Force measurement_change evaluation to
absolute value
Gregg Liming :: Mon Nov 6 2006 - Added measurement_change method to
report latest change in measurement
Matthew Williams :: Thu Nov 2 2006 - Upgraded all libwww related
libraries. We moved from v5.68 to v5.805. This upgrade is intended to
resolve incompatibilities between previously upgraded libraries.
Jason Sharpee :: Tue Oct 31 2006 - Fix Default fade rate
Matthew Williams :: Mon Oct 30 2006 - Committed Ben Griffith's updates
to rrd_graph_web. rrd_graph_web.pl was leaking memory due to a bug in
the RRD library. Ben has split off the graph generation stuff into a
separate system call. As well, the CSS file has been renamed as it was
previously misspelled.
Gregg Liming :: Mon Oct 30 2006 - Fix direct dim quoting in combo boxes
Matthew Williams :: Sun Oct 29 2006 - Fixed logic in &state. If $@ was
set upon entry to &state, then a Weather_Item eval error would be
printed if an undefined Weather item was being evaluated and $valid was
set to 1. In other words, a Weather_Item eval error would be printed
even if it was a previous eval error that caused $@ to be populated. In
the reworked logic, the print statement is only reached if an eval
statement is actually executed and an error is generated by that eval
statement.
Matthew Williams :: Sun Oct 29 2006 - Modifed ia5 earthquake interface
to use earthquakes.txt instead of earthquakes.finger. Also added a
default earthquakes.txt into standard data directory.
Matthew Williams :: Sun Oct 29 2006 - Highly modified standard MD5.pm to
always use the pure PERL interface, not the object file based interface.
This is to prevent incompatibilities with locally installed versions of
object files.
Matthew Williams :: Sun Oct 29 2006 - Added set_clock method to allow
easier setting of the DSC system clock.
Matthew Williams :: Sun Oct 29 2006 - Added sending of initial poll as
sometimes the first command sent generates an API Command Syntax Error.
The poll is a NOP, so we use it to work around this problem before
sending "real" commands.
Matthew Williams :: Sat Oct 28 2006 - Updated LWP library.
Matthew Williams :: Sat Oct 28 2006 - Changing case of mediatypes.pm to
MediaTypes.pm to prepare for library upgrade.
Matthew Williams :: Sat Oct 28 2006 - Added new config parms to more
precisely control which weather elements are populated by each internet
weather module. Fixed problem with wind gust handling in weather_aws.
Thanks to David Satterfield for reporting this bug.
Matthew Williams :: Sat Oct 28 2006 - Added units to reported wind speeds.
Matthew Williams :: Sat Oct 28 2006 - Fixed bug where negative numbers
in sensors weren't supported. Credit to Howard Plato for identifying the
bug.
Matthew Williams :: Sat Oct 28 2006 - Added ti103 and ncpuxa to
@Serial_Item::supported_interfaces and
@X10_Interface::X10_Interface_Names. Fixed small typo in comments within
Device_Item.pm.
Matthew Williams :: Thu Oct 26 2006 - Added configurable levels of
warnings within Dummy_Interface to allow users to suppress warnings when
Dummy_Interfaces are not a bad thing (rare, but possible). One example
of this situation is when there is no X10 transmitter present, only a
receiver. Each X10_Item will then have a Dummy_Interface as its
{interface} as we can not transmit these codes.
Matthew Williams :: Thu Oct 26 2006 - Modified definition of process
item to use double quotes around URL, instead of single quotes, so that
Windows doesn't choke on it.
Gregg Liming :: Thu Oct 26 2006 - Enable an ability to prevent state
updates to BSC items if the state value hasn't changed. The default is
to set state anytime a BSC info is received. The method
"always_set_state" can be used to disable this function. Fix implemented
based on suggestions from Martin Hagelin.
Gregg Liming :: Tue Oct 24 2006 - Allow optional use of "tk" in device
parm. Also support tk, alpha, etc. devices in route_display_rooms as.
These and previous display related mods suggested as mod/bug fixes per
David Satterfield.
Gregg Liming :: Tue Oct 24 2006 - Removed extaneous return from
main::display
Matthew Williams :: Tue Oct 24 2006 - Modified @INC to make mh lib
directories relative to $Pgm_Root (instead of the current directory) and
changed call in comic_dailystrips.pl to include full path to mh. This
fixes the problem of dailystrips not being able to find its required
libraries. In particular, on my system, if I didn't have a non-mh copy
of URI::_foreign.pm, then dailystrips would not work. More detail: one
of the first things that dailystrips does is to change the CWD to
'basedir' which makes the current directory relative INC library paths
no longer work.
Gregg Liming :: Tue Oct 24 2006 - Correct main::display so that multiple
devices will have their display functions called.
Matthew Williams :: Tue Oct 24 2006 - Added recognition of mode=mute and
mode=offline parameters to prevent Audrey from speaking.
Matthew Williams :: Tue Oct 24 2006 - Added additional delays between
each initialization command to prevent buffer overruns.
Matthew Williams :: Tue Oct 24 2006 - Escaped URL in process definition
as & was incorrectly being interpreted by the shell. Bug report and fix
from David Satterfield.
Matthew Williams :: Mon Oct 23 2006 - Removed debug statement from
handy_net_utilities.pl regarding loading the Jabber library. Added
Digest::base - required by other Digest libraries.
Gregg Liming :: Mon Oct 23 2006 - Ensure incoming data is defined (i.e.,
valid) before accepting for subsequent processing
Matthew Williams :: Sat Oct 21 2006 - Changed some responds to speaks
and fixed problem where rain would be reported when rain fall was 0.00
units (Perl treats '0.00' as a true value).
Matthew Williams :: Sat Oct 21 2006 - Added TLS support to jabber.
Updated Authen::SASL libraries and added Auth::SASL::Perl pod.
Matthew Williams :: Sat Oct 21 2006 - Fixed typo in windchill calculation.
Jason Sharpee :: Sat Oct 21 2006 - Remove debug prints
Jason Sharpee :: Sat Oct 21 2006 - Handle retransmissions and drop
duplicates. Remove debuging print statements
Gregg Liming :: Thu Oct 19 2006 - Fix ability for a BSC_Item to be set.
Set values are "folded" into one of state, level and/or text based on
the state value passed to set. Uid is automatically detected and persisted.
Gregg Liming :: Thu Oct 19 2006 - Added uid method to xAP_Item and
automatically extract xAP uid during data parse
Jim Duda :: Wed Oct 18 2006 - I filled in the restore_item member
function to allow the process id (pid) to be retained through a restart
or code reload. Before this change, any processes started before the
reload would be orphaned to mh and could not be stopped.
Jim Duda :: Wed Oct 18 2006 - I corrected a race condition which occured
across a restart or a reload due to a timer update condition. The timer
was getting reset to the initial period value instead of the remaining
value attached to the timer.
Matthew Williams :: Tue Oct 17 2006 - Patched handy_net_utilities.pl to
correctly access the Net::Jabber library. Upgraded Digest libraries to
latest versions so that the Net::Jabber library works.
Bruce Winter :: Tue Oct 17 2006 - Timo Sariwating sent in Nico's
K8000.zip code for supporting the Vellman K8000 board
Jason Sharpee :: Tue Oct 17 2006 - Push the speed of the interface up a
little to the brink of failure ;)
Jason Sharpee :: Sun Oct 15 2006 - Make the acknowledge mode
configurable in derived classes.
Jason Sharpee :: Sun Oct 15 2006 - Prevent loops on unavailable devices.
Slow up command stack processing to give the bus some time to respond to
incoming messages. Upon device add, query the devices initial status.
Matthew Williams :: Sun Oct 15 2006 - Changed X10_Sensor constructor to
not pass its $id to the X10_Item constructor to prevent the standard X10
states being added to the X10_Sensor object. This was causing duplicate
events. Thanks to Chris Barrett for reporting the bug and helping to
diagnose the problem.
Jason Sharpee :: Sat Oct 14 2006 - Optimize the state retrieving code
Jason Sharpee :: Sat Oct 14 2006 - Turn on acknowledge confirmation.
Jason Sharpee :: Sat Oct 14 2006 - Implement command queue system.
Implement Acknowledge messages. Turn on acknowledge at protocol level.
Various fixes and code cleanups.
Jason Sharpee :: Sat Oct 14 2006 - Set the default acknowledgement
protocols off. Make the 2way device support work for all other commands,
not just lights.
Jason Sharpee :: Sat Oct 14 2006 - Support UPB PIM 'busy signal' and
resend command until it is processed. Bug reported by Adam D. (thank you)
Jason Sharpee :: Sat Oct 14 2006 - Created a generic 'Scene' object for
MH such that any device can participate in a 'software' scene even if
the hardware doesnt.
Jason Sharpee :: Sat Oct 14 2006 - Created a generic 'Scene' object for
MH such that any device can participate in a 'software' scene even if
the hardware doesnt.
Gregg Liming :: Thu Oct 12 2006 - Prefer raw_text to text in respond_telnet
Gregg Liming :: Thu Oct 12 2006 - Make telnet server use tracked respond
and allow telnet to be supported by speach echo tag
Gregg Liming :: Thu Oct 12 2006 - Make $search_command_string use
object's respond--not global respond
Jason Sharpee :: Thu Oct 12 2006 - Add support for UPB_Link (UPBL)
device definition: UPBL, upb_family_movie, myPIM, 49,1
Jason Sharpee :: Thu Oct 12 2006 - Add UPB_Link class.
Jason Sharpee :: Thu Oct 12 2006 - Add support for UPB_Link sub class.
Add Support for 'status' generic command. Fix: Argument parsing on
device state report.
Jason Sharpee :: Thu Oct 12 2006 - Fix: UPB Link recognition
Matthew Williams :: Tue Oct 10 2006 - Added RainTotal and RainRate as
valid internet sourced weather elements.
Gregg Liming :: Tue Oct 10 2006 - Extend
AnalogSensor_Item->map_to_weather to include an optional graph_title
argument that will be used by RRDs when creating graphs.
Matthew Williams :: Sun Oct 8 2006 - Added &:: in front of calls to
convert_c2f. Thanks to Chris Barrett for finding the first bug in 2.103!
Gregg Liming :: Sun Oct 8 2006 - Modified to illustrate use of
AnalogSensor_Item tokens
|
http://sourceforge.net/p/misterhouse/mailman/misterhouse-announce/thread/472E93C9.4050007@gmail.com/
|
CC-MAIN-2014-15
|
refinedweb
| 5,826
| 63.7
|
1.5 Calling Functions and Methods
Scala has functions in addition to methods. It is simpler to use mathematical functions such as min or pow in Scala than in Java—you need not call static methods from a class.
sqrt(2) // Yields 1.4142135623730951 pow(2, 4) // Yields 16.0 min(3, Pi) // Yields 3.0
The mathematical functions are defined in the scala.math package. You can import them with the statement
import scala.math._ // In Scala, the _ character is a "wildcard," like * in Java
We discuss the import statement in more detail in Chapter 7. For now, just use import packageName._ whenever you need to import a particular package.
Scala doesn’t have static methods, but it has a similar feature, called singleton objects, which we will discuss in detail in Chapter 6. Often, a class has a companion object whose methods act just like static methods do in Java. For example, the BigInt companion object to the BigInt class has a method probablePrime that generates a random prime number with a given number of bits:
BigInt.probablePrime(100, scala.util.Random)
Try this in the REPL; you’ll get a number such as 1039447980491200275486540240713. Note that the call BigInt.probablePrime is similar to a static method call in Java.
Scala methods without parameters often don’t use parentheses. For example, the API of the StringOps class shows a method distinct, without (), to get the distinct letters in a string. You call it as
"Hello".distinct
The rule of thumb is that a parameterless method that doesn’t modify the object has no parentheses. We discuss this further in Chapter 5.
|
http://www.informit.com/articles/article.aspx?p=1849235&seqNum=5
|
CC-MAIN-2019-51
|
refinedweb
| 276
| 67.65
|
I have a set of data that I want to display in a dataTable EXCEPT for the rows where type='NAM'.
Is there some way to do this with rich:dataTable?
If not I can alter my query, but I'd prefer to do it in richfaces if possible.
Version 3.3.X.
Thanks,
TDR
I don't think it does (But I'd be delighted to be shown something I've been missing all this time !)
The other thing is that it's not always possible - let alone wise - to limit your queries. We're using JPA, and sometimes we want our tables to show the "child" collection of a master record. Unfortunately, with JPAQL, there's no way to filter the query of child collections (since JPAQL doesn't have WITH, so we can't have "LEFT JOIN m.child WITH ..."). Oh, the amount of horrid workarounds I've seen, with people trying to maintain their own lists.
The simplest solution, I reckon, is to have a stateless utility bean, and put your filtering in there - eg. with Seam:
@Name("filterBean")
@Scope(SESSION)
public class FilterBean {
public static List<T> notNam( Collection<T> collection ) {
List<T> result = new ArrayList<T>();
// filter away .....
return result;
}
Your xhtml is then :
<rich:datatable
value = "#{ filterBean.notNam ( yourBean.yourCollection ) }"
You can then let the users add or remove to the collection, and still let Hibernate or whatever look after the merging (since the collection is still the full collection retrieved from the database).
|
https://developer.jboss.org/thread/156315
|
CC-MAIN-2017-34
|
refinedweb
| 251
| 69.21
|
Math::Geometry::Delaunay - Quality Mesh Generator and Delaunay Triangulator
Version 0.14
use Math::Geometry::Delaunay qw(TRI_CCDT); # generate Delaunay triangulation # and Voronoi diagram for a point set my $point_set = [ [1,1], [7,1], [7,3], [3,3], [3,5], [1,5] ]; my $tri = new Math::Geometry::Delaunay(); $tri->addPoints($point_set); $tri->doEdges(1); $tri->doVoronoi(1); # called in void context $tri->triangulate(); # populates the following lists $tri->elements(); # triangles $tri->nodes(); # points $tri->edges(); # triangle edges $tri->vnodes(); # Voronoi diagram points $tri->vedges(); # Voronoi edges and rays
# quality mesh of a planar straight line graph # with cross-referenced topological output my $tri = new Math::Geometry::Delaunay(); $tri->addPolygon($point_set); $tri->minimum_angle(23); $tri->doEdges(1); # called in scalar context my $mesh_topology = $tri->triangulate(TRI_CCDT); # returns cross-referenced topology # make two lists of triangles that touch boundary segments my @tris_with_boundary_segment; my @tris_with_boundary_point; foreach my $triangle (@{$mesh_topology->{elements}}) { my $nodes_on_boundary_count = ( grep $_->{marker} == 1, @{$triangle->{nodes}} ); if ($nodes_on_boundary_count == 2) { push @tris_with_boundary_segment, $triangle; } elsif ($nodes_on_boundary_count == 1) { push @tris_with_boundary_point, $triangle; } }
This is a Perl interface to the Jonathan Shewchuk's Triangle library.
." -- from
Triangle has several option switches that can be used in different combinations to choose a class of triangulation and then configure options within that class. To clarify the composition of option strings, or just to give you a head start, a few constants are supplied to configure different classes of mesh output.
TRI_CONSTRAINED = 'Y' for "Constrained Delaunay" TRI_CONFORMING = 'Dq0' for "Conforming Delaunay" TRI_CCDT = 'q' for "Constrained Conforming Delaunay" TRI_VORONOI = 'v' to generate the Voronoi diagram
For an illustration of these terms, see:
The constructor returns a Math::Geometry::Delaunay object.
my $tri = Math::Geometry::Delaunay->new();
Run the triangulation with specified options, and either populate the object's output lists, or return a hash reference giving access to a cross-referenced representation of the mesh topology.
Common options can be set prior to calling
triangulate. The full range of Triangle's options can also be passed to
triangulate as a string, or list of strings. For example:
my $tri = Math::Geometry::Delaunay->new('pzq0eQ'); my $tri = Math::Geometry::Delaunay->new(TRI_CCDT, 'q15', 'a3.5');
Triangle's command line switches are documented here:
After triangulate is invoked in void context, the output mesh data can be retrieved from the following methods, all of which return a reference to an array.
$tri->triangulate(); # void context - no return value requested # output lists now available $points = $tri->nodes(); # array of vertices $tris = $tri->elements(); # array of triangles $edges = $tri->edges(); # all the triangle edges $segs = $tri->segments(); # the PSLG segments $vpoints = $tri->vnodes(); # points in the voronoi diagram $vedges = $tri->vedges(); # edges in the voronoi diagram
Data may not be available for all lists, depending on which option switches were used. By default, nodes and elements are generated, while edges are not.
The members of the lists returned have these formats:
nodes: [x, y, < zero or more attributes >, < boundary marker >] elements: [[x0, y0], [x1, y1], [x2, y2], < another three vertices, if "o2" switch used >, < zero or more attributes > ] edges: [[x0, y0], [x1, y1], < boundary marker >] segments: [[x0, y0], [x1, y1], < boundary marker >] vnodes: [x, y, < zero or more attributes >] vedges: [< vertex or vector >, < vertex or vector >, < ray flag >]
Boundary markers are 1 or 0. An edge or segment with only one end on a boundary has boundary marker 0.
The ray flag is 0 if the edge is not a ray, or 1 or 2, to indicate which vertex is actually a unit vector indicating the direction of the ray.
Import of the mesh data from the C data structures will be deferred until actually requested from the list fetching methods above. For speed and lower memory footprint, access only what you need, and consider suppressing output you don't need with option switches.
When triangulate is invoked in scalar or array context, it returns a hash ref containing the cross-referenced nodes, elements, edges, and PSLG segments of the triangulation. In array context, with the "v" switch enabled, the Voronoi topology is the second item returned.
my $topology = $tri->triangulate(); $topology now looks like this: { nodes => [ { # a node point => [x0, x1], edges => [edgeref, ...], segments => [edgeref, ...], # a subset of edges elements => [elementref, ...], marker => 1 or 0 or undefined, # boundary marker attributes => [attr0, ...] }, ... more nodes like that ], elements => [ { # a triangle nodes => [noderef0, noderef1, noderef2], edges => [edgeref0, edgeref1], neighbors => [neighref0, neighref1, neighref2], attributes => [attrib0, ...] }, ... more triangles like that ], edges => [ { nodes => [noderef0, noderef1], # only one for a ray elements => [elemref0, elemref1], # one if on boundary vector => undefined or [x, y], # ray direction marker => 1 or 0 or undefined, # boundary marker index => <integer> # edge's index in edge list }, ... more edges like that ], segments => [ { nodes => [noderef0, noderef1], elements => [elemref0, elemref1], # one if on boundary marker => 1 or 0 or undefined # boundary marker }, ... more segments ] }
Corresponding Delaunay triangles and Voronoi nodes have the same index number in their respective lists.
In the topological output, any element in a triangulation has a record of its own index number that can by used to look up the corresponding node in the Voronoi diagram topology, or vice versa, like so:
($topo, $voronoi_topo) = $tri->triangulate('v'); # get a triangle reference where the index is not obvious $element = $topo->{nodes}->[-1]->{elements}->[-1]; # this gets a reference to the corresponding node in the Voronoi diagram $voronoi_node = $voronoi_topo->{nodes}->[$element->{index}];
Corresponding edges in the Delaunay and Voronoi outputs have the same index number in their respective edge lists.
In the topological output, any edge in a triangulation has a record of its own index number that can by used to look up the corresponding edge in the Voronoi diagram topology, or vice versa, like so:
($topo, $voronoi_topo) = $tri->triangulate('ev'); # get an edge reference where it's not obvious what the edge's index is $delaunay_edge = $topo->{nodes}->[-1]->{edges}->[-1]; # this gets a reference to the corresponding edge in the Voronoi diagram $voronoi_edge = $voronoi_topo->{edges}->[$delaunay_edge->{index}];
Corresponds to the "a" switch.
With one argument, sets the maximum triangle area constraint for the triangulation. Returns the value supplied. With no argument, returns the current area constraint.
Passing -1 to
area_constraint() will disable the global area constraint.
Corresponds to the "q" switch.
With one argument, sets the minimum angle allowed for triangles added in the triangulation. Returns the value supplied. With no argument, returns the current minimum angle constraint.
Passing -1 to
minimum_angle() will cause the "q" switch to be omitted from the option string.
These methods simply add or remove the corresponding letters from the option string. Pass in a true or false value to enable or disable. Invoke with no argument to read the current state.
Triangle prints a basic summary of the meshing operation to STDOUT unless the "Q" switch is present. This module includes the "Q" switch by default, but you can override this by passing a false value to
quiet().
If you would like to see even more output regarding the triangulation process, there are are three levels of verbosity configurable with repeated "V" switches. Passing a number from 1 to 3 to the
verbose() method will enable the corresponding level of verbosity.
Takes a reference to an array of vertices, each vertex itself an reference to an array containing two coordinates and zero or more attributes. Attributes are floating point numbers.
# vertex format # [x, y, < zero or more attributes as floating point numbers >] $tri->addPoints([[$x0, $y0], [$x1, $y1], ... ]);
Use addVertices to add vertices that are not part of a PSLG. Use addPoints to add points that are not part of a polygon or polyline. In other words, they do the same thing.
Takes a reference to an array of segments.
# segment format # [[$x0, $y0], [$x1, $y1]] $tri->addSegments([ $segment0, $segment1, ... ]);
If your segments are contiguous, it's better to use addPolyline, or addPolygon.
This method is provided because some point and polygon processing algorithms result in segments that represent polygons, but list the segments in a non-contiguous order, and have shared vertices repeated in each segment's record.
The segments added with this method will be checked for duplicate vertices, and references to these will be merged.
Triangle can handle duplicate vertices, but we would rather not feed them in on purpose.
Takes a reference to an array of vertices describing a curve. Creates PSLG segments for each pair of adjacent vertices. Adds the new segments and vertices to the triangulation input.
$tri->addPolyline([$vertex0, $vertex1, $vertex2, ...]);
Takes a reference to an array of vertices describing a polygon. Creates PSLG segments for each pair of adjacent vertices and creates and additional segment linking the last vertex to the first,to close the polygon. Adds the new segments and vertices to the triangulation input.
$tri->addPolygon([$vertex0, $vertex1, $vertex2, ...]);
Like addPolygon, but describing a hole or concavity - an area of the output mesh that should not be triangulated.
There are two ways to specify a hole. Either provide a list of vertices, like for addPolygon, or provide a single vertex that lies inside of a polygon, to identify that polygon as a hole.
# first way $tri->addHole([$vertex0, $vertex1, $vertex2, ...]); # second way $tri->addPolygon( [ [0,0], [1,0], [1,1], [0,1] ] ); $tri->addHole( [0.5,0.5] );
Hole marker points can also be used, in combination with the "c" option, to cause or preserve concavities in a boundary when Triangle would otherwise enclose a PSLG in a convex hull.
Takes a polygon describing a region, and an attribute or area constraint. With both the "A" and "a" switches in effect, three arguments allow you to specify both an attribute and an optional area constraint.
The first argument may alternately be a single vertex that lies inside of another polygon, to identify that polygon as a region.
To be used in conjunction with the "A" and "a" switches.
# with the "A" switch $tri->addRegion(\@polygon, < attribute > ); # with the "a" switch $tri->addRegion(\@polygon, < area constraint > ); # with both "Aa" $tri->addRegion(\@polygon, < attribute >, < area constraint > );
If the "A" switch is used, each triangle generated within the bounds of a region will have that region's attribute added to the end of the triangle's attributes list, while each triangle not within a region will have a "0" added to the end of its attribute list.
If the "a" switch is used without a number following, each triangle generated within the bounds of a region will be subject to that region's area constraint.
If the "A" or "a" switches are not in effect, addRegion has the same effect as addPolygon.
The following methods retrieve the output lists after the triangulate method has been invoked in void context.
Triangle's output data is not imported from C to Perl until one of these methods is invoked, and then only what's needed to construct the list requested. So there may be a speed or memory advantage to accessing the output in this way - only what you need, when you need it.
The methods prefixed with "v" access the Voronoi diagram nodes and edges, if one was generated.
Returns a reference to a list of nodes (vertices or points).
my $pointlist = $tri->nodes(); # retrieve nodes/vertices/points
The nodes in the list have this structure:
[x, y, < zero or more attributes >, < boundary marker >]
Returns a reference to a list of elements.
$triangles = $tri->elements(); # retrieve triangle list
The elements in the list have this structure:
[[x0, y0], [x1, y1], [x2, y2], < another three vertices, if "o2" switch used > < zero or more attributes > ]
Returns a reference to a list of segments.
$segs = $tri->segments(); # retrieve the PSLG segments
The segments in the list have this structure:
[[x0, y0], [x1, y1], < boundary marker >]
Returns a reference to a list of edges.
$edges = $tri->edges(); # retrieve all the triangle edges
The edges in the list have this structure:
[[x0, y0], [x1, y1], < boundary marker >]
Note that the edge list is not produced by default. Request that it be generated by invoking
doEdges(1), or passing the 'e' switch to
triangulate().
Returns a reference to a list of nodes in the Voronoi diagram.
$vpointlist = $tri->vnodes(); # retrieve Voronoi vertices
The Voronoi diagram nodes in the list have this structure:
[x, y, < zero or more attributes >]
Returns a reference to a list of edges in the Voronoi diagram. Some of these edges are actually rays.
$vedges = $tri->vedges(); # retrieve Voronoi diagram edges and rays
The Voronoi diagram edges in the list have this structure:
[< vertex or vector >, < vertex or vector >, < ray flag >]
If the edge is a true edge, the ray flag will be 0. If the edge is actually a ray, the ray flag will either be 1 or 2, to indicate whether the the first, or second vertex should be interpreted as a direction vector for the ray.
This function is meant as a development and debugging aid, to "dump" the geometric data structures specific to this package to a graphical representation. Takes key-value pairs to specify topology hashes, output file, image dimensions, and styles for the elements in the various output lists.
The topology hash input for the
topo or
vtopo keys is just the hash returned by
triangulate. The value for the
file key is a file name string. Omit
file to print to STDOUT. For
size, provide and array ref with width and height, in pixels. For output list styles, keys correspond to the output list names, and values consist of references to arrays containing style configurations, as demonstrated below.
Only geometry that has a style configuration will be displayed. The following example includes everything. To display a subset, just omit any of the style configuration key-value pairs.
($topo, $vtopo) = $tri->triangulate('ve'); to_svg( topo => $topo, vtopo => $vtopo, file => "enchilada.svg", # omit for STDOUT size => [800, 600], # width, height in pixels # line width or optional # svg color point radius extra CSS nodes => ['black' , 0.3], edges => ['#CCCCCC', 0.7], segments => ['blue' , 0.9, 'stroke-dasharray:1 1;'], elements => ['pink'] , # string or callback; see below # these require Voronoi input (vtopo) vnodes => ['purple' , 0.3], vedges => ['#FF0000', 0.7], vrays => ['purple' , 0.6], circles => ['orange' , 0.6], );
Note that for display purposes
vedges does not include the infinite rays in the Voronoi diagram. To see the complete Voronoi diagram, including segments representing the infinite rays, you should include style configuration for the
vrays key, as in the example above.
Elements (triangles) only need one style config entry, for color. (An optional second entry would be a string for additional CSS.) In this case, the first entry can also be a reference to a callback function. A reference to the triangle being processed for display will be passed to the callback function. Therefore the callback function can determine a color based on any features or relationships of that triangle.
Typically you might color each triangle according to the region it's in, by using Triangle's 'A' switch, and then reading the region attribute from the last item in the triangle's attribute list.
my $region_colors_callback = sub { my $tri_ref = shift; return ('gray','blue','green')[$tri_ref->{attributes}->[-1]]; };
But any other data accessible through the triangle reference can be used to calculate a color. For instance, the triangle's three nodes can carry any number of attributes, which are interpolated during mesh generation. You might shade each triangle according to the average of a node attribute.
my $tri_nodes_average_callback = sub { my $tri_ref = shift; my $sum = 0; # calculate average of the eighth attribute in all nodes foreach my $node (@{$tri_ref->{nodes}}) { $sum += $node->{attributes}->[7]; } return &attrib_val_to_grayscale_hexcode( $sum / 3 ); };
Warning: not yet thoroughly tested; may move elsewhere
One use of the Voronoi diagram of a tessellated polygon is to derive an approximation of the polygon's medial axis by pruning infinite rays and perhaps trimming or refining remaining branches. The approximation improves as intervals between sample points on the polygon become shorter. But it's not always desirable to multiply the number of polygon points to achieve short intervals.
At any point on the true medial axis, there is a maximum inscribed circle, with it's center on the medial axis, and tangent to the polygon in at least two places.
The
mic_adjust() function moves each Voronoi node so that it becomes the center of a circle that is tangent to the polygon at two points. In simple cases this is a maximum inscribed circle, and the point is on the medial axis. And when it's not, it still should be a much better approximation than the original point location. The radius to the tangent on the polygon is stored with the updated Voronoi node.
After calling
mic_adjust(), the modified Voronoi topology can be used as a list of maximum inscribed circles, from which can be derive a straighter, better medial axis approximation, without having to increase the number of sample points on the polygon.
($topo, $voronoi_topo) = $tri->triangulate('e'); mic_adjust($topo, $voronoi_topo); # modifies $voronoi_topo in place foreach my $node (@{$voronoi_topo->{nodes}}) { $mic_center = $node->{point}; $mic_radius = $node->{radius}; ... }
Constructing a true medial axis is much more involved - a subject for a different module. Until that module appears, running topology through
mic_adjust() and then walking and pruning the Voronoi topology might help fill the gap.
Currently Triangle's option strings are exposed to give more complete access to its features. More of these options, and perhaps certain common combinations of them, will likely be wrapped in method-call getter-setters. I would prefer to preserve the ability to use the option strings directly, but it may be better at some point to hide them completely behind a more descriptive interface.
Michael E. Sheldrake,
<sheldrake at cpan.org>
Triangle's author is Jonathan Richard Shewchuk
Please report any bugs or feature requests to
bug-math-geometry-delaunay at rt.cpan.org
or through the web interface at
I will be notified, and then you'll automatically be notified of progress on your bug as I make changes.
You can find documentation for this module with the perldoc command.
perldoc Math::Geometry::Delaunay
You can also look for information at:
Thanks go to Far Leaves Tea in Berkeley for providing oolongs and refuge, and a place for paths to intersect.
This Perl binding to Triangle is free software; you can redistribute it and/or modify it under the terms of either: the GNU General Public License as published by the Free Software Foundation; or the Artistic License.
See for more information.
Triangle by Jonathan Richard Shewchuk, copyright 2005, includes the following notice in the C source code. Please refer to the C source, included in with this Perl module distribution, for the full notice.
This program may be freely redistributed under the condition that the copyright notices (including this entire header and the copyright notice printed when the `-h' switch is selected) are not removed, and no compensation is received. Private, research, and institutional use is free. You may distribute modified versions of this code UNDER THE CONDITION THAT THIS CODE AND ANY MODIFICATIONS MADE TO IT IN THE SAME FILE REMAIN UNDER COPYRIGHT OF THE ORIGINAL AUTHOR, BOTH SOURCE AND OBJECT CODE ARE MADE FREELY AVAILABLE WITHOUT CHARGE, AND CLEAR NOTICE IS GIVEN OF THE MODIFICATIONS. Distribution of this code as part of a commercial system is permissible ONLY BY DIRECT ARRANGEMENT WITH THE AUTHOR. (If you are not directly supplying this code to a customer, and you are instead telling them how they can obtain it for free, then you are not required to make any arrangement with me.)
|
http://search.cpan.org/~sheldrake/Math-Geometry-Delaunay-0.14/lib/Math/Geometry/Delaunay.pm
|
CC-MAIN-2014-23
|
refinedweb
| 3,245
| 50.77
|
Liane Praza's Weblog
(Open)Solaris: getting started
OpenSolaris has arrived. It is
an amazing thing to be able to share with the world what we've all been
pouring our lives into for so long. I realized that a great place to start
would be my first putback to Solaris as part of the kernel group. I'd had
more than a passing familiarity with Solaris as part of the team that released
Sun Cluster 3.0. As the cluster software was intricately tied to Solaris, I
had a number of opportunities to do minor modifications to Solaris to make it
interoperate better with the clustering software. But, by 2001 I was in the
big leagues -- I had joined the larger team primarily responsible for the
code released today in OpenSolaris.
Almost everyone new to Solaris starts by fixing a few bugs, and
I expect that will be common for new people contributing to OpenSolaris too. Fixing a small-ish bug is
the best way to figure out what's really involved in putting code back into
(Open)Solaris. My first bug was
4314534: NFS cannot be controlled by SRM. Essentially, our resource
management tools work on LWPs, not kernel threads. NFS ran as a bunch of
kernel threads, so administrators were unable to have NFS as a managed
resource; it often took priority over other applications on the system. A
senior engineer had already suggested an approach:
A better way to solve this would be to have nfsd (or lockd) create the
lwps. nfsd can park a thread in the kernel (in some nfssys call) that
blocks until additional server threads are needed. It can then return to
user level, call thread_create (with THR_BOUND) for however many lwps are
needed, and park itself again. Since this will only happen when growing the
NFS server thread pool, the performance impact should be negligible. The
newly created lwps will similarly make an nfssys call to park themselves in
the kernel waiting for work to do. The threads parked in the kernel should
still be interruptible so that signals and /proc control works correctly.
If the server pool needs to shrink, an appropriate number of lwps simply
return to user level and exit.
The userland code was pretty simple, and is shared between nfsd and lockd in
thrpool.c. svcwait()
calls svcblock() which hangs around in
the kernel (by using _nfssys(SVCPOOL_WAIT, &id)) until a thread is
needed. Then it starts up a new thread for
svcstart():
svcwait()
svcblock()
_nfssys(SVCPOOL_WAIT, &id)
svcstart()
/*
* Thread to call into the kernel and do work on behalf of NFS.
*/
static void *
svcstart(void *arg)
{
int id = (int)arg;
int err;
while ((err = _nfssys(SVCPOOL_RUN, &id)) != 0) {
/*
* Interrupted by a signal while in the kernel.
* this process is still alive, try again.
*/
if (err == EINTR)
continue;
else
break;
}
/*
* If we weren't interrupted by a signal, but did
* return from the kernel, this thread's work is done,
* and it should exit.
*/
thr_exit(NULL);
return (NULL);
}
SVCPOOL_WAIT and SVCPOOL_RUN were new sub-options
to the _nfssys() system call. They needed to be defined in
nfssys.h
then added in
nfs_sys.c.
SVCPOOL_WAIT
SVCPOOL_RUN
_nfssys()
nfssys.h
nfs_sys.c
I also had to make the additions and modifications to
usr/src/uts/common/rpc/svc.c (unfortunately still encumbered) to
signal the userland thread instead of directly creating new kernel thread
workers. The design is described by the comment for
p_signal_create_thread and friends in
rpc/svc.h:
usr/src/uts/common/rpc/svc.c
p_signal_create_thread
rpc/svc.h
/*
* Userspace thread creator variables.
* Thread creation is actually done in userland, via a thread
* that is parked in the kernel. When that thread is signaled,
* it returns back down to the daemon from whence it came and
* does the lwp create.
*
* A parallel "creator" thread runs in the kernel. That is the
* thread that will signal for the user thread to return to
* userland and do its work.
*
* Since the thread doesn't always exist (there could be a race
* if two threads are created in rapid succession), we set
* p_signal_create_thread to FALSE when we're ready to accept work.
*
* p_user_exit is set to true when the service pool is about
* to close. This is done so that the user creation thread
* can be informed and cleanup any userland state.
*/
Of course, much to my chagrin, the change had unforeseen implications,
which caused bug
4528299. Fixing that was fun and required changes to
lwp.c. I'll talk about that in a subsequent post.
lwp.c
None of this is particularly sexy or subtle, but.. hopefully now you
see the type of place we all start with Solaris (and now OpenSolaris). A disclaimer is also
required. I'm by no means an NFS expert -- those who were simply allowed
me into their code to accomplish a specific task. Check out blogs by actual
NFS experts like Spencer Shepler and
David Robinson for more detailed
NFS information.
Technorati Tag: OpenSolaris
Technorati Tag: Solaris
Today's Page Hits: 117
|
http://blogs.sun.com/lianep/date/20050614
|
crawl-002
|
refinedweb
| 839
| 72.26
|
Tech Tips archive
May 09, 2000
WELCOME to the Java Developer Connection (JDC)
Tech Tips, May 09, 2000.
This issue of the JDC Tech Tips is written by Glen McCluskey.
These tips were developed using Java
2 SDK, Standard Edition,
v 1.2.2, and are not guaranteed to work with other versions.
If you've used the standard Java package java.io, you're probably
familiar with I/O classes such as InputStream and BufferedReader.
These classes support sequential I/O on files. That is, you read
a file starting at the beginning, or write a file from its
beginning or by appending to it.
java.io
InputStream
BufferedReader
The class java.io.RandomAccessFile operates a little differently.
It supports random access, that is, access where you can set
a file pointer to an arbitrary offset (represented as a 64-bit
long value), and then perform I/O from that position.
java.io.RandomAccessFile
Unlike classes such as FileInputStream, RandomAccessFile is not
part of the InputStream/OutputStream hierarchy; you can't say:
FileInputStream, RandomAccessFile
InputStream/OutputStream
InputStream istr = new RandomAccessFile(...);
RandomAccessFile identifies file locations according to byte
offsets. In the Java language, bytes and characters are
distinct. A character is made up of two bytes, so a particular
byte offset in a file of characters doesn't necessarily represent
a location of a character.
RandomAccessFile
The RandomAccessFile class implements the DataInput and DataOutput
interfaces. These support methods like readInt and writeUTF to read
and write standard data types in a uniform way. For example, if you
use writeInt to write an integer to a file, you can then use readInt
to read the integer back from the file, with byte-ordering issues
automatically handled for you.
DataInput
DataOutput
readInt
writeUTF
writeInt
To see how RandomAccessFile might be useful, consider an application
with a large legacy database of fixed-length records. These records
are accessed in random order. For example, the records might
represent a hash table on disk, or some type of complex linked data
structure. The application needs to read a specific record in the
database without having to read all the records before it.
Here is an illustration of this application using two programs, the
first is a C program that writes a database. The database represents
the legacy part of the application. The format of records in the
database is:
number of records as a two-byte short
name of a person, up to 25 bytes,
unused bytes 0 filled
birthdate month as a two-byte short
birthdate day as a two-byte short
birthdate year as a two-byte short
...
The C program looks like this:
#include <stdio.h>
#include <&string.h>
/* structure of a record */
struct Rec {
char* name;
short month;
short day;
short year;
};
/* birthdate/name record */
struct Rec data[] = {
{"Jane Jones", 3, 17, 1959},
{"Bill Smith", 2, 27, 1947},
{"Maria Thomas", 12, 23, 1954},
{"Mortimer Smedley Williams",
9, 24, 1957},
{"Jennifer Garcia Throckmorton",
11, 9, 1963}
};
short NUMVALUES = sizeof(data) /
sizeof(struct Rec);
/* write a short to a file */
void writeShort(FILE* fp, short s) {
fputc((s >> 8) & 0xff, fp);
fputc(s & 0xff, fp);
}
/* write a sequence of
bytes to a file */
void writeBytes(FILE* fp, char* buf, size_t n) {
fwrite(buf, 1, n, fp);
}
int main() {
int i;
/* open the output file */
FILE* fpout = fopen("out.data", "wb");
if (fpout == NULL) {
fprintf(stderr, "Cannot open
output file\n");
return 1;
}
/* write out the number of values */
writeShort(fpout, NUMVALUES);
/* write the data to the file */
for (i = 0; i < NUMVALUES; i++) {
struct Rec* p = &data[i];
char outbuf[25];
/* write the name, truncating
if necessary */
strncpy(outbuf, p->name,
sizeof outbuf);
writeBytes(fpout, outbuf,
sizeof outbuf);
/* write month/day/year */
writeShort(fpout, p->month);
writeShort(fpout, p->day);
writeShort(fpout, p->year);
}
fclose(fpout);
return 0;
}
You need to be careful about byte ordering when you write data to
a file for later reading by another application. For example, when
the above program writes out short values to the file, it must
ensure that the two bytes of the short are written in the order
that RandomAccessFile.readShort expects them--high byte first,
then low byte. You can't use readShort to read a legacy database
that has values whose bytes are reversed--low byte first, then
high byte. You'd need to read raw bytes and assemble the short
value yourself.
RandomAccessFile.readShort
The Java program that reads the file looks like this:
import java.io.RandomAccessFile;
import java.io.IOException;
public class RAFDemo {
// starting offset in data file,
// past the count of records
static final int STARTING_OFFSET = 2;
// length of a name
static final int NAME_LENGTH = 25;
// bytes in a record (name length +
three shorts)
static final int BYTES_IN_RECORD =
NAME_LENGTH + 2 + 2 + 2;
public static void main(String args[])
throws IOException {
RandomAccessFile raf =
new RandomAccessFile("
out.data", "r");
// read the number of data records
short numvalues = raf.readShort();
byte namebuf[] = new byte[NAME_LENGTH];
// read each record, going backwards
// through the file
for (int i = numvalues - 1; i >= 0; i--) {
// seek to the record
raf.seek(STARTING_OFFSET + i *
BYTES_IN_RECORD);
// read the name as a vector of bytes
raf.read(namebuf);
// convert the name to a string
StringBuffer namesb = new StringBuffer();
for (int j = 0; j < NAME_LENGTH; j++) {
if (namebuf[j] == 0) {
break;
}
else {
namesb.append((char)namebuf[j]);
}
}
// read month/day/year
short month = raf.readShort();
short day = raf.readShort();
short year = raf.readShort();
// display the results
System.out.println(
namesb.toString() + " " +
month + " " + day + "
" + year);
}
}
}
To demonstrate that it can access parts of the database at
random, the program reads the file records in backwards order
and then displays the records. If you run the program, output is:
Jennifer Garcia Throckmor 11 9 1963
Mortimer Smedley Williams 9 24 1957
Maria Thomas 12 23 1954
Bill Smith 2 27 1947
Jane Jones 3 17 1959
The first name has been truncated to 25 characters, to fit the
requirements of record layout stated above.
One issue related to RandomAccessFile concerns strings. The
RAFDemo example just presented reads a legacy database. Strings
in a database record, such as "Jane Jones", are represented
in RAFDemo as a sequence of bytes. To convert the bytes to
a string, the program converts each byte to a character and then
appends it to a StringBuffer.
RAFDemo
StringBuffer
Suppose, however, that you want to use RandomAccessFile with full
16-bit Unicode characters. How can you do this? One way is to use
the readUTF and writeUTF methods found in DataInput and
DataOutput. These represent strings as UTF sequences; 7-bit ASCII
characters are represented as themselves, and other characters as
two or three bytes. The methods read or write two bytes of length
information, followed by the UTF representation as a stream of
bytes. Because the length is stored as two bytes, you cannot write
extremely long strings this way.
readUTF
Another approach to writing strings is to use the writeChars
method. This method writes a sequence of characters (there's no
readChars method). If you use writeChars, you need to write out
the string length first using writeInt.
writeChars
readChars
If you use RandomAccessFile to access fixed-length records
containing strings, you need to determine how you're going to
represent the records. The complication is that strings are
typically variable in length. You need to either truncate strings,
so that all are a fixed length (as in the example above), or
represent the strings in a separate file and record string numbers
in the actual records. For example, you might use an integer field
in a fixed-length record to store a value "37", where 37 represents
the 37th string in a separate file.
For further information about java.io.RandomAccessFile, see "The
Java Language Specification" section 22.23. Also see
"Java 2 Platform, Standard Edition, v 1.2.2 API: Specification: Class RandomAccessFile"
Suppose that you're doing some programming in the Java programming language,
and you have a class that implements an interface. Let's call the
interface A:
interface A {
public void f1();
public void f2();
public void f3();
public void f4();
public void f5();
}
The interface has five methods, but you're only interested in the
first one, f1. So you say:
class B implements A {
public void f1() {/*...*/}
}
Unfortunately, this usage is invalid, and results in a compile
error. For a class to implement an interface, it must define all
the interface's methods. If you make B abstract, the error goes
away, but you can't create objects of an abstract class. If you
extend B to a non-abstract class C, you're presented with the
error again.
To deal with this problem, use "adapter" classes. An adapter
class for A looks like this:
abstract class A_ADAPTER implements A {
public void f1() {}
public void f2() {}
public void f3() {}
public void f4() {}
public void f5() {}
}
Notice that the adapter class implements all the methods of the
interface as dummy methods that do nothing. If you want to extend
f1 to provide your own functionality, you then say:
class B extends A_ADAPTER {
public void f1() {/*...*/}
}
In this case, a user of class B gets the overriding version of the
f1 method, and the dummy version of the f2-f5 methods found in the
abstract class A_ADAPTER.
One place where adapters are used is AWT event handling. The
WindowListener interface specifies seven events that relate to
window handling, and WindowAdapter defines dummy methods for these
events:
WindowListener) {}
WindowAdapter provides dummy implementations of all the methods
that are specified by WindowListener. So if you extend the
WindowAdapter class, you only need to provide implementations
of methods whose default functionality you want to override.
Here's an example that extends WindowAdapter:
import java.awt.event.*;
import javax.swing.*;
public class AdapterDemo {
public static void main(String args[]) {
// set up a frame
JFrame frame =
new JFrame("AdapterDemo");
// set up listeners for
// window iconification
// and for window closing
frame.addWindowListener(
new WindowAdapter() {
public void windowIconified(
WindowEvent e) {
System.out.println(e);
}
public void windowClosing(
WindowEvent e) {
System.exit(0);
}
});
// set up panels and labels
JPanel panel = new JPanel();
JLabel label =
new JLabel("This is a test");
panel.add(label);
// position and display frame
frame.getContentPane().add(panel);
frame.setSize(300, 200);
frame.setLocation(200, 200);
frame.setVisible(true);
}
}
This particular example sets up listeners for the WindowClosing
and WindowIconified (minimized) events, and ignores the others.
Notation like:
WindowClosing
WindowIconified
frame.addWindowListener(new WindowAdapter() {...});
defines an anonymous inner class that extends WindowAdapter.
Similar adapter classes are used for keyboard and mouse event
handling.
For further information about adapters, see the section "AWT
Adapters" in Chapter 9 of the book Graphic Java--Mastering the
JFC, 3rd Edition, Volume 1, AWT, by David Geary. Also see
"Java 2 Platform, Standard Edition, v 1.2.2 API: Specification:
Class WindowAdapter".
The names on the JDC
mailing list
are used for internal Sun Microsystem".
|
http://java.sun.com/developer/TechTips/2000/tt0509.html
|
crawl-002
|
refinedweb
| 1,814
| 62.17
|
ANN_MLP output training value of 1 causes error
When I try to train the network's output neurons to produce a value of 1, it gives me an error saying that "OpenCV Error: One of arguments' values is out of range (Some of new output training vector components run exceed the original range too much)".
The input images are:
dove.png
flowers.png
peacock.png
statue.png
My full code is listed below. Near the end of the code I assign the value of 0.9 and it works. When I switch those values to 1, it fails. Thanks for any help you can provide. Otherwise, the training and testing are successful.
This is odd because when doing the XOR operation, it can train for 1:...
Anyway, here's the code:
(more)(more)
#include <opencv2/opencv.hpp> using namespace cv; #pragma comment(lib, "opencv_world331.lib") #include <iostream> #include <iomanip> using namespace cv; using namespace ml; using namespace std; float round_float(const float input) { return floor(input + 0.5f); } void add_noise(Mat &mat, float scale) { for (int j = 0; j < mat.rows; j++) { for (int i = 0; i < mat.cols; i++) { float noise = static_cast<float>(rand() % 256); noise /= 255.0f; mat.at<float>(j, i) = (mat.at<float>(j, i) + noise*scale) / (1.0f + scale); if (mat.at<float>(j, i) < 0) mat.at<float>(j, i) = 0; else if (mat.at<float>(j, i) > 1) mat.at<float>(j, i) = 1; } } } int main(void) { const int image_width = 64; const int image_height = 64; // Read in 64 row x 64 column images Mat dove = imread("dove.png", IMREAD_GRAYSCALE); Mat flowers = imread("flowers.png", IMREAD_GRAYSCALE); Mat peacock = imread("peacock.png", IMREAD_GRAYSCALE); Mat statue = imread("statue.png", IMREAD_GRAYSCALE); // Reshape from 64 rows x 64 columns image to 1 row x (64*64) columns dove = dove.reshape(0, 1); flowers = flowers.reshape(0, 1); peacock = peacock.reshape(0, 1); statue = statue.reshape(0, 1); // Convert CV_8UC1 to CV_32FC1 Mat flt_dove(dove.rows, dove.cols, CV_32FC1); for (int j = 0; j < dove.rows; j++) for (int i = 0; i < dove.cols; i++) flt_dove.at<float>(j, i) = dove.at<unsigned char>(j, i) / 255.0f; Mat flt_flowers(flowers.rows, flowers.cols, CV_32FC1); for (int j = 0; j < flowers.rows; j++) for (int i = 0; i < flowers.cols; i++) flt_flowers.at<float>(j, i) = flowers.at<unsigned char>(j, i) / 255.0f; Mat flt_peacock(peacock.rows, peacock.cols, CV_32FC1); for (int j = 0; j < peacock.rows; j++) for (int i = 0; i < peacock.cols; i++) flt_peacock.at<float>(j, i) = peacock.at<unsigned char>(j, i) / 255.0f; Mat flt_statue = Mat(statue.rows, statue.cols, CV_32FC1); for (int j = 0; j < statue.rows; j++) for (int i = 0; i < statue.cols; i++) flt_statue.at<float>(j, i) = statue.at<unsigned char>(j, i) / 255.0f; Ptr<ANN_MLP> mlp = ANN_MLP::create(); // Slow the learning process //mlp->setBackpropMomentumScale(0.1); // Neural network elements const int num_input_neurons = dove.cols; // One input neuron per grayscale pixel const int num_output_neurons = 2; // 4 images to classify, so number of bits needed is ceiling ...
what are you trying to achieve here ? ann needs one-hot encoding, setting both output neurons to 0.9 does not make any sense.
I remembered error problem in python 3.5...the index is out of range.. You set value 0.9 is a type of float. When you set value of one..it is not type float. If you want to set value of 1... change to (0,0) instead of (0,1). And see what happened.
@berak Thanks for the information. I am using the encoding scheme where there are n classifications, and ceiling(ln(n)/ln(2)) output neurons. Does one-hot encoding learn faster?
@supra56 -- I just train to give the output values of 0.1 or 0.9 now. Thanks for your expertise.
Anyway, I didn't think having an output value of 1 would cause an error... Setting the activation function to
SIGMOID_SYMgives you a range of [-1.7159, 1.7159]. That leaves lots of room for the output value to be 1. :(
@sjhalayka , if you have 15 classes, you have to set one of your outputs to 1 and the other 14 to 0.
the prediction will return the index of the largest number (the classID), that's all there is to it.
the error stems from either setting more than one neuron to 1, or having all of them at 0
@berak I understand one hot encoding; I just choose not to use it. My copy of "Practical Neural Network Recipes in C++" also uses the scheme that I'm using (see page 16 of 493, if you can find a copy). In fact, it warns against one-hot encoding. Who knows?
your book is from 1993, that is 24 years ago now ! (you probably werent even born then)
That is true, the book is old, but it's not like one-hot encoding is some kind of up and coming leading-edge research area. :D
I was like 16 when that book came out, yeah.
|
https://answers.opencv.org/question/180316/ann_mlp-output-training-value-of-1-causes-error/?answer=180374
|
CC-MAIN-2019-35
|
refinedweb
| 845
| 79.97
|
I have heard endless good things about TypeScript in the last couple years, but I've never really had a chance to use it. So when I was tasked with writing a new API from scratch at work, I decided to use the opportunity to learn TypeScript by jumping into the deep end.
So far, here are my positive takeaways:
- I'm a huge fan of the added intellisense in my IDE (VS Code). I've always found the intellisense for regular JavaScript packages to be a bit flaky for some reason, but it's rock solid with TypeScript.
- The "might be undefined" checks have definitely saved me some time by pointing out places where I need to add a few null checks after
.get()ing something from a
Map, etc.
- I have always liked being able to spell out my classes in JavaScript; I've often gone to extreme lengths to document JS classes with JSDoc.
But I've run into a few significant frustrations that have really slowed me down, and I'm hoping some of my much more experienced TypeScript DEV friends will be able to help me figure them out! 😎
Class types
I can't figure out how to use or declare class types, especially when I need to pass around subclasses that extend a certain base class. This came up for me because I'm using Objection.js, an ORM package that makes heavy use of static getters on classes. I need to pass around subclasses of Objection's
Model class to check relationship mappings and make queries, so I need a way to say, "This parameter is a class object that extends
Model". I wish I had something like:
function handleRelations(modelClass: extends Model) ...
The best I've found so far is to use a rather annoying interface and update it every time I need to use another method from Objection's extensive API, like:
interface IModel { new(): Model query(): QueryBuilder tableName: string idColumn: string | string[] relationMappings: object // etc. } function handleRelations(modelClass: IModel) ...
This works, but it's rather annoying to have to reinvent the wheel this way. Is there a more explicit way to tell TypeScript, "I mean a class extending this type, not an instance of this type"?
Overriding methods with different return types
This is more a best-practice question than anything else. I've run into some cases where a base class declares a method that returns a particular type, but subclasses need to override that method and return a different type. One example is the
idColumn static getter used by Objection models, which can return either a
string or a
string[].
I've found that if I simply declare the base class as returning one type and the subclass as returning another, I get yelled at:
class Animal extends Model { static get idColumn(): string { return 'name' } } class Dog extends Animal { static get idColumn(): string[] { return ['name', 'tag'] } } /* ERROR Class static side 'typeof Dog' incorrectly extends base class static side 'typeof Animal'. Types of property 'idColumn' are incompatible. Type 'string[]' is not assignable to type 'string'. */
If I declare the base class with a Union type, that seems to work, although adding another layer of subclass trying to use the original base class's type no breaks because of the middle class:
class Animal extends Model { static get idColumn(): string | string[] { return 'name' } } class Dog extends Animal { static get idColumn(): string[] { return ['name', 'tag'] } } class Poodle extends Dog { static get idColumn(): string { return 'nom' } } /* Class static side 'typeof Poodle' incorrectly extends base class static side 'typeof Dog'... */
So I'm now torn. I like to be as specific as I can in my method signatures, but it seems I have two choices here: either always use the full union type
string | string[] as the return type of the
idColumn getter for all subclasses, or simply don't declare a return type for subclasses, only the base class:
class Animal extends Model { static get idColumn(): string | string[] { return 'name' } } class Dog extends Animal { // this? static get idColumn(): string | string[] { return ['name', 'tag'] } // or this? static get idColumn() { return ['name', 'tag'] } }
So my question here is, which is better? Is there an accepted paradigmatic solution here? I don't really like either; the former feels slightly misleading, but the latter feels incomplete. I'm leaning toward the latter in this case since it's immediately obvious what the type of a constant return value is, but in more complex cases involving an actual method with some complicated logic, I'm not sure how I'd handle it.
Dealing with simple objects
Okay, this is a more minor annoyance, but it really bugs me. If I just want to say, "This function accepts/returns a plain ol' object with arbitrary keys and values", the only syntax I can find is:
{ [key: string] : any }
Used once on it's own, that's not the worst thing I've ever seen, but I have a method that accepts an object-to-object Map and returns another one, and the method signature looks like this:
function converter(input: Map<{ [key: string] : any }, { [key: string] : any }>): Map<{ [key: string] : any }, { [key: string] : any }>
That's... that's not okay. I've run into more complex example as well, cases where I'm declaring interfaces with nested objects and such, and this syntax makes them near impossible to read. So my solution has been to declare a trivial interface called
SimpleObject to represent, well, a simple object:
interface SimpleObject { [key: string] : any }
And like, that works, but whenever I show anyone my code I have to explain this situation, and it just seems like an oversight that there's apparently no native name for simple objects in TypeScript. Am I missing something?
Conclusion
Thanks to anyone who took the time to read this, and thanks a million to anyone who helps me out or leaves a comment! I'm enjoying TypeScript on the whole, and I'm sure little quirks like this will become natural after a while, but if there is a better way to handle them, I'd love to know! 😁
Discussion
If you look closely to the problems you are having, they are pretty much all class oriented. This is exactly what I found when picking up typescript and eventually abandoned classes and shift to a more functional programming oriented coding style.
I just feel that functions are first class citizen and works better with Typescript then classes. With the way of packaging nowadays, there is not much practical you cannot do without classes.
For example, I would rather use "knex" to build the queries wrapped with functions instead of using an ORM (in your case objection) because I feel like it is more straight forward and faster to get things done, and you have more control over what you want to return.
I definitely get this perspective, and often I do prefer a functional approach over a class based approach. However, in my experience using both query builders like knex and ORMs like Objection, I find the mental mapping between my code and the database much easier to keep straight when I have a class for each table, especially the way that Objection uses static properties like
idColumnand
relationshipMappingsto represent database constraints. Others may feel differently, but it's how my brain works.
MDN explains the Class construct internals nicely. They imply the differences between a Class and Function are minimal.
With the Class, hoisting is not done and the class body is always in strict mode.
developer.mozilla.org/en-US/docs/W...
That is exactly my point. Class in JS is just merely syntactic sugar. It introduces extra layer of complexity with virtually no gain. And that extra regconitive complexity makes it worse when you add typing on top of it.
We could say compilers are syntatic sugar for assembly language too but compilers save time and improve quality.
The Class is not just syntactic sugar as it doesn't hoist and is always strict mode. Functions can hoist and run non strict mode.
Discounting the benefits of Typing via classes is always just subjective.
Many of us prefer Typescript for it's awesome typing support making tons of runtime errors history.
Compilers in certain languages are proven to save time and improve quality (C/C++ for example) and by definition it serves the sole purpose of syntactic sugar. JS Class is arguable.
The strict mode argument is not too convincing either. It is not like we cannot run functions in strict mode. It is basically saying 'if you are afraid that you forget to write that one line of declaration, get used to always writing a class for everything'. Why not just get used to always use strict mode instead?
As I mentioned, very little difference either way. I just don't blanketly subscribe to the 'toss class support for functions' argument. Both work exactly as billed.
The difference is the unnecessary complexity which is big on terms of maintainability of code.
And I don't "blindly subscribe" to the idea. I actually tried to work with both. And coming from an OOP background it was a huge paradigm shift for me. I would suggest you to do the same and explore more.
Saying the class is more complex is subjective.
It is not subjective unless you can point out what can not be achieved without class.
Hi Edward, I have the same experience with your approach to use
typeand
functionsmore than class for simple procedure, transforms, api-layer, and do it in a semi Data Oriented Design way.
The root of the problem is actually the by-the-book OOP usage which doesn't scale for huge projects.
I still use class though to scope different logics and contain data that seemingly has its own runtime.
Interesting idea with DOD Alan, this paradigm seems interestingly common in heavy computation.
I wonder though, would you be able to achieve similar code structure with interfaces?
It is common in heavy computation. DOD is an old code structure design, it was found again on the age of PS3 if I'm not mistaken, because the machine limitation cannot match game developers ambition at that time.
With TypeScript's type (interface is just a syntactic sugar of TypeScript's type) and function, you can achieve a similar code structure, although for a different reason. In programs with heavy computation DoD helps with creating cache-friendly code, in the javascript environment, performance doesn't seem to increase much, but in terms of readability and extensibility, it really improves them.
I have to disagree here. While it's true that the
classsyntax in JS is syntactic sugar on top of functions, that sugar is very sweet. You say it's an extra layer of complexity, but that depends on where you look: it's true that it's an extra layer of syntax on top of the underlying functions and prototype chains, but in my experience
classdeclarations are often way less complex than constructor function and prototype chain statements for the developer reading them.
These two block of code do exactly the same thing. Which is more complex?
vs...
I would strongly argue that the second is less complex for the developer using the code.
Unless what you meant was that classes as a paradigm are syntactic sugar that add unnecessary complexity, regardless of the language in question, in which case I have to disagree even more strongly, though that's a much longer conversation.
One more thing that's bugging me though:
That's just not true. Even if we suppose that classes and functions provide exactly the same capabilities and classes provide no new unique powers, the complexity that matters more in day to day life is the mental complexity for readers of the code. Some developers have an easier time thinking in functional terms and passing objects around between functions. Others (myself included) often find it far easier to think in object oriented terms, where functions are expressed as methods on objects rather than passing objects to functions. In practical terms, it's deeply subjective which paradigm is more complex.
Thanks Ken for the elegant explanation of why some of us prefer the Class construct. Indeed it is more simple; in my mind. It promotes encapsulation in a more clear manner; to me, as well as a default strict mode.
Lots of old school JavaScript interviewers will still ask you about "hoisting" which is non-existent by default with the Class. Why do anything but use the Class? If it's not an issue any longer, why do interviewers want to test your knowledge of "hoisting" even today?
Thanks for the complement, now let me disagree with you 😁
Strict mode isn't something I really worry about; I write strict JS by habit at this point, and I especially don't worry about it since I've started using modules, which are also strict mode by default.
I definitely wouldn't say that hoisting is irrelevant or not an issue any more. One way I still use it all the time is when I write utility scripts. Consider this script:.
Tragically, I also still work on an old Angular.js 1.x project, and we do something similar to structure our Factory and Service files:
In this case, the returned object at the top of the service acts as a sort of Table of Contents for the service. Anyone who opens that service knows immediately what methods it provides, and again, they can ctrl+click directly to the one they're concerned with.
So I wouldn't say that hoisting doesn't matter any more. And as you can probably tell by my examples here, I also don't think classes are the best thing for all cases. But I do love me some classes when dealing with a large amount and variety of structured data with data-type-specific functionality that can be encapsulated as class methods!
Hi Ken, I will start with my appreciation for you taking the time to type in some examples for the discussion. That really helps understanding your rationale and where our disagreement come from.
Let's address the code comparison first. I think class makes it less complex only if you have to stick with inheritance. Let's take a look at the following code:
I went with a factory approach (or what Alan previously mentioned, a semi Data Oriented Design), and the code pretty much look the same as your example with class, except there is no class. However, the benefit here is that you can adopt infinite number of "traits" to your object through composition, which makes it a lot more scalable. On the flip side, you may run into situations when you need multiple inheritance in the case of classes.
This is definitely not I meant. My argument in the discussion here is specifically about classes in Typescript (even Javascript is fine by me. They don't have much gain in my opinion, but there is not much loss either so whichever way is fine).
Again, as Alan has also mentioned in a previous reply, the problem here is the by-the-look OOP. Javascript classes are not actually classes and operate quite different from other class-base languages. I think the problem was not so bad until type enforcement kicks in. You will eventually find yourself running into walls trying to apply common OOP paradigms/pattern. You writing up this post is a good example.
Again, the context here is Typescript. I am not going to claim that class in general is more complex (hell no). But you can see from the example I gave, there is not much different in outcome from a readability perspective, which is what I mean by virtually no gain. The complexity comes from Javascript's expression of classes being misleading and the headaches of trying to apply OOP on top of it.
That definitely clears up your point quite a lot, and there's a lot less distance between our positions than it seemed at first, so I really appreciate the clarification and your example.
I definitely agree in general with composition-over-inheritance approaches like the one you've demonstrated, especially if you have a wide variety of features that need to be combined depending on circumstance. But to be honest, I haven't really run into many circumstances IRL where it's been an issue.
To return to my specific example, I think there's a lot of value to be found in subclassing a common Model class to represent each table in my database, especially given the use fo static getters to represent metadata like which columns are the primary keys and how different tables are related. Additionally, while your example demonstrates how to simulate private instance vars using closures with the
_name,
_energy, and
_breedvars, if you were to modify your example above to add these vars to the returned object and to add static properties to the factory functions, it just feels more and more to me like you're writing a polyfill for the
classkeyword. And at that point, I honestly feel that
classdeclarations are far more readable than these sorts of factory functions, especially when you have several long-time Java devs on your team who are now coming up to speed on JavaScript (as I do) and you want to give them a graceful transition.
And that actually brings me to something else that I'd love to hear your feedback on. You said:
This is something I've heard expressed many, many times by other devs, that JavaScript's classes are fundamentally different from classes in other languages in important ways that make them misleading to devs who transition from these other languages. But in my experience, having written classes in Java, Python, Ruby, and JavaScript (and, in case there's any doubt, as someone who has a very deep understanding of JavaScript's prototype system and how
extendsworks under the hood), I just really haven't found that to be true, aside from the lack of certain functionality like private and protected members, which seem to be coming down the pipe anyhow.
So as someone who clearly has both a strong opinion on the subject and a better understanding of by-the-book OOP and classic design patterns than I do (admittedly, my theory suffers there), what do you see as the most important differences between
classes in JavaScript and other languages, and most importantly, what do you see as misleading about them? I'm genuinely anxious to know, because I've recently entered a role where, as I mentioned, I'm training up a few long-time Java devs in the ways of the web, and I'm anxious to avoid any misconceptions.
This convo is fun :D
I'll throw some opinion that hopefully will help you with this.
Java community and its derivative (Spring Boot, PHP Laravel, Ruby on Rails) to put the "smartness" of their library in the runtime bootstrap process and Objection.js is one of the libraries that walks into their path. In time this will conflict with TypeScript's approach to get types right, which is more of functional approach to type correctness (rust, Haskell, elm).
Let me take a detour a bit:
Edward's example of an object factory has a perfect type and perfect JavaScript encapsulation which is very convenient for people who cares about encapsulation and OOP in general.
As Edward might notice, OOP's paradigm to mix data and operations in a single instance a.k.a
classis where it gets problematic. And it is encouraged by languages like Java and javascript because the structure/prototype is described in the runtime, thus it can be queried a.k.a
Reflection. Reflection is NOT wrong. It's a great feature, but the side effect is that it encourages the wrong approach to a problem, the storytelling.
Structures should be written like how we describe a character in a story, explicit and at once:
And operations should be written like how we describe a scene in a story, step by step, chronologically.
Let that new paradigm sink in. Then, let's rewrite the Animal/Dog code with some bonus code (because I really want to show you guys how this paradigm is development-scalable).
The code above shows a really easy way to get a pretty complex idea done in a simple manner, only by separating
operationsand
structureas opposed to the classical OOP where
methodand
propertyis in one place so that it's confusing whether we should write
attack()or
receiveDamage().
Let's go back to the case of ObjectionJS, we've detoured pretty far.
TypeScript clearly doesn't do much good to the usage of ObjectionJS as it's very complex in terms of type correctness (e.g. idColumn could be string or string[]).
I'd treat ObjectionJS modules as another "unknown territory" in the application, like
localStorage.get,
fetch,
fs.readFileSync,
redisClient.get, etc. Let it be functions that return
unknown. You could practically give
unknownor if not possible
any(forgive me, lord) to the
idColumnand other static method return type.
Now create a funnel function where it returns that unknown object as a result of ObjectionJS query with a precise type or return an error if it is not the expected result.
To scale this pattern let's make a function factory a.k.a higher-order function for it. I'll be using io-ts for the parser to demonstrate the new paradigm. Also, check out io-ts if you haven't, it's a cool lib.
And using the fetch function would be
If you're really sure that your database will always return the correct schema, do this, but I don't recommend this.
The code is long and it's already the optimal amount of code to achieve type correctness in your application.
I guess enforcing strict TypeScript in the ObjectionJS is not the best angle to approach this problem. ObjectionJS is of a different paradigm, and let it be that way because we can't change how it behaves nor we can put a strict TypeScript rule to it.
Let ObjectionJS be unknown. As a substitute, enforce type correctness in the business logic, detached from the resource facing layer.
Ken;
You had asked "How would you restructure that program to use a class?" with respect to the goodness of "hoisting".
If multiple components need to use something in common, I usually abstract the component to an Angular Service today. It gives me that ability to re-use anything anywhere. The only drawback is that I have to import the service in order to reuse the code within it.
@Alan, thanks for the in-depth response! I'll have to take some time to read through it and consider it. Interestingly, I notice that Objection.js actually provides typings, though they seem rather convoluted and maybe more intended for internal library use; what do you think? github.com/Vincit/objection.js/blo...
@john Peters, sure, I think that's a great approach, and personally I don't consider an extra import a drawback at all; if anything, I prefer smaller individual modules, so I'm happy to ad an extra import in exchange for a smaller overall file 😁
@Ken I would take the shortest, easiest, and safest path that scales both in performance and development. TypeScript strict typing is relieving me from constantly fearing "undefined is not a function" issue, but if objection typing turns out to be a burden more than a help to my team, I would consider excluding objection from the strict typing in favor of development efficiency. It's just my opinion though, you know the lib better and might prove me wrong on this.
If you find value in using subclassing in your case, then go for it. I am not going to pretend to be the know-it-all :)
So we pretty much have the same background :)
I think my biggest complaint about JS classes is the encapsulation. Let's see the following code as example:
As you can see
person.talkis not encapsulated as a part of the class
Person. Instead, the context is related to where it is called instead. This problem is especially painful when you work with frontend code (e.g. React). You will find the context being mutable, and will be forced to
bindthem everywhere. So as Alan also mentioned in the other reply, I tend to go with functions and closures in order to workaround this hustle.
Ah I see. Yeah that's definitely a frustration sometimes, and I've dealt with the React issues you mention. That said though, I wouldn't tie that to JavaScript's class system at all; that's just how objects in general work in JavaScript, and it has its pros and cons. While it's true that it can cause some issues, it also facilitates the composition-over-inheritance style you mentioned above, as it lets you copy methods from one object directly to another without any fancy footwork. Pros and cons, I guess
Interesting for sure! I have never seen this before.
Class Encapsulation seems to imply the name property only for the class object. So the behavior you've shown would be expected because mockElement.onClick is not a Person object. Right?
Indeed changing the assignment to const mockElement = this.person gives proper context when calling mockElement.Talk();
It looks to me like the class object's context is not mutable. That's a good thing.
Actually, class object's context is mutable. Let's take a closer look at the example again:
You can actually manipulate the reference of
this. This is what makes it misleading in an OOP perspective because you would have thought the context is part of the encapsulation in the definition. The problem is not strictly coming from javascript classes, but more from the discrepancy of the expected behaviour of how class should be vs how javascript class actually is.
But I really don't think it has anything to do with classes. I think a better statement would be, "The problem is coming from the discrepancy of the expected behavior of how objects should be vs how javascript objects actually are". IMHO, the confusion is identical using a factory:
I can't see this example being any less confusing than the class example just because we don't use the
newkeyword. The confusion all boils down to this step:
Regardless of how we built the
personobject, what's confusing is that the
talkmethod loses its
thiscontext when attached to something else.
Now of course, one way to solve this problem is to use purely private vars and closures like you did in your Animal example, but personally, I have one really big problem with that approach: it makes the properties themselves inaccessible. You can no longer do
doggo.name = 'Fido'to rename your dog. And hey, If all you need is private vars, go for it, but I don't think this approach covers all cases, or even most.
You can, of course, use a getter and a setter for each public property to make them accessible while keeping the closure and its advantages, but at that point the complexity of the code really ramps up while the readability falls, and personally, I just don't know if it's worth the trade-off:
That up there feels like a lot of boilerplate to produce an object with three properties, just so I can occasionally write
myBtn.click = myDoggo.speakinstead of
myBtn.click = () => myDoggo.speak().
This is definitely a personal preference, but I don't think the relatively minor tradeoff of context-free methods is worth it. I personally don't use them nearly often enough to justify that kind of a change across the board. If you do, hey, maybe it's for you, but I personally am so used to JavaScript objects and how functions and
thiswork that it's barely even a frustration, and tbh I just really love the elegance of the
classsyntax. Unpopular opinion, but IMO it will be even better once the class field and private class field syntaxes become standard.
