
id
stringlengths 6
6
| text
stringlengths 20
17.2k
| title
stringclasses 1
value |
|---|---|---|
246192
|
Contour Features {#tutorial_js_contour_features}
================
@prev_tutorial{tutorial_js_contours_begin}
@next_tutorial{tutorial_js_contour_properties}
Goal
----
- To find the different features of contours, like area, perimeter, centroid, bounding box etc
- You will learn plenty of functions related to contours.
1. Moments
----------
Image moments help you to calculate some features like center of mass of the object, area of the
object etc. Check out the wikipedia page on [Image
Moments](http://en.wikipedia.org/wiki/Image_moment)
We use the function: **cv.moments (array, binaryImage = false)**
@param array raster image (single-channel, 8-bit or floating-point 2D array) or an array ( 1×N or N×1 ) of 2D points.
@param binaryImage if it is true, all non-zero image pixels are treated as 1's. The parameter is used for images only.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_moments.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
From this moments, you can extract useful data like area, centroid etc. Centroid is given by the
relations, \f$C_x = \frac{M_{10}}{M_{00}}\f$ and \f$C_y = \frac{M_{01}}{M_{00}}\f$. This can be done as
follows:
@code{.js}
let cx = M.m10/M.m00
let cy = M.m01/M.m00
@endcode
2. Contour Area
---------------
Contour area is given by the function **cv.contourArea()** or from moments, **M['m00']**.
We use the function: **cv.contourArea (contour, oriented = false)**
@param contour input vector of 2D points (contour vertices)
@param oriented oriented area flag. If it is true, the function returns a signed area value, depending on the contour orientation (clockwise or counter-clockwise). Using this feature you can determine orientation of a contour by taking the sign of an area. By default, the parameter is false, which means that the absolute value is returned.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_area.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
3. Contour Perimeter
--------------------
It is also called arc length. It can be found out using **cv.arcLength()** function.
We use the function: **cv.arcLength (curve, closed)**
@param curve input vector of 2D points.
@param closed flag indicating whether the curve is closed or not.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_perimeter.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
4. Contour Approximation
------------------------
It approximates a contour shape to another shape with less number of vertices depending upon the
precision we specify. It is an implementation of [Douglas-Peucker
algorithm](http://en.wikipedia.org/wiki/Ramer-Douglas-Peucker_algorithm). Check the wikipedia page
for algorithm and demonstration.
We use the function: **cv.approxPolyDP (curve, approxCurve, epsilon, closed)**
@param curve input vector of 2D points stored in cv.Mat.
@param approxCurve result of the approximation. The type should match the type of the input curve.
@param epsilon parameter specifying the approximation accuracy. This is the maximum distance between the original curve and its approximation.
@param closed If true, the approximated curve is closed (its first and last vertices are connected). Otherwise, it is not closed.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_approxPolyDP.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
5. Convex Hull
--------------
Convex Hull will look similar to contour approximation, but it is not (Both may provide same results
in some cases). Here, **cv.convexHull()** function checks a curve for convexity defects and
corrects it. Generally speaking, convex curves are the curves which are always bulged out, or
at-least flat. And if it is bulged inside, it is called convexity defects. For example, check the
below image of hand. Red line shows the convex hull of hand. The double-sided arrow marks shows the
convexity defects, which are the local maximum deviations of hull from contours.

We use the function: **cv.convexHull (points, hull, clockwise = false, returnPoints = true)**
@param points input 2D point set.
@param hull output convex hull.
@param clockwise orientation flag. If it is true, the output convex hull is oriented clockwise. Otherwise, it is oriented counter-clockwise. The assumed coordinate system has its X axis pointing to the right, and its Y axis pointing upwards.
@param returnPoints operation flag. In case of a matrix, when the flag is true, the function returns convex hull points. Otherwise, it returns indices of the convex hull points.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_convexHull.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
6. Checking Convexity
---------------------
There is a function to check if a curve is convex or not, **cv.isContourConvex()**. It just return
whether True or False. Not a big deal.
@code{.js}
cv.isContourConvex(cnt);
@endcode
7. Bounding Rectangle
---------------------
There are two types of bounding rectangles.
### 7.a. Straight Bounding Rectangle
It is a straight rectangle, it doesn't consider the rotation of the object. So area of the bounding
rectangle won't be minimum.
We use the function: **cv.boundingRect (points)**
@param points input 2D point set.
Try it
------
\htmlonly
<iframe src="../../js_contour_features_boundingRect.html" width="100%"
onload="this.style.height=this.contentDocument.body.scrollHeight +'px';">
</iframe>
\endhtmlonly
##
| |
246239
|
Getting Started with Videos {#tutorial_py_video_display}
===========================
Goal
----
- Learn to read video, display video, and save video.
- Learn to capture video from a camera and display it.
- You will learn these functions : **cv.VideoCapture()**, **cv.VideoWriter()**
Capture Video from Camera
-------------------------
Often, we have to capture live stream with a camera. OpenCV provides a very simple interface to do this.
Let's capture a video from the camera (I am using the built-in webcam on my laptop), convert it into
grayscale video and display it. Just a simple task to get started.
To capture a video, you need to create a **VideoCapture** object. Its argument can be either the
device index or the name of a video file. A device index is just the number to specify which camera.
Normally one camera will be connected (as in my case). So I simply pass 0 (or -1). You can select
the second camera by passing 1 and so on. After that, you can capture frame-by-frame. But at the
end, don't forget to release the capture.
@code{.py}
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
# Our operations on the frame come here
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# Display the resulting frame
cv.imshow('frame', gray)
if cv.waitKey(1) == ord('q'):
break
# When everything done, release the capture
cap.release()
cv.destroyAllWindows()@endcode
`cap.read()` returns a bool (`True`/`False`). If the frame is read correctly, it will be `True`. So you can
check for the end of the video by checking this returned value.
Sometimes, cap may not have initialized the capture. In that case, this code shows an error. You can
check whether it is initialized or not by the method **cap.isOpened()**. If it is `True`, OK.
Otherwise open it using **cap.open()**.
You can also access some of the features of this video using **cap.get(propId)** method where propId
is a number from 0 to 18. Each number denotes a property of the video (if it is applicable to that
video). Full details can be seen here: cv::VideoCapture::get().
Some of these values can be modified using **cap.set(propId, value)**. Value is the new value you
want.
For example, I can check the frame width and height by `cap.get(cv.CAP_PROP_FRAME_WIDTH)` and `cap.get(cv.CAP_PROP_FRAME_HEIGHT)`. It gives me
640x480 by default. But I want to modify it to 320x240. Just use `ret = cap.set(cv.CAP_PROP_FRAME_WIDTH,320)` and
`ret = cap.set(cv.CAP_PROP_FRAME_HEIGHT,240)`.
@note If you are getting an error, make sure your camera is working fine using any other camera application
(like Cheese in Linux).
Playing Video from file
-----------------------
Playing video from file is the same as capturing it from camera, just change the camera index to a video file name. Also while
displaying the frame, use appropriate time for `cv.waitKey()`. If it is too less, video will be very
fast and if it is too high, video will be slow (Well, that is how you can display videos in slow
motion). 25 milliseconds will be OK in normal cases.
@code{.py}
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('vtest.avi')
while cap.isOpened():
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
cv.imshow('frame', gray)
if cv.waitKey(1) == ord('q'):
break
cap.release()
cv.destroyAllWindows()
@endcode
@note Make sure a proper version of ffmpeg or gstreamer is installed. Sometimes it is a headache to
work with video capture, mostly due to wrong installation of ffmpeg/gstreamer.
Saving a Video
--------------
So we capture a video and process it frame-by-frame, and we want to save that video. For images, it is
very simple: just use `cv.imwrite()`. Here, a little more work is required.
This time we create a **VideoWriter** object. We should specify the output file name (eg:
output.avi). Then we should specify the **FourCC** code (details in next paragraph). Then number of
frames per second (fps) and frame size should be passed. And the last one is the **isColor** flag. If it is
`True`, the encoder expect color frame, otherwise it works with grayscale frame.
[FourCC](http://en.wikipedia.org/wiki/FourCC) is a 4-byte code used to specify the video codec. The
list of available codes can be found in [fourcc.org](https://fourcc.org/codecs.php). It is
platform dependent. The following codecs work fine for me.
- In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID is more preferable. MJPG results in high
size video. X264 gives very small size video)
- In Windows: DIVX (More to be tested and added)
- In OSX: MJPG (.mp4), DIVX (.avi), X264 (.mkv).
FourCC code is passed as `cv.VideoWriter_fourcc('M','J','P','G')` or
`cv.VideoWriter_fourcc(*'MJPG')` for MJPG.
The below code captures from a camera, flips every frame in the vertical direction, and saves the video.
@code{.py}
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv.VideoWriter_fourcc(*'XVID')
out = cv.VideoWriter('output.avi', fourcc, 20.0, (640, 480))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
frame = cv.flip(frame, 0)
# write the flipped frame
out.write(frame)
cv.imshow('frame', frame)
if cv.waitKey(1) == ord('q'):
break
# Release everything if job is finished
cap.release()
out.release()
cv.destroyAllWindows()
@endcode
| |
246242
|
Drawing Functions in OpenCV {#tutorial_py_drawing_functions}
===========================
Goal
----
- Learn to draw different geometric shapes with OpenCV
- You will learn these functions : **cv.line()**, **cv.circle()** , **cv.rectangle()**,
**cv.ellipse()**, **cv.putText()** etc.
Code
----
In all the above functions, you will see some common arguments as given below:
- img : The image where you want to draw the shapes
- color : Color of the shape. for BGR, pass it as a tuple, eg: (255,0,0) for blue. For
grayscale, just pass the scalar value.
- thickness : Thickness of the line or circle etc. If **-1** is passed for closed figures like
circles, it will fill the shape. *default thickness = 1*
- lineType : Type of line, whether 8-connected, anti-aliased line etc. *By default, it is
8-connected.* cv.LINE_AA gives anti-aliased line which looks great for curves.
### Drawing Line
To draw a line, you need to pass starting and ending coordinates of line. We will create a black
image and draw a blue line on it from top-left to bottom-right corners.
@code{.py}
import numpy as np
import cv2 as cv
# Create a black image
img = np.zeros((512,512,3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv.line(img,(0,0),(511,511),(255,0,0),5)
@endcode
### Drawing Rectangle
To draw a rectangle, you need top-left corner and bottom-right corner of rectangle. This time we
will draw a green rectangle at the top-right corner of image.
@code{.py}
cv.rectangle(img,(384,0),(510,128),(0,255,0),3)
@endcode
### Drawing Circle
To draw a circle, you need its center coordinates and radius. We will draw a circle inside the
rectangle drawn above.
@code{.py}
cv.circle(img,(447,63), 63, (0,0,255), -1)
@endcode
### Drawing Ellipse
To draw the ellipse, we need to pass several arguments. One argument is the center location (x,y).
Next argument is axes lengths (major axis length, minor axis length). angle is the angle of rotation
of ellipse in anti-clockwise direction. startAngle and endAngle denotes the starting and ending of
ellipse arc measured in clockwise direction from major axis. i.e. giving values 0 and 360 gives the
full ellipse. For more details, check the documentation of **cv.ellipse()**. Below example draws a
half ellipse at the center of the image.
@code{.py}
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
@endcode
### Drawing Polygon
To draw a polygon, first you need coordinates of vertices. Make those points into an array of shape
ROWSx1x2 where ROWS are number of vertices and it should be of type int32. Here we draw a small
polygon of with four vertices in yellow color.
@code{.py}
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
@endcode
@note If third argument is False, you will get a polylines joining all the points, not a closed
shape.
@note cv.polylines() can be used to draw multiple lines. Just create a list of all the lines you
want to draw and pass it to the function. All lines will be drawn individually. It is a much better
and faster way to draw a group of lines than calling cv.line() for each line.
### Adding Text to Images:
To put texts in images, you need specify following things.
- Text data that you want to write
- Position coordinates of where you want put it (i.e. bottom-left corner where data starts).
- Font type (Check **cv.putText()** docs for supported fonts)
- Font Scale (specifies the size of font)
- regular things like color, thickness, lineType etc. For better look, lineType = cv.LINE_AA
is recommended.
We will write **OpenCV** on our image in white color.
@code{.py}
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(img,'OpenCV',(10,500), font, 4,(255,255,255),2,cv.LINE_AA)
@endcode
### Result
So it is time to see the final result of our drawing. As you studied in previous articles, display
the image to see it.

Additional Resources
--------------------
-# The angles used in ellipse function is not our circular angles. For more details, visit [this
discussion](http://answers.opencv.org/question/14541/angles-in-ellipse-function/).
Exercises
---------
-# Try to create the logo of OpenCV using drawing functions available in OpenCV.
| |
246255
|
Contour Features {#tutorial_py_contour_features}
================
@prev_tutorial{tutorial_py_contours_begin}
@next_tutorial{tutorial_py_contour_properties}
Goal
----
In this article, we will learn
- To find the different features of contours, like area, perimeter, centroid, bounding box etc
- You will see plenty of functions related to contours.
1. Moments
----------
Image moments help you to calculate some features like center of mass of the object, area of the
object etc. Check out the wikipedia page on [Image
Moments](http://en.wikipedia.org/wiki/Image_moment)
The function **cv.moments()** gives a dictionary of all moment values calculated. See below:
@code{.py}
import numpy as np
import cv2 as cv
img = cv.imread('star.jpg', cv.IMREAD_GRAYSCALE)
assert img is not None, "file could not be read, check with os.path.exists()"
ret,thresh = cv.threshold(img,127,255,0)
contours,hierarchy = cv.findContours(thresh, 1, 2)
cnt = contours[0]
M = cv.moments(cnt)
print( M )
@endcode
From this moments, you can extract useful data like area, centroid etc. Centroid is given by the
relations, \f$C_x = \frac{M_{10}}{M_{00}}\f$ and \f$C_y = \frac{M_{01}}{M_{00}}\f$. This can be done as
follows:
@code{.py}
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])
@endcode
2. Contour Area
---------------
Contour area is given by the function **cv.contourArea()** or from moments, **M['m00']**.
@code{.py}
area = cv.contourArea(cnt)
@endcode
3. Contour Perimeter
--------------------
It is also called arc length. It can be found out using **cv.arcLength()** function. Second
argument specify whether shape is a closed contour (if passed True), or just a curve.
@code{.py}
perimeter = cv.arcLength(cnt,True)
@endcode
4. Contour Approximation
------------------------
It approximates a contour shape to another shape with less number of vertices depending upon the
precision we specify. It is an implementation of [Douglas-Peucker
algorithm](http://en.wikipedia.org/wiki/Ramer-Douglas-Peucker_algorithm). Check the wikipedia page
for algorithm and demonstration.
To understand this, suppose you are trying to find a square in an image, but due to some problems in
the image, you didn't get a perfect square, but a "bad shape" (As shown in first image below). Now
you can use this function to approximate the shape. In this, second argument is called epsilon,
which is maximum distance from contour to approximated contour. It is an accuracy parameter. A wise
selection of epsilon is needed to get the correct output.
@code{.py}
epsilon = 0.1*cv.arcLength(cnt,True)
approx = cv.approxPolyDP(cnt,epsilon,True)
@endcode
Below, in second image, green line shows the approximated curve for epsilon = 10% of arc length.
Third image shows the same for epsilon = 1% of the arc length. Third argument specifies whether
curve is closed or not.

5. Convex Hull
--------------
Convex Hull will look similar to contour approximation, but it is not (Both may provide same results
in some cases). Here, **cv.convexHull()** function checks a curve for convexity defects and
corrects it. Generally speaking, convex curves are the curves which are always bulged out, or
at-least flat. And if it is bulged inside, it is called convexity defects. For example, check the
below image of hand. Red line shows the convex hull of hand. The double-sided arrow marks shows the
convexity defects, which are the local maximum deviations of hull from contours.

There is a little bit things to discuss about it its syntax:
@code{.py}
hull = cv.convexHull(points[, hull[, clockwise[, returnPoints]]])
@endcode
Arguments details:
- **points** are the contours we pass into.
- **hull** is the output, normally we avoid it.
- **clockwise** : Orientation flag. If it is True, the output convex hull is oriented clockwise.
Otherwise, it is oriented counter-clockwise.
- **returnPoints** : By default, True. Then it returns the coordinates of the hull points. If
False, it returns the indices of contour points corresponding to the hull points.
So to get a convex hull as in above image, following is sufficient:
@code{.py}
hull = cv.convexHull(cnt)
@endcode
But if you want to find convexity defects, you need to pass returnPoints = False. To understand it,
we will take the rectangle image above. First I found its contour as cnt. Now I found its convex
hull with returnPoints = True, I got following values:
[[[234 202]], [[ 51 202]], [[ 51 79]], [[234 79]]] which are the four corner points of rectangle.
Now if do the same with returnPoints = False, I get following result: [[129],[ 67],[ 0],[142]].
These are the indices of corresponding points in contours. For eg, check the first value:
cnt[129] = [[234, 202]] which is same as first result (and so on for others).
You will see it again when we discuss about convexity defects.
6. Checking Convexity
---------------------
There is a function to check if a curve is convex or not, **cv.isContourConvex()**. It just return
whether True or False. Not a big deal.
@code{.py}
k = cv.isContourConvex(cnt)
@endcode
7. Bounding Rectangle
---------------------
There are two types of bounding rectangles.
### 7.a. Straight Bounding Rectangle
It is a straight rectangle, it doesn't consider the rotation of the object. So area of the bounding
rectangle won't be minimum. It is found by the function **cv.boundingRect()**.
Let (x,y) be the top-left coordinate of the rectangle and (w,h) be its width and height.
@code{.py}
x,y,w,h = cv.boundingRect(cnt)
cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
@endcode
### 7.b. Rotated Rectangle
Here, bounding rectangle is drawn with minimum area, so it considers the rotation also. The function
used is **cv.minAreaRect()**. It returns a Box2D structure which contains following details - (
center (x,y), (width, height), angle of rotation ). But to draw this rectangle, we need 4 corners of
the rectangle. It is obtained by the function **cv.boxPoints()**
@code{.py}
rect = cv.minAreaRect(cnt)
box = cv.boxPoints(rect)
box = np.int0(box)
cv.drawContours(img,[box],0,(0,0,255),2)
@endcode
Both the rectangles are shown in a single image. Green rectangle shows the normal bounding rect. Red
rectangle is the rotated rect.

8. Minimum Enclosing Circle
---------------------------
Next we find the circumcircle of an object using the function **cv.minEnclosingCircle()**. It is a
circle which completely covers the object with minimum area.
@code{.py}
(x,y),radius = cv.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
cv.circle(img,center,radius,(0,255,0),2)
@endcode

9. Fitting an Ellipse
---------------------
Next one is to fit an ellipse to an object. It returns the rotated rectangle in which the ellipse is
inscribed.
@code{.py}
ellipse = cv.fitEllipse(cnt)
cv.ellipse(img,ellipse,(0,255,0),2)
@endcode

10. Fitting a Line
------------------
Similarly we can fit a line to a set of points. Below image contains a set of white points. We can
approximate a straight line to it.
@code{.py}
rows,cols = img.shape[:2]
[vx,vy,x,y] = cv.fitLine(cnt, cv.DIST_L2,0,0.01,0.01)
lefty = int((-x*vy/vx) + y)
righty = int(((cols-x)*vy/vx)+y)
cv.line(img,(cols-1,righty),(0,lefty),(0,255,0),2)
@endcode

| |
246321
|
### Visualizing images
It is very useful to see intermediate results of your algorithm during development process. OpenCV
provides a convenient way of visualizing images. A 8U image can be shown using:
@add_toggle_cpp
@snippet samples/cpp/tutorial_code/core/mat_operations/mat_operations.cpp imshow 1
@end_toggle
@add_toggle_java
@snippet samples/java/tutorial_code/core/mat_operations/MatOperations.java imshow 1
@end_toggle
@add_toggle_python
@snippet samples/python/tutorial_code/core/mat_operations/mat_operations.py imshow 1
@end_toggle
A call to waitKey() starts a message passing cycle that waits for a key stroke in the "image"
window. A 32F image needs to be converted to 8U type. For example:
@add_toggle_cpp
@snippet samples/cpp/tutorial_code/core/mat_operations/mat_operations.cpp imshow 2
@end_toggle
@add_toggle_java
@snippet samples/java/tutorial_code/core/mat_operations/MatOperations.java imshow 2
@end_toggle
@add_toggle_python
@snippet samples/python/tutorial_code/core/mat_operations/mat_operations.py imshow 2
@end_toggle
@note Here cv::namedWindow is not necessary since it is immediately followed by cv::imshow.
Nevertheless, it can be used to change the window properties or when using cv::createTrackbar
| |
246374
|
Adding borders to your images {#tutorial_copyMakeBorder}
=============================
@tableofcontents
@prev_tutorial{tutorial_filter_2d}
@next_tutorial{tutorial_sobel_derivatives}
| | |
| -: | :- |
| Original author | Ana Huamán |
| Compatibility | OpenCV >= 3.0 |
Goal
----
In this tutorial you will learn how to:
- Use the OpenCV function **copyMakeBorder()** to set the borders (extra padding to your
image).
Theory
------
@note The explanation below belongs to the book **Learning OpenCV** by Bradski and Kaehler.
-# In our previous tutorial we learned to use convolution to operate on images. One problem that
naturally arises is how to handle the boundaries. How can we convolve them if the evaluated
points are at the edge of the image?
-# What most of OpenCV functions do is to copy a given image onto another slightly larger image and
then automatically pads the boundary (by any of the methods explained in the sample code just
below). This way, the convolution can be performed over the needed pixels without problems (the
extra padding is cut after the operation is done).
-# In this tutorial, we will briefly explore two ways of defining the extra padding (border) for an
image:
-# **BORDER_CONSTANT**: Pad the image with a constant value (i.e. black or \f$0\f$
-# **BORDER_REPLICATE**: The row or column at the very edge of the original is replicated to
the extra border.
This will be seen more clearly in the Code section.
- **What does this program do?**
- Load an image
- Let the user choose what kind of padding use in the input image. There are two options:
-# *Constant value border*: Applies a padding of a constant value for the whole border.
This value will be updated randomly each 0.5 seconds.
-# *Replicated border*: The border will be replicated from the pixel values at the edges of
the original image.
The user chooses either option by pressing 'c' (constant) or 'r' (replicate)
- The program finishes when the user presses 'ESC'
Code
----
The tutorial code's is shown lines below.
@add_toggle_cpp
You can also download it from
[here](https://raw.githubusercontent.com/opencv/opencv/4.x/samples/cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp)
@include samples/cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp
@end_toggle
@add_toggle_java
You can also download it from
[here](https://raw.githubusercontent.com/opencv/opencv/4.x/samples/java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java)
@include samples/java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java
@end_toggle
@add_toggle_python
You can also download it from
[here](https://raw.githubusercontent.com/opencv/opencv/4.x/samples/python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py)
@include samples/python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py
@end_toggle
Explanation
-----------
### Declare the variables
First we declare the variables we are going to use:
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp variables
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java variables
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py variables
@end_toggle
Especial attention deserves the variable *rng* which is a random number generator. We use it to
generate the random border color, as we will see soon.
### Load an image
As usual we load our source image *src*:
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp load
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java load
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py load
@end_toggle
### Create a window
After giving a short intro of how to use the program, we create a window:
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp create_window
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java create_window
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py create_window
@end_toggle
### Initialize arguments
Now we initialize the argument that defines the size of the borders (*top*, *bottom*, *left* and
*right*). We give them a value of 5% the size of *src*.
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp init_arguments
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java init_arguments
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py init_arguments
@end_toggle
### Loop
The program runs in an infinite loop while the key **ESC** isn't pressed.
If the user presses '**c**' or '**r**', the *borderType* variable
takes the value of *BORDER_CONSTANT* or *BORDER_REPLICATE* respectively:
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp check_keypress
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java check_keypress
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py check_keypress
@end_toggle
### Random color
In each iteration (after 0.5 seconds), the random border color (*value*) is updated...
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp update_value
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java update_value
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py update_value
@end_toggle
This value is a set of three numbers picked randomly in the range \f$[0,255]\f$.
### Form a border around the image
Finally, we call the function **copyMakeBorder()** to apply the respective padding:
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp copymakeborder
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java copymakeborder
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py copymakeborder
@end_toggle
- The arguments are:
-# *src*: Source image
-# *dst*: Destination image
-# *top*, *bottom*, *left*, *right*: Length in pixels of the borders at each side of the image.
We define them as being 5% of the original size of the image.
-# *borderType*: Define what type of border is applied. It can be constant or replicate for
this example.
-# *value*: If *borderType* is *BORDER_CONSTANT*, this is the value used to fill the border
pixels.
### Display the results
We display our output image in the image created previously
@add_toggle_cpp
@snippet cpp/tutorial_code/ImgTrans/copyMakeBorder_demo.cpp display
@end_toggle
@add_toggle_java
@snippet java/tutorial_code/ImgTrans/MakeBorder/CopyMakeBorder.java display
@end_toggle
@add_toggle_python
@snippet python/tutorial_code/ImgTrans/MakeBorder/copy_make_border.py display
@end_toggle
Results
-------
-# After compiling the code above, you can execute it giving as argument the path of an image. The
result should be:
- By default, it begins with the border set to BORDER_CONSTANT. Hence, a succession of random
colored borders will be shown.
- If you press 'r', the border will become a replica of the edge pixels.
- If you press 'c', the random colored borders will appear again
- If you press 'ESC' the program will exit.
Below some screenshot showing how the border changes color and how the *BORDER_REPLICATE*
option looks:

| |
246459
|
# How to run deep networks on Android device {#tutorial_android_dnn_intro}
@tableofcontents
@prev_tutorial{tutorial_dev_with_OCV_on_Android}
@next_tutorial{tutorial_android_ocl_intro}
@see @ref tutorial_table_of_content_dnn
| | |
| -: | :- |
| Original author | Dmitry Kurtaev |
| Compatibility | OpenCV >= 4.9 |
## Introduction
In this tutorial you'll know how to run deep learning networks on Android device
using OpenCV deep learning module.
Tutorial was written for Android Studio 2022.2.1.
## Requirements
- Download and install Android Studio from https://developer.android.com/studio.
- Get the latest pre-built OpenCV for Android release from https://github.com/opencv/opencv/releases
and unpack it (for example, `opencv-4.X.Y-android-sdk.zip`, minimum version 4.9 is required).
- Download MobileNet object detection model from https://github.com/chuanqi305/MobileNet-SSD.
Configuration file `MobileNetSSD_deploy.prototxt` and model weights `MobileNetSSD_deploy.caffemodel`
are required.
## Create an empty Android Studio project and add OpenCV dependency
Use @ref tutorial_dev_with_OCV_on_Android tutorial to initialize your project and add OpenCV.
## Make an app
Our sample will takes pictures from a camera, forwards it into a deep network and
receives a set of rectangles, class identifiers and confidence values in range [0, 1].
- First of all, we need to add a necessary widget which displays processed
frames. Modify `app/src/main/res/layout/activity_main.xml`:
@include android/mobilenet-objdetect/res/layout/activity_main.xml
- Modify `/app/src/main/AndroidManifest.xml` to enable full-screen mode, set up
a correct screen orientation and allow to use a camera.
@code{.xml}
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android">
<application
android:label="@string/app_name">
@endcode
@snippet android/mobilenet-objdetect/gradle/AndroidManifest.xml mobilenet_tutorial
- Replace content of `app/src/main/java/com/example/myapplication/MainActivity.java` and set a custom package name if necessary:
@snippet android/mobilenet-objdetect/src/org/opencv/samples/opencv_mobilenet/MainActivity.java mobilenet_tutorial_package
@snippet android/mobilenet-objdetect/src/org/opencv/samples/opencv_mobilenet/MainActivity.java mobilenet_tutorial
- Put downloaded `deploy.prototxt` and `mobilenet_iter_73000.caffemodel`
into `app/src/main/res/raw` folder. OpenCV DNN model is mainly designed to load ML and DNN models
from file. Modern Android does not allow it without extra permissions, but provides Java API to load
bytes from resources. The sample uses alternative DNN API that initializes a model from in-memory
buffer rather than a file. The following function reads model file from resources and converts it to
`MatOfBytes` (analog of `std::vector<char>` in C++ world) object suitable for OpenCV Java API:
@snippet android/mobilenet-objdetect/src/org/opencv/samples/opencv_mobilenet/MainActivity.java mobilenet_tutorial_resource
And then the network initialization is done with the following lines:
@snippet android/mobilenet-objdetect/src/org/opencv/samples/opencv_mobilenet/MainActivity.java init_model_from_memory
See also [Android documentation on resources](https://developer.android.com/guide/topics/resources/providing-resources.html)
- Take a look how DNN model input is prepared and inference result is interpreted:
@snippet android/mobilenet-objdetect/src/org/opencv/samples/opencv_mobilenet/MainActivity.java mobilenet_handle_frame
`Dnn.blobFromImage` converts camera frame to neural network input tensor. Resize and statistical
normalization are applied. Each line of network output tensor contains information on one detected
object in the following order: confidence in range [0, 1], class id, left, top, right, bottom box
coordinates. All coordinates are in range [0, 1] and should be scaled to image size before rendering.
- Launch an application and make a fun!

| |
246535
|
YOLO DNNs {#tutorial_dnn_yolo}
===============================
@tableofcontents
@prev_tutorial{tutorial_dnn_openvino}
@next_tutorial{tutorial_dnn_javascript}
| | |
| -: | :- |
| Original author | Alessandro de Oliveira Faria |
| Extended by | Abduragim Shtanchaev |
| Compatibility | OpenCV >= 4.9.0 |
Running pre-trained YOLO model in OpenCV
----------------------------------------
Deploying pre-trained models is a common task in machine learning, particularly when working with
hardware that does not support certain frameworks like PyTorch. This guide provides a comprehensive
overview of exporting pre-trained YOLO family models from PyTorch and deploying them using OpenCV's
DNN framework. For demonstration purposes, we will focus on the [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX/blob/main)
model, but the methodology applies to other supported models.
@note Currently, OpenCV supports the following YOLO models:
- [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX/blob/main),
- [YOLONas](https://github.com/Deci-AI/super-gradients/tree/master),
- [YOLOv10](https://github.com/THU-MIG/yolov10/tree/main),
- [YOLOv9](https://github.com/WongKinYiu/yolov9),
- [YOLOv8](https://github.com/ultralytics/ultralytics/tree/main),
- [YOLOv7](https://github.com/WongKinYiu/yolov7/tree/main),
- [YOLOv6](https://github.com/meituan/YOLOv6/blob/main),
- [YOLOv5](https://github.com/ultralytics/yolov5),
- [YOLOv4](https://github.com/Tianxiaomo/pytorch-YOLOv4).
This support includes pre and post-processing routines specific to these models. While other older
version of YOLO are also supported by OpenCV in Darknet format, they are out of the scope of this tutorial.
Assuming that we have successfully trained YOLOX model, the subsequent step involves exporting and
running this model with OpenCV. There are several critical considerations to address before
proceeding with this process. Let's delve into these aspects.
### YOLO's Pre-proccessing & Output
Understanding the nature of inputs and outputs associated with YOLO family detectors is pivotal.
These detectors, akin to most Deep Neural Networks (DNN), typically exhibit variation in input
sizes contingent upon the model's scale.
| Model Scale | Input Size |
|--------------|--------------|
| Small Models <sup>[1](https://github.com/Megvii-BaseDetection/YOLOX/tree/main#standard-models)</sup>| 416x416 |
| Midsize Models <sup>[2](https://github.com/Megvii-BaseDetection/YOLOX/tree/main#standard-models)</sup>| 640x640 |
| Large Models <sup>[3](https://github.com/meituan/YOLOv6/tree/main#benchmark)</sup>| 1280x1280 |
This table provides a quick reference to understand the different input dimensions commonly used in
various YOLO models inputs. These are standard input shapes. Make sure you use input size that you
trained model with, if it is differed from from the size mentioned in the table.
The next critical element in the process involves understanding the specifics of image pre-processing
for YOLO detectors. While the fundamental pre-processing approach remains consistent across the YOLO
family, there are subtle yet crucial differences that must be accounted for to avoid any degradation
in performance. Key among these are the `resize type` and the `padding value` applied post-resize.
For instance, the [YOLOX model](https://github.com/Megvii-BaseDetection/YOLOX/blob/ac58e0a5e68e57454b7b9ac822aced493b553c53/yolox/data/data_augment.py#L142)
utilizes a `LetterBox` resize method and a padding value of `114.0`. It is imperative to ensure that
these parameters, along with the normalization constants, are appropriately matched to the model being
exported.
Regarding the model's output, it typically takes the form of a tensor with dimensions [BxNxC+5] or
[BxNxC+4], where 'B' represents the batch size, 'N' denotes the number of anchors, and 'C' signifies
the number of classes (for instance, 80 classes if the model is trained on the COCO dataset).
The additional 5 in the former tensor structure corresponds to the objectness score (obj), confidence
score (conf), and the bounding box coordinates (cx, cy, w, h). Notably, the YOLOv8 model's output
is shaped as [BxNxC+4], where there is no explicit objectness score, and the object score is directly
inferred from the class score. For the YOLOX model, specifically, it is also necessary to incorporate
anchor points to rescale predictions back to the image domain. This step will be integrated into
the ONNX graph, a process that we will detail further in the subsequent sections.
| |
246536
|
### PyTorch Model Export
Now that we know know the parameters of the pre-precessing we can go on and export the model from
Pytorch to ONNX graph. Since in this tutorial we are using YOLOX as our sample model, lets use its
export for demonstration purposes (the process is identical for the rest of the YOLO detectors except `YOLOv10` model, see details on how to export it later in the post).
To exporting YOLOX we can just use [export script](https://github.com/Megvii-BaseDetection/YOLOX/blob/ac58e0a5e68e57454b7b9ac822aced493b553c53/tools/export_onnx.py). Particularly we need following commands:
@code{.bash}
git clone https://github.com/Megvii-BaseDetection/YOLOX.git
cd YOLOX
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth # download pre-trained weights
python3 -m tools.export_onnx --output-name yolox_s.onnx -n yolox-s -c yolox_s.pth --decode_in_inference
@endcode
**NOTE:** Here `--decode_in_inference` is to include anchor box creation in the ONNX graph itself.
It sets [this value](https://github.com/Megvii-BaseDetection/YOLOX/blob/ac58e0a5e68e57454b7b9ac822aced493b553c53/yolox/models/yolo_head.py#L210C16-L210C39)
to `True`, which subsequently includes anchor generation function.
Below we demonstrated the minimal version of the export script (which could be used for models other
than YOLOX) in case it is needed. However, usually each YOLO repository has predefined export script.
@code{.py}
import onnx
import torch
from onnxsim import simplify
# load the model state dict
ckpt = torch.load(ckpt_file, map_location="cpu")
model.load_state_dict(ckpt)
# prepare dummy input
dummy_input = torch.randn(args.batch_size, 3, exp.test_size[0], exp.test_size[1])
#export the model
torch.onnx._export(
model,
dummy_input,
"yolox.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: 'batch'},
"output": {0: 'batch'}})
# use onnx-simplifier to reduce reduent model.
onnx_model = onnx.load(args.output_name)
model_simp, check = simplify(onnx_model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, args.output_name)
@endcode
#### Exporting YOLOv10 model
In oder to run YOLOv10 one needs to cut off postporcessing with dynamic shapes from torch and then convert it to ONNX. If someone is looking for on how to cut off the postprocessing, there is this [forked branch](https://github.com/Abdurrahheem/yolov10/tree/ash/opencv-export) from official YOLOv10. The forked branch cuts of the postprocessing by [returning output](https://github.com/Abdurrahheem/yolov10/blob/4fdaafd912c8891642bfbe85751ea66ec20f05ad/ultralytics/nn/modules/head.py#L522) of the model before postprocessing procedure itself. To convert torch model to ONNX follow this proceduce.
@code{.bash}
git clone git@github.com:Abdurrahheem/yolov10.git
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
python export_opencv.py --model=<model-name> --imgsz=<input-img-size>
@endcode
By default `--model="yolov10s"` and `--imgsz=(480,640)`. This will generate file `yolov10s.onnx`, which can be use for inference in OpenCV
| |
251138
|
### Saturation Arithmetics
As a computer vision library, OpenCV deals a lot with image pixels that are often encoded in a
compact, 8- or 16-bit per channel, form and thus have a limited value range. Furthermore, certain
operations on images, like color space conversions, brightness/contrast adjustments, sharpening,
complex interpolation (bi-cubic, Lanczos) can produce values out of the available range. If you just
store the lowest 8 (16) bits of the result, this results in visual artifacts and may affect a
further image analysis. To solve this problem, the so-called *saturation* arithmetics is used. For
example, to store r, the result of an operation, to an 8-bit image, you find the nearest value
within the 0..255 range:
\f[I(x,y)= \min ( \max (\textrm{round}(r), 0), 255)\f]
Similar rules are applied to 8-bit signed, 16-bit signed and unsigned types. This semantics is used
everywhere in the library. In C++ code, it is done using the `cv::saturate_cast<>` functions that
resemble standard C++ cast operations. See below the implementation of the formula provided above:
```.cpp
I.at<uchar>(y, x) = saturate_cast<uchar>(r);
```
where cv::uchar is an OpenCV 8-bit unsigned integer type. In the optimized SIMD code, such SSE2
instructions as paddusb, packuswb, and so on are used. They help achieve exactly the same behavior
as in C++ code.
@note Saturation is not applied when the result is 32-bit integer.
### Fixed Pixel Types. Limited Use of Templates
Templates is a great feature of C++ that enables implementation of very powerful, efficient and yet
safe data structures and algorithms. However, the extensive use of templates may dramatically
increase compilation time and code size. Besides, it is difficult to separate an interface and
implementation when templates are used exclusively. This could be fine for basic algorithms but not
good for computer vision libraries where a single algorithm may span thousands lines of code.
Because of this and also to simplify development of bindings for other languages, like Python, Java,
Matlab that do not have templates at all or have limited template capabilities, the current OpenCV
implementation is based on polymorphism and runtime dispatching over templates. In those places
where runtime dispatching would be too slow (like pixel access operators), impossible (generic
`cv::Ptr<>` implementation), or just very inconvenient (`cv::saturate_cast<>()`) the current implementation
introduces small template classes, methods, and functions. Anywhere else in the current OpenCV
version the use of templates is limited.
Consequently, there is a limited fixed set of primitive data types the library can operate on. That
is, array elements should have one of the following types:
- 8-bit unsigned integer (uchar)
- 8-bit signed integer (schar)
- 16-bit unsigned integer (ushort)
- 16-bit signed integer (short)
- 32-bit signed integer (int)
- 32-bit floating-point number (float)
- 64-bit floating-point number (double)
- a tuple of several elements where all elements have the same type (one of the above). An array
whose elements are such tuples, are called multi-channel arrays, as opposite to the
single-channel arrays, whose elements are scalar values. The maximum possible number of
channels is defined by the #CV_CN_MAX constant, which is currently set to 512.
For these basic types, the following enumeration is applied:
```.cpp
enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 };
```
Multi-channel (n-channel) types can be specified using the following options:
- #CV_8UC1 ... #CV_64FC4 constants (for a number of channels from 1 to 4)
- CV_8UC(n) ... CV_64FC(n) or CV_MAKETYPE(CV_8U, n) ... CV_MAKETYPE(CV_64F, n) macros when
the number of channels is more than 4 or unknown at the compilation time.
@note `#CV_32FC1 == #CV_32F, #CV_32FC2 == #CV_32FC(2) == #CV_MAKETYPE(CV_32F, 2)`, and
`#CV_MAKETYPE(depth, n) == ((depth&7) + ((n-1)<<3)`. This means that the constant type is formed from the
depth, taking the lowest 3 bits, and the number of channels minus 1, taking the next
`log2(CV_CN_MAX)` bits.
Examples:
```.cpp
Mat mtx(3, 3, CV_32F); // make a 3x3 floating-point matrix
Mat cmtx(10, 1, CV_64FC2); // make a 10x1 2-channel floating-point
// matrix (10-element complex vector)
Mat img(Size(1920, 1080), CV_8UC3); // make a 3-channel (color) image
// of 1920 columns and 1080 rows.
Mat grayscale(img.size(), CV_MAKETYPE(img.depth(), 1)); // make a 1-channel image of
// the same size and same
// channel type as img
```
Arrays with more complex elements cannot be constructed or processed using OpenCV. Furthermore, each
function or method can handle only a subset of all possible array types. Usually, the more complex
the algorithm is, the smaller the supported subset of formats is. See below typical examples of such
limitations:
- The face detection algorithm only works with 8-bit grayscale or color images.
- Linear algebra functions and most of the machine learning algorithms work with floating-point
arrays only.
- Basic functions, such as cv::add, support all types.
- Color space conversion functions support 8-bit unsigned, 16-bit unsigned, and 32-bit
floating-point types.
The subset of supported types for each function has been defined from practical needs and could be
extended in future based on user requests.
### InputArray and OutputArray
Many OpenCV functions process dense 2-dimensional or multi-dimensional numerical arrays. Usually,
such functions take `cv::Mat` as parameters, but in some cases it's more convenient to use
`std::vector<>` (for a point set, for example) or `cv::Matx<>` (for 3x3 homography matrix and such). To
avoid many duplicates in the API, special "proxy" classes have been introduced. The base "proxy"
class is cv::InputArray. It is used for passing read-only arrays on a function input. The derived from
InputArray class cv::OutputArray is used to specify an output array for a function. Normally, you should
not care of those intermediate types (and you should not declare variables of those types
explicitly) - it will all just work automatically. You can assume that instead of
InputArray/OutputArray you can always use `cv::Mat`, `std::vector<>`, `cv::Matx<>`, `cv::Vec<>` or `cv::Scalar`. When a
function has an optional input or output array, and you do not have or do not want one, pass
cv::noArray().
### Error Handling
OpenCV uses exceptions to signal critical errors. When the input data has a correct format and
belongs to the specified value range, but the algorithm cannot succeed for some reason (for example,
the optimization algorithm did not converge), it returns a special error code (typically, just a
boolean variable).
The exceptions can be instances of the cv::Exception class or its derivatives. In its turn,
cv::Exception is a derivative of `std::exception`. So it can be gracefully handled in the code using
other standard C++ library components.
