
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 48
51
| id
int64 600M
3.67B
| node_id
stringlengths 18
24
| number
int64 2
7.88k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| comments
listlengths 0
30
| created_at
timestamp[s]date 2020-04-14 18:18:51
2025-11-26 16:16:56
| updated_at
timestamp[s]date 2020-04-29 09:23:05
2025-11-30 03:52:07
| closed_at
timestamp[s]date 2020-04-29 09:23:05
2025-11-21 12:31:19
⌀ | author_association
stringclasses 4
values | type
null | active_lock_reason
null | draft
null | pull_request
null | body
stringlengths 0
228k
⌀ | closed_by
dict | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 4
values | sub_issues_summary
dict | issue_dependencies_summary
dict | is_pull_request
bool 1
class | closed_at_time_taken
duration[s] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/478
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/478/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/478/comments
|
https://api.github.com/repos/huggingface/datasets/issues/478/events
|
https://github.com/huggingface/datasets/issues/478
| 673,178,317
|
MDU6SXNzdWU2NzMxNzgzMTc=
| 478
|
Export TFRecord to GCP bucket
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Nevermind, I restarted my python session and it worked fine...\r\n\r\n---\r\n\r\nI had an authentification error, and I authenticated from another terminal. After that, no more error but it was not working. Restarting the sessions makes it work :)"
] | 2020-08-05T01:08:32
| 2020-08-05T01:21:37
| 2020-08-05T01:21:36
|
NONE
| null | null | null | null |
Previously, I was writing TFRecords manually to GCP bucket with : `with tf.io.TFRecordWriter('gs://my_bucket/x.tfrecord')`
Since `0.4.0` is out with the `export()` function, I tried it. But it seems TFRecords cannot be directly written to GCP bucket.
`dataset.export('local.tfrecord')` works fine,
but `dataset.export('gs://my_bucket/x.tfrecord')` does not work.
There is no error message, I just can't find the file on my bucket...
---
Looking at the code, `nlp` is using `tf.data.experimental.TFRecordWriter`, while I was using `tf.io.TFRecordWriter`.
**What's the difference between those 2 ? How can I write TFRecords files directly to GCP bucket ?**
@jarednielsen @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/478/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/478/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:13:04
|
https://api.github.com/repos/huggingface/datasets/issues/477
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/477/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/477/comments
|
https://api.github.com/repos/huggingface/datasets/issues/477/events
|
https://github.com/huggingface/datasets/issues/477
| 673,142,143
|
MDU6SXNzdWU2NzMxNDIxNDM=
| 477
|
Overview.ipynb throws exceptions with nlp 0.4.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23109219?v=4",
"events_url": "https://api.github.com/users/mandy-li/events{/privacy}",
"followers_url": "https://api.github.com/users/mandy-li/followers",
"following_url": "https://api.github.com/users/mandy-li/following{/other_user}",
"gists_url": "https://api.github.com/users/mandy-li/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mandy-li",
"id": 23109219,
"login": "mandy-li",
"node_id": "MDQ6VXNlcjIzMTA5MjE5",
"organizations_url": "https://api.github.com/users/mandy-li/orgs",
"received_events_url": "https://api.github.com/users/mandy-li/received_events",
"repos_url": "https://api.github.com/users/mandy-li/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mandy-li/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandy-li/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mandy-li",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Thanks for reporting this issue\r\n\r\nThere was a bug where numpy arrays would get returned instead of tensorflow tensors.\r\nThis is fixed on master.\r\n\r\nI tried to re-run the colab and encountered this error instead:\r\n\r\n```\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no attribute 'to_tensor'\r\n```\r\n\r\nThis is because the dataset returns a Tensor and not a RaggedTensor.\r\nBut I think we should always return a RaggedTensor unless the length of the sequence is fixed (it that case they can be stack into a Tensor).",
"Hi, I got another error (on Colab):\r\n\r\n```python\r\n# You can read a few attributes of the datasets before loading them (they are python dataclasses)\r\nfrom dataclasses import asdict\r\n\r\nfor key, value in asdict(datasets[6]).items():\r\n print('👉 ' + key + ': ' + str(value))\r\n\r\n---------------------------------------------------------------------------\r\n\r\nTypeError Traceback (most recent call last)\r\n\r\n<ipython-input-6-b8ace6c227a2> in <module>()\r\n 2 from dataclasses import asdict\r\n 3 \r\n----> 4 for key, value in asdict(datasets[6]).items():\r\n 5 print('👉 ' + key + ': ' + str(value))\r\n\r\n/usr/local/lib/python3.6/dist-packages/dataclasses.py in asdict(obj, dict_factory)\r\n 1008 \"\"\"\r\n 1009 if not _is_dataclass_instance(obj):\r\n-> 1010 raise TypeError(\"asdict() should be called on dataclass instances\")\r\n 1011 return _asdict_inner(obj, dict_factory)\r\n 1012 \r\n\r\nTypeError: asdict() should be called on dataclass instances\r\n```",
"Indeed we'll update the cola with the new release coming up this week."
] | 2020-08-04T23:18:15
| 2021-08-03T06:02:15
| 2021-08-03T06:02:15
|
NONE
| null | null | null | null |
with nlp 0.4.0, the TensorFlow example in Overview.ipynb throws the following exceptions:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-5-48907f2ad433> in <module>
----> 1 features = {x: train_tf_dataset[x].to_tensor(default_value=0, shape=[None, tokenizer.max_len]) for x in columns[:3]}
2 labels = {"output_1": train_tf_dataset["start_positions"].to_tensor(default_value=0, shape=[None, 1])}
3 labels["output_2"] = train_tf_dataset["end_positions"].to_tensor(default_value=0, shape=[None, 1])
4 tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
<ipython-input-5-48907f2ad433> in <dictcomp>(.0)
----> 1 features = {x: train_tf_dataset[x].to_tensor(default_value=0, shape=[None, tokenizer.max_len]) for x in columns[:3]}
2 labels = {"output_1": train_tf_dataset["start_positions"].to_tensor(default_value=0, shape=[None, 1])}
3 labels["output_2"] = train_tf_dataset["end_positions"].to_tensor(default_value=0, shape=[None, 1])
4 tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
AttributeError: 'numpy.ndarray' object has no attribute 'to_tensor'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/477/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/477/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 363 days, 6:44:00
|
https://api.github.com/repos/huggingface/datasets/issues/474
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/474/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/474/comments
|
https://api.github.com/repos/huggingface/datasets/issues/474/events
|
https://github.com/huggingface/datasets/issues/474
| 672,407,330
|
MDU6SXNzdWU2NzI0MDczMzA=
| 474
|
test_load_real_dataset when config has BUILDER_CONFIGS that matter
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/698010?v=4",
"events_url": "https://api.github.com/users/marcotcr/events{/privacy}",
"followers_url": "https://api.github.com/users/marcotcr/followers",
"following_url": "https://api.github.com/users/marcotcr/following{/other_user}",
"gists_url": "https://api.github.com/users/marcotcr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/marcotcr",
"id": 698010,
"login": "marcotcr",
"node_id": "MDQ6VXNlcjY5ODAxMA==",
"organizations_url": "https://api.github.com/users/marcotcr/orgs",
"received_events_url": "https://api.github.com/users/marcotcr/received_events",
"repos_url": "https://api.github.com/users/marcotcr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/marcotcr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marcotcr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/marcotcr",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"The `data_dir` parameter has been removed. Now the error is `ValueError: Config name is missing`\r\n\r\nAs mentioned in #470 I think we can have one test with the first config of BUILDER_CONFIGS, and another test that runs all of the configs in BUILDER_CONFIGS",
"This was fixed in #527 \r\n\r\nClosing this one, but feel free to re-open if you have other questions"
] | 2020-08-03T23:46:36
| 2020-09-07T14:53:13
| 2020-09-07T14:53:13
|
NONE
| null | null | null | null |
It a dataset has custom `BUILDER_CONFIGS` with non-keyword arguments (or keyword arguments with non default values), the config is not loaded during the test and causes an error.
I think the problem is that `test_load_real_dataset` calls `load_dataset` with `data_dir=temp_data_dir` ([here](https://github.com/huggingface/nlp/blob/master/tests/test_dataset_common.py#L200)). This causes [this line](https://github.com/huggingface/nlp/blob/master/src/nlp/builder.py#L201) to always be false because `config_kwargs` is not `None`. [This line](https://github.com/huggingface/nlp/blob/master/src/nlp/builder.py#L222) will be run instead, which doesn't use `BUILDER_CONFIGS`.
For an example, you can try running the test for lince:
` RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_lince`
which yields
> E TypeError: __init__() missing 3 required positional arguments: 'colnames', 'classes', and 'label_column'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/474/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/474/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 34 days, 15:06:37
|
https://api.github.com/repos/huggingface/datasets/issues/469
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/469/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/469/comments
|
https://api.github.com/repos/huggingface/datasets/issues/469/events
|
https://github.com/huggingface/datasets/issues/469
| 671,876,963
|
MDU6SXNzdWU2NzE4NzY5NjM=
| 469
|
invalid data type 'str' at _convert_outputs in arrow_dataset.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30617486?v=4",
"events_url": "https://api.github.com/users/Murgates/events{/privacy}",
"followers_url": "https://api.github.com/users/Murgates/followers",
"following_url": "https://api.github.com/users/Murgates/following{/other_user}",
"gists_url": "https://api.github.com/users/Murgates/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Murgates",
"id": 30617486,
"login": "Murgates",
"node_id": "MDQ6VXNlcjMwNjE3NDg2",
"organizations_url": "https://api.github.com/users/Murgates/orgs",
"received_events_url": "https://api.github.com/users/Murgates/received_events",
"repos_url": "https://api.github.com/users/Murgates/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Murgates/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Murgates/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Murgates",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! Did you try to set the output format to pytorch ? (or tensorflow if you're using tensorflow)\r\nIt can be done with `dataset.set_format(\"torch\", columns=columns)` (or \"tensorflow\").\r\n\r\nNote that for pytorch, string columns can't be converted to `torch.Tensor`, so you have to specify in `columns=` the list of columns you want to keep (`input_ids` for example)",
"Hello . Yes, I did set the output format as below for the two columns \r\n\r\n `train_dataset.set_format('torch',columns=['Text','Label'])`\r\n ",
"I think you're having this issue because you try to format strings as pytorch tensors, which is not possible.\r\nIndeed by having \"Text\" in `columns=['Text','Label']`, you try to convert the text values to pytorch tensors.\r\n\r\nInstead I recommend you to first tokenize your dataset using a tokenizer from transformers. For example\r\n\r\n```python\r\nfrom transformers import BertTokenizer\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\n\r\ntrain_dataset.map(lambda x: tokenizer(x[\"Text\"]), batched=True)\r\ntrain_dataset.set_format(\"torch\", column=[\"input_ids\"])\r\n```\r\n\r\nAnother way to fix your issue would be to not set the format to pytorch, and leave the dataset as it is by default. In that case, the strings are returned normally when you get examples from your dataloader. It means that you would have to tokenize the examples in the training loop (or using a data collator) though.\r\n\r\nLet me know if you have other questions",
"Hi, actually the thing is I am getting the same error and even after tokenizing them I am passing them through batch_encode_plus.\r\nI dont know what seems to be the problem is. I even converted it into 'pt' while passing them through batch_encode_plus but when I am evaluating my model , i am getting this error\r\n\r\n\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-145-ca218223c9fc> in <module>()\r\n----> 1 val_loss, predictions, true_val = evaluate(dataloader_validation)\r\n 2 val_f1 = f1_score_func(predictions, true_val)\r\n 3 tqdm.write(f'Validation loss: {val_loss}')\r\n 4 tqdm.write(f'F1 Score (Weighted): {val_f1}')\r\n\r\n6 frames\r\n/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataset.py in <genexpr>(.0)\r\n 160 \r\n 161 def __getitem__(self, index):\r\n--> 162 return tuple(tensor[index] for tensor in self.tensors)\r\n 163 \r\n 164 def __len__(self):\r\n\r\nTypeError: new(): invalid data type 'str' ",
"> Hi, actually the thing is I am getting the same error and even after tokenizing them I am passing them through batch_encode_plus.\r\n> I dont know what seems to be the problem is. I even converted it into 'pt' while passing them through batch_encode_plus but when I am evaluating my model , i am getting this error\r\n> \r\n> TypeError Traceback (most recent call last)\r\n> in ()\r\n> ----> 1 val_loss, predictions, true_val = evaluate(dataloader_validation)\r\n> 2 val_f1 = f1_score_func(predictions, true_val)\r\n> 3 tqdm.write(f'Validation loss: {val_loss}')\r\n> 4 tqdm.write(f'F1 Score (Weighted): {val_f1}')\r\n> \r\n> 6 frames\r\n> /usr/local/lib/python3.6/dist-packages/torch/utils/data/dataset.py in (.0)\r\n> 160\r\n> 161 def **getitem**(self, index):\r\n> --> 162 return tuple(tensor[index] for tensor in self.tensors)\r\n> 163\r\n> 164 def **len**(self):\r\n> \r\n> TypeError: new(): invalid data type 'str'\r\n\r\nI got the same error and fix it .\r\nyou can check your input where there may be string contained.\r\nsuch as\r\n```\r\na = [1,2,3,4,'<unk>']\r\ntorch.tensor(a)\r\n```",
"I didn't know tokenizers could return strings in the token ids. Which tokenizer are you using to get this @Doragd ?",
"> I didn't know tokenizers could return strings in the token ids. Which tokenizer are you using to get this @Doragd ?\r\n\r\ni'm sorry that i met this issue in another place (not in huggingface repo). ",
"@akhilkapil do you have strings in your dataset ? When you set the dataset format to \"pytorch\" you should exclude columns with strings as pytorch can't make tensors out of strings",
"Closing due to inactivity."
] | 2020-08-03T07:48:29
| 2023-07-20T15:54:17
| 2023-07-20T15:54:17
|
NONE
| null | null | null | null |
I trying to build multi label text classifier model using Transformers lib.
I'm using Transformers NLP to load the data set, while calling trainer.train() method. It throws the following error
File "C:\***\arrow_dataset.py", line 343, in _convert_outputs
v = command(v)
TypeError: new(): invalid data type 'str'
I'm using pyarrow 1.0.0. And I have simple custom data set with Text and Integer Label.
Ex: Data
Text , Label #Column Header
I'm facing an Network issue, 1
I forgot my password, 2
Error StackTrace:
File "C:\**\transformers\trainer.py", line 492, in train
for step, inputs in enumerate(epoch_iterator):
File "C:\**\tqdm\std.py", line 1104, in __iter__
for obj in iterable:
File "C:\**\torch\utils\data\dataloader.py", line 345, in __next__
data = self._next_data()
File "C:\**\torch\utils\data\dataloader.py", line 385, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "C:\**\torch\utils\data\_utils\fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "C:\**\torch\utils\data\_utils\fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "C:\**\nlp\arrow_dataset.py", line 414, in __getitem__
output_all_columns=self._output_all_columns,
File "C:\**\nlp\arrow_dataset.py", line 403, in _getitem
outputs, format_type=format_type, format_columns=format_columns, output_all_columns=output_all_columns
File "C:\**\nlp\arrow_dataset.py", line 343, in _convert_outputs
v = command(v)
TypeError: new(): invalid data type 'str'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/469/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/469/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1081 days, 8:05:48
|
https://api.github.com/repos/huggingface/datasets/issues/468
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/468/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/468/comments
|
https://api.github.com/repos/huggingface/datasets/issues/468/events
|
https://github.com/huggingface/datasets/issues/468
| 671,622,441
|
MDU6SXNzdWU2NzE2MjI0NDE=
| 468
|
UnicodeDecodeError while loading PAN-X task of XTREME dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Indeed. Solution 1 is the simplest.\r\n\r\nThis is actually a recurring problem.\r\nI think we should scan all the datasets with regexpr to fix the use of `open()` without encodings.\r\nAnd probably add a test in the CI to forbid using this in the future.",
"I'm happy to tackle the broader problem - will open a PR when it's ready!",
"That would be awesome!",
"I've created a simple function that seems to do the trick:\r\n\r\n```python\r\ndef apply_encoding_on_file_open(filepath: str):\r\n \"\"\"Apply UTF-8 encoding for all instances where a non-binary file is opened.\"\"\"\r\n \r\n with open(filepath, 'r', encoding='utf-8') as input_file:\r\n regexp = re.compile(r\"\"\"\r\n (?!.*\\b(?:encoding|rb|wb|wb+|ab|ab+)\\b)\r\n (open)\r\n \\((.*)\\)\r\n \"\"\")\r\n input_text = input_file.read()\r\n match = regexp.search(input_text)\r\n \r\n if match:\r\n print('Found match!', match.group())\r\n # append utf-8 encoding to matching groups in-place\r\n output = regexp.sub(lambda m: m.group()[:-1]+', encoding=\"utf-8\")', input_text)\r\n with open(filepath, 'w', encoding='utf-8') as output_file:\r\n output_file.write(output)\r\n else:\r\n print(\"No match found!\")\r\n```\r\n\r\nThe regexp does a negative lookahead to avoid matching on cases where the encoding is already specified or when binary files are involved.\r\n\r\nFrom an implementation perspective:\r\n\r\n* Would it make sense to include this function in `nlp-cli` so that we can run something like\r\n```\r\nnlp-cli fix_encoding path/to/folder\r\n```\r\nand the command recursively fixes all files in the target?\r\n* What is the desired behaviour in the CI test? Here we could either have a simple script that we run as a `job` in the CI and raises an error if a missing encoding is detected. Alternatively we could incorporate this behaviour into the CLI and run that in the CI.\r\n\r\nPlease let me know what you prefer among the alternatives.\r\n",
"I realised I was overthinking the problem, so decided to just run the regexp over the codebase and make the PR. In other words, we can ignore my comments about using the CLI 😸 "
] | 2020-08-02T14:05:10
| 2020-08-20T08:16:08
| 2020-08-20T08:16:08
|
MEMBER
| null | null | null | null |
Hi 🤗 team!
## Description of the problem
I'm running into a `UnicodeDecodeError` while trying to load the PAN-X subset the XTREME dataset:
```
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-5-1d61f439b843> in <module>
----> 1 dataset = load_dataset("xtreme", "PAN-X.en", data_dir='./data')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
528 ignore_verifications = ignore_verifications or save_infos
529 # Download/copy dataset processing script
--> 530 module_path, hash = prepare_module(path, download_config=download_config, dataset=True)
531
532 # Get dataset builder class from the processing script
/usr/local/lib/python3.6/dist-packages/nlp/load.py in prepare_module(path, download_config, dataset, force_local_path, **download_kwargs)
265
266 # Download external imports if needed
--> 267 imports = get_imports(local_path)
268 local_imports = []
269 library_imports = []
/usr/local/lib/python3.6/dist-packages/nlp/load.py in get_imports(file_path)
156 lines = []
157 with open(file_path, mode="r") as f:
--> 158 lines.extend(f.readlines())
159
160 logger.info("Checking %s for additional imports.", file_path)
/usr/lib/python3.6/encodings/ascii.py in decode(self, input, final)
24 class IncrementalDecoder(codecs.IncrementalDecoder):
25 def decode(self, input, final=False):
---> 26 return codecs.ascii_decode(input, self.errors)[0]
27
28 class StreamWriter(Codec,codecs.StreamWriter):
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 111: ordinal not in range(128)
```
## Steps to reproduce
Install from nlp's master branch
```python
pip install git+https://github.com/huggingface/nlp.git
```
then run
```python
from nlp import load_dataset
# AmazonPhotos.zip is located in data/
dataset = load_dataset("xtreme", "PAN-X.en", data_dir='./data')
```
## OS / platform details
- `nlp` version: latest from master
- Platform: Linux-4.15.0-72-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.1.0 (True)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
## Proposed solution
Either change [line 762](https://github.com/huggingface/nlp/blob/7ada00b1d62f94eee22a7df38c6b01e3f27194b7/datasets/xtreme/xtreme.py#L762) in `xtreme.py` to include UTF-8 encoding:
```
# old
with open(filepath) as f
# new
with open(filepath, encoding='utf-8') as f
```
or raise a warning that suggests setting the locale explicitly, e.g.
```python
import locale
locale.setlocale(locale.LC_ALL, 'C.UTF-8')
```
I have a preference for the first solution. Let me know if you agree and I'll be happy to implement the simple fix!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/468/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/468/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 17 days, 18:10:58
|
https://api.github.com/repos/huggingface/datasets/issues/445
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/445/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/445/comments
|
https://api.github.com/repos/huggingface/datasets/issues/445/events
|
https://github.com/huggingface/datasets/issues/445
| 666,836,658
|
MDU6SXNzdWU2NjY4MzY2NTg=
| 445
|
DEFAULT_TOKENIZER import error in sacrebleu
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"This issue was resolved by #447 "
] | 2020-07-28T07:31:30
| 2020-07-28T12:58:56
| 2020-07-28T12:58:56
|
CONTRIBUTOR
| null | null | null | null |
Latest Version 0.3.0
When loading the metric "sacrebleu" there is an import error due to the wrong path

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/445/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/445/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5:27:26
|
https://api.github.com/repos/huggingface/datasets/issues/444
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/444/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/444/comments
|
https://api.github.com/repos/huggingface/datasets/issues/444/events
|
https://github.com/huggingface/datasets/issues/444
| 666,280,842
|
MDU6SXNzdWU2NjYyODA4NDI=
| 444
|
Keep loading old file even I specify a new file in load_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10594453?v=4",
"events_url": "https://api.github.com/users/joshhu/events{/privacy}",
"followers_url": "https://api.github.com/users/joshhu/followers",
"following_url": "https://api.github.com/users/joshhu/following{/other_user}",
"gists_url": "https://api.github.com/users/joshhu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/joshhu",
"id": 10594453,
"login": "joshhu",
"node_id": "MDQ6VXNlcjEwNTk0NDUz",
"organizations_url": "https://api.github.com/users/joshhu/orgs",
"received_events_url": "https://api.github.com/users/joshhu/received_events",
"repos_url": "https://api.github.com/users/joshhu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/joshhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joshhu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/joshhu",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Same here !",
"This is the only fix I could come up with without touching the repo's code.\r\n```python\r\nfrom nlp.builder import FORCE_REDOWNLOAD\r\ndataset = load_dataset('csv', data_file='./a.csv', download_mode=FORCE_REDOWNLOAD, version='0.0.1')\r\n```\r\nYou'll have to change the version each time you want to load a different csv file.\r\nIf you're willing to add a ```print```, you can go to ```nlp.load``` and add ```print(builder_instance.cache_dir)``` right before the ```return ds``` in the ```load_dataset``` method. It'll print the cache folder, and you'll just have to erase it (and then you won't need the change here above)."
] | 2020-07-27T13:08:06
| 2020-07-29T13:57:22
| 2020-07-29T13:57:22
|
NONE
| null | null | null | null |
I used load a file called 'a.csv' by
```
dataset = load_dataset('csv', data_file='./a.csv')
```
And after a while, I tried to load another csv called 'b.csv'
```
dataset = load_dataset('csv', data_file='./b.csv')
```
However, the new dataset seems to remain the old 'a.csv' and not loading new csv file.
Even worse, after I load a.csv, the load_dataset function keeps loading the 'a.csv' afterward.
Is this a cache problem?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/444/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/444/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 0:49:16
|
https://api.github.com/repos/huggingface/datasets/issues/443
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/443/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/443/comments
|
https://api.github.com/repos/huggingface/datasets/issues/443/events
|
https://github.com/huggingface/datasets/issues/443
| 666,246,716
|
MDU6SXNzdWU2NjYyNDY3MTY=
| 443
|
Cannot unpickle saved .pt dataset with torch.save()/load()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"This seems to be fixed in a non-released version. \r\n\r\nInstalling nlp from source\r\n```\r\ngit clone https://github.com/huggingface/nlp\r\ncd nlp\r\npip install .\r\n```\r\nsolves the issue. "
] | 2020-07-27T12:13:37
| 2020-07-27T13:05:11
| 2020-07-27T13:05:11
|
CONTRIBUTOR
| null | null | null | null |
Saving a formatted torch dataset to file using `torch.save()`. Loading the same file fails during unpickling:
```python
>>> import torch
>>> import nlp
>>> squad = nlp.load_dataset("squad.py", split="train")
>>> squad
Dataset(features: {'source_text': Value(dtype='string', id=None), 'target_text': Value(dtype='string', id=None)}, num_rows: 87599)
>>> squad = squad.map(create_features, batched=True)
>>> squad.set_format(type="torch", columns=["source_ids", "target_ids", "attention_mask"])
>>> torch.save(squad, "squad.pt")
>>> squad_pt = torch.load("squad.pt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/torch/serialization.py", line 593, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/torch/serialization.py", line 773, in _legacy_load
result = unpickler.load()
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/nlp/splits.py", line 493, in __setitem__
raise ValueError("Cannot add elem. Use .add() instead.")
ValueError: Cannot add elem. Use .add() instead.
```
where `create_features` is a function that tokenizes the data using `batch_encode_plus` and returns a Dict with `input_ids`, `target_ids` and `attention_mask`.
```python
def create_features(batch):
source_text_encoding = tokenizer.batch_encode_plus(
batch["source_text"],
max_length=max_source_length,
pad_to_max_length=True,
truncation=True)
target_text_encoding = tokenizer.batch_encode_plus(
batch["target_text"],
max_length=max_target_length,
pad_to_max_length=True,
truncation=True)
features = {
"source_ids": source_text_encoding["input_ids"],
"target_ids": target_text_encoding["input_ids"],
"attention_mask": source_text_encoding["attention_mask"]
}
return features
```
I found a similar issue in [issue 5267 in the huggingface/transformers repo](https://github.com/huggingface/transformers/issues/5267) which was solved by downgrading to `nlp==0.2.0`. That did not solve this problem, however.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/443/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/443/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:51:34
|
https://api.github.com/repos/huggingface/datasets/issues/442
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/442/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/442/comments
|
https://api.github.com/repos/huggingface/datasets/issues/442/events
|
https://github.com/huggingface/datasets/issues/442
| 666,201,810
|
MDU6SXNzdWU2NjYyMDE4MTA=
| 442
|
[Suggestion] Glue Diagnostic Data with Labels
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3662782?v=4",
"events_url": "https://api.github.com/users/ggbetz/events{/privacy}",
"followers_url": "https://api.github.com/users/ggbetz/followers",
"following_url": "https://api.github.com/users/ggbetz/following{/other_user}",
"gists_url": "https://api.github.com/users/ggbetz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ggbetz",
"id": 3662782,
"login": "ggbetz",
"node_id": "MDQ6VXNlcjM2NjI3ODI=",
"organizations_url": "https://api.github.com/users/ggbetz/orgs",
"received_events_url": "https://api.github.com/users/ggbetz/received_events",
"repos_url": "https://api.github.com/users/ggbetz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ggbetz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ggbetz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ggbetz",
"user_view_type": "public"
}
|
[
{
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets",
"id": 2067401494,
"name": "Dataset discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion"
}
] |
open
| false
| null |
[] |
[] | 2020-07-27T10:59:58
| 2020-08-24T15:13:20
| null |
NONE
| null | null | null | null |
Hello! First of all, thanks for setting up this useful project!
I've just realised you provide the the [Glue Diagnostics Data](https://huggingface.co/nlp/viewer/?dataset=glue&config=ax) without labels, indicating in the `GlueConfig` that you've only a test set.
Yet, the data with labels is available, too (see also [here](https://gluebenchmark.com/diagnostics#introduction)):
https://www.dropbox.com/s/ju7d95ifb072q9f/diagnostic-full.tsv?dl=1
Have you considered incorporating it?
| null |
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/442/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/442/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/439
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/439/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/439/comments
|
https://api.github.com/repos/huggingface/datasets/issues/439/events
|
https://github.com/huggingface/datasets/issues/439
| 665,964,673
|
MDU6SXNzdWU2NjU5NjQ2NzM=
| 439
|
Issues: Adding a FAISS or Elastic Search index to a Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"`DPRContextEncoder` and `DPRContextEncoderTokenizer` will be available in the next release of `transformers`.\r\n\r\nRight now you can experiment with it by installing `transformers` from the master branch.\r\nYou can also check the docs of DPR [here](https://huggingface.co/transformers/master/model_doc/dpr.html).\r\n\r\nMoreover all the indexing features will also be available in the next release of `nlp`.",
"@lhoestq Thanks for the info ",
"@lhoestq I tried installing transformer from the master branch. Python imports for DPR again didnt' work. Anyways, Looking forward to trying it in the next release of nlp ",
"@nsankar have you tried with the latest version of the library?",
"@yjernite it worked. Thanks"
] | 2020-07-27T04:25:17
| 2020-10-28T01:46:24
| 2020-10-28T01:46:24
|
NONE
| null | null | null | null |
It seems the DPRContextEncoder, DPRContextEncoderTokenizer cited[ in this documentation](https://huggingface.co/nlp/faiss_and_ea.html) is not implemented ? It didnot work with the standard nlp installation . Also, I couldn't find or use it with the latest nlp install from github in Colab. Is there any dependency on the latest PyArrow 1.0.0 ? Is it yet to be made generally available ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/439/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/439/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 92 days, 21:21:07
|
https://api.github.com/repos/huggingface/datasets/issues/438
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/438/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/438/comments
|
https://api.github.com/repos/huggingface/datasets/issues/438/events
|
https://github.com/huggingface/datasets/issues/438
| 665,865,490
|
MDU6SXNzdWU2NjU4NjU0OTA=
| 438
|
New Datasets: IWSLT15+, ITTB
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
open
| false
| null |
[] |
[
"Thanks Sam, we now have a very detailed tutorial and template on how to add a new dataset to the library. It typically take 1-2 hours to add one. Do you want to give it a try ?\r\nThe tutorial on writing a new dataset loading script is here: https://huggingface.co/nlp/add_dataset.html\r\nAnd the part on how to share a new dataset is here: https://huggingface.co/nlp/share_dataset.html",
"Hi @sshleifer, I'm trying to add IWSLT using the link you provided but the download urls are not working. Only `[en, de]` pair is working. For others language pairs it throws a `404` error.\r\n\r\n"
] | 2020-07-26T21:43:04
| 2020-08-24T15:12:15
| null |
CONTRIBUTOR
| null | null | null | null |
**Links:**
[iwslt](https://pytorchnlp.readthedocs.io/en/latest/_modules/torchnlp/datasets/iwslt.html)
Don't know if that link is up to date.
[ittb](http://www.cfilt.iitb.ac.in/iitb_parallel/)
**Motivation**: replicate mbart finetuning results (table below)
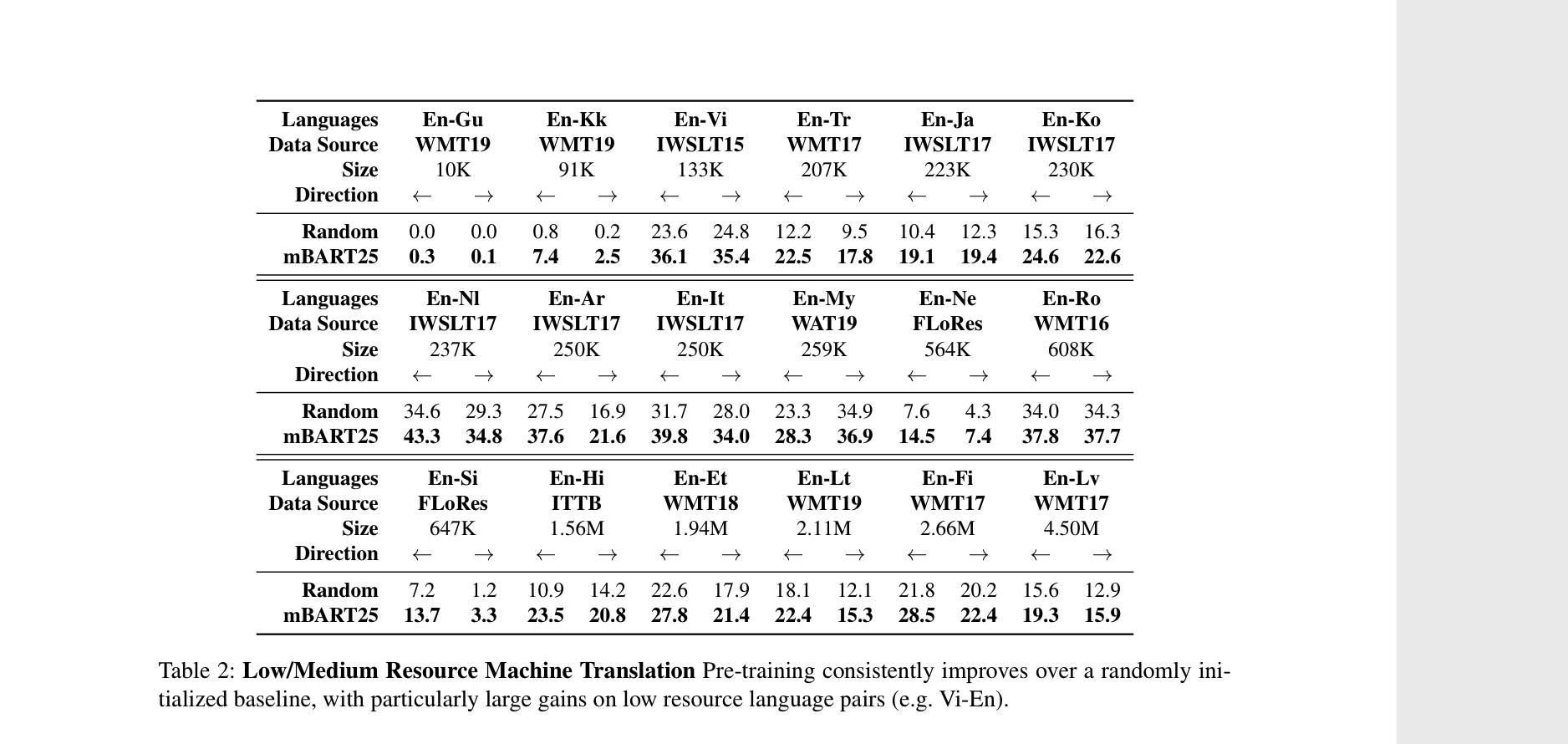
For future readers, we already have the following language pairs in the wmt namespaces:
```
wmt14: ['cs-en', 'de-en', 'fr-en', 'hi-en', 'ru-en']
wmt15: ['cs-en', 'de-en', 'fi-en', 'fr-en', 'ru-en']
wmt16: ['cs-en', 'de-en', 'fi-en', 'ro-en', 'ru-en', 'tr-en']
wmt17: ['cs-en', 'de-en', 'fi-en', 'lv-en', 'ru-en', 'tr-en', 'zh-en']
wmt18: ['cs-en', 'de-en', 'et-en', 'fi-en', 'kk-en', 'ru-en', 'tr-en', 'zh-en']
wmt19: ['cs-en', 'de-en', 'fi-en', 'gu-en', 'kk-en', 'lt-en', 'ru-en', 'zh-en', 'fr-de']
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/438/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/438/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/436
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/436/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/436/comments
|
https://api.github.com/repos/huggingface/datasets/issues/436/events
|
https://github.com/huggingface/datasets/issues/436
| 665,582,167
|
MDU6SXNzdWU2NjU1ODIxNjc=
| 436
|
Google Colab - load_dataset - PyArrow exception
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Indeed, we’ll make a new PyPi release next week to solve this. Cc @lhoestq ",
"+1! this is the reason our tests are failing at [TextAttack](https://github.com/QData/TextAttack) \r\n\r\n(Though it's worth noting if we fixed the version number of pyarrow to 0.16.0 that would fix our problem too. But in this case we'll just wait for you all to update)",
"Came to raise this issue, great to see other already have and it's being fixed so soon!\r\n\r\nAs an aside, since no one wrote this already, it seems like the version check only looks at the second part of the version number making sure it is >16, but pyarrow newest version is 1.0.0 so the second past is 0!",
"> Indeed, we’ll make a new PyPi release next week to solve this. Cc @lhoestq\r\n\r\nYes definitely",
"please fix this on pypi! @lhoestq ",
"Is this issue fixed ?",
"We’ll release the new version later today. Apologies for the delay.",
"I just pushed the new version on pypi :)",
"Thanks for the update."
] | 2020-07-25T13:05:20
| 2020-08-20T08:08:18
| 2020-08-20T08:08:18
|
NONE
| null | null | null | null |
With latest PyArrow 1.0.0 installed, I get the following exception . Restarting colab has the same issue
ImportWarning: To use `nlp`, the module `pyarrow>=0.16.0` is required, and the current version of `pyarrow` doesn't match this condition. If you are running this in a Google Colab, you should probably just restart the runtime to use the right version of `pyarrow`.
The error goes only when I install version 0.16.0
i.e. !pip install pyarrow==0.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/436/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/436/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 25 days, 19:02:58
|
https://api.github.com/repos/huggingface/datasets/issues/435
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/435/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/435/comments
|
https://api.github.com/repos/huggingface/datasets/issues/435/events
|
https://github.com/huggingface/datasets/issues/435
| 665,507,141
|
MDU6SXNzdWU2NjU1MDcxNDE=
| 435
|
ImportWarning for pyarrow 1.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HanGuo97",
"id": 18187806,
"login": "HanGuo97",
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HanGuo97",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"This was fixed in #434 \r\nWe'll do a release later this week to include this fix.\r\nThanks for reporting",
"I dont know if the fix was made but the problem is still present : \r\nInstaled with pip : NLP 0.3.0 // pyarrow 1.0.0 \r\nOS : archlinux with kernel zen 5.8.5",
"Yes it was fixed in `nlp>=0.4.0`\r\nYou can update with pip",
"Sorry, I didn't got the updated version, all is now working perfectly thanks"
] | 2020-07-25T03:44:39
| 2020-09-08T17:57:15
| 2020-08-03T16:37:32
|
NONE
| null | null | null | null |
The following PR raised ImportWarning at `pyarrow ==1.0.0` https://github.com/huggingface/nlp/pull/265/files
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HanGuo97",
"id": 18187806,
"login": "HanGuo97",
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HanGuo97",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/435/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/435/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 9 days, 12:52:53
|
https://api.github.com/repos/huggingface/datasets/issues/433
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/433/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/433/comments
|
https://api.github.com/repos/huggingface/datasets/issues/433/events
|
https://github.com/huggingface/datasets/issues/433
| 665,311,025
|
MDU6SXNzdWU2NjUzMTEwMjU=
| 433
|
How to reuse functionality of a (generic) dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3375489?v=4",
"events_url": "https://api.github.com/users/ArneBinder/events{/privacy}",
"followers_url": "https://api.github.com/users/ArneBinder/followers",
"following_url": "https://api.github.com/users/ArneBinder/following{/other_user}",
"gists_url": "https://api.github.com/users/ArneBinder/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ArneBinder",
"id": 3375489,
"login": "ArneBinder",
"node_id": "MDQ6VXNlcjMzNzU0ODk=",
"organizations_url": "https://api.github.com/users/ArneBinder/orgs",
"received_events_url": "https://api.github.com/users/ArneBinder/received_events",
"repos_url": "https://api.github.com/users/ArneBinder/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ArneBinder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArneBinder/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ArneBinder",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @ArneBinder, we have a few \"generic\" datasets which are intended to load data files with a predefined format:\r\n- csv: https://github.com/huggingface/nlp/tree/master/datasets/csv\r\n- json: https://github.com/huggingface/nlp/tree/master/datasets/json\r\n- text: https://github.com/huggingface/nlp/tree/master/datasets/text\r\n\r\nYou can find more details about this way to load datasets here in the documentation: https://huggingface.co/nlp/loading_datasets.html#from-local-files\r\n\r\nMaybe your brat loading script could be shared in a similar fashion?",
"> Maybe your brat loading script could be shared in a similar fashion?\r\n\r\n@thomwolf that was also my first idea and I think I will tackle that in the next days. I separated the code and created a real abstract class `AbstractBrat` to allow to inherit from that (I've just seen that the dataset_loader loads the first non abstract class), now `Brat` is very similar in its functionality to https://github.com/huggingface/nlp/tree/master/datasets/text but inherits from `AbstractBrat`.\r\n\r\nHowever, it is still not clear to me how to add a specific dataset (as explained in https://huggingface.co/nlp/add_dataset.html) to your repo that uses this format/abstract class, i.e. re-using the `features` entry of the `DatasetInfo` object and `_generate_examples()`. Again, by doing so, the only remaining entries/functions to define would be `_DESCRIPTION`, `_CITATION`, `homepage` and `_URL` (which is all copy-paste stuff) and `_split_generators()`.\r\n \r\nIn a lack of better ideas, I tried sth like below, but of course it does not work outside `nlp` (`AbstractBrat` is currently defined in [datasets/brat.py](https://github.com/ArneBinder/nlp/blob/5e81fb8710546ee7be3353a7f02a3045e9a8351e/datasets/brat/brat.py)):\r\n```python\r\nfrom __future__ import absolute_import, division, print_function\r\n\r\nimport os\r\n\r\nimport nlp\r\n\r\nfrom datasets.brat.brat import AbstractBrat\r\n\r\n_CITATION = \"\"\"\r\n@inproceedings{lauscher2018b,\r\n title = {An argument-annotated corpus of scientific publications},\r\n booktitle = {Proceedings of the 5th Workshop on Mining Argumentation},\r\n publisher = {Association for Computational Linguistics},\r\n author = {Lauscher, Anne and Glava\\v{s}, Goran and Ponzetto, Simone Paolo},\r\n address = {Brussels, Belgium},\r\n year = {2018},\r\n pages = {40–46}\r\n}\r\n\"\"\"\r\n\r\n_DESCRIPTION = \"\"\"\\\r\nThis dataset is an extension of the Dr. Inventor corpus (Fisas et al., 2015, 2016) with an annotation layer containing \r\nfine-grained argumentative components and relations. It is the first argument-annotated corpus of scientific \r\npublications (in English), which allows for joint analyses of argumentation and other rhetorical dimensions of \r\nscientific writing.\r\n\"\"\"\r\n\r\n_URL = \"http://data.dws.informatik.uni-mannheim.de/sci-arg/compiled_corpus.zip\"\r\n\r\n\r\nclass Sciarg(AbstractBrat):\r\n\r\n VERSION = nlp.Version(\"1.0.0\")\r\n\r\n def _info(self):\r\n\r\n brat_features = super()._info().features\r\n return nlp.DatasetInfo(\r\n # This is the description that will appear on the datasets page.\r\n description=_DESCRIPTION,\r\n # nlp.features.FeatureConnectors\r\n features=brat_features,\r\n # If there's a common (input, target) tuple from the features,\r\n # specify them here. They'll be used if as_supervised=True in\r\n # builder.as_dataset.\r\n #supervised_keys=None,\r\n # Homepage of the dataset for documentation\r\n homepage=\"https://github.com/anlausch/ArguminSci\",\r\n citation=_CITATION,\r\n )\r\n\r\n def _split_generators(self, dl_manager):\r\n \"\"\"Returns SplitGenerators.\"\"\"\r\n # TODO: Downloads the data and defines the splits\r\n # dl_manager is a nlp.download.DownloadManager that can be used to\r\n # download and extract URLs\r\n dl_dir = dl_manager.download_and_extract(_URL)\r\n data_dir = os.path.join(dl_dir, \"compiled_corpus\")\r\n print(f'data_dir: {data_dir}')\r\n return [\r\n nlp.SplitGenerator(\r\n name=nlp.Split.TRAIN,\r\n # These kwargs will be passed to _generate_examples\r\n gen_kwargs={\r\n \"directory\": data_dir,\r\n },\r\n ),\r\n ]\r\n``` \r\n\r\nNevertheless, many thanks for tackling the dataset accessibility problem with this great library!",
"As temporary fix I've created [ArneBinder/nlp-formats](https://github.com/ArneBinder/nlp-formats) (contributions welcome).",
"Hi! You can either copy&paste the builder script and import the builder from there or use `datasets.load_dataset_builder` inside the script and call the methods of the returned builder object."