I think that is a fair statement. Regardless, that was fun discussion and I think I learnt something from it :)
Definitely 😁 Thanks to everyone in this thread for the back and forth, it was a good discussion and we made it out without any flames
Ken, thanks for the banter;
."
"I can immediately see the outline"...
Do you mean at the program layer? Is this really different than a class construct where as you pointed out the syntax doesn't require the function keyword?
"ctrl+click my way into whichever part I need to read or mess with at the moment"
From the command line of an IDE? Or in browser console/debug mode?
"Anyone who opens that service knows immediately what methods it provides, and again, they can ctrl+click directly to the one they're concerned with."
I hated AngularJs for the inability to get Service's to expose their properties and functions using Intellisense/Autocomplete. I think you are showing something that worked for AngularJs?
"So I wouldn't say that hoisting doesn't matter any more."
How would you define Hoisting and when to use it over other constructs?
I do mean at the program layer, yes. As far as whether it's really different than a class, I mean... yeah, it is. How would you restructure that program to use a class? Unless you want to go the Java route and use a Main class:
If that's what you mean by using a class construct, then we just have very different preferences, because that's a nightmare to me.
But even if that's your personal preference, the point is that I still see plenty of code written this way by other developers, and it doesn't make sense unless you understand that function declarations are hoisted. My comment was mostly in response to when you said:
My point is that hoisting is still a fundamental aspect of JavaScript and it's pretty important to understand, or at least be aware of, even if you have to look it up from time to time. Not understanding hoisting can lead to some subtle, hard-to-find bugs; I've been there a few times.
Either, I suppose, though I was mostly thinking of an IDE context. My point is that anyone reading my code (including myself) can open the file and see the overview of the file, then quickly jump to the relevant function using standard IDE tools. And IIRC, ctrl+click works in browser dev tools' "Sources"/"Debug" tabs as well.
Totally agree, my biggest frustration with AngularJS is the total lack of intellisense. And no, unfortunately, this doesn't help with intellisense; in fact, it's more important in cases where intellisense doesn't work. The point is that when you see some code saying,
dataService.getVendor(id), you can jump over to
data-service.js, easily see the available methods, and ctrl+click stright to
getVendor()without needing ctrl+f or other mechanisms. It's even more useful in a service that uses its own methods internally, since ctrl+f is less useful in that case.
Hoisting is a step in the interpretation of a JavScript scope wherein all declarations are basically plucked out of their place in the script and moved to the top of the scope. It's not really something you use or don't use, it's just the way JavaScript works.
It's important to note, however, that declarations are hoisted, but initializations are not. So for example, in this code:
You'll get
undefinedas your output. However, function declarations are special because they don't have separate declaration and initialization steps, it's all-in-one, so they get hoisted completely to the top:
And
constand
letare a bit weirder. They do get hoisted, but there's this weird thing called the Temporal Dead Zone where they're defined but not initialized and you'll still get errors if you try to reference them... so a lot of people say they "aren't hoisted", which is technically not true, but it might as well be.
Hopefully that all made sense... it's a weird bit of rather esoteric JavaScript knowledge that you can basically look up when you need it.
Ken thank you for spending so much time on this. Definitely something for me to study.
Thanks for the amazing quote! I copied to my twitter. Hope it's OK.
twitter.com/kore_sar/status/121395...
No problem!
For the first one
function handleRelations(modelClass: extends Model) ...
here is a very simple TypeScript Playground example example.
TLDR;
In terms of readability for
see this TypeScript Playground example
TLDR;
When I have a chance, I'll check out the other issues you're having.
Huh,
Record<T>is a pretty handy trick. Definitely nicer than the bare syntax. And yeah, in cases where it gets too complicated I definitely do declare little types, but it seems like a lot of overhead to have to declare a local type for every function that uses Maps or Sets of objects like that... I'll have to think about that one.
Regarding passing around classes and subclasses, in your example,
modelClass: Modelis still and instance of some class extending
Model, rather than a class itself. I need to reference the classes themselves to get at static methods and properties. Here's a playground example (in a broken state) showing what I mean.
Thanks for the responses!
Ahh, I see what you mean. My bad. You can do this
TLDR;
Does that handle your use case?
Oh man yes it does, that's exactly what I was looking for! I didn't realize that was a thing! Thanks!
Or even better using generics:
Generics for sure, but it still needs to be
typeof Modelas he doesn’t want an instance of the class.
I missed that. In that case, he shouldn't use a
classhere, rather:
I rarely use classes aside from React components (pre-hooks) as I prefer functions even though I'm not a full FP kind of person, but they are still used by many. 😉
For sure, a
typeis an option. It just depends on what he wants to do in that function. If an
interfaceor
typeis used and he wanted to create an instance of the
Modelclass, using an
interfaceor
typewould not work. If he wanted to use it for duck typing in his function, then an
interfaceor
typewould suffice.
Here's a sample TypeScript Playground for those interested.
Very interesting. I didn't realise you could combine
newwith
typeof Tparams.
Yeah
Modelisn't my class, it's provided by Objection.js, an ORM library I'm using. As mentioned in the post, I need to access static properties of various subclasses of
Model, so I need to pass around the classes themselves.
1)
function handleRelations<T extends Model>(modelClass: T) {
Look up Generics Constraints in the typescript manual.
2) That's not a Typecript question, that's an object-oriented question. The answer is "you can't, and shouldn't".
If I have an Animal[] and .map it to call a function on each return value...
animals.map(a => a.idColumn().whatIsValidHere)
... then what is always safe for
whatisvalidhereif it's sometimes a string sometimes an array sometimes an Invoice, etc.
3)
is a bit more useful. Stick in /shared/ or wherever you keep such things.
You beat me to it!
typeof Modeland
T extends Modelare the useful features here, but I also agree with Edward Tam - you should probably eschew subclassing in general. "Is a" object relationships are the tightest form of coupling that exists. Instead use functions or even mixins, if you must attach "methods" to your objects. You probably don't need a base class when you have interfaces and mixins available to you.
is ais strong, but can be loosened with Factories and Bridge Pattern
Haven't found a good use for the Bridge Pattern, but I've often wondered why more ORMs aren't using Factories/mixins
It can help to be able to ask quick questions on gitter.im/Microsoft/TypeScript or launchpass.com/fullstacktypescript
Awesome, thanks! I'll keep those groups handy
JS lover too until I met TS here. I've led a big full-stack app project using TypeScript so I probably can give you some insight.
I agree with this comment by Edward Tam. I suggest not to rely much on class and class extensions as TypeScript doesn't have good support for OOP extensions. Even though TS was born from OOP paradigm, it's actually easier to just use
typeand namespaced-functions is the form of
static methods in a class. I use class only if I need a long-running data scope which seemingly has "a separate runtime" and I use it rarely.
I would recommend watching this youtube.com/watch?v=yy8jQgmhbAU and youtube.com/watch?v=aKLntZcp27M. Even though it's rust and c++ it gave a lot of insight on how to make code that is development-scalable, meaning adding/changing/removing features in the future will not be as hard as when you use by the book OOP, which I mistakenly use in my first projects.
Also, check this out, TypeScript 3.5's feature higher-order type inference which is super neat.
It's nice to see more people embracing TypeScript. Welcome to the ecosystem, good luck and have fun.
Out of interest, do you use an ORM with TS? If so which one? I have yet to find one that doesn't seem like it wants to work strictly in the OOP paradigm. I need an ORM that properly supports relational data structures like ternary relationships. The only one that looks bearable is Objection which essentially seems to be a query builder that holds a representation of your schema in code to provide helpers to do easy queries and eager loading etc. Unfortunately as you've pointed out, it doesn't really have support for TS.
So, I wrote this article a couple months ago now, and since then I've developed my project into a pretty sizable codebase, still using Objection with TypeScript. IMHO, it works fine. I understand what a few other commenters have said about TypeScript and classes, but after digging in a bit deeper, I haven't encountered any problems I couldn't pretty easily work around. I like Objection a lot; I think it occupies a pretty nice middle ground between query builders and ORMs where it gives you some very nice class-based features out of the box, but still provides low-level access to SQL queries when you need it in a way that many Hibernate-style ORMs do not.
Interfaces are not for reinventing the wheel.
Your interfaces should be defined first and should contain the minimum common behaviour between similar objects that will implement them.
Think of an interface as a contract that needs to be fulfilled by the classes that implement it.
This means any method that only needs to use a specific behaviour that multiple objects contain, only needs to accept any object that implements it.
The point is that the base classes are already defined in the library I'm using, and I was only using the interface as a hack to be able to pass around the classes in the way I needed to. I understand the purpose and usefulness of interfaces as a construct, but that wasn't my situation.
Making this a typed language you need to expect that it makes more limitations on the code you write to help you avoid any bugs or errors at runtime. I think the first two points you mentioned are designed in Typescript to help you code in a way that doesn't violate Liskov Substitution Principle which is one of the SOLID design principles.
en.m.wikipedia.org/wiki/Liskov_sub...
The second point, absolutely. Not the first point though; what I was reaching for but couldn't find was
typeof Model, as in
function foo(model: typeof Model).
Interface defintions are not strictly needed. They only provide the abilty for other users to inject their own implementation of a pattern. This stops the need to always use just one concrete class and is favored mostly by testers.
I think the issue when you try to change the signature of a subclass, is that any subclass should be assignable to their superclass.
See in the example: Playground
You can run it and see the error. I understand that in your point of view you could perfectly handle that case, but that's a sample use case.
Very good question. When moving to Typescript and the concept of the Classes and ability to extend a base class, one rule must be absolutely followed. The is-a relationship is paramount. The parent must be a type of base.
Base classes don't really return anything (other than hosting properties and funtions) rather, they morph all things public to be a part of the parent.
This is where intellisense shines because no API is needed as the editor discovers all props and functions as you type.
In your example you do not need to override the getter for Id. Why? Because it's in the base class. When referring to static properties one must call out the class that contains them.
If each of the static methods are to return the same thing you only need one in the base class. DRY is good.
Each class's
idColumngetter returns a different thing, as shown in the example code. That's why I was overriding them.
Instead of this you can just use the
objecttype?
Not sure if someone mentioned it, but do you know about the 'object' (typescriptlang.org/docs/handbook/b...) type?
Change the string or string[] returns to type of any. To fix complaints. Just put in checks when used.
We disallow type any in our code. It removes any benefits you get from using a typed language
I am dealing with Typescript for a while now but this sure demystified certain things ^ pretty cool!
|
https://practicaldev-herokuapp-com.global.ssl.fastly.net/kenbellows/my-confusions-about-typescript-1odm
|
CC-MAIN-2020-50
|
refinedweb
| 7,111
| 61.36
|
There comes a time in every developer's life where they need to parse a string representation of a date. I had the pleasure of talking with Maggie Pint about a new feature currently in stage 2 with the tc39 committee, temporals.
Learn how to contribute to the next version of JavaScript first issue.
This proposal allows a JavaScript programmer the ability to write code for finding out the current timezone difference between their's and another time zone.
const { Temporal } = require('proposal-temporal') let londonTz = Temporal.TimeZone.from('Asia/Shanghai'); console.log(now.toString(londonTz));
A complete polyfill can be found here. Feel to test it out today and experiment with the polyfill, but keep in mind it is not production ready yet.
tc39
/
proposal-temporal
Provides standard objects and functions for working with dates and times.
Temporal
Provides standard objects and functions for working with dates and times.
NOTE: The Polyfill, specification text and documentation are under continuing development and should be understood to be unstable.
Champions
- Maggie Pint (@maggiepint)
- Philipp Dunkel (@pipobscure)
- Matt Johnson (@mj1856)
- Brian Terlson (@bterlson)
- Shane Carr (@sffc)
- Ujjwal Sharma (@ryzokuken)
- Philip Chimento (@ptomato)
- Jason Williams (@jasonwilliams)
- Justin Grant (@justingrant)
Status
This proposal is currently stage 2.
Stage 3 Reviewers:
- Richard Gibson
- Bradley Farias
- Daniel Ehrenberg
Overview / Motivation
Date has been a long-standing pain point in ECMAScript
This proposes
Temporal, a global
Object that acts as a top-level namespace (like
Math), that brings a modern date/time API to the ECMAScript language
For a detailed breakdown of motivations, see
Fixing JavaScript Date
Principles:
- All Temporal objects are immutable.
- Date values can…
I share only one feature from the proposal, I encourage you to read more info in the spec and test it out today in consoles.
Join us live for Open Source Fridays
If you’re looking for a deep dive into contributing to open-source projects like this, join us on Fridays on Twitch. You can find the future schedule on GitHub Virtual Meetup page.
If you missed our previous OSF stream, or want to rewatch, you can find the full video over on our YouTube.
Posted on by:
Brian Douglas
Brian is a developer advocate at GitHub, which means he likes chatting with developers about developer things and sometimes writes code.
Discussion
nice article. check out moment.js and its sister utc transform library. great stuff :) thank you.
|
https://dev.to/github/learn-how-the-javascript-advances-datetime-with-proposal-temporal-59hf
|
CC-MAIN-2020-40
|
refinedweb
| 398
| 53.21
|
If the English word begins with a consonant, move the consonant to the end of the word and add "ay". The letter Y should be considered a consonant.
If the English word begins with a vowel (A, E, I, O, or U), simply add "way" to the end of the word.
(This is a simplified dialect of Pig Latin, of course.)
Ask the user for a word (one string) and output its Pig Latin translation (one string). You may assume that the input does not contain digits, punctuation, or spaces. The input may be in any combination of uppercase or lowercase. The case of your output does not matter. Use IO.outputStringAnswer() to output.
so far my code is :
public class PigLatin { public static void main(String[] args) { System.out.println("Please enter a phrase that you want me to translate into Pig Latin: "); String prepig = IO.readString(); char prepig1 = Character.toLowerCase(prepig.charAt(0)); if (prepig1 == "a" || prepig1 == "e" || prepig1 == "i" || prepig1 == "o" || prepig1 == "u") { String finalstr = prepig + "way"; System.out.println(finalstr); } else { String first = prepig.substring(0,1); String slice = prepig.substring(1,prepig.length()); System.out.println(slice + first + "ay"); } } }
However in eclipse, this line
if (prepig1 == "a" || prepig1 == "e" || prepig1 == "i" || prepig1 == "o" || prepig1 == "u")
is in red and it says "Incompatible operand types char and String"
What does this mean and how can I fix it?
Thanks
|
http://www.dreamincode.net/forums/topic/269462-converting-words-to-pig-latin/page__p__1568266
|
CC-MAIN-2013-20
|
refinedweb
| 233
| 75.1
|
In many ways, our global chatbox will look a lot like the chatbox that we built in Photon. However, rather than having separate chatrooms, we'll create one single global chatbox for everyone. There will also be major API differences to keep in mind—in Photon, we were able to use RPCs to conveniently call a function on all connected clients which handled chat messages. However, in PubNub we will need to handle incoming messages, parse them, and process them as chat messages.
In this chatbox example, we'll expand our chatbox with extra functions such as the
/me command. Additionally, you'll be able to change your name (which will be announced to the room):
using UnityEngine; using System.Collections; public class ...
No credit card required
|
https://www.oreilly.com/library/view/unity-multiplayer-games/9781849692328/ch05s06.html
|
CC-MAIN-2018-51
|
refinedweb
| 127
| 64.41
|
01 June 2011 15:22 [Source: ICIS news]
SINGAPORE (ICIS)--Reliance Industries will reduce its domestic list prices of polyethylene (PE) and polypropylene (PP), with effect from 2 June, because of lower import prices for June shipments and continued weak demand, a source close to the company said on Wednesday.
The lower PE and PP prices, which would fall by as much as Indian rupee (Rs) 2/kg ($0.04/kg), mark the company’s second consecutive weekly price reductions.
The Indian petrochemical major will lower its linear low density polyethylene (LLDPE) film and low density polyethylene (LDPE) film prices by Rs2/kg to Rs73/kg ?xml:namespace>
However, Reliance Industries will not change its price of high density polyethylene (HDPE) film, which is currently at Rs74/kg DEL.
“HDPE [film] prices were unchanged, because southeast Asian [prices] have only marginally decreased,” an industry source said.
Reliance’s new PP prices for raffia will be at Rs86.25–86.50/kg
The price of biaxially oriented polypropylene (BOPP) film will be reduced by Rs1.5/kg to Rs88.50–89/kg, the source added.
Reliance’s protections on PE and PP prices for its customers will be stopped from 2 June, the source added.
“Local makers are under pressure, as the polymer imports are priced much lower than expectation. We can see that producers everywhere are facing problems in selling, so they have to lower offers to attract buyers,” a trader said.
Import prices of HDPE and LLDPE film were discussed on Wednesday at $1,330–1,360/tonne CFR (cost and freight) Mumbai, while PP raffia was discussed at $1,640–1,670/tonne CFR Mumbai, according to market sources.
($1 = Rs44.82)
For more on polyethylene and polypropylene, please visit ICIS chemical intelligence
For more on Reliance Industries,
|
http://www.icis.com/Articles/2011/06/01/9465310/indias-reliance-industries-cuts-pe-pp-prices-by-up-to-rs2kg.html
|
CC-MAIN-2014-10
|
refinedweb
| 300
| 61.67
|
Introduction: :(
I did search on the Interweb for tutorials and information on how to build this kind of device but, unfortunately, there was only one single piece of information:
I did actually re-create this instructable and, after 6 weeks constant toil, got it to work but decided to create a separate, simpler version, which is this one documented here!
With absolutely no previous radio frequency (RF) experience, the challenge was to learn how a repeater works by playing around with a software defined radio (SDR) and then build one from scratch with the necessary hardware filters, amplifiers and controls.
The 'RepeaterDuino' / 'RepeatDuino' / 'RFBoostDuino' / 'RFRepeatDuino' / 'OpenRFRepeater' / 'PeoplesRepeater' / 'PirateRepeater' is born!
Step 1: How It Works
The cell phone base station signals are constantly being transmitted from one or more masts owned by the phone company. In my case, I can only reliably receive the 4G signal if I stand on a roof or raise my phone up a pole like a flag so an external antenna mounted 20 feet up a pole is necessary.
The external antenna receives the good quality signal and sends it down a shielded cable to a filter which very accurately stops everything except a very small slice of frequencies. For my phone, these frequencies are centered around 806 MHz and have a spread, or bandwidth, of 30 MHz.
The signal then goes into a LNA (Low Noise Amplifier) which does a fair bit of amplification at low power and .... as it says on the tin, very low noise aberrations. It's much more efficient to 'cascade' the amplifiers rather than try and do everything with one device.
Next is the Variable Gain Amplifier, or VGA, which does most of the grunt work and has the ability to be controlled by a microprocessor by means of very simple SPI code. The gain needs to be controlled as sometimes the base station signal can be quite strong and we don't want to damage our phone or create a feedback loop between the two antennae. The antennae have to be spaced well apart or separated by thick walls or metal sheeting.
Simultaneously, the signal comes out of the BPF and routes into an RSSI (Received Signal Strength Indicator) which provides an analogue signal ie a DC voltage to the micro controller, which can turn down the VGA if the signal is too strong. At the moment, control of the VGA is manual by means of a slide potentiometer.
The amplified signal goes out of the VGA into a plate antenna which is located inside the building and transmits the signal to the cell phone.
Step 2: Video Demonstarion
This video above shows all the main components of the repeater, which is demonstrated using my own phone and a spectrum analyser, which has a small 'whip' antenna located right next to the plate antenna. The spectrum analyser is actually a Software Defined Radio (SDR) which can be bought for as little as $10!
Step 3: Building the Band Pass Filters
Legal:
Please check your local laws / telecoms regulations before embarking on this project.
Tools and Components Required:
- Small electric oven
- Stop watch
- K type thermometer
- PCB board (see file attached - it opens with 'Design Spark' software)
- Lead free solder paste
- CTS USD020A duplexer
- UFL sockets - male.
- UFL cable - female to female
Just before we start, we are only using one side of the duplexer and the other side is available if the project needs to be expanded at a later date.
Apply small dabs of solder paste to the PCB paying special attention to the actual terminals of the filter. Carefully place the filter and UFL sockets on the PCB and apply a small amount of downward pressure.
Put the PCB in the oven and follow the manufacturer's temperature profile (see attached PDF) by monitoring with a stopwatch and thermometer. The profile is different to most other SMT components as the filters are large blocks of ceramic that take longer to get hot.
Notice that the filters are machined with tiny scour marks - these are tuning marks made at the factory to get super accurate results.
The antenna socket is in the middle and the 806 MHz socket, when looking at the first photo, is on the right hand side.
Step 4: Low Noise Amplifier Module
Components:
- U1 n/a 2-Stage Bypass LNA Qorvo QPL9065
- R1, 2, 3, 5, 7 0 Ω RES, 0402, +/-5%, 1/16W Various
- R10 39K RES, 0402, +/-5%, 1/16W Various
- C1 0.5 pF CAP, 0402, +/-0.1pF, 50V, C0G Murata GJM1555C1HR50BB01D
- R9 5.1 Ω RES, 0402, +/-5%, 1/16W various
- L1 1.5 nH IND, 0402, +/-0.1nH, 1000mA Murata LQP15MN1N5B02D
- L4 6.8 nH IND, 0402, +/-2%, 700mA Murata LQG15HS6N8J02
- C2, 3, 4, 5, 7 100 pF CAP, 0402, +/-5%, 50V Various
- C6, 8 0.1 uF CAP, 0402, 20%, 16V, Y5V Various
- C9 10 pF CAP, 0201, 2%, 50V Murata GRM0335C1H100GA01
- C12 4.7 uF CAP, 0603, 20%, 10V, Y5V Various
- C10, 11 10 pF CAP, 0402, 2%, 50V various
- L2 2.2 nH IND, 0402, +/-0.2nH, 1000mA Murata LQW15AN2N2C10
- L5 18 nH IND, 0603, 5% Coilcraft 0603CS-18NXJL
- LNA Amp PCB and paste mask stencil - see attached file.
Use the solder mask stencil to apply solder paste and reflow in an electric oven. with a standard reflow profile.
Rather than actually build the whole PCB from scratch, the Qorvo evaluation board is a good option: Evaluation Board.
Step 5: Variable Gain Amplifier
Component: TQM879028-PCB2140
I made my life a lot easier by, in this case, purchasing this device as an evaluation board: Evaluation board. The circuit comes with a detachable USB adaptor and software so that in can be controlled by a PC for testing. The device is supplied by a company called Qorvo and their customer service is excellent!
In this project the device is wired up to an Arduino Uno and controlled by 3 wire SPI. Looking at the photo:
- The black wire, bottom left goes to ground.
- The red wire, top left, goes to 5V.
- The red wire, top right, goes to 5V.
- The white wire, pin 5 from the left, front, goes to Arduino Uno pin13 (Clock).
- The blue wire, pin 4 from the left, rear, goes to Uno pin 10 (Chip Select)
- The grey wire, pin 5, rear, goes to Uno pin 11 (MOSI).
The code for controlling the device is very simple:
#include <SPI.h> const int slaveSelectPin = 10; void setup() { pinMode(slaveSelectPin, OUTPUT); SPI.begin(); } void loop() { // Sets the VGA to 40 out of a max of 63: digitalPotWrite(40); delay(1000); } void digitalPotWrite(int rabbits) { digitalWrite(slaveSelectPin, LOW); SPI.transfer(rabbits); digitalWrite(slaveSelectPin, HIGH); }
Step 6: RSSI
Components:
- AD8318
- Male SMA, female UFL cable
This component can be bought cheaply on Ebay HERE. It plugs into the input of the LNA board (or the output of the filter) via a male SMA, female UFL cable.
I hacked the output by attaching a green and red wire to the PCB although it actually only needs the red wire, which goes to an analogue input (0) on the Uno. The code for reading the signal is very simple:
int rssiValue = analogRead(0);
Step 7: TFT Screen
Component:2.2" 18-bit color TFT LCD display with microSD card breakout
Apart from the TFT screen, there is a 10 x 3 0.1" strip of PCB for allowing multiple connections on the SPI bus.
The screen wiring is fairly obvious except that:
- D/C connects to pin 9 on the Uno.
- CS connects to pin 7.
- MOSI to pin 11.
- SCK to pin 13.
The code requires the following:
Step 8: Antennae
The outside antenna is HERE and is a Quad Band Cellular Antenna with a male SMA connector. It connects to the middle UFL socket on the filter PCB.
The inside antenna is a plate type as shown in the photo (protective case removed) and also requires a male SMA. This connects to the output of the VGA amp.
IMPORTANT: The two antennae must be isolated from one another by thick stone walls or metal sheeting and the gain on the VGA should not be increased to such an extent that you get feedback between the device signal input and output. If a strong signal is suddenly supplied to the input of the device it may damage cell phones in the near vicinity.
Step 9: Main PCB
Components: Alps RSA0N Series Slide Potentiometer with a 18.5 x 1.5 mm Dia. Shaft, 10kΩ, ±20%, 0.5W, Through Hole
This board is actually from another one of my projects, but is perfect for a base for this one (See Stepper Motor PCB file attached). The Arduino Uno sits under the PCB at the top left corner with the appropriate headers. The slider potentiometer sits on the far right.
Step 10: Arduino Uno Code
There's nothing unusual about the Arduino code, except that reading the VGA via SPI must be terminated with 'SPI.end();' on each read.
Code:
const int slaveSelectPin = 10; // LE for the VGA. int sensorPin = A3; // select the input pin for the potentiometer float sensorValue = 1.00; int rabbits; int rssiValue = 0; // Use hardware SPI (on Uno, #13, #12, #11) and the above for CS/DC //Adafruit_ILI9341 tft = Adafruit_ILI9341(TFT_CS, TFT_DC); // If using the breakout, change pins as desired Adafruit_ILI9341 tft = Adafruit_ILI9341(TFT_CS, TFT_DC, TFT_MOSI, TFT_CLK, TFT_RST, TFT_MISO); void setup() { Serial.begin(9600); Serial.println("ILI9341 Test!"); writePotToVGA(); tft.begin(); tft.setRotation(3); tft.fillScreen(ILI9341_BLACK); rectangle1(); introText(); staticText (); //delay(5000); // set the slaveSelectPin as an output: pinMode(slaveSelectPin, OUTPUT); // initialize SPI: // SPI.begin(); // digitalPotWrite(10); // delay(5000); // digitalPotWrite(20); // delay(5000); // digitalPotWrite(30); // delay(5000); // SPI.end(); //tft.fillScreen(ILI9341_BLACK); } void loop(void) { rssiValue = analogRead(0); Serial.println(rssiValue); testText(); //digitalPotWrite(40); delay(1000); writePotToVGA(); } void writePotToVGA() { sensorValue = analogRead(sensorPin); sensorValue = sensorValue*63/1023; rabbits = sensorValue; SPI.begin(); digitalWrite(slaveSelectPin, LOW); SPI.transfer(rabbits); digitalWrite(slaveSelectPin, HIGH); SPI.end(); } void digitalPotWrite(int rabbits) { // take the SS pin low to select the chip: digitalWrite(slaveSelectPin, LOW); // send in the address and value via SPI: // SPI.transfer(address); SPI.transfer(rabbits); // take the SS pin high to de-select the chip: digitalWrite(slaveSelectPin, HIGH); } unsigned long introText() { tft.setRotation(3); rectangle2 (); tft.setTextColor(ILI9341_GREEN); tft.setTextSize(3); tft.setCursor(20, 20); tft.println("4G Repeater"); tft.setCursor(20, 200); tft.println("Band 20, 806 Mhz"); } unsigned long testText() { rssiValue = analogRead(0); sensorValue = analogRead(sensorPin); sensorValue = sensorValue*63/1023; tft.setRotation(3); rectangle2 (); tft.setTextColor(ILI9341_GREEN); tft.setTextSize(3); tft.setCursor(250, 70); tft.println(sensorValue,0); tft.setCursor(250, 100); tft.println(rssiValue); delay (1000); } void rectangle2 () { tft.fillRect(220, 65, 100, 65, ILI9341_BLUE); // x,y,(from top left corner)w,h } void rectangle1 () { tft.fillRect(0, 65, 320, 65, ILI9341_RED); // x,y,(from top left corner)w,h } void staticText () { tft.setCursor(10, 70); tft.println("VGA gain:"); tft.setCursor(10, 100); tft.println("RSSI level:"); }
Step 11: Testing the Device
Check with your cell phone network which band your phone uses for 4G eg band 20, or try and locate it with an SDR.
A cheap SDR (Software Defined Radio) - see photo - can be also used to monitor the performance of the cell phone repeater. Pay no more than $10!
Position the SDR antenna right next to the repeater's plate antenna and tune the SDR to about 806 MHz. As the slider pot is moved from left to right, an increase in brightness of the lines on the waterfall should be seen. They may even turn to yellow or even red. Adjust the gain and FFT settings in the software to get coherent results.
A phone can also be used to check the device is working, the SDR must be used in the first instance and all phones nearby should be turned off to avoid damaging them during initial testing. There are apps available for smart phones to monitor signal strength more accurately than the regular 'bar' type displays.
Step 12: Final
The device is big and clunky with lots of wires going all over the place but it works really well and, being bolted to one PCB, is pretty solid. It now needs some long term testing to check that none of the components break down too quickly etc. Eventually, at some time in the future, it will get reduced to one small Arduino shield with the ability to user change the filters for different 4G bands.
In terms of power and range, in it's current configuration the power is probably at about 1mA which is giving an effective range of about 3 metres. This might seem very low, but it's actually very beneficial to run at low power as it's normally under the threshold for serious transmit licensing (check your local regulations) and it's very much less likely to cause feedback with the external pole mounted antennae. The only downside is that the cell phone has to be within 3 metres of the internal antenna.
Please feel free to ask questions or make constructive criticism but be aware that I know very little about RF so may not be able to answer the more technical queries.
Thank you!
16 Discussions
Hello, nice build. Iam thinking of building something similar. But I have a question but I do not know if you can answer it. I found this. Could this be used in your setup?
Very nice and handy project. Congartulations!
The question is, this booster should work well for amplifying the received signals from BTS tower and receiving them in your cell phone. But you will need an extra booster for the reverse path to coney your signals to the exteriors. How did you manage to solve this part of the problem?!
Would you ever consider selling one of these fully assembled ?
Where do you find the USD020A duplexer for sale in small quantities?
Wow! Great project...
I really enjoyed learning.
I have also made one booster... But it doesn't require any power source. But works great.
Being a small techie, can't invest a lot.
Anyway it'd be my pleasure if you look at my project
It's amazing that you made it work after all, how long did it take? And how much you had to pay for components? I see that corvo board is sold at $180+
6 months to learn RF and build the device. Yes, the Qorvo board is expensive and I think with all the mistakes I've made it has cost me nearly $1,000 dollars.
Fortunately, it won the Hackaday 'Design your Concept' semi finals prize which was big cash injection for the project :)
I think the final Arduino shield will retail at something like $120 sometime next year at my current rate of progress.
How are you progressing on your Arduino shield for this? I'm very intersted in getting one - or even buying a complete setup if your are selling.
BTW - Love your work. I'm guessing you basically live 'off-the-grid' based on the few comments and pictures I've seen of your place and the work you do. Bravo!
You must be the 'Maker' version of Einstein.
Wow, even more than I expected! Your current result already is great, I wish you best luck in making this somewhat more repeatable (making a product out of it is very difficult, but it would be absolutely fantastic if you can make it)
Neat.
Wow! Great project! Congratulations and thanks for posting
I have a question though . Why if you capture the signal by external antenna and pass it into a coax why can't that same signal be re radiated out inside the building or whatever with some added amplification . Why the need to totally remake the signal when the signal already exists and has been captured?
I'm not really remaking the signal - there's no ADCs and the Arduino is just used for control and monitoring. The signal is filtered and amplified - that's it! The filtering is to stop interference with other signals such as TV and radio. The amplifier to account for losses in the cables and the filter.
Have a go at building it - you don't have to have the Arduino, VGA and RSSI if you just use the LNA circuit and the filter. The VGA does not work without the LNA before it. The filter is then probably the hardest bit to do - you need a PCB and the ceramic filter - I have some spare PCBs if you need one.
I see OK I'll have a closer look at that
We all learn radio theory fairly quickly . Remembering it and putting it to good use is the question . I like this . I have a genuine need for such a device as I must keep my phone against the window while standing on tiptoes on the dogs back . If I move the signal is lost . I will try this out and see what I get . Thanks
Yes - I started it in January, so that's nearly 6 months I've taken to get this far. Honestly ..... I promise you I have absolutely no previous radio experience - I've not ever build a crystal radio or designed RF PCBs - not in this lifetime anyway.
I started by learning to use an SDR in January. Steep learning curve!
|
https://www.instructables.com/id/Arduino-Cell-Phone-4G-Signal-Booster-Repeater/
|
CC-MAIN-2018-34
|
refinedweb
| 2,910
| 63.29
|
Introducing GraphQL Code Generator
Explore our services and get in touch.
TL;DR
-
- The GraphQL codegen library can generate any code for any language — including type definitions, data models, query builder, resolvers, ORM code, complete full stack platforms!! and any specific code for your needs
- I wrote the code generator based on my experience with other robust code generators (such as Swagger codegen).
- You can create your own custom GraphQL codegen templates in 10 minutes, that fit exactly your needs — you can even generate an entire application based on your GraphQL schema!
- Template-based implementation is simpler and easier to maintain, and I think that eventually single engine with multiple templates will match all use-cases (for example, writing the Flow template took only 10 minutes)
- Real life use-cases always needs customizations (for example, Shopify wrote their own codegen that they need to maintain because the other codegen tools weren’t flexible enough. If they would use this tool, they would just need to create a new template — which is simpler and easier to maintain)
- Share templates with the community — move the community forward by having an eco-system of templates that probably match most of the use-cases, learning from the Swagger codegen community
The source code of the video examples are available here
Note:
This blog post refers to an outdated version, please check for the latest docs!
Do more than just generating
About a year ago, I started writing code and apps using GraphQL.
Doing that, while coming from a production and Enterprise background, I looked for the tools available on the GraphQL ecosystem and compared it to the tools I used back then.
There were a few code generators out there, but immediately I was missing a tool that is similar to the Swagger code generator. Also, the possibilities GraphQL gives us are much greater than Swagger so I knew there was a big opportunity here.
So I started writing the code-generator for GraphQL, and I used my years of experience with Swagger code generator as inspiration.
The magic behind every good code generator, is the ability to change and extend the results quickly, while maintaining a simple (yet flexible) data structure based on your GraphQL schema and documents.
Code generators are also good for wrapping your data layer with a consistent code — for example, you can generate a function that executes the GraphQL document through your network interface, fetches the data and returns the response wrapped in a custom structure.
Use cases
Typings — So yes, of course you can generate Typescript and Flow typings, Swift, Java and C#.
But the thing is, that it’s much easier to add or change those generators, in fast, creating the Flow codegen took 10 minutes!
And that means that you don’t need to rely on us to create the generator that you need — you can create your own custom generator in a matter of minutes and share it with the whole community!
Generate your backend — From your GraphQL definitions, you can generate your backend code! You can generate your resolvers, your data models, query builders, mutations, filters and more! Now maybe you can understand what the GraphQL Backend as a service platforms are doing… exactly that! So you can use the GraphQL-First approach and generate a full functioning backend from just your GraphQL schema! But there is a big difference — it’s completely open source, you can generate just parts of it and write your own custom code or even change the templates! So you generate backend can be Node, Typescript, .NET, Java, Ruby, Python or anything you wish! And you can learn from the other community generators from other languages.
This is just the start and there is much more to explore, but we are already using it for a few production apps (for example Schneider-Electric’s new online management platform), generating from a GraphQL schema with decorators a complete Mongoose ORM models with Typescript for the whole app! (the generator’s templates are available here, and soon will be available as part of the built-in generators!)
In the next weeks we will release more generators and templates using SQL ORMs, but we would love to hear your use cases and to see which generators the community will come up with.
Generate REST APIs — You can use your GraphQL Schema to generate Swagger definitions and then in turn generate full functional, completely documented REST APIs without the need to maintain, support and update them!
Generate your frontend — This is sometimes less useful, but can be very helpful for generic admin panels or specific generic React components. We’ve already done that as well, creating a full React Material admin template that is being completely generated from a GraphQL schema. The nice thing is that we’ve made it so that when you edit the template it feels just like you are editing regular React code with regaulr IDE support.
Add your own — Can you think about another use case? Suggest it on our Github repo and let’s try to create a template for it.
Relations to other tools and prior art:
- GraphQL as a service platforms — Graphcool, Scaphold and other GBaas are doing very similar things under the hood, but not open source and for their specific use cases and specific backend stacks and languages. I would love to help them migrate into our codegen so they won’t have to maintain their own code generators and just focus on their special and unique offerings.
- Apollo Codegen — Apollo codegen has written specific code for each implementation (Typescript, Swift, etc..). That’s great but when there is a small issue, it is much harder to include and release that change fast. Also, users might requests features that are very specific for their own use cases and including those changes in the main repo without affecting the rest of the users can be very hard. I would love to migrate Apollo’s current implementation to our templates (most of them are already included in this version) and help the wonderful Apollo team better maintain and support their users. Please let me know of any use case or issues you are currently facing and need support with.
Getting Started
To get started with the GraphQL code generator, start by installing NodeJS, and then install:
npm install graphql-code-generator
Then, make sure that your GraphQL schema is available for use — either in JSON file or development server.
Also, make sure your GraphQL documents are inside .graphql or .graphqls files (you don’t have to, you can also put in JavaScript files with
graphql-tag package, and the generator will find it automatically!).
Now, run the generator with your config (this example uses remote GraphQL server with local GraphQL documents, and generates TypeScript typings to ./types/ directory):
gql-gen — url — template typescript — out ./types/graphql-typings.d.ts “./src/**/*.graphql”
That’s it! your schema and documents are now TypeScript typings! and you won’t see any IDE or linter error when using GraphQL!
This code generator can also generate only the server side schema — so you can use it in both client and server!
Take it to the next level
As time went by, I noticed that there are more GraphQL developers that struggle with the same issue — development environments such as Swift does not play along with JSON, and need to have data structures (structs) defined in order to get a better experience (otherwise, you have to treat you data as a dictionary).
I created more templates, and at the moment there are generators for the following:
- TypeScript
- Flow
- Swift (with Apollo)
BTW — We are looking for more GraphQL developers which use different environments in order to add more generators and support those GraphQL communities — for example, someone from the community is already working on a C# template.
How it works?
First, we start with the GraphQL schema defined in our server-side, and try to understand it’s structure and the links between the types and scalars (called GraphQL introspection query), then we modify the structure of this metadata into a custom structure that will later be simple to use.
Now, we need to use a code template (usually based on a template engine, such as Handlebars.js or Mustache), and compile it with the data structure we created earlier.
Let’s take the following GraphQL schema:
type Person { name: String age: Int }
The code generator transforms this definition into a custom JSON data structure, for example:
{ "models": [ { "name": "Person", "fields": [ { "name": "name", "type": "string", "required": true }, { "name": "age", "type": "number", "required": false } ] } ] }
Now, we have a generic JSON structure, and if we want to turn our schema into TypeScript type definition, we need to compile it with the following template:
{{#each models}} export type {{name}} = { {{#each fields}} {{name ~}} {{#unless required ~}} ? {{~ /unless ~}} : {{ type }}; {{/each}} } {{/each}}
Now when we use the two together, we will get:
export type Person { name: string; age?: number; }
This is a simple example, because in real life, GraphQL allows use to do much more in our schema: define enums, custom scalars, unions, interfaces, custom directives, add arguments in each field, and more.
Now let’s take in to the next level — because GraphQL schema isn’t everything GraphQL has — in our client side, we define our Query, Mutation, Subscription and Fragment, along with directives, arguments and more — those are called documents.
The idea is basically the same: we take the client side documents, transform it into a simple structure, then compile it with a template.
Code Generator Implementation
The code generator is a CLI util, written in TypeScript and NodeJS, that every developer can use, regardless the environment or the language in use.
Using
graphql npm package, I was able to load the schema and execute Introspection query, then recursively iterate over the types and links, and define a custom structure for the Models.
Then, do the same for client side documents, while assisting the server side schema to understand the types (the full custom structure is here).
The trick in client side documents is to create the correct selection set object, in each document.
For example, when using this schema:
type Person { name: String age: Int } type Query { me: Person }
And your query is only for the name field:
query myQuery { me { name } }
We want to generate a new type, called MyQuery_Me which based on the server side type Person, but only with the fields we wanted — name.
So while building the custom structure, we use a config flag called flatten per each language, because there are languages that allows us to flatten the inner types we just explained, and group them all together (for example, TypeScript allows you to create module or namespace, but in Swift, you have to create a recursive structs).
The next step is to implement the template for for server side and client side, the template engine I picked is Handlebars.js because it comes with a set of great template utils (such as each, if and unless), but allows you to create a custom helpers — and this is a feature I wanted to preserve and allow other developers use when creating custom templates — so each language template can implement it own template, config and template helpers!
Also, with Handlebars.js you can create a partial templates and use them inside each other, so you can easily create a recursive template to load itself — which it very useful when dealing with infinite inner-types (exactly what’s GraphQL has)
Summary
I’m very excited about this release.
The graphql code-gen has come a long way and is used in many production apps, both from our users and our clients.
But it’s just the beginning! Please join our community and feel free to contact me directly for any question or help you might need.
|
https://the-guild.dev/blog/graphql-code-generator
|
CC-MAIN-2021-31
|
refinedweb
| 1,984
| 53.04
|
28 March 2010 19:28 [Source: ICIS news]
SAN ANTONIO, Texas (ICIS news)--The European second-quarter butadiene (BD) contract price of €1,275/tonne ($1,700/tonne) does not reflect true market fundamentals and is too high, a major butadiene consumer said on Sunday.
“€1,275/tonne is too high,” it said on the sidelines of the International Petrochemical Conference (IPC).
The consumer said that supply and demand would be in better balance in the second quarter.
Supply issues would be largely resolved, it said, referring to SABIC’s problems in the ?xml:namespace>
The consumer said that the planned turnaround of a major consuming unit from mid-May until the end of June had not been considered. This shutdown would have the potential to free up around 30,000 tonnes of butadiene - a considerable volume for the European market, it said.
“We are concerned about true demand - we wonder whether demand is a result of overstocking,” it said. “Underlying demand is just not that strong.”
The automotive sector - a key end user of butadiene in tyres - was still cause for concern.
The consumer said that figures showed that European car sales in the first quarter were shaping up to be well below pre-recession levels. This was attributed to the removal of the incentive schemes implemented by several European governments in 2009 to boost demand.
“The automotive industry is not running well,” it said, adding that predictions for the near-to-medium term were not encouraging.
It said that tyre producers were able to offset operations in
“We can’t play the [butadiene] arbitrage and unlike SBR there is competition for our end-product,” it said. “There are alternatives, so we are under pressure to be competitive.”
The consumer said that it could not understand where the €1,275/tonne contract price had come from, as it had offers of €1,200/tonne and €1,250/tonne.
The contract is settled on a free delivered (FD) northwest Europe (NWE) basis.
Hosted by the National Petrochemical & Refiners Association (NPRA), the IPC continues through Tuesday.
($1 = €0.75)
|
http://www.icis.com/Articles/2010/03/28/9346419/npra-10-europe-q2-butadiene-contract-does-not-reflect.html
|
CC-MAIN-2013-48
|
refinedweb
| 348
| 52.19
|
Creating a Ghost Blog on an Azure App Service
Premier
App Dev Manager Chris Tjoumas walks through how to setup continuous deployment of a blog using Ghost, Azure Functions, and Azure App Services.
*There is an update to this post as of 4/18/20 with additional details for 64 bit support.
Have you ever wanted to run your own blogging website but not sure if you want to build your own site or purchase an existing service? I had the same question myself and when I was studying for an Azure certification, I came across a demo of using this Ghost platform and the Azure Container Registry (ACR). It turns out this is fully open source and they provide both images and source code. I started to play around with setting up the ACR, but of course if you have content and you push an updated Ghost image to your registry, it will wipe out any information you have and I didn’t want to spend more time figuring out a way to keep the database it uses persistent. I then started looking at using the open source nodejs-based software and saw that Scott Hanselman had written about this – twice. First he showed how to modify the source code to get this to run on Azure, then posted an updated blog showing how this was updated to allow for a single click to deploy to Azure. This would take various parameters for your resource group, location, subscription, web app name, Sku, etc and deploy Ghost as an App Service to your subscription. When Ghost upgraded to version 1.x (current version is now 2.25.4 as of 7/1/2019), this deployment stopped working. Luckily for us, Radoslav Gatev fixed this with a Ghost-Azure project.
In this post, I’m going to be starting from another GitHub repo which branched off of Radoslav’s, as updates were no longer being made there. Since I wanted to ensure I had the latest working version, I started using Yannick Reekmans’ project. You can probably use either one, but I’ve done all of my testing with the latter and started my repo from there.
What I would like to do is setup two apps – one for staging and one for production. Radoslav wrote a nice Azure function which will check the official Ghost GitHub repo for an updated release and merge it into a repo of your choice. I would like to be able to use my staging app to get the release updates so I can test them and then decide if/when I want to merge that into my production app. So, let’s start by creating your own GitHub repo and get your staging and production ghost apps up and running:
- Fork the repo from here:
- Notice you will have an azure and azure-prod repo. What we want to do is use the azure branch as our staging branch and the production as, well, our production branch
- We are now going to create two Ghost app services – one for staging and one for production
- Create the staging app
- In your GitHub account/repo, make sure you are on the “azure” branch and click the “Deploy to Azure” button to get the ghost blog installed.
- Choose the free app service and fill the form out and click deploy
- Once the deployment is successful, after a few minutes, your self-hosted Ghost blog is up and running in Azure
- Create your production app
- In your GitHub account/repo, switch to the “azure-prod” branch and click the “Deploy to Azure” button to get the ghost blog installed.
- This time, choose at least Basic so you can setup a custom domain and fill the form out and deploy again
- You now have your production app service up and running
Note: If you end up setting up a custom domain, you will need to add that domain to your App Service Application Settings. In here, you create a new setting named “url” and the value will be your domain.
Automatic Updates of Ghost software
What we want to do now is to setup continuous deployment with our staging and production apps so that when we make a change to our staging ghost blog app source in GitHub, the app will pull these changes and deploy this new build. This way, we can run our staging app and verify everything works as expected. We then want to setup the same continuous deployment for our production app so a new production build will kick off when an update to the production branch is detected. For our production app, we won’t be making changes to the code though, we will simply be merging our staging repo into our production repo.
Finally, instead of relying on ourselves to make updates to the ghost blog (which you can certainly do!), I’d rather pull in updates from the official Ghost blog repo. So, we’ll use an Azure Function which will monitor the official repo for changes and, once detected, merge them into our staging branch. We’ll want to also get notified when an update is made, which I’ll show later, so we can go and check out our staging app before merging our staging to our production. Note: This is very important! The official Ghost repo pushes new releases often and there is a possibility that an update may break your app. As a matter of fact, on 6/25/19 when release 2.25.2 was released, I received a notification e-mail that my staging app build failed. While my prod app remained on build 2.25.1 and worked fine, I had the option of fixing my dev app or waiting. I began working on fixing the issue, figuring it was more to do with our app being tweaked to work on Azure. Just as I was about to test the changes, the Ghost team had a fix for it in release 2.25.3; less than a day later. I guess sometimes it just pays to wait 🙂
On to setting up our continuous deployment…
- There really isn’t anything you need to do here other than to ensure automatic deployment is setup through Deployment Center, which it should be once you perform the deploy to Azure. But, let’s check it here and become familiar with Deployment Center. For now, we will leave the default to Kudu since we just have a simple deployment need. But, as we want to do automated testing, gate checks, etc, you can use Azure Pipelines.
- Navigate to your App Service in the Azure Portal and click on Deployment Center
Notice the Build is set to Kudu and the Branch is set to “azure”, which we said is our staging branch. What this does is, behind the scenes, creates a WebHook so that any change made to this branch will be detected and a new build will kick off.
- We’ll want to setup an alert so that once we create our Azure Function to automatically merge updates from the official Ghost repo, we know when our staging app had a new release deployed so we can test it and then merge that into our own production branch. To do this, we’ll create an Azure Function and use SendGrid to send an e-mail when a deployment (success or failure) is performed
- First, let’s create the SendGrid service. In the Azure portal, click Create a resource and search for SendGrid
- Click Create
- In the new Create a New SendGrid Account blade, fill out the required fields. For the subscription, a Free Trial should be more than sufficient as it allows for 25,000 emails per month and I don’t plan on having that many updates!
- Once you click Create to create your SendGrid account, your account will be created after a few moments. Either by searching in the Azure portal for your SendGrid account, or clicking the resource in the notification once it’s deployed, go to your SendGrid account.
- Navigate to Configurations and copy the username and the SMTP server so you can generate the SendGrid API key. In order to use the SendGrid account by Azure Functions, we need to provide this SendGrid API as input to the Azure Function.
- To generate a SendGrid API Key, go to the SendGrid portal by going back to the main SendGrid blade in the Azure portal and clicking Manage. This will open a new browser window showing the SendGrid portal.
- In the portal, expand the Settings section on the left and click on API Keys
- Click on Create API Key.
- In the Create API Key window, enter an API Key Name and select the API access. I’ll leave mine as Full Access and click the Create & View button.
- Once the API key is created, click on the key to copy it to the clipboard.
- We’ll now need to configure the Azure Function with the SendGrid API Key. Back in the Azure portal, click +Create a resource and type in Function App and click Create. Give it a name, select your subscription, select the resource group your ghost blog resources are, and leave the Runtime stack as .NET. Navigate to your Azure Function and click on + New function and select In-portal and click Continue. Select Webhook + API and click Create. Select the name of your Azure function (the top-level of the function app tree) and click Platform features at the top and select the Configuration link. Here we want to add an Application setting. For this setting, the name will be the SendGrid API Key name (from step ix above) and the value is your SendGrid API key you copied from step x. Click Update and then Save.
- Back on your Azure Function, click the Integrate button under your function and under Outputs, click the + New Output option
- Select the SendGrid binding and click the Select button to add the binding.
- Now you can fill out the necessary information for the output:
- Message parameter name: leave this as the default “message”
- To address: enter the e-mail you’d like to receive notifications
- Message subject: keep this blank so we can update this programmatically in our function
- SendGrid API Key App Setting: When you click on this field, you’ll see the app setting we added to the Azure Function which holds the SendGrid API.
- From address: the address sending this e-mail
- Message Text: Again, keep this blank so we can update programmatically in our function
- Click Save
- What we’d like to do is know if the deployment was a success or not. So, our Azure function is going to find this in the json that the Azure App Service post deployment webhook delivers via Kudu. What I’m interested in is the status of the deployment so we know if it was successful or not. The JSON from an Azure Web app deployment will look like:
What we want to pull out is the “status” field. But, before we leave this page, we can go ahead and hook this deployment event up to our function app. Back in your function app, select the trigger and at the top, click the </> Get function URL link. Hop back over to your ghost staging app’s kudu page and select Tools–>Web hooks. In the Add Subscriber Url section, paste in your function URL, leaving the dropdown set as “PostDeployment” and click Add Url. Now, once any deployment completes to your staging app, it will trigger your function app, so let’s go ahead and write that to grab the status and send the email using SendGrid.You may also want to know the version which is being deployed. This will be stored in the “message” field so I’ve also added logic to pull that out and put into the e-mail.
- Navigate back to your Function app and select your HttpTrigger. At the top, add a new reference to SendGrid:
#r "SendGrid"
- Also, add this using statement:
using SendGrid.Helpers.Mail;
- Then, add a new parameter of type mail to the end of the Run function and remove the async keyword as you cannot use the out parameter needed for SendMail with an async function. Your signature now looks like:
public static void Run(HttpRequest req, ILogger log, out SendGridMessage message)
- You’ll also need to modify the requestBody assignment for a non-async function and put a bit of logic in to pull out the status and do something with it. This is fairly self-explanatory, including creation of usage of the SendGridMessage object, as you can see in my function below in its entirety:
#r "Newtonsoft.Json" #r "SendGrid" using System.Net; using SendGrid.Helpers.Mail; using Microsoft.AspNetCore.Mvc; using Microsoft.Extensions.Primitives; using Newtonsoft.Json; public static void Run(HttpRequest req, ILogger log, out SendGridMessage message) { log.LogInformation("C# HTTP trigger function processed a request."); string requestBody = new StreamReader(req.Body).ReadToEnd(); dynamic data = JsonConvert.DeserializeObject(requestBody); string status = data.status; string release = data.message; int startIndex = release.IndexOf("v"); int endIndex = release.Length - startIndex; release = release.Substring(startIndex, endIndex); //log.LogInformation("Status: " + status); string content, subject; if ( status.Equals("success") ) { subject = "Ghost Blog - New Deployment for Staging App - Success"; content = "A new deployment (release " + release.Trim() + ") was successfully completed!"; } else { subject = "Ghost Blog - New Deployment for Staging App - Failed"; content = "A new deployment (release " + release.Trim() + ") was triggered but failed!"; } log.LogInformation(content); message = new SendGridMessage(); message.AddContent("text/plain", content); message.Subject = subject; }
- We aren’t quite done yet though. With Azure Functions 2, you will need to add the Storage extensions to the app. To do so, follow these steps:
- In the Overview tab of your function, select Stop, if you’ve tested it and have it running. This will unlock files in your app so that changes can be made.
- Choose the Platform features tab under the Development tools and select Advanced Tools (Kudu). This will open the Kudu endpoint of your app in a new window.
- In the Kudu window, select Debug console > CMD
- In the command window, navigate to D:\home\site\wwwroot and choose the delete icon next to bin to delete the folder.
- Choose the edit icon next to the extensions.csproj file to open the online editor.
- Inside the <ItemGroup> element, add the following: <PackageReference Include=”Microsoft.Azure.WebJobs.Extensions.Storage” Version=”3.0.0″ /> and click Save.
- Back in the console at the wwwroot folder, run the following command to rebuild the referenced assemblies in the bin folder: dotnet build extensions.csproj -o bin –no-incremental –packages D:\home\.nuget
- Back in the Overview tab in the portal, click Start to restart the function app.
- To put this all in practice, as mentioned earlier, we want to detect when the official Ghost repository is updated and automatically merge that into our ghost staging app. Luckily, an Azure Function was already created to do this which we will use. Thanks to the work we did above, once the function detects a new release in the official repo and it merges that into our staging app, we’ll get an e-mail letting us know there has been an update so we can go test it, then perform a merge from our staging app repo to our production app repo which will automatically deploy the latest release to our production app. So, let’s go ahead and create the new function app:
- First, let’s fork over the function app from here:
- Once it’s forked over, we’ll create our function app and use our newly forked github repo, with a few application setting updates in order to hook everything up correctly.
- Once your function app is created, click the + icon next to Functions and set up your project
- Select Visual Studio
- Use Deployment Center in order to have a continuous deployment pipeline
- Use the Finish and go to Deployment Center button below to navigate to Deployment Center and finish setting up your app. This will take you through a new wizard to configure a variety of deployment options, which we will be using GitHub. I’m going to keep it simple and use Kudu. Select your Ghost-Release-Uploader repo and click Finish
- Update the app settings per the README in GitHub.
- Also, this function app targets Azure Functions runtime 1 so you will need to go to your function app settings and switch to runtime version to 1. Once this is done, restart your function app and go to the deployment center to ensure everything runs correctly.
- One thing to note, you may not have an actual release for the function app to compare against. To test this, go to<username>/<your ghost repo, which should be Ghost-Azure>/releases/latest. If you get a “Not Found” message returned, you need to create a release in your repo. Once that is done, re-run the API call to check the latest release and ensure you are getting a response. Also, for your git password, you’ll need to create and use a token here. Finally, make sure the release name is valid as the function will compare the release number in your repo against the official Ghost repo.
That’s it! You have successfully created your staging and production Ghost blog web apps, setup an Azure function to poll the official Ghost GitHub repo for a new release and merge an update into your staging repo, and created an Azure function to use send you an e-mail when a successful (or unsuccessful) release was pushed to your staging app. Now the only thing left to do is start working on your blog!
The deploy is failing for me. Here is the output from the failure:
Command: deploy.cmd
Handling node.js deployment.
Creating app_offline.htm
KuduSync.NET from: ‘D:\home\site\repository’ to: ‘D:\home\site\wwwroot’
Deleting file: ‘hostingstart.html’
Copying file: ‘.gitignore’
Copying file: ‘azuredeploy.json’
Copying file: ‘config.development.json’
Copying file: ‘config.production.json’
Copying file: ‘db.js’
Copying file: ‘entry.js’
Copying file: ‘Gruntfile.js’
Copying file: ‘iisnode.yml’
Copying file: ‘index.js’
Copying file: ‘LICENSE’
Copying file: ‘MigratorConfig.js’
Copying file: ‘package.json’
Copying file: ‘PRIVACY.md’
Copying file: ‘README.md’
Copying file: ‘renovate.json’
Copying file: ‘yarn.lock’
Copying file: ‘content\adapters\README.md’
Copying file: ‘content\data\README.md’
Copying file: ‘content\images\README.md’
Copying file: ‘content\logs\README.md’
Copying file: ‘content\settings\README.md’
Copying file: ‘content\themes\casper\author.hbs’
Copying file: ‘content\themes\casper\default.hbs’
Copying file: ‘content\themes\casper\error-404.hbs’
Copying file: ‘content\themes\casper\error.hbs’
Copying file: ‘content\themes\casper\gulpfile.js’
Copying file: ‘content\themes\casper\index.hbs’
Copying file: ‘content\themes\casper\package.json’
Copying file: ‘content\themes\casper\page.hbs’
Copying file: ‘content\themes\casper\post.hbs’
Copying file: ‘content\themes\casper\README.md’
Copying file: ‘content\themes\casper\renovate.json’
Copying file: ‘content\themes\casper\tag.hbs’
Copying file: ‘content\themes\casper\yarn.lock’
Copying file: ‘content\themes\casper\assets\screenshot-desktop.jpg’
Copying file: ‘content\themes\casper\assets\screenshot-mobile.jpg’
Copying file: ‘content\themes\casper\assets\built\global.css’
Copying file: ‘content\themes\casper\assets\built\global.css.map’
Copying file: ‘content\themes\casper\assets\built\infinitescroll.js’
Copying file: ‘content\themes\casper\assets\built\infinitescroll.js.map’
Copying file: ‘content\themes\casper\assets\built\jquery.fitvids.js’
Copying file: ‘content\themes\casper\assets\built\jquery.fitvids.js.map’
Copying file: ‘content\themes\casper\assets\built\screen.css’
Copying file: ‘content\themes\casper\assets\built\screen.css.map’
Copying file: ‘content\themes\casper\assets\css\csscomb.json’
Copying file: ‘content\themes\casper\assets\css\global.css’
Copying file: ‘content\themes\casper\assets\css\screen.css’
Omitting next output lines…
Using start-up script index.js from package.json.
Node.js versions available on the platform are: 0.6.20, 0.8.2, 0.8.19, 0.8.26, 0.8.27, 0.8.28, 0.10.5, 0.10.18, 0.10.21, 0.10.24, 0.10.26, 0.10.28, 0.10.29, 0.10.31, 0.10.32, 0.10.40, 0.12.0, 0.12.2, 0.12.3, 0.12.6, 4.0.0, 4.1.0, 4.1.2, 4.2.1, 4.2.2, 4.2.3, 4.2.4, 4.3.0, 4.3.2, 4.4.0, 4.4.1, 4.4.6, 4.4.7, 4.5.0, 4.6.0, 4.6.1, 4.8.4, 5.0.0, 5.1.1, 5.3.0, 5.4.0, 5.5.0, 5.6.0, 5.7.0, 5.7.1, 5.8.0, 5.9.1, 6.0.0, 6.1.0, 6.2.2, 6.3.0, 6.5.0, 6.6.0, 6.7.0, 6.9.0, 6.9.1, 6.9.2, 6.9.4, 6.9.5, 6.10.0, 6.10.3, 6.11.1, 6.11.2, 6.11.5, 6.12.2, 6.12.3, 7.0.0, 7.1.0, 7.2.0, 7.3.0, 7.4.0, 7.5.0, 7.6.0, 7.7.0, 7.7.4, 7.10.0, 7.10.1, 8.0.0, 8.1.4, 8.4.0, 8.5.0, 8.7.0, 8.8.0, 8.8.1, 8.9.0, 8.9.3, 8.9.4, 8.10.0, 8.11.1, 10.0.0, 10.6.0, 10.14.1, 10.15.2.
Selected node.js version 10.15.2. Use package.json file to choose a different version.
Selected npm version 6.4.1
Updating iisnode.yml at D:\home\site\wwwroot\iisnode.yml
Running npm install
Failed exitCode=-4048, command=”D:\Program Files (x86)\nodejs\10.15.2\node.exe” “D:\Program Files (x86)\npm\6.4.1\node_modules\npm\bin\npm-cli.js” install –production –no-package-lock
removed 45 packages in 32.519s
Checking database
D:\home\site\wwwroot\node_modules\knex-migrator\lib\utils.js:38
throw new errors.KnexMigrateError({
^
InternalServerError: Please provide a file named MigratorConfig.js in your project root.
Failed exitCode=1, command=”D:\Program Files (x86)\nodejs\10.15.2\node.exe” db.js
at new KnexMigrateError (D:\home\site\wwwroot\node_modules\knex-migrator\lib\errors.js:7:26)
at Object.loadConfig (D:\home\site\wwwroot\node_modules\knex-migrator\lib\utils.js:38:19)
An error has occurred during web site deployment.
at new KnexMigrator (D:\home\site\wwwroot\node_modules\knex-migrator\lib\index.js:18:24)
at Object.<anonymous> (D:\home\site\wwwroot\db.js:2:20):283:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:743:3)
D:\home\site\wwwroot\node_modules\knex-migrator\lib\utils.js:38\r\n throw new errors.KnexMigrateError({\r\n ^\r\nInternalServerError: Please provide a file named MigratorConfig.js in your project root.\r\n at new KnexMigrateError (D:\home\site\wwwroot\node_modules\knex-migrator\lib\errors.js:7:26)\r\n at Object.loadConfig (D:\home\site\wwwroot\node_modules\knex-migrator\lib\utils.js:38:19)\r\n at new KnexMigrator (D:\home\site\wwwroot\node_modules\knex-migrator\lib\index.js:18:24)\r\n at Object.<anonymous> (D:\home\site\wwwroot\db.js:2:20)\r\n at Module._compile (internal/modules/cjs/loader.js:689:30)\r\n at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)\r\n at Module.load (internal/modules/cjs/loader.js:599:32)\r\n at tryModuleLoad (internal/modules/cjs/loader.js:538:12)\r\n at Function.Module._load (internal/modules/cjs/loader.js:530:3)\r\n at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)\r\n at startup (internal/bootstrap/node.js:283:19)\r\n at bootstrapNodeJSCore (internal/bootstrap/node.js:743:3)\r\nD:\Program Files (x86)\SiteExtensions\Kudu\82.10503.3890\bin\Scripts\starter.cmd deploy.cmd
Is this repo out of date and no longer working or are there additional steps I’m missing?
Hi Josh,The repo is actually highly active and there are times when something will break since Azure is a slightly different deployment method than what the Ghost team is targeting. I checked and am seeing the same issue so I’ll investigate this and get back to you.Chris
Hi Josh,
The error you are seeing is actually different than what I’m seeing. With the latest 2.28.0 release, there is a permissions issue with nql-map-key-values. When these issues arise, the Ghost team is pretty quick in fixing them so generally a new release will address it. In looking at the repo for changes, there is a change for this:. My guess is that the next release will address the issue I’m seeing. If you cloned the repo in the last 3 days, you would be pulling the 2.28.0 release, so once the next release is out, you should try updating your repo to that version and then re-deply and see if that fixes it for you.Also, please look at a follow-up post I made:. If you are cloning from my repo, you should be ok as I downgraded a library to a version which uses 32-bit. However, if you are using another repo, you will have an issue until you follow this post to upgrade your Azure App service to 64-bit.
Thanks,Chris
Step 2 – I don’t see the two repos Azure and Azure production after forking. Am I supposed to fork twice or am I missing something obvious?
Hi Joshua,
I just checked on this and no, you’re not missing anything; it looks like Yannick updated his repo branches and now has “master” and “2x”. I would assume these are the same as “azure-prod” and “azure”, respectively. However, I have not tested with this since he made the update so you can play with that and see if that works as expected or you can try the same with the originator’s (Radoslav) at, or you can fork mine which should match this article:. Also, if you want the updated Release Uploader Azure Function, I don’t know if Yannick or Radoslav updated theirs, but it was only working for version 2.x – once it got to 3.x, it didn’t pick it up so I updated mine to catch all releases:.
Good luck!
Chris
Hi Chris, I got problem with the web hook. I followed your steps and created a Function App to include your sample code, and configured the Webhook from the Ghost Kudu, but the Kudu says ServiceUnavailable, and Function returns ” Status: 500 Internal Server Error”, log output as:
2020-02-28T12:17:56.551 [Error] Executed ‘Functions.HttpTrigger1’ (Failed, Id=668dc65f-b684-4f55-ae30-3a418254ec02)
Object reference not set to an instance of an object.
Would you kindly have a check on this? Thanks.
Hi Joshua –
I believe from your comment the error is somewhere in your Azure Function. If you haven’t already, try debugging your Azure Function through the portal with test input. To do this, go to your Azure Function and click on HttpTrigger1, which will show your Azure Function code. On the right hand side, click “Test”. Here, put in the JSON I put as an example in this post which we are parsing as output from our web app deployment. Once you have this, click the Run button at the bottom and this will test your function with this output. If you are getting a 500 here, then you have an error in your code; you can print log statements to help debug and figure out where your error is. Hope this helps!
Thanks,
Chris
|
https://devblogs.microsoft.com/premier-developer/creating-a-ghost-blog-on-an-azure-app-service/?WT.mc_id=docs-blog-jessde
|
CC-MAIN-2020-34
|
refinedweb
| 4,665
| 65.12
|
The inittab file contains more information than the dhcptags file. The inittab file also uses a different syntax.
A sample dhcptags entry is as follows:
33 StaticRt - IPList Static_Routes
33 is the numeric code that is passed in the DHCP packet. StaticRt is the option name. IPList indicates that the data type for StaticRt must be a list of IP addresses. Static_Routes is a more descriptive name.
The inittab file consists of one-line records that describe each option. The format is similar to the format that defines symbols in dhcptab. The following table describes the syntax of the inittab file.
Description
Name of the option. The option name must be unique within its option category, and not overlap with other option names in the Standard, Site, and Vendor categories. For example, you cannot have two Site options with the same name, and you should not create a Site option with the same name as a Standard option.
Identifies the namespace in which the option belongs. Must be one of the following: Standard, Site, Vendor, Field, or Internal.
Identifies the option when sent over the network. In most cases, the code uniquely identifies the option, without a category. However, in the case of internal categories such as Field or Internal, a code might be used for other purposes. The code might not be globally unique. The code should be unique within the option's category, and not overlap with codes in the Standard and Site fields.
Describes the data that is associated with this option. Valid types are IP, ASCII, Octet, Boolean, Unumber8, Unumber16, Unumber32, Unumber64, Snumber8, Snumber16, Snumber32, and Snumber64. For numbers, an initial U or S indicates that the number is unsigned or signed. The digits at the end indicate how many bits are in the number. For example, Unumber8 is an unsigned 8-bit number. The type is not case sensitive.
Describes how many units of data make up a whole value for this option.
Describes how many whole values are allowed for this option. 0 indicates an infinite number.
Describes which programs can use this information. Consumers should be set to sdmi, where:
snoop
in.dhcpd
dhcpmgr
dhcpinfo
A sample inittab entry is as follows:
StaticRt - Standard, 33, IP, 2, 0, sdmi
This entry describes an option that is named StaticRt. The option is in the Standard category, and is option code 33. The expected data is a potentially infinite number of pairs of IP addresses because the type is IP, the granularity is 2, and the maximum is infinite (0). The consumers of this option are sdmi: snoop, in.dhcpd, dhcpmgr, and dhcpinfo.
|
http://docs.oracle.com/cd/E19253-01/816-4554/dhcp-ref-10/index.html
|
CC-MAIN-2017-04
|
refinedweb
| 438
| 67.35
|
Search the Community
Showing results for tags 'navigation'.
Horizontal website menu: scrollTo section on click
lauxpaux posted a topic in GSAPHello, I'm pretty new at this and this is my first post so I'll try to be as clear as possible but bare with me please. The codepen attached is essentially what I want to do for this site in terms of functionality. I'm struggling with the menu portion because it is a horizontal website and I can't just add the ids to the href. I tried using scrollTo but I haven't had any luck so I'm wondering if someone can help me. The idea is to have the menu flow throughout all the sections in a sticky-like position. When you click on one of the menu links it sends you to the corresponding section regardless of where you are on the website. Right now I'm thinking scrollTo but I'm open to other methods/animations as long as it takes you to the particular sections which is what I can't figure out. I'd appreciate any help. Thanks!
Toggle navigation resize issue
Dawid posted a topic in GSAPHi, i am just getting to know gsap and i have a little problem :/. I am writting a page in gatsby and made a mobile side menu with gsap but i noticed that when the menu is opened for the first time and closed, after resizing the window, the menu doesn't change its position on the x-axis and starts sticking out. const Header = () => { const [isOpen, setIsOpen] = useState(false) const menuRef = useRef(null) const menuBtn = useRef(null) const tl = useRef() const toggleOpen = () => { setIsOpen(!isOpen) } useEffect(() => { const nav = menuRef.current const mainMenuLists = [...nav.querySelectorAll("ul:nth-of-type(1) li")] const socialLists = [...nav.querySelectorAll("ul:nth-of-type(2) li")] const btn = menuBtn.current const upLine = btn.querySelector("span:nth-of-type(1)") const centerLine = btn.querySelector("span:nth-of-type(2)") const downLine = btn.querySelector("span:nth-of-type(3)") tl.current = gsap .timeline() .to([upLine, downLine], { y: "-50%", duration: 0.3 }) .to(upLine, { duration: 0.1, rotation: 45 }, 0.2) .to(downLine, { duration: 0.1, rotation: -45 }, 0.2) .to(centerLine, { duration: 0.1, autoAlpha: 0 }, 0.2) .to(nav, { x: "0", duration: 0.5, autoAlpha: 1 }) .staggerFromTo( mainMenuLists, 1, { x: "-=15px", autoAlpha: 0 }, { x: "0", autoAlpha: 1 }, 0.2 ) .staggerFromTo( socialLists, 0.5, { y: "+=3px", autoAlpha: 0 }, { y: "0", autoAlpha: 1 }, 0.1 ) .reverse() }, []) useEffect(() => { tl.current.reversed(!isOpen) }, [isOpen]) return ( <HeaderComponent> <Logo> <AniLink path="/" hex="#333"> <LogoImg /> </AniLink> </Logo> <OpenMenuBtn ref={menuBtn} onClick={toggleOpen}> <span /> <span /> <span /> </OpenMenuBtn> <Nav menuRef={menuRef} setIsOpen={setIsOpen} /> </HeaderComponent> ) } const Nav = styled.nav` position: fixed; top: 0; left: 0; bottom: 0; right: 0; transform: translateX(100%); background-color: #ccc; z-index: 99; ` const Navigation = ({ setIsOpen, menuRef}) => { return ( <Nav ref={menuRef} onClick={() => setIsOpen(false)}> ... </Nav> ) } I think i know what the problem is. Timeline is created when the component is mounted and the first time the menu is opened it pops up getting translate (0). When I close the menu, the animation returns back and gsap assigns to the translate (x), value from the start of the animation. because the animation is set to reverse (I know it's obvious) . I wonder if there is any possibility to change the value of position x only when the animation returns?(Because I can't/ i don't know how do this animation differently: D) short demo
play/reverse tween with ScrollTrigger
_Greg _ posted a topic in GSAPHi! How can i use links (like navigation) to play/reverse tween and scroll to trigger position, tween must be played/reversed with scrolltrigger or on click button I think something like window.scrollTo(trigger-start/end position) but I can't figure out how to calculate the position of triggers Thank you!