The exception is typically thrown either using the `#CV_Error(errcode, description)` macro, or its
printf-like `#CV_Error_(errcode, (printf-spec, printf-args))` variant, or using the
#CV_Assert(condition) macro that checks the condition and throws an exception when it is not
satisfied. For performance-critical code, there is #CV_DbgAssert(condition) that is only retained in
the Debug configuration. Due to the automatic memory management, all the intermediate buffers are
automatically deallocated in case of a sudden error. You only need to add a try statement to catch
exceptions, if needed:
```.cpp
try
{
... // call OpenCV
}
catch (const cv::Exception& e)
{
const char* err_msg = e.what();
std::cout << "exception caught: " << err_msg << std::endl;
}
```
| |
251185
|
class Arguments(NewOpenCVTests):
def _try_to_convert(self, conversion, value):
try:
result = conversion(value).lower()
except Exception as e:
self.fail(
'{} "{}" is risen for conversion {} of type {}'.format(
type(e).__name__, e, value, type(value).__name__
)
)
else:
return result
def test_InputArray(self):
res1 = cv.utils.dumpInputArray(None)
# self.assertEqual(res1, "InputArray: noArray()") # not supported
self.assertEqual(res1, "InputArray: empty()=true kind=0x00010000 flags=0x01010000 total(-1)=0 dims(-1)=0 size(-1)=0x0 type(-1)=CV_8UC1")
res2_1 = cv.utils.dumpInputArray((1, 2))
self.assertEqual(res2_1, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=2 dims(-1)=2 size(-1)=1x2 type(-1)=CV_64FC1")
res2_2 = cv.utils.dumpInputArray(1.5) # Scalar(1.5, 1.5, 1.5, 1.5)
self.assertEqual(res2_2, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=4 dims(-1)=2 size(-1)=1x4 type(-1)=CV_64FC1")
a = np.array([[1, 2], [3, 4], [5, 6]])
res3 = cv.utils.dumpInputArray(a) # 32SC1
self.assertEqual(res3, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=6 dims(-1)=2 size(-1)=2x3 type(-1)=CV_32SC1")
a = np.array([[[1, 2], [3, 4], [5, 6]]], dtype='f')
res4 = cv.utils.dumpInputArray(a) # 32FC2
self.assertEqual(res4, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=3 dims(-1)=2 size(-1)=3x1 type(-1)=CV_32FC2")
a = np.array([[[1, 2]], [[3, 4]], [[5, 6]]], dtype=float)
res5 = cv.utils.dumpInputArray(a) # 64FC2
self.assertEqual(res5, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=3 dims(-1)=2 size(-1)=1x3 type(-1)=CV_64FC2")
a = np.zeros((2,3,4), dtype='f')
res6 = cv.utils.dumpInputArray(a)
self.assertEqual(res6, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=6 dims(-1)=2 size(-1)=3x2 type(-1)=CV_32FC4")
a = np.zeros((2,3,4,5), dtype='f')
res7 = cv.utils.dumpInputArray(a)
self.assertEqual(res7, "InputArray: empty()=false kind=0x00010000 flags=0x01010000 total(-1)=120 dims(-1)=4 size(-1)=[2 3 4 5] type(-1)=CV_32FC1")
def test_InputArrayOfArrays(self):
res1 = cv.utils.dumpInputArrayOfArrays(None)
# self.assertEqual(res1, "InputArray: noArray()") # not supported
self.assertEqual(res1, "InputArrayOfArrays: empty()=true kind=0x00050000 flags=0x01050000 total(-1)=0 dims(-1)=1 size(-1)=0x0")
res2_1 = cv.utils.dumpInputArrayOfArrays((1, 2)) # { Scalar:all(1), Scalar::all(2) }
self.assertEqual(res2_1, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=2 dims(-1)=1 size(-1)=2x1 type(0)=CV_64FC1 dims(0)=2 size(0)=1x4")
res2_2 = cv.utils.dumpInputArrayOfArrays([1.5])
self.assertEqual(res2_2, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=1 dims(-1)=1 size(-1)=1x1 type(0)=CV_64FC1 dims(0)=2 size(0)=1x4")
a = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
res3 = cv.utils.dumpInputArrayOfArrays([a, b])
self.assertEqual(res3, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=2 dims(-1)=1 size(-1)=2x1 type(0)=CV_32SC1 dims(0)=2 size(0)=2x3")
c = np.array([[[1, 2], [3, 4], [5, 6]]], dtype='f')
res4 = cv.utils.dumpInputArrayOfArrays([c, a, b])
self.assertEqual(res4, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=3 dims(-1)=1 size(-1)=3x1 type(0)=CV_32FC2 dims(0)=2 size(0)=3x1")
a = np.zeros((2,3,4), dtype='f')
res5 = cv.utils.dumpInputArrayOfArrays([a, b])
self.assertEqual(res5, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=2 dims(-1)=1 size(-1)=2x1 type(0)=CV_32FC4 dims(0)=2 size(0)=3x2")
# TODO: fix conversion error
#a = np.zeros((2,3,4,5), dtype='f')
#res6 = cv.utils.dumpInputArray([a, b])
#self.assertEqual(res6, "InputArrayOfArrays: empty()=false kind=0x00050000 flags=0x01050000 total(-1)=2 dims(-1)=1 size(-1)=2x1 type(0)=CV_32FC1 dims(0)=4 size(0)=[2 3 4 5]")
def test_unsupported_numpy_data_types_string_description(self):
for dtype in (object, str, np.complex128):
test_array = np.zeros((4, 4, 3), dtype=dtype)
msg = ".*type = {} is not supported".format(test_array.dtype)
if sys.version_info[0] < 3:
self.assertRaisesRegexp(
Exception, msg, cv.utils.dumpInputArray, test_array
)
else:
self.assertRaisesRegex(
Exception, msg, cv.utils.dumpInputArray, test_array
)
def test_numpy_writeable_flag_is_preserved(self):
array = np.zeros((10, 10, 1), dtype=np.uint8)
array.setflags(write=False)
with self.assertRaises(Exception):
cv.rectangle(array, (0, 0), (5, 5), (255), 2)
def test_20968(self):
pixel = np.uint8([[[40, 50, 200]]])
_ = cv.cvtColor(pixel, cv.COLOR_RGB2BGR) # should not raise exception
def test_parse_to_bool_convertible(self):
try_to_convert = partial(self._try_to_convert, cv.utils.dumpBool)
for convertible_true in (True, 1, 64, np.int8(123), np.int16(11), np.int32(2),
np.int64(1), np.bool_(12)):
actual = try_to_convert(convertible_true)
self.assertEqual('bool: true', actual,
msg=get_conversion_error_msg(convertible_true, 'bool: true', actual))
for convertible_false in (False, 0, np.uint8(0), np.bool_(0), np.int_(0)):
actual = try_to_convert(convertible_false)
self.assertEqual('bool: false', actual,
msg=get_conversion_error_msg(convertible_false, 'bool: false', actual))
| |
251277
|
#!/usr/bin/env python
from __future__ import print_function
import numpy as np
import cv2 as cv
from tests_common import NewOpenCVTests
class Imgproc_Tests(NewOpenCVTests):
def test_python_986(self):
cntls = []
img = np.zeros((100,100,3), dtype=np.uint8)
color = (0,0,0)
cnts = np.array(cntls, dtype=np.int32).reshape((1, -1, 2))
try:
cv.fillPoly(img, cnts, color)
assert False
except:
assert True
| |
251599
|
package org.opencv.utils;
import java.util.ArrayList;
import java.util.List;
import org.opencv.core.CvType;
import org.opencv.core.Mat;
import org.opencv.core.MatOfByte;
import org.opencv.core.MatOfDMatch;
import org.opencv.core.MatOfKeyPoint;
import org.opencv.core.MatOfPoint;
import org.opencv.core.MatOfPoint2f;
import org.opencv.core.MatOfPoint3f;
import org.opencv.core.Point;
import org.opencv.core.Point3;
import org.opencv.core.Size;
import org.opencv.core.Rect;
import org.opencv.core.RotatedRect;
import org.opencv.core.Rect2d;
import org.opencv.core.DMatch;
import org.opencv.core.KeyPoint;
public class Converters {
public static Mat vector_Point_to_Mat(List<Point> pts) {
return vector_Point_to_Mat(pts, CvType.CV_32S);
}
public static Mat vector_Point2f_to_Mat(List<Point> pts) {
return vector_Point_to_Mat(pts, CvType.CV_32F);
}
public static Mat vector_Point2d_to_Mat(List<Point> pts) {
return vector_Point_to_Mat(pts, CvType.CV_64F);
}
public static Mat vector_Point_to_Mat(List<Point> pts, int typeDepth) {
Mat res;
int count = (pts != null) ? pts.size() : 0;
if (count > 0) {
switch (typeDepth) {
case CvType.CV_32S: {
res = new Mat(count, 1, CvType.CV_32SC2);
int[] buff = new int[count * 2];
for (int i = 0; i < count; i++) {
Point p = pts.get(i);
buff[i * 2] = (int) p.x;
buff[i * 2 + 1] = (int) p.y;
}
res.put(0, 0, buff);
}
break;
case CvType.CV_32F: {
res = new Mat(count, 1, CvType.CV_32FC2);
float[] buff = new float[count * 2];
for (int i = 0; i < count; i++) {
Point p = pts.get(i);
buff[i * 2] = (float) p.x;
buff[i * 2 + 1] = (float) p.y;
}
res.put(0, 0, buff);
}
break;
case CvType.CV_64F: {
res = new Mat(count, 1, CvType.CV_64FC2);
double[] buff = new double[count * 2];
for (int i = 0; i < count; i++) {
Point p = pts.get(i);
buff[i * 2] = p.x;
buff[i * 2 + 1] = p.y;
}
res.put(0, 0, buff);
}
break;
default:
throw new IllegalArgumentException("'typeDepth' can be CV_32S, CV_32F or CV_64F");
}
} else {
res = new Mat();
}
return res;
}
public static Mat vector_Point3i_to_Mat(List<Point3> pts) {
return vector_Point3_to_Mat(pts, CvType.CV_32S);
}
public static Mat vector_Point3f_to_Mat(List<Point3> pts) {
return vector_Point3_to_Mat(pts, CvType.CV_32F);
}
public static Mat vector_Point3d_to_Mat(List<Point3> pts) {
return vector_Point3_to_Mat(pts, CvType.CV_64F);
}
public static Mat vector_Point3_to_Mat(List<Point3> pts, int typeDepth) {
Mat res;
int count = (pts != null) ? pts.size() : 0;
if (count > 0) {
switch (typeDepth) {
case CvType.CV_32S: {
res = new Mat(count, 1, CvType.CV_32SC3);
int[] buff = new int[count * 3];
for (int i = 0; i < count; i++) {
Point3 p = pts.get(i);
buff[i * 3] = (int) p.x;
buff[i * 3 + 1] = (int) p.y;
buff[i * 3 + 2] = (int) p.z;
}
res.put(0, 0, buff);
}
break;
case CvType.CV_32F: {
res = new Mat(count, 1, CvType.CV_32FC3);
float[] buff = new float[count * 3];
for (int i = 0; i < count; i++) {
Point3 p = pts.get(i);
buff[i * 3] = (float) p.x;
buff[i * 3 + 1] = (float) p.y;
buff[i * 3 + 2] = (float) p.z;
}
res.put(0, 0, buff);
}
break;
case CvType.CV_64F: {
res = new Mat(count, 1, CvType.CV_64FC3);
double[] buff = new double[count * 3];
for (int i = 0; i < count; i++) {
Point3 p = pts.get(i);
buff[i * 3] = p.x;
buff[i * 3 + 1] = p.y;
buff[i * 3 + 2] = p.z;
}
res.put(0, 0, buff);
}
break;
default:
throw new IllegalArgumentException("'typeDepth' can be CV_32S, CV_32F or CV_64F");
}
} else {
res = new Mat();
}
return res;
}
public static void Mat_to_vector_Point2f(Mat m, List<Point> pts) {
Mat_to_vector_Point(m, pts);
}
public static void Mat_to_vector_Point2d(Mat m, List<Point> pts) {
Mat_to_vector_Point(m, pts);
}
public static void Mat_to_vector_Point(Mat m, List<Point> pts) {
if (pts == null)
throw new IllegalArgumentException("Output List can't be null");
int count = m.rows();
int type = m.type();
if (m.cols() != 1)
throw new IllegalArgumentException("Input Mat should have one column\n" + m);
pts.clear();
if (type == CvType.CV_32SC2) {
int[] buff = new int[2 * count];
m.get(0, 0, buff);
for (int i = 0; i < count; i++) {
pts.add(new Point(buff[i * 2], buff[i * 2 + 1]));
}
} else if (type == CvType.CV_32FC2) {
float[] buff = new float[2 * count];
m.get(0, 0, buff);
for (int i = 0; i < count; i++) {
pts.add(new Point(buff[i * 2], buff[i * 2 + 1]));
}
} else if (type == CvType.CV_64FC2) {
double[] buff = new double[2 * count];
m.get(0, 0, buff);
for (int i = 0; i < count; i++) {
pts.add(new Point(buff[i * 2], buff[i * 2 + 1]));
}
} else {
throw new IllegalArgumentException(
"Input Mat should be of CV_32SC2, CV_32FC2 or CV_64FC2 type\n" + m);
}
}
public static void Mat_to_vector_Point3i(Mat m, List<Point3> pts) {
Mat_to_vector_Point3(m, pts);
}
public static void Mat_to_vector_Point3f(Mat m, List<Point3> pts) {
Mat_to_vector_Point3(m, pts);
}
public static void Mat_to_vector_Point3d(Mat m, List<Point3> pts) {
Mat_to_vector_Point3(m, pts);
}
| |
251746
|
package org.opencv.test.dnn;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.opencv.core.Core;
import org.opencv.core.Mat;
import org.opencv.core.MatOfFloat;
import org.opencv.core.MatOfByte;
import org.opencv.core.Scalar;
import org.opencv.core.Size;
import org.opencv.dnn.DictValue;
import org.opencv.dnn.Dnn;
import org.opencv.dnn.Layer;
import org.opencv.dnn.Net;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.test.OpenCVTestCase;
public class DnnTensorFlowTest extends OpenCVTestCase {
private final static String ENV_OPENCV_DNN_TEST_DATA_PATH = "OPENCV_DNN_TEST_DATA_PATH";
private final static String ENV_OPENCV_TEST_DATA_PATH = "OPENCV_TEST_DATA_PATH";
String modelFileName = "";
String sourceImageFile = "";
Net net;
private static void normAssert(Mat ref, Mat test) {
final double l1 = 1e-5;
final double lInf = 1e-4;
double normL1 = Core.norm(ref, test, Core.NORM_L1) / ref.total();
double normLInf = Core.norm(ref, test, Core.NORM_INF) / ref.total();
assertTrue(normL1 < l1);
assertTrue(normLInf < lInf);
}
@Override
protected void setUp() throws Exception {
super.setUp();
String envDnnTestDataPath = System.getenv(ENV_OPENCV_DNN_TEST_DATA_PATH);
if(envDnnTestDataPath == null){
isTestCaseEnabled = false;
return;
}
File dnnTestDataPath = new File(envDnnTestDataPath);
modelFileName = new File(dnnTestDataPath, "dnn/tensorflow_inception_graph.pb").toString();
String envTestDataPath = System.getenv(ENV_OPENCV_TEST_DATA_PATH);
if(envTestDataPath == null) throw new Exception(ENV_OPENCV_TEST_DATA_PATH + " has to be defined!");
File testDataPath = new File(envTestDataPath);
File f = new File(testDataPath, "dnn/grace_hopper_227.png");
sourceImageFile = f.toString();
if(!f.exists()) throw new Exception("Test image is missing: " + sourceImageFile);
net = Dnn.readNetFromTensorflow(modelFileName);
}
public void testGetLayerTypes() {
List<String> layertypes = new ArrayList();
net.getLayerTypes(layertypes);
assertFalse("No layer types returned!", layertypes.isEmpty());
}
public void testGetLayer() {
List<String> layernames = net.getLayerNames();
assertFalse("Test net returned no layers!", layernames.isEmpty());
String testLayerName = layernames.get(0);
DictValue layerId = new DictValue(testLayerName);
assertEquals("DictValue did not return the string, which was used in constructor!", testLayerName, layerId.getStringValue());
Layer layer = net.getLayer(layerId);
assertEquals("Layer name does not match the expected value!", testLayerName, layer.get_name());
}
public void checkInceptionNet(Net net)
{
Mat image = Imgcodecs.imread(sourceImageFile);
assertNotNull("Loading image from file failed!", image);
Mat inputBlob = Dnn.blobFromImage(image, 1.0, new Size(224, 224), new Scalar(0), true, true);
assertNotNull("Converting image to blob failed!", inputBlob);
net.setInput(inputBlob, "input");
Mat result = new Mat();
try {
net.setPreferableBackend(Dnn.DNN_BACKEND_OPENCV);
result = net.forward("softmax2");
}
catch (Exception e) {
fail("DNN forward failed: " + e.getMessage());
}
assertNotNull("Net returned no result!", result);
result = result.reshape(1, 1);
Core.MinMaxLocResult minmax = Core.minMaxLoc(result);
assertEquals("Wrong prediction", (int)minmax.maxLoc.x, 866);
Mat top5RefScores = new MatOfFloat(new float[] {
0.63032645f, 0.2561979f, 0.032181446f, 0.015721032f, 0.014785315f
}).reshape(1, 1);
Core.sort(result, result, Core.SORT_DESCENDING);
normAssert(result.colRange(0, 5), top5RefScores);
}
public void testTestNetForward() {
checkInceptionNet(net);
}
public void testReadFromBuffer() {
File modelFile = new File(modelFileName);
byte[] modelBuffer = new byte[ (int)modelFile.length() ];
try {
FileInputStream fis = new FileInputStream(modelFile);
fis.read(modelBuffer);
fis.close();
} catch (IOException e) {
fail("Failed to read a model: " + e.getMessage());
}
net = Dnn.readNetFromTensorflow(new MatOfByte(modelBuffer));
checkInceptionNet(net);
}
public void testGetAvailableTargets() {
List<Integer> targets = Dnn.getAvailableTargets(Dnn.DNN_BACKEND_OPENCV);
assertTrue(targets.contains(Dnn.DNN_TARGET_CPU));
}
}
| |
253192
|

--------------------------------------------------------------------------------
PyTorch is a Python package that provides two high-level features:
- Tensor computation (like NumPy) with strong GPU acceleration
- Deep neural networks built on a tape-based autograd system
You can reuse your favorite Python packages such as NumPy, SciPy, and Cython to extend PyTorch when needed.
Our trunk health (Continuous Integration signals) can be found at [hud.pytorch.org](https://hud.pytorch.org/ci/pytorch/pytorch/main).
<!-- toc -->
- [More About PyTorch](#more-about-pytorch)
- [A GPU-Ready Tensor Library](#a-gpu-ready-tensor-library)
- [Dynamic Neural Networks: Tape-Based Autograd](#dynamic-neural-networks-tape-based-autograd)
- [Python First](#python-first)
- [Imperative Experiences](#imperative-experiences)
- [Fast and Lean](#fast-and-lean)
- [Extensions Without Pain](#extensions-without-pain)
- [Installation](#installation)
- [Binaries](#binaries)
- [NVIDIA Jetson Platforms](#nvidia-jetson-platforms)
- [From Source](#from-source)
- [Prerequisites](#prerequisites)
- [NVIDIA CUDA Support](#nvidia-cuda-support)
- [AMD ROCm Support](#amd-rocm-support)
- [Intel GPU Support](#intel-gpu-support)
- [Get the PyTorch Source](#get-the-pytorch-source)
- [Install Dependencies](#install-dependencies)
- [Install PyTorch](#install-pytorch)
- [Adjust Build Options (Optional)](#adjust-build-options-optional)
- [Docker Image](#docker-image)
- [Using pre-built images](#using-pre-built-images)
- [Building the image yourself](#building-the-image-yourself)
- [Building the Documentation](#building-the-documentation)
- [Previous Versions](#previous-versions)
- [Getting Started](#getting-started)
- [Resources](#resources)
- [Communication](#communication)
- [Releases and Contributing](#releases-and-contributing)
- [The Team](#the-team)
- [License](#license)
<!-- tocstop -->
## More About PyTorch
[Learn the basics of PyTorch](https://pytorch.org/tutorials/beginner/basics/intro.html)
At a granular level, PyTorch is a library that consists of the following components:
| Component | Description |
| ---- | --- |
| [**torch**](https://pytorch.org/docs/stable/torch.html) | A Tensor library like NumPy, with strong GPU support |
| [**torch.autograd**](https://pytorch.org/docs/stable/autograd.html) | A tape-based automatic differentiation library that supports all differentiable Tensor operations in torch |
| [**torch.jit**](https://pytorch.org/docs/stable/jit.html) | A compilation stack (TorchScript) to create serializable and optimizable models from PyTorch code |
| [**torch.nn**](https://pytorch.org/docs/stable/nn.html) | A neural networks library deeply integrated with autograd designed for maximum flexibility |
| [**torch.multiprocessing**](https://pytorch.org/docs/stable/multiprocessing.html) | Python multiprocessing, but with magical memory sharing of torch Tensors across processes. Useful for data loading and Hogwild training |
| [**torch.utils**](https://pytorch.org/docs/stable/data.html) | DataLoader and other utility functions for convenience |
Usually, PyTorch is used either as:
- A replacement for NumPy to use the power of GPUs.
- A deep learning research platform that provides maximum flexibility and speed.
Elaborating Further:
### A GPU-Ready Tensor Library
If you use NumPy, then you have used Tensors (a.k.a. ndarray).

PyTorch provides Tensors that can live either on the CPU or the GPU and accelerates the
computation by a huge amount.
We provide a wide variety of tensor routines to accelerate and fit your scientific computation needs
such as slicing, indexing, mathematical operations, linear algebra, reductions.
And they are fast!
### Dynamic Neural Networks: Tape-Based Autograd
PyTorch has a unique way of building neural networks: using and replaying a tape recorder.
Most frameworks such as TensorFlow, Theano, Caffe, and CNTK have a static view of the world.
One has to build a neural network and reuse the same structure again and again.
Changing the way the network behaves means that one has to start from scratch.
With PyTorch, we use a technique called reverse-mode auto-differentiation, which allows you to
change the way your network behaves arbitrarily with zero lag or overhead. Our inspiration comes
from several research papers on this topic, as well as current and past work such as
[torch-autograd](https://github.com/twitter/torch-autograd),
[autograd](https://github.com/HIPS/autograd),
[Chainer](https://chainer.org), etc.
While this technique is not unique to PyTorch, it's one of the fastest implementations of it to date.
You get the best of speed and flexibility for your crazy research.

### Python First
PyTorch is not a Python binding into a monolithic C++ framework.
It is built to be deeply integrated into Python.
You can use it naturally like you would use [NumPy](https://www.numpy.org/) / [SciPy](https://www.scipy.org/) / [scikit-learn](https://scikit-learn.org) etc.
You can write your new neural network layers in Python itself, using your favorite libraries
and use packages such as [Cython](https://cython.org/) and [Numba](http://numba.pydata.org/).
Our goal is to not reinvent the wheel where appropriate.
### Imperative Experiences
PyTorch is designed to be intuitive, linear in thought, and easy to use.
When you execute a line of code, it gets executed. There isn't an asynchronous view of the world.
When you drop into a debugger or receive error messages and stack traces, understanding them is straightforward.
The stack trace points to exactly where your code was defined.
We hope you never spend hours debugging your code because of bad stack traces or asynchronous and opaque execution engines.
### Fast and Lean
PyTorch has minimal framework overhead. We integrate acceleration libraries
such as [Intel MKL](https://software.intel.com/mkl) and NVIDIA ([cuDNN](https://developer.nvidia.com/cudnn), [NCCL](https://developer.nvidia.com/nccl)) to maximize speed.
At the core, its CPU and GPU Tensor and neural network backends
are mature and have been tested for years.
Hence, PyTorch is quite fast — whether you run small or large neural networks.
The memory usage in PyTorch is extremely efficient compared to Torch or some of the alternatives.
We've written custom memory allocators for the GPU to make sure that
your deep learning models are maximally memory efficient.
This enables you to train bigger deep learning models than before.
### Extensions Without Pain
Writing new neural network modules, or interfacing with PyTorch's Tensor API was designed to be straightforward
and with minimal abstractions.
You can write new neural network layers in Python using the torch API
[or your favorite NumPy-based libraries such as SciPy](https://pytorch.org/tutorials/advanced/numpy_extensions_tutorial.html).
If you want to write your layers in C/C++, we provide a convenient extension API that is efficient and with minimal boilerplate.
No wrapper code needs to be written. You can see [a tutorial here](https://pytorch.org/tutorials/advanced/cpp_extension.html) and [an example here](https://github.com/pytorch/extension-cpp).
##
| |
253193
|
Installation
### Binaries
Commands to install binaries via Conda or pip wheels are on our website: [https://pytorch.org/get-started/locally/](https://pytorch.org/get-started/locally/)
#### NVIDIA Jetson Platforms
Python wheels for NVIDIA's Jetson Nano, Jetson TX1/TX2, Jetson Xavier NX/AGX, and Jetson AGX Orin are provided [here](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048) and the L4T container is published [here](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch)
They require JetPack 4.2 and above, and [@dusty-nv](https://github.com/dusty-nv) and [@ptrblck](https://github.com/ptrblck) are maintaining them.
### From Source
#### Prerequisites
If you are installing from source, you will need:
- Python 3.9 or later
- A compiler that fully supports C++17, such as clang or gcc (gcc 9.4.0 or newer is required, on Linux)
- Visual Studio or Visual Studio Build Tool on Windows
\* PyTorch CI uses Visual C++ BuildTools, which come with Visual Studio Enterprise,
Professional, or Community Editions. You can also install the build tools from
https://visualstudio.microsoft.com/visual-cpp-build-tools/. The build tools *do not*
come with Visual Studio Code by default.
\* We highly recommend installing an [Anaconda](https://www.anaconda.com/download) environment. You will get a high-quality BLAS library (MKL) and you get controlled dependency versions regardless of your Linux distro.
An example of environment setup is shown below:
* Linux:
```bash
$ source <CONDA_INSTALL_DIR>/bin/activate
$ conda create -y -n <CONDA_NAME>
$ conda activate <CONDA_NAME>
```
* Windows:
```bash
$ source <CONDA_INSTALL_DIR>\Scripts\activate.bat
$ conda create -y -n <CONDA_NAME>
$ conda activate <CONDA_NAME>
$ call "C:\Program Files\Microsoft Visual Studio\<VERSION>\Community\VC\Auxiliary\Build\vcvarsall.bat" x64
```
##### NVIDIA CUDA Support
If you want to compile with CUDA support, [select a supported version of CUDA from our support matrix](https://pytorch.org/get-started/locally/), then install the following:
- [NVIDIA CUDA](https://developer.nvidia.com/cuda-downloads)
- [NVIDIA cuDNN](https://developer.nvidia.com/cudnn) v8.5 or above
- [Compiler](https://gist.github.com/ax3l/9489132) compatible with CUDA
Note: You could refer to the [cuDNN Support Matrix](https://docs.nvidia.com/deeplearning/cudnn/reference/support-matrix.html) for cuDNN versions with the various supported CUDA, CUDA driver and NVIDIA hardware
If you want to disable CUDA support, export the environment variable `USE_CUDA=0`.
Other potentially useful environment variables may be found in `setup.py`.
If you are building for NVIDIA's Jetson platforms (Jetson Nano, TX1, TX2, AGX Xavier), Instructions to install PyTorch for Jetson Nano are [available here](https://devtalk.nvidia.com/default/topic/1049071/jetson-nano/pytorch-for-jetson-nano/)
##### AMD ROCm Support
If you want to compile with ROCm support, install
- [AMD ROCm](https://rocm.docs.amd.com/en/latest/deploy/linux/quick_start.html) 4.0 and above installation
- ROCm is currently supported only for Linux systems.
By default the build system expects ROCm to be installed in `/opt/rocm`. If ROCm is installed in a different directory, the `ROCM_PATH` environment variable must be set to the ROCm installation directory. The build system automatically detects the AMD GPU architecture. Optionally, the AMD GPU architecture can be explicitly set with the `PYTORCH_ROCM_ARCH` environment variable [AMD GPU architecture](https://rocm.docs.amd.com/projects/install-on-linux/en/latest/reference/system-requirements.html#supported-gpus)
If you want to disable ROCm support, export the environment variable `USE_ROCM=0`.
Other potentially useful environment variables may be found in `setup.py`.
##### Intel GPU Support
If you want to compile with Intel GPU support, follow these
- [PyTorch Prerequisites for Intel GPUs](https://www.intel.com/content/www/us/en/developer/articles/tool/pytorch-prerequisites-for-intel-gpus.html) instructions.
- Intel GPU is supported for Linux and Windows.
If you want to disable Intel GPU support, export the environment variable `USE_XPU=0`.
Other potentially useful environment variables may be found in `setup.py`.
#### Get the PyTorch Source
```bash
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive
```
#### Install Dependencies
**Common**
```bash
conda install cmake ninja
# Run this command on native Windows
conda install rust
# Run this command from the PyTorch directory after cloning the source code using the “Get the PyTorch Source“ section below
pip install -r requirements.txt
```
**On Linux**
```bash
pip install mkl-static mkl-include
# CUDA only: Add LAPACK support for the GPU if needed
conda install -c pytorch magma-cuda121 # or the magma-cuda* that matches your CUDA version from https://anaconda.org/pytorch/repo
# (optional) If using torch.compile with inductor/triton, install the matching version of triton
# Run from the pytorch directory after cloning
# For Intel GPU support, please explicitly `export USE_XPU=1` before running command.
make triton
```
**On MacOS**
```bash
# Add this package on intel x86 processor machines only
pip install mkl-static mkl-include
# Add these packages if torch.distributed is needed
conda install pkg-config libuv
```
**On Windows**
```bash
pip install mkl-static mkl-include
# Add these packages if torch.distributed is needed.
# Distributed package support on Windows is a prototype feature and is subject to changes.
conda install -c conda-forge libuv=1.39
```
#### I
| |
253194
|
nstall PyTorch
**On Linux**
If you would like to compile PyTorch with [new C++ ABI](https://gcc.gnu.org/onlinedocs/libstdc++/manual/using_dual_abi.html) enabled, then first run this command:
```bash
export _GLIBCXX_USE_CXX11_ABI=1
```
Please **note** that starting from PyTorch 2.5, the PyTorch build with XPU supports both new and old C++ ABIs. Previously, XPU only supported the new C++ ABI. If you want to compile with Intel GPU support, please follow [Intel GPU Support](#intel-gpu-support).
If you're compiling for AMD ROCm then first run this command:
```bash
# Only run this if you're compiling for ROCm
python tools/amd_build/build_amd.py
```
Install PyTorch
```bash
export CMAKE_PREFIX_PATH="${CONDA_PREFIX:-'$(dirname $(which conda))/../'}:${CMAKE_PREFIX_PATH}"
python setup.py develop
```
**On macOS**
```bash
python3 setup.py develop
```
**On Windows**
If you want to build legacy python code, please refer to [Building on legacy code and CUDA](https://github.com/pytorch/pytorch/blob/main/CONTRIBUTING.md#building-on-legacy-code-and-cuda)
**CPU-only builds**
In this mode PyTorch computations will run on your CPU, not your GPU
```cmd
python setup.py develop
```
Note on OpenMP: The desired OpenMP implementation is Intel OpenMP (iomp). In order to link against iomp, you'll need to manually download the library and set up the building environment by tweaking `CMAKE_INCLUDE_PATH` and `LIB`. The instruction [here](https://github.com/pytorch/pytorch/blob/main/docs/source/notes/windows.rst#building-from-source) is an example for setting up both MKL and Intel OpenMP. Without these configurations for CMake, Microsoft Visual C OpenMP runtime (vcomp) will be used.
**CUDA based build**
In this mode PyTorch computations will leverage your GPU via CUDA for faster number crunching
[NVTX](https://docs.nvidia.com/gameworks/content/gameworkslibrary/nvtx/nvidia_tools_extension_library_nvtx.htm) is needed to build Pytorch with CUDA.
NVTX is a part of CUDA distributive, where it is called "Nsight Compute". To install it onto an already installed CUDA run CUDA installation once again and check the corresponding checkbox.
Make sure that CUDA with Nsight Compute is installed after Visual Studio.
Currently, VS 2017 / 2019, and Ninja are supported as the generator of CMake. If `ninja.exe` is detected in `PATH`, then Ninja will be used as the default generator, otherwise, it will use VS 2017 / 2019.
<br/> If Ninja is selected as the generator, the latest MSVC will get selected as the underlying toolchain.
Additional libraries such as
[Magma](https://developer.nvidia.com/magma), [oneDNN, a.k.a. MKLDNN or DNNL](https://github.com/oneapi-src/oneDNN), and [Sccache](https://github.com/mozilla/sccache) are often needed. Please refer to the [installation-helper](https://github.com/pytorch/pytorch/tree/main/.ci/pytorch/win-test-helpers/installation-helpers) to install them.
You can refer to the [build_pytorch.bat](https://github.com/pytorch/pytorch/blob/main/.ci/pytorch/win-test-helpers/build_pytorch.bat) script for some other environment variables configurations
```cmd
cmd
:: Set the environment variables after you have downloaded and unzipped the mkl package,
:: else CMake would throw an error as `Could NOT find OpenMP`.
set CMAKE_INCLUDE_PATH={Your directory}\mkl\include
set LIB={Your directory}\mkl\lib;%LIB%
:: Read the content in the previous section carefully before you proceed.
:: [Optional] If you want to override the underlying toolset used by Ninja and Visual Studio with CUDA, please run the following script block.
:: "Visual Studio 2019 Developer Command Prompt" will be run automatically.
:: Make sure you have CMake >= 3.12 before you do this when you use the Visual Studio generator.
set CMAKE_GENERATOR_TOOLSET_VERSION=14.27
set DISTUTILS_USE_SDK=1
for /f "usebackq tokens=*" %i in (`"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -version [15^,17^) -products * -latest -property installationPath`) do call "%i\VC\Auxiliary\Build\vcvarsall.bat" x64 -vcvars_ver=%CMAKE_GENERATOR_TOOLSET_VERSION%
:: [Optional] If you want to override the CUDA host compiler
set CUDAHOSTCXX=C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\HostX64\x64\cl.exe
python setup.py develop
```
##### Adjust Build Options (Optional)
You can adjust the configuration of cmake variables optionally (without building first), by doing
the following. For example, adjusting the pre-detected directories for CuDNN or BLAS can be done
with such a step.
On Linux
```bash
export CMAKE_PREFIX_PATH="${CONDA_PREFIX:-'$(dirname $(which conda))/../'}:${CMAKE_PREFIX_PATH}"
python setup.py build --cmake-only
ccmake build # or cmake-gui build
```
On macOS
```bash
export CMAKE_PREFIX_PATH="${CONDA_PREFIX:-'$(dirname $(which conda))/../'}:${CMAKE_PREFIX_PATH}"
MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python setup.py build --cmake-only
ccmake build # or cmake-gui build
```
### Docker Image
#### Using pre-built images
You can also pull a pre-built docker image from Docker Hub and run with docker v19.03+
```bash
docker run --gpus all --rm -ti --ipc=host pytorch/pytorch:latest
```
Please note that PyTorch uses shared memory to share data between processes, so if torch multiprocessing is used (e.g.
for multithreaded data loaders) the default shared memory segment size that container runs with is not enough, and you
should increase shared memory size either with `--ipc=host` or `--shm-size` command line options to `nvidia-docker run`.
#### Building the image yourself
**NOTE:** Must be built with a docker version > 18.06
The `Dockerfile` is supplied to build images with CUDA 11.1 support and cuDNN v8.
You can pass `PYTHON_VERSION=x.y` make variable to specify which Python version is to be used by Miniconda, or leave it
unset to use the default.
```bash
make -f docker.Makefile
# images are tagged as docker.io/${your_docker_username}/pytorch
```
You can also pass the `CMAKE_VARS="..."` environment variable to specify additional CMake variables to be passed to CMake during the build.
See [setup.py](./setup.py) for the list of available variables.
```bash
make -f docker.Makefile
```
### Building the Documentation
To build documentation in various formats, you will need [Sphinx](http://www.sphinx-doc.org) and the
readthedocs theme.
```bash
cd docs/
pip install -r requirements.txt
```
You can then build the documentation by running `make <format>` from the
`docs/` folder. Run `make` to get a list of all available output formats.
If you get a katex error run `npm install katex`. If it persists, try
`npm install -g katex`
> Note: if you installed `nodejs` with a different package manager (e.g.,
`conda`) then `npm` will probably install a version of `katex` that is not
compatible with your version of `nodejs` and doc builds will fail.
A combination of versions that is known to work is `node@6.13.1` and
`katex@0.13.18`. To install the latter with `npm` you can run
```npm install -g katex@0.13.18```
### Previous Versions
Installation instructions and binaries for previous PyTorch versions may be found
on [our website](https://pytorch.org/previous-versions).
## Getting Started
Three-pointers to get you started:
- [Tutorials: get you started with understanding and using PyTorch](https://pytorch.org/tutorials/)
- [Examples: easy to understand PyTorch code across all domains](https://github.com/pytorch/examples)
- [The API Reference](https://pytorch.org/docs/)
- [Glossary](https://github.com/pytorch/pytorch/blob/main/GLOSSARY.md)
## Res
| |
262479
|
# mypy: allow-untyped-defs
r"""
This package adds support for CUDA tensor types.
It implements the same function as CPU tensors, but they utilize
GPUs for computation.
It is lazily initialized, so you can always import it, and use
:func:`is_available()` to determine if your system supports CUDA.
:ref:`cuda-semantics` has more details about working with CUDA.
"""
import importlib
import os
import threading
import traceback
import warnings
from functools import lru_cache
from typing import Any, Callable, cast, List, Optional, Tuple, Union
import torch
import torch._C
from torch import device as _device
from torch._utils import _dummy_type, _LazySeedTracker, classproperty
from torch.types import Device
from . import gds
from ._utils import _get_device_index
from .graphs import (
CUDAGraph,
graph,
graph_pool_handle,
is_current_stream_capturing,
make_graphed_callables,
)
from .streams import Event, ExternalStream, Stream
try:
from torch._C import _cudart # type: ignore[attr-defined]
except ImportError:
_cudart = None
_initialized = False
_tls = threading.local()
_initialization_lock = threading.Lock()
_queued_calls: List[
Tuple[Callable[[], None], List[str]]
] = [] # don't invoke these until initialization occurs
_is_in_bad_fork = getattr(torch._C, "_cuda_isInBadFork", lambda: False)
_device_t = Union[_device, str, int, None]
_HAS_PYNVML = False
_PYNVML_ERR = None
try:
from torch import version as _version
try:
if not _version.hip:
import pynvml # type: ignore[import]
else:
import amdsmi # type: ignore[import]
_HAS_PYNVML = True
except ModuleNotFoundError:
pass
finally:
del _version
except ImportError as err:
_PYNVML_ERR = err # sometimes a lib is installed but the import fails for some other reason, so we log the error for later
_lazy_seed_tracker = _LazySeedTracker()
# Define dummy _CudaDeviceProperties type if PyTorch was compiled without CUDA
if hasattr(torch._C, "_CudaDeviceProperties"):
_CudaDeviceProperties = torch._C._CudaDeviceProperties
else:
_CudaDeviceProperties = _dummy_type("_CudaDeviceProperties") # type: ignore[assignment, misc]
if hasattr(torch._C, "_cuda_exchangeDevice"):
_exchange_device = torch._C._cuda_exchangeDevice
else:
def _exchange_device(device: int) -> int:
if device < 0:
return -1
raise RuntimeError("PyTorch was compiled without CUDA support")
if hasattr(torch._C, "_cuda_maybeExchangeDevice"):
_maybe_exchange_device = torch._C._cuda_maybeExchangeDevice
else:
def _maybe_exchange_device(device: int) -> int:
if device < 0:
return -1
raise RuntimeError("PyTorch was compiled without CUDA support")
has_half: bool = True
has_magma: bool = torch._C._has_magma
default_generators: Tuple[torch._C.Generator] = () # type: ignore[assignment]
def _is_compiled() -> bool:
r"""Return true if compile with CUDA support."""
return hasattr(torch._C, "_cuda_getDeviceCount")
def _nvml_based_avail() -> bool:
return os.getenv("PYTORCH_NVML_BASED_CUDA_CHECK") == "1"
def is_available() -> bool:
r"""Return a bool indicating if CUDA is currently available."""
if not _is_compiled():
return False
if _nvml_based_avail():
# The user has set an env variable to request this availability check that attempts to avoid fork poisoning by
# using NVML at the cost of a weaker CUDA availability assessment. Note that if NVML discovery/initialization
# fails, this assessment falls back to the default CUDA Runtime API assessment (`cudaGetDeviceCount`)
return device_count() > 0
else:
# The default availability inspection never throws and returns 0 if the driver is missing or can't
# be initialized. This uses the CUDA Runtime API `cudaGetDeviceCount` which in turn initializes the CUDA Driver
# API via `cuInit`
return torch._C._cuda_getDeviceCount() > 0
def is_bf16_supported(including_emulation: bool = True):
r"""Return a bool indicating if the current CUDA/ROCm device supports dtype bfloat16."""
# Check for ROCm, if true return true, no ROCM_VERSION check required,
# since it is supported on AMD GPU archs.
if torch.version.hip:
return True
# If CUDA is not available, than it does not support bf16 either
if not is_available():
return False
device = torch.cuda.current_device()
# Check for CUDA version and device compute capability.
# This is a fast way to check for it.
cuda_version = torch.version.cuda
if (
cuda_version is not None
and int(cuda_version.split(".")[0]) >= 11
and torch.cuda.get_device_properties(device).major >= 8
):
return True
if not including_emulation:
return False
# Finally try to create a bfloat16 device.
return _check_bf16_tensor_supported(device)
@lru_cache(maxsize=16)
def _check_bf16_tensor_supported(device: _device_t):
try:
torch.tensor([1.0], dtype=torch.bfloat16, device=device)
return True
except Exception:
return False
def _sleep(cycles):
torch._C._cuda_sleep(cycles)
def _extract_arch_version(arch_string: str):
"""Extracts the architecture string from a CUDA version"""
base = arch_string.split("_")[1]
if base.endswith("a"):
base = base[:-1]
return int(base)
def _check_capability():
incorrect_binary_warn = """
Found GPU%d %s which requires CUDA_VERSION >= %d to
work properly, but your PyTorch was compiled
with CUDA_VERSION %d. Please install the correct PyTorch binary
using instructions from https://pytorch.org
""" # noqa: F841
old_gpu_warn = """
Found GPU%d %s which is of cuda capability %d.%d.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability supported by this library is %d.%d.
"""
if torch.version.cuda is not None: # on ROCm we don't want this check
CUDA_VERSION = torch._C._cuda_getCompiledVersion() # noqa: F841
for d in range(device_count()):
capability = get_device_capability(d)
major = capability[0]
minor = capability[1]
name = get_device_name(d)
current_arch = major * 10 + minor
min_arch = min(
(_extract_arch_version(arch) for arch in torch.cuda.get_arch_list()),
default=35,
)
if current_arch < min_arch:
warnings.warn(
old_gpu_warn
% (d, name, major, minor, min_arch // 10, min_arch % 10)
)
def _check_cubins():
incompatible_device_warn = """
{} with CUDA capability sm_{} is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities {}.
If you want to use the {} GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
"""
if torch.version.cuda is None: # on ROCm we don't want this check
return
arch_list = get_arch_list()
if len(arch_list) == 0:
return
supported_sm = [_extract_arch_version(arch) for arch in arch_list if "sm_" in arch]
for idx in range(device_count()):
cap_major, cap_minor = get_device_capability(idx)
# NVIDIA GPU compute architectures are backward compatible within major version
supported = any(sm // 10 == cap_major for sm in supported_sm)
if not supported:
device_name = get_device_name(idx)
capability = cap_major * 10 + cap_minor
warnings.warn(
incompatible_device_warn.format(
device_name, capability, " ".join(arch_list), device_name
)
)
def is_initialized():
r"""Return whether PyTorch's CUDA state has been initialized."""
return _initialized and not _is_in_bad_fork()
| |
270703
|
iv>
See below for a quickstart install and usage examples, and see our [Docs](https://docs.ultralytics.com/) for full documentation on training, validation, prediction and deployment.
<details open>
<summary>Install</summary>
Pip install the ultralytics package including all [requirements](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) in a [**Python>=3.8**](https://www.python.org/) environment with [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/).
[](https://pypi.org/project/ultralytics/) [](https://pepy.tech/project/ultralytics) [](https://pypi.org/project/ultralytics/)
```bash
pip install ultralytics
```
For alternative installation methods including [Conda](https://anaconda.org/conda-forge/ultralytics), [Docker](https://hub.docker.com/r/ultralytics/ultralytics), and Git, please refer to the [Quickstart Guide](https://docs.ultralytics.com/quickstart/).
[](https://anaconda.org/conda-forge/ultralytics) [](https://hub.docker.com/r/ultralytics/ultralytics)
</details>
<details open>
<summary>Usage</summary>
### CLI
YOLO may be used directly in the Command Line Interface (CLI) with a `yolo` command:
```bash
yolo predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg'
```
`yolo` can be used for a variety of tasks and modes and accepts additional arguments, i.e. `imgsz=640`. See the YOLO [CLI Docs](https://docs.ultralytics.com/usage/cli/) for examples.
### Python
YOLO may also be used directly in a Python environment, and accepts the same [arguments](https://docs.ultralytics.com/usage/cfg/) as in the CLI example above:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Train the model
train_results = model.train(
data="coco8.yaml", # path to dataset YAML
epochs=100, # number of training epochs
imgsz=640, # training image size
device="cpu", # device to run on, i.e. device=0 or device=0,1,2,3 or device=cpu
)
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("path/to/image.jpg")
results[0].show()
# Export the model to ONNX format
path = model.export(format="onnx") # return path to exported model
```
See YOLO [Python Docs](https://docs.ultralytics.com/usage/python/) for more examples.
</details>
## <div align="center">Models</div>
YO
| |
270730
|
.skipif(not ONLINE, reason="environment is offline")
@pytest.mark.skipif(not IS_TMP_WRITEABLE, reason="directory is not writeable")
def test_track_stream():
"""
Tests streaming tracking on a short 10 frame video using ByteTrack tracker and different GMC methods.
Note imgsz=160 required for tracking for higher confidence and better matches.
"""
video_url = "https://github.com/ultralytics/assets/releases/download/v0.0.0/decelera_portrait_min.mov"
model = YOLO(MODEL)
model.track(video_url, imgsz=160, tracker="bytetrack.yaml")
model.track(video_url, imgsz=160, tracker="botsort.yaml", save_frames=True) # test frame saving also
# Test Global Motion Compensation (GMC) methods
for gmc in "orb", "sift", "ecc":
with open(ROOT / "cfg/trackers/botsort.yaml", encoding="utf-8") as f:
data = yaml.safe_load(f)
tracker = TMP / f"botsort-{gmc}.yaml"
data["gmc_method"] = gmc
with open(tracker, "w", encoding="utf-8") as f:
yaml.safe_dump(data, f)
model.track(video_url, imgsz=160, tracker=tracker)
def test_val():
"""Test the validation mode of the YOLO model."""
YOLO(MODEL).val(data="coco8.yaml", imgsz=32, save_hybrid=True)
def test_train_scratch():
"""Test training the YOLO model from scratch using the provided configuration."""
model = YOLO(CFG)
model.train(data="coco8.yaml", epochs=2, imgsz=32, cache="disk", batch=-1, close_mosaic=1, name="model")
model(SOURCE)
def test_train_pretrained():
"""Test training of the YOLO model starting from a pre-trained checkpoint."""
model = YOLO(WEIGHTS_DIR / "yolo11n-seg.pt")
model.train(data="coco8-seg.yaml", epochs=1, imgsz=32, cache="ram", copy_paste=0.5, mixup=0.5, name=0)
model(SOURCE)
def test_all_model_yamls():
"""Test YOLO model creation for all available YAML configurations in the `cfg/models` directory."""
for m in (ROOT / "cfg" / "models").rglob("*.yaml"):
if "rtdetr" in m.name:
if TORCH_1_9: # torch<=1.8 issue - TypeError: __init__() got an unexpected keyword argument 'batch_first'
_ = RTDETR(m.name)(SOURCE, imgsz=640) # must be 640
else:
YOLO(m.name)
@pytest.mark.skipif(WINDOWS, reason="Windows slow CI export bug https://github.com/ultralytics/ultralytics/pull/16003")
def test_workflow():
"""Test the complete workflow including training, validation, prediction, and exporting."""
model = YOLO(MODEL)
model.train(data="coco8.yaml", epochs=1, imgsz=32, optimizer="SGD")
model.val(imgsz=32)
model.predict(SOURCE, imgsz=32)
model.export(format="torchscript") # WARNING: Windows slow CI export bug
def test_predict_callback_and_setup():
"""Test callback functionality during YOLO prediction setup and execution."""
def on_predict_batch_end(predictor):
"""Callback function that handles operations at the end of a prediction batch."""
path, im0s, _ = predictor.batch
im0s = im0s if isinstance(im0s, list) else [im0s]
bs = [predictor.dataset.bs for _ in range(len(path))]
predictor.results = zip(predictor.results, im0s, bs) # results is List[batch_size]
model = YOLO(MODEL)
model.add_callback("on_predict_batch_end", on_predict_batch_end)
dataset = load_inference_source(source=SOURCE)
bs = dataset.bs # noqa access predictor properties
results = model.predict(dataset, stream=True, imgsz=160) # source already setup
for r, im0, bs in results:
print("test_callback", im0.shape)
print("test_callback", bs)
boxes = r.boxes # Boxes object for bbox outputs
print(boxes)
@pytest.mark.parametrize("model", MODELS)
def test_results(model):
"""Ensure YOLO model predictions can be processed and printed in various formats."""
results = YOLO(WEIGHTS_DIR / model)([SOURCE, SOURCE], imgsz=160)
for r in results:
r = r.cpu().numpy()
print(r, len(r), r.path) # print numpy attributes
r = r.to(device="cpu", dtype=torch.float32)
r.save_txt(txt_file=TMP / "runs/tests/label.txt", save_conf=True)
r.save_crop(save_dir=TMP / "runs/tests/crops/")
r.to_json(normalize=True)
r.to_df(decimals=3)
r.to_csv()
r.to_xml()
r.plot(pil=True)
r.plot(conf=True, boxes=True)
print(r, len(r), r.path) # print after methods
def test_labels_and_crops():
"""Test output from prediction args for saving YOLO detection labels and crops; ensures accurate saving."""
imgs = [SOURCE, ASSETS / "zidane.jpg"]
results = YOLO(WEIGHTS_DIR / "yolo11n.pt")(imgs, imgsz=160, save_txt=True, save_crop=True)
save_path = Path(results[0].save_dir)
for r in results:
im_name = Path(r.path).stem
cls_idxs = r.boxes.cls.int().tolist()
# Check correct detections
assert cls_idxs == ([0, 7, 0, 0] if r.path.endswith("bus.jpg") else [0, 0, 0]) # bus.jpg and zidane.jpg classes
# Check label path
labels = save_path / f"labels/{im_name}.txt"
assert labels.exists()
# Check detections match label count
assert len(r.boxes.data) == len([line for line in labels.read_text().splitlines() if line])
# Check crops path and files
crop_dirs = list((save_path / "crops").iterdir())
crop_files = [f for p in crop_dirs for f in p.glob("*")]
# Crop directories match detections
assert all(r.names.get(c) in {d.name for d in crop_dirs} for c in cls_idxs)
# Same number of crops as detections
assert len([f for f in crop_files if im_name in f.name]) == len(r.boxes.data)
@pytest.mark.skipif(not ONLINE, reason="environment is offline")
def test_data_utils():
"""Test utility functions in ultralytics/data/utils.py, including dataset stats and auto-splitting."""
from ultralytics.data.utils import HUBDatasetStats, autosplit
from ultralytics.utils.downloads import zip_directory
# from ultralytics.utils.files import WorkingDirectory
# with WorkingDirectory(ROOT.parent / 'tests'):
for task in TASKS:
file = Path(TASK2DATA[task]).with_suffix(".zip") # i.e. coco8.zip
download(f"https://github.com/ultralytics/hub/raw/main/example_datasets/{file}", unzip=False, dir=TMP)
stats = HUBDatasetStats(TMP / file, task=task)
stats.get_json(save=True)
stats.process_images()
autosplit(TMP / "coco8")
zip_directory(TMP / "coco8/images/val") # zip
@pytest.mark.skipif(not ONLINE, reason="environment is offline")
def test_data_converter():
"""Test dataset conversion functions from COCO to YOLO format and class mappings."""
from ultralytics.data.converter import coco80_to_coco91_class, convert_coco
file = "instances_val2017.json"
download(f"https://github.com/ultralytics/assets/releases/download/v0.0.0/{file}", dir=TMP)
convert_coco(labels_dir=TMP, save_dir=TMP / "yolo_labels", use_segments=True, use_keypoints=False, cls91to80=True)
coco80_to_coco91_class()
def test_data_annotator():
"""Automatically annotate data using specified detection and segmentation models."""
from ultralytics.data.annotator import auto_annotate
auto_annotate(
ASSETS,
det_model=WEIGHTS_DIR / "yolo11n.pt",
sam_model=WEIGHTS_DIR / "mobile_sam.pt",
output_dir=TMP / "auto_annotate_labels",
)
def test_
| |
270749
|
docs.ultralytics.com
| |
270751
|
<p align="left" style="margin-bottom: -20px;"><p>
=== "Pip install (recommended)"
Install the `ultralytics` package using pip, or update an existing installation by running `pip install -U ultralytics`. Visit the Python Package Index (PyPI) for more details on the `ultralytics` package: [https://pypi.org/project/ultralytics/](https://pypi.org/project/ultralytics/).
[](https://pypi.org/project/ultralytics/)
[](https://pepy.tech/project/ultralytics)
```bash
# Install the ultralytics package from PyPI
pip install ultralytics
```
You can also install the `ultralytics` package directly from the GitHub [repository](https://github.com/ultralytics/ultralytics). This might be useful if you want the latest development version. Make sure to have the Git command-line tool installed on your system. The `@main` command installs the `main` branch and may be modified to another branch, i.e. `@my-branch`, or removed entirely to default to `main` branch.
```bash
# Install the ultralytics package from GitHub
pip install git+https://github.com/ultralytics/ultralytics.git@main
```
=== "Conda install"
Conda is an alternative package manager to pip which may also be used for installation. Visit Anaconda for more details at [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). Ultralytics feedstock repository for updating the conda package is at [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
```bash
# Install the ultralytics package using conda
conda install -c conda-forge ultralytics
```
!!! note
If you are installing in a CUDA environment best practice is to install `ultralytics`, `pytorch` and `pytorch-cuda` in the same command to allow the conda package manager to resolve any conflicts, or else to install `pytorch-cuda` last to allow it override the CPU-specific `pytorch` package if necessary.
```bash
# Install all packages together using conda
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
```
### Conda Docker Image
Ultralytics Conda Docker images are also available from [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics). These images are based on [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) and are an simple way to start using `ultralytics` in a Conda environment.
```bash
# Set image name as a variable
t=ultralytics/ultralytics:latest-conda
# Pull the latest ultralytics image from Docker Hub
sudo docker pull $t
# Run the ultralytics image in a container with GPU support
sudo docker run -it --ipc=host --gpus all $t # all GPUs
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
```
=== "Git clone"
Clone the `ultralytics` repository if you are interested in contributing to the development or wish to experiment with the latest source code. After cloning, navigate into the directory and install the package in editable mode `-e` using pip.
[](https://github.com/ultralytics/ultralytics)
[](https://github.com/ultralytics/ultralytics)
```bash
# Clone the ultralytics repository
git clone https://github.com/ultralytics/ultralytics
# Navigate to the cloned directory
cd ultralytics
# Install the package in editable mode for development
pip install -e .
```
=== "Docker"
Utilize Docker to effortlessly execute the `ultralytics` package in an isolated container, ensuring consistent and smooth performance across various environments. By choosing one of the official `ultralytics` images from [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics), you not only avoid the complexity of local installation but also benefit from access to a verified working environment. Ultralytics offers 5 main supported Docker images, each designed to provide high compatibility and efficiency for different platforms and use cases:
[](https://hub.docker.com/r/ultralytics/ultralytics)
[](https://hub.docker.com/r/ultralytics/ultralytics)
- **Dockerfile:** GPU image recommended for training.
- **Dockerfile-arm64:** Optimized for ARM64 architecture, allowing deployment on devices like Raspberry Pi and other ARM64-based platforms.
- **Dockerfile-cpu:** Ubuntu-based CPU-only version suitable for inference and environments without GPUs.
- **Dockerfile-jetson:** Tailored for NVIDIA Jetson devices, integrating GPU support optimized for these platforms.
- **Dockerfile-python:** Minimal image with just Python and necessary dependencies, ideal for lightweight applications and development.
- **Dockerfile-conda:** Based on Miniconda3 with conda installation of ultralytics package.
Below are the commands to get the latest image and execute it:
```bash
# Set image name as a variable
t=ultralytics/ultralytics:latest
# Pull the latest ultralytics image from Docker Hub
sudo docker pull $t
# Run the ultralytics image in a container with GPU support
sudo docker run -it --ipc=host --gpus all $t # all GPUs
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
```
The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
```bash
# Mount local directory to a directory inside the container
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
```
Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
For advanced Docker usage, feel free to explore the [Ultralytics Docker Guide](./guides/docker-quickstart.md).
See the `ultralytics` [pyproject.toml](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) file for a list of dependencies. Note that all examples above install all required dependencies.
!!! tip
| |
270752
|
[PyTorch](https://www.ultralytics.com/glossary/pytorch) requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally/).
<a href="https://pytorch.org/get-started/locally/">
<img width="800" alt="PyTorch Installation Instructions" src="https://github.com/ultralytics/docs/releases/download/0/pytorch-installation-instructions.avif">
</a>
## Use Ultralytics with CLI
The Ultralytics command line interface (CLI) allows for simple single-line commands without the need for a Python environment. CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLO from the command line.