] | 2020-07-24T17:27:37
| 2022-10-04T17:59:34
| 2022-10-04T17:59:33
|
NONE
| null | null | null | null |
I have written a generic dataset for corpora created with the Brat annotation tool ([specification](https://brat.nlplab.org/standoff.html), [dataset code](https://github.com/ArneBinder/nlp/blob/brat/datasets/brat/brat.py)). Now I wonder how to use that to create specific dataset instances. What's the recommended way to reuse formats and loading functionality for datasets with a common format?
In my case, it took a bit of time to create the Brat dataset and I think others would appreciate to not have to think about that again. Also, I assume there are other formats (e.g. conll) that are widely used, so having this would really ease dataset onboarding and adoption of the library.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/433/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/433/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 802 days, 0:31:56
|
https://api.github.com/repos/huggingface/datasets/issues/426
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/426/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/426/comments
|
https://api.github.com/repos/huggingface/datasets/issues/426/events
|
https://github.com/huggingface/datasets/issues/426
| 664,203,897
|
MDU6SXNzdWU2NjQyMDM4OTc=
| 426
|
[FEATURE REQUEST] Multiprocessing with for dataset.map, dataset.filter
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] |
[
"Yes that's definitely something we plan to add ^^",
"Yes, that would be nice. We could take a look at what tensorflow `tf.data` does under the hood for instance.",
"So `tf.data.Dataset.map()` returns a `ParallelMapDataset` if `num_parallel_calls is not None` [link](https://github.com/tensorflow/tensorflow/blob/2b96f3662bd776e277f86997659e61046b56c315/tensorflow/python/data/ops/dataset_ops.py#L1623).\r\n\r\nThere, `num_parallel_calls` is turned into a tensor and and fed to `gen_dataset_ops.parallel_map_dataset` where it looks like tensorflow takes over.\r\n\r\nWe could start with something simple like a thread or process pool that `imap`s over some shards.\r\n ",
"Multiprocessing was added in #552 . You can set the number of processes with `.map(..., num_proc=...)`. It also works for `filter`\r\n\r\nClosing this one, but feel free to reo-open if you have other questions",
"@lhoestq Great feature implemented! Do you have plans to add it to official tutorials [Processing data in a Dataset](https://huggingface.co/docs/datasets/processing.html?highlight=save#augmenting-the-dataset)? It took me sometime to find this parallel processing api.",
"Thanks for the heads up !\r\n\r\nI just added a paragraph about multiprocessing:\r\nhttps://huggingface.co/docs/datasets/master/processing.html#multiprocessing"
] | 2020-07-23T05:00:41
| 2021-03-12T09:34:12
| 2020-09-07T14:48:04
|
NONE
| null | null | null | null |
It would be nice to be able to speed up `dataset.map` or `dataset.filter`. Perhaps this is as easy as sharding the dataset sending each shard to a process/thread/dask pool and using the new `nlp.concatenate_dataset()` function to join them all together?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/426/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/426/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 46 days, 9:47:23
|
https://api.github.com/repos/huggingface/datasets/issues/425
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/425/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/425/comments
|
https://api.github.com/repos/huggingface/datasets/issues/425/events
|
https://github.com/huggingface/datasets/issues/425
| 664,029,848
|
MDU6SXNzdWU2NjQwMjk4NDg=
| 425
|
Correct data structure for PAN-X task in XTREME dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Thanks for noticing ! This looks more reasonable indeed.\r\nFeel free to open a PR",
"Hi @lhoestq \r\nI made the proposed changes to the `xtreme.py` script. I noticed that I also need to change the schema in the `dataset_infos.json` file. More specifically the `\"features\"` part of the PAN-X.LANG dataset:\r\n\r\n```json\r\n\"features\":{\r\n \"word\":{\r\n \"dtype\":\"string\",\r\n \"id\":null,\r\n \"_type\":\"Value\"\r\n },\r\n \"ner_tag\":{\r\n \"dtype\":\"string\",\r\n \"id\":null,\r\n \"_type\":\"Value\"\r\n },\r\n \"lang\":{\r\n \"dtype\":\"string\",\r\n \"id\":null,\r\n \"_type\":\"Value\"\r\n }\r\n}\r\n```\r\nTo fit the code above the fields `\"word\"`, `\"ner_tag\"`, and `\"lang\"` would become `\"words\"`, `ner_tags\"` and `\"langs\"`. In addition the `dtype` should be changed from `\"string\"` to `\"list\"`.\r\n\r\n I made this changes but when trying to test this locally with `dataset = load_dataset(\"xtreme\", \"PAN-X.en\", data_dir='./data')` I face the issue that the `dataset_info.json` file is always overwritten by a downloaded version with the old settings, which then throws an error because the schema does not match. This makes it hard to test the changes locally. Do you have any suggestions on how to deal with that?\r\n",
"Hi !\r\n\r\nYou have to point to your local script.\r\nFirst clone the repo and then:\r\n\r\n```python\r\ndataset = load_dataset(\"./datasets/xtreme\", \"PAN-X.en\")\r\n```\r\nThe \"xtreme\" directory contains \"xtreme.py\".\r\n\r\nYou also have to change the features definition in the `_info` method. You could use:\r\n\r\n```python\r\nfeatures = nlp.Features({\r\n \"words\": [nlp.Value(\"string\")],\r\n \"ner_tags\": [nlp.Value(\"string\")],\r\n \"langs\": [nlp.Value(\"string\")],\r\n})\r\n```\r\n\r\nHope this helps !\r\nLet me know if you have other questions.",
"Thanks, I am making progress. I got a new error `NonMatchingSplitsSizesError ` (see traceback below), which I suspect is due to the fact that number of rows in the dataset changed (one row per word --> one row per sentence) as well as the number of bytes due to the slightly updated data structure. \r\n\r\n```python\r\nNonMatchingSplitsSizesError: [{'expected': SplitInfo(name='validation', num_bytes=1756492, num_examples=80536, dataset_name='xtreme'), 'recorded': SplitInfo(name='validation', num_bytes=1837109, num_examples=10000, dataset_name='xtreme')}, {'expected': SplitInfo(name='test', num_bytes=1752572, num_examples=80326, dataset_name='xtreme'), 'recorded': SplitInfo(name='test', num_bytes=1833214, num_examples=10000, dataset_name='xtreme')}, {'expected': SplitInfo(name='train', num_bytes=3496832, num_examples=160394, dataset_name='xtreme'), 'recorded': SplitInfo(name='train', num_bytes=3658428, num_examples=20000, dataset_name='xtreme')}]\r\n```\r\nI can fix the error by replacing the values in the `datasets_infos.json` file, which I tested for English. However, to update this for all 40 datasets manually is slightly painful. Is there a better way to update the expected values for all datasets?",
"You can update the json file by calling\r\n```\r\nnlp-cli test ./datasets/xtreme --save_infos --all_configs\r\n```",
"One more thing about features. I mentioned\r\n\r\n```python\r\nfeatures = nlp.Features({\r\n \"words\": [nlp.Value(\"string\")],\r\n \"ner_tags\": [nlp.Value(\"string\")],\r\n \"langs\": [nlp.Value(\"string\")],\r\n})\r\n```\r\n\r\nbut it's actually not consistent with the way we write datasets. Something like this is simpler to read and more consistent with the way we define datasets:\r\n\r\n```python\r\nfeatures = nlp.Features({\r\n \"words\": nlp.Sequence(nlp.Value(\"string\")),\r\n \"ner_tags\": nlp.Sequence(nlp.Value(\"string\")),\r\n \"langs\": nlp.Sequence(nlp.Value(\"string\")),\r\n})\r\n```\r\n\r\nSorry about that",
"Closing this since PR #437 fixed the problem and has been merged to `master`. "
] | 2020-07-22T20:29:20
| 2020-08-02T13:30:34
| 2020-08-02T13:30:34
|
MEMBER
| null | null | null | null |
Hi 🤗 team!
## Description of the problem
Thanks to the fix from #416 I am now able to load the NER task in the XTREME dataset as follows:
```python
from nlp import load_dataset
# AmazonPhotos.zip is located in data/
dataset = load_dataset("xtreme", "PAN-X.en", data_dir='./data')
dataset_train = dataset['train']
```
However, I am not sure that `load_dataset()` is returning the correct data structure for NER.
Currently, every row in `dataset_train` is of the form
```python
{'word': str, 'ner_tag': str, 'lang': str}
```
but I think we actually want something like
```python
{'words': List[str], 'ner_tags': List[str], 'langs': List[str]}
```
so that each row corresponds to a _sequence_ of words associated with each example. With the current data structure I do not think it is possible to transform `dataset_train` into a form suitable for training because we do not know the boundaries between examples.
Indeed, [this line](https://github.com/google-research/xtreme/blob/522434d1aece34131d997a97ce7e9242a51a688a/third_party/utils_tag.py#L58) in the XTREME repo, processes the texts as lists of sentences, tags, and languages.
## Proposed solution
Replace
```python
with open(filepath) as f:
data = csv.reader(f, delimiter="\t", quoting=csv.QUOTE_NONE)
for id_, row in enumerate(data):
if row:
lang, word = row[0].split(":")[0], row[0].split(":")[1]
tag = row[1]
yield id_, {"word": word, "ner_tag": tag, "lang": lang}
```
from [these lines](https://github.com/huggingface/nlp/blob/ce7d3a1d630b78fe27188d1706f3ea980e8eec43/datasets/xtreme/xtreme.py#L881-L887) of the `_generate_examples()` function with something like
```python
guid_index = 1
with open(filepath, encoding="utf-8") as f:
words = []
ner_tags = []
langs = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
if words:
yield guid_index, {"words": words, "ner_tags": ner_tags, "langs": langs}
guid_index += 1
words = []
ner_tags = []
else:
# pan-x data is tab separated
splits = line.split("\t")
# strip out en: prefix
langs.append(splits[0][:2])
words.append(splits[0][3:])
if len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
else:
# examples have no label in test set
labels.append("O")
```
If you agree, me or @lvwerra would be happy to implement this and create a PR.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/425/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/425/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 10 days, 17:01:14
|
https://api.github.com/repos/huggingface/datasets/issues/418
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/418/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/418/comments
|
https://api.github.com/repos/huggingface/datasets/issues/418/events
|
https://github.com/huggingface/datasets/issues/418
| 661,914,873
|
MDU6SXNzdWU2NjE5MTQ4NzM=
| 418
|
Addition of google drive links to dl_manager
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I think the problem is the way you wrote your urls. Try the following structure to see `https://drive.google.com/uc?export=download&id=your_file_id` . \r\n\r\n@lhoestq ",
"Oh sorry, I think `_get_drive_url` is doing that. \r\n\r\nHave you tried to use `dl_manager.download_and_extract(_get_drive_url(_TRAIN_URL)`? it should work with google drive links.\r\n",
"Yes it worked, thank you!"
] | 2020-07-20T14:52:02
| 2020-07-20T15:39:32
| 2020-07-20T15:39:32
|
CONTRIBUTOR
| null | null | null | null |
Hello there, I followed the template to create a download script of my own, which works fine for me, although I had to shun the dl_manager because it was downloading nothing from the drive links and instead use gdown.
This is the script for me:
```python
class EmoConfig(nlp.BuilderConfig):
"""BuilderConfig for SQUAD."""
def __init__(self, **kwargs):
"""BuilderConfig for EmoContext.
Args:
**kwargs: keyword arguments forwarded to super.
"""
super(EmoConfig, self).__init__(**kwargs)
_TEST_URL = "https://drive.google.com/file/d/1Hn5ytHSSoGOC4sjm3wYy0Dh0oY_oXBbb/view?usp=sharing"
_TRAIN_URL = "https://drive.google.com/file/d/12Uz59TYg_NtxOy7SXraYeXPMRT7oaO7X/view?usp=sharing"
class EmoDataset(nlp.GeneratorBasedBuilder):
""" SemEval-2019 Task 3: EmoContext Contextual Emotion Detection in Text. Version 1.0.0 """
VERSION = nlp.Version("1.0.0")
force = False
def _info(self):
return nlp.DatasetInfo(
description=_DESCRIPTION,
features=nlp.Features(
{
"text": nlp.Value("string"),
"label": nlp.features.ClassLabel(names=["others", "happy", "sad", "angry"]),
}
),
supervised_keys=None,
homepage="https://www.aclweb.org/anthology/S19-2005/",
citation=_CITATION,
)
def _get_drive_url(self, url):
base_url = 'https://drive.google.com/uc?id='
split_url = url.split('/')
return base_url + split_url[5]
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
if(not os.path.exists("emo-train.json") or self.force):
gdown.download(self._get_drive_url(_TRAIN_URL), "emo-train.json", quiet = True)
if(not os.path.exists("emo-test.json") or self.force):
gdown.download(self._get_drive_url(_TEST_URL), "emo-test.json", quiet = True)
return [
nlp.SplitGenerator(
name=nlp.Split.TRAIN,
gen_kwargs={
"filepath": "emo-train.json",
"split": "train",
},
),
nlp.SplitGenerator(
name=nlp.Split.TEST,
gen_kwargs={"filepath": "emo-test.json", "split": "test"},
),
]
def _generate_examples(self, filepath, split):
""" Yields examples. """
with open(filepath, 'rb') as f:
data = json.load(f)
for id_, text, label in zip(data["text"].keys(), data["text"].values(), data["Label"].values()):
yield id_, {
"text": text,
"label": label,
}
```
Can someone help me in adding gdrive links to be used with default dl_manager or adding gdown as another dl_manager, because I'd like to add this dataset to nlp's official database.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/418/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/418/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:47:30
|
https://api.github.com/repos/huggingface/datasets/issues/415
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/415/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/415/comments
|
https://api.github.com/repos/huggingface/datasets/issues/415/events
|
https://github.com/huggingface/datasets/issues/415
| 660,687,076
|
MDU6SXNzdWU2NjA2ODcwNzY=
| 415
|
Something is wrong with WMT 19 kk-en dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32014649?v=4",
"events_url": "https://api.github.com/users/ChenghaoMou/events{/privacy}",
"followers_url": "https://api.github.com/users/ChenghaoMou/followers",
"following_url": "https://api.github.com/users/ChenghaoMou/following{/other_user}",
"gists_url": "https://api.github.com/users/ChenghaoMou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ChenghaoMou",
"id": 32014649,
"login": "ChenghaoMou",
"node_id": "MDQ6VXNlcjMyMDE0NjQ5",
"organizations_url": "https://api.github.com/users/ChenghaoMou/orgs",
"received_events_url": "https://api.github.com/users/ChenghaoMou/received_events",
"repos_url": "https://api.github.com/users/ChenghaoMou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ChenghaoMou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ChenghaoMou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ChenghaoMou",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
open
| false
| null |
[] |
[] | 2020-07-19T08:18:51
| 2020-07-20T09:54:26
| null |
NONE
| null | null | null | null |
The translation in the `train` set does not look right:
```
>>>import nlp
>>>from nlp import load_dataset
>>>dataset = load_dataset('wmt19', 'kk-en')
>>>dataset["train"]["translation"][0]
{'kk': 'Trumpian Uncertainty', 'en': 'Трамптық белгісіздік'}
>>>dataset["validation"]["translation"][0]
{'kk': 'Ақша-несие саясатының сценарийін қайта жазсақ', 'en': 'Rewriting the Monetary-Policy Script'}
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/415/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/415/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/414
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/414/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/414/comments
|
https://api.github.com/repos/huggingface/datasets/issues/414/events
|
https://github.com/huggingface/datasets/issues/414
| 660,654,013
|
MDU6SXNzdWU2NjA2NTQwMTM=
| 414
|
from_dict delete?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"events_url": "https://api.github.com/users/hackerxiaobai/events{/privacy}",
"followers_url": "https://api.github.com/users/hackerxiaobai/followers",
"following_url": "https://api.github.com/users/hackerxiaobai/following{/other_user}",
"gists_url": "https://api.github.com/users/hackerxiaobai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hackerxiaobai",
"id": 22817243,
"login": "hackerxiaobai",
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"organizations_url": "https://api.github.com/users/hackerxiaobai/orgs",
"received_events_url": "https://api.github.com/users/hackerxiaobai/received_events",
"repos_url": "https://api.github.com/users/hackerxiaobai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hackerxiaobai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hackerxiaobai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hackerxiaobai",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"`from_dict` was added in #350 that was unfortunately not included in the 0.3.0 release. It's going to be included in the next release that will be out pretty soon though.\r\nRight now if you want to use `from_dict` you have to install the package from the master branch\r\n```\r\npip install git+https://github.com/huggingface/nlp.git\r\n```",
"> `from_dict` was added in #350 that was unfortunately not included in the 0.3.0 release. It's going to be included in the next release that will be out pretty soon though.\r\n> Right now if you want to use `from_dict` you have to install the package from the master branch\r\n> \r\n> ```\r\n> pip install git+https://github.com/huggingface/nlp.git\r\n> ```\r\nOK, thank you.\r\n"
] | 2020-07-19T07:08:36
| 2020-07-21T02:21:17
| 2020-07-21T02:21:17
|
NONE
| null | null | null | null |
AttributeError: type object 'Dataset' has no attribute 'from_dict'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"events_url": "https://api.github.com/users/hackerxiaobai/events{/privacy}",
"followers_url": "https://api.github.com/users/hackerxiaobai/followers",
"following_url": "https://api.github.com/users/hackerxiaobai/following{/other_user}",
"gists_url": "https://api.github.com/users/hackerxiaobai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hackerxiaobai",
"id": 22817243,
"login": "hackerxiaobai",
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"organizations_url": "https://api.github.com/users/hackerxiaobai/orgs",
"received_events_url": "https://api.github.com/users/hackerxiaobai/received_events",
"repos_url": "https://api.github.com/users/hackerxiaobai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hackerxiaobai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hackerxiaobai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hackerxiaobai",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/414/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/414/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 19:12:41
|
https://api.github.com/repos/huggingface/datasets/issues/413
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/413/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/413/comments
|
https://api.github.com/repos/huggingface/datasets/issues/413/events
|
https://github.com/huggingface/datasets/issues/413
| 660,063,655
|
MDU6SXNzdWU2NjAwNjM2NTU=
| 413
|
Is there a way to download only NQ dev?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1563902?v=4",
"events_url": "https://api.github.com/users/tholor/events{/privacy}",
"followers_url": "https://api.github.com/users/tholor/followers",
"following_url": "https://api.github.com/users/tholor/following{/other_user}",
"gists_url": "https://api.github.com/users/tholor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tholor",
"id": 1563902,
"login": "tholor",
"node_id": "MDQ6VXNlcjE1NjM5MDI=",
"organizations_url": "https://api.github.com/users/tholor/orgs",
"received_events_url": "https://api.github.com/users/tholor/received_events",
"repos_url": "https://api.github.com/users/tholor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tholor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tholor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tholor",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Unfortunately it's not possible to download only the dev set of NQ.\r\n\r\nI think we could add a way to download only the test set by adding a custom configuration to the processing script though.",
"Ok, got it. I think this could be a valuable feature - especially for large datasets like NQ, but potentially also others. \r\nFor us, it will in this case make the difference of using the library or keeping the old downloads of the raw dev datasets. \r\nHowever, I don't know if that fits into your plans with the library and can also understand if you don't want to support this.",
"I don't think we could force this behavior generally since the dataset script authors are free to organize the file download as they want (sometimes the mapping between split and files can be very much nontrivial) but we can add an additional configuration for Natural Question indeed as @lhoestq indicate."
] | 2020-07-18T10:28:23
| 2022-02-11T09:50:21
| 2022-02-11T09:50:21
|
NONE
| null | null | null | null |
Maybe I missed that in the docs, but is there a way to only download the dev set of natural questions (~1 GB)?
As we want to benchmark QA models on different datasets, I would like to avoid downloading the 41GB of training data.
I tried
```
dataset = nlp.load_dataset('natural_questions', split="validation", beam_runner="DirectRunner")
```
But this still triggered a big download of presumably the whole dataset. Is there any way of doing this or are splits / slicing options only available after downloading?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/413/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/413/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 572 days, 23:21:58
|
https://api.github.com/repos/huggingface/datasets/issues/412
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/412/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/412/comments
|
https://api.github.com/repos/huggingface/datasets/issues/412/events
|
https://github.com/huggingface/datasets/issues/412
| 660,047,139
|
MDU6SXNzdWU2NjAwNDcxMzk=
| 412
|
Unable to load XTREME dataset from disk
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @lewtun, you have to provide the full path to the downloaded file for example `/home/lewtum/..`",
"I was able to repro. Opening a PR to fix that.\r\nThanks for reporting this issue !",
"Thanks for the rapid fix @lhoestq!"
] | 2020-07-18T09:55:00
| 2020-07-21T08:15:44
| 2020-07-21T08:15:44
|
MEMBER
| null | null | null | null |
Hi 🤗 team!
## Description of the problem
Following the [docs](https://huggingface.co/nlp/loading_datasets.html?highlight=xtreme#manually-downloading-files) I'm trying to load the `PAN-X.fr` dataset from the [XTREME](https://github.com/google-research/xtreme) benchmark.
I have manually downloaded the `AmazonPhotos.zip` file from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1) and am running into a `FileNotFoundError` when I point to the location of the dataset.
As far as I can tell, the problem is that `AmazonPhotos.zip` decompresses to `panx_dataset` and `load_dataset()` is not looking in the correct path:
```
# path where load_dataset is looking for fr.tar.gz
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/
# path where it actually exists
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/panx_dataset/
```
## Steps to reproduce the problem
1. Manually download the XTREME benchmark from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1)
2. Run the following code snippet
```python
from nlp import load_dataset
# AmazonPhotos.zip is in the root of the folder
dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
```
3. Here is the stack trace
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-26786bb5fa93> in <module>
----> 1 dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
464 split_dict = SplitDict(dataset_name=self.name)
465 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 466 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
467 # Checksums verification
468 if verify_infos:
/usr/local/lib/python3.6/dist-packages/nlp/datasets/xtreme/b8c2ed3583a7a7ac60b503576dfed3271ac86757628897e945bd329c43b8a746/xtreme.py in _split_generators(self, dl_manager)
725 panx_dl_dir = dl_manager.extract(panx_path)
726 lang = self.config.name.split(".")[1]
--> 727 lang_folder = dl_manager.extract(os.path.join(panx_dl_dir, lang + ".tar.gz"))
728 return [
729 nlp.SplitGenerator(
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in extract(self, path_or_paths)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
170 return tuple(mapped)
171 # Singleton
--> 172 return function(data_struct)
173
174
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in <lambda>(path)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
203 elif urlparse(url_or_filename).scheme == "":
204 # File, but it doesn't exist.
--> 205 raise FileNotFoundError("Local file {} doesn't exist".format(url_or_filename))
206 else:
207 # Something unknown
FileNotFoundError: Local file /root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/fr.tar.gz doesn't exist
```
## OS and hardware
```
- `nlp` version: 0.3.0
- Platform: Linux-4.15.0-72-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.1.0 (True)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/412/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/412/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 22:20:44
|
https://api.github.com/repos/huggingface/datasets/issues/409
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/409/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/409/comments
|
https://api.github.com/repos/huggingface/datasets/issues/409/events
|
https://github.com/huggingface/datasets/issues/409
| 659,128,611
|
MDU6SXNzdWU2NTkxMjg2MTE=
| 409
|
train_test_split error: 'dict' object has no attribute 'deepcopy'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20516801?v=4",
"events_url": "https://api.github.com/users/morganmcg1/events{/privacy}",
"followers_url": "https://api.github.com/users/morganmcg1/followers",
"following_url": "https://api.github.com/users/morganmcg1/following{/other_user}",
"gists_url": "https://api.github.com/users/morganmcg1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/morganmcg1",
"id": 20516801,
"login": "morganmcg1",
"node_id": "MDQ6VXNlcjIwNTE2ODAx",
"organizations_url": "https://api.github.com/users/morganmcg1/orgs",
"received_events_url": "https://api.github.com/users/morganmcg1/received_events",
"repos_url": "https://api.github.com/users/morganmcg1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/morganmcg1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/morganmcg1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/morganmcg1",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"It was fixed in 2ddd18d139d3047c9c3abe96e1e7d05bb360132c.\r\nCould you pull the latest changes from master @morganmcg1 ?",
"Thanks @lhoestq, works fine now!"
] | 2020-07-17T10:36:28
| 2020-07-21T14:34:52
| 2020-07-21T14:34:52
|
NONE
| null | null | null | null |
`train_test_split` is giving me an error when I try and call it:
`'dict' object has no attribute 'deepcopy'`
## To reproduce
```
dataset = load_dataset('glue', 'mrpc', split='train')
dataset = dataset.train_test_split(test_size=0.2)
```
## Full Stacktrace
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-12-feb740dbec9a> in <module>
1 dataset = load_dataset('glue', 'mrpc', split='train')
----> 2 dataset = dataset.train_test_split(test_size=0.2)
~/anaconda3/envs/fastai2_me/lib/python3.7/site-packages/nlp/arrow_dataset.py in train_test_split(self, test_size, train_size, shuffle, seed, generator, keep_in_memory, load_from_cache_file, train_cache_file_name, test_cache_file_name, writer_batch_size)
1032 "writer_batch_size": writer_batch_size,
1033 }
-> 1034 train_kwargs = cache_kwargs.deepcopy()
1035 train_kwargs["split"] = "train"
1036 test_kwargs = cache_kwargs.deepcopy()
AttributeError: 'dict' object has no attribute 'deepcopy'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20516801?v=4",
"events_url": "https://api.github.com/users/morganmcg1/events{/privacy}",
"followers_url": "https://api.github.com/users/morganmcg1/followers",
"following_url": "https://api.github.com/users/morganmcg1/following{/other_user}",
"gists_url": "https://api.github.com/users/morganmcg1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/morganmcg1",
"id": 20516801,
"login": "morganmcg1",
"node_id": "MDQ6VXNlcjIwNTE2ODAx",
"organizations_url": "https://api.github.com/users/morganmcg1/orgs",
"received_events_url": "https://api.github.com/users/morganmcg1/received_events",
"repos_url": "https://api.github.com/users/morganmcg1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/morganmcg1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/morganmcg1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/morganmcg1",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/409/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/409/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 3:58:24
|
https://api.github.com/repos/huggingface/datasets/issues/407
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/407/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/407/comments
|
https://api.github.com/repos/huggingface/datasets/issues/407/events
|
https://github.com/huggingface/datasets/issues/407
| 658,672,736
|
MDU6SXNzdWU2NTg2NzI3MzY=
| 407
|
MissingBeamOptions for Wikipedia 20200501.en
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Fixed. Could you try again @mitchellgordon95 ?\r\nIt was due a file not being updated on S3.\r\n\r\nWe need to make sure all the datasets scripts get updated properly @julien-c ",
"Works for me! Thanks.",
"I found the same issue with almost any language other than English. (For English, it works). Will someone need to update the file on S3 again?",
"This is because only some languages are already preprocessed (en, de, fr, it) and stored on our google storage.\r\nWe plan to have a systematic way to preprocess more wikipedia languages in the future.\r\n\r\nFor the other languages you have to process them on your side using apache beam. That's why the lib asks for a Beam runner."
] | 2020-07-16T23:48:03
| 2021-01-12T11:41:16
| 2020-07-17T14:24:28
|
CONTRIBUTOR
| null | null | null | null |
There may or may not be a regression for the pre-processed Wikipedia dataset. This was working fine 10 commits ago (without having Apache Beam available):
```
nlp.load_dataset('wikipedia', "20200501.en", split='train')
```
And now, having pulled master, I get:
```
Downloading and preparing dataset wikipedia/20200501.en (download: 16.99 GiB, generated: 17.07 GiB, total: 34.06 GiB) to /home/hltcoe/mgordon/.cache/huggingface/datasets/wikipedia/20200501.en/1.0.0/76b0b2747b679bb0ee7a1621e50e5a6378477add0c662668a324a5bc07d516dd...
Traceback (most recent call last):
File "scripts/download.py", line 11, in <module>
fire.Fire(download_pretrain)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 138, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 468, in _Fire
target=component.__name__)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 672, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "scripts/download.py", line 6, in download_pretrain
nlp.load_dataset('wikipedia', "20200501.en", split='train')
File "/exp/mgordon/nlp/src/nlp/load.py", line 534, in load_dataset
save_infos=save_infos,
File "/exp/mgordon/nlp/src/nlp/builder.py", line 460, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/exp/mgordon/nlp/src/nlp/builder.py", line 870, in _download_and_prepare
"\n\t`{}`".format(usage_example)
nlp.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, S
park, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.en', beam_runner='DirectRunner')`
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/407/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/407/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 14:36:25
|
https://api.github.com/repos/huggingface/datasets/issues/406
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/406/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/406/comments
|
https://api.github.com/repos/huggingface/datasets/issues/406/events
|
https://github.com/huggingface/datasets/issues/406
| 658,581,764
|
MDU6SXNzdWU2NTg1ODE3NjQ=
| 406
|
Faster Shuffling?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I think the slowness here probably come from the fact that we are copying from and to python.\r\n\r\n@lhoestq for all the `select`-based methods I think we should stay in Arrow format and update the writer so that it can accept Arrow tables or batches as well. What do you think?",
"> @lhoestq for all the `select`-based methods I think we should stay in Arrow format and update the writer so that it can accept Arrow tables or batches as well. What do you think?\r\n\r\nI just tried with `writer.write_table` with tables of 1000 elements and it's slower that the solution in #405 \r\n\r\nOn my side (select 10 000 examples):\r\n- Original implementation: 12s\r\n- Batched solution: 100ms\r\n- solution using arrow tables: 350ms\r\n\r\nI'll try with arrays and record batches to see if we can make it work.",
"I tried using `.take` from pyarrow recordbatches but it doesn't improve the speed that much:\r\n```python\r\nimport nlp\r\nimport numpy as np\r\n\r\ndset = nlp.Dataset.from_file(\"dummy_test_select.arrow\") # dummy dataset with 100000 examples like {\"a\": \"h\"*512}\r\nindices = np.random.randint(0, 100_000, 1000_000)\r\n```\r\n\r\n```python\r\n%%time\r\nbatch_size = 10_000\r\nwriter = ArrowWriter(schema=dset.schema, path=\"dummy_path\",\r\n writer_batch_size=1000, disable_nullable=False)\r\nfor i in tqdm(range(0, len(indices), batch_size)):\r\n table = pa.concat_tables(dset._data.slice(int(i), 1) for i in indices[i : min(len(indices), i + batch_size)])\r\n batch = table.to_pydict()\r\n writer.write_batch(batch)\r\nwriter.finalize()\r\n# 9.12s\r\n```\r\n\r\n\r\n```python\r\n%%time\r\nbatch_size = 10_000\r\nwriter = ArrowWriter(schema=dset.schema, path=\"dummy_path\", \r\n writer_batch_size=1000, disable_nullable=False)\r\nfor i in tqdm(range(0, len(indices), batch_size)):\r\n batch_indices = indices[i : min(len(indices), i + batch_size)]\r\n # First, extract only the indices that we need with a mask\r\n mask = [False] * len(dset)\r\n for k in batch_indices:\r\n mask[k] = True\r\n t_batch = dset._data.filter(pa.array(mask))\r\n # Second, build the list of indices for the filtered table, and taking care of duplicates\r\n rev_positions = {}\r\n duplicates = 0\r\n for i, j in enumerate(sorted(batch_indices)):\r\n if j in rev_positions:\r\n duplicates += 1\r\n else:\r\n rev_positions[j] = i - duplicates\r\n rev_map = [rev_positions[j] for j in batch_indices]\r\n # Third, use `.take` from the combined recordbatch\r\n t_combined = t_batch.combine_chunks() # load in memory\r\n recordbatch = t_combined.to_batches()[0]\r\n table = pa.Table.from_arrays(\r\n [recordbatch[c].take(pa.array(rev_map)) for c in range(len(dset._data.column_names))],\r\n schema=writer.schema\r\n )\r\n writer.write_table(table)\r\nwriter.finalize()\r\n# 3.2s\r\n```\r\n",
"Shuffling is now significantly faster thanks to #513 \r\nFeel free to play with it now :)\r\n\r\nClosing this one, but feel free to re-open if you have other questions",
"> Shuffling is now significantly faster thanks to #513 Feel free to play with it now :)\r\n> \r\n> Closing this one, but feel free to re-open if you have other questions\r\n\r\nI have a similar issue. My code is \r\n\r\n```\r\n for batch_num in range(num_batches):\r\n print(f'--> {batch_num=}\\n') if verbose else None\r\n # - Get batch\r\n shuffled_dataset = dataset.shuffle(buffer_size=buffer_size, seed=seed)\r\n raw_text_batch = shuffled_dataset.take(batch_size)\r\n tokenized_batch = map(raw_text_batch)\r\n if verbose:\r\n time_start = time.time()\r\n print(f'{raw_text_batch=}')\r\n print(f'{tokenized_batch=}')\r\n print(f'{next(iter(raw_text_batch))=}')\r\n print(f'{next(iter(tokenized_batch))=}')\r\n print(f'Time it took: {time.time() - time_start} seconds \\a\\n')\r\n ```\r\n\r\nwithout the suffle it takes 4.5 secs with it takes 87.1 secs. Is this difference expected? my dataset version is:\r\n```\r\n(beyond_scale) brando9@ampere1:~/beyond-scale-language-data-diversity$ pip list | grep dataset\r\ndatasets 2.14.3\r\n```\r\n\r\n@lhoestq thoughts?\r\n\r\n",
"still slow even with update to `2.14.4` most recent as of this writing\r\n\r\n```\r\nTime it took: 4.301205635070801 seconds \r\n\r\n--> batch_num=0\r\n\r\nraw_text_batch=<datasets.iterable_dataset.IterableDataset object at 0x7f1fea7c2a40>\r\ntokenized_batch=<datasets.iterable_dataset.IterableDataset object at 0x7f1fea7c2f20>\r\nnext(iter(raw_text_batch))={'text': \"No matter which style you choose, you can be sure of one thing: our quality and craftsmanship are the best in the business. It's who we are and what we believe in. And it's evident every day on the factory floor where our dedicated teams take great pride in every stitch.\", 'timestamp': '2019-04-19T06:43:50Z', 'url': 'https://institchescustoms.com/katzkin.html'}\r\nnext(iter(tokenized_batch))={'input_ids': tensor([ 2949, 2300, 543, 3918, 345, 3853, 11, 345, 460, 307,\r\n 1654, 286, 530, 1517, 25, 674, 3081, 290, 5977, 49820,\r\n 389, 262, 1266, 287, 262, 1597, 13, 632, 338, 508,\r\n 356, 389, 290, 644, 356, 1975, 287, 13, 843, 340,\r\n 338, 10678, 790, 1110, 319, 262, 8860, 4314, 810, 674,\r\n 7256, 3466, 1011, 1049, 11293, 287, 790, 24695, 13, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\r\n 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256]), 'attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,\r\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\r\n 0, 0, 0, 0, 0, 0, 0, 0])}\r\nTime it took: 102.99258613586426 seconds\r\n```",
"Shuffling leads to doing random access in many different locations on disk which is slower than reading contiguous data.\r\n\r\nThere is a super fast approximate shuffling algorithm implemented for iterable datasets though:\r\n\r\n```python\r\niterable_dataset = dataset.to_iterable_dataset(num_shards=1024)\r\nshuffled_dataset = iterable_dataset.shuffle(buffer_size=1000)\r\n```\r\n\r\n(the first batch might be a bit slow to get because the algorithm first fills a buffer before returning the first batch, see the [docs](https://huggingface.co/docs/datasets/v2.14.4/en/stream#shuffle) for more info)"
] | 2020-07-16T21:21:53
| 2023-08-16T09:52:39
| 2020-09-07T14:45:25
|
CONTRIBUTOR
| null | null | null | null |
Consider shuffling bookcorpus:
```
dataset = nlp.load_dataset('bookcorpus', split='train')
dataset.shuffle()
```
According to tqdm, this will take around 2.5 hours on my machine to complete (even with the faster version of select from #405). I've also tried with `keep_in_memory=True` and `writer_batch_size=1000`.
But I can also just write the lines to a text file:
```
batch_size = 100000
with open('tmp.txt', 'w+') as out_f:
for i in tqdm(range(0, len(dataset), batch_size)):
batch = dataset[i:i+batch_size]['text']
print("\n".join(batch), file=out_f)
```
Which completes in a couple minutes, followed by `shuf tmp.txt > tmp2.txt` which completes in under a minute. And finally,
```
dataset = nlp.load_dataset('text', data_files='tmp2.txt')
```
Which completes in under 10 minutes. I read up on Apache Arrow this morning, and it seems like the columnar data format is not especially well-suited to shuffling rows, since moving items around requires a lot of book-keeping.
Is shuffle inherently slow, or am I just using it wrong? And if it is slow, would it make sense to try converting the data to a row-based format on disk and then shuffling? (Instead of calling select with a random permutation, as is currently done.)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/406/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/406/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 52 days, 17:23:32
|
https://api.github.com/repos/huggingface/datasets/issues/395
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/395/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/395/comments
|
https://api.github.com/repos/huggingface/datasets/issues/395/events
|
https://github.com/huggingface/datasets/issues/395
| 657,454,983
|
MDU6SXNzdWU2NTc0NTQ5ODM=
| 395
|
Memory issue when doing select
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[] | 2020-07-15T15:43:38
| 2020-07-16T08:07:31
| 2020-07-16T08:07:31
|
MEMBER
| null | null | null | null |
As noticed in #389, the following code loads the entire wikipedia in memory.
