
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 48
51
| id
int64 600M
3.67B
| node_id
stringlengths 18
24
| number
int64 2
7.88k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| comments
listlengths 0
30
| created_at
timestamp[s]date 2020-04-14 18:18:51
2025-11-26 16:16:56
| updated_at
timestamp[s]date 2020-04-29 09:23:05
2025-11-30 03:52:07
| closed_at
timestamp[s]date 2020-04-29 09:23:05
2025-11-21 12:31:19
⌀ | author_association
stringclasses 4
values | type
null | active_lock_reason
null | draft
null | pull_request
null | body
stringlengths 0
228k
⌀ | closed_by
dict | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 4
values | sub_issues_summary
dict | issue_dependencies_summary
dict | is_pull_request
bool 1
class | closed_at_time_taken
duration[s] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2021
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2021/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2021/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2021/events
|
https://github.com/huggingface/datasets/issues/2021
| 826,988,016
|
MDU6SXNzdWU4MjY5ODgwMTY=
| 2,021
|
Interactively doing save_to_disk and load_from_disk corrupts the datasets object?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\nCan you give us a minimal reproducible example? This [part](https://huggingface.co/docs/datasets/master/processing.html#controling-the-cache-behavior) of the docs explains how to control caching."
] | 2021-03-10T02:48:34
| 2021-03-13T10:07:41
| 2021-03-13T10:07:41
|
NONE
| null | null | null | null |
dataset_info.json file saved after using save_to_disk gets corrupted as follows.

Is there a way to disable the cache that will save to /tmp/huggiface/datastes ?
I have a feeling there is a serious issue with cashing.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2021/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2021/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 7:19:07
|
https://api.github.com/repos/huggingface/datasets/issues/2012
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2012/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2012/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2012/events
|
https://github.com/huggingface/datasets/issues/2012
| 825,634,064
|
MDU6SXNzdWU4MjU2MzQwNjQ=
| 2,012
|
No upstream branch
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
[
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"What's the issue exactly ?\r\n\r\nGiven an `upstream` remote repository with url `https://github.com/huggingface/datasets.git`, you can totally rebase from `upstream/master`.\r\n\r\nIt's mentioned at the beginning how to add the `upstream` remote repository\r\n\r\nhttps://github.com/huggingface/datasets/blob/987df6b4e9e20fc0c92bc9df48137d170756fd7b/ADD_NEW_DATASET.md#L10-L14",
"~~What difference is there with the default `origin` remote that is set when you clone the repo?~~ I've just understood that this applies to **forks** of the repo 🤡 "
] | 2021-03-09T09:48:55
| 2021-03-09T11:33:31
| 2021-03-09T11:33:31
|
CONTRIBUTOR
| null | null | null | null |
Feels like the documentation on adding a new dataset is outdated?
https://github.com/huggingface/datasets/blob/987df6b4e9e20fc0c92bc9df48137d170756fd7b/ADD_NEW_DATASET.md#L49-L54
There is no upstream branch on remote.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2012/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2012/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1:44:36
|
https://api.github.com/repos/huggingface/datasets/issues/2010
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2010/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2010/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2010/events
|
https://github.com/huggingface/datasets/issues/2010
| 825,567,635
|
MDU6SXNzdWU4MjU1Njc2MzU=
| 2,010
|
Local testing fails
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"I'm not able to reproduce on my side.\r\nCan you provide the full stacktrace please ?\r\nWhat version of `python` and `dill` do you have ? Which OS are you using ?",
"```\r\nco_filename = '<ipython-input-2-e0383a102aae>', returned_obj = [0]\r\n \r\n def create_ipython_func(co_filename, returned_obj):\r\n def func():\r\n return returned_obj\r\n \r\n code = func.__code__\r\n> code = CodeType(*[getattr(code, k) if k != \"co_filename\" else co_filename for k in code_args])\r\nE TypeError: an integer is required (got type bytes)\r\n\r\ntests/test_caching.py:152: TypeError\r\n```\r\n\r\nPython 3.8.8 \r\ndill==0.3.1.1\r\n",
"I managed to reproduce. This comes from the CodeType init signature that is different in python 3.8.8\r\nI opened a PR to fix this test\r\nThanks !"
] | 2021-03-09T09:01:38
| 2021-03-09T14:06:03
| 2021-03-09T14:06:03
|
CONTRIBUTOR
| null | null | null | null |
I'm following the CI setup as described in
https://github.com/huggingface/datasets/blob/8eee4fa9e133fe873a7993ba746d32ca2b687551/.circleci/config.yml#L16-L19
in a new conda environment, at commit https://github.com/huggingface/datasets/commit/4de6dbf84e93dad97e1000120d6628c88954e5d4
and getting
```
FAILED tests/test_caching.py::RecurseDumpTest::test_dump_ipython_function - TypeError: an integer is required (got type bytes)
1 failed, 2321 passed, 5109 skipped, 10 warnings in 124.32s (0:02:04)
```
Seems like a discrepancy with CI, perhaps a lib version that's not controlled?
Tried with `pyarrow=={1.0.0,0.17.1,2.0.0}`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2010/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2010/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5:04:25
|
https://api.github.com/repos/huggingface/datasets/issues/2009
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2009/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2009/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2009/events
|
https://github.com/huggingface/datasets/issues/2009
| 825,541,366
|
MDU6SXNzdWU4MjU1NDEzNjY=
| 2,009
|
Ambiguous documentation
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
[
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
] |
[
"Hi @theo-m !\r\n\r\nA few lines above this line, you'll find that the `_split_generators` method returns a list of `SplitGenerator`s objects:\r\n\r\n```python\r\ndatasets.SplitGenerator(\r\n name=datasets.Split.VALIDATION,\r\n # These kwargs will be passed to _generate_examples\r\n gen_kwargs={\r\n \"filepath\": os.path.join(data_dir, \"dev.jsonl\"),\r\n \"split\": \"dev\",\r\n },\r\n),\r\n```\r\n\r\nNotice the `gen_kwargs` argument passed to the constructor of `SplitGenerator`: this dict will be unpacked as keyword arguments to pass to the `_generat_examples` method (in this case the `filepath` and `split` arguments).\r\n\r\nLet me know if that helps!",
"Oh ok I hadn't made the connection between those two, will offer a tweak to the comment and the template then - thanks!"
] | 2021-03-09T08:42:11
| 2021-03-12T15:01:34
| 2021-03-12T15:01:34
|
CONTRIBUTOR
| null | null | null | null |
https://github.com/huggingface/datasets/blob/2ac9a0d24a091989f869af55f9f6411b37ff5188/templates/new_dataset_script.py#L156-L158
Looking at the template, I find this documentation line to be confusing, the method parameters don't include the `gen_kwargs` so I'm unclear where they're coming from.
Happy to push a PR with a clearer statement when I understand the meaning.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2009/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2009/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 6:19:23
|
https://api.github.com/repos/huggingface/datasets/issues/2007
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2007/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2007/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2007/events
|
https://github.com/huggingface/datasets/issues/2007
| 824,518,158
|
MDU6SXNzdWU4MjQ1MTgxNTg=
| 2,007
|
How to not load huggingface datasets into memory
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"So maybe a summary here: \r\nIf I could fit a large model with batch_size = X into memory, is there a way I could train this model for huge datasets with keeping setting the same? thanks ",
"The `datastets` library doesn't load datasets into memory. Therefore you can load a dataset that is terabytes big without filling up your RAM.\r\n\r\nThe only thing that's loaded into memory during training is the batch used in the training step.\r\nSo as long as your model works with batch_size = X, then you can load an even bigger dataset and it will work as well with the same batch_size.\r\n\r\nNote that you still have to take into account that some batches take more memory than others, depending on the texts lengths. If it works for a batch with batch_size = X and with texts of maximum length, then it will work for all batches.\r\n\r\nIn your case I guess that there are a few long sentences in the dataset. For those long sentences you get a memory error on your GPU because they're too long. By passing `max_train_samples` you may have taken a subset of the dataset that only contain short sentences. That's probably why in your case it worked only when you set `max_train_samples`.\r\nI'd suggest you to reduce the batch size so that the batches with long sentences can be loaded on the GPU.\r\n\r\nLet me know if that helps or if you have other questions"
] | 2021-03-08T12:35:26
| 2021-08-04T18:02:25
| 2021-08-04T18:02:25
|
NONE
| null | null | null | null |
Hi
I am running this example from transformers library version 4.3.3:
(Here is the full documentation https://github.com/huggingface/transformers/issues/8771 but the running command should work out of the box)
USE_TF=0 deepspeed run_seq2seq.py --model_name_or_path google/mt5-base --dataset_name wmt16 --dataset_config_name ro-en --source_prefix "translate English to Romanian: " --task translation_en_to_ro --output_dir /test/test_large --do_train --do_eval --predict_with_generate --max_train_samples 500 --max_val_samples 500 --max_source_length 128 --max_target_length 128 --sortish_sampler --per_device_train_batch_size 8 --val_max_target_length 128 --deepspeed ds_config.json --num_train_epochs 1 --eval_steps 25000 --warmup_steps 500 --overwrite_output_dir
(Here please find the script: https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py)
If you do not pass max_train_samples in above command to load the full dataset, then I get memory issue on a gpu with 24 GigBytes of memory.
I need to train large-scale mt5 model on large-scale datasets of wikipedia (multiple of them concatenated or other datasets in multiple languages like OPUS), could you help me how I can avoid loading the full data into memory? to make the scripts not related to data size?
In above example, I was hoping the script could work without relying on dataset size, so I can still train the model without subsampling training set.
thank you so much @lhoestq for your great help in advance
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2007/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2007/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 149 days, 5:26:59
|
https://api.github.com/repos/huggingface/datasets/issues/2005
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2005/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2005/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2005/events
|
https://github.com/huggingface/datasets/issues/2005
| 824,275,035
|
MDU6SXNzdWU4MjQyNzUwMzU=
| 2,005
|
Setting to torch format not working with torchvision and MNIST
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Adding to the previous information, I think `torch.utils.data.DataLoader` is doing some conversion. \r\nWhat I tried:\r\n```python\r\ntrain_dataset = load_dataset('mnist')\r\n```\r\nI don't use any `map` or `set_format` or any `transform`. I use this directly, and try to load batches using the `DataLoader` with batch size 2, I get an output like this for the `image`:\r\n\r\n```\r\n[[tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor([0, 0]), tensor...\r\n```\r\nFor `label`, it works fine:\r\n```\r\ntensor([7, 6])\r\n```\r\nNote that I didn't specify conversion to torch tensors anywhere.\r\n\r\nBasically, there are two problems here:\r\n1. `dataset.map` doesn't return tensor type objects, even though it uses the transforms, the grayscale conversion in transform was done, but the output was lists only.\r\n2. The `DataLoader` performs its own conversion, which may be not desired.\r\n\r\nI understand that we can't change `DataLoader` because it is a torch functionality, however, is there a way we can handle image data to allow using it with torch `DataLoader` and `torchvision` properly?\r\n\r\nI think if the `image` was a torch tensor (N,H,W,C), or a list of torch tensors (H,W,C), before it is passed to `DataLoader`, then we might not face this issue. ",
"What's the feature types of your new dataset after `.map` ?\r\n\r\nCan you try with adding `features=` in the `.map` call in order to set the \"image\" feature type to `Array2D` ?\r\nThe default feature type is lists of lists, we've not implemented shape verification to use ArrayXD instead of nested lists yet",
"Hi @lhoestq\r\n\r\nRaw feature types are like this:\r\n```\r\nImage:\r\n<class 'list'> 60000 #(type, len)\r\n<class 'list'> 28\r\n<class 'list'> 28\r\n<class 'int'>\r\nLabel:\r\n<class 'list'> 60000\r\n<class 'int'>\r\n```\r\nInside the `prepare_feature` method with batch size 100000 , after processing, they are like this:\r\n\r\nInside Prepare Train Features\r\n```\r\nImage:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nAfter map, the feature type are like this:\r\n```\r\nImage:\r\n<class 'list'> 60000\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'list'> 28\r\n<class 'float'>\r\nLabel:\r\n<class 'list'> 60000\r\n<class 'int'>\r\n```\r\n\r\nAfter dataloader with batch size 2, the batch features are like this:\r\n```\r\nImage:\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\n<hr>\r\n\r\nWhen I was setting the format of `train_dataset` to 'torch' after mapping - \r\n```\r\nImage:\r\n<class 'list'> 60000\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nCorresponding DataLoader batch:\r\n```\r\nFrom DataLoader batch features\r\nImage:\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nI will check with features and get back.\r\n\r\n\r\n\r\n",
"Hi @lhoestq\r\n\r\n# Using Array3D\r\nI tried this:\r\n```python\r\nfeatures = datasets.Features({\r\n \"image\": datasets.Array3D(shape=(1,28,28),dtype=\"float32\"),\r\n \"label\": datasets.features.ClassLabel(names=[\"0\", \"1\", \"2\", \"3\", \"4\", \"5\", \"6\", \"7\", \"8\", \"9\"]),\r\n })\r\ntrain_dataset = raw_dataset.map(prepare_features, features = features,batched=True, batch_size=10000)\r\n```\r\nand it didn't fix the issue.\r\n\r\nDuring the `prepare_train_features:\r\n```\r\nImage:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nAfter the `map`:\r\n\r\n```\r\nImage:\r\n<class 'list'> 60000\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'list'> 28\r\n<class 'float'>\r\nLabel:\r\n<class 'list'> 60000\r\n<class 'int'>\r\n```\r\nFrom the DataLoader batch:\r\n```\r\nImage:\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\nIt is the same as before.\r\n\r\n---\r\n\r\nUsing `datasets.Sequence(datasets.Array2D(shape=(28,28),dtype=\"float32\"))` gave an error during `map`:\r\n\r\n```python\r\nArrowNotImplementedError Traceback (most recent call last)\r\n<ipython-input-95-d28e69289084> in <module>()\r\n 3 \"label\": datasets.features.ClassLabel(names=[\"0\", \"1\", \"2\", \"3\", \"4\", \"5\", \"6\", \"7\", \"8\", \"9\"]),\r\n 4 })\r\n----> 5 train_dataset = raw_dataset.map(prepare_features, features = features,batched=True, batch_size=10000)\r\n\r\n15 frames\r\n/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc)\r\n 446 num_proc=num_proc,\r\n 447 )\r\n--> 448 for k, dataset in self.items()\r\n 449 }\r\n 450 )\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py in <dictcomp>(.0)\r\n 446 num_proc=num_proc,\r\n 447 )\r\n--> 448 for k, dataset in self.items()\r\n 449 }\r\n 450 )\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)\r\n 1307 fn_kwargs=fn_kwargs,\r\n 1308 new_fingerprint=new_fingerprint,\r\n-> 1309 update_data=update_data,\r\n 1310 )\r\n 1311 else:\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)\r\n 202 }\r\n 203 # apply actual function\r\n--> 204 out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n 205 datasets: List[\"Dataset\"] = list(out.values()) if isinstance(out, dict) else [out]\r\n 206 # re-apply format to the output\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)\r\n 335 # Call actual function\r\n 336 \r\n--> 337 out = func(self, *args, **kwargs)\r\n 338 \r\n 339 # Update fingerprint of in-place transforms + update in-place history of transforms\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, update_data)\r\n 1580 if update_data:\r\n 1581 batch = cast_to_python_objects(batch)\r\n-> 1582 writer.write_batch(batch)\r\n 1583 if update_data:\r\n 1584 writer.finalize() # close_stream=bool(buf_writer is None)) # We only close if we are writing in a file\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)\r\n 274 typed_sequence = TypedSequence(batch_examples[col], type=col_type, try_type=col_try_type)\r\n 275 typed_sequence_examples[col] = typed_sequence\r\n--> 276 pa_table = pa.Table.from_pydict(typed_sequence_examples)\r\n 277 self.write_table(pa_table, writer_batch_size)\r\n 278 \r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_pydict()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib.asarray()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib.array()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/arrow_writer.py in __arrow_array__(self, type)\r\n 95 out = pa.ExtensionArray.from_storage(type, pa.array(self.data, type.storage_dtype))\r\n 96 else:\r\n---> 97 out = pa.array(self.data, type=type)\r\n 98 if trying_type and out[0].as_py() != self.data[0]:\r\n 99 raise TypeError(\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib.array()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/array.pxi in pyarrow.lib._sequence_to_array()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()\r\n\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowNotImplementedError: extension\r\n```",
"# Convert raw tensors to torch format\r\nStrangely, converting to torch tensors works perfectly on `raw_dataset`:\r\n```python\r\nraw_dataset.set_format('torch',columns=['image','label'])\r\n```\r\nTypes:\r\n```\r\nImage:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nUsing this for transforms:\r\n```python\r\ndef prepare_features(examples):\r\n images = []\r\n labels = []\r\n for example_idx, example in enumerate(examples[\"image\"]):\r\n if transform is not None:\r\n images.append(transform(\r\n examples[\"image\"][example_idx].numpy()\r\n ))\r\n else:\r\n images.append(examples[\"image\"][example_idx].numpy())\r\n labels.append(examples[\"label\"][example_idx])\r\n output = {\"label\":labels, \"image\":images}\r\n return output\r\n```\r\n\r\nInside `prepare_train_features`:\r\n```\r\nImage:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nAfter `map`:\r\n```\r\nImage:\r\n<class 'list'> 60000\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'>\r\n```\r\nDataLoader batch:\r\n\r\n```\r\nImage:\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\n\r\n---\r\n\r\n## Using `torch` format:\r\n```\r\nImage:\r\n<class 'list'> 60000\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'>\r\n```\r\nDataLoader batches:\r\n\r\n```\r\nImage:\r\n<class 'list'> 1\r\n<class 'list'> 28\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\n\r\n---\r\n## Using the features - `Array3D`:\r\n\r\n```\r\nImage:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'list'> 10000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nAfter `map`:\r\n```\r\nImage:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 60000\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nAfter DataLoader `batch`:\r\n```\r\nImage:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'> 1\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'> 28\r\n<class 'torch.Tensor'>\r\nLabel:\r\n<class 'torch.Tensor'> 2\r\n<class 'torch.Tensor'>\r\n```\r\n\r\nThe last one works perfectly.\r\n\r\n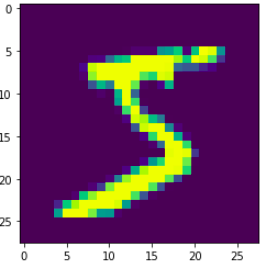\r\n\r\nI wonder why this worked, and others didn't.\r\n\r\n\r\n\r\n\r\n\r\n\r\n",
"Concluding, the way it works right now is:\r\n\r\n1. Converting raw dataset to `torch` format.\r\n2. Use the transform and apply using `map`, ensure the returned values are tensors. \r\n3. When mapping, use `features` with `image` being `Array3D` type.",
"What the dataset returns depends on the feature type.\r\nFor a feature type that is Sequence(Sequence(Sequence(Value(\"uint8\")))), a dataset formatted as \"torch\" return lists of lists of tensors. This is because the lists lengths may vary.\r\nFor a feature type that is Array3D on the other hand it returns one tensor. This is because the size of the tensor is fixed and defined bu the Array3D type.",
"Okay, that makes sense.\r\nRaw images are list of Array2D, hence we get a single tensor when `set_format` is used. But, why should I need to convert the raw images to `torch` format when `map` does this internally?\r\n\r\nUsing `Array3D` did not work with `map` when raw images weren't `set_format`ted to torch type.",
"I understand that `map` needs to know what kind of output tensors are expected, and thus converting the raw dataset to `torch` format is necessary. Closing the issue since it is resolved."
] | 2021-03-08T07:38:11
| 2021-03-09T17:58:13
| 2021-03-09T17:58:13
|
CONTRIBUTOR
| null | null | null | null |
Hi
I am trying to use `torchvision.transforms` to handle the transformation of the image data in the `mnist` dataset. Assume I have a `transform` variable which contains the `torchvision.transforms` object.
A snippet of what I am trying to do:
```python
def prepare_features(examples):
images = []
labels = []
for example_idx, example in enumerate(examples["image"]):
if transform is not None:
images.append(transform(
np.array(examples["image"][example_idx], dtype=np.uint8)
))
else:
images.append(torch.tensor(np.array(examples["image"][example_idx], dtype=np.uint8)))
labels.append(torch.tensor(examples["label"][example_idx]))
output = {"label":labels, "image":images}
return output
raw_dataset = load_dataset('mnist')
train_dataset = raw_dataset.map(prepare_features, batched=True, batch_size=10000)
train_dataset.set_format("torch",columns=["image","label"])
```
After this, I check the type of the following:
```python
print(type(train_dataset["train"]["label"]))
print(type(train_dataset["train"]["image"][0]))
```
This leads to the following output:
```python
<class 'torch.Tensor'>
<class 'list'>
```
I use `torch.utils.DataLoader` for batches, the type of `batch["train"]["image"]` is also `<class 'list'>`.
I don't understand why only the `label` is converted to a torch tensor, why does the image not get converted? How can I fix this issue?
Thanks,
Gunjan
EDIT:
I just checked the shapes, and the types, `batch[image]` is a actually a list of list of tensors. Shape is (1,28,2,28), where `batch_size` is 2. I don't understand why this is happening. Ideally it should be a tensor of shape (2,1,28,28).
EDIT 2:
Inside `prepare_train_features`, the shape of `images[0]` is `torch.Size([1,28,28])`, the conversion is working. However, the output of the `map` is a list of list of list of list.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2005/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2005/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 10:20:02
|
https://api.github.com/repos/huggingface/datasets/issues/2003
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2003/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2003/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2003/events
|
https://github.com/huggingface/datasets/issues/2003
| 824,034,678
|
MDU6SXNzdWU4MjQwMzQ2Nzg=
| 2,003
|
Messages are being printed to the `stdout`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1367529?v=4",
"events_url": "https://api.github.com/users/mahnerak/events{/privacy}",
"followers_url": "https://api.github.com/users/mahnerak/followers",
"following_url": "https://api.github.com/users/mahnerak/following{/other_user}",
"gists_url": "https://api.github.com/users/mahnerak/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mahnerak",
"id": 1367529,
"login": "mahnerak",
"node_id": "MDQ6VXNlcjEzNjc1Mjk=",
"organizations_url": "https://api.github.com/users/mahnerak/orgs",
"received_events_url": "https://api.github.com/users/mahnerak/received_events",
"repos_url": "https://api.github.com/users/mahnerak/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mahnerak/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mahnerak/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mahnerak",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"This is expected to show this message to the user via stdout.\r\nThis way the users see it directly and can cancel the downloading if they want to.\r\nCould you elaborate why it would be better to have it in stderr instead of stdout ?",
"@lhoestq, sorry for the late reply\r\n\r\nI completely understand why you decided to output a message that is always shown. The only problem is that the message is printed to the `stdout`. For example, if the user runs `python run_glue.py > log_file`, it will redirect `stdout` to the file named `log_file`, and the message will not be shown to the user.\r\n\r\nInstead, we should print this message to `stderr`. Even in the case of `python run_glue.py > log_file` only `stdout` is being redirected and so the message is always shown.",
"We now log these messages to `stderr` (the built-in `logging` module's default behavior). "
] | 2021-03-07T22:09:34
| 2023-07-25T16:35:21
| 2023-07-25T16:35:21
|
NONE
| null | null | null | null |
In this code segment, we can see some messages are being printed to the `stdout`.
https://github.com/huggingface/datasets/blob/7e60bb509b595e8edc60a87f32b2bacfc065d607/src/datasets/builder.py#L545-L554
According to the comment, it is done intentionally, but I don't really understand why don't we log it with a higher level or print it directly to the `stderr`.
In my opinion, this kind of messages should never printed to the stdout. At least some configuration/flag should make it possible to provide in order to explicitly prevent the package to contaminate the stdout.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2003/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2003/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 869 days, 18:25:47
|
https://api.github.com/repos/huggingface/datasets/issues/2001
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2001/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2001/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2001/events
|
https://github.com/huggingface/datasets/issues/2001
| 823,946,706
|
MDU6SXNzdWU4MjM5NDY3MDY=
| 2,001
|
Empty evidence document ("provenance") in KILT ELI5 dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/donggyukimc",
"id": 16605764,
"login": "donggyukimc",
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/donggyukimc",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Why did you close this issue? How did you end up finding the evidence documents? I'm running into a similar issue with other KILT tasks."
] | 2021-03-07T15:41:35
| 2022-12-19T19:25:14
| 2021-03-17T05:51:01
|
NONE
| null | null | null | null |
In the original KILT benchmark(https://github.com/facebookresearch/KILT),
all samples has its evidence document (i.e. wikipedia page id) for prediction.
For example, a sample in ELI5 dataset has the format including provenance (=evidence document) like this
`{"id": "1kiwfx", "input": "In Trading Places (1983, Akroyd/Murphy) how does the scheme at the end of the movie work? Why would buying a lot of OJ at a high price ruin the Duke Brothers?", "output": [{"answer": "I feel so old. People have been askinbg what happened at the end of this movie for what must be the last 15 years of my life. It never stops. Every year/month/fortnight, I see someone asking what happened, and someone explaining. Andf it will keep on happening, until I am 90yrs old, in a home, with nothing but the Internet and my bladder to keep me going. And there it will be: \"what happens at the end of Trading Places?\""}, {"provenance": [{"wikipedia_id": "242855", "title": "Futures contract", "section": "Section::::Abstract.", "start_paragraph_id": 1, "start_character": 14, "end_paragraph_id": 1, "end_character": 612, "bleu_score": 0.9232808519770748}]}], "meta": {"partial_evidence": [{"wikipedia_id": "520990", "title": "Trading Places", "section": "Section::::Plot.\n", "start_paragraph_id": 7, "end_paragraph_id": 7, "meta": {"evidence_span": ["On television, they learn that Clarence Beeks is transporting a secret USDA report on orange crop forecasts.", "On television, they learn that Clarence Beeks is transporting a secret USDA report on orange crop forecasts. Winthorpe and Valentine recall large payments made to Beeks by the Dukes and realize that the Dukes plan to obtain the report to corner the market on frozen orange juice.", "Winthorpe and Valentine recall large payments made to Beeks by the Dukes and realize that the Dukes plan to obtain the report to corner the market on frozen orange juice."]}}]}}`
However, KILT ELI5 dataset from huggingface datasets library only contain empty list of provenance.
`{'id': '1oy5tc', 'input': 'in football whats the point of wasting the first two plays with a rush - up the middle - not regular rush plays i get those', 'meta': {'left_context': '', 'mention': '', 'obj_surface': [], 'partial_evidence': [], 'right_context': '', 'sub_surface': [], 'subj_aliases': [], 'template_questions': []}, 'output': [{'answer': 'In most cases the O-Line is supposed to make a hole for the running back to go through. If you run too many plays to the outside/throws the defense will catch on.\n\nAlso, 2 5 yard plays gets you a new set of downs.', 'meta': {'score': 2}, 'provenance': []}, {'answer': "I you don't like those type of plays, watch CFL. We only get 3 downs so you can't afford to waste one. Lots more passing.", 'meta': {'score': 2}, 'provenance': []}]}
`
should i perform other procedure to obtain evidence documents?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/donggyukimc",
"id": 16605764,
"login": "donggyukimc",
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/donggyukimc",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2001/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2001/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 9 days, 14:09:26
|
https://api.github.com/repos/huggingface/datasets/issues/2000
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/2000/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/2000/comments
|
https://api.github.com/repos/huggingface/datasets/issues/2000/events
|
https://github.com/huggingface/datasets/issues/2000
| 823,899,910
|
MDU6SXNzdWU4MjM4OTk5MTA=
| 2,000
|
Windows Permission Error (most recent version of datasets)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73881148?v=4",
"events_url": "https://api.github.com/users/itsLuisa/events{/privacy}",
"followers_url": "https://api.github.com/users/itsLuisa/followers",
"following_url": "https://api.github.com/users/itsLuisa/following{/other_user}",
"gists_url": "https://api.github.com/users/itsLuisa/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/itsLuisa",
"id": 73881148,
"login": "itsLuisa",
"node_id": "MDQ6VXNlcjczODgxMTQ4",
"organizations_url": "https://api.github.com/users/itsLuisa/orgs",
"received_events_url": "https://api.github.com/users/itsLuisa/received_events",
"repos_url": "https://api.github.com/users/itsLuisa/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/itsLuisa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itsLuisa/subscriptions",
"type": "User",
"url": "https://api.github.com/users/itsLuisa",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @itsLuisa !\r\n\r\nCould you give us more information about the error you're getting, please?\r\nA copy-paste of the Traceback would be nice to get a better understanding of what is wrong :) ",
"Hello @SBrandeis , this is it:\r\n```\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 537, in incomplete_dir\r\n yield tmp_dir\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 578, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 656, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 982, in _prepare_split\r\n num_examples, num_bytes = writer.finalize()\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\arrow_writer.py\", line 297, in finalize\r\n self.write_on_file()\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\arrow_writer.py\", line 230, in write_on_file\r\n pa_array = pa.array(typed_sequence)\r\n File \"pyarrow\\array.pxi\", line 222, in pyarrow.lib.array\r\n File \"pyarrow\\array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\arrow_writer.py\", line 97, in __arrow_array__\r\n out = pa.array(self.data, type=type)\r\n File \"pyarrow\\array.pxi\", line 305, in pyarrow.lib.array\r\n File \"pyarrow\\array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow\\error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow\\error.pxi\", line 107, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Expected bytes, got a 'list' object\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"C:/Users/Luisa/Documents/Uni/WS 2020,21/Neural Networks/Final_Project/NN_Project/data_loading.py\", line 122, in <module>\r\n main()\r\n File \"C:/Users/Luisa/Documents/Uni/WS 2020,21/Neural Networks/Final_Project/NN_Project/data_loading.py\", line 111, in main\r\n dataset = datasets.load_dataset(\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\load.py\", line 740, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 586, in download_and_prepare\r\n self._save_info()\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\contextlib.py\", line 131, in __exit__\r\n self.gen.throw(type, value, traceback)\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\datasets\\builder.py\", line 543, in incomplete_dir\r\n shutil.rmtree(tmp_dir)\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\shutil.py\", line 740, in rmtree\r\n return _rmtree_unsafe(path, onerror)\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\shutil.py\", line 618, in _rmtree_unsafe\r\n onerror(os.unlink, fullname, sys.exc_info())\r\n File \"C:\\Users\\Luisa\\AppData\\Local\\Programs\\Python\\Python38\\lib\\shutil.py\", line 616, in _rmtree_unsafe\r\n os.unlink(fullname)\r\nPermissionError: [WinError 32] Der Prozess kann nicht auf die Datei zugreifen, da sie von einem anderen Prozess verwendet wird: 'C:\\\\Users\\\\Luisa\\\\.cache\\\\huggingface\\\\datasets\\\\sample\\\\default-20ee7d51a6a9454f\\\\0.0.0\\\\5fc4c3a355ea77ab446bd31fca5082437600b8364d29b2b95264048bd1f398b1.incomplete\\\\sample-train.arrow'\r\n\r\nProcess finished with exit code 1\r\n```",
"Hi @itsLuisa, thanks for sharing the Traceback.\r\n\r\nYou are defining the \"id\" field as a `string` feature:\r\n```python\r\nclass Sample(datasets.GeneratorBasedBuilder):\r\n ...\r\n\r\n def _info(self):\r\n return datasets.DatasetInfo(\r\n features=datasets.Features(\r\n {\r\n \"id\": datasets.Value(\"string\"),\r\n # ^^ here\r\n \"tokens\": datasets.Sequence(datasets.Value(\"string\")),\r\n \"pos_tags\": datasets.Sequence(datasets.features.ClassLabel(names=[...])),\r\n[...]\r\n```\r\n\r\nBut in the `_generate_examples`, the \"id\" field is a list:\r\n```python\r\nids = list()\r\n```\r\n\r\nChanging:\r\n```python\r\n\"id\": datasets.Value(\"string\"),\r\n```\r\nInto:\r\n```python\r\n\"id\": datasets.Sequence(datasets.Value(\"string\")),\r\n```\r\n\r\nShould fix your issue.\r\n\r\nLet me know if this helps!",
"It seems to be working now, thanks a lot for the help, @SBrandeis !",
"Glad to hear it!\r\nI'm closing the issue"
] | 2021-03-07T11:55:28
| 2021-03-09T12:42:57
| 2021-03-09T12:42:57
|
NONE
| null | null | null | null |
Hi everyone,
Can anyone help me with why the dataset loading script below raises a Windows Permission Error? I stuck quite closely to https://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py , only I want to load the data from three local three-column tsv-files (id\ttokens\tpos_tags\n). I am using the most recent version of datasets. Thank you in advance!
Luisa
My script:
```
import datasets
import csv
logger = datasets.logging.get_logger(__name__)
class SampleConfig(datasets.BuilderConfig):
def __init__(self, **kwargs):
super(SampleConfig, self).__init__(**kwargs)
class Sample(datasets.GeneratorBasedBuilder):
BUILDER_CONFIGS = [
SampleConfig(name="conll2003", version=datasets.Version("1.0.0"), description="Conll2003 dataset"),
]
def _info(self):
return datasets.DatasetInfo(
description="Dataset with words and their POS-Tags",
features=datasets.Features(
{
"id": datasets.Value("string"),
"tokens": datasets.Sequence(datasets.Value("string")),
"pos_tags": datasets.Sequence(
datasets.features.ClassLabel(
names=[
"''",
",",
"-LRB-",
"-RRB-",
".",
":",
"CC",
"CD",
"DT",
"EX",
"FW",
"HYPH",
"IN",
"JJ",
"JJR",
"JJS",
"MD",
"NN",
"NNP",
"NNPS",
"NNS",
"PDT",
"POS",
"PRP",
"PRP$",
"RB",
"RBR",
"RBS",
"RP",
"TO",
"UH",
"VB",
"VBD",
"VBG",
"VBN",
"VBP",
"VBZ",
"WDT",
"WP",
"WRB",
"``"
]
)
),
}
),
supervised_keys=None,
homepage="https://catalog.ldc.upenn.edu/LDC2011T03",
citation="Weischedel, Ralph, et al. OntoNotes Release 4.0 LDC2011T03. Web Download. Philadelphia: Linguistic Data Consortium, 2011.",
)
def _split_generators(self, dl_manager):
loaded_files = dl_manager.download_and_extract(self.config.data_files)
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": loaded_files["train"]}),
datasets.SplitGenerator(name=datasets.Split.TEST, gen_kwargs={"filepath": loaded_files["test"]}),
datasets.SplitGenerator(name=datasets.Split.VALIDATION, gen_kwargs={"filepath": loaded_files["val"]})
]
def _generate_examples(self, filepath):
logger.info("generating examples from = %s", filepath)
with open(filepath, encoding="cp1252") as f:
data = csv.reader(f, delimiter="\t")
ids = list()
tokens = list()
pos_tags = list()
for id_, line in enumerate(data):
#print(line)
if len(line) == 1:
if tokens:
yield id_, {"id": ids, "tokens": tokens, "pos_tags": pos_tags}
ids = list()
tokens = list()
pos_tags = list()
else:
ids.append(line[0])
tokens.append(line[1])
pos_tags.append(line[2])
# last example
yield id_, {"id": ids, "tokens": tokens, "pos_tags": pos_tags}
def main():
dataset = datasets.load_dataset(
"data_loading.py", data_files={
"train": "train.tsv",
"test": "test.tsv",
"val": "val.tsv"
}
)
#print(dataset)
if __name__=="__main__":
main()
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SBrandeis",
"id": 33657802,
"login": "SBrandeis",
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SBrandeis",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2000/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/2000/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 0:47:29
|
https://api.github.com/repos/huggingface/datasets/issues/1997
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1997/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1997/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1997/events
|
https://github.com/huggingface/datasets/issues/1997
| 823,679,465
|
MDU6SXNzdWU4MjM2Nzk0NjU=
| 1,997
|
from datasets import MoleculeDataset, GEOMDataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5087210?v=4",
"events_url": "https://api.github.com/users/futianfan/events{/privacy}",
"followers_url": "https://api.github.com/users/futianfan/followers",
"following_url": "https://api.github.com/users/futianfan/following{/other_user}",
"gists_url": "https://api.github.com/users/futianfan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/futianfan",
"id": 5087210,
"login": "futianfan",
"node_id": "MDQ6VXNlcjUwODcyMTA=",
"organizations_url": "https://api.github.com/users/futianfan/orgs",
"received_events_url": "https://api.github.com/users/futianfan/received_events",
"repos_url": "https://api.github.com/users/futianfan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/futianfan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/futianfan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/futianfan",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] |
[] | 2021-03-06T15:50:19
| 2021-03-06T16:13:26
| 2021-03-06T16:13:26
|
NONE
| null | null | null | null |
I met the ImportError: cannot import name 'MoleculeDataset' from 'datasets'. Have anyone met the similar issues? Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5087210?v=4",
"events_url": "https://api.github.com/users/futianfan/events{/privacy}",
"followers_url": "https://api.github.com/users/futianfan/followers",
"following_url": "https://api.github.com/users/futianfan/following{/other_user}",
"gists_url": "https://api.github.com/users/futianfan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/futianfan",
"id": 5087210,
"login": "futianfan",
"node_id": "MDQ6VXNlcjUwODcyMTA=",
"organizations_url": "https://api.github.com/users/futianfan/orgs",
"received_events_url": "https://api.github.com/users/futianfan/received_events",
"repos_url": "https://api.github.com/users/futianfan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/futianfan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/futianfan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/futianfan",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1997/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1997/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:23:07
|
https://api.github.com/repos/huggingface/datasets/issues/1996
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1996/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1996/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1996/events
|
https://github.com/huggingface/datasets/issues/1996
| 823,573,410
|
MDU6SXNzdWU4MjM1NzM0MTA=
| 1,996
|
Error when exploring `arabic_speech_corpus`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6879673?v=4",
"events_url": "https://api.github.com/users/elgeish/events{/privacy}",
"followers_url": "https://api.github.com/users/elgeish/followers",
"following_url": "https://api.github.com/users/elgeish/following{/other_user}",
"gists_url": "https://api.github.com/users/elgeish/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/elgeish",
"id": 6879673,
"login": "elgeish",
"node_id": "MDQ6VXNlcjY4Nzk2NzM=",
"organizations_url": "https://api.github.com/users/elgeish/orgs",
"received_events_url": "https://api.github.com/users/elgeish/received_events",
"repos_url": "https://api.github.com/users/elgeish/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/elgeish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elgeish/subscriptions",
"type": "User",
"url": "https://api.github.com/users/elgeish",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"Thanks for reporting! We'll fix that as soon as possible",
"Actually soundfile is not a dependency of this dataset.\r\nThe error comes from a bug that was fixed in this commit: https://github.com/huggingface/datasets/pull/1767/commits/c304e63629f4453367de2fd42883a78768055532\r\nBasically the library used to consider the `import soundfile` in the docstring as a dependency, while it's just here as a code example.\r\n\r\nUpdating the viewer to the latest version of `datasets` should fix this issue\r\n",
"Hi! The viewer at https://huggingface.co/datasets/arabic_speech_corpus works fine. Closing."
] | 2021-03-06T05:55:20
| 2022-10-05T13:24:26
| 2022-10-05T13:24:26
|
NONE
| null | null | null | null |
Navigate to https://huggingface.co/datasets/viewer/?dataset=arabic_speech_corpus
Error:
```
ImportError: To be able to use this dataset, you need to install the following dependencies['soundfile'] using 'pip install soundfile' for instance'
Traceback:
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/script_runner.py", line 332, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp-viewer/run.py", line 233, in <module>
configs = get_confs(option)
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/caching.py", line 604, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/streamlit/caching.py", line 588, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp-viewer/run.py", line 145, in get_confs
module_path = nlp.load.prepare_module(path, dataset=True
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/datasets/load.py", line 342, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1996/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1996/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 578 days, 7:29:06
|
https://api.github.com/repos/huggingface/datasets/issues/1994
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1994/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1994/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1994/events
|
https://github.com/huggingface/datasets/issues/1994
| 822,871,238
|
MDU6SXNzdWU4MjI4NzEyMzg=
| 1,994
|
not being able to get wikipedia es language
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"@lhoestq I really appreciate if you could help me providiing processed datasets, I do not really have access to enough resources to run the apache-beam and need to run the codes on these datasets. Only en/de/fr currently works, but I need all the languages more or less. thanks ",
"Hi @dorost1234, I think I can help you a little. I’ve processed some Wikipedia datasets (Spanish inclusive) using the HF/datasets library during recent research.\r\n\r\n@lhoestq Could you help me to upload these preprocessed datasets to Huggingface's repositories? To be more precise, I've built datasets from the following languages using the 20201201 dumps: Spanish, Portuguese, Russian, French, Japanese, Chinese, and Turkish. Process these datasets have high costs that most of the community can't afford. I think these preprocessed datasets I have could be helpful for someone without access to high-resource machines to process Wikipedia's dumps like @dorost1234\r\n\r\n",
"Thank you so much @jonatasgrosman , I greatly appreciate your help with them. \r\nYes, I unfortunately does not have access to a good resource and need it for my\r\nresearch. I greatly appreciate @lhoestq your help with uploading the processed datasets in huggingface datasets. This would be really helpful for some users like me with not access to high-memory GPU resources.\r\n\r\nthank you both so much again.\r\n\r\nOn Sat, Mar 6, 2021 at 12:55 AM Jonatas Grosman <notifications@github.com>\r\nwrote:\r\n\r\n> Hi @dorost1234 <https://github.com/dorost1234>, I think I can help you a\r\n> little. I’ve processed some Wikipedia datasets (Spanish inclusive) using\r\n> the HF/datasets library during recent research.\r\n>\r\n> @lhoestq <https://github.com/lhoestq> Could you help me to upload these\r\n> preprocessed datasets to Huggingface's repositories? To be more precise,\r\n> I've built datasets from the following languages using the 20201201 dumps:\r\n> Spanish, Portuguese, Russian, French, Japanese, Chinese, and Turkish.\r\n> Process these datasets have high costs that most of the community can't\r\n> afford. I think these preprocessed datasets I have could be helpful for\r\n> someone without access to high-resource machines to process Wikipedia's\r\n> dumps like @dorost1234 <https://github.com/dorost1234>\r\n>\r\n> —\r\n> You are receiving this because you were mentioned.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/1994#issuecomment-791798195>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AS37NMWMK5GFJFU3ACCJFUDTCFVNZANCNFSM4YUZIF4A>\r\n> .\r\n>\r\n",
"Hi @dorost1234, so sorry, but looking at my files here, I figure out that I've preprocessed files using the HF/datasets for all the languages previously listed by me (Portuguese, Russian, French, Japanese, Chinese, and Turkish) except the Spanish (on my tests I've used the [wikicorpus](https://www.cs.upc.edu/~nlp/wikicorpus/) instead).\r\n\r\nOnly with the Spanish Wikipedia's dump, I had the same `KeyError: '000nbsp'` problem already reported here https://github.com/huggingface/datasets/issues/577\r\n\r\nSo nowadays, even with access to a high resource machine, you couldn't be able to get Wikipedia's Spanish data using the HF/datasets :(\r\n\r\n\r\n\r\n\r\n",
"Thanks a lot for the information and help. This would be great to have\nthese datasets.\n@lhoestq <https://github.com/lhoestq> Do you know a way I could get\nsmaller amount of these data like 1 GBtype of each language to deal with\ncomputatioanl requirements? thanks\n\nOn Sat, Mar 6, 2021 at 5:36 PM Jonatas Grosman <notifications@github.com>\nwrote:\n\n> Hi @dorost1234 <https://github.com/dorost1234>, so sorry, but looking at\n> my files here, I figure out that I've preprocessed files using the\n> HF/datasets for all the languages previously listed by me (Portuguese,\n> Russian, French, Japanese, Chinese, and Turkish) except the Spanish (on my\n> tests I've used the wikicorpus <https://www.cs.upc.edu/~nlp/wikicorpus/>\n> instead).\n>\n> Only with the Spanish Wikipedia's dump, I had the same KeyError: '000nbsp'\n> problem already reported here #577\n> <https://github.com/huggingface/datasets/issues/577>\n>\n> So nowadays, even with access to a high resource machine, you couldn't be\n> able to get Wikipedia's Spanish data using the HF/datasets :(\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/1994#issuecomment-791985546>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AS37NMWMO7WOHWLOROPD6Q3TCJKXPANCNFSM4YUZIF4A>\n> .\n>\n",
"Hi ! As mentioned above the Spanish configuration have parsing issues from `mwparserfromhell`. I haven't tested with the latest `mwparserfromhell` >=0.6 though. Which version of `mwparserfromhell` are you using ?\r\n\r\n> @lhoestq Could you help me to upload these preprocessed datasets to Huggingface's repositories? To be more precise, I've built datasets from the following languages using the 20201201 dumps: Spanish, Portuguese, Russian, French, Japanese, Chinese, and Turkish. Process these datasets have high costs that most of the community can't afford. I think these preprocessed datasets I have could be helpful for someone without access to high-resource machines to process Wikipedia's dumps like @dorost1234\r\n\r\nThat would be awesome ! Feel free to ping me on slack so we can put the processed wikipedia files on google storage with the other ones we've already preprocessed.\r\n\r\n> Do you know a way I could get smaller amount of these data like 1 GBtype of each language to deal with computatioanl requirements? thanks\r\n\r\nI'd suggest to copy the [wikipedia.py](https://github.com/huggingface/datasets/blob/master/datasets/wikipedia/wikipedia.py) to a new script `custom_wikipedia.py` and modify it to only download and process only a subset of the raw data files.\r\nYou can for example replace [this line](https://github.com/huggingface/datasets/blob/64e59fc45ca2134218b3e42e83fddddbe840ff74/datasets/wikipedia/wikipedia.py#L446) by:\r\n```python\r\n if total_bytes >= (1 << 30): # stop if the total amount of data is >= 1GB\r\n break\r\n else:\r\n xml_urls.append(_base_url(lang) + fname)\r\n```\r\n\r\nThen you can load your custom wikipedia dataset with\r\n```python\r\nload_dataset(\"path/to/my/custom_wikipedia.py\", f\"{date}.{language}\")\r\n```",
"Hi @lhoestq!\r\n\r\n> Hi ! As mentioned above the Spanish configuration have parsing issues from mwparserfromhell. I haven't tested with the latest mwparserfromhell >=0.6 though. Which version of mwparserfromhell are you using ?\r\n\r\nI'm using the latest mwparserfromhell version (0.6)\r\n\r\n> That would be awesome ! Feel free to ping me on slack so we can put the processed wikipedia files on google storage with the other ones we've already preprocessed.\r\n\r\nI'll ping you there 👍 ",
"Thank you so much @jonatasgrosman and @lhoestq this would be a great help. I am really thankful to you both and to wonderful Huggingface dataset library allowing us to train models at scale."