!!! example
=== "Syntax"
Ultralytics `yolo` commands use the following syntax:
```bash
yolo TASK MODE ARGS
```
- `TASK` (optional) is one of ([detect](tasks/detect.md), [segment](tasks/segment.md), [classify](tasks/classify.md), [pose](tasks/pose.md), [obb](tasks/obb.md))
- `MODE` (required) is one of ([train](modes/train.md), [val](modes/val.md), [predict](modes/predict.md), [export](modes/export.md), [track](modes/track.md), [benchmark](modes/benchmark.md))
- `ARGS` (optional) are `arg=value` pairs like `imgsz=640` that override defaults.
See all `ARGS` in the full [Configuration Guide](usage/cfg.md) or with the `yolo cfg` CLI command.
=== "Train"
Train a detection model for 10 [epochs](https://www.ultralytics.com/glossary/epoch) with an initial learning_rate of 0.01
```bash
yolo train data=coco8.yaml model=yolo11n.pt epochs=10 lr0=0.01
```
=== "Predict"
Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
yolo predict model=yolo11n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
```
=== "Val"
Val a pretrained detection model at batch-size 1 and image size 640:
```bash
yolo val model=yolo11n.pt data=coco8.yaml batch=1 imgsz=640
```
=== "Export"
Export a yolo11n classification model to ONNX format at image size 224 by 128 (no TASK required)
```bash
yolo export model=yolo11n-cls.pt format=onnx imgsz=224,128
```
=== "Special"
Run special commands to see version, view settings, run checks and more:
```bash
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfg
```
!!! warning
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
- `yolo predict model=yolo11n.pt imgsz=640 conf=0.25` ✅
- `yolo predict model yolo11n.pt imgsz 640 conf 0.25` ❌ (missing `=`)
- `yolo predict model=yolo11n.pt, imgsz=640, conf=0.25` ❌ (do not use `,`)
- `yolo predict --model yolo11n.pt --imgsz 640 --conf 0.25` ❌ (do not use `--`)
[CLI Guide](usage/cli.md){ .md-button }
## Use Ultralytics with Python
YOLO's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification in their projects. This makes YOLO's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLO within your Python projects.
!!! example
```python
from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO("yolo11n.yaml")
# Load a pretrained YOLO model (recommended for training)
model = YOLO("yolo11n.pt")
# Train the model using the 'coco8.yaml' dataset for 3 epochs
results = model.train(data="coco8.yaml", epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
# Perform object detection on an image using the model
results = model("https://ultralytics.com/images/bus.jpg")
# Export the model to ONNX format
success = model.export(format="onnx")
```
[Python Guide](usage/python.md){.md-button .md-button--primary}
## Ultra
| |
270754
|
### How do I install Ultralytics using pip?
To install Ultralytics with pip, execute the following command:
```bash
pip install ultralytics
```
For the latest stable release, this will install the `ultralytics` package directly from the Python Package Index (PyPI). For more details, visit the [ultralytics package on PyPI](https://pypi.org/project/ultralytics/).
Alternatively, you can install the latest development version directly from GitHub:
```bash
pip install git+https://github.com/ultralytics/ultralytics.git
```
Make sure to have the Git command-line tool installed on your system.
### Can I install Ultralytics YOLO using conda?
Yes, you can install Ultralytics YOLO using conda by running:
```bash
conda install -c conda-forge ultralytics
```
This method is an excellent alternative to pip and ensures compatibility with other packages in your environment. For CUDA environments, it's best to install `ultralytics`, `pytorch`, and `pytorch-cuda` simultaneously to resolve any conflicts:
```bash
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
```
For more instructions, visit the [Conda quickstart guide](guides/conda-quickstart.md).
### What are the advantages of using Docker to run Ultralytics YOLO?
Using Docker to run Ultralytics YOLO provides an isolated and consistent environment, ensuring smooth performance across different systems. It also eliminates the complexity of local installation. Official Docker images from Ultralytics are available on [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics), with different variants tailored for GPU, CPU, ARM64, NVIDIA Jetson, and Conda environments. Below are the commands to pull and run the latest image:
```bash
# Pull the latest ultralytics image from Docker Hub
sudo docker pull ultralytics/ultralytics:latest
# Run the ultralytics image in a container with GPU support
sudo docker run -it --ipc=host --gpus all ultralytics/ultralytics:latest
```
For more detailed Docker instructions, check out the [Docker quickstart guide](guides/docker-quickstart.md).
### How do I clone the Ultralytics repository for development?
To clone the Ultralytics repository and set up a development environment, use the following steps:
```bash
# Clone the ultralytics repository
git clone https://github.com/ultralytics/ultralytics
# Navigate to the cloned directory
cd ultralytics
# Install the package in editable mode for development
pip install -e .
```
This approach allows you to contribute to the project or experiment with the latest source code. For more details, visit the [Ultralytics GitHub repository](https://github.com/ultralytics/ultralytics).
### Why should I use Ultralytics YOLO CLI?
The Ultralytics YOLO command line interface (CLI) simplifies running object detection tasks without requiring Python code. You can execute single-line commands for tasks like training, validation, and prediction straight from your terminal. The basic syntax for `yolo` commands is:
```bash
yolo TASK MODE ARGS
```
For example, to train a detection model with specified parameters:
```bash
yolo train data=coco8.yaml model=yolo11n.pt epochs=10 lr0=0.01
```
Check out the full [CLI Guide](usage/cli.md) to explore more commands and usage examples.
<!-- Article Links -->
[Ultralytics HUB]: https://hub.ultralytics.com
[API Key]: https://hub.ultralytics.com/settings?tab=api+keys
[pip]: https://pypi.org/project/ultralytics/
[DVC for experiment tracking]: https://dvc.org/doc/dvclive/ml-frameworks/yolo
[Comet ML]: https://bit.ly/yolov8-readme-comet
[Ultralytics HUB]: https://hub.ultralytics.com
[ClearML]: ./integrations/clearml.md
[MLFlow]: ./integrations/mlflow.md
[Neptune]: https://neptune.ai/
[Tensorboard]: ./integrations/tensorboard.md
[Ray Tune]: ./integrations/ray-tune.md
[Weights & Biases]: ./integrations/weights-biases.md
[Ultralytics-Snippets]: ./integrations/vscode.md
| |
270760
|
## Export
Export a YOLO11n Pose model to a different format like ONNX, CoreML, etc.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-pose.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
Available YOLO11-pose export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n-pose.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
## FAQ
### What is Pose Estimation with Ultralytics YOLO11 and how does it work?
Pose estimation with Ultralytics YOLO11 involves identifying specific points, known as keypoints, in an image. These keypoints typically represent joints or other important features of the object. The output includes the `[x, y]` coordinates and confidence scores for each point. YOLO11-pose models are specifically designed for this task and use the `-pose` suffix, such as `yolo11n-pose.pt`. These models are pre-trained on datasets like [COCO keypoints](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml) and can be used for various pose estimation tasks. For more information, visit the [Pose Estimation Page](#pose-estimation).
### How can I train a YOLO11-pose model on a custom dataset?
Training a YOLO11-pose model on a custom dataset involves loading a model, either a new model defined by a YAML file or a pre-trained model. You can then start the training process using your specified dataset and parameters.
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.yaml") # build a new model from YAML
model = YOLO("yolo11n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="your-dataset.yaml", epochs=100, imgsz=640)
```
For comprehensive details on training, refer to the [Train Section](#train).
### How do I validate a trained YOLO11-pose model?
Validation of a YOLO11-pose model involves assessing its accuracy using the same dataset parameters retained during training. Here's an example:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
```
For more information, visit the [Val Section](#val).
### Can I export a YOLO11-pose model to other formats, and how?
Yes, you can export a YOLO11-pose model to various formats like ONNX, CoreML, TensorRT, and more. This can be done using either Python or the Command Line Interface (CLI).
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
Refer to the [Export Section](#export) for more details.
### What are the available Ultralytics YOLO11-pose models and their performance metrics?
Ultralytics YOLO11 offers various pretrained pose models such as YOLO11n-pose, YOLO11s-pose, YOLO11m-pose, among others. These models differ in size, accuracy (mAP), and speed. For instance, the YOLO11n-pose model achieves a mAP<sup>pose</sup>50-95 of 50.4 and an mAP<sup>pose</sup>50 of 80.1. For a complete list and performance details, visit the [Models Section](#models).
| |
270761
|
---
comments: true
description: Learn about object detection with YOLO11. Explore pretrained models, training, validation, prediction, and export details for efficient object recognition.
keywords: object detection, YOLO11, pretrained models, training, validation, prediction, export, machine learning, computer vision
---
# Object Detection
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/object-detection-examples.avif" alt="Object detection examples">
[Object detection](https://www.ultralytics.com/glossary/object-detection) is a task that involves identifying the location and class of objects in an image or video stream.
The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/5ku7npMrW40?si=6HQO1dDXunV8gekh"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Object Detection with Pre-trained Ultralytics YOLO Model.
</p>
!!! tip
YOLO11 Detect models are the default YOLO11 models, i.e. `yolo11n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11)
YOLO11 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) dataset.
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
{% include "macros/yolo-det-perf.md" %}
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](https://cocodataset.org/) dataset. <br>Reproduce by `yolo val detect data=coco.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val detect data=coco.yaml batch=1 device=0|cpu`
## Train
Train YOLO11n on the COCO8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.yaml") # build a new model from YAML
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n.yaml").load("yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Build a new model from YAML and start training from scratch
yolo detect train data=coco8.yaml model=yolo11n.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco8.yaml model=yolo11n.yaml pretrained=yolo11n.pt epochs=100 imgsz=640
```
### Dataset format
YOLO detection dataset format can be found in detail in the [Dataset Guide](../datasets/detect/index.md). To convert your existing dataset from other formats (like COCO etc.) to YOLO format, please use [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) tool by Ultralytics.
## Val
Validate trained YOLO11n model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
```
=== "CLI"
```bash
yolo detect val model=yolo11n.pt # val official model
yolo detect val model=path/to/best.pt # val custom model
```
## Predict
Use a trained YOLO11n model to run predictions on images.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
```bash
yolo detect predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
```
See full `predict` mode details in the [Predict](../modes/predict.md) page.
## Export
Export a YOLO11n model to a different format like ONNX, CoreML, etc.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
Available YOLO11 export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
| |
270762
|
## FAQ
### How do I train a YOLO11 model on my custom dataset?
Training a YOLO11 model on a custom dataset involves a few steps:
1. **Prepare the Dataset**: Ensure your dataset is in the YOLO format. For guidance, refer to our [Dataset Guide](../datasets/detect/index.md).
2. **Load the Model**: Use the Ultralytics YOLO library to load a pre-trained model or create a new model from a YAML file.
3. **Train the Model**: Execute the `train` method in Python or the `yolo detect train` command in CLI.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolo11n.pt")
# Train the model on your custom dataset
model.train(data="my_custom_dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo detect train data=my_custom_dataset.yaml model=yolo11n.pt epochs=100 imgsz=640
```
For detailed configuration options, visit the [Configuration](../usage/cfg.md) page.
### What pretrained models are available in YOLO11?
Ultralytics YOLO11 offers various pretrained models for object detection, segmentation, and pose estimation. These models are pretrained on the COCO dataset or ImageNet for classification tasks. Here are some of the available models:
- [YOLO11n](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt)
- [YOLO11s](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11s.pt)
- [YOLO11m](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11m.pt)
- [YOLO11l](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11l.pt)
- [YOLO11x](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11x.pt)
For a detailed list and performance metrics, refer to the [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11) section.
### How can I validate the accuracy of my trained YOLO model?
To validate the accuracy of your trained YOLO11 model, you can use the `.val()` method in Python or the `yolo detect val` command in CLI. This will provide metrics like mAP50-95, mAP50, and more.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load the model
model = YOLO("path/to/best.pt")
# Validate the model
metrics = model.val()
print(metrics.box.map) # mAP50-95
```
=== "CLI"
```bash
yolo detect val model=path/to/best.pt
```
For more validation details, visit the [Val](../modes/val.md) page.
### What formats can I export a YOLO11 model to?
Ultralytics YOLO11 allows exporting models to various formats such as ONNX, TensorRT, CoreML, and more to ensure compatibility across different platforms and devices.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load the model
model = YOLO("yolo11n.pt")
# Export the model to ONNX format
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=onnx
```
Check the full list of supported formats and instructions on the [Export](../modes/export.md) page.
### Why should I use Ultralytics YOLO11 for object detection?
Ultralytics YOLO11 is designed to offer state-of-the-art performance for object detection, segmentation, and pose estimation. Here are some key advantages:
1. **Pretrained Models**: Utilize models pretrained on popular datasets like COCO and ImageNet for faster development.
2. **High Accuracy**: Achieves impressive mAP scores, ensuring reliable object detection.
3. **Speed**: Optimized for real-time inference, making it ideal for applications requiring swift processing.
4. **Flexibility**: Export models to various formats like ONNX and TensorRT for deployment across multiple platforms.
Explore our [Blog](https://www.ultralytics.com/blog) for use cases and success stories showcasing YOLO11 in action.
| |
270763
|
---
comments: true
description: Master instance segmentation using YOLO11. Learn how to detect, segment and outline objects in images with detailed guides and examples.
keywords: instance segmentation, YOLO11, object detection, image segmentation, machine learning, deep learning, computer vision, COCO dataset, Ultralytics
model_name: yolo11n-seg
---
# Instance Segmentation
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/instance-segmentation-examples.avif" alt="Instance segmentation examples">
[Instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
The output of an instance segmentation model is a set of masks or contours that outline each object in the image, along with class labels and confidence scores for each object. Instance segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/o4Zd-IeMlSY?si=37nusCzDTd74Obsp"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Run Segmentation with Pre-Trained Ultralytics YOLO Model in Python.
</p>
!!! tip
YOLO11 Segment models use the `-seg` suffix, i.e. `yolo11n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11)
YOLO11 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) dataset.
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
{% include "macros/yolo-seg-perf.md" %}
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](https://cocodataset.org/) dataset. <br>Reproduce by `yolo val segment data=coco-seg.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val segment data=coco-seg.yaml batch=1 device=0|cpu`
## Train
Train YOLO11n-seg on the COCO8-seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-seg.yaml") # build a new model from YAML
model = YOLO("yolo11n-seg.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n-seg.yaml").load("yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Build a new model from YAML and start training from scratch
yolo segment train data=coco8-seg.yaml model=yolo11n-seg.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo segment train data=coco8-seg.yaml model=yolo11n-seg.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo segment train data=coco8-seg.yaml model=yolo11n-seg.yaml pretrained=yolo11n-seg.pt epochs=100 imgsz=640
```
### Dataset format
YOLO segmentation dataset format can be found in detail in the [Dataset Guide](../datasets/segment/index.md). To convert your existing dataset from other formats (like COCO etc.) to YOLO format, please use [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) tool by Ultralytics.
## Val
Validate trained YOLO11n-seg model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO8-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
metrics.box.maps # a list contains map50-95(B) of each category
metrics.seg.map # map50-95(M)
metrics.seg.map50 # map50(M)
metrics.seg.map75 # map75(M)
metrics.seg.maps # a list contains map50-95(M) of each category
```
=== "CLI"
```bash
yolo segment val model=yolo11n-seg.pt # val official model
yolo segment val model=path/to/best.pt # val custom model
```
## Predict
Use a trained YOLO11n-seg model to run predictions on images.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
```bash
yolo segment predict model=yolo11n-seg.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
```
See full `predict` mode details in the [Predict](../modes/predict.md) page.
## Export
Export a YOLO11n-seg model to a different format like ONNX, CoreML, etc.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-seg.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-seg.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
Available YOLO11-seg export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n-seg.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
| |
270764
|
## FAQ
### How do I train a YOLO11 segmentation model on a custom dataset?
To train a YOLO11 segmentation model on a custom dataset, you first need to prepare your dataset in the YOLO segmentation format. You can use tools like [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) to convert datasets from other formats. Once your dataset is ready, you can train the model using Python or CLI commands:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11 segment model
model = YOLO("yolo11n-seg.pt")
# Train the model
results = model.train(data="path/to/your_dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo segment train data=path/to/your_dataset.yaml model=yolo11n-seg.pt epochs=100 imgsz=640
```
Check the [Configuration](../usage/cfg.md) page for more available arguments.
### What is the difference between [object detection](https://www.ultralytics.com/glossary/object-detection) and instance segmentation in YOLO11?
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, whereas instance segmentation not only identifies the bounding boxes but also delineates the exact shape of each object. YOLO11 instance segmentation models provide masks or contours that outline each detected object, which is particularly useful for tasks where knowing the precise shape of objects is important, such as medical imaging or autonomous driving.
### Why use YOLO11 for instance segmentation?
Ultralytics YOLO11 is a state-of-the-art model recognized for its high accuracy and real-time performance, making it ideal for instance segmentation tasks. YOLO11 Segment models come pretrained on the [COCO dataset](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml), ensuring robust performance across a variety of objects. Additionally, YOLO supports training, validation, prediction, and export functionalities with seamless integration, making it highly versatile for both research and industry applications.
### How do I load and validate a pretrained YOLO segmentation model?
Loading and validating a pretrained YOLO segmentation model is straightforward. Here's how you can do it using both Python and CLI:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolo11n-seg.pt")
# Validate the model
metrics = model.val()
print("Mean Average Precision for boxes:", metrics.box.map)
print("Mean Average Precision for masks:", metrics.seg.map)
```
=== "CLI"
```bash
yolo segment val model=yolo11n-seg.pt
```
These steps will provide you with validation metrics like [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP), crucial for assessing model performance.
### How can I export a YOLO segmentation model to ONNX format?
Exporting a YOLO segmentation model to ONNX format is simple and can be done using Python or CLI commands:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolo11n-seg.pt")
# Export the model to ONNX format
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-seg.pt format=onnx
```
For more details on exporting to various formats, refer to the [Export](../modes/export.md) page.
| |
270766
|
---
comments: true
description: Discover how to detect objects with rotation for higher precision using YOLO11 OBB models. Learn, train, validate, and export OBB models effortlessly.
keywords: Oriented Bounding Boxes, OBB, Object Detection, YOLO11, Ultralytics, DOTAv1, Model Training, Model Export, AI, Machine Learning
model_name: yolo11n-obb
---
# Oriented Bounding Boxes [Object Detection](https://www.ultralytics.com/glossary/object-detection)
<!-- obb task poster -->
Oriented object detection goes a step further than object detection and introduce an extra angle to locate objects more accurate in an image.
The output of an oriented object detector is a set of rotated bounding boxes that exactly enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.
<!-- youtube video link for obb task -->
!!! tip
YOLO11 OBB models use the `-obb` suffix, i.e. `yolo11n-obb.pt` and are pretrained on [DOTAv1](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/DOTAv1.yaml).
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/Z7Z9pHF8wJc"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Object Detection using Ultralytics YOLO Oriented Bounding Boxes (YOLO-OBB)
</p>
## Visual Samples
| Ships Detection using OBB | Vehicle Detection using OBB |
| :------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------: |
|  |  |
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11)
YOLO11 pretrained OBB models are shown here, which are pretrained on the [DOTAv1](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/DOTAv1.yaml) dataset.
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
{% include "macros/yolo-obb-perf.md" %}
- **mAP<sup>test</sup>** values are for single-model multiscale on [DOTAv1](https://captain-whu.github.io/DOTA/index.html) dataset. <br>Reproduce by `yolo val obb data=DOTAv1.yaml device=0 split=test` and submit merged results to [DOTA evaluation](https://captain-whu.github.io/DOTA/evaluation.html).
- **Speed** averaged over DOTAv1 val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val obb data=DOTAv1.yaml batch=1 device=0|cpu`
## Train
Train YOLO11n-obb on the DOTA8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.yaml") # build a new model from YAML
model = YOLO("yolo11n-obb.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n-obb.yaml").load("yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Build a new model from YAML and start training from scratch
yolo obb train data=dota8.yaml model=yolo11n-obb.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo obb train data=dota8.yaml model=yolo11n-obb.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo obb train data=dota8.yaml model=yolo11n-obb.yaml pretrained=yolo11n-obb.pt epochs=100 imgsz=640
```
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/uZ7SymQfqKI"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How to Train Ultralytics YOLO-OBB (Oriented Bounding Boxes) Models on DOTA Dataset using Ultralytics HUB
</p>
### Dataset format
OBB dataset format can be found in detail in the [Dataset Guide](../datasets/obb/index.md).
## Val
Validate trained YOLO11n-obb model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the DOTA8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val(data="dota8.yaml") # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
metrics.box.maps # a list contains map50-95(B) of each category
```
=== "CLI"
```bash
yolo obb val model=yolo11n-obb.pt data=dota8.yaml # val official model
yolo obb val model=path/to/best.pt data=path/to/data.yaml # val custom model
```
## Predict
Use a trained YOLO11n-obb model to run predictions on images.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/boats.jpg") # predict on an image
```
=== "CLI"
```bash
yolo obb predict model=yolo11n-obb.pt source='https://ultralytics.com/images/boats.jpg' # predict with official model
yolo obb predict model=path/to/best.pt source='https://ultralytics.com/images/boats.jpg' # predict with custom model
```
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/5XYdm5CYODA"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How to Detect and Track Storage Tanks using Ultralytics YOLO-OBB | Oriented Bounding Boxes | DOTA
</p>
See full `predict` mode details in the [Predict](../modes/predict.md) page.
| |
270767
|
## Export
Export a YOLO11n-obb model to a different format like ONNX, CoreML, etc.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-obb.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
Available YOLO11-obb export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n-obb.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
## FAQ
### What are Oriented Bounding Boxes (OBB) and how do they differ from regular bounding boxes?
Oriented Bounding Boxes (OBB) include an additional angle to enhance object localization accuracy in images. Unlike regular bounding boxes, which are axis-aligned rectangles, OBBs can rotate to fit the orientation of the object better. This is particularly useful for applications requiring precise object placement, such as aerial or satellite imagery ([Dataset Guide](../datasets/obb/index.md)).
### How do I train a YOLO11n-obb model using a custom dataset?
To train a YOLO11n-obb model with a custom dataset, follow the example below using Python or CLI:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pretrained model
model = YOLO("yolo11n-obb.pt")
# Train the model
results = model.train(data="path/to/custom_dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo obb train data=path/to/custom_dataset.yaml model=yolo11n-obb.pt epochs=100 imgsz=640
```
For more training arguments, check the [Configuration](../usage/cfg.md) section.
### What datasets can I use for training YOLO11-OBB models?
YOLO11-OBB models are pretrained on datasets like [DOTAv1](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/DOTAv1.yaml) but you can use any dataset formatted for OBB. Detailed information on OBB dataset formats can be found in the [Dataset Guide](../datasets/obb/index.md).
### How can I export a YOLO11-OBB model to ONNX format?
Exporting a YOLO11-OBB model to ONNX format is straightforward using either Python or CLI:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.pt")
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-obb.pt format=onnx
```
For more export formats and details, refer to the [Export](../modes/export.md) page.
### How do I validate the accuracy of a YOLO11n-obb model?
To validate a YOLO11n-obb model, you can use Python or CLI commands as shown below:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-obb.pt")
# Validate the model
metrics = model.val(data="dota8.yaml")
```
=== "CLI"
```bash
yolo obb val model=yolo11n-obb.pt data=dota8.yaml
```
See full validation details in the [Val](../modes/val.md) section.
| |
270768
|
---
comments: true
description: Master image classification using YOLO11. Learn to train, validate, predict, and export models efficiently.
keywords: YOLO11, image classification, AI, machine learning, pretrained models, ImageNet, model export, predict, train, validate
model_name: yolo11n-cls
---
# Image Classification
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/image-classification-examples.avif" alt="Image classification examples">
[Image classification](https://www.ultralytics.com/glossary/image-classification) is the simplest of the three tasks and involves classifying an entire image into one of a set of predefined classes.
The output of an image classifier is a single class label and a confidence score. Image classification is useful when you need to know only what class an image belongs to and don't need to know where objects of that class are located or what their exact shape is.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/5BO0Il_YYAg"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Explore Ultralytics YOLO Tasks: Image Classification using Ultralytics HUB
</p>
!!! tip
YOLO11 Classify models use the `-cls` suffix, i.e. `yolo11n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml).
## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11)
YOLO11 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) dataset.
[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
{% include "macros/yolo-cls-perf.md" %}
- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set. <br>Reproduce by `yolo val classify data=path/to/ImageNet device=0`
- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
## Train
Train YOLO11n-cls on the MNIST160 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 64. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.yaml") # build a new model from YAML
model = YOLO("yolo11n-cls.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n-cls.yaml").load("yolo11n-cls.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="mnist160", epochs=100, imgsz=64)
```
=== "CLI"
```bash
# Build a new model from YAML and start training from scratch
yolo classify train data=mnist160 model=yolo11n-cls.yaml epochs=100 imgsz=64
# Start training from a pretrained *.pt model
yolo classify train data=mnist160 model=yolo11n-cls.pt epochs=100 imgsz=64
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo classify train data=mnist160 model=yolo11n-cls.yaml pretrained=yolo11n-cls.pt epochs=100 imgsz=64
```
### Dataset format
YOLO classification dataset format can be found in detail in the [Dataset Guide](../datasets/classify/index.md).
## Val
Validate trained YOLO11n-cls model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the MNIST160 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.top1 # top1 accuracy
metrics.top5 # top5 accuracy
```
=== "CLI"
```bash
yolo classify val model=yolo11n-cls.pt # val official model
yolo classify val model=path/to/best.pt # val custom model
```
## Predict
Use a trained YOLO11n-cls model to run predictions on images.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
```bash
yolo classify predict model=yolo11n-cls.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
```
See full `predict` mode details in the [Predict](../modes/predict.md) page.
## Export
Export a YOLO11n-cls model to a different format like ONNX, CoreML, etc.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n-cls.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
Available YOLO11-cls export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n-cls.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
| |
270771
|
# Model Training with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-yolov8-ecosystem-integrations.avif" alt="Ultralytics YOLO ecosystem and integrations">
## Introduction
Training a [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) model involves feeding it data and adjusting its parameters so that it can make accurate predictions. Train mode in Ultralytics YOLO11 is engineered for effective and efficient training of object detection models, fully utilizing modern hardware capabilities. This guide aims to cover all the details you need to get started with training your own models using YOLO11's robust set of features.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How to Train a YOLO model on Your Custom Dataset in Google Colab.
</p>
## Why Choose Ultralytics YOLO for Training?
Here are some compelling reasons to opt for YOLO11's Train mode:
- **Efficiency:** Make the most out of your hardware, whether you're on a single-GPU setup or scaling across multiple GPUs.
- **Versatility:** Train on custom datasets in addition to readily available ones like COCO, VOC, and ImageNet.
- **User-Friendly:** Simple yet powerful CLI and Python interfaces for a straightforward training experience.
- **Hyperparameter Flexibility:** A broad range of customizable hyperparameters to fine-tune model performance.
### Key Features of Train Mode
The following are some notable features of YOLO11's Train mode:
- **Automatic Dataset Download:** Standard datasets like COCO, VOC, and ImageNet are downloaded automatically on first use.
- **Multi-GPU Support:** Scale your training efforts seamlessly across multiple GPUs to expedite the process.
- **Hyperparameter Configuration:** The option to modify hyperparameters through YAML configuration files or CLI arguments.
- **Visualization and Monitoring:** Real-time tracking of training metrics and visualization of the learning process for better insights.
!!! tip
* YOLO11 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
## Usage Examples
Train YOLO11n on the COCO8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. The training device can be specified using the `device` argument. If no argument is passed GPU `device=0` will be used if available, otherwise `device='cpu'` will be used. See Arguments section below for a full list of training arguments.
!!! example "Single-GPU and CPU Training Example"
Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.yaml") # build a new model from YAML
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n.yaml").load("yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Build a new model from YAML and start training from scratch
yolo detect train data=coco8.yaml model=yolo11n.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco8.yaml model=yolo11n.yaml pretrained=yolo11n.pt epochs=100 imgsz=640
```
### Multi-GPU Training
Multi-GPU training allows for more efficient utilization of available hardware resources by distributing the training load across multiple GPUs. This feature is available through both the Python API and the command-line interface. To enable multi-GPU training, specify the GPU device IDs you wish to use.
!!! example "Multi-GPU Training Example"
To train with 2 GPUs, CUDA devices 0 and 1 use the following commands. Expand to additional GPUs as required.
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model with 2 GPUs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1])
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model using GPUs 0 and 1
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640 device=0,1
```
### Apple M1 and M2 MPS Training
With the support for Apple M1 and M2 chips integrated in the Ultralytics YOLO models, it's now possible to train your models on devices utilizing the powerful Metal Performance Shaders (MPS) framework. The MPS offers a high-performance way of executing computation and image processing tasks on Apple's custom silicon.
To enable training on Apple M1 and M2 chips, you should specify 'mps' as your device when initiating the training process. Below is an example of how you could do this in Python and via the command line:
!!! example "MPS Training Example"
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model with MPS
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device="mps")
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model using MPS
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640 device=mps
```
While leveraging the computational power of the M1/M2 chips, this enables more efficient processing of the training tasks. For more detailed guidance and advanced configuration options, please refer to the [PyTorch MPS documentation](https://pytorch.org/docs/stable/notes/mps.html).
### Resuming Interrupted Trainings
Resuming training from a previously saved state is a crucial feature when working with deep learning models. This can come in handy in various scenarios, like when the training process has been unexpectedly interrupted, or when you wish to continue training a model with new data or for more epochs.
When training is resumed, Ultralytics YOLO loads the weights from the last saved model and also restores the optimizer state, [learning rate](https://www.ultralytics.com/glossary/learning-rate) scheduler, and the epoch number. This allows you to continue the training process seamlessly from where it was left off.
You can easily resume training in Ultralytics YOLO by setting the `resume` argument to `True` when calling the `train` method, and specifying the path to the `.pt` file containing the partially trained model weights.
Below is an example of how to resume an interrupted training using Python and via the command line:
!!! example "Resume Training Example"
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("path/to/last.pt") # load a partially trained model
# Resume training
results = model.train(resume=True)
```
=== "CLI"
```bash
# Resume an interrupted training
yolo train resume model=path/to/last.pt
```
By setting `resume=True`, the `train` function will continue training from where it left off, using the state stored in the 'path/to/last.pt' file. If the `resume` argument is omitted or set to `False`, the `train` function will start a new training session.
Remember that checkpoints are saved at the end of every epoch by default, or at fixed intervals using the `save_period` argument, so you must complete at least 1 epoch to resume a training run.
| |
270772
|
## Train Settings
The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy). Key training settings include batch size, learning rate, momentum, and weight decay. Additionally, the choice of optimizer, [loss function](https://www.ultralytics.com/glossary/loss-function), and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
{% include "macros/train-args.md" %}
!!! info "Note on Batch-size Settings"
The `batch` argument can be configured in three ways:
- **Fixed [Batch Size](https://www.ultralytics.com/glossary/batch-size)**: Set an integer value (e.g., `batch=16`), specifying the number of images per batch directly.
- **Auto Mode (60% GPU Memory)**: Use `batch=-1` to automatically adjust batch size for approximately 60% CUDA memory utilization.
- **Auto Mode with Utilization Fraction**: Set a fraction value (e.g., `batch=0.70`) to adjust batch size based on the specified fraction of GPU memory usage.
## Augmentation Settings and Hyperparameters
Augmentation techniques are essential for improving the robustness and performance of YOLO models by introducing variability into the [training data](https://www.ultralytics.com/glossary/training-data), helping the model generalize better to unseen data. The following table outlines the purpose and effect of each augmentation argument:
{% include "macros/augmentation-args.md" %}
These settings can be adjusted to meet the specific requirements of the dataset and task at hand. Experimenting with different values can help find the optimal augmentation strategy that leads to the best model performance.
!!! info
For more information about training augmentation operations, see the [reference section](../reference/data/augment.md).
## Logging
In training a YOLO11 model, you might find it valuable to keep track of the model's performance over time. This is where logging comes into play. Ultralytics' YOLO provides support for three types of loggers - Comet, ClearML, and TensorBoard.
To use a logger, select it from the dropdown menu in the code snippet above and run it. The chosen logger will be installed and initialized.
### Comet
[Comet](../integrations/comet.md) is a platform that allows data scientists and developers to track, compare, explain and optimize experiments and models. It provides functionalities such as real-time metrics, code diffs, and hyperparameters tracking.
To use Comet:
!!! example
=== "Python"
```python
# pip install comet_ml
import comet_ml
comet_ml.init()
```
Remember to sign in to your Comet account on their website and get your API key. You will need to add this to your environment variables or your script to log your experiments.
### ClearML
[ClearML](https://clear.ml/) is an open-source platform that automates tracking of experiments and helps with efficient sharing of resources. It is designed to help teams manage, execute, and reproduce their ML work more efficiently.
To use ClearML:
!!! example
=== "Python"
```python
# pip install clearml
import clearml
clearml.browser_login()
```
After running this script, you will need to sign in to your ClearML account on the browser and authenticate your session.
### TensorBoard
[TensorBoard](https://www.tensorflow.org/tensorboard) is a visualization toolkit for [TensorFlow](https://www.ultralytics.com/glossary/tensorflow). It allows you to visualize your TensorFlow graph, plot quantitative metrics about the execution of your graph, and show additional data like images that pass through it.
To use TensorBoard in [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb):
!!! example
=== "CLI"
```bash
load_ext tensorboard
tensorboard --logdir ultralytics/runs # replace with 'runs' directory
```
To use TensorBoard locally run the below command and view results at http://localhost:6006/.
!!! example
=== "CLI"
```bash
tensorboard --logdir ultralytics/runs # replace with 'runs' directory
```
This will load TensorBoard and direct it to the directory where your training logs are saved.
After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
| |
270774
|
---
comments: true
description: Learn how to evaluate your YOLO11 model's performance in real-world scenarios using benchmark mode. Optimize speed, accuracy, and resource allocation across export formats.
keywords: model benchmarking, YOLO11, Ultralytics, performance evaluation, export formats, ONNX, TensorRT, OpenVINO, CoreML, TensorFlow, optimization, mAP50-95, inference time
---
# Model Benchmarking with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-yolov8-ecosystem-integrations.avif" alt="Ultralytics YOLO ecosystem and integrations">
## Introduction
Once your model is trained and validated, the next logical step is to evaluate its performance in various real-world scenarios. Benchmark mode in Ultralytics YOLO11 serves this purpose by providing a robust framework for assessing the speed and [accuracy](https://www.ultralytics.com/glossary/accuracy) of your model across a range of export formats.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/j8uQc0qB91s?start=105"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Ultralytics Modes Tutorial: Benchmark
</p>
## Why Is Benchmarking Crucial?
- **Informed Decisions:** Gain insights into the trade-offs between speed and accuracy.
- **Resource Allocation:** Understand how different export formats perform on different hardware.
- **Optimization:** Learn which export format offers the best performance for your specific use case.
- **Cost Efficiency:** Make more efficient use of hardware resources based on benchmark results.
### Key Metrics in Benchmark Mode
- **mAP50-95:** For [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and pose estimation.
- **accuracy_top5:** For [image classification](https://www.ultralytics.com/glossary/image-classification).
- **Inference Time:** Time taken for each image in milliseconds.
### Supported Export Formats
- **ONNX:** For optimal CPU performance
- **TensorRT:** For maximal GPU efficiency
- **OpenVINO:** For Intel hardware optimization
- **CoreML, TensorFlow SavedModel, and More:** For diverse deployment needs.
!!! tip
* Export to ONNX or OpenVINO for up to 3x CPU speedup.
* Export to TensorRT for up to 5x GPU speedup.
## Usage Examples
Run YOLO11n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a full list of export arguments.
!!! example
=== "Python"
```python
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
benchmark(model="yolo11n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
=== "CLI"
```bash
yolo benchmark model=yolo11n.pt data='coco8.yaml' imgsz=640 half=False device=0
```
## Arguments
Arguments such as `model`, `data`, `imgsz`, `half`, `device`, and `verbose` provide users with the flexibility to fine-tune the benchmarks to their specific needs and compare the performance of different export formats with ease.
| Key | Default Value | Description |
| --------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `model` | `None` | Specifies the path to the model file. Accepts both `.pt` and `.yaml` formats, e.g., `"yolo11n.pt"` for pre-trained models or configuration files. |
| `data` | `None` | Path to a YAML file defining the dataset for benchmarking, typically including paths and settings for [validation data](https://www.ultralytics.com/glossary/validation-data). Example: `"coco8.yaml"`. |
| `imgsz` | `640` | The input image size for the model. Can be a single integer for square images or a tuple `(width, height)` for non-square, e.g., `(640, 480)`. |
| `half` | `False` | Enables FP16 (half-precision) inference, reducing memory usage and possibly increasing speed on compatible hardware. Use `half=True` to enable. |
| `int8` | `False` | Activates INT8 quantization for further optimized performance on supported devices, especially useful for edge devices. Set `int8=True` to use. |
| `device` | `None` | Defines the computation device(s) for benchmarking, such as `"cpu"`, `"cuda:0"`, or a list of devices like `"cuda:0,1"` for multi-GPU setups. |
| `verbose` | `False` | Controls the level of detail in logging output. A boolean value; set `verbose=True` for detailed logs or a float for thresholding errors. |
## Export Formats
Benchmarks will attempt to run automatically on all possible export formats below.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
## FAQ
### How do I benchmark my YOLO11 model's performance using Ultralytics?
Ultralytics YOLO11 offers a Benchmark mode to assess your model's performance across different export formats. This mode provides insights into key metrics such as [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP50-95), accuracy, and inference time in milliseconds. To run benchmarks, you can use either Python or CLI commands. For example, to benchmark on a GPU:
!!! example
=== "Python"
```python
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
benchmark(model="yolo11n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
=== "CLI"
```bash
yolo benchmark model=yolo11n.pt data='coco8.yaml' imgsz=640 half=False device=0
```
For more details on benchmark arguments, visit the [Arguments](#arguments) section.
### What are the benefits of exporting YOLO11 models to different formats?
Exporting YOLO11 models to different formats such as ONNX, TensorRT, and OpenVINO allows you to optimize performance based on your deployment environment. For instance:
- **ONNX:** Provides up to 3x CPU speedup.
- **TensorRT:** Offers up to 5x GPU speedup.
- **OpenVINO:** Specifically optimized for Intel hardware.
These formats enhance both the speed and accuracy of your models, making them more efficient for various real-world applications. Visit the [Export](../modes/export.md) page for complete details.
### Why is benchmarking crucial in evaluating YOLO11 models?
Benchmarking your YOLO11 models is essential for several reasons:
- **Informed Decisions:** Understand the trade-offs between speed and accuracy.
- **Resource Allocation:** Gauge the performance across different hardware options.
- **Optimization:** Determine which export format offers the best performance for specific use cases.
- **Cost Efficiency:** Optimize hardware usage based on benchmark results.
Key metrics such as mAP50-95, Top-5 accuracy, and inference time help in making these evaluations. Refer to the [Key Metrics](#key-metrics-in-benchmark-mode) section for more information.
### Which export formats are supported by YOLO11, and what are their advantages?
YOLO11 supports a variety of export formats, each tailored for specific hardware and use cases:
- **ONNX:** Best for CPU performance.
- **TensorRT:** Ideal for GPU efficiency.
- **OpenVINO:** Optimized for Intel hardware.
- **CoreML & [TensorFlow](https://www.ultralytics.com/glossary/tensorflow):** Useful for iOS and general ML applications.
For a complete list of supported formats and their respective advantages, check out the [Supported Export Formats](#supported-export-formats) section.
### What arguments can I use to fine-tune my YOLO11 benchmarks?
When running benchmarks, several arguments can be customized to suit specific needs:
- **model:** Path to the model file (e.g., "yolo11n.pt").
- **data:** Path to a YAML file defining the dataset (e.g., "coco8.yaml").
- **imgsz:** The input image size, either as a single integer or a tuple.
- **half:** Enable FP16 inference for better performance.
- **int8:** Activate INT8 quantization for edge devices.
- **device:** Specify the computation device (e.g., "cpu", "cuda:0").
- **verbose:** Control the level of logging detail.
For a full list of arguments, refer to the [Arguments](#arguments) section.
| |
270776
|
FAQ
### How do I train a custom [object detection](https://www.ultralytics.com/glossary/object-detection) model with Ultralytics YOLO11?
Training a custom object detection model with Ultralytics YOLO11 involves using the train mode. You need a dataset formatted in YOLO format, containing images and corresponding annotation files. Use the following command to start the training process:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pre-trained YOLO model (you can choose n, s, m, l, or x versions)
model = YOLO("yolo11n.pt")
# Start training on your custom dataset
model.train(data="path/to/dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Train a YOLO model from the command line
yolo train data=path/to/dataset.yaml epochs=100 imgsz=640
```
For more detailed instructions, you can refer to the [Ultralytics Train Guide](../modes/train.md).
### What metrics does Ultralytics YOLO11 use to validate the model's performance?
Ultralytics YOLO11 uses various metrics during the validation process to assess model performance. These include:
- **mAP (mean Average Precision)**: This evaluates the accuracy of object detection.
- **IOU (Intersection over Union)**: Measures the overlap between predicted and ground truth bounding boxes.
- **[Precision](https://www.ultralytics.com/glossary/precision) and [Recall](https://www.ultralytics.com/glossary/recall)**: Precision measures the ratio of true positive detections to the total detected positives, while recall measures the ratio of true positive detections to the total actual positives.
You can run the following command to start the validation:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pre-trained or custom YOLO model
model = YOLO("yolo11n.pt")
# Run validation on your dataset
model.val(data="path/to/validation.yaml")
```
=== "CLI"
```bash
# Validate a YOLO model from the command line
yolo val data=path/to/validation.yaml
```
Refer to the [Validation Guide](../modes/val.md) for further details.
### How can I export my YOLO11 model for deployment?
Ultralytics YOLO11 offers export functionality to convert your trained model into various deployment formats such as ONNX, TensorRT, CoreML, and more. Use the following example to export your model:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load your trained YOLO model
model = YOLO("yolo11n.pt")
# Export the model to ONNX format (you can specify other formats as needed)
model.export(format="onnx")
```
=== "CLI"
```bash
# Export a YOLO model to ONNX format from the command line
yolo export model=yolo11n.pt format=onnx
```
Detailed steps for each export format can be found in the [Export Guide](../modes/export.md).
### What is the purpose of the benchmark mode in Ultralytics YOLO11?
Benchmark mode in Ultralytics YOLO11 is used to analyze the speed and [accuracy](https://www.ultralytics.com/glossary/accuracy) of various export formats such as ONNX, TensorRT, and OpenVINO. It provides metrics like model size, `mAP50-95` for object detection, and inference time across different hardware setups, helping you choose the most suitable format for your deployment needs.
!!! example
=== "Python"
```python
from ultralytics.utils.benchmarks import benchmark
# Run benchmark on GPU (device 0)
# You can adjust parameters like model, dataset, image size, and precision as needed
benchmark(model="yolo11n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
=== "CLI"
```bash
# Benchmark a YOLO model from the command line
# Adjust parameters as needed for your specific use case
yolo benchmark model=yolo11n.pt data='coco8.yaml' imgsz=640 half=False device=0
```
For more details, refer to the [Benchmark Guide](../modes/benchmark.md).
### How can I perform real-time object tracking using Ultralytics YOLO11?
Real-time object tracking can be achieved using the track mode in Ultralytics YOLO11. This mode extends object detection capabilities to track objects across video frames or live feeds. Use the following example to enable tracking:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a pre-trained YOLO model
model = YOLO("yolo11n.pt")
# Start tracking objects in a video
# You can also use live video streams or webcam input
model.track(source="path/to/video.mp4")
```
=== "CLI"
```bash
# Perform object tracking on a video from the command line
# You can specify different sources like webcam (0) or RTSP streams
yolo track source=path/to/video.mp4
```
For in-depth instructions, visit the [Track Guide](../modes/track.md).
| |
270777
|
---
comments: true
description: Learn how to export your YOLO11 model to various formats like ONNX, TensorRT, and CoreML. Achieve maximum compatibility and performance.
keywords: YOLO11, Model Export, ONNX, TensorRT, CoreML, Ultralytics, AI, Machine Learning, Inference, Deployment
---
# Model Export with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-yolov8-ecosystem-integrations.avif" alt="Ultralytics YOLO ecosystem and integrations">
## Introduction
The ultimate goal of training a model is to deploy it for real-world applications. Export mode in Ultralytics YOLO11 offers a versatile range of options for exporting your trained model to different formats, making it deployable across various platforms and devices. This comprehensive guide aims to walk you through the nuances of model exporting, showcasing how to achieve maximum compatibility and performance.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/WbomGeoOT_k?si=aGmuyooWftA0ue9X"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How To Export Custom Trained Ultralytics YOLO Model and Run Live Inference on Webcam.
</p>
## Why Choose YOLO11's Export Mode?
- **Versatility:** Export to multiple formats including ONNX, TensorRT, CoreML, and more.
- **Performance:** Gain up to 5x GPU speedup with TensorRT and 3x CPU speedup with ONNX or OpenVINO.
- **Compatibility:** Make your model universally deployable across numerous hardware and software environments.
- **Ease of Use:** Simple CLI and Python API for quick and straightforward model exporting.
### Key Features of Export Mode
Here are some of the standout functionalities:
- **One-Click Export:** Simple commands for exporting to different formats.
- **Batch Export:** Export batched-inference capable models.
- **Optimized Inference:** Exported models are optimized for quicker inference times.
- **Tutorial Videos:** In-depth guides and tutorials for a smooth exporting experience.
!!! tip
* Export to [ONNX](../integrations/onnx.md) or [OpenVINO](../integrations/openvino.md) for up to 3x CPU speedup.
* Export to [TensorRT](../integrations/tensorrt.md) for up to 5x GPU speedup.
## Usage Examples
Export a YOLO11n model to a different format like ONNX or TensorRT. See the Arguments section below for a full list of export arguments.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
## Arguments
This table details the configurations and options available for exporting YOLO models to different formats. These settings are critical for optimizing the exported model's performance, size, and compatibility across various platforms and environments. Proper configuration ensures that the model is ready for deployment in the intended application with optimal efficiency.
{% include "macros/export-args.md" %}
Adjusting these parameters allows for customization of the export process to fit specific requirements, such as deployment environment, hardware constraints, and performance targets. Selecting the appropriate format and settings is essential for achieving the best balance between model size, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy).
## Export Formats
Available YOLO11 export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolo11n.onnx`. Usage examples are shown for your model after export completes.
{% include "macros/export-table.md" %}
## FAQ
### How do I export a YOLO11 model to ONNX format?
Exporting a YOLO11 model to ONNX format is straightforward with Ultralytics. It provides both Python and CLI methods for exporting models.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
```
For more details on the process, including advanced options like handling different input sizes, refer to the [ONNX section](../integrations/onnx.md).
### What are the benefits of using TensorRT for model export?
Using TensorRT for model export offers significant performance improvements. YOLO11 models exported to TensorRT can achieve up to a 5x GPU speedup, making it ideal for real-time inference applications.
- **Versatility:** Optimize models for a specific hardware setup.
- **Speed:** Achieve faster inference through advanced optimizations.
- **Compatibility:** Integrate smoothly with NVIDIA hardware.
To learn more about integrating TensorRT, see the [TensorRT integration guide](../integrations/tensorrt.md).
### How do I enable INT8 quantization when exporting my YOLO11 model?
INT8 quantization is an excellent way to compress the model and speed up inference, especially on edge devices. Here's how you can enable INT8 quantization:
!!! example
=== "Python"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # Load a model
model.export(format="engine", int8=True)
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=engine int8=True # export TensorRT model with INT8 quantization
```
INT8 quantization can be applied to various formats, such as TensorRT and CoreML. More details can be found in the [Export section](../modes/export.md).
### Why is dynamic input size important when exporting models?
Dynamic input size allows the exported model to handle varying image dimensions, providing flexibility and optimizing processing efficiency for different use cases. When exporting to formats like ONNX or TensorRT, enabling dynamic input size ensures that the model can adapt to different input shapes seamlessly.
To enable this feature, use the `dynamic=True` flag during export:
!!! example
=== "Python"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.export(format="onnx", dynamic=True)
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=onnx dynamic=True
```
For additional context, refer to the [dynamic input size configuration](#arguments).
### What are the key export arguments to consider for optimizing model performance?
Understanding and configuring export arguments is crucial for optimizing model performance:
- **`format:`** The target format for the exported model (e.g., `onnx`, `torchscript`, `tensorflow`).
- **`imgsz:`** Desired image size for the model input (e.g., `640` or `(height, width)`).
- **`half:`** Enables FP16 quantization, reducing model size and potentially speeding up inference.
- **`optimize:`** Applies specific optimizations for mobile or constrained environments.
- **`int8:`** Enables INT8 quantization, highly beneficial for edge deployments.
For a detailed list and explanations of all the export arguments, visit the [Export Arguments section](#arguments).
| |
270778
|
---
comments: true
description: Learn how to validate your YOLO11 model with precise metrics, easy-to-use tools, and custom settings for optimal performance.
keywords: Ultralytics, YOLO11, model validation, machine learning, object detection, mAP metrics, Python API, CLI
---
# Model Validation with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-yolov8-ecosystem-integrations.avif" alt="Ultralytics YOLO ecosystem and integrations">
## Introduction
Validation is a critical step in the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) pipeline, allowing you to assess the quality of your trained models. Val mode in Ultralytics YOLO11 provides a robust suite of tools and metrics for evaluating the performance of your [object detection](https://www.ultralytics.com/glossary/object-detection) models. This guide serves as a complete resource for understanding how to effectively use the Val mode to ensure that your models are both accurate and reliable.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/j8uQc0qB91s?start=47"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Ultralytics Modes Tutorial: Validation
</p>
## Why Validate with Ultralytics YOLO?
Here's why using YOLO11's Val mode is advantageous:
- **Precision:** Get accurate metrics like mAP50, mAP75, and mAP50-95 to comprehensively evaluate your model.
- **Convenience:** Utilize built-in features that remember training settings, simplifying the validation process.
- **Flexibility:** Validate your model with the same or different datasets and image sizes.
- **[Hyperparameter Tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning):** Use validation metrics to fine-tune your model for better performance.
### Key Features of Val Mode
These are the notable functionalities offered by YOLO11's Val mode:
- **Automated Settings:** Models remember their training configurations for straightforward validation.
- **Multi-Metric Support:** Evaluate your model based on a range of accuracy metrics.
- **CLI and Python API:** Choose from command-line interface or Python API based on your preference for validation.