```python
import nlp
w = nlp.load_dataset("wikipedia", "20200501.en", split="train")
w.select([0])
```
This is caused by [this line](https://github.com/huggingface/nlp/blob/master/src/nlp/arrow_dataset.py#L626) for some reason, that tries to serialize the function with all the wikipedia data with it.
It's not the case with `.map` or `.filter`.
However functions that are based on `.select` like `.shuffle`, `.shard`, `.train_test_split`, `.sort` are affected.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/395/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/395/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 16:23:53
|
https://api.github.com/repos/huggingface/datasets/issues/388
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/388/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/388/comments
|
https://api.github.com/repos/huggingface/datasets/issues/388/events
|
https://github.com/huggingface/datasets/issues/388
| 656,707,497
|
MDU6SXNzdWU2NTY3MDc0OTc=
| 388
|
🐛 [Dataset] Cannot download wmt14, wmt15 and wmt17
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2826602?v=4",
"events_url": "https://api.github.com/users/SamuelCahyawijaya/events{/privacy}",
"followers_url": "https://api.github.com/users/SamuelCahyawijaya/followers",
"following_url": "https://api.github.com/users/SamuelCahyawijaya/following{/other_user}",
"gists_url": "https://api.github.com/users/SamuelCahyawijaya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SamuelCahyawijaya",
"id": 2826602,
"login": "SamuelCahyawijaya",
"node_id": "MDQ6VXNlcjI4MjY2MDI=",
"organizations_url": "https://api.github.com/users/SamuelCahyawijaya/orgs",
"received_events_url": "https://api.github.com/users/SamuelCahyawijaya/received_events",
"repos_url": "https://api.github.com/users/SamuelCahyawijaya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SamuelCahyawijaya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SamuelCahyawijaya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SamuelCahyawijaya",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] |
[
"similar slow download speed here for nlp.load_dataset('wmt14', 'fr-en')\r\n`\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 658M/658M [1:00:42<00:00, 181kB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 918M/918M [1:39:38<00:00, 154kB/s]\r\nDownloading: 2%|▉ | 40.9M/2.37G [04:48<5:03:06, 128kB/s]\r\n`\r\nCould we just download a specific subdataset in 'wmt14', such as 'newstest14'? ",
"> The code runs but the download speed is extremely slow, the same behaviour is not observed on wmt16 and wmt18\r\n\r\nThe original source for the files may provide slow download speeds.\r\nWe can probably host these files ourselves.\r\n\r\n> When trying to download wmt17 zh-en, I got the following error:\r\n> ConnectionError: Couldn't reach https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-zh.tar.gz\r\n\r\nLooks like the file`UNv1.0.en-zh.tar.gz` is missing, or the url changed. We need to fix that\r\n\r\n> Could we just download a specific subdataset in 'wmt14', such as 'newstest14'?\r\n\r\nRight now I don't think it's possible. Maybe @patrickvonplaten knows more about it\r\n",
"Yeah, the download speed is sadly always extremely slow :-/. \r\nI will try to check out the `wmt17 zh-en` bug :-) ",
"Maybe this can be used - https://stuncorpusprod.blob.core.windows.net/corpusfiles/UNv1.0.en-zh.tar.gz.00 ",
"These issues seem to be fixed now."
] | 2020-07-14T15:36:41
| 2022-10-04T18:01:28
| 2022-10-04T18:01:28
|
NONE
| null | null | null | null |
1. I try downloading `wmt14`, `wmt15`, `wmt17`, `wmt19` with the following code:
```
nlp.load_dataset('wmt14','de-en')
nlp.load_dataset('wmt15','de-en')
nlp.load_dataset('wmt17','de-en')
nlp.load_dataset('wmt19','de-en')
```
The code runs but the download speed is **extremely slow**, the same behaviour is not observed on `wmt16` and `wmt18`
2. When trying to download `wmt17 zh-en`, I got the following error:
> ConnectionError: Couldn't reach https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-zh.tar.gz
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/388/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/388/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 812 days, 2:24:47
|
https://api.github.com/repos/huggingface/datasets/issues/387
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/387/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/387/comments
|
https://api.github.com/repos/huggingface/datasets/issues/387/events
|
https://github.com/huggingface/datasets/issues/387
| 656,361,357
|
MDU6SXNzdWU2NTYzNjEzNTc=
| 387
|
Conversion through to_pandas output numpy arrays for lists instead of python objects
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"To convert from arrow type we have three options: to_numpy, to_pandas and to_pydict/to_pylist.\r\n\r\n- to_numpy and to_pandas return numpy arrays instead of lists but are very fast.\r\n- to_pydict/to_pylist can be 100x slower and become the bottleneck for reading data, but at least they return lists.\r\n\r\nMaybe we can have to_pydict/to_pylist as the default and use to_numpy or to_pandas when the format (set by `set_format`) is 'numpy' or 'pandas'"
] | 2020-07-14T06:24:01
| 2020-07-17T11:37:00
| 2020-07-17T11:37:00
|
MEMBER
| null | null | null | null |
In a related question, the conversion through to_pandas output numpy arrays for the lists instead of python objects.
Here is an example:
```python
>>> dataset._data.slice(key, 1).to_pandas().to_dict("list")
{'sentence1': ['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .'], 'sentence2': ['Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'], 'label': [1], 'idx': [0], 'input_ids': [array([ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292,
1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938,
4267, 12223, 21811, 1117, 2554, 119, 102])], 'token_type_ids': [array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0])], 'attention_mask': [array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1])]}
>>> type(dataset._data.slice(key, 1).to_pandas().to_dict("list")['input_ids'][0])
<class 'numpy.ndarray'>
>>> dataset._data.slice(key, 1).to_pydict()
{'sentence1': ['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .'], 'sentence2': ['Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'], 'label': [1], 'idx': [0], 'input_ids': [[101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/387/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/387/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 5:12:59
|
https://api.github.com/repos/huggingface/datasets/issues/382
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/382/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/382/comments
|
https://api.github.com/repos/huggingface/datasets/issues/382/events
|
https://github.com/huggingface/datasets/issues/382
| 655,290,482
|
MDU6SXNzdWU2NTUyOTA0ODI=
| 382
|
1080
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/60942503?v=4",
"events_url": "https://api.github.com/users/saq194/events{/privacy}",
"followers_url": "https://api.github.com/users/saq194/followers",
"following_url": "https://api.github.com/users/saq194/following{/other_user}",
"gists_url": "https://api.github.com/users/saq194/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/saq194",
"id": 60942503,
"login": "saq194",
"node_id": "MDQ6VXNlcjYwOTQyNTAz",
"organizations_url": "https://api.github.com/users/saq194/orgs",
"received_events_url": "https://api.github.com/users/saq194/received_events",
"repos_url": "https://api.github.com/users/saq194/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/saq194/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saq194/subscriptions",
"type": "User",
"url": "https://api.github.com/users/saq194",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-07-11T22:29:07
| 2020-07-11T22:49:38
| 2020-07-11T22:49:38
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/382/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/382/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:20:31
|
|
https://api.github.com/repos/huggingface/datasets/issues/381
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/381/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/381/comments
|
https://api.github.com/repos/huggingface/datasets/issues/381/events
|
https://github.com/huggingface/datasets/issues/381
| 655,277,119
|
MDU6SXNzdWU2NTUyNzcxMTk=
| 381
|
NLp
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68147610?v=4",
"events_url": "https://api.github.com/users/Spartanthor/events{/privacy}",
"followers_url": "https://api.github.com/users/Spartanthor/followers",
"following_url": "https://api.github.com/users/Spartanthor/following{/other_user}",
"gists_url": "https://api.github.com/users/Spartanthor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Spartanthor",
"id": 68147610,
"login": "Spartanthor",
"node_id": "MDQ6VXNlcjY4MTQ3NjEw",
"organizations_url": "https://api.github.com/users/Spartanthor/orgs",
"received_events_url": "https://api.github.com/users/Spartanthor/received_events",
"repos_url": "https://api.github.com/users/Spartanthor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Spartanthor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Spartanthor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Spartanthor",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-07-11T20:50:14
| 2020-07-11T20:50:39
| 2020-07-11T20:50:39
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/381/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/381/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:00:25
|
|
https://api.github.com/repos/huggingface/datasets/issues/378
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/378/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/378/comments
|
https://api.github.com/repos/huggingface/datasets/issues/378/events
|
https://github.com/huggingface/datasets/issues/378
| 655,226,316
|
MDU6SXNzdWU2NTUyMjYzMTY=
| 378
|
[dataset] Structure of MLQA seems unecessary nested
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Same for the RACE dataset: https://github.com/huggingface/nlp/blob/master/datasets/race/race.py\r\n\r\nShould we scan all the datasets to remove this pattern of un-necessary nesting?",
"You're right, I think we don't need to use the nested dictionary. \r\n"
] | 2020-07-11T15:16:08
| 2020-07-15T16:17:20
| 2020-07-15T16:17:20
|
MEMBER
| null | null | null | null |
The features of the MLQA dataset comprise several nested dictionaries with a single element inside (for `questions` and `ids`): https://github.com/huggingface/nlp/blob/master/datasets/mlqa/mlqa.py#L90-L97
Should we keep this @mariamabarham @patrickvonplaten? Was this added for compatibility with tfds?
```python
features=nlp.Features(
{
"context": nlp.Value("string"),
"questions": nlp.features.Sequence({"question": nlp.Value("string")}),
"answers": nlp.features.Sequence(
{"text": nlp.Value("string"), "answer_start": nlp.Value("int32"),}
),
"ids": nlp.features.Sequence({"idx": nlp.Value("string")})
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/378/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/378/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 1:01:12
|
https://api.github.com/repos/huggingface/datasets/issues/377
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/377/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/377/comments
|
https://api.github.com/repos/huggingface/datasets/issues/377/events
|
https://github.com/huggingface/datasets/issues/377
| 655,215,790
|
MDU6SXNzdWU2NTUyMTU3OTA=
| 377
|
Iyy!!!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68154535?v=4",
"events_url": "https://api.github.com/users/ajinomoh/events{/privacy}",
"followers_url": "https://api.github.com/users/ajinomoh/followers",
"following_url": "https://api.github.com/users/ajinomoh/following{/other_user}",
"gists_url": "https://api.github.com/users/ajinomoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ajinomoh",
"id": 68154535,
"login": "ajinomoh",
"node_id": "MDQ6VXNlcjY4MTU0NTM1",
"organizations_url": "https://api.github.com/users/ajinomoh/orgs",
"received_events_url": "https://api.github.com/users/ajinomoh/received_events",
"repos_url": "https://api.github.com/users/ajinomoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ajinomoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ajinomoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ajinomoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-07-11T14:11:07
| 2020-07-11T14:30:51
| 2020-07-11T14:30:51
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/377/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/377/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:19:44
|
|
https://api.github.com/repos/huggingface/datasets/issues/376
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/376/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/376/comments
|
https://api.github.com/repos/huggingface/datasets/issues/376/events
|
https://github.com/huggingface/datasets/issues/376
| 655,047,826
|
MDU6SXNzdWU2NTUwNDc4MjY=
| 376
|
to_pandas conversion doesn't always work
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"**Edit**: other topic previously in this message moved to a new issue: https://github.com/huggingface/nlp/issues/387",
"Could you try to update pyarrow to >=0.17.0 ? It should fix the `to_pandas` bug\r\n\r\nAlso I'm not sure that structures like list<struct> are fully supported in the lib (none of the datasets use that).\r\nIt can cause issues when using dataset transforms like `filter` for example"
] | 2020-07-10T21:33:31
| 2022-10-04T18:05:39
| 2022-10-04T18:05:39
|
MEMBER
| null | null | null | null |
For some complex nested types, the conversion from Arrow to python dict through pandas doesn't seem to be possible.
Here is an example using the official SQUAD v2 JSON file.
This example was found while investigating #373.
```python
>>> squad = load_dataset('json', data_files={nlp.Split.TRAIN: ["./train-v2.0.json"]}, download_mode=nlp.GenerateMode.FORCE_REDOWNLOAD, version="1.0.0", field='data')
>>> squad['train']
Dataset(schema: {'title': 'string', 'paragraphs': 'list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>'}, num_rows: 442)
>>> squad['train'][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 589, in __getitem__
format_kwargs=self._format_kwargs,
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 529, in _getitem
outputs = self._unnest(self._data.slice(key, 1).to_pandas().to_dict("list"))
File "pyarrow/array.pxi", line 559, in pyarrow.lib._PandasConvertible.to_pandas
File "pyarrow/table.pxi", line 1367, in pyarrow.lib.Table._to_pandas
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 766, in table_to_blockmanager
blocks = _table_to_blocks(options, table, categories, ext_columns_dtypes)
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 1101, in _table_to_blocks
list(extension_columns.keys()))
File "pyarrow/table.pxi", line 881, in pyarrow.lib.table_to_blocks
File "pyarrow/error.pxi", line 105, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Not implemented type for Arrow list to pandas: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
```
cc @lhoestq would we have a way to detect this from the schema maybe?
Here is the schema for this pretty complex JSON:
```python
>>> squad['train'].schema
title: string
paragraphs: list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>
child 0, item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
child 0, qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>
child 0, item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>
child 0, question: string
child 1, id: string
child 2, answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 3, is_impossible: bool
child 4, plausible_answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 1, context: string
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/376/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/376/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 815 days, 20:32:08
|
https://api.github.com/repos/huggingface/datasets/issues/375
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/375/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/375/comments
|
https://api.github.com/repos/huggingface/datasets/issues/375/events
|
https://github.com/huggingface/datasets/issues/375
| 655,023,307
|
MDU6SXNzdWU2NTUwMjMzMDc=
| 375
|
TypeError when computing bertscore
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13269577?v=4",
"events_url": "https://api.github.com/users/willywsm1013/events{/privacy}",
"followers_url": "https://api.github.com/users/willywsm1013/followers",
"following_url": "https://api.github.com/users/willywsm1013/following{/other_user}",
"gists_url": "https://api.github.com/users/willywsm1013/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/willywsm1013",
"id": 13269577,
"login": "willywsm1013",
"node_id": "MDQ6VXNlcjEzMjY5NTc3",
"organizations_url": "https://api.github.com/users/willywsm1013/orgs",
"received_events_url": "https://api.github.com/users/willywsm1013/received_events",
"repos_url": "https://api.github.com/users/willywsm1013/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/willywsm1013/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willywsm1013/subscriptions",
"type": "User",
"url": "https://api.github.com/users/willywsm1013",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I am not able to reproduce this issue on my side.\r\nCould you give us more details about the inputs you used ?\r\n\r\nI do get another error though:\r\n```\r\n~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/bert_score/utils.py in bert_cos_score_idf(model, refs, hyps, tokenizer, idf_dict, verbose, batch_size, device, all_layers)\r\n 371 return sorted(list(set(l)), key=lambda x: len(x.split(\" \")))\r\n 372 \r\n--> 373 sentences = dedup_and_sort(refs + hyps)\r\n 374 embs = []\r\n 375 iter_range = range(0, len(sentences), batch_size)\r\n\r\nValueError: operands could not be broadcast together with shapes (0,) (2,)\r\n```\r\nThat's because it gets numpy arrays as input and not lists. See #387 ",
"The other issue was fixed by #403 \r\n\r\nDo you still get this issue @willywsm1013 ?\r\n"
] | 2020-07-10T20:37:44
| 2022-06-01T15:15:59
| 2022-06-01T15:15:59
|
NONE
| null | null | null | null |
Hi,
I installed nlp 0.3.0 via pip, and my python version is 3.7.
When I tried to compute bertscore with the code:
```
import nlp
bertscore = nlp.load_metric('bertscore')
# load hyps and refs
...
print (bertscore.compute(hyps, refs, lang='en'))
```
I got the following error.
```
Traceback (most recent call last):
File "bert_score_evaluate.py", line 16, in <module>
print (bertscore.compute(hyps, refs, lang='en'))
File "/home/willywsm/anaconda3/envs/torcher/lib/python3.7/site-packages/nlp/metric.py", line 200, in compute
output = self._compute(predictions=predictions, references=references, **metrics_kwargs)
File "/home/willywsm/anaconda3/envs/torcher/lib/python3.7/site-packages/nlp/metrics/bertscore/fb176889831bf0ce995ed197edc94b2e9a83f647a869bb8c9477dbb2d04d0f08/bertscore.py", line 105, in _compute
hashcode = bert_score.utils.get_hash(model_type, num_layers, idf, rescale_with_baseline)
TypeError: get_hash() takes 3 positional arguments but 4 were given
```
It seems like there is something wrong with get_hash() function?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/375/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/375/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 690 days, 18:38:15
|
https://api.github.com/repos/huggingface/datasets/issues/373
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/373/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/373/comments
|
https://api.github.com/repos/huggingface/datasets/issues/373/events
|
https://github.com/huggingface/datasets/issues/373
| 654,845,133
|
MDU6SXNzdWU2NTQ4NDUxMzM=
| 373
|
Segmentation fault when loading local JSON dataset as of #372
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I've seen this sort of thing before -- it might help to delete the directory -- I've also noticed that there is an error with the json Dataloader for any data I've tried to load. I've replaced it with this, which skips over the data feature population step:\r\n\r\n\r\n```python\r\nimport os\r\n\r\nimport pyarrow.json as paj\r\n\r\nimport nlp as hf_nlp\r\n\r\nfrom nlp import DatasetInfo, BuilderConfig, SplitGenerator, Split, utils\r\nfrom nlp.arrow_writer import ArrowWriter\r\n\r\n\r\nclass JSONDatasetBuilder(hf_nlp.ArrowBasedBuilder):\r\n BUILDER_CONFIG_CLASS = BuilderConfig\r\n\r\n def _info(self):\r\n return DatasetInfo()\r\n\r\n def _split_generators(self, dl_manager):\r\n \"\"\" We handle string, list and dicts in datafiles\r\n \"\"\"\r\n if isinstance(self.config.data_files, (str, list, tuple)):\r\n files = self.config.data_files\r\n if isinstance(files, str):\r\n files = [files]\r\n return [SplitGenerator(name=Split.TRAIN, gen_kwargs={\"files\": files})]\r\n splits = []\r\n for split_name in [Split.TRAIN, Split.VALIDATION, Split.TEST]:\r\n if split_name in self.config.data_files:\r\n files = self.config.data_files[split_name]\r\n if isinstance(files, str):\r\n files = [files]\r\n splits.append(SplitGenerator(name=split_name, gen_kwargs={\"files\": files}))\r\n return splits\r\n\r\n def _prepare_split(self, split_generator):\r\n fname = \"{}-{}.arrow\".format(self.name, split_generator.name)\r\n fpath = os.path.join(self._cache_dir, fname)\r\n\r\n writer = ArrowWriter(path=fpath)\r\n\r\n generator = self._generate_tables(**split_generator.gen_kwargs)\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False):\r\n writer.write_table(table)\r\n num_examples, num_bytes = writer.finalize()\r\n\r\n split_generator.split_info.num_examples = num_examples\r\n split_generator.split_info.num_bytes = num_bytes\r\n\r\n def _generate_tables(self, files):\r\n for i, file in enumerate(files):\r\n pa_table = paj.read_json(\r\n file\r\n )\r\n yield i, pa_table\r\n\r\n```",
"Yes, deleting the directory solves the error whenever I try to rerun.\r\n\r\nBy replacing the json-loader, you mean the cached file in my `site-packages` directory? e.g. `/home/XXX/.cache/lib/python3.7/site-packages/nlp/datasets/json/(...)/json.py` \r\n\r\nWhen I was testing this out before the #372 PR was merged I had issues installing it properly locally. Since the `json.py` script was downloaded instead of actually using the one provided in the local install. Manually updating that file seemed to solve it, but it didn't seem like a proper solution. Especially when having to run this on a remote compute cluster with no access to that directory.",
"I see, diving in the JSON file for SQuAD it's a pretty complex structure.\r\n\r\nThe best solution for you, if you have a dataset really similar to SQuAD would be to copy and modify the SQuAD data processing script. We will probably add soon an option to be able to specify file path to use instead of the automatic URL encoded in the script but in the meantime you can:\r\n- copy the [squad script](https://github.com/huggingface/nlp/blob/master/datasets/squad/squad.py) in a new script for your dataset\r\n- in the new script replace [these `urls_to_download `](https://github.com/huggingface/nlp/blob/master/datasets/squad/squad.py#L99-L102) by `urls_to_download=self.config.data_files`\r\n- load the dataset with `dataset = load_dataset('path/to/your/new/script', data_files={nlp.Split.TRAIN: \"./datasets/train-v2.0.json\"})`\r\n\r\nThis way you can reuse all the processing logic of the SQuAD loading script.",
"This seems like a more sensible solution! Thanks, @thomwolf. It's been a little daunting to understand what these scripts actually do, due to the level of abstraction and central documentation.\r\n\r\nAm I correct in assuming that the `_generate_examples()` function is the actual procedure for how the data is loaded from file? Meaning that essentially with a file containing another format, that is the only function that requires re-implementation? I'm working with a lot of datasets that, due to licensing and privacy, cannot be published. As this library is so neatly integrated with the transformers library and gives easy access to public sets such as SQUAD and increased performance, it is very neat to be able to load my private sets as well. As of now, I have just been working on scripts for translating all my data into the SQUAD-format before using the json script, but I see that it might not be necessary after all. ",
"Yes `_generate_examples()` is the main entry point. If you change the shape of the returned dictionary you also need to update the `features` in the `_info`.\r\n\r\nI'm currently writing the doc so it should be easier soon to use the library and know how to add your datasets.\r\n",
"Could you try to update pyarrow to >=0.17.0 @vegarab ?\r\nI don't have any segmentation fault with my version of pyarrow (0.17.1)\r\n\r\nI tested with\r\n```python\r\nimport nlp\r\ns = nlp.load_dataset(\"json\", data_files=\"train-v2.0.json\", field=\"data\", split=\"train\")\r\ns[0]\r\n# {'title': 'Normans', 'paragraphs': [{'qas': [{'question': 'In what country is Normandy located?', 'id':...\r\n```",
"Also if you want to have your own dataset script, we now have a new documentation !\r\nSee here:\r\nhttps://huggingface.co/nlp/add_dataset.html",
"@lhoestq \r\nFor some reason, I am not able to reproduce the segmentation fault, on pyarrow==0.16.0. Using the exact same environment and file.\r\n\r\nAnyhow, I discovered that pyarrow>=0.17.0 is required to read in a JSON file where the pandas structs contain lists. Otherwise, pyarrow complains when attempting to cast the struct:\r\n```py\r\nimport nlp\r\n>>> s = nlp.load_dataset(\"json\", data_files=\"datasets/train-v2.0.json\", field=\"data\", split=\"train\")\r\nUsing custom data configuration default\r\n>>> s[0]\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/nlp/arrow_dataset.py\", line 558, in __getitem__\r\n format_kwargs=self._format_kwargs,\r\n File \"/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/nlp/arrow_dataset.py\", line 498, in _getitem\r\n outputs = self._unnest(self._data.slice(key, 1).to_pandas().to_dict(\"list\"))\r\n File \"pyarrow/array.pxi\", line 559, in pyarrow.lib._PandasConvertible.to_pandas\r\n File \"pyarrow/table.pxi\", line 1367, in pyarrow.lib.Table._to_pandas\r\n File \"/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/pyarrow/pandas_compat.py\", line 766, in table_to_blockmanager\r\n blocks = _table_to_blocks(options, table, categories, ext_columns_dtypes)\r\n File \"/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/pyarrow/pandas_compat.py\", line 1101, in _table_to_blocks\r\n list(extension_columns.keys()))\r\n File \"pyarrow/table.pxi\", line 881, in pyarrow.lib.table_to_blocks\r\n File \"pyarrow/error.pxi\", line 105, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowNotImplementedError: Not implemented type for Arrow list to pandas: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>\r\n>>> s\r\nDataset(schema: {'title': 'string', 'paragraphs': 'list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>'}, num_rows: 35)\r\n```\r\n\r\nUpgrading to >=0.17.0 provides the same dataset structure, but accessing the records is possible without the same exception. \r\n\r\n",
"Very happy to see some extended documentation! ",
"#376 seems to be reporting the same issue as mentioned above. ",
"This issue helped me a lot, thanks.\r\nHope this issue will be fixed soon."
] | 2020-07-10T15:04:25
| 2022-10-04T18:05:47
| 2022-10-04T18:05:47
|
CONTRIBUTOR
| null | null | null | null |
The last issue was closed (#369) once the #372 update was merged. However, I'm still not able to load a SQuAD formatted JSON file. Instead of the previously recorded pyarrow error, I now get a segmentation fault.
```
dataset = nlp.load_dataset('json', data_files={nlp.Split.TRAIN: ["./datasets/train-v2.0.json"]}, field='data')
```
causes
```
Using custom data configuration default
Downloading and preparing dataset json/default (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/XXX/.cache/huggingface/datasets/json/default/0.0.0...
0 tables [00:00, ? tables/s]Segmentation fault (core dumped)
```
where `./datasets/train-v2.0.json` is downloaded directly from https://rajpurkar.github.io/SQuAD-explorer/.
This is consistent with other SQuAD-formatted JSON files.
When attempting to load the dataset again, I get the following:
```
Using custom data configuration default
Traceback (most recent call last):
File "dataloader.py", line 6, in <module>
'json', data_files={nlp.Split.TRAIN: ["./datasets/train-v2.0.json"]}, field='data')
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/load.py", line 524, in load_dataset
save_infos=save_infos,
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 382, in download_and_prepare
with incomplete_dir(self._cache_dir) as tmp_data_dir:
File "/home/XXX/.conda/envs/torch/lib/python3.7/contextlib.py", line 112, in __enter__
return next(self.gen)
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 368, in incomplete_dir
os.makedirs(tmp_dir)
File "/home/XXX/.conda/envs/torch/lib/python3.7/os.py", line 223, in makedirs
mkdir(name, mode)
FileExistsError: [Errno 17] File exists: '/home/XXX/.cache/huggingface/datasets/json/default/0.0.0.incomplete'
```
(Not sure if you wanted this in the previous issue #369 or not as it was closed.)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/373/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/373/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 816 days, 3:01:22
|
https://api.github.com/repos/huggingface/datasets/issues/369
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/369/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/369/comments
|
https://api.github.com/repos/huggingface/datasets/issues/369/events
|
https://github.com/huggingface/datasets/issues/369
| 654,186,890
|
MDU6SXNzdWU2NTQxODY4OTA=
| 369
|
can't load local dataset: pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"I am able to reproduce this with the official SQuAD `train-v2.0.json` file downloaded directly from https://rajpurkar.github.io/SQuAD-explorer/",
"I am facing this issue in transformers library 3.0.2 while reading a csv using datasets.\r\nIs this fixed in latest version? \r\nI updated the latest version 4.0.1 but still getting this error. What could cause this error?"
] | 2020-07-09T16:16:53
| 2020-12-15T23:07:22
| 2020-07-10T14:52:06
|
CONTRIBUTOR
| null | null | null | null |
Trying to load a local SQuAD-formatted dataset (from a JSON file, about 60MB):
```
dataset = nlp.load_dataset(path='json', data_files={nlp.Split.TRAIN: ["./path/to/file.json"]})
```
causes
```
Traceback (most recent call last):
File "dataloader.py", line 9, in <module>
["./path/to/file.json"]})
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/load.py", line 524, in load_dataset
save_infos=save_infos,
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 483, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 719, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False):
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/tqdm/std.py", line 1129, in __iter__
for obj in iterable:
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/datasets/json/88c1bc5c68489f7eda549ed05a5a738527c613b3e7a4ee3524d9d233353a949b/json.py", line 53, in _generate_tables
file, read_options=self.config.pa_read_options, parse_options=self.config.pa_parse_options,
File "pyarrow/_json.pyx", line 191, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 85, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)
```
I haven't been able to find any reports of this specific pyarrow error here or elsewhere.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/369/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/369/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 22:35:13
|
https://api.github.com/repos/huggingface/datasets/issues/368
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/368/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/368/comments
|
https://api.github.com/repos/huggingface/datasets/issues/368/events
|
https://github.com/huggingface/datasets/issues/368
| 654,087,251
|
MDU6SXNzdWU2NTQwODcyNTE=
| 368
|
load_metric can't acquire lock anymore
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ydshieh",
"id": 2521628,
"login": "ydshieh",
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ydshieh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I found that, in the same process (or the same interactive session), if I do\r\n\r\nimport nlp\r\n\r\nm1 = nlp.load_metric('glue', 'mrpc')\r\nm2 = nlp.load_metric('glue', 'sst2')\r\n\r\nI will get the same error `ValueError: Cannot acquire lock, caching file might be used by another process, you should setup a unique 'experiment_id'`."
] | 2020-07-09T14:04:09
| 2020-07-10T13:45:20
| 2020-07-10T13:45:20
|
NONE
| null | null | null | null |
I can't load metric (glue) anymore after an error in a previous run. I even removed the whole cache folder `/home/XXX/.cache/huggingface/`, and the issue persisted. What are the steps to fix this?
Traceback (most recent call last):
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/metric.py", line 101, in __init__
self.filelock.acquire(timeout=1)
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/filelock.py", line 278, in acquire
raise Timeout(self._lock_file)
filelock.Timeout: The file lock '/home/XXX/.cache/huggingface/metrics/glue/1.0.0/1-glue-0.arrow.lock' could not be acquired.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "examples_huggingface_nlp.py", line 268, in <module>
main()
File "examples_huggingface_nlp.py", line 242, in main
dataset, metric = get_dataset_metric(glue_task)
File "examples_huggingface_nlp.py", line 77, in get_dataset_metric
metric = nlp.load_metric('glue', glue_config, experiment_id=1)
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/load.py", line 440, in load_metric
**metric_init_kwargs,
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/metric.py", line 104, in __init__
"Cannot acquire lock, caching file might be used by another process, "
ValueError: Cannot acquire lock, caching file might be used by another process, you should setup a unique 'experiment_id' for this run.
I0709 15:54:41.008838 139854118430464 filelock.py:318] Lock 139852058030936 released on /home/XXX/.cache/huggingface/metrics/glue/1.0.0/1-glue-0.arrow.lock
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/368/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/368/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 23:41:11
|
https://api.github.com/repos/huggingface/datasets/issues/365
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/365/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/365/comments
|
https://api.github.com/repos/huggingface/datasets/issues/365/events
|
https://github.com/huggingface/datasets/issues/365
| 653,845,964
|
MDU6SXNzdWU2NTM4NDU5NjQ=
| 365
|
How to augment data ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Using batched map is probably the easiest way at the moment.\r\nWhat kind of augmentation would you like to do ?",
"Some samples in the dataset are too long, I want to divide them in several samples.",
"Using batched map is the way to go then.\r\nWe'll make it clearer in the docs that map could be used for augmentation.\r\n\r\nLet me know if you think there should be another way to do it. Or feel free to close the issue otherwise.",
"It just feels awkward to use map to augment data. Also it means it's not possible to augment data in a non-batched way.\r\n\r\nBut to be honest I have no idea of a good API...",
"Or for non-batched samples, how about returning a tuple ?\r\n\r\n```python\r\ndef aug(sample):\r\n # Simply copy the existing data to have x2 amount of data\r\n return sample, sample\r\n\r\ndataset = dataset.map(aug)\r\n```\r\n\r\nIt feels really natural and easy, but :\r\n\r\n* it means the behavior with batched data is different\r\n* I don't know how doable it is backend-wise\r\n\r\n@lhoestq ",
"As we're working with arrow's columnar format we prefer to play with batches that are dictionaries instead of tuples.\r\nIf we have tuple it implies to re-format the data each time we want to write to arrow, which can lower the speed of map for example.\r\n\r\nIt's also a matter of coherence, as we don't want users to be confused whether they have to return dictionaries for some functions and tuples for others when they're doing batches."
] | 2020-07-09T07:52:37
| 2020-07-10T09:12:07
| 2020-07-10T08:22:15
|
NONE
| null | null | null | null |
Is there any clean way to augment data ?
For now my work-around is to use batched map, like this :
```python
def aug(samples):
# Simply copy the existing data to have x2 amount of data
for k, v in samples.items():
samples[k].extend(v)
return samples
dataset = dataset.map(aug, batched=True)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/365/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/365/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 0:29:38
|
https://api.github.com/repos/huggingface/datasets/issues/362
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/362/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/362/comments
|
https://api.github.com/repos/huggingface/datasets/issues/362/events
|
https://github.com/huggingface/datasets/issues/362
| 653,766,245
|
MDU6SXNzdWU2NTM3NjYyNDU=
| 362
|
[dateset subset missing] xtreme paws-x
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/cosmeowpawlitan/events{/privacy}",
"followers_url": "https://api.github.com/users/cosmeowpawlitan/followers",
"following_url": "https://api.github.com/users/cosmeowpawlitan/following{/other_user}",
"gists_url": "https://api.github.com/users/cosmeowpawlitan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cosmeowpawlitan",
"id": 50871412,
"login": "cosmeowpawlitan",
"node_id": "MDQ6VXNlcjUwODcxNDEy",
"organizations_url": "https://api.github.com/users/cosmeowpawlitan/orgs",
"received_events_url": "https://api.github.com/users/cosmeowpawlitan/received_events",
"repos_url": "https://api.github.com/users/cosmeowpawlitan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cosmeowpawlitan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cosmeowpawlitan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cosmeowpawlitan",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"You're right, thanks for pointing it out. We will update it "
] | 2020-07-09T05:04:54
| 2020-07-09T12:38:42
| 2020-07-09T12:38:42
|
CONTRIBUTOR
| null | null | null | null |
I tried nlp.load_dataset('xtreme', 'PAWS-X.es') but get the value error
It turns out that the subset for Spanish is missing
https://github.com/google-research-datasets/paws/tree/master/pawsx
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/362/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/362/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 7:33:48
|
https://api.github.com/repos/huggingface/datasets/issues/361
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/361/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/361/comments
|
https://api.github.com/repos/huggingface/datasets/issues/361/events
|
https://github.com/huggingface/datasets/issues/361
| 653,757,376
|
MDU6SXNzdWU2NTM3NTczNzY=
| 361
|
🐛 [Metrics] ROUGE is non-deterministic
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi, can you give a full self-contained example to reproduce this behavior?",
"> Hi, can you give a full self-contained example to reproduce this behavior?\r\n\r\nThere is a notebook in the post ;)",
"> If I run the ROUGE metric 2 times, with same predictions / references, the scores are slightly different.\r\n> \r\n> Refer to [this Colab notebook](https://colab.research.google.com/drive/1wRssNXgb9ldcp4ulwj-hMJn0ywhDOiDy?usp=sharing) for reproducing the problem.\r\n> \r\n> Example of F-score for ROUGE-1, ROUGE-2, ROUGE-L in 2 differents run :\r\n> \r\n> > ['0.3350', '0.1470', '0.2329']\r\n> > ['0.3358', '0.1451', '0.2332']\r\n> \r\n> Why ROUGE is not deterministic ?\r\n\r\nThis is because of rouge's `BootstrapAggregator` that uses sampling to get confidence intervals (low, mid, high).\r\nYou can get deterministic scores per sentence pair by using\r\n```python\r\nscore = rouge.compute(rouge_types=[\"rouge1\", \"rouge2\", \"rougeL\"], use_aggregator=False)\r\n```\r\nOr you can set numpy's random seed if you still want to use the aggregator.",
"Maybe we can set all the random seeds of numpy/torch etc. while running `metric.compute` ?",
"We should probably indeed!",
"Now if you re-run the notebook, the two printed results are the same @colanim\r\n```\r\n['0.3356', '0.1466', '0.2318']\r\n['0.3356', '0.1466', '0.2318']\r\n```\r\nHowever across sessions, the results may change (as numpy's random seed can be different). You can prevent that by setting your seed:\r\n```python\r\nrouge = nlp.load_metric('rouge', seed=42)\r\n```",
"> \r\n\r\nMinor nit: Note that \"aggregator\" is misspelled in this command. Should be `use_aggregator=False`. ",
"Thanks, I fixed the code snippet"
] | 2020-07-09T04:39:37
| 2022-09-09T15:20:55
| 2020-07-20T23:48:37
|
NONE
| null | null | null | null |
If I run the ROUGE metric 2 times, with same predictions / references, the scores are slightly different.
Refer to [this Colab notebook](https://colab.research.google.com/drive/1wRssNXgb9ldcp4ulwj-hMJn0ywhDOiDy?usp=sharing) for reproducing the problem.
Example of F-score for ROUGE-1, ROUGE-2, ROUGE-L in 2 differents run :
> ['0.3350', '0.1470', '0.2329']
['0.3358', '0.1451', '0.2332']
---
Why ROUGE is not deterministic ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/361/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/361/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 11 days, 19:09:00
|
https://api.github.com/repos/huggingface/datasets/issues/360
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/360/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/360/comments
|
https://api.github.com/repos/huggingface/datasets/issues/360/events
|
https://github.com/huggingface/datasets/issues/360
| 653,687,176
|
MDU6SXNzdWU2NTM2ODcxNzY=
| 360
|
[Feature request] Add dataset.ragged_map() function for many-to-many transformations
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Actually `map(batched=True)` can already change the size of the dataset.\r\nIt can accept examples of length `N` and returns a batch of length `M` (can be null or greater than `N`).\r\n\r\nI'll make that explicit in the doc that I'm currently writing.",
"You're two steps ahead of me :) In my testing, it also works if `M` < `N`.\r\n\r\nA batched map of different length seems to work if you directly overwrite all of the original keys, but fails if any of the original keys are preserved.\r\n\r\nFor example,\r\n```python\r\n# Create a dummy dataset\r\ndset = load_dataset(\"wikitext\", \"wikitext-2-raw-v1\")[\"test\"]\r\ndset = dset.map(lambda ex: {\"length\": len(ex[\"text\"]), \"foo\": 1})\r\n\r\n# Do an allreduce on each batch, overwriting both keys\r\ndset.map(lambda batch: {\"length\": [sum(batch[\"length\"])], \"foo\": [1]})\r\n# Dataset(schema: {'length': 'int64', 'foo': 'int64'}, num_rows: 5)\r\n\r\n# Now attempt an allreduce without touching the `foo` key\r\ndset.map(lambda batch: {\"length\": [sum(batch[\"length\"])]})\r\n# This fails with the error message below\r\n```\r\n\r\n```bash\r\n File \"/path/to/nlp/src/nlp/arrow_dataset.py\", line 728, in map\r\n arrow_schema = pa.Table.from_pydict(test_output).schema\r\n File \"pyarrow/io.pxi\", line 1532, in pyarrow.lib.Codec.detect\r\n File \"pyarrow/table.pxi\", line 1503, in pyarrow.lib.Table.from_arrays\r\n File \"pyarrow/public-api.pxi\", line 390, in pyarrow.lib.pyarrow_wrap_table\r\n File \"pyarrow/error.pxi\", line 85, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Column 1 named foo expected length 1 but got length 2\r\n```\r\n\r\nAdding the `remove_columns=[\"length\", \"foo\"]` argument to `map()` solves the issue. Leaving the above error for future visitors. Perfect, thank you!"
] | 2020-07-09T01:04:43
| 2020-07-09T19:31:51
| 2020-07-09T19:31:51
|
CONTRIBUTOR
| null | null | null | null |
`dataset.map()` enables one-to-one transformations. Input one example and output one example. This is helpful for tokenizing and cleaning individual lines.
`dataset.filter()` enables one-to-(one-or-none) transformations. Input one example and output either zero/one example. This is helpful for removing portions from the dataset.
However, some dataset transformations are many-to-many. Consider constructing BERT training examples from a dataset of sentences, where you map `["a", "b", "c"] -> ["a[SEP]b", "a[SEP]c", "b[SEP]c", "c[SEP]b", ...]`
I propose a more general `ragged_map()` method that takes in a batch of examples of length `N` and return a batch of examples `M`. This is different from the `map(batched=True)` method, which takes examples of length `N` and returns a batch of length `N`, processing individual examples in parallel. I don't have a clear vision of how this would be implemented efficiently and lazily, but would love to hear the community's feedback on this.