] | 2021-03-05T08:31:48
| 2021-03-11T20:46:21
| null |
NONE
| null | null | null | null |
Hi
I am trying to run a code with wikipedia of config 20200501.es, getting:
Traceback (most recent call last):
File "run_mlm_t5.py", line 608, in <module>
main()
File "run_mlm_t5.py", line 359, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
File "/dara/libs/anaconda3/envs/success432/lib/python3.7/site-packages/datasets-1.2.1-py3.7.egg/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/dara/libs/anaconda3/envs/success432/lib/python3.7/site-packages/datasets-1.2.1-py3.7.egg/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/dara/libs/anaconda3/envs/success432/lib/python3.7/site-packages/datasets-1.2.1-py3.7.egg/datasets/builder.py", line 1050, in _download_and_prepare
"\n\t`{}`".format(usage_example)
datasets.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.es', beam_runner='DirectRunner')`
thanks @lhoestq for any suggestion/help
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1994/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1994/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1993
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1993/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1993/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1993/events
|
https://github.com/huggingface/datasets/issues/1993
| 822,758,387
|
MDU6SXNzdWU4MjI3NTgzODc=
| 1,993
|
How to load a dataset with load_from disk and save it again after doing transformations without changing the original?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! That looks like a bug, can you provide some code so that we can reproduce ?\r\nIt's not supposed to update the original dataset",
"Hi, I experimented with RAG. \r\n\r\nActually, you can run the [use_own_knowldge_dataset.py](https://github.com/shamanez/transformers/blob/rag-end-to-end-retrieval/examples/research_projects/rag/use_own_knowledge_dataset.py#L80). In the 80 you can save the dataset object to the disk with save_to_disk. Then in order to compute the embeddings in this use **load_from_disk**. \r\n\r\nThen finally save it. You can see the original dataset object (CSV after splitting also will be changed)\r\n\r\nOne more thing- when I save the dataset object with **save_to_disk** it name the arrow file with cache.... rather than using dataset. arrow. Can you add a variable that we can feed a name to save_to_disk function?",
"@lhoestq I also found that cache in tmp directory gets updated after transformations. This is really problematic when using datasets interactively. Let's say we use the shards function to a dataset loaded with csv, atm when we do transformations to shards and combine them it updates the original csv cache. ",
"I plan to update the save_to_disk method in #2025 so I can make sure the new save_to_disk doesn't corrupt your cache files.\r\nBut from your last message it looks like save_to_disk isn't the root cause right ?",
"ok, one more thing. When we use save_to_disk there are two files other than .arrow. dataset_info.json and state.json. Sometimes most of the fields in the dataset_infor.json are null, especially when saving dataset objects. Anyways I think load_from_disk uses the arrow files mentioned in state.json right? ",
"> Anyways I think load_from_disk uses the arrow files mentioned in state.json right?\r\n\r\nYes exactly",
"Perfect. For now, I am loading the dataset from CSV in my interactive process and will wait until you make the PR!"
] | 2021-03-05T05:25:50
| 2021-03-22T04:05:50
| 2021-03-22T04:05:50
|
NONE
| null | null | null | null |
I am using the latest datasets library. In my work, I first use **load_from_disk** to load a data set that contains 3.8Gb information. Then during my training process, I update that dataset object and add new elements and save it in a different place.
When I save the dataset with **save_to_disk**, the original dataset which is already in the disk also gets updated. I do not want to update it. How to prevent from this?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1993/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1993/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 16 days, 22:40:00
|
https://api.github.com/repos/huggingface/datasets/issues/1992
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1992/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1992/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1992/events
|
https://github.com/huggingface/datasets/issues/1992
| 822,672,238
|
MDU6SXNzdWU4MjI2NzIyMzg=
| 1,992
|
`datasets.map` multi processing much slower than single processing
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29157715?v=4",
"events_url": "https://api.github.com/users/hwijeen/events{/privacy}",
"followers_url": "https://api.github.com/users/hwijeen/followers",
"following_url": "https://api.github.com/users/hwijeen/following{/other_user}",
"gists_url": "https://api.github.com/users/hwijeen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hwijeen",
"id": 29157715,
"login": "hwijeen",
"node_id": "MDQ6VXNlcjI5MTU3NzE1",
"organizations_url": "https://api.github.com/users/hwijeen/orgs",
"received_events_url": "https://api.github.com/users/hwijeen/received_events",
"repos_url": "https://api.github.com/users/hwijeen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hwijeen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwijeen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hwijeen",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
open
| false
| null |
[] |
[
"Hi @hwijeen, you might want to look at issues #1796 and #1949. I think it could be something related to the I/O operations being performed.",
"I see that many people are experiencing the same issue. Is this problem considered an \"official\" bug that is worth a closer look? @lhoestq",
"Yes this looks like a bug. On my side I haven't managed to reproduce it but @theo-m has. We'll investigate this !",
"Thank you for the reply! I would be happy to follow the discussions related to the issue.\r\nIf you do not mind, could you also give a little more explanation on my p.s.2? I am having a hard time figuring out why the single processing `map` uses all of my cores.\r\n@lhoestq @theo-m ",
"Regarding your ps2: It depends what function you pass to `map`.\r\nFor example, fast tokenizers from `transformers` in Rust tokenize texts and parallelize the tokenization over all the cores.",
"I am still experiencing this issue with datasets 1.9.0..\r\nHas there been a further investigation? \r\n<img width=\"442\" alt=\"image\" src=\"https://user-images.githubusercontent.com/29157715/126143387-8b5ddca2-a896-4e18-abf7-4fbf62a48b41.png\">\r\n",
"Hi. Is there any update on this issue? I am desperately trying to decrease my times, and multiprocessing \"should\" be the solution, but it literally takes 5 times longer.",
"Which version of `datasets` are you using ?",
"Hi,\r\n\r\nI’m running into the same issue and trying to come up with a simple benchmark. \r\n\r\n# environment info\r\nI have a total of 80 CPUs.\r\n\r\n- `datasets` version: 2.4.0\r\n- Platform: Linux-4.18.0-305.65.1.el8_4.x86_64-x86_64-with-glibc2.28\r\n- Python version: 3.10.4\r\n- PyArrow version: 8.0.0\r\n- Pandas version: 1.4.3\r\n\r\n# How to reproduce\r\n\r\n```py\r\nIn [1]: from datasets import Dataset, set_caching_enabled \r\nIn [2]: import numpy as np \r\nIn [3]: set_caching_enabled(False) \r\nIn [4]: d = Dataset.from_dict({'foo': np.random.randn(1000,256)}) \r\nIn [9]: d.set_format('np')\r\nIn [14]: def sort(array): \r\n ...: np.sort(array) \r\n# multiprocessing disabled\r\nIn [19]: %%timeit \r\n ...: d.map(sort, input_columns='foo') \r\n78.8 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) \r\n# multiprocessing enabled \r\nIn [27]: %%timeit \r\n ...: d.map(sort, input_columns='foo',num_proc=10) \r\n858 ms ± 45.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) \r\n```",
"Spawning multiple processes has an overhead. For small datasets the processing is likely to be faster than spawning the processes and passing the data to them.\r\n\r\nEspecially since your dataset is in memory: the data has to be copied to the subprocesses.\r\nOn the other hand, datasets loaded from disk are much faster to reload from a subprocess thanks to memory mapping.",
"Thanks for the clarifications! \r\n\r\nIndeed, when saving then loading the above dataset to disk, and increasing the number of rows to 10K or 100K, the performance gap narrows.\r\n\r\n```py\r\n# with 10000 rows\r\nIn [3]: %%timeit\r\n ...: d.map(sort, input_columns='foo')\r\n578 ms ± 5.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\r\nIn [4]: %%timeit \r\n ...: d.map(sort, input_columns='foo',num_proc=10) \r\n1.06 s ± 47.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\r\n\r\n# with 100000 rows\r\nIn [6]: %%timeit\r\n ...: d.map(sort, input_columns='foo')\r\n5.8 s ± 25.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\r\nIn [7]: %%timeit\r\n ...: d.map(sort, input_columns='foo',num_proc=10)\r\n7.23 s ± 154 ms per loop (mean ± std. dev. of 7 runs, 1 loop each\r\n```",
"any updates on this issue? \r\nI'm using `datasets=2.12.0`. Adding `num_proc` to the mapping function makes it at least 5x slower than using a single process.",
"What kind of function are you passing to `map` ? How many CPUs do you have and what did you set for `num_proc` ?",
"Hello! Any solution for this? Thanks!"
] | 2021-03-05T02:10:02
| 2024-06-08T20:18:03
| null |
NONE
| null | null | null | null |
Hi, thank you for the great library.
I've been using datasets to pretrain language models, and it often involves datasets as large as ~70G.
My data preparation step is roughly two steps: `load_dataset` which splits corpora into a table of sentences, and `map` converts a sentence into a list of integers, using a tokenizer.
I noticed that `map` function with `num_proc=mp.cpu_count() //2` takes more than 20 hours to finish the job where as `num_proc=1` gets the job done in about 5 hours. The machine I used has 40 cores, with 126G of RAM. There were no other jobs when `map` function was running.
What could be the reason? I would be happy to provide information necessary to spot the reason.
p.s. I was experiencing the imbalance issue mentioned in [here](https://github.com/huggingface/datasets/issues/610#issuecomment-705177036) when I was using multi processing.
p.s.2 When I run `map` with `num_proc=1`, I see one tqdm bar but all the cores are working. When `num_proc=20`, only 20 cores work.
| null |
{
"+1": 9,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 9,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1992/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1992/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1990
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1990/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1990/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1990/events
|
https://github.com/huggingface/datasets/issues/1990
| 822,384,502
|
MDU6SXNzdWU4MjIzODQ1MDI=
| 1,990
|
OSError: Memory mapping file failed: Cannot allocate memory
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Do you think this is trying to bring the dataset into memory and if I can avoid it to save on memory so it only brings a batch into memory? @lhoestq thank you",
"It's not trying to bring the dataset into memory.\r\n\r\nActually, it's trying to memory map the dataset file, which is different. It allows to load large dataset files without filling up memory.\r\n\r\nWhat dataset did you use to get this error ?\r\nOn what OS are you running ? What's your python and pyarrow version ?",
"Dear @lhoestq \r\nthank you so much for coming back to me. Please find info below:\r\n1) Dataset name: I used wikipedia with config 20200501.en\r\n2) I got these pyarrow in my environment:\r\npyarrow 2.0.0 <pip>\r\npyarrow 3.0.0 <pip>\r\n\r\n3) python version 3.7.10\r\n4) OS version \r\n\r\nlsb_release -a\r\nNo LSB modules are available.\r\nDistributor ID:\tDebian\r\nDescription:\tDebian GNU/Linux 10 (buster)\r\nRelease:\t10\r\nCodename:\tbuster\r\n\r\n\r\nIs there a way I could solve the memory issue and if I could run this model, I am using GeForce GTX 108, \r\nthanks \r\n",
"I noticed that the error happens when loading the validation dataset.\r\nWhat value of `data_args.validation_split_percentage` did you use ?",
"Dear @lhoestq \r\n\r\nthank you very much for the very sharp observation, indeed, this happens there, I use the default value of 5, I basically plan to subsample a part of the large dataset and choose it as validation set. Do you think this is bringing the data into memory during subsampling? Is there a way I could avoid this?\r\n\r\nThank you very much for the great help.\r\n\r\n\r\nOn Mon, Mar 8, 2021 at 11:28 AM Quentin Lhoest ***@***.***>\r\nwrote:\r\n\r\n> I noticed that the error happens when loading the validation dataset.\r\n> What value of data_args.validation_split_percentage did you use ?\r\n>\r\n> —\r\n> You are receiving this because you authored the thread.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/datasets/issues/1990#issuecomment-792655644>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AS37NMS337ZUJ7HGGVVCCR3TCSREFANCNFSM4YTYAQ2A>\r\n> .\r\n>\r\n",
"Methods like `dataset.shard`, `dataset.train_test_split`, `dataset.select` etc. don't bring the dataset in memory. \r\nThe only time when samples are brought to memory is when you access elements via `dataset[0]`, `dataset[:10]`, `dataset[\"my_column_names\"]`.\r\n\r\nBut it's possible that trying to use those methods to build your validation set doesn't fix the issue since, if I understand correctly, the error happens when when the dataset arrow file is opened (just before the 5% percentage is applied).\r\n\r\nDid you try to reproduce this issue in a google colab ? This would be super helpful to investigate why this happened.\r\n\r\nAlso maybe you can try clearing your cache at `~/.cache/huggingface/datasets` and try again. If the arrow file was corrupted somehow, removing it and rebuilding may fix the issue."
] | 2021-03-04T18:21:58
| 2021-08-04T18:04:25
| 2021-08-04T18:04:25
|
NONE
| null | null | null | null |
Hi,
I am trying to run a code with a wikipedia dataset, here is the command to reproduce the error. You can find the codes for run_mlm.py in huggingface repo here: https://github.com/huggingface/transformers/blob/v4.3.2/examples/language-modeling/run_mlm.py
```
python run_mlm.py --model_name_or_path bert-base-multilingual-cased --dataset_name wikipedia --dataset_config_name 20200501.en --do_train --do_eval --output_dir /dara/test --max_seq_length 128
```
I am using transformer version: 4.3.2
But I got memory erorr using this dataset, is there a way I could save on memory with dataset library with wikipedia dataset?
Specially I need to train a model with multiple of wikipedia datasets concatenated. thank you very much @lhoestq for your help and suggestions:
```
File "run_mlm.py", line 441, in <module>
main()
File "run_mlm.py", line 233, in main
split=f"train[{data_args.validation_split_percentage}%:]",
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 740, in as_dataset
map_tuple=True,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/utils/py_utils.py", line 225, in map_nested
return function(data_struct)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 757, in _build_single_dataset
in_memory=in_memory,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 829, in _as_dataset
in_memory=in_memory,
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 215, in read
return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 236, in read_files
pa_table = self._read_files(files, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 171, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 302, in _get_dataset_from_filename
pa_table = ArrowReader.read_table(filename, in_memory=in_memory)
File "/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py", line 322, in read_table
stream = stream_from(filename)
File "pyarrow/io.pxi", line 782, in pyarrow.lib.memory_map
File "pyarrow/io.pxi", line 743, in pyarrow.lib.MemoryMappedFile._open
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 99, in pyarrow.lib.check_status
OSError: Memory mapping file failed: Cannot allocate memory
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1990/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1990/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 152 days, 23:42:27
|
https://api.github.com/repos/huggingface/datasets/issues/1989
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1989/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1989/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1989/events
|
https://github.com/huggingface/datasets/issues/1989
| 822,328,147
|
MDU6SXNzdWU4MjIzMjgxNDc=
| 1,989
|
Question/problem with dataset labels
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url": "https://api.github.com/users/ioana-blue/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ioana-blue",
"id": 17202292,
"login": "ioana-blue",
"node_id": "MDQ6VXNlcjE3MjAyMjky",
"organizations_url": "https://api.github.com/users/ioana-blue/orgs",
"received_events_url": "https://api.github.com/users/ioana-blue/received_events",
"repos_url": "https://api.github.com/users/ioana-blue/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ioana-blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ioana-blue/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ioana-blue",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It seems that I get parsing errors for various fields in my data. For example now I get this:\r\n```\r\n File \"../../../models/tr-4.3.2/run_puppets.py\", line 523, in <module>\r\n main()\r\n File \"../../../models/tr-4.3.2/run_puppets.py\", line 249, in main\r\n datasets = load_dataset(\"csv\", data_files=data_files)\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/load.py\", line 740, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py\", line 572, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py\", line 650, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py\", line 1028, in _prepare_split\r\n writer.write_table(table)\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/arrow_writer.py\", line 292, in write_table\r\n pa_table = pa_table.cast(self._schema)\r\n File \"pyarrow/table.pxi\", line 1311, in pyarrow.lib.Table.cast\r\n File \"pyarrow/table.pxi\", line 265, in pyarrow.lib.ChunkedArray.cast\r\n File \"/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/pyarrow/compute.py\", line 87, in cast\r\n return call_function(\"cast\", [arr], options)\r\n File \"pyarrow/_compute.pyx\", line 298, in pyarrow._compute.call_function\r\n File \"pyarrow/_compute.pyx\", line 192, in pyarrow._compute.Function.call\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 84, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Failed to parse string: https://www.netgalley.com/catalog/book/121872\r\n```",
"Not sure if this helps, this is how I load my files (as in the sample scripts on transformers):\r\n\r\n```\r\n if data_args.train_file.endswith(\".csv\"):\r\n # Loading a dataset from local csv files\r\n datasets = load_dataset(\"csv\", data_files=data_files)\r\n```",
"Since this worked out of the box in a few examples before, I wonder if it's some quoting issue or something else. ",
"Hi @ioana-blue,\r\nCan you share a sample from your .csv? A dummy where you get this error will also help.\r\n\r\nI tried this csv:\r\n```csv\r\nfeature,label\r\n1.2,not nurse\r\n1.3,nurse\r\n1.5,surgeon\r\n```\r\nand the following snippet:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"csv\",data_files=['test.csv'])\r\n\r\nprint(d)\r\nprint(d['train']['label'])\r\n```\r\nand this works perfectly fine for me:\r\n```sh\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['feature', 'label'],\r\n num_rows: 3\r\n })\r\n})\r\n['not nurse', 'nurse', 'surgeon']\r\n```\r\nI'm sure your csv is more complicated than this one. But it is hard to tell where the issue might be without looking at a sample.",
"I've had versions where it worked fain. For this dataset, I had all kind of parsing issues that I couldn't understand. What I ended up doing is strip all the columns that I didn't need and also make the label 0/1. \r\n\r\nI think one line that may have caused a problem was the csv version of this:\r\n\r\n```crawl-data/CC-MAIN-2017-47/segments/1510934806225.78/wet/CC-MAIN-20171120203833-20171120223833-00571.warc.wet.gz Rose Blakey is an aspiring journalist. She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead-end waitressing job. ^M ('Rose', '', 'Blakey') journalist F 38 journalist https://www.netgalley.com/catalog/book/121872 _ is desperate to escape the from the small Australian town in which _ lives. Rejection after rejection mean _ is stuck in what _ sees as a dead-end waitressing job. She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead-end waitressing job.```\r\n\r\nThe error I got in this case is this one: https://github.com/huggingface/datasets/issues/1989#issuecomment-790842771\r\n\r\nNote, this line was part of a much larger file and until this line I guess it was working fine. ",
"Hi @ioana-blue,\r\n\r\nWhat is the separator you're using for the csv? I see there are only two commas in the given line, but they don't seem like appropriate points. Also, is this a string part of one line, or an entire line? There should also be a label, right?",
"Sorry for the confusion, the sample above was from a tsv that was used to derive the csv. Let me construct the csv again (I had remove it). \r\n\r\nThis is the line in the csv - this is the whole line:\r\n```crawl-data/CC-MAIN-2017-47/segments/1510934806225.78/wet/CC-MAIN-20171120203833-20171120223833-00571.warc.wet.gz,Rose Blakey is an aspiring journalist. She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead,\"('Rose', '', 'Blakey')\",journalist,F,38,journalist,https://www.netgalley.com/catalog/book/121872,_ is desperate to escape the from the small Australian town in which _ lives. Rejection after rejection mean _ is stuck in what _ sees as a dead-end waitressing job., She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead-end waitressing job.```",
"Hi,\r\nJust in case you want to use tsv directly, you can use the separator argument while loading the dataset.\r\n```python\r\nd = load_dataset(\"csv\",data_files=['test.csv'],sep=\"\\t\")\r\n```\r\n\r\nAdditionally, I don't face the issues with the following csv (same as the one you provided):\r\n\r\n```sh\r\nlink1,text1,info1,info2,info3,info4,info5,link2,text2,text3\r\ncrawl-data/CC-MAIN-2017-47/segments/1510934806225.78/wet/CC-MAIN-20171120203833-20171120223833-00571.warc.wet.gz,Rose Blakey is an aspiring journalist. She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead,\"('Rose', '', 'Blakey')\",journalist,F,38,journalist,https://www.netgalley.com/catalog/book/121872,_ is desperate to escape the from the small Australian town in which _ lives. Rejection after rejection mean _ is stuck in what _ sees as a dead-end waitressing job., She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead-end waitressing job.\r\n```\r\nOutput after loading:\r\n```sh\r\n{'link1': 'crawl-data/CC-MAIN-2017-47/segments/1510934806225.78/wet/CC-MAIN-20171120203833-20171120223833-00571.warc.wet.gz', 'text1': 'Rose Blakey is an aspiring journalist. She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead', 'info1': \"('Rose', '', 'Blakey')\", 'info2': 'journalist', 'info3': 'F', 'info4': 38, 'info5': 'journalist', 'link2': 'https://www.netgalley.com/catalog/book/121872', 'text2': '_ is desperate to escape the from the small Australian town in which _ lives. Rejection after rejection mean _ is stuck in what _ sees as a dead-end waitressing job.', 'text3': ' She is desperate to escape the from the small Australian town in which she lives. Rejection after rejection mean she is stuck in what she sees as a dead-end waitressing job.'}\r\n```\r\nCan you check once if the tsv works for you directly using the separator argument? The conversion from tsv to csv could create issues, I'm only guessing though.",
"thanks for the tip. very strange :/ I'll check my datasets version as well. \r\n\r\nI will have more similar experiments soon so I'll let you know if I manage to get rid of this. ",
"No problem at all. I thought I'd be able to solve this but I'm unable to replicate the issue :/"
] | 2021-03-04T17:06:53
| 2023-07-24T14:39:33
| 2023-07-24T14:39:33
|
NONE
| null | null | null | null |
Hi, I'm using a dataset with two labels "nurse" and "not nurse". For whatever reason (that I don't understand), I get an error that I think comes from the datasets package (using csv). Everything works fine if the labels are "nurse" and "surgeon".
This is the trace I get:
```
File "../../../models/tr-4.3.2/run_puppets.py", line 523, in <module>
main()
File "../../../models/tr-4.3.2/run_puppets.py", line 249, in main
datasets = load_dataset("csv", data_files=data_files)
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/load.py", line 740, in load_dataset
builder_instance.download_and_prepare(
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py", line 572, in download_and_prepare
self._download_and_prepare(
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py", line 650, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/builder.py", line 1028, in _prepare_split
writer.write_table(table)
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/datasets/arrow_writer.py", line 292, in write_table
pa_table = pa_table.cast(self._schema)
File "pyarrow/table.pxi", line 1311, in pyarrow.lib.Table.cast
File "pyarrow/table.pxi", line 265, in pyarrow.lib.ChunkedArray.cast
File "/dccstor/redrug_ier/envs/last-tr/lib/python3.8/site-packages/pyarrow/compute.py", line 87, in cast
return call_function("cast", [arr], options)
File "pyarrow/_compute.pyx", line 298, in pyarrow._compute.call_function
File "pyarrow/_compute.pyx", line 192, in pyarrow._compute.Function.call
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Failed to parse string: not nurse
```
Any ideas how to fix this? For now, I'll probably make them numeric.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1989/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1989/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 871 days, 21:32:40
|
https://api.github.com/repos/huggingface/datasets/issues/1988
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1988/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1988/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1988/events
|
https://github.com/huggingface/datasets/issues/1988
| 822,324,605
|
MDU6SXNzdWU4MjIzMjQ2MDU=
| 1,988
|
Readme.md is misleading about kinds of datasets?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/878399?v=4",
"events_url": "https://api.github.com/users/surak/events{/privacy}",
"followers_url": "https://api.github.com/users/surak/followers",
"following_url": "https://api.github.com/users/surak/following{/other_user}",
"gists_url": "https://api.github.com/users/surak/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/surak",
"id": 878399,
"login": "surak",
"node_id": "MDQ6VXNlcjg3ODM5OQ==",
"organizations_url": "https://api.github.com/users/surak/orgs",
"received_events_url": "https://api.github.com/users/surak/received_events",
"repos_url": "https://api.github.com/users/surak/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/surak/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/surak/subscriptions",
"type": "User",
"url": "https://api.github.com/users/surak",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! Yes it's possible to use image data. There are already a few of them available (MNIST, CIFAR..)"
] | 2021-03-04T17:04:20
| 2021-08-04T18:05:23
| 2021-08-04T18:05:23
|
NONE
| null | null | null | null |
Hi!
At the README.MD, you say: "efficient data pre-processing: simple, fast and reproducible data pre-processing for the above public datasets as well as your own local datasets in CSV/JSON/text. "
But here:
https://github.com/huggingface/datasets/blob/master/templates/new_dataset_script.py#L82-L117
You mention other kinds of datasets, with images and so on. I'm confused.
Is it possible to use it to store, say, imagenet locally?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1988/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1988/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 153 days, 1:01:03
|
https://api.github.com/repos/huggingface/datasets/issues/1987
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1987/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1987/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1987/events
|
https://github.com/huggingface/datasets/issues/1987
| 822,308,956
|
MDU6SXNzdWU4MjIzMDg5NTY=
| 1,987
|
wmt15 is broken
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It's reachable for the viewer and me, so I suppose it was down at that moment?"
] | 2021-03-04T16:46:25
| 2022-10-05T13:12:26
| 2022-10-05T13:12:26
|
CONTRIBUTOR
| null | null | null | null |
While testing the hotfix, I tried a random other wmt release and found wmt15 to be broken:
```
python -c 'from datasets import load_dataset; load_dataset("wmt15", "de-en")'
Downloading: 2.91kB [00:00, 818kB/s]
Downloading: 3.02kB [00:00, 897kB/s]
Downloading: 41.1kB [00:00, 19.1MB/s]
Downloading and preparing dataset wmt15/de-en (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/stas/.cache/huggingface/datasets/wmt15/de-en/1.0.0/39ad5f9262a0910a8ad7028ad432731ad23fdf91f2cebbbf2ba4776b9859e87f...
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/load.py", line 740, in load_dataset
builder_instance.download_and_prepare(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/builder.py", line 578, in download_and_prepare
self._download_and_prepare(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/builder.py", line 634, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/stas/.cache/huggingface/modules/datasets_modules/datasets/wmt15/39ad5f9262a0910a8ad7028ad432731ad23fdf91f2cebbbf2ba4776b9859e87f/wmt_utils.py", line 757, in _split_generators
downloaded_files = dl_manager.download_and_extract(urls_to_download)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 283, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 191, in download
downloaded_path_or_paths = map_nested(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 203, in map_nested
mapped = [
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 204, in <listcomp>
_single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 160, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 160, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 142, in _single_map_nested
return function(data_struct)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 214, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 274, in cached_path
output_path = get_from_cache(
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 614, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/wmt/wmt15/resolve/main/training-parallel-nc-v10.tgz
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1987/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1987/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 579 days, 20:26:01
|
https://api.github.com/repos/huggingface/datasets/issues/1986
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1986/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1986/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1986/events
|
https://github.com/huggingface/datasets/issues/1986
| 822,176,290
|
MDU6SXNzdWU4MjIxNzYyOTA=
| 1,986
|
wmt datasets fail to load
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32322564?v=4",
"events_url": "https://api.github.com/users/sabania/events{/privacy}",
"followers_url": "https://api.github.com/users/sabania/followers",
"following_url": "https://api.github.com/users/sabania/following{/other_user}",
"gists_url": "https://api.github.com/users/sabania/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sabania",
"id": 32322564,
"login": "sabania",
"node_id": "MDQ6VXNlcjMyMzIyNTY0",
"organizations_url": "https://api.github.com/users/sabania/orgs",
"received_events_url": "https://api.github.com/users/sabania/received_events",
"repos_url": "https://api.github.com/users/sabania/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sabania/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sabania/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sabania",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"caching issue, seems to work again.."
] | 2021-03-04T14:18:55
| 2021-03-04T14:31:07
| 2021-03-04T14:31:07
|
NONE
| null | null | null | null |
~\.cache\huggingface\modules\datasets_modules\datasets\wmt14\43e717d978d2261502b0194999583acb874ba73b0f4aed0ada2889d1bb00f36e\wmt_utils.py in _split_generators(self, dl_manager)
758 # Extract manually downloaded files.
759 manual_files = dl_manager.extract(manual_paths_dict)
--> 760 extraction_map = dict(downloaded_files, **manual_files)
761
762 for language in self.config.language_pair:
TypeError: type object argument after ** must be a mapping, not list
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32322564?v=4",
"events_url": "https://api.github.com/users/sabania/events{/privacy}",
"followers_url": "https://api.github.com/users/sabania/followers",
"following_url": "https://api.github.com/users/sabania/following{/other_user}",
"gists_url": "https://api.github.com/users/sabania/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sabania",
"id": 32322564,
"login": "sabania",
"node_id": "MDQ6VXNlcjMyMzIyNTY0",
"organizations_url": "https://api.github.com/users/sabania/orgs",
"received_events_url": "https://api.github.com/users/sabania/received_events",
"repos_url": "https://api.github.com/users/sabania/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sabania/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sabania/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sabania",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1986/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1986/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:12:12
|
https://api.github.com/repos/huggingface/datasets/issues/1984
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1984/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1984/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1984/events
|
https://github.com/huggingface/datasets/issues/1984
| 821,816,588
|
MDU6SXNzdWU4MjE4MTY1ODg=
| 1,984
|
Add tests for WMT datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Dummy data generation is deprecated now. Closing."
] | 2021-03-04T06:46:42
| 2022-11-04T14:19:16
| 2022-11-04T14:19:16
|
MEMBER
| null | null | null | null |
As requested in #1981, we need tests for WMT datasets, using dummy data.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1984/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1984/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 610 days, 7:32:34
|
https://api.github.com/repos/huggingface/datasets/issues/1983
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1983/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1983/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1983/events
|
https://github.com/huggingface/datasets/issues/1983
| 821,746,008
|
MDU6SXNzdWU4MjE3NDYwMDg=
| 1,983
|
The size of CoNLL-2003 is not consistant with the official release.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/39556019?v=4",
"events_url": "https://api.github.com/users/h-peng17/events{/privacy}",
"followers_url": "https://api.github.com/users/h-peng17/followers",
"following_url": "https://api.github.com/users/h-peng17/following{/other_user}",
"gists_url": "https://api.github.com/users/h-peng17/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/h-peng17",
"id": 39556019,
"login": "h-peng17",
"node_id": "MDQ6VXNlcjM5NTU2MDE5",
"organizations_url": "https://api.github.com/users/h-peng17/orgs",
"received_events_url": "https://api.github.com/users/h-peng17/received_events",
"repos_url": "https://api.github.com/users/h-peng17/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/h-peng17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h-peng17/subscriptions",
"type": "User",
"url": "https://api.github.com/users/h-peng17",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\nif you inspect the raw data, you can find there are 946 occurrences of `-DOCSTART- -X- -X- O` in the train split and `14041 + 946 = 14987`, which is exactly the number of sentences the authors report. `-DOCSTART-` is a special line that acts as a boundary between two different documents and is filtered out in our implementation.\r\n\r\n@lhoestq What do you think about including these lines? ([Link](https://github.com/flairNLP/flair/issues/1097) to a similar issue in the flairNLP repo)",
"We should mention in the Conll2003 dataset card that these lines have been removed indeed.\r\n\r\nIf some users are interested in using these lines (maybe to recombine documents ?) then we can add a parameter to the conll2003 dataset to include them.\r\n\r\nBut IMO the default config should stay the current one (without the `-DOCSTART-` stuff), so that you can directly train NER models without additional preprocessing. Let me know what you think",
"@lhoestq Yes, I agree adding a small note should be sufficient.\r\n\r\nCurrently, NLTK's `ConllCorpusReader` ignores the `-DOCSTART-` lines so I think it's ok if we do the same. If there is an interest in the future to use these lines, then we can include them.",
"I added a mention of this in conll2003's dataset card:\r\nhttps://github.com/huggingface/datasets/blob/fc9796920da88486c3b97690969aabf03d6b4088/datasets/conll2003/README.md#conll2003\r\n\r\nEdit: just saw your PR @mariosasko (noticed it too late ^^)\r\nLet me take a look at it :)"
] | 2021-03-04T04:41:34
| 2022-10-05T13:13:26
| 2022-10-05T13:13:26
|
NONE
| null | null | null | null |
Thanks for the dataset sharing! But when I use conll-2003, I meet some questions.
The statistics of conll-2003 in this repo is :
\#train 14041 \#dev 3250 \#test 3453
While the official statistics is:
\#train 14987 \#dev 3466 \#test 3684
Wish for your reply~
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1983/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1983/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 580 days, 8:31:52
|
https://api.github.com/repos/huggingface/datasets/issues/1981
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1981/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1981/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1981/events
|
https://github.com/huggingface/datasets/issues/1981
| 821,411,109
|
MDU6SXNzdWU4MjE0MTExMDk=
| 1,981
|
wmt datasets fail to load
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"@stas00 Mea culpa... May I fix this tomorrow morning?",
"yes, of course, I reverted to the version before that and it works ;)\r\n\r\nbut since a new release was just made you will probably need to make a hotfix.\r\n\r\nand add the wmt to the tests?",
"Sure, I will implement a regression test!",
"@stas00 it is fixed. @lhoestq are you releasing the hot fix or would you prefer me to do it?",
"I'll do a patch release for this issue early tomorrow.\r\n\r\nAnd yes we absolutly need tests for the wmt datasets: The missing tests for wmt are an artifact from the early development of the lib but now we have tools to generate automatically the dummy data used for tests :)",
"still facing the same issue or similar:\r\nfrom datasets import load_dataset\r\nwtm14_test = load_dataset('wmt14',\"de-en\",cache_dir='./datasets')\r\n\r\n~.cache\\huggingface\\modules\\datasets_modules\\datasets\\wmt14\\43e717d978d2261502b0194999583acb874ba73b0f4aed0ada2889d1bb00f36e\\wmt_utils.py in _split_generators(self, dl_manager)\r\n758 # Extract manually downloaded files.\r\n759 manual_files = dl_manager.extract(manual_paths_dict)\r\n--> 760 extraction_map = dict(downloaded_files, **manual_files)\r\n761\r\n762 for language in self.config.language_pair:\r\n\r\nTypeError: type object argument after ** must be a mapping, not list"
] | 2021-03-03T19:21:39
| 2021-03-04T14:16:47
| 2021-03-03T22:48:36
|
CONTRIBUTOR
| null | null | null | null |
on master:
```
python -c 'from datasets import load_dataset; load_dataset("wmt14", "de-en")'
Downloading and preparing dataset wmt14/de-en (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/stas/.cache/huggingface/datasets/wmt14/de-en/1.0.0/43e717d978d2261502b0194999583acb874ba73b0f4aed0ada2889d1bb00f36e...
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 740, in load_dataset
builder_instance.download_and_prepare(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/builder.py", line 578, in download_and_prepare
self._download_and_prepare(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/builder.py", line 634, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/stas/.cache/huggingface/modules/datasets_modules/datasets/wmt14/43e717d978d2261502b0194999583acb874ba73b0f4aed0ada2889d1bb00f36e/wmt_utils.py", line 760, in _split_generators
extraction_map = dict(downloaded_files, **manual_files)
```
it worked fine recently. same problem if I try wmt16.
git bisect points to this commit from Feb 25 as the culprit https://github.com/huggingface/datasets/commit/792f1d9bb1c5361908f73e2ef7f0181b2be409fa
@albertvillanova
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1981/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1981/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3:26:57
|
https://api.github.com/repos/huggingface/datasets/issues/1977
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1977/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1977/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1977/events
|
https://github.com/huggingface/datasets/issues/1977
| 820,312,022
|
MDU6SXNzdWU4MjAzMTIwMjI=
| 1,977
|
ModuleNotFoundError: No module named 'apache_beam' for wikipedia datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"I sometimes also get this error with other languages of the same dataset:\r\n\r\n File \"/dara/libs/anaconda3/envs/code/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/arrow_reader.py\", line 322, in read_table\r\n stream = stream_from(filename)\r\n File \"pyarrow/io.pxi\", line 782, in pyarrow.lib.memory_map\r\n File \"pyarrow/io.pxi\", line 743, in pyarrow.lib.MemoryMappedFile._open\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\nOSError: Memory mapping file failed: Cannot allocate memory\r\n\r\n@lhoestq \r\n",
"Hi ! Thanks for reporting\r\nSome wikipedia configurations do require the user to have `apache_beam` in order to parse the wikimedia data.\r\n\r\nOn the other hand regarding your second issue\r\n```\r\nOSError: Memory mapping file failed: Cannot allocate memory\r\n```\r\nI've never experienced this, can you open a new issue for this specific error and provide more details please ?\r\nFor example what script did you use to get this, what language did you use, what's your environment details (os, python version, pyarrow version).."
] | 2021-03-02T19:21:28
| 2021-03-03T10:17:40
| null |
NONE
| null | null | null | null |
Hi
I am trying to run run_mlm.py code [1] of huggingface with following "wikipedia"/ "20200501.aa" dataset:
`python run_mlm.py --model_name_or_path bert-base-multilingual-cased --dataset_name wikipedia --dataset_config_name 20200501.aa --do_train --do_eval --output_dir /tmp/test-mlm --max_seq_length 256
`
I am getting this error, but as per documentation, huggingface dataset provide processed version of this dataset and users can load it without requiring setup extra settings for apache-beam. could you help me please to load this dataset?
Do you think I can run run_ml.py with this dataset? or anyway I could subsample and train the model? I greatly appreciate providing the processed version of all languages for this dataset, which allow the user to use them without setting up apache-beam,. thanks
I really appreciate your help.
@lhoestq
thanks.
[1] https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py
error I get:
```
>>> import datasets
>>> datasets.load_dataset("wikipedia", "20200501.aa")
Downloading and preparing dataset wikipedia/20200501.aa (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /dara/temp/cache_home_2/datasets/wikipedia/20200501.aa/1.0.0/4021357e28509391eab2f8300d9b689e7e8f3a877ebb3d354b01577d497ebc63...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/dara/temp/libs/anaconda3/envs/codes/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/load.py", line 746, in load_dataset
use_auth_token=use_auth_token,
File "/dara/temp/libs/anaconda3/envs/codes/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 573, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/dara/temp/libs/anaconda3/envs/codes/lib/python3.7/site-packages/datasets-1.3.0-py3.7.egg/datasets/builder.py", line 1099, in _download_and_prepare
import apache_beam as beam
ModuleNotFoundError: No module named 'apache_beam'
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1977/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1977/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1973
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1973/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1973/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1973/events
|
https://github.com/huggingface/datasets/issues/1973
| 820,077,312
|
MDU6SXNzdWU4MjAwNzczMTI=
| 1,973
|
Question: what gets stored in the datasets cache and why is it so huge?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url": "https://api.github.com/users/ioana-blue/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ioana-blue",
"id": 17202292,
"login": "ioana-blue",
"node_id": "MDQ6VXNlcjE3MjAyMjky",
"organizations_url": "https://api.github.com/users/ioana-blue/orgs",
"received_events_url": "https://api.github.com/users/ioana-blue/received_events",
"repos_url": "https://api.github.com/users/ioana-blue/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ioana-blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ioana-blue/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ioana-blue",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"Echo'ing this observation: I have a few datasets in the neighborhood of 2GB CSVs uncompressed, and when I use something like `Dataset.save_to_disk()` it's ~18GB on disk.\r\n\r\nIf this is unexpected behavior, would be happy to help run debugging as needed.",
"Thanks @ioana-blue for pointing out this problem (and thanks also @justin-yan). You are right that current implementation of the datasets caching files take too much memory. We are definitely changing this and optimizing the defaults, so that the file sizes are considerably reduced. I will come back to you as soon as this is fixed.",
"Thank you! Also I noticed that the files don't seem to be cleaned after the jobs finish. Last night I had only 3 jobs running, but the cache was still at 180GB. ",
"And to clarify, it's not memory, it's disk space. Thank you!",
"Hi ! As Albert said they can sometimes take more space that expected but we'll fix that soon.\r\n\r\nAlso, to give more details about caching: computations on a dataset are cached by default so that you don't have to recompute them the next time you run them.\r\n\r\nSo by default the cache files stay on your disk when you job is finished (so that if you re-execute it, it will be reloaded from the cache).\r\nFeel free to clear your cache after your job has finished, or disable caching using\r\n```python\r\nimport datasets\r\n\r\ndatasets.set_caching_enabled(False)\r\n```",
"Thanks for the tip, this is useful. ",
"Hi @ioana-blue, we have optimized Datasets' disk usage in the latest release v1.5.\r\n\r\nFeel free to update your Datasets version\r\n```shell\r\npip install -U datasets\r\n```\r\nand see if it better suits your needs.",
"Thank you!"
] | 2021-03-02T14:35:53
| 2021-03-30T14:03:59
| 2021-03-16T09:44:00
|
NONE
| null | null | null | null |
I'm running several training jobs (around 10) with a relatively large dataset (3M samples). The datasets cache reached 178G and it seems really large. What is it stored in there and why is it so large? I don't think I noticed this problem before and seems to be related to the new version of the datasets library. Any insight? Thank you!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1973/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1973/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 13 days, 19:08:07
|
https://api.github.com/repos/huggingface/datasets/issues/1972
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1972/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1972/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1972/events
|
https://github.com/huggingface/datasets/issues/1972
| 819,752,761
|
MDU6SXNzdWU4MTk3NTI3NjE=
| 1,972
|
'Dataset' object has no attribute 'rename_column'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23195502?v=4",
"events_url": "https://api.github.com/users/farooqzaman1/events{/privacy}",
"followers_url": "https://api.github.com/users/farooqzaman1/followers",
"following_url": "https://api.github.com/users/farooqzaman1/following{/other_user}",
"gists_url": "https://api.github.com/users/farooqzaman1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/farooqzaman1",
"id": 23195502,
"login": "farooqzaman1",
"node_id": "MDQ6VXNlcjIzMTk1NTAy",
"organizations_url": "https://api.github.com/users/farooqzaman1/orgs",
"received_events_url": "https://api.github.com/users/farooqzaman1/received_events",
"repos_url": "https://api.github.com/users/farooqzaman1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/farooqzaman1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/farooqzaman1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/farooqzaman1",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! `rename_column` has been added recently and will be available in the next release"
] | 2021-03-02T08:01:49
| 2022-06-01T16:08:47
| 2022-06-01T16:08:47
|
NONE
| null | null | null | null |
'Dataset' object has no attribute 'rename_column'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1972/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1972/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 456 days, 8:06:58
|
https://api.github.com/repos/huggingface/datasets/issues/1965
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1965/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1965/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1965/events
|
https://github.com/huggingface/datasets/issues/1965
| 818,833,460
|
MDU6SXNzdWU4MTg4MzM0NjA=
| 1,965
|
Can we parallelized the add_faiss_index process over dataset shards ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\nAs far as I know not all faiss indexes can be computed in parallel and then merged. \r\nFor example [here](https://github.com/facebookresearch/faiss/wiki/Special-operations-on-indexes#splitting-and-merging-indexes) is is mentioned that only IndexIVF indexes can be merged.\r\nMoreover faiss already works using multithreading to parallelize the workload over your different CPU cores. You can find more info [here](https://github.com/facebookresearch/faiss/wiki/Threads-and-asynchronous-calls#internal-threading)\r\nSo I feel like the gains we would get by implementing a parallel `add_faiss_index` would not be that important, but let me know what you think.\r\n",
"Actually, you are right. I also had the same idea. I am trying this in the context of end-ton-end retrieval training in RAG. So far I have parallelized the embedding re-computation within the training loop by using datasets shards. \r\n\r\nThen I was thinking of can I calculate the indexes for each shard and combined them with **concatenate** before I save.",
"@lhoestq As you mentioned faiss is already using multiprocessing. I tried to do the add_index with faiss for a dataset object inside a RAY actor and the process became very slow... if fact it takes so much time. It is because a ray actor comes with a single CPU core unless we assign it more. I also tried assigning more cores but still running add_index in the main process is very fast. "
] | 2021-03-01T12:47:34
| 2021-03-04T19:40:56
| 2021-03-04T19:40:42
|
NONE
| null | null | null | null |
I am thinking of making the **add_faiss_index** process faster. What if we run the add_faiss_index process on separate dataset shards and then combine them before (dataset.concatenate) saving the faiss.index file ?