-?
gsap Menu navigation
lauren_d posted a topic in GSAPHi, I've been trying to make a gallery navigation like this: where the menu is a gallery of images and moves when you drag the canvas and then you have the select to sort the diverse articles, the animation is beautiful. I'm guessing I have to use a plugin to do the sorting like they use (flickity), but I'm kind of lost on how to make the canvas. I just want to be able to drag my canvas in fullview and integrate it with images which would be Links. I'm not expecting any of you to tell me the answer. I'd be more than happy if you just simply point me in the right direction. And sorry if my english is not good, it's not my first language. Thank you all for your time!
-
MorphSVG menu icons help please
Johanna posted a topic in GSAPHi all, I'm trying to make a menu with SVG icons that morph into Xs and back on click. So far I can get them to morph and morph back as the menu closes but I'm stuck on trying to get one icon to revert back to its original shape when I click the other icon. Where am I going wrong?!
Drag/swipe navigation with timeline and Angular
lewisSME posted a topic in GSAPHi, I'm using Angular UI-router to build a one-page site with a looping, draggable navigation, and want to use TimelineMax to animate a sprite on the transitions. What I've got so far (see Codepen link) is that when the user drags or swipes the target area, the animation plays or reverses (depending on swipe direction) and the new section loads. So far so good. However, I want the drag/swipe action to actually control the progress of the sprite, so that users can scrub through the timeline. Then, when they release the drag or swipe, the rest of the animation to play and the next page to load. Another thing I've noticed is that once I've swiped through all section of the page and looped back the beginning, the sprite no longer animates - the Timeline just jumps to the next sprite image. If you change direction it then starts working again. Any help greatly appreciated! NB: The individual page content won't load on the Codepen demo, not sure why, but it doesn't matter to the issue I'm trying to resolve here. Cheers. doing this with getElementById or something else. Many thanks for any help function initActionPlan() { $(".actionPlanLink").each(function(index, element) { $(this).on("click", gotoActionSection); }); } function gotoActionSection(e) { if(currentSectionNum != $(e.currentTarget).index()){ if(currentSection) { TweenLite.to(currentSection, 0.5, {autoAlpha:0}); } currentSection = $(".tabsContainer")[1]; TweenLite.to(currentSection, 0.2, {autoAlpha:1}); } } //OpenClose Action Plan function actionInit(){ initActionPlan(); $(".actionPlanLink")[1].click(); } actionInit();
- Hello again, I'm now moving on to the menu. How do I setup the menu (styled it etc..), so what I want is that once you click on a menubutton it auto scrolls down to that page/section. And my question is. How do I do that? Because when I look at the demo of this I don't see any demo with an actual functioning menu. There is a lot about effects and animations, but nothing in it about how to make all of that work with a navigation also. Does anyone got some kind of tutorial on 'How to make a menu that scroll to page/section'? Maybe there is a tutorial somewhere that I have missed?
Scrollorama Vertical navigation
Samis posted a topic in GSAPHi! I´m wondering if the Super scrollorama has some kind of vertical navigation like this one: I´m trying to figure out some kind of vertical menu, where you´re able to click on one item, and it takes you to the right portion of animation. Is it possible? How? Thanks a lot!
|
https://greensock.com/tags/navigation/?_nodeSelectName=cms_records17_node&_noJs=1
|
CC-MAIN-2021-49
|
refinedweb
| 1,310
| 65.32
|
[Changes for 0.29 - 2008-12-13] * Publisher and index fixes * We don't need to force select_timeout anymore, and it causes explosions if called during global destruction, when $$self->[0] (_part_ of the pseudohash) may have gone missing already, but the object itself is still there. So $$self->{anything} explodes with "not a hash reference" _sometimes_, despite $$self always being an arrayref. ..friends don't let friends use pseudohashes. [Changes for 0.28 - 2008-08-15] * We now require DBM::Deep 1.00 or later. * Improved data consistency in DBM::Deep backend so it won't sometimes die with a "not an ARRAY reference" message. Reported by: Matthew Pitts [Changes for 0.27 - 2007-10-09] * Adjust tests so it no longer fails with newer versions of DBM::Deep. [Changes for 0.26 - 2007-05-31] * Repair a broken attempt at PAUSE uploading. [Changes for 0.25 - 2007-05-31] * The DBM::Deep tests of t/basic.t now explicitly passes the temporary database file to the backend; now it won't hangs on OSX anymore. Contributed by: Arne Skjærholt [Changes for 0.24 - 2007-02-26] * Typo fix in Memcached driver. [Changes for 0.23 - 2007-02-19] * New ->disconnect API to explicitly disconnect from the backend store. Contributed by: Alex Vandiver [Changes for 0.22 - 2006-12-11] * INCOMPATIBLE CHANGE to Jifty::DBI backend: "key" column changed to "data_key" because "key" is a reserved word in some SQL databases. Contributed by: Jesse Vincent [Changes for 0.21 - 2006-10-26] * Speed up ->modify calls for the Memcached backend. * Normalized internal keys for channels, messages and data so they can't clash. [Changes for 0.20 - 2006-10-25] * Memcached: Remove the debug messages accidentally left in ->lock and ->unlock. * New ->modify API for IPC::PubSub and Cache to atomically manipulate cache. * Time::HiRes is now required to reduce locking contention. [Changes for 0.11 - 2006-10-25] * The Memcached backend now takes a namespace parameter to avoid collision. * The ->lock, ->unlock, ->fetch, ->store APIs in IPC::PubSub now works again. [Changes for 0.10 - 2006-10-25] * Renamed from MessageBus.pm to IPC::PubSub. * IPC::PubSub's factory methods are now ->new_subscriber and ->new_publisher. * New ->channels API for Publisher and Subscriber objects. * New ->publish, ->unpublish and ->expiry APIs for Publisher objects. * New ->subscribe, ->unsubscribe APIs for Subscriber objects. [Changes for 0.04 - 2006-10-24] * Expose ->lock, ->unlock, ->fetch, ->store APIs into the IPC::PubSub object. * Implement ->lock and ->unlock methods for non-Memcached backends. * The tests are no longer entirely skipped when memcached is not running. [Changes for 0.03 - 2006-10-24] * New backend: JiftyDBI. * Multiple publishers now work in DBM_Deep and Memcached backends. * Memcached now atomically handles publisher announcement and removal. [Changes for 0.02 - 2006-10-24] * Thanks to mstrout++ this thing actually works now. :-) * Switched from Class::InsideOut to Class::Accessor::Fast. [Changes for 0.01 - 2006-10-24] * Initial release to CPAN of this three-hours-old hack.
|
https://metacpan.org/changes/distribution/IPC-PubSub
|
CC-MAIN-2016-30
|
refinedweb
| 497
| 71.61
|
This is a follow-up from a previous question, in which I was trying to figure out the main cause for my code running slowly. I think I've narrowed it down to a minimal example below. I have a basic database structure as follows:
public class Foo { public int Id { get; set; } public string Bar { get; set; } } public class FooContext : DbContext { public DbSet<Foo> Foos { get; set; } }
Now, if I had a list of
Foo objects, and wanted to add them to the database, the suggested way would be to use
AddRange(). But I noticed it was taking a long time, and is affected poorly by the number of items in the collection, even with a small amount like 200. So I wrote it out manually, and viola, it runs faster!
class Program { static void Main(string[] args) { var foos = Enumerable.Range(0, 200).Select(index => new Foo { Bar = index.ToString() }); // Make sure the timing doesn't include the first connection using (var context = new FooContext()) { context.Database.Connection.Open(); } var s1 = Stopwatch.StartNew(); using (var context = new FooContext()) { context.Foos.AddRange(foos); context.SaveChanges(); } s1.Stop(); var s2 = Stopwatch.StartNew(); using (var context = new FooContext()) { // Ignore the lack of sanitization, this is for demonstration purposes var query = string.Join(";\n", foos.Select(f => "INSERT INTO Foos ([Bar]) VALUES (" + f.Bar + ")")); context.Database.ExecuteSqlCommand(query); } s2.Stop(); Console.WriteLine("Normal way: {0}", s1.Elapsed); Console.WriteLine("Hard way : {0}", s2.Elapsed); Console.ReadKey(); } }
My initial thought was that Entity Framework might be using a separate transaction for each entry, but logging the SQL shows that's not the case. So why is there such a difference in execution time?
While doing some research on your question I came across this enlightening article:
Here's a quote:
Each object that was inserted required two SQL statements - one to insert a record, and additional one to obtain identity of the new record
This becomes a problem when inserting multiple records. A problem which is intensified by the fact that each record is inserted one at a time (But this is outside the context of your question since you're already testing the one by one insert). So if you're inserting 200 records, that's 400 sql statements being executed one by one.
So from my understanding EF is simply not built for bulk insertion. Even if it's as simple as inserting 200 records. Which to me seems like a big let down.
I started thinking, "Then what is EF good for anyway. It can't even insert a couple of records". Well i'll give EF props in two areas:
So simply put, it seems like, if you have an operation that requires inserting a bunch of records, it might be best to use SqlBulkCopy. Which can insert thousands of records in seconds.
I know this might not be the answer you want to hear, because believe me it upsets me as well since I use EF alot, but I don't see any way around it
Since you can't live with it and can't live without it, have you considered calling SaveChangesAsync() instead?
I searched far and wide to find a way to disable primary key synchronization but could not find any for EF 6 and lesser.
EF core passes a true from DBContext.SaveChanges() to what I believe eventually triggers this synchronization. The other overload allows callers to pass false as the controlling parameter.
|
https://entityframeworkcore.com/knowledge-base/45206015/why-is-entity-framework-so-slow-to-add-multiple-items-in-one-savechanges---
|
CC-MAIN-2022-21
|
refinedweb
| 579
| 63.09
|
span8
span4
span8
span4
user selects one feature class (published parameter) and fme writes to one to six formats(like csv, shape, dgn, acad, xls,mapinfo etc...)
in the fmw i am asking formats to write via published parameter
output_format =dwg,shape, xls like(comma separated)
then i used python prg to split these values create new attribute for each format(yes)
import fme import fmeobjects import math def frq(feature): my_list = feature.getAttribute('_list{}') ESRISHAPE='' XLSXW='' CSV='' AUTOCAD_OD='' AUTOCAD_DWF='' FILEGDB='' for item in my_list: if item=="ESRISHAPE": ESRISHAPE="YES" if item=="FILEGDB": FILEGDB="YES" if item=="XLSXW": XLSXW="YES" if item=="CSV": CSV="YES" if item=="AUTOCAD_OD": AUTOCAD_OD="YES" if item=="DWF": AUTOCAD_DWF="YES" feature.setAttribute("ESRISHAPE", ESRISHAPE) feature.setAttribute("XLSXW", XLSXW) feature.setAttribute("CSV", CSV) feature.setAttribute("AUTOCAD_OD", AUTOCAD_OD) feature.setAttribute("AUTOCAD_DWF", AUTOCAD_DWF) feature.setAttribute("FILEGDB", FILEGDB)
at the end i am checking these values using multiple test filters and sending to each writes
now my question is
if user wants to write 3 formats then all the features are going to each test filter transformers(6 filters for six formats)
dwg=yes then goes to dwg writer
dgn = yes then goes to dgn writer
........
........
all the features goes to 6 diffrent feature filter for testing the attrib value
i think , we can write same fmw in more optimized way? my worry is , if i have to write only three formats then why all the features should go to six filters ? this is the huge load for fme right?
can we do something for the optimization?
Does it look like this?
Notice both Passed/Failed are connected to the next Tester, but only one of them should ever occur.
I think if you do this then you will have only one extra copy. Yes, the data goes to each Tester, but it passes through because the Tester is not group-based. You don't get a copy of the data at every Tester, a copy occurs only when that test is true. So if the number of formats is n, then you'll get n+1 copies at most (and maybe not even that since the final tester has no failed output connected).
I think what might be more important is to be using a FeatureWriter transformer, instead of a writer. Then things will happen in parallel and the data won't be cached at each writer. eg - see Dale's answer to a previous question.
If you really want to make sure you only get n copies of the data, then make a count of the chosen formats and use a Cloner to create that many copies. Then you can use a single TestFilter to separate each cloned set and point it to the correct writer (you'd need to be able to map the clone number to a particular format, but that shouldn't be too hard).
Hope this helps.
In your PythonCaller, I would replace the function by a class and instead of creating six attributes, I would create a copy of the feature with the attribute "FORMAT" set to the required format for each format requested by the user.
Then only one AttributeFilter (on the FORMAT attribute) is required to filter features based on the format requested.
Python code:
import fme import fmeobjects class FeatureProcessor(object): def __init__(self): pass def input(self,feature): my_list = feature.getAttribute('_list{}') for item in my_list: if item=="ESRISHAPE": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "ESRISHAPE") self.pyoutput(outputFeature) if item=="FILEGDB": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "FILEGDB") self.pyoutput(outputFeature) if item=="XLSXW": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "XLSXW") self.pyoutput(outputFeature) if item=="CSV": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "CSV") self.pyoutput(outputFeature) if item=="AUTOCAD_OD": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "AUTOCAD_OD") self.pyoutput(outputFeature) if item=="DWF": outputFeature = feature.clone() outputFeature.setAttribute("FORMAT", "AUTOCAD_DWF") self.pyoutput(outputFeature) def close(self): pass
Hi Mark,
I used testfilter in this way. is this costlier than tester ?
So you are essentially cloning the features 6 times, regardless of how many formats are chosen.
What about simply exploding the format list, and using a featureWriter set to generic format? In the parameters you can set to Output Format to an attribute. All you need to do is ensure that your format names exactly match those used by fme.
I used a similar process:
Have a "Choice with alias (multiple)" published parameter with a list of formats.
Then use a Tester transformer to see if the format is in the chosen list (eg parameter contains ESRISHAPE for Shape output etc.)
Then use a dynamic Shape writer to write to Shape files.
Repeat this for each format in the list.
If you allow the user to pick just one format at the time, you can use "Choice with alias" published parameter with a list of formats.instead, followed by the Generic writer.
Answers Answers and Comments
12 People are following this question.
FeatureWriter cannot configure dynamic schema based on schema feature when fanning out destination dataset? 5 Answers
DataSet Fanout for FeatureWriter 3 Answers
Is batch deploy with attribute fanout possible? 2 Answers
Can I copy attributes from feature type into the FeatureWriter Transformer? You can do it into a FeatureWriter but not the transformer. I'm trying to convert some of my Writers to use the FeatureWriter Transformer. 1 Answer
"Could not disable Load Only Mode for feature type" 1 Answer
|
https://knowledge.safe.com/questions/54847/how-to-write-to-many-formats-in-optimized-way.html?childToView=54962
|
CC-MAIN-2020-24
|
refinedweb
| 905
| 57.47
|
Let us consider a game, in which a player can get some score with 3, 5 or 10 in each move. A target score is also given. Our task is to find how many possible ways are there to reach that target score with those three points.
By the dynamic programming approach, we will create a list of all score from 0 to n, and for each value of 3, 5, 10, we simply update the table.
Input: The maximum score to reach using 3, 5 and 10. Let the input is 50. Output: Number of ways to reach using (3, 5, 10)50: 14
countWays(n)
There is only 3 possible score, they are 3, 5 and 10
Input: n is the maximum score to reach.
Output: The number of possible ways to reach score n.
Begin create table of size n+1 set all table entries to 0 table[0] := 1 for i := 3 to n, do table[i] := table[i] + table[i-3] done for i := 5 to n, do table[i] := table[i] + table[i-5] done for i := 10 to n, do table[i] := table[i] + table[i-10] done return table[n] End
#include <iostream> using namespace std; // Returns number of ways to reach score n int countWay(int n) { int table[n+1], i; //table to store count for each value of i for(int i = 0; i<=n; i++) { table[i] = 0; // Initialize all table values as 0 } table[0] = 1; //set for 1 for input as 0 for (i=3; i<=n; i++) //try to solve using 3 table[i] += table[i-3]; for (i=5; i<=n; i++) //try to solve using 5 table[i] += table[i-5]; for (i=10; i<=n; i++) //try to solve using 10 table[i] += table[i-10]; return table[n]; } int main() { int n; cout << "Enter max score: "; cin >> n; cout << "Number of ways to reach using (3, 5, 10)" << n <<": " << countWay(n); }
Enter max score: 50 Number of ways to reach using (3, 5, 10)50: 14
|
https://www.tutorialspoint.com/Count-number-of-ways-to-reach-a-given-score-in-a-game
|
CC-MAIN-2020-24
|
refinedweb
| 345
| 71.11
|
Had a nice chat with the bods on the BEA stand today amoungst other things I found out how to do the equivalent of the @AsyncWebService annotation that we have been working on in OC4J. Turns out it was just staring me in the face and that they just use different terminology. (Need to use the buffered and callback features)
So to compare this is our version:
@WebService @AsyncWebService public class StockQuote { public float getStockQuote(String ticker) { return 100f; } }
So the basic version for stock quote would look like:
@WebService(...) @WLHttpTransport(...) @BufferQueue(name="my.jms.queue") public class StockQuote { @Callback private StockQuoteResponse _response; @WebMethod() @MessageBuffer(retryCount=10, retryDelay="10 seconds") @Oneway() public void getStockPrice(String ticker) { _response.getStockPriceResponse(100f); } }
The downside is that at least based on the documentation I have is that you cannot do this with JAX-WS. This might be something they have fixed in the 10.3 build; but I haven't got my hands on this yet to take a look. I will drill down with the BEA people as we have contact to find out how this is resolved in 10.3.
|
http://kingsfleet.blogspot.com/2008/05/asyncwebservice-iin-bea-weblogic.html
|
CC-MAIN-2019-13
|
refinedweb
| 188
| 58.01
|
By appending a pair of square brackets after a datatype, you can have a array of that datatype. For example,
in the declaration
int[] v,]; // 10 is the number of items // the keyword “new” in
myA = new int[10];, even though myA isn't a class. This is one of Java's syntax idiosyncrasy. -dimensional Array. (or n-dimensional)
The syntax for n-dimensional array is similar to 1-dimensional array, but with multiple square bracket pairs instead of one.
In the following example, we show the syntax of 3 things:
public class Ar2 { public static void main(String[] args) { // declaring that myA is a 2-dimensional array int[][] myA; // give the.
Note: list-like things such as general lists, vectors (tuple), keyed-lists (hash table, associative array), and may other types are in the package “java.util.Collections”.
Java Tutorial: arraybasics
Java Lang Spec: arrays
|
http://xahlee.info/java-a-day/arrays.html
|
CC-MAIN-2013-48
|
refinedweb
| 146
| 52.09
|
I am completely lost with this assignment. Can someone help me with it? Here are our instructions:
This assignment will use the following description to implement a Dialog class for the Leap Year Problem. You need to decompose this problem into 2 classes:
1.The Date.java class. Implement a public class Date that represents a date composed of a month , day, and a year. Declare month, day, and year as integers. They are the 3 instance variables. Remember that you need to write a constructor Date and 4 methods:
"daysIs()" which returns a day
"monthIs()" which returns a month
"yearIs()" which returns a year
"isLeapYear()" is needed in the class Date. It has one parameter "year" and returns a boolean. Write the method isLeapYear() knowing that a year is defined to be a leapyear it is a multiple of 4, and if it is is a multiple of 100, it must also be a multiple of 400. isLeapYear() thus decides when a year is a leap year. (see the discussion on "Hints for Assign5" to discover specific examples of a LeapYear).
2.The DateJDialog.java class: which implements the GUI. Please use the Dialog boxes developed in the book in chapter2 in pages 99-100 in the code-listing 2-32 (NamesDialog.java) for input and output.
Remember that you will prompt the user to enter:
1.a day;
2.a month;
3.a year
And out of these 3 you will be able to create a Date. Then you will use the dialog box to tell the user whether the year entered was a leapyear or not a leapyear.
The purpose of the Date.java that you will implement is to decide whether a year is a leap year. Here is a definition of when a year is considered a leap year :
1.
year y1 is a leap year if it is multiple of 4.
2.
year y1 is a leap year if it is a multiple of 100, it must be a multiple of 400.
3.
Otherwise y1 is not a leap year.
Do not forget to compile the 2 java files. To verify that the DateJDialog.java works, in TextPad after you compile DateJDialog.java, Click on Tools, Click on "Run Java Application".
|
http://www.javaprogrammingforums.com/%20whats-wrong-my-code/28736-help-java-homework-printingthethread.html
|
CC-MAIN-2015-32
|
refinedweb
| 377
| 76.11
|
installed with header files (and a C++ compiler of course):
- Debian/Ubuntu:
sudo apt-get install libtag1-dev
- Fedora/RHEL:
sudo yum install taglib-devel
- Brew:
brew install taglib
- MacPorts:
sudo port install taglib
Then do:
gem install taglib-ruby
OS X C++ compiler override
Not all versions of TagLib get along with
clang++, the default C++ compiler
on OS X. To compile taglib-ruby's C++ extensions with a different compiler
during installation, set the
TAGLIB_RUBY_CXX environement variable.
TAGLIB_RUBY_CXX=g++-4.2 gem install taglib-ruby
Usage
Complete API documentation can be found on rubydoc.info.
Begin with the TagLib namespace.
Release Notes
Contributing
Building
Install dependencies (uses bundler, install it via
gem install bundler
if you don't have it):
bundle install
Regenerate SWIG wrappers if you made changes in
.i files (use at least
version 2.0.5 of SWIG):
rake swig
Force regeneration of all SWIG wrappers:
touch ext/*/*.i rake swig
Compile extensions:
rake clean compile
Run tests:
rake test
Run irb with library:
irb -Ilib -rtaglib
Build and install gem into system gems:
rake install
Workflow
-).
|
http://www.rubydoc.info/gems/taglib-ruby/frames
|
CC-MAIN-2015-14
|
refinedweb
| 182
| 50.57
|
Subject: Re: [boost] [filesystem] Version 3 of Boost.Filesystem added to trunk
From: Beman Dawes (bdawes_at_[hidden])
Date: 2010-06-06 13:16:19
On Sat, Jun 5, 2010 at 4:20 AM, Andrey Semashev
<andrey.semashev_at_[hidden]> wrote:
> On 06/02/2010 07:07 PM, Beman Dawes wrote:
>>
>> Because version 3 will break some user code, both v2 and v3 will be
>> shipped for several releases. For 1.44, the default is v2 and the
>> user has to explicitly switch to v3.
>>
>> I'd really appreciate it if some Boosters could give v3 a try on your
>> own code that uses Boost.Filesystem.
>
> I think that the approach of manual switching between v2 and v3 is not very
> good. The packagers will not be able to ship both versions of the library in
> Linux distributions, which effectively means that v3 will not get adopted.
>
> Also, if I want my code to be compatible with both versions of the library,
> I cannot see a way to detect which version is currently installed. This is
> the case with my Boost.Log - it's not compatible with v3, mostly because
> path is not a template anymore. I would like people to be able to use
> Boost.Log regardless of which Boost.Filesystem their application uses.
You and Scott McMurray have convinced me that this is a real problem.
>
> I would really prefer to have both versions of the library available at any
> time. Either as two separate libraries (like signals and signals2) or as two
> parts of one library (like spirit v2 and classic). In the latter case it
> could be compiled into one binary, with v2 and v3 being in different
> namespaces and "namespace filesystem" being an alias to one of them.
That's the approach I'm prototyping. Looks promising. Stay tuned...
Thanks,
--Beman
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk
|
https://lists.boost.org/Archives/boost/2010/06/167703.php
|
CC-MAIN-2021-10
|
refinedweb
| 326
| 74.59
|
Implementation status: partially implemented
Synopsis
#include <stdio.h>
int fputc(int c, FILE *stream);
Description
Writes a character (an unsigned char) specified by the argument c to the specified stream and advances the position indicator for the stream.
Arguments:
c - a character,
stream - an output file.
The last data modification and last file status change timestamps of the file are marked for update between the successful execution of
fputc() and the next successful completion of a call to
fflush() or
fclose() on the same stream or a call to
exit() or
abort().
Return value
On success the character written to the stream is returned. Otherwise
EOF, the error indicator for the stream is set, and
errno is set to indicate the error.
Errors
[.
[
EFBIG] An attempt was made to write to a file that exceeds the file size limit of the process.
[
EFBIG] The file is a regular file and an attempt was made to write at or beyond the offset maximum.
[ is also sent to the thread.
[
ENOMEM] Insufficient storage space is available.
[
ENXIO] A request was made of a nonexistent device, or the request was outside the capabilities of the device.
Implementation tasks
- Implement error handling for the function
|
http://phoenix-rtos.com/documentation/libphoenix/posix/fputc
|
CC-MAIN-2020-34
|
refinedweb
| 201
| 54.63
|
Concurrency In Python
Page Contents
References
- Concurrent Execution, Python Standard Library Documentation.
- Threading – Manage concurrent threads, PyMOTW.
An Introduction To Concurrency
When a program can interleave statements from multiple workflows we can say the program is concurrent. This can be done via processes and threads. The main difference between the two is that a process has its own address space and cannot access the memory of other processes directly. A thread, on the otherhand, runs within a process. It can access the entire address space of the process it belongs to.
Here I will mostly talk about threads...
Correctness Properties
Safety. We want our programs to be safe so that having multiple threads try to access shared resources etc does not cause errors and that all our threads can run continuously:
- Mutual exclusion - critical sections must not overlap.
- Deadlock - occurs when no process can make usefull progress.
- Deadly embrace - progress is mutually dependent, so for example, process A is waiting on a resource held by process B, but process B is waiting on a different resource held by process A.
- Livelock - every process is computing without progressing meaningfully.
Liveness. We want our programs to produce something useful! I.e, each process is allocated the resources it needs to do its job:
- Starvation - occurs when some requests never get dealt with.
- Fairness - contention for resource is resolved fairly
What Is A "Critical Region"
A critical region is a section of code which must only be executed by one thread at any one time. Lets take, for example, a shared counter. Let's say that there are N threads, each of which increments the counter when some event occurs. The pseudo code that increments the counter is:
var = counter value var = var + 1 counter value = var
Without any protection it is quite possible to get this interleaving:
Counter value is 5 Thread A: var = 5 Thread B: var = 5 Thread B: var = var + 1 = 6 Thread B: counter value = 6 Thread A: var = var + 1 = 6 Thread A: counter value = 6 Counter value is 6 (oops!)
The value of the counter at the end of this sequence is wrong. It should have been incremented twice, once by thread A and once by thread B, giving it a new value of 7. As it stands it ends up being 6!
Clearly from the point just before a thread reads the counter to just after it stores the incremented value, a thread must not be interrupted by another thread that is also trying to increment the counter. If we make our pseudo code this:
ENTER CRITICAL REGION var = counter value var = var + 1 counter value = var LEAVE CRITICAL REGION
The the malfunctioning interleaving we saw above cannot happed because we have placed this "guard" around the access to the counter. This guard stops more than 1 thread being in this section of code at once. Thus, our previous sequence would now look like this:
Counter value is 5 Thread A: Enters critical region Thread B: Tries to enter critical region but cannot. Blocks! Thread A: var = var + 1 = 6 Thread A: counter value = 6 Thread A: Leaves critical region Thread B: Unblocks and enters critical region Thread B: var = 6 Thread B: var = var + 1 = 7 Thread B: counter value = 7 Thread B: Leaves critical region Counter value is 7 (yay!)
So, how do we define critical regions in Pyhon? We use Locks, Recursive Locks, Semaphores, and Condition Objects, which we will come to later....
The Advantages Of Threads
So, why use threads? Because sometimes programs are waiting doing nothing, so by having more threads, whilst one thread is waiting on say an internet query, the other thread can be getting on doing useful work. Esessntially you can get more work done. It can be more efficient to have multiple threads in one process rather than many processes.
So... to give myself some structure writing this and to revise a little I looked back at my uni notes which were for Java and made almost 15 years ago now! The principles haven't changed and rather than always looking up the docs and coding as I go I though writing this would cement it in my head for Python. So here goes...
Create A Thread
The Python Standard Library provides the class
Thread, which can either have a callable
passed into the constructor or the class itself can be subclassed (only override
__init__() and
run().
Passing A Callable To The Thead Constructor
Create a thread by passing a callable (usually a functionm) to the
Thread constructor as
demonstrated below.
from threading import Thread def my_thread(arg1): print("Have arg1 = {}".format(arg1)) for i in range(10): print(i) threads = [] for i in range(5): thread = Thread( target = my_thread, name = "my_thread_{}".format(i), args=(5-i,)) threads.append(thread) thread.start() for thread in threads: print( "Waiting for thread {} with name '{}'".format( thread.ident, thread.name)) thread.join() # Block until this thread has finished
The above example starts 5 threads, which don't do anything particularly interesting except print out the argument they were passed and then a sequence of 10 numbers. The output should be enough to convince you that the seperate flows of execution are running concurrently however.
To
Thread we can pass an
args option which has to be a tuple. Each member
of that tuple is passed as an argument to the callable
my_thread. The
Thread
is told to run the function
my_thread through the use of the
target keyword.
The thread's
name keyword argument isn't used by the thread, but it can be retrieved
using the
thread.name property. You can set it to anything you like and it does not
have to be unique.
Once each thread is created it is immediately started using
thread.start(). As soon
as this call completes the thread is active and can be scheduled at any time.
Once a thread is active it is given a unqiue identified, which we print out in the "Waiting for thread..."
message using the property
thread.ident. Note, that although the identified is unique, as soon as a thread dies it's
ident may be reused by new threads.
Subclassing Thread
If you subclass
Thread you must override the
run() method
and optionally the constructor.
from threading import Thread class MyThread(Thread): def __init__(self, arg1): super(MyThread, self).__init__() self._arg1 = arg1 def run(self): print("Have arg1 = {}".format(self._arg1)) for i in range(10): print(i) threads = [] for i in range(5): thread = MyThread(5-i) threads.append(thread) thread.start() for thread in threads: print( "Waiting for thread {} with name '{}'".format( thread.ident, thread.name)) thread.join() # Block until this thread has finished
I dont think there is much difference between giving
Thread a
target
and just sublassing it. The later just has a more object oriented feel about it I guess.
Waiting For A Thread To End
In the above examples you will have seen the command
thread.join(). The
join()
method is part of the
Thread object and causes the calling thread of execution to block
until the thread has terminated.
Create A Semaphore
The following snippet creates a semaphore with an initial value of 2. This means that up to 2 threads can be in the critical section that this semaphore can establish at any one time. If a 3rd thread were to try and enter it would block until 1 or more of the existing threads had left the CR.
num_resources = 2 my_sem = threading.Semaphore(num_resources)
To use the semaphore to define a critical region you can do this:
with my_sem: # do something critical # get to here and you're outside the with block and therefore # no longer in the critical region
This is a nice and safe way of using a semaphore. At the start of the
with
block, the semaphore will have its
acquire() function called automatically
for you. Then the code in the
with block is executed. When the
with
block is exited, for any reason, be it exception or otherwise, the semaphore will have
its
release() method called.
You can, of course, call the
acquire() and
release() methods
yourself. You might do it like this:
my_sem.aqcuire() try: # do some work finally: my_sem.release()
Notice that we have used a
try block to ensure that no matter
what happens, the semaphore will be released, whether you return from
within the
try block or throw an exception etc.
Sometimes you will write things like this:
my_sem.acquire() if some condition: my_sem.release() return some error # do critical work my_sem.release()
This is quite error prone because you have to remember to release the
semaphore wherever you end the normal flow of execution. You are much
much much better off using a
with block, or failing that
the
try/finally block structures shown above.
Create A (Recursive) Lock
A lock is like a sempahore with an initial value of 1. It is effectively a mutex. It allows one and only one thread access to the resource or critical section that it defines.
You create a lock as follows:
my_lock = threading.Lock() #< Created unlocked
Just like the semaphore the lock has methods
acquire() and
release().
The lock can also be used with the
with block in the same way.
A thread cannot re-take a lock that it has already aquired. If it tries to it will block:
my_lock.acquire() my_lock.acquire() #< This WILL block!
If you want a thread to be able to take a lock and then, take it again before releasing
it - this is called recursive locking then you need to use an
RLock:
my_rlock = threading.RLock() my_rlock.acquire() my_rlock.acquire() #< Will NOT block
The Bounded Buffer Problem: Asynchronous Message Passing
In this scenario there a is thread that creates a load of data. It could be a thread on your server, accepting client connections, reading data from the client and then passing the the received data on to another thread in your application that will process the data.
The thread getting the data that is getting pumped into your program's analysis algorithm is called the producer. The algorithm thread is said be be the consumer because it is consuming the data.
If we didn't have a queue in between these two threads they would have to operate in lock-step. The producer would get data over the network. It would then have to wait for the analysis (consumer) thread to be available so it could pass the data through to it. If the analysis thread was busy it would have to wait and so it could miss some incoming data. The same for the analysis thread. It will have to wait until data is available. If there is a sudden load on the network and there is a large delay in receiving data, the analysis thread will sit idle until suddenly a glut of data is received.
What we want to do is to decouple these two threads so that if the producer is busy, there is still enough data available to occupy the consumer. If the consumer is busy, the producer has somewhere to stash the data quickly so it can get back to its task. This is done by placing a buffer between the two processes.
We need to make sure of two things. The consumer must not read from and empty buffer (underflow) and the producer must not write to a full buffer (overflow).
Now, in Python, the standard library already gives us such a thread
safe buffer. It is found in
collections.deque:
Deques support
thread-safe, memory efficient appends and pops from either side of the deque
with approximately the same .
O(1) performance in either direction
Although, therefore, we would never implement this ourselves, it is a
nice exercise to try so that we can
threading library.
This can be implemented using this two semaphores. See the following pseudo code:
put_data: spaces.acquire() # Decrements the semaphore. If there are no spaces, # will block until one becomes available write value into queue elements.release() # Increments the semaphore. May unblock any process # waiting for elements. get_data: elements.acquire() # Decrements the semaphore. If there are no elements # will block until one becomes available read value from queue spaces.release() # Increments the semaphore, May unblock any process # waiting for a space to become available.
Lets try implementing this. TODO - this is UNTESTED code...
import threading class MyQueue(object): def __init__(self, size): self._size = size self._q = [None] * self._size self._start = 0; self._end = 0; self._elements = threading.Semaphore(0) self._spaces = threading.Semaphore(self._size) self._cr = threading.Lock() def enqueue(self, item): # Wait for a space to become available self._spaces.acquire() # Enter a critical region. We require this because if there are # multiple writers we could have multiple threads executing this logic # so we must enforce mutual exclusion. with self._cr: self._q[self._end] = item self._end = (self._end + 1) % self._size # Signal anyone waiting for an element to become available... self._elements.release() def dequeue(self): item = None # Wait for an element to be available in the buffer self._elements.acquire() # Enter a critical region. We require this because if there are # multiple readers we could have multiple threads executing this logic # so we must enforce mutual exclusion. with self._cr: item = self._q[self._start] self._start = (self._start + 1) % self._size # Signal anyone waiting for a space to become available... self._spaces.release() return item
But, in Python we can use condition variables. Here I replicate, with added comments, the example from the Python docs. We can see that only the one condition variable is required, rather than a pair of semaphores, which makes the implementation a little cleaner.
import threading # Somewhere create a condition variable cv = threading.Condition() # Consume one item in one thread cv.acquire() #< Lock is acquired while not an_item_is_available(): #< Therefore this executes in the CR cv.wait() #< Lock is released and thread sleeps # until cv.notify[All]() is called. # When cw.wait() unblocks it re-acquires the lock so at this point # we are back inside the CR get_an_available_item() cv.release() # Produce one item in another thread cv.acquire() make_an_item_available() cv.notify() cv.release()
The Dining Philosophers Problem: Sharing Resources
N philosophers sit around a table with N-1 forks available. To eat, each philosopher must pick up two forks, on to their left and one to their right. They pick up both forks to eat and once finished put down both forks and think for a while before eating again.
We must make sure that no philosopher starves! Dead philosophers are bad! We'd also like to make things fair... one fat philosopher who gobbles up 99% of the food will upset the others!
This problem demonstrates the concepts of deadlock and possible livelock.
|
https://jehtech.com/python/concurrency.html
|
CC-MAIN-2021-25
|
refinedweb
| 2,479
| 73.17
|
Recently Jake Archibald did a "bold claim" on Twitter about the use of
Array.prototype.reduce, and it inspired me to summarize what I think and what I tweeted in a nice blog post.
The inspiration
TL;DR
It depends on your priorities, but there is no "perfect" solution:
- If you value immutability and the functional style, and performance is not a priority, then between
for…ofand
reduce, pick
reduce.
- If you value performance and readability for the vast majority of devs, and you are sure mutation will not be an issue, then use
for…of.
- If you want "the best of both worlds", then you could try libraries like Immer or Immutable.js.
Let's dive in!
So, first, we will talk about mutations. Let's say we want a function that takes an object and a key, and returns the same object but adding that key with the
null value. We can do it either with or without mutations:
const object = {}; // Without mutations const addNullKey = (target = {}, key) => ({ ...target, [key]: null }); // With mutations const insertNullKey = (target = {}, key) => { target[key] = null; return target; }; const foo = addNullKey(object, "foo"); // `object` isn't mutated const bar = insertNullKey(object, "bar"); // `object` is mutated
After running this code,
foo has a copy of
object, with the added property
foo in it (so the value is
{ foo: null }), and
bar has a reference to
object with the added property
bar (value
{ bar: null }), but it also changes the original
object with mutation. Even if you don't care about the mutation itself, you have the comparison problem:
foo === object; // false because foo is a new object bar === object; // true, because is the same object
So you need to do a deep comparison to actually get if that
bar has different properties compared to the original
object. You could argue that to avoid that comparison problem and mutation, we can change
insertNullKey to be something like this:
const insertNullKey = (target = {}, key) => { const copy = Object.assign({}, target); copy[key] = null; return copy; };
But with that change you're falling into the same territory as
addNullKey, but with more boilerplate code.
The way of the for…of
We are targeting readability and performance, so let's go with
for…of! Imagine we have an array of 5000 elements (those good ol' and super realistic benchmark arrays), and we want to now create an object with every element in that array being a key with the value
null. We can reuse our friend
insertNullKey here:
const array = [ /* 5000 elements */ ]; const insertNullKey = (target = {}, key) => { target[key] = null; return target; }; const object = {}; for (key of array) { insertNullKey(object, key); }
This is fine and dandy until we realize that in other place in the same scope there is an async function messing with our nice object, with something like:
setTimeout(() => { insertNullKey(object, "derp"); }, 100);
And boom,
object suddenly has a
derp property we don't want. To fix this, we then need to move the
for…of to a separate function, like this:
const array = [ /* 5000 elements */ ]; const insertNullKey = (target = {}, key) => { target[key] = null; return target; }; const arrayToNulledKeys = source => { const output = {}; for (key of array) { insertNullKey(output, key); } return output; }; const object = arrayToNulledKeys(array);
Yey! We got it, a
for…of that uses mutation safely! ...... but now is kinda hard to read, right? So the benefit of readability is lost. The cleanest version of the for…of is actually:
const array = [ /* 5000 elements */ ]; const object = {}; for (key of array) { object[key] = null; }
No reuse other than copy and paste, but far easier to read.
The way of
reduce
Now, let's take a look at the
reduce approach. Generally, if you prefer this approach, you also try to avoid mutations, so for this one, we can use our other friend
addNullKey:
const array = [ /* 5000 elements */ ]; const addNullKey = (target = {}, key) => ({ ...target, [key]: null }); const object = array.reduce(addNullKey, {});
That's it. It doesn't need any extra abstractions to make it secure, you don't need to move
reduce to an external function, is just that.
Now, the thing is: This has a horrible performance penalty (people way smarter than me mentioned it with O notation and everything). In short: We are generating an entirely new copy of the object for every lap in that reduce loop, so we are generating 5000 objects, every one bigger than the previous, just to be "immutable/secure".
So everything sucks?
Not really. I mean if you're only working with Vanilla JS then yup, you should decide if you want strict immutability/chaining/functional style with very poor performance and use
reduce, or a more readable/performant without immutability and use
for…of. For this specific example (and several others that use reduce to transform an array to an object) you could also use Object.entries/Object.fromEntries with
map, which is like a middle point between
for…of and
reduce (functional style with immutability and good enough performance):
const array = [ /* 5000 elements */ ]; const object = Object.fromEntries(array.map(key => [key, null]));
Then again, that is if you're only using Vanilla JS. Using libraries like Immer or Immutable, you can use either the
for…of or the
reduce approach, and get good performance and immutability.
The way of the libraries
I love to use the platform every time is possible, and I'm not a big fan of frameworks or adding libraries just for the sake of it. So, I'm not saying that you should use libraries with this (maybe one of the snippets above already works for you), but if you want to use libraries, you can get a
for…of with immutability using Immer like this:
import { produce } from "immer"; const array = [ /* 5000 elements */ ]; const object = produce({}, draft => { for (key of array) { draft[key] = null; } });
Or you can get a
reduce with great performance using Immutable like this:
import { Map } from "immutable"; const array = [ /* 5000 elements */ ]; const object = array.reduce( (previous, current) => previous.set(current, null), Map({}) );
This is the way
Sorry for the nerdy reference to The Mandalorian, but I think that the tweet Jake did was taken as an "attack against
reduce" when it was only his opinion based on his point of view, so is not that he has banned the use of
reduce or something like that.
We web developers just recently had a huge debate over Twitter about
let vs
const, and we need to understand that the best and the worst thing about JavaScript is that it allows you to do anything you want, so you can code with the style you want, using the tools you want. You just need to be aware of the effects of your choices, taking performance, mutations, and other technicalities like that into consideration, but also the human side of coding with the readability of the final code.
From my point of view is more important to have a concise style to have good readability, than choosing between
for…of and
reduce.
Thanks for taking the time to read this!
Discussion (4)
Nice article. One thing to note with reduce is that there is a gotcha with async/await. Since async functions always return a promise, using an async operator with reduce will end up with a list of promises, which we will need to resolve manually at the end. For..of on the other hand can simply follow the standard await pattern.
I think I never saw code that goes from a reduce to a Promise (generally I used map, filter or something like that). If you have a list of promises, remember async/await is just syntax sugar, so you can use Promise.all or Promise.allSetled 😄
Sure. I think map and filter all have the same behavior as well. We can always get around it, it is just a bit tricky sometime.
I think this article explains the behavior quite well.
Thanks for the post! Great breakdown.
I'm gonna chime in here to be that guy that says "do the thing that makes the most sense semantically".
If what you're doing is best expressed as "working through each item" use "for...of". If it's best expressed as "condensing a series of items down to a single item" use reduce.
|
https://dev.to/lukeshiru/reduce-or-for-of-1lg
|
CC-MAIN-2021-49
|
refinedweb
| 1,375
| 56.29
|
Hi, I’m not sure why but this particular challenge is really causing an issue on my end. After I submit my code I am unable to submit and check if it’s correct. I’ve tried Safari, Chrome, Firefox on two Macs and Safari on iPadOS. Not sure why this is but maybe you can fix it for me? Much appreciated!
I’m sorry, but I don’t get what you mean. It freezes after you submit the solution without any output to the console? Or what happens there?
Ok, I’ll try and explain more. I have the code typed in but I cannot pass the tests. I might get a running tests update from the console, but it doesn’t seem to move on from there for whatever reason. I don’t get rejected but after that point it simply seems unusable and the only way to get the site going and stable again is to close that and move on to some other material. This is consistent no matter where I use it. Really strange.
please provide the challenge link and your code
My Code:
<ParentComponent> <ChildComponent /> </ParentComponent>
Please paste all of your code. We cannot tell where you have placed that in the editor.
That page causes huge problems for my machine. I am not able to copy it after going and selecting it multiple times trying to do so. It becomes unresponsive. I was able to take a screenshot, that’s the best I can do.
You are causing an infinite loop by rendering the
<ParentComponent> within the
ParentComponent. So, it is calling itself many, many times over.
Be careful with the terminology in the intstructions:
Compose the two together by rendering the
ChildComponentwithin the
ParentComponent.
Hope this clarifies.
This works for me. Remove the ParentComponent tags and just have the ChildComponent:
const ChildComponent = () => { return ( <div> <p>I am the child</p> </div> ); }; class ParentComponent extends React.Component { constructor(props) { super(props); } render() { return ( <div> <h1>I am the parent</h1> { /* change code below this line */ } <ChildComponent /> { /* change code above this line */ } </div> ); } };
I feel very foolish, but thanks!!
Don’t worry about it. I have only been up for a few hours and have done multiple silly things posting on here this morning already.
|
https://forum.freecodecamp.org/t/cant-submit-code-in-react-create-a-component-with-composition/409509
|
CC-MAIN-2020-40
|
refinedweb
| 381
| 66.23
|
#include <Servo.h> Servo servo1; int servoPin = 9; void setup(){ servo1.attach(servoPin); } void loop(){ servo1.write(0); delay(1000); servo1.write(90); delay(1000); servo1.write(180); delay(1000); }
Save and upload the compiled program to your Arduino. The servo motor should initialize at zero degrees, pause for a second, then move to 90 degrees, pause for a second, then move to 180 degrees, pause for a second and start over.
The first line of code loads the <Servo.h> library that facilitates the control of the servo. In the next line, you are creating an object in the library to reference the specific servo motor throughout the code. Multiple servos can be controlled, so for this example, we will use servo1 to designate our servo. The pin used to connect the servo, serverPin, is used in the
attach() function,
servo1.attach(servoPin);.
To move the servos to any direction, use the
write() function,
servo1.write(angle); . Angle should be in degrees (0-180). The angle changes the pulse width sent to the servo motor which then determines the amount of rotation.
Using the
servo.writeMicroseconds() Function
The command
servo.write(angle) works for most servo motors, but not really for all. Some servo motors have a range of 180 degrees, some have a range of 90 degrees, and some have anywhere in between. Using the command
servo.write(angle) allows for a maximum of 180 steps. However, there is a command that allows up to 1000 steps–
servo.writeMicroseconds(). For most applications, the simpler
servo.write(angle) will work out just fine. But if you want more precise control, you may want to use
servo.writeMicroseconds().
From the previous code, change the command from
servo1.write() to
servo1.writeMicroseconds(). Change the angular values from (0,90,180) degrees to (1000,1500,2000) microseconds. Upload and run the program using the same hardware setup. For a servo motor capable of a range up to 180, the values will be 1000 Microseconds = 0 degrees, 1500 Microseconds = 90 degrees, and 2000 Microseconds = 180 degrees.
#include <Servo.h> Servo servo1; int servoPin = 9; void setup(){ servo1.attach(servoPin); } void loop(){ servo1.writeMicroseconds(1000); delay(1000); servo1.writeMicroseconds(1500); delay(1000); servo1.writeMicroseconds(2000); delay(1000); }
Depending on the servo motor you are using, you may notice a difference. Interestingly on my setup, while monitoring the pulses on an oscilloscope, I noticed that when using
servo1.write(0);, the pulse width was only about 700 microseconds, not 1000 which is the way the function should work when set at zero degrees. But when using
servo1.writeMicroseconds(1000); the output was exactly 1000 microseconds.
Controlling a Servo Motor with Push-Button Switches
Build your circuit as shown in the diagram above, then upload the code shown below.
#include<Servo.h> int pos = 90; int pin4 = 4; int pin3 = 3; int LedHi = 5; int LedLow = 6; Servo servo1; void setup() { pinMode(LedHi, OUTPUT); pinMode(LedLow, OUTPUT); pinMode(pin4, INPUT); pinMode(pin3, INPUT); Serial.begin(9600); servo1.attach(9); } void loop() { while (digitalRead(pin3) == HIGH && pos < 180) { digitalWrite(LedLow, LOW); pos++; servo1.write(pos); Serial.print("Degrees rotation= "); Serial.println(pos); if (pos == 180) { Serial.print("Reached top end "); digitalWrite(LedHi, HIGH); } delay(10); } while (digitalRead(pin4) == HIGH && pos > 0) { digitalWrite(LedHi, LOW); pos--; servo1.write(pos); Serial.print("Degrees rotation= "); Serial.println(pos); if (pos == 0) { Serial.print("Reached low end "); digitalWrite(LedLow, HIGH); } delay(10); } }
After uploading the compiled code, open the Serial Monitor on your Arduino. As you push on either button, the servo should increase or decrease as shown on the serial monitor. Initially, the code will set the servo at 90 degrees. Use the button connected to pin 3 to increase the angle. When you reach 180 degrees, the high end of the rotation, the led connected to pin 5 will turn on. When you reach the low end of the range which is 0 degrees, the led connected to pin 6 will turn on.
To determine the result of the button push, a while statement verifies the button and the angle of the shaft.
while (digitalRead(pin3) == HIGH && pos < 180) determines that the button was pushed (HIGH) and the angle is less than 180, so the program adds one degree and loops on. The second button
while (digitalRead(pin4) == HIGH && pos > 0) determines that the button was pushed (HIGH) and the angle is greater than 0. This causes the angle to decrease by one and loops on. The LedHi and LedLow level for leds are each controlled by an if statement that checks the angle to see if it’s 0 or 180. The leds are turned off as soon as the angle changes in each of the two while statements.
Controlling a Servo Motor a Potentiometer
Build the circuit as shown in the diagram using a 10K potentiometer to control the servo motor. Then upload the code below.
#include <Servo.h> int LowLed = 5; int HiLed = 6; Servo servo1; int pot = A0; int val; void setup() { servo1.attach(9); pinMode(LowLed, OUTPUT); pinMode(HiLed, OUTPUT); Serial.begin(9600); } void loop() { val = analogRead(pot); val = map(val, 0, 1023, 0, 180); servo1.write(val); Serial.println(val); if (val == 0) digitalWrite(LowLed, HIGH); if (val == 180) digitalWrite(HiLed, HIGH); if (val > 0) digitalWrite(LowLed, LOW); if (val < 180) digitalWrite(HiLed, LOW); delay(10); }
After uploading the code, open the Serial Monitor on your Arduino. As you adjust the potentiometer, the rotation of the servo will change accordingly. When you reach the lower limit of the range, the Low Led will turn on, and as you reach the upper limit, the High Led will turn on.
The code is straightforward. The first line of code in the
Loop() Function should be:
val = analogRead(pot); val = map(val, 0, 1023, 0, 180); servo1.write(val);
An Analog Read takes in the voltage from the potentiometer as an analog signal. It accepts the values of the full range of input accepted in an Arduino (0-5V). It captures it as an integer in the range of (0-1023). So for example, a DC value of 0V would be captured as the integer 0; a full range value of 5V would be captured as the integer 1023, and half the input range of 2.5V would be captured as the integer 512, half of 1023.
The next line of code
val = map(val, 0, 1023, 0, 180); maps out the value of val within the range of 0,1023, to a value of 0,180.
The next line of code
servo1.write(val); is the
write() command that takes the integer stored in val as the argument and applies it to the servo. The servo receives a pulse from the
servo1.write(val); and the pulse width is determined by the value of val. The servo uses the width of this pulse to determine its rotation.
How to Write Arduino Sensor Data to a CSV File on a Computer
May 28, 2020
|
https://www.circuitbasics.com/controlling-servo-motors-with-arduino/
|
CC-MAIN-2020-29
|
refinedweb
| 1,168
| 66.64
|
How do I wait for an asynchronous closure? I am making an async network request and getting its results in a closure but somewhere I have to know that my request has been completed so I can get the values
You can approach this several ways. The easiest is to post a notification or call a delegate method from your completion handler. Make sure you stay aware of the thread you’re working with. You may need to dispatch to the main thread to perform your delegation, callbacks, or notifications.
When you’re working with several tasks that must finish before moving forward, use a dispatch group to keep count until they’re all done, and then send your update information.
If you truly need to stop execution until the request returns (and this is usually a bad thing with the possible exception of synchronous execution in playgrounds), you can use a run loop to stop things until your asynchronous call returns control. This breaks a lot of best practice rules. It can be mighty handy when you don’t want to start building lots of helper classes in a quick demo or proof of concept, where the emphasis is on procedural tasks.
6 Comments
Why not use a semaphore?
some_async_call {
// some work
// semaphore signal
}
// semaphore wait
I second the semaphore solution. Also, there is nothing bad in pausing the execution if you’re already on a separate thread.
Semaphore I thought as I read the text. I see two other people got there first and I also don’t understand how the posted solution could work.
If the completion handler is stopping the right run loop, that must imply it is running on the thread that started the task (which goes on to start a run loop). For that to work in general, there must already be a run loop running on the thread,
I started with semaphore, found it wasn’t working right with the threading, and ended up with the run loops. I’m feeling too lazy right now to get it working with semaphore. If you want to go ahead and fix it, I’ll update with attribution. Have at it.
I too ran into the issue with DispatchSemaphore as you describe, but I don’t think it’s too blame. Were you doing a command line application or playground? Looking at the docs for geocodeAddressDictionary, it states that “Your completion handler block will be executed on the main thread”. Without the call to CFRunLoopRun (which I believe is implicit using an application, correct?), there is no event loop for the completion handler to be inserted into. Playing around using a semaphore in SyncMaker, putting the for loop into a DispatchQueue.async, and calling CFRunLoopRun does work. Of course that still necessitates the need to manage the run loop in this example, but in a generic application where something else is managing the run loop, the code remains portable.
import Foundation
/// A generic Cocoa-Style completion handler
typealias CompletionHandler = (T?, Error?) -> Void
/// A generic result type that returns a value or an error
enum Result { case success(T), error(Error), uninitialized }
class SyncMaker {
var semaphore = DispatchSemaphore(value: 0)
var result: Result = .uninitialized
func completion() -> CompletionHandler {
return {
(value: Value?, error: Error?) in
var result: Result = .uninitialized
// Fetch result
switch(value, error) {
case (let value?, _): result = .success(value)
case (_, let error?): result = .error(error)
default: break
}
// Store result, return control
self.result = result
self.semaphore.signal()
}
}
// Perform task (that must use custom completion handler) and wait
func run(_ task: @escaping () -> Void) -> Result {
task()
semaphore.wait()
return result
}
}
// Example of using SyncMaker
import CoreLocation
import Contacts
struct BadKarma: Error {}
func getCityState(from zip: String) throws -> String {
let geoCoder = CLGeocoder()
let infoDict = [
CNPostalAddressPostalCodeKey: zip,
CNPostalAddressISOCountryCodeKey: "US"]
let syncMaker = SyncMaker()
let result = syncMaker.run {
geoCoder.geocodeAddressDictionary(
infoDict,
completionHandler: syncMaker.completion())
}
switch result {
case .error(let complaint): throw(complaint)
case .success(let placemarks):
guard placemarks.count > 0 else { break }
let mark = placemarks[0]
guard let address = mark.addressDictionary,
let city = address["City"],
let state = address["State"]
else { break }
return "\(city), \(state)"
default: break
}
throw BadKarma()
}
let queue = DispatchQueue(label: "SynkMaker")
let loop = CFRunLoopGetCurrent()
queue.async {
do {
for zip in ["10001", "20500", "90210"] {
print("zip: \(zip), citystate:", try getCityState(from: zip))
}
} catch { print(error) }
CFRunLoopStop(loop)
}
CFRunLoopRun()
Thanks for looking into the docs. And yes, as I stated, this is primarily for playgrounds.
|
http://ericasadun.com/2017/04/04/dear-erica-working-synchronously-with-asynchronous-calls/
|
CC-MAIN-2017-17
|
refinedweb
| 733
| 55.84
|
SPChangeQuery class
Defines a query that is performed against the change log in Microsoft SharePoint Foundation.
Microsoft.SharePoint.SPChangeQuery
Namespace: Microsoft.SharePointNamespace: Microsoft.SharePoint
Assembly: Microsoft.SharePoint (in Microsoft.SharePoint.dll)
Use an SPChangeQuery object to define a query that you can pass as an argument to a GetChanges method of the SPList, SPWeb, SPSite, or SPContentDatabase class.
The properties of the SPChangeQuery class can be used to specify filters for the query. There are two types of properties: those that apply to the type of object that has been changed, and those that apply to the type of change that occurred. Use these properties in conjunction with the SPChangeQuery constructor to define a query that will return specific data from the change log.
The following example is a console application that prints out the login names of users who have been added to groups within a site collection, as well as the groups to which they have been added and the date of the change.
using System; using Microsoft.SharePoint; namespace Test { class ConsoleApp { static void Main(string[] args) { using (SPSite siteCollection = new SPSite("")) { using (SPWeb rootSite = siteCollection.RootWeb) { // Construct a query. SPChangeQuery query = new SPChangeQuery(false, false); // Set a limit on the number of changes returned on a single trip. query.FetchLimit = 500; // object type query.Group = true; // change type query.GroupMembershipAdd = true; // Get the users and groups for the site collection. SPUserCollection users = rootSite.AllUsers; SPGroupCollection groups = rootSite.Groups; // Convert to local time. SPTimeZone timeZone = rootSite.RegionalSettings.TimeZone; // total changes int total = 0; // Loop until we reach the end of the log. while (true) { SPChangeCollection changes = siteCollection.GetChanges(query); total += changes.Count; // running total foreach (SPChangeGroup change in changes) { // Try to get the group name. string groupName = String.Empty; try { SPGroup group = groups.GetByID(change.Id); groupName = group.Name; } catch (SPException) { groupName = "Unknown"; } // Try to get the user name. string loginName = String.Empty; try { SPUser user = users.GetByID(change.UserId); loginName = user.LoginName; } catch (SPException) { loginName = "Unknown"; } // Write to the console. Console.WriteLine("\nDate: {0}", timeZone.UTCToLocalTime(change.Time).ToString()); Console.WriteLine("{0} was added to the {1} group.", loginName, groupName); } //(); } } }
|
https://msdn.microsoft.com/en-us/library/microsoft.sharepoint.spchangequery(v=office.15).aspx
|
CC-MAIN-2017-47
|
refinedweb
| 354
| 62.04
|
if-else (C# Reference)
The if statement selects a statement for execution based on the value of a Boolean expression. In the following example, the Boolean variable result is set to true and then checked in the if statement. The output is: The variable is set to true.
If the expression in the parenthesis is evaluated to be true, then the Console.WriteLine("The variable is set to true.");: 2 Sample Output Enter a character: 2 The character is not an alphabetic character. Additional sample might look as follows: Run #2: Enter a character: A The character is uppercase. Run #3: Enter a character: h The character is lowercase. * */ }.
public class IfTest3 {."); } } } /* Sample Input: E Sample Output:. */
For more information, see the C# Language Specification. The language specification is the definitive source for C# syntax and usage.
|
https://msdn.microsoft.com/en-US/library/5011f09h(d=printer,v=vs.100).aspx
|
CC-MAIN-2015-35
|
refinedweb
| 137
| 60.11
|
We are about to switch to a new forum software. Until then we have removed the registration on this forum.
Hey guys! Newbie here (to the forum). So I just updated my macbook OS to OSX10.10.5 (Yosemite) and have some issues with java when I try to run a sketch in Processing.
The sketch:
import processing.sound.*; SoundFile file; void setup() { size(640, 360); background(255); // Load a soundfile from the /data folder of the sketch and play it back file = new SoundFile(this, "buzz.wav"); file.play(); } void draw() { }
The console after I press 'run':
# # A fatal error has been detected by the Java Runtime Environment: # # SIGILL (0x4) at pc=0x000000019a2e4547, pid=559, tid=61807 # # JRE version: Java(TM) SE Runtime Environment (8.0_60-b27) (build 1.8.0_60-b27) # Java VM: Java HotSpot(TM) 64-Bit Server VM (25.60-b23 mixed mode bsd-amd64 compressed oops) # Problematic frame: # C [libsndfile.1.dylib+0x2547] psf_open_file+0xc3 # # Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again # # An error report file with more information is saved as: # /Users/Andy/hs_err_pid559.log # # If you would like to submit a bug report, please visit: # # The crash happened outside the Java Virtual Machine in native code. # See problematic frame for where to report the bug. # Could not run the sketch (Target VM failed to initialize). Make sure that you haven't set the maximum available memory too high. For more information, read revisions.txt and Help → Troubleshooting.
I never had any issues with Processing before updating my OS so I have no idea what's going on... So far I've tried updating Java to version 8, uninstalling it and reverting back to the Apple Java 6, restarting my machine but no luck with any of these so far :(
Any help/guidance would be amazing! Thanks!!! :)
|
https://forum.processing.org/two/discussion/12313/java-error-on-osx-10-10-5
|
CC-MAIN-2020-34
|
refinedweb
| 318
| 66.84
|
This release of ASP.NET builds upon the substrate for building Web applications introduced in version 1.0. All of the architectural features of the ASP.NET 1.x runtime are still present in 2.0, but elements were added to make development of Web applications more intuitive and efficient. One of the most significant additions is the partial class codebehind model, in which instead of manually declaring control
variables
in your codebehind file, ASP.NET generates a sibling class that is merged with your class definition to provide control variable declarations. The events in the lifetime of a Page were augmented as well, to include many pre- and post-events to give more granular access to points in time during a Page's lifecycle. The other major change architecturally is the compilation model. It is now possible to deploy Web sites as nothing but binary assemblies, as well as all source, and many gradients in between. Developers now have many more options for both development and deployment of Web applications with ASP.NET.
ASP.NET 2.0
INTRODUCES SEVERAL FEATURES
that make it easier to build compelling, unified user interfaces. In this chapter we look at the three primary new user interface elements of ASP.NET 2.0: master pages, themes and skins, and navigation controls.
Master pages
introduce a standard way of sharing a common look and feel across many pages of your site in a model that is intuitive and flexible to use.
Themes
and
skins
provide a way of
centralizing
all of the style-
related
elements of your site, including stylesheets, server-side control attributes, and resources like images or JavaScript files. Once these elements are localized, it is straightforward to replace them with a new set of elements, either statically for the entire site or dynamically on a
per-client
basis. Finally,
navigation controls
include standard
implementations
of
menus
, tree views, and "bread crumbs" to quickly add navigational elements to your site. This chapter covers the details of using each of these features, as well as a look at the new control adapter architecture for altering control rendering based on browser type.
It is very common in Web site design to define a standard "look and feel" for all pages. This may include common headers, footers,
menus
, and so on that provide a
core
set of features and appearance throughout the site. For dynamic sites, built with technologies like ASP or ASP.NET, it is extremely useful if these common features of all pages are
factored
into some type of page template, allowing each page to consist only of its own unique content and providing a central location for making site-wide changes in appearance and behavior. As a simple, concrete example of a site that would benefit from some type of page template technique, consider the page displayed in Figure 2-1.
This particular page has a header at the top, a footer at the bottom, a navigation bar on the left, and an area for page-specific content filling out the remainder. Ideally, the header, footer, and navigation bar should be defined only once and somehow propagated to all pages in the site.
This is precisely the problem that master pages in ASP.NET 2.0 solve simply and cleanly. By defining one master page and then creating many content pages based on that one master page, you can very easily create sites with a common look and feel driven by a single template (the master page).
Master pages in ASP.NET 2.0 are a general solution to site templating. They provide site-level page templates, a mechanism for fine-grained content replacement, programmatic and declarative control over which template a page should use, and perhaps most compelling of all, integrated designer support. Figure 2-2 shows the conceptual relationship between a master page and content pages that are tied to the master page.
The implementation of master pages in ASP.NET 2.0 consists of two conceptual elements: master pages and content pages.
Master pages
act as the templates for content pages, and
content pages
provide content to populate pieces of master pages that require "filling out." A master page is
essentially
a standard ASP.NET page except that it uses the extension of .master and a directive of <%@ Master %>, as shown in Listing 2-1.
<!-- File: SiteTemplate.master -->
<%@ Master Language="C#" %>
<html xmlns="" >
<head runat="server">
<title>Default title</title>
</head>
<body>
<form runat="server">
<h2>Common header</h2>
<asp:ContentPlaceHolder
<h2>Common footer</h2>
<asp:ContentPlaceHolder
</asp:ContentPlaceHolder>
</form>
</body>
</html>
Content pages, in contrast, are just ordinary .aspx files that specify an associated master page in their page directive using the MasterPageFile attribute. These pages must contain only instances of the Content control, as their sole purpose is to supply content for the inherited master page template. Each Content control must map to a specific ContentPlaceHolder control defined in the referenced master page, the contents of which will be inserted into the master page's placeholder at rendering time. The content page in Listing 2-2 provides content for the SiteTemplate.master master page shown earlier.
<%-- file: default.aspx--%>
<%@ Page Language="C#"
MasterPageFile="SiteTemplate.master" Title="Home Page" %>
<asp:Content
This is the content for the default page.
</asp:Content>
Note that with this mechanism we are able to specify content to be placed at very specific locations in the master page template. The example in Listing 2-2 shows how the subtle problem of generating unique page titles with templates is
solved
easily by using the new Title attribute of the @Page directive. This Title attribute works with any page (even one that is not using a master page) as long as the <head> element is
marked
with runat="server", but it is particularly useful when using master pages since content pages inherit their title from master pages by default. Listing 2-2 also illustrates how master pages can supply default content for placeholders, so if the content page decides not to provide a Content control for a particular placeholder, it will have a default rendering.
With the fundamental mechanics of master pages in place, we can now
revisit
the templated example shown in Figure 2-1. This example defines a master page containing
replaceable
-content placeholder controls for the header, navigation bar, and footer. The master page template lays out the page using these elements, and the content page
supplies
the inner content for the page. Figure 2-3 shows the rendering of this example using master and content pages.
Even more compelling is the fact that master pages are
understood
by the designer in Visual Studio 2005. When you are visually editing a content page, it displays the content of the inherited master page in a grayed out region, so it is obvious what the ultimate rendering of the page will look like. Figure 2-4 shows our continuing example of using master pages as it would appear when editing a content page
affiliated
with our master page.
The implementation of master and content pages is quite similar to the approach taken by many developers building their own custom templating mechanism in ASP.NET 1.x. In particular, the MasterPage class derives from UserControl and thus inherits the same generic container functionality that
user
controls provide. The templates defined by master pages are injected into the generated control hierarchy for the
requested
page. This injection happens just before the Page class' Init event; this way, all of the controls will be in place prior to Init, when it is common to perform programmatic manipulation of controls. The actual merging of the master page's control hierarchy and the page's control hierarchy is performed as
follows
:
The top-level control of the master page (which will be named the same as the file containing the master page) will be inserted as the root control in the new page hierarchy.
The contents of each Content control in the page is then injected as a collection of child controls underneath the corresponding ContentPlaceHolder control.
Figure 2-5 shows a sample content page with an associated master page and the resulting merged control hierarchy that is created just prior to the Init event during the page processing.
One of the implications of this implementation is that the master page itself is just another control in your Page class' hierarchy, and you can perform any of the
tasks
you are used to performing on controls with the master page directly. The current master page associated with any given page is always available via the Master property accessor. As an example of interacting with the master page, in the default.aspx page shown in Figure 2-5 you could add code to programmatically access the HtmlForm that was implicitly added by the master page, as shown in Listing 2-3.
void Page_Load(object sender, EventArgs e)
{
HtmlForm f = (HtmlForm)Master.FindControl("_theForm");
if (f != null)
{
// use f here...
}
}
It is a
fairly
common requirement to change some aspects of a master page depending on when and where it is being applied. For example, you may want to selectively enable or disable a collection of links in a master page based on which page is currently being accessed. While something like this is possible using the programmatic access to controls on the master page described earlier, it is
generally
better to build logic into your master page to manipulate the controls and to expose that logic as
methods
or properties on the master page. For example, Listing 2-4 shows a master page with a panel control containing a set of hyperlink controls, along with a corresponding property, ShowNavigationLinks, that controls the visibility of these links.
<%-- File: SiteTemplate.master --%>
<%@ Master Language="C#" %>
<script runat="server">
public bool ShowNavigationLinks
{
get { return _navigationLinksPanel.Visible; }
set { _navigationLinksPanel.Visible = value; }
}
</script>
<html xmlns="" >
<head runat="server">
<title>Default title</title>
</head>
<body>
<form id="form1" runat="server">
<!-- ... -->
<asp:Panel
<asp:HyperLinkHome</asp:HyperLink><br />
<asp:HyperLinkPage 1</asp:HyperLink><br />
<asp:HyperLinkPage 2</asp:HyperLink>
</asp:Panel>
<!-- ... -->
</form>
</body>
</html>
A particular page could then access the master page via the Master property of the Page class, cast the result to the master page type, and set the ShowNavigationLinks property of the master page to true or false. Listing 2-5 shows a sample content page that disables the links via the exposed property.
<%@ Page Language="C#" MasterPageFile="~/SiteTemplate.master" %>
<script runat="server">
protected void Page_Load(object sender, EventArgs e)
{
((ASP.sitetemplate_master)Master).ShowNavigationLinks = false;
}
</script>
<!-- ... -->
You can take this one step further and eliminate the cast by using the MasterType directive in the content page. Adding a MasterType directive causes ASP.NET to generate a
typesafe
version of the Page class' Master property that is strongly typed to the master page referenced in the VirtualPath attribute. It essentially takes care of doing the cast for you, with the added advantage of IntelliSense in Visual Studio 2005 showing you all of the properties defined in your master page. Listing 2-6 shows an example of using the MasterType directive to create this strongly typed accessor and the simplified code for modifying the same property we modified before.
<%@ Page Language="C#" MasterPageFile="~/SiteTemplate.master" %>
<%@ MasterType VirtualPath="~/SiteTemplate.master" %>
<script runat="server">
protected void Page_Load(object sender, EventArgs e)
{
Master.ShowNavigationLinks = false;
}
</script>
<!-- ... -->
The MasterType directive also supports a TypeName attribute that you can use instead of the VirtualPath attribute if, for example, you don't want to create a hard-coded
affiliation
between your content page and its master page. You might find it useful to create multiple master pages that could be applied to a page based on some criterion (like a user preference stored in profile or the request's time of day). In this case you couldn't use the VirtualPath attribute, as the cast would fail if the master page changed. Instead, you could create a base class that inherits from MasterPage, add the necessary properties and methods to that base class, and then have all of your master pages inherit from that common master page base class. Your pages would then use the TypeName attribute in their MasterType directive to gain strongly typed access to the common base class.
Listings 2-7, 2-8, and 2-9 show a sample common base class, a master page that inherits from that base class, and a content page that uses the TypeName attribute to strongly type the Master property to the shared base class, respectively.