- **Data Compatibility:** Works seamlessly with datasets used during the training phase as well as custom datasets.
!!! tip
* YOLO11 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolo11n.pt` or `model('yolo11n.pt').val()`
## Usage Examples
Validate trained YOLO11n model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
```
=== "CLI"
```bash
yolo detect val model=yolo11n.pt # val official model
yolo detect val model=path/to/best.pt # val custom model
```
## Arguments for YOLO Model Validation
When validating YOLO models, several arguments can be fine-tuned to optimize the evaluation process. These arguments control aspects such as input image size, batch processing, and performance thresholds. Below is a detailed breakdown of each argument to help you customize your validation settings effectively.
{% include "macros/validation-args.md" %}
Each of these settings plays a vital role in the validation process, allowing for a customizable and efficient evaluation of YOLO models. Adjusting these parameters according to your specific needs and resources can help achieve the best balance between accuracy and performance.
### Example Validation with Arguments
The below examples showcase YOLO model validation with custom arguments in Python and CLI.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Customize validation settings
validation_results = model.val(data="coco8.yaml", imgsz=640, batch=16, conf=0.25, iou=0.6, device="0")
```
=== "CLI"
```bash
yolo val model=yolo11n.pt data=coco8.yaml imgsz=640 batch=16 conf=0.25 iou=0.6 device=0
```
| |
270779
|
## FAQ
### How do I validate my YOLO11 model with Ultralytics?
To validate your YOLO11 model, you can use the Val mode provided by Ultralytics. For example, using the Python API, you can load a model and run validation with:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Validate the model
metrics = model.val()
print(metrics.box.map) # map50-95
```
Alternatively, you can use the command-line interface (CLI):
```bash
yolo val model=yolo11n.pt
```
For further customization, you can adjust various arguments like `imgsz`, `batch`, and `conf` in both Python and CLI modes. Check the [Arguments for YOLO Model Validation](#arguments-for-yolo-model-validation) section for the full list of parameters.
### What metrics can I get from YOLO11 model validation?
YOLO11 model validation provides several key metrics to assess model performance. These include:
- mAP50 (mean Average Precision at IoU threshold 0.5)
- mAP75 (mean Average Precision at IoU threshold 0.75)
- mAP50-95 (mean Average Precision across multiple IoU thresholds from 0.5 to 0.95)
Using the Python API, you can access these metrics as follows:
```python
metrics = model.val() # assumes `model` has been loaded
print(metrics.box.map) # mAP50-95
print(metrics.box.map50) # mAP50
print(metrics.box.map75) # mAP75
print(metrics.box.maps) # list of mAP50-95 for each category
```
For a complete performance evaluation, it's crucial to review all these metrics. For more details, refer to the [Key Features of Val Mode](#key-features-of-val-mode).
### What are the advantages of using Ultralytics YOLO for validation?
Using Ultralytics YOLO for validation provides several advantages:
- **[Precision](https://www.ultralytics.com/glossary/precision):** YOLO11 offers accurate performance metrics including mAP50, mAP75, and mAP50-95.
- **Convenience:** The models remember their training settings, making validation straightforward.
- **Flexibility:** You can validate against the same or different datasets and image sizes.
- **Hyperparameter Tuning:** Validation metrics help in fine-tuning models for better performance.
These benefits ensure that your models are evaluated thoroughly and can be optimized for superior results. Learn more about these advantages in the [Why Validate with Ultralytics YOLO](#why-validate-with-ultralytics-yolo) section.
### Can I validate my YOLO11 model using a custom dataset?
Yes, you can validate your YOLO11 model using a [custom dataset](https://docs.ultralytics.com/datasets/). Specify the `data` argument with the path to your dataset configuration file. This file should include paths to the [validation data](https://www.ultralytics.com/glossary/validation-data), class names, and other relevant details.
Example in Python:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Validate with a custom dataset
metrics = model.val(data="path/to/your/custom_dataset.yaml")
print(metrics.box.map) # map50-95
```
Example using CLI:
```bash
yolo val model=yolo11n.pt data=path/to/your/custom_dataset.yaml
```
For more customizable options during validation, see the [Example Validation with Arguments](#example-validation-with-arguments) section.
### How do I save validation results to a JSON file in YOLO11?
To save the validation results to a JSON file, you can set the `save_json` argument to `True` when running validation. This can be done in both the Python API and CLI.
Example in Python:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Save validation results to JSON
metrics = model.val(save_json=True)
```
Example using CLI:
```bash
yolo val model=yolo11n.pt save_json=True
```
This functionality is particularly useful for further analysis or integration with other tools. Check the [Arguments for YOLO Model Validation](#arguments-for-yolo-model-validation) for more details.
| |
270780
|
---
comments: true
description: Discover efficient, flexible, and customizable multi-object tracking with Ultralytics YOLO. Learn to track real-time video streams with ease.
keywords: multi-object tracking, Ultralytics YOLO, video analytics, real-time tracking, object detection, AI, machine learning
---
# Multi-Object Tracking with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/multi-object-tracking-examples.avif" alt="Multi-object tracking examples">
Object tracking in the realm of video analytics is a critical task that not only identifies the location and class of objects within the frame but also maintains a unique ID for each detected object as the video progresses. The applications are limitless—ranging from surveillance and security to real-time sports analytics.
## Why Choose Ultralytics YOLO for Object Tracking?
The output from Ultralytics trackers is consistent with standard [object detection](https://www.ultralytics.com/glossary/object-detection) but has the added value of object IDs. This makes it easy to track objects in video streams and perform subsequent analytics. Here's why you should consider using Ultralytics YOLO for your object tracking needs:
- **Efficiency:** Process video streams in real-time without compromising [accuracy](https://www.ultralytics.com/glossary/accuracy).
- **Flexibility:** Supports multiple tracking algorithms and configurations.
- **Ease of Use:** Simple Python API and CLI options for quick integration and deployment.
- **Customizability:** Easy to use with custom trained YOLO models, allowing integration into domain-specific applications.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/hHyHmOtmEgs?si=VNZtXmm45Nb9s-N-"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Object Detection and Tracking with Ultralytics YOLO.
</p>
## Real-world Applications
| Transportation | Retail | Aquaculture |
| :--------------------------------: | :------------------------------: | :--------------------------: |
| ![Vehicle Tracking][vehicle track] | ![People Tracking][people track] | ![Fish Tracking][fish track] |
| Vehicle Tracking | People Tracking | Fish Tracking |
## Features at a Glance
Ultralytics YOLO extends its object detection features to provide robust and versatile object tracking:
- **Real-Time Tracking:** Seamlessly track objects in high-frame-rate videos.
- **Multiple Tracker Support:** Choose from a variety of established tracking algorithms.
- **Customizable Tracker Configurations:** Tailor the tracking algorithm to meet specific requirements by adjusting various parameters.
## Available Trackers
Ultralytics YOLO supports the following tracking algorithms. They can be enabled by passing the relevant YAML configuration file such as `tracker=tracker_type.yaml`:
- [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - Use `botsort.yaml` to enable this tracker.
- [ByteTrack](https://github.com/ifzhang/ByteTrack) - Use `bytetrack.yaml` to enable this tracker.
The default tracker is BoT-SORT.
## Tracking
!!! warning "Tracker Threshold Information"
If object confidence score will be low, i.e lower than [`track_high_thresh`](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/trackers/bytetrack.yaml#L5), then there will be no tracks successfully returned and updated.
To run the tracker on video streams, use a trained Detect, Segment or Pose model such as YOLO11n, YOLO11n-seg and YOLO11n-pose.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load an official or custom model
model = YOLO("yolo11n.pt") # Load an official Detect model
model = YOLO("yolo11n-seg.pt") # Load an official Segment model
model = YOLO("yolo11n-pose.pt") # Load an official Pose model
model = YOLO("path/to/best.pt") # Load a custom trained model
# Perform tracking with the model
results = model.track("https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
results = model.track("https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # with ByteTrack
```
=== "CLI"
```bash
# Perform tracking with various models using the command line interface
yolo track model=yolo11n.pt source="https://youtu.be/LNwODJXcvt4" # Official Detect model
yolo track model=yolo11n-seg.pt source="https://youtu.be/LNwODJXcvt4" # Official Segment model
yolo track model=yolo11n-pose.pt source="https://youtu.be/LNwODJXcvt4" # Official Pose model
yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # Custom trained model
# Track using ByteTrack tracker
yolo track model=path/to/best.pt tracker="bytetrack.yaml"
```
As can be seen in the above usage, tracking is available for all Detect, Segment and Pose models run on videos or streaming sources.
## Configuration
!!! warning "Tracker Threshold Information"
If object confidence score will be low, i.e lower than [`track_high_thresh`](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/trackers/bytetrack.yaml#L5), then there will be no tracks successfully returned and updated.
### Tracking Arguments
Tracking configuration shares properties with Predict mode, such as `conf`, `iou`, and `show`. For further configurations, refer to the [Predict](../modes/predict.md#inference-arguments) model page.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Configure the tracking parameters and run the tracker
model = YOLO("yolo11n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
```
=== "CLI"
```bash
# Configure tracking parameters and run the tracker using the command line interface
yolo track model=yolo11n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
```
### Tracker Selection
Ultralytics also allows you to use a modified tracker configuration file. To do this, simply make a copy of a tracker config file (for example, `custom_tracker.yaml`) from [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) and modify any configurations (except the `tracker_type`) as per your needs.
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load the model and run the tracker with a custom configuration file
model = YOLO("yolo11n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
```
=== "CLI"
```bash
# Load the model and run the tracker with a custom configuration file using the command line interface
yolo track model=yolo11n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
```
For a comprehensive list of tracking arguments, refer to the [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) page.
##
| |
270781
|
Python Examples
### Persisting Tracks Loop
Here is a Python script using [OpenCV](https://www.ultralytics.com/glossary/opencv) (`cv2`) and YOLO11 to run object tracking on video frames. This script still assumes you have already installed the necessary packages (`opencv-python` and `ultralytics`). The `persist=True` argument tells the tracker that the current image or frame is the next in a sequence and to expect tracks from the previous image in the current image.
!!! example "Streaming for-loop with tracking"
```python
import cv2
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLO11 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
```
Please note the change from `model(frame)` to `model.track(frame)`, which enables object tracking instead of simple detection. This modified script will run the tracker on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
### Plotting Tracks Over Time
Visualizing object tracks over consecutive frames can provide valuable insights into the movement patterns and behavior of detected objects within a video. With Ultralytics YOLO11, plotting these tracks is a seamless and efficient process.
In the following example, we demonstrate how to utilize YOLO11's tracking capabilities to plot the movement of detected objects across multiple video frames. This script involves opening a video file, reading it frame by frame, and utilizing the YOLO model to identify and track various objects. By retaining the center points of the detected bounding boxes and connecting them, we can draw lines that represent the paths followed by the tracked objects.
!!! example "Plotting tracks over multiple video frames"
```python
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
# Store the track history
track_history = defaultdict(lambda: [])
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Get the boxes and track IDs
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Plot the tracks
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y center point
if len(track) > 30: # retain 90 tracks for 90 frames
track.pop(0)
# Draw the tracking lines
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# Display the annotated frame
cv2.imshow("YOLO11 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
```
### Multithreaded Tracking
Multithreaded tracking provides the capability to run object tracking on multiple video streams simultaneously. This is particularly useful when handling multiple video inputs, such as from multiple surveillance cameras, where concurrent processing can greatly enhance efficiency and performance.
In the provided Python script, we make use of Python's `threading` module to run multiple instances of the tracker concurrently. Each thread is responsible for running the tracker on one video file, and all the threads run simultaneously in the background.
To ensure that each thread receives the correct parameters (the video file, the model to use and the file index), we define a function `run_tracker_in_thread` that accepts these parameters and contains the main tracking loop. This function reads the video frame by frame, runs the tracker, and displays the results.
Two different models are used in this example: `yolo11n.pt` and `yolo11n-seg.pt`, each tracking objects in a different video file. The video files are specified in `video_file1` and `video_file2`.
The `daemon=True` parameter in `threading.Thread` means that these threads will be closed as soon as the main program finishes. We then start the threads with `start()` and use `join()` to make the main thread wait until both tracker threads have finished.
Finally, after all threads have completed their task, the windows displaying the results are closed using `cv2.destroyAllWindows()`.
!!! example "Streaming for-loop with tracking"
```python
import threading
import cv2
from ultralytics import YOLO
# Define model names and video sources
MODEL_NAMES = ["yolo11n.pt", "yolo11n-seg.pt"]
SOURCES = ["path/to/video.mp4", "0"] # local video, 0 for webcam
def run_tracker_in_thread(model_name, filename):
"""
Run YOLO tracker in its own thread for concurrent processing.
Args:
model_name (str): The YOLO11 model object.
filename (str): The path to the video file or the identifier for the webcam/external camera source.
"""
model = YOLO(model_name)
results = model.track(filename, save=True, stream=True)
for r in results:
pass
# Create and start tracker threads using a for loop
tracker_threads = []
for video_file, model_name in zip(SOURCES, MODEL_NAMES):
thread = threading.Thread(target=run_tracker_in_thread, args=(model_name, video_file), daemon=True)
tracker_threads.append(thread)
thread.start()
# Wait for all tracker threads to finish
for thread in tracker_threads:
thread.join()
# Clean up and close windows
cv2.destroyAllWindows()
```
This example can easily be extended to handle more video files and models by creating more threads and applying the same methodology.
##
| |
270783
|
---
comments: true
description: Harness the power of Ultralytics YOLO11 for real-time, high-speed inference on various data sources. Learn about predict mode, key features, and practical applications.
keywords: Ultralytics, YOLO11, model prediction, inference, predict mode, real-time inference, computer vision, machine learning, streaming, high performance
---
# Model Prediction with Ultralytics YOLO
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-yolov8-ecosystem-integrations.avif" alt="Ultralytics YOLO ecosystem and integrations">
## Introduction
In the world of [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv), the process of making sense out of visual data is called 'inference' or 'prediction'. Ultralytics YOLO11 offers a powerful feature known as **predict mode** that is tailored for high-performance, real-time inference on a wide range of data sources.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/QtsI0TnwDZs?si=ljesw75cMO2Eas14"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How to Extract the Outputs from Ultralytics YOLO Model for Custom Projects.
</p>
## Real-world Applications
| Manufacturing | Sports | Safety |
| :-----------------------------------------------: | :--------------------------------------------------: | :-----------------------------------------: |
| ![Vehicle Spare Parts Detection][car spare parts] | ![Football Player Detection][football player detect] | ![People Fall Detection][human fall detect] |
| Vehicle Spare Parts Detection | Football Player Detection | People Fall Detection |
## Why Use Ultralytics YOLO for Inference?
Here's why you should consider YOLO11's predict mode for your various inference needs:
- **Versatility:** Capable of making inferences on images, videos, and even live streams.
- **Performance:** Engineered for real-time, high-speed processing without sacrificing [accuracy](https://www.ultralytics.com/glossary/accuracy).
- **Ease of Use:** Intuitive Python and CLI interfaces for rapid deployment and testing.
- **Highly Customizable:** Various settings and parameters to tune the model's inference behavior according to your specific requirements.
### Key Features of Predict Mode
YOLO11's predict mode is designed to be robust and versatile, featuring:
- **Multiple Data Source Compatibility:** Whether your data is in the form of individual images, a collection of images, video files, or real-time video streams, predict mode has you covered.
- **Streaming Mode:** Use the streaming feature to generate a memory-efficient generator of `Results` objects. Enable this by setting `stream=True` in the predictor's call method.
- **Batch Processing:** The ability to process multiple images or video frames in a single batch, further speeding up inference time.
- **Integration Friendly:** Easily integrate with existing data pipelines and other software components, thanks to its flexible API.
Ultralytics YOLO models return either a Python list of `Results` objects, or a memory-efficient Python generator of `Results` objects when `stream=True` is passed to the model during inference:
!!! example "Predict"
=== "Return a list with `stream=False`"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # pretrained YOLO11n model
# Run batched inference on a list of images
results = model(["image1.jpg", "image2.jpg"]) # return a list of Results objects
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
result.save(filename="result.jpg") # save to disk
```
=== "Return a generator with `stream=True`"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # pretrained YOLO11n model
# Run batched inference on a list of images
results = model(["image1.jpg", "image2.jpg"], stream=True) # return a generator of Results objects
# Process results generator
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
result.save(filename="result.jpg") # save to disk
```
## Inference Sources
YOLO11 can process different types of input sources for inference, as shown in the table below. The sources include static images, video streams, and various data formats. The table also indicates whether each source can be used in streaming mode with the argument `stream=True` ✅. Streaming mode is beneficial for processing videos or live streams as it creates a generator of results instead of loading all frames into memory.
!!! tip
Use `stream=True` for processing long videos or large datasets to efficiently manage memory. When `stream=False`, the results for all frames or data points are stored in memory, which can quickly add up and cause out-of-memory errors for large inputs. In contrast, `stream=True` utilizes a generator, which only keeps the results of the current frame or data point in memory, significantly reducing memory consumption and preventing out-of-memory issues.
| Source | Example | Type | Notes |
| ----------------------------------------------------- | ------------------------------------------ | --------------- | ------------------------------------------------------------------------------------------- |
| image | `'image.jpg'` | `str` or `Path` | Single image file. |
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | URL to an image. |
| screenshot | `'screen'` | `str` | Capture a screenshot. |
| PIL | `Image.open('image.jpg')` | `PIL.Image` | HWC format with RGB channels. |
| [OpenCV](https://www.ultralytics.com/glossary/opencv) | `cv2.imread('image.jpg')` | `np.ndarray` | HWC format with BGR channels `uint8 (0-255)`. |
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC format with BGR channels `uint8 (0-255)`. |
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW format with RGB channels `float32 (0.0-1.0)`. |
| CSV | `'sources.csv'` | `str` or `Path` | CSV file containing paths to images, videos, or directories. |
| video ✅ | `'video.mp4'` | `str` or `Path` | Video file in formats like MP4, AVI, etc. |
| directory ✅ | `'path/'` | `str` or `Path` | Path to a directory containing images or videos. |
| glob ✅ | `'path/*.jpg'` | `str` | Glob pattern to match multiple files. Use the `*` character as a wildcard. |
| YouTube ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | URL to a YouTube video. |
| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | URL for streaming protocols such as RTSP, RTMP, TCP, or an IP address. |
| multi-stream ✅ | `'list.streams'` | `str` or `Path` | `*.streams` text file with one stream URL per row, i.e. 8 streams will run at batch-size 8. |
| webcam ✅ | `0` | `int` | Index of the connected camera device to run inference on. |
Below are code examples for using each source type:
!!! example "Prediction sources"
=== "image"
| |
270784
|
Run inference on an image file.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define path to the image file
source = "path/to/image.jpg"
# Run inference on the source
results = model(source) # list of Results objects
```
=== "screenshot"
Run inference on the current screen content as a screenshot.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define current screenshot as source
source = "screen"
# Run inference on the source
results = model(source) # list of Results objects
```
=== "URL"
Run inference on an image or video hosted remotely via URL.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define remote image or video URL
source = "https://ultralytics.com/images/bus.jpg"
# Run inference on the source
results = model(source) # list of Results objects
```
=== "PIL"
Run inference on an image opened with Python Imaging Library (PIL).
```python
from PIL import Image
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Open an image using PIL
source = Image.open("path/to/image.jpg")
# Run inference on the source
results = model(source) # list of Results objects
```
=== "OpenCV"
Run inference on an image read with OpenCV.
```python
import cv2
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Read an image using OpenCV
source = cv2.imread("path/to/image.jpg")
# Run inference on the source
results = model(source) # list of Results objects
```
=== "numpy"
Run inference on an image represented as a numpy array.
```python
import numpy as np
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype="uint8")
# Run inference on the source
results = model(source) # list of Results objects
```
=== "torch"
Run inference on an image represented as a [PyTorch](https://www.ultralytics.com/glossary/pytorch) tensor.
```python
import torch
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
# Run inference on the source
results = model(source) # list of Results objects
```
=== "CSV"
Run inference on a collection of images, URLs, videos and directories listed in a CSV file.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define a path to a CSV file with images, URLs, videos and directories
source = "path/to/file.csv"
# Run inference on the source
results = model(source) # list of Results objects
```
=== "video"
Run inference on a video file. By using `stream=True`, you can create a generator of Results objects to reduce memory usage.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define path to video file
source = "path/to/video.mp4"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
=== "directory"
Run inference on all images and videos in a directory. To also capture images and videos in subdirectories use a glob pattern, i.e. `path/to/dir/**/*`.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define path to directory containing images and videos for inference
source = "path/to/dir"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
=== "glob"
Run inference on all images and videos that match a glob expression with `*` characters.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define a glob search for all JPG files in a directory
source = "path/to/dir/*.jpg"
# OR define a recursive glob search for all JPG files including subdirectories
source = "path/to/dir/**/*.jpg"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
=== "YouTube"
Run inference on a YouTube video. By using `stream=True`, you can create a generator of Results objects to reduce memory usage for long videos.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Define source as YouTube video URL
source = "https://youtu.be/LNwODJXcvt4"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
=== "Stream"
Use the stream mode to run inference on live video streams using RTSP, RTMP, TCP, or IP address protocols. If a single stream is provided, the model runs inference with a [batch size](https://www.ultralytics.com/glossary/batch-size) of 1. For multiple streams, a `.streams` text file can be used to perform batched inference, where the batch size is determined by the number of streams provided (e.g., batch-size 8 for 8 streams).
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Single stream with batch-size 1 inference
source = "rtsp://example.com/media.mp4" # RTSP, RTMP, TCP, or IP streaming address
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
For single stream usage, the batch size is set to 1 by default, allowing efficient real-time processing of the video feed.
=== "Multi-Stream"
To handle multiple video streams simultaneously, use a `.streams` text file containing the streaming sources. The model will run batched inference where the batch size equals the number of streams. This setup enables efficient processing of multiple feeds concurrently.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Multiple streams with batched inference (e.g., batch-size 8 for 8 streams)
source = "path/to/list.streams" # *.streams text file with one streaming address per line
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
```
Example `.streams` text file:
```txt
rtsp://example.com/media1.mp4
rtsp://example.com/media2.mp4
rtmp://example2.com/live
tcp://192.168.1.100:554
...
```
Each row in the file represents a streaming source, allowing you to monitor and perform inference on several video streams at once.
=== "Webcam"
You can run inference on a connected camera device by passing the index of that particular camera to `source`.
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Run inference on the source
results = model(source=0, stream=True) # generator of Results objects
```
## Inference Arg
| |
270786
|
Results
All Ultralytics `predict()` calls will return a list of `Results` objects:
!!! example "Results"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Run inference on an image
results = model("bus.jpg") # list of 1 Results object
results = model(["bus.jpg", "zidane.jpg"]) # list of 2 Results objects
```
`Results` objects have the following attributes:
| Attribute | Type | Description |
| ------------ | --------------------- | ---------------------------------------------------------------------------------------- |
| `orig_img` | `numpy.ndarray` | The original image as a numpy array. |
| `orig_shape` | `tuple` | The original image shape in (height, width) format. |
| `boxes` | `Boxes, optional` | A Boxes object containing the detection bounding boxes. |
| `masks` | `Masks, optional` | A Masks object containing the detection masks. |
| `probs` | `Probs, optional` | A Probs object containing probabilities of each class for classification task. |
| `keypoints` | `Keypoints, optional` | A Keypoints object containing detected keypoints for each object. |
| `obb` | `OBB, optional` | An OBB object containing oriented bounding boxes. |
| `speed` | `dict` | A dictionary of preprocess, inference, and postprocess speeds in milliseconds per image. |
| `names` | `dict` | A dictionary of class names. |
| `path` | `str` | The path to the image file. |
`Results` objects have the following methods:
| Method | Return Type | Description |
| ------------- | --------------- | ----------------------------------------------------------------------------------- |
| `update()` | `None` | Update the boxes, masks, and probs attributes of the Results object. |
| `cpu()` | `Results` | Return a copy of the Results object with all tensors on CPU memory. |
| `numpy()` | `Results` | Return a copy of the Results object with all tensors as numpy arrays. |
| `cuda()` | `Results` | Return a copy of the Results object with all tensors on GPU memory. |
| `to()` | `Results` | Return a copy of the Results object with tensors on the specified device and dtype. |
| `new()` | `Results` | Return a new Results object with the same image, path, and names. |
| `plot()` | `numpy.ndarray` | Plots the detection results. Returns a numpy array of the annotated image. |
| `show()` | `None` | Show annotated results to screen. |
| `save()` | `None` | Save annotated results to file. |
| `verbose()` | `str` | Return log string for each task. |
| `save_txt()` | `None` | Save predictions into a txt file. |
| `save_crop()` | `None` | Save cropped predictions to `save_dir/cls/file_name.jpg`. |
| `tojson()` | `str` | Convert the object to JSON format. |
For more details see the [`Results` class documentation](../reference/engine/results.md).
### Boxes
`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats.
!!! example "Boxes"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Run inference on an image
results = model("bus.jpg") # results list
# View results
for r in results:
print(r.boxes) # print the Boxes object containing the detection bounding boxes
```
Here is a table for the `Boxes` class methods and properties, including their name, type, and description:
| Name | Type | Description |
| --------- | ------------------------- | ------------------------------------------------------------------ |
| `cpu()` | Method | Move the object to CPU memory. |
| `numpy()` | Method | Convert the object to a numpy array. |
| `cuda()` | Method | Move the object to CUDA memory. |
| `to()` | Method | Move the object to the specified device. |
| `xyxy` | Property (`torch.Tensor`) | Return the boxes in xyxy format. |
| `conf` | Property (`torch.Tensor`) | Return the confidence values of the boxes. |
| `cls` | Property (`torch.Tensor`) | Return the class values of the boxes. |
| `id` | Property (`torch.Tensor`) | Return the track IDs of the boxes (if available). |
| `xywh` | Property (`torch.Tensor`) | Return the boxes in xywh format. |
| `xyxyn` | Property (`torch.Tensor`) | Return the boxes in xyxy format normalized by original image size. |
| `xywhn` | Property (`torch.Tensor`) | Return the boxes in xywh format normalized by original image size. |
For more details see the [`Boxes` class documentation](../reference/engine/results.md#ultralytics.engine.results.Boxes).
### Masks
`Masks` object can be used index, manipulate and convert masks to segments.
!!! example "Masks"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n-seg Segment model
model = YOLO("yolo11n-seg.pt")
# Run inference on an image
results = model("bus.jpg") # results list
# View results
for r in results:
print(r.masks) # print the Masks object containing the detected instance masks
```
Here is a table for the `Masks` class methods and properties, including their name, type, and description:
| Name | Type | Description |
| --------- | ------------------------- | --------------------------------------------------------------- |
| `cpu()` | Method | Returns the masks tensor on CPU memory. |
| `numpy()` | Method | Returns the masks tensor as a numpy array. |
| `cuda()` | Method | Returns the masks tensor on GPU memory. |
| `to()` | Method | Returns the masks tensor with the specified device and dtype. |
| `xyn` | Property (`torch.Tensor`) | A list of normalized segments represented as tensors. |
| `xy` | Property (`torch.Tensor`) | A list of segments in pixel coordinates represented as tensors. |
For more details see the [`Masks` class documentation](../reference/engine/results.md#ultralytics.engine.results.Masks).
### Keypoints
`Keypoints` object can be used index, manipulate and normalize coordinates.
!!! example "Keypoints"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n-pose Pose model
model = YOLO("yolo11n-pose.pt")
# Run inference on an image
results = model("bus.jpg") # results list
# View results
for r in results:
print(r.keypoints) # print the Keypoints object containing the detected keypoints
```
Here is a table for the `Keypoints` class methods and properties, including their name, type, and description:
| Name | Type | Description |
| --------- | ------------------------- | ----------------------------------------------------------------- |
| `cpu()` | Method | Returns the keypoints tensor on CPU memory. |
| `numpy()` | Method | Returns the keypoints tensor as a numpy array. |
| `cuda()` | Method | Returns the keypoints tensor on GPU memory. |
| `to()` | Method | Returns the keypoints tensor with the specified device and dtype. |
| `xyn` | Property (`torch.Tensor`) | A list of normalized keypoints represented as tensors. |
| `xy` | Property (`torch.Tensor`) | A list of keypoints in pixel coordinates represented as tensors. |
| `conf` | Property (`torch.Tensor`) | Returns confidence values of keypoints if available, else None. |
For more details see the [`Keypoints` class documentation](../reference/engine/results.md#ultralytics.engine.results.Keypoints).
### Probs
`Prob
| |
270787
|
s` object can be used index, get `top1` and `top5` indices and scores of classification.
!!! example "Probs"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n-cls Classify model
model = YOLO("yolo11n-cls.pt")
# Run inference on an image
results = model("bus.jpg") # results list
# View results
for r in results:
print(r.probs) # print the Probs object containing the detected class probabilities
```
Here's a table summarizing the methods and properties for the `Probs` class:
| Name | Type | Description |
| ---------- | ------------------------- | ----------------------------------------------------------------------- |
| `cpu()` | Method | Returns a copy of the probs tensor on CPU memory. |
| `numpy()` | Method | Returns a copy of the probs tensor as a numpy array. |
| `cuda()` | Method | Returns a copy of the probs tensor on GPU memory. |
| `to()` | Method | Returns a copy of the probs tensor with the specified device and dtype. |
| `top1` | Property (`int`) | Index of the top 1 class. |
| `top5` | Property (`list[int]`) | Indices of the top 5 classes. |
| `top1conf` | Property (`torch.Tensor`) | Confidence of the top 1 class. |
| `top5conf` | Property (`torch.Tensor`) | Confidences of the top 5 classes. |
For more details see the [`Probs` class documentation](../reference/engine/results.md#ultralytics.engine.results.Probs).
### OBB
`OBB` object can be used to index, manipulate, and convert oriented bounding boxes to different formats.
!!! example "OBB"
```python
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n-obb.pt")
# Run inference on an image
results = model("boats.jpg") # results list
# View results
for r in results:
print(r.obb) # print the OBB object containing the oriented detection bounding boxes
```
Here is a table for the `OBB` class methods and properties, including their name, type, and description:
| Name | Type | Description |
| ----------- | ------------------------- | --------------------------------------------------------------------- |
| `cpu()` | Method | Move the object to CPU memory. |
| `numpy()` | Method | Convert the object to a numpy array. |
| `cuda()` | Method | Move the object to CUDA memory. |
| `to()` | Method | Move the object to the specified device. |
| `conf` | Property (`torch.Tensor`) | Return the confidence values of the boxes. |
| `cls` | Property (`torch.Tensor`) | Return the class values of the boxes. |
| `id` | Property (`torch.Tensor`) | Return the track IDs of the boxes (if available). |
| `xyxy` | Property (`torch.Tensor`) | Return the horizontal boxes in xyxy format. |
| `xywhr` | Property (`torch.Tensor`) | Return the rotated boxes in xywhr format. |
| `xyxyxyxy` | Property (`torch.Tensor`) | Return the rotated boxes in xyxyxyxy format. |
| `xyxyxyxyn` | Property (`torch.Tensor`) | Return the rotated boxes in xyxyxyxy format normalized by image size. |
For more details see the [`OBB` class documentation](../reference/engine/results.md#ultralytics.engine.results.OBB).
## Plotting Results
The `plot()` method in `Results` objects facilitates visualization of predictions by overlaying detected objects (such as bounding boxes, masks, keypoints, and probabilities) onto the original image. This method returns the annotated image as a NumPy array, allowing for easy display or saving.
!!! example "Plotting"
```python
from PIL import Image
from ultralytics import YOLO
# Load a pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Run inference on 'bus.jpg'
results = model(["bus.jpg", "zidane.jpg"]) # results list
# Visualize the results
for i, r in enumerate(results):
# Plot results image
im_bgr = r.plot() # BGR-order numpy array
im_rgb = Image.fromarray(im_bgr[..., ::-1]) # RGB-order PIL image
# Show results to screen (in supported environments)
r.show()
# Save results to disk
r.save(filename=f"results{i}.jpg")
```
### `plot()` Method Parameters
The `plot()` method supports various arguments to customize the output:
| Argument | Type | Description | Default |
| ------------ | --------------- | -------------------------------------------------------------------------- | ------------- |
| `conf` | `bool` | Include detection confidence scores. | `True` |
| `line_width` | `float` | Line width of bounding boxes. Scales with image size if `None`. | `None` |
| `font_size` | `float` | Text font size. Scales with image size if `None`. | `None` |
| `font` | `str` | Font name for text annotations. | `'Arial.ttf'` |
| `pil` | `bool` | Return image as a PIL Image object. | `False` |
| `img` | `numpy.ndarray` | Alternative image for plotting. Uses the original image if `None`. | `None` |
| `im_gpu` | `torch.Tensor` | GPU-accelerated image for faster mask plotting. Shape: (1, 3, 640, 640). | `None` |
| `kpt_radius` | `int` | Radius for drawn keypoints. | `5` |
| `kpt_line` | `bool` | Connect keypoints with lines. | `True` |
| `labels` | `bool` | Include class labels in annotations. | `True` |
| `boxes` | `bool` | Overlay bounding boxes on the image. | `True` |
| `masks` | `bool` | Overlay masks on the image. | `True` |
| `probs` | `bool` | Include classification probabilities. | `True` |
| `show` | `bool` | Display the annotated image directly using the default image viewer. | `False` |
| `save` | `bool` | Save the annotated image to a file specified by `filename`. | `False` |
| `filename` | `str` | Path and name of the file to save the annotated image if `save` is `True`. | `None` |
| `color_mode` | `str` | Specify the color mode, e.g., 'instance' or 'class'. | `'class'` |
## Thread-Safe Inference
Ensuring thread safety during inference is crucial when you are running multiple YOLO models in parallel across different threads. Thread-safe inference guarantees that each thread's predictions are isolated and do not interfere with one another, avoiding race conditions and ensuring consistent and reliable outputs.
When using YOLO models in a multi-threaded application, it's important to instantiate separate model objects for each thread or employ thread-local storage to prevent conflicts:
!!! example "Thread-Safe Inference"
Instantiate a single model inside each thread for thread-safe inference:
```python
from threading import Thread
from ultralytics import YOLO
def thread_safe_predict(model, image_path):
"""Performs thread-safe prediction on an image using a locally instantiated YOLO model."""
model = YOLO(model)
results = model.predict(image_path)
# Process results
# Starting threads that each have their own model instance
Thread(target=thread_safe_predict, args=("yolo11n.pt", "image1.jpg")).start()
Thread(target=thread_safe_predict, args=("yolo11n.pt", "image2.jpg")).start()
```
For an in-depth look at thread-safe inference with YOLO models and step-by-step instructions, please refer to our [YOLO Thread-Safe Inference Guide](../guides/yolo-thread-safe-inference.md). This guide will provide you with all the necessary information to avoid common pitfalls and ensure that your multi-threaded inference runs smoothly.
## Streaming Sou
| |
270788
|
rce `for`-loop
Here's a Python script using OpenCV (`cv2`) and YOLO to run inference on video frames. This script assumes you have already installed the necessary packages (`opencv-python` and `ultralytics`).
!!! example "Streaming for-loop"
```python
import cv2
from ultralytics import YOLO
# Load the YOLO model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "path/to/your/video/file.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLO Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
```
This script will run predictions on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
[car spare parts]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a0f802a8-0776-44cf-8f17-93974a4a28a1
[football player detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/7d320e1f-fc57-4d7f-a691-78ee579c3442
[human fall detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/86437c4a-3227-4eee-90ef-9efb697bdb43
## FAQ
### What is Ultralytics YOLO and its predict mode for real-time inference?
Ultralytics YOLO is a state-of-the-art model for real-time [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification. Its **predict mode** allows users to perform high-speed inference on various data sources such as images, videos, and live streams. Designed for performance and versatility, it also offers batch processing and streaming modes. For more details on its features, check out the [Ultralytics YOLO predict mode](#key-features-of-predict-mode).
### How can I run inference using Ultralytics YOLO on different data sources?
Ultralytics YOLO can process a wide range of data sources, including individual images, videos, directories, URLs, and streams. You can specify the data source in the `model.predict()` call. For example, use `'image.jpg'` for a local image or `'https://ultralytics.com/images/bus.jpg'` for a URL. Check out the detailed examples for various [inference sources](#inference-sources) in the documentation.
### How do I optimize YOLO inference speed and memory usage?
To optimize inference speed and manage memory efficiently, you can use the streaming mode by setting `stream=True` in the predictor's call method. The streaming mode generates a memory-efficient generator of `Results` objects instead of loading all frames into memory. For processing long videos or large datasets, streaming mode is particularly useful. Learn more about [streaming mode](#key-features-of-predict-mode).
### What inference arguments does Ultralytics YOLO support?
The `model.predict()` method in YOLO supports various arguments such as `conf`, `iou`, `imgsz`, `device`, and more. These arguments allow you to customize the inference process, setting parameters like confidence thresholds, image size, and the device used for computation. Detailed descriptions of these arguments can be found in the [inference arguments](#inference-arguments) section.
### How can I visualize and save the results of YOLO predictions?
After running inference with YOLO, the `Results` objects contain methods for displaying and saving annotated images. You can use methods like `result.show()` and `result.save(filename="result.jpg")` to visualize and save the results. For a comprehensive list of these methods, refer to the [working with results](#working-with-results) section.
| |
270791
|
---
comments: true
description: Discover OBB dataset formats for Ultralytics YOLO models. Learn about their structure, application, and format conversions to enhance your object detection training.
keywords: Oriented Bounding Box, OBB Datasets, YOLO, Ultralytics, Object Detection, Dataset Formats
---
# Oriented Bounding Box (OBB) Datasets Overview
Training a precise [object detection](https://www.ultralytics.com/glossary/object-detection) model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
## Supported OBB Dataset Formats
### YOLO OBB Format
The YOLO OBB format designates bounding boxes by their four corner points with coordinates normalized between 0 and 1. It follows this format:
```bash
class_index x1 y1 x2 y2 x3 y3 x4 y4
```
Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the [bounding box](https://www.ultralytics.com/glossary/bounding-box)'s center point (xy), width, height, and rotation.
<p align="center"><img width="800" src="https://github.com/ultralytics/docs/releases/download/0/obb-format-examples.avif" alt="OBB format examples"></p>
An example of a `*.txt` label file for the above image, which contains an object of class `0` in OBB format, could look like:
```bash
0 0.780811 0.743961 0.782371 0.74686 0.777691 0.752174 0.776131 0.749758
```
## Usage
To train a model using these OBB formats:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Create a new YOLO11n-OBB model from scratch
model = YOLO("yolo11n-obb.yaml")
# Train the model on the DOTAv1 dataset
results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=1024)
```
=== "CLI"
```bash
# Train a new YOLO11n-OBB model on the DOTAv1 dataset
yolo obb train data=DOTAv1.yaml model=yolo11n-obb.pt epochs=100 imgsz=1024
```
## Supported Datasets
Currently, the following datasets with Oriented Bounding Boxes are supported:
- [DOTA-v1](dota-v2.md): The first version of the DOTA dataset, providing a comprehensive set of aerial images with oriented bounding boxes for object detection.
- [DOTA-v1.5](dota-v2.md): An intermediate version of the DOTA dataset, offering additional annotations and improvements over DOTA-v1 for enhanced object detection tasks.
- [DOTA-v2](dota-v2.md): DOTA (A Large-scale Dataset for Object Detection in Aerial Images) version 2, emphasizes detection from aerial perspectives and contains oriented bounding boxes with 1.7 million instances and 11,268 images.
- [DOTA8](dota8.md): A small, 8-image subset of the full DOTA dataset suitable for testing workflows and Continuous Integration (CI) checks of OBB training in the `ultralytics` repository.
### Incorporating your own OBB dataset
For those looking to introduce their own datasets with oriented bounding boxes, ensure compatibility with the "YOLO OBB format" mentioned above. Convert your annotations to this required format and detail the paths, classes, and class names in a corresponding YAML configuration file.
## Convert Label Formats
### DOTA Dataset Format to YOLO OBB Format
Transitioning labels from the DOTA dataset format to the YOLO OBB format can be achieved with this script:
!!! example
=== "Python"
```python
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb("path/to/DOTA")
```
This conversion mechanism is instrumental for datasets in the DOTA format, ensuring alignment with the Ultralytics YOLO OBB format.
It's imperative to validate the compatibility of the dataset with your model and adhere to the necessary format conventions. Properly structured datasets are pivotal for training efficient object detection models with oriented bounding boxes.
## FAQ
### What are Oriented Bounding Boxes (OBB) and how are they used in Ultralytics YOLO models?
Oriented Bounding Boxes (OBB) are a type of bounding box annotation where the box can be rotated to align more closely with the object being detected, rather than just being axis-aligned. This is particularly useful in aerial or satellite imagery where objects might not be aligned with the image axes. In Ultralytics YOLO models, OBBs are represented by their four corner points in the YOLO OBB format. This allows for more accurate object detection since the bounding boxes can rotate to fit the objects better.
### How do I convert my existing DOTA dataset labels to YOLO OBB format for use with Ultralytics YOLO11?
You can convert DOTA dataset labels to YOLO OBB format using the `convert_dota_to_yolo_obb` function from Ultralytics. This conversion ensures compatibility with the Ultralytics YOLO models, enabling you to leverage the OBB capabilities for enhanced object detection. Here's a quick example:
```python
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb("path/to/DOTA")
```
This script will reformat your DOTA annotations into a YOLO-compatible format.
### How do I train a YOLO11 model with oriented bounding boxes (OBB) on my dataset?
Training a YOLO11 model with OBBs involves ensuring your dataset is in the YOLO OBB format and then using the Ultralytics API to train the model. Here's an example in both Python and CLI:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Create a new YOLO11n-OBB model from scratch
model = YOLO("yolo11n-obb.yaml")
# Train the model on the custom dataset
results = model.train(data="your_dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Train a new YOLO11n-OBB model on the custom dataset
yolo obb train data=your_dataset.yaml model=yolo11n-obb.yaml epochs=100 imgsz=640
```
This ensures your model leverages the detailed OBB annotations for improved detection [accuracy](https://www.ultralytics.com/glossary/accuracy).
### What datasets are currently supported for OBB training in Ultralytics YOLO models?
Currently, Ultralytics supports the following datasets for OBB training:
- [DOTA-v1](dota-v2.md): The first version of the DOTA dataset, providing a comprehensive set of aerial images with oriented bounding boxes for object detection.
- [DOTA-v1.5](dota-v2.md): An intermediate version of the DOTA dataset, offering additional annotations and improvements over DOTA-v1 for enhanced object detection tasks.
- [DOTA-v2](dota-v2.md): This dataset includes 1.7 million instances with oriented bounding boxes and 11,268 images, primarily focusing on aerial object detection.
- [DOTA8](dota8.md): A smaller, 8-image subset of the DOTA dataset used for testing and continuous integration (CI) checks.
These datasets are tailored for scenarios where OBBs offer a significant advantage, such as aerial and satellite image analysis.
### Can I use my own dataset with oriented bounding boxes for YOLO11 training, and if so, how?
Yes, you can use your own dataset with oriented bounding boxes for YOLO11 training. Ensure your dataset annotations are converted to the YOLO OBB format, which involves defining bounding boxes by their four corner points. You can then create a YAML configuration file specifying the dataset paths, classes, and other necessary details. For more information on creating and configuring your datasets, refer to the [Supported Datasets](#supported-datasets) section.
| |
270804
|
---
comments: true
description: Learn about dataset formats compatible with Ultralytics YOLO for robust object detection. Explore supported datasets and learn how to convert formats.
keywords: Ultralytics, YOLO, object detection datasets, dataset formats, COCO, dataset conversion, training datasets
---
# Object Detection Datasets Overview
Training a robust and accurate [object detection](https://www.ultralytics.com/glossary/object-detection) model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
## Supported Dataset Formats
### Ultralytics YOLO format
The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
```yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
```
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
<p align="center"><img width="750" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie.avif" alt="Example labelled image"></p>
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
<p align="center"><img width="428" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie-1.avif" alt="Example label file"></p>
When using the Ultralytics YOLO format, organize your training and validation images and labels as shown in the [COCO8 dataset](coco8.md) example below.
<p align="center"><img width="800" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie-2.avif" alt="Example dataset directory structure"></p>
## Usage
Here's how you can use these formats to train your model:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
```
## Supported Datasets
Here is a list of the supported datasets and a brief description for each:
- [Argoverse](argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
- [COCO](coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
- [LVIS](lvis.md): A large-scale object detection, segmentation, and captioning dataset with 1203 object categories.
- [COCO8](coco8.md): A smaller subset of the first 4 images from COCO train and COCO val, suitable for quick tests.
- [COCO128](coco.md): A smaller subset of the first 128 images from COCO train and COCO val, suitable for tests.
- [Global Wheat 2020](globalwheat2020.md): A dataset containing images of wheat heads for the Global Wheat Challenge 2020.
- [Objects365](objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
- [OpenImagesV7](open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
- [SKU-110K](sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
- [VisDrone](visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
- [VOC](voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
- [xView](xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
- [Roboflow 100](roboflow-100.md): A diverse object detection benchmark with 100 datasets spanning seven imagery domains for comprehensive model evaluation.
- [Brain-tumor](brain-tumor.md): A dataset for detecting brain tumors includes MRI or CT scan images with details on tumor presence, location, and characteristics.
- [African-wildlife](african-wildlife.md): A dataset featuring images of African wildlife, including buffalo, elephant, rhino, and zebras.
- [Signature](signature.md): A dataset featuring images of various documents with annotated signatures, supporting document verification and fraud detection research.
### Adding your own dataset
If you have your own dataset and would like to use it for training detection models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
## Port or Convert Label Formats
### COCO Dataset Format to YOLO Format
You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
!!! example
=== "Python"
```python
from ultralytics.data.converter import convert_coco
convert_coco(labels_dir="path/to/coco/annotations/")
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
| |
270805
|
## FAQ
### What is the Ultralytics YOLO dataset format and how to structure it?
The Ultralytics YOLO format is a structured configuration for defining datasets in your training projects. It involves setting paths to your training, validation, and testing images and corresponding labels. For example:
```yaml
path: ../datasets/coco8 # dataset root directory
train: images/train # training images (relative to 'path')
val: images/val # validation images (relative to 'path')
test: # optional test images
names:
0: person
1: bicycle
2: car
# ...
```
Labels are saved in `*.txt` files with one file per image, formatted as `class x_center y_center width height` with normalized coordinates. For a detailed guide, see the [COCO8 dataset example](coco8.md).
### How do I convert a COCO dataset to the YOLO format?
You can convert a COCO dataset to the YOLO format using the Ultralytics conversion tools. Here's a quick method:
```python
from ultralytics.data.converter import convert_coco
convert_coco(labels_dir="path/to/coco/annotations/")
```
This code will convert your COCO annotations to YOLO format, enabling seamless integration with Ultralytics YOLO models. For additional details, visit the [Port or Convert Label Formats](#port-or-convert-label-formats) section.
### Which datasets are supported by Ultralytics YOLO for object detection?
Ultralytics YOLO supports a wide range of datasets, including:
- [Argoverse](argoverse.md)
- [COCO](coco.md)
- [LVIS](lvis.md)
- [COCO8](coco8.md)
- [Global Wheat 2020](globalwheat2020.md)
- [Objects365](objects365.md)
- [OpenImagesV7](open-images-v7.md)
Each dataset page provides detailed information on the structure and usage tailored for efficient YOLO11 training. Explore the full list in the [Supported Datasets](#supported-datasets) section.
### How do I start training a YOLO11 model using my dataset?
To start training a YOLO11 model, ensure your dataset is formatted correctly and the paths are defined in a YAML file. Use the following script to begin training:
!!! example
=== "Python"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # Load a pretrained model
results = model.train(data="path/to/your_dataset.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo detect train data=path/to/your_dataset.yaml model=yolo11n.pt epochs=100 imgsz=640
```
Refer to the [Usage](#usage) section for more details on utilizing different modes, including CLI commands.
### Where can I find practical examples of using Ultralytics YOLO for object detection?
Ultralytics provides numerous examples and practical guides for using YOLO11 in diverse applications. For a comprehensive overview, visit the [Ultralytics Blog](https://www.ultralytics.com/blog) where you can find case studies, detailed tutorials, and community stories showcasing object detection, segmentation, and more with YOLO11. For specific examples, check the [Usage](../../modes/predict.md) section in the documentation.
| |
270807
|
# FAQ
### What is the COCO dataset and why is it important for computer vision?
The [COCO dataset](https://cocodataset.org/#home) (Common Objects in Context) is a large-scale dataset used for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and captioning. It contains 330K images with detailed annotations for 80 object categories, making it essential for benchmarking and training computer vision models. Researchers use COCO due to its diverse categories and standardized evaluation metrics like mean Average [Precision](https://www.ultralytics.com/glossary/precision) (mAP).
### How can I train a YOLO model using the COCO dataset?
To train a YOLO11 model using the COCO dataset, you can use the following code snippets:
!!! example "Train Example"
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo detect train data=coco.yaml model=yolo11n.pt epochs=100 imgsz=640
```
Refer to the [Training page](../../modes/train.md) for more details on available arguments.
### What are the key features of the COCO dataset?
The COCO dataset includes:
- 330K images, with 200K annotated for object detection, segmentation, and captioning.
- 80 object categories ranging from common items like cars and animals to specific ones like handbags and sports equipment.
- Standardized evaluation metrics for object detection (mAP) and segmentation (mean Average Recall, mAR).
- **Mosaicing** technique in training batches to enhance model generalization across various object sizes and contexts.
### Where can I find pretrained YOLO11 models trained on the COCO dataset?
Pretrained YOLO11 models on the COCO dataset can be downloaded from the links provided in the documentation. Examples include:
- [YOLO11n](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt)
- [YOLO11s](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11s.pt)
- [YOLO11m](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11m.pt)
- [YOLO11l](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11l.pt)
- [YOLO11x](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11x.pt)
These models vary in size, mAP, and inference speed, providing options for different performance and resource requirements.
### How is the COCO dataset structured and how do I use it?
The COCO dataset is split into three subsets:
1. **Train2017**: 118K images for training.
2. **Val2017**: 5K images for validation during training.