I feel theoretically this will reduce the accuracy of retrieval since it affects the indexing process.
@lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1965/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1965/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 6:53:08
|
https://api.github.com/repos/huggingface/datasets/issues/1964
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1964/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1964/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1964/events
|
https://github.com/huggingface/datasets/issues/1964
| 818,624,864
|
MDU6SXNzdWU4MTg2MjQ4NjQ=
| 1,964
|
Datasets.py function load_dataset does not match squad dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/44536699?v=4",
"events_url": "https://api.github.com/users/LeopoldACC/events{/privacy}",
"followers_url": "https://api.github.com/users/LeopoldACC/followers",
"following_url": "https://api.github.com/users/LeopoldACC/following{/other_user}",
"gists_url": "https://api.github.com/users/LeopoldACC/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LeopoldACC",
"id": 44536699,
"login": "LeopoldACC",
"node_id": "MDQ6VXNlcjQ0NTM2Njk5",
"organizations_url": "https://api.github.com/users/LeopoldACC/orgs",
"received_events_url": "https://api.github.com/users/LeopoldACC/received_events",
"repos_url": "https://api.github.com/users/LeopoldACC/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LeopoldACC/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeopoldACC/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LeopoldACC",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\n\r\nTo fix 1, an you try to run this code ?\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nload_dataset(\"squad\", download_mode=\"force_redownload\")\r\n```\r\nMaybe the file your downloaded was corrupted, in this case redownloading this way should fix your issue 1.\r\n\r\nRegarding your 2nd point, you're right that loading the raw json this way doesn't give you a dataset with the column \"context\", \"question\" and \"answers\". Indeed the squad format is a very nested format so you have to preprocess the data. You can do it this way:\r\n```python\r\ndef process_squad(examples):\r\n \"\"\"\r\n Process a dataset in the squad format with columns \"title\" and \"paragraphs\"\r\n to return the dataset with columns \"context\", \"question\" and \"answers\".\r\n \"\"\"\r\n out = {\"context\": [], \"question\": [], \"answers\":[]} \r\n for paragraphs in examples[\"paragraphs\"]: \r\n for paragraph in paragraphs: \r\n for qa in paragraph[\"qas\"]: \r\n answers = [{\"answer_start\": answer[\"answer_start\"], \"text\": answer[\"text\"].strip()} for answer in qa[\"answers\"]] \r\n out[\"context\"].append(paragraph[\"context\"].strip()) \r\n out[\"question\"].append(qa[\"question\"].strip()) \r\n out[\"answers\"].append(answers) \r\n return out\r\n\r\ndatasets = load_dataset(extension, data_files=data_files, field=\"data\")\r\ncolumn_names = datasets[\"train\"].column_names\r\n\r\nif set(column_names) == {\"title\", \"paragraphs\"}:\r\n datasets = datasets.map(process_squad, batched=True, remove_columns=column_names)\r\n```\r\n\r\nHope that helps :)",
"Thks for quickly answering!\r\n### 1 I try the first way,but seems not work \r\n```\r\nTraceback (most recent call last):\r\n File \"examples/question-answering/run_qa.py\", line 503, in <module>\r\n main()\r\n File \"examples/question-answering/run_qa.py\", line 218, in main\r\n datasets = load_dataset(data_args.dataset_name, download_mode=\"force_redownload\")\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/load.py\", line 746, in load_dataset\r\n use_auth_token=use_auth_token,\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/builder.py\", line 573, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/builder.py\", line 633, in _download_and_prepare\r\n self.info.download_checksums, dl_manager.get_recorded_sizes_checksums(), \"dataset source files\"\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/utils/info_utils.py\", line 39, in verify_checksums\r\n raise NonMatchingChecksumError(error_msg + str(bad_urls))\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json']\r\n```\r\n### 2 I try the second way,and run the examples/question-answering/run_qa.py,it lead to another bug orz..\r\n```\r\nTraceback (most recent call last):\r\n File \"examples/question-answering/run_qa.py\", line 523, in <module>\r\n main()\r\n File \"examples/question-answering/run_qa.py\", line 379, in main\r\n load_from_cache_file=not data_args.overwrite_cache,\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/arrow_dataset.py\", line 1120, in map\r\n update_data = does_function_return_dict(test_inputs, test_indices)\r\n File \"/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/arrow_dataset.py\", line 1091, in does_function_return_dict\r\n function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)\r\n File \"examples/question-answering/run_qa.py\", line 339, in prepare_train_features\r\n if len(answers[\"answer_start\"]) == 0:\r\nTypeError: list indices must be integers or slices, not str\r\n```\r\n## may be the function prepare_train_features in run_qa.py need to fix,I think is that the prep\r\n```python\r\nfor i, offsets in enumerate(offset_mapping):\r\n # We will label impossible answers with the index of the CLS token.\r\n input_ids = tokenized_examples[\"input_ids\"][i]\r\n cls_index = input_ids.index(tokenizer.cls_token_id)\r\n\r\n # Grab the sequence corresponding to that example (to know what is the context and what is the question).\r\n sequence_ids = tokenized_examples.sequence_ids(i)\r\n\r\n # One example can give several spans, this is the index of the example containing this span of text.\r\n sample_index = sample_mapping[i]\r\n answers = examples[answer_column_name][sample_index]\r\n print(examples,answers)\r\n # If no answers are given, set the cls_index as answer.\r\n if len(answers[\"answer_start\"]) == 0:\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Start/end character index of the answer in the text.\r\n start_char = answers[\"answer_start\"][0]\r\n end_char = start_char + len(answers[\"text\"][0])\r\n\r\n # Start token index of the current span in the text.\r\n token_start_index = 0\r\n while sequence_ids[token_start_index] != (1 if pad_on_right else 0):\r\n token_start_index += 1\r\n\r\n # End token index of the current span in the text.\r\n token_end_index = len(input_ids) - 1\r\n while sequence_ids[token_end_index] != (1 if pad_on_right else 0):\r\n token_end_index -= 1\r\n\r\n # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).\r\n if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Otherwise move the token_start_index and token_end_index to the two ends of the answer.\r\n # Note: we could go after the last offset if the answer is the last word (edge case).\r\n while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:\r\n token_start_index += 1\r\n tokenized_examples[\"start_positions\"].append(token_start_index - 1)\r\n while offsets[token_end_index][1] >= end_char:\r\n token_end_index -= 1\r\n tokenized_examples[\"end_positions\"].append(token_end_index + 1)\r\n\r\n return tokenized_examples\r\n``` ",
"## I have fixed it, @lhoestq \r\n### the first section change as you said and add [\"id\"]\r\n```python\r\ndef process_squad(examples):\r\n \"\"\"\r\n Process a dataset in the squad format with columns \"title\" and \"paragraphs\"\r\n to return the dataset with columns \"context\", \"question\" and \"answers\".\r\n \"\"\"\r\n # print(examples)\r\n out = {\"context\": [], \"question\": [], \"answers\":[],\"id\":[]} \r\n for paragraphs in examples[\"paragraphs\"]: \r\n for paragraph in paragraphs: \r\n for qa in paragraph[\"qas\"]: \r\n answers = [{\"answer_start\": answer[\"answer_start\"], \"text\": answer[\"text\"].strip()} for answer in qa[\"answers\"]] \r\n out[\"context\"].append(paragraph[\"context\"].strip()) \r\n out[\"question\"].append(qa[\"question\"].strip()) \r\n out[\"answers\"].append(answers) \r\n out[\"id\"].append(qa[\"id\"]) \r\n return out\r\ncolumn_names = datasets[\"train\"].column_names if training_args.do_train else datasets[\"validation\"].column_names\r\n# print(datasets[\"train\"].column_names)\r\nif set(column_names) == {\"title\", \"paragraphs\"}:\r\n datasets = datasets.map(process_squad, batched=True, remove_columns=column_names)\r\n# Preprocessing the datasets.\r\n# Preprocessing is slighlty different for training and evaluation.\r\nif training_args.do_train:\r\n column_names = datasets[\"train\"].column_names\r\nelse:\r\n column_names = datasets[\"validation\"].column_names\r\n# print(column_names)\r\nquestion_column_name = \"question\" if \"question\" in column_names else column_names[0]\r\ncontext_column_name = \"context\" if \"context\" in column_names else column_names[1]\r\nanswer_column_name = \"answers\" if \"answers\" in column_names else column_names[2]\r\n```\r\n### the second section\r\n```python\r\ndef prepare_train_features(examples):\r\n # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results\r\n # in one example possible giving several features when a context is long, each of those features having a\r\n # context that overlaps a bit the context of the previous feature.\r\n tokenized_examples = tokenizer(\r\n examples[question_column_name if pad_on_right else context_column_name],\r\n examples[context_column_name if pad_on_right else question_column_name],\r\n truncation=\"only_second\" if pad_on_right else \"only_first\",\r\n max_length=data_args.max_seq_length,\r\n stride=data_args.doc_stride,\r\n return_overflowing_tokens=True,\r\n return_offsets_mapping=True,\r\n padding=\"max_length\" if data_args.pad_to_max_length else False,\r\n )\r\n\r\n # Since one example might give us several features if it has a long context, we need a map from a feature to\r\n # its corresponding example. This key gives us just that.\r\n sample_mapping = tokenized_examples.pop(\"overflow_to_sample_mapping\")\r\n # The offset mappings will give us a map from token to character position in the original context. This will\r\n # help us compute the start_positions and end_positions.\r\n offset_mapping = tokenized_examples.pop(\"offset_mapping\")\r\n\r\n # Let's label those examples!\r\n tokenized_examples[\"start_positions\"] = []\r\n tokenized_examples[\"end_positions\"] = []\r\n\r\n for i, offsets in enumerate(offset_mapping):\r\n # We will label impossible answers with the index of the CLS token.\r\n input_ids = tokenized_examples[\"input_ids\"][i]\r\n cls_index = input_ids.index(tokenizer.cls_token_id)\r\n\r\n # Grab the sequence corresponding to that example (to know what is the context and what is the question).\r\n sequence_ids = tokenized_examples.sequence_ids(i)\r\n\r\n # One example can give several spans, this is the index of the example containing this span of text.\r\n sample_index = sample_mapping[i]\r\n answers = examples[answer_column_name][sample_index]\r\n # print(examples,answers,offset_mapping,tokenized_examples)\r\n # If no answers are given, set the cls_index as answer.\r\n if len(answers) == 0:#len(answers[\"answer_start\"]) == 0:\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Start/end character index of the answer in the text.\r\n start_char = answers[0][\"answer_start\"]\r\n end_char = start_char + len(answers[0][\"text\"])\r\n\r\n # Start token index of the current span in the text.\r\n token_start_index = 0\r\n while sequence_ids[token_start_index] != (1 if pad_on_right else 0):\r\n token_start_index += 1\r\n\r\n # End token index of the current span in the text.\r\n token_end_index = len(input_ids) - 1\r\n while sequence_ids[token_end_index] != (1 if pad_on_right else 0):\r\n token_end_index -= 1\r\n\r\n # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).\r\n if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):\r\n tokenized_examples[\"start_positions\"].append(cls_index)\r\n tokenized_examples[\"end_positions\"].append(cls_index)\r\n else:\r\n # Otherwise move the token_start_index and token_end_index to the two ends of the answer.\r\n # Note: we could go after the last offset if the answer is the last word (edge case).\r\n while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:\r\n token_start_index += 1\r\n tokenized_examples[\"start_positions\"].append(token_start_index - 1)\r\n while offsets[token_end_index][1] >= end_char:\r\n token_end_index -= 1\r\n tokenized_examples[\"end_positions\"].append(token_end_index + 1)\r\n return tokenized_examples\r\n```",
"I'm glad you managed to fix run_qa.py for your case :)\r\n\r\nRegarding the checksum error, I'm not able to reproduce on my side.\r\nThis errors says that the downloaded file doesn't match the expected file.\r\n\r\nCould you try running this and let me know if you get the same output as me ?\r\n```python\r\nfrom datasets.utils.info_utils import get_size_checksum_dict\r\nfrom datasets import cached_path\r\n\r\nget_size_checksum_dict(cached_path(\"https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json\"))\r\n# {'num_bytes': 30288272, 'checksum': '3527663986b8295af4f7fcdff1ba1ff3f72d07d61a20f487cb238a6ef92fd955'}\r\n```",
"I run the code,and it show below:\r\n```\r\n>>> from datasets.utils.info_utils import get_size_checksum_dict\r\n>>> from datasets import cached_path\r\n>>> get_size_checksum_dict(cached_path(\"https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json\"))\r\nDownloading: 30.3MB [04:13, 120kB/s]\r\n{'num_bytes': 30288272, 'checksum': '3527663986b8295af4f7fcdff1ba1ff3f72d07d61a20f487cb238a6ef92fd955'}\r\n```",
"Alright ! So in this case redownloading the file with `download_mode=\"force_redownload\"` should fix it. Can you try using `download_mode=\"force_redownload\"` again ?\r\n\r\nNot sure why it didn't work for you the first time though :/"
] | 2021-03-01T08:41:31
| 2022-10-05T13:09:47
| 2022-10-05T13:09:47
|
NONE
| null | null | null | null |
### 1 When I try to train lxmert,and follow the code in README that --dataset name:
```shell
python examples/question-answering/run_qa.py --model_name_or_path unc-nlp/lxmert-base-uncased --dataset_name squad --do_train --do_eval --per_device_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2 --max_seq_length 384 --doc_stride 128 --output_dir /home2/zhenggo1/checkpoint/lxmert_squad
```
the bug is that:
```
Downloading and preparing dataset squad/plain_text (download: 33.51 MiB, generated: 85.75 MiB, post-processed: Unknown size, total: 119.27 MiB) to /home2/zhenggo1/.cache/huggingface/datasets/squad/plain_text/1.0.0/4c81550d83a2ac7c7ce23783bd8ff36642800e6633c1f18417fb58c3ff50cdd7...
Traceback (most recent call last):
File "examples/question-answering/run_qa.py", line 501, in <module>
main()
File "examples/question-answering/run_qa.py", line 217, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/load.py", line 746, in load_dataset
use_auth_token=use_auth_token,
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/builder.py", line 573, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/builder.py", line 633, in _download_and_prepare
self.info.download_checksums, dl_manager.get_recorded_sizes_checksums(), "dataset source files"
File "/home2/zhenggo1/anaconda3/envs/lpot/lib/python3.7/site-packages/datasets/utils/info_utils.py", line 39, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json']
```
And I try to find the [checksum link](https://github.com/huggingface/datasets/blob/master/datasets/squad/dataset_infos.json)
,is the problem plain_text do not have a checksum?
### 2 When I try to train lxmert,and use local dataset:
```
python examples/question-answering/run_qa.py --model_name_or_path unc-nlp/lxmert-base-uncased --train_file $SQUAD_DIR/train-v1.1.json --validation_file $SQUAD_DIR/dev-v1.1.json --do_train --do_eval --per_device_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2 --max_seq_length 384 --doc_stride 128 --output_dir /home2/zhenggo1/checkpoint/lxmert_squad
```
The bug is that
```
['title', 'paragraphs']
Traceback (most recent call last):
File "examples/question-answering/run_qa.py", line 501, in <module>
main()
File "examples/question-answering/run_qa.py", line 273, in main
answer_column_name = "answers" if "answers" in column_names else column_names[2]
IndexError: list index out of range
```
I print the answer_column_name and find that local squad dataset need the package datasets to preprocessing so that the code below can work:
```
if training_args.do_train:
column_names = datasets["train"].column_names
else:
column_names = datasets["validation"].column_names
print(datasets["train"].column_names)
question_column_name = "question" if "question" in column_names else column_names[0]
context_column_name = "context" if "context" in column_names else column_names[1]
answer_column_name = "answers" if "answers" in column_names else column_names[2]
```
## Please tell me how to fix the bug,thks a lot!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1964/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1964/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 583 days, 4:28:16
|
https://api.github.com/repos/huggingface/datasets/issues/1963
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1963/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1963/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1963/events
|
https://github.com/huggingface/datasets/issues/1963
| 818,289,967
|
MDU6SXNzdWU4MTgyODk5Njc=
| 1,963
|
bug in SNLI dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! The labels -1 correspond to the examples without gold labels in the original snli dataset.\r\nFeel free to remove these examples if you don't need them by using\r\n```python\r\ndata = data.filter(lambda x: x[\"label\"] != -1)\r\n```"
] | 2021-02-28T19:36:20
| 2022-10-05T13:13:46
| 2022-10-05T13:13:46
|
NONE
| null | null | null | null |
Hi
There is label of -1 in train set of SNLI dataset, please find the code below:
```
import numpy as np
import datasets
data = datasets.load_dataset("snli")["train"]
labels = []
for d in data:
labels.append(d["label"])
print(np.unique(labels))
```
and results:
`[-1 0 1 2]`
version of datasets used:
`datasets 1.2.1 <pip>
`
thanks for your help. @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1963/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1963/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 583 days, 17:37:26
|
https://api.github.com/repos/huggingface/datasets/issues/1959
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1959/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1959/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1959/events
|
https://github.com/huggingface/datasets/issues/1959
| 818,055,644
|
MDU6SXNzdWU4MTgwNTU2NDQ=
| 1,959
|
Bug in skip_rows argument of load_dataset function ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73159756?v=4",
"events_url": "https://api.github.com/users/LedaguenelArthur/events{/privacy}",
"followers_url": "https://api.github.com/users/LedaguenelArthur/followers",
"following_url": "https://api.github.com/users/LedaguenelArthur/following{/other_user}",
"gists_url": "https://api.github.com/users/LedaguenelArthur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LedaguenelArthur",
"id": 73159756,
"login": "LedaguenelArthur",
"node_id": "MDQ6VXNlcjczMTU5NzU2",
"organizations_url": "https://api.github.com/users/LedaguenelArthur/orgs",
"received_events_url": "https://api.github.com/users/LedaguenelArthur/received_events",
"repos_url": "https://api.github.com/users/LedaguenelArthur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LedaguenelArthur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LedaguenelArthur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LedaguenelArthur",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\ntry `skiprows` instead. This part is not properly documented in the docs it seems.\r\n\r\n@lhoestq I'll fix this as part of a bigger PR that fixes typos in the docs."
] | 2021-02-27T23:32:54
| 2021-03-09T10:21:32
| 2021-03-09T10:21:32
|
NONE
| null | null | null | null |
Hello everyone,
I'm quite new to Git so sorry in advance if I'm breaking some ground rules of issues posting... :/
I tried to use the load_dataset function, from Huggingface datasets library, on a csv file using the skip_rows argument described on Huggingface page to skip the first row containing column names
`test_dataset = load_dataset('csv', data_files=['test_wLabel.tsv'], delimiter='\t', column_names=["id", "sentence", "label"], skip_rows=1)`
But I got the following error message
`__init__() got an unexpected keyword argument 'skip_rows'`
Have I used the wrong argument ? Am I missing something or is this a bug ?
Thank you very much for your time,
Best regards,
Arthur
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1959/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1959/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 9 days, 10:48:38
|
https://api.github.com/repos/huggingface/datasets/issues/1958
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1958/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1958/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1958/events
|
https://github.com/huggingface/datasets/issues/1958
| 818,037,548
|
MDU6SXNzdWU4MTgwMzc1NDg=
| 1,958
|
XSum dataset download link broken
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1156974?v=4",
"events_url": "https://api.github.com/users/himat/events{/privacy}",
"followers_url": "https://api.github.com/users/himat/followers",
"following_url": "https://api.github.com/users/himat/following{/other_user}",
"gists_url": "https://api.github.com/users/himat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/himat",
"id": 1156974,
"login": "himat",
"node_id": "MDQ6VXNlcjExNTY5NzQ=",
"organizations_url": "https://api.github.com/users/himat/orgs",
"received_events_url": "https://api.github.com/users/himat/received_events",
"repos_url": "https://api.github.com/users/himat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/himat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/himat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/himat",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Never mind, I ran it again and it worked this time. Strange."
] | 2021-02-27T21:47:56
| 2021-02-27T21:50:16
| 2021-02-27T21:50:16
|
NONE
| null | null | null | null |
I did
```
from datasets import load_dataset
dataset = load_dataset("xsum")
```
This returns
`ConnectionError: Couldn't reach http://bollin.inf.ed.ac.uk/public/direct/XSUM-EMNLP18-Summary-Data-Original.tar.gz`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1156974?v=4",
"events_url": "https://api.github.com/users/himat/events{/privacy}",
"followers_url": "https://api.github.com/users/himat/followers",
"following_url": "https://api.github.com/users/himat/following{/other_user}",
"gists_url": "https://api.github.com/users/himat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/himat",
"id": 1156974,
"login": "himat",
"node_id": "MDQ6VXNlcjExNTY5NzQ=",
"organizations_url": "https://api.github.com/users/himat/orgs",
"received_events_url": "https://api.github.com/users/himat/received_events",
"repos_url": "https://api.github.com/users/himat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/himat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/himat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/himat",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1958/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1958/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:02:20
|
https://api.github.com/repos/huggingface/datasets/issues/1956
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1956/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1956/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1956/events
|
https://github.com/huggingface/datasets/issues/1956
| 818,013,741
|
MDU6SXNzdWU4MTgwMTM3NDE=
| 1,956
|
[distributed env] potentially unsafe parallel execution
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"You can pass the same `experiment_id` for all the metrics of the same group, and use another `experiment_id` for the other groups.\r\nMaybe we can add an environment variable that sets the default value for `experiment_id` ? What do you think ?",
"Ah, you're absolutely correct, @lhoestq - it's exactly the equivalent of the shared secret. Thank you!"
] | 2021-02-27T20:38:45
| 2021-03-01T17:24:42
| 2021-03-01T17:24:42
|
CONTRIBUTOR
| null | null | null | null |
```
metric = load_metric('glue', 'mrpc', num_process=num_process, process_id=rank)
```
presumes that there is only one set of parallel processes running - and will intermittently fail if you have multiple sets running as they will surely overwrite each other. Similar to https://github.com/huggingface/datasets/issues/1942 (but for a different reason).
That's why dist environments use some unique to a group identifier so that each group is dealt with separately.
e.g. the env-way of pytorch dist syncing is done with a unique per set `MASTER_ADDRESS+MASTER_PORT`
So ideally this interface should ask for a shared secret to do the right thing.
I'm not reporting an immediate need, but am only flagging that this will hit someone down the road.
This problem can be remedied by adding a new optional `shared_secret` option, which can then be used to differentiate different groups of processes. and this secret should be part of the file lock name and the experiment.
Thank you
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1956/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1956/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 20:45:57
|
https://api.github.com/repos/huggingface/datasets/issues/1954
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1954/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1954/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1954/events
|
https://github.com/huggingface/datasets/issues/1954
| 817,565,563
|
MDU6SXNzdWU4MTc1NjU1NjM=
| 1,954
|
add a new column
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"Hi\r\nnot sure how change the lable after creation, but this is an issue not dataset request. thanks ",
"Hi ! Currently you have to use `map` . You can see an example of how to do it in this comment: https://github.com/huggingface/datasets/issues/853#issuecomment-727872188\r\n\r\nIn the future we'll add support for a more native way of adding a new column ;)"
] | 2021-02-26T18:17:27
| 2021-04-29T14:50:43
| 2021-04-29T14:50:43
|
NONE
| null | null | null | null |
Hi
I'd need to add a new column to the dataset, I was wondering how this can be done? thanks
@lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1954/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1954/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 61 days, 20:33:16
|
https://api.github.com/repos/huggingface/datasets/issues/1949
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1949/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1949/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1949/events
|
https://github.com/huggingface/datasets/issues/1949
| 816,986,936
|
MDU6SXNzdWU4MTY5ODY5MzY=
| 1,949
|
Enable Fast Filtering using Arrow Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"Hi @gchhablani :)\r\nThanks for proposing your help !\r\n\r\nI'll be doing a refactor of some parts related to filtering in the scope of https://github.com/huggingface/datasets/issues/1877\r\nSo I would first wait for this refactor to be done before working on the filtering. In particular because I plan to make things simpler to manipulate.\r\n\r\nYour feedback on this refactor would also be appreciated since it also aims at making the core code more accessible (basically my goal is that no one's ever \"having troubles getting started\" ^^)\r\n\r\nThis will be available in a few days, I will be able to give you more details at that time if you don't mind waiting a bit !",
"Sure! I don't mind waiting. I'll check the refactor and try to understand what you're trying to do :)"
] | 2021-02-26T02:53:37
| 2021-02-26T19:18:29
| null |
CONTRIBUTOR
| null | null | null | null |
Hi @lhoestq,
As mentioned in Issue #1796, I would love to work on enabling fast filtering/mapping. Can you please share the expectations? It would be great if you could point me to the relevant methods/files involved. Or the docs or maybe an overview of `arrow_dataset.py`. I only ask this because I am having trouble getting started ;-;
Any help would be appreciated.
Thanks,
Gunjan
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1949/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1949/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1948
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1948/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1948/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1948/events
|
https://github.com/huggingface/datasets/issues/1948
| 816,689,329
|
MDU6SXNzdWU4MTY2ODkzMjk=
| 1,948
|
dataset loading logger level
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"These warnings are showed when there's a call to `.map` to say to the user that a dataset is reloaded from the cache instead of being recomputed.\r\nThey are warnings since we want to make sure the users know that it's not recomputed.",
"Thank you for explaining the intention, @lhoestq \r\n\r\n1. Could it be then made more human-friendly? Currently the hex gibberish tells me nothing of what's really going on. e.g. the following is instructive, IMHO:\r\n\r\n```\r\nWARNING: wmt16/ro-en/train dataset was loaded from cache instead of being recomputed\r\nWARNING: wmt16/ro-en/validation dataset was loaded from cache instead of being recomputed\r\nWARNING: wmt16/ro-en/test dataset was loaded from cache instead of being recomputed\r\n```\r\nnote that it removes the not so useful hex info and tells the user instead which split it's referring to - but probably no harm in keeping the path if it helps the debug. But the key is that now the warning is telling me what it is it's warning me about.\r\n```\r\nWarning:Loading cache path\r\n```\r\non the other hand isn't telling what it is warning about.\r\n\r\nAnd I still suggest this is INFO level, otherwise you need to turn all 'using cache' statements to WARNING to be consistent. The user is most likely well aware the cache is used for models, etc. So this feels very similar.\r\n\r\n2. Should there be a way for a user to void warranty by having a flag - `I know I'm expecting the cached version to load if it's available - please do not warn me about it=True`\r\n\r\nTo explain the need: Warnings are a problem, they constantly take attention away because they could be the harbinger of a problem. Therefore I prefer not to have any warnings in the log, and if I get any I usually try to deal with those so that my log is clean. \r\n\r\nIt's less of an issue for somebody doing long runs. It's a huge issue for someone who does a new run every few minutes and on the lookout for any potential problems which is what I have been doing a lot of integrating DeepSpeed and other things. And since there are already problems to deal with during the integration it's nice to have a clean log to start with. \r\n\r\nI hope my need is not unreasonable and I was able to explain it adequately. \r\n\r\nThank you.",
"Hey, any news about the issue? So many warnings when I'm really ok with the dataset not being recomputed :)"
] | 2021-02-25T18:33:37
| 2023-07-12T17:19:30
| 2023-07-12T17:19:30
|
CONTRIBUTOR
| null | null | null | null |
on master I get this with `--dataset_name wmt16 --dataset_config ro-en`:
```
WARNING:datasets.arrow_dataset:Loading cached processed dataset at /home/stas/.cache/huggingface/datasets/wmt16/ro-en/1.0.0/9dc00622c30446e99c4c63d12a484ea4fb653f2f37c867d6edcec839d7eae50f/cache-2e01bead8cf42e26.arrow
WARNING:datasets.arrow_dataset:Loading cached processed dataset at /home/stas/.cache/huggingface/datasets/wmt16/ro-en/1.0.0/9dc00622c30446e99c4c63d12a484ea4fb653f2f37c867d6edcec839d7eae50f/cache-ac3bebaf4f91f776.arrow
WARNING:datasets.arrow_dataset:Loading cached processed dataset at /home/stas/.cache/huggingface/datasets/wmt16/ro-en/1.0.0/9dc00622c30446e99c4c63d12a484ea4fb653f2f37c867d6edcec839d7eae50f/cache-810c3e61259d73a9.arrow
```
why are those WARNINGs? Should be INFO, no?
warnings should only be used when a user needs to pay attention to something, this is just informative - I'd even say it should be DEBUG, but definitely not WARNING.
Thank you.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1948/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1948/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 866 days, 22:45:53
|
https://api.github.com/repos/huggingface/datasets/issues/1945
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1945/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1945/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1945/events
|
https://github.com/huggingface/datasets/issues/1945
| 816,421,966
|
MDU6SXNzdWU4MTY0MjE5NjY=
| 1,945
|
AttributeError: 'DatasetDict' object has no attribute 'concatenate_datasets'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"sorry my mistake, datasets were overwritten closing now, thanks a lot"
] | 2021-02-25T13:09:45
| 2021-02-25T13:20:35
| 2021-02-25T13:20:26
|
NONE
| null | null | null | null |
Hi
I am trying to concatenate a list of huggingface datastes as:
` train_dataset = datasets.concatenate_datasets(train_datasets)
`
Here is the `train_datasets` when I print:
```
[Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 120361
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 2670
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 6944
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 38140
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 173711
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 1655
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 4274
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 2019
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 2109
}), Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'question1', 'question2', 'token_type_ids'],
num_rows: 11963
})]
```
I am getting the following error:
`AttributeError: 'DatasetDict' object has no attribute 'concatenate_datasets'
`
I was wondering if you could help me with this issue, thanks a lot
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorost1234",
"id": 79165106,
"login": "dorost1234",
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorost1234",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1945/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1945/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:10:41
|
https://api.github.com/repos/huggingface/datasets/issues/1942
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1942/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1942/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1942/events
|
https://github.com/huggingface/datasets/issues/1942
| 816,037,520
|
MDU6SXNzdWU4MTYwMzc1MjA=
| 1,942
|
[experiment] missing default_experiment-1-0.arrow
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Hi !\r\n\r\nThe cache at `~/.cache/huggingface/metrics` stores the users data for metrics computations (hence the arrow files).\r\n\r\nHowever python modules (i.e. dataset scripts, metric scripts) are stored in `~/.cache/huggingface/modules/datasets_modules`.\r\n\r\nIn particular the metrics are cached in `~/.cache/huggingface/modules/datasets_modules/metrics/`\r\n\r\nFeel free to take a look at your cache and let me know if you find any issue that would help explaining why you had an issue with `rouge` with no connection. I'm doing some tests on my side to try to reproduce the issue you have\r\n",
"Thank you for clarifying that the metrics files are to be found elsewhere, @lhoestq \r\n\r\n> The cache at ~/.cache/huggingface/metrics stores the users data for metrics computations (hence the arrow files).\r\n\r\ncould it be renamed to reflect that? otherwise it misleadingly suggests that it's the metrics. Perhaps `~/.cache/huggingface/metrics-user-data`?\r\n\r\nAnd there are so many `.lock` files w/o corresponding files under `~/.cache/huggingface/metrics/`. Why are they there? \r\n\r\nfor example after I wipe out the dir completely and do one training I end up with:\r\n```\r\n~/.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow.lock\r\n```\r\nwhat is that lock file locking when nothing is running?",
"The lock files come from an issue with filelock (see comment in the code [here](https://github.com/benediktschmitt/py-filelock/blob/master/filelock.py#L394-L398)). Basically on unix there're always .lock files left behind. I haven't dove into this issue",
"are you sure you need an external lock file? if it's a single purpose locking in the same scope you can lock the caller `__file__` instead, e.g. here is how one can `flock` the script file itself to ensure atomic printing:\r\n\r\n```\r\nimport fcntl\r\ndef printflock(*msgs):\r\n \"\"\" print in multiprocess env so that the outputs from different processes don't get interleaved \"\"\"\r\n with open(__file__, \"r\") as fh:\r\n fcntl.flock(fh, fcntl.LOCK_EX)\r\n try:\r\n print(*msgs)\r\n finally:\r\n fcntl.flock(fh, fcntl.LOCK_UN)\r\n```\r\n",
"OK, this issue is not about caching but some internal conflict/race condition it seems, I have just run into it on my normal env:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 356, in _finalize\r\n self.data = Dataset(**reader.read_files([{\"filename\": f} for f in file_paths]))\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 236, in read_files\r\n pa_table = self._read_files(files, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 171, in _read_files\r\n pa_table: pa.Table = self._get_dataset_from_filename(f_dict, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 302, in _get_dataset_from_filename\r\n pa_table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 322, in read_table\r\n stream = stream_from(filename)\r\n File \"pyarrow/io.pxi\", line 782, in pyarrow.lib.memory_map\r\n File \"pyarrow/io.pxi\", line 743, in pyarrow.lib.MemoryMappedFile._open\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 97, in pyarrow.lib.check_status\r\nFileNotFoundError: [Errno 2] Failed to open local file '/home/stas/.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow'. Detail: [errno 2] No such file or directory\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"examples/seq2seq/run_seq2seq.py\", line 655, in <module>\r\n main()\r\n File \"examples/seq2seq/run_seq2seq.py\", line 619, in main\r\n test_results = trainer.predict(\r\n File \"/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer_seq2seq.py\", line 121, in predict\r\n return super().predict(test_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)\r\n File \"/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer.py\", line 1706, in predict\r\n output = self.prediction_loop(\r\n File \"/mnt/nvme1/code/huggingface/transformers-master/src/transformers/trainer.py\", line 1813, in prediction_loop\r\n metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))\r\n File \"examples/seq2seq/run_seq2seq.py\", line 556, in compute_metrics\r\n result = metric.compute(predictions=decoded_preds, references=decoded_labels)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 388, in compute\r\n self._finalize()\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 358, in _finalize\r\n raise ValueError(\r\nValueError: Error in finalize: another metric instance is already using the local cache file. Please specify an experiment_id to avoid colision between distributed metric instances.\r\n```\r\n\r\nI'm just running `run_seq2seq.py` under DeepSpeed:\r\n\r\n```\r\nexport BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0,1 deepspeed --num_gpus=2 examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --do_train --do_predict --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 --max_train_samples 100 --max_val_samples 100 --max_test_samples 100 --dataset_name wmt16 --dataset_config ro-en --source_prefix \"translate English to Romanian: \" --deepspeed examples/tests/deepspeed/ds_config.json\r\n```\r\n\r\nIt finished the evaluation OK and crashed on the prediction part of the Trainer. But the eval / predict parts no longer run under Deepspeed, it's just plain ddp.\r\n\r\nIs this some kind of race condition? It happens intermittently - there is nothing else running at the same time.\r\n\r\nBut if 2 independent instances of the same script were to run at the same time it's clear to see that this problem would happen. Perhaps it'd help to create a unique hash which is shared between all processes in the group and use that as the default experiment id?\r\n",
"When you're using metrics in a distributed setup, there are two cases:\r\n1. you're doing two completely different experiments (two evaluations) and the 2 metrics jobs have nothing to do with each other\r\n2. you're doing one experiment (one evaluation) but use multiple processes to feed the data to the metric.\r\n\r\nIn case 1. you just need to provide two different `experiment_id` so that the metrics don't collide.\r\nIn case 2. they must have the same experiment_id (or use the default one), but in this case you also need to provide the `num_processes` and `process_id`\r\n\r\nIf understand correctly you're in situation 2.\r\n\r\nIf so, you make sure that you instantiate the metrics with both the right `num_processes` and `process_id` parameters ?\r\n\r\nIf they're not set, then the cache files of the two metrics collide it can cause issues. For example if one metric finishes before the other, then the cache file is deleted and the other metric gets a FileNotFoundError\r\nThere's more information in the [documentation](https://huggingface.co/docs/datasets/loading_metrics.html#distributed-setups) if you want\r\n\r\nHope that helps !",
"Thank you for explaining that in a great way, @lhoestq \r\n\r\nSo the bottom line is that the `transformers` examples are broken since they don't do any of that. At least `run_seq2seq.py` just does `metric = load_metric(metric_name)`\r\n\r\nWhat test would you recommend to reliably reproduce this bug in `examples/seq2seq/run_seq2seq.py`?",
"To give more context, we are just using the metrics for the `comput_metric` function and nothing else. Is there something else we can use that just applies the function to the full arrays of predictions and labels? Because that's all we need, all the gathering has already been done because the datasets Metric multiprocessing relies on file storage and thus does not work in a multi-node distributed setup (whereas the Trainer does).\r\n\r\nOtherwise, we'll have to switch to something else to compute the metrics :-(",
"OK, it definitely leads to a race condition in how it's used right now. Here is how you can reproduce it - by injecting a random sleep time different for each process before the locks are acquired. \r\n```\r\n--- a/src/datasets/metric.py\r\n+++ b/src/datasets/metric.py\r\n@@ -348,6 +348,16 @@ class Metric(MetricInfoMixin):\r\n\r\n elif self.process_id == 0:\r\n # Let's acquire a lock on each node files to be sure they are finished writing\r\n+\r\n+ import time\r\n+ import random\r\n+ import os\r\n+ pid = os.getpid()\r\n+ random.seed(pid)\r\n+ secs = random.randint(1, 15)\r\n+ time.sleep(secs)\r\n+ print(f\"sleeping {secs}\")\r\n+\r\n file_paths, filelocks = self._get_all_cache_files()\r\n\r\n # Read the predictions and references\r\n@@ -385,7 +395,10 @@ class Metric(MetricInfoMixin):\r\n\r\n if predictions is not None:\r\n self.add_batch(predictions=predictions, references=references)\r\n+ print(\"FINALIZE START\")\r\n+\r\n self._finalize()\r\n+ print(\"FINALIZE END\")\r\n\r\n self.cache_file_name = None\r\n self.filelock = None\r\n```\r\n\r\nthen run with 2 procs: `python -m torch.distributed.launch --nproc_per_node=2`\r\n```\r\nexport BS=16; rm -r output_dir; PYTHONPATH=src USE_TF=0 CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 examples/seq2seq/run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --do_train --do_predict --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 --max_train_samples 10 --max_val_samples 10 --max_test_samples 10 --dataset_name wmt16 --dataset_config ro-en --source_prefix \"translate English to Romanian: \"\r\n```\r\n\r\n```\r\n***** Running Evaluation *****\r\n Num examples = 10\r\n Batch size = 16\r\n 0%| | 0/1 [00:00<?, ?it/s]FINALIZE START\r\nFINALIZE START\r\nsleeping 11\r\nFINALIZE END\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:11<00:00, 11.06s/it]\r\nsleeping 11\r\nTraceback (most recent call last):\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 368, in _finalize\r\n self.data = Dataset(**reader.read_files([{\"filename\": f} for f in file_paths]))\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 236, in read_files\r\n pa_table = self._read_files(files, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 171, in _read_files\r\n pa_table: pa.Table = self._get_dataset_from_filename(f_dict, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 302, in _get_dataset_from_filename\r\n pa_table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/arrow_reader.py\", line 322, in read_table\r\n stream = stream_from(filename)\r\n File \"pyarrow/io.pxi\", line 782, in pyarrow.lib.memory_map\r\n File \"pyarrow/io.pxi\", line 743, in pyarrow.lib.MemoryMappedFile._open\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 97, in pyarrow.lib.check_status\r\nFileNotFoundError: [Errno 2] Failed to open local file '/home/stas/.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow'. Detail: [errno 2] No such file or directory\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"examples/seq2seq/run_seq2seq.py\", line 645, in <module>\r\n main()\r\n File \"examples/seq2seq/run_seq2seq.py\", line 601, in main\r\n metrics = trainer.evaluate(\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer_seq2seq.py\", line 74, in evaluate\r\n return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer.py\", line 1703, in evaluate\r\n output = self.prediction_loop(\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer.py\", line 1876, in prediction_loop\r\n metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))\r\n File \"examples/seq2seq/run_seq2seq.py\", line 556, in compute_metrics\r\n result = metric.compute(predictions=decoded_preds, references=decoded_labels)\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 402, in compute\r\n self._finalize()\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 370, in _finalize\r\n raise ValueError(\r\nValueError: Error in finalize: another metric instance is already using the local cache file. Please specify an experiment_id to avoid colision between distributed metric instances.\r\n```",
"I tried to adjust `run_seq2seq.py` and trainer to use the suggested dist env:\r\n```\r\n import torch.distributed as dist\r\n metric = load_metric(metric_name, num_process=dist.get_world_size(), process_id=dist.get_rank())\r\n```\r\nand in `trainer.py` added to call just for rank 0:\r\n```\r\n if self.is_world_process_zero() and self.compute_metrics is not None and preds is not None and label_ids is not None:\r\n metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))\r\n```\r\nand then the process hangs in a deadlock. \r\n\r\nHere is the tb:\r\n```\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/filelock.py\", line 275 in acquire\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 306 in _check_all_processes_locks\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 501 in _init_writer\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 440 in add_batch\r\n File \"/mnt/nvme1/code/huggingface/datasets-master/src/datasets/metric.py\", line 397 in compute\r\n File \"examples/seq2seq/run_seq2seq.py\", line 558 in compute_metrics\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer.py\", line 1876 in prediction_loop\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer.py\", line 1703 in evaluate\r\n File \"/mnt/nvme1/code/huggingface/transformers-mp-pp/src/transformers/trainer_seq2seq.py\", line 74 in evaluate\r\n File \"examples/seq2seq/run_seq2seq.py\", line 603 in main\r\n File \"examples/seq2seq/run_seq2seq.py\", line 651 in <module>\r\n```\r\n\r\nBut this sounds right, since in the above diff I set up a distributed metric and only called one process - so it's blocking on waiting for other processes to do the same.\r\n\r\nSo one working solution is to leave:\r\n\r\n```\r\n metric = load_metric(metric_name)\r\n```\r\nalone, and only call `compute_metrics` from rank 0\r\n```\r\n if self.is_world_process_zero() and self.compute_metrics is not None and preds is not None and label_ids is not None:\r\n metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))\r\n```\r\n\r\nso we now no longer use the distributed env as far as `datasets` is concerned, it's just a single process.\r\n\r\nAre there any repercussions/side-effects to this proposed change in Trainer? If it always gathers all inputs on rank 0 then this is how it should have been done in first place - i.e. only run for rank 0. It appears that currently it was re-calculating the metrics on all processes on the same data just to throw the results away other than for rank 0. Unless I missed something.\r\n",
"But no, since \r\n`\r\n metric = load_metric(metric_name)\r\n`\r\nis called for each process, the race condition is still there. So still getting:\r\n\r\n```\r\nValueError: Error in finalize: another metric instance is already using the local cache file. Please specify an experiment_id to avoid colision between distributed metric instances.\r\n```\r\n\r\ni.e. the only way to fix this is to `load_metric` only for rank 0, but this requires huge changes in the code and all end users' code.\r\n",
"OK, here is a workaround that works. The onus here is absolutely on the user:\r\n\r\n```\r\ndiff --git a/examples/seq2seq/run_seq2seq.py b/examples/seq2seq/run_seq2seq.py\r\nindex 2a060dac5..c82fd83ea 100755\r\n--- a/examples/seq2seq/run_seq2seq.py\r\n+++ b/examples/seq2seq/run_seq2seq.py\r\n@@ -520,7 +520,11 @@ def main():\r\n\r\n # Metric\r\n metric_name = \"rouge\" if data_args.task.startswith(\"summarization\") else \"sacrebleu\"\r\n- metric = load_metric(metric_name)\r\n+ import torch.distributed as dist\r\n+ if dist.is_initialized():\r\n+ metric = load_metric(metric_name, num_process=dist.get_world_size(), process_id=dist.get_rank())\r\n+ else:\r\n+ metric = load_metric(metric_name)\r\n\r\n def postprocess_text(preds, labels):\r\n preds = [pred.strip() for pred in preds]\r\n@@ -548,12 +552,17 @@ def main():\r\n # Some simple post-processing\r\n decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)\r\n\r\n+ kwargs = dict(predictions=decoded_preds, references=decoded_labels)\r\n+ if metric_name == \"rouge\":\r\n+ kwargs.update(use_stemmer=True)\r\n+ result = metric.compute(**kwargs) # must call for all processes\r\n+ if result is None: # only process with rank-0 will return metrics, others None\r\n+ return {}\r\n+\r\n if metric_name == \"rouge\":\r\n- result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)\r\n # Extract a few results from ROUGE\r\n result = {key: value.mid.fmeasure * 100 for key, value in result.items()}\r\n else:\r\n- result = metric.compute(predictions=decoded_preds, references=decoded_labels)\r\n result = {\"bleu\": result[\"score\"]}\r\n\r\n prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]\r\n```\r\n\r\nThis is not user-friendly to say the least. And it's still wasteful as we don't need other processes to do anything.\r\n\r\nBut it solves the current race condition.\r\n\r\nClearly this calls for a design discussion as it's the responsibility of the Trainer to handle this and not user's. Perhaps in the `transformers` land?",
"I don't see how this could be the responsibility of `Trainer`, who hasn't the faintest idea of what a `datasets.Metric` is. The trainer takes a function `compute_metrics` that goes from predictions + labels to metric results, there is nothing there. That computation is done on all processes \r\n\r\nThe fact a `datasets.Metric` object cannot be used as a simple compute function in a multi-process environment is, in my opinion, a bug in `datasets`. Especially since, as I mentioned before, the multiprocessing part of `datasets.Metric` has a deep flaw since it can't work in a multinode environment. So you actually need to do the job of gather predictions and labels yourself.\r\n\r\nThe changes you are proposing Stas are making the code less readable and also concatenate all the predictions and labels `number_of_processes` times I believe, which is not going to make the metric computation any faster.\r\n\r\n",
"Right, to clarify, I meant it'd be good to have it sorted on the library side and not requiring the user to figure it out. This is too complex and error-prone and if not coded correctly the bug will be intermittent which is even worse.\r\n\r\nOh I guess I wasn't clear in my message - in no way I'm proposing that we use this workaround code - I was just showing what I had to do to make it work.\r\n\r\nWe are on the same page.\r\n\r\n> The changes you are proposing Stas are making the code less readable and also concatenate all the predictions and labels number_of_processes times I believe, which is not going to make the metric computation any faster.\r\n\r\nAnd yes, this is another problem that my workaround introduces. Thank you for pointing it out, @sgugger \r\n",
"> The fact a datasets.Metric object cannot be used as a simple compute function in a multi-process environment is, in my opinion, a bug in datasets\r\n\r\nYes totally, this use case is supposed to be supported by `datasets`. And in this case there shouldn't be any collision between the metrics. I'm looking into it :)\r\nMy guess is that at one point the metric isn't using the right file name. It's supposed to use one with a unique uuid in order to avoid the collisions.",
"I just opened #1966 to fix this :)\r\n@stas00 if have a chance feel free to try it !",
"Thank you, @lhoestq - I will experiment and report back. \r\n\r\nedit: It works! Thank you",
"Fixed in https://github.com/huggingface/datasets/pull/1966"
] | 2021-02-25T03:02:15
| 2022-10-05T13:08:45
| 2022-10-05T13:08:45
|
CONTRIBUTOR
| null | null | null | null |
the original report was pretty bad and incomplete - my apologies!