// File: CommonMasterPage.cs
namespace EssentialAspDotNet
{
public abstract class CommonMasterPage : MasterPage
{
public abstract bool ShowNavigationLinks {get; set; }
}
}
<%--File: SiteTemplate.master--%>
<%@ Master Language="C#" Inherits="EssentialAspDotNet.CommonMasterPage"
%>
<script runat="server">
public override bool ShowNavigationLinks
{
get { return _navigationLinksPanel.Visible; }
set { _navigationLinksPanel.Visible = value; }
}
</script>
<!-- ... -->
<%@ Page Language="C#" MasterPageFile="~/SiteTemplate.master" %>
<%@ MasterType TypeName="EssentialAspDotNet.CommonMasterPage" %>
<script runat="server">
protected void Page_Load(object sender, EventArgs e)
{
Master.ShowNavigationLinks = false;
}
</script>
<!-- ... -->
Using a common base class for a master page makes the most sense if you plan on having multiple master pages that could be affiliated with a page and then adding the ability to change the affiliation at runtime. To change the master page affiliation, you can use the MasterPageFile property, which is exposed as a public property on the Page class and can be modified in the code for any page. Any modifications to this property must be made in a handler for the PreInit event of the Page class for it to take effect, since the creation of and merging with the master page happens just prior to the Init event firing. Keep in mind that if you do change the master page programmatically, the new master page must have the same set of ContentPlaceHolder controls with matching identifiers as the original master page;
otherwise
, the mapping between Content controls and their corresponding placeholders will break.
The override of the OnPreInit method in Listing 2-10 could be added to any Page class using a master page to programmatically change the master page affiliation.
protected override void OnPreInit(EventArgs e)
{
this.MasterPageFile = "AlternateSiteTemplate.master";
base.OnPreInit(e);
}
As you begin to use master pages in your site design, you will run into some issues that may not have occurred before if you have never used a site-level templating mechanism. The first issue is that of relative paths in referenced resources like images or stylesheets. When you are creating a master page, you must keep in mind that the directory from which relative paths are going to be evaluated may very well change based on the page being accessed. Consider the directory structure of the site shown in Figure 2-6.
If you were to add a reference to the Check.gif image in the images directory from the Site.master in the masterpages directory, you might be tempted to add a simple image element like this:
<img src="../images/check.gif" />
Unfortunately, this would only work for pages that were in a similar relative directory location to the image as the master page was (like page1.aspx). Any other page (like default.aspx) would not correctly resolve the relative path. One solution to this problem is to use the root
path
reference syntax in ASP.NET and ensure that all relative references are made from server-side controls (which is the only place this syntax works). So the
preceding
image reference would become:
<img src="~/images/check.gif" runat="server" />
Another option is to rely on the fact that relative path references in server-side controls are evaluated relative to the master page in which they are placed. This means that it would also be sufficient to change the image reference to:
<img src="../images/check.gif" runat="server" />
Server-side path references in pages that reference master pages are still relative to the page itself, so you should not have to change any techniques you may already have in place to deal with relative references in pages.
Another common request when ASP.NET developers first encounter master pages is to somehow enforce that all pages in an application be required to be content pages referencing a specific master page. While there is no "must use" attribute, you can
designate
a master page to be used by default for all pages in an application by adding a pages element to your web.config file specifying a common master page:
<configuration>
<pages masterPageFile="~/sitetemplate.master" />
</configuration>
Like any settings specified at the application level, individual pages can elect to override the default masterPageFile attribute, but adding this to your configuration file will guarantee that no pages will be added to your application
accidentally
without an associated master page.
Finally, you may find that it is useful to have a "meta" master page, that is, a master page for a set of master pages. Master pages support arbitrarily deep nesting, so you can create whatever level of master pages you decide makes sense for your application. Just like pages that have master pages, master pages that have master pages must consist exclusively of Content controls. Within these Content controls, master pages can then add additional ContentPlaceHolder controls for the actual pages to use. Note that pages that reference a master page which itself has a master page can only provide Content elements for ContentPlaceHolder controls on the immediate parent master page. There is no way to directly populate placeholders on a master page two or more levels up from a particular page. As an example, consider the master page definition (in a file called MetaTemplate.master) in Listing 2-11.
<%@ Master %>
<html xmlns="" >
<head runat="server">
<title>Default title</title>
</head>
<body>
<form id="_theForm" runat="server">
<h2>Header</h2>
<asp:ContentPlaceHolder
<h2>Footer</h2>
</form>
</body>
</html>
We can now define another master page, which in
turn
specifies this master page as its master and provides Content elements for each of the ContentPlaceHolder controls in the parent master page, as shown in Listing 2-12.
<%@ Master MasterPageFile="~/MetaTemplate.master" %>
<asp:Content
<table>
<tr>
<td><asp:ContentPlaceHolder</td>
<td><asp:ContentPlaceHolder</td>
</tr>
</table>
</asp:Content>
You may also find it useful to create alternate master pages based on the user agent string (browser type) sent by the client. If you want to leverage some browser-specific features in your master page, it may make sense to create multiple versions of the master page for the variations across browser types. ASP.NET 2.0 supports device filters to do this
declaratively
, which are prefix strings that you can apply to the MasterPageFile attribute to
indicate
which browser type should map to which master page. Prefix strings map to .browser files that have regular expressions defined to determine which browser is being used to access the site from the user agent string. You can include other device filter strings by adding additional .browser files to your local App_Browsers directory. Keep in mind that, as in the earlier example of dynamic master pages, each master page must have the same set of ContentPlaceHolder controls for this technique to work properly. Listing 2-13 shows a sample content page with alternate master page files specified for Internet Explorer (IE) and Mozilla browsers.
<%@ Page Language="C#"
MasterPageFile="~/SiteTemplate.master"
ie:MasterPageFile="~/IESiteTemplate.master"
mozilla:MasterPageFile="~/FirefoxSiteTemplate.master" %>
<!-- ... -->
Essential ASP.NET With Examples in C#
Pro ASP.NET MVC Framework
|
http://flylib.com/books/en/4.169.1.18/1/
|
CC-MAIN-2013-20
|
refinedweb
| 3,233
| 51.89
|
Just resurrecting an oldish thread for a moment...
I've got the JellyUnit stuff working now so that JUnit tests can be written
(and dynamically generated) in Jelly script.
So Jelly can be used to create TestSuite and TestCase objects, possibly
dynamically using information from beans, XML, SOAP, SQL etc. Then Jelly can
run the tests or they can be called from inside any existing JUnit
TestRunner .
From: "Vincent Massol" <vmassol@octo.com>
> > -----Original Message-----
> > From: Jeff Turner [mailto:jeff@socialchange.net.au]
> > Sent: 01 July 2002 02:48
> > To: Jakarta Commons Developers List
> > Subject: Re: [jelly] http and validation tag libraries
> >
>
> [snip]
> >
> > Somewhat curious as to why everyone's so keen to reuse the JUnit API
> 8-)
> > I've found it to be so tightly engineered and 'pattern dense' that
> it's
> > hard to reuse outside it's intended scope. JUnit goes to a lot of
> effort
> > to isolate TestCases, and for functional testing we *want* to share
> > information like session data. Once you've thrown away the testXxx()
> > method introspection, startUp(), tearDown(), and all that, what's
> left?
> >
>
> - Mostly the tools and the front ends (TestRunner) : you can find JUnit
> integration in any IDE. In addition, why reinvent a new testing
> framework API when there is one already. I do agree with your remark of
> TestCase isolation for functional test cases. However, it does not seem
> to be such a problem to use JUnit for that (see my other email on the
> same thread). That said, I need to verify that what I wrote is correct
> ...
>
> Then you get the following additional benefits :
> - people already know how to use your framework because the interface
> (TestRunner) is standard (de facto)
> - you get documentation/support/etc for free for your testing front end
> - the JUnit name is a good seller ... :-)
Agreed.
Incidentally the trick to integrating JellyUnit test cases into an existing
JUnit TestRunner framework is to write a single adapter class as follows,
where a Jelly script 'suite.jelly' is assumed to be on the classpath in the
same package as the TestFoo class...
import junit.framework.TestSuite;
import org.apache.commons.jelly.tags.junit.JellyTestSuite;
/**
* A helper class to run jelly test cases in a JUnit TestRunner
*/
public class TestFoo extends JellyTestSuite {
public static TestSuite suite() throws Exception {
return createTestSuite(TestFoo.class, "suite.jelly");
}
}>
|
http://mail-archives.apache.org/mod_mbox/commons-dev/200207.mbox/%3C051801c23198$30dc9e30$9865fea9@spiritsoft.com%3E
|
CC-MAIN-2016-44
|
refinedweb
| 386
| 52.39
|
import "golang.org/x/tools/godoc/util"
Package util contains utility types and functions for godoc.
IsText reports whether a significant prefix of s looks like correct UTF-8; that is, if it is likely that s is human-readable text.
IsTextFile reports whether the file has a known extension indicating a text file, or if a significant chunk of the specified file looks like correct UTF-8; that is, if it is likely that the file contains human- readable text.
An RWValue wraps a value and permits mutually exclusive access to it and records the time the value was last set.
A Throttle permits throttling of a goroutine by calling the Throttle method repeatedly..
Package util imports 5 packages (graph) and is imported by 3 packages. Updated 2017-08-16. Refresh now. Tools for package owners.
|
http://godoc.org/golang.org/x/tools/godoc/util
|
CC-MAIN-2017-34
|
refinedweb
| 137
| 53.1
|
Opened 7 years ago
Closed 7 years ago
#7764 closed enhancement (fixed)
Reset Registration with school servers - short term solution
Description
Laptops should automatically register and re-register with school servers when they detect that they are connected to a new one. In today's builds (8.2), you have to push a button to register, and there is no way to unregister or reregister with a new school.
This is the feature request that matches up with the short term fix for 8.2 to allow resetting of the registration through the control panel.
Attachments (3)
Change History (28)
comment:1 Changed 7 years ago by kimquirk
- Type changed from defect to enhancement
comment:2 Changed 7 years ago by gregorio
- Cc gregorio added
- Owner changed from gregorio to mstone
comment:3 Changed 7 years ago by kimquirk
- Component changed from not assigned to sugar
- Keywords blocks:8.2.0 r? added
- Summary changed from Reset Registration with school servers to Reset Registration with school servers - short term solution
To clarify, this is the short term fix request. I just need the one CLI command to remove the schoolserver items from the config file. This will not deal with issues on the school server.
Changed 7 years ago by erikos
cli command to reset the school server
comment:4 Changed 7 years ago by erikos
- Action Needed changed from never set to review
comment:5 Changed 7 years ago by marco
- Keywords r- added; r? removed
I think the options handling could be cleanup up a lot, but this is consistent with the code we have there right now and it's no good time for refactoring. We should open a separate ticket about it.
I don't think the patch really works. Command line is in a separate process. I guess you should save the profile and require a restart.
Changed 7 years ago by erikos
added restart and saving of the profile
comment:6 Changed 7 years ago by erikos
- Keywords r? added; r- removed
comment:7 Changed 7 years ago by marco
- Keywords r+ added; r? removed
comment:8 Changed 7 years ago by erikos
- Action Needed changed from review to package
pushed to git
comment:9 Changed 7 years ago by marco
- Action Needed changed from package to test in build
comment:10 Changed 7 years ago by marco
- Priority changed from high to blocker
comment:11 Changed 7 years ago by erikos
- Action Needed changed from test in build to qa signoff
- Keywords joyride-2330:? added
|TestCase|
connect to a schoolserver using the 'Register' option in the xo-palette on the home-view. open a terminal activity and use the command line interface of the control panel to reset the registration 'sugar-control-panel -c registration'. After restarting sugar try to connect to the schoolserver again.
comment:12 Changed 7 years ago by kimquirk
- Keywords relnote added
comment:13 Changed 7 years ago by joe
- Cc joe added
comment:14 Changed 7 years ago by mchua
- Owner changed from mstone to frances
assigning to frances to test and verify in release candidate - see above testcase by erikos.
comment:15 Changed 7 years ago by mchua
- Action Needed changed from qa signoff to unknown
- Owner changed from frances to erikos
This doesn't seem to be fixed yet. On a freshly installed (copy-nand) 765 (gg-765-2, to be exact) running the test case erikos put up does not pass, as the 'Register' option doesn't reappear in the XO-palette in Home view after running the '-c registration' command. (Am I missing something?)
I also tried (separately) typing the sugar-control-panel command in Terminal as root, and rebooting the entire machine (instead of just restarting Sugar), to no avail. Handing back to erikos.
comment:16 Changed 7 years ago by gregorio
- Keywords blocks-:8.2.0 added; blocks:8.2.0 removed
Hi Erikos,
Is this fixed?
Why can't we verify it?
Thanks,
Greg S
comment:17 Changed 7 years ago by kimquirk
- Keywords blocks-:8.2.0 removed
- Milestone changed from 8.2.0 (was Update.2) to 9.1.0
Doesn't work for me in 8.2-767.
Changed 7 years ago by erikos
make the default value for the backup url an empty string
comment:18 Changed 7 years ago by erikos
- Action Needed changed from unknown to review
- Keywords r? added; r+ removed
The patch above for sugar-toolkit (which makes the backup-url an empty string by default) and the change (pro.backup1 = ) below in sugar should fix the issue. Tested on the XO, without an actual schoolserver though.
def clear_registration(): """Clear the registration with the schoolserver """ pro = profile.get_profile() pro.backup1 = None pro.save() return 1
So to fix this we would need a new sugar and sugar-toolkit package :/
comment:19 Changed 7 years ago by erikos
This is the clearer patch for sugar.
diff --git a/src/controlpanel/model/network.py b/src/controlpanel/model/network.py index cbe0473..b70c952 100644 --- a/src/controlpanel/model/network.py +++ b/src/controlpanel/model/network.py @@ -87,7 +87,7 @@ def clear_registration(): """Clear the registration with the schoolserver """ pro = profile.get_profile() - pro.backup1 = None + pro.backup1 = '' pro.save() return 1
comment:20 Changed 7 years ago by marco
Simon, can you explain why the current code does not work.
comment:21 Changed 7 years ago by erikos
We set it to pro.backup1 to None when we reset the registration, but this is never written to the profile.;a=blob;f=src/sugar/profile.py;h=1b08202c8ecedd63694d73412dfdd7778b81a6d5;hb=9e852bbbbd95baba541390faba3d08cafd09df95#l105
comment:22 Changed 7 years ago by erikos
After discussion with marco, we decided that removing the option might be the better solution. This actually would only need a change in sugar-toolkit as well.
diff --git a/src/sugar/profile.py b/src/sugar/profile.py index 1b08202..6c5dcd2 100644 --- a/src/sugar/profile.py +++ b/src/sugar/profile.py @@ -102,8 +102,13 @@ class Profile(object): _set_key(cp, 'Buddy', 'NickName', self.nick_name.encode('utf8')) if self.color: _set_key(cp, 'Buddy', 'Color', self.color.to_string()) - if self.backup1: + + if self.backup1 is None: + if cp.has_option('Server', 'Backup1'): + cp.remove_section('Server') + else: _set_key(cp, 'Server', 'Backup1', self.backup1) + if self.jabber_server is not None: _set_key(cp, 'Jabber', 'Server', self.jabber_server)
comment:23 Changed 7 years ago by erikos
- Cc mchua added
joyride-2513 has the fix. Can someone with a schoolserver please test?
comment:24 Changed 7 years ago by joe
- Cc frances added
comment:25 Changed 7 years ago by mchua
- Resolution set to fixed
- Status changed from new to closed
tested with joyride-2513 - verified w/ XS at 1cc.
Please make a CLI option for this as discussed in the recent release meeting.
|
http://dev.laptop.org/ticket/7764
|
CC-MAIN-2015-48
|
refinedweb
| 1,131
| 65.73
|
correction in program
Dear sir in this program you are creating object of ArrayList class and through you are adding items or values using add method. While add() method do not get integer type arguments so this program generating error: at arr.add(i);
add(int ,object);
add method
Yes there is a compiling problem caused by the add method and the int data type. I looked up the add method, apparently it takes a boolean argument. Would like to see this code if I could get it to work.
MISTAKES CORRECTION - Java Beginners
MISTAKES CORRECTION Dear Sir,
The under mentioned Java Sleep programe was received through your favor. But when I compiled...; hai frnd....
thats not an issue..
you can run the program without
Java Util Examples List
examples that demonstrate the syntax and example code of
java util package... example of java program is provided that shows you how
you can iterate...
example.
The
Java Logging Program
This section
util packages in java
util packages in java write a java program to display present date and after 25days what will be the date?
import java.util.*;
import java.text.*;
class FindDate{
public static void main(String[] args
MISTAKES CORRECTION - Java Beginners
Lang
Java remove()
Java remove()
...() method through the following java program.
This method removes the last element..., the remove method has already been called.
In the program code given below, we
remove space - Java Beginners
remove space I want to remove all line in text file using java. i want all text in single line.
example.
Input file
This is text.
I want remove all line.
Output file
This is text
Java util package Examples
Hide/remove titlebar of JInternalframe - Java Beginners
Hide/remove titlebar of JInternalframe i am designing a account management application using java.
so to give good look i want to hide/remove... about swing at:
|
http://roseindia.net/tutorialhelp/allcomments/5428
|
CC-MAIN-2014-42
|
refinedweb
| 312
| 65.93
|
So I dug it out, read it, and realised how horrible it
was. I was tempted to rewrite it, but instead I decided
to google for "perl duplicate files" first. I found a couple of other scripts there, but they were pretty horrible too. In particular the first file there, which is basically a comparison between doing in perl vs shell, does a checksum hashing on every file. So I decided I would indeed write my own, which turned out to be about 7 times faster that this one (which was in turn twice as fast as my original script):
#!/usr/bin/perl -w
use strict;
use File::Find;
use Digest::MD5;
my %files;
my $wasted = 0;
find(\&check_file, $ARGV[0] || ".");
local $" = ", ";
foreach my $size (sort {$b <=> $a} keys %files) {
next unless @{$files{$size}} > 1;
my %md5;
foreach my $file (@{$files{$size}}) {
open(FILE, $file) or next;
binmode(FILE);
push @{$md5{Digest::MD5->new->addfile(*FILE)->hexdigest}},$file;
}
foreach my $hash (keys %md5) {
next unless @{$md5{$hash}} > 1;
print "$size: @{$md5{$hash}}\n";
$wasted += $size * (@{$md5{$hash}} - 1);
}
}
1 while $wasted =~ s/^([-+]?\d+)(\d{3})/$1,$2/;
print "$wasted bytes in duplicated files\n";
sub check_file {
-f && push @{$files{(stat(_))[7]}}, $File::Find::name;
}
[download]
Tony
If the other monks here think it's solid and all, you
should OO it and send it to the author of File::Find as
File::Find::Duplicates. =)
Interesting. I just went through the similar problem of
combining four computer's worth of archives. In some
cases I had near duplicates due to slight doc changes and
the like, so I wanted a bit more information. I had a second
program do the deletes. (About 9,000 files)
I couldn't go by dates, due to bad file management
Note that the file statement uses the 3 arg version.
I had some badly named files such as ' ha'. I wish I could
remember the monk name that pointed out the documentation
for me.
#!/usr/bin/perl
# allstat.pl
use warnings;
use strict;
use File::Find;
use File::Basename;
use Digest::MD5;
my %hash;
my @temp;
while (my $dir = shift @ARGV) {
die "Give me a directory to search\n" unless (-d "$dir");
File::Find::find (\&wanted,"$dir");
}
exit;
sub wanted {
return unless (-f $_);
my $md5;
my $base = File::Basename::basename($File::Find::name, "");
my $size = -s "$base";
if ($size >= 10000000) { # They slowed down the check enough that I
+ skip them
if ($size >= 99999999) { $size = 99999999; }
$md5 = 'a'x32; # At this point I'll just hand check, less than a
+dozen files
}
else {
$md5 = md5file("$base");
}
if ($File::Find::name =~ /\t/) { # Just in case, this screws up our
+tab delimited file
warn "'$File::Find::name' has tabs in it\n";
}
printf("%32s\t%8d\t%s\t%s\n", $md5, $size, $File::Find::name, $base)
+;
}
sub md5file {
my ($file) = @_;
unless (open FILE, "<", "$file" ) {
warn "Can't open '$file': $!";
return -1; #Note we don't want to die just because of one file.
}
binmode(FILE);
my $chksum = Digest::MD5->new->addfile(*FILE)->hexdigest;
close(FILE);
return $chksum;
}
[download]
The CRC32 found in Compress::Zlib runs 82% faster than Digest::MD5 on my system, using the following benchmark program:
#!/usr/bin/perl -w
use strict;
use IO::File;
use Compress::Zlib ();
use Digest::MD5;
use Benchmark;
use constant BUFSIZE => 32768;
sub crc32
{
my $fh = shift;
binmode($fh);
sysseek($fh, 0, 0); # rewind
my $buffer = ' ' x BUFSIZE;
my $crc = 0;
while ($fh->sysread($buffer, BUFSIZE))
{
$crc = Compress::Zlib::crc32($buffer, $crc);
}
return $crc;
}
sub md5
{
my $fh = shift;
seek($fh, 0, 0); # rewind
my $md5 = Digest::MD5->new();
$md5->addfile($fh);
return $md5->digest;
}
foreach my $file (@ARGV)
{
my $fh = IO::File->new($file);
binmode($fh);
next if !defined($fh);
Benchmark::cmpthese(-10, {
"crc32 $file", sub { crc32($fh) },
"md5 $file", sub { md5($fh) }
});
}
[download]
I am new to perl (and to writing code) and I have just been in an excellent
course organized by Barcelona_pm. I have rewritten lemming code as an exercise of using Moose. To improve speed, following above suggestions, files with similar size are first identified and, afterwards, md5 value is calculated in these files. Because this is baby-code, please feell free to recomend any RTFM $manual that I sould review to improve the code. Thanks for this great language!
(I have to thank Alba from Barcelona_pm for suggestions on how to improve the code).
This is the definition of the object "FileDups"
package FileDups;
use Digest::MD5;
use Moose;
use namespace::autoclean;
has 'name' => (is => 'ro', isa => 'Str', required => 1,);
has 'pathname' => (is => 'ro', isa => 'Str', required => 1,);
has 'max_size' => (is => 'ro', isa => 'Num', required => 1,);
has 'big' => (is => 'rw', isa => 'Bool', required => 1, default =
+> 0);
has 'unread' => (is => 'rw', isa => 'Bool', required => 1, default =
+> 0);
has 'dupe' => (is => 'rw', isa => 'Bool', required => 1, default =
+> 0);
has 'md5' => (is => 'ro', isa => 'Str', lazy => 1, builder =
+> '_calculate_md5');
has 'size' => (is => 'ro', isa => 'Num', lazy => 1, builder =
+> '_calculate_size');
sub _calculate_size {
my $self = shift;
my $size = -s $self->name;
if (-s $self->name > $self->max_size) {
$size = $self->max_size;
$self->big(1);
}
return $size;
}
sub _calculate_md5 {
my $self = shift;
my $file = $self->pathname;
my $size = $self->size;
my $chksum = 0;
if ($size == $self->max_size) {
$chksum = 'a'x32;
} else {
my $fh;
unless (open $fh, "<", "$file" ) {
$self->unread(1);
return -1; #return -1 and exit from subrutine if file can
+not be opened
}
binmode($fh);
$chksum = Digest::MD5->new->addfile($fh)->hexdigest;
close($fh);
}
return $chksum;
}
;1
[download]
And this is the main package that lists duplicate files, big files and unread files.
#!/usr/bin/env perl
# References:
#
use strict;
use warnings;
use File::Find;
use lib qw(lib);
use FileDups;
use Data::Dumper;
# Hash of => [array of [array]], [array of objects]
my (%dup, %sizes, @object, $number_files, $number_size_dups);
my $max_size = 99999999; # Size above of whitch md5 will n
+ot be calculated
my $return = "Press return to continue \n\n";
my $line = "-"x70 . "\n";
while (my $dir = shift @ARGV) { # Find and classify files
die "\"$dir\" is not a directory. Give me a directory to search\n"
+ unless (-d "$dir");
File::Find::find (\&wanted,"$dir");
}
print "\n";
foreach (@object) { # Calculates md5 for files with equ
+al size
if ($sizes{$_->size} == "1") {
$number_size_dups += 1; print "$number_size_dups Files with th
+e same size \r";
$_->dupe(1); # The object has another object with t
+he same size
$_->md5; # Calculates md5
}
}
foreach (@object) { # Creates a hash of md5 values
if ($_->dupe == 1) { # for files with the same size
if (exists $dup{$_->md5}) {
push @{$dup{$_->md5}}, [$_->size, $_->name, $_->pathname];
} else {
$dup{$_->md5} = [ [$_->size, $_->name, $_->pathname] ];
}
}
}
print "\n\nDuplicated files\n $line $return"; my $pausa4 = <>;
foreach (sort keys %dup)
{ # sort hash by md5sum
if ($#{$dup{$_}} > 0) # $_ = keys
{ # if we have more than 1 array whithin th
+e same hash
printf("\n%8s %10.10s %s\n", "Size", "Name", "Pathname");
foreach ( @{$dup{$_}} ) # $_ = keys, $dupes{keys} =
+list of references (scalars)
{ # iterate trough the first dimension of t
+he array
printf("%8d %10.10s %s\n",@{$_}); # dereference referen
+ce to array
}
}
}
my $r1 = &list_files("Big files","big",@object); # List big files
my $r2 = &list_files("Unread files","unread",@object); # List unrea
+d files
sub wanted {
return unless (-f $_);
my $file = FileDups->new(name => $_, pathname => $File::Find::name
+, max_size => $max_size);
$number_files += 1; print "$number_files Files seen\r";
if ($file->size == $max_size) { # Identifies big files
$sizes{$file->size} = "0"; # We do not check md5 for bi
+g files
} elsif (exists $sizes{$file->size}) { # There are more the
+n one file with this size
$sizes{$file->size} = "1";
} else {
$sizes{$file->size} = "0"; # This is a new size value,
+not duplicated
}
push @object, $file; # Puts the object in the @obje
+ct array
}
sub list_files { # List objects according to criter
+ia:
my ($title,$criteria,@object) = @_; # (a) big files; (b)
+unread files
print "\n \n $title \n" . $line; my $pausa = <>;
foreach (@object) {
if ($_->$criteria) {
printf(" %10.10s %s\n",$_->name,$_->pathname);
}
}
print $line;
}
[download]
#!/usr/bin/perl -w
# usesage: dupDisplay.pl fileMD5.txt [remove]
# input file has the following form:
# 8e773d2546655b84dd1fdd31c735113e 304048 /media/PICTURES-1/my
+media/pictures/pics/20041004-kids-camera/im001020.jpg im001020.jpg
# e01d4d804d454dd1fb6150fc74a0912d 296663 /media/PICTURES-1/my
+media/pictures/pics/20041004-kids-camera/im001021.jpg im001021.jpg
use strict;
use warnings;
my %seen;
my $fileCNT = 0;
my $origCNT = 0;
my $delCNT = 0;
my $failCNT = 0;
my $remove = 'remove' if $ARGV[1];
$remove = '' if !$ARGV[1];
print "\n\n ... running in NON removal mode.\n\n" if !$remove;
open IN,"< $ARGV[0]" or die ".. we don't see a file to read: $ARGV[0]"
+;
open OUT,"> $ARGV[0]_new.temp" or die ".. we can't write the file: $AR
+GV[0]_new.temp";
open OUTdel,"> $ARGV[0]_deleted" or die ".. we can't write the file: $
+ARGV[0]_deleted";
open OUTfail,"> $ARGV[0]_failed" or die ".. we can't write the file: $
+ARGV[0]_failed";
print "\n ... starting to read find duplicats in: $ARGV[0]\n";
if(! -d './trash/'){mkdir './trash/' or die " !! couldn't make trash d
+irectory.\n $! \n";}
while(<IN>){
my $line = $_;
chomp $line;
$fileCNT++;
my ($md5,$filesize,$pathfile,$file) = split /\t+/,$line,4;
if(exists $seen{"$md5:$filesize"}){
my $timenow = time;
my $trashFile = './trash/' . $file . "_" . $timenow; # moves dup
+licate file to trash with timestamp extension.
#if( ! unlink($pathfile){print OUTfail "$pathfile\n"; $failCNT+
++;}
if($remove){if( ! rename $pathfile,$trashFile){print OUTfail "$pa
+thfile\n"; $failCNT++;}}
$seen{"$md5:$filesize"} .= "\n $pathfile";
$delCNT++;
print " files: $fileCNT originals: $origCNT files to delete: $d
+elCNT failed: $failCNT \r";
}else{
$seen{"$md5:$filesize"} = "$pathfile";
printf OUT ("%32s\t%8d\t%s\t%s\n", $md5,$filesize,$pathfile,$file
+);
$origCNT++;
print " files: $fileCNT originals: $origCNT files to delete: $d
+elCNT failed: $failCNT \r";
}
}
foreach my $key (keys %seen){
print OUTdel " $seen{$key}\n";
}
print " files: $fileCNT originals: $origCNT files to delete: $delCNT
+ failed: $failCNT \n\n";
[download]
Interesting. I wrote my own that does pretty much the same
thing, but in a different way (I only use one hash, so I
suspect it will use less memory (but see response below for
the final word)).
#! /usr/bin/perl -w
use strict;
use File::Find;
use Digest::MD5;
my %digest;
my $total_bytes = 0;
my $dups = 0;
sub wanted {
return unless -f $_;
my $bytes = -s _;
return unless $bytes;
if( !open IN, $_ ) {
print "Cannot open $_ for input: $!\n";
return;
}
my $md5 = Digest::MD5->new;
my $d = $md5->addfile( *IN )->digest;
close IN;
if( defined $digest{$d} ) {
print "$bytes\t$digest{$d}\t$File::Find::name\n";
$total_bytes += $bytes;
++$dups;
}
else {
$digest{$d} = $File::Find::name;
}
}
foreach my $d ( @ARGV ) {
print "=== directory $d\n";
find \&wanted, $d;
}
printf "Statistics:
Duplicates: %12d
Bytes: %12d
KBytes: %12d
MBytes: %12d
GBytes: %12d\n",
$dups,
$total_bytes,
$total_bytes / (1024**1),
$total_bytes / (1024**2),
$total_bytes / (1024**3);
[download]
It is very verbose, but that's because I pipe the output
into something that can be handed off to users in a
spreadsheet so that they can do their own housekeeping
(2Gb of duplicates in 45Go of files...).
BTW, you can also save a squidgin of memory by using
the digest() method, rather than the hexdigest() method,
since the value is not intended for human consumption.
The first script will only do MD5 hashes on files if there is more than one file with the same file size, then compares the MD5s for the files of that size. Yours MD5's *everything*, then compares *all* the MD5s. If a file has a unique filesize, it *can't* have a duplicate.
Depending on the make up of the files, this can have a dramatic effect:
Files: 15272
Duplicates: 999
Bytes: 15073525
[download]
First script:
real 0m11.855s
user 0m2.590s
sys 0m1.640s
Second script:
real 0m49.589s
user 0m17.110s
sys 0m6.500s
[download]
Admittedly, if all your files were the same size there would be no difference, but in most cases, the first script will win. But hey...
The code for script three is below
Benchmarks:
scenario 1: a bundle of MP3 files
number of files: 5969
Number of duplicates: 11
Total size of all files: 16,560,706,048 (~16 gigs)
(script one - original, MD5 hash files with same file size)
...
37,411,688 bytes in duplicated files
real 5m1.753s
user 1m48.760s
sys 0m31.010s
[download]
Duplicates: 11
Bytes: 37411688
real 17m1.262s
user 6m56.060s
sys 1m59.830s
[download]
real 6m25.131s
user 2m42.310s
sys 0m32.450s
[download]
37,411,688 bytes in duplicated files
real 0m48.545s
user 0m2.150s
sys 0m1.460s
[download]
Scenario 2: home directory
number of files: 15280
Number of duplicates: 998
Total size of all files: 677,698,560 (677 megs)
Script one results
15,073,517 bytes in duplicated files
real 0m9.745s
user 0m2.610s
sys 0m1.220s
[download]
Duplicates: 998
Bytes: 15073517
real 0m51.197s
user 0m17.520s
sys 0m6.700s
[download]
real 0m18.332s
user 0m8.080s
sys 0m5.270s
[download]
15,069,331 bytes in duplicated files
real 0m12.924s
user 0m3.110s
sys 0m2.510s
[download]
The third script is slower than the first in this situation as it must do multiple compares (ie a with b, a with c, a with d) rather than using the MD5 hashing technique It would be even slower if we counted small files (timed at around 23 seconds). Both 1 and 3 are still *much* faster than 2 though. The fdupes benchmarks are just in there for comparison to show how a bad algorithm can slow down a fast language.
Also note that not using MD5 hashes means I suffer if there are three or more identical, large, files, but I wanted to be *absolutely* sure not to get any false positives and MD5 hashing doesn't (quite) do that. So I do a byte-for-byte comparison between possible pairs.
There is almost certainally another way - we could do two passes using the MD5 technique, creating MD5 hashes for the first (say) 200 bytes of each file in the first pass, then MD5-ing on the whole file if the first ones match. This should give us good performance on both large numbers of duplicated small files *and* small numbers of duplicates of large files. But that's something for another day, and I somehow *prefer* to do byte-by-byte checks. Paranoia, I guess.
Anyway - here's the code...
fdupes.pl (usage: fdupes.pl <start dir>):
#!/usr/bin/perl -w
# Usage: ./fdupes.pl <start directory>
use strict;
use Term::ReadKey;
use File::Find;
# testing - 0 for interactive mode, 1 to skip all deletion etc
my $testing = 0;
# skip files smaller than 100 bytes. Set to zero if you like...
my $minsize = 100;
my $filecount = my $bytecount = my $fileschecked = my $wasted = 0;
my %files = ();
&usage unless (@ARGV);
sub wanted {
return unless -f;
my $filesize = (stat($_))[7];
$bytecount += $filesize;
return unless $filesize > $minsize; # skip small files
$filecount++;
push @{$files{$filesize}}, $File::Find::name;
}
find(\&wanted, $ARGV[0] || ".");
# update progress display 1000 times maximum
my $update_period = int($filecount/1000)+1;
if ($fileschecked % $update_period == 0) {
print "Progress: $fileschecked/$filecount\r";
# note \r does carriage return, but NO LINE FEED
# for progress display
}
my @dupesets;
# list of lists - @{$dupesets[0]} = (file1, file2)
# where file1 and file2 are dupes
foreach my $size (keys %files) {
my @entries = @{$files{$size}};
my $samesizecount = scalar @entries;
if (@{$files{$size}} == 1) { # unique size
$fileschecked++;
}
# duplicates by file size.. Check if files are the same
while (my $base = shift @entries) {
# get first entry in list under filesize
my @dupes = ();
my $count = 0;
while ($count <= $#entries) {
# go through all @entries
my $compare = $entries[$count];
if (&same($base, $compare)) {
# remove "compare" from list so it can't be used
# on next run
splice(@entries, $count,1);
# removed "compare" from list - update progress
if (++$fileschecked % $update_period == 0) {
print "Progress: $fileschecked/$filecount\r";
}
if (@dupes) {
# already have some dupes - just add duplicate
# #n to list
push @dupes, $compare;
$wasted += $size;
} else {
# no dupes yet - include base file and duplicate
# #1 in list
push @dupes, ($base, $compare);
$wasted += $size;
}
} else {
$count++;
# only increase counter if not a dupe - note splice
# will break $array[$position] loop otherwise
}
}
if (@dupes) {
push @dupesets, \@dupes;
}
# "base" file removed from list of files to check - update
# progress meter
if (++$fileschecked % $update_period == 0) {
print "Progress: $fileschecked/$filecount\r";
}
}
}
if (@dupesets) {
my @deletelist = ();
# at least one set of duplicates exists
# number of sets of duplicates
my $dupesetcount = scalar(@dupesets);
my $dupesetcounter = 0;
foreach my $setref (@dupesets) {
if ($testing) {
print @$setref, "\n";
}
$dupesetcounter++;
my @dupes = @$setref;
print "Duplicates found ($dupesetcounter / $dupesetcount)",
"... Should I keep...\n";
my $count = 0;
# print up list of options of which file to keep
while ($count <= $#dupes) { # go through all @entries
my $entry = $dupes[$count];
print $count + 1, " : $entry\n";
$count++;
}
# alternative options - keep all files, skip to end
print "0: All\n";
print "A: Skip all remaining duplicates\n";
# use ReadKey to get user input
ReadMode 4; # Turn off controls keys
my $key = '';
while (not defined ($key = ReadKey(-1))) {
# No key yet
}
ReadMode 0; # Reset tty mode before exiting
if ($key eq 'A') {
# skip any remaining dupes and get to deletion bit
}
# not a number or 'A' - default to zero (ie keep all files)
$key = '0' unless ($key =~ /^\d+$/);
if ($key == 0) { # ALL - don't delete anything
#print "you chose: ALL\n";
} elsif (defined $dupes[$key-1]) {
print "you chose: ", $dupes[$key-1], "\n";
my @list_to_delete = @dupes;
# remove file to keep from list
splice(@list_to_delete, $key-1, 1);
# add rest to deletelist
push @deletelist, @list_to_delete;
} else {
#print "you chose: invalid number... (nothing will",
# " be deleted)\n";
}
print "\n";
}
# confirm deletion if any files are needing deleting
if (@deletelist) {
print "\n------------------------\n";
print "list of files to delete:\n";
foreach (@deletelist) {
print "$_\n";
}
print "\nAre you *sure* you want to delete all these files?",
" (Y/N)\n";
ReadMode 4; # Turn off controls keys
my $key = '';
while (not defined ($key = ReadKey(-1))) {
# No key yet
}
ReadMode 0; # Reset tty mode before exiting
if (lc($key) eq 'y') {
print "deleting\n";
unlink @deletelist;
} else {
print "wussing out\n";
}
}
1 while $wasted =~ s/^([-+]?\d+)(\d{3})/$1,$2/;
print "$wasted bytes in duplicated files\n";
}
# routine to check equivalence in files. pass 1 checks first
# "line" of file (up to \n char), rest of file checked if 1st
# line matches
sub same {
local($a, $b) = @_;
open(A, $a) || die;
open(B, $b) || die;
if (<A> ne <B>) { # FIRST LINE is not the same
return 0; # not duplicates
} else { # try WHOLE FILE
local $/ = undef;
return <A> eq <B>;
}
}
sub usage {
print "Usage: $0 <start directory>\n";
exit;
}
[download]
1. Keep it simple
2. Just remember to pull out 3 in the morning
3. A good puzzle will wake me up
Many. I like to torture myself
0. Socks just get in the way
Results (284 votes). Check out past polls.
|
http://www.perlmonks.org/?node_id=49198
|
CC-MAIN-2016-44
|
refinedweb
| 3,142
| 66.07
|
This is your resource to discuss support topics with your peers, and learn from each other.
04-26-2013 04:05 AM
Hi there,
I'm developing a PB app using Qt4.8. I would like to know where I can store configuration data. The link
Does this mean that in my app, I can simply copy config data to "~/appConfig.dat" (i.e. tilda forward slash which is a unix convention for going to home directory)
Cheers,
Ben
Solved! Go to Solution.
04-26-2013 04:30 AM
You can store the config data in the the app storage directory which can be accesed by using the path /accounts/1000/appdata/namespace.application/data". You can also use the System Navigator in the IDE to see the app directory structure. I have included more documentation on this topic below. Even though it's for BB10, most of details also apply to PlayBook.
|
https://supportforums.blackberry.com/t5/Native-Development/Playbook-development-Qt4-8-storing-app-config-data/td-p/2334939
|
CC-MAIN-2017-09
|
refinedweb
| 153
| 66.03
|
The objective of this post is to explain how to parse a JSON string with MicroPython running on the ESP32.
Introduction
The objective of this post is to explain how to parse a JSON string with MicroPython running on the ESP32. If you need help setting MicroPython on the ESP32, please check this previous post for a detailed guide. The guide also explains how to connect to the Python prompt.
In order to parse a JSON string, we will use the MicroPython uJSON library. You can also check the documentation of the library at Github.
Since we are going to use the command line for testing the code, we will need a tool to help us compress the JSON content in a single line, so we can easily paste it. So, we will use this website, which can receive a JSON string and compress it to a single line. Then, we can past it to Putty just by copying the JSON and right clicking on the terminal window.
The code
After connecting to the Python prompt, we are ready to start coding. So, the first thing we need to do is importing the uJSON module. Just type the expression bellow and hit enter.
import ujson
After that, we should have access to the ujson object, which makes available a method called loads. This method receives as input the JSON string and returns an object corresponding to the parsed JSON [1]. We will start with a simple JSON structure, which is the one shown bellow.
{ "name":"John" },
After compressing it to a one liner, we get the JSON string shown bellow.
{"name":"John"},
So, we will now pass this string as input of the previously mentioned loads method. Note that we will enclose the string between “”” in each side, in order to escape the quotes from the JSON structure. We will store the object in a variable called parsed.
parsed = ujson.loads("""{"name":"John"}""")
Now, we will confirm that we have the content of the JSON correctly in our returning object. So we will print it. Additionally, we will print the type of the object with the type function.
print (parsed) print (type(parsed))
After running the whole previous code, we should get an output similar to figure 1. Note that the type of our object with the parsed content is a Python dictionary, making it perfect for accessing the content in a key-value style.
Figure 1 – Parsing the JSON string.
Now, we will access the value for the key equal to “name”. It should return “John”. In order to access the value for that key in the dictionary, send the command bellow. Note that it is like accessing an array value but instead of using an index, we use a key, in the format of a string.
print(parsed["name"])
You should get an output similar to figure 2. Note that the name “John” is printed on the console.
Figure 2 – Accessing the parsed values of the dictionary object.
To finalize our example, we will now parse a more complex structure, as shown bellow. This could represent, for example, a message sent from an IoT device.
{ "device":"temperature", "id":543, "values":[1,2,3] }
After compressing, we get the following:
{"device":"temperature","id":543,"values":[1,2,3]}
So, we will now parse it and print all the keys existing in our JSON structure. We will also print the type of the “values” structure, to understand how it is mapped by the parser.
parsed = ujson.loads("""{"device":"temperature","id":543,"values":[1,2,3]}""") print (parsed["device"]) print (parsed["id"]) print (parsed["values"]) print(type(parsed["values"]))
You should get a result similar to figure 3. As can be seen, all the values for each key are printed correctly. In the case of the “values” key, the structure inside the dictionary is a list, rather than a string representation of the values. Naturally, this is much better since we can operate over those values with all the functions available for lists, making them easier to manipulate.
Figure 3 – Result of the JSON content parsed.
References
[1]
Pingback: ESP32 MicroPython: Encoding JSON | techtutorialsx
Pingback: ESP32 / ESP8266 MicroPython: HTTP GET Requests | techtutorialsx
Pingback: ESP32 / ESP8266 MicroPython: HTTP POST Requests | techtutorialsx
|
https://techtutorialsx.com/2017/05/23/esp32-micropython-parsing-json/
|
CC-MAIN-2017-34
|
refinedweb
| 709
| 63.7
|
Content-type: text/html
Standard C Library (libc.so, libc.a)
#include <stdio.h>
int pclose (
FILE *stream );
Interfaces documented on this reference page conform to industry standards as follows:
pclose(): XPG4, XPG4-UNIX
Refer to the standards(5) reference page for more information about industry standards and associated tags.
Points to a FILE structure for an open pipe returned by a previous call to the popen() function.
The pclose() function closes a pipe between the calling program and a shell command to be executed. Use the pclose() function to close any stream you have opened with the popen() function. The pclose() function waits for the associated process to end, and then returns the exit status of the command. If the original processes and the process started with the popen() function concurrently read or write a common file, neither should use buffered I/O. If they do, the results are unpredictable.
Upon successful completion, the pclose() function returns the exit status of the command.
If an error is detected, pclose() sets errno to an appropriate value and returns a value of -1.
If the pclose() function fails, errno may be set to the following value: The status of the child process could not be obtained.
Functions: fclose(3), popen(3), wait(2)
Standards: standards(5) delim off
|
http://backdrift.org/man/tru64/man3/pclose.3.html
|
CC-MAIN-2017-04
|
refinedweb
| 217
| 63.9
|
Android has been steadily gaining momentum as a mobile application platform and is now prevalent enough that developers ought to learn at least the basics of developing Android apps. For developers new to Android, the good news is that learning to develop for Android is far easier than learning to develop for iOS, at least without the help of higher-level tools such as Xamarin Studio. To start writing truly native Android apps, you will need to learn the Java language and obtain an IDE for your preferred OS platform (Windows, Mac, or Linux). Google's Android Studio or JetBrains' IntelliJ IDEA (upon which Android Studio is built) are two excellent and free Android IDE options. Alternatively, Eclipse remains a viable option for Android application development.
In this article, I'll discuss what it takes to create a sample Android application that provides minimal user interactivity. In doing so, I'll touch on aspects such as the lifecycle of an Android app and navigation. However, I will not cover more specific topics such as networking, local storage, and data binding. At the end of the day, though, Android development is easy to learn because once you've mastered the basics, everything else is as simple as learning a new set of classes.
Getting Ready to Build an Android App
Both IntelliJ IDEA and Android Studio come with a nice installer that sets up most, but not all, the necessary Android components. After the setup program is completed, you still need to perform a few steps yourself. In particular, you should list the versions of the Android operating system you intend to support in the IDE. For each selected version, you then need to download specific binaries and, optionally, examples. To perform these tasks, you use the Android SDK Manager tool, which is integrated into the user interface in both Android Studio and IntelliJ IDEA, as shown in Figure 1. Through the SDK Manager, you select the version of the Android platform you intend to build for, and the tool downloads and installs binaries, additional tools, and optionally, samples.
At this point, you're ready to start building your first Android application. The project wizard is nearly the same regardless of the IDE you use, whether it's Android Studio, IntelliJ IDEA, or Eclipse. For the purposes of this article, I'll be using IntelliJ IDEA Community Edition. It is worth noting, though, that Android Studio is built from the same codebase as IntelliJ IDEA Community Edition.
Straight out of the project wizard, the first Android application is fairly simple: a manifest file, one activity class, and one basic graphic layout. This is a fully functional application in the sense that it compiles well and can be installed on devices. However, it doesn't yet support any form of interaction.
Making Sense of Activities
An Android application is built around one or more screens. Each screen requires its own activity class. The activity class is expected to contain any code behind the screen—specifically code that initializes the view and handles events. Let's have a look at the activity class for the app's main screen. The class is named MyActivity and lives in the src folder. Any Android activity class inherits from the system-defined Activity class, as shown in the following example:
public class MyActivity extends Activity { @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); } }
At the very minimum, an activity class overrides the onCreate method defined on the base class. In the override, you first call the base method, then set the content view. In the previous code snippet, the expression R.layout.main references the project file where the layout of the view is saved.
You can think of the activity class as the equivalent of the code-behind class of a .NET Framework application. There you will handle references to UI elements and set event handlers. To define the graphical layout, you use a WYSIWYG editor integrated in the IDE (IntelliJ IDEA, Android Studio, or Eclipse). The graphical editor works as expected and lets you pick visual widgets from a palette and drop them on a drawing surface. Figure 2 shows the application's UI that I created with the graphical editor.
The graphical editor produces an XML file that can also be edited manually through an ad hoc text editor in the IDE. Overall, the Android XML layout language is in some ways similar to XAML and, as with XAML in Visual Studio, you can create and edit the XML file using either a visual or a text editor. You compose the UI hierarchy through panel components such as the LinearLayout or RelativeLayout elements, which map closely to StackPanel elements in XAML. Listing 1 shows the XML code for the graphical layout shown in Figure 2.
Each Android UI widget is required to indicate explicitly its width and height. However, you often use relative measurements for this. For example, wrap_content indicates that the size of the component is enough to incorporate any content. Likewise, fill_parent indicates that width or height needs to be as big as the container component. If you intend to use fixed measures, you should use either the dp or dip qualifier to mark those values as device-independent pixels. You should avoid using any other measure qualifier, as dp (or dip) ensures the best scaling experience for the UI on smaller or larger devices.
Finally, you should note the special syntax required to assign an ID to a visual element or to bind a resource. The at sign (@) indicates a reference. Thus @string/messageDontTouch refers to a string resource named messageDontTouch.
Resources are stored in special XML files under the res project folder. Basically, Android compiles resources into a dynamically created class—this happens in a way that's analogous to how .resx files are processed in .NET code. The name of this dynamically created class is R, and it exposes properties for nearly any type of resource in the project. For IDs, there's an extra plus sign (+) to take into account. The + sign associated with ID resources exists to explicitly indicate that the resource must be added to the list. This is to distinguish between Android native IDs and user-defined IDs.
Finding References to Visual Elements
In .NET, any element defined from within the graphical layout can be consumed from code via an object reference. In .NET, however, UI object references are automatically managed by Visual Studio and the C# compiler through the mechanism of partial classes. In Android, you are responsible for defining object references yourself. To do so, you first add a private member to the class for each graphical component to reference:
private TextView message; private ImageView droid;
Next, directly in the code of onCreate or, better yet, in a distinct method, you initialize the private members:
message = (TextView) findViewById(R.id.message); droid = (ImageView) findViewById(R.id.imageView);
The type cast is necessary because findViewById—a method defined on the base Activity class—always returns a generic View object. This part of Android programming is quite boring but necessary, and, at least for the time being, there's no other way to accomplish it.
Adding Event Handlers
To add a handler to events fired by visual component, you follow the same pattern as in C#, except that the Java syntax is more boring. You first define an explicit handler:
private View.OnClickListener droidTapListener;
Next, you bind the event handler to some code that will run in response to the event:
droidTapListener = new View.OnClickListener() { public void onClick(View v) { touchDroid(); } }; droid.setOnClickListener(droidTapListener);
In this example, touchDroid is just an internal method that actually performs the task. Note the verbosity of the Java syntax. In C# you would have simply bound touchDroid to the event. In Android, you also need to explicitly make the event assignment using an event-specific method. For the click event, the method is setOnClickListener. In the touchDroid method, you perform any task associated with the event and then use references to visual elements to update the UI.
The Manifest File
The manifest file is mandatory for any Android application and is created for you along with the project. The manifest file contains information that the app presents to the operating system when the app is installed on the device. This information includes the app's package name and icon and the name of the starter activity. Optionally, the manifest can contain requested permissions that the user should grant to the application so that the app can run. These permissions typically include the permission to access items such as contacts, network, phone state, local storage, vibration, and others.
Declaring all necessary permissions is crucial, as the application won't work otherwise. The Android API, in fact, implements a security layer that prevents the API call from working if it requires permission and the app doesn't declare that permission in the manifest file. The manifest file is saved as an XML file named AndroidManifest.xml.
Launching a New Activity
As mentioned, an activity is the class that represents a screen displayed to the user. For an application that needs to navigate across multiple screens, multiple activity classes are required. So to enable a new screen, you start by adding a new Java class to the project, giving it its own layout and logic. Next, you must register the activity class in the manifest file, as shown in Listing 2.
The sample manifest requests two permissions and defines the FeedHunterActivity class as the primary activity—the startup activity—and RssFeedListActivity as a secondary activity launched only programmatically. Here's the code you need to launch an activity—for example, you can call the code in response to a click or a touch gesture.
private void goGetFeed() { Intent i = new Intent(this, RssFeedListActivity.class); startActivity(i); }
In Android, an intent is the description of an operation to be performed. The most significant of these actions is the launch of a new activity. The startActivity method defined on the Activity base class gets the intent that wraps up the type of the activity to launch and launches it. Activities are placed one on top of the other in a system-managed stack that users navigate through using the Back button. Activities in the stack are never rearranged, only pushed and popped from the stack as navigation occurs.
When you start a new activity using the startActivity method, the operation takes the form of a fire-and-forget action. If you want the original activity to receive data back from the spawned activity, then you use the startActivityForResult method instead. In this case, to receive data back from the launched activity, you have to override the method onActivityResult, as follows:
@Override public void onActivityResult(int requestCode, int resultCode, Intent intent) { : }
The data exchange takes place through the putExtra and getExtras methods of the Intent object. Methods operate on a dictionary, and the new activity stores data that the original will read back.
The Bottom Line
I hope you've seen from the example app we've covered here that the basic facts of Android programming are not hard to understand and apply. For .NET developers, mapping aspects of Android to known subjects is relatively easy. Such knowledge won't turn a novice Android developer into an expert right away, but at least it puts you in a good position to jump into developing Android apps.
|
https://www.itprotoday.com/android/get-started-building-android-apps
|
CC-MAIN-2021-31
|
refinedweb
| 1,917
| 53.21
|
Test Driven Development and Neo4J: Using @Rule and Avoiding Containers
The Java Zone is brought to you in partnership with ZeroTurnaround. Discover how you can skip the build and redeploy process by using JRebel by ZeroTurnaround.
Been doing some coding with Neo4J. Pretty interesting experience so far, but one thing is for sure: being able to write seriously sophisticated code that has a large, complex model underneath it, from inside unit tests that run in a few milliseconds is, as the bloodsucking credit card commercial says, priceless. There are still a couple of challenges to consider, but the reality is with a simple custom rule (using JUnit 4), you can have an embedded database that will be ready for each test, and cleaned up after each one.
Here is the code. Because of the inability to put a @Rule inside a rule implementation, the folder is passed in. Notice the shutdown is commented out. Per my prior post, that is because the folder is already gone by the time this gets called. Turns out it‘s not really needed. If you manage the resource yourself, however, you have to call shutdown or your deletes will not wipe the dir completely.
package com.ontometrics.testing; import org.junit.rules.ExternalResource; import org.junit.rules.TemporaryFolder; import org.neo4j.graphdb.Transaction; import org.neo4j.kernel.EmbeddedGraphDatabase; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * Custom @Rule implementation for making an embeddable graph database for use * in tests. * <p> * Does the setup and teardown of the database, creates a transaction. * * see EmbeddedGraphDatabase, {</code>link ExternalResource} */ public class TestGraphDatabase extends ExternalResource { private static final Logger log = LoggerFactory.getLogger(TestGraphDatabase.class); public TemporaryFolder tempFolder; private EmbeddedGraphDatabase database; private Transaction transaction; public TestGraphDatabase(TemporaryFolder tempFolder) { this.tempFolder = tempFolder; } @Override protected void before() throws Throwable { super.before(); } @Override protected void after() { super.after(); transaction.finish(); // database.shutdown(); } public EmbeddedGraphDatabase getDatabase() { if (database == null) { log.debug("created database in: {}", tempFolder.getRoot().getAbsolutePath()); database = new EmbeddedGraphDatabase(tempFolder.getRoot().getAbsolutePath()); transaction = database.beginTx(); } return database; } public Transaction getTransaction() { return transaction; } }
Yeah, the formatting of code on here is abysmally bad.
Also,
I wait until the database is asked for because getting the temp folder
in Before was not working. You could do it there instead since we are
passing the folder in.
I am burnt to a crisp on container-based testing in Java. My new meanderings are that if there is a need for a container, it‘s probably not until long into the development cycle. Which brought up a bunch of interesting questions:
- Doesn‘t the Rule in JUnit attempt to solve the same problem that the container does? When we write our own classes for things like EntityManagers, we quickly get dispirited about the question of how we are going to make these things magically materialize in all the places that we need them. But is that really such a big problem?? For instance, I wrote a few tests that used this rule and put objects in the db, created relations, retrieved them, etc. Then I wanted to make a repository for my entity. So I did a generic repository that uses Reflection (did this in Spring, something like it in Seam). Only, this time, I didn‘t jump right away into the Container Fry Pan. So the Repository needs an EM, big deal. Let‘s start by making one and setting it. Then I got to thinking, ‘why not make a test class (not in compile scope) that just makes your repositories for you, sticks the EM inside, then returns it? Or, why not embed a Rule for each major repository in that package‘s test equivalent? So PersonRepository extends ExternalResource.. ? Actually, PersonRepository extends TestRepository and that class could get the EMF wiring?
- Is there really a requirement to start calling the container into service from the very beginning? Frankly, what if we went totally naked on the domain side then had a controller layer that had some generic injection protocol (our own annotations) so we could develop all the way up through that layer with no container and then could turn on CDI or its ilk once we were up on that floor?
- Isn‘t there a container equivalent of the very anemia Spring was supposedly made to cure?? Yes there is friends. We‘ve all seen the DI projects where the same simplistic patterns of DAOs are repeated robotically to an inane degree.
- If we move away from a per-domain object/single persistence entry point, doesn‘t the container become less important? The Weld maven archetype had this idea and some of their docs too. So, instead of making a PersonRepository that ends up with 80 methods in it, you have controllers injected with the EM and then different functional requirements of the Person are associated with their context more directly. So, for instance, if we have a social bent to our app, we might have a FriendsController that manages invites and the like, and if we have security another called PersonalSecurityController that has those interactions. To me, this is less anemic, less prone to bloat, and less monocultural. It‘s also plenty easy to do without seeing the container as the master puppeteer who has to bring all the forces together.
This was what I was getting at in my post about Play. The container guys have both over played their hand and lost site of the real costs of their approach, and by staying reactionary, have failed to redirect their attention forward, and half their audience is too young to even remember the supposed glory of their birth. Furthermore, as Agile continues to turn more and more into Lean, we will see that the decade of the DI container has been anything }}
|
https://dzone.com/articles/test-driven-development-and
|
CC-MAIN-2015-48
|
refinedweb
| 961
| 55.74
|
collective.lesscss 1.1
This package allow theme developers to add LESS stylesheets into a Plone site.
Contents
Introduction
This package allow theme developers to add LESS stylesheets into a Plone site.
LESS
LESS extends CSS with dynamic behavior such as variables, mixins, operations and functions. LESS runs on both the client-side (Chrome, Safari, Firefox) and server-side, with Node.js and Rhino.
You can find more information about LESS at
Integration with Plone
This package clone the portal_css behavior, extending it to meet both client-side and server-side LESS resources compiling methods.
It adds a portal_less tool to the portal, enables an import/export GS profile lessregistry.xml, overrides the default Products.ResourceRegistries viewlet by adding the LESS resources part for the <head> tag.
Adding LESS resources
This package is intended to be used in conjunction with an user defined Plone Theme package. As a developer, you can include as many LESS resources as you may need to build your theme. You can add LESS resources using a GS profile named lessregistry.xml. The syntax is cloned from cssregistry.xml profile:
<?xml version="1.0"?> <object name="portal_less" meta_type="LESS Stylesheets Registry"> <stylesheet title="++bootstrap++less/bootstrap.less" authenticated="False" enabled="on" id="++bootstrap++less/bootstrap.less" rendering="link"/> </object>
Control Panel
You can manage the way the LESS resources compile by accessing the LESS resources configlet located at the site setup. By default, client-side LESS resources compile mode is enabled.
Client side compiling
Client-side compiling is intended to use while in (theme) development mode.
collective.lesscss will use the standard method for compiling client-side by using the less.js (v1.3, at the time of this writting) and exposing the LESS resources after the portal_css ones:
<link rel="stylesheet/less" type="text/css" href="styles.less"> <!-- Here goes the rest of portal_javascript resources --> <script src="less.js" type="text/javascript"></script>
Server side compiling
Server-side compiled LESS resources are recommended in production mode. By unsetting this option, the site will server-side compile them into CSS resources and enable a volatile cache on them. Node.js is used for server side compiling, so you should have a Node.js installed in your system and less package installed as well. It’s recommended to let buildout handle this for you:
[buildout] parts = ... nodejs ... ... [nodejs] recipe = gp.recipe.node url = npms = less scripts = lessc
This will download and compile Node.js and less extension. The lessc executable will be available at bin directory of your buildout. Please, review for more references.
In case you already have Node.js and less extension in your system it’s required for you to create a symbolic link of lessc executable at bin directory of your buildout.
IMPORTANT NOTE: Server-side compiling requires to have declared the resources via plone.resource package in your theme package! Example:
<plone:static
And furthermore, if you aren’t using plone.app.themimg for develop your theme you should declare the type you are using for your resources by creating this class somewhere in your theme (e.g. traversal.py):
from plone.resource.traversal import ResourceTraverser class BootstrapTraverser(ResourceTraverser): """The theme traverser. Allows traveral to /++bootstrap++<name> using ``plone.resource`` to fetch things stored either on the filesystem or in the ZODB. """ name = 'bootstrap'
and later on, declare the adapter via zcml:
<adapter name="bootstrap" for="* zope.publisher.interfaces.IRequest" provides="zope.traversing.interfaces.ITraversable" factory=".traversal.BootstrapTraverser" />
So, you should now be able to access to the resources inside the resources directory by accessing:
Twitter bootstrap integration
You can check out the package for a full example on how to integrate LESS resources in your theme package.
Contributors
Victor Fernandez de Alba [sneridagh], Author
Changelog
1.1 (2014-03-11)
- updated nodejs to version 0.10.26 [seppeljordan]
- updated version of less.js to 1.6.3 [jaroel]
1.0b2 (2012-04-14)
- Fix pypi distribution [sneridagh]
1.0b1 (2012-04-13)
- A portal_less inherited from CSSRegistry [sneridagh]
- Import/Export GS profile [sneridagh]
- A viewlet to include less files [sneridagh]
- Register less.js in portal_javascripts [sneridagh]
- A site wide configuration with : transform server side / client wide. [sneridagh]
- Provide documented buildout to install nodejs to compile your files server side [sneridagh]
- Make the results in cached with memoize [sneridagh]
- test with twitter’s bootstrap sources [sneridagh]
- Author: Victor Fernandez de Alba
- Keywords: plone zope less css
- License: gpl
- Categories
- Package Index Owner: seppeljordan, jaroel, sneridagh
- Package Index Maintainer: sneridagh
- DOAP record: collective.lesscss-1.1.xml
|
https://pypi.python.org/pypi/collective.lesscss/1.1
|
CC-MAIN-2016-22
|
refinedweb
| 754
| 50.23
|
SYNOPSIS
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg0, ..., const char *argn, (char *)0);
int execle(const char *path, const char *arg0, ..., const char *argn, (char *)0, char *const envp[]);
int execlp(const char *file, const char *arg0, ..., const char *argn, (char *)0);
int execlpe(const char *file, const char *arg0, ..., const char *argn, (char *)0, char *const envp[]);
int execv(const char *path, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
DESCRIPTION
The
An interpreter script begins with a line of the form:
#! pathname [arg]
where pathname is the
path of the interpreter, and arg is an optional argument.
When an interpreter script is executed, the system executes the
specified interpreter.
The path name specified in the interpreter file is passed as
argv[0] to the interpreter. If arg
was specified in the interpreter file, it is passed as argv[1]
to the interpreter. The remaining arguments to the interpreter
are the arguments passed to the
When a C-language program is executed as a result of this call, it is entered as a C-language function as follows:
int main(int argc, char *argv[]);
where argc is the argument count and argv is an array of pointers to the arguments themselves. In addition, the global variable environ is initialized to point to an array of pointers to the environment strings. The argv and environ arrays are each terminated by a NULL pointer. The NULL pointer terminating the argv array is not counted in argc.
Conforming multi-threaded applications do not use the environ variable to access or modify any environment variable while any other thread is concurrently modifying any environment variable. A call to any function dependent on any environment variable is considered a use of environ.
The arguments specified by a program with an
The number of bytes available for combined argument and environment lists of the new process is specified by ARG_MAX. String terminators and in the calling process image are set to the default action in the new process image.
No functions registered by
No shared memory or memory mapped segments attached to the calling process image are attached to the new process image.
At a minimum, the new process also inherits the following attributes from the calling process image:
- Process ID (see PORTING ISSUES)
- Parent process ID
- Process group ID
- Session membership
- Real user ID
- Real group ID
- Time left until an alarm clock signal
- Current working directory
- File mode creation mask
- Process signal mask
- Pending signals
- Process execution times, as returned by
times()
- Semaphore adjustment values
- Controlling terminal.
- Interval timers
- nice value
A call to an
PARAMETERS
- path
Specifies the path name of the new process image file.
- file
Is used to construct a path name that identifies the new process image file. If it contains a slash character, the argument is used as the path name for this file. Otherwise, the path prefix for this file is obtained by a search of the directories in the environment variable PATH. If PATH is not set, the current directory is searched.
- arg0, ..., argn
Point to null-terminated character strings. These strings constitute the argument list for the new process image. The list is terminated by a NULL pointer. The argument arg0 should point to a file name that is associated with the process being started by the
exec()function.
- argv
Is the argument list for the new process image. This should contain an array of pointers to character strings, and the array should be terminated by a NULL pointer. The value in argv[0] should point to a file name that is associated with the process being started by the
exec()function.
- envp
Specifies the environment for the new process image. This should contain an array of pointers to character strings, and the array should be terminated by a NULL pointer.
RETURN VALUES
If successful, the
- E2BIG
The number of bytes used by the new process image's argument list and environment list is greater than ARG_MAX bytes.
- EACCES
Search permission is denied for a directory listed in the new process image file's path prefix, or the new process image file denies execution permission, or the new process image file is not a regular file.
- ENAMETOOLONG
The length of path or file (or an element of $PATH prefixed to file) exceeds PATH_MAX, or a path name component is longer than NAME_MAX.
- ENOENT
A component of path or file does not name an existing file, or path or file is an empty string.
- ENOEXEC
The new process image file has the appropriate access permissions, but is not in the proper format.
- ENOMEM
The new process image requires more memory than is allowed by the hardware or system-imposed memory management constraints.
- ENOTDIR
A component of the new process image file's path prefix is not a directory.
- ETXTBSY
The
exec()function was called from a non-NuTCRACKER Platform process, other than from the child of a vfork()operation.
CONFORMANCE
MULTITHREAD SAFETY LEVEL
Except for
PORTING ISSUES
The NuTCRACKER Platform uses the Win32
You may not call an
The Windows file systems do not support set-user-ID and set-group-ID bits for files. Hence there is no support for automatically setting effective user and/or group IDs at process execution time.
If the process being executed is not a NuTCRACKER Platform process, only the standard file descriptors (0, 1, 2 - stdin, stdout, stderr) are available to the new process. However, if that process then invokes a NuTCRACKER Platform process, all inherited file descriptors are available to the grandchild NuTCRACKER Platform process.
You must ensure that any path name arguments you pass to non-NuTCRACKER Platform applications are in Win32 format, as only NuTCRACKER Platform applications recognize the NuTCRACKER Platform format. Refer to Path Names in the Windows Concepts chapter of the PTC MKS Toolkit UNIX to Windows Porting Guide for more information.
Priorities are inherited by new threads in the same way as on UNIX systems. Even the first thread created by a native Win32 process inherits priority in this manner. However, further creation of threads not under control of the NuTCRACKER Platform might revert to THREAD_PRIORITY_NORMAL.
AVAILABILITY
PTC MKS Toolkit for Professional Developers
PTC MKS Toolkit for Enterprise Developers
PTC(), _NutQueryPid(), alarm(), atexit(), chmod(), exit(), fcntl(), fork(), getenv(), getitimer(), getpid(), mmap(), pthread_create(), putenv(), semop(), setlocale(), setpriority(), shmat(), sigaction(), sigpending(), sigprocmask(), times(), umask(), vfork()
PTC MKS Toolkit 10.0 Documentation Build 6.
|
http://www.mkssoftware.com/docs/man3/execl.3.asp
|
CC-MAIN-2015-48
|
refinedweb
| 1,100
| 51.07
|
#include <sys/types.h>
#include <netinet/in.h>
#include <alias.h>
Function prototypes are given in the main body of the text.
A certain amount of flexibility is built into the packet aliasing engine. In the simplest mode of operation, a many-to-one address mapping takes place between the.
struct libalias * LibAliasInit(struct libalias *) This function is used to initialize internal data structures. When called the first time, a NULL pointer should be passed as an argument. The following mode bits are always set after calling LibAliasInit(). See the description of LibAliasSetMode() below for the meaning of these mode bits. function should be called when a program stops using the aliasing engine; amongst other things, it clears out any firewall has not been LibAliasSetMode(struct libalias *, unsigned int flags, unsigned int mask) This function sets or clears mode bits according to the value of flags. Only bits marked in mask are affected. The following mode bits are defined in <alias.h>:
void LibAliasSetFWBase(struct libalias *, unsigned int base, unsigned int num) Set the firewall range allocated for punching firewall holes (with the PKT_ALIAS_PUNCH_FW flag). The range is cleared for all rules on initialization.
void LibAliasSkinnyPort(struct libalias *,.
Along with LibAliasInit() and LibAliasSetAddress(), the two packet handling functions, LibAliasIn() and LibAliasOut(), comprise the minimal set of functions needed for a basic IP masquerading implementation.
int LibAliasIn(struct libalias *, char *buffer, int maxpacketsize) An incoming packet coming from a remote machine to the local network is de-aliased by this function. The IP packet is pointed to by buffer, and maxpacketsize indicates the size of the data structure containing the packet and should be at least as large as the actual packet size.
Return codes:
int LibAliasOut(struct libalias *, char *buffer, int maxpacketsize) An outgoing packet coming from the local network to a remote machine is aliased by this function. The IP packet is pointed to by buffer, and.
Return codes:
struct alias_link * LibAliasRedirectPort(struct libalias *, LibAliasSetAddress() is to be used. Even if LibAliasSetAddress() is called to change the address after LibAliasRedirectPort() is called, a zero reference will track this change.
If the link is further set up to operate. The remote port specification will almost always internally readable numbers to network byte order. Addresses are also in network byte order, which is implicit in the use of the struct, in_addr data type.
struct alias_link * LibAliasRedirectAddr(struct libalias *, LibAliasSetAddress() is to be used. Even if LibAliasSetAddress() is called to change the address after LibAliasRedirectAddr() is called, a zero reference will track this change.
If the link is further set up to operate with load sharing, then the local_addr argument is ignored, and is selected dynamically from the server pool, as described in LibAliasAddServer() below.
If subsequent calls to Lib: *, the server pool, using a real-time load sharing algorithm. Multiple sessions may be initiated from the same client, and each session could be directed to a different host based on the load balance across server pool hosts when the sessions are initiated. If load sharing is desired for just a few specific services, the configuration on LSNAT could be defined to restrict load sharing multiple times to add entries to the link, Ns, partially functions. If an invalid pointer is passed to LibAliasRedirectDelete(), then a program crash or unpredictable operation could result, so care is needed when will.
Outgoing fragments are handled within LibAliasOut() by changing the address according to any applicable mapping set by LibAliasRedirectAddr(), or the default aliasing address set by Lib LibAliasSaveFragment(struct libalias *, char *ptr) When LibAliasIn() returns PKT_ALIAS_UNRESOLVED_FRAGMENT, this function can be used to save the pointer to the unresolved fragment.
It is implicitly assumed that ptr points to a block of memory allocated *.
void LibAliasSetTarget(struct libalias *, struct in_addr addr) When an incoming packet not associated with any pre-existing aliasing link arrives at the host machine, it will be sent to the address indicated by a call to LibAliasSetTarget().
If this function is called with an INADDR_NONE address argument, then all new incoming packets go to the address set by Lib LibAliasCheckNewLink(struct libalias *) This function returns a non-zero value when a new aliasing link is created. In circumstances where incoming traffic is being sequentially elsewhere, LibAliasInternetChecksum() will return zero.
int LibAliasUnaliasOut(struct libalias *, (e.g. logging)..
(local addr, alias addr)
Address mappings are searched when creating new dynamic links..
To add support for a new protocol, load the corresponding module. For example:
kldload alias_ftp
When support for a protocol is no longer needed, its module can be unloaded:
kldunload alias_ftp
While compiled for a userland libalias, all the modules are plain libraries, residing in /usr/lib, and recognizable with the libalias_ prefix.