3. **Test2017**: 20K images for benchmarking trained models. Results need to be submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
The dataset's YAML configuration file is available at [coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml), which defines paths, classes, and dataset details.
| |
270829
|
---
comments: true
description: Learn how to structure datasets for YOLO classification tasks. Detailed folder structure and usage examples for effective training.
keywords: YOLO, image classification, dataset structure, CIFAR-10, Ultralytics, machine learning, training data, model evaluation
---
# Image Classification Datasets Overview
### Dataset Structure for YOLO Classification Tasks
For [Ultralytics](https://www.ultralytics.com/) YOLO classification tasks, the dataset must be organized in a specific split-directory structure under the `root` directory to facilitate proper training, testing, and optional validation processes. This structure includes separate directories for training (`train`) and testing (`test`) phases, with an optional directory for validation (`val`).
Each of these directories should contain one subdirectory for each class in the dataset. The subdirectories are named after the corresponding class and contain all the images for that class. Ensure that each image file is named uniquely and stored in a common format such as JPEG or PNG.
**Folder Structure Example**
Consider the CIFAR-10 dataset as an example. The folder structure should look like this:
```
cifar-10-/
|
|-- train/
| |-- airplane/
| | |-- 10008_airplane.png
| | |-- 10009_airplane.png
| | |-- ...
| |
| |-- automobile/
| | |-- 1000_automobile.png
| | |-- 1001_automobile.png
| | |-- ...
| |
| |-- bird/
| | |-- 10014_bird.png
| | |-- 10015_bird.png
| | |-- ...
| |
| |-- ...
|
|-- test/
| |-- airplane/
| | |-- 10_airplane.png
| | |-- 11_airplane.png
| | |-- ...
| |
| |-- automobile/
| | |-- 100_automobile.png
| | |-- 101_automobile.png
| | |-- ...
| |
| |-- bird/
| | |-- 1000_bird.png
| | |-- 1001_bird.png
| | |-- ...
| |
| |-- ...
|
|-- val/ (optional)
| |-- airplane/
| | |-- 105_airplane.png
| | |-- 106_airplane.png
| | |-- ...
| |
| |-- automobile/
| | |-- 102_automobile.png
| | |-- 103_automobile.png
| | |-- ...
| |
| |-- bird/
| | |-- 1045_bird.png
| | |-- 1046_bird.png
| | |-- ...
| |
| |-- ...
```
This structured approach ensures that the model can effectively learn from well-organized classes during the training phase and accurately evaluate performance during testing and validation phases.
## Usage
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="path/to/dataset", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo detect train data=path/to/data model=yolo11n-cls.pt epochs=100 imgsz=640
```
## Supported Datasets
Ultralytics supports the following datasets with automatic download:
- [Caltech 101](caltech101.md): A dataset containing images of 101 object categories for [image classification](https://www.ultralytics.com/glossary/image-classification) tasks.
- [Caltech 256](caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
- [CIFAR-10](cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
- [CIFAR-100](cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
- [Fashion-MNIST](fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
- [ImageNet](imagenet.md): A large-scale dataset for [object detection](https://www.ultralytics.com/glossary/object-detection) and image classification with over 14 million images and 20,000 categories.
- [ImageNet-10](imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
- [Imagenette](imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
- [Imagewoof](imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
- [MNIST](mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
- [MNIST160](mnist.md): First 8 images of each MNIST category from the MNIST dataset. Dataset contains 160 images total.
### Adding your own dataset
If you have your own dataset and would like to use it for training classification models with Ultralytics, ensure that it follows the format specified above under "Dataset format" and then point your `data` argument to the dataset directory.
| |
270830
|
## FAQ
### How do I structure my dataset for YOLO classification tasks?
To structure your dataset for Ultralytics YOLO classification tasks, you should follow a specific split-directory format. Organize your dataset into separate directories for `train`, `test`, and optionally `val`. Each of these directories should contain subdirectories named after each class, with the corresponding images inside. This facilitates smooth training and evaluation processes. For an example, consider the CIFAR-10 dataset format:
```
cifar-10-/
|-- train/
| |-- airplane/
| |-- automobile/
| |-- bird/
| ...
|-- test/
| |-- airplane/
| |-- automobile/
| |-- bird/
| ...
|-- val/ (optional)
| |-- airplane/
| |-- automobile/
| |-- bird/
| ...
```
For more details, visit [Dataset Structure for YOLO Classification Tasks](#dataset-structure-for-yolo-classification-tasks).
### What datasets are supported by Ultralytics YOLO for image classification?
Ultralytics YOLO supports automatic downloading of several datasets for image classification, including:
- [Caltech 101](caltech101.md)
- [Caltech 256](caltech256.md)
- [CIFAR-10](cifar10.md)
- [CIFAR-100](cifar100.md)
- [Fashion-MNIST](fashion-mnist.md)
- [ImageNet](imagenet.md)
- [ImageNet-10](imagenet10.md)
- [Imagenette](imagenette.md)
- [Imagewoof](imagewoof.md)
- [MNIST](mnist.md)
These datasets are structured in a way that makes them easy to use with YOLO. Each dataset's page provides further details about its structure and applications.
### How do I add my own dataset for YOLO image classification?
To use your own dataset with Ultralytics YOLO, ensure it follows the specified directory format required for the classification task, with separate `train`, `test`, and optionally `val` directories, and subdirectories for each class containing the respective images. Once your dataset is structured correctly, point the `data` argument to your dataset's root directory when initializing the training script. Here's an example in Python:
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="path/to/your/dataset", epochs=100, imgsz=640)
```
More details can be found in the [Adding your own dataset](#adding-your-own-dataset) section.
### Why should I use Ultralytics YOLO for image classification?
Ultralytics YOLO offers several benefits for image classification, including:
- **Pretrained Models**: Load pretrained models like `yolo11n-cls.pt` to jump-start your training process.
- **Ease of Use**: Simple API and CLI commands for training and evaluation.
- **High Performance**: State-of-the-art [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed, ideal for real-time applications.
- **Support for Multiple Datasets**: Seamless integration with various popular datasets like CIFAR-10, ImageNet, and more.
- **Community and Support**: Access to extensive documentation and an active community for troubleshooting and improvements.
For additional insights and real-world applications, you can explore [Ultralytics YOLO](https://www.ultralytics.com/yolo).
### How can I train a model using Ultralytics YOLO?
Training a model using Ultralytics YOLO can be done easily in both Python and CLI. Here's an example:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-cls.pt") # load a pretrained model
# Train the model
results = model.train(data="path/to/dataset", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo detect train data=path/to/data model=yolo11n-cls.pt epochs=100 imgsz=640
```
These examples demonstrate the straightforward process of training a YOLO model using either approach. For more information, visit the [Usage](#usage) section.
| |
270837
|
---
comments: true
description: Explore the supported dataset formats for Ultralytics YOLO and learn how to prepare and use datasets for training object segmentation models.
keywords: Ultralytics, YOLO, instance segmentation, dataset formats, auto-annotation, COCO, segmentation models, training data
---
# Instance Segmentation Datasets Overview
## Supported Dataset Formats
### Ultralytics YOLO format
The dataset label format used for training YOLO segmentation models is as follows:
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
2. One row per object: Each row in the text file corresponds to one object instance in the image.
3. Object information per row: Each row contains the following information about the object instance:
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
- Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
The format for a single row in the segmentation dataset file is as follows:
```
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
```
In this format, `<class-index>` is the index of the class for the object, and `<x1> <y1> <x2> <y2> ... <xn> <yn>` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.
Here is an example of the YOLO dataset format for a single image with two objects made up of a 3-point segment and a 5-point segment.
```
0 0.681 0.485 0.670 0.487 0.676 0.487
1 0.504 0.000 0.501 0.004 0.498 0.004 0.493 0.010 0.492 0.0104
```
!!! tip
- The length of each row does **not** have to be equal.
- Each segmentation label must have a **minimum of 3 xy points**: `<class-index> <x1> <y1> <x2> <y2> <x3> <y3>`
### Dataset YAML format
The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
```yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8-seg # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
```
The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
`names` is a dictionary of class names. The order of the names should match the order of the object class indices in the YOLO dataset files.
## Usage
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo segment train data=coco8-seg.yaml model=yolo11n-seg.pt epochs=100 imgsz=640
```
## Supported Datasets
## Supported Datasets
- [COCO](coco.md): A comprehensive dataset for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and captioning, featuring over 200K labeled images across a wide range of categories.
- [COCO8-seg](coco8-seg.md): A compact, 8-image subset of COCO designed for quick testing of segmentation model training, ideal for CI checks and workflow validation in the `ultralytics` repository.
- [COCO128-seg](coco.md): A smaller dataset for [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) tasks, containing a subset of 128 COCO images with segmentation annotations.
- [Carparts-seg](carparts-seg.md): A specialized dataset focused on the segmentation of car parts, ideal for automotive applications. It includes a variety of vehicles with detailed annotations of individual car components.
- [Crack-seg](crack-seg.md): A dataset tailored for the segmentation of cracks in various surfaces. Essential for infrastructure maintenance and quality control, it provides detailed imagery for training models to identify structural weaknesses.
- [Package-seg](package-seg.md): A dataset dedicated to the segmentation of different types of packaging materials and shapes. It's particularly useful for logistics and warehouse automation, aiding in the development of systems for package handling and sorting.
### Adding your own dataset
If you have your own dataset and would like to use it for training segmentation models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
## Port or Convert Label Formats
### COCO Dataset Format to YOLO Format
You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
!!! example
=== "Python"
```python
from ultralytics.data.converter import convert_coco
convert_coco(labels_dir="path/to/coco/annotations/", use_segments=True)
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
## Auto-Annotation
Auto-annotation is an essential feature that allows you to generate a segmentation dataset using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.
### Generate Segmentation Dataset Using a Detection Model
To auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:
!!! example
=== "Python"
```python
from ultralytics.data.annotator import auto_annotate
auto_annotate(data="path/to/images", det_model="yolo11x.pt", sam_model="sam_b.pt")
```
| Argument | Type | Description | Default |
| ------------ | ----------------------- | ----------------------------------------------------------------------------------------------------------- | -------------- |
| `data` | `str` | Path to a folder containing images to be annotated. | `None` |
| `det_model` | `str, optional` | Pre-trained YOLO detection model. Defaults to `'yolo11x.pt'`. | `'yolo11x.pt'` |
| `sam_model` | `str, optional` | Pre-trained SAM segmentation model. Defaults to `'sam_b.pt'`. | `'sam_b.pt'` |
| `device` | `str, optional` | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | `''` |
| `output_dir` | `str or None, optional` | Directory to save the annotated results. Defaults to a `'labels'` folder in the same directory as `'data'`. | `None` |
The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](../../models/sam.md), the device to run the models on, and the output directory for saving the annotated results.
By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
| |
270853
|
# Pose Estimation Datasets Overview
## Supported Dataset Formats
### Ultralytics YOLO format
The dataset label format used for training YOLO pose models is as follows:
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
2. One row per object: Each row in the text file corresponds to one object instance in the image.
3. Object information per row: Each row contains the following information about the object instance:
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
- Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
Here is an example of the label format for pose estimation task:
Format with Dim = 2
```
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> ... <pxn> <pyn>
```
Format with Dim = 3
```
<class-index> <x> <y> <width> <height> <px1> <py1> <p1-visibility> <px2> <py2> <p2-visibility> <pxn> <pyn> <p2-visibility>
```
In this format, `<class-index>` is the index of the class for the object,`<x> <y> <width> <height>` are coordinates of [bounding box](https://www.ultralytics.com/glossary/bounding-box), and `<px1> <py1> <px2> <py2> ... <pxn> <pyn>` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
### Dataset YAML format
The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
```yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8-pose # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Keypoints
kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
# Classes dictionary
names:
0: person
```
The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
`names` is a dictionary of class names. The order of the names should match the order of the object class indices in the YOLO dataset files.
(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face. For example if we assume five keypoints of facial landmark: [left eye, right eye, nose, left mouth, right mouth], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3] (just exchange the left-right index, i.e. 0-1 and 3-4, and do not modify others like nose in this example).
## Usage
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Start training from a pretrained *.pt model
yolo pose train data=coco8-pose.yaml model=yolo11n-pose.pt epochs=100 imgsz=640
```
## Supported Datasets
This section outlines the datasets that are compatible with Ultralytics YOLO format and can be used for training pose estimation models:
### COCO-Pose
- **Description**: COCO-Pose is a large-scale [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and pose estimation dataset. It is a subset of the popular COCO dataset and focuses on human pose estimation. COCO-Pose includes multiple keypoints for each human instance.
- **Label Format**: Same as Ultralytics YOLO format as described above, with keypoints for human poses.
- **Number of Classes**: 1 (Human).
- **Keypoints**: 17 keypoints including nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
- **Usage**: Suitable for training human pose estimation models.
- **Additional Notes**: The dataset is rich and diverse, containing over 200k labeled images.
- [Read more about COCO-Pose](coco.md)
### COCO8-Pose
- **Description**: [Ultralytics](https://www.ultralytics.com/) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation.
- **Label Format**: Same as Ultralytics YOLO format as described above, with keypoints for human poses.
- **Number of Classes**: 1 (Human).
- **Keypoints**: 17 keypoints including nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
- **Usage**: Suitable for testing and debugging object detection models, or for experimenting with new detection approaches.
- **Additional Notes**: COCO8-Pose is ideal for sanity checks and CI checks.
- [Read more about COCO8-Pose](coco8-pose.md)
### Tiger-Pose
- **Description**: [Ultralytics](https://www.ultralytics.com/) This animal pose dataset comprises 263 images sourced from a [YouTube Video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0), with 210 images allocated for training and 53 for validation.
- **Label Format**: Same as Ultralytics YOLO format as described above, with 12 keypoints for animal pose and no visible dimension.
- **Number of Classes**: 1 (Tiger).
- **Keypoints**: 12 keypoints.
- **Usage**: Great for animal pose or any other pose that is not human-based.
- [Read more about Tiger-Pose](tiger-pose.md)
### Hand Keypoints
- **Description**: Hand keypoints pose dataset comprises nearly 26K images, with 18776 images allocated for training and 7992 for validation.
- **Label Format**: Same as Ultralytics YOLO format as described above, but with 21 keypoints for human hand and visible dimension.
- **Number of Classes**: 1 (Hand).
- **Keypoints**: 21 keypoints.
- **Usage**: Great for human hand pose estimation.
- [Read more about Hand Keypoints](hand-keypoints.md)
### Adding your own dataset
If you have your own dataset and would like to use it for training pose estimation models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
### Conversion Tool
Ultralytics provides a convenient conversion tool to convert labels from the popular COCO dataset format to YOLO format:
!!! example
=== "Python"
```python
from ultralytics.data.converter import convert_coco
convert_coco(labels_dir="path/to/coco/annotations/", use_keypoints=True)
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format. The `use_keypoints` parameter specifies whether to include keypoints (for pose estimation) in the converted labels.
| |
270854
|
## FAQ
### What is the Ultralytics YOLO format for pose estimation?
The Ultralytics YOLO format for pose estimation datasets involves labeling each image with a corresponding text file. Each row of the text file stores information about an object instance:
- Object class index
- Object center coordinates (normalized x and y)
- Object width and height (normalized)
- Object keypoint coordinates (normalized pxn and pyn)
For 2D poses, keypoints include pixel coordinates. For 3D, each keypoint also has a visibility flag. For more details, see [Ultralytics YOLO format](#ultralytics-yolo-format).
### How do I use the COCO-Pose dataset with Ultralytics YOLO?
To use the COCO-Pose dataset with Ultralytics YOLO:
1. Download the dataset and prepare your label files in the YOLO format.
2. Create a YAML configuration file specifying paths to training and validation images, keypoint shape, and class names.
3. Use the configuration file for training:
```python
from ultralytics import YOLO
model = YOLO("yolo11n-pose.pt") # load pretrained model
results = model.train(data="coco-pose.yaml", epochs=100, imgsz=640)
```
For more information, visit [COCO-Pose](coco.md) and [train](../../modes/train.md) sections.
### How can I add my own dataset for pose estimation in Ultralytics YOLO?
To add your dataset:
1. Convert your annotations to the Ultralytics YOLO format.
2. Create a YAML configuration file specifying the dataset paths, number of classes, and class names.
3. Use the configuration file to train your model:
```python
from ultralytics import YOLO
model = YOLO("yolo11n-pose.pt")
results = model.train(data="your-dataset.yaml", epochs=100, imgsz=640)
```
For complete steps, check the [Adding your own dataset](#adding-your-own-dataset) section.
### What is the purpose of the dataset YAML file in Ultralytics YOLO?
The dataset YAML file in Ultralytics YOLO defines the dataset and model configuration for training. It specifies paths to training, validation, and test images, keypoint shapes, class names, and other configuration options. This structured format helps streamline dataset management and model training. Here is an example YAML format:
```yaml
path: ../datasets/coco8-pose
train: images/train
val: images/val
names:
0: person
```
Read more about creating YAML configuration files in [Dataset YAML format](#dataset-yaml-format).
### How can I convert COCO dataset labels to Ultralytics YOLO format for pose estimation?
Ultralytics provides a conversion tool to convert COCO dataset labels to the YOLO format, including keypoint information:
```python
from ultralytics.data.converter import convert_coco
convert_coco(labels_dir="path/to/coco/annotations/", use_keypoints=True)
```
This tool helps seamlessly integrate COCO datasets into YOLO projects. For details, refer to the [Conversion Tool](#conversion-tool) section.
| |
270859
|
## FAQ
### What are Ultralytics callbacks and how can I use them?
**Ultralytics callbacks** are specialized entry points triggered during key stages of model operations like training, validation, exporting, and prediction. These callbacks allow for custom functionality at specific points in the process, enabling enhancements and modifications to the workflow. Each callback accepts a `Trainer`, `Validator`, or `Predictor` object, depending on the operation type. For detailed properties of these objects, refer to the [Reference section](../reference/cfg/__init__.md).
To use a callback, you can define a function and then add it to the model with the `add_callback` method. Here's an example of how to return additional information during prediction:
```python
from ultralytics import YOLO
def on_predict_batch_end(predictor):
"""Handle prediction batch end by combining results with corresponding frames; modifies predictor results."""
_, image, _, _ = predictor.batch
image = image if isinstance(image, list) else [image]
predictor.results = zip(predictor.results, image)
model = YOLO("yolo11n.pt")
model.add_callback("on_predict_batch_end", on_predict_batch_end)
for result, frame in model.predict():
pass
```
### How can I customize Ultralytics training routine using callbacks?
To customize your Ultralytics training routine using callbacks, you can inject your logic at specific stages of the training process. Ultralytics YOLO provides a variety of training callbacks such as `on_train_start`, `on_train_end`, and `on_train_batch_end`. These allow you to add custom metrics, processing, or logging.
Here's an example of how to log additional metrics at the end of each training epoch:
```python
from ultralytics import YOLO
def on_train_epoch_end(trainer):
"""Custom logic for additional metrics logging at the end of each training epoch."""
additional_metric = compute_additional_metric(trainer)
trainer.log({"additional_metric": additional_metric})
model = YOLO("yolo11n.pt")
model.add_callback("on_train_epoch_end", on_train_epoch_end)
model.train(data="coco.yaml", epochs=10)
```
Refer to the [Training Guide](../modes/train.md) for more details on how to effectively use training callbacks.
### Why should I use callbacks during validation in Ultralytics YOLO?
Using **callbacks during validation** in Ultralytics YOLO can enhance model evaluation by allowing custom processing, logging, or metrics calculation. Callbacks such as `on_val_start`, `on_val_batch_end`, and `on_val_end` provide entry points to inject custom logic, ensuring detailed and comprehensive validation processes.
For instance, you might want to log additional validation metrics or save intermediate results for further analysis. Here's an example of how to log custom metrics at the end of validation:
```python
from ultralytics import YOLO
def on_val_end(validator):
"""Log custom metrics at end of validation."""
custom_metric = compute_custom_metric(validator)
validator.log({"custom_metric": custom_metric})
model = YOLO("yolo11n.pt")
model.add_callback("on_val_end", on_val_end)
model.val(data="coco.yaml")
```
Check out the [Validation Guide](../modes/val.md) for further insights on incorporating callbacks into your validation process.
### How do I attach a custom callback for the prediction mode in Ultralytics YOLO?
To attach a custom callback for the **prediction mode** in Ultralytics YOLO, you define a callback function and register it with the prediction process. Common prediction callbacks include `on_predict_start`, `on_predict_batch_end`, and `on_predict_end`. These allow for modification of prediction outputs and integration of additional functionalities like data logging or result transformation.
Here is an example where a custom callback is used to log predictions:
```python
from ultralytics import YOLO
def on_predict_end(predictor):
"""Log predictions at the end of prediction."""
for result in predictor.results:
log_prediction(result)
model = YOLO("yolo11n.pt")
model.add_callback("on_predict_end", on_predict_end)
results = model.predict(source="image.jpg")
```
For more comprehensive usage, refer to the [Prediction Guide](../modes/predict.md) which includes detailed instructions and additional customization options.
### What are some practical examples of using callbacks in Ultralytics YOLO?
Ultralytics YOLO supports various practical implementations of callbacks to enhance and customize different phases like training, validation, and prediction. Some practical examples include:
1. **Logging Custom Metrics**: Log additional metrics at different stages, such as the end of training or validation epochs.
2. **[Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation)**: Implement custom data transformations or augmentations during prediction or training batches.
3. **Intermediate Results**: Save intermediate results such as predictions or frames for further analysis or visualization.
Example: Combining frames with prediction results during prediction using `on_predict_batch_end`:
```python
from ultralytics import YOLO
def on_predict_batch_end(predictor):
"""Combine prediction results with frames."""
_, image, _, _ = predictor.batch
image = image if isinstance(image, list) else [image]
predictor.results = zip(predictor.results, image)
model = YOLO("yolo11n.pt")
model.add_callback("on_predict_batch_end", on_predict_batch_end)
for result, frame in model.predict():
pass
```
Explore the [Complete Callback Reference](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/utils/callbacks/base.py) to find more options and examples.
| |
270860
|
---
comments: true
description: Learn to integrate YOLO11 in Python for object detection, segmentation, and classification. Load, train models, and make predictions easily with our comprehensive guide.
keywords: YOLO11, Python, object detection, segmentation, classification, machine learning, AI, pretrained models, train models, make predictions
---
# Python Usage
Welcome to the YOLO11 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLO11 into your Python projects for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification. Here, you'll learn how to load and use pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable resource for anyone looking to incorporate YOLO11 into their Python projects, allowing you to quickly implement advanced object detection capabilities. Let's get started!
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/GsXGnb-A4Kc?start=58"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Mastering Ultralytics YOLO11: Python
</p>
For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code.
!!! example "Python"
```python
from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO("yolo11n.yaml")
# Load a pretrained YOLO model (recommended for training)
model = YOLO("yolo11n.pt")
# Train the model using the 'coco8.yaml' dataset for 3 epochs
results = model.train(data="coco8.yaml", epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
# Perform object detection on an image using the model
results = model("https://ultralytics.com/images/bus.jpg")
# Export the model to ONNX format
success = model.export(format="onnx")
```
## [Train](../modes/train.md)
Train mode is used for training a YOLO11 model on a custom dataset. In this mode, the model is trained using the specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can accurately predict the classes and locations of objects in an image.
!!! example "Train"
=== "From pretrained (recommended)"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt") # pass any model type
results = model.train(epochs=5)
```
=== "From scratch"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.yaml")
results = model.train(data="coco8.yaml", epochs=5)
```
=== "Resume"
```python
model = YOLO("last.pt")
results = model.train(resume=True)
```
[Train Examples](../modes/train.md){ .md-button }
## [Val](../modes/val.md)
Val mode is used for validating a YOLO11 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its [accuracy](https://www.ultralytics.com/glossary/accuracy) and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
!!! example "Val"
=== "Val after training"
```python
from ultralytics import YOLO
# Load a YOLO11 model
model = YOLO("yolo11n.yaml")
# Train the model
model.train(data="coco8.yaml", epochs=5)
# Validate on training data
model.val()
```
=== "Val on another dataset"
```python
from ultralytics import YOLO
# Load a YOLO11 model
model = YOLO("yolo11n.yaml")
# Train the model
model.train(data="coco8.yaml", epochs=5)
# Validate on separate data
model.val(data="path/to/separate/data.yaml")
```
[Val Examples](../modes/val.md){ .md-button }
## [Predict](../modes/predict.md)
Predict mode is used for making predictions using a trained YOLO11 model on new images or videos. In this mode, the model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model predicts the classes and locations of objects in the input images or videos.
!!! example "Predict"
=== "From source"
```python
import cv2
from PIL import Image
from ultralytics import YOLO
model = YOLO("model.pt")
# accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam
results = model.predict(source="0")
results = model.predict(source="folder", show=True) # Display preds. Accepts all YOLO predict arguments
# from PIL
im1 = Image.open("bus.jpg")
results = model.predict(source=im1, save=True) # save plotted images
# from ndarray
im2 = cv2.imread("bus.jpg")
results = model.predict(source=im2, save=True, save_txt=True) # save predictions as labels
# from list of PIL/ndarray
results = model.predict(source=[im1, im2])
```
=== "Results usage"
```python
# results would be a list of Results object including all the predictions by default
# but be careful as it could occupy a lot memory when there're many images,
# especially the task is segmentation.
# 1. return as a list
results = model.predict(source="folder")
# results would be a generator which is more friendly to memory by setting stream=True
# 2. return as a generator
results = model.predict(source=0, stream=True)
for result in results:
# Detection
result.boxes.xyxy # box with xyxy format, (N, 4)
result.boxes.xywh # box with xywh format, (N, 4)
result.boxes.xyxyn # box with xyxy format but normalized, (N, 4)
result.boxes.xywhn # box with xywh format but normalized, (N, 4)
result.boxes.conf # confidence score, (N, 1)
result.boxes.cls # cls, (N, 1)
# Segmentation
result.masks.data # masks, (N, H, W)
result.masks.xy # x,y segments (pixels), List[segment] * N
result.masks.xyn # x,y segments (normalized), List[segment] * N
# Classification
result.probs # cls prob, (num_class, )
# Each result is composed of torch.Tensor by default,
# in which you can easily use following functionality:
result = result.cuda()
result = result.cpu()
result = result.to("cpu")
result = result.numpy()
```
[Predict Examples](../modes/predict.md){ .md-button }
## [Export](../modes/export.md)
Export mode is used for exporting a YOLO11 model to a format that can be used for deployment. In this mode, the model is converted to a format that can be used by other software applications or hardware devices. This mode is useful when deploying the model to production environments.
!!! example "Export"
=== "Export to ONNX"
Export an official YOLO11n model to ONNX with dynamic batch-size and image-size.
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.export(format="onnx", dynamic=True)
```
=== "Export to TensorRT"
Export an official YOLO11n model to TensorRT on `device=0` for acceleration on CUDA devices.
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.export(format="onnx", device=0)
```
[Export Examples](../modes/export.md){ .md-button }
| |
270861
|
## [Track](../modes/track.md)
Track mode is used for tracking objects in real-time using a YOLO11 model. In this mode, the model is loaded from a checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful for applications such as surveillance systems or self-driving cars.
!!! example "Track"
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official detection model
model = YOLO("yolo11n-seg.pt") # load an official segmentation model
model = YOLO("path/to/best.pt") # load a custom model
# Track with the model
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True)
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml")
```
[Track Examples](../modes/track.md){ .md-button }
## [Benchmark](../modes/benchmark.md)
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLO11. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation) or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
!!! example "Benchmark"
=== "Python"
Benchmark an official YOLO11n model across all export formats.
```python
from ultralytics.utils.benchmarks import benchmark
# Benchmark
benchmark(model="yolo11n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
[Benchmark Examples](../modes/benchmark.md){ .md-button }
## Using Trainers
`YOLO` model class is a high-level wrapper on the Trainer classes. Each YOLO task has its own trainer that inherits from `BaseTrainer`.
!!! tip "Detection Trainer Example"
```python
from ultralytics.models.yolo import DetectionPredictor, DetectionTrainer, DetectionValidator
# trainer
trainer = DetectionTrainer(overrides={})
trainer.train()
trained_model = trainer.best
# Validator
val = DetectionValidator(args=...)
val(model=trained_model)
# predictor
pred = DetectionPredictor(overrides={})
pred(source=SOURCE, model=trained_model)
# resume from last weight
overrides["resume"] = trainer.last
trainer = detect.DetectionTrainer(overrides=overrides)
```
You can easily customize Trainers to support custom tasks or explore R&D ideas. Learn more about Customizing `Trainers`, `Validators` and `Predictors` to suit your project needs in the Customization Section.
[Customization tutorials](engine.md){ .md-button }
## FAQ
### How can I integrate YOLO11 into my Python project for object detection?
Integrating Ultralytics YOLO11 into your Python projects is simple. You can load a pre-trained model or train a new model from scratch. Here's how to get started:
```python
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO("yolo11n.pt")
# Perform object detection on an image
results = model("https://ultralytics.com/images/bus.jpg")
# Visualize the results
for result in results:
result.show()
```
See more detailed examples in our [Predict Mode](../modes/predict.md) section.
### What are the different modes available in YOLO11?
Ultralytics YOLO11 provides various modes to cater to different [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) workflows. These include:
- **[Train](../modes/train.md)**: Train a model using custom datasets.
- **[Val](../modes/val.md)**: Validate model performance on a validation set.
- **[Predict](../modes/predict.md)**: Make predictions on new images or video streams.
- **[Export](../modes/export.md)**: Export models to various formats like ONNX, TensorRT.
- **[Track](../modes/track.md)**: Real-time object tracking in video streams.
- **[Benchmark](../modes/benchmark.md)**: Benchmark model performance across different configurations.
Each mode is designed to provide comprehensive functionalities for different stages of model development and deployment.
### How do I train a custom YOLO11 model using my dataset?
To train a custom YOLO11 model, you need to specify your dataset and other hyperparameters. Here's a quick example:
```python
from ultralytics import YOLO
# Load the YOLO model
model = YOLO("yolo11n.yaml")
# Train the model with custom dataset
model.train(data="path/to/your/dataset.yaml", epochs=10)
```
For more details on training and hyperlinks to example usage, visit our [Train Mode](../modes/train.md) page.
### How do I export YOLO11 models for deployment?
Exporting YOLO11 models in a format suitable for deployment is straightforward with the `export` function. For example, you can export a model to ONNX format:
```python
from ultralytics import YOLO
# Load the YOLO model
model = YOLO("yolo11n.pt")
# Export the model to ONNX format
model.export(format="onnx")
```
For various export options, refer to the [Export Mode](../modes/export.md) documentation.
### Can I validate my YOLO11 model on different datasets?
Yes, validating YOLO11 models on different datasets is possible. After training, you can use the validation mode to evaluate the performance:
```python
from ultralytics import YOLO
# Load a YOLO11 model
model = YOLO("yolo11n.yaml")
# Train the model
model.train(data="coco8.yaml", epochs=5)
# Validate the model on a different dataset
model.val(data="path/to/separate/data.yaml")
```
Check the [Val Mode](../modes/val.md) page for detailed examples and usage.
| |
270862
|
---
comments: true
description: Explore the YOLO11 command line interface (CLI) for easy execution of detection tasks without needing a Python environment.
keywords: YOLO11 CLI, command line interface, YOLO11 commands, detection tasks, Ultralytics, model training, model prediction
---
# Command Line Interface Usage
The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment. CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/GsXGnb-A4Kc?start=19"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Mastering Ultralytics YOLO: CLI
</p>
!!! example
=== "Syntax"
Ultralytics `yolo` commands use the following syntax:
```bash
yolo TASK MODE ARGS
Where TASK (optional) is one of [detect, segment, classify, pose, obb]
MODE (required) is one of [train, val, predict, export, track, benchmark]
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
```
See all ARGS in the full [Configuration Guide](cfg.md) or with `yolo cfg`
=== "Train"
Train a detection model for 10 [epochs](https://www.ultralytics.com/glossary/epoch) with an initial learning_rate of 0.01
```bash
yolo train data=coco8.yaml model=yolo11n.pt epochs=10 lr0=0.01
```
=== "Predict"
Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
yolo predict model=yolo11n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
```
=== "Val"
Val a pretrained detection model at batch-size 1 and image size 640:
```bash
yolo val model=yolo11n.pt data=coco8.yaml batch=1 imgsz=640
```
=== "Export"
Export a YOLO11n classification model to ONNX format at image size 224 by 128 (no TASK required)
```bash
yolo export model=yolo11n-cls.pt format=onnx imgsz=224,128
```
=== "Special"
Run special commands to see version, view settings, run checks and more:
```bash
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfg
```
Where:
- `TASK` (optional) is one of `[detect, segment, classify, pose, obb]`. If it is not passed explicitly YOLO11 will try to guess the `TASK` from the model type.
- `MODE` (required) is one of `[train, val, predict, export, track, benchmark]`
- `ARGS` (optional) are any number of custom `arg=value` pairs like `imgsz=320` that override defaults. For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`
!!! warning
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
- `yolo predict model=yolo11n.pt imgsz=640 conf=0.25` ✅
- `yolo predict model yolo11n.pt imgsz 640 conf 0.25` ❌
- `yolo predict --model yolo11n.pt --imgsz 640 --conf 0.25` ❌
## Train
Train YOLO11n on the COCO8 dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](cfg.md) page.
!!! example
=== "Train"
Start training YOLO11n on COCO8 for 100 epochs at image-size 640.
```bash
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
```
=== "Resume"
Resume an interrupted training.
```bash
yolo detect train resume model=last.pt
```
## Val
Validate trained YOLO11n model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
=== "Official"
Validate an official YOLO11n model.
```bash
yolo detect val model=yolo11n.pt
```
=== "Custom"
Validate a custom-trained model.
```bash
yolo detect val model=path/to/best.pt
```
## Predict
Use a trained YOLO11n model to run predictions on images.
!!! example
=== "Official"
Predict with an official YOLO11n model.
```bash
yolo detect predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg'
```
=== "Custom"
Predict with a custom model.
```bash
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'
```
## Export
Export a YOLO11n model to a different format like ONNX, CoreML, etc.
!!! example
=== "Official"
Export an official YOLO11n model to ONNX format.
```bash
yolo export model=yolo11n.pt format=onnx
```
=== "Custom"
Export a custom-trained model to ONNX format.
```bash
yolo export model=path/to/best.pt format=onnx
```
Available YOLO11 export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`.
{% include "macros/export-table.md" %}
See full `export` details in the [Export](../modes/export.md) page.
## Overriding default arguments
Default arguments can be overridden by simply passing them as arguments in the CLI in `arg=value` pairs.
!!! tip
=== "Train"
Train a detection model for `10 epochs` with `learning_rate` of `0.01`
```bash
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=10 lr0=0.01
```
=== "Predict"
Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
yolo segment predict model=yolo11n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
```
=== "Val"
Validate a pretrained detection model at batch-size 1 and image size 640:
```bash
yolo detect val model=yolo11n.pt data=coco8.yaml batch=1 imgsz=640
```
## Overriding default config file
You can override the `default.yaml` config file entirely by passing a new file with the `cfg` arguments, i.e. `cfg=custom.yaml`.
To do this first create a copy of `default.yaml` in your current working dir with the `yolo copy-cfg` command.
This will create `default_copy.yaml`, which you can then pass as `cfg=default_copy.yaml` along with any additional args, like `imgsz=320` in this example:
!!! example
=== "CLI"
```bash
yolo copy-cfg
yolo cfg=default_copy.yaml imgsz=320
```
## FAQ
| |
270865
|
---
comments: true
description: Optimize your YOLO model's performance with the right settings and hyperparameters. Learn about training, validation, and prediction configurations.
keywords: YOLO, hyperparameters, configuration, training, validation, prediction, model settings, Ultralytics, performance optimization, machine learning
---
YOLO settings and hyperparameters play a critical role in the model's performance, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy). These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/GsXGnb-A4Kc?start=87"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Mastering Ultralytics YOLO: Configuration
</p>
Ultralytics commands use the following syntax:
!!! example
=== "CLI"
```bash
yolo TASK MODE ARGS
```
=== "Python"
```python
from ultralytics import YOLO
# Load a YOLO11 model from a pre-trained weights file
model = YOLO("yolo11n.pt")
# Run MODE mode using the custom arguments ARGS (guess TASK)
model.MODE(ARGS)
```
Where:
- `TASK` (optional) is one of ([detect](../tasks/detect.md), [segment](../tasks/segment.md), [classify](../tasks/classify.md), [pose](../tasks/pose.md), [obb](../tasks/obb.md))
- `MODE` (required) is one of ([train](../modes/train.md), [val](../modes/val.md), [predict](../modes/predict.md), [export](../modes/export.md), [track](../modes/track.md), [benchmark](../modes/benchmark.md))
- `ARGS` (optional) are `arg=value` pairs like `imgsz=640` that override defaults.
Default `ARG` values are defined on this page from the `cfg/defaults.yaml` [file](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/default.yaml).
#### Tasks
YOLO models can be used for a variety of tasks, including detection, segmentation, classification and pose. These tasks differ in the type of output they produce and the specific problem they are designed to solve.
- **Detect**: For identifying and localizing objects or regions of interest in an image or video.
- **Segment**: For dividing an image or video into regions or pixels that correspond to different objects or classes.
- **Classify**: For predicting the class label of an input image.
- **Pose**: For identifying objects and estimating their keypoints in an image or video.
- **OBB**: Oriented (i.e. rotated) bounding boxes suitable for satellite or medical imagery.
| Argument | Default | Description |
| -------- | ---------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `task` | `'detect'` | Specifies the YOLO task to be executed. Options include `detect` for [object detection](https://www.ultralytics.com/glossary/object-detection), `segment` for segmentation, `classify` for classification, `pose` for pose estimation and `obb` for oriented bounding boxes. Each task is tailored to specific types of output and problems within image and video analysis. |
[Tasks Guide](../tasks/index.md){ .md-button }
#### Modes
YOLO models can be used in different modes depending on the specific problem you are trying to solve. These modes include:
- **Train**: For training a YOLO11 model on a custom dataset.
- **Val**: For validating a YOLO11 model after it has been trained.
- **Predict**: For making predictions using a trained YOLO11 model on new images or videos.
- **Export**: For exporting a YOLO11 model to a format that can be used for deployment.
- **Track**: For tracking objects in real-time using a YOLO11 model.
- **Benchmark**: For benchmarking YOLO11 exports (ONNX, TensorRT, etc.) speed and accuracy.
| Argument | Default | Description |
| -------- | --------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `mode` | `'train'` | Specifies the mode in which the YOLO model operates. Options are `train` for model training, `val` for validation, `predict` for inference on new data, `export` for model conversion to deployment formats, `track` for object tracking, and `benchmark` for performance evaluation. Each mode is designed for different stages of the model lifecycle, from development through deployment. |
[Modes Guide](../modes/index.md){ .md-button }
## Train Settings
The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, [learning rate](https://www.ultralytics.com/glossary/learning-rate), momentum, and weight decay. Additionally, the choice of optimizer, [loss function](https://www.ultralytics.com/glossary/loss-function), and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
{% include "macros/train-args.md" %}
!!! info "Note on Batch-size Settings"
The `batch` argument can be configured in three ways:
- **Fixed [Batch Size](https://www.ultralytics.com/glossary/batch-size)**: Set an integer value (e.g., `batch=16`), specifying the number of images per batch directly.
- **Auto Mode (60% GPU Memory)**: Use `batch=-1` to automatically adjust batch size for approximately 60% CUDA memory utilization.
- **Auto Mode with Utilization Fraction**: Set a fraction value (e.g., `batch=0.70`) to adjust batch size based on the specified fraction of GPU memory usage.
[Train Guide](../modes/train.md){ .md-button }
## Predict Settings
The prediction settings for YOLO models encompass a range of hyperparameters and configurations that influence the model's performance, speed, and accuracy during inference on new data. Careful tuning and experimentation with these settings are essential to achieve optimal performance for a specific task. Key settings include the confidence threshold, Non-Maximum Suppression (NMS) threshold, and the number of classes considered. Additional factors affecting the prediction process are input data size and format, the presence of supplementary features such as masks or multiple labels per box, and the particular task the model is employed for.
Inference arguments:
{% include "macros/predict-args.md" %}
Visualization arguments:
{% include "macros/visualization-args.md" %}
[Predict Guide](../modes/predict.md){ .md-button }
## Validation Settings
The val (validation) settings for YOLO models involve various hyperparameters and configurations used to evaluate the model's performance on a validation dataset. These settings influence the model's performance, speed, and accuracy. Common YOLO validation settings include batch size, validation frequency during training, and performance evaluation metrics. Other factors affecting the validation process include the validation dataset's size and composition, as well as the specific task the model is employed for.
{% include "macros/validation-args.md" %}
Careful tuning and experimentation with these settings are crucial to ensure optimal performance on the validation dataset and detect and prevent [overfitting](https://www.ultralytics.com/glossary/overfitting).
[Val Guide](../modes/val.md){ .md-button }
## Export Settings
Export settings for YOLO models encompass configurations and options related to saving or exporting the model for use in different environments or platforms. These settings can impact the model's performance, size, and compatibility with various systems. Key export settings include the exported model file format (e.g., ONNX, TensorFlow SavedModel), the target device (e.g., CPU, GPU), and additional features such as masks or multiple labels per box. The export process may also be affected by the model's specific task and the requirements or constraints of the destination environment or platform.
{% include "macros/export-args.md" %}
It is crucial to thoughtfully configure these settings to ensure the exported model is optimized for the intended use case and functions effectively in the target environment.
[Export Guide](../modes/export.md){ .md-button }
## Augmentation Settings
Augmentation techniques are essential for improving the robustness and performance of YOLO models by introducing variability into the [training data](https://www.ultralytics.com/glossary/training-data), helping the model generalize better to unseen data. The following table outlines the purpose and effect of each augmentation argument:
{% include "macros/augmentation-args.md" %}
These settings can be adjusted to meet the specific requirements of the dataset and task at hand. Experimenting with different values can help find the optimal augmentation strategy that leads to the best model performance.
| |
270866
|
## Logging, Checkpoints and Plotting Settings
Logging, checkpoints, plotting, and file management are important considerations when training a YOLO model.
- Logging: It is often helpful to log various metrics and statistics during training to track the model's progress and diagnose any issues that may arise. This can be done using a logging library such as TensorBoard or by writing log messages to a file.
- Checkpoints: It is a good practice to save checkpoints of the model at regular intervals during training. This allows you to resume training from a previous point if the training process is interrupted or if you want to experiment with different training configurations.
- Plotting: Visualizing the model's performance and training progress can be helpful for understanding how the model is behaving and identifying potential issues. This can be done using a plotting library such as matplotlib or by generating plots using a logging library such as TensorBoard.
- File management: Managing the various files generated during the training process, such as model checkpoints, log files, and plots, can be challenging. It is important to have a clear and organized file structure to keep track of these files and make it easy to access and analyze them as needed.
Effective logging, checkpointing, plotting, and file management can help you keep track of the model's progress and make it easier to debug and optimize the training process.
| Argument | Default | Description |
| ---------- | -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `project` | `'runs'` | Specifies the root directory for saving training runs. Each run will be saved in a separate subdirectory within this directory. |
| `name` | `'exp'` | Defines the name of the experiment. If not specified, YOLO automatically increments this name for each run, e.g., `exp`, `exp2`, etc., to avoid overwriting previous experiments. |
| `exist_ok` | `False` | Determines whether to overwrite an existing experiment directory if one with the same name already exists. Setting this to `True` allows overwriting, while `False` prevents it. |
| `plots` | `False` | Controls the generation and saving of training and validation plots. Set to `True` to create plots such as loss curves, [precision](https://www.ultralytics.com/glossary/precision)-[recall](https://www.ultralytics.com/glossary/recall) curves, and sample predictions. Useful for visually tracking model performance over time. |
| `save` | `False` | Enables the saving of training checkpoints and final model weights. Set to `True` to periodically save model states, allowing training to be resumed from these checkpoints or models to be deployed. |
## FAQ
### How do I improve the performance of my YOLO model during training?
Improving YOLO model performance involves tuning hyperparameters like batch size, learning rate, momentum, and weight decay. Adjusting augmentation settings, selecting the right optimizer, and employing techniques like early stopping or [mixed precision](https://www.ultralytics.com/glossary/mixed-precision) can also help. For detailed guidance on training settings, refer to the [Train Guide](../modes/train.md).
### What are the key hyperparameters to consider for YOLO model accuracy?
Key hyperparameters affecting YOLO model accuracy include:
- **Batch Size (`batch`)**: Larger batch sizes can stabilize training but may require more memory.
- **Learning Rate (`lr0`)**: Controls the step size for weight updates; smaller rates offer fine adjustments but slow convergence.
- **Momentum (`momentum`)**: Helps accelerate gradient vectors in the right directions, dampening oscillations.
- **Image Size (`imgsz`)**: Larger image sizes can improve accuracy but increase computational load.
Adjust these values based on your dataset and hardware capabilities. Explore more in the [Train Settings](#train-settings) section.
### How do I set the learning rate for training a YOLO model?
The learning rate (`lr0`) is crucial for optimization. A common starting point is `0.01` for SGD or `0.001` for Adam. It's essential to monitor training metrics and adjust if necessary. Use cosine learning rate schedulers (`cos_lr`) or warmup techniques (`warmup_epochs`, `warmup_momentum`) to dynamically modify the rate during training. Find more details in the [Train Guide](../modes/train.md).
### What are the default inference settings for YOLO models?
Default inference settings include:
- **Confidence Threshold (`conf=0.25`)**: Minimum confidence for detections.
- **IoU Threshold (`iou=0.7`)**: For Non-Maximum Suppression (NMS).
- **Image Size (`imgsz=640`)**: Resizes input images prior to inference.
- **Device (`device=None`)**: Selects CPU or GPU for inference.
For a comprehensive overview, visit the [Predict Settings](#predict-settings) section and the [Predict Guide](../modes/predict.md).
### Why should I use mixed precision training with YOLO models?
Mixed precision training, enabled with `amp=True`, helps reduce memory usage and can speed up training by utilizing the advantages of both FP16 and FP32. This is beneficial for modern GPUs, which support mixed precision natively, allowing more models to fit in memory and enable faster computations without significant loss in accuracy. Learn more about this in the [Train Guide](../modes/train.md).
| |
270869
|
Box (horizontal) Instances
To manage bounding box data, the `Bboxes` class will help to convert between box coordinate formatting, scale box dimensions, calculate areas, include offsets, and more!
```python
import numpy as np
from ultralytics.utils.instance import Bboxes
boxes = Bboxes(
bboxes=np.array(
[
[22.878, 231.27, 804.98, 756.83],
[48.552, 398.56, 245.35, 902.71],
[669.47, 392.19, 809.72, 877.04],
[221.52, 405.8, 344.98, 857.54],
[0, 550.53, 63.01, 873.44],
[0.0584, 254.46, 32.561, 324.87],
]
),
format="xyxy",
)
boxes.areas()
# >>> array([ 4.1104e+05, 99216, 68000, 55772, 20347, 2288.5])
boxes.convert("xywh")
print(boxes.bboxes)
# >>> array(
# [[ 413.93, 494.05, 782.1, 525.56],
# [ 146.95, 650.63, 196.8, 504.15],
# [ 739.6, 634.62, 140.25, 484.85],
# [ 283.25, 631.67, 123.46, 451.74],
# [ 31.505, 711.99, 63.01, 322.91],
# [ 16.31, 289.67, 32.503, 70.41]]
# )
```
See the [`Bboxes` reference section](../reference/utils/instance.md#ultralytics.utils.instance.Bboxes) for more attributes and methods available.
!!! tip
Many of the following functions (and more) can be accessed using the [`Bboxes` class](#bounding-box-horizontal-instances) but if you prefer to work with the functions directly, see the next subsections on how to import these independently.
### Scaling Boxes
When scaling and image up or down, corresponding bounding box coordinates can be appropriately scaled to match using `ultralytics.utils.ops.scale_boxes`.
```{ .py .annotate }
import cv2 as cv
import numpy as np
from ultralytics.utils.ops import scale_boxes
image = cv.imread("ultralytics/assets/bus.jpg")
h, w, c = image.shape
resized = cv.resize(image, None, (), fx=1.2, fy=1.2)
new_h, new_w, _ = resized.shape
xyxy_boxes = np.array(
[
[22.878, 231.27, 804.98, 756.83],
[48.552, 398.56, 245.35, 902.71],
[669.47, 392.19, 809.72, 877.04],
[221.52, 405.8, 344.98, 857.54],
[0, 550.53, 63.01, 873.44],
[0.0584, 254.46, 32.561, 324.87],
]
)
new_boxes = scale_boxes(
img1_shape=(h, w), # original image dimensions
boxes=xyxy_boxes, # boxes from original image
img0_shape=(new_h, new_w), # resized image dimensions (scale to)
ratio_pad=None,
padding=False,
xywh=False,
)
print(new_boxes) # (1)!
# >>> array(
# [[ 27.454, 277.52, 965.98, 908.2],
# [ 58.262, 478.27, 294.42, 1083.3],
# [ 803.36, 470.63, 971.66, 1052.4],
# [ 265.82, 486.96, 413.98, 1029],
# [ 0, 660.64, 75.612, 1048.1],
# [ 0.0701, 305.35, 39.073, 389.84]]
# )
```
1. Bounding boxes scaled for the new image size
### Bounding Box Format Conversions
#### XYXY → XYWH
Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height) format where (x1, y1) is the top-left corner and (x2, y2) is the bottom-right corner.
```python
import numpy as np
from ultralytics.utils.ops import xyxy2xywh
xyxy_boxes = np.array(
[
[22.878, 231.27, 804.98, 756.83],
[48.552, 398.56, 245.35, 902.71],
[669.47, 392.19, 809.72, 877.04],
[221.52, 405.8, 344.98, 857.54],
[0, 550.53, 63.01, 873.44],
[0.0584, 254.46, 32.561, 324.87],
]
)
xywh = xyxy2xywh(xyxy_boxes)
print(xywh)
# >>> array(
# [[ 413.93, 494.05, 782.1, 525.56],
# [ 146.95, 650.63, 196.8, 504.15],
# [ 739.6, 634.62, 140.25, 484.85],
# [ 283.25, 631.67, 123.46, 451.74],
# [ 31.505, 711.99, 63.01, 322.91],
# [ 16.31, 289.67, 32.503, 70.41]]
# )
```
### All Bounding Box Conversions
```python
from ultralytics.utils.ops import (
ltwh2xywh,
ltwh2xyxy,
xywh2ltwh, # xywh → top-left corner, w, h
xywh2xyxy,
xywhn2xyxy, # normalized → pixel
xyxy2ltwh, # xyxy → top-left corner, w, h
xyxy2xywhn, # pixel → normalized
)
for func in (ltwh2xywh, ltwh2xyxy, xywh2ltwh, xywh2xyxy, xywhn2xyxy, xyxy2ltwh, xyxy2xywhn):
print(help(func)) # print function docstrings
```
See docstring for each function or visit the `ultralytics.utils.ops` [reference page](../reference/utils/ops.md) to read more about each function.