Please see the complete version here: https://github.com/huggingface/datasets/issues/1942#issuecomment-786336481
------------
As mentioned here https://github.com/huggingface/datasets/issues/1939 metrics don't get cached, looking at my local `~/.cache/huggingface/metrics` - there are many `*.arrow.lock` files but zero metrics files.
w/o the network I get:
```
FileNotFoundError: [Errno 2] No such file or directory: '~/.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow
```
there is just `~/.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow.lock`
I did run the same `run_seq2seq.py` script on the instance with network and it worked just fine, but only the lock file was left behind.
this is with master.
Thank you.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1942/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1942/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 587 days, 10:06:30
|
https://api.github.com/repos/huggingface/datasets/issues/1941
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1941/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1941/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1941/events
|
https://github.com/huggingface/datasets/issues/1941
| 815,985,167
|
MDU6SXNzdWU4MTU5ODUxNjc=
| 1,941
|
Loading of FAISS index fails for index_name = 'exact'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2992022?v=4",
"events_url": "https://api.github.com/users/mkserge/events{/privacy}",
"followers_url": "https://api.github.com/users/mkserge/followers",
"following_url": "https://api.github.com/users/mkserge/following{/other_user}",
"gists_url": "https://api.github.com/users/mkserge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mkserge",
"id": 2992022,
"login": "mkserge",
"node_id": "MDQ6VXNlcjI5OTIwMjI=",
"organizations_url": "https://api.github.com/users/mkserge/orgs",
"received_events_url": "https://api.github.com/users/mkserge/received_events",
"repos_url": "https://api.github.com/users/mkserge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mkserge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mkserge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mkserge",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Thanks for reporting ! I'm taking a look",
"Index training was missing, I fixed it here: https://github.com/huggingface/datasets/commit/f5986c46323583989f6ed1dabaf267854424a521\r\n\r\nCan you try again please ?",
"Works great 👍 I just put a minor comment on the commit, I think you meant to pass the `train_size` from the one obtained from the config.\r\n\r\nThanks for a quick response!"
] | 2021-02-25T01:30:54
| 2021-02-25T14:28:46
| 2021-02-25T14:28:46
|
CONTRIBUTOR
| null | null | null | null |
Hi,
It looks like loading of FAISS index now fails when using index_name = 'exact'.
For example, from the RAG [model card](https://huggingface.co/facebook/rag-token-nq?fbclid=IwAR3bTfhls5U_t9DqsX2Vzb7NhtRHxJxfQ-uwFT7VuCPMZUM2AdAlKF_qkI8#usage).
Running `transformers==4.3.2` and datasets installed from source on latest `master` branch.
```bash
(venv) sergey_mkrtchyan datasets (master) $ python
Python 3.8.6 (v3.8.6:db455296be, Sep 23 2020, 13:31:39)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
>>> tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
>>> retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
Using custom data configuration dummy.psgs_w100.nq.no_index-dummy=True,with_index=False
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.no_index-dummy=True,with_index=False/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
Using custom data configuration dummy.psgs_w100.nq.exact-50b6cda57ff32ab4
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.exact-50b6cda57ff32ab4/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
0%| | 0/10 [00:00<?, ?it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 425, in from_pretrained
return cls(
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 387, in __init__
self.init_retrieval()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 458, in init_retrieval
self.index.init_index()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 284, in init_index
self.dataset = load_dataset(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 734, in as_dataset
datasets = utils.map_nested(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/utils/py_utils.py", line 195, in map_nested
return function(data_struct)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 769, in _build_single_dataset
post_processed = self._post_process(ds, resources_paths)
File "/Users/sergey_mkrtchyan/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb/wiki_dpr.py", line 205, in _post_process
dataset.add_faiss_index("embeddings", custom_index=index)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/arrow_dataset.py", line 2516, in add_faiss_index
super().add_faiss_index(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 416, in add_faiss_index
faiss_index.add_vectors(self, column=column, train_size=train_size, faiss_verbose=faiss_verbose)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 281, in add_vectors
self.faiss_index.add(vecs)
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/__init__.py", line 104, in replacement_add
self.add_c(n, swig_ptr(x))
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/swigfaiss.py", line 3263, in add
return _swigfaiss.IndexHNSW_add(self, n, x)
RuntimeError: Error in virtual void faiss::IndexHNSW::add(faiss::Index::idx_t, const float *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/IndexHNSW.cpp:356: Error: 'is_trained' failed
>>>
```
The issue seems to be related to the scalar quantization in faiss added in this commit: 8c5220307c33f00e01c3bf7b8. Reverting it fixes the issue.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2992022?v=4",
"events_url": "https://api.github.com/users/mkserge/events{/privacy}",
"followers_url": "https://api.github.com/users/mkserge/followers",
"following_url": "https://api.github.com/users/mkserge/following{/other_user}",
"gists_url": "https://api.github.com/users/mkserge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mkserge",
"id": 2992022,
"login": "mkserge",
"node_id": "MDQ6VXNlcjI5OTIwMjI=",
"organizations_url": "https://api.github.com/users/mkserge/orgs",
"received_events_url": "https://api.github.com/users/mkserge/received_events",
"repos_url": "https://api.github.com/users/mkserge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mkserge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mkserge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mkserge",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1941/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1941/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 12:57:52
|
https://api.github.com/repos/huggingface/datasets/issues/1940
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1940/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1940/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1940/events
|
https://github.com/huggingface/datasets/issues/1940
| 815,770,012
|
MDU6SXNzdWU4MTU3NzAwMTI=
| 1,940
|
Side effect when filtering data due to `does_function_return_dict` call in `Dataset.map()`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/918006?v=4",
"events_url": "https://api.github.com/users/francisco-perez-sorrosal/events{/privacy}",
"followers_url": "https://api.github.com/users/francisco-perez-sorrosal/followers",
"following_url": "https://api.github.com/users/francisco-perez-sorrosal/following{/other_user}",
"gists_url": "https://api.github.com/users/francisco-perez-sorrosal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/francisco-perez-sorrosal",
"id": 918006,
"login": "francisco-perez-sorrosal",
"node_id": "MDQ6VXNlcjkxODAwNg==",
"organizations_url": "https://api.github.com/users/francisco-perez-sorrosal/orgs",
"received_events_url": "https://api.github.com/users/francisco-perez-sorrosal/received_events",
"repos_url": "https://api.github.com/users/francisco-perez-sorrosal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/francisco-perez-sorrosal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/francisco-perez-sorrosal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/francisco-perez-sorrosal",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] |
[
"Thanks for the report !\r\n\r\nCurrently we don't have a way to let the user easily disable this behavior.\r\nHowever I agree that we should support stateful processing functions, ideally by removing `does_function_return_dict`.\r\n\r\nWe needed this function in order to know whether the `map` functions needs to write data or not. if `does_function_return_dict` returns False then we don't write anything.\r\n\r\nInstead of checking the output of the processing function outside of the for loop that iterates through the dataset to process it, we can check the output of the first processed example and at that point decide if we need to write data or not.\r\n\r\nTherefore it's definitely possible to fix this unwanted behavior, any contribution going into this direction is welcome :)",
"Thanks @mariosasko for the PR!"
] | 2021-02-24T19:18:56
| 2021-03-23T15:26:49
| 2021-03-23T15:26:49
|
CONTRIBUTOR
| null | null | null | null |
Hi there!
In my codebase I have a function to filter rows in a dataset, selecting only a certain number of examples per class. The function passes a extra argument to maintain a counter of the number of dataset rows/examples already selected per each class, which are the ones I want to keep in the end:
```python
def fill_train_examples_per_class(example, per_class_limit: int, counter: collections.Counter):
label = int(example['label'])
current_counter = counter.get(label, 0)
if current_counter < per_class_limit:
counter[label] = current_counter + 1
return True
return False
```
At some point I invoke it through the `Dataset.filter()` method in the `arrow_dataset.py` module like this:
```python
...
kwargs = {"per_class_limit": train_examples_per_class_limit, "counter": Counter()}
datasets['train'] = datasets['train'].filter(fill_train_examples_per_class, num_proc=1, fn_kwargs=kwargs)
...
```
The problem is that, passing a stateful container (the counter,) provokes a side effect in the new filtered dataset obtained. This is due to the fact that at some point in `filter()`, the `map()`'s function `does_function_return_dict` is invoked in line [1290](https://github.com/huggingface/datasets/blob/96578adface7e4bc1f3e8bafbac920d72ca1ca60/src/datasets/arrow_dataset.py#L1290).
When this occurs, the state of the counter is initially modified by the effects of the function call on the 1 or 2 rows selected in lines 1288 and 1289 of the same file (which are marked as `test_inputs` & `test_indices` respectively in lines 1288 and 1289. This happens out of the control of the user (which for example can't reset the state of the counter before continuing the execution,) provoking in the end an undesired side effect in the results obtained.
In my case, the resulting dataset -despite of the counter results are ok- lacks an instance of the classes 0 and 1 (which happen to be the classes of the first two examples of my dataset.) The rest of the classes I have in my dataset, contain the right number of examples as they were not affected by the effects of `does_function_return_dict` call.
I've debugged my code extensively and made a workaround myself hardcoding the necessary stuff (basically putting `update_data=True` in line 1290,) and then I obtain the results I expected without the side effect.
Is there a way to avoid that call to `does_function_return_dict` in map()'s line 1290 ? (e.g. extracting the required information that `does_function_return_dict` returns without making the testing calls to the user function on dataset rows 0 & 1)
Thanks in advance,
Francisco Perez-Sorrosal
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1940/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1940/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 26 days, 20:07:53
|
https://api.github.com/repos/huggingface/datasets/issues/1939
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1939/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1939/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1939/events
|
https://github.com/huggingface/datasets/issues/1939
| 815,680,510
|
MDU6SXNzdWU4MTU2ODA1MTA=
| 1,939
|
[firewalled env] OFFLINE mode
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Thanks for reporting and for all the details and suggestions.\r\n\r\nI'm totally in favor of having a HF_DATASETS_OFFLINE env variable to disable manually all the connection checks, remove retries etc.\r\n\r\nMoreover you may know that the use case that you are mentioning is already supported from `datasets` 1.3.0, i.e. you already can:\r\n- first load datasets and metrics from an instance with internet connection\r\n- then be able to reload datasets and metrics from another instance without connection (as long as the filesystem is shared)\r\n\r\nThis is already implemented, but currently it only works if the requests return a `ConnectionError` (or any error actually). Not sure why it would hang instead of returning an error.\r\n\r\nMaybe this is just a issue with the timeout value being not set or too high ?\r\nIs there a way I can have access to one of the instances on which there's this issue (we can discuss this offline) ?\r\n",
"I'm on master, so using all the available bells and whistles already.\r\n\r\nIf you look at the common issues - it for example tries to look up files if they appear in `_PACKAGED_DATASETS_MODULES` which it shouldn't do.\r\n\r\n--------------\r\n\r\nYes, there is a nuance to it. As I mentioned it's firewalled - that is it has a network but making any calls outside - it just hangs in:\r\n\r\n```\r\nsin_addr=inet_addr(\"xx.xx.xx.xx\")}, [28->16]) = 0\r\nclose(5) = 0\r\nsocket(AF_INET, SOCK_STREAM|SOCK_CLOEXEC, IPPROTO_TCP) = 5\r\nconnect(5, {sa_family=AF_INET, sin_port=htons(3128), sin_addr=inet_addr(\"yy.yy.yy.yy\")}, 16^C) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)\r\n```\r\nuntil it times out.\r\n\r\nThat's why we need to be able to tell the software that there is no network to rely on even if there is one (good for testing too).\r\n\r\nSo what I'm thinking is that this is a simple matter of pre-ambling any network call wrappers with:\r\n\r\n```\r\nif HF_DATASETS_OFFLINE:\r\n assert \"Attempting to make a network call under Offline mode\"\r\n```\r\n\r\nand then fixing up if there is anything else to fix to make it work.\r\n\r\n--------------\r\n\r\nOtherwise I think the only other problem I encountered is that we need to find a way to pre-cache metrics, for some reason it's not caching it and wanting to fetch it from online.\r\n\r\nWhich is extra strange since it already has those files in the `datasets` repo itself that is on the filesystem.\r\n\r\nThe workaround I had to do is to copy `rouge/rouge.py` (with the parent folder) from the datasets repo to the current dir - and then it proceeded.",
"Ok understand better the hanging issue.\r\nI guess catching connection errors is not enough, we should also avoid all the hangings.\r\nCurrently the offline mode tests are only done by simulating an instant connection fail that returns an error, let's have another connection mock that hangs instead.\r\n\r\nI'll also take a look at why you had to do this for `rouge`.\r\n",
"FWIW, I think instant failure on the behalf of a network call is the simplest solution to correctly represent the environment and having the caller to sort it out is the next thing to do, since here it is the case of having no functional network, it's just that the software doesn't know this is the case, because there is some network. So we just need to help it to bail out instantly rather than hang waiting for it to time out. And afterwards everything else you said.",
"Update on this: \r\n\r\nI managed to create a mock environment for tests that makes the connections hang until timeout.\r\nI managed to reproduce the issue you're having in this environment.\r\n\r\nI'll update the offline test cases to also test the robustness to connection hangings, and make sure we set proper timeouts where it's needed in the code. This should cover the _automatic_ section you mentioned.",
"Fabulous! I'm glad you were able to reproduce the issues, @lhoestq!",
"I lost access to the firewalled setup, but I emulated it with:\r\n\r\n```\r\nsudo ufw enable\r\nsudo ufw default deny outgoing\r\n```\r\n(thanks @mfuntowicz)\r\n\r\nI was able to test `HF_DATASETS_OFFLINE=1` and it worked great - i.e. didn't try to reach out with it and used the cached files instead.\r\n\r\nThank you!"
] | 2021-02-24T17:13:42
| 2021-03-05T05:09:54
| 2021-03-05T05:09:54
|
CONTRIBUTOR
| null | null | null | null |
This issue comes from a need to be able to run `datasets` in a firewalled env, which currently makes the software hang until it times out, as it's unable to complete the network calls.
I propose the following approach to solving this problem, using the example of `run_seq2seq.py` as a sample program. There are 2 possible ways to going about it.
## 1. Manual
manually prepare data and metrics files, that is transfer to the firewalled instance the dataset and the metrics and run:
```
DATASETS_OFFLINE=1 run_seq2seq.py --train_file xyz.csv --validation_file xyz.csv ...
```
`datasets` must not make any network calls and if there is a logic to do that and something is missing it should assert that this or that action requires network and therefore it can't proceed.
## 2. Automatic
In some clouds one can prepare a datastorage ahead of time with a normal networked environment but which doesn't have gpus and then one switches to the gpu instance which is firewalled, but it can access all the cached data. This is the ideal situation, since in this scenario we don't have to do anything manually, but simply run the same application twice:
1. on the non-firewalled instance:
```
run_seq2seq.py --dataset_name wmt16 --dataset_config ro-en ...
```
which should download and cached everything.
2. and then immediately after on the firewalled instance, which shares the same filesystem
```
DATASETS_OFFLINE=1 run_seq2seq.py --dataset_name wmt16 --dataset_config ro-en ...
```
and the metrics and datasets should be cached by the invocation number 1 and any network calls be skipped and if the logic is missing data it should assert and not try to fetch any data from online.
## Common Issues
1. for example currently `datasets` tries to look up online datasets if the files contain json or csv, despite the paths already provided
```
if dataset and path in _PACKAGED_DATASETS_MODULES:
```
2. it has an issue with metrics. e.g. I had to manually copy `rouge/rouge.py` from the `datasets` repo to the current dir - or it was hanging.
I had to comment out `head_hf_s3(...)` calls to make things work. So all those `try: head_hf_s3(...)` shouldn't be tried with `DATASETS_OFFLINE=1`
Here is the corresponding issue for `transformers`: https://github.com/huggingface/transformers/issues/10379
Thanks.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1939/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1939/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 8 days, 11:56:12
|
https://api.github.com/repos/huggingface/datasets/issues/1937
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1937/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1937/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1937/events
|
https://github.com/huggingface/datasets/issues/1937
| 815,163,943
|
MDU6SXNzdWU4MTUxNjM5NDM=
| 1,937
|
CommonGen dataset page shows an error OSError: [Errno 28] No space left on device
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10104354?v=4",
"events_url": "https://api.github.com/users/yuchenlin/events{/privacy}",
"followers_url": "https://api.github.com/users/yuchenlin/followers",
"following_url": "https://api.github.com/users/yuchenlin/following{/other_user}",
"gists_url": "https://api.github.com/users/yuchenlin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuchenlin",
"id": 10104354,
"login": "yuchenlin",
"node_id": "MDQ6VXNlcjEwMTA0MzU0",
"organizations_url": "https://api.github.com/users/yuchenlin/orgs",
"received_events_url": "https://api.github.com/users/yuchenlin/received_events",
"repos_url": "https://api.github.com/users/yuchenlin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuchenlin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuchenlin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuchenlin",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
| null |
[] |
[
"Facing the same issue for [Squad](https://huggingface.co/datasets/viewer/?dataset=squad) and [TriviaQA](https://huggingface.co/datasets/viewer/?dataset=trivia_qa) datasets as well.",
"We just fixed the issue, thanks for reporting !"
] | 2021-02-24T06:47:33
| 2021-02-26T11:10:06
| 2021-02-26T11:10:06
|
CONTRIBUTOR
| null | null | null | null |
The page of the CommonGen data https://huggingface.co/datasets/viewer/?dataset=common_gen shows

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1937/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1937/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 4:22:33
|
https://api.github.com/repos/huggingface/datasets/issues/1934
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1934/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1934/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1934/events
|
https://github.com/huggingface/datasets/issues/1934
| 814,437,190
|
MDU6SXNzdWU4MTQ0MzcxOTA=
| 1,934
|
Add Stanford Sentiment Treebank (SST)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] |
[
"Dataset added in release [1.5.0](https://github.com/huggingface/datasets/releases/tag/1.5.0), I think I can close this."
] | 2021-02-23T12:53:16
| 2021-03-18T17:51:44
| 2021-03-18T17:51:44
|
CONTRIBUTOR
| null | null | null | null |
I am going to add SST:
- **Name:** The Stanford Sentiment Treebank
- **Description:** The first corpus with fully labeled parse trees that allows for a complete analysis of the compositional effects of sentiment in language
- **Paper:** [Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- **Data:** https://nlp.stanford.edu/sentiment/index.html
- **Motivation:** Already requested in #353, SST is a popular dataset for Sentiment Classification
What's the difference with the [_SST-2_](https://huggingface.co/datasets/viewer/?dataset=glue&config=sst2) dataset included in GLUE? Essentially, SST-2 is a version of SST where:
- the labels were mapped from real numbers in [0.0, 1.0] to a binary label: {0, 1}
- the labels of the *sub-sentences* were included only in the training set
- the labels in the test set are obfuscated
So there is a lot more information in the original SST. The tricky bit is, the data is scattered into many text files and, for one in particular, I couldn't find the original encoding ([*but I'm not the only one*](https://groups.google.com/g/word2vec-toolkit/c/QIUjLw6RqFk/m/_iEeyt428wkJ) 🎵). The only solution I found was to manually replace all the è, ë, ç and so on into an `utf-8` copy of the text file. I uploaded the result in my Dropbox and I am using that as the main repo for the dataset.
Also, the _sub-sentences_ are built at run-time from the information encoded in several text files, so generating the examples is a bit more cumbersome than usual. Luckily, the dataset is not enormous.
I plan to divide the dataset in 2 configs: one with just whole sentences with their labels, the other with sentences _and their sub-sentences_ with their labels. Each config will be split in train, validation and test. Hopefully this makes sense, we may discuss it in the PR I'm going to submit.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1934/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1934/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 23 days, 4:58:28
|
https://api.github.com/repos/huggingface/datasets/issues/1924
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1924/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1924/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1924/events
|
https://github.com/huggingface/datasets/issues/1924
| 813,599,733
|
MDU6SXNzdWU4MTM1OTk3MzM=
| 1,924
|
Anonymous Dataset Addition (i.e Anonymous PR?)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22492839?v=4",
"events_url": "https://api.github.com/users/PierreColombo/events{/privacy}",
"followers_url": "https://api.github.com/users/PierreColombo/followers",
"following_url": "https://api.github.com/users/PierreColombo/following{/other_user}",
"gists_url": "https://api.github.com/users/PierreColombo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PierreColombo",
"id": 22492839,
"login": "PierreColombo",
"node_id": "MDQ6VXNlcjIyNDkyODM5",
"organizations_url": "https://api.github.com/users/PierreColombo/orgs",
"received_events_url": "https://api.github.com/users/PierreColombo/received_events",
"repos_url": "https://api.github.com/users/PierreColombo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PierreColombo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PierreColombo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PierreColombo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\nI guess you can add a dataset without the fields that must be kept anonymous, and then update those when the anonymity period is over.\r\nYou can also make the PR from an anonymous org.\r\nPinging @yjernite just to make sure it's ok",
"Hello,\r\nI would prefer to do the reverse: adding a link to an anonymous paper without the people names/institution in the PR. Would it be conceivable ?\r\nCheers\r\n",
"Sure, I think it's ok on our side",
"Yup, sounds good!"
] | 2021-02-22T15:22:30
| 2022-10-05T13:07:11
| 2022-10-05T13:07:11
|
CONTRIBUTOR
| null | null | null | null |
Hello,
Thanks a lot for your librairy.
We plan to submit a paper on OpenReview using the Anonymous setting. Is it possible to add a new dataset without breaking the anonimity, with a link to the paper ?
Cheers
@eusip
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1924/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1924/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 589 days, 21:44:41
|
https://api.github.com/repos/huggingface/datasets/issues/1922
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1922/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1922/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1922/events
|
https://github.com/huggingface/datasets/issues/1922
| 813,140,806
|
MDU6SXNzdWU4MTMxNDA4MDY=
| 1,922
|
How to update the "wino_bias" dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22306304?v=4",
"events_url": "https://api.github.com/users/JieyuZhao/events{/privacy}",
"followers_url": "https://api.github.com/users/JieyuZhao/followers",
"following_url": "https://api.github.com/users/JieyuZhao/following{/other_user}",
"gists_url": "https://api.github.com/users/JieyuZhao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JieyuZhao",
"id": 22306304,
"login": "JieyuZhao",
"node_id": "MDQ6VXNlcjIyMzA2MzA0",
"organizations_url": "https://api.github.com/users/JieyuZhao/orgs",
"received_events_url": "https://api.github.com/users/JieyuZhao/received_events",
"repos_url": "https://api.github.com/users/JieyuZhao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JieyuZhao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JieyuZhao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JieyuZhao",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"Hi @JieyuZhao !\r\n\r\nYou can edit the dataset card of wino_bias to update the URL via a Pull Request. This would be really appreciated :)\r\n\r\nThe dataset card is the README.md file you can find at https://github.com/huggingface/datasets/tree/master/datasets/wino_bias\r\nAlso the homepage url is also mentioned in the wino_bias.py so feel free to update it there as well.\r\n\r\nYou can create a Pull Request directly from the github interface by editing the files you want and submit a PR, or from a local clone of the repository.\r\n\r\nThanks for noticing !"
] | 2021-02-22T05:39:39
| 2021-02-22T10:35:59
| null |
CONTRIBUTOR
| null | null | null | null |
Hi all,
Thanks for the efforts to collect all the datasets! But I think there is a problem with the wino_bias dataset. The current link is not correct. How can I update that?
Thanks!
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1922/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1922/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1919
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1919/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1919/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1919/events
|
https://github.com/huggingface/datasets/issues/1919
| 812,626,872
|
MDU6SXNzdWU4MTI2MjY4NzI=
| 1,919
|
Failure to save with save_to_disk
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/M-Salti",
"id": 9285264,
"login": "M-Salti",
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"type": "User",
"url": "https://api.github.com/users/M-Salti",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi thanks for reporting and for proposing a fix :)\r\n\r\nI just merged a fix, feel free to try it from the master branch !",
"Closing since this has been fixed by #1923"
] | 2021-02-20T14:18:10
| 2021-03-03T17:40:27
| 2021-03-03T17:40:27
|
CONTRIBUTOR
| null | null | null | null |
When I try to save a dataset locally using the `save_to_disk` method I get the error:
```bash
FileNotFoundError: [Errno 2] No such file or directory: '/content/squad/train/squad-train.arrow'
```
To replicate:
1. Install `datasets` from master
2. Run this code:
```python
from datasets import load_dataset
squad = load_dataset("squad") # or any other dataset
squad.save_to_disk("squad") # error here
```
The problem is that the method is not creating a directory with the name `dataset_path` for saving the dataset in (i.e. it's not creating the *train* and *validation* directories in this case). After creating the directory the problem resolves.
I'll open a PR soon doing that and linking this issue.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1919/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1919/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 11 days, 3:22:17
|
https://api.github.com/repos/huggingface/datasets/issues/1917
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1917/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1917/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1917/events
|
https://github.com/huggingface/datasets/issues/1917
| 812,390,178
|
MDU6SXNzdWU4MTIzOTAxNzg=
| 1,917
|
UnicodeDecodeError: windows 10 machine
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/900951?v=4",
"events_url": "https://api.github.com/users/yosiasz/events{/privacy}",
"followers_url": "https://api.github.com/users/yosiasz/followers",
"following_url": "https://api.github.com/users/yosiasz/following{/other_user}",
"gists_url": "https://api.github.com/users/yosiasz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yosiasz",
"id": 900951,
"login": "yosiasz",
"node_id": "MDQ6VXNlcjkwMDk1MQ==",
"organizations_url": "https://api.github.com/users/yosiasz/orgs",
"received_events_url": "https://api.github.com/users/yosiasz/received_events",
"repos_url": "https://api.github.com/users/yosiasz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yosiasz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yosiasz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yosiasz",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"upgraded to php 3.9.2 and it works!"
] | 2021-02-19T22:13:05
| 2021-02-19T22:41:11
| 2021-02-19T22:40:28
|
NONE
| null | null | null | null |
Windows 10
Php 3.6.8
when running
```
import datasets
oscar_am = datasets.load_dataset("oscar", "unshuffled_deduplicated_am")
print(oscar_am["train"][0])
```
I get the following error
```
file "C:\PYTHON\3.6.8\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 58: character maps to <undefined>
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/900951?v=4",
"events_url": "https://api.github.com/users/yosiasz/events{/privacy}",
"followers_url": "https://api.github.com/users/yosiasz/followers",
"following_url": "https://api.github.com/users/yosiasz/following{/other_user}",
"gists_url": "https://api.github.com/users/yosiasz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yosiasz",
"id": 900951,
"login": "yosiasz",
"node_id": "MDQ6VXNlcjkwMDk1MQ==",
"organizations_url": "https://api.github.com/users/yosiasz/orgs",
"received_events_url": "https://api.github.com/users/yosiasz/received_events",
"repos_url": "https://api.github.com/users/yosiasz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yosiasz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yosiasz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yosiasz",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1917/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1917/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:27:23
|
https://api.github.com/repos/huggingface/datasets/issues/1915
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1915/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1915/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1915/events
|
https://github.com/huggingface/datasets/issues/1915
| 812,229,654
|
MDU6SXNzdWU4MTIyMjk2NTQ=
| 1,915
|
Unable to download `wiki_dpr`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18504534?v=4",
"events_url": "https://api.github.com/users/nitarakad/events{/privacy}",
"followers_url": "https://api.github.com/users/nitarakad/followers",
"following_url": "https://api.github.com/users/nitarakad/following{/other_user}",
"gists_url": "https://api.github.com/users/nitarakad/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nitarakad",
"id": 18504534,
"login": "nitarakad",
"node_id": "MDQ6VXNlcjE4NTA0NTM0",
"organizations_url": "https://api.github.com/users/nitarakad/orgs",
"received_events_url": "https://api.github.com/users/nitarakad/received_events",
"repos_url": "https://api.github.com/users/nitarakad/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nitarakad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nitarakad/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nitarakad",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Thanks for reporting ! This is a bug. For now feel free to set `ignore_verifications=False` in `load_dataset`.\r\nI'm working on a fix",
"I just merged a fix :)\r\n\r\nWe'll do a patch release soon. In the meantime feel free to try it from the master branch\r\nThanks again for reporting !",
"Closing since this has been fixed by #1925"
] | 2021-02-19T18:11:32
| 2021-03-03T17:40:48
| 2021-03-03T17:40:48
|
NONE
| null | null | null | null |
I am trying to download the `wiki_dpr` dataset. Specifically, I want to download `psgs_w100.multiset.no_index` with no embeddings/no index. In order to do so, I ran:
`curr_dataset = load_dataset("wiki_dpr", embeddings_name="multiset", index_name="no_index")`
However, I got the following error:
`datasets.utils.info_utils.UnexpectedDownloadedFile: {'embeddings_index'}`
I tried adding in flags `with_embeddings=False` and `with_index=False`:
`curr_dataset = load_dataset("wiki_dpr", with_embeddings=False, with_index=False, embeddings_name="multiset", index_name="no_index")`
But I got the following error:
`raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))
datasets.utils.info_utils.ExpectedMoreDownloadedFiles: {‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_5’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_15’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_30’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_36’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_18’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_41’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_13’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_48’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_10’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_23’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_14’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_34’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_43’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_40’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_47’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_3’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_24’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_7’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_33’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_46’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_42’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_27’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_29’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_26’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_22’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_4’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_20’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_39’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_6’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_16’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_8’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_35’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_49’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_17’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_25’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_0’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_38’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_12’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_44’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_1’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_32’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_19’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_31’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_37’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_9’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_11’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_21’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_28’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_45’, ‘https://dl.fbaipublicfiles.com/rag/rag_multiset_embeddings/wiki_passages_2’}`
Is there anything else I need to set to download the dataset?
**UPDATE**: just running `curr_dataset = load_dataset("wiki_dpr", with_embeddings=False, with_index=False)` gives me the same error.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1915/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1915/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 11 days, 23:29:16
|
https://api.github.com/repos/huggingface/datasets/issues/1911
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1911/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1911/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1911/events
|
https://github.com/huggingface/datasets/issues/1911
| 812,009,956
|
MDU6SXNzdWU4MTIwMDk5NTY=
| 1,911
|
Saving processed dataset running infinitely
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20911334?v=4",
"events_url": "https://api.github.com/users/ayubSubhaniya/events{/privacy}",
"followers_url": "https://api.github.com/users/ayubSubhaniya/followers",
"following_url": "https://api.github.com/users/ayubSubhaniya/following{/other_user}",
"gists_url": "https://api.github.com/users/ayubSubhaniya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ayubSubhaniya",
"id": 20911334,
"login": "ayubSubhaniya",
"node_id": "MDQ6VXNlcjIwOTExMzM0",
"organizations_url": "https://api.github.com/users/ayubSubhaniya/orgs",
"received_events_url": "https://api.github.com/users/ayubSubhaniya/received_events",
"repos_url": "https://api.github.com/users/ayubSubhaniya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ayubSubhaniya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayubSubhaniya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ayubSubhaniya",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"@thomwolf @lhoestq can you guys please take a look and recommend some solution.",
"am suspicious of this thing? what's the purpose of this? pickling and unplickling\r\n`self = pickle.loads(pickle.dumps(self))`\r\n\r\n```\r\n def save_to_disk(self, dataset_path: str, fs=None):\r\n \"\"\"\r\n Saves a dataset to a dataset directory, or in a filesystem using either :class:`datasets.filesystem.S3FileSystem` or any implementation of ``fsspec.spec.AbstractFileSystem``.\r\n\r\n Args:\r\n dataset_path (``str``): path (e.g. ``dataset/train``) or remote uri (e.g. ``s3://my-bucket/dataset/train``) of the dataset directory where the dataset will be saved to\r\n fs (Optional[:class:`datasets.filesystem.S3FileSystem`,``fsspec.spec.AbstractFileSystem``], `optional`, defaults ``None``): instance of :class:`datasets.filesystem.S3FileSystem` or ``fsspec.spec.AbstractFileSystem`` used to download the files from remote filesystem.\r\n \"\"\"\r\n assert (\r\n not self.list_indexes()\r\n ), \"please remove all the indexes using `dataset.drop_index` before saving a dataset\"\r\n self = pickle.loads(pickle.dumps(self))\r\n ```",
"It's been 24 hours and sadly it's still running. With not a single byte written",
"Tried finding the root cause but was unsuccessful.\r\nI am using lazy tokenization with `dataset.set_transform()`, it works like a charm with almost same performance as pre-compute.",
"Hi ! This very probably comes from the hack you used.\r\n\r\nThe pickling line was added an a sanity check because save_to_disk uses the same assumptions as pickling for a dataset object. The main assumption is that memory mapped pyarrow tables must be reloadable from the disk. In your case it's not possible since you altered the pyarrow table.\r\nI would suggest you to rebuild a valid Dataset object from your new pyarrow table. To do so you must first save your new table to a file, and then make a new Dataset object from that arrow file.\r\n\r\nYou can save the raw arrow table (without all the `datasets.Datasets` metadata) by calling `map` with `cache_file_name=\"path/to/outut.arrow\"` and `function=None`. Having `function=None` makes the `map` write your dataset on disk with no data transformation.\r\n\r\nOnce you have your new arrow file, load it with `datasets.Dataset.from_file` to have a brand new Dataset object :)\r\n\r\nIn the future we'll have a better support for the fast filtering method from pyarrow so you don't have to do this very unpractical workaround. Since it breaks somes assumptions regarding the core behavior of Dataset objects, this is very discouraged.",
"Thanks, @lhoestq for your response. Will try your solution and let you know."
] | 2021-02-19T13:09:19
| 2021-02-23T07:34:44
| null |
NONE
| null | null | null | null |
I have a text dataset of size 220M.
For pre-processing, I need to tokenize this and filter rows with the large sequence.
My tokenization took roughly 3hrs. I used map() with batch size 1024 and multi-process with 96 processes.
filter() function was way to slow, so I used a hack to use pyarrow filter table function, which is damm fast. Mentioned [here](https://github.com/huggingface/datasets/issues/1796)
```dataset._data = dataset._data.filter(...)```
It took 1 hr for the filter.
Then i use `save_to_disk()` on processed dataset and it is running forever.
I have been waiting since 8 hrs, it has not written a single byte.
Infact it has actually read from disk more than 100GB, screenshot below shows the stats using `iotop`.
Second process is the one.
<img width="1672" alt="Screenshot 2021-02-19 at 6 36 53 PM" src="https://user-images.githubusercontent.com/20911334/108508197-7325d780-72e1-11eb-8369-7c057d137d81.png">
I am not able to figure out, whether this is some issue with dataset library or that it is due to my hack for filter() function.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1911/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1911/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1907
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1907/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1907/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1907/events
|
https://github.com/huggingface/datasets/issues/1907
| 811,520,569
|
MDU6SXNzdWU4MTE1MjA1Njk=
| 1,907
|
DBPedia14 Dataset Checksum bug?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/918006?v=4",
"events_url": "https://api.github.com/users/francisco-perez-sorrosal/events{/privacy}",
"followers_url": "https://api.github.com/users/francisco-perez-sorrosal/followers",
"following_url": "https://api.github.com/users/francisco-perez-sorrosal/following{/other_user}",
"gists_url": "https://api.github.com/users/francisco-perez-sorrosal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/francisco-perez-sorrosal",
"id": 918006,
"login": "francisco-perez-sorrosal",
"node_id": "MDQ6VXNlcjkxODAwNg==",
"organizations_url": "https://api.github.com/users/francisco-perez-sorrosal/orgs",
"received_events_url": "https://api.github.com/users/francisco-perez-sorrosal/received_events",
"repos_url": "https://api.github.com/users/francisco-perez-sorrosal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/francisco-perez-sorrosal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/francisco-perez-sorrosal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/francisco-perez-sorrosal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! :)\r\n\r\nThis looks like the same issue as https://github.com/huggingface/datasets/issues/1856 \r\nBasically google drive has quota issues that makes it inconvenient for downloading files.\r\n\r\nIf the quota of a file is exceeded, you have to wait 24h for the quota to reset (which is painful).\r\n\r\nThe error says that the checksum of the downloaded file doesn't match because google drive returns a text file with the \"Quota Exceeded\" error instead of the actual data file.",
"Thanks @lhoestq! Yes, it seems back to normal after a couple of days."
] | 2021-02-18T22:25:48
| 2021-02-22T23:22:05
| 2021-02-22T23:22:04
|
CONTRIBUTOR
| null | null | null | null |
Hi there!!!
I've been using successfully the DBPedia dataset (https://huggingface.co/datasets/dbpedia_14) with my codebase in the last couple of weeks, but in the last couple of days now I get this error:
```
Traceback (most recent call last):
File "./conditional_classification/basic_pipeline.py", line 178, in <module>
main()
File "./conditional_classification/basic_pipeline.py", line 128, in main
corpus.load_data(limit_train_examples_per_class=args.data_args.train_examples_per_class,
File "/home/fp/dev/conditional_classification/conditional_classification/datasets_base.py", line 83, in load_data
datasets = load_dataset(self.name, split=dataset_split)
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/load.py", line 609, in load_dataset
builder_instance.download_and_prepare(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/builder.py", line 526, in download_and_prepare
self._download_and_prepare(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/builder.py", line 586, in _download_and_prepare
verify_checksums(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 39, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k']
```
I've seen this has happened before in other datasets as reported in #537.
I've tried clearing my cache and call again `load_dataset` but still is not working. My same codebase is successfully downloading and using other datasets (e.g. AGNews) without any problem, so I guess something has happened specifically to the DBPedia dataset in the last few days.
Can you please check if there's a problem with the checksums?
