
ChartVerse
Collection
8 items
•
Updated
•
3
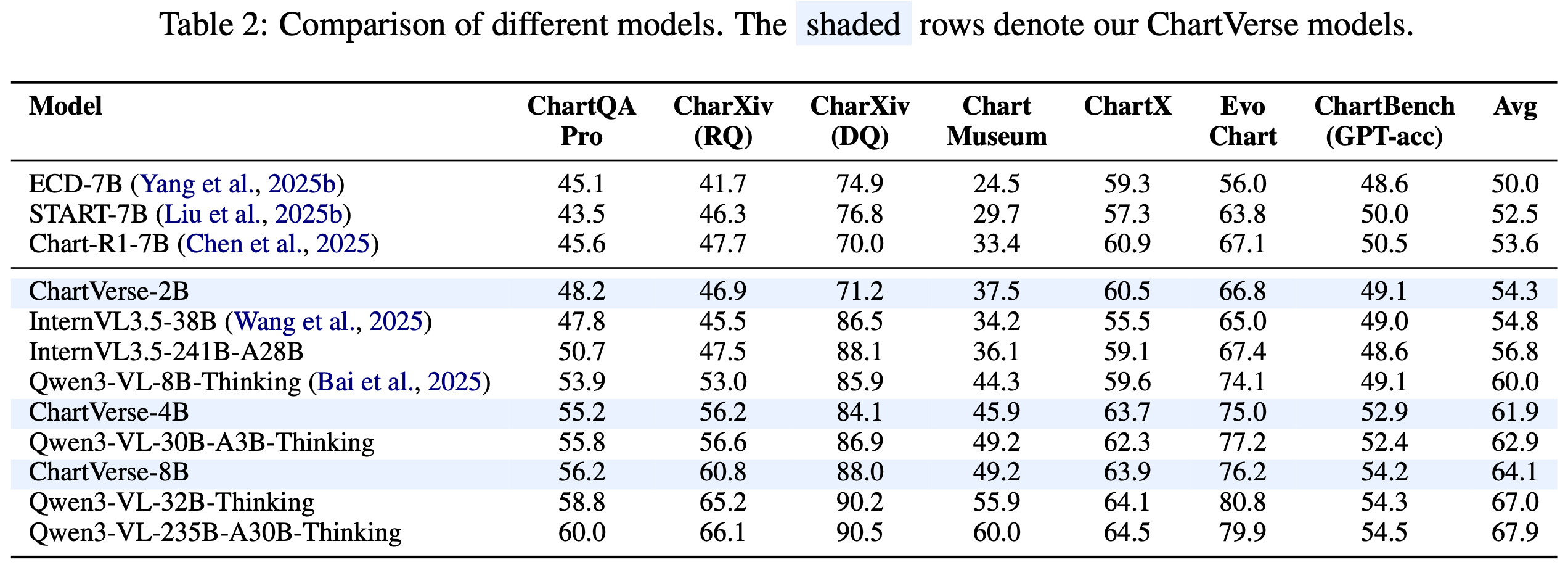
ChartVerse-2B is a compact yet powerful Vision Language Model (VLM) specialized for complex chart reasoning, developed as part of the opendatalab/ChartVerse project. For more details about our method, datasets, and full model series, please visit our Project Page.
Despite its 2B parameter size, ChartVerse-2B achieves superior performance compared to larger chart-specific models like ECD-7B, START-7B, and Chart-R1-7B, demonstrating that high-quality training data can substantially offset model size limitations.
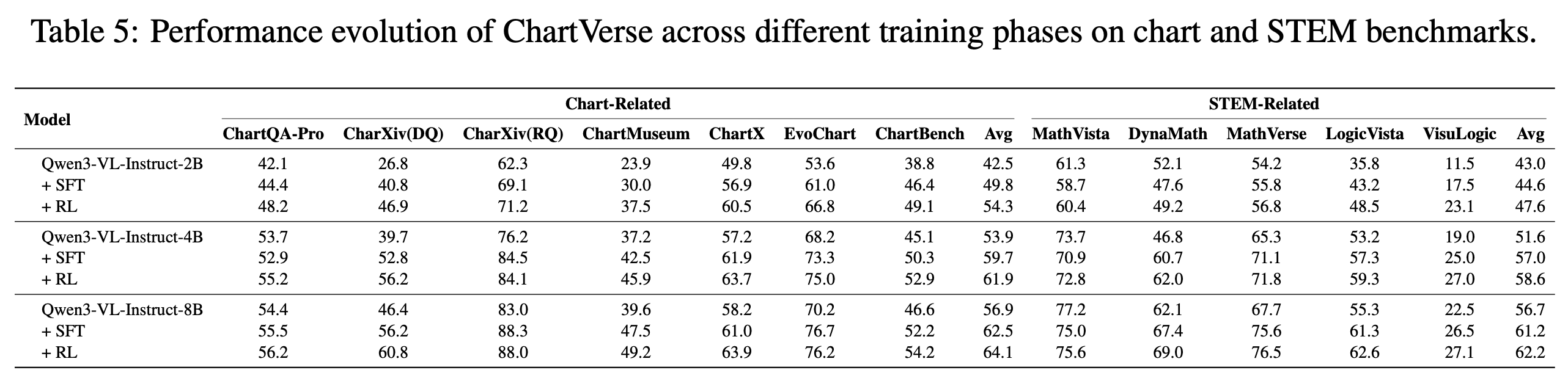
Supervised Fine-Tuning (SFT):
Reinforcement Learning (RL):
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
# 1. Load Model
model_path = "opendatalab/ChartVerse-2B"
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_path)
# 2. Prepare Input
image_path = "path/to/your/chart.png"
query = "Which region demonstrates the greatest proportional variation in annual revenue compared to its typical revenue level?"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": query},
],
}
]
# 3. Inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=16384)
output_text = processor.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
@misc{liu2026chartversescalingchartreasoning,
title={ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch},
author={Zheng Liu and Honglin Lin and Chonghan Qin and Xiaoyang Wang and Xin Gao and Yu Li and Mengzhang Cai and Yun Zhu and Zhanping Zhong and Qizhi Pei and Zhuoshi Pan and Xiaoran Shang and Bin Cui and Conghui He and Wentao Zhang and Lijun Wu},
year={2026},
eprint={2601.13606},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.13606},
}
This model is released under the Apache 2.0 License.