There is a configuration file, /etc/libalias.conf, with the following contents (by default):
/usr/lib/libalias_cuseeme.so /usr/lib/libalias_ /usr/lib/libalias_irc.so /usr/lib/libalias_nbt.so /usr/lib/libalias_pptp.so /usr/lib/libalias_skinny.so /usr/lib/libalias_smedia.so
This file contains the paths to the modules that libalias will load. To load/unload a new module, just add its path to libalias.conf and call LibAliasRefreshModules() from the program. In case the application provides a SIGHUP signal handler, add a call to LibAliasRefreshModules() inside the handler, and every time you want to refresh the loaded modules, send it the SIGHUP signal:
kill -HUP <process_pid>
/* Protocol and userland module handlers chains. */ LIST_HEAD(handler_chain, proto_handler) handler_chain ... ... SLIST_HEAD(dll_chain, dll) dll_chain ...
handler_chain keeps track of all the protocol handlers loaded, while ddl_chain tracks which userland modules are loaded.
handler_chain is composed of struct proto_handler entries:
struct proto_handler { u_int pri; int16_t dir; uint8_t proto; int (*fingerprint)(struct libalias *la, struct ip *pip, struct alias_data *ah); int (*protohandler)(struct libalias *la, struct ip *pip, struct alias_data *ah); TAILQ_ENTRY(proto_handler) link; };
where:
The fingerprint function has the dual role of checking if the incoming packet is found, and if it belongs to any categories that this module can handle.
The protohandler function actually manipulates the packet to make libalias correctly NAT it.
When a packet enters libalias, if it meets a module hook, handler_chain is searched to see if there is an handler that matches this type of a packet (it checks protocol and direction of packet). Then, if more than one handler is found, it starts with the module with the lowest priority number: it calls the fingerprint function and interprets the result.
If the result value is equal to 0 then it calls the protocol handler of this handler and returns. Otherwise, it proceeds to the next eligible module until the handler_chain is exhausted.
Inside libalias, the module hook looks like this:
struct alias_data ad = { lnk, &original_address, &alias_address, &alias_port, &ud->uh_sport, /* original source port */ &ud->uh_dport, /* original dest port */ 256 /* maxpacketsize */ };
...
/* walk out chain */ err = find_handler(IN, UDP, la, pip, &ad);
All data useful to a module are gathered together in an alias_data structure, then find_handler() is called. The find_handler() function is responsible for walking the handler chain; it receives as input parameters:
In this case, find_handler() will search only for modules registered for supporting INcoming UDP packets.
As was mentioned earlier, libalias in userland is a bit different, as care must be taken in module handling as well (avoiding duplicate load of modules, avoiding modules with same name, etc.) so dll_chain was introduced.
dll_chain contains a list of all userland libalias modules loaded.
When an application calls LibAliasRefreshModules(), libalias first unloads all the loaded modules, then reloads all the modules listed in /etc/libalias.conf: for every module loaded, a new entry is added to dll_chain.
dll_chain is composed of struct dll entries:
struct dll { /* name of module */ char name[DLL_LEN]; /* * ptr to shared obj obtained through * dlopen() - use this ptr to get access * to any symbols from a loaded module * via dlsym() */ void *handle; struct dll *next; };Whenever a module is loaded in userland, an entry is added to dll_chain, then every protocol handler present in that module is resolved and registered in handler_chain.
struct proto_handler handlers[] = { { .pri = 666, .dir = IN|OUT, .proto = UDP|TCP, .fingerprint = fingerprint, .protohandler= protohandler, }, { EOH } };
The variable handlers is the "most important thing" in a module since it describes the handlers present and lets the outside world use it in an opaque way.
It must ALWAYS be present in every module, and it MUST retain the name handlers, otherwise attempting to load a module in userland will fail and complain about missing symbols: for more information about module load/unload, please refer to LibAliasRefreshModules(), LibAliasLoadModule() and LibAliasUnloadModule() in alias.c.
handlers contains all the proto_handler structures present in a module.
static int mod_handler(module_t mod, int type, void *data) { int error;When running as KLD, mod_handler() registers/deregisters the module using LibAliasAttachHandlers() and LibAliasDetachHandlers(), respectively.
switch (type) { case MOD_LOAD: error = LibAliasAttachHandlers(handlers); break; case MOD_UNLOAD: error = LibAliasDetachHandlers(handlers); break; default: error = EINVAL; } return (error); }
Every module must contain at least 2 functions: one fingerprint function and a protocol handler function.
#ifdef _KERNEL static #endif int fingerprint(struct libalias *la, struct ip *pip, struct alias_data *ah) {and they must accept exactly these input parameters.
... }
#ifdef _KERNEL static #endif int protohandler(struct libalias *la, struct ip *pip, struct alias_data *ah) {
... }
#include <signal.h>
and this just after the header section:
static void signal_handler(int);
signal(SIGHUP, signal_handler);
and place the signal_handler() function somewhere in main.c:
static void signal_handler(int sig) {
LibAliasRefreshModules(); }
Otherwise, if an application already traps the SIGHUP signal, just add a call to LibAliasRefreshModules() in the signal handler function.
LibAliasRefreshModules()
recompile and you are done.
struct libalias { ...so all applications using libalias will be able to handle their own logs, if they want, accessing logDesc. Moreover, every change to a log buffer is automatically added to syslog(3) with the LOG_SECURITY facility and the LOG_INFO level.
/* log descriptor */ #ifdef KERNEL_LOG char *logDesc; /* * ptr to an auto-malloced * memory buffer when libalias * works as kld */ #else FILE *logDesc; /* * ptr to /var/log/alias.log * when libalias runs as a * userland lib */ #endif
... }
Please direct any comments about this manual page service to Ben Bullock. Privacy policy.
|
https://nxmnpg.lemoda.net/3/libalias
|
CC-MAIN-2019-39
|
refinedweb
| 1,672
| 51.78
|
# Blockchain RSA-based random
There’s a problem we needed to address in the course of developing our games. It’s complicated to generate a random number in a distributed network. Almost all blockchains have already faced this issue. Indeed, in networks where there is no trust between anyone, the creation of a random number solves a wide range of problems.
In this article, we explain how we solved this problem for our games. The first of these was [Waves Xmas Tree](https://2019.wavesplatform.com/).

Initially, we planned to generate a number using information from the blockchain. However, on further investigation, it became clear that the process used to create a number this way could be manipulated. We had to discard this solution.
We came up with a workaround, using a ‘commit-reveal’ scheme. The server proposed a number from 1 to 5, added ‘salt’ to it and hashed the result using the [Keccak function](https://en.wikipedia.org/wiki/SHA-3). The server pre-debugged a smart contract with an already saved number. The result was that the game was effectively reduced to the user guessing the number hidden by the hash.
The player placed their bet and the server sent a hidden number and ‘salt’ to a smart contract. To put it another way, the cards were revealed. Afterwards, the server verified the numbers and decided whether the user had won or lost.
If the server didn’t send the number and ‘salt’ for verification, then the user won. In this case, it was necessary to deploy a smart contract in advance and arrange potential winnings for each game. This was inconvenient, expensive and time-consuming. At that time, though, there was no other secure solution.
Shortly afterwards, the Tradisys team proposed adding the **rsaVerify()** function to the Waves protocol. This checks the validity of an RSA signature based on public and private keys. As a result of our proposal, the function was added.
We built three new games: [Dice Roller](https://www.dappocean.io/dapp/DICES), [Coin Flip](https://www.dappocean.io/dapp/COINFLIP) and [Ride On Waves](https://www.dappocean.io/dapp/WRIDER). In each of them, the new random number technology was implemented. Let’s take a closer look at how it works.

Let’s look at the random number generation first. You can find the smart contract [here](https://wavesexplorer.com/testnet/address/3MrfW5HU9H1r5yAGY5Gzcr1A7ACNPLKsDcC).
Go to the **Script tab** and choose **Decompiled**. You will see the smart contract’s code (or script).

The smart contract code consists of a list of functions. The ones that are @Callable can be run via **Invocation transactions**. We are interested in two of them: **bet** and **withdraw**:
* func bet (playerChoice)
* func withdraw (gameId, rsaSign)
1. The user chooses the range and bet size.

2. The client arranges the bet function. For the image above it would be **bet («50»)**
3. The client sends an Invocation transaction to the smart contract address (broadcast InvocationTx). A transaction as a Call parameter contains the bet function. This means that the Invocation transaction starts the execution of the bet function on the smart contract (choice: String).
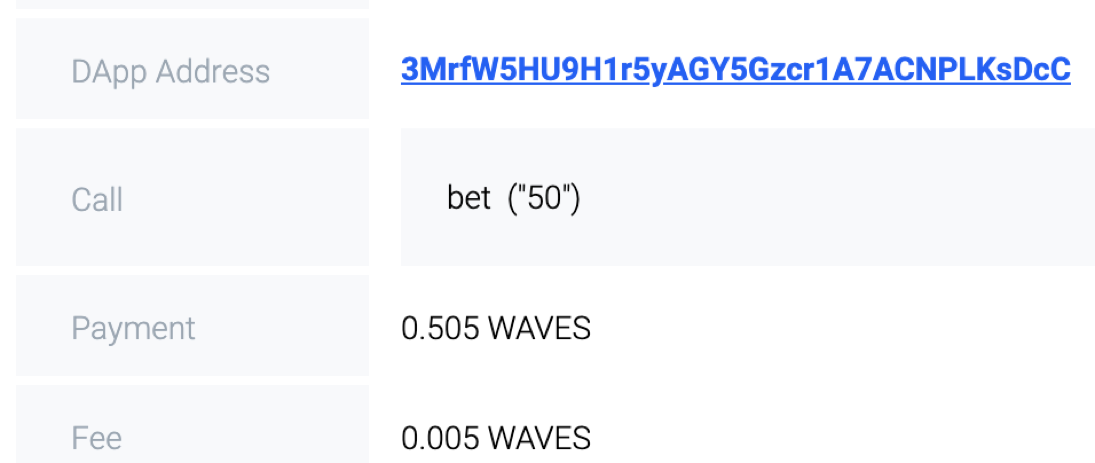
4. Let’s look at the bet function:
```
@Callable(i)
func bet (playerChoice) = {
let newGameNum = IncrementGameNum()
let gameId = toBase58String(i.transactionId)
let pmt = extract(i.payment)
let betNotInWaves = isDefined(pmt.assetId)
let feeNotInWaves = isDefined(pmt.assetId)
let winAmt = ValidateBetAndDefineWinAmt(pmt.amount, playerChoice)
let txIdUsed = isDefined(getString(this, gameId))
if (betNotInWaves)
then throw ("Bet amount must be in Waves")
else if (feeNotInWaves)
then throw ("Transaction's fee must be in Waves")
else if (txIdUsed)
then throw ("Passed txId had been used before. Game aborted.")
else {
let playerPubKey58 = toBase58String(i.callerPublicKey)
let gameDataStr = FormatGameDataStr(STATESUBMITTED, playerChoice, playerPubKey58, height, winAmt, "")
ScriptResult(WriteSet(cons(DataEntry(RESERVATIONKEY, ValidateAndIncreaseReservedAmt(winAmt)), cons(DataEntry(GAMESCOUNTERKEY, newGameNum), cons(DataEntry(gameId, gameDataStr), nil)))), TransferSet(cons(ScriptTransfer(SERVER, COMMISSION, unit), nil)))
}
}
```
The function records a new game in the smart contract state:
* Unique new game id (game id)
* Game state = SUBMITTED
* Player choice (the range is 50)
* Public key
* Potential reward (depends on the player’s bet)
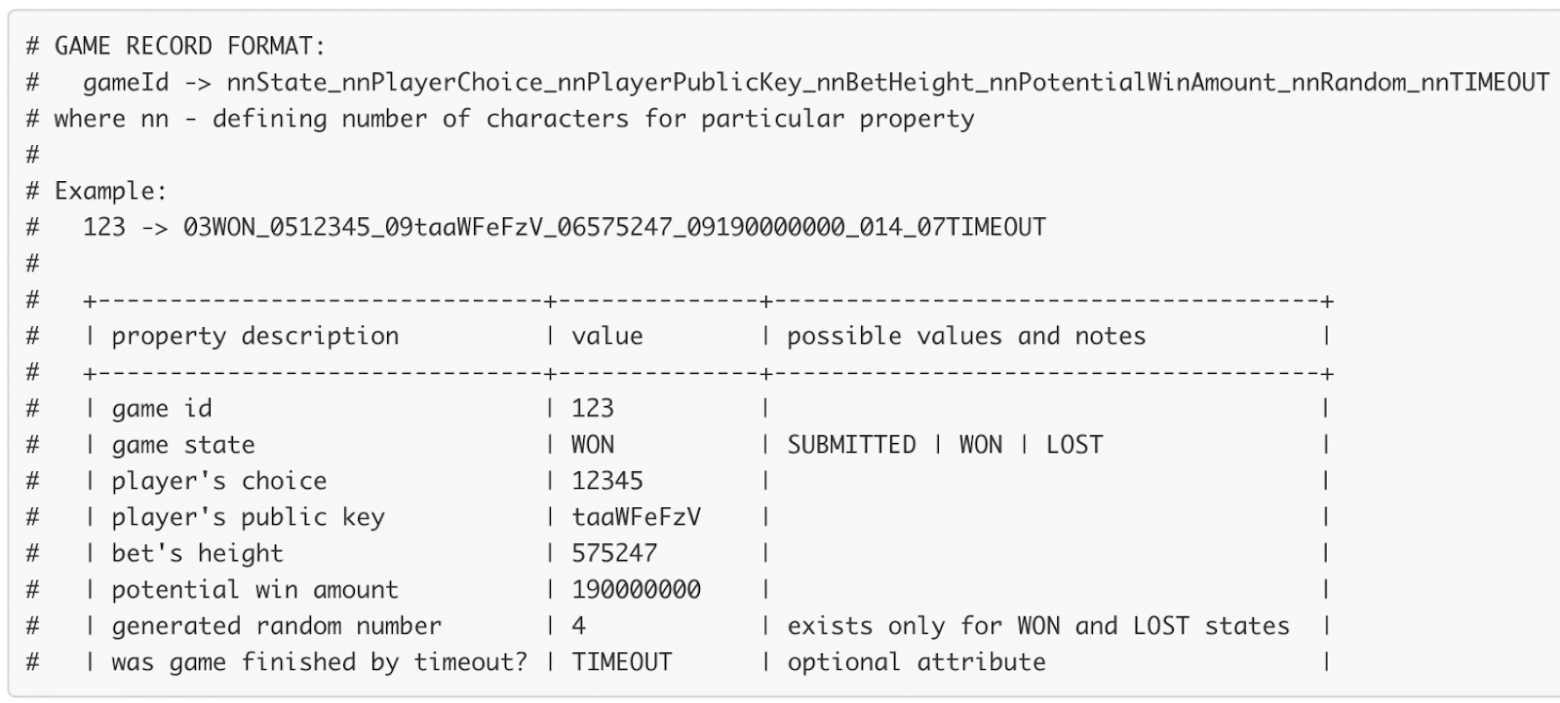
This is how the key-value database looks on the blockchain:
```
{
"type": "string",
"value": "03WON_0283_448t8Jn9P3717UnXFEVD5VWjfeGE5gBNeWg58H2aJeQEgJ_06574069_09116020000_0229",
"key": "2GKTX6NLTgUrE4iy9HtpSSHpZ3G8W4cMfdjyvvnc21dx"
}
```
‘Key’ is the **game id** for a new game. The remaining data is contained in the field ‘value’. These entries are stored in the **Data** tab of the smart contract:


5. The server finds the sent transaction (the new game) via blockchain API. Game id is already recorded in the blockchain, so it’s impossible to change or delete it.
6. The server forms a withdraw function (gameId, rsaSign) such as:
withdraw («FwsuaaShC6DMWdSWQ5osGWtYkVbTEZrsnxqDbVx5oUpq», «base64:Gy69dKdmXUEsAmUrpoWxDLTQOGj5/qO8COA+QjyPVYTAjxXYvEESJbSiCSBRRCOAliqCWwaS161nWqoTL/TltiIvw3nKyd4RJIBNSIgEWGM1tEtNwwnRwSVHs7ToNfZ2Dvk/GgPUqLFDSjnRQpTHdHUPj9mQ8erWw0r6cJXrzfcagKg3yY/0wJ6AyIrflR35mUCK4cO7KumdvC9Mx0hr/ojlHhN732nuG8ps4CUlRw3CkNjNIajBUlyKQwpBKmmiy3yJa/QM5PLxqdppmfFS9y0sxgSlfLOgZ51xRDYuS8NViOA7c1JssH48ZtDbBT5yqzRJXs3RnmZcMDr/q0x6Bg==»)
7. The server sends an Invocation transaction to the smart contract (broadcast InvocationTx). The transaction contains a call to the generated withdraw function (gameId, rsaSign):

The function contains **game id** and an RSA signature of a unique id. The signature result is unchangeable.
*What does this mean?*
We take the same value (game id) and apply the RSA signature method to it. This is how the RSA algorithm works. It’s impossible to manipulate the final number because **game id** and the result of the RSA algorithm are unknown. It’s also pointless to try to guess a number.
8. The blockchain receives a transaction that runs the withdraw function (gameId, rsaSign).
9. There is a call for the GenerateRandIn function inside the withdraw function (gameId, rsaSign). This is a random number generator.
```
# @return 1 ... 100
func GenerateRandInt (gameId,rsaSign) = {
# verify RSA signature to proof random
let rsaSigValid = rsaVerify (SHA256, toBytes(gameId), rsaSign, RSAPUBLIC)
if (rsaSigValid)
then {
let rand = (toInt(sha256(rsaSign)) % 100)
if ((0 > rand))
then ((-1 * rand) + 1)
else (rand + 1)
}
else throw ("Invalid RSA signature")
}
```
**rand** is a random number
Firstly, the string that is a result of the RSA signature is taken. Then, it is hashed via SHA-256 (**sha256(rsaSign)**).
We can’t predict the signature result and subsequent hashing. Thus, it is impossible to affect its generation. To get a number in a specific range (e.g. from 1 to 100), the conversion functions toInt and % 100 ([mod](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BA%D0%BE%D0%BC) analogue) are applied.
At the beginning of the article, we mentioned the **rsaVerify()** function that allows checking of the validity of an RSA signature by a private key against a public one. Here is a part of GenerateRandInt (gameId, rsaSign):
rsaVerify (SHA256, toBytes(gameId), rsaSign, RSAPUBLIC)
To start with, RSAPUBLIC public key and rsaSign string are taken. The signature is checked for validity. If the check is successful, the number is generated. Otherwise, the system considers that the signature is not valid (Invalid RSA signature).
The server has to sign the game id using a private key and send a valid RSA signature within 2,880 blocks. The option is managed while the smart contract is deploying. If nothing happens in the stated time, the user wins. In this case, the reward has to be sent by the user independently. It turns out that cheating is unprofitable for the server because this leads to a loss. There is an example below.

The user plays [Dice Roller](https://www.dappocean.io/dapp/DICES). He chooses 2 of 6 cube faces, with a bet of 14 WAVES. If the server does not send a valid RSA signature to the smart contract within a set time (2,880 blocks), the user will receive 34.44 WAVES.
For number generation, we use an oracle, an external system rather than the blockchain. The server implements an RSA signature for the game id. The smart contract checks signature validity and determines the winner. If the server sends nothing, then the user would win automatically.
This method ensures that manipulation is technically impossible. All Tradisys games are based on the algorithm described above – ensuring our games are fair and transparent. Everything can be publicly audited to ensure honesty.
|
https://habr.com/ru/post/464395/
| null | null | 1,468
| 50.02
|
In this hack I will show you how to add true translucency to your menus with only a slight modification to your program.
Computer interfaces are pretty sophisticated these days. Years ago, we considered ourselves lucky to simply have menu bars at all; now, we need menus with sophisticated effects like animation, shadows, and translucency.
You've already seen how to achieve visual effects by overriding the paint() method of a parent component and then rendering the children into a buffer [Hack #9]. It would be nice to do the same thing here, but there's just one small problem. Overriding the paint() method of the JMenu wouldn't do any good because the JMenu doesn't draw what we think of as a menua list of menu items that pop up when you click on the menu's title. The JMenu actually only draws the title at the top of a menu. The rest of the menu is drawn by a JPopupMenu created as a member of the JMenu. Unfortunately this member is marked private, which means you can't substitute your own JPopupMenu subclass for the standard version.
Fortunately there is a way out. Like all Swing components, the menu components delegate their actual drawing to a separate set of Look and Feel classes in the javax.swing.plaf package. If you override the right plaf classes for the menu items and pop-up menu, then you should be able to create the desired translucent effect. It just takes a little subclassing.
All MenuItems are implemented by some form of the javax.swing.plaf. MenuItemUI class. When creating custom UI classes, it is always best to start by subclassing something in the javax.swing.plaf.basic package (in this case, BasicMenuItemUI) because it handles most of the heavy lifting for you, as shown in Figure.
public class CustomMenuItemUI extends BasicMenuItemUI {
public static ComponentUI createUI(JComponent c) {
return new CustomMenuItemUI();
}
public void paint(Graphics g, JComponent comp) {
// paint to the buffered image
BufferedImage bufimg = new BufferedImage(
comp.getWidth(),
comp.getHeight(),
BufferedImage.TYPE_INT_ARGB);
Graphics2D g2 = bufimg.createGraphics();
// restore the foreground color in case the superclass needs it
g2.setColor(g.getColor());
super.paint(g2,comp);
// do an alpha composite
Graphics2D gx = (Graphics2D) g;
gx.setComposite(AlphaComposite.getInstance(
AlphaComposite.SRC_OVER,0.8f));
gx.drawImage(bufimg,0,0,null);
}
}
No constructor is required because all UI classes have a no-arg constructor automatically. All UI classes also need a static createUI() method to create a new instance of the class, as you can see in the example. In the paint() method, instead of drawing on the graphics object passed in, the code creates a buffered image with the same dimensions as the component, and then calls super.paint(). This will draw the component onto the buffered image instead of the screen. Once the painting is done, it can apply a transform and then draw the image buffer onto the real Graphics. In this case, the transform is an alpha composite of 0.8. This means that instead of drawing the buffer as is, it will draw the buffer partially transparent (80% solid, in this case). This will draw the bufferedimage into the real graphics with a translucent effect. You can vary the strength of the translucency by modifying the second parameter to the AlphaComposite.getInstance() method (1 results in a solid, 0 is totally transparent).
If you stopped with just the custom menu items, the menus would seem a bit translucent, but the rest of the window wouldn't shine through. This is because the menu items are inside of another component; in fact, they're inside of three! The JMenu puts all of the menu items inside of a JPopupMenu, which is placed inside of a JPanel, and then the whole deal is put in a layered pane at the top of the frame. The layered pane is already transparent, so you don't need to worry about it, but the JPanel and JPopupMenu are going to be a problem. Figure handles the custom UI for these.
public class CustomPopupMenuUI extends BasicPopupMenuUI {
public static ComponentUI createUI(JComponent c) {
return new CustomPopupMenuUI();
}
public void installUI(JComponent c) {
super.installUI(c);
popupMenu.setOpaque(false);
}
public Popup getPopup(JPopupMenu popup, int x, int y) {
Popup pp = super.getPopup(popup,x,y);
JPanel panel = (JPanel)popup.getParent();
panel.setOpaque(false);
return pp;
}
}
The custom pop-up menu UI used here is similar to the CustomMenuItemUI (from Figure). It has a static create UI menu and no constructor. The pop-up menu is already stored as a protected member of the BasicPopupMenuUI parent class, so I can access it easily. The installUI() method is called right after the JPopupMenu is created, so this is the best place to put a call to setOpaque(false). For most L&Fs, this will make the component transparent.
That takes care of the pop-up menu, but what about the parent JPanel? The JPanel is created and initialized deep within the javax.swing.PopupFactory class, so it's pretty well out of reach. This is one place where having access to the JRE source code is invaluable. Without that, this entire hack would have been impossible to figure out. Fortunately, we have access to the finished JPopupMenu from within the getPopup method. I overrode that to call the superclass and then grab the newly minted parent of the pop-up menu and cast it to a JPanel. Now, I can finally set it to be transparent, too.
With your two custom UI classes in place, test them out with Figure, which shows a frame containing two sets of menus and a few components. Before creating any components, the program installed the custom UI classes with two calls to UIManager.put().
Any time you want to override part of a L&F, you can use UIManager.put().
public class MenuTest {
public static void main(String[] args) throws Exception {
UIManager.put("PopupMenuUI","CustomPopupMenuUI");
UIManager.put("MenuItemUI","CustomMenuItemUI");
JFrame frame = new JFrame();
JMenuBar mb = new JMenuBar();
frame.setJMenuBar(mb);
JMenu menu = new JMenu("File");
mb.add(menu);
menu.add(new JMenuItem("Open"));
menu.add(new JMenuItem("Save"));
menu.add(new JMenuItem("Close"));
menu.add(new JMenuItem("Exit"));
menu = new JMenu("Edit");
mb.add(menu);
menu.add(new JMenuItem("Cut"));
menu.add(new JMenuItem("Copy"));
menu.add(new JMenuItem("Paste"));
menu.add(new JMenuItem("Paste Special.."));
frame.getContentPane().setLayout(new BorderLayout());
frame.getContentPane().add("North",new JButton("Button"));
frame.getContentPane().add("Center",new JLabel("a label"));
frame.getContentPane().add("South",new JCheckBox("checkbox"));
frame.pack();
frame.setSize(200,150);
frame.show();
}
}
With all of the code in place, you can compile it and get something that looks like Figure.
One bug you will notice is that after you open the menu and start moving the cursor between menu items, the background won't shine through anymore. This is because Swing, in an effort to speed up the UI, only repaints the parts it knows have changed. It repaints the menu item, but not the frame contents below (the button and label, in this case) because it thinks they are obscured by the menu item. Of course, the menu item is translucent, so the components should shine through, but Swing doesn't know that. To fix the problem, you'll need to develop a full repaint manager [Hack #53] that will force Swing to always repaint the entire component tree, instead of just the menu items. It's a bit slower, but worth it if you really want this effect:
UIManager.put("MenuItemUI","CustomMenuItemUI");
RepaintManager.setCurrentManager(new FullRepaintManager());
One more bug is that the menu must fit within the frame. There are two kinds of menus in Swing: heavyweight and lightweight. Lightweight menus are normal Swing components. Heavyweight menus, on the other hand, are drawn in their own top-level window. This means that there are two windows being drawn: one for the real frame and one for the menu. If you use heavyweight menus, the effect will stop completely because the windows themselves can't be transparent. Normally, Swing will use lightweight menus, but if the menu has to be drawn outside of the framewhich can happen if you have a small window or a really large menuthen it will switch to heavyweight menus automatically and nothing can switch it back until the application restarts. This means you should always make sure your menus fit inside of your windows.
This hack shows just one example of how you can completely change a component's behavior by customizing its Look and Feel class. Java2D gives you the power to create a wide variety of graphical hacks. As an extension of this technique, you could try blurring the components underneath the menu or create a properly smoothed drop
|
http://codeidol.com/community/java/add-translucence-to-menus/12897/
|
CC-MAIN-2017-39
|
refinedweb
| 1,462
| 56.15
|
Summary: Learn how to use the XmlFormView ASP.NET control, together with InfoPath Forms Services, to create custom Web pages to render browser-enabled, interactive InfoPath forms. (21 printed pages)
Mike Talley, Microsoft Corporation
Namita Sheokand, Microsoft Corporation
Published: June 2006
Updated: April 2007
Applies to: Microsoft Office InfoPath 2007, Microsoft Office SharePoint Server 2007
Contents
Overview of the XmlFormView Control
Creating Custom Web Pages in SharePoint Server
Coding with the XmlFormView Control
Deploying Custom Web Pages to a Non-Root SharePoint Site
Recommended Development and Deployment Practices
Considerations When Using the XmlFormView Control
Conclusion
Additional Resources
A browser-enabled InfoPath form template is functionally equivalent to a form designed to run in Microsoft Office InfoPath 2007, but when it is published to and opened from a server running InfoPath Forms Services, it does not require Office InfoPath 2007 to be installed on the computer that uses the form. InfoPath Forms Services, as part of either Microsoft Office Forms Server 2007 or Microsoft Office SharePoint Server 2007, includes the XmlFormView ASP.NET control, which you can use to render a browser-enabled form in a custom Web page. The XmlFormView control benefits enterprises that want to incorporate the functionality of InfoPath forms into their organizational Web infrastructure.
Because InfoPath Forms Services is an extension to Windows SharePoint Services 3.0, the steps to open, configure, and add the XmlFormView control to a new Web page require common SharePoint Server development techniques, such as using the Internet Information Services (IIS) Manager to find the path of the SharePoint site, opening the site in Microsoft Visual Studio 2005, and configuring the Web configuration file for debugging.
This article describes the following tasks:
Creating a new Web page on a SharePoint server and adding the XmlFormView control to the page.
Creating and publishing a browser-enabled form template.
Writing code to control the XmlFormView control.
Deploying a custom Web page by using a SharePoint Server feature package.
Requirements
To complete the tasks in this article, you must have the following applications installed on your computer:
Microsoft Office InfoPath 2007
Microsoft Office SharePoint Server 2007 or Microsoft Office Forms Server 2007
Microsoft Visual Studio 2005
This section contains the following four tasks, which are required to create a custom Web page managed by Windows SharePoint Services.
Opening the SharePoint site and creating a Web page
Setting page properties and adding the XmlFormView control
Configuring SharePoint Server and resetting IIS
Debugging the custom Web page
Each procedure in this section builds on the previous procedure, so it is important that you do them in order.
Visual Studio 2005 must be installed on the server running InfoPath Forms Services.
The following procedure creates the custom Web page at port 80 using the root site collection. Although port 80 is the default site collection of a SharePoint server, you can use any SharePoint site and are not limited to using the root site collection.
For information about how to deploy a custom Web page to a site other than the root site collection, see Deploying a Custom Web Page to a Non-Root SharePoint Site.
Click Start, click Administrative Tools, and then click Internet Information Services (IIS) Manager.
Click the plus sign (+) next to ServerName (local computer) (where ServerName is the name of your server), to expand the list of IIS services available on the server.
Expand Web sites to show the list of Web sites that are managed by IIS.
Right-click SharePoint - 80, and then click Properties.
On the ASP.NET tab of the SharePoint - 80 Properties dialog box, highlight and copy the text in the File location box, without copying the web.config that may appear at the end of the File location string. This string typically looks like one of the following paths:
C:\Inetpub\wwwroot\wss\VirtualDirectories\80
C:\Inetpub\wwwroot\wss\VirtualDirectories\GUID
Start Visual Studio 2005.
On the File menu, click Open, and then click Web Site.
Click File System, and in the Folder box, paste the file location path you copied (see Figure 1), and then click Open.
Right-click the path of the Web site in Solution Explorer and select New Folder.
Type a name for the folder, such as XmlFormView.
Right-click the new folder and select Add New Item. The default template, Web Form, should be selected.
Type a name for the new Web form a name, such as MyCustomPage, and select Visual C# as the Language.
Select Place code in separate file, and then click Add.
All custom Web pages that include the XmlFormView control require the page to have session state enabled and other default options either removed or modified. Follow these steps to set up the page to host the XmlFormView control, add the XmlFormView control to the Visual Studio Toolbox, and then add it to the Web page.
In the Document Properties for the new Web form, click True for the EnableSessionState property.
Click Source in the lower-left corner to view the page in source mode.
Remove the default Doctype declaration tag. This tag begins with <!DOCTYPE html PUBLIC.
<!DOCTYPE html PUBLIC
Modify the Body tag to contain the following style attribute:
style="margin: 0px;overflow:auto;padding:20px"
Modify the Form tag to contain the following enctype attribute:
enctype
enctype="multipart/form-data"
The encoding type (enctype) attribute is necessary only if you intend to use the File Attachment control in a form loaded into the XmlFormView control. If this attribute is not set correctly, the File Attachment control will appear to function but will not upload a file to the server that is running InfoPath Forms Services.
When you are finished, your page should look similar to the following:
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="MyCustomPage.aspx.cs" Inherits="CustomPage_MyCustomPage" EnableSessionState="True" %>
<html >
<head runat="server">
<title>Untitled Page</title>
</head>
<body style="margin: 0px;overflow:auto;padding:20px">
<form id="form1" runat="server" enctype="multipart/form-data">
<div>
</div>
</form>
</body>
</html>
Click Design in the lower-left corner to view the page in design mode.
Expand the Toolbox, usually located on the left side in Visual Studio, and add the XmlFormView control to the General section:
In the Toolbox, collapse the Standard section and expand the General section.
Right-click underneath the General title and select Choose Items.
In the Choose Toolbox Items dialog box, on the .NET Framework Components tab, select XmlFormView, and then click OK.
If you do not see XmlFormView, click Browse and locate the Microsoft.Office.InfoPath.Server.dll assembly. It is typically located at Drive:\Program Files\Microsoft Office Servers\12.0\Bin, where Drive is the location where Office Forms Server 2007 or Office SharePoint Server 2007 is installed.
Select the Microsoft.Office.InfoPath.Server.dll assembly, and then click OK.
In the Choose Toolbox Items dialog box, select XmlFormView, and then click OK.
In the General section of the Toolbox, drag the XmlFormView control to the new page. Then your new page should look similar to Figure 2.
Select the XmlFormView1 control on the page.
In the Data Binding section of the control's property sheet, paste the URL to browser-enabled form template in the XsnLocation property of the control.
For information about how to create and publish a browser-enabled form template to use for this value, see Loading a Browser-enabled InfoPath Form Templates into the Control.
Save the new Web form.
Before you can successfully debug your custom Web page in Visual Studio, you must use the Start Options command on the Website menu to specify the URL to the page on the SharePoint site. Then you save the Visual Studio solution, and reset the IIS service so that SharePoint Server will recognize your changes.
In Visual Studio, on the Website menu, click Start Options.
In the Start action section, click Start URL, and then type the URL to your custom page, for example:
Where ServerName is the name of your server, XmlFormView is the name of the folder that you created in Visual Studio, and MyCustomPage is the name that you used to save the Web form page.
Click OK.
On the File menu, click Save All, and give the solution a name and location.
Click Start, click All Programs, click Microsoft Visual Studio 2005, click Visual Studio Tools, and then open a Visual Studio 2005 Command Prompt window.
At the command prompt, type iisreset and press ENTER.
After Internet services successfully restarted appears, close the Visual Studio 2005 Command Prompt window.
To debug the custom Web page, you must modify the Web options for the SharePoint site, contained in the web.config file. The following procedure automatically adds this flag to the web.config file.
Save the custom Web page.
Press F5 to start debugging.
If you receive a message that states the web.config file not being configured for debugging, click OK. This automatically adds the debug flag to the web.config file.
If you do not have a browser-enabled form template to test the XmlFormView1 control, use the following procedures to create and publish a basic browser-enabled form template.
This section shows how to create a browser-enabled form template and publish it to a SharePoint site.
The XsnLocation property of an XmlFormView control must point to a form template published on the server. The form template must be browser-enabled, and it must reside in the same site collection as the custom Web form.
The easiest way to create a form template that can be displayed in an XmlFormView control is to create a new blank form template that is compatible with InfoPath and InfoPath Forms Services. A form template that is compatible with InfoPath and InfoPath Forms Services is known as a browser-compatible form template. A form template that is published to a server that is running InfoPath Forms Services is known as a browser-enabled form template.
Some controls, structures, and data connections that are available in standard form templates are not available in Web-compatible form templates. Exceptions such as these to the Design Once feature set of Office InfoPath 2007 can be displayed in the Design Checker task pane when the form template's compatibility setting is InfoPath and InfoPath Forms Services. For more information about the features that work with InfoPath Forms Services, see Introduction to browser-compatible form templates.
Open Office InfoPath 2007 and, in the Getting Started dialog box, click Design a Form Template.
In the Design a Form Template dialog box, click Form Template, click Blank, and then click Enable browser-compatible features only, as shown in Figure 3.
In the task pane, click Controls.
Add a Date Picker control to the form.
Right-click the Date Picker and select Date Picker Properties.
Click the function button to the right of the Value box.
In the Insert Formula dialog box, click Insert Function.
Click the today function, and then click OK.
Click OK two more times to close all dialog boxes. This inserts the current date in the Date Picker control when the form is opened.
Add an Optional Section to the form.
Right-click the Optional Section and select Section Properties.
On the Data tab, click Include the section in the form by default.
On the Display tab, click Conditional Formatting.
In the Conditional Format dialog box, click Add.
Confirm that the first drop-down box contains field1, the field bound to the Date Picker control. Otherwise, change it to field1.
In the third box under If this condition is true, click the drop-down list and select Use a formula.
Click the today function, click OK, and then click OK again.
In the Conditional Format dialog box, open the Shading drop-down list and select a color, and then click OK.
Repeat steps 15 through 19, and select a different color to use when field1 is later than today's date, and for when field1 is earlier than today's date.
Use the second drop-down list to specify is greater than and is less than operations. This provides some interactivity so that you know the form is working in the XmlFormView control.
When you are finished, click OK in the Conditional Format dialog box, and then click OK to dismiss the Section Properties dialog box.
The final form will look similar to Figure 4.
On the File menu, click Save, and save the form template to the local hard disk.
On the File menu, click Publish.
In the Publishing Wizard dialog box, select To a SharePoint server with or without InfoPath Forms Services, and then click Next.
Type the URL of your server that is running InfoPath Forms Services.
Because the form template and the custom Web page must be located in the same site collection, publish the form template to the root site collection by entering, where ServerName is the name of the server that is running InfoPath Forms Services.
Select Enable this form to be filled out by using a browser, select Document library, and then click Next.
Click Create a new document library, and then click Next.
Type a name for the new document library, and then click Next.
Click Next to skip adding columns to the document library.
Click Publish.
After the form template is published, click Open this form in the browser in the Publishing Wizard dialog box.
In the Address bar in Microsoft Internet Explorer, copy the XsnLocation portion of the URL, starting after the equal sign (=) with "http" and ending with ".xsn", and then close the browser window.
In the Publishing Wizard dialog box, click Close.
After you create and publish your form template, you can use various methods to control the behavior of the XmlFormView control, such as changing the editing state, controlling whether the header and footer toolbars are visible, and controlling where the completed form is saved. You can control these options programmatically, or you can control them declaratively by setting properties in the Visual Studio user interface (UI). This section includes an example of changing the EditingStatus property.
You may also want to pass values from the Web page to the XmlFormView control, or pass values from the XmlFormView control to the Web page. Examples are provided for doing these tasks programmatically.
If you do not want the form to be displayed when the Web page loads, set the EditingStatus property of the XmlFormView control to Init. You can do this either in the properties of the XmlFormControl1 control or in the tag of the control instance in the source page, which would look similar to the following example.
<cc1:XmlFormView
In this control tag, ~sitecollection is used as a SharePoint variable to facilitate deploying the custom Web page to multiple site collections. If you do not need to deploy the custom Web page to multiple site collections, you can just enter the fully qualified URL. For more information about deploying a custom Web page to a site collection, see Deploying a Custom Web Page to a Non-Root SharePoint Site later in this article.
You can programmatically change the EditingStatus property of the form to XmlFormView.EditingStatus.Editing to initialize and render the form template in the XmlFormView1 control after the user performs some action on the Web page, such as clicking a button in the page. The following example, which assumes you have added a using Microsoft.Office.InfoPath.Server.Controls; directive to the top of the code-behind page, shows how to do this.
protected void Button1_Click(object sender, EventArgs e)
{
XmlFormView1.EditingStatus = XmlFormView.EditingStatus.Editing;
}
When the EditingStatus property is set to XmlFormView.EditingState.Init, the XmlForm property of the XmlFormView control cannot access the XmlForm class and any of its associated functionality. For example, the MainDataSource property is not available and you cannot work with the form's underlying XML data. Before you can access the XmlForm class using the XmlForm property, the EditingStatus property must be set to XmlFormView.EditingState.Editing.
For code in the page to be able to set the value of a field in the InfoPath form, it must be within an appropriate event handler. The XmlForm property of the XmlFormView control, which provides access to the XmlForm class and its MainDataSource property for working with the underlying XML data of the form, can only be accessed during one of the following events:
Initialize
NotifyHost
SubmitToHost
The Initialize event is executed whenever an InfoPath form is loaded into the XmlFormView control. This occurs when the Web page is first loaded, when the XsnLocation or XmlLocation properties of the XmlFormView control are set to point to a different form template or form, and when the EditingStatus property is modified from XmlFormView.EditingState.Init to XmlFormView.EditingState.Editing.
If the code is in an event handler of another control on the page, such as the System.Web.UI.WebControls.Button.Click handler of a button, the code must first call the inherited System.Web.UI.WebControls.WebParts.Part.DataBind method of the XmlFormView control before accessing the data of the form, as shown in the following example. This example assumes you have added using System.Xml; and using System.Xml.XPath; directives to the top of the code-behind page, and that you have an ASP.NET TextBox control on the page named TextBox1 to receive the data.
protected void Button2_Click(object sender, EventArgs e)
{
// XmlFormView control's DataBind method to bind to
// its data source.
XmlFormView1.DataBind();
//", XmlFormView1.XmlForm.NamespaceManager.
LookupNamespace("my").ToString());
// Set TextBox1 on the page to the value in the form's field2.
TextBox1.Text = xNavMain.SelectSingleNode(
"/my:myFields/my:field2", xNameSpace).ToString();
}
The following procedure sets the value of field2 in the form to the value in the TextBox1 control on the Web page whenever the Initialize event handler of the XmlFormView control executes. This example requires that you add a Text Box control to both the Web page and the InfoPath browser-enabled form template rendered in the XmlFormView control.
In the Design view of your Web page, add a TextBox control to the page. In InfoPath design mode, add a Text Box control to your form template and republish it to the document library on the SharePoint site.
Switch to the Source view of your Web page and locate the tag for the XmlFormView1 control. It should look similar to the following example.
<cc1:XmlFormView
ServerName and DocumentLibrary correspond to the name of your server that is running InfoPath Forms Services and the name of the document library where your form template is published.
Declare the name of the Initialize event handler in the XmlFormView1 control tag:
<cc1:XmlFormView
Alternatively, you can double-click the blank text box next to this event in the Properties Windows when the XmlFormView1 control is selected.
Right-click inside the Web page Source window, and then click View Code. This opens a new code-behind window.
Add the following using statements.
using System.Xml;
using System.Xml.XPath;
In the same window, add the code for the Initialize event handler.
protected void XmlFormView1_Initialize(object sender,
Initialize the form's field2 to the value in TextBox1.
fTextBox1.SetValue(TextBox1.Text);
}
In the call to the System.Xml.XmlNamespaceManager.AddNamespace method, substitute the correct XML namespace with that of the form template you are loading.
To get the value of the namespace, open the form template in Design mode, display the Data Source task pane, right-click myFields, click Properties, and then click Details.
In the call to the System.Xml.XPath.XPathNavigator.SelectSingleNode method, change the XPath expression to select the field in the example, "my:myFields/my:field2", to the expression for the field in your form that you want to populate with the value from the text box in the Web page.
"my:myFields/my:field2"
To copy the XPath expression to select any field or group in the form's data source to the clipboard, right-click the field or group in the Data Source task pane, and then click Copy XPath.
Office InfoPath 2007 provides a new kind of data connection for submitting data from a form based on a form template that is hosted in another environment back to the hosting environment, which in this case is to the custom Web page that contains the XmlFormView control. This new data connection, called the SubmitToHostAdapter, has the corresponding manifest.xsf entry in the form definition file (.xsf).
<xsf:submitToHostAdapter</xsf:submitToHostAdapter>
The following procedure sets the value of field2 in the form to the value in the TextBox1 control on the Web page whenever the SubmitToHost event handler of the XmlFormView control executes. This occurs when the user clicks the Submit button on the toolbar.
Follow these steps to create a SubmitToHostAdapter data connection in a form template that is hosted in a custom Web page.
Open the InfoPath form template in design mode.
On the Tools menu, click Data Connections.
Click Add.
In the Data Connection Wizard, click Create a new connection to and Submit data, and then click Next.
Select To the hosting environment, such as an ASP.NET page or a hosting application, as shown in Figure 5, and then click Next.
Type a name for the new data connection, and then click Finish.
After you create the new SubmitToHostAdapter data connection, enable the form to submit its XML data to the hosting environment by following these steps:
On the Tools menu, click Submit Options.
Select Allow users to submit this form.
In the first drop-down list, select Hosting environment, and in the second list, select the name you gave to the data connection.
It should look similar to Figure 6.
Republish the form template to the same document library on the SharePoint server, or create a new document library.
After you republish the form template, you must create an event handler for the SubmitToHost event of the XmlFormView control in your custom Web page. To do this, follow these steps:
Switch to the Source view of your Web page and locate the tag for XmlFormView1. It should look similar to the following example.
<cc1:XmlFormView
ServerName and DocumentLibrary correspond to the name of the server that is running InfoPath Forms Services and your document library name.
Declare the name of the SubmitToHost event handler in the XmlFormView1 control tag.
<cc1:XmlFormView
Right-click inside the Web page Source window, and then click View Code. This opens the code-behind window. In this window, add the following SubmitToHost code.
protected void XmlFormView1_SubmitToHost(object sender,
SubmitToHost TextBox1 on the page to the value in the form's field2.
TextBox1.Text = xNavMain.SelectSingleNode(
"/my:myFields/my:field2", xNameSpace).ToString();
}
Substitute the correct XML namespace with that of the form template you are loading into the XmlFormView control, and change the XPath of the field in the example, "my:myFields/my:field2", to the XPath of the field in your form that will be used to populate the Text Box control on the Web page.
"my:myFields/my:field2"
When the form is submitted, TextBox1 will be set to the value in my:field2.
my:field2
An alternative method of passing a value from the form to the Web page is to use the NotifyHost event handler and the value passed to the Notification property by the NotifyHost method of the XmlForm class in the form template's business logic code, rather than the SubmitToHost event handler, which is triggered by submitting the form. Note that using the NotifyHost event handler means that the XML data is not validated before making the form data available to the Web page.
The following example contains the complete code for the code-behind Microsoft.Office.InfoPath.Server.Controls;
using System.Xml;
using System.Xml.XPath;
public partial class XmlFormView_MyPage : System.Web.UI.Page
{
protected void Button1_Click(object sender, EventArgs e)
{
XmlFormView1.EditingStatus = XmlFormView.EditingState.Editing;
}
protected void Button2_Click(object sender, EventArgs e)
{
XmlFormView1.DataBind();
XPathNavigator xNavMain =
XmlFormView1.XmlForm.MainDataSource.CreateNavigator();
XmlNamespaceManager xNameSpace =
new XmlNamespaceManager(new NameTable());
xNameSpace.AddNamespace("my",XmlFormView1.XmlForm.
NamespaceManager.LookupNamespace("my").ToString());
TextBox1.Text = xNavMain.SelectSingleNode(
"/my:myFields/my:field2",xNameSpace).ToString() ;
}
protected void XmlFormView1_Initialize(object sender,
Initialize = xNavMain.SelectSingleNode(
"/my:myFields/my:field2", xNameSpace2);
fTextBox.SetValue(TextBox1.Text);
}
protected void XmlFormView1_SubmitToHost(object sender,
SubmitToHost1 = xNavMain.SelectSingleNode(
"my:myFields/my:field2", xNameSpace);
TextBox1.Text = xNavMain.SelectSingleNode(
"/my:myFields/my:field2", xNameSpace).ToString();
}
}
When you create a custom Web page as described earlier in this article, the .aspx page can belong only to the root site collection of the SharePoint server. To create a page under a non-root site collection, you must deploy the custom Web page as a SharePoint feature. A SharePoint feature is a package of Windows SharePoint Services elements that can be activated for a specific scope to perform a particular goal or task.
A SharePoint feature requires two simple XML files and is deployed using the stsadm.exe command-line tool on the server, which you can automate by using a batch file.
Create a folder under the local Features folder on your server, typically located at C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\12\TEMPLATE\FEATURES.
Add your custom .aspx page to this folder.
Create the Feature.xml and Module.xml files based on the following examples, and add them to the same location.
Sample Feature.xml
<?xml version="1.0"?>
<Feature Id="8C4DD0CB-5A94-44da-9B7F-E9ED49C2B2DC" Title="Custom Web page"
Description="This simple example feature adds an aspx page with a hosted
XmlFormView control" Version="1.0.0.0" Scope="Web"
xmlns="">
<ElementManifests>
<ElementManifest Location="Module.xml"/>
</ElementManifests>
</Feature>
In the Feature.xml file, set the value of the Id attribute of the Feature element to a GUID generated by using the Create GUID command on the Tools menu in Visual Studio. Alternatively, you can create a simple console application to create a GUID using the following line of C# code:
System.Console.WriteLine(System.Guid.NewGuid().ToString().ToUpper());
You only have to set the Id attribute value one time for a given feature. If you are upgrading an existing feature, you do not have to generate a new GUID for the Id attribute each time you upgrade the feature.
Sample Module.xml
<?xml version="1.0"?>
<Elements xmlns="">
<Module Name="file" Url="" Path="">
<File Url="XmlFormViewPage.aspx" />
</Module>
</Elements>
In the Module.xml file, set the value of the Url attribute of the File element to the name of your .aspx page.
Deploy the feature to SharePoint Server. The command-line syntax to deploy a feature is as follows.
C:\Program Files\Common Files\Microsoft Shared\Web Server
Extensions\12\bin\stsadm -o installfeature –filename
FeatureFolderName\Feature.xml
Activate the feature on a SharePoint site collection. The command-line syntax to activate a feature is as follows.
C:\Program Files\Common Files\Microsoft Shared\Web Server
Extensions\12\bin\stsadm -o activatefeature –filename
FeatureFolderName\Feature.xml -url
Replace ServerName and SiteCollection with the actual names of your SharePoint server and the site collection name to which the feature will be activated. You can create a batch file and run these command lines sequentially.
Instead of using a fully-qualified server name, you can use the ~sitecollection.
In a real-world scenario, a custom Web page that contains an XmlFormView control is not located on the root site of a SharePoint server. However, the recommended method of developing a custom Web page is from the root site of the SharePoint server as shown in this article. When the Web page is ready to be deployed, a custom feature package can be used to deploy the Web page to a site collection as described in the section Deploying a Custom Web Page to a Non-Root SharePoint Site.
When you are deploying to a site collection, replace all fully-qualified URLs with tokenized URLs that will function in the site collection. For example, an XsnLocation parameter references a form template in the following location.
XsnLocation=""
When the Web page is deployed to a site collection, the ~sitecollection token is substituted for the ServerName and SiteCollectionName values.
XsnLocation="~sitecollection/DocumentLibraryName/Forms/template.xsn"
Consider the following issues when you are using the XmlFormView control in a custom Web page.
Only one XmlFormView control can be added per Web form (.aspx page).
For security reasons, the XsnLocation, XmlLocation, and SaveLocation properties of the XmlFormView control must specify locations in the same site collection as the custom page. For the example custom page created using the procedure described earlier, the value specified for the XsnLocation property is in the root site collection on the SharePoint server.
InfoPath Forms Services, as part of either Microsoft Office Forms Server 2007 or Microsoft Office SharePoint Server 2007, is required in order to render the form inside the XmlFormView control.
The custom Web page containing the XmlFormView control should be located in the same IIS Web application as SharePoint Server. For more information about using a different Web application, see the InfoPath Team Blog entry Forms Services and multiple IIS Web Applications.
You can use the XmlFormView control to provide interactive InfoPath forms to users in a custom Web page that does not require the InfoPath 2007 client to be installed on the user's computer. The XmlFormView control is present on servers running InfoPath Forms Services, as part of either Microsoft Office Forms Server 2007 or Microsoft Office SharePoint Server 2007. The various properties, methods, and events of the control enable you to seamlessly integrate InfoPath forms into an existing Web infrastructure.
For more information about developing with InfoPath, see the following resources:
InfoPath Developer Portal
Information about InfoPath developer resources.
Microsoft Office InfoPath Home Page
Office Online site that provides information about InfoPath form design, declarative logic, and other features available through the InfoPath user interface.
Microsoft Office Forms Server TechCenter
Information on TechNet about planning for and managing a server that is running InfoPath Forms Services.
Microsoft Office Forms Server 2007 SDK
Information about developing applications for InfoPath Forms Services, which is available as part of either Microsoft Office Forms Server 2007 or Microsoft Office SharePoint Server 2007.
InfoPath Developer Reference for Managed Code
Information about developing form templates and applications for Office InfoPath 2007 using managed code.
The following entry has to be added to the web.config to use the XmlFormView control:
<SafeControl Assembly="Microsoft.Office.InfoPath.Server, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" Namespace="Microsoft.Office.InfoPath.Server.Controls" TypeName="*" />
If you get the nasty error "The type 'Microsoft.Office.InfoPath.XmlForm' is defined in an assembly that is not referenced." when trying to view the page in a browser, ensure you have the following lines in the web.config file of the SharePoint web application
------web.config------------
<compilation batch="false" debug="false"> <assemblies> ...
...
<add assembly="Microsoft.Office.InfoPath.Server, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71E9BCE111E9429C" /> <add assembly="Microsoft.Office.InfoPath, Version=12.0.0.0, Culture=neutral, PublicKeyToken=71E9BCE111E9429C" /> </assemblies>
--------web.config---------------------
|
http://msdn.microsoft.com/en-us/aa701078.aspx
|
crawl-002
|
refinedweb
| 5,165
| 54.32
|
I am in a beginning C programming class and I have this assignment: Write a program that creates an N*N magic square, i.e., a square arrangement of the numbers 1,2,�,N^2 in which the sum of rows, columns, and diagonals are the same. The user will specify the size of the square matrix: N. The value N must be an odd number between 1 and 15. I am using visual studio 2010. Also I am only allowed to use C89. My program will not compile and I have been trying to fix my problems, but I still have a few left that I cannot figure out. I understand that my main problem is visual studio doesn't support variable array size so I tried to compensate for this, but clearly I failed. I would really appreciate any help because this program is really frustrating me! Thank you! These are my errors: error C2057: expected constant expression1 error C2466: cannot allocate an array of constant size 0error C2057: expected constant expression error C2466: cannot allocate an array of constant size 0 error C2087: 'magic_square' : missing subscripterror C2133: 'magic_square' : unknown sizeerror C2143: syntax error : missing ';' before ')'error C2143: syntax error : missing ';' before ')'
#include <stdio.h>
#define array_size 15
int main (void)
{
int row, column, row1, column1, size, n = 2, magic_square [array_size][array_size];
for ( ; ; ) {
printf ("Enter size of magic square: ");
scanf ("%d", &size);
if (size % 2 == 0)
printf ("Enter an odd number!\n");
else if (size <= 0 || size > 15)
printf ("Enter a number between 1 and 15!\n");
else {
int magic_square [size][size];
for (row = 0; row < size; row++)
for (column = 0; column < size; column++)
magic_square [row][column] = 0;
row = 0;
column = (size/2);
magic_square [row][column] = 1;
for (n, n<= size*size, n++) {
if (--row < 0)
row = (size -1);
if (++column > size -1)
column = 0;
if (magic_square [row][column] != 0) {
if (++row > (size -1))
row = 0;
if (--column < 0)
column = size - 1;
while (magic_square [row][column] != 0)
if (++row > (size -1))
row = 0;
}
magic_square [row][column] = n;
}
for (row = 0; row < size; row++)
for (column = 0; column < size; column++)
printf ("M\n", magic_square [row][column]);
}
}
return 0;
}
|
http://www.chegg.com/homework-help/questions-and-answers/beginning-c-programming-class-assignment-write-program-creates-n-n-magic-square-e-square-a-q3306706
|
CC-MAIN-2015-32
|
refinedweb
| 359
| 65.46
|
Ok I have tried a few ways to get this loop to terminate before using the ending variable in the function but I cannot seem to figure it out. This is just my latest attempt. I want this program to end when the user enters 0 but it always returns a square root for 0 (which of course is 0) before terminating. Did I really forget how to do this much while on vacation?
Code:#include <iostream> #include <cmath> using namespace std; void wierdsquareroot (double x) { cout << "The square root is " << sqrt(x) << endl; } int main () // Program calculates the square root of a number { double num; do { if (num != 0) { cout << "Enter a number (a double): "; cin >> num; wierdsquareroot (num); } }while (num != 0); }
|
http://cboard.cprogramming.com/cplusplus-programming/131792-function-calling-before-loop-ends.html
|
CC-MAIN-2014-52
|
refinedweb
| 123
| 76.35
|
Table of Contents
Introduction
Hello Everyone, in this article, we will explore how we could get React Native Contacts from the user phone book.
For this example we will use React Native Expo to access the phone’s contacts system, to get the list of contacts, we can also edit and delete them.
Similar to some of the famous apps use the user’s contacts.
You could add a functionality in your app to ask the user to invite his friends from his contacts list.
Or if you are developing an alternative messenger app, getting the users’ contact might be a core function to add.
Environment Setup
If you haven’t created a React Native Expo project already, you can do it right now.
Simply run this command
expo init new-app
Next, we need to install the Expo contacts API which will provide us with all the tools needed to access and manipulate the contacts system.
expo install expo-contacts
Contacts Basic Usage
Before we can access the Contacts system, there is one important step to take care of.
In order to access the list of contacts, we need to get the CONTACTS permission from our user.
So we need to handle this permission granting and denying properly.
Getting Contacts list
import React, { useEffect, useState} from 'react'; import * as Contacts from 'expo-contacts'; import { StyleSheet, View, Text, FlatList } from 'react-native' export default function App() { const [contacts, setContacts ] = useState([]) useEffect(() => { (async () => { const { status } = await Contacts.requestPermissionsAsync(); if (status === 'granted') { const { data } = await Contacts.getContactsAsync({ fields: [Contacts.Fields.PhoneNumbers], }); if (data.length > 0) { setContacts(data) } } })(); }, []); return ( <View style={styles.container}> <FlatList data={contacts} renderItem={({item}) => { return ( <Text>{`${item.name} (${item.phoneNumbers ? item.phoneNumbers[0].number : ''})`}</Text> ) }} /> </View> ); } const styles = StyleSheet.create({ container: { flex: 1, backgroundColor: '#fff', alignItems: 'center', justifyContent: 'center', }, });
As you might have noticed, we have imported the expo-contacts we have just installed at the top.
Then we created a simple state variable to store the list of contacts via the useState hook.
Next we will be using the useEffect hook to handle getting the contacts list from the system.
Starting by asking from the permission Contacts.requestPermissionsAsync(), and continue once it’s granted only.
You could go a bit further and display a text message to let the user know, he/she needs permission if it doesn’t exist or he/she denied it before.
Next we can access the contacts via Contacts.getContactsAsync()
The argument we are adding is the Contact Query, it will return the list of contacts based on it, if it’s null, it will return all that exists.
We can query using
The return result looks like this.
{ "contactType": "person", "firstName": "User Name", "id": "351", "imageAvailable": false, "lookupKey": "161A368D-D614-4A15-8DC6-665FDBCFAE55", "name": "User Name", "phoneNumbers": [ {"label": "mobile", "type": "2", "id": "1601", "isPrimary": 0, "number": "+1 23456789"}, {"label": "mobile", "type": "2", "id": "1120", "isPrimary": 0, "number": "+2 09876543"} ] }
And finally we are rendering the list of contacts using a Flatlist in our render method.
Adding Contacts
Adding a new contact to the user contacts list.
const contact = { [Contacts.Fields.FirstName]: 'John', [Contacts.Fields.LastName]: 'Doe', [Contacts.Fields.Company]: 'React Native Master', };
const contactId = await Contacts.addContactAsync(contact);
Remove Contact
Removing a contact from the user contact system.
await Contacts.removeContactAsync('161A368D-D614-4A15-8DC6-665FDBCFAE55');
Conclusion
There you have it, a quick explanation of the React Native Contacts, I hope you enjoyed reading this article and found it as informative as you have expected.
I have shared the code of this project on github and expo.io, feel free to use it at your will.
Stay tuned and happy coding.
|
https://reactnativemaster.com/react-native-contacts/
|
CC-MAIN-2021-04
|
refinedweb
| 609
| 56.15
|
Just Showing Off
May 19, 2017
Here’s the email that convinced my correspondent that there might be something interesting in Scheme and Scheme macros:
Let’s consider a simple program to calculate the nth fibonacci number. Mathematically, the definition is that the nth fibonacci number is the sum of the n-1th fibonacci number and the n-2th fibonacci number, with the first two fibonacci numbers being 1 and 1. That translates directly to Scheme like this:(define (fib n) (if (< n 2) 1 (+ (fib (- n 1)) (fib (- n 2)))))
Timing the calculation shows that it quickly grows slow as n grows large, which makes sense because the algorithm takes exponential time to repeatedly recalculate all the smaller fibonacci numbers:> (time (fib 40)) (time (fib 40)) no collections 15069 ms elapsed cpu time 15064 ms elapsed real time 0 bytes allocated 165580141
Fifteen seconds is a long time to calculate a small number.
It is easy to write a Scheme macro that memoizes, or caches, the results of the subproblems inherent in the fibonacci calculation. Here’s the macro:(define-syntax define-memoized (syntax-rules () ((define-memoized (f arg ...) body ...) (define f (let ((cache (list))) (lambda (arg ...) (cond ((assoc `(,arg ...) cache) => cdr) (else (let ((val (begin body ...))) (set! cache (cons (cons `(,arg ...) val) cache)) val)))))))))
We’ll explain that in a moment. But first let’s look at how to write the fibonacci function using that macro:(define-memoized (fib n) (if (< n 2) 1 (+ (fib (- n 1)) (fib (- n 2)))))
That is, of course, exactly the same as the earlier fibonacci function, except that we used
define-memoizedinstead of simple
defineto write the function. But look at what a difference the memoization makes:> (time (fib 40)) (time (fib 40)) no collections 0 ms elapsed cpu time 0 ms elapsed real time 5456 bytes allocated 165580141
We’ve gone from fifteen seconds to zero without doing any work, which is astonishing! Even calculating a number like
(fib 4000)doesn’t cause any trauma:> (time (fib 4000)) (time (fib 4000)) no collections 141 ms elapsed cpu time 144 ms elapsed real time 1364296 bytes allocated 64574884490948173531376949015369595644413900640151342708407577598177210359034088 91444947780728724174376074152378381889749922700974218315248201906276355079874370 42751068564702163075936230573885067767672020696704775060888952943005092911660239 47866841763853953813982281703936665369922709095308006821399524780721049955829191 40702994362208777929645917401261014865952038117045259114133194933608057714170864 57836066360819419152173551158109939739457834939838445927496726613615480616157565 95818944317619922097369917676974058206341892088144549337974422952140132621568340 70101627342272782776272615306630309305298205175744474242803310752241946621965578 04131017595052316172225782924860810023912187851892996757577669202694023487336446 62725774717740924068828300186439425921761082545463164628807702653752619616157324 434040342057336683279284098590801501
How does it work? The high-level explanation is that the macro modifies
fibto store internally, in
cache, the result of previous function calls with the same parameters, and return them directly instead of recalculating them. Thus, when
(fib 40)requires the result of
(fib 39)and
(fib 38), the results are already available and don’t need to be recomputed. The
cachedata structure is known in Scheme parlance as an a-list (an association list), meaning it is a linked list of key/value pairs where the key is n and the value is
(fib n). Function
assoclooks up the key in the cache,
`(,arg ...)is a quasi-quotation that expands the arguments to the function (
fibtakes only one argument, but the macro admits functions that take more than one). The
=>symbol is syntax that passes the result of a
condpredicate to its consequent, and
cdris a function that extracts the value from the key/value pair. The
elseclause of the
condcalculates a never-before-seen value in the
letexpression, then updates the cache with
set!and returns the newly-computed value.
You can run the program at.
I’ve been using
define-memoized for years. I suppose now that R6RS has standardized hash tables I ought to rewrite it, because hash tables ought to be faster than a-lists, but I’ve never bothered; it’s so easy to write just the way it is, and every time I use the new hash table functions I have to look up how to use them again, and why fix something that isn’t broken. I love Scheme!
Can this also be done without a macro?
@Steve: You could write a memoizing
fibfunction without using a macro, by writing the memoization yourself inside the function, but you could not write
define-memoizedwithout using a macro.
Thanks.
MUMPS
When I first started programming, dealing with files could be a bit complicated. Then I started programming in MUMPS, and it became a non-issue, because in MUMPS everything is stored in a sparse, multi-dimensional array.
While I liked the way they handled storage, another feature was the ability to handle multiple tasks and multiple users on small systems. I heard of a fellow who had a side business he ran on a PC-AT (6 or 8 MHz 8086, < 3 MB RAM). It was for accounting and supported multiple simultaneous users. The only other language I have heard that had such a capability is Forth: I have actually heard of 1 Forth system which handled 50 tasks with a Z80 8-bit CPU.
Ah, hi.
The D programming language is, more or less, a simplified and regularized dialect of C++, and it may have had (through Andrei Alexandrescu, a D enthusiast and C++ committee member) significant influence on more modern versions of C++. In particular, the modern C++ “constexpr” keyword and compile-time execution of functions seem directly influenced by D.
To Schemers, metacircularity and hygienic macros are old hat. To those of us brought up in the C tradition, they are new and exciting. D provides the first by including a D interpreter in the D compiler, so that deterministic D code whose input is provably immutable can be executed and its result may be used as data in the compilation of the rest of the program. Just as a Scheme macro is only a Scheme function whose input is a list representing the abstract syntax tree of a program, so indeed are D functions executable by the compiler during the compilation. The following small program, when compiled with all optimizations disabled …
import std.stdio;
private uint fib(in uint n) pure nothrow @nogc
{
if (n == 0) {
return 1;
}
return n * fib(n - 1);
}
private immutable uint f5 = fib(5); // 120, to be precise
int main()
{
stdout.writeln(f5);
return 0;
}
reduces to the equivalent program
import std.stdio;
int main()
{
stdout.writeln(120);
return 0;
}
Hygienic macros are not as easy to give small examples for, but a beautiful large example is found in D’s own standard library: in particular, the std.regex module, wherein typical messy regular expressions are compiled to D code and inlined thereafter using the facility above.
Yes, again, Scheme has done this for decades. It’s new and exciting for us plebeians though.
(Argh! I called the function above “fib” instead of “fac”! Please forgive me!)
In Python 3.2 they added the @lru_cache decorator (least recently used cache) which does function memoization (which until today I always read as memoRization) and allows the user to set a max size for the cache for long running processes. The docs use the Fibonacci sequence as their example. These ease of writing your own decorators is often an example I use as a non standard reason Python is great.
What I like about Python is the large number of libraries. An example (after Raymond Hettinger): a script that walks down a directory tree and lists all duplicate files (with the same content). I think Python is great, but there are, of course, many other great languages.
Personally I just love the concept of list comprehension. It facilitates a concise way of filtering and executing operations on the list members. Quite some programming languages support it. I mostly use it in Python now, had some fun with it in XQuery a few years back as well.
Specific to Python: if you change every defined list with [] to () in above example, everything becomes generators and gets computed lazily, i.e. the powers of 2 are computed first before the next number is even determined from the input string.
@Rutger: I like list comprehensions, too. That’s why I provide them in the Standard Prelude. Likewise pattern matching.
Using the Wolfram Language (also know as “Mathematica”), one can easily memoize functions. It’s even easier than the method shown above!
Let’s use the Fibonacci function as an example. A naive implementation,
fib, would look like:
fib[0] := 1;
fib[1] := 1;
fib[n_] := fib[n - 1] + fib[n - 2];
Calculating the 30th Fibonacci number takes about 3 seconds on my machine. To memoize the function, we simply replace
fib[n_] := ...with
fib[n_] := fib[n] = .... This gives us
fib[0] := 1;
fib[1] := 1;
fib[n_] := fib[n] = fib[n - 1] + fib[n - 2];
Now computing the 30th Fibonacci number takes about 0.1 seconds on my machine (30x speedup). I like this idiom because of how easy it is to incorporate memoization into your code.
|
https://programmingpraxis.com/2017/05/19/just-showing-off/2/
|
CC-MAIN-2019-04
|
refinedweb
| 1,455
| 61.06
|
- NAME
- DESCRIPTION
- How do I flush/unbuffer a set up a footer format to be used with write()?
- How can I write() into a string?
- How can I output my numbers with commas added?
- How can I translate tildes (~) in a filename?
- How come when I open open a file without blocking?
- How do I create a file only if it doesn't exist?
-.22 $, $Date: 1997/04/24 22:44:02 $)
DESCRIPTION
This section deals with I/O and the "f" issues: filehandles, flushing, formats, and footers.
How do I flush/unbuffer a, as in the older:(); $sock->print("GET /\015\012"); $document = join('', $sock->getlines()); print "DOC IS: $document\n";
Note the hardcoded carriage return and newline in their octal equivalents. This is the ONLY way (currently) to assure a proper flush on all platforms, including Macintosh.. Replacing a sequence of bytes with another sequence of the same length is one. Another is using the
$DB_RECNO array bindings as documented in DB_File. Yet another is manipulating files with all lines the same length.)
The general solution is to create a temporary copy of the text file with the changes you want, then copy that over the original.
;
How do I make a temporary file name?
Use the process ID and/or the current time-value. If you need to have many temporary files in one process, use a counter:
BEGIN { use IO::File; use Fcntl; my $temp_dir = -d '/tmp' ? '/tmp' : $ENV{TMP} || $ENV{TEMP}; my $base_name = sprintf("%s/%d-%d-0000", $temp_dir, $$, time()); sub temp_file { my $fh = undef; my $count = 0; until (defined($fh) || $count > 100) { $base_name =~ s/-(\d+)$/"-" . (1 + $1)/e; $fh = IO::File->new($base_name, O_WRONLY|O_EXCL|O_CREAT, 0644) } if (defined($fh)) { return ($fh, $base_name); } else { return (); } } }
Or you could simply use IO::Handle::new_tmpfile.
How can I manipulate fixed-record-length files?
The most efficient way is using pack() and unpack(). This is faster than using substr().|"); $_ = <PS>; print; while (<PS>) { ($pid, $tt, $stat, $time, $command) = unpack($PS_T, $_); for $var (qw!pid tt stat time command!) { print "$var: <$$var>\n"; } print 'line=', pack($PS_T, $pid, $tt, $stat, $time, $command), "\n"; }
How can I make a filehandle local to a subroutine? How do I pass filehandles between subroutines? How do I make an array of filehandles?
You may have some success with typeglobs, as we always had to use in days of old:
local(*FH);
But while still supported, that isn't the best to go about getting local filehandles. Typeglobs have their drawbacks. You may well want to use the
FileHandle module, which creates new filehandles for you (see FileHandle):
use FileHandle; sub findme { my $fh = FileHandle->new(); open($fh, "</etc/hosts") or die "no /etc/hosts: $!"; while (<$fh>) { print if /\b127\.(0\.0\.)?1\b/; } # $fh automatically closes/disappears here }
Internally, Perl believes filehandles to be of class IO::Handle. You may use that module directly if you'd like (see IO::Handle), or one of its more specific derived classes.
Once you have IO::File or FileHandle objects, you can pass them between subroutines or store them in hashes as you would any other scalar values:
use FileHandle; # Storing filehandles in a hash and array foreach $filename (@names) { my $fh = new FileHandle($filename) or die; $file{$filename} = $fh; push(@files, $fh); } # Using the filehandles in the array foreach $file (@files) { print $file "Testing\n"; } # You have to do the { } ugliness when you're specifying the # filehandle by anything other than a simple scalar variable. print { $files[2] } "Testing\n"; # Passing filehandles to subroutines sub debug { my $filehandle = shift; printf $filehandle "DEBUG: ", @_; } debug($fh, "Testing\n"); the file read-write it wipes it out?
Because you're using something like this, which truncates the file and then gives you read-write access:
open(FH, "+> /path/name"); # WRONG
Whoops. You should instead use this, which will fail if the file doesn't exist.
open(FH, "+< /path/name"); # open for update
If this is an issue, try:
sysopen(FH, "/path/name", O_RDWR|O_CREAT, 0644);
Error checking is left as an exercise for the reader..