Or this is related to any other stuff? I've seen that the path in the cache for the dataset is `/home/fp/.cache/huggingface/datasets/d_bpedia14/dbpedia_14/2.0.0/a70413e39e7a716afd0e90c9e53cb053691f56f9ef5fe317bd07f2c368e8e897...` and includes `d_bpedia14` instead maybe of `dbpedia_14`. Was this maybe a bug introduced recently?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/918006?v=4",
"events_url": "https://api.github.com/users/francisco-perez-sorrosal/events{/privacy}",
"followers_url": "https://api.github.com/users/francisco-perez-sorrosal/followers",
"following_url": "https://api.github.com/users/francisco-perez-sorrosal/following{/other_user}",
"gists_url": "https://api.github.com/users/francisco-perez-sorrosal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/francisco-perez-sorrosal",
"id": 918006,
"login": "francisco-perez-sorrosal",
"node_id": "MDQ6VXNlcjkxODAwNg==",
"organizations_url": "https://api.github.com/users/francisco-perez-sorrosal/orgs",
"received_events_url": "https://api.github.com/users/francisco-perez-sorrosal/received_events",
"repos_url": "https://api.github.com/users/francisco-perez-sorrosal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/francisco-perez-sorrosal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/francisco-perez-sorrosal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/francisco-perez-sorrosal",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1907/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1907/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 0:56:16
|
https://api.github.com/repos/huggingface/datasets/issues/1906
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1906/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1906/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1906/events
|
https://github.com/huggingface/datasets/issues/1906
| 811,405,274
|
MDU6SXNzdWU4MTE0MDUyNzQ=
| 1,906
|
Feature Request: Support for Pandas `Categorical`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7731709?v=4",
"events_url": "https://api.github.com/users/justin-yan/events{/privacy}",
"followers_url": "https://api.github.com/users/justin-yan/followers",
"following_url": "https://api.github.com/users/justin-yan/following{/other_user}",
"gists_url": "https://api.github.com/users/justin-yan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/justin-yan",
"id": 7731709,
"login": "justin-yan",
"node_id": "MDQ6VXNlcjc3MzE3MDk=",
"organizations_url": "https://api.github.com/users/justin-yan/orgs",
"received_events_url": "https://api.github.com/users/justin-yan/received_events",
"repos_url": "https://api.github.com/users/justin-yan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/justin-yan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/justin-yan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/justin-yan",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
open
| false
| null |
[] |
[
"We already have a ClassLabel type that does this kind of mapping between the label ids (integers) and actual label values (strings).\r\n\r\nI wonder if actually we should use the DictionaryType from Arrow and the Categorical type from pandas for the `datasets` ClassLabel feature type.\r\nCurrently ClassLabel corresponds to `pa.int64()` in pyarrow and `dtype('int64')` in pandas (so the label names are lost during conversions).\r\n\r\nWhat do you think ?",
"Now that I've heard you explain ClassLabel, that makes a lot of sense! While DictionaryType for Arrow (I think) can have arbitrarily typed keys, so it won't cover all potential cases, pandas' Category is *probably* the most common use for that pyarrow type, and ClassLabel should match that perfectly?\r\n\r\nOther thoughts:\r\n\r\n- changing the resulting patype on ClassLabel might be backward-incompatible? I'm not totally sure if users of the `datasets` library tend to directly access the `patype` attribute (I don't think we really do, but we haven't been using it for very long yet).\r\n- would ClassLabel's dtype change to `dict[int64, string]`? It seems like in practice a ClassLabel (when not explicitly specified) would be constructed from the DictionaryType branch of `generate_from_arrow_type`, so it's not totally clear to me that anyone ever actually accesses/uses that dtype?\r\n- I don't quite know how `.int2str` and `.str2int` are used in practice - would those be kept? Perhaps the implementation might actually be substantially smaller if we can just delegate to pyarrow's dict methods?\r\n\r\nAnother idea that just occurred to me: add a branch in here to generate a ClassLabel if the dict key is int64 and the values are string: https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L932 , and then don't touch anything else.\r\n\r\nIn practice, I don't think this would be backward-incompatible in a way anyone would care about since the current behavior just throws an exception, and this way, we could support *reading* a pandas Categorical into a `Dataset` as a ClassLabel. I *think* from there, while it would require some custom glue it wouldn't be too hard to convert the ClassLabel into a pandas Category if we want to go back - I think this would improve on the current behavior without risking changing the behavior of ClassLabel in a backward-incompat way.\r\n\r\nThoughts? I'm not sure if this is overly cautious. Whichever approach you think is better, I'd be happy to take it on!\r\n",
"I think we can first keep the int64 precision but with an arrow Dictionary for ClassLabel, and focus on the connection with arrow and pandas.\r\n\r\nIn this scope, I really like the idea of checking for the dictionary type:\r\n\r\n> Another idea that just occurred to me: add a branch in here to generate a ClassLabel if the dict key is int64 and the values are string: https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L932 , and then don't touch anything else.\r\n\r\nThis looks like a great start.\r\n\r\nThen as you said we'd have to add the conversion from classlabel to the correct arrow dictionary type. Arrow is already able to convert from arrow Dictionary to pandas Categorical so it should be enough.\r\n\r\nI can see two things that we must take case of to make this change backward compatible:\r\n- first we must still be able to load an arrow file with arrow int64 dtype and `datasets` ClassLabel type without crashing. This can be fixed by casting the arrow int64 array to an arrow Dictionary array on-the-fly when loading the table in the ArrowReader.\r\n- then we still have to return integers when accessing examples from a ClassLabel column. Currently it would return the strings values since it's based on the pandas behavior for converting from pandas to python/numpy. To do so we just have to adapt the python/numpy extractors in formatting.py (it takes care of converting an arrow table to a dictionary of python objects by doing arrow table -> pandas dataframe -> python dictionary)\r\n\r\nAny help on this matter is very much welcome :)"
] | 2021-02-18T19:46:05
| 2021-02-23T14:38:50
| null |
CONTRIBUTOR
| null | null | null | null |
```
from datasets import Dataset
import pandas as pd
import pyarrow
df = pd.DataFrame(pd.Series(["a", "b", "c", "a"], dtype="category"))
pyarrow.Table.from_pandas(df)
Dataset.from_pandas(df)
# Throws NotImplementedError
# TODO(thom) this will need access to the dictionary as well (for labels). I.e. to the py_table
```
I'm curious if https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L796 could be built out in a way similar to `Sequence`?
e.g. a `Map` class (or whatever name the maintainers might prefer) that can accept:
```
index_type = generate_from_arrow_type(pa_type.index_type)
value_type = generate_from_arrow_type(pa_type.value_type)
```
and then additional code points to modify:
- FeatureType: https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L694
- A branch to handle Map in get_nested_type: https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L719
- I don't quite understand what `encode_nested_example` does but perhaps a branch there? https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L755
- Similarly, I don't quite understand why `Sequence` is used this way in `generate_from_dict`, but perhaps a branch here? https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L775
I couldn't find other usages of `Sequence` outside of defining specific datasets, so I'm not sure if that's a comprehensive set of touchpoints.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1906/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1906/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1898
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1898/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1898/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1898/events
|
https://github.com/huggingface/datasets/issues/1898
| 810,157,251
|
MDU6SXNzdWU4MTAxNTcyNTE=
| 1,898
|
ALT dataset has repeating instances in all splits
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33179372?v=4",
"events_url": "https://api.github.com/users/10-zin/events{/privacy}",
"followers_url": "https://api.github.com/users/10-zin/followers",
"following_url": "https://api.github.com/users/10-zin/following{/other_user}",
"gists_url": "https://api.github.com/users/10-zin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/10-zin",
"id": 33179372,
"login": "10-zin",
"node_id": "MDQ6VXNlcjMzMTc5Mzcy",
"organizations_url": "https://api.github.com/users/10-zin/orgs",
"received_events_url": "https://api.github.com/users/10-zin/received_events",
"repos_url": "https://api.github.com/users/10-zin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/10-zin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/10-zin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/10-zin",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Thanks for reporting. This looks like a very bad issue. I'm looking into it",
"I just merged a fix, we'll do a patch release soon. Thanks again for reporting, and sorry for the inconvenience.\r\nIn the meantime you can load `ALT` using `datasets` from the master branch",
"Thanks!!! works perfectly in the bleading edge master version",
"Closed by #1899"
] | 2021-02-17T12:51:42
| 2021-02-19T06:18:46
| 2021-02-19T06:18:46
|
NONE
| null | null | null | null |
The [ALT](https://huggingface.co/datasets/alt) dataset has all the same instances within each split :/
Seemed like a great dataset for some experiments I wanted to carry out, especially since its medium-sized, and has all splits.
Would be great if this could be fixed :)
Added a snapshot of the contents from `explore-datset` feature, for quick reference.

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1898/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1898/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 17:27:04
|
https://api.github.com/repos/huggingface/datasets/issues/1895
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1895/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1895/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1895/events
|
https://github.com/huggingface/datasets/issues/1895
| 809,630,271
|
MDU6SXNzdWU4MDk2MzAyNzE=
| 1,895
|
Bug Report: timestamp[ns] not recognized
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7731709?v=4",
"events_url": "https://api.github.com/users/justin-yan/events{/privacy}",
"followers_url": "https://api.github.com/users/justin-yan/followers",
"following_url": "https://api.github.com/users/justin-yan/following{/other_user}",
"gists_url": "https://api.github.com/users/justin-yan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/justin-yan",
"id": 7731709,
"login": "justin-yan",
"node_id": "MDQ6VXNlcjc3MzE3MDk=",
"organizations_url": "https://api.github.com/users/justin-yan/orgs",
"received_events_url": "https://api.github.com/users/justin-yan/received_events",
"repos_url": "https://api.github.com/users/justin-yan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/justin-yan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/justin-yan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/justin-yan",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Thanks for reporting !\r\n\r\nYou're right, `string_to_arrow` should be able to take `\"timestamp[ns]\"` as input and return the right pyarrow timestamp type.\r\nFeel free to suggest a fix for `string_to_arrow` and open a PR if you want to contribute ! This would be very appreciated :)\r\n\r\nTo give you more context:\r\n\r\nAs you may know we define the features types of a dataset using the `Features` object in combination with feature types like `Value`. For example\r\n```python\r\nfeatures = Features({\r\n \"age\": Value(\"int32\")\r\n})\r\n```\r\nHowever under the hood we are actually using pyarrow to store the data, and so we have a mapping between the feature types of `datasets` and the types of pyarrow.\r\n\r\nFor example, the `Value` feature types are created from a pyarrow type with `Value(str(pa_type))`.\r\nHowever it looks like the conversion back to a pyarrow type doesn't work with `\"timestamp[ns]\"`.\r\nThis is the `string_to_arrow` function you highlighted that does this conversion, so we should fix that.\r\n\r\n",
"Thanks for the clarification @lhoestq !\r\n\r\nThis may be a little bit of a stupid question, but I wanted to clarify one more thing before I took a stab at this:\r\n\r\nWhen the features get inferred, I believe they already have a pyarrow schema (https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L234).\r\n\r\nWe then convert it to a string (https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L778) only to convert it back into the arrow type (https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L143, and https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L35). Is there a reason for this round-trip?\r\n\r\nI'll open a PR later to add `timestamp` support to `string_to_arrow`, but I'd be curious to understand since it feels like there may be some opportunities to simplify!",
"The objective in terms of design is to make it easy to create Features in a pythonic way. So for example we use a string to define a Value type.\r\nThat's why when inferring the Features from an arrow schema we have to find the right string definitions for Value types. I guess we could also have a constructor `Value.from_arrow_type` to avoid recreating the arrow type, but this could create silent errors if the pyarrow type doesn't have a valid mapping with the string definition. The \"round-trip\" is used to enforce that the ground truth is the string definition, not the pyarrow type, and also as a sanity check.\r\n\r\nLet me know if that makes sense ",
"OK I think I understand now:\r\n\r\nFeatures are datasets' internal representation of a schema type, distinct from pyarrow's schema.\r\nValue() corresponds to pyarrow's \"primitive\" types (e.g. `int` or `string`, but not things like `list` or `dict`).\r\n`get_nested_type()` (https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L698) and `generate_from_arrow_type()` (https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L778) *should* be inverses of each other, and similarly, for the primitive values, `string_to_arrow()` and `Value.__call__` (https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L146) should be inverses of each other?\r\n\r\nThanks for taking the time to answer - I just wanted to make sure I understood before opening a PR so I'm not disrupting anything about how the codebase is expected to work!",
"Yes you're totally right :)"
] | 2021-02-16T20:38:04
| 2021-02-19T18:27:11
| 2021-02-19T18:27:11
|
CONTRIBUTOR
| null | null | null | null |
Repro:
```
from datasets import Dataset
import pandas as pd
import pyarrow
df = pd.DataFrame(pd.date_range("2018-01-01", periods=3, freq="H"))
pyarrow.Table.from_pandas(df)
Dataset.from_pandas(df)
# Throws ValueError: Neither timestamp[ns] nor timestamp[ns]_ seems to be a pyarrow data type.
```
The factory function seems to be just "timestamp": https://arrow.apache.org/docs/python/generated/pyarrow.timestamp.html#pyarrow.timestamp
It seems like https://github.com/huggingface/datasets/blob/master/src/datasets/features.py#L36-L43 could have a little bit of additional structure for handling these cases? I'd be happy to take a shot at opening a PR if I could receive some guidance on whether parsing something like `timestamp[ns]` and resolving it to timestamp('ns') is the goal of this method.
Alternatively, if I'm using this incorrectly (e.g. is the expectation that we always provide a schema when timestamps are involved?), that would be very helpful to know as well!
```
$ pip list # only the relevant libraries/versions
datasets 1.2.1
pandas 1.0.3
pyarrow 3.0.0
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1895/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1895/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 21:49:07
|
https://api.github.com/repos/huggingface/datasets/issues/1894
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1894/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1894/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1894/events
|
https://github.com/huggingface/datasets/issues/1894
| 809,609,654
|
MDU6SXNzdWU4MDk2MDk2NTQ=
| 1,894
|
benchmarking against MMapIndexedDataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"Hi sam !\r\nIndeed we can expect the performances to be very close since both MMapIndexedDataset and the `datasets` implem use memory mapping. With memory mapping what determines the I/O performance is the speed of your hard drive/SSD.\r\n\r\nIn terms of performance we're pretty close to the optimal speed for reading text, even though I found recently that we could still slightly improve speed for big datasets (see [here](https://github.com/huggingface/datasets/issues/1803)).\r\n\r\nIn terms of number of examples and example sizes, the only limit is the available disk space you have.\r\n\r\nI haven't used `psrecord` yet but it seems to be a very interesting tool for benchmarking. Currently for benchmarks we only have github actions to avoid regressions in terms of speed. But it would be cool to have benchmarks with comparisons with other dataset tools ! This would be useful to many people",
"Also I would be interested to know what data types `MMapIndexedDataset` supports. Is there some documentation somewhere ?",
"no docs haha, it's written to support integer numpy arrays.\r\n\r\nYou can build one in fairseq with, roughly:\r\n```bash\r\n\r\nwget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip\r\nunzip wikitext-103-raw-v1.zip\r\nexport dd=$HOME/fairseq-py/wikitext-103-raw\r\n\r\nexport mm_dir=$HOME/mmap_wikitext2\r\nmkdir -p gpt2_bpe\r\nwget -O gpt2_bpe/encoder.json https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json\r\nwget -O gpt2_bpe/vocab.bpe https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe\r\nwget -O gpt2_bpe/dict.txt https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt\r\nfor SPLIT in train valid; do \\\r\n python -m examples.roberta.multiprocessing_bpe_encoder \\\r\n --encoder-json gpt2_bpe/encoder.json \\\r\n --vocab-bpe gpt2_bpe/vocab.bpe \\\r\n --inputs /scratch/stories_small/${SPLIT}.txt \\\r\n --outputs /scratch/stories_small/${SPLIT}.bpe \\\r\n --keep-empty \\\r\n --workers 60; \\\r\ndone\r\n\r\nmkdir -p $mm_dir\r\nfairseq-preprocess \\\r\n --only-source \\\r\n --srcdict gpt2_bpe/dict.txt \\\r\n --trainpref $dd/wiki.train.bpe \\\r\n --validpref $dd/wiki.valid.bpe \\\r\n --destdir $mm_dir \\\r\n --workers 60 \\\r\n --dataset-impl mmap\r\n```\r\n\r\nI'm noticing in my benchmarking that it's much smaller on disk than arrow (200mb vs 900mb), and that both incur significant cost by increasing the number of data loader workers. \r\nThis somewhat old [post](https://ray-project.github.io/2017/10/15/fast-python-serialization-with-ray-and-arrow.html) suggests there are some gains to be had from using `pyarrow.serialize(array).tobuffer()`. I haven't yet figured out how much of this stuff `pa.Table` does under the hood.\r\n\r\nThe `MMapIndexedDataset` bottlenecks we are working on improving (by using arrow) are:\r\n1) `MMapIndexedDataset`'s index, which stores offsets, basically gets read in its entirety by each dataloading process.\r\n2) we have separate, identical, `MMapIndexedDatasets` on each dataloading worker, so there's redundancy there; we wonder if there is a way that arrow can somehow dedupe these in shared memory.\r\n\r\nIt will take me a few hours to get `MMapIndexedDataset` benchmarks out of `fairseq`/onto a branch in this repo, but I'm happy to invest the time if you're interested in collaborating on some performance hacking."
] | 2021-02-16T20:04:58
| 2021-02-17T18:52:28
| null |
CONTRIBUTOR
| null | null | null | null |
I am trying to benchmark my datasets based implementation against fairseq's [`MMapIndexedDataset`](https://github.com/pytorch/fairseq/blob/master/fairseq/data/indexed_dataset.py#L365) and finding that, according to psrecord, my `datasets` implem uses about 3% more CPU memory and runs 1% slower for `wikitext103` (~1GB of tokens).
Questions:
1) Is this (basically identical) performance expected?
2) Is there a scenario where this library will outperform `MMapIndexedDataset`? (maybe more examples/larger examples?)
3) Should I be using different benchmarking tools than `psrecord`/how do you guys do benchmarks?
Thanks in advance! Sam
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1894/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1894/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1893
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1893/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1893/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1893/events
|
https://github.com/huggingface/datasets/issues/1893
| 809,556,503
|
MDU6SXNzdWU4MDk1NTY1MDM=
| 1,893
|
wmt19 is broken
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"This was also mentioned in https://github.com/huggingface/datasets/issues/488 \r\n\r\nThe bucket where is data was stored seems to be unavailable now. Maybe we can change the URL to the ones in https://conferences.unite.un.org/uncorpus/en/downloadoverview ?",
"Closing since this has been fixed by #1912"
] | 2021-02-16T18:39:58
| 2021-03-03T17:42:02
| 2021-03-03T17:42:02
|
CONTRIBUTOR
| null | null | null | null |
1. Check which lang pairs we have: `--dataset_name wmt19`:
Please pick one among the available configs: ['cs-en', 'de-en', 'fi-en', 'gu-en', 'kk-en', 'lt-en', 'ru-en', 'zh-en', 'fr-de']
2. OK, let's pick `ru-en`:
`--dataset_name wmt19 --dataset_config "ru-en"`
no cookies:
```
Traceback (most recent call last):
File "./run_seq2seq.py", line 661, in <module>
main()
File "./run_seq2seq.py", line 317, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 740, in load_dataset
builder_instance.download_and_prepare(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/builder.py", line 572, in download_and_prepare
self._download_and_prepare(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/builder.py", line 628, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/stas/.cache/huggingface/modules/datasets_modules/datasets/wmt19/436092de5f3faaf0fc28bc84875475b384e90a5470fa6afaee11039ceddc5052/wmt_utils.py", line 755, in _split_generators
downloaded_files = dl_manager.download_and_extract(urls_to_download)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/download_manager.py", line 276, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/download_manager.py", line 191, in download
downloaded_path_or_paths = map_nested(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/py_utils.py", line 233, in map_nested
mapped = [
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/py_utils.py", line 234, in <listcomp>
_single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/py_utils.py", line 190, in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/py_utils.py", line 190, in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True)) for v in pbar]
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/py_utils.py", line 172, in _single_map_nested
return function(data_struct)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/download_manager.py", line 211, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 274, in cached_path
output_path = get_from_cache(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 584, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-ru.tar.gz
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1893/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1893/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 14 days, 23:02:04
|
https://api.github.com/repos/huggingface/datasets/issues/1892
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1892/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1892/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1892/events
|
https://github.com/huggingface/datasets/issues/1892
| 809,554,174
|
MDU6SXNzdWU4MDk1NTQxNzQ=
| 1,892
|
request to mirror wmt datasets, as they are really slow to download
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Yes that would be awesome. Not only the download speeds are awful, but also some files are missing.\r\nWe list all the URLs in the datasets/wmt19/wmt_utils.py so we can make a script to download them all and host on S3.\r\nAlso I think most of the materials are under the CC BY-NC-SA 3.0 license (must double check) so it should be possible to redistribute the data with no issues.\r\n\r\ncc @patrickvonplaten who knows more about the wmt scripts",
"Yeah, the scripts are pretty ugly! A big refactor would make sense here...and I also remember that the datasets were veeery slow to download",
"I'm downloading them.\r\nI'm starting with the ones hosted on http://data.statmt.org which are the slowest ones",
"@lhoestq better to use our new git-based system than just raw S3, no? (that way we have built-in CDN etc.)",
"Closing since the urls were changed to mirror urls in #1912 ",
"Hi there! What about mirroring other datasets like [CCAligned](http://www.statmt.org/cc-aligned/) as well? All of them are really slow to download..."
] | 2021-02-16T18:36:11
| 2021-10-26T06:55:42
| 2021-03-25T11:53:23
|
CONTRIBUTOR
| null | null | null | null |
Would it be possible to mirror the wmt data files under hf? Some of them take hours to download and not because of the local speed. They are all quite small datasets, just extremely slow to download.
Thank you!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1892/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1892/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 36 days, 17:17:12
|
https://api.github.com/repos/huggingface/datasets/issues/1891
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1891/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1891/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1891/events
|
https://github.com/huggingface/datasets/issues/1891
| 809,550,001
|
MDU6SXNzdWU4MDk1NTAwMDE=
| 1,891
|
suggestion to improve a missing dataset error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"This is the current error thrown for missing datasets:\r\n```\r\nFileNotFoundError: Couldn't find a dataset script at C:\\Users\\Mario\\Desktop\\projects\\datasets\\missing_dataset\\missing_dataset.py or any data file in the same directory. Couldn't find 'missing_dataset' on the Hugging Face Hub either: FileNotFoundError: Dataset 'missing_dataset' doesn't exist on the Hub. If the repo is private, make sure you are authenticated with `use_auth_token=True` after logging in with `huggingface-cli login`.\r\n```\r\n\r\nSeems much more informative, so I think we can close this issue."
] | 2021-02-16T18:29:13
| 2022-10-05T12:48:38
| 2022-10-05T12:48:38
|
CONTRIBUTOR
| null | null | null | null |
I was using `--dataset_name wmt19` all was good. Then thought perhaps wmt20 is out, so I tried to use `--dataset_name wmt20`, got 3 different errors (1 repeated twice), none telling me the real issue - that `wmt20` isn't in the `datasets`:
```
True, predict_with_generate=True)
Traceback (most recent call last):
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 323, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 274, in cached_path
output_path = get_from_cache(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 584, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/wmt20/wmt20.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 335, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 274, in cached_path
output_path = get_from_cache(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/utils/file_utils.py", line 584, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/wmt20/wmt20.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./run_seq2seq.py", line 661, in <module>
main()
File "./run_seq2seq.py", line 317, in main
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 706, in load_dataset
module_path, hash, resolved_file_path = prepare_module(
File "/mnt/nvme1/code/huggingface/datasets-master/src/datasets/load.py", line 343, in prepare_module
raise FileNotFoundError(
FileNotFoundError: Couldn't find file locally at wmt20/wmt20.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/wmt20/wmt20.py.
The file is also not present on the master branch on github.
```
Suggestion: if it is not in a local path, check that there is an actual `https://github.com/huggingface/datasets/tree/master/datasets/wmt20` first and assert "dataset `wmt20` doesn't exist in datasets", rather than trying to find a load script - since the whole repo is not there.
The error occured when running:
```
cd examples/seq2seq
export BS=16; rm -r output_dir; PYTHONPATH=../../src USE_TF=0 CUDA_VISIBLE_DEVICES=0 python ./run_seq2seq.py --model_name_or_path t5-small --output_dir output_dir --adam_eps 1e-06 --do_eval --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 128 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --task translation_en_to_ro --val_max_target_length 128 --warmup_steps 500 --max_val_samples 500 --dataset_name wmt20 --dataset_config "ro-en" --source_prefix "translate English to Romanian: "
```
Thanks.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1891/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1891/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 595 days, 18:19:25
|
https://api.github.com/repos/huggingface/datasets/issues/1877
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1877/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1877/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1877/events
|
https://github.com/huggingface/datasets/issues/1877
| 808,462,272
|
MDU6SXNzdWU4MDg0NjIyNzI=
| 1,877
|
Allow concatenation of both in-memory and on-disk datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"I started working on this. My idea is to first add the pyarrow Table wrappers InMemoryTable and MemoryMappedTable that both implement what's necessary regarding copy/pickle. Then have another wrapper that takes the concatenation of InMemoryTable/MemoryMappedTable objects.\r\n\r\nWhat's important here is that concatenating two tables into one doesn't double the memory used (`total_allocated_bytes()` stays the same).",
"Hi @lhoestq @albertvillanova,\r\n\r\nI checked the linked issues and PR, this seems like a great idea. Would you mind elaborating on the in-memory and memory-mapped datasets? \r\nBased on my understanding, it is something like this, please correct me if I am wrong:\r\n1. For in-memory datasets, we don't have any dataset files so the entire dataset is pickled to the cache during loading, and then whenever required it is unpickled .\r\n2. For on-disk/memory-mapped datasets, we have the data files provided, so they can be re-loaded from the paths, and only the file-paths are stored while pickling.\r\n\r\nIf this is correct, will the feature also handle pickling/unpickling of a concatenated dataset? Will this be cached?\r\n\r\nThis also leads me to ask whether datasets are chunked during pickling? \r\n\r\nThanks,\r\nGunjan",
"Hi ! Yes you're totally right about your two points :)\r\n\r\nAnd in the case of a concatenated dataset, then we should reload each sub-table depending on whether it's in-memory or memory mapped. That means the dataset will be made of several blocks in order to keep track of what's from memory and what's memory mapped. This allows to pickle/unpickle concatenated datasets",
"Hi @lhoestq\r\n\r\nThanks, that sounds nice. Can you explain where the issue of the double memory may arise? Also, why is the existing `concatenate_datasets` not sufficient for this purpose?",
"Hi @lhoestq,\r\n\r\nWill the `add_item` feature also help with lazy writing (or no caching) during `map`/`filter`?",
"> Can you explain where the issue of the double memory may arise?\r\n\r\nWe have to keep each block (in-memory vs memory mapped) separated in order to be able to reload them with pickle.\r\nOn the other hand we also need to have the full table from mixed in-memory and memory mapped data in order to iterate or extract data conveniently. That means that each block is accessible twice: once in the full table, and once in the separated blocks. But since pyarrow tables concatenation doesn't double the memory, then building the full table doesn't cost memory which is what we want :)\r\n\r\n> Also, why is the existing concatenate_datasets not sufficient for this purpose?\r\n\r\nThe existing `concatenate_datasets` doesn't support having both in-memory and memory mapped data together (there's no fancy block separation logic). It works for datasets fully in-memory or fully memory mapped but not a mix of the two.\r\n\r\n> Will the add_item feature also help with lazy writing (or no caching) during map/filter?\r\n\r\nIt will enable the implementation of the fast, masked filter from this discussion: https://github.com/huggingface/datasets/issues/1949\r\nHowever I don't think this will affect map."
] | 2021-02-15T11:39:46
| 2021-03-26T16:51:58
| 2021-03-26T16:51:58
|
MEMBER
| null | null | null | null |
This is a prerequisite for the addition of the `add_item` feature (see #1870).
Currently there is one assumption that we would need to change: a dataset is either fully in memory (dataset._data_files is empty), or the dataset can be reloaded from disk (using the dataset._data_files).
This assumption is used for pickling for example:
- in-memory dataset can just be pickled/unpickled in-memory
- on-disk dataset can be unloaded to only keep the filepaths when pickling, and then reloaded from the disk when unpickling
Maybe let's have a design that allows a Dataset to have a Table that can be rebuilt from heterogenous sources like in-memory tables or on-disk tables ? This could also be further extended in the future
One idea would be to define a list of sources and each source implements a way to reload its corresponding pyarrow Table.
Then the dataset would be the concatenation of all these tables.
Depending on the source type, the serialization using pickle would be different. In-memory data would be copied while on-disk data would simply be replaced by the path to these data.
If you have some ideas you would like to share about the design/API feel free to do so :)
cc @albertvillanova
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1877/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1877/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 39 days, 5:12:12
|
https://api.github.com/repos/huggingface/datasets/issues/1876
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1876/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1876/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1876/events
|
https://github.com/huggingface/datasets/issues/1876
| 808,025,859
|
MDU6SXNzdWU4MDgwMjU4NTk=
| 1,876
|
load_dataset("multi_woz_v22") NonMatchingChecksumError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5945326?v=4",
"events_url": "https://api.github.com/users/Vincent950129/events{/privacy}",
"followers_url": "https://api.github.com/users/Vincent950129/followers",
"following_url": "https://api.github.com/users/Vincent950129/following{/other_user}",
"gists_url": "https://api.github.com/users/Vincent950129/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Vincent950129",
"id": 5945326,
"login": "Vincent950129",
"node_id": "MDQ6VXNlcjU5NDUzMjY=",
"organizations_url": "https://api.github.com/users/Vincent950129/orgs",
"received_events_url": "https://api.github.com/users/Vincent950129/received_events",
"repos_url": "https://api.github.com/users/Vincent950129/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Vincent950129/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vincent950129/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Vincent950129",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Thanks for reporting !\r\nThis is due to the changes made in the data files in the multiwoz repo: https://github.com/budzianowski/multiwoz/pull/59\r\nI'm opening a PR to update the checksums of the data files.",
"I just merged the fix. It will be available in the new release of `datasets` later today.\r\nYou'll be able to get the new version with\r\n```\r\npip install --upgrade datasets\r\n```",
"Hi, I still meet the error when loading the datasets after upgradeing datasets.\r\n\r\nraise NonMatchingChecksumError(error_msg + str(bad_urls))\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dialog_acts.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/test/dialogues_001.json']",
"This must be related to https://github.com/budzianowski/multiwoz/pull/72\r\nThose files have changed, let me update the checksums for this dataset.\r\n\r\nFor now you can use `ignore_verifications=True` in `load_dataset` to skip the checksum verification."
] | 2021-02-14T19:14:48
| 2021-08-04T18:08:00
| 2021-08-04T18:08:00
|
NONE
| null | null | null | null |
Hi, it seems that loading the multi_woz_v22 dataset gives a NonMatchingChecksumError.
To reproduce:
`dataset = load_dataset('multi_woz_v22','v2.2_active_only',split='train')`
This will give the following error:
```
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dialog_acts.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_001.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_003.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_004.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_005.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_006.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_007.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_008.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_009.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_010.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_012.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_013.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_014.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_015.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_016.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/train/dialogues_017.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dev/dialogues_001.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dev/dialogues_002.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/test/dialogues_001.json', 'https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/test/dialogues_002.json']
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1876/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1876/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 170 days, 22:53:12
|
https://api.github.com/repos/huggingface/datasets/issues/1872
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1872/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1872/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1872/events
|
https://github.com/huggingface/datasets/issues/1872
| 807,711,935
|
MDU6SXNzdWU4MDc3MTE5MzU=
| 1,872
|
Adding a new column to the dataset after set_format was called
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"events_url": "https://api.github.com/users/villmow/events{/privacy}",
"followers_url": "https://api.github.com/users/villmow/followers",
"following_url": "https://api.github.com/users/villmow/following{/other_user}",
"gists_url": "https://api.github.com/users/villmow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/villmow",
"id": 2743060,
"login": "villmow",
"node_id": "MDQ6VXNlcjI3NDMwNjA=",
"organizations_url": "https://api.github.com/users/villmow/orgs",
"received_events_url": "https://api.github.com/users/villmow/received_events",
"repos_url": "https://api.github.com/users/villmow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/villmow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/villmow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/villmow",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! Indeed if you add a column to a formatted dataset, then the new dataset gets a new formatting in which:\r\n```\r\nnew formatted columns = (all columns - previously unformatted columns)\r\n```\r\nTherefore the new column is going to be formatted using the `torch` formatting.\r\n\r\nIf you want your new column to be unformatted you can re-run this line:\r\n```python\r\ndata.set_format(\"torch\", columns=[\"some_integer_column1\", \"some_integer_column2\"], output_all_columns=True)\r\n```",
"Hi, thanks that solved my problem. Maybe mention that in the documentation. ",
"Ok cool :) \r\nAlso I just did a PR to mention this behavior in the documentation",
"Closed by #1888"
] | 2021-02-13T09:14:35
| 2021-03-30T14:01:45
| 2021-03-30T14:01:45
|
NONE
| null | null | null | null |
Hi,
thanks for the nice library. I'm in the process of creating a custom dataset, which has a mix of tensors and lists of strings. I stumbled upon an error and want to know if its a problem on my side.
I load some lists of strings and integers, then call `data.set_format("torch", columns=["some_integer_column1", "some_integer_column2"], output_all_columns=True)`. This converts the integer columns into tensors, but keeps the lists of strings as they are. I then call `map` to add a new column to my dataset, which is a **list of strings**. Once I iterate through my dataset, I get an error that the new column can't be converted into a tensor (which is probably caused by `set_format`).
Below some pseudo code:
```python
def augment_func(sample: Dict) -> Dict:
# do something
return {
"some_integer_column1" : augmented_data["some_integer_column1"], # <-- tensor
"some_integer_column2" : augmented_data["some_integer_column2"], # <-- tensor
"NEW_COLUMN": targets, # <-- list of strings
}
data = datasets.load_dataset(__file__, data_dir="...", split="train")
data.set_format("torch", columns=["some_integer_column1", "some_integer_column2"], output_all_columns=True)
augmented_dataset = data.map(augment_func, batched=False)
for sample in augmented_dataset:
print(sample) # fails
```
and the exception:
```python
Traceback (most recent call last):
File "dataset.py", line 487, in <module>
main()
File "dataset.py", line 471, in main
for sample in augmented_dataset:
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 697, in __iter__
yield self._getitem(
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1069, in _getitem
outputs = self._convert_outputs(
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 890, in _convert_outputs
v = map_nested(command, v, **map_nested_kwargs)
File "lib/python3.8/site-packages/datasets/utils/py_utils.py", line 225, in map_nested
return function(data_struct)
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 850, in command
return [map_nested(command, i, **map_nested_kwargs) for i in x]
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 850, in <listcomp>
return [map_nested(command, i, **map_nested_kwargs) for i in x]
File "lib/python3.8/site-packages/datasets/utils/py_utils.py", line 225, in map_nested
return function(data_struct)
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 850, in command
return [map_nested(command, i, **map_nested_kwargs) for i in x]
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 850, in <listcomp>
return [map_nested(command, i, **map_nested_kwargs) for i in x]
File "lib/python3.8/site-packages/datasets/utils/py_utils.py", line 225, in map_nested
return function(data_struct)
File "lib/python3.8/site-packages/datasets/arrow_dataset.py", line 851, in command
return torch.tensor(x, **format_kwargs)
TypeError: new(): invalid data type 'str'
```
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1872/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1872/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 45 days, 4:47:10
|
https://api.github.com/repos/huggingface/datasets/issues/1867
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1867/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1867/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1867/events
|
https://github.com/huggingface/datasets/issues/1867
| 807,127,181
|
MDU6SXNzdWU4MDcxMjcxODE=
| 1,867
|
ERROR WHEN USING SET_TRANSFORM()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avacaondata",
"id": 35173563,
"login": "avacaondata",
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avacaondata",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @alejandrocros it looks like an incompatibility with the current Trainer @sgugger \r\nIndeed currently the Trainer of `transformers` doesn't support a dataset with a transform\r\n\r\nIt looks like it comes from this line: https://github.com/huggingface/transformers/blob/f51188cbe74195c14c5b3e2e8f10c2f435f9751a/src/transformers/trainer.py#L442\r\n\r\nThis line sets the format to not return certain unused columns. But this has two issues:\r\n1. it forgets to also set the format_kwargs (this causes the error you got):\r\n```python\r\ndataset.set_format(type=dataset.format[\"type\"], columns=columns, format_kwargs=dataset.format[\"format_kwargs\"])\r\n```\r\n2. the Trainer wants to keep only the fields that are used as input for a model. However for a dataset with a transform, the output fields are often different from the columns fields. For example from a column \"text\" in the dataset, the strings can be transformed on-the-fly into \"input_ids\". If you want your dataset to only output certain fields and not other you must change your transform function.\r\n",
"FYI that option can be removed with `remove_unused_columns = False` in your `TrainingArguments`, so there is a workaround @alexvaca0 while the fix in `Trainer` is underway.\r\n\r\n@lhoestq I think I will just use the line you suggested and if someone is using the columns that are removed in their transform they will need to change `remove_unused_columns` to `False`. We might switch the default of that argument in the next version if that proves too bug-proof.",
"I've tried your solutions @sgugger @lhoestq and the good news is that it throws no error. However, TPU training is taking forever, in 1 hour it has only trained 1 batch of 8192 elements, which doesn't make much sense... Is it possible that \"on the fly\" tokenization of batches is slowing down TPU training to that extent?",
"I'm pretty sure this is because of padding but @sgugger might know better",
"I don't know what the value of `padding` is in your lines of code pasted above so I can't say for sure. The first batch will be very slow on TPU since it compiles everything, so that's normal (1 hour is long but 8192 elements is also large). Then if your batches are not of the same lengths, it will recompile everything at each step instead of using the same graph, which will be very slow, so you should double check you are using padding to make everything the exact same shape. ",
"I have tried now on a GPU and it goes smooth! Amazing feature .set_transform() instead of .map()! Now I can pre-train my model without the hard disk limitation. Thanks for your work all HuggingFace team!! :clap: ",
"In the end, to make it work I turned to A-100 gpus instead of TPUS, among other changes. Set_transform doesn't work as expected and slows down training very much even in GPUs, and applying map destroys the disk, as it multiplies by 100 the size of the data passed to it (due to inefficient implementation converting strings to int64 floats I guess). For that reason, I chose to use datasets to load the data as text, and then edit the Collator from Transformers to tokenize every batch it receives before processing it. That way, I'm being able to train fast, without memory breaks, without the disk being unnecessarily filled, while making use of GPUs almost all the time I'm paying for them (the map function over the whole dataset took ~15hrs, in which you're not training at all). I hope this info helps others that are looking for training a language model from scratch cheaply, I'm going to close the issue as the optimal solution I found after many experiments to the problem posted in it is explained above. ",
"Great comment @alexvaca0 . I think that we could re-open the issue as a reformulation of why it takes so much space to save the arrow. Saving a 1% of oscar corpus takes more thank 600 GB (it breaks when it pass 600GB because it is the free memory that I have at this moment) when the full dataset is 1,3 TB. I have a 1TB M.2 NVMe disk that I can not train on because the saved .arrow files goes crazily big. If you can share your Collator I will be grateful. "
] | 2021-02-12T10:38:31
| 2021-03-01T14:04:24
| 2021-02-24T12:00:43
|
NONE
| null | null | null | null |
Hi, I'm trying to use dataset.set_transform(encode) as @lhoestq told me in this issue: https://github.com/huggingface/datasets/issues/1825#issuecomment-774202797
However, when I try to use Trainer from transformers with such dataset, it throws an error:
```
TypeError: __init__() missing 1 required positional argument: 'transform'
[INFO|trainer.py:357] 2021-02-12 10:18:09,893 >> The following columns in the training set don't have a corresponding argument in `AlbertForMaskedLM.forward` and have been ignored: text.
Exception in device=TPU:0: __init__() missing 1 required positional argument: 'transform'
Traceback (most recent call last):
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 330, in _mp_start_fn
_start_fn(index, pf_cfg, fn, args)
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/torch_xla/distributed/xla_multiprocessing.py", line 324, in _start_fn
fn(gindex, *args)
File "/home/alejandro_vaca/transformers/examples/language-modeling/run_mlm_wwm.py", line 368, in _mp_fn
main()
File "/home/alejandro_vaca/transformers/examples/language-modeling/run_mlm_wwm.py", line 332, in main
data_collator=data_collator,
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/trainer.py", line 286, in __init__
self._remove_unused_columns(self.train_dataset, description="training")
File "/anaconda3/envs/torch-xla-1.7/lib/python3.6/site-packages/transformers/trainer.py", line 359, in _remove_unused_columns
dataset.set_format(type=dataset.format["type"], columns=columns)
File "/home/alejandro_vaca/datasets/src/datasets/fingerprint.py", line 312, in wrapper
out = func(self, *args, **kwargs)
File "/home/alejandro_vaca/datasets/src/datasets/arrow_dataset.py", line 818, in set_format
_ = get_formatter(type, **format_kwargs)
File "/home/alejandro_vaca/datasets/src/datasets/formatting/__init__.py", line 112, in get_formatter
return _FORMAT_TYPES[format_type](**format_kwargs)
TypeError: __init__() missing 1 required positional argument: 'transform'
```
The code I'm using:
```{python}
def tokenize_function(examples):
# Remove empty lines
examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
return tokenizer(examples["text"], padding=padding, truncation=True, max_length=data_args.max_seq_length)
datasets.set_transform(tokenize_function)
data_collator = DataCollatorForWholeWordMask(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=datasets["train"] if training_args.do_train else None,
eval_dataset=datasets["val"] if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
)
```
I've installed from source, master branch.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avacaondata",
"id": 35173563,
"login": "avacaondata",
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avacaondata",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1867/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1867/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 12 days, 1:22:12
|
https://api.github.com/repos/huggingface/datasets/issues/1864
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1864/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1864/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1864/events
|
https://github.com/huggingface/datasets/issues/1864
| 806,172,843
|
MDU6SXNzdWU4MDYxNzI4NDM=
| 1,864
|
Add Winogender Schemas
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NielsRogge",
"id": 48327001,
"login": "NielsRogge",
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NielsRogge",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] |
[
"Nevermind, this one is already available on the hub under the name `'wino_bias'`: https://huggingface.co/datasets/wino_bias"
] | 2021-02-11T08:18:38
| 2021-02-11T08:19:51
| 2021-02-11T08:19:51
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** Winogender Schemas
- **Description:** Winogender Schemas (inspired by Winograd Schemas) are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias in automated coreference resolution systems.
- **Paper:** https://arxiv.org/abs/1804.09301
- **Data:** https://github.com/rudinger/winogender-schemas (see data directory)
- **Motivation:** Testing gender bias in automated coreference resolution systems, improve coreference resolution in general.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NielsRogge",
"id": 48327001,
"login": "NielsRogge",
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NielsRogge",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1864/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1864/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:01:13
|
https://api.github.com/repos/huggingface/datasets/issues/1863
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1863/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1863/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1863/events
|
https://github.com/huggingface/datasets/issues/1863
| 806,171,311
|
MDU6SXNzdWU4MDYxNzEzMTE=
| 1,863
|
Add WikiCREM
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NielsRogge",
"id": 48327001,
"login": "NielsRogge",
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NielsRogge",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
open
| false
| null |
[] |
[
"Hi @NielsRogge I would like to work on this dataset.\r\n\r\nThanks!",
"Hi @udapy, are you working on this?"
] | 2021-02-11T08:16:00
| 2021-03-07T07:27:13
| null |
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** WikiCREM
- **Description:** A large unsupervised corpus for coreference resolution.
- **Paper:** https://arxiv.org/abs/1905.06290
- **Github repo:**: https://github.com/vid-koci/bert-commonsense
- **Data:** https://ora.ox.ac.uk/objects/uuid:c83e94bb-7584-41a1-aef9-85b0e764d9e3
- **Motivation:** Coreference resolution, common sense reasoning
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1863/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1863/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1859
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1859/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1859/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1859/events
|
https://github.com/huggingface/datasets/issues/1859
| 805,479,025
|
MDU6SXNzdWU4MDU0NzkwMjU=
| 1,859
|
Error "in void don't know how to serialize this type of index" when saving index to disk when device=0 (GPU)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3995321?v=4",
"events_url": "https://api.github.com/users/corticalstack/events{/privacy}",
"followers_url": "https://api.github.com/users/corticalstack/followers",
"following_url": "https://api.github.com/users/corticalstack/following{/other_user}",
"gists_url": "https://api.github.com/users/corticalstack/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/corticalstack",
"id": 3995321,
"login": "corticalstack",
"node_id": "MDQ6VXNlcjM5OTUzMjE=",
"organizations_url": "https://api.github.com/users/corticalstack/orgs",
"received_events_url": "https://api.github.com/users/corticalstack/received_events",
"repos_url": "https://api.github.com/users/corticalstack/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/corticalstack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/corticalstack/subscriptions",
"type": "User",
"url": "https://api.github.com/users/corticalstack",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @corticalstack ! Thanks for reporting. Indeed in the recent versions of Faiss we must use `getDevice` to check if the index in on GPU.\r\n\r\nI'm opening a PR",
"I fixed this issue. It should work fine now.\r\nFeel free to try it out by installing `datasets` from source.\r\nOtherwise you can wait for the next release of `datasets` (in a few days)",
"Thanks for such a quick fix and merge to master, pip installed git master, tested all OK"
] | 2021-02-10T12:41:00
| 2021-02-10T18:32:12
| 2021-02-10T18:17:47
|
NONE
| null | null | null | null |
Error serializing faiss index. Error as follows:
`Error in void faiss::write_index(const faiss::Index*, faiss::IOWriter*) at /home/conda/feedstock_root/build_artifacts/faiss-split_1612472484670/work/faiss/impl/index_write.cpp:453: don't know how to serialize this type of index`
Note:
`torch.cuda.is_available()` reports:
```
Cuda is available
cuda:0
```
Adding index, device=0 for GPU.
`dataset.add_faiss_index(column='embeddings', index_name='idx_embeddings', device=0)`
However, during a quick debug, self.faiss_index has no attr "device" when checked in` search.py, method save`, so fails to transform gpu index to cpu index. If I add index without device, index is saved OK.
```
def save(self, file: str):
"""Serialize the FaissIndex on disk"""
import faiss # noqa: F811
if (
hasattr(self.faiss_index, "device")
and self.faiss_index.device is not None
and self.faiss_index.device > -1
):
index = faiss.index_gpu_to_cpu(self.faiss_index)
else:
index = self.faiss_index
faiss.write_index(index, file)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1859/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1859/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5:36:47
|
https://api.github.com/repos/huggingface/datasets/issues/1857
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1857/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1857/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1857/events
|
https://github.com/huggingface/datasets/issues/1857
| 805,391,107
|
MDU6SXNzdWU4MDUzOTExMDc=
| 1,857
|
Unable to upload "community provided" dataset - 400 Client Error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1376337?v=4",
"events_url": "https://api.github.com/users/mwrzalik/events{/privacy}",
"followers_url": "https://api.github.com/users/mwrzalik/followers",
"following_url": "https://api.github.com/users/mwrzalik/following{/other_user}",
"gists_url": "https://api.github.com/users/mwrzalik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mwrzalik",
"id": 1376337,
"login": "mwrzalik",
"node_id": "MDQ6VXNlcjEzNzYzMzc=",
"organizations_url": "https://api.github.com/users/mwrzalik/orgs",
"received_events_url": "https://api.github.com/users/mwrzalik/received_events",
"repos_url": "https://api.github.com/users/mwrzalik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mwrzalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mwrzalik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mwrzalik",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! We're in the process of switching the community datasets to git repos, exactly like what we're doing for models.\r\nYou can find an example here:\r\nhttps://huggingface.co/datasets/lhoestq/custom_squad/tree/main\r\n\r\nWe'll update the CLI in the coming days and do a new release :)\r\n\r\nAlso cc @julien-c maybe we can make improve the error message ?"