My specific use case is creating an end-to-end ELECTRA data pipeline. I would like to take the raw WikiText data and generate training examples from this using the `ragged_map()` method, then export to TFRecords and train quickly. This would be a reproducible pipeline with no bash scripts. Currently I'm relying on scripts like https://github.com/google-research/electra/blob/master/build_pretraining_dataset.py, which are less general.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/360/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/360/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 18:27:08
|
https://api.github.com/repos/huggingface/datasets/issues/359
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/359/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/359/comments
|
https://api.github.com/repos/huggingface/datasets/issues/359/events
|
https://github.com/huggingface/datasets/issues/359
| 653,656,279
|
MDU6SXNzdWU2NTM2NTYyNzk=
| 359
|
ArrowBasedBuilder _prepare_split parse_schema breaks on nested structures
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi, it depends on what it is in your `dataset_builder.py` file. Can you share it?\r\n\r\nIf you are just loading `json` files, you can also directly use the `json` script (which will find the schema/features from your JSON structure):\r\n\r\n```python\r\nfrom nlp import load_dataset\r\nds = load_dataset(\"json\", data_files=rel_datafiles)\r\n```",
"The behavior I'm seeing is from the `json` script. \r\nI hacked this together to overcome the error with the `JSON` dataloader\r\n\r\n```\r\nclass DatasetBuilder(hf_nlp.ArrowBasedBuilder):\r\n BUILDER_CONFIG_CLASS = BuilderConfig\r\n\r\n def _info(self):\r\n return DatasetInfo()\r\n\r\n def _split_generators(self, dl_manager):\r\n \"\"\" We handle string, list and dicts in datafiles\r\n \"\"\"\r\n if isinstance(self.config.data_files, (str, list, tuple)):\r\n files = self.config.data_files\r\n if isinstance(files, str):\r\n files = [files]\r\n return [SplitGenerator(name=Split.TRAIN, gen_kwargs={\"files\": files})]\r\n splits = []\r\n for split_name in [Split.TRAIN, Split.VALIDATION, Split.TEST]:\r\n if split_name in self.config.data_files:\r\n files = self.config.data_files[split_name]\r\n if isinstance(files, str):\r\n files = [files]\r\n splits.append(SplitGenerator(name=split_name, gen_kwargs={\"files\": files}))\r\n return splits\r\n\r\n def _prepare_split(self, split_generator):\r\n fname = \"{}-{}.arrow\".format(self.name, split_generator.name)\r\n fpath = os.path.join(self._cache_dir, fname)\r\n\r\n writer = ArrowWriter(path=fpath)\r\n\r\n generator = self._generate_tables(**split_generator.gen_kwargs)\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False):\r\n writer.write_table(table)\r\n num_examples, num_bytes = writer.finalize()\r\n\r\n split_generator.split_info.num_examples = num_examples\r\n split_generator.split_info.num_bytes = num_bytes\r\n # this is where the error is coming from\r\n # def parse_schema(schema, schema_dict):\r\n # for field in schema:\r\n # if pa.types.is_struct(field.type):\r\n # schema_dict[field.name] = {}\r\n # parse_schema(field.type, schema_dict[field.name])\r\n # elif pa.types.is_list(field.type) and pa.types.is_struct(field.type.value_type):\r\n # schema_dict[field.name] = {}\r\n # parse_schema(field.type.value_type, schema_dict[field.name])\r\n # else:\r\n # schema_dict[field.name] = Value(str(field.type))\r\n # \r\n # parse_schema(writer.schema, features)\r\n # self.info.features = Features(features)\r\n\r\n def _generate_tables(self, files):\r\n for i, file in enumerate(files):\r\n pa_table = paj.read_json(\r\n file\r\n )\r\n yield i, pa_table\r\n```\r\n\r\nSo I basically just don't populate the `self.info.features` though this doesn't seem to cause any problems in my downstream applications. \r\n\r\nThe other workaround I was doing was to just use pyarrow.json to build a table and then to create the Dataset with its constructor or from_table methods. `load_dataset` has nice split logic, so I'd prefer to use that.\r\n\r\n",
"Also noticed that if you for example in a loader script\r\n\r\n```\r\nfrom nlp import ArrowBasedBuilder\r\n\r\nclass MyBuilder(ArrowBasedBuilder):\r\n...\r\n\r\n```\r\nand use that in the subclass, it will be on the module's __dict__ and will be selected before the `MyBuilder` subclass, and it will raise `NotImplementedError` on its `_generate_examples` method... In the code it check for abstract classes but Builder and ArrowBasedBuilder aren't abstract classes, they're regular classes with `@abstract_methods`.",
"Indeed this is part of a more general limitation which is the fact that we should generate and update the `features` from the auto-inferred Arrow schema when they are not provided (also happen when a user change the schema using `map()`, the features should be auto-generated and guessed as much as possible to keep the `features` synced with the underlying Arrow table schema).\r\n\r\nWe will try to solve this soon."
] | 2020-07-08T23:24:05
| 2020-07-10T14:52:06
| 2020-07-10T14:52:06
|
NONE
| null | null | null | null |
I tried using the Json dataloader to load some JSON lines files. but get an exception in the parse_schema function.
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-23-9aecfbee53bd> in <module>
55 from nlp import load_dataset
56
---> 57 ds = load_dataset("../text2struct/model/dataset_builder.py", data_files=rel_datafiles)
58
59
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
481 try:
482 # Prepare split will record examples associated to the split
--> 483 self._prepare_split(split_generator, **prepare_split_kwargs)
484 except OSError:
485 raise OSError("Cannot find data file. " + (self.manual_download_instructions or ""))
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _prepare_split(self, split_generator)
736 schema_dict[field.name] = Value(str(field.type))
737
--> 738 parse_schema(writer.schema, features)
739 self.info.features = Features(features)
740
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in parse_schema(schema, schema_dict)
734 parse_schema(field.type.value_type, schema_dict[field.name])
735 else:
--> 736 schema_dict[field.name] = Value(str(field.type))
737
738 parse_schema(writer.schema, features)
<string> in __init__(self, dtype, id, _type)
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in __post_init__(self)
55
56 def __post_init__(self):
---> 57 self.pa_type = string_to_arrow(self.dtype)
58
59 def __call__(self):
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in string_to_arrow(type_str)
32 if str(type_str + "_") not in pa.__dict__:
33 raise ValueError(
---> 34 f"Neither {type_str} nor {type_str + '_'} seems to be a pyarrow data type. "
35 f"Please make sure to use a correct data type, see: "
36 f"https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions"
ValueError: Neither list<item: string> nor list<item: string>_ seems to be a pyarrow data type. Please make sure to use a correct data type, see: https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions
```
If I create the dataset imperatively, using a pyarrow table, the dataset is created correctly. If I override the `_prepare_split` method to avoid calling the validate schema, the dataset can load as well.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/359/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/359/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 15:28:01
|
https://api.github.com/repos/huggingface/datasets/issues/355
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/355/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/355/comments
|
https://api.github.com/repos/huggingface/datasets/issues/355/events
|
https://github.com/huggingface/datasets/issues/355
| 653,451,013
|
MDU6SXNzdWU2NTM0NTEwMTM=
| 355
|
can't load SNLI dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I just added the processed files of `snli` on our google storage, so that when you do `load_dataset` it can download the processed files from there :)\r\n\r\nWe are thinking about having available those processed files for more datasets in the future, because sometimes files aren't available (like for `snli`), or the download speed is too slow, or sometimes the files take time to be processed.",
"Closing this one. Feel free to re-open if you have other questions :)",
"Thank you!"
] | 2020-07-08T16:54:14
| 2020-07-18T05:15:57
| 2020-07-15T07:59:01
|
CONTRIBUTOR
| null | null | null | null |
`nlp` seems to load `snli` from some URL based on nlp.stanford.edu. This subdomain is frequently down -- including right now, when I'd like to load `snli` in a Colab notebook, but can't.
Is there a plan to move these datasets to huggingface servers for a more stable solution?
Btw, here's the stack trace:
```
File "/content/nlp/src/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/content/nlp/src/nlp/builder.py", line 466, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/content/nlp/src/nlp/datasets/snli/e417f6f2e16254938d977a17ed32f3998f5b23e4fcab0f6eb1d28784f23ea60d/snli.py", line 76, in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
File "/content/nlp/src/nlp/utils/download_manager.py", line 217, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/content/nlp/src/nlp/utils/download_manager.py", line 156, in download
lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,
File "/content/nlp/src/nlp/utils/py_utils.py", line 190, in map_nested
return function(data_struct)
File "/content/nlp/src/nlp/utils/download_manager.py", line 156, in <lambda>
lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,
File "/content/nlp/src/nlp/utils/file_utils.py", line 198, in cached_path
local_files_only=download_config.local_files_only,
File "/content/nlp/src/nlp/utils/file_utils.py", line 356, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://nlp.stanford.edu/projects/snli/snli_1.0.zip
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/355/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/355/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 6 days, 15:04:47
|
https://api.github.com/repos/huggingface/datasets/issues/353
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/353/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/353/comments
|
https://api.github.com/repos/huggingface/datasets/issues/353/events
|
https://github.com/huggingface/datasets/issues/353
| 653,250,611
|
MDU6SXNzdWU2NTMyNTA2MTE=
| 353
|
[Dataset requests] New datasets for Text Classification
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"color": "008672",
"default": true,
"description": "Extra attention is needed",
"id": 1935892884,
"name": "help wanted",
"node_id": "MDU6TGFiZWwxOTM1ODkyODg0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/help%20wanted"
},
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
open
| false
| null |
[] |
[
"Pinging @mariamabarham as well",
"- `nlp` has MR! It's called `rotten_tomatoes`\r\n- SST is part of GLUE, or is that just SST-2?\r\n- `nlp` also has `ag_news`, a popular news classification dataset\r\n\r\nI'd also like to see:\r\n- the Yahoo Answers topic classification dataset\r\n- the Kaggle Fake News classification dataset",
"Thanks @jxmorris12 for pointing this out. \r\n\r\nIn glue we only have SST-2 maybe we can add separately SST-1.\r\n",
"This is the homepage for the Amazon dataset: https://www.kaggle.com/datafiniti/consumer-reviews-of-amazon-products\r\n\r\nIs there an easy way to download kaggle datasets programmatically? If so, I can add this one!",
"Hi @jxmorris12 for now I think our `dl_manager` does not download from Kaggle.\r\n@thomwolf , @lhoestq",
"Pretty sure the quora dataset is the same one I implemented here: https://github.com/huggingface/nlp/pull/366",
"Great list. Any idea if Amazon Reviews has been added?\r\n\r\n- ~40 GB of text (sadly no emoji)\r\n- popular MLM pre-training dataset before bigger datasets like WebText https://arxiv.org/abs/1808.01371\r\n- turns out that binarizing the 1-5 star rating leads to great Pos/Neg/Neutral dataset, T5 paper claims to get very high accuracy (98%!) on this with small amount of finetuning https://arxiv.org/abs/2004.14546\r\n\r\nApologies if it's been included (great to see where) and if not, it's one of the better medium/large NLP dataset for semi-supervised learning, albeit a bit out of date. \r\n\r\nThanks!! \r\n\r\ncc @sshleifer ",
"On the Amazon Reviews dataset, the original UCSD website has noted these are now updated to include product reviews through 2018 -- actually quite recent compared to many other datasets. Almost certainly the largest NLP dataset out there with labels!\r\nhttps://jmcauley.ucsd.edu/data/amazon/ \r\n\r\nAny chance someone has time to onboard this dataset in a HF way?\r\n\r\ncc @sshleifer ",
"@albertvillanova How up to date is this issue? I see that some of these datasets are now on huggingface but have not been checked off the list",
"The OHSUMED dataset is already available as a community dataset at [community-datasets/ohsumed](https://huggingface.co/datasets/community-datasets/ohsumed).\n\nThe community version includes:\n\n- Full dataset with 348,566 references from MEDLINE\n- Train/test splits (54,709 / 293,855 examples)\n- All original fields (title, abstract, MeSH terms, author, source, publication type)\n\nGiven this existing implementation, we might want to Mark OHSUMED as completed in the issue list.",
"I notice that several datasets from this list are already available:\n\n1. OHSUMED: Available as [community-datasets/ohsumed](https://huggingface.co/datasets/community-datasets/ohsumed)\n2. EUR-Lex: Available in two versions:\n - [coastalcph/multi_eurlex](https://huggingface.co/datasets/coastalcph/multi_eurlex)\n - [NLP-AUEB/eurlex](https://huggingface.co/datasets/NLP-AUEB/eurlex)\n3. PubMed: Available as [ncbi/pubmed](https://huggingface.co/datasets/ncbi/pubmed)\n\nIs this issue not updated, or am I missing something? The only dataset from the remaining list that seems to truly need addition is the MPQA dataset.",
"MPQA is definitely on the hub: https://huggingface.co/datasets/jxm/mpqa"
] | 2020-07-08T12:17:58
| 2025-04-05T09:28:15
| null |
MEMBER
| null | null | null | null |
We are missing a few datasets for Text Classification which is an important field.
Namely, it would be really nice to add:
- [x] TREC-6 dataset (see here for instance: https://pytorchnlp.readthedocs.io/en/latest/source/torchnlp.datasets.html#torchnlp.datasets.trec_dataset) **[done]**
- #386
- [x] Yelp-5
- #1315
- [x] Movie review (Movie Review (MR) dataset [156]) **[done (same as rotten_tomatoes)]**
- [x] SST (Stanford Sentiment Treebank) **[include in glue]**
- #1934
- [ ] Multi-Perspective Question Answering (MPQA) dataset **[require authentication (indeed manual download)]**
- [x] Amazon. This is a popular corpus of product reviews collected from the Amazon website [159]. It contains labels for both binary classification and multi-class (5-class) classification
- #791
- #1389
- [x] 20 Newsgroups. The 20 Newsgroups dataset **[done]**
- #410
- [x] Sogou News dataset **[done]**
- #450
- [x] Reuters news. The Reuters-21578 dataset [165] **[done]**
- #471
- [x] DBpedia. The DBpedia dataset [170]
- #1116
- [ ] Ohsumed. The Ohsumed collection [171] is a subset of the MEDLINE database
- [ ] EUR-Lex. The EUR-Lex dataset
- [x] WOS. The Web Of Science (WOS) dataset **[done]**
- #424
- [ ] PubMed. PubMed [173]
- [x] TREC-QA: TREC-6 + TREC-50
- See above: TREC-6 dataset
- [x] Quora. The Quora dataset [180]
- #366
All these datasets are cited in https://arxiv.org/abs/2004.03705
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/353/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/353/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/347
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/347/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/347/comments
|
https://api.github.com/repos/huggingface/datasets/issues/347/events
|
https://github.com/huggingface/datasets/issues/347
| 652,106,567
|
MDU6SXNzdWU2NTIxMDY1Njc=
| 347
|
'cp950' codec error from load_dataset('xtreme', 'tydiqa')
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/cosmeowpawlitan/events{/privacy}",
"followers_url": "https://api.github.com/users/cosmeowpawlitan/followers",
"following_url": "https://api.github.com/users/cosmeowpawlitan/following{/other_user}",
"gists_url": "https://api.github.com/users/cosmeowpawlitan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cosmeowpawlitan",
"id": 50871412,
"login": "cosmeowpawlitan",
"node_id": "MDQ6VXNlcjUwODcxNDEy",
"organizations_url": "https://api.github.com/users/cosmeowpawlitan/orgs",
"received_events_url": "https://api.github.com/users/cosmeowpawlitan/received_events",
"repos_url": "https://api.github.com/users/cosmeowpawlitan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cosmeowpawlitan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cosmeowpawlitan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cosmeowpawlitan",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"This is probably a Windows issue, we need to specify the encoding when `load_dataset()` reads the original CSV file.\r\nTry to find the `open()` statement called by `load_dataset()` and add an `encoding='utf-8'` parameter.\r\nSee issues #242 and #307 ",
"It should be in `xtreme.py:L755`:\r\n```python\r\n if self.config.name == \"tydiqa\" or self.config.name.startswith(\"MLQA\") or self.config.name == \"SQuAD\":\r\n with open(filepath) as f:\r\n data = json.load(f)\r\n```\r\n\r\nCould you try to add the encoding parameter:\r\n```python\r\nopen(filepath, encoding='utf-8')\r\n```",
"Hello @jerryIsHere :) Did it work ?\r\nIf so we may change the dataset script to force the utf-8 encoding",
"@lhoestq sorry for being that late, I found 4 copy of xtreme.py. I did the changes as what has been told to all of them.\r\nThe problem is not solved",
"Could you provide a better error message so that we can make sure it comes from the opening of the `tydiqa`'s json files ?\r\n",
"@lhoestq \r\nThe error message is same as before:\r\nException has occurred: UnicodeDecodeError\r\n'cp950' codec can't decode byte 0xe2 in position 111: illegal multibyte sequence\r\n File \"D:\\python\\test\\test.py\", line 3, in <module>\r\n dataset = load_dataset('xtreme', 'tydiqa')\r\n\r\n\r\n\r\nI said that I found 4 copy of xtreme.py and add the 「, encoding='utf-8'」 parameter to the open() function\r\nthese python script was found under this directory\r\nC:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python37\\Lib\\site-packages\\nlp\\datasets\\xtreme\r\n",
"Hi there !\r\nI encountered the same issue with the IMDB dataset on windows. It threw an error about charmap not being able to decode a symbol during the first time I tried to download it. I checked on a remote linux machine I have, and it can't be reproduced.\r\nI added ```encoding='UTF-8'``` to both lines that have ```open``` in ```imdb.py``` (108 and 114) and it worked for me.\r\nThank you !",
"> Hi there !\r\n> I encountered the same issue with the IMDB dataset on windows. It threw an error about charmap not being able to decode a symbol during the first time I tried to download it. I checked on a remote linux machine I have, and it can't be reproduced.\r\n> I added `encoding='UTF-8'` to both lines that have `open` in `imdb.py` (108 and 114) and it worked for me.\r\n> Thank you !\r\n\r\nHello !\r\nGlad you managed to fix this issue on your side.\r\nDo you mind opening a PR for IMDB ?",
"> This is probably a Windows issue, we need to specify the encoding when `load_dataset()` reads the original CSV file.\r\n> Try to find the `open()` statement called by `load_dataset()` and add an `encoding='utf-8'` parameter.\r\n> See issues #242 and #307\r\n\r\nSorry for not responding for about a month.\r\nI have just found that it is necessary to change / add the environment variable as what was told in #242.\r\nEverything works after I add the new environment variable and restart my PC.\r\n\r\nI think the encoding issue for windows isn't limited to the open() function call specific to few dataset, but actually in the entire library, depends on the machine / os you use.",
"Since #481 we shouldn't have other issues with encodings as they need to be set to \"utf-8\" be default.\r\n\r\nClosing this one, but feel free to re-open if you gave other questions"
] | 2020-07-07T08:14:23
| 2020-09-07T14:51:45
| 2020-09-07T14:51:45
|
CONTRIBUTOR
| null | null | null | null |

I guess the error is related to python source encoding issue that my PC is trying to decode the source code with wrong encoding-decoding tools, perhaps :
https://www.python.org/dev/peps/pep-0263/
I guess the error was triggered by the code " module = importlib.import_module(module_path)" at line 57 in the source code: nlp/src/nlp/load.py / (https://github.com/huggingface/nlp/blob/911d5596f9b500e39af8642fe3d1b891758999c7/src/nlp/load.py#L51)
Any ideas?
p.s. tried the same code on colab, that runs perfectly
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/347/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/347/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 62 days, 6:37:22
|
https://api.github.com/repos/huggingface/datasets/issues/345
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/345/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/345/comments
|
https://api.github.com/repos/huggingface/datasets/issues/345/events
|
https://github.com/huggingface/datasets/issues/345
| 651,761,201
|
MDU6SXNzdWU2NTE3NjEyMDE=
| 345
|
Supporting documents in ELI5
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29262273?v=4",
"events_url": "https://api.github.com/users/saverymax/events{/privacy}",
"followers_url": "https://api.github.com/users/saverymax/followers",
"following_url": "https://api.github.com/users/saverymax/following{/other_user}",
"gists_url": "https://api.github.com/users/saverymax/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/saverymax",
"id": 29262273,
"login": "saverymax",
"node_id": "MDQ6VXNlcjI5MjYyMjcz",
"organizations_url": "https://api.github.com/users/saverymax/orgs",
"received_events_url": "https://api.github.com/users/saverymax/received_events",
"repos_url": "https://api.github.com/users/saverymax/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/saverymax/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saverymax/subscriptions",
"type": "User",
"url": "https://api.github.com/users/saverymax",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @saverymax ! For licensing reasons, the original team was unable to release pre-processed CommonCrawl documents. Instead, they provided a script to re-create them from a CommonCrawl dump, but it unfortunately requires access to a medium-large size cluster:\r\nhttps://github.com/facebookresearch/ELI5#downloading-support-documents-from-the-commoncrawl\r\n\r\nIn order to make the task accessible to people who may not have access to this kind of infrastructure, we suggest to use Wikipedia as a knowledge source rather than the full CommonCrawl. The following blog post shows how you can create Wikipedia support documents and get a performance that is on par with a system that uses CommonCrawl pages.\r\nhttps://yjernite.github.io/lfqa.html#task_description\r\n\r\nHope that helps, using ElasticSearch to index Wiki40b and create the documents should take about 4 hours. Let us know if you have any trouble with the blog post though!",
"Hi, thanks for the quick response. The blog post is quite an interesting working example, thanks for sharing it.\r\nTwo follow-up points/questions about my original question:\r\n\r\n1. Yes, I read that the facebook team could not share the CommonCrawl b/c of licensing reasons. They state \"No, we are not allowed to host processed Reddit or CommonCrawl data,\" which indicates they could also not share the Reddit data for licensing reasons. But it seems that HuggingFace is able to share the Reddit data, so why not a subset of CommonCrawl?\r\n\r\n2. Thanks for the suggestion about ElasticSearch and Wiki40b. This is good to know about performance. I definitely could do the indexing and querying myself. What I like about the ELI5 dataset though, at least what is suggested by the paper, is that to create the dataset they had already selected the top 100 web sources and made a single support document from those. Though it doesn't appear to be too sophisticated an approach, having a single support document pre-computed (without having to run the facebook code or a replacement with another dataset) is super useful for my work, especially since I'm not working on developing the latest and greatest retrieval model. Of course, I don't expect HF NLP datasets to be perfectly tailored to my use-case. I know there is overhead to any project, I'm just illustrating a use-case of ELI5 which is not possible with the data provided as-is. If it's for licensing reasons, that is perfectly acceptable a reason, and I appreciate your response."
] | 2020-07-06T19:14:13
| 2020-10-27T15:38:45
| 2020-10-27T15:38:45
|
NONE
| null | null | null | null |
I was attempting to use the ELI5 dataset, when I realized that huggingface does not provide the supporting documents (the source documents from the common crawl). Without the supporting documents, this makes the dataset about as useful for my project as a block of cheese, or some other more apt metaphor. According to facebook, the entire document collection is quite large. However, it would still be helpful to at least include a subset of the supporting documents i.e., having some data is better than having a block of cheese, in my case at least.
If you choose not to include them, it would be helpful to have documentation mentioning this specifically. It is especially confusing because the hf nlp ELI5 dataset has the key `'document'` but there are no documents to be found :(
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/345/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/345/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 112 days, 20:24:32
|
https://api.github.com/repos/huggingface/datasets/issues/342
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/342/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/342/comments
|
https://api.github.com/repos/huggingface/datasets/issues/342/events
|
https://github.com/huggingface/datasets/issues/342
| 651,333,194
|
MDU6SXNzdWU2NTEzMzMxOTQ=
| 342
|
Features should be updated when `map()` changes schema
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"`dataset.column_names` are being updated but `dataset.features` aren't indeed..."
] | 2020-07-06T08:03:23
| 2020-07-23T10:15:16
| 2020-07-23T10:15:16
|
MEMBER
| null | null | null | null |
`dataset.map()` can change the schema and column names.
We should update the features in this case (with what is possible to infer).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/342/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/342/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 17 days, 2:11:53
|
https://api.github.com/repos/huggingface/datasets/issues/337
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/337/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/337/comments
|
https://api.github.com/repos/huggingface/datasets/issues/337/events
|
https://github.com/huggingface/datasets/issues/337
| 650,035,887
|
MDU6SXNzdWU2NTAwMzU4ODc=
| 337
|
[Feature request] Export Arrow dataset to TFRecords
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-07-02T15:47:12
| 2020-07-22T09:16:12
| 2020-07-22T09:16:12
|
CONTRIBUTOR
| null | null | null | null |
The TFRecord generation process is error-prone and requires complex separate Python scripts to download and preprocess the data. I propose to combine the user-friendly features of `nlp` with the speed and efficiency of TFRecords. Sample API:
```python
# use these existing methods
ds = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
ds = ds.map(lambda ex: tokenizer(ex))
ds.set_format("tensorflow", columns=["input_ids", "token_type_ids", "attention_mask"])
# then add this method
ds.export(folder="/my/tfrecords", prefix="myrecord", num_shards=8, format="tfrecord")
```
which would create files like so:
```bash
/my/tfrecords/myrecord_1.tfrecord
/my/tfrecords/myrecord_2.tfrecord
...
```
I would be happy to contribute this method. We could use a similar approach for PyTorch. Thoughts?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/337/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/337/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 19 days, 17:29:00
|
https://api.github.com/repos/huggingface/datasets/issues/336
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/336/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/336/comments
|
https://api.github.com/repos/huggingface/datasets/issues/336/events
|
https://github.com/huggingface/datasets/issues/336
| 649,914,203
|
MDU6SXNzdWU2NDk5MTQyMDM=
| 336
|
[Dataset requests] New datasets for Open Question Answering
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"color": "008672",
"default": true,
"description": "Extra attention is needed",
"id": 1935892884,
"name": "help wanted",
"node_id": "MDU6TGFiZWwxOTM1ODkyODg0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/help%20wanted"
},
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
] |
[] | 2020-07-02T13:03:03
| 2020-07-16T09:04:22
| 2020-07-16T09:04:22
|
MEMBER
| null | null | null | null |
We are still a few datasets missing for Open-Question Answering which is currently a field in strong development.
Namely, it would be really nice to add:
- WebQuestions (Berant et al., 2013) [done]
- CuratedTrec (Baudis et al. 2015) [not open-source]
- MS-MARCO (NGuyen et al. 2016) [done]
- SearchQA (Dunn et al. 2017) [done]
- FEVER (Thorne et al. 2018) - [ done]
All these datasets are cited in http://arxiv.org/abs/2005.11401
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/336/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/336/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 13 days, 20:01:19
|
https://api.github.com/repos/huggingface/datasets/issues/331
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/331/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/331/comments
|
https://api.github.com/repos/huggingface/datasets/issues/331/events
|
https://github.com/huggingface/datasets/issues/331
| 648,533,199
|
MDU6SXNzdWU2NDg1MzMxOTk=
| 331
|
Loading CNN/Daily Mail dataset produces `nlp.utils.info_utils.NonMatchingSplitsSizesError`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"I couldn't reproduce on my side.\r\nIt looks like you were not able to generate all the examples, and you have the problem for each split train-test-validation.\r\nCould you try to enable logging, try again and send the logs ?\r\n```python\r\nimport logging\r\nlogging.basicConfig(level=logging.INFO)\r\n```",
"here's the log\r\n```\r\n>>> import nlp\r\nimport logging\r\nlogging.basicConfig(level=logging.INFO)\r\nnlp.load_dataset('cnn_dailymail', '3.0.0')\r\n>>> import logging\r\n>>> logging.basicConfig(level=logging.INFO)\r\n>>> nlp.load_dataset('cnn_dailymail', '3.0.0')\r\nINFO:nlp.load:Checking /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py for additional imports.\r\nINFO:filelock:Lock 140443095301136 acquired on /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py.lock\r\nINFO:nlp.load:Found main folder for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail\r\nINFO:nlp.load:Found specific version folder for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad\r\nINFO:nlp.load:Found script file from https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py to /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/cnn_dailymail.py\r\nINFO:nlp.load:Updating dataset infos file from https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/dataset_infos.json to /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/dataset_infos.json\r\nINFO:nlp.load:Found metadata file for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/cnn_dailymail.json\r\nINFO:filelock:Lock 140443095301136 released on /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py.lock\r\nINFO:nlp.info:Loading Dataset Infos from /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad\r\nINFO:nlp.builder:Generating dataset cnn_dailymail (/u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0)\r\nINFO:nlp.builder:Dataset not on Hf google storage. Downloading and preparing it from source\r\nDownloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.26 GiB, total: 1.81 GiB) to /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0...\r\nINFO:nlp.utils.info_utils:All the checksums matched successfully.\r\nINFO:nlp.builder:Generating split train\r\nINFO:nlp.arrow_writer:Done writing 285161 examples in 1240618482 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-train.arrow.\r\nINFO:nlp.builder:Generating split validation\r\nINFO:nlp.arrow_writer:Done writing 13255 examples in 56637485 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-validation.arrow.\r\nINFO:nlp.builder:Generating split test\r\nINFO:nlp.arrow_writer:Done writing 11379 examples in 48931393 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-test.arrow.\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/load.py\", line 520, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py\", line 431, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py\", line 488, in _download_and_prepare\r\n verify_splits(self.info.splits, split_dict)\r\n File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/utils/info_utils.py\", line 70, in verify_splits\r\n raise NonMatchingSplitsSizesError(str(bad_splits))\r\nnlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='test', num_bytes=49424491, num_examples=11490, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='test', num_bytes=48931393, num_examples=11379, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='train', num_bytes=1249178681, num_examples=287113, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='train', num_bytes=1240618482, num_examples=285161, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='validation', num_bytes=57149241, num_examples=13368, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='validation', num_bytes=56637485, num_examples=13255, dataset_name='cnn_dailymail')}]\r\n```",
"> here's the log\r\n> \r\n> ```\r\n> >>> import nlp\r\n> import logging\r\n> logging.basicConfig(level=logging.INFO)\r\n> nlp.load_dataset('cnn_dailymail', '3.0.0')\r\n> >>> import logging\r\n> >>> logging.basicConfig(level=logging.INFO)\r\n> >>> nlp.load_dataset('cnn_dailymail', '3.0.0')\r\n> INFO:nlp.load:Checking /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py for additional imports.\r\n> INFO:filelock:Lock 140443095301136 acquired on /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py.lock\r\n> INFO:nlp.load:Found main folder for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail\r\n> INFO:nlp.load:Found specific version folder for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad\r\n> INFO:nlp.load:Found script file from https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py to /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/cnn_dailymail.py\r\n> INFO:nlp.load:Updating dataset infos file from https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/dataset_infos.json to /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/dataset_infos.json\r\n> INFO:nlp.load:Found metadata file for dataset https://s3.amazonaws.com/datasets.huggingface.co/nlp/datasets/cnn_dailymail/cnn_dailymail.py at /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad/cnn_dailymail.json\r\n> INFO:filelock:Lock 140443095301136 released on /u/jm8wx/.cache/huggingface/datasets/720d2e20d8dc6d98f21195a39cc934bb41dd0a40b57ea3d323661a7c5d70522c.d44c2417f4e0fe938ede0a684dcbb1fa9b4789de22e8a99c43103d4b4c374b3b.py.lock\r\n> INFO:nlp.info:Loading Dataset Infos from /p/qdata/jm8wx/datasets/nlp/src/nlp/datasets/cnn_dailymail/9645e0bc96f647decf46541f6f4bef6936ee82ace653ac362bab03309a46d4ad\r\n> INFO:nlp.builder:Generating dataset cnn_dailymail (/u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0)\r\n> INFO:nlp.builder:Dataset not on Hf google storage. Downloading and preparing it from source\r\n> Downloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.26 GiB, total: 1.81 GiB) to /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0...\r\n> INFO:nlp.utils.info_utils:All the checksums matched successfully.\r\n> INFO:nlp.builder:Generating split train\r\n> INFO:nlp.arrow_writer:Done writing 285161 examples in 1240618482 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-train.arrow.\r\n> INFO:nlp.builder:Generating split validation\r\n> INFO:nlp.arrow_writer:Done writing 13255 examples in 56637485 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-validation.arrow.\r\n> INFO:nlp.builder:Generating split test\r\n> INFO:nlp.arrow_writer:Done writing 11379 examples in 48931393 bytes /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0.incomplete/cnn_dailymail-test.arrow.\r\n> Traceback (most recent call last):\r\n> File \"<stdin>\", line 1, in <module>\r\n> File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/load.py\", line 520, in load_dataset\r\n> builder_instance.download_and_prepare(\r\n> File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py\", line 431, in download_and_prepare\r\n> self._download_and_prepare(\r\n> File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py\", line 488, in _download_and_prepare\r\n> verify_splits(self.info.splits, split_dict)\r\n> File \"/p/qdata/jm8wx/datasets/nlp/src/nlp/utils/info_utils.py\", line 70, in verify_splits\r\n> raise NonMatchingSplitsSizesError(str(bad_splits))\r\n> nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='test', num_bytes=49424491, num_examples=11490, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='test', num_bytes=48931393, num_examples=11379, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='train', num_bytes=1249178681, num_examples=287113, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='train', num_bytes=1240618482, num_examples=285161, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='validation', num_bytes=57149241, num_examples=13368, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='validation', num_bytes=56637485, num_examples=13255, dataset_name='cnn_dailymail')}]\r\n> ```\r\n\r\nWith `nlp == 0.3.0` version, I'm not able to reproduce this error on my side.\r\nWhich version are you using for reproducing your bug?\r\n\r\n```\r\n>> nlp.load_dataset('cnn_dailymail', '3.0.0')\r\n\r\n8.90k/8.90k [00:18<00:00, 486B/s]\r\n\r\nDownloading: 100%\r\n9.37k/9.37k [00:00<00:00, 234kB/s]\r\n\r\nDownloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.26 GiB, total: 1.81 GiB) to /root/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0...\r\nDownloading:\r\n159M/? [00:09<00:00, 16.7MB/s]\r\n\r\nDownloading:\r\n376M/? [00:06<00:00, 62.6MB/s]\r\n\r\nDownloading:\r\n2.11M/? [00:06<00:00, 333kB/s]\r\n\r\nDownloading:\r\n46.4M/? [00:02<00:00, 18.4MB/s]\r\n\r\nDownloading:\r\n2.43M/? [00:00<00:00, 2.62MB/s]\r\n\r\nDataset cnn_dailymail downloaded and prepared to /root/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0. Subsequent calls will reuse this data.\r\n{'test': Dataset(schema: {'article': 'string', 'highlights': 'string'}, num_rows: 11490),\r\n 'train': Dataset(schema: {'article': 'string', 'highlights': 'string'}, num_rows: 287113),\r\n 'validation': Dataset(schema: {'article': 'string', 'highlights': 'string'}, num_rows: 13368)}\r\n\r\n>> ...\r\n\r\n```",
"In general if some examples are missing after processing (hence causing the `NonMatchingSplitsSizesError `), it is often due to either\r\n1) corrupted cached files\r\n2) decoding errors\r\n\r\nI just checked the dataset script for code that could lead to decoding errors but I couldn't find any. Before we try to dive more into the processing of the dataset, could you try to clear your cache ? Just to make sure that it isn't 1)",
"Yes thanks for the support! I cleared out my cache folder and everything works fine now"
] | 2020-06-30T22:21:33
| 2020-07-09T13:03:40
| 2020-07-09T13:03:40
|
CONTRIBUTOR
| null | null | null | null |
```
>>> import nlp
>>> nlp.load_dataset('cnn_dailymail', '3.0.0')
Downloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.26 GiB, total: 1.81 GiB) to /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/p/qdata/jm8wx/datasets/nlp/src/nlp/load.py", line 520, in load_dataset
builder_instance.download_and_prepare(
File "/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py", line 431, in download_and_prepare
self._download_and_prepare(
File "/p/qdata/jm8wx/datasets/nlp/src/nlp/builder.py", line 488, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/p/qdata/jm8wx/datasets/nlp/src/nlp/utils/info_utils.py", line 70, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='test', num_bytes=49424491, num_examples=11490, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='test', num_bytes=48931393, num_examples=11379, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='train', num_bytes=1249178681, num_examples=287113, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='train', num_bytes=1240618482, num_examples=285161, dataset_name='cnn_dailymail')}, {'expected': SplitInfo(name='validation', num_bytes=57149241, num_examples=13368, dataset_name='cnn_dailymail'), 'recorded': SplitInfo(name='validation', num_bytes=56637485, num_examples=13255, dataset_name='cnn_dailymail')}]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/331/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/331/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 8 days, 14:42:07
|
https://api.github.com/repos/huggingface/datasets/issues/329
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/329/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/329/comments
|
https://api.github.com/repos/huggingface/datasets/issues/329/events
|
https://github.com/huggingface/datasets/issues/329
| 648,446,979
|
MDU6SXNzdWU2NDg0NDY5Nzk=
| 329
|
[Bug] FileLock dependency incompatible with filesystem
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi, can you give details on your environment/os/packages versions/etc?",
"Environment is Ubuntu 18.04, Python 3.7.5, nlp==0.3.0, filelock=3.0.12.\r\n\r\nThe external volume is Amazon FSx for Lustre, and it by default creates files with limited permissions. My working theory is that FileLock creates a lockfile that isn't writable, and thus there's no way to acquire it by removing the .lock file. But Python is able to create new files and write to them outside of the FileLock package.\r\n\r\nWhen I attempt to use FileLock within a Docker container by writing to `/root/.cache/hello.txt`, it succeeds. So there's some permissions issue. But it's not a Docker configuration issue; I've replicated it without Docker.\r\n```bash\r\necho \"hello world\" >> hello.txt\r\nls -l\r\n\r\n-rw-rw-r-- 1 ubuntu ubuntu 10 Jun 30 19:52 hello.txt\r\n```",
"Looks like the `flock` syscall does not work on Lustre filesystems by default: https://github.com/benediktschmitt/py-filelock/issues/67.\r\n\r\nI added the `-o flock` option when mounting the filesystem, as [described here](https://docs.aws.amazon.com/fsx/latest/LustreGuide/getting-started-step2.html), which fixed the issue.",
"Awesome, thanks a lot for sharing your fix!",
"I'm wondering if this can be revisited. In some managed environments the same person using HF cannot change the file-system mount flags, (and the organization may be unwilling to change these flags due to other concerns) but can ensure that there won't be concurrent writes, for example because HF is offline and the models/datasets were downloaded earlier. \r\n\r\nThe real fix would be to FileLock itself, which does not seem very active and seems to not deal with failed system flock calls , which would be one way to fix this, as they mention in the issue below also raised by @jarednielsen \r\n\r\nhttps://github.com/tox-dev/py-filelock/issues/67",
"> I'm wondering if this can be revisited. In some managed environments the same person using HF cannot change the file-system mount flags, (and the organization may be unwilling to change these flags due to other concerns) but can ensure that there won't be concurrent writes, for example because HF is offline and the models/datasets were downloaded earlier.\r\n\r\nI am one of those users. Is there a work around for this?\r\n",
"The machines I use have a shared FS which has the filelock problem as well as a local one that does not. Using some env vars (HF_HOME, which controls both models and datasets, and HF_DATASETS_OFFLINE) for both transformers and datasets library one can influence where these downloads happen, and whether the locks get taken. I think some of the relevant documentation is here https://huggingface.co/docs/transformers/installation#cache-setup. I do end up using different settings when I download the models and when I use them, and have to rsync the models to the local file system using a separate script. ",
"Thanks @orm011 . These filesystems are such a pain. I'll dig around, looks like setting `cache_dir` to a non-lustre filesystem works for `transformers` but not `datasets`.",
"Note I `export HF_HOME=` in the shell prior to running python (I do not use the `cache_dir` argument, I think I ran into similar issues with it, nor `HF_DATASETS_CACHE` , though maybe that works, or maybe you can set it in python prior to importing the library ), and I change no other variables. Then `datasets.load_dataset()` works without any additional flags, and they go into `HF_HOME/datasets/` and the models go into `HF_HOME/transformers/` (and the lock files are all there as well). ",
"I am using a shared cluster with a lustre system that I can't change. I am unable to download or load datsets onto the filesystem because of file lock. @thomwolf can this issue be reopened? ",
"> I am using a shared cluster with a lustre system that I can't change. I am unable to download or load datsets onto the filesystem because of file lock. @thomwolf can this issue be reopened?\r\n\r\nHi, I am having this issue as well. Has there been a solution for this? Thanks!"