## Plotting
### Drawing Annotations
Ultr
| |
270870
|
alytics includes an Annotator class that can be used to annotate any kind of data. It's easiest to use with [object detection bounding boxes](../modes/predict.md#boxes), [pose key points](../modes/predict.md#keypoints), and [oriented bounding boxes](../modes/predict.md#obb).
#### Horizontal Bounding Boxes
```{ .py .annotate }
import cv2 as cv
import numpy as np
from ultralytics.utils.plotting import Annotator, colors
names = { # (1)!
0: "person",
5: "bus",
11: "stop sign",
}
image = cv.imread("ultralytics/assets/bus.jpg")
ann = Annotator(
image,
line_width=None, # default auto-size
font_size=None, # default auto-size
font="Arial.ttf", # must be ImageFont compatible
pil=False, # use PIL, otherwise uses OpenCV
)
xyxy_boxes = np.array(
[
[5, 22.878, 231.27, 804.98, 756.83], # class-idx x1 y1 x2 y2
[0, 48.552, 398.56, 245.35, 902.71],
[0, 669.47, 392.19, 809.72, 877.04],
[0, 221.52, 405.8, 344.98, 857.54],
[0, 0, 550.53, 63.01, 873.44],
[11, 0.0584, 254.46, 32.561, 324.87],
]
)
for nb, box in enumerate(xyxy_boxes):
c_idx, *box = box
label = f"{str(nb).zfill(2)}:{names.get(int(c_idx))}"
ann.box_label(box, label, color=colors(c_idx, bgr=True))
image_with_bboxes = ann.result()
```
1. Names can be used from `model.names` when [working with detection results](../modes/predict.md#working-with-results)
#### Oriented Bounding Boxes (OBB)
```python
import cv2 as cv
import numpy as np
from ultralytics.utils.plotting import Annotator, colors
obb_names = {10: "small vehicle"}
obb_image = cv.imread("datasets/dota8/images/train/P1142__1024__0___824.jpg")
obb_boxes = np.array(
[
[0, 635, 560, 919, 719, 1087, 420, 803, 261], # class-idx x1 y1 x2 y2 x3 y2 x4 y4
[0, 331, 19, 493, 260, 776, 70, 613, -171],
[9, 869, 161, 886, 147, 851, 101, 833, 115],
]
)
ann = Annotator(
obb_image,
line_width=None, # default auto-size
font_size=None, # default auto-size
font="Arial.ttf", # must be ImageFont compatible
pil=False, # use PIL, otherwise uses OpenCV
)
for obb in obb_boxes:
c_idx, *obb = obb
obb = np.array(obb).reshape(-1, 4, 2).squeeze()
label = f"{obb_names.get(int(c_idx))}"
ann.box_label(
obb,
label,
color=colors(c_idx, True),
rotated=True,
)
image_with_obb = ann.result()
```
#### Bounding Boxes Circle Annotation [Circle Label](https://docs.ultralytics.com/reference/utils/plotting/#ultralytics.utils.plotting.Annotator.circle_label)
```python
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator
model = YOLO("yolo11s.pt")
names = model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
writer = cv2.VideoWriter("Ultralytics circle annotation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
break
annotator = Annotator(im0)
results = model.predict(im0)
boxes = results[0].boxes.xyxy.cpu()
clss = results[0].boxes.cls.cpu().tolist()
for box, cls in zip(boxes, clss):
annotator.circle_label(box, label=names[int(cls)])
writer.write(im0)
cv2.imshow("Ultralytics circle annotation", im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
writer.release()
cap.release()
cv2.destroyAllWindows()
```
#### Bounding Boxes Text Annotation [Text Label](https://docs.ultralytics.com/reference/utils/plotting/#ultralytics.utils.plotting.Annotator.text_label)
```python
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator
model = YOLO("yolo11s.pt")
names = model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
writer = cv2.VideoWriter("Ultralytics text annotation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
while True:
ret, im0 = cap.read()
if not ret:
break
annotator = Annotator(im0)
results = model.predict(im0)
boxes = results[0].boxes.xyxy.cpu()
clss = results[0].boxes.cls.cpu().tolist()
for box, cls in zip(boxes, clss):
annotator.text_label(box, label=names[int(cls)])
writer.write(im0)
cv2.imshow("Ultralytics text annotation", im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
writer.release()
cap.release()
cv2.destroyAllWindows()
```
See the [`Annotator` Reference Page](../reference/utils/plotting.md#ultralytics.utils.plotting.Annotator) for additional insight.
## Miscellaneous
### Code Profiling
Check duration for code to run/process either using `with` or as a decorator.
```python
from ultralytics.utils.ops import Profile
with Profile(device="cuda:0") as dt:
pass # operation to measure
print(dt)
# >>> "Elapsed time is 9.5367431640625e-07 s"
```
### Ultralytics Supported Formats
Want or need to use the formats of [images or videos types supported](../modes/predict.md#image-and-video-formats) by Ultralytics programmatically? Use these constants if you need.
```python
from ultralytics.data.utils import IMG_FORMATS, VID_FORMATS
print(IMG_FORMATS)
# {'tiff', 'pfm', 'bmp', 'mpo', 'dng', 'jpeg', 'png', 'webp', 'tif', 'jpg'}
print(VID_FORMATS)
# {'avi', 'mpg', 'wmv', 'mpeg', 'm4v', 'mov', 'mp4', 'asf', 'mkv', 'ts', 'gif', 'webm'}
```
### Make Divisible
Calculates the nearest whole number to `x` to make evenly divisible when divided by `y`.
```python
from ultralytics.utils.ops import make_divisible
make_divisible(7, 3)
# >>> 9
make_divisible(7, 2)
# >>> 8
```
## FAQ
### What utilities are included in
| |
270887
|
rmance Metrics
!!! performance
=== "Detection"
See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pre-trained classes.
| Model | YAML | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|---------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
| [yolov5nu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5nu.pt) | [yolov5n.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
| [yolov5su.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5su.pt) | [yolov5s.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 43.0 | 120.7 | 1.27 | 9.1 | 24.0 |
| [yolov5mu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5mu.pt) | [yolov5m.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 49.0 | 233.9 | 1.86 | 25.1 | 64.2 |
| [yolov5lu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5lu.pt) | [yolov5l.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 52.2 | 408.4 | 2.50 | 53.2 | 135.0 |
| [yolov5xu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5xu.pt) | [yolov5x.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 53.2 | 763.2 | 3.81 | 97.2 | 246.4 |
| | | | | | | | |
| [yolov5n6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5n6u.pt) | [yolov5n6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 42.1 | 211.0 | 1.83 | 4.3 | 7.8 |
| [yolov5s6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5s6u.pt) | [yolov5s6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 48.6 | 422.6 | 2.34 | 15.3 | 24.6 |
| [yolov5m6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5m6u.pt) | [yolov5m6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 53.6 | 810.9 | 4.36 | 41.2 | 65.7 |
| [yolov5l6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5l6u.pt) | [yolov5l6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 55.7 | 1470.9 | 5.47 | 86.1 | 137.4 |
| [yolov5x6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5x6u.pt) | [yolov5x6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 56.8 | 2436.5 | 8.98 | 155.4 | 250.7 |
## Usage Examples
This example provides simple YOLOv5 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
!!! example
=== "Python"
[PyTorch](https://www.ultralytics.com/glossary/pytorch) pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv5n model
model = YOLO("yolov5n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv5n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
```
=== "CLI"
CLI commands are available to directly run the models:
```bash
# Load a COCO-pretrained YOLOv5n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolov5n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLOv5n model and run inference on the 'bus.jpg' image
yolo predict model=yolov5n.pt source=path/to/bus.jpg
```
## Citations and Acknowledgements
If you use YOLOv5 or YOLOv5u in your research, please cite the Ultralytics YOLOv5 repository as follows:
!!! quote ""
=== "BibTeX"
```bibtex
@software{yolov5,
title = {Ultralytics YOLOv5},
author = {Glenn Jocher},
year = {2020},
version = {7.0},
license = {AGPL-3.0},
url = {https://github.com/ultralytics/yolov5},
doi = {10.5281/zenodo.3908559},
orcid = {0000-0001-5950-6979}
}
```
Please note that YOLOv5 models are provided under [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) and [Enterprise](https://www.ultralytics.com/license) licenses.
## FAQ
| |
270895
|
---
comments: true
description: Discover a variety of models supported by Ultralytics, including YOLOv3 to YOLOv10, NAS, SAM, and RT-DETR for detection, segmentation, and more.
keywords: Ultralytics, supported models, YOLOv3, YOLOv4, YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOv9, YOLOv10, SAM, NAS, RT-DETR, object detection, image segmentation, classification, pose estimation, multi-object tracking
---
# Models Supported by Ultralytics
Welcome to Ultralytics' model documentation! We offer support for a wide range of models, each tailored to specific tasks like [object detection](../tasks/detect.md), [instance segmentation](../tasks/segment.md), [image classification](../tasks/classify.md), [pose estimation](../tasks/pose.md), and [multi-object tracking](../modes/track.md). If you're interested in contributing your model architecture to Ultralytics, check out our [Contributing Guide](../help/contributing.md).
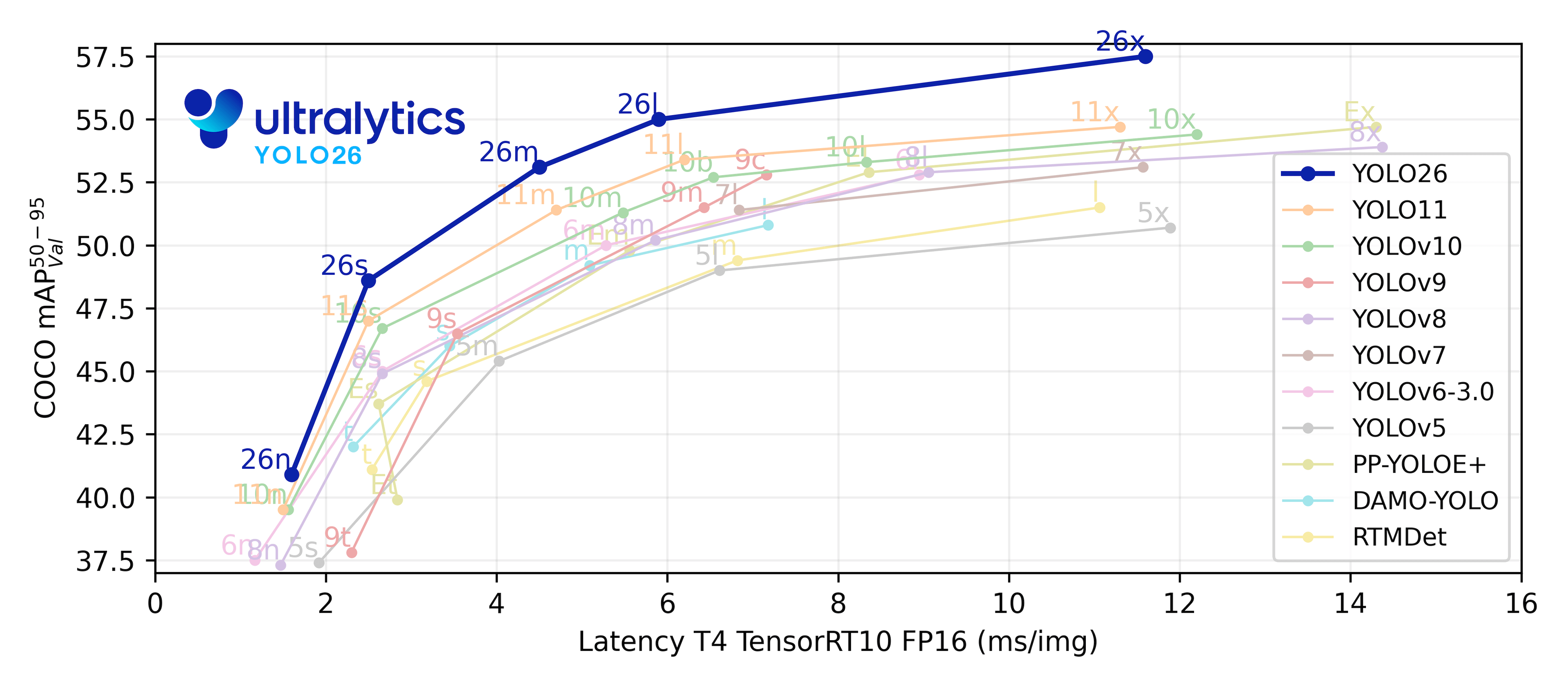
## Featured Models
Here are some of the key models supported:
1. **[YOLOv3](yolov3.md)**: The third iteration of the YOLO model family, originally by Joseph Redmon, known for its efficient real-time object detection capabilities.
2. **[YOLOv4](yolov4.md)**: A darknet-native update to YOLOv3, released by Alexey Bochkovskiy in 2020.
3. **[YOLOv5](yolov5.md)**: An improved version of the YOLO architecture by Ultralytics, offering better performance and speed trade-offs compared to previous versions.
4. **[YOLOv6](yolov6.md)**: Released by [Meituan](https://about.meituan.com/) in 2022, and in use in many of the company's autonomous delivery robots.
5. **[YOLOv7](yolov7.md)**: Updated YOLO models released in 2022 by the authors of YOLOv4.
6. **[YOLOv8](yolov8.md)**: The latest version of the YOLO family, featuring enhanced capabilities such as [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), pose/keypoints estimation, and classification.
7. **[YOLOv9](yolov9.md)**: An experimental model trained on the Ultralytics [YOLOv5](yolov5.md) codebase implementing Programmable Gradient Information (PGI).
8. **[YOLOv10](yolov10.md)**: By Tsinghua University, featuring NMS-free training and efficiency-accuracy driven architecture, delivering state-of-the-art performance and latency.
9. **[YOLO11](yolo11.md) 🚀 NEW**: Ultralytics' latest YOLO models delivering state-of-the-art (SOTA) performance across multiple tasks.
10. **[Segment Anything Model (SAM)](sam.md)**: Meta's original Segment Anything Model (SAM).
11. **[Segment Anything Model 2 (SAM2)](sam-2.md)**: The next generation of Meta's Segment Anything Model (SAM) for videos and images.
12. **[Mobile Segment Anything Model (MobileSAM)](mobile-sam.md)**: MobileSAM for mobile applications, by Kyung Hee University.
13. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: FastSAM by Image & Video Analysis Group, Institute of Automation, Chinese Academy of Sciences.
14. **[YOLO-NAS](yolo-nas.md)**: YOLO Neural Architecture Search (NAS) Models.
15. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: Baidu's PaddlePaddle Realtime Detection [Transformer](https://www.ultralytics.com/glossary/transformer) (RT-DETR) models.
16. **[YOLO-World](yolo-world.md)**: Real-time Open Vocabulary Object Detection models from Tencent AI Lab.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/MWq1UxqTClU?si=nHAW-lYDzrz68jR0"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Run Ultralytics YOLO models in just a few lines of code.
</p>
## Getting Started: Usage Examples
This example provides simple YOLO training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for [object detection](https://www.ultralytics.com/glossary/object-detection). For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md) and [Pose](../tasks/pose.md) docs.
!!! example
=== "Python"
[PyTorch](https://www.ultralytics.com/glossary/pytorch) pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()`, `SAM()`, `NAS()` and `RTDETR()` classes to create a model instance in Python:
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
```
=== "CLI"
CLI commands are available to directly run the models:
```bash
# Load a COCO-pretrained YOLOv8n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLOv8n model and run inference on the 'bus.jpg' image
yolo predict model=yolov8n.pt source=path/to/bus.jpg
```
## Contributing New Models
Interested in contributing your model to Ultralytics? Great! We're always open to expanding our model portfolio.
1. **Fork the Repository**: Start by forking the [Ultralytics GitHub repository](https://github.com/ultralytics/ultralytics).
2. **Clone Your Fork**: Clone your fork to your local machine and create a new branch to work on.
3. **Implement Your Model**: Add your model following the coding standards and guidelines provided in our [Contributing Guide](../help/contributing.md).
4. **Test Thoroughly**: Make sure to test your model rigorously, both in isolation and as part of the pipeline.
5. **Create a Pull Request**: Once you're satisfied with your model, create a pull request to the main repository for review.
6. **Code Review & Merging**: After review, if your model meets our criteria, it will be merged into the main repository.
For detailed steps, consult our [Contributing Guide](../help/contributing.md).
##
| |
270896
|
FAQ
### What are the key advantages of using Ultralytics YOLOv8 for object detection?
Ultralytics YOLOv8 offers enhanced capabilities such as real-time object detection, instance segmentation, pose estimation, and classification. Its optimized architecture ensures high-speed performance without sacrificing [accuracy](https://www.ultralytics.com/glossary/accuracy), making it ideal for a variety of applications. YOLOv8 also includes built-in compatibility with popular datasets and models, as detailed on the [YOLOv8 documentation page](../models/yolov8.md).
### How can I train a YOLOv8 model on custom data?
Training a YOLOv8 model on custom data can be easily accomplished using Ultralytics' libraries. Here's a quick example:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a YOLOv8n model
model = YOLO("yolov8n.pt")
# Train the model on custom dataset
results = model.train(data="custom_data.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo train model=yolov8n.pt data='custom_data.yaml' epochs=100 imgsz=640
```
For more detailed instructions, visit the [Train](../modes/train.md) documentation page.
### Which YOLO versions are supported by Ultralytics?
Ultralytics supports a comprehensive range of YOLO (You Only Look Once) versions from YOLOv3 to YOLOv10, along with models like NAS, SAM, and RT-DETR. Each version is optimized for various tasks such as detection, segmentation, and classification. For detailed information on each model, refer to the [Models Supported by Ultralytics](../models/index.md) documentation.
### Why should I use Ultralytics HUB for [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) projects?
Ultralytics HUB provides a no-code, end-to-end platform for training, deploying, and managing YOLO models. It simplifies complex workflows, enabling users to focus on model performance and application. The HUB also offers cloud training capabilities, comprehensive dataset management, and user-friendly interfaces. Learn more about it on the [Ultralytics HUB](../hub/index.md) documentation page.
### What types of tasks can YOLOv8 perform, and how does it compare to other YOLO versions?
YOLOv8 is a versatile model capable of performing tasks including object detection, instance segmentation, classification, and pose estimation. Compared to earlier versions like YOLOv3 and YOLOv4, YOLOv8 offers significant improvements in speed and accuracy due to its optimized architecture. For a deeper comparison, refer to the [YOLOv8 documentation](../models/yolov8.md) and the [Task pages](../tasks/index.md) for more details on specific tasks.
| |
270904
|
differences between YOLOv3, YOLOv3-Ultralytics, and YOLOv3u?
YOLOv3 is the third iteration of the YOLO (You Only Look Once) [object detection](https://www.ultralytics.com/glossary/object-detection) algorithm developed by Joseph Redmon, known for its balance of [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed, utilizing three different scales (13x13, 26x26, and 52x52) for detections. YOLOv3-Ultralytics is Ultralytics' adaptation of YOLOv3 that adds support for more pre-trained models and facilitates easier model customization. YOLOv3u is an upgraded variant of YOLOv3-Ultralytics, integrating the anchor-free, objectness-free split head from YOLOv8, improving detection robustness and accuracy for various object sizes. For more details on the variants, refer to the [YOLOv3 series](https://github.com/ultralytics/yolov3).
### How can I train a YOLOv3 model using Ultralytics?
Training a YOLOv3 model with Ultralytics is straightforward. You can train the model using either Python or CLI:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv3n model
model = YOLO("yolov3n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
# Load a COCO-pretrained YOLOv3n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolov3n.pt data=coco8.yaml epochs=100 imgsz=640
```
For more comprehensive training options and guidelines, visit our [Train mode documentation](../modes/train.md).
### What makes YOLOv3u more accurate for object detection tasks?
YOLOv3u improves upon YOLOv3 and YOLOv3-Ultralytics by incorporating the anchor-free, objectness-free split head used in YOLOv8 models. This upgrade eliminates the need for pre-defined anchor boxes and objectness scores, enhancing its capability to detect objects of varying sizes and shapes more precisely. This makes YOLOv3u a better choice for complex and diverse object detection tasks. For more information, refer to the [Why YOLOv3u](#overview) section.
### How can I use YOLOv3 models for inference?
You can perform inference using YOLOv3 models by either Python scripts or CLI commands:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv3n model
model = YOLO("yolov3n.pt")
# Run inference with the YOLOv3n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
```
=== "CLI"
```bash
# Load a COCO-pretrained YOLOv3n model and run inference on the 'bus.jpg' image
yolo predict model=yolov3n.pt source=path/to/bus.jpg
```
Refer to the [Inference mode documentation](../modes/predict.md) for more details on running YOLO models.
### What tasks are supported by YOLOv3 and its variants?
YOLOv3, YOLOv3-Ultralytics, and YOLOv3u primarily support object detection tasks. These models can be used for various stages of model deployment and development, such as Inference, Validation, Training, and Export. For a comprehensive set of tasks supported and more in-depth details, visit our [Object Detection tasks documentation](../tasks/detect.md).
### Where can I find resources to cite YOLOv3 in my research?
If you use YOLOv3 in your research, please cite the original YOLO papers and the Ultralytics YOLOv3 repository. Example BibTeX citation:
!!! quote ""
=== "BibTeX"
```bibtex
@article{redmon2018yolov3,
title={YOLOv3: An Incremental Improvement},
author={Redmon, Joseph and Farhadi, Ali},
journal={arXiv preprint arXiv:1804.02767},
year={2018}
}
```
For more citation details, refer to the [Citations and Acknowledgements](#citations-and-acknowledgements) section.
| |
270906
|
ection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pre-trained classes.
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
=== "Detection (Open Images V7)"
See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [Open Image V7](../datasets/detect/open-images-v7.md), which include 600 pre-trained classes.
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
| ----------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
=== "Segmentation (COCO)"
See [Segmentation Docs](../tasks/segment.md) for usage examples with these models trained on [COCO](../datasets/segment/coco.md), which include 80 pre-trained classes.
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
| -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | --------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
=== "Classification (ImageNet)"
See [Classification Docs](../tasks/classify.md) for usage examples with these models trained on [ImageNet](../datasets/classify/imagenet.md), which include 1000 pre-trained classes.
| Model | size<br><sup>(pixels) | acc<br><sup>top1 | acc<br><sup>top5 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) at 640 |
| -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-cls.pt) | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-cls.pt) | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-cls.pt) | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-cls.pt) | 224 | 76.8 | 93.5 | 163.0 | 0.87
| |
270907
|
| 37.5 | 99.7 |
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-cls.pt) | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
=== "Pose (COCO)"
See [Pose Estimation Docs](../tasks/pose.md) for usage examples with these models trained on [COCO](../datasets/pose/coco.md), which include 1 pre-trained class, 'person'.
| Model | size<br><sup>(pixels) | mAP<sup>pose<br>50-95 | mAP<sup>pose<br>50 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
| ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
=== "OBB (DOTAv1)"
See [Oriented Detection Docs](../tasks/obb.md) for usage examples with these models trained on [DOTAv1](../datasets/obb/dota-v2.md#dota-v10), which include 15 pre-trained classes.
| Model | size<br><sup>(pixels) | mAP<sup>test<br>50 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|----------------------------------------------------------------------------------------------|-----------------------| -------------------- | -------------------------------- | ------------------------------------- | -------------------- | ----------------- |
| [YOLOv8n-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-obb.pt) | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| [YOLOv8s-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-obb.pt) | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| [YOLOv8m-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-obb.pt) | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| [YOLOv8l-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-obb.pt) | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| [YOLOv8x-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-obb.pt) | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
## Usage Examples
This example provides simple YOLOv8 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for object detection. For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md), [OBB](../tasks/obb.md) docs and [Pose](../tasks/pose.md) docs.
!!! example
=== "Python"
[PyTorch](https://www.ultralytics.com/glossary/pytorch) pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
```
=== "CLI"
CLI commands are available to directly run the models:
```bash
# Load a COCO-pretrained YOLOv8n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
# Load a COCO-pretrained YOLOv8n model and run inference on the 'bus.jpg' image
yolo predict model=yolov8n.pt source=path/to/bus.jpg
```
## Citations and Acknowledgements
If yo
| |
270908
|
u use the YOLOv8 model or any other software from this repository in your work, please cite it using the following format:
!!! quote ""
=== "BibTeX"
```bibtex
@software{yolov8_ultralytics,
author = {Glenn Jocher and Ayush Chaurasia and Jing Qiu},
title = {Ultralytics YOLOv8},
version = {8.0.0},
year = {2023},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0002-7603-6750, 0000-0003-3783-7069},
license = {AGPL-3.0}
}
```
Please note that the DOI is pending and will be added to the citation once it is available. YOLOv8 models are provided under [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) and [Enterprise](https://www.ultralytics.com/license) licenses.
## FAQ
### What is YOLOv8 and how does it differ from previous YOLO versions?
YOLOv8 is the latest iteration in the Ultralytics YOLO series, designed to improve real-time object detection performance with advanced features. Unlike earlier versions, YOLOv8 incorporates an **anchor-free split Ultralytics head**, state-of-the-art backbone and neck architectures, and offers optimized [accuracy](https://www.ultralytics.com/glossary/accuracy)-speed tradeoff, making it ideal for diverse applications. For more details, check the [Overview](#overview) and [Key Features](#key-features) sections.
### How can I use YOLOv8 for different computer vision tasks?
YOLOv8 supports a wide range of computer vision tasks, including object detection, instance segmentation, pose/keypoints detection, oriented object detection, and classification. Each model variant is optimized for its specific task and compatible with various operational modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). Refer to the [Supported Tasks and Modes](#supported-tasks-and-modes) section for more information.
### What are the performance metrics for YOLOv8 models?
YOLOv8 models achieve state-of-the-art performance across various benchmarking datasets. For instance, the YOLOv8n model achieves a mAP (mean Average Precision) of 37.3 on the COCO dataset and a speed of 0.99 ms on A100 TensorRT. Detailed performance metrics for each model variant across different tasks and datasets can be found in the [Performance Metrics](#performance-metrics) section.
### How do I train a YOLOv8 model?
Training a YOLOv8 model can be done using either Python or CLI. Below are examples for training a model using a COCO-pretrained YOLOv8 model on the COCO8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch):
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
```bash
yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
```
For further details, visit the [Training](../modes/train.md) documentation.
### Can I benchmark YOLOv8 models for performance?
Yes, YOLOv8 models can be benchmarked for performance in terms of speed and accuracy across various export formats. You can use PyTorch, ONNX, TensorRT, and more for benchmarking. Below are example commands for benchmarking using Python and CLI:
!!! example
=== "Python"
```python
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
=== "CLI"
```bash
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
```
For additional information, check the [Performance Metrics](#performance-metrics) section.
| |
270910
|
your Python applications. Ultralytics provides user-friendly Python API and CLI commands to streamline development.
### Train Usage
!!! tip
We strongly recommend to use `yolov8-worldv2` model for custom training, because it supports deterministic training and also easy to export other formats i.e onnx/tensorrt.
[Object detection](https://www.ultralytics.com/glossary/object-detection) is straightforward with the `train` method, as illustrated below:
!!! example
=== "Python"
[PyTorch](https://www.ultralytics.com/glossary/pytorch) pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLOWorld()` class to create a model instance in python:
```python
from ultralytics import YOLOWorld
# Load a pretrained YOLOv8s-worldv2 model
model = YOLOWorld("yolov8s-worldv2.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
```
=== "CLI"
```bash
# Load a pretrained YOLOv8s-worldv2 model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolov8s-worldv2.yaml data=coco8.yaml epochs=100 imgsz=640
```
### Predict Usage
Object detection is straightforward with the `predict` method, as illustrated below:
!!! example
=== "Python"
```python
from ultralytics import YOLOWorld
# Initialize a YOLO-World model
model = YOLOWorld("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Execute inference with the YOLOv8s-world model on the specified image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
```
=== "CLI"
```bash
# Perform object detection using a YOLO-World model
yolo predict model=yolov8s-world.pt source=path/to/image.jpg imgsz=640
```
This snippet demonstrates the simplicity of loading a pre-trained model and running a prediction on an image.
### Val Usage
Model validation on a dataset is streamlined as follows:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Create a YOLO-World model
model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Conduct model validation on the COCO8 example dataset
metrics = model.val(data="coco8.yaml")
```
=== "CLI"
```bash
# Validate a YOLO-World model on the COCO8 dataset with a specified image size
yolo val model=yolov8s-world.pt data=coco8.yaml imgsz=640
```
### Track Usage
Object tracking with YOLO-World model on a video/images is streamlined as follows:
!!! example
=== "Python"
```python
from ultralytics import YOLO
# Create a YOLO-World model
model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Track with a YOLO-World model on a video
results = model.track(source="path/to/video.mp4")
```
=== "CLI"
```bash
# Track with a YOLO-World model on the video with a specified image size
yolo track model=yolov8s-world.pt imgsz=640 source="path/to/video/file.mp4"
```
!!! note
The YOLO-World models provided by Ultralytics come pre-configured with [COCO dataset](../datasets/detect/coco.md) categories as part of their offline vocabulary, enhancing efficiency for immediate application. This integration allows the YOLOv8-World models to directly recognize and predict the 80 standard categories defined in the COCO dataset without requiring additional setup or customization.
### Set prompts

The YOLO-World framework allows for the dynamic specification of classes through custom prompts, empowering users to tailor the model to their specific needs **without retraining**. This feature is particularly useful for adapting the model to new domains or specific tasks that were not originally part of the [training data](https://www.ultralytics.com/glossary/training-data). By setting custom prompts, users can essentially guide the model's focus towards objects of interest, enhancing the relevance and accuracy of the detection results.
For instance, if your application only requires detecting 'person' and 'bus' objects, you can specify these classes directly:
!!! example
=== "Custom Inference Prompts"
```python
from ultralytics import YOLO
# Initialize a YOLO-World model
model = YOLO("yolov8s-world.pt") # or choose yolov8m/l-world.pt
# Define custom classes
model.set_classes(["person", "bus"])
# Execute prediction for specified categories on an image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
```
You can also save a model after setting custom classes. By doing this you create a version of the YOLO-World model that is specialized for your specific use case. This process embeds your custom class definitions directly into the model file, making the model ready to use with your specified classes without further adjustments. Follow these steps to save and load your custom YOLOv8 model:
!!! example
=== "Persisting Models with Custom Vocabulary"
First load a YOLO-World model, set custom classes for it and save it:
```python
from ultralytics import YOLO
# Initialize a YOLO-World model
model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt
# Define custom classes
model.set_classes(["person", "bus"])
# Save the model with the defined offline vocabulary
model.save("custom_yolov8s.pt")
```
After saving, the custom_yolov8s.pt model behaves like any other pre-trained YOLOv8 model but with a key difference: it is now optimized to detect only the classes you have defined. This customization can significantly improve detection performance and efficiency for your specific application scenarios.
```python
from ultralytics import YOLO
# Load your custom model
model = YOLO("custom_yolov8s.pt")
# Run inference to detect your custom classes
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
```
### Benefits of Saving with Custom Vocabulary
- **Efficiency**: Streamlines the detection process by focusing on relevant objects, reducing computational overhead and speeding up inference.
- **Flexibility**: Allows for easy adaptation of the model to new or niche detection tasks without the need for extensive retraining or data collection.
- **Simplicity**: Simplifies deployment by eliminating the need to repeatedly specify custom classes at runtime, making the model directly usable with its embedded vocabulary.
- **Performance**: Enhances detection [accuracy](https://www.ultralytics.com/glossary/accuracy) for specified classes by focusing the model's attention and resources on recognizing the defined objects.
This approach provides a powerful means of customizing state-of-the-art object detection models for specific tasks, making advanced AI more accessible and applicable to a broader range of practical applications.
## Reproduce official results from scratch(Experimental)
### Prepar
| |
270929
|
---
comments: true
description: Learn how to export YOLO11 models to CoreML for optimized, on-device machine learning on iOS and macOS. Follow step-by-step instructions.
keywords: CoreML export, YOLO11 models, CoreML conversion, Ultralytics, iOS object detection, macOS machine learning, AI deployment, machine learning integration
---
# CoreML Export for YOLO11 Models
Deploying [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models on Apple devices like iPhones and Macs requires a format that ensures seamless performance.
The CoreML export format allows you to optimize your [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics) models for efficient [object detection](https://www.ultralytics.com/glossary/object-detection) in iOS and macOS applications. In this guide, we'll walk you through the steps for converting your models to the CoreML format, making it easier for your models to perform well on Apple devices.
## CoreML
<p align="center">
<img width="100%" src="https://github.com/ultralytics/docs/releases/download/0/coreml-overview.avif" alt="CoreML Overview">
</p>
[CoreML](https://developer.apple.com/documentation/coreml) is Apple's foundational machine learning framework that builds upon Accelerate, BNNS, and Metal Performance Shaders. It provides a machine-learning model format that seamlessly integrates into iOS applications and supports tasks such as image analysis, [natural language processing](https://www.ultralytics.com/glossary/natural-language-processing-nlp), audio-to-text conversion, and sound analysis.
Applications can take advantage of Core ML without the need to have a network connection or API calls because the Core ML framework works using on-device computing. This means model inference can be performed locally on the user's device.
## Key Features of CoreML Models
Apple's CoreML framework offers robust features for on-device machine learning. Here are the key features that make CoreML a powerful tool for developers:
- **Comprehensive Model Support**: Converts and runs models from popular frameworks like TensorFlow, [PyTorch](https://www.ultralytics.com/glossary/pytorch), scikit-learn, XGBoost, and LibSVM.
<p align="center">
<img width="100%" src="https://github.com/ultralytics/docs/releases/download/0/coreml-supported-models.avif" alt="CoreML Supported Models">
</p>
- **On-device [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml)**: Ensures data privacy and swift processing by executing models directly on the user's device, eliminating the need for network connectivity.
- **Performance and Optimization**: Uses the device's CPU, GPU, and Neural Engine for optimal performance with minimal power and memory usage. Offers tools for model compression and optimization while maintaining [accuracy](https://www.ultralytics.com/glossary/accuracy).
- **Ease of Integration**: Provides a unified format for various model types and a user-friendly API for seamless integration into apps. Supports domain-specific tasks through frameworks like Vision and Natural Language.
- **Advanced Features**: Includes on-device training capabilities for personalized experiences, asynchronous predictions for interactive ML experiences, and model inspection and validation tools.
## CoreML Deployment Options
Before we look at the code for exporting YOLO11 models to the CoreML format, let's understand where CoreML models are usually used.
CoreML offers various deployment options for machine learning models, including:
- **On-Device Deployment**: This method directly integrates CoreML models into your iOS app. It's particularly advantageous for ensuring low latency, enhanced privacy (since data remains on the device), and offline functionality. This approach, however, may be limited by the device's hardware capabilities, especially for larger and more complex models. On-device deployment can be executed in the following two ways.
- **Embedded Models**: These models are included in the app bundle and are immediately accessible. They are ideal for small models that do not require frequent updates.
- **Downloaded Models**: These models are fetched from a server as needed. This approach is suitable for larger models or those needing regular updates. It helps keep the app bundle size smaller.
- **Cloud-Based Deployment**: CoreML models are hosted on servers and accessed by the iOS app through API requests. This scalable and flexible option enables easy model updates without app revisions. It's ideal for complex models or large-scale apps requiring regular updates. However, it does require an internet connection and may pose latency and security issues.
## Exporting YOLO11 Models to CoreML
Exporting YOLO11 to CoreML enables optimized, on-device machine learning performance within Apple's ecosystem, offering benefits in terms of efficiency, security, and seamless integration with iOS, macOS, watchOS, and tvOS platforms.
### Installation
To install the required package, run:
!!! tip "Installation"
=== "CLI"
```bash
# Install the required package for YOLO11
pip install ultralytics
```
For detailed instructions and best practices related to the installation process, check our [YOLO11 Installation guide](../quickstart.md). While installing the required packages for YOLO11, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
### Usage
Before diving into the usage instructions, be sure to check out the range of [YOLO11 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
!!! example "Usage"
=== "Python"
```python
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Export the model to CoreML format
model.export(format="coreml") # creates 'yolo11n.mlpackage'
# Load the exported CoreML model
coreml_model = YOLO("yolo11n.mlpackage")
# Run inference
results = coreml_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
```bash
# Export a YOLO11n PyTorch model to CoreML format
yolo export model=yolo11n.pt format=coreml # creates 'yolo11n.mlpackage''
# Run inference with the exported model
yolo predict model=yolo11n.mlpackage source='https://ultralytics.com/images/bus.jpg'
```
For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
## Deploying Exported YOLO11 CoreML Models
Having successfully exported your Ultralytics YOLO11 models to CoreML, the next critical phase is deploying these models effectively. For detailed guidance on deploying CoreML models in various environments, check out these resources:
- **[CoreML Tools](https://apple.github.io/coremltools/docs-guides/)**: This guide includes instructions and examples to convert models from [TensorFlow](https://www.ultralytics.com/glossary/tensorflow), PyTorch, and other libraries to Core ML.
- **[ML and Vision](https://developer.apple.com/videos/)**: A collection of comprehensive videos that cover various aspects of using and implementing CoreML models.
- **[Integrating a Core ML Model into Your App](https://developer.apple.com/documentation/coreml/integrating-a-core-ml-model-into-your-app)**: A comprehensive guide on integrating a CoreML model into an iOS application, detailing steps from preparing the model to implementing it in the app for various functionalities.
## Summary
In this guide, we went over how to export Ultralytics YOLO11 models to CoreML format. By following the steps outlined in this guide, you can ensure maximum compatibility and performance when exporting YOLO11 models to CoreML.
For further details on usage, visit the [CoreML official documentation](https://developer.apple.com/documentation/coreml).
Also, if you'd like to know more about other Ultralytics YOLO11 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of valuable resources and insights there.
| |
270930
|
## FAQ
### How do I export YOLO11 models to CoreML format?
To export your [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics) models to CoreML format, you'll first need to ensure you have the `ultralytics` package installed. You can install it using:
!!! example "Installation"
=== "CLI"
```bash
pip install ultralytics
```
Next, you can export the model using the following Python or CLI commands:
!!! example "Usage"
=== "Python"
```python
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
model.export(format="coreml")
```
=== "CLI"
```bash
yolo export model=yolo11n.pt format=coreml
```
For further details, refer to the [Exporting YOLO11 Models to CoreML](../modes/export.md) section of our documentation.
### What are the benefits of using CoreML for deploying YOLO11 models?
CoreML provides numerous advantages for deploying [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics) models on Apple devices:
- **On-device Processing**: Enables local model inference on devices, ensuring [data privacy](https://www.ultralytics.com/glossary/data-privacy) and minimizing latency.
- **Performance Optimization**: Leverages the full potential of the device's CPU, GPU, and Neural Engine, optimizing both speed and efficiency.
- **Ease of Integration**: Offers a seamless integration experience with Apple's ecosystems, including iOS, macOS, watchOS, and tvOS.
- **Versatility**: Supports a wide range of machine learning tasks such as image analysis, audio processing, and natural language processing using the CoreML framework.
For more details on integrating your CoreML model into an iOS app, check out the guide on [Integrating a Core ML Model into Your App](https://developer.apple.com/documentation/coreml/integrating-a-core-ml-model-into-your-app).
### What are the deployment options for YOLO11 models exported to CoreML?
Once you export your YOLO11 model to CoreML format, you have multiple deployment options:
1. **On-Device Deployment**: Directly integrate CoreML models into your app for enhanced privacy and offline functionality. This can be done as:
- **Embedded Models**: Included in the app bundle, accessible immediately.
- **Downloaded Models**: Fetched from a server as needed, keeping the app bundle size smaller.
2. **Cloud-Based Deployment**: Host CoreML models on servers and access them via API requests. This approach supports easier updates and can handle more complex models.
For detailed guidance on deploying CoreML models, refer to [CoreML Deployment Options](#coreml-deployment-options).
### How does CoreML ensure optimized performance for YOLO11 models?
CoreML ensures optimized performance for [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics) models by utilizing various optimization techniques:
- **Hardware Acceleration**: Uses the device's CPU, GPU, and Neural Engine for efficient computation.
- **Model Compression**: Provides tools for compressing models to reduce their footprint without compromising accuracy.
- **Adaptive Inference**: Adjusts inference based on the device's capabilities to maintain a balance between speed and performance.
For more information on performance optimization, visit the [CoreML official documentation](https://developer.apple.com/documentation/coreml).
### Can I run inference directly with the exported CoreML model?
Yes, you can run inference directly using the exported CoreML model. Below are the commands for Python and CLI:
!!! example "Running Inference"
=== "Python"
```python
from ultralytics import YOLO
coreml_model = YOLO("yolo11n.mlpackage")
results = coreml_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
```bash
yolo predict model=yolo11n.mlpackage source='https://ultralytics.com/images/bus.jpg'
```
For additional information, refer to the [Usage section](#usage) of the CoreML export guide.
| |
270932
|
# Interactive [Object Detection](https://www.ultralytics.com/glossary/object-detection): Gradio & Ultralytics YOLO11 🚀
## Introduction to Interactive Object Detection
This Gradio interface provides an easy and interactive way to perform object detection using the [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics/) model. Users can upload images and adjust parameters like confidence threshold and intersection-over-union (IoU) threshold to get real-time detection results.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/pWYiene9lYw"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Gradio Integration with Ultralytics YOLO11
</p>
## Why Use Gradio for Object Detection?
- **User-Friendly Interface:** Gradio offers a straightforward platform for users to upload images and visualize detection results without any coding requirement.
- **Real-Time Adjustments:** Parameters such as confidence and IoU thresholds can be adjusted on the fly, allowing for immediate feedback and optimization of detection results.
- **Broad Accessibility:** The Gradio web interface can be accessed by anyone, making it an excellent tool for demonstrations, educational purposes, and quick experiments.
<p align="center">
<img width="800" alt="Gradio example screenshot" src="https://github.com/ultralytics/docs/releases/download/0/gradio-example-screenshot.avif">
</p>
## How to Install the Gradio
```bash
pip install gradio
```
## How to Use the Interface
1. **Upload Image:** Click on 'Upload Image' to choose an image file for object detection.
2. **Adjust Parameters:**
- **Confidence Threshold:** Slider to set the minimum confidence level for detecting objects.
- **IoU Threshold:** Slider to set the IoU threshold for distinguishing different objects.
3. **View Results:** The processed image with detected objects and their labels will be displayed.
## Example Use Cases
- **Sample Image 1:** Bus detection with default thresholds.
- **Sample Image 2:** Detection on a sports image with default thresholds.
## Usage Example
This section provides the Python code used to create the Gradio interface with the Ultralytics YOLO11 model. Supports classification tasks, detection tasks, segmentation tasks, and key point tasks.
```python
import gradio as gr
import PIL.Image as Image
from ultralytics import ASSETS, YOLO
model = YOLO("yolo11n.pt")
def predict_image(img, conf_threshold, iou_threshold):
"""Predicts objects in an image using a YOLO11 model with adjustable confidence and IOU thresholds."""
results = model.predict(
source=img,
conf=conf_threshold,
iou=iou_threshold,
show_labels=True,
show_conf=True,
imgsz=640,
)
for r in results:
im_array = r.plot()
im = Image.fromarray(im_array[..., ::-1])
return im
iface = gr.Interface(
fn=predict_image,
inputs=[
gr.Image(type="pil", label="Upload Image"),
gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
],
outputs=gr.Image(type="pil", label="Result"),
title="Ultralytics Gradio",
description="Upload images for inference. The Ultralytics YOLO11n model is used by default.",
examples=[
[ASSETS / "bus.jpg", 0.25, 0.45],
[ASSETS / "zidane.jpg", 0.25, 0.45],
],
)
if __name__ == "__main__":
iface.launch()
```
## Parameters Explanation
| Parameter Name | Type | Description |
| ---------------- | ------- | -------------------------------------------------------- |
| `img` | `Image` | The image on which object detection will be performed. |
| `conf_threshold` | `float` | Confidence threshold for detecting objects. |
| `iou_threshold` | `float` | Intersection-over-union threshold for object separation. |
### Gradio Interface Components
| Component | Description |
| ------------ | ---------------------------------------- |
| Image Input | To upload the image for detection. |
| Sliders | To adjust confidence and IoU thresholds. |
| Image Output | To display the detection results. |
## FAQ
### How do I use Gradio with Ultralytics YOLO11 for object detection?
To use Gradio with Ultralytics YOLO11 for object detection, you can follow these steps:
1. **Install Gradio:** Use the command `pip install gradio`.
2. **Create Interface:** Write a Python script to initialize the Gradio interface. You can refer to the provided code example in the [documentation](#usage-example) for details.
3. **Upload and Adjust:** Upload your image and adjust the confidence and IoU thresholds on the Gradio interface to get real-time object detection results.
Here's a minimal code snippet for reference:
```python
import gradio as gr
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
def predict_image(img, conf_threshold, iou_threshold):
results = model.predict(
source=img,
conf=conf_threshold,
iou=iou_threshold,
show_labels=True,
show_conf=True,
)
return results[0].plot() if results else None
iface = gr.Interface(
fn=predict_image,
inputs=[
gr.Image(type="pil", label="Upload Image"),
gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
],
outputs=gr.Image(type="pil", label="Result"),
title="Ultralytics Gradio YOLO11",
description="Upload images for YOLO11 object detection.",
)
iface.launch()
```
### What are the benefits of using Gradio for Ultralytics YOLO11 object detection?
Using Gradio for Ultralytics YOLO11 object detection offers several benefits:
- **User-Friendly Interface:** Gradio provides an intuitive interface for users to upload images and visualize detection results without any coding effort.
- **Real-Time Adjustments:** You can dynamically adjust detection parameters such as confidence and IoU thresholds and see the effects immediately.
- **Accessibility:** The web interface is accessible to anyone, making it useful for quick experiments, educational purposes, and demonstrations.
For more details, you can read this [blog post](https://www.ultralytics.com/blog/ai-and-radiology-a-new-era-of-precision-and-efficiency).
### Can I use Gradio and Ultralytics YOLO11 together for educational purposes?
Yes, Gradio and Ultralytics YOLO11 can be utilized together for educational purposes effectively. Gradio's intuitive web interface makes it easy for students and educators to interact with state-of-the-art [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models like Ultralytics YOLO11 without needing advanced programming skills. This setup is ideal for demonstrating key concepts in object detection and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv), as Gradio provides immediate visual feedback which helps in understanding the impact of different parameters on the detection performance.
### How do I adjust the confidence and IoU thresholds in the Gradio interface for YOLO11?
In the Gradio interface for YOLO11, you can adjust the confidence and IoU thresholds using the sliders provided. These thresholds help control the prediction [accuracy](https://www.ultralytics.com/glossary/accuracy) and object separation:
- **Confidence Threshold:** Determines the minimum confidence level for detecting objects. Slide to increase or decrease the confidence required.
- **IoU Threshold:** Sets the intersection-over-union threshold for distinguishing between overlapping objects. Adjust this value to refine object separation.
For more information on these parameters, visit the [parameters explanation section](#parameters-explanation).
### What are some practical applications of using Ultralytics YOLO11 with Gradio?
Practical applications of combining Ultralytics YOLO11 with Gradio include:
- **Real-Time Object Detection Demonstrations:** Ideal for showcasing how object detection works in real-time.
- **Educational Tools:** Useful in academic settings to teach object detection and computer vision concepts.
- **Prototype Development:** Efficient for developing and testing prototype object detection applications quickly.
- **Community and Collaborations:** Making it easy to share models with the community for feedback and collaboration.
For examples of similar use cases, check out the [Ultralytics blog](https://www.ultralytics.com/blog/monitoring-animal-behavior-using-ultralytics-yolov8).
Providing this information within the documentation will help in enhancing the usability and accessibility of Ultralytics YOLO11, making it more approachable for users at all levels of expertise.
| |
270944
|
### Exporting TensorRT with INT8 Quantization
Exporting Ultralytics YOLO models using TensorRT with INT8 [precision](https://www.ultralytics.com/glossary/precision) executes post-training quantization (PTQ). TensorRT uses calibration for PTQ, which measures the distribution of activations within each activation tensor as the YOLO model processes inference on representative input data, and then uses that distribution to estimate scale values for each tensor. Each activation tensor that is a candidate for quantization has an associated scale that is deduced by a calibration process.
When processing implicitly quantized networks TensorRT uses INT8 opportunistically to optimize layer execution time. If a layer runs faster in INT8 and has assigned quantization scales on its data inputs and outputs, then a kernel with INT8 precision is assigned to that layer, otherwise TensorRT selects a precision of either FP32 or FP16 for the kernel based on whichever results in faster execution time for that layer.
!!! tip
It is **critical** to ensure that the same device that will use the TensorRT model weights for deployment is used for exporting with INT8 precision, as the calibration results can vary across devices.
#### Configuring INT8 Export
The arguments provided when using [export](../modes/export.md) for an Ultralytics YOLO model will **greatly** influence the performance of the exported model. They will also need to be selected based on the device resources available, however the default arguments _should_ work for most [Ampere (or newer) NVIDIA discrete GPUs](https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/). The calibration algorithm used is `"ENTROPY_CALIBRATION_2"` and you can read more details about the options available [in the TensorRT Developer Guide](https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c). Ultralytics tests found that `"ENTROPY_CALIBRATION_2"` was the best choice and exports are fixed to using this algorithm.
- `workspace` : Controls the size (in GiB) of the device memory allocation while converting the model weights.
- Adjust the `workspace` value according to your calibration needs and resource availability. While a larger `workspace` may increase calibration time, it allows TensorRT to explore a wider range of optimization tactics, potentially enhancing model performance and [accuracy](https://www.ultralytics.com/glossary/accuracy). Conversely, a smaller `workspace` can reduce calibration time but may limit the optimization strategies, affecting the quality of the quantized model.
- Default is `workspace=4` (GiB), this value may need to be increased if calibration crashes (exits without warning).