] | 2021-02-10T10:39:01
| 2021-08-03T05:06:13
| 2021-08-03T05:06:13
|
NONE
| null | null | null | null |
Hi,
i'm trying to a upload a dataset as described [here](https://huggingface.co/docs/datasets/v1.2.0/share_dataset.html#sharing-a-community-provided-dataset). This is what happens:
```
$ datasets-cli login
$ datasets-cli upload_dataset my_dataset
About to upload file /path/to/my_dataset/dataset_infos.json to S3 under filename my_dataset/dataset_infos.json and namespace username
About to upload file /path/to/my_dataset/my_dataset.py to S3 under filename my_dataset/my_dataset.py and namespace username
Proceed? [Y/n] Y
Uploading... This might take a while if files are large
400 Client Error: Bad Request for url: https://huggingface.co/api/datasets/presign
huggingface.co migrated to a new model hosting system.
You need to upgrade to transformers v3.5+ to upload new models.
More info at https://discuss.hugginface.co or https://twitter.com/julien_c. Thank you!
```
I'm using the latest releases of datasets and transformers.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1857/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1857/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 173 days, 18:27:12
|
https://api.github.com/repos/huggingface/datasets/issues/1856
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1856/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1856/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1856/events
|
https://github.com/huggingface/datasets/issues/1856
| 805,360,200
|
MDU6SXNzdWU4MDUzNjAyMDA=
| 1,856
|
load_dataset("amazon_polarity") NonMatchingChecksumError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19946372?v=4",
"events_url": "https://api.github.com/users/yanxi0830/events{/privacy}",
"followers_url": "https://api.github.com/users/yanxi0830/followers",
"following_url": "https://api.github.com/users/yanxi0830/following{/other_user}",
"gists_url": "https://api.github.com/users/yanxi0830/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yanxi0830",
"id": 19946372,
"login": "yanxi0830",
"node_id": "MDQ6VXNlcjE5OTQ2Mzcy",
"organizations_url": "https://api.github.com/users/yanxi0830/orgs",
"received_events_url": "https://api.github.com/users/yanxi0830/received_events",
"repos_url": "https://api.github.com/users/yanxi0830/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yanxi0830/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanxi0830/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yanxi0830",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! This issue may be related to #996 \r\nThis comes probably from the Quota Exceeded error from Google Drive.\r\nCan you try again tomorrow and see if you still have the error ?\r\n\r\nOn my side I didn't get any error today with `load_dataset(\"amazon_polarity\")`",
"+1 encountering this issue as well",
"@lhoestq Hi! I encounter the same error when loading `yelp_review_full`.\r\n\r\n```\r\nfrom datasets import load_dataset\r\ndataset_yp = load_dataset(\"yelp_review_full\")\r\n```\r\n\r\nWhen you say the \"Quota Exceeded from Google drive\". Is this a quota from the dataset owner? or the quota from our (the runner) Google Drive?",
"+1 Also encountering this issue",
"> When you say the \"Quota Exceeded from Google drive\". Is this a quota from the dataset owner? or the quota from our (the runner) Google Drive?\r\n\r\nEach file on Google Drive can be downloaded only a certain amount of times per day because of a quota. The quota is reset every day. So if too many people download the dataset the same day, then the quota is likely to exceed.\r\nThat's a really bad limitations of Google Drive and we should definitely find another host for these dataset than Google Drive.\r\nFor now I would suggest to wait and try again later..\r\n\r\nSo far the issue happened with CNN DailyMail, Amazon Polarity and Yelp Reviews. \r\nAre you experiencing the issue with other datasets ? @calebchiam @dtch1997 ",
"@lhoestq Gotcha, that is quite problematic...for what it's worth, I've had no issues with the other datasets I tried, such as `yelp_reviews_full` and `amazon_reviews_multi`.",
"Same issue today with \"big_patent\", though the symptoms are slightly different.\r\n\r\nWhen running\r\n\r\n```py\r\nfrom datasets import load_dataset\r\nload_dataset(\"big_patent\", split=\"validation\")\r\n```\r\n\r\nI get the following\r\n`FileNotFoundError: Local file \\huggingface\\datasets\\downloads\\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\\bigPatentData\\train.tar.gz doesn't exist`\r\n\r\nI had to look into `6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5` (which is a file instead of a folder) and got the following:\r\n\r\n`<!DOCTYPE html><html><head><title>Google Drive - Quota exceeded</title><meta http-equiv=\"content-type\" content=\"text/html; charset=utf-8\"/><link href=/static/doclist/client/css/4033072956-untrustedcontent.css rel=\"stylesheet\" nonce=\"JV0t61Smks2TEKdFCGAUFA\"><link rel=\"icon\" href=\"//ssl.gstatic.com/images/branding/product/1x/drive_2020q4_32dp.png\"/><style nonce=\"JV0t61Smks2TEKdFCGAUFA\">#gbar,#guser{font-size:13px;padding-top:0px !important;}#gbar{height:22px}#guser{padding-bottom:7px !important;text-align:right}.gbh,.gbd{border-top:1px solid #c9d7f1;font-size:1px}.gbh{height:0;position:absolute;top:24px;width:100%}@media all{.gb1{height:22px;margin-right:.5em;vertical-align:top}#gbar{float:left}}a.gb1,a.gb4{text-decoration:underline !important}a.gb1,a.gb4{color:#00c !important}.gbi .gb4{color:#dd8e27 !important}.gbf .gb4{color:#900 !important}\r\n</style><script nonce=\"iNUHigT+ENVQ3UZrLkFtRw\"></script></head><body><div id=gbar><nobr><a target=_blank class=gb1 href=\"https://www.google.fr/webhp?tab=ow\">Search</a> <a target=_blank class=gb1 href=\"http://www.google.fr/imghp?hl=en&tab=oi\">Images</a> <a target=_blank class=gb1 href=\"https://maps.google.fr/maps?hl=en&tab=ol\">Maps</a> <a target=_blank class=gb1 href=\"https://play.google.com/?hl=en&tab=o8\">Play</a> <a target=_blank class=gb1 href=\"https://www.youtube.com/?gl=FR&tab=o1\">YouTube</a> <a target=_blank class=gb1 href=\"https://news.google.com/?tab=on\">News</a> <a target=_blank class=gb1 href=\"https://mail.google.com/mail/?tab=om\">Gmail</a> <b class=gb1>Drive</b> <a target=_blank class=gb1 style=\"text-decoration:none\" href=\"https://www.google.fr/intl/en/about/products?tab=oh\"><u>More</u> »</a></nobr></div><div id=guser width=100%><nobr><span id=gbn class=gbi></span><span id=gbf class=gbf></span><span id=gbe></span><a target=\"_self\" href=\"/settings?hl=en_US\" class=gb4>Settings</a> | <a target=_blank href=\"//support.google.com/drive/?p=web_home&hl=en_US\" class=gb4>Help</a> | <a target=_top id=gb_70 href=\"https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://drive.google.com/uc%3Fexport%3Ddownload%26id%3D1J3mucMFTWrgAYa3LuBZoLRR3CzzYD3fa&service=writely&ec=GAZAMQ\" class=gb4>Sign in</a></nobr></div><div class=gbh style=left:0></div><div class=gbh style=right:0></div><div class=\"uc-main\"><div id=\"uc-text\"><p class=\"uc-error-caption\">Sorry, you can't view or download this file at this time.</p><p class=\"uc-error-subcaption\">Too many users have viewed or downloaded this file recently. Please try accessing the file again later. If the file you are trying to access is particularly large or is shared with many people, it may take up to 24 hours to be able to view or download the file. If you still can't access a file after 24 hours, contact your domain administrator.</p></div></div><div class=\"uc-footer\"><hr class=\"uc-footer-divider\">© 2021 Google - <a class=\"goog-link\" href=\"//support.google.com/drive/?p=web_home\">Help</a> - <a class=\"goog-link\" href=\"//support.google.com/drive/bin/answer.py?hl=en_US&answer=2450387\">Privacy & Terms</a></div></body></html>`",
"A similar issue arises when trying to stream the dataset\r\n\r\n```python\r\n>>> from datasets import load_dataset\r\n>>> iter_dset = load_dataset(\"amazon_polarity\", split=\"test\", streaming=True)\r\n>>> iter(iter_dset).__next__()\r\n\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n~\\lib\\tarfile.py in nti(s)\r\n 186 s = nts(s, \"ascii\", \"strict\")\r\n--> 187 n = int(s.strip() or \"0\", 8)\r\n 188 except ValueError:\r\n\r\nValueError: invalid literal for int() with base 8: 'e nonce='\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nInvalidHeaderError Traceback (most recent call last)\r\n~\\lib\\tarfile.py in next(self)\r\n 2288 try:\r\n-> 2289 tarinfo = self.tarinfo.fromtarfile(self)\r\n 2290 except EOFHeaderError as e:\r\n\r\n~\\lib\\tarfile.py in fromtarfile(cls, tarfile)\r\n 1094 buf = tarfile.fileobj.read(BLOCKSIZE)\r\n-> 1095 obj = cls.frombuf(buf, tarfile.encoding, tarfile.errors)\r\n 1096 obj.offset = tarfile.fileobj.tell() - BLOCKSIZE\r\n\r\n~\\lib\\tarfile.py in frombuf(cls, buf, encoding, errors)\r\n 1036\r\n-> 1037 chksum = nti(buf[148:156])\r\n 1038 if chksum not in calc_chksums(buf):\r\n\r\n~\\lib\\tarfile.py in nti(s)\r\n 188 except ValueError:\r\n--> 189 raise InvalidHeaderError(\"invalid header\")\r\n 190 return n\r\n\r\nInvalidHeaderError: invalid header\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nReadError Traceback (most recent call last)\r\n<ipython-input-5-6b9058341b2b> in <module>\r\n----> 1 iter(iter_dset).__next__()\r\n\r\n~\\lib\\site-packages\\datasets\\iterable_dataset.py in __iter__(self)\r\n 363\r\n 364 def __iter__(self):\r\n--> 365 for key, example in self._iter():\r\n 366 if self.features:\r\n 367 # we encode the example for ClassLabel feature types for example\r\n\r\n~\\lib\\site-packages\\datasets\\iterable_dataset.py in _iter(self)\r\n 360 else:\r\n 361 ex_iterable = self._ex_iterable\r\n--> 362 yield from ex_iterable\r\n 363\r\n 364 def __iter__(self):\r\n\r\n~\\lib\\site-packages\\datasets\\iterable_dataset.py in __iter__(self)\r\n 77\r\n 78 def __iter__(self):\r\n---> 79 yield from self.generate_examples_fn(**self.kwargs)\r\n 80\r\n 81 def shuffle_data_sources(self, seed: Optional[int]) -> \"ExamplesIterable\":\r\n\r\n~\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\amazon_polarity\\56923eeb72030cb6c4ea30c8a4e1162c26b25973475ac1f44340f0ec0f2936f4\\amazon_polarity.py in _generate_examples(self, filepath, files)\r\n 114 def _generate_examples(self, filepath, files):\r\n 115 \"\"\"Yields examples.\"\"\"\r\n--> 116 for path, f in files:\r\n 117 if path == filepath:\r\n 118 lines = (line.decode(\"utf-8\") for line in f)\r\n\r\n~\\lib\\site-packages\\datasets\\utils\\streaming_download_manager.py in __iter__(self)\r\n 616\r\n 617 def __iter__(self):\r\n--> 618 yield from self.generator(*self.args, **self.kwargs)\r\n 619\r\n 620\r\n\r\n~\\lib\\site-packages\\datasets\\utils\\streaming_download_manager.py in _iter_from_urlpath(cls, urlpath, use_auth_token)\r\n 644 ) -> Generator[Tuple, None, None]:\r\n 645 with xopen(urlpath, \"rb\", use_auth_token=use_auth_token) as f:\r\n--> 646 yield from cls._iter_from_fileobj(f)\r\n 647\r\n 648 @classmethod\r\n\r\n~\\lib\\site-packages\\datasets\\utils\\streaming_download_manager.py in _iter_from_fileobj(cls, f)\r\n 624 @classmethod\r\n 625 def _iter_from_fileobj(cls, f) -> Generator[Tuple, None, None]:\r\n--> 626 stream = tarfile.open(fileobj=f, mode=\"r|*\")\r\n 627 for tarinfo in stream:\r\n 628 file_path = tarinfo.name\r\n\r\n~\\lib\\tarfile.py in open(cls, name, mode, fileobj, bufsize, **kwargs)\r\n 1603 stream = _Stream(name, filemode, comptype, fileobj, bufsize)\r\n 1604 try:\r\n-> 1605 t = cls(name, filemode, stream, **kwargs)\r\n 1606 except:\r\n 1607 stream.close()\r\n\r\n~\\lib\\tarfile.py in __init__(self, name, mode, fileobj, format, tarinfo, dereference, ignore_zeros, encoding, errors, pax_headers, debug, errorlevel, copybufsize)\r\n 1484 if self.mode == \"r\":\r\n 1485 self.firstmember = None\r\n-> 1486 self.firstmember = self.next()\r\n 1487\r\n 1488 if self.mode == \"a\":\r\n\r\n~\\lib\\tarfile.py in next(self)\r\n 2299 continue\r\n 2300 elif self.offset == 0:\r\n-> 2301 raise ReadError(str(e))\r\n 2302 except EmptyHeaderError:\r\n 2303 if self.offset == 0:\r\n\r\nReadError: invalid header\r\n\r\n```",
"This error still happens, but for a different reason now: Google Drive returns a warning instead of the dataset.",
"Met the same issue +1",
"Hi ! Thanks for reporting. Google Drive changed the way to bypass the warning message recently.\r\n\r\nThe latest release `1.18.4` fixes this for datasets loaded in a regular way.\r\n\r\nWe opened a PR to fix this recently for streaming mode at #3843 - we'll do a new release once the fix is merged :)",
"Fixed by:\r\n- #3787 \r\n- #3843"
] | 2021-02-10T10:00:56
| 2022-03-15T13:55:24
| 2022-03-15T13:55:23
|
NONE
| null | null | null | null |
Hi, it seems that loading the amazon_polarity dataset gives a NonMatchingChecksumError.
To reproduce:
```
load_dataset("amazon_polarity")
```
This will give the following error:
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-3-8559a03fe0f8> in <module>()
----> 1 dataset = load_dataset("amazon_polarity")
3 frames
/usr/local/lib/python3.6/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
37 if len(bad_urls) > 0:
38 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 39 raise NonMatchingChecksumError(error_msg + str(bad_urls))
40 logger.info("All the checksums matched successfully" + for_verification_name)
41
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?id=0Bz8a_Dbh9QhbaW12WVVZS2drcnM&export=download']
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1856/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1856/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 398 days, 3:54:27
|
https://api.github.com/repos/huggingface/datasets/issues/1854
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1854/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1854/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1854/events
|
https://github.com/huggingface/datasets/issues/1854
| 805,204,397
|
MDU6SXNzdWU4MDUyMDQzOTc=
| 1,854
|
Feature Request: Dataset.add_item
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"Hi @sshleifer.\r\n\r\nI am not sure of understanding the need of the `add_item` approach...\r\n\r\nBy just reading your \"Desired API\" section, I would say you could (nearly) get it with a 1-column Dataset:\r\n```python\r\ndata = {\"input_ids\": [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])]}\r\nds = Dataset.from_dict(data)\r\nassert (ds[\"input_ids\"][0] == np.array([4,4,2])).all()\r\n```",
"Hi @sshleifer :) \r\n\r\nWe don't have methods like `Dataset.add_batch` or `Dataset.add_entry/add_item` yet.\r\nBut that's something we'll add pretty soon. Would an API that looks roughly like this help ? Do you have suggestions ?\r\n```python\r\nimport numpy as np\r\nfrom datasets import Dataset\r\n\r\ntokenized = [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])\r\n\r\n# API suggestion (not available yet)\r\nd = Dataset()\r\nfor input_ids in tokenized:\r\n d.add_item({\"input_ids\": input_ids})\r\n\r\nprint(d[0][\"input_ids\"])\r\n# [4, 4, 2]\r\n```\r\n\r\nCurrently you can define a dataset with what @albertvillanova suggest, or via a generator using dataset builders. It's also possible to [concatenate datasets](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=concatenate#datasets.concatenate_datasets).",
"Your API looks perfect @lhoestq, thanks!"
] | 2021-02-10T06:06:00
| 2021-04-23T10:01:30
| 2021-04-23T10:01:30
|
CONTRIBUTOR
| null | null | null | null |
I'm trying to integrate `huggingface/datasets` functionality into `fairseq`, which requires (afaict) being able to build a dataset through an `add_item` method, such as https://github.com/pytorch/fairseq/blob/master/fairseq/data/indexed_dataset.py#L318, as opposed to loading all the text into arrow, and then `dataset.map(binarizer)`.
Is this possible at the moment? Is there an example? I'm happy to use raw `pa.Table` but not sure whether it will support uneven length entries.
### Desired API
```python
import numpy as np
tokenized: List[np.NDArray[np.int64]] = [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])
def build_dataset_from_tokenized(tokenized: List[np.NDArray[int]]) -> Dataset:
"""FIXME"""
dataset = EmptyDataset()
for t in tokenized: dataset.append(t)
return dataset
ds = build_dataset_from_tokenized(tokenized)
assert (ds[0] == np.array([4,4,2])).all()
```
### What I tried
grep, google for "add one entry at a time", "datasets.append"
### Current Code
This code achieves the same result but doesn't fit into the `add_item` abstraction.
```python
dataset = load_dataset('text', data_files={'train': 'train.txt'})
tokenizer = RobertaTokenizerFast.from_pretrained('roberta-base', max_length=4096)
def tokenize_function(examples):
ids = tokenizer(examples['text'], return_attention_mask=False)['input_ids']
return {'input_ids': [x[1:] for x in ids]}
ds = dataset.map(tokenize_function, batched=True, num_proc=4, remove_columns=['text'], load_from_cache_file=not overwrite_cache)
print(ds['train'][0]) => np array
```
Thanks in advance!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1854/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1854/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 72 days, 3:55:30
|
https://api.github.com/repos/huggingface/datasets/issues/1849
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1849/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1849/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1849/events
|
https://github.com/huggingface/datasets/issues/1849
| 804,292,971
|
MDU6SXNzdWU4MDQyOTI5NzE=
| 1,849
|
Add TIMIT
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"@patrickvonplaten Could you please help me with how the output text has to be represented in the data? TIMIT has Words, Phonemes and texts. Also has lot on info on the speaker and the dialect. Could you please help me? An example of how to arrange it would be super helpful!\r\n\r\n",
"Hey @vrindaprabhu - sure I'll help you :-) Could you open a first PR for TIMIT where you copy-paste more or less the `librispeech_asr` script: https://github.com/huggingface/datasets/blob/28be129db862ec89a87ac9349c64df6b6118aff4/datasets/librispeech_asr/librispeech_asr.py#L93 (obviously replacing all the naming and links correctly...) and then you can list all possible outputs in the features dict: https://github.com/huggingface/datasets/blob/28be129db862ec89a87ac9349c64df6b6118aff4/datasets/librispeech_asr/librispeech_asr.py#L104 (words, phonemes should probably be of kind `datasets.Sequence(datasets.Value(\"string\"))` and texts I think should be of type `\"text\": datasets.Value(\"string\")`.\r\n\r\nWhen you've opened a first PR, I think it'll be much easier for us to take a look together :-) ",
"I am sorry! I created the PR [#1903](https://github.com/huggingface/datasets/pull/1903#). Requesting your comments! CircleCI tests are failing, will address them along with your comments!"
] | 2021-02-09T07:29:41
| 2021-03-15T05:59:37
| 2021-03-15T05:59:37
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *TIMIT*
- **Description:** *The TIMIT corpus of read speech has been designed to provide speech data for the acquisition of acoustic-phonetic knowledge and for the development and evaluation of automatic speech recognition systems*
- **Paper:** *Homepage*: http://groups.inf.ed.ac.uk/ami/corpus/ / *Wikipedia*: https://en.wikipedia.org/wiki/TIMIT
- **Data:** *https://deepai.org/dataset/timit*
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1849/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1849/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 33 days, 22:29:56
|
https://api.github.com/repos/huggingface/datasets/issues/1844
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1844/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1844/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1844/events
|
https://github.com/huggingface/datasets/issues/1844
| 803,588,125
|
MDU6SXNzdWU4MDM1ODgxMjU=
| 1,844
|
Update Open Subtitles corpus with original sentence IDs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19476123?v=4",
"events_url": "https://api.github.com/users/Valahaar/events{/privacy}",
"followers_url": "https://api.github.com/users/Valahaar/followers",
"following_url": "https://api.github.com/users/Valahaar/following{/other_user}",
"gists_url": "https://api.github.com/users/Valahaar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Valahaar",
"id": 19476123,
"login": "Valahaar",
"node_id": "MDQ6VXNlcjE5NDc2MTIz",
"organizations_url": "https://api.github.com/users/Valahaar/orgs",
"received_events_url": "https://api.github.com/users/Valahaar/received_events",
"repos_url": "https://api.github.com/users/Valahaar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Valahaar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Valahaar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Valahaar",
"user_view_type": "public"
}
|
[
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] |
closed
| false
| null |
[] |
[
"Hi ! You're right this can can useful.\r\nThis should be easy to add, so feel free to give it a try if you want to contribute :)\r\nI think we just need to add it to the _generate_examples method of the OpenSubtitles dataset builder [here](https://github.com/huggingface/datasets/blob/master/datasets/open_subtitles/open_subtitles.py#L103)",
"Hey @lhoestq , absolutely yes! Just one question before I start implementing. The ids found in the zip file have this format: \r\n(the following is line `22497315` of the `ids` file of the `de-en` dump)\r\n\r\n\r\n`de/2017/7006210/7063319.xml.gz en/2017/7006210/7050201.xml.gz 335 339 340` (every space is actually a tab, aside from the space between `339` and `340`)\r\n\r\n\r\nWhere filenames encode the information like this: `lang/year/imdb_id/opensubtitles_id.xml.gz` whereas the numbers correspond to the sentence ids which are linked together (i.e. sentence `335` of the German subtitle corresponds to lines `339` and `340` of the English file)\r\n\r\nThat being said, do you think I should stick to the raw sentence id (and replace the current sequential id) or should I include more detailed metadata (or both things maybe)?\r\n\r\nGoing with raw ID is surely simpler, but including `year`, `imdbId` and `subtitleId` should save space as they're just integers; besides, any operation (like filtering or grouping) will be much easier if users don't have to manually parse the ids every time.\r\nAs for the language-specific sentenceIds, what could be the best option? A list of integers or a comma-separated string?\r\n\r\n**Note:** I did not find any official information about this encoding, but it appears to check out:\r\nhttps://www.imdb.com/title/tt7006210/, https://www.opensubtitles.org/en/subtitles/7063319 and https://www.opensubtitles.org/en/subtitles/7050201 all link to the same episode, so I guess (I hope!) it's correct.\r\n\r\n",
"I like the idea of having `year`, `imdbId` and `subtitleId` as columns for filtering for example.\r\nAnd for the `sentenceIds` a list of integers is fine.",
"Thanks for improving it @Valahaar :) ",
"Something like this? (adapted from [here](https://github.com/huggingface/datasets/blob/master/datasets/open_subtitles/open_subtitles.py#L114))\r\n\r\n```python\r\nresult = (\r\n sentence_counter,\r\n {\r\n \"id\": str(sentence_counter),\r\n \"meta\": {\r\n \"year\": year,\r\n \"imdbId\": imdb_id,\r\n \"subtitleId\": {l1: l1_sub_id, l2: l2_sub_id},\r\n \"sentenceIds\": {l1: [... source_sids ...], l2: [... target_sids ...]},\r\n # or maybe src/tgt? I'd go with the first one for consistency with 'translation'\r\n \"subtitleId\": {\"src\": l1_sub_id, \"tgt\": l2_sub_id},\r\n \"sentenceIds\": {\"src\": [... source_sids ...], \"tgt\": [... target_sids ...]},\r\n },\r\n \"translation\": {l1: x, l2: y},\r\n },\r\n )\r\n```\r\nOr at top level, avoiding nesting into 'meta'?",
"Merged in #1865, closing. Thanks :)"
] | 2021-02-08T13:55:13
| 2021-02-12T17:38:58
| 2021-02-12T17:38:58
|
CONTRIBUTOR
| null | null | null | null |
Hi! It would be great if you could add the original sentence ids to [Open Subtitles](https://huggingface.co/datasets/open_subtitles).
I can think of two reasons: first, it's possible to gather sentences for an entire document (the original ids contain media id, subtitle file id and sentence id), therefore somewhat allowing for document-level machine translation (and other document-level stuff which could be cool to have); second, it's possible to have parallel sentences in multiple languages, as they share the same ids across bitexts.
I think I should tag @abhishekkrthakur as he's the one who added it in the first place.
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19476123?v=4",
"events_url": "https://api.github.com/users/Valahaar/events{/privacy}",
"followers_url": "https://api.github.com/users/Valahaar/followers",
"following_url": "https://api.github.com/users/Valahaar/following{/other_user}",
"gists_url": "https://api.github.com/users/Valahaar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Valahaar",
"id": 19476123,
"login": "Valahaar",
"node_id": "MDQ6VXNlcjE5NDc2MTIz",
"organizations_url": "https://api.github.com/users/Valahaar/orgs",
"received_events_url": "https://api.github.com/users/Valahaar/received_events",
"repos_url": "https://api.github.com/users/Valahaar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Valahaar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Valahaar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Valahaar",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1844/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1844/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 3:43:45
|
https://api.github.com/repos/huggingface/datasets/issues/1843
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1843/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1843/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1843/events
|
https://github.com/huggingface/datasets/issues/1843
| 803,565,393
|
MDU6SXNzdWU4MDM1NjUzOTM=
| 1,843
|
MustC Speech Translation
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
open
| false
| null |
[] |
[
"Hi @patrickvonplaten I would like to work on this dataset. \r\n\r\nThanks! ",
"That's awesome! Actually, I just noticed that this dataset might become a bit too big!\r\n\r\nMuST-C is the main dataset used for IWSLT19 and should probably be added as a standalone dataset. Would you be interested also in adding `datasets/MuST-C` instead?\r\n\r\nDescription: \r\n_MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems for speech translation from English into several languages. For each target language, MuST-C comprises several hundred hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual transcriptions and translations._\r\n\r\nPaper: https://www.aclweb.org/anthology/N19-1202.pdf\r\n\r\nDataset: https://ict.fbk.eu/must-c/ (One needs to fill out a short from to download the data, but it's very easy).\r\n\r\nIt would be awesome if you're interested in adding this datates. I'm very happy to guide you through the PR! I think the easiest way to start would probably be to read [this README on how to add a dataset](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md) and open a PR. Think you can copy & paste some code from:\r\n\r\n- Librispeech_asr: https://github.com/huggingface/datasets/blob/master/datasets/librispeech_asr/librispeech_asr.py\r\n- Flores Translation: https://github.com/huggingface/datasets/blob/master/datasets/flores/flores.py\r\n\r\nThink all the rest can be handled on the PR :-) ",
"Hi @patrickvonplaten \r\nI have tried downloading this dataset, but the connection seems to reset all the time. I have tried it via the browser, wget, and using gdown . But it gives me an error message. _\"The server is busy or down, pls try again\"_ (rephrasing the message here)\r\n\r\nI have completed adding 4 datasets in the previous data sprint (including the IWSLT dataset #1676 ) ...so just checking if you are able to download it at your end. Otherwise will write to the dataset authors to update the links. \r\n\r\n\r\n\r\n\r\n",
"Let me check tomorrow! Thanks for leaving this message!",
"cc @patil-suraj for notification ",
"@skyprince999, I think I'm getting the same error you're getting :-/\r\n\r\n```\r\nSorry, you can't view or download this file at this time.\r\n\r\nToo many users have viewed or downloaded this file recently. Please try accessing the file again later. If the file you are trying to access is particularly large or is shared with many people, it may take up to 24 hours to be able to view or download the file. If you still can't access a file after 24 hours, contact your domain administrator.\r\n```\r\n\r\nIt would be great if you could write the authors to see whether they can fix it.\r\nAlso cc @lhoestq - do you think we could mirror the dataset? ",
"Also there are huge those datasets. Think downloading MuST-C v1.2 amounts to ~ 1000GB... because there are 14 possible configs each around 60-70GB. I think users mostly will only use one of the 14 configs so that they would only need, in theory, will have to download ~60GB which is ok. But I think this functionality doesn't exist yet in `datasets` no? cc @lhoestq ",
"> Also cc @lhoestq - do you think we could mirror the dataset?\r\n\r\nYes we can mirror it if the authors are fine with it. You can create a dataset repo on huggingface.co (possibly under the relevant org) and add the mirrored data files.\r\n\r\n> I think users mostly will only use one of the 14 configs so that they would only need, in theory, will have to download ~60GB which is ok. But I think this functionality doesn't exist yet in datasets no? cc @lhoestq\r\n\r\nIf there are different download links for each configuration we can make the dataset builder download only the files related to the requested configuration.",
"I have written to the dataset authors, highlighting this issue. Waiting for their response. \r\n\r\nUpdate on 25th Feb: \r\nThe authors have replied back, they are updating the download link and will revert back shortly! \r\n\r\n```\r\nfirst of all thanks a lot for being interested in MuST-C and for building the data-loader.\r\n\r\nBefore answering your request, I'd like to clarify that the creation, maintenance, and expansion of MuST-c are not supported by any funded project, so this means that we need to find economic support for all these activities. This also includes permanently moving all the data to AWS or GCP. We are working at this with the goal of facilitating the use of MuST-C, but this is not something that can happen today. We hope to have some news ASAP and you will be among the first to be informed.\r\n\r\nI hope you understand our situation.\r\n```\r\n\r\n",
"Awesome, actually @lhoestq let's just ask the authors if we should host the dataset no? They could just use our links then as well for their website - what do you think? Is it fine to use our AWS dataset storage also as external links? ",
"Yes definitely. Shall we suggest them to create a dataset repository under their org on huggingface.co ? @julien-c \r\nThe dataset is around 1TB",
"Sounds good! \r\n\r\nOrder of magnitude is storage costs ~$20 per TB per month (not including bandwidth). \r\n\r\nHappy to provide this to the community as I feel this is an important dataset. Let us know what the authors want to do!\r\n\r\n",
"Great! @skyprince999, do you think you could ping the authors here or link to this thread? I think it could be a cool idea to host the dataset on our side then",
"Done. They replied back, and they want to have a call over a meet/ skype. Is that possible ? \r\nBtw @patrickvonplaten you are looped in that email (_pls check you gmail account_) ",
"Hello! Any news on this?",
"@gegallego there were some concerns regarding dataset usage & attribution by a for-profit company, so couldn't take it forward. Also the download links were unstable. \r\nBut I guess if you want to test the fairseq benchmarks, you can connect with them directly for downloading the dataset. ",
"Yes, that dataset is not easy to download... I had to copy it to my Google Drive and use `rsync` to be able to download it.\r\nHowever, we could add the dataset with a manual download, right?",
"yes that is possible. I couldn't unfortunately complete this PR, If you would like to add it, please feel free to do it. ",
"> https://ict.fbk.eu/must-c/\n\n@patrickvonplaten \n\nThe above link does not work anymore. Can you share a new link?"
] | 2021-02-08T13:27:45
| 2025-08-25T09:01:54
| null |
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *IWSLT19*
- **Description:** *The Speech Translation Task addresses the translation of English audio into German and Portuguese text.*
- **Hompage:** *https://sites.google.com/view/iwslt-evaluation-2019/speech-translation*
- **Data:** *https://sites.google.com/view/iwslt-evaluation-2019/speech-translation* - all data under "Allowed Training Data" and "Development and Evalutaion Data for TED/How2"
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1843/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1843/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1842
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1842/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1842/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1842/events
|
https://github.com/huggingface/datasets/issues/1842
| 803,563,149
|
MDU6SXNzdWU4MDM1NjMxNDk=
| 1,842
|
Add AMI Corpus
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"Available here: ~https://huggingface.co/datasets/ami~ https://huggingface.co/datasets/edinburghcstr/ami",
"@mariosasko actually the \"official\" AMI dataset can be found here: https://huggingface.co/datasets/edinburghcstr/ami -> the old one under `datasets/ami` doesn't work and should be deleted. \r\n\r\nThe new one was tested by fine-tuning a Wav2Vec2 model on it + we uploaded all the processed audio directly into it",
"@patrickvonplaten Thanks for correcting me! I've updated the link."
] | 2021-02-08T13:25:00
| 2023-02-28T16:29:22
| 2023-02-28T16:29:22
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *AMI*
- **Description:** *The AMI Meeting Corpus is a multi-modal data set consisting of 100 hours of meeting recordings. For a gentle introduction to the corpus, see the corpus overview. To access the data, follow the directions given there. Around two-thirds of the data has been elicited using a scenario in which the participants play different roles in a design team, taking a design project from kick-off to completion over the course of a day. The rest consists of naturally occurring meetings in a range of domains. Detailed information can be found in the documentation section.*
- **Paper:** *Homepage*: http://groups.inf.ed.ac.uk/ami/corpus/
- **Data:** *http://groups.inf.ed.ac.uk/ami/download/* - Select all cases in 1) and select "Individual Headsets" & "Microphone array" for 2)
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1842/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1842/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 750 days, 3:04:22
|
https://api.github.com/repos/huggingface/datasets/issues/1841
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1841/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1841/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1841/events
|
https://github.com/huggingface/datasets/issues/1841
| 803,561,123
|
MDU6SXNzdWU4MDM1NjExMjM=
| 1,841
|
Add ljspeech
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[] | 2021-02-08T13:22:26
| 2021-03-15T05:59:02
| 2021-03-15T05:59:02
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *ljspeech*
- **Description:** *This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain. The audio was recorded in 2016-17 by the LibriVox project and is also in the public domain.)*
- **Paper:** *Homepage*: https://keithito.com/LJ-Speech-Dataset/
- **Data:** *https://keithito.com/LJ-Speech-Dataset/*
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/ljspeech
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1841/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1841/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 34 days, 16:36:36
|
https://api.github.com/repos/huggingface/datasets/issues/1840
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1840/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1840/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1840/events
|
https://github.com/huggingface/datasets/issues/1840
| 803,560,039
|
MDU6SXNzdWU4MDM1NjAwMzk=
| 1,840
|
Add common voice
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"I have started working on adding this dataset.",
"Hey @BirgerMoell - awesome that you started working on Common Voice. Common Voice is a bit special since, there is no direct download link to download the data. In these cases we usually consider two options:\r\n\r\n1) Find a hacky solution to extract the download link somehow from the XLM tree of the website \r\n2) If this doesn't work we force the user to download the data himself and add a `\"data_dir\"` as an input parameter. E.g. you can take a look at how it is done for [this](https://github.com/huggingface/datasets/blob/66f2a7eece98d2778bd22bb5034cb7c2376032d4/datasets/arxiv_dataset/arxiv_dataset.py#L66) \r\n\r\nAlso the documentation here: https://huggingface.co/docs/datasets/add_dataset.html?highlight=data_dir#downloading-data-files-and-organizing-splits (especially the \"note\") might be helpful.",
"Let me know if you have any other questions",
"I added a Work in Progress pull request (hope that is ok). I've made a card for the dataset and filled out the common_voice.py file with information about the datset (not completely).\r\n\r\nI didn't manage to get the tagging tool working locally on my machine but will look into that later.\r\n\r\nLeft to do.\r\n\r\n- Tag the dataset\r\n- Add missing information and update common_voice.py\r\n\r\nhttps://github.com/huggingface/datasets/pull/1886",
"Awesome! I left a longer comment on the PR :-)",
"I saw that this current datasets package holds common voice version 6.1, how to add the new version 7.0 that is already available?",
"Will me merged next week - we're working on it :-)",
"Common voice still appears to be a 6.1. Is the plan still to upgrade to 7.0?",
"We actually already have the code and everything ready to add Common Voice 7.0 to `datasets` but are still waiting for the common voice authors to give us the green light :-) \r\n\r\nAlso gently pinging @phirework and @milupo here",
"Common Voice 7.0 is available here now: https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0",
"For anyone else stumbling upon this thread, the 8.0 version is also available now: https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0"
] | 2021-02-08T13:21:05
| 2022-03-20T15:23:40
| 2021-03-15T05:56:21
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *common voice*
- **Description:** *Mozilla Common Voice Dataset*
- **Paper:** Homepage: https://voice.mozilla.org/en/datasets
- **Data:** https://voice.mozilla.org/en/datasets
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/common_voice
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1840/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1840/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 34 days, 16:35:16
|
https://api.github.com/repos/huggingface/datasets/issues/1839
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1839/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1839/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1839/events
|
https://github.com/huggingface/datasets/issues/1839
| 803,559,164
|
MDU6SXNzdWU4MDM1NTkxNjQ=
| 1,839
|
Add Voxforge
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
open
| false
| null |
[] |
[] | 2021-02-08T13:19:56
| 2021-02-08T13:28:31
| null |
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *voxforge*
- **Description:** *VoxForge is a language classification dataset. It consists of user submitted audio clips submitted to the website. In this release, data from 6 languages is collected - English, Spanish, French, German, Russian, and Italian. Since the website is constantly updated, and for the sake of reproducibility, this release contains only recordings submitted prior to 2020-01-01. The samples are splitted between train, validation and testing so that samples from each speaker belongs to exactly one split.*
- **Paper:** *Homepage*: http://www.voxforge.org/
- **Data:** *http://www.voxforge.org/home/downloads*
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/voxforge
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1839/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1839/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1838
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1838/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1838/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1838/events
|
https://github.com/huggingface/datasets/issues/1838
| 803,557,521
|
MDU6SXNzdWU4MDM1NTc1MjE=
| 1,838
|
Add tedlium
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"Hi @patrickvonplaten \r\nI can have a look to this dataset later since I am trying to add the OpenSLR dataset https://github.com/huggingface/datasets/pull/2173\r\nHopefully I have enough space since the compressed file is 21GB. The release 3 is even bigger: 54GB :-0",
"Resolved via https://github.com/huggingface/datasets/pull/4309"
] | 2021-02-08T13:17:52
| 2022-10-04T14:34:12
| 2022-10-04T14:34:12
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *tedlium*
- **Description:** *The TED-LIUM 1-3 corpus is English-language TED talks, with transcriptions, sampled at 16kHz. It contains about 118 hours of speech.*
- **Paper:** Homepage: http://www.openslr.org/7/, https://lium.univ-lemans.fr/en/ted-lium2/ &, https://www.openslr.org/51/
- **Data:** http://www.openslr.org/7/
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/tedlium
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1838/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1838/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 603 days, 1:16:20
|
https://api.github.com/repos/huggingface/datasets/issues/1837
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1837/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1837/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1837/events
|
https://github.com/huggingface/datasets/issues/1837
| 803,555,650
|
MDU6SXNzdWU4MDM1NTU2NTA=
| 1,837
|
Add VCTK
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
closed
| false
| null |
[] |
[
"@patrickvonplaten I'd like to take this, if nobody has already done it. I have added datasets before through the datasets sprint, but I feel rusty on the details, so I'll look at the guide as well as similar audio PRs (#1878 in particular comes to mind). If there is any detail I should be aware of please, let me know! Otherwise, I'll try to write up a PR in the coming days.",
"That sounds great @jaketae - let me know if you need any help i.e. feel free to ping me on a first PR :-)"
] | 2021-02-08T13:15:28
| 2021-12-28T15:05:08
| 2021-12-28T15:05:08
|
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** *VCTK*
- **Description:** *This CSTR VCTK Corpus includes speech data uttered by 110 English speakers with various accents. Each speaker reads out about 400 sentences, which were selected from a newspaper, the rainbow passage and an elicitation paragraph used for the speech accent archive.*
- **Paper:** Homepage: https://datashare.ed.ac.uk/handle/10283/3443
- **Data:** https://datashare.ed.ac.uk/handle/10283/3443
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/vctk
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1837/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1837/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 323 days, 1:49:40
|
https://api.github.com/repos/huggingface/datasets/issues/1836
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1836/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1836/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1836/events
|
https://github.com/huggingface/datasets/issues/1836
| 803,531,837
|
MDU6SXNzdWU4MDM1MzE4Mzc=
| 1,836
|
test.json has been removed from the limit dataset repo (breaks dataset)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/237550?v=4",
"events_url": "https://api.github.com/users/Paethon/events{/privacy}",
"followers_url": "https://api.github.com/users/Paethon/followers",
"following_url": "https://api.github.com/users/Paethon/following{/other_user}",
"gists_url": "https://api.github.com/users/Paethon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Paethon",
"id": 237550,
"login": "Paethon",
"node_id": "MDQ6VXNlcjIzNzU1MA==",
"organizations_url": "https://api.github.com/users/Paethon/orgs",
"received_events_url": "https://api.github.com/users/Paethon/received_events",
"repos_url": "https://api.github.com/users/Paethon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Paethon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Paethon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Paethon",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"Thanks for the heads up ! I'm opening a PR to fix that"
] | 2021-02-08T12:45:53
| 2021-02-10T16:14:58
| 2021-02-10T16:14:58
|
NONE
| null | null | null | null |
https://github.com/huggingface/datasets/blob/16042b233dbff2a7585110134e969204c69322c3/datasets/limit/limit.py#L51
The URL is not valid anymore since test.json has been removed in master for some reason. Directly referencing the last commit works:
`https://raw.githubusercontent.com/ilmgut/limit_dataset/0707d3989cd8848f0f11527c77dcf168fefd2b23/data`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1836/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1836/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 3:29:05
|
https://api.github.com/repos/huggingface/datasets/issues/1835
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1835/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1835/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1835/events
|
https://github.com/huggingface/datasets/issues/1835
| 803,524,790
|
MDU6SXNzdWU4MDM1MjQ3OTA=
| 1,835
|
Add CHiME4 dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] |
open
| false
| null |
[] |
[
"@patrickvonplaten not sure whether it is still needed, but willing to tackle this issue",
"Hey @patrickvonplaten, I have managed to download the zip on [here]( http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/download.html) and successfully uploaded all the files on a hugging face dataset: \r\n\r\nhttps://huggingface.co/datasets/ksbai123/Chime4\r\n\r\nHowever I am getting this error when trying to use the dataset viewer:\r\n\r\n\r\n\r\nCan you take a look and let me know if I have missed any files please",
"@patrickvonplaten ?",
"Hi @KossaiSbai,\r\n\r\nThanks for your contribution.\r\n\r\nAs the issue is not strictly related to the `datasets` library, but to the specific implementation of the CHiME4 dataset, I have opened an issue in the Discussion tab of the dataset: https://huggingface.co/datasets/ksbai123/Chime4/discussions/2\r\nLet's continue the discussion there!",
"Hi, please help me understand this dataset. I am trying to run ESPnet chime4 recepie. I downloaded the dataset (https://www.chimechallenge.org/challenges/chime4/download) and it doesn't look like the official site (https://www.chimechallenge.org/challenges/chime4/data#Audio):\n\n<img width=\"220\" alt=\"Image\" src=\"https://github.com/user-attachments/assets/91d2d727-bc65-4c45-ad87-b643fc26a40e\" />\n\nThere is no \n├── audio\n├── transcriptions\n└── WSJ0\nonly \n├── annotations\n\nsame in your huggingface card. \nHow can I access the missing data?"
] | 2021-02-08T12:36:38
| 2025-01-26T16:18:59
| null |
CONTRIBUTOR
| null | null | null | null |
## Adding a Dataset
- **Name:** Chime4
- **Description:** Chime4 is a dataset for automatic speech recognition. It is especially useful for evaluating models in a noisy environment and for multi-channel ASR
- **Paper:** Dataset comes from a channel: http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/ . Results paper:
- **Data:** http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/download.html
- **Motivation:** So far there are very little datasets for speech in `datasets`. Only `lbirispeech_asr` so far.
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1835/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1835/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1832
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1832/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1832/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1832/events
|
https://github.com/huggingface/datasets/issues/1832
| 802,880,897
|
MDU6SXNzdWU4MDI4ODA4OTc=
| 1,832
|
Looks like nokogumbo is up-to-date now, so this is no longer needed.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68724553?v=4",
"events_url": "https://api.github.com/users/JimmyJim1/events{/privacy}",
"followers_url": "https://api.github.com/users/JimmyJim1/followers",
"following_url": "https://api.github.com/users/JimmyJim1/following{/other_user}",
"gists_url": "https://api.github.com/users/JimmyJim1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JimmyJim1",
"id": 68724553,
"login": "JimmyJim1",
"node_id": "MDQ6VXNlcjY4NzI0NTUz",
"organizations_url": "https://api.github.com/users/JimmyJim1/orgs",
"received_events_url": "https://api.github.com/users/JimmyJim1/received_events",
"repos_url": "https://api.github.com/users/JimmyJim1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JimmyJim1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JimmyJim1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JimmyJim1",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2021-02-07T06:52:07
| 2021-02-08T17:27:29
| 2021-02-08T17:27:29
|
NONE
| null | null | null | null |
Looks like nokogumbo is up-to-date now, so this is no longer needed.