] | 2020-06-30T19:45:31
| 2024-12-26T15:13:39
| 2020-06-30T21:33:06
|
CONTRIBUTOR
| null | null | null | null |
I'm downloading a dataset successfully with
`load_dataset("wikitext", "wikitext-2-raw-v1")`
But when I attempt to cache it on an external volume, it hangs indefinitely:
`load_dataset("wikitext", "wikitext-2-raw-v1", cache_dir="/fsx") # /fsx is an external volume mount`
The filesystem when hanging looks like this:
```bash
/fsx
----downloads
----94be...73.lock
----wikitext
----wikitext-2-raw
----wikitext-2-raw-1.0.0.incomplete
```
It appears that on this filesystem, the FileLock object is forever stuck in its "acquire" stage. I have verified that the issue lies specifically with the `filelock` dependency:
```python
open("/fsx/hello.txt").write("hello") # succeeds
from filelock import FileLock
with FileLock("/fsx/hello.lock"):
open("/fsx/hello.txt").write("hello") # hangs indefinitely
```
Has anyone else run into this issue? I'd raise it directly on the FileLock repo, but that project appears abandoned with the last update over a year ago. Or if there's a solution that would remove the FileLock dependency from the project, I would appreciate that.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/329/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/329/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1:47:35
|
https://api.github.com/repos/huggingface/datasets/issues/328
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/328/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/328/comments
|
https://api.github.com/repos/huggingface/datasets/issues/328/events
|
https://github.com/huggingface/datasets/issues/328
| 648,326,841
|
MDU6SXNzdWU2NDgzMjY4NDE=
| 328
|
Fork dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"To be able to generate the Arrow dataset you need to either use our csv or json utilities `load_dataset(\"json\", data_files=my_json_files)` OR write your own custom dataset script (you can find some inspiration from the [squad](https://github.com/huggingface/nlp/blob/master/datasets/squad/squad.py) script for example). Custom dataset scripts can be called locally with `nlp.load_dataset(path_to_my_script_directory)`.\r\n\r\nThis should help you get what you call \"Dataset1\".\r\n\r\nThen using some dataset transforms like `.map` for example you can get to \"DatasetNER\" and \"DatasetREL\".\r\n",
"Thanks for the helpful advice, @lhoestq -- I wasn't quite able to get the json recipe working - \r\n\r\n```\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/pyarrow/ipc.py in __init__(self, source)\r\n 60 \r\n 61 def __init__(self, source):\r\n---> 62 self._open(source)\r\n 63 \r\n 64 \r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/pyarrow/ipc.pxi in pyarrow.lib._RecordBatchStreamReader._open()\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\nArrowInvalid: Tried reading schema message, was null or length 0\r\n```\r\n\r\nBut I'm going to give the generator_dataset_builder a try.\r\n\r\n1 more quick question -- can .map be used to output different length mappings -- could I skip one, or yield 2, can you map_batch ",
"You can use `.map(my_func, batched=True)` and return less examples, or more examples if you want",
"Thanks this answers my question. I think the issue I was having using the json loader were due to using gzipped jsonl files.\r\n\r\nThe error I get now is :\r\n\r\n```\r\n\r\nUsing custom data configuration test\r\n---------------------------------------------------------------------------\r\n\r\nValueError Traceback (most recent call last)\r\n\r\n<ipython-input-38-29082a31e5b2> in <module>\r\n 5 print(ner_datafiles)\r\n 6 \r\n----> 7 ds = nlp.load_dataset(\"json\", \"test\", data_files=ner_datafiles[0])\r\n 8 \r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)\r\n 522 download_mode=download_mode,\r\n 523 ignore_verifications=ignore_verifications,\r\n--> 524 save_infos=save_infos,\r\n 525 )\r\n 526 \r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)\r\n 430 verify_infos = not save_infos and not ignore_verifications\r\n 431 self._download_and_prepare(\r\n--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 433 )\r\n 434 # Sync info\r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 481 try:\r\n 482 # Prepare split will record examples associated to the split\r\n--> 483 self._prepare_split(split_generator, **prepare_split_kwargs)\r\n 484 except OSError:\r\n 485 raise OSError(\"Cannot find data file. \" + (self.manual_download_instructions or \"\"))\r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _prepare_split(self, split_generator)\r\n 736 schema_dict[field.name] = Value(str(field.type))\r\n 737 \r\n--> 738 parse_schema(writer.schema, features)\r\n 739 self.info.features = Features(features)\r\n 740 \r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in parse_schema(schema, schema_dict)\r\n 734 parse_schema(field.type.value_type, schema_dict[field.name])\r\n 735 else:\r\n--> 736 schema_dict[field.name] = Value(str(field.type))\r\n 737 \r\n 738 parse_schema(writer.schema, features)\r\n\r\n<string> in __init__(self, dtype, id, _type)\r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in __post_init__(self)\r\n 55 \r\n 56 def __post_init__(self):\r\n---> 57 self.pa_type = string_to_arrow(self.dtype)\r\n 58 \r\n 59 def __call__(self):\r\n\r\n~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in string_to_arrow(type_str)\r\n 32 if str(type_str + \"_\") not in pa.__dict__:\r\n 33 raise ValueError(\r\n---> 34 f\"Neither {type_str} nor {type_str + '_'} seems to be a pyarrow data type. \"\r\n 35 f\"Please make sure to use a correct data type, see: \"\r\n 36 f\"https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions\"\r\n\r\nValueError: Neither list<item: int64> nor list<item: int64>_ seems to be a pyarrow data type. Please make sure to use a correct data type, see: https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions.\r\n```\r\n\r\nIf I just create a pa- table manually like is done in the jsonloader -- it seems to work fine. Ths JSON I'm trying to load isn't overly complex - 1 integer field, the rest text fields with a nested list of objects with text fields .",
"I'll close this -- It's still unclear how to go about troubleshooting the json example as I mentioned above. If I decide it's worth the trouble, I'll create another issue, or wait for a better support for using nlp for making custom data-loaders."
] | 2020-06-30T16:42:53
| 2020-07-06T21:43:59
| 2020-07-06T21:43:59
|
NONE
| null | null | null | null |
We have a multi-task learning model training I'm trying to convert to using the Arrow-based nlp dataset.
We're currently training a custom TensorFlow model but the nlp paradigm should be a bridge for us to be able to use the wealth of pre-trained models in Transformers.
Our preprocessing flow parses raw text and json with Entity and Relations annotations and creates 2 datasets for training a NER and Relations prediction heads.
Is there some good way to "fork" dataset-
EG
1. text + json -> Dataset1
1. Dataset1 -> DatasetNER
1. Dataset1 -> DatasetREL
or
1. text + json -> Dataset1
1. Dataset1 -> DatasetNER
1. Dataset1 + DatasetNER -> DatasetREL
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/328/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/328/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 6 days, 5:01:06
|
https://api.github.com/repos/huggingface/datasets/issues/326
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/326/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/326/comments
|
https://api.github.com/repos/huggingface/datasets/issues/326/events
|
https://github.com/huggingface/datasets/issues/326
| 648,126,103
|
MDU6SXNzdWU2NDgxMjYxMDM=
| 326
|
Large dataset in Squad2-format
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47894090?v=4",
"events_url": "https://api.github.com/users/flozi00/events{/privacy}",
"followers_url": "https://api.github.com/users/flozi00/followers",
"following_url": "https://api.github.com/users/flozi00/following{/other_user}",
"gists_url": "https://api.github.com/users/flozi00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/flozi00",
"id": 47894090,
"login": "flozi00",
"node_id": "MDQ6VXNlcjQ3ODk0MDkw",
"organizations_url": "https://api.github.com/users/flozi00/orgs",
"received_events_url": "https://api.github.com/users/flozi00/received_events",
"repos_url": "https://api.github.com/users/flozi00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/flozi00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/flozi00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/flozi00",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I'm pretty sure you can get some inspiration from the squad_v2 script. It looks like the dataset is quite big so it will take some time for the users to generate it, but it should be reasonable.\r\n\r\nAlso you are saying that you are still making the dataset grow in size right ?\r\nIt's probably good practice to let the users do their training/evaluations with the exact same version of the dataset.\r\nWe allow for each dataset to specify a version (ex: 1.0.0) and increment this number every time there are new samples in the dataset for example. Does it look like a good solution for you ? Or would you rather have one final version with the full dataset ?",
"It would also be good if there is any possibility for versioning, I think this way is much better than the dynamic way.\nIf you mean that part to put the tiles into one is the generation it would take up to 15-20 minutes on home computer hardware.\nAre there any compression or optimization algorithms while generating the dataset ?\nOtherwise the hardware limit is around 32 GB ram at the moment.\nIf everything works well we will add some more gigabytes of data in future what would make it pretty memory costly.",
"15-20 minutes is fine !\r\nAlso there's no RAM limitations as we save to disk every 1000 elements while generating the dataset by default.\r\nAfter generation, the dataset is ready to use with (again) no RAM limitations as we do memory-mapping.",
"Wow, that sounds pretty cool.\nActually I have the problem of running out of memory while tokenization on our local machine.\nThat wouldn't happen again, would it ?",
"You can do the tokenization step using `my_tokenized_dataset = my_dataset.map(my_tokenize_function)` that writes the tokenized texts on disk as well. And then `my_tokenized_dataset` will be a memory-mapped dataset too, so you should be fine :)",
"Does it have an affect to the trainings speed ?",
"In your training loop, loading the tokenized texts is going to be fast and pretty much negligible compared to a forward pass. You shouldn't expect any slow down.",
"Closing this one. Feel free to re-open if you have other questions"
] | 2020-06-30T12:18:59
| 2020-07-09T09:01:50
| 2020-07-09T09:01:50
|
CONTRIBUTOR
| null | null | null | null |
At the moment we are building an large question answering dataset and think about sharing it with the huggingface community.
Caused the computing power we splitted it into multiple tiles, but they are all in the same format.
Right now the most important facts about are this:
- Contexts: 1.047.671
- questions: 1.677.732
- Answers: 6.742.406
- unanswerable: 377.398
It is already cleaned
<pre><code>
train_data = [
{
'context': "this is the context",
'qas': [
{
'id': "00002",
'is_impossible': False,
'question': "whats is this",
'answers': [
{
'text': "answer",
'answer_start': 0
}
]
},
{
'id': "00003",
'is_impossible': False,
'question': "question2",
'answers': [
{
'text': "answer2",
'answer_start': 1
}
]
}
]
}
]
</code></pre>
Cause it is growing every day we are thinking about an structure like this:
We host an Json file, containing all the download links and the script can load it dynamically.
At the moment it is around ~20GB
Any advice how to handle this, or an ready to use template ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/326/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/326/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 8 days, 20:42:51
|
https://api.github.com/repos/huggingface/datasets/issues/324
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/324/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/324/comments
|
https://api.github.com/repos/huggingface/datasets/issues/324/events
|
https://github.com/huggingface/datasets/issues/324
| 647,525,725
|
MDU6SXNzdWU2NDc1MjU3MjU=
| 324
|
Error when calculating glue score
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47185867?v=4",
"events_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/events{/privacy}",
"followers_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/followers",
"following_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/following{/other_user}",
"gists_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/D-i-l-r-u-k-s-h-i",
"id": 47185867,
"login": "D-i-l-r-u-k-s-h-i",
"node_id": "MDQ6VXNlcjQ3MTg1ODY3",
"organizations_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/orgs",
"received_events_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/received_events",
"repos_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i/subscriptions",
"type": "User",
"url": "https://api.github.com/users/D-i-l-r-u-k-s-h-i",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"The glue metric for cola is a metric for classification. It expects label ids as integers as inputs.",
"I want to evaluate a sentence pair whether they are semantically equivalent, so I used MRPC and it gives the same error, does that mean we have to encode the sentences and parse as input?\r\n\r\nusing BertTokenizer;\r\n```\r\nencoded_reference=tokenizer.encode(reference, add_special_tokens=False)\r\nencoded_prediction=tokenizer.encode(prediction, add_special_tokens=False)\r\n```\r\n\r\n`glue_score = glue_metric.compute(encoded_prediction, encoded_reference)`\r\n```\r\n\r\nValueError Traceback (most recent call last)\r\n<ipython-input-9-4c3a3ce7b583> in <module>()\r\n----> 1 glue_score = glue_metric.compute(encoded_prediction, encoded_reference)\r\n\r\n6 frames\r\n/usr/local/lib/python3.6/dist-packages/nlp/metric.py in compute(self, predictions, references, timeout, **metrics_kwargs)\r\n 198 predictions = self.data[\"predictions\"]\r\n 199 references = self.data[\"references\"]\r\n--> 200 output = self._compute(predictions=predictions, references=references, **metrics_kwargs)\r\n 201 return output\r\n 202 \r\n\r\n/usr/local/lib/python3.6/dist-packages/nlp/metrics/glue/27b1bc63e520833054bd0d7a8d0bc7f6aab84cc9eed1b576e98c806f9466d302/glue.py in _compute(self, predictions, references)\r\n 101 return pearson_and_spearman(predictions, references)\r\n 102 elif self.config_name in [\"mrpc\", \"qqp\"]:\r\n--> 103 return acc_and_f1(predictions, references)\r\n 104 elif self.config_name in [\"sst2\", \"mnli\", \"mnli_mismatched\", \"mnli_matched\", \"qnli\", \"rte\", \"wnli\", \"hans\"]:\r\n 105 return {\"accuracy\": simple_accuracy(predictions, references)}\r\n\r\n/usr/local/lib/python3.6/dist-packages/nlp/metrics/glue/27b1bc63e520833054bd0d7a8d0bc7f6aab84cc9eed1b576e98c806f9466d302/glue.py in acc_and_f1(preds, labels)\r\n 60 def acc_and_f1(preds, labels):\r\n 61 acc = simple_accuracy(preds, labels)\r\n---> 62 f1 = f1_score(y_true=labels, y_pred=preds)\r\n 63 return {\r\n 64 \"accuracy\": acc,\r\n\r\n/usr/local/lib/python3.6/dist-packages/sklearn/metrics/_classification.py in f1_score(y_true, y_pred, labels, pos_label, average, sample_weight, zero_division)\r\n 1097 pos_label=pos_label, average=average,\r\n 1098 sample_weight=sample_weight,\r\n-> 1099 zero_division=zero_division)\r\n 1100 \r\n 1101 \r\n\r\n/usr/local/lib/python3.6/dist-packages/sklearn/metrics/_classification.py in fbeta_score(y_true, y_pred, beta, labels, pos_label, average, sample_weight, zero_division)\r\n 1224 warn_for=('f-score',),\r\n 1225 sample_weight=sample_weight,\r\n-> 1226 zero_division=zero_division)\r\n 1227 return f\r\n 1228 \r\n\r\n/usr/local/lib/python3.6/dist-packages/sklearn/metrics/_classification.py in precision_recall_fscore_support(y_true, y_pred, beta, labels, pos_label, average, warn_for, sample_weight, zero_division)\r\n 1482 raise ValueError(\"beta should be >=0 in the F-beta score\")\r\n 1483 labels = _check_set_wise_labels(y_true, y_pred, average, labels,\r\n-> 1484 pos_label)\r\n 1485 \r\n 1486 # Calculate tp_sum, pred_sum, true_sum ###\r\n\r\n/usr/local/lib/python3.6/dist-packages/sklearn/metrics/_classification.py in _check_set_wise_labels(y_true, y_pred, average, labels, pos_label)\r\n 1314 raise ValueError(\"Target is %s but average='binary'. Please \"\r\n 1315 \"choose another average setting, one of %r.\"\r\n-> 1316 % (y_type, average_options))\r\n 1317 elif pos_label not in (None, 1):\r\n 1318 warnings.warn(\"Note that pos_label (set to %r) is ignored when \"\r\n\r\nValueError: Target is multiclass but average='binary'. Please choose another average setting, one of [None, 'micro', 'macro', 'weighted'].\r\n\r\n```",
"MRPC is also a binary classification task, so its metric is a binary classification metric.\r\n\r\nTo evaluate if pairs of sentences are semantically equivalent, maybe you could take a look at models that compute if one sentence entails the other or not (typically the kinds of model that could work well on the MRPC task).",
"Closing this one. Feel free to re-open if you have other questions :)"
] | 2020-06-29T16:53:48
| 2020-07-09T09:13:34
| 2020-07-09T09:13:34
|
NONE
| null | null | null | null |
I was trying glue score along with other metrics here. But glue gives me this error;
```
import nlp
glue_metric = nlp.load_metric('glue',name="cola")
glue_score = glue_metric.compute(predictions, references)
```
```
---------------------------------------------------------------------------
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-b9210a524504> in <module>()
----> 1 glue_score = glue_metric.compute(predictions, references)
6 frames
/usr/local/lib/python3.6/dist-packages/nlp/metric.py in compute(self, predictions, references, timeout, **metrics_kwargs)
191 """
192 if predictions is not None:
--> 193 self.add_batch(predictions=predictions, references=references)
194 self.finalize(timeout=timeout)
195
/usr/local/lib/python3.6/dist-packages/nlp/metric.py in add_batch(self, predictions, references, **kwargs)
207 if self.writer is None:
208 self._init_writer()
--> 209 self.writer.write_batch(batch)
210
211 def add(self, prediction=None, reference=None, **kwargs):
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
155 if self.pa_writer is None:
156 self._build_writer(pa_table=pa.Table.from_pydict(batch_examples))
--> 157 pa_table: pa.Table = pa.Table.from_pydict(batch_examples, schema=self._schema)
158 if writer_batch_size is None:
159 writer_batch_size = self.writer_batch_size
/usr/local/lib/python3.6/dist-packages/pyarrow/types.pxi in __iter__()
/usr/local/lib/python3.6/dist-packages/pyarrow/array.pxi in pyarrow.lib.asarray()
/usr/local/lib/python3.6/dist-packages/pyarrow/array.pxi in pyarrow.lib.array()
/usr/local/lib/python3.6/dist-packages/pyarrow/array.pxi in pyarrow.lib._sequence_to_array()
TypeError: an integer is required (got type str)
```
I'm not sure whether I'm doing this wrong or whether it's an issue. I would like to know a workaround. Thank you.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/324/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/324/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 9 days, 16:19:46
|
https://api.github.com/repos/huggingface/datasets/issues/321
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/321/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/321/comments
|
https://api.github.com/repos/huggingface/datasets/issues/321/events
|
https://github.com/huggingface/datasets/issues/321
| 647,271,526
|
MDU6SXNzdWU2NDcyNzE1MjY=
| 321
|
ERROR:root:mwparserfromhell
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26505641?v=4",
"events_url": "https://api.github.com/users/Shiro-LK/events{/privacy}",
"followers_url": "https://api.github.com/users/Shiro-LK/followers",
"following_url": "https://api.github.com/users/Shiro-LK/following{/other_user}",
"gists_url": "https://api.github.com/users/Shiro-LK/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Shiro-LK",
"id": 26505641,
"login": "Shiro-LK",
"node_id": "MDQ6VXNlcjI2NTA1NjQx",
"organizations_url": "https://api.github.com/users/Shiro-LK/orgs",
"received_events_url": "https://api.github.com/users/Shiro-LK/received_events",
"repos_url": "https://api.github.com/users/Shiro-LK/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Shiro-LK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shiro-LK/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Shiro-LK",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"It looks like it comes from `mwparserfromhell`.\r\n\r\nWould it be possible to get the bad `section` that causes this issue ? The `section` string is from `datasets/wikipedia.py:L548` ? You could just add a `try` statement and print the section if the line `section_text.append(section.strip_code().strip())` crashes.\r\n\r\nIt will help us know if we have to fix it on our side or if it is a `mwparserfromhell` issue.",
"Hi, \r\n\r\nThank you for you answer.\r\nI have try to print the bad section using `try` and `except`, but it is a bit weird as the error seems to appear 3 times for instance, but the two first error does not print anything (as if the function did not go in the `except` part).\r\nFor the third one, I got that (I haven't display the entire text) :\r\n\r\n> error : ==== Parque nacional Cajas ====\r\n> {{AP|Parque nacional Cajas}}\r\n> [[Archivo:Ecuador cajas national park.jpg|thumb|left|300px|Laguna del Cajas]]\r\n> El parque nacional Cajas está situado en los [[Cordillera de los Andes|Andes]], al sur del [[Ecuador]], en la provincia de [[Provincia de Azuay|Azuay]], a 33\r\n> [[km]] al noroccidente de la ciudad de [[Cuenca (Ecuador)|Cuenca]]. Los accesos más comunes al parque inician todos en Cuenca: Desde allí, la vía Cuenca-Mol\r\n> leturo atraviesa en Control de [[Surocucho]] en poco más de 30 minutos de viaje; más adelante, esta misma carretera pasa a orillas de la laguna La Toreadora donde están el Centro Administrativo y de Información del parque. Siguiendo de largo hacia [[Molleturo]], por esta vía se conoce el sector norte del Cajas y se serpentea entre varias lagunas mayores y menores.\r\n> Para acceder al parque desde la costa, la vía Molleturo-Cuenca es también la mejor opción.\r\n\r\nHow can I display the link instead of the text ? I suppose it will help you more ",
"The error appears several times as Apache Beam retries to process examples up to 4 times irc.\r\n\r\nI just tried to run this text into `mwparserfromhell` but it worked without the issue.\r\n\r\nI used this code (from the `wikipedia.py` script):\r\n```python\r\nimport mwparserfromhell as parser\r\nimport re\r\nimport six\r\n\r\nraw_content = r\"\"\"==== Parque nacional Cajas ====\r\n{{AP|Parque nacional Cajas}}\r\n[[Archivo:Ecuador cajas national park.jpg|thumb|left|300px|Laguna del Cajas]]\r\nEl parque nacional Cajas está situado en los [[Cordillera de los Andes|Andes]], al sur del [[Ecuador]], en la provincia de [[Provincia de Azuay|Azuay]], a 33\r\n[[km]] al noroccidente de la ciudad de [[Cuenca (Ecuador)|Cuenca]]. Los accesos más comunes al parque inician todos en Cuenca: Desde allí, la vía Cuenca-Mol\r\nleturo atraviesa en Control de [[Surocucho]] en poco más de 30 minutos de viaje; más adelante, esta misma carretera pasa a orillas de la laguna La Toreadora donde están el Centro Administrativo y de Información del parque. Siguiendo de largo hacia [[Molleturo]], por esta vía se conoce el sector norte del Cajas y se serpentea entre varias lagunas mayores y menores.\r\n\"\"\"\r\n\r\nwikicode = parser.parse(raw_content)\r\n\r\n# Filters for references, tables, and file/image links.\r\nre_rm_wikilink = re.compile(\"^(?:File|Image|Media):\", flags=re.IGNORECASE | re.UNICODE)\r\n\r\ndef rm_wikilink(obj):\r\n return bool(re_rm_wikilink.match(six.text_type(obj.title)))\r\n\r\ndef rm_tag(obj):\r\n return six.text_type(obj.tag) in {\"ref\", \"table\"}\r\n\r\ndef rm_template(obj):\r\n return obj.name.lower() in {\"reflist\", \"notelist\", \"notelist-ua\", \"notelist-lr\", \"notelist-ur\", \"notelist-lg\"}\r\n\r\ndef try_remove_obj(obj, section):\r\n try:\r\n section.remove(obj)\r\n except ValueError:\r\n # For unknown reasons, objects are sometimes not found.\r\n pass\r\n\r\nsection_text = []\r\nfor section in wikicode.get_sections(flat=True, include_lead=True, include_headings=True):\r\n for obj in section.ifilter_wikilinks(matches=rm_wikilink, recursive=True):\r\n try_remove_obj(obj, section)\r\n for obj in section.ifilter_templates(matches=rm_template, recursive=True):\r\n try_remove_obj(obj, section)\r\n for obj in section.ifilter_tags(matches=rm_tag, recursive=True):\r\n try_remove_obj(obj, section)\r\n\r\n section_text.append(section.strip_code().strip())\r\n```",
"Not sure why we're having this issue. Maybe could you get also the file that's causing that ?",
"thanks for your answer.\r\nHow can I know which file is causing the issue ? \r\nI am trying to load the spanish wikipedia data. ",
"Because of the way Apache Beam works we indeed don't have access to the file name at this point in the code.\r\nWe'll have to use some tricks I think :p \r\n\r\nYou can append `filepath` to `title` in `wikipedia.py:L512` for example. [[EDIT: it's L494 my bad]]\r\nThen just do `try:...except:` on the call of `_parse_and_clean_wikicode` L500 I guess.\r\n\r\nThanks for diving into this ! I tried it myself but I run out of memory on my laptop\r\nAs soon as we have the name of the file it should be easier to find what's wrong.",
"Thanks for your help.\r\n\r\nI tried to print the \"title\" of the document inside the` except (mwparserfromhell.parser.ParserError) as e`,the title displayed was : \"Campeonato Mundial de futsal de la AMF 2015\". (Wikipedia ES) Is it what you were looking for ?",
"Thanks a lot @Shiro-LK !\r\n\r\nI was able to reproduce the issue. It comes from [this table on wikipedia](https://es.wikipedia.org/wiki/Campeonato_Mundial_de_futsal_de_la_AMF_2015#Clasificados) that can't be parsed.\r\n\r\nThe file in which the problem occurs comes from the wikipedia dumps, and it can be downloaded [here](https://dumps.wikimedia.org/eswiki/20200501/eswiki-20200501-pages-articles-multistream6.xml-p6424816p7924815.bz2)\r\n\r\nParsing the file this way raises the parsing issue:\r\n\r\n```python\r\nimport mwparserfromhell as parser\r\nfrom tqdm.auto import tqdm\r\nimport bz2\r\nimport six\r\nimport logging\r\nimport codecs\r\nimport xml.etree.cElementTree as etree\r\n\r\nfilepath = \"path/to/eswiki-20200501-pages-articles-multistream6.xml-p6424816p7924815.bz2\"\r\n\r\ndef _extract_content(filepath):\r\n \"\"\"Extracts article content from a single WikiMedia XML file.\"\"\"\r\n logging.info(\"generating examples from = %s\", filepath)\r\n with open(filepath, \"rb\") as f:\r\n f = bz2.BZ2File(filename=f)\r\n if six.PY3:\r\n # Workaround due to:\r\n # https://github.com/tensorflow/tensorflow/issues/33563\r\n utf_f = codecs.getreader(\"utf-8\")(f)\r\n else:\r\n utf_f = f\r\n # To clear root, to free-up more memory than just `elem.clear()`.\r\n context = etree.iterparse(utf_f, events=(\"end\",))\r\n context = iter(context)\r\n unused_event, root = next(context)\r\n for unused_event, elem in tqdm(context, total=949087):\r\n if not elem.tag.endswith(\"page\"):\r\n continue\r\n namespace = elem.tag[:-4]\r\n title = elem.find(\"./{0}title\".format(namespace)).text\r\n ns = elem.find(\"./{0}ns\".format(namespace)).text\r\n id_ = elem.find(\"./{0}id\".format(namespace)).text\r\n # Filter pages that are not in the \"main\" namespace.\r\n if ns != \"0\":\r\n root.clear()\r\n continue\r\n raw_content = elem.find(\"./{0}revision/{0}text\".format(namespace)).text\r\n root.clear()\r\n\r\n if \"Campeonato Mundial de futsal de la AMF 2015\" in title:\r\n yield (id_, title, raw_content)\r\n\r\nfor id_, title, raw_content in _extract_content(filepath):\r\n wikicode = parser.parse(raw_content)\r\n```\r\n\r\nThe copied the raw content that can't be parsed [here](https://pastebin.com/raw/ZbmevLyH).\r\n\r\nThe minimal code to reproduce is:\r\n```python\r\nimport mwparserfromhell as parser\r\nimport requests\r\n\r\nraw_content = requests.get(\"https://pastebin.com/raw/ZbmevLyH\").content.decode(\"utf-8\")\r\nwikicode = parser.parse(raw_content)\r\n\r\n```\r\n\r\nI will create an issue on mwparserfromhell's repo to see if we can fix that\r\n",
"This going to be fixed in the next `mwparserfromhell` release :)",
"Fixed in `mwparserfromhell` version 0.6."
] | 2020-06-29T11:10:43
| 2022-02-14T15:21:46
| 2022-02-14T15:21:46
|
NONE
| null | null | null | null |
Hi,
I am trying to download some wikipedia data but I got this error for spanish "es" (but there are maybe some others languages which have the same error I haven't tried all of them ).
`ERROR:root:mwparserfromhell ParseError: This is a bug and should be reported. Info: C tokenizer exited with non-empty token stack.`
The code I have use was :
`dataset = load_dataset('wikipedia', '20200501.es', beam_runner='DirectRunner')`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/321/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/321/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 595 days, 4:11:03
|
https://api.github.com/repos/huggingface/datasets/issues/320
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/320/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/320/comments
|
https://api.github.com/repos/huggingface/datasets/issues/320/events
|
https://github.com/huggingface/datasets/issues/320
| 647,188,167
|
MDU6SXNzdWU2NDcxODgxNjc=
| 320
|
Blog Authorship Corpus, Non Matching Splits Sizes Error, nlp viewer
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
| null |
[] |
[
"I wonder if this means downloading failed? That corpus has a really slow server.",
"This dataset seems to have a decoding problem that results in inconsistencies in the number of generated examples.\r\nSee #215.\r\nThat's why we end up with a `NonMatchingSplitsSizesError `."
] | 2020-06-29T07:36:35
| 2020-06-29T14:44:42
| 2020-06-29T14:44:42
|
CONTRIBUTOR
| null | null | null | null |
Selecting `blog_authorship_corpus` in the nlp viewer throws the following error:
```
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train', num_bytes=614706451, num_examples=535568, dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation', num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='validation', num_bytes=32553710, num_examples=28521, dataset_name='blog_authorship_corpus')}]
Traceback:
File "/home/sasha/streamlit/lib/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp-viewer/run.py", line 172, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp-viewer/run.py", line 132, in get
builder_instance.download_and_prepare()
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 488, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/utils/info_utils.py", line 70, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
```
@srush @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/320/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/320/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 7:08:07
|
https://api.github.com/repos/huggingface/datasets/issues/319
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/319/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/319/comments
|
https://api.github.com/repos/huggingface/datasets/issues/319/events
|
https://github.com/huggingface/datasets/issues/319
| 646,792,487
|
MDU6SXNzdWU2NDY3OTI0ODc=
| 319
|
Nested sequences with dicts
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Oh yes, this is a backward compatibility feature with tensorflow_dataset in which a `Sequence` or `dict` is converted in a `dict` of `lists`, unfortunately it is not very intuitive, see here: https://github.com/huggingface/nlp/blob/master/src/nlp/features.py#L409\r\n\r\nTo avoid this behavior, you can just define the list in the feature with a simple list or a tuple (which is also simpler to write).\r\nIn your case, the features could be as follow:\r\n``` python\r\n...\r\nfeatures=nlp.Features({\r\n \"title\": nlp.Value(\"string\"),\r\n \"vertexSet\": [[{\r\n \"name\": nlp.Value(\"string\"),\r\n \"sent_id\": nlp.Value(\"int32\"),\r\n \"pos\": nlp.features.Sequence(nlp.Value(\"int32\")),\r\n \"type\": nlp.Value(\"string\"),\r\n }]],\r\n ...\r\n }),\r\n...\r\n```"
] | 2020-06-27T23:45:17
| 2020-07-03T10:22:00
| 2020-07-03T10:22:00
|
CONTRIBUTOR
| null | null | null | null |
Am pretty much finished [adding a dataset](https://github.com/ghomasHudson/nlp/blob/DocRED/datasets/docred/docred.py) for [DocRED](https://github.com/thunlp/DocRED), but am getting an error when trying to add a nested `nlp.features.sequence(nlp.features.sequence({key:value,...}))`.
The original data is in this format:
```python
{
'title': "Title of wiki page",
'vertexSet': [
[
{ 'name': "mention_name",
'sent_id': "mention in which sentence",
'pos': ["postion of mention in a sentence"],
'type': "NER_type"},
{another mention}
],
[another entity]
]
...
}
```
So to represent this I've attempted to write:
```
...
features=nlp.Features({
"title": nlp.Value("string"),
"vertexSet": nlp.features.Sequence(nlp.features.Sequence({
"name": nlp.Value("string"),
"sent_id": nlp.Value("int32"),
"pos": nlp.features.Sequence(nlp.Value("int32")),
"type": nlp.Value("string"),
})),
...
}),
...
```
This is giving me the error:
```
pyarrow.lib.ArrowTypeError: Could not convert [{'pos': [[0,2], [2,4], [3,5]], "type": ["ORG", "ORG", "ORG"], "name": ["Lark Force", "Lark Force", "Lark Force", "sent_id": [0, 3, 4]}..... with type list: was not a dict, tuple, or recognized null value for conversion to struct type
```
Do we expect the pyarrow stuff to break when doing this deeper nesting? I've checked that it still works when you do `nlp.features.Sequence(nlp.features.Sequence(nlp.Value("string"))` or `nlp.features.Sequence({key:value,...})` just not nested sequences with a dict.
If it's not possible, I can always convert it to a shallower structure. I'd rather not change the DocRED authors' structure if I don't have to though.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/319/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/319/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5 days, 10:36:43
|
https://api.github.com/repos/huggingface/datasets/issues/317
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/317/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/317/comments
|
https://api.github.com/repos/huggingface/datasets/issues/317/events
|
https://github.com/huggingface/datasets/issues/317
| 646,555,384
|
MDU6SXNzdWU2NDY1NTUzODQ=
| 317
|
Adding a dataset with multiple subtasks
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/294483?v=4",
"events_url": "https://api.github.com/users/erickrf/events{/privacy}",
"followers_url": "https://api.github.com/users/erickrf/followers",
"following_url": "https://api.github.com/users/erickrf/following{/other_user}",
"gists_url": "https://api.github.com/users/erickrf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/erickrf",
"id": 294483,
"login": "erickrf",
"node_id": "MDQ6VXNlcjI5NDQ4Mw==",
"organizations_url": "https://api.github.com/users/erickrf/orgs",
"received_events_url": "https://api.github.com/users/erickrf/received_events",
"repos_url": "https://api.github.com/users/erickrf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/erickrf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erickrf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/erickrf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"For one dataset you can have different configurations that each have their own `nlp.Features`.\r\nWe imagine having one configuration per subtask for example.\r\nThey are loaded with `nlp.load_dataset(\"my_dataset\", \"my_config\")`.\r\n\r\nFor example the `glue` dataset has many configurations. It is a bit different from your case though because each configuration is a dataset by itself (sst2, mnli).\r\nAnother example is `wikipedia` that has one configuration per language."
] | 2020-06-26T23:14:19
| 2020-10-27T15:36:52
| 2020-10-27T15:36:52
|
NONE
| null | null | null | null |
I intent to add the datasets of the MT Quality Estimation shared tasks to `nlp`. However, they have different subtasks -- such as word-level, sentence-level and document-level quality estimation, each of which having different language pairs, and some of the data reused in different subtasks.
For example, in [QE 2019,](http://www.statmt.org/wmt19/qe-task.html) we had the same English-Russian and English-German data for word-level and sentence-level QE.
I suppose these datasets could have both their word and sentence-level labels inside `nlp.Features`; but what about other subtasks? Should they be considered a different dataset altogether?
I read the discussion on #217 but the case of QE seems a lot simpler.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/317/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/317/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 122 days, 16:22:33
|
https://api.github.com/repos/huggingface/datasets/issues/315
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/315/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/315/comments
|
https://api.github.com/repos/huggingface/datasets/issues/315/events
|
https://github.com/huggingface/datasets/issues/315
| 645,888,943
|
MDU6SXNzdWU2NDU4ODg5NDM=
| 315
|
[Question] Best way to batch a large dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
open
| false
| null |
[] |
[
"Update: I think I've found a solution.\r\n\r\n```python\r\noutput_types = {\"input_ids\": tf.int64, \"token_type_ids\": tf.int64, \"attention_mask\": tf.int64}\r\ndef train_dataset_gen():\r\n for i in range(len(train_dataset)):\r\n yield train_dataset[i]\r\ntf_dataset = tf.data.Dataset.from_generator(train_dataset_gen, output_types=output_types)\r\n```\r\n\r\nloads WikiText-2 in 20 ms, and WikiText-103 in 20 ms. It appears to be lazily loading via indexing train_dataset.",
"Yes this is the current best solution. We should probably show it in the tutorial notebook.\r\n\r\nNote that this solution unfortunately doesn't allow to train on TPUs (yet). See #193 ",
"This approach still seems quite slow. When using TFRecords with a similar training loop, I get ~3.0-3.5 it/s on multi-node, multi-GPU training. I notice a pretty severe performance regression when scaling, with observed performance numbers. Since the allreduce step takes less than 100ms/it and I've achieved 80% scaling efficiency up to 64 GPUs, it must be the data pipeline.\r\n\r\n| Nodes | GPUs | Iterations/Second |\r\n| --- | --- | --- |\r\n| 1 | 2 | 2.01 |\r\n| 1 | 8 | 0.81 |\r\n| 2 | 16 | 0.37 |\r\n\r\nHere are performance metrics over 10k steps. The iteration speed appears to follow some sort of caching pattern. I would love to use `nlp` in my project, but a slowdown from 3.0 it/s to 0.3 it/s is too great to stomach.\r\n\r\n<img width=\"1361\" alt=\"Screen Shot 2020-07-02 at 8 29 22 AM\" src=\"https://user-images.githubusercontent.com/4564897/86378156-2f8d3900-bc3e-11ea-918b-c395c3df5377.png\">\r\n",
"An interesting alternative to investigate here would be to use the tf.io library which has some support for Arrow to TF conversion: https://www.tensorflow.org/io/api_docs/python/tfio/arrow/ArrowDataset\r\n\r\nThere are quite a few types supported, including lists so if the unsupported columns are dropped then we could maybe have a zero-copy mapping from Arrow to TensorFlow, including tokenized inputs and 1D tensors like the ones we mostly use in NLP: https://github.com/tensorflow/io/blob/322b3170c43ecac5c6af9e39dbd18fd747913e5a/tensorflow_io/arrow/python/ops/arrow_dataset_ops.py#L44-L72\r\n\r\nHere is an introduction on Arrow to TF using tf.io: https://medium.com/tensorflow/tensorflow-with-apache-arrow-datasets-cdbcfe80a59f",
"Interesting. There's no support for strings, but it does enable int and floats so that would work for tokenized inputs. \r\n\r\nArrowStreamDataset requires loading from a \"record batch iterator\", which can be instantiated from in-memory arrays as described here: https://arrow.apache.org/docs/python/ipc.html. \r\n\r\nBut the nlp.Dataset stores its data as a `pyarrow.lib.Table`, and the underlying features are `pyarrow.lib.ChunkedArray`. I can't find any documentation about lazily creating a record batch iterator from a ChunkedArray or a Table. Have you had any success?\r\n\r\nI can't find [any uses](https://grep.app/search?q=ArrowDataset&filter[lang][0]=Python) of tfio.arrow.ArrowDataset on GitHub.",
"You can use `to_batches` maybe?\r\nhttps://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_batches",
"Also note that since #322 it is now possible to do\r\n```python\r\nids = [1, 10, 42, 100]\r\nbatch = dataset[ids]\r\n```\r\nFrom my experience it is quite fast but it can take lots of memory for large batches (haven't played that much with it).\r\nLet me know if you think there could be a better way to implement it. (current code is [here](https://github.com/huggingface/nlp/blob/78628649962671b4aaa31a6b24e7275533416845/src/nlp/arrow_dataset.py#L463))",
"Thanks @lhoestq! That format is much better to work with.\r\n\r\nI put together a benchmarking script. This doesn't measure the CPU-to-GPU efficiency, nor how it scales with multi-GPU multi-node training where many processes are making the same demands on the same dataset. But it does show some interesting results:\r\n\r\n```python\r\nimport nlp\r\nimport numpy as np\r\nimport tensorflow as tf\r\nimport time\r\n\r\ndset = nlp.load_dataset(\"wikitext\", \"wikitext-2-raw-v1\", split=\"train\")\r\ndset = dset.filter(lambda ex: len(ex[\"text\"]) > 0)\r\nbsz = 1024\r\nn_batches = 100\r\n\r\ndef single_item_gen():\r\n for i in range(len(dset)):\r\n yield dset[i]\r\n\r\ndef sequential_batch_gen():\r\n for i in range(0, len(dset), bsz):\r\n yield dset[i:i+bsz]\r\n\r\ndef random_batch_gen():\r\n for i in range(len(dset)):\r\n indices = list(np.random.randint(len(dset), size=(bsz,)))\r\n yield dset[indices]\r\n\r\noutput_types = {\"text\": tf.string}\r\nsingle_item = tf.data.Dataset.from_generator(single_item_gen, output_types=output_types).batch(bsz)\r\ninterleaved = tf.data.Dataset.range(10).interleave(\r\n lambda idx: tf.data.Dataset.from_generator(single_item_gen, output_types=output_types),\r\n cycle_length=10,\r\n)\r\nsequential_batch = tf.data.Dataset.from_generator(sequential_batch_gen, output_types=output_types)\r\nrandom_batch = tf.data.Dataset.from_generator(random_batch_gen, output_types=output_types)\r\n\r\ndef iterate(tf_dset):\r\n start = time.perf_counter()\r\n for i, batch in enumerate(tf_dset.take(n_batches)):\r\n pass\r\n elapsed = time.perf_counter() - start\r\n print(f\"{tf_dset} took {elapsed:.3f} secs\")\r\n\r\niterate(single_item)\r\niterate(interleaved)\r\niterate(sequential_batch)\r\niterate(random_batch)\r\n```\r\n\r\nResults:\r\n```\r\n<BatchDataset shapes: {text: <unknown>}, types: {text: tf.string}> took 23.005 secs\r\n<InterleaveDataset shapes: {text: <unknown>}, types: {text: tf.string}> took 0.135 secs\r\n<FlatMapDataset shapes: {text: <unknown>}, types: {text: tf.string}> took 0.074 secs\r\n<FlatMapDataset shapes: {text: <unknown>}, types: {text: tf.string}> took 0.550 secs\r\n```\r\n\r\n- Batching a generator which fetches a single item is terrible.\r\n- Interleaving performs well on a single process, but doesn't scale well to multi-GPU training. I believe the bottleneck here is in Arrow dataset locking or something similar. The numbers from the table above are with interleaving.\r\n- The sequential access dominates the random access (7x faster). Is there any way to bring random access times closer to sequential access? Maybe re-indexing the dataset after shuffling each pass over the data.",
"Hey @jarednielsen \r\n\r\nThanks for this very interesting analysis!! IMHO to read text data one should use `tf.data.TextLineDataset`. It would be interesting to compare what you have done with simply load with a `TextLineDataset` and see if there is a difference.\r\n\r\nA good example can be found here https://www.tensorflow.org/tutorials/load_data/text",
"Thanks! I'm not actually loading in raw text data, that was just the synthetic data I created for this benchmark. A more realistic use case would be a dataset of tokenized examples, which would be a dict of lists of integers. TensorFlow's TextLineDataset greedily loads the dataset into the graph itself, which can lead to out-of-memory errors - one of the main reason I'm so drawn to the `nlp` library is its zero-copy no-RAM approach to dataset loading and mapping. \r\n\r\nIt's quite helpful for running a preprocessing pipeline - a sample ELECTRA pipeline I've built is here: https://github.com/jarednielsen/deep-learning-models/blob/nlp/models/nlp/common/preprocess.py.",
"Sorry, I think I badly expressed myself, my bad. What I suggested is to compare with the usual loading textual data in pure TF with `TextLineDataset` with `nlp`. I know it is not recommended with very large datasets to use it, but I was curious to see how it behaves compared to a processing with `nlp` on smaller datasets.\r\n\r\nBTW your script looks very interesting, thanks for sharing!!"