- TensorRT will report `UNSUPPORTED_STATE` during export if the value for `workspace` is larger than the memory available to the device, which means the value for `workspace` should be lowered.
- If `workspace` is set to max value and calibration fails/crashes, consider reducing the values for `imgsz` and `batch` to reduce memory requirements.
- <u><b>Remember</b> calibration for INT8 is specific to each device</u>, borrowing a "high-end" GPU for calibration, might result in poor performance when inference is run on another device.
- `batch` : The maximum batch-size that will be used for inference. During inference smaller batches can be used, but inference will not accept batches any larger than what is specified.
!!! note
During calibration, twice the `batch` size provided will be used. Using small batches can lead to inaccurate scaling during calibration. This is because the process adjusts based on the data it sees. Small batches might not capture the full range of values, leading to issues with the final calibration, so the `batch` size is doubled automatically. If no [batch size](https://www.ultralytics.com/glossary/batch-size) is specified `batch=1`, calibration will be run at `batch=1 * 2` to reduce calibration scaling errors.
Experimentation by NVIDIA led them to recommend using at least 500 calibration images that are representative of the data for your model, with INT8 quantization calibration. This is a guideline and not a _hard_ requirement, and <u>**you will need to experiment with what is required to perform well for your dataset**.</u> Since the calibration data is required for INT8 calibration with TensorRT, make certain to use the `data` argument when `int8=True` for TensorRT and use `data="my_dataset.yaml"`, which will use the images from [validation](../modes/val.md) to calibrate with. When no value is passed for `data` with export to TensorRT with INT8 quantization, the default will be to use one of the ["small" example datasets based on the model task](../datasets/index.md) instead of throwing an error.
!!! example
=== "Python"
```{ .py .annotate }
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(
format="engine",
dynamic=True, # (1)!
batch=8, # (2)!
workspace=4, # (3)!
int8=True,
data="coco.yaml", # (4)!
)
# Load the exported TensorRT INT8 model
model = YOLO("yolov8n.engine", task="detect")
# Run inference
result = model.predict("https://ultralytics.com/images/bus.jpg")
```
1. Exports with dynamic axes, this will be enabled by default when exporting with `int8=True` even when not explicitly set. See [export arguments](../modes/export.md#arguments) for additional information.
2. Sets max batch size of 8 for exported model, which calibrates with `batch = 2 * 8` to avoid scaling errors during calibration.
3. Allocates 4 GiB of memory instead of allocating the entire device for conversion process.
4. Uses [COCO dataset](../datasets/detect/coco.md) for calibration, specifically the images used for [validation](../modes/val.md) (5,000 total).
=== "CLI"
```bash
# Export a YOLOv8n PyTorch model to TensorRT format with INT8 quantization
yolo export model=yolov8n.pt format=engine batch=8 workspace=4 int8=True data=coco.yaml # creates 'yolov8n.engine''
# Run inference with the exported TensorRT quantized model
yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
```
???+ warning "Calibration Cache"
TensorRT will generate a calibration `.cache` which can be re-used to speed up export of future model weights using the same data, but this may result in poor calibration when the data is vastly different or if the `batch` value is changed drastically. In these circumstances, the existing `.cache` should be renamed and moved to a different directory or deleted entirely.
#### Advantages of using YOLO with TensorRT INT8
- **Reduced model size:** Quantization from FP32 to INT8 can reduce the model size by 4x (on disk or in memory), leading to faster download times. lower storage requirements, and reduced memory footprint when deploying a model.
- **Lower power consumption:** Reduced precision operations for INT8 exported YOLO models can consume less power compared to FP32 models, especially for battery-powered devices.
- **Improved inference speeds:** TensorRT optimizes the model for the target hardware, potentially leading to faster inference speeds on GPUs, embedded devices, and accelerators.
??? note "Note on Inference Speeds"
The first few inference calls with a model exported to TensorRT INT8 can be expected to have longer than usual preprocessing, inference, and/or postprocessing times. This may also occur when changing `imgsz` during inference, especially when `imgsz` is not the same as what was specified during export (export `imgsz` is set as TensorRT "optimal" profile).
#### Drawbacks of using YOLO with TensorRT INT8
- **Decreases in evaluation metrics:** Using a lower precision will mean that `mAP`, `Precision`, `Recall` or any [other metric used to evaluate model performance](../guides/yolo-performance-metrics.md) is likely to be somewhat worse. See the [Performance results section](#ultralytics-yolo-tensorrt-export-performance) to compare the differences in `mAP50` and `mAP50-95` when exporting with INT8 on small sample of various devices.
- **Increased development times:** Finding the "optimal" settings for INT8 calibration for dataset and device can take a significant amount of testing.
- **Hardware dependency:** Calibration and performance gains could be highly hardware dependent and model weights are less transferable.
## Ultralytics YOLO TensorRT Export Performance
### NVIDIA A100
!!! tip "Performance"
| |
270951
|
### Step 4: Preprocess the Data
Fortunately, all labels in the marine litter data set are already formatted as YOLO .txt files. However, we need to rearrange the structure of the image and label directories in order to help our model process the image and labels. Right now, our loaded data set directory follows this structure:
<p align="center">
<img width="400" src="https://github.com/ultralytics/docs/releases/download/0/marine-litter-bounding-box-1.avif" alt="Loaded Dataset Directory">
</p>
But, YOLO models by default require separate images and labels in subdirectories within the train/val/test split. We need to reorganize the directory into the following structure:
<p align="center">
<img width="400" src="https://github.com/ultralytics/docs/releases/download/0/yolo-directory-structure.avif" alt="Yolo Directory Structure">
</p>
To reorganize the data set directory, we can run the following script:
!!! example "Preprocess the Data"
=== "Python"
```python
# Function to reorganize dir
def organize_files(directory):
for subdir in ["train", "test", "val"]:
subdir_path = os.path.join(directory, subdir)
if not os.path.exists(subdir_path):
continue
images_dir = os.path.join(subdir_path, "images")
labels_dir = os.path.join(subdir_path, "labels")
# Create image and label subdirs if non-existent
os.makedirs(images_dir, exist_ok=True)
os.makedirs(labels_dir, exist_ok=True)
# Move images and labels to respective subdirs
for filename in os.listdir(subdir_path):
if filename.endswith(".txt"):
shutil.move(os.path.join(subdir_path, filename), os.path.join(labels_dir, filename))
elif filename.endswith(".jpg") or filename.endswith(".png") or filename.endswith(".jpeg"):
shutil.move(os.path.join(subdir_path, filename), os.path.join(images_dir, filename))
# Delete .xml files
elif filename.endswith(".xml"):
os.remove(os.path.join(subdir_path, filename))
if __name__ == "__main__":
directory = f"{work_dir}/trash_ICRA19/dataset"
organize_files(directory)
```
Next, we need to modify the .yaml file for the data set. This is the setup we will use in our .yaml file. Class ID numbers start from 0:
```yaml
path: /path/to/dataset/directory # root directory for dataset
train: train/images # train images subdirectory
val: train/images # validation images subdirectory
test: test/images # test images subdirectory
# Classes
names:
0: plastic
1: bio
2: rov
```
Run the following script to delete the current contents of config.yaml and replace it with the above contents that reflect our new data set directory structure. Be certain to replace the work_dir portion of the root directory path in line 4 with your own working directory path we retrieved earlier. Leave the train, val, and test subdirectory definitions. Also, do not change {work_dir} in line 23 of the code.
!!! example "Edit the .yaml File"
=== "Python"
```python
# Contents of new confg.yaml file
def update_yaml_file(file_path):
data = {
"path": "work_dir/trash_ICRA19/dataset",
"train": "train/images",
"val": "train/images",
"test": "test/images",
"names": {0: "plastic", 1: "bio", 2: "rov"},
}
# Ensures the "names" list appears after the sub/directories
names_data = data.pop("names")
with open(file_path, "w") as yaml_file:
yaml.dump(data, yaml_file)
yaml_file.write("\n")
yaml.dump({"names": names_data}, yaml_file)
if __name__ == "__main__":
file_path = f"{work_dir}/trash_ICRA19/config.yaml" # .yaml file path
update_yaml_file(file_path)
print(f"{file_path} updated successfully.")
```
### Step 5: Train the YOLO11 model
Run the following command-line code to fine tune a pretrained default YOLO11 model.
!!! example "Train the YOLO11 model"
=== "CLI"
```bash
!yolo task=detect mode=train data={work_dir}/trash_ICRA19/config.yaml model=yolo11n.pt epochs=2 batch=32 lr0=.04 plots=True
```
Here's a closer look at the parameters in the model training command:
- **task**: It specifies the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) task for which you are using the specified YOLO model and data set.
- **mode**: Denotes the purpose for which you are loading the specified model and data. Since we are training a model, it is set to "train." Later, when we test our model's performance, we will set it to "predict."
- **epochs**: This delimits the number of times YOLO11 will pass through our entire data set.
- **batch**: The numerical value stipulates the training [batch sizes](https://www.ultralytics.com/glossary/batch-size). Batches are the number of images a model processes before it updates its parameters.
- **lr0**: Specifies the model's initial [learning rate](https://www.ultralytics.com/glossary/learning-rate).
- **plots**: Directs YOLO to generate and save plots of our model's training and evaluation metrics.
For a detailed understanding of the model training process and best practices, refer to the [YOLO11 Model Training guide](../modes/train.md). This guide will help you get the most out of your experiments and ensure you're using YOLO11 effectively.
### Step 6: Test the Model
We can now run inference to test the performance of our fine-tuned model:
!!! example "Test the YOLO11 model"
=== "CLI"
```bash
!yolo task=detect mode=predict source={work_dir}/trash_ICRA19/dataset/test/images model={work_dir}/runs/detect/train/weights/best.pt conf=0.5 iou=.5 save=True save_txt=True
```
This brief script generates predicted labels for each image in our test set, as well as new output image files that overlay the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) atop the original image.
Predicted .txt labels for each image are saved via the `save_txt=True` argument and the output images with bounding box overlays are generated through the `save=True` argument.
The parameter `conf=0.5` informs the model to ignore all predictions with a confidence level of less than 50%.
Lastly, `iou=.5` directs the model to ignore boxes in the same class with an overlap of 50% or greater. It helps to reduce potential duplicate boxes generated for the same object.
we can load the images with predicted bounding box overlays to view how our model performs on a handful of images.
!!! example "Display Predictions"
=== "Python"
```python
# Show the first ten images from the preceding prediction task
for pred_dir in glob.glob(f"{work_dir}/runs/detect/predict/*.jpg")[:10]:
img = Image.open(pred_dir)
display(img)
```
The code above displays ten images from the test set with their predicted bounding boxes, accompanied by class name labels and confidence levels.
### Step 7: Evaluate the Model
We can produce visualizations of the model's [precision](https://www.ultralytics.com/glossary/precision) and recall for each class. These visualizations are saved in the home directory, under the train folder. The precision score is displayed in the P_curve.png:
<p align="center">
<img width="800" src="https://github.com/ultralytics/docs/releases/download/0/precision-confidence-curve.avif" alt="Precision Confidence Curve">
</p>
The graph shows an exponential increase in precision as the model's confidence level for predictions increases. However, the model precision has not yet leveled out at a certain confidence level after two [epochs](https://www.ultralytics.com/glossary/epoch).
The [recall](https://www.ultralytics.com/glossary/recall) graph (R_curve.png) displays an inverse trend:
<p align="center">
<img width="800" src="https://github.com/ultralytics/docs/releases/download/0/recall-confidence-curve.avif" alt="Recall Confidence Curve">
</p>
Unlike precision, recall moves in the opposite direction, showing greater recall with lower confidence instances and lower recall with higher confidence instances. This is an apt example of the trade-off in precision and recall for classification models.
| |
270960
|
---
comments: true
description: Learn to simplify the logging of YOLO11 training with Comet ML. This guide covers installation, setup, real-time insights, and custom logging.
keywords: YOLO11, Comet ML, logging, machine learning, training, model checkpoints, metrics, installation, configuration, real-time insights, custom logging
---
# Elevating YOLO11 Training: Simplify Your Logging Process with Comet ML
Logging key training details such as parameters, metrics, image predictions, and model checkpoints is essential in [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml)—it keeps your project transparent, your progress measurable, and your results repeatable.
[Ultralytics YOLO11](https://www.ultralytics.com/) seamlessly integrates with Comet ML, efficiently capturing and optimizing every aspect of your YOLO11 [object detection](https://www.ultralytics.com/glossary/object-detection) model's training process. In this guide, we'll cover the installation process, Comet ML setup, real-time insights, custom logging, and offline usage, ensuring that your YOLO11 training is thoroughly documented and fine-tuned for outstanding results.
## Comet ML
<p align="center">
<img width="640" src="https://www.comet.com/docs/v2/img/landing/home-hero.svg" alt="Comet ML Overview">
</p>
[Comet ML](https://www.comet.com/site/) is a platform for tracking, comparing, explaining, and optimizing machine learning models and experiments. It allows you to log metrics, parameters, media, and more during your model training and monitor your experiments through an aesthetically pleasing web interface. Comet ML helps data scientists iterate more rapidly, enhances transparency and reproducibility, and aids in the development of production models.
## Harnessing the Power of YOLO11 and Comet ML
By combining Ultralytics YOLO11 with Comet ML, you unlock a range of benefits. These include simplified experiment management, real-time insights for quick adjustments, flexible and tailored logging options, and the ability to log experiments offline when internet access is limited. This integration empowers you to make data-driven decisions, analyze performance metrics, and achieve exceptional results.
## Installation
To install the required packages, run:
!!! tip "Installation"
=== "CLI"
```bash
# Install the required packages for YOLO11 and Comet ML
pip install ultralytics comet_ml torch torchvision
```
## Configuring Comet ML
After installing the required packages, you'll need to sign up, get a [Comet API Key](https://www.comet.com/signup), and configure it.
!!! tip "Configuring Comet ML"
=== "CLI"
```bash
# Set your Comet Api Key
export COMET_API_KEY=<Your API Key>
```
Then, you can initialize your Comet project. Comet will automatically detect the API key and proceed with the setup.
!!! example "Initialize Comet project"
=== "Python"
```python
import comet_ml
comet_ml.login(project_name="comet-example-yolo11-coco128")
```
If you are using a Google Colab notebook, the code above will prompt you to enter your API key for initialization.
## Usage
Before diving into the usage instructions, be sure to check out the range of [YOLO11 models offered by Ultralytics](../models/yolo11.md). This will help you choose the most appropriate model for your project requirements.
!!! example "Usage"
=== "Python"
```python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt")
# Train the model
results = model.train(
data="coco8.yaml",
project="comet-example-yolo11-coco128",
batch=32,
save_period=1,
save_json=True,
epochs=3,
)
```
After running the training code, Comet ML will create an experiment in your Comet workspace to track the run automatically. You will then be provided with a link to view the detailed logging of your [YOLO11 model's training](../modes/train.md) process.
Comet automatically logs the following data with no additional configuration: metrics such as mAP and loss, hyperparameters, model checkpoints, interactive confusion matrix, and image [bounding box](https://www.ultralytics.com/glossary/bounding-box) predictions.
## Understanding Your Model's Performance with Comet ML Visualizations
Let's dive into what you'll see on the Comet ML dashboard once your YOLO11 model begins training. The dashboard is where all the action happens, presenting a range of automatically logged information through visuals and statistics. Here's a quick tour:
**Experiment Panels**
The experiment panels section of the Comet ML dashboard organize and present the different runs and their metrics, such as segment mask loss, class loss, precision, and [mean average precision](https://www.ultralytics.com/glossary/mean-average-precision-map).
<p align="center">
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/comet-ml-dashboard-overview.avif" alt="Comet ML Overview">
</p>
**Metrics**
In the metrics section, you have the option to examine the metrics in a tabular format as well, which is displayed in a dedicated pane as illustrated here.
<p align="center">
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/comet-ml-metrics-tabular.avif" alt="Comet ML Overview">
</p>
**Interactive [Confusion Matrix](https://www.ultralytics.com/glossary/confusion-matrix)**
The confusion matrix, found in the Confusion Matrix tab, provides an interactive way to assess the model's classification [accuracy](https://www.ultralytics.com/glossary/accuracy). It details the correct and incorrect predictions, allowing you to understand the model's strengths and weaknesses.
<p align="center">
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/comet-ml-interactive-confusion-matrix.avif" alt="Comet ML Overview">
</p>
**System Metrics**
Comet ML logs system metrics to help identify any bottlenecks in the training process. It includes metrics such as GPU utilization, GPU memory usage, CPU utilization, and RAM usage. These are essential for monitoring the efficiency of resource usage during model training.
<p align="center">
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/comet-ml-system-metrics.avif" alt="Comet ML Overview">
</p>
## Customizing Comet ML Logging
Comet ML offers the flexibility to customize its logging behavior by setting environment variables. These configurations allow you to tailor Comet ML to your specific needs and preferences. Here are some helpful customization options:
### Logging Image Predictions
You can control the number of image predictions that Comet ML logs during your experiments. By default, Comet ML logs 100 image predictions from the validation set. However, you can change this number to better suit your requirements. For example, to log 200 image predictions, use the following code:
```python
import os
os.environ["COMET_MAX_IMAGE_PREDICTIONS"] = "200"
```
### Batch Logging Interval
Comet ML allows you to specify how often batches of image predictions are logged. The `COMET_EVAL_BATCH_LOGGING_INTERVAL` environment variable controls this frequency. The default setting is 1, which logs predictions from every validation batch. You can adjust this value to log predictions at a different interval. For instance, setting it to 4 will log predictions from every fourth batch.
```python
import os
os.environ["COMET_EVAL_BATCH_LOGGING_INTERVAL"] = "4"
```
### Disabling Confusion Matrix Logging
In some cases, you may not want to log the confusion matrix from your validation set after every [epoch](https://www.ultralytics.com/glossary/epoch). You can disable this feature by setting the `COMET_EVAL_LOG_CONFUSION_MATRIX` environment variable to "false." The confusion matrix will only be logged once, after the training is completed.
```python
import os
os.environ["COMET_EVAL_LOG_CONFUSION_MATRIX"] = "false"
```
### Offline Logging
If you find yourself in a situation where internet access is limited, Comet ML provides an offline logging option. You can set the `COMET_MODE` environment variable to "offline" to enable this feature. Your experiment data will be saved locally in a directory that you can later upload to Comet ML when internet connectivity is available.
```python
import os
os.environ["COMET_MODE"] = "offline"
```
##
| |
270971
|
arguments for all of the various Ultralytics [tasks] and [modes]! That's a lot to remember and it can be easy to forget if the argument is `save_frame` or `save_frames` (it's definitely `save_frames` by the way). This is where the `ultra.kwargs` snippets can help out!
!!! example
To insert the [predict] method, including all [inference arguments], use `ultra.kwargs-predict`, which will insert the following code (including comments).
```python
model.predict(
source=src, # (str, optional) source directory for images or videos
imgsz=640, # (int | list) input images size as int or list[w,h] for predict
conf=0.25, # (float) minimum confidence threshold
iou=0.7, # (float) intersection over union (IoU) threshold for NMS
vid_stride=1, # (int) video frame-rate stride
stream_buffer=False, # (bool) buffer incoming frames in a queue (True) or only keep the most recent frame (False)
visualize=False, # (bool) visualize model features
augment=False, # (bool) apply image augmentation to prediction sources
agnostic_nms=False, # (bool) class-agnostic NMS
classes=None, # (int | list[int], optional) filter results by class, i.e. classes=0, or classes=[0,2,3]
retina_masks=False, # (bool) use high-resolution segmentation masks
embed=None, # (list[int], optional) return feature vectors/embeddings from given layers
show=False, # (bool) show predicted images and videos if environment allows
save=True, # (bool) save prediction results
save_frames=False, # (bool) save predicted individual video frames
save_txt=False, # (bool) save results as .txt file
save_conf=False, # (bool) save results with confidence scores
save_crop=False, # (bool) save cropped images with results
stream=False, # (bool) for processing long videos or numerous images with reduced memory usage by returning a generator
verbose=True, # (bool) enable/disable verbose inference logging in the terminal
)
```
This snippet has fields for all the keyword arguments, but also for `model` and `src` in case you've used a different variable in your code. On each line containing a keyword argument, a brief description is included for reference.
### All Code Snippets
The best way to find out what snippets are available is to download and install the extension and try it out! If you're curious and want to take a look at the list beforehand, you can visit the [repo] or [extension page on the VS Code marketplace] to view the tables for all available snippets.
## Conclusion
The Ultralytics-Snippets extension for VS Code is designed to empower data scientists and machine learning engineers to build [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) applications using Ultralytics YOLO more efficiently. By providing pre-built code snippets and useful examples, we help you focus on what matters most: creating innovative solutions. Please share your feedback by visiting the [extension page on the VS Code marketplace] and leaving a review. ⭐
## FAQ
### How do I request a new snippet?
New snippets can be requested using the Issues on the Ultralytics-Snippets [repo].
### How much does the Ultralytics-Extension Cost?
It's 100% free!
### Why don't I see a code snippet preview?
VS Code uses the key combination <kbd>Ctrl</kbd>+<kbd>Space</kbd> to show more/less information in the preview window. If you're not seeing a snippet preview when you type in a code snippet prefix, using this key combination should restore the preview.
### How do I disable the extension recommendation in Ultralytics?
If you use VS Code and have started to see a message prompting you to install the Ultralytics-snippets extension, and don't want to see the message any more, there are two ways to disable this message.
1. Install Ultralytics-snippets and the message will no longer be shown 😆!
2. You can using `yolo settings vscode_msg False` to disable the message from showing without having to install the extension. You can learn more about the [Ultralytics Settings] on the [quickstart] page if you're unfamiliar.
### I have an idea for a new Ultralytics code snippet, how can I get one added?
Visit the Ultralytics-snippets [repo] and open an Issue or Pull Request!
### How do I uninstall the Ultralytics-Snippets Extension?
Like any other VS Code extension, you can uninstall it by navigating to the Extensions menu in VS Code. Find the Ultralytics-snippets extension in the menu and click the cog icon (⚙) and then click on "Uninstall" to remove the extension.
<p align="center">
<br>
<img src="https://github.com/ultralytics/docs/releases/download/0/vscode-extension-menu.avif" alt="VS Code extension menu">
<br>
</p>
<!-- Article Links -->
[top]: #ultralytics-vs-code-extension
[export]: ../modes/export.md
[predict]: ../modes/predict.md
[track]: ../modes/track.md
[train]: ../modes/train.md
[val]: ../modes/val.md
[tasks]: ../tasks/index.md
[modes]: ../modes/index.md
[models]: ../models/index.md
[working with inference results]: ../modes/predict.md#working-with-results
[inference arguments]: ../modes/predict.md#inference-arguments
[Simple Utilities page]: ../usage/simple-utilities.md
[Ultralytics Settings]: ../quickstart.md/#ultralytics-settings
[quickstart]: ../quickstart.md
[Discord]: https://ultralytics.com/discord
[Discourse]: https://community.ultralytics.com
[Reddit]: https://reddit.com/r/Ultralytics
[GitHub]: https://github.com/ultralytics
[community poll]: https://community.ultralytics.com/t/what-do-you-use-to-write-code/89/1
[memes]: https://community.ultralytics.com/c/off-topic/memes-jokes/11
[repo]: https://github.com/Burhan-Q/ultralytics-snippets
[extension page on the VS Code marketplace]: https://marketplace.visualstudio.com/items?itemName=Ultralytics.ultralytics-snippets
[neovim install]: https://github.com/Burhan-Q/ultralytics-snippets?tab=readme-ov-file#use-with-neovim
[2021]: https://survey.stackoverflow.co/2021#section-most-popular-technologies-integrated-development-environment
[2022]: https://survey.stackoverflow.co/2022/#section-most-popular-technologies-integrated-development-environment
[2023]: https://survey.stackoverflow.co/2023/#section-most-popular-technologies-integrated-development-environment
[2024]: https://survey.stackoverflow.co/2024/technology/#1-integrated-development-environment
| |
271004
|
---
comments: true
description: Learn how to train YOLOv5 on your own custom datasets with easy-to-follow steps. Detailed guide on dataset preparation, model selection, and training process.
keywords: YOLOv5, custom dataset, model training, object detection, machine learning, AI, YOLO model, PyTorch, dataset preparation
---
📚 This guide explains how to train your own **custom dataset** with [YOLOv5](https://github.com/ultralytics/yolov5) 🚀.
## Before You Start
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.8.0**](https://www.python.org/) environment, including [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
```bash
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
```
## Train On Custom Data
<a href="https://www.ultralytics.com/hub" target="_blank">
<img width="100%" src="https://github.com/ultralytics/docs/releases/download/0/ultralytics-active-learning-loop.avif" alt="Ultralytics active learning"></a>
<br>
<br>
Creating a custom model to detect your objects is an iterative process of collecting and organizing images, labeling your objects of interest, training a model, deploying it into the wild to make predictions, and then using that deployed model to collect examples of edge cases to repeat and improve.
!!! question "Licensing"
Ultralytics offers two licensing options:
- The [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE), an [OSI-approved](https://opensource.org/license) open-source license ideal for students and enthusiasts.
- The [Enterprise License](https://www.ultralytics.com/license) for businesses seeking to incorporate our AI models into their products and services.
For more details see [Ultralytics Licensing](https://www.ultralytics.com/license).
YOLOv5 models must be trained on labelled data in order to learn classes of objects in that data. There are two options for creating your dataset before you start training:
## Option 1: Create a <a href="https://roboflow.com/?ref=ultralytics">Roboflow</a> Dataset
### 1.1 Collect Images
Your model will learn by example. Training on images similar to the ones it will see in the wild is of the utmost importance. Ideally, you will collect a wide variety of images from the same configuration (camera, angle, lighting, etc.) as you will ultimately deploy your project.
If this is not possible, you can start from [a public dataset](https://universe.roboflow.com/?ref=ultralytics) to train your initial model and then [sample images from the wild during inference](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) to improve your dataset and model iteratively.
### 1.2 Create Labels
Once you have collected images, you will need to annotate the objects of interest to create a ground truth for your model to learn from.
<p align="center"><a href="https://app.roboflow.com/?model=yolov5&ref=ultralytics" title="Create a Free Roboflow Account"><img width="450" src="https://github.com/ultralytics/docs/releases/download/0/roboflow-annotate.avif" alt="YOLOv5 accuracies"></a></p>
[Roboflow Annotate](https://roboflow.com/annotate?ref=ultralytics) is a simple web-based tool for managing and labeling your images with your team and exporting them in [YOLOv5's annotation format](https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics).
### 1.3 Prepare Dataset for YOLOv5
Whether you [label your images with Roboflow](https://roboflow.com/annotate?ref=ultralytics) or not, you can use it to convert your dataset into YOLO format, create a YOLOv5 YAML configuration file, and host it for importing into your training script.
[Create a free Roboflow account](https://app.roboflow.com/?model=yolov5&ref=ultralytics) and upload your dataset to a `Public` workspace, label any unannotated images, then generate and export a version of your dataset in `YOLOv5 Pytorch` format.
Note: YOLOv5 does online augmentation during training, so we do not recommend applying any augmentation steps in Roboflow for training with YOLOv5. But we recommend applying the following preprocessing steps:
<p align="center"><img width="450" src="https://github.com/ultralytics/docs/releases/download/0/roboflow-preprocessing-steps.avif" alt="Recommended Preprocessing Steps"></p>
- **Auto-Orient** - to strip EXIF orientation from your images.
- **Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).
Generating a version will give you a snapshot of your dataset, so you can always go back and compare your future model training runs against it, even if you add more images or change its configuration later.
<p align="center"><img width="450" src="https://github.com/ultralytics/docs/releases/download/0/roboflow-export.avif" alt="Export in YOLOv5 Format"></p>
Export in `YOLOv5 Pytorch` format, then copy the snippet into your training script or notebook to download your dataset.
<p align="center"><img width="450" src="https://github.com/ultralytics/docs/releases/download/0/roboflow-dataset-download-snippet.avif" alt="Roboflow dataset download snippet"></p>
## Opt
| |
271005
|
ion 2: Create a Manual Dataset
### 2.1 Create `dataset.yaml`
[COCO128](https://www.kaggle.com/datasets/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](https://cocodataset.org/) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of [overfitting](https://www.ultralytics.com/glossary/overfitting). [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or `*.txt` files with image paths) and 2) a class `names` dictionary:
```yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
```
### 2.2 Create Labels
After using an annotation tool to label your images, export your labels to **YOLO format**, with one `*.txt` file per image (if no objects in image, no `*.txt` file is required). The `*.txt` file specifications are:
- One row per object
- Each row is `class x_center y_center width height` format.
- Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, divide `x_center` and `width` by image width, and `y_center` and `height` by image height.
- Class numbers are zero-indexed (start from 0).
<p align="center"><img width="750" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie.avif" alt="Roboflow annotations"></p>
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
<p align="center"><img width="428" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie-1.avif" alt="Roboflow dataset preprocessing"></p>
### 2.3 Organize Directories
Organize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:
```bash
../datasets/coco128/images/im0.jpg # image
../datasets/coco128/labels/im0.txt # label
```
<p align="center"><img width="700" src="https://github.com/ultralytics/docs/releases/download/0/yolov5-dataset-structure.avif" alt="YOLOv5 dataset structure"></p>
## 3. Select a Model
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the second-smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
<p align="center"><img width="800" alt="YOLOv5 models" src="https://github.com/ultralytics/docs/releases/download/0/yolov5-model-comparison.avif"></p>
## 4. Train
Train a YOLOv5s model on COCO128 by specifying dataset, batch-size, image size and either pretrained `--weights yolov5s.pt` (recommended), or randomly initialized `--weights '' --cfg yolov5s.yaml` (not recommended). Pretrained weights are auto-downloaded from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).
```bash
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt
```
!!! tip
💡 Add `--cache ram` or `--cache disk` to speed up training (requires significant RAM/disk resources).
!!! tip
💡 Always train from a local dataset. Mounted or network drives like Google Drive will be very slow.
All training results are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc. For more details see the Training section of our tutorial notebook. <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/models/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
## 5. Visual
| |
271007
|
I train YOLOv5 on my custom dataset?
Training YOLOv5 on a custom dataset involves several steps:
1. **Prepare Your Dataset**: Collect and label images. Use tools like [Roboflow](https://roboflow.com/?ref=ultralytics) to organize data and export in [YOLOv5 format](https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics).
2. **Setup Environment**: Clone the YOLOv5 repo and install dependencies:
```bash
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
```
3. **Create Dataset Configuration**: Write a `dataset.yaml` file defining train/val paths and class names.
4. **Train the Model**:
```bash
python train.py --img 640 --epochs 3 --data dataset.yaml --weights yolov5s.pt
```
### What tools can I use to annotate my YOLOv5 dataset?
You can use [Roboflow Annotate](https://roboflow.com/annotate?ref=ultralytics), an intuitive web-based tool for labeling images. It supports team collaboration and exports in YOLOv5 format. After collecting images, use Roboflow to create and manage annotations efficiently. Other options include tools like LabelImg and CVAT for local annotations.
### Why should I use Ultralytics HUB for training my YOLO models?
Ultralytics HUB offers an end-to-end platform for training, deploying, and managing YOLO models without needing extensive coding skills. Benefits of using Ultralytics HUB include:
- **Easy Model Training**: Simplifies the training process with preconfigured environments.
- **Data Management**: Effortlessly manage datasets and version control.
- **Real-time Monitoring**: Integrates tools like [Comet](https://bit.ly/yolov5-readme-comet) for real-time metrics tracking and visualization.
- **Collaboration**: Ideal for team projects with shared resources and easy management.
### How do I convert my annotated data to YOLOv5 format?
To convert annotated data to YOLOv5 format using Roboflow:
1. **Upload Your Dataset** to a Roboflow workspace.
2. **Label Images** if not already labeled.
3. **Generate and Export** the dataset in `YOLOv5 Pytorch` format. Ensure preprocessing steps like Auto-Orient and Resize (Stretch) to the square input size (e.g., 640x640) are applied.
4. **Download the Dataset** and integrate it into your YOLOv5 training script.
### What are the licensing options for using YOLOv5 in commercial applications?
Ultralytics offers two licensing options:
- **AGPL-3.0 License**: An open-source license suitable for non-commercial use, ideal for students and enthusiasts.
- **Enterprise License**: Tailored for businesses seeking to integrate YOLOv5 into commercial products and services. For detailed information, visit our [Licensing page](https://www.ultralytics.com/license).
For more details, refer to our guide on [Ultralytics Licensing](https://www.ultralytics.com/license).
| |
271009
|
v5 with PyTorch Hub
### Simple Example
This example loads a pretrained YOLOv5s model from PyTorch Hub as `model` and passes an image for inference. `'yolov5s'` is the lightest and fastest YOLOv5 model. For details on all available models please see the [README](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
```python
import torch
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Image
im = "https://ultralytics.com/images/zidane.jpg"
# Inference
results = model(im)
results.pandas().xyxy[0]
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
```
### Detailed Example
This example shows **batched inference** with **PIL** and **[OpenCV](https://www.ultralytics.com/glossary/opencv)** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
```python
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Images
for f in "zidane.jpg", "bus.jpg":
torch.hub.download_url_to_file("https://ultralytics.com/images/" + f, f) # download 2 images
im1 = Image.open("zidane.jpg") # PIL image
im2 = cv2.imread("bus.jpg")[..., ::-1] # OpenCV image (BGR to RGB)
# Inference
results = model([im1, im2], size=640) # batch of images
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # im1 predictions (tensor)
results.pandas().xyxy[0] # im1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
```
<img src="https://github.com/ultralytics/docs/releases/download/0/yolo-inference-results-zidane.avif" width="500" alt="YOLO inference results on zidane.jpg">
<img src="https://github.com/ultralytics/docs/releases/download/0/yolo-inference-results-on-bus.avif" width="300" alt="YOLO inference results on bus.jpg">
For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
### Inference Settings
YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
```python
model.conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
agnostic = False # NMS class-agnostic
multi_label = False # NMS multiple labels per box
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
max_det = 1000 # maximum number of detections per image
amp = False # Automatic Mixed Precision (AMP) inference
results = model(im, size=320) # custom inference size
```
### Device
Models can be transferred to any device after creation:
```python
model.cpu() # CPU
model.cuda() # GPU
model.to(device) # i.e. device=torch.device(0)
```
Models can also be created directly on any `device`:
```python
model = torch.hub.load("ultralytics/yolov5", "yolov5s", device="cpu") # load on CPU
```
💡 ProTip: Input images are automatically transferred to the correct model device before inference.
### Silence Outputs
Models can be loaded silently with `_verbose=False`:
```python
model = torch.hub.load("ultralytics/yolov5", "yolov5s", _verbose=False) # load silently
```
### Input Channels
To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
```python
model = torch.hub.load("ultralytics/yolov5", "yolov5s", channels=4)
```
In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
### Number of Classes
To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
```python
model = torch.hub.load("ultralytics/yolov5", "yolov5s", classes=10)
```
In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
### Force Reload
If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
```python
model = torch.hub.load("ultralytics/yolov5", "yolov5s", force_reload=True) # force reload
```
### Screenshot Inference
To run inference on your desktop screen:
```python
import torch
from PIL import ImageGrab
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Image
im = ImageGrab.grab() # take a screenshot
# Inference
results = model(im)
```
### Multi-GPU Inference
YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
```python
import threading
import torch
def run(model, im):
"""Performs inference on an image using a given model and saves the output; model must support `.save()` method."""
results = model(im)
results.save()
# Models
model0 = torch.hub.load("ultralytics/yolov5", "yolov5s", device=0)
model1 = torch.hub.load("ultralytics/yolov5", "yolov5s", device=1)
# Inference
threading.Thread(target=run, args=[model0, "https://ultralytics.com/images/zidane.jpg"], daemon=True).start()
threading.Thread(target=run, args=[model1, "https://ultralytics.com/images/bus.jpg"], daemon=True).start()
```
### Training
T
| |
271010
|
o load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](./train_custom_data.md) for model training.
```python
import torch
model = torch.hub.load("ultralytics/yolov5", "yolov5s", autoshape=False) # load pretrained
model = torch.hub.load("ultralytics/yolov5", "yolov5s", autoshape=False, pretrained=False) # load scratch
```
### Base64 Results
For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
```python
results = model(im) # inference
results.ims # array of original images (as np array) passed to model for inference
results.render() # updates results.ims with boxes and labels
for im in results.ims:
buffered = BytesIO()
im_base64 = Image.fromarray(im)
im_base64.save(buffered, format="JPEG")
print(base64.b64encode(buffered.getvalue()).decode("utf-8")) # base64 encoded image with results
```
### Cropped Results
Results can be returned and saved as detection crops:
```python
results = model(im) # inference
crops = results.crop(save=True) # cropped detections dictionary
```
### Pandas Results
Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
```python
results = model(im) # inference
results.pandas().xyxy[0] # Pandas DataFrame
```
<details>
<summary>Pandas Output (click to expand)</summary>
```python
print(results.pandas().xyxy[0])
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
```
</details>
### Sorted Results
Results can be sorted by column, i.e. to sort license plate digit detection left-to-right (x-axis):
```python
results = model(im) # inference
results.pandas().xyxy[0].sort_values("xmin") # sorted left-right
```
### Box-Cropped Results
Results can be returned and saved as detection crops:
```python
results = model(im) # inference
crops = results.crop(save=True) # cropped detections dictionary
```
### JSON Results
Results can be returned in JSON format once converted to `.pandas()` dataframes using the `.to_json()` method. The JSON format can be modified using the `orient` argument. See pandas `.to_json()` [documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_json.html) for details.
```python
results = model(ims) # inference
results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
```
<details>
<summary>JSON Output (click to expand)</summary>
```json
[
{
"xmin": 749.5,
"ymin": 43.5,
"xmax": 1148.0,
"ymax": 704.5,
"confidence": 0.8740234375,
"class": 0,
"name": "person"
},
{
"xmin": 433.5,
"ymin": 433.5,
"xmax": 517.5,
"ymax": 714.5,
"confidence": 0.6879882812,
"class": 27,
"name": "tie"
},
{
"xmin": 115.25,
"ymin": 195.75,
"xmax": 1096.0,
"ymax": 708.0,
"confidence": 0.6254882812,
"class": 0,
"name": "person"
},
{
"xmin": 986.0,
"ymin": 304.0,
"xmax": 1028.0,
"ymax": 420.0,
"confidence": 0.2873535156,
"class": 27,
"name": "tie"
}
]
```
</details>
## Custom Models
This example loads a custom 20-class [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml)-trained YOLOv5s model `'best.pt'` with PyTorch Hub.
```python
import torch
model = torch.hub.load("ultralytics/yolov5", "custom", path="path/to/best.pt") # local model
model = torch.hub.load("path/to/yolov5", "custom", path="path/to/best.pt", source="local") # local repo
```
## TensorRT, ONNX and OpenVINO Models
PyTorch Hub supports inference on most YOLOv5 export formats, including custom trained models. See [TFLite, ONNX, CoreML, TensorRT Export tutorial](./model_export.md) for details on exporting models.
💡 ProTip: **TensorRT** may be up to 2-5X faster than PyTorch on [**GPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6963)
💡 ProTip: **ONNX** and **OpenVINO** may be up to 2-3X faster than PyTorch on [**CPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6613)
```python
import torch
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.pt") # PyTorch
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.torchscript") # TorchScript
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.onnx") # ONNX
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s_openvino_model/") # OpenVINO
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.engine") # TensorRT
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.mlmodel") # CoreML (macOS-only)
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.tflite") # TFLite
model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s_paddle_model/") # PaddlePaddle
```
## Supported Environm
| |
271023
|
---
comments: true
description: Dive deep into the powerful YOLOv5 architecture by Ultralytics, exploring its model structure, data augmentation techniques, training strategies, and loss computations.
keywords: YOLOv5 architecture, object detection, Ultralytics, YOLO, model structure, data augmentation, training strategies, loss computations, deep learning, machine learning
---
# Ultralytics YOLOv5 Architecture
YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and [image recognition](https://www.ultralytics.com/glossary/image-recognition).
## 1. Model Structure
YOLOv5's architecture consists of three main parts:
- **Backbone**: This is the main body of the network. For YOLOv5, the backbone is designed using the `New CSP-Darknet53` structure, a modification of the Darknet architecture used in previous versions.
- **Neck**: This part connects the backbone and the head. In YOLOv5, `SPPF` and `New CSP-PAN` structures are utilized.
- **Head**: This part is responsible for generating the final output. YOLOv5 uses the `YOLOv3 Head` for this purpose.
The structure of the model is depicted in the image below. The model structure details can be found in `yolov5l.yaml`.

YOLOv5 introduces some minor changes compared to its predecessors:
1. The `Focus` structure, found in earlier versions, is replaced with a `6x6 Conv2d` structure. This change boosts efficiency [#4825](https://github.com/ultralytics/yolov5/issues/4825).
2. The `SPP` structure is replaced with `SPPF`. This alteration more than doubles the speed of processing.
To test the speed of `SPP` and `SPPF`, the following code can be used:
<details>
<summary>SPP vs SPPF speed profiling example (click to open)</summary>
```python
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
"""Initializes an SPP module with three different sizes of max pooling layers."""
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
"""Applies three max pooling layers on input `x` and concatenates results along channel dimension."""
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
"""Initializes an SPPF module with a specific configuration of MaxPool2d layer."""
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
"""Applies sequential max pooling and concatenates results with input tensor."""
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
"""Compares outputs and performance of SPP and SPPF on a random tensor (8, 32, 16, 16)."""
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"SPP time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"SPPF time: {time.time() - t_start}")
if __name__ == "__main__":
main()
```
result:
```
True
SPP time: 0.5373051166534424
SPPF time: 0.20780706405639648
```
</details>
## 2. Data Augmentation Techniques
YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce [overfitting](https://www.ultralytics.com/glossary/overfitting). These techniques include:
- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage [object detection](https://www.ultralytics.com/glossary/object-detection) models to better handle various object scales and translations.

- **Copy-Paste Augmentation**: An innovative data augmentation method that copies random patches from an image and pastes them onto another randomly chosen image, effectively generating a new training sample.

- **Random Affine Transformations**: This includes random rotation, scaling, translation, and shearing of the images.

- **MixUp Augmentation**: A method that creates composite images by taking a linear combination of two images and their associated labels.

- **Albumentations**: A powerful library for image augmenting that supports a wide variety of augmentation techniques.
- **HSV Augmentation**: Random changes to the Hue, Saturation, and Value of the images.

- **Random Horizontal Flip**: An augmentation method that randomly flips images horizontally.

## 3. Training Strategies
YOLOv5 applies several sophisticated training strategies to enhance the model's performance. They include:
- **Multiscale Training**: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
- **AutoAnchor**: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
- **Warmup and Cosine LR Scheduler**: A method to adjust the [learning rate](https://www.ultralytics.com/glossary/learning-rate) to enhance model performance.
- **Exponential Moving Average (EMA)**: A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
- **[Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision) Training**: A method to perform operations in half-[precision](https://www.ultralytics.com/glossary/precision) format, reducing memory usage and enhancing computational speed.
- **Hyperparameter Evolution**: A strategy to automatically tune hyperparameters to achieve optimal performance.
| |
271025
|
---
comments: true
description: Learn to freeze YOLOv5 layers for efficient transfer learning, reducing resources and speeding up training while maintaining accuracy.
keywords: YOLOv5, transfer learning, freeze layers, machine learning, deep learning, model training, PyTorch, Ultralytics
---
📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **[transfer learning](https://www.ultralytics.com/glossary/transfer-learning)**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
## Before You Start
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.8.0**](https://www.python.org/) environment, including [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
```bash
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
```
## Freeze Backbone
All layers that match the train.py `freeze` list in train.py will be frozen by setting their gradients to zero before training starts.
```python
# Freeze
freeze = [f"model.{x}." for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f"freezing {k}")
v.requires_grad = False
```
To see a list of module names:
```python
for k, v in model.named_parameters():
print(k)
"""Output:
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
"""
```
Looking at the model architecture we can see that the model backbone is layers 0-9:
```yaml
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, C3, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C3, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv5 v6.0 head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C3, [512, False]] # 13
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
```
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
```bash
python train.py --freeze 10
```
## Freeze All Layers
To freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:
```bash
python train.py --freeze 24
```
## Results
We train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained `--weights yolov5m.pt`:
```bash
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
```
### Accuracy Comparison
The results show that freezing speeds up training, but reduces final [accuracy](https://www.ultralytics.com/glossary/accuracy) slightly.


<img width="922" alt="Table results" src="https://github.com/ultralytics/docs/releases/download/0/table-results.avif">
### GPU Utilization Comparison
Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.


## Sup
| |
271039
|
---
comments: true
description: Discover how to achieve optimal mAP and training results using YOLOv5. Learn essential dataset, model selection, and training settings best practices.
keywords: YOLOv5 training, mAP, dataset best practices, model selection, training settings, YOLOv5 guide, YOLOv5 tutorial, machine learning
---
📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀.
Most of the time good results can be obtained with no changes to the models or training settings, **provided your dataset is sufficiently large and well labelled**. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users **first train with all default settings** before considering any changes. This helps establish a performance baseline and spot areas for improvement.
If you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, [confusion matrix](https://www.ultralytics.com/glossary/confusion-matrix), training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.
We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.
## Dataset
- **Images per class.** ≥ 1500 images per class recommended
- **Instances per class.** ≥ 10000 instances (labeled objects) per class recommended
- **Image variety.** Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.
- **Label consistency.** All instances of all classes in all images must be labelled. Partial labelling will not work.
- **Label [accuracy](https://www.ultralytics.com/glossary/accuracy).** Labels must closely enclose each object. No space should exist between an object and it's [bounding box](https://www.ultralytics.com/glossary/bounding-box). No objects should be missing a label.
- **Label verification.** View `train_batch*.jpg` on train start to verify your labels appear correct, i.e. see [example](./train_custom_data.md#local-logging) mosaic.
- **Background images.** Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). No labels are required for background images.
<a href="https://arxiv.org/abs/1405.0312"><img width="800" src="https://github.com/ultralytics/docs/releases/download/0/coco-analysis.avif" alt="COCO Analysis"></a>
## Model Selection
Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
<p align="center"><img width="700" alt="YOLOv5 Models" src="https://github.com/ultralytics/docs/releases/download/0/yolov5-model-comparison.avif"></p>
- **Start from Pretrained weights.** Recommended for small to medium-sized datasets (i.e. [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml)). Pass the name of the model to the `--weights` argument. Models download automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).
```shell
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
```
- **Start from Scratch.** Recommended for large datasets (i.e. [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [OIv6](https://storage.googleapis.com/openimages/web/index.html)). Pass the model architecture YAML you are interested in, along with an empty `--weights ''` argument:
```bash
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml
```
## Training Settings
Before modifying anything, **first train with default settings to establish a performance baseline**. A full list of train.py settings can be found in the [train.py](https://github.com/ultralytics/yolov5/blob/master/train.py) argparser.
- **[Epochs](https://www.ultralytics.com/glossary/epoch).** Start with 300 epochs. If this overfits early then you can reduce epochs. If [overfitting](https://www.ultralytics.com/glossary/overfitting) does not occur after 300 epochs, train longer, i.e. 600, 1200 etc. epochs.
- **Image size.** COCO trains at native resolution of `--img 640`, though due to the high amount of small objects in the dataset it can benefit from training at higher resolutions such as `--img 1280`. If there are many small objects then custom datasets will benefit from training at native or higher resolution. Best inference results are obtained at the same `--img` as the training was run at, i.e. if you train at `--img 1280` you should also test and detect at `--img 1280`.
- **[Batch size](https://www.ultralytics.com/glossary/batch-size).** Use the largest `--batch-size` that your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided.
- **Hyperparameters.** Default hyperparameters are in [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml). We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP. Reduction in loss component gain hyperparameters like `hyp['obj']` will help reduce overfitting in those specific loss components. For an automated method of optimizing these hyperparameters, see our [Hyperparameter Evolution Tutorial](./hyperparameter_evolution.md).