__Originally posted by @dependabot in https://github.com/discourse/discourse/pull/11373#issuecomment-738993432__
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1832/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1832/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 10:35:22
|
https://api.github.com/repos/huggingface/datasets/issues/1831
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1831/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1831/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1831/events
|
https://github.com/huggingface/datasets/issues/1831
| 802,868,854
|
MDU6SXNzdWU4MDI4Njg4NTQ=
| 1,831
|
Some question about raw dataset download info in the project .
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/27874014?v=4",
"events_url": "https://api.github.com/users/svjack/events{/privacy}",
"followers_url": "https://api.github.com/users/svjack/followers",
"following_url": "https://api.github.com/users/svjack/following{/other_user}",
"gists_url": "https://api.github.com/users/svjack/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/svjack",
"id": 27874014,
"login": "svjack",
"node_id": "MDQ6VXNlcjI3ODc0MDE0",
"organizations_url": "https://api.github.com/users/svjack/orgs",
"received_events_url": "https://api.github.com/users/svjack/received_events",
"repos_url": "https://api.github.com/users/svjack/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/svjack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/svjack/subscriptions",
"type": "User",
"url": "https://api.github.com/users/svjack",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"Hi ! The `dl_manager` is a `DownloadManager` object and is responsible for downloading the raw data files.\r\nIt is used by dataset builders in their `_split_generators` method to download the raw data files that are necessary to build the datasets splits.\r\n\r\nThe `Conll2003` class is a dataset builder, and so you can download all the raw data files by calling `_split_generators` with a download manager:\r\n```python\r\nfrom datasets import DownloadManager\r\nfrom datasets.load import import_main_class\r\n\r\nconll2003_builder = import_main_class(...)\r\n\r\ndl_manager = DownloadManager()\r\nsplis_generators = conll2003_builder._split_generators(dl_manager)\r\n```\r\n\r\nThen you can see what files have been downloaded with\r\n```python\r\ndl_manager.get_recorded_sizes_checksums()\r\n```\r\nIt returns a dictionary with the format {url: {num_bytes: int, checksum: str}}\r\n\r\nThen you can get the actual location of the downloaded files with\r\n```python\r\nfrom datasets import cached_path\r\n\r\nlocal_path_to_downloaded_file = cached_path(url)\r\n```\r\n\r\n------------------\r\n\r\nNote that you can also get the urls from the Dataset object:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nconll2003 = load_dataset(\"conll2003\")\r\nprint(conll2003[\"train\"].download_checksums)\r\n```\r\nIt returns the same dictionary with the format {url: {num_bytes: int, checksum: str}}",
"I am afraid that there is not a very straightforward way to get that location.\r\n\r\nAnother option, from _split_generators would be to use:\r\n- `dl_manager._download_config.cache_dir` to get the directory where all the raw downloaded files are:\r\n ```python\r\n download_dir = dl_manager._download_config.cache_dir\r\n ```\r\n- the function `datasets.utils.file_utils.hash_url_to_filename` to get the filenames of the raw downloaded files:\r\n ```python\r\n filenames = [hash_url_to_filename(url) for url in urls_to_download.values()]\r\n ```\r\nTherefore the complete path to the raw downloaded files would be the join of both:\r\n```python\r\ndownloaded_paths = [os.path.join(download_dir, filename) for filename in filenames]\r\n```\r\n\r\nMaybe it would be interesting to make these paths accessible more easily. I could work on this. What do you think, @lhoestq ?",
"Sure it would be nice to have an easier access to these paths !\r\nThe dataset builder could have a method to return those, what do you think ?\r\nFeel free to work on this @albertvillanova , it would be a nice addition :) \r\n\r\nYour suggestion does work as well @albertvillanova if you complete it by specifying `etag=` to `hash_url_to_filename`.\r\n\r\nThe ETag is obtained by a HEAD request and is used to know if the file on the remote host has changed. Therefore if a file is updated on the remote host, then the hash returned by `hash_url_to_filename` is different.",
"Once #1846 will be merged, the paths to the raw downloaded files will be accessible as:\r\n```python\r\nbuilder_instance.dl_manager.downloaded_paths\r\n``` "
] | 2021-02-07T05:33:36
| 2021-02-25T14:10:18
| 2021-02-25T14:10:18
|
NONE
| null | null | null | null |
Hi , i review the code in
https://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py
in the _split_generators function is the truly logic of download raw datasets with dl_manager
and use Conll2003 cls by use import_main_class in load_dataset function
My question is that , with this logic it seems that i can not have the raw dataset download location
in variable in downloaded_files in _split_generators.
If someone also want use huggingface datasets as raw dataset downloader,
how can he retrieve the raw dataset download path from attributes in
datasets.dataset_dict.DatasetDict ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1831/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1831/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 18 days, 8:36:42
|
https://api.github.com/repos/huggingface/datasets/issues/1830
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1830/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1830/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1830/events
|
https://github.com/huggingface/datasets/issues/1830
| 802,790,075
|
MDU6SXNzdWU4MDI3OTAwNzU=
| 1,830
|
using map on loaded Tokenizer 10x - 100x slower than default Tokenizer?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7662740?v=4",
"events_url": "https://api.github.com/users/wumpusman/events{/privacy}",
"followers_url": "https://api.github.com/users/wumpusman/followers",
"following_url": "https://api.github.com/users/wumpusman/following{/other_user}",
"gists_url": "https://api.github.com/users/wumpusman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wumpusman",
"id": 7662740,
"login": "wumpusman",
"node_id": "MDQ6VXNlcjc2NjI3NDA=",
"organizations_url": "https://api.github.com/users/wumpusman/orgs",
"received_events_url": "https://api.github.com/users/wumpusman/received_events",
"repos_url": "https://api.github.com/users/wumpusman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wumpusman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wumpusman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wumpusman",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"Hi @wumpusman \r\n`datasets` has a caching mechanism that allows to cache the results of `.map` so that when you want to re-run it later it doesn't recompute it again.\r\nSo when you do `.map`, what actually happens is:\r\n1. compute the hash used to identify your `map` for the cache\r\n2. apply your function on every batch\r\n\r\nThis can explain the time difference between your different experiments.\r\n\r\nThe hash computation time depends of how complex your function is. For a tokenizer, the hash computation scans the lists of the words in the tokenizer to identify this tokenizer. Usually it takes 2-3 seconds.\r\n\r\nAlso note that you can disable caching though using\r\n```python\r\nimport datasets\r\n\r\ndatasets.set_caching_enabled(False)\r\n```",
"Hi @lhoestq ,\r\n\r\nThanks for the reply. It's entirely possible that is the issue. Since it's a side project I won't be looking at it till later this week, but, I'll verify it by disabling caching and hopefully I'll see the same runtime. \r\n\r\nAppreciate the reference,\r\n\r\nMichael",
"I believe this is an actual issue, tokenizing a ~4GB txt file went from an hour and a half to ~10 minutes when I switched from my pre-trained tokenizer(on the same dataset) to the default gpt2 tokenizer.\r\nBoth were loaded using:\r\n```\r\nAutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)\r\n```\r\nI trained the tokenizer using ByteLevelBPETokenizer from the Tokenizers library and save it to a tokenizer.json file.\r\n\r\nI have tested the caching ideas above, changing the number of process, the TOKENIZERS_PARALLELISM env variable, keep_in_memory=True and batching with different sizes.\r\n\r\nApologies I can't really upload much code, but wanted to back up the finding and hopefully a fix/the problem can be found.\r\nI will comment back if I find a fix as well.",
"Hi @johncookds do you think this can come from one tokenizer being faster than the other one ? Can you try to compare their speed without using `datasets` just to make sure ?",
"Hi yes, I'm closing the loop here with some timings below. The issue seems to be at least somewhat/mainly with the tokenizer's themselves. Moreover legacy saves of the trainer tokenizer perform faster but differently than the new tokenizer.json saves(note nothing about the training process/adding of special tokens changed between the top two trained tokenizer tests, only the way it was saved). This is only a 3x slowdown vs like a 10x but I think the slowdown is most likely due to this.\r\n\r\n```\r\ntrained tokenizer - tokenizer.json save (same results for AutoTokenizer legacy_format=False):\r\nTokenizer time(seconds): 0.32767510414123535\r\nTokenized avg. length: 323.01\r\n\r\ntrained tokenizer - AutoTokenizer legacy_format=True:\r\nTokenizer time(seconds): 0.09258866310119629\r\nTokenized avg. length: 301.01\r\n\r\nGPT2 Tokenizer from huggingface\r\nTokenizer time(seconds): 0.1010282039642334\r\nTokenized avg. length: 461.21\r\n```",
"@lhoestq ,\r\n\r\nHi, which version of datasets has datasets.set_caching_enabled(False)? I get \r\nmodule 'datasets' has no attribute 'set_caching_enabled'. To hopefully get around this, I reran my code on a new set of data, and did so only once.\r\n\r\n@johncookds , thanks for chiming in, it looks this might be an issue of Tokenizer.\r\n\r\n**Tokenizer**: The runtime of GPT2TokenizerFast.from_pretrained(\"gpt2\") on 1000 chars is: **143 ms**\r\n**SlowTokenizer**: The runtime of a locally saved and loaded Tokenizer using the same vocab on 1000 chars is: **4.43 s**\r\n\r\nThat being said, I compared performance on the map function:\r\n\r\nRunning Tokenizer versus using it in the map function for 1000 chars goes from **141 ms** to **356 ms** \r\nRunning SlowTokenizer versus using it in the map function for 1000 chars with a single element goes from **4.43 s** to **9.76 s**\r\n\r\nI'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\n@lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nRegards,\r\n\r\nMichael",
"Thanks for the experiments @johncookds and @wumpusman ! \r\n\r\n> Hi, which version of datasets has datasets.set_caching_enabled(False)?\r\n\r\nCurrently you have to install `datasets` from source to have this feature, but this will be available in the next release in a few days.\r\n\r\n> I'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\nCould you also try with double the number of characters ? This should let us have an idea of the fixed cost (hashing) and the dynamic cost (actual tokenization, grows with the size of the input)\r\n\r\n> @lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nFeel free to post an issue on the `transformers` repo. Also I'm sure there should be related issues so you can also look for someone with the same concerns on the `transformers` repo.",
"@lhoestq,\r\n\r\nI just checked that previous run time was actually 3000 chars. I increased it to 6k chars, again, roughly double.\r\n\r\nSlowTokenizer **7.4 s** to **15.7 s**\r\nTokenizer: **276 ms** to **616 ms**\r\n\r\nI'll post this issue on Tokenizer, seems it hasn't quite been raised (albeit I noticed a similar issue that might relate).\r\n\r\nRegards,\r\n\r\nMichael",
"Hi, \r\nI'm following up here as I found my exact issue. It was with saving and re-loading the tokenizer. When I trained then processed the data without saving and reloading it, it was 10x-100x faster than when I saved and re-loaded it.\r\nBoth resulted in the exact same tokenized datasets as well. \r\nThere is additionally a bug where the older legacy tokenizer save does not preserve a learned tokenizing behavior if trained from scratch.\r\nUnderstand its not exactly Datasets related but hope it can help someone if they have the same issue.\r\nThanks!"
] | 2021-02-06T21:00:26
| 2021-02-24T21:56:14
| null |
NONE
| null | null | null | null |
This could total relate to me misunderstanding particular call functions, but I added words to a GPT2Tokenizer, and saved it to disk (note I'm only showing snippets but I can share more) and the map function ran much slower:
````
def save_tokenizer(original_tokenizer,text,path="simpledata/tokenizer"):
words_unique = set(text.split(" "))
for i in words_unique:
original_tokenizer.add_tokens(i)
original_tokenizer.save_pretrained(path)
tokenizer2 = GPT2Tokenizer.from_pretrained(os.path.join(experiment_path,experiment_name,"tokenizer_squad"))
train_set_baby=Dataset.from_dict({"text":[train_set["text"][0][0:50]]})
````
I then applied the dataset map function on a fairly small set of text:
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The run time for train_set_baby.map was 6 seconds, and the batch itself was 2.6 seconds
**100% 1/1 [00:02<00:00, 2.60s/ba] CPU times: user 5.96 s, sys: 36 ms, total: 5.99 s Wall time: 5.99 s**
In comparison using (even after adding additional tokens):
`
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")`
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The time is
**100% 1/1 [00:00<00:00, 34.09ba/s] CPU times: user 68.1 ms, sys: 16 µs, total: 68.1 ms Wall time: 62.9 ms**
It seems this might relate to the tokenizer save or load function, however, the issue appears to come up when I apply the loaded tokenizer to the map function.
I should also add that playing around with the amount of words I add to the tokenizer before I save it to disk and load it into memory appears to impact the time it takes to run the map function.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1830/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1830/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1827
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1827/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1827/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1827/events
|
https://github.com/huggingface/datasets/issues/1827
| 802,353,974
|
MDU6SXNzdWU4MDIzNTM5NzQ=
| 1,827
|
Regarding On-the-fly Data Loading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Possible duplicate\r\n\r\n#1776 https://github.com/huggingface/datasets/issues/\r\n\r\nreally looking PR for this feature",
"Hi @acul3 \r\n\r\nIssue #1776 talks about doing on-the-fly data pre-processing, which I think is solved in the next release as mentioned in the issue #1825. I also look forward to using this feature, though :)\r\n\r\nI wanted to ask about on-the-fly data loading from the cache (before pre-processing).",
"Hi ! Currently when you load a dataset via `load_dataset` for example, then the dataset is memory-mapped from an Arrow file on disk. Therefore there's almost no RAM usage even if your dataset contains TB of data.\r\nUsually at training time only one batch of data at a time is loaded in memory.\r\n\r\nDoes that answer your question or were you thinking about something else ?",
"Hi @lhoestq,\r\n\r\nI apologize for the late response. This answers my question. Thanks a lot."
] | 2021-02-05T17:43:48
| 2021-02-18T13:55:16
| 2021-02-18T13:55:16
|
CONTRIBUTOR
| null | null | null | null |
Hi,
I was wondering if it is possible to load images/texts as a batch during the training process, without loading the entire dataset on the RAM at any given point.
Thanks,
Gunjan
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1827/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1827/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 12 days, 20:11:28
|
https://api.github.com/repos/huggingface/datasets/issues/1825
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1825/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1825/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1825/events
|
https://github.com/huggingface/datasets/issues/1825
| 802,073,925
|
MDU6SXNzdWU4MDIwNzM5MjU=
| 1,825
|
Datasets library not suitable for huge text datasets.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"events_url": "https://api.github.com/users/avacaondata/events{/privacy}",
"followers_url": "https://api.github.com/users/avacaondata/followers",
"following_url": "https://api.github.com/users/avacaondata/following{/other_user}",
"gists_url": "https://api.github.com/users/avacaondata/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avacaondata",
"id": 35173563,
"login": "avacaondata",
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"organizations_url": "https://api.github.com/users/avacaondata/orgs",
"received_events_url": "https://api.github.com/users/avacaondata/received_events",
"repos_url": "https://api.github.com/users/avacaondata/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avacaondata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avacaondata/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avacaondata",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] |
[
"Hi ! Looks related to #861 \r\n\r\nYou are right: tokenizing a dataset using map takes a lot of space since it can store `input_ids` but also `token_type_ids`, `attention_mask` and `special_tokens_mask`. Moreover if your tokenization function returns python integers then by default they'll be stored as int64 which can take a lot of space. Padding can also increase the size of the tokenized dataset.\r\n\r\nTo make things more convenient, we recently added a \"lazy map\" feature that allows to tokenize each batch at training time as you mentioned. For example you'll be able to do\r\n```python\r\nfrom transformers import BertTokenizer\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\n\r\ndef encode(batch):\r\n return tokenizer(batch[\"text\"], padding=\"longest\", truncation=True, max_length=512, return_tensors=\"pt\")\r\n\r\ndataset.set_transform(encode)\r\nprint(dataset.format)\r\n# {'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}\r\nprint(dataset[:2])\r\n# {'input_ids': tensor([[ 101, 2572, 3217, ... 102]]), 'token_type_ids': tensor([[0, 0, 0, ... 0]]), 'attention_mask': tensor([[1, 1, 1, ... 1]])}\r\n\r\n```\r\nIn this example the `encode` transform is applied on-the-fly on the \"text\" column.\r\n\r\nThis feature will be available in the next release 2.0 which will happen in a few days.\r\nYou can already play with it by installing `datasets` from source if you want :)\r\n\r\nHope that helps !",
"How recently was `set_transform` added? I am actually trying to implement it and getting an error:\r\n\r\n`AttributeError: 'Dataset' object has no attribute 'set_transform'\r\n`\r\n\r\nI'm on v.1.2.1.\r\n\r\nEDIT: Oh, wait I see now it's in the v.2.0. Whoops! This should be really useful.",
"Yes indeed it was added a few days ago. The code is available on master\r\nWe'll do a release next week :)\r\n\r\nFeel free to install `datasets` from source to try it out though, I would love to have some feedbacks",
"For information: it's now available in `datasets` 1.3.0.\r\nThe 2.0 is reserved for even cooler features ;)",
"Hi @alexvaca0 , we have optimized Datasets' disk usage in the latest release v1.5.\r\n\r\nFeel free to update your Datasets version\r\n```shell\r\npip install -U datasets\r\n```\r\nand see if it better suits your needs."
] | 2021-02-05T11:06:50
| 2021-03-30T14:04:01
| 2021-03-16T09:44:00
|
NONE
| null | null | null | null |
Hi,
I'm trying to use datasets library to load a 187GB dataset of pure text, with the intention of building a Language Model. The problem is that from the 187GB it goes to some TB when processed by Datasets. First of all, I think the pre-tokenizing step (with tokenizer.map()) is not really thought for datasets this big, but for fine-tuning datasets, as this process alone takes so much time, usually in expensive machines (due to the need of tpus - gpus) which is not being used for training. It would possibly be more efficient in such cases to tokenize each batch at training time (receive batch - tokenize batch - train with batch), so that the whole time the machine is up it's being used for training.
Moreover, the pyarrow objects created from a 187 GB datasets are huge, I mean, we always receive OOM, or No Space left on device errors when only 10-12% of the dataset has been processed, and only that part occupies 2.1TB in disk, which is so many times the disk usage of the pure text (and this doesn't make sense, as tokenized texts should be lighter than pure texts).
Any suggestions??
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1825/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1825/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 38 days, 22:37:10
|
https://api.github.com/repos/huggingface/datasets/issues/1821
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1821/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1821/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1821/events
|
https://github.com/huggingface/datasets/issues/1821
| 801,747,647
|
MDU6SXNzdWU4MDE3NDc2NDc=
| 1,821
|
Provide better exception message when one of many files results in an exception
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/david-waterworth",
"id": 5028974,
"login": "david-waterworth",
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"type": "User",
"url": "https://api.github.com/users/david-waterworth",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi!\r\n\r\nThank you for reporting this issue. I agree that the information about the exception should be more clear and explicit.\r\n\r\nI could take on this issue.\r\n\r\nOn the meantime, as you can see from the exception stack trace, HF Datasets uses pandas to read the CSV files. You can pass arguments to `pandas.read_csv` by passing additional keyword arguments to `load_dataset`. For example, you may find useful this argument:\r\n- `error_bad_lines` : bool, default True\r\n Lines with too many fields (e.g. a csv line with too many commas) will by default cause an exception to be raised, and no DataFrame will be returned. If False, then these “bad lines” will be dropped from the DataFrame that is returned.\r\n\r\nYou could try:\r\n```python\r\ndatasets = load_dataset(\"csv\", data_files=dict(train=train_files, validation=validation_files), error_bad_lines=False)\r\n```\r\n"
] | 2021-02-05T00:49:03
| 2021-02-09T17:39:27
| 2021-02-09T17:39:27
|
NONE
| null | null | null | null |
I find when I process many files, i.e.
```
train_files = glob.glob('rain*.csv')
validation_files = glob.glob(validation*.csv')
datasets = load_dataset("csv", data_files=dict(train=train_files, validation=validation_files))
```
I sometimes encounter an error due to one of the files being misformed (i.e. no data, or a comma in a field that isn't quoted, etc).
For example, this is the tail of an exception which I suspect is due to a stray comma.
> File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
> File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
> File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
> File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
> File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
> pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 559, saw 3
It would be nice if the exception trace contained the name of the file being processed (I have 250 separate files!)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1821/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1821/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 16:50:24
|
https://api.github.com/repos/huggingface/datasets/issues/1818
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1818/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1818/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1818/events
|
https://github.com/huggingface/datasets/issues/1818
| 800,958,776
|
MDU6SXNzdWU4MDA5NTg3NzY=
| 1,818
|
Loading local dataset raise requests.exceptions.ConnectTimeout
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15032072?v=4",
"events_url": "https://api.github.com/users/Alxe1/events{/privacy}",
"followers_url": "https://api.github.com/users/Alxe1/followers",
"following_url": "https://api.github.com/users/Alxe1/following{/other_user}",
"gists_url": "https://api.github.com/users/Alxe1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Alxe1",
"id": 15032072,
"login": "Alxe1",
"node_id": "MDQ6VXNlcjE1MDMyMDcy",
"organizations_url": "https://api.github.com/users/Alxe1/orgs",
"received_events_url": "https://api.github.com/users/Alxe1/received_events",
"repos_url": "https://api.github.com/users/Alxe1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Alxe1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Alxe1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Alxe1",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! Thanks for reporting. This was indeed a bug introduced when we moved the `json` dataset loader inside the `datasets` package (before that, the `json` loader was fetched online, as all the other dataset scripts).\r\n\r\nThis should be fixed on master now. Feel free to install `datasets` from source to try it out.\r\nThe fix will be available in the next release of `datasets` in a few days"
] | 2021-02-04T05:55:23
| 2022-06-01T15:38:42
| 2022-06-01T15:38:42
|
NONE
| null | null | null | null |
Load local dataset:
```
dataset = load_dataset('json', data_files=["../../data/json.json"])
train = dataset["train"]
print(train.features)
train1 = train.map(lambda x: {"labels": 1})
print(train1[:2])
```
but it raised requests.exceptions.ConnectTimeout:
```
/Users/littlely/myvirtual/tf2/bin/python3.7 /Users/littlely/projects/python_projects/pytorch_learning/nlp/dataset/transformers_datasets.py
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 160, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/connection.py", line 84, in create_connection
raise err
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/connection.py", line 74, in create_connection
sock.connect(sa)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 677, in urlopen
chunked=chunked,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 381, in _make_request
self._validate_conn(conn)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 978, in _validate_conn
conn.connect()
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 309, in connect
conn = self._new_conn()
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 167, in _new_conn
% (self.host, self.timeout),
urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/adapters.py", line 449, in send
timeout=timeout
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 727, in urlopen
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/retry.py", line 439, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/json/json.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/projects/python_projects/pytorch_learning/nlp/dataset/transformers_datasets.py", line 12, in <module>
dataset = load_dataset('json', data_files=["../../data/json.json"])
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/load.py", line 591, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/load.py", line 263, in prepare_module
head_hf_s3(path, filename=name, dataset=dataset, max_retries=download_config.max_retries)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 232, in head_hf_s3
max_retries=max_retries,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 523, in http_head
max_retries=max_retries,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 458, in _request_with_retry
raise err
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 454, in _request_with_retry
response = requests.request(verb.upper(), url, **params)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/sessions.py", line 530, in request
resp = self.send(prep, **send_kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/sessions.py", line 643, in send
r = adapter.send(request, **kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/adapters.py", line 504, in send
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/json/json.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
Process finished with exit code 1
```
Why it want to connect a remote url when I load local datasets, and how can I fix it?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1818/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1818/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 482 days, 9:43:19
|
https://api.github.com/repos/huggingface/datasets/issues/1817
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1817/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1817/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1817/events
|
https://github.com/huggingface/datasets/issues/1817
| 800,870,652
|
MDU6SXNzdWU4MDA4NzA2NTI=
| 1,817
|
pyarrow.lib.ArrowInvalid: Column 1 named input_ids expected length 599 but got length 1500
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9610770?v=4",
"events_url": "https://api.github.com/users/LuCeHe/events{/privacy}",
"followers_url": "https://api.github.com/users/LuCeHe/followers",
"following_url": "https://api.github.com/users/LuCeHe/following{/other_user}",
"gists_url": "https://api.github.com/users/LuCeHe/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LuCeHe",
"id": 9610770,
"login": "LuCeHe",
"node_id": "MDQ6VXNlcjk2MTA3NzA=",
"organizations_url": "https://api.github.com/users/LuCeHe/orgs",
"received_events_url": "https://api.github.com/users/LuCeHe/received_events",
"repos_url": "https://api.github.com/users/LuCeHe/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LuCeHe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LuCeHe/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LuCeHe",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\nThe error you have is due to the `input_ids` column not having the same number of examples as the other columns.\r\nIndeed you're concatenating the `input_ids` at this line:\r\n\r\nhttps://github.com/LuCeHe/GenericTools/blob/431835d8e13ec24dceb5ee4dc4ae58f0e873b091/KerasTools/lm_preprocessing.py#L134\r\n\r\nHowever the other columns are kept unchanged, and therefore you end up with an `input_ids` column with 599 elements while the others columns like `attention_mask` have 1500.\r\n\r\nTo fix that you can instead concatenate them all using\r\n```python\r\nconcatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\r\n```\r\n\r\nAlso you may need to drop the \"text\" column before applying `group_texts` since strings can't be concatenated with lists. You can drop it at the tokenization step:\r\n```python\r\ndset = dset.map(\r\n tokenize_function,\r\n batched=True,\r\n remove_columns=[\"text\"]\r\n)\r\n```",
"You saved my life."
] | 2021-02-04T02:30:23
| 2022-10-05T12:42:57
| 2022-10-05T12:42:57
|
NONE
| null | null | null | null |
I am trying to preprocess any dataset in this package with GPT-2 tokenizer, so I need to structure the datasets as long sequences of text without padding. I've been following a couple of your tutorials and here you can find the script that is failing right at the end
https://github.com/LuCeHe/GenericTools/blob/master/KerasTools/lm_preprocessing.py
In the last iteration of the last dset.map, it gives the error that I copied in the title. Another issue that I have, if I leave the batch_size set as 1000 in the last .map, I'm afraid it's going to lose most text, so I'm considering setting both writer_batch_size and batch_size to 300 K, but I'm not sure it's the best way to go.
Can you help me?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1817/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1817/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 608 days, 10:12:34
|
https://api.github.com/repos/huggingface/datasets/issues/1811
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1811/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1811/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1811/events
|
https://github.com/huggingface/datasets/issues/1811
| 799,211,060
|
MDU6SXNzdWU3OTkyMTEwNjA=
| 1,811
|
Unable to add Multi-label Datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Thanks for adding this dataset! As far as I know `supervised_keys` is mostly a holdover from TFDS, but isn't really used, so feel free to drop it (@lhoestq or @thomwolf correct me if I'm wrong). It definitely shouldn't be blocking :) ",
"I can confirm that it comes from TFDS and is not used at the moment.",
"Thanks @yjernite @lhoestq \r\n\r\nThe template for new dataset makes it slightly confusing. I suppose the comment suggesting its update can be removed.",
"Closing this issue since it was answered."
] | 2021-02-02T11:50:56
| 2021-02-18T14:16:31
| 2021-02-18T14:16:31
|
CONTRIBUTOR
| null | null | null | null |
I am trying to add [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) dataset. The dataset contains two labels per image - `fine label` and `coarse label`. Using just one label in supervised keys as
`supervised_keys=("img", "fine_label")` raises no issue. But trying `supervised_keys=("img", "fine_label","coarse_label")` leads to this error :
```python
Traceback (most recent call last):
File "test_script.py", line 2, in <module>
d = load_dataset('./datasets/cifar100')
File "~/datasets/src/datasets/load.py", line 668, in load_dataset
**config_kwargs,
File "~/datasets/src/datasets/builder.py", line 896, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "~/datasets/src/datasets/builder.py", line 247, in __init__
info.update(self._info())
File "~/.cache/huggingface/modules/datasets_modules/datasets/cifar100/61d2489b2d4a4abc34201432541b7380984ec714e290817d9a1ee318e4b74e0f/cifar100.py", line 79, in _info
citation=_CITATION,
File "<string>", line 19, in __init__
File "~/datasets/src/datasets/info.py", line 136, in __post_init__
self.supervised_keys = SupervisedKeysData(*self.supervised_keys)
TypeError: __init__() takes from 1 to 3 positional arguments but 4 were given
```
Is there a way I can fix this?
Also, what does adding `supervised_keys` do? Is it necessary? How would I specify `supervised_keys` for a multi-input, multi-label dataset?
Thanks,
Gunjan
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1811/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1811/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 16 days, 2:25:35
|
https://api.github.com/repos/huggingface/datasets/issues/1810
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1810/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1810/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1810/events
|
https://github.com/huggingface/datasets/issues/1810
| 799,168,650
|
MDU6SXNzdWU3OTkxNjg2NTA=
| 1,810
|
Add Hateful Memes Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] |
open
| false
| null |
[] |
[
"I am not sure, but would `datasets.Sequence(datasets.Sequence(datasets.Sequence(datasets.Value(\"int\")))` work?",
"Also, I found the information for loading only subsets of the data [here](https://github.com/huggingface/datasets/blob/master/docs/source/splits.rst).",
"Hi @lhoestq,\r\n\r\nRequest you to check this once.\r\n\r\nThanks,\r\nGunjan",
"Hi @gchhablani since Array2D doesn't support images of different sizes, I would suggest to store in the dataset the paths to the image file instead of the image data. This has the advantage of not decompressing the data (images are often compressed using jpeg, png etc.). Users can still apply `.map` to load the images if they want to. Though it would en up being Sequences features.\r\n\r\nIn the future we'll add support for ragged tensors for this case and update the relevant dataset with this feature."
] | 2021-02-02T10:53:59
| 2021-12-08T12:03:59
| null |
CONTRIBUTOR
| null | null | null | null |
## Add Hateful Memes Dataset
- **Name:** Hateful Memes
- **Description:** [https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set]( https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set)
- **Paper:** [https://arxiv.org/pdf/2005.04790.pdf](https://arxiv.org/pdf/2005.04790.pdf)
- **Data:** [This link](https://drivendata-competition-fb-hateful-memes-data.s3.amazonaws.com/XjiOc5ycDBRRNwbhRlgH.zip?AWSAccessKeyId=AKIARVBOBDCY4MWEDJKS&Signature=DaUuGgZWUgDHzEPPbyJ2PhSJ56Q%3D&Expires=1612816874)
- **Motivation:** Including multi-modal datasets to 🤗 datasets.
I will be adding this dataset. It requires the user to sign an agreement on DrivenData. So, it will be used with a manual download.
The issue with this dataset is that the images are of different sizes. The image datasets added so far (CIFAR-10 and MNIST) have a uniform shape throughout.
So something like
```python
datasets.Array2D(shape=(28, 28), dtype="uint8")
```
won't work for the images. How would I add image features then? I checked `datasets/features.py` but couldn't figure out the appropriate class for this. I'm assuming I would want to avoid re-sizing at all since we want the user to be able to access the original images.
Also, in case I want to load only a subset of the data, since the actual data is around 8.8GB, how would that be possible?
Thanks,
Gunjan
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1810/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1810/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1808
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1808/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1808/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1808/events
|
https://github.com/huggingface/datasets/issues/1808
| 798,879,180
|
MDU6SXNzdWU3OTg4NzkxODA=
| 1,808
|
writing Datasets in a human readable format
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghost",
"id": 10137,
"login": "ghost",
"node_id": "MDQ6VXNlcjEwMTM3",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"repos_url": "https://api.github.com/users/ghost/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghost",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] |
closed
| false
| null |
[] |
[
"AFAIK, there is currently no built-in method on the `Dataset` object to do this.\r\nHowever, a workaround is to directly use the Arrow table backing the dataset, **but it implies loading the whole dataset in memory** (correct me if I'm mistaken @lhoestq).\r\n\r\nYou can convert the Arrow table to a pandas dataframe to save the data as csv as follows:\r\n```python\r\narrow_table = dataset.data\r\ndataframe = arrow_table.to_pandas()\r\ndataframe.to_csv(\"/path/to/file.csv\")\r\n```\r\n\r\nSimilarly, you can convert the dataset to a Python dict and save it as JSON:\r\n```python\r\nimport json\r\narrow_table = dataset.data\r\npy_dict = arrow_table.to_pydict()\r\nwith open(\"/path/to/file.json\", \"w+\") as f:\r\n json.dump(py_dict, f)\r\n```",
"Indeed this works as long as you have enough memory.\r\nIt would be amazing to have export options like csv, json etc. !\r\n\r\nIt should be doable to implement something that iterates through the dataset batch by batch to write to csv for example.\r\nThere is already an `export` method but currently the only export type that is supported is `tfrecords`.",
"Hi! `datasets` now supports `Dataset.to_csv` and `Dataset.to_json` for saving data in a human readable format."
] | 2021-02-02T02:55:40
| 2022-06-01T15:38:13
| 2022-06-01T15:38:13
|
NONE
| null | null | null | null |
Hi
I see there is a save_to_disk function to save data, but this is not human readable format, is there a way I could save a Dataset object in a human readable format to a file like json? thanks @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1808/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1808/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 484 days, 12:42:33
|
https://api.github.com/repos/huggingface/datasets/issues/1805
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1805/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1805/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1805/events
|
https://github.com/huggingface/datasets/issues/1805
| 798,498,053
|
MDU6SXNzdWU3OTg0OTgwNTM=
| 1,805
|
can't pickle SwigPyObject objects when calling dataset.get_nearest_examples from FAISS index
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6608232?v=4",
"events_url": "https://api.github.com/users/abarbosa94/events{/privacy}",
"followers_url": "https://api.github.com/users/abarbosa94/followers",
"following_url": "https://api.github.com/users/abarbosa94/following{/other_user}",
"gists_url": "https://api.github.com/users/abarbosa94/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abarbosa94",
"id": 6608232,
"login": "abarbosa94",
"node_id": "MDQ6VXNlcjY2MDgyMzI=",
"organizations_url": "https://api.github.com/users/abarbosa94/orgs",
"received_events_url": "https://api.github.com/users/abarbosa94/received_events",
"repos_url": "https://api.github.com/users/abarbosa94/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abarbosa94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abarbosa94/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abarbosa94",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! Indeed we used to require mapping functions to be picklable with `pickle` or `dill` in order to cache the resulting datasets. And FAISS indexes are not picklable unfortunately.\r\n\r\nBut since #1703 this is no longer required (the caching will simply be disabled). This change will be available in the next release of `datasets`, or you can also install `datasets` from source.",
"I totally forgot to answer this issue, I'm so sorry. \r\n\r\nI was able to get it working by installing `datasets` from source. Huge thanks!"
] | 2021-02-01T16:14:17
| 2021-03-06T14:32:46
| 2021-03-06T14:32:46
|
CONTRIBUTOR
| null | null | null | null |
So, I have the following instances in my dataset
```
{'question': 'An astronomer observes that a planet rotates faster after a meteorite impact. Which is the most likely effect of
this increase in rotation?',
'answer': 'C',
'example_id': 'ARCCH_Mercury_7175875',
'options':[{'option_context': 'One effect of increased amperage in the planetary world (..)', 'option_id': 'A', 'option_text': 'Planetary density will decrease.'},
(...)]}
```
The `options` value is always an list with 4 options, each one is a dict with `option_context`; `option_id` and `option_text`.
I would like to overwrite the `option_context` of each instance of my dataset for a dpr result that I am developing. Then, I trained a model already and save it in a FAISS index
```
dpr_dataset = load_dataset(
"text",
data_files=ARC_CORPUS_TEXT,
cache_dir=CACHE_DIR,
split="train[:100%]",
)
dpr_dataset.load_faiss_index("embeddings", f"{ARC_CORPUS_FAISS}")
torch.set_grad_enabled(False)
```
Then, as a processor of my dataset, I created a map function that calls the `dpr_dataset` for each _option_
```
def generate_context(example):
question_text = example['question']
for option in example['options']:
question_with_option = question_text + " " + option['option_text']
tokenize_text = question_tokenizer(question_with_option, return_tensors="pt").to(device)
question_embed = (
question_encoder(**tokenize_text)
)[0][0].cpu().numpy()
_, retrieved_examples = dpr_dataset.get_nearest_examples(
"embeddings", question_embed, k=10
)
# option["option_context"] = retrieved_examples["text"]
# option["option_context"] = " ".join(option["option_context"]).strip()
#result_dict = {
# 'example_id': example['example_id'],
# 'answer': example['answer'],
# 'question': question_text,
#options': example['options']
# }
return example
```
I intentionally commented on this portion of the code.
But when I call the `map` method, `ds_with_context = dataset.map(generate_context,load_from_cache_file=False)`
It calls the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-55-75a458ce205c> in <module>
----> 1 ds_with_context = dataset.map(generate_context,load_from_cache_file=False)
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in <dictcomp>(.0)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1257 fn_kwargs=fn_kwargs,
1258 new_fingerprint=new_fingerprint,
-> 1259 update_data=update_data,
1260 )
1261 else:
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
155 }
156 # apply actual function
--> 157 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
158 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
159 # re-apply format to the output
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
156 kwargs_for_fingerprint["fingerprint_name"] = fingerprint_name
157 kwargs[fingerprint_name] = update_fingerprint(
--> 158 self._fingerprint, transform, kwargs_for_fingerprint
159 )
160
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in update_fingerprint(fingerprint, transform, transform_args)
103 for key in sorted(transform_args):
104 hasher.update(key)
--> 105 hasher.update(transform_args[key])
106 return hasher.hexdigest()
107
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in update(self, value)
55 def update(self, value):
56 self.m.update(f"=={type(value)}==".encode("utf8"))
---> 57 self.m.update(self.hash(value).encode("utf-8"))
58
59 def hexdigest(self):
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in hash(cls, value)
51 return cls.dispatch[type(value)](cls, value)
52 else:
---> 53 return cls.hash_default(value)
54
55 def update(self, value):
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in hash_default(cls, value)
44 @classmethod
45 def hash_default(cls, value):
---> 46 return cls.hash_bytes(dumps(value))
47
48 @classmethod
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in dumps(obj)
387 file = StringIO()
388 with _no_cache_fields(obj):
--> 389 dump(obj, file)
390 return file.getvalue()
391
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in dump(obj, file)
359 def dump(obj, file):
360 """pickle an object to a file"""
--> 361 Pickler(file, recurse=True).dump(obj)
362 return
363
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in dump(self, obj)
452 raise PicklingError(msg)
453 else:
--> 454 StockPickler.dump(self, obj)
455 stack.clear() # clear record of 'recursion-sensitive' pickled objects
456 return
/usr/lib/python3.7/pickle.py in dump(self, obj)
435 if self.proto >= 4:
436 self.framer.start_framing()
--> 437 self.save(obj)
438 self.write(STOP)
439 self.framer.end_framing()
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in save_function(pickler, obj)
554 dill._dill._create_function,
555 (obj.__code__, globs, obj.__name__, obj.__defaults__, obj.__closure__, obj.__dict__, fkwdefaults),
--> 556 obj=obj,
557 )
558 else:
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
636 else:
637 save(func)
--> 638 save(args)
639 write(REDUCE)
640
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/usr/lib/python3.7/pickle.py in save_tuple(self, obj)
784 write(MARK)
785 for element in obj:
--> 786 save(element)
787
788 if id(obj) in memo:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
885 k, v = tmp[0]
886 save(k)
--> 887 save(v)
888 write(SETITEM)
889 # else tmp is empty, and we're done
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
885 k, v = tmp[0]
886 save(k)
--> 887 save(v)
888 write(SETITEM)
889 # else tmp is empty, and we're done
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
522 reduce = getattr(obj, "__reduce_ex__", None)
523 if reduce is not None:
--> 524 rv = reduce(self.proto)
525 else:
526 reduce = getattr(obj, "__reduce__", None)
TypeError: can't pickle SwigPyObject objects
```
Which I have no idea how to solve/deal with it
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6608232?v=4",
"events_url": "https://api.github.com/users/abarbosa94/events{/privacy}",
"followers_url": "https://api.github.com/users/abarbosa94/followers",
"following_url": "https://api.github.com/users/abarbosa94/following{/other_user}",
"gists_url": "https://api.github.com/users/abarbosa94/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abarbosa94",
"id": 6608232,
"login": "abarbosa94",
"node_id": "MDQ6VXNlcjY2MDgyMzI=",
"organizations_url": "https://api.github.com/users/abarbosa94/orgs",
"received_events_url": "https://api.github.com/users/abarbosa94/received_events",
"repos_url": "https://api.github.com/users/abarbosa94/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abarbosa94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abarbosa94/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abarbosa94",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1805/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1805/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 32 days, 22:18:29
|
https://api.github.com/repos/huggingface/datasets/issues/1803
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1803/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1803/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1803/events
|
https://github.com/huggingface/datasets/issues/1803
| 798,243,904
|
MDU6SXNzdWU3OTgyNDM5MDQ=
| 1,803
|
Querying examples from big datasets is slower than small datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hello, @lhoestq / @gaceladri : We have been seeing similar behavior with bigger datasets, where querying time increases. Are you folks aware of any solution that fixes this problem yet? ",
"Hi ! I'm pretty sure that it can be fixed by using the Arrow IPC file format instead of the raw streaming format but I haven't tested yet.\r\nI'll take a look at it soon and let you know",
"My workaround is to shard the dataset into splits in my ssd disk and feed the data in different training sessions. But it is a bit of a pain when we need to reload the last training session with the rest of the split with the Trainer in transformers.\r\n\r\nI mean, when I split the training and then reloads the model and optimizer, it not gets the correct global_status of the optimizer, so I need to hardcode some things. I'm planning to open an issue in transformers and think about it.\r\n```\r\nfrom datasets import load_dataset\r\n\r\nbook_corpus = load_dataset(\"bookcorpus\", split=\"train[:25%]\")\r\nwikicorpus = load_dataset(\"wikicorpus\", split=\"train[:25%]\")\r\nopenwebtext = load_dataset(\"openwebtext\", split=\"train[:25%]\")\r\n\r\nbig_dataset = datasets.concatenate_datasets([wikicorpus, openwebtext, book_corpus])\r\nbig_dataset.shuffle(seed=42)\r\nbig_dataset = big_dataset.map(encode, batched=True, num_proc=20, load_from_cache_file=True, writer_batch_size=5000)\r\nbig_dataset.set_format(type='torch', columns=[\"text\", \"input_ids\", \"attention_mask\", \"token_type_ids\"])\r\n\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./linear_bert\",\r\n overwrite_output_dir=True,\r\n per_device_train_batch_size=71,\r\n save_steps=500,\r\n save_total_limit=10,\r\n logging_first_step=True,\r\n logging_steps=100,\r\n gradient_accumulation_steps=9,\r\n fp16=True,\r\n dataloader_num_workers=20,\r\n warmup_steps=24000,\r\n learning_rate=0.000545205002870214,\r\n adam_epsilon=1e-6,\r\n adam_beta2=0.98,\r\n weight_decay=0.01,\r\n max_steps=138974, # the total number of steps after concatenating 100% datasets\r\n max_grad_norm=1.0,\r\n)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=big_dataset,\r\n tokenizer=tokenizer))\r\n```\r\n\r\nI do one training pass with the total steps of this shard and I use len(bbig)/batchsize to stop the training (hardcoded in the trainer.py) when I pass over all the examples in this split.\r\n\r\nNow Im working, I will edit the comment with a more elaborated answer when I left the work.",
"I just tested and using the Arrow File format doesn't improve the speed... This will need further investigation.\r\n\r\nMy guess is that it has to iterate over the record batches or chunks of a ChunkedArray in order to retrieve elements.\r\n\r\nHowever if we know in advance in which chunk the element is, and at what index it is, then we can access it instantaneously. But this requires dealing with the chunked arrays instead of the pyarrow Table directly which is not practical.",
"I have a dataset with about 2.7 million rows (which I'm loading via `load_from_disk`), and I need to fetch around 300k (particular) rows of it, by index. Currently this is taking a really long time (~8 hours). I tried sharding the large dataset but overall it doesn't change how long it takes to fetch the desired rows.\r\n\r\nI actually have enough RAM that I could fit the large dataset in memory. Would having the large dataset in memory speed up querying? To find out, I tried to load (a column of) the large dataset into memory like this:\r\n```\r\ncolumn_data = large_ds['column_name']\r\n```\r\nbut in itself this takes a really long time.\r\n\r\nI'm pretty stuck - do you have any ideas what I should do? ",
"Hi ! Feel free to post a message on the [forum](https://discuss.huggingface.co/c/datasets/10). I'd be happy to help you with this.\r\n\r\nIn your post on the forum, feel free to add more details about your setup:\r\nWhat are column names and types of your dataset ?\r\nHow was the dataset constructed ?\r\nIs the dataset shuffled ?\r\nIs the dataset tokenized ?\r\nAre you on a SSD or an HDD ?\r\n\r\nI'm sure we can figure something out.\r\nFor example on my laptop I can access the 6 millions articles from wikipedia in less than a minute.",
"Thanks @lhoestq, I've [posted on the forum](https://discuss.huggingface.co/t/fetching-rows-of-a-large-dataset-by-index/4271?u=abisee).",
"Fixed by #2122."