] | 2020-06-25T22:30:20
| 2020-10-27T15:38:17
| null |
CONTRIBUTOR
| null | null | null | null |
I'm training on large datasets such as Wikipedia and BookCorpus. Following the instructions in [the tutorial notebook](https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb), I see the following recommended for TensorFlow:
```python
train_tf_dataset = train_tf_dataset.filter(remove_none_values, load_from_cache_file=False)
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x].to_tensor(default_value=0, shape=[None, tokenizer.max_len]) for x in columns[:3]}
labels = {"output_1": train_tf_dataset["start_positions"].to_tensor(default_value=0, shape=[None, 1])}
labels["output_2"] = train_tf_dataset["end_positions"].to_tensor(default_value=0, shape=[None, 1])
### Question about this last line ###
tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
```
This code works for something like WikiText-2. However, scaling up to WikiText-103, the last line takes 5-10 minutes to run. I assume it is because tf.data.Dataset.from_tensor_slices() is pulling everything into memory, not lazily loading. This approach won't scale up to datasets 25x larger such as Wikipedia.
So I tried manual batching using `dataset.select()`:
```python
idxs = np.random.randint(len(dataset), size=bsz)
batch = dataset.select(idxs).map(lambda example: {"input_ids": tokenizer(example["text"])})
tf_batch = tf.constant(batch["ids"], dtype=tf.int64)
```
This appears to create a new Apache Arrow dataset with every batch I grab, and then tries to cache it. The runtime of `dataset.select([0, 1])` appears to be much worse than `dataset[:2]`. So using `select()` doesn't seem to be performant enough for a training loop.
Is there a performant scalable way to lazily load batches of nlp Datasets?
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/315/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/315/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| null |
https://api.github.com/repos/huggingface/datasets/issues/312
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/312/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/312/comments
|
https://api.github.com/repos/huggingface/datasets/issues/312/events
|
https://github.com/huggingface/datasets/issues/312
| 645,025,561
|
MDU6SXNzdWU2NDUwMjU1NjE=
| 312
|
[Feature request] Add `shard()` method to dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi Jared,\r\nInteresting, thanks for raising this question. You can also do that after loading with `dataset.select()` or `dataset.filter()` which let you keep only a specific subset of rows in a dataset.\r\nWhat is your use-case for sharding?",
"Thanks for the pointer to those functions! It's still a little more verbose since you have to manually calculate which ids each rank would keep, but definitely works.\r\n\r\nMy use case is multi-node, multi-GPU training and avoiding global batches of duplicate elements. I'm using horovod. You can shuffle indices, or set random seeds, but explicitly sharding the dataset up front is the safest and clearest way I've found to do so."
] | 2020-06-24T22:48:33
| 2020-07-06T12:35:36
| 2020-07-06T12:35:36
|
CONTRIBUTOR
| null | null | null | null |
Currently, to shard a dataset into 10 pieces on different ranks, you can run
```python
rank = 3 # for example
size = 10
dataset = nlp.load_dataset('wikitext', 'wikitext-2-raw-v1', split=f"train[{rank*10}%:{(rank+1)*10}%]")
```
However, this breaks down if you have a number of ranks that doesn't divide cleanly into 100, such as 64 ranks. Is there interest in adding a method shard() that looks like this?
```python
rank = 3
size = 64
dataset = nlp.load_dataset("wikitext", "wikitext-2-raw-v1", split="train").shard(rank=rank, size=size)
```
TensorFlow has a similar API: https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shard. I'd be happy to contribute this code.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/312/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/312/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 11 days, 13:47:03
|
https://api.github.com/repos/huggingface/datasets/issues/307
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/307/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/307/comments
|
https://api.github.com/repos/huggingface/datasets/issues/307/events
|
https://github.com/huggingface/datasets/issues/307
| 644,187,262
|
MDU6SXNzdWU2NDQxODcyNjI=
| 307
|
Specify encoding for MRPC
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-06-23T22:24:49
| 2020-06-25T12:16:09
| 2020-06-25T12:16:09
|
CONTRIBUTOR
| null | null | null | null |
Same as #242, but with MRPC: on Windows, I get a `UnicodeDecodeError` when I try to download the dataset:
```python
dataset = nlp.load_dataset('glue', 'mrpc')
```
```python
Downloading and preparing dataset glue/mrpc (download: Unknown size, generated: Unknown size, total: Unknown size) to C:\Users\Python\.cache\huggingface\datasets\glue\mrpc\1.0.0...
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in incomplete_dir(dirname)
369 try:
--> 370 yield tmp_dir
371 if os.path.isdir(dirname):
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
--> 431 self._download_and_prepare(
432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
482 # Prepare split will record examples associated to the split
--> 483 self._prepare_split(split_generator, **prepare_split_kwargs)
484 except OSError:
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in _prepare_split(self, split_generator)
663 generator = self._generate_examples(**split_generator.gen_kwargs)
--> 664 for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
665 example = self.info.features.encode_example(record)
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\notebook.py in __iter__(self, *args, **kwargs)
217 try:
--> 218 for obj in super(tqdm_notebook, self).__iter__(*args, **kwargs):
219 # return super(tqdm...) will not catch exception
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:
1130 yield obj
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\7fc58099eb3983a04c8dac8500b70d27e6eceae63ffb40d7900c977897bb58c6\glue.py in _generate_examples(self, data_file, split, mrpc_files)
514 examples = self._generate_example_mrpc_files(mrpc_files=mrpc_files, split=split)
--> 515 for example in examples:
516 yield example["idx"], example
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\7fc58099eb3983a04c8dac8500b70d27e6eceae63ffb40d7900c977897bb58c6\glue.py in _generate_example_mrpc_files(self, mrpc_files, split)
576 reader = csv.DictReader(f, delimiter="\t", quoting=csv.QUOTE_NONE)
--> 577 for n, row in enumerate(reader):
578 is_row_in_dev = [row["#1 ID"], row["#2 ID"]] in dev_ids
~\Miniconda3\envs\nlp\lib\csv.py in __next__(self)
110 self.fieldnames
--> 111 row = next(self.reader)
112 self.line_num = self.reader.line_num
~\Miniconda3\envs\nlp\lib\encodings\cp1252.py in decode(self, input, final)
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 1180: character maps to <undefined>
```
The fix is the same: specify `utf-8` encoding when opening the file. The previous fix didn't work as MRPC's download process is different from the others in GLUE.
I am going to propose a new PR :)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/307/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/307/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 13:51:20
|
https://api.github.com/repos/huggingface/datasets/issues/305
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/305/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/305/comments
|
https://api.github.com/repos/huggingface/datasets/issues/305/events
|
https://github.com/huggingface/datasets/issues/305
| 644,148,149
|
MDU6SXNzdWU2NDQxNDgxNDk=
| 305
|
Importing downloaded package repository fails
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
[
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] |
closed
| false
| null |
[] |
[] | 2020-06-23T21:09:05
| 2020-07-30T16:44:23
| 2020-07-30T16:44:23
|
MEMBER
| null | null | null | null |
The `get_imports` function in `src/nlp/load.py` has a feature to download a package as a zip archive of the github repository and import functions from the unpacked directory. This is used for example in the `metrics/coval.py` file, and would be useful to add BLEURT (@ankparikh).
Currently however, the code seems to have trouble with imports within the package. For example:
```
import nlp
coval = nlp.load_metric('coval')
```
yields:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/yacine/Code/nlp/src/nlp/load.py", line 432, in load_metric
metric_cls = import_main_class(module_path, dataset=False)
File "/home/yacine/Code/nlp/src/nlp/load.py", line 57, in import_main_class
module = importlib.import_module(module_path)
File "/home/yacine/anaconda3/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/yacine/Code/nlp/src/nlp/metrics/coval/a78807df33ac45edbb71799caf2b3b47e55df4fd690267808fe963a5e8b30952/coval.py", line 21, in <module>
from .coval_backend.conll import reader # From: https://github.com/ns-moosavi/coval
File "/home/yacine/Code/nlp/src/nlp/metrics/coval/a78807df33ac45edbb71799caf2b3b47e55df4fd690267808fe963a5e8b30952/coval_backend/conll/reader.py", line 2, in <module>
from conll import mention
ModuleNotFoundError: No module named 'conll'
```
Not sure what the fix would be there.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/305/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/305/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 36 days, 19:35:18
|
https://api.github.com/repos/huggingface/datasets/issues/304
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/304/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/304/comments
|
https://api.github.com/repos/huggingface/datasets/issues/304/events
|
https://github.com/huggingface/datasets/issues/304
| 644,091,970
|
MDU6SXNzdWU2NDQwOTE5NzA=
| 304
|
Problem while printing doc string when instantiating multiple metrics.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/51091425?v=4",
"events_url": "https://api.github.com/users/codehunk628/events{/privacy}",
"followers_url": "https://api.github.com/users/codehunk628/followers",
"following_url": "https://api.github.com/users/codehunk628/following{/other_user}",
"gists_url": "https://api.github.com/users/codehunk628/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/codehunk628",
"id": 51091425,
"login": "codehunk628",
"node_id": "MDQ6VXNlcjUxMDkxNDI1",
"organizations_url": "https://api.github.com/users/codehunk628/orgs",
"received_events_url": "https://api.github.com/users/codehunk628/received_events",
"repos_url": "https://api.github.com/users/codehunk628/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/codehunk628/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codehunk628/subscriptions",
"type": "User",
"url": "https://api.github.com/users/codehunk628",
"user_view_type": "public"
}
|
[
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] |
closed
| false
| null |
[] |
[] | 2020-06-23T19:32:05
| 2020-07-22T09:50:58
| 2020-07-22T09:50:58
|
CONTRIBUTOR
| null | null | null | null |
When I load more than one metric and try to print doc string of a particular metric,. It shows the doc strings of all imported metric one after the other which looks quite confusing and clumsy.
Attached [Colab](https://colab.research.google.com/drive/13H0ZgyQ2se0mqJ2yyew0bNEgJuHaJ8H3?usp=sharing) Notebook for problem clarification..
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/304/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/304/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 28 days, 14:18:53
|
https://api.github.com/repos/huggingface/datasets/issues/302
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/302/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/302/comments
|
https://api.github.com/repos/huggingface/datasets/issues/302/events
|
https://github.com/huggingface/datasets/issues/302
| 643,910,418
|
MDU6SXNzdWU2NDM5MTA0MTg=
| 302
|
Question - Sign Language Datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://api.github.com/users/AmitMY/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AmitMY",
"id": 5757359,
"login": "AmitMY",
"node_id": "MDQ6VXNlcjU3NTczNTk=",
"organizations_url": "https://api.github.com/users/AmitMY/orgs",
"received_events_url": "https://api.github.com/users/AmitMY/received_events",
"repos_url": "https://api.github.com/users/AmitMY/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AmitMY/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AmitMY/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AmitMY",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
closed
| false
| null |
[] |
[
"Even more complicating - \r\n\r\nAs I see it, datasets can have \"addons\".\r\nFor example, the WebNLG dataset is a dataset for data-to-text. However, a work of mine and other works enriched this dataset with text plans / underlying text structures. In that case, I see a need to load the dataset \"WebNLG\" with \"plans\" addon.\r\n\r\nSame for sign language - if there is a dataset of videos, one addon can be to run OpenPose, another to run ARKit4 pose estimation, and another to run PoseNet, or even just a video embedding addon. (which are expensive to run individually for everyone who wants to use these data)\r\n\r\nThis is something I dabbled with my own implementation to a [research datasets library](https://github.com/AmitMY/meta-scholar/) and I love to get the discussion going on these topics.",
"This is a really cool idea !\r\nThe example for data objects you gave for the RWTH-PHOENIX-Weather 2014 T dataset can totally fit inside the library.\r\n\r\nFor your point about formats like `ilex`, `eaf`, or `srt`, it is possible to use any library in your dataset script.\r\nHowever most user probably won't need these libraries, as most datasets don't need them, and therefore it's unlikely that we will have them in the minimum requirements to use `nlp` (we want to keep it as light-weight as possible). If a user wants to load your dataset and doesn't have the libraries you need, an error is raised asking the user to install them.\r\n\r\nMore generally, we plan to have something like a `requirements.txt` per dataset. This could also be a place for addons as you said. What do you think ?",
"Thanks, Quentin, I think a `requirements.txt` per dataset will be a good thing.\r\nI will work on adding this dataset next week, and once we sort all of the kinks, I'll add more."
] | 2020-06-23T14:53:40
| 2020-11-25T11:25:33
| 2020-11-25T11:25:33
|
CONTRIBUTOR
| null | null | null | null |
An emerging field in NLP is SLP - sign language processing.
I was wondering about adding datasets here, specifically because it's shaping up to be large and easily usable.
The metrics for sign language to text translation are the same.
So, what do you think about (me, or others) adding datasets here?
An example dataset would be [RWTH-PHOENIX-Weather 2014 T](https://www-i6.informatik.rwth-aachen.de/~koller/RWTH-PHOENIX-2014-T/)
For every item in the dataset, the data object includes:
1. video_path - path to mp4 file
2. pose_path - a path to `.pose` file with human pose landmarks
3. openpose_path - a path to a `.json` file with human pose landmarks
4. gloss - string
5. text - string
6. video_metadata - height, width, frames, framerate
------
To make it a tad more complicated - what if sign language libraries add requirements to `nlp`? for example, sign language is commonly annotated using `ilex`, `eaf`, or `srt` files, which are all loadable as text, but there is no reason for the dataset to parse that file by itself, if libraries exist to do so.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://api.github.com/users/AmitMY/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AmitMY",
"id": 5757359,
"login": "AmitMY",
"node_id": "MDQ6VXNlcjU3NTczNTk=",
"organizations_url": "https://api.github.com/users/AmitMY/orgs",
"received_events_url": "https://api.github.com/users/AmitMY/received_events",
"repos_url": "https://api.github.com/users/AmitMY/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AmitMY/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AmitMY/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AmitMY",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/302/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/302/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 154 days, 20:31:53
|
https://api.github.com/repos/huggingface/datasets/issues/301
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/301/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/301/comments
|
https://api.github.com/repos/huggingface/datasets/issues/301/events
|
https://github.com/huggingface/datasets/issues/301
| 643,763,525
|
MDU6SXNzdWU2NDM3NjM1MjU=
| 301
|
Setting cache_dir gives error on wikipedia download
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33862536?v=4",
"events_url": "https://api.github.com/users/hallvagi/events{/privacy}",
"followers_url": "https://api.github.com/users/hallvagi/followers",
"following_url": "https://api.github.com/users/hallvagi/following{/other_user}",
"gists_url": "https://api.github.com/users/hallvagi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hallvagi",
"id": 33862536,
"login": "hallvagi",
"node_id": "MDQ6VXNlcjMzODYyNTM2",
"organizations_url": "https://api.github.com/users/hallvagi/orgs",
"received_events_url": "https://api.github.com/users/hallvagi/received_events",
"repos_url": "https://api.github.com/users/hallvagi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hallvagi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hallvagi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hallvagi",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Whoops didn't mean to close this one.\r\nI did some changes, could you try to run it from the master branch ?",
"Now it works, thanks!"
] | 2020-06-23T11:31:44
| 2020-06-24T07:05:07
| 2020-06-24T07:05:07
|
NONE
| null | null | null | null |
First of all thank you for a super handy library! I'd like to download large files to a specific drive so I set `cache_dir=my_path`. This works fine with e.g. imdb and squad. But on wikipedia I get an error:
```
nlp.load_dataset('wikipedia', '20200501.de', split = 'train', cache_dir=my_path)
```
```
OSError Traceback (most recent call last)
<ipython-input-2-23551344d7bc> in <module>
1 import nlp
----> 2 nlp.load_dataset('wikipedia', '20200501.de', split = 'train', cache_dir=path)
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
385 with utils.temporary_assignment(self, "_cache_dir", tmp_data_dir):
386 reader = ArrowReader(self._cache_dir, self.info)
--> 387 reader.download_from_hf_gcs(self._cache_dir, self._relative_data_dir(with_version=True))
388 downloaded_info = DatasetInfo.from_directory(self._cache_dir)
389 self.info.update(downloaded_info)
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/arrow_reader.py in download_from_hf_gcs(self, cache_dir, relative_data_dir)
231 remote_dataset_info = os.path.join(remote_cache_dir, "dataset_info.json")
232 downloaded_dataset_info = cached_path(remote_dataset_info)
--> 233 os.rename(downloaded_dataset_info, os.path.join(cache_dir, "dataset_info.json"))
234 if self._info is not None:
235 self._info.update(self._info.from_directory(cache_dir))
OSError: [Errno 18] Invalid cross-device link: '/home/local/NTU/nn/.cache/huggingface/datasets/025fa4fd4f04aaafc9e939260fbc8f0bb190ce14c61310c8ae1ddd1dcb31f88c.9637f367b6711a79ca478be55fe6989b8aea4941b7ef7adc67b89ff403020947' -> '/data/nn/nlp/wikipedia/20200501.de/1.0.0.incomplete/dataset_info.json'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33862536?v=4",
"events_url": "https://api.github.com/users/hallvagi/events{/privacy}",
"followers_url": "https://api.github.com/users/hallvagi/followers",
"following_url": "https://api.github.com/users/hallvagi/following{/other_user}",
"gists_url": "https://api.github.com/users/hallvagi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hallvagi",
"id": 33862536,
"login": "hallvagi",
"node_id": "MDQ6VXNlcjMzODYyNTM2",
"organizations_url": "https://api.github.com/users/hallvagi/orgs",
"received_events_url": "https://api.github.com/users/hallvagi/received_events",
"repos_url": "https://api.github.com/users/hallvagi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hallvagi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hallvagi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hallvagi",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/301/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/301/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 19:33:23
|
https://api.github.com/repos/huggingface/datasets/issues/297
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/297/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/297/comments
|
https://api.github.com/repos/huggingface/datasets/issues/297/events
|
https://github.com/huggingface/datasets/issues/297
| 643,444,625
|
MDU6SXNzdWU2NDM0NDQ2MjU=
| 297
|
Error in Demo for Specific Datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/60150701?v=4",
"events_url": "https://api.github.com/users/s-jse/events{/privacy}",
"followers_url": "https://api.github.com/users/s-jse/followers",
"following_url": "https://api.github.com/users/s-jse/following{/other_user}",
"gists_url": "https://api.github.com/users/s-jse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/s-jse",
"id": 60150701,
"login": "s-jse",
"node_id": "MDQ6VXNlcjYwMTUwNzAx",
"organizations_url": "https://api.github.com/users/s-jse/orgs",
"received_events_url": "https://api.github.com/users/s-jse/received_events",
"repos_url": "https://api.github.com/users/s-jse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/s-jse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/s-jse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/s-jse",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
| null |
[] |
[
"Thanks for reporting these errors :)\r\n\r\nI can actually see two issues here.\r\n\r\nFirst, datasets like `natural_questions` require apache_beam to be processed. Right now the import is not at the right place so we have this error message. However, even the imports are fixed, the nlp viewer doesn't actually have the resources to process NQ right now so we'll have to wait until we have a version that we've already processed on our google storage (that's what we've done for wikipedia for example).\r\n\r\nSecond, datasets like `newsroom` require manual downloads as we're not allowed to redistribute the data ourselves (if I'm not wrong). An error message should be displayed saying that we're not allowed to show the dataset.\r\n\r\nI can fix the first issue with the imports but for the second one I think we'll have to see with @srush to show a message for datasets that require manual downloads (it can be checked whether a dataset requires manual downloads if `dataset_builder_instance.manual_download_instructions is not None`).\r\n\r\n",
"I added apache-beam to the viewer. We can think about how to add newsroom. ",
"We don't plan to host the source files of newsroom ourselves for now.\r\nYou can still get the dataset if you follow the download instructions given by `dataset = load_dataset('newsroom')` though.\r\nThe viewer also shows the instructions now.\r\n\r\nClosing this one. If you have other questions, feel free to re-open :)"
] | 2020-06-23T00:38:42
| 2020-07-17T17:43:06
| 2020-07-17T17:43:06
|
NONE
| null | null | null | null |
Selecting `natural_questions` or `newsroom` dataset in the online demo results in an error similar to the following.

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/297/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/297/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 24 days, 17:04:24
|
https://api.github.com/repos/huggingface/datasets/issues/296
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/296/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/296/comments
|
https://api.github.com/repos/huggingface/datasets/issues/296/events
|
https://github.com/huggingface/datasets/issues/296
| 643,423,717
|
MDU6SXNzdWU2NDM0MjM3MTc=
| 296
|
snli -1 labels
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"@jxmorris12 , we use `-1` to label examples for which `gold label` is missing (`gold label = -` in the original dataset). ",
"Thanks @mariamabarham! so the original dataset is missing some labels? That is weird. Is standard practice just to discard those examples training/eval?",
"Yes the original dataset is missing some labels maybe @sleepinyourhat , @gangeli can correct me if I'm wrong \r\nFor my personal opinion at least if you want your model to learn to predict no answer (-1) you can leave it their but otherwise you can discard them. ",
"thanks @mariamabarham :)"
] | 2020-06-22T23:33:30
| 2020-06-23T14:41:59
| 2020-06-23T14:41:58
|
CONTRIBUTOR
| null | null | null | null |
I'm trying to train a model on the SNLI dataset. Why does it have so many -1 labels?
```
import nlp
from collections import Counter
data = nlp.load_dataset('snli')['train']
print(Counter(data['label']))
Counter({0: 183416, 2: 183187, 1: 182764, -1: 785})
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/296/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/296/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 15:08:28
|
https://api.github.com/repos/huggingface/datasets/issues/295
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/295/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/295/comments
|
https://api.github.com/repos/huggingface/datasets/issues/295/events
|
https://github.com/huggingface/datasets/issues/295
| 643,245,412
|
MDU6SXNzdWU2NDMyNDU0MTI=
| 295
|
Improve input warning for evaluation metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19514537?v=4",
"events_url": "https://api.github.com/users/Tiiiger/events{/privacy}",
"followers_url": "https://api.github.com/users/Tiiiger/followers",
"following_url": "https://api.github.com/users/Tiiiger/following{/other_user}",
"gists_url": "https://api.github.com/users/Tiiiger/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tiiiger",
"id": 19514537,
"login": "Tiiiger",
"node_id": "MDQ6VXNlcjE5NTE0NTM3",
"organizations_url": "https://api.github.com/users/Tiiiger/orgs",
"received_events_url": "https://api.github.com/users/Tiiiger/received_events",
"repos_url": "https://api.github.com/users/Tiiiger/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tiiiger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tiiiger/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tiiiger",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-06-22T17:28:57
| 2020-06-23T14:47:37
| 2020-06-23T14:47:37
|
NONE
| null | null | null | null |
Hi,
I am the author of `bert_score`. Recently, we received [ an issue ](https://github.com/Tiiiger/bert_score/issues/62) reporting a problem in using `bert_score` from the `nlp` package (also see #238 in this repo). After looking into this, I realized that the problem arises from the format `nlp.Metric` takes input.
Here is a minimal example:
```python
import nlp
scorer = nlp.load_metric("bertscore")
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
scorer.add(lp, lg)
score = scorer.compute(lang="en")
```
The problem in the above code is that `scorer.add()` expects a list of strings as input for the references. As a result, the `scorer` here would take a list of characters in `lg` to be the references. The correct implementation would be calling
```python
scorer.add(lp, [lg])
```
I just want to raise this issue to you to prevent future user errors of a similar kind. I assume some simple type checking can prevent this from happening?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/295/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/295/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 21:18:40
|
https://api.github.com/repos/huggingface/datasets/issues/294
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/294/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/294/comments
|
https://api.github.com/repos/huggingface/datasets/issues/294/events
|
https://github.com/huggingface/datasets/issues/294
| 643,181,179
|
MDU6SXNzdWU2NDMxODExNzk=
| 294
|
Cannot load arxiv dataset on MacOS?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url": "https://api.github.com/users/JohnGiorgi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JohnGiorgi",
"id": 8917831,
"login": "JohnGiorgi",
"node_id": "MDQ6VXNlcjg5MTc4MzE=",
"organizations_url": "https://api.github.com/users/JohnGiorgi/orgs",
"received_events_url": "https://api.github.com/users/JohnGiorgi/received_events",
"repos_url": "https://api.github.com/users/JohnGiorgi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JohnGiorgi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JohnGiorgi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JohnGiorgi",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"I couldn't replicate this issue on my macbook :/\r\nCould you try to play with different encodings in `with open(path, encoding=...) as f` in scientific_papers.py:L108 ?",
"I was able to track down the file causing the problem by adding the following to `scientific_papers.py` (starting at line 116):\r\n\r\n```python\r\n from json import JSONDecodeError\r\n try:\r\n d = json.loads(line)\r\n summary = \"\\n\".join(d[\"abstract_text\"])\r\n except JSONDecodeError:\r\n print(path, line)\r\n```\r\n\r\n\r\n\r\nFor me it was at: `/Users/johngiorgi/.cache/huggingface/datasets/f87fd498c5003cbe253a2af422caa1e58f87a4fd74cb3e67350c635c8903b259/arxiv-dataset/train.txt` with `\"article_id\": \"1407.3051\"`.\r\n\r\nNot really 100% sure at the moment, but it looks like this specific substring from `\"article_text\"` may be causing the problem?\r\n\r\n```\r\n\"after the missing - mass scale adjustment , the validity of the corrections was tested in the @xmath85 productions at 1.69 gev/@xmath1 . in fig . [\", \"fig : calibrations ] ( a ) , we show the missing - mass spectrum in the @xmath86 region in the @xmath87 reaction at 1.69 gev/@xmath1 . a fitting result with a lorentzian function for the @xmath86 ( dashed line ) and the three - body phas\r\n```\r\n\r\nperhaps because it appears to be truncated. I (think) I can recreate the problem by doing the following:\r\n\r\n```python\r\nimport json\r\n\r\n# A minimal example of the json file that causes the error\r\ninvalid_json = '{\"article_id\": \"1407.3051\", \"article_text\": [\"the missing - mass resolution was obtained to be 2.8 @xmath3 0.1 mev/@xmath4 ( fwhm ) , which corresponds to the missing - mass resolution of 3.2 @xmath3 0.2 mev/@xmath4 ( fwhm ) at the @xmath6 cusp region in the @xmath0 reaction .\", \"this resolution is at least by a factor of 2 better than the previous measurement with the same reaction ( 3.2@xmath595.5 mev/@xmath4 in @xmath84 ) @xcite .\", \"after the missing - mass scale adjustment , the validity of the corrections was tested in the @xmath85 productions at 1.69 gev/@xmath1 . in fig . [\", \"fig : calibrations ] ( a ) , we show the missing - mass spectrum in the @xmath86 region in the @xmath87 reaction at 1.69 gev/@xmath1 . a fitting result with a lorentzian function for the @xmath86 ( dashed line ) and the three - body phas' \r\n# The line of code from `scientific_papers.py` which appears to cause the error\r\njson.loads(invalid_json)\r\n```\r\n\r\nThis is as far as I get before I am stumped.",
"I just checked inside `train.txt` and this line isn't truncated for me (line 163577).\r\nCould you try to clear your cache and re-download the dataset ?",
"Ah the turn-it-off-turn-it-on again solution! That did it, thanks a lot :) "
] | 2020-06-22T15:46:55
| 2020-06-30T15:25:10
| 2020-06-30T15:25:10
|
CONTRIBUTOR
| null | null | null | null |
I am having trouble loading the `"arxiv"` config from the `"scientific_papers"` dataset on MacOS. When I try loading the dataset with:
```python
arxiv = nlp.load_dataset("scientific_papers", "arxiv")
```
I get the following stack trace:
```bash
JSONDecodeError Traceback (most recent call last)
<ipython-input-2-8e00c55d5a59> in <module>
----> 1 arxiv = nlp.load_dataset("scientific_papers", "arxiv")
~/miniconda3/envs/t2t/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
~/miniconda3/envs/t2t/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
~/miniconda3/envs/t2t/lib/python3.7/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
481 try:
482 # Prepare split will record examples associated to the split
--> 483 self._prepare_split(split_generator, **prepare_split_kwargs)
484 except OSError:
485 raise OSError("Cannot find data file. " + (self.manual_download_instructions or ""))
~/miniconda3/envs/t2t/lib/python3.7/site-packages/nlp/builder.py in _prepare_split(self, split_generator)
662
663 generator = self._generate_examples(**split_generator.gen_kwargs)
--> 664 for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
665 example = self.info.features.encode_example(record)
666 writer.write(example)
~/miniconda3/envs/t2t/lib/python3.7/site-packages/tqdm/std.py in __iter__(self)
1106 fp_write=getattr(self.fp, 'write', sys.stderr.write))
1107
-> 1108 for obj in iterable:
1109 yield obj
1110 # Update and possibly print the progressbar.
~/miniconda3/envs/t2t/lib/python3.7/site-packages/nlp/datasets/scientific_papers/107a416c0e1958cb846f5934b5aae292f7884a5b27e86af3f3ef1a093e058bbc/scientific_papers.py in _generate_examples(self, path)
114 # "section_names": list[str], list of section names.
115 # "sections": list[list[str]], list of sections (list of paragraphs)
--> 116 d = json.loads(line)
117 summary = "\n".join(d["abstract_text"])
118 # In original paper, <S> and </S> are not used in vocab during training
~/miniconda3/envs/t2t/lib/python3.7/json/__init__.py in loads(s, encoding, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
346 parse_int is None and parse_float is None and
347 parse_constant is None and object_pairs_hook is None and not kw):
--> 348 return _default_decoder.decode(s)
349 if cls is None:
350 cls = JSONDecoder
~/miniconda3/envs/t2t/lib/python3.7/json/decoder.py in decode(self, s, _w)
335
336 """
--> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end())
338 end = _w(s, end).end()
339 if end != len(s):
~/miniconda3/envs/t2t/lib/python3.7/json/decoder.py in raw_decode(self, s, idx)
351 """
352 try:
--> 353 obj, end = self.scan_once(s, idx)
354 except StopIteration as err:
355 raise JSONDecodeError("Expecting value", s, err.value) from None
JSONDecodeError: Unterminated string starting at: line 1 column 46983 (char 46982)
163502 examples [02:10, 2710.68 examples/s]
```
I am not sure how to trace back to the specific JSON file that has the "Unterminated string". Also, I do not get this error on colab so I suspect it may be MacOS specific. Copy pasting the relevant lines from `transformers-cli env` below:
- Platform: Darwin-19.5.0-x86_64-i386-64bit
- Python version: 3.7.5
- PyTorch version (GPU?): 1.5.0 (False)
- Tensorflow version (GPU?): 2.2.0 (False)
Any ideas?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url": "https://api.github.com/users/JohnGiorgi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JohnGiorgi",
"id": 8917831,
"login": "JohnGiorgi",
"node_id": "MDQ6VXNlcjg5MTc4MzE=",
"organizations_url": "https://api.github.com/users/JohnGiorgi/orgs",
"received_events_url": "https://api.github.com/users/JohnGiorgi/received_events",
"repos_url": "https://api.github.com/users/JohnGiorgi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JohnGiorgi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JohnGiorgi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JohnGiorgi",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/294/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/294/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 7 days, 23:38:15
|
https://api.github.com/repos/huggingface/datasets/issues/290
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/290/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/290/comments
|
https://api.github.com/repos/huggingface/datasets/issues/290/events
|
https://github.com/huggingface/datasets/issues/290
| 641,978,286
|
MDU6SXNzdWU2NDE5NzgyODY=
| 290
|
ConnectionError - Eli5 dataset download
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8490096?v=4",
"events_url": "https://api.github.com/users/JovanNj/events{/privacy}",
"followers_url": "https://api.github.com/users/JovanNj/followers",
"following_url": "https://api.github.com/users/JovanNj/following{/other_user}",
"gists_url": "https://api.github.com/users/JovanNj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JovanNj",
"id": 8490096,
"login": "JovanNj",
"node_id": "MDQ6VXNlcjg0OTAwOTY=",
"organizations_url": "https://api.github.com/users/JovanNj/orgs",
"received_events_url": "https://api.github.com/users/JovanNj/received_events",
"repos_url": "https://api.github.com/users/JovanNj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JovanNj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JovanNj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JovanNj",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It should ne fixed now, thanks for reporting this one :)\r\nIt was an issue on our google storage.\r\n\r\nLet me now if you're still facing this issue.",
"It works now, thanks for prompt help!"
] | 2020-06-19T13:40:33
| 2020-06-20T13:22:24
| 2020-06-20T13:22:24
|
NONE
| null | null | null | null |
Hi, I have a problem with downloading Eli5 dataset. When typing `nlp.load_dataset('eli5')`, I get ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/eli5/LFQA_reddit/1.0.0/explain_like_im_five-train_eli5.arrow
I would appreciate if you could help me with this issue.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/290/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/290/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 23:41:51
|
https://api.github.com/repos/huggingface/datasets/issues/288
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/288/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/288/comments
|
https://api.github.com/repos/huggingface/datasets/issues/288/events
|
https://github.com/huggingface/datasets/issues/288
| 641,888,610
|
MDU6SXNzdWU2NDE4ODg2MTA=
| 288
|
Error at the first example in README: AttributeError: module 'dill' has no attribute '_dill'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/14964542?v=4",
"events_url": "https://api.github.com/users/wutong8023/events{/privacy}",
"followers_url": "https://api.github.com/users/wutong8023/followers",
"following_url": "https://api.github.com/users/wutong8023/following{/other_user}",
"gists_url": "https://api.github.com/users/wutong8023/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wutong8023",
"id": 14964542,
"login": "wutong8023",
"node_id": "MDQ6VXNlcjE0OTY0NTQy",
"organizations_url": "https://api.github.com/users/wutong8023/orgs",
"received_events_url": "https://api.github.com/users/wutong8023/received_events",
"repos_url": "https://api.github.com/users/wutong8023/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wutong8023/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wutong8023/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wutong8023",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It looks like the bug comes from `dill`. Which version of `dill` are you using ?",
"Thank you. It is version 0.2.6, which version is better?",
"0.2.6 is three years old now, maybe try a more recent one, e.g. the current 0.3.2 if you can?",
"Thanks guys! I upgraded dill and it works.",
"Awesome"
] | 2020-06-19T11:01:22
| 2020-06-21T09:05:11
| 2020-06-21T09:05:11
|
NONE
| null | null | null | null |
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:469: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:470: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:471: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:472: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:473: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:476: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
/Users/parasol_tree/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6
return f(*args, **kwds)
/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Traceback (most recent call last):
File "/Users/parasol_tree/Resource/019 - Github/AcademicEnglishToolkit /test.py", line 7, in <module>
import nlp
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/__init__.py", line 27, in <module>
from .arrow_dataset import Dataset
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/arrow_dataset.py", line 31, in <module>
from nlp.utils.py_utils import dumps
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/utils/__init__.py", line 20, in <module>
from .download_manager import DownloadManager, GenerateMode
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/utils/download_manager.py", line 25, in <module>
from .py_utils import flatten_nested, map_nested, size_str
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/utils/py_utils.py", line 244, in <module>
class Pickler(dill.Pickler):
File "/Users/parasol_tree/anaconda3/lib/python3.6/site-packages/nlp/utils/py_utils.py", line 247, in Pickler
dispatch = dill._dill.MetaCatchingDict(dill.Pickler.dispatch.copy())
AttributeError: module 'dill' has no attribute '_dill'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/288/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/288/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 22:03:49
|
https://api.github.com/repos/huggingface/datasets/issues/283
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/283/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/283/comments
|
https://api.github.com/repos/huggingface/datasets/issues/283/events
|
https://github.com/huggingface/datasets/issues/283
| 641,270,439
|
MDU6SXNzdWU2NDEyNzA0Mzk=
| 283
|
Consistent formatting of citations
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
] |
[] | 2020-06-18T14:48:45
| 2020-06-22T17:30:46
| 2020-06-22T17:30:46
|
CONTRIBUTOR
| null | null | null | null |
The citations are all of a different format, some have "```" and have text inside, others are proper bibtex.
Can we make it so that they all are proper citations, i.e. parse by the bibtex spec:
https://bibtexparser.readthedocs.io/en/master/
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/283/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/283/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 2:42:01
|
https://api.github.com/repos/huggingface/datasets/issues/281
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/281/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/281/comments
|
https://api.github.com/repos/huggingface/datasets/issues/281/events
|
https://github.com/huggingface/datasets/issues/281
| 641,067,856
|
MDU6SXNzdWU2NDEwNjc4NTY=
| 281
|
Private/sensitive data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "https://api.github.com/users/MFreidank/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MFreidank",
"id": 6368040,
"login": "MFreidank",
"node_id": "MDQ6VXNlcjYzNjgwNDA=",
"organizations_url": "https://api.github.com/users/MFreidank/orgs",
"received_events_url": "https://api.github.com/users/MFreidank/received_events",
"repos_url": "https://api.github.com/users/MFreidank/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MFreidank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MFreidank/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MFreidank",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @MFreidank, you should already be able to load a dataset from local sources, indeed. (ping @lhoestq and @jplu)\r\n\r\nWe're also thinking about the ability to host private datasets on a hosted bucket with permission management, but that's further down the road.",
"Hi @MFreidank, it is possible to load a dataset from your local storage, but only CSV/TSV and JSON are supported. To load a dataset in JSON format:\r\n\r\n```\r\nnlp.load_dataset(path=\"json\", data_files={nlp.Split.TRAIN: [\"path/to/train.json\"], nlp.Split.TEST: [\"path/to/test.json\"]})\r\n```\r\n\r\nFor CSV/TSV datasets, you have to replace `json` by `csv`.",
"Hi @julien-c @jplu,\r\nThanks for sharing this solution with me, it helps, this is what I was looking for. \r\nIf not already there and only missed by me, this could be a great addition in the docs.\r\n\r\nClosing my issue as resolved, thanks again."
] | 2020-06-18T09:47:27
| 2020-06-20T13:15:12
| 2020-06-20T13:15:12
|
CONTRIBUTOR
| null | null | null | null |
Hi all,
Thanks for this fantastic library, it makes it very easy to do prototyping for NLP projects interchangeably between TF/Pytorch.
Unfortunately, there is data that cannot easily be shared publicly as it may contain sensitive information.
Is there support/a plan to support such data with NLP, e.g. by reading it from local sources?
Use case flow could look like this: use NLP to prototype an approach on similar, public data and apply the resulting prototype on sensitive/private data without the need to rethink data processing pipelines.