The CPAN module File::Lock offers similar functionality and (if you have dynamic loading) won't require you to rebuild perl if your flock() can't lock network files., 0644)?
Anyway, this is what to do:
use Fcntl; sysopen(FH, "numfile", O_RDWR|O_CREAT, 0644).
Don't forget to set binmode() under DOS-like platforms when operating on files that have anything other than straight text in them. See the docs on open() and on binmode() for more details.]; print "file $file updated at ", scalar(localtime($file)), "\n";");
Otherwise you'll have to write your own multiplexing print function -- or your own tee program -- or use Tom Christiansen's, at, which is written in Perl.
In theory a IO::Tee class could be written, but to date we haven't seen such.?
You should); }
You should look into getting the Term::ReadKey extension from CPAN.
How do I open a file without blocking?
You: $!":
How do I create a file only if it doesn't exist?
You need to use the O_CREAT and O_EXCL flags from the Fcntl module in conjunction with sysopen():
use Fcntl; sysopen(FH, "/tmp/somefile", O_WRONLY|O_EXCL|O_CREAT, 0644) or die "can't open /tmp/somefile: $!":
Be warned that neither creation nor deletion of files is guaranteed to be an atomic operation over NFS. That is, two processes might both successful create or unlink the same file!)
Error checking.
Why does Perl let me delete read-only files? Why does
-i clobber protected files? Isn't this a bug in Perl?
This is elaborately and painstakingly described in the "Far More Than You Every.
AUTHOR AND COPYRIGHT
Copyright (c) 1997 Tom Christiansen and Nathan Torkington. All rights reserved. See perlfaq for distribution information.
1 POD Error
The following errors were encountered while parsing the POD:
- Around line 61:
alternative text 'perlvar/$' contains non-escaped | or /
|
https://metacpan.org/pod/release/MICB/perl5.004_59/pod/perlfaq5.pod
|
CC-MAIN-2015-32
|
refinedweb
| 989
| 64.1
|
Writing Macros
You must write macros on your computer, not on the ERX system. The macros can contain loops, variables, string and numeric values, and conditional statements. Macros can invoke other macros (as long as they are contained within the same macro file), including themselves, but infinite recursion is not permitted. Macros are case-insensitive.
Macros consist of control expressions and noncontrol expressions. Control expressions are enclosed by control brackets, which are angle-bracket and number sign pairs, like this: <# controlExpression #>. Examples of control expressions include the macro name and macro end statements, and while loops. A control expression can include multiple operation statements if you separate the statements with semicolons (;). For example:<# i:=0; while i++ < 3 #>
All macros must have names consisting only of letters, numbers, and the underline character (_). The first character of a macro name cannot be a number. If you include more than one macro within a macro file, each macro must have a unique name. The first line of a macro defines the macro's name:<# macroName #>
Noncontrol expressions are not enclosed by control brackets and simply become part of the generated CLI command text.
You must end all macros with the following control expression:<# endtmpl #>
You can add comments to your control expressions to clarify the code by prefacing the comment with forward slashes (//) inside the control brackets:<# endtmpl //A comment in the macro end expression #>
Text after the // is ignored when the macro is run and is not displayed by the CLI.
You can also add comments outside the control expressions by prefacing the comment with an exclamation point (!). The CLI displays these comments if you use the test or verbose keywords with the macro command; the CLI never regards these comments as commands.!This is a comment outside any control expression
You can improve the readability of a macro by using tabs to indent expressions. Leading and trailing tabs have no effect on the macro output, because they are removed when the macro is run.
Example
The following is a simple macro that you can use to configure the IP interface on the Fast Ethernet port of the SRP module after you have restored the factory defaults:<# ipInit #><# ipAddress := env.getline ("IP Address of System?") #>enaconf tint f0/0ip addr <# ipAddress; `\n' #>ip route 10.0.0.0 255.0.0.0 192.168.1.1host pk 10.10.0.166 ftp<# endtmpl #>
Environment Commands
Macros use environment commands to write data to the macro output, to determine a value, or to call other commands. Table 7-1 describes the environment commands that are currently supported.
Table 7-1 Environment commands
Variables
A local variable enables you to store a value used by the macro while it executes. The macro can modify the value during execution. Local variables can be integers, real numbers, or strings. The initial value
of local variables is zero.
Like macros, local variables must have a name consisting only of letters, numbers, or the underline character (_). The variable name must not begin with a number. You must not use a reserved keyword as a
variable name.
Literals
A literal is an exact representation of numeric or string values. Every number is a literal. Place single or double quotation marks around a string to identify it as a string literal. You can specify special characters within a literal string by prefacing them with a backslash as follows:
Examples4298.6`string literal'"count""\t this string starts with a tab and ends with a tab \t"
Operators
You can use operators to perform specific actions on local variables or literals, resulting in some string or numeric value. Table 7-2 lists the available macro operators in order of precedence by operation type. Operators within a given row are equal in precedence.
Table 7-2 Macro operators
Table 7-3 briefly describes the action performed by each operator.
Table 7-3 Operator actions
Assignment
Use the assignment operator (:=) to set the value of a local variable. The expression to the right of the operator is evaluated, and then the result is assigned to the local variable to the left of the operator. The expression to the right of the operator can include the local variable if you want to modify its current value.
Example<# i := i + 1 #><# count := count - 2 #>
Increment and Decrement
You can use the increment operator (++) to increase the value of a local variable by one. You specify when the value is incremented by the placement of the operator. Incrementing occurs after the expression is evaluated if you place the operator to the right of the operand. Incrementing occurs before the expression is evaluated if you place the operator to the left of the operand.
Example 1<# i := 0; j := 10 #><# j := j - i++ #>
In Example 1, the result is that i equals 1 and j equals 10, because the expression is evaluated (10 - 0 = 10) before i is incremented.
Example 2<# i := 0; j := 10 #><# j := j - ++i #>
In Example 2, the result is still that i equals 1, but now j equals 9, because i is incremented to 1 before the expression is evaluated (10 - 1 = 9).
Similarly, you can use the decrement operator (- -) to decrement local variables. Placement of the operator has the same effect as for the increment operator.
When a local variable with a string value is used with the increment or decrement operators, the value is permanently converted to an integer equal to the length in characters of the string value.
String Operations
The combine operator ($) concatenates two strings into one longer string. Numeric expressions are converted to strings before the operation proceeds. The variable local evaluates to "want a big":<# local := "want a " $ "big" #>
Extraction Operations
The extraction operations are substring (substr), randomize (rand), round, and truncate. These operators are equal in precedence, and all take precedence over the string operator.
You can use the substring operator (substr) to extract a shorter string from a longer string. To use the substring operator, you must specify the source string, an offset value, and a count value. You can specify the string directly, or you can specify a local variable that contains the string. The offset value indicates the place of the first character of the substring to be extracted; "0" indicates the first character in the source string. The count value indicates the length of the substring. If the source string has fewer characters than the sum of the offset and count values, then the resulting substring has fewer characters than indicated by the count value.
Example<# local := "want a " $ "big" $ " string" #><# substr(local, 5, 12) #> The result is "a big string"<# substr(local, 0, 10) #> The result is "want a big"<# substr("ready", 0, 4) #> The result is "read"
The random operator produces a random integer value from the specified inclusive range; in the following example, the result is between 1 and 10:<# number:= rand(1,10) #>
The round operator rounds off the number to the nearest integer:<# decimal:= 4.7 #><# round(decimal) #> The result is decimal is now 5
The truncate operator truncates noninteger numbers to the value left of the decimal point:<# decimal:= 4.7 #><# truncate(decimal) #> The result is decimal is now 4
Arithmetic Operations
The arithmetic operations are multiply (*), divide (/), modulo (%), add (+), and subtract (-). Multiply, divide, and modulo are equal in precedence, but each has a higher precedence relative to add and subtract. Add and subtract are equal in precedence.
Example<# 4 % 3 + 12 - 6 #> The result is 7
When a local variable with a string value is used with arithmetic operators, the value is temporarily converted to an integer equal to the length in characters of the string value. You can use the env.atoi commands to avoid this situation.
Relational Operations
The relational operations compare the value of the expression to the left of the operator with the value of the expression to the right. The result of the comparison is 1 if the comparison is true and 0 if the comparison is false.
If the expressions on both sides of the operator are strings, they are compared alphabetically. If only one expression is a string, the numeric value is used for comparison. Arithmetic operators have a higher precedence.
Example<# i := 9; i++ < 10 #> The result is 1<# i := 9; ++i < 10 #> The result is 0
Logical Operations
You can use the logical operators AND (&&), OR (||), and NOT (!) to evaluate expressions. The result of the operation is a 1 if the operation is true and 0 if the operation is false.
For the logical AND, the result of the operation is true (1) if the values of the expressions to the left and right of the operator are both nonzero. The result of the operation is false (0) if either value is zero. The evaluation halts when an expression is evaluated as zero.
For the logical OR, the result of the operation is true (1) if the values of the expression on either the left or right of the operator is nonzero. The result of the operation is false (0) if both values are zero. The evaluation halts when an expression is evaluated as nonzero.
The NOT operator must precede the operand. The operation inverts the value of the operand; that is, a nonzero expression becomes 0, and a zero expression becomes 1. For the logical NOT, the result of the operation is true (1) if it evaluates to zero, or false if it evaluates to nonzero.
Example<# i := 6; i >= 3 && i <= 10 #> The result is 1<# i := 1; i >= 3 && i <= 10 #> The result is 0<# i := 6; i >= 3 || i <= 10 #> The result is 1<# i := 1; i >= 3 && i <= 10 #> The result is 0<# i := 5; !i #> The result is 0<# i := 5; j := 0; !i && !j #> The result is 0<# i := 5; j := 0; !i || !j #> The result is 1
Relational operators have a higher precedence than logical AND and OR. The NOT operator is equal in precedence to the increment and decrement operators.
Miscellaneous Operations
The positive (+) and negative (-) operations must precede the operand. The result of a positive operation is the absolute value of the operand. The result of a negative operation is the negative value of the operand; that is, a +(-5) becomes 5 and a -(-2) becomes 2. These operators have the same precedence as the increment and decrement operators. If there is an operand on both sides of these operators, they are interpreted as the add and subtract operators.
Example# local_abs := +local #><# local_neg := -local #>
All operations are performed in the order implied by the precedence of the operators. However, you can modify this order by using parentheses (( )) to group operands and operators. Operations within parentheses are performed first. The result is that of the operation(s) within the parentheses.
Example<# 4 % (3 + 12) - 6 #> The result is -6<# 5 && 2 > 1 #> The result is 1<# (5 && 2) > 1 #> The result is 0
Results of control expressions are written to the output stream when the expression consists of the following:
- A single local variable
- A single literal element
- An operation whose result is not used by one of the following operations:
Example<# localvar #> value of localvar is written<# " any string" #> " any string" written<# 4 % 3 + 12 - 6 #> "7" is written<# 4 % (3 + 12) - 6 #> "-6" is written<# i := i + 1 #> nothing is written<# count := (count - 2) #> nothing is written
Conditional Execution
You can use if or while constructs in macros to enable conditional execution of commands.
If Constructs
If constructs provide a means to execute portions of the macro based on conditions that you specify. An if construct consists of the following components:
- An opening if expression
- A group of any number of additional expressions
- (Optional) Any number of elseif expressions and groups of associated expressions
- (Optional) An else expression and any associated group of expressions
- An endif expression to indicate the end of the if structure
The if expression and any optional elseif expressions must include either a lone environment value command, a local variable, a literal, or some operation using one or more operators.
Only one of the groups of expressions within the if construct is executed, according to the following scheme:
- The if expression is evaluated. If the result is true (nonzero), the associated expression group is executed.
- If the result is false (zero), then the first elseif expression, if present, is evaluated. If the result is true (nonzero), the associated expression group is executed.
- If the result of evaluating the first elseif expression is false (zero), the next elseif expression is evaluated, if present. If the result is true (nonzero), the associated expression group is executed.
If all elseif expressions evaluate to false (zero) or if no elseif expressions are present, then the else expression group—if present—is executed.
- This evaluation process continues until an expression evaluates to nonzero. If there is no nonzero evaluation, then no expression group is executed.
You can write an empty expression group so that no action is performed if this group is selected for execution. You can nest if structures within other if structures or while structures.
The following sample macro demonstrates various if structures:
While Constructs
While constructs provide a means to repeatedly execute one or more portions of the macro based on a condition that changes during the execution. A while construct consists of the following components:
- An opening while expression
- A group of any number of additional expressions
- An endwhile expression to indicate the end of the while structure
The while expression must include either a lone environment value command, a local variable, a literal, or some operation using one or more operators. Each time that this expression evaluates to nonzero, the associated expression group is executed.
You can place an iteration expression after the while expression. This optional expression is evaluated after each execution of the while expression group.
You can include if structures within a while structure. You can also include special control expressions indicated by the break or continue expressions. The break expression breaks out of the while structure by halting execution of the expression group and executing the first expression after the endwhile statement. The continue expression skips over the rest of the expression group, evaluates any iteration expression, then continues with the execution of the while structure. The while structure is limited to 100,000 repetitions by default. You can nest up to ten while structures.
Example
The following sample macro demonstrates various while structures:
Invoking Other Macros
Macros can invoke other macros within the same macro file; a macro can also invoke a macro from another macro file if the invocation takes place in literal text, that is, not within a control expression. A macro can invoke itself directly or indirectly (an invoked macro can invoke the macro that invoked it); the number of nested invocations is limited to 10 to prevent infinite recursion.
Within each macro, you can specify parameters that must be passed to the macro when it is invoked by another. You must specify named variables enclosed in parentheses after the macro name in the first line of the macro, as shown in this example:<# macroName (count, total) #>
Additional parameters can be passed as well. Parameters can be local variables, environmental variables, literals, or operations. The invoking macro passes local variables by reference to the invoked macro. Passing parameters has no effect on the invoking macro unless the parameter is a local variable that is changed by the invoked macro. When the invoked macro completes execution, the local variable assumes the new value for the invoking macro.
The invoked macro can use the param[n] expression to access parameters passed to it, where n is the number of the parameter passed. This is useful if optional parameters can be passed to a macro or if the same iterative algorithm needs to process the parameters.
Use the expression param[0] to return the total number of parameters passed to the macro. Use the return keyword to halt execution of the invoked macro and resume execution of the invoking macro. Use the exit keyword to halt execution of all macros.
Example 1
The following sample macro demonstrates macro invocation:
Example 2
The following macro in file macro1.mac invokes a macro from within another file, macro2.mac:<# callAnotherMacro #><# localVar := 5 #>macro macro2.mac macroName2 <# localVar #> string1<# endtmpl #>
This macro passes the value of localVar to macroName2. The value of localVar remains at 5 for callAnotherMacro, regardless of any operations upon that variable in the second macro. In other words, an invoked macro in another file cannot return any values to the invoking macro.
The output of callAnotherMacro looks like this:host1#macro verbose macro1.mac callAnotherMacrohost1#!Macro 'callAnotherMacro' in the file 'macro1.mac' starting executionmacro macro2.mac macroName2 5 string1!Macro 'macroName2' in the file 'macro2.mac' starting execution!Macro 'macroName2' in the file 'macro2.mac' ending executionhost1#!Macro 'callAnotherMacro' in the file 'macro1.mac' ending execution
The invoked macro cannot invoke a third macro from another file. Only a single level of invocation is supported.
|
http://www.juniper.net/techpubs/software/erx/erx50x/swconfig-system-basics/html/macros-config2.html
|
crawl-002
|
refinedweb
| 2,854
| 53.1
|
A.
The algorithm produces a shape that starts off resembling a (slightly wonky) spiral:
After 40 steps, things are beginning to look shaky:
After 200 steps:
By 2000 steps, it resembles a scribble:
20000 steps:
200000 steps:
The Python code below produces these figures (alter the variable
nsteps and, possibly, the plot line width and marker size).
import sys import math import time import matplotlib.pyplot as plt nsteps = 2000 # Cache the first CACHE_NMAX square numbers. CACHE_NMAX = 1000 squares = [a**2 for a in range(CACHE_NMAX+1)] def get_pairs(n2): """Find all pairs of integers ia and ib such that ia^2 + ib^2 = n2.""" pairs = [] # Index into the list of squares with ia <= ib to find values # a = ia**2, b = ib**2 satisfying a + b == n2. Increase ia up to # the square root of n2 and, for each value of ia, decrease ib from the # square root of n2 until a + b < n2. ia = 0 ib = int(math.sqrt(n2)) + 1 if ib > CACHE_NMAX: sys.exit('Size of squared numbers cache, CACHE_NMAX = {}, exceeded.' .format(CACHE_NMAX)) while True: a = squares[ia] if a > n2 // 2: break while True: b = squares[ib] if a + b < n2: break elif a + b == n2: # add all possible orientations for a vector of this length # to land on a lattice point. pairs.extend([(ia, ib), (-ia, ib), (ia, -ib), (-ia, -ib), (ib, ia), (ib, -ia), (-ib, ia), (-ib, -ia)]) ib -= 1 ia += 1 return set(pairs) def get_vecs(nsteps): """Get the vectors forming the Babylonian spiral up to nsteps steps.""" # Start at the origin; the first step is to (0, 1). vecs = [(0, 0), (0, 1)] n2 = 1 for step in range(nsteps): # The previous vector and its angle. x0, y0 = vecs[-1] theta = math.atan2(y0, x0) # Find the next set of candidate vectors longer than (x0, y0) that # land on a lattice point. pairs = [] while not pairs: n2 += 1 pairs = get_pairs(n2) # Pick the new vector with the smallest (clockwise) angular deviation # from the previous one. x1, y1 = min(pairs, key=lambda v: (theta - math.atan2(v[1], v[0])) % math.tau) vecs.append((x1, y1)) return vecs def get_pos(nsteps): """Get the positions of points on the Babylonian spiral up to nsteps.""" vecs = get_vecs(nsteps) # Start at the origin and add on subsequent vectors, one at a time. pos = [vecs[0]] x, y = pos[0] for i in range(1, len(vecs)): x, y = vecs[i][0] + x, vecs[i][1] + y pos.append((x, y)) return pos start = time.time() pos = get_pos(nsteps) end = time.time() print('Time taken: {:g} s'.format(end - start)) DPI = 72 fig, ax = plt.subplots(figsize=(800 / DPI, 800 / DPI), dpi=DPI) plt.plot(*zip(*pos), lw=0.5, c='tab:purple', marker='.', ms=2) plt.axis('equal') plt.savefig('babylonian-spiral-{}.png'.format(nsteps), dpi=DPI) plt.show()
Comments are pre-moderated. Please be patient and your comment will appear soon.
Florian 2 months, 2 weeks ago
I think there is a bug in get_pos(nsteps).Link | Reply
Instead of:
x, y = vecs[i][0] + x, vecs[i][7] + y
It should say:
x, y = vecs[i][0] + x, vecs[i][1] + y
christian 2 months, 2 weeks ago
I think you're right! Not sure how that 1 became a 7. I've fixed it now: thanks for pointing this out.Link | Reply
New Comment
|
https://scipython.com/blog/the-babylonian-spiral/
|
CC-MAIN-2021-39
|
refinedweb
| 562
| 74.69
|
Subject: [ggl] abs warning on Linux
From: Barend Gehrels (barend)
Date: 2011-10-22 13:38:58
Hi,
On 22-10-2011 4:49, V D wrote:
> Hi Barend,
>
> Is it possible to know what/where was the patch for this ? I'm trying
> to move to TTMath instead of double because I'm having precision
> problems.
> But I cannot get it to compile because of abs.
>
> I get errors such as:
>
> /boost/geometry/algorithms/detail/overlay/assign_parents.hpp:80:
> error: cannot convert 'ttmath::Big<1ul, 32ul>' to 'int' for argument
> '1' to 'int abs(int)'/
> /boost/geometry/strategies/cartesian/cart_intersect.hpp:350: error:
> cannot convert 'ttmath::Big<1ul, 32ul>' to 'int' for argument '1' to
> 'int abs(int)'/
>
The cause is that ttmath does not support std::abs. Therefore there is a
small stub necessary, which should be included like this:
#include <boost/geometry/extensions/contrib/ttmath_stub.hpp>
The stub does not much but is essential:
- it enables the ADL finding of: sqrt,abs,sin,cos and some other
math-functions (IMO ttmath should do this itself, I have to contact the
author if he agrees and is willing to do this)
- it defines ttmath_big, which is alas necessary everywhere T() is used
(in quite some places). The reason is that ttmath's default constructor
does not initialize to zero. Which is what T() expects. Have to contact
about this too.
- it defines pi
- it can cast coordinates from/to strings (necessary to read from WKT)
- it can cast coordinates numerically (supporting boost::numeric_cast)
(which is not supported by ttmath intentionally, but sometimes, e.g. by
writing to non-ttmath SVG map's, necessary
So alas you need this stub.
The ggl's ttmath_big is not templated, which is actually (now that I
review it) limiting but we can easily add a templated version.
Regards, Barend
-------------- next part --------------
An HTML attachment was scrubbed...
URL:
Geometry list run by mateusz at loskot.net
|
https://lists.boost.org/geometry/2011/10/1630.php
|
CC-MAIN-2020-50
|
refinedweb
| 323
| 53.92
|
Hi Guys
Im new to programming and Java, but im willing to learn and trying hard using a book `Objects first with Java`.
Im trying to create a program for a Library where Members can join and loan books. But i keep getting an Error when using the Iterator.
My code is below:
import java.util.ArrayList; import java.util.Iterator; /** * Write a description of class Library here. * * @author (your name) * @version (a version number or a date) */ public class Library { private ArrayList<Book> books; private ArrayList<Member> members; private int nextMemberNumber; /** * Constructor for objects of class Library */ public Library() { books = new ArrayList<Book>(); members = new ArrayList<Member>(); nextMemberNumber = 1; } public void AddNewMember( Member newMember ) { members.add(newMember); nextMemberNumber++; } public int NumberOfMembers() { return members.size(); } public void ShowMembers( String getDetails ) { Iterator<Member> it = members.iterator(); while(it.hasNext()) { Member t = it.next(); System.out.println(t.getMember());// --------------------This is where the error is when i complie. getMmember? } } public int numberOfMembers() { return members.size(); } }
Any help would be great, i can see people really know what there talking about on here thats why i joined. Thanks Guys
Willo
|
http://www.javaprogrammingforums.com/collections-generics/19984-system-out-println-error-when-using-iterator.html
|
CC-MAIN-2016-36
|
refinedweb
| 187
| 50.94
|
Seeing as Java doesn't have nullable types, nor does it have a TryParse(),
how do you handle input validation without throwing an exceptions?
The usual way:
String userdata = /*value from gui*/
int val;
try
{
...
when i write
System.out.println(0123);
83
System.out.println((int)0123F);
123
This is probably pretty basic, but to save me an hour or so of grief can anyone tell me how you can work out the number of bits required to represent ...
How would i go about doing calculations with extremely large numbers in Java? i have tried long but that maxes out at 9223372036854775807, and when using an integer it does not ...
Is there a neater way for getting the length of an int as this?
int length = String.valueOf(1000).length();
The Java code is as follows:
String s = "0.01";
int i = Integer.parseInt(s);
I am getting a number format exception when trying to do it
int temp = Integer.parseInt("C050005C",16);
I'd like to round integers down to their nearest 1000 in Java.
So for example:
Why can't do you this if you try to find out whether an int is between to numbers:
if(10 < x < 20)
if(10<x && x<20)
I have a class that stores a large number of int member variables, each defined as follows:
int
public final static int int1 = int1value;
public final static int int2 = int2value;
...
public final static ...
"Unsigned int" into a short and back. Is this possible? How to do it if so?
Grrrr. I forgot how signed numbers are implemented. The question makes no sense. Thanks anyway. I ...
I was wondering what the easiest way is to convert an integer to the equivalent number of blank spaces. I need it for the spaces between nodes when printing a binary ...
I recently was part of a small java programming competition at my school. My partner and I have just finished our first pure oop class and most of the questions were ...
Guys if the int c=10001; which is a binary value.If i want to process it like multiplying it by 10 how to do that?
Is it possible to define something like this in java?
C# code:
public enum Character
{
A = 1,
B = 2,
C = 4,
...
I have numbers like 1100, 1002, 1022 etc. I would like to have the individual digits, for example for the first number 1100 I want to have 1, 1, 0, 0.
How ...
I'm having trouble representing a mobile number in one of my applications.
I was wondering if there is an Integer class that will allow you to store such a number starting with ...
I want to convert a string of 5 numbers separated by commas into integers and store them into an array.
// person class
public class Person {
private String ...
I want to generate some random integers in Java, but this according to some distribution laws.
More specific:
I'm using this piece of code to get a Cell formula with JXL :
FormulaCell c=null;
String f="";
try {
c = (FormulaCell) mySheet.getCell(C,R);
} catch (Exception e) {e.printStackTrace();}
try {
...
How can I convert an int number from decimal to binary .
for example
int x=10; radix 10
how can i make another integer has the binary representation of x
such as:
int y=1010 radix ...
In Java, I would like to be able to do operations on really big integers (that can't be stored in a long), how can I do that?
What is the best way ...
I am in a situation where I want to use mutable versions of things like Integer. Do I have to use these classes (below) or does Java have something built in?
I cant seem to find the answer im looking for regarding a simple question.
How to round up any number to the nearest int?
I.e. whether the number is 0.2, 0.7, 0.2222, 0.4324, ...
I have the following code:
Why does Java think that this is not a valid long.
long
@Test
public void testOffendingBinaryString() {
String offendingString = "1000000000000000000010101000000000000000000000000000000000000000";
assertEquals(64, offendingString.length());
Long.parseLong(offendingString, 2);
}
Possible Duplicate:
Java problem-Whats the reason behind and what will be probable output
long milli=24*60*60*1000;
long micro=24*60*60*1000*1000;
long result=micro/milli;
Given a number:
int number = 1234;
String stringNumber = "1234";
I'm trying to read a string's character to get the numeric value.
String cardNumber = in.next();
int currentIndex = cardNumber.length() - 1;
while (currentIndex >= 0)
{
...
How would I go about doing arithmetic, + - / * % !, with arbitrarily large integers without using java.math.BigInteger?
For instance, the factorial of 90 returns 0 in Java.
I would ...
Why is NumberFormatException is thrown when i try Integer.parseInt("80000010", 16)?? That IS a 32-bit number, which is the size of java's int.
EDIT:
The best part is this...
Integer.parseInt("80000010", 16)
int z = 0x80000010;
System.err.println("equal to ...
Is there any method or quick way to check whether a number is an Integer ( belongs to Z field) in java
I thought of maybe subtracting it from the rounded number, ...
Ok so I'm working on a program that takes in an image, isolates a block of pixels into an array, and then gets each individual rgb value for each pixel in ...
So at the top of my code I declared the variable
private long counter;
And when I try to give it a number that's really long it gives an error, Im trying to ...
private long counter;
Sometimes I see API's using long or Long or int or Integer, and I can't figure how the decision is made for that?
When should I choose what?
Long
Integer
I am designing an archive format(Just for fun) in Java using this template-
First 4 bytes: Number of files in the archive
Next 4 bytes: Number of bytes in the filename
Next N bytes: ...
Here is my simple question
We can convert integer, float, double to String like String s = "" + i; so why do we need String s = Integer.toString(i); ? just requirements ...
integer, float, double
String s = "" + i;
String s = Integer.toString(i);
I've been doing some little code quizes just to catch back up on my coding after graduating but this one got my stump. Here's the question:
Given a number n and two ...
I created a my own SortedSet here is the code for adding something to the array. (I know there are better and simpler ways to do this than an Array but ...
I want to be able to tell if a any number in an int[] appears 3 or more times? How can I do this?
Would be awesome to have method
boolean hasTriples(int[] numbers) ...
I'm extremely new to Java and just wanted to confirm what Double is? Is it similar to Float or Int? Any help would be appreciated. I also sometimes see the uppercase ...
Double
I had a bug that caused an integer overflow, resulting in wrong (negative) timestamps being written to the database. The code is fixed already, but I want to fix the wrong ...
Can any one give me some predefined methods or user defined methods to convert string numbers(example : 123455) to comma separated integer value (example : 1,23,455).
Thanks in advance,
sathish
I write the bitstream for a JPEG Encoder, I'm facing this problem:
I built Pairs for the AC Cosinus Coefficients (after Quantization) in an int[]array. Each Pair: (Number of Zeros/ Category of ...
Example int i=185;
Then I want to get that 'i' contains 3 digits and those digits are 1,8, and 5.
int i=185;
I am having difficulty of creating a method to display first n digits of a number when 'n' is determined by the user.
For example, user inputs an integer '1234567' and ...
I usually use "" + i for convenient. But compare about perfomance myself, I thought String.valueOf(i) will be faster. Is it right? Which one should I use?
UPDATE: I've read your answers, ...
"" + i
String.valueOf(i)
Consider this snippet from the Java language specification.
class Test {
public static void main(String[] args) {
int i = 1000000;
System.out.println(i * i);
long l = i;
System.out.println(l * l);
}
}
-727379968
1000000000000
I am trying to beautify a program by displaying 1.2 if it is 1.2 and 1 if it is 1 problem is I have stored the numbers into the arraylist as ...
I'm busy with making an expression tree for school, I've already build the part in which the tree is being made and printing the result of the arithmetic expression also works.
I have to write in a buffer some integer values. But in the API is specified that the number is Integer, Numeric Unsigned and must have at maximum 4 bytes .
How ...
This is mine code, not fully finished, and sorry for Polish language but it's easy to get it.
So, this is about vet, 4 variables are for price per visitor:
1. ...
I am trying to convert an int to a byte[] and back again, but I think I am doing something wrong along the way. My code is basically:
byte[] array = new ...
Hello everyone I am new here, so I hope I don't get a "fine" of 10 posts if this question is not proper for this forum anyway, here is my problem. I am new to java, thus still very confused on classes methods interfaces etc etc but trying to learn it all.. I have in one folder a selectionSort I wrote ...
I am doing a hw assignment and I am stuck. I have 3 files: RollingDice2(has the main method) PairOfDice Die So this is what my problem is it has to roll some dies and find some numbers so like how I have it now RollingDice rolls 2 dices and finds the sum but how the RollingDice gets it roll it must ...
You should separate out how you STORE it from how you DISPLAY it. a number does not have commas in it. If you want to store something with commas in it, then you're not storing a number, you're storing a string. If you want to store a string, then don't consider it as a number.
I'm having a little trouble as to taking two int []'s and if there are two elements that are the same, skipping over them. In the end I need the program to print out the elements that don't have any duplicates at all. For instance: int [] a = {4, 5, 5} int [] b = {6, 6, 3} The program ...
Hello! I have a problem. I want to make a program that reads all the integers that are typed in and when a certain integer is typed in (lets say 0) it stops and then adds them all toghether. I was thinking of a while and for loop. And to place the integers to an array. But how do i add ...
Hello! I wonder if it is possible to initialize a variable without giving it an value? The part of my program I'm having trouble with: Java Code: //*The program will ask for 10 ints, when 10 ints have been taken in from //input the software will print the 2 biggest and the 2 smallest int. I've got it //to work if ...
public class DigitExtractor { private static int intNumber; public DigitExtractor(int anInteger) { intNumber = anInteger; String number = String.valueOf(intNumber); char charNumber = number.charAt(4); int x = number.charAt(3); int x1 = number.charAt(2); int x2 = number.charAt(1); int x3 = number.charAt(0); } public static String nextDigit() { I dont understand if I return one number is only gives me that number. Even if ...
Write a Java method to convert a given positive integer m to a positional number system in base n (n is in between 2 and 36). The result is a string consisting of digits and lowercase latin letters if needed. public static String toSysString (int m, int n) Example: toSysString (14, 4) == "32"
It should work pretty fast. How do you know that it's slow? Do you use a profiler? Also, do you try to create a new rand object on each loop of the for loop, or do you create one rand object before the for loop and use the same object inside of the loop? Please do the latter, not the former. ...
class Rational{ int num; int denom; int swap; public Rational(){ this.num = 0; this.denom = 0; } public Rational(int num, int denom){ this.num = num; this.denom = denom; } public Rational (int swap){ this.swap = swap; } public static void printRational (Rational r){ System.out.println (r.num + "/" + r.denom + " " + "i"); System.out.println ((r.num / r.denom) + " " ...
sentinel value? It looks like you are trying to parse the string. There is no built in method for this (that I know of) so you will have to write your own. Depending on what you know about the format of the string, you might want to use the String methods split(), or substring() to start with. (A telephone "number" ...
while(go==true) { int[] info = new int[69]; System.out.print("Enter username: "); username = reader.nextLine(); //use "Hellfire010" if you're going to try this out try{ URL score = new URL("" + username); BufferedReader in = new BufferedReader(new InputStreamReader(score.openStream())); String inputLine, ScoreList = ""; while ((inputLine = in.readLine()) != null) { ScoreList = (ScoreList + inputLine); } System.out.println(ScoreList); in.close(); }catch (IOException e) { System.err.println("Caught ...
public class test { public static void main(String args[]) { int n = 23121888; int part1 = n / 1000000; int part2 = (n % 1000000 - y)/10000; int part3 = n % 10000; System.out.println("Part 1 : " + part1 + "\nPart2 : " + part2 + "\nPart3 : " + part3); } }
I know you use charAt( ); for specifying a specific char in a string. What is the code to specify an int inside an int which is more than one digit long EG: four digit int int = 1234 how do i say intAt(0); the number (int) at position 0 within the initial int I want to specify each one individually ...
Shame on both of you. I recommend getting these books. Introduction to Java Programming (Y. Daniel Llang) Absolute Java Two of the best that i have seen. First Step Into Java - Dev Shed. This one to me at first seemed quite good. But then it started to feel like it was trying to teach Java to a 5th grader. The ...
I've tried using a string such as "-0xdeadbeef" or "+0xdeadbeef" with the same results. Is not the natural size of an Integer object 32 bits? So the max is 0xFFFFFFFF. my example of 0xdeadbeef is well within this. I'm not sure how the run time system is seeing it as a negative number?? Still stuck!! Mike
Both methods work fine if there is a single write that is ,when i use a print(int) or write(int) of PrintWriter OR writeInt(int) of DataOutputStream to write one integer data it works fine..the same is causing problems when i do three consecutive writes into the socket using either of the methods.. any help would be of great help for my project:) ...
If you are just told to strip it down into digits but not told to do anything with the digits then you don't need to keep the digits in integer variables. Just print them out as you get them. If you were not told an order in which you need to print them, print them in any order that makes the ...
Thank you gentlemen, but what you wrote did not solve my problem ... I am so new in java that it may be easyer for me to walk on hands... Can i solve this problem lets say in one command? Somehow? Could you please give me some example? Because i think i may learn it best on hand of an example ...
Hi, new to the site, looking for a few answers and i stumbled on a few forums. Most people give good advice, but there are a few that are annoying. If someone posts on these forums, its assumed they've 'googled' for an answer, as that would be the fastest way to resolve something. The purpose of these posts is to get ...
Hello! I want a code to select randomly let's say 3 numbers from a pool of numbers like (1,2,4,7,8,34) which have evenly distributed probabilities. How this can be done? I have found only how to pick a number randomly from a range of integers, but this is not my case, as I don't want the possibility of a number being selected ...
Hello, I need to know an integer value as part of a real number, like this: double a = 0; double x = 0; x = 1500.00; a = (x / 1000); now "a" must be equal to 1. Pascal has a function INT (a = INT(x/1000)), and what about java ? Thanks for help, guido
here is my jsp code.... dont know hw to proceed nxt....
DecimalFormat df = new DecimalFormat("#.###"); NumberFormatter format = new NumberFormatter(df); n the above code i have to convert decimal number to integer, how the below code will fit to it or any other way new Integer(((Number)formatter.parseObject(string)).intVal ue()) What kind of drugs are you taking currently? What kind of decimal format do you expect from an number with no decimals? The sentence ...
Number classes don't 'store this internal radix'. They use it in the code, as e.g. % 10 or / 10 or & 0xff or >>> 8. In the latter cases you can see that it is impossible to claim that the radix (256) is 'stored' anywhere at all. However as noted BigDecimal uses binary internally, much to my surprise. Doesn't alter ...
|
http://www.java2s.com/Questions_And_Answers/Java-Data-Type/Integer/number.htm
|
CC-MAIN-2018-17
|
refinedweb
| 2,996
| 74.39
|
The event handler GeneralEvents_OnLogError is getting executed recursively.
Scenario:
Have a collection of items for which 1 same process has to be performed.
But if there is any error thrown during the execution for any item, TestComplete should close and restart the application and continue the same process with the next item in the collection.
But the GeneralEvents_OnLogError gets executed infinitely if an error occurs.
Ideally script execution should end once the main is completely executed.
Kindly let me know what could be the possible root cause of the issue?
Thanks in advance!
Please find the sample code below.
indexValue = 0 list = [1,2,3,5,10,8]
def main(): launchApplication() while indexValue<len(list): performTask(list(indexValue)) indexValue = indexValue + 1 Log.Message("Process Completed") def GeneralEvents_OnLogError(Sender, LogParams): global indexValue indexValue= indexValue+ 1 CloseOpenApplcaition() main()
It's generally not a good idea to do a recursive call like that in an event handler. Basically, you have a function that is getting an error, that error triggers the event, that event then goes back and calls the same function that generates the same error which calls the event... etc.
Instead of using the OnLogError event, what I would do is utilize exception handling within def main. I'm not familiar with python but I'm certain it has that kind of handling (see). Wrap the code that potentially could have the error in a "try" block, handle the exception in the "exception" block. The exception block would have the call to "CloseApplication". Here's what I THINK it should look like:
indexValue = 0 list = [1,2,3,5,10,8] def main(): launchApplication() while indexValue<len(list): try: performTask(list(indexValue)) except Error: CloseOpenApplication() indexValue = indexValue + 1 Log.Message("Process Completed")
Basically, in the loop, if an error happens performing the task, it throws the exception. The except block handles it and closes the application. the index is then increased as necessary and the loop continues.
Thanks a lot Robert for your detailed reply. 🙂
I have a further query for the solution that you have suggested.
In performTask method, if the error occurs due to some unexpected window, or any other issue where UI objects are involved, will the exception handling of python handle it?
I believe the Python exception handling can only handle python errors and not the UI window errors.
I may be completely wrong as I am new to Test Complete.
Kindly post your thoughts on this.
You are right, try...except will not handle UI errors. I'd suggest you another solution:
def main(): while indexValue<len(list): launchApplication() performTask(list(indexValue)) indexValue = indexValue + 1 Log.Message("Process Completed") def GeneralEvents_OnLogError(Sender, LogParams): CloseOpenApplcaition() def launchApplication(): if(not isAppRunning()): startApp()
The main idea is that you call launchApp() function in every iteration of the while loop and start the app only if it is not started yet. In the OnLogError event handler you just close your app
Thanks for your reply.
But I am not sure if this will work
The requirement is to run performTask method for every item of the list.
I believe in your suggestion,the script execution would stop once any error occurs for an item(i.e. once the code enters OnLogError method).
But instead of stopping the execution, I need to continue the process with the next item in the list.
I have been able to achieve this with my code(posted in the question) but the issue that I am facing is that the GeneralEvents_OnLogError is getting executed recursively even after completing the process for all the items.
Kindly guide me how can I handle this.
You need to uncheck the option
Tools - Current Project Properties - Playback - Stop on Error
and then my solution will work for you.
Correct. UI indentification issues will not raise as a Python exception. However, a best practice is to always verify an object exists before interacting with it, especially when using "Find" methods or if you are navigating to a new page, form, etc. So, in those checks for the object, you could raise an exception manually if the object does not exist which would then trigger the exception handling.
@karkadil: The issue here is that the error occurs in performTask method after which generalevents_onlogerror is invoked and the control goes back to the step where error occured (which again causes failure since the application is closed by the onlogerror method).
I need to close then reopen the application and start the same (performTask) for the next item in the list.
Any suggestions, how can I achieve this?
|
https://community.smartbear.com/t5/TestComplete-Desktop-Testing/GeneralEvents-OnLogError-Running-Infinitely/m-p/165277/highlight/true
|
CC-MAIN-2020-29
|
refinedweb
| 765
| 54.42
|
Hello, I think I have the problem... it's a doozy. :-) lexGetc is returning 255 for EOF instead of -1. This is because lexLookAhead is calling int lexGeta(), which returns the value from char lexGetc(). In the cast from char to int, it gives 255 instead of -1, even though the char is not unsigned. On Intel and Alpha, it gives -1, which is the correct behavior (right?). The attached little test program illustrates this: on Intel and Alpha, it stops at the end of the file; on PPC and ARM, it infinite loops. Because it is common to PPC and ARM, this is not related to endianness. This is obviously not a gnome-pim problem, so I'm closing this bug. This would be a compiler issue, right? Until this is fixed, it would appear that everything using bison to parse files is broken on PPC and ARM. Thanks, -Adam P. Adam C Powell IV wrote: > Package: gnome-pim > Version: 1.0.55-1 > Severity: normal > > gnomecal and gnomecard do not start on PPC. strace shows them loading > the file just fine using a read (8,"blahblah"..., 4096) = 4096 until the > end of the file, then the length of the file remainder, then it loops > on: > > read(8, "", 4096) = 0 > > after it finishes loading the file. If there is no file, then it starts > fine and one can make a calendar and address book, but after quitting > and saving, neither of them can start again, because they infinite loop > while trying to load the file, even if it's just eighty characters long. > > This has been a problem for a long time (like, months). It just came up > today on debian-powerpc that gnomecal does indeed work, and we tried > stracing. > > Thanks, > > -Aham P. > > -- System Information > Debian Release: 2.2 > Kernel Version: Linux ebedmelech 2.2.15pre17-atydbg #1 Wed Apr 5 > 22:04:31 EDT 2000 ppc unknown > > Versions of the packages gnome-pim depends on: > ii gdk-imlib1 1.9.8-4 Gdk-Imlib is an imaging library for > use with > ii libart2 1.0.56-3 The Gnome canvas widget > ii libaudiofile0 0.1.9-0.1 The Audiofile Library > ii libc6 2.1.3-8 GNU C Library: Shared libraries and > Timezone > ii libesd0 0.2.17-7 Enlightened Sound Daemon - Shared > libraries > ii libglib1.2 1.2.7-2 The GLib library of C routines > ii libgnome32 1.0.56-3 The Gnome libraries > ii libgnomesuppor 1.0.56-3 The Gnome libraries (Support > libraries) > ii libgnomeui32 1.0.56-3 The Gnome libraries (User Interface) > ii libgnorba27 1.0.56-3 Gnome CORBA services > ii libgtk1.2 1.2.7-1 The GIMP Toolkit set of widgets for X > ii liborbit0 0.5.0-5 Libraries for ORBit - a CORBA ORB > ii xlib6g 3.3.6-6 shared libraries required by X clients > > ii zlib1g 1.1.3-5 compression library - runtime
#include <stdio.h> static char mygetc (FILE *the) { return fgetc (the); } void main() { FILE *f; int c; f = fopen ("killme.c","r"); do { c = mygetc (f); printf ("|%d=%c", c,c); fflush (stdout); } while (c!=EOF); }
|
https://lists.debian.org/debian-powerpc/2000/04/msg00224.html
|
CC-MAIN-2015-48
|
refinedweb
| 525
| 76.62
|
On Sun, Jan 02, 2011 at 09:26:08PM -0500, Brian Olson wrote: >. Yes, that's what I meant. > I think I saw that memory is being allocated and zeroed, so > s->use_wordexp will default to off, as it should. Yes indeed. > Index: libavformat/img2.c > =================================================================== > --- libavformat/img2.c (revision 26178) > +++ libavformat/img2.c (working copy) > [...] > @@ -117,6 +124,14 @@ > return CODEC_ID_NONE; > } > > +static int is_wordexp(const char* path) { > +#if HAVE_WORDEXP > + return 0 != strspn(path, "*?[](){}\\"); > +#else > + return 0; > +#endif > +} This looks wrong. This won't detect expressions such as "pict*.jpeg". And it would look cleaner without #if: static int is_wordexp(const char* path) { return HAVE_WORDEXP && strcspn(path, "*?[](){}\\") != strlen(path); } Aurel
|
http://ffmpeg.org/pipermail/ffmpeg-devel/2011-January/105484.html
|
CC-MAIN-2014-41
|
refinedweb
| 110
| 52.76
|
NAME
XAO::Base - Set of base classes for the XAO family of products
DESCRIPTION
XAO::Base is really a collection of some very basic modules that are used throughout XAO suite. They include:
- XAO::Errors
Generator of error namespaces for use in error throwing catching. See the XAO::Errors manpage.
- XAO::Objects
Loader of dynamic objects, practically everything else in the XAO suite depends on this module. See the XAO::Objects manpage.
- XAO::Projects
Registry of projects and context switcher. Mostly used in XAO::Web to store site configurations and database handlers in mod_perl environment, but is not limited to that. See the XAO::Projects manpage.
- XAO::SimpleHash
Probably the oldest object in the suite, represents interface to a hash with some extended functionality like URI style references to hashes. See the XAO::SimpleHash manpage.
- XAO::Utils
Variety of small exportable subroutines -- random key generation, text utilities, debugging. See the XAO::Utils manpage.
- XAO::DO::Config
Base configuration object that allows to embed other configuration objects into it. See the XAO::DO::Config manpage.
AUTHORS
XAO Inc., Copyright (C) 1997-2003
|
https://metacpan.org/pod/XAO::Base
|
CC-MAIN-2019-43
|
refinedweb
| 181
| 52.66
|
Stitch Fix is a Data Science company that aspires to help you to find the style that you love. Data Science helps us make most of our business and strategic decisions.
At Stitch Fix, our Data Scientists run 1000s of Spark jobs every day. This post describes the tooling we’ve put in place to abstract the complexity of developing and scheduling these jobs in production and executing them on an elastic number of clusters.
Infrastructure
Stitch Fix’s data infrastructure is housed completely on Amazon AWS. A huge advantage to running in that environment is that storage can easily be decoupled from compute. That decoupled storage layer is S3.
This allows us to be flexible and gives us the ability to run multiple clusters against the same data layer. We have also built tooling that allows our Data Scientists to create and terminate ad-hoc clusters without much hassle.
The transient nature of the clusters should not be an issue or concern for Data Scientists. They should not worry about the execution environment and how to interact with it. Genie and the tools around it, help us in making that possible.
Let’s have a closer look at Genie.
Genie
Genie has been an integral part of Stitch Fix’s Compute infrastructure. It was created and open sourced by Netflix (Genie) and this is where it fits within our Spark architecture.
Genie helps us accomplish the following unique functions.
Spark Indirection
At Stitch Fix, we run our own custom builds of Apache Spark. This means we can bump minor versions, add patches, and add custom scripts to our heart’s content.
Today our Spark 2.x version may reference a custom build of Spark 2.1.0, tomorrow it might reference a custom build of Spark 2.2.0.
At the end of the day, Data scientists don’t want to worry if they’re running our build of Spark 2.1.0 or Spark 2.2.0.
Red/Black Cluster Deployment
If we ever need to redeploy our clusters, we can do so without disrupting the workflow and without any coordination with our Data Science teams. Genie’s data model specifically supports it.
Here is an overview of the additional tooling we built for Spark.
Babylon
Babylon is our internal tool that helps a Spark job start and head to Genie.
Sheriff of Babylon
Sheriff is our command line tool and Genie client library that we built to abstract Data Scientists’ interactions with Genie. Sheriff handles job submissions. Thus, Data Scientists don’t have to be concerned about Genie’s API calls. The same command line is used to both iterate on jobs during development and schedule them in production.
Overrides
Default settings have been useful for Data Scientists. These include executor memory (4G), executor cores (3) and driver_memory (4G). This gets the applications started without worrying about relevant Spark parameters and helps usher in newer Data Scientists into our team with ease.
For resource intensive ETLs, we recommend overriding the default values.
sheriff is used to add overrides to default values setup via Genie.
Run Commands
These commands in
sheriff essentially form a translational layer of a Data Scientist’s intent to Genie API calls.
The command
run_spark helps run any Spark jobs from sheriff with ease.
It packages code dependencies and manages shipping the job off to genie with relevant parameters and tags.
To help run Spark SQL jobs, we have the command
run_sql.
This command takes a sql file and packages it into a spark job that will write its results into another table on S3,
even automatically creating the Metastore definition if it does not already exist.
Additionally, we have
run_with_json to help configure your options in a JSON file,
and version it separately in GitHub, rather than having a massively long command line.
Additional Tools in Babylon
Custom SparkContext
Another great time and stress reliever, is our wrapper around the
HiveContext in Spark.
HiveContext, inherits from Spark’s
SQLContext, and adds support for writing queries using HiveQL.
A call to our custom
SparkContext class helps easily define a Spark job and use the built-in methods.
It especially helps facilitate the communication between our Spark build and the Hive Metastore.
Metastore Library
We have a Scala library called SFS3 that facilitates reading and writing to our data warehouse (S3 + Hive Metastore). It allows us to collect custom stats on our data and construct data lineage. It’s a easy-to-use API for writing and saving Spark DataFrame objects of table data. E.g.
write_dataframe(self, df, hiveschema, partitions=None, create=True, add_partitions=False, drop_first=False)
This allows to write across multiple partitions while registering each new or updated partition with Metastore.
Table Statistics
Incorporating Broadcast joins can make jobs much more efficient,
but can also cause incredible failures if incorrect statistics are stored in the Hive Metastore.
We automate this collection of statistics via our
TableAnalyzer tool.
Python Query API
For people who prefer to stay in pure Python, we have another library that hides some of the details of Spark. It allows users to write queries that, behind the scenes, utilize Spark machinery (the subject of a future blog post). E.g.
from stitchfix_data_lib import query df = query('SELECT COUNT(*) from <table_name>', using='spark-sql')
Diagnostic Tool
And finally, we also have a Diagnostic tool that has the ability to recommend and provide pointers based on the error messages in the log output. Sample Diagnostic Reports would look like this
========= Report ========== Script error - AttributeError: 'DataFrame' object has no attribute 'union'
========= Report ========== Script error - import error (bad name or module not installed): No module named fire
To be continued..
Our goal to help Data Scientists have the resources they need has been a motivating factor behind our infrastructure decisions. Having a resourceful tool like Genie has proven to work well for our use case.
The next blog post in this series will explore other parts of this Spark infrastructure.
Thanks for reading.
|
https://multithreaded.stitchfix.com/blog/2017/08/10/genie-in-a-box/
|
CC-MAIN-2021-04
|
refinedweb
| 1,000
| 55.13
|
If you’ve worked with an Arduino and used a Windows development machine, you’ll probably have used the Arduino IDE to deploy code, and used the IDE’s built in serial monitor to read messages back from the Arduino device. And if you want to use these messages in a .NET application, there’s already good support in the .NET Framework – but what about .NET Core?
In this post, I’ll look at how to use VSCode to create an Arduino simple project which writes to a serial port, and deploy this to an Arduino Uno using VSCode. Then I’ll write about how to use the preview NuGet package to read this data using .NET Core. I’ll finish up with some issues I’ve observed.
Note – this article about .NET Core targets Windows 10 32-bit/64-bit editions – this won’t work if you’re targeting ARM devices with Windows 10 IoT Core (i.e. win10-arm). I’ll cover targeting the ARM platform in a later post.
Also, you’ll obviously need an Arduino for this – I’ve found an Arduino UNO is ideal.
This post has two main sections – setting up a example project on an Arduino using VSCode to write data to a serial port, and then how to access this data using a .NET Core application.
Writing data to a serial port with an Arduino
Setting up VSCode for Arduino development
First of all, you’ll need VSCode on your development machine – you can download it from here. I’ll not describe this in detail – it’s pretty much a point and click installer.
You’ll also need the Arduino IDE installed on your machine so VSCode can access the necessary libraries – you can download it from here. Again this is a very straightforward installation.
Next, install the Arduino extension for VSCode. There are great instructions here – but in summary, from VSCode:
- Hit ‘Ctrl + P’
- Type:
ext install vscode-arduino
At this point, you’ll have the Arduino extension for VSCode, presently at version 0.2.4.
Create an Arduino project in VSCode which writes to the serial port
From VSCode, you can create a new Arduino project with the following steps:
- Create a folder on your development machine to hold the Arduino project – I’ve called mine ArduinoSerialExample
- Open this folder in VSCode.
- In VSCode, hit ‘Ctrl + Shift + P’ to open the VSCode Command Palette.
- Type: Arduino: Initialize – VSCode will offer to create a file with extension app.ino.
- Rename this to ArduinoSerialExample.ino. It’s important that this file (also known as an Arduino sketch) has the same name as the parent directory.
- At this point, VSCode will ask what Arduino device is being used – I’m using an Arduino UNO, so I selected this from the list.
Your VSCode workspace is now initialised for Arduino development.
- Update the code in the ArduinoSerialExample.ino file to have the contents shown below.
int i = 0; void setup(){ Serial.begin(9600); } void loop(){ Serial.print("Hello Pi "); Serial.println(i); delay(1000); i++; }
Important tip – if you copy and paste into VSCode, make sure you don’t accidentally copy unexpected unicode characters, as these will cause compiler errors.
- Now hit ‘Ctrl + Shift + R’ to compile (also known as Verify) the script – if everything works, you should see an output similar to the text below.
[Starting] Verify sketch - ArduinoSerialExample.ino Loading configuration... Initialising packages... Preparing boards... Verifying... Sketch uses 1,868 bytes (5%) of program storage space. Maximum is 32,256 bytes. Global variables use 198 bytes (9%) of dynamic memory, leaving 1,850 bytes for local variables. Maximum is 2,048 bytes. [Done] Finished verify sketch - ArduinoSerialExample.ino
Test this project works with a real Arduino
There’s a couple of last steps – connecting the physical Arduino to your development machine, and choosing the serial port.
If you look at the bottom right corner of VSCode, you should see that there’s still a prompt to select the serial port (as shown below).
Once I plugged my Arduino UNO into a USB port on my machine, I was able to click on theprompt (highlighted in a red box in the image above), and VSCode prompts me to select a serial port, as shown below.
I selected COM4, and this updates VSCode to show the serial port in the bottom right corner of the screen, as shown below.
I’m now ready to rest the Arduino is writing to the serial port.
I can upload the sketch to the Arduino by hitting ‘Ctrl + Shift + U’ – this will re-compile the sketch and upload it to the Arduino.
Next, hit open the command palette again (by hitting ‘Ctrl + Shift + P’, and type ‘Arduino Open Serial Monitor’, and select the option to open the Serial Monitor from the dropdown list.
The serial monitor opens, and I’m able to see output being logged to the console from the Arduino through the serial port COM4, as shown below.
Accessing the serial port data on a PC using .NET Core
TL:DR; I’ve uploaded the project to GitHub here.
First set up the .NET Core 2 solution – a console project and a .NET Standard 2.0 class library
Create a new project to hold your .NET solution. I like to manage solutions using the command line – I create a solution using the command:
dotnet new sln -n ReadSerialDataFromArduino
Inside this solution folder, create a new .NET Core console project – I do this using the command:
dotnet new console -n ReadFromArduino
Also create a new .NET Standard 2.0 library project inside the solution folder – again, I do this using the command:
dotnet new classlib -n ReadSerialInputFromUSB
Now we can add these two projects to the solution using the commands below
dotnet sln add .\ReadFromArduino\ReadFromArduino.csproj dotnet sln add .\ReadSerialInputFromUSB\ReadSerialInputFromUSB.csproj
And we can see the projects in the solution using the command below:
dotnet sln list
And this command presents the expected output of:
Project reference(s) -------------------- ReadFromArduino\ReadFromArduino.csproj ReadSerialInputFromUSB\ReadSerialInputFromUSB.csproj
Finally for this section, I want to add the library as a reference to my console application with the command:
dotnet add .\ReadFromArduino\ReadFromArduino.csproj reference .\ReadSerialInputFromUSB\ReadSerialInputFromUSB.csproj
Add the .NET Core System.IO.Ports preview package
The System.IO.Ports package (available here on nuget.org) allows access to the serial port through a .NET Core application. I can add this to my .NET Standard 2.0 class library by navigating into the ReadSerialInputFromUSB directory, and run the command below:
dotnet add package System.IO.Ports --version 4.4.0-preview2-25405-01
So now the project structure is is place – we can add the bits of code that actually do things.
Let’s use C# to list what serial ports are available to us. I’ve created a class in the ReadSerialInputFromUSB project named SerialInformation, and added a static method called GetPorts().
using System; using System.IO.Ports; namespace ReadSerialInputFromUSB { public class SerialInformation { public static void GetPorts() { Console.WriteLine("Serial ports available:"); Console.WriteLine("-----------------------"); foreach(var portName in SerialPort.GetPortNames()) { Console.WriteLine(portName); } } } }
And we can access this through the main method in the ReadFromArduino project:
using ReadSerialInputFromUSB; namespace ReadFromArduino { class Program { static void Main(string[] args) { SerialInformation.GetPorts(); } } }
If we build this and run the project (using dotnet build and dotnet run) the output is:
Serial ports available: ----------------------- COM4
This is exactly what we’d expect from earlier, where VSCode identified COM4 as the port being used by the Arduino.
And if we can get the data from the Arduino into a variable and write to the console, we can do that by using the DataReceived event and using the ReadExisting() method on the serial port object, as shown below:
public void ReadFromPort() { // Initialise the serial port on COM4. // obviously we would normally parameterise this, but // this is for demonstration purposes only. this.SerialPort = new SerialPort("COM4") { BaudRate = 9600, Parity = Parity.None, StopBits = StopBits.One, DataBits = 8, Handshake = Handshake.None }; // Subscribe to the DataReceived event. this.SerialPort.DataReceived += SerialPortDataReceived; // Now open the port. this.SerialPort.Open(); } private void SerialPortDataReceived(object sender, SerialDataReceivedEventArgs e) { var serialPort = (SerialPort)sender; // Read the data that's in the serial buffer. var serialdata = serialPort.ReadExisting(); // Write to debug output. Debug.Write(serialdata); }
I can call this in my console project’s main method using the code below:
static void Main(string[] args) { SerialInformation.GetPorts(); var serialInformation = new SerialInformation(); serialInformation.ReadFromPort(); Console.ReadKey(); serialInformation.SerialPort.Close(); }
So when I run this console application, the COM4 serial port is opened, and writes whatever it receives to the debug output.
You can see the source code for the Serial.IO.Ports library on GitHub in the CoreFX library, and there’s access to the nightly builds on myget.org.
This library is great for connecting to (and reading from) serial ports using a .NET Core application running on a Windows x32/x64 machine. However, one issue is this library doesn’t work with ARM – either for Windows 10 IoT Core or for Linux.
Wrapping up
Using the Serial.IO.Ports preview library available on NuGet, it’s possible to read from serial ports using a .NET Core 2 application on a Windows 32-bit/64-bit machine, and I’ve a very simple example of how to do this available on GitHub here. So far there’s not an implementation in the Serial.IO.Ports library which works for ARM architectures, but I’ll look at options for closing this gap in future posts.
About me: I regularly post about .NET – if you’re interested, please follow me on Twitter, or have a look at my previous posts here. Thanks!