] | 2021-02-01T11:08:23
| 2021-08-04T18:11:01
| 2021-08-04T18:10:42
|
MEMBER
| null | null | null | null |
After some experiments with bookcorpus I noticed that querying examples from big datasets is slower than small datasets.
For example
```python
from datasets import load_dataset
b1 = load_dataset("bookcorpus", split="train[:1%]")
b50 = load_dataset("bookcorpus", split="train[:50%]")
b100 = load_dataset("bookcorpus", split="train[:100%]")
%timeit _ = b1[-1]
# 12.2 µs ± 70.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
%timeit _ = b50[-1]
# 92.5 µs ± 1.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit _ = b100[-1]
# 177 µs ± 3.13 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
It looks like the time to fetch the example increases with the size of the dataset.
This is maybe due to the use of the Arrow streaming format to store the data on disk. I guess pyarrow needs to iterate through the file as a stream to find the queried sample.
Maybe switching to the Arrow IPC file format could help fixing this issue.
Indeed according to the [documentation](https://arrow.apache.org/docs/format/Columnar.html?highlight=arrow1#ipc-file-format), it's identical to the streaming format except that it contains the memory offsets of each sample, which could fix the issue:
> We define a “file format” supporting random access that is build with the stream format. The file starts and ends with a magic string ARROW1 (plus padding). What follows in the file is identical to the stream format. At the end of the file, we write a footer containing a redundant copy of the schema (which is a part of the streaming format) plus memory offsets and sizes for each of the data blocks in the file. This enables random access any record batch in the file. See File.fbs for the precise details of the file footer.
cc @gaceladri since it can help speed up your training when this one is fixed.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1803/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1803/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 184 days, 7:02:19
|
https://api.github.com/repos/huggingface/datasets/issues/1797
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1797/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1797/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1797/events
|
https://github.com/huggingface/datasets/issues/1797
| 797,357,901
|
MDU6SXNzdWU3OTczNTc5MDE=
| 1,797
|
Connection error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46243662?v=4",
"events_url": "https://api.github.com/users/smile0925/events{/privacy}",
"followers_url": "https://api.github.com/users/smile0925/followers",
"following_url": "https://api.github.com/users/smile0925/following{/other_user}",
"gists_url": "https://api.github.com/users/smile0925/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/smile0925",
"id": 46243662,
"login": "smile0925",
"node_id": "MDQ6VXNlcjQ2MjQzNjYy",
"organizations_url": "https://api.github.com/users/smile0925/orgs",
"received_events_url": "https://api.github.com/users/smile0925/received_events",
"repos_url": "https://api.github.com/users/smile0925/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/smile0925/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/smile0925/subscriptions",
"type": "User",
"url": "https://api.github.com/users/smile0925",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! For future references let me add a link to our discussion here : https://github.com/huggingface/datasets/issues/759#issuecomment-770684693\r\n\r\nLet me know if you manage to fix your proxy issue or if we can do something on our end to help you :)"
] | 2021-01-30T07:32:45
| 2021-08-04T18:09:37
| 2021-08-04T18:09:37
|
NONE
| null | null | null | null |
Hi
I am hitting to the error, help me and thanks.
`train_data = datasets.load_dataset("xsum", split="train")`
`ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/xsum/xsum.py`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1797/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1797/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 186 days, 10:36:52
|
https://api.github.com/repos/huggingface/datasets/issues/1796
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1796/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1796/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1796/events
|
https://github.com/huggingface/datasets/issues/1796
| 797,329,905
|
MDU6SXNzdWU3OTczMjk5MDU=
| 1,796
|
Filter on dataset too much slowww
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20911334?v=4",
"events_url": "https://api.github.com/users/ayubSubhaniya/events{/privacy}",
"followers_url": "https://api.github.com/users/ayubSubhaniya/followers",
"following_url": "https://api.github.com/users/ayubSubhaniya/following{/other_user}",
"gists_url": "https://api.github.com/users/ayubSubhaniya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ayubSubhaniya",
"id": 20911334,
"login": "ayubSubhaniya",
"node_id": "MDQ6VXNlcjIwOTExMzM0",
"organizations_url": "https://api.github.com/users/ayubSubhaniya/orgs",
"received_events_url": "https://api.github.com/users/ayubSubhaniya/received_events",
"repos_url": "https://api.github.com/users/ayubSubhaniya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ayubSubhaniya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayubSubhaniya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ayubSubhaniya",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"When I use the filter on the arrow table directly, it works like butter. But I can't find a way to update the table in `Dataset` object.\r\n\r\n```\r\nds_table = dataset.data.filter(mask=dataset['flag'])\r\n```",
"@thomwolf @lhoestq can you guys please take a look and recommend some solution.",
"Hi ! Currently the filter method reads the dataset batch by batch to write a new, filtered, arrow file on disk. Therefore all the reading + writing can take some time.\r\nUsing a mask directly on the arrow table doesn't do any read or write operation therefore it's way quicker.\r\n\r\nReplacing the old table by the new one should do the job:\r\n```python\r\ndataset._data = dataset._data.filter(...)\r\n```\r\n\r\nNote: this is a **workaround** and in general users shouldn't have to do that. In particular if you did some `shuffle` or `select` before that then it would not work correctly since the indices mapping (index from `__getitem__` -> index in the table) would not be valid anymore. But if you haven't done any `shuffle`, `select`, `shard`, `train_test_split` etc. then it should work.\r\n\r\nIdeally it would be awesome to update the filter function to allow masking this way !\r\nIf you would like to give it a shot I will be happy to help :) ",
"Yes, would be happy to contribute. Thanks",
"Hi @lhoestq @ayubSubhaniya,\r\n\r\nIf there's no progress on this one, can I try working on it?\r\n\r\nThanks,\r\nGunjan",
"Sure @gchhablani feel free to start working on it, this would be very appreciated :)\r\nThis feature is would be really awesome, especially since arrow allows to mask really quickly and without having to rewrite the dataset on disk",
"Hi @lhoestq, any updates on this issue? The `filter` method is still veryyy slow 😕 ",
"No update so far, we haven't worked on this yet :/\r\n\r\nThough PyArrow is much more stable than 3 years ago so it would be a good time to dive into this",
"Hi @lhoestq, thanks a lot for the update! \r\n\r\nI would like to work on this(if possible). Could you please give me some steps regarding how should I approach this? Also any references would be great! ",
"I just played a bit with it to make sure using `table.filter()` is fine, but actually it seems to create a new table **in memory** :/\nThis is an issue since it can quickly fill the RAM, and `datasets`'s role is to make sure you can load bigger-than-memory datasets. Therefore I don't think it's a good idea in the end to use `table.filter()`\n\nAnyway I just ran OP's code an it runs in 20ms now on my side thanks to the I/O optimizations we did.\n\nAnother way to speed up `filter` is to add support pyarrow expressions though, using e.g. arrow formatting + dataset.filter (runs in 10ms on my side):\n\n```python\nimport pyarrow.dataset as pds\nimport pyarrow.compute as pc\n\nexpr = pc.field(\"flag\") == True # or any condition\n\nfiltered = dataset.with_format(\"arrow\").filter(\n lambda t: pds.dataset(t).to_table(columns={\"mask\": expr})[0].to_numpy(),\n batched=True,\n).with_format(None)\n```\n\nor simply with numpy:\n\n```python\nfiltered = dataset.with_format(\"np\").filter(\n lambda flags_array: flags_array == True, # or any condition\n input_columns=[\"flag\"]\n batched=True,\n).with_format(None)",
"I can confirm that it's still extremely slow to use the `filter` function, and even trying workarounds like iterating on the dataset to create a mask for the `select` function is very slow (10-20 it/s) on a very small dataset with 5 fields.",
"You can iterate faster on the dataset if you format it with zero-copy formats like `with_format(\"arrow\")`, `with_format(\"numpy\")` or `with_format(\"polars\")`. This is useful to use arrow/numpy/polars functions in map() or filter() and accelerate your data pipeline"
] | 2021-01-30T04:09:19
| 2025-05-15T13:19:55
| null |
NONE
| null | null | null | null |
I have a dataset with 50M rows.
For pre-processing, I need to tokenize this and filter rows with the large sequence.
My tokenization took roughly 12mins. I used `map()` with batch size 1024 and multi-process with 96 processes.
When I applied the `filter()` function it is taking too much time. I need to filter sequences based on a boolean column.
Below are the variants I tried.
1. filter() with batch size 1024, single process (takes roughly 3 hr)
2. filter() with batch size 1024, 96 processes (takes 5-6 hrs ¯\\\_(ツ)\_/¯)
3. filter() with loading all data in memory, only a single boolean column (never ends).
Can someone please help?
Below is a sample code for small dataset.
```
from datasets import load_dataset
dataset = load_dataset('glue', 'mrpc', split='train')
dataset = dataset.map(lambda x: {'flag': random.randint(0,1)==1})
def _amplify(data):
return data
dataset = dataset.filter(_amplify, batch_size=1024, keep_in_memory=False, input_columns=['flag'])
```
| null |
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1796/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1796/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1790
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1790/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1790/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1790/events
|
https://github.com/huggingface/datasets/issues/1790
| 796,678,157
|
MDU6SXNzdWU3OTY2NzgxNTc=
| 1,790
|
ModuleNotFoundError: No module named 'apache_beam', when specific languages.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6331508?v=4",
"events_url": "https://api.github.com/users/miyamonz/events{/privacy}",
"followers_url": "https://api.github.com/users/miyamonz/followers",
"following_url": "https://api.github.com/users/miyamonz/following{/other_user}",
"gists_url": "https://api.github.com/users/miyamonz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/miyamonz",
"id": 6331508,
"login": "miyamonz",
"node_id": "MDQ6VXNlcjYzMzE1MDg=",
"organizations_url": "https://api.github.com/users/miyamonz/orgs",
"received_events_url": "https://api.github.com/users/miyamonz/received_events",
"repos_url": "https://api.github.com/users/miyamonz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/miyamonz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/miyamonz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/miyamonz",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] |
[
"Hi !\r\n\r\nApache Beam is a framework used to define data transformation pipelines. These pipeline can then be run in many runtimes: DataFlow, Spark, Flink, etc. There also exist a local runner called the DirectRunner.\r\nWikipedia is a dataset that requires some parsing, so to allow the processing to be run on this kind of runtime we're using Apache Beam.\r\n\r\nAt Hugging Face we've already processed certain versions of wikipedia (the `20200501.en` one for example) so that users can directly download the processed version instead of using Apache Beam to process it.\r\nHowever for the japanese language we haven't processed it so you'll have to run the processing on your side.\r\nSo you do need Apache Beam to process `20200501.ja`.\r\n\r\nYou can install Apache Beam with\r\n```\r\npip install apache-beam\r\n```\r\n\r\nI think we can probably improve the error message to let users know of this subtlety.\r\nWhat #498 implied is that Apache Beam is not needed when you process a dataset that doesn't use Apache Beam.",
"Thanks for your reply! \r\nI understood.\r\n\r\nI tried again with installing apache-beam, add ` beam_runner=\"DirectRunner\"` and an anther `mwparserfromhell` is also required so I installed it.\r\nbut, it also failed. It exited 1 without error message.\r\n\r\n```py\r\nimport datasets\r\n# BTW, 20200501.ja doesn't exist at wikipedia, so I specified date argument\r\nwiki = datasets.load_dataset(\"wikipedia\", language=\"ja\", date=\"20210120\", cache_dir=\"./datasets\", beam_runner=\"DirectRunner\")\r\nprint(wiki)\r\n```\r\nand its log is below\r\n```\r\nUsing custom data configuration 20210120.ja\r\nDownloading and preparing dataset wikipedia/20210120.ja-date=20210120,language=ja (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to ./datasets/wikipedia/20210120.ja-date=20210120,language=ja/0.0.0/4021357e28509391eab2f8300d9b689e7e8f3a877ebb3d354b01577d497ebc63...\r\nKilled\r\n```\r\n\r\nI also tried on another machine because it may caused by insufficient resources.\r\n```\r\n$ python main.py\r\nUsing custom data configuration 20210120.ja\r\nDownloading and preparing dataset wikipedia/20210120.ja-date=20210120,language=ja (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to ./datasets/wikipedia/20210120.ja-date=20210120,language=ja/0.0.0/4021357e28509391eab2f8300d9b689e7e8f3a877ebb3d354b01577d497ebc63...\r\n\r\nTraceback (most recent call last):\r\n File \"main.py\", line 3, in <module>\r\n wiki = datasets.load_dataset(\"wikipedia\", language=\"ja\", date=\"20210120\", cache_dir=\"./datasets\", beam_runner=\"DirectRunner\")\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/load.py\", line 609, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/builder.py\", line 526, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/builder.py\", line 1069, in _download_and_prepare\r\n pipeline_results = pipeline.run()\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/pipeline.py\", line 561, in run\r\n return self.runner.run_pipeline(self, self._options)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/direct/direct_runner.py\", line 126, in run_pipeline\r\n return runner.run_pipeline(pipeline, options)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 182, in run_pipeline\r\n self._latest_run_result = self.run_via_runner_api(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 193, in run_via_runner_api\r\n return self.run_stages(stage_context, stages)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 358, in run_stages\r\n stage_results = self._run_stage(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 549, in _run_stage\r\n last_result, deferred_inputs, fired_timers = self._run_bundle(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 595, in _run_bundle\r\n result, splits = bundle_manager.process_bundle(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 888, in process_bundle\r\n self._send_input_to_worker(process_bundle_id, transform_id, elements)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 765, in _send_input_to_worker\r\n data_out.write(byte_stream)\r\n File \"apache_beam/coders/stream.pyx\", line 42, in apache_beam.coders.stream.OutputStream.write\r\n File \"apache_beam/coders/stream.pyx\", line 47, in apache_beam.coders.stream.OutputStream.write\r\n File \"apache_beam/coders/stream.pyx\", line 109, in apache_beam.coders.stream.OutputStream.extend\r\nAssertionError: OutputStream realloc failed.\r\n```\r\n\r\n",
"Hi @miyamonz,\r\n\r\nI tried replicating this issue using the same snippet used by you. I am able to download the dataset without any issues, although I stopped it in the middle because the dataset is huge.\r\n\r\nBased on a similar issue [here](https://github.com/google-research/fixmatch/issues/23), it could be related to your environment setup, although I am just guessing here. Can you share these details?",
"thanks for your reply and sorry for my late response.\r\n\r\n## environment\r\nmy local machine environment info\r\n- Ubuntu on WSL2\r\n\r\n`lsb_release -a`\r\n```\r\nNo LSB modules are available.\r\nDistributor ID: Ubuntu\r\nDescription: Ubuntu 20.04.2 LTS\r\nRelease: 20.04\r\nCodename: focal\r\n```\r\n\r\nRTX 2070 super\r\nInside WSL, there is no nvidia-msi command. I don't know why.\r\nBut, `torch.cuda.is_available()` is true and when I start something ML training code GPU usage is growing up, so I think it works.\r\n\r\nFrom PowerShell, there is nvidia-smi.exe and result is below.\r\n```\r\n+-----------------------------------------------------------------------------+\r\n| NVIDIA-SMI 470.05 Driver Version: 470.05 CUDA Version: 11.3 |\r\n|-------------------------------+----------------------+----------------------+\r\n| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |\r\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\r\n| | | MIG M. |\r\n|===============================+======================+======================|\r\n| 0 NVIDIA GeForce ... WDDM | 00000000:09:00.0 On | N/A |\r\n| 0% 30C P8 19W / 175W | 523MiB / 8192MiB | 3% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n\r\n+-----------------------------------------------------------------------------+\r\n| Processes: |\r\n| GPU GI CI PID Type Process name GPU Memory |\r\n| ID ID Usage |\r\n|=============================================================================|\r\n| 0 N/A N/A 1728 C+G Insufficient Permissions N/A |\r\n| 0 N/A N/A 3672 C+G ...ekyb3d8bbwe\\YourPhone.exe N/A |\r\n| 0 N/A N/A 6304 C+G ...2txyewy\\TextInputHost.exe N/A |\r\n| 0 N/A N/A 8648 C+G C:\\Windows\\explorer.exe N/A |\r\n| 0 N/A N/A 9536 C+G ...y\\ShellExperienceHost.exe N/A |\r\n| 0 N/A N/A 10668 C+G ...5n1h2txyewy\\SearchApp.exe N/A |\r\n| 0 N/A N/A 10948 C+G ...artMenuExperienceHost.exe N/A |\r\n| 0 N/A N/A 11988 C+G ...8wekyb3d8bbwe\\Cortana.exe N/A |\r\n| 0 N/A N/A 12464 C+G ...cw5n1h2txyewy\\LockApp.exe N/A |\r\n| 0 N/A N/A 13280 C+G ...upport\\CEF\\Max Helper.exe N/A |\r\n| 0 N/A N/A 15948 C+G ...t\\GoogleIMEJaRenderer.exe N/A |\r\n| 0 N/A N/A 16128 C+G ...ram Files\\Slack\\Slack.exe N/A |\r\n| 0 N/A N/A 19096 C+G ...8bbwe\\WindowsTerminal.exe N/A |\r\n+-----------------------------------------------------------------------------+\r\n```\r\n\r\nI don't know what should I show in such a case. If it's not enough, please tell me some commands.\r\n\r\n---\r\n## what I did\r\nI surveyed more and I found 2 issues.\r\n\r\nAbout the first one, I wrote it as a new issue.\r\nhttps://github.com/huggingface/datasets/issues/2031\r\n\r\nThe error I mentioned in the previous comment above, which occurred on my local machine, is no longer occurring.\r\n\r\nBut, it still failed. In the previous comment, I wrote `AssertionError: OutputStream realloc failed.` happen on another machine. It also happens on my local machine.\r\n\r\nHere's what I've tried.\r\n\r\nthe wikipedia.py downloads these xml.bz2 files based on dumpstatus.json\r\nIn Japanese Wikipedia dataset that I specified, it will download these 6 files.\r\n\r\n\r\n`https://dumps.wikimedia.org/jawiki/20210120/dumpstatus.json`\r\nand filtered json based on wikipedia.py is below.\r\n```json\r\n {\r\n \"jobs\": {\r\n \"articlesmultistreamdump\": {\r\n \"files\": {\r\n \"jawiki-20210120-pages-articles-multistream1.xml-p1p114794.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream1.xml-p1p114794.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream2.xml-p114795p390428.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream2.xml-p114795p390428.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream3.xml-p390429p902407.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream3.xml-p390429p902407.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream4.xml-p902408p1721646.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream4.xml-p902408p1721646.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream5.xml-p1721647p2807947.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream5.xml-p1721647p2807947.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream6.xml-p2807948p4290013.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream6.xml-p2807948p4290013.bz2\"\r\n }\r\n }\r\n }\r\n }\r\n }\r\n```\r\n\r\nSo, I tried running with fewer resources by modifying this line.\r\nhttps://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikipedia.py#L524\r\nI changed it like this. just change filepaths list.\r\n` | \"Initialize\" >> beam.Create(filepaths[:1])`\r\n\r\nand I added a print line inside for the loop of _extract_content.\r\nlike this `if(i % 100000 == 0): print(i)`\r\n\r\nfirst, without modification, it always stops after all _extract_content is done.\r\n\r\n- `filepaths[:1]` then it succeeded.\r\n- `filepaths[:2]` then it failed.\r\nI don't try all patterns because each pattern takes a long time.\r\n\r\n### my opinion\r\nIt seems it's successful when the entire file size is small.\r\n \r\nso, at least it doesn't file-specific issue.\r\n\r\n\r\nI don't know it's true but I think when beam_writter writes into a file, it consumes memory depends on its entire file.\r\nbut It's correct Apache Beam's behavior? I'm not familiar with this library.\r\n",
"I don't know if this is related, but there is this issue on the wikipedia processing that you reported at #2031 (open PR is at #2037 ) .\r\nDoes the fix your proposed at #2037 helps in your case ?\r\n\r\nAnd for information, the DirectRunner of Apache Beam is not optimized for memory intensive tasks, so you must be right when you say that it uses the memory for the entire file.",
"the #2037 doesn't solve my problem directly, but I found the point!\r\n\r\nhttps://github.com/huggingface/datasets/blob/349ac4398a3bcae6356f14c5754483383a60e8a4/datasets/wikipedia/wikipedia.py#L523\r\nthis `beam.transforms.Reshuffle()` cause the memory error.\r\n\r\nit makes sense if I consider the shuffle means. Beam's reshuffle seems need put all data in memory.\r\nPreviously I doubt that this line causes error, but at that time another bug showed in #2037 made error, so I can't found it.\r\n\r\nAnyway, I comment out this line, and run load_dataset, then it works!\r\n\r\n```python\r\nwiki = datasets.load_dataset(\r\n \"./wikipedia.py\",\r\n cache_dir=\"./datasets\",\r\n beam_runner=\"DirectRunner\",\r\n language=\"ja\",\r\n date=\"20210120\",\r\n)[\"train\"]\r\n```\r\n\r\n\r\nDataset has already shuffle function. https://github.com/huggingface/datasets/blob/349ac4398a3bcae6356f14c5754483383a60e8a4/src/datasets/arrow_dataset.py#L2069\r\nSo, though I don't know it's difference correctly, but I think Beam's reshuffle isn't be needed. How do you think?",
"The reshuffle is needed when you use parallelism.\r\nThe objective is to redistribute the articles evenly on the workers, since the `_extract_content` step generated many articles per file. By using reshuffle, we can split the processing of the articles of one file into several workers. Without reshuffle, all the articles of one file would be processed on the same worker that read the file, making the whole process take a very long time.",
"Maybe the reshuffle step can be added only if the runner is not a DirectRunner ?"
] | 2021-01-29T08:17:24
| 2021-03-25T12:10:51
| null |
CONTRIBUTOR
| null | null | null | null |
```py
import datasets
wiki = datasets.load_dataset('wikipedia', '20200501.ja', cache_dir='./datasets')
```
then `ModuleNotFoundError: No module named 'apache_beam'` happend.
The error doesn't appear when it's '20200501.en'.
I don't know Apache Beam, but according to #498 it isn't necessary when it's saved to local. is it correct?
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1790/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1790/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/1786
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1786/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1786/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1786/events
|
https://github.com/huggingface/datasets/issues/1786
| 795,462,816
|
MDU6SXNzdWU3OTU0NjI4MTY=
| 1,786
|
How to use split dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/78090287?v=4",
"events_url": "https://api.github.com/users/kkhan188/events{/privacy}",
"followers_url": "https://api.github.com/users/kkhan188/followers",
"following_url": "https://api.github.com/users/kkhan188/following{/other_user}",
"gists_url": "https://api.github.com/users/kkhan188/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kkhan188",
"id": 78090287,
"login": "kkhan188",
"node_id": "MDQ6VXNlcjc4MDkwMjg3",
"organizations_url": "https://api.github.com/users/kkhan188/orgs",
"received_events_url": "https://api.github.com/users/kkhan188/received_events",
"repos_url": "https://api.github.com/users/kkhan188/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kkhan188/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kkhan188/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kkhan188",
"user_view_type": "public"
}
|
[
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] |
closed
| false
| null |
[] |
[
"By default, all 3 splits will be loaded if you run the following:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"lambada\")\r\nprint(dataset[\"train\"])\r\nprint(dataset[\"valid\"])\r\n\r\n```\r\n\r\nIf you wanted to do load this manually, you could do this:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ndata_files = {\r\n \"train\": \"data/lambada/train.txt\",\r\n \"valid\": \"data/lambada/valid.txt\",\r\n \"test\": \"data/lambada/test.txt\",\r\n}\r\nds = load_dataset(\"text\", data_files=data_files)\r\n```",
"Thank you for the quick response! "
] | 2021-01-27T21:37:47
| 2021-04-23T15:17:39
| 2021-04-23T15:17:39
|
NONE
| null | null | null | null |

Hey,
I want to split the lambada dataset into corpus, test, train and valid txt files (like penn treebank) but I am not able to achieve this. What I am doing is, executing the lambada.py file in my project but its not giving desired results. Any help will be appreciated!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1786/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1786/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 85 days, 17:39:52
|
https://api.github.com/repos/huggingface/datasets/issues/1785
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1785/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1785/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1785/events
|
https://github.com/huggingface/datasets/issues/1785
| 795,458,856
|
MDU6SXNzdWU3OTU0NTg4NTY=
| 1,785
|
Not enough disk space (Needed: Unknown size) when caching on a cluster
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4341867?v=4",
"events_url": "https://api.github.com/users/olinguyen/events{/privacy}",
"followers_url": "https://api.github.com/users/olinguyen/followers",
"following_url": "https://api.github.com/users/olinguyen/following{/other_user}",
"gists_url": "https://api.github.com/users/olinguyen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/olinguyen",
"id": 4341867,
"login": "olinguyen",
"node_id": "MDQ6VXNlcjQzNDE4Njc=",
"organizations_url": "https://api.github.com/users/olinguyen/orgs",
"received_events_url": "https://api.github.com/users/olinguyen/received_events",
"repos_url": "https://api.github.com/users/olinguyen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/olinguyen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/olinguyen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/olinguyen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! \r\n\r\nWhat do you mean by \"disk_usage(\".\").free` can't compute on the cluster's shared disk\" exactly ?\r\nDoes it return 0 ?",
"Yes, that's right. It shows 0 free space even though there is. I suspect it might have to do with permissions on the shared disk.\r\n\r\n```python\r\n>>> disk_usage(\".\")\r\nusage(total=999999, used=999999, free=0)\r\n```",
"That's an interesting behavior...\r\nDo you know any other way to get the free space that works in your case ?\r\nAlso if it's a permission issue could you try fix the permissions and let mus know if that helped ?",
"I think its an issue on the clusters end (unclear exactly why -- maybe something with docker containers?), will close the issue",
"Were you able to figure it out?",
"@philippnoah I had fixed it with a small hack where I patched `has_sufficient_disk_space` to always return `True`. you can do that with an import without having to modify the `datasets` package",
"@olinguyen Thanks for the suggestion, it works but I had to to edit builder.py in the installed package. Can you please explain how were you able to do this using import?",
"I was able to patch the builder code in my notebook before the load data call and it works. \r\n```\r\nimport datasets\r\ndatasets.builder.has_sufficient_disk_space = lambda needed_bytes, directory='.': True\r\n```",
"import datasets\r\n datasets.builder.has_sufficient_disk_space = lambda needed_bytes, directory='.': True"
] | 2021-01-27T21:30:59
| 2024-12-04T02:57:00
| 2021-01-30T01:07:56
|
CONTRIBUTOR
| null | null | null | null |
I'm running some experiments where I'm caching datasets on a cluster and accessing it through multiple compute nodes. However, I get an error when loading the cached dataset from the shared disk.
The exact error thrown:
```bash
>>> load_dataset(dataset, cache_dir="/path/to/cluster/shared/path")
OSError: Not enough disk space. Needed: Unknown size (download: Unknown size, generated: Unknown size, post-processed: Unknown size)
```
[`utils.has_sufficient_disk_space`](https://github.com/huggingface/datasets/blob/8a03ab7d123a76ee744304f21ce868c75f411214/src/datasets/utils/py_utils.py#L332) fails on each job because of how the cluster system is designed (`disk_usage(".").free` can't compute on the cluster's shared disk).
This is exactly where the error gets thrown:
https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L502
```python
if not utils.has_sufficient_disk_space(self.info.size_in_bytes or 0, directory=self._cache_dir_root):
raise IOError(
"Not enough disk space. Needed: {} (download: {}, generated: {}, post-processed: {})".format(
utils.size_str(self.info.size_in_bytes or 0),
utils.size_str(self.info.download_size or 0),
utils.size_str(self.info.dataset_size or 0),
utils.size_str(self.info.post_processing_size or 0),
)
)
```
What would be a good way to circumvent this? my current fix is to manually comment out that part, but that is not ideal.
Would it be possible to pass a flag to skip this check on disk space?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4341867?v=4",
"events_url": "https://api.github.com/users/olinguyen/events{/privacy}",
"followers_url": "https://api.github.com/users/olinguyen/followers",
"following_url": "https://api.github.com/users/olinguyen/following{/other_user}",
"gists_url": "https://api.github.com/users/olinguyen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/olinguyen",
"id": 4341867,
"login": "olinguyen",
"node_id": "MDQ6VXNlcjQzNDE4Njc=",
"organizations_url": "https://api.github.com/users/olinguyen/orgs",
"received_events_url": "https://api.github.com/users/olinguyen/received_events",
"repos_url": "https://api.github.com/users/olinguyen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/olinguyen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/olinguyen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/olinguyen",
"user_view_type": "public"
}
|
{
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1785/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1785/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 3:36:57
|
https://api.github.com/repos/huggingface/datasets/issues/1784
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1784/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1784/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1784/events
|
https://github.com/huggingface/datasets/issues/1784
| 794,659,174
|
MDU6SXNzdWU3OTQ2NTkxNzQ=
| 1,784
|
JSONDecodeError on JSON with multiple lines
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\n\r\nThe `json` dataset script does support this format. For example loading a dataset with this format works on my side:\r\n```json\r\n{\"key1\":11, \"key2\":12, \"key3\":13}\r\n{\"key1\":21, \"key2\":22, \"key3\":23}\r\n```\r\n\r\nCan you show the full stacktrace please ? Also which version of datasets and pyarrow are you using ?\r\n\r\n",
"Hi Quentin!\r\n\r\nI apologize for bothering you. There was some issue with my pyarrow version as far as I understand. I don't remember the exact version I was using as I didn't check it.\r\n\r\nI repeated it with `datasets 1.2.1` and `pyarrow 2.0.0` and it worked.\r\n\r\nClosing this issue. Again, sorry for the bother.\r\n\r\nThanks,\r\nGunjan"
] | 2021-01-27T00:19:22
| 2021-01-31T08:47:18
| 2021-01-31T08:47:18
|
CONTRIBUTOR
| null | null | null | null |
Hello :),
I have been trying to load data using a JSON file. Based on the [docs](https://huggingface.co/docs/datasets/loading_datasets.html#json-files), the following format is supported:
```json
{"key1":11, "key2":12, "key3":13}
{"key1":21, "key2":22, "key3":23}
```
But, when I try loading a dataset with the same format, I get a JSONDecodeError : `JSONDecodeError: Extra data: line 2 column 1 (char 7142)`. Now, this is expected when using `json` to load a JSON file. But I was wondering if there are any special arguments to pass when using `load_dataset` as the docs suggest that this format is supported.
When I convert the JSON file to a list of dictionaries format, I get AttributeError: `AttributeError: 'list' object has no attribute 'keys'`. So, I can't convert them to list of dictionaries either.
Please let me know :)
Thanks,
Gunjan
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1784/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1784/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 8:27:56
|
https://api.github.com/repos/huggingface/datasets/issues/1783
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1783/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1783/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1783/events
|
https://github.com/huggingface/datasets/issues/1783
| 794,544,495
|
MDU6SXNzdWU3OTQ1NDQ0OTU=
| 1,783
|
Dataset Examples Explorer
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30875246?v=4",
"events_url": "https://api.github.com/users/ChewKokWah/events{/privacy}",
"followers_url": "https://api.github.com/users/ChewKokWah/followers",
"following_url": "https://api.github.com/users/ChewKokWah/following{/other_user}",
"gists_url": "https://api.github.com/users/ChewKokWah/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ChewKokWah",
"id": 30875246,
"login": "ChewKokWah",
"node_id": "MDQ6VXNlcjMwODc1MjQ2",
"organizations_url": "https://api.github.com/users/ChewKokWah/orgs",
"received_events_url": "https://api.github.com/users/ChewKokWah/received_events",
"repos_url": "https://api.github.com/users/ChewKokWah/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ChewKokWah/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ChewKokWah/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ChewKokWah",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @ChewKokWah,\r\n\r\nWe're working on it! In the meantime, you can still find the dataset explorer at the following URL: https://huggingface.co/datasets/viewer/",
"Glad to see that it still exist, this existing one is more than good enough for me, it is feature rich, simple to use and concise. \r\nHope similar feature can be retain in the future version."
] | 2021-01-26T20:39:02
| 2021-02-01T13:58:44
| 2021-02-01T13:58:44
|
NONE
| null | null | null | null |
In the Older version of the Dataset, there are a useful Dataset Explorer that allow user to visualize the examples (training, test and validation) of a particular dataset, it is no longer there in current version.
Hope HuggingFace can re-enable the feature that at least allow viewing of the first 20 examples of a particular dataset, or alternatively can extract 20 examples for each datasets and make those part of the Dataset Card Documentation.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30875246?v=4",
"events_url": "https://api.github.com/users/ChewKokWah/events{/privacy}",
"followers_url": "https://api.github.com/users/ChewKokWah/followers",
"following_url": "https://api.github.com/users/ChewKokWah/following{/other_user}",
"gists_url": "https://api.github.com/users/ChewKokWah/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ChewKokWah",
"id": 30875246,
"login": "ChewKokWah",
"node_id": "MDQ6VXNlcjMwODc1MjQ2",
"organizations_url": "https://api.github.com/users/ChewKokWah/orgs",
"received_events_url": "https://api.github.com/users/ChewKokWah/received_events",
"repos_url": "https://api.github.com/users/ChewKokWah/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ChewKokWah/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ChewKokWah/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ChewKokWah",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1783/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1783/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5 days, 17:19:42
|
https://api.github.com/repos/huggingface/datasets/issues/1781
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1781/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1781/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1781/events
|
https://github.com/huggingface/datasets/issues/1781
| 793,914,556
|
MDU6SXNzdWU3OTM5MTQ1NTY=
| 1,781
|
AttributeError: module 'pyarrow' has no attribute 'PyExtensionType' during import
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/45964869?v=4",
"events_url": "https://api.github.com/users/PalaashAgrawal/events{/privacy}",
"followers_url": "https://api.github.com/users/PalaashAgrawal/followers",
"following_url": "https://api.github.com/users/PalaashAgrawal/following{/other_user}",
"gists_url": "https://api.github.com/users/PalaashAgrawal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PalaashAgrawal",
"id": 45964869,
"login": "PalaashAgrawal",
"node_id": "MDQ6VXNlcjQ1OTY0ODY5",
"organizations_url": "https://api.github.com/users/PalaashAgrawal/orgs",
"received_events_url": "https://api.github.com/users/PalaashAgrawal/received_events",
"repos_url": "https://api.github.com/users/PalaashAgrawal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PalaashAgrawal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PalaashAgrawal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PalaashAgrawal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! I'm not able to reproduce the issue. Can you try restarting your runtime ?\r\n\r\nThe PyExtensionType is available in pyarrow starting 0.17.1 iirc. If restarting your runtime doesn't fix this, can you try updating pyarrow ?\r\n```\r\npip install pyarrow --upgrade\r\n```",
"We should bump up the version test of pyarrow maybe no?\r\n\r\nhttps://github.com/huggingface/datasets/blob/master/src/datasets/__init__.py#L60",
"Yes indeed.\r\n\r\nAlso it looks like Pyarrow 3.0.0 got released on pypi 10 hours ago. This might be related to the bug, I'll investigate\r\nEDIT: looks like the 3.0.0 release doesn't have unexpected breaking changes for us, so I don't think the issue comes from that",
"Maybe colab moved to pyarrow 0.16 by default (instead of 0.14 before)?",
"Installing datasets installs pyarrow>=0.17.1 so in theory it doesn't matter which version of pyarrow colab has by default (which is currently pyarrow 0.14.1).\r\n\r\nAlso now the colab runtime refresh the pyarrow version automatically after the update from pip (previously you needed to restart your runtime).\r\n\r\nI guess what happened is that Colab didn't refresh pyarrow for some reason, and the AttributeError was raised *before* the pyarrow version check from `datasets` at https://github.com/huggingface/datasets/blob/master/src/datasets/__init__.py#L60",
"Yes colab doesn’t reload preloaded library unless you restart the instance. Maybe we should move the check on top of the init ",
"Yes I'll do that :)",
"I updated the pyarrow version check in #1782",
"restarting worked for me\r\n> ```\r\n\r\nyes it worked for me"
] | 2021-01-26T04:18:35
| 2024-07-07T17:55:12
| 2022-10-05T12:37:06
|
NONE
| null | null | null | null |
I'm using Colab. And suddenly this morning, there is this error. Have a look below!

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1781/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1781/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 617 days, 8:18:31
|
https://api.github.com/repos/huggingface/datasets/issues/1777
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1777/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1777/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1777/events
|
https://github.com/huggingface/datasets/issues/1777
| 793,273,770
|
MDU6SXNzdWU3OTMyNzM3NzA=
| 1,777
|
GPT2 MNLI training using run_glue.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/76427077?v=4",
"events_url": "https://api.github.com/users/nlp-student/events{/privacy}",
"followers_url": "https://api.github.com/users/nlp-student/followers",
"following_url": "https://api.github.com/users/nlp-student/following{/other_user}",
"gists_url": "https://api.github.com/users/nlp-student/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nlp-student",
"id": 76427077,
"login": "nlp-student",
"node_id": "MDQ6VXNlcjc2NDI3MDc3",
"organizations_url": "https://api.github.com/users/nlp-student/orgs",
"received_events_url": "https://api.github.com/users/nlp-student/received_events",
"repos_url": "https://api.github.com/users/nlp-student/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nlp-student/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nlp-student/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nlp-student",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2021-01-25T10:53:52
| 2021-01-25T11:12:53
| 2021-01-25T11:12:53
|
NONE
| null | null | null | null |
Edit: I'm closing this because I actually meant to post this in `transformers `not `datasets`
Running this on Google Colab,
```
!python run_glue.py \
--model_name_or_path gpt2 \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_gpu_train_batch_size 10 \
--gradient_accumulation_steps 32\
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir models/gpt2/mnli/
```
I get the following error,
```
"Asking to pad but the tokenizer does not have a padding token. "
ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
```
Do I need to modify the trainer to work with GPT2 ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/76427077?v=4",
"events_url": "https://api.github.com/users/nlp-student/events{/privacy}",
"followers_url": "https://api.github.com/users/nlp-student/followers",
"following_url": "https://api.github.com/users/nlp-student/following{/other_user}",
"gists_url": "https://api.github.com/users/nlp-student/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nlp-student",
"id": 76427077,
"login": "nlp-student",
"node_id": "MDQ6VXNlcjc2NDI3MDc3",
"organizations_url": "https://api.github.com/users/nlp-student/orgs",
"received_events_url": "https://api.github.com/users/nlp-student/received_events",
"repos_url": "https://api.github.com/users/nlp-student/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nlp-student/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nlp-student/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nlp-student",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1777/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1777/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:19:01
|
https://api.github.com/repos/huggingface/datasets/issues/1776
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1776/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1776/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1776/events
|
https://github.com/huggingface/datasets/issues/1776
| 792,755,249
|
MDU6SXNzdWU3OTI3NTUyNDk=
| 1,776
|
[Question & Bug Report] Can we preprocess a dataset on the fly?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_url": "https://api.github.com/users/shuaihuaiyi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shuaihuaiyi",
"id": 14048129,
"login": "shuaihuaiyi",
"node_id": "MDQ6VXNlcjE0MDQ4MTI5",
"organizations_url": "https://api.github.com/users/shuaihuaiyi/orgs",
"received_events_url": "https://api.github.com/users/shuaihuaiyi/received_events",
"repos_url": "https://api.github.com/users/shuaihuaiyi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shuaihuaiyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuaihuaiyi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shuaihuaiyi",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"We are very actively working on this. How does your dataset look like in practice (number/size/type of files)?",
"It's a text file with many lines (about 1B) of Chinese sentences. I use it to train language model using https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py",
"Indeed I will submit a PR in a fez days to enable processing on-the-fly :)\r\nThis can be useful in language modeling for tokenization, padding etc.\r\n",
"any update on this issue? ...really look forward to use it ",
"Hi @acul3,\r\n\r\nPlease look at the discussion on a related Issue #1825. I think using `set_transform` after building from source should do.",
"@gchhablani thank you so much\r\n\r\nwill try look at it"
] | 2021-01-24T09:28:24
| 2021-05-20T04:15:58
| 2021-05-20T04:15:58
|
NONE
| null | null | null | null |
I know we can use `Datasets.map` to preprocess a dataset, but I'm using it with very large corpus which generates huge cache file (several TB cache from a 400 GB text file). I have no disk large enough to save it. Can we preprocess a dataset on the fly without generating cache?
BTW, I tried raising `writer_batch_size`. Seems that argument doesn't have any effect when it's larger than `batch_size`, because you are saving all the batch instantly after it's processed. Please check the following code:
https://github.com/huggingface/datasets/blob/0281f9d881f3a55c89aeaa642f1ba23444b64083/src/datasets/arrow_dataset.py#L1532
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_url": "https://api.github.com/users/shuaihuaiyi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shuaihuaiyi",
"id": 14048129,
"login": "shuaihuaiyi",
"node_id": "MDQ6VXNlcjE0MDQ4MTI5",
"organizations_url": "https://api.github.com/users/shuaihuaiyi/orgs",
"received_events_url": "https://api.github.com/users/shuaihuaiyi/received_events",
"repos_url": "https://api.github.com/users/shuaihuaiyi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shuaihuaiyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuaihuaiyi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shuaihuaiyi",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1776/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1776/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 115 days, 18:47:34
|
https://api.github.com/repos/huggingface/datasets/issues/1775
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/1775/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/1775/comments
|
https://api.github.com/repos/huggingface/datasets/issues/1775/events
|
https://github.com/huggingface/datasets/issues/1775
| 792,742,120
|
MDU6SXNzdWU3OTI3NDIxMjA=
| 1,775
|
Efficient ways to iterate the dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11826803?v=4",
"events_url": "https://api.github.com/users/zhongpeixiang/events{/privacy}",
"followers_url": "https://api.github.com/users/zhongpeixiang/followers",
"following_url": "https://api.github.com/users/zhongpeixiang/following{/other_user}",
"gists_url": "https://api.github.com/users/zhongpeixiang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zhongpeixiang",
"id": 11826803,
"login": "zhongpeixiang",
"node_id": "MDQ6VXNlcjExODI2ODAz",
"organizations_url": "https://api.github.com/users/zhongpeixiang/orgs",
"received_events_url": "https://api.github.com/users/zhongpeixiang/received_events",
"repos_url": "https://api.github.com/users/zhongpeixiang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zhongpeixiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhongpeixiang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zhongpeixiang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It seems that selecting a subset of colums directly from the dataset, i.e., dataset[\"column\"], is slow.",
"I was wrong, ```dataset[\"column\"]``` is fast."
] | 2021-01-24T07:54:31
| 2021-01-24T09:50:39
| 2021-01-24T09:50:39
|
CONTRIBUTOR
| null | null | null | null |
For a large dataset that does not fits the memory, how can I select only a subset of features from each example?
If I iterate over the dataset and then select the subset of features one by one, the resulted memory usage will be huge. Any ways to solve this?
Thanks
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11826803?v=4",
"events_url": "https://api.github.com/users/zhongpeixiang/events{/privacy}",
"followers_url": "https://api.github.com/users/zhongpeixiang/followers",
"following_url": "https://api.github.com/users/zhongpeixiang/following{/other_user}",
"gists_url": "https://api.github.com/users/zhongpeixiang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zhongpeixiang",
"id": 11826803,
"login": "zhongpeixiang",
"node_id": "MDQ6VXNlcjExODI2ODAz",
"organizations_url": "https://api.github.com/users/zhongpeixiang/orgs",
"received_events_url": "https://api.github.com/users/zhongpeixiang/received_events",
"repos_url": "https://api.github.com/users/zhongpeixiang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zhongpeixiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhongpeixiang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zhongpeixiang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1775/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/1775/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1:56:08
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.