Many thanks for your responses ahead of time and kind regards,
MFreidank
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "https://api.github.com/users/MFreidank/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MFreidank",
"id": 6368040,
"login": "MFreidank",
"node_id": "MDQ6VXNlcjYzNjgwNDA=",
"organizations_url": "https://api.github.com/users/MFreidank/orgs",
"received_events_url": "https://api.github.com/users/MFreidank/received_events",
"repos_url": "https://api.github.com/users/MFreidank/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MFreidank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MFreidank/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MFreidank",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/281/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/281/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 3:27:45
|
https://api.github.com/repos/huggingface/datasets/issues/280
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/280/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/280/comments
|
https://api.github.com/repos/huggingface/datasets/issues/280/events
|
https://github.com/huggingface/datasets/issues/280
| 640,677,615
|
MDU6SXNzdWU2NDA2Nzc2MTU=
| 280
|
Error with SquadV2 Metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32203792?v=4",
"events_url": "https://api.github.com/users/avinregmi/events{/privacy}",
"followers_url": "https://api.github.com/users/avinregmi/followers",
"following_url": "https://api.github.com/users/avinregmi/following{/other_user}",
"gists_url": "https://api.github.com/users/avinregmi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avinregmi",
"id": 32203792,
"login": "avinregmi",
"node_id": "MDQ6VXNlcjMyMjAzNzky",
"organizations_url": "https://api.github.com/users/avinregmi/orgs",
"received_events_url": "https://api.github.com/users/avinregmi/received_events",
"repos_url": "https://api.github.com/users/avinregmi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avinregmi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinregmi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avinregmi",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[] | 2020-06-17T19:10:54
| 2020-06-19T08:33:41
| 2020-06-19T08:33:41
|
NONE
| null | null | null | null |
I can't seem to import squad v2 metrics.
**squad_metric = nlp.load_metric('squad_v2')**
**This throws me an error.:**
```
ImportError Traceback (most recent call last)
<ipython-input-8-170b6a170555> in <module>
----> 1 squad_metric = nlp.load_metric('squad_v2')
~/env/lib64/python3.6/site-packages/nlp/load.py in load_metric(path, name, process_id, num_process, data_dir, experiment_id, in_memory, download_config, **metric_init_kwargs)
426 """
427 module_path = prepare_module(path, download_config=download_config, dataset=False)
--> 428 metric_cls = import_main_class(module_path, dataset=False)
429 metric = metric_cls(
430 name=name,
~/env/lib64/python3.6/site-packages/nlp/load.py in import_main_class(module_path, dataset)
55 """
56 importlib.invalidate_caches()
---> 57 module = importlib.import_module(module_path)
58
59 if dataset:
/usr/lib64/python3.6/importlib/__init__.py in import_module(name, package)
124 break
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
127
128
/usr/lib64/python3.6/importlib/_bootstrap.py in _gcd_import(name, package, level)
/usr/lib64/python3.6/importlib/_bootstrap.py in _find_and_load(name, import_)
/usr/lib64/python3.6/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
/usr/lib64/python3.6/importlib/_bootstrap.py in _load_unlocked(spec)
/usr/lib64/python3.6/importlib/_bootstrap_external.py in exec_module(self, module)
/usr/lib64/python3.6/importlib/_bootstrap.py in _call_with_frames_removed(f, *args, **kwds)
~/env/lib64/python3.6/site-packages/nlp/metrics/squad_v2/a15e787c76889174874386d3def75321f0284c11730d2a57e28fe1352c9b5c7a/squad_v2.py in <module>
16
17 import nlp
---> 18 from .evaluate import evaluate
19
20 _CITATION = """\
ImportError: cannot import name 'evaluate'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/280/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/280/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 13:22:47
|
https://api.github.com/repos/huggingface/datasets/issues/279
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/279/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/279/comments
|
https://api.github.com/repos/huggingface/datasets/issues/279/events
|
https://github.com/huggingface/datasets/issues/279
| 640,611,692
|
MDU6SXNzdWU2NDA2MTE2OTI=
| 279
|
Dataset Preprocessing Cache with .map() function not working as expected
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"When you're processing a dataset with `.map`, it checks whether it has already done this computation using a hash based on the function and the input (using some fancy serialization with `dill`). If you found that it doesn't work as expected in some cases, let us know !\r\n\r\nGiven that, you can still force to re-process using `.map(my_func, load_from_cache_file=False)` if you want to.\r\n\r\nI am curious about the problem you have with splits. It makes me think about #160 that was an issue of version 0.1.0. What version of `nlp` are you running ? Could you give me more details ?",
"Thanks, that's helpful! I was running 0.1.0, but since upgraded to 0.2.1. I can't reproduce the issue anymore as I've cleared the cache & everything now seems to be running fine since the upgrade. I've added some checks to my code, so if I do encounter it again I will reopen this issue.",
"Just checking in, the cache sometimes still does not work when I make changes in my processing function in version `1.2.1`. The changes made to my data processing function only propagate to the dataset when I use `load_from_cache_file=False` or clear the cache. Is this a system-specific issue?",
"Hi @sarahwie \r\nThe data are reloaded from the cache if the hash of the function you provide is the same as a computation you've done before. The hash is computed by recursively looking at the python objects of the function you provide.\r\n\r\nIf you think there's an issue, can you share the function you used or a google colab please ?",
"I can't reproduce it, so I'll close for now."
] | 2020-06-17T17:17:21
| 2021-07-06T21:43:28
| 2021-04-18T23:43:49
|
NONE
| null | null | null | null |
I've been having issues with reproducibility when loading and processing datasets with the `.map` function. I was only able to resolve them by clearing all of the cache files on my system.
Is there a way to disable using the cache when processing a dataset? As I make minor processing changes on the same dataset, I want to be able to be certain the data is being re-processed rather than loaded from a cached file.
Could you also help me understand a bit more about how the caching functionality is used for pre-processing? E.g. how is it determined when to load from a cache vs. reprocess.
I was particularly having an issue where the correct dataset splits were loaded, but as soon as I applied the `.map()` function to each split independently, they somehow all exited this process having been converted to the test set.
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/279/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/279/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 305 days, 6:26:28
|
https://api.github.com/repos/huggingface/datasets/issues/278
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/278/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/278/comments
|
https://api.github.com/repos/huggingface/datasets/issues/278/events
|
https://github.com/huggingface/datasets/issues/278
| 640,518,917
|
MDU6SXNzdWU2NDA1MTg5MTc=
| 278
|
MemoryError when loading German Wikipedia
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4698028?v=4",
"events_url": "https://api.github.com/users/gregburman/events{/privacy}",
"followers_url": "https://api.github.com/users/gregburman/followers",
"following_url": "https://api.github.com/users/gregburman/following{/other_user}",
"gists_url": "https://api.github.com/users/gregburman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gregburman",
"id": 4698028,
"login": "gregburman",
"node_id": "MDQ6VXNlcjQ2OTgwMjg=",
"organizations_url": "https://api.github.com/users/gregburman/orgs",
"received_events_url": "https://api.github.com/users/gregburman/received_events",
"repos_url": "https://api.github.com/users/gregburman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gregburman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gregburman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gregburman",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi !\r\n\r\nAs you noticed, \"big\" datasets like Wikipedia require apache beam to be processed.\r\nHowever users usually don't have an apache beam runtime available (spark, dataflow, etc.) so our goal for this library is to also make available processed versions of these datasets, so that users can just download and use them right away.\r\n\r\nThis is the case for english and french wikipedia right now: we've processed them ourselves and now they are available from our google storage. However we've not processed the german one (yet).",
"Hi @lhoestq \r\n\r\nThank you for your quick reply. I thought this might be the case, that the processing was done for some languages and not for others. Is there any set timeline for when other languages (German, Italian) will be processed?\r\n\r\nGiven enough memory, is it possible to process the data ourselves by specifying the `beam_runner`?",
"Adding them is definitely in our short term objectives. I'll be working on this early next week :)\r\n\r\nAlthough if you have an apache beam runtime feel free to specify the beam runner. You can find more info [here](https://github.com/huggingface/nlp/blob/master/docs/beam_dataset.md) on how to make it work on Dataflow but you can adapt it for Spark or any other beam runtime (by changing the `runner`).\r\n\r\nHowever if you don't have a beam runtime and even if you have enough memory, I discourage you to use the `DirectRunner` on the german or italian wikipedia. According to Apache Beam documentation it was made for testing purposes and therefore it is memory-inefficient.",
"German is [almost] done @gregburman",
"I added the German and the Italian Wikipedia to our google cloud storage:\r\nFirst update the `nlp` package to 0.3.0:\r\n```bash\r\npip install nlp --upgrade\r\n```\r\nand then\r\n```python\r\nfrom nlp import load_dataset\r\nwiki_de = load_dataset(\"wikipedia\", \"20200501.de\")\r\nwiki_it = load_dataset(\"wikipedia\", \"20200501.it\")\r\n```\r\nThe datasets are downloaded and directly ready to use (no processing).",
"Hi @lhoestq \r\n\r\nWow, thanks so much, that's **really** incredible! I was considering looking at creating my own Beam Dataset, as per the doc you linked, but instead opted to process the data myself using `wikiextractor`. However, now that this is available, I'll definitely switch across and use it.\r\n\r\nThanks so much for the incredible work, this really helps out our team considerably!\r\n\r\nHave a great (and well-deserved ;) weekend ahead!\r\n\r\nP.S. I'm not sure if I should close the issue here - if so I'm happy to do so.",
"Thanks for your message, glad I could help :)\r\nClosing this one."
] | 2020-06-17T15:06:21
| 2020-06-19T12:53:02
| 2020-06-19T12:53:02
|
NONE
| null | null | null | null |
Hi, first off let me say thank you for all the awesome work you're doing at Hugging Face across all your projects (NLP, Transformers, Tokenizers) - they're all amazing contributions to us working with NLP models :)
I'm trying to download the German Wikipedia dataset as follows:
```
wiki = nlp.load_dataset("wikipedia", "20200501.de", split="train")
```
However, when I do so, I get the following error:
```
Downloading and preparing dataset wikipedia/20200501.de (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/ubuntu/.cache/huggingface/datasets/wikipedia/20200501.de/1.0.0...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ubuntu/anaconda3/envs/albert/lib/python3.7/site-packages/nlp/load.py", line 520, in load_dataset
save_infos=save_infos,
File "/home/ubuntu/anaconda3/envs/albert/lib/python3.7/site-packages/nlp/builder.py", line 433, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/ubuntu/anaconda3/envs/albert/lib/python3.7/site-packages/nlp/builder.py", line 824, in _download_and_prepare
"\n\t`{}`".format(usage_example)
nlp.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.de', beam_runner='DirectRunner')`
```
So, following on from the example usage at the bottom, I tried specifying `beam_runner='DirectRunner`, however when I do this after about 20 min after the data has all downloaded, I get a `MemoryError` as warned.
This isn't an issue for the English or French Wikipedia datasets (I've tried both), as neither seem to require that `beam_runner` be specified. Can you please clarify why this is an issue for the German dataset?
My nlp version is 0.2.1.
Thank you!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/278/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/278/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 21:46:41
|
https://api.github.com/repos/huggingface/datasets/issues/277
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/277/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/277/comments
|
https://api.github.com/repos/huggingface/datasets/issues/277/events
|
https://github.com/huggingface/datasets/issues/277
| 640,163,053
|
MDU6SXNzdWU2NDAxNjMwNTM=
| 277
|
Empty samples in glue/qqp
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"We are only wrapping the original dataset.\r\n\r\nMaybe try to ask on the GLUE mailing list or reach out to the original authors?",
"Tanks for the suggestion, I'll try to ask GLUE benchmark.\r\nI'll first close the issue, post the following up here afterwards, and reopen the issue if needed. "
] | 2020-06-17T05:54:52
| 2020-06-21T00:21:45
| 2020-06-21T00:21:45
|
CONTRIBUTOR
| null | null | null | null |
```
qqp = nlp.load_dataset('glue', 'qqp')
print(qqp['train'][310121])
print(qqp['train'][362225])
```
```
{'question1': 'How can I create an Android app?', 'question2': '', 'label': 0, 'idx': 310137}
{'question1': 'How can I develop android app?', 'question2': '', 'label': 0, 'idx': 362246}
```
Notice that question 2 is empty string.
BTW, I have checked and these two are the only naughty ones in all splits of qqp.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/277/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/277/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 18:26:53
|
https://api.github.com/repos/huggingface/datasets/issues/275
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/275/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/275/comments
|
https://api.github.com/repos/huggingface/datasets/issues/275/events
|
https://github.com/huggingface/datasets/issues/275
| 639,439,052
|
MDU6SXNzdWU2Mzk0MzkwNTI=
| 275
|
NonMatchingChecksumError when loading pubmed dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48441753?v=4",
"events_url": "https://api.github.com/users/DavideStenner/events{/privacy}",
"followers_url": "https://api.github.com/users/DavideStenner/followers",
"following_url": "https://api.github.com/users/DavideStenner/following{/other_user}",
"gists_url": "https://api.github.com/users/DavideStenner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/DavideStenner",
"id": 48441753,
"login": "DavideStenner",
"node_id": "MDQ6VXNlcjQ4NDQxNzUz",
"organizations_url": "https://api.github.com/users/DavideStenner/orgs",
"received_events_url": "https://api.github.com/users/DavideStenner/received_events",
"repos_url": "https://api.github.com/users/DavideStenner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/DavideStenner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DavideStenner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/DavideStenner",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] |
[
"For some reason the files are not available for unauthenticated users right now (like the download service of this package). Instead of downloading the right files, it downloads the html of the error.\r\nAccording to the error it should be back again in 24h.\r\n\r\n\r\n"
] | 2020-06-16T07:31:51
| 2020-06-19T07:37:07
| 2020-06-19T07:37:07
|
NONE
| null | null | null | null |
I get this error when i run `nlp.load_dataset('scientific_papers', 'pubmed', split = 'train[:50%]')`.
The error is:
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-7742dea167d0> in <module>()
----> 1 df = nlp.load_dataset('scientific_papers', 'pubmed', split = 'train[:50%]')
2 df = pd.DataFrame(df)
3 gc.collect()
3 frames
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
431 verify_infos = not save_infos and not ignore_verifications
432 self._download_and_prepare(
--> 433 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
434 )
435 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
468 # Checksums verification
469 if verify_infos:
--> 470 verify_checksums(self.info.download_checksums, dl_manager.get_recorded_sizes_checksums())
471 for split_generator in split_generators:
472 if str(split_generator.split_info.name).lower() == "all":
/usr/local/lib/python3.6/dist-packages/nlp/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums)
34 bad_urls = [url for url in expected_checksums if expected_checksums[url] != recorded_checksums[url]]
35 if len(bad_urls) > 0:
---> 36 raise NonMatchingChecksumError(str(bad_urls))
37 logger.info("All the checksums matched successfully.")
38
NonMatchingChecksumError: ['https://drive.google.com/uc?id=1b3rmCSIoh6VhD4HKWjI4HOW-cSwcwbeC&export=download', 'https://drive.google.com/uc?id=1lvsqvsFi3W-pE1SqNZI0s8NR9rC1tsja&export=download']
```
I'm currently working on google colab.
That is quite strange because yesterday it was fine.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48441753?v=4",
"events_url": "https://api.github.com/users/DavideStenner/events{/privacy}",
"followers_url": "https://api.github.com/users/DavideStenner/followers",
"following_url": "https://api.github.com/users/DavideStenner/following{/other_user}",
"gists_url": "https://api.github.com/users/DavideStenner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/DavideStenner",
"id": 48441753,
"login": "DavideStenner",
"node_id": "MDQ6VXNlcjQ4NDQxNzUz",
"organizations_url": "https://api.github.com/users/DavideStenner/orgs",
"received_events_url": "https://api.github.com/users/DavideStenner/received_events",
"repos_url": "https://api.github.com/users/DavideStenner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/DavideStenner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DavideStenner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/DavideStenner",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/275/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/275/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 0:05:16
|
https://api.github.com/repos/huggingface/datasets/issues/274
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/274/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/274/comments
|
https://api.github.com/repos/huggingface/datasets/issues/274/events
|
https://github.com/huggingface/datasets/issues/274
| 639,156,625
|
MDU6SXNzdWU2MzkxNTY2MjU=
| 274
|
PG-19
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/108653?v=4",
"events_url": "https://api.github.com/users/lucidrains/events{/privacy}",
"followers_url": "https://api.github.com/users/lucidrains/followers",
"following_url": "https://api.github.com/users/lucidrains/following{/other_user}",
"gists_url": "https://api.github.com/users/lucidrains/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucidrains",
"id": 108653,
"login": "lucidrains",
"node_id": "MDQ6VXNlcjEwODY1Mw==",
"organizations_url": "https://api.github.com/users/lucidrains/orgs",
"received_events_url": "https://api.github.com/users/lucidrains/received_events",
"repos_url": "https://api.github.com/users/lucidrains/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucidrains/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucidrains/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucidrains",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] |
[
"Sounds good! Do you want to give it a try?",
"Ok, I'll see if I can figure it out tomorrow!",
"Got around to this today, and so far so good, I'm able to download and load pg19 locally. However, I think there may be an issue with the dummy data, and testing in general.\r\n\r\nThe problem lies in the fact that each book from pg19 actually resides as its own text file in a google cloud folder that denotes the split, where the book id is the name of the text file. https://console.cloud.google.com/storage/browser/deepmind-gutenberg/train/ I don't believe there's anywhere else (even in the supplied metadata), where the mapping of id -> split can be found.\r\n\r\nTherefore I end up making a network call `tf.io.gfile.listdir` to get all the files within each of the split directories. https://github.com/lucidrains/nlp/commit/adbacbd85decc80db2347d0882e7dab4faa6fd03#diff-cece8f166a85dd927caf574ba303d39bR78\r\n\r\nDoes this network call need to be eventually stubbed out for testing?",
"Ohh nevermind, I think I can use `download_custom` here with `listdir` as the custom function. Ok, I'll keep trying to make the dummy data work!"
] | 2020-06-15T21:02:26
| 2020-07-06T15:35:02
| 2020-07-06T15:35:02
|
CONTRIBUTOR
| null | null | null | null |
Hi, and thanks for all your open-sourced work, as always!
I was wondering if you would be open to adding PG-19 to your collection of datasets. https://github.com/deepmind/pg19 It is often used for benchmarking long-range language modeling.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/108653?v=4",
"events_url": "https://api.github.com/users/lucidrains/events{/privacy}",
"followers_url": "https://api.github.com/users/lucidrains/followers",
"following_url": "https://api.github.com/users/lucidrains/following{/other_user}",
"gists_url": "https://api.github.com/users/lucidrains/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucidrains",
"id": 108653,
"login": "lucidrains",
"node_id": "MDQ6VXNlcjEwODY1Mw==",
"organizations_url": "https://api.github.com/users/lucidrains/orgs",
"received_events_url": "https://api.github.com/users/lucidrains/received_events",
"repos_url": "https://api.github.com/users/lucidrains/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucidrains/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucidrains/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucidrains",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/274/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/274/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 20 days, 18:32:36
|
https://api.github.com/repos/huggingface/datasets/issues/270
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/270/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/270/comments
|
https://api.github.com/repos/huggingface/datasets/issues/270/events
|
https://github.com/huggingface/datasets/issues/270
| 638,121,617
|
MDU6SXNzdWU2MzgxMjE2MTc=
| 270
|
c4 dataset is not viewable in nlpviewer demo
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6441313?v=4",
"events_url": "https://api.github.com/users/rajarsheem/events{/privacy}",
"followers_url": "https://api.github.com/users/rajarsheem/followers",
"following_url": "https://api.github.com/users/rajarsheem/following{/other_user}",
"gists_url": "https://api.github.com/users/rajarsheem/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rajarsheem",
"id": 6441313,
"login": "rajarsheem",
"node_id": "MDQ6VXNlcjY0NDEzMTM=",
"organizations_url": "https://api.github.com/users/rajarsheem/orgs",
"received_events_url": "https://api.github.com/users/rajarsheem/received_events",
"repos_url": "https://api.github.com/users/rajarsheem/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rajarsheem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajarsheem/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rajarsheem",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
| null |
[] |
[
"C4 is too large to be shown in the viewer"
] | 2020-06-13T08:26:16
| 2020-10-27T15:35:29
| 2020-10-27T15:35:13
|
NONE
| null | null | null | null |
I get the following error when I try to view the c4 dataset in [nlpviewer](https://huggingface.co/nlp/viewer/)
```python
ModuleNotFoundError: No module named 'langdetect'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 54, in <module>
configs = get_confs(option.id)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 48, in get_confs
builder_cls = nlp.load.import_main_class(module_path, dataset=True)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/load.py", line 57, in import_main_class
module = importlib.import_module(module_path)
File "/usr/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/datasets/c4/88bb1b1435edad3fb772325710c4a43327cbf4a23b9030094556e6f01e14ec19/c4.py", line 29, in <module>
from .c4_utils import (
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/datasets/c4/88bb1b1435edad3fb772325710c4a43327cbf4a23b9030094556e6f01e14ec19/c4_utils.py", line 29, in <module>
import langdetect
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/270/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/270/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 136 days, 7:08:57
|
https://api.github.com/repos/huggingface/datasets/issues/269
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/269/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/269/comments
|
https://api.github.com/repos/huggingface/datasets/issues/269/events
|
https://github.com/huggingface/datasets/issues/269
| 638,106,774
|
MDU6SXNzdWU2MzgxMDY3NzQ=
| 269
|
Error in metric.compute: missing `original_instructions` argument
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zphang",
"id": 1668462,
"login": "zphang",
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"repos_url": "https://api.github.com/users/zphang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zphang",
"user_view_type": "public"
}
|
[
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[] | 2020-06-13T06:26:54
| 2020-06-18T07:41:44
| 2020-06-18T07:41:44
|
NONE
| null | null | null | null |
I'm running into an error using metrics for computation in the latest master as well as version 0.2.1. Here is a minimal example:
```python
import nlp
rte_metric = nlp.load_metric('glue', name="rte")
rte_metric.compute(
[0, 0, 1, 1],
[0, 1, 0, 1],
)
```
```
181 # Read the predictions and references
182 reader = ArrowReader(path=self.data_dir, info=None)
--> 183 self.data = reader.read_files(node_files)
184
185 # Release all of our locks
TypeError: read_files() missing 1 required positional argument: 'original_instructions'
```
I believe this might have been introduced with cc8d2508b75f7ba0e5438d0686ee02dcec43c7f4, which added the `original_instructions` argument. Elsewhere, an empty-string default is provided--perhaps that could be done here too?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/269/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/269/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 5 days, 1:14:50
|
https://api.github.com/repos/huggingface/datasets/issues/267
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/267/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/267/comments
|
https://api.github.com/repos/huggingface/datasets/issues/267/events
|
https://github.com/huggingface/datasets/issues/267
| 637,415,545
|
MDU6SXNzdWU2Mzc0MTU1NDU=
| 267
|
How can I load/find WMT en-romanian?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] |
[
"I will take a look :-) "
] | 2020-06-12T01:09:37
| 2020-06-19T08:24:19
| 2020-06-19T08:24:19
|
CONTRIBUTOR
| null | null | null | null |
I believe it is from `wmt16`
When I run
```python
wmt = nlp.load_dataset('wmt16')
```
I get:
```python
AssertionError: The dataset wmt16 with config cs-en requires manual data.
Please follow the manual download instructions: Some of the wmt configs here, require a manual download.
Please look into wmt.py to see the exact path (and file name) that has to
be downloaded.
.
Manual data can be loaded with `nlp.load(wmt16, data_dir='<path/to/manual/data>')
```
There is no wmt.py,as the error message suggests, and wmt16.py doesn't have manual download instructions.
Any idea how to do this?
Thanks in advance!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/267/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/267/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 7 days, 7:14:42
|
https://api.github.com/repos/huggingface/datasets/issues/263
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/263/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/263/comments
|
https://api.github.com/repos/huggingface/datasets/issues/263/events
|
https://github.com/huggingface/datasets/issues/263
| 637,028,015
|
MDU6SXNzdWU2MzcwMjgwMTU=
| 263
|
[Feature request] Support for external modality for language datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "https://api.github.com/users/aleSuglia/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aleSuglia",
"id": 1479733,
"login": "aleSuglia",
"node_id": "MDQ6VXNlcjE0Nzk3MzM=",
"organizations_url": "https://api.github.com/users/aleSuglia/orgs",
"received_events_url": "https://api.github.com/users/aleSuglia/received_events",
"repos_url": "https://api.github.com/users/aleSuglia/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aleSuglia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aleSuglia/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aleSuglia",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
closed
| false
| null |
[] |
[
"Thanks a lot, @aleSuglia for the very detailed and introductive feature request.\r\nIt seems like we could build something pretty useful here indeed.\r\n\r\nOne of the questions here is that Arrow doesn't have built-in support for generic \"tensors\" in records but there might be ways to do that in a clean way. We'll probably try to tackle this during the summer.",
"I was looking into Facebook MMF and apparently they decided to use LMDB to store additional features associated with every example: https://github.com/facebookresearch/mmf/blob/master/mmf/datasets/databases/features_database.py\r\n\r\n",
"I saw the Mozilla common_voice dataset in model hub, which has mp3 audio recordings as part it. It's use predominantly maybe in ASR and TTS, but dataset is a Language + Voice Dataset similar to @aleSuglia's point about Language + Vision. \r\n\r\nhttps://huggingface.co/datasets/common_voice",
"Hey @thomwolf, are there any updates on this? I would love to contribute if possible!\r\n\r\nThanks, \r\nAlessandro ",
"Hi @aleSuglia :) In today's new release 1.17 of `datasets` we introduce a new feature type `Image` that allows to store images directly in a dataset, next to text features and labels for example. There is also an `Audio` feature type, for datasets containing audio data. For tensors there are `Array2D`, `Array3D`, etc. feature types\r\n\r\nNote that both Image and Audio feature types take care of decoding the images/audio data if needed. The returned images are PIL images, and the audio signals are decoded as numpy arrays.\r\n\r\nAnd `datasets` also leverage end-to-end zero copy from the arrow data for all of them, for maximum speed :)"
] | 2020-06-11T13:42:18
| 2022-02-10T13:26:35
| 2022-02-10T13:26:35
|
CONTRIBUTOR
| null | null | null | null |
# Background
In recent years many researchers have advocated that learning meanings from text-based only datasets is just like asking a human to "learn to speak by listening to the radio" [[E. Bender and A. Koller,2020](https://openreview.net/forum?id=GKTvAcb12b), [Y. Bisk et. al, 2020](https://arxiv.org/abs/2004.10151)]. Therefore, the importance of multi-modal datasets for the NLP community is of paramount importance for next-generation models. For this reason, I raised a [concern](https://github.com/huggingface/nlp/pull/236#issuecomment-639832029) related to the best way to integrate external features in NLP datasets (e.g., visual features associated with an image, audio features associated with a recording, etc.). This would be of great importance for a more systematic way of representing data for ML models that are learning from multi-modal data.
# Language + Vision
## Use case
Typically, people working on Language+Vision tasks, have a reference dataset (either in JSON or JSONL format) and for each example, they have an identifier that specifies the reference image. For a practical example, you can refer to the [GQA](https://cs.stanford.edu/people/dorarad/gqa/download.html#seconddown) dataset.
Currently, images are represented by either pooling-based features (average pooling of ResNet or VGGNet features, see [DeVries et.al, 2017](https://arxiv.org/abs/1611.08481), [Shekhar et.al, 2019](https://www.aclweb.org/anthology/N19-1265.pdf)) where you have a single vector for every image. Another option is to use a set of feature maps for every image extracted from a specific layer of a CNN (see [Xu et.al, 2015](https://arxiv.org/abs/1502.03044)). A more recent option, especially with large-scale multi-modal transformers [Li et. al, 2019](https://arxiv.org/abs/1908.03557), is to use FastRCNN features.
For all these types of features, people use one of the following formats:
1. [HD5F](https://pypi.org/project/h5py/)
2. [NumPy](https://numpy.org/doc/stable/reference/generated/numpy.savez.html)
3. [LMDB](https://lmdb.readthedocs.io/en/release/)
## Implementation considerations
I was thinking about possible ways of implementing this feature. As mentioned above, depending on the model, different visual features can be used. This step usually relies on another model (say ResNet-101) that is used to generate the visual features for each image used in the dataset. Typically, this step is done in a separate script that completes the feature generation procedure. The usual processing steps for these datasets are the following:
1. Download dataset
2. Download images associated with the dataset
3. Write a script that generates the visual features for every image and store them in a specific file
4. Create a DataLoader that maps the visual features to the corresponding language example
In my personal projects, I've decided to ignore HD5F because it doesn't have out-of-the-box support for multi-processing (see this PyTorch [issue](https://github.com/pytorch/pytorch/issues/11929)). I've been successfully using a NumPy compressed file for each image so that I can store any sort of information in it.
For ease of use of all these Language+Vision datasets, it would be really handy to have a way to associate the visual features with the text and store them in an efficient way. That's why I immediately thought about the HuggingFace NLP backend based on Apache Arrow. The assumption here is that the external modality will be mapped to a N-dimensional tensor so easily represented by a NumPy array.
Looking forward to hearing your thoughts about it!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 18,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 23,
"url": "https://api.github.com/repos/huggingface/datasets/issues/263/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/263/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 608 days, 23:44:17
|
https://api.github.com/repos/huggingface/datasets/issues/261
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/261/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/261/comments
|
https://api.github.com/repos/huggingface/datasets/issues/261/events
|
https://github.com/huggingface/datasets/issues/261
| 636,372,380
|
MDU6SXNzdWU2MzYzNzIzODA=
| 261
|
Downloading dataset error with pyarrow.lib.RecordBatch
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5248968?v=4",
"events_url": "https://api.github.com/users/cuent/events{/privacy}",
"followers_url": "https://api.github.com/users/cuent/followers",
"following_url": "https://api.github.com/users/cuent/following{/other_user}",
"gists_url": "https://api.github.com/users/cuent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cuent",
"id": 5248968,
"login": "cuent",
"node_id": "MDQ6VXNlcjUyNDg5Njg=",
"organizations_url": "https://api.github.com/users/cuent/orgs",
"received_events_url": "https://api.github.com/users/cuent/received_events",
"repos_url": "https://api.github.com/users/cuent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cuent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cuent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cuent",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:\r\n```\r\nWARNING: The following packages were previously imported in this runtime:\r\n [pyarrow]\r\nYou must restart the runtime in order to use newly installed versions.\r\n```\r\nYou just have to restart the runtime and it should be fine.\r\nIf you don't restart, then it breaks like in your message.",
"Yeah, that worked! Thanks :) "
] | 2020-06-10T16:04:19
| 2020-06-11T14:35:12
| 2020-06-11T14:35:12
|
NONE
| null | null | null | null |
I am trying to download `sentiment140` and I have the following error
```
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
418 verify_infos = not save_infos and not ignore_verifications
419 self._download_and_prepare(
--> 420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
422 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
472 try:
473 # Prepare split will record examples associated to the split
--> 474 self._prepare_split(split_generator, **prepare_split_kwargs)
475 except OSError:
476 raise OSError("Cannot find data file. " + (self.MANUAL_DOWNLOAD_INSTRUCTIONS or ""))
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _prepare_split(self, split_generator)
652 for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
653 example = self.info.features.encode_example(record)
--> 654 writer.write(example)
655 num_examples, num_bytes = writer.finalize()
656
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write(self, example, writer_batch_size)
143 self._build_writer(pa_table=pa.Table.from_pydict(example))
144 if writer_batch_size is not None and len(self.current_rows) >= writer_batch_size:
--> 145 self.write_on_file()
146
147 def write_batch(
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_on_file(self)
127 else:
128 # All good
--> 129 self._write_array_on_file(pa_array)
130 self.current_rows = []
131
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in _write_array_on_file(self, pa_array)
96 def _write_array_on_file(self, pa_array):
97 """Write a PyArrow Array"""
---> 98 pa_batch = pa.RecordBatch.from_struct_array(pa_array)
99 self._num_bytes += pa_array.nbytes
100 self.pa_writer.write_batch(pa_batch)
AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
```
I installed the last version and ran the following command:
```python
import nlp
sentiment140 = nlp.load_dataset('sentiment140', cache_dir='/content')
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5248968?v=4",
"events_url": "https://api.github.com/users/cuent/events{/privacy}",
"followers_url": "https://api.github.com/users/cuent/followers",
"following_url": "https://api.github.com/users/cuent/following{/other_user}",
"gists_url": "https://api.github.com/users/cuent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cuent",
"id": 5248968,
"login": "cuent",
"node_id": "MDQ6VXNlcjUyNDg5Njg=",
"organizations_url": "https://api.github.com/users/cuent/orgs",
"received_events_url": "https://api.github.com/users/cuent/received_events",
"repos_url": "https://api.github.com/users/cuent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cuent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cuent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cuent",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/261/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/261/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 22:30:53
|
https://api.github.com/repos/huggingface/datasets/issues/259
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/259/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/259/comments
|
https://api.github.com/repos/huggingface/datasets/issues/259/events
|
https://github.com/huggingface/datasets/issues/259
| 636,239,529
|
MDU6SXNzdWU2MzYyMzk1Mjk=
| 259
|
documentation missing how to split a dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2873355?v=4",
"events_url": "https://api.github.com/users/fotisj/events{/privacy}",
"followers_url": "https://api.github.com/users/fotisj/followers",
"following_url": "https://api.github.com/users/fotisj/following{/other_user}",
"gists_url": "https://api.github.com/users/fotisj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fotisj",
"id": 2873355,
"login": "fotisj",
"node_id": "MDQ6VXNlcjI4NzMzNTU=",
"organizations_url": "https://api.github.com/users/fotisj/orgs",
"received_events_url": "https://api.github.com/users/fotisj/received_events",
"repos_url": "https://api.github.com/users/fotisj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fotisj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fotisj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fotisj",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"this seems to work for my specific problem:\r\n\r\n`self.train_ds, self.test_ds, self.val_ds = map(_prepare_ds, ('train', 'test[:25%]+test[50%:75%]', 'test[75%:]'))`",
"Currently you can indeed split a dataset using `ds_test = nlp.load_dataset('imdb, split='test[:5000]')` (works also with percentages).\r\n\r\nHowever right now we don't have a way to shuffle a dataset but we are thinking about it in the discussion in #166. Feel free to share your thoughts about it.\r\n\r\nOne trick that you can do until we have a better solution is to shuffle and split the indices of your dataset:\r\n```python\r\nimport nlp\r\nfrom sklearn.model_selection import train_test_split\r\n\r\nimdb = nlp.load_dataset('imbd', split='test')\r\ntest_indices, val_indices = train_test_split(range(len(imdb)))\r\n```\r\n\r\nand then to iterate each split:\r\n```python\r\nfor i in test_indices:\r\n example = imdb[i]\r\n ...\r\n```\r\n",
"I added a small guide [here](https://github.com/huggingface/nlp/tree/master/docs/splits.md) that explains how to split a dataset. It is very similar to the tensorflow datasets guide, as we kept the same logic.",
"Thanks a lot, the new explanation is very helpful!\r\n\r\nAbout using train_test_split from sklearn: I stumbled across the [same error message as this user ](https://github.com/huggingface/nlp/issues/147 )and thought it can't be used at the moment in this context. Will check it out again.\r\n\r\nOne of the problems is how to shuffle very large datasets, which don't fit into the memory. Well, one strategy could be shuffling data in sections. But in a case where the data is sorted by the labels you have to swap larger sections first. \r\n",
"We added a way to shuffle datasets (shuffle the indices and then reorder to make a new dataset).\r\nYou can do `shuffled_dset = dataset.shuffle(seed=my_seed)`. It shuffles the whole dataset.\r\nThere is also `dataset.train_test_split()` which if very handy (with the same signature as sklearn).\r\n\r\nClosing this issue as we added the docs for splits and tools to split datasets. Thanks again for your feedback !",
"https://huggingface.co/docs/datasets/v1.0.1/package_reference/builder_classes.html#datasets.Split still links to https://github.com/huggingface/datasets/tree/main/docs/splits.md which is a 404\r\n",
"The updated documentation doesn't link to this anymore: https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/builder_classes#datasets.Split"
] | 2020-06-10T13:18:13
| 2023-03-14T13:56:07
| 2020-06-18T22:20:24
|
NONE
| null | null | null | null |
I am trying to understand how to split a dataset ( as arrow_dataset).
I know I can do something like this to access a split which is already in the original dataset :
`ds_test = nlp.load_dataset('imdb, split='test') `
But how can I split ds_test into a test and a validation set (without reading the data into memory and keeping the arrow_dataset as container)?
I guess it has something to do with the module split :-) but there is no real documentation in the code but only a reference to a longer description:
> See the [guide on splits](https://github.com/huggingface/nlp/tree/master/docs/splits.md) for more information.
But the guide seems to be missing.
To clarify: I know that this has been modelled after the dataset of tensorflow and that some of the documentation there can be used [like this one](https://www.tensorflow.org/datasets/splits). But to come back to the example above: I cannot simply split the testset doing this:
`ds_test = nlp.load_dataset('imdb, split='test'[:5000]) `
`ds_val = nlp.load_dataset('imdb, split='test'[5000:])`
because the imdb test data is sorted by class (probably not a good idea anyway)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/259/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/259/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 8 days, 9:02:11
|
https://api.github.com/repos/huggingface/datasets/issues/258
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/258/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/258/comments
|
https://api.github.com/repos/huggingface/datasets/issues/258/events
|
https://github.com/huggingface/datasets/issues/258
| 635,859,525
|
MDU6SXNzdWU2MzU4NTk1MjU=
| 258
|
Why is dataset after tokenization far more larger than the orginal one ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hi ! This is because `.map` added the new column `input_ids` to the dataset, and so all the other columns were kept. Therefore the dataset size increased a lot.\r\n If you want to only keep the `input_ids` column, you can stash the other ones by specifying `remove_columns=[\"title\", \"text\"]` in the arguments of `.map`",
"Hi ! Thanks for your reply.\r\n\r\nBut since size of `input_ids` < size of `text`, I am wondering why\r\nsize of `input_ids` + `text` > 2x the size of `text` 🤔",
"Hard to tell... This is probably related to the way apache arrow compresses lists of integers, that may be different from the compression of strings.",
"Thanks for your point. 😀, It might be answer.\r\nSince this is hard to know, I'll close this issue.\r\nBut if somebody knows more details, please comment below ~ 😁"
] | 2020-06-10T01:27:07
| 2020-06-10T12:46:34
| 2020-06-10T12:46:34
|
CONTRIBUTOR
| null | null | null | null |
I tokenize wiki dataset by `map` and cache the results.
```
def tokenize_tfm(example):
example['input_ids'] = hf_fast_tokenizer.convert_tokens_to_ids(hf_fast_tokenizer.tokenize(example['text']))
return example
wiki = nlp.load_dataset('wikipedia', '20200501.en', cache_dir=cache_dir)['train']
wiki.map(tokenize_tfm, cache_file_name=cache_dir/"wikipedia/20200501.en/1.0.0/tokenized_wiki.arrow")
```
and when I see their size
```
ls -l --block-size=M
17460M wikipedia-train.arrow
47511M tokenized_wiki.arrow
```
The tokenized one is over 2x size of original one.
Is there something I did wrong ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/258/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/258/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 11:19:27
|
https://api.github.com/repos/huggingface/datasets/issues/257
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/257/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/257/comments
|
https://api.github.com/repos/huggingface/datasets/issues/257/events
|
https://github.com/huggingface/datasets/issues/257
| 635,620,979
|
MDU6SXNzdWU2MzU2MjA5Nzk=
| 257
|
Tokenizer pickling issue fix not landed in `nlp` yet?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Yes, the new release of tokenizers solves this and should be out soon.\r\nIn the meantime, you can install it with `pip install tokenizers==0.8.0-dev2`",
"If others run into this issue, a quick fix is to use python 3.6 instead of 3.7+. Serialization differences between the 3rd party `dataclasses` package for 3.6 and the built in `dataclasses` in 3.7+ cause the issue.\r\n\r\nProbably a dumb fix, but it works for me."