|
https://jeremylindsayni.wordpress.com/category/iot/page/2/
|
CC-MAIN-2019-30
|
refinedweb
| 1,615
| 57.16
|
Note: this log overlaps in time with ChangeLog-9194. There was a time during which changes which had been merged into the official CVS (which produced releases such as 1.4A1 and 1.4A2) went into what has become ChangeLog-9194, and changes which existed only at Cygnus went into this file (ChangeLog-9395). Eventually the Cygnus release became Cyclic CVS (as it was then called), which became CVS 1.5, so probably all the changes in both (what are now) ChangeLog-9194 and ChangeLog-9395 made it into 1.5. Sun Dec 31 17:33:47 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * import.c (add_rev): Revert portion of 31 Aug 95 change which passes -u to ci instead of using a hard link. * sanity.sh (import): Add test for above-fixed bug. Sun Dec 31 16:40:41 1995 Peter Chubb <peterc@bookworm.sw.oz.au> and Jim Kingdon <kingdon@cyclic.com> * admin.c (admin_fileproc): Call freevers_ts before returning. Mon Dec 25 12:20:06 1995 Peter Wemm <peter@haywire.DIALix.COM> * logmsg.c (rcsinfo_proc): initialise line and line_chars_allocated so they dont cause malloc problems within getline(). This was causing rcsinfo templates to not work. Sun Dec 24 01:38:36 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (authenticate_connection): clarify protocol. * login.c (login): deprolixify the password prompt. Sat Dec 23 10:46:41 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * myndbm.h, myndbm.c (dbm_store): New function. * myndbm.h (DBM): Add modified and filename fields. * myndbm.c (dbm_open, dbm_close): Manipulate new fields. dbm_open no longer fails if the file doesn't exist and O_CREAT is set. * cvs.h (CVSROOTADM_VALTAGS): Added. * tag.c, cvs.h (tag_check_valid): New function. * update.c (update), checkout.c (checkout_proc), commit.c (commit), diff.c (diff), patch.c (patch_proc), rtag.c (rtag_proc), tag.c (tag): Call it. * sanity.sh: Test for rejection of invalid tagname. Fri Dec 22 18:21:39 1995 Karl Fogel <kfogel@csxt.cs.oberlin.edu> * client.c (start_server): don't use kerberos if authenticating server was specified. Fri Dec 22 16:35:57 1995 Karl Fogel <kfogel@csxt.cs.oberlin.edu> * login.c (login): deal with new scramble methods. (get_cvs_password): same. * server.c (check_repository_password): remove arbitrary limit on line length. (authenticate_connection): use a separate variable for the descrambled password, now that we no longer scramble in place. Set `error_use_protocol' to 1 and just use error() where used to do its job inline. * cvs.h (scramble, descramble): adjust prototype. * scramble.c (scramble, descramble): return char *. Fri Dec 22 13:00:00 1995 Jim Kingdon <kingdon@peary.cyclic.com> * release.c (release): If SERVER_SUPPORT is not defined, still set up arg_start_idx. * release.c (release): When calling unedit, set argv[1] to NULL (since argc is only 1). * edit.c: Pass dosrcs 0 to all calls to start_recursion. None of the fileprocs were using it, so it just slowed things down and caused potentially harmful checks for rcs files. * edit.c (send_notifications): In client case, do not readlock. Thu Dec 21 16:00:00 1995 Jim Kingdon <kingdon@peary.cyclic.com> Clean up Visual C++ lint: * client.c (read_line): Change input_index and result_size to size_t. (update_entries): Remove unused variables buf2, size_left, size_read. (handle_mode): Prototype. * client.c, client.h (send_to_server, read_from_server): Change len to size_t. * client.c (send_to_server): Change wrtn to size_t. (read_from_server): Change red to size_t. * client.c, myndbm.c, edit.c, fileattr.c: Include getline.h. * checkin.c, commit.c, update.c: Include fileattr.h. * commit.c, update.c: Include edit.h. * edit.c (onoff_filesdoneproc): Prototype. (ncheck_fileproc,edit_fileproc): Change "return" to "return 0". (notify_do): Cast a signed value to unsigned before comparing with unsigned value. Thu Dec 21 15:24:37 1995 Karl Fogel <kfogel@occs.cs.oberlin.edu> * client.c: don't include socket headers twice just because both HAVE_KERBEROS and AUTH_CLIENT_SUPPORT are set. (start_kerberos_server): if fail to connect to kerberos, print out a more specific error message, mainly so pcl-cvs can know what happened and not panic. (start_server): don't assume sprintf() returns len written (only some systems provide this); instead, have send_to_server() calculate the length itself. (send_modified): same. (send_fileproc): same. (send_file_names): same. Wed Dec 20 14:00:28 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * update.c (ignore_files): Move from here... * ignore.c (ignore_files): ...to here. No longer static. Take new argument PROC. * cvs.h (ignore_files): Declare. * client.c (send_filesdoneproc): Split off from update_filesdone_proc. Pass new function send_ignproc to ignore_files (to ask server about ignored file before printing "?"). * server.c: Rename outbuf from but_to_net and take it from do_cvs_command to a global. Move initialization accordingly. (serve_questionable): New function. (requests): Add it. * update.c (update_filesdone_proc): Remove client stuff. Pass new function update_ignproc to ignore_files. * cvs.h (joining, do_update): Move declarations from here... * update.h: ...to here. * cvs.h: Include update.h. * update.c, client.c: Don't include update.h * ignore.c, cvs.h: New variable ign_inhibit_server, set on -I !. * import.c (import): Pass -I ! to server if specified. (import_descend): If server, ignore CVS directories even if -I !. * update.c (update), import.c (import): Only call ign_setup before argument processing; don't call it again afterwards in client case. * sanity.sh (ignore): Test above-fixed bugs and other ignore behaviors. (dotest): New function. Move modules checkin from modules test to start, so that other tests can use mkmodules without a warning message. Wed Dec 20 13:06:17 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (send_to_server): don't check string's length twice. Wed Dec 20 02:05:19 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (login): took out debugging printf's. (login): Removed unused variable `p'. Wed Dec 20 00:27:36 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (login): prefix scrambled password with 'A', so we know which version of scrambling was used. This may be useful in the future. (get_cvs_password): skip past the leading 'A'. Scramble $CVS_PASSWORD before returning it. * scramble.c: made this work. Tue Dec 19 17:45:11 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (cvs_password): new static var, init to NULL. (login): scramble() the password before using it. Verify the password with the server. Check CVSroot more carefully to insure that it is "fully-qualified". (get_cvs_password): if cvs_password is not NULL, just return it. Never prompt -- just tell user why failed, then exit. Try CVS_PASSWORD environment variable first. (construct_cvspass_filename): try CVS_PASSFILE environment variable first. * client.h (connect_to_pserver): update prototype. * client.c (cvsroot_parsed): new static var. (parse_cvsroot): set `cvsroot_parsed' to 1 when done. (connect_to_pserver): return int. Take `verify_only' arg. If it is non-zero, perform password verification with the server and then shut down the connection and return. Call parse_cvsroot() before doing anything. * server.c (authenticate_connection): deal with verification requests as well as authorization requests. descramble() the password before hashing it. * cvs.h: prototype scramble() and descramble(). * Makefile.in: build scramble.o. * scramble.c: new file, provides trivial encoding but NOT real encryption. Mon Dec 18 20:57:58 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (login): don't insert extra newlines. They were harmless, but confusing. Mon Dec 18 15:32:32 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * hash.c, hash.h (findnode_fn): New function. * hash.c (hashp): Tweak hash function so that findnode_fn works. * update.c (ignore_files): Call findnode_fn, not findnode. Mon Dec 18 09:34:56 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * myndbm.c: Remove arbitrary limit. * client.c: Fix comment--Windows 95 requires NO_SOCKET_TO_FD, not Windows NT. Mon Dec 18 01:06:20 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (server_sock): replaces `server_socket'. (start_kerberos_server): added FIXME comment about how NO_SOCKET_TO_FD is not dealt with in the kerberos case. (connect_to_pserver): deal with NO_SOCKET_TO_FD case. (read_line): deal with NO_SOCKET_TO_FD case. (read_from_server): deal with NO_SOCKET_TO_FD case. (send_to_server): deal with NO_SOCKET_TO_FD case. (get_responses_and_close): deal with NO_SOCKET_TO_FD case. * client.c (send_to_server): error check logging. (start_server): error check opening of logfiles. (read_from_server): error check logging. (read_line): use fwrite() to log, & error_check it. Don't log if using socket style, because read_from_server() already logged for us. Mon Dec 18 00:52:26 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (use_socket_style): new static var, init to 0. (server_socket): new static var. (connect_to_pserver): don't deal with logging here. Caller changed. (start_kerberos_server): don't deal with logging here either. Caller changed. Mon Dec 18 00:40:46 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (send_modified): don't error-check `to_server'; send_to_server() does that now. Mon Dec 18 00:19:16 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (get_cvs_password): Init `linebuf' to NULL. free() `linebuf' and reset it for each new line. (login): same as above. * client.c: Removed all the varargs prototyping gunk. (to_server, from_server): make these static. (from_server_logfile, to_server_logfile): new vars. (start_server): init above two new vars to NULL. (send_to_server): return void. Correct bug in which amount to be written would be too high if the loop ever ran more than once. Log to `to_server_logfile' if it's non-NULL. (read_from_server): new func, does raw reading from server. Logs to `from_server_logfile' if it's non-NULL. (update_entries): just use read_from_server() instead of looping to fread() directly from `from_server'. (read_line): Log to `from_server_logfile' if it's non-NULL. * client.h: send_to_server() returns void now. (read_from_server): prototype. Sun Dec 17 19:38:03 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * checkout.c (checkout_proc), client.c, lock.c (readers_exist), login.c, modules.c (cat_module, do_module): Remove arbitrary limits. * client.c (send_to_server): Fix typo (NULL -> '\0'). (get_responses_and_close): Set server_started to 0 instead of setting to_server and from_server to NULL. * client.c: Make to_server and from_server static. Sun Dec 17 17:59:04 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.h (to_server, from_server): don't declare these anymore. They are now entirely private to client.c (and in fact will go away soon there too). Sun Dec 17 15:40:58 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.h: update prototype of send_to_server(). * client.c, watch.c, update.c, tag.c, status.c, rtag.c, remove.c, release.c, patch.c, log.c, import.c, history.c, edit.c, diff.c, commit.c, client.c, checkout.c, admin.c, add.c: Convert all send_to_server() calls that used formatting to send pre-formatted strings instead. And don't error check send_to_server(), because it does its own error checking now. * client.c (send_to_server): don't use vasprintf(), just fwrite a certain number of bytes to the server. And do error checking here, so our callers don't have to. (send_arg): use send_to_server() instead of putc()'ing directly to `to_server'. Sun Dec 17 14:37:52 1995 Karl Fogel <kfogel@floss.cyclic.com> * options.h.in (AUTH_CLIENT_SUPPORT, AUTH_SERVER_SUPPORT): Define to 1 but leave commented out, instead of #undef'ing them. This treats them like everything else in this file. * client.c: define server_started, init to 0. (start_server): set server_started to 1. * client.h: declare `server_started', extern. AUTH_CLIENT_SUPPORT moved here from cvs.h. * cvs.h: moved AUTH_CLIENT_SUPPORT stuff to client.h. * edit.c (notify_check): use new var server_started. Sun Dec 17 00:44:17 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * client.c (get_responses_and_close): Really stop ignoring ECHILD errors. The Nov 30 1995 change claimed to do this, but the code was not actually changed. * update.c (ignore_files): Revert H.J. Lu change; it was wrong for directories and sometimes looked at sb.st_mode when it wasn't set. * import.c (import_descend): Revert H.J. Lu change; it was wrong for directories and the extra lstat call was an unnecessary performance hit. * sanity.sh (import): Add test for the second of these two bugs. Sat Dec 16 17:26:08 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * client.c (send_to_server): Remove arbitrary limit. Also remove !HAVE_VPRINTF code; all relevant systems have vprintf these days. Sat Dec 16 21:35:31 1995 Karl Fogel <kfogel@floss.cyclic.com> * checkout.c (checkout): use send_to_server() now. Sat Dec 16 21:18:16 1995 H.J. Lu (hjl@gnu.ai.mit.edu) (applied by kfogel@cyclic.com) * import.c (import_descend): We ignore an entry if it is 1. not a file, nor a link, nor a directory, or 2. a file and on the ignore list. * update.c (ignore_files): We ignore any thing which is 1. not a file, or 2. it is a file on the ignore list. Sat Dec 16 00:14:19 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (send_to_server): corrected comment. * client.h: prototype new func send_to_server(). * add.c, admin.c, client.c, commit.c, diff.c, edit.c, history.c, import.c, log.c, patch.c, release.c, remove.c, rtag.c, status.c, tag.c, update.c, watch.c: Use send_to_server() instead of writing directly to to_server. * client.c: conditionally include the right stuff for variable arg lists. (send_to_server): new func. Fri Dec 15 23:10:22 1995 Karl Fogel <kfogel@floss.cyclic.com> * error.c: expanded comments. * client.c (connect_to_pserver): verbosify errors. (connect_to_pserver): use send() and recv(), not write() and read(). Sockets are not file descriptors on all systems. Fri Dec 15 22:36:05 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (connect_to_pserver): oops, removed old debugging printf. Fri Dec 15 18:21:16 1995 Karl Fogel (kfogel@floss.cyclic.com) * client.c (auth_server_port_number): don't call htons(); init_sockaddr() does that for us. (init_sockaddr): zero the sockadder_in struct before doing anything with it. IBM TCP/IP docs recommend this, and it can't hurt. Fri Dec 15 15:21:53 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (connect_to_pserver): new var `port_number', initialize with new func auth_server_port_number() and pass to init_sockaddr(). (auth_server_port_number): new func. Right now it just returns `htons (CVS_AUTH_PORT)'. We'll probably add the ability to specify the port at run time soon, anyway, so having this function will make that easier. Wed Dec 6 18:08:40 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * cvs.h: Add CVSREP. * find_names.c (find_dirs): Skip CVSREP too. * fileattr.h, fileattr.c: New files, to manipulate file attributes. * hash.c (nodetypestring), hash.h (enum ntype): Add FILEATTR. * hash.c, hash.h (list_isempty): New function. * recurse.c (do_recursion): Call fileattr_startdir before processing files in a directory and fileattr_write and fileattr_free (after files, before recursing). * watch.c, watch.h: New files, to handle notification features. * edit.c, edit.h: New file, to handle new read-only checkout features. * client.c, server.c: Add "Mode" request, to change the mode of a file when it is checked in. * main.c (cmds): Add "watch", "edit", "unedit", "watchers", "editors". * main.c: Split command help from usg into new variable cmd_usage, which. (main): Add --help-commands option to print out cmd_usage. * cvs.h: Declare watch, edit, unedit, watchers, editors. * client.c, client.h: Add client_watch, client_edit, client_unedit, client_watchers, client_editors. * client.c, server.c: Add notification stuff. * update.c (checkout_file, patch_file), checkin.c (Checkin): Check _watched attribute when deciding read-only or read-write. * commit.c (checkaddfile): Call fileattr_newfile to set attributes on newly created files. * release.c (release): * cvs.h: Add CVSADM_NOTIFY and CVSADM_NOTIFYBAK. * recurse.c (do_recursion): Call notify_check. * commit.c (commit_fileproc): Call notify_do after committing file. * client.c (get_responses_and_close): Set to_server and from_server to NULL so that it is possible to tell whether we are speaking to the server. * cvs.h: Add CVSROOTADM_NOTIFY. * mkmodules.c (main): Add CVSROOTADM_NOTIFY to filelist. * Makefile.in (SOURCES,OBJECTS,HEADERS): Add new files mentioned above. * lock.c, cvs.h (lock_tree_for_write, lock_tree_cleanup): New functions, taken from old commit.c writelock code. As part of this, fsortcmp and lock_filesdoneproc go from commit.c to lock.c. So does locklist but it gets renamed to lock_tree_list. * commit.c: Use lock_tree_*. Fri Dec 15 10:37:00 1995 J.T. Conklin <jtc@slave.cygnus.com> * tag.c (tag_usage): Added -r and -D flags to usage string. (tag): Detect when user specifies both -r and -D arguments. Pass -r and -D arguments to server. Thu Dec 14 11:56:13 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (start_rsh_server): use RSH_NEEDS_BINARY_FLAG to conditionalize "-b" option to "rsh". * run.c (filter_stream_through_program): document return value and error behavior. * client.c (filter_through_gunzip): pass the supposedly superfluous "-d" option to gunzip, to avoid stimulating what seems to be an argument-passing bug in spawn() under OS/2 with IBM C/C++. Yucko. Wed Dec 13 20:08:37 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * options.h.in (RCSBIN_DFLT): Recommend specifying -b in inetd.conf for pserver. That is a pretty good solution. Wed Dec 13 18:29:59 1995 Preston L. Bannister <pbannister@ca.mdis.com> and Karl Fogel <kfogel@floss.cyclic.com> * client.c (send_modified): make sure that vers and vers->options are non-NULL before strcmp()'ing them with "-kb". Initialize `bin' near where it is used, not at beginning of function. (update_entries): make sure `options' is non-NULL before strcmp()'ing with "-kb". Initialize `bin' near where it is used, not at beginning of function. Tue Dec 12 18:56:38 1995 Karl Fogel <kfogel@totoro.cyclic.com> * options.h.in (RCSBIN_DFLT): document the probable need for this to be set in the authenticating server. Tue Dec 12 11:56:43 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * server.c (expand_proc): If mfile is non-NULL, return it too as part of the expansion. * sanity.sh (modules): Add tests for above-fixed bug. Mon Dec 11 21:39:07 1995 Karl Fogel <kfogel@floss.cyclic.com> * dog.c (flea_bath): Take `suds' arg. All collars changed. Mon Dec 11 15:58:47 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (login): if client password file doesn't exist, create it, duh. * main.c (main): die if CVSroot has access-method but no username. * root.c: added some comments. * main.c: removed all code pertaining to the "-a" option. We specify access-method in CVSroot now. * client.c (parse_cvsroot): new var, `access_method'. If CVSroot is prepended with an access method (i.e., ":pserver:user@host:/path"), then handle it. * login.c (login): use || when checking if CVSroot is "fully qualified". Prepend ":pserver:" before writing to ~/.cvspass. (get_cvs_password): Take no parameters; we'll just use CVSroot to get the password. Mon Dec 11 12:43:35 1995 adamg <adamg@microsoft.com> * error.c, client.c, remove.c, main.c: Add explicit casts for some function pointers to remove warnings under MS VC. * main.c (main): remove use of NEED_CALL_SOCKINIT in favor of the more generic INITIALIZE_SOCKET_SUBSYSTEM. Note that the code assumes that if INITIALIZE_SOCKET_SUBSYSTEM() returns, socket subsystem initialization has been successful. Sat Dec 9 22:01:41 1995 Dan O'Connor <doconnor@tii.com> * commit.c (check_fileproc): pass RUN_REALLY flag to run_exec, because it's okay to examine the file with noexec set. Sat Dec 9 20:28:01 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (update_entries): new var, `bin, init to 0. Use it in determining whether to convert the file. (send_modified): same as above. Fri Dec 8 17:47:39 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (downcase_string): removed. (check_repository_password): don't deal with case-insensitivity anymore. * options.h.in (CVS_PASSWORDS_CASE_SENSITIVE): deleted this. No need for it anymore. Thu Dec 7 21:08:39 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (check_repository_password): when checking for false prefix-matches, look for ':', not '@'. Duh. Thu Dec 7 18:44:51 1995 Karl Fogel <kfogel@floss.cyclic.com> * options.h.in (CVS_PASSWORDS_CASE_SENSITIVE): replaces CVS_PASSWORDS_CASE_INSENSITIVE; passwords are now insensitive by default. Expanded explanatory comment. * login.c (get_cvs_password): Use memset(), not bzero(). I botched this change earlier. * server.c (check_repository_password): no need to check xmalloc()'s return value. (check_repository_password): check for false prefix-matches (for example, username is "theo" and linebuf contains user "theocracy"). Thu Dec 7 14:49:16 1995 Jim Meyering (meyering@comco.com) * filesubr.c (isaccessible): Rename from isaccessable. Update callers. * cvs.h: Update prototype. * main.c (main): Update callers. * server.c (main): Update callers. Thu Dec 7 12:50:20 1995 Adam Glass <glass@NetBSD.ORG> * cvs.h: "isaccessible" is the correct spelling. Also add "const" to second arg to make prototype match declaration. Thu Dec 7 11:06:51 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c, login.c: memset() instead of bzero(). Thu Dec 7 00:08:53 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (authenticate_connection): document server's side of the Authentication Protocol too. * client.c (connect_to_pserver): when printing out "unrecognized response", also print out the offending response. * server.c (check_password): take `repository' arg too now. Call check_repository_password() before checking /etc/passwd. (check_repository_password): new func. * options.h.in (CVS_PASSWORDS_CASE_INSENSITIVE): new define, unset by default. Wed Dec 6 18:51:16 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (check_password): If user has a null password, then return 1 if arg is also null. Reverse sense of return value. Caller changed. Wed Dec 6 14:42:57 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (check_password): new func. (authenticate_connection): call above new func. * login.c (login): use construct_cvspass_filename(). If CVSroot is not "fully-qualified", then insist the user qualify it before going on. (get_cvs_password): fleshed out. Now reads from ~/.cvspass, or prompts if no appropriate password found. (construct_cvspass_filename): new func. * server.c (authenticate_connection): send ACK or NACK to client. * client.c (connect_to_pserver): check for ACK vs NACK response from server after sending authorization request. * login.c (get_cvs_password): new func. * client.c (connect_to_pserver): use new func get_cvs_password(). Prototype it at top of file. Hmmm. Wed Dec 6 13:29:22 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c: same as below (AUTH_SERVER_SUPPORT). * main.c: same as below (AUTH_SERVER_SUPPORT where appropriate). * login.c: same same as below. * cvs.h: same as below. * client.c: use AUTH_CLIENT_SUPPORT, not CVS_LOGIN. * options.h.in (AUTH_CLIENT_SUPPORT, AUTH_SERVER_SUPPORT): these replace CVS_LOGIN. Wed Dec 6 00:04:58 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (authenticate_connection): expanded comment. Tue Dec 5 23:37:39 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (connect_to_pserver): read password from prompt for now. * server.c (authenticate_connection): if the password passes muster, then don't abort. Tue Dec 5 22:46:37 1995 Karl Fogel <kfogel@floss.cyclic.com> * subr.c (strip_trailing_newlines): new func. * client.c (connect_to_pserver): took out print statements. * server.c (authenticate_connection): removed print statments. Use new func strip_trailing_newlines() to purify `repository', `username', and `password'. Run a primitive password check, just for testing. * client.c (connect_to_pserver): use CVS_AUTH_PORT. Take tofdp, fromfdp, and log args. Caller changed. (get_responses_and_close): either kerberos and CVS_LOGIN might have one fd for both directions, so adjust #ifdef accordingly. * cvs.h (CVS_AUTH_PORT): new define, default to 2401. Prototype strip_trailing_newlines(). Tue Dec 5 16:53:35 1995 Karl Fogel <kfogel@floss.cyclic.com> * server.c (authenticate_connection): new func. * client.c (init_sockaddr): func moved here from login.c. (connect_to_pserver): same as above. Take no args, now. Include <sys/socket.h>, <netinet/in.h>, <netdb.h>, if CVS_LOGIN. * cvs.h: Declare use_authenticating_server, as extern int. Declare connect_to_pserver(). * main.c (main): call authenticate_connection(). Removed testing code. Add 'a' to the short-option string in the getopt() call. * login.c (connect_to_pserver): moved to client.c. Tue Dec 5 16:01:42 1995 Peter Chubb <peterc@bookworm.sw.oz.au> (patch applied by Karl Fogel <kfogel@cyclic.com>) * update.c (join_file): if vers->vn_user is "0", file has been removed on the current branch, so print an error and return. Mon Dec 4 14:27:42 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * Version 1.6.3. Mon Dec 4 16:28:25 1995 Norbert Kiesel <nk@col.sw-ley.de> * release.c (release): add return (0) as last line * cvs.h: declare program_path * main.c define program_path (main): set program_path * release.c (release): use program_path for update_cmd Mon Dec 4 11:22:42 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * Version 1.6.2. Sun Dec 3 20:02:29 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * rcs.h (struct rcsnode), rcs.c (freercsnode): Add expand field. * rcs.h (RCSEXPAND): New #define. * rcs.c (RCS_reparsercsfile): Record keyword expansion in expand field of struct rcsnode. * update.c (checkout_file): Set keyword expansion in Entries file from rcs file if there is nowhere else to set it from. * client.c (send_modified, update_entries) [LINES_CRLF_TERMINATED]: If -kb is in effect, don't convert. * update.c (update_file_proc), commit.c (check_fileproc), rcscmds.c (RCS_merge): Direct stdout to DEVNULL rather than passing -s option to grep. This avoids trouble with respect to finding a grep which support -s and whether we should use the (GNU grep) -q option if it exists. * options.h.in: Change "@ggrep_path@" to "grep". Fri Dec 1 11:53:19 1995 Norbert Kiesel <nk@col.sw-ley.de> * rcs.c (RCS_gettag): new parameter return_both force return both tags: the symbolic and the numeric one. (RCS_getversion): new parameter return_both is forwarded to RCS_gettag. * rtag.c, tag.c, commit.c, patch.c, update.c: pass 0 as additional last parameter to RCS_getversion and RCS_gettag * rcs.h (RCS_gettag): new parameter return_both. (RCS_getversion): new parameter return_both. * cvs.h (struct vers_ts): add vn_tag slot for symbolic tag name * vers_ts.c (Version_TS): call RCS_getversion with 1 for return_both and split output into vn_rcs and vn_tag (freevers_ts): free vn_tag * update.c (checkout_file): use vn_tag instead of vn_rcs when calling 'rcs co' to allow rcs expansion of :$Name : Thu Nov 30 20:44:30 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (get_responses_and_close): undo previous change regarding waitpid(). The problem has been solved by modifying os2/waitpid.c instead of its callers. Thu Nov 30 16:37:10 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c: All these changes are for OS/2, which will no longer have a separate client.c: (start_kerberos_server): new func, contains code that used to be in start_server(). (start_server): moved kerberos code to above function, reorganized the rest. Added authentication clause. (call_in_directory): test errno against EACCESS, if EACCESS is defined (this is for OS/2's oddball mkdir). (change_mode): don't set execute permission on anything if EXECUTE_PERMISSION_LOSES is defined. (get_responses_and_close): if START_RSH_WITH_POPEN_RW, then use pclose() instead of fclose(). If waitpid errors with ECHILD, don't die. This is okay. (start_rsh_server): alternate definition if START_RSH_WITH_POPEN_RW. * main.c: [all these changes conditional on CVS_LOGIN: ] Don't prototype connect_to_pserver, don't enter it in cmds[] (actually, it was never in there, I don't know why my previous change said it was). (use_authenticating_server): new global var. (main): if "-a", then set above new var to TRUE. (usg): document "-a" option. Wed Nov 29 12:55:10 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c: Prototype connect_to_pserver(), and enter it in cmds[]. (main): test some extremely primitive authentication. * login.c: Include <sys/socket.h> (connect_to_pserver): new func. (init_sockaddr): new func. Mon Nov 20 14:07:41 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * Makefile.in (TAGFILES): Separate out from DISTFILES, for C code. (TAGS,tags): Use TAGFILES not DISTFILES. Sun Nov 19 11:22:43 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * recurse.c (do_recursion): Don't call server_pause_check if there are writelocks around. Revise comment to reflect fact we are no longer relying on a writelock'd operations being "unable" to generate enough data to pause. Sun Nov 19 10:04:50 1995 Peter Wemm <peter@haywire.DIALix.COM> * server.c, server.h, options.h.in: Implement hooks for doing simple flow control on the server to prevent VM exhaustion on a slow network with a fast server. * recurse.c: Call the flow control check at a convenient location while no locks are active. This is a convenience tradeoff against accurate flow control - if you have a large directory it will all be queued up, bypassing the flow control check until the next directory is processed. Sat Nov 18 16:22:06 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c, update.c, vers_ts.c, server.c, rcs.c, lock.c, ignore.c, entries.c, diff.c, commit.c, checkin.c: Use new macro `existence_error', instead of comparing errno to ENOENT directly. Fri Nov 17 14:56:12 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (start_server): removed alternate version of this func, since os2/client.c will now be used under OS/2. Thu Nov 16 22:57:12 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (start_server): ifdef HAVE_POPEN_RW, use a different version of start_server(). This is maybe not the cleanest cut to make, but it's better than mucking around with yet more #ifdefs in the middle of the old start_server() function. Once things are up, I may reposition this code. Wed Nov 15 15:33:37 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c (main): ifdef NEED_CALL_SOCKINIT, then call SockInit(). Only OS/2 needs this initialization. Tue Nov 14 18:54:01 1995 Greg A. Woods <woods@most.weird.com> * patch.c: - fix orientation of test for result of getline() call - use fputs() not printf() when just copying file out * cvsbug.sh: - add space after #! - new rcs id - allow version to be edited by Makefile. * Makefile.in: - make Makefile a dependent of all (this might not be perfect, but it at least gives you a chance to catch up on the second go-around). - filter cvsbug.sh in a manner similar to cvsinit.sh to get the version number set from version.c Tue Nov 14 13:28:17 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * sanity.sh: Call old log file check.plog, not check.olog. * sanity.sh: Convert remaining tests from old-style ('***' on fail and nothing on pass), to new-style (FAIL on fail and PASS on pass). * sanity.sh: Fix ability to run only some of the tests (always run tests 1-4.75 to set up repository, document better how it works). * sanity.sh: Change "completed successfully" to "completed" in message--many tests, but not all, exit if they fail. Tue Nov 14 15:10:00 1995 Greg A. Woods <woods@most.weird.com> * sanity.sh: test 63 doesn't work and probably can't Tue Nov 14 12:22:00 1995 Greg A. Woods <woods@most.weird.com> * sanity.sh: many minor tweaks: - make the optional arguments almost work - use a function 'directory_cmp' instead of 'diff -r' - fix up a few more tests that weren't working.... Mon Nov 13 07:33:55 1995 Karl Fogel <kfogel@floss.cyclic.com> * cvs.h: ifdef USE_OWN_POPEN, #include "popen.h". Only OS/2 has its own popen()/pclose() right now. Mon Nov 13 04:06:10 1995 Karl Fogel <kfogel@floss.cyclic.com> * cvs.h: conform to 80 column standard (yes, I'm a pedant). Sat Nov 11 13:45:13 1995 Karl Fogel <kfogel@floss.cyclic.com> * client.c (process_prune_candidates): use unlink_file_dir() to remove the directory, instead of invoking "rm" via run_exec(). Fri Nov 10 14:38:56 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c (main): removed "#define KF_GETOPT_LONG 1", since that change is no longer in testing. Thu Nov 9 20:32:12 1995 Karl Fogel <kfogel@floss.cyclic.com> * release.c (release): Use Popen(), not popen(). Wed Nov 8 10:20:20 1995 Jim Meyering (meyering@comco.com) * entries.c (ParseTag): Remove dcl of unused local. * patch.c: Include getline.h. Wed Nov 8 11:57:31 1995 Norbert Kiesel <nk@col.sw-ley.de> * options.h.in: add configuration option STEXID_SUPPORT (default is off i.e. old semantics) * filesubr.c (isaccessable): new function. Checks access-rights for files like access(), but is getxid-safe. Falls back to access() if SETXID_SUPPORT is not enabled. (isfile): replace stat() by isaccessable(file, F_OK) (isreadable): replace access() by isaccessable() (iswritable): ditto (make_directory): rename local variable buf to sb * cvs.h: add prototype for new function isaccessable. * server.c (serve_root): replace access() by isaccessable() * cvsrc.c (read_cvsrc): replace access() by isreadable() * main.c (main): replace access() by isaccessable() Wed Nov 8 10:22:41 1995 Greg A. Woods <woods@most.weird.com> * entries.c (fgetentent): change definition to static to match the declaration at the top of the file Tue Nov 7 16:59:25 1995 J.T. Conklin <jtc@lestat.cygnus.com> * rcs.c (RCS_getbranch, RCS_getdate, RCS_getrevtime, RCS_gettag, RCS_getversion, RCS_head): Use assert() instead of attempting to "do the right thing" with a bogus RCSNode argument. Mon Nov 6 14:24:34 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * vers_ts.c: Remove ctime define. It is just asking for trouble. Mon Nov 6 11:58:26 1995 Karl Fogel <kfogel@floss.cyclic.com> * vers_ts.c: ifdef ctime, undef it before redefining it. It is a macro on some systems. * lock.c: don't prototype ctime() here. (See note below about fgetentent() in entries.c.) Sun Nov 5 16:06:01 1995 Karl Fogel <kfogel@floss.cyclic.com> * entries.c (fgetentent): don't prototype ctime here; we include cvs.h, which includes system.h, which includes <time.h> unconditionally (either as <time.h> or <sys/time.h>). Anyway, IBM C/C++ chokes on mid-function, or even mid-file, prototypes. Sigh. Thu Nov 2 21:51:04 1995 Dan Wilder <dan@gasboy.com> * rtag.c (rtag): Fix typo ("-T" -> "-F"). Tue Oct 31 19:09:11 1995 Dan Wilder <dan@gasboy.com> * diff.c (diff_dirproc): just return R_SKIP_ALL if dir not exist. (diff_file_nodiff): don't complain if file doesn't exist, just ignore. Tue Oct 31 09:25:10 1995 Norbert Kiesel <nk@col.sw-ley.de> * sanity.sh: Use absolute pathname for mkmodules. Sat Oct 28 01:01:41 1995 Jim Meyering (meyering@comco.com) * entries.c (ParseTag): Use getline instead of fgets. Fri Oct 27 13:44:20 1995 Karl Fogel <kfogel@floss.cyclic.com> * cvs.h: do nothing about alloca ifdef ALLOCA_IN_STDLIB. I am rather suspicious of this solution, and will not be surprised to find out that there's a Right Way to handle this situation ("this situation" being that OS/2 simply declares alloca in <stdlib.h>). Suggestions are welcome; see src/cvs.h and lib/system.h to see why I was getting a conflict in the first place. Wed Oct 25 16:03:20 1995 J.T. Conklin <jtc@slave.cygnus.com> * cvs.h (struct entnode): Add user field. * entries.c (fputentent): New function, write entries line. (write_ent_proc): Call fputentent to write entries line. (Entnode_Create): New function, construct new Entnode. (Entnode_Destroy): New function, destruct old Entnode. (AddEntryNode): Changed to take an Entnode argument instead of separate user, version, timestamp, etc. arguments. (fgetentent): Changed to return Entnode. (struct entent, free_entent): Removed. Wed Oct 25 12:44:32 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * admin.c (admin): Don't rely on ANSI C string concatenation; SunOS 4.1.3 /bin/cc doesn't support it. Tue Oct 24 22:34:22 1995 Anthony J. Lill <ajlill@ajlc.waterloo.on.ca> * import.c (expand_at_signs): Check errno as well as return value from putc. Some systems bogusly return EOF when successfully writing 0xff. Tue Oct 24 14:32:45 1995 Norbert Kiesel <nk@col.sw-ley.de> * admin.c (admin): use getcaller() instead of getpwuid * subr.c (getcaller): prefer getlogin() to $USER and $LOGNAME (especially useful for NT where getuid always returns 0) Tue Oct 24 06:22:08 1995 Jim Meyering (meyering@comco.com) * cvsrc.c (read_cvsrc): Use getline instead of fgets. * patch.c (patch_fileproc): Use getline instead of fgets. * entries.c (fgetentent): Use getline instead of fgets. Use xmalloc to allocate space for each returned entry. Since LINE is no longer static, save it in struct entent. (struct entent): New member, line. (free_entent): New function. (Entries_Open): Call it after each call to fgetentent. Tue Oct 24 11:13:15 1995 Norbert Kiesel <nk@col.sw-ley.de> * cvs.h: Declare valloc again, but this time with the right signature (also changed in libs/valloc.c) Mon Oct 23 12:17:03 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * logmsg.c (do_editor): Check for errors from stdio calls. Mon Oct 23 12:37:06 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * cvs.h: Don't declare valloc. Some systems (e.g. linux) declare it in stdlib.h in a conflicting way. Mon Oct 23 08:41:25 1995 Jim Meyering (meyering@comco.com) * commit.c (commit_filesdoneproc): Use getline instead of fgets. * logmsg.c (do_editor): Use getline instead of fgets. (rcsinfo_proc): Likewise. * logmsg.c (do_editor): Lose if fclose of temp file output stream fails. Mon Oct 23 11:59:41 1995 Norbert Kiesel <nk@col.sw-ley.de> * cvs.h: add valloc declaration * server.h: add server_cleanup prototype * server.c: remove server_cleanup prototype * mkmodules.c (server_cleanup): fix parameter type * server.c: encapsulate wait_sig in #ifdef sun (it's only used in code which is also encapsulated in #ifdef sun) * rcscmds.c (RCS_deltag, RCS_lock): add definition of noerr parameter * error.c: include cvs.h instead of config.h, add USE(rcsid) * error.c (error): fix parameter type * update.c (join_file): encapsulate recent changes from garyo within #ifdef SERVER_SUPPORT Sun Oct 22 13:47:53 1995 J.T. Conklin <jtc@slave.cygnus.com> * client.c (update_entries): Fix memory leak; free mode_string and file_timestamp. (send_fileproc): Fix memory leak; call freevers_ts before exiting. * module.c (do_module): Partially fix memory leak; added variable so that the address of memory allocated by line2argv is retained, but comment out the call to free_names. Freeing the vector at that point loses because some of the elements may be used later in the function. (cat_module): fix memory leak. * recurse.c (start_recursion): Fix memory leak; free return value of Name_Repository after it has been used. Sat Oct 21 23:24:26 1995 Jim Meyering (meyering@comco.com) * client.c (send_modified) [LINES_CRLF_TERMINATED]: Comment text after #endif. Fri Oct 20 14:41:49 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * sanity.sh: Add test 87a, to test for bug fixed by garyo in change below. Fri Oct 20 10:59:58 1995 Gary Oberbrunner <garyo@darkstar.avs.com> * update.c (join_file): send file back to client even if no conflicts were detected, by calling Register(). Fri Oct 20 10:46:45 1995 Norbert Kiesel <nk@col.sw-ley.de> * lock.c: Add prototype for Check_Owner Thu Oct 19 16:38:14 1995 Jim Meyering (meyering@comco.com) * lock.c (Check_Owner): Declare function `static int'. Thu Oct 19 14:58:40 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * expand_path.c (expand_variable): Fix typo ('*'->'('). Thu Oct 19 14:58:40 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * commit.c (commit_filesdoneproc): Check for errors from fopen, fgets, and fclose. * rcscmds.c (RCS_merge): Remove comment about rcsmerge -E. Hacking CVS was never a very good solution; the situation is fixed in RCS 5.7, and is documented in ../INSTALL. Thu Oct 19 15:06:15 1995 Jim Meyering (meyering@comco.com) * filesubr.c (xchmod): Parenthesize arithmetic in operand of | to placate gcc -Wall. * expand_path.c (expand_path): Parenthesize assignments used as truth values to placate gcc -Wall. * commit.c (checkaddfile): Remove dcls of unused variables. * lock.c (unlock): Remove dcl of unused variable. Thu Oct 19 14:58:40 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * root.c (Create_Root): If noexec, don't create CVS/Root. Wed Oct 18 11:19:40 1995 J.T. Conklin <jtc@slave.cygnus.com> * lock.c (unlock): Change order of comparison so that Check_Owner is called only if other conditions are true. This performance enhancement was broken when the AFS support was added. Wed Oct 18 12:51:33 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c (main): check if argv[0] is "pserver" with else-if, not if, since we've already asked if it's "kserver". Tue Oct 17 18:09:23 1995 Warren Jones <wjones@tc.fluke.com> and Jim Kingdon <kingdon@harvey.cyclic.com> * sanity.sh: Deal with supplying a relative cvs filename, or with a cvs filename which doesn't have basename "cvs". Mon Oct 16 15:58:31 1995 Vince Demarco <vdemarco@bou.shl.com> * parseinfo.c (Parse_Info): if the Keyword isn't ALL the current version doesn't use the expanded variable, It should. Mon Oct 16 15:58:31 1995 Gary Oberbrunner <garyo@avs.com> and Jim Kingdon <kingdon@harvey.cyclic.com> * server.c (server_register): Don't pass NULL to printf if tag, date, or conflict is NULL. Thu Oct 12 12:13:42 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c (main): begin to handle "pserver"; support not complete yet, however. Thu Oct 12 02:52:13 1995 Roland McGrath <roland@churchy.gnu.ai.mit.edu> * expand_path.c: Don't #include <pwd.h>, since cvs.h already does, and not all systems' <pwd.h>s are protected from multiple inclusion. * login.c: Likewise. Wed Oct 11 15:23:24 1995 Karl Fogel <kfogel@floss.cyclic.com> * login.c (login): handle everything correctly now. Wed Oct 11 12:02:48 1995 Norbert Kiesel <nk@col.sw-ley.de> * rcs.c (RCS_gettag): support RCS keyword Name Tue Oct 10 19:11:16 1995 Karl Fogel <kfogel@floss.cyclic.com> * options.h.in (CVS_LOGIN): discuss, but leave commented out. The "cvs login" command is still under construction; however, the repository was changing so fast that instead of creating a branch and dealing with the attendant hair, I'm just developing on the trunk, making sure that everything is surrounded by "#ifdef CVS_LOGIN ... #endif" so I don't get in anyone's way. * login.c: include cvs.h before checking CVS_LOGIN, so it has a chance to get defined before we ask if it's defined. (login): oops, use semi not comma in `for' loop init. * Makefile.in (SOURCES, OBJECTS): include login.c, login.o. * main.c: added protoype for login(). Added "login" entry to cmds[]. (usg): added line about "login". * login.c: new file. Tue Oct 10 18:33:47 1995 Karl Fogel <kfogel@totoro.cyclic.com> * Makefile.in (COMMON_OBJECTS): added error.o. (OBJECTS): took error.o out; it's in COMMON_OBJECTS now. Tue Oct 10 12:02:37 1995 Thorsten Lockert <tholo@sigmasoft.com> * cvsbug.sh: Cater to lame versions of sh (4.4BSD ash) by using ${foo-bar} instead of `if....`. Tue Oct 10 12:02:37 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * remove.c (remove_fileproc): If noexec, don't remove file. Check for error when removing file. Sun Oct 8 12:32:15 1995 Peter Wemm <peter@haywire.DIALix.COM> * run.c: detect/use POSIX/BSD style reliable signals for critical section masking etc. Helps prevent stray locks on interruption. Sat Oct 7 23:26:54 1995 Norbert Kiesel <nk@col.sw-ley.de> * admin.c (admin): If group CVS_ADMIN_GROUP exists, allow only users in that group to use "cvs admin". * options.h.in: Default CVS_ADMIN_GROUP to "cvsadmin". Sat Oct 7 23:05:24 1995 Norbert Kiesel <nk@col.sw-ley.de> * add.c, checkout.c, commit.c, cvs.h, filesubr.c, import.c, lock.c, main.c, modules.c, options.h.in: New variable cvsumask which is used to set mode of files in repository (regardless of umask in effect when cvs is run). Sat Oct 7 22:40:17 1995 Stephen Bailey <sjbailey@sand.npl.washington.edu> * lock.c: Include AFSCVS ifdefs to deal with AFS's lack of correspondance between userid's from stat and from geteuid. Sat Oct 7 22:28:49 1995 Scott Carson <sdc@TracerTech.COM> * add.c (add): Pass -ko, not -k -ko, to set keyword expansion options. * admin.c (admin): Don't skip first argument when sending to server. Fri Oct 6 21:45:03 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * version.c: Version 1.6.1. Fri Oct 6 21:31:28 1995 Jeff Johnson <jbj@brewster.jbj.org> * cvs.h, admin.c, client.c, commit.c, log.c, modules.c, parseinfo.c, patch.c, recurse.c, rtag.c, status.c, tag.c: Prototype when dealing in pointers to functions. Fri Oct 6 21:07:22 1995 Mark H. Wilkinson <mhw@minster.york.ac.uk> * cvsrc.c (read_cvsrc): fix look up of command names in cvsrc file to use full name from command table rather than possible nickname in argv. Fixes errors with things like `cvs di' when cvsrc has `diff -u5' in it. Thu Aug 3 01:03:52 1995 Vince DeMarco <vdemarco@bou.shl.com> * parseinfo.c (Parse_Info): Add code to call expand_path function instead of using built in code. * wrapper.c (wrap_add): Add code to call expand_path function to expand all built in variables. * expand_path.c (New file): expand things that look like environmental variables (only expand local CVS environmental variables) and user names like ~/. * cvs.h: Declare expand_path. * Makefile.in (SOURCES, OBJECTS): Added expand_path.c, expand_path.o. Fri Oct 6 14:03:09 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * ignore.c (ign_setup): Don't try to look for a file in CVSroot if client. (The recent tightening of the error checking detects this). * commit.c (checkaddfile): Don't try to pass options if it is "". Thu Oct 5 18:04:46 1995 Karl Fogel <kfogel@totoro.cyclic.com> * sanity.sh: unset CVSREAD, since it causes the script to bomb. Thu Oct 5 18:29:17 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * remove.c, add.c, commit.c, cvs.h: Remove CVSEXT_OPT stuff; it has been broken for ages and the options are already stored in the Entries file. Thu Oct 5 18:20:13 1995 Norbert Kiesel <nk@col.sw-ley.de> * commit.c (checkaddfile): New argument options; pass it to RCS. (commit_fileproc): Pass it. Tue Oct 3 09:26:00 1995 Karl Fogel <kfogel@totoro.cyclic.com> * version.c: upped to 1.6. Mon Oct 2 18:10:35 1995 Larry Jones <larry.jones@sdrc.com> * server.c: if HAVE_SYS_BSDTYPES_H, include <sys/bsdtypes.h>. Mon Oct 2 10:34:53 1995 Karl Fogel <kfogel@totoro.cyclic.com> * version.c: Upped version to 1.5.95. Mon Oct 2 15:16:47 1995 Norbert Kiesel <nk@col.sw-ley.de> * tag.c, rtag.c: pass "mov" instead of "add" if tag will be moved (i.e. invoked with -F) Sun Oct 1 18:36:34 1995 Karl Fogel <kfogel@totoro.cyclic.com> * version.c: upped to 1.5.94. * server.c: reverted earlier ISC change (of Sep. 28). * version.c: upped to 1.5.93, for Peter Wemm's new SVR4 patch. Sun Oct 1 14:51:59 1995 Harlan Stenn <Harlan.Stenn@pfcs.com> * main.c: don't #include <pwd.h>; cvs.h does that already. Fri Sep 29 15:21:35 1995 Karl Fogel <kfogel@floss.cyclic.com> * version.c: upped to 1.5.91 for another pre-1.6 release. Fri Sep 29 14:41:14 1995 <bmeier@rzu.unizh.ch> * root.c: start rcsid[] with "CVSid". Fri Sep 29 13:22:44 1995 Jim Blandy <jimb@totoro.cyclic.com> * diff.c (diff): Doc fix. Fri Sep 29 14:32:36 1995 Norbert Kiesel <nk@col.sw-ley.de> * repos.c (Short_Repository): chop superfluous "/". * tag.c (pretag_proc): correct user-visible string. * rtag.c (pretag_proc): correct user-visible string. Fri Sep 29 13:45:36 1995 Karl Fogel <kfogel@floss.cyclic.com> * cvs.h (USE): if __GNUC__ != 2, expand to a dummy var instead of nothing. Thu Sep 28 13:37:05 1995 Larry Jones <larry.jones@sdrc.com> * server.c: ifdef ISC, include <sys/bsdtypes.h>. Fri Sep 29 07:54:22 1995 Mike Sutton <mws115@llcoolj.dayton.saic.com> * filesubr.c (last_component): Don't use ANSI style declaration. Wed Sep 27 15:24:00 1995 Del <del@matra.com.au> * tag.c, rtag.c: Pass a few extra options to the script named in taginfo (del/add, and revision number). * tag.c: Support a -r option (at long last). Also needs a -f option to tag the head if there is no matching -r tag. Tue Sep 26 11:41:08 1995 Karl Fogel <kfogel@totoro.cyclic.com> * version.c: Upped version to 1.5.89 for test release preceding 1.6. Wed Sep 20 15:32:49 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * ignore.c (ign_add_file): Check for errors from fopen and fclose. Tue Sep 19 18:02:16 1995 Jim Blandy <jimb@totoro.cyclic.com> * Makefile.in (DISTFILES): Remove sanity.el from this list; the file has been deleted. Thu Sep 14 14:17:52 1995 Peter Wemm <peter@haywire.dialix.com> * import.c: Recover from being unable to open the user file. * update.c (join_file): Print a message in the case where the file was added. * mkmodules.c: Deal with .db as well as .pag/.dir (for use with BSD 4.4 and real dbm support). Mon Sep 11 15:44:13 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * release.c (release): Revise comment regarding why and how we skip argv[0]. Mon Sep 11 10:03:59 1995 Karl Fogel <kfogel@floss.cyclic.com> * release.c (release): use return value of pclose to determine success of update. Mon Sep 11 09:56:33 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * release.c (release_delete): Fix comment. Sun Sep 10 18:48:35 1995 Karl Fogel <kfogel@floss.cyclic.com> * release.c (release): made work with client/server. Don't ask if <arg> is mentioned in `modules'. Fri Sep 8 13:25:55 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * sanity.sh: When committing a removal, send stdout to LOGFILE; this is no longer a silent operation. * sanity.sh: Remove OUTPUT variable; it is unused. * client.c: Add comment regarding deleting temp file. * main.c: Add comment regarding getopt REQUIRE_ORDER. Thu Sep 7 20:24:46 1995 Karl Fogel <kfogel@floss.cyclic.com> * main.c (main): use getopt_long(), accept "--help" and "--version". Don't assume EOF is -1. Thu Sep 7 19:18:00 1995 Jim Blandy <jimb@cyclic.com> * cvs.h (unlink_file_dir): Add prototype for this. Thu Sep 7 14:38:06 1995 Karl Fogel <kfogel@floss.cyclic.com> * ALL FILES: add semicolon, as indicated below. * cvs.h (USE): don't provide semicolon in the expansion of the USE macro; we'd rather the callers provided it themselves because that way etags doesn't get fooled. Mon Sep 4 23:30:41 1995 Magnus Hyllander <mhy@os.se> * checkout.c: cvs export now takes -k option and does not default to -kv. * checkout.c, cvs.h, modules.c: Modules file now takes -e option for cvs export. Mon Sep 4 23:30:41 1995 Kirby Koster <koster@sctc.com> * commit.c: When committing a removal, print a message saying what we are doing. Wed Aug 2 10:06:51 1995 Vince DeMarco <vdemarco@bou.shl.com> * server.c: fix compiler warnings (on NeXT) (declare functions as static inline instead of just static) functions: get_buffer_date, buf_append_char, and buf_append_data Mon Sep 4 22:31:28 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * client.c (update_entries), import.c (expand_at_signs): Check for errors from fread and putc. Fri Sep 1 00:03:17 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * sanity.sh: Fix TODO item pathname. * sanity.el: Removed. It was out of date, didn't do much, and I doubt anyone was using it. * no_diff.c (No_Difference): Don't change the modes of the files. Thu Aug 31 13:14:34 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * version.c: Change version to 1.5.1. * client.c (start_rsh_server): Don't pass -d to "cvs server" invocation via rsh (restore change which was lost when NT stuff was merged in). * sanity.sh: Add TODO item suggesting test for bug which this fixes. Wed Aug 30 12:36:37 1995 Jim Blandy <jimb@totoro.cyclic.com> * sanity.sh (basic1): Make sure first-dir is deleted before running this set of tests. * subr.c: Extract file twiddling functions to a different file, because we want to use different versions of many of these routines under Windows NT. (copy_file, isdir, islink, isfile, isreadable, iswritable, open_file, make_directory, make_directories, xchmod, rename_file, link_file, unlink_file, xcmp, tmpnam, unlink_file_dir, deep_remove_dir): Moved to... * filesubr.c: ...this file, which is new. * Makefile.in (SOURCES): Mention filesubr.c. (COMMON_OBJECTS): Mention filesubr.o. * subr.c: Extract process execution guts to a different file, because we want to replace these routines entirely under Windows NT. (VA_START, va_alist, va_dcl): Move this stuff... (run_add_arg, run_init_prog): and these declarations... (run_prog, run_argv, run_argc, run_argc_allocated): and these variables... (run_setup, run_arg, run_args, run_add_arg, run_init_prog, run_exec, run_print, Popen): and these functions... * run.c: To this file, which is new. * Makefile.in (SOURCES): Mention run.c. (COMMON_OBJECTS): Mention run.o. * status.c (status): Call ign_setup, if client_active. Otherwise, we don't end up ignoring CVS directories and such. * server.c (mkdir_p, dirswitch): Use CVS_MKDIR instead of mkdir. * repos.c (Name_Repository): Use the isabsolute function instead of checking the first character of the path. * root.c (Name_Root): Same. * release.c (release): Use fncmp instead of strcmp to compare filenames. * rcs.c (RCS_parse, RCS_parsercsfile) [LINES_CRLF_TERMINATED]: Abort, because we have strong reason to believe this code is wrong. * patch.c (patch): Register signal handlers iff the signal name is #defined. * no_diff.c (No_Difference): Don't try to include server_active in trace message unless SERVER_SUPPORT is #defined. * modules.c (do_module): Use CVS_MKDIR instead of mkdir. * mkmodules.c (main): Call last_component instead of writing it out. * main.c (main): Call last_component instead of writing it out. Break up the long copyright string into several strings; Microsoft Visual C++ can't handle a line that long. Feh. Use fncmp instead of strcmp to compare filenames. Register signal handlers iff the signal name is #defined. * lock.c (readers_exist): Don't check return value of closedir. Most of the rest of the code doesn't, and some systems don't provide a return value anyway. (set_lock): Use CVS_MKDIR instead of mkdir. * import.c (import): Use the isabsolute function instead of checking the first character of the path. Try to delete the temporary file again after we close it, so it'll get deleted on systems that don't let you delete files that are open. (add_rev): Instead of making a hard link to the working file and checking in the revision with ci -r, use ci -u and restore the permission bits. (comtable): Include lines from SYSTEM_COMMENT_TABLE, if it is #defined. (add_rcs_file) [LINES_CRLF_TERMINATED]: Abort, because we have strong reason to believe this code is wrong. (import_descend_dir): Use CVS_MKDIR instead of mkdir. * history.c (read_hrecs): Open the file with OPEN_BINARY. * find_names.c (add_entries_proc, fsortcmp): Add prototypes. * entries.c (write_ent_proc): Add prototype. * hash.c (walklist): Add prototype for PROC argument. (sortlist): Add prototype for COMP argument. (printnode): Add a prototype, and make it static. * cvs.h (wrap_add_file, wrap_add): Add extern decls for these; they're used in import.c and update.c. * wrapper.c (wrap_add_file, wrap_add): Remove them from here. * cvs.h (RUN_NORMAL, RUN_COMBINED, RUN_REALLY, RUN_STDOUT_APPEND, RUN_STDERR_APPEND, RUN_SIGNIGNORE, RUN_TTY, run_arg, run_print, run_setup, run_args, run_exec, Popen, piped_child, close_on_exec, filter_stream_through_program, waitpid): Move all these declarations and definitions to the same section. * cvs.h (error_set_cleanup): Fix prototype. * cvs.h (isabsolute, last_component): New extern decls. * cvs.h (link_file): Function is deleted; remove extern decl. * cvs.h (DEATH_STATE, DEATH_SUPPORT): Move #definitions of these above the point where we #include rcs.h, since rcs.h tests them (or DEATH_SUPPORT, at least). * cvs.h (DEVNULL): #define this iff it isn't already #defined. config.h may want to override it. * cvs.h (SERVER_SUPPORT, CLIENT_SUPPORT): Don't #define these here; let config.h do that. On some systems, we don't have any server support. * cvs.h: Don't #include <io.h> or <direct.h>; we take care of those in lib/system.h. * commit.c (commit): Open logfile with the OPEN_BINARY flag. (precommit_proc): Use the isabsolute function, instead of comparing the first character with /. (remove_file, checkaddfile): Use CVS_MKDIR instead of mkdir. * client.c (send_repository): Use larger line buffers. * client.c [LINES_CRLF_TERMINATED] (update_entries): If we've just received a gzipped file, copy it over, converting LF to CRLF, instead of just renaming it into place. [LINES_CRLF_TERMINATED] (send_modified): Convert file to LF format before sending with gzip. (send_modified): Don't be disturbed if we get fewer than sb.st_size characters when we read. The read function may be collapsing CRLF to LF for us. * client.c: Add forward declarations for all the cvs command functions we call. * client.c: Add forward static declarations for all the handle_mumble functions. On some systems, RSH converts LF to CRLF; this screws us up. * client.c (rsh_pid): Declare this iff RSH_NOT_TRANSPARENT is not #defined. (get_responses_and_close): Use SHUTDOWN_SERVER if it is #defined. Only wait for rsh process to exit if RSH_NOT_TRANSPARENT is not #defined. (start_rsh_server): Declare and define only if RSH_NOT_TRANSPARENT is not #defined. Use piped_child, instead of writing all that out. (start_server): Only try to call start_rsh_server if RSH_NOT_TRANSPARENT is not #defined. Use START_SERVER if it is #defined. Convert file descriptors to stdio file pointers using the FOPEN_BINARY_WRITE and FOPEN_BINARY_READ strings. * client.h (rsh_pid): Don't declare this; it's never used elsewhere. (supported_request): Add external declaration for this; it's used in checkout.c. Move process-running functions to run.c; we need to totally replace these on other systems, like Windows NT. * client.c (close_on_exec, filter_stream_through_program): Moved to run.c. * run.c (close_on_exec, filter_stream_through_program): Here they are. * add.c (add_directory): Use CVS_MKDIR instead of straight mkdir. * checkout.c (checkout, build_dirs_and_chdir): Same. (checkout_proc): Use fncmp instead of strcmp. * client.c (call_in_directory): Use CVS_MKDIR instead of straight mkdir. * client.c (handle_checksum): Cast return value of strtol. Wed Aug 30 10:35:46 1995 Stefan Monnier <stefan.monnier@epfl.ch> * main.c (main): Allow -d to override CVSROOT_ENV. Thu Aug 24 18:57:49 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * cvs.h, rcscmds.c (RCS_unlock, RCS_deltag, RCS_lock): Add extra parameter for whether to direct stderr to DEVNULL. * checkin.c, tag.c, rtag.c, import.c, commit.c: Pass extra argument. 1 if stderr had been directed to DEVNULL before rcscmds.c was in use, 0 if it was RUN_TTY. * cvs.h: Add comment regarding attic. Tue Aug 22 10:09:29 1995 Alexander Dupuy <dupuy@smarts.com> * rcs.c (whitespace): Cast to unsigned char in case char is signed and value is negative. Tue Aug 22 10:09:29 1995 Kirby Koster <koster@sctc.com> and Jim Kingdon <kingdon@harvey.cyclic.com> * update.c (join_file): If vers->vn_user is NULL, just return. Tue Aug 22 10:09:29 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * server.c, client.c: Add comments about modes and umasks. Mon Aug 21 12:54:14 1995 Rick Sladkey <jrs@world.std.com> * update.c (update_filesdone_proc): If pipeout, don't try to create CVS/Root. Mon Aug 21 12:54:14 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * client.c (start_rsh_server): Don't pass -d to "cvs server" invocation via rsh. * server.c (serve_root): Report errors via pending_error_text. (serve_valid_requests): Check for pending errors. Sun Aug 20 00:59:46 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * options.h.in: Document usage of DIFF in update.c * update.c: Use DIFF -c, not DIFF -u. The small improvement in diff size is not worth the hassle in terms of everyone having to make sure that DIFF is GNU diff (IMHO). Sat Aug 19 22:05:46 1995 Jim Blandy <jimb@totoro.cyclic.com> * recurse.c (start_recursion): Doc fix. * server.c (do_cvs_command): Clear error_use_protocol in the child. (server): Set error_use_protocol. Sun Aug 13 15:33:37 1995 Jim Kingdon <kingdon@harvey.cyclic.com> * server.c (do_cvs_command): Don't select on exceptions. Fri Aug 4 00:13:47 1995 Jim Meyering (meyering@comco.com) * Makefile.in (LDFLAGS): Set to @LDFLAGS@. (options.h): Depend on ../config.status and options.h.in. Add rule to build it from dependents. * add.c: Include save-cwd.h. (add_directory): Use save_cwd and restore_cwd instead of explicit getwd then chdir. * import.c (import_descend_dir): Likewise. * modules.c (do_module): Likewise. * recurse.c (save_cwd, restore_cwd, free_cwd): Remove functions. New versions have been broken out into save-cwd.c. (do_dir_proc): Adapt to handle status code returned by new versions of save_cwd and restore_cwd -- and one fewer argument to restore_cwd. (unroll_files_proc): Likewise. * wrapper.c (wrap_name_has): Add default: abort () to switch statement to avoid warning from gcc -Wall. (wrap_matching_entry): Remove dcl of unused TEMP. (wrap_tocvs_process_file): Remove dcl of unused ERR. (wrap_fromcvs_process_file): Likewise. * cvs.h: Remove prototype for error. Instead, include error.h. Also, remove trailing white space. Thu Aug 3 10:12:20 1995 Jim Meyering (meyering@comco.com) * import.c (import_descend_dir): Don't print probably-bogus CWD in error messages saying `cannot get working directory'. Sun Jul 30 20:52:04 1995 James Kingdon <kingdon@harvey.cyclic.com> * parseinfo.c (Parse_Info): Revise comments and indentation. Sun Jul 30 15:30:16 1995 Vince DeMarco <vdemarco@bou.shl.com> * history.c: put ifdef SERVER_SUPPORT around tracing code incase the client/server code is not compiled into the program. Sat Jul 29 16:59:49 1995 James Kingdon <kingdon@harvey.cyclic.com> * subr.c (deep_remove_dir): Use struct dirent, not struct direct. Sat Jul 29 18:32:06 1995 Vince DeMarco <vdemarco@bou.shl.com> * add.c: Check wrap_name_has. * diff.c, checkin.c, import.c: have code call unlink_file_dir in the appropriate places instead of just calling unlink_file. * checkin.c: Remove one unlink call. * import.c (comtable): Add .m .psw .pswm. * import.c (add_rcs_file): Remove tocvsPath before returning. * subr.c (unlink_file_dir): Add new function. unlinks the file if it is a file. or will do a recursive delete if the path is actually a directory. (deep_remove_dir): New function, helps unlink_file_dir. * mkmodules.c: Added CVSROOTADM_WRAPPER (cvswrappers file) to the checkout file list. Fri Jul 28 16:27:56 1995 James Kingdon <kingdon@harvey.cyclic.com> * checkout.c (safe_location): Use PATH_MAX not MAXPATHLEN. Fri Jul 28 19:37:03 1995 Paul Eggert <eggert@twinsun.com> * log.c (cvslog, log_fileproc): Pass all options (except -l) to rlog as-is, so that users can put spaces in options, can specify multiple -d options, etc. (ac, av): New variables. (log_option_with_arg, options): Remove. (log_fileproc): Don't prepend `/' to file name if update_dir is empty. Tue Jul 25 00:52:26 1995 James Kingdon <kingdon@harvey.cyclic.com> * checkout.c (safe_location): Don't use PROTO in function definition. Mon Jul 24 18:32:06 1995 Vince DeMarco <vdemarco@bou.shl.com> * checkout.c (safe_location): fix a compiler warning. (Declare safe_location). Changed code in safe_location to call getwd instead of getcwd. getwd is declared in the ../lib directory and used exclusively thoughout the code. (this helps portability on non POSIX systems). * wrapper.c: updated Andrew Athan's email address. * main.c: fix an ifdef so the code will compile. syntax error in the ifdef for CVS_NOADMIN. Mon Jul 24 13:25:00 1995 Del <del@babel.dialix.oz.au> * checkout.c: New procedure safe_location. Ensures that you don't check out into the repository itself. * tag.c, rtag.c, cvs.h, mkmodules.c: Added a "taginfo" file in CVSROOT to perform pre-tag checks. * main.c, options.h.in: Added a compile time option to disable the admin command. Fri Jul 21 17:07:42 1995 James Kingdon <kingdon@harvey.cyclic.com> * update.c, status.c, patch.c, checkout.c, import.c, release.c, rtag.c, tag.c: Now -q and -Q options just print an error message telling you to use global -q and -Q options. The non-global options were a mess because some commands accepted them and some did not, and they were redundant with -q and -Q global options. * rcs.c, cvs.h, commit.c, log.c, find_names.c: Remove CVS.dea stuff. It is slower than the alternatives and I don't think anyone ever actually used it. Fri Jul 21 10:35:10 1995 Vince DeMarco <vdemarco@bou.shl.com> * Makefile.in (SOURCES, OBJECTS): Add wrapper.c, wrapper.o. * add.c, admin.c, checkout.c, commit.c, diff.c, import.c, log.c, remove.c, status.c: Call wrap_setup at start of commands. * add.c (add): Check for wrapper, as well as directory, in repository. * checkin.c: Add tocvsPath variable and associated handling. * cvs.h: Add wrapper declarations. * diff.c: Add tocvsPath variable and associated handling. * import.c: Add -W option, CVSDOTWRAPPER handling. (import_descend): check wrap_name_has. (update_rcs_file, add_rev, add_rcs_file): add tocvsPath variable and associated handling. * no_diff.c: Add tocvsPath variable and associated handling. * recurse.c (start_recursion): Check wrap_name_has. * update.c: Copy, don't merge, copy-by-merge files. Attempt to use -j on a copy-by-merge file generates a warning and no further action. * update.c: Add CVSDOTWRAPPER handling. * wrapper.c: Added. Fri Jul 21 00:20:52 1995 James Kingdon <kingdon@harvey.cyclic.com> * client.c: Revert David Lamkin patch, except for the bits about removing temp_filename and the .rej file. * sanity.sh (errmsg1): Test for the underlying bug which Lamkin kludged around. * client.c (call_in_directory): Set short_pathname to include the filename, not just the directory. Improve comments regarding what is passed to FUNC. Thu Jul 20 17:51:54 1995 David Lamkin <drl@net-tel.co.uk> * client.c (short_pathname): Fixes the fetching of the whole file after a patch to bring it up to date has failed: - failed_patches[] now holds short path to file that failed - patch temp files are unlinked where the patch is done Thu Jul 20 12:37:10 1995 James Kingdon <kingdon@harvey.cyclic.com> * cvs.h: Declare error_set_cleanup * main.c: Call it. (error_cleanup): New function. Thu Jul 20 12:17:16 1995 Mark H. Wilkinson <mhw@minster.york.ac.uk> * add.c, admin.c, checkin.c, checkout.c, classify.c, client.c, client.h, commit.c, create_adm.c, cvs.h, diff.c, entries.c, history.c, import.c, log.c, main.c, modules.c, no_diff.c, patch.c, release.c, remove.c, repos.c, rtag.c, server.c, server.h, status.c, subr.c, tag.c, update.c, vers_ts.c, version.c: Put client code inside #ifdef CLIENT_SUPPORT, server code inside #ifdef SERVER_SUPPORT. When reporting version, report whether client and/or server are compiled in. Wed Jul 19 18:00:00 1995 Jim Blandy <jimb@cyclic.com> * subr.c (copy_file): Declare local var n to be an int, not a size_t. size_t is unsigned, and the return values of read and write are definitely not unsigned. * cvs.h [HAVE_IO_H]: #include <io.h>. [HAVE_DIRECT_H]: #include <direct.h>. Fri Jul 14 22:28:46 1995 Jim Blandy <jimb@totoro.cyclic.com> * server.c (dirswitch, serve_static_directory, serve_sticky, serve_lost, server_write_entries, serve_checkin_prog, serve_update_prog): Include more information in error messages. (Thanks, DJM.) * cvsbug.sh: Use /usr/sbin/sendmail, unless it doesn't exist, in which case use /usr/lib/sendmail. (Thanks, DJM.) * server.c (server, server_cleanup): Use "/tmp" instead of "/usr/tmp" when the TMPDIR environment variable isn't set. This is what the rest of the code uses. Thu Jul 13 11:03:17 1995 Jim Meyering (meyering@comco.com) * recurse.c (free_cwd): New function. (save_cwd, restore_cwd): Use it instead of simply freeing any string. The function also closes any open file descriptor. * import.c (comtable): Now static. (comtable): Put braces around each element of initializer. * cvs.h: Add prototype for xgetwd. * recurse.c (save_cwd, restore_cwd): New functions to encapsulate run-time solution to secure-SunOS vs. fchown problem. (do_dir_proc, unroll_files_proc): Use new functions instead of open-coded fchdir/chdir calls with cpp directives. * sanity.sh: Change out of TESTDIR before removing it. Some versions of rm fail when asked to delete the current directory. Wed Jul 12 22:35:04 1995 Jim Meyering (meyering@comco.com) * client.c (get_short_pathname): Add const qualifier to parameter dcl. (copy_a_file): Remove set-but-not-used variable, LEN. (handle_clear_static_directory): Likewise: SHORT_PATHNAME. (set_sticky): Likewise: LEN. (handle_set_sticky): Likewise: SHORT_PATHNAME. (handle_clear_sticky): Likewise: SHORT_PATHNAME. (start_rsh_server): Convert perl-style `cond || stmt' to more conventional C-style `if (cond) stmt.' Sheesh. Remove dcl of unused file-static, SEND_CONTENTS. * history.c: Remove dcls of set-but-not-used file-statics, HISTSIZE, HISTDATA. (read_hrecs): Don't set them. * import.c (add_rev): Remove dcl of set-but-not-used local, RETCODE. * repos.c (Name_Repository): Remove dcl of set-but-not-used local, HAS_CVSADM. * cvsrc.c (read_cvsrc): Parenthesize assignment used as truth value. Tue Jul 11 16:49:41 1995 J.T. Conklin <jtc@rtl.cygnus.com> * hash.h (struct entnode, Entnode): moved from here... * cvs.h: to here. Wed Jul 12 19:45:24 1995 Dominik Westner (dominik@gowest.ppp.informatik.uni-muenchen.de) * client.c (server_user): new var. (parse_cvsroot): set above if repo is "user@host:/dir". (start_rsh_server): if server_user set, then use it. Wed Jul 12 10:53:36 1995 Karl Fogel <kfogel@floss.cyclic.com> * sanity.sh: remove the TESTDIR after done. * cvsbug.sh (GNATS_ADDR): now bug-cvs@prep.ai.mit.edu again. Tue Jul 11 15:53:08 1995 Greg A. Woods <woods@most.weird.com> * options.h.in: depend on configure for grep and diff, now that changes to configure.in are applied. Tue Jul 11 14:32:14 1995 Michael Shields <shields@tembel.org> * Makefile.in (LDFLAGS): Pick up from configure. Tue Jul 11 14:20:00 1995 Loren James Rittle <rittle@supra.comm.mot.com> * import.c (add_rev), commit.c (remove_file, ci_new_rev), checkin.c (Checkin), subr.c (make_message_rcslegal), cvs.h: Always perform sanity check and fix-up on messages to be passed directly to RCS via the '-m' switch. RCS 5.7 requires that a non-total-whitespace, non-null message be provided or it will abort with an error. CVS is not setup to handle any returned error from 'ci' gracefully and, thus, the repository entered a trashed state. * sanity.sh: Add regression tests for new code and interactions with RCS 5.7. Sun Jul 9 19:03:00 1995 Greg A. Woods <woods@most.weird.com> * .cvsignore: added new backup file * options.h.in: our new configure.in finds the right diff and grep paths now.... * subr.c: quote the string in run_print() for visibility - indent a comment - Jun Hamano's xchmod() patch to prevent writable files (from previous local changes) * logmsg.c: fix a NULL pointer de-reference - clean up some string handling code... (from previous local changes) * parseinfo.c: add hack to expand $CVSROOT in an *info file. - document "ALL" and "DEFAULT" in opening comment for Parse_Info() - fix the code to match the comments w.r.t. callbacks for "ALL" - add a line of trace output... (from previous local changes) * mkmodules.c: add support for comments in CVSROOT/checkoutlist - add CVSroot used by something other .o, ala main.c (from previous local changes) * main.c, cvs.h: add support for $VISUAL as log msg editor (from previous local changes) * status.c: add support for -q and -Q (from previous local changes) Sun Jul 9 18:44:32 1995 Karl Fogel <kfogel@floss.cyclic.com> * log.c: trivial change to test ChangeLog stuff. Sat Jul 8 20:33:57 1995 Paul Eggert <eggert@twinsun.com> * history.c: (history_write): Don't assume that fopen(..., "a") lets one interleave writes to the history file from different processes without interlocking. Use open's O_APPEND option instead. Throw in an lseek to lessen the race bugs on non-Posix hosts. * cvs.h, subr.c (Fopen): Remove. * log.c (log_fileproc): Pass working file name to rlog, so that the name is reported correctly. Fri Jul 7 18:29:37 1995 Michael Hohmuth <hohmuth@inf.tu-dresden.de> * client.c, client.h (client_import_setup): New function. (client_import_done, client_process_import_file): Add comments regarding now-redundant code. * import.c (import): Call client_import_setup. Tue Jul 4 09:21:26 1995 Bernd Leibing <bernd.leibing@rz.uni-ulm.de> * rcs.c (RCS_parsercsfile_i): Rename error to l_error; SunOS4 /bin/cc doesn't like a label and function with the same name. Sun Jul 2 12:51:33 1995 Fred Appelman <Fred.Appelman@cv.ruu.nl> * logmsg.c: Rename strlist to str_list to avoid conflict with Unixware 2.01. Thu Jun 29 17:37:22 1995 Paul Eggert <eggert@twinsun.com> * rcs.c (RCS_check_kflag): Allow RCS 5.7's new -kb option. Wed Jun 28 09:53:14 1995 James Kingdon <kingdon@harvey.cyclic.com> * Makefile.in (HEADERS): Remove options.h.in. (DISTFILES): Add options.h.in. Depend on options.h in addition to HEADERS. Tue Jun 27 22:37:28 1995 Vince Demarco <vdemarco@bou.shl.com> * subr.c: Don't try to do fancy waitstatus stuff for NeXT, lib/wait.h is sufficient. Mon Jun 26 15:17:45 1995 James Kingdon <kingdon@harvey.cyclic.com> * Makefile.in (DISTFILES): Remove RCS-patches and convert.sh. Fri Jun 23 13:38:28 1995 J.T. Conklin (jtc@rtl.cygnus.com) * server.c (dirswitch, serve_co): Use CVSADM macro instead of literal "CVS". Fri Jun 23 00:00:51 1995 James Kingdon <kingdon@harvey.cyclic.com> * README-rm-add: Do not talk about patching RCS, that only confuses people. * RCS-patches, convert.sh: Removed (likewise). Thu Jun 22 10:41:41 1995 James Kingdon <kingdon@harvey.cyclic.com> * subr.c: Change -1 to (size_t)-1 when comparing against a size_t. Wed Jun 21 16:51:54 1995 nk@ipgate.col.sw-ley.de (Norbert Kiesel) * create_adm.c, entries.c, modules.c: Avoid coredumps if timestamps, tags, etc., are NULL. Tue Jun 20 15:52:53 1995 Jim Meyering (meyering@comco.com) * checkout.c (checkout): Remove dcl of unused variable. * client.c (call_in_directory, handle_clear_static_directory, handle_set_sticky, handle_clear_sticky, send_a_repository, send_modified, send_dirent_proc): Remove dcls of unused variables. * server.c (receive_file, serve_modified, server_cleanup): Remove dcls of unused variables. * subr.c (copy_file): Remove dcl of unused variable. * vers_ts.c (time_stamp_server): Remove dcl of unused variable. Mon Jun 19 13:49:35 1995 Jim Blandy <jimb@totoro.cyclic.com> * sanity.sh: Fix commencement message --- the test suite says "Ok." when it's done. Fri Jun 16 11:23:44 1995 Jim Meyering (meyering@comco.com) * entries.c (fgetentent): Parenthesize assignment in if-conditional. Thu Jun 15 17:33:28 1995 J.T. Conklin <jtc@rtl.cygnus.com> * server.c (get_buffer_data, buf_append_char, buf_append_data): Don't conditionalize use of "inline". Autoconf takes care of defining it away on systems that don't grok it. Thu Jun 15 13:43:38 1995 Jim Kingdon (kingdon@cyclic.com) * options.h.in (DIFF): Default to "diff" not "diff -a" since diff might not support the -a option. Wed Jun 14 11:29:42 1995 J.T. Conklin <jtc@rtl.cygnus.com> * import.c (import_descend): Initialize dirlist to NULL. * subr.c (copy_file): Fix infinite loop. * server.c (serve_directory): fix a memory leak. * checkout.c, commit.c, diff.c, history.c, import.c, log.c, patch.c, release.c, remove.c, rtag.c, status.c, tag.c, update.c: Use send_arg() to send command line arguments to server. * commit.c (fsortcmp), find_names (fsortcmp), hash.c (hashp, findnode), hash.h (findnode), rcs.c (RCS_addnode, RCS_check_kflag, RCS_check_tag, RCS_isdead, RCS_parse, RCS_parsercsfile_i), rcs.h (RCS_addnode, RCS_check_kflag, RCS_check_tag, RCS_parse): Added const qualifiers as appropriate. * rcs.h (RCS_isdead): Added prototype. * hash.h (walklist, sortlist): correct function prototypes. * ignore.c (ign_setup): don't bother checking to see if file exists before calling ign_add_file. Fri Jun 9 11:24:06 1995 J.T. Conklin <jtc@rtl.cygnus.com> * all source files (rcsid): Added const qualifer. * ignore.c (ign_default): Added const qualifier. * subr.c (numdots): Added const qualifier to function argument. * cvs.h (numdots): Added const qualifier to prototype argument. * client.c (change_mode): Tied consecutive if statements testing the same variable together with else if. * import.c (import_descend): Build list of subdirectories when reading directory, and then process the subdirectories in that list. This change avoids I/O overhead of rereading directory and reloading ignore list (.cvsignore) for each subdirectory. Thu Jun 8 11:54:24 1995 J.T. Conklin <jtc@rtl.cygnus.com> * import.c (import_descend): Use 4.4BSD d_type field if it is present. * lock.c (set_lockers_name): Use %lu in format and cast st_uid field to unsigned long. * import.c (import): Use RCS_check_kflag() to check -k options. (keyword_usage, str2expmode, strn2expmode, expand_names): Removed. * rcs.c (RCS_check_kflag): Added keyword_usage array from import.c for more descriptive error messages. * subr.c (run_setup, run_args): Changed variable argument processing to work on machines that use <varargs.h>. * subr.c (copy_file, xcmp): Changed to read the file(s) by blocks rather than by reading the whole file into a huge buffer. The claim that this was reasonable because source files tend to be small does not hold up in real world situations. CVS is used to manage non-source files, and mallocs of 400K+ buffers (x2 for xcmp) can easily fail due to lack of available memory or even memory pool fragmentation. (block_read): New function, taken from GNU cmp and slightly modified. * subr.c (xcmp): Added const qualifier to function arguments. * cvs.h (xcmp): Added const qualifer to prototype arguments. Wed Jun 7 11:28:31 1995 J.T. Conklin <jtc@rtl.cygnus.com> * cvs.h (Popen): Added prototype. (Fopen, open_file, isreadable, iswritable, isdir, isfile, islink, make_directory, make_directories, rename_file, link_file, unlink_file, copy_file): Added const qualifer to prototype arguments. * subr.c (Fopen, Popen, open_file, isreadable, iswritable, isdir, isfile, islink, make_directory, make_directories, rename_file, link_file, unlink_file, copy_file): Added const qualifier to function arguments. * logmsg.c (logfile_write), recurse.c (do_recursion, addfile): Don't cast void functions to a void expression. There is at least one compiler (MPW) that balks at this. * rcs.c (keysize, valsize): Change type to size_t. * add.c (add_directory): Don't cast umask() argument to int. * import.c (add_rcs_file): Changed type of mode to mode_t. * rcscmds.c (RCS_merge): New function. * cvs.h (RCS_merge): Declare. * update.c (merge_file, join_file): Call RCS_merge instead of invoking rcsmerge directly. * cvs.h: Include <stdlib.h> if HAVE_STDC_HEADERS, otherwise declared getenv(). * cvsrc.c, ignore.c, main.c: Removed getenv() declaration. * client.c (mode_to_string): Changed to take mode_t instead of struct statb argument. Simplified implementation, no longer overallocates storage for returned mode string. * client.h (mode_to_string): Updated declaration. * server.c (server_updated): Updated for new calling conventions, pass st_mode instead of pointer to struct statb. * cvs.h (CONST): Removed definition, use of const qualifier is determined by autoconf. * history.c, modules.c, parseinfo.c: Use const instead of CONST. * add.c, admin.c, checkout.c, commit.c, diff.c, import.c, log.c, main.c, mkmodules.c, patch.c, recurse.c, remove.c, rtag.c, server.c, status.c, subr.c, tag.c, update.c: Changed function arguments "char *argv[]" to "char **argv" to silence lint warnings about performing arithmetic on arrays. Tue Jun 6 18:57:21 1995 Jim Blandy <jimb@totoro.cyclic.com> * version.c: Fix up version string, to say that this is Cyclic CVS. Tue Jun 6 15:26:16 1995 J.T. Conklin <jtc@rtl.cygnus.com> * subr.c (run_setup, run_args, run_add_arg, xstrdup): Add const qualifier to format argument. * cvs.h (run_setup, run_args, xstrdup): Likewise. * Makefile.in (SOURCES): Added rcscmds.c. (OBJECTS): Added rcscmds.o. * rcscmds.c: New file, with new functions RCS_settag, RCS_deltag, RCS_setbranch, RCS_lock, RCS_unlock. * checkin.c, commit.c, import.c, rtag.c, tag.c: Call above functions instead of exec'ing rcs commands. * cvs.h: Declare new functions. Mon May 29 21:40:54 1995 J.T. Conklin (jtc@rtl.cygnus.com) * recurse.c (start_recursion, do_recursion): Set entries to NULL after calling Entries_Close(). Sat May 27 08:08:18 1995 Jim Meyering (meyering@comco.com) * Makefile.in (check): Export RCSBIN only if there exists an `rcs' executable in ../../rcs/src. Before, tests would fail when the directory existed but contained no executables. (distclean): Remove options.h, now that it's generated. (Makefile): Regenerate only *this* file when Makefile.in is out of date. Depend on ../config.status. Fri May 26 14:34:28 1995 J.T. Conklin <jtc@rtl.cygnus.com> * entries.c (Entries_Open): Added missing fclose(). (Entries_Close): Don't write Entries unless Entries.Log exists. * entries.c (Entries_Open): Renamed from ParseEntries; changed to process Entries Log files left over from previous crashes or aborted runs. (Entries_Close): New function, write out Entries file if neccessary and erase Log file. (Register): Append changed records to Log file instead of re-writing file. (fgetentent): New function, parse one Entry record from a file. (AddEntryNode): It's no longer an error for two records with the same name to be added to the list. New records replace older ones. * cvs.h (Entries_Open, Entries_Close): Add prototypes. (CVSADM_ENTLOG): New constant, name of Entries Log file. * add.c, checkout.c, client.c, find_names.c, recurse.c: Use Entries_Open()/Entries_Close() instead of ParseEntries()/dellist(). * add.c, admin.c, checkout.c, client.c, commit.c, diff.c, history.c, import.c, log.c, patch.c, release.c, remove.c, rtag.c, server.c, status.c, tag.c, update.c: Changed conditionals so that return value of *printf is tested less than 0 instead of equal to EOF. Thu May 25 08:30:12 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * subr.c (xmalloc): Never try to malloc zero bytes; if the user asks for zero bytes, malloc one instead. Wed May 24 12:44:25 1995 Ken Raeburn <raeburn@cujo.cygnus.com> * subr.c (xmalloc): Don't complain about NULL if zero bytes were requested. Tue May 16 21:49:05 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * subr.c (xmalloc): Never try to malloc zero bytes; if the user asks for zero bytes, malloc one instead. Mon May 15 14:35:11 1995 J.T. Conklin <jtc@rtl.cygnus.com> * lock.c (L_LOCK_OWNED): Removed. * add.c, checkout.c, client.c, create_adm.c, cvs.h, entries.c, find_names.c modules.c, recurse.c, release.c, repos.c, update.c: removed CVS 1.2 compatibility/upgrade code. Mon May 8 11:25:07 1995 J.T. Conklin <jtc@rtl.cygnus.com> * lock.c (write_lock): Missed one instance where rmdir(tmp) should have been changed to clear_lock(). Wed May 3 11:08:32 1995 J.T. Conklin <jtc@rtl.cygnus.com> * create_adm.c, entries.c, import.c, root.c: Changed conditionals so that return value of *printf is tested less than 0 instead of equal to EOF --- That's all Standard C requires. Wed May 3 18:03:37 1995 Samuel Tardieu <tardieu@emma.enst.fr> * rcs.h: removed #ifdef CVS_PRIVATE and #endif because cvs didn't compile anymore. Mon May 1 13:58:53 1995 J.T. Conklin <jtc@rtl.cygnus.com> * rcs.c, rcs.h: Implemented lazy parsing of rcs files. RCS_parsercsfile_i modified to read only the first two records of rcs files, a new function RCS_reparsercsfile is called only when additional information (tags, revision numbers, dates, etc.) is required. Mon May 1 12:20:02 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * Makefile.in (INCLUDES): Include -I. for options.h. Fri Apr 28 16:16:33 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * Makefile.in (SOURCES, HEADERS, DISTFILES): Updated. (dist-dir): Renamed from dist; changed to work with DISTDIR variable passed from parent. We don't want to include a file the user has to edit in the distribution. * options.h: No longer distributed. * options.h.in: Distribute this instead. * ../INSTALL, ../README: Installation instructions updated. * client.c (start_rsh_server): Send the remote command to rsh as a single string. Fri Apr 28 00:29:49 1995 Noel Cragg <noel@vo.com> * commit.c: Added initializer for FORCE_CI * sanity.sh: Fix tests added 25 Apr -- they were expecting the server to make noise, but the CVS_SERVER variable had been accidentally set with the `-Q' flag. Ran all tests -- both locally and remotely -- to verify that the change didn't break anything. Thu Apr 27 12:41:52 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * Makefile.in: Revise comment regarding check vs. remotecheck. Thu Apr 27 12:52:28 1995 Bryan O'Sullivan <bos@cyclic.com> * client.c (start_rsh_server): If the CVS_RSH environment variable is set, use its contents as the name of the program to invoke instead of `rsh'. Thu Apr 27 12:18:38 1995 Noel Cragg <noel@vo.com> * checkout.c (checkout): To fix new bug created by Apr 23 change, re-enabled "expand-module" functionality, because it has the side effect of setting the checkin/update programs for a directory. To solve the local/remote checkout problem that prompted this change in the first place, I performed the next change. * server.c (expand_proc): Now returns expansions for aliases only. Wed Apr 26 12:07:42 1995 J.T. Conklin <jtc@rtl.cygnus.com> * rcs.c (getrcskey): Rewritten to process runs of whitespace chars and rcs @ strings instead of using state variables "white" and "funky". Fri Apr 7 15:49:25 1995 J.T. Conklin <jtc@rtl.cygnus.com> * lock.c (unlock): Only call stat if we need to. Wed Apr 26 10:48:44 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (new_entries_line): Don't prototype. Tue Apr 25 22:19:16 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * sanity.sh: Add new tests to catch bugs in Apr 23 change. Tue Apr 25 17:10:55 1995 Roland McGrath <roland@baalperazim.frob.com> * create_adm.c (Create_Admin): Use getwd instead of getcwd. Sun Apr 23 20:58:32 1995 Noel Cragg <noel@vo.com> * checkout.c (checkout): Disabled "expand-module" functionality on remote checkout, since it makes modules behave like aliases (see longer note there). This change necessitated the change below. Also merged the like parts of a conditional. * client.c (call_in_directory): Changed the algorithm that created nested and directories and the "CVS" administration directories therein. The algoithm wrongly assumed that the name of the directory that that was to be created and the repository name were the same, which breaks modules. * create_adm.c (Create_Admin), module.c (do_module), server.c (server_register), subr.c, entries.c: Added fprintfs for trace-mode debugging. * client.c (client_send_expansions): Argument to function didn't have a type -- added one. * server.c (new_entries_line): Arguments to this function are never used -- reoved them and fixed callers. Sat Apr 22 11:17:20 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * rcs.c (RCS_parse): If we can't open the file, give an error message (except for ENOENT in case callers rely on that). Wed Apr 19 08:52:37 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (send_repository): Check for CVSADM_ENTSTAT in `dir', not in `.'