## Further Reading
If you'd like to know more, a good place to start is Karpathy's 'Recipe for Training [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn)', which has great ideas for training that apply broadly across all ML domains: [https://karpathy.github.io/2019/04/25/recipe/](https://karpathy.github.io/2019/04/25/recipe/)
Good luck 🍀 and let us know if you have any other questions!
| |
271040
|
| Argument | Type | Default | Description |
| --------------- | -------------- | ---------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | `str` | `'ultralytics/assets'` | Specifies the data source for inference. Can be an image path, video file, directory, URL, or device ID for live feeds. Supports a wide range of formats and sources, enabling flexible application across [different types of input](/modes/predict.md/#inference-sources). |
| `conf` | `float` | `0.25` | Sets the minimum confidence threshold for detections. Objects detected with confidence below this threshold will be disregarded. Adjusting this value can help reduce false positives. |
| `iou` | `float` | `0.7` | [Intersection Over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) threshold for Non-Maximum Suppression (NMS). Lower values result in fewer detections by eliminating overlapping boxes, useful for reducing duplicates. |
| `imgsz` | `int or tuple` | `640` | Defines the image size for inference. Can be a single integer `640` for square resizing or a (height, width) tuple. Proper sizing can improve detection [accuracy](https://www.ultralytics.com/glossary/accuracy) and processing speed. |
| `half` | `bool` | `False` | Enables half-[precision](https://www.ultralytics.com/glossary/precision) (FP16) inference, which can speed up model inference on supported GPUs with minimal impact on accuracy. |
| `device` | `str` | `None` | Specifies the device for inference (e.g., `cpu`, `cuda:0` or `0`). Allows users to select between CPU, a specific GPU, or other compute devices for model execution. |
| `max_det` | `int` | `300` | Maximum number of detections allowed per image. Limits the total number of objects the model can detect in a single inference, preventing excessive outputs in dense scenes. |
| `vid_stride` | `int` | `1` | Frame stride for video inputs. Allows skipping frames in videos to speed up processing at the cost of temporal resolution. A value of 1 processes every frame, higher values skip frames. |
| `stream_buffer` | `bool` | `False` | Determines whether to queue incoming frames for video streams. If `False`, old frames get dropped to accomodate new frames (optimized for real-time applications). If `True', queues new frames in a buffer, ensuring no frames get skipped, but will cause latency if inference FPS is lower than stream FPS. |
| `visualize` | `bool` | `False` | Activates visualization of model features during inference, providing insights into what the model is "seeing". Useful for debugging and model interpretation. |
| `augment` | `bool` | `False` | Enables test-time augmentation (TTA) for predictions, potentially improving detection robustness at the cost of inference speed. |
| `agnostic_nms` | `bool` | `False` | Enables class-agnostic Non-Maximum Suppression (NMS), which merges overlapping boxes of different classes. Useful in multi-class detection scenarios where class overlap is common. |
| `classes` | `list[int]` | `None` | Filters predictions to a set of class IDs. Only detections belonging to the specified classes will be returned. Useful for focusing on relevant objects in multi-class detection tasks. |
| `retina_masks` | `bool` | `False` | Uses high-resolution segmentation masks if available in the model. This can enhance mask quality for segmentation tasks, providing finer detail. |
| `embed` | `list[int]` | `None` | Specifies the layers from which to extract feature vectors or [embeddings](https://www.ultralytics.com/glossary/embeddings). Useful for downstream tasks like clustering or similarity search. |
| `project` | `str` | `None` | Name of the project directory where prediction outputs are saved if `save` is enabled. |
| `name` | `str` | `None` | Name of the prediction run. Used for creating a subdirectory within the project folder, where prediction outputs are stored if `save` is enabled. |
| |
271041
|
| Argument | Default | Description |
| ----------------- | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| `model` | `None` | Specifies the model file for training. Accepts a path to either a `.pt` pretrained model or a `.yaml` configuration file. Essential for defining the model structure or initializing weights. |
| `data` | `None` | Path to the dataset configuration file (e.g., `coco8.yaml`). This file contains dataset-specific parameters, including paths to training and [validation data](https://www.ultralytics.com/glossary/validation-data), class names, and number of classes. |
| `epochs` | `100` | Total number of training epochs. Each [epoch](https://www.ultralytics.com/glossary/epoch) represents a full pass over the entire dataset. Adjusting this value can affect training duration and model performance. |
| `time` | `None` | Maximum training time in hours. If set, this overrides the `epochs` argument, allowing training to automatically stop after the specified duration. Useful for time-constrained training scenarios. |
| `patience` | `100` | Number of epochs to wait without improvement in validation metrics before early stopping the training. Helps prevent [overfitting](https://www.ultralytics.com/glossary/overfitting) by stopping training when performance plateaus. |
| `batch` | `16` | [Batch size](https://www.ultralytics.com/glossary/batch-size), with three modes: set as an integer (e.g., `batch=16`), auto mode for 60% GPU memory utilization (`batch=-1`), or auto mode with specified utilization fraction (`batch=0.70`). |
| `imgsz` | `640` | Target image size for training. All images are resized to this dimension before being fed into the model. Affects model [accuracy](https://www.ultralytics.com/glossary/accuracy) and computational complexity. |
| `save` | `True` | Enables saving of training checkpoints and final model weights. Useful for resuming training or [model deployment](https://www.ultralytics.com/glossary/model-deployment). |
| `save_period` | `-1` | Frequency of saving model checkpoints, specified in epochs. A value of -1 disables this feature. Useful for saving interim models during long training sessions. |
| `cache` | `False` | Enables caching of dataset images in memory (`True`/`ram`), on disk (`disk`), or disables it (`False`). Improves training speed by reducing disk I/O at the cost of increased memory usage. |
| `device` | `None` | Specifies the computational device(s) for training: a single GPU (`device=0`), multiple GPUs (`device=0,1`), CPU (`device=cpu`), or MPS for Apple silicon (`device=mps`). |
| `workers` | `8` | Number of worker threads for data loading (per `RANK` if Multi-GPU training). Influences the speed of data preprocessing and feeding into the model, especially useful in multi-GPU setups. |
| `project` | `None` | Name of the project directory where training outputs are saved. Allows for organized storage of different experiments. |
| `name` | `None` | Name of the training run. Used for creating a subdirectory within the project folder, where training logs and outputs are stored. |
| `exist_ok` | `False` | If True, allows overwriting of an existing project/name directory. Useful for iterative experimentation without needing to manually clear previous outputs. |
| `pretrained` | `True` | Determines whether to start training from a pretrained model. Can be a boolean value or a string path to a specific model from which to load weights. Enhances training efficiency and model performance. |
| `optimizer` | `'auto'` | Choice of optimizer for training. Options include `SGD`, `Adam`, `AdamW`, `NAdam`, `RAdam`, `RMSProp` etc., or `auto` for automatic selection based on model configuration. Affects convergence speed and stability. |
| `verbose` | `False` | Enables verbose output during training, providing detailed logs and progress updates. Useful for debugging and closely monitoring the training process. |
| `seed` | `0` | Sets the random seed for training, ensuring reproducibility of results across runs with the same configurations. |
| `deterministic` | `True` | Forces deterministic algorithm use, ensuring reproducibility but may affect performance and speed due to the restriction on non-deterministic algorithms. |
| `single_cls` | `False` | Treats all classes in multi-class datasets as a single class during training. Useful for binary classification tasks or when focusing on object presence rather than classification. |
| `rect` | `False` | Enables rectangular training, optimizing batch composition for minimal padding. Can improve efficiency and speed but may affect model accuracy. |
| `cos_lr` | `False` | Utilizes a cosine [learning rate](https://www.ultralytics.com/glossary/learning-rate) scheduler, adjusting the learning rate following a cosine curve over epochs. Helps in managing learning rate for better convergence. |
| `close_mosaic` | `10` | Disables mosaic [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) in the last N epochs to stabilize training before completion. Setting to 0 disables this feature. |
| `resume` | `False` | Resumes training from the last saved checkpoint. Automatically loads model weights, optimizer state, and epoch count, continuing training seamlessly. |
| `amp` | `True` | Enables Automatic [Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision) (AMP) training, reducing memory usage and possibly speeding up training with minimal impact on accuracy. |
| `fraction` | `1.0` | Specifies the fraction of the dataset to use for training. Allows for training on a subset of the full dataset, useful for experiments or when resources are limited. |
| `profile` | `False` | Enables profiling of ONNX and TensorRT speeds during training, useful for optimizing model deployment. |
| `freeze` | `None` | Freezes the first N layers of the model or specified layers by index, reducing the number of trainable parameters. Useful for fine-tuning or [transfer learning](https://www.ultralytics.com/glossary/transfer-learning). |
| `lr0` | `0.01` | Initial learning rate (i.e. `SGD=1E-2`, `Adam=1E-3`) . Adjusting this value is crucial for the optimization process, influencing how rapidly model weights are updated. |
| `lrf` | `0.01` | Final learning rate as a fraction of the initial rate = (`lr0 * lrf`), used in conjunction with schedulers to adjust the learning rate over time. |
| `momentum` | `0.937` | Momentum factor for SGD or beta1 for [Adam optimizers](https://www.ultralytics.com/glossary/adam-optimizer), influencing the incorporation of past gradients in the current update. |
| `weight_decay` | `0.0005` | L2 [regularization](https://www.ultralytics.com/glossary/regularization) term, penalizing large weights to prevent overfitting. |
| `warmup_epochs` | `3.0` | Number of epochs for learning rate warmup, gradually increasing the learning rate from a low value to the initial learning rate to stabilize training early on. |
| `warmup_momentum` | `0.8` | Initial momentum for warmup phase, gradually adjusting to the set momentum over the warmup period. |
| `warmup_bias_lr` | `0.1` | Learning rate for bias parameters during the warmup phase, helping stabilize model training in the initial epochs. |
| `box` | `7.5` | Weight of the box loss component in the [loss function](https://www.ultralytics.com/glossary/loss-function), influencing how much emphasis is placed on accurately predicting [bounding box](https://www.ultralytics.com/glossary/bounding-box) coordinates. |
| `cls` | `0.5` | Weight of the classification loss in the total loss function, affecting the importance of correct class prediction relative to other components. |
| `dfl` | `1.5` | Weight of the distribution focal loss, used in certain YOLO versions for fine-grained classification. |
| |
271045
|
| Argument | Type | Default | Description |
| ----------- | ---------------- | --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `format` | `str` | `'torchscript'` | Target format for the exported model, such as `'onnx'`, `'torchscript'`, `'tensorflow'`, or others, defining compatibility with various deployment environments. |
| `imgsz` | `int` or `tuple` | `640` | Desired image size for the model input. Can be an integer for square images or a tuple `(height, width)` for specific dimensions. |
| `keras` | `bool` | `False` | Enables export to Keras format for [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) SavedModel, providing compatibility with TensorFlow serving and APIs. |
| `optimize` | `bool` | `False` | Applies optimization for mobile devices when exporting to TorchScript, potentially reducing model size and improving performance. |
| `half` | `bool` | `False` | Enables FP16 (half-precision) quantization, reducing model size and potentially speeding up inference on supported hardware. |
| `int8` | `bool` | `False` | Activates INT8 quantization, further compressing the model and speeding up inference with minimal [accuracy](https://www.ultralytics.com/glossary/accuracy) loss, primarily for edge devices. |
| `dynamic` | `bool` | `False` | Allows dynamic input sizes for ONNX, TensorRT and OpenVINO exports, enhancing flexibility in handling varying image dimensions. |
| `simplify` | `bool` | `True` | Simplifies the model graph for ONNX exports with `onnxslim`, potentially improving performance and compatibility. |
| `opset` | `int` | `None` | Specifies the ONNX opset version for compatibility with different ONNX parsers and runtimes. If not set, uses the latest supported version. |
| `workspace` | `float` | `4.0` | Sets the maximum workspace size in GiB for TensorRT optimizations, balancing memory usage and performance. |
| `nms` | `bool` | `False` | Adds Non-Maximum Suppression (NMS) to the CoreML export, essential for accurate and efficient detection post-processing. |
| `batch` | `int` | `1` | Specifies export model batch inference size or the max number of images the exported model will process concurrently in `predict` mode. |
| `device` | `str` | `None` | Specifies the device for exporting: GPU (`device=0`), CPU (`device=cpu`), MPS for Apple silicon (`device=mps`) or DLA for NVIDIA Jetson (`device=dla:0` or `device=dla:1`). |
| |
271046
|
| Argument | Type | Default | Range | Description |
| ----------------- | ------- | ------------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `hsv_h` | `float` | `0.015` | `0.0 - 1.0` | Adjusts the hue of the image by a fraction of the color wheel, introducing color variability. Helps the model generalize across different lighting conditions. |
| `hsv_s` | `float` | `0.7` | `0.0 - 1.0` | Alters the saturation of the image by a fraction, affecting the intensity of colors. Useful for simulating different environmental conditions. |
| `hsv_v` | `float` | `0.4` | `0.0 - 1.0` | Modifies the value (brightness) of the image by a fraction, helping the model to perform well under various lighting conditions. |
| `degrees` | `float` | `0.0` | `-180 - +180` | Rotates the image randomly within the specified degree range, improving the model's ability to recognize objects at various orientations. |
| `translate` | `float` | `0.1` | `0.0 - 1.0` | Translates the image horizontally and vertically by a fraction of the image size, aiding in learning to detect partially visible objects. |
| `scale` | `float` | `0.5` | `>=0.0` | Scales the image by a gain factor, simulating objects at different distances from the camera. |
| `shear` | `float` | `0.0` | `-180 - +180` | Shears the image by a specified degree, mimicking the effect of objects being viewed from different angles. |
| `perspective` | `float` | `0.0` | `0.0 - 0.001` | Applies a random perspective transformation to the image, enhancing the model's ability to understand objects in 3D space. |
| `flipud` | `float` | `0.0` | `0.0 - 1.0` | Flips the image upside down with the specified probability, increasing the data variability without affecting the object's characteristics. |
| `fliplr` | `float` | `0.5` | `0.0 - 1.0` | Flips the image left to right with the specified probability, useful for learning symmetrical objects and increasing dataset diversity. |
| `bgr` | `float` | `0.0` | `0.0 - 1.0` | Flips the image channels from RGB to BGR with the specified probability, useful for increasing robustness to incorrect channel ordering. |
| `mosaic` | `float` | `1.0` | `0.0 - 1.0` | Combines four training images into one, simulating different scene compositions and object interactions. Highly effective for complex scene understanding. |
| `mixup` | `float` | `0.0` | `0.0 - 1.0` | Blends two images and their labels, creating a composite image. Enhances the model's ability to generalize by introducing label noise and visual variability. |
| `copy_paste` | `float` | `0.0` | `0.0 - 1.0` | Copies objects from one image and pastes them onto another, useful for increasing object instances and learning object occlusion. |
| `copy_paste_mode` | `str` | `flip` | - | Copy-Paste augmentation method selection among the options of (`"flip"`, `"mixup"`). |
| `auto_augment` | `str` | `randaugment` | - | Automatically applies a predefined augmentation policy (`randaugment`, `autoaugment`, `augmix`), optimizing for classification tasks by diversifying the visual features. |
| `erasing` | `float` | `0.4` | `0.0 - 0.9` | Randomly erases a portion of the image during classification training, encouraging the model to focus on less obvious features for recognition. |
| `crop_fraction` | `float` | `1.0` | `0.1 - 1.0` | Crops the classification image to a fraction of its size to emphasize central features and adapt to object scales, reducing background distractions. |
| |
271048
|
| Argument | Type | Default | Description |
| --------- | ------- | -------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | `str` | `None` | Specifies the source directory for images or videos. Supports file paths and URLs. |
| `persist` | `bool` | `False` | Enables persistent tracking of objects between frames, maintaining IDs across video sequences. |
| `tracker` | `str` | `botsort.yaml` | Specifies the tracking algorithm to use, e.g., `bytetrack.yaml` or `botsort.yaml`. |
| `conf` | `float` | `0.3` | Sets the confidence threshold for detections; lower values allow more objects to be tracked but may include false positives. |
| `iou` | `float` | `0.5` | Sets the [Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) threshold for filtering overlapping detections. |
| `classes` | `list` | `None` | Filters results by class index. For example, `classes=[0, 2, 3]` only tracks the specified classes. |
| `verbose` | `bool` | `True` | Controls the display of tracking results, providing a visual output of tracked objects. |
| |
271051
|
| Argument | Type | Default | Description |
| ------------- | --------------- | ----------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `show` | `bool` | `False` | If `True`, displays the annotated images or videos in a window. Useful for immediate visual feedback during development or testing. |
| `save` | `bool` | `False` or `True` | Enables saving of the annotated images or videos to file. Useful for documentation, further analysis, or sharing results. Defaults to True when using CLI & False when used in Python. |
| `save_frames` | `bool` | `False` | When processing videos, saves individual frames as images. Useful for extracting specific frames or for detailed frame-by-frame analysis. |
| `save_txt` | `bool` | `False` | Saves detection results in a text file, following the format `[class] [x_center] [y_center] [width] [height] [confidence]`. Useful for integration with other analysis tools. |
| `save_conf` | `bool` | `False` | Includes confidence scores in the saved text files. Enhances the detail available for post-processing and analysis. |
| `save_crop` | `bool` | `False` | Saves cropped images of detections. Useful for dataset augmentation, analysis, or creating focused datasets for specific objects. |
| `show_labels` | `bool` | `True` | Displays labels for each detection in the visual output. Provides immediate understanding of detected objects. |
| `show_conf` | `bool` | `True` | Displays the confidence score for each detection alongside the label. Gives insight into the model's certainty for each detection. |
| `show_boxes` | `bool` | `True` | Draws bounding boxes around detected objects. Essential for visual identification and location of objects in images or video frames. |
| `line_width` | `None` or `int` | `None` | Specifies the line width of bounding boxes. If `None`, the line width is automatically adjusted based on the image size. Provides visual customization for clarity. |
| |
271052
|
| Argument | Type | Default | Description |
| ------------- | ------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `data` | `str` | `None` | Specifies the path to the dataset configuration file (e.g., `coco8.yaml`). This file includes paths to [validation data](https://www.ultralytics.com/glossary/validation-data), class names, and number of classes. |
| `imgsz` | `int` | `640` | Defines the size of input images. All images are resized to this dimension before processing. |
| `batch` | `int` | `16` | Sets the number of images per batch. Use `-1` for AutoBatch, which automatically adjusts based on GPU memory availability. |
| `save_json` | `bool` | `False` | If `True`, saves the results to a JSON file for further analysis or integration with other tools. |
| `save_hybrid` | `bool` | `False` | If `True`, saves a hybrid version of labels that combines original annotations with additional model predictions. |
| `conf` | `float` | `0.001` | Sets the minimum confidence threshold for detections. Detections with confidence below this threshold are discarded. |
| `iou` | `float` | `0.6` | Sets the [Intersection Over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) threshold for Non-Maximum Suppression (NMS). Helps in reducing duplicate detections. |
| `max_det` | `int` | `300` | Limits the maximum number of detections per image. Useful in dense scenes to prevent excessive detections. |
| `half` | `bool` | `True` | Enables half-[precision](https://www.ultralytics.com/glossary/precision) (FP16) computation, reducing memory usage and potentially increasing speed with minimal impact on [accuracy](https://www.ultralytics.com/glossary/accuracy). |
| `device` | `str` | `None` | Specifies the device for validation (`cpu`, `cuda:0`, etc.). Allows flexibility in utilizing CPU or GPU resources. |
| `dnn` | `bool` | `False` | If `True`, uses the [OpenCV](https://www.ultralytics.com/glossary/opencv) DNN module for ONNX model inference, offering an alternative to [PyTorch](https://www.ultralytics.com/glossary/pytorch) inference methods. |
| `plots` | `bool` | `False` | When set to `True`, generates and saves plots of predictions versus ground truth for visual evaluation of the model's performance. |
| `rect` | `bool` | `False` | If `True`, uses rectangular inference for batching, reducing padding and potentially increasing speed and efficiency. |
| `split` | `str` | `val` | Determines the dataset split to use for validation (`val`, `test`, or `train`). Allows flexibility in choosing the data segment for performance evaluation. |
| `project` | `str` | `None` | Name of the project directory where validation outputs are saved. |
| `name` | `str` | `None` | Name of the validation run. Used for creating a subdirectory within the project folder, where valdiation logs and outputs are stored. |
| |
271054
|
---
comments: true
description: Enhance your security with real-time object detection using Ultralytics YOLO11. Reduce false positives and integrate seamlessly with existing systems.
keywords: YOLO11, Security Alarm System, real-time object detection, Ultralytics, computer vision, integration, false positives
---
# Security Alarm System Project Using Ultralytics YOLO11
<img src="https://github.com/ultralytics/docs/releases/download/0/security-alarm-system-ultralytics-yolov8.avif" alt="Security Alarm System">
The Security Alarm System Project utilizing Ultralytics YOLO11 integrates advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) capabilities to enhance security measures. YOLO11, developed by Ultralytics, provides real-time [object detection](https://www.ultralytics.com/glossary/object-detection), allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
- **Real-time Detection:** YOLO11's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
- **[Accuracy](https://www.ultralytics.com/glossary/accuracy):** YOLO11 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/_1CmwUzoxY4"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Security Alarm System Project with Ultralytics YOLO11 <a href="https://www.ultralytics.com/glossary/object-detection">Object Detection</a>
</p>
### Code
#### Set up the parameters of the message
???+ note
App Password Generation is necessary
- Navigate to [App Password Generator](https://myaccount.google.com/apppasswords), designate an app name such as "security project," and obtain a 16-digit password. Copy this password and paste it into the designated password field as instructed.
```python
password = ""
from_email = "" # must match the email used to generate the password
to_email = "" # receiver email
```
#### Server creation and authentication
```python
import smtplib
server = smtplib.SMTP("smtp.gmail.com: 587")
server.starttls()
server.login(from_email, password)
```
#### Email Send Function
```python
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
def send_email(to_email, from_email, object_detected=1):
"""Sends an email notification indicating the number of objects detected; defaults to 1 object."""
message = MIMEMultipart()
message["From"] = from_email
message["To"] = to_email
message["Subject"] = "Security Alert"
# Add in the message body
message_body = f"ALERT - {object_detected} objects has been detected!!"
message.attach(MIMEText(message_body, "plain"))
server.sendmail(from_email, to_email, message.as_string())
```
#### Object Detection and Alert Sender
```python
from time import time
import cv2
import torch
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
class ObjectDetection:
def __init__(self, capture_index):
"""Initializes an ObjectDetection instance with a given camera index."""
self.capture_index = capture_index
self.email_sent = False
# model information
self.model = YOLO("yolo11n.pt")
# visual information
self.annotator = None
self.start_time = 0
self.end_time = 0
# device information
self.device = "cuda" if torch.cuda.is_available() else "cpu"
def predict(self, im0):
"""Run prediction using a YOLO model for the input image `im0`."""
results = self.model(im0)
return results
def display_fps(self, im0):
"""Displays the FPS on an image `im0` by calculating and overlaying as white text on a black rectangle."""
self.end_time = time()
fps = 1 / round(self.end_time - self.start_time, 2)
text = f"FPS: {int(fps)}"
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 1.0, 2)[0]
gap = 10
cv2.rectangle(
im0,
(20 - gap, 70 - text_size[1] - gap),
(20 + text_size[0] + gap, 70 + gap),
(255, 255, 255),
-1,
)
cv2.putText(im0, text, (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 2)
def plot_bboxes(self, results, im0):
"""Plots bounding boxes on an image given detection results; returns annotated image and class IDs."""
class_ids = []
self.annotator = Annotator(im0, 3, results[0].names)
boxes = results[0].boxes.xyxy.cpu()
clss = results[0].boxes.cls.cpu().tolist()
names = results[0].names
for box, cls in zip(boxes, clss):
class_ids.append(cls)
self.annotator.box_label(box, label=names[int(cls)], color=colors(int(cls), True))
return im0, class_ids
def __call__(self):
"""Run object detection on video frames from a camera stream, plotting and showing the results."""
cap = cv2.VideoCapture(self.capture_index)
assert cap.isOpened()
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
frame_count = 0
while True:
self.start_time = time()
ret, im0 = cap.read()
assert ret
results = self.predict(im0)
im0, class_ids = self.plot_bboxes(results, im0)
if len(class_ids) > 0: # Only send email If not sent before
if not self.email_sent:
send_email(to_email, from_email, len(class_ids))
self.email_sent = True
else:
self.email_sent = False
self.display_fps(im0)
cv2.imshow("YOLO11 Detection", im0)
frame_count += 1
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
server.quit()
```
#### Call the Object Detection class and Run the Inference
```python
detector = ObjectDetection(capture_index=0)
detector()
```
That's it! When you execute the code, you'll receive a single notification on your email if any object is detected. The notification is sent immediately, not repeatedly. However, feel free to customize the code to suit your project requirements.
#### Email Received Sample
<img width="256" src="https://github.com/ultralytics/docs/releases/download/0/email-received-sample.avif" alt="Email Received Sample">
| |
271059
|
---
comments: true
description: Learn how to deploy Ultralytics YOLO11 on NVIDIA Jetson devices using TensorRT and DeepStream SDK. Explore performance benchmarks and maximize AI capabilities.
keywords: Ultralytics, YOLO11, NVIDIA Jetson, JetPack, AI deployment, embedded systems, deep learning, TensorRT, DeepStream SDK, computer vision
---
# Ultralytics YOLO11 on NVIDIA Jetson using DeepStream SDK and TensorRT
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/wWmXKIteRLA"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> How to Run Multiple Streams with DeepStream SDK on Jetson Nano using Ultralytics YOLO11
</p>
This comprehensive guide provides a detailed walkthrough for deploying Ultralytics YOLO11 on [NVIDIA Jetson](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/) devices using DeepStream SDK and TensorRT. Here we use TensorRT to maximize the inference performance on the Jetson platform.
<img width="1024" src="https://github.com/ultralytics/docs/releases/download/0/deepstream-nvidia-jetson.avif" alt="DeepStream on NVIDIA Jetson">
!!! note
This guide has been tested with both [Seeed Studio reComputer J4012](https://www.seeedstudio.com/reComputer-J4012-p-5586.html) which is based on NVIDIA Jetson Orin NX 16GB running JetPack release of [JP5.1.3](https://developer.nvidia.com/embedded/jetpack-sdk-513) and [Seeed Studio reComputer J1020 v2](https://www.seeedstudio.com/reComputer-J1020-v2-p-5498.html) which is based on NVIDIA Jetson Nano 4GB running JetPack release of [JP4.6.4](https://developer.nvidia.com/jetpack-sdk-464). It is expected to work across all the NVIDIA Jetson hardware lineup including latest and legacy.
## What is NVIDIA DeepStream?
[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate [neural networks](https://www.ultralytics.com/glossary/neural-network-nn) and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
## Prerequisites
Before you start to follow this guide:
- Visit our documentation, [Quick Start Guide: NVIDIA Jetson with Ultralytics YOLO11](nvidia-jetson.md) to set up your NVIDIA Jetson device with Ultralytics YOLO11
- Install [DeepStream SDK](https://developer.nvidia.com/deepstream-getting-started) according to the JetPack version
- For JetPack 4.6.4, install [DeepStream 6.0.1](https://docs.nvidia.com/metropolis/deepstream/6.0.1/dev-guide/text/DS_Quickstart.html)
- For JetPack 5.1.3, install [DeepStream 6.3](https://docs.nvidia.com/metropolis/deepstream/6.3/dev-guide/text/DS_Quickstart.html)
!!! tip
In this guide we have used the Debian package method of installing DeepStream SDK to the Jetson device. You can also visit the [DeepStream SDK on Jetson (Archived)](https://developer.nvidia.com/embedded/deepstream-on-jetson-downloads-archived) to access legacy versions of DeepStream.
## DeepStream Configuration for YOLO11
Here we are using [marcoslucianops/DeepStream-Yolo](https://github.com/marcoslucianops/DeepStream-Yolo) GitHub repository which includes NVIDIA DeepStream SDK support for YOLO models. We appreciate the efforts of marcoslucianops for his contributions!
1. Install dependencies
```bash
pip install cmake
pip install onnxsim
```
2. Clone the following repository
```bash
git clone https://github.com/marcoslucianops/DeepStream-Yolo
cd DeepStream-Yolo
```
3. Download Ultralytics YOLO11 detection model (.pt) of your choice from [YOLO11 releases](https://github.com/ultralytics/assets/releases). Here we use [yolov8s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt).
```bash
wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt
```
!!! note
You can also use a [custom trained YOLO11 model](https://docs.ultralytics.com/modes/train/).
4. Convert model to ONNX
```bash
python3 utils/export_yoloV8.py -w yolov8s.pt
```
!!! note "Pass the below arguments to the above command"
For DeepStream 6.0.1, use opset 12 or lower. The default opset is 16.
```bash
--opset 12
```
To change the inference size (default: 640)
```bash
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
```
Example for 1280:
```bash
-s 1280
or
-s 1280 1280
```
To simplify the ONNX model (DeepStream >= 6.0)
```bash
--simplify
```
To use dynamic batch-size (DeepStream >= 6.1)
```bash
--dynamic
```
To use static batch-size (example for batch-size = 4)
```bash
--batch 4
```
5. Set the CUDA version according to the JetPack version installed
For JetPack 4.6.4:
```bash
export CUDA_VER=10.2
```
For JetPack 5.1.3:
```bash
export CUDA_VER=11.4
```
6. Compile the library
```bash
make -C nvdsinfer_custom_impl_Yolo clean && make -C nvdsinfer_custom_impl_Yolo
```
7. Edit the `config_infer_primary_yoloV8.txt` file according to your model (for YOLOv8s with 80 classes)
```bash
[property]
...
onnx-file=yolov8s.onnx
...
num-detected-classes=80
...
```
8. Edit the `deepstream_app_config` file
```bash
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
```
9. You can also change the video source in `deepstream_app_config` file. Here a default video file is loaded
```bash
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
```
### Run Inference
```bash
deepstream-app -c deepstream_app_config.txt
```
!!! note
It will take a long time to generate the TensorRT engine file before starting the inference. So please be patient.
<div align=center><img width=1000 src="https://github.com/ultralytics/docs/releases/download/0/yolov8-with-deepstream.avif" alt="YOLO11 with deepstream"></div>
!!! tip
If you want to convert the model to FP16 [precision](https://www.ultralytics.com/glossary/precision), simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
| |
271062
|
---
comments: true
description: Explore the most effective ways to assess and refine YOLO11 models for better performance. Learn about evaluation metrics, fine-tuning processes, and how to customize your model for specific needs.
keywords: Model Evaluation, Machine Learning Model Evaluation, Fine Tuning Machine Learning, Fine Tune Model, Evaluating Models, Model Fine Tuning, How to Fine Tune a Model
---
# Insights on Model Evaluation and Fine-Tuning
## Introduction
Once you've [trained](./model-training-tips.md) your computer vision model, evaluating and refining it to perform optimally is essential. Just training your model isn't enough. You need to make sure that your model is accurate, efficient, and fulfills the [objective](./defining-project-goals.md) of your computer vision project. By evaluating and fine-tuning your model, you can identify weaknesses, improve its accuracy, and boost overall performance.
In this guide, we'll share insights on model evaluation and fine-tuning that'll make this [step of a computer vision project](./steps-of-a-cv-project.md) more approachable. We'll discuss how to understand evaluation metrics and implement fine-tuning techniques, giving you the knowledge to elevate your model's capabilities.
## Evaluating Model Performance Using Metrics
Evaluating how well a model performs helps us understand how effectively it works. Various metrics are used to measure performance. These [performance metrics](./yolo-performance-metrics.md) provide clear, numerical insights that can guide improvements toward making sure the model meets its intended goals. Let's take a closer look at a few key metrics.
### Confidence Score
The confidence score represents the model's certainty that a detected object belongs to a particular class. It ranges from 0 to 1, with higher scores indicating greater confidence. The confidence score helps filter predictions; only detections with confidence scores above a specified threshold are considered valid.
_Quick Tip:_ When running inferences, if you aren't seeing any predictions and you've checked everything else, try lowering the confidence score. Sometimes, the threshold is too high, causing the model to ignore valid predictions. Lowering the score allows the model to consider more possibilities. This might not meet your project goals, but it's a good way to see what the model can do and decide how to fine-tune it.
### Intersection over Union
[Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) is a metric in [object detection](https://www.ultralytics.com/glossary/object-detection) that measures how well the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
<p align="center">
<img width="100%" src="https://github.com/ultralytics/docs/releases/download/0/intersection-over-union-overview.avif" alt="Intersection over Union Overview">
</p>
### Mean Average [Precision](https://www.ultralytics.com/glossary/precision)
[Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) is a way to measure how well an object detection model performs. It looks at the precision of detecting each object class, averages these scores, and gives an overall number that shows how accurately the model can identify and classify objects.
Let's focus on two specific mAP metrics:
- *mAP@.5:* Measures the average precision at a single IoU (Intersection over Union) threshold of 0.5. This metric checks if the model can correctly find objects with a looser [accuracy](https://www.ultralytics.com/glossary/accuracy) requirement. It focuses on whether the object is roughly in the right place, not needing perfect placement. It helps see if the model is generally good at spotting objects.
- *mAP@.5:.95:* Averages the mAP values calculated at multiple IoU thresholds, from 0.5 to 0.95 in 0.05 increments. This metric is more detailed and strict. It gives a fuller picture of how accurately the model can find objects at different levels of strictness and is especially useful for applications that need precise object detection.
Other mAP metrics include mAP@0.75, which uses a stricter IoU threshold of 0.75, and mAP@small, medium, and large, which evaluate precision across objects of different sizes.
<p align="center">
<img width="100%" src="https://github.com/ultralytics/docs/releases/download/0/mean-average-precision-overview.avif" alt="Mean Average Precision Overview">
</p>
## Evaluating YOLO11 Model Performance
With respect to YOLO11, you can use the [validation mode](../modes/val.md) to evaluate the model. Also, be sure to take a look at our guide that goes in-depth into [YOLO11 performance metrics](./yolo-performance-metrics.md) and how they can be interpreted.
### Common Community Questions
When evaluating your YOLO11 model, you might run into a few hiccups. Based on common community questions, here are some tips to help you get the most out of your YOLO11 model:
#### Handling Variable Image Sizes
Evaluating your YOLO11 model with images of different sizes can help you understand its performance on diverse datasets. Using the `rect=true` validation parameter, YOLO11 adjusts the network's stride for each batch based on the image sizes, allowing the model to handle rectangular images without forcing them to a single size.
The `imgsz` validation parameter sets the maximum dimension for image resizing, which is 640 by default. You can adjust this based on your dataset's maximum dimensions and the GPU memory available. Even with `imgsz` set, `rect=true` lets the model manage varying image sizes effectively by dynamically adjusting the stride.
#### Accessing YOLO11 Metrics
If you want to get a deeper understanding of your YOLO11 model's performance, you can easily access specific evaluation metrics with a few lines of Python code. The code snippet below will let you load your model, run an evaluation, and print out various metrics that show how well your model is doing.
!!! example "Usage"
=== "Python"
```python
from ultralytics import YOLO
# Load the model
model = YOLO("yolo11n.pt")
# Run the evaluation
results = model.val(data="coco8.yaml")
# Print specific metrics
print("Class indices with average precision:", results.ap_class_index)
print("Average precision for all classes:", results.box.all_ap)
print("Average precision:", results.box.ap)
print("Average precision at IoU=0.50:", results.box.ap50)
print("Class indices for average precision:", results.box.ap_class_index)
print("Class-specific results:", results.box.class_result)
print("F1 score:", results.box.f1)
print("F1 score curve:", results.box.f1_curve)
print("Overall fitness score:", results.box.fitness)
print("Mean average precision:", results.box.map)
print("Mean average precision at IoU=0.50:", results.box.map50)
print("Mean average precision at IoU=0.75:", results.box.map75)
print("Mean average precision for different IoU thresholds:", results.box.maps)
print("Mean results for different metrics:", results.box.mean_results)
print("Mean precision:", results.box.mp)
print("Mean recall:", results.box.mr)
print("Precision:", results.box.p)
print("Precision curve:", results.box.p_curve)
print("Precision values:", results.box.prec_values)
print("Specific precision metrics:", results.box.px)
print("Recall:", results.box.r)
print("Recall curve:", results.box.r_curve)
```
The results object also includes speed metrics like preprocess time, inference time, loss, and postprocess time. By analyzing these metrics, you can fine-tune and optimize your YOLO11 model for better performance, making it more effective for your specific use case.
## How Does Fine-Tuning Work?
Fine-tuning involves taking a pre-trained model and adjusting its parameters to improve performance on a specific task or dataset. The process, also known as model retraining, allows the model to better understand and predict outcomes for the specific data it will encounter in real-world applications. You can retrain your model based on your model evaluation to achieve optimal results.
| |
271087
|
## Results
After you've successfully completed the hyperparameter tuning process, you will obtain several files and directories that encapsulate the results of the tuning. The following describes each:
### File Structure
Here's what the directory structure of the results will look like. Training directories like `train1/` contain individual tuning iterations, i.e. one model trained with one set of hyperparameters. The `tune/` directory contains tuning results from all the individual model trainings:
```plaintext
runs/
└── detect/
├── train1/
├── train2/
├── ...
└── tune/
├── best_hyperparameters.yaml
├── best_fitness.png
├── tune_results.csv
├── tune_scatter_plots.png
└── weights/
├── last.pt
└── best.pt
```
### File Descriptions
#### best_hyperparameters.yaml
This YAML file contains the best-performing hyperparameters found during the tuning process. You can use this file to initialize future trainings with these optimized settings.
- **Format**: YAML
- **Usage**: Hyperparameter results
- **Example**:
```yaml
# 558/900 iterations complete ✅ (45536.81s)
# Results saved to /usr/src/ultralytics/runs/detect/tune
# Best fitness=0.64297 observed at iteration 498
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
# Best fitness hyperparameters are printed below.
lr0: 0.00269
lrf: 0.00288
momentum: 0.73375
weight_decay: 0.00015
warmup_epochs: 1.22935
warmup_momentum: 0.1525
box: 18.27875
cls: 1.32899
dfl: 0.56016
hsv_h: 0.01148
hsv_s: 0.53554
hsv_v: 0.13636
degrees: 0.0
translate: 0.12431
scale: 0.07643
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.08631
mosaic: 0.42551
mixup: 0.0
copy_paste: 0.0
```
#### best_fitness.png
This is a plot displaying fitness (typically a performance metric like AP50) against the number of iterations. It helps you visualize how well the genetic algorithm performed over time.
- **Format**: PNG
- **Usage**: Performance visualization
<p align="center">
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/best-fitness.avif" alt="Hyperparameter Tuning Fitness vs Iteration">
</p>
#### tune_results.csv
A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), as well as the hyperparameters used.
- **Format**: CSV
- **Usage**: Per-iteration results tracking.
- **Example**:
```csv
fitness,lr0,lrf,momentum,weight_decay,warmup_epochs,warmup_momentum,box,cls,dfl,hsv_h,hsv_s,hsv_v,degrees,translate,scale,shear,perspective,flipud,fliplr,mosaic,mixup,copy_paste
0.05021,0.01,0.01,0.937,0.0005,3.0,0.8,7.5,0.5,1.5,0.015,0.7,0.4,0.0,0.1,0.5,0.0,0.0,0.0,0.5,1.0,0.0,0.0
0.07217,0.01003,0.00967,0.93897,0.00049,2.79757,0.81075,7.5,0.50746,1.44826,0.01503,0.72948,0.40658,0.0,0.0987,0.4922,0.0,0.0,0.0,0.49729,1.0,0.0,0.0
0.06584,0.01003,0.00855,0.91009,0.00073,3.42176,0.95,8.64301,0.54594,1.72261,0.01503,0.59179,0.40658,0.0,0.0987,0.46955,0.0,0.0,0.0,0.49729,0.80187,0.0,0.0
```
#### tune_scatter_plots.png
This file contains scatter plots generated from `tune_results.csv`, helping you visualize relationships between different hyperparameters and performance metrics. Note that hyperparameters initialized to 0 will not be tuned, such as `degrees` and `shear` below.
- **Format**: PNG
- **Usage**: Exploratory data analysis
<p align="center">
<img width="1000" src="https://github.com/ultralytics/docs/releases/download/0/tune-scatter-plots.avif" alt="Hyperparameter Tuning Scatter Plots">
</p>
#### weights/
This directory contains the saved [PyTorch](https://www.ultralytics.com/glossary/pytorch) models for the last and the best iterations during the hyperparameter tuning process.
- **`last.pt`**: The last.pt are the weights from the last epoch of training.
- **`best.pt`**: The best.pt weights for the iteration that achieved the best fitness score.
Using these results, you can make more informed decisions for your future model trainings and analyses. Feel free to consult these artifacts to understand how well your model performed and how you might improve it further.
## Conclusion
The hyperparameter tuning process in Ultralytics YOLO is simplified yet powerful, thanks to its genetic algorithm-based approach focused on mutation. Following the steps outlined in this guide will assist you in systematically tuning your model to achieve better performance.
### Further Reading
1. [Hyperparameter Optimization in Wikipedia](https://en.wikipedia.org/wiki/Hyperparameter_optimization)
2. [YOLOv5 Hyperparameter Evolution Guide](../yolov5/tutorials/hyperparameter_evolution.md)
3. [Efficient Hyperparameter Tuning with Ray Tune and YOLO11](../integrations/ray-tune.md)
For deeper insights, you can explore the `Tuner` class source code and accompanying documentation. Should you have any questions, feature requests, or need further assistance, feel free to reach out to us on [GitHub](https://github.com/ultralytics/ultralytics/issues/new/choose) or [Discord](https://discord.com/invite/ultralytics).
## FAQ
### How do I optimize the [learning rate](https://www.ultralytics.
| |
271096
|
## FAQ
### What is the best way to avoid bias in data collection for computer vision projects?
Avoiding bias in data collection ensures that your computer vision model performs well across various scenarios. To minimize bias, consider collecting data from diverse sources to capture different perspectives and scenarios. Ensure balanced representation among all relevant groups, such as different ages, genders, and ethnicities. Regularly review and update your dataset to identify and address any emerging biases. Techniques such as oversampling underrepresented classes, data augmentation, and fairness-aware algorithms can also help mitigate bias. By employing these strategies, you maintain a robust and fair dataset that enhances your model's generalization capability.
### How can I ensure high consistency and accuracy in data annotation?
Ensuring high consistency and accuracy in data annotation involves establishing clear and objective labeling guidelines. Your instructions should be detailed, with examples and illustrations to clarify expectations. Consistency is achieved by setting standard criteria for annotating various data types, ensuring all annotations follow the same rules. To reduce personal biases, train annotators to stay neutral and objective. Regular reviews and updates of labeling rules help maintain accuracy and alignment with project goals. Using automated tools to check for consistency and getting feedback from other annotators also contribute to maintaining high-quality annotations.
### How many images do I need for training Ultralytics YOLO models?
For effective [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 [epochs](https://www.ultralytics.com/glossary/epoch). More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLO11 training guide](../modes/train.md).
### What are some popular tools for data annotation?
Several popular open-source tools can streamline the data annotation process:
- **[Label Studio](https://github.com/HumanSignal/label-studio)**: A flexible tool supporting various annotation tasks, project management, and quality control features.
- **[CVAT](https://www.cvat.ai/)**: Offers multiple annotation formats and customizable workflows, making it suitable for complex projects.
- **[Labelme](https://github.com/wkentaro/labelme)**: Ideal for quick and straightforward image annotation with polygons.
These tools can help enhance the efficiency and accuracy of your annotation workflows. For extensive feature lists and guides, refer to our [data annotation tools documentation](../datasets/index.md).
### What types of data annotation are commonly used in computer vision?
Different types of data annotation cater to various computer vision tasks:
- **Bounding Boxes**: Used primarily for object detection, these are rectangular boxes around objects in an image.
- **Polygons**: Provide more precise object outlines suitable for instance segmentation tasks.
- **Masks**: Offer pixel-level detail, used in [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation) to differentiate objects from the background.
- **Keypoints**: Identify specific points of interest within an image, useful for tasks like pose estimation and facial landmark detection.
Selecting the appropriate annotation type depends on your project's requirements. Learn more about how to implement these annotations and their formats in our [data annotation guide](#what-is-data-annotation).
| |
271106
|
---
comments: true
description: Learn how to crop and extract objects using Ultralytics YOLO11 for focused analysis, reduced data volume, and enhanced precision.
keywords: Ultralytics, YOLO11, object cropping, object detection, image processing, video analysis, AI, machine learning
---
# Object Cropping using Ultralytics YOLO11
## What is Object Cropping?
Object cropping with [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics/) involves isolating and extracting specific detected objects from an image or video. The YOLO11 model capabilities are utilized to accurately identify and delineate objects, enabling precise cropping for further analysis or manipulation.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/ydGdibB5Mds"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Object Cropping using Ultralytics YOLO
</p>
## Advantages of Object Cropping?
- **Focused Analysis**: YOLO11 facilitates targeted object cropping, allowing for in-depth examination or processing of individual items within a scene.
- **Reduced Data Volume**: By extracting only relevant objects, object cropping helps in minimizing data size, making it efficient for storage, transmission, or subsequent computational tasks.
- **Enhanced Precision**: YOLO11's [object detection](https://www.ultralytics.com/glossary/object-detection) [accuracy](https://www.ultralytics.com/glossary/accuracy) ensures that the cropped objects maintain their spatial relationships, preserving the integrity of the visual information for detailed analysis.
## Visuals
| Airport Luggage |
| :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|  |
| Suitcases Cropping at airport conveyor belt using Ultralytics YOLO11 |
!!! example "Object Cropping using YOLO11 Example"
=== "Object Cropping"
```python
import os
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolo11n.pt")
names = model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
crop_dir_name = "ultralytics_crop"
if not os.path.exists(crop_dir_name):
os.mkdir(crop_dir_name)
# Video writer
video_writer = cv2.VideoWriter("object_cropping_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
idx = 0
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
results = model.predict(im0, show=False)
boxes = results[0].boxes.xyxy.cpu().tolist()
clss = results[0].boxes.cls.cpu().tolist()
annotator = Annotator(im0, line_width=2, example=names)
if boxes is not None:
for box, cls in zip(boxes, clss):
idx += 1
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
crop_obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
cv2.imwrite(os.path.join(crop_dir_name, str(idx) + ".png"), crop_obj)
cv2.imshow("ultralytics", im0)
video_writer.write(im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
```
### Arguments `model.predict`
{% include "macros/predict-args.md" %}
## FAQ
### What is object cropping in Ultralytics YOLO11 and how does it work?
Object cropping using [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics) involves isolating and extracting specific objects from an image or video based on YOLO11's detection capabilities. This process allows for focused analysis, reduced data volume, and enhanced [precision](https://www.ultralytics.com/glossary/precision) by leveraging YOLO11 to identify objects with high accuracy and crop them accordingly. For an in-depth tutorial, refer to the [object cropping example](#object-cropping-using-ultralytics-yolo11).
### Why should I use Ultralytics YOLO11 for object cropping over other solutions?
Ultralytics YOLO11 stands out due to its precision, speed, and ease of use. It allows detailed and accurate object detection and cropping, essential for [focused analysis](#advantages-of-object-cropping) and applications needing high data integrity. Moreover, YOLO11 integrates seamlessly with tools like OpenVINO and TensorRT for deployments requiring real-time capabilities and optimization on diverse hardware. Explore the benefits in the [guide on model export](../modes/export.md).
### How can I reduce the data volume of my dataset using object cropping?
By using Ultralytics YOLO11 to crop only relevant objects from your images or videos, you can significantly reduce the data size, making it more efficient for storage and processing. This process involves training the model to detect specific objects and then using the results to crop and save these portions only. For more information on exploiting Ultralytics YOLO11's capabilities, visit our [quickstart guide](../quickstart.md).
### Can I use Ultralytics YOLO11 for real-time video analysis and object cropping?
Yes, Ultralytics YOLO11 can process real-time video feeds to detect and crop objects dynamically. The model's high-speed inference capabilities make it ideal for real-time applications such as surveillance, sports analysis, and automated inspection systems. Check out the [tracking and prediction modes](../modes/predict.md) to understand how to implement real-time processing.
### What are the hardware requirements for efficiently running YOLO11 for object cropping?
Ultralytics YOLO11 is optimized for both CPU and GPU environments, but to achieve optimal performance, especially for real-time or high-volume inference, a dedicated GPU (e.g., NVIDIA Tesla, RTX series) is recommended. For deployment on lightweight devices, consider using CoreML for iOS or TFLite for Android. More details on supported devices and formats can be found in our [model deployment options](../guides/model-deployment-options.md).
| |
271113
|
---
comments: true
description: Learn how to use Ultralytics YOLO11 for real-time object blurring to enhance privacy and focus in your images and videos.
keywords: YOLO11, object blurring, real-time processing, privacy protection, image manipulation, video editing, Ultralytics
---
# Object Blurring using Ultralytics YOLO11 🚀
## What is Object Blurring?
Object blurring with [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics/) involves applying a blurring effect to specific detected objects in an image or video. This can be achieved using the YOLO11 model capabilities to identify and manipulate objects within a given scene.
<p align="center">
<br>
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/ydGdibB5Mds"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
allowfullscreen>
</iframe>
<br>
<strong>Watch:</strong> Object Blurring using Ultralytics YOLO11
</p>
## Advantages of Object Blurring?
- **Privacy Protection**: Object blurring is an effective tool for safeguarding privacy by concealing sensitive or personally identifiable information in images or videos.
- **Selective Focus**: YOLO11 allows for selective blurring, enabling users to target specific objects, ensuring a balance between privacy and retaining relevant visual information.
- **Real-time Processing**: YOLO11's efficiency enables object blurring in real-time, making it suitable for applications requiring on-the-fly privacy enhancements in dynamic environments.
!!! example "Object Blurring using YOLO11 Example"
=== "Object Blurring"
```python
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolo11n.pt")
names = model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Blur ratio
blur_ratio = 50
# Video writer
video_writer = cv2.VideoWriter("object_blurring_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
results = model.predict(im0, show=False)
boxes = results[0].boxes.xyxy.cpu().tolist()
clss = results[0].boxes.cls.cpu().tolist()
annotator = Annotator(im0, line_width=2, example=names)
if boxes is not None:
for box, cls in zip(boxes, clss):
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
blur_obj = cv2.blur(obj, (blur_ratio, blur_ratio))
im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])] = blur_obj
cv2.imshow("ultralytics", im0)
video_writer.write(im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
```
### Arguments `model.predict`
{% include "macros/predict-args.md" %}
## FAQ
### What is object blurring with Ultralytics YOLO11?
Object blurring with [Ultralytics YOLO11](https://github.com/ultralytics/ultralytics/) involves automatically detecting and applying a blurring effect to specific objects in images or videos. This technique enhances privacy by concealing sensitive information while retaining relevant visual data. YOLO11's real-time processing capabilities make it suitable for applications requiring immediate privacy protection and selective focus adjustments.
### How can I implement real-time object blurring using YOLO11?
To implement real-time object blurring with YOLO11, follow the provided Python example. This involves using YOLO11 for [object detection](https://www.ultralytics.com/glossary/object-detection) and OpenCV for applying the blur effect. Here's a simplified version:
```python
import cv2
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
while cap.isOpened():
success, im0 = cap.read()
if not success:
break
results = model.predict(im0, show=False)
for box in results[0].boxes.xyxy.cpu().tolist():
obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])] = cv2.blur(obj, (50, 50))
cv2.imshow("YOLO11 Blurring", im0)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
```
### What are the benefits of using Ultralytics YOLO11 for object blurring?
Ultralytics YOLO11 offers several advantages for object blurring:
- **Privacy Protection**: Effectively obscure sensitive or identifiable information.
- **Selective Focus**: Target specific objects for blurring, maintaining essential visual content.
- **Real-time Processing**: Execute object blurring efficiently in dynamic environments, suitable for instant privacy enhancements.
For more detailed applications, check the [advantages of object blurring section](#advantages-of-object-blurring).
### Can I use Ultralytics YOLO11 to blur faces in a video for privacy reasons?
Yes, Ultralytics YOLO11 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with [OpenCV](https://www.ultralytics.com/glossary/opencv) to apply a blur effect. Refer to our guide on [object detection with YOLO11](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
### How does YOLO11 compare to other object detection models like Faster R-CNN for object blurring?
Ultralytics YOLO11 typically outperforms models like Faster R-CNN in terms of speed, making it more suitable for real-time applications. While both models offer accurate detection, YOLO11's architecture is optimized for rapid inference, which is critical for tasks like real-time object blurring. Learn more about the technical differences and performance metrics in our [YOLO11 documentation](https://docs.ultralytics.com/models/yolov8/).
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.