] | 2020-06-09T17:12:34
| 2020-06-10T21:45:32
| 2020-06-09T17:26:53
|
NONE
| null | null | null | null |
Unless I recreate an arrow_dataset from my loaded nlp dataset myself (which I think does not use the cache by default), I get the following error when applying the map function:
```
dataset = nlp.load_dataset('cos_e')
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2', cache_dir=cache_dir)
for split in dataset.keys():
dataset[split].map(lambda x: some_function(x, tokenizer))
```
```
06/09/2020 10:09:19 - INFO - nlp.builder - Constructing Dataset for split train[:10], from /home/sarahw/.cache/huggingface/datasets/cos_e/default/0.0.1
Traceback (most recent call last):
File "generation/input_to_label_and_rationale.py", line 390, in <module>
main()
File "generation/input_to_label_and_rationale.py", line 263, in main
dataset[split] = dataset[split].map(lambda x: input_to_explanation_plus_label(x, tokenizer, max_length, datasource=data_args.task_name, wt5=(model_class=='t5'), expl_only=model_args.rationale_only), batched=False)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/arrow_dataset.py", line 522, in map
cache_file_name = self._get_cache_file_path(function, cache_kwargs)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/arrow_dataset.py", line 381, in _get_cache_file_path
function_bytes = dumps(function)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/utils/py_utils.py", line 257, in dumps
dump(obj, file)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/nlp/utils/py_utils.py", line 250, in dump
Pickler(file).dump(obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 445, in dump
StockPickler.dump(self, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 485, in dump
self.save(obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 1410, in save_function
pickler.save_reduce(_create_function, (obj.__code__,
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 690, in save_reduce
save(args)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 899, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 899, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 1147, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 690, in save_reduce
save(args)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 884, in save_tuple
save(element)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 601, in save
self.save_reduce(obj=obj, *rv)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 715, in save_reduce
save(state)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 912, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 969, in save_dict
self._batch_setitems(obj.items())
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 995, in _batch_setitems
save(v)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 601, in save
self.save_reduce(obj=obj, *rv)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 715, in save_reduce
save(state)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 558, in save
f(self, obj) # Call unbound method with explicit self
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/site-packages/dill/_dill.py", line 912, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 969, in save_dict
self._batch_setitems(obj.items())
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 995, in _batch_setitems
save(v)
File "/home/sarahw/miniconda3/envs/project_huggingface/lib/python3.8/pickle.py", line 576, in save
rv = reduce(self.proto)
TypeError: cannot pickle 'Tokenizer' object
```
Fix seems to be in the tokenizers [`0.8.0.dev1 pre-release`](https://github.com/huggingface/tokenizers/issues/87), which I can't install with any package managers.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/257/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/257/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:14:19
|
https://api.github.com/repos/huggingface/datasets/issues/256
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/256/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/256/comments
|
https://api.github.com/repos/huggingface/datasets/issues/256/events
|
https://github.com/huggingface/datasets/issues/256
| 635,596,295
|
MDU6SXNzdWU2MzU1OTYyOTU=
| 256
|
[Feature request] Add a feature to dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Do you have an example of what you would like to do? (you can just add a field in the output of the unction you give to map and this will add this field in the output table)",
"Given another source of data loaded in, I want to pre-add it to the dataset so that it aligns with the indices of the arrow dataset prior to performing map.\r\n\r\nE.g. \r\n```\r\nnew_info = list of length dataset['train']\r\n\r\ndataset['train'] = dataset['train'].map(lambda x: some_function(x, new_info[index of x]))\r\n\r\ndef some_function(x, new_info_x):\r\n # adds new_info[index of x] as a field to x\r\n x['new_info'] = new_info_x\r\n return x\r\n```\r\nI was thinking to instead create a new field in the arrow dataset so that instance x contains all the necessary information when map function is applied (since I don't have index information to pass to map function).",
"This is what I have so far: \r\n\r\n```\r\nimport pyarrow as pa\r\nfrom nlp.arrow_dataset import Dataset\r\n\r\naug_dataset = dataset['train'][:]\r\naug_dataset['new_info'] = new_info\r\n\r\n#reformat as arrow-table\r\nschema = dataset['train'].schema\r\n\r\n# this line doesn't work:\r\nschema.append(pa.field('new_info', pa.int32()))\r\n\r\ntable = pa.Table.from_pydict(\r\n aug_dataset,\r\n schema=schema\r\n)\r\ndataset['train'] = Dataset(table) \r\n```",
"Maybe you can use `with_indices`?\r\n\r\n```python\r\nnew_info = list of length dataset['train']\r\n\r\ndef some_function(indice, x):\r\n # adds new_info[index of x] as a field to x\r\n x['new_info'] = new_info_x[indice]\r\n return x\r\n\r\ndataset['train'] = dataset['train'].map(some_function, with_indices=True)\r\n```",
"Oh great. That should work. I missed that in the documentation- thanks :) "
] | 2020-06-09T16:38:12
| 2020-06-09T16:51:42
| 2020-06-09T16:51:42
|
NONE
| null | null | null | null |
Is there a straightforward way to add a field to the arrow_dataset, prior to performing map?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/256/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/256/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 0:13:30
|
https://api.github.com/repos/huggingface/datasets/issues/254
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/254/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/254/comments
|
https://api.github.com/repos/huggingface/datasets/issues/254/events
|
https://github.com/huggingface/datasets/issues/254
| 635,057,568
|
MDU6SXNzdWU2MzUwNTc1Njg=
| 254
|
[Feature request] Be able to remove a specific sample of the dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Oh yes you can now do that with the `dataset.filter()` method that was added in #214 "
] | 2020-06-09T02:22:13
| 2020-06-09T08:41:38
| 2020-06-09T08:41:38
|
NONE
| null | null | null | null |
As mentioned in #117, it's currently not possible to remove a sample of the dataset.
But it is a important use case : After applying some preprocessing, some samples might be empty for example. We should be able to remove these samples from the dataset, or at least mark them as `removed` so when iterating the dataset, we don't iterate these samples.
I think it should be a feature. What do you think ?
---
Any work-around in the meantime ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/254/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/254/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 6:19:25
|
https://api.github.com/repos/huggingface/datasets/issues/252
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/252/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/252/comments
|
https://api.github.com/repos/huggingface/datasets/issues/252/events
|
https://github.com/huggingface/datasets/issues/252
| 634,563,239
|
MDU6SXNzdWU2MzQ1NjMyMzk=
| 252
|
NonMatchingSplitsSizesError error when reading the IMDB dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url": "https://api.github.com/users/antmarakis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/antmarakis",
"id": 17463361,
"login": "antmarakis",
"node_id": "MDQ6VXNlcjE3NDYzMzYx",
"organizations_url": "https://api.github.com/users/antmarakis/orgs",
"received_events_url": "https://api.github.com/users/antmarakis/received_events",
"repos_url": "https://api.github.com/users/antmarakis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/antmarakis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antmarakis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/antmarakis",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"I just tried on my side and I didn't encounter your problem.\r\nApparently the script doesn't generate all the examples on your side.\r\n\r\nCan you provide the version of `nlp` you're using ?\r\nCan you try to clear your cache and re-run the code ?",
"I updated it, that was it, thanks!",
"Hello, I am facing the same problem... how do you clear the huggingface cache?",
"Hi ! The cache is at ~/.cache/huggingface\r\nYou can just delete this folder if needed :)"
] | 2020-06-08T12:26:24
| 2021-08-27T15:20:58
| 2020-06-08T14:01:26
|
NONE
| null | null | null | null |
Hi!
I am trying to load the `imdb` dataset with this line:
`dataset = nlp.load_dataset('imdb', data_dir='/A/PATH', cache_dir='/A/PATH')`
but I am getting the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/load.py", line 517, in load_dataset
save_infos=save_infos,
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/builder.py", line 363, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/builder.py", line 421, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/mounts/Users/cisintern/antmarakis/anaconda3/lib/python3.7/site-packages/nlp/utils/info_utils.py", line 70, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=33442202, num_examples=25000, dataset_name='imdb'), 'recorded': SplitInfo(name='train', num_bytes=5929447, num_examples=4537, dataset_name='imdb')}, {'expected': SplitInfo(name='unsupervised', num_bytes=67125548, num_examples=50000, dataset_name='imdb'), 'recorded': SplitInfo(name='unsupervised', num_bytes=0, num_examples=0, dataset_name='imdb')}]
```
Am I overlooking something? Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url": "https://api.github.com/users/antmarakis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/antmarakis",
"id": 17463361,
"login": "antmarakis",
"node_id": "MDQ6VXNlcjE3NDYzMzYx",
"organizations_url": "https://api.github.com/users/antmarakis/orgs",
"received_events_url": "https://api.github.com/users/antmarakis/received_events",
"repos_url": "https://api.github.com/users/antmarakis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/antmarakis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antmarakis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/antmarakis",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/252/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/252/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1:35:02
|
https://api.github.com/repos/huggingface/datasets/issues/249
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/249/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/249/comments
|
https://api.github.com/repos/huggingface/datasets/issues/249/events
|
https://github.com/huggingface/datasets/issues/249
| 633,393,443
|
MDU6SXNzdWU2MzMzOTM0NDM=
| 249
|
[Dataset created] some critical small issues when I was creating a dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"Thanks for noticing all these :) They should be easy to fix indeed",
"Alright I think I fixed all the problems you mentioned. Thanks again, that will be useful for many people.\r\nThere is still more work needed for point 7. but we plan to have some nice docs soon."
] | 2020-06-07T12:58:54
| 2020-06-12T08:28:51
| 2020-06-12T08:28:51
|
CONTRIBUTOR
| null | null | null | null |
Hi, I successfully created a dataset and has made a pr #248.
But I have encountered several problems when I was creating it, and those should be easy to fix.
1. Not found dataset_info.json
should be fixed by #241 , eager to wait it be merged.
2. Forced to install `apach_beam`
If we should install it, then it might be better to include it in the pakcage dependency or specified in `CONTRIBUTING.md`
```
Traceback (most recent call last):
File "nlp-cli", line 10, in <module>
from nlp.commands.run_beam import RunBeamCommand
File "/home/yisiang/nlp/src/nlp/commands/run_beam.py", line 6, in <module>
import apache_beam as beam
ModuleNotFoundError: No module named 'apache_beam'
```
3. `cached_dir` is `None`
```
File "/home/yisiang/nlp/src/nlp/datasets/bookscorpus/aea0bd5142d26df645a8fce23d6110bb95ecb81772bb2a1f29012e329191962c/bookscorpus.py", line 88, in _split_generators
downloaded_path_or_paths = dl_manager.download_custom(_GDRIVE_FILE_ID, download_file_from_google_drive)
File "/home/yisiang/nlp/src/nlp/utils/download_manager.py", line 128, in download_custom
downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)
File "/home/yisiang/nlp/src/nlp/utils/py_utils.py", line 172, in map_nested
return function(data_struct)
File "/home/yisiang/nlp/src/nlp/utils/download_manager.py", line 126, in url_to_downloaded_path
return os.path.join(self._download_config.cache_dir, hash_url_to_filename(url))
File "/home/yisiang/miniconda3/envs/nlppr/lib/python3.7/posixpath.py", line 80, in join
a = os.fspath(a)
```
This is because this line
https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/src/nlp/commands/test.py#L30-L32
And I add `--cache_dir="...."` to `python nlp-cli test datasets/<your-dataset-folder> --save_infos --all_configs` in the doc, finally I could pass this error.
But it seems to ignore my arg and use `/home/yisiang/.cache/huggingface/datasets/bookscorpus/plain_text/1.0.0` as cahe_dir
4. There is no `pytest`
So maybe in the doc we should specify a step to install pytest
5. Not enough capacity in my `/tmp`
When run test for dummy data, I don't know why it ask me for 5.6g to download something,
```
def download_and_prepare
...
if not utils.has_sufficient_disk_space(self.info.size_in_bytes or 0, directory=self._cache_dir_root):
raise IOError(
"Not enough disk space. Needed: {} (download: {}, generated: {})".format(
utils.size_str(self.info.size_in_bytes or 0),
utils.size_str(self.info.download_size or 0),
> utils.size_str(self.info.dataset_size or 0),
)
)
E OSError: Not enough disk space. Needed: 5.62 GiB (download: 1.10 GiB, generated: 4.52 GiB)
```
I add a `processed_temp_dir="some/dir"; raw_temp_dir="another/dir"` to 71, and the test passed
https://github.com/huggingface/nlp/blob/a67a6c422dece904b65d18af65f0e024e839dbe8/tests/test_dataset_common.py#L70-L72
I suggest we can create tmp dir under the `/home/user/tmp` but not `/tmp`, because take our lab server for example, everyone use `/tmp` thus it has not much capacity. Or at least we can improve error message, so the user know is what directory has no space and how many has it lefted. Or we could do both.
6. name of datasets
I was surprised by the dataset name `books_corpus`, and didn't know it is from `class BooksCorpus(nlp.GeneratorBasedBuilder)` . I change it to `Bookscorpus` afterwards. I think this point shold be also on the doc.
7. More thorough doc to how to create `dataset.py`
I believe there will be.
**Feel free to close this issue** if you think these are solved.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/249/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/249/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 19:29:57
|
https://api.github.com/repos/huggingface/datasets/issues/246
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/246/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/246/comments
|
https://api.github.com/repos/huggingface/datasets/issues/246/events
|
https://github.com/huggingface/datasets/issues/246
| 632,380,054
|
MDU6SXNzdWU2MzIzODAwNTQ=
| 246
|
What is the best way to cache a dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/112599?v=4",
"events_url": "https://api.github.com/users/Mistobaan/events{/privacy}",
"followers_url": "https://api.github.com/users/Mistobaan/followers",
"following_url": "https://api.github.com/users/Mistobaan/following{/other_user}",
"gists_url": "https://api.github.com/users/Mistobaan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mistobaan",
"id": 112599,
"login": "Mistobaan",
"node_id": "MDQ6VXNlcjExMjU5OQ==",
"organizations_url": "https://api.github.com/users/Mistobaan/orgs",
"received_events_url": "https://api.github.com/users/Mistobaan/received_events",
"repos_url": "https://api.github.com/users/Mistobaan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mistobaan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mistobaan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mistobaan",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Everything is already cached by default in 🤗nlp (in particular dataset\nloading and all the “map()” operations) so I don’t think you need to do any\nspecific caching in streamlit.\n\nTell us if you feel like it’s not the case.\n\nOn Sat, 6 Jun 2020 at 13:02, Fabrizio Milo <notifications@github.com> wrote:\n\n> For example if I want to use streamlit with a nlp dataset:\n>\n> @st.cache\n> def load_data():\n> return nlp.load_dataset('squad')\n>\n> This code raises the error \"uncachable object\"\n>\n> Right now I just fixed with a constant for my specific case:\n>\n> @st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})\n>\n> But I was curious to know what is the best way in general\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/246>, or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHKAKO7CWGX2QY55UXLRVIO3ZANCNFSM4NV333RQ>\n> .\n>\n",
"Closing this one. Feel free to re-open if you have other questions !"
] | 2020-06-06T11:02:07
| 2020-07-09T09:15:07
| 2020-07-09T09:15:07
|
NONE
| null | null | null | null |
For example if I want to use streamlit with a nlp dataset:
```
@st.cache
def load_data():
return nlp.load_dataset('squad')
```
This code raises the error "uncachable object"
Right now I just fixed with a constant for my specific case:
```
@st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})
```
But I was curious to know what is the best way in general
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/246/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/246/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 32 days, 22:13:00
|
https://api.github.com/repos/huggingface/datasets/issues/245
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/245/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/245/comments
|
https://api.github.com/repos/huggingface/datasets/issues/245/events
|
https://github.com/huggingface/datasets/issues/245
| 631,985,108
|
MDU6SXNzdWU2MzE5ODUxMDg=
| 245
|
SST-2 test labels are all -1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"this also happened to me with `nlp.load_dataset('glue', 'mnli')`",
"Yes, this is because the test sets for glue are hidden so the labels are\nnot publicly available. You can read the glue paper for more details.\n\nOn Sat, 6 Jun 2020 at 18:16, Jack Morris <notifications@github.com> wrote:\n\n> this also happened to me with nlp.load_datasets('glue', 'mnli')\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/245#issuecomment-640083980>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHMVQD2EDX2HTZUXG5DRVJTWRANCNFSM4NVG3AKQ>\n> .\n>\n",
"Thanks @thomwolf!",
"@thomwolf shouldn't this be visible in the .info and/or in the .features?",
"It should be in the datasets card (the README.md and on the hub) in my opinion. What do you think @yjernite?",
"I checked both before I got to looking at issues, so that would be fine as well.\r\n\r\nSome additional thoughts on this: Is there a specific reason why the \"test\" split even has a \"label\" column if it isn't tagged. Shouldn't there just not be any. Seems more transparent",
"I'm a little confused with the data size.\r\n`sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\nFrom the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification. \r\nWhy in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ? \r\n\r\n",
"> I'm a little confused with the data size.\r\n> `sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\n> From the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification.\r\n> Why in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ?\r\n\r\nHave you figured out this problem? AFAIK, the original sst-2 dataset is totally different from the GLUE/sst-2. Do you think so?",
"@yc1999 Sorry, I didn't solve this conflict. In the end, I just use a local data file provided by the previous work I followed(for consistent comparison), not use `datasets` package.\r\n\r\nRelated information: https://github.com/thunlp/OpenAttack/issues/146#issuecomment-766323571",
"@yc1999 I find that the original SST-2 dataset (6,920/872/1,821) can be loaded from https://huggingface.co/datasets/gpt3mix/sst2 or built with SST data and the scripts in https://github.com/prrao87/fine-grained-sentiment/tree/master/data/sst.\r\nThe GLUE/SST-2 dataset (67,349/872/1,821) should be a completely different version.\r\n"
] | 2020-06-05T21:41:42
| 2021-12-08T00:47:32
| 2020-06-06T16:56:41
|
CONTRIBUTOR
| null | null | null | null |
I'm trying to test a model on the SST-2 task, but all the labels I see in the test set are -1.
```
>>> import nlp
>>> glue = nlp.load_dataset('glue', 'sst2')
>>> glue
{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349), 'validation': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 872), 'test': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 1821)}
>>> list(l['label'] for l in glue['test'])
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/245/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/245/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 19:14:59
|
https://api.github.com/repos/huggingface/datasets/issues/242
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/242/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/242/comments
|
https://api.github.com/repos/huggingface/datasets/issues/242/events
|
https://github.com/huggingface/datasets/issues/242
| 631,733,683
|
MDU6SXNzdWU2MzE3MzM2ODM=
| 242
|
UnicodeDecodeError when downloading GLUE-MNLI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"It should be good now, thanks for noticing and fixing it ! I would say that it was because you are on windows but not 100% sure",
"On Windows Python supports Unicode almost everywhere, but one of the notable exceptions is open() where it uses the locale encoding schema. So platform independent python scripts would always set the encoding='utf-8' in calls to open explicitly. \r\nIn the meantime: since Python 3.7 Windows users can set the default encoding for everything including open() to Unicode by setting this environment variable: set PYTHONUTF8=1 (details can be found in [PEP 540](https://www.python.org/dev/peps/pep-0540/))\r\n\r\nFor me this fixed the problem described by the OP."
] | 2020-06-05T16:30:01
| 2020-06-09T16:06:47
| 2020-06-08T08:45:03
|
CONTRIBUTOR
| null | null | null | null |
When I run
```python
dataset = nlp.load_dataset('glue', 'mnli')
```
I get an encoding error (could it be because I'm using Windows?) :
```python
# Lots of error log lines later...
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:
1130 yield obj
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\5256cc2368cf84497abef1f1a5f66648522d5854b225162148cb8fc78a5a91cc\glue.py in _generate_examples(self, data_file, split, mrpc_files)
529
--> 530 for n, row in enumerate(reader):
531 if is_cola_non_test:
~\Miniconda3\envs\nlp\lib\csv.py in __next__(self)
110 self.fieldnames
--> 111 row = next(self.reader)
112 self.line_num = self.reader.line_num
~\Miniconda3\envs\nlp\lib\encodings\cp1252.py in decode(self, input, final)
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 6744: character maps to <undefined>
```
Anyway this can be solved by specifying to decode in UTF when reading the csv file. I am proposing a PR if that's okay.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/242/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/242/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 16:15:02
|
https://api.github.com/repos/huggingface/datasets/issues/240
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/240/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/240/comments
|
https://api.github.com/repos/huggingface/datasets/issues/240/events
|
https://github.com/huggingface/datasets/issues/240
| 631,434,677
|
MDU6SXNzdWU2MzE0MzQ2Nzc=
| 240
|
Deterministic dataset loading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Yes good point !",
"I think using `sorted(glob.glob())` would actually solve this problem. Can you think of other reasons why dataset loading might not be deterministic? @mariamabarham @yjernite @lhoestq @thomwolf . \r\n\r\nI can do a sweep through the dataset scripts and fix the glob.glob() if you guys are ok with it",
"I'm pretty sure it would solve the problem too.\r\n\r\nThe only other dataset that is not deterministic right now is `blog_authorship_corpus` (see #215) but this is a problem related to string encodings.",
"I think we should do the same also for `os.list_dir`"
] | 2020-06-05T09:03:26
| 2020-06-08T09:18:14
| 2020-06-08T09:18:14
|
CONTRIBUTOR
| null | null | null | null |
When calling:
```python
import nlp
dataset = nlp.load_dataset("trivia_qa", split="validation[:1%]")
```
the resulting dataset is not deterministic over different google colabs.
After talking to @thomwolf, I suspect the reason to be the use of `glob.glob` in line:
https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/datasets/trivia_qa/trivia_qa.py#L180
which seems to return an ordering of files that depends on the filesystem:
https://stackoverflow.com/questions/6773584/how-is-pythons-glob-glob-ordered
I think we should go through all the dataset scripts and make sure to have deterministic behavior.
A simple solution for `glob.glob()` would be to just replace it with `sorted(glob.glob())` to have everything sorted by name.
What do you think @lhoestq?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/240/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/240/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 3 days, 0:14:48
|
https://api.github.com/repos/huggingface/datasets/issues/239
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/239/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/239/comments
|
https://api.github.com/repos/huggingface/datasets/issues/239/events
|
https://github.com/huggingface/datasets/issues/239
| 631,340,440
|
MDU6SXNzdWU2MzEzNDA0NDA=
| 239
|
[Creating new dataset] Not found dataset_info.json
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] |
[
"I think you can just `rm` this directory and it should be good :)",
"@lhoestq - this seems to happen quite often (already the 2nd issue). Can we maybe delete this automatically?",
"Yes I have an idea of what's going on. I'm sure I can fix that",
"Hi, I rebase my local copy to `fix-empty-cache-dir`, and try to run again `python nlp-cli test datasets/bookcorpus --save_infos --all_configs`.\r\n\r\nI got this, \r\n```\r\nTraceback (most recent call last):\r\n File \"nlp-cli\", line 10, in <module>\r\n from nlp.commands.run_beam import RunBeamCommand\r\n File \"/home/yisiang/nlp/src/nlp/commands/run_beam.py\", line 6, in <module>\r\n import apache_beam as beam\r\nModuleNotFoundError: No module named 'apache_beam'\r\n```\r\nAnd after I installed it. I got this\r\n```\r\nFile \"/home/yisiang/nlp/src/nlp/datasets/bookcorpus/aea0bd5142d26df645a8fce23d6110bb95ecb81772bb2a1f29012e329191962c/bookcorpus.py\", line 88, in _split_generators\r\n downloaded_path_or_paths = dl_manager.download_custom(_GDRIVE_FILE_ID, download_file_from_google_drive)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 128, in download_custom\r\n downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)\r\n File \"/home/yisiang/nlp/src/nlp/utils/py_utils.py\", line 172, in map_nested\r\n return function(data_struct)\r\n File \"/home/yisiang/nlp/src/nlp/utils/download_manager.py\", line 126, in url_to_downloaded_path\r\n return os.path.join(self._download_config.cache_dir, hash_url_to_filename(url))\r\n File \"/home/yisiang/miniconda3/envs/nlppr/lib/python3.7/posixpath.py\", line 80, in join\r\n a = os.fspath(a)\r\n```\r\nThe problem is when I print `self._download_config.cache_dir` using pdb, it is `None`.\r\n\r\nDid I miss something ? Or can you provide a workaround first so I can keep testing my script ?",
"I'll close this issue because I brings more reports in another issue #249 ."
] | 2020-06-05T06:15:04
| 2020-06-07T13:01:04
| 2020-06-07T13:01:04
|
CONTRIBUTOR
| null | null | null | null |
Hi, I am trying to create Toronto Book Corpus. #131
I ran
`~/nlp % python nlp-cli test datasets/bookcorpus --save_infos --all_configs`
but this doesn't create `dataset_info.json` and try to use it
```
INFO:nlp.load:Checking datasets/bookcorpus/bookcorpus.py for additional imports.
INFO:filelock:Lock 139795325778640 acquired on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.load:Found main folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus
INFO:nlp.load:Found specific version folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9
INFO:nlp.load:Found script file from datasets/bookcorpus/bookcorpus.py to /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.py
INFO:nlp.load:Couldn't find dataset infos file at datasets/bookcorpus/dataset_infos.json
INFO:nlp.load:Found metadata file for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.json
INFO:filelock:Lock 139795325778640 released on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.builder:Overwrite dataset info from restored data version.
INFO:nlp.info:Loading Dataset info from /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0
Traceback (most recent call last):
File "nlp-cli", line 37, in <module>
service.run()
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/commands/test.py", line 78, in run
builders.append(builder_cls(name=config.name, data_dir=self._data_dir))
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/dataset_info.json'
```
btw, `ls /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/` show me nothing is in the directory.
I have also pushed the script to my fork [bookcorpus.py](https://github.com/richardyy1188/nlp/blob/bookcorpusdev/datasets/bookcorpus/bookcorpus.py).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/239/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/239/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 2 days, 6:46:00
|
https://api.github.com/repos/huggingface/datasets/issues/238
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/238/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/238/comments
|
https://api.github.com/repos/huggingface/datasets/issues/238/events
|
https://github.com/huggingface/datasets/issues/238
| 631,260,143
|
MDU6SXNzdWU2MzEyNjAxNDM=
| 238
|
[Metric] Bertscore : Warning : Empty candidate sentence; Setting recall to be 0.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] |
closed
| false
| null |
[] |
[
"This print statement comes from the official implementation of bert_score (see [here](https://github.com/Tiiiger/bert_score/blob/master/bert_score/utils.py#L343)). The warning shows up only if the attention mask outputs no candidate.\r\nRight now we want to only use official code for metrics to have fair evaluations, so I'm not sure we can do anything about it. Maybe you can try to create an issue on their [repo](https://github.com/Tiiiger/bert_score) ?"
] | 2020-06-05T02:14:47
| 2020-06-29T17:10:19
| 2020-06-29T17:10:19
|
NONE
| null | null | null | null |
When running BERT-Score, I'm meeting this warning :
> Warning: Empty candidate sentence; Setting recall to be 0.
Code :
```
import nlp
metric = nlp.load_metric("bertscore")
scores = metric.compute(["swag", "swags"], ["swags", "totally something different"], lang="en", device=0)
```
---
**What am I doing wrong / How can I hide this warning ?**
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/238/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/238/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 24 days, 14:55:32
|
https://api.github.com/repos/huggingface/datasets/issues/237
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/237/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/237/comments
|
https://api.github.com/repos/huggingface/datasets/issues/237/events
|
https://github.com/huggingface/datasets/issues/237
| 631,199,940
|
MDU6SXNzdWU2MzExOTk5NDA=
| 237
|
Can't download MultiNLI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"You should use `load_dataset('glue', 'mnli')`",
"Thanks! I thought I had to use the same code displayed in the live viewer:\r\n```python\r\n!pip install nlp\r\nfrom nlp import load_dataset\r\ndataset = load_dataset('multi_nli', 'plain_text')\r\n```\r\nYour suggestion works, even if then I got a different issue (#242). ",
"Glad it helps !\nThough I am not one of hf team, but maybe you should close this issue first."
] | 2020-06-04T23:05:21
| 2020-06-06T10:51:34
| 2020-06-06T10:51:34
|
CONTRIBUTOR
| null | null | null | null |
When I try to download MultiNLI with
```python
dataset = load_dataset('multi_nli')
```
I get this long error:
```python
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-13-3b11f6be4cb9> in <module>
1 # Load a dataset and print the first examples in the training set
2 # nli_dataset = nlp.load_dataset('multi_nli')
----> 3 dataset = load_dataset('multi_nli')
4 # nli_dataset = nlp.load_dataset('multi_nli', split='validation_matched[:10%]')
5 # print(nli_dataset['train'][0])
~\Miniconda3\envs\nlp\lib\site-packages\nlp\load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
514
515 # Download and prepare data
--> 516 builder_instance.download_and_prepare(
517 download_config=download_config,
518 download_mode=download_mode,
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
417 with utils.temporary_assignment(self, "_cache_dir", tmp_data_dir):
418 verify_infos = not save_infos and not ignore_verifications
--> 419 self._download_and_prepare(
420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
455 split_dict = SplitDict(dataset_name=self.name)
456 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 457 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
458 # Checksums verification
459 if verify_infos:
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\multi_nli\60774175381b9f3f1e6ae1028229e3cdb270d50379f45b9f2c01008f50f09e6b\multi_nli.py in _split_generators(self, dl_manager)
99 def _split_generators(self, dl_manager):
100
--> 101 downloaded_dir = dl_manager.download_and_extract(
102 "http://storage.googleapis.com/tfds-data/downloads/multi_nli/multinli_1.0.zip"
103 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in download_and_extract(self, url_or_urls)
214 extracted_path(s): `str`, extracted paths of given URL(s).
215 """
--> 216 return self.extract(self.download(url_or_urls))
217
218 def get_recorded_sizes_checksums(self):
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in extract(self, path_or_paths)
194 path_or_paths.
195 """
--> 196 return map_nested(
197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
168 return tuple(mapped)
169 # Singleton
--> 170 return function(data_struct)
171
172
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in <lambda>(path)
195 """
196 return map_nested(
--> 197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
199
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
231 if is_zipfile(output_path):
232 with ZipFile(output_path, "r") as zip_file:
--> 233 zip_file.extractall(output_path_extracted)
234 zip_file.close()
235 elif tarfile.is_tarfile(output_path):
~\Miniconda3\envs\nlp\lib\zipfile.py in extractall(self, path, members, pwd)
1644
1645 for zipinfo in members:
-> 1646 self._extract_member(zipinfo, path, pwd)
1647
1648 @classmethod
~\Miniconda3\envs\nlp\lib\zipfile.py in _extract_member(self, member, targetpath, pwd)
1698
1699 with self.open(member, pwd=pwd) as source, \
-> 1700 open(targetpath, "wb") as target:
1701 shutil.copyfileobj(source, target)
1702
OSError: [Errno 22] Invalid argument: 'C:\\Users\\Python\\.cache\\huggingface\\datasets\\3e12413b8ec69f22dfcfd54a79d1ba9e7aac2e18e334bbb6b81cca64fd16bffc\\multinli_1.0\\Icon\r'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/237/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/237/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 1 day, 11:46:13
|
https://api.github.com/repos/huggingface/datasets/issues/234
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/234/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/234/comments
|
https://api.github.com/repos/huggingface/datasets/issues/234/events
|
https://github.com/huggingface/datasets/issues/234
| 630,534,427
|
MDU6SXNzdWU2MzA1MzQ0Mjc=
| 234
|
Huggingface NLP, Uploading custom dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "https://api.github.com/users/Nouman97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nouman97",
"id": 42269506,
"login": "Nouman97",
"node_id": "MDQ6VXNlcjQyMjY5NTA2",
"organizations_url": "https://api.github.com/users/Nouman97/orgs",
"received_events_url": "https://api.github.com/users/Nouman97/received_events",
"repos_url": "https://api.github.com/users/Nouman97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nouman97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nouman97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nouman97",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"What do you mean 'custom' ? You may want to elaborate on it when ask a question.\r\n\r\nAnyway, there are two things you may interested\r\n`nlp.Dataset.from_file` and `load_dataset(..., cache_dir=)`",
"To load a dataset you need to have a script that defines the format of the examples, the splits and the way to generate examples. As your dataset has the same format of squad, you can just copy the squad script (see the [datasets](https://github.com/huggingface/nlp/tree/master/datasets) forlder) and just replace the url to load the data to your local or remote path.\r\n\r\nThen what you can do is `load_dataset(<path/to/your/script>)`",
"Also if you want to upload your script, you should be able to use the `nlp-cli`.\r\n\r\nUnfortunately the upload feature was not shipped in the latest version 0.2.0. so right now you can either clone the repo to use it or wait for the next release. We will add some docs to explain how to upload datasets.\r\n",
"Since the latest release 0.2.1 you can use \r\n```bash\r\nnlp-cli upload_dataset <path/to/dataset>\r\n```\r\nwhere `<path/to/dataset>` is a path to a folder containing your script (ex: `squad.py`).\r\nThis will upload the script under your namespace on our S3.\r\n\r\nOptionally the folder can also contain `dataset_infos.json` generated using\r\n```bash\r\nnlp-cli test <path/to/dataset> --all_configs --save_infos\r\n```\r\n\r\nThen you should be able to do\r\n```python\r\nnlp.load_dataset(\"my_namespace/dataset_name\")\r\n```"
] | 2020-06-04T05:59:06
| 2020-07-06T09:33:26
| 2020-07-06T09:33:26
|
NONE
| null | null | null | null |
Hello,
Does anyone know how we can call our custom dataset using the nlp.load command? Let's say that I have a dataset based on the same format as that of squad-v1.1, how am I supposed to load it using huggingface nlp.
Thank you!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "https://api.github.com/users/Nouman97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nouman97",
"id": 42269506,
"login": "Nouman97",
"node_id": "MDQ6VXNlcjQyMjY5NTA2",
"organizations_url": "https://api.github.com/users/Nouman97/orgs",
"received_events_url": "https://api.github.com/users/Nouman97/received_events",
"repos_url": "https://api.github.com/users/Nouman97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nouman97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nouman97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nouman97",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/234/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/234/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 32 days, 3:34:20
|
https://api.github.com/repos/huggingface/datasets/issues/233
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/233/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/233/comments
|
https://api.github.com/repos/huggingface/datasets/issues/233/events
|
https://github.com/huggingface/datasets/issues/233
| 630,432,132
|
MDU6SXNzdWU2MzA0MzIxMzI=
| 233
|
Fail to download c4 english corpus
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/donggyukimc",
"id": 16605764,
"login": "donggyukimc",
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/donggyukimc",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] |
[
"Hello ! Thanks for noticing this bug, let me fix that.\r\n\r\nAlso for information, as specified in the changelog of the latest release, C4 currently needs to have a runtime for apache beam to work on. Apache beam is used to process this very big dataset and it can work on dataflow, spark, flink, apex, etc. You can find more info on beam datasets [here](https://github.com/huggingface/nlp/blob/master/docs/beam_dataset.md).\r\n\r\nOur goal in the future is to make available an already-processed version of C4 (as we do for wikipedia for example) so that users without apache beam runtimes can load it.",
"@lhoestq I am facing `IsADirectoryError` while downloading with this command.\r\nCan you pls look into it & help me.\r\nI'm using version 0.4.0 of `nlp`.\r\n\r\n```\r\ndataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n```\r\n\r\nHere's the complete stack trace.\r\n\r\n```\r\nDownloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, post-processed: Unknown sizetotal: Unknown size) to /home/devops/.cache/huggingface/datasets/c4/en/2.3.0/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7...\r\n\r\n---------------------------------------------------------------------------\r\nIsADirectoryError Traceback (most recent call last)\r\n<ipython-input-11-f622e6705e03> in <module>\r\n----> 1 dataset = load_dataset(\"c4\", 'en', data_dir='.', beam_runner='DirectRunner')\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)\r\n 547 # Download and prepare data\r\n 548 builder_instance.download_and_prepare(\r\n--> 549 download_config=download_config, download_mode=download_mode, ignore_verifications=ignore_verifications,\r\n 550 )\r\n 551 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)\r\n 461 if not downloaded_from_gcs:\r\n 462 self._download_and_prepare(\r\n--> 463 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 464 )\r\n 465 # Sync info\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos)\r\n 964 pipeline = beam_utils.BeamPipeline(runner=beam_runner, options=beam_options,)\r\n 965 super(BeamBasedBuilder, self)._download_and_prepare(\r\n--> 966 dl_manager, verify_infos=False, pipeline=pipeline,\r\n 967 ) # TODO handle verify_infos in beam datasets\r\n 968 # Run pipeline\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 516 split_dict = SplitDict(dataset_name=self.name)\r\n 517 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)\r\n--> 518 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n 519 # Checksums verification\r\n 520 if verify_infos:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/datasets/c4/096df5a27756d51957c959a2499453e60a08154971fceb017bbb29f54b11bef7/c4.py in _split_generators(self, dl_manager, pipeline)\r\n 187 if self.config.realnewslike:\r\n 188 files_to_download[\"realnews_domains\"] = _REALNEWS_DOMAINS_URL\r\n--> 189 file_paths = dl_manager.download_and_extract(files_to_download)\r\n 190 \r\n 191 if self.config.webtextlike:\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download_and_extract(self, url_or_urls)\r\n 218 extracted_path(s): `str`, extracted paths of given URL(s).\r\n 219 \"\"\"\r\n--> 220 return self.extract(self.download(url_or_urls))\r\n 221 \r\n 222 def get_recorded_sizes_checksums(self):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in download(self, url_or_urls)\r\n 156 lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,\r\n 157 )\r\n--> 158 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)\r\n 159 return downloaded_path_or_paths\r\n 160 \r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/download_manager.py in _record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)\r\n 106 flattened_downloaded_path_or_paths = flatten_nested(downloaded_path_or_paths)\r\n 107 for url, path in zip(flattened_urls_or_urls, flattened_downloaded_path_or_paths):\r\n--> 108 self._recorded_sizes_checksums[url] = get_size_checksum_dict(path)\r\n 109 \r\n 110 def download_custom(self, url_or_urls, custom_download):\r\n\r\n/data/anaconda/envs/hf/lib/python3.6/site-packages/nlp/utils/info_utils.py in get_size_checksum_dict(path)\r\n 77 \"\"\"Compute the file size and the sha256 checksum of a file\"\"\"\r\n 78 m = sha256()\r\n---> 79 with open(path, \"rb\") as f:\r\n 80 for chunk in iter(lambda: f.read(1 << 20), b\"\"):\r\n 81 m.update(chunk)\r\n\r\nIsADirectoryError: [Errno 21] Is a directory: '/'\r\n\r\n```\r\n\r\nCan anyone please try to see what I am doing wrong or is this a bug?",
"I have the same problem as @prashant-kikani",
"Looks like a bug in the dataset script, can you open an issue ?",
"I see the same issue as @prashant-kikani. I'm using `datasets` version 1.2.0 to download C4."
] | 2020-06-04T01:06:38
| 2021-01-08T07:17:32
| 2020-06-08T09:16:59
|
NONE
| null | null | null | null |
i run following code to download c4 English corpus.
```
dataset = nlp.load_dataset('c4', 'en', beam_runner='DirectRunner'
, data_dir='/mypath')
```
and i met failure as follows
```
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/adam/.cache/huggingface/datasets/c4/en/2.3.0...
Traceback (most recent call last):
File "download_corpus.py", line 38, in <module>
, data_dir='/home/adam/data/corpus/en/c4')
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/load.py", line 520, in load_dataset
save_infos=save_infos,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 420, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 816, in _download_and_prepare
dl_manager, verify_infos=False, pipeline=pipeline,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 457, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/datasets/c4/f545de9f63300d8d02a6795e2eb34e140c47e62a803f572ac5599e170ee66ecc/c4.py", line 175, in _split_generators
dl_manager.download_checksums(_CHECKSUMS_URL)
AttributeError: 'DownloadManager' object has no attribute 'download_checksums
```
can i get any advice?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/233/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/233/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 4 days, 8:10:21
|
https://api.github.com/repos/huggingface/datasets/issues/228
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/228/comments
|
https://api.github.com/repos/huggingface/datasets/issues/228/events
|
https://github.com/huggingface/datasets/issues/228
| 629,952,402
|
MDU6SXNzdWU2Mjk5NTI0MDI=
| 228
|
Not able to access the XNLI dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aswin-giridhar",
"id": 11817160,
"login": "aswin-giridhar",
"node_id": "MDQ6VXNlcjExODE3MTYw",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aswin-giridhar",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
] |
[
"Added pull request to change the name of the file from dataset_infos.json to dataset_info.json",
"Thanks for reporting this bug !\r\nAs it seems to be just a cache problem, I closed your PR.\r\nI think we might just need to clear and reload the `xnli` cache @srush ? ",
"Update: The dataset_info.json error is gone, but we have a new one instead:\r\n```\r\nConnectionError: Couldn't reach https://www.nyu.edu/projects/bowman/xnli/XNLI-1.0.zip\r\n```\r\nI am not able to reproduce on my side unfortunately. Any idea @srush ?",
"xnli is now properly shown in the viewer.\r\nClosing this one."
] | 2020-06-03T12:25:14
| 2020-07-17T17:44:22
| 2020-07-17T17:44:22
|
NONE
| null | null | null | null |
When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 86, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 72, in get
builder_instance = builder_cls(name=conf)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
```
Is it possible to see if the dataset_info.json is correctly placed?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/228/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
| 44 days, 5:19:08
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.