. * sanity.sh: Add TODO list. Revise some comments. Add tests of one working directory adding a file and other updating it. Sat Apr 8 14:52:55 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * Makefile.in (CFLAGS): Let configure set the default for CFLAGS. Under GCC, we want -g -O. Fri Apr 7 15:49:25 1995 J.T. Conklin <jtc@rtl.cygnus.com> * root.c (Name_Root): merge identical adjacent conditionals. * create_admin.c (Create_Admin): Rearranged check for CVSADM and OCVSADM directories so that CVSADM pathname is only built once. * update.c (update_dirleave_proc): Removed code to remove CVS administration directory if command_name == "export" and to create CVS/Root file if it is not present. Identical code in update_filesdone_proc() will perform these same actions. Also removed code that read and verfied CVS/Root. This is expensive, and if it is necessary should happen in the general recursion processor rather than in the update callbacks. * lock.c (masterlock): New variable, pathname of master lockdir. (set_lock): removed lockdir argument, now constructs it itself and stores it in masterlock. (clear_lock): new function, removes master lockdir. (Reader_Lock, write_lock): call clear_lock instead of removing master lockdir. (Reader_Lock, write_lock): #ifdef'd out CVSTFL code. * main.c (main): register Lock_Cleanup signal handler. * lock.c (Reader_Lock, write_lock): no longer register Lock_Cleanup. * main.c (main): initialize new array hostname. * lock.c (Reader_Lock, write_lock): Use global hostname array. * logmsg.c (logfile_write): Likewise. * recurse.c (do_dir_proc, unroll_files_proc): Use open()/fchdir() instead of getwd()/chdir() on systems that support the fchdir() system call. Fri Apr 7 06:57:20 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c: Include the word "server" in error message for memory exhausted, so the user knows which machine ran out of memory. * sanity.sh: For remote, set CVS_SERVER to test the right server, rather than a random one from the PATH. * commit.c [DEATH_STATE]: Pass -f to `ci'. Thu Apr 6 13:05:15 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * commit.c (checkaddfile): If we didn't manage to fopen the file, don't try to fclose it. * client.c (handle_m, handle_e): Use fwrite, rather than a loop of putc's. Sometimes these streams are unbuffered. Tue Apr 4 11:33:56 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * (DISTFILES): Include cvsbug.sh, ChangeLog, NOTES, RCS-patches, README-rm-add, ChangeLog.fsf, sanity.sh, sanity.el, and .cvsignore. Mon Mar 27 08:58:42 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * rcs.c (RCS_parsercsfile_i): Accept `dead' state regardless of DEATH_STATE define. Revise comments regarding DEATH_STATE versus CVSDEA versus the scheme which uses a patched RCS. * README-rm-add, RCS-patches: Explain what versions of CVS need RCS patches. Sat Mar 25 18:51:39 1995 Roland McGrath <roland@churchy.gnu.ai.mit.edu> * server.c (server_cleanup): Only do the abysmal kludge of waiting for command and draining the pipe #ifdef sun. The code makes assumptions not valid on all systems, and is only there to workaround a SunOS bug. Wed Mar 22 21:55:56 1995 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (mkdir_p): Call stat only if we get the EACCES. Faster and more elegant. Tue Jan 31 20:59:19 1995 Ken Raeburn <raeburn@cujo.cygnus.com> * server.c: Try to avoid starting the "rm -rf" at cleanup time until after subprocesses have finished. (command_fds_to_drain, max_command_fd): New variables. (do_cvs_command): Set them. (command_pid_is_dead): New variable. (wait_sig): New function. (server_cleanup): If command_pid is nonzero, wait for it to die, draining output from it in the meantime. If nonzero SIG was passed, send a signal to the subprocess, to encourage it to die soon. * main.c (usage): Argument is now `const char *const *'. * cvs.h (usage): Changed prototype. (USE): Make new variable `const'. * add.c (add_usage), admin.c (admin_usage), checkout.c (checkout_usage, export_usage, checkout), commit.c (commit_usage), diff.c (diff_usage), history.c (history_usg), import.c (import_usage, keyword_usage), log.c (log_usage), main.c (usg), patch.c (patch_usage), release.c (release_usage), remove.c (remove_usage), rtag.c (rtag_usage), server.c (server), status.c (status_usage), tag.c (tag_usage), update.c (update_usage): Usage messages are now const arrays of pointers to const char. * import.c (comtable): Now const. * main.c (rcsid): Now static. (cmd): Now const. (main): Local variable CM now points to const. * server.c (outbuf_memory_error): Local var MSG now const. * client.c (client_commit_usage): Deleted. Sat Dec 31 15:51:55 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * logmsg.c (do_editor): Allocate enough space for trailing '\0'. Fri Mar 3 11:59:49 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * cvsbug.sh: Call it "Cyclic CVS" now, not "Remote CVS". Call it version C1.4A, not 1.4A2-remote. Send bugs to cyclic-cvs, not remote-cvs. * classify.c (Classify_File): Put check for dead file inside "#ifdef DEATH_SUPPORT". Thu Feb 23 23:03:43 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * update.c (join_file): Don't pass the -E option to rcsmerge here, either (see Jan 22 change). Mon Feb 13 13:28:46 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * cvsbug.sh: Send bug reports to remote-cvs@cyclic.com, rather than to the ordinary CVS bug address. This does mean we'll have to wade through GNATS-style bug reports, sigh. Wed Feb 8 06:42:27 1995 Roland McGrath <roland@churchy.gnu.ai.mit.edu> * server.c: Don't include <sys/stat.h>; system.h already does, and 4.3BSD can't take it twice. * subr.c [! HAVE_VPRINTF] (run_setup, run_args): Don't use va_dcl in declaration. Declare the a1..a8 args which are used in the sprintf call. * cvs.h [! HAVE_VPRINTF] (run_setup, run_args): Don't prototype args, to avoid conflicting with the function definitions themselves. Tue Feb 7 20:10:00 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * client.c (update_entries): Pass the patch subprocess the switch "-b ~", not "-b~"; the latter form seems not to work with patch version 2.0 and earlier --- it takes the next argv element as the backup suffix, and thus doesn't notice that the patch file's name has been specified, thus doesn't find the patch, thus... *aargh* Fri Feb 3 20:28:21 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * log.c (log_option_with_arg): New function. (cvslog): Use it and send_arg to handle the rlog options that take arguments. The code used to use send_option_string for everything, which assumes that "-d1995/01/02" is equivalent to "-d -1 -9 -9 -5 ...". Tue Jan 31 15:02:01 1995 Jim Blandy <jimb@floss.life.uiuc.edu> * server.c: #include <sys/stat.h> for the new stat call in mkdir_p. (mkdir_p): Don't try to create the intermediate directory if it exists already. Some systems return EEXIST, but others return EACCES, which we can't otherwise distinguish from a real access problem. Sun Jan 22 15:25:45 1995 Jim Blandy <jimb@totoro.bio.indiana.edu> * update.c (merge_file): My rcsmerge doesn't accept a -E option, and it doesn't look too important, so don't pass it. Fri Jan 20 14:24:58 1995 Ian Lance Taylor <ian@sanguine.cygnus.com> * client.c (do_deferred_progs): Don't try to chdir to toplevel_wd if it has not been set. (process_prune_candidates): Likewise. Mon Nov 28 09:59:14 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (client_commit): Move guts of function from here... * commit.c (commit): ...to here. Mon Nov 28 15:14:36 1994 Ken Raeburn <raeburn@cujo.cygnus.com> * server.c (buf_input_data, buf_send_output): Start cpp directives in column 1, otherwise Sun 4 pcc complains. Mon Nov 28 09:59:14 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (add_prune_candidate): Don't try to prune ".". Tue Nov 22 05:27:10 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c, client.c: More formatting cleanups. * client.h, client.c: New variable client_prune_dirs. * update.c (update), checkout.c (checkout): Set it. * client.c (add_prune_candidate, process_prune_candidates): New functions. (send_repository, call_in_directory, get_responses_and_close): Call them. Wed Nov 23 01:17:32 1994 Ian Lance Taylor (ian@tweedledumb.cygnus.com) * server.c (do_cvs_command): Don't select on STDOUT_FILENO unless we have something to write. Tue Nov 22 05:27:10 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * remove.c (remove_fileproc): Only call server_checked_in if we actually are changing the entries file. * server.c (server_write_entries): New function. (dirswitch, do_cvs_command): Call it. (serve_entry, serve_updated): Just update in-memory data structures, don't mess with CVS/Entries file. Mon Nov 21 10:15:11 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (server_checked_in): Set scratched_file to NULL after using it. * checkin.c (Checkin): If the file was changed by the checkin, call server_updated not server_checked_in. Sun Nov 20 08:01:51 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (send_repository): Move check for update_dir NULL to before where we check last_update_dir. Check for "" here too. * client.c (send_repository): Use new argument dir. * client.c: Pass new argument dir to send_repository and send_a_repository. * server.c, server.h (server_prog): New function. * modules.c (do_modules): Call it if server_expanding. * client.c: Support Set-checkin-prog and Set-update-prog responses. * server.c, client.c: Add Checkin-prog and Update-prog requests. Fri Nov 18 14:04:38 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (get_short_pathname, is_cvsroot_level, call_in_directory): Base whether this is new-style or old-style based on whether we actually used the Directory request, not based on whether the pathname is absolute. Rename directory_supported to use_directory. * server.c: Rename use_relative_pathnames to use_dir_and_repos. * client.c (send_a_repository): If update_dir is absolute, don't use it to try to reconstruct how far we have recursed. * server.c, server.h, client.c, client.h, vers_ts.c, update.h: More cosmetic changes (identation, PARAMS vs. PROTO, eliminate alloca, etc.) to remote CVS to make it more like the rest of CVS. * server.c: Make server_temp_dir just the dir name, not the name with "%s" at the end. * server.c, client.c: Add "Max-dotdot" request, and use it to make extra directories in server_temp_dir if needed. Thu Nov 17 09:03:28 1994 Jim Kingdon <kingdon@cygnus.com> * client.c: Fix two cases where NULL was used and 0 was meant. Mon Nov 14 08:48:41 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (serve_unchanged): Set noexec to 0 when calling Register. * update.c (merge_file): Don't call xcmp if noexec. Fri Nov 11 13:58:22 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (call_in_directory): Deal with it if reposdirname is not a subdirectory of toplevel_repos. Mon Nov 7 09:12:01 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * patch.c: If file is removed and we don't have a tag or date, just print "current release". * classify.c (Classify_File): Treat dead files appropriately. Fri Nov 4 07:33:03 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * main.c (main) [SERVER_SUPPORT]: Move call to getwd past where we know whether we are the server or not. Set CurDir to "<remote>" if we are the server. * client.c: Remove #if 0'd function option_with_arg. Remove #if 0'd code pertaining to the old way of logging the session. * client.c (start_rsh_server): Don't invoke the server with the -d option. * server.c (serve_root): Test root for validity, just like main.c does for non-remote CVS. * main.c (main): If `cvs server' happens with a colon in the CVSroot, just handle it normally; don't make it an error. Wed Nov 2 11:09:38 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (send_dirent_proc): If dir does not exist, just return R_SKIP_ALL. * server.c, client.c: Add Directory request and support for local relative pathnames (along with the repository absolute pathnames). * update.c, add.c, checkout.c, checkin.c, cvs.h, create_adm.c, commit.c, modules.c, server.c, server.h, remove.c, client.h: Pass update_dir to server_* functions. Include update_dir in more error messages. Fri Oct 28 08:54:00 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c: Reformat to bring closer to cvs standards for brace position, comment formatting, etc. * sanity.sh: Remove wrong "last mod" line. Convert more tests to put PASS or FAIL in log file. Change it so arguments to the script specify which tests to run. * client.c, client.h, server.c, checkout.c: Expand modules in separate step from the checkout itself. Sat Oct 22 20:33:35 1994 Ken Raeburn (raeburn@kr-pc.cygnus.com) * update.c (join_file): When checking for null return from RCS_getversion, still do return even if quiet flag is set. Thu Oct 13 07:36:11 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (send_files): Call send_repository even if toplevel_repos was NULL. * server.c (server_updated): If joining, don't remove file. * update.c (join_file): If server and file is unmodified, check it out before joining. After joining, call server_updated. New argument repository. * server.c, server.h (server_copy_file): New function. * update.c (update_file_proc, join_file): Call it. * client.c (copy_file, handle_copy_file): New functions. * client.c (responses): Add "Copy-file". * client.c, client.h: Make toplevel_wd, failed_patches and failed_patches_count extern. * client.c (client_update): Move guts of function from here... * update.c (update): ...to here. * client.c, checkout.c: Likewise for checkout. * client.c (is_cvsroot_level): New function. (handle_set_sticky, handle_clear_sticky, handle_clear_static_directory): Call it, instead of checking short_pathname for a slash. * client.c, client.h (client_process_import_file, client_import_done): New functions. * import.c (import, import_descend): Use them. * import.c (import_descend): If server, don't mention ignored CVS directories. * import.c (import_descend_dir): If client, don't print warm fuzzies, or make directories in repository. If server, print warm fuzzies to stdout not stderr. * client.c (send_modified): New function, broken out from send_fileproc. (send_fileproc): Call it. * client.c (handle_clear_sticky, handle_set_sticky, handle_clear_static_directory, handle_set_static_directory): If command is export, just return. (call_in_directory, update_entries): If command is export, don't create CVS directories, CVS/Entries files, etc. * update.c (update_filesdone_proc): Don't remove CVS directories if client_active. * client.c (send_a_repository): Instead of insisting that repository end with update_dir, just strip as many pathname components from the end as there are in update_dir. * Makefile.in (remotecheck): New target, pass -r to sanity.sh. * sanity.sh: Accept -r argument which means to test remote cvs. * tag.c (tag), rtag.c (rtag), patch.c (patch), import.c (import), admin.c (admin), release.c (release): If client_active, connect to the server and send the right requests. * main.c (cmds): Add these commands. (main): Remove code which would strip hostname off cvsroot and try the command locally. There are no longer any commands which are not supported. * client.c, client.h (client_rdiff, client_tag, client_rtag, client_import, client_admin, client_export, client_history, client_release): New functions. * server.c (serve_rdiff, serve_tag, serve_rtag, serve_import, serve_admin, serve_export, serve_history, serve_release): New functions. (requests): List them. * server.c: Declare cvs commands (add, admin, etc.). * cvs.h, server.h: Don't declare any of them here. * main.c: Restore declarations of cvs commands which were previously removed. * cvs.h: New define DEATH_STATE, commented out for now. * rcs.c (RCS_parsercsfile_i), commit.c (remove_file, checkaddfile) [DEATH_STATE]: Use RCS state to record a dead file. Mon Oct 3 09:44:54 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * status.c (status_fileproc): Now that ts_rcs is just one time, don't try to print the second time from it. (Same as raeburn 20 Aug change, it accidentally got lost in 1.4 Alpha-1 merge). * cvs.h (CVSDEA): Added (but commented out for now). * rcs.c (RCS_parsercsfile_i) [CVSDEA]: Also look in CVSDEA to see if something is dead. * commit.c (ci_new_rev, mark_file) [CVSDEA]: New functions. (remove_file, checkaddfile) [CVSDEA]: Use them instead of ci -K. * find_names.c (find_dirs) [CVSDEA]: Don't match CVSDEA directories. * update.c (checkout_file): Check RCS_isdead rather than relying on co to not create the file. * sanity.sh: Direct output to logfile, not /dev/null. * subr.c (run_exec): Print error message if we are unable to exec. * commit.c (remove_file): Call Scratch_Entry when removing tag from file. The DEATH_SUPPORT ifdef was erroneous. Sun Oct 2 20:33:27 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * commit.c (checkaddfile): Instead of calling isdir before attempting to create the directory, just ignore EEXIST errors from mkdir. (This removes some DEATH_SUPPORT ifdefs which actually had nothing to do with death support). Thu Sep 29 09:23:57 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * diff.c (diff): Search attic too if we have a second tag/date. (diff_fileproc): If we have a second tag/date, don't do all the checking regarding the user file. Mon Sep 26 12:02:15 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * checkin.c (Checkin): Check for error from unlink_file. Mon Sep 26 08:51:10 1994 Anthony J. Lill (ajlill@ajlc.waterloo.on.ca) * rcs.c (getrcskey): Allocate space for terminating '\0' if necessary. Sat Sep 24 09:07:37 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * commit.c (commit_fileproc): Set got_message = 1 when calling do_editor (accidentally omitted from last change). Fri Sep 23 11:59:25 1994 Jim Kingdon (kingdon@lioth.cygnus.com) Revert buggy parts of Rich's change of 1 Nov 1993 (keeping the dynamic buffer allocation, which was the point of that change). * logmsg.c (do_editor): Reinstate message arg, but make it char **messagep instead of char *message. Change occurances of message to *messagep. Char return type from char * back to void. * cvs.h: Change do_editor declaration. * commit.c: Reinstate got_message variable (commit_filesdoneproc, commit_fileproc, commit_direntproc): Use it. * import.c (import), commit.c (commit_fileproc, commit_direntproc): Pass &message to do_editor; don't expect it to return a value. * client.c (client_commit): Likewise. * import.c (import): Deal with it if message is NULL. Wed Sep 21 09:43:25 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (server_updated): If the file doesn't exist, skip it. * diff.c, client.h, client.c: Rename diff_client_senddate to client_senddate and move from diff.c to client.c. * client.c (client_update, client_checkout): Use it. Sat Sep 17 08:36:58 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * checkout.c (checkout_proc): Don't pass NULL to Register for version. (should fix "cvs co -r <nonexistent-tag> <file>" coredump on Solaris). Fri Sep 16 08:38:02 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * diff.c (diff_fileproc): Set top_rev from vn_user, not vn_rcs. Rename it to user_file_rev because it need not be the head of any branch. (diff_file_nodiff): After checking user_file_rev, if we have both use_rev1 and use_rev2, compare them instead of going on to code which assumes use_rev2 == NULL. Thu Sep 15 08:20:23 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * status.c (status): Return a value in client_active case. Thu Sep 15 15:02:12 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * server.c (serve_modified): Create the file even if the size is zero. Thu Sep 15 08:20:23 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * lock.c (readers_exist): Clear errno each time around the loop, not just the first time. * client.c (start_server): Don't send Global_option -q twice. * no_diff.c (No_Difference): Check for error from unlink. * no_diff.c, cvs.h (No_Difference): New args repository, update_dir. Call server_update_entries if needed. Use update_dir in error message. * classify.c (Classify_File): Pass new args to No_Difference. * server.c (server_update_entries, server_checked_in, server_updated): Don't do anything if noexec. * client.c (send_fileproc): Rather than guessing how big the gzip output may be, just realloc the buffer as needed. Tue Sep 13 13:22:03 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * lock.c: Check for errors from unlink, readdir, and closedir. * classify.c (Classify_File): Pass repository and update_dir to sticky_ck. (sticky_ck): New args repository and update_dir. * server.c, server.h (server_update_entries): New function. * classify.c (sticky_ck): Call it. * client.c: New response "New-entry". * client.c (send_fileproc): Send tag/date from vers->entdata, not from vers itself. Mon Sep 12 07:07:05 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c: Clean up formatting ("= (errno)" -> "= errno"). * cvs.h: Declare strerror. * client.c: Add code to deal with Set-sticky and Clear-sticky responses, and Sticky request. * server.c: Add code to deal with Sticky request. * server.c, server.h (server_set_sticky): New function. * create_adm.c (Create_Admin), update.c (update, update_dirent_proc), commit.c (commit_dirleaveproc): Call it. * client.c, client.h (send_files): Add parameter aflag. * add.c (add), diff.c (diff), log.c (cvslog), remove.c (cvsremove), status.c (status), client.c (client_commit, client_update, client_checkout): Pass it. * client.c (client_update): Add -A flag. Fri Sep 9 07:05:35 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * entries.c (WriteTag): Check for error from unlink_file. * server.c (server_updated): Initialize size to 0. Previously if the file was zero length, the variable size got used without being set. Thu Sep 8 14:23:05 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (serve_repository): Check for error from fopen on CVSADM_ENT. * update.c (update, update_dirent_proc): Check for errors when removing Entries.Static. * client.c: Add code to deal with Set-static-directory and Clear-static-directory responses, and Static-directory request. * server.c, server.h (server_clear_entstat, server_set_entstat): New functions. * update.c, checkout.c, modules.c: Call them. * server.c: Add code to deal with Static-directory request. * server.c, client.c: Use strchr and strrchr instead of index and rindex. * server.c (serve_unchanged, serve_lost): Change comments which referred to changing timestamp; we don't always change the timestamp in those cases anymore. Wed Sep 7 10:58:12 1994 J.T. Conklin (jtc@rtl.cygnus.com) * cvsrc.c (read_cvsrc): Don't call getenv() three times when one time will do. * subr.c (xmalloc, xrealloc): Change type of bytes argument from int to size_t and remove the test that checks if it is less than zero. * cvs.h (xmalloc, xrealloc): Update prototype. Thu Sep 1 12:22:20 1994 Jim Kingdon (kingdon@cygnus.com) * update.c (merge_file, join_file): Pass -E to rcsmerge. (merge_file): If rcsmerge doesn't change the file, say so. * recurse.c, cvs.h (start_recursion): New argument wd_is_repos. * recurse.c (start_recursion): Use it instead of checking whether command_name is rtag to find out if we are cd'd to the repository. * client.c, update.c, commit.c, status.c, diff.c, log.c, admin.c, remove.c, tag.c: Pass 0 for wd_is_repos. * rtag.c, patch.c: Pass 1 for wd_is_repos. * classify.c, cvs.h (Classify_File): New argument pipeout. * classify.c (Classify_File): If pipeout, don't complain if the file is already there. * update.c, commit.c, status.c: Change callers. * mkmodules.c (main): Don't print "reminders" if commitinfo, loginfo, rcsinfo, or editinfo files are missing. Mon Aug 22 23:22:59 1994 Ken Raeburn (raeburn@kr-pc.cygnus.com) * server.c (strerror): Static definition replaced by extern declaration. Sun Aug 21 07:16:27 1994 Ken Raeburn (raeburn@kr-pc.cygnus.com) * client.c (update_entries): Run "patch" with input from /dev/null, so if it's the wrong version, it fails quickly rather than waiting for EOF from terminal before failing. Sat Aug 20 04:16:33 1994 Ken Raeburn (raeburn@cujo.cygnus.com) * server.c (serve_unchanged): Instead of creating a file with a zero timestamp, rewrite the entries file to have "=" in the timestamp field. * vers_ts.c (mark_lost, mark_unchanged): New macros. (time_stamp_server): Use them, for clarity. Interpret "=" timestamp as an unchanged file. A zero-timestamp file should never be encountered now in use_unchanged mode. * client.c (start_server): If CVS_CLIENT_PORT indicates a non-positive port number, skip straight to rsh connection. * status.c (status_fileproc): Fix ts_rcs reference when printing version info, to correspond to new Entries file format. Don't print it at all if server_active, because it won't have any useful data. Thu Aug 18 14:38:21 1994 Ken Raeburn (raeburn@cujo.cygnus.com) * cvs.h (status): Declare. * client.c (client_status): New function. * client.h (client_status): Declare. * main.c (cmds): Include it. * server.c (serve_status): New function. (requests): Add it. * status.c (status): Do the remote thing if client_active. * client.c (supported_request): New function. (start_server): Use it. * server.c (receive_partial_file): New function, broken out from serve_modified. Operate with fixed-size local buffer, instead of growing stack frame by entire file size. (receive_file): New function, broken out from serve_modified. (serve_modified): Call it. (server): Print out name of unrecognized request. More generic stream-filtering support: * client.c (close_on_exec, filter_stream_through_program): New functions. (server_fd): New variable. (get_responses_and_close): Direct non-rsh connection is now indicated by server_fd being non-negative. File descriptors for to_server and from_server may now be different in case "tee" filtering is being done. Wait for rsh_pid specifically. (start_server): Use filter_stream_through_program for "tee" filter, and enable it for direct Kerberos-authenticated connections. Use dup to create new file descriptors for server connection if logging is enabled. (start_rsh_server): Disable code that deals with logging. Per-file compression support: * cvs.h (gzip_level): Declare. * main.c (usg): Describe new -z argument. (main): Recognize it and set gzip_level. * client.c (filter_through_gzip, filter_through_gunzip): New functions to handle compression. (update_entries): If size starts with "z", uncompress (start_server): If gzip_level is non-zero and server supports it, issue gzip-file-contents request. (send_fileproc): Optionally compress file contents. Use a slightly larger buffer, anticipating the worst case. * server.c (gzip_level): Define here. (receive_file): Uncompress file contents if needed. (serve_modified): Recognize "z" in file size and pass receive_file appropriate flag. (buf_read_file_to_eof, buf_chain_length): New functions. (server_updated): Call them when sending a compressed file. (serve_gzip_contents): New function; set gzip_level. (requests): Added gzip-file-contents request. Wed Aug 17 09:37:44 1994 J.T. Conklin (jtc@cygnus.com) * find_names.c (find_dirs): Use 4.4BSD filesystem feature (it contains the file type in the dirent structure) to avoid stat'ing each file. * commit.c (remove_file,checkaddfile): Change type of umask variables from int to mode_t. * subr.c (): Likewise. Tue Aug 16 19:56:34 1994 Mark Eichin (eichin@cygnus.com) * diff.c (diff_fileproc): Don't use diff_rev* because they're invariant across calls -- add new variable top_rev. (diff_file_nodiff): After checking possible use_rev* values, if top_rev is set drop it in as well (if we don't already have two versions) and then clear it for next time around. Wed Aug 10 20:50:47 1994 Mark Eichin (eichin@cygnus.com) * diff.c (diff_fileproc): if ts_user and ts_rcs match, then the file is at the top of the tree -- so we might not even have a copy. Put the revision into diff_rev1 or diff_rev2. Wed Aug 10 14:55:38 1994 Ken Raeburn (raeburn@cujo.cygnus.com) * server.c (do_cvs_command): Use waitpid. * subr.c (run_exec): Always use waitpid. * Makefile.in (CC, LIBS): Define here, in case "make" is run in this directory instead of top level. Wed Aug 10 13:57:06 1994 Mark Eichin (eichin@cygnus.com) * client.c (krb_get_err_text): use HAVE_KRB_GET_ERR_TEXT to determine if we need to use the array or the function. * main.c: ditto. Tue Aug 9 16:43:30 1994 Ken Raeburn (raeburn@cujo.cygnus.com) * entries.c (ParseEntries): If timestamp is in old format, rebuild it in the new format. Fudge an unmatchable entry that won't trigger this code next time around, if the file is modified. * vers_ts.c (time_stamp): Only put st_mtime field into timestamp, and use GMT time for it. With st_ctime or in local time, copying trees between machines in different time zones makes all the files look modified. (time_stamp_server): Likewise. Tue Aug 9 19:40:51 1994 Mark Eichin (eichin@cygnus.com) * main.c (main): use krb_get_err_text function instead of krb_err_txt array. Thu Aug 4 15:37:50 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * main.c (main): When invoked as kserver, set LOGNAME and USER environment variables to the remote user name. Thu Aug 4 07:44:37 1994 Mark Eichin (eichin@cygnus.com) * client.c: (handle_valid_requests): if we get an option that has rq_enableme set, then send that option. If it is UseUnchanged, set use_unchanged so that the rest of the client knows about it. (Could become a more general method for dealing with protocol upgrades.) (send_fileproc): if use_unchanged didn't get set, send an old-style "Lost" request, otherwise send an "Unchanged" request. * server.c (serve_unchanged): new function, same as serve_lost, but used in the opposite case. (requests): add new UseUnchanged and Unchanged requests, and make "Lost" optional (there isn't a good way to interlock these.) * server.h (request.status): rq_enableme, new value for detecting compatibility changes. * vers_ts.c (time_stamp_server): swap meaning of zero timestamp if use_unchanged is set. Tue Jul 26 10:19:30 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * sanity.sh: Separate CVSROOT_FILENAME, which must be the filename of the root, from CVSROOT, which can include a hostname for testing remote CVS. (but the tests aren't yet prepared to deal with the bugs in remote CVS). * import.c (update_rcs_file): Change temporary file name in TMPDIR from FILE_HOLDER to cvs-imp<process-id>. * sanity.sh: Add ">/dev/null" and "2>/dev/null" many places to suppress spurious output. Comment out tests which don't work (cvs add on top-level directory, cvs diff when non-committed adds or removes have been made, cvs release, test 53 (already commented as broken), retagging without deleting old tag, test 63). Now 'make check' runs without any failures. Fri Jul 15 12:58:29 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * Makefile.in (install): Do not depend upon installdirs. Thu Jul 14 15:49:42 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c, server.c: Don't try to handle alloca here; it's handled by cvs.h. Tue Jul 12 13:32:40 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (update_entries): Reset stored_checksum_valid if we quit early because of a patch failure. Fri Jul 8 11:13:05 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (responses): Mark "Remove-entry" as optional. Thu Jul 7 14:07:58 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * server.c (server_updated): Add new checksum argument. If it is not NULL, and the client supports the "Checksum" response, send it. * server.h (server_updated): Update prototype. * update.c: Include md5.h. (update_file_proc): Pass new arguments to patch_file and server_updated. (patch_file): Add new checksum argument. Set it to the MD5 checksum of the version of the file being checked out. (merge_file): Pass new argument to server_updated. * client.c: Include md5.h. (stored_checksum_valid, stored_checksum): New static variables. (handle_checksum): New static function. (update_entries): If a checksum was received, check it against the MD5 checksum of the final file. (responses): Add "Checksum". (start_server): Clear stored_checksum_valid. * commit.c (commit_fileproc): Pass new argument to server_updated. * client.h (struct response): Move definition in from client.c, add status field. (responses): Declare. * client.c (struct response): Remove definition; moved to client.h. (responses): Make non-static. Initialize status field. * server.c (serve_valid_responses): Check and record valid responses, just as in handle_valid_requests in client.c. * diff.c (diff_client_senddate): New function. (diff): Use it to send -D arguments to server. Wed Jul 6 12:52:37 1994 J.T. Conklin (jtc@phishhead.cygnus.com) * rcs.c (RCS_parsercsfile_i): New function, parse RCS file referenced by file ptr argument. (RCS_parsercsfile): Open file and pass its file ptr to above function. (RCS_parse): Likewise. Wed Jul 6 01:25:38 1994 Ian Lance Taylor (ian@tweedledumb.cygnus.com) * client.c (update_entries): Print message indicating that an unpatchable file will be refetched. (client_update): Print message when refetching unpatchable files. Fri Jul 1 07:16:29 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * client.c (send_dirent_proc): Don't call send_a_repository if repository is "". Fri Jul 1 13:58:11 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (last_dirname, last_repos): Move out of function. (failed_patches, failed_patches_count): New static variables. (update_entries): If patch program fails, save short_pathname in failed_patches array, only exit program if retcode is -1, and return out of the function rather than update the Entries line. (start_server): Clear toplevel_repos, last_dirname, last_repos. (client_update): If failed_patches is not NULL after doing first update, do another update, but remove all the failed files first. Thu Jun 30 09:08:57 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (requests): Add request "Global_option". (serve_global_option): New function, to handle it. * client.c (start_server): Deal with global options. Check for errors from fprintf. * client.c (send_fileproc): Split out code which sends repository into new function send_a_repository. Also, deal with update_dir being ".". (send_dirent_proc): Call send_a_repository. * add.c (add): If client_active, do special processing for directories. (add_directory): If server_active, don't try to create CVSADM directory. Thu Jun 30 11:58:52 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (update_entries): If patch succeeds, remove the backup file. * server.c (server_updated): Add new argument file_info. If it is not NULL, use it rather than sb to get the file mode. * server.h (server_updated): Update prototype for new argument. * update.c (update_file_proc): Pass new arguments to patch_file and server_updated. (patch_file): Add new argument file_info. Don't use -p to check out new version, check it out into file and rename that to file2. If result is not readable, assume file is dead and set docheckout. Call xchmod on file2. Close the patch file after checking for a binary diff. Set file_info to the results of stat on file2. (merge_file): Pass new argument to server_updated. * commit.c (commit_fileproc): Pass new argument to server_updated. Wed Jun 29 13:00:41 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (krb_realmofhost): Declare, since it's not the current <krb.h>. (start_server): Save the name returned by gethostbyname. Call krb_realmofhost to get the realm. Pass the resulting realm to krb_sendauth. Pass the saved real name to krb_sendauth, rather than server_host. * update.c (update_file_proc): Pass &docheckout to patch_file. If it is set to 1, fall through to T_CHECKOUT case. (patch_file): Add docheckout argument. Set it to 1 if we can't make a patch. Check out the files and run diff rather than rcsdiff. If either file does not end in a newline, we can't make a patch. If the patch starts with the string "Binary", assume one or the other is a binary file, and that we can't make a patch. Tue Jun 28 11:57:29 1994 Ian Lance Taylor (ian@sanguine.cygnus.com) * client.c (update_entries): If the patch file is empty, don't run patch program; avoids error message. * classify.c (Classify_File): Return T_CHECKOUT, not T_PATCH, if the file is in the Attic. * cvs.h (enum classify_type): Add T_PATCH. * config.h (PATCH_PROGRAM): Define. * classify.c (Classify_File): If user file exists and is not modified, and using the same -k options, return T_PATCH instead of T_CHECKOUT. * update.c (patches): New static variable. (update): Add u to gnu_getopt argument. Handle it. (update_file_proc): Handle T_PATCH. (patch_file): New static function. * server.h (enum server_updated_arg4): Add SERVER_PATCHED. * server.c (server_updated): Handle SERVER_PATCHED by sending "Patched" command. (serve_ignore): New static function. (requests): Add "update-patches". (client_update): If the server supports "update-patches", send -u. * client.c (struct update_entries_data): Change contents field from int to an unnamed enum. (update_entries): Correponding change. If contents is UPDATE_ENTRIES_PATCH, pass the input to the patch program. (handle_checked_in): Initialize contents to enum value, not int. (handle_updated, handle_merged): Likewise. (handle_patched): New static function. (responses): Add "Patched". * commit.c (check_fileproc): Handle T_PATCH. * status.c (status_fileproc): Likewise. * client.c (start_server): If CVS_CLIENT_PORT is set in the environment, connect to that port, rather than looking up "cvs" in /etc/services. For debugging. Tue Jun 21 12:48:16 1994 Ken Raeburn (raeburn@cujo.cygnus.com) * update.c (joining): Return result of comparing pointer with NULL, not result of casting (truncating, on Alpha) pointer to int. * main.c (main) [HAVE_KERBEROS]: Impose a umask if starting as Kerberos server, so temp directories won't be world-writeable. * update.c (update_filesdone_proc) [CVSADM_ROOT]: If environment variable CVS_IGNORE_REMOTE_ROOT is set and repository is remote, don't create CVS/Root file. * main.c (main): If env var CVS_IGNORE_REMOTE_ROOT is set, don't check CVS/Root. Fri Jun 10 18:48:32 1994 Mark Eichin (eichin@cygnus.com) * server.c (O_NDELAY): use POSIX O_NONBLOCK by default, unless it isn't available (in which case substitute O_NDELAY.) Thu Jun 9 19:17:44 1994 Mark Eichin (eichin@cygnus.com) * server.c (server_cleanup): chdir out of server_temp_dir before deleting it (so that it works on non-BSD systems.) Code for choice of directory cloned from server(). Fri May 27 18:16:01 1994 Ian Lance Taylor (ian@tweedledumb.cygnus.com) * client.c (update_entries): Add return type of void. (get_responses_and_close): If using Kerberos and from_server and to_server are using the same file descriptor, use shutdown, not fclose. Close from_server. (start_server): New function; most of old version renamed to start_rsh_server. (start_rsh_server): Mostly renamed from old start_server. (send_fileproc): Use %lu and cast sb.st_size in fprintf call. (send_files): Remove unused variables repos and i. (option_no_arg): Comment out; unused. * main.c (main): Initialize cvs_update_env to 0. If command is "kserver", authenticate and change command to "server". If command is "server", don't call Name_Root, don't check access to history file, and don't assume that CVSroot is not NULL. * server.c (my_memmove): Removed. (strerror): Change check from STRERROR_MISSING to HAVE_STRERROR. (serve_root): Likewise for putenv. (serve_modified): Initialize buf to NULL. (struct output_buffer, buf_try_send): Remove old buffering code. (struct buffer, struct buffer_data, BUFFER_DATA_SIZE, allocate_buffer_datas, get_buffer_data, buf_empty_p, buf_append_char, buf_append_data, buf_read_file, buf_input_data, buf_copy_lines): New buffering code. (buf_output, buf_output0, buf_send_output, set_nonblock, set_block, buf_send_counted, buf_copy_counted): Rewrite for new buffering code. (protocol, protocol_memory_error, outbuf_memory_error, do_cvs_command, server_updated): Rewrite for new buffering code. (input_memory_error): New function. (server): Put Rcsbin at start of PATH in environment. * Makefile.in: Add @includeopt@ to DEFS. Fri May 20 08:13:10 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * cvs.h, classify.c (Classify_File): New argument update_dir. Include it in user messages. * commit.c (check_fileproc), status.c (status_fileproc), update.c (update_file_proc): Pass update_dir to Classify_File. * commit.c (check_fileproc), update.c (checkout_file): Include update_dir in user messages. * commit.c (check_fileproc) update.c (update_file_proc): Re-word "unknown status" message. * server.c (server_checked_in): Deal with the case where scratched_file is set rather than entries_line. * entries.c (Register): Write file even if server_active. * add.c (add): Add comment about how we depend on above behavior. Tue May 17 08:16:42 1994 Jim Kingdon (kingdon@lioth.cygnus.com) * mkmodules.c: Add dummy server_active and server_cleanup, to go with the dummy Lock_Cleanup already there. * server.c (server_cleanup): No longer static. Sat May 7 10:17:17 1994 Jim Kingdon (kingdon@lioth.cygnus.com) Deal with add and remove: * commit.c (checkaddfile): If CVSEXT_OPT or CVSEXT_LOG file does not exist, just silently keep going. (remove_file): If server_active, remove file before creating temporary file with that name. * server.c (serve_remove, serve_add): New functions. (requests): Add them. * server.c (server_register): If options is NULL, it means there are no options. * server.c, server.h (server_scratch_entry_only): New function. New variable kill_scratched_file. (server_scratch, server_updated): Deal with kill_scratched_file. * commit.c (commit_fileproc): If server_active, call server_scratch_entry_only and server_updated. * add.c (add): Add client_active code. (add): If server_active, call server_checked_in for each file added. * remove.c (remove): Add client_active code. (remove_fileproc): If server_active, call server_checked_in. * main.c (cmds), client.c, client.h: New functions client_add and client_remove. * Move declarations of add, cvsremove, diff, and cvslog from main.c to cvs.h. * client.c (call_in_directory): Update comment regarding Root and Repository files. (send_fileproc): Only send Entries line if Version_TS really finds an entry. If it doesn't find one, send Modified. (update_entries): If version is empty or starts with 0 or -, create a dummy timestamp. Thu May 5 19:02:51 1994 Per Bothner (bothner@kalessin.cygnus.com) * recurse/c (start_recursion): If we're doing rtag, and thus have cd'd to the reporsitory, add ,v to a file name before stat'ing. Wed Apr 20 15:01:45 1994 Ian Lance Taylor (ian@tweedledumb.cygnus.com) * client.c (client_commit): Call ign_setup. (client_update, client_checkout): Likewise. * diff.c (diff): If client, call ign_setup. * log.c (cvslog): Likewise. * update.h (ignlist): Change definition to declaration to avoid depending upon common semantics (not required by ANSI C, and not the default on Irix 5). * update.c (ignlist): Define. Tue Apr 19 00:02:54 1994 John Gilmore (gnu@cygnus.com) Add support for remote `cvs log'; clean up `cvs diff' a bit. * client.c (send_arg): Make external. (send_option_string): New function. (client_diff_usage): Remove, unused. (client_diff): Just call diff, not do_diff. (client_log): Add. * client.h (client_log, send_arg, send_option_string): Declare. * cvs.h (cvslog): Declare. * diff.c (do_diff): Fold back into diff(), distinguish by checking client_active. (diff): Remove `-*' arg parsing crud; use send_option_string. * log.c (cvslog): If a client, start the server, pass options and files, and handle server responses. * main.c (cmds): Add client_log. (main): Remove obnoxious message every time CVS/Root is used. Now CVS will be quiet about it -- unless there is a conflict between $CVSROOT or -d value versus CVS/Root. * server.c (serve_log): Add. (requests): Add "log". Mon Apr 18 22:07:53 1994 John Gilmore (gnu@cygnus.com) Add support for remote `cvs diff'. * diff.c (diff): Break guts out into new fn do_diff. Add code to handle starting server, writing args, sending files, and retrieving responses. (includes): Use PARAMS for static function declarations. * client.c (to_server, from_server, rsh_pid, get_responses_and_close, start_server, send_files, option_with_arg): Make external. (send_file_names): New function. (client_diff): New function. * client.h (client_diff, to_server, from_server, rsh_pid, option_with_arg, get_responses_and_close, start_server, send_file_names, send_files): Declare. * cvs.h (diff): Declare. * main.c (cmds): Add client_diff to command table. * server.c (serve_diff): New function. (requests): Add serve_diff. (server): Bug fix: avoid free()ing incremented cmd pointer. * update.h (update_filesdone_proc): Declare with PARAMS. Sat Apr 16 04:20:09 1994 John Gilmore (gnu@cygnus.com) * root.c (Name_root): Fix tyop (CVSroot when root meant). Sat Apr 16 03:49:36 1994 John Gilmore (gnu@cygnus.com) Clean up remote `cvs update' to properly handle ignored files (and files that CVS can't identify), and to create CVS/Root entries on the client side, not the server side. * client.c (send_fileproc): Handle the ignore list. (send_dirent_proc): New function for handling ignores. (send_files): Use update_filesdone_proc and send_dirent_proc while recursing through the local filesystem. * update.h: New file. * update.c: Move a few things into update.h so that client.c can use them. Fri Mar 11 13:13:20 1994 Ian Lance Taylor (ian@tweedledumb.cygnus.com) * server.c: If O_NDELAY is not defined, but O_NONBLOCK is, define O_NDELAY to O_NONBLOCK. Wed Mar 9 21:08:30 1994 Jim Kingdon (kingdon@lioth.cygnus.com) Fix some spurious remote CVS errors caused by the CVS/Root patches: * update.c (update_filesdone_proc): If server_active, don't try to create CVS/Root. * root.c (Name_Root): Make error messages which happen if root is not an absolute pathname or if it doesn't exist a bit clearer. Skip them if root contains a colon. Mon Nov 1 15:54:51 1993 K. Richard Pixley (rich@sendai.cygnus.com) * client.c (client_commit): dynamically allocate message. Tue Jun 1 17:03:05 1993 david d `zoo' zuhn (zoo at cirdan.cygnus.com) * server.h: remove alloca cruft * server.c: replace with better alloca cruft Mon May 24 11:25:11 1993 Jim Kingdon (kingdon@lioth.cygnus.com) * entries.c (Scratch_Entry): Update our local Entries file even if server_active. * server.c (server_scratch, server_register): If both Register and Scratch_Entry happen, use whichever one happened later. If neither happen, silently continue. * client.c (client_checkout): Initialize tag and date (eichin and I independently discovered this bug at the same time). Wed May 19 10:11:51 1993 Mark Eichin (eichin@cygnus.com) * client.c (update_entries): handle short reads over the net (SVR4 fread is known to be broken, specifically for short reads off of streams.) Tue May 18 15:53:44 1993 Jim Kingdon (kingdon@lioth.cygnus.com) * server.c (do_cvs_command): Fix fencepost error in setting num_to_check. * server.c (do_cvs_command): If terminated with a core dump, print message and set dont_delete_temp. (server_cleanup): If dont_delete_temp, don't delete it. * client.c (get_server_responses): Don't change cmd since we are going to "free (cmd)". * server.c: Rename memmove to my_memmove pending a real fix. * server.c (do_cvs_command): Set num_to_check to largest descriptor we try to use, rather than using (non-portable) getdtablesize. Wed May 12 15:31:40 1993 Jim Kingdon (kingdon@lioth.cygnus.com) Add CVS client feature: * client.{c,h}: New files. * cvs.h: Include client.h. * main.c: If CVSROOT has a colon, use client commands instead. * vers_ts.c (Version_TS): If repository arg is NULL, don't worry about the repository. * logmsg.c (do_editor): If repository or changes is NULL, just don't use those features. * create_adm.c (Create_Admin), callers: Move the test for whether the repository exists from here to callers. * repos.c (Name_Repository): Don't test whether the repository exists if client_active set (might be better to move test to callers). Add CVS server feature: * server.{c,h}: New files. * cvs.h: Include server.h. * checkin.c (Checkin): Call server_checked_in. * update.c (update_file_proc, merge_files): Call server_updated. * entries.c (Register): Call server_register. (Scratch_Entry): Call server_scratch. * main.c: Add server to cmds. * vers_ts.c (Version_TS): If server_active, call new function time_stamp_server to set ts_user. For older changes, there might be some relevant stuff in the bottom of the NEWS file, but I'm afraid probably a lot of them are lost in the mists of time.
|
http://opensource.apple.com/source/cvs/cvs-42/cvs/src/ChangeLog-9395
|
CC-MAIN-2014-52
|
refinedweb
| 21,758
| 62.64
|
Choosing the Right School for Your Child
Deciding What's Important To You
Deciding where your child will go to school is one of the biggest decisions a parent makes. Before you can really choose the right school for your child, you must first figure out what is important to you in a school. People choose one school over another for many different reasons including religious, location, cost, time commitment, test scores, curriculum, etc. Once you know what you require in a school then you can begin by seeing what is available in your area and determine which one best fits the needs for your child and family. Some of the most common choices are public, charter, private, coop, and homeschool.
Public Schools
Public schools are probably the most common and readily available schools. In the United States, there are close to 100,000 public schools. Public schools are free to attend and are supported by taxpayer money. Most educational standards are set by the state in which they are in. However, the federal government also has requirements they must meet in order to receive federal taxpayer money.
Public schools cannot refuse any school age student within their district placement. If the student has special needs, such as, speech or physical rehab the school still has to provide for their needs.
Teachers in public schools generally have at least a Bachelor's and are certified to teach. The schools are accredited to ensure they meet national standards. The administration and the academic programs must be reviewed periodically to make sure they still comply with the standards set by their accreditation.
Public schools may or may not have programs like band and football depending on their size and funding. Some schools may offer classes for children who excel in science or math while others may not sponsor them.
Magnet schools are part of the public school system, but do not have to let everyone that is in the district attend. These schools concentrate on academics and often a students test scores determine whether they can attend a magnet school, or not..
Learning a Little History
Charter Schools
Charter schools are like public schools in that they are free of cost to the student. They are harder to get into and often use a lottery system to determine who attends. Apply early to make sure your child has the best chance of acceptance.
The teachers usually still certified and have at least a Bachelor's degree. Charter schools are usually accredited like public schools. The class ratio is generally better distributed than in some public classrooms where they may be overcrowded. They are government funded by taxpayer money, but often get extra funding from private sources. Because of the extra funding charter schools can sometimes offer extra programs that a regular public school may not be able to afford.
Private Schools
Private schools depend on their own funding instead of taxpayer funds.They charge a tuition for each student to attend to help cover the costs. Tuition varies from school to school. Some schools charge several thousands of dollars per year to attend, while others charge only a few thousand dollars a year to attend. If costs is a deciding factor, you may want to check on scholarships as many private schools offer them. In states where they have vouchers some private schools will take them to cover your tuition.
Perhaps one of the main reasons people opt out of free public education and choose private schools is the for religious freedoms. Public schools have to keep religion out of the schools. Whereas, private schools can teach bible classes and even have children attend chapel. They can use curriculum that includes bits and pieces throughout it to teach your child how to be Godly and live a moral life. Of course, not all private schools offer religious classes or use religious friendly curriculum.
Private schools may have higher academic scores. They often use curriculum that is harder than what the public school uses. The student versus teacher ratio is usually much smaller than in a public school. Teachers in a private school may or may not be certified. Children in a public school may be exposed to drugs and gangs more than a child attending a private school.
Field Trip at the Alamo in San Antonio, Texas
Homeschooling
Homeschooling is where parents opt to teach their children from home instead of placing them in a traditional school setting. Parents choose curriculum from the enormous choices out there and buy their children books to use at home for school. Parents then commit to spend time each day teaching their children.
Laws vary from state to state on homeschooling. If you think homeschooling is the way you want your children to learn you should check with the nearest homeschool association to see what your state requires. You should be able to find the nearest homeschool association by putting homeschool associations in your search engine.
Curriculum can cost lots of money, but often you can find it used at a reduced price through a homeschool association or group. There are many different curriculums out on the market. You may want to look up several on the web and see which one best fits your needs and budget.
The library is a great asset to any homeschool situation. You can enhance curriculum greatly by utilizing the local library. Museums are great field trip experiences too. One of the great things about homeschooling is that you get to decide what if any field trips your child takes.
There are thousands of articles on the web for homeschoolers. They will help you get started if this is the way you decide you want to teach your children.
Co-op Schools
Co-op schools are founded on the principal that we need to educate the whole child. Children need to learn emotionally, socially, physically, and intellectually. Co-ops generally prefer hands on learning activities combined with assigned work.
Co-op's are a community of people with common goals. They all work together to enhance each child's education. They believe it is the parents responsibility to teach the children not the states.
Co-op's differ from homeschooling in that there is interactive group learning, projects, and discussions. There is also accountability. Since other people are also teaching the child parents must make sure their child complies and completes all their lessons on time. Another reason co-ops work well is where one parent does not do well in math, but is great in history they can teach each others children. This ensures each child benefits from the expertise and strengthens of each of their teachers.
Co-op schools tend to have high academic standards. Placement tests are generally given to make sure each child is on the appropriate level of instruction. If your child is on second grade math, but still needs first grade language arts he can be placed in both. In a public school system the child would just have to continue on with first grade math even if it did not challenge him.
Costs are much lower in a co-op compared to a private school because of parent participation. Parents also save more than if they homeschooled alone because the co-op can share the expense of costs for things like microscopes and chemistry equipment and supplies. Parents still usually buy the books used by their child in the co-op like they would in homeschool, but often the group can get a discount for buying in bulk and maybe free shipping.
Another advantage to a co-op school is that children may be able to participate in electives like drama and art. The possibilities for electives is only limited as the group of individuals teaching the course. A disadvantage of a co-op school is that each parent has to teach some class and help in some way. Some parents may not feel comfortable or have the time to do this. In some cases co-op schools will let you pay extra to enroll you child in them even if you do not teach.
For harder subjects like upper level math classes in high school the co-op may choose to hire a teacher who has a level of expertise and a degree. This keeps students on track in harder classes where parents may feel unable to teach them.
Co-op schools may not be for everyone, but they are certainly do present an interesting choice in todays education.
Which school is right for your child?
As you can see, parents have many choices out there for schools. A child's education is one of a parents greatest responsibilities. They are the future work force and leaders of America. As parents we need to make the best choices possible in regards to our children's education. They need a strong foundation to build on, so even in the lower grades a parent needs to make the best choices.
Whether you decide that choice is a public school, charter school, private school, co-op school, or a homeschool commit yourself to making time to help them learn each day and grow as individuals that can make a difference in the coming generations.
Public school teachers in America are often baby-sitters today, especially in areas with low-income housings, ghettos and gangs. I "thumbs up" this article though.
I know the public schools are poorly run and teachers have more than they can do or teach in each day. So, this helps me in finding the right school for several family members. Well written and non-biased writting
|
https://hubpages.com/education/-Choosing-the-RIght-School-for-Your-Child
|
CC-MAIN-2017-34
|
refinedweb
| 1,615
| 71.65
|
Current source can be found at
Search Criteria
Package Details: albumart 1.6.6-3
Dependencies (3)
Required by (0)
Sources (3)
Latest Comments
k0zu commented on 2017-01-21 22:08
gadget3000 commented on 2014-06-28 09:17
Fixed
FiyreWyrkz commented on 2014-06-24 03:12
Hosting has moved for the source-
gadget3000 commented on 2014-02-13 23:39
I don't actually use this anymore so I've uploaded half a fix but there's still issues with unicode encodings.
bo0ts commented on 2013-10-15 18:39
The dependency pyxml does not exist on either AUR or the normal repositories.
Markus00000 commented on 2013-07-13 10:04
I get this error on launch:
Traceback (most recent call last):
File "/usr/bin/albumart-qt", line 154, in <module>
sys.exit(runGui())
File "/usr/bin/albumart-qt", line 86, in runGui
import albumart_dialog
File "/usr/lib/albumart/albumart_dialog.py", line 27, in <module>
from qt import *
RuntimeError: the sip module implements API v10.0 but the qt module requires API v9.2
Anonymous comment on 2013-05-15 04
cra commented on 2011-10-03 11:44
I fixed the PKGBUILD, you can get/view it here:
gadget3000 commented on 2011-09-15 18:31
Hi gt_swagger. Could you change to PKGBUILD to get this to work with python2 please. Change 'python' in depends to 'python2', run setup.py with python2 and put the line 'sed "s/\#\!\/usr\/bin\/python/\#\!\/usr\/bin\/python2/" -i $pkgdir/usr/bin/albumart-qt' after the patch. Thanks.
Anonymous comment on 2010-11-14 00:28
uses python2, not 3... i could at least get it to launch with "python2 /usr/bin/albumart-qt" in command line
Anonymous comment on 2010-05-31 06:15
The download server seems to be over its bandwidth limit. However, the following mirror worked for me:
|
https://aur.archlinux.org/packages/albumart/?ID=13017&comments=all
|
CC-MAIN-2017-13
|
refinedweb
| 312
| 63.39
|
just a follow up on this: I was able to recreate the scope object for my module by import "itself" from the project's init framework, which is executed after the Python initMODULE function is called, and since at that point the module has had its Py_InitModule() called, I assume that doing a PyImport_ImportModuleEx() after that won't have any other consequences. Here is the relevant code:: InInit<DlInit::pyextModuleA>::performInitialize() { ... initialize buff here { using namespace python; // Obtain the handle on the already imported module to create a // scope. PyObject* m = ::PyImport_ImportModuleEx( "libDLpyextModuleA", 0, 0, 0 ); assert( m != 0 ); scope module_scope( object( borrowed<PyObject>( m ) ) ); // Boost.Python declarations using initialized objects here. module_scope.attr( "buff" ) = buff; } } This "seems to work" (i.e. it compiles and doesn't crash and I can obtain the correct initialized value for the initialized buff). I think with this in mind, I could probably leave the initMODULE functions empty and always put my Boost.Python declarations in the project's performInitialize() methods. Do you see any potential problems with this? I'm sure some other projects must have had to do a similar trick. I guess my question boils down to: "can one safely declare new things for Python once the module has already been initialized?" (i.e. by "declare new things" I mean insert Boost.Python declarations, for example, could I declare a new class within a function call? (i.e not the initMODULE function))
|
https://mail.python.org/pipermail/cplusplus-sig/2003-September/005310.html
|
CC-MAIN-2017-17
|
refinedweb
| 241
| 57.16
|
Learn Svelte 3.0 - Svelte Tutorial for Beginners. In this tutorial, we're going to take a look at the basics by building a simple, fictional app. Svelte.js is the new kid on the block to compete against the big 3 (Angular, Vue and React) in the frontend javascript framework space.
Svelte.js is the new kid on the block to compete against the big 3 (Angular, Vue and React) in the frontend javascript framework space.
Let's get started!
To get started, you will need Node.js with NPM installed. Visit to download and install it if it's not on your machine yet. You can open up your terminal and type 'node -v' to determine if it's installed.
Once node.js is installed, in your terminal, type:
> npx degit sveltejs/template svelte-project > cd svelte-project > npm install (or npm i)
This downloads Svelte, hops you into the new folder, and then installs the dependencies associated with Svelte.
Next, open up the new folder in your preferred code editor. If you're using VSC (Visual Studio Code), you can type "code ." in the svelte folder via the terminal and it will open up VSC in that folder.
Finally, we'll run the dev server by typing:
> npm run dev
You can visit your new Svelte app by visiting in your browser!
It's worth taking a look at the files and folders found within your Svelte app.
> node_modules > public > src .gitignore package-lock.json package.json README.md rollup.config.js
It's surprisingly very simplistic upon first glance, as compared to the file and folder structure as found in competitors such as Angular and Vue.
At the bottom we see rollup.config.js which is a module bundler for JavaScript. Think of it as a competitor to Webpack and Parcel.
Next up, we have /src which includes main.js and App.svelte.
main.js is the starting/entry point of the app.
import App from './App.svelte'; const app = new App({ target: document.body, props: { name: 'world' } }); export default app;
As you can see, it imports the other file at the top, which is the starting component for the app. It also specifies a target, which specifies where the app output will go, and any properties in the form of a props object.
In App.svelte:
<script> export let name; </script> <style> h1 { color: purple; } </style> <h1>Hello {name}!</h1>
Here, we have the 3 basic building blocks of a modern Javascript framework:
Unfortunately, as of writing this, there is not an official Svelte router. There are numerous routers people have developed. We're going to use one of these unofficial routers to help us navigate througout the different components of our Svelte app.
First, we need to install at in the terminal:
npm install --save svero
Here's the github page for svero if you want to learn more.
After it's installed, visit *App.svelte *and update it to match the following:
<script> import { Router, Route } from 'svero'; import Header from './Header.svelte'; import Index from './pages/Index.svelte'; import About from './pages/About.svelte'; </script> <style> </style> <Header/> <div class="container"> <Router> <Route path="*" component={Index} /> <Route path="/about" component={About} /> </Router> </div>
First, we're importing the router at the top. Then, we're importing a few files that don't yet exist (we'll create those in a second).
Then, we're nesting a
Let's create those files now.
<strong>/pages/About.svelte</strong>:
<script> export let router = {}; // Those contains useful information about current route status router.path; // /test router.route; // Route Object router.params; // /about/bill/123/kansas { who: 'bill', where: 'kansas' } </script> <h1>About me</h1> <p>This is my router path: {router.path}</p>
At the top here, we're demonstrating how you can access various router properties with the router library that we're using.
<strong>/pages/Index.svelte</strong>:
<h1>I'm homeee</h1> <p>Lorem ipsum dolor sit amet, consectetur adipisicing elit. Perspiciatis, laborum dignissimos? Ab blanditiis veniam a aspernatur autem, harum, quia dolor pariatur labore asperiores recusandae nihil dolorem exercitationem id itaque tempora?</p>
In this case, we're only specifying the templating. If you don't need logic or style, just omit those sections of the component.
<strong>/scr/Header.svelte</strong>:
<script> import {Link} from "svero" </script> <header> <Link href="/home" className="logo">Hello!</Link> <nav> <ul> <li><Link href="/home">Home</Link></li> <li><Link href="/about">About</Link></li> </ul> </nav> </header>
Instead of using regular tags, we're using Link from svero. Also, notice className instead of class, when we're using the Link component.
If you save everything, it should be ready to rock! But it's rather ugly, too.
This is all straight forward CSS stuff, with exception to one concept.
Visit App.svelte and specify the following within the style tags:
<style> :global(body) { /* this will apply to <body> */ margin: 0; padding: 0; } .container { width: 80%; margin: 4em auto; } </style>
Notice :global(selector). If you're referencing any CSS elements that aren't present in the current component's template as HTML tags, you can use this global selector format.
<strong>Header.svelte</strong>:
<style> header { display: flex; justify-content: space-between; background: rgb(0, 195, 255); } nav ul { display: flex; list-style-type: none; margin: 0; } :global(header a) { padding: 1em; display: block; color: white !important; } :global(.logo) { font-weight: bold; } </style>
Now, we're going to cover some of the basic stuff in Svelte. Interpolation is simply displaying a variable of some sort in the template.
Open up Index.svelte and update it:
<script> let bro = 'Bro'; </script> <h1>{bro}</h1>
As you can see, very, very simple.
Let's create a method that's called when a user clicks a button, and let's make it do something:
<script> let bro = 'Bro'; function clickEvent() { bro = 'Dude'; } </script> <h1>{bro}</h1> <button on:click={clickEvent}>Click me</button>
Easy, easy stuff! You can also change :click to other events, such as mouseover and it will work just the same.
Update the component as follows:
<script> let person = { status: 'dude' } </script> {#if person.status == 'dude'} <h1>Dude!!</h1> {/if}
If we want an else statement:
<script> let person = { status: 'bro' } </script> {#if person.status == 'dude'} <h1>Dude!!</h1> {:else} <h1>{person.status}</h1> {/if}
Once again, very simple to understand.
If you want else if, that's easy too:
<script> let person = { status: 'woah' } </script> {#if person.status == 'dude'} <h1>Dude!!</h1> {:else if person.status == 'bro'} <h1>bro!!</h1> {:else} <h1>{person.status}</h1> {/if}
Awesome!
Many times, you need to iterate over an array of some sort. This is how you achieve that with Svelte:
<script> let persons = [ { status: 'dude', tagline: 'Yo sup' }, { status: 'bro', tagline: 'Gnarly, man' }, { status: 'chick', tagline: 'Watchoo want boo?' }, ] </script> <ul> {#each persons as {status, tagline }, i} <li>{i+1}: <strong>{status} </strong>({tagline})</li> {/each} </ul>
So, we simply define an array (or an array of objects in our case), and we iterate over them in the template using #each.
This is a powerful concept to understand, as many times, you will be receiving data from a backend in the form of an array or an array of objects, and you will need to output the results to your template.
Forms are a critical part of any app, so let's discover how we can communicate form-based data to and from Svelte via 2 way data binding:
<script> let name = 'broseph'; </script> <h1>{name}</h1> <input bind:value={name}>
In this case, name is being set in the component logic, but it's also something that can be set and updated in real time via the component template (the input textfield).
Another example of this reactivity in forms is with a checkbox:
<script> let status = false; </script> <label> <input type="checkbox" bind:checked={status}> Do you want to lear more svelte? </label> {#if status} <p>Of course I want to learn more</p> {:else} <p>Nah, I want to keep being a newbie</p> {/if}
Here, we've mixed what we learned with template conditionals with two-way data binding. Awesome!
Many times, you don't want to store data at the component level. Rather, you want to store your data in a central location that your components can easily access.
To do this, create the file /src/stores.js with the following code:
import { writable } from 'svelte/store'; export const status = writable('dude');
Next, inside Index.svelte replace the previous code with:
<script> import { status } from '../stores.js'; let the_status; const stat = status.subscribe(val => { the_status = val; }) </script> <h1>{the_status}</h1>
As you can see, we must subscribe to status and then we can access the value as shown in the h1.
How about updating the property from our component?
Adjust the code to:
<script> import { status } from '../stores.js'; let the_status; const stat = status.subscribe(val => { the_status = val; }) function changeStore() { status.update(n => n = 'bro'); } </script> <h1 on:mouseover={changeStore}>{the_status}</h1>
So, when you hover your mouse over the h1 element, we're updating the status property as such.
Also, because we are subscribing to the property stat, to avoid memory issues, you should unsubscribe to the value on the lifecycle onDestroy().
<script> import { onDestroy } from 'svelte'; import { status } from '../stores.js'; let the_status; const stat = status.subscribe(val => { the_status = val; }) function changeStore() { status.update(n => n = 'bro'); } onDestroy(stat); </script> <h1 on:mouseover={changeStore}>{the_status}</h1>
Great!
We can use modern browser's fetch to grab data from an API. This could be from your own backend, or from a public test API in our case.
Visit Index.svelte and update it:
<script> import { onMount } from "svelte"; let data = []; onMount(async function() { const response = await fetch(""); const json = await response.json(); data = json; console.log(data); }); </script> <ul> {#each data as {title}} <li><p>{title}</p></li> {/each} </ul>
Easy!
To build out your Svelte app, run:
> npm run build
This outputs everything inside of the /public/ folder.
You can use the FTP to upload the contents of this folder to a web server and it will work. You can even install something like lite-server via NPM and launch it within the directory locally.
My current sponsor is Linode.com and I'm going to show you how to launch this static site using their service!
First, join up at Linode. Next, once logged in, click Create Linode:
Next for Distribution, choose Debian. Select a region, then choose a Nanode 1GB. Then, choose a password and click Create.
Wait for it to boot the server up. Once that's done, click Launch Console. Wait until it prompts you for a localhost login. Choose "glish" at the top once it does.
Specify "root" for the login and your chosen password from earlier.
Once logged in, we need to install nginx which is an open source web server.
apt-get install nginx
Once it's finished, we have to start it up:
systemctl start nginx
Now, in the linode dashboard, grab your site's IP address and visit it in the browser. You will see a Welcome message, which means the server is now ready to rock!
Right now, that welcome message is being served by default from /var/www/html -- but when we pull in our project, it's going to be stored in a /public folder. So, we need to modify that root folder to: /var/www/html/public so that it serves from that folder.
To do this: > cd /etc/nginx/sites-enabled > nano default
Using your keyboard arrow keys, navigate to the area shown below in the picture and add /public:
Then hit CTRL-O and hit Enter. Then hit CTRL-X to exit out of nano.
Next, we have to restart the server:
> service nginx restart
Now, if you refresh the server IP in the browser, you will receive a 404 not found. That's because we haven't yet pulled in our project.
Let's install git on our server:
> apt-get install git
Next, let's hop into our html folder:
> cd /var/www/html
Great! Now, we have to push our local project using git on our local machine. Which means, we'll first need to create a repo at github.com.
Once you do that, in your local console within the project folder we worked in, type:
> git init > git add . > git commit -m "first commit" > git remote add origin [the origin github displayed after creating the repo] > git push -u origin master
Now, back in our server's console, type:
> rm /var/www/html/* > git clone[yourusername]/[yourreponame].git .
We need to install nodejs and npm:
> curl -sL | bash - > apt-get install -y nodejs > curl -L | sudo sh
Next, run:
> npm i > npm run build
Great! Now, check your browser and you should see the app working!
You can also set up a domain and all of that good stuff, but this tutorial is already long enough!
We only just scratched the surface here, but we covered a lot of ground already and it's now worth going over it one more time to commit it to memory. Stay tuned, we just might cover more Svelte!
Thanks for reading ❤
javascript angular vue-js reactjs>
|
https://morioh.com/p/80bbf09f89a2
|
CC-MAIN-2020-40
|
refinedweb
| 2,223
| 65